TRABAJO DE INVESTIGACIÓN
Bi-GRU Relation Extraction Model Based on Keywords
Atención
Yuanyuan Zhang1†, Yu Chen2, Shengkang Yu1, Xiaoqin Gu1, Mengqiong Song1, Yu Peng1, Jianxia Chen2
& Qi Liu2
1Technical Training Center of State Grid Hubei Electric Power Co., Limitado. Wuhan 430070, Porcelana
2Hubei University of Technology, School of Computer Science, Wuhan 430068, Porcelana
Palabras clave: Relation extraction; Bi-GRU; CRF keywords attention; Hidden similarity
Citación: zhang, Y.Y. et al.: Bi-GRU Relation Extraction Model Based on Keywords Attention. Data Intelligence 4(3), 552-572
(2022). DOI: 10.1162/dint_a_00147
Receive: Oct. 11, 2021; Revised: Ene. 15, 2022; Aceptado: Feb. 10, 2022
ABSTRACTO
Relational extraction plays an important role in the field of natural language processing to predict semantic
relationships between entities in a sentence. Actualmente, most models have typically utilized the natural
language processing tools to capture high-level features with an attention mechanism to mitigate the adverse
effects of noise in sentences for the prediction results. Sin embargo, in the task of relational classification, estos
attention mechanisms do not take full advantage of the semantic information of some keywords which have
information on relational expressions in the sentences. Por lo tanto, we propose a novel relation extraction model
based on the attention mechanism with keywords, named Relation Extraction Based on Keywords Attention (REKA).
En particular, the proposed model makes use of bi-directional GRU (Bi-GRU) to reduce computation, obtain the
representation of sentences , and extracts prior knowledge of entity pair without any NLP tools. Besides the calculation
of the entity-pair similarity, Keywords attention in the REKA model also utilizes a linear-chain conditional random
campo (CRF) combining entity-pair features, similarity features between entity-pair features, and its hidden
vectores, to obtain the attention weight resulting from the marginal distribution of each word. experimentos
demonstrate that the proposed approach can utilize keywords incorporating relational expression semantics
in sentences without the assistance of any high-level features and achieve better performance than traditional
methods.
†
Autor correspondiente: Yuanyuan Zhang (Correo electrónico: 16823650@qq.com; ORCID: 0000-0002-5353-2989).
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
t
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
© 2022 Academia China de Ciencias. Publicado bajo una atribución Creative Commons 4.0 Internacional (CC POR 4.0) licencia.
Bi-GRU Relation Extraction Model Based on Keywords Attention
1. INTRODUCCIÓN
Abundant data on the Web are generated and shared every day, thus the relational facts of subjects
(entidades) in the text are often utilized to represent the text information to capture associations among those
datos. Generally, triples are utilized to represent entities and their relations which often indicate unambiguous
facts about entities. Por ejemplo, a triple (e1, r, e2) denotes that entity e1 has a relation r with another entity
e2. Gráficos de conocimiento (KG) such as FreeBase [1] and DBpedia [2] are real examples of such representations
in the triple form.
Relation extraction is a sub-task of natural language processing (NLP) that can discover relations between
entity pairs and given unstructured text data. Previous work in the area of relation extraction from text
heavily depends on kernel and feature methods [3]. Recent research studies utilize data-driven Deep Neural
Networks (DNNs) methods to eliminate RE of the conventional NLP approaches since these DNN-based
methods [4–6] can automatically learn features instead of manually designed features based on the various
NLP tool-kits. Most of them surpassed the traditional methods and achieved excellent results for the RE
tareas. Among them, both DNNs-based supervised and distant supervision methods are the most popular
and reliable solutions for RE but have their own characteristics. Supervised methods have better performance
for the specific domain, while distant supervision methods have better performance for generic domains.
Por lo tanto, it is difficult to specify which kind of the above two methods are the best. Por eso, the following
part introduces the DNN-based supervised methods in detail according to the research of the paper.
According to the structure of DNNs, DNN-based Supervised RE usually is classified into various types
such as CNN [6–10], RNN [5, 11, 12], or Mix structure. Además, some variant RNN networks have
been developed in RE systems such as the Long Short Term Memory network ( LSTM ) [13-15], and Gated
Recurrent Unit ( GRU ) [16]. Each kind of DNN has its own characteristics and advantages in dealing with
various language tasks. Por ejemplo, due to the parallel processing ability, the CNNs are good at addressing
local and structural information, but rarely capture global features and time sequence information. En cambio,
RNNs, LSMTs, and GRUs, which are suitable for modeling sequence and problem transformation, poder
alleviate these problems that CNNs cannot overcome.
Sin embargo, these structural RNNs-based methods have a common drawback which is that many external
artificial features are introduced without an effective feature filter mechanism [17]. Por lo tanto, the semantic-
oriented approaches are utilized to improve the ability of semantic representation via capturing the internal
association of text and the attention mechanisms. To alleviate the influence of word-level noise within
oraciones, many efforts have been devoted to getting rid of irrelevant words [18–21], especially, the recent
state-of-the-art attention-based methods such as [19, 22, 23].
Although the inner-sentence noise can be alleviated by the attention mechanisms with the caculation of
weights for the each word independently, there are some information for better extraction through some
continuous words such as phrases. Yu et al.[24] proposes an attention mechanism based on the conditional
random fields (CRF), which incorporates such keywords information into the neural relation extractor.
Data Intelligence
553
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
t
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
Compared with other strong feature-based classifiers and all baseline neural models, the CRF mechanism
is important for this model to construct a better attention weight.
Based on the above analysis, we propose a novel relation extraction model based on the attention
mechanism with keywords, named Relation Extraction Based on Keywords Attention (REKA) , cual
incorporates an attention mechanism based on the keywords-identifiable of relation that is similar to the
segments in the [24]. Different from the model in [24], our model makes use of bi-directional GRU (Bi-
GRU) to reduce computation without any NLP tools. En particular, the CRF attention mechanism includes
two components: entity pair attention and segment attention.
The proposed entity pair attention means adding additional weight to the entity part of the dataset so
that it plays a more decisive role when entering the code. The proposed segment attention is assumed that
each sentence has a binary sequence of states corresponding to it and that each state variable in the
sequence corresponds to a word in the sentence. This binary state variable indicates whether the
corresponding word is related to the relation extraction task with 0 y 1, respectivamente. Inspired by the [24],
we utilized a linear-chain CRF incorporating segment attention to obtain the marginal distribution of each
state variable as an attention weight.
To summarize, the contributions of the proposed REKA model are shown as follows:
• Propose a novel Bi-GRU model based on an attention mechanism with keywords to handle the
relation extraction.
• Both entity pair similarity features and segment features are incorporated in the proposed attention
mechanism with keywords.
• Achieves state-of-the-art performance without any other NLP tools assistance.
• Be more interpretable than the original Bi-GRU model.
2. RELATED WORK
2.1 RNN-Based Relation Extraction Models
Recientemente, relation extraction research focuses on extracting relational features with neural networks[25–27].
Zhang et al. [28] claimed that RNN-based relation extraction models have better performance than that
the CNN-based models since CNN’s can only obtain the local features, but RNNs are good at learning
long-distance dependency between entities. Después, LSTM [15] is proposed by using the gate mechanism
to solve the problem of gradient explosion in RNN models. Based on this, Xu et al. [5] propose a model
with LSTM via the shortest dependency path (SDP) between entities, named the SDP-LSTM model, en el cual
there are four types of information, including Word vectors, POS tags, Grammatical relations, and WordNet
hypernyms, to support external information. To address the problem of shallow architecture difficultly
represented by the potential space in different network levels, Xu et al. [29] can obtain the abstract features
along the two sub-paths of SDP.
