Dialogue State Tracking with Incremental Reasoning
Lizi Liao, Le Hong Long, Yunshan Ma, Wenqiang Lei, Tat-Seng Chua
计算机学院
National University of Singapore
{liaolizi.llz, yunshan.ma, wenqianglei}@gmail.com
lehonglong@u.nus.edu
chuats@comp.nus.edu.sg
抽象的
Tracking dialogue states to better interpret
user goals and feed downstream policy
learning is a bottleneck in dialogue
管理. Common practice has been
to treat it as a problem of classifying
dialogue content into a set of pre-defined
slot-value pairs, or generating values for
different slots given the dialogue history.
Both have limitations on considering
dependencies that occur on dialogues, 和
are lacking of reasoning capabilities. 这
paper proposes to track dialogue states
gradually with reasoning over dialogue
turns with the help of
the back-end
数据. Empirical results demonstrate that
our method outperforms the state-of-the-
art methods in terms of
joint belief
accuracy for MultiWOZ 2.1, a large-scale
human–human dialogue dataset across
multiple domains.
1
介绍
to monitor
Dialogue State Tracking (夏令时) usually works
as a core component
the user’s
intentional states (or belief states) and is cru-
cial for appropriate dialogue management. A
state in DST typically consists of a set of
dialogue acts and slot value pairs. 考虑
the task of restaurant reservation as shown in
数字 1. In each turn,
the user may inform
the agent of particular goals (例如. single one as
通知(food=Indian) or composed one as
通知(area=center,food=Jamaican)).
Such goals given during a turn are referred as
turn belief. The joint belief
is the set of accu-
mulated turn goals updated until the current turn,
which summarizes the information needed to
successfully maintain and finish the dialogue.
557
传统上, dialogue system is supported by
a domain ontology, which defines a collection
of slots and the values that each slot can take.
The aim of DST is to identify good features or
图案, and map to entries such as specific slot-
value pairs in the ontology. It is often treated as
a classification problem. 所以, most efforts
center on (1) finding salient features: from hand-
crafted features (Wang and Lemon, 2013; Sun
等人。, 2014A), semantic dictionaries (Henderson
等人。, 2014乙; 拉斯托吉等人。, 2017), to neural
network extracted features (Mrkˇsi´c 等人。, 2017);
或者 (2) investigating effective mappings: 从
rule-based models (孙等人。, 2014乙), generative
型号 (Thomson and Young, 2010; 威廉姆斯
and Young, 2007), to discriminative ones (李
and Eskenazi, 2013; Ren et al., 2018; Xie
等人。, 2018). 另一方面, some researchers
attack these methods’ over-dependence on domain
ontology. They perform DST in the absence of
a comprehensive domain ontology and handle
unknown slot values by generating words from
dialogue history or knowledge source (Rastogi
等人。, 2017; Xu and Hu, 2018; Wu et al., 2019).
然而, the critical problem of modeling the
dependencies and reasoning over dialogue history
is not well researched. Many existing methods
work on turn level only, which takes in the cur-
rent turn utterance and outputs the corresponding
turn belief (Henderson et al., 2014乙; Zilka and
Jurcicek, 2015; 拉斯托吉等人。, 2017; Xu and Hu,
2018). Compared to joint belief, the resulting
turn belief only reflects single turn informa-
的, and thus is of less practical use. 所以,
the joint belief
more recent efforts target at
that summarizes the dialogue history. 一般来说
请讲, they accumulate turn beliefs by rules
((Mrkˇsi´c 等人。, 2017; Zhong et al., 2018); Nouri
and Hosseini-Asl, 2018) or model information
across turns via various recurrent neural networks
(RNNs) (文等人。, 2017; Ramadan et al., 2018).
计算语言学协会会刊, 卷. 9, PP. 557–569, 2021. https://doi.org/10.1162/tacl 00384
动作编辑器: Wenjie (Maggie) 李. 提交批次: 7/2020; 修改批次: 1/2021; 已发表 5/2021.
C(西德:2) 2021 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
provides valuable hints for it to reason about
user goals and update belief states. It is therefore
natural to construct a bipartite graph based on the
database where the entities and entity attributes are
the two groups of nodes; with edges connecting
them to express attribute belonging relation. 作为
the example in Figure 1, the database does not
contain restaurant entity serving Jamaican food
and located in center area. Thus there would
be no two-hop path between these two nodes.
Existing methods like Wu et al. (2019) have to
understand it via system utterances, while a DST
reasoning over database would easily obtain such
clues explicitly.
在本文中, we propose to do reasoning over
turns and reasoning over database in Dialogue
State Tracking (ReDST) for task-oriented systems.
For reasoning over turns, we model dialogue
state tracking as a recursive process in which
the current joint belief relies on the generated
current turn belief and last joint belief. Motivated
by the limited length of single turn utterance
and the good performance of pre-trained BERT
(Devlin et al., 2019), we formalize the turn belief
prediction as a token and sequence classification
问题. It follows a multitask learning setting
with augmented utterance inputs. To integrate
结果, an incremental
最后
inference module is applied for more robust
belief updates. For reasoning over a database,
we abstract the back-end database as a bipartite
图形, and propagate extracted beliefs over the
graph to obtain more realistic dialogue states.
Contributions are summarized as:
turn belief
• We propose to rethink the dialogue state
tracking problem for task-oriented agents,
pointing out the need for proper reasoning
over turns and reasoning over back-end data.
• We represent the database into a bipartite
graph and perform belief propagation on
它, which enables the belief
到
gain insight on potential candidates and
detect conflicting requirements along the
conversation course.
tracker
augmented
• With the help from pre-trained Transformer
models working
short
在
utterance for achieving more accurate turn
信仰, we incrementally infer joint belief
via reasoning in a turn by turn style and
outperform state-of-the-art methods by a
large margin.
数字 1: An example dialogue for illustration. Turn
belief labels are provided based on turn information,
while the joint belief captures most updated user
intention up to the current turn.
Although these RNN based methods model dia-
logue in turn by turn style, they usually feed
the whole turn utterance directly to the RNN,
which contains a large portion of noise, and result
in unsatisfactory performance (Liao et al., 2018;
张等人。, 2019乙). 最近, 有
works that directly merge fixed window of past
轮流 (Perez and Liu, 2017; Wu et al., 2019) as new
input and achieve state-of-the-art performance
(Wu et al., 2019). 尽管如此, their capability of
modeling long-range dependencies and doing rea-
soning in the interactive dialogue process is rather
limited. 例如, (Wu et al., 2019) performs
gated copy to generate slot values from dialogue
历史. Although certain turns of utterances are
exposed to the model, since the interactive signals
are lost when concatenating turns together, it fails
to do in-depth reasoning over turns.
such methods
Very recently, there is research starting to work
in turn-by-turn style with pre-trained models.
