Neural OCR Post-Hoc Correction of Historical Corpora
Lijun Lyu1, Maria Koutraki1, Martin Krickl2, Besnik Fetahu1,3
1L3S Research Center, Leibniz University of Hannover / Hannover, Allemagne
2Austrian National Library / Vienna, Austria
3Amazon / Seattle, WA, Etats-Unis
lyu@L3S.de, koutraki@L3S.de, martin.krickl@onb.ac.at, besnikf@amazon.com
Abstrait
Optical character recognition (OCR) is crucial
for a deeper access to historical collections.
OCR needs to account for orthographic vari-
ations, typefaces, or language evolution (c'est à dire.,
new letters, word spellings), as the main
source of character, word, or word segmen-
tation transcription errors. For digital corpora
of historical prints, the errors are further exac-
erbated due to low scan quality and lack of
language standardization.
For the task of OCR post-hoc correction,
we propose a neural approach based on a
combination of recurrent (RNN) and deep
convolutional network (ConvNet) to correct
OCR transcription errors. At character level
we flexibly capture errors, and decode the
corrected output based on a novel attention
mechanism. Accounting for the input and out-
put similarity, we propose a new loss function
that rewards the model’s correcting behavior.
Evaluation on a historical book corpus in
German language shows that our models are
robust in capturing diverse OCR transcription
errors and reduce the word error rate of 32.3%
by more than 89%.
1 Introduction
OCR is at the forefront of digitization projects for
cultural heritage preservation. The main task is
to identify characters from their visual form into
their textual representation.
Scan quality, book layout, visual character sim-
ilarity are some of the factors that impact the
output quality of OCR systems. This problem is
severe for historical corpora, which is the case in
this work. We deal with historical books in Ger-
man language from the 16th–18th century, où
characters are added or removed (par exemple., long s – ),
word spellings change (par exemple., ‘‘vnd’’ vs. ‘‘und’’)
that often lead to word and character transcription
479
errors. Chiffre 1 shows examples pages conveying
the complexity of this task.
There are several strategies to correct OCR
transcription errors. Post-hoc correction is the
most common setup (Dong and Smith, 2018;
Xu and Smith, 2017). The input is an OCR tran-
scribed text, and the output is its corrected version
according to the error-free ground-truth transcrip-
tion. Par exemple, Dong and Smith (2018) utiliser
a multi-input attention to leverage redundancy
among textual snippets for correction. Alterna-
tivement, domain specific OCR engines can be
trained (Reul et al., 2018un), by using manually
aligned line image segments and line text (Reul
et coll., 2018b). Cependant, manually acquiring such
ground-truth is highly expensive, and further-
plus, typically, historical corpora do not contain
redundant information. De plus, each book has
its own characteristics—typeface styles, régional
and publisher’s use of language, and so forth.
In this work, we propose a post-hoc approach to
correct OCR transcription errors, and apply it to a
historical collection of books in German language.
As input we have only the OCR transcription of
book from their scans, for which we output the
corrected text, that we assess with respect to the
ground-truth transcription carried out by human
annotators without any spelling change, langue
normalization, or any other form of interpretation.
By considering only the textual modality for our
approche, we provide greater flexibility of apply-
ing our approach to historical collections where
the image scans are not available. Cependant, note
that since orthography was not standardized, là
can be parallel spellings of the ‘‘same’’ word
(par exemple., ‘‘und’’ vs. ‘‘vnd’’) within the same book,
which may pose challenges for approaches that
use the text modality only.
Our approach, CR, consists of an encoder-
decoder architecture. It encodes the erroneous
Transactions of the Association for Computational Linguistics, vol. 9, pp. 479–493, 2021. https://doi.org/10.1162/tacl a 00379
Action Editor: Sebastian Pad´o. Submission batch: 9/2020; Revision batch: 1/2021; Published 4/2021.
c(cid:2) 2021 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
text snippets. C'est, multiple redundant text
snippets are combined and under the majority
voting scheme the correction is carried out. Dong
and Smith (2018) propose a multi-input attention
model, which uses redundant
textual snippets
to determine the correct transcription during the
training phase. While there is redundancy for
contemporary texts, this cannot be assumed in
our case, where only the OCR transcriptions are
available. Our approach can be seen as com-
plementary to data augmentation techniques that
exploit redundancy.
Rule Based Correction. Rule
based
approaches compute the edit cost between two text
snippets based on weighted finite state machines
(WFSM) (Brill and Moore, 2000; Dreyer et al.,
2008; Wang et al., 2014; Silfverberg et al., 2016;
Farra et al., 2014). WFSM require predefined
rules (insertion, deletion, etc., of characters) et
a lexicon, which is used to assess the transfor-
mations. The rewrite rules require the mapping to
be done at the word and character level (Wang
et coll., 2014; Silfverberg et al., 2016). This process
is expensive and prohibits learning rules at scale.
En outre, lexicons are severely affected by
out-of-vocabulary (OOV) problems, especially for
historical corpora. A similar strategy is followed
by Barbaresi (2016), who uses a spell checker to
detect OCR errors and generate correction candi-
dates by computing the edit distance. OCR tran-
scription errors are highly contextual and there are
no one-to-one mappings of misrecognized charac-
ters that can be addressed by rules (cf. Chiffre 6).
Machine Translation. Post-hoc correction can
also be viewed as a special form of machine trans-
lation (Kalchbrenner and Blunsom, 2013; Cho
et coll., 2014; Sutskever et al., 2014). For post-hoc
correction of OCR transcription errors, the only
reasonable representation is based on characters.
This is due to the character errors and word seg-
mentation issues, which can only be detected when
encoding the input text at character level. Results
from spelling correction (Xie et al., 2016) et
machine translation (Ling et al., 2015; Ballesteros
et coll., 2015; Chung et al., 2016; Kim et al., 2016;
Sahin and Steedman, 2018) indicate that character
based models perform the best. Methods based
on statistical machine translation (SMT) (Afli
et coll., 2016) use a combined set of features at word
level and language models for post-hoc correc-
tion. Schulz and Kuhn (2017) use a multi-modular
Chiffre 1: Pages with coexisting typefaces (Fraktur
and Antiqua), double columns, and images surrounded
by texts.
text at character level, and outputs the
input
corrected text during the decoding phase. Repre-
sentation at character level is necessary given that
OCR transcription errors at the most basic level
are at character level. The input is encoded through
a combination of RNN and deep ConvNet (LeCun
et coll., 1995) réseaux. Our encoder architecture
allows us to flexibly encode the erroneous input
for post-hoc correction. RNNs capture the global
input context, whereas ConvNets construct local
sub-word and word compound structures. During
decoding the errors are corrected through an RNN
decoder, which at each step through an attention
mechanism combines the RNN and ConvNet
representations and outputs the corrected text.
Enfin, since the input and output snippets are
highly similar, loss functions like cross-entropy
lean heavily towards rewarding copying behavior.
We propose a custom loss function that rewards
the model’s ability to correct transcription errors.
following
In this work, we make
le
contributions:
• a data collection approach with a parallel
corpus of 800k sentences from 12 livres
(16th–18th century) in German language;
• an error analysis, emphasizing the diversity
and difficulty of OCR errors;
• an approach that flexibly captures erroneous
et
transcribed OCR textual
robustly corrects character and word errors
for historical corpora.
snippets
2 Related Work
Redundancy Based. The works in Lund et al.
