A Survey on Automated Fact-Checking
Zhijiang Guo∗, Michael Schlichtkrull∗, Andreas Vlachos
Department of Computer Science and Technology
University of Cambridge, UK
{zg283,mss84,av308}@cam.ac.uk
Astratto
Fact-checking has become increasingly im-
portant due to the speed with which both
information and misinformation can spread
in the modern media ecosystem. Therefore,
researchers have been exploring how fact-
checking can be automated, using techniques
based on natural language processing, machine
apprendimento, knowledge representation, and data-
bases to automatically predict the veracity of
claims. in questo documento, we survey automated
fact-checking stemming from natural language
processing, and discuss its connections to re-
lated tasks and disciplines. In this process, we
present an overview of existing datasets and
models, aiming to unify the various definitions
given and identify common concepts. Finalmente,
we highlight challenges for future research.
1
introduzione
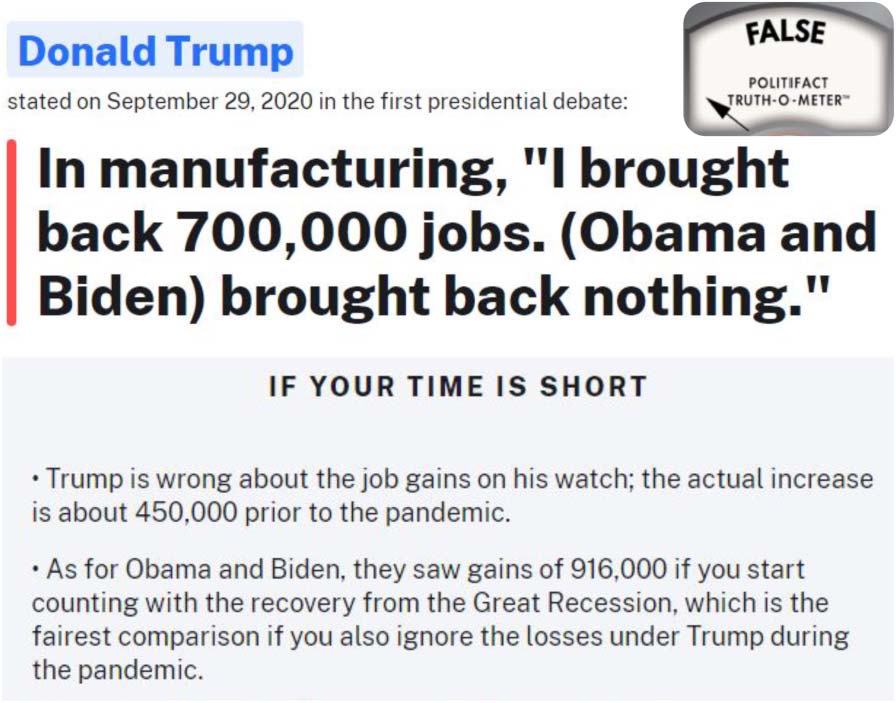
Fact-checking is the task of assessing whether
claims made in written or spoken language are
VERO. This is an essential task in journalism, E
is commonly conducted manually by dedicated
organizations such as PolitiFact. In addition to
external fact-checking, internal fact-checking is
also performed by publishers of newspapers, mag-
azines, and books prior to publishing in order to
promote truthful reporting. Figura 1 shows an ex-
ample from PolitiFact, together with the evidence
(summarized) and the verdict.
Fact-checking is a time-consuming task. To as-
sess the claim in Figure 1, a journalist would need
to search through potentially many sources to
find job gains under Trump and Obama, evaluate
the reliability of each source, and make a com-
parison. This process can take professional fact-
checkers several hours or days (Hassan et al.,
2015; Adair et al., 2017). Compounding the prob-
lem, fact-checkers often work under strict and
∗Equal contribution.
tight deadlines, especially in the case of internal
processes (Borel, 2016; Godler and Reich, 2017),
and some studies have shown that less than half
of all published articles have been subject to veri-
ficazione (Lewis et al., 2008). Given the amount of
new information that appears and the speed with
which it spreads, manual validation is insufficient.
Automating the fact-checking process has been
discussed in the context of computational journal-
ism (Flew et al., 2010; Cohen et al., 2011; Graves,
2018), and has received significant attention in
the artificial intelligence community. Vlachos and
Riedel (2014) proposed structuring it as a sequence
of components—identifying claims to be checked,
finding appropriate evidence, producing verdicts
—that can be modeled as natural language pro-
cessazione (PNL) compiti. This motivated the develop-
ment of automated pipelines consisting of subtasks
that can be mapped to tasks well-explored in
the NLP community. Advances were made possi-
ble by the development of datasets, consisting of
either claims collected from fact-checking web-
sites, for example Liar (Wang, 2017), or purpose-
made for research, Per esempio, FEVER (Thorne
et al., 2018UN).
A growing body of research is exploring the
various tasks and subtasks necessary for the au-
tomation of fact checking, and to meet the need
for new methods to address emerging challenges.
Early developments were surveyed in Thorne and
Vlachos (2018), which remains the closest to an
exhaustive overview of the subject. Tuttavia, their
proposed framework does not include work on
determining which claims to verify (cioè., claim
detection), nor does their survey include the re-
cent work on producing explainable, convincing
verdicts (cioè., justification production).
Several recent papers have surveyed research
focusing on individual components of the task.
Zubiaga et al. (2018) and Islam et al. (2020)
focus on identifying rumors on social media,
K¨uc¸ ¨uk and Can (2020) and Hardalov et al. (2021)
178
Operazioni dell'Associazione per la Linguistica Computazionale, vol. 10, pag. 178–206, 2022. https://doi.org/10.1162/tacl a 00454
Redattore di azioni: Yulan He. Lotto di invio: 6/2021; Lotto di revisione: 9/2021; Pubblicato 2/2022.
C(cid:3) 2022 Associazione per la Linguistica Computazionale. Distribuito sotto CC-BY 4.0 licenza.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
and da Silva et al. (2019) surveyed research on
fake news detection and fact checking with a focus
on social media data, while this survey covers fact
checking across domains and sources, including
newswire, science, eccetera.
In this survey, we present a comprehensive
and up-to-date survey of automated fact-checking,
unifying various definitions developed in previ-
ous research into a common framework. We begin
by defining the three stages of our fact-checking
framework—claim detection, evidence retrieval,
and claim verification, the latter consisting of ver-
dict prediction and justification production. Noi
then give an overview of the existing datasets
and modeling strategies, taxonomizing these and
contextualizing them with respect to our frame-
lavoro. We finally discuss key research challenges
that have been addressed, and give directions for
challenges that we believe should be tackled by
future research. We accompany the survey with a
repository,1 which lists the resources mentioned
in our survey.
2 Task Definition
Figura 2 shows a NLP framework for automated
fact-checking consisting of three stages: (io) claim
detection to identify claims that require veri-
ficazione; (ii) evidence retrieval to find sources
supporting or refuting the claim; E (iii) claim
verification to assess the veracity of the claim
based on the retrieved evidence. Evidence retrieval
and claim verification are sometimes tackled as a
single task referred to as factual verification, while
claim detection is often tackled separately. Claim
verification can be decomposed into two parts
that can be tackled separately or jointly: verdict
prediction, where claims are assigned truthful-
ness labels, and justification production, Dove
explanations for verdicts must be produced.
2.1 Claim Detection
The first stage in automated fact-checking is claim
detection, where claims are selected for verifica-
zione. Commonly, detection relies on the concept
of check-worthiness. Hassan et al. (2015) Di-
fined check-worthy claims as those for which
the general public would be interested in know-
ing the truth. Per esempio, ‘‘over six million
Americans had COVID-19 in January’’ would
1www.github.com/Cartus/Automated-Fact
-Checking-Resources.
Figura 1: An example of a fact-checked statement.
Referring to the manufacturing sector, Donald Trump
said ‘‘I brought back 700,000 jobs. Obama and Biden
brought back nothing.’’ The fact-checker gave the
verdict False based on the collected evidence.
on detecting the stance of a given piece of ev-
idence towards a claim, and Kotonya and Toni
(2020UN) on producing explanations and justifica-
tions for fact-checks. Finalmente, Nakov et al. (2021UN)
surveyed automated approaches to assist fact-
checking by humans. While these surveys are
extremely useful in understanding various aspects
of fact-checking technology, they are fragmented
and focused on specific subtasks and components;
our aim is to give a comprehensive and exhaustive
birds-eye view of the subject as a whole.
A number of papers have surveyed related
compiti. Lazer et al. (2018) and Zhou and Zafarani
(2020) surveyed work on fake news, including
descriptive work on the problem, as well as work
seeking to counteract fake news through compu-
tational means. A comprehensive review of NLP
approaches to fake news detection was also pro-
vided in Oshikawa et al. (2020). Tuttavia, fake
news detection differs in scope from fact check-
ing, as the former focuses on assessing news arti-
cles, and includes labeling items based on aspects
not related to veracity, such as satire detection
(Oshikawa et al., 2020; Zhou and Zafarani, 2020).
Inoltre, other factors—such as the audience
reached by the claim, and the intentions and forms
of the claim—are often considered. These factors
also feature in the context of propaganda detec-
zione, recently surveyed by Da San Martino et al.
(2020B). Unlike these efforts, the works discussed
in this survey concentrate on assessing veracity of
general-domain claims. Finalmente, Shu et al. (2017)
179
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Verdict Prediction
Claim
Detection
Evidence
Retrieval
Justification Production
Figura 2: A natural language processing framework for automated fact-checking.
be check-worthy, as opposed to ‘‘water is wet’’.
This can involve a binary decision for each po-
tential claim, or an importance-ranking of claims
(Atanasova et al., 2018; Barr´on-Cede˜no et al.,
2020). The latter parallels standard practice in in-
ternal journalistic fact-checking, where deadlines
often require fact-checkers to employ a triage
system (Borel, 2016).
Another instantiation of claim detection based
on check-worthiness is rumor detection. A rumor
can be defined as an unverified story or state-
ment circulating (typically on social media) (Mamma
et al., 2016; Zubiaga et al., 2018). Rumor detec-
tion considers language subjectivity and growth
of readership through a social network (Qazvinian
et al., 2011). Typical input to a rumor detection
system is a stream of social media posts, Dove-
upon a binary classifier has to determine if each
post is rumorous. Metadata, such as the number
of likes and re-posts, is often used as features
to identify rumors (Zubiaga et al., 2016; Gorrell
et al., 2019; Zhang et al., 2021).
Check-worthiness and rumorousness can be
subjective. Per esempio, the importance placed
on countering COVID-19 misinformation is not
uniform across every social group. The check-
worthiness of each claim also varies over time,
as countering misinformation related to current
events is in many cases understood to be more
important than countering older misinformation
(per esempio., misinformation about COVID-19 has a
greater societal impact in 2021 than misinfor-
mation about the Spanish flu). Inoltre, older
rumors may have already been debunked by jour-
nalists, reducing their impact. Misinformation that
is harmful to marginalized communities may also
be judged to be less check-worthy by the general
public than misinformation that targets the ma-
jority. Conversely, claims originating from mar-
ginalized groups may be subject to greater scrutiny
than claims originating from the majority; for
esempio, journalists have been shown to assign
greater trust and therefore lower need for verifica-
tion to stories produced by male sources (Barnoy
and Reich, 2019). Such biases could be repli-
cated in datasets that capture the (often implicit)
decisions made by journalists about which claims
to prioritize.
Instead of using subjective concepts, Konstanti-
novskiy et al. (2021) framed claim detection as
whether a claim makes an assertion about the
world that is checkable, questo è, whether it is verifi-
able with readily available evidence. Claims based
on personal experiences or opinions are uncheck-
able. Per esempio, ‘‘I woke up at 7 am today’’ is
not checkable because appropriate evidence can-
not be collected; ‘‘cubist art is beautiful’’ is not
checkable because it is a subjective statement.
2.2 Evidence Retrieval
Evidence retrieval aims to find information be-
yond the claim—for example, testo, tables, knowl-
edge bases, images, relevant metadata—to indicate
veracity. Some earlier efforts do not use any ev-
idence beyond the claim itself (Wang, 2017;
Rashkin et al., 2017; Volkova et al., 2017; Dungs
et al., 2018). Relying on surface patterns of claims
without considering the state of the world fails to
identify well-presented misinformation, including
machine-generated claims (Schuster et al., 2020).
Recent developments in natural language gener-
ation have exacerbated this issue (Radford et al.,
2019; Brown et al., 2020), with machine-generated
text sometimes being perceived as more trustwor-
thy than human-written text (Zellers et al., 2019).
In addition to enabling verification, evidence is
essential for generating verdict justifications to
convince users of fact-checks.
Stance detection can be viewed as an in-
stantiation of evidence retrieval, which typically
assumes a more limited amount of potential evi-
dence and predicts its stance towards the claim.
180
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Per esempio, Ferreira and Vlachos (2016) used
news article headlines from the Emergent project2
as evidence to predict whether articles supported,
refuted, or merely reported a claim. The Fake
News Challenge (Pomerleau and Rao, 2017)
further used entire documents, allowing for ev-
idence from multiple sentences. More recently,
Hanselowski et al. (2019) filtered out irrelevant
sentences in the summaries of fact-checking ar-
ticles to obtain fine-grained evidence via stance
detection. While both stance detection and evi-
dence retrieval in the context of claim verification
are classification tasks, what is considered ev-
idence in the former is broader, including, for
esempio, a social media post responding ‘‘@AJE-
News @germanwings yes indeed:-(.’’ to a claim
(Gorrell et al., 2019).
A fundamental issue is that not all available
information is trustworthy. Most fact-checking
approaches implicitly assume access to a trusted
information source such as encyclopedias (per esempio.,
Wikipedia [Thorne et al., 2018UN]) or results
provided (and thus vetted) by search engines
(Augenstein et al., 2019). Evidence is then de-
fined as information that can be retrieved from
this source, and veracity as coherence with the
evidence. For real-world applications, evidence
must be curated through the manual efforts of
journalists (Borel, 2016), automated means (Li
et al., 2015), or their combination. Per esempio,
Full Fact uses tables and legal documents from
government organizations as evidence.3
2.3 Verdict Prediction
Given an identified claim and the pieces of evi-
dence retrieved for it, verdict prediction attempts
to determine the veracity of the claim. The simplest
approach is binary classification, Per esempio, la-
beling a claim as true or false (Nakashole and
Mitchell, 2014; Popat et al., 2016; Potthast et al.,
2018). When evidence is used to verify the claim,
it is often preferable to use supported/refuted (by
evidence) instead of true/false respectively, as in
many cases the evidence itself is not assessed by
the systems. More broadly it would be dangerous
to make such strong claims about the world given
the well-known limitations (Graves, 2018).
2www.cjr.org/tow center reports/craig
silverman lies damn lies viral content.php.
3www.fullfact.org/about/frequently-asked
-questions.
Many versions of the task employ finer-grained
classification schemes. A simple extension is to
use an additional label denoting a lack of informa-
tion to predict the veracity of the claim (Thorne
et al., 2018UN). Beyond that, some datasets and
systems follow the approach taken by journalis-
tic fact-checking agencies, employing multi-class
labels representing degrees of truthfulness (Wang,
2017; Alhindi et al., 2018; Shahi and Nandini,
2020; Augenstein et al., 2019).
2.4 Justification Production
Justifying decisions is an important part of
journalistic fact-checking, as fact-checkers need
to convince readers of their interpretation of
the evidence (Uscinski and Butler, 2013; Borel,
2016). Debunking purely by calling something
false often fails to be persuasive, and can induce
a ‘‘backfire’’ effect where belief in the erroneous
claim is reinforced (Lewandowsky et al., 2012).
