文章
Communicated by Simon Shaolei Du
Every Local Minimum Value Is the Global Minimum Value
of Induced Model in Nonconvex Machine Learning
Kenji Kawaguchi
kawaguch@mit.edu
和, 剑桥, 嘛 02139, 美国.
Jiaoyang Huang
jiaoyang@math.harvard.edu
哈佛大学, 剑桥, 嘛 02138, 美国.
Leslie Pack Kaelbling
lpk@csail.mit.edu
和, 剑桥, 嘛 02139, 美国.
For nonconvex optimization in machine learning, this article proves that
every local minimum achieves the globally optimal value of the per-
turbable gradient basis model at any differentiable point. 因此,
nonconvex machine learning is theoretically as supported as convex ma-
chine learning with a handcrafted basis in terms of the loss at differen-
tiable local minima, except in the case when a preference is given to the
handcrafted basis over the perturbable gradient basis. The proofs of these
results are derived under mild assumptions. 因此, the proven re-
sults are directly applicable to many machine learning models, 包括-
ing practical deep neural networks, without any modification of practical
方法. 此外, as special cases of our general results, this article
improves or complements several state-of-the-art theoretical results on
深度神经网络, deep residual networks, and overparameterized
deep neural networks with a unified proof technique and novel geomet-
ric insights. A special case of our results also contributes to the theoretical
foundation of representation learning.
1 介绍
Deep learning has achieved considerable empirical success in machine
learning applications. 然而, insufficient work has been done on the-
oretically understanding deep learning, partly because of the nonconvexity
and high-dimensionality of the objective functions used to train deep mod-
这. 一般来说, theoretical understanding of nonconvex, high-dimensional
optimization is challenging. 的确, finding a global minimum of a gen-
eral nonconvex function (Murty & Kabadi, 1987) and training certain types
神经计算 31, 2293–2323 (2019) © 2019 麻省理工学院.
https://doi.org/10.1162/neco_a_01234
在知识共享下发布
归因 4.0 国际的 (抄送 4.0) 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2294
K. Kawaguchi, J. 黄, 和L. Kaelbling
of neural networks (布鲁姆 & Rivest, 1992) are both NP-hard. Considering
the NP-hardness for a general set of relevant problems, it is necessary to
use additional assumptions to guarantee efficient global optimality in deep
学习. 因此, recent theoretical studies have proven global opti-
mality in deep learning by using additional strong assumptions such as
linear activation, random activation, semirandom activation, gaussian in-
看跌期权, single hidden-layer network, and significant overparameterization
(Choromanska, Henaff, Mathieu, Ben Arous, & 乐存, 2015; Kawaguchi,
2016; Hardt & Ma, 2017; 阮 & Hein, 2017, 2018; Brutzkus & Glober-
儿子, 2017; Soltanolkotabi, 2017; 锗, 李, & Ma, 2017; Goel & Klivans, 2017;
Zhong, 歌曲, Jain, Bartlett, & Dhillon, 2017; 李 & Yuan, 2017; Kawaguchi,
Xie, & 歌曲, 2018; Du & 李, 2018).
A study proving efficient global optimality in deep learning is thus
closely related to the search for additional assumptions that might not hold
in many practical applications. Toward widely applicable practical theory,
we can also ask a different type of question: If standard global optimal-
ity requires additional assumptions, then what type of global optimality
不? 换句话说, instead of searching for additional assumptions
to guarantee standard global optimality, we can also search for another type
of global optimality under mild assumptions. 此外, instead of an ar-
bitrary type of global optimality, it is preferable to develop a general theory
of global optimality that not only works under mild assumptions but also
produces the previous results with the previous additional assumptions,
while predicting new results with future additional assumptions. This type
of general theory may help not only to explain when and why an exist-
ing machine learning method works but also to predict the types of future
methods that will or will not work.
As a step toward this goal, this article proves a series of theoretical re-
苏丹. The major contributions are summarized as follows:
• For nonconvex optimization in machine learning with mild assump-
系统蒸发散, we prove that every differentiable local minimum achieves
global optimality of the perturbable gradient basis model class. 这
result is directly applicable to many existing machine learning mod-
这, including practical deep learning models, and to new models to
be proposed in the future, nonconvex and convex.
• The proposed general theory with a simple and unified proof tech-
nique is shown to be able to prove several concrete guarantees that
improve or complement several state-of-the-art results.
• In general, the proposed theory allows us to see the effects of the
design of models, 方法, and assumptions on the optimization
landscape through the lens of the global optima of the perturbable
gradient basis model class.
Because a local minimum θ in Rdθ only requires the θ to be locally optimal
in Rdθ , it is nontrivial that the local minimum is guaranteed to achieve the
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2295
globally optimality in Rdθ of the induced perturbable gradient basis model
班级. The reason we can possibly prove something more than many worst-
case results in general nonconvex optimization is that we explicitly take
advantage of mild assumptions that commonly hold in machine learning
and deep learning. 尤其, we assume that an objective function to
be optimized is structured with a sum of weighted errors, where each error
is an output of composition of a loss function and a function of a hypothe-
sis class. 而且, we make mild assumptions on the loss function and a
hypothesis class, all of which typically hold in practice.
2 Preliminaries
This section defines the problem setting and common notation.
2.1 Problem Description. Let x ∈ X and y ∈ Y be an input vector and
a target vector, 分别. Define ((希
i=1 as a training data set of size
米. Let θ ∈ Rdθ be a parameter vector to be optimized. Let f (X; 我 ) ∈ Rdy be
the output of a model or a hypothesis, 然后让 (西德:3) : Rdy × Y → R≥0 be a loss
function. 这里, dθ , dy ∈ N>0. We consider the following standard objective
function L to train a model f (X; 我 ):
, 做))米
L(我 ) =
米(西德:2)
我=1
λ
我
(西德:3)( F (希
; 我 ), 做).
This article allows the weights λ
1
λ
= · · · = λm = 1
1
L as a special case.
, . . . , λm > 0 to be arbitrarily fixed. 和
米 , all of our results hold true for the standard average loss
2.2 符号. Because the focus of this article is the optimization of the
vector θ , the following notation is convenient: (西德:3)y(q) = (西德:3)(q, y) and fx(q) =
F (X; q). Then we can write
L(我 ) =
米(西德:2)
我=1
λ
我
(西德:3)做 ( fxi (我 )) =
米(西德:2)
我=1
我((西德:3)做
λ
◦ fxi )(我 ).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
, . . . , ϕ
We use the following standard notation for differentiation. Given a
scalar-valued or vector-valued function ϕ : Rd → Rd(西德:6)
with components
(西德:6)× ¯d be the
ϕ = (ϕ
d(西德:6) ) and variables (v
1
matrix-valued function with each entry (∂v ϕ)我, j
. Note that if ϕ is a
scalar-valued function, ∂v ϕ outputs a row vector. 此外, ∂ϕ = ∂v ϕ if
(v
, 让
∂
ϕ with respect to the kth variable of
k
ϕ. For the syntax of any differentiation map ∂, given functions ϕ and ζ , 让
, . . . , v
1
ϕ : Rd → R be the partial derivative ∂
d ) are the input variables of ϕ. Given a function ϕ : Rd → Rd(西德:6)
, . . . , v ¯d ), let ∂v ϕ : Rd → Rd
= ∂ϕ
∂v
1
k
j
我
2296
K. Kawaguchi, J. 黄, 和L. Kaelbling
∂ϕ(ζ (q)) = (∂ϕ)(ζ (q)) be the (部分的) derivative ∂ϕ evaluated at an output
ζ (q) of a function ζ .
Given a matrix M ∈ Rd×d(西德:6)
, . . . ,
, vec(中号) = [M1,1
M1,d(西德:6) , . . . , Md,d(西德:6) ]T represents the standard vectorization of the matrix M.
Given a set of n matrices or vectors {中号( j)}n
= [中号(1),
中号(2), . . . , 中号(n)]
to be a block matrix of each column block being
中号(1), 中号(2), . . . , 中号(n). 相似地, given a set I = {i1
, . . . , 在) in-
creasing, 定义 [中号( j)] j∈I = [中号(i1 )
j=1, 定义 [中号( j)]n
, . . . , 在} 和 (i1
· · · M(在 )].
, . . . , Md,2
, . . . , Md,1
, M1,2
j=1
3 Nonconvex Optimization Landscapes for Machine Learning
This section shows our first main result that under mild assumptions, 电动车-
ery differentiable local minimum achieves the global optimality of the per-
turbable gradient basis model class.
3.1 Assumptions. Given a hypothesis class f and data set, 让 (西德:8) 是
a set of nondifferentiable points θ as (西德:8) = {θ ∈ Rdθ : (∃i ∈ {1, . . . , 米})[ fxi
is not differentiable at θ ]}. 相似地, define ˜(西德:8) = {θ ∈ Rdθ : (∀(西德:9) > 0)(∃θ (西德:6) ∈
乙(我 , (西德:9)))(∃i ∈ {1, . . . , 米})[ fxi is not differentiable at θ (西德:6)
]}. 这里, 乙(我 , (西德:9)) 是个
open ball with the center θ and the radius (西德:9). In common nondifferentiable
models f such as neural networks with rectified linear units (ReLUs) 和
pooling operations, we have that (西德:8) = ˜(西德:8), and the Lebesgue measure of
(西德:8)(= ˜(西德:8)) is zero.
This section uses the following mild assumptions.
i ∈ {1, . . . , 米},
Assumption 1 (Use of Common Loss criteria). For all
the function (西德:3)做 : q (西德:9)→ (西德:3)(q, 做) ∈ R≥0 is differentiable and convex (例如, 这
squared loss, cross-entropy loss, or polynomial hinge loss satisfies this
assumption).
Assumption 2 (Use of Common Model Structures). There exists a function
G : Rdθ → Rdθ such that fxi (我 ) =
k fxi (我 ) for all i ∈ {1, . . . , 米} 和
k=1 g(我 )k
all θ ∈ Rdθ \ (西德:8).
(西德:3)
∂
dθ
k
迪
(西德:3)
(西德:3)
k=1 yk log exp(qk )
(西德:6) 经验值(qk
Assumption 1 is satisfied by simply using common loss criteria that
include the squared loss (西德:3)(q, y) = (西德:10)q − y(西德:10)2
2, cross-entropy loss (西德:3)(q, y) =
-
(西德:6) ) , and smoothed hinge loss (西德:3)(q, y) = (max{0, 1 -
yq})p with p ≥ 2 (the hinge loss with dy = 1). Although the objective func-
tion L : 我 (西德:9)→ L(我 ) used to train a complex machine learning model (例如, A
neural network) is nonconvex in θ , the loss criterion (西德:3)做 : q (西德:9)→ (西德:3)(q, 做) is usu-
ally convex in q. 在本文中, the cross-entropy loss includes the softmax
function, and thus fx(我 ) is the pre-softmax output of the last layer in related
deep learning models.
Assumption 2 is satisfied by simply using a common architecture in
deep learning or a classical machine learning model. 例如, consider
a deep neural network of the form fx(我 ) = Wh(X; 你) + 乙, where h(X; 你) 是
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2297
dθ
∂
(西德:3)
an output of an arbitrary representation at the last hidden layer and θ =
vec([瓦, 乙, 你]). Then assumption 2 holds because fxi (我 ) =
k fxi (我 ),
where g(我 )k
k for all k corresponding to the parameters (瓦, 乙) in the last
= θ
layer and g(我 )k
= 0 for all other k corresponding to u. 一般来说, because g
is a function of θ , assumption 2 is easily satisfiable. Assumption 2 不
require the model f (X; 我 ) to be linear in θ or x.
k=1 g(我 )k
Note that we allow the nondifferentiable points to exist in L(我 ); 为了
例子, the use of ReLU is allowed. For a nonconvex and nondifferen-
tiable function, we can still have first-order and second-order necessary
conditions of local minima (例如, Rockafellar & Wets, 2009, theorem 13.24).
