OpenFact: Factuality Enhanced Open Knowledge Extraction
Linfeng Song∗, Ante Wang∗,†, Xiaoman Pan, Hongming Zhang, Dian Yu, Lifeng Jin,
Haitao Mi, Jinsong Su†, Yue Zhang‡ and Dong Yu
Tencent AI Lab, Bellevue, WA, 美国
†School of Informatics, Xiamen University, 中国
‡School of Engineering, Westlake University, 中国
lfsong@global.tencent.com
抽象的
We focus on the factuality property during
the extraction of an OpenIE corpus named
OpenFact, which contains more than 12 米尔-
lion high-quality knowledge triplets. We break
down the factuality property into two im-
portant aspects—expressiveness and ground-
edness—and we propose a comprehensive
framework to handle both aspects. To enhance
expressiveness, we formulate each knowledge
piece in OpenFact based on a semantic frame.
We also design templates, extra constraints,
and adopt human efforts so that most Open-
Fact triplets contain enough details. For ground-
埃德内斯, we require the main arguments of each
triplet to contain linked Wikidata1 entities. A
human evaluation suggests that the OpenFact
triplets are much more accurate and contain
denser
information compared to OPIEC-
链接 (Gashteovski et al., 2019), one recent
high-quality OpenIE corpus grounded to Wiki-
数据. Further experiments on knowledge base
completion and knowledge base question an-
swering show the effectiveness of OpenFact
over OPIEC-Linked as supplementary knowl-
edge to Wikidata as the major KG.
1
介绍
Open information extraction (OIE, Etzioni et al.,
2008) aims to extract factual and informative
知识, which can further be used to enhance
major knowledge bases (Martinez-Rodriguez et al.,
2018) or on downstream tasks (Stanovsky et al.,
2015). Most current OIE systems (Fader et al., 2011;
Mausam et al., 2012; Del Corro and Gemulla,
2013; 安吉尔等人。, 2015) organize knowledge
into subject-relation-object (SRO) 三元组, 和他们
use templates to extract such knowledge triples.
∗Equal contribution, work done during an internship of
Ante Wang at Tencent AI Lab.
1https://www.wikidata.org/.
Figure 1a and 1b show a Wikipedia2 fragment
and the corresponding SRO triple from OPIEC-
链接 (Gashteovski et al., 2019), a major OIE
语料库.
Previous OIE efforts (Fader et al., 2011;
Mausam et al., 2012; Del Corro and Gemulla,
2013; 安吉尔等人。, 2015; Stanovsky et al., 2018;
Cui et al., 2018) mainly focus on extracting SRO
triples that are closer to human annotated out-
puts on benchmarks. 然而, they overlook the
factuality issue, where many extracted triples may
convey incomplete or even incorrect informa-
的. This issue can be categorized into two main
aspects. The first aspect is the lack of expres-
siveness, where complex knowledge is poorly or-
ganized or critical information is dropped due to
the fixed SRO schema and the template-based ex-
traction system. Taking Figure 1b as an example,
关系 (‘‘surpassed Washington Monument
to become’’) is a long span containing multi-
ple events, and important temporal information
(‘‘during its construction’’) is not captured. 这
second aspect regards groundedness that measures
the degree of a triplet being linked to known en-
乳头. 例如, a standard OIE system can
extract ‘‘
levels for visitors.’’ The extracted triple lacks
groundedness particularly because it is unclear
what ‘‘the tower’’ refers to. Lacking factuality
diminishes the usability of the OIE triples as
supplementary knowledge to major KGs.
Later work proposes to use either nested SRO
三元组 (Bhutani et al., 2016) or n-ary triples
(Christensen et al., 2011; Akbik and L¨oser, 2012;
Gashteovski et al., 2017; 赵等人。, 2021) 到
enrich SRO schema with properties such as po-
larity. A recent effort (Gashteovski et al., 2019)
2https://www.wikipedia.org/.
686
计算语言学协会会刊, 卷. 11, PP. 686–702, 2023. https://doi.org/10.1162/tacl 00569
动作编辑器: Doug Downey. 提交批次: 9/2022; 修改批次: 12/2022; 已发表 6/2023.
C(西德:3) 2023 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Figure 1c, OpenFact is based on semantic role
labeling (SRL, Palmer et al., 2005) for expres-
siveness.4 Here each OpenFact triplet contains
a predicate, which may mention a relation or
an event, and several core arguments from the
corresponding semantic frame. To further ensure
that each OpenFact knowledge triplet describes
detailed factual information, we require it to con-
tain a certain combination of semantic arguments
(例如, (Arg0, Arg1, ArgM-Tmp)), and we manually
design multiple such combinations to ensure cov-
erage. We also resort to some affordable human
efforts to manually verify some extracted knowl-
edge triplets, which are then used to train a quality
checker to automatically filter low-quality triplets
from the remaining data.
To improve groundedness, we extend the core
论据 (Arg0, Arg1, Arg2, ArgM-Loc) 和
associated Wikidata entities to ensure that the
is not about some ambigu-
knowledge triplet
ous entity (例如, ‘‘the tower’’). As the result, 我们的
OpenFact triplets (例如, ‘‘surpassed(Arg0:这 [Eif-
fel Tower], Arg1:这 [Washington Monument],
ArgM-Tmp:During its construction)’’) can pro-
vide more expressive and grounded information
than previous OIE triples (例如, the example in
Figure 1b).
A human evaluation on 200 randomly sam-
pled triplets show that 86.5% of OpenFact triplets
convey precise factual information, while it is
仅有的 54.0% for OPIEC-Linked. Further exper-
iments on knowledge base completion (KBC)
and knowledge base question answering (KBQA)
benchmarks (Safavi and Koutra, 2020; Yih et al.,
2016) over Wikidata show that OpenFact pro-
vides more useful complementary information
than OPIEC-Linked and significantly improves
highly competitive baseline systems.5
总之, we make the following contri-
butions:
• We propose a comprehensive approach to ad-
dress the factuality issue of open informa-
tion extraction from two key aspects: 表达-
siveness and groundedness.
4Though this shares a similar spirit to SRLIE (Christensen
等人。, 2011), SRLIE converts the extracted semantic frames
back into traditional SRO or n-ary triples and loses some
critical information.
5Code and data are available at https://github
数字 1: (A) A Wikipedia fragment and (乙) the cor-
responding OPIEC-Linked (Gashteovski et al., 2019)
三元组. Throughout this paper, we use ‘‘[]’’ to indicate
the mentions of Wikidata entities. (C) Our Open-
Fact fragment, where orange, gray, and blue boxes
represent relations, 论据, and Wikidata entities,
分别.
further extracts more substantial properties (例如,
空间和时间), and a refined3 OIE corpus
(OPIEC-Linked) 的 5.8 millions triples is ex-
tracts from Wikipedia where both the subject
and the object contains linked Wikidata entities.
Although this effort can partially improve expres-
siveness and groundedness, the factuality issue is
not discussed and formally addressed. Besides,
simply keeping extra properties or linked entities
without a comprehensive solution may not en-
sure that most triples contain precise factual infor-
运动. 例如, though both subject and
object are grounded for the triple in Figure 1b, 它
erroneously mixes two events (IE。, ‘‘surpass’’ and
‘‘become’’) and lacks critical information (例如,
时间) to describe precise factual information.
在本文中, we propose a comprehensive so-
lution to address the factuality issue, 这是
then used to construct a corpus of OIE knowl-
edge named OpenFact. The corpus contains more
比 12 million accurate factual knowledge triplets
extracted from Wikipedia, a reliable knowledge
source with broad coverage. Comparing with pre-
vious OIE corpora, factuality is thoroughly en-
hanced in OpenFact. 具体来说, 如图所示
3OPIEC-Linked is obtained by applying filtering rules on
the initial OPIEC corpus to enhance quality.
.com/Soistesimmer/OpenFact.
