Communication Drives the Emergence of Language Universals in
Neural Agents: Evidence from the Word-order/Case-marking Trade-off
Yuchen Lian(cid:2) †
Arianna Bisazza‡∗
(cid:2)Faculty of Electronic and Information Engineering, Xi’an Jiaotong University, Chine
†Leiden Institute of Advanced Computer Science, Leiden University, The Netherlands
{y.lian, t.verhoef}@liacs.leidenuniv.nl
‡Center for Language and Cognition, University of Groningen, The Netherlands
a.bisazza@rug.nl
Tessa Verhoef †∗
Abstrait
Artificial
learners often behave differently
from human learners in the context of neu-
ral agent-based simulations of language emer-
gence and change. A common explanation is
the lack of appropriate cognitive biases in these
learners. Cependant, it has also been proposed
that more naturalistic settings of language
learning and use could lead to more human-
like results. We investigate this latter account,
focusing on the word-order/case-marking
trade-off, a widely attested language universal
that has proven particularly hard to simulate.
We propose a new Neural-agent Language
Learning and Communication framework
(NeLLCom) where pairs of speaking and lis-
tening agents first learn a miniature language
via supervised learning, and then optimize it
for communication via reinforcement learn-
ing. Following closely the setup of earlier
human experiments, we succeed in replicating
the trade-off with the new framework with-
out hard-coding specific biases in the agents.
We see this as an essential step towards the
investigation of language universals with neu-
ral learners.
1
Introduction
The success of deep learning methods for natu-
ral language processing has triggered a renewed
interest in agent-based computational modeling
of language emergence and evolution processes
(Lazaridou and Baroni, 2020; Chaabouni et al.,
2022). An important challenge in this line of
travail, cependant, is that such artificial learners of-
ten behave differently from human learners (Galke
et coll., 2022; Rita et al., 2022; Chaabouni et al.,
2019un).
∗Shared senior authorship.
One of the proposed explanations for these
mismatches is the difference in cognitive biases
between human and neural network (NN) based
learners. Par exemple, the neural-agent iterated
learning simulations of Chaabouni et al. (2019b)
and Lian et al. (2021) did not succeed in repli-
cating the trade-off between word-order and case
marking, which is widely attested in human lan-
guages (Sinnem¨aki, 2008; Futrell et al., 2015)
and has also been observed in artificial language
learning experiments with humans (Fedzechkina
et coll., 2017). Plutôt, those simulations resulted
in the preservation of languages with redundant
coding mechanisms, which the authors mainly at-
tributed to the lack of a human-like least-effort
bias in the neural agents. Besides human-like
cognitive biases, it has been proposed that more
natural settings of language learning and use could
lead to more human-like patterns of language
emergence and change (Mordatch and Abbeel,
2018; Lazaridou and Baroni, 2020; Kouwenhoven
et coll., 2022; Galke et al., 2022). In this work, nous
follow up on this second account and investigate
whether neural agents that strive to be understood
by other agents display more human-like lan-
guage preferences.
To achieve that, we design a Neural-agent Lan-
guage Learning and Communication (NeLLCom)
framework that combines Supervised Learning
(SL) with Reinforcement Learning (RL), inspiré
by Lazaridou et al. (2020) and Lowe et al. (2020).
Spécifiquement, we use SL to teach our agents pre-
defined languages characterized by different lev-
els of word order freedom and case marking.
Alors, we employ RL to let pairs of speaking and
listening agents talk to each other while optimiz-
ing communication success (also known as self-
play in the emergent communication literature).
1033
Transactions of the Association for Computational Linguistics, vol. 11, pp. 1033–1047, 2023. https://doi.org/10.1162/tacl a 00587
Action Editor: Yejin Choi. Submission batch: 2/2023; Revision batch: 5/2023; Published 8/2023.
c(cid:4) 2023 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
8
7
2
1
5
4
4
7
6
/
/
t
je
un
c
_
un
_
0
0
5
8
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
We closely compare the results of our simula-
tion to those of an experiment with a very similar
setup and miniature languages involving human
learners (Fedzechkina et al., 2017), and show that
a human-like trade-off can indeed appear during
neural-agent communication. Although some of
our results differ from those of the human ex-
periments, we make an important contribution
towards developing a neural-agent framework
that can replicate language universals without the
need to hard-code any ad-hoc bias in the agents.
