Attention-Passing Models for
Robust and Data-Efficient End-to-End Speech Translation
Matthias Sperber1, Graham Neubig2,
Jan Niehues1, Alex Waibel1,2
1Karlsruhe Institute of Technology, Germany
2Carnegie Mellon University, USA
{first}.{last}@kit.edu, gneubig@cs.cmu.edu
Abstract
Speech translation has traditionally been ap-
proached through cascaded models consisting
of a speech recognizer trained on a corpus of
transcribed speech, and a machine translation
system trained on parallel texts. Several recent
works have shown the feasibility of collapsing
the cascade into a single, direct model that can
be trained in an end-to-end fashion on a corpus
of translated speech. However, experiments
are inconclusive on whether the cascade or the
direct model is stronger, and have only been
conducted under the unrealistic assumption
that both are trained on equal amounts of data,
ignoring other available speech recognition
and machine translation corpora.
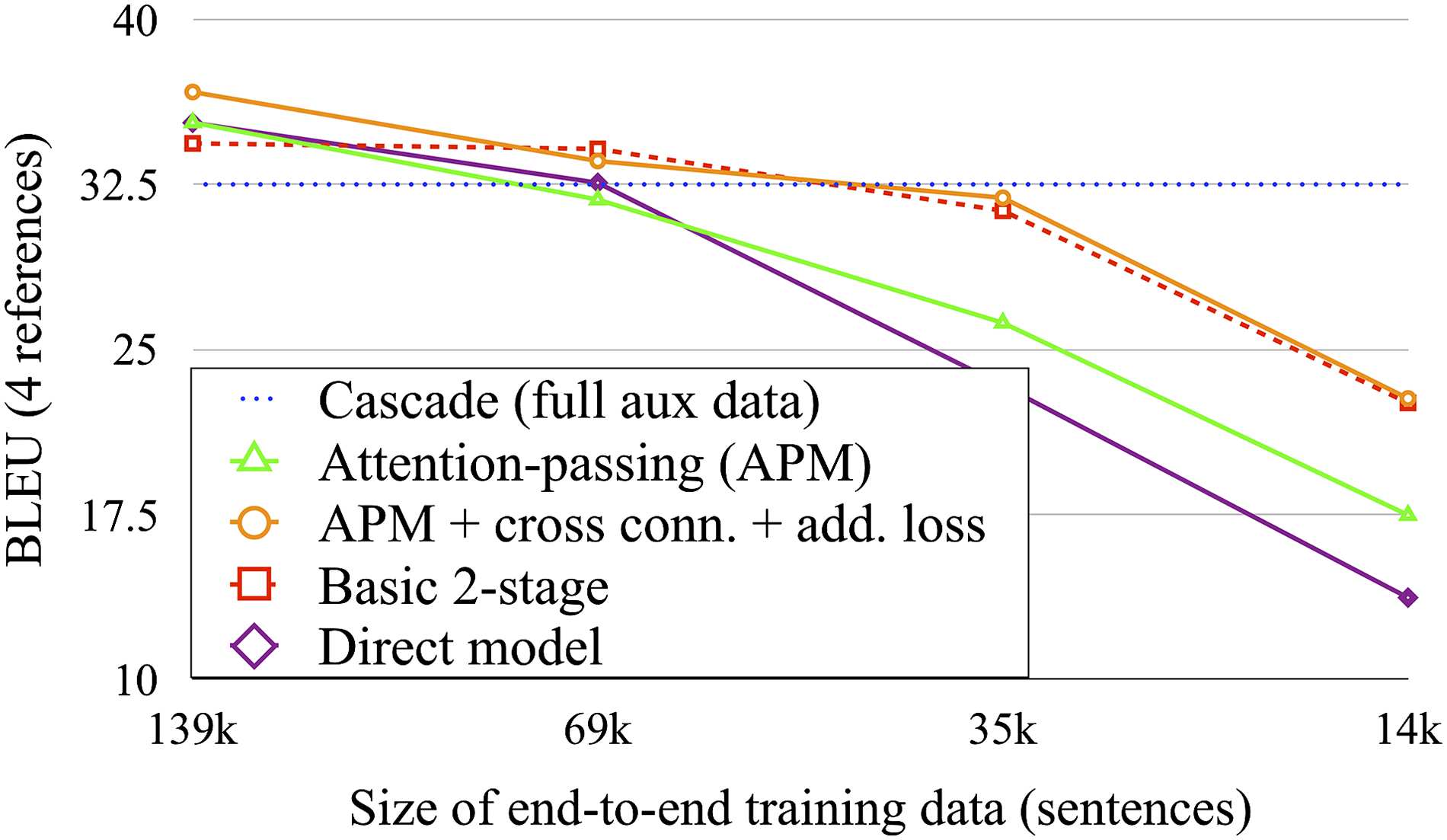
In this paper, we demonstrate that direct speech
translation models require more data to per-
form well than cascaded models, and although
they allow including auxiliary data through
multi-task training, they are poor at exploiting
such data, putting them at a severe disadvan-
tage. As a remedy, we propose the use of end-
to-end trainable models with two attention
mechanisms, the first establishing source speech
to source text alignments, the second modeling
source to target text alignment. We show that
such models naturally decompose into multi-
task–trainable recognition and translation tasks
and propose an attention-passing technique
that alleviates error propagation issues in a
previous formulation of a model with two
attention stages. Our proposed model outper-
forms all examined baselines and is able to
exploit auxiliary training data much more
effectively than direct attentional models.
1
Introduction
Speech translation takes audio signals of speech
as input and produces text translations as output.
Although traditionally realized by cascading an
313
it
automatic speech recognition (ASR) and a ma-
chine translation (MT) component, recent work
is feasible to use a single
has shown that
sequence-to-sequence model
instead (Duong
et al., 2016; Weiss et al., 2017; B´erard et al.,
2018; Anastasopoulos and Chiang, 2018). An
appealing property of such direct models is that
we no longer suffer from propagation of errors,
where the speech recognizer passes an erroneous
source text to the machine translation component,
potentially leading to compounding follow-up