554
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
t
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
Since dependency trees are directed graphs, it is necessary to identify whether the relation implies the
reverse direction or the first entity is related to the second entity. Por lo tanto, the SPD is divided into two
sub-paths, each directed from the entity towards the ancestor node. Sin embargo, one-directional LSTM models
lack representation of the complete sequential information. De este modo, the bidirectional LSTM model (BiLSTM)
is utilized by Zhang et al. [30] to obtain the sentence level representation with several lexical features. El
experimental results demonstrate word embedding as an input feature alone is enough to achieve excellent
resultados. Sin embargo, the SDP can filter the input text but has no extracted features. To address this issue, el
attention mechanism is introduced for BiLSTM-based RE[31].
2.2 Attention Mechanisms for Relation Extraction
Since useful information can be presented anywhere in the sentence, some researchers recently have
presented attention-based models which can obtain the important semantic information in a sentence.
Zhou et al. [31] propose the attention mechanism in BiLSTM, which automatically got the important
features only with the raw text. Similar to the work of Zhou et al. [31], Xiao et al. [32] propose a two-level
BiLSTM architecture based on a two-level attention mechanism to extract a high-level representation of the
raw sentence.
Although the attention mechanism is used to capture the important features extracted by the model, [31]
just presents a random weight without the consideration of prior knowledge. Por lo tanto, EAtt-BiGRU
proposed by Qin et al. [33] leverages the entity pair as prior knowledge to form attention weight. Different
from Zhou et al.’s [31] trabajar, EAtt-BiGRU applies bi-directional GRU (Bi-GRU) to reduce computation,
capture the representation of sentences and adopt a GRU to extract prior knowledge of entity pairs. zhang
et al. [34] propose a Bi-GRU model based on another attention mechanism with the SDP for the prior
conocimiento, extracting sentence-level features and attention weights. Nguyen et al. [35] have proposed to
use a special attention mechanism and introduced dependency analysis that takes into account the
interconnections between potential features.
With the proposed BERT model, which has achieved excellent performance on various NLP tasks, más
and more studies have started to try to use the BERT model in search matching tasks and achieved very
good results. In the latest study on pre-trained models, Wei et al. [36] achieved high metric scores using
BERT. Although the BERT model has excellent encoding ability and can fully capture the semantic information
of the context in the sentence, it still has problems such as high training costs and long prediction time.
Our model is inspired by Lee et al. [22], but different from the previous works that can only get word-
level or sentence-level attention and rarely obtain the degree of correlation between entities and other
related words, our model utilizes Bi-GRU instead of BiLSTM to reduce computation. Meaning while,
inspired by the attention model designed by Yu et al. [24] for the relation extraction, which is capable of
learning phrase-like features and capturing reasonably related segments as relational expressions based on
Data Intelligence
555
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
the CRF, we propose a novel attention mechanism combining the entity pair attention with the segment
attention via CRF together.
Although the above methods provide a solid foundation for the research of supervised RE, there are still
limitations among them. Por ejemplo, the insufficient training corpus puzzles the further development of
the supervised RE. Por lo tanto, Mintz et al. [37] propose a distant supervision approach strongly based on
an assumption in the selection of training examples. Distant supervision methods also achieved excellent
results for the RE [38–40]. Sin embargo, it also has some drawbacks, Por ejemplo, the noise in the data sets is
obvious. De este modo, it is difficult to demonstrate which two kinds of above methods are currently the best. Por eso,
we just research the supervised methods in this paper.
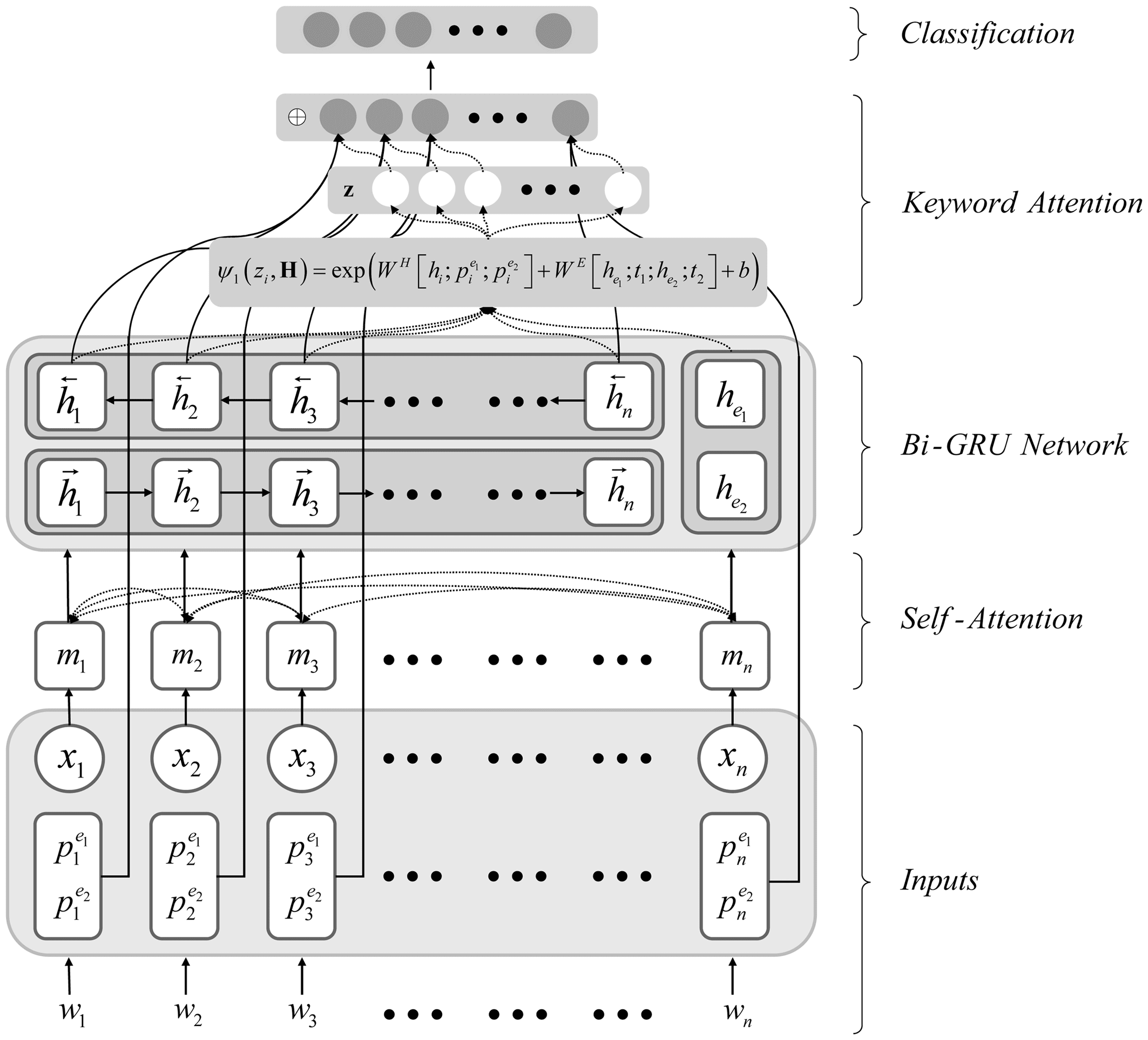
3. METODOLOGÍA
The proposed REKA model consists of four components, the structure of which is shown in Figure 1, y
the role of each layer is as follows:
• The input layer that contains word vector information and location information.
• The self-attention layer that processes the word vectors to obtain word representations.
• To obtain contextual information about each word in a sentence The Bi-GRU layer is used.
• The keyword-attention layer extracts the key information in the sentence and passes it to the final
classification layer.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. The systematic architecture of the REKA model.
556
Data Intelligence
Bi-GRU Relation Extraction Model Based on Keywords Attention
3.1 Input Layer
The REKA model’s input layer is designed to transform the original input of the sentence into an embedding
vector containing various feature information, where the input sentences are denoted by {w1, w2, …, wn}
y {
is a vector of the relative position features information of every word to the entity pair
ej{1,2}.
mi
mi
p p
,
1
2
p…
,
,
}
mi
norte
j
j
j
To further enhance the model’s ability to better capture the semantic information in sentences, a pre-
training model of embedded language models (ELMo) [43] word embedding is utilized in this paper, cual
proposes a better solution for multiple meanings of words, unlike the previous work of word2vec by
Mikolov et al. [41] and GloVe by Pennington et al. [42], in which one word corresponds to a vector that
is stationary.
