Morphological Analysis Using a Sequence Decoder
Ekin Aky ¨urek∗ Erenay Dayanık∗ Deniz Yuret†
Koc¸ University Artificial Intelligence Laboratory, ˙Istanbul, Truthahn
eakyurek13,edayanik16,dyuret@ku.edu.tr
Abstrakt
We introduce Morse, a recurrent encoder-
decoder model that produces morphological
analyses of each word in a sentence. Der
encoder turns the relevant information about
the word and its context into a fixed size
vector representation and the decoder gen-
erates the sequence of characters for the
lemma followed by a sequence of individ-
ual morphological features. We show that
generating morphological features individu-
ally rather than as a combined tag allows the
model to handle rare or unseen tags and to out-
perform whole-tag models. Zusätzlich, gen-
erating morphological features as a sequence
rather than, Zum Beispiel, an unordered set
to produce an arbitrary
allows our model
number of features that represent multiple
inflectional groups in morphologically com-
plex languages. We obtain state-of-the-art
results in nine languages of different mor-
phological complexity under low-resource,
high-resource, and transfer learning settings.
We also introduce TrMor2018, a new high-
accuracy Turkish morphology data set. Unser
Morse implementation and the TrMor2018
data set are available online to support future
research.1
1
Einführung
Morse is a recurrent encoder-decoder model that
takes sentences in plain text as input and produces
both lemmas and morphological features of each
word as output. Tisch 1 presents an example:
The ambiguous Turkish word ‘‘masalı’’ has three
∗Equal contribution.
†Corresponding author.
1Sehen
https://github.com/ai-ku/Morse.jl
for a Morse implementation in Julia/Knet (Yuret, 2016)
and https://github.com/ai-ku/TrMor2018 for
the new Turkish data set.
567
possible morphological analyses: the accusative
and possessive forms of the stem ‘‘masal’’ (tale)
and the +With form of the stem ‘‘masa’’ (table),
all expressed with the same surface form (Oflazer,
1994). Morse attempts to output
the correct
analysis of each word based on its context in
a sentence.
Accurate morphological analysis and disam-
biguation are important prerequisites for further
syntactic and semantic processing, especially in
morphologically complex languages. Many lan-
guages mark case, number, person, und so weiter.
using morphology, which helps discover
Die
correct syntactic dependencies. In agglutinative
languages, syntactic dependencies can even be
between subword units. Zum Beispiel, Oflazer
et al. (1999) observes that words in Turkish can
have dependencies to any one of the inflectional
groups of a derived word: in ‘‘mavi masalı oda’’
(room with a blue table) the adjective ‘‘mavi’’
(Blau) modifies the noun root ‘‘masa’’ (table)
even though the final part of speech of ‘‘masalı’’
is an adjective. This dependency would be dif-
ficult to represent without a detailed analysis of
morphology.
We combined the following ideas to attack
morphological analysis in the Morse model:
• Morse does not require an external rule-based
analyzer or dictionary, avoiding the parallel
maintenance of multiple systems.
• Morse performs lemmatization and tagging
jointly by default; we also report on sepa-
rating the two tasks.
• Morse outputs morphological tags one fea-
ture at a time, giving it the ability to learn
unseen/rare tags.
• Morse generates features as a variable size
seqeunce rather than a fixed set, allowing it
to represent derivational morphology.
Transactions of the Association for Computational Linguistics, Bd. 7, S. 567–579, 2019. https://doi.org/10.1162/tacl a 00286
Action Editor: Hinrich Sch¨utze. Submission batch: 12/2018; Revision batch: 4/2019; Published 9/2019.
C(cid:3) 2019 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Context & analysis of ‘‘masalı’’
masalı yaz. (write the tale.)
masal+Noun+A3sg+Pnon+Acc
babamın masalı (my father’s tale)
masal+Noun+A3sg+P3sg+Nom
mavi masalı oda (room with a blue table)
masa+Noun+A3sg+Pnon+NomˆDB+Adj+With
Tisch 1: Morphological analyses for Turkish word
masalı. An example context and its translation is
given before each analysis.
We evaluated our model on several Turkish data
sets (Yuret and T¨ure, 2006; Yıldız et al., 2016) Und
eight languages from the Universal Dependencies
data set (UD; Nivre et al., 2016) in low-resource,
high-resource, and transfer learning settings for
comparison with existing work. We realized that
existing Turkish data sets either had low inter-
annotator agreement or small test sets, which made
model comparison difficult because of noise and
statistical significance problems. To address these
issues we also created a new Turkish data set,
TrMor2018, which contains 460 K tagged tokens
and has been verified to be 96% accurate by
trained annotators. We report our results on this
new data set as well as previously available data
sets.
The main contributions of this work are:
• A new encoder-decoder model that performs
joint lemmatization and morphological tag-
ging which can handle unknown words, un-
seen tag sequences, and multiple inflectional
groups.
• State-of-the-art results on nine languages of
varying morphological complexity in low-
resource, high-resource, and transfer learning
settings.
• Release of a new morphology data set for
Turkish.
We discuss related work in Section 2, detail our
model’s input output representation and individual
components in Section 3, describe our data sets and
introduce our new Turkish data set in Section 4,
present our experiments and results in Section 5,
and conclude in Section 6.
2 Related Work
Morphological word analysis has been typically
performed by solving multiple subproblems. In
the first
one common approach the subproblems of
lemmatization (z.B., finding the stem ‘‘masal’’
für
two examples in Table 1 Und
‘‘masa’’ for the third) and morphological tagging
(z.B., producing +Noun+A3sg+Pnon+Acc in
the first example) are attacked separately. In
another common approach a language-dependent
rule-based morphological analyzer outputs all
possible lemma+tag analyses for a given word,
and a statistical disambiguator picks the correct
one in a given context. Even though Morse
attacks these problems jointly, the prior work is
best presented within these traditional divisions,
contrasting various approaches with Morse where
appropriate.
2.1 Lemmatization and Tagging
Early work in this area typically performed
lemmatization and tagging separately. Zum Beispiel-
reichlich, the Shortest Edit Script (SES) Ansatz
to lemmatization classifies lemmas based on the
mimimum sequence of operations that converts
a wordform into a lemma (Chrupala, 2006).
