Meta-Learning a Cross-lingual Manifold for Semantic Parsing
Tom Sherborne and Mirella Lapata
Institute for Language, Cognition and Computation
School of Informatics, Università di Edimburgo
10 Crichton Street, Edinburgh EH8 9AB, UK
tom.sherborne@ed.ac.uk, mlap@inf.ed.ac.uk
Astratto
Localizing a semantic parser to support new
languages requires effective cross-lingual gen-
eralization. Recent work has found success
with machine-translation or zero-shot meth-
ods, although these approaches can struggle
to model how native speakers ask questions.
We consider how to effectively leverage min-
imal annotated examples in new languages
for few-shot cross-lingual semantic parsing.
We introduce a first-order meta-learning algo-
rithm to train a semantic parser with maximal
sample efficiency during cross-lingual trans-
fer. Our algorithm uses high-resource lan-
guages to train the parser and simultaneously
optimizes for cross-lingual generalization to
lower-resource languages. Results across six
languages on ATIS demonstrate that our
combination of generalization steps yields
accurate semantic parsers sampling ≤10% of
source training data in each new language.
Our approach also trains a competitive model
on Spider using English with generalization
to Chinese similarly sampling ≤10% of train-
ing data.1
1
introduzione
A semantic parser maps natural language (NL)
utterances to logical forms (LF) or executable pro-
grams in some machine-readable language (per esempio.,
SQL). Recent improvement in the capability of
semantic parsers has focused on domain transfer
within English (Su and Yan, 2017; Suhr et al.,
2020), compositional generalization (Yin and
Neubig, 2017; Herzig and Berant, 2021; Scholak
et al., 2021), E, more recently, cross-lingual
metodi (Duong et al., 2017; Susanto and Lu,
2017B; Richardson et al., 2018).
Within cross-lingual semantic parsing, there
has been an effort to bootstrap parsers with min-
1Our code and data are available at github.com
/tomsherborne/xgr.
49
imal data to avoid the cost and labor required
to support new languages. Recent proposals in-
clude using machine translation to approximate
training data for supervised learning (Moradshahi
et al., 2020; Sherborne et al., 2020; Nicosia et al.,
2021) and zero-shot models, which engineer cross-
lingual similarity with auxiliary losses (van der
Goot et al., 2021; Yang et al., 2021; Sherborne
and Lapata, 2022). These shortcuts bypass costly
data annotation but present limitations such as
‘‘translationese’’ artifacts from machine transla-
zione (Koppel and Ordan, 2011) or undesirable
domain shift (Sherborne and Lapata, 2022). How-
ever, annotating a minimally sized data sample
can potentially overcome these limitations while
incurring significantly reduced costs compared
to full dataset translation (Garrette and Baldridge,
2013).
We argue that a few-shot approach is more
realistic for an engineer motivated to support ad-
ditional languages for a database—as one can
rapidly retrieve a high-quality sample of transla-
tions and combine these with existing supported
languages (cioè., English). Beyond semantic pars-
ing, cross-lingual few-shot approaches have also
succeeded at leveraging a small number of anno-
tations within a variety of tasks (Zhao et al., 2021,
inter alia) including natural language inference,
paraphrase identification, part-of-speech-tagging,
and named-entity recognition. Recentemente, the ap-
plication of meta-learning to domain generali-
zation has further demonstrated capability for
models to adapt to new domains with small sam-
ples (Gu et al., 2018; Li et al., 2018; Wang et al.,
2020B).
In this work, we synthesize these directions
into a meta-learning algorithm for cross-lingual
semantic parsing. Our approach explicitly opti-
mizes for cross-lingual generalization using fewer
training samples per new language without per-
formance degradation. We also require minimal
Operazioni dell'Associazione per la Linguistica Computazionale, vol. 11, pag. 49–67, 2023. https://doi.org/10.1162/tacl a 00533
Redattore di azioni: Wei Lu. Lotto di invio: 7/2022; Lotto di revisione: 9/2022; Pubblicato 1/2023.
C(cid:3) 2023 Associazione per la Linguistica Computazionale. Distribuito sotto CC-BY 4.0 licenza.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
T
l
UN
C
_
UN
_
0
0
5
3
3
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
computational overhead beyond standard gradient-
descent training and no external dependencies be-
yond in-task data and a pre-trained encoder. Nostro
algorithm, Cross-Lingual Generalization Reptile
(XG-REPTILE) unifies two-stage meta-learning into
a single process and outperforms prior and con-
stituent methods on all languages, given identical
data constraints. The proposed algorithm is still
model-agnostic and applicable to more tasks re-
quiring sample-efficient cross-lingual transfer.
Our innovation is the combination of both
intra-task and inter-language steps to jointly learn
the parsing task and optimal cross-lingual trans-
fer. Specifically, we interleave learning the overall
task from a high-resource language and learn-
ing cross-lingual transfer from a minimal sample
of a lower-resource language. Results on ATIS
(Hemphill et al., 1990) in six languages (English,
French, Portuguese, Spanish, German, Chinese)
and Spider (Yu et al., 2018) in two languages (In-
glish, Chinese) demonstrate our proposal works
in both single- and cross-domain environments.
Our contributions are as follows:
• We introduce XG-REPTILE, a first-order
meta-learning algorithm for cross-lingual
generalization. XG-REPTILE approximates an
optimal manifold using support languages
with cross-lingual regularization using tar-
Ottenere
languages to train for explicit cross-
lingual similarity.
• We showcase sample-efficient cross-lingual
transfer within two challenging semantic
parsing datasets across multiple languages.
Our approach yields more accurate parsing
in a few-shot scenario and demands 10×
fewer samples than prior methods.
• We establish a cross-domain and cross-
lingual parser obtaining promising results for
both Spider in English (Yu et al., 2018) E
CSpider in Chinese (Min et al., 2019).
2 Related Work
Meta-Learning
for Generalization Meta-
Learning2 has recently emerged as a promising
technique for generalization, delivering high
performance on unseen domains by learning to
2We refer the interested reader to Wang et al. (2020B),
Hospedales et al. (2022), and Wang et al. (2021B) for more
extensive surveys on meta-learning.
Imparare, questo è, improving learning over multiple
episodes (Hospedales et al., 2022; Wang et al.,
2021B). A popular approach is Model-Agnostic
Meta-Learning (Finn et al., 2017, MAML),
wherein the goal is to train a model on a variety
of learning tasks, such that it can solve new tasks
using a small number of training samples. In ef-
fect, MAML facilitates task-specific fine-tuning
using few samples in a two-stage process. MAML
requires computing higher-order gradients (cioè.,
‘‘gradient through a gradient’’) which can often
be prohibitively expensive for complex models.
This limitation has motivated first-order ap-
proaches to MAML which offer similar perfor-
mance with improved computational efficiency.
In this vein,
the Reptile algorithm (Nichol
et al., 2018) transforms the higher-order gradi-
ent approach into K successive first-order steps.
Reptile-based training approximates a solution
manifold across tasks (cioè., a high-density pa-
rameter sub-region biased for strong cross-task
then similarly followed by rapid
likelihood),
fine-tuning. By learning an optimal
initializa-
zione, meta-learning proves useful for low-resource
adaptation by minimizing the data required
for out-of-domain tuning on new tasks. Kedia
et al. (2021) also demonstrate the utility of Reptile
to improve single-task performance. We build on
this to examine single-task cross-lingual transfer
using the manifold learned with Reptile.
Meta-Learning for Semantic Parsing A va-
riety of NLP applications have adopted meta-
learning in zero- and few-shot learning scenarios
as a method of explicitly training for general-
ization (Lee et al., 2021; Hedderich et al., 2021).
Within semantic parsing, there has been increasing
interest in cross-database generalization, moti-
vated by datasets such as Spider (Yu et al., 2018)
requiring navigation of unseen databases (Herzig
and Berant, 2017; Suhr et al., 2020).
Approaches to generalization have included
simulating source and target domains (Givoli and
Reichart, 2019) and synthesizing new training data
based on unseen databases (Zhong et al., 2020;
Xu et al., 2020UN). Meta-learning has demonstrated
fast adaptation to new data within a monolin-
gual low-resource setting (Huang et al., 2018; Guo
et al., 2019; Lee et al., 2019; Sole et al., 2020).
Allo stesso modo, Chen et al. (2020) utilize Reptile to
improve generalization of a model, trained on
source domains, to fine-tune on new domains.
50
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
T
l
UN
C
_
UN
_
0
0
5
3
3
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Our work builds on Wang et al. (2021UN), who
explicitly promote monolingual cross-domain
generalization by ‘‘meta-generalizing’’ across dis-
joint, domain-specific batches during training.
Cross-lingual Semantic Parsing A surge of in-
terest in cross-lingual NLU has seen the creation of
many benchmarks across a breadth of languages
(Conneau et al., 2018; Hu et al., 2020; Liang
et al., 2020), thereby motivating significant ex-
ploration of cross-lingual transfer (Nooralahzadeh
et al., 2020; Xia et al., 2021; Xu et al., 2021;
Zhao et al., 2021, inter alia). Previous approaches
to cross-lingual semantic parsing assume parallel
multilingual training data (Jie and Lu, 2014) E
exploit multi-language inputs for training without
resource constraints (Susanto and Lu, 2017UN,B).
There has been recent interest in evaluating if
machine translation is an economic proxy for cre-
ating training data in new languages (Sherborne
et al., 2020; Moradshahi et al., 2020). Zero-shot
approaches to cross-lingual parsing have also
been explored using auxiliary training objectives
(Yang et al., 2021; Sherborne and Lapata, 2022).
