Best-First Beam Search
Clara Meister(西德:2) Tim Vieira(西德:2) Ryan Cotterell∗, (西德:2)
(西德:2)ETH Z¨urich (西德:2)Johns Hopkins University ∗University of Cambridge
clara.meister@inf.ethz.ch tim.vieira@gmail.com
ryan.cotterell@inf.ethz.ch
抽象的
Decoding for many NLP tasks requires an ef-
fective heuristic algorithm for approximating
exact search because the problem of searching
the full output space is often intractable, 或者
impractical in many settings. The default algo-
rithm for this job is beam search—a pruned
version of breadth-first search. Quite surpris-
英利, beam search often returns better results
than exact inference due to beneficial search
bias for NLP tasks. 在这项工作中, we show that
the standard implementation of beam search
can be made up to 10x faster in practice. 我们的
method assumes that the scoring function is
monotonic in the sequence length, 哪个
allows us to safely prune hypotheses that can-
not be in the final set of hypotheses early on.
We devise effective monotonic approxima-
tions to popular nonmonontic scoring functions,
including length normalization and mutual
information decoding. 最后, we propose a
memory-reduced variant of best-first beam search,
which has a similar beneficial search bias in
terms of downstream performance, but runs in
a fraction of the time.
1
介绍
Beam search is a common heuristic algorithm for
decoding structured predictors (例如, neural ma-
chine translation models and transition-based
parsers). Because of the widespread adoption of
recurrent neural networks and other non-Markov
型号, traditional dynamic programming solu-
系统蒸发散, such as the Viterbi algorithm (Viterbi,
1967), are prohibitively inefficient; this makes
beam search a common component of many state-
of-the-art NLP systems. Despite offering no
formal guarantee of finding the highest-scoring
hypothesis under the model, beam search yields
impressive performance on a variety of tasks—
795
unexpectedly providing a beneficial search bias
over exact search for many tasks (Stahlberg and
Byrne, 2019).
Within NLP, most research on beam search has
focused on altering the log-probability scoring
function to return improved results, 例如,
higher BLEU scores (Wu et al., 2016; Murray and
蒋, 2018; Shu and Nakayama, 2018; 哪个
等人。, 2018) or a more diverse set of outputs
(Vijayakumar et al., 2016). 然而, little work
has been done to speed up beam search itself.
Filling this gap, this paper focuses on reform-
ulating beam search in order to make it faster.
We propose best-first beam search, a priori-
tized version of traditional beam search that is up
to an order of magnitude faster in practice while
still returning the same set of results. We add-
itionally discuss an even faster heuristic version
of our algorithm that further limits the number of
candidate solutions, leading to a smaller memory
footprint while still finding good solutions.
Concretely, we offer a novel interpretation of
beam search as an agenda-based algorithm where
traditional beam search is recovered by utilizing
a length-based prioritization scheme. We prove
that a specific best-first prioritization scheme, 作为
in classic A∗ search (Hart et al., 1968), allows
for the elimination of paths that will necessarily
fall off the beam; for many scoring functions,
including standard log-probability scoring, 我们可以
still guarantee the same k hypotheses as traditional
beam search are returned. 的确, our algorithm
returns beam search’s top hypothesis the first time
it encounters a complete hypothesis, allowing the
program to stop early. 更远, we discuss the ap-
plication of best-first beam search to several
popular scoring functions in the literature (He et
等人。, 2016; 李等人。, 2016); this demonstrates that we
have a general framework for adapting a variety
of rescoring methods and alternate objectives to
work with our algorithm.
计算语言学协会会刊, 卷. 8, PP. 795–809, 2020. https://doi.org/10.1162/tacl 00346
动作编辑器: Kristina Toutanova. 提交批次: 2/2020; 修改批次: 6/2020; 已发表 12/2020.
C(西德:3) 2020 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Empirically, we compare best-first beam search
to ordinary beam search on two NLP sequence-to-
sequence tasks: neural machine translation (NMT)
and abstractive summarization (AS). On NMT,
we find that our algorithm achieves roughly a
30% speed-up over traditional beam search with
increased gains for larger beams (例如, ≈ 10x
for a beam of 500). We find similar results
hold for AS. 最后, we show that our memory-
reduced version, which limits the number of active
hypotheses, leads to additional speed-ups over
best-first beam search across beam sizes while
maintaining similar BLEU scores.
2 Sequence Transduction
A core operation in structured prediction models
is the determination of the highest-scoring output
for a given input under a learned scoring model.
y(西德:2) def= arg max
y∈Y(X)
分数(X, y)
(1)
where x is an input and Y(X) is a set of well-
formed outputs for the input. An important ex-
ample of (1) is maximum a posteriori (MAP),
字, every valid sequence begins and ends with
distinguished tokens (BOS and EOS, 分别).1
此外, each sequence has at most length
nmax(X)—which is typically dependent on x—a
restriction we impose to ensure termination. 一些
applications may require a stronger coupling
between Y(X) and x (例如, |X| = |y|). We drop the
dependence of Y and nmax on x when it is clear
from context.
Scoring. We consider a general additively de-
composable scoring model of the form
分数(X, y) =
Ny(西德:2)
t=1
分数(X, y
6:
7:
8:
9:
10:
11:
12:
13:
14:
continue
POPS[|y|] ← POPS[|y|] + 1
if y.last() = EOS :
Q.push((西德:6)sh, y◦ EOS(西德:7))
别的:
for y ∈ V :
s ← score(X, y ◦ y)
sh ← s+ h(X, y ◦ y)
Q.push((西德:6)sh, y ◦ y(西德:7))
15:
16: return Q.pop() if not Q.empty() else null
3.1 Choice Points of 2
Here we review the components of our meta
algorithm (the highlighted sections in Alg. 2) 那
can be varied to recover different search strategies:
1 (西德:2) : y × y → {True, False}. A priority queue
Q maintains the set of active hypotheses.
Elements in this set are ordered according to
a generic comparator (西德:2). When its peek() (或者
pop()) methods are called, the first element
ordered by (西德:2) is returned (or returned and
已删除).
2 停止(·) : 收藏(西德:6)y(西德:7) → {True, False}.
