REVIEW
Communicated by Fernando Perez-Peña
Advancements in Algorithms and Neuromorphic
Hardware for Spiking Neural Networks
Amirhossein Javanshir
a.javanshir@deakin.edu.au
School of Engineering, Deakin University, Geelong, VIC 3216, Australia
Thanh Thi Nguyen
thanh.nguyen@deakin.edu.au
School of Information Technology, Deakin University (Burwood Campus)
Burwood, VIC 3125, Australia
M.. UN. Parvez Mahmud
m.a.mahmud@deakin.edu.au
Abbas Z. Kouzani
abbas.kouzani@deakin.edu.au
School of Engineering, Deakin University, Geelong, VIC 3216, Australia
Artificial neural networks (ANNs) have experienced a rapid advancement
for their success in various application domains, including autonomous
driving and drone vision. Researchers have been improving the perfor-
mance efficiency and computational requirement of ANNs inspired by
the mechanisms of the biological brain. Spiking neural networks (SNNs)
provide a power-efficient and brain-inspired computing paradigm for
machine learning applications. Cependant, evaluating large-scale SNNs on
classical von Neumann architectures (central processing units/graphics
processing units) demands a high amount of power and time. Donc,
hardware designers have developed neuromorphic platforms to execute
SNNs in and approach that combines fast processing and low power con-
sumption. Recently, field-programmable gate arrays (FPGAs) have been
considered promising candidates for implementing neuromorphic solu-
tions due to their varied advantages, such as higher flexibility, shorter de-
sign, and excellent stability. This review aims to describe recent advances
in SNNs and the neuromorphic hardware platforms (digital, analog, hy-
brid, and FPGA based) suitable for their implementation. We present
that biological background of SNN learning, such as neuron models and
information encoding techniques, followed by a categorization of SNN
entraînement. En outre, we describe state-of-the-art SNN simulators. Fur-
thermore, we review and present FPGA-based hardware implementation
of SNNs. Enfin, we discuss some future directions for research in this
field.
Neural Computation 34, 1289–1328 (2022) © 2022 Massachusetts Institute of Technology
https://doi.org/10.1162/neco_a_01499
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1290
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
1 Introduction
Au cours des dernières années, artificial neural networks (ANNs) have become the best-
known approach in artificial intelligence (AI) and have achieved superb
performance in various domains, such as computer vision (Abiodun et al.,
2018), automotive control (Kuutti, Fallah, & Bowden, 2020), flight control
(Gu, Valavanis, Rutherford, & Rizzo, 2019), and medical systems (Shahid,
Rappon, & Berta, 2019). Taking inspiration from the brain, the third gener-
ation of neural networks, known as spiking neural networks (SNNs), a
been developed to bridge the gap between machine learning and neuro-
science (Maass, 1997). Unlike ANNs that process data values, SNNs use dis-
crete events (or spikes) to encode and process data, which makes them more
energy efficient and more computationally powerful than ANNs (Jang,
Simeone, Gardner, & Gruning, 2019).
SNNs and ANNs are different in terms of their neuron models. ANNs
typically use computation units, such as sigmoid, rectified linear unit
(ReLU), or tanh and have no memory, whereas SNNs use a nondifferen-
tiable neuron model and have memory, such as leaky integrate-and-fire
(LIF). Cependant, simulation of large-scale SNN models on classical von
Neumann architectures (central processing units (CPUs)/graphics process-
ing units (GPUs)) demands a large amount of time and power. Donc,
high-speed and low-power hardware implementation of SNNs is essential.
Neuromorphic platforms, which are based on event-driven computation,
provide an attractive solution to these problems. Thanks to neuromorphic
hardware benefits, SNNs have become applicable to emerging domains,
such as the Internet of Things and edge computing (Mead, 1990; Calimera,
Macii, & Poncino, 2013).
Neuromorphic hardware can be divided into analog, digital, and mixed-
mode (analog/digital) conception. Although analog implementation offers
small area and low power consumption, digital implementation is more
flexible and less costly for processing large-scale SNN models (Indiveri
et autres. 2011; Seo & Seok, 2015). Field-programmable gate arrays (FPGAs)
have been considered a suitable candidate for implementing digital neu-
romorphic platforms. Compared to ASICs, FPGAs offer shorter design and
implementation time and excellent stability (Perez-Peña, Cifredo-Chacon,
& Quiros-Olozabal, 2020). There have been several attempts to implement
SNNs on single FPGA devices, which demonstrate promising speed-up
compared to CPU implementation and lower power consumption com-
pared to GPU implementation (Ju, Fang, Yan, R., Xu, & Tang, 2020; Zhang
et autres. 2020).
Dans cette revue, we introduce recent progress in spiking neural net-
works and neuromorphic hardware platforms suitable for their implemen-
tation. Section 2 introduces the SNNs’ operation and typical spiking neuron
and encoding schemes. Section 3 discusses the learning algorithms for
SNNs, including unsupervised, supervised, and conversion approaches.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1291
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
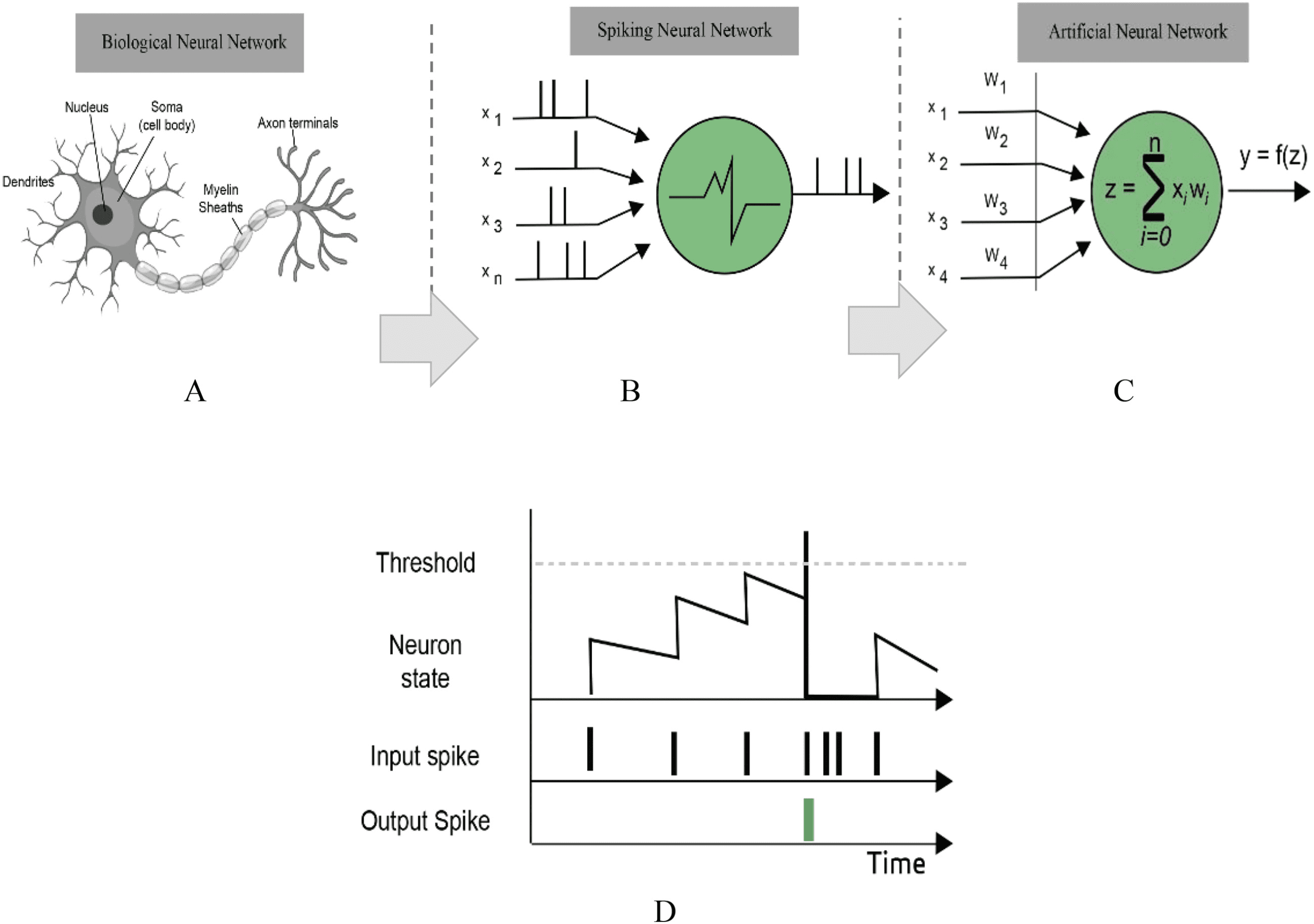
Chiffre 1: Schematic of a biological neural network, spiking neural network,
artificial neural network, and behavior of a leaky-integrate-and-fire spiking
neuron.
Performance comparison of the hardware and software implementations of
SNNs is given in section 5. In section 6, major challenges and future perspec-
tives of spiking neural networks and their neuromorphic implementations
are given. Section 7 concludes.
2 Spiking Neural Networks
Spiking neural networks, considered the third generation of neural net-
travaux (Maass, 1997), communicate by sequences of spikes, discrete events
that take place at points in time, as depicted in Figure 1. SNNs have been
widely used in numerous applications, including the brain-machine inter-
face (Mashford, Yepes, Kiral-Kornek, Tang, & Harrer, 2017), machine con-
trol and navigation systems (Tang & Michmizos, 2018), speech recognition
(Dominguez-Morales et al. 2018), event detection (Osswald, Ieng, Benos-
man, & Indiveri, 2017), forecasting (Lisitsa & Zhilenkov, 2017), fast signal
traitement (Simeone, 2018), decision making (Wei, Bu, & Dai, 2017), et
classification problems (Dora, Subramanien, Suresh, & Sundararajan, 2016).
They have increasingly received attention as powerful computational plat-
forms that can be implemented in software or hardware. Tableau 1 shows the
differences between SNNs and ANNs in terms of neuron, topology, et
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1292
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Tableau 1: Comparison between SNNs and ANNs.
Spiking Neural Network
Artificial Neural Network
Neurone
Spiking neuron (par exemple., integrate and
Artificial neuron (sigmoid,
fire, Hodgkin-Huxley, Izhikevich)
ReLU, tanh)
Information
Spike trains
representation
Scalars
Computation
Differential equations
Activation function
mode
Topology
LSM, Hopfield Network, RSNN,
RNN, CNN, LSTM, DBN,
SCNN
DNC
Features
Real-time, low power, online
Online learning,
learning, hardware friendly,
biological close, fast and
massively parallel data processing
computation intensive,
moderate parallelization
of computations
their features. A spiking neuron has a similar structure as an ANN neuron
but different behavior. There are various spiking neuron models.
2.1 Spiking Neuron Model. A spiking neuron has a similar structure
to that of an ANN neuron but shows different behavior. Over time, many
different neuron models have developed in the literature, such as Hodgkin-
Huxley (HH), Izhikevich, leaky integrate-and-fire (LIF), and spike response
models. These models differ not only on which biological characteristics of
real neurons they can reproduce but also based on their computational com-
plexity. Dans cette section, we review four popular and representative neuron
models that are widely used in the literature in terms of their biological
plausibility, the neuronal properties or behaviors that can be exhibited by
each model and computational efficiency, and the number of floating-point
operations needed to accomplish 1 millisecond (ms) of model simulation.
2.1.1 Hodgkin-Huxley Model. The HH model is the first biological model
of a spiking neuron that describes how action potentials in the neuron are
initiated and propagated (Hodgkin & Huxley, 1952). It shows the math-
ematical description of electric current through the membrane potential,
which can be calculated as
I = C
dv
dt
+ GNam3h(V − VNa) + Gkn4(V − Vk) + GL(V − VL),
(2.1)
where I is the external current, C is the capacitance of the circuit; VNa, Vk and
VL are called reverse potentials; and GNa, Gk, and GL are parameters model-
ing conductance of sodium, potassium, and leakage channels, respectivement.
Gating parameters n controls the potassium channel, while m and h control
the sodium channel. These parameters are determined by equations 2.2, 2.3,
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
et 2.4, respectivement:
dm
dt
dn
dt
dh
dt
= αm(V )(1 − m) − βm(v )m
= αn(V )(1 − n) − βn(v )n
= α
h(V )(1 − h) − β
h(v )h.
1293
(2.2)
(2.3)
(2.4)
The HH model, the most biologically plausible spiking neuron model,
accurately capture the dynamics of many real neurons (Gerstner & Kistler
2002). Cependant, it is too computationally expensive due to the feedback
loop initiated and the differential equations for n, m, and h to be calcu-
lated continuously. De plus, the Hodgkin-Huxley model requires about
1200 floating-point computations (FLOPS) par 1 ms of simulation (Paugam-
Moisy & Bohte, 2012). Donc, this model is less suitable for com-
putational intelligence applications, such as large-scale neural network
simulations.
2.1.2 Izhikevich Model. This biologically plausible spiking neuron model
was proposed by Izhikevich (2003). This two-dimensional model can repro-
duce a large variety of spiking dynamics (Izhikevich, 2004). The model can
be described mathematically as
= 0.04υ2 + 5υ + 140 − u + je(t),
dv (t)
dt
du(t)
dt
ème) = c and u(υ > υ
υ(υ > υ
= a(bυ − u),
ème) = u + d.
(2.5)
(2.6)
(2.7)
Izhikevich is a 2D spiking neural model that offers a good trade-off be-
tween biological plausibility and computational efficiency. It can produce
various spiking dynamics and requires 13 FLOPS per 1 ms of simulation
(Paugam-Moisy & Bohte, 2012). Izhikevich is a suitable model for simula-
tion or implementation of spiking neural networks, such as hippocampus
simulation and engineering problems.
2.1.3 Integrate-and-Fire Model. Integrate-and-fire (IF), one of the simple
models, integrates input spikes to membrane potential; if it reaches the
defined threshold, an output spike is generated, and membrane potential
changes to a resting state. (Gerstner, Kistler, Naud, & Paninski, 2014; Gerst-
ner & Kistler, 2002). This model can be determined by
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1294
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Cm
dv
dt
= I(t), ν ← vrest when ν ≥ ν
ème
,
(2.8)
where Cm is the membrane capacitance, ν
th is the threshold, ν is the mem-
brane potential, and vrest is the resting potential. This model is the lowest one
in terms of computational power consumption. In a machine learning con-
text, spiking neurons are most often based on this simple model, which is
prevalent for digital hardware implementations (Nitzsche, Pachideh, Luhn,
& Becker, 2021). The leaky integrate-and-fire model, an important type of IF
neuron model, adds a leak to the membrane potential. This model is defined
by the following equation,
τ
leak
dv
dt
= [υ(t) − υrest] + rmI(t), υ ← υrest when υ ≥ υ
ème
,
(2.9)
leak
= rmcm is the membrane time constant and rm is the membrane
where τ
resistance. The LIF model is one of the widely used spiking neuron mod-
els because of its very low computational cost (it requires only five FLOPS;
Izhikevich, 2004), its accuracy in terms of replicating the spiking behavior
of biological neurons, and its speed in simulating (Brette et al., 2007; Maass,
1997). Donc, it is particularly attractive for large-scale network simu-
lation (Aamir et al., 2018; Benjamin et al., 2014; Merolla et al., 2014). Le
LIF model is very popular for analog hardware implementations since the
neuron’s integration and decay dynamics can easily be modeled by the be-
havior of subthreshold transistors and capacitors (Aamir et al., 2018).
There are also more complex types of IF model such as exponential
integrate-and-fire, quadratic integrate-and-fire, and adaptive exponential
integrate-and-fire (Borst & Theunissen, 1999).
2.1.4 Spike Response Model. The spike response model (SRM) is a bio-
inspired spiking neuron that describes more precisely the effect of input
spikes on the membrane potential. Similar to the LIF model, an SRM neu-
ron generates spikes whenever its internal membrane potential reaches the
threshold (Gerstner & Kistler, 2002). Cependant, in contrast to LIF, it includes
a function dependent on reset and refractory periods. De plus, unlike the
LIF model that uses differential equations for the voltage potential, the SRM
is formulated using response kernels (filters). The SRM model mathemati-
cal formulation is expressed as
υ(t) = η(t − ˆt) +
(cid:2) +∞
−∞
κ (t − ˆt, s) je(t − s)ds,
(2.10)
where υ(t) is the neuron’s internal potential, ˆt is the emission time of the
last neuron output spike, η describes the state of the action potential, κ is
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1295
a linear response to an input spike, et moi(t) represents the stimulating or
external current.
The 1D spike response model is simpler than other models on the level
of the spike generation mechanism. It offers low computational cost, as it
requires 50 computations (FLOPS) par 1 ms simulation. Cependant, it pro-
vides poor biological plausibility compared with the Hodgkin and Hux-
ley model (Paugam-Moisy, 2006). This model is computationally complex
when used in digital systems. Cependant, the equations that define it can be
modeled by analog circuits since the postsynaptic potential function can be
seen as charging and discharging RC circuits (Iakymchuk, Rosado-Muñoz,
Guerrero-Martínez, Bataller-Mompeán, & Francés-Víllora, 2015).
