Learning Neural Sequence-to-Sequence Models from
Weak Feedback with Bipolar Ramp Loss
Laura Jehl∗
Carolin Lawrence∗
计算语言学
Heidelberg University
69120 Heidelberg, 德国
{jehl, lawrence}@cl.uni-heidelberg.de
Stefan Riezler
计算语言学 & IWR
Heidelberg University
69120 Heidelberg, 德国
riezler@cl.uni-heidelberg.de
抽象的
In many machine learning scenarios, supervi-
sion by gold labels is not available and conse-
quently neural models cannot be trained directly
by maximum likelihood estimation. In a weak
supervision scenario, metric-augmented objec-
tives can be employed to assign feedback to
model outputs, which can be used to extract a
supervision signal for training. We present sev-
eral objectives for two separate weakly super-
vised tasks, machine translation and semantic
解析. We show that objectives should ac-
tively discourage negative outputs in addition
to promoting a surrogate gold structure. 这
notion of bipolarity is naturally present in
ramp loss objectives, which we adapt to neu-
ral models. We show that bipolar ramp loss
objectives outperform other non-bipolar ramp
loss objectives and minimum risk training on
both weakly supervised tasks, as well as on a
supervised machine translation task. Addition-
盟友, we introduce a novel token-level ramp
loss objective, which is able to outperform
even the best sequence-level ramp loss on both
weakly supervised tasks.
1
介绍
Sequence-to-sequence neural models are stan-
dardly trained using a maximum likelihood esti-
运动 (MLE) 客观的. 然而, MLE training
requires full supervision by gold target structures,
which in many scenarios are too difficult or
expensive to obtain. 例如, in semantic
parsing for question-answering it is often easier
to collect gold answers rather than gold parses
∗Both authors contributed equally to this publication.
233
(Clarke et al., 2010; Berant et al., 2013; Pasupat
and Liang, 2015; Rajpurkar et al., 2016, inter alia).
In machine translation, there are many domains
for which no gold references exist, although cross-
lingual document-level links are present for many
multilingual data collections.
In this paper we investigate methods where a
supervision signal for output structures can be
extracted from weak feedback. In the following,
we use learning from weak feedback, or weakly
supervised learning, to refer to a scenario where
output structures generated by the model are
judged according to an external metric, 和这个
feedback is used to extract a supervision signal that
guides the learning process. Metric-augmented
sequence-level objectives from reinforcement
学习 (威廉姆斯, 1992; Ranzato et al., 2016),
minimum risk training (MRT) (Smith and Eisner,
2006; Shen et al., 2016) or margin-based struc-
tured prediction objectives (Taskar et al., 2005;
Edunov et al., 2018) can be seen as instances of
such algorithms.
In natural
language processing applications,
such algorithms have mostly been used in com-
bination with full supervision tasks, allowing to
compute a feedback score from metrics such as
BLEU or F-score that measure the similarity
of output structures against gold structures. 我们的
main interest is in weak supervision tasks where
the calculation of a feedback score cannot fall
back onto gold structures. 例如, matching
proposed answers to a gold answer can guide a
semantic parser towards correct parses, and match-
ing proposed translations against
linked doc-
uments can guide learning in machine translation.
In such scenarios the judgments by the external
metric may be unreliable and thus unable to select
a good update direction. It is our intuition that
计算语言学协会会刊, 卷. 7, PP. 233–248, 2019. 动作编辑器: Phil Blunsom.
提交批次: 11/2018; 修改批次: 1/2019; 已发表 5/2019.
C(西德:3) 2019 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
我
A
C
_
A
_
0
0
2
6
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
a more reliable signal can be produced by not
just encouraging outputs that are good according
to weak positive feedback, but also by actively
discouraging bad structures. 这样, a system
can more effectively learn what distinguishes good
outputs from bad ones. We call an objective that
incorporates this idea a bipolar objective. The bi-
polar idea is naturally captured by the structured
ramp loss objective (Chapelle et al., 2009), 埃斯佩-
cially in the formulation by Gimpel and Smith
(2012) and Chiang (2012), who use ramp loss to
separate a hope from a fear output in a linear
structured prediction model. We employ several
ramp loss objectives for two weak supervision
任务, and adapt them to neural models.
第一的, we turn to the task of semantic parsing
in a setup where only question-answer pairs, 但
no gold semantic parses, are given. We assume
a baseline system has been trained using a small
supervised data set of question-parse pairs under
the MLE objective. The goal is to improve this
system by leveraging a larger data set of question-
answer pairs. During learning, the semantic parser
suggests parses for which corresponding answers
are retrieved. These answers are then compared to
the gold answer and the resulting weak supervision
signal guides the semantic parser towards finding
correct parses. We can show that a bipolar ramp
loss objective can improve upon the baseline by
超过 12 percentage points in F1 score.
第二, we use ramp losses on a machine
translation task where only weak supervision in
the form of cross-lingual document-level links
is available. We assume a translation system
has been trained using MLE on out-of-domain
数据. We then investigate whether document-
level links can be used as a weak supervision
signal to adapt the translation system to the target
domain. We formulate ramp loss objectives that
incorporate bipolar supervision from relevant and
irrelevant documents. We also present a metric
that allows us to include bipolar supervision in
an MRT objective. Experiments show that bipolar
supervision is crucial for obtaining gains over the
基线. Even with this very weak supervision,
we are able to achieve an improvement of over 0.4%
BLEU over the baseline using a bipolar ramp loss.