Cross-lingual
learning has also been gaining
traction in the adjacent field of spoken-language
understanding (SLU). For datasets such as Multi-
ATIS (Upadhyay et al., 2018), MultiATIS++ (Xu
et al., 2020B), and MTOP (Li et al., 2021),
zero-shot cross-lingual transfer has been studied
through specialized decoding methods (Zhu et al.,
2020), machine translation (Nicosia et al., 2021),
and auxiliary objectives (van der Goot et al.,
2021).
Cross-lingual semantic parsing has mostly
remained orthogonal to the cross-database gen-
eralization challenges raised by datasets such as
Spider (Yu et al., 2018). While we primarily
present findings for multilingual ATIS into SQL
(Hemphill et al., 1990), we also train a parser on
both Spider and its Chinese version (Min et al.,
2019). To the best of our knowledge, we are
the first to explore a multilingual approach to
this cross-database benchmark. We use Reptile to
learn the overall task and leverage domain gener-
alization techniques (Li et al., 2018; Wang et al.,
2021UN) for sample-efficient cross-lingual transfer.
3 Problem Definition
a natural language utterance and a relational data-
base context to an executable program expressed
in a logical form (LF) lingua:
P = pθ (Q, D)
(1)
As formalized in Equation (1), we learn pa-
rameters, θ, using paired data (Q, P, D) Dove
P is the logical form equivalent of natural lan-
guage question Q. In this work, our LFs are all
executable SQL queries and therefore grounded
in a database D. A single-domain dataset refer-
ences only one D database for all (Q, P ), whereas
a multi-domain dataset demands reasoning about
unseen databases to generalize to new queries.
This is expressed as a ‘zero-shot’ problem if the
databases at test time, Dtest, were unseen during
training. This challenge demands a parser capa-
ble of domain generalization beyond observed
databases. This is in addition to the structured
prediction challenge of semantic parsing.
Cross-Lingual Generalization Prototypical se-
mantic parsing datasets express the question, Q, In
English only. As discussed in Section 1, our parser
should be capable of mapping from additional
languages to well-formed, executable programs.
Tuttavia, prohibitive expense limits us from
reproducing a monolingual model for each addi-
tional language and previous work demonstrates
accuracy improvement by training multilingual
models (Jie and Lu, 2014). In aggiunta a
challenges of structured prediction and domain
generalization, we jointly consider cross-lingual
generalization. Training primarily relies on exist-
ing English data (cioè., QEN samples) and we show
that our meta-learning algorithm in Section 4
leverages a small sample of training data in new
languages for accurate parsing. We express this
sample, Sl, for some language, l, COME:
Sl = (Ql, P, D)Nl
i=0
(2)
where Nl
is the sample size from l, assumed
to be smaller than the original English dataset
(cioè., Nl (cid:4) NEN). Where available, we extend
this paradigm to develop models for L different
languages simultaneously in a multilingual setup
by combining samples as:
Semantic Parsing We wish to learn a param-
eterized parsing function, pθ, which maps from
SL = {Sl1, Sl2, . . . , SlN
}
(3)
51
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
T
l
UN
C
_
UN
_
0
0
5
3
3
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
We can express cross-lingual generalization as:
pθ (P | Ql, D) → pθ (P | QEN, D)
(4)
where pθ (P | QEN, D) is the predicted distri-
bution over all possible output SQL sequences
conditioned on an English question, QEN, and a
database D. Our goal is for the prediction from a
new language, Ql, to converge towards this ex-
isting distribution using the same parameters θ,
constrained to fewer samples in l than English.
We aim to maximize the accuracy of predict-
ing programs on unseen test data from each
non-English language l. The key challenge is
learning a performant distribution over each new
language with minimal available samples. Questo
includes learning to incorporate each l into the
parsing task and modeling the language-specific
surface form of questions. Our setup is akin to
few-shot learning; Tuttavia, the number of ex-
amples needed for satisfactory performance is an
empirical question. We are searching for both
minimal sample sizes and maximal sampling ef-
ficiency. We discuss our sampling strategy in
Sezione 5.2 with results at multiple sizes of SL
in Section 6.
4 Methodology
We combine two meta-learning techniques for
cross-lingual semantic parsing. The first is the
Reptile algorithm outlined in Section 2. Reptile
optimizes for dense likelihood regions within the
parameters (cioè., a solution manifold) through pro-
moting inter-batch generalization (Nichol et al.,
2018). Standard Reptile iteratively optimizes the
manifold for an improved initialization across
objectives. Rapid fine-tuning yields the final
task-specific model. The second technique is the
first-order approximation of DG-MAML (Li et al.,
2018; Wang et al., 2021UN). This single-stage pro-
cess optimizes for domain generalization by
simulating ‘‘source’’ and ‘‘target’’ batches from
different domains to explicitly optimize for cross-
batch generalization. Our algorithm, XG-REPTILE,
combines these paradigms to optimize a target
loss with the overall learning ‘‘direction’’ de-
rived as the optimal manifold learned via Rep-
tile. This trains an accurate parser demonstrating
sample-efficient cross-lingual transfer within an
efficient single-stage learning process.
Figura 1: One iteration of XG-REPTILE. (1) Run K
iterations of gradient descent over K support batches to
learn φK, (2) compute ∇macro, the difference between
φK and φ1, (3) find the loss on the target batch using
φK, E (4) compute the final gradient update from
∇macro and the target loss.
4.1 The XG-REPTILE Algorithm
Each learning episode of XG-REPTILE comprises
intra-task learning and
two component steps:
inter-language generalization to jointly learn pars-
ing and cross-lingual transfer. Alternating these
processes trains a competitive parser from multi-
ple languages with low computational overhead
beyond existing gradient-descent training. Nostro
two stages of
approach combines the typical
meta-learning to produce a single model without
a fine-tuning requirement.
Task Learning Step We first sample from the
high-resource language (cioè., SEN) K ‘‘support’’
batches of examples, BS = {(QEN, P, D)}. For
each of K batches: We compute predictions,
compute losses, calculate gradients and adjust pa-
rameters using some optimizer (see illustration in
Figura 1). After K successive optimization steps
the initial weights in this episode, φ1, have been
optimized to φK. The difference between final
and initial weights is calculated as:
∇macro = φK − φ1
(5)
This ‘‘macro-gradient’’ step is equivalent to a
Reptile step (Nichol et al., 2018), representing
learning a solution manifold as an approximation
of overall learning trajectory.
52
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
T
l
UN
C
_
UN
_
0
0
5
3
3
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
k=1 from SEN
Copy φ1 ← θt−1
Sample K support batches {BS}K
Sample target language l from L languages
Sample target batch BT from Sl
for k ← 1 to K [Inner Loop] do
(cid:3)
← Forward
(cid:2)
Algorithm 1 XG-REPTILE
Require: Support data, SEN, target data, SL
Require: Inner learning rate, α, outer learning rate, β
1: Initialise θ1, the vector of initial parameters
2: for t ← 1 to T do
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15: end for
end for
Macro grad: ∇macro ← φK − φ1
BT , φK
Target Step: LT ← Forward
Total gradient: ∇Σ = ∇macro + ∇φK
Update θt ← SGD (θt−1, ∇Σ, β)
LS
k
φk ← Adam
BS
k , φk−1
φk−1, ∇LS
k , α
LT
(cid:3)
(cid:2)
(cid:2)
(cid:3)
1
K proportionality requires 10% of target-language
data relative to support. We demonstrate in
Sezione 6 that we can use a smaller < 1
K quantity
per target language to increase sample efficiency.
Gradient Analysis Following Nichol et al.
(2018), we express gk = ∇LS
k , the gradient in
a single step of the inner loop (Line 9), as:
gk = ¯gi + ¯Hk (φk − φ1) + O
(cid:3)
(cid:2)
α2
(7)
We use a Taylor series expansion to approximate
gk by ¯gk, the gradient at the original point, φ1,
the Hessian matrix of the gradient at the initial
point, ¯Hk, the step difference between position
φk and the initial position and some scalar terms
with marginal influence, O
α2
(cid:2)
(cid:3)
.
Cross-Lingual Step The second step samples
one ‘‘target’’ batch, BT = (Ql, P, D), from a
sampled target language (i.e., Sl ⊂ SL). We com-
pute the cross-entropy loss and gradients from the
prediction of the model at φK on BT :
LT = Loss (pφK (Ql, D) , P )
(6)
We evaluate the parser at φK on a target lan-
guage we desire to generalize to. We show below
that the gradient of LT comprises the loss at φK
and additional terms maximizing the inner product
between the high-likelihood manifold and the tar-
get loss. The total gradient encourages intra-task
and cross-lingual learning (see Figure 1).
Algorithm 1 outlines the XG-REPTILE process
(loss calculation and batch processing are simpli-
fied for brevity). We repeat this process over T
episodes to train model pθ to convergence. If we
optimized for target data to align with individual
support batches (i.e., K = 1) then we may observe
batch-level noise in cross-lingual generalization.
Our intuition is that aligning the target gradient
with an approximation of the task manifold, i.e.,
∇macro, will overcome this noise and align new
languages to a more mutually beneficial direction
during training. We observe this intuitive behavior
during learning in Section 6.
We efficiently generalize to low-resource
languages by exploiting the asymmetric data re-
quirements between steps: One batch of the target
language is required for K batches of the source
language. For example, if K = 10 then using this
By evaluating Equation (7) at i = 1 and rewrit-
ing the difference as a sum of gradient steps (e.g.,
Equations (8) and (9)), we arrive at an expression
for gk shown in Equation (10) expressing the gra-
dient as an initial component, ˆgk, and the product
of the Hessian at k, with all prior gradient steps.