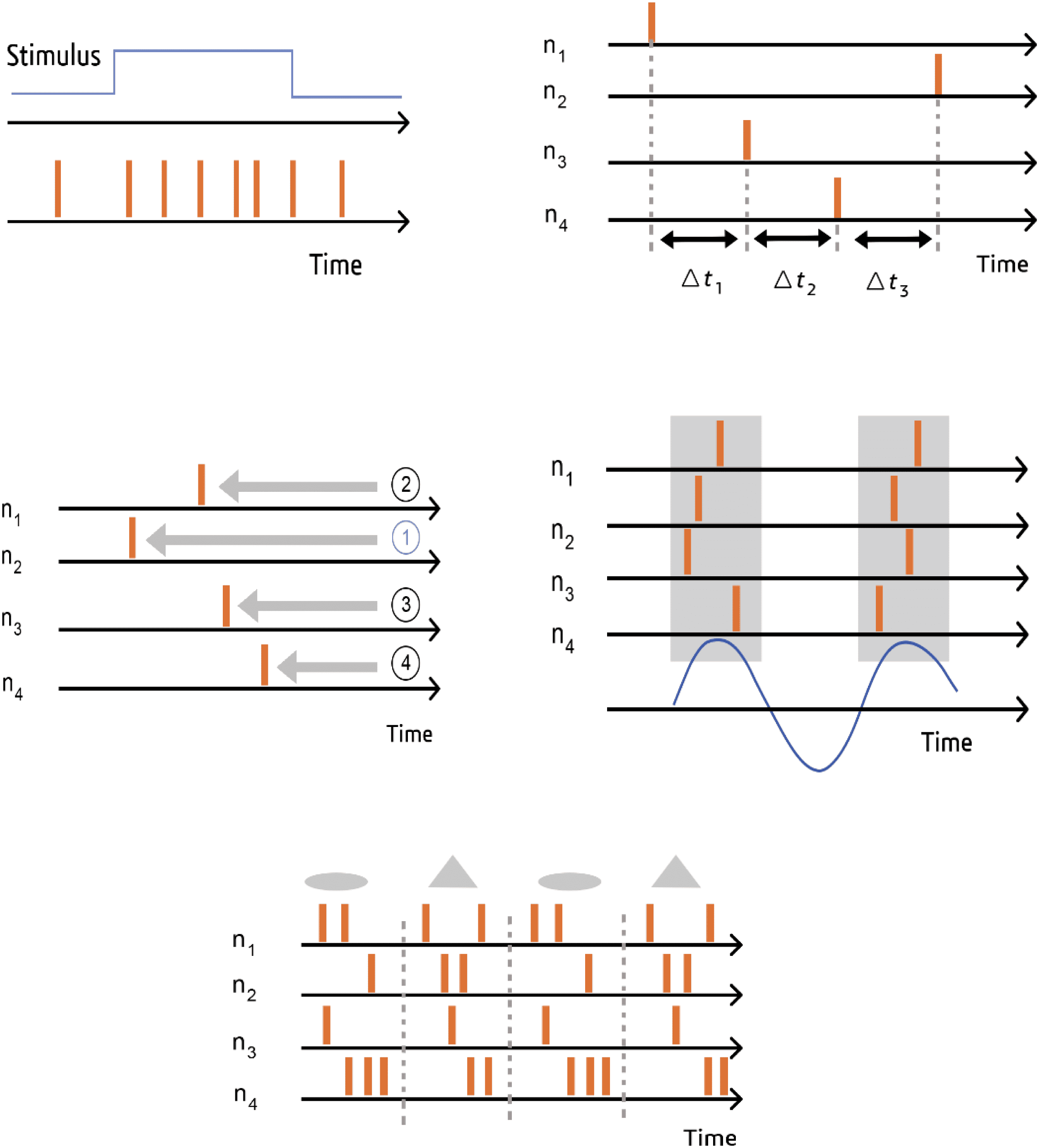
3 Information Coding
Neural coding is still a high-impact research domain for both neuroscien-
tists and computational artificial intelligence researchers (Borst & Theunis-
sen, 1999) Neurons use spikes to communicate with each other in SNN
architectures. Donc, frame-based images and feature vectors need to be
encoded to spike trains, a process called an encoding scheme. This scheme
has a significant influence on the performance of the network. Choosing
the optimal coding approaches is related to the choice of the neuron model,
application target, and hardware constraints (Thiele, 2019). Rate encod-
ing and temporal encoding are the two main encoding schemes (Kiselev,
2016).
Rate coding or frequency coding is one of the most used approaches
to encode information in SNNs where information is conveyed in the fir-
ing rate. Temporal coding is another efficient coding approach for SNNs,
where information is conveyed in the exact timing of spikes (Brette, 2015).
Temporal coding is normally used for time series processing. Various ap-
proaches are used to generate spikes based on temporal coding, tel que
latency code, rank-order coding (ROC), phase coding, and population cod-
ing. In latency coding, information is encoded in the timing of response
related to the encoding window (Fontaine & Peremans, 2009). Rank-order
coding strategies depend on the order of spike arrivals rather than on the
exact timing (Thorpe, Delorme, & Van Rullen, 2001). Compared to rate cod-
ing, ROC is able to bring more information with fewer spikes. Cependant,
it is sensitive to noise. The phase coding strategy encodes information in
the phase of a pulse according to the background oscillations. This method
has been used in robotic navigation and olfactory systems (Kayser, Mon-
temurro, Logothetis, & Panzeri, 2009). In the population coding method,
several neurons are used to encode one value. Sparse code is one of the ex-
amples of the population coding scheme (Wu, Amari, & Nakahara, 2002;
Tkaˇcik, Prentice, Balasubramanian, & Schneidman, 2010). An example of
spike-based information coding strategies is presented in Figure 2.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1296
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: Spike-based information coding strategies, rate coding, latency cod-
, . . . , n4 are labels of
ing, rank coding, phase coding, and population coding. n1
neurons; (cid:9)t is the relative timing of spikes; and the numbers in the circles shows
the order of spike arrival.
4 Algorithms for SNNs
Learning in a spiking neural network is an arduous task. Backpropagation-
based gradient descent learning is a very successful method in traditional
artificial neural networks; cependant, training SNNs is difficult due to the
nondifferentiable nature of spike events. Par conséquent, considerable research
effort has been mobilized to develop suitable learning algorithms that can
Advancements in Spiking Neural Networks
1297
be applied to multilayer SNNs, which are thus interesting for deep learning.
There are four main strategies for training SNNs: unsupervised learning,
supervised learning, conversion from trained ANNs, and evolutionary al-
gorithm. These strategies are briefly reviewed in the following subsections.
4.1 Unsupervised Learning. Unsupervised learning is the process of
learning without preexisting labels. Unsupervised learning of SNNs is
based on the Hebbian rule that consists of adapting the network’s synaptic
connections to the data received by the neurons (Caporale & Dan, 2008). Le
spike-timing-dependent plasticity (STDP) algorithm is an implementation
of Hebb’s rule. STDP is a phenomenon observed in the brain and describes
how the efficacy of a synapse changes as a function of the relative timing
of presynaptic and postsynaptic spikes. A presynaptic spike in this context
is the spike arriving at the synapse of the neuron. The postsynaptic spike
is the spike emitted by the neuron itself (Markram, Gerstner, & Sjöström,
2011). The mechanism of STDP is based on the concept that the synapses
that are likely to have contributed to the firing of the neuron should be re-
inforced. De la même manière, the synapses that did not contribute or contributed in a
negative way should be weakened (Dan & Poo, 2006).
STDP is frequently used as part of the learning technique in unsuper-
vised learning in SNNs. According to STDP, a synaptic weight is strength-
ened if a presynaptic neuron fires shortly before the postsynaptic neuron.
Similar to that, the synaptic weight is weakened if the presynaptic spike
comes briefly after the postsynaptic neuron (Xu et al. 2020). The most ob-
served STDP rule is described by equation 4.1:
(cid:4)
(cid:5)
(cid:3)
+A+ exp
(cid:9)w =
−A− exp
(cid:9)t = tpost − tpre,
−(cid:9)t
τ
+(cid:9)t
τ
(cid:4)
(cid:5)
si (cid:9)t > 0
si (cid:9)t ≤ 0
(4.1)
(4.2)
where w is the synaptic weights, τ is the time constant, and A+ and A− are
constant parameters indicating the strength of potentiation and depression.
Au cours des dernières années, significant research efforts have been focused on train-
ing SNNs using STDP. Qu, Zhao, Wang, and Wang (2020) developed
two novel hardware-friendly methods, lateral inhibition and homeostasis,
which reduce the number of inhibitory connections that lead to lowering the
hardware overhead. An STDP rule was used to adapt the synapse weight
between input and the learning layer and achieved 92% reconnaissance
accuracy on the MNIST data set. Xu et al. (2020) proposed a hybrid learn-
ing framework, named deep CovDenseSNN, that combines the biological
plausibility of SNNs and feature extraction of CNNs. An unsupervised
STDP learning rule was used to update the parameters of their proposed
deep CovDenseSNN model, which is suitable for neuromorphic hard-
ware implementation. Supervised learning and reinforcement learning are
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1298
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
other types of STDP methods for learning (Mozafari, Ganjtabesh, Nowzari-
Dalini, Thorpe, & Masquelier, 2018; Mozafari, Kheradpisheh, Masquelier,
Nowzari-Dalini, & Ganjtabesh, 2018).
Lee, Panda, Srinivasan, and Roy (2018) proposed a semisupervised
strategy to train a convolutional SNN with multiple hidden layers. Le
training scheme had two steps: initializing the weights of the network
by unsupervised learning (namely, SSTDP), and then employing the su-
pervised gradient descent backpropagation (BP) algorithm to fine-tune
the synaptic weight. Pretraining approaches led to better generalization,
faster training time, et 99.28% accuracy on the MNIST database. Tavanaei,
Kirby, and Maida (2018) developed a novel method to train multilayer spik-
ing convolutional neural networks (SCNNs). The training process includes
unsupervised (a novel STDP learning scheme for feature extraction) and su-
pervised (a supervised learning scheme to train spiking CNNs (ConvNets))
components.
4.2 Supervised Learning. One of the first algorithms to train SNNs
using backpropagation errors is SpikeProp, proposed by Bohte, Kok,
and La Poutre (2002). This model is applied successfully to classification
problems using a three-layer architecture. A later advanced version of
SpikeProp called spike train SpikeProp (ST-SpikeProp) used the weight up-
dating rule of the output layer to train the single-layer SNNs (Xu, Zeng,
Han, & Lequel, 2013). In order to solve the nondifferentiable problem of
SNNs, Wu et al. (2018). Proposed the spatiotemporal backpropagation
(STBP) algorithme, which combines the timing-dependent temporal domain
and the layer-by-layer spatial domain. Supervised learning using tempo-
ral coding has shown a significant decrease in the energy consumption of
SNNs. Mostafa (2017) developed a direct training approach via backpropa-
gation error with the temporal coding scheme. His network has no convolu-
tional layers, and the preprocessing method is not general. Zhou, Chen, Ye,
and Li (2019) improved on Mostafa’s work by incorporating convolutional
layers into the SNN, developing a new kernel operation, and proposing a
new way to preprocess the input data. Their SCNN achieved high recog-
nition accuracy with less trainable parameters. Stromatias, Soto, Serrano-
Gotarredona, and Linares-Barranco (2017) presented a supervised method
for training a classifier by using the stochastic gradient descent (SGD) al-
gorithm and then converting it to an SNN. In other work, Zheng and
Mazumder (2018un) proposed backpropagation-based learning for training
SNNs. Their proposed learning algorithm is suitable for implementation in
neuromorphic hardware.
4.3 Conversion from Trained ANN. In the third technique, an offline-
trained ANN is converted to an SNN so that the transformed network
can take advantage of a well-established, fully trained ANN model. Ce
approach is often called “spike transcoding” or “spike conversion.”
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1299
Converting an ANN to SNN offers several benefits. D'abord, a simulation of the
exact spike dynamics in a large network can be computationally expensive,
particularly if high firing rates and precise spike times are required. Là-
fore, this approach allows applying SNNs to complex benchmark tasks that
require large networks, such as ImageNet or CIFAR-10, and the accuracy
loss compared to their formal ANNs is small (Sengupta, Ye, Wang, Liu,
& Roy, 2018; Hu, Tang, & Pan, 2018). Deuxième, we can leverage highly ef-
ficient training techniques developed for ANNs and many state-of-the-art
deep networks for classification tasks for conversion to SNNs. De plus,
the optimization process can be performed on ANNs. This permits the use
of state-of-the-art optimization procedures and GPUs for training (Diehl
et coll., 2015). The main disadvantage is that the conversion technique fails
to provide on-chip learning capability. En outre, some particularities of
SNNs, which do not exist in the corresponding ANNs, cannot be considered
during training. For this reason, the inference performance of the SNNs is
typically lower than that of the original ANNs (Pfeiffer & Pfeil, 2018).
Significant research has been carried out to convert an ANN to an SNN
with successful performance on the MNIST data set. Diehl et al. (2015) pro-
posed a technique for converting an ANN into an SNN that has the min-
imum performance loss in the conversion process, and a recognition rate
de 98.64% was achieved on the MNIST database. In another work, Rueck-
auer, Lungu, Hu, Pfeiffer, and Liu (2017) converted continuous-valued deep
CNN to accurate spiking equivalent. This network, which includes com-
mon operations such as softmax, max-pooling, batch normalization, bi-
ases, and inception modules, demonstrates a recognition rate of 99.44% sur
the MNIST data set. Xu, Tang, Xing, and Li (2017) proposed a conversion
method that is suitable for mapping on neuromorphic hardware. They pre-
sented a threshold rescaling method to reduce the loss and achieved a maxi-
mum accuracy of 99.17% on the MNIST data set. Xu et al. (2020) established
an efficient and hardware-friendly conversion rule to convert CNNs into
spiking CNNs. They proposed an “n-scaling” weight mapping method that
achieves high accuracy and low-latency classification on the MNIST data
ensemble. Wang, Xu, Yan, and Tang (2020) proposed a weights-thresholds balance
conversion technique that needs fewer memory resources and achieves
high recognition accuracy on the MNIST data set. In contrast to the exist-
ing conversion techniques, which focus on the approximation between the
artificial neurons’ activation values and the spiking neurons’ firing rates,
they focused on the relationship between weights and thresholds of spik-
ing neurons during the conversion process.
4.4 Evolutionary Spiking Neural Networks. Evolutionary algorithms
(EAs) are population-based metaheuristics. Historically, their design was
motivated by observations about natural evolution in biological popula-
tion. Such algorithms can be used to directly optimize the network topol-
ogy and model hyperparameters or optimize synaptic weights and delays
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1300
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
(Saleh, Hameed, Najib, & Salleh, 2014; Schaffer, 2015). Actuellement, evolution-
ary algorithms such as differential evolution (DE), grammatical evolution
(GE), harmony search algorithm (HSA), and particle swarm optimization
(PSO) are used to learn the synaptic weights of SNNs. Vazquez (2010),
López-Vázquez et al. (2019), and Yusuf et al. (2017) have shown how the
synaptic weights of a spiking neuron, including integrate-and-fire, Izhike-
vich, and spike response model (SRM) models can be trained by using al-
gorithms such as DE, GE, and HSA to perform classification tasks. Vazquez
and Garro (2011) applied the PSO algorithm to train the synaptic weights of
a spiking neuron in linear and nonlinear classification problems. They dis-
covered that input patterns of the same class produce equal firing rates.
The parallel differential evolution approach was introduced by Pavlidis,
Tasoulis, Plagianakos, Nikiforidis, and Vrahatis (2005) for training super-
vised feedforward SNNs. Their approach is tested on exclusive-OR, lequel
does not represent its benefits. Evolutionary algorithms can be an alter-
native to exhaustive search. Cependant, they are very time-consuming, Non-
tably because the fitness function is computationally expensive (Gavrilov
& Panchenko, 2016).
Tableau 2 shows the models for developing SNNs—their architectures and
learning type along with their accuracy rates on the MNIST data set. Ce
comparison provides an insight into different SNN architectures and learn-
ing mechanisms to choose the right tool for the right purpose in future
investigations.
The new concepts and architectures are still frequently tested on MNIST.
Cependant, we argue that the MNIST data set does not include temporal
information and does not provide spike events generated from sensors.
Compared to a static data set, a dynamic data set contains richer tem-
poral features and therefore is more suitable to exploit an SNN’s po-
tential ability. The event-based benchmark data sets include N-MNIST
(Orchard, Jayawant, Cohen, & Thakor, 2015), CIFAR10-DVS (Hongmin Li,
Liu, Ji, Li, & Shi, 2017), N-CARS (Sironi, Brambilla, Bourdis, Lagorce, &
Benosman, 2018), DVS-Gesture (Amir et al., 2017), and SHD (Cramer, Strad-
mann, Schemmel, & Zenke, 2020). Tableau 3 shows the models for developing
SNNs—their architectures and learning type along with their accuracy rates
on the neuromorphic data sets.
5 Available Hardware and Software/Frameworks
Different methods can be used for neural network implementation. Com-
putational cost, speed, and configurability are the main concerns for the
implementations. Although CPU-based simulations offer a relatively high-
speed execution, they are designed to be used for general-purpose and
everyday applications. They also offer a serial implementation that lim-
its the number of neurons that can be implemented at the same time.
Hardware implementations instead can provide a platform for parallel
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1301
)
%
(
t
s
e
T
/
g
n
je
n
je
un
r
T
UN
C
e
je
p
m
un
S
e
je
toi
R.
g
n
je
n
r
un
e
L
e
p
oui
T
g
n
je
n
r
un
e
L
e
p
oui
T
n
o
r
toi
e
N
n
o
je
t
un
r
toi
g
fi
n
o
C
e
r
toi
t
c
toi
r
t
S
d
o
h
t
e
M.
g
n
je
d
o
c
n
E
e
p
oui
T
–
k
r
o
w
t
e
N
e
c
n
e
r
e
F
e
R.
.
)
T
S
je
N
(
t
e
S
un
t
un
D
s
t
je
g
je
D
n
e
t
t
je
r
w
d
n
un
H
n
o
oui
c
un
r
toi
c
c
UN
r
je
e
h
T
d
n
un
s
je
e
d
o
M.
g
n
je
n
r
un
e
L
N
N
S
t
n
e
c
e
R.