ELMo is a real trained model, in which a sentence or a paragraph is fed into and inferred the word vector
corresponding to each word based on the context. One of the obvious benefits of ELMo is that the multiple-
meaning words can be understood in the context of the preceding and following words.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
After the word embedding process, {x1, x2, …, xn} is the dw dimensional vector and input into the next
layer as the position feature vector.
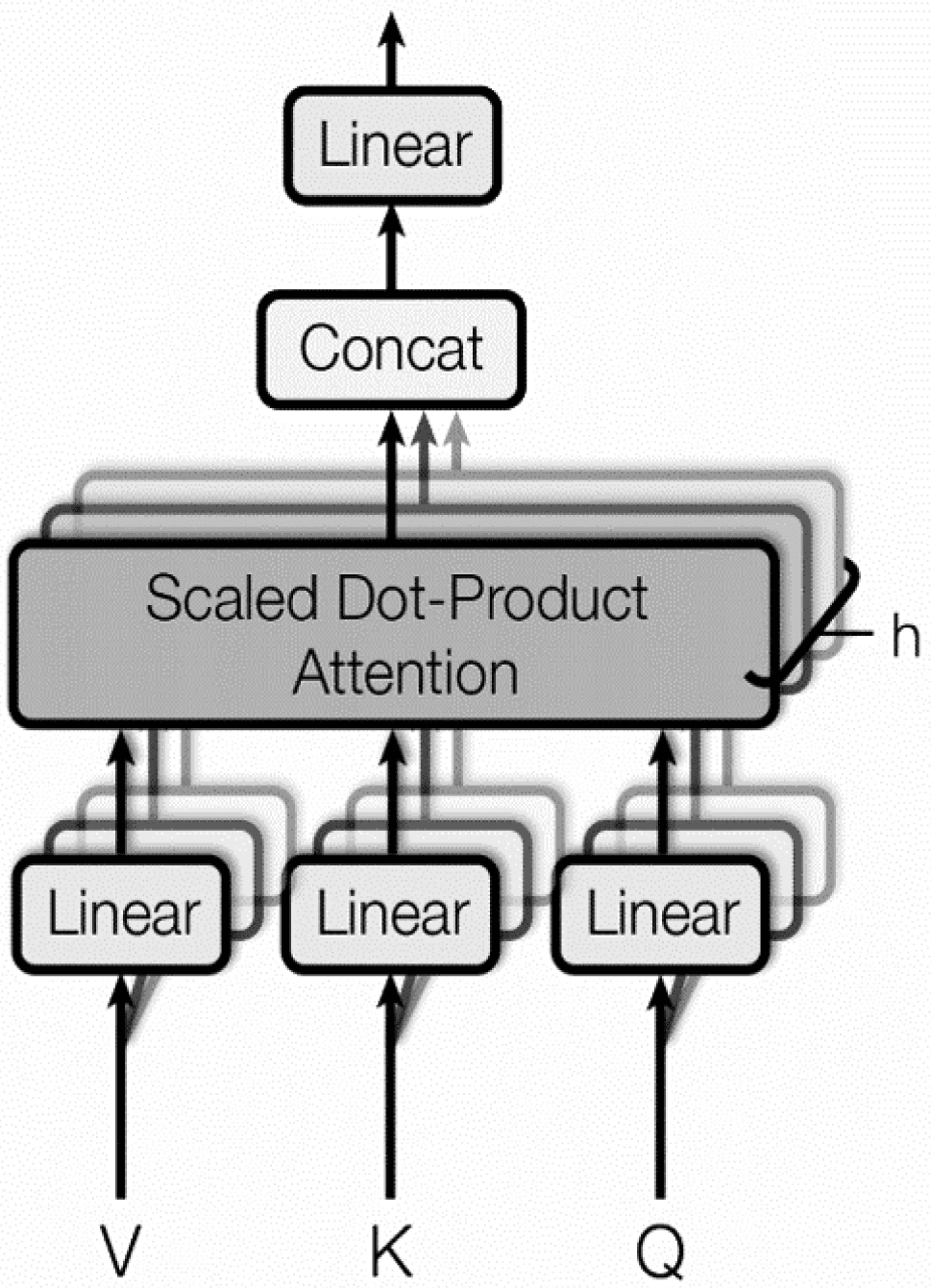
3.2 Multi-Head Attention Layer
Although this paper makes use of non-fixed word vectors in the input layer, we use the Multi-Headed
Atención (MHA) mechanism to process the output vectors in the input layer to help the model further
understand the deep semantic information in the sentences and to address the problem of long-term
dependencies. MHA is a special kind of self-attention mechanism [17, 19], in which the symmetric similarity
matrix of the sequences can be constructed from a sequence of word vectors resulting from the input layer.
As shown in Figure 2, given a key K, a queries Q, and a value V, the multi-head attention module will
execute the attention h times, the calculation process uses the following equation (1–3):
Cifra 2. A sample of Multi-Head Attention [17]
Data Intelligence
557
Bi-GRU Relation Extraction Model Based on Keywords Attention
MultiHead (
Q K V W
)
,
,
=
METRO
where head
i
=
Atención
…
cabeza ;
1
Concat[
(
k
W Q W K W V
i
;cabeza
r
)
,
,
q
V
i
i
Atención (
Q K V
,
,
)
=
softmax
⎛
⎜
⎝
(cid:2)
QK
d
w
⎞
⎟
⎠
V
]
(1)
(2)
(3)
METRO
∈
R
d
×
d
w
w
W.
aquí
sc aled dot-product attention calculation when calculated and connected in series, Wi
key and value of ith head, respectivamente [17].
is the trainable parameter, WM is the
V is query,
q, Wi
k, Wi
W.
i
W.
i
W.
i
,
,
,
w
w
w
w
w
w
k
∈
R
d
×
r d
/
V
∈
R
d
×
r d
/
q
∈
R
d
×
r d
/
The inputs Q, k, V are all equal to the word embedding vector {x1, x2, …, xn} in the multi -head attention[17].
The output of the MHA self-attention is a sequence of features with information about the context of the
input sentences.