errors. Another advantage is the ability to train
all model parameters jointly.
Despite these obvious advantages, two prob-
lems persist: (1) Reports on whether direct models
outperform cascaded models (Fig. 1a,d) are in-
conclusive, with some work in favor of direct
models (Weiss et al., 2017), some work in favor of
cascaded models (Kano et al., 2017; B´erard et al.,
2018), and one work in favor of direct models
for two out of the three examined language pairs
(Anastasopoulos and Chiang, 2018). (2) Cascaded
and direct models have been compared under
identical data situations, but this is an unrealistic
assumption: In practice, cascaded models can be
trained on much more abundant independent ASR
and MT corpora, whereas end-to-end models
require hard-to-acquire end-to-end corpora of
speech utterances paired with textual translations.
Our first contribution is a closer investigation
of these two issues. Regarding the question of
whether direct models or cascaded models are
generally stronger, we hypothesize that direct
models require more data to work well, due to the
more complex mapping between inputs (source
speech) and outputs (target text). This would imply
that direct models outperform cascades when
enough data are available, but underperform in
low-data scenarios. We conduct experiments and
this
present empirical evidence in favor of
Transactions of the Association for Computational Linguistics, vol. 7, pp. 313–325, 2019. Action Editor: Adam Lopez.
Submission batch: 12/2018; Revision batch: 2/2019; Published 6/2019.
c(cid:13) 2019 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
7
0
1
9
2
3
0
9
2
/
/
t
l
a
c
_
a
_
0
0
2
7
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
(Kano et al., 2017) to ease trainability, although no
experiments under varying data conditions have
been conducted. We hypothesize that such a model
may help to address the identified data efficiency
issue: Unlike multi-task training for the direct
model that trains auxiliary models on additional
data but then discards many of the additionally
learned parameters, the two-stage model uses all
parameters of sub-models in the final end-to-end
model. Empirical results confirm that the two-
stage model is indeed successful at improving data
efficiency, but suffers from some degradation in
translation accuracy under high data conditions
compared with the direct model. One reason for
this degradation is that this model re-introduces
the problem of error propagation, because the sec-
ond stage of the model depends on the decoder
states of the first model stage which often contain
errors.