The algorithm terminates according to
configurable stopping criterion based on the
current set of elements in Q.
5If the last token of y(西德:12) is the end symbol (例如, EOS), then y(西德:12)
is not expanded any further. One can either regard y(西德:12) as any
other hypothesis albeit with y(西德:12) ◦ yt = y(西德:12) or keep appending
EOS (IE。, y(西德:12) ◦ yt = y(西德:12) ◦ EOS ) so that time step and length can
be regarded as synonymous. We adopt the latter standard for
comparability with subsequent algorithms.
797
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Beam Search
H, y(西德:12)(西德:7) ⇐⇒ |y| < |y|(cid:12)
(cid:6)sh, y(cid:7) (cid:2) (cid:6)s(cid:12)
h)
or (|y| = |y|(cid:12) and sh ≥ s(cid:12)
stop(Q) ⇐⇒
y.last() = EOS ∀y ∈ Q
k = beam size
0
(cid:6)sh, y(cid:7) (cid:2) (cid:6)s(cid:12)
h, y(cid:12)(cid:7) ⇐⇒ |y| < |y|(cid:12)
h)
or (|y| = |y|(cid:12) and sh ≥ s(cid:12)
stop(Q) ⇐⇒
y.last() = EOS ∀y ∈ Q
k = ∞
0
1
2
3
4
1
2
3
4
Best-First Beam Search
A∗ Beam Search
(cid:6)sh, y(cid:7) (cid:2) (cid:6)s(cid:12)
or (sh = s(cid:12)
h, y(cid:12)(cid:7) ⇐⇒ sh > s(西德:12)
h and |y| < |y|(cid:12))
h
(cid:6)sh, y(cid:7) (cid:2) (cid:6)s(cid:12)
or (sh = s(cid:12)
h, y(cid:12)(cid:7) ⇐⇒ sh > s(西德:12)
h and |y| < |y|(cid:12))
h
stop(Q) ⇐⇒
Q.peek().last() = EOS
k = beam size
0
stop(Q) ⇐⇒
Q.peek().last() = EOS
k = beam size
any admissible heuristic
A∗ Search
h, y(cid:12)(cid:7) ⇐⇒ sh > s(西德:12)
h and |y| < |y|(cid:12))
h
(cid:6)sh, y(cid:7) (cid:2) (cid:6)s(cid:12)
or (sh = s(cid:12)
(cid:6)sh, y(cid:7) (cid:2) (cid:6)s(cid:12)
or (sh = s(cid:12)
h, y(cid:12)(cid:7) ⇐⇒ sh > s(西德:12)
h and |y| < |y|(cid:12))
h
stop(Q) ⇐⇒
Q.peek().last() = EOS
k = ∞
0
stop(Q) ⇐⇒
Q.peek().last() = EOS
k = ∞
any admissible heuristic
Breadth-First Search
Best-First Search
Table 1: Values at choice points for various search algorithms. Note that any admissible heuristic may
be used for variants of A∗ search.
3 k ∈ N>0. Only k paths of a given length
are considered. If the algorithm has already
encountered k paths of a given length,
subsequent paths of that
length are not
evaluated. If we take k = ∞, we recover
unpruned search algorithms.
4 H(·, ·) : x × y → R. A heuristic function
H(X, y) can be used during search to change
the priority in which paths are evaluated.
We note that with pruning, a heuristic may
change the value of the k-optimal hypothesis
(see § 4.1).
Recovering Beam Search. To recover beam
search from Algorithm 2, we use the choice
points from Table 1. Explicitly, the comparator
prioritizes hypotheses from earlier time steps
第一的, but breaks ties with the hypotheses’ scores
under the model. We note that while the standard
algorithm for beam search does not prioritize by
score within a time step, variations of the algorithm
use this strategy so they can use early-stopping
策略 (Klein et al., 2017; Huang et al., 2017).
Beam search terminates once either all hypotheses
end in EOS or the queue is empty (IE。, 当。。。的时候
k beams have been extended nmax time steps but
none end in EOS). In the second case, no complete
hypothesis is found. 最后, choosing the heuris-
tic h(X, y) = 0 makes the algorithm a case of
standard best-first search.
注意, while standard beam search returns a
放, Alg 2 only returns the k-optimal hypothesis.
This behavior is sufficient for the majority of
use cases for beam search. 然而, if the full
set of k hypotheses is desired, the stopping crite-
rion can be changed to evaluate true only when
k hypotheses are complete. Under the other beam
search settings, this would probably return the
same set as beam search (see § 4.1).
Recovering A∗. To recover the traditional A∗
search algorithm, we use the comparator that
prioritizes hypotheses with a higher score first; 领带
are broken by hypothesis length. The algorithm
terminates when the first item of Q contains an
EOS. If we take k = ∞, best-first beam search
recovers A∗. Any admissible heuristic may be
used for h(X, y).
Definition 3.1. Admissible Heuristic. A heuristic
h is admissible if it never overestimates the future
cost—or underestimates the future reward—of
continuing down a path.
3.2 Best-First Beam Search
In its original form, A∗ search may traverse the
entire O(|V|nmax) 图形, which as discussed ear-
lier, is intractable for many decoding problems.
While standard beam search addresses this prob-
lem by limiting the search space,
it still has
computational inefficiencies—namely, 我们必须
analyze k hypotheses of a given length (IE。, 时间
step), regardless of how poor their scores may
already be, before considering longer hypotheses.
798
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
然而, prioritization by length is not strictly
necessary for finding a k-optimal hypothesis. 作为
is done in A∗, we can use score as the prioritiza-
tion scheme and still guarantee optimality–or k-
optimality–of the paths returned by the algorithm.
We define A∗ beam search as the A∗ algorithm
where breadth is limited to size k. 更远, 我们
define best-first beam search as the case of A∗
beam search when no heuristic is used (见表 1
for algorithm settings). This formulation has two
large advantages over standard beam search: (1)
we gain the ability to remove paths from the
queue that are guaranteed to fall off the beam
和 (2) we can terminate the algorithm the first
time a complete hypothesis is encountered. 我们
can therefore reduce the computation required for
decoding while still returning the same set of
结果.