This need is even greater for automated fact-
checking, which may employ black-box compo-
nents. When developers deploy black-box models
whose decision-making processes cannot be un-
derstood, these artefacts can lead to unintended,
harmful consequences (O’Neil, 2016). Develop-
ing techniques that explain model predictions has
been suggested as a potential remedy to this prob-
lem (Lipton, 2018), and recent work has focused
on the generation of justifications (see Kotonya
and Toni’s [2020UN] survey of explainable claim
verification). Research so far has focused on jus-
tification production for claim verification, COME
the latter is often the most scrutinized stage in
fact-checking. Nevertheless, explainability may
also be desirable and necessary for the other stages
in our framework.
Justification production for claim verification
typically relies on one of four strategies. Primo,
attention weights can be used to highlight the
salient parts of the evidence, in which case jus-
tifications typically consist of scores for each
evidence token (Popat et al., 2018; Shu et al.,
2019; Lu and Li, 2020). Secondo, decision-making
processes can be designed to be understandable by
human experts, Per esempio, by relying on logic-
based systems (Gad-Elrab et al., 2019; Ahmadi
et al., 2019); in this case, the justification is
typically the derivation for the veracity of the
claim. Finalmente, the task can be modeled as a form
of summarization, where systems generate textual
181
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Dataset
Type
Input
#Inputs
Evidence
Verdict
Sources
Worthy
CredBank (Mitra and Gilbert, 2015)
Worthy
Weibo (Ma et al., 2016)
Worthy
PHEME (Zubiaga et al., 2016)
Worthy
RumourEval19 (Gorrell et al., 2019)
Worthy
DAST (Lillie et al., 2019)
Suspicious (Volkova et al., 2017)
Worthy
CheckThat20-T1 (Barr´on-Cede˜no et al., 2020) Worthy
Worthy
CheckThat21-T1A (Nakov et al., 2021B)
Worthy
Debate (Hassan et al., 2015)
Worthy
ClaimRank (Gencheva et al., 2017)
Worthy
CheckThat18-T1 (Atanasova et al., 2018)
Checkable
CitationReason (Redi et al., 2019)
Checkable
PolitiTV (Konstantinovskiy et al., 2021)
Aggregate
Aggregate
Individual
Individual
Individual
Individual
Individual
Individual
Statement
Statement
Statement
Statement
Statement
1,049 Meta
5,656 Meta
Text/Meta
Text/Meta
Text/Meta
✗
✗
✗
✗
✗
✗
330
446
220
131,584
8,812
17,282
1,571
5,415
16,200
4,000 Meta
6,304
✗
Twitter
5 Classes
Twitter/Weibo
2 Classes
Twitter
3 Classes
Twitter/Reddit
3 Classes
Reddit
3 Classes
Twitter
2/5 Classes
Twitter
Ranking
Twitter
2 Classes
Transcript
3 Classes
Transcript
Ranking
Ranking
Transcript
13 Classes Wikipedia
Transcript
7 Classes
Lang
In
En/Ch
En/De
In
Da
In
En/Ar
Many
In
In
En/Ar
In
In
Tavolo 1: Summary of claim detection datasets. Input can be a set of posts (aggregate) or an individual
post from social media, or a statement. Evidence include text and metadata. Verdict can be a multi-class
label or a rank list.
explanations for their decisions (Atanasova et al.,
2020B). While some of these justification types
require additional components, we did not intro-
duce a fourth stage in our framework as in some
cases the decision-making process of the model is
self-explanatory (Gad-Elrab et al., 2019; Ahmadi
et al., 2019).
A basic form of justification is to show which
pieces of evidence were used to reach a verdict.
Tuttavia, a justification must also explain how
the retrieved evidence was used, explain any as-
sumptions or commonsense facts employed, E
show the reasoning process taken to reach the
verdict. Presenting the evidence returned by a re-
trieval system can as such be seen as a rather
weak baseline for justification production, as it
does not explain the process used to reach the
verdict. There is furthermore a subtle difference
between evaluation criteria for evidence and justi-
fications: Good evidence facilitates the production
of a correct verdict; a good justification accurately
reflects the reasoning of the model through a read-
able and plausible explanation, regardless of the
correctness of the verdict. This introduces differ-
ent considerations for justification production, for
esempio, readability (how accessible an explana-
tion is to humans), plausibility (how convincing
an explanation is), and faithfulness (how accu-
rately an explanation reflects the reasoning of the
modello) (Jacovi and Goldberg, 2020).
3 Datasets
Datasets can be analyzed along three axes aligned
with three stages of the fact-checking framework
(Figura 2): the input, the evidence used, and ver-
dicts and justifications that constitute the out-
put. In this section we bring together efforts that
emerged in different communities using different
terminologies, but nevertheless could be used to
develop and evaluate models for the same task.
3.1 Input
We first consider the inputs to claim detection
(summarized in Table 1) as their format and con-
tent influences the rest of the process. A typical
input is a social media post with textual con-
tent. Zubiaga et al. (2016) constructed PHEME
based on source tweets in English and German
that sparked a high number of retweets exceeding
a predefined threshold. Derczynski et al. (2017)
introduced the shared task RumourEval using the
English section of PHEME; for the 2019 iteration
of the shared task, this dataset was further ex-
panded to include Reddit and new Twitter posts
(Gorrell et al., 2019). Following the same anno-
tation strategy, Lillie et al. (2019) constructed a
Danish dataset by collecting posts from Reddit. In-
stead of considering only source tweets, subtasks
in CheckThat (Barr´on-Cede˜no et al., 2020; Nakov
et al., 2021B) viewed every post as part of the
input. A set of auxiliary questions, such as ‘‘does
it contain a factual claim?’’, ‘‘is it of general in-
terest?’’, were created to help annotators identify
check-worthy posts. Since an individual post may
contain limited context, other works (Mitra and
Gilbert, 2015; Ma et al., 2016; Zhang et al., 2021)
represented each claim by a set of relevant posts,
Per esempio, the thread they originate from.
The second type of textual input is a docu-
ment consisting of multiple claims. For Debate
(Hassan et al., 2015), professionals were asked to
182
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Dataset
Input
#Inputs
Evidence
Verdict
Sources
Lang
Statement
CrimeVeri (Bachenko et al., 2008)
Statement
Politifact (Vlachos and Riedel, 2014)
Statement
StatsProperties (Vlachos and Riedel, 2015)
Statement
Emergent (Ferreira and Vlachos, 2016)
Statement
CreditAssess (Popat et al., 2016)
Statement
PunditFact (Rashkin et al., 2017)
Statement
Liar (Wang, 2017)
Verify (Baly et al., 2018)
Statement
CheckThat18-T2 (Barr´on-Cede˜no et al., 2018) Statement
Statement
Snopes (Hanselowski et al., 2019)
Statement
MultiFC (Augenstein et al., 2019)
Statement
Climate-FEVER (Diggelmann et al., 2020)
Statement
SciFact (Wadden et al., 2020)
Statement
PUBHEALTH (Kotonya and Toni, 2020B)
Statement
COVID-Fact (Saakyan et al., 2021)
Statement
X-Fact (Gupta and Srikumar, 2021)
Answer
cQA (Mihaylova et al., 2018)
Answer
AnswerFact (Zhang et al., 2020)
Article
NELA (Horne et al., 2018)
Article
BuzzfeedNews (Potthast et al., 2018)
Article
BuzzFace (Santia and Williams, 2018)
Article
FA-KES (Salem et al., 2019)
Article
FakeNewsNet (Shu et al., 2020)
Article
FakeCovid (Shahi and Nandini, 2020)
275 ✗
2 Classes
106 Text/Meta 5 Classes
Numeric
3 Classes
2 Classes
2/6 Classes
6 Classes
2 Classes
3 Classes
3 Classes
In
Crime
In
Fact Check
In
Internet
7,092 KG
Emergent
In
300 Testo
Fact Check/Wiki En
5,013 Testo
4,361 ✗
In
Fact Check
In
Fact Check
12,836 Meta
Ar/En
Fact Check
422 Testo
150 ✗
In
Transcript
In
Fact Check
6,422 Testo
In
36,534 Text/Meta 2–27 Classes Fact Check
In
1,535 Testo
In
1,409 Testo
In
11,832 Testo
In
4,086 Testo
Many
31,189 Testo
In
422 Meta
In
60,864 Testo
136,000 ✗
In
In
In
In
In
Many
Climate
Scienza
Fact Check
Forum
Fact Check
Forum
Amazon
News
Facebook
Facebook
VDC
Fact Check
Fact Check
4 Classes
3 Classes
4 Classes
2 Classes
7 Classes
2 Classes
5 Classes
2 Classes
4 Classes
4 Classes
2 Classes
2 Classes
2 Classes
1,627 Meta
2,263 Meta
804 ✗
23,196 Meta
5,182 ✗
Tavolo 2: Summary of factual verification datasets with natural inputs. KG denotes knowledge graphs.
ChectThat18 has been extended later (Hasanain et al., 2019; Barr´on-Cede˜no et al., 2020; Nakov et al.,
2021B). NELA has been updated by adding more data from more diverse sources (Nørregaard et al.,
2019; Gruppi et al., 2020, 2021).
select check-worthy claims from U.S. presidential
debates to ensure good agreement and shared un-
derstanding of the assumptions. D'altra parte,
Konstantinovskiy et al. (2021) collected checkable
claims from transcripts by crowd-sourcing, Dove
workers labeled claims based on a predefined tax-
onomy. Different from prior works focused on
the political domain, Redi et al. (2019) sampled
sentences that contain citations from Wikipedia ar-
ticles, and asked crowd-workers to annotate them
based on citation policies.
Prossimo, we discuss the inputs to factual verifica-
zione. The most popular type of input to verification
is textual claims, which is expected given they are
often the output of claim detection. These tend to
be sentence-level statements, which is a practice
common among fact-checkers in order to include
only the context relevant to the claim (Mena,
2019). Many existing efforts (Vlachos and Riedel,
2014; Wang, 2017; Hanselowski et al., 2019;
Augenstein et al., 2019) constructed datasets by
crawling real-world claims from dedicated web-
sites (per esempio., Politifact) due to their availability (Vedere
Tavolo 2). Unlike previous work that focus on
English, Gupta and Srikumar (2021) collected
non-English claims from 25 languages.
Others extract claims from specific domains,
such as science (Wadden et al., 2020), clima
(Diggelmann et al., 2020), and public health
(Kotonya and Toni, 2020B). Alternative forms of
sentence-level inputs, such as answers from ques-
tion answering forums, have also been considered
(Mihaylova et al., 2018; Zhang et al., 2020). There
have been approaches that consider a passage
(Mihalcea and Strapparava, 2009; P´erez-Rosas
et al., 2018) or an entire article (Horne et al., 2018;
Santia and Williams, 2018; Shu et al., 2020) as in-
put. Tuttavia, the implicit assumption that every
claim in it is either factually correct or incorrect is
problematic, and thus rarely practised by human
fact-checkers (Uscinski and Butler, 2013).
In order to better control the complexity of
the task, efforts listed in Table 3 created claims
artificially. Thorne et al. (2018UN) had annota-
tors mutate sentences from Wikipedia articles
to create claims. Following the same approach,
Khouja (2020) and Nørregaard and Derczynski
(2021) constructed Arabic and Danish datasets,
183
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Dataset
Input
#Inputs
Evidence
Verdict
Sources
Lang
KLinker (Ciampaglia et al., 2015)
PredPath (Shi and Weninger, 2016)
KStream (Shiralkar et al., 2017)
UFC (Kim and Choi, 2020)
LieDetect (Mihalcea and Strapparava, 2009)
FakeNewsAMT (P´erez-Rosas et al., 2018)
FEVER (Thorne et al., 2018UN)
HOVER (Jiang et al., 2020)
WikiFactCheck (Sathe et al., 2020)
VitaminC (Schuster et al., 2021)
TabFact (Chen et al., 2020)
InfoTabs (Gupta et al., 2020)
Sem-Tab-Fact (Wang et al., 2021)
FEVEROUS (Aly et al., 2021)
ANT (Khouja, 2020)
DanFEVER (Nørregaard and Derczynski, 2021)
Triple
Triple
Triple
Triple
Passage
Passage
Statement
Statement
Statement
Statement
Statement
Statement
Statement
Statement
Statement
Statement
10,000
3,559
18,431
1,759
600
680
185,445
26,171
124,821
488,904
92,283
23,738
5,715
87,026
4,547
6,407
KG
KG
KG
KG
✗
✗
Testo
Testo
Testo
Testo
Tavolo
Tavolo
Tavolo
Text/Table
✗
Testo
Google/Wiki
Google/Wiki
Google/Wiki/WSDM
2 Classes
2 Classes
2 Classes
2 Classes Wiki
News
2 Classes
News
2 Classes
3 Classes Wiki
3 Classes Wiki
2 Classes Wiki
3 Classes Wiki
2 Classes Wiki
3 Classes Wiki
3 Classes Wiki
3 Classes Wiki
3 Classes
News
3 Classes Wiki
In
In
In
In
In
In
In
In
In
In
In
In
In
In
Ar
Da
Tavolo 3: Summary of factual verification datasets with artificial inputs. Google denotes Google Relation
Extraction Corpora, and WSDM means the WSDM Cup 2017 Triple Scoring challenge.
rispettivamente. Another frequently considered op-
tion is subject-predicate-object triples, for exam-
ple, (London, city in, UK). The popularity of
triples as input stems from the fact that they
facilitate fact-checking against knowledge bases
(Ciampaglia et al., 2015; Shi and Weninger, 2016;
Shiralkar et al., 2017; Kim and Choi, 2020) come
as DBpedia (Auer et al., 2007), SemMedDB
(Kilicoglu et al., 2012), and KBox (Nam et al.,
2018). Tuttavia, such approaches implicitly as-
sume the non-trivial conversion of text into triples.
3.2 Evidence
A popular type of evidence often considered is
metadati, such as publication date, fonti, user
profiles, and so forth. Tuttavia, while it offers
information complementary to textual sources or
structural knowledge which is useful when the
latter are unavailable (Wang, 2017; Potthast et al.,
2018), it does not provide evidence grounding
the claim.
Textual sources, such as news articles, aca-
demic papers, and Wikipedia documents, are one
of the most commonly used types of evidence
for fact-checking. Ferreira and Vlachos (2016)
used the headlines of selected news articles, E
Pomerleau and Rao (2017) used the entire articles
instead as the evidence for the same claims. In-
stead of using news articles, Alhindi et al. (2018)
and Hanselowski et al. (2019) extracted sum-
maries accompanying fact-checking articles about
the claims as evidence. Documents from special-
ized domains such as science and public health
have also been considered (Wadden et al., 2020;
Kotonya and Toni, 2020B; Zhang et al., 2020).
The aforementioned works assume that evi-
dence is given for every claim, which is not
conducive to developing systems that need to re-
trieve evidence from a large knowledge source.
Therefore, Thorne et al. (2018UN) and Jiang et al.
(2020) considered Wikipedia as the source of ev-
idence and annotated the sentences supporting or
refuting each claim. Schuster et al. (2021) con-
structed VitaminC based on factual revisions to
Wikipedia, in which evidence pairs are nearly
identical in language and content, with the ex-
ception that one supports a claim while the other
does not. Tuttavia, these efforts restricted world
knowledge to a single source (Wikipedia), ignor-
ing the challenge of retrieving evidence from het-
erogeneous sources on the web. To address this,
other works (Popat et al., 2016; Baly et al., 2018;
Augenstein et al., 2019) retrieved evidence from
the Internet, but the search results were not anno-
tated. Così, it is possible that irrelevant informa-
tion is present in the evidence, while information
that is necessary for verification is missing.
Though the majority of studies focus on unstruc-
tured evidence (cioè., textual sources), structured
knowledge has also been used. Per esempio, IL
truthfulness of a claim expressed as an edge in a
knowledge base (per esempio., DBpedia) can be predicted
by the graph topology (Ciampaglia et al., 2015;
Shi and Weninger, 2016; Shiralkar et al., 2017).
Tuttavia, while graph topology can be an indica-
tor of plausibility, it does not provide conclusive
evidence. A claim that is not represented by a path
in the graph, or that is represented by an unlikely
sentiero, is not necessarily false. The knowledge base
approach assumes that true facts relevant to the
184
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
claim are present in the graph; but given the in-
completeness of even the largest knowledge bases,
this is not realistic (Bordes et al., 2013; Socher
et al., 2013).