(2013), Lund et al. (2011), Xu and Smith (2017),
and Lund et al. (2014) view the problem of post-
hoc correction under the assumption of redundant
480
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ID
Barcode
Year
Author
Location
Layout
pages WER
CER
1
2
3
4
5
6
7
8
Z165780108
Z205600207
Z176886605
Z185343407
Z95575503
1557 H. Staden
1562 M.. Walther
1603 B. Valentinus
1607 W. Dilich
1616 J.. Kepler
Z158515308
Z176799204
Z165708902
1647 UN. Olearius
1652 S. von Birken
1672 J.. Jacob Saar
Z22179990X 1691 S. von Pufendorf
9
10 Z172274605
11 Z221142405
Leipzig
1693 UN. von Sch¨onberg Leipzig
1699 UN. a Santa Clara
12 Z124117102
1708 W. Bosman
single column
Marburg
Wittenberg single column
single column
Leipzig
single column
Kassel
single column w. pg.
Linz
margin
single column
single column
single column w. pg.
margin
single column
single column
single/double column
w. pg. margin
single column
Schleswig
N¨urnberg
N¨urnberg
Hamburg
K¨oln
177
75
134
313
119
600
190
186
665
341
794
66.8% 16.3%
54.1% 12%
46.8% 14.3%
60.8% 17.1%
17.2%
59%
51.8% 17.7%
55.9% 13.8%
10.4%
33%
32.7% 7.7%
67.6% 30.5%
51.4% 16.1%
601
37.8% 6.7%
Tableau 1: Detailed book information can be accessed from the ¨ONB portal using the barcode.
approach combining dictionary lookup and SMT
for word segmentation and error correction. Comment-
jamais, the dataset used for training is limited to
books of the same topic, and requires manual
supervision in terms of feature engineering.
Sequence Learning. As is shown later, charac-
ter based RNN models (Xie et al., 2016; Schnober
et coll., 2016) are insufficient to capture the com-
plexity of compound-rich languages like German.
Alternativement, ConvNets have been successfully
applied in sequence learning (Gehring et al.,
2017b,un). Although the performance of ConvN
et alone is insufficient for post-hoc correction,
we show that their combination yields optimal
post-hoc correction performance.
OCR Engines. Slightly related are the works of
Reul et al. (2018un,b), which retrain OCR engines
on a specific domain. The assumption is that clean
line scans with the same fontface are available. Dans
this way, the trained OCR engines are more robust
in transcribing text scans of the same fontface.
Chiffre 1 shows that this is rarely the case, et
many characters induce orthographic ambiguity.
En outre, in many cases the OCR process
is unknown, with image scans being the only
material available.
3 Data Collection & Ground-Truth
Dans cette section, we describe our data collection
efforts and the ground-truth construction process.
Actuellement, there is no large-scale historical corpus
in German language that can be used for post-hoc
correction of OCR transcribed texts. The collected
corpus and constructed ground-truth of more than
854k pairs of OCR transcribed textual snippets
and their corresponding manual transcriptions,
together with the source code are available.1
3.1 Book Corpus
We first describe the process behind selecting our
corpus of historical books in German language.
As our input textual snippets for OCR post-hoc
correction we consider the publicly available his-
torical collection of transcribed books, which are
freely accessible by the Austrian National Library
(OeNB).2 The transcription of books from their
image scans is done in partnership with Google
Books project, which uses Google’s proprietary
OCR frameworks. Given that
this process is
an automated process, the transcriptions are not
error free.
For the ground-truth transcriptions we turn
to another publicly available collection, namely,
Deutsches Textarchiv (DTA).3 It contains man-
ually transcribed books based on community
efforts. The transcriptions are error free and as
such are suitable to be used as our ground-truth.
We consider the overlap of books present in both
DTA and OeNB, providing us with the erroneous
input textual snippet from OeNB and the corre-
sponding target error-free transcription from DTA.
Tableau 1 shows our books corpus, consisting
of the overlap between these two repositories,
1https://github.com/GarfieldLyu/OCR POST DE.
2https://www.onb.ac.at/.
3http://www.deutschestextarchiv.de/.
481
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: Vocabulary overlap between books.
avec 12 books in German language from the
16th–18th centuries. Understandably, considering
the publication period, there is little overlap across
the different books. Chiffre 2 shows the vocab-
ulary overlap between books, which on average
is around 20%. This presents an indicator of a
corpus with high diversity and low redundancy,
representing a realistic and challenging evaluation
scenario for post-hoc correction.
3.2 Ground-Truth Construction
The constructed ground-truth consists of
le
mapped OCR transcribed text to their manually
transcribed counterparts, resulting in a paral-
lel corpus of OCRed input text and the target
manually transcribed counterparts.
To construct the parallel corpus is challenging.
OCR transcribed books contain all pages (par exemple.,
content and blank pages), while the manually
transcribed books keep only the content pages.
En outre, books are typically transcribed line
by line by OCR systems, which often fail to detect
page layout boundaries (multi-column layouts or
printed margins). Donc, accurate ground-truth
construction even at page level is challenging.
An important aspect is the granularity of paral-
lel snippets. Chiffre 3 shows the average sentence
length distribution for OCR and manually tran-
scribed books. We consider sentences, which are
demarcated by the symbol ‘‘/’’, when this infor-
mation is not available we fall back to text lines.
The average sentence length is 5–6 tokens, avec
an average of up to 100 characters.
Donc, we consider snippets of 5 tokens for
mapping, as longer ones (par exemple., paragraphs), sont
Chiffre 3: Sentence length distributions.
highly error prone. En outre, depending on
scan quality, page content (par exemple., if it contains
figures or tables),
the error rates from OCR
transcriptions can vary greatly from page to page,
making it impossible to consider lengthier snippets
for the automated and large-scale ground-truth
construction.
To construct an accurate ground-truth for OCR
post-hoc correction, we propose the following two
steps: (je) approximate matching, et (ii) accurate
refinement.
3.2.1 Approximate Snippet Matching
From the OCR transcribed books, we generate
textual snippets of 5 tokens length and compute
approximate matches to snippets of 5–104 tokens
from the manually transcribed books. Approxi-
mate matching at this stage is required for two
raisons: (je) text lines from OCR and manually
transcribed books are not aligned at line level
in the books, et (ii) an exhaustive pair-wise
comparison of all possible snippets of length 5 est
very expensive.
We rely on an efficient technique known as
locality sensitive hashing (LSH) (Rajaraman and
Ullman, 2011) to put textual snippets that are
loosely similar into the same bucket, and then
based on the Jaccard similarity determine the
highest matching pair. The hashing signatures and
the Jaccard similarity are computed on character
tri-grams.
The resulting mappings are not error free, et
often contain extra or missing words. Such errors
are introduced often due to the OCR engines
4Lengthier snippets are necessary due to segmentation
errors, resulting in longer snippets.
482
Ideal
Chiffre 4:
snippet alignment. Gap
characters ‘‘-’’ and additional characters are removed
from both sides.
textual
breaking over the multi-column layouts of books,
inclusion of table/figure captions, word segmenta-
tion errors (under or over segmentation). Snippets
from OCR transcriptions that do not have a
matching above a threshold (< 0.8) are dropped.
Matching Coverage: Finally, to ensure that
our ground-truth construction approach does not
severely affect coverage of the matched pairs,
we conduct a manual analysis of two books with
different layouts (books ID 6 and 11, cf. Table 1)
for 10 randomly selected pages from each book.