687
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
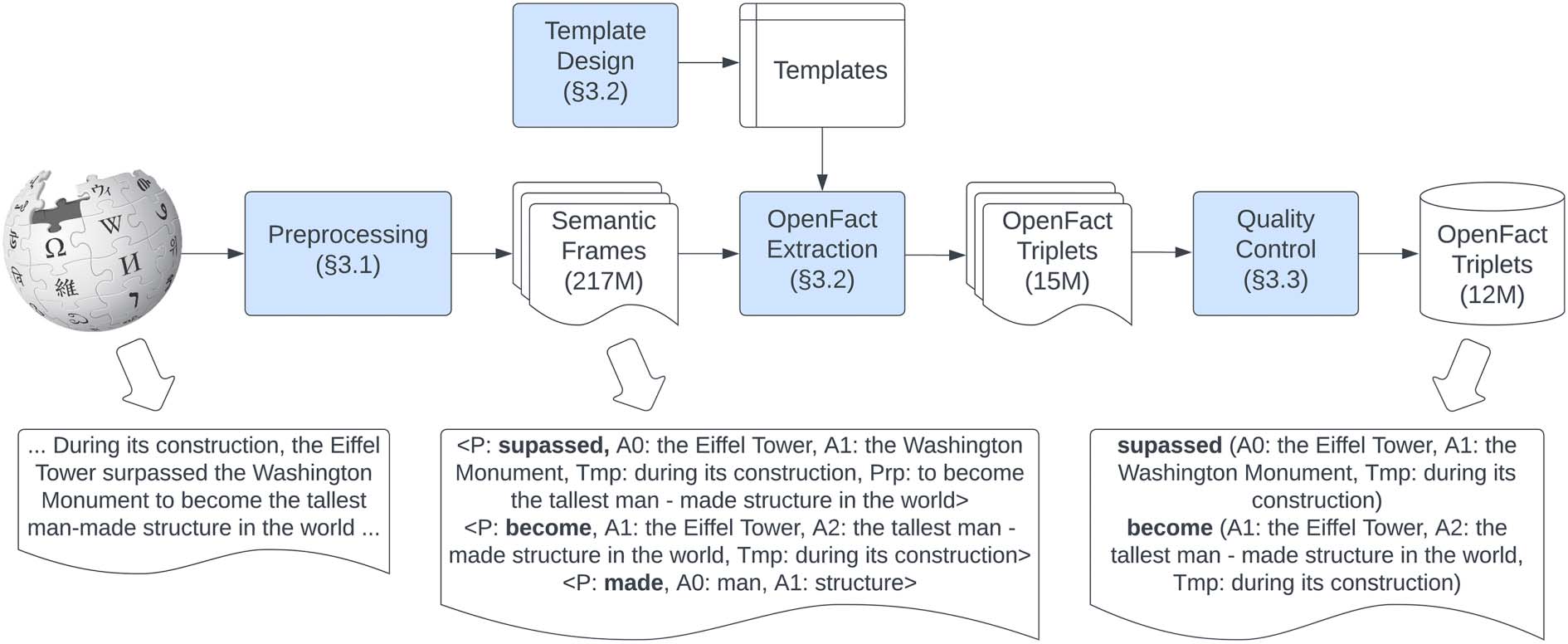
数字 2: The pipeline for OpenFact construction with the corresponding outputs for the example in Figure 1a.
Numbers (例如, ‘‘12M’’) indicates the number of extracted items. ‘‘P’’, ‘‘A0’’, ‘‘A1’’, ‘‘A2’’, and ‘‘Tmp’’ are
short for predicate, Arg0, Arg1, Arg2, and ArgM-Tmp, 分别.
• Using our approach, we construct OpenFact,
an OIE corpus containing 12 million accu-
rate factual knowledge triplets.
• Human evaluation and experiments on both
KBQA and KBC show superiority of Open-
Fact over OPIEC, a state-of-the-art OIE
语料库.
2 OpenFact Construction
We choose the Wikipedia dump of May 20, 2021,
to construct OpenFact, as Wikipedia has been
considered to be a reliable knowledge source
with broad coverage. 数字 2 shows the overall
pipeline, which includes Wiki dump preprocess-
英 (§2.1), triplet extraction (§2.2), and quality
控制 (§2.3). We also conduct an analysis on all
the extracted OpenFact triplets (§2.4).
2.1 预处理
We conduct three preprocessing steps (维基百科
dump cleaning, text processing, and SRL pars-
英) to obtain the input data for triplet extraction.
Wikipedia Dump Cleaning
In a Wikipedia
dump, each page contains not only the main
content but also the special tokens and keywords
from a markup language. 所以, the first step
is to clean the special markup tokens and refor-
mat each page into plain text. 例如, 这
markup {{convert|5464|km|mi||sp=us}}
should be reformatted into the plain text ‘‘5,464
kilometer (3,395 mile)’’. 为此, we adopt a
popular tool (Pan et al., 2017) to remove all un-
desired markups (例如, text formatting notations,
HTML tags, citations, external links, 模板)
and only keep the internal links that naturally
indicate the mentions of Wikidata entities.
Text Processing After obtaining the Wiki-
pedia dump in plain texts, we perform sentence
segmentation, tokenization, and entity mention
detection using SpaCy.6 Since there are plenty
of missing entity links in the original Wikipedia
页面 (Adafre and de Rijke, 2005), we adopt a
dense retrieval based entity linker (Wu et al.,
2020) to link some extracted entity mentions to
维基百科. Note that we only keep the linking
results when the model probability of the top
candidate exceeds 0.5 to ensure quality. 最后,
we map all Wikipedia titles to Wikidata IDs.
SRL Parsing The last step in preprocessing
is to obtain the semantic frames from SRL pars-
英. 具体来说, we adopt the SRL parser from
AllenNLP,7 an implementation of Shi and Lin
(2019), to parse for all the sentences extracted
from Wikipedia by preprocessing. Since standard
SRL parsing omits the situations where the main
predicate can be a verbal phrase (例如, ‘‘come up
with’’), we further extend those predicates into
phrasal predicates. 为此, we collect 390
frequent verbal phrases for matching.
6https://spacy.io/.
7https://demo.allennlp.org/semantic-role
-labeling.
688
[lattice tower] 在 [Champ de Mars] 在 [巴黎],
[法国])
supassed(Arg1=the [Eiffel Tower], Arg2=the
[Washington Monument], ArgM-Tmp=during its
建造)
constructed(Arg1=The [Eiffel Tower], ArgM-
Tmp=from 1887 到 1889)
桌子 1: Example templates and a representa-
tive OpenFact triplet. The requirements for the
main predicate is in ‘‘verb:tense voice’’ format
with the verb being either a linking verb or a
regular verb.
2.2 Triplet Extraction
In this stage, we design multiple templates to
obtain candidate OpenFact triplets from the ex-
tracted semantic frames in the previous stage.
桌子 1 lists example templates and the corre-
sponding OpenFact triplets. Each template con-
tains the requirements on the main predicate and
a subset of six important semantic roles: Arg0
(agent), Arg1 (病人), Arg2 (beneficiary), ArgM-
Tmp (时间), ArgM-Loc (地点), and ArgM-Neg
(否定). Particularly, we make requirements
on predicates regarding the verb type (linking or
常规的), tense (present or past), and voice (交流电-
tive or passive) in order to ensure the quality of
the automatically extracted triplets. Besides, 我们
further impose the following restrictions when
designing and applying the templates:8
• Each template should take at least two argu-
评论, and their combination needs to cap-
ture meaningful
信息. 我们
factual
manually design multiple combinations that
satisfy this requirement. 例如, (Arg1,
ArgM-Tmp, ArgM-Loc) can be used to ex-
tract ‘‘born(Arg1=Barack Obama, ArgM-
Tmp=1961, ArgM-Loc=Honolulu, Hawaii)’’.
另一方面, (ArgM-Tmp, ArgM-Loc)
is not a meaningful combination, as it can
barely match a sound example.