F
o
oui
r
un
m
m
toi
S
:
2
e
je
b
un
T
7
2
.
9
9
0
0
0
,
0
1
/
0
0
0
,
0
6
+
d
je
o
h
s
e
r
h
t
e
je
b
un
je
r
un
V
d
e
s
je
v
r
e
p
toi
s
n
U
F
je
L
UN
N
g
n
je
d
o
c
r
e
d
r
o
k
n
un
R.
N
N
C
g
n
je
k
je
p
S
)
1
2
0
2
(
g
n
o
D
&
toi
F
)
1
2
0
2
(
4
.
7
9
0
0
0
,
0
1
/
0
0
0
,
0
6
P.
B
–
je
je
D
T
S
d
e
s
je
v
r
e
p
toi
S
M.
R.
S
r
un
e
n
L
je
0
1
–
0
0
5
–
4
8
7
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
S
.
je
un
t
e
je
h
g
e
d
un
s
r
je
M.
4
.
1
9
2
9
9
0
.
9
9
3
4
.
9
9
0
0
0
,
0
1
/
0
0
0
,
0
6
0
0
0
,
0
1
/
0
0
0
,
0
6
n
o
je
s
r
e
v
n
o
c
e
c
n
un
je
un
b
0
0
0
,
0
1
/
0
0
0
,
0
6
d
je
o
h
s
e
r
h
t
–
s
t
h
g
je
e
W
0
0
0
,
0
7
e
je
toi
r
n
o
je
s
r
e
v
n
o
C
d
e
s
je
v
r
e
p
toi
S
d
e
s
je
v
r
e
p
toi
S
P.
D
T
S
.
g
n
je
n
r
un
e
je
d
e
s
un
b
–
e
k
je
p
s
d
je
r
b
oui
H
d
e
s
je
v
r
e
p
toi
s
n
U
D
T
S
P.
D
T
S
d
e
s
je
v
r
e
p
toi
s
n
U
F
je
oui
k
un
e
je
n
o
N
F
je
L
F
je
L
F
je
0
1
–
C
F
8
2
1
–
P.
M.
2
–
3
C
4
6
–
2
P.
M.
–
3
C
4
6
C
F
0
1
–
P.
2
–
5
C
4
6
–
P.
2
–
5
C
5
g
n
je
d
o
c
e
t
un
R.
g
n
je
d
o
c
e
t
un
R.
N
N
C
g
n
je
k
je
p
S
)
0
2
0
2
(
.
je
un
t
e
toi
X
N
N
S
p
e
e
D
)
0
2
0
2
(
.
je
un
t
e
g
n
un
W
P.
–
5
C
4
2
–
5
C
2
1
–
8
2
×
8
2
@
6
C
6
g
n
je
d
o
c
e
t
un
R.
0
1
–
0
0
4
–
0
0
4
–
4
8
7
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
S
e
s
n
e
D
v
o
p C
e
e
D
N
N
S
)
0
2
0
2
(
.
je
un
t
e
toi
Q
)
0
2
0
2
(
.
je
un
t
e
toi
X
0
5
.
8
9
0
0
0
,
0
1
/
0
0
0
,
0
6
je
un
r
o
p
m
e
T
d
e
s
je
v
r
e
p
toi
S
F
je
oui
k
un
e
je
n
o
N
UN
N
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
C
g
n
je
k
je
p
S
)
9
1
0
2
(
.
je
un
t
e
toi
o
h
Z
e
t
un
m
je
X
o
r
p
p
un
t
n
e
c
s
e
d
8
.
7
9
0
0
0
,
0
1
/
0
0
0
,
0
6
g
n
je
n
r
un
e
je
e
n
je
je
n
Ô
d
e
s
je
v
r
e
p
toi
S
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
D
G
c
je
t
s
un
h
c
o
t
s
7
1
.
8
9
0
0
0
,
0
1
/
0
0
0
,
0
5
d
e
z
je
je
un
m
r
o
N
d
e
s
je
v
r
e
p
toi
S
F
je
L
F
je
L
0
1
–
2
1
1
8
–
4
8
7
UN
N
N
N
S
0
1
–
0
0
1
–
0
0
3
–
4
8
7
g
n
je
d
o
c
e
t
un
R.
N
N
S
d
n
un
g
n
e
h
Z
r
e
d
m
toi
z
un
M.
)
un
8
1
0
2
(
n
un
r
d
n
e
un
R.
j
d
n
un
je
n
r
un
k
je
toi
K
)
8
1
0
2
(
)
8
1
0
2
(
.
je
un
t
e
e
e
L
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
+
g
n
je
n
je
un
r
t
e
r
p
8
2
.
9
9
0
0
0
,
0
1
/
0
0
0
,
0
6
d
e
s
un
b
–
P.
D
T
S
d
e
s
je
v
r
e
p
toi
s
je
m
e
S
F
je
L
C
F
0
1
–
C
F
0
0
2
–
P.
2
–
5
C
0
5
–
P.
2
–
5
C
0
2
–
8
2
×
8
2
g
n
je
d
o
c
e
t
un
R.
N
N
S
e
s
n
e
D
v
o
p C
e
e
D
6
3
.
9
9
0
0
0
,
0
1
/
0
0
0
,
0
6
n
o
je
t
un
g
un
p
o
r
p
k
c
un
B
d
e
s
je
v
r
e
p
toi
S
0
6
.
8
9
0
0
0
,
0
1
/
0
0
0
,
0
6
g
n
je
n
r
un
e
je
.
p
e
r
P.
D
T
S
h
t
o
B
P.
D
T
S
–
P.
B
d
n
un
F
je
L
F
je
L
o
0
1
–
un
2
–
5
c
4
6
–
un
2
–
5
c
2
1
–
8
2
×
8
2
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
S
p
e
e
D
d
n
un
un
h
t
s
e
r
h
S
C
F
0
1
–
C
F
0
0
5
1
–
P.
2
–
5
C
4
6
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
C
g
n
je
k
je
p
S
.
je
un
t
e
je
e
un
n
un
v
un
T
)
8
1
0
2
(
d
r
un
h
c
r
Ô
)
8
1
0
2
(
4
1
.
7
9
0
0
0
,
0
1
/
0
0
0
,
0
6
je
un
r
o
p
m
e
T
d
e
s
je
v
r
e
p
toi
S
F
je
oui
k
un
e
je
n
o
N
0
1
–
0
0
4
–
0
0
4
–
4
8
7
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
S
)
7
1
0
2
(
un
F
un
t
s
o
M.
7
1
.
9
9
2
4
.
8
9
0
0
0
,
0
1
/
0
0
0
,
0
6
0
0
0
,
0
2
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
e
je
toi
r
n
o
je
s
r
e
v
n
o
C
D
G
c
je
t
s
un
h
c
o
t
S
d
e
s
je
v
r
e
p
toi
S
d
e
s
je
v
r
e
p
toi
S
F
je
L
F
je
o
0
1
–
F
4
2
0
1
–
s
2
–
5
c
4
6
–
s
2
–
5
c
2
3
–
8
2
×
8
2
g
n
je
d
o
c
e
t
un
R.
t
e
N
v
n
o
C
g
n
je
k
je
p
S
)
7
1
0
2
(
.
je
un
t
e
toi
X
UN
N
g
n
je
d
o
c
je
un
r
o
p
m
e
T
N
N
C
g
n
je
k
je
p
S
.
je
un
t
e
s
un
je
t
un
m
o
r
t
S
)
7
1
0
2
(
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1302
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Tableau 3: Summary of Recent SNN Learning Models and Their Accuracy on
Event-Based Data Set.
Réseau
Type
Learning Rule and Structure
Configuration
SNN
ANN-to-SNN conversion
Reference
Kugele et al.
(2020)
Wu et al.
(2018)
Wu et al.
(2019)
Spiking
MLP
SNN
Zheng et al.
(2020)
ResNet17
SNN
Spatiotemporal backpropagation
(STBP) 34 × 34 × 2-800-10
Spatiotemporal backpropagation (STBP)
128C3(Encoding)-128C3-AP2-384C3-
384C3-AP2-1024FC-512FC-Voting
Threshold-dependent batch
normalization method based on
spatiotemporal backpropagation
(STBP-tdBN)
Lee et al.
(2016)
Yao et al.
(2021)
SNN
Spiking
CNN
Supervised backpropagation
(34 × 34 × 2)-800-10
Temporal-wise attention SNN
(TA-SNN)
Data Set
Californie %
N-MNIST
CIFAR-DVS
DvsGesture
N-Cars
N_MNIST
95.54
66.61
96.97
94.07
98.78
N-MNIST
CIFAR-DVS
99.53
60.5
CIFAR-DVS
DvsGesture
67.80
96.87
N-MNIST
98.66
DvsGesture
98.61
(1) Input-MP4-64C3-128C3-AP2-128C3-
CIFAR-DVS
72
AP2-256FC-11
(2) Input-32C3-AP2-64C3-AP2-128C3-
AP2-256C3-AP2-512C3-AP4-256FC-
10
(3) Input-128FC-128FC-20
ANN-to-SNN conversion
SHD
91.08
N-MNIST
95.72
Neil and Liu
(2016)
Spiking
CNN
implementations. Although analog implementation is relatively efficient,
it suffers from an expensive and long design and implementation process.
FPGA instead offers a configurable platform that offers parallel processing,
which makes it a suitable candidate for SNN implementations.
5.1 Available Software. There are many different SNN simulators—for
exemple, BindsNET, Nengo, NeMo, Brian2GeNN, Nest, and CARLsim. Ex-
isting simulators have different levels of biological models, computational
speed, and support for hardware platforms. They are classified into three
main groups depending on how the neural model dynamic evaluation is
computed: event driven (asynchronous), where the membrane potential
is modified only when a spike arrives; clock-driven (synchronous), où
the neural state is updated at every tick of a clock; and hybrid strategies
(asynchronous and synchronous) (Rudolph-Lilith, Dubois, & Destexhe,
2012).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1303
Event-driven simulators are not as widely used as clock-driven simula-
tors due to their implementation complexity. De plus, they are difficult
to parallelize due to their sequential nature. Their main advantage is their
higher operation speed because they do not calculate small update steps for
a neuron. Another benefit of event-driven simulators is that the timing of
spikes can be represented with high precision. These simulators are more
suitable for neural network layers with low and sparse activity (Naveros,
Garrido, Carrillo, Ros, & Luque, 2017).
The majority of SNN simulators are clock-driven. Because of high par-
allelism, clock-driven simulators take full advantage of parallel computing
resources in CPU and GPU platforms. Their platforms perform better for
small and medium-size groups of neurons with a low to medium math-
ematical complexity, whereas GPU clock-driven platforms perform better
for large-size groups of neurons with high mathematical complexity. Le
main advantage of clock-driven simulators is that they are suitable for sim-
ulating large networks when a large number of events is triggered. Many of
these simulators are built on top of the existing deep learning frameworks
because they are structurally similar to simulating an ANN. Their main
disadvantages are that spike timings are aligned to ticks of the clock and
threshold conditions are checked only at the ticks of the clock (Brette et al.,
2007). Selecting the most appropriate technique requires a trade-off among
three elements: (1) neural network architecture (par exemple., number of neurons,
neural model complexity, number of input and output synapses, mean fir-
ing rates), (2) hardware resources (number of CPU and GPU cores, RAM
size), et (3) simulation requirements and targets.
Among the SNN simulators that have been reported in the literature are
BindsNET (Hazan et al., 2018), Nengo (Bekolay et al., 2014), NeMo (Fid-
jeland, Roesch, Shanahan, & Luk, 2009), GeNN (Yavuz et al., 2016), Cerveau
2 (Stimberg, Brette, & Homme bon, 2019), Brian2GeNN (Stimberg, Good-
man, & Nowotny, 2020), NEST (Gewaltig & Diesmann, 2007), CARLsim
(Beyeler, Carlson, Chou, Dutt, & Krichmar, 2015; Chou et al., 2018), Neu-
Cube (Kasabov, 2014), PyNN (Davison, 2009), ANNarchy (Vitay, Dinkel-
bach, & Hamker, 2015), and NEURON (Hines & Carnevale 1997). Il y a
some major criteria for choosing an SNN simulator. It should be open ac-
cess; easy to debug and run; and support various hardware such as ASIC
and FPGA to execute the simulation and support the level of biological com-
plexity. We describe the main features of prominent existing SNNs simula-
tors in Table 3.
BindsNET is an open-source Python package for rapid building and sim-
ulation of SNNs, which developed on top of the PyTorch deep learning li-
brary for its matrix computation. BindsNET allows researchers to test the
software prototypes on CPUs or GPUs and then deploy the model to dedi-
cated hardware (Hazan et al., 2018).
Nengo is a neural simulator based on the neural engineering framework
for simulating both large-scale spiking and nonspiking neural models. Il
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1304
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
is written in Python and supports the TensorFlow back end. This Python
library allows users to define neuron types, learning rules, and optimization
méthodes (Bekolay et al., 2014).
NeMo, a C++ class library for simulating SNNs, can simulate tens of
thousands of neurons on a single workstation. It has bindings for Matlab
and Python and one of the supported back ends for the PyNN simulator
interface (Fidjeland et al. 2009).
GeNN is an open-source library for accelerating SNN simulations on
CPUs or GPUs via code generation technology (Yavuz, Tourneur, & Nowotny,
2016).
Brain is a popular open-source simulator for SNNs written in Python. Il
is highly flexible, easily extensible, and commonly used in computational
neuroscience. Version 2 of Brain allows scientists to efficiently simulate
SNN models (Stimberg et al., 2019). In a newly developed software pack-
âge, Brian2GeNN, the GPU-enhanced neural network simulator (GeNN)
can be used to accelerate simulation in the Brain simulator (Stimberg et al.,
2020).
Another popular and open-source simulator for SNNs is NEST, focus-
ing on the dynamics, size, and structure of neural network. It is suitable
for large networks of spiking neurons (Gewaltig et al. 2007). CARLsim is a
user-friendly and GPU-accelerated SNN library written in C++ that sup-
ports CPU-GPU co-execution (Beyeler et al., 2015). Version 4 of CARLsim
has been improved to simulate large-scale SNN models in with real-time
constraints (Chou et al. 2018). Tableau 4 shows the features of the most SNNs
simulation software.
5.2 Available Hardware. Spiking neuromorphic hardware can be sub-
divided into analog and digital or mixed-mode (analog/digital) conception.
Analog hardware uses physical processes to model certain computational
functions of artificial neurons. The advantage of this approach is that
operations that might be costly to implement as an explicit mathematical
operation can be realized very efficiently by the natural dynamics of the sys-
thème (Neil & Liu, 2016). En plus, real-valued physical variables could
have almost infinite precision. Analog hardware implementations differ on
the degree to which analog elements are used. Many implementations per-
form only the computation in the neuron with analog elements, keeping
the communication of spike signals digital (Camuñas, Linares-Barranco, &
Serrano-Gotarredona, 2019).
Digital hardware represents all variables of the neurons by bits, juste
like a classical computer. This means that the precision of variables
depends on the number of bits used to represent the variables. This pre-
cision also strongly influences the energy consumption of the basic op-
erations and the memory requirements for variable storage. Le grand
advantage of digital designs compared to analog hardware is that the preci-
sion of variables is controllable and guaranteed. En plus, digital hard-
ware can be designed with established state-of-the-art techniques for chip
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1305
o
t
,
)
C
je
S
UN
,
UN
G
P.
F
,
.
g
.
e
(
e
r
un
w
d
r
un
h
t
n
e
r
e
F
F
je
d
o
t
d
e
t
c
e
n
n
o
c
e
b
n
un
c
T
E
N
s
d
n
je
B
•
n
o
s
N
N
S
g
n
je
n
je
un
r
t
r
o
F
oui
r
un
r
b
je
je
m
oui
g
je
UN
n
e
p
Ô
e
h
t
h
t
je
.
s
n
o
je
t
un
je
toi
m
je
s
e
h
t
e
t
toi
c
e
X
e
w
e
c
un
F
r
e
t
n
je
n
un
e
d
je
v
o
r
P.
•
r
e
t
toi
p
m
o
c
r
o
F
oui
r
un
r
b
je
je
e
h
t
o
t
n
je
d
e
t
un
r
g
e
t
n
je
s
un
h
t
e
s
un
t
un
d
n
o
je
s
je
v
h
c
r
o
T
UN
.
g
n
je
n
r
un
e
je
e
n
je
h
c
un
m
F
o
n
je
un
m
o
d
e
h
t
n
je
n
o
je
t
un
c
je
je
p
p
un
r
o
F
e
je
b
un
t
je
toi
S
.
t
n
e
m
n
o
r
je
v
n
e
g
n
je
n
r
un
e
je
t
n
e
m
e
c
r
o
F
n
je
e
r
.
s
k
s
un
t
n
o
je
s
je
v
o
g
n
e
N
,
je
h
je
o
L
o
g
n
e
N
,
UN
G
P.
F
o
g
n
e
N
s
un
h
c
toi
s
,
s
d
n
e
k
c
un
b
n
o
je
t
un
je
toi
m
je
s
s
un
H
.
s
k
r
o
w
t
e
n
je
un
r
toi
e
n
g
n
je
k
je
p
s
F
o
s
r
o
je
v
un
h
e
b
je
e
v
e
je
–
h
g
je
h
n
o
s
e
s
toi
c
o
F
.
s
U
P.
C
n
o
n
o
je
t
toi
c
e
X
e
d
e
d
un
e
r
h
t
je
t
je
toi
m
s
t
r
o
p
p
toi
S
e
v
je
t
p
un
d
un
,
g
n
je
n
r
un
e
je
p
e
e
d
h
t
je
w
p
je
e
h
o
t
d
e
n
g
je
s
e
d
e
r
un
s
e
je
r
un
r
b
je
je
s
'
o
g
n
e
N
.