然而, subdifferential calculus of a nonconvex function requires careful
treatment at nondifferentiable points (see Rockafellar & Wets, 2009; Kakade
& 李, 2018; 戴维斯, Drusvyatskiy, Kakade, & 李, 2019), and deriving guar-
antees at nondifferentiable points is left to a future study.
3.2 Theory for Critical Points. Before presenting the first main result,
this section provides a simpler result for critical points to illustrate the ideas
behind the main result for local minima. We define the (theoretical) 对象-
tive function Lθ of the gradient basis model class as
Lθ (A) =
米(西德:2)
我=1
λ
我
(西德:3) ( fθ (希
; A), 做) ,
(西德:3)
∂
A
k
dθ
k=1
; A) =
在哪里 { fθ (希
k fxi (我 ) : α ∈ Rdθ } is the induced gradient basis
model class. The following theorem shows that every differentiable crit-
ical point of our original objective L (including every differentiable local
minimum and saddle point) achieves the global minimum value of Lθ . 这
complete proofs of all the theoretical results are presented in appendix A.
Theorem 1. Let assumptions 1 和 2 hold. Then for any critical point θ ∈ (Rdθ \
(西德:8)) of L, the following holds:
L(我 ) = inf
α∈Rdθ
Lθ (A).
An important aspect in theorem 1 is that Lθ on the right-hand side is
convex, while L on the left-hand side can be nonconvex or convex. 这里,
following convention, inf S is defined to be the infimum of a subset S of R
(the set of affinely extended real numbers); 那是, if S has no lower bound,
inf S = −∞ and inf ∅ = ∞. Note that theorem 1 vacuously holds true if
there is no critical point for L. To guarantee the existence of a minimizer
在一个 (nonempty) subspace S ⊆ Rdθ for L (or Lθ ), a classical proof requires
two conditions: a lower semicontinuity of L (or Lθ ) and the existence of a
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2298
K. Kawaguchi, J. 黄, 和L. Kaelbling
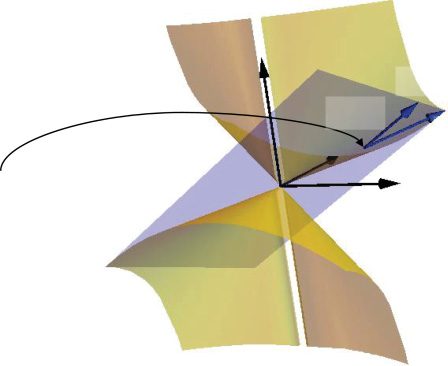
数字 1: Illustration of gradient basis model class and theorem 1 with θ ∈ R2
and fX (我 ) ∈ R3 (迪
= 1). Theorem 1 translates the local condition of θ in the pa-
rameter space R2 (on the left) to the global optimality in the output space R3 (在
正确的). The subspace TfX (我 ) is the space of the outputs of the gradient basis
model class. Theorem 1 states that fX (我 ) is globally optimal in the subspace as
fX (我 ) ∈ argminf∈T fX (我 )
dist(F, y) for any differentiable critical point θ of L.
q ∈ S for which the set {q(西德:6) ∈ S : L(q(西德:6)
袖珍的 (see Bertsekas, 1999, for different conditions).
) ≤ L(q)} (或者 {q(西德:6) ∈ S : Lθ (q(西德:6)
) ≤ Lθ (q)}) 是
3.2.1 Geometric View. This section presents the geometric interpretation
of theorem 1 that provides an intuitive yet formal description of gradient
basis model class. 数字 1 illustrates the gradient basis model class and
theorem 1 with θ ∈ R2 and fX (我 ) ∈ R3. 这里, we consider the following map
from the parameter space to the concatenation of the output of the model
at x1
, . . . , xm:
, x2
fX : θ ∈ Rdθ (西德:9)→ ( fx1 (我 )
(西德:15), fx2 (我 )
(西德:15), . . . , fxm (我 )
(西德:15)
(西德:15) ∈ Rmdy .
)
In the output space Rmdy of fX, the objective function L induces the notion
米)(西德:15) ∈ Rmdy to a vector f =
of distance from the target vector y = (y(西德:15)
1
(F(西德:15)
1
米)(西德:15) ∈ Rmdy as
, . . . , y(西德:15)
, . . . , F(西德:15)
dist(F, y) =
米(西德:2)
我=1
λ
我
(西德:3)(fi
, 做).
We consider the affine subspace TfX (我 ) of Rmdy that passes through the point
fX (我 ) and is spanned by the set of vectors {∂
1 fX (我 ), . . . , ∂
dθ fX (我 )},
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2299
TfX (我 )
= span({∂
1 fX (我 ), . . . , ∂
dθ fX (我 )}) + { fX (我 )},
where the sum of the two sets represents the Minkowski sum of the
套.
Then the subspace TfX (我 ) is the space of the outputs of the gradient ba-
sis model class in general beyond the low-dimensional illustration. 这是
because by assumption 2, for any given θ ,
TfX (我 )
=
=
(西德:4)
dθ(西德:2)
(西德:4)
k=1
dθ(西德:2)
k=1
(西德:5)
(G(我 )k
+ A
k)∂
k fX (我 ) : α ∈ Rdθ
(西德:5)
A
k
∂
k fX (我 ) : α ∈ Rdθ
,
(3.1)
(西德:3)
dθ
和
k=1
= span({∂
∂
k fX (我 ) = ( fθ (x1
A
k
1 fX (我 ), . . . , ∂
; A)(西德:15), . . . , fθ (xm; A)(西德:15))(西德:15). 换句话说, TfX (我 )
; A)(西德:15), . . . , fθ (xm; A)(西德:15))(西德:15).
dθ fX (我 )}) (西德:16) ( fθ (x1
所以, 一般来说, theorem 1 states that under assumptions 1 和 2,
fX (我 ) is globally optimal in the subspace TfX (我 ) 作为
fX (我 ) ∈ argmin
f∈T fX (我 )
dist(F, y),
for any differentiable critical point θ of L. Theorem 1 concludes this global
optimality in the affine subspace of the output space based on the local
condition in the parameter space (IE。, differentiable critical point). A key
idea behind theorem 1 is to consider the map between the parameter space
and the output space, which enables us to take advantage of assumptions 1
和 2.
数字 2 illustrates the gradient basis model class and theorem 1 与一个
union of manifolds and a tangent space. Under the constant rank condition,
the image of the map fX locally forms a single manifold. 更确切地说, 如果
there exists a small neighborhood U(我 ) of θ such that fX is differentiable in
U(我 ) and rank(∂ fX (我 (西德:6)
)) = r is constant with some r for all θ (西德:6) ∈ U(我 ) (缺点-
stant rank condition), then the rank theorem states that the image fX (U(我 ))
is a manifold of dimension r (李, 2013, theorem 4.12). We note that the rank
map θ (西德:9)→ rank(∂ fX (我 )) is lower semicontinuous (IE。, if rank(∂ fX (我 )) = r,
then there exists a neighborhood U(我 ) of θ such that rank(∂ fX (我 (西德:6)
)) ≥ r for
any θ (西德:6) ∈ U(我 )). 所以, if ∂ fX (我 ) at θ has the maximum rank in a small
neighborhood of θ , then the constant rank condition is satisfied.
For points θ where the constant rank condition is violated, the image of
the map fX is no longer a single manifold. 然而, locally it decomposes
as a union of finitely many manifolds. 更确切地说, if there exists a small
neighborhood U(我 ) of θ such that fX is analytic over U(我 ) (this condition
is satisfied for commonly used activation functions such as ReLU, sigmoid,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2300
K. Kawaguchi, J. 黄, 和L. Kaelbling
1
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
数字 2: Illustration of gradient basis model class and theorem 1 with man-
ifold and tangent space. The space R2 (西德:16) θ on the left is the parameter space,
and the space R3 (西德:16) fX (我 ) on the right is the output space. The surface M ⊂ R3
on the right is the image of fX, which is a union of finitely many manifolds.
The tangent space TfX (我 ) is the space of the outputs of the gradient basis model
班级. Theorem 1 states that if θ is a differentiable critical point of L, then fX (我 )
is globally optimal in the tangent space TfX (我 ).
and hyperbolic tangent at any differentiable point), then the image fX (U(我 ))
admits a locally finite partition M into connected submanifolds such that
whenever M (西德:18)= 米(西德:6) ∈ M with ¯M ∩ M(西德:6) (西德:18)= ∅ ( ¯M is the closure of M), 我们有
(西德:6) ⊂ ¯M, dim(中号
(西德:6)
中号
) < dim(M).
See Hardt (1975) for the proof.
If the point θ satisfies the constant rank condition, then TfX (θ ) is exactly
the tangent space of the manifold formed by the image fX (U(θ )). Otherwise,
locally the image decomposes into a finite union M of submanifolds. In this
case, TfX (θ ) belongs to the span of the tangent space of those manifolds in
M as
TfX (θ )
⊂ {TpM : p = fX (θ ), M ∈ M},
where TpM is the tangent space of the manifold M at the point p.
3.2.2 Examples. In this section, we show through examples that theorem
1 generalizes the previous results in special cases while providing new the-
oretical insights based on the gradient basis model class and its geometric
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
c
o
_
a
_
0
1
2
3
4
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2301
view. In the following, whenever the form of f is specified, we require only
assumption 1 because assumption 2 is automatically satisfied by a given f .
For classical machine learning models, example 1 shows that the gradi-
ent basis model class is indeed equivalent to a given model class. From the
geometric view, this means that for any θ , the tangent space T fX (θ ) is equal
to the whole image M of fX (i.e., TfX (θ ) does not depend on θ ). This reduces
theorem 1 to the statement that every critical point of L is a global minimum
of L.
k
θ
(cid:3)
dθ
k=1
Example 1: Classical Machine Learning Models. For any basis func-
tion model f (x; θ ) =
φ(x)k in classical machine learning with any
fixed feature map φ : X → Rdθ , we have that fθ (x; α) = f (x; α), and hence
infθ ∈Rdθ L(θ ) = infα∈Rdθ Lθ (α), as well as (cid:8) = ∅. In other words, in this spe-
cial case, theorem 1 states that every critical point of L is a global minimum
of L. Here, we do not assume that a critical point or a global minimum exists
or can be attainable. Instead, the statement logically means that if a point is
a critical point, then the point is a global minimum. This type of statement
vacuously holds true if there is no critical point.
For overparameterized deep neural networks, example 2 shows that the
induced gradient basis model class is highly expressive such that it must
contain the globally optimal model of a given model class of deep neural
networks. In this example, the tangent space TfX (θ ) is equal to the whole
output space Rmdy . This reduces theorem 1 to the statement that every criti-
cal point of L is a global minimum of L for overparameterized deep neural
networks.
Intuitively, in Figure 1 or 2, we can increase the number of parameters
and raise the number of partial derivatives ∂
k fX (θ ) in order to increase the
= Rmdy . This is in-
dimensionality of the tangent space TfX (θ ) so that TfX (θ )
deed what happens in example 2, as well as in the previous studies of sig-
nificantly overparameterized deep neural networks (Allen-Zhu, Li, & Song,
2018; Du, Lee, Li, Wang, & Zhai, 2018; Zou et al., 2018). In the previous
studies, the significant overparameterization is required so that the tangent
= Rmdy
space TfX (θ ) does not change from the initial tangent space TfX (θ (0) )
during training. Thus, theorem 1, with its geometric view, provides the
novel algebraic and geometric insights into the results of the previous stud-
ies and the reason why overparameterized deep neural networks are easy
to be optimized despite nonconvexity.