MarMoT (Mueller et al., 2013) predicts the se-
quence of morphological tags in a sentence using
a pruned higher-order conditional random field.
do
extended
SES was
joint
Zu
später
lemmatization and morphological
tagging in
Morfette (Chrupala et al., 2008), where two
separate maximum entropy models are trained for
predicting the lemma and the morphological tag
and a third model returns a probability distribution
over lemma-tag pairs. MarMoT was extended
to Lemming (M¨uller et al., 2015), which used
a joint log-linear model of lemmatization and
tagging and provided empirical evidence that
jointly modeling morphological tags and lemmata
is mutually beneficial.
We chose to perform lemmatization and
tagging jointly in Morse partly for linguistic
Gründe dafür: as Table 1 zeigt an, a tag like +Noun+
A3sg+Pnon+Acc can be correct with respect to
one lemma (masal) and not another (masa). Für
comparison with some of the earlier work, we did
train Morse to only generate the morphological tag
and observed some improvement in low-resource
and transfer-learning settings, but no significant
improvement in high-resource experiments.
More recent work started experimenting with
deep learning models. Heigold et al. (2017)
outperformed MarMoT in morphological tagging
568
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Language
Swedish
Bulgarian
Hungarian
Portuguese
100sent
9.19
14.38
15.78
6.04
1000sent
1.02
2.68
3.93
0.82
Tisch 2: Percentage of tags in the test data that
have been observed fewer than 5 times in the
training data for four languages and two training
sizes (100 Und 1000 Sätze).
using a character-based recurrent neural network
encoder similar to Morse, combined with a whole-
tag classifier. To address the data sparseness
problem this work was extended in Cotterell and
Heigold (2017) with transfer learning, improving
performance on low resource languages by up to
30% using a related-high resource language.
Morse uses a character-based encoder that turns
the relevant features of the word and its context
into fixed-size vector representations similar to
Heigold et al. (2017). Our main contribution
is the sequence decoder
that generates the
characters of the lemma and/or morphological
features sequentially one at a time. This is similar
to the way rule-based systems such as finite
state transducers output morphological analyses.
One advantage of generating features one at a
Zeit (z.B., +Acc) rather than as a combined
tag (z.B., +Noun+A3sg+Pnon+Acc) is sample
efficiency. Tisch 2 shows the percentage of tags
in the test data that have been observed rarely
in the training data for several languages. In low
resource experiments, we show that our sequence
decoder significantly outperforms a variant that is
trained to output full tags similar to Heigold et al.
(2017), especially with unseen or rare tags.
Malaviya et al. (2018) also avoid the data
sparsity problem associated with whole tags
using a neural factor graph model to predict a
set of features, improving the transfer learning
Leistung. In contrast with Malaviya et al.
(2018), Morse generates a variable number of
features as a sequence rather than a fixed set. Das
allows it to adequately represent derivations in
morphologically complex words. Zum Beispiel, In
the last analysis in Table 1, morphological features
of the word ‘‘masalı’’ consist of two inflectional
groups (IGs), a noun group and an adjective
Gruppe, separated by a derivational boundary
denoted by ‘‘ˆDB’’. In ‘‘mavi masalı oda’’ (Zimmer
with a blue table) the adjective ‘‘mavi’’ (Blau)
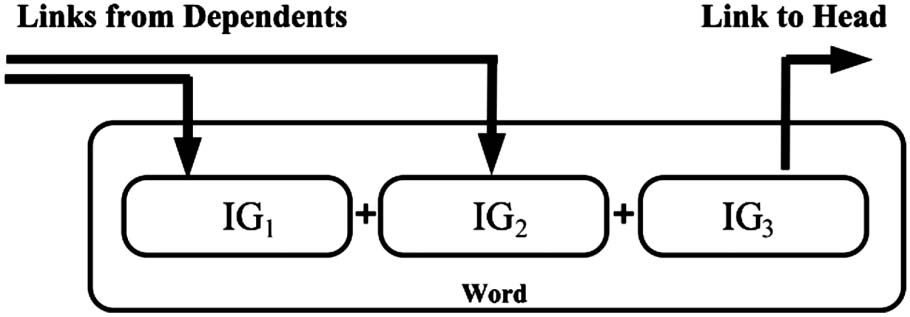
Figur 1: Multiple inflectional groups in a word may
have independent syntactic relationships. Figure from
Eryi˘git and Oflazer (2006).
modifies the noun root ‘‘masa’’ (table) sogar
though the final part of speech of ‘‘masalı’’ is an
adjective. Allgemein, each IG in a morphologically
complex word may have independent syntactic
dependencies, wie in der Abbildung gezeigt 1. Daher, für
languages like Turkish, it is linguistically essential
to be able to represent multiple IGs with a variable
number of features (Eryi˘git et al., 2008). Der
sequence-decoder approach of Morse outperforms
the neural factor graph model of Malaviya et al.
(2018) in both low-resource and transfer learning
settings.
2.2 Analysis and Disambiguation
Morphological analysis is the task of producing
all possible morphological parses for a given
word. For morphologically simple languages like
English, a dictionary is typically sufficient for this
Aufgabe (Baayen et al., 1995). For morphologically
complex languages like Turkish, the analysis can be
performed by language dependent rule-based sys-
tems such as finite-state transducers that encode mor-
phophonemics and morphotactics (Koskenniemi,
1981, 1983; Karttunen and Wittenburg, 1983). Der
first rule-based analyzer for Turkish was devel-
oped in Oflazer (1994), we used an updated ver-
sion of this analyzer (Oflazer, 2018) when creating
our new Turkish data set.
Morphological disambiguation systems take
the possible parses for a given word from an
analyzer and predict the correct one in a given
context using rule-based (Karlsson et al., 1995;
Oflazer and Kuru¨oz, 1994; Oflazer and T¨ur,
1996; Daybelge and C¸ ic¸ekli, 2007; Daoud, 2009),
statistical (Hakkani-T¨ur et al., 2002; Yuret and
T¨ure, 2006; Hajiˇc et al., 2007), or neural network
based (Yıldız et al., 2016; Shen et al., 2016; Toleu
et al., 2017) Techniken. Hakkani-Tür et al. (2018)
provide a comprehensive summary for Turkish
disambiguators.