Generally speaking,
take the
previous turn’s belief state and the current turn
to generate new dialogue
utterances as input
状态 (Chao and Lane, 2019; Kim et al., 2020;
陈等人。, 2020). 然而, there exists a long
ignored fact that as an agent’s central component,
the state tracker not only receives dialogue
history but also observes the back-end database
or knowledge base. Such an information source
558
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2 相关工作
2.1 Dialogue State Tracking
A plethora of research has been focused on DST.
We briefly discuss them in general chronological
命令. At the early stage, traditional dialogue state
trackers combine semantic information extracted
by Language Understanding (LU) modules to
do DST (威廉姆斯和杨, 2007; 威廉姆斯,
2014). Such trackers accumulate errors from the
LU part and possibly suffer from information
loss of dialogue context. Subsequent word-based
(Henderson et al., 2014乙; Zilka and Jurcicek,
2015) trackers thus forgo the LU part and directly
infer states using dialogue history. Hand-crafted
semantic dictionaries are utilized to hold all
key terms, rephrases and alternative mentions to
delexicalize for achieving generalization (Rastogi
等人。, 2017).
最近, most approaches for dialogue state
tracking rely on deep learning models (文等人。,
2017; Ramadan et al., 2018). (Mrkˇsi´c 等人。,
2017)
leveraged pre-trained word vectors to
resolve lexical/morphological ambiguity. As it
treats slots independently that might result
在
missing relations among slots (Ouyang et al.,
2020), Zhong et al. (2018) proposed global mod-
ules to share parameters between estimators for
different slots. 相似地, (Nouri and Hosseini-Asl
2018) used only one recurrent network with global
conditioning to reduce latency while preserving
表现. 一般来说, these methods represent
the dialogue state as a distribution over all candi-
date slot values that are defined in the ontology.
This is often solved as a classification or matching
问题. 然而, these methods rely heavily
on a comprehensive ontology, which often might
not be available. 所以, Rastogi et al. (2017)
introduced a sophisticated candidate generation
战略, 尽管 (Perez and Liu, 2017) followed
the general paradigm of machine reading and
proposed to solve it using an end-to-end memory
网络. Xu and Hu (2018) utilized the pointer
network to extract slot values from utterances,
while Wu et al. (2019) integrated copy mechanism
to generate slot values.
然而,
these methods
tend to largely
ignore the dialogue logic and dependencies.
例如,
inter-utterance information and
correlations between slot values have been shown
to be challenging, let alone the frequent goal
shifting of users. 最后, reasoning over
turns is sensible. We first aim to improve the
turn belief prediction, then model the joint belief
prediction as an updating process. Very recently,
we see such design leveraged by several works.
例如, Chao and Lane (2019) leverage
BERT model to extract slot values for each turn,
then employ a rule-based update mechanism to
track dialogue states across turns. Ren et al. (2019)
encode previous dialogue state and current turn
utterances using Bi-LSTM, then hierarchically
decode domains, 插槽, and values one after
其他. 同时, Kim et al. (2020)
encode these inputs with BERT model while
predicting operation gates and generating possible
价值观. 仍然, such methods largely ignore the fact
that as an agent, it has access to the back-end
data structure which can be leveraged to further
improve the performance of DST.
2.2 Incremental Reasoning
The ability to do reasoning over the dialogue
history is essential for dialogue state trackers.
在
the turn level, we aim to extract more
accurate slot values from user utterance with
the help of contextualized semantic inference.
Contextualized representation learning in NLP
dates back to Collobert and Weston (2008)
but has had a resurgence in the recent year.
Contextualized word vectors were pre-trained
using machine translation data and transferred
to text classification and QA tasks (McCann et al.,
2017). Most recently, BERT (Devlin et al., 2019)
employed Transformer layers (Vaswani et al.,
2017) with a masked language modeling objective
and achieved superior performance across various
任务. In DST, we also observe a wide adoption
of such models (Shan et al., 2020; Liao et al.,
2021). 例如, Kim et al. (2020) and Heck
等人。, (2020) adopted the pre-trained BERT as
base network. Hosseini-Asl et al. (2020) applied
the pre-trained GPT-2 (Alec et al., 2019) 模型
as the base network for dialogue state tracking.
At dialogue context level, since we perform
reasoning via belief propagation through graph,
our work is also related to a wide range of graph
reasoning studies. As a relatively early work,
the page-ranking algorithm (Page et al., 1999)
used a random walk with restart mechanism to
perform multi-hop reasoning. Almost at the same
时间, loopy belief propagation (Murphy et al.,
1999) was proposed to calculate the approximate
marginal probabilities of vertices in a graph based
559
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
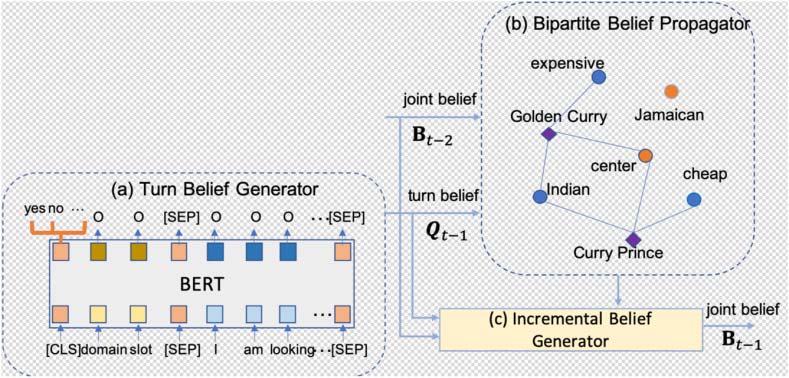
数字 2: The architecture of the proposed ReDST model, which comprises (A) a turn belief generator, (乙) A
bipartite belief propagator, 和 (C) an incremental belief generator. The turn belief generator will predict values
for domain slot pairs. Together with the last joint belief, the beliefs will be aggregated via the bipartite belief
propagator based on the database structure. Then the incremental belief generator infers the final joint belief.
on partial information. 最近几年, 研究
on graph reasoning has moved to learn symbolic
inference rules from relational paths in the KG
(Xiong et al., 2017; Das et al., 2017). 在这些之下
settings, a large number of entities and many
types of relationships are usually involved. 在
夏令时, Chen et al. (2020) leveraged schema graphs
containing slot relations, but their method heavily
relied on a complete slot ontology. Zhou and
小的 (2019) incorporated a dynamically evolving
knowledge graph to explicitly learn relationships
插槽. In our work, only the attribute-belonging
relations are captured, and the constructed graph
is simply a bipartite graph. We thus resort to
heuristic belief propagation on the bipartite graph
for reasoning. Further exploring more advanced
models are treated as our future work.