Example 2: Overparameterized Deep Neural Networks. Theorem 1 im-
plies that every critical point (and every local minimum) is a global mini-
mum for sufficiently overparameterized deep neural networks. Let n be the
number of units in each layer of a fully connected feedforward deep neu-
ral network. Let us consider a significant overparameterization such that
n ≥ m. Let us write a fully connected feedforward deep neural network with
the trainable parameters (θ , u) by f (x; θ ) = Wφ(x; u), where W ∈ Rdy×n is
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
c
o
_
a
_
0
1
2
3
4
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2302
K. Kawaguchi, J. Huang, and L. Kaelbling
the weight matrix in the last layer, θ = vec(W ), u contains the rest of the
parameters, and φ(x; u) is the output of the last hidden layer. Denote xi
=
)(cid:15), 1](cid:15) to contain the constant term to account for the bias term in the
[(x(raw)
i
= 1
first layer. Assume that the input samples are normalized as (cid:10)x(raw)
< 1 − δ with some δ > 0
for all i ∈ {1, . . . , 米} and distinct as (X(raw)
我
for all i(西德:6) (西德:18)= i. Assume that the activation functions are ReLU activation func-
系统蒸发散. Then we can efficiently set u to guarantee rank([φ(希
我=1) ≥ m (例如,
by choosing u to make each unit of the last layer to be active only for each
sample xi).1 Theorem 1 implies that every critical point θ with this u is a
global minimum of the whole set of trainable parameters (我 , 你) 因为
infα Lθ (A) = inf f1
, 做) (with assumption 1).
(西德:15)X(raw)
)
我(西德:6)
; 你)]米
(西德:3)( fi
,…, fm
(西德:3)
λ
我
(西德:10)
2
我
米
我=1
For deep neural networks, 例子 3 shows that standard networks have
the global optimality guarantee with respect to the representation learned at
the last layer, and skip connections further ensure the global optimality with
respect to the representation learned at each hidden layer. 这是因为
adding the skip connections incurs new partial derivatives {∂
k that
span the tangent space containing the output of the best model with the
corresponding learned representation.
k fX (我 )}
例子 3: Deep Neural Networks and Learned Representations. 骗局-
sider a feedforward deep neural network, and let I (skip) ⊆ {1, . . . , H} be the
set of indices such that there exists a skip connection from the (l − 1)th layer
to the last layer for all l ∈ I (skip) ; 那是, in this example,
F (X; 我 ) =
(西德:2)
l∈I (skip)
瓦 (l+1)H(我)(X; 你),
where θ = vec([[瓦 (l+1)]l∈I (skip) , 你]) ∈ Rdθ with W (l+1) ∈ Rdy×dl and u ∈ Rdu .
The conclusion in this example holds for standard deep neural networks
without skip connections too, since we always have H ∈ I (skip) for standard
深度神经网络. Let assumption 1 hold. Then theorem 1 implies that
for any critical point θ ∈ (Rdθ \ (西德:8)) of L, the following holds:
L(我 ) = inf
α∈Rdθ
L(skip)
我
(A),
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1
> 0 和 (瓦 (1)希 )我(西德:6) ≤ 0 for all i
例如, choose the first layer’s weight matrix W (1) such that for all i ∈ {1, . . . , 米},
(西德:6) (西德:18)= i. This can be achieved by choosing the ith row
(西德:15), (西德:9) - 1] 和 0 < (cid:9) ≤ δ for i ≤ m. Then choose the weight matrices
(cid:6) (cid:18)= j. This
(W (1)xi )i
of W (1) to be [(x(raw)
for the lth layer for all l ≥ 2 such that for all j, W (l)
j, j
; u)]m
guarantees rank([φ(xi
(cid:18)= 0 and W (l)
j(cid:6), j
= 0 for all j
)
i
i=1 ) ≥ m.
Every Local Minimum Value Is the Global Minimum Value
2303
where
L(skip)
θ
(α) =
m(cid:2)
i=1
λ
i
(cid:3)yi
⎛
⎝
(cid:2)
l∈I (skip)
α(l+1)
w
h(l)(xi
; u) +
⎞
(αu)k
∂uk fxi (θ )
⎠ ,
du(cid:2)
k=1
with α = vec([[α(l+1)]l∈I (skip) , αu]) ∈ Rdθ with α(l+1) ∈ Rdy×dl and αu ∈ Rdu .
vec(W (H+1) ) f (x; θ ))vec(W (H+1)), and thus assump-
This is because f (x; θ ) = (∂
; u) is the representation learned
tion 2 is automatically satisfied. Here, h(l)(xi
at the l-layer. Therefore, infα∈Rdθ L(skip)
(α) is at most the global minimum
value of the basis models with the learned representations of the last layer
and all hidden layers with the skip connections.
θ
3.3 Theory for Local Minima. We are now ready to present our first
main result. We define the (theoretical) objective function ˜Lθ of the per-
turbable gradient basis model class as
˜Lθ (α, (cid:9), S) =
m(cid:2)
i=1
λ
i
(cid:3)( ˜fθ (xi
; α, (cid:9), S), yi),
where ˜fθ (xi
; α, (cid:9), S) is a perturbed gradient basis model defined as
˜fθ (xi
; α, (cid:9), S) =
dθ(cid:2)
|S|(cid:2)
k=1
j=1
α
k, j
∂
k fxi (θ + (cid:9)S j ).
2
, . . . , S|S| ∈ Rdθ and α ∈ Rdθ ×|S|
Here, S is a finite set of vectors S1
be the set of all vectors v ∈ Rdθ such that (cid:10)v(cid:10)
for any i ∈ {1, . . . , m}. Let S ⊆
S j
(cid:9)S j ) (cid:18)= ∂
S ⊆
fin
The following theorem shows that every differentiable local minimum
denote a finite subset S of a set S(cid:6)
∈ V[θ , (cid:9)], we have fxi (θ + (cid:9)S j ) = fxi (θ ), but it is possible to have ∂
k fxi (θ ). This enables the greater expressivity of ˜fθ (xi
. Let V[θ , (cid:9)]
≤ 1 and fxi (θ + (cid:9)v ) = fxi (θ )
. For an
k fxi (θ +
; α, (cid:9), S) with a
V[θ , (cid:9)] when compared with fθ (xi
fin S(cid:6)
; α).
of L achieves the global minimum value of ˜Lθ :
Theorem 2. Let assumptions 1 and 2 hold. Then, for any local minimum θ ∈
(Rdθ \ ˜(cid:8)) of L, the following holds: there exists (cid:9)
0),
> 0 such that for any (西德:9) ∈ [0, (西德:9)
0
L(我 ) = inf
˜Lθ (A, (西德:9), S).
f in
S⊆
V[我,(西德:9)],
α∈Rdθ ×|S|
(3.2)
To understand the relationship between theorems 1 和 2, let us consider
the following general inequalities: for any θ ∈ (Rdθ \ ˜(西德:8)) 和 (西德:9) ≥ 0 存在
sufficiently small,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2304
K. Kawaguchi, J. 黄, 和L. Kaelbling
L(我 ) ≥ inf
α∈Rdθ
Lθ (A) ≥ inf
S⊆
V[我 ,(西德:9) ],
α∈Rdθ ×|S|
f in
˜Lθ (A, (西德:9), S).
这里, whereas theorem 1 states that the first inequality becomes equality as
L(我 ) = infα∈Rdθ Lθ (A) at every differentiable critical point, theorem 2 状态
that both inequalities become equality as
L(我 ) = inf
α∈Rdθ
Lθ (A) = inf
S⊆
V[我,(西德:9)],
α∈Rdθ ×|S|
f in
˜Lθ (A, (西德:9), S)
at every differentiable local minimum.
fin
k fxi (我 )}dθ
V[我 , (西德:9)] and α ∈ Rdθ ×|S|
From theorem 1 to theorem 2, the power of increasing the number of pa-
rameters (including overparameterization) is further improved. The right-
hand side in equation 3.2 is the global minimum value over the variables
S ⊆
. 这里, as dθ increases, we may obtain the global
minimum value of a larger search space Rdθ ×|S|
, which is similar to theorem
1. A concern in theorem 1 is that as dθ increases, we may also significantly
increase the redundancy among the elements in {∂
k=1. Although this
remains a valid concern, theorem 2 allows us to break the redundancy by
the globally optimal S ⊆
V[我 , (西德:9)] to some degree.
例如, consider f (X; 我 ) = g(瓦 (我)H(我)(X; 你); 你), which represents a
deep neural network, with some lth-layer output h(我)(X; 你) ∈ Rdl , a trainable
weight matrix W (我), and an arbitrary function g to compute the rest of the for-
×m
ward pass. 这里, θ = vec([瓦 (我), 你]). Let h(我)(X; 你) = [H(我)(希
和, similarly, F (X; 我 ) = g(瓦 (我)H(我)(X; 你); 你) ∈ Rdy×m. 然后, all vectors v cor-
responding to any elements in the left null space of h(我)(X; 你) are in V[我 , (西德:9)]
(IE。, v
k is set to perturb
瓦 (我) by an element in the left null space). 因此, as the redundancy increases
such that the dimension of the left null space of h(我)(X; 你) 增加, 我们有
a larger space of V[我 , (西德:9)], for which a global minimum value is guaranteed
at a local minimum.
= 0 for all k corresponding to u and the rest of v
; 你)]米
我=1
∈ Rdl
fin
k
3.3.1 Geometric View. This section presents the geometric interpretation
of the perturbable gradient basis model class and theorem 2. 数字 3 illus-
trates the perturbable gradient basis model class and theorem 2 with θ ∈ R2
and fX (我 ) ∈ R3. 数字 4 illustrates them with a union of manifolds and tan-
gent spaces at a singular point. Given a (西德:9) (≤ (西德:9)
0), define the affine subspace
˜TfX (我 ) of the output space Rmdy by
˜TfX (我 )
= span({f ∈ Rmdy : (∃v ∈ V[我 , (西德:9)])[f ∈ TfX (我 +(西德:9)v )]}).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2305
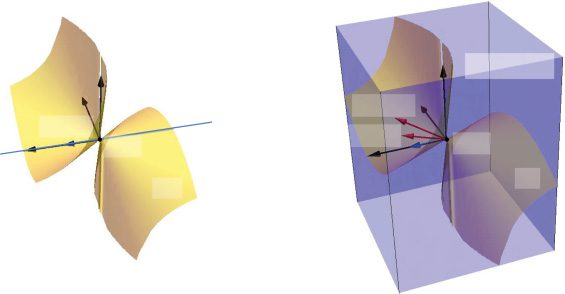
数字 3: Illustration of perturbable gradient basis model class and theorem 2
with θ ∈ R2 and fX (我 ) ∈ R3 (迪
= 1). Theorem 2 translates the local condition of
θ in the parameter space R2 (on the left) to the global optimality in the output
space R3 (on the right). The subspace ˜TfX (我 ) is the space of the outputs of the
perturbable gradient basis model class. Theorem 2 states that fX (我 ) is globally
optimal in the subspace as fX (我 ) ∈ argminf∈ ˜T fX (我 )
dist(F, y) for any differentiable
local minima θ of L. 在这个例子中, ˜TfX (我 ) is the whole output space R3, 尽管
TfX (我 ) 不是, illustrating the advantage of the perturbable gradient basis over the
= R3, fX (我 ) must be globally optimal in the whole
gradient basis. Since ˜TfX (我 )
output space R3.
Then the subspace ˜TfX (我 ) is the space of the outputs of the perturbable gra-
dient basis model class in general beyond the low-dimensional illustration
(this follows equation 3.1 and the definition of the perturbable gradient ba-
sis model). 所以, 一般来说, theorem 2 states that under assumptions
1 和 2, fX (我 ) is globally optimal in the subspace ˜TfX (我 ) 作为
fX (我 ) ∈ argmin
f∈ ˜T fX (我 )
dist(F, y)
for any differentiable local minima θ of L. Theorem 2 concludes the global
optimality in the affine subspace of the output space based on the local con-
dition in the parameter space—that is, differentiable local minima. 这里, A
(differentiable) local minimum θ is required to be optimal only in an ar-
bitrarily small local neighborhood in the parameter space, and yet fX (我 ) 是
guaranteed to be globally optimal in the affine subspace of the output space.