• If a sentence matches multiple templates,
only the one with the highest number of
arguments is used for triplet extraction. 为了
each pair of templates, we guarantee that
the union of their arguments is also a valid
template, so that there is no ambiguity on
choosing templates.
• All extracted semantic arguments except for
ArgM-Tmp and ArgM-Neg need to contain
在
least one linked Wikidata entity. 这
ensures that the corresponding triplet can
be grounded to some well-known entity, 在-
creasing the chance of the triplet describing
some factual information.
• Each triplet with a past-tense (or past-
participle) predicate needs to contain ArgM-
Tmp to alleviate time-related ambiguity. 为了
实例, ‘‘surpassed(Arg0=the Eiffel Tower,
Arg1=the Washington Monument)’’ becomes
ambiguous without the time property.
With these restriction rules, we extract around
15 million candidate triplets from 217 百万
semantic frames. Though SpaCy-based text pro-
cessing and SRL parsing can introduce errors,
the imposed restrictions help limit further prop-
agation of these errors. Besides, we introduce a
neural quality controller (§2.3) to prune erroneous
triplets.
2.3 Quality Control
Despite the imposed restrictions during extrac-
的, some obtained triplets can still contain too
much noise. Our observation reveals that lacking
enough details is the major reason. 例如,
‘‘invented(Arg0=A German company, Arg1=the
first practical jet aircraft, ArgM-Tmp=in 1939)’’
is not precise, because its Arg0 (‘‘A German
company’’) misses essential details. To further
improve our data, we resort to human annotators
to examine the quality for some triplets, 前
training a model to automatically examine the
quality of the remaining triplets. 尤其, 我们
ask annotators to label whether a triplet contain
quality issues, and what semantic roles cause the
issue.9 We hire professional annotators and set
additional requirements on English proficiency
and a bachelor’s degree.
8We release all templates for triplet extraction in the
9Detailed guidelines will be provided in the Appendix
附录.
given more space.
689
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Quality Checker With the annotated data, 我们
train a quality checker to automatically examine
all remaining triplets. Particularly, an input triplet
t is first serialized into a token sequence with
special BERT tokens [CLS] 和 [SEP]:
tserial = [[CLS], tp, [SEP], ta1, . . . taN ],
(1)
where tp and tai represent the tokens of the main
predicate and an argument inside t, 分别,
and N indicates the number of arguments in t.
The arguments are linearized in the order of their
appearance in the original sentence. 下一个, 这
quality checker adopts a BERT-base (Devlin et al.,
2019) encoder with multiple binary classification
heads for predicting the quality for the overall
triplet and each semantic role, 分别.
数字 3: Percentages for the most frequent predicates
except for ‘‘is’’.
H = BERT(tserial),
p(qx|t) = sigmoid(W x · h[CLS]),
(2)
(3)
需要 18.1 words on average (μ) with standard
deviation (σ) 存在 10.7 字. Here we conduct
more detailed analyses in the following aspects:
where x ∈ X = [whole, a0, a1, a2, loc, tmp],
which represents all aspects of each triplet t for
quality evaluation, W x and p(qx|t) are the linear
classifier and the quality score of the correspond-
ing item, 分别, and h[CLS] indicates the
BERT hidden state for the [CLS] 代币.
Training We adopt binary cross-entropy loss
to train the checker:
L = −
(西德:2)
(西德:3)
x∈X
ˆqx log p(qx|t)+
(西德:4)
(1 − ˆqx)(1 − log p(qx|t))
,
(4)
where ˆqx ∈ [0, 1] is the annotated quality for
aspect x. AdamW (Loshchilov and Hutter, 2018)
is used as the optimizer with learning rate and
number of epochs set to 10−5 and 10, 分别.
Inference During inference, we only use the
linear classifier for the whole aspect (Eq. 3 和
x = whole) to determine triplet quality, 而
quality classification results on the other aspects
(a0, a1, a2, loc, and tmp) only serve as auxiliary
losses during training. Following standard prac-
泰斯, we keep each triplet if the score of the whole
classifier exceeds 0.5.
2.4 Data Statistics
Predicates We find 14,641 distinct predicates
among all the extracted OpenFact triplets. 数字 3
shows the percentages of the most frequent pred-
icates. We exclude the most frequent predicate
‘‘is’’, which counts for 36% of all triplets for bet-
ter visualization. Predicate ‘‘is’’ usually involves
in definitions in Wikipedia, such as ‘‘The Eif-
fel Tower is a wrought-iron lattice tower on the
Champ de Mars in Paris, France’’. Our extraction
procedure favors those definition-based triplets,
as they usually give enough details. The remain-
ing top frequent predicates form a flat distribution
with the percentage ranging from 2.25% 到 0.75%.
许多人 (例如, ‘‘released’’, ‘‘announced’’,
‘‘held’’, and ‘‘established’’) do not have obvious
corresponding relations in Wikidata.
Entities Figure 4 shows the distribution of
OpenFact triplets over the number of contained
Wikidata entities, where more than 66% 的
triplets contain more than three entities. This in-
dicates that most of our triplets capture more
complex relations than standard Wikidata triples,
which only capture the relation between two en-
乳头. 另一方面, 0.39% of triplets con-
tain only 1 实体, as they are obtained from the
templates with only one main argument. Typical
examples are ‘‘constructed(Arg1=The [Eiffel
Tower], ArgM-Tmp=from 1887 to 1889’’.
We obtain more than 12 million OpenFact triplets
after all the steps in Figure 2, where each triplet
Arguments Figure 5 shows the distribution of
OpenFact triplets over the number of arguments.
690
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4: Distribution of OpenFact triplets over the
number of entities.
数字 6: The argument average lengths.
the tail entity, which is missing from the input
KG. This task is important due to the fact that
knowledge graphs are usually highly incomplete
(West et al., 2014).
Traditional efforts on KBC (Nickel et al.,
2011; Bordes et al., 2013; Trouillon et al., 2016;
Dettmers et al., 2018; Balaˇzevi´c et al., 2019) fo-
cus on learning the knowledge graph embedding
(KGE). 另一方面, adopting pretrained
language models (PLMs) to this task by lineariz-
ing each candidate KG triple into a sequence
has recently gained popularity (Yao et al., 2019;
Saxena et al., 2022).
Baseline: Combine KGE with PLM as a
Pipeline We first build our baseline system
by combining a major KGE system (ComplEx;
Trouillon et al., 2016) with a PLM model (KG-
BERT; Yao et al., 2019) into a pipeline to lever-
age the advantages of both approaches. Inside
the pipeline, the KGE system first produces a list
of k-best candidates, which are then ranked by
the PLM model to pick the final output. 我们
choose ComplEx and KG-BERT, which both
show highly competitive performances in several
major benchmarks.
正式地, given an input query (H, r, ?), 我们
first adopt ComplEx to infer the k-best tail entities
(例如, 的) over all the entities in a knowledge graph
with defined scoring function:
φ(r, H, 的) = Re((西德:5)wr, eh, eti
(西德:6)),
(5)
where eh, eti are the embeddings for h, 的, 关于-
spectively, and wr is the learned representation
vector for relation r. 关于(X) denotes the real vector
component for vector x, 和 (西德:5)·, ·, ·(西德:6) represents the
Hermitian product.10
10For details are shown in §3 of Trouillon et al. (2016).
数字 5: Distribution of OpenFact triplets over the
number of arguments.
Most triplets (> 97.3%) contain either 2 或者 3
论据, indicating that most of the triplets con-
sist a moderate amount of information. The most
frequent argument combination are (Arg1, Arg2),
(Arg0, Arg1, ArgM-Tmp), (Arg1, ArgM-Tmp), 和
(Arg0, Arg1) that count for 42.2%, 27.7%, 17.1%,
和 13.2%, 分别. 这 (Arg1, Arg2) combi-
nation accounts for the highest percent as it covers
all the triplets with a linking verb (例如, ‘‘is’’).
数字 6 further visualizes the average lengths
for all the argument types, where most types take
4.5 到 13 words except for ArgM-Neg. The reason
is that it only needs one word to represent nega-
tion in most cases, while it can requires a lot of
words for other components.