3 ReDST Model
The proposed ReDST model in Figure 2 consists
of three components: a turn belief generator,
a bipartite graph belief propagator, 和一个在-
cremental belief generator. Instead of predicting
the joint belief directly from dialogue history,
we perform two-stage inference: It first obtains
turn belief from augmented turn utterance via
transformer models. 然后, it reasons over turn
belief and last joint belief with the help of the
bipartite graph propagation results. Based on this,
it incrementally infers the final joint belief.
To facilitate the model description in detail, 我们
first introduce our mathematical notations here.
We define X = {(U1, R1), ··· (UT , RT )} 作为
set of user utterance and system response pairs in
T turns of dialogue, and B = {B1, ··· , BT }
as the joint belief states at each turn. 尽管
Bt summarizes the dialogue history up to the
current turn t, we also model the turn belief Qt
that corresponds to the belief state of a specific
转动 (Ut, Rt), and denote Dt as the domain of
this specific turn. 下列的 (Wu et al., 2019),
we design our state tracker to handle multiple
任务. 因此, each Bt or Qt consists of tuples
喜欢 (domain, slot, 价值). Suppose there are K
不同的 (domain, slot) pairs in total, we denote
Yk as the true slot value for the k-th (domain, slot)
pair.
3.1 BERT-based Turn Belief Generator
Denoting Xt = (Ut, Rt) as the t-th turn utterance,
the goal of turn belief generator is to predict
accurate state for this specific utterance. 虽然
the dialogue history X can accumulate in arbitrary
length, the turn utterance Xt is often relatively
in oftentimes. To utilize contextualized
short
representation for extracting beliefs and enjoy
the good performance of pre-trained encoders,
560
we fine-tune BERT as our base network while
attaching the sequence classification and token
classification layers in a multitask learning setting.
The token classification task extracts specific
slot value spans. The sequence classification task
decides which domain the turn is talking about
and whether a specific (domain, slot) pair takes
the gate value like yes, 不, doncare, none, 或者
generate from token classification, 等等.
The model architecture of BERT is a multi-
layer bidirectional Transformer encoder based on
the original Transformer model (Vaswani et al.,
2017). The input representation is a concate-
nation of WordPiece embeddings (Wu et al.,
2016), positional embeddings, and the seg-
ment embedding. As we need to predict
这
values for each (domain, slot) pair, we aug-
the input sequence as follows. 认为
蒙特
as Xt =
我们有
the original utterance
x1, ··· , xN , the augmented utterance is then X (西德:3)
t =
[CLS], domain, slot, [SEP], x1, ··· , xN , [SEP].
The specific (domain, slot) works as queries to
extract the answer span. We denote the outputs of
BERT as H = h1, …, hN +5.1 The BERT model
is pre-trained with two strategies on large-scale
unlabeled text, 那是, masked language model and
next sentence prediction, which provide a power-
ful context-dependent sentence representation.
We use the hidden state h1 corresponding to
[CLS] as the aggregated sequence representation
to do the domain dt and gate zt classification:
dt = sof tmax(Wdm · (h1)时间 + bdm),
zt = sof tmax(Wgt · (h1)时间 + bgt)
where Wdm is trainable weight matrix and bdm
is the bias for domain classification. And Wgt is
trainable weight matrix and bgt is the bias for gate
classification.
For token classification, we feed the hidden
states of other tokens h2, ··· , hN +5 into a softmax
layer to classify over the token labels S, 我, 氧,
[SEP] 经过
一起. 对于前者, the cross-entropy loss
Lsc is computed between the predicted d, z and
the true one-hot label ˆd, ˆz,
Lsc = −log(d · (ˆd)时间 ) − log(z · (ˆz)时间 ).
(2)
对于后者, we apply another cross-entropy
loss Ltc between each token label in the input
顺序.
Ltc = −
氮 +5(西德:2)
n=2
日志(yn
· (ˆyn)时间 ).
(3)
We optimize the turn belief generator via a
weighted sum of these two loss functions as below
over all training samples:
Lturn = αLsc + βLtc.
(4)
3.1.1 Filter for Improving Efficiency
As in turn belief, most of the slots will get the
value not mentioned. To enhance the efficiency of
our model, we further design a gate mechanism
similar to Wu et al. (2019) to filter out such slots
第一的, for which we can skip the generation process
and predict the value none directly. We apply the
separate training objective as the cross entropy
loss computed between the predicted slot gate
pf ilter
as below:
s
and the true one-hot label qf ilter
s
Lf ilter = −log(pf ilter
s
· (qf ilter
s
)时间 ),
where for prediction, we calculate HXt =
fBERT (Xt) as contextualized word representa-
tions for turn utterance, and then apply query
attention to classify whether the slot should be
filtered,
η = Sof tmax(HXt
· (qs)时间 ),
pf ilter
s
= Sof tmax(Wf ilter · (ηT · HXt)时间 ).
Wf ilter is the weight matrix and qs is the [CLS]
position’s output from a BERT encoder for the
domain-slot query.
yn = sof tmax(Wtc · (hn)时间 + btc),
(1)
3.2 Joint Belief Reasoning
where Wtc is trainable weight matrix and btc is
the bias for token classification.
To jointly model the sequence classification
and token classification, we optimize their loss
1For ease of illustration, we ignore the WordPiece
separation effect on token numbers.
the turn level belief
Now we can predict
state for each turn. 直观地, we can directly
apply our turn belief generator on concatenated
dialogue history to obtain the joint belief as
is hardly
in Wu et al. (2019). 然而,
它
treating all
an optimal practice. First of all,
lose the
utterances as a long sequence will
561
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
iterative character of dialogue, 从而导致
information loss. 第二, current models like
recurrent networks or Transformers are known
for not being able to model
the long-range
dependencies well. Long sequences introduce
这
difficulty to the modeling as well as
computational complexity of Transformers. 这
WordPiece separation operation makes sequences
even longer. 所以, we simulate the dialogue
procedure as a recursive process where current
joint belief Bt relies on the last joint belief Bt−1
and the current turn belief Qt. Generally speaking,
we use Bt−1 and Qt to perform belief propagation
on the bipartite graph constructed based on the
back-end database to obtain credibility score for
each slot value pairs. 然后, we do incremental
belief reasoning over the recursive process using
different methods.