For book 6, which has good scan quality, for
snippets of 5 tokens, we are able to find a relevant
match from the manual transcription on average
for 270 out of 300 snippets per page. The dropped
snippets in absolute majority of the cases consist
of footnotes or page headings. In the case of book
11, which has a bad scan quality and is of double
column layout, from 400 snippets, only 200 have
a match. Upon inspection, we find that this is
mostly due to the erroneous transcription by OCR
systems, which mistakenly merges lines from
different columns into a single line. These snippets
are corrupted, and cannot be matched to snippets
extracted from the manually transcribed books.
3.2.2 Accurate Refinement
The main issue with the approximate matching
through LSH, is that there are extra words appear-
ing at the head or end of either the input or
output snippets. The extra tokens stem mostly
from snippets that match lengthier or shorter
ones due to word segmentation errors. Such addi-
tional/missing words are not desirable, and thus,
in this stage we refine the above snippet mappings.
We perform a local pairwise sequence alignment5
that finds the best matching local sub-snippets.
The remaining extra characters are removed (e.g.,
tokens ‘‘fen’’ and ‘‘Willk¨uhr’’ are removed as
they are not part of a local alignment).
5https://biopython.org/DIST/docs/api/Bio
.pairwise2-module.html.
483
Figure 5: Book OCR error type distribution.
4 Data Analysis
Based on a manual analysis of a random sample
of 100 snippet pairs taken from each book from
our ground-truth, we analyze the various OCR
transcription error types.
This is a crucial step towards developing
post-hoc correction models in a systematic man-
ner. OCR errors are highly contextual and are
dependent on several factors, and as such there
are no one-to-one rules that can be used to cor-
rect OCR errors. Furthermore, these errors are
increased when dealing with historical corpora,
as fontfaces, book layouts, and language use are
highly unstandardized.
the
We
between
differentiate
following
errors: (i) over-segmentation is an error when
multiple words are merged into one, (ii) under-
segmentation when a word is split into two, and
(iii) word error, typically caused by misrecog-
nized characters, converting it into an invalid
word or changing its meaning to a different valid
word.
4.1 Error Types and Distribution
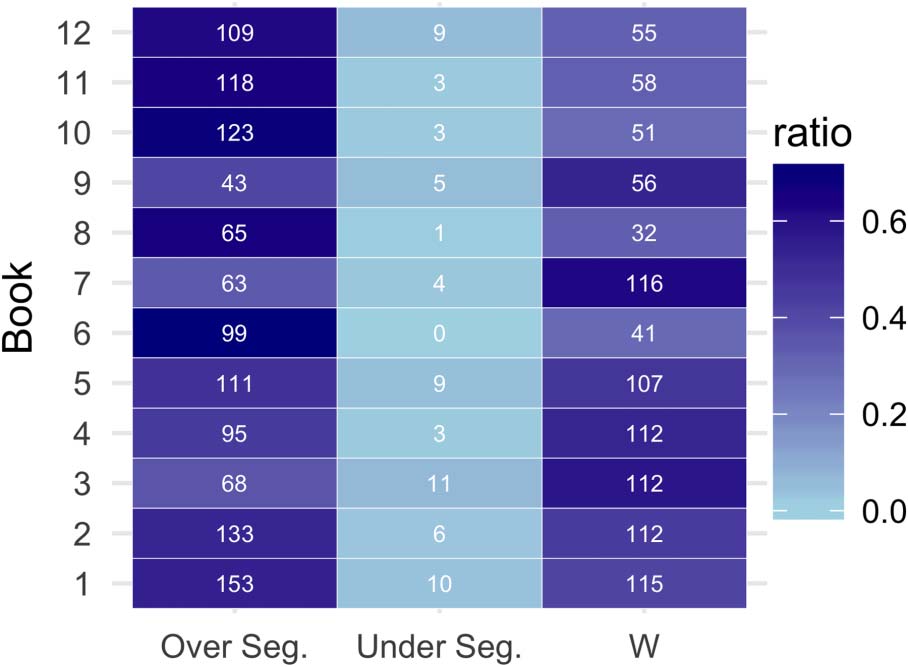
Figure 5 shows an overview of the error types for
the different books in our corpus.
Over-segmentation is one of the most common
OCR transcription errors, with 54% of the cases.
The errors often arise due to OCR systems mis-
recognizing spaces between words and characters
in a word, as these are often not clearly distin-
guishable. These errors are challenging since the
words may represent valid words, which is an
even more challenging problem for compound
rich languages like German.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
l
a
c
_
a
_
0
0
3
7
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
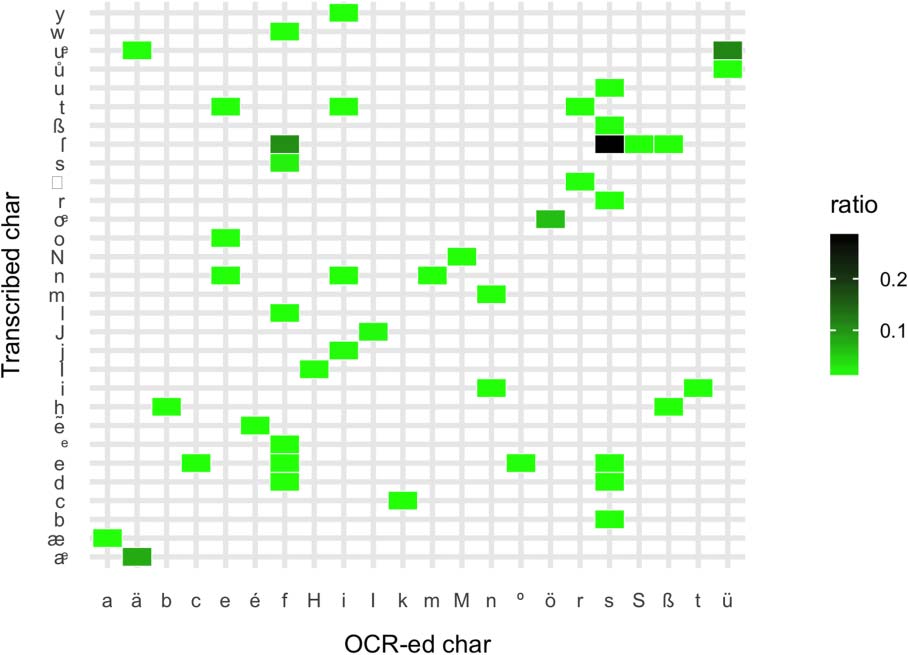
Figure 6: The misrecognized character (x–axis) and
their valid transcriptions (y–axis).
Under-segmentation errors are less common
(with 3%), and are mostly due to line-breaks and
book layouts.
Word-errors represent the second most fre-
quent OCR error category with 43%. These errors
are often caused due to the orthographic visual
similarity between characters, thus resulting in
invalid words or changing the word’s meaning
altogether. Other relevant factors are the scan
quality or book layouts.
Figure 6 shows that word errors are contextual,
with no simple mappings between misrecgonized
characters. An indicator that they are not solely
due to visual character similarity, as they are often
misrecognized to completely different characters.
5 Neural OCR Post-Hoc Correction
Figure 7 shows an overview of our encoder-
decoder architecture for post-hoc OCR correction.