The mathematical property that makes this
short-circuiting of computation possible is the
monotonicity of the scoring function. 注意
not all scoring functions are monotonic, 但很多
important ones are, including log-probability (5).
We discuss effective approximations for popular
non-monotonic scoring functions in § 5.
Definition 3.2. Monotonicity. A scoring function
分数(·, ·) is monotonic in t if for all x, y
Lemma 4.2. The first hypothesis that best-first
beam search pops that ends in EOS is k-optimal.
Proof. Let y be the first hypothesis popped by
best-first beam search ending in EOS. By rules of
the priority queue, no other active hypothesis has a
higher score than y. 此外, by monotonicity
of the scoring function, no other hypothesis can
subsequently have score greater than y. 所以
y must be k-optimal.
Lemma 4.3. If best-first beam search pops a
假设, then beam search necessarily pops
that same hypothesis.
Proof. We prove the lemma by induction on
hypothesis length. The base case holds trivially:
For hypotheses of length 0, both best-first beam
search and beam search must pop the (西德:6)BOS(西德:7) as it is
the only item in the queue after initialization.
By the inductive hypothesis, suppose Lemma 4.3
holds for hypotheses of length < t. Suppose best-
first beam search pops a hypothesis y = y
∀i ∈ 1, . . . , k. This implies that for beam search,
y≤t+j would not be in the top-k paths at
time step t + j since by Lemma 4.3, paths
{y(1)
} would also be evaluated by
beam search. Therefore y cannot be in H
BS, 哪个
is a contradiction.
≤t+j, . . . , y(k)
≤t+j
案件 2: For no time step t + j (j ≥ 0) do we
pop k paths. This can only happen if the algorithm
stops early, 即, we have found k complete
hypotheses y(1), . . . , y(k). If this is the case, 然后
by rules of the priority queue, each y(1), . . . , y(k)
must have score greater than score(X, y
BS,
which is a contradiction.
Non-monotonic
Scoring Functions. Non-
monotonic scoring functions (Definition 3.2)
break the assumptions of § 4.1, in which case
best-first beam search is not guaranteed to return a
k-optimal hypothesis. 然而, when the scoring
801
function is boundable from above, we can alter
the original stopping criterion ( 2 in Alg. 2) 这样的
that k-optimality is again guaranteed.
Given our assumed restriction on the search
space—namely, |y(西德:2) ∈ Y(X)| ≤ nmax(X)—we can
upper-bound the maximal score of any hypothesis
under the scoring function in use. 正式地, 为了
any function score we have:
停止(问) ⇐⇒
分数(X, ˆy) ≥ score(X, y(西德:12)) + U(X, y(西德:12))
∀y(西德:12) ∈ Q
(6)
where ˆy is the best complete hypothesis found
so far and U(X, y(西德:12)) is the score function-
dependent upper bound on how much the score
of y(西德:12) can increase as y(西德:12) is expanded further.7
在这种情况下, best-first beam search only
terminates once no other hypothesis in Q can
have a score greater
finished
假设. We note that Huang et al. (2017) use a
similar scheme for optimal stopping with bounded
length normalization. We discuss examples of
non-monotonic scoring functions in § 5.
than the best
A Note on Heuristics. Our analysis shows the
equivalence of beam search and best-first beam
搜索, 那是, when h(X, y) = 0. The analysis
does not hold for arbitrary admissible heuristics. A
poor heuristic (例如, one that grossly overestimates
the future score of continuing down one path)
may cause other items to be pruned from best-first
beam search that otherwise would have remained
on the beam in standard beam search.
4.2 Runtime
Theorem 4.6. The runtime of best-first beam
search is O(nmaxk (|V| 日志(k) + 日志(nmax)))
Proof. We pop at most nmax · k items. 每个
pop requires us to push |V| 项目. Each push
requires log(k) time when the priority queue is
implemented with a min–max heap (Atkinson
等人。, 1986) and incrementally pruned so that it
has no more than k items. After pushing those
|V| 项目, we have to perform a percolation in the
priority queue of priority queues, which requires
日志(nmax) 时间. This yields O(nmaxk (|V| 日志(k)+
日志(nmax))) 时间.
Theorem 4.7. The runtime of standard beam
search is O(nmax k |V| 日志(k)).
7For monotonic scoring functions, we have U (X, y(西德:12)) = 0.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Proof. The proof is the same as Theorem 4.6,
but we can forgo the percolation step in the
queue of queues because standard beam search
proceeds in order of hypothesis length. 这产生
氧(nmaxk|V| 日志(k)).
Although the theoretical bound of best-first
beam search has an additional log factor compared
with standard beam search, we find this to be neg-
ligible in practice. 相当, we find number of calls
to score, the scoring function under our model
(例如, a neural network), is often the bottleneck
operation when decoding neural networks (see § 6
for empirical evidence). In terms of this metric,
the beam search algorithm makes O(knmax) calls
to score, as score is called once for each active
hypothesis in B and B may evolve for nmax rounds.
The worst-case number of calls to score will be
the same as for beam search, which follows from
Lemma 4.3.
5 Scoring Functions
Even before the findings of Stahlberg and Byrne
(2019), it was well known that the best-scoring
hypothesis with respect to the traditional likeli-
hood objective can be far from ideal in practice
(Wu et al., 2016; Murray and Chiang, 2018;
杨等人。, 2018). For language generation tasks
具体来说, the results returned by neural models
using the standard scoring function are often short
and default to high-frequency words (Vinyals and
Le, 2015; Shen et al., 2016).
To alleviate such problems, methods that revise
hypothesis scores to incorporate preferences for
更长, less repetitive, or more diverse options
have been introduced and are often used in prac-
泰斯. While most such techniques change the
scoring function such that it is no longer mono-
tonic, we can still guarantee the k-optimality
of the returned hypothesis for (upper) bounded
scoring functions using the methods discussed
in § 4.1. In the remainder of this section, 我们
present alternate scoring schemes adapted to work
with best-first beam search. 此外, 我们
present several heuristics which, while breaking
the k-optimality guarantee, provide another set of
decoding strategies worth exploring.