3.2.1 Bipartite Graph Belief Propagator
As the central component for dialogue systems,
the dialogue state tracker has access to the back-
end database most of the time. In the course
of the task-oriented dialogue, the user and agent
interact with each other to reach the same stage of
information awareness regarding a specific task.
The user expresses requirements that, 经常, 是
hard to meet. The agent resorts to the back-end
database and responds accordingly. Then the user
would adjust their requirements to get the task
done. In most existing DSTs, the tracker has to
infer such adjustment requirements from dialogue
历史. With reasoning over the agent’s database,
we expect to harvest more accurate clues explicitly
for belief update.
最后, we abstract
the database as
a bipartite graph G = (V, 乙), where vertices
are partitioned into two groups: The entity set
Vent and attribute set Vattr, where V = Vent ∪
Vattr and Vent ∩ Vattr = φ. The entities within
Vent and Vattr are totally disconnected. Edges
link two vertices from each of Vent and Vattr,
representing the attribute belonging relationship.
During each turn, we first map the predicted Qt
and last joint belief Bt−1 to belief distributions
over the graph via the function g(·). Here we
apply fuzzy match and calculate the similarity
with a threshold (西德:5) to realize g(·). We use BERT
tokenizer to tokenize both dialogue and database
entries. The mapping is done based on a pre-
set threshold on the token level overlap ratio. 为了
例子, the generated ‘cambridge punt ##er’ will
be mapped to the database entry ‘the cambridge
punt ##er’ when their overlap ratio is larger than
(西德:5). In our experiment, we find that approximately
60.5% of entity names and 12.2% other slot values
can be mapped.2 This mapping operation actually
helps to correct some minor errors made in span
extraction or generation.
After the mapping of beliefs to the database
bipartite graph via g(·), we start to do belief
propagation over the graph. Generally speaking,
there are two kinds of belief propagation in the
bipartite graph. The first is from Vent to Vattr.
It simulates the situation when a venue entity is
提及, its attributes will be activated. 为了
例子, after a restaurant is recommended, A
nearby hotel will have the same location value
with it. The second one is from Vattr to Vent.
This simulates the situation when an attribute is
提及, all entities having this attribute will
also receive the propagated beliefs. If an entity
gets more attributes mentioned, it will receive
more propagated beliefs. Suppose the propagation
result is ct for the current turn t, it can be viewed
as the credibility scores of the state values after
reasoning over the database graph. We reason over
this set of entries via doing belief propagation in
the bipartite graph to obtain the certainty scores
for them as below:
ct = γ · g(Bt−1) + η · g(Qt) · (我 + Wadj),
(5)
where γ is a hyper-parameter for modeling the
credibility decay, because newly provided slot
values usually reflect more updated user intention.
η adjusts the effect of propagated beliefs. Wadj
is the adjacency matrix of the bipartite graph.
Note that the belief propagation method is rather
simple but effective. We tried more advanced
methods such as loopy belief propagation (墨菲
等人。, 1999). 然而, we did not see obvious
性能增益, which might be due to the
relatively small bipartite graph size (273 节点
in total). 还, we suspect that graph reasoning
might be more helpful for down stream tasks such
as action prediction. We will explore further in
未来.
3.2.2 Incremental Belief Generator
With the credibility scores ct obtained from the
belief propagator, we now incrementally infer the
2Over half of the slot values are time, 人们, stay, 天,
ETC. There are no such nodes in the bipartite graph but we
keep these slot values’ existence in the belief vector
562
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
current joint belief Bt. 从数学上来说, 我们有
Bt = f (Qt, Bt−1, ct).
(6)
The function f integrates evidence from the
turn belief, last joint belief, and the propagated
credibility scores. There are wide variety of
models that can be applied. We may leverage the
straight-forward Multi-Layer Perceptron (多层线性规划) 到
model the interactions between these beliefs (他
等人。, 2017) 深. Due to the sequential nature
of the belief generator, we can also apply GRU
cells to predict the beliefs turn by turn (Cho et al.,
2014). 直观地, given these remaining and new
belief entries as well as credibility scores, 这
essential task here is to reason out what entries
to keep, update, or delete. 所以, we make
use of these information to carry out the operation
classification task. There are three operations keep,
update, and delete to choose from for each domain
slot. For the GRU case, the detailed equation for
operation classification is as below:
ht = GRU (W · [G(Qt), ct], ht−1)
opk = sof tmax(Wopk
· (ht)时间 + bopk ),
where W · [G(Qt), ct] and ht−1 are the inputs to the
GRU cell. [, ] denotes vector concatenation. Wopk
and bopk are the weight matrix and bias vector for
the corresponding k-th (domain, slot) pair. 后
the operation op in the current turn t is predicted,
we obtain the corresponding current joint belief
Bt via performing corresponding operations.
4 实验
4.1 数据集
We carry out experiments on MultiWOZ 2.1
(埃里克等人。, 2019). It is a multi-domain dialogue
dataset spanning seven distinct domains and
containing over 10,000 对话. As compared to
多WOZ 2.0, it fixed substantial noisy dialogue
state annotations and dialogue utterances that
could negatively impact the performance of state-
tracking models. In MultiWOZ 2.1,
有
30 domain-slot pairs and over 4,500 可能的
价值观, which is different from existing standard
datasets like WOZ (文等人。, 2017) and DSTC2
(Henderson et al., 2014A), which have fewer than
ten slots and only a few hundred values. We follow
the original training, 验证, and testing split
and directly use the DST labels. Since the hospital
and police domain have very few dialogues (10%
compared to others) and only appear in the training
放, we only use the other five domains in our
实验.
4.2 Settings
Training Details Our model is trained in a two-
stage style. We first train the turn belief generator
using the Adam optimizer with a batch size of 32.
We adopt the bert-base-uncased version of BERT
and initialize the learning rate for fine-tuning as
3e-5. The α and β in Equation 4 are set to 0.05
和 1.0, 分别. We use the average of the
last four hidden layer outputs of BERT as the final
representation of each token.
During the later reasoning stage, regarding
incremental belief reasoning, we use a fully
connected two-layer feed-forward neural network
with ReLU activation for MLP. The hidden size
is set to 500, and the learning rate is initialized
作为 0.002. For GRU, we set the learning rate as
0.005. We pre-process turn utterances to alleviate
the problem of ground truth absence, 例如,
formalize time values into standard forms. 相似的
to Heck et al. (2020), we also make use of the
system acts to enrich the system utterances.
