Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
Predicting an Optimal Virtual Data Model for Uniform
Access to Large Heterogeneous Data
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
LabRI-SBA, Enterprise Information Systems
ESI-SBA Institute; Fraunhofer IAIS
Algeria; Deutschland
Email: {cb.bachirbelmehdi;n.keskes}@esi-sba.dz; abderrahmane.khiat@iais.fraunhofer.de
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
T
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
von
Der
Wachstum
für
approaches
virtualization
generated
uniform
Systeme,
Die
Daten
In
Zugang
Daten
einschließlich
Daten
against
von
schema
als
solch
common
Die
Design
built
GRAPH
types
Sie
address
Wir
groß
predict
Weil
To
datasets,
join
Zu
OPTIMA
–
technologies,
Und
TABULAR,
solch
viele
sources
Modell
load,
Zu
original
use
fixed
A
on-the-fly
oder
von
An
depend
Problem
Die
neu
A
present
heterogeneous
optimal
Die
DOCUMENT,
als
Abfragen,
Kriterien,
von
Ansatz
In
Daten
A
virtual
Daten
von
Und
supports
implementation
Apache-Spark
Und
industry
requires
Zu
end-users
von
Ontology-Based
any
without
TABULAR
neu
perform
Data
prior
als
Und
join
flexible
z.B.,
verwandeln,
mehr
Sind
oder
join
solch
d ata
efficient
better
Access
b ig
business
(ODBA)
m aterialization.
Data
Während
Sei
Abfragen
Virtual
Daten.
can
mehr
Sind
daher,
Diese
Daten
Modell,
Daten
Daten
Die
nur
relevant
Und,
Abfragen.
plan,
virtual
Die
An
Und
manner
nested
als
Die
query
optimal
builds
Das
(1)
selecting
distributed
Modell
Ansatz
Und
unser
Graphx,
out-of-the-box
relational,
Merkmale
verwenden
currently
implements
d ata
tabular,
leverages
zwei
s ources
Daten
principal
(2)
calls
extracted
deep
Modell
von
A
aus
state-of-the-art
Daten
m odels:
In
virtual
five
Und
Extensive
ein
Modell
accuracy
stored
experiments
0.831,
von
Und
Neo4j,
show
A
30%
daher,
über
Auswahl
Größe,
integra-
Operationen.
Daten
query
Existing
Modell
–
A
Daten
andere
suitable
Zu
hart
Und
Abfragen
Zu
learn-
SPARQL
Big
Modelle,
Eigentum
Mo-
unser
reduction
Die
für
für
OBDA
Das
document-based,
Cassandra,
z.B.,
MySQL,
Die
Zeit
Auswahl.
returning
Ist
Ausführung
Modell
wide-columnar,
Und
optimal
über
von
CSV
virtual
für
40%
jeweils.
mit
tabular
Modell
Die
tion
Data
on-the-fly
approaches
uniform
Modelle,
für
manche
predict
Operationen.
groß
An
query
ing
Abfragen.
Data
GRAPH
graph,
goDB,
Ansatz
In
query
graph
Und
method
Schlüsselwörter:
Data
Virtualization,
Big
Data,
OBDA,
Deep
Learning.
1.
EINFÜHRUNG
Massive
Daten
von
generated
[1].
Jahre
Die
leading
weniger
gebraucht,
von
consumed
über
Und
Daten
approaches
von
anders
Volumen
In
(relational,
[3,
Daten
4].
Das
platforms
Jedoch,
A
Zu
anders
Ist
Der
aim
In
stored
Ist
(cloud,
applications,
Die
transactions,
Information
machines
aus
extracted
oder
Wissen
applications
Zu
mehr
get
various
mainframes),
Modern
sources
Und
[2].
gap
raises
Die
insights
Folglich,
für
enabling
need
von
(Oracle,
Ist
represented
”Data
approaches
keep
Das
Die
effective
Die
MongoDB,
increasing
un-
Ist
Daten
wachsend
In-
Daten
von
Verfahren
Das
usw.),
für-
anders
[6]”
virtualization
In
drastically
exploited
Volumen
von
tegration
groß
A
Ist
resided
mats
graph,
no-relational
[5]).
1
© 2023 Chinesische Akademie der Wissenschaft. Veröffentlicht unter einer Creative Commons Namensnennung
4.0 International (CC BY 4.0) Lizenz.
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
2
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
tackle this challenge by creating a virtual data model under which the heterogeneous for-
mats are homogenized on-the-fly without data materialization [7], thus reducing cost, Und
simplifying data management, updates, and maintenance. Ontology-based data access
(OBDA) [8] also implements a virtual data model and addressed data integration chal-
lenges with practical knowledge representation models, ontology-based mappings, und ein
unique query language SPARQL1 [9].
Existing approaches [10, 11, 12] use by design only one virtual data model2 (z.B.,
TABULAR) to load and transform the requested data into a uniform model to be joined
and aggregated; while other data models, such as GRAPH or DOCUMENT, sind mehr
suitable [13]. Zum Beispiel, approaches using a fixed TABULAR virtual model (TABU-
LAR is a model that uses predefined structures, d.h., table definitions) can have downside
performances for SPARQL queries that involve many join operations on very large data.
Im Gegensatz, other data models such as GRAPH (a model that structures data into a set
of nodes, Beziehungen, properties, Und, am wichtigsten, stores relationships at the indi-
vidual record level) perform better for such queries. Andererseits, the TABULAR
model performs better for queries that involve selection or projection. The problem to be
addressed in this paper is defined as, given a query, ”which virtual data model is optimal
d.h., the model that has the lowest query execution time (cost)? and how to select it?”.
It is very challenging, Jedoch, to automatically select the optimal virtual model
based on queries since it is not realistic to compute the query execution time for all
SPARQL queries against all virtual data models to get the actual cost. Außerdem,
the query behavior on data virtualization is quite hard to predict since the behavior de-
pends not only on the virtual data model but also on query planning. To the best of our
Wissen, existing machine learning techniques [14, 15, 16] [17] were established in the
literature for cost estimation of SPARQL queries; most of them, Jedoch, are designed
for querying uniform data, z.B., RDF3 and not for distributed data sources.
To address these research questions, we developed OPTIMA – an OBDA extensible
framework that predicts the optimal virtual data model GRAPH or TABULAR, using a
deep learning algorithm to join data from sources databases that support Property Graph,
Relational, Tabular Document-based, and Wide-Columnar models. The proposed algo-
rithm uses one hot vector encoding to transform different SPARQL features into hidden
Darstellungen. Nächste, it embeds these representations into a tree-structured model, welche
is used to classify the virtual model GRAPH or TABULAR that has the lowest query
execution time.
Extensive experiments show that our approach is successfully running, returning the
optimal virtual model with an accuracy of 0.831, thus reducing the query execution time
of over 40% for the TABULAR model selection and over 30% for the GRAPH model
Auswahl.
The article is structured as follows. The underlying concepts about ontology-based
big data access are given in Section 2. Our approach is described in detail in Section 3.
Further description of deep learning model is presented in Section 4. Experimental results
are reported and explained in Section 5. Related Work is presented in Section 6. Abschnitt 7
1SPARQL is a query language for Resource Description Framework (RDF).
2We denote GRAPH and TABULAR when referring to the type of virtual data model; while we denote Property
Graph, Document-based, Wide-Columnar, Relational, and Tabular when addressing the source model.
3Resource Description Framework (RDF) is a standard designed as a data model for describing metadata.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
.