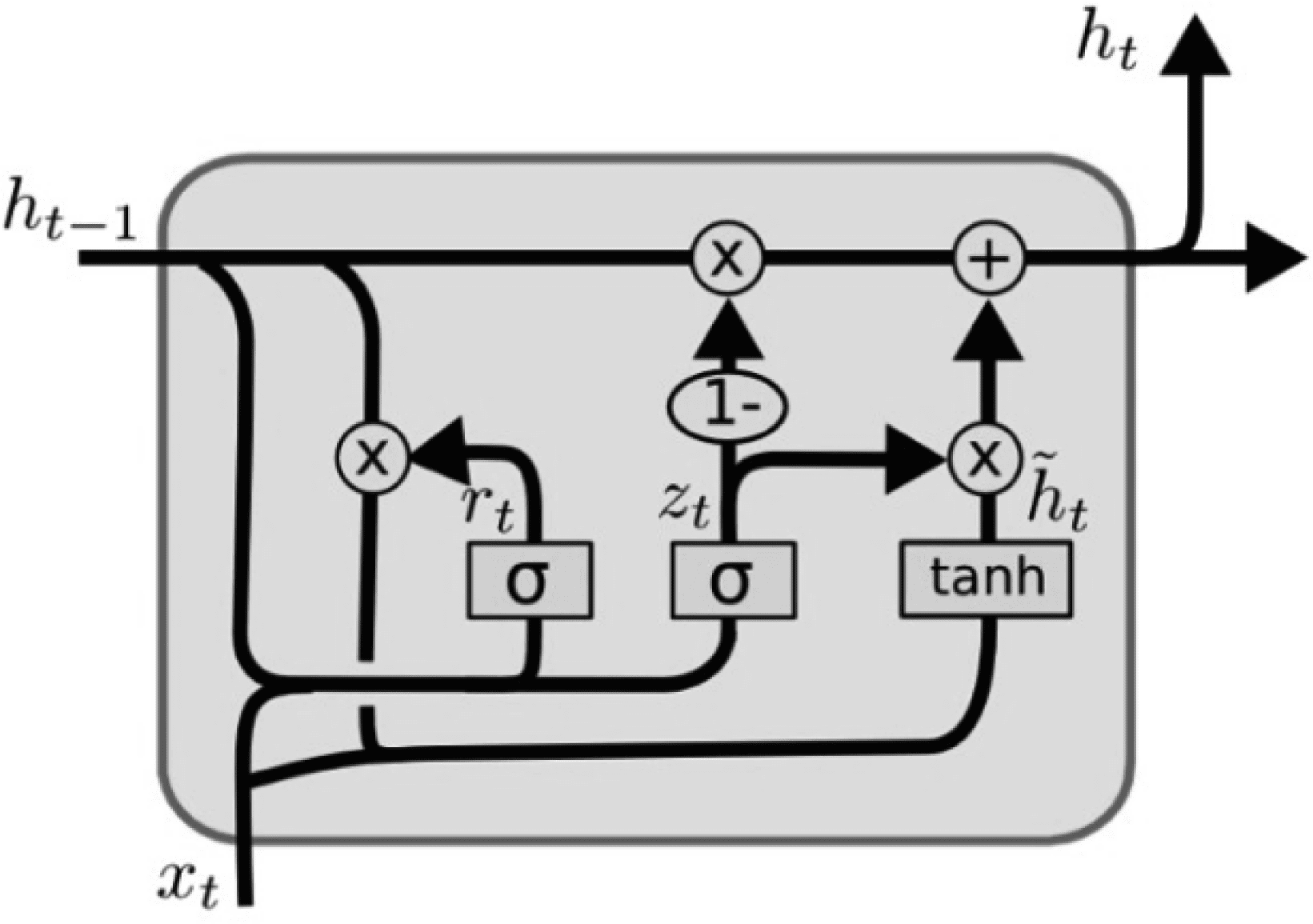
3.3 Bi-GRU Network
The Bi-GRU network layer was used to obtain semantic information in sentences about the output
sequence of the MHA self-attentive layer. As shown in Figure 3, GRU optimizes the LSTM by retaining only
two gate operations including a new gate and a reset gate, thus its units, por lo tanto, have fewer parameters
and converge faster than LSTM units.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
t
/
.
i
The GRU unit’s processing of mi is represented in this paper for simplicity as GRU(mi). Por lo tanto, el
Cifra 3. The GRU unit
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
equation (4–6) for calculating the contextualized word representation is obtained as follows:
(cid:2)(cid:2)(cid:3)
(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:3)
h GRU m
t
t
(cid:4)(cid:2)(cid:2)
(cid:4)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)
(
h GRU m
t
t
(cid:2)(cid:2)(cid:3) (cid:4)(cid:2)(cid:2)
[
]
h h
;
t
t
h
t
=
=
=
)
(
)
(4)
(5)
(6)
558
Data Intelligence
Bi-GRU Relation Extraction Model Based on Keywords Attention
The input M resulting from the MHA self-attention layer is fed into the Bi-GRU network step by step. A
simultaneous use of past and future feature information at a given time step, we connect the hidden state
R at
h
R with the hidden sta te of the backward GRU network
of the forward GRU network
(cid:2)(cid:2)(cid:3)
h ∈
(cid:2)(cid:2)(cid:3)
h ∈
h
d
d
t
t
each step.
Where dh is used to denote the hidden state of the GRU network unit dimension, {h1, h2, …, hn} is denoted
the hidden state vector of each word, The arrow represents the direction of the GRU unit.
3.4 Keywords Attention based on CRF
Although attention mechanisms have achieved state-of-the-art results in a variety of NLP tasks, most of
them do not fully exploit the keywords information in the sentences. This is because keywords usually refer
to important words for solving relational extraction tasks, and the performance of the models would be
improved if information about these keywords could be exploited.
The goal of the attention mechanism with keywords proposed in this paper is to assign more reasonable
weights to the hidden layer vectors, where attention weights are also a set of linear combinations of scalars.
A more reasonable weight assignment indicates that the model pays more attention to the more important
words in the sentence compared to other words, and all the weights in this attention mechanism with
keywords take values between 0 y 1.
Sin embargo, there is a different approach to the calculation of the weights between the traditional attention
mechanisms and the proposed model. En particular, the proposed model defines a state variable z for each
word in the sentence, it means that the word corresponding to z is irrelevant to the relational classification
of this sentence when z equals 0, and vice versa if z equals 1. De este modo, each sentence of the input model has
a corresponding sequence of z. From the above description, the expected value of a hidden state N, el
probability of its corresponding word, will be selected and calculated as the following equation (7):
norte
∑=
i
(
p zi =
)1
h
h
i
(7)
In order to calculate the p(zi = 1|h), the CRF is introduced here to calculate the sequence of weights
for the hidden sequence vectors H = {h1, h2, …, hn}, where H represents the input sequence and hi represents
the hidden output of the GRU layer for the i th word in the sentence. CRF provides a calculation of transfer
probabilities for the computation of conditional probabilities in between sequences.
The linear-chain CRF defines a range of conditional probability p(zi = 1|h) given H with the following
definition (8–9):
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
pag
(
z H
)
z
(
h
)
z H
,
=
z
1
h
(
(
∏ c
ψ
) c C
∈
(
= ∑ ∏ c
ψ
′
z H
,
)
′
∈
z
∈
c C
Data Intelligence
z
)
(8)
(9)
559
Bi-GRU Relation Extraction Model Based on Keywords Attention
Where is the set of state sequences, z(h) denotes the normalization constant and ZC is the subset of
z given by individual clique c, y(ZC, h) is the potential function of this clique. It is defined by the following
equation (10):
(
ψ
∏
∈
c C
)
=
cz H
,
norte
∏
=
1
i
(
ψ
1
z
i
,
h
i
)
−
norte
1
∏
=
1
i
(
ψ
2
z z
,
i
i
+
1
)
(10)
For feature extraction, the feature extractor makes use of two types of feature functions, the vertex feature
function y1(zi, h), the edge feature function y2(zi, zi+1). y1 represents the mapping of the output h of GRU
to the state variable z, and y2 simulates the transition of two state variables at adjacent time steps. El
equations for their definitions are shown as the following equation (11–13) respectivamente:
(
ψ
1
iz
,
h
)
=
(
W.
exp.
+
h
F
1
W.
mi
F
2
+
)
b
=
F
1
[
h
i
;
1
mi
pag
i
;
h t
;
mi
2
]
;
F
2
2
=
[
(
z zψ
,
2
i
i
)
+ =
1
exp.
1
mi
;
mi
2
h t h t
;
;
1
)
t
z z
,
i
+
1
i
(
W.
]
2
(11)
(12)
(13)
Where WH and WE are trainable parameters, b is a trainable bias term. They calculate the contextual
information as a feature score for each state variable, which takes advantage of the entity location features
mi
ip p as well as keyword features embedded vectors (entity pair hidden similarity features t1, t2, and entity
1
i
pair features
mi
2
h h ).