Length Normalization. Length normalization
is a widely used hypothesis scoring method that
aims to counteract the propensity for shorter se-
quences to have higher scores under neural mod-
这;
this is done by normalizing scores by
hypothesis length (see Murray and Chiang [2018]
for more detail).
For early stopping in beam search with length
normalization, 黄等人。. (2017) propose bound-
ing the additive length reward as the minimum of
a pre-determined optimal sequence length ratio r
and the final sequence length Ny:
scoreLN(X, y) = score(X, y)
+ β · min{r|X|, Ny}
(7)
where β is the scaling parameter for the reward.
We note, 然而, that the same can be done with
the maximum sequence length nmax such that the
traditional length reward used by He et al. (2016)
is recovered:
scoreLN(X, y) = score(X, y) + β min{nmax, Ny}
= score(X, y) + βNy
(8)
We formally propose two methods for length
normalization. We use the scoring functions in (7)
或者 (8) with either: (1) the following heuristic:
(西德:3)
H(X, y) =
for y.last () = EOS
0
β max{b − |y|, 0} for y.last () (西德:18)= EOS
(9)
where b can be r|X| or nmax;8 或者 (2) 停止
criterion as in (6) albeit with scoring function
scoreLN and upper-bound function:
U(X, y) = β max{0, b − |y|}
(10)
Despite their similarities, these two methods are
not guaranteed to return the same results. Whereas
the second method will return the same k-optimal
hypotheses as beam search, using a heuristic
during pruned search means we can no longer
guarantee the k-optimality of the results with
respect to the scoring function as the heuristic
may push hypotheses off of the beam. We present
experimental results for both methods in § 6.
Mutual Information. Maximum mutual infor-
mation decoding (李等人。, 2016) aims to alleviate
the inherent preference of neural models for high-
frequency tokens when using the log-probability
8We enforce r|X| < nmax.
802
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
l
a
c
_
a
_
0
0
3
4
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
decoding objective. Rather than choosing the
hypothesis y to maximize conditional probability
with respect to the input x, we instead choose y to
maximize pointwise mutual information (PMI):
PMI(x; y) = log
p(x, y)
p(x)p(y)
(11)
Note that (11) is equivalent to log p(y|x)
p(y) , which can
be rewritten as log p(y | x) − log p(y), making
the objective additive and thus (11) can conform
to (4).
From this last form, we can see how mutual
information decoding penalizes high-frequency
and generic outputs; the negative p(y) term, as Li
et al. (2016) point out, acts as an ‘‘anti-language
model.’’ One unfortunate side effect of this
objective is that ungrammatical and nonsensical
outputs, which have probabilities close to 0 under a
language model like p(y), end up with high scores
because of the second term in the score function.
To address this problem, and to upper-bound
the scoring function, we propose lower-bounding
the language model term by a hyperparameter
1 ≥ ε > 0. We additionally use the strength
hyperparameter λ employed by Li et al. (2016):
scorePMI(X, y) = 对数 p(y | X)
− λ log max{p(y), ε} (12)
Similarly to our methods for length normali-
扎化, we can use the scoring function in (12)
either with the heuristic:
(西德:3)
H(X, y) =
0
−λ log ε(nmax−|y|)
for y.last () = EOS
for y.last () (西德:18)= EOS
(13)
or with stopping criterion as in (6) albeit with
scorePMI and upper-bound function:
U(X, y) = −λ log ε(nmax − |y|)
(14)
Because −λ log ε is the best possible score at any
given time step, clearly we can bound the increase
in scorePMI by the above function. 然而, as with
our length normalization strategy, we lose the k-
optimality guarantee with the heuristic method
for mutual
information decoding. We present
experimental results for both methods in § 6.
6 实验
We run our algorithm on several language-related
tasks that typically use beam search for decoding:
NMT and AS. 具体来说, experiments are per-
formed on IWSLT’14 De-En (Cettolo et al., 2012),
WMT’17 De-En (Bojar et al., 2017), MTTT Fr-En
(Duh, 2018), and CNN-DailyMail (Hermann et al.,
2015) using both Transformers (Vaswani et al.,
2017) and Convolutional sequence-to-sequence
型号 (Gehring et al., 2017).
For reproducibility, we use the data pre-processing
scripts provided by fairseq (Ott et al., 2019) 和
follow their methods for training sequence trans-
duction models. Hyperparameters are set in accor-
dance with previous works. 具体来说, 在
IWSLT’14 and MTTT tasks, we follow the rec-
ommended Transformer settings for IWSLT’14 in
fairseq,9 which are based on Vaswani et al. (2017)
and Gehring et al. (2017). Hyperparameters for
models trained on the WMT task are set following
version 3 of the Tensor2Tensor toolkit (Vaswani
等人。, 2018). We use byte-pair encoding (BPE;
Sennrich et al. 2016) for all languages. Vocabulary
sizes for WMT and IWSLT’14 are set from rec-
ommendations for the respective tasks in fairseq;
for the MTTT tasks, vocabulary sizes are tuned
on models trained with standard label-smoothing
regularization. 相似地,
the CNN/DailyMail
dataset is pre-processed and uses BPE following
the same steps as (刘易斯等人。, 2019); 模型
hyperparameters are likewise copied. Details are
available on fairseq’s Web site.10
We use BLEU (Papineni et al., 2002) (evaluated
using SacreBLEU [邮政, 2018]) for MT metrics
and ROUGE-L (林, 2004) for abstractive summar-
ization metrics. We build our decoding framework
in SGNMT.11
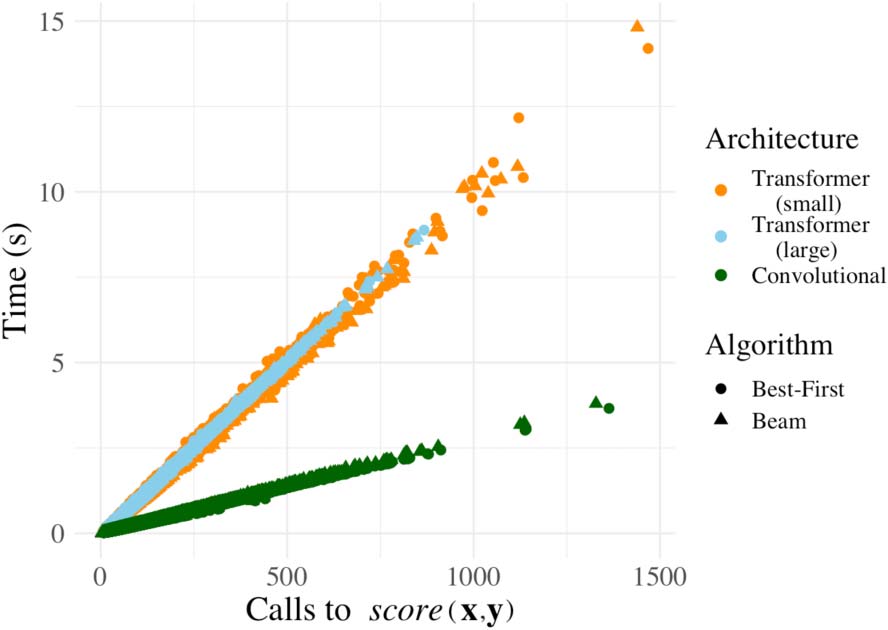
6.1 Running Time
表中 2, we report values as the average number
of calls to the scoring function per input; 我们
do not use wall-clock time as this is heavily
dependent on hardware. See Fig. 1 for empirical
justification of the correlation between calls to the
scoring function and runtime on the hardware our
9https://github.com/pytorch/fairseq/tree
/master/examples/translation.