最后, we turn to a fully supervised machine
translation task. In supervised learning, MLE train-
ing in a fully supervised scenario has also been
associated with two issues. 第一的, it can cause
exposure bias (Ranzato et al., 2016) 因为
during training the model receives its context
from the gold structures of the training data, 但
at test time the context is drawn from the model
distribution instead. 第二, the MLE objective
is agnostic to the final evaluation metric, causing
a loss-evaluation mismatch (Wiseman and Rush,
2016). Our experiments use a similar setup as
Edunov et al. (2018), who apply structured pre-
diction losses to two fully supervised sequence-
to-sequence tasks, but do not consider structured
ramp loss objectives. Like our predecessors, 我们
want to understand whether training a pre-trained
machine translation model further with a metric-
informed sequence-level objective will improve
translation performance by alleviating the above-
mentioned issues. By gauging the potential of
applying bipolar ramp loss in a full supervision
scenario, we achieve best results for a bipolar
ramp loss, improving the baseline by over 0.4%
蓝线.
总共, we show that bipolar ramp loss is
superior to other sequence-level objectives for all
investigated tasks, supporting our intuition that a
bipolar approach is crucial where strong positive
supervision is not available. In addition to adapting
the ramp loss objective to weak supervision, 我们的
ramp loss objective can also be adapted to operate
at the token level, which makes it particularly
suitable for neural models as they produce their
outputs token by token. A token-level objective
also better emulates the behavior of the ramp loss
for linear models, which only update the weights of
features that differ between hope and fear. 最后,
the token-level objective allows us to capture
token-level errors in a setup where MLE training
is not available. Using this objective, we obtain
additional gains on top of the sequence-level ramp
loss for weakly supervised tasks.
2 相关工作
Training neural models with metric-augmented
objectives has been explored for various NLP tasks
in supervised and weakly supervised scenarios.
MRT for neural models has previously been
used for machine translation (Shen et al., 2016)
and semantic parsing (Liang et al., 2017; Guu
等人。, 2017).1 Other objectives based on classical
1Note that Liang et al. (2017) refer to their objective as an
instantiation of REINFORCE, however they build an average
over several outputs for one input and thus the objective more
accurately falls under the heading of MRT.
234
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
我
A
C
_
A
_
0
0
2
6
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
structured prediction losses have been used for both
machine translation and summarization (Edunov
等人。, 2018), as well as semantic parsing (伊耶尔
等人。, 2017; Misra et al., 2018). Objectives inspired
by REINFORCE have, 例如, been ap-
plied to machine translation (Ranzato et al., 2016;
Norouzi et al., 2016), 语义解析 (梁
等人。, 2017; Mou et al., 2017; Guu et al., 2017),
and reading comprehension (Choi et al., 2017;
杨等人。, 2017).2
Misra et al. (2018) are the first to compare
several objectives for neural semantic parsing.
For semantic parsing, they find that objectives
employing structured prediction losses perform
最好的. Edunov et al. (2018) compare different clas-
sical structured prediction objectives including
MRT on a fully supervised machine translation
任务. They find MRT to perform best. 然而,
they only obtain larger gains by interpolating
MRT with the MLE loss. Neither Misra et al.
(2018) nor Edunov et al. (2018) investigate objec-
tives that correspond to the bipolar ramp loss that
is central in our work.
The ramp loss objective (Chapelle et al., 2009)
has been applied to supervised phrase-based
machine translation (Gimpel and Smith, 2012;
蒋, 2012). We adapt these objectives to neural
models and adapt them to incorporate bipolar
weak supervision, while also introducing a novel
token-level ramp loss objective.
3 Neural Sequence-to-Sequence Learning
et
Our neural sequence-to-sequence models utilize
an encoder-decoder setup (Cho et al., 2014;
吸勺
等人。, 2014) with an attention
机制 (Bahdanau et al., 2015). 具体来说,
we employ the framework NEMATUS (Sennrich
等人。, 2017). Given an input sequence x =
x1, x2, . . . X|X|, the probability that a model assigns
for an output sequence y = y1, y2, . . . y|y| is given
j=1 πw(yj|y
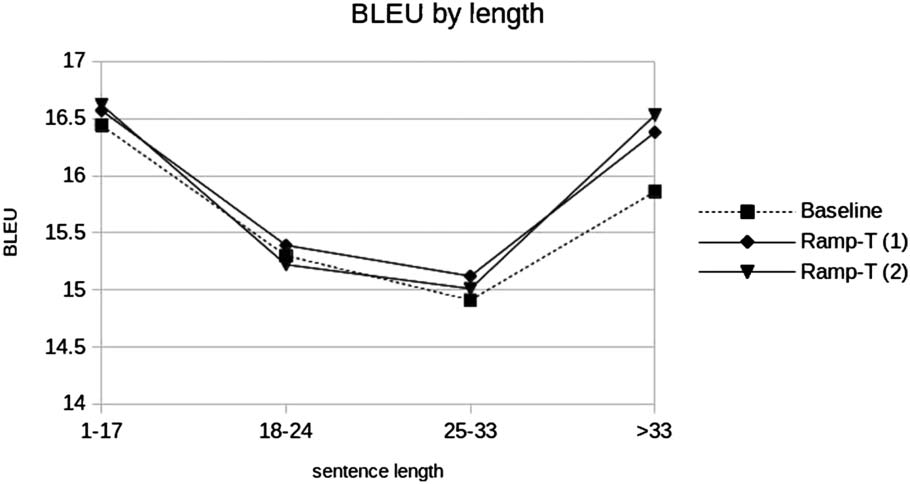
we also see the biggest gap between MLE and
RAMP−-T of 0.52 和 0.67% BLEU for the two
runs. This increase is mitigated by much weaker
increases in the bottom brackets. A possible
explanation for the weaker performance of MLE in
the top bracket is the observation that hypotheses
produced by the MLE system are longer than
数字 4: Improvements in BLEU scores by Wikipedia
article for the RAMP−-T runs.