T
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
/
T
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA3
concludes with an outlook on possible future work.
2. Preliminaries
Our proposed approach requires the following inputs (1) data sources using different
Modelle. (2) Semantic Mapping that describes mapping in RDF Mapping Language, (3)
information about data sources (password, usw.), Und (4) a set of SPARQL queries. To
guide the subsequent description of our approach, we provide the following definitions:
Definition 1 (Data Source Schema) Dataset Schema is a set of Sd ∪ Sc ∪ Sr ∪ Sg ∪ St
considered by our approach; we introduce each model briefly as follows:
• Document-based Sd [18]: A document d is a JSON object o. An object is formed by a
set of key/value pairs (aka fields) o = { k1 . . . kn }; a key is a string, while a value can
be either a primitive value (z.B., a string), an array of values, an object, or null.
• Wide-Columnar Sc [19]: A table t is the unit of wide-column identified by name and
composed by a set of column-families f . The table’s rows are identified by a unique key.
Each row of the table can contain up to n records. The record is a pair of identifiers id
and a value. A wide-column is, in fact, a Hash structure expressed as: t = Hashtable <
key, Hashrow < f , Hashrecord < id, value >>>.
• Relational Sr [20]: A relation schema R with a set Σ of PKs, FKs and attributes A =<
A1, . . . , An > is denoted R(A1, . . . , Ein) is a set of n − tuples < d1, ..., dn > where each
di is an element of dom(Ai) or is null. The relation instance is the extension of the
relation. A value of null represents a missing or unknown value.
• Property Graph Sg [21] G = (V, E, λ , µ) is a directed, edge-labeled, attributed multi-
graph where V is a set of nodes, E ⊆ (V xV ) is a set of directed edges, λ : E → Σ is an edge
labeling function assigning a label from the alphabet Σ to each edge. Properties can be
assigned to edges and nodes by the function µ : (V ∪ E)xK → S where K is a set of property
keys and S the set of property values.
• Tabular St [22] is a set of tables T = { t1 . . . tn }. Each table tx integrates one or
more column groups, as tx = { GC1 . . . GCn }. Each column group integrates different
columns representing the atomic values to be stored in the table, GCx = { Cx
1 . . .Cx
N }.
We denote an entity of a data source by es
an object; where s is the schema entity, x its name and ax
either edges or columns. A data source consists of one or more entities, d = {NEIN}.
x = {ai}, representing either a node, a table or
i are its attributes representing
Definition 2 (Semantic Mapping) Semantic mappings are bridges (links) between the
ontology and sources schemata elements. We differentiate between two types of semantic
mappings [12]:
• Entity mapping: men = (e, C) a relation mapping an entity e from d onto an ontology
class c.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
/
T
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
T
.
/
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
4
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
• Attribute mapping: mat =(A, P) a relation mapping an attribute a from an entity e onto
an ontology property p.
Definition 3 (Star-Shaped Query) A Star-Shaped Query (SSQ) is a set of triples (sub-
ject, predicate, Objekt) patterns – BGPs4 sharing the same subject [23]. We denote
SSQ by stx = (cid:8)ti = (X, pi, oi) | t ∈ BGPq
(cid:9) where x is the shared subject, whereas BGPq =
{(si, pi, oi) | pi ∈ O}, is the triple patterns of SSQ.
Definition 4 (Connection SSQ) The joins of data coming from different data sources
are represented actually by the connections between star-shaped queries i.e., two SSQs
sta, stb (Thema, predicate, Objekt) are connected if the object of sta is the subject of stb.
in Verbindung gebracht(sta, stb) → ∃ti = (si, pi, B) ∈ sta.
Definition 5 (Relevant Entities to SSQ) [24] An entity e is relevant to a SSQ st if it con-
tains attributes ai mapping to every triple property pi of the SSQ i.e., relevant(e, st) →
∀pi ∈ prop(st)∃a j ∈ e | (pi, a j) ∈ Mat , where prop is a relation returning the set of prop-
erties of a given SSQ.
Definition 6 (Entity Wrapping) it is a function wrap that takes one or more relevant
entities to SSQ and returns a Virtual Model [24]. It loads entity elements and organizes
them according to Virtual model schema wrap : En → PS.
Definition 7 (Virtual Data Model) Virtual Data Model is the data structure of the com-
putation unit of the query engine to load, transform and join only the relevant data. Es ist
built and populated on-the-fly and not materialized, d.h., used only during query process-
ing then cleared. Virtual Data Model has a schema that organizes data according to its
Struktur. We consider two types of schema, GRAPH or TABULAR.
• Structure of a GRAPH [25] (in-memory) is similar as Property Graph. A GRAPH
G = (V, E) is a set of vertices V = {1 . . . N} and a set of m directed edges E. Der
directed edge (ich, J) ∈ E connects the source vertex i ∈ V with the target vertex i ∈ V .
GRAPH stores relationships at the individual record level.
• Structure of a TABULAR (in-memory) [26] is the same structure as the Tabular model
defined above. TABULAR has predefined structures.
Definition 8 (Graph and Data Parallel) During the querying execution,
Modell, GRAPH or TABULAR is partitioned, distributed, and queried in parallel.
the Virtual
• GRAPH Parallel5 is executed after loading relevant entities into the DEE. Graph-
Parallel Systems consist of a property graph G = (V, E, P) and a vertex-program Q
that is instantiated simultaneously on all the vertices.
• Data Parallel [27] concerns the TABULAR model, which is executed after loading rele-
vant entities into the DEE. Data-Parallel computation derives parallelism by processing
independent data on separate resources.
4Basic Graph Pattern (BGP) is a set of Triple Patterns, where BGPs is set of BGP.
5https://gist.github.com/shagunsodhani/c72bc1928aeef40280c9
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
.