Evaluation Metrics Similar to Wu et al. (2019),
we adopt the evaluation metric joint goal accuracy
to evaluate the performance. It is a relatively
strict elevation standard. The joint goal accuracy
compares the predicted belief states to the ground
truth Bt at each turn t. The joint accuracy is 1.0 如果
and only if all (domain, slot, 价值) triplets are
predicted correctly at each turn, otherwise it is 0.
Baselines We denote the two versions of ReDST
与不同的
incremental reasoning modules
as ReDST M LP , and ReDST GRU . 他们是
compared with the following baselines.
DST Reader
(Gao et al., 2019): It treats DST
as a reading comprehension problem. Given the
历史, it learns to extract slot values as spans.
HyST (Goel et al., 2019):
It combines a
hierarchical encoder in a fixed vocabulary system
with an open vocabulary n-gram copy-based
系统.
TRADE (Wu et al., 2019): It concatenates
the whole dialogue history as input and uses a
generative state tracker with a copy mechanism to
generate value for each slot separately.
563
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
DST-Picklist
(张等人。, 2019A): Given the
whole dialogue history as input, it uses two BERT-
based encoders and takes a hybrid approach
of predefined ontology-based DST and open
vocabulary-based DST. It defines picklist-based
slots for classification and span-based slots for
span extraction like DSTRead (Gao et al., 2019).
SOM (Kim et al., 2020): It works in turn-by-turn
style and considers state as an explicit fixed-sized
记忆, and adopts a selectively overwriting
mechanism for generating values with copy.
SST (陈等人。, 2020): It leverages a graph
attention matching network to fuse information
from utterances and schema graphs. A recurrent
graph attention network controls state updating. 它
relies on a predefined ontology.
4.3 DST Results
We first compare our model with the state-of-the-
art methods. 如表所示 1, we observe that
our method outperforms all the other baselines.
例如, in terms of joint accuracy, 哪个
is a rather strict metric, ReDST GRU improves
the performance by 46.2%, 17.4%, 和 1.3% 作为
compared to open-vocabulary based methods: 这
DST Reader, TRADE, and SOM, 分别.
Based on results in Table 1, the methods such
as DST-Picklist and SST perform better than
our method. 然而, they rely heavily on a
predefined ontology. In such methods, the value
candidates for each slot to choose from are fixed
already. They cannot handle unknown slot values,
which largely limits their application in real-life
scenarios.
We observe that a large portion of baselines
work on relatively long window-sized dialogue
历史. FJST directly encodes the raw dialogue
history using recurrent neural networks. 在骗子-
特拉斯特, HJST first encodes turn utterance to vectors
using a word-level RNN, and then encodes the
whole history to vectors using a context level
RNN. 然而, the lower performance of HJST
demonstrates its inefficiency in learning useful
features in this task. Based on HJST, HyST man-
ages to achieve better performance by further
integrating a copy-based module. 仍然, the perfor-
mance is lower than TRADE, which encodes the
raw concatenated whole dialogue history, gener-
ates or copies slot values with extra slot gates.
Generally speaking, these baselines are based on
predefined
ontology
打开-
词汇
模型
FJST
HJST
HyST
DST-Picklist
SST
DST Reader
TRADE
TRADE w/o gate
SOM
ReDST M LP
ReDST GRU
Joint Acc
0.378
0.356
0.381
0.533
0.552
0.364
0.453
0.411
0.525
0.511
0.532
桌子 1: The multi-domain DST evaluation
results on the MultiWOZ 2.1 dataset. 这
ReDST GRU method achieves the highest
joint accuracy.
recurrent neural networks for encoding dialogue
历史. Since the interactions between user and
agent can be arbitrarily long and recurrent neural
networks are not effective in modeling long-range
dependencies, they might not be a good choice
to model the dialogue for DST. 相反,
single turn utterances usually are short and con-
tain relatively simple information as compared
to complicated dialogue history. It is thus better
to generate belief in turn level and then integrate
them via reasoning. According to the comparisons
of baselines, the superior performance of SST,
SOM, and ReDSTs validate this design.
而且, we also tested the performance of
TRADE without the slot gate. The performance
drops dramatically–from 0.453 到 0.411 in terms
of joint accuracy. We suspect that this is due
to lengthy dialogue history, where the decoder
and copy mechanism start to lose focus. It might
generate some value that appears in dialogue
history but is not the ground truth. 所以, 这
slot gate is used to decide which slot value should
be taken, which resembles the inference in some
感觉. To validate this, we feed the single turn
utterances to TRADE and generate the turn beliefs
as output. 有趣的是, we find that it performs
similar with gate or without it, which validates our
guess. 然而, such resembled inference is not
足够的. When the dialogue history becomes long,
the gating mechanism will lose its focus easily.
因此, we report the results of TRADE and
ReDST GRU on the last four turns of dialogues in
桌子 2. The better performance of ReDST GRU
564
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
模型
TRADE
ReDST GRU
T-3
0.411
0.487
T-2
0.339
0.440
T-1
0.269
0.391
时间
0.282
0.377
Setting
ReDST M LP
ReDST GRU
w BP
0.511
0.532
w/o BP
0.507
0.530
桌子 2: The last four turns’ joint accuracy of
TRADE and proposed ReDST. (T refers to the
last turn of each dialogue session.)
桌子 4: The joint accuracy results for ReDST
methods with or without bipartite graph reasoning.
模型
TRADE
SOM
ReDST
Joint Acc
0.697
0.799
0.808
桌子 3: The turn belief generation results of
TRADE, SOM, and proposed ReDST.
further validates the importance of reasoning over
轮流. 通常, as the interactive dialogue goes
在, users might frequently adjust
their goals,
which requires special consideration. Since turn
utterance is relatively more straightforward and
dialogue is turn by turn in nature, doing DST turn
by turn is a useful and practical design.
4.4 Component Analysis
Since our model makes use of the advanced
BERT structure to learn the contextualized
表示, we first test how much contribution
the BERT has made. 所以, we carried out a
study on a turn belief generator and compare it
with SOM and the BiLSTM baseline TRADE on
the single turn utterance. 如表所示 3, 我们
observe that the BERT-based SOM and ReDST
indeed perform better than single turn TRADE.
This is due to the usage of pre-trained BERT
in learning better-contextualized features. 在里面
multitask setting of our design, both the token
classification and sequence classification tasks
benefit from BERT’s strength. 而且, 我们
notice that when doing the single turn setting,
the system response usually depends on certain
information mentioned in the former turn user
发声. 所以, we concatenate the former
turn utterance to each current single turn as the
input for BERT. Under this setting, we achieved
in performance regarding joint
a large boost
accuracy as in Table 3. It provides an excellent
base for the later stage inferences.