for RAMP−-T. For the top bracket, 假设
lengths exceed reference lengths for all systems.
然而, for MLE this over-generation is more
severe at 106% of the reference length, compared
to RAMP−-T at 102%, potentially causing a higher
loss in precision.
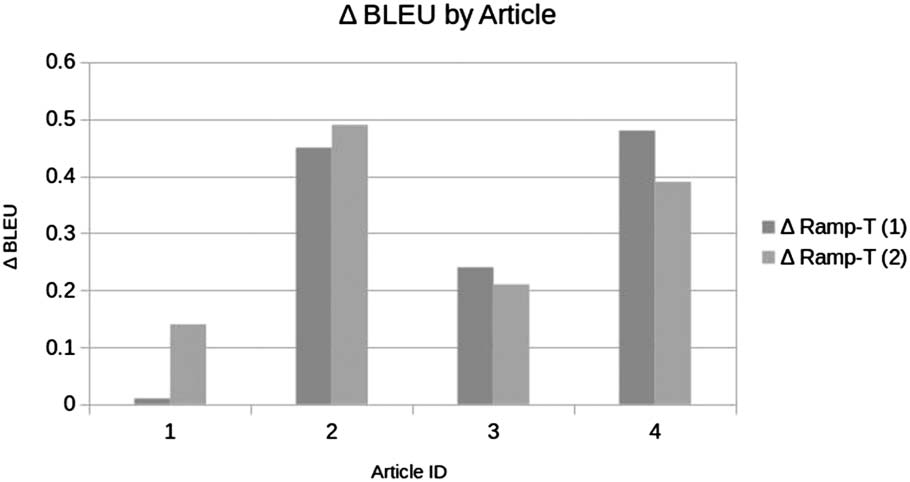
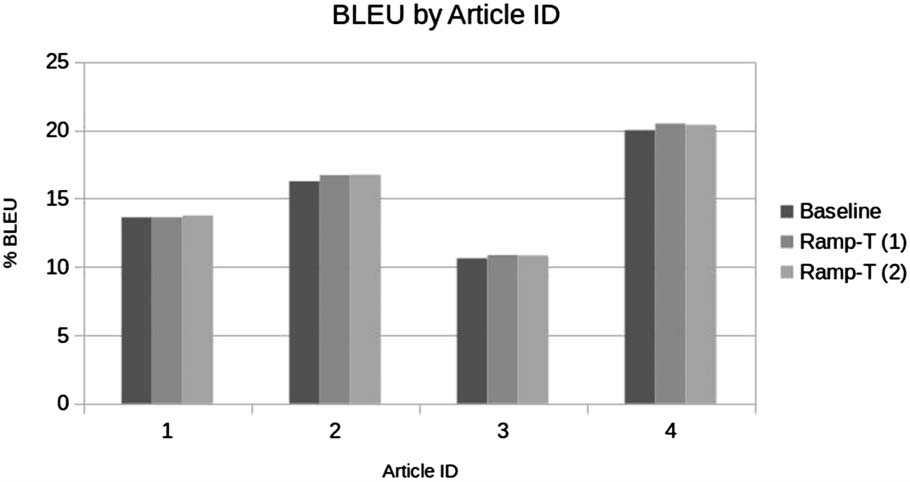
As our test set consists of parallel sentences
extracted from four Wikipedia articles, 我们可以
examine the performance for each article sepa-
率地. 数字 3 shows the results. We observe
large differences in performance according to arti-
cle ID. These are probably caused by some articles
being more similar to the out-of-domain training
data than others. Comparing RAMP−-T and MLE,
we see that RAMP−-T outperforms MLE for each
article by a small margin. 数字 4 shows the
size of the improvements by article. We observe
that margins are bigger on articles with better
baseline performance. This suggests that there are
challenges arising from domain mismatch that
are not addressed by our method.