3 OpenFact for Downstream Tasks
We choose knowledge base completion (KBC)
and knowledge base question answering (KBQA)
to evaluate the usefulness of OpenFact.
3.1 Knowledge Base Completion
Automatic KBC aims to infer missing facts based
on existing information in a knowledge graph.
例如, given a knowledge triple (H, r, ?)
with a head h and relation r, the goal is to infer
691
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
As the next step, given each hypothesis triple
(H, r, 的) with th i-th candidate tail entity ti, 我们
use the KG-BERT model to determine the like-
lihood of this triple being valid, before picking
the hypothesis triple with the highest likelihood
score as the final output. 尤其, each tri-
普莱 (H, r, 的) is first linearized into a sequence of
代币:
(西德:5)
X =
[CLS]H[SEP]r[SEP]t[SEP]
(西德:6)
,
(6)
在哪里 [CLS] 和 [SEP] are BERT (Devlin
等人。, 2019) special tokens. Then a BERT en-
coder with a linear layer (多层线性规划) is adopted to
predict the likelihood p(的|H, r) of ti being the
correct tail:
p(的|H, r) =sigmoid
H =BERT(X),
(西德:7)
多层线性规划(H[CLS])
(西德:8)
,
(7)
where H[CLS] is the output hidden state of [CLS]
from BERT.
ComplEx and KG-BERT are trained separately,
where we completely follow the previous work
(Safavi and Koutra, 2020) to prepare the Com-
plEx system. As high-quality negative samples are
essential to train a robust KG-BERT (Lv et al.,
2022) 模型, we collect the top-k link predic-
tion results from the pretrained ComplEx system
as the negative triples instead of randomly se-
lection from the overall KG as early practices.
KG-BERT is trained with binary cross-entropy
loss to determine the correctness of each input
triple:
LKG-BERT = −yi log(p(的|H, r))-
(1 − yi) 日志(1 − p(的|H, r)),
(8)
where yi (yi ∈ {0, 1}) is the label on whether ti
is the valid tail for query (H, r, ?).
最后, we calculate the ranking score for a
candidate triple considering both the scores from
both ComplEx and KG-BERT:
scoreRank = scoreComplEx + ω · scoreKG-BERT,
(9)
where ω is a scaling hyperparameter.
OpenFact for KBC We do not change the
model structure but propose to incorporate one
relevant OpenFact triplet to enhance the corre-
sponding candidate KG triple, so that the KG-
BERT model in the pipeline system can leverage
692
richer information to make more accurate rank-
ing decisions.
Particularly, given a KG triple (H, r, t), we first
triplets (例如, 磷 (Ah, 在))
gather the OpenFact
where h and t are contained by its arguments
(IE。, h ∈ Ah and t ∈ Ar) correspondingly. 为了
simplicity, we only keep the most similar Open-
Fact triplet if multiple ones are obtained, 在哪里
a similarity score is calculated by comparing a
linearized11 OpenFact triplet with the linearized
target KG triple using SentenceBERT (Reimers
和古列维奇, 2019). We then concatenate them
as a sequence of tokens:
X’ = [CLS]H[SEP]r[SEP]t
[SEP]h Ah P At t[SEP].
(10)
This is similar with Eq. 6, and the resulting token
sequence is then taken to the KG-BERT model to
pick the final tail entity as in Eq. 7.
3.2 Knowledge Base Question Answering
Knowledge Base Question Answering (KBQA)
aims to answer factoid questions based on a
knowledge base. It is an important task and such
systems have been integrated in popular web
search engines and conversational assistants. 这
main challenge of this task is to properly map
each query in natural language to KG entities
and relations. Since knowledge graphs are often
sparse with many missing links, this poses addi-
tional challenges, especially increasing the need
for multi-hop reasoning (Saxena et al., 2020).
We further evaluate OpenFact on this task, 作为
OpenFact triplets are in a closer format to natu-
ral language than KG triples. Besides, the dense
knowledge provide by OpenFact may help bridge
many multi-hop situations.
Baseline: UniK-QA (Oguz et al., 2022)
它有
been recently proposed to solve multiple QA
tasks as one unified process. The system consists
of a pretrained Dense Passage Retriever (DPR;
Karpukhin et al., 2020) and a Fusion-in-Decoder
(FiD; Izacard and Grave, 2021) 模型. We adopt
UniK-QA as our baseline due to its strong per-
formances over multiple KBQA benchmarks.
Given an input question q and the associated
KG triples obtained by entity linking and 2-hop
expansion on the target KG, UniK-QA first uses
11Each OpenFact triple is empirically linearized in the
order of ‘‘Arg0 Neg Prd Arg1 Arg2 Loc Tmp.’’
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
系统
ComplEx†
KG-BERT
Pipeline
+OPIEC
+OpenFact
MRR
0.465
0.263
0.522
0.526
0.535
CoDEx-S
Hits@1
Hits@10
0.372
0.183
0.420
0.426
0.430
0.646
0.429
0.724
0.726
0.736
MRR
0.337
0.209
0.392
0.394
0.403
CoDEx-M
Hits@1
Hits@10
0.262
0.155
0.300
0.305
0.313
0.476
0.307
0.567
0.568
0.578
桌子 2: Main results on knowledge base completion. † denotes results from previous work.
the DPR module to rank the KG triples. 下一个,
the sorted KG triples are linearized and com-
bined into passages of at most 100 代币, 后
which top-n passages [p1, . . . , pn] are fed into
the FiD model for generating the final answer
autoregressively:
aj = FiD-Dec([H1, . . . , Hn], A
much useful knowledge. Many ‘‘Wrong’’ triplets
contain obvious errors, such as ‘‘
significantly higher quality and is much denser
than OPIEC-Linked.
We further analyze the erroneous triplets
of OpenFact and show representative cases in
桌子 4, where the top and bottom groups corre-
spond to the ‘‘Mixed’’ and ‘‘Missing’’ categories,
分别. For the ‘‘Mixed’’ category, we list
all the 3 instances rated as this type out of the
200 instances for human evaluation. 从这些
instances and other OpenFact data, we find that
most defects in this category are caused by SRL
parsing errors, like erroneous argument-type de-
保护 (例如, the first example where the Arg1
and Arg2 arguments are mistakenly swapped)
and erroneous argument-boundary detection (例如,
the second and third examples where the time
Mixed
Missing
链接的(Arg1=with [澳大利亚] 和 [新的
西兰岛], Arg2=Every important island
or group in [Oceania])
曾是(Arg1=[Cuba], Arg2=able to ex-
change one ton of sugar for 4.5 吨
的 [Soviet] 油, ArgM-Tmp=in 1987)
lab’s
helped(Arg0=the
rapid reports, Arg1=to predict
这
[Israeli] – [英国人] – [法语] attack on
[埃及] three days before it began on 29
十月, Arg2=the [我们。] 政府,
ArgM-tmp=as Detachment B took over
from A and flew over targets that remain
classified)
[Wiesbaden]
born(Arg1=a [Tajik],
[俄语], 和
[Soviet] 作曲家, ArgM-Loc=in the
city of [Dushanbe], [Tajik SSR])
[护照], Arg1=the
熊(Arg0=Her
stamps of two dozen countries, 包括
[阿尔及利亚] . . . 和 [Union of Soviet
Socialist Republics])
reaches(Arg0=the [非洲人] dust, Arg1 =
这 [美国])
turned(Arg1=[索罗斯], Arg2=into a pariah
在 [匈牙利] and a number of other
国家)
桌子 4: Error analysis on OpenFact.
information is mistakenly mixed into other
论据).