This illuminates the fact that nonconvex optimization in machine learning
has a particular structure beyond general nonconvex optimization.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2306
K. Kawaguchi, J. 黄, 和L. Kaelbling
数字 4: Illustration of perturbable gradient basis model class and theorem 2
with manifold and tangent space at a singular point. The surface M ⊂ R3 is
the image of fX, which is a union of finitely many manifolds. The line TfX (我 )
on the left panel is the space of the outputs of the gradient basis model class.
= R3 on the right panel is the space of the outputs of the
The whole space ˜TfX (我 )
perturbable gradient basis model class. The space ˜TfX (我 ) is the span of the set of
, TfX (我 (西德:6) ), and TfX (我 (西德:6)(西德:6) ). Theorem 2 states that
the vectors in the tangent spaces TfX (我 )
if θ is a differentiable local minimum of L, then fX (我 ) is globally optimal in the
space ˜TfX (我 ).
4 Applications to Deep Neural Networks
The previous section showed that all local minima achieve the global op-
timality of the perturbable gradient basis model class with several direct
consequences for special cases. 在这个部分, as consequences of theorem
2, we complement or improve the state-of-the-art results in the literature.
4.1 例子: ResNets. As an example of theorem 2, we set f to be the
function of a certain type of residual networks (ResNets) that Shamir (2018)
studied. 那是, both Shamir (2018) and this section set f as
F (X; 我 ) = W (X + Rz(X; 你)),
(4.1)
where θ = vec([瓦, 右, 你]) ∈ Rdθ with W ∈ Rdy×dx , R ∈ Rdx×dz , and u ∈ Rdu .
这里, z(X; 你) ∈ Rdz represents an output of deep residual functions with
a parameter vector u. No assumption is imposed on the form of z(X; 你),
and z(X; 你) can represent an output of possibly complicated deep resid-
ual functions that arise in ResNets. 例如, the function f can rep-
resent deep preactivation ResNets (他, 张, Ren, & Sun, 2016), 哪个
are widely used in practice. To simplify theoretical study, Shamir (2018) 作为-
sumed that every entry of the matrix R is unconstrained (例如, instead of R
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2307
representing convolutions). We adopt this assumption based on the previ-
ous study (Shamir, 2018).
4.1.1 Background. Along with an analysis of approximate critical points,
Shamir (2018) proved the following main result, 主张 1, under the
assumptions PA1, PA2, and PA3:
PA1: The output dimension dy = 1.
PA2: For any y, the function (西德:3)y is convex and twice differentiable.
PA3: On any bounded subset of the domain of L, the function Lu(瓦, 右),
its gradient ∇Lu(瓦, 右), and its Hessian ∇2Lu(瓦, 右) are all Lipschitz
continuous in (瓦, 右), where Lu(瓦, 右) = L(我 ) with a fixed u.
Proposition 1 (Shamir, 2018). Let f be specified by equation 4.1, Let assumptions
PA1, PA2, and PA3 hold. Then for any local minimum θ of L,
米(西德:2)
L(我 ) ≤ inf
W∈Rdy ×dx
我=1
λ
我
(西德:3)做 (Wxi).
Shamir (2018) remarked that it is an open problem whether proposi-
的 1 and another main result in the article can be extended to networks
with dy > 1 (multiple output units). Note that Shamir (2018) also provided
主张 1 with an expected loss and an analysis for a simpler decou-
pled model, Wx + Vz(X; 你). For the simpler decoupled model, our theo-
rem 1 immediately concludes that given any u, every critical point with
respect to θ−u = (瓦, 右) achieves a global minimum value with respect
; 你)) : W ∈ Rdy×dx , R ∈ Rdx×dz }
to θ−u as L(θ−u) = inf {
(≤ infW∈Rdy ×dx
(西德:3)做 (Wxi)). This holds for every critical point θ since any
critical point θ must be a critical point with respect to θ−u.
(西德:3)做 (Wxi
+ Rz(希
米
我=1
米
我=1
(西德:3)
(西德:3)
λ
我
λ
我
4.2 Result. The following theorem shows that every differentiable local
minimum achieves the global minimum value of ˜L(ResNet)
(the right-hand
side in equation 4.2), which is no worse than the upper bound in propo-
, 你) 或者
位置 1 and is strictly better than the upper bound as long as z(希
; A, (西德:9), S) is nonnegligible. 的确, the global minimum value of ˜L(ResNet)
˜fθ (希
(the right-hand side in equation 4.2) is no worse than the global minimum
value of all models parameterized by the coefficients of the basis x and
z(X; 你), and further improvement is guaranteed through a nonnegligible
˜fθ (希
; A, (西德:9), S).
我
我
Theorem 3. Let
f be specified by equation 4.1. Let assumption 1 hold. 作为-
sume that dy ≤ min{dx, dz}. Then for any local minimum θ ∈ (Rdθ \ ˜(西德:8)) of L, 这
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2308
K. Kawaguchi, J. 黄, 和L. Kaelbling
following holds: there exists (西德:9)
0
> 0 such that for any (西德:9) ∈ (0, (西德:9)
0),
˜L(ResNet)
我
(A, αw, αr, (西德:9), S),
(4.2)
L(我 ) =
inf
S⊆
V[我 ,(西德:9)],
α∈Rdθ ×|S|,
αw∈Rdy ×dx ,αr∈Rdy ×dz
f in
在哪里
˜L(ResNet)
我
(A, αw, αr, (西德:9), S) =
米(西德:2)
我=1
λ
我
(西德:3)做 (αwxi
+ αrz(希
; 你) + ˜fθ (希
; A, (西德:9), S)).
Theorem 3 also successfully solved the first part of the open problem in
the literature (Shamir, 2018) by discarding the assumption of dy = 1. 从
the geometric view, theorem 3 states that the span ˜TfX (我 ) of the set of the
vectors in the tangent spaces {TfX (我 +(西德:9)v ) : v ∈ V[我 , (西德:9)]} contains the output of
the best basis model with the linear feature x and the learned nonlinear
(西德:18)= Tf (我 ) 和
; 你). Similar to the examples in Figures 3 和 4, ˜TfX (我 )
feature z(希
the output of the best basis model with these features is contained in ˜TfX (我 )
but not in Tf (我 ).
Unlike the recent study on ResNets (Kawaguchi & 本吉奥, 2019), our the-
orem 3 predicts the value of L through the global minimum value of a large
search space (IE。, the domain of ˜L(ResNet)
) and is proven as a consequence of
our general theory (IE。, theorem 2) with a significantly different proof idea
(参见部分 4.3) and with the novel geometric insight.
我
4.2.1 例子: Deep Nonlinear Networks with Locally Induced Partial Linear
结构. We specify f to represent fully connected feedforward networks
with arbitrary nonlinearity σ and arbitrary depth H as follows:
F (X; 我 ) = W (H+1)H(H)(X; 我 ),
(4.3)
在哪里
H(我)(X; 我 ) = σ (我)(瓦 (我)H(l−1)(X; 我 )),
for all l ∈ {1, . . . , H} with h(0)(X; 我 ) = x. 这里, θ = vec([瓦 (我)]H+1
l=1 ) ∈ Rdθ with
瓦 (我) ∈ Rdl
= dx. 此外, σ (我) : Rdl → Rdl repre-
sents an arbitrary nonlinear activation function per layer l and is allowed
to differ among different layers.
= dy, and d0
×dl−1 , dH+1
4.2.2 Background. Given the difficulty of theoretically understanding
深度神经网络, 好人, 本吉奥, and Courville (2016) noted that
theoretically studying simplified networks (IE。, deep linear networks) 是
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2309
worthwhile. 例如, Saxe, 麦克莱兰, and Ganguli (2014) empiri-
cally showed that deep linear networks may exhibit several properties anal-
ogous to those of deep nonlinear networks. 因此, the theoretical
study of deep linear neural networks has become an active area of research
(Kawaguchi, 2016; Hardt & Ma, 2017; Arora, 科恩, Golowich, & 胡, 2018;
Arora, 科恩, & Hazan, 2018; Bartlett, Helmbold, & 长的, 2019; Du & 胡,
2019).
Along this line, Laurent and Brecht (2018) recently proved the following
main result, 主张 2, under the assumptions PA4, PA5, and PA6:
PA4: Every activation function is identity as σ (我)(q) = q for every l ∈
{1, . . . , H} (IE。, deep linear networks).
PA5: For any y, the function (西德:3)y is convex and differentiable.
PA6: The thinnest layer is either the input layer or the output layer as
min{dx, 迪} ≤ min{d1
, . . . , dH}.
Proposition 2 (Laurent & Brecht, 2018). Let f be specified by equation 4.3. Let
assumptions PA4, PA5, and PA6 hold. Then every local minimum θ of L is a global
minimum.
4.2.3 Result. Instead of studying deep linear networks, we now consider
a partial linear structure locally induced by a parameter vector with nonlin-
ear activation functions. This relaxes the linearity assumption and extends
our understanding of deep linear networks to deep nonlinear networks.
直观地, Jn,t[我 ] is a set of partial linear structures locally induced
by a vector θ , which is now formally defined as follows. Given a θ ∈ Rdθ ,
let Jn,t[我 ] be a set of all sets J = {J(t+1), . . . , J(H+1)} such that each set J =
{J(t+1), . . . , J(H+1)} ∈ Jn,t[我 ] satisfies the following conditions: there exists
(西德:9) > 0 such that for all l ∈ {t + 1, t + 2, . . . , H + 1},
为了
全部
(k, 我 (西德:6), 我) ∈ J(我) × B(我 , (西德:9)) ×
1. J(我) ⊆ {1, . . . , dl
, 我 (西德:6)
2. H(我)(希
} 和 |J(我)| ≥ n.
))k
= (瓦 (我)H(l−1)(希
, 我 (西德:6)
)k
{1, . . . , 米}.
3. 瓦 (l+1)
我, j
= 0 对全部 (我, j) ∈ ({1, . . . , dl+1
} \ J(l+1)) × J(我) if l ≤ H − 1.
Let (西德:14)n,t be the set of all parameter vectors θ such that Jn,t[我 ] is nonempty.
As the definition reveals, a neural network with a θ ∈ (西德:14)
迪,t can be a standard
deep nonlinear neural network (with no linear units).
Theorem 4. Let f be specified by equation 4.3. Let assumption 1 hold. Then for
any t ∈ {1, . . . , H}, at every local minimum θ ∈ ((西德:14)
\ ˜(西德:8)) of L, 下列
迪,t
holds. 那里存在 (西德:9)
> 0 such that for any (西德:9) ∈ (0, (西德:9)
0),
0
L(我 ) =
inf
V[我 ,(西德:9)],
S⊆
f in
α∈Rdθ ×|S|,A
H
∈Rdt
˜L( f f )
我 ,t (A, A
H
, (西德:9), S),
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2310
在哪里
K. Kawaguchi, J. 黄, 和L. Kaelbling
˜L( f f )
我 ,t (A, A
H
, (西德:9), S) =
米(西德:2)
我=1
λ
我
(西德:3)做
(西德:10)
H(西德:2)
l=t
A(l+1)
H
H(我)(希
; 你) + ˜fθ (希
; A, (西德:9), S)
,
(西德:11)
with α
H
= vec([A(l+1)
H
l=t ) ∈ Rdt , A(l+1)
]H
H
∈ Rdy×dl and dt = dy
(西德:3)
H
l=t dl.
Theorem 4 is a special case of theorem 2. A special case of theorem 4
then results in one of the main results in the literature regarding deep
linear neural networks, 那是, every local minimum is a global min-
imum. Consider any deep linear network with dy ≤ min{d1
, . . . , dH}.
Then every local minimum θ is in (西德:14)
迪,0. 因此, theorem
4 is reduced to the statement that for any local minimum, L(我 ) =
(西德:3)
(西德:3)做 (αxxi), 哪个
infα
H
is the global minimum value. 因此, every local minimum is a global
minimum for any deep linear neural network with dy ≤ min{d1
, . . . , dH}.
所以, theorem 4 successfully generalizes the recent previous result in
the literature (主张 2) for a common scenario of dy ≤ dx.