Another type of structural knowledge is semi-
structured data (per esempio., tables), which is ubiquitous
thanks to its ability to convey important infor-
mation in a concise and flexible manner. Early
work by Vlachos and Riedel (2015) used tables
extracted from Freebase (Bollacker et al., 2008)
to verify claims retrieved from the web about
statistics of countries such as population, infla-
zione, and so on. Chen et al. (2020) and Gupta
et al. (2020) studied fact-checking textual claims
against tables and info-boxes from Wikipedia.
Wang et al. (2021) extracted tables from scien-
tific articles and required evidence selection in
the form of cells selected from tables. Aly et al.
(2021) further considered both text and table for
factual verification, while explicitly requiring the
retrieval of evidence.
3.3 Verdict and Justification
The verdict in early efforts (Bachenko et al., 2008;
Mihalcea and Strapparava, 2009) is a binary label
(cioè., true/false). Tuttavia, fact-checkers usually
employ multi-class labels to represent degrees
of truthfulness (VERO, mostly-true, mixture, eccetera.),4
which were considered by Vlachos and Riedel
(2014) and Wang (2017). Recentemente, Augenstein
et al. (2019) collected claims from different
fonti, where the number of labels vary greatly,
ranging from 2 A 27. Due to the difficulty of
mapping veracity labels onto the same scale, Essi
didn’t attempt to harmonize them across sources.
D'altra parte, other efforts (Hanselowski
et al., 2019; Kotonya and Toni, 2020B; Gupta
and Srikumar, 2021) performed normalization by
post-processing the labels based on rules to sim-
plify the veracity label. Per esempio, Hanselowski
et al. (2019) mapped mixture, unproven, and un-
determined onto not enough information.
Unlike prior datasets that only required out-
putting verdicts, FEVER (Thorne et al., 2018UN)
expected the output to contain both sentences
forming the evidence and a label (per esempio., support, Rif-
fute, not enough information). Later datasets with
both natural (Hanselowski et al., 2019; Wadden
et al., 2020) and artificial claims (Jiang et al.,
2020; Schuster et al., 2021) also adopted this
4www.snopes.com/fact-check-ratings.
scheme, where the output expected is a combina-
tion of multi-class labels and extracted evidence.
Most existing datasets do not contain textual
explanations provided by journalists as justifica-
tion for verdicts. Alhindi et al. (2018) extended
the Liar dataset with summaries extracted from
fact-checking articles. While originally intended
as an auxiliary task to improve claim verification,
these justifications have been used as explana-
zioni (Atanasova et al., 2020B). Recentemente, Kotonya
and Toni (2020B) constructed the first dataset
that explicitly includes gold explanations. These
consist of fact-checking articles and other news
items, which can be used to train natural lan-
guage generation models to provide post-hoc
justifications for the verdicts, Tuttavia, using
fact-checking articles is not realistic, as they are
not available during inference, which makes the
trained system unable to provide justifications
based on retrieved evidence.
4 Modeling Strategies
We now turn to surveying modeling strategies for
the various components of our framework. IL
most common approach is to build separate mod-
els for each component and apply them in pipeline
fashion. Nevertheless, joint approaches have also
been developed, either through end-to-end learn-
ing or by modeling the joint output distributions
of multiple components.
4.1 Claim Detection
Claim detection is typically framed as a classifi-
cation task, where models predict whether claims
are checkable or check-worthy. This is challeng-
ing, especially in the case of check-worthiness:
Rumorous and non-rumorous information is of-
ten difficult to distinguish, and the volume of
claims analyzed in real-world scenarios (per esempio., Tutto
posts published to a social network every day)
prohibits the retrieval and use of evidence. Early
systems employed supervised classifiers with fea-
ture engineering, relying on surface features like
Reddit karma and up-votes (Aker et al., 2017),
Twitter-specific types (Enayet and El-Beltagy,
2017), named entities and verbal forms in po-
litical transcripts (Zuo et al., 2018), or lexical and
syntactic features (Zhou et al., 2020).
Neural network approaches based on sequence-
or graph-modeling have recently become popu-
lar, as they allow models to use the context of
185
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
surrounding social media activity to inform deci-
sions. This can be highly beneficial, as the ways
in which information is discussed and shared
by users are strong indicators of rumorousness
(Zubiaga et al., 2016). Kochkina et al. (2017)
employed an LSTM (Hochreiter e Schmidhuber,
1997) to model branches of tweets, Ma et al.
(2018) used Tree-LSTMs (Tai et al., 2015) A
directly encode the structure of threads, E
Guo et al. (2018) modeled the hierarchy by using
attention networks. Recent work explored fusing
more domain-specific features into neural models
(Zhang et al., 2021). Another popular approach is
to use Graph Neural Networks (Kipf and Welling,
2017) to model the propagation behaviour of a
potentially rumorous claim (Monti et al., 2019; Li
et al., 2020; Yang et al., 2020UN).
Some works tackle claim detection and claim
verification jointly, labeling potential claims as
true rumors, false rumors, or non-rumors (Buntain
and Golbeck, 2017; Ma et al., 2018). This allows
systems to exploit specific features useful for both
compiti, such as the different spreading patterns
of false and true rumors (Zubiaga et al., 2016).
Veracity predictions made by such systems are
to be considered preliminary, as they are made
without evidence.
4.2 Evidence Retrieval and
Claim Verification
As mentioned in Section 2, evidence retrieval
and claim verification are commonly addressed
together. Systems mostly operate as a pipeline
consisting of an evidence retrieval module and
a verification module (Thorne et al., 2018B), Ma
there are exceptions where these two modules are
trained jointly (Yin and Roth, 2018).
Claim verification can be seen as a form of
Recognizing Textual Entailment (RTE; Dagan
et al., 2010; Bowman et al., 2015), predicting
whether the evidence supports or refutes the claim.
Typical retrieval strategies include commercial
search APIs, Lucene indices, entity linking, O
ranking functions like dot-products of TF-IDF
vettori (Thorne et al., 2018B). Recentemente, dense
retrievers employing learned representations and
fast dot-product indexing (Johnson et al., 2017)
have shown strong performance (Lewis et al.,
2020; Maillard et al., 2021). To improve preci-
sion, more complex models—for example, stance
detection systems—can be deployed as second,
fine-grained filters to re-rank retrieved evidence
(Thorne et al., 2018B; Nie et al., 2019B,UN;
Hanselowski et al., 2019). Allo stesso modo, evidence
can be re-ranked implicitly during verification in
late-fusion systems (Ma et al., 2019; Schlichtkrull
et al., 2021). An alternative approach was pro-
posed by Fan et al. (2020), who retrieved evidence
using question generation and question answering
via search engine results. Some work avoids re-
trieval by making a closed-domain assumption and
evaluating in a setting where appropriate evidence
has already been found (Ferreira and Vlachos,
2016; Chen et al., 2020; Zhong et al., 2020UN;
Yang et al., 2020B; Eisenschlos et al., 2020); Questo,
Tuttavia, is unrealistic. Finalmente, Allein et al. (2021)
took into account the timestamp of the evidence
in order to improve veracity prediction accuracy.
If only a single evidence document is retrieved,
verification can be directly modeled as RTE. How-
ever, both real-world claims (Augenstein et al.,
2019; Hanselowski et al., 2019; Kotonya and Toni,
2020B), as well as those created for research pur-
poses (Thorne et al., 2018UN; Jiang et al., 2020;
Schuster et al., 2021) often require reasoning over
and combining multiple pieces of evidence. UN
simple approach is to treat multiple pieces of evi-
dence as one by concatenating them into a single
corda (Luken et al., 2018; Nie et al., 2019UN), E
then employ a textual entailment model to infer
whether the evidence supports or refutes the claim.
More recent systems employ specialized compo-
nents to aggregate multiple pieces of evidence.
This allows the verification of more complex
claims where several pieces of information must
be combined, and addresses the case where the
retrieval module returns several highly related
documents all of which could (but might not)
contain the right evidence (Yoneda et al., 2018;
Zhou et al., 2019; Ma et al., 2019; Liu et al., 2020;
Zhong et al., 2020B; Schlichtkrull et al., 2021).
Some early work does not include evidence
retrieval at all, performing verification purely on
the basis of surface forms and metadata (Wang,
2017; Rashkin et al., 2017; Dungs et al., 2018).
Recentemente, Lee et al. (2020) considered using the
information stored in the weights of a large pre-
trained language model—BERT (Devlin et al.,
2019)—as the only source of evidence, as it has
been shown competitive in knowledge base com-
pletion (Petroni et al., 2019). Without explicitly
considering evidence such approaches are likely
to propagate biases learned during training, E
186
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
render justification production impossible (Lee
et al., 2021; Pan et al., 2021).
4.3 Justification Production
Approaches for justification production can be
separated into three categories, which we ex-
amine along the three dimensions discussed in
Section 2.4—readability, plausibility, and faith-
fulness. Primo, some models include components
that can be analyzed as justifications by human
experts, primarily attention modules. Popat et al.
(2018) selected evidence tokens that have higher
attention weights as explanations. Allo stesso modo, co-
Attenzione (Shu et al., 2019; Lu and Li, 2020) E
self-attention (Yang et al., 2019) were used to
highlight the salient excerpts from the evidence.
Wu et al. (2020B) further combined decision trees
and attention weights to explain which tokens
were salient, and how they influenced predictions.
Recent studies have shown the use of attention
as explanation to be problematic. Some tokens
with high attention scores can be removed without
affecting predictions, while some tokens with low
(non-zero) scores turn out to be crucial (Jain and
Wallace, 2019; Serrano and Smith, 2019; Pruthi
et al., 2020). Explanations provided by attention
may therefore not be sufficiently faithful. Further-
more, as they are difficult for non-experts and/or
those not well-versed in the architecture of the
model to grasp, they lack readability.
Another approach is to construct decision-
making processes that can be fully grasped by
human experts. Rule-based methods use Horn
rules and knowledge bases to mine explanations
(Gad-Elrab et al., 2019; Ahmadi et al., 2019),
which can be directly understood and verified.
These rules are mined from a pre-constructed
knowledge base, such as DBpedia (Auer et al.,
2007). This limits what can be fact-checked to
claims that are representable as triples, and to in-
formation present in the (often manually curated)
knowledge base.
Finalmente, some recent work has focused on
building models which—like human experts—can
generate textual explanations for their decisions.
Atanasova et al. (2020B) used an extractive ap-
proach to generate summaries, while Kotonya and
Toni (2020B) adopted the abstractive approach.
A potential issue is that such models can gener-
ate explanations that do not represent their actual
veracity prediction process, but which are never-
theless plausible with respect to the decision. Questo
is especially an issue with abstractive models,
where hallucinations can produce very mislead-
ing justifications (Maynez et al., 2020). Also,
the model of Atanasova et al. (2020B) assumes
fact-checking articles provided as input during
inference, which is unrealistic.
5 Related Tasks
Misinformation and Disinformation Misin-
formation is defined as constituting a claim that
contradicts or distorts common understandings of
verifiable facts (Guess and Lyons, 2020). On the
other hand, disinformation is defined as the subset
of misinformation that is deliberately propagated.
This is a question of intent: disinformation is
meant to deceive, while misinformation may be
inadvertent or unintentional (Tucker et al., 2018).
Fact-checking can help detect misinformation, Ma
not distinguish it from disinformation. A recent
survey (Alam et al., 2021) proposed to integrate
both factuality and harmfulness into a frame-
work for multi-modal disinformation detection.
Although misinformation and conspiracy theories
overlap conceptually, conspiracy theories do not
hinge exclusively on the truth value of the claims
being made, as they are sometimes proved to be
VERO (Sunstein and Vermeule, 2009). A related
problem is propaganda detection, which overlaps
with disinformation detection, but also includes
identifying particular techniques such as appeals
to emotion, logical fallacies, whataboutery, O
cherry-picking (Da San Martino et al., 2020B).
Propaganda and the deliberate or acciden-
tal dissemination of misleading information has
been studied extensively. Jowett and O’Donnell
(2019) address the subject from a communications
perspective, Taylor (2003) provides a historical
approach, and Goldman and O’Connor (2021)
tackle the related subject of epistemology and
trust in social settings from a philosophical per-
spective. For fact-checking and the identification
of misinformation by journalists, we direct the
reader to Silverman (2014) and Borel (2016).
Detecting Previously Fact-checked Claims
While in this survey we focus on methods for
verifying claims by finding the evidence rather
than relying on previously conducted fact checks,
misleading claims are often repeated (Hassan
et al., 2017); thus it is useful to detect whether a
claim has already been fact-checked. Shaar et al.
187
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
(2020) formulated this task recently as ranking,
and constructed two datasets. The social media
version of the task then featured at the shared task
CheckThat! (Barr´on-Cede˜no et al., 2020; Nakov
et al., 2021B). This task was also explored by Vo
and Lee (2020) from a multi-modal perspective,
where claims about images were matched against
previously fact-checked claims. More recently,
Sheng et al. (2021) and Kazemi et al. (2021) con-
structed datasets for this task in languages beyond
English. Hossain et al. (2020) detected misinfor-
mation by adopting a similar strategy. If a tweet
was matched to any known COVID-19 related
misconceptions, then it would be classified as
misinformative. Matching claims against previ-
ously verified ones is a simpler task that can often
be reduced to sentence-level similarity (Shaar
et al., 2020), which is well studied in the context
of textual entailment. Nevertheless, new claims
and evidence emerge regularly. Previous fact-
checks can be useful, but they can become out-
dated and potentially misleading over time.
6 Research Challenges
Choice of Labels The use of
fine-grained
labels by fact-checking organizations has re-
cently come under criticism (Uscinski and Butler,
2013). In-between labels like ‘‘mostly true’’ often
represent ‘‘meta-ratings’’ for composite claims
consisting of multiple elementary claims of differ-
ent veracity. Per esempio, a politician might claim
improvements to unemployment and productivity;
if one part is true and the other false, a fact-checker
might label the full statement ‘‘half true’’. Noisy
labels resulting from composite claims could be
avoided by intervening at the dataset creation
stage to manually split such claims, or by learning
to do so automatically. The separation of claims
into truth and falsehood can be too simplistic, COME
true claims can still mislead. Examples include
cherry-picking, where evidence is chosen to sug-
gest a misleading trend (Asudeh et al., 2020),
and technical truth, where true information is
presented in a way that misleads (per esempio., ‘‘I have
never lost a game of chess’’ is also true if the
speaker has never played chess). A major chal-
lenge is integrating analysis of such claims into
the existing frameworks. This could involve new
labels identifying specific forms of deception, COME
is done in propaganda detection (Da San Martino
et al., 2020UN), or a greater focus on producing
justifications to show why claims are misleading
(Atanasova et al., 2020B; Kotonya and Toni, 2020B).
Sources and Subjectivity Not all information
is equally trustworthy, and sometimes trustworthy
sources contradict each other. This challenges the
assumptions made by most current fact-checking
research relying on a single source considered au-
thoritative, such as Wikipedia. Methods must be
developed to address the presence of disagreeing
or untrustworthy evidence. Recent work proposed
integrating credibility assessment as a part of
the fact-checking task (Wu et al., 2020UN). Questo
could be done, Per esempio, by assessing the
agreement between evidence sources, or by as-
sessing the degree to which sources cohere with
known facts (Li et al., 2015; Dong et al., 2015;
Zhang et al., 2019). Allo stesso modo, check-worthiness
is a subjective concept varying along axes includ-
ing target audience, recency, and geography. One
solution is to focus solely on objective checka-
bility (Konstantinovskiy et al., 2021). Tuttavia,
the practical limitations of fact-checking (per esempio., IL
deadlines of journalists and the time-constraints
of media consumers) often force the use of a
triage system (Borel, 2016). This can introduce
biases regardless of the intentions of journalists
and system-developers to use objective criteria
(Uscinski and Butler, 2013; Uscinski, 2015).