569
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Morse performs morphological analysis and
disambiguation with a joint model partly to
avoid using a separate morphological analyzer
or dictionary. Having a single system combining
morphological analysis and disambiguation is
easier to use and maintain. The additional con-
straints brought by an external morphological
analyzer or dictionary are certainly beneficial, Aber
the benefit appears to be limited with sufficient
Daten: In our experiments, (1) we outperform earlier
systems that use separate morphological analysis
and disambiguation components, Und (2) Wann
we use Morse only to disambiguate among the
analyses generated by a rule-based analyzer, Die
accuracy gain is less than 1% compared with
generating analyses from scratch.
3 Modell
Morse produces
the morphological analysis
(lemma plus morphological features) für jede
word in a given sentence. It is loosely based on the
sequence-to-sequence encoder-decoder network
approach proposed by Sutskever et al. (2014)
für maschinelle Übersetzung. Jedoch, we use three
distinct encoders to create embeddings of various
input features. Erste, a word encoder creates an
embedding for each word based on its characters.
Zweite, a context encoder creates an embedding
for the context of each word based on the word
embeddings of all words to the left and to the
Rechts. Dritte, an output encoder creates an output
embedding using the morphological features of
the last two words. These embeddings are fed
to the decoder, which produces the lemma and
features of a target word
the morphological
one character/feature at a time. Im Folgenden
subsections, we explain each component in detail.
We have experimented with other
a time. A sample output for a word looks like
[si1, . . . , siRi, fi1, . . . , fiMi] where sij ∈ A is an
alphanumeric character in the lemma, Ri is the
length of the lemma, Mi is the number of features,
and fij ∈ T is a morphological feature from a fea-
ture set such as T = {Noun,Adj,Nom,A3sg, . . .}.
Eingang-
output formats, as described in Section 5: Wir
found that jointly producing the lemma and the
morphological features is more difficult
als
producing only morphological features in low-
resource settings but gives similar performance
in high-resource settings. We also found that
generating the morphological tag one feature at a
time rather than as a complete tag is advantageous,
more so in morphologically complex languages
and in low-resource settings.
3.2 Word Encoder
We map each character wij to an A dimensional
character embedding vector aij ∈ RA. The word
encoder
takes each word and processes the
character embeddings from left to right producing
hidden states [hi1, . . . , hiLi] where hij ∈ RH .
The final hidden state ei = hiLi is used as the
word embedding for word wi. The top left box
in Abbildung 2 depicts the word encoder. We also
experimented with external word embeddings but
did not observe any significant improvement.
hij = LSTM(aij, hij−1)
hi0 = 0
ei = hiLi
(1)
(2)
(3)
3.1 Input Output
3.3 Context Encoder
The input to the model consists of an N word sen-
tence S = [w1, . . . , wN ], where wi is the i’th word
in the sentence. Each word is input as a sequence
of characters wi = [wi1, . . . , wiLi], wij ∈ A
where A is the set of alphanumeric characters and
Li is the number of characters in word wi.
The output for each word consists of a lemma,
a part-of-speech tag and a set of morphologi-
cal features—for example, [M, A, S, A, l, Noun,
A3sg, P3sg, Nom] for ‘‘masalı’’. The lemma is
produced one character at a time, and the mor-
phological information is produced one feature at
We use a bidirectional long short-term memory
Netzwerk (LSTM) for the context encoder. Der
inputs are the word embeddings e1, · · · , eN
produced by the word encoder. The context
encoder processes them in both directions and
constructs a unique context embedding for each
target word in the sentence. For a word wi
we define its corresponding context embedding
ci ∈ R2H as the concatenation of the forward
←−
c i ∈ RH hidden
(cid:2)ci ∈ RH and the backward
states that are produced after the forward and
backward LSTMs process the word embedding ei.
570
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Figur 2: Model illustration for the sentence “Sonra g¨ulerek elini kardes¸inin omzuna koydu” (Then he laughed and
put his hand on his brother’s shoulder) and target word ‘‘elini’’ (his hand). We use the morphological features of the
words preceding the target as input to the output encoder: ‘‘Sonra+Adv g¨ul+Verb+PosˆDB+Adverb+ByDoingSo’’.
The bottom left box in Figure 2 depicts creation
of the context vector for the target word ‘‘elini’’.
embedding for word wi. The middle left box in
Figur 2 depicts the output encoder.
(cid:2)c i = LSTMf (NEIN, (cid:2)ci−1)
←−
c i = LSTMb(NEIN,
←−
c N +1 = 0
←−
c i]
c i = [(cid:2)ci;
(cid:2)C 0 =
←−
c i+1)
tij = LSTM(bij, tij−1)
ti0 = ti−1,Mi−1
oi = ti−1,Mi−1
(8)
(9)
(10)
(4)
(5)
(6)
(7)
3.4 Output Encoder
The output encoder captures information about
the morphological features of words processed
prior to each target word. Zum Beispiel, in order
to assign the correct possessive marker to the
word ‘‘masalı’’ (tale) in ‘‘babamın masalı’’ (Mein
father’s tale), it would be useful to know that the
previous word ‘‘babamın’’ (my father’s) has a
genitive marker. During training we use the gold
morphological features, during testing we use the
output of the model.
The output encoder only uses the morphological
Merkmale, not the lemma characters, of the previous
words as input: [f11, . . . , f1M1, f21, . . . , fi−1,Mi−1].