We also tested the effect of reasoning over
the database. For a clear comparison, we ignore
the evidence obtained via bipartite graph belief
propagation while keeping other settings the same.
To show it more clearly, we re-organize the
results in Table 4. It can be observed that both
ReDST M LP and ReDST GRU gain a bit from
belief propagation. It validates the usefulness of
database reasoning. 然而, since the graph
is rather small, the performance improvement is
rather limited. Similar patterns are found in Chen
等人。, (2020) and we suspect that it will be more
helpful with larger database structure. 还, 我们
will further explore its usage in down-stream tasks
such as action prediction.
For different incremental reasoning modules,
the results are also shown in Table 1. We find
that ReDST GRU performs better. 然而, 我们
notice that simply accumulating turn belief as in
Zhong et al. (2018) performs very well. The rule
is to add newly predicted turn belief entries to the
last joint belief. When different values for a slot
出现, only keep the new one. Although this rule
seems simple, it actually reflects the dialogue’s
interactive and updating nature. We tried to
directly apply this rule on the ground truth turn
belief to generate joint belief. It results in 0.963
joint accuracy. 然而, a critical problem of
such accumulation rule is that when the generated
turn belief is wrong, it will not be able to add a
missing entry or delete a wrong entry. By applying
GRU in ReDST GRU , it manages to modify a bit
with the help of database evidence. 仍然, 有
large space for more powerful reasoning models
to address this error accumulation issue. 我们将
further investigate in this direction.
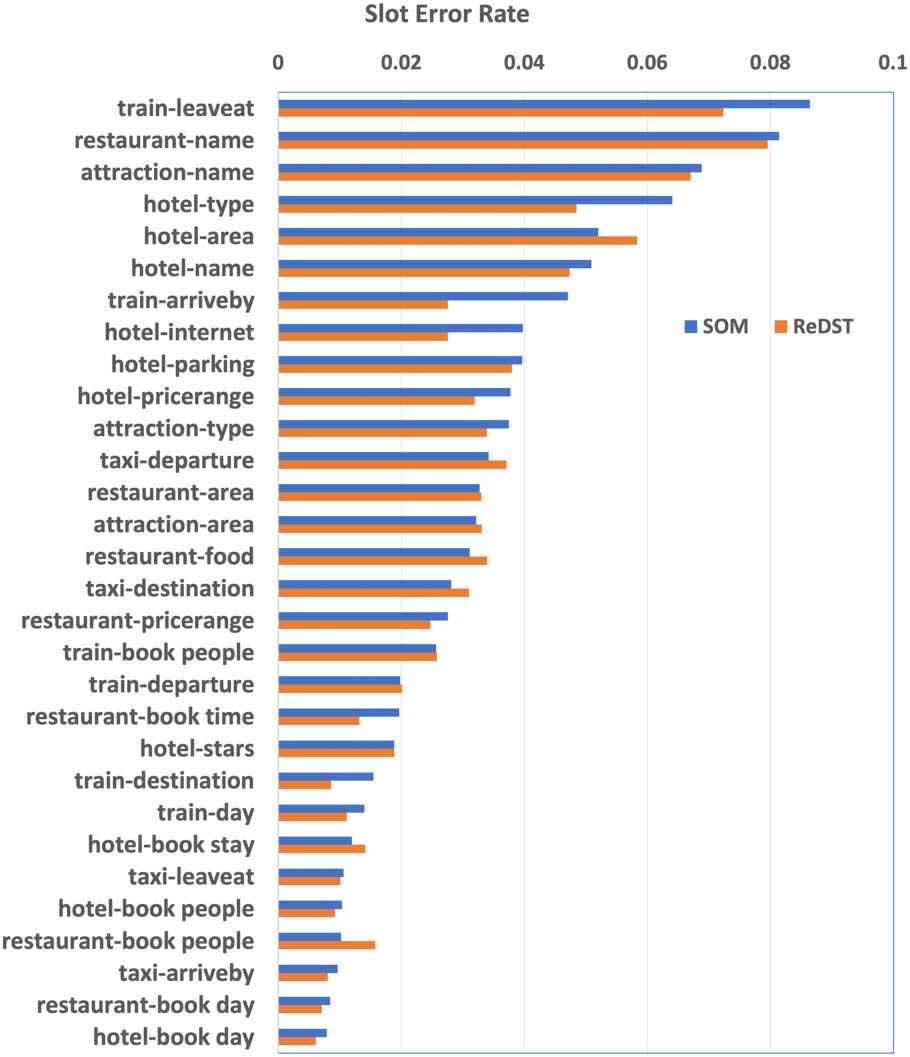
4.5 误差分析
We also provide error analysis regarding each slot
for ReDST GRU in Figure 3. To make it more clear,
we also list the results of SOM for comparison. 我们
observe that a large portion of the improvements
for our method are on name entities and time-
related slots. As mentioned in Wu et al. (2019),
name slots in the attraction, 餐厅, 和
hotel domains have the highest error rates. 它
is partly because these slots have a relatively
565
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
algorithms for performing reasoning over turns
and on graphs for generating more accurate
summarization of user intention.
致谢
This research is supported by the National Re-
search Foundation, 新加坡, under its Inter-
national Research Centres in Singapore Funding
倡议. 有什么意见, 发现, and conclusions
or recommendations expressed in this material are
those of the author(s) and do not reflect the views
of National Research Foundation, 新加坡.
参考
Radford Alec, Wu Jeffrey, Child Rewon, Luan
大卫, Amodei Dario, and Sutskever Ilya. 2019.
Language models are unsupervised multitask
learners. Technical report, OpenAI.
end-to-end dialogue
Guan-Lin Chao and Ian Lane. 2019. BERT-
夏令时: Scalable
状态
tracking with bidirectional encoder represen-
tations from transformer. In INTERSPEECH,
pages 1468–1472. DOI: https://doi.org
/10.21437/Interspeech.2019-1355
Lu Chen, Boer Lv, Chi Wang, Su Zhu, Bowen
Tan, and Kai Yu. 2020. Schema-guided
multi-domain dialogue state tracking with
In AAAI,
graph attention neural networks.
7521–7528. DOI: https://土井
页面
.org/10.1609/aaai.v34i05.6250
Kyunghyun Cho, Bart van Merrienboer, Caglar
Gulcehre, Dzmitry Bahdanau, Fethi Bougares,
Holger Schwenk, and Yoshua Bengio. 2014.