We refer to Nichol et al. (2018) for further vali-
dation that the gradient of this product maximizes
the cross-batch expectation—therefore promoting
cross-batch generalization and towards the solu-
tion manifold. The final gradient (Equation (11)) is
the accumulation over gk steps and is equivalent
to Equation (5). ∇macro comprises both gradi-
ents of K steps and additional terms maximiz-
ing the inner-product of cross-batch gradients.
Use gj = ¯gj + O(α)
φk − φ1 = −α
k−1(cid:4)
j=1
gj
gk = ¯gi − α ¯Hi
(cid:3)
(cid:2)
α2
¯gj + O
k−1(cid:4)
j=1
∇macro =
K(cid:4)
k=1
gk
(8)
(9)
(10)
(11)
We can similarly express the gradient of the
target batch as Equation (12) where the term,
¯HT ∇macro,
is the cross-lingual generalization
product similar to the intra-task generalization
seen above.
gT = ¯gT − α ¯HT ∇macro + O
(cid:3)
(cid:2)
α2
(12)
53
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Equation (13) shows an example final gradi-
ent when K = 2. Within the parentheses are
the cross-batch and cross-lingual gradient prod-
ucts as components promoting fast learning across
multiple axes of generalization.
∇Σ = g1 + g2 + gT
= ¯g1 + ¯g2 + ¯gT
− α
(cid:2)
¯H2¯g1 + ¯HT [¯g1 + ¯g2]
(13)
(cid:3)
(cid:3)
(cid:2)
α2
+ O
The key hyperparameter in XG-REPTILE is the
number of inner-loop steps K representing a
trade-off between manifold approximation and
target step frequency. At small K, the manifold
approximation may be poor,
leading to sub-
optimal learning. At large K, then improved mani-
fold approximation incurs fewer target batch steps
per epoch, leading to weaked cross-lingual trans-
fer. In practice, K is set empirically, and Section 6
identifies an optimal region for our task.
XG-REPTILE can be viewed as generalizing
two existing algorithms. Without the LT loss,
our approach is equivalent to Reptile and lacks
cross-lingual alignment. If K = 1, then XG-
to DG-FMAML (Wang
REPTILE is equivalent
et al., 2021a) but
lacks generalization across
support batches. Our unification of these al-
gorithms represent the best of both approaches
and outperforms both techniques within semantic
parsing. Another perspective is that XG-REPTILE
learns a regularized manifold, with immediate
cross-lingual capability, as opposed to standard
Reptile, which requires fine-tuning to transfer
across tasks. We identify how this contrast in
transfer in
approaches influences cross-lingual
Section 6.
5 Experimental Design
We evaluate XG-REPTILE against several com-
parison systems across multiple languages. Where
possible, we re-implement existing models and
use identical data splits to isolate the contribu-
tion of our training algorithm.
training pairs with 493 and 448 examples for
validation and testing, respectively. We report
performance as execution accuracy to test if pre-
dicted SQL queries can retrieve accurate data-
base results.
We also evaluate on Spider (Yu et al., 2018),
combining English and Chinese (Min et al., 2019,
CSpider) versions as a cross-lingual task. The
latter translates all questions to Chinese but re-
tains the English database. Spider is significantly
more challenging; it contains 10,181 questions
and 5,693 unique SQL queries for 200 multi-table
databases over 138 domains. We use the same
split as Wang et al. (2021a) to measure general-
ization to unseen databases/table-schema during
testing. This split uses 8,659 examples from 146
databases for training and 1,034 examples from
20 databases for validation. The test set contains
2,147 examples from 40 held-out databases and
is held privately by the authors. To our knowl-
edge, we report the first multilingual approach
for Spider by training one model for English and
Chinese. Our challenge is now multi-dimensional,
requiring cross-lingual and cross-domain gener-
alization. Following Yu et al. (2018), we report
exact set match accuracy for evaluation.
5.2 Sampling for Generalization
Training for cross-lingual generalization often
uses parallel samples across languages. We illus-
trate this in Equation (14), where y1 is the equiv-
alent output for inputs, x1, in each language:
EN : (x1, y1) DE : (x1, y1) ZH : (x1, y1)
(14)
However, high sample overlap risks trivializing
the task because models are not learning from
new pairs, but instead matching only new inputs
to known outputs. A preferable evaluation will
test composition of novel outputs from unseen
inputs:
EN : (x1, y1) DE : (x2, y2) ZH : (x2, y2)
(15)
5.1 Data
We report results on two semantic parsing data-
sets. First on ATIS (Hemphill et al., 1990), us-
ing the multilingual version from Sherborne and
Lapata (2022) pairing utterances in six languages
(English, French, Portuguese, Spanish, German,
Chinese) to SQL queries. ATIS is split into 4,473
Equation (15) samples exclusive, disjoint datasets
for English and target languages during training.
In other words, this process is subtractive—for
example, a 5% sample of German (or Chinese)
target data leaves 95% of data as the English
support. This is similar to K-fold cross-validation
used to evaluate across many data splits. We
54
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
sample data for our experiments with Equa-
tion (15). It is also possible to use Equation (16),
where target samples are also disjoint, but we
find this setup results in too few English exam-
ples for effective learning.
EN : (x1, y1) DE : (x2, y2) ZH : (x3, y3)
(16)
5.3 Semantic Parsing Models
We use a Transformer encoder-decoder model
similar to Sherborne and Lapata (2022) for our
ATIS experiments. We use the same mBART50
encoder (Tang et al., 2021) and train a Trans-
former decoder from scratch to generate SQL.
For Spider, we use the RAT-SQL model
(Wang et al., 2020a), which has formed the
basis of many performant submissions to the
Spider leaderboard. RAT-SQL can successfully
reason about unseen databases and table schema
using a novel schema-linking approach within
the encoder. We use the version from Wang
et al. (2021a) with mBERT (Devlin et al., 2019)
input embeddings for a unified model between
English and Chinese inputs. Notably, RAT-SQL
can be over-reliant on lexical similarity features
between input questions and tables (Wang et al.,
2020a). This raises the challenge of generaliz-
ing to Chinese where such overlap is null. For
fair comparison, we implement identical models
as prior work on each dataset and only evaluate
the change in training algorithm. This is why we
use an mBART50 encoder component for ATIS
experiments and different mBERT input embed-
dings for Spider experiments.
5.4 Comparison Systems
Translate-Test A monolingual Transformer is
trained on source English data (SEN). Ma-
chine translation is used to translate test
data from additional languages into English.
Logical forms are predicted from translated
data using the English model.
Translate-Train Machine translation is used to
translate English training data into each tar-
get language. A monolingual Transformer is
trained on translated training data and logical
forms are predicted using this model.
Train-EN∪All A Transformer
is
trained on
English data and samples from all target
languages together in a single stage (i.e.,
SEN ∪SL). This is superior to training without
English (e.g., on SL only); we contrast to this
approach for more competitive comparison.
TrainEN→FT-All We first train on English sup-
port data, SEN, and then fine-tune on target
samples, SL.
Reptile-EN→FT-All Initial training uses Rep-
tile (Nichol et al., 2018) on English support
data, SEN, followed by fine-tuning on tar-
get samples, SL. This is a typical usage of
Reptile for training a low-resource multi-
domain parser (Chen et al., 2020).
We also compare to DG-FMAML (Wang et al.,
2021a) as a special case of XG-REPTILE when
K = 1. Additionally, we omit pairwise versions
of XG-REPTILE (e.g., separate models general-
izing from English to individual
languages).
These approaches demand more computation and
demonstrated no significant improvement over a
multi-language approach. All Machine Transla-
tion uses Google Translate (Wu et al., 2016).
We compare our algorithm against several strong
baselines and adjacent training methods including:
5.5 Training Configuration
Monolingual Training A monolingual Trans-
former
is trained on gold-standard pro-
fessionally translated data for each new
language. This is a monolingual upper bound
without few-shot constraints.
Multilingual Training A multilingual Trans-
former is trained on the union of all data
from the ‘‘Monolingual Training’’ method.
This ideal upper bound uses all data in all
languages without few-shot constraints.
Experiments focus on the expansion from English
to additional languages, where we use English as
the ‘‘support’’ language and additional languages
as ‘‘target’’. Key hyperparameters are outlined in
Table 1. We train each model using the given opti-
mizers with early stopping where model selection
is through minimal validation loss for combined
support and target languages. Input utterances
are tokenized using SentencePiece (Kudo and
Richardson, 2018) and Stanza (Qi et al., 2020)
for ATIS and Spider, respectively. All experi-
ments are implemented in PyTorch on a single
55
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ATIS
Spider
16
10
SGD
1 × 10−4
Batch Size
Inner Optimizer
Inner LR
Outer Optimizer Adam (Kingma and Ba, 2015)
1 × 10−3
Outer LR
Optimum K
10
Max Train Steps
Training Time
5 × 10−4
3
12 hours
2.5 days
20,000
Table 1: Experimental hyperparameters for XG-
REPTILE on ATIS and Spider set primarily by
replicating prior work.
V100 GPU. We report key results for ATIS aver-
aged over three seeds and five random data splits.
For Spider, we submit the best singular model
from five random splits to the leaderboard.
6 Results and Analysis
We contrast XG-REPTILE to baselines for ATIS
in Table 2 and present further analysis within
Figure 2. Results for the multi-domain Spider
are shown in Table 3. Our findings support our
hypothesis that XG-REPTILE is a superior algo-
rithm for jointly training a semantic parser and
encouraging cross-lingual generalization with im-
proved sample efficiency. Given the same data,
XG-REPTILE produces more mutually beneficial
parameters for both model requirements with
only modifications to the training loop.
Comparison across Generalization Strategies
We compare XG-REPTILE to established learn-
ing algorithms in Table 2. Across baselines,
we find that single-stage training, that is, Train-
EN∪All or machine-translation based mod-
els, perform below two-stage approaches. The
strongest competitor is the Reptile-EN→FT-All
model, highlighting the effectiveness of Reptile
for single-task generalization (Kedia et al., 2021).