最后, we present an examination of example
outputs. 桌子 6 shows an example of a long
sentence from Article 2, which describes the
German town of Sch¨uttorf. This article is orig-
inally in German, meaning that our model is
241
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
我
A
C
_
A
_
0
0
2
6
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
MLE
来源
Towards the end of the 19th century, a strong textile industry was developing itself in Sch¨uttorf
with several large local businesses (Schlikker & S¨ohne, Gathmann & Gerdemann, G. Sch¨umer &
钴. and ten Wolde, later Carl Remy; today’s RoFa is not one of the original textile companies,
but was founded by H. Lammering and later taken over by Gerhard Schlikker jun., Levert Rost
and Wilhelm Edel;
Ende des 19. Jahrhunderts, eine starke Textilindustrie, die sich in Ettorf mit mehreren
großen lokalen Unternehmen (Schlikker & S¨ohne, Gathmann & Ger´eann, G. Schal
& 钴. und zehn Wolde, sp¨ater Carl Remy) entwickelt hat; die heutige RoFa ist nicht
einer der urspr¨unglichen Textilunternehmen, sondern wurde von H. Lammering [gegr¨undet] und
sp¨ater von Gerhard Schaloker Junge, Levert Rost und Wilhelm Edel ¨ubernommen.
RAMP−-T Ende des 19. Jahrhunderts entwickelte sich [in Sch¨uttorf] eine starke Textilindustrie mit mehreren
großen lokalen Unternehmen (Schlikker & S¨ohne, Gathmann & Gerdemann, G. Schal & 钴.
und zehn Wolde, sp¨ater Carl Remy; die heutige RoFa ist nicht eines der urspr ¨unglichen
Textilunternehmen, sondern wurde von H. Lammering [gegr¨undet] und sp¨ater von Gerhard
Schaloker Junge, Levert Rost und Wilhelm Edel ¨ubernommen.
gegen Ende des 19. Jahrhunderts entwickelte sich in Sch¨uttorf eine starke Textilindustrie mit
mehreren großen lokalen Unternehmen (Schlikker & S¨ohne, Gathmann & Gerdemann, G.
Sch¨umer & 钴. und ten Wolde, sp¨ater Carl Remy, die heutige RoFa ist keine urspr¨ungliche
Textilfirma, sondern wurde von H. Lammering gegr¨undet und sp¨ater von Gerhard Schlikker jun.,
Levert Rost und Wilhelm Edel ¨ubernommen.)
参考
桌子 6: MT example from Article 2 in the test set. All translation errors are underlined. Incorrect
proper names are also set in cursive. Omissions are inserted in brackets and set in cursive [like this].
Improvements by RAMP−-T over MLE are marked in boldface.
back-translating from English into German. 这
reference contains some awkward or even un-
grammatical phrases such as ‘‘was developing
itself’’, a literal translation from German. 这
example also illustrates that translating Wikipedia
involves handling frequent proper names (那里
是 11 proper names in the example). Both mod-
els struggle with translating proper names, 但
RAMP−-T produces the correct phrase ‘‘Gathmann
& Gerdemann’’, while MLE fails to do so. 这
RAMP−-T translation is also fully grammatical,
whereas MLE incorrectly translates the main verb
phrase ‘‘was developing itself’’ into a relative clause,
and contains an agreement error in the translation
of the noun phrase ‘‘one of the original textile
companies’’. Although making fewer errors in
grammar and proper name translation, RAMP−-T
contains two deletion errors and MLE only con-
tains one. This could be caused by the active opti-
mization of sentence length in the ramp loss model.
6 Fully Supervised Machine Translation
Our work focuses on weakly supervised tasks,
but we also conduct experiments using a fully
supervised MT task. These experiments are
motivated on the one hand by adapting the findings
of Gimpel and Smith (2012) to the neural MT
范例, and on the other hand by expanding the
work by Edunov et al. (2018) on applying classical
structured prediction losses to neural MT.
Ramp Loss Objectives. For fully supervised
MT we assume access to one or more reference
translations ¯y for each input x. The reward
BLEU+1(y, ¯y) is a per-sentence approximation of
the BLEU score.11 Table 7 shows the different
definitions of y+ and y−, which give rise to
不同的
ramp losses. RAMP, RAMP1, 和
RAMP2 are defined analogously to the other
任务. We again include a hyperparameter α > 0
interpolating cost function and model score when
searching for y+ and y−. Gimpel and Smith
(2012) also include the perceptron loss in their
分析. PERC1 is a re-formulation of the Collins
perceptron (柯林斯, 2002) where the reference is
used as y+ and ˆy is used as y−. A comparison with
PERC1 is not possible for the weakly supervised
tasks in the previous sections, as gold structures
are not available for these tasks. With neural MT
and subword methods we are able to compute
this loss for any reference without running into
the problem of reachability that was faced by
phrase-based MT (Liang et al., 2006). 然而,
11We use the BLEU score with add-1 smoothing for n > 1,
as proposed by Chen and Cherry (2014).
242
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
我
A
C
_
A
_
0
0
2
6
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Loss
RAMP
RAMP1
RAMP2
PERC1
PERC2
y+
arg maxy πw(y|X) − α(1 − BLEU+1(y, ¯y))
ˆy
arg maxy πw(y|X) − α(1 − BLEU+1(y, ¯y))
¯y
arg maxy BLEU+1(y, ¯y)
y−
arg maxy πw(y|X) + A(1 − BLEU+1(y, ¯y))
arg maxy πw(y|X) + A(1 − BLEU+1(y, ¯y))
ˆy
ˆy
ˆy
桌子 7: Configurations for y+ and y− for fully supervised MT. ˆy is the highest-probability model output, ¯y is a
gold standard reference. πw(y|X) is the probability of y according to the model. The arg maxy is taken over the
k-best list K(X). BLEU+1 is smoothed per-sentence BLEU and α is a scaling factor.
using sequence-level training towards a reference
can lead to degenerate solutions where the model
gives low probability to all its predictions (沉
等人。, 2016). PERC2 addresses this problem by
replacing ¯y by a surrogate translation that achieves
the highest BLEU+1 score in K(X). 这种方法
is also used by Edunov et al. (2018) 为了
loss functions which require an oracle. PERC1
corresponds to equation (9), PERC2 to equation
(10) of Gimpel and Smith (2012).