Addressing this challenge will require the de-
velopment of systems allowing for real-time in-
teraction with users to take into account their
evolving needs.
and Biases Synthetic
Dataset Artefacts
datasets constructed through crowd-sourcing are
common (Zeichner et al., 2012; Hermann et al.,
2015; Williams et al., 2018). It has been shown
that models tend to rely on biases in these datasets,
without learning the underlying task (Gururangan
et al., 2018; Poliak et al., 2018; McCoy et al.,
2019). For fact-checking, Schuster et al. (2019)
showed that the predictions of models trained
on FEVER (Thorne et al., 2018UN) were largely
driven by indicative claim words. The FEVER 2.0
shared task explored how to generate adversarial
claims and build systems resilient to such attacks
(Thorne et al., 2019). Alleviating such biases and
increasing the robustness to adversarial examples
remains an open question. Potential solutions
include leveraging better modeling approaches
(Utama et al., 2020UN,B; Karimi Mahabadi et al.,
188
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
2020; Thorne and Vlachos, 2021), collecting
data by adversarial games (Eisenschlos et al.,
2021), or context-sensitive inference (Schuster
et al., 2021).
Multimodality Information (either in claims
or evidence) can be conveyed through multiple
modalities such as text, tables, images, audio, O
video. Though the majority of existing works have
focused on text, some efforts also investigated how
to incorporate multimodal information, including
claim detection with misleading images (Zhang
et al., 2018), propaganda detection over mixed
images and text (Dimitrov et al., 2021), and claim
verification for images (Zlatkova et al., 2019;
Nakamura et al., 2020). Monti et al. (2019) argued
that rumors should be seen as signals propagat-
ing through a social network. Rumor detection is
therefore inherently multimodal, requiring anal-
ysis of both graph structure and text. Available
multimodal corpora are either small in size (Zhang
et al., 2018; Zlatkova et al., 2019) or constructed
based on distant supervision (Nakamura et al.,
2020). The construction of large-scale annotated
datasets paired with evidence beyond metadata
will facilitate the development of multimodal
fact-checking systems.
Multilinguality Claims can occur
in multi-
ple languages, often different from the one(S)
evidence is available in, calling for multilin-
gual fact-checking systems. While misinformation
spans both geographic and linguistic boundaries,
most work in the field has focused on English.
A possible approach for multilingual verification
is to use translation systems for existing methods
(Dementieva and Panchenko, 2020), but relevant
datasets in more languages are necessary for test-
ing multilingual models’ performance within each
lingua, and ideally also for training. Currently,
there exist a handful of datasets for factual verifi-
cation in languages other than English (Baly et al.,
2018; Lillie et al., 2019; Khouja, 2020; Shahi
and Nandini, 2020; Nørregaard and Derczynski,
2021), but they do not offer a cross-lingual set-
su. More recently, Gupta and Srikumar (2021)
introduced a multilingual dataset covering 25 lan-
guages, but found that adding training data from
other languages did not improve performance.
How to effectively align, coordinate, and lever-
age resources from different languages remains an
open question. One promising direction is to dis-
till knowledge from high-resource to low-resource
languages (Kazemi et al., 2021).
Faithfulness A significant unaddressed chal-
lenge in justification production is faithfulness.
As we discuss in Section 4.3, some justifications
—such as those generated abstractively (Maynez
et al., 2020)—may not be faithful. This can be
highly problematic, especially if these justifica-
tions are used to convince users of the validity of
model predictions (Lertvittayakumjorn and Toni,
2019). Faithfulness is difficult to evaluate for,
as human evaluators and human-produced gold
standards often struggle to separate highly plau-
sible, unfaithful explanations from faithful ones
(Jacovi and Goldberg, 2020). In the model in-
terpretability domain, several recent papers have
introduced strategies for testing or guaranteeing
faithfulness. These include introducing formal cri-
teria that models should uphold (Yu et al., 2019),
measuring the accuracy of predictions after re-
moving some or all of the predicted non-salient
input elements (Yeh et al., 2019; DeYoung
et al., 2020; Atanasova et al., 2020UN), or disprov-
ing the faithfulness of techniques by counterex-
ample (Jain and Wallace, 2019; Wiegreffe and
Pinter, 2019). Further work is needed to develop
such techniques for justification production.
From Debunking to Early Intervention and
Prebunking The prevailing application of auto-
mated fact-checking is to discover and intervene
against circulating misinformation, also referred
to as debunking. Efforts have been made to re-
spond quickly after the appearance of a piece of
misinformation (Monti et al., 2019), but common
to all approaches is that intervention takes place
reactively after misinformation has already been
introduced to the public. NLP technology could
also be leveraged in proactive strategies. Prior
work has employed network analysis and similar
techniques to identify key actors for interven-
tion in social networks (Farajtabar et al., 2017);
using NLP, such techniques could be extended
to take into account the information shared by
these actors, in addition to graph-based features
(Nakov, 2020; Mu and Aletras, 2020). Another
direction is to disseminate countermessaging be-
fore misinformation can spread widely; questo è
also known as pre-bunking, and has been shown
to be more effective than post-hoc debunking
(van der Linden et al., 2017; Roozenbeek et al.,
189
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
2020; Lewandowsky and van der Linden, 2021).
NLP could play a crucial role both in early de-
tection and in the creation of relevant coun-
termessaging. Finalmente, training people to create
misinformation has been shown to increase resis-
tance towards false claims (Roozenbeek and van
der Linden, 2019). NLP could be used to facilitate
this process, or to provide an adversarial oppo-
nent for gamifying the creation of misinformation.
This could be seen as a form of dialogue agent to
educate users, however there are as of yet no
resources for the development of such systems.
7 Conclusione
We have reviewed and evaluated current auto-
mated fact-checking research by unifying the task
formulations and methodologies across different
research efforts into one framework comprising
claim detection, evidence retrieval, verdict predic-
zione, and justification production. Based on the
proposed framework, we have provided an exten-
sive overview of the existing datasets and mod-
eling strategies. Finalmente, we have identified vital
challenges for future research to address.
Ringraziamenti
Zhijiang Guo, Michael Schlichtkrull, and Andreas
Vlachos are supported by the ERC grant
AVeriTeC (GA 865958), The latter is further
supported by the EU H2020 grant MONITIO
(GA 965576). The authors would like to thank
Rami Aly, Christos Christodoulopoulos, Nedjma
Ousidhoum, and James Thorne for useful com-
ments and suggestions.
Riferimenti
Jun Yang,
Bill Adair, Chengkai Li,
E
Cong Yu. 2017. Progress toward ‘‘the holy
to automate
grail’’: The continued quest
fact-checking. Negli Atti di
IL 2017
Computation+Journalism Symposium.
Naser Ahmadi, Joohyung Lee, Paolo Papotti,
and Mohammed Saeed. 2019. Explainable fact
checking with probabilistic answer set pro-
gramming. Negli Atti del 2019 Truth
and Trust Online Conference (TTO 2019),
190
London, UK, October 4–5, 2019. https://
doi.org/10.36370/tto.2019.15
Ahmet Aker, Leon Derczynski, and Kalina
Bontcheva. 2017. Simple open stance classi-
fication for rumor analysis. Negli Atti di
the International Conference Recent Advances
nell'elaborazione del linguaggio naturale, RANLP 2017,
pages 31–39, Varna, Bulgaria. INCOMA Ltd.
Firoj Alam, Stefano Cresci, Tanmoy Chakraborty,
Fabrizio Silvestri, Dimiter Dimitrov, Giovanni
Da San Martino, Shaden Shaar, Hamed Firooz,
and Preslav Nakov. 2021. A survey on multi-
modal disinformation detection. arXiv preprint
arXiv:2103.12541. https://doi.org/10
.26615/978-954-452-049-6_005
Tariq Alhindi, Savvas Petridis, and Smaranda
Muresan. 2018. Where is your evidence:
Improving fact-checking by justification mod-
eling. In Proceedings of the First Workshop
on Fact Extraction and VERification (FEVER),
pages 85–90, Brussels, Belgium. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/W18-5513
Liesbeth Allein, Isabelle Augenstein, and Marie-
Francine Moens. 2021. Time-aware evidence
ranking for fact-checking. Web Semantics.
Rami Aly, Zhijiang Guo, M. Schlichtkrull,
James Thorne, Andreas Vlachos, Christos
Christodoulopoulos, O. Cocarascu, and Arpit
Mittal. 2021. FEVEROUS: Fact Extraction and
VERification over unstructured and structured
informazione. 35th Conference on Neural Infor-
mation Processing Systems (NeurIPS 2021)
Track on Datasets and Benchmarks. https://
doi.org/10.1016/j.websem.2021
.100663
Abolfazl Asudeh, H. V. Jagadish, You (Will)
Wu, and Cong Yu. 2020. On detecting cherry-
picked trendlines. Proceedings of the VLDB
Endowment, 13(6):939–952. https://doi
.org/10.14778/3380750.3380762
Pepa Atanasova, Llu´ıs M`arquez, Alberto Barr´on-
Cede˜no, Tamer Elsayed, Reem Suwaileh, Wajdi
Zaghouani, Spas Kyuchukov, Giovanni Da
San Martino, and Preslav Nakov. 2018. Over-
view of the CLEF-2018 CheckThat! lab on auto-
matic identification and verification of political
claims. task 1: Check-worthiness. In Working
Notes of CLEF 2018 – Conference and Labs
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
of the Evaluation Forum, Avignon, France,
September 10–14, 2018, volume 2125 Di
CEUR Workshop Proceedings. CEUR-WS.org.
https://doi.org/10.1007/978-3-319
-98932-7 32
Pepa Atanasova, Jakob Grue Simonsen, Christina
Lioma, and Isabelle Augenstein. 2020UN. A diag-
nostic study of explainability techniques for text
classificazione. Negli Atti del 2020 Contro-
ference on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 3256–3274,
Online. Association for Computational Linguis-
tic. https://doi.org/10.18653/v1
/2020.emnlp-main.263
Pepa Atanasova, Jakob Grue Simonsen, Christina
Lioma, and Isabelle Augenstein. 2020B. Gen-
erating fact checking explanations. Nel professionista-
ceedings of the 58th Annual Meeting of the
Associazione per la Linguistica Computazionale,
pages 7352–7364, Online. Association for Com-
Linguistica putazionale. https://doi.org
/10.18653/v1/2020.acl-main.656
S¨oren Auer, Christian Bizer, Georgi Kobilarov,
Jens Lehmann, Richard Cyganiak, and Zachary
G. Ives. 2007. DBpedia: A nucleus for a web
In The Semantic Web, 6th
of open data.
International Semantic Web Conference, 2nd
Asian Semantic Web Conference, ISWC 2007 +
ASWC 2007, Busan, Korea, November 11–15,
2007, volume 4825 of Lecture Notes in
Computer Science, pages 722–735. Springer.
https://doi.org/10.1007/978-3-540
-76298-0 52
Negli Atti di
Isabelle Augenstein, Christina Lioma, Dongsheng
Wang, Lucas Chaves Lima, Casper Hansen,
Christian Hansen, and Jakob Grue Simonsen.
2019. MultiFC: A real-world multi-domain
dataset for evidence-based fact checking of
IL 2019 Contro-
claims.
ference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
cessazione (EMNLP-IJCNLP), pages 4685–4697,
Hong Kong, China. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D19-1475
in civil and criminal narratives. In Procedi-
the 22nd International Conference
ings di
on Computational Linguistics (Coling 2008),
pages 41–48, Manchester, UK. Coling 2008
Organizing Committee. https://doi.org
/10.3115/1599081.1599087
Ramy Baly, Mitra Mohtarami, James Glass,
Llu´ıs M`arquez, Alessandro Moschitti, E
Preslav Nakov. 2018. Integrating stance de-
tection and fact checking in a unified corpus.
Negli Atti del 2018 Conference of the
North American Chapter of the Association
for Computational Linguistics: Human Lan-
guage Technologies, Volume 2 (Short Papers),
pages 21–27, New Orleans, Louisiana. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/N18-2004
Aviv Barnoy and Zvi Reich. 2019. The When,
Why, How and So-What of Verifications. vol-
ume 20, pages 2312–2330. Taylor & Francis.
https://doi.org/10.1080/1461670X
.2019.1593881
Alberto Barr´on-Cede˜no, Tamer Elsayed, Preslav
Nakov, Giovanni Da San Martino, Maram
Hasanain, Reem Suwaileh, Fatima Haouari,
Nikolay Babulkov, Bayan Hamdan, Alex
Nikolov, Shaden Shaar, and Zien Sheikh Ali.
2020. Overview of CheckThat! 2020: Auto-
matic identification and verification of claims
in social media. In Experimental IR Meets Mul-
tilinguality, Multimodality, and Interaction –
11th International Conference of the CLEF
Association, CLEF 2020, Thessaloniki, Greece,
September 22–25, 2020, Proceedings, volume
12260 of Lecture Notes in Computer Science,
pages 215–236. Springer.
Alberto Barr´on-Cede˜no, Tamer Elsayed, Reem
Suwaileh, Llu´ıs M`arquez, Pepa Atanasova,
Wajdi Zaghouani, Spas Kyuchukov, Giovanni
Da San Martino, and Preslav Nakov. 2018.
Overview of the CLEF-2018 CheckThat! lab
on automatic identification and verification of
political claims. task 2: Factuality. In Working
Notes of CLEF 2018 – Conference and Labs
of the Evaluation Forum, Avignon, France,
September 10–14, 2018, volume 2125 of CEUR
Workshop Proceedings. CEUR-WS.org.
Joan Bachenko, Eileen Fitzpatrick, and Michael
Schonwetter. 2008. Verification and implemen-
tation of language-based deception indicators
Kurt D. Bollacker, Colin Evans, Praveen Paritosh,
Tim Sturge, and Jamie Taylor. 2008. Freebase:
A collaboratively created graph database for
191
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
structuring human knowledge. Negli Atti
of the ACM SIGMOD International Confer-
ence on Management of Data, SIGMOD 2008,
Vancouver, BC, Canada, June 10–12, 2008,
pages 1247–1250. ACM. https://doi.org
/10.1145/1376616.1376746
Antoine Bordes, Nicolas Usunier, Alberto Garc´ıa-
Dur´an, Jason Weston, and Oksana Yakhnenko.
2013. Translating embeddings for modeling
multi-relational data. In Advances in Neural In-
formation Processing Systems 26: 27th Annual
Conference on Neural Information Processing
Sistemi 2013. Proceedings of a meeting held
December 5–8, 2013, Lake Tahoe, Nevada,
stati Uniti, pages 2787–2795.
Brooke Borel. 2016. The Chicago Guide to
Fact-checking. University of Chicago Press.
https://doi.org/10.7208/chicago
/9780226291093.001.0001
Samuel R. Bowman, Gabor Angeli, Christopher
Potts, e Christopher D. Equipaggio. 2015. UN
large annotated corpus for learning natural lan-
guage inference. Negli Atti del 2015
Conference on Empirical Methods in Natural
Language Processing, pages 632–642, Lisbon,
Portugal. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/D15-1075
Tom B. Brown, Benjamin Mann, Nick Ryder,
Melanie Subbiah,
Jared Kaplan, Prafulla
Dhariwal, Arvind Neelakantan, Pranav Shyam,
Girish Sastry, Amanda Askell, Sandhini
Agarwal, Ariel Herbert-Voss, Gretchen Krueger,
Tom Henighan, Rewon Child, Aditya Ramesh,
Daniel M. Ziegler,
Jeffrey Wu, Clemens
Inverno, Christopher Hesse, Mark Chen, Eric
Sigler, Mateusz Litwin, Scott Gray, Benjamin
Chess, Jack Clark, Christopher Berner, Sam
McCandlish, Alec Radford, Ilya Sutskever,
and Dario Amodei. 2020. Language models
are few-shot learners. In Advances in Neural
Information Processing Systems 33: Annual
Conference on Neural Information Processing
Sistemi 2020, NeurIPS 2020, December 6–12,
2020, virtual.
Cody Buntain and Jennifer Golbeck. 2017.