For the ‘‘Missing’’ category, we observe two
prevalent types of defects, and we list two typical
examples for each type. As shown in the first
two examples of this category, one major type of
defect is caused by the absent of critical entity
information in the arguments. 例如, 这
missing name of ‘‘the Soviet composer’’ in the
first example makes the whole instance too vague
to be factual. The second example suffers from a
similar situation as it fails to mention who ‘‘the
owner of the passports’’ is. Although we force
each argument to contain at least one entity during
the extraction process, it cannot guarantee that all
essential entities are included. The other major
type of defects are due to the missing of critical
time or location information, as it is nontrivial
to determine whether a OpenFact triplet requires
time or location to be factual. For the last two
cases of this category, both the time when ‘‘the
African dust reaches the United States’’ and the
time when ‘‘Soros is turned into a pariah in
匈牙利 …’’ are missing.
694
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
OIE KN
CoDEx-S
CoDEx-M
2-hop 3-hop 4-hop
2-hop 3-hop 4-hop
OPIEC
0.629
0.077
0.012
0.344
0.055
0.011
OpenFact
0.843
0.351
0.248
0.560
0.069
0.062
桌子 5: The percent of devset KG triples where
head and tail can be connected by one OIE triplet.
4.2 Evaluation on KBC
evaluate
Datasets We
on CoDEx-S and
CoDEx-M (Safavi and Koutra, 2020) 那是
extracted from Wikidata with CoDEx-M being
much more challenging than CoDEx-S. The entity
number and the distinct relation-type number
for CoDEx-S/CoDEx-M are 2,034/17,050 和
42/51, 分别. The number of train/dev
/test instances for CoDEx-S and CoDEx-M are
32,888/1,827/1,828 和 185,584/10,310/10,311,
分别.
系统
In addition to ComplEx, KG-BERT,
and Pipeline (§3.1), we also compare our model
(+OpenFact) 和 (+OPIEC): They both add ex-
tra knowledge (OpenFact vs OPIEC-Linked) 到
the Pipeline system. All three pipeline systems
share the same model architecture except for the
adopted knowledge (None vs OPIEC vs Open-
Fact), which helps validate the effectiveness of
OpenFact.
Settings For fair comparison, the KG-BERT for
both the baselines and our model are trained us-
ing Adam (Kingma and Ba, 2014) 为了 4 纪元
with linear scheduler and initial learning rate set
到 5 × 10−5. Their batch sizes on CoDEx-S and
CoDEx-M are 256 和 1024, 分别. We set
k as 25 to get a considerable amount of nega-
tive samples. Besides, to balance the positive and
negative sample numbers, we penalize negative
samples with their instance weights as 0.2.
We evaluate in the form of link prediction,
where a system is required to predict the missing
entities from inputs that are in the format of
(?, r, t) 或者 (H, r, ?). The performance is evaluated
with mean reciprocal rank (MRR) and Hits@k.
We set ω as 2.5/5/5 on CoDEx-S and 2.5/5/7.5
on CoDEx-M for Pipeline/Pipeline+OPIEC/
Pipeline+OpenFact according to development
实验.
数字 7: The MRR scores on the CoDEx-m test set
across different hops between head and tail entities.
措辞, where we also compare with the reported
numbers of ComplEx. We can draw the follow-
ing conclusions. 第一的, the Pipeline model shows
significantly better performances than using just a
single module (ComplEx and KG-BERT), as it can
enjoy the benefits from both knowledge graph
embedding and a large-scale PLM. 第二,
enhancing the KG-BERT module of Pipeline
with the knowledge from either OPIEC-Linked or
OpenFact can further improve the performance.
Comparatively, using OpenFact gives larger per-
formance gains over OPIEC-Linked with the gaps
on CoDEx-S and CoDEx-M being 0.9 MRR
点 (0.4 Hits@1 points) 和 0.9 MRR points
(0.8 Hits@1 points), 分别. This indicates
that OpenFact is a better supplement than OPIEC-
Linked for major KGs like Wikidata.
Analysis We further analyze a few aspects to
pinpoint where the gains of OpenFact come from.
As listed in Table 5, we first compare OpenFact
with OPIEC-Linked regarding the coverage rates
on the devset KG triples across different num-
ber of hops. OpenFact consistently covers more
percents of KG triples than OPIEC-Linked across
all numbers of hops. For both OPIEC-Linked and
OpenFact, the coverage rate drops when increas-
ing the number of hops, while the advantages of
OpenFact become more significant. 例如,
OpenFact covers 20.6 (24.8% 与 1.2%) 和 5.6
(6.2% 与 1.1%) times more than OPIEC-Linked on
the 4-hop instances of CoDEx-S and CoDEx-M,
分别.
Main Results Table 2 shows the main test re-
sults on CoDEx-S and CoDEx-M for link pre-
如图 7, we also compare the
MRR score of OpenFact with OPIEC-Linked
695
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
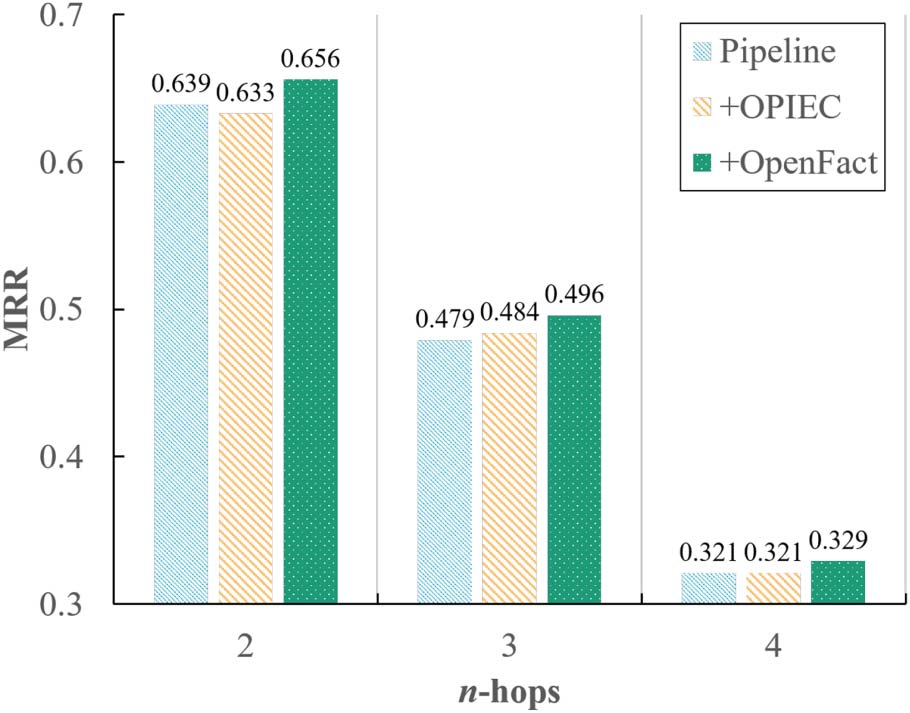
regarding the number of hops from the head en-
tity to the tail entity on the known part of the
input knowledge graph. 尤其, we choose
CoDEx-M (the more challenging dataset) and cat-
egorize its test instances into 3 groups according
to the number of hops. We observe consistent
performance gains from +OPIEC to +OpenFact
for all groups. The percent of relative gains along
the number of hops are 3.6% (0.656/0.639), 2.4%
(0.496/0.484), 和 2.4% (0.329/0.321), indicating
that OpenFact can be helpful for a large variety
of situations instead of for certain cases.
4.3 Evaluation on KBQA
Dataset We evaluate on the WebQSP dataset
(Yih et al., 2016), which consists of 3,098/1,639
training/testing question-answer pairs. Since Web-
QSP uses Freebase (Bollacker et al., 2008) 作为
the knowledge source, we map each Freebase
entity id to the corresponding Wikidata id if there
is any,12 and we find the corresponding Wikidata
entities for nearly half of the Freebase entities.
Comparing Systems One system for compari-
son is the UniK-QA (Oguz et al., 2022) 基线,
which only accesses the associated KG triples of
each input question. 此外, we also compare
our model (+OpenFact) using extra OpenFact
knowledge with another baseline (+OPIEC) 使用
OPIEC-Linked (Gashteovski et al., 2019) 知识-
边缘. For fair comparison, all three systems take
the same number of parameters.