10https://github.com/pytorch/fairseq/blob
/master/examples/bart/README.cnn.md.
11https://github.com/ucam-smt/sgnmt.
803
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
IWSLT’14 De-En
k = 5
(35.6)
k = 10
(35.4)
k = 100
(34.7)
k = 500
(7.9)
k = 10
(33.0)
MTTT Fr-En
k = 100
(9.9)
k = 500
(1.2)
CNN-DailyMail
k = 5
(31.5)
k = 10
(30.9)
k = 100
(29.1)
BF beam search
885 (836%) 200 (33%) 305 (43%) 2960 (92%)
Beam search (ES) 107 (7%) 210 (9%) 2047 (12%) 7685 (27%) 196 (9%) 1310 (58%) 4182 (98%) 224 (19%) 357 (22%) 3942 (59%)
Beam search
93 (24%) 169 (36%) 1275 (79%) 1168 (736%) 184 (16%)
867 (138%)
2286
2066
9770
5673
8281
115
229
266
214
435
桌子 2: Average number of calls (rounded to nearest whole digit) to score, the sequence transduction
模型, per generated sequence when using different decoding algorithms. Green percentages are
performance improvements over standard beam search. Beam search (ES) refers to the OpenNMT
early-stopping method (Klein et al., 2017). All methods provably return the same solution and thus,
evaluation metrics (in dark blue) for a given beam size are identical.
IWSLT’14 De-En
k
方法
search error
蓝线
# calls
10
100
10
100
shrinking
early
BF BS
shrinking
early
BF BS
shrinking
early
BF BS
shrinking
early
BF BS
0%
0%
-
31.7%
31.7%
-
35.4
35.4
35.4
13.2
13.2
34.7
WMT’17 De-En
0%
0%
-
1.7%
1.7%
-
28.6
28.6
28.6
26.4
26.4
26.9
229 (0%)
225 (2%)
169 (36%)
2278 (0%)
1738 (31%)
1275 (79%)
260 (0%)
252 (3%)
230 (12%)
2587 (0%)
2402 (8%)
2046 (26%)
桌子 3: 蓝线, search error, and average number
of calls to score for different stopping criterion.
‘‘shrinking’’ refers to the shrinking beam method
of Bahdanau et al. (2015) and ‘‘early’’ refers
to the stopping criterion of Huang et al. (2017).
Note that neither method is guaranteed to return
the same result as standard beam search. 搜索
error and performance increases are with respect
to standard beam search.
表中 4. We find that both methods,
那
是, changing the stopping criterion and using a
heuristic during search, provide improvements
over baseline BLEU scores albeit with different
hyperparameter settings; increases are similar to
improvements reported by Murray and Chiang
(2018). 尤其, using a heuristic causes a large
percentage of search errors with respect to stand-
ard beam search using the same scoring function.
然而, the difference in results appears to be
beneficial in terms of BLEU.
数字 1: Number of calls to scoring function score
与. total sequence generation time. Each point is a
decoded sequence. Colors represent different model
architectures and shapes signify the decoding algorithm
用过的 (beam sizes 3 和 10 are included for each). 那里
is no notable difference in the overhead (time-wise) 的
best-first beam search and beam search.
experiments were run on. For reference, in our
实验, the scoring function took on average
> 99% of the total computation time, even with
larger beam sizes, when overhead of the search
algorithm is most significant.
We find that best-first (BF) beam search leads to
significant speed-ups over both traditional beam
search and beam search with early stopping, 与一个
performance increase12 of ≈ 8x for a beam size of
500. We likewise find that best-first beam search
offers speed-ups over early stopping methods that
are not guaranteed to return the same results as
standard beam search (见表 3).
6.2 Length Normalization
We experiment with both forms of
length
normalization presented in § 5 and provide results
12Performance increase is defined as (old − new)/新的.
804
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
IWSLT’14 De-En
β
# calls
乙
k
search BLEU
错误
Heuristic
Stopping Criterion
5 0.8 |X|
115 (0%)
10 1.2 |X|
229 (0%)
73 (58%) -
5 0.5 nmax
10 0.5 nmax 130 (76%) -
40.6% 33.9 +0.3
54.7% 33.8 +0.5
33.7 +0.1
33.7 +0.4
Baseline
Heuristic
Stopping Criterion
k
ε
β
# calls
search BLEU
错误
-
-
5 -
33.2
.05 115
10 -
.05 229
33.0
.05 129 (0%) 42.7% 33.2
5 .02
.05 256 (0%) 42.7% 33.0
10 .02
5 3e–4 .05 114 (1%) 29.2% 33.2
10 5e–5 .05 224 (2%) 26.6% 33.0
Heuristic
Stopping Criterion
MTTT Fr-En
5 0.8 .7|X| 100 (8%)
10 1.0 .7|X| 196 (9%)
5 1.0 nmax
10 1.2 nmax
65 (66%) -
88 (143%) -
16.2% 33.5 +0.2
25.2% 33.6 +0.6
34.1 +0.8
34.1 +1.1
桌子 4: BLEU search error, and average number
of calls to score for output obtained with length
normalization scoring function on the IWSLT’14
De-En and MTTT Fr-En test sets. Increase in BLEU
is over baseline with no length normalization.