We map each morphological feature fij
to a
B dimensional feature embedding vector bij ∈
RB. A unidirectional LSTM is run over the
morphological features of the last two words to
produce hidden states [t11, . . . , ti−1,Mi−1] Wo
tij ∈ RH . The final hidden state preceding the
target word oi = ti−1,Mi−1 is used as the output
3.5 Decoder
The decoder is implemented as a 2-layer LSTM
network that outputs the correct lemma+tag for a
single target word.2 By conditioning on the three
encoder embeddings and its own hidden state, Die
decoder learns to generate yi = [yi1, . . . , yiKi]
where yi is the correct sequence for the target
word wi in sentence S, yij ∈ A ∪ T represents
both lemma characters and morphological feature
tokens, and Ki
is the total number of output
tokens (Lemma + Merkmale) for word wi. Der erste
layer of the decoder is initialized with the context
embedding ci.
i0 = relu(Wd × ci ⊕ Wdb)
d1
ij = LSTM(yij−1, d1
d1
ij−1)
(11)
(12)
where Wd ∈ RH×2H , Wdb ∈ RH , and ⊕ is
element-wise summation. We initialize the second
2We also experimented with two variants of our
Modell: MorseTag only outputs morphological features, Und
MorseDisamb uses the decoder to rank probabilities of a set
of analyses provided by a rule-based system.
571
lang
DA
RU
FI
ES
train
80378
75964
162621
384554
dev
10332
11877
18290
37349
test
10023
11548
21041
12069
|T|
159
734
2243
404
|F|
44
39
93
46
|R|
train
lang
66645
0.03% SV
0.27% BG 124336
20166
0.68% HU
PT 211820
0.03%
dev
9797
16089
11418
11158
test
20377
15724
10448
10468
|T|
211
439
716
380
|F|
40
45
73
47
|R|
0.06%
0.03%
1.03%
0.03%
Tisch 3: Data statistics of UD Version 2.1 Treebanks. The values in the {train, dev, test} columns are
the number of tokens in the splits. |T | gives the number of distinct tags (Pos + morphological features),
|F | the number of distinct feature values. |R| gives the unseen tag percentage in the test set.
layer with the word and output embeddings after
combining them by element-wise summation.
d2
i0 = ei + oi
ij = LSTM(d1
d2
ij, d2
ij−1)
(13)
(14)
We parameterize the distribution over possible
morphological features and characters at each time
step as
P(yij|d2
ij) = softmax(Ws × d2
ij
⊕ Wsb)
(15)
Wo, Ws ∈ R|Y|×H , and Wsb ∈ R|Y| Wo
Y = A ∪ T is the set of characters and
morphological features in output vocabulary. Der
right side of Figure 2 depicts the decoder.
4 Data Sets
We evaluate Morse on several different languages
and data sets. First we describe the multilingual
data sets we used from the UD data sets (Nivre
et al., 2016). We then describe two existing data
sets for Turkish and introduce our new data set
TrMor2018.
4.1 Universal Dependency Data Sets
We tested Morse on eight languages selected from
the UD data sets Version 2.1 (Nivre et al., 2016).
In Table 3, we summarize the corpus statistics.
Speziell, we use the CoNLL-U format3 for
the input files, take column 2 (FORM) as input,
and predict columns 3 (LEMMA), 4 (UPOSTAG),
Und 6 (FEATS). We show the number of distinct
features with |F |, the number of distinct composite
tags with |T |, and the unseen composite tag
percentage with |R| to indicate the morphological
complexity of a language.
4.2 Turkish Data Sets
For Turkish we evaluate our model on three data
sets described in Table 4. These data sets contain
3http://universaldependencies.org/format.html
572
Dataset
TrMor2006Train
TrMor2006Test
TrMor2016Test
TrMor2018
Ambig
398290
379
9460
216803
Unamb
439234
483
9802
243866
Total
837524
862
19262
460669
Tisch 4: Number of ambiguous, unambiguous,
and all tokens for data sets TrMor2006 (Yuret
and T¨ure, 2006), TrMor2016 (Yıldız et al.,
2016) (which shares the same training set), Und
TrMor2018 (introduced in this paper).
derivational as well as inflectional morphology
represented by multiple inflectional groups as
described in the Introduction. Im Gegensatz, the UD
data sets only preserve information in the last
inflectional group.
The first data set, TrMor2006, was provided
by Kemal Oflazer and published in Yuret and
T¨ure (2006) based on a Turkish newspaper data
set. The training set was disambiguated semi-
automatically and has limited accuracy. The test
set was hand-tagged but is very small (862 tokens)
to reliably distinguish between models with sim-
ilar accuracy. We randomly extracted 100 sen-
tences from the training set and used them as the
development set while training our model.
The second data set, TrMor2016, was prepared
by Yıldız et al. (2016). The training set is the
same as TrMor2006 but they manually retagged
a subset of the training set containing roughly
20,000 tokens to be used as a larger test set.
Unfortunately they did not exclude the sentences
in the test set from the training set
in their
experiments. Außerdem, they do not provide
any inter-annotator agreement results on the new
test set.
Given the problems associated with these data
sets, we decided to prepare a new data set,
TrMor2018, that we release with this paper. Unser
goal is to provide a data set with high inter-
annotator agreement that is large enough to allow
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
dev/test sets of sufficient size to distinguish model
performances in a statistically significant manner.
The new data set consists of 34,673 sentences and
460,669 tokens in total from different genres of
Turkish text.
TrMor2018 was annotated semi-automatically
in multiple passes. The initial pass was performed
automatically by a previous state-of-the-art model
(Yuret and T¨ure, 2006). The resulting data were
spot checked in multiple passes for mistakes
and inconsistencies by annotators, prioritizing
ambiguous high-frequency words. Any systematic
errors discovered were corrected by hand-written
scripts.
In order to monitor our progress, we randomly
selected a subset and disambiguated all of it
manually. This subset contains 2,090 Sätze
Und 26,819 Wörter. Two annotators annotated each
word independently and we assigned the final
morphological tag of each word based on the
adjudication by a third. Taking this hand-tagged
subset as the gold standard, we measure the noise
level in the corresponding semi-automatic results
after every pass. Wichtig, the hand-tagged
subset is only used for evaluating the noise level
of the main data set (d.h., we do not use it for
training or testing, and we do not use the identity
of the mistakes to inform our passes). Our current
release of TrMor2018 has a disagreement level of
4.4% with the hand-tagged subset, which is the
current state-of-the-art for Turkish morphological
data sets.
5 Experiments and Results
and provide
In this section we describe our training procedure,
give experimental results, compare with related
Modelle,
an ablation analysis.