At its core, the encoder combines RNN and deep
ConvNets for representation of the erroneous
OCR transcribed snippets at the character level.
During the decoder phase an RNN model corrects
the errors one character at a time by using an
attention mechanism that combines the encoder
representations, a process repeated until an end of
a sentence is encountered.
5.1 Encoder Network
We encode the erroneous OCR snippets at the
character level for three reasons. First, word
representation is not feasible due to word errors.
Second, only in this way can we capture erroneous
characters. Finally, we avoid OOV issues, as there
are no vocabularies for historical corpora.
484
Figure 7: Approach overview.
The encoder consists of a RNN and a deep
ConvNet network. The intuition is that RNNs
capture the global context on how OCR errors are
situated in the text, while deep ConvNets capture
and enforce local sub-word/phrase context. This
is necessary for word segmentation errors, which
might bias RNN models towards more frequent
tokens (e.g., ‘‘alle in’’ vs. ‘‘allein’’).6
5.1.1 Recurrent Encoder
(cid:3)
.
(cid:2)−−−−→
LST M(X),
First, we apply a bidirectional LSTM (Hochreiter
and Schmidhuber, 1997) that reads the erroneous
OCR snippet X = (x1, . . . , xT ), encoding it into
←−−−−
LST M(X)
hT =
We use recurrent models because of their ability
to detect erroneous characters and to capture the
global context of the OCR errors. In § 4 we
showed that for most of the erroneous characters,
the target transcribed characters vary, a variation
that can be resolved by the general context of the
snippet.
Finally, we will use hT
to conditionally
initialize the decoder, since the input and output
snippets are highly similar.
5.1.2 Convolutional Encoder
We find that 57% of errors are word segmentation
errors. Often, these errors have a local behavior,
such as merging or splitting words. While in the-
ory this information can be captured by the RNN
encoder, we notice that they are biased towards
frequent sub-words in the corpora with tokens
being wrongly split or merged.
We apply deep ConvNets to capture the local
context (i.e., compound information) of tokens.
ConvNets through their kernels limit the influence
that characters beyond a token’s context may have
6Both tokens are correct, with the first being more
frequent.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
l
a
c
_
a
_
0
0
3
7
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
in determining whether the subsequent decoded
characters forming a token should be split or
merged.
We set the kernel size to 3 and test several con-
figurations in terms of ConvNet layers, which we
empirically assess in § 7.2. Since we are encoding
the OCR input at character level, determining the
right granularity of representation is not trivial.
Hence, the multiple layers l will flexibly learn
from fine to coarse grained representation of the
input. The learned representation at layer l is
denoted as hl =
l, . . . , hT
. In between each
of the layers, we apply non-linearity such as gated
linear units (Dauphin et al., 2017) to control how
much information should pass from the bottom to
the top layers.
h1
(cid:4)
(cid:5)
l
5.2 Decoder Network
the corrected textual
The decoder is a single LSTM layer, which
snippet one
generates
character at a time. We initialize it with the last
hidden state from the BiLSTM encoder hT , that
is, o1 = hT in Equation (1), which biases the
decoder to generate sequences that are similar to
the input text.
(cid:6)
p
oi|oi − 1, . . . , o1, x
(cid:7)
(cid:6)
(cid:7)
= g
oi − 1, di, ci
(1)
where di is the current hidden state of the decoder,
and oi−1
represents the previously generated
character. ci is the context vector from the encoded
OCR input snippe, which combines the RNN
and deep ConvNet input representations through
a multi-layer attention mechanism, which we
explain below.
5.2.1 Multi-layer Attention
Using jointly RNNs with deep ConvNets as
encoders allows for greater flexibility in capturing
the complexities of OCR errors. Furthermore, the
multi-layers of the ConvNets capture from fine
to coarse grained local structures of the input.
To harness this encoding flexibility, we compute
the context vector ci for each decoder step di as
following.
First, for each decoder state di at step i,
we compute the weight of the representations
computed by the deep ConvNet at the different
layers. The weights, computed in Equation 2,
correspond to the softmax scores, which are
computed based on the dot product between di
485
and the hidden layers hl
ConvNet.
j from the l layers of the
al
ij =
(cid:8)
exp(el
ij)
T
k=1 exp(el
; el
ij = di · hl
j
(2)
ik)
At each layer l in the ConvNet encoder, the
attention weights assess the importance of the
representations at the different granularity levels
in correcting the OCR errors during the decoder
phase. To compute ci, we combine the RNN and
deep ConvNet representations, as scaled by the
attention weights as following:
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
l
a
c
_
a
_
0
0
3
7
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ci =
1
L
L(cid:9)
T(cid:9)
l=1
j=1
al
ij
· [hl
j, hj]
(3)
5.3 Weighted Loss Training
Conventionally, encoder-decoder architectures
are trained using the cross-entropy loss, L =
−Ptgt · log Ppred, with Ptgt and Ppred being the
target and the predicted probability distributions
of some discrete vocabulary.
For OCR post-hoc correction, cross-entropy
does not properly capture the nature of this task.
Models are biased to simply copy from input to
output, which in this task represent the majority of
cases. In this way, failure at correcting erroneous
characters diminish, as all time-steps are treated
equally. We propose a weighted loss function
that rewards higher models for their correcting
behavior. The modified loss function is shown in
Equation 4.
(cid:6)
(cid:7)
L(cid:5) = L ·
1 − λPsrc · Ptgt
; 0 < λ < 1
(4)
The new loss function combines the cross-
entropy loss L and an additional factor that
considers the source and target characters. The
second part of the equation captures the amount
of desirable copying from input to output. If the
input and output characters are the same, then
Psrc · Ptgt yields 1, otherwise 0, where Psrc and
Ptgt are one-hot character encodings of the input
and output snippets. λ controls by how much
we want to dampen this behavior. L(cid:5) rewards
higher the model’s ability to correct erroneous
sequences.
6 Experimental Setup
In this section, we introduce the experimental
setup and the competing methods for the task of
post-hoc OCR correction.
6.1 Evaluation Scenarios
According to our error analysis in § 4 and the
highly diverging vocabularies across books (cf.
§ 3.1), we distinguish two evaluation scenarios.
Here we use part of the ground-truth, where we
select instances by first sampling pages from the
books, namely the instance pairs coming from the
sampled pages.
We assess the performance of models for two
significant factors that may impact their correction
behavior: (i) eval–1 assesses the model’s post-hoc
correction behavior on unseen OCR transcription
errors related to the book source and publication
date, and diverging book content (cf. Figure 2),
and (ii) eval–2 tests the impact on correction
performance when models have encountered all
OCR errors based on random sampling.
eval–1: We split the data along the temporal
axis, with training instances coming from books
from the 16th and 18th centuries, and test instances
from the 17th century. This scenario is challeng-
ing as there are diverging error types due to scan
quality, and other orthographic variations related
to the publishers and other book characteristics.
The 17th century books have more diverse errors,
as there are more books, and the initial OCR
transcription error rates are higher.
We use 70% of the data for training, and 10%
and 20% for validation and testing, with 269k,
27k, and 89k instances respectively.
eval–2: We randomly construct
the training,
validation, and testing splits, thus ensuring that
the models have observed all error types, which
should result in better post-hoc correction behav-
ior. Furthermore, contrary to eval–1, where the
splits are dictated by the publication date of the
books, in this case, we use slightly different splits
for training, validation, and testing. We use 65%,
10%, and 25%, for training, validation, and test-
ing, respectively. The absolute number is 417k,
42k, and 166k, respectively.