We release the NeLLCom framework1 to facil-
itate future work simulating the emergence of
different language universals.
2 Background
Word Order vs. Case Marking Trade-off A
research focus of linguistic typology is to iden-
tify language universals (Greenberg, 1963), c'est à dire.,
patterns occurring systematically among the large
diversity of natural languages. The origins of such
universals are the object of long-standing de-
bates. The trade-off between word order and case
marking is an important and well-known example
of such a pattern that has been widely attested
(Comrie, 1989; Blake, 2001). Spécifiquement, lan-
guages with more flexible constituent order tend
to have rich morphological case systems (par exemple.,
Russian, Tamil, Turkish), while languages with
more fixed order tend to have little or no case
marking (par exemple., English or Chinese). En plus,
quantitative measures also revealed that the func-
tional use of word order has a statistically sig-
nificant inverse correlation with the presence of
morphological cases based on typological data
(Sinnem¨aki, 2008; Futrell et al., 2015).
Various experiments with human participants
(Fedzechkina et al., 2012, 2017; Tal and Arnon,
2022) were conducted to reveal
the under-
lying cause of this correlation. En particulier,
Fedzechkina et al. (2017), who highly inspired
this work, applied a miniature language learning
approach to study whether the trade-off could be
explained by a human learning bias to reduce
production effort while remaining informative.
In their experiment, two groups of 20 partici-
pants were asked to learn one of two predefined
miniature languages. Both languages contained
1All code and data are available at https://github
.com/Yuchen-Lian/NeLLCom.
optional markers but differed in terms of word
order (fixed vs. flexible). After three days of
entraînement, both groups reproduced the initial word
order distribution, however the flexible-order lan-
guage learners used case marking significantly
more often than the fixed-order language learn-
ers. De plus, an asymmetric marker-using strat-
egy was found in the flexible-order language
learners, whereby markers tended to be used more
often in combination with the less frequent lan-
guage. Ainsi, most participants displayed an in-
verse correlation between the use of constituent
order and case marking during language learn-
ing, which the authors attributed to a unifying
information-theoretic principle of balancing effort
with robust information transmission.
Agent-based Simulations of Language Evo-
lution Computational models have been used
widely to study the origins of language struc-
ture (Kirby, 2001; Steels, 2016; De Boer, 2006;
Van Everbroeck, 2003). En particulier, Lupyan and
Christiansen (2002) were able to mimic the human
acquisition patterns of four languages with very
different word order and case marking properties,