However, XG-REPTILE performs above all base-
lines across sample rates. Practically, 1%, 5%,
10% correspond to 45, 225, and 450 example
pairs, respectively. We identify significant im-
provements (p < 0.01; relative to the closest
model using an independent
t-test) in cross-
lingual transfer through jointly learning to parse
and multi-language generalization while main-
taining single-stage training efficiency.
56
Compared to the upper bounds, XG-REPTILE
performs above Monolingual Training at ≥ 1%
sampling, which further supports the prior ben-
efit of multilingual modeling (Susanto and Lu,
2017a). Multilingual Training is only marginally
stronger than XG-REPTILE at 1% and 5% sam-
pling despite requiring many more examples.
XG-REPTILE@10% improves on this model by
an average +1.3%. Considering that our upper
bound uses 10× the data of XG-REPTILE@10%,
this accuracy gain highlights the benefit of ex-
plicit cross-lingual generalization. This is con-
sistent at higher sample sizes (see Figure 2(c)
for German).
At the smallest sample size, XG-REPTILE@1%,
demonstrates a +12.4% and +13.2% improve-
ment relative to Translate-Train and Translate-
Test. Machine translation is often viable for
cross-lingual transfer (Conneau et al., 2018). How-
ever, we find that mistranslation of named entities
incurs an exaggerated parsing penalty—leading
to inaccurate logical forms (Sherborne et al.,
2020). This suggests that sample quality has an
exaggerated influence on semantic parsing perfor-
mance. When training XG-REPTILE with MT data,
we also observe a lower Target-language aver-
age of 66.9%. This contrast further supports the
importance of sample quality in our context.
XG-REPTILE improves cross-lingual generaliza-
tion across all languages at equivalent and lower
sample sizes. At 1%, it improves by an average
+15.7% over the closest model, Reptile-EN→
FT-All. Similarly, at 5%, we find +9.8% gain,
and at 10%, we find +8.9% relative to the clos-
est competitor. Contrasting across sample sizes—
our best approach is @10%, however, this is
+3.5% above @1%, suggesting that smaller
samples could be sufficient if 10% sampling is
unattainable. This relative stability is an improve-
ment compared to the 17.7%, 11.2%, or 10.3%
difference between @1% and @10% for other
models. This implies that XG-REPTILE better uti-
lizes smaller samples than adjacent methods.
Across languages at 1%, XG-REPTILE improves
primarily for languages dissimilar to English
(Ahmad et al., 2019) to better minimize the
cross-lingual transfer gap. For Chinese (ZH), we
see that XG-REPTILE@1% is +26.4% above the
closest baseline. This contrasts with the smallest
gain, +8.5% for German, with greater similar-
ity to English. Our improvement also yields less
variability across target languages—the standard
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ZX-PARSE (Sherborne and Lapata, 2022)
Monolingual Training
Multilingual Training
Translate-Train
Translate-Test
@1%
@5%
@10%
Train-EN∪All
Train-EN→FT-All
Reptile-EN→FT-All
XG-REPTILE
Train-EN∪All
Train-EN→FT-All
Reptile-EN→FT-All
XG-REPTILE
Train-EN∪All
Train-EN→FT-All
Reptile-EN→FT-All
XG-REPTILE
EN
76.9
77.2
73.9
—
—
69.7 ± 1.4
71.2 ± 2.3
73.2 ± 0.7
73.8 ± 0.3
67.3 ± 1.6
69.2 ± 1.9
69.5 ± 1.8
74.4 ± 1.3
65.7 ± 1.9
67.4 ± 1.9
72.8 ± 1.8
75.8 ± 1.3
FR
70.2
67.8
72.5
55.9
58.2
44.0 ± 3.5
53.3 ± 5.2
58.9 ± 4.8
70.4 ± 1.8
55.2 ± 4.5
58.9 ± 5.3
65.3 ± 3.8
73.0 ± 0.9
61.5 ± 1.7
63.8 ± 5.8
66.3 ± 4.2
74.2 ± 0.2
PT
63.4
66.1
73.1
56.1
57.3
42.2 ± 3.7
49.7 ± 5.4
54.8 ± 3.4
70.8 ± 0.7
54.7 ± 4.5
54.8 ± 5.4
61.3 ± 6.0
71.6 ± 1.1
62.1 ± 2.3
60.3 ± 5.3
64.6 ± 4.9
72.8 ± 0.6
ES
59.7
64.1
70.4
57.1
57.9
38.3 ± 6.8
56.1 ± 2.7
52.8 ± 4.4
68.9 ± 2.3
44.4 ± 4.5
52.8 ± 4.5
59.6 ± 2.6
71.6 ± 0.7
53.7 ± 3.2
59.6 ± 4.0
62.3 ± 6.4
72.1 ± 0.7
DE
69.3
66.6
72.0
60.1
56.9
45.8 ± 2.6
52.5 ± 6.7
60.6 ± 3.6
69.1 ± 1.2
55.8 ± 2.9
60.6 ± 6.5
64.9 ± 5.1
71.1 ± 0.6
62.7 ± 2.3
64.5 ± 6.5
66.6 ± 5.0
73.0 ± 0.6
ZH
60.2
64.9
70.5
56.1
51.4
41.7 ± 3.6
39.0 ± 4.0
41.7 ± 4.0
68.1 ± 1.2
52.3 ± 4.3
41.7 ± 9.5
56.9 ± 9.2
69.5 ± 0.5
60.6 ± 2.4
58.4 ± 6.4
60.7 ± 3.6
72.8 ± 0.5
Target Avg
64.6 ± 5.0
65.9 ± 1.4
71.7 ± 1.2
57.1 ± 1.8
56.3 ± 2.8
42.4 ± 2.8
50.1 ± 6.6
53.8 ± 7.4
69.5 ± 1.1
52.5 ± 4.7
53.8 ± 7.4
61.6 ± 3.6
71.4 ± 1.3
60.1 ± 3.7
61.3 ± 2.7
64.1 ± 2.6
73.0 ± 0.8
Table 2: Denotation accuracy using varying learning algorithms including XG-REPTILE at 1%, 5%,
and 10% sampling rates for target dataset size relative to support dataset for ATIS. We report
for English, French, Portuguese, Spanish, German, and Chinese. Target Avg reports the average
denotation accuracy across non-English languages ± standard deviation across languages. For few-shot
experiments, we also report the standard deviation (±) across random samples. Best few-shot results
per language are bolded.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
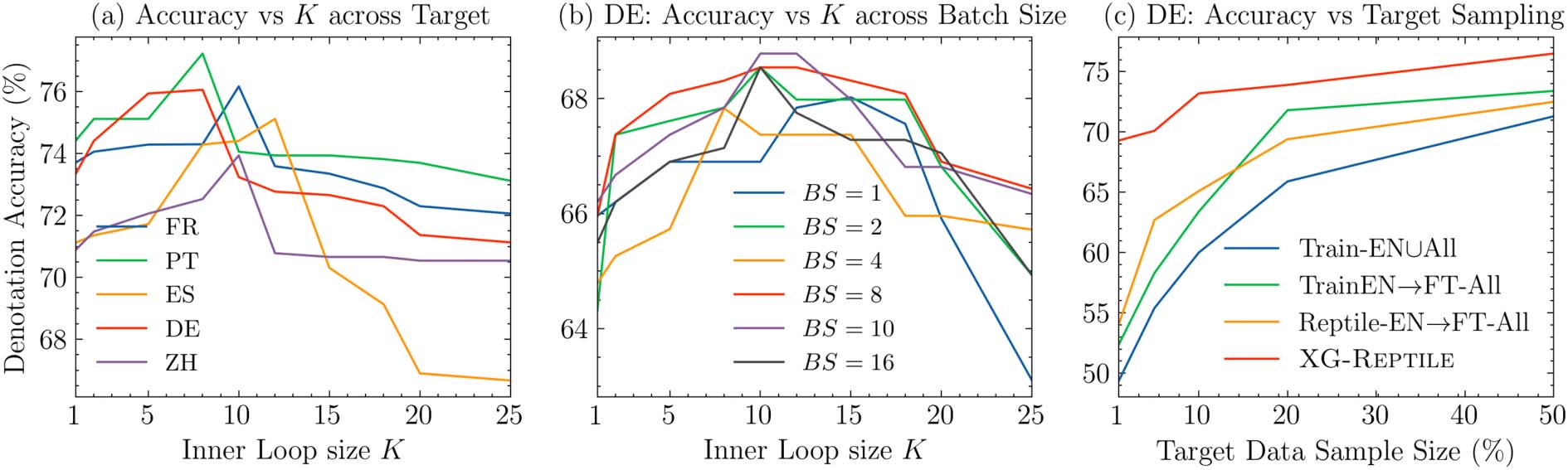
Figure 2: Ablation Experiments on ATIS (a) accuracy against inner loop size K across languages, (b) accuracy
against K for German when varying batch size, and (c) accuracy against dataset sample size relative to support
dataset from 1% to 50% for German. For (b), the K = 1 case is equivalent to DG-FMAML (Wang et al., 2021a).
deviation across languages for XG-REPTILE@1%
is 1.1, compared to 2.8 for Train-EN∪All or 7.4
for Reptile-EN→FT-All.
We can also compare to ZX-PARSE, the method
of Sherborne and Lapata (2022) that engineers
cross-lingual latent alignment for zero-shot se-
mantic parsing without data in target languages.
language, XG-
With 45 samples per
REPTILE@1% improves by an average of +4.9%.
for distant
is more beneficial
XG-REPTILE
languages—cross-lingual
transfer penalty be-
tween English and Chinese is −12.3% for ZX-
PARSE compared to −5.7% in our case. While
these systems are not truly comparable, given
target
different data requirements, this contrast is prac-
tically useful for comparison between zero- and
few-shot localization.