Automatically identifying fake news in pop-
ular twitter threads. In 2017 IEEE International
Conference on Smart Cloud (SmartCloud),
pages 208–215. IEEE. https://doi.org
/10.1109/SmartCloud.2017.40
Wenhu Chen, Hongmin Wang, Jianshu Chen,
Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou
Zhou, and William Yang Wang. 2020. TabFact:
A large-scale dataset for table-based fact ver-
ification. In 8th International Conference on
Learning Representations, ICLR 2020. Addis
Ababa, Ethiopia.
Giovanni Luca Ciampaglia, Prashant Shiralkar,
Luis M. Rocha, Johan Bollen, Filippo Menczer,
and Alessandro Flammini. 2015. Computa-
tional fact checking from knowledge networks.
PloS One, 10(6):e0128193. https://doi
.org/10.1371/journal.pone.0128193,
PubMed: 26083336
Sarah Cohen, Chengkai Li, Jun Yang, and Cong
Yu. 2011. Computational journalism: A call
to arms to database researchers. In CIDR
2011, Fifth Biennial Conference on Innova-
tive Data Systems Research, Asilomar, CA,
USA, January 9–12, 2011, Online Proceedings,
pages 148–151. www.cidrdb.org.
Giovanni Da San Martino, Alberto Barr´on-
Cede˜no, Henning Wachsmuth, Rostislav Petrov,
and Preslav Nakov. 2020UN. SemEval-2020
task 11: Detection of propaganda techniques
in news articles. In Proceedings of the Four-
teenth Workshop on Semantic Evaluation,
pages 1377–1414, Barcelona (Online). Interna-
tional Committee for Computational Linguis-
tic. https://doi.org/10.18653/v1
/2020.semeval-1.186
Giovanni Da San Martino, Stefano Cresci, Alberto
Barr´on-Cede˜no, Seunghak Yu, Roberto Di
Pietro, and Preslav Nakov. 2020B. A survey on
computational propaganda detection. Nel professionista-
ceedings of
the Twenty-Ninth International
Joint Conference on Artificial Intelligence,
IJCAI 2020, pages 4826–4832. ijcai.org.
https://doi.org/10.24963/ijcai.2020
/672
Fernando Cardoso Durier da Silva, Rafael Vieira,
and Ana Cristina Bicharra Garcia. 2019. Can
machines learn to detect fake news? A survey
focused on social media. In 52nd Hawaii
International Conference on System Sciences,
HICSS 2019, Grand Wailea, Maui, Hawaii,
192
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
USA, January 8–11, 2019, pages 1–8. Scholar-
Spazio. https://doi.org/10.24251/HICSS
.2019.332
Ido Dagan, Bill Dolan, Bernardo Magnini, E
Dan Roth. 2010. Recognizing textual entail-
ment: Rational, evaluation and approaches.
Natural Language Engineering, 16(1):105.
https://doi.org/10.1017/S1351324909
990234
Daryna Dementieva and A. Panchenko. 2020.
Fake news detection using multilingual evi-
dence. 2020 IEEE 7th International Conference
on Data Science and Advanced Analytics
(DSAA), pages 775–776. https://doi.org
/10.1109/DSAA49011.2020.00111
Leon Derczynski, Kalina Bontcheva, Maria
Liakata, Rob Procter, Geraldine Wong Sak Hoi,
and Arkaitz Zubiaga. 2017. SemEval-2017 task
8: RumourEval: Determining rumour veracity
and support for rumours. Negli Atti di
the 11th International Workshop on Seman-
tic Evaluation (SemEval-2017), pages 69–76,
Vancouver, Canada. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/S17-2006
Jacob Devlin, Ming-Wei Chang, Kenton Lee, E
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. Negli Atti di
IL 2019
Conference of the North American Chapter
of the Association for Computational Linguis-
tic: Tecnologie del linguaggio umano, Volume
1 (Long and Short Papers), pages 4171–4186,
Minneapolis, Minnesota. Association for Com-
Linguistica putazionale.
Jay DeYoung, Sarthak Jain, Nazneen Fatema
Rajani, Eric Lehman, Caiming Xiong, Richard
Socher, and Byron C. Wallace. 2020. ERASER:
A benchmark to evaluate rationalized NLP
models. In Proceedings of the 58th Annual
the Association for Computa-
Meeting of
linguistica nazionale, pages 4443–4458, Online.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/2020
.acl-main.408
Dimitar Dimitrov, Bishr Bin Ali, Shaden Shaar,
Firoj Alam, Fabrizio Silvestri, Hamed Firooz,
Preslav Nakov, and Giovanni Da San Martino.
2021. Detecting propaganda techniques in
memes. In Proceedings of the 59th Annual
Riunione dell'Associazione per il Computazionale
Linguistics and the 11th International Joint
Conferenza sull'elaborazione del linguaggio naturale
(Volume 1: Documenti lunghi), pages 6603–6617,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2021.acl-long.516
Xin Luna Dong, Evgeniy Gabrilovich, Kevin
Murphy, Van Dang, Wilko Horn, Camillo
Lugaresi, Shaohua Sun, and Wei Zhang. 2015.
Knowledge-based trust: Estimating the trust-
worthiness of web sources. Atti del
VLDB Endowment, 8(9):938–949. https://
doi.org/10.14778/2777598.2777603
Sebastian Dungs, Ahmet Aker, Norbert Fuhr, E
Kalina Bontcheva. 2018. Can rumour stance
alone predict veracity? Negli Atti del
27th International Conference on Computa-
linguistica nazionale, pages 3360–3370, Santa Fe,
New Mexico, USA. Associazione per il calcolo-
linguistica nazionale.
Julian Eisenschlos, Bhuwan Dhingra,
IL 2021 Conference of
Jannis
Bulian, Benjamin B¨orschinger, and Jordan
Boyd-Graber. 2021. Fool Me Twice: Entail-
ment from Wikipedia gamification. In Procedi-
ings di
the North
American Chapter of the Association for Com-
Linguistica putazionale: Human Language Tech-
nologies, pages 352–365, Online. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/2021.naacl
-main.32
Julian Eisenschlos, Syrine Krichene, and Thomas
M¨uller. 2020. Understanding tables with inter-
mediate pre-training. In Findings of the Associ-
ation for Computational Linguistics: EMNLP
2020, pages 281–296, Online. Associazione per
Linguistica computazionale. https://doi
.org/10.18653/v1/2020.findings
-emnlp.27
Thomas Diggelmann, Jordan L. Boyd-Graber,
Jannis Bulian, Massimiliano Ciaramita, E
Markus Leippold. 2020. CLIMATE-FEVER:
A dataset for verification of real-world climate
claims. CoRR, abs/2012.00614.
Omar Enayet and Samhaa R. El-Beltagy. 2017.
NileTMRG at SemEval-2017 task 8: Determin-
ing rumour and veracity support for rumours
on Twitter. In Proceedings of the 11th In-
ternational Workshop on Semantic Evaluation
193
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
(SemEval-2017), pages 470–474, Vancouver,
Canada. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/S17-2082
Angela Fan, Aleksandra Piktus, Fabio Petroni,
Guillaume Wenzek, Marzieh Saeidi, Andreas
Vlachos, Antoine Bordes, and Sebastian Riedel.
2020. Generating fact checking briefs. Nel professionista-
ceedings of the 2020 Conference on Empiri-
cal Methods in Natural Language Processing
(EMNLP), pages 7147–7161, Online. Associa-
tion for Computational Linguistics.
Mehrdad Farajtabar, Jiachen Yang, Xiaojing
Ye, Huan Xu, Rakshit Trivedi, Elias Khalil,
Shuang Li, Le Song, and Hongyuan Zha. 2017.
Fake news mitigation via point process based
intervention. In Proceedings of the 34th In-
ternational Conference on Machine Learning,
volume 70 of Proceedings of Machine Learning
Research, pages 1097–1106. PMLR.
William Ferreira and Andreas Vlachos. 2016.
Emergent: a novel data-set for stance classifi-
catione. Negli Atti del 2016 Conferenza
of the North American Chapter of the Associ-
ation for Computational Linguistics: Umano
Language Technologies, pages 1163–1168,
San Diego, California. Association for Compu-
linguistica nazionale. https://doi.org/10
.18653/v1/N16-1138
Terry Flew, Christina Spurgeon, Anna Daniel,
and Adam Swift. 2010. The promise of com-
journalism. Journalism Practice,
putational
6:157–171. https://doi.org/10.1080
/17512786.2011.616655
Mohamed H. Gad-Elrab, Daria Stepanova, Jacopo
Urbani, and Gerhard Weikum. 2019. ExFaKT:
A framework for explaining facts over knowl-
edge graphs and text. Negli Atti del
Twelfth ACM International Conference on Web
Search and Data Mining, WSDM 2019, Mel-
bourne, VIC, Australia, February 11–15, 2019,
pages 87–95. ACM. https://doi.org/10
.1145/3289600.3290996
Pepa Gencheva, Preslav Nakov, Llu´ıs M`arquez,
Alberto Barr´on-Cede˜no, and Ivan Koychev.
2017. A context-aware approach for detect-
ing worth-checking claims in political debates.
In Proceedings of the International Conference
Recent Advances in Natural Language Pro-
cessazione, RANLP 2017, pages 267–276, Varna,
Bulgaria. INCOMA Ltd. https://doi.org
/10.26615/978-954-452-049-6_037
Yigal Godler and Zvi Reich. 2017. Journal-
istic evidence: Cross-verification as a con-
stituent of mediated knowledge. Giornalismo,
18(5):558–574. https://doi.org/10.1177
/1464884915620268
Alvin Goldman and Cailin O’Connor. 2021.
Social Epistemology. In Edward N. Zalta, edi-
tor, The Stanford Encyclopedia of Philosophy,
Primavera 2021 edition. Metaphysics Research Lab,
Stanford University.
Genevieve Gorrell, Ahmet Aker, Kalina
Bontcheva, Leon Derczynski, Elena Kochkina,
Maria Liakata, and Arkaitz Zubiaga. 2019.
SemEval-2019 task 7: RumourEval, determin-
ing rumour veracity and support for rumours.
In Proceedings of the 13th International Work-
shop on Semantic Evaluation, SemEval@NAACL-
HLT 2019, Minneapolis, MN, USA, June 6–7,
2019, pages 845–854. Association for Compu-
linguistica nazionale. https://doi.org/10
.18653/v1/S19-2147
Lucas Graves. 2018. Understanding the promise
and limits of automated fact-checking. Reuters
Institute for the Study of Journalism.
Maur´ıcio Gruppi, Benjamin D. Horne, and Sibel
Adali. 2020. NELA-GT-2019: A large multi-
labeled news dataset for the study of misinfor-
mation in news articles. CoRR, abs/2003.08444.
Maur´ıcio Gruppi, Benjamin D. Horne, and Sibel
Adali. 2021. NELA-GT-2020: A large multi-
labeled news dataset for the study of misinfor-
mation in news articles. CoRR, abs/2102.04567.
Andrew M. Guess and Benjamin A. Lyons.
2020. Misinformation, disinformation, and on-
line propaganda.
In Nathaniel Persily and
Joshua A. Tucker, editors, Social Media and
Democracy: The State of the Field, Prospects
for Reform, pages 10–33. Cambridge Univer-
sity Press. https://doi.org/10.1017
/9781108890960.003
Han Guo, Juan Cao, Yazi Zhang, Junbo Guo, E
Jintao Li. 2018. Rumor detection with hierar-
chical social attention network. Negli Atti
the 27th ACM International Conference
Di
on Information and Knowledge Management,
CIKM 2018, Torino, Italy, October 22–26,
194
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
2018, pages 943–951. ACM. https://doi
.org/10.1145/3269206.3271709
Ashim Gupta and Vivek Srikumar. 2021. X-Fact:
A new benchmark dataset for multilingual fact
checking. In Proceedings of the 59th Annual
Riunione dell'Associazione per il Computazionale
Linguistics and the 11th International Joint
Conferenza sull'elaborazione del linguaggio naturale
(Volume 2: Short Papers), pages 675–682,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2021.acl-short.86
INFOTABS:
Vivek Gupta, Maitrey Mehta, Pegah Nokhiz, E
Vivek Srikumar. 2020.
Infer-
ence on tables as semi-structured data. Nel professionista-
ceedings of the 58th Annual Meeting of the
Associazione per la Linguistica Computazionale,
pages 2309–2324, Online. Associazione per
Linguistica computazionale. https://doi
.org/10.18653/v1/2020.acl-main.210
Suchin Gururangan, Swabha Swayamdipta,
Omer Levy, Roy Schwartz, Samuel Bowman,
and Noah A. Smith. 2018, Jun. Annotation
language inference data.
artifacts in natural
Negli Atti di
IL 2018 Conference of
the North American Chapter of the Associa-
tion for Computational Linguistics: Umano
Language Technologies, Volume 2 (Short Pa-
pers), pages 107–112, New Orleans, Louisiana.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/N18
-2017
Andreas Hanselowski, Christian Stab, Claudia
Schulz, Zile Li, and Iryna Gurevych. 2019.
A richly annotated corpus for different tasks
in automated fact-checking. Negli Atti di
the 23rd Conference on Computational Natural
Language Learning (CoNLL), pages 493–503,
Hong Kong, China. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/K19-1046
Momchil Hardalov, Arnav Arora, Preslav Nakov,
and Isabelle Augenstein. 2021. A survey on
stance detection for mis- and disinformation
identification. ArXiv, abs/2103.00242.
Maram Hasanain, Reem Suwaileh, Tamer
Elsayed, Alberto Barr´on-Cede˜no, and Preslav
Nakov. 2019. Overview of the CLEF-2019
CheckThat! lab: Automatic identification and
verification of claims. task 2: Evidence and
factuality. In Working Notes of CLEF 2019 –
Conference and Labs of the Evaluation Forum,
Lugano, Svizzera, September 9–12, 2019,
volume 2380 of CEUR Workshop Proceedings.
CEUR-WS.org.
Naeemul Hassan, Chengkai Li,
and Mark
Tremayne. 2015. Detecting check-worthy fac-
tual claims in presidential debates. In Procedi-
ings of the 24th ACM International Conference
on Information and Knowledge Management,
CIKM 2015, Melbourne, VIC, Australia,
October 19–23, 2015, pages 1835–1838. ACM.
https://doi.org/10.1145/2806416
.2806652
Naeemul Hassan, Gensheng Zhang, Fatma
Arslan, Josue Caraballo, Damian Jimenez,
Siddhant Gawsane, Shohedul Hasan, Minumol
Joseph, Aaditya Kulkarni, Anil Kumar Nayak,
Vikas Sable, Chengkai Li, and Mark Tremayne.
2017. ClaimBuster: The first-ever end-to-end
fact-checking system. Proceedings of the VLDB
Endowment, 10(12):1945–1948. https://
doi.org/10.14778/3137765.3137815
Karl Moritz Hermann, Tom´as Kocisk´y, Edoardo
Grefenstette, Lasse Espeholt, Will Kay,
Mustafa Suleyman, and Phil Blunsom. 2015.
Teaching machines to read and comprehend.
In Advances in Neural Information Processing
Sistemi 28: Annual Conference on Neural
Information Processing Systems 2015, Decem-
ber 7–12, 2015, Montreal, Quebec, Canada,
pages 1693–1701.
Sepp Hochreiter e Jürgen Schmidhuber. 1997.
Memoria a lungo termine. Neural Computa-
zione, 9(8):1735–1780. https://doi.org/10
.1162/neco.1997.9.8.1735, PubMed:
9377276
Benjamin D. Horne, Sara Khedr, and Sibel
Adali. 2018. Sampling the news producers: UN
large news and feature data set for the study
of the complex media landscape. In Procedi-
ings of the Twelfth International Conference
on Web and Social Media, ICWSM 2018,
Stanford, California, USA, Giugno 25-28, 2018,
pages 518–527. AAAI Press.