using a simple recurrent network (Elman, 1990).
Modern deep learning methods have also been
used to simulate patterns of language emer-
gence and change (Chaabouni et al., 2019un,b,
2020, 2021; Lian et al., 2021; Lazaridou et al.,
2018; Ren et al., 2020). Despite several inter-
esting results, many report
the emergence of
languages and patterns that significantly dif-
fer from human ones. Par exemple, Chaabouni
et autres. (2019un) found an anti-efficient encoding
scheme that surprisingly opposes Zipf’s Law,
a fundamental feature of human language. Rita
et autres. (2020) obtained a more efficient encoding
by explicitly imposing a length penalty on speak-
ers and pushing listeners to guess the intended
meaning as early as possible. Focusing on the
order/marking trade-off, Chaabouni et al. (2019b)
implemented an iterated learning setup inspired
by Kirby et al. (2014) where agents acquire a lan-
guage through SL, and then transmit it to a new
learner, iterating over multiple generations. Le
trade-off did not appear in their simulations. Lian
et autres. (2021) extended the study by introducing
several crucial factors from the language evolu-
tion field (par exemple., input variability, learning bottle-
neck), but no clear trade-off was found. To our
1034
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
8
7
2
1
5
4
4
7
6
/
/
t
je
un
c
_
un
_
0
0
5
8
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
8
7
2
1
5
4
4
7
6
/
/
t
je
un
c
_
un
_
0
0
5
8
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
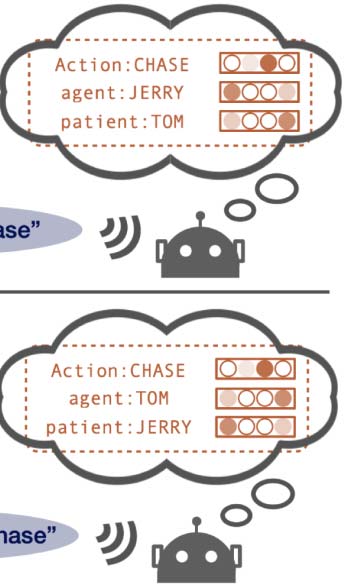
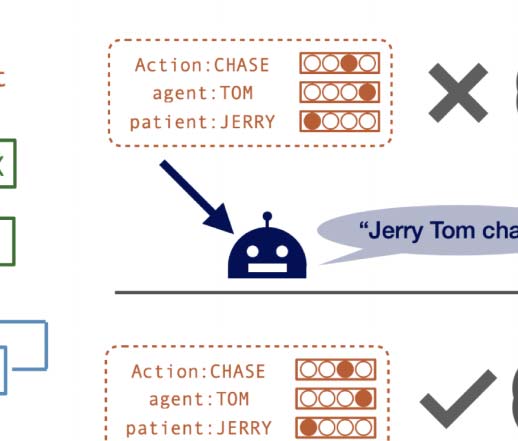
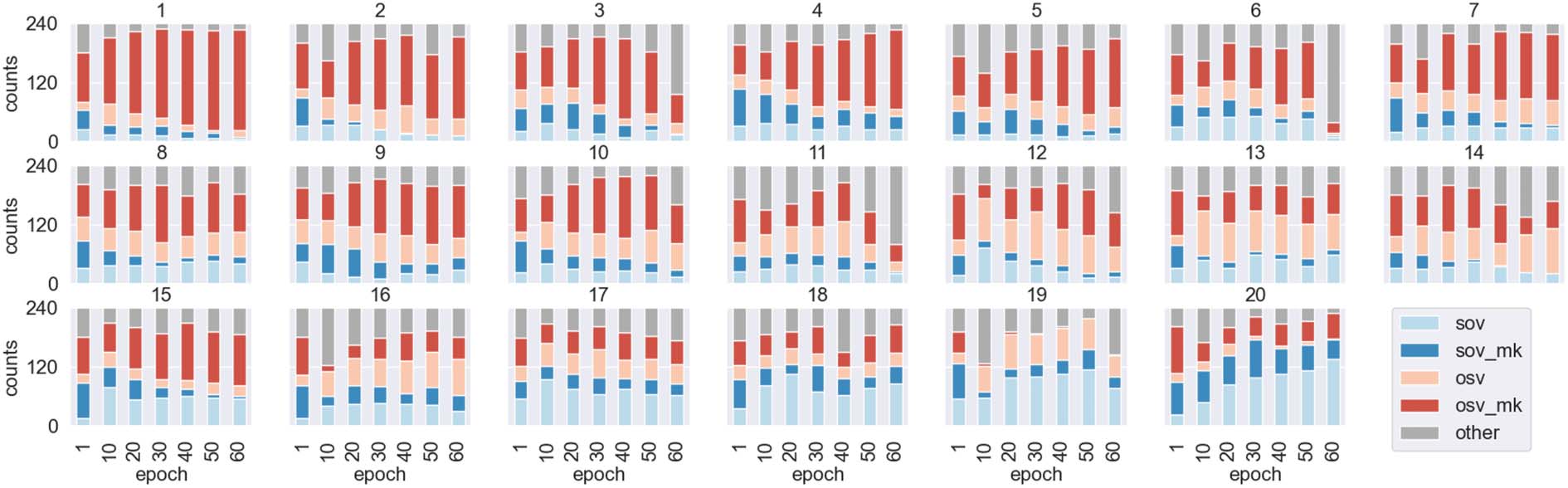
Chiffre 1: Agent architectures and a high-level overview of the meaning reconstruction game.
connaissance, no study with neural agents has suc-
cessfully replicated the emergence of this trade-
off so far.
3 NeLLCom: Language Learning and
Communication Framework
This section introduces the Neural-agent Lan-
guage Learning and Communication (NeLLCom)
framework, which we make publicly available.
Our goal differs from that of most work in
emergent communication, where language-like
protocols are expected to arise from sets of
random symbols through interaction (Lazaridou
et coll., 2018; Havrylov and Titov, 2017; Chaabouni
et coll., 2019un; Chaabouni et al., 2022; Bouchacourt
and Baroni, 2018). We are instead interested in
observing how a given language with specific
properties changes as the result of learning and
utiliser. Spécifiquement, in this work, agents need to
learn miniature languages with varying word or-
der distributions and case marking rules. While
this can be achieved by a standard SL procedure,
we hypothesize that human-like regularization
patterns will only appear when our agents strive
to be understood by other agents. We simulate
such a need via RL, using a measure of commu-
nication success as the optimization objective.