Learning phrase representations using rnn
encoder–decoder for statistical machine trans-
关系. In EMNLP, pages 1724–1734.
Ronan Collobert and Jason Weston. 2008. A
unified architecture for natural language pro-
cessing: Deep neural networks with multitask
In ICML, pages 160–167. DOI:
学习.
https://doi.org/10.1145/1390156
.1390177
Rajarshi Das, Shehzaad Dhuliawala, Manzil
Zaheer, Luke Vilnis, Ishan Durugkar, Akshay
Krishnamurthy, Alex Smola, and Andrew
麦卡勒姆. 2017. Go for a walk and arrive at
the answer: Reasoning over paths in knowledge
数字 3: Slot error rate on the test set. The error rate
for name slots on restaurant, hotel, and attraction
domain drops 4.2% 一般.
large number of possible values that are hard
to recognize. In ReDST GRU , we map beliefs
into a bipartite graph constructed via database
and do belief propagation on it. This helps
to improve the accuracy on name slots. 还,
the classification gate design helps to improve
performance on Yes/No slots. We also observe that
the performance for taxi destination becomes
更差. This is due to the value co-reference
phenomenon where the user might just mention
‘taxi to the hotel’ to refer to the hotel name
mentioned earlier. These findings are interesting
and we will explore it further.
5 结论
We rethink DST from the angle of agent and
point out the urgent need for in-depth reasoning
other than being obsessed with generating values
from history text as a whole. We demonstrated
the importance of doing reasoning over turns
and over the database. In detail, we fine-tuned
pre-trained BERT for more accurate turn level
belief generation while doing belief propagation in
bipartite graph to harvest more clues. 实验
on a large-scale multi-domain dataset demonstrate
the superior performance of the proposed method.
将来, we will explore more advanced
566
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
bases using reinforcement
preprint arXiv:1711.05851.
学习. arXiv
Jacob Devlin, Ming-Wei Chang, Kenton Lee, 和
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
理解. In NAACL, pages 4171–4186.
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek
Sethi, Sanchit Agarwal, Shuyang Gao,
and Dilek Hakkani-T¨ur. 2019. 多WOZ
2.1: Multi-domain dialogue
correc-
tions and state tracking baselines. CoRR,
abs/1907.01669.
状态
Shuyang Gao, Abhishek Sethi, Sanchit Agarwal,
Tagyoung Chung, and Dilek Hakkani-Tur.
2019. Dialog state tracking: A neural read-
In SIGDIAL,
ing comprehension approach.
pages 264–273. DOI: https://doi.org
/10.18653/v1/W19-5932
Rahul Goel, Shachi Paul, and Dilek Hakkani-T¨ur.
2019. HyST: A hybrid approach for flexible
and accurate dialogue state tracking. arXiv
preprint arXiv:1907.00883. DOI: https://
doi.org/10.21437/Interspeech
.2019-1863
Xiangnan He, Lizi Liao, Hanwang Zhang,
Liqiang Nie, Xia Hu, and Tat-Seng Chua.
2017. Neural collaborative filtering. In WWW,
pages 173–182.
Michael Heck, Carel van Niekerk, Nurul Lubis,
Christian Geishauser, Hsien-Chin Lin, Marco
Moresi, and Milica Gaˇsi´c. 2020. Trippy: A
triple copy strategy for value independent neural
dialog state tracking. In SIGDIAL, pages 35–44.
和
Matthew Henderson, Blaise Thomson,
贾森·D. 威廉姆斯. 2014A. 这
第二
dialog state tracking challenge. In SIGDIAL,
pages 263–272. DOI: https://doi.org
/10.3115/v1/W14-4337
Matthew Henderson, Blaise Thomson,
和
Steve Young. 2014乙. Word-based dialog
state tracking with recurrent neural net-
作品. In SIGDIAL, pages 292–299. DOI:
https://doi.org/10.3115/v1/W14
-4340
Ehsan Hosseini-Asl, Bryan McCann, Chien-
and Richard
Sheng Wu, Semih Yavuz,
Socher. 2020. A simple language model
任务导向的对话. arXiv 预印本
为了
arXiv:2005.00796.
Sungdong Kim, Sohee Yang, Gyuwan Kim, 和
Sang-Woo Lee. 2020. Efficient dialogue state
tracking by selectively overwriting memory. 在
前交叉韧带, pages 567–582.
Sungjin Lee
and Maxine Eskenazi. 2013.
Recipe for building robust spoken dialog state
trackers: Dialog state tracking challenge system
description. In SIGDIAL, pages 414–422.
Lizi Liao, Yunshan Ma, Xiangnan He, Richang
洪, and Tat-seng Chua. 2018. 知识-
aware multimodal dialogue systems. In Pro-
the 26th ACM international
ceedings of
conference on Multimedia, pages 801–809.
DOI: https://doi.org/10.1145/3240508
.3240605
Lizi Liao, Tongyao Zhu, Long Lehong, and Tat-
Seng Chua. 2021. Multi-domain dialogue state
tracking with recursive inference. In The Web
会议. To appear.
Bryan McCann,
James Bradbury, Caiming
Xiong, and Richard Socher. 2017. Learned
in translation: Contextualized word vectors. 在
NIPS, pages 6294–6305.
Nikola Mrkˇsi´c, Diarmuid ´O. S´eaghdha, Tsung-
Hsien Wen, Blaise Thomson, and Steve
tracker: 数据-
Young. 2017. Neural belief
In ACL,
driven dialogue
pages 1777–1788. DOI: https://doi.org
/10.18653/v1/P17-1163
追踪.
状态
Kevin P. 墨菲, Yair Weiss, and Michael I.
约旦. 1999. Loopy belief propagation for
approximate inference: An empirical study. 在
UAI, pages 467–475.
Elnaz Nouri and Ehsan Hosseini-Asl. 2018.
Toward scalable neural dialogue state tracking
模型. arXiv 预印本 arXiv:1812.00899.
Yawen Ouyang, Moxin Chen, Xinyu Dai,
Yinggong Zhao, Shujian Huang, and Jiajun
陈. 2020. Dialogue state tracking with
explicit slot connection modeling. In ACL,
pages 34–40. DOI: https://doi.org
/10.18653/v1/2020.acl-main.5
567
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Lawrence Page, Sergey Brin, Rajeev Motwani,
and Terry Winograd. 1999, The pagerank
citation ranking: Bringing order to the Web.
Stanford InfoLab.