The results demonstrate that Morse, Erstellen
analyses with its sequence decoder, significantly
outperforms the state of the art in low-resource,
high-resource, and transfer-learning experiments.
We also experimented with two variants of our
model for more direct comparisons: MorseTag
which only predicts tags without lemmas, Und
MorseDisamb which chooses among the analyses
generated by a rule-based morphological analyzer.
5.1 Training
All LSTM units have H = 512 hidden units in our
experiments. The size of the character embedding
vectors are A = 64 in the word encoder. Im
decoder part, the size of the output embedding
vectors is B = 256. We initialized model
parameters with Xavier initialization (Glorot and
Bengio, 2010).
Sind
Unser
verwenden
trained
Netzwerke
back-
propagation through time with stochastic gradient
descent. The learning rate is set to lr = 1.6 und ist
decayed based on the development accuracy. Wir
apply learning rate decay by a factor of 0.8 wenn die
development set accuracy is not improved after
5 consecutive epochs. Likewise, early-stopping
is forced if the development set accuracy is not
improved after 10 consecutive epochs, returning
the model with the best dev accuracy. To reduce
overfitting, dropout is applied with the rates of 0.5
for low-resource and 0.3 in high-resource settings
for each of the LSTM units as well as embedding
layers.
5.2 Multilingual Results
For comparison with existing work, we evaluated
our model on four pairs of high/low resource lan-
guage pairs: Danish/Swedish (DA/SV), Russian/
Bulgarian (RU/BG), Finnish/Hungarian (FI/HU),
and Spanish/Portuguese (ES/PT). Tisch 5 com-
pares the accuracy and Table 6 compares the F1
scores of four related models:4 (1) Cotterell: A
classification-based model with a similar encoder
that predicts whole tags rather than individual fea-
tures (Cotterell and Heigold, 2017), (2) Malaviya:
a neural factor graph model that predicts a fixed
number of morphological features rather than
variable length feature sequences (Malaviya et al.,
2018), (3) Morse: our model with joint prediction
of the lemma and the tag (the lemma is ignored
in scoring), Und (4) MorseTag: a version of our
model that predicts only the morphological tag
without the lemma (Cotterell and Malaviya only
predict tags). We compare results in three different
settings: (1) LR100 and LR1000 columns show
the low-resource setting where we experiment
mit 100 Und 1000 sentences of training data in
Swedish, Bulgarian, Hungarian, and Portuguese,
(2) XFER100 and XFER1000 columns show the
transfer learning setting where the related high,
resource language is used to help improve the
results of the low-resource language (which has
nur 100/1000 Sätze), Und (3) HR column
4Accuracy is for the whole-tag ignoring the lemma.
The F1 score is based on the precision and recall of
each morphological feature ignoring the lemma, similar to
Malaviya et al. (2018).
573
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
T
l
A
C
_
A
_
0
0
2
8
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
HR/LR
DA/SV
RU/BG
FI/HU
ES/PT
Modell
Cotterell
Malaviya
Morse
MorseTag
Cotterell
Malaviya
Morse
MorseTag
Cotterell
Malaviya
Morse
MorseTag
Cotterell
Malaviya
Morse
MorseTag
LR100
15.11
29.47
62.45(0.69)
66.19(1.23)
29.05
27.81
59.82(1.65)
66.97(1.34)
21.97
33.32
49.58(1.27)
54.87(0.72)
18.91
58.82
70.57(0.54)
70.80(1.14)
XFER100
66.06
63.22
72.70(0.59)
76.70(0.72)
52.76
46.89
69.27(0.54)
75.78(0.26)
51.74
45.41
54.84(0.71)
57.12(0.36)
79.40
77.75
80.01(0.38)
81.60(0.16)
LR1000
68.64
71.32
86.44(0.17)
88.31(0.17)
59.20
39.25
87.71(0.26)
88.96(0.41)
50.75
45.90
72.28(0.74)
73.55(0.72)
74.22
76.26
86.29(0.31)
86.24(0.28)
XFER1000
82.26
77.43
87.55(0.22)
88.97(0.54)
71.90
67.56
88.70(0.16)
90.52(0.21)
61.80
63.93
71.33(1.83)
73.86(1.28)
85.85
85.02
87.51(0.27)
88.01(0.13)
HR
91.79
92.68(0.19)
93.35(0.23)
82.02
85.43(0.12)
86.51(0.36)
85.25
91.24(0.28)
91.42(0.84)
93.09
92.95(0.21)
92.89(0.18)
Tisch 5: Accuracy comparisons for UDv2.1 data sets. Tisch 6 gives F1 comparisons which are similar.
LR is the low-resource language, HR is the high-resource language, XFER represents HR to LR transfer
learning. 100/1000 indicate the number of sentences in the training set for low-resource experiments.
Morse and MorseTag rows give the average of 5 experiments with standard deviation in parentheses.
Statistically significant leaders (P < 0.05) are marked in bold. Some experiments have multiple leaders
marked when their difference is not statistically significant.
HR/LR
DA/SV
RU/BG
FI/HU
ES/PT
Model
Cotterell
Malaviya
Morse
MorseTag
Cotterell
Malaviya
Morse
MorseTag
Cotterell
Malaviya
Morse
MorseTag
Cotterell
Malaviya
Morse
MorseTag
LR100
08.36
54.09
72.77(0.74)
74.91(1.26)
14.32
40.97
68.90(1.36)
75.52(1.16)
13.30
54.88
65.17(1.17)
72.21(0.67)
07.10
73.67
80.06(0.73)
80.07(0.92)
XFER100
73.95
78.75
81.39(0.27)
84.27(0.48)
58.41
64.46
76.86(0.41)
83.60(0.06)
68.15
68.63
71.77(0.42)
74.17(0.14)
86.03
88.42
88.11(0.25)
88.99(0.42)
LR1000
76.36
84.42
91.52(0.07)
92.39(0.26)
67.22
60.23
92.38(0.13)
93.08(0.37)
58.68
74.05
85.96(0.42)
87.17(0.38)
81.62
87.13
92.43(0.28)
92.29(0.28)
XFER1000
87.88
87.56
92.42(0.15)
93.04(0.35)
77.89
82.06
93.12(0.21)
94.24(0.11)
75.96
85.06
85.91(0.86)
87.39(0.53)
91.91
92.35
93.31(0.20)
93.56(0.14)
HR
94.18
95.18(0.11)
95.50(0.21)
90.63
93.08(0.03)
93.55(0.13)
90.54
95.34(0.20)
95.37(0.52)
96.57
96.52(0.10)
96.44(0.13)
Table 6: F1 comparisons for UDv2.1 data sets. See Table 5 for column descriptions.