Search error and performance increases are with
respect to standard beam search decoding using
the same scoring function.
6.3 Mutual Information
We train a language model on the IWSLT dataset
and use it to calculate p(y) 从 (12) as margin-
alizing over y is intractable (see Li et al. [2016] 为了
further justification). We run experiments using
both of the methods discussed in § 5 and present
results in Table 5. We find that both methods
provide results of equivalent BLEU score compared
with the baseline output, 即, results obtained
with the unbounded PMI objective and beam
搜索. 再次, despite the high search error rate
demonstrated by the heuristic method, 评估
metrics are still comparable.
6.4 Memory Usage
We conduct a set of experiments where we limit
total queue capacity to k·γ for γ ∈ {1, . . . , nmax},
as described in § 3.3, and report the BLEU score of
the resulting set of hypotheses.
如表所示 6, we find that restricting
the queue capacity does not harm output quality
和, additionally, leads to even greater runtime
performance increase. 例如, runtime for
decoding of IWSLT’14 with a beam size of
10 can be improved by > 3x while returning
results with better evaluation metrics. We find
that improvements are even more pronounced
for larger beam sizes. Across beam widths and
任务, we find that search error (with respect to
standard beam search) is quite low for γ = 5.
此外, for smaller γ, the change in BLEU
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
桌子 5: BLEU scores with mutual
信息
scoring function on IWSLT’14 De-En. Baseline
is PMI decoding with unbounded p(y), 那是,
ε = 0. Search error is with respect to beam search
decoding of baseline with same β.
k
5
10
5
10
C
2
5
nmax
2
5
nmax
2
5
nmax
2
5
nmax
IWSLT’14 De-En
搜索
蓝线
错误
# calls
22.7% 35.7 +0.1
4.4% 35.8 +0.2
-
35.6
43.8 (163%)
79.8 (44%)
93.0 (24%)
22.6% 35.7 +0.3
4.5% 35.6 +0.2
-
35.4
48.4 (374%)
126.9 (81%)
169.0 (36%)
WMT’17 De-En
29.0% 29.7 +0.2
1.2% 29.5 +0.0
-
29.5
77.5 (75%)
115.8 (12%)
118.8 (10%)
36.6% 29.5 +0.2
2.6% 29.3 +0.0
-
29.3
97.3 (165%)
230.0 (12%)
230.2 (12%)
桌子 6: BLEU scores and the number of calls
to score on the IWSLT’14 De-En validation
set and WMT’17 De-En test set with queue
size restricted to nmax · k. Note that γ = nmax is
the standard best-first beam search algorithm.
Performance increases are over standard beam
搜索. Search error is with respect to beam
search with same beam width.
score demonstrates that search error in this context
does not necessarily hurt the quality of results.
7 相关工作
Our work is most similar to that of Zhou and
汉森 (2005), who propose beam stack search.
然而, they are focused on exact inference and
still evaluate hypotheses in breadth-first order.
805
此外, their algorithm requires O(nmaxk)
记忆; although best-first beam search has
the same requirements, we introduce effective
methods for reducing them, 即, 记忆-
reduced best-first beam search.
黄等人。. (2017) propose and prove the
optimality of an early-stopping criterion for beam
搜索. The authors find in practice though that
reduction in computation from their algorithm was
generally not significant. We build on this work
and introduce additional methods for avoiding
unnecessary computation. Our method leads to
better performance, 如表所示 2.
克莱因和曼宁 (2003) use A∗ for PCFG
解析; 然而, they use the un-pruned version
for exact search, which is not applicable for
NMT or AS as the memory requirements of
the algorithm are far too large for these tasks.
随后, Pauls and Klein (2009) provide a
method for pruning this search algorithm, 甚至
using a threshold rather than explicitly limiting
the state space. 黄等人。. (2012) also adapt A∗
for a k-best decoding algorithm. Although their
methods differ notably from ours, they likewise
use pruning techniques that allow for substantial
speedups.
Stahlberg and Byrne (2019) create an exact
inference algorithm for decoding and use it
to analyze the output of neural NMT models.
Whereas they likewise utilize the monotonicity
of the scoring function to make their method
tractable, they do not focus on speed or mimicking
the results of standard beam search.
8 结论
为了
We propose best-first beam search, an algorithm
faster decoding while still
that allows
guaranteeing k-optimality. We provide results on
several sequence-to-sequence transduction tasks
that show the speed-ups that our algorithm
provides over standard beam search for decoding
neural models. We adapt several popular alternate
scoring functions to best-first beam search and
provide a framework that can be used to
adapt other scoring methods such as coverage
normalization (Wu et al., 2016) or diverse beam
搜索 (Vijayakumar et al., 2016). We also provide
a memory-reduced version of our algorithm,
which returns competitive results in a fraction
of the time needed for standard beam search.
参考
中号. D. Atkinson, J. 右. Sack, 氮. Santoro, 和T.
Strothotte, 1986. Min-max heaps and general-
ized priority queues. Communications of ACM:
29(10). DOI: https://doi.org/10.1145
/6617.6621
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
本吉奥. 2015. Neural machine translation by
jointly learning to align and translate.
在
Proceedings of the International Conference
on Learning Representations.
Ondˇrej Bojar, Rajen Chatterjee, Christian
Federmann, Yvette Graham, Barry Haddow,
Shujian Huang, Matthias Huck, Philipp Koehn,
Qun Liu, Varvara Logacheva, Christof Monz,
Matteo Negri, Matt Post, Raphael Rubino,
Lucia Specia, and Marco Turchi. 2017.