实验装置. We conduct experiments
on the IWSLT 2014 German–English task, 哪个
is based on Cettolo et al. (2012) in the same way
as Edunov et al. (2018). The training set contains
160K sentence pairs. We set the maximum sen-
tence length to 50 and use BPE with 14,000
merge operations. Edunov et al. (2018) sample 7K
sentences from the training set as heldout data.
We do the same, but only use one tenth of the data
as heldout set to be able to validate often.
Our baseline system (MLE) is a BiLSTM
encoder-decoder with attention, which is trained
using the MLE objective. Word embedding and
hidden layer dimensions are set to 256. We use
batches of 64 sentences for baseline training and
batches of 40 inputs for training RAMP and
PERC variants. MRT makes an update after each
input using all sampled outputs and resulting in a
batch size of 1. All experiments use dropout for
regularization, with dropout probability set to 0.2
for embedding and hidden layers and to 0.1 为了
source and target layers. During MLE-training,
the model is validated every 2500 updates and
training is stopped if the MLE loss on the heldout
set worsens for 10 consecutive validations.
For metric-augmented training, we use SGD
for optimization with learning rates optimized on
the development set. Ramp losses and PERC2 use
a k-best list of size 16. For ramp loss training,
we set α = 10. RAMP and PERC variants both
use a learning rate of 0.001. A new k-best list is
generated for each input using the current model
参数. We compare ramp loss to MRT as
如上所述. For MRT, we use SGD with a
learning rate of 0.01 and set S = 16 和S(西德:5) = 10.
As Edunov et al. (2018) observe beam search
to work better than sampling for MRT, we also
run an experiment in this configuration, but find
no difference between results. As beam search
runs significantly slower, we only report sampling
实验.
The model is validated on the development
set after every 200 updates for experiments with
batch size 40 and after 8,000 updates for MRT
experiments with batch size 1. The stopping
point is determined by the BLEU score on the
heldout set after 25 validations. As we are training
on the same data as the MLE baseline, 我们
also apply dropout during ramp loss training to
prevent overfitting. BLEU scores are computed
with Moses’ multi-bleu.perl on tokenized,
truecased output. Each experiment is run 3 次
and results are averaged over the runs.
Experimental Results. 如表所示 8,
all experiments except for PERC1 yield improve-
ments over MLE, confirming that sequence-
level losses that update towards the reference
can lead to degenerate solutions. For MRT, 我们的
findings show similar performance to the initial
experiments reported by Edunov et al. (2018),
who gain 0.24 BLEU points on the same test
set.12 PERC2 and RAMP2,
improve over the
12See their Table 2. Using interpolation with the MLE
客观的, Edunov et al. (2018) 达到 +0.7 BLEU points.
As we are only interested in the effect of sequence-level
目标, we do not add MLE interpolation. The best model
by Edunov et al. (2018) achieved a BLEU score of 32.91%.
It is possible that these scores are not directly comparable to
ours due to different pre- and post-processing. They also use
a multi-layer CNN architecture (Gehring et al., 2017), 哪个
has been shown to outperform a simple RNN architecture
such as ours.
243
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
我
A
C
_
A
_
0
0
2
6
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1 MLE
2 MRT
3
PERC1
PERC2
RAMP1
RAMP2
RAMP
RAMP-T
4
5
6
7
8
中号
64
1
40
40
40
40
40
40
% 蓝线
Δ
31.99
32.17 ± 0.02
31.91 ± 0.02
32.22 ± 0.03
32.36∗ ± 0.05
32.19 ± 0.01
32.44∗∗ ± 0.00
32.33∗ ± 0.00
+ 0.18
- 0.08
+ 0.23
+ 0.37
+ 0.20
+ 0.45
+ 0.34
桌子 8: BLEU scores for fully supervised MT
实验. Boldfaced results are significantly
better than MLE at p < 0.01 according to
multeval (Clark et al., 2011). ∗ marks a sig-
nificant difference to MRT and PERC2, and ∗∗
marks a difference to RAMP1.
MLE baseline and PERC1, but perform on a
par with MRT and each other. Both RAMP and
RAMP1 are able to outperform MRT, PERC2,
and RAMP2, with the bipolar objective RAMP
also outperforming RAMP1 by a narrow margin.
The main difference between RAMP and RAMP1,
compared to PERC2 and RAMP2, is the fact that
the latter objectives use ˆy as y−, whereas the
former use a fear translation with high prob-
ability and low BLEU+1. We surmise that for
this fully supervised task, selecting a y− which
has some known negative characteristics is more
important for success than finding a good y+.