L
C
n
e
p
Ô
o
g
n
e
N
d
n
un
,
r
e
k
un
N
N
p
S
je
U
P.
C
n
o
n
o
je
t
toi
c
e
X
e
d
e
d
un
e
r
h
t
je
t
je
toi
m
s
t
r
o
p
p
toi
S
.
g
n
je
je
e
d
o
m
e
v
je
t
je
n
g
o
c
d
n
un
,
je
o
r
t
n
o
c
.
s
n
o
je
t
un
r
toi
g
fi
n
o
c
e
r
un
w
d
r
un
h
d
n
un
s
je
e
d
o
m
n
o
r
toi
e
n
t
n
e
r
e
F
F
je
d
e
t
un
je
toi
m
je
s
o
t
n
un
C
.
g
n
je
n
r
un
e
je
e
n
je
h
c
un
m
n
je
s
n
o
je
t
un
c
je
je
p
p
un
r
o
F
je
e
t
un
d
d
n
un
c
d
o
o
G
.
s
U
P.
G
d
e
je
b
un
n
e
–
UN
D
U
C
n
o
n
toi
r
n
un
C
n
toi
r
o
t
s
r
e
s
toi
w
o
je
je
un
h
c
je
h
w
,
2
n
je
un
r
B
d
n
un
N
N
e
G
h
t
o
b
F
o
e
g
un
t
n
un
v
d
un
s
e
k
un
T
•
r
e
h
t
r
toi
F
oui
n
un
t
toi
o
h
t
je
je
je
w
s
r
o
t
un
r
e
je
e
c
c
un
U
P.
G
UN
D
V
N
n
o
s
t
p
je
r
c
s
2
n
un
je
r
B
r
je
e
h
t
o
t
s
n
e
t
oui
b
e
c
n
un
m
r
o
F
r
e
p
s
e
c
n
un
h
n
e
oui
r
un
r
b
je
je
N
N
e
G
2
n
un
je
r
B
e
h
t
g
n
je
s
U
.
g
n
je
m
m
un
r
g
o
r
p
oui
r
un
s
s
e
c
e
n
•
r
e
t
s
un
F
s
e
m
je
t
F
o
s
d
e
r
d
n
toi
h
.
m
e
t
s
oui
s
g
n
je
t
un
r
e
p
o
r
o
un
m
j
je
je
un
s
t
r
o
p
p
toi
S
•
•
•
•
•
•
•
•
•
•
•
+
+
C
n
o
h
t
oui
P.
(
)
e
g
un
k
c
un
p
+
+
C
n
o
h
t
oui
P.
(
)
e
g
un
k
c
un
p
n
e
v
je
r
d
–
k
c
o
je
C
s
e
Oui
s
e
Oui
T
E
N
s
d
n
B
je
n
e
v
je
r
d
–
k
c
o
je
C
s
e
Oui
s
e
Oui
o
g
n
e
N
+
+
C
n
e
v
je
r
d
–
k
c
o
je
C
s
e
Oui
s
e
Oui
o
M.
e
N
+
+
C
n
o
h
t
oui
P.
(
)
e
g
un
k
c
un
p
n
e
v
je
r
d
–
k
c
o
je
C
s
e
Oui
s
e
Oui
N
N
e
G
2
n
un
je
r
B
g
n
je
m
m
un
r
g
o
r
P.
s
e
r
toi
t
un
e
F
e
g
un
toi
g
n
un
L
n
o
je
t
un
je
toi
m
je
S
U
P.
G
n
e
p
Ô
e
c
r
toi
o
S
r
o
t
un
je
toi
m
je
S
.
e
r
un
w
t
F
o
S
N
N
S
n
w
o
n
K
–
t
s
e
B
e
h
t
F
o
s
e
r
toi
t
un
e
F
:
4
e
je
b
un
T
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1306
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
.
r
o
je
v
un
h
e
b
e
s
n
o
p
s
e
r
n
e
v
je
g
un
t
fi
t
s
e
b
t
un
h
t
N
N
S
n
un
F
o
s
r
e
t
e
m
un
r
un
p
n
e
p
o
s
d
n
je
F
.
t
r
o
F
F
e
je
un
m
je
n
je
m
h
t
je
w
e
r
toi
t
un
e
F
w
e
n
un
d
d
un
o
t
s
r
e
s
toi
s
w
o
je
je
UN
.
s
k
r
o
w
t
e
n
je
un
r
toi
e
n
•
•
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
F
o
e
r
toi
t
c
toi
r
t
s
d
n
un
,
e
z
je
s
,
s
c
je
m
un
n
oui
d
e
h
t
n
o
s
toi
c
o
F
t
un
h
t
s
je
e
d
o
m
r
o
F
d
e
t
je
toi
s
e
s
un
e
r
c
n
je
o
t
k
r
o
w
t
e
n
je
un
c
o
je
un
n
je
r
e
t
toi
p
m
o
c
e
r
o
c
je
t
je
toi
m
F
o
e
g
un
t
n
un
v
d
un
e
k
un
t
n
un
C
.
s
m
e
t
s
oui
s
je
un
r
toi
e
n
•
d
e
z
je
m
je
je
t
p
o
g
n
d
je
v
o
r
p
oui
b
e
c
n
un
m
r
o
F
r
e
p
d
n
un
oui
t
je
je
je
b
je
X
e
fl
n
e
e
w
t
e
b
s
e
c
n
un
je
un
B
•
oui
je
je
un
c
je
g
o
je
o
je
b
F
o
r
e
b
m
toi
n
e
g
r
un
je
un
F
o
s
n
o
je
t
un
t
n
e
m
e
je
p
m
je
+
+
C
/
UN
D
U
C
.
n
o
je
t
un
je
toi
m
je
s
e
h
t
p
toi
d
e
e
p
s
o
t
r
o
oui
r
o
m
e
m
e
je
b
un
je
je
un
v
un
e
h
t
g
n
je
k
je
p
s
r
o
F
e
c
un
F
r
e
t
n
je
g
n
je
n
toi
t
e
c
un
F
r
e
t
n
je
g
n
je
m
m
un
r
g
o
r
p
e
s
toi
–
o
t
–
oui
s
un
e
n
un
s
e
d
je
v
o
r
P.
•
r
e
t
e
m
un
r
un
p
c
je
t
un
m
o
t
toi
un
d
e
t
un
r
g
e
t
n
je
n
un
s
e
d
je
v
o
r
P.
•
.
s
e
r
toi
t
un
e
F
je
e
d
o
m
e
je
b
je
s
toi
un
je
p
.
s
e
je
c
n
e
d
n
e
p
e
d
je
un
m
je
n
je
m
h
t
je
w
t
n
e
je
c
fi
F
e
oui
r
o
m
e
m
d
n
un
t
s
un
F
t
s
e
B
•
•
+
+
C
n
o
h
t
oui
P.
(
)
e
g
un
k
c
un
p
+
+
C
n
o
h
t
oui
P.
(
)
e
g
un
k
c
un
p
d
je
r
b
oui
H
o
N
s
e
Oui
T
S
E
N
n
e
v
je
r
d
–
k
c
o
je
C
s
e
Oui
s
e
Oui
m
je
s
L
R.
UN
C
g
n
je
m
m
un
r
g
o
r
P.
s
e
r
toi
t
un
e
F
e
g
un
toi
g
n
un
L
n
o
je
t
un
je
toi
m
je
S
U
P.
G
.
d
e
toi
n
je
t
n
o
C
:
4
e
je
b
un
T
n
e
p
Ô
e
c
r
toi
o
S
r
o
t
un
je
toi
m
je
S
Advancements in Spiking Neural Networks
1307
design and manufacturing. The digital solutions could be implemented on
either FPGAs or application-specific integrated circuits (ASICs) (Schuman
et coll., 2017). Alternativement, due to the high production costs of ASICs, other
research groups have focused on implementing SNNs on FPGAs.
5.2.1 Learning with Neuromorphic Hardware. Learning mechanisms are
crucial for the ability of neuromorphic systems to adapt to specific applica-
tion. Various types of learning can be performed depending on the number
of hyperparameters included in the learning, and the learning time can be
greatly varied. When such learning is performed in a neuromorphic chip,
the learning is referred to as on-chip training (Lee, Lee, Kim, Lee, & Seo,
2020). In order to perform on-chip training, the neuromorphic chip should
have almost all of the functions required for learning (Walter, Röhrbein,
& Knoll, 2015). Off-chip training is a method of implementing learning
outside a neuromorphic chip using, Par exemple, software. After external
learning is completed, the weights are postprocessed according to the neu-
romorphic system, or the neuromorphic system is fabricated using the post-
processed weights.
Whether to implement on-chip or off-chip training depends on the
application under consideration. If the objective is to design a general ac-
celerator for machine learning, obviously the chip should allow on-chip
entraînement (Burr et al., 2015). If the purpose is to perform a unique machine
learning task on embedded low-power hardware, off-chip learning, lequel
potentially is power consuming, can be realized only once, after which the
resulting network is programmed on-chip. At that point, one could argue
that in some cases, the system should need to adapt to its sensing environ-
ment while operating, which is referred to as online learning. One solution
is to enable off-chip training between operation times and update or fine-
tune the SNNs during inactive or loading time. Cependant, cette approche
still brings some drawbacks; Par exemple, it requires adding a memory that
would store the input data acquired during operation. En outre, online
learning is still being researched because machine learning currently has
the major drawback of forgetting, which means that a trained network can-
not learn a new task without losing accuracy on its previously learned task
(Zheng & Mazumder, 2018b).
For many years, STDP has been the algorithm of choice for implement-
ing machine learning tasks in spiking neuromorphic systems (Diehl &
Cook, 2014). It is popular in the neuromorphic community for several rea-
sons. D'abord, the field of neuromorphic computing has traditionally been in-
spired by biology. This is the reason that early approaches for learning in
neuromorphic hardware have been inspired by mechanisms observed in
le cerveau. En outre, STDP is straightforward to implement in analog
neuromorphic hardware. Its time dependence is often modeled by an ex-
ponential decay, which can simply be calculated by analog electronic ele-
ments. Enfin, if we want to apply supervised learning, these algorithms
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1308
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
require either complex neurons and synaptic models or floating-point val-
ues communication of gradients between layers, and thus between neuro-
cores, which makes their hardware implementation impractical. De plus,
if weight update is performed online (c'est à dire., during inference), feedforward
operation must be paused for learning, which adds an operational delay to
the system.
5.2.2 Large-Scale Neuromorphic Hardware. Appraisal of large-scale neu-
ral networks requires dedicated hardware to be highly configurable. Le
well-known neuromorphic architectures TrueNorth (Merolla et al., 2014),
Neurogrid (Benjamin et al., 2014), BrainScaleS (Schemmel et al., 2010), Loihi
(Davies et al., 2018), and SpiNNaker (Furber, Galluppi, Temple, & Plana,
2014) pursue various characteristics to emulate networks of spiking neu-
rons. (Note that this review addresses the well-known fully digital and
mixed digital-analog neuromorphic hardware.)
The IBM TrueNorth chip is a neuromorphic platform implemented in
digital electronics. This chip is designed for large-scale networks evaluation
and closer to human brain structure rather than von Neumann architecture
used in conventional computers. A single TrueNorth chip contains 5.4 bil-
lion transistors and 4096 neurosynaptic cores. Each core includes 12.75 KB
of local static random-access memory (SRAM), 256 neurons, 265 axons, et
un 265 × 265 synapse crossbar. This chip can simulate up to 1 million neurons
et 265 million synapses. A TrueNorth chip is programmable via Corelet
programming language (Merolla et al., 2014).
Neurogrid is a mixed digital-analog neuromorphic device that targets
real-time simulation of biological brains. The Neurogrid board is com-
posed of 16 complementary metal-oxide-semiconductor (CMOS) Neuro-
Core chips, each of which has 256 × 256 analog neurons fabricated in a
180 nm CMOS technology. This board is able to perform real-time biological
simulations of the brain with billions of synaptic connections and 1 million
neurons (Benjamin et al., 2014).
BrainScaleS is a mixed-mode analog/digital neuromorphic hardware
système, based on physical emulations of neuron, synapse, and plasticity
models, that targets the emulation of brain-size neural networks. The sys-
tem is composed of 8-inch silicon wafers capable of simulation up to 50 ×
106 plastic synapses and 200,000 neurons. Adaptive exponential IF neuron
models and synapses in an analog network core structure have been imple-
mented in the BrainScaleS system. The communication units in the system
are digital, while the pro-cessing units are analog circuits (Schemmel et al.,
2010).
A fully digital neuromorphic research chip known as Loihi has been de-
signed by Intel labs to implement SNNs. The chip is fabricated in Intel’s
14 nm process technology and contains 128 cores, along with three manag-
ing Lakemont cores. The Loihi chip can implement up to 130,000 neurons
et 130 million synapses. De plus, a learning engine embedded in each
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1309
core enables on-chip learning, with various learning rules, which makes
Loihi more flexible for supervisor/nonsupervisor and reinforcing models.
It can process information faster and more efficiently than conventional pro-
cessors up to 1000 et 10,000, respectivement, which makes it an ideal candi-
date for solving specific types of optimization problems (Davies et al., 2018).
SpiNNaker is a large, digital neuromorphic system designed to simu-
late large-scale neural computational models in real time. The SpiNNaker
board consists of 48 chips, each one containing 18 ARM microprocessors
and a network on chip (NoC). Each core contains an ARM968 and a di-
rect memory Access (DMA) controller to implement almost 1000 spiking
neurons in real time. One of the advantages of the SpiNNaker is using an
asynchronous scheme of communication. The PyNN interface makes the
SpiNNaker board programmable. PyNN is a Python library that provides
various spiking neuron model and synaptic plasticity rules. This neuromor-
phic platform has been used in neuroscience applications, such as the sim-
ulation of the visual cortex or the cerebellum (Furber, 2016).
The main features of these neuromorphic systems are shown in Table 5.
Note that for the execution of the network, only the learning approaches
that are implemented on-chip to run online are reviewed in this table.
5.2.3 FPGA-Based Implementation of SNN. SNN algorithms have parallel
and distributed nature. Today’s computer architecture and software are not
suitable for SNN execution. An alternative approach is to accelerate SNN
applications through dedicated hardware. Neuromorphic hardware is de-
signed to minimize energy and cost while keeping maximum accuracy. Il
presents promising speed-ups compared with software programs running
on CPUs, with lower power consumption than GPU.
Several neuromorphic accelerators have been used for implementing
SNNs. Cependant, they encounter some limitations, such as maximum fan-
in/fan-out of a neuron and synaptic precision, and are not suited for embed-
ded systems due to their high cost (Ji et al., 2016). FPGAs as a programmable
and low-cost device can address this issue: they exhibit high performance
and reconfiguration capability and are more energy efficient than current
CPUs and GPUs. En outre, they support parallel processing and con-
tain enough local memory to restore weights, which make them a suitable
candidate for implementing SNNs (Guo, Yantir, Fouda, Eltawil, & Salama,
2021). Rahman (2017) demonstrated that with a single CPU, the process-
ing time is slow (autour 1 minute per image). Cependant, with the success-
ful FPGA hardware acceleration and the use of a more complex network
with a higher number of filters and convolutional layers, it will be pos-
sible to use SNNs in real-time scenarios (1 second per image). Compared
to application-specific integrated circuits (ASICs), FPGAs are suitable can-
didates for implementing digital neuromorphic platforms. They provide
rapid design and fabrication time, low cost, high flexibility, more straight-
forward computer interface, and excellent stability. While the improvement
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1310
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
r
e
w
o
P.
g
n
je
n
r
un
e
L
)
p
je
h
c
(
e
n
je
je
n
Ô
e
s
p
un
n
oui
S
r
e
b
m
toi
N
e
s
p
un
n
oui
S
je
e
d
o
M.
n
o
r
toi
e
N
r
e
b
m
toi
N
)
p
je
h
c
(
n
o
r
toi
e
N
je
e
d
o
M.
p
je
h
C
–
n
Ô
g
n
je
n
r
un
e
L
p
je
h
C
un
e
r
UN
)
2
m
m
(
)
m
n
(
oui
g
o
je
o
n
h
c
e
T
s
c
je
n
o
r
t
c
e
je
E
m
r
o
F
t
un
je
P.
r
e
p
W
k
2
s
e
Oui
K
0
0
1
t
je
b
–
4
g
n
je
k
je
p
S
2
1
5
e
v
je
t
p
un
d
UN
)
P.
D
T
S
(
s
e
Oui
0
5
0
8
1
S
Ô
M.
C
C
je
S
UN
–
je
un
t
je
g
je
d
/
g
o
je
un
n
UN
S
e
je
un
c
S
n
je
un
r
B
.
s
n
o
je
t
un
t
n
e
m
e
je
p
m
je
s
m
e
t
s
oui
S
c
je
h
p
r
o
m
o
r
toi
e
N
F
o
oui
r
un
m
m
toi
S
:
5
e
je
b
un
T
)
p
je
h
c
s
r
o
t
un
je
toi
d
o
m
r
e
p
(
W
m
5
6
o
N
M.
6
5
2
4
,
oui
r
un
n
je
B
n
o
je
je
je
je
m
1
e
je
toi
d
o
m
)
k
un
e
p
(
je
un
t
je
g
je
d
je
un
je
t
n
e
n
o
p
X
e
F
je
F
je
L
o
N
0
3
4
8
2
S
Ô
M.
C
C
je
S
UN
–
je
un
t
je
g
je
D
h
t
r
o
N
e
toi
r
T
r
e
p
(
W
1
s
e
Oui
M.
6
1
e
je
b
un
m
m
un
r
g
o
r
P.
0
0
0
,
6
1
H
H
,
H
Z
je
,
F
je
L
c
je
t
p
un
n
oui
s
(
s
e
Oui
2
0
1
m
n
0
3
1
S
Ô
M.