Settings Following previous work (Oguz et al.,
2022), we split 10% training data as the develop-
ment set and take Hits@1 as the evaluation metric.
Following the setup of vanilla UniK-QA, 我们用
the pretrained DPR checkpoint from Karpukhin
等人. (2020) without further finetuning, 和我们
adopt the standard T5-base (Raffel et al., 2020)
checkpoint to initialize the FiD model, 这是
then trained using the Adam optimizer (Kingma
learning rate,
and Ba, 2014) with batch size,
and training steps set to 64, 10−4, 和 1,000,
分别.
Main Results Figure 8 visualizes the Hits@1
scores of UniK-QA with only associated KG
三元组, +OPIEC with extra OPIEC-Linked knowl-
边缘, and +OpenFact with extra OpenFact trip-
12We build the mapping from the ‘‘Freebase ID’’ property
(P646) of each Wikidata entity.
数字 8: Main UniK-QA performance with the num-
ber of allowed extra passages from either OPIEC-
Linked or OpenFact. † denotes the score reported in
Oguz et al. (2022).
让我们. For both +OPIEC and +OpenFact, we re-
port the scores with growing amounts of passages
(知识), as we usually obtain multiple pieces
of relevant triplets. Both +OPIEC and +Open-
Fact improve the final performance, while +Open-
Fact gives significantly more gains with 10 或者
more extra passages. Particularly with at most 20
extra passages, +OpenFact outperforms UniK-
QA and +OPIEC by 1.4 和 1.2 Hits@1 points.
The reason can be that OpenFact provides richer
high-quality knowledge compared to OPIEC-
链接. According to our statistics, 平均数
number of relevant passages by OPIEC-Linked
and OpenFact are 4.7 和 12.8, 分别.
5 相关工作
Though open information extraction has re-
ceived increasing attention, there are only a few
publicly available large-scale Open-IE databases,
such as TextRunner (Yates et al., 2007), ReVerb
(Fader et al., 2011), PATTY (Nakashole et al.,
2012), WiseNet 2.0 (Moro and Navigli, 2013),
DefIE (Bovi et al., 2015), and OPIEC (Gashteovski
等人。, 2019). 另一方面, NELL (卡尔森
等人。, 2010; 米切尔等人。, 2018) uses a prede-
fined seed ontology (包括 123 categories and
55 关系) instead of extracting from scratch.
All these Open-IE corpora organize data into tra-
ditional SRO or n-ary triples. Some incorporate
either automatic entity linking results (林等人。,
2012; Nakashole et al., 2012; Bovi et al., 2015) 或者
the natural links retained from the source data
(Moro and Navigli, 2013; Gashteovski et al.,
2019) simply for alleviating the ambiguity of
extracted triples.
696
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
另一方面, we focus on extracting
triplets that contain enough expressiveness and
groundedness to retain factuality. To do that, 我们
adopt a comprehensive framework that imposes
carefully designed restrictions and templates to
filter unqualified triplets. We also resort to hu-
man annotations in descent-scale to train a quality
checker for further data filtering. Previous studies
either rely on system confidence scores and lexi-
cal features for heuristics-based filtering (Kolluru
等人。, 2020) or clean data to enable self-training
(Nayak et al., 2021). 此外, our triplets
adopt the format of semantic frames that contains
rich semantic roles. 因此, our triplets can be more
expressive than standard SRO or n-ary triples.
6 结论
We have introduced OpenFact, an OIE corpus
的 12 million accurate factual knowledge triplets
extracted from Wikipedia. Different from exist-
ing OIE work, we focused on the factuality of
extracted triplets with a comprehensive approach
to enhance such property. 具体来说, OpenFact
is based on frame semantics instead of the standard
SRO or n-ary schema, and we design automatic
restriction rules and multiple dedicated templates
to enhance expressiveness. Besides, we extended
the core arguments of each OpenFact triplet with
linked Wikidata-entity mentions for grounded-
内斯. We also resorted to a quality checker trained
with descent-scale human annotations to further
improve our knowledge quality. A human study
revealed that 86.5% of OpenFact triplets are pre-
cise, while it is only 54.0% for OPIEC-Linked
(Gashteovski et al., 2019), a recent high-quality
OIE corpus closest to ours in spirit. Further ex-
periments on knowledge base completion and
knowledge base question answering show that
OpenFact provides more useful knowledge than
OPIEC-Linked,
significantly improving very
strong baselines.
Future work includes designing dynamic tem-
plates where the combination of arguments is
based on both prior knowledge and the predicate
(Zeng et al., 2018).
参考
Sisay Fissaha Adafre and Maarten de Rijke.
2005. Discovering missing links in Wikipedia.
在诉讼程序中
the 3rd International
Workshop on Link Discovery, pages 90–97.
https://doi.org/10.1145/1134271
.1134284
Alan Akbik and Alexander L¨oser. 2012. Kraken:
N-ary facts in open information extraction.
In Proceedings of the Joint Workshop on Auto-
matic Knowledge Base Construction and Web-
scale Knowledge Extraction (AKBC-WEKEX),
pages 52–56.
Gabor Angeli, Melvin Jose Johnson Premkumar,
and Christopher D. 曼宁. 2015. Leveraging
linguistic structure for open domain informa-
tion extraction. In Proceedings of the 53rd
Annual Meeting of the Association for Com-
putational Linguistics and the 7th International
Joint Conference on Natural Language Process-
英 (体积 1: Long Papers), pages 344–354.
https://doi.org/10.3115/v1/P15-1034
Ivana Balaˇzevi´c, Carl Allen, and Timothy
Hospedales. 2019. Tucker: Tensor factorization
for knowledge graph completion. In Proceed-
ings of
这 2019 Conference on Empirical
Methods in Natural Language Processing and
the 9th International Joint Conference on Nat-
ural Language Processing (EMNLP-IJCNLP),
pages 5185–5194. https://doi.org/10
.18653/v1/D19-1522
Nikita Bhutani, H. V. Jagadish, and Dragomir
Radev. 2016. Nested propositions in open in-
formation extraction. 在诉讼程序中
这
2016 实证方法会议
自然语言处理, pages 55–64.
https://doi.org/10.18653/v1/D16
-1006
Kurt Bollacker, Colin Evans, Praveen Paritosh,
Tim Sturge, and Jamie Taylor. 2008. 自由的-
根据: A collaboratively created graph database
for structuring human knowledge. In Pro-
ceedings of the 2008 ACM SIGMOD inter-
national conference on Management of data,
pages 1247–1250. https://doi.org/10
.1145/1376616.1376746
Antoine Bordes, Nicolas Usunier, Alberto Garcia-
Duran, Jason Weston, and Oksana Yakhnenko.
2013. Translating embeddings for modeling
multi-relational data. Advances in Neural In-
formation Processing Systems, 26.
697
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Claudio Delli Bovi, Luca Telesca, and Roberto
Navigli. 2015. Large-scale information ex-
traction from textual definitions through deep
syntactic and semantic analysis. Transactions of
the Association for Computational Linguistics,
3:529–543. https://doi.org/10.1162
/tacl_a_00156
Andrew Carlson, Justin Betteridge, Bryan Kisiel,
Burr Settles, Estevam R. Hruschka, and Tom
中号. 米切尔. 2010. Toward an architecture
for never-ending language learning. In Twenty-
Fourth AAAI Conference on Artificial Intelli-
根杰斯. https://doi.org/10.1609/aaai
.v24i1.7519
Janara Christensen, Stephen Soderland, and Oren
Etzioni. 2011. An analysis of open information
extraction based on semantic role labeling. 在
Proceedings of the Sixth International Confer-
ence on Knowledge Capture, pages 113–120.
https://doi.org/10.1145/1999676
.1999697
Lei Cui, Furu Wei, and Ming Zhou. 2018. 新-
ral open information extraction. In Proceedings
of the 56th Annual Meeting of the Associa-
tion for Computational Linguistics (体积 2:
Short Papers), pages 407–413. https://土井
.org/10.18653/v1/P18-2065
Luciano Del Corro and Rainer Gemulla. 2013.