6.2 Evaluation Metrics
length of the transcribed sequence, in characters
for CER and number of words for WER.
6.3 Baselines
In the following we describe the approaches
we compare against. In all cases, the input is
represented at character level with 128 embed-
ding dimensions. The cell units (i.e., LSTMs and
ConvNets) are of 256 dimensions.
CH: Xie et al. (2016) use an RNN model for
spelling correction, a task slightly similar to OCR
post-hoc correction. Yet, the error types and their
distribution are of a different nature. CH is a stan-
dard attention based encoder-decoder (Bahdanau
et al., 2015), that corresponds to our CR model
without ConvNets and the custom loss function.
CHλ: To assess the impact of the introduced
loss function, we train CH with the custom loss
(cf. § 5.3). The optimal λ is set based on the
validation set. This presents the ablated model of
our approach CR without the ConvNet encoder
and mult-layer attention.
PB: Cohn et al. (2016) propose a symmetric
attention mechanism for RNN based encoder-
decoder models. That is, encoder and decoder
timesteps are strongly aligned. A similar align-
ment between input and output is expected for
this task.
Transformer: By pretraining on large corpora,
Transformers have (Vaswani et al., 2017) achieved
the state-of-the-art results in various NLP tasks.
In our case, pretraining on historical corpora is
not possible due to the scarcity of such data, while
pretraining on contemporary German corpora did
not show any improvement. The self-attention
mechanism is highly flexible in capturing intra-
input and input-output dependencies, which is
very important for post-hoc correction. We use
the implementation in TK (Gagnon-Marchand
and LJQ., n.d.) with 3 layers and 8 attention
heads, and 512 dimensions for the output model,
and encode input at character level.
To assess the post-hoc correction performance of
the models, we use standard evaluation metrics
for this task: (i) word error rate (WER), and (ii)
character error rate (CER). The error rates mea-
sure the number of word/character substitutions,
insertions, and deletions, normalized by the total
Other Approaches: ConvSeq (Gehring et al.,
2017b), part of our encoder network, yields per-
formance below all the other competitors, hence
we do not include its results here. Similarly, rule-
based models based on FST (Silfverberg et al.,
2016) yield poor performance. We believe this is
486
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
l
a
c
_
a
_
0
0
3
7
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
due to the inability to establish one-to-one map-
ping of rules for correction, and the requirement
for valid word vocabularies.
6.4 CR: Approach Configuration
For our approach CR, based on a validation set,
the number of ConvNet layers is set to k = 1 and
k = 3, and set λ = 0.3 and λ = 0.1, for eval–1
and eval–2, respectively.
7 Evaluation
In this section, we provide a detailed evaluation
discussion and discuss limitations.
1. Post-hoc correction evaluation as measured
through WER and CER metrics.
2. Ablation study for our approach CR.
3. Performance of CR for post-hoc correction
at page level.
4. Robustness and generalizability of our
approach for post-hoc correction.
5. CR model behavior error analysis.
7.1 Post-Hoc OCR Error Correction
All post-hoc OCR correction approaches under
comparison significantly reduce the amount of
OCR errors. Tables 2 and 3 provide an overview
of the performance as measured through WER
and CER metrics.
eval–1. Table 2 shows the results for competing
approaches for the eval–1 scenario. This scenario
mainly shows how well the models generalize
in terms of language evolution, where instances
come from books written in a different century.
Note that, apart from the temporal dimension,
another important aspect is that of publisher’s spe-
cific attributes. Dependent on the publisher, there
are orthographic variations, vocabulary, and other
stylistic features, such as font-face, and so on.
In principle, low WER translates into fewer
word segmentation (WS) errors, with WS errors
being some of the most frequent errors (cf.
Figure 5). Hence, reducing WER is critical for
post-hoc OCR correction models. Our model, CR,
achieves the best performance with the lowest
score of WER=5.98%. This presents a relative
decrease of Δ = 82% compared to the WER in
the original OCR text snippets. In terms of CER
WER
CER
OCR
CH
CHλ=0.4
PB
Transformer
CR
33.3
7.64 ((cid:2)77%)
7.46 ((cid:2)78%)
11.45 ((cid:2)66%)
8.11 ((cid:2)76%)
5.98 ((cid:2)82%)∗
6.1
2.79 ((cid:2)54%)
2.53 ((cid:2)59%)
3.05 ((cid:2)50%)
2.24 ((cid:2)63%)
2.07 ((cid:2)66%)∗
Table 2: Correction results for eval–1. CR
achieves highly significant (∗) improvements over
the best baseline CHλ.
WER
CER
OCR
CH
CHλ=0.3
PB
Transformer
CR
32.3
4.08 ((cid:2)87%)
4.09 ((cid:2)87%)
9.21 ((cid:2)71%)
4.50 ((cid:2)86%)
3.59 ((cid:2)89%)∗
5.4
1.32 ((cid:2)76%)
1.35 ((cid:2)75%)
1.93 ((cid:2)64%)
1.07 ((cid:2)80%)∗
1.31 ((cid:2)76%)
Table 3: Correction results for eval–2. CR
obtains highly significant
improvements
over the best baseline CHλ for WER, while
Transformer has significantly the lowest CER.
(∗)
we have a relative decrease of Δ = 66%, namely,
with CER=2.07%.
Comparing our approach CR against CHλ (the
best competing approach in eval–1), we achieve
highly significant (p < .001) lower WER and
CER scores, as measured according to the non-
parametric Wilcoxon signed-rank test with correc-
tion.7 For WER and CER, CR compared to CHλ
obtains a relative error reduction of 21.7% and
25.8%, respectively. This shows that ConvNets
allow for flexibility in capturing the different con-
stituents of a word compound, that in turn may
result in either over or under segmentation error.
Against the other competitors the reduction
rates are even greater. Transformers has the low-
est CER among the competitors, yet compared
to CR its CER has a 8% relative increase. PB,
performs the worst, mainly due to the character
shifts (left or right) incurred due to word segmen-
tation errors. Thus, strictly enforcing the attention
mechanism along very close or the same positions
7We test for normality of distributions, and conclude that
the produced WER and CER measures do not follow a normal
distribution.
487
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
l
a
c
_
a
_
0
0
3
7
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
in the encoder-decoder results in sub-optimal
post-hoc OCR correction behavior.
eval–2. Table 3 shows the results for the eval–2
scenario. Due to the randomized instances for
the models have greater
training and testing,
ability in correcting OCR errors. Contrary to
eval–1, where the models were tested on instances
coming from later centuries, in this scenario, the
models do not suffer from language evolution
aspects and other book specific characteristics.
Therefore,
this presents an easier evaluation
scenario.
Here too the models show a similar behavior as
for eval–1. The only difference in this case being
that our approach CR does not achieve the best
CER reduction rates. CR obtains highly significant
lower (p < .001) WER rates than the Transformer.
On the other hand, Transformer achieves the best
CER rates among all competitors (p < .001).
The significance tests are measured using the
non-parametric Wilcoxon signed-rank test.
This presents an interesting observation, show-
ing that Transformers are capable in learning all
the complex cases of character errors. This behav-
ior can be attributed to their capability in learning
complex intra-input and input-output dependen-
cies. However, in terms of WER, we see that a
large reduction is achieved through ConvNets in
CR, yielding the lowest WER rates, with a relative
decrease of 89% in terms of WER. This conclusion
can be achieved when we inspect CHλ, which is
the ablated CR model without ConvNet encoders.