Julien Perez and Fei Liu. 2017. Dialog state track-
英, a machine reading approach using memory
In EACL, pages 305–314. DOI:
网络.
https://doi.org/10.18653/v1/E17
-1029
Osman Ramadan, Paweł Budzianowski, 和
Milica Gasic. 2018. Large-scale multi-domain
belief tracking with knowledge sharing. 在
前交叉韧带, pages 432–437. DOI: https://土井
.org/10.18653/v1/P18-2069
Abhinav Rastogi, Dilek Hakkani-T¨ur, and Larry
Heck. 2017. Scalable multi-domain dia-
In ASRU Workshop,
logue state tracking.
pages 561–568. DOI: https://doi.org
/10.1109/ASRU.2017.8268986
Liliang Ren, Jianmo Ni, and Julian McAuley.
2019. Scalable and accurate dialogue state
tracking via hierarchical sequence generation.
In EMNLP, pages 1876–1885.
Liliang Ren, Kaige Xie, Lu Chen, and Kai
于. 2018. Towards universal dialogue state
追踪. In EMNLP, pages 2780–2786.
Yong Shan, Zekang Li, Jinchao Zhang, Fandong
猛, Yang Feng, Cheng Niu, and Jie Zhou.
2020. A contextual hierarchical attention
network with adaptive objective for dialogue
state tracking. In ACL, pages 6322–6333. DOI:
https://doi.org/10.18653/v1/2020
.acl-main.563
Kai Sun, Lu Chen, Su Zhu, and Kai Yu.
2014A. A generalized rule based tracker for
dialogue state tracking. In SLT Workshop,
pages 330–335. DOI: https://doi.org
/10.1109/SLT.2014.7078596
Kai Sun, Lu Chen, Su Zhu, and Kai Yu. 2014乙.
The sjtu system for dialog state tracking chal-
许久 2. In SIGDIAL, pages 318–326. DOI:
https://doi.org/10.3115/v1/W14
-4343
Blaise Thomson and Steve Young. 2010. Bayesian
update of dialogue state: A POMDP frame-
work for spoken dialogue systems. Computer
Speech & 语言, 24(4):562–588. DOI:
https://doi.org/10.1016/j.csl
.2009.07.003
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N.
Gomez, Łukasz Kaiser, and Illia Polosukhin.
2017. Attention is all you need. In NIPS,
pages 5998–6008.
Zhuoran Wang and Oliver Lemon. 2013. A
simple and generic belief tracking mechanism
for the dialog state tracking challenge: 在
the believability of observed information. 在
SIGDIAL, pages 423–432.
时间. H. Wen, D. Vandyke, 氮. Mrkˇs´ıc, 中号. Gaˇs´ıc,
L. 中号. Rojas-Barahona, 磷. H. Su, S. Ultes,
和S. Young. 2017. A network-based end-
trainable
to-end
dialogue
task-oriented
In EACL, pages 438–449. DOI:
系统.
https://doi.org/10.18653/v1/E17
-1042
贾森·D. 威廉姆斯. 2014. Web-style ranking
and slu combination for dialog state track-
In SIGDIAL, pages 282–291. DOI:
英.
https://doi.org/10.3115/v1/W14
-4339
贾森·D. Williams and Steve Young. 2007.
Partially observable markov decision pro-
cesses for spoken dialog systems. Computer
Speech & 语言, 21(2):393–422. DOI:
https://doi.org/10.1016/j.csl
.2006.06.008
Chien-Sheng Wu, Andrea Madotto, Ehsan
Hosseini-Asl, Caiming Xiong, Richard Socher,
and Pascale Fung. 2019. Transferable multi-
domain state generator
task-oriented
dialogue systems. In ACL, pages 808–819.
为了
Yonghui Wu, Mike Schuster, Zhifeng Chen,
Quoc V. Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin
高, Klaus Macherey, Jeff Klingner, Apurva
Shah, Melvin Johnson, Xiaobing Liu, Łukasz
Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku
Kudo, Hideto Kazawa, Keith Stevens, 乔治
Kurian, Nishant Patil, Wei Wang, Cliff Young,
Jason SmithJason Smith, Jason Riesa, Alex
Rudnick, Oriol Vinyals, Greg Corrado, Macduff
休斯, and Jeffrey Dean. 2016. Google’s
neural machine translation system: Bridging the
568
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
gap between human and machine translation.
arXiv 预印本 arXiv:1609.08144.
https://doi.org/10.18653/v1/2020
.emnlp-main.243
Kaige Xie, Cheng Chang, Liliang Ren, Lu Chen,
and Kai Yu. 2018. Cost-sensitive active
在
learning for dialogue
SIGDIAL, pages 209–213. DOI: https://
doi.org/10.18653/v1/W18-5022
追踪.
状态
Wenhan Xiong, Thien Hoang, and William Yang
王. 2017. Deeppath: A reinforcement
learning method for knowledge graph rea-
soning. In EMNLP, pages 564–573. DOI:
https://doi.org/10.18653/v1/D17
-1060
Puyang Xu and Qi Hu. 2018. An end-to-
end approach for handling unknown slot
values in dialogue state tracking. In ACL,
pages 1448–1457.
Jian-Guo Zhang, Kazuma Hashimoto, Chien-
Sheng Wu, Yao Wan, Philip S. 于, 理查德
Socher, and Caiming Xiong. 2019A. Find
slot-value
or classify? Dual
predictions on multi-domain dialog state track-
英. arXiv 预印本 arXiv:1910.03544. DOI:
strategy for
Zheng Zhang, Lizi Liao, Minlie Huang, Xiaoyan
朱, and Tat-Seng Chua. 2019乙. Neural mul-
timodal belief tracker with adaptive attention
for dialogue systems. In The World Wide
Web Conference, pages 2401–2412. DOI:
https://doi.org/10.1145/3308558
.3313598
Victor Zhong, Caiming Xiong, and Richard
Socher. 2018. Global-locally self-attentive en-
coder for dialogue state tracking. In ACL,
1458–1467. DOI: https://土井
页面
.org/10.18653/v1/P18-1135
Li Zhou and Kevin Small. 2019. Multi-domain
dialogue state tracking as dynamic knowledge
graph enhanced question answering. arXiv
preprint arXiv:1911.06192.
lstm-based
Lukas Zilka and Filip Jurcicek. 2015. Incre-
精神的
tracker.
In ASRU Workshop, pages 757–762. DOI:
https://doi.org/10.1109/ASRU.2015
.7404864
dialog
状态
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
8
4
1
9
2
3
7
3
9
/
/
t
我
A
C
_
A
_
0
0
3
8
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
569