,mi
mi
2
1
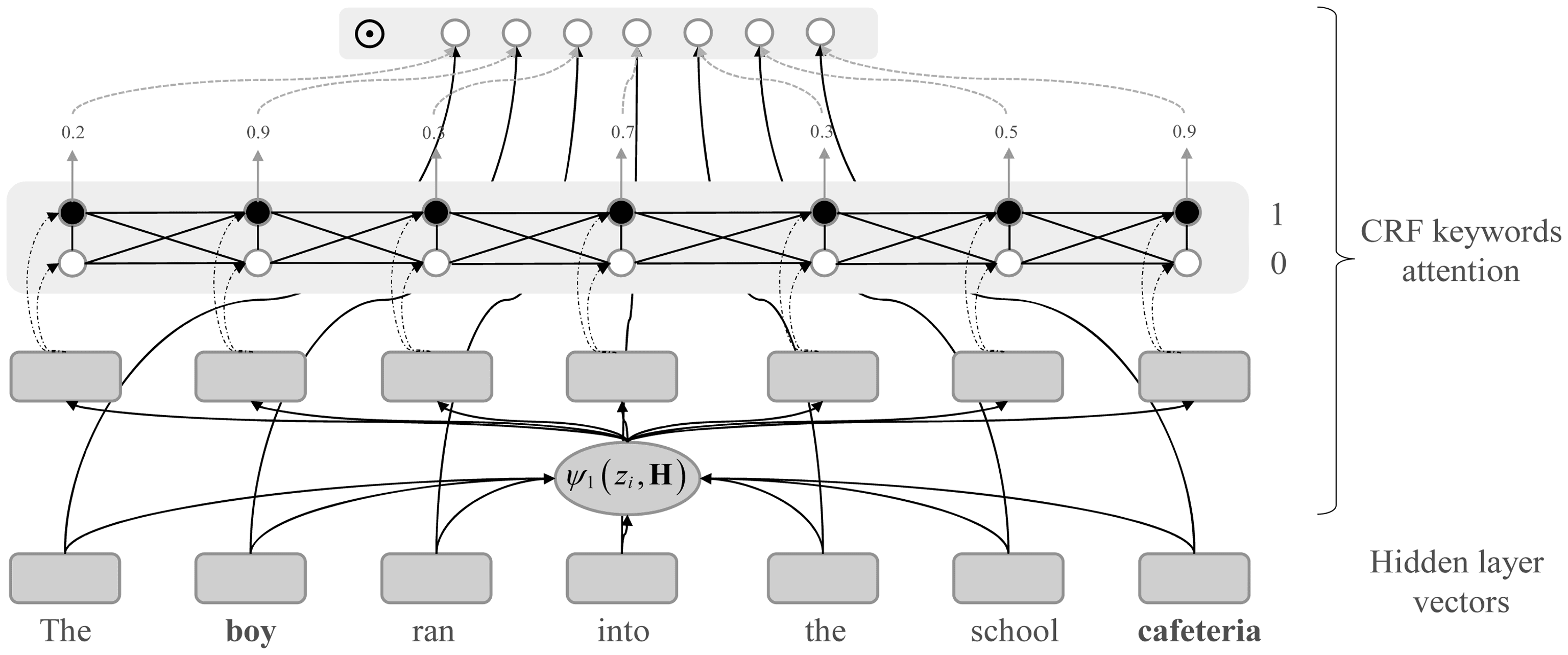
For the hidden vector output by the words after the Bi-GRU layer, the CRF keyword attention mechanism
performs soft selection by assigning higher weights to the words in the sentence that are more relevant to
the classification. The processing of the sentence by the CRF keywords attention mechanism is shown in
Cifra 4, The CRF keyword attention in the figure assigns different weights to each word with an example
sentence “The boy ran into the school cafeteria”. In addition to the two entity words “boy” and “cafeteria”,
“into” in the sentence was also assigned a higher weight relative to the other words, due to the fact that a
is the word associated with the relational classification.
Cifra 4. CRF keywords attention mechanism architecture shown with an example sentence “The boy ran into the school
cafeteria”.
560
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
t
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
Entity position feature: The proposed attention mechanism with keywords in this paper not only obtains
word embedding features but also incorporates position embedding features.
In order to represent contextual information as well as the relative location features of entities
mi
p p ,
2
i
this paper connects them with the output of their corresponding hidden layers hi, as shown by F1 in Equation
y
12. There is a definition such as
…
,
,mi
i
y
y
y
,
.
⋅
⋅
1
ctxt
cand
i
ctxt
cand
norte
Positional vectors ar e similar to word embedding in that it transforms a relative positional scalar into a
, where L is the
feature embedding vector by traversing through the embedding matrix
maximum sentence length, dp is the dimension of the position vector.
posW
∈R
−
l
( 2 1)
pd
×
Entity hidden similarity features: Extracting entity hidden similarity features as entity features are used to
replace the traditional entity feature extraction method in this paper, thus avoiding the use of traditional
NLP tools, and its calculation process is defined as shown in Equation (14-15).
=
j
a
i
exp.
⎛
⎝
k
∑
=
1
k
exp.
(
⎛
⎝
h
mi
(
(cid:2)
)
j
⎞
⎠
C
i
(cid:2)
)
j
⎞
⎠
C
k
h
mi
t
∈
{1,2}
j
k
= ∑
j
a c
i
i
=
1
i
(14)
(15)
en este documento, entities are categorized according to their similarity to their hidden vectors.
C
∈R
2 hd
×
k
denotes a potential vector constructed to represent the classes of similar entities, where K is a hyperparameter
representing the number of classes in which entities are classified by their hidden similarity.
The j th entity hidden similarity feature t j is calculated by weighting the similarity of c with the hidden
layer output
jeh based on the j th entity.
Entity features are structured by cascading the hidden states corresponding to the entity locations and
the potential type representation of the entity pair, shown as F2 in Equation (12).
3.5 Classification Layer
To compute the probability p of the output distribution of the state variable, A softmax layer has been
added after the keyword attention layer, which is shown in Equation 16.
p y
(
norte
)
=
softmax
(
W N
y
)
+
b
y
(16)
Of which |R| is the number of relationship categories, byR|R| is a biased term, Wy that maps the expected
value of the hidden state N to the feature score of the relational label.
Data Intelligence
561
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
3.6 Capacitación
The proposed keywords attention is calculated concerning the cross-entropy loss of the relation extraction.
This loss function is defined as shown in Equation 17.
|
|
D
′ ∑L
= -
(
p y
registro
i
( )
)
S θ
,
i
( )
=
1
i
(17)
Where |D| is the size of the training data dataset and (S(i), y(i)) is the i th sample in the dataset. The AdaDelta
optimizer is utilized to minimize the loss calculation parameter h in this paper.
To prevent overfitting, L2 regularisation is added to the loss function, where l1, l2 are the hyperparameters
of the regularisation. The second regularizer attempts to compel the model to process a small number of
significant words and returns a sparse weight distribution. The resulting objective function L is shown in
Ecuación 18.
L L
=
′
+
4. EXPERIMENTS
4.1 Dataset and Metric
2
λ θ λ
2
2
+
1
norte
∑
(
p z
i
=
1
h
)
i
(18)
To evaluate the experiment, we used the SemEval-2010 Task 8 dataset for our experiment, SemEval-2010
Tarea 8 dataset is a benchmark dataset that is widely used in the field of relationship extraction. The dataset
tiene 19 relationship types, including nine directional relationships and others. As shown in Table 1.
Mesa 1. Types of relationships in the dataset and their percentages.
Número
Rate
Capacitación
Testing
Capacitación
Testing
454
328
312
292
261
258
233
231
192
156
1410
1003
941
845
717
716
690
634
540
504
17.63
12.54
11.76
10.56
8.96
8.95
8.63
7.92
6.75
6.30
16.71
12.07
11.48
10.75
9.61
9.50
8.58
8.50
7.07
5.74
Tipo
Otro
Cause-Effect
Component-Whole
Entity-Destination
Product-Producer
Entity-Origin
Member-Collection
Message-Topic
Content-Container
Instrument-Agency
The dataset includes 10717 oraciones, of which 8000 samples were used for training and other 2717
samples for testing. The evaluation metrics used here are the macro averaged F1 score based, which is the
official evaluation metric of the dataset.
562
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
t
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
4.2 Detalles de implementacion
en este documento, a publicly available pre-trained EMLo model is used to initialize the word embeddings in
the REKA model, and the other weights in the model are initialized randomly using the zero-mean Gaussian
distribución, the relevant hyperparameters are shown in Table 2, The grid search was used for the selection
of regularised coefficient values for l1 and l2 from 0 a 0.2.