RAMP, which fulfills both criteria, still out-
performs RAMP2. This result re-confirms the
superiority of bipolar objectives compared to non-
bipolar ones. Although still improving over MLE,
token-level ramp loss RAMP-T is outperformed
by RAMP by a small margin. This result suggests
that when using a metric-augmented objective on
top of an MLE-trained model in a full super-
vision scenario without domain shift, there is
little room for improvement from token-level
supervision, while gains can still be obtained from
additional sequence-level information captured by
the external metric, such as information about the
sequence length.
To summarize, our findings on a fully super-
vised task show the same small margin for
improvement as Edunov et al. (2018), without
any further tuning of performance (e.g., by inter-
polation with the MLE objective). Bipolar RAMP
is found to outperform the other losses. This
observation is also consistent with the results
by Gimpel and Smith (2012) for phrase-based
244
MT. We conclude that for fully supervised MT,
deliberately selecting a hope and fear translation
is beneficial.
7 Conclusion
We presented a study of weakly supervised
learning objectives for three neural sequence-to-
sequence learning tasks. In our first task of seman-
tic parsing, question-answer pairs provide a weak
supervision signal to find parses that execute to the
correct answer. We show that ramp loss can out-
perform MRT if it incorporates bipolar supervision
where parses that receive negative feedback are
actively discouraged. The best overall objective is
constituted by the token-level ramp loss. Next, we
turn to weak supervision for machine translation
in form of cross-lingual document-level links. We
present two ramp loss objectives that combine
bipolar weak supervision from a linked document
d+ and an irrelevant document d−. Again, the
bipolar ramp loss objectives outperform MRT,
and the best overall result is obtained using token-
level ramp loss. Finally, to tie our work to previous
work on supervised machine translation, we con-
duct experiments in a fully supervised scenario
where gold references are available and a metric-
augmented loss is desired to reduce the exposure
bias and the loss-evaluation mismatch. Again, the
bipolar ramp loss objective performs best, but we
find that the overall margin for improvement is
small without any additional engineering. We con-
clude that ramp loss objectives show promise for
neural sequence-to-sequence learning, especially
when it comes to weakly supervised tasks where
the MLE objective cannot be applied. In contrast to
ramp losses that either operate only in the undesir-
able region of the search space (‘‘cost-augmented
decoding’’ as in RAMP1) or only in the desir-
able region of the search space (‘‘cost-diminished
decoding’’ as in RAMP2), bipolar RAMP operates
in both regions of the search space when extract-
ing supervision signals from weak feedback. We
showed that MRT can be turned into a bipolar
objective by defining a metric that assigns neg-
ative values to bad outputs. This improves the
performance of MRT objectives. However, the
ramp loss objective is still superior as it is easy to
implement and efficient to compute. Furthermore,
on weakly supervised tasks our novel token-level
ramp loss objective RAMP-T can obtain further
improvements over its sequence-level counterpart
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
l
a
c
_
a
_
0
0
2
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
because it can more directly assess which tokens
in a sequence are crucial to its success or failure.
Acknowledgments
The research reported in this paper was supported
in part by DFG grants RI-2221/4-1 and RI 2221/
2-1. We would like to thank the reviewers for their
helpful comments.
Kyunghyun Cho, Bart van Merri¨enboer, Caglar
Gulcehre, Dzmitry Bahdanau, Fethi Bougares,
Holger Schwenk, and Yoshua Bengio. 2014.
Learning Phrase Representations using RNN
Encoder–Decoder for Statistical Machine Trans-
lation. In Proceedings of the 2014 Conference
on Empirical Methods in Natural Language
Processing (EMNLP). Doha, Qatar.
References
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
jointly learning to align and translate. In Inter-
national Conference on Learning Representa-
tions (ICLR). San Diego, CA.
Luisa Bentivogli, Arianna Bisazza, Mauro Cettolo,
and Marcello Federico. 2016. Neural versus
phrase-based machine translation quality: A
case study. In Proceedings of the 2016 Con-
ference on Empirical Methods in Natural
Language Processing (EMNLP). Austin, TX.
Jonathan Berant, Andrew Chou, Roy Frostig,
and Percy Liang. 2013. Semantic parsing on
freebase from question-answer pairs. In Pro-
ceedings of the 2013 Conference on Empirical
Methods in Natural Language Processing
(EMNLP). Seattle, WA.
Mauro Cettolo, Christian Girardi, and Marcello
Federico. 2012. WIT3: Web Inventory of
Transcribed and Translated Talks. In Proceed-
ings of the 16th Conference of the European
Association for Machine Translation (EAMT).
Trento, Italy.
Olivier Chapelle, Chuong B. Do, Choon H. Teo,
Quoc V. Le, and Alex J. Smola. 2009. Tighter
bounds for structured estimation. In Advances
in Neural
Information Processing Systems
(NIPS). Vancouver, Canada.
Boxing Chen and Colin Cherry. 2014. A sys-
tematic comparison of smoothing techniques
for sentence-level BLEU. In Proceedings of the
9th Workshop on Statistical Machine Trans-
lation. Baltimore, MD.
David Chiang. 2012. Hope and fear for discrim-
inative training of statistical translation models.
Journal of Machine Learning Research,
13(1):1159–1187.