Similar SL+RL paradigms have been used in
the context of communicative AI (Li et al., 2016;
Strub et al., 2017; Das et al., 2017). En particulier,
Lazaridou et al. (2020) and Lowe et al. (2020)
explore different ways of combining SL and RL
to teach agents to communicate with humans in
natural language. A well-known problem in that
setup is that languages tend to drift away from
their original form as agents adapt to commu-
nication. In our context, we are specifically in-
terested in studying how this drift compares to
human experiments of artificial language learn-
ing. Our implementation is partly based on the
EGG toolkit2 (Kharitonov et al., 2019).
3.1 The Task
NeLLCom agents communicate about a simpli-
fied world using pre-defined artificial languages.
Speaking agents convey a meaning m by gener-
ating an utterance u, whereas listening agents try
to map an utterance u to its respective meaning
m. The meaning space includes agent-patient-
action triplets, such as dog-cat-follow, dog-mouse-
suivre, defined as triplets m = {UN, un, p}, où
A is an action, a the agent, and p the patient.
Utterances are variable-length sequences of sym-
bols taken from a fixed-size vocabulary: u =
[w1, . . . , wI ], wi ∈ V . Evaluation is conducted
on meanings unseen during training.
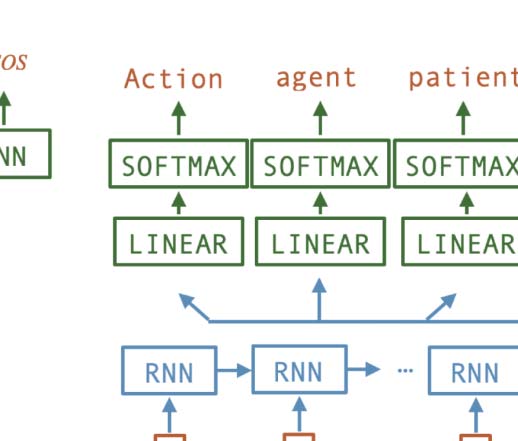
3.2 Agent Architectures
Both speaking and listening agents contain an
encoder and a decoder, however their architectures
are mirrored as the meanings and sentences are
represented differently (voir la figure 1).
Speaker: Linear-to-sequence
In a speaker net-
travail (S), the encoder receives the hot-vector
representations of A, un, and p, and projects them
to latent representations or embeddings. The order
of these three elements is irrelevant. The concate-
nation of the embeddings followed by a linear
2https://github.com/facebookresearch/EGG.
1035
layer becomes the latent meaning representation,3
based on which the Recurrent Neural Network
(RNN) decoder generates a sequence of symbols.4
Listener: Sequence-to-linear The listener net-
travail (L) works in the reverse way: Its RNN
encoder takes an utterance as input and sends its
encoded representation to the decoder, which tries
to predict the corresponding meaning. Specifi-
cally, the final RNN cell is fed to the decoder,
which passes it through three parallel linear layers,
for A, un, and p, respectivement. Enfin, each of the
three elements is generated by a softmax layer.
In Chaabouni et al. (2019b), the same net-
work was trained to be both speaker and listener,
which was made possible by the symmetric
sequence-to-sequence architecture used in their
setup. Par contre, our agents can only behave
as either speaker or listener.5 As another dif-
ference, we represent meanings as unordered
attribute-values instead of sequences, which we
find important to avoid any ordering bias in the
meaning representation. We note that the frame-
work is rather general: Dans les études futures, it could
be adapted to different meaning spaces and differ-
ent artificial languages, as well as different types
of neural sequence encoders/decoders.
3.3 Supervised Language Learning
SL is a natural choice to teach agents a specific
langue. This procedure requires a dataset D of
meaning-utterance pairs (cid:6)m, toi(cid:7) where u is the
gold-standard generated for m by a predefined
grammar (see grammar details in Section 4.1).
The learning objectives differ between speaker
and listener agents.
Speaker Given D, the speaker’s parameters θS
are optimized by minimizing the cross-entropy
perte:
Losssup
(S) = −
je(cid:2)
je = 1
log pθS (wi|w