Hyper-parameter
dropout rate
l1
l2
r
batch size
r1
dr
da
DH
k
dp
Mesa 2. Hyperparameters of our model.
Descripción
Keyword attention layer
Bi-GRU layer
Word embedding layer
Multi-head attention layer
Regularization coeffi cient
Number of Heads
Size of mini-batch
Initial learning rate
The decay rate of leaming
Size of attention layer
Size of hidden layer
Number of the similar entities’ classes
Size of position embeddings
Value
0.5
0.6
0.8
0.8
[0, 0.2]
4
50
4
0.5
50
512
4
50
4.3 Comparison Models
The proposed REKA model is to be compared with the below benchmark model.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
.
t
i
(1)
(2)
(3)
(4)
(5)
SVM: The SVM [44] is a Non-Neural Model, which achieves top results in the SemEval-2010 task,
but it uses a lot of handcrafted and computationally intensive features such as WordNet, ProBank,
FrameNet, etc..
MV-RNN. The MV-RNN [45] is an SDP-based model, SDP is a semantic structural feature in
oraciones. Models with SDP can be iterated along the shortest dependency path between entities.
CNN. The CNN [4] is an end-to-end model on the SemEval-2010 task, which means that the data
from the input end is directly obtained from the output end. This model builds a convolutional
neural network to learn the feature vector of sentence level.
BiLSTM. The BiLSTM [30] is proposed to obtain sentence-level representations on the SemEval-2010
task with bidirectional long short-term memory networks. It is the classic RNN-based relation
extraction model.
DepNN. The DepNN [46] employs an RNN to model subtrees and a CNN to capture features on
the shortest path in sentences.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Data Intelligence
563
Bi-GRU Relation Extraction Model Based on Keywords Attention
(6)
(7)
(8)
(9)
FCM. The FCM [45] decomposes each sentence into sub-structures, then extracts their features
separately and finally merges them into the classification layer.
SDP-LSTM. The SDP-LSTM [5] employs the long short term memory (LSTM) to capture features along
the shortest dependency path (SDP). The model is a convolutional neural network for classification
by ranking and uses a loss function with pairwise rank.
Purely self-attention [47]. Only a self-attentive coding layer was utilized and combined with a
position-aware encoder for relational classification.
CASREL BERT [36]. CASREL BERT presents a cascade binary tagging framework (CASREL) y
implements a new tagging framework that achieves some performance improvements.
(10) Entity-Aware BERT [48]. The method builds on BERT with structured predictions and an entity-aware
self-attentive layer, achieving excellent performance on the SemEval 2010 Tarea 8 conjunto de datos.
4.4 Experimental Results
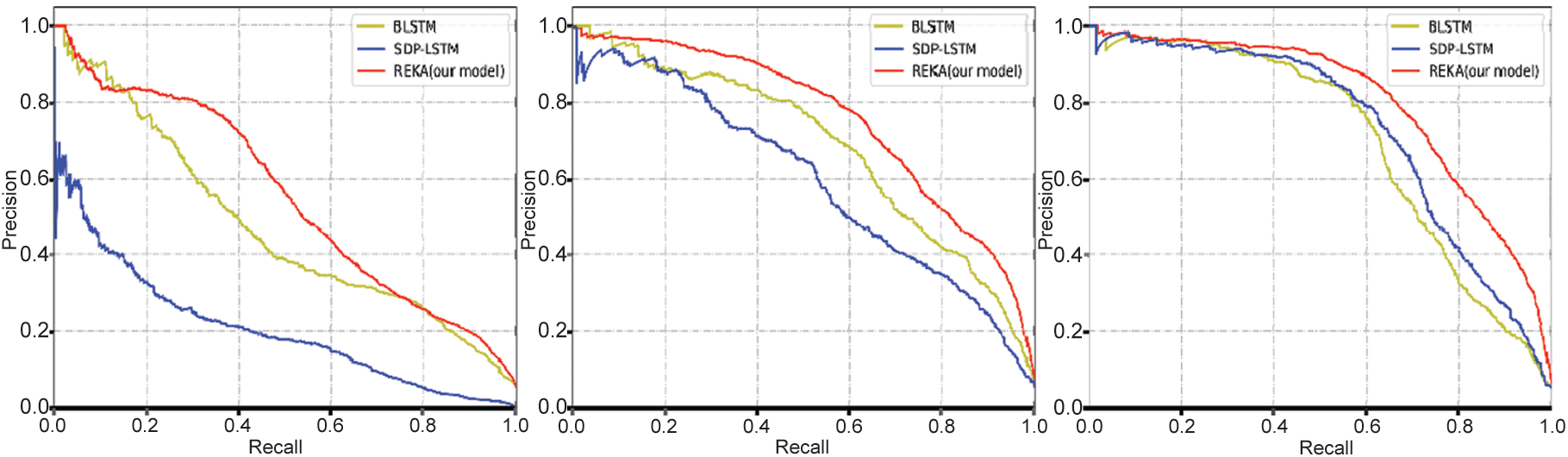
To evaluate the proposed models further, we chose the RNN-based model from the above models
for comparison. The Precision-Recall (PR) curves and complexity analysis of the models are shown in
Cifra 5.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
/
t
i
Cifra 5. Precision-Recall curves of different used numbers of datasets (1%, 20%, 100%, respectivamente) y
compared with RNN methods.
The comparison results between the REKA model and other models are shown in Table 3, the average
precisions (AP) of REKA compared with RNN methods are shown in Table 4.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
564
Data Intelligence
Bi-GRU Relation Extraction Model Based on Keywords Attention
Mesa 3. Comparison of the results of the Semeval-2010 Task 8 test dataset.
Modelo
SVM[42]
MV-RNN[43]
CNN[4]
BiLSTM[20]
DepNN[44]
FCM[45]
SDP-LSTM[5]
Purely Self-Attention[47]
CASREL BERT
Entity-Aware BERT[48]
REKA Model
Additional Featuresa
POS, WN, etc..
POS, NER, WN
PE, WN
None,
+ PF, POS, etc..
DEP
SDP, NER
SDP
PE
PE
PE
PE
Notas: a. (Where WN, DEP, SDP, PE are WordNet, dependency features, shortest dependency path, position embeddings, respectivamente).
F1
82.3
82.4
82.7
82.7
84.3
83.6
83.0
83.7
83.8
87.5
88.8
84.8
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
t
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 4. Average precision score for our model and compared methods (micro-averaged over all classes).
a
1%
20%
100%
BiLSTM
SDP-LSTM
0.26
0.60
0.73
0.47
0.68
0.70
REKA
0.55
0.76
0.81
Notas: a. (The fi rst columns show how much of testing data has been used. Performance is on the SemEval-2010 task dataset).
The experimental results show that the proposed REKA model is superior to the conventional model with
fewer features but is lower than the Entity-Aware BERT and CASREL BERT. Sin embargo, the pre-trained model
file of the BERT is so large that it takes longer to be trained with higher hardware performance requirements.
As shown in Table 5, we conducted ablation experiments on the development dataset in order to explore
the contribution of the various components of the keywords-aware attention mechanism to the experimental
resultados. We gradually stripped the individual components from the original model, the experimental results
showed that the F1-score decreased by 0.2 when the position embedding component was stripped from
el modelo. MHA, pre-trained EMLo word embeddings, and entity is hidden similarity features provide F1
puntuaciones de 0.5, 1.2, y 0.8 respectively for the model. En particular, a 2.3% improvement of F1 is a result
of the keywords-aware attention. Por lo tanto, experimental results demonstrate that these components
contribute to the model in a complementary way rather than working individually and achieve an F1 score
de 84.6 via the combination of all components.
Data Intelligence
565
Bi-GRU Relation Extraction Model Based on Keywords Attention
Mesa 5. The effect of components on the F1-score of the model.