7.2 Ablation Study
In the ablation study we analyze the impact of the
varying components introduced in CR.
levels of abstractions
ConvNet Layers. The number of
layers
in
provides different
encoding the OCR input. Table 4 shows CR’s
performance with varying number of layers trained
using the standard cross-entropy loss. Increasing
the number of layers for k > 5 does not yield
performance improvements. We note that for
the different evaluation scenarios, the number of
necessary layers varies. Par exemple, in eval–2
the number of optimal layers is 3. This can be
attributed to the higher diversity of errors in the
randomized validation instances, Et ainsi, le
need for more layers to capture the OCR errors.
Loss Function. The loss function in § 5.3
rewards higher the model’s correcting behavior.
488
eval–1
eval–2
WER CER WER CER
CRk=1
CRk=2
CRk=3
CRk=4
CRk=5
CRk=6
CRk=7
CRk=8
CRk=9
CRk=10
6.18
6.46
6.47
6.93
6.63
6.68
6.58
6.56
6.59
6.32
2.15
2.30
2.26
2.51
2.40
2.52
2.60
2.48
2.69
2.52
3.72
4.18
3.61
3.54
3.92
3.94
3.90
3.64
3.84
3.61
1.29
1.46
1.26
1.31
1.38
1.50
1.50
1.54
1.60
1.62
Tableau 4: WER and CER values for CR with
varying number of ConvNet layers trained
using standard loss function.
eval–1
eval–2
WER CER WER CER
CRλ=0.1
CRλ=0.2
CRλ=0.3
CRλ=0.4
CRλ=0.5
CRλ=0.6
6.22
6.31
5.98
6.37
6.37
6.63
2.16
2.17
2.07
2.17
2.16
2.22
3.59
3.79
4.24
3.90
3.83
3.90
1.31
1.42
1.51
1.33
1.45
1.41
Tableau 5: WER and CER results for CR with
different λ for custom loss function.
Tableau 5 shows the ablation results for CR with
varying λ values for L(cid:5) and fixed ConvNet layers
(k = 1 and k = 3) as the best performing
configurations in Table 4. Here too due to
the different characteristics of the evaluation
scenarios, different λ values are optimal for CR.
We note that for eval–1, a higher λ of 0.3 yields the
best performance. This shows that for diverging
train and test sets (par exemple., eval–1), the models need
more stringent guidance in distinguishing copying
from correcting behavior.
7.3 Page Level Performance
Evaluation results in § 7.1 convey the ability
of models to correct erroneous input at snippet
level. Cependant, there are challenges on applying
post-hoc correction models on real-world OCR
transcriptions, which do not have their textual con-
tent separated into coherent and non-overlapping
snippets.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
action
description
#Train
#Dev
#Test Book IDs
S
M.
R.
accuracy of token segmentation
accuracy of token merging
accuracy of token character replace-
ment (insertion/update/delete)
Tableau 6: Page level actions are used to measure
the model’s performance at page level.
page
S
M.
R.
actions
9
10
16
17
–
–
0.737 (19)
0.878 (66)
0.586 (29)
0.976 (83)
0.960 (50) 0.0 (1) 0.652 (23)
0.621 (29)
0.933 (90)
–
85
112
73
119
Tableau 7: Precision for S, M., R actions. In brackets
are the number of undertaken actions, et le
rightmost column has all actions.
Dans cette section, for our model CR, at page level
we assess the accuracy of undertaken actions in
correcting the erroneous input text to its target
formulaire. Tableau 6 shows the set of actions that a
model can undertake. We carry out a manual
evaluation on an out-of-corpus book (book code
Z168355305), that is not present in our ground-
truth, for which we randomly sample a set of
4 pages.
We apply CR, namely, assess the accuracy of
actions of correction during the decoding phase,
over the OCR transcribed pages line by line with
a window of 5 tokens. For each decoding step that
produces an output that is different from the input,
we assess the accuracy of that action. Tableau 7
shows the precision of CR for the different set of
actions for the different pages. The results show
that CR is robust and can be applied without much
change even at page level with high accuracy of
post-hoc correction behavior.
7.4 Robustness
We conduct a robustness test of the CR approach
to check: (je) in-group post-hoc correction perfor-
mance, where test instances come from the same
books as the training ones, et (ii) out-of-group,
where we train on one group and test on the rest
of the groups. Tableau 8 shows the groups of books
we use for (je) et (ii).
Tableau 9 shows the in-group and out-of-group
post-hoc correction scores for CR when using
G1
G2
G3
312k
58.9k
217.3k
34.7k
6.5k
24k
86.1k
17.2k
59.8k
(8, 5, 12, 11)
(2, 1, 3, 10)
(4, 7, 6, 9)
Tableau 8: Book splits for assessing CR robustness.
G1
G2
G3
WER CER WER CER WER CER
5.8
31.2
OCR 28.1
7.1
5.7
2.9
5.6
4.4
6.3
4.4
4.8
34.0
standard loss function
24.7
15.9
18.9
custom loss function
24.2
17.0
18.7
5.6
4.1
4.6
2.8
5.1
4.3
18.9
20.2
10.4
18.4
20.3
10.3
4.9
4.9
2.6
4.4
4.4
2.5
G1
G2
G3
G1
G2
G3
10.1
21.5
16.9
10.1
21.5
16.9
Tableau 9: CR results with k = 1 trained using the
standard and custom loss function with λ = 0.1.
a single ConvNet layer, using the standard and
the custom loss functions, respectivement. It can
be seen that when the models are trained on a
similar corpus (in-group), the error reduction is
significantly higher compared to the evaluation
on the out-of-group corpus. En outre, we note
that the custom loss function consistently provides
better trained models for post-hoc correction.
The results in Table 9 show that CR is robust
providing highly significant decrease in terms of
WER and CER, with an average of WER decrease
de 52% for in-group with both the standard and
custom loss. Whereas the out-of-group WER
reduction is with 34% et 35% using the standard
and custom loss, respectivement. In terms of CER,
for in-group we get a CER decrease of 47.6% et
50% for standard and custom loss, respectivement.
The advantage of the custom loss is shown for
out-of-group evaluation, where the CER decrease
is much more significant with 16.71% for standard
loss function compared to 23.3% using the custom
loss function.
From the three groups, when training on G3
the out-of-group post-hoc correction performance
is the highest. This shows that on historical
corpora, depending on the initial OCR error rate
and possibly the error types due to the book’s
489
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
characteristics impact significantly the correction
performance.
7.5 Error Analysis
Here we analyze the structure of some typical
errors that we fail to correct.
de
Dans
termes
Word Segmentation.
over-
segmentation,
the importance of the ConvNet
layers in CR is shown when compared against
CH and CHλ. Common word segmentation errors
for CH and CHλ are, Par exemple, ‘‘Jndem’’
to ‘‘Jn’’ and ‘‘dem’’, ‘‘Jedoch’’ to ‘‘Je’’ and
‘‘doch’’.
to ‘‘vor beyftre-
ichen’’. Most of these errors can be traced back to
frequent constituents of the compound that exist
in isolation too.