Eunsol Choi, Daniel Hewlett, Jakob Uszkoreit,
Illia Polosukhin, Alexandre Lacoste, and
Jonathan Berant. 2017. Coarse-to-dine question
answering for long documents. In Proceedings
of
the Asso-
ciation for Computational Linguistics (ACL).
Vancouver, Canada.
the 55th Annual Meeting of
Jonathan H. Clark, Chris Dyer, Alon Lavie, and
Noah A. Smith. 2011. Better hypothesis testing
for statistical machine translation: Controlling
for optimizer instability. In Proceedings of
the 2011 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies
(HLT-NAACL). Portland, OR.
James Clarke, Dan Goldwasser, Ming-Wei Chang,
and Dan Roth. 2010. Driving Semantic Parsing
from the World’s Response. In Proceedings of
the 14th Conference on Computational Natural
Language Learning. Uppsala, Sweden.
Michael Collins. 2002. Discriminative training
methods for hidden Markov models: Theory
and experiments with perceptron algorithms.
the 2002 Conference on
In Proceedings of
Empirical Methods
in Natural Language
Processing (EMNLP). Philadelphia, PA.
Long Duong, Hadi Afshar, Dominique Estival,
Glen Pink, Philip Cohen, and Mark Johnson.
2018. Active learning for deep semantic
parsing. In Proceedings of the 56th Annual
Meeting of the Association for Computational
Linguistics (ACL), Melbourne, Australia.
Sergey Edunov, Myle Ott, Michael Auli, David
Grangier, and Marc’Aurelio Ranzato. 2018.
Classical structured prediction losses for se-
quence to sequence learning. In Proceedings
of the 2018 Conference of the North American
245
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
l
a
c
_
a
_
0
0
2
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Chapter of the Association for Computational
Linguistics: Human Language Technologies
(HLT-NAACL). New Orleans, LA.
Andreas Eisele and Yu Chen. 2010. MultiUN:
A multilingual corpus from united nation
documents. In Proceedings of the Seventh con-
ference on International Language Resources
and Evaluation (LREC). Valetta, Malta.
Jonas Gehring, Michael Auli, David Grangier,
Denis Yarats, and Yann N. Dauphin. 2017.
Convolutional sequence to sequence learning.
In Proceedings of the 34th International Con-
ference on Machine Learning (ICML). Sydney,
Australia.
Kevin Gimpel and Noah A. Smith. 2012. Struc-
tured ramp loss minimization for machine
translation. In Proceedings of the 2012 Con-
ference of
the North American Chapter of
the Association for Computational Linguistics:
Human Language Technologies (HLT-NAACL).
Montreal, Canada.
Evan Greensmith, Peter L. Bartlett, and Jonathan
Baxter. 2004. Variance reduction techniques
for gradient estimation in reinforcement learn-
ing. Journal of Machine Learning Research,
5:1471–1530.
Kelvin Guu, Panupong Pasupat, Evan Liu, and
Percy Liang. 2017. From language to programs:
Bridging reinforcement learning and maximum
the
marginal
55th Annual Meeting of the Association for
Computational Linguistics (ACL). Vancouver,
Canada.
likelihood. In Proceedings of
Carolin Haas and Stefan Riezler. 2016. A cor-
pus and semantic parser for multilingual nat-
ural language querying of openStreetMap. In
Proceedings of the 2016 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies (HLT-NAACL). San Diego, CA.
Tamir Hazan, Joseph Keshet, and David A.
loss minimization
McAllester. 2010. Direct
for structured prediction. In Advances in Neu-
ral Information Processing Systems (NIPS).
Vancouver, Canada.
Mohit
Iyyer, Wen-tau Yih, and Ming-Wei
Chang. 2017. Search-based neural structured
learning for sequential question answering.
In Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(ACL). Vancouver, Canada.
Laura Jehl and Stefan Riezler. 2016. Learning to
translate from graded and negative relevance
the 26th
information.
International Conference on Computational
Linguistics (COLING). Osaka, Japan.
In Proceedings of
Philipp Koehn. 2005. Europarl: A parallel corpus
for statistical machine translation. In Proceed-
ings of
the Machine Translation Summit,
volume 5. Phuket, Thailand.
Tom´aˇs Koˇcisk´y, G´abor Melis,
Edward
Grefenstette, Chris Dyer, Wang Ling, Phil
Blunsom, and Karl Moritz Hermann. 2016.
Semantic parsing with semi-supervised se-
quential autoencoders. In Proceedings of the
2016 Conference on Empirical Methods in
Natural Language Processing
(EMNLP).
Austin, TX.
Carolin Lawrence and Stefan Riezler. 2018. Im-
proving a neural semantic parser by counter-
factual learning from human bandit feedback.
In Proceedings of the 56th Annual Meeting of
the Association for Computational Linguistics
(ACL). Melbourne, Australia.
Chen Liang, Jonathan Berant, Quoc V. Le,
Kenneth D. Forbus, and Ni Lao. 2017.
Neural symbolic machines: learning semantic
parsers on freebase with weak supervision. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(ACL), Vancouver, Canada.
Percy Liang, Alexandre Bouchard-Cˆot´e, Dan
Klein, and Ben Taskar. 2006. An end-to-end
discriminative approach to machine translation.
In Proceedings of the 21st International Con-
ference on Computational Linguistics and
the 44th Annual Meeting of the Association
for Computational Linguistics (ACL). Sydney,
Australia.