gives the high-resource setting where we use the
full training data with the high resource languages
Danish, Russian, Finnish, and Spanish.5
For transfer experiments we use a simple
transfer scheme: training with the high-resource
language for 10 epochs and using the resulting
5Malaviya is missing from the HR column because we
could not train it with large data sets in a reasonable amount
of time. For Cotterell we used the SPECIFIC model given in
Malaviya et al. (2018) in all experiments.
model to initialize the compatible weights of the
model for the low-resource language. All LSTM
weights and embeddings for identical tokens are
transferred exactly, new token embeddings are
initialized randomly.
In all low-resource, transfer-learning, and high-
resource experiments, Morse and MorseTag per-
form significantly better than the two related models
(with the single exception of the high-resource
experiment on Spanish, a morphologically simple
574
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
t
l
a
c
_
a
_
0
0
2
8
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Method
(Yuret and T¨ure, 2006)
(Sak et al., 2007)
(Yıldız et al., 2016)
(Shen et al., 2016)
Morse
MorseDisamb
TrMor2006
95.82
96.28
-
96.41
95.94
96.52
TrMor2016
-
-
92.20
-
92.63
92.82
TrMor2018
-
-
-
-
97.67
98.59
Table 7: Test set lambda+tag accuracy of several models on Turkish data sets: TrMor2006 (Yuret and
T¨ure, 2006), TrMor2016 (Yıldız et al., 2016), TrMor2018 (published with this paper).
language, where the difference with Cotterell is
not statistically significant). This supports the
hypothesis that the sequence decoder of Morse is
more sample-efficient than a whole-tag model or
a neural factor graph model.
Tag-only prediction in MorseTag generally
outperforms joint lemma-tag prediction in Morse
but the difference decreases or disappears with
more training data and in simpler languages. In
half of the high-resource experiments, their differ-
ence is not statistically significant. The difference
is also insignificant in most of the experiments,
with the morphologically simplest language pair
Spanish/Portuguese.
5.3 Turkish Results
Table 7 shows the lemma+tag test accuracy of
several systems for different Turkish data sets.
We masked digits and Prop (proper noun) tags
in our evaluations. The older models use a hand-
built morphological analyzer (Oflazer, 1994) that
gives a list of possible lemma+tag analyses and
trains a disambiguator to pick the correct one in
the given context. Standard Morse works without
a list of analyses, the decoder can generate the
lemma+tag from scratch. Older disambiguators
always obtain 100% accuracy on unambiguous
tokens with a single analysis, whereas Morse may
fail to generate the correct lemma+tag pair. In
order to make a fair comparison we also tested
a version of Morse that disambiguates among a
given set of analyses by comparing the probability
assigned to them by the decoder (MorseDisamb).
MorseDisamb gives the best results across
all three data sets. The best scores are printed
in bold where the difference is statistically
significant. None of the differences in TrMor2006
are statistically significant because of the small
size of the test set. In TrMor2016 both Morse
and MorseDisamb give state of the art results.
The TrMor2018 results were obtained using an
Method
word
word+context
word+context+output
A
94.38
96.21
96.43
U
98.70
98.52
98.80
T
96.72
97.69
97.79
Table 8: Ablation analysis test set performances
on the TrMor2018 data set. A: Ambiguous Accu-
racy, U: Unambiguous accuracy, T: Total accuracy.
average of 5 random splits into 80%, 10%, and
10% for training, validation, and test sets.
Note that the numbers for the three data sets
are significantly different. Each result naturally
reflects the remaining errors and biases in the
corresponding data set, which might result in
the true accuracy figure being higher or lower.
Despite of these imperfections, we believe the
new TrMor2018 data set will allow for better
comparison of different models in terms of learn-
ing efficiency thanks to its larger size and lower
noise level.
5.4 Ablation Analysis
In this section, the contributions of the individual
components of the full model are analyzed. In the
following three ablation studies, we disassemble
or change individual modules to investigate the
change in the performance of the model. We use
the TrMor2018 data set in the first two experi-
ments and UD data sets in the last experiment.
Table 8 presents the results.
We start our ablation studies by removing both
the context encoder and the output encoder, leav-
ing only the word encoder. The resulting model
(word) is a standard sequence-to-sequence model
that only uses the characters in the target word
without any context information. This gives us a
baseline and shows that more than 95% of the
wordforms can be correctly tagged ignoring the
context.
575
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
t
l
a
c
_
a
_
0
0
2
8
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Lang
SV
BG
HU
PT
Tok
12
4
108
3
count=0
Tag
0.0
0.0
0.0
0.0
Seq
8.33
0.0
20.37
0.0
count<100
Tag
81.28
81.32
53.54
63.29
Seq
82.82
83.41
59.24
67.63
Tok
844
910
2333
207
count≥100
Tag
94.49
96.62
78.24
93.04
Tok
19521
14810
8007
9991
Seq
94.65
97.37
80.67
92.25
Table 9: Test accuracy for tags that were observed 0, < 100, and ≥ 100 times in the 1000 sentence
training sets. Tok is the number of tokens with the specified count, Tag is the accuracy using a
whole-tag classifier, Seq is the accuracy using a sequence decoder.
Dataset
TRMor2006
TRMor2016
TRMor2018
UD-DA
UD-ES
UD-FI
UD-RU
count=0
count<5
count≥5
Tok
30
79
0
1019
593
2279
1656
Acc
86.67
2.53
-
71.84
79.26
61.34
77.48
Tok
16
579
1702
1023
627
1802
1587
Acc
100.0
93.78
82.78
94.72
95.37
88.85
94.39
Tok
816
18570
45119
7981
10780
16989
8305
Acc
98.9
98.48
99.48
98.93
99.36
98.21
99.22
Table 10: Test accuracy for lemmas that were observed 0, < 5, and ≥ 5 times in the TRMor and UD
data sets. Tok is the number of tokens with the specified count, Acc is the accuracy using Morse.