; 你)) = infαx∈Rdx
\ ˜(西德:8) = (西德:14)
A(l+1)
H
H(我)(希
(西德:3)做 (
H
l=0
米
我=1
米
我=1
迪,0
(西德:3)
(西德:3)
∈Rdt
λ
我
λ
我
Beyond deep linear networks, theorem 4 illustrates both the benefit of
the locally induced structure and the overparameterization for deep non-
(西德:3)
linear networks. In the first term,
我 ,t , we bene-
fit by decreasing t (a more locally induced structure) and increasing the
width of the lth layer for any l ≥ t (overparameterization). The second term,
˜fθ (希
我 ,t , is the general term that is always present from theorem
2, where we benefit from increasing dθ because α ∈ Rdθ ×|S|
; A, (西德:9), S) in L(ff)
; 你), in L(ff)
A(l+1)
H
H(我)(希
H
l=t
.
From the geometric view, theorem 4 captures the intuition that the span
˜TfX (我 ) of the set of the vectors in the tangent spaces {TfX (我 +(西德:9)v ) : v ∈ V[我 , (西德:9)]}
contains the best basis model with the linear feature for deep linear net-
作品, as well as the best basis models with more nonlinear features as
more local structures arise. Similar to the examples in Figures 3 和 4,
(西德:18)= Tf (我 ) and the output of the best basis models with those features
˜TfX (我 )
are contained in ˜TfX (我 ) but not in Tf (我 ).
A similar local structure was recently considered in Kawaguchi, 黄,
and Kaelbling (2019). 然而, both the problem settings and the obtained
results largely differ from those in Kawaguchi et al. (2019). 此外,
theorem 4 is proven as a consequence of our general theory (theorem 2),
and accordingly, the proofs largely differ from each other as well. Theo-
rem 4 also differs from recent results on the gradient decent algorithm for
deep linear networks (Arora, 科恩, Golowich, & 胡, 2018; Arora, 科恩,
& Hazan, 2018; Bartlett et al., 2019; Du & 胡, 2019), since we analyze the
loss surface instead of a specific algorithm and theorem 4 applies to deep
nonlinear networks as well.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2311
4.3 Proof Idea in Applications of Theorem 2. Theorems 3 和 4 是
simple consequences of theorem 2, and their proof is illustrative as a means
of using theorem 2 in future studies with different additional assumptions.
The high-level idea behind the proofs in the applications of theorem 2 是
captured in the geometric view of theorem 2 (see Figures 3 和 4). 那是,
given a desired guarantee, we check whether the space ˜TfX (我 ) is expressive
enough to contain the output of the desired model corresponding to the
desired guarantee.
To simplify the use of theorem 2, we provide the following lemma. 这
lemma states that the expressivity of the model ˜fθ (X; A, (西德:9), S) 尊重地
到 (A, S) is the same as that of ˜fθ (X; A, (西德:9), S) + ˜fθ (X; A(西德:6), (西德:9), S(西德:6)
) with respect to
(A, A(西德:6), S, S(西德:6)
). As shown in its proof, this is essentially because ˜fθ is linear in
V[我 , (西德:9)] 和S(西德:6) ⊆
A, and a union of two sets S ⊆
V[我 , (西德:9)] remains a finite
subset of V[我 , (西德:9)].
Lemma 1. For any θ , 任何 (西德:9) ≥ 0, any S(西德:6) ⊆
{ ˜fθ (X; A, (西德:9), S) : α ∈ Rdθ ×|S|, S ⊆
α ∈ Rdθ ×|S|, A(西德:6) ∈ Rdθ ×|S(西德:6)|, S ⊆
V[我 , (西德:9)], and any x, it holds that
V[我 , (西德:9)]} = { ˜fθ (X; A, (西德:9), S) + ˜fθ (X; A(西德:6), (西德:9), S(西德:6)) :
f in
V[我 , (西德:9)]}.
f in
fin
fin
f in
(西德:3)
; A(西德:6), (西德:9), S(西德:6)
+ αrz(希
A(l+1)
H
; A(西德:6), (西德:9), S(西德:6)
Based on theorem 2 and lemma 1, the proofs of theorems 3 和
4 are reduced to a simple search for finding S(西德:6) ⊆
V[我 , (西德:9)] 这样
fin
) with respect to α(西德:6)
˜fθ (希
the expressivity of
is no worse than
the expressivity of αwxi
; 你) with respect to (αw, αr) (see theo-
H
(see theorem
rem 3) and that of
l=t
H
4). 换句话说, { ˜fθ (希
+ αrz(希
; 你) : αw ∈
) : A(西德:6) ∈ Rdθ ×|S(西德:6)|} ⊇
Rdy×dx , αr ∈ Rdy×dz } (see theorem 3) 和 { ˜fθ (希
(西德:3)
∈ Rdt } (see theorem 4). Only with this search for
{
S(西德:6)
, theorem 2 together with lemma 1 implies the desired statements for the-
orems 3 和 4 (see sections A.4 and A.5 in the appendix for further details).
因此, theorem 2 also enables simple proofs.
) : A(西德:6) ∈ Rdθ ×|S(西德:6)|} ⊇ {αwxi
; A(西德:6), (西德:9), S(西德:6)
; 你) with respect to α(l+1)
; 你) : A
H
A(l+1)
H
H(我)(希
H(我)(希
H
l=t
5 结论
This study provided a general theory for nonconvex machine learning
and demonstrated its power by proving new competitive theoretical re-
sults with it. 一般来说, the proposed theory provides a mathematical tool
to study the effects of hypothesis classes f , 方法, and assumptions
through the lens of the global optima of the perturbable gradient basis
model class.
In convex machine learning with a model output f (X; 我 ) = θ (西德:15)x with a
(nonlinear) feature output x = φ(X(raw)), achieving a critical point ensures
the global optimality in the span of the fixed basis x = φ(X(raw)). In noncon-
vex machine learning, we have shown that achieving a critical point en-
sures the global optimality in the span of the gradient basis ∂ fx(我 ), 哪个
coincides with the fixed basis x = φ(X(raw)) in the case of the convex machine
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2312
K. Kawaguchi, J. 黄, 和L. Kaelbling
学习. 因此, whether convex or nonconvex, achieving a critical point en-
sures the global optimality in the span of some basis, which might be ar-
bitrarily bad (or good) depending on the choice of the handcrafted basis
φ(X(raw)) = ∂ fx(我 ) (for the convex case) or the induced basis ∂ fx(我 ) (为了
nonconvex case). 所以, in terms of the loss values at critical points,
nonconvex machine learning is theoretically as justified as the convex one,
except in the case when a preference is given to φ(X(raw)) over ∂ fx(我 ) (两个都
of which can be arbitrarily bad or good). The same statement holds for local
minima and perturbable gradient basis.
附录: Proofs of Theoretical Results
In this appendix, we provide complete proofs of the theoretical results.
A.1 Proof of Theorem 1. The proof of theorem 1 combines lemma 2 和
assumptions 1 和 2 by taking advantage of the structure of the objective
function L. Although lemma 2 is rather weak and assumptions 1 和 2 是
mild (in the sense that they usually hold in practice), a right combination of
these with the structure of L can prove the desired statement.
Lemma 2. Assume that for any i ∈ {1, . . . , 米}, the function (西德:3)做 : q (西德:9)→ (西德:3)(q, 做) 是
differentiable. Then for any critical point θ ∈ (Rdθ \ (西德:8)) of L, the following holds:
for any k ∈ {1, . . . , dθ },
米(西德:2)
我=1
λ
我
∂(西德:3)做 ( fxi (我 ))∂
k fxi (我 ) = 0.
Proof of Lemma 2. Let θ be an arbitrary critical point θ ∈ (Rdθ \ (西德:8)) 的
L. 自从 (西德:3)做 : Rdy → R is assumed to be differentiable and fxi
是
differentiable at the given θ , the composition ((西德:3)做
◦ fxi ) is also differen-
tiable, and ∂
k fxi (我 ). 此外, L is differentiable
◦ fxi ) = ∂(西德:3)做 ( fxi (我 ))∂
because a sum of differentiable functions is differentiable. 所以, 为了
any critical point θ of L, we have that ∂L(我 ) = 0, 和, 因此, ∂
kL(我 ) =
(西德:3)
k fxi (我 ) = 0, for any k ∈ {1, . . . , dθ }, from linearity of dif-
(西德:2)
∂(西德:3)做 ( fxi (我 ))∂
k((西德:3)做
∈ Rdy
米
我=1
λ
我
ferentiation operation.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Proof of Theorem 1. Let θ ∈ (Rdθ \ (西德:8)) be an arbitrary critical point
fxi (我 ) =
of L. From assumption 2, there exists a function g such that
(西德:3)
dθ
k=1 g(我 )k
∂
k fxi (我 ) for all i ∈ {1, . . . , 米}. 然后, for any α ∈ Rdθ ,
Lθ (A) ≥
米(西德:2)
我=1
λ
我
(西德:3)做 ( fxi (我 )) + λ
我
∂(西德:3)做 ( fxi (我 ))( fθ (希
; A) − f (希
; 我 ))
Every Local Minimum Value Is the Global Minimum Value
2313
=
米(西德:2)
我=1
λ
我
(西德:3)做 ( fxi (我 )) +
米(西德:2)
dθ(西德:2)
A
k
k=1
我=1
(西德:12)
λ
我
∂(西德:3)做 ( fxi (我 ))∂
(西德:13)(西德:14)
=0 from Lemma 2
k fxi (我 )
(西德:15)
-
米(西德:2)
我=1
λ
我
∂(西德:3)做 ( fxi (我 )) F (希
; 我 )
=
米(西德:2)
我=1
λ
我
(西德:3)做 ( fxi (我 )) -
dθ(西德:2)
k=1
G(我 )k
米(西德:2)
我=1
(西德:12)
= L(我 ),
λ
我
∂(西德:3)做 ( fxi (我 ))∂
(西德:13)(西德:14)
=0 from Lemma 2
,
k fxi (我 )
(西德:15)
where the first line follows from assumption 1 (differentiable and convex
(西德:3)做 ), the second line follows from linearity of summation, and the third line
follows from assumption 2. 因此, 一方面, we have that L(我 ) ≤
k fxi (我 ) ∈
infα∈Rdθ Lθ (A). 另一方面, since f (希
{ fθ (希
k fxi (我 ) : α ∈ Rdθ }, we have that L(我 ) ≥ infα∈Rdθ Lθ (A).
Combining these yields the desired statement of L(我 ) = infα∈Rdθ Lθ (A). (西德:2)
k=1 g(我 )k
; A) =
; 我 ) =
dθ
k=1
A
k
(西德:3)
(西德:3)
∂
∂
dθ
A.2 Proof of Theorem 2. The proof of theorem 2 uses lemma 3, 这
structure of the objective function L, and assumptions 1 和 2.
Lemma 3. Assume that for any i ∈ {1, . . . , 米}, the function (西德:3)做 : q (西德:9)→ (西德:3)(q, 做)
is differentiable. Then for any local minimum θ ∈ (Rdθ \ ˜(西德:8)) of L, 下列
holds: there exists (西德:9)
0), any v ∈ V[我 , (西德:9)], and any
k ∈ {1, . . . , dθ },
> 0 such that for any (西德:9) ∈ [0, (西德:9)
0
米(西德:2)
我=1
λ
我
∂(西德:3)做 ( fxi (我 ))∂
k fxi (我 + (西德:9)v ) = 0.
Proof of Lemma 3. Let θ ∈ (Rdθ \ ˜(西德:8)) be an arbitrary local minimum of L.
Since θ is a local minimum of L, by the definition of a local minimum,
there exists (西德:9)
1). Then for any
(西德:9) ∈ [0, (西德:9)
/2) and any ν ∈ V[我 , (西德:9)], the vector (我 + (西德:9)v ) is also a local minimum
1
因为
> 0 such that L(我 ) ≤ L(我 (西德:6)
) for all θ (西德:6) ∈ B(我 , (西德:9)
1
L(我 + (西德:9)v ) = L(我 ) ≤ L(我 (西德:6)
)
for all θ (西德:6) ∈ B(我 + (西德:9)v, (西德:9)
1) (the inclusion follows from the tri-
angle inequality), which satisfies the definition of a local minimum for
(我 + (西德:9)v ).