Dipendra Misra, Ming-Wei Chang, Xiaodong
He, and Wen-tau Yih. 2018. Policy shaping
and generalized update equations for semantic
parsing from denotations. In Proceedings of
246
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
l
a
c
_
a
_
0
0
2
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
the 2018 Conference on Empirical Methods
in Natural Language Processing (EMNLP).
Brussels, Belgium.
Lili Mou, Zhengdong Lu, Hang Li, and Zhi
Jin. 2017. Coupling distributed and symbolic
execution for natural
In
Proceedings of
the 34th International Con-
ference on Machine Learning (ICML). Sydney,
Australia.
language queries.
Eric W. Noreen. 1989. Computer
Intensive
Methods for Testing Hypotheses: An Intro-
duction. Wiley, New York.
Mohammad Norouzi, Samy Bengio, Zhifeng
Chen, Navdeep Jaitly, Mike Schuster, Yonghui
Wu, and Dale Schuurmans. 2016. Reward
augmented maximum likelihood for neural struc-
tured prediction. In Advances in Neural Infor-
mation Processing Systems (NIPS). Barcelona,
Spain.
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2001, BLEU: A method
for automatic evaluation of machine trans-
lation. Technical Report IBM Research Divi-
sion Technical Report, RC22176 (W0190-022),
Yorktown Heights, NY.
Panupong Pasupat and Percy Liang. 2015. Com-
positional semantic parsing on semi-structured
tables. In Proceedings of
the 53rd Annual
Meeting of the Association for Computational
Linguistics and the 7th International Joint
Conference on Natural Language Processing
(ACL-IJCNLP). Beijing, China.
Pranav Rajpurkar,
Jian Zhang, Konstantin
Lopyrev, and Percy Liang. 2016. SQuAD:
100,000+ Questions for machine comprehen-
the 2016
sion of
Conference on Empirical Methods in Natural
Language Processing (EMNLP). Austin, TX.
In Proceedings of
text.
Marc’Aurelio Ranzato, Sumit Chopra, Michael
Auli, and Wojciech Zaremba. 2016. Sequence
level training with recurrent neural networks.
In International Conference on Learning
Representations (ICLR). San Juan, Puerto Rico.
247
Shigehiko Schamoni, Felix Hieber, Artem
Sokolov, and Stefan Riezler. 2014. Learning
translational and knowledge-based similarities
from relevance rankings for cross-language
retrieval. In Proceedings of the 52nd Annual
Meeting of the Association for Computational
Linguistics (ACL). Baltimore, MD.
Rico Sennrich, Orhan Firat, Kyunghyun Cho,
Julian
Alexandra Birch, Barry Haddow,
Hitschler, Marcin Junczys-Dowmunt, Samuel
L¨aubli, Antonio Valerio Miceli Barone, Jozef
Mokry, and Maria Nadejde. 2017. Nematus:
A toolkit for neural machine translation. In
Proceedings of the Software Demonstrations of
the 15th Conference of the European Chapter of
the Association for Computational Linguistics
(EACL). Valencia, Spain.
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of rare
words with subword units. In Proceedings of
the 54th Annual Meeting of the Association
for Computational Linguistics (ACL). Berlin,
Germany.
Shiqi Shen, Yong Cheng, Zhongjun He, Wei He,
Hua Wu, Maosong Sun, and Yang Liu. 2016.
Minimum Risk Training for neural machine
translation. In Proceedings of the 54th Annual
Meeting of the Association for Computational
Linguistics (ACL). Berlin, Germany.
David A. Smith and Jason Eisner. 2006. Minimum
risk annealing for training log-linear models. In
Proceedings of the COLING/ACL 2006 Main
Conference Poster Sessions. Sydney, Australia.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.
2014. Sequence to sequence learning with
neural networks. In Advances in Neural Infor-
mation Processing Systems (NIPS). Montreal,
Canada.
Ben Taskar, Vassil Chatalbashev, Daphne Koller,
and Carlos Guestrin. 2005. Learning structured
prediction models: A large margin approach.
In Proceedings of the 22nd International Con-
ference on Machine Learning (ICML), Bonn,
Germany.
Ben Taskar, Carlos Guestrin, and Daphne
Koller. 2004. Max-margin Markov networks.
In Advances in Neural Information Processing
Systems (NIPS). Vancouver, Canada.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
l
a
c
_
a
_
0
0
2
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Ronald J. Williams. 1992. Simple statistical
gradient-following algorithms for connectionist
learning. Machine Learning,
reinforcement
20:229–256.
Sam Wiseman and Alexander M. Rush. 2016.
Sequence-to-sequence learning as beam-search
the 2016
optimization.
Conference on Empirical Methods in Natural
Language Processing (EMNLP). Austin, TX.
In Proceedings of
Zhilin Yang, Junjie Hu, Ruslan Salakhutdinov,
and William Cohen. 2017. Semi-supervised
QA with generative domain-adaptive nets. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(ACL). Vancouver, Canada.
Matthew D. Zeiler. 2012. ADADELTA: An
adaptive learning rate method. ArXiv e-prints,
cs.LG/1212.5701v1.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
5
1
9
2
3
1
7
4
/
/
t
l
a
c
_
a
_
0
0
2
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
248