Our third contribution, therefore, is an attention-
passing variant of the two-stage model that, rather
than passing on possibly erroneous decoder states
from the first to the second stage, passes on only
the computed attention context vectors (Fig. 1c).
We can view this approach as replacing the early
decision on a source-side transcript by an early
decision only on the attention scores needed to
compute the same transcript, where the attention
scores are expectedly more robust to errors in
source text decoding. We explore several variants
of this model and show that it outperforms both
the direct model and the vanilla two-stage model,
while maintaining the improved data efficiency of
the latter. Through an analysis, we further observe
a trade-off between sensitivity to error propagation
and data efficiency.
2 Baseline Models
This section introduces two types of end-to-end
trainable models for speech translation, along with
a cascaded approach, which will serve as our
baselines. All models are based on the attentional
encoder-decoder architecture of Bahdanau et al.
(2015) with character-level outputs, and use the
architecture described in §2.1 as audio encoders.
The end-to-end trainable models include a direct
model and a two-stage model. Both are limited1 by
the fact that they can only be trained on end-to-end
1Prior work noted that in severe low-resource situations
it may actually be easier to collect speech paired with
translations than transcriptions (Duong et al., 2016). How-
ever, we focus on well-resourced languages for which ASR
Figure 1: Conceptual diagrams for various speech trans-
lation approaches. Cascade (a) uses separate machine
translation and speech recognition models. The direct
model (d) is a standard attentional encoder-decoder
model. The basic 2-stage model (b) uses two attention
stages and passes source-text decoder states to the
translation component. Our proposed attention-passing
model (c) applies two attention stages, but passes con-
text vectors to the translation component for improved
robustness.
hypothesis. Next, for a more realistic comparison
with regard to data conditions, we train a direct
speech translation model using more auxiliary
ASR and MT training data than end-to-end data.
This can be implemented through multi-task train-
ing (Weiss et al., 2017; B´erard et al., 2018). Our
results show that the auxiliary data are beneficial
only to a limited extent, and that direct multi-
task models are still heavily dependent on the
end-to-end data.
As our second contribution, we apply a
two-stage model (Tu et al., 2017; Kano et al.,
2017) as an alternative solution to our problem,
hoping that such models may overcome the data
efficiency shortcoming of the direct model. Two-
stage models consist of a first-stage attentional
sequence-to-sequence model that performs speech
recognition and then passes the decoder states as
input to a second attentional model that performs
translation (Fig. 1b). This architecture is closer to
cascaded translation while maintaining end-to-
end trainability. Introducing supervision from
the source-side transcripts midway through the
model creates inductive bias that guides the com-
plex transformation between source speech and
target
through a reasonable intermediate
representation closely tied to the source text. The
architecture has been proposed by Tu et al. (2017)
to realize a reconstruction objective, and a similar
model was also applied to speech translation
text
314
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
7
0
1
9
2
3
0
9
2
/
/
t
l
a
c
_
a
_
0
0
2
7
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
data, which is much harder to obtain than ASR
or MT data used to train traditional cascades.2
§3 will introduce multi-task training as a way to
overcome this limitation.