‘‘vorbeyftreichen’’
Character Error. There are easy charac-
ter errors such as ‘‘mein’’ which is OCRed to
‘‘mcin’’ and is fixed by all approaches. Cependant,
for some words like ‘‘l¨ofcken’’, models like CH
and Transformer correct them to the right word
‘‘l¨ofeten’’. CR fails to do so due to some frequent
character bigrams such as ‘‘ck’’ that are very
frequent in the dataset.
8 Conclusion
In this work we assessed several approaches
towards post-hoc correction. We find out that
OCR transcription errors are contextual, and a
large set are due word-segmentation, suivi de
word-errors. Models like Transformers have lim-
ited utility in this task, as pre-training is difficult to
undertake, given the scarcity of historical corpora.
We proposed a OCR post-hoc correction
approach for historical corpora, which provides
flexible means to capturing various OCR tran-
to language
scription errors that are subject
evolution,
issues.
Through our approach CR we achieve great
WER reduction rates with 82% et 89% pour
eval–1 and eval–2 scenarios, respectivement.
typeface and book layout
En outre, ablation studies show that all the
introduced components in CR yield consistent
improvement over the competitors. Apart from
post-hoc correction performance at snippet level,
CR proved to be robust at page level too, where the
undertaken correction steps are highly accurate.
Enfin, we construct a release a new dataset
for post-hoc correction of historical corpora in
German language, consisting of more than 850k
parallel textual snippets, which can help facilitate
research for historical and low-resource corpora.
7.6 Dataset Limitations
Remerciements
The OCR quality can vary greatly across books,
and from page to page. Based on manual inspec-
tion, we note that in some cases the WER can go
well beyond 80%. It is expected that in such cases
that the post-hoc OCR correction will vary too.
Other possible issues include competing spellings
for the same word, which may cause the models
to encode conflicting information, yet, for tran-
scribing historical texts, language normalization
(c'est à dire., opting for one spelling) is not recommended,
as the meaning of the texts may change.
Language Evolution. There is a significant
difference between eval–1 and eval–2 in terms of
correction results. One explanation is due to the
word spelling variations across centuries. Some
examples include the substitution of single char-
acters in words, which if not known would lead to
systematic correction mistakes, par exemple., j → i, v → u,
un. Accordingly, due to the missing
information about the spelling change in eval–1,
the corresponding WER and CER rates are higher.
→ s, ¨a → e
This work was partially funded by Travelogues
(DFG: 398697847 and FWF: I 3795-G28).
Les références
Haithem Afli, Zhengwei Qiu, Andy Way, et
P´araic Sheridan. 2016. Using SMT for OCR
texts. En Pro-
error correction of historical
ceedings of the Tenth International Conference
on Language Resources and Evaluation LREC
2016, Portoroˇz, Slovenia, May 23–28, 2016.
European Language Resources Association
(ELRA).
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
jointly learning to align and translate. In 3rd
International Conference on Learning Repre-
sentations, ICLR 2015, San Diego, Californie, Etats-Unis,
May 7–9, 2015, Conference Track Proceedings.
Miguel Ballesteros, Chris Dyer, and Noah A.
Forgeron. 2015. Improved transition-based parsing
490
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
by modeling characters instead of words with
lstms. In Proceedings of the 2015 Conference
on Empirical Methods in Natural Language
Processing, EMNLP 2015, Lisbon, Portugal,
September 17–21, 2015, pages 349–359. Le
Association for Computational Linguistics.
EST CE QUE JE: https://doi.org/10.18653/v1
/D15-1041
Adrien Barbaresi. 2016. Bootstrapped OCR
error detection for a less-resourced language
variant. In Proceedings of the 13th Conference
on Natural Language Processing, KONVENS
2016, Bochum, Allemagne, September 19–21,
2016, volume 16 of Bochumer Linguistische
Arbeitsberichte.
Eric Brill and Robert C. Moore. 2000. Un
improved error model
for noisy channel
spelling correction. In 38th Annual Meeting
of the Association for Computational Linguis-
tics, Hong Kong, Chine, October 1–8, 2000,
pages 286–293. ACL. EST CE QUE JE: https://est ce que je
.org/10.3115/1075218.1075255
Kyunghyun Cho, Bart van Merrienboer, C¸ aglar
G¨ulc¸ehre, Dzmitry Bahdanau, Fethi Bougares,
Holger Schwenk, and Yoshua Bengio. 2014.
Learning phrase representations using RNN
encoder-decoder for statistical machine trans-
lation. In Proceedings of the 2014 Conference
on Empirical Methods in Natural Language
Processing, EMNLP 2014, October 25–29,
2014, Doha, Qatar, A meeting of SIGDAT,
a Special
the ACL,
Interest Group of
pages 1724–1734. ACL.
Junyoung Chung, Kyunghyun Cho, and Yoshua
Bengio. 2016. A character-level decoder with-
out explicit segmentation for neural machine
translation. In Proceedings of the 54th Annual
Meeting of the Association for Computational
Linguistics, ACL 2016, August 7–12, 2016,
Berlin, Allemagne, Volume 1: Long Papers. Le
Association for Computer Linguistics. EST CE QUE JE:
https://doi.org/10.18653/v1/P16
-1160
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina
Vymolova, Kaisheng Yao, Chris Dyer, et
Incorporating
Gholamreza Haffari.
structural alignment biases into an attentional
In NAACL HLT
neural
translation model.
2016.
the North
2016, Le 2016 Conference of
the Association for
American Chapter of
Computational Linguistics: Human Language
Technologies, San Diego California, Etats-Unis,
June 12–17, 2016, pages 876–885. EST CE QUE JE:
https://doi.org/10.18653/v1/N16
-1102
Yann N. Dauphin, Angela Fan, Michael Auli, et
David Grangier. 2017. Language modeling with
gated convolutional networks. In Proceedings
de
the 34th International Conference on
Machine Learning, ICML 2017, Sydney, NSW,
Australia, 6–11 August 2017, volume 70 de
Proceedings of Machine Learning Research,
pages 933–941. PMLR.
Rui Dong and David Smith. 2018. Multi-input
attention for unsupervised OCR correction. Dans
Proceedings of the 56th Annual Meeting of
the Association for Computational Linguis-
tics, ACL 2018, Melbourne, Australia, Juillet
15–20, 2018, Volume 1: Long Papers,
pages 2363–2372. Association for Computa-
tional Linguistics. EST CE QUE JE: https://doi.org
/10.18653/v1/P18-1220
Markus Dreyer, Jason Smith, and Jason Eisner.
2008. Latent-variable modeling of string trans-
ductions with finite-state methods. Dans 2008
Conference on Empirical Methods in Na-
tural Language Processing, EMNLP 2008,
Proceedings of the Conference, 25–27 October
2008, Honolulu, Hawaii, Etats-Unis, A meeting of
SIGDAT, a Special Interest Group of the ACL,
pages 1080–1089. ACL.
Noura Farra, Nadi Tomeh, Alla Rozovskaya, et
Nizar Habash. 2014. Generalized character-
level spelling error correction. In Proceedings
of the 52nd Annual Meeting of the Association
for Computational Linguistics, ACL 2014,
June 22–27, 2014, Baltimore, MARYLAND, Etats-Unis,
Volume 2: Short Papers, pages 161–167. Le
Association for Computer Linguistics. EST CE QUE JE:
https://doi.org/10.3115/v1/P14
-2027
Jonas Gehring, Michael Auli, David Grangier,
and Yann N. Dauphin. 2017un. A convo-
lutional encoder model for neural machine
translation. In Proceedings of the 55th Annual
Meeting of
the Association for Computa-
tional Linguistics, ACL 2017, Vancouver,
491
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Canada, Juillet 30 – August 4, Volume 1: Long
Papers, pages 123–135. Association for Com-
putational Linguistics. EST CE QUE JE: https://est ce que je
.org/10.18653/v1/P17-1012, PMID:
28964987, PMCID: PMC6754825
Jonas Gehring, Michael Auli, David Grangier,
Denis Yarats, and Yann N. Dauphin. 2017b.