We then improve the model by adding the con-
text encoder (word+context). We observe a 1.83%
increase in ambiguous word accuracy and 0.97%
in overall accuracy. This version is capable of
learning more than only a single morphologic anal-
ysis of each wordform. As an example, the lemma
‘‘r¨oportaj’’ (interview) has 5 distinct wordforms
observed in the training set. We tested both models
on the never before seen wordform ‘‘r¨oportajı’’
in ‘‘Benden bu r¨oportajı yalanlamamı rica etti.’’
(I was asked to deny the interview). Whereas
(word) failed by selecting the most frequently
occurring tag of ‘‘r¨oportaj’’ in the training set
(Noun+A3sg+Pnon+Nom), word+context dis-
ambiguated the target wordform successfully
(+Noun+A3sg+Pnon+Acc), demonstrating the
ability to generalize to unseen wordforms.
Finally, we add the output encoder to re-
construct the full Morse model (word+context+
output). We observe a further 0.22% increase in
ambiguous word accuracy and 0.10% increase in
overall accuracy. These experiments show that
each of the model components have a positive
contribution to the overall performance.
We believe our ablation models have several
advantages over a standard sequence-to-sequence
model: Both the input and the output of the system
needs to be partly character based to analyze
morphology and to output lemmas. This leads
To compare our
to long input and output sequences. By running
the decoder separately for each word, we avoid
the necessity to squeeze the information in the
whole input sequence into a single vector. A
standard sequence-to-sequence model would also
be more difficult to evaluate as it may produce
zero or multiple outputs for a single input token or
produce outputs that are out of order. A per-word
decoder avoids these alignment problems as well.
approach to whole-tag
classifiers like Heigold et al. (2017), we created
two versions of the (word+context) model, one
with a sequence decoder and one with a whole-tag
classifier. We trained these models on Turkish and
UD data sets to test unseen/rare tag and lemma
generation. Table 9 shows the accuracy of each
model on three sets of tags: unseen tags, tags
that were seen less than 100 times and tags that
were seen at least 100 times in the training set. The
sequence decoder generally performs better across
different frequency ranges. In particular, results
confirm that the sequence decoder can generate
some unseen tags correctly while the whole-tag
classifier in principle cannot. We observe that
the advantage is smaller for more frequent tags,
in fact the whole-tag classifier performs better
tags in Portuguese, a
with the most frequent
morphologically simple language. A similar trend
is observed in Table 10 for lemma generation:
576
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
t
l
a
c
_
a
_
0
0
2
8
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Morse is able to generate a significant percent of
the unseen/rare lemmas correctly.
6 Conclusion
character-based
In this paper, we presented Morse, a language-
independent
encoder-decoder
architecture for morphological analysis, and
TrMor2018, a new Turkish morphology data set
manually confirmed to have 96% inter-annotator
agreement. The Morse encoder uses two different
unidirectional LSTMs to obtain word and output
embeddings and a bidirectional LSTM to obtain
the context embedding of a target word. The
Morse decoder outputs the lemma of the word one
character at a time followed by the morphological
tag, one feature at a time. We evaluated Morse
on nine different languages, and obtained state-
of-the-art results on all of them. We provided
empirical evidence that producing morphological
features as a sequence outperforms methods that
produce whole tags or feature sets, and the
advantage is more significant
in low-resource
settings.
To our knowledge, Morse is the first deep
learning model that performs joint lemmatization
and tagging, performs well with unknown and
rare wordforms and tags, and can produce a
variable number of features in multiple inflectional
groups to represent derivations in morphologically
complex languages.
Acknowledgments
We would like to thank Kemal Oflazer and
all student annotators for their help in creating
the TrMor2018 data set, and the editors and
anonymous reviewers for their many helpful
comments. This work was supported by the
Scientific and Technological Research Council
of Turkey (T ¨UB˙ITAK) grants 114E628 and
215E201.
References
R. Harald Baayen, Richard Piepenbrock, and Leon
Gulikers. 1995. The CELEX lexical database
(release 2). Distributed by the Linguistic Data
Consortium, University of Pennsylvania.
Grzegorz Chrupala. 2006. Simple data-driven
context-sensitive lemmatization. Procesamiento
del Lenguaje Natural, 37.
Grzegorz Chrupala, Georgiana Dinu, and Josef
van Genabith. 2008. Learning morphology with
Morfette. In LREC 2008.
Ryan Cotterell and Georg Heigold. 2017. Cross-
lingual character-level neural morphological
tagging. In Proceedings of the 2017 Conference
on Empirical Methods in Natural Language
Processing, pages 748–759, Copenhagen.
Daoud Daoud. 2009. Synchronized morphological
and syntactic disambiguation for Arabic. Advances
in Computational Linguistics, 41:73–86.
Turhan Daybelge and ˙Ilyas C¸ ic¸ekli. 2007. A
rule-based morphological disambiguator for
Turkish. In Proceedings of Recent Advances in
Natural Language Processing (RANLP 2007),
Borovets, pages 145–149.
G¨uls¸en Eryi˘git,
and Kemal
Joakim Nivre,
Oflazer. 2008. Dependency parsing of Turkish.
Computational Linguistics, 34(3):357–389.
G¨uls¸en Eryi˘git
and Kemal Oflazer. 2006.
Statistical dependency parsing of Turkish. In
Proceedings of the 11th EACL, pages 89–96.
Trento.
Xavier Glorot
and Yoshua Bengio. 2010.
Understanding the difficulty of training deep
feedforward neural networks. In Proceedings
the Thirteenth International Conference
of
Statistics,
on Artificial
pages 249–256.
Intelligence
and
Jan Hajiˇc, Jan Votrubec, Pavel Krbec, Pavel
Kvˇetoˇn. 2007. The best of two worlds: Coop-
eration of statistical and rule-based taggers
for Czech. In Proceedings of the Workshop
on Balto-Slavonic Natural Language Pro-
cessing: Information Extraction and Enabling
Technologies, pages 67–74.