/2) ⊆ B(我 , (西德:9)
1
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2314
K. Kawaguchi, J. 黄, 和L. Kaelbling
2
Since θ ∈ (Rdθ \ ˜(西德:8)), there exists (西德:9)
, . . . , fxm are differen-
> 0 such that fx1
2). 自从 (西德:3)做 : Rdy → R is assumed to be differentiable and
2), the composition ((西德:3)做
◦ fxi ) is also dif-
◦ fxi ) = ∂(西德:3)做 ( fxi (我 ))∂
k fxi (我 ) in B(我 , (西德:9)
2). 此外, L is
2) because a sum of differentiable functions is differ-
tiable in B(我 , (西德:9)
∈ Rdy is differentiable in B(我 , (西德:9)
fxi
ferentiable, and ∂
k((西德:3)做
differentiable in B(我 , (西德:9)
entiable.
= min((西德:9)
所以, 和 (西德:9)
0) 和
any ν ∈ V[我 , (西德:9)], the vector (我 + (西德:9)v ) is a differentiable local minimum, 和
hence the first-order necessary condition of differentiable local minima im-
plies that
2), we have that for any (西德:9) ∈ [0, (西德:9)
/2, (西德:9)
1
0
∂
kL(我 + (西德:9)v ) =
米(西德:2)
我=1
λ
我
∂(西德:3)做 ( fxi (我 ))∂
k fxi (我 + (西德:9)v ) = 0,
for any k ∈ {1, . . . , dθ }, where we used the fact that fxi (我 ) = fxi (我 + (西德:9)v ) 为了
(西德:2)
any v ∈ V[我 , (西德:9)].
Proof of Theorem 2. Let θ ∈ (Rdθ \ ˜(西德:8)) be an arbitrary local minimum of
L. 自从 (Rdθ \ ˜(西德:8)) ⊆ (Rdθ \ (西德:8)), from assumption 2, there exists a function g
k fxi (我 ) for all i ∈ {1, . . . , 米}. Then from lemma
such that fxi (我 ) =
3, there exists (西德:9)
V[我 , (西德:9)] and any
0), any S ⊆
α ∈ Rdθ ×|S|
> 0 such that for any (西德:9) ∈ [0, (西德:9)
k=1 g(我 )k
(西德:3)
fin
∂
dθ
0
,
˜Lθ (A, (西德:9), S) ≥
=
米(西德:2)
我=1
米(西德:2)
我=1
λ
我
(西德:3)做 ( fxi (我 )) + λ
我
∂(西德:3)做 ( fxi (我 ))( ˜fθ (希
; A, (西德:9), S) − f (希
; 我 ))
λ
我
(西德:3)做 ( fxi (我 )) +
dθ(西德:2)
|S|(西德:2)
k=1
j=1
A
k, j
米(西德:2)
我=1
(西德:12)
λ
我
∂(西德:3)做 ( fxi (我 ))∂
(西德:13)(西德:14)
=0 from Lemma 3
k fxi (我 + (西德:9)S j )
(西德:15)
-
米(西德:2)
我=1
λ
我
∂(西德:3)做 ( fxi (我 )) F (希
; 我 )
=
米(西德:2)
我=1
λ
我
(西德:3)做 ( fxi (我 )) -
dθ(西德:2)
k=1
G(我 )k
米(西德:2)
我=1
(西德:12)
= L(我 ),
λ
我
∂(西德:3)做 ( fxi (我 ))∂
(西德:13)(西德:14)
=0 from Lemma 3
,
k fxi (我 )
(西德:15)
where the first line follows from assumption 1 (differentiable and con-
vex (西德:3)做 ), the second line follows from linearity of summation and the
; A, (西德:9), S), and the third line follows from assumption 2.
definition of ˜fθ (希
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2315
(西德:3)
因此, 一方面, there exists (西德:9)
L(我 ) ≤ inf{ ˜Lθ (A, (西德:9), S) : S ⊆
dθ
F (希
L(我 ) ≤ inf{ ˜Lθ (A, (西德:9), S) : S ⊆
the desired statement.
0),
V[我 , (西德:9)], α ∈ Rdθ ×|S|}. 另一方面, 自从
; A, (西德:9), S) : α ∈ Rdθ , S = 0}, we have that
V[我 , (西德:9)], α ∈ Rdθ ×|S|}. Combining these yields
(西德:2)
> 0 such that for any (西德:9) ∈ [0, (西德:9)
k fxi (我 ) ∈ { ˜fθ (希
k=1 g(我 )k
; 我 ) =
fin
fin
∂
0
A.3 Proof of Lemma 1. As shown in the proof of lemma 1, 引理 1 是
a simple consequence of the following facts: ˜fθ is linear in α and a union of
two sets S ⊆
fin
Proof of Lemma 1. Let S(西德:6) ⊆
fin
V[我 , (西德:9)] be fixed. 然后,
V[我 , (西德:9)] is still a finite subset of V[我 , (西德:9)].
V[我 , (西德:9)] 和S(西德:6) ⊆
fin
{ ˜fθ (X; A, (西德:9), S) : α ∈ Rdθ ×|S|, S ⊆
(西德:6)
fin
V[我 , (西德:9)]}
) : α ∈ Rdθ ×|S∪S(西德:6)|, S ⊆
) + ˜fθ (X; A(西德:6), (西德:9), S
(西德:6)
V[我 , (西德:9)]}
fin
) : α ∈ Rdθ ×|S\S
(西德:6)|, A(西德:6) ∈ Rdθ ×|S
(西德:6)|,
= { ˜fθ (X; A, (西德:9), S ∪ S
(西德:6)
= { ˜fθ (X; A, (西德:9), S \ S
V[我 , (西德:9)]}
S ⊆
fin
= { ˜fθ (X; A, (西德:9), S ∪ S
(西德:6)
) + fθ (X; A(西德:6), (西德:9), S
(西德:6)
) : α ∈ Rdθ ×|S∪S(西德:6)|, A(西德:6) ∈ Rdθ ×|S(西德:6)|,
S ⊆
fin
V[我 , (西德:9)]}
= { ˜fθ (X; A, (西德:9), S) + fθ (X; A(西德:6), (西德:9), S
(西德:6)
) : α ∈ Rdθ ×|S|, A(西德:6) ∈ Rdθ ×|S(西德:6)|,
S ⊆
fin
V[我 , (西德:9)]},
fin
where the second line follows from the facts that a finite union of finite sets
is finite and hence S ∪ S(西德:6) ⊆
V[我 , (西德:9)] (IE。, the set in the first line is a superset
of ⊇, the set in the second line), and that α ∈ Rdθ ×|S∪S(西德:6)|
can vanish the extra
terms due to S(西德:6)
) (IE。, the set in the first line is a subset
的, ⊆, the set in the second line). The last line follows from the same facts.
The third line follows from the definition of ˜fθ (X; A, (西德:9), S). The fourth line
follows from the following equality due to the linearity of ˜fθ in α:
in ˜fθ (X; A, (西德:9), S ∪ S(西德:6)
(西德:6)
) : A(西德:6) ∈ Rdθ ×|S
(西德:6)|}
{ ˜fθ (X; A(西德:6), (西德:9), S
⎧
⎨
dθ(西德:2)
|S|(西德:2)
=
⎩
k=1
j=1
(A(西德:6)
k, j
+ ¯α(西德:6)
k, j )∂
k fx(我 + (西德:9)S
(西德:6)
j ) : A(西德:6) ∈ Rdθ ×|S
(西德:6)|
(西德:6)|, ¯α(西德:6) ∈ Rdθ ×|S
= { ˜fθ (X; A(西德:6), (西德:9), S
(西德:6)
) + ˜fθ (X; ¯α(西德:6), (西德:9), S
(西德:6)
) : A(西德:6) ∈ Rdθ ×|S
(西德:6)|, ¯α(西德:6) ∈ Rdθ ×|S
(西德:6)|}.
⎫
⎬
⎭
(西德:2)
A.4 Proof of Theorem 3. As shown in the proof of theorem 3, thanks to
theorem 2 and lemma 1, the remaining task to prove theorem 3 is to find a set
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2316
K. Kawaguchi, J. 黄, 和L. Kaelbling
V[我 , (西德:9)] 这样 { ˜fθ (希
S(西德:6) ⊆
+ αrz(希
αw ∈ Rdy×dx , αr ∈ Rdy×dz }. Let Null(中号) be the null space of a matrix M.
; A(西德:6), (西德:9), S(西德:6)) : A(西德:6) ∈ Rdθ ×|S
(西德:6)|} ⊇ {αwxi
fin
; 你) :
Proof of Theorem 3. Let θ ∈ (Rdθ \ ˜(西德:8)) be an arbitrary local mini-
is specified by equation 4.1, and hence f (X; 我 ) =
mum of L. Since f
(∂
vec(瓦 ) F (X; 我 ))vec(瓦 ), assumption 2 is satisfied. 因此, from theorem 2,
there exists (西德:9)
> 0 such that for any (西德:9) ∈ [0, (西德:9)
0),
0
L(我 ) =
inf
V[我 ,(西德:9)],α∈Rdθ ×|S|
S⊆
fin
米(西德:2)
我=1
λ
我
(西德:3)( ˜fθ (希
; A, (西德:9), S), 做),
在哪里
|S|(西德:2)
˜fθ (希
; A, (西德:9), S) =
αw, j(希
+ (右 + (西德:9)v
r, j )zi, j ) + (瓦 + (西德:9)vw, j )A
r, jzi, j
j=1
+ (∂u fxi (我 + (西德:9)S j ))A
你, j
,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
with α = [α·1
, v
vec([vw, j
r, j
, vw, j
这里, αw, j
be fixed.
, . . . , α·|S|] ∈ Rdθ ×|S|, α· j
你, j]) ∈ Rdθ , and zi, j
, v
∈ Rdy×dx , A
r, j
= vec([αw, j
, 你 + (西德:9)v
你, j
= z(希
∈ Rdx×dz , and α
, v
r, j
r, j
, A
你, j]) ∈ Rdθ , S j
, A
=
你, j ) for all j ∈ {1, . . . , |S|}.
, v
0)
∈ Rdu . Let (西德:9) ∈ (0, (西德:9)
你, j
Consider the case of rank(瓦 ) ≥ dy. Define ¯S such that | ¯S| = 1 and ¯S1
0 ∈ Rdθ , which is in V[我 , (西德:9)]. Then by setting αu,1
that Wαr,1
sible since rank(瓦 ) ≥ dy), we have that
− αw,1R with an arbitrary matrix αr,1
= α(1)
r,1
=
= 0 and rewriting αr,1 这样的
∈ Rdy×dz (this is pos-
{ ˜fθ (希
; A, (西德:9), ¯S) : α ∈ Rdθ ×| ¯S|}
r,1 zi,1 : αw,1
+ A(1)
⊇ {αw,1希
∈ Rdy×dx , A(1)
r,1
∈ Rdy×dz }.
2
= 0 ∈ Rdθ , and set ¯S(西德:6)
Consider the case of rank(瓦 ) < dy. Since W ∈ Rdy×dx and rank(W ) < dy ≤
min(dx, dz) ≤ dx, we have that Null(W ) (cid:18)= {0}, and there exists a vector a ∈
= 1. Let a be such a vector. Define ¯S(cid:6)
Rdx such that a ∈ Null(W ) and (cid:10)a(cid:10)
as follows: | ¯S(cid:6)| = dydz + 1, ¯S(cid:6)
j for all j ∈ {2, . . . , dydz +
= ab(cid:15)
1} such that vw, j
∈ Rdz is an arbitrary
= 0, v
= 0, and v
u, j
r, j
≤ 1. Then ¯S(cid:6)
column vector with (cid:10)b j
∈ V[θ , (cid:9)] for all j ∈ {1, . . . , dydz + 1}.