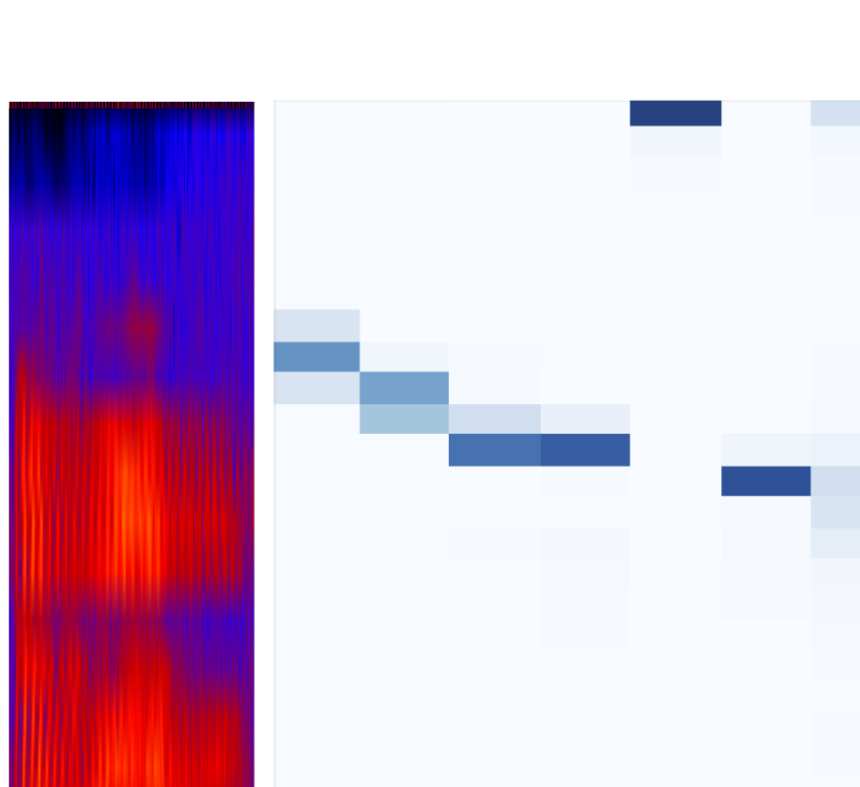
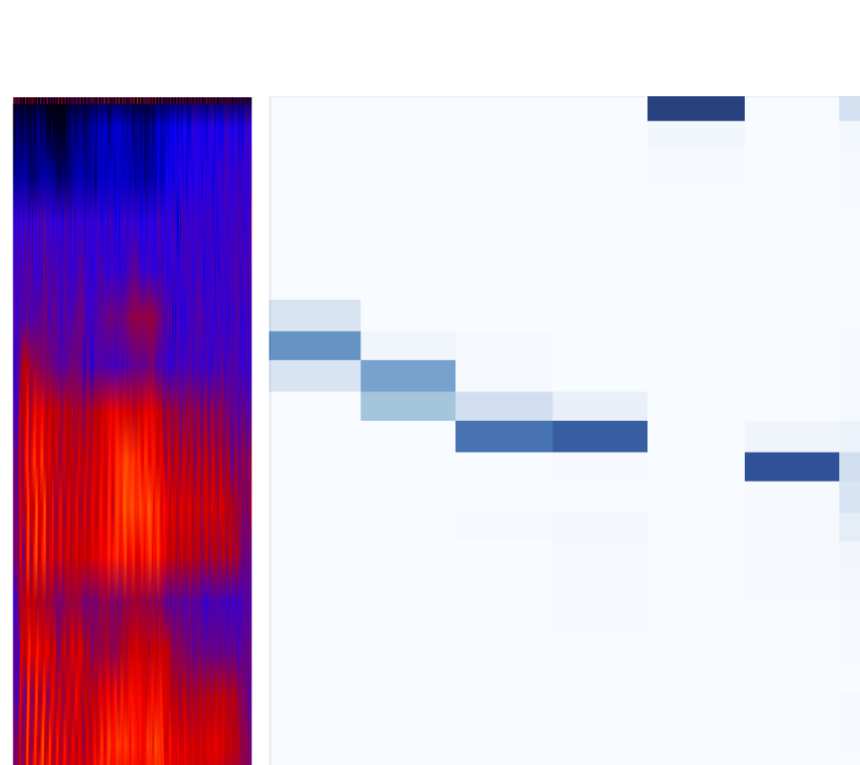
2.1 Audio Encoder
Sequence-to-sequence models can be adopted for
audio inputs by directly feeding speech features
(here, Mel filterbank features) instead of word
embeddings as encoder inputs (Chorowski et al.,
2015; Chan et al., 2016). Such an encoder trans-
forms M feature vectors x1:M into L encoded
vectors e1:L, performing downsampling such
that L