/
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
T
/
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA5
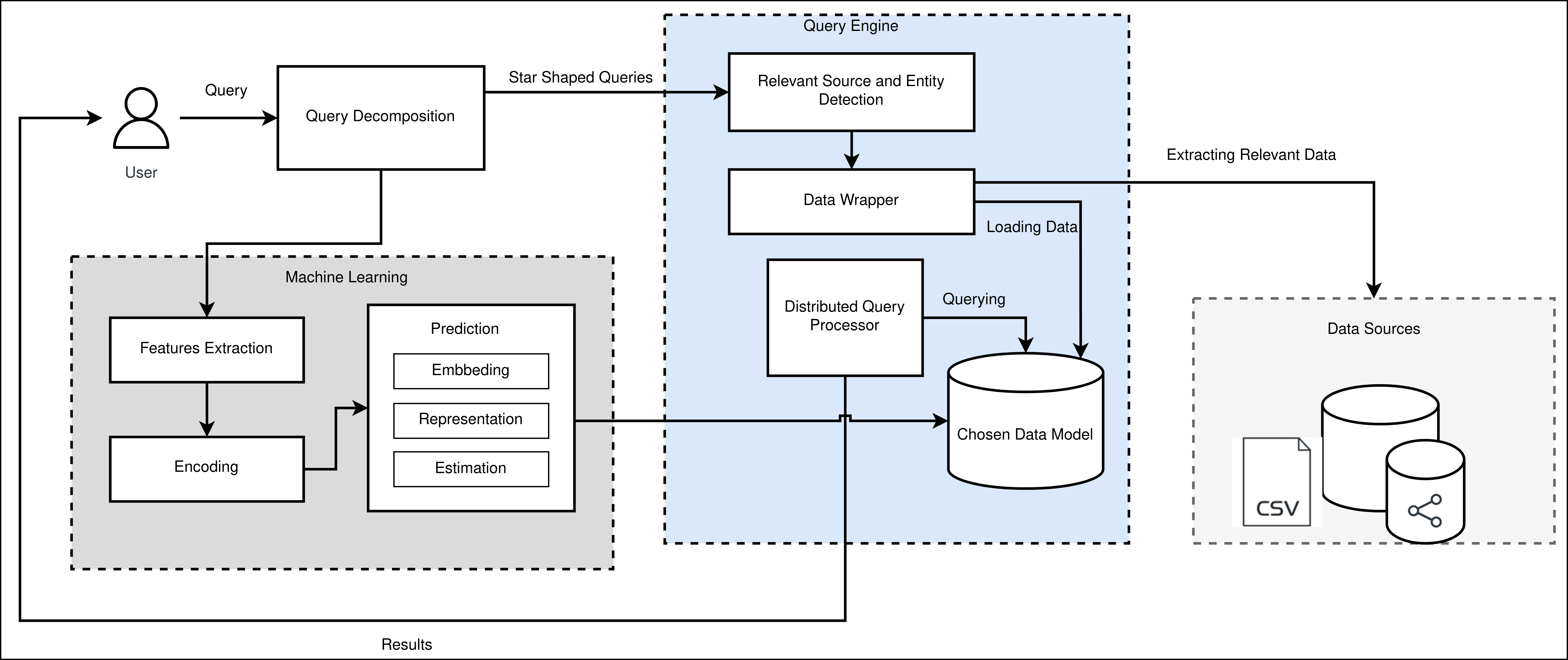
Feige. 1: Predicting Optimal Virtual Model on top of OBDA
3. Predicting Optimal Virtual Model for Querying Large
Heterogeneous Data
To solve the problem of selecting the optimal virtual data model and thus efficiently
query large heterogeneous data, we propose an approach that leverages OBDA method-
ology and deep learning. Our Solution follows OBDA and supports two types of virtual
data models, GRAPH and TABULAR, to load and join data from sources with various
Modelle, d.h., property graph, document-based, wide-columnar, relational, and tabular. Wir
used a deep learning algorithm that predicts the optimal virtual model based on query
behavior. More precisely, the algorithm extracts and encodes significant features from
input SPARQL query into representations that are then embedded into a tree-structured
model to classify the virtual model, GRAPH or TABULAR, that has the lowest cost i.e.,
query execution time. Below we describe each part of our proposed approach illustrated
in Abbildung 1.
3.1 Virtual Data Model Prediction
Our distinctive deep learning model, built on top of OBDA layers, aims to select the
optimal virtual data model based on query behavior. Our algorithm analyzes and extracts
features from the input SPARQL query and uses One-Hot Vector encoding6 to transform
different features into hidden representations. Nächste, these representations are embedded
into a tree-structured model, which can effectively learn the representations of query plan
features and predicts the cost against each virtual data model. As an output, the proposed
algorithm returns the optimal virtual model, GRAPH or TABULAR, that has the lowest
query execution time. Our deep learning algorithm is detailed in section 4. Once the
optimal model is predicted, the rest of the OBDA layers (z.B., query decomposition, entity
detection, and operations, z.B., join, limit) follow the optimal virtual data model, GRAPH
or TABULAR.
6One-hot vector is a 1 × N matrix (vector) used to distinguish each word in a vocabulary from every other word in the vocabulary.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
.
T
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
6
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
3.2 Query Decomposition & Relevant Entity Detection
Once the optimal virtual model is selected, our approach decomposes the input
SPARQL query into star-shaped queries to identify conjunctive queries [28]. More pre-
cisely, in SPARQL, the conjunction is expressed using shared variables across sets of
triple patterns, also called basic graph patterns (BGP). Based on this characterization, Wir
divide the query’s BGP into a set of sub-BGPs, where each sub-BGP contains all the
triple patterns sharing the same subject variable – called star-shaped query – SSQ (Defini-
tion 3). Most approaches for query decomposition in OBDA systems follow subject-based
method because triples sharing the same subject correspond to the same entity, z.B., table
or object in the data source, thus avoiding traversing data to find specific entities to be
joined and extra joins that can be very expensive.
Nächste, our approach analyzes each star-shaped query and retrieves semantic map-
pings that are already predefined i.e., correspondences between SSQ elements/variables
(d.h., ontology class or property) and data sources’ entities (z.B., table) or attributes (z.B.,
column name) in addition to data source type (z.B., relational) [see Definition 2]. A cor-
respondence that maps every triple property of a star-shaped query is called a relevant
entity (Definition 5). Endlich, loading those entities defined by data sources’ models into
the optimal virtual data model, GRAPH or TABULAR, requires data mapping and trans-
Formation, zum Beispiel, mapping and transforming a table from a relational model into a
GRAPH or TABULAR. Außerdem, star-shaped SPARQL operations (z.B., Projection,
filtering, grouping, usw.) are also translated into GRAPH or TABULAR operations.
3.3 Data Mapping and Transformation
Once the relevant entities and sources are identified using semantic mappings as
shown above, our approach maps and transforms relevant entities (z.B., a table) from their
original models (z.B., relational) [Definition 1] to data that comply with optimal virtual
data model predicted, GRAPH or TABULAR (Definition 7). This conversion occurs at
query-time, which allows for the parallel execution of expensive operations, z.B., join
(Definition 6).
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
.