Influence of K on Performance
In Figure 2(a)
we study how variation in the key hyperparame-
ter K, the size of the inner-loop in Algorithm 1
or the number of batches used to approximate
the solution manifold influences model per-
formance across languages (single run at 5%
sampling). When K = 1, the model learns gen-
eralization from batch-wise similarity, which is
equivalent to DG-FMAML (Wang et al., 2021a).
We empirically find that increasing K beyond
57
one benefits performance by encouraging cross-
lingual generalization with the task over a sin-
gle batch, and it is, therefore, beneficial to align
an out-of-domain example with the overall di-
rection of training. However, as theorized in
Section 4, increasing K also decreases the fre-
quency of the outer step within an epoch leading
to poor cross-lingual transfer at high K. This
trade-off yields an optimal operating regime for
this hyper-parameter. We use K = 10 in our
experiments as the center of this region. Given
this setting of K, the target sample size must be
10% of the support sample size for training
in a single epoch. However, Table 2 identi-
fies XG-REPTILE as the most capable algorithm
for ‘‘over-sampling’’ smaller target samples for
resource-constrained generalization.
Influence of Batch Size on Performance We
consider two further case studies to analyze
XG-REPTILE performance. For clarity, we focus
on German; however, these trends are consistent
across all target languages. Figure 2(b) exam-
ines if the effects of cross-lingual transfer within
XG-REPTILE are sensitive to batch size during train-
ing (single run at 5% sampling). A dependence
between K and batch size could imply that the
desired inter-task and cross-lingual generaliza-
tion outlined in Equation (13) is an unrealistic,
edge-case phenomenon. This is not
the case,
and a trend of optimal K setting is consistent
across many batch sizes. This suggests that K is
an independent hyper-parameter requiring tuning
alongside existing experimental settings.
Performance across Larger Sample Sizes We
consider a wider range of target data sample
sizes between 1% and 50% in Figure 2(c). We
observe that baseline approaches converge to be-
tween 69.3% and 73.9% at 50% target sample size.
Surprisingly, the improvement of XG-REPTILE is
retained at higher sample sizes with an accuracy
of 76.5%. The benefit of XG-REPTILE is still great-
est at low sample sizes with +5.4% improvement
at 1%; however, we maintain a +2.6% gain over
the closest system at 50%. While low sampling
is the most economical, the consistent benefit
of XG-REPTILE suggests a promising strategy for
other cross-lingual tasks.
Learning Spider and CSpider Our results on
Spider and CSpider are shown in Table 3. We
EN
ZH
Dev
Test Dev
Test
50.4
65.2
68.9
46.9
56.8 — 32.5 —
63.5 — 48.9 —
Monolingual
DG-MAML
DG-FMAML
XG-REPTILE
Multilingual
56.8
XG-REPTILE @1%
59.6
@5%
@10% 59.2
56.5
58.1
59.7
47.0
47.3
48.0
45.6
45.6
46.0
Table 3: Exact set match accuracy for RAT-SQL
trained on Spider (English) and CSpider (Chi-
nese) comparing XG-REPTILE to DG-MAML and
DG-FMAML (Wang et al., 2021a). We exper-
iment with sampling between 1% to 10% of
Chinese examples relative to English. Monolin-
gual and multilingual best results are bolded.
compare XG-REPTILE to monolingual approaches
from Wang et al. (2021a) and discuss cross-lingual
results when sampling between 1% and 10% of
CSpider target during training.
In the monolingual setting, XG-REPTILE shows
significant improvement (p < 0.01; using an inde-
pendent samples t-test) compared to DG-FMAML
with +6.7% for English and +16.4% for Chinese
dev accuracy. This further supports our claim that
generalizing with a task manifold is superior to
batch-level generalization.
Our results are closer to DG-MAML (Wang
et al., 2021a), a higher-order meta-learning
method requiring computational resources and
training times exceeding 4× the requirements
for XG-REPTILE. XG-REPTILE yields accuracies
−5.4% and −1.5% below DG-MAML for En-
glish and Chinese, where DG-FMAML performs
much lower at −12.1% (EN) and −17.9% (ZH).
Our results suggest that XG-REPTILE is a supe-
rior first-order meta-learning algorithm rivaling
prior work with greater computational demands.3
In the multilingual setting, we observe that
XG-REPTILE performs competitively using as lit-
tle as 1% of Chinese examples. While training
sampling 1% and 5% perform similarly—the best
model sees 10% of CSpider samples during train-
ing to yield accuracy only −0.9% (test) below
3We compare against DG-MAML as the best public
available model on the CSpider leaderboard at the time of
writing.
58
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
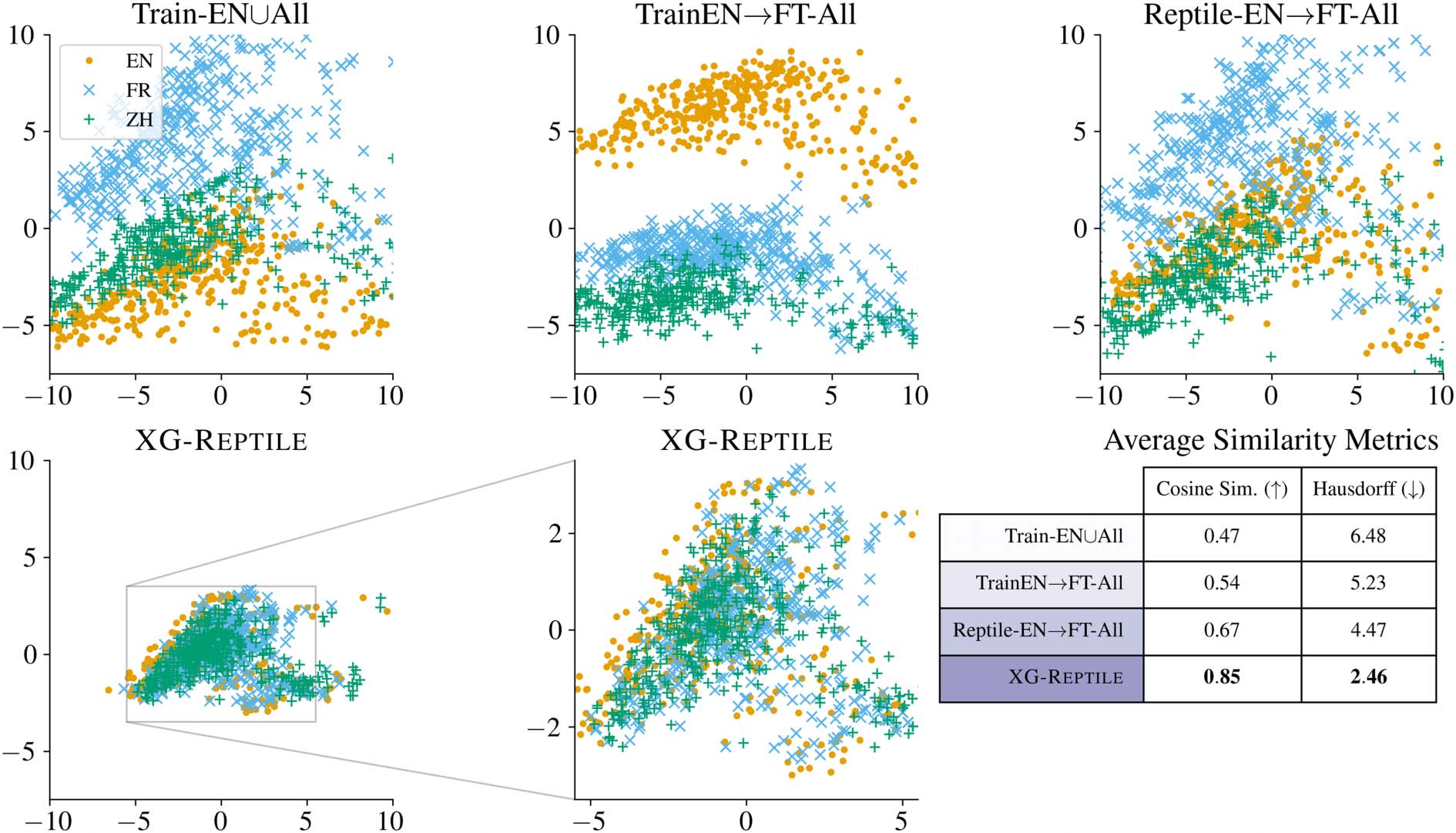
Figure 3: PCA Visualizations of sentence-averaged encodings for English (EN), French (FR), and Chinese (ZH)
from the ATIS test set (@1% sampling from Table 2). We identify the regularized weight manifold that improves
cross-lingual transfer using XG-REPTILE. We also improve in two similarity metrics averaged across languages.
the monolingual DG-MAML model. While per-
formance does not match monolingual models,
the multilingual approach has additional utility in
serving more users. As a zero-shot setup, predict-
ing SQL from CSpider inputs through the model
trained for English yields 7.9% validation accu-
racy, underscoring that cross-lingual transfer for
this dataset is non-trivial.