Findings of the 2017 conference on machine
翻译. In Proceedings of the Conference
on Machine Translation, 体积 2: Shared
Task Papers, 哥本哈根, 丹麦. DOI:
https://doi.org/10.18653/v1/W17-4717
Mauro Cettolo, Christian Girardi, and Marcello
Federico. 2012. Wit3: Web inventory of
transcribed and translated talks. In Proceedings
of the Conference of the European Association
for Machine Translation.
Edsger W. Dijkstra. 1959. A note on two problems
in connexion with graphs. Numerische Mathe-
matik 1(1). DOI: https://doi.org/10.1007
/BF01386390
Kevin Duh. 2018. The multitarget TED talks task.
http://www.cs.jhu.edu/∼kevinduh
/a/multitarget-tedtalks/
Sergey Edunov, Myle Ott, Michael Auli, 和
David Grangier. 2018. Understanding back-
translation at scale. 在诉讼程序中 2018
Conference on Empirical Methods in Natural
语言处理. 布鲁塞尔, 比利时, 作为-
sociation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/D18
-1045
Jonas Gehring, Michael Auli, David Grangier, 和
Yann Dauphin. 2017. A convolutional encoder
model for neural machine translation. In Pro-
ceedings of
the 55th Annual Meeting of
the Association for Computational Linguistics
806
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(体积 1: Long Papers). Vancouver, 加拿大.
计算语言学协会.
DOI: https://doi.org/10.18653/v1
/P17-1012, PMID: 28964987, PMCID:
PMC6754825
Peter E. 哈特, Nils J. Nilsson, and Bertram
拉斐尔. 1968. A formal basis for the heuristic
determination of minimum cost paths. IEEE
Transactions on Systems Science and Cyber-
网络学, 4(2). DOI: https://doi.org/10
.1109/TSSC.1968.300136
Wei He, Zhongjun He, Hua Wu, and Haifeng
王. 2016. Improved neural machine transla-
tion with SMT features. 在诉讼程序中
AAAI 人工智能会议.
Karl Moritz Hermann, Tomas Kocisky, 爱德华
格芬施泰特, Lasse Espeholt, Will Kay,
Mustafa Suleyman, and Phil Blunsom. 2015.
Teaching machines to read and comprehend,
神经信息处理的进展
系统.
Liang Huang, Kai Zhao, and Mingbo Ma. 2017.
When to finish? Optimal beam search for neural
text generation (modulo beam size). In Proceed-
这 2017 Conference on Empirical
ings of
Methods in Natural Language Processing,
哥本哈根, 丹麦. Association for Com-
putational Linguistics. DOI: https://土井
.org/10.18653/v1/D17-1227, PMID:
28564569
Zhiheng Huang, Yi Chang, Bo Long, 让-
Francois Crespo, Anlei Dong, Sathiya Keerthi,
and Su-Lin Wu. 2012. Iterative Viterbi A*
algorithm for k-best sequential decoding. 在
Proceedings of the 50th Annual Meeting of
the Association for Computational Linguistics
(体积 1: Long Papers), Jeju Island, 韩国.
计算语言学协会.
Dan Klein and Christopher D. 曼宁. 2003.
A* parsing: Fast exact Viterbi parse selection.
在诉讼程序中 2003 Human Language
Technology Conference of the North American
Chapter of the Association for Computatio-
nal Linguistics. DOI: https://doi.org
/10.3115/1073445.1073461
OpenNMT: Open-source toolkit
for neural
machine translation. In Proceedings of ACL
2017, 系统演示, Vancouver,
加拿大. Association for Computational Lin-
语言学. DOI: https://doi.org/10.18653
/v1/P17-4012
Philipp Koehn and Rebecca Knowles. 2017. Six
challenges for neural machine translation. 在
Proceedings of the First Workshop on Neural
机器翻译, Vancouver. 协会
for Computational Linguistics. DOI: https://
/10.18653/v1/W17-3204
John D. 拉弗蒂, Andrew McCallum, 和
Fernando C. 氮. 佩雷拉. 2001. Conditional ran-
dom fields: Probabilistic models for segment-
ing and labeling sequence data. In Proceedings
of the International Conference on Machine
学习, ICML ’01, 旧金山, CA, 美国.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
征收, Veselin Stoyanov, and Luke Zettlemoyer.
2019. 捷运: Denoising sequence-to-sequence
pre-training for natural language generation,
翻译, and comprehension. In arXiv:1910.
13461. DOI: https://doi.org/10.18653
/v1/2020.acl-main.703
Jiwei Li, 米歇尔·加莱, Chris Brockett, Jianfeng
高, and Bill Dolan. 2016. A diversity-
promoting objective function for neural con-
versation models. 在诉讼程序中 2016
Conference of the North American Chapter of
the Association for Computational Linguistics:
人类语言技术, 圣地亚哥,
加利福尼亚州. Association for Computational
语言学.
Chin-Yew Lin. 2004. ROUGE: A package for
automatic evaluation of summaries. In Text Sum-
marization Branches Out, 巴塞罗那, 西班牙.
计算语言学协会.
Andrew McCallum, Dayne Freitag, and Fernando
C. 氮. 佩雷拉. 2000. Maximum entropy Markov
models for information extraction and segmen-
站. 在诉讼程序中
国际
Conference on Machine Learning, ICML 00.
旧金山, CA, 美国.
Guillaume Klein, Yoon Kim, Yuntian Deng,
Jean Senellart, and Alexander Rush. 2017.
Kenton Murray and David Chiang. 2018. 正确的-
ing length bias in neural machine translation.
807
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
In Proceedings of the Third Conference on
机器翻译: Research Papers, 比利时,
布鲁塞尔. Association for Computational Lin-
语言学. DOI: https://doi.org/10.18653
/v1/W18-6322
乔金·尼弗尔, Igor M. 博古斯拉夫斯基, and Leonid L.
Iomdin. 2008. Parsing the SynTagRus treebank
of Russian. In Proceedings of the 22nd Interna-
tional Conference on Computational Linguis-
抽动症 (Coling 2008), 曼彻斯特, 英国. Coling
2008 Organizing Committee. DOI: https://
doi.org/10.3115/1599081.1599162
Myle Ott, Sergey Edunov, Alexei Baevski, Angela
Fan, Sam Gross, Nathan Ng, David Grangier,
and Michael Auli. 2019. fairseq: A fast, exten-
sible toolkit for sequence modeling. In Pro-
ceedings of NAACL-HLT: Demonstrations.