Modelo
Our model
– Position embedding
– Multi-head attention
– Pre-trained EMLo word embeddings
– Entity hidden similarity features
– Keyword-aware attention
5. CONCLUSIÓN
Dev F1
84.6
84.4
83.9
82.7
81.9
79.6
en este documento, we propose a novel Bi-GRU network model based on an attention mechanism with
keywords for the task of RE on the SemEval-2010 task dataset. This model adequately extracts features that
are available in the dataset through the keyword attention mechanism and achieved F1 score of 84.8
without the use of other NLP tools. To calculate the marginal distribution for each word, we used the
similarity between the output of the hidden vectors by the entity words in the hidden layer and the relative
position feature vectors between the entity words in the CRF keyword attention mechanism, which is
chosen as the attention weight. Our further research will be carried out on attention mechanisms that can
better extract key information from sentences, and we are planning to use this for the identification of
relationships between several entities.
EXPRESIONES DE GRATITUD
This work is supported by the Science and Technology Project of Hubei Electric Power Co., LIMITADO., Estado
Grid (149).2020
CONTRIBUCIONES DE AUTOR
Yuanyuan Zhang (Correo electrónico: 16823650@qq.com, ORCID:0000-0002-5353-2989): has participated in the
proposed model design and writing of the manuscript.
Yu Chen (Correo electrónico: 1148848330@qq.com, ORCID: 0000-0001-7316-3570): has participated in the coding,
the experiment and analysis, writing the manuscript.
Shengkang Yu (Correo electrónico: 12052033@qq.com, ORCID:0000-0001-6374-3395): has participated in the part
of the experiment and analysis.
Xiaoqin Gu (Correo electrónico: 1564785699@qq.com, ORCID: 0000-0001-6308-8474): has participated in the part
of the experiment and analysis.
566
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
t
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
Mengqiong Song (Correo electrónico: 297365728@qq.com, ORCID:0000-0002-2816-5670): has participated in the
part of the experiment and analysis.
Yu Peng (Correo electrónico: 1039079148@qq.com, ORCID:0000-0002-5353-2989): has participated in the revision
of the manuscript.
Jianxia Chen (Correo electrónico: 1607447166@qq.com, ORCID: 0000-0001-6662-1895): has participated in the
model design, problem analysis, writing and revision of the manuscript.
Qi Liu (Correo electrónico:260129443@qq.com, ORCID:0000-0003-1066-898X): has participated in the writing and
revision of the manuscript.
REFERENCIAS
[1] Bollacker, K., evans, C., Paritosh, PAG., Sturge, T., & taylor, J.: Free-base: a collaboratively created graph
database for structuring human knowledge. En: Proceedings of the 2008 ACM SIGMOD international
conference on Management of data, páginas. 1247–1250 (2008, Junio)
[2] Auer, S., Bizer, C., Kobilarov, GRAMO., Lehmann, J., Cyganiak, r., & Ives, Z.: Dbpedia: A nucleus for a web of open
datos. In The semantic web, páginas. 722–735 (2007). Saltador, Berlina, Heidelberg
[3] Pawar, S., Palshikar, G.K., & Bhattacharyya, PAG.: Relation extraction: A survey. arXiv preimpresión arXiv:1712.05191
(2017)
[4] Zeng, D., Liu, K., Dejar, S., zhou, GRAMO., & zhao, J.: Relation classification via convolutional deep neural network.
En: Proceedings of COLING 2014, the 25th international conference on computational linguistics: technical
documentos, páginas. 2335–2344 (2014, Agosto)
[5] Xu, y., Mou, l., li, GRAMO., Chen, y., Peng, h., & Jin, Z.: Classifying relations via long short term memory networks
along shortest dependency paths. En: Actas de la 2015 conference on empirical methods in natural
language processing, páginas. 1785–1794 (2015, Septiembre)
Liu, C., Sol, w., chao, w., & Che, w.: Convolution neural network for relation extraction. En: Internacional
conference on advanced data mining and applications, páginas. 231–242 (2013, December). Saltador, Berlina,
Heidelberg
[6]
[7] Nguyen, T.H., & Grishman, r.: Relation extraction: Perspective from convolutional neural networks. En:
Proceedings of the 1st workshop on vector space modeling for natural language processing, páginas. 39–48
(2015, Junio)
Santos, C.N.D., Xiang, B., & zhou, B.: Classifying relations by ranking with convolutional neural networks.
arXiv preimpresión arXiv:1504.06580 (2015)
[8]
[9] Chen, y.: Convolutional neural network for sentence classification (Tesis de maestría, Universidad de Waterloo)
(2015)
[10] Kalchbrenner, NORTE., Grefenstette, MI., & Blunsom, PAG.: A convolutional neural network for modelling sentences.
arXiv preimpresión arXiv:1404.2188 (2014)
[11] elman, J.L. Distributed representations, simple recurrent networks, and grammatical structure. Machine
aprendiendo 7(2), 195–225 (1991)
[12] zhang, D., & Wang, D.: Relation classification via recurrent neural network. arXiv preimpresión arXiv:1508.01006
(2015)
Data Intelligence
567
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
[13] zhang, S., Zheng, D., Hu, X., & Cual, METRO.: Bidirectional long short-term memory networks for relation
clasificación. En: Proceedings of the 29th Pacific Asia conference on language, information and
computation, páginas. 73–78 (2015, Octubre)
[14] Sundermeyer, METRO., Schlüter, r., & Ney, h.: LSTM neural networks for language modeling. En: Thirteenth
annual conference of the international speech communication association (2012)
[15] Hochreiter, S., & Schmidhuber, J.: Memoria larga a corto plazo. Computación neuronal 9(8), 1735–1780 (1997)
[16] Chung, J., Gulcehre, C., Dar, K., & bengio, y.: Empirical evaluation of gated recurrent neural networks on
sequence modeling. arXiv preimpresión arXiv:1412.3555 (2014)
[17] Wang, h., Qin, K., Zakari, R. y., Lu, GRAMO., & Yin, J.: Deep neural network-based relation extraction: un
descripción general. Neural Computing and Applications, 1–21 (2022)
[18] Xu, y., Mou, l., li, GRAMO., Chen, y., Peng, h., & Jin, Z.: Classifying relations via long short term memory
networks along shortest dependency paths. En: Actas de la 2015 conference on empirical methods
in natural language processing, páginas. 1785–1794 (2015, Septiembre)
[19] zhang, y., Zhong, v., Chen, D., Angeli, GRAMO., & Manning, C.D.: Position-aware attention and supervised data
improve slot filling. En: Conference on Empirical Methods in Natural Language Processing (2017)
[20] zhang, y., chi, PAG., & Manning, C.D.: Graph convolution over pruned dependency trees improves relation
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
extraction. arXiv preimpresión arXiv:1809.10185 (2018)
[21] Liu, T., zhang, X., zhou, w., & Jia, w.: Neural relation extraction via inner-sentence noise reduction and
transferir aprendizaje. arXiv preimpresión arXiv:1808.06738 (2018)
[22] Sotavento, J., SEO, S., & Choi, Y.S.: Semantic relation classification via bidirectional lstm networks with entity-aware
attention using latent entity typing. Symmetry 11(6), 785 (2019)
[23] Wang, h., Qin, K., Lu, GRAMO., luo, GRAMO., & Liu, GRAMO.: Direction-sensitive relation extraction using bi-sdp attention
modelo. Knowledge-Based Systems 198, 105928 (2020)
[24] Yu, B., zhang, Z., Liu, T., Wang, B., li, S., & li, P.: Beyond Word Attention: Using Segment Attention in
Neural Relation Extraction. En: IJCAI, páginas. 5401–5407 (2019, Agosto)
[25] Aydar, METRO., Bozal, o., & Ozbay, F.: Neural relation extraction: a survey. arXiv e-prints, arXiv-2007 (2020)
[26] Socher, r., Huval, B., Manning, C.D., & Ng, A.Y.: Semantic compositionality through recursive matrix-vector
spaces. En: Actas de la 2012 joint conference on empirical methods in natural language processing
and computational natural language learning, páginas. 1201–1211 (2012, Julio)
[27] Zeng, D., Liu, K., Chen, y., & zhao, J.: Distant supervision for relation extraction via piecewise convolutional
neural networks. En: Proceedings of the 2015 conference on empirical methods in natural language
Procesando, páginas. 1753–1762 (2015, Septiembre)
[28] zhang, D., & Wang, D.: Relation classification via recurrent neural network. arXiv preimpresión arXiv:1508.01006
(2015)
[29] Xu, y., Jia, r., Mou, l., li, GRAMO., Chen, y., Lu, y., & Jin, Z.: Improved relation classification by deep recurrent
neural networks with data augmentation. arXiv preimpresión arXiv:1601.03651 (2016)
[30] zhang, S., Zheng, D., Hu, X., & Cual, METRO.: Bidirectional long short-term memory networks for relation
clasificación. En: Proceedings of the 29th Pacific Asia conference on language, information and
computation, páginas. 73–78 (2015, Octubre)
[31] zhou, PAG., Shi, w., tian, J., chi, Z., li, B., hao, h., & Xu, B.: Attention-based bidirectional long short-term
memory networks for relation classification. En: Proceedings of the 54th annual meeting of the association
for computational linguistics (volumen 2: Short papers), páginas. 207–212 (2016, Agosto)
568
Data Intelligence
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
[32] xiao, METRO., & Liu, C.: Semantic relation classification via hierarchical recurrent neural network with attention.