Varying the target sample size demonstrates
more variable effects for Spider compared to
ATIS. Notably, increasing the sample size yields
poorer English performance beyond the optimal
XG-REPTILE@5% setting for English. This may
be a consequence of the cross-database challenge
in Spider—information shared across languages
may be less beneficial than for single-domain
ATIS. The least performant model for both lan-
guages is XG-REPTILE@1%. Low performance
here for Chinese can be expected, but the perfor-
mance for English is surprising. We suggest that
this result is a consequence of ‘‘over-sampling’’
of the target data disrupting the overall training
process. That is, for 1% sampling and optimal
K = 4, the target data is ‘‘over-used’’ 25× for
each epoch of support data. We further observe
diminishing benefits for English with additional
Chinese samples. While we trained a competi-
tive parser with minimal Chinese data, this effect
could be a consequence of how RAT-SQL can-
not exploit certain English-oriented learning fea-
tures (e.g., lexical similarity scores). Future work
could explore cross-lingual strategies to unify
entity modeling for improved feature sharing.
Visualizing the Manifold Analysis of XG-
REPTILE in Section 4 relies on a theoretical ba-
sis that first-order meta-learning creates a dense
high-likelihood sub-region in the parameters (i.e.,
optimal manifold). Under these conditions, repre-
sentations of new domains should cluster within
the manifold to allow for rapid adaptation with
minimal samples. This contrasts with methods
without meta-learning, which provide no guaran-
tees of representation density. However, metrics
in Tables 2 and 3 do not directly explain if this
expected effect arises. To this end, we visualize
ATIS test set encoder outputs using PCA (Halko
et al., 2011) in Figure 3. We contrast English
(support) and French and Chinese as the most
and least similar target languages. Using PCA al-
lows for direct interpretation of low-dimensional
distances across approaches. Cross-lingual sim-
ilarity is a proxy for manifold alignment—as
our goal is accurate cross-lingual transfer from
59
closely aligned representations from source and
languages (Xia et al., 2021; Sherborne
target
and Lapata, 2022).
Analyzing Figure 3, we observe meta-learning
methods (Reptile-EN→FT-All, XG-REPTILE) to fit
target languages closer to the support (English,
yellow circle). In contrast, methods not utilizing
meta-learning (Train-EN∪All, Train-EN→FT-All)
appear less ordered with weaker representation
overlap. Encodings from XG-REPTILE are less
separable across languages and densely clus-
tered, suggesting the regularized manifold hypoth-
esized in Section 4 ultimately yields improved
cross-lingual transfer. Visualizing encodings from
English in the Reptile-EN model before fine-
tuning produces a similar cluster (not shown),
however, required fine-tuning results in ‘‘spread-
ing’’ leading to less cross-lingual similarity.
We also quantitatively examine the average
encoding change in Figure 3 using cosine simi-
larity and Hausdorff distance (Patra et al., 2019)
between English and each target language. Cosine
similarity is measured pair-wise across parallel
inputs in each language to gauge similarity from
representations with equivalent SQL outputs. As
a measure of mutual proximity between sets,
Hausdorff distance denotes a worst-case dis-
tance between languages to measure more general
‘‘closeness’’. Under both metrics, XG-REPTILE
yields the best performance with the most sub-
stantial pair-wise similarity and Hausdorff simi-
larity. These indicators for cross-lingual similarity
further support
the observation that our ex-
pected behavior is legitimately occurring during
training.
Our
findings better explain why our XG-
REPTILE performs above other training algorithms.
Specifically, our results suggest that XG-REPTILE
learns a regularized manifold which produces
stronger cross-lingual similarity and improved
parsing compared to Reptile fine-tuning a man-
ifold. This contrast will inform future work for
cross-lingual meta-learning where XG-REPTILE
can be applied.
Error Analysis We can also examine where
the improved cross-lingual
transfer influences
parsing performance. Similar to Figure 3, we con-
sider the results of models using 1% sampling as
the worst-case performance and examine where
XG-REPTILE improves on other methods on the
test set (448 examples) over five languages.
Figure 4: Contrast between SQL from a French input
from ATIS for Train-EN∪All and XG-REPTILE. The
entities ‘‘San Jos´e’’ and ‘‘Phoenix’’ are not observed
in the 1% sample of French data but are mentioned
in the English support data. The Train-EN∪All ap-
proach fails to connect attributes seen in English when
generating SQL from French inputs (×). Training
with XG-REPTILE better leverages support data to gen-
erate accurate SQL from other languages ((cid:2)).
Accurate semantic parsing requires sophisti-
cated entity handling to translate mentioned proper
nouns from utterance to logical form. In our
few-shot sampling scenario, most entities will
appear in the English support data (e.g., ‘‘Den-
ver’’ or ‘‘American Airlines’’), and some will
be mentioned within the target language sam-
ple (e.g., ‘‘Mine´apolis’’ or ‘‘Nueva York’’ in
Spanish). These samples cannot include all possi-
ble entities—effective cross-lingual learning must
‘‘connect’’ these entities from the support data to
the target language—such that these names can
be parsed when predicting SQL from the target
language. As shown in Figure 4, the failure to rec-
ognize entities from support data, for inference on
target languages, is a critical failing of all models
besides XG-REPTILE.
60
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
The improvement in cross-lingual similarity
using XG-REPTILE expresses a specific improve-
ment in entity recognition. Compared to the worst
performing model, Train-EN∪All, 55% of im-
provement accounts for handling entities absent
from the 1% target sample but present in the 99%
English support data. While XG-REPTILE can gen-
erate accurate SQL, other models are limited in
expressivity to fall back on using seen entities
from the 1% sample. This notably accounts for
60% of improvement in parsing Chinese, with
minimal orthographic overlap to English, indi-
cating that XG-REPTILE better leverages support
data without reliance on token similarity. In 48%
of improved parses, entity mishandling is the
sole error—highlighting how limiting poor cross-
lingual transfer is for our task.
from target
Our model also improves handling of novel
modifiers (e.g., ‘‘on a weekday’’, ‘‘round-trip’’)
language samples. Modi-
absent
fiers are often realized as additional sub-queries
and filtering logic in SQL outputs. Comparing
XG-REPTILE to Train-EN∪All, 33% of improve-
ment is related to modifier handling. Less capable
systems fall back on modifiers observed from the
target sample or ignore them entirely to generate
inaccurate SQL.
While XG-REPTILE better links parsing knowl-
edge from English to target
languages—the
problem is not solved. Outstanding errors in all
languages primarily relate to query complexity,
and the cross-lingual transfer gap is not closed.
Furthermore, our error analysis suggests a future
direction for optimal sample selection to minimize
the error from interpreting unseen phenomena.
7 Conclusion
We propose XG-REPTILE, a meta-learning algo-
rithm for few-shot cross-lingual generalization
in semantic parsing. XG-REPTILE is able to bet-
ter utilize fewer samples to learn an economical
multilingual semantic parser with minimal cost
and improved sample efficiency. Compared to
adjacent training algorithms and zero-shot ap-
proaches, we obtain more accurate and consistent
logical forms across languages similar and dis-
similar to English. Results on ATIS show clear
benefit across many languages and results on Spi-
der demonstrate that XG-REPTILE is effective in a
challenging cross-lingual and cross-database sce-
nario. We focus our study on semantic parsing,
however, this algorithm could be beneficial in
other low-resource cross-lingual tasks. In future
work we plan to examine how to better align enti-
ties in low-resource languages to further improve
parsing accuracy.
Acknowledgments
We thank the action editor and anonymous re-
their constructive feedback. The
viewers for
authors also thank Nikita Moghe, Seraphina
Goldfarb-Tarrant, Ondrej Bohdal, and Heather
Lent for their insightful comments on earlier ver-
sions of this paper. We gratefully acknowledge
the support of the UK Engineering and Physical
Sciences Research Council (grants EP/L016427/1
(Sherborne) and EP/W002876/1 (Lapata)) and
the European Research Council (award 681760,
Lapata).
References
Wasi Ahmad, Zhisong Zhang, Xuezhe Ma,
Eduard Hovy, Kai-Wei Chang, and Nanyun
Peng. 2019. On difficulties of cross-lingual
transfer with order differences: A case study on
dependency parsing. In Proceedings of the 2019
Conference of the North American Chapter
of the Association for Computational Linguis-
tics: Human Language Technologies, Volume 1
(Long and Short Papers), pages 2440–2452,
Minneapolis, Minnesota. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/N19-1253
Xilun Chen, Asish Ghoshal, Yashar Mehdad,
Luke Zettlemoyer, and Sonal Gupta. 2020.
Low-resource domain adaptation for compo-
sitional task-oriented semantic parsing. In Pro-
ceedings of the 2020 Conference on Empirical
Methods in Natural Language Processing
(EMNLP), pages 5090–5100, Online. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D18-1269
Alexis Conneau, Ruty Rinott, Guillaume Lample,
Adina Williams, Samuel Bowman, Holger
Schwenk, and Veselin Stoyanov. 2018. XNLI:
Evaluating cross-lingual sentence representa-
tions. In Proceedings of the 2018 Conference on
Empirical Methods in Natural Language Pro-
cessing, pages 2475–2485, Brussels, Belgium.
Association for Computational Linguistics.
61
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. In Proceedings of
the 2019
Conference of the North American Chapter
of the Association for Computational Linguis-
tics: Human Language Technologies, Volume
1 (Long and Short Papers), pages 4171–4186,
Minneapolis, Minnesota. Association for Com-
putational Linguistics.
Long Duong, Hadi Afshar, Dominique Estival,
Glen Pink, Philip Cohen, and Mark Johnson.
2017. Multilingual semantic parsing and code-
switching. In Proceedings of the 21st Con-
ference on Computational Natural Language
Learning (CoNLL 2017), pages 379–389,
Vancouver, Canada. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/K17-1038
Chelsea Finn, Pieter Abbeel, and Sergey Levine.
2017. Model-agnostic meta-learning for fast
adaptation of deep networks. In Proceedings
of the 34th International Conference on Ma-
chine Learning, ICML 2017, Sydney, NSW,
Australia, 6–11 August 2017, volume 70 of
Proceedings of Machine Learning Research,
pages 1126–1135. PMLR.