(cid:10)
j
= 0 for all j ∈ {1, . . . , dydz + 1} and by rewriting
= 0 and α
By setting α
r, j
(cid:3)
dydz+1
αw, j and αw, j
(cid:9) q jaT for all j ∈ {2, . . . , dydz + 1} with
−
= α(1)
αw,1
w,1
j=2
∈ Rdy (this is possible since (cid:9) > 0 is fixed first and αw, j
an arbitrary vector q j
is arbitrary), we have that
j where b j
= 1
你, j
1
2
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2317
(西德:6)
; A, (西德:9), ¯S
{ ˜fθ (希
⎧
⎨
) : α ∈ Rdθ ×| ¯S(西德:6)|}
⎛
⊇
A(1)
w,1希
⎩
+
⎝α(1)
w,1右 +
dydz+1(西德:2)
j=2
⎞
(西德:15)
q jb
j
⎠ zi,1 : q j
∈ Rdy , b j
∈ Rdz
⎫
⎬
⎭
.
Since q j
A(2)
w,1
− α(1)
∈ Rdy and b j
w,1R with an arbitrary matrix α(2)
w,1
∈ Rdz are arbitrary, we can rewrite
∈ Rdy×dz , yielding
(西德:3)
dydz+1
j=2
q jb j
=
{ ˜fθ (希
; A, (西德:9), ¯S
(西德:6)
⊇ {A(1)
w,1希
) : α ∈ Rdθ ×| ¯S(西德:6)|}
w,1zi,1 : A(1)
w,1
+ A(2)
∈ Rdy×dx , A(2)
w,1
∈ Rdy×dz }.
By summarizing above, in both cases of rank(瓦 ), there exists a set S(西德:6) ⊆
fin
V[我 , (西德:9)] 这样
V[我 , (西德:9)]}
(西德:6)
{ ˜fθ (希
= { ˜fθ (希
; A, (西德:9), S) : α ∈ Rdθ ×|S|, S ⊆
; A, (西德:9), S) + ˜fθ (希
: α ∈ Rdθ ×|S|, A(西德:6) ∈ Rdθ ×|S
; A, (西德:9), S) + αwxi
fin
; A(西德:6), (西德:9), S
(西德:6)|, S ⊆
+ αrz(希
w ∈ Rdy×dx , A(2)
r
: α ∈ Rdθ ×|S|, A(1)
)
⊇ { ˜fθ (希
V[我 , (西德:9)]}
fin
, 你)
∈ Rdy×dz , S ⊆
V[我 , (西德:9)]},
fin
where the second line follows from lemma 1. 另一方面, 自从
the set in the first line is a subset of the set in the last line, { ˜fθ (希
; A, (西德:9), S) :
α ∈ Rdθ ×|S|, S ⊆
, 你) : α ∈ Rdθ ×|S|,
+ αrz(希
; A, (西德:9), S) + αwxi
fin
w ∈ Rdy×dx , A(2)
V[我 , (西德:9)]}. This immediately implies the
A(1)
(西德:2)
desired statement from theorem 2.
V[我 , (西德:9)]} = { ˜fθ (希
∈ Rdy×dz , S ⊆
fin
r
A.5 Proof of Theorem 4. As shown in the proof of theorem 4, 谢谢
to theorem 2 and lemma 1, the remaining task to prove theorem 4
) : A(西德:6) ∈ Rdθ ×|S(西德:6)|} ⊇
is to find a set S(西德:6) ⊆
V[我 , (西德:9)] 这样 { ˜fθ (希
(西德:3)
fin
∈ Rdt }. Let M(我(西德:6)
{
; 你) : A
.
H
; A(西德:6), (西德:9), S(西德:6)
) · · · M(l+1)中号(我) = I if l > l(西德:6)
H(我)(希
H
l=t
A(l+1)
H
Proof of Theorem 4. Since f is specified by equation 4.3 和, 因此,
F (X; 我 ) = (∂
vec(瓦 (H+1) ) F (X; 我 ))vec(瓦 (H+1)),
\
assumption 2 is satisfied. Let t ∈ {0, . . . , H} be fixed. Let θ ∈ ((西德:14)
˜(西德:8)) be an arbitrary local minimum of L. Then from theorem 2, 那里
for any (西德:9) ∈ [0, (西德:9)
存在 (西德:9)
V[我 ,(西德:9)],α∈Rdθ ×|S|
(西德:3)
fin
k fxi (我 +
A
米
我=1
(西德:9)S j ).
0), L(我 ) = infS⊆
(西德:3)
(西德:3)|S|
j=1
; A, (西德:9), S), 做), where ˜fθ (希
> 0 这样
0
(西德:3)( ˜fθ (希
; A, (西德:9), S) =
dθ
k=1
迪,t
λ
我
k, j
∂
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2318
K. Kawaguchi, J. 黄, 和L. Kaelbling
Let J = {J(t+1), . . . , J(H+1)} ∈ Jn,t[我 ] be fixed. Without loss of generality,
for simplicity of notation, we can permute the indices of the units of each
1) ∩ {我 (西德:6) ∈
layer such that J(t+1), . . . , J(H+1) ⊇ {1, . . . , 迪}. Let ˜B(我 , (西德:9)
Rdθ : 瓦 (l+1)
} \
J(l+1)) × J(我)}. Because of the definition of the set J, in ˜B(我 , (西德:9)
> 0
being sufficiently small, we have that for any l ∈ {t, . . . , H},
= 0 for all l ∈ {t + 1, . . . , H − 1} 和所有 (我, j) ∈ ({1, . . . , dl+1
1) = B(我 , (西德:9)
1) 和 (西德:9)
我, j
1
fxi (我 ) =A(H+1) · · · A(l+2)[A(l+1) C(l+1)]H(我)(希
; 我 ) + ϕ(我)
希 (我 ),
在哪里
希 (我 ) =
ϕ(我)
H−1(西德:2)
我(西德:6)=l
和
A(H+1) · · · A(我
(西德:6)+3)C(我
(西德:6)+2) ˜h(我
(西德:6)+1)(希
; 我 )
˜h(我)(希
; 我 ) = σ (我)(乙(我) ˜h(l−1)(希
; 我 )),
for all l ≥ t + 2 with ˜h(t+1)(希
; 我 ) = σ (t+1)([ξ (我) 乙(我)] H(t)(希
; 我 )). 这里,
(西德:22)
(西德:23)
A(我) C(我)
ξ (我)
乙(我)
= W (我)
−dy )×dy . Let (西德:9)
−dy ), and ξ (我) ∈
with A(我) ∈ Rdy×dy , C(我) ∈ Rdy×(dl−1
右(dl
/2)) 是
, (西德:9)
1
1
fixed so that both the equality from theorem 2 and the above form of fxi
hold in ˜B(我 , (西德:9)). Let R(我) = [A(我) C(我)].
> 0 be a such number, 然后让 (西德:9) ∈ (0, min((西德:9)
−dy ), 乙(我) ε R(dl
−dy )×(dl−1
0
We will now find sets S(t), . . . , S(H) ⊆
fin
V[我 , (西德:9)] 这样
{ ˜fθ (希
; A, (西德:9), S(我)) : α ∈ Rdθ } ⊇ {A(l+1)
H
H(我)(希
; 你) : A(l+1)
H
∈ Rdy×dl }.
Find S(我) with l = H: 自从
(∂
vec(右(H+1) ) fxi (我 ))vec(A(H+1)
H
) = α(H+1)
H
H(H)(希
; 我 ),
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
S(H) = {0}⊆
fin
V[我 , (西德:9)] (在哪里 0 ∈ Rdθ ) is the desired set.
Find S(我) with l ∈ {t, . . . , H − 1}: With α(l+1)
r
∈ Rdl+1
×dl , we have that
(∂
vec(右(l+1) ) fxi (我 ))vec(A(l+1)
r
) =A(H+1) · · · A(l+2)A(l+1)
r
H(我)(希
; 我 ).
所以,
A(l+1)
r
∈ Rdl+1
如果
×dl } ⊇ {A(l+1)
H
rank(A(H+1) · · · A(l+2)) ≥ dy,
∈ Rdy×dl }, S(我) = {0} ⊆
自从 {A(H+1) · · · A(l+2)A(l+1)
:
V[我 , (西德:9)] (在哪里 0 ∈ Rdθ )
r
fin
Every Local Minimum Value Is the Global Minimum Value
2319
is the desired set. Let us consider the remaining case: let rank(A(H+1)
· · · A(l+2)) < dy and let l ∈ {t, . . . , H − 1} be fixed. Let l∗ = min{l(cid:6) ∈ Z+
:
l + 3 ≤ l(cid:6) ≤ H + 2 ∧ rank(A(H+1) · · · A(l(cid:6)
)) ≥ dy}, where A(H+1) · · · A(H+2) (cid:3)
Idy and the minimum exists since the set
is finite and contains
at
and
rank(A(H+1) · · · A(l(cid:6)
l(cid:6) ∈ {l + 2, l + 3, . . . , l∗ − 1}. Thus,
for all l(cid:6) ∈ {l + 1, l + 2, . . . , l∗ − 2}, there exists a vector al(cid:6) ∈ Rdy such that
least H + 2 (nonempty). Then rank(A(H+1) · · · A(l∗
)) < dH+1
)) ≥ dH+1
for all
al(cid:6) ∈ Null(A(H+1) · · · A(l(cid:6)+1)) and (cid:10)al(cid:6) (cid:10)
2
= 1.
Let al(cid:6) denote such a vector. Consider S(l) such that the weight matrices W
are perturbed with ¯θ + (cid:9)S(l)
j as
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
)
˜A(l(cid:6)
j
= A(l(cid:6)
(cid:15)
) + (cid:9)al(cid:6) b
l(cid:6), j and ˜R(l+1)
j
= R(l+1) + (cid:9)al+1b
(cid:15)
l+1, j
2
(cid:10)
(cid:10)
for all l(cid:6) ∈ {l + 2, l + 3, . . . , l∗ − 2}, where (cid:10)bl(cid:6), j
(cid:10)S(l)
j
responding to A(l(cid:6)
V[θ , (cid:9)], since A(H+1) · · · A(l(cid:6)+1) ˜A(l
2, l + 3, . . . , l∗ − 2} and A(H+1) · · · A(l+2) ˜R(l+1)
|S(l)| = 2N with some integer N to be chosen later. Define S(l)
1, . . . , N by setting S(l)
not necessarily zero. By setting α
Rdl
2 is bounded such that
≤ 1. That is, the entries of S j are all zeros except the entries cor-
) (for l(cid:6) ∈ {l + 2, l + 3, . . . , l∗ − 2}) and R(l+1). Then S(l)
∈
j
= A(H+1) · · · A(l(cid:6)+1)A(l(cid:6)
l(cid:6) ∈ {l +
for all
= A(H+1) · · · A(l+2)R(l+1). Let
j+N for j =
= 0 whereas bl+1, j is
∈
j except that bl+1, j+N
= −α
j for all j ∈ {1, . . . , N}, with α
= S(l)
∗ ×dl
j+N
j+N
)
)
j
j
j
(cid:6)
∗ −1 ,
˜fθ (xi
=
; α, (cid:9), S(l))
N(cid:2)
A(H+1) · · · A(l∗
)(α
j
+ α
j+N ) ˜A(l∗−2) · · · ˜A(l+2)R(l+1)h(l)(xi
; θ )
j=1
+
N(cid:2)
j=1
(∂
vec(A(l
∗ −1) )
xi (θ + (cid:9)S j ))vec(α
ϕ(l)
j
+ α
j+N )
+ (cid:9)
N(cid:2)
j=1
A(H+1) · · · A(l∗
)α
j ˜A(l∗−2) · · · ˜A(l+2)al+1b
(cid:15)
l+1, jh(l)(xi
; θ )
= (cid:9)
N(cid:2)
j=1
A(H+1) · · · A(l
∗
)α
j ˜A(l
∗−2) · · · ˜A(l+2)al+1b
(cid:15)
l+1, jh(l)(xi
; θ ),
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
c
o
_
a
_
0
1
2
3
4
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2320
K. Kawaguchi, J. Huang, and L. Kaelbling
where we used the fact that ∂
Since rank(A(H+1) · · · A(l∗
∈ Rdy×dl
{ 1
(cid:9)
j : α(cid:6)
α(cid:6)
∗ −1 }, we have that ∀α(cid:6)
j
j
ϕ(l)
xi (θ + (cid:9)S j ) does not contain bl+1, j.