/
/
T
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
T
/
ich
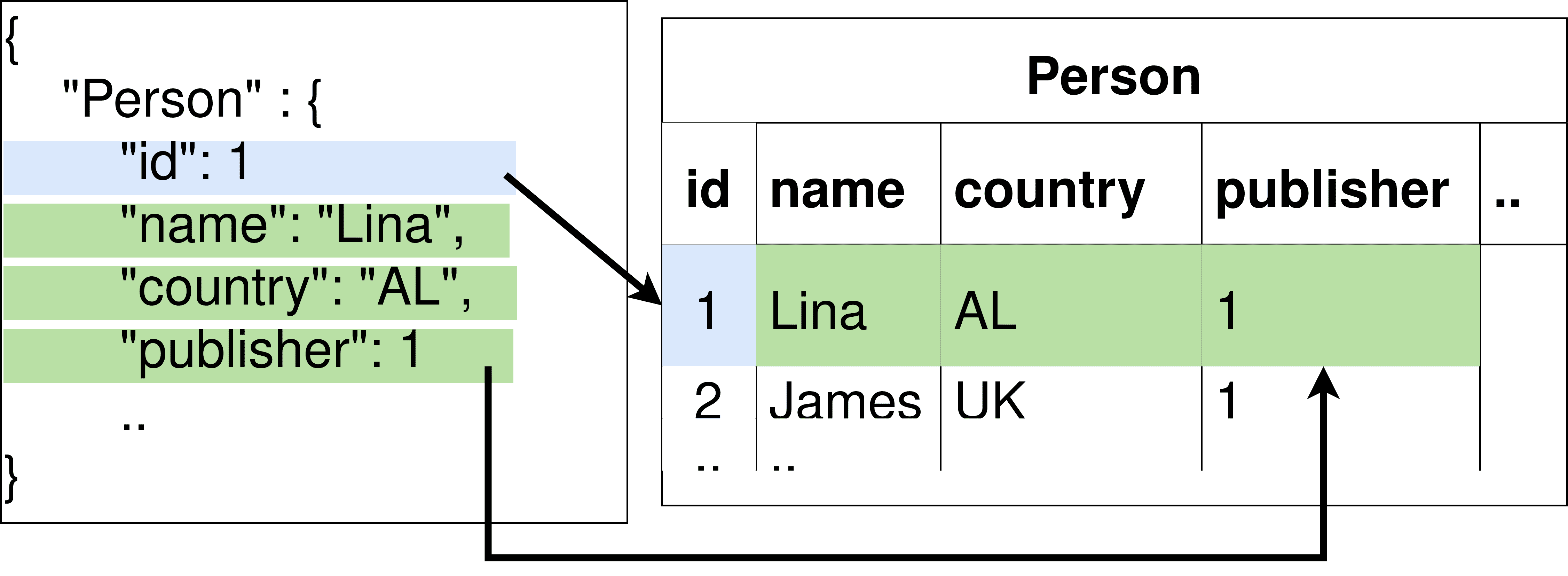
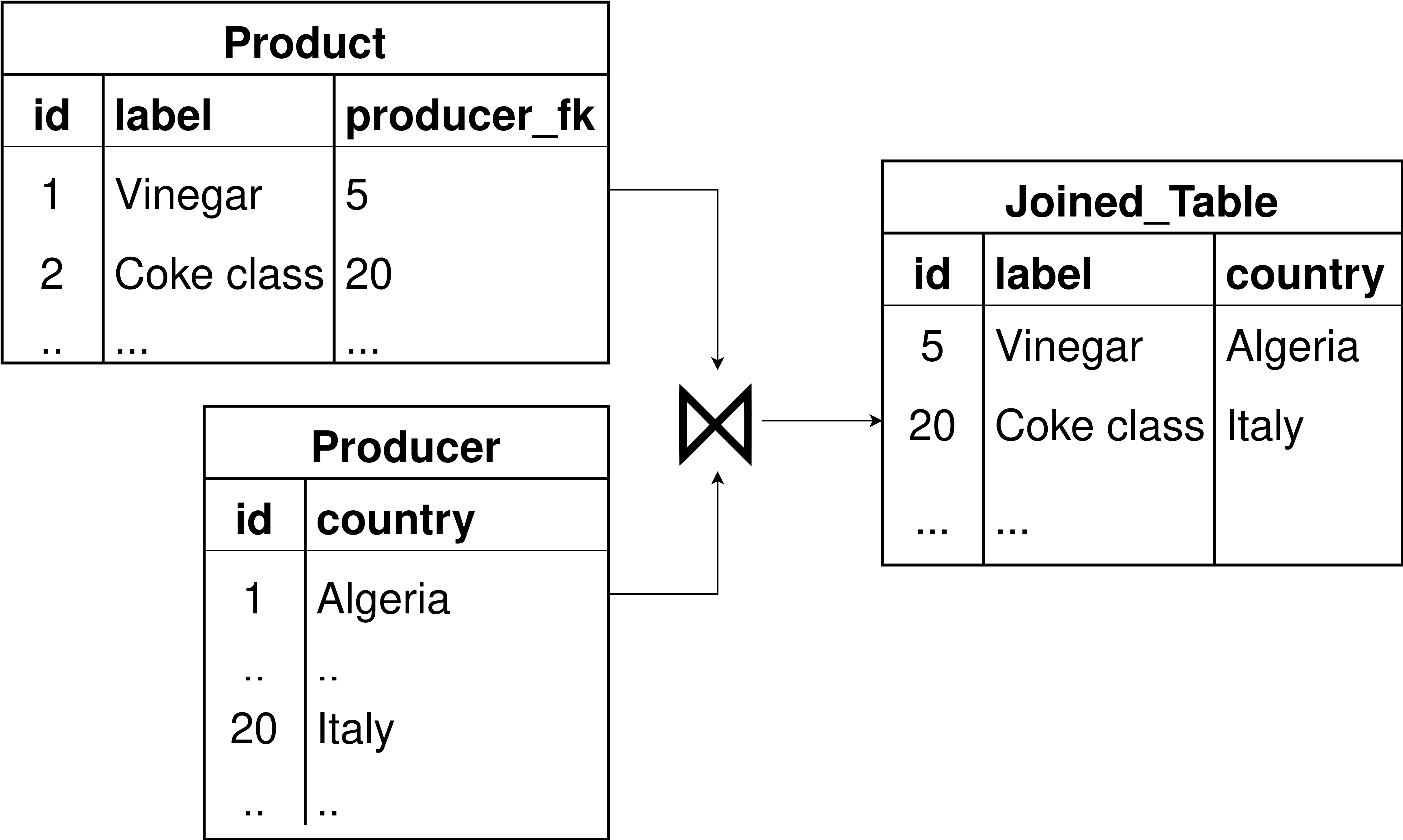
(A) Transforming Relational to GRAPH
(B) Transforming Document-based to TABULAR
Feige. 2: Transformation Process
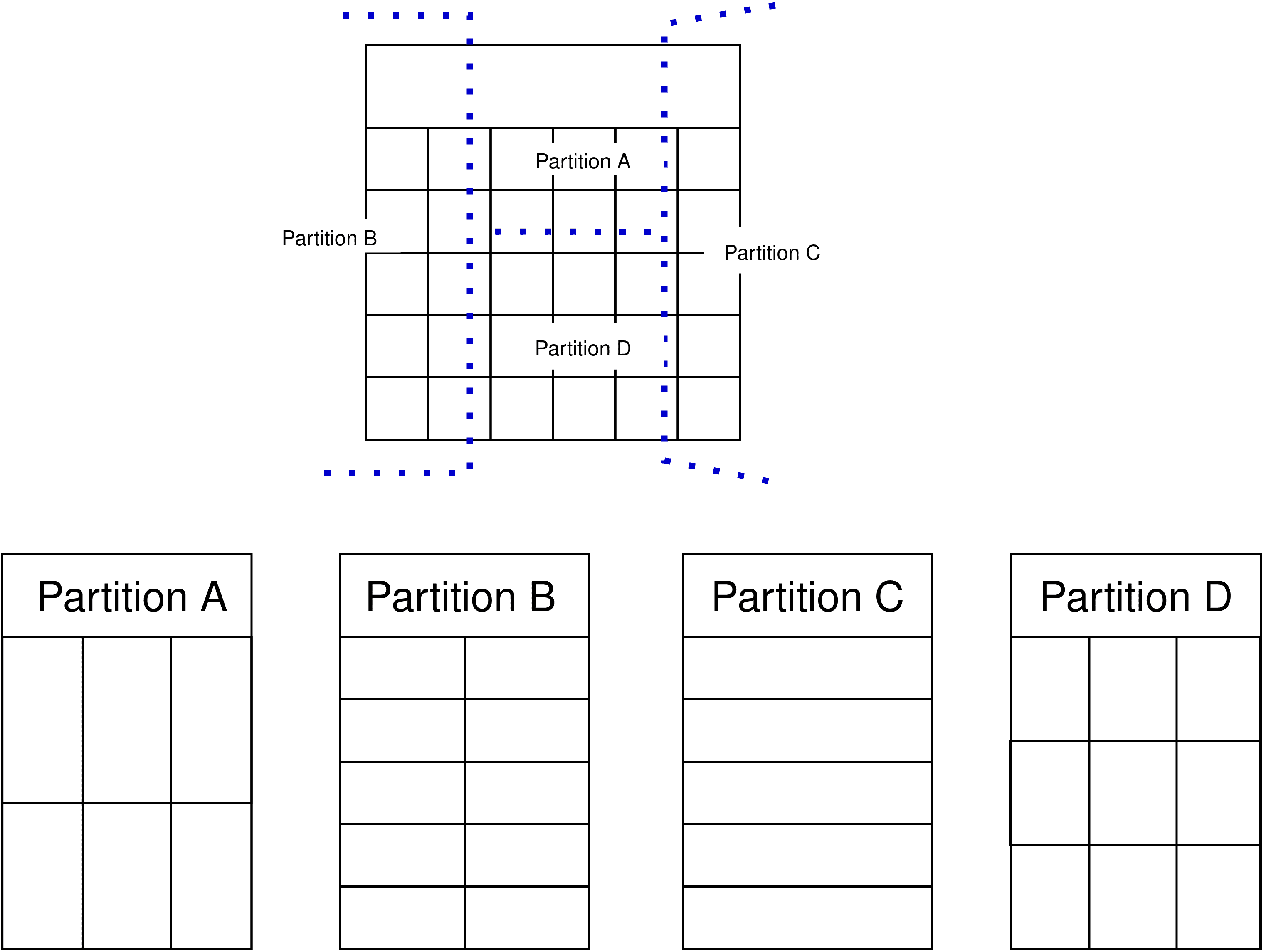
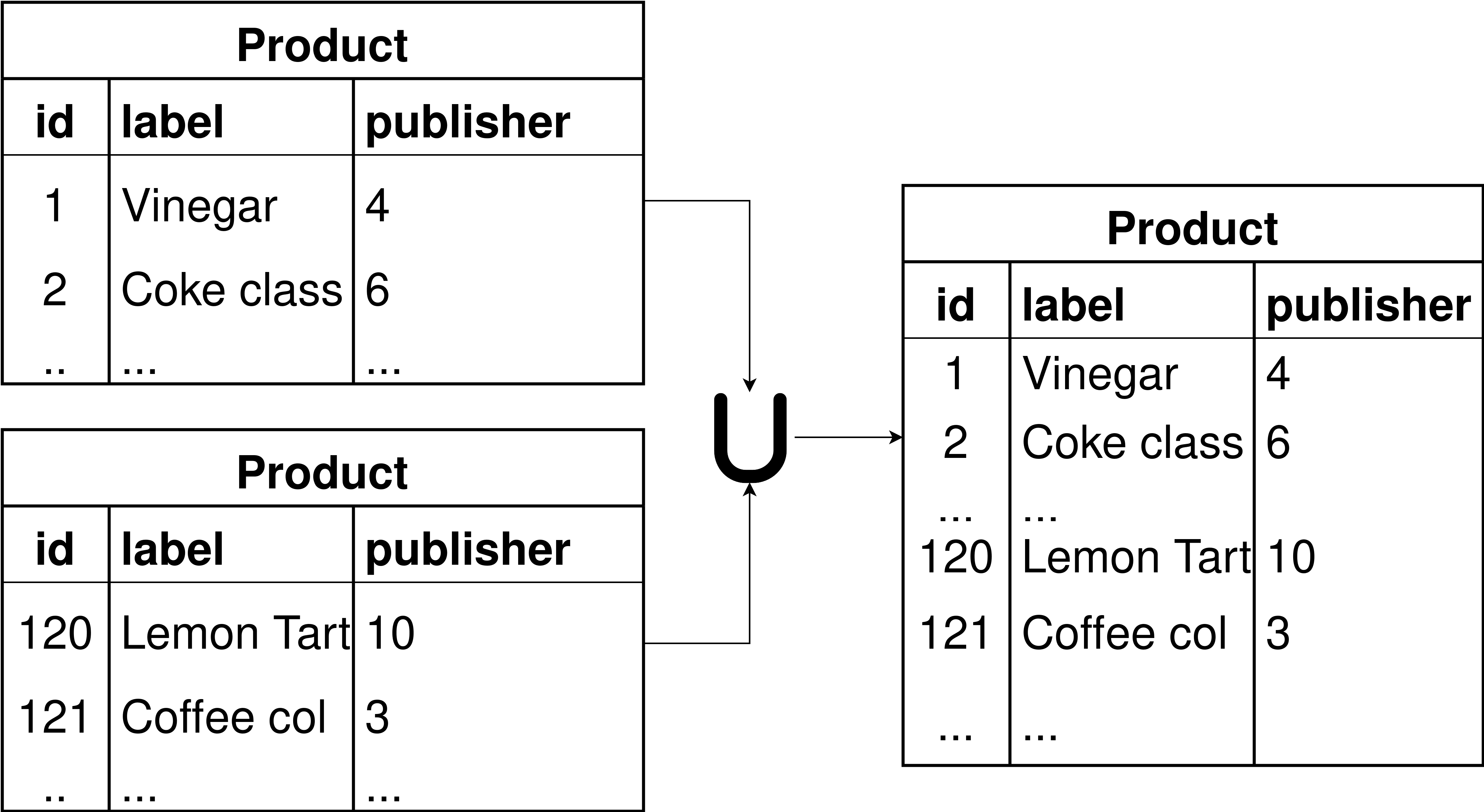
Each star-shaped query corresponds to one relevant entity, and thus one single virtual
data model is created. This is the case when the relevant entity, according to the mapping,