En: Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics:
Technical Papers, páginas. 1254–1263 (2016, December)
[33] Qin, PAG., Xu, w., & guo, J.: Designing an adaptive attention mechanism for relation classification. En: 2017
International Joint Conference on Neural Networks (IJCNN), páginas. 4356–4362 (2017, Puede). IEEE
[34] zhang, C., Cual, C., gao, S., NO, X., Xu, w., Cual, l., … & Yin, y.: Multi-gram CNN-based self-attention model
for relation classification. IEEE Access 7, 5343–5357 (2018)
[35] zhang, C., Cual, C., gao, S., NO, X., Xu, w., Cual, l., … & Yin, y.: Multi-gram CNN-based self-attention model
for relation classification. IEEE Access 7, 5343–5357 (2018)
[36] Wei, Z., Su, J., Wang, y., tian, y., & Chang, y.: A novel cascade binary tagging framework for relational triple
extraction. arXiv preimpresión arXiv:1909.03227 (2019)
[37] Mintz, METRO., Bills, S., Snow, r., & Jurafsky, D.: Distant supervision for relation extraction without labeled data.
En: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint
Conference on Natural Language Processing of the AFNLP, páginas. 1003–1011 (2009, Agosto)
[38] Él, y., li, Z., Cual, P., Chen, Z., Liu, A., zhao, l., & zhou, X.: End-to-end relation extraction based on
bootstrapped multi-level distant supervision. World Wide Web 23(5), 2933–2956 (2020)
[39] Han, X., Liu, Z., & Sol, METRO.: Neural knowledge acquisition via mutual attention between knowledge graph
and text. En: Proceedings of the AAAI Conference on Artificial Intelligence 32(1) (2018, Abril)
[40] Wang, GRAMO., zhang, w., Wang, r., zhou, y., Chen, X., zhang, w., … & Chen, h.: Label-free distant supervision
for relation extraction via knowledge graph embedding. En: Actas de la 2018 conference on empirical
methods in natural language processing, páginas. 2246–2255 (2018)
[41] Mikolov, T., Chen, K., Corrado, GRAMO., & Dean, J.: Efficient estimation of word representations in vector space.
arXiv preimpresión arXiv:1301.3781 (2013)
[42] Pennington, J., Socher, r., & Manning, C.D.: Glove: Global vectors for word representation. En procedimientos
of the 2014 conference on empirical methods in natural language processing (EMNLP), páginas. 1532–1543
(2014, Octubre)
[43] Sarzynska-Wawer, J., Wawer, A., Pawlak, A., Szymanowska, J., Stefaniak, I., Jarkiewicz, METRO., & Okruszek, l.:
Detecting formal thought disorder by deep contextualized word representations. Psychiatry Research 304,
114135 (2021)
[44] Rink, B., & Harabagiu, S.: Utd: Classifying semantic relations by combining lexical and semantic resources.
En: Proceedings of the 5th international workshop on semantic evaluation, páginas. 256–259 (2010, Julio)
[45] Socher, r., Huval, B., Manning, C.D., & Ng, A.Y.: Semantic compositionality through recursive matrix-vector
spaces. En: Actas de la 2012 joint conference on empirical methods in natural language processing
and computational natural language learning, páginas. 1201–1211 (2012, Julio)
[46] Liu, y., Wei, F., li, S., Ji, h., zhou, METRO., & Wang, h.: A dependency-based neural network for relation
clasificación. arXiv preimpresión arXiv:1507.04646 (2015)
[47] Bilan, I., & Roth, B.: Position-aware self-attention with relative positional encodings for slot filling. arXiv
preprint arXiv:1807.03052 (2018)
[48] Wang, h., Broncearse, METRO., Yu, METRO., Chang, S., Wang, D., Xu, K., … & Potdar, S.: Extracting multiple-relations in
one-pass with pre-trained transformers. arXiv preimpresión arXiv:1902.01030 (2019)
Data Intelligence
569
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
t
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Bi-GRU Relation Extraction Model Based on Keywords Attention
AUTHOR BIOGRAPHY
Yuanyuan Zhang (1979–), masculino, Doctor. graduated from Wuhan University,
associate professor and senior engineer of Technical Training Center of State
Grid Hubei Electric Power Co., Limitado. Research direction: intelligent substation
tecnología, intelligent power grid operation and inspection technology,
Correo electrónico: 16823650@qq.com, ORCID: 0000-0002-5353-2989
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
Yu Chen (1996–), masculino, graduate student of Hubei University of Technology,
research direction: Artificial Intelligent, NLP, Correo electrónico: 1148848330@qq.com,
ORCID: 0000-0001-7316-3570
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
/
t
i
Shengkang Yu (1993–), masculino, master graduated from Huazhong University
of Science and Technology, lecturer and intermediate engineer of Technical
Training Center of State Grid Hubei Electric Power Co.,Ltd. Research direction:
fault diagnosis of electrical equipment, Correo electrónico: 120520338@qq.com., ORCID:
0000-0001-6374-3395
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
570
Data Intelligence
Bi-GRU Relation Extraction Model Based on Keywords Attention
Xiaoqin Gu (1973–), femenino, master graduated from Hubei University,
lecturer of Technical Training Center of State Grid Hubei Electric Power Co.,
Limitado., Research direction: power grid operation
tecnología, Correo electrónico:
1564785699@qq.com. ORCID: 0000-0001-6308-8474
Mengqiong Song (1991–), femenino, master graduated from Wuhan University,
intermediate engineer of Technical Training Center of State Grid Hubei
Electric Power Co., Limitado. Research direction: power grid operation technology,
Correo electrónico: 297365728@qq.com, ORCID: 0000-0002-2816-5670
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
/
t
i
Yu Peng, femenino, graduated from Wuhan University. Research direction: grid
power electronics, Correo electrónico: 1039079148@qq.com, ORCID: 0000-0002-5353-
2989
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Data Intelligence
571
Bi-GRU Relation Extraction Model Based on Keywords Attention
Jianxia Chen is an associate professor in School of Computer Science at
Hubei University of Technology. She obtained her MS at Huazhong University
de Ciencia & Technology in China. She has worked as a research fellow on
the CCF in China and ACM in USA. Her particular research interests are in
knowledge graph and recommendation systems.
ORCID: 0000-0001-6662-1895
Qi Liu, femenino, graduate student of Hubei University of Technology, investigación
direction: Artificial Intelligent, NLP, Correo electrónico: 260129443@qq.com., ORCID:
0000-0003-1066-898X
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
3
5
5
2
2
0
3
8
4
1
2
d
norte
_
a
_
0
0
1
4
7
pag
d
.
t
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
572
Data Intelligence