)) ≥ dy and {A(H+1) · · · A(l∗
∗ −1 } =
j : α
∈ Rdl
vec(A(l
∗ −1) )
∗ ×dl
∈ Rdy×dl
)α
∗ −1 , ∃α ∈ Rdθ ×|S|,
j
˜fθ (xi
; α, (cid:9), S(l)) =
N(cid:2)
j=1
α(cid:6)
j
˜A(l∗−2) · · · ˜A(l+2)al+1b
(cid:15)
l+1, jh(l)(xi
; θ ).
Let N = 2N1. Define S(l)
that bl∗−2, j+N1
−α(cid:6)
j for all j ∈ {1, . . . , N1
= S(l)
= 0, whereas bl∗−2, j is not necessarily zero. By setting α(cid:6)
for j = 1, . . . , N1 by setting S(l)
j+N1
j+N1
j except
=
j+N1
˜fθ (xi
; α, (cid:9), S(l)) = (cid:9)
α(cid:6)
(cid:15)
jal∗−2b
l∗−2, j
˜A(l∗−3) · · · ˜A(l+2)al+1b
(cid:15)
l+1, jh(l)(xi
; θ ).
},
N1(cid:2)
j=1
By induction,
˜fθ (xi
; α, (cid:9), S(l)) = (cid:9)t
Nt(cid:2)
j=1
α(cid:6)
jal∗−2bl∗−2, jal∗−3bl∗−3, j
(cid:15)
· · · al+1b
l+1, jh(l)(xi
; θ ),
where t = (l∗ − 2) − (l + 2) + 1 is finite. By setting α(cid:6)
j
al−1 for all l = l∗ − 2, . . . , l ((cid:9) > 0),
˜fθ (希
; A, (西德:9), S(我)) =
Nt(西德:2)
j=1
(西德:15)
l+1, jh(我)(希
q jb
; 我 ).
= 1
(西德:9)t q ja(西德:15)
l∗−2 and bl, j
=
Since q jbl+1, j are arbitrary, with sufficiently large Nt (Nt = dydl suffices), 我们
can set
∈ Rdθ ×dl , 因此
(西德:3)
= α(我)
H
for any α(我)
H
Nt
j=1 q jbl+1, j
{ ˜fθ (希
; A, (西德:9), S(我)) : α ∈ Rdθ ×|S(我)|} ⊇ {A(我)
h h(我)(希
; 我 ) : A(我)
H
∈ Rdθ ×dl }.
到目前为止, we have found the sets S(t), . . . , S(H) ⊆
; A, (西德:9), S(我)) : α ∈ Rdθ } ⊇ {A(l+1)
{ ˜fθ (希
1, we can combine these, yielding
H
H(我)(希
; 你) : A(l+1)
H
V[我 , (西德:9)] 这样
∈ Rdy×dl }. From lemma
fin
{ ˜fθ (希
; A, (西德:9), S) : α ∈ Rdθ , S ⊆
(西德:4)
H(西德:2)
V[我 , (西德:9)]}
fin
=
˜fθ (希
; A(我), (西德:9), S(我)) + ˜fθ (希
; A, (西德:9), S) : A(t), . . . , A(H) ∈ Rdθ ,
l=t
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2321
(西德:24)
V[我 , (西德:9)]
α ∈ Rdθ , S ⊆
(西德:4)
fin
H(西德:2)
l=t
α ∈ Rdθ ×|S|, S ⊆
(西德:24)
V[我 , (西德:9)]
.
fin
⊇
A(l+1)
H
H(我)(希
; 你) + ˜fθ (希
; A, (西德:9), S) : A(l+1)
H
∈ Rdy×dl ,
Since the set in the first line is a subset of the set in the last line, the equality
holds in the above equation. This immediately implies the desired state-
(西德:2)
ment from theorem 2.
致谢
We gratefully acknowledge support from NSF grants 1523767 和 1723381,
AFOSR grant FA9550-17-1-0165, ONR grant N00014-18-1-2847, Honda Re-
搜索, and the MIT-Sensetime Alliance on AI. 有什么意见, 发现, 和
conclusions or recommendations expressed in this material are our own
and do not necessarily reflect the views of our sponsors.
参考
Allen-Zhu, Z。, 李, Y。, & 歌曲, Z. (2018). A convergence theory for deep learning via over-
parameterization. arXiv:1811.03962.
Arora, S。, 科恩, N。, Golowich, N。, & 胡, 瓦. (2018). A convergence analysis of gradient
descent for deep linear neural networks. arXiv:1810.02281.
Arora, S。, 科恩, N。, & Hazan, 乙. (2018). On the optimization of deep networks:
Implicit acceleration by overparameterization. 国际会议录
Conference on Machine Learning.
Bartlett, 磷. L。, Helmbold, D. P。, & 长的, 磷. 中号. (2019). Gradient descent with identity
initialization efficiently learns positive-definite linear transformations by deep
residual networks. 神经计算, 31(3), 477–502.
Bertsekas, D. 磷. (1999). Nonlinear programming. Belmont, 嘛: Athena Scientific.
布鲁姆, A. L。, & Rivest, 右. L. (1992). Training a 3-node neural network is NP-complete.
Neural Networks, 5(1), 117–127.
Brutzkus, A。, & Globerson, A. (2017). Globally optimal gradient descent for a con-
vnet with gaussian inputs. In Proceedings of the International Conference on Machine
学习 (PP. 605–614).
Choromanska, A。, Henaff, M。, Mathieu, M。, Ben Arous, G。, & 乐存, 是. (2015). 这
loss surfaces of multilayer networks. In Proceedings of the Eighteenth International
Conference on Artificial Intelligence and Statistics (PP. 192–204).
戴维斯, D ., Drusvyatskiy, D ., Kakade, S。, & 李, J. D. (2019). Stochastic subgradient
method converges on tame functions. 在米. Overton (埃德。), Foundations of compu-
tational mathematics (PP. 1–36). 柏林: 施普林格.
Du, S. S。, & 胡, 瓦. (2019). Width provably matters in optimization for deep linear neural
网络. arXiv:1901.08572.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2322
K. Kawaguchi, J. 黄, 和L. Kaelbling
Du, S. S。, & 李, J. D. (2018). On the power of over-parameterization in neural networks
with quadratic activation. arXiv:1803.01206.
Du, S. S。, 李, J. D ., 李, H。, 王, L。, & Zhai, X. (2018). Gradient descent finds global
minima of deep neural networks. arXiv:1811.03804.
锗, R。, 李, J. D ., & Ma, 时间. (2017). Learning one-hidden-layer neural networks with land-
scape design. arXiv:1711.00501.
Goel, S。, & Klivans, A. (2017). Learning depth-three neural networks in polynomial time.
arXiv:1709.06010.
好人, 我。, 本吉奥, Y。, & 考维尔, A. (2016). 深度学习. 剑桥, 嘛:
与新闻界.
Hardt, M。, & Ma, 时间. (2017). Identity matters in deep learning. arXiv:1611.04231.
Hardt, 右. 中号. (1975). Stratification of real analytic mappings and images. Invent.
Math., 28, 193–208.
他, K., 张, X。, Ren, S。, & Sun, J. (2016). Identity mappings in deep residual
网络. In Proceedings of the European Conference on Computer Vision (PP. 630–
645). 柏林: 施普林格.
Kakade, S. M。, & 李, J. D. (2018). Provably correct automatic subdifferentiation for
qualified programs. 在S. 本吉奥, H. 瓦拉赫, K. Grauman, 氮. Cesa-Bianchi, &
右. 加内特 (编辑。), Advances in neural information processing systems, 31 (PP. 7125–
7135). 红钩, 纽约: 柯兰.
Kawaguchi, K. (2016). Deep learning without poor local minima. 在D中. 李, 中号.
Sugiyama, U. Luxburg, 我. Guyon, & 右. 加内特 (编辑。), Advances in neural infor-
mation processing systems, 29 (PP. 586–594). 红钩, 纽约: 柯兰.
Kawaguchi, K., & 本吉奥, 是. (2019). Depth with nonlinearity creates no bad local
minima in ResNets. Neural Networks, 118, 167–174.
Kawaguchi, K., 黄, J。, & Kaelbling, L. 磷. (2019). Effect of depth and width on
local minima in deep learning. 神经计算, 31(6), 1462–1498.
Kawaguchi, K., Xie, B., & 歌曲, L. (2018). Deep semi-random features for nonlinear
function approximation. In Proceedings of the 32nd AAAI Conference on Artificial
智力. 帕洛阿尔托, CA: AAAI出版社.
Laurent, T。, & Brecht, J. (2018). Deep linear networks with arbitrary loss: All local
minima are global. In Proceedings of the International Conference on Machine Learning
(PP. 2908–2913).
李, J. 中号. (2013). Introduction to smooth manifolds (2nd 版。). 纽约: 施普林格.
李, Y。, & Yuan, 是. (2017). Convergence analysis of two-layer neural networks with
ReLU activation. In I. Guyon, U. V. Luxburg, S. 本吉奥, 氮. 瓦拉赫, 右. 弗格斯,
S. Vishwanathan, & 右. 加内特 (编辑。), Advances in neural information processing
系统, 30 (PP. 597–607). 红钩, 纽约: 柯兰.
Murty, K. G。, & Kabadi, S. 氮. (1987). Some NP-complete problems in quadratic and
nonlinear programming. Mathematical Programming, 39(2), 117–129.
阮, Q., & Hein, 中号. (2017). The loss surface of deep and wide neural
网络. In Proceedings of the International Conference on Machine Learning
(PP. 2603–2612).
阮, Q., & Hein, 中号. (2018). Optimization landscape and expressivity of
deep CNNS. In Proceedings of the International Conference on Machine Learning
(PP. 3727–3736).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Every Local Minimum Value Is the Global Minimum Value
2323
Rockafellar, 右. T。, & Wets, 右. J.-B. (2009). Variational analysis. 纽约: 施普林格
科学 & Business Media.
Saxe, A. M。, 麦克莱兰, J. L。, & 甘古利, S. (2014). Exact solutions to the nonlinear
dynamics of learning in deep linear neural networks. arXiv:1312.6120.
Shamir, 氧. (2018). Are ResNets provably better than linear predictors? 在S. 本吉奥,
H. 瓦拉赫, H. 拉罗谢尔, K. Grauman, 氮. Cesa-Bianchi, & 右. 加内特 (编辑。),
Advances in neural information processing systems, 31. 红钩, 纽约: 柯兰.
Soltanolkotabi, 中号. (2017). Learning ReLUs via gradient descent. In I. Guyon, U. V.
Luxburg, S. 本吉奥, H. 瓦拉赫, 右. 弗格斯, S. Vishwanathan, & 右. 加内特 (编辑。),
Advances in neural information processing systems, 30 (PP. 2007–2017). 红钩,
纽约: 柯兰.
Zhong, K., 歌曲, Z。, Jain, P。, Bartlett, 磷. L。, & Dhillon, 我. S. (2017). Recovery guar-
antees for one-hidden-layer neural networks. 国际会议录
Conference on Machine Learning (PP. 4140–4149).
Zou, D ., 曹, Y。, 周, D ., & Gu, 问. (2018). Stochastic gradient descent optimizes over-
parameterized deep ReLU networks. arXiv:1811.08888.
Received March 15, 2019; accepted July 19, 2019.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
1
1
2
2
2
9
3
1
8
6
5
1
6
5
n
e
C
哦
_
A
_
0
1
2
3
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3