could be retrieved only from one data source, z.B., one relational table. Ansonsten, wenn die
relevant entity according to the mapping could be retrieved from multiple sources, Dann
the virtual model for the entity is the union of temporary virtual models created for each
source (Figur 4).
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA7
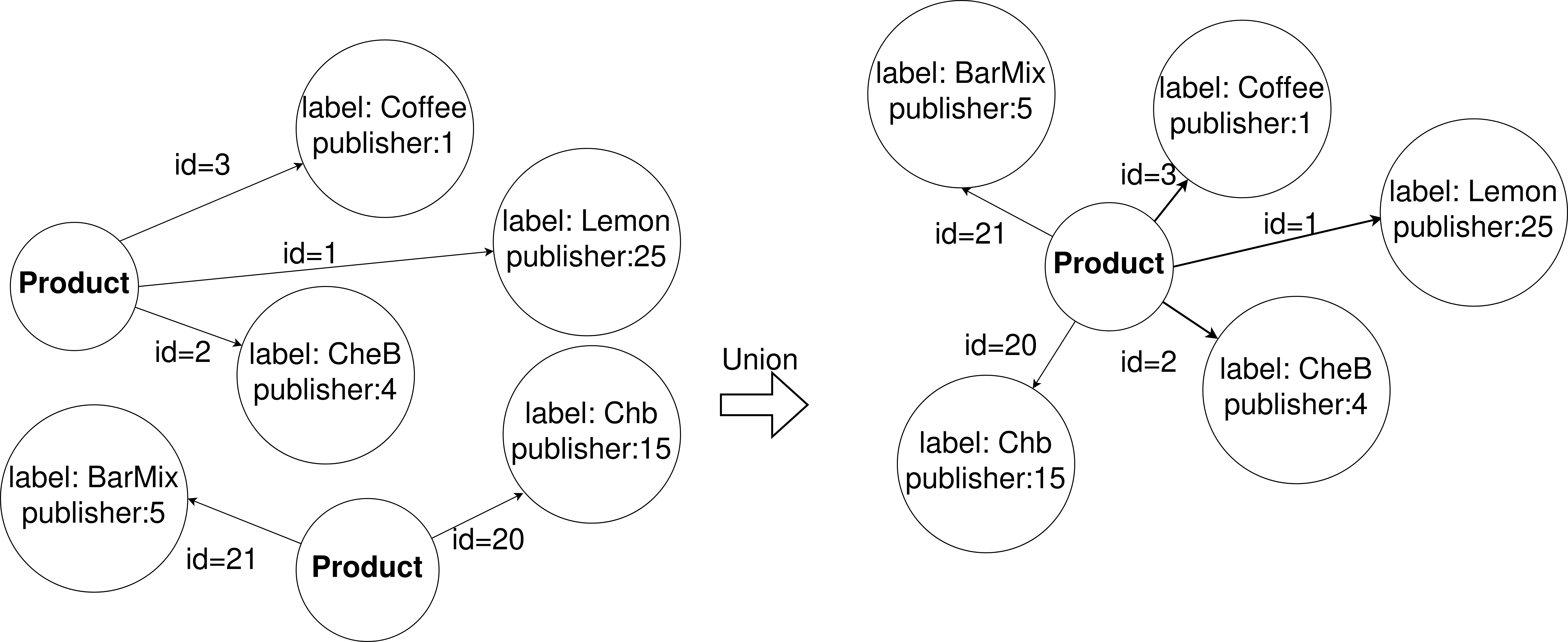
Below we describe data source models transformation by wrappers into GRAPH and
TABULAR.