Dilek Zeynep Hakkani-T¨ur, Kemal Oflazer, and
G¨okhan T¨ur. 2002. Statistical morphological
disambiguation for agglutinative languages.
Computers and the Humanities, 36(4):381–410.
Dilek Zeynep Hakkani-Tür, Murat Sarac¸lar,
Gökhan Tür, Kemal Oflazer, and Deniz
Yuret. 2018, Morphological disambiguation
for Turkish. In K. Oflazer and M. Sarac¸lar,
editors, Turkish Natural Language Processing,
Theory and Applications of Natural Language
577
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
t
l
a
c
_
a
_
0
0
2
8
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Processing, chapter 3, Springer International
Publishing.
Georg Heigold, G¨unter Neumann, and Josef
van Genabith. 2017. An extensive empirical
evaluation of character-based morphological
tagging for 14 languages. In Proceedings of the
15th Conference of the European Chapter of
the Association for Computational Linguistics,
volume 1, pages 505–513.
Fred Karlsson, Atro Voutilainen, Juha Heikkila,
and Arto Anttila, editors. 1995. Constraint
Grammar: A Language-Independent System for
Parsing Unrestricted Text, Walter de Gruyter
& Co., Hawthorne, NJ.
Lauri Karttunen and Kent Wittenburg. 1983. A
two-level morphological analysis of English.
Texas Linguistic Forum, 22:217–228.
Kimmo Koskenniemi. 1981. An application of the
to Finnish. Computational
two-level model
Morphosyntax: Report on Research, 1984:19–41.
Kimmo Koskenniemi. 1983. Two-level model for
morphological analysis. In IJCAI, volume 83,
pages 683–685.
Chaitanya Malaviya, Matthew R. Gormley, and
Graham Neubig. 2018. Neural factor graph models
for cross-lingual morphological
tagging. In
Proceedings of the 56th Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Long Papers), pages 2653–2663.
Thomas Mueller, Helmut Schmid, and Hinrich
Sch¨utze. 2013. Efficient higher-order CRFs
for morphological tagging. In Proceedings of
the 2013 Conference on Empirical Methods in
Natural Language Processing, pages 322–332,
Seattle, WA.
Thomas M¨uller, Ryan Cotterell, Alexander Fraser,
and Hinrich Sch¨utze. 2015. Joint lemmatiza-
tion and morphological tagging with lemming.
the 2015 Conference on
In Proceedings of
in Natural Language
Empirical Methods
Processing, pages 2268–2274, Lisbon.
Joakim Nivre, Marie-Catherine de Marneffe,
Jan Hajic,
Filip Ginter, Yoav Goldberg,
Christopher D. Manning, Ryan T. McDonald,
Slav Petrov, Sampo Pyysalo, Natalia Silveira,
Reut Tsarfaty, and Daniel Zeman. 2016.
Universal dependencies v1: A multilingual
treebank collection. In LREC.
Kemal Oflazer. 1994. Two-level description of
Turkish morphology. Literary and Linguistic
Computing, 9(2):137–148.
Kemal Oflazer. 2018, Morphological processing
for Turkish. In K. Oflazer and M. Sarac¸lar,
editors, Turkish Natural Language Processing,
Theory and Applications of Natural Language
Processing, Chapter 2, Springer International
Publishing.
Kemal Oflazer, Dilek Zeynep Hakkani-T¨ur, and
G¨okhan T¨ur. 1999. Design for a Turkish treebank.
In Proceedings of the Workshop on Linguis-
tically Interpreted Corpora, EACL 99. Bergen.
Kemal Oflazer and ˙Ilker Kuru¨oz. 1994. Tagging
and morphological disambiguation of Turkish
text. In Proceedings of the Fourth Conference
on Applied Natural Language Processing,
pages 144–149.
Kemal Oflazer
and Gokhan T¨ur.
1996.
Combining hand-crafted rules and unsupervised
learning in constraint-based morphological
disambiguation. In Conference on Empirical
Methods in Natural Language Processing.
Has¸im Sak, Tunga G¨ung¨or,
and Murat
Sarac¸lar. 2007, Morphological disambiguation
of Turkish text with perceptron algorithm.
In Alexander Gelbukh, editor, Computational
Linguistics and Intelligent Text Processing:
8th International Conference, CICLing 2007,
pages 107–118. Springer, Berlin Heidelberg.
Qinlan Shen, Daniel Clothiaux, Emily Tagtow,
Patrick Littell, and Chris Dyer. 2016. The role
of context in neural morphological disambigua-
tion. In COLING, pages 181–191.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.
2014. Sequence to sequence learning with
neural networks. In Proceedings of the 27th
International Conference on Neural Information
Processing Systems, NIPS’14, pages 3104–3112,
Cambridge, MA.
Alymzhan Toleu, Gulmira Tolegen, and Aibek
Makazhanov. 2017. Character-aware neural
morphological disambiguation. In Proceedings
578
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
t
l
a
c
_
a
_
0
0
2
8
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
of the 55th Annual Meeting of the Association
for Computational Linguistics (Volume 2: Short
Papers), volume 2, pages 666–671.
Deniz Yuret. 2016. Knet: Beginning deep learning
with 100 lines of julia. In Machine Learning
Systems Workshop at NIPS 2016.
Eray Yıldız, C¸ a˘glar Tirkaz, H. Bahadır S¸ ahin,
Mustafa Tolga Eren, and Ozan S¨onmez. 2016. A
morphology-aware network for morphological
disambiguation. In Proceedings of the Thirtieth
AAAI Conference on Artificial Intelligence,
AAAI’16, pages 2863–2869.
Deniz Yuret and Ferhan T¨ure. 2006. Learning
morphological disambiguation rules for Turkish.
In Proceedings of
the main conference on
Human Language Technology Conference of
the North American Chapter of the Association
of Computational Linguistics, pages 328–334.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
6
1
9
2
3
5
9
2
/
/
t
l
a
c
_
a
_
0
0
2
8
6
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
579