Dan Garrette and Jason Baldridge. 2013. Learn-
ing a part-of-speech tagger from two hours of
annotation. In Proceedings of the 2013 Confer-
ence of the North American Chapter of the Asso-
ciation for Computational Linguistics: Human
Language Technologies, pages 138–147, At-
lanta, Georgia. Association for Computational
Linguistics.
Ofer Givoli and Roi Reichart. 2019. Zero-shot
In Pro-
instructions.
semantic parsing for
ceedings of
the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 4454–4464, Florence, Italy. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/P19-1438
Jiatao Gu, Yong Wang, Yun Chen, Victor O. K.
Li, and Kyunghyun Cho. 2018. Meta-learning
for low-resource neural machine translation.
In Proceedings of
the 2018 Conference on
Empirical Methods in Natural Language Pro-
cessing, pages 3622–3631, Brussels, Belgium.
Association for Computational Linguistics.
Daya Guo, Duyu Tang, Nan Duan, Ming Zhou,
and Jian Yin. 2019. Coupling retrieval and
meta-learning for context-dependent semantic
parsing. In Proceedings of the 57th Annual
Meeting of the Association for Computational
Linguistics, pages 855–866, Florence, Italy.
Association for Computational Linguistics.
Nathan Halko, Per-Gunnar Martinsson, and Joel
A. Tropp. 2011. Finding structure with random-
ness: probabilistic algorithms for construct-
ing approximate matrix decompositions. SIAM
Review, 53(2):217–288. https://doi.org
/10.1137/090771806
Michael A. Hedderich, Lukas Lange, Heike Adel,
Jannik Str¨otgen, and Dietrich Klakow. 2021.
A survey on recent approaches for natural
language processing in low-resource scenar-
ios. In Proceedings of the 2021 Conference
of the North American Chapter of the Associ-
ation for Computational Linguistics: Human
Language Technologies, pages 2545–2568,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.naacl-main.201
Charles T. Hemphill, John J. Godfrey, and
George R. Doddington. 1990. The ATIS spo-
ken language systems pilot corpus. In Speech
and Natural Language: Proceedings of a Work-
shop Held at Hidden Valley, Pennsylvania,
June 24–27,1990. https://doi.org/10
.3115/116580.116613
Jonathan Herzig and Jonathan Berant. 2017. Neu-
ral semantic parsing over multiple knowledge-
bases. In Proceedings of
the 55th Annual
Meeting of
the Association for Computa-
tional Linguistics (Volume 2: Short Papers),
pages 623–628, Vancouver, Canada. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/P17-2098
Jonathan Herzig and Jonathan Berant. 2021.
Span-based semantic parsing for composi-
tional generalization. In Proceedings of
the
59th Annual Meeting of
the Association
for Computational Linguistics and the 11th
International Joint Conference on Natural Lan-
guage Processing (Volume 1: Long Papers),
pages 908–921, Online. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2021.acl-long.74
62
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Timothy M. Hospedales, Antreas Antoniou,
Paul Micaelli, and Amos J. Storkey. 2022.
Meta-learning in neural networks: A survey.
IEEE Transactions on Pattern Analysis and
Machine Intelligence, 44(09):5149–5169.
Junjie Hu, Sebastian Ruder, Aditya Siddhant,
Graham Neubig, Orhan Firat, and Melvin
Johnson. 2020. XTREME: A massively mul-
tilingual multi-task benchmark for evaluating
cross-lingual generalisation. In Proceedings of
the 37th International Conference on Machine
Learning, volume 119 of Proceedings of Ma-
chine Learning Research, pages 4411–4421.
PMLR.
Po-Sen Huang, Chenglong Wang, Rishabh
Singh, Wen-tau Yih, and Xiaodong He. 2018.
Natural language to structured query gener-
ation via meta-learning. In Proceedings of
the 2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
Volume 2 (Short Papers), pages 732–738, New
Orleans, Louisiana. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/N18-2115
Zhanming Jie and Wei Lu. 2014. Multilingual
semantic parsing: Parsing multiple languages
into semantic representations. In Proceedings
of COLING 2014, the 25th International Con-
ference on Computational Linguistics: Techni-
cal Papers, pages 1291–1301, Dublin, Ireland.
Dublin City University and Association for
Computational Linguistics.
Akhil Kedia, Sai Chetan Chinthakindi, and
Wonho Ryu. 2021. Beyond Reptile: Meta-
learned dot-product maximization between
improved single-task regular-
gradients for
ization. In Findings of
the Association for
Computational Linguistics: EMNLP 2021,
pages 407–420, Punta Cana, Dominican Re-
public. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.findings-emnlp.37
Diederik P. Kingma and Jimmy Ba. 2015. Adam:
A method for stochastic optimization. In 3rd
International Conference on Learning Repre-
sentations, ICLR 2015, San Diego, CA, USA,
May 7-9, 2015, Conference Track Proceedings.
Moshe Koppel and Noam Ordan. 2011. Trans-
lationese and its dialects. In Proceedings of
the 49th Annual Meeting of the Association for
Computational Linguistics: Human Language
Technologies, pages 1318–1326, Portland,
Oregon, USA. Association for Computational
Linguistics.
Taku Kudo and John Richardson. 2018. Sen-
tencePiece: A simple and language indepen-
dent subword tokenizer and detokenizer for
neural text processing. In Proceedings of the
2018 Conference on Empirical Methods in
Natural Language Processing: System Demon-
strations, pages 66–71, Brussels, Belgium.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/D18
-2012
Dongjun Lee,
Jaesik Yoon,
Jongyun Song,
Sang-gil Lee, and Sungroh Yoon. 2019. One-
shot learning for text-to-sql generation. CoRR,
abs/1905.11499.
the 59th Annual Meeting of
Hung-yi Lee, Ngoc Thang Vu, and Shang-Wen
Li. 2021. Meta learning and its applications
to natural language processing. In Proceed-
ings of
the
Association for Computational Linguistics and
the 11th International Joint Conference on
Natural Language Processing: Tutorial Ab-
stracts, pages 15–20, Online. Association for
Computational Linguistics.
Da Li, Yongxin Yang, Yi-Zhe Song, and
Timothy Hospedales. 2018. Learning to gener-
alize: Meta-learning for domain generalization.
Proceedings of the AAAI Conference on Artifi-
cial Intelligence, 32(1). https://doi.org
/10.1609/aaai.v32i1.11596
Haoran Li, Abhinav Arora, Shuohui Chen,
Anchit Gupta, Sonal Gupta, and Yashar
Mehdad. 2021. MTOP: A comprehensive mul-
tilingual task-oriented semantic parsing bench-
mark. In Proceedings of the 16th Conference
of the European Chapter of the Association
for Computational Linguistics: Main Volume,
pages 2950–2962, Online. Association for
Computational Linguistics.
Yaobo Liang, Nan Duan, Yeyun Gong, Ning
Wu, Fenfei Guo, Weizhen Qi, Ming Gong,
Linjun Shou, Daxin Jiang, Guihong Cao,
Xiaodong Fan, Ruofei Zhang, Rahul Agrawal,
63
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Edward Cui, Sining Wei, Taroon Bharti,
Ying Qiao, Jiun-Hung Chen, Winnie Wu,
Shuguang Liu, Fan Yang, Daniel Campos,
Rangan Majumder, and Ming Zhou. 2020.
XGLUE: A new benchmark datasetfor cross-
lingual pre-training, understanding and genera-
tion. In Proceedings of the 2020 Conference on
Empirical Methods in Natural Language Pro-
cessing (EMNLP), pages 6008–6018, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.emnlp-main.484
Qingkai Min, Yuefeng Shi, and Yue Zhang.
2019. A pilot study for Chinese SQL semantic
parsing. In Proceedings of the 2019 Conference
on Empirical Methods in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 3652–3658, Hong
Kong, China. Association for Computational
Linguistics.
Mehrad Moradshahi, Giovanni Campagna, Sina
Semnani, Silei Xu, and Monica Lam. 2020.
Localizing open-ontology QA semantic parsers
in a day using machine translation. In Pro-
ceedings of the 2020 Conference on Empirical
Methods in Natural Language Processing
(EMNLP), pages 5970–5983, Online. Associ-
ation for Computational Linguistics.
Alex Nichol, Joshua Achiam, and John Schulman.
2018. On first-order meta-learning algorithms.
CoRR, abs/1803.02999v3.
Massimo Nicosia, Zhongdi Qu, and Yasemin
Altun. 2021. Translate & fill: Improving zero-
shot multilingual semantic parsing with syn-
the Association
thetic data. In Findings of
for Computational Linguistics: EMNLP 2021,
pages 3272–3284, Punta Cana, Dominican
Republic. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.findings-emnlp.279
Farhad Nooralahzadeh, Giannis Bekoulis,
Johannes Bjerva, and Isabelle Augenstein.
2020. Zero-shot cross-lingual transfer with meta
learning. In Proceedings of the 2020 Confer-
ence on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 4547–4562,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.emnlp-main.368
Barun Patra, Joel Ruben Antony Moniz, Sarthak
Garg, Matthew R. Gormley, and Graham
Neubig. 2019. Bilingual lexicon induction with
semi-supervision in non-isometric embedding
spaces. In Proceedings of
the 57th Annual
Meeting of the Association for Computational
Linguistics, pages 184–193, Florence, Italy.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/P19
-1018
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason
Bolton, and Christopher D. Manning. 2020.
Stanza: A python natural language processing
toolkit for many human languages. In Pro-
ceedings of the 58th Annual Meeting of the
Association for Computational Linguistics: Sys-
tem Demonstrations, pages 101–108, Online.
Association for Computational Linguistics.