• For the virtual data model of type GRAPH, the structure returned of relevant data on
different data sources using existing data access methods [24] is schema-less data, z.B.,
RDD (Resilient Distributed Dataset). Then necessary structural adaptations are em-
ployed, which consist of converting schema-less to GRAPH following the mapping
Verfahren. The data is represented as a table with specific columns for the Tabular and
Relational models defined by CSV and MySQL. Then the mapping process is defined
as follows (see Figure 2a): for each table row, a vertex is created with the same label
as the table’s name (z.B., table ’Person’ corresponds to all vertices with the label ’Per-
son’) in addition to the root vertex. Edges are created between vertices and the root
Scheitel, whereas the properties of each vertex are the columns of the table (z.B., column
’name’ corresponds to property ’name’), and the values of the properties are the table’s
cell information. The same process is applied to property graphs defined by neo4j,
document-based, and Wide-Column models (z.B., an XML file) defined by MongoDB
and Cassandra.
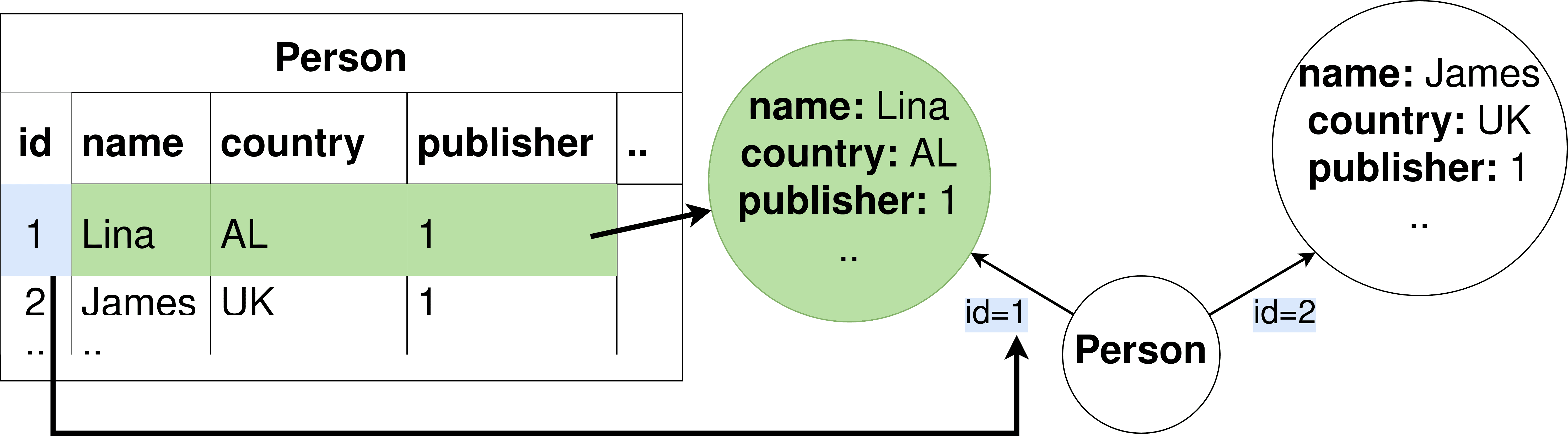
• As for the virtual data model of type TABULAR, the structure returned of relevant
data on different data sources using existing data access methods is organized into
named columns, z.B., DataFrame. Adaptations are needed, which consist of convert-
ing DataFrame to TABULAR following a mapping process. Zum Beispiel, the selected
object as a relevant entity of documented-based and wide-columnar stored in MongoDB
and Cassandra is parsed to create a virtual TABULAR (see Figure 2a), which consists
of a table with a name similar to the root object’s name (z.B., a table ’Person’ from
object name ’Person’). A new row is inserted by iterating through object elements into
the corresponding table. The corresponding key-values are saved under the column
representing the cell information. The same process is applied to other models.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
T
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
/
T
ich
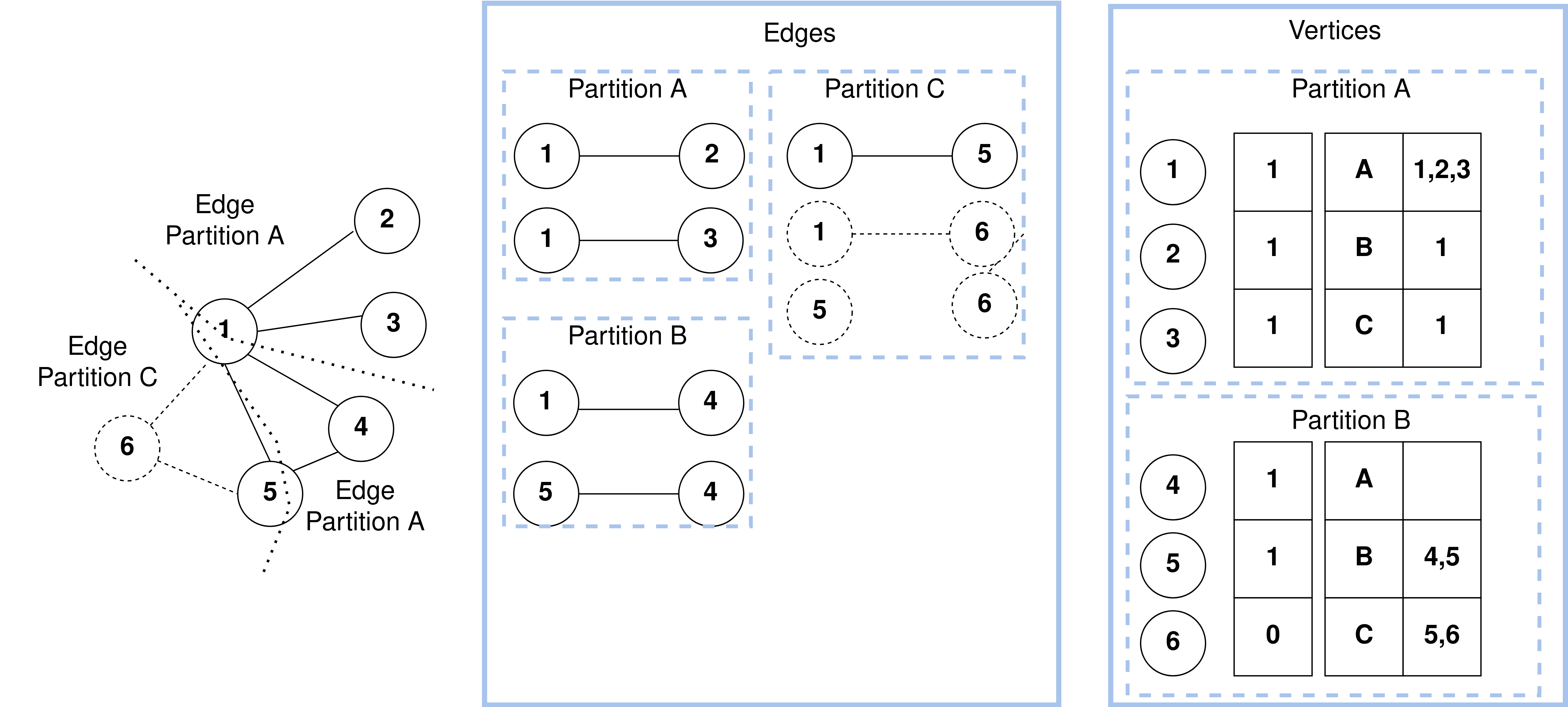
(A) GRAPH Parallel [25]
Feige. 3: Parallel Mechanism for GRAPH and TABULAR
(B) TABULAR Parallel
We highlighted below how SPARQL and star-shaped queries operations are translated
into Virtual Data model operations in case of GRAPH and TABULAR.