Tamanna Hossain, Robert L. Logan IV, Arjuna
Ugarte, Yoshitomo Matsubara, Sean Young,
195
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
and Sameer Singh. 2020. COVIDLies: De-
tecting COVID-19 misinformation on social
media. In Proceedings of the 1st Workshop
on NLP for COVID-19 (Part 2) at EMNLP
2020, Online. Associazione per il calcolo
Linguistica. https://doi.org/10.18653
/v1/2020.nlpcovid19-2.11
Md. Rafiqul Islam, Shaowu Liu, Xianzhi Wang,
and Guandong Xu. 2020. Deep learning for
misinformation detection on online social net-
works: a survey and new perspectives. So-
cial Network Analysis and Mining, 10(1):82.
https://doi.org/10.1007/s13278
-020-00696-X, PubMed: 33014173
Alon Jacovi and Yoav Goldberg. 2020. Towards
faithfully interpretable NLP systems: How
should we define and evaluate faithfulness? In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 4198–4205, Online. Association for Com-
Linguistica putazionale. https://doi.org
/10.18653/v1/2020.acl-main.386
Sarthak Jain and Byron C. Wallace. 2019. A-
tention is not Explanation. Negli Atti di
IL 2019 Conferenza del Nord America
Chapter of
the Association for Computa-
linguistica nazionale: Human Language Tech-
nologies, Volume 1 (Long and Short Papers),
pages 3543–3556, Minneapolis, Minnesota.
Associazione per la Linguistica Computazionale.
Yichen Jiang, Shikha Bordia, Zheng Zhong,
Charles Dognin, Maneesh Singh, and Mohit
Bansal. 2020. HoVer: A dataset for many-hop
fact extraction and claim verification. In Find-
ings di
the Association for Computational
Linguistica: EMNLP 2020, pages 3441–3460,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2020.findings-emnlp.309
Jeff Johnson, Matthijs Douze, and Herv´e J´egou.
2017. Billion-scale similarity search with
GPUs. CoRR, abs/1702.08734.
Garth S. Jowett and Victoria O’Donnell. 2019.
Propaganda & Persuasion, 7th edition. SAGE
Publications.
Rabeeh Karimi Mahabadi, Yonatan Belinkov,
and James Henderson. 2020. End-to-end bias
mitigation by modelling biases in corpora. In
the 58th Annual Meeting
Proceedings of
of the Association for Computational Linguis-
tic, pages 8706–8716, Online. Associazione per
Linguistica computazionale. https://doi
.org/10.18653/v1/2020.acl-main
.769
fact-checking.
Ashkan Kazemi, Kiran Garimella, Devin Gaffney,
and Scott Hale. 2021. Claim matching beyond
English to scale global
In
Proceedings of the 59th Annual Meeting of the
Associazione per la Linguistica Computazionale
and the 11th International Joint Conference
on Natural Language Processing (Volume 1:
Documenti lunghi), pages 4504–4517, Online.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/2021
.acl-long.347
Jude Khouja. 2020. Stance prediction and
claim verification: An Arabic perspective.
Negli Atti di
the Third Workshop on
Fact Extraction and VERification (FEVER),
pages 8–17, Online. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/2020.fever-1.2
Halil Kilicoglu, Dongwook Shin, Marcelo
Fiszman, Graciela Rosemblat, and Thomas C.
Rindflesch. 2012. SemMedDB: A PubMed-
scale repository of biomedical semantic pre-
dications. Bioinformatics, 28(23):3158–3160.
https://doi.org/10.1093/bioinformatics
/bts591, PubMed: 23044550
Jiseong Kim and Key-sun Choi. 2020. Unsu-
pervised fact checking by counter-weighted
positive and negative evidential paths in a
knowledge graph. In Proceedings of the 28th
Conferenza internazionale sul calcolo
Linguistica, pages 1677–1686, Barcelona, Spain
(Online). International Committee on Compu-
linguistica nazionale.
Thomas N. Kipf and Max Welling. 2017.
Semi-supervised classification with graph con-
In 5th International
volutional networks.
Conference on Learning Representations, ICLR
2017, Toulon, France, April 24–26, 2017, Contro-
ference Track Proceedings. OpenReview.net.
Elena Kochkina, Maria Liakata, and Isabelle
Augenstein. 2017. Turing at SemEval-2017 task
8: Sequential approach to rumor stance classi-
fication with branch-LSTM. Negli Atti di
the 11th International Workshop on Semantic
Evaluation (SemEval-2017), pages 475–480,
196
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Vancouver, Canada. Association for Compu-
linguistica nazionale. https://doi.org/10
.18653/v1/S17-2083
Lev Konstantinovskiy, Oliver Price, Mevan
Babakar, and Arkaitz Zubiaga. 2021. Toward
automated factchecking: Developing an anno-
tation schema and benchmark for consistent
automated claim detection. Digital Threats:
Research and Practice, 2(2):1–16. https://
doi.org/10.1145/3412869
Neema Kotonya and Francesca Toni. 2020UN.
Explainable automated fact-checking: A sur-
vey. In Proceedings of the 28th International
Conference on Computational Linguistics,
pages 5430–5443, Barcelona, Spain (Online).
International Committee on Computational Lin-
guistics. https://doi.org/10.18653
/v1/2020.coling-main.474
automated
fact-checking
Neema Kotonya and Francesca Toni. 2020B.
Explainable
for
public health claims. Negli Atti del
2020 Conferenza sui metodi empirici
nell'elaborazione del linguaggio naturale (EMNLP),
pages 7740–7754, Online. Associazione per
Linguistica computazionale.
Dilek K¨uc¸ ¨uk and Fazli Can. 2020. Stance de-
tection: A survey. ACM Computing Surveys,
53(1):12:1–12:37.
David M. J. Lazer, Matthew A. Baum, Yochai
Benkler, Adam J. Berinsky, Kelly M. Greenhill,
Filippo Menczer, Miriam J. Metzger, Brendan
Nyhan, Gordon Pennycook, David Rothschild,
Michael Schudson, Steven A. Sloman, Cass R.
Sunstein, Emily A. Thorson, Duncan J. Watts,
and Jonathan L. Zittrain. 2018. The science
of fake news. Scienza, 359(6380):1094–1096.
https://doi.org/10.1126/science
.aao2998, PubMed: 29590025
Nayeon Lee, Yejin Bang, Andrea Madotto, E
Pascale Fung. 2021. Towards few-shot fact-
checking via perplexity. Negli Atti di
IL 2021 Conferenza del Nord America
Capitolo dell'Associazione per il calcolo
Linguistica: Tecnologie del linguaggio umano,
pages 1971–1981, Online. Associazione per
Linguistica computazionale.
Nayeon Lee, Belinda Z. Li, Sinong Wang,
Wen-tau Yih, Hao Ma, and Madian Khabsa.
2020. Language models as fact checkers?
197
Negli Atti di
the Third Workshop on
Fact Extraction and VERification (FEVER),
pages 36–41, Online. Association for Compu-
linguistica nazionale.
Piyawat Lertvittayakumjorn and Francesca Toni.
2019. Human-grounded evaluations of expla-
nation methods for text classification. Nel professionista-
ceedings of the 2019 Conferenza sull'Empirico
Methods in Natural Language Processing and
the 9th International Joint Conference on Nat-
elaborazione del linguaggio urale (EMNLP-IJCNLP),
pages 5195–5205, Hong Kong, China. Associ-
ation for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1523
Stephan Lewandowsky, Ullrich K. H. Ecker,
Colleen M. Seifert, Norbert Schwarz, and John
Cook. 2012. Misinformation and its correction:
Continued influence and successful debiasing.
Psychological Science in the Public Interest,
Supplement, 13(3):106–131. https://doi.org
/10.1177/1529100612451018, PubMed:
26173286
Stephan Lewandowsky and Sander van der
Linden. 2021. Countering misinformation and
fake news through inoculation and prebunk-
ing. European Review of Social Psychology,
0(0):1–38. https://doi.org/10.1080
/10463283.2021.1876983
Justin Matthew Wren Lewis, Andy Williams,
Robert Arthur Franklin, James Thomas, E
Nicholas Alexander Mosdell. 2008. The qual-
ity and independence of british journalism.
Mediawise.
Patrick S. H. Lewis, Ethan Perez, Aleksandra
Piktus, Fabio Petroni, Vladimir Karpukhin,
Naman Goyal, Heinrich K¨uttler, Mike Lewis,
Wen-tau Yih, Tim Rockt¨aschel, Sebastian
Riedel, and Douwe Kiela. 2020. Retrieval-
augmented generation for knowledge-intensive
NLP tasks. In Advances in Neural Information
Processing Systems 33: Annual Conference on
Neural Information Processing Systems 2020,
NeurIPS 2020, December 6–12, 2020, virtual.
Jiawen Li, Yudianto Sujana, and Hung-Yu
Kao. 2020. Exploiting microblog conversa-
tion structures to detect rumors. In Procedi-
ings of the 28th International Conference on
Linguistica computazionale, pages 5420–5429,
Barcelona, Spain (Online). International Com-
mittee on Computational Linguistics.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Yaliang Li, Jing Gao, Chuishi Meng, Qi Li, Lu Su,
Bo Zhao, Wei Fan, and Jiawei Han. 2015. A sur-
vey on truth discovery. SIGKDD Explorations,
17(2):1–16. https://doi.org/10.1145
/2897350.2897352
Anders Edelbo Lillie, Emil Refsgaard Middelboe,
and Leon Derczynski. 2019. Joint rumour stance
and veracity prediction. Negli Atti del
22nd Nordic Conference on Computational
Linguistica, pages 208–221, Turku, Finland.
Link¨oping University Electronic Press.
Zachary C. Lipton. 2018. The mythos of
interpretability. Communications of
modello
ACM, 61(10):36–43. https://doi.org
/10.1145/3233231
Zhenghao Liu, Chenyan Xiong, Maosong Sun,
e Zhiyuan Liu. 2020. Fine-grained fact ver-
ification with kernel graph attention network.
In Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 7342–7351, Online. Associazione per
Linguistica computazionale.
Yi-Ju Lu and Cheng-Te Li. 2020. GCAN:
Graph-aware co-attention networks for explain-
able fake news detection on social media. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguis-
tic, pages 505–514, Online. Associazione per
Linguistica computazionale.
Jackson Luken, Nanjiang Jiang, and Marie-
Catherine de Marneffe. 2018. QED: A fact ver-
ification system for the FEVER shared task.
the First Workshop on
Negli Atti di
Fact Extraction and VERification (FEVER),
pages 156–160, Brussels, Belgium. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/W18-5526
Jing Ma, Wei Gao, Shafiq Joty, and Kam-Fai
Wong. 2019. Sentence-level evidence embed-
ding for claim verification with hierarchical
IL
attention networks.
57esima Assemblea Annuale dell'Associazione per
Linguistica computazionale, pages 2561–2571,
Florence, Italy. Associazione per il calcolo
Linguistica.
Negli Atti di
Jing Ma, Wei Gao, Prasenjit Mitra, Sejeong
Kwon, Bernard J. Jansen, Kam-Fai Wong, E
Meeyoung Cha. 2016. Detecting rumors from
microblogs with recurrent neural networks. In
Proceedings of the Twenty-Fifth International
Joint Conference on Artificial Intelligence,
IJCAI 2016, New York, NY, USA, 9-15 Luglio
2016, pages 3818–3824. IJCAI/AAAI Press.
Jing Ma, Wei Gao, and Kam-Fai Wong. 2018.
Rumor detection on Twitter with tree-structured
recursive neural networks. Negli Atti di
the 56th Annual Meeting of the Association
for Computational Linguistics (Volume 1: Lungo
Carte), pages 1980–1989, Melbourne, Australia.
Associazione per la Linguistica Computazionale.
Jean Maillard, Vladimir Karpukhin, Fabio Petroni,
Wen-tau Yih, Barlas Oguz, Veselin Stoyanov,
and Gargi Ghosh. 2021. Multi-task retrieval
for knowledge-intensive tasks. Negli Atti
of the 59th Annual Meeting of the Association
for Computational Linguistics and the 11th
International Joint Conference on Natural
Language Processing (Volume 1: Long Pa-
pers), pages 1098–1111, Online. Association
for Computational Linguistics. https://doi
.org/10.18653/v1/2021.acl-long.89
Joshua Maynez, Shashi Narayan, Bernd Bohnet,
and Ryan McDonald. 2020. On faithfulness
and factuality in abstractive summarization. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguis-
tic, pages 1906–1919, Online. Association
for Computational Linguistics. https://doi
.org/10.18653/v1/2020.acl-main.173
Tom McCoy, Ellie Pavlick, and Tal Linzen. 2019.
Right for the wrong reasons: Diagnosing syn-
tactic heuristics in natural language inference.
In Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 3428–3448, Florence, Italy. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/P19-1334
Paul Mena. 2019. Principles and boundaries of
fact-checking: Journalists’ perceptions. Jour-
nalism Practice, 13(6):657–672.
Rada Mihalcea and Carlo Strapparava. 2009. IL
lie detector: Explorations in the automatic recog-
nition of deceptive language. Negli Atti
of the ACL-IJCNLP 2009 Conference Short
Carte, pages 309–312, Suntec, Singapore.
Associazione per la Linguistica Computazionale.
Tsvetomila Mihaylova, Preslav Nakov, Llu´ıs
M`arquez, Alberto Barr´on-Cede˜no, Mitra
198
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Mohtarami, Georgi Karadzhov, and James R.
Glass. 2018. Fact checking in community fo-
rums. Negli Atti di
the Thirty-Second
AAAI Conference on Artificial Intelligence,
(AAAI-18), the 30th innovative Applications
of Artificial Intelligence (IAAI-18), and the
8th AAAI Symposium on Educational Ad-
vances in Artificial Intelligence (EAAI-18), Nuovo
Orleans, Louisiana, USA, February 2–7, 2018,
pages 5309–5316. AAAI Press.
Tanushree Mitra and Eric Gilbert. 2015. CRED-
BANK: A large-scale social media corpus with
associated credibility annotations. In Procedi-
ings of the Ninth International Conference on
Web and Social Media, ICWSM 2015, Univer-
sity of Oxford, Oxford, UK, May 26–29, 2015,
pages 258–267. AAAI Press.
Federico Monti, Fabrizio Frasca, Davide Eynard,
Damon Mannion, and Michael M. Bronstein.
2019. Fake news detection on social media
using geometric deep learning. CoRR, abs/1902
.06673.
Yida Mu and Nikolaos Aletras. 2020. Identifying
twitter users who repost unreliable news sources
with linguistic information. PeerJ Computer
Scienza, 6. https://doi.org/10.7717
/peerj-cs.325, PubMed: 33816975
Kai Nakamura, Sharon Levy, and William Yang
Wang. 2020. Fakeddit: A new multimodal
benchmark dataset for fine-grained fake news
detection. In Proceedings of The 12th Lan-
guage Resources and Evaluation Conference,
LREC 2020, Marseille, France, May 11-16,
2020, pages 6149–6157. European Language
Resources Association.
Ndapandula Nakashole and Tom M. Mitchell.
2014. Language-aware truth assessment of
fact candidates. In Proceedings of the 52nd
Annual Meeting of the Association for Com-
Linguistica putazionale (Volume 1: Long Pa-
pers), pages 1009–1019, Baltimore, Maryland.
Associazione per la Linguistica Computazionale.
https://doi.org/10.3115/v1/P14-1095
Preslav Nakov. 2020. Can we spot the ‘‘fake
news’’ before it was even written? CoRR,
abs/2008.04374.
Preslav Nakov, David P. UN. Corney, Maram
Hasanain, Firoj Alam, Tamer Elsayed, Alberto
Barr´on-Cede˜no, Paolo Papotti, Shaden Shaar,
and Giovanni Da San Martino. 2021UN. Auto-
mated fact-checking for assisting human fact-
checkers. CoRR, abs/2103.07769. https://
doi.org/10.24963/ijcai.2021/619
Preslav Nakov, Giovanni Da San Martino, Tamer
Elsayed, Alberto Barr´on-Cede˜no, Rub´en
M´ıguez, Shaden Shaar, Firoj Alam, Fatima
Haouari, Maram Hasanain, Nikolay Babulkov,
Alex Nikolov, Gautam Kishore Shahi, Julia
Maria Struß, and Thomas Mandl. 2021B.