Convolutional sequence to sequence learning.
the 34th International
In Proceedings of
Conference on Machine Learning, ICML 2017,
Sydney, NSW, Australia, 6–11 August 2017,
volume 70 of Proceedings of Machine Learning
Research, pages 1243–1252. PMLR.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural Computa-
tion, 9(8):1735–1780. EST CE QUE JE: https://est ce que je
.org/10.1162/neco.1997.9.8.1735,
PMID: 9377276
Nal Kalchbrenner and Phil Blunsom. 2013.
Recurrent continuous translation models. Dans
Actes du 2013 Conference on Em-
pirical Methods in Natural Language Pro-
cessation, EMNLP 2013, 18–21 October 2013,
Grand Hyatt Seattle, Seattle, Washington, Etats-Unis,
A meeting of SIGDAT, a Special Interest Group
of the ACL, pages 1700–1709. ACL.
Yoon Kim, Yacine Jernite, Donne la vie. Sontag, et
Alexander M. Rush. 2016. Character-aware
language models. In Proceedings of
neural
the Thirtieth AAAI Conference on Artificial
Intelligence, February 12–17, 2016, Phoenix,
Arizona, Etats-Unis, pages 2741–2749. AAAI Press.
Yann LeCun, Yoshua Bengio, et d'autres. 1995.
Convolutional networks for images, speech, et
time series. The handbook of brain theory and
neural networks, 3361(10):1995.
Wang Ling, Isabel Trancoso, Chris Dyer, et
Alan W. Noir. 2015. Character-based neural
machine translation. CoRR, abs/1511.04586.
William B. Lund, Douglas
binarization
thresholding
J.. Kennard,
and Eric K. Ringger. 2013. Combining
valeurs
multiple
In Document
to improve OCR output.
Recognition and Retrieval XX, part of
le
IS&T-SPIE Electronic Imaging Symposium,
Burlingame, California, Etats-Unis, February 5–7,
2013, Procédure, volume 8658 of SPIE
Procédure, page 86580R. SPIE.
William B. Lund, Eric K. Ringger,
et
Daniel David Walker. 2014. How well does
multiple OCR error correction generalize? Dans
Document Recognition and Retrieval XXI, San
Francisco, California, Etats-Unis, February 5–6,
2014, volume 9021 of SPIE Proceedings,
pages 90210A–90210A–13. SPIE.
William B. Lund, Daniel David Walker, et
Eric K. Ringger. 2011. Progressive alignment
and discriminative error correction for multiple
OCR engines. Dans 2011 International Conference
on Document Analysis and Recognition, ICDAR
2011, Beijing, Chine, September 18–21, 2011,
pages 764–768. IEEE Computer Society.
Anand Rajaraman and Jeffrey David Ullman.
2011. Mining of Massive Datasets, Cambridge
Presse universitaire. 3.
Christian Reul, Uwe Springmann, Christoph
Wick, and Frank Puppe. 2018un. Improving OCR
accuracy on early printed books by utilizing
cross fold training and voting. In 13th IAPR
International Workshop on Document Analysis
Systems, DAS 2018, Vienna, Austria, Avril
24–27, 2018, pages 423–428.
Christian Reul, Uwe Springmann, Christoph
Wick, and Frank Puppe. 2018b. State of the
art optical character recognition of 19th century
fraktur scripts using open source engines.
CoRR, abs/1810.03436.
G¨ozde G¨ul Sahin and Mark Steedman. 2018.
Character-level models versus morphology
in semantic role labeling. In Proceedings of
the 56th Annual Meeting of the Association
for Computational Linguistics, ACL 2018,
July 15–20, 2018,
Melbourne, Australia,
Volume 1: Long Papers, pages 386–396. Asso-
ciation for Computational Linguistics. EST CE QUE JE:
https://doi.org/10.18653/v1/P18
-1036, PMID: 30102173
Carsten Schnober, Steffen Eger, Erik-Lˆan Do
Dinh, and Iryna Gurevych. 2016. Still not there?
Comparing traditional sequence-to-sequence
models to encoder-decoder neural networks
on monotone string translation tasks.
Dans
COLING 2016, 26th International Conference
on Computational Linguistics, Proceedings of
the Conference: Technical Papers, Décembre
492
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Jules Gagnon-Marchand and LJQ. n.d. https://
github.com/Lsdefine/attention-is
-all-you-need-keras/blob/master
/transformer.py.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017.
Attention is all you need. In Advances in
Neural Information Processing Systems 30:
Annual Conference on Neural
Information
Processing Systems 2017, 4–9 December 2017,
Long Beach, Californie, Etats-Unis, pages 5998–6008.
Ziqi Wang, Gu Xu, Hang Li, and Ming Zhang.
2014. A probabilistic approach to string trans-
formation. IEEE Transactions on Knowledge
and Data Engineering, 26(5):1063–1075. EST CE QUE JE:
https://doi.org/10.1109/TKDE.2013
.11
Ziang Xie, Anand Avati, Naveen Arivazhagan,
Dan Jurafsky, and Andrew Y. Ng. 2016.
Neural
language correction with character-
based attention. CoRR, abs/1603.09727.
Shaobin Xu and David A. Forgeron. 2017. Retrieving
and combining repeated passages to improve
OCR. Dans 2017 ACM/IEEE Joint Conference on
Digital Libraries, JCDL 2017, Toronto, ON,
Canada, June 19–23, 2017, pages 269–272.
IEEE Computer Society.
11–16, 2016, Osaka, Japan, pages 1703–1714.
ACL.
Sarah
et
Schulz
Jonas Kuhn.
2017.
Multi-modular domain-tailored OCR post-
le 2017
In Proceedings of
correction.
dans
sur
Conference
Natural
EMNLP
Language
2017, Copenhagen, Denmark,
Septembre
9–11, 2017, pages 2716–2726. Associa-
tion for Computational Linguistics. EST CE QUE JE:
https://doi.org/10.18653/v1/D17
-1288
Empirical Methods
Processing,
Miikka Silfverberg, Pekka Kauppinen,
et
Krister Lind´en. 2016. Data-driven spelling
correction using weighted finite-state methods.
In Proceedings of
the SIGFSM Workshop
on Statistical NLP and Weighted Automata,
pages 51–59. Association for Computa-
tional Linguistics, Berlin, Allemagne. EST CE QUE JE:
https://doi.org/10.18653/v1/W16
-2406
Ilya Sutskever, Oriol Vinyals, and Quoc V.
Le. 2014. Sequence to sequence learning
with neural networks. In Advances in Neural
Information Processing Systems 27: Annual
Conference on Neural Information Processing
Systems 2014, December 8–13 2014, Montréal,
Québec, Canada, pages 3104–3112.
493
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
3
7
9
1
9
2
4
0
6
2
/
/
t
je
un
c
_
un
_
0
0
3
7
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3