Kyle Richardson, Jonathan Berant, and Jonas
Kuhn. 2018. Polyglot semantic parsing in
the 2018 Confer-
APIs. In Proceedings of
ence of the North American Chapter of the
Association for Computational Linguistics:
Human Language Technologies, Volume 1
(Long Papers), pages 720–730, New Orleans,
Louisiana. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/N18-1066
Torsten Scholak, Nathan Schucher, and Dzmitry
Bahdanau. 2021. PICARD: Parsing incremen-
tally for constrained auto-regressive decoding
from language models. In Proceedings of the
2021 Conference on Empirical Methods in Nat-
ural Language Processing, pages 9895–9901,
Online and Punta Cana, Dominican Republic.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.emnlp-main.779
Tom Sherborne and Mirella Lapata. 2022.
Zero-shot cross-lingual semantic parsing. In
Proceedings of the 60th Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Long Papers), pages 4134–4153,
Dublin,
Ireland. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/2022.acl-long.285
Tom Sherborne, Yumo Xu, and Mirella Lapata.
2020. Bootstrapping a crosslingual semantic
64
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
parser. In Findings of
the Association for
Computational Linguistics: EMNLP 2020,
pages 499–517, Online. Association for Com-
putational Linguistics. https://doi.org/10
.18653/v1/2020.findings-emnlp.45
Yu Su and Xifeng Yan. 2017. Cross-domain
semantic parsing via paraphrasing. In Pro-
ceedings of the 2017 Conference on Empirical
Methods in Natural Language Processing,
pages 1235–1246, Copenhagen, Denmark.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/D17
-1127
Alane Suhr, Ming-Wei Chang, Peter Shaw, and
Kenton Lee. 2020. Exploring unexplored gener-
alization challenges for cross-database semantic
parsing. In Proceedings of the 58th Annual
Meeting of
the Association for Computa-
tional Linguistics, pages 8372–8388, Online.
Association for Computational Linguistics.
Yibo Sun, Duyu Tang, Nan Duan, Yeyun Gong,
Xiaocheng Feng, Bing Qin, and Daxin Jiang.
2020. Neural semantic parsing in low-resource
settings with back-translation and meta-
learning. Proceedings of the AAAI Conference
on Artificial Intelligence, 34(05):8960–8967.
https://doi.org/10.1609/aaai.v34i05
.6427
Raymond Hendy Susanto and Wei Lu. 2017a.
Neural architectures for multilingual semantic
parsing. In Proceedings of the 55th Annual
Meeting of
the Association for Computa-
tional Linguistics (Volume 2: Short Papers),
pages 38–44, Vancouver, Canada. Association
for Computational Linguistics. https://doi
.org/10.18653/v1/P17-2007
Raymond Hendy Susanto and Wei Lu. 2017b.
Semantic parsing with neural hybrid trees. Pro-
ceedings of the AAAI Conference on Artificial
Intelligence, 31(1).
Shyam Upadhyay, Manaal Faruqui, G¨okhan
T¨ur, Dilek Hakkani-T¨ur, and Larry P. Heck.
2018. (Almost) Zero-shot cross-lingual spoken
language understanding. In 2018 IEEE Inter-
national Conference on Acoustics, Speech and
Signal Processing, ICASSP 2018, Calgary, AB,
Canada, April 15-20, 2018, pages 6034–6038.
IEEE.
Rob van der Goot,
Ibrahim Sharaf, Aizhan
Imankulova, Ahmet ¨Ust¨un, Marija Stepanovi´c,
Alan Ramponi, Siti Oryza Khairunnisa,
Mamoru Komachi, and Barbara Plank. 2021.
From masked language modeling to trans-
lation: Non-English auxiliary tasks improve
zero-shot spoken language understanding. In
Proceedings of the 2021 Conference of the
North American Chapter of the Association
for Computational Linguistics: Human Lan-
guage Technologies, pages 2479–2497, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.naacl-main.197
Bailin Wang, Mirella Lapata, and Ivan Titov.
2021a. Meta-learning for domain generaliza-
tion in semantic parsing. In Proceedings of
the 2021 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 366–379, Online. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2021.naacl-main.33
Bailin Wang, Richard Shin, Xiaodong Liu,
Oleksandr Polozov, and Matthew Richardson.
2020a. RAT-SQL: Relation-aware schema en-
coding and linking for text-to-SQL parsers. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguis-
tics, pages 7567–7578, Online. Association for
Computational Linguistics. https://doi.org
/10.18653/v1/2020.acl-main.677
Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen,
Naman Goyal, Vishrav Chaudhary, Jiatao Gu,
and Angela Fan. 2021. Multilingual translation
from denoising pre-training. In Findings of
the Association for Computational Linguistics:
ACL-IJCNLP 2021, pages 3450–3466, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.findings-acl.304
Jindong Wang, Cuiling Lan, Chang Liu, Yidong
Ouyang, and Tao Qin. 2021b. Generalizing
to unseen domains: A survey on domain gen-
eralization. In Proceedings of
the Thirtieth
International Joint Conference on Artificial
Intelligence, IJCAI-21, pages 4627–4635. In-
ternational Joint Conferences on Artificial In-
telligence Organization. https://doi.org
/10.24963/ijcai.2021/628
65
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Yaqing Wang, Quanming Yao, James T. Kwok,
and Lionel M. Ni. 2020b. Generalizing from a
few examples: A survey on few-shot learning.
ACM Computing Survey, 53(3). https://doi
.org/10.1145/3386252
Yonghui Wu, Mike Schuster, Zhifeng Chen,
Quoc V. Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin
Gao, Klaus Macherey, Jeff Klingner, Apurva
Shah, Melvin Johnson, Xiaobing Liu, Lukasz
Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku
Kudo, Hideto Kazawa, Keith Stevens, George
Kurian, Nishant Patil, Wei Wang, Cliff Young,
Jason Smith, Jason Riesa, Alex Rudnick, Oriol
Vinyals, Greg Corrado, Macduff Hughes, and
Jeffrey Dean. 2016. Google’s neural ma-
chine translation system: Bridging the gap
between human and machine translation. CoRR,
abs/1609.08144v2.
Mengzhou Xia, Guoqing Zheng, Subhabrata
Mukherjee, Milad Shokouhi, Graham Neubig,
and Ahmed Hassan Awadallah. 2021. MetaXL:
Meta representation transformation for low-
resource cross-lingual learning. In Proceedings
of the 2021 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 499–511, Online. Association for Com-
putational Linguistics.
Silei Xu, Sina Semnani, Giovanni Campagna,
and Monica Lam. 2020a. AutoQA: From
databases to QA semantic parsers with only
In Proceedings of
synthetic training data.
the 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 422–434, Online. Association for Com-
putational Linguistics.
Weijia Xu, Batool Haider, Jason Krone, and
Saab Mansour. 2021. Soft layer selection with
meta-learning for zero-shot cross-lingual trans-
fer. In Proceedings of the 1st Workshop on
Meta Learning and Its Applications to Natural
Language Processing, pages 11–18, Online.
Association for Computational Linguistics.
Weijia Xu, Batool Haider, and Saab Mansour.
2020b. End-to-end slot alignment and recogni-
tion for cross-lingual NLU. In Proceedings of
the 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 5052–5063, Online. Association for
Computational Linguistics.
Jingfeng Yang, Federico Fancellu, Bonnie
Webber, and Diyi Yang. 2021. Frustratingly
simple but surprisingly strong: Using language-
independent features for zero-shot cross-lingual
semantic parsing. In Proceedings of the 2021
Conference on Empirical Methods in Natural
Language Processing,
5848–5856,
Online and Punta Cana, Dominican Republic.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.emnlp-main.472
pages
Pengcheng Yin and Graham Neubig. 2017. A
syntactic neural model
for general-purpose
code generation. In Proceedings of the 55th
Annual Meeting of the Association for Compu-
tational Linguistics (Volume 1: Long Papers),
pages 440–450, Vancouver, Canada. Associa-
tion for Computational Linguistics.
Tao Yu, Rui Zhang, Kai Yang, Michihiro
Yasunaga, Dongxu Wang, Zifan Li, James Ma,
Irene Li, Qingning Yao, Shanelle Roman, Zilin
Zhang, and Dragomir Radev. 2018. Spider:
A large-scale human-labeled dataset for com-
plex and cross-domain semantic parsing and
text-to-SQL task. In Proceedings of the 2018
Conference on Empirical Methods in Natu-
ral Language Processing, pages 3911–3921,
Brussels, Belgium. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1425
Mengjie Zhao, Yi Zhu, Ehsan Shareghi, Ivan
Vuli´c, Roi Reichart, Anna Korhonen, and
Hinrich Sch¨utze. 2021. A closer look at few-
shot crosslingual transfer: The choice of shots
matters. In Proceedings of the 59th Annual
Meeting of the Association for Computational
Linguistics and the 11th International Joint
Conference on Natural Language Processing
(Volume 1: Long Papers), pages 5751–5767,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.acl-long.447
Victor Zhong, Mike Lewis, Sida I. Wang, and
Luke Zettlemoyer. 2020. Grounded adapta-
tion for zero-shot executable semantic parsing.
66
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
In Proceedings of
the 2020 Conference on
Empirical Methods in Natural Language Pro-
cessing (EMNLP), pages 6869–6882, Online.
Association for Computational Linguistics.
Qile Zhu, Haidar Khan, Saleh Soltan, Stephen
Rawls, and Wael Hamza. 2020. Don’t parse,
insert: Multilingual semantic parsing with
insertion based decoding. In Proceedings of the
24th Conference on Computational Natural
Language Learning, pages 496–506, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.conll-1.40
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
3
2
0
6
7
8
7
3
/
/
t
l
a
c
_
a
_
0
0
5
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
67