Clausie: Clause-based open information ex-
牵引力. 在诉讼程序中
the 22nd Inter-
national Conference on World Wide Web,
355–366. https://doi.org/10
页面
.1145/2488388.2488420
Tim Dettmers, Pasquale Minervini, Pontus
Stenetorp, and Sebastian Riedel. 2018. 骗局-
volutional 2d knowledge graph embeddings. 在
Proceedings of the AAAI Conference on Ar-
tificial Intelligence. https://doi.org/10
.1609/aaai.v32i1.11573
Jacob Devlin, Ming-Wei Chang, Kenton Lee, 和
Kristina Toutanova. 2019. BERT: Pre-training
transformers for lan-
of deep bidirectional
guage understanding. 在诉讼程序中
2019 Conference of
the North American
Chapter of
the Association for Computa-
tional Linguistics: Human Language Tech-
逻辑的, 体积 1 (Long and Short Papers),
pages 4171–4186.
Oren Etzioni, Michele Banko, Stephen Soderland,
and Daniel S. Weld. 2008. Open information
extraction from the web. Communications of
the ACM, 51(12):68–74. https://doi.org
/10.1145/1409360.1409378
Anthony Fader, Stephen Soderland, and Oren
Etzioni. 2011. Identifying relations for open
information extraction. 在诉讼程序中
2011 Conference on Empirical Methods in Nat-
ural Language Processing, pages 1535–1545.
Kiril Gashteovski, Rainer Gemulla, and Luciano
del Corro. 2017. Minie: Minimizing facts in
open information extraction. 在诉讼程序中
这 2017 经验方法会议
自然语言处理博士. https://
doi.org/10.18653/v1/D17-1278
Kiril Gashteovski, Sebastian Wanner, Sven
Hertling, Samuel Broscheit,
and Rainer
Gemulla. 2019. {OPIEC}: An open informa-
tion extraction corpus. In Automated Knowl-
edge Base Construction (AKBC).
Gautier
Izacard and ´Edouard Grave. 2021.
Leveraging passage retrieval with generative
models for open domain question answer-
英. In Proceedings of the 16th Conference
of the European Chapter of the Association
for Computational Linguistics: Main Volume,
874–880. https://doi.org/10
页面
.18653/v1/2021.eacl-main.74
Vladimir Karpukhin, Barlas Oguz, Sewon Min,
Patrick Lewis, Ledell Wu, Sergey Edunov,
Danqi Chen, and Wen-tau Yih. 2020. Dense
passage retrieval for open-domain question
answering. 在诉讼程序中 2020 骗局-
ference on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 6769–6781.
https://doi.org/10.18653/v1/2020
.emnlp-main.550
Diederik P. Kingma and Jimmy Ba. 2014.
亚当: A method for stochastic optimization.
arXiv 预印本 arXiv:1412.6980.
Keshav Kolluru, Samarth Aggarwal, Vipul
Rathore, Mausam, and Soumen Chakrabarti.
2020. IMoJIE: Iterative memory-based joint
open information extraction. In Proceedings
of the ACL, pages 5871–5886. https://土井
.org/10.18653/v1/2020.acl-main
.521
698
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Thomas Lin, Mausam, and Oren Etzioni. 2012.
Entity linking at web scale. 在诉讼程序中
the Joint Workshop on Automatic Knowledge
Base Construction and Web-scale Knowledge
萃取 (AKBC-WEKEX), pages 84–88.
Ilya Loshchilov and Frank Hutter. 2018.
Decoupled weight decay regularization.
在
International Conference on Learning Repre-
句子.
Xin Lv, Yankai Lin, Yixin Cao, Lei Hou, Juanzi
李, Zhiyuan Liu, Peng Li, and Jie Zhou. 2022.
Do pre-trained models benefit knowledge graph
completion? A reliable evaluation and a rea-
sonable approach. In Findings of the Associa-
tion for Computational Linguistics: 前交叉韧带 2022,
pages 3570–3581. https://doi.org/10
.18653/v1/2022.findings-acl.282
Jose L. Martinez-Rodriguez, Ivan L´opez-Ar´evalo,
and Ana B. Rios-Alvarado. 2018. OpenIE-
based approach for knowledge graph construc-
tion from text. Expert Systems with Applications,
113:339–355. https://doi.org/10.1016
/j.eswa.2018.07.017
Mausam, Michael Schmitz, Stephen Soderland,
Robert Bart, and Oren Etzioni. 2012. Open lan-
guage learning for information extraction. 在
诉讼程序 2012 Joint Conference on
Empirical Methods in Natural Language Pro-
cessing and Computational Natural Language
学习, pages 523–534.
Tom Mitchell, William Cohen, Estevam
Hruschka, Partha Talukdar, Bishan Yang,
Justin Betteridge, Andrew Carlson, Bhavana
Dalvi, Matt Gardner, Bryan Kisiel, 等人. 2018.
Never-ending learning. Communications of the
ACM, 61(5):103–115. https://doi.org
/10.1145/3191513
Andrea Moro and Roberto Navigli. 2013. Inte-
grating syntactic and semantic analysis into
the open information extraction paradigm. 在
Twenty-Third International Joint Conference
on Artificial Intelligence.
Ndapandula Nakashole, Gerhard Weikum, 和
Fabian Suchanek. 2012. Patty: A taxonomy
of relational patterns with semantic types. 在
诉讼程序 2012 Joint Conference on
Empirical Methods in Natural Language Pro-
cessing and Computational Natural Language
学习, pages 1135–1145.
Tapas Nayak, Navonil Majumder, and Soujanya
Poria. 2021. Improving distantly supervised
relation extraction with self-ensemble noise fil-
tering. In Proceedings of the RANLP 2021,
pages 1031–1039. https://doi.org/10
.26615/978-954-452-072-4_116
Maximilian Nickel, Volker Tresp, and Hans-Peter
Kriegel. 2011. A three-way model for collec-
tive learning on multi-relational data. In Pro-
ceedings of the 28th International Conference
on Machine Learning.
Barlas Oguz, Xilun Chen, Vladimir Karpukhin,
Stan Peshterliev, Dmytro Okhonko, 迈克尔
Schlichtkrull, Sonal Gupta, Yashar Mehdad,
and Scott Yih. 2022. UniK-QA: Unified rep-
resentations of structured and unstructured
knowledge for open-domain question answer-
英. In Findings of the Association for Compu-
tational Linguistics: 全国AACL 2022. https://
doi.org/10.18653/v1/2022.findings
-naacl.115
Martha Palmer, Daniel Gildea,
and Paul
Kingsbury. 2005. The proposition bank: 一个
annotated corpus of semantic roles. Computa-
tional Linguistics, 31(1):71–106. https://
doi.org/10.1162/0891201053630264
Xiaoman Pan, Boliang Zhang, Jonathan May,
Joel Nothman, Kevin Knight, and Heng Ji.
2017. Cross-lingual name tagging and linking
为了 282 语言. In Proceedings of the 55th
Annual Meeting of the Association for Com-
putational Linguistics (体积 1: Long Pa-
pers), pages 1946–1958, Vancouver, 加拿大.
计算语言学协会.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, 迈克尔
Matena, Yanqi Zhou, Wei Li, and Peter J. 刘.
2020. Exploring the limits of transfer learning
with a unified text-to-text transformer. 杂志
of Machine Learning Research, 21(140):1–67.
Nils Reimers
and Iryna Gurevych. 2019.
Sentence-bert: Sentence embeddings using
Siamese BERT-networks. 在诉讼程序中
这 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 3982–3992. https://doi.org/10
.18653/v1/D19-1410
699
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Tara Safavi and Danai Koutra. 2020. Codex: A
comprehensive knowledge graph completion
benchmark. 在诉讼程序中 2020 骗局-
ference on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 8328–8350.
https://doi.org/10.18653/v1/2020
.emnlp-main.669
Apoorv Saxena, Adrian Kochsiek, and Rainer
Gemulla. 2022. Sequence-to-sequence knowl-
edge graph completion and question answering.