DOI: https://doi.org/10.18653/v1
/N19-4009
Kishore Papineni, Salim Roukos, Todd Ward, 和
Wei-Jing Zhu. 2002. 蓝线: A method for
automatic evaluation of machine translation.
In Proceedings of the Annual Meeting on Asso-
ciation for Computational Linguistics. DOI:
https://doi.org/10.3115/1073083
.1073135
Adam Pauls and Dan Klein. 2009. 分层的
search for parsing. In Proceedings of Human
语言技术: 这 2009 Annual Con-
ference of the North American Chapter of the
计算语言学协会,
博尔德, 科罗拉多州. Association for Computa-
tional Linguistics. DOI: https://doi.org
/10.3115/1620754.1620835
Matt Post. 2018. A call for clarity in reporting
BLEU scores. In Proceedings of the Confer-
ence on Machine Translation: Research Pa-
pers. DOI: https://doi.org/10.18653
/v1/W18-6319
Rico Sennrich, Barry Haddow, and Alexandra
Birch.2016. Neural machine translation of rare
words with subword units. 在诉讼程序中
the Annual Meeting of the Association for Com-
putational Linguistics. DOI: https://土井
.org/10.18653/v1/P16-1162
Iulian Serban, Tim Klinger, Gerald Tesauro,
Kartik Talamadupula, Bowen Zhou, Yoshua
本吉奥, and Aaron Courville. 2017. Multireso-
lution recurrent neural networks: An application
to dialogue response generation.
Shiqi Shen, Yong Cheng, Zhongjun He, Wei
他, Hua Wu, Maosong Sun, and Yang Liu.
2016. Minimum risk training for neural machine
翻译. In Proceedings of the 54th Annual
Meeting of the Association for Computational
语言学 (体积 1: Long Papers), 柏林,
德国. Association for Computational Lin-
语言学. DOI: https://doi.org/10.18v653
/v1/P16-1159, PMID: 27069146
Raphael Shu and Hideki Nakayama. 2018. 我是-
proving beam search by removing monotonic
constraint for neural machine translation. 在
Proceedings of the 56th Annual Meeting of
the Association for Computational Linguis-
抽动症 (体积 2: Short Papers), 墨尔本,
for Computational
澳大利亚. 协会
语言学.
Felix Stahlberg and Bill Byrne. 2019. On NMT
search errors and model errors: Cat got your
tongue? In Proceedings of the Conference on
Empirical Methods in Natural Language Pro-
cessing and the 9th International Joint Con-
ference on Natural Language Processing
(EMNLP-IJCNLP). 香港, 中国. DOI:
https://doi.org/10.18653/v1/D19
-1331
伊利亚·苏茨克维尔, Oriol Vinyals, and Quoc V. Le.
2014, Sequence to sequence learning with neu-
ral networks. In Advances in Neural Inform-
ation Processing Systems.
Ben Taskar, Carlos Guestrin, and Daphne Koller.
2004. Max-margin markov networks. In Ad-
Information Processing
vances
系统.
in Neural
Ashish Vaswani, Samy Bengio, Eugene Brevdo,
Francois Chollet, Aidan N. Gomez, Stephan
Gouws, Llion Jones, Łukasz Kaiser, Nal
Kalchbrenner, Niki Parmar, Ryan Sepassi,
Noam Shazeer, and Jakob Uszkoreit. 2018.
Tensor2tensor for neural machine translation.
CoRR.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017.
808
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Attention is all you need. In Advances in Neural
Information Processing Systems.
Tim Vieira, Ryan Cotterell, and Jason Eisner.
2016. Speed-accuracy tradeoffs in tagging with
variable-order CRFs and structured sparsity.
In Proceedings of the Conference on Empiri-
cal Methods in Natural Language Processing.
DOI: https://doi.org/10.18653/v1
/D16-1206
Ashwin K. Vijayakumar, Michael Cogswell,
Ramprasaath R. Selvaraju, Qing Sun, Stefan
李, David J. Crandall, and Dhruv Batra.
2016. Diverse beam search: Decoding diverse
solutions from neural sequence models. CoRR,
abs/1610.02424.
Oriol Vinyals and Quoc V. Le. 2015. A neural
conversational model. DOI: https://土井
.org/10.1109/TIT.1967.1054010
Andrew Viterbi. 1967. Error bounds for convolu-
tional codes and an asymptotically optimum
decoding algorithm. IEEE Transactions on
Information Theory, 13(2).
Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku
Kudo, Hideto Kazawa, Keith Stevens, 乔治
Kurian, Nishant Patil, Wei Wang, Cliff Young,
Jason Smith, Jason Riesa, Alex Rudnick,
Oriol Vinyals, Gregory S. 科拉多, Macduff
休斯, and Jeffrey Dean. 2016. Google’s
neural machine translation system: Bridging the
gap between human and machine translation.
Yilin Yang, Liang Huang, and Mingbo Ma.
2018. Breaking the beam search curse: A
study of (re-)scoring methods and stopping
criteria for neural machine translation. In Pro-
ceedings of the 2018 Conference on Empiri-
cal Methods in Natural Language Processing,
布鲁塞尔, 比利时. Association for Computa-
tional Linguistics. DOI: https://doi.org
/10.18653/v1/D18-1342
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime
Carbonell, Russ R. Salakhutdinov, and Quoc V.
Le. 2019. XLNet: Generalized autoregressive
pretraining for
在
神经信息处理的进展
系统.
language understanding.
Yonghui Wu, Mike Schuster, Zhifeng Chen,
Quoc V. Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin
高, Klaus Macherey, Jeff Klingner, Apurva
Shah, Melvin Johnson, Xiaobing Liu, Lukasz
Rong Zhou and Eric A. 汉森. 2005. Beam-
stack search: Integrating backtracking with beam
搜索. In Proceedings of the International Con-
ference on International Conference on Auto-
mated Planning and Scheduling, ICAPS05.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
6
1
9
2
3
7
9
0
/
/
t
我
A
C
_
A
_
0
0
3
4
6
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
809