C
C
je
S
UN
–
je
un
t
je
g
je
D
r
e
k
un
N
N
p
S
je
)
p
je
h
c
oui
t
je
c
je
t
s
un
je
p
)
s
e
je
toi
r
W
7
.
2
s
e
Oui
M.
0
0
1
d
e
r
un
h
S
0
0
0
,
5
6
e
v
je
t
p
un
d
UN
o
N
8
6
1
0
8
1
S
Ô
M.
C
C
je
S
UN
–
je
un
t
je
g
je
d
/
g
o
je
un
n
UN
d
je
r
g
o
r
toi
e
N
W
5
4
.
≈
s
e
Oui
M.
6
2
1
e
t
je
r
d
n
e
d
c
je
t
un
r
d
un
toi
q
F
je
UN
/
N
0
0
0
,
1
3
1
F
je
L
e
v
je
t
p
un
d
UN
h
t
je
w
(
s
e
Oui
0
6
m
n
4
1
S
Ô
M.
C
C
je
S
UN
–
je
un
t
je
g
je
D
je
h
je
o
L
oui
t
je
c
je
t
s
un
je
p
)
e
je
toi
r
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1311
potential using FPGAs is high, there are still many open research questions
that limit the current mainstream appeal of FPGAs.
Implementation of neural networks on FPGAs is time-consuming com-
pared to CPUs and GPUs. An important reason that FPGAs are still not as
widely used as general-purpose hardware platforms like CPUs and GPUs
in neural network computing is their relatively low programmability (Hof-
mann, 2019). Software frameworks such as Caffe and TensorFlow support
only hardware units like CPUs and GPUs and can be executed on such
operating systems. Although high-level synthesis (HLS) improves devel-
opment cycle on FPGAs, efficient HLS system designs still require a deep
understanding of hardware details, which can be a problem for general neu-
ral network developers (Zhang & Kouzani, 2020). There is still a need for
FPGA-based frameworks that support the mainstream software neural net-
work libraries like TensorFlow and Caffe.
Several studies have reported different approaches for implementing
SNNs on FPGAs for various applications. FPGA-based implementation of
SNNs has been presented for classifying musical notes (Cerezuela-Escudero
et coll., 2015), electrocardiogram (ECG), edge detection (Qi et al., 2014), réel-
time image dewarping (Molin et al., 2015), locomotion systems (Guerra-
Hernandez et al., 2017), biomimetic pattern generation (Ambroise, Levi,
Joucla, Yvert, & Saïghi, 2013), and event-driven vision processing (Youse-
fzadeh, Serrano-Gotarredona, & Linares-Barranco, 2015).
Note that we focus here on recent FPGA-based implementation of SNNs
for image classification domain, currently a significant field of machine
learning. Many research groups are now concentrating their efforts on
developing reservoir computing for solving various classification and
recognition problems. Tanaka et al. (2019) summarized recent advance in
physical reservoir computing, such as analog circuits, and FPGA. Yi et al.
(2016) developed a real-time, hardware-based FPGA architecture of the
reservoir computing method of recurrent neural network (RNN) entraînement.
Numerous studies have been focusing on designing a suitable neuromor-
phic architecture for liquid state machines (LSMs) on FPGAs (Liu, Jin, & Li,
2018; Wang, Jin, & Li, 2015; Jin, Liu, & Li, 2016).
There have been several attempts to implement SNNs on FPGAs for
pattern recognition. Ju et al. (2020) proposed an FPGA-based deep SNN
implementation. They applied a hardware-friendly, spiking, max-pooling
operation and two parallel methods, shift register and coarse-grained par-
allel, to improve the data reuse rate. The FPGA implementation obtained
22 times lower power consumption than a GPU implementation and 41
times speed-up compared to a CPU implementation. Abderrahmane and
Miramond (2019) explored a spike-based neural network for embedded ar-
tificial intelligence applications. They implemented two architectures, temps-
multiplexed and fully parallel, on an FPGA platform. Cependant, the FPGA
on-chip memory is not sufficient for deeper networks with these two ar-
chitectures. Efficient memory access is essential to store the parameters
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1312
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
and evaluation of a SNN. On-chip memory has a limitation, and off-chip
memory consumes more energy than on-chip memory. Ainsi, designing a
suitable architecture can reduce memory access. Nallathambi and Chandra-
choodan (2020) proposed a novel probabilistic spike propagation method
that reduces the number of off-chip memory accesses required to evaluate
a SNN, thus saving time and energy.
To take advantage of both event-based and frame-based process-
ing, Yousefzadeh, Orchard, Stromatias, Serrano-Gotarredona, and Linares-
Barranco (2018) proposed a hybrid neural network that combines SNN and
ANN features. Their implementation on an FPGA consumes 7 uJ per frame
and obtains 97% accuracy on the MNIST database. In similar work, Losh
and Llamocca (2019) designed spiking hybrid network (SHiNe), FPGA-
based hardware that achieved reasonable accuracy (90%) for the MNIST
data set. The SHiNe design has significantly lower FPGA resource utiliza-
tion (à propos 35% less) due to two factors: the neural network (the SHiNe
network is significantly simpler than the standard neural network, requir-
ing only 1 bit per signal) and neuron implementation (each SHiNe neuron
includes only a counter and a set of comparators). They have also imple-
mented an approach named thrifting, which limits the number of allowed
connections from neurons in one layer to a neuron in the next layer. Their
FPGA designs on the Zynq XC7Z010 PSoC board consume far less power
than the GPU or CPU implementations. Zhang et al. (2020) developed an
FPGA-based SNN implementation that provides 908,578 times speed-up
compared with software implementation. They reduced the consumption
of hardware resources by using arithmetic shift instead of multiplication
opérations, which can speed up the training efficiency.
Han, Li, Zheng, and Zhang (2020) proposed an FPGA-based SNN hard-
ware implementation that supports up to 16.384 neurons and 16.8 million
synapses with 0.477 W power consumption. They used a hybrid updating
algorithm that included a time-stepped and event-driven algorithm. En addition-
dition to on-chip block random access memory (RAM), they used an exter-
nal DDR memory to optimize the latency of memory access.
Kuang et al. (2019) introduced a real-time FPGA-based implementation
of SNNs that significantly reduces the cost of hardware resources with
multiplier-less approximation. Their proposed systems are suitable for bio-
inspired neuromorphic platform and online applications. An FPGA-based
parallel neuromorphic processor for SNNs presented in Wang, Li, Shao,
Dey, and Li (2017) successfully tackled several critical problems related to
memory organization and parallel processing. UN 59.4 times training speed-
up was achieved by the 32-way parallel design and reduced up to 20%
energy consumption by using the approximate multipliers in their proces-
sor design. An FPGA-based SNN hardware implementation with biolog-
ically realistic neuron and synapse proposed by Fang, Shrestha, Zhao, Li,
and Qiu (2019) applied a population encoding scheme to convert a con-
tinuous value into spike events. The FPGA implementation achieves 196
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1313
times lower power consumption and 10.1 times speed-up compared to a
GPU implementation. Their experiments demonstrate that temporal SNN
est 8.43 times speed-up compared with rate SNN on FPGA platform.
Tableau 6 presents the performance of recent FPGA-based implementations
of SNNs in terms of network configuration, system performance, and target
device.
6 Challenges and Future Research Directions
Spiking neural networks are capable of modeling information processing in
le cerveau, such as pattern recognition. They offer promising event-driven
traitement, fast inferences, and low power consumption. Spiking CNNs
offer a high potential for classification tasks in low-power neuromorphic
hardware, as they combine both spike-based computing of SNNs and high
CNN accuracy s (Diehl et al., 2015). En plus, deep SNN offers a promis-
ing computational paradigm for improving energy efficiency and reducing
classification latency. Cependant, training spiking CNNs and deep SNNs re-
mains challenging because of nondifferentiable spiking dynamics. To tackle
this problem, we provided an overview of the state-of-the-art learning
rules for SNNs in the section 3. One solution is direct supervised learning,
which takes advantage of reducing power consumption and a straightfor-
ward technique. This strategy is based on the backpropagation-like tech-
nique (Lee et al., 2016) and conventional gradient descent. Cependant, direct
training-based strategies still provide less efficiency and stability in cop-
ing with a complex database. An alternative technique to direct supervised
learning is converting a trained CNN to a SNN by transferring the CNN
operations directly into a SNN equivalent. Various approaches have been
employed to convert CNNs to SNNs, such as threshold rescaling (Xu et al.,
2017), n-scaling weight mapping (Yang et al., 2020), and weights-thresholds
équilibre (Wang, Xu, Yan, & Tang, 2020).
The conversion rule has solved the learning issue for deep SNNs. Comment-
jamais, it is not apparent that the conversion method can scale to deeper ar-
chitectures and address the complex task. En outre, there is a possibility
of accuracy loss during the conversion of CNNs to SNNs. Other hardware-
friendly approaches are local learning rules, such as STDP (Kheradpisheh,
Ganjtabesh, Thorpe, & Masquelier, 2018).
This method can be a suitable option design and a biologically plausi-
ble learning algorithm for hardware implementation. En plus, STDP
is a good choice for online learning, which allows a fast real-time learning
process and reduces the computational complexity.
Spiking neural networks are poorly served by classical von Neumann
computing architectures due to the dynamic nature of neurons; in addi-
tion, the classic computing architecture requires an extreme amount of time
and power. Ainsi, neuromorphic platforms are ideally suited for execut-
ing SNNs. These platforms offer better parallel implementation than that
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1314
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
1
5
1
,
0
)
Ô
S
/
J.
n
(
z
H
M.
0
0
2
r
e
d
n
toi
d
n
o
c
e
s
r
e
p
s
e
m
un
r
F
6
8
0
,
3
1
s
e
v
e
je
h
c
UN
S
L
H
o
d
un
v
je
V
UN
F
1
2
E
D
4
–
3
0
X
n
je
je
je
X
UN
G
P.
F
2
0
1
U
C
Z
7
.
9
9
0
1
–
R.
UN
F
je
C
d
o
h
t
e
m
n
o
je
s
r
e
v
n
o
c
n
o
d
e
s
un
b
N
N
S
n
un
s
e
k
un
p
un
h
c
n
un
P.
9
7
.
0
9
N
H
V
S
6
9
)
3
1
–
G
G
V
(
)
1
2
0
2
(
.
je
un
t
e
oui
c
n
e
je
c
fi
F
e
oui
g
r
e
n
e
n
un
s
e
v
e
je
h
c
UN
o
d
un
v
je
V
–
0
2
8
0
E
T
z
n
e
r
T
r
un
d
un
r
je
un
c
je
t
p
Ô
d
o
h
t
e
m
n
o
je
s
r
e
v
n
o
c
n
o
d
e
s
un
b
N
N
S
)
1
2
0
2
(
.
je
un
t
e
je
d
un
r
r
o
C
e
c
n
un
m
r
o
F
r
e
P.
m
e
t
s
oui
S
e
g
un
toi
g
n
un
L
m
r
o
F
t
un
je
P.
UN
G
P.
F
)
%
(
UN
C
oui
g
o
je
o
p
o
T
/
je
e
d
o
M.
g
n
je
d
o
c
n
E
e
c
n
e
r
e
F
e
R.
/
je
o
o
T
e
r
un
w
t
F
o
S
n
o
je
t
je
n
g
o
c
e
R.
d
n
un
n
o
r
toi
e
N
/
e
p
oui
T
k
r
o
w
t
e
N
.
s
N
N
S
F
o
n
o
je
t
un
t
n
e
m
e
je
p
m
je
d
e
s
un
B
–
UN
P.
G
F
F
o
oui
r
un
m
m
toi
S
:
6
e
je
b
un
T
t
un
g
n
je
n
n
toi
r
S
P.
F
k
3
.
8
2
s
e
v
e
je
h
c
UN
UN
/
N
z
H
M.
5
2
4
+
e
je
un
c
S
un
r
t
je
UN
G
P.
F
8
1
1
U
C
V
U
8
.
1
8
N
H
V
S
1
.
3
9
X
e
t
r
je
V
X
n
je
je
je
X
0
1
–
R.
UN
F
je
C
)
t
e
N
X
e
je
UN
(
N
N
C
g
n
je
k
je
p
S
)
1
2
0
2
(
.
je
un
t
e
g
n
toi
UN
%
0
9
o
t
e
s
o
je
c
oui
b
s
e
s
s
e
c
c
un
oui
r
o
m
e
m
7
8
.
6
7
d
o
h
t
e
m
n
un
d
o
o
h
c
un
r
d
n
un
h
C
p
je
h
c
–
F
F
o
F
o
r
e
b
m
toi
n
e
h
t
s
e
c
toi
d
e
R.
UN
/
N
V
e
n
o
je
c
oui
C
je
e
t
n
je
0
1
R.
UN
F
je
C
n
o
je
s
r
e
v
n
o
c
n
o
d
e
s
un
b
N
N
C
g
n
je
k
je
p
S
d
n
un
je
b
m
un
h
t
un
je
je
un
N
)
0
2
0
2
(
k
c
o
je
c
z
H
M.
0
6
1
t
un
W
2
9
.
4
s
e
m
toi
s
n
o
C
g
o
je
je
r
e
V
T
5
2
3
7
X
e
t
n
je
K
je
0
1
–
R.
UN
F
je
C
)
N
N
D
T
(
t
e
n
je
un
r
toi
e
n
oui
un
je
e
d
–
e
m
T
je
)
0
2
0
2
(
.
je
un
t
e
g
n
o
H
oui
c
n
e
je
c
fi
F
e
oui
g
r
e
n
e
n
je
t
n
e
m
e
v
o
r
p
m
je
×
6
9
1
d
n
un
p
toi
d
e
e
p
s
×
0
1
s
n
je
un
t
b
Ô
oui
c
n
e
toi
q
e
r
F
U
P.
G
h
t
je
w
d
e
r
un
p
m
o
c
UN
/
N
V
e
n
o
je
c
oui
C
W
7
7
4
.
0
F
o
n
o
je
t
p
m
toi
s
n
o
c
r
e
w
o
p
w
o
je
oui
r
e
v
d
n
un
,
oui
c
n
e
toi
q
e
r
F
k
c
o
je
c
z
H
M.
0
0
2
r
e
d
n
toi
S
P.
F
1
6
1
s
e
v
e
je
h
c
UN
UN
/
N
X
n
je
je
je
X
6
0
7
C
Z
3
4
.
3
8
T
S
je
N
M.
7
.
7
9
T
S
je
N
M.
6
0
.
7
9
d
n
un
d
e
p
p
e
t
s
–
e
m
je
t
e
h
t
F
o
d
je
r
b
oui
h
g
n
je
t
un
d
p
toi
n
e
v
je
r
d
–
t
n
e
v
e
n
o
s
s
je
o
P.
/
n
o
r
toi
e
n
F
je
L
/
s
m
h
t
je
r
o
g
je
un
0
1
–
0
0
2
1
–
0
0
2
1
–
4
8
7
g
n
je
d
o
c
n
e
F
je
L
/
e
je
toi
r
n
o
je
s
r
e
v
n
o
c
n
o
d
e
s
un
b
N
N
S
)
0
2
0
2
(
.
je
un
t
e
g
n
un
F
/
g
n
je
d
o
c
n
o
je
t
un
je
toi
p
o
p
/
n
o
r
toi
e
n
0
1
×
0
0
6
×
4
8
7
un
n
o
d
e
s
un
b
N
N
S
d
r
un
w
r
o
F
d
e
e
F
UN
)
0
2
0
2
(
n
un
H
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1315
×
1
4
s
n
je
un
t
b
o
d
n
un
oui
c
n
e
toi
q
e
r
F
k
c
o
je
c
z
H
M.
0
5
1
r
e
d
n
toi
S
P.
F
4
6
1
s
e
v
e
je
h
c
UN
r
e
w
o
p
W
6
.
4
d
n
un
p
toi
–
d
e
e
p
s
.
n
o
je
t
p
m
toi
s
n
o
c
UN
/
N
q
n
oui
Z
X
n
je
je
je
X
2
0
1
U
C
Z
T
S
je
N
M.
4
9
.
8
9
o
0
1
–
F
8
2
1
–
s
2
–
5
c
4
6
–
s
2
–
5
c
4
6
–
8
2
×
8
2
/
g
n
je
d
o
c
n
e
m
r
o
F
je
n
toi
d
e
X
fi
/
n
o
r
toi
e
n
F
je
/
e
je
toi
r
n
o
je
s
r
e
v
n
o
c
n
o
d
e
s
un
b
N
N
S
p
e
e
D
)
0
2
0
2
(
.
je
un
t
e
toi
J.
z
H
M.
0
0
1
t
un
W
m
7
3
2
s
e
m
toi
s
n
o
C
UN
/
N
c
n
oui
Z
X
n
je
je
je
X
h
c
e
e
p
s
6
4
je
T
d
e
s
un
b
)
M.
S
L
(
e
n
je
h
c
un
m
e
t
un
t
s
d
toi
q
je
L
je
)
9
1
0
2
(
.
je
un
t
e
toi
L
je
e
c
n
un
m
r
o
F
r
e
P.
m
e
t
s
oui
S
e
g
un
toi
g
n
un
L
m
r
o
F
t
un
je
P.
UN
G
P.
F
)
%
(
UN
C
oui
g
o
je
o
p
o
T
/
je
e
d
o
M.
g
n
je
d
o
c
n
E
e
c
n
e
r
e
F
e
R.
/
je
o
o
T
e
r
un
w
t
F
o
S
n
o
je
t
je
n
g
o
c
e
R.
d
n
un
n
o
r
toi
e
N
/
e
p
oui
T
k
r
o
w
t
e
N
.
d
e
toi
n
je
t
n
o
C
:
6
e
je
b
un
T
oui
c
n
e
toi
q
e
r
F
k
c
o
je
c
d
n
un
e
t
un
r
k
c
o
je
c
z
H
M.