The CLEF-2021 CheckThat! lab on detecting
check-worthy claims, previously fact-checked
claims, and fake news. In Advances in Infor-
mation Retrieval – 43rd European Conference
on IR Research, ECIR 2021, Virtual Event,
Marzo 28 – April 1, 2021, Proceedings, Part II,
volume 12657 of Lecture Notes in Computer
Scienza, pages 639–649. Springer. https://
doi.org/10.1007/978-3-030-72240-1 75
Sangha Nam, Eun-Kyung Kim,
Jiho Kim,
Yoosung Jung, Kijong Han, and Key-Sun Choi.
2018. A korean knowledge extraction sys-
tem for enriching a kbox. In COLING 2018,
The 27th International Conference on Com-
Linguistica putazionale: System Demonstra-
zioni, Santa Fe, New Mexico, August 20–26,
2018, pages 20–24. Associazione per il calcolo-
linguistica nazionale.
Yixin Nie, Haonan Chen, and Mohit Bansal.
2019UN. Combining fact extraction and verifica-
tion with neural semantic matching networks.
In The Thirty-Third AAAI Conference on Arti-
ficial Intelligence, AAAI 2019, The Thirty-First
Innovative Applications of Artificial Intelli-
gence Conference, IAAI 2019, The Ninth AAAI
Symposium on Educational Advances in Ar-
tificial
Intelligenza, EAAI 2019, Honolulu,
Hawaii, USA, Gennaio 27 – Febbraio 1, 2019,
pages 6859–6866. AAAI Press. https://doi
.org/10.1609/aaai.v33i01.33016859
Yixin Nie, Songhe Wang, and Mohit Bansal.
2019B. Revealing the importance of seman-
tic retrieval for machine reading at scale. In
Atti del 2019 Conference on Empir-
ical Methods in Natural Language Processing
and the 9th International Joint Conference
on Natural Language Processing (EMNLP-
IJCNLP), pages 2553–2566, Hong Kong,
199
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
China. Association for Computational Linguis-
tic. https://doi.org/10.18653/v1
/D19-1258
Jeppe Nørregaard and Leon Derczynski. 2021.
DanFEVER: Claim verification dataset for dan-
ish. In Proceedings of the 23rd Nordic Confer-
ence on Computational Linguistics, NoDaLiDa
2021, Reykjavik, Iceland (Online), May 31 –
Giugno 2, 2021, pages 422–428. Link¨oping Uni-
versity Electronic Press, Sweden.
Jeppe Nørregaard, Benjamin D. Horne, E
Sibel Adali. 2019. NELA-GT-2018: A large
multi-labeled news dataset for the study of mis-
information in news articles. Negli Atti
of the Thirteenth International Conference on
Web and Social Media, ICWSM 2019, Munich,
Germany, June 11–14, 2019, pages 630–638.
AAAI Press.
Cathy O’Neil. 2016. Weapons of Math De-
struction: How Big Data Increases Inequality
and Threatens Democracy. Crown Publishing
Group, USA.
Ray Oshikawa, Jing Qian, and William Yang
Wang. 2020. A survey on natural language
processing for fake news detection. Nel professionista-
the 12th Language Resources
ceedings of
and Evaluation Conference, pages 6086–6093,
Marseille, France. European Language Re-
sources Association.
Liangming Pan, Wenhu Chen, Wenhan Xiong,
Min-Yen Kan, and William Yang Wang. 2021.
Zero-shot fact verification by claim generation.
In Proceedings of the 59th Annual Meeting of
the Association for Computational Linguistics
and the 11th International Joint Conference
on Natural Language Processing, ACL/IJCNLP
2021, (Volume 2: Short Papers), Virtual Event,
August 1–6, 2021, pages 476–483. Association
for Computational Linguistics.
Ver´onica
P´erez-Rosas, Bennett Kleinberg,
Alexandra Lefevre, and Rada Mihalcea. 2018.
Automatic detection of fake news. In Procedi-
ings of the 27th International Conference on
Linguistica computazionale, pages 3391–3401,
Santa Fe, New Mexico, USA. Associazione per
Linguistica computazionale.
Fabio Petroni, Tim Rockt¨aschel, Sebastian Riedel,
Patrick Lewis, Anton Bakhtin, Yuxiang Wu,
and Alexander Miller. 2019. Language models
as knowledge bases? Negli Atti del 2019
Conference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
cessazione (EMNLP-IJCNLP), pages 2463–2473,
Hong Kong, China. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D19-1250
Adam Poliak,
Jason Naradowsky, Aparajita
Haldar, Rachel Rudinger, and Benjamin Van
Durme. 2018. Hypothesis only baselines in
language inference. Negli Atti
natural
of the Seventh Joint Conference on Lexical
and Computational Semantics, pages 180–191,
New Orleans, Louisiana. Association for Com-
Linguistica putazionale. https://doi.org
/10.18653/v1/S18-2023
Dean Pomerleau and Delip Rao. 2017. The fake
news challenge: Exploring how artificial in-
telligence technologies could be leveraged to
combat fake news. Fake News Challenge.
Kashyap Popat, Subhabrata Mukherjee, Jannik
Str¨otgen, and Gerhard Weikum. 2016. Credi-
bility assessment of textual claims on the web.
In Proceedings of the 25th ACM International
Conference on Information and Knowledge
Management, CIKM 2016, Indianapolis, IN,
USA, October 24–28, 2016, pages 2173–2178.
ACM. https://doi.org/10.1145/2983323
.2983661
Kashyap Popat, Subhabrata Mukherjee, Andrew
Yates, and Gerhard Weikum. 2018. DeClarE:
Debunking fake news and false claims using
evidence-aware deep learning. Negli Atti
del 2018 Conferenza sui metodi empirici
nell'elaborazione del linguaggio naturale, pages 22–32,
Brussels, Belgium. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D18-1003
Martin Potthast, Johannes Kiesel, Kevin Reinartz,
Janek Bevendorff, and Benno Stein. 2018.
A stylometric inquiry into hyperpartisan and
fake news. In Proceedings of the 56th Annual
Meeting of
the Association for Computa-
linguistica nazionale (Volume 1: Documenti lunghi),
pages 231–240, Melbourne, Australia. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/P18-1022
Danish Pruthi, Mansi Gupta, Bhuwan Dhingra,
Graham Neubig, and Zachary C. Lipton. 2020.
200
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Learning to deceive with attention-based
explanations. In Proceedings of the 58th An-
nual Meeting of the Association for Computa-
linguistica nazionale, pages 4782–4793, Online.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/2020
.acl-main.432
Vahed Qazvinian, Emily Rosengren, Dragomir R.
Radev, and Qiaozhu Mei. 2011. Rumor has it:
Identifying misinformation in microblogs. In
Atti del 2011 Conference on Empir-
ical Methods in Natural Language Processing,
pages 1589–1599, Edinburgh, Scotland, UK.
Associazione per la Linguistica Computazionale.
Alec Radford, Jeffrey Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI blog, 1(8):9.
Hannah Rashkin, Eunsol Choi, Jin Yea Jang,
Svitlana Volkova, and Yejin Choi. 2017. Truth
of varying shades: Analyzing language in fake
news and political fact-checking. In Procedi-
IL 2017 Conferenza sull'Empirico
ings di
Metodi nell'elaborazione del linguaggio naturale,
pages 2931–2937, Copenhagen, Denmark.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/D17
-1317
Miriam Redi, Besnik Fetahu,
Jonathan T.
Morgan, and Dario Taraborelli. 2019. Citation
Needed: A taxonomy and algorithmic as-
sessment of wikipedia’s verifiability. In The
World Wide Web Conference, WWW 2019,
San Francisco, CA, USA, May 13–17, 2019,
pages 1567–1578. ACM. https://doi.org
/10.1145/3308558.3313618
Jon Roozenbeek and Sander van der Linden.
2019. The fake news game: Actively inoculat-
ing against the risk of misinformation. Journal
of Risk Research, 22(5):570–580.
Jon Roozenbeek, Sander van der Linden, E
Thomas Nygren. 2020. Prebunking interven-
tions based on the psychological
theory of
‘‘inoculation’’ can reduce susceptibility to
misinformation across cultures. The Harvard
Kennedy School Misinformation Review, 1(2).
https://doi.org/10.1080/13669877
.2018.1443491
Arkadiy Saakyan, Tuhin Chakrabarty,
E
Smaranda Muresan. 2021. COVID-Fact: Fact
extraction and verification of real-world claims
on COVID-19 pandemic. Negli Atti del
59esima Assemblea Annuale dell'Associazione per
Computational Linguistics and the 11th Inter-
national Joint Conference on Natural Language
in lavorazione, ACL/IJCNLP 2021, (Volume 1:
Documenti lunghi), Virtual Event, August 1–6, 2021,
pages 2116–2129. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/2021.acl-long.165
Fatima K. Abu Salem, Roaa Al Feel, Shady
Elbassuoni, Mohamad Jaber, and May Farah.
2019. FA-KES: A fake news dataset around the
syrian war. In Proceedings of the Thirteenth
International Conference on Web and Social
Media, ICWSM 2019, Munich, Germany, Giugno
11–14, 2019, pages 573–582. AAAI Press.
Giovanni C. Santia and Jake Ryland Williams.
2018. BuzzFace: A news veracity dataset with
facebook user commentary and egos. Nel professionista-
ceedings of the Twelfth International Confer-
ence on Web and Social Media, ICWSM 2018,
Stanford, California, USA, June 25–28, 2018,
pages 531–540. AAAI Press.
Aalok Sathe, Salar Ather, Tuan Manh Le, Nathan
Perry, and Joonsuk Park. 2020. Automated
fact-checking of claims from wikipedia. Nel professionista-
ceedings of The 12th Language Resources and
Evaluation Conference, LREC 2020, Marseille,
France, May 11–16, 2020, pages 6874–6882.
European Language Resources Association.
Michael Sejr Schlichtkrull, Vladimir Karpukhin,
Barlas Oguz, Mike Lewis, Wen-tau Yih, E
Sebastian Riedel. 2021. Joint verification and
reranking for open fact checking over tables.
Negli Atti di
the 59th Annual Meet-
the Association for Computational
ing of
Linguistics and the 11th International Joint
Conferenza sull'elaborazione del linguaggio naturale
(Volume 1: Documenti lunghi), pages 6787–6799,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2021.acl-long.529
Tal Schuster, Adam Fisch, and Regina Barzilay.
2021. Get your Vitamin C! robust fact verifica-
tion with contrastive evidence. Negli Atti
del 2021 Conferenza del Nord America
Capitolo dell'Associazione per il calcolo
Linguistica: Tecnologie del linguaggio umano,
201
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
pages 624–643, Online. Association for Com-
Linguistica putazionale. https://doi.org
/10.18653/v1/2021.naacl-main.52
Online. Association for Computational Linguis-
tic. https://doi.org/10.18653/v1
/2021.acl-long.425
Tal
Schuster, Roei
Schuster, Darsh
J.
Shah, and Regina Barzilay. 2020. The limi-
tations of stylometry for detecting machine-
generated fake news. Linguistica computazionale,
46(2):499–510. https://doi.org/10.1162
/coli a 00380
Tal Schuster, Darsh Shah, Yun Jie Serene Yeo,
Daniel Roberto Filizzola Ortiz, Enrico Santus,
and Regina Barzilay. 2019. Towards debias-
ing fact verification models. Negli Atti
del 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 3419–3425, Hong Kong, China. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1341
Sofia Serrano and Noah A. Smith. 2019. Is at-
tention interpretable? Negli Atti del
57esima Assemblea Annuale dell'Associazione per
Linguistica computazionale, pages 2931–2951,
Florence, Italy. Associazione per il calcolo
Linguistica. https://doi.org/10.18653
/v1/P19-1282
Shaden Shaar, Nikolay Babulkov, Giovanni
Da San Martino, and Preslav Nakov. 2020. Quello
is a known lie: Detecting previously fact-
checked claims. In Proceedings of the 58th
Annual Meeting of the Association for Compu-
linguistica nazionale, pages 3607–3618, Online.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/2020
.acl-main.332
Gautam Kishore Shahi and Durgesh Nandini.
2020. FakeCovid – a multilingual cross-domain
fact check news dataset for covid-19. In Work-
shop Proceedings of
the 14th International
AAAI Conference on Web and Social Media.
Qiang Sheng, Juan Cao, Xueyao Zhang, Xirong
Li, and Lei Zhong. 2021. Article reranking
by memory-enhanced key sentence matching
for detecting previously fact-checked claims.
Negli Atti di
the 59th Annual Meet-
ing of
the Association for Computational
Linguistics and the 11th International Joint
Conferenza sull'elaborazione del linguaggio naturale
(Volume 1: Documenti lunghi), pages 5468–5481,
202
Baoxu Shi and Tim Weninger. 2016. Discrimi-
native predicate path mining for fact checking
in knowledge graphs. Knowledge Based Sys-
tems, 104:123–133. https://doi.org/10
.1016/j.knosys.2016.04.015
Prashant Shiralkar, Alessandro Flammini, Filippo
Menczer, and Giovanni Luca Ciampaglia. 2017.
Finding streams in knowledge graphs to support
fact checking. In 2017 IEEE International
Conference on Data Mining, ICDM 2017, Nuovo
Orleans, LA, USA, November 18–21, 2017,
pages 859–864.
IEEE Computer Society.
https://doi.org/10.1109/ICDM.2017
.105
Kai Shu, Limeng Cui, Suhang Wang, Dongwon
Lee, and Huan Liu. 2019. dEFEND: Explain-
able fake news detection. Negli Atti del
25th ACM SIGKDD International Conference
on Knowledge Discovery & Data Mining, KDD
2019, Anchorage, AK, USA, August 4–8, 2019,
pages 395–405. ACM. https://doi.org
/10.1145/3292500.3330935
Kai Shu, Deepak Mahudeswaran, Suhang Wang,
Dongwon Lee, and Huan Liu. 2020. FakeNews-
Net: A data repository with news content, social
context, and spatiotemporal
information for
studying fake news on social media. Big Data,
8(3):171–188. https://doi.org/10.1109
/ICDM.2017.105, PubMed: 32491943
Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang,
and Huan Liu. 2017. Fake news detection on so-
cial media: A data mining perspective. SIGKDD
Explorations, 19(1):22–36. https://doi
.org/10.1145/3137597.3137600
Craig Silverman. 2014. Verification Handbook:
An Ultimate Guideline on Digital Age Sourc-
ing for Emergency Coverage, European Jour-
nalism Centre.
Riccardo Socher, Danqi Chen, Christopher D.
Equipaggio, and Andrew Y. Di. 2013. Reasoning
with neural tensor networks for knowledge base
completion. In Advances in Neural Information
Processing Systems 26: 27th Annual Confer-
ence on Neural Information Processing Systems
2013. Proceedings of a meeting held December
5–8, 2013, Lake Tahoe, Nevada, stati Uniti,
pages 926–934.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Cass R. Sunstein and Adrian Vermeule. 2009.
Conspiracy theories: Causes and cures. Jour-
nal of Political Philosophy, 17(2):202–227.
https://doi.org/10.1111/j.1467
-9760.2008.00325.X
Negli Atti di
Kai Sheng Tai, Riccardo Socher, and Christopher
D. Equipaggio. 2015. Improved semantic repre-
sentations from tree-structured long short-term
IL
memory networks.
53rd Annual Meeting of
the Association
for Computational Linguistics and the 7th
International Joint Conference on Natural Lan-
guage Processing (Volume 1: Documenti lunghi),
pages 1556–1566, Beijing, China. Association
for Computational Linguistics.
Philip M. Taylor. 2003. Munitions of the mind: UN
history of propaganda from the ancient world
to the present era, 3rd edition. Manchester
Stampa universitaria.