In Proceedings of the 60th Annual Meeting
of the Association for Computational Linguis-
抽动症. https://doi.org/10.18653/v1
/2022.acl-long.201
Apoorv Saxena, Aditay Tripathi, and Partha
Talukdar. 2020. Improving multi-hop question
answering over knowledge graphs using knowl-
edge base embeddings. 在诉讼程序中
58th Annual Meeting of the Association for
计算语言学, pages 4498–4507.
https://doi.org/10.18653/v1/2020
.acl-main.412
Peng Shi and Jimmy Lin. 2019. Simple BERT
models for relation extraction and semantic
role labeling. arXiv 预印本 arXiv:1904.05255.
Gabriel Stanovsky, Ido Dagan, and Mausam.
2015. Open IE as an intermediate structure
for semantic tasks. In Proceedings of the 53rd
Annual Meeting of the Association for Compu-
tational Linguistics and the 7th International
Joint Conference on Natural Language Process-
英 (体积 2: Short Papers), pages 303–308.
https://doi.org/10.3115/v1/P15-2050
Gabriel
Stanovsky,
Julian Michael, 卢克
Zettlemoyer, and Ido Dagan. 2018. Supervised
open information extraction. 在诉讼程序中
这 2018 Conference of the North American
Chapter of the Association for Computational
语言学: 人类语言技术,
体积 1 (Long Papers), pages 885–895.
https://doi.org/10.18653/v1/N18
-1081
Th´eo Trouillon,
Johannes Welbl, Sebastian
Riedel, ´Eric Gaussier, and Guillaume Bouchard.
2016. Complex embeddings for simple link
In International Conference on
prediction.
Machine Learning, pages 2071–2080. PMLR.
Robert West, Evgeniy Gabrilovich, Kevin
墨菲, Shaohua Sun, Rahul Gupta, 和
700
Dekang Lin. 2014. Knowledge base comple-
tion via search-based question answering. 在
Proceedings of the 23rd International Con-
ference on World Wide Web, pages 515–526.
https://doi.org/10.1145/2566486
.2568032
Ledell Wu, Fabio Petroni, Martin Josifoski,
Sebastian Riedel, and Luke Zettlemoyer. 2020.
Scalable zero-shot entity linking with dense
entity retrieval. 在诉讼程序中 2020 骗局-
ference on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 6397–6407,
在线的. Association for Computational Lin-
语言学. https://doi.org/10.18653/v1
/2020.emnlp-main.519
Liang Yao, Chengsheng Mao, and Yuan Luo.
2019. KG-BERT: Bert for knowledge graph
completion. arXiv 预印本 arXiv:1909.03193.
Alexander Yates, Michele Banko, 马修
Broadhead, 迈克尔·J. Cafarella, Oren Etzioni,
and Stephen Soderland. 2007. Textrunner:
Open information extraction on the web. In Pro-
ceedings of Human Language Technologies:
The Annual Conference of the North Ameri-
can Chapter of the Association for Computa-
tional Linguistics (NAACL-HLT), pages 25–26.
https://doi.org/10.3115/1614164
.1614177
Wen-tau Yih, Matthew Richardson, Christopher
Meek, Ming-Wei Chang, and Jina Suh. 2016.
The value of semantic parse labeling for knowl-
edge base question answering. In Proceedings
of the 54th Annual Meeting of the Association
for Computational Linguistics (体积 2: Short
文件), pages 201–206.
Ying Zeng, Yansong Feng, Rong Ma, 郑
王, Rui Yan, Chongde Shi, and Dongyan
赵. 2018. Scale up event extraction learn-
ing via automatic training data generation. 在
Proceedings of the AAAI Conference on Arti-
ficial Intelligence. https://doi.org/10
.1609/aaai.v32i1.12030
Yang Zhao,
Jiajun Zhang, Yu Zhou, 和
Chengqing Zong. 2021. Knowledge graphs
enhanced neural machine translation. In Pro-
ceedings of
the Twenty-Ninth International
Conference on International Joint Conferences
on Artificial Intelligence, pages 4039–4045.
https://doi.org/10.24963/ijcai.2020
/559
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A The Data Annotation Guideline for
Quality Control (§2.3)
Task Definition Given a triplet that contains a
predicate, its arguments, and their contained en-
tity mentions, the goal is to detect whether the
triplet contains enough details to convey precise
factual information. If it does not, the annotator
needs to point out all arguments that cause the
问题. 桌子 6 lists a few examples to better visu-
alize the goal of this annotation. The top group
and bottom group contain positive and negative
examples with erroneous parts labeled in red.
There are generally two main types of triplets:
One type of triplets describe some constant sta-
这, such as the first case in the upper group;
the other type of triplets describe an event,
such as the remaining two cases in the upper
团体. Due to the time-sensitive nature of most
事件, an event-type require usually requires
some specific time property to be precise.
Possible argument
types are Arg0, Arg1,
Arg2, ArgM-Tmp (时间), ArgM-Loc (地点),
and ArgM-Neg (否定). Here Arg0 and Arg1
can be considered as the subject and object for
regular verbs, while Arg2 is called beneficiary.
Taking ‘‘John gave an apple to Tom’’ for exam-
普莱, the predicate is ‘‘gave’’, ‘‘John’’ is Arg0
(the executor to perform ‘‘give’’), ‘‘an apple’’
is Arg1 (the thing being given), and ‘‘Tom’’ is
Arg2 (the beneficiary for this action). 注意
the meaning of beneficiary is not literal. 为了
实例, the beneficiary of ‘‘John threw a rock
to Tom’’ is also ‘‘Tom’’.
For the first example in the bottom group, 我们
should select both ‘‘Arg0’’ and ‘‘ArgM-Tmp’’
as erroneous arguments. ‘‘Arg0’’ is selected be-
cause the subject of event ‘‘visited’’ is required
包含(Arg0=[Upper Redwater Lake], Arg1=fish
populations of [walleye] , [smallmouth bass] 和
[northern pike])
risen(Arg1=hazelnut production in Turkey, ArgM-
Tmp=since 1964, when a law on a Guarantee of Pur-
chase was introduced, after which a large part of the
peasants in the Black Sea region became hazelnut
cultivators)
进行(Arg1=the Velhas Conquistas, Arg0=by the
Portuguese, ArgM-Tmp=during the 16th and 17th
世纪)
(ArgM-Tmp=During
访问过
服务,
Arg1=Prince Charles ’ Gloucestershire home, 高的-
grove)
长的
他的
ruled(Arg0=Kettil Karlsson, Arg1=as Regent of
瑞典, ArgM-Tmp=for half a year in 1465 前
dying from bubonic plague)
graduated(Arg0=he, Arg1=Bachelor of Laws (LL.B.),
ArgM-Tmp=in 1930)
桌子 6: Examples for annotation introduction.
to make the whole triplet precise. Since ‘‘Arg0’’
is missing, ‘‘ArgM-Tmp’’ becomes unclear be-
cause it is unclear what ‘‘his’’ refers. 为了
second example in the bottom group, 我们需要
to choose ‘‘Arg1’’, which should be the place
of being ‘‘ruled’’, not the title of the ruler. 为了
the third example in the bottom group, 我们需要
to choose ‘‘Arg0’’, because ‘‘he’’ is not precise
without knowing what this pronoun refers to.
B All Templates for Triplet Extraction
As listed in Table 7. Note that we only select the
argument combination with the highest number
of arguments for each type of predicate (例如,
linking verb:展示).
701
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Requirements on Predicates
Argument Combination
linking verb:展示
linking verb:过去的
reg verb:present active
reg verb:past active
reg verb : present passive
reg verb:past passive
桌子 7: All templates used in Triplet Extraction (§2.2).
702
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
6
9
2
1
4
1
0
3
0
/
/
t
我
A
C
_
A
_
0
0
5
6
9
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3