5
2
1
r
e
d
n
toi
r
e
w
o
p
W
m
1
6
1
je
un
t
o
t
.
n
o
je
t
p
m
toi
s
n
o
c
e
m
un
r
F
r
e
p
s
m
6
3
5
.
5
6
n
je
s
t
je
toi
s
e
R.
3
.
6
1
0
2
o
d
un
v
je
V
t
je
b
–
2
3
g
n
je
s
toi
,
oui
c
n
e
toi
q
e
r
F
k
c
o
je
c
n
o
je
s
je
c
e
r
p
t
n
je
o
p
–
d
e
X
fi
z
H
M.
0
0
1
t
un
W
5
4
7
.
0
s
e
m
toi
s
n
o
C
4
.
6
1
0
2
o
d
un
v
je
V
6
0
7
–
C
Z
q
n
oui
Z
X
n
je
je
je
X
–
0
1
0
Z
7
C
X
C
0
0
4
G
L
C
1
7
V
X
n
je
je
je
X
T
0
9
6
UN
/
N
L
D
H
g
o
je
je
r
e
V
je
je
je
X
je
t
un
r
t
S
je
e
je
je
un
r
un
p
oui
je
je
toi
F
h
t
je
w
S
P.
F
K
0
7
d
n
un
e
r
toi
t
c
e
t
je
h
c
r
un
d
e
X
e
je
p
je
t
je
toi
m
–
e
m
je
t
h
t
je
w
oui
c
n
e
toi
q
e
r
F
k
c
o
je
c
e
r
toi
t
c
e
t
je
h
c
r
un
0
1
.
8
1
e
t
je
L
L
D
H
V
z
H
M.
0
5
r
e
d
n
toi
S
P.
F
6
5
2
s
e
v
e
je
h
c
UN
e
m
je
r
P.
s
toi
t
r
un
toi
Q
V
e
n
o
je
c
oui
C
je
e
t
n
je
s
toi
p
r
o
c
5
9
T
S
je
N
M.
0
7
.
7
9
T
S
je
N
M.
8
9
.
8
9
4
8
.
8
9
T
S
je
N
M.
3
9
T
S
je
N
M.
0
7
.
7
9
)
N
N
C
(
g
n
je
d
o
c
n
e
n
o
s
s
je
o
P.
/
n
o
r
toi
e
n
0
1
–
s
2
–
5
c
4
6
–
s
2
–
5
c
2
1
–
8
2
×
8
2
–
t
n
e
d
n
e
p
e
d
–
g
n
je
m
je
t
–
e
k
je
p
s
n
o
)
P.
D
T
S
(
oui
t
je
c
je
t
s
un
je
p
je
)
e
N
H
S
(
k
r
o
w
t
e
n
d
je
r
b
oui
h
g
n
je
k
je
p
S
un
c
c
o
m
un
je
L
d
n
un
h
s
o
L
,
n
o
je
t
un
c
fi
je
t
c
e
r
,
e
t
un
r
g
e
t
n
je
.
g
n
je
n
r
un
e
je
oui
c
n
e
toi
q
e
r
F
–
d
e
X
fi
/
n
o
r
toi
e
n
e
r
fi
d
n
un
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
n
o
d
e
s
un
b
g
n
je
d
o
c
n
e
e
je
c
oui
c
–
oui
t
toi
d
0
1
–
4
6
–
6
9
1
)
9
1
0
2
(
F
je
e
je
toi
r
n
o
je
s
r
e
v
n
o
c
N
N
S
o
t
N
N
D
)
9
1
0
2
(
o
toi
G
d
n
un
n
o
r
toi
e
n
F
je
L
/
s
e
je
toi
r
g
n
je
n
r
un
e
je
.
e
s
p
un
n
oui
s
d
e
s
un
b
–
e
c
n
un
t
c
toi
d
n
o
c
)
N
C
F
(
0
1
–
0
0
2
1
–
0
0
2
1
–
4
8
7
P.
D
T
S
n
o
d
e
s
un
b
N
N
S
r
e
oui
un
je
–
e
e
r
h
T
)
9
1
0
2
(
.
je
un
t
e
g
n
un
toi
K
0
1
–
0
0
3
–
0
0
3
–
4
8
7
je
g
n
je
d
o
c
e
t
un
r
/
n
o
r
toi
e
n
F
je
g
n
je
n
r
un
e
je
)
9
1
0
2
(
d
n
o
m
un
r
je
M.
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
n
o
d
e
s
un
b
N
N
S
d
n
un
e
n
un
m
h
un
r
r
e
d
b
UN
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1316
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
z
H
M.
0
0
1
t
un
r
e
w
o
p
W
M.
3
9
2
d
n
un
p
toi
d
e
e
p
s
×
7
.
0
1
s
n
je
un
t
b
Ô
je
je
s
toi
t
r
un
toi
Q
g
o
je
je
r
e
V
5
1
1
–
2
E
D
c
je
s
un
r
e
T
T
S
je
N
M.
6
2
.
6
9
n
o
r
toi
e
n
F
je
L
m
h
t
je
r
o
g
je
un
0
1
–
6
5
2
–
6
5
2
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
e
h
t
n
o
d
e
s
un
b
N
N
S
)
9
1
0
2
(
.
je
un
t
e
g
n
un
h
Z
e
c
n
un
m
r
o
F
r
e
P.
m
e
t
s
oui
S
e
g
un
toi
g
n
un
L
m
r
o
F
t
un
je
P.
UN
G
P.
F
)
%
(
UN
C
oui
g
o
je
o
p
o
T
/
je
e
d
o
M.
g
n
je
d
o
c
n
E
e
c
n
e
r
e
F
e
R.
/
je
o
o
T
e
r
un
w
t
F
o
S
n
o
je
t
je
n
g
o
c
e
R.
d
n
un
n
o
r
toi
e
N
/
e
p
oui
T
k
r
o
w
t
e
N
.
d
e
toi
n
je
t
n
o
C
:
6
e
je
b
un
T
oui
g
r
e
n
e
e
r
o
m
%
0
3
d
n
un
g
n
je
n
je
un
r
t
r
o
F
e
h
t
n
un
h
t
g
n
je
oui
F
je
s
s
un
je
c
r
o
F
t
n
e
je
c
fi
F
e
.
e
n
je
je
e
s
un
b
t
n
e
je
c
fi
F
e
oui
g
r
e
n
e
e
r
o
m
%
9
2
o
t
p
toi
s
je
t
je
UN
/
N
s
e
m
toi
s
n
o
c
d
n
un
oui
c
n
e
toi
q
e
r
F
k
c
o
je
c
s
s
e
je
o
t
je
un
toi
q
e
s
je
h
c
je
h
w
W
M.
3
6
3
,
e
m
un
r
F
h
c
un
e
r
o
F
J.
toi
7
n
un
h
t
z
H
M.
0
2
2
r
e
d
n
toi
S
P.
F
K
8
5
s
e
v
e
je
h
c
UN
L
D
H
X
n
je
je
je
X
6
–
X
e
t
r
je
V
X
n
je
je
je
X
6
–
N
UN
T
R.
UN
P.
S
UN
/
N
UN
/
N
X
n
je
je
je
X
0
5
1
X
L
–
6
n
un
t
r
un
p
S
g
n
je
s
s
e
c
o
r
p
s
m
2
5
1
s
e
v
e
je
h
c
UN
L
T
R.
X
n
je
je
je
X
r
e
w
o
p
W
5
.
1
d
n
un
e
g
un
m
/
e
m
je
je
t
k
c
o
je
c
z
H
M.
5
7
t
un
n
o
je
t
p
m
toi
s
n
o
c
oui
c
n
e
toi
q
e
r
F
0
5
1
X
L
–
6
n
un
t
r
un
p
S
z
H
M.
0
6
1
r
e
d
n
toi
s
m
8
.
6
5
1
n
je
e
g
un
m
je
t
toi
p
n
je
n
un
s
e
s
s
e
c
o
r
P.
o
d
un
v
je
V
7
X
je
t
r
UN
X
n
je
je
je
X
h
c
e
e
p
s
6
4
je
T
d
e
s
un
b
)
M.
S
L
(
e
n
je
h
c
un
m
e
t
un
t
s
d
toi
q
je
je
je
)
8
1
0
2
(
.
je
un
t
e
toi
L
je
s
toi
p
r
o
c
1
.
3
9
e
p
un
c
S
oui
t
je
C
9
.
7
9
T
S
je
N
M.
–
E
%
9
0
.
7
9
T
S
je
N
M.
8
9
.
6
9
T
S
je
N
M.
4
6
.
7
9
T
S
je
N
M.
2
9
–
t
n
e
d
n
e
p
e
d
–
g
n
je
m
je
t
–
e
k
je
p
s
n
o
)
P.
D
T
S
(
oui
t
je
c
je
t
s
un
je
p
g
n
je
d
o
c
n
e
n
o
s
s
je
o
P.
/
n
o
r
toi
e
n
F
je
L
k
r
o
w
t
e
n
je
un
r
toi
e
n
d
je
r
b
oui
h
r
e
oui
un
je
–
o
w
T
)
7
1
0
2
(
h
e
d
un
z
F
e
s
toi
o
Oui
g
n
je
d
o
c
n
e
je
un
r
o
p
m
e
t
/
n
o
r
toi
e
n
F
je
L
.
n
o
je
t
un
g
un
p
o
r
p
k
c
un
b
0
1
–
0
0
6
–
8
4
7
g
n
je
s
toi
d
e
n
je
un
r
t
N
N
S
d
r
un
w
r
o
F
d
e
e
F
UN
)
7
1
0
2
(
.
je
un
t
e
un
F
un
t
s
o
M.
0
1
–
0
0
5
–
0
0
5
–
4
8
7
n
o
r
toi
e
n
F
je
L
k
r
o
w
t
e
n
je
un
r
toi
e
n
oui
un
je
e
d
–
e
m
T
je
)
5
1
0
2
(
.
je
un
t
e
g
n
toi
h
C
k
r
o
w
t
e
n
F
e
je
je
e
b
p
e
e
d
g
n
je
k
je
p
S
je
)
4
1
0
2
(
toi
L
d
n
un
je
je
e
N
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1317
provided by CPUs and less power consumption than GPUs. FPGA offers a
programmable and very flexible platform for SNN implementation. Com-
pare to ASICs, FPGAs provide better stability, rapid design time, faster fab-
rication time, and higher flexibility. The FPGA implementation of SNNs
achieves significantly lower power consumption than GPU implementation
and better speed-up compared to the CPU implementation (Abderrahmane
& Miramond, 2019; Nallathambi & Chandrachoodan, 2020).
In the case of the hardware implementation of deep SNNs, the number of
neurons, relations, and weights can be very large, leading to an increase
in the size of memory. FPGAs’ on-chip memory is not sufficient to store all
parameters of the network. Donc, an external memory like SRAM is
required next to the on-chip memory to store the parameters and data flow
into the architecture. Ainsi, choosing a suitable information coding method
and designing an effective architecture can reduce memory fetches. Differ-
ent architectures have been used for FPGA-based implementation of SNNs
such as fully parallel and time-multiplexed. Designing an FPGA architec-
ture depends on the application target.
Focusing on the advancement of SNNs and their neuromorphic imple-
mentations, the following research aspects need to be considered, and more
work is required to resolve the remaining challenges and limitations:
• One of the key challenges in developing SNNs is to deploy suitable
training and learning algorithms, which profoundly affect applica-
tion accuracy and execution cost.
• Another unsolved challenge is how information is encoded with
spikes. Although neural coding has a remarkable effect on the fulfill-
ment of SNNs, the questions remain as to what the best encoding ap-
proach is and how to develop a learning algorithm to be well matched
by the encoding scheme. Designing a learning algorithm that is capa-
ble of training hidden neurons in an interconnected SNN has become
a major challenge.
Neuromorphic computing is at an early stage, and much progress is
needed in both algorithm and hardware that are capable of exhibiting
human-like intelligence.
7 Conclusion
Spiking neural networks have been considered the third generation of neu-
ral network, offering a high-speed real-time implementation of a complex
problem in a bio-inspired, power-efficient manner. This review offers an
overview of recent strategies to train SNNs and highlights two popular
deep learning methods: spiking CNNs and deep, fully connected SNNs,
in terms of their learning rule, network architecture, and experiment and
recognition accuracy. This review also discussed current SNN simulators,
comparing three main approaches: clock-driven, event driven, and hybrid;
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1318
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
it presented a survey of the work done on hardware implementation of
SNNs; and demonstrated that FPGAs are a promising candidate for acceler-
ation of SNNs and can achieve better speed-up than CPUs and less energy
consumption than GPUs.
Les références
Aamir, S. UN., Stradmann, Y., Müller, P., Pehle, C., Hartel, UN., Grübl, UN., . . . Meier, K.
(2018). An accelerated LIF neuronal network array for a large-scale mixed-signal
neuromorphic architecture. IEEE Transactions on Circuits and Systems I: Regular
Papers, 65(12), 4299–4312. 10.1109/TCSI.2018.2840718
Abderrahmane, N., & Miramond, B. (2019). Information coding and hardware archi-
tecture of spiking neural networks. In Proceedings of the 22nd Euromicro Conference
on Digital System Design (pp. 291–298). Piscataway, New Jersey: IEEE.
Abiodun, Ô. JE., Jantan, UN., Omolara, UN. E., Dada, K. V., Mohamed, N. UN., & Arshad, H.
(2018). State-of-the-art in artificial neural network applications: A survey. Heliyon,
4(11), e00938. 10.1016/j.heliyon.2018.e00938, PubMed: 30519653
Ambroise, M., Levi, T., Joucla, S., Yvert, B., & Saïghi, S. (2013). Real-time biomimetic
central pattern generators in an FPGA for hybrid experiments. Frontiers in Neu-
roscience, 7, 215. 10.3389/fnins.2013.00215, PubMed: 24319408
Amir, UN., Taba, B., Berger, D., Melano, T., McKinstry, J., & Di Nolfo, C. (2017). A low
pouvoir, fully event-based gesture recognition system. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition (pp. 7243–7252). Piscataway,
New Jersey: IEEE.
Aung, M.. T. L., Qu, C., Lequel, L., Luo, T., Goh, R.. S. M., & Wong, W. F. (2021).
DeepFire: Acceleration of convolutional spiking neural network on modern
field programmable gate arrays. In Proceedings of the 31st International Confer-
ence on Field-Programmable Logic and Applications (pp. 28–32). Piscataway, New Jersey:
IEEE.
Bekolay, T., Bergstra, J., Hunsberger, E., DeWolf, T., Stewart, T. C., Rasmussen, D.,
. . . Eliasmith, C. (2014). Nengo: A Python tool for building large-scale func-
tional brain models. Frontiers in Neuroinformatics, 7, 48. 10.3389/fninf.2013.00048,
PubMed: 24431999
Benjamin, B. V., Gao, P., McQuinn, E., Choudhary, S., Chandrasekaran, UN. R., Bussat,
J.. M., . . . Boahen, K. (2014). Neurogrid: A mixed-analog-digital multichip sys-
tem for large-scale neural simulations. In Proceedings of the IEEE, 102(5), 699–716.
10.1109/JPROC.2014.2313565
Beyeler, M., Carlson, K. D., Chou, T. S., Dutt, N., & Krichmar, J.. L. (2015). A user-
friendly and highly optimized library for the creation of neurobiologically de-
tailed spiking neural networks. In Proceedings of the International Joint Conference
on Neural Networks. Piscataway, New Jersey: IEEE.
Bohte, S. M., Kok, J.. N., & La Poutre, H. (2002). Error-backpropagation in temporally
encoded networks of spiking neurons. Neurocomputing, 48(14), 17–37. 10.1016/
S0925-2312(01)00658-0
Borst, UN., & Theunissen, F. E. (1999). Information theory and neural coding. Nature
Neurosciences, 2(11), 947–957. 10.1038/14731, PubMed: 10526332
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1319
Brette, R.. (2015). Philosophy of the spike: Rate-based vs. spike-based theories of
le cerveau. Frontiers in Systems Neuroscience, 9, 151. 10.3389/fnsys.2015.00151,
PubMed: 26617496
Brette, R., Rudolph, M., Carnevale, T., Hines, M., Beeman, D., Bower, J.. M., . . .
Zirpe, M.. (2007). Simulation of networks of spiking neurons: A review of tools
and strategies. Journal of Computational Neuroscience, 23(3), 349–398. 10.1007/
s10827-007-0038-6, PubMed: 17629781
Burr, G. W., Narayanan, P., Shelby, R.. M., Sidler, S., Boybat, JE., di Nolfo, C., &
Leblebici, Oui. (2015). Large-scale neural networks implemented with non-volatile
memory as the synaptic weight element: Comparative performance analysis (ac-
curacy, speed, and power). In Proceedings of the 2015 IEEE International Electron
Devices Meeting. Piscataway, New Jersey: IEEE.
Calimera, UN., Macii, E., & Poncino, M.. (2013). The human brain project and neuro-
morphic computing. Functional Neurology, 28(3), 191. 24139655
Camuñas-Mesa, L. UN., Linares-Barranco, B., & Serrano-Gotarredona, T. (2019). Neu-
romorphic spiking neural networks and their memristor-CMOS hardware imple-
mentations. Materials, 12(17), 2745.