James Thorne and Andreas Vlachos. 2018. Auto-
mated fact checking: Task formulations, meth-
ods and future directions. Negli Atti del
27th International Conference on Computa-
linguistica nazionale, pages 3346–3359, Santa Fe,
New Mexico, USA. Associazione per il calcolo-
linguistica nazionale.
James Thorne and Andreas Vlachos. 2021. Elastic
weight consolidation for better bias inocula-
zione. In Proceedings of the 16th Conference
of the European Chapter of the Association
for Computational Linguistics: Main Volume,
pages 957–964, Online. Association for Com-
Linguistica putazionale. https://doi.org
/10.18653/v1/2021.eacl-main.82
James Thorne, Andreas Vlachos, Christos
Christodoulopoulos, and Arpit Mittal. 2018UN.
FEVER: A large-scale dataset for fact ex-
traction and VERification. Negli Atti di
IL 2018 Conferenza del Nord America
Capitolo dell'Associazione per il calcolo
Linguistica: Tecnologie del linguaggio umano,
Volume 1 (Documenti lunghi), pages 809–819, Nuovo
Orleans, Louisiana. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/N18-1074
James Thorne, Andreas Vlachos, Oana Cocarascu,
Christos Christodoulopoulos, and Arpit Mittal.
2018B. The fact extraction and VERifica-
zione (FEVER) shared task. Negli Atti di
the First Workshop on Fact Extraction and
VERification (FEVER), pages 1–9, Brussels,
Belgium. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/W18-5501
James Thorne, Andreas Vlachos, Oana Cocarascu,
Christos Christodoulopoulos, and Arpit Mittal.
2019. The FEVER2.0 shared task. In Procedi-
ings of the Second Workshop on Fact Extrac-
tion and VERification (FEVER), pages 1–6,
Hong Kong, China. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D19-6601
Joshua A. Tucker, Andrew Guess, Pablo Barber´a,
Cristian Vaccari, Alexandra Siegel, Sergey
Sanovich, Denis Stukal, and Brendan Nyhan.
2018. Social media, political polarization, E
political disinformation: A review of the scien-
tific literature. Political Polarization, and Polit-
ical Disinformation: A Review of the Scientific
Letteratura (Marzo 19, 2018). https://doi
.org/10.2139/ssrn.3144139
Joseph E. Uscinski. 2015. The epistemology
of fact checking (is still na`ıve): Rejoinder
to amazeen. Critical Review, 27(2):243–252.
https://doi.org/10.1080/08913811
.2015.1055892
Joseph E. Uscinski and Ryden W. Butler. 2013.
The epistemology of fact checking. Critical
Review, 25(2):162–180.
Prasetya Ajie Utama, Nafise Sadat Moosavi, E
Iryna Gurevych. 2020UN. Mind the trade-off:
Debiasing NLU models without degrading
the in-distribution performance. In Procedi-
IL
ings di
Associazione per la Linguistica Computazionale,
pages 8717–8729, Online. Associazione per
Linguistica computazionale.
the 58th Annual Meeting of
Prasetya Ajie Utama, Nafise Sadat Moosavi,
and Iryna Gurevych. 2020B. Towards debi-
asing NLU models from unknown biases.
IL 2020 Conference on
Negli Atti di
Empirical Methods in Natural Language Pro-
cessazione (EMNLP), pages 7597–7610, Online.
Associazione per la Linguistica Computazionale.
Sander van der Linden, Anthony Leiserowitz,
Seth Rosenthal, and Edward Maibach. 2017.
Inoculating the public against misinforma-
tion about climate change. Global Challenges,
1(2):1600008. https://doi.org/10.1002
/gch2.201600008, PubMed: 31565263
203
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Andreas Vlachos and Sebastian Riedel. 2014.
Fact checking: Task definition and dataset con-
struction. Negli Atti di
the ACL 2014
Workshop on Language Technologies and
Computational Social Science, pages 18–22,
Baltimore, MD, USA. Association for Compu-
linguistica nazionale. https://doi.org/10
.3115/v1/W14-2508
Andreas Vlachos and Sebastian Riedel. 2015.
Identification and verification of
simple
claims about statistical properties. In Procedi-
ings di
IL 2015 Conferenza sull'Empirico
Metodi nell'elaborazione del linguaggio naturale,
pages 2596–2601, Lisbon, Portugal. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D15-1312
Nguyen Vo and Kyumin Lee. 2020. Where are
the facts? searching for fact-checked infor-
mation to alleviate the spread of fake news.
IL 2020 Conference on
Negli Atti di
Empirical Methods in Natural Language Pro-
cessazione (EMNLP), pages 7717–7731, Online.
Associazione per la Linguistica Computazionale.
Svitlana Volkova, Kyle Shaffer, Jin Yea Jang,
and Nathan Hodas. 2017. Separating facts from
fiction: Linguistic models to classify suspi-
cious and trusted news posts on Twitter. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(Volume 2: Short Papers), pages 647–653,
Vancouver, Canada. Association for Compu-
linguistica nazionale. https://doi.org/10
.18653/v1/P17-2102
David Wadden, Shanchuan Lin, Kyle Lo, Lucy
Lu Wang, Madeleine van Zuylen, Arman
Cohan, and Hannaneh Hajishirzi. 2020. Fact
or Fiction: Verifying scientific claims. Nel professionista-
ceedings of the 2020 Conferenza sull'Empirico
Metodi nell'elaborazione del linguaggio naturale
(EMNLP), pages 7534–7550, Online. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/2020.emnlp-main
.609
Nancy Xin Ru Wang, Diwakar Mahajan,
Marina Danilevsky, and Sara Rosenthal. 2021.
SemEval-2021 task 9: Fact verification and
evidence finding for tabular data in scientific
documents (SEM-TAB-FACTS). In Procedi-
ings of the 15th International Workshop on
Semantic Evaluation, SemEval@ACL/IJCNLP
2021, Virtual Event
/ Bangkok, Thailand,
agosto 5-6, 2021, pages 317–326. Association
for Computational Linguistics.
William Yang Wang. 2017. ‘‘Liar, Liar Pants
on Fire’’: A new benchmark dataset for fake
news detection. In Proceedings of the 55th
Annual Meeting of the Association for Compu-
linguistica nazionale (Volume 2: Short Papers),
pages 422–426, Vancouver, Canada. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/P17-2067
Sarah Wiegreffe and Yuval Pinter. 2019. Atten-
tion is not not explanation. Negli Atti di
IL 2019 Conference on Empirical Methods in
Natural Language Processing and the 9th Inter-
national Joint Conference on Natural Language
in lavorazione (EMNLP-IJCNLP), pages 11–20,
Hong Kong, China. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D19-1002
Adina Williams, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through
inference. Negli Atti del 2018 Contro-
ference of
the North American Chapter of
the Association for Computational Linguis-
tic: Tecnologie del linguaggio umano, Volume 1
(Documenti lunghi), pages 1112–1122, New Orleans,
Louisiana. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/N18-1101
Lianwei Wu, Yuan Rao, Xiong Yang,
Wanzhen Wang, and Ambreen Nazir. 2020UN.
Evidence-aware hierarchical interactive atten-
tion networks for explainable claim verification.
Christian Bessiere, editor, Negli Atti di
the Twenty-Ninth International Joint Con-
ference on Artificial Intelligence, IJCAI-20,
pages 1388–1394. International Joint Confer-
ences on Artificial Intelligence Organization.
Lianwei Wu, Yuan Rao, Yongqiang Zhao, Hao
Liang, and Ambreen Nazir. 2020B. DTCA:
Decision tree-based co-attention networks for
explainable claim verification. In Procedi-
IL
ings di
Associazione per la Linguistica Computazionale,
pages 1024–1035, Online. Associazione per
Linguistica computazionale.
the 58th Annual Meeting of
Fan Yang, Shiva K. Pentyala, Sina Mohseni,
Mengnan Du, Hao Yuan, Rhema Linder,
204
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Eric D. Ragan, Shuiwang Ji, and Xia (Ben)
Eh. 2019. XFake: Explainable fake news
detector with visualizations. In The World
Wide Web Conference, WWW 2019, San
Francesco, CA, USA, May 13–17, 2019,
pages 3600–3604. ACM. https://doi
.org/10.1145/3308558.3314119
Xiaoyu Yang, Yuefei Lyu, Tian Tian, Yifei Liu,
Yudong Liu, and Xi Zhang. 2020UN. Rumor
detection on social media with graph struc-
tured adversarial learning. Christian Bessiere,
the Twenty-Ninth
editor, Negli Atti di
Conferenza congiunta internazionale sull'artificiale
Intelligenza, IJCAI 2020, pages 1417–1423.
ijcai.org. https://doi.org/10.24963
/ijcai.2020/197
Xiaoyu Yang, Feng Nie, Yufei Feng, Quan
Liu, Zhigang Chen, and Xiaodan Zhu. 2020B.
Program enhanced fact verification with
verbalization and graph attention network.
Negli Atti di
IL 2020 Conference on
Empirical Methods in Natural Language Pro-
cessazione (EMNLP), pages 7810–7825, Online.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/2020
.emnlp-main.628
Inouye,
Chih-Kuan Yeh, Cheng-Yu Hsieh, Arun Sai
Suggala, David I.
and Pradeep
Ravikumar. 2019. On the (In)fidelity and sensi-
tivity of explanations. In Advances in Neu-
ral Information Processing Systems 32: Annual
Conference on Neural Information Process-
ing Systems 2019, NeurIPS 2019, Decem-
ber 8–14, 2019, Vancouver, BC, Canada,
pages 10965–10976.
Wenpeng Yin and Dan Roth. 2018. TwoWingOS:
A two-wing optimization strategy for eviden-
tial claim verification. Negli Atti del
2018 Conference on Empirical Methods in Nat-
elaborazione del linguaggio urale, Brussels, Belgium,
ottobre 31 – novembre 4, 2018, pages 105–114.
Associazione per la Linguistica Computazionale.
Takuma Yoneda, Jeff Mitchell, Johannes Welbl,
Pontus Stenetorp, and Sebastian Riedel. 2018.
UCL machine reading group: Four factor frame-
work for fact finding (HexaF). Negli Atti
the First Workshop on Fact Extraction
Di
and VERification (FEVER), pages 97–102,
Brussels, Belgium. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/W18-5515
Mo Yu, Shiyu Chang, Yang Zhang, and Tommi
Jaakkola. 2019. Rethinking cooperative ratio-
nalization: Introspective extraction and com-
plement control. Negli Atti del 2019
Conference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
cessazione (EMNLP-IJCNLP), pages 4094–4103,
Hong Kong, China. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D19-1420
Negli Atti di
Naomi Zeichner, Jonathan Berant, and Ido Dagan.
2012. Crowdsourcing inference-rule evalua-
the 50th Annual
zione.
Meeting of
the Association for Computa-
linguistica nazionale (Volume 2: Short Papers),
pages 156–160, Jeju Island, Korea. Association
for Computational Linguistics.
Rowan Zellers, Ari Holtzman, Hannah Rashkin,
Yonatan Bisk, Ali Farhadi, Franziska Roesner,
and Yejin Choi. 2019. Defending against neural
fake news. In Advances in Neural Information
Processing Systems 32: Annual Conference
on Neural
Information Processing Systems
2019, NeurIPS 2019, December 8–14, 2019,
Vancouver, BC, Canada, pages 9051–9062.
Daniel Yue Zhang, Lanyu Shang, Biao Geng,
Shuyue Lai, Ke Li, Hongmin Zhu, Md. Tanvir
Al Amin, and Dong Wang. 2018. FauxBuster:
A content-free fauxtography detector using so-
cial media comments. In IEEE International
Conference on Big Data, Big Data 2018,
Seattle, WA, USA, December 10–13, 2018,
pages 891–900. IEEE.
Wenxuan Zhang, Yang Deng, Jing Ma, and Wai
Lam. 2020. AnswerFact: Fact checking in prod-
uct question answering. Negli Atti di
IL 2020 Conferenza sui metodi empirici
nell'elaborazione del linguaggio naturale (EMNLP),
pages 2407–2417, Online. Associazione per
Linguistica computazionale.
Xueyao Zhang, Juan Cao, Xirong Li, Qiang
Sheng, Lei Zhong, and Kai Shu. 2021. Mining
dual emotion for
In
WWW ’21: The Web Conference 2021, Virtual
fake news detection.
205
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Event / Ljubljana, Slovenia, April 19–23, 2021,
pages 3465–3476. ACM / IW3C2. https://
doi.org/10.1145/3442381.3450004
the 57th Annual Meeting of
Yi Zhang, Zachary Ives, and Dan Roth. 2019.
Evidence-based trustworthiness. In Procedi-
ings di
IL
Associazione per la Linguistica Computazionale,
pages 413–423, Florence, Italy. Associazione per
Linguistica computazionale. https://doi
.org/10.18653/v1/P19-1040
Wanjun Zhong, Duyu Tang, Zhangyin Feng,
Nan Duan, MingZhou, Ming Gong, Linjun
Shou, Daxin Jiang, Jiahai Wang, and Jian
Yin. 2020UN. LogicalFactChecker: Leveraging
fact checking with
for
logical operations
graph module network. Negli Atti del
58esima Assemblea Annuale dell'Associazione per
Linguistica computazionale, pages 6053–6065,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2020.acl-main.539
Wanjun Zhong, Jingjing Xu, Duyu Tang, Zenan
Xu, Nan Duan, MingZhou, Jiahai Wang, E
Jian Yin. 2020B. Reasoning over semantic-level
graph for fact checking. Negli Atti del
58esima Assemblea Annuale dell'Associazione per
Linguistica computazionale, pages 6170–6180,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2020.acl-main.549
Jie Zhou, Xu Han, Cheng Yang, Zhiyuan Liu,
Lifeng Wang, Changcheng Li, and Maosong
Sun. 2019. GEAR: Graph-based evidence
fact verifi-
aggregating and reasoning for
catione. Negli Atti di
the 57th Annual
Riunione dell'Associazione per il Computazionale
Linguistica, pages 892–901, Florence, Italy.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/P19
-1085
Xinyi Zhou, Atishay Jain, Vir V. Phoha, and Reza
Zafarani, New York, NY, USA. 2020. Fake
news early detection: A theory-driven model.
Digital Threats: Research and Practice, 1(2).
https://doi.org/10.1145/3377478
Xinyi Zhou and Reza Zafarani. 2020. A survey
of fake news: Fundamental theories, detection
metodi, and opportunities. Calcolo ACM
Sondaggi, 53(5):109:1–109:40. https://doi
.org/10.1145/3395046
Dimitrina Zlatkova, Preslav Nakov, and Ivan
Koychev. 2019. Fact-checking meets fauxtog-
raphy: Verifying claims about images. Nel professionista-
ceedings of the 2019 Conferenza sull'Empirico
Methods in Natural Language Processing and
the 9th International Joint Conference on Nat-
elaborazione del linguaggio urale (EMNLP-IJCNLP),
pages 2099–2108, Hong Kong, China. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1216
Arkaitz Zubiaga, Ahmet Aker, Kalina Bontcheva,
Maria Liakata, and Rob Procter. 2018. De-
tection and resolution of rumors in social
media: A survey. ACM Computing Surveys,
51(2):32:1–32:36. https://doi.org/10
.1145/3161603
Arkaitz Zubiaga, Maria Liakata, Rob Procter,
Geraldine Wong Sak Hoi, and Peter Tolmie.
2016. Analysing how people orient
to and
spread rumors in social media by looking at con-
versational threads. PloS One, 11(3):e0150989.
https://doi.org/10.1371/journal
.pone.0150989, PubMed: 26943909
Chaoyuan Zuo, Ayla Karakas, and Ritwik
Banerjee. 2018. A hybrid recognition system
for check-worthy claims using heuristics and
supervised learning. In Working Notes of CLEF
2018 – Conference and Labs of the Evaluation
Forum, Avignon, France, September 10–14,
2018, volume 2125 of CEUR Workshop Pro-
ceedings. CEUR-WS.org.
206
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
4
5
4
1
9
8
7
0
1
8
/
/
T
l
UN
C
_
UN
_
0
0
4
5
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3