3.4 Distributed Query Processing
Distributed Query Processing is where the virtual model is actually joined and ex-
ecuted. Our approach uses Big Data engines (z.B., SPARK) that offer users the ability
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
8
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
(A) Union of TEMPORARY GRAPHs
(B) Union of TEMPORARY TABULARs
Feige. 4: Union Operation of TEMPORARY Virtual Model
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
(A) Join of GRAPHs
Feige. 5: Join Operation of Virtual Model
(B) Join of TABULARs
to manipulate the data model of its computation unit (d.h., virtual data model). This al-
lows the implementation of different data models that can be more suitable for various
Abfragen. We consider two types of data models, GRAPH and TABULAR, which allow
for graph-parallel (see Figure 3a) and data-parallel (see Figure 3b) Berechnung, thus af-
fecting the query performance. Our approach uses several different data models (Eigentum
graph, document-based, wide-columnar, relational, and tabular) to demonstrate its capa-
bility to cover and access various heterogeneous data sources. We should point out that
we did not employ any query optimization function to choose the most efficient query
execution plan; stattdessen, we focused on the join operation. Zum Beispiel, if our predictive
model predicts based on the input SPARQL query that the optimal virtual model is of type
GRAPH, then for each relevant entity, one virtual GRAPH model is generated, following
our proposed transformation process (see Subsection 3.3). Once generated, our approach
joins those GRAPHs or TABULARs (d.h., a virtual model for each relevant entity) into
a FINAL Virtual, GRAPH, or TABULAR (siehe Abbildung 5). Below we describe the join
process and operations using GRAPH or TABULAR virtual models.
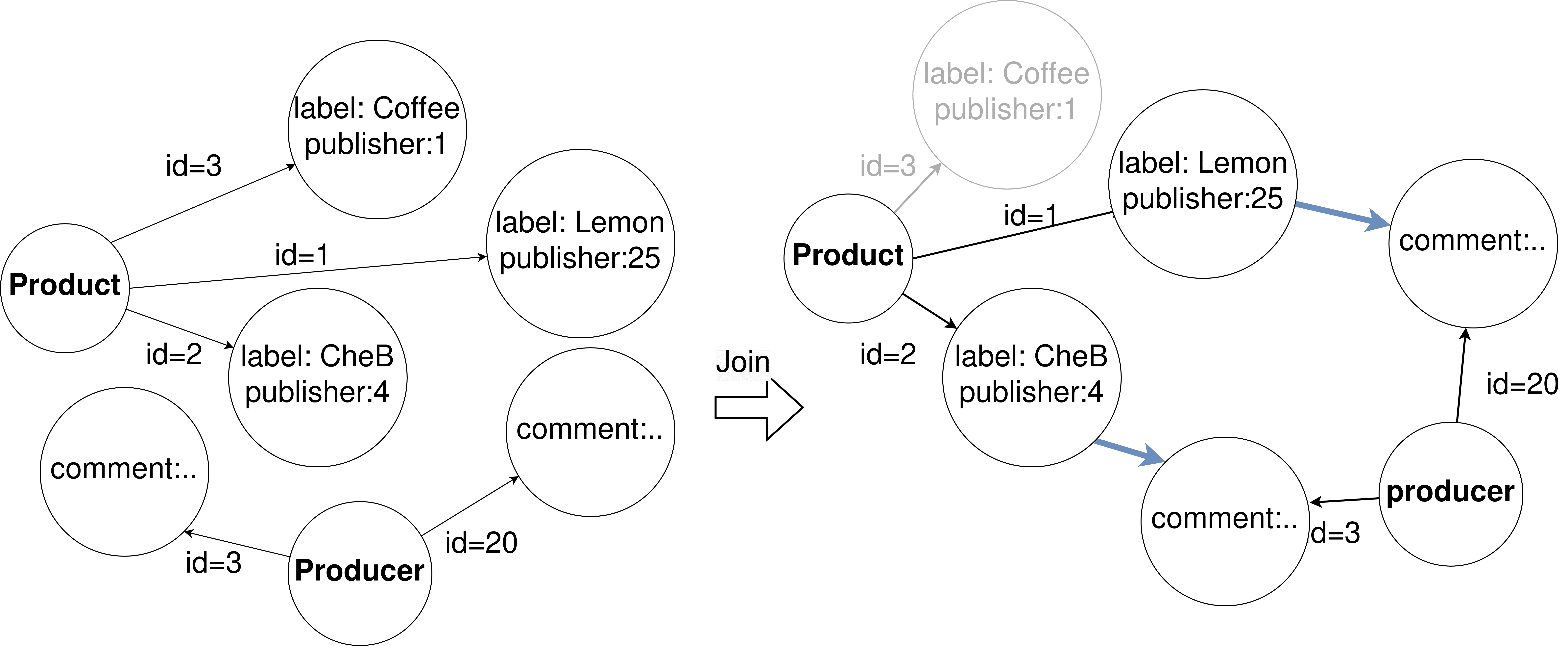
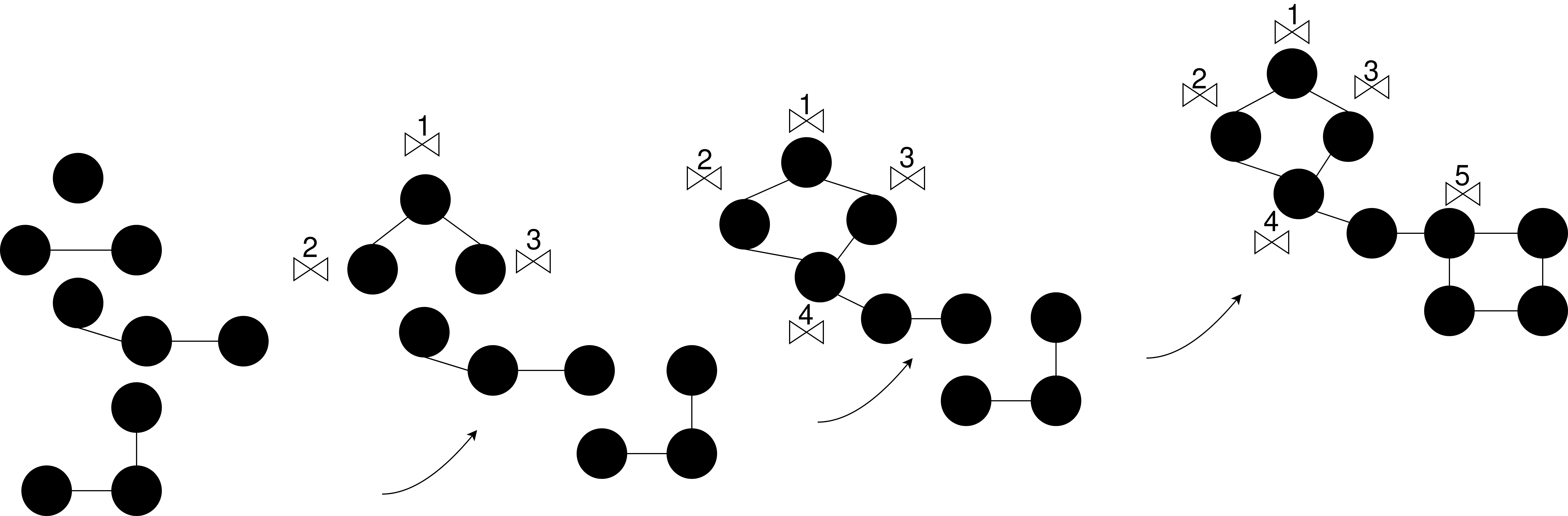
Joining Virtual Data Model: The data join coming from different data sources are
represented actually by the connections between star-shaped queries i.e., two SSQs
sta, stb (Thema, predicate, Objekt) are connected if the object of sta is the subject
of stb. These connections are translated into an array of join pairs (see green SSQ
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
.
T
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
T
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA9
(A) Multi-Join Algorithm of GRAPHs
(B) Incremental Join Algorithm of TABULARs [12]
Feige. 6: Join Algorithms for GRAPH and TABULAR
in Figure 4a).As for GRAPH, the FINAL Virtual GRAPH (Figure 5a) is created by
iterating through the GRAPHs join pairs following a multi-way join algorithm (Feige-
ure 6a) which has been proven beneficial in terms of performance based on research
Literatur [29]. The multi-way join algorithm can join two or more relations simul-
taneously, which is suitable for graph-parallel computation. In der Praxis, new edges
are created for each joined pair to link GRAPHs, such as an edge source point to
one of the GRAPH vertices and its destination points to the second GRAPH. Der
FINAL Virtual GRAPH is the result of the newly created edges and the union of the
joined pair vertices. Endlich, we filter out vertices’ identifiers that have no destina-
tion. Außerdem, to make the joining of GRAPHs faster, we selected only projec-
tion columns’ IDs before joining GRAPHs since it is heavy to scan over columns.
Ähnlich, the FINAL Virtual TABULAR i.e., joined TABULARs (Figure 5b) is cre-
ated by applying join between the respective tables following incrementally joined
(Figure 6b), which is revealed to be very efficient [30]. This is done by using a prede-
fined method ’join’ that takes the joined pairs’ names and the name of the foreign
key column as an argument. Außerdem, we adopted the same strategy proposed
In [24], which employs a filter before data transformation, thus reducing the number
of the values of the attributes to be transformed and then joined which revealed high
efficiency.
––• Star-Shaped/SPARQL Operations to GRAPH/TaABULAR Operations GRAPH
and TABULAR have different structures; daher, the interaction with GRAPH is
possible through Graph Pattern Matching operations (z.B., Cypher-like), while the in-