Caporale, N., & Dan, Oui. (2008). Spike-timing-dependent plasticity: A Hebbian
learning rule. Annu. Rev. Neurosci., 31, 25–46. 10.1146/annurev.neuro.31.060407
.125639, PubMed: 18275283
Cerezuela-Escudero, E.,
Jimenez-Fernandez, UN., Paz-Vicente, R., Dominguez-
Morales, M., Linares-Barranco, UN., & Jimenez-Moreno, G. (2015). Musical notes
classification with neuromorphic auditory system using FPGA and a convolu-
tional spiking network. In Proceedings of the International Joint Conference on Neural
Networks (pp. 1–7). Piscataway, New Jersey: IEEE.
Chou, T. S., Kashyap, H. J., Xing, J., Listopad, S., Rounds, E. L., Beyeler, M., . . . Krich-
mar, J.. L. (2018). CARLsim 4: An open source library for large scale, biologically
detailed spiking neural network simulation using heterogeneous clusters. En Pro-
ceedings of the International Joint Conference on Neural Networks (pp. 1–8). Piscat-
away, New Jersey: IEEE.
Chung, J., Shin, T., & Kang, Oui. (2015). Insight: A neuromorphic computing system for
evaluation of large neural networks. arXiv:1508.01008.
Corradi, F., Adriaans, G., & Stuijk, S. (2021). Gyro: A digital spiking neural network
architecture for multi-sensory data analytics. In Proceedings of the 2021 Drone Sys-
tems Engineering and Rapid Simulation and Performance Evaluation: Methods and Tools
(pp. 9–15). New York: ACM.
Cramer, B., Stradmann, Y., Schemmel, J., & Zenke, F. (2020). The Heidelberg spiking
data sets for the systematic evaluation of spiking neural networks. IEEE Transac-
tions on Neural Networks and Learning Systems, PP(99), 1–14.
Dan, Y., & Poo, M.. M.. (2006). Spike timing-dependent plasticity: From synapse
to perception. Physiol. Rev, 86, 1033–1048. 10.1152/physrev.00030.2005,
PubMed: 16816145
Davies, M., Srinivasa, N., Lin, T. H., Chinya, G., Cao, Y., Choday, S. H., . . . Liao, Oui.
(2018). Loihi: A neuromorphic manycore processor with on-chip learning. IEEE
Micro, 38(1), 82–99. 10.1109/MM.2018.112130359
Davison, UN. P., Brüderle, D., Eppler, J.. M., Kremkow, J., Muller, E., Pecevski, D.,
. . . Yger, P.. (2009). PyNN: A common interface for neuronal network simulators.
Frontiers in Neuroinformatics, 2, 11. 19194529
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1320
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Diehl, P.. U., & Cook, M.. (2014). Efficient implementation of STDP rules on SpiN-
Naker neuromorphic hardware. In Proceedings of the 2014 International Joint Con-
ference on Neural Networks (pp. 4288–4295). Piscataway, New Jersey: IEEE.
Diehl, P.. U., Neil, D., Binas, J., Cook, M., Liu, S. C., & Pfeiffer, M.. (2015). Fast-
classifying, high-accuracy spiking deep networks through weight and threshold
balancing. In Proceedings of the 2015 International Joint Conference on Neural Net-
travaux (pp. 1–8). Piscataway, New Jersey: IEEE.
Dominguez-Morales,
J.. P., Liu, Q.,
Jimenez-
Fernandez, UN., Davidson, S., & Furber, S. (2018). Deep spiking neural network
model for time-variant signals classification: A real-time speech recognition ap-
proach. In Proceedings of the 2018 International Joint Conference on Neural Networks
(pp. 1–8). Piscataway, New Jersey: IEEE.
James, R., Gutierrez-Galan, D.,
Dora, S., Subramanien, K., Suresh, S., & Sundararajan, N. (2016). Development of a
self-regulating evolving spiking neural network for classification problem. Neu-
rocomputing, 171, 1216–1229. 10.1016/j.neucom.2015.07.086
Fang, H., Shrestha, UN., Zhao, Z., Li, Y., & Qiu, Q. (2019). An event-driven neuro-
morphic system with biologically plausible temporal dynamics. In Proceedings of
le 2019 IEEE/ACM International Conference on Computer-Aided Design (pp. 1–8).
Piscataway, New Jersey: IEEE.
Fidjeland, UN. K., Roesch, E. B., Shanahan, M.. P., & Luk, W. (2009). NeMo: A plat-
form for neural modelling of spiking neurons using GPUs. In Proceedings of the
20th IEEE International Conference on Application-Specific Systems, Architectures and
Processors (pp. 137–144). Piscataway, New Jersey: IEEE.
Fontaine, B., & Peremans, H. (2009). Bat echolocation processing using first-spike
latency coding. Neural Networks, 22(10), 1372–1382. 10.1016/j.neunet.2009.05.002,
PubMed: 19481904
Fu, Q., & Dong, H. (2021). An ensemble unsupervised spiking neural network for
objective recognition. Neurocomputing, 419, 47–58. 10.1016/j.neucom.2020.07.109
Furber, S. (2016). Large-scale neuromorphic computing systems. Journal of Neural
Engineering, 13(5), 051001. 10.1088/1741-2560/13/5/051001, PubMed: 27529195
Furber, S. B., Galluppi, F., Temple, S., & Plana, L. UN. (2014). The SpiNNaker project.
In Proceedings of the IEEE, 102(5), 652–665. 10.1109/JPROC.2014.2304638
Gavrilov, UN. V., & Panchenko, K. Ô. (2016). Methods of learning for spiking neural
réseaux. A survey. In Proceedings of the 13th International Scientific-Technical Con-
ference on Actual Problems of Electronics Instrument Engineering (vol. 2, pp. 455–460).
Piscataway, New Jersey: IEEE.
Gerstner, W., & Kistler, W. M.. (2002). Spiking neuron models: Single neurons, popula-
tion, plasticity. Cambridge: la presse de l'Universite de Cambridge.
Gerstner, W., Kistler, W. M., Naud, R., & Paninski, L. (2014). Neuronal dynamics: Depuis
single neurons to networks and models of cognition. Cambridge: Cambridge Univer-
sity Press.
Gewaltig, M.. O., & Diesmann, M.. (2007). Nest (neural simulation tool). Scholarpedia,
2(4), 1430. 10.4249/scholarpedia.1430
Gu, W., Valavanis, K. P., Rutherford, M.. J., & Rizzo, UN. (2019). A survey of artificial
neural networks with model-based control techniques for flight control of un-
manned aerial vehicles. In Proceedings of the 2019 International Conference on Un-
manned Aircraft Systems (pp. 362–371). Piscataway, New Jersey: IEEE.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1321
Guerra-Hernandez, E. JE., Espinal, UN., Batres-Mendoza, P., Garcia-Capulin, C. H.,
Romero-Troncoso, R.. D. J., & Rostro-Gonzalez, H. (2017). A FPGA-based neuro-
morphic locomotion system for multi-legged robots. IEEE Access, 5, 8301–8312.
10.1109/ACCESS.2017.2696985
Guo, S., Wang, L., Wang, S., Deng, Y., Lequel, Z., Li, S., . . . Dou, Q. (2019). A sys-
tolic SNN inference accelerator and its co-optimized software framework. En Pro-
ceedings of the 2019 on Great Lakes Symposium on VLSI (pp. 63–68). New York:
ACM.
Guo, W., Yantir, H. E., Fouda, M.. E., Eltawil, UN. M., & Salama, K. N. (2021). Toward
the optimal design and FPGA implementation of spiking neural networks. IEEE
Transactions on Neural Networks and Learning Systems.
Han, J., Li, Z., Zheng, W., & Zhang, Oui. (2020). Hardware implementation of spik-
ing neural networks on FPGA. Tsinghua Science and Technology, 25(4), 479–486.
10.26599/TST.2019.9010019
Hazan, H., Saunders, D. J., Khan, H., Patel, D., Sanghavi, D. T., Siegelmann,
H. T., & Kozma, R.. (2018). BindsNET: A machine learning-oriented spiking neu-
ral networks library in Python. Frontiers in Neuroinformatics, 12, 89. 10.3389/
fninf.2018.00089, PubMed: 30631269
Hines, M.. L., & Carnevale, N. T. (1997). The NEURON simulation environment. Neu-
ral Computation, 9(6), 1179–1209. 10.1162/neco.1997.9.6.1179, PubMed: 9248061
Hodgkin, UN. L., & Huxley, UN. F. (1952). A quantitative description of membrane cur-
rent and its application to conduction and excitation in nerve. Journal of Physiol-
ogie, 117(4), 500–544. 10.1113/jphysiol.1952.sp004764
Hofmann, J., (2019). An improved framework for and case studies in FPGA-based applica-
tion acceleration computer vision, in-network processing and spiking neural networks.
PhD diss., Technische Universität Darmstadt.
Hong, T., Kang, Y., & Chung, J.. (2020). InSight: An FPGA-based neuromorphic com-
puting system for deep neural networks. Journal of Low Power Electronics and Ap-
plications, 10(4), 36. 10.3390/jlpea10040036
Hongmin Li, Liu, H., Ji, X., Li, G., & Luping Shi, L. (2017). CIFAR10-DVS: An event-
stream dataset for object classification. Frontiers in Neuroscience, 11, 309.
Hu, Y., Tang, H. & Pan, G. (2018). Spiking deep residual network. arXiv:1805.01352.
Iakymchuk, T., Rosado-Muñoz, UN., Guerrero-Martínez, J.. F., Bataller-Mompeán, M.,
& Francés-Víllora, J.. V. (2015). Simplified spiking neural network architecture and
STDP learning algorithm applied to image classification. EURASIP Journal on Im-
age and Video Processing, 2015(1), 1–11. 10.1186/s13640-015-0059-4
Indiveri, G., Linares-Barranco, B., Hamilton, T.
J., Van Schaik, UN., Etienne-
Cummings, R., Delbruck, T., . . . & Boahen, K. (2011). Neuromorphic silicon neu-
ron circuits. Frontiers in Neuroscience, 5, 73.
Izhikevich, E. M.. (2003). Simple model of spiking neurons. IEEE Transactions on Neu-
ral Networks, 14(6), 1569–1572. 10.1109/TNN.2003.820440, PubMed: 18244602
Izhikevich, E. M.. (2004). Which model to use for cortical spiking neurons? IEEE
Transactions on Neural Networks, 15(5), 1063–1070. 10.1109/TNN.2004.832719,
PubMed: 15484883
Jang, H., Simeone, O., Gardner, B., & Gruning, UN. (2019). An introduction to proba-
bilistic spiking neural networks: Probabilistic models, learning rules, and appli-
cations. IEEE Signal Processing Magazine, 36(6), 64–77. 10.1109/MSP.2019.2935234
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1322
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Ji, Y., Zhang, Y., Li, S., Chi, P., Jiang, C., Qu, P., . . . Chen, W. (2016). NEUTRAMS:
Neural network transformation and co-design under neuromorphic hardware
constraints. In Proceedings of the 49th Annual IEEE/ACM International Symposium
on Microarchitecture (pp. 1–13). Piscataway, New Jersey: IEEE.
Jin, Y., Liu, Y., & Li, P.. (2016). SSO-LSM: A sparse and self-organizing architecture for
liquid state machine based neural processors. In Proceedings of the IEEE/ACM In-
ternational Symposium on Nanoscale Architectures (pp. 55–60). Piscataway, New Jersey: IEEE.
Ju, X., Fang, B., Yan, R., Xu, X., & Tang, H. (2020). An FPGA implementation of deep
spiking neural networks for low-power and fast classification. Neural Computa-
tion, 32(1), 182–204. 10.1162/neco_a_01245, PubMed: 31703174
Kasabov, N. K. (2014). NeuCube: A spiking neural network architecture for map-
ping, learning and understanding of spatio-temporal brain data. Neural Networks,
52, 62–76. 10.1016/j.neunet.2014.01.006, PubMed: 24508754
Kayser, C., Montemurro, M.. UN., Logothetis, N. K., & Panzeri, S. (2009). Spike-
phase coding boosts and stabilizes information carried by spatial and tem-
poral spike patterns. Neurone, 61(4), 597–608. 10.1016/j.neuron.2009.01.008,
PubMed: 19249279
Kheradpisheh, S. R., Ganjtabesh, M., Thorpe, S. J., & Masquelier, T. (2018). STDP-
based spiking deep convolutional neural networks for object recognition. Neural
Networks, 99, 56–67. 10.1016/j.neunet.2017.12.005, PubMed: 29328958
Kiselev, M.. (2016). Rate coding vs. temporal coding: Is optimum between? En Pro-
ceedings of the International Joint Conference on Neural Networks (pp. 1355–1359).
Piscataway, New Jersey: IEEE.
Kuang, Z., Wang, J., Lequel, S., Faire, G., Deng, B., & Wei, X. (2019). Digital implementa-
tion of the spiking neural network and its digit recognition. In Proceedings of the
Chinese Control and Decision Conference (pp. 3621–3625). Piscataway, New Jersey: IEEE.
Kugele, UN., Pfeil, T., Pfeiffer, M., & Chicca, E. (2020). Efficient processing of spatio-
temporal data streams with spiking neural networks. Frontiers in Neuroscience, 14,
439. 10.3389/fnins.2020.00439, PubMed: 32431592
Kulkarni, S. R., & Rajendran, B. (2018). Spiking neural networks for handwritten
digit recognition: Supervised learning and network optimization. Neural Net-
travaux, 103, 118–127. 10.1016/j.neunet.2018.03.019, PubMed: 29674234
Kuutti, S., Fallah, S., & Bowden, R.. (2020). Training adversarial agents to exploit
weaknesses in deep control policies. In Proceedings of the IEEE International Con-
ference on Robotics and Automation (pp. 108–114). Piscataway, New Jersey: IEEE.
Lee, C., Panda, P., Srinivasan, G., & Roy, K. (2018). Training deep spiking convolu-
tional neural networks with STDP-based unsupervised pre-training followed by
supervised fine-tuning. Frontiers in Neuroscience, 12, 435.
Lee, J.. E., Lee, C., Kim, D.W., Lee, D.& Seo, Oui. H. (2020). An on-chip learning method
for neuromorphic systems based on non-ideal synapse devices. Electronics, 9(11),
1946. 32051761
Lee, J.. H., Delbruck, T., & Pfeiffer, M.. (2016). Training deep spiking neural networks
using backpropagation. Frontiers in Neuroscience, 10, 508.
Lisitsa, D., & Zhilenkov, UN. UN. (2017). Prospects for the development and application
of spiking neural networks. In Proceedings of the IEEE Conference of Russian Young
Researchers in Electrical and Electronic Engineering (pp. 926–929). Piscataway, New Jersey:
IEEE.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1323
Liu, Y., Jin, Y., & Li, P.. (2018). Online adaptation and energy minimization for hard-
ware recurrent spiking neural networks. ACM Journal on Emerging Technologies in
Computing Systems, 14(1), 1–21.
Liu, Y., Yenamachintala, S. S., & Li, P.. (2019). Energy-efficient FPGA spiking neu-
ral accelerators with supervised and unsupervised spike-timing-dependent-
plasticity. ACM Journal on Emerging Technologies in Computing Systems, 15(3), 1–19.
López-Vázquez, G., Ornelas-Rodríguez, M., Espinal, UN., Soria-Alcaraz, J.. UN., Rojas-
Domínguez, UN., Puga-Soberanes, H. J., . . . Rostro-González, H. (2019). Evolving
random topologies of spiking neural networks for pattern recognition. Computer
Science and Information Technology, 9(7), 41–56.
Losh, M., & Llamocca, D. (2019). A low-power spike-like neural network design.
Electronics, 8(12), 1479. 10.3390/electronics8121479
Maass, W. (1997). Networks of spiking neurons: The third generation of neural net-
work models. Neural Networks, 10(9), 1659–1671. 10.1016/S0893-6080(97)00011-7
Markram, H., Gerstner, W., & Sjöström, P.. J.. (2011). A history of spike-timing-
dependent plasticity. Front. Synaptic Neurosci., 3, 4. 10.3389/fnsyn.2011.00004,
PubMed: 22007168
Mashford, B. S., Yepes, UN. J., Kiral-Kornek, JE., Tang, J., & Harrer, S. (2017). Neural-
network-based analysis of EEG data using the neuromorphic TrueNorth chip
for brain-machine interfaces. IBM Journal of Research and Development, 61(2/3),
7–1.
Mead, C. (1990). Neuromorphic electronic systems. In Proceedings of the IEEE, 78(10),
1629–1636. 10.1109/5.58356
Merolla, P.. UN., Arthur, J.. V., Alvarez-Icaza, R., Cassidy, UN. S., Sawada, J., Akopyan,
F., . . . Brezzo, B. (2014). A million spiking-neuron integrated circuit with a scal-
able communication network and interface. Science, 345(6197), 668–673. 10.1126/
science.1254642, PubMed: 25104385
Mirsadeghi, M., Shalchian, M., Kheradpisheh, S. R., & Masquelier, T. (2021). STiDi-
BP: Spike time displacement based error backpropagation in multilayer spiking
neural networks. Neurocomputing, 427, 131–140. 10.1016/j.neucom.2020.11.052
Molin, J.. L., Figliolia, T., Sanni, K., Doxas, JE., Andreou, UN., & Etienne-Cummings,
R.. (2015). FPGA emulation of a spike-based, stochastic system for real-time im-
age dewarping. In Proceedings of the IEEE 58th International Midwest Symposium on
Circuits and Systems (pp. 1–4). Piscataway, New Jersey: IEEE.
Mostafa, H. (2017). Supervised learning based on temporal coding in spiking neural
réseaux. IEEE Transactions on Neural Networks and Learning Systems, 29(7), 3227–
3235. 28783639
Mostafa, H., Pedroni, B. U., Sheik, S., & Cauwenberghs, G. (2017). Fast classification
using sparsely active spiking networks. Dans 2017 IEEE International Symposium on
Circuits and Systems (pp. 1–4).
Mozafari, M., Ganjtabesh, M., Nowzari-Dalini, UN., Thorpe, S. J., & Masquelier, T.
(2018). Combining STDP and reward-modulated STDP in deep convolutional spiking
neural networks for digit recognition. arXiv:1804.00227.
Mozafari, M., Kheradpisheh, S. R., Masquelier, T., Nowzari-Dalini, UN., & Ganjtabesh,
M.. (2018). First-spike-based visual categorization using reward-modulated
STDP. IEEE Transactions on Neural Networks and Learning Systems, 29(12), 6178–
6190. 10.1109/TNNLS.2018.2826721, PubMed: 29993898
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1324
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Nallathambi, UN., & Chandrachoodan, N. (2020). Probabilistic spike propagation for
FPGA implementation of spiking neural networks. arXiv:2001.09725.
Naveros, F., Garrido, J.. UN., Carrillo, R.. R., Ros, E., & Luque, N. R.. (2017). Event-
and time-driven techniques using parallel CPU-GPU co-processing for spiking
neural networks. Frontiers in Neuroinformatics, 11, 7. 10.3389/fninf.2017.00007,
PubMed: 28223930
Neil, D., & Liu, S. C. (2014). Minitaur, an event-driven FPGA-based spiking network
accelerator. IEEE Transactions on Very Large-Scale Integration Systems, 22(12), 2621–
2628. 10.1109/TVLSI.2013.2294916
Neil, D., & Liu, S. C. (2016). Effective sensor fusion with event-based sensors and
deep network architectures. In Proceedings of the 2016 IEEE International Sympo-
sium on Circuits and Systems (pp. 2282–2285). Piscataway, New Jersey: IEEE.
Nitzsche, S., Pachideh, B., Luhn, N., & Becker, J.. (2021). Digital hardware imple-
mentation of optimized spiking neurons. In Proceedings of the 2021 International
Conference on Neuromorphic Computing (pp. 126–134). New York: ACM.
Orchard, G., Jayawant, UN., Cohen, G. K., & Thakor, N. (2015). Converting static im-
age datasets to spiking neuromorphic datasets using saccades. Frontiers in Neu-
roscience, 9, 437. 10.3389/fnins.2015.00437
Osswald, M., Ieng, S. H., Benosman, R., & Indiveri, G. (2017). A spiking neural net-
work model of 3D perception for event-based neuromorphic stereo vision sys-
thèmes. Rapports scientifiques, 7(1), 1–12. 10.1038/s41598-016-0028-x, PubMed: 28127051
Panchapakesan, S., Fang, Z., & Li, J.. (2021). SyncNN: Evaluating and accelerating
spiking neural networks on FPGAs. In Proceedings of the 31st International Con-
ference on Field-Programmable Logic and Applications (pp. 286–293). Piscataway, New Jersey:
IEEE.
Paugam-Moisy, H. (2006). Spiking neuron networks a survey. paugam-idiap-rr-06-
11.pdf
Paugam-Moisy, H., & Bohte, S. M.. (2012). Computing with spiking neuron networks.
In G. Rozenberg, T. Bäck, & J.. N. Kok, (Éd.), Handbook of natural computing (vol.
1, pp. 1–47). Berlin: Springer.
Pavlidis, N. G., Tasoulis, Ô. K., Plagianakos, V. P., Nikiforidis, G., & Vrahatis, M.. N.
(2005). Spiking neural network training using evolutionary algorithms. En Pro-
ceedings of the 2005 IEEE International Joint Conference on Neural Networks (vol. 4,
pp. 2190–2194). Piscataway, New Jersey: IEEE. 10.1109/IJCNN.2005.1556240
Perez-Peña, F., Cifredo-Chacon, M.. UN., & Quiros-Olozabal, UN. (2020). Digital neuro-
morphic real-time platform. Neurocomputing, 371, 91–99.
Pfeiffer, M., & Pfeil, T. (2018). Deep learning with spiking neurons: Opportuni-
ties and challenges. Frontiers in Neuroscience, 12, 774. 10.3389/fnins.2018.00774,
PubMed: 30410432
Qi, Y., Zhang, B., Taha, T. M., Chen, H., & Hasan, R.. (2014). FPGA design of a
multicore neuromorphic processing system. In Proceedings of the IEEE National
Aerospace and Electronics Conference (pp. 255–258). Piscataway, New Jersey: IEEE.
Qu, L., Zhao, Z., Wang, L., & Wang, Oui. (2020). Efficient and hardware-friendly meth-
ods to implement competitive learning for spiking neural networks. Neural Com-
puting and Applications, 32(17), 13479–13490.
Rahman, T. (2017). Classification of roadside material using convolutional neural network
and a proposed implementation of the network through Zedboard Zynq 7000 FPGA. Pur-
due University.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1325
Rudolph-Lilith, M., Dubois, M., & Destexhe, UN. (2012). Analytical integrate- et-
fire neuron models with conductance-based dynamics and realistic postsynaptic
potential time course for event-driven simulation strategies. Neural Computation,
24(6), 1426–1461. 10.1162/NECO_a_00278, PubMed: 22364504
Rueckauer, B., Lungu, je. UN., Hu, Y., Pfeiffer, M., & Liu, S. C. (2017). Conver-
sion of continuous-valued deep networks to efficient event-driven networks for
image classification. Frontiers in Neuroscience, 11, 682. 10.3389/fnins.2017.00682,
PubMed: 29375284
Saleh, UN. Y., Hameed, H., Najib, M.& Salleh, M.. (2014). A novel hybrid algorithm
of differential evolution with evolving spiking neural network for pre-synaptic
neurons optimization. International Journal of Advances in Soft Computing and Its
Applications, 6(1), 1–16.
Schaffer, J.. D. (2015). Evolving spiking neural networks: A novel growth algorithm
corrects the teacher. In Proceedings of the IEEE Symposium on Computational Intelli-
gence for Security and Defense Applications (pp. 1–8). Piscataway, New Jersey: IEEE.
Schemmel, J., Brüderle, D., Grübl, UN., Hock, M., Meier, K., & Millner, S. (2010). UN
wafer-scale neuromorphic hardware system for large-scale neural modeling. Dans
Proceedings of the IEEE International Symposium on Circuits and Systems (pp. 1947–
1950). Piscataway, New Jersey: IEEE.
Schuman, C. D., Potok, T. E., Patton, R.. M., Birdwell, J.. D., Dean, M.. E., Rose, G. S.,
& Plank, J.. S. (2017). A survey of neuromorphic computing and neural networks in
hardware. arXiv:1705.06963.
Sengupta, UN., Ye, Y., Wang, R., Liu, C., & Roy, K. (2018). Going deeper in spiking neural
réseaux: VGG and residual architectures. arXiv:1802.02627.
Seo, J.. S., & Seok, M.. (2015). Digital CMOS neuromorphic processor design featuring
unsupervised online learning. In Proceedings of the IFIP/IEEE International Confer-
ence on Very Large Scale Integration (pp. 49–51). Piscataway, New Jersey: IEEE.
Shahid, N., Rappon, T., & Berta, W. (2019). Applications of artificial neural net-
works in health care organizational decision-making: A scoping review. PLOS
Un, 14(2), e0212356.
Shrestha, S. B., & Orchard, G. (2018). Slayer: Spike layer error reassignment in time.
Advances in neural information processing systems, 31.
Simeone, Ô. (2018). Neuromorphic computing and learning: A stochastic signal processing
perspective. https://nms.kcl.ac.uk/osvaldo.simeone/SNN_v30.pdf
Sironi, UN., Brambilla, M., Bourdis, N., Lagorce, X., & Benosman, R.. (2018). HATS:
Histograms of averaged time surfaces for robust event-based object classification.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Piscataway, New Jersey: IEEE. 10.1109/CVPR.2018.00186
Stimberg, M., Brette, R., & Homme bon, D. F. (2019). Brian 2, an intuitive and efficient
neural simulator. eLife, 8, e47314. 10.7554/eLife.47314, PubMed: 31429824
Stimberg, M., Homme bon, D. F., & Nowotny, T. (2020). Brian2GeNN: Accelerating
spiking neural network simulations with graphics hardware. Rapports scientifiques,
10(1), 1–12. 10.1038/s41598-019-54957-7, PubMed: 31913322
Stromatias, E., Soto, M., Serrano-Gotarredona, T., & Linares-Barranco, B. (2017). Un
event-driven classifier for spiking neural networks fed with synthetic or dynamic
vision sensor data. Frontiers in Neuroscience, 11, 350. 10.3389/fnins.2017.00350,
PubMed: 28701911
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1326
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Tanaka, G., Yamane, T., Héroux, J.. B., Nakane, R., Kanazawa, N., Takeda, S., . . . Hi-
rose, UN. (2019). Recent advances in physical reservoir computing: A review. Neural
Networks, 115, 100–123. 10.1016/j.neunet.2019.03.005, PubMed: 30981085
Tang, G., & Michmizos, K. P.. (2018). Gridbot: An autonomous robot controlled by a
spiking neural network mimicking the brain’s navigational system. In Proceedings
of the International Conference on Neuromorphic Systems (pp. 1–8). New York: ACM.
Tavanaei, UN., Kirby, Z., & Maida, UN. S. (2018). Training spiking ConvNets by STDP
and gradient descent. In Proceedings of the International Joint Conference on Neural
Networks (pp. 1–8). Piscataway, New Jersey: IEEE.
Thiele, J.. C. (2019). Deep learning in event-based neuromorphic systems. PhD diss., Uni-
versité Paris Saclay.
Thorpe, S., Delorme, UN., & Van Rullen, R.. (2001). Spike-based strategies for rapid
traitement. Neural Networks, 14(6–7), 715–725. 10.1016/S0893-6080(01)00083-1,
PubMed: 11665765
Tkaˇcik, G., Prentice, J.. S., Balasubramanian, V., & Schneidman, E. (2010). Opti-
mal population coding by noisy spiking neurons. In Proceedings of the National
Académie des Sciences, 107(32), 14419–14424.
Vazquez, R.. UN. (2010). Izhikevich neuron model and its application in pattern recog-
nition. Australian Journal of Intelligent Information Processing Systems, 11, 35–40.
Vázquez, R.. UN., & Garro, B. UN. (2011). Training spiking neurons by means of par-
ticle swarm optimization. In Proceedings of the International Conference in Swarm
Intelligence (pp. 242–249). Berlin: Springer.
Vitay, J., Dinkelbach, H. Ü., & Hamker, F. H. (2015). ANNarchy: A code generation
approach to neural simulations on parallel hardware. Frontiers in Neuroinformat-
ics, 9, 19. 10.3389/fninf.2015.00019, PubMed: 26283957
Walter, F., Röhrbein, F., & Knoll, UN. (2015). Neuromorphic implementations of neu-
robiological learning algorithms for spiking neural networks. Neural Networks,
72, 152–167. 10.1016/j.neunet.2015.07.004, PubMed: 26422422
Wang, Q., Jin, Y., & Li, P.. (2015). General-purpose LSM learning processor archi-
tecture and theoretically guided design space exploration. In Proceedings of the
2015 IEEE Biomedical Circuits and Systems Conference (pp. 1–4). Piscataway, New Jersey:
IEEE.
Wang, Q., Li, Y., Shao, B., Dey, S., & Li, P.. (2017). Energy efficient parallel neuromor-
phic architectures with approximate arithmetic on FPGA. Neurocomputing, 221,
146–158. 10.1016/j.neucom.2016.09.071
Wang, Y., Xu, Y., Yan, R., & Tang, H. (2020). Deep spiking neural networks with bi-
nary weights for object recognition. IEEE Transactions on Cognitive and Develop-
mental Systems, 13(3), 514–523. 10.1109/TCDS.2020.2971655
Wei, H., Bu, Y., & Dai, D. (2017). A decision-making model based on a spiking neural
circuit and synaptic plasticity. Cognitive Neurodynamics, 11(5), 415–431. 10.1007/
s11571-017-9436-2, PubMed: 29067130
Wu, S., Amari, S. JE., & Nakahara, H. (2002). Population coding and decoding in a neu-
ral field: A computational study. Neural Computation, 14(5), 999–1026. 10.1162/
089976602753633367, PubMed: 11972905
Wu, Y., Deng, L., Li, G., Zhu, J., & Shi, L. (2018). Spatio-temporal backpropagation
for training high-performance spiking neural networks. Frontiers in Neuroscience,
12, 331.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Advancements in Spiking Neural Networks
1327
Wu, Y., Deng, L., Li, G., Zhu, J., Xie, Y., & Shi, L. (2019). Direct training for spik-
ing neural networks: Faster, larger, better. In Proceedings of the AAAI Conference
on Artificial Intelligence (vol. 33, pp. 1311–1318). Menlo Park, Californie: AAAI Press.
10.1609/aaai.v33i01.33011311
Xu, Q., Peng, J., Shen, J., Tang, H., & Pan, G. (2020). Deep CovDenseSNN: UN
hierarchical event-driven dynamic framework with spiking neurons in noisy
environnement. Neural Networks, 121, 512–519. 10.1016/j.neunet.2019.08.034,
PubMed: 31733521
Xu, Y., Tang, H., Xing, J., & Li, H. (2017). Spike trains encoding and threshold rescal-
ing method for deep spiking neural networks. In Proceedings of the 2017 IEEE Sym-
posium Series on Computational Intelligence (pp. 1–6). Piscataway, New Jersey: IEEE.
Xu, Y., Zeng, X., Han, L., & Lequel, J.. (2013). A supervised multi-spike learning algo-
rithm based on gradient descent for spiking neural networks. Neural Networks,
43, 99–113. 10.1016/j.neunet.2013.02.003, PubMed: 23500504
Lequel, X., Zhang, Z., Zhu, W., Yu, S., Liu, L., & Wu, N. (2020). Deterministic conversion
rule for CNNs to efficient spiking convolutional neural networks. Science China
Information Sciences, 63(2), 1–19.
Yao, M., Gao, H., Zhao, G., Wang, D., Lin, Y., Lequel, Z., & Li, G. (2021). Temporal-wise
attention spiking neural networks for event streams classification. In Proceedings
of the IEEE/CVF International Conference on Computer Vision (pp. 10221–10230).
Piscataway, New Jersey: IEEE
Yavuz, E., Tourneur, J., & Nowotny, T. (2016). GeNN: A code generation framework
for accelerated brain simulations. Rapports scientifiques, 6(1), 1–14. 10.1038/srep18854,
PubMed: 28442746
Faire, Y., Liao, Y., Wang, B., Fu, X., Shen, F., Hou, H., & Liu, L. (2016). FPGA
based spike-time dependent encoder and reservoir design in neuromorphic
computing processors. Microprocessors and Microsystems, 46, 175–183. 10.1016/
j.micpro.2016.03.009
Yousefzadeh, UN., Orchard, G., Stromatias, E., Serrano-Gotarredona, T., & Linares-
Barranco, B. (2018). Hybrid neural network, an efficient low–power digital hard-
ware implementation of event-based artificial neural network. In Proceedings of
the IEEE International Symposium on Circuits and Systems (pp. 1–5). Piscataway, New Jersey:
IEEE.
Yousefzadeh, UN., Serrano-Gotarredona, T., & Linares-Barranco, B. (2015). Fast
pipeline 128 × 128 pixel spiking convolution core for event-driven vision process-
ing in FPGAs. In Proceedings of the International Conference on Event-Based Control,
Communication, and Signal Processing (pp. 1–8). Piscataway, New Jersey: IEEE.
Yusuf, Z. M., Hamed, H. N. UN., Yusuf, L. M., & Isa, M.. UN. (2017). Evolving spik-
ing neural network (ESNN) and harmony search algorithm (HSA) for parameter
optimization. In Proceedings of the Sixth International Conference on Electrical Engi-
neering and Informatics (pp. 1–6). Piscataway, New Jersey: IEEE.
Zhang, C. M., Qiao, G. C., Hu, S. G., Wang, J.. J., Liu, Z. W., Liu, Oui. UN., . . . & Liu,
Oui. (2019). A versatile neuromorphic system based on simple neuron model. AIP
Advances, 9(1), 015324.
Zhang, G., Li, B., Wu, J., Wang, R., Lan, Y., Sun, L., . . . & Chen, Oui. (2020). A low-cost
and high-speed hardware implementation of spiking neural network. Neurocom-
puting, 382, 106–115. 10.1016/j.neucom.2019.11.045
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1328
UN. Javanshir, T. Nguyen, M.. Mahmud, et un. Kouzani
Zhang, Z., & Kouzani, UN. Z. (2020). Implementation of DNNs on IoT devices. Neural
Computing and Applications, 32(5), 1327–1356. 10.1007/s00521-019-04550-w
Zheng, H., Wu, Y., Deng, L., Hu, Oui. & Li, G. (2020). Going deeper with directly trained
larger spiking neural networks. arXiv:2011.05280.
Zheng, N., & Mazumder, P.. (2018un). Online supervised learning for hardware-
based multilayer spiking neural networks through the modulation of weight-
dependent spike-timing-dependent plasticity. IEEE Transactions on Neural Net-
works and Learning Systems, 29(9), 4287–4302. 10.1109/TNNLS.2017.2761335,
PubMed: 29990088
Zheng, N., & Mazumder, P.. (2018b). A low-power hardware architecture for on-line
supervised learning in multi-layer spiking neural networks. In Proceedings of the
2018 IEEE International Symposium on Circuits and Systems (pp. 1–5). Piscataway,
New Jersey: IEEE.
Zhou, S., Chen, Y., Ye, Q., & Li, J.. (2019). Direct training based spiking convolutional
neural networks for object recognition. arXiv:1909.10837.
Received August 1, 2021; accepted January 18, 2022.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
n
e
c
o
un
r
t
je
c
e
–
p
d
/
je
F
/
/
/
/
3
4
6
1
2
8
9
2
0
2
3
3
1
8
n
e
c
o
_
un
_
0
1
4
9
9
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3