teraction with TABULAR is possible through SQL-like functions. We highlighted be-
low how SPARQL and star-shaped operations are translated into Virtual Data model
Operationen, GRAPH, and TABULAR.
– Projection:
this operation requires accessing FINAL Virtual GRAPH and TABU-
LAR. For GRAPH, we used the hash map method to get the properties’ indexes by
iterating over the projected vertices and collecting the linked vertices into one vertex.
This helps reduce the operations (z.B., limit) execution time by executing operations
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
/
T
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
T
/
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
10
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
on a single vertex instead of multiple vertices. Contrary to the FINAL TABULAR,
which is projected using a predefined method ’project’ that takes as an argument
the projection variables and returns a projected FINAL TABULAR.
– Filtering: Performing filtering on a given property of Virtual GRAPHS needs access-
ing data through an index rather than the property name. daher, we used a hash
map that stores the property name and index. We get the right property index by
matching the property name from the filter with the one from the hash map. As for
the Virtual TABULAR model, filters are executed over the TABULAR columns. Wir
use a predefined method ’filter’ that takes as an argument the filter statement
and returns a filtered virtual TABULAR model.
– Ordering and Limit:
to be able to sort or show a limited number of data of the
GRAPH, we extracted triples from the FINAL GRAPH. Nächste, we used a prede-
fined ordering method, e.g.,’sortBy’ and limited method ’take’, that takes the
vertex property value as input and outputs sorted or limited FINAL GRAPH. Als
for the TABULAR model, it can be sorted and limited using predefined methods
’orderBy’ and ’limit’ respectively. These methods take the ordering column
or number of needed rows in case of Limit as an argument and return an ordered or
limited FINAL TABULAR.
3.4.1 Query Execution
Optimizing query execution time is a very crucial step when it comes to loading and
joining data. Jedoch, time optimization depends not only on the virtual data model, d.h.,
GRAPH or TABULAR, but also on the execution plan of operations, z.B., applying a filter
before joining data. We disabled any query optimization by engine Apache SPARK and
Graphx to emphasize the join operation when querying multiple data sources.
Optimization Strategy for GRAPH. To join GRAPHs, we applied a multi-way join
Algorithmus (Figure 6a) which has been proven beneficial in terms of performance based on
research literature [29]. The multi-way join algorithm can join two or more relations at
die selbe Zeit, which is suitable for graph-parallel computation. Außerdem, to make the
join of GRAPHs faster, we selected only projection columns and their ID before joining
GRAPHs since it is heavy to scan over columns (unlike the TABULAR strategy given
nächste).
Optimization Strategies for TABULAR. To join TABULARs, research has proven
that incremental data processing approaches [30] for data-parallel achieve better perfor-
mance since they rely on updating the results of a query when updates are streamed rather
than re-computing these queries and may require less memory than batch processing.
daher, we followed the incremental join; if TABULAR is selected as an optimal vir-
tual data model based on query behavior, the FINAL Virtual TABULAR is created by
iterating through the TABULARs that are created from the relevant entities and incre-
mentally joined (see Figure 6b). Außerdem, we adopted the same strategy as described
von [24] where we applied a filter before data transformation, thus reducing the number
of the values of the attributes to be transformed and then joined, which revealed very
efficient.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
.
T
/
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
/
T
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA11
4. Deep Learning Model
This section describes our deep learning model to predict the virtual data model of
type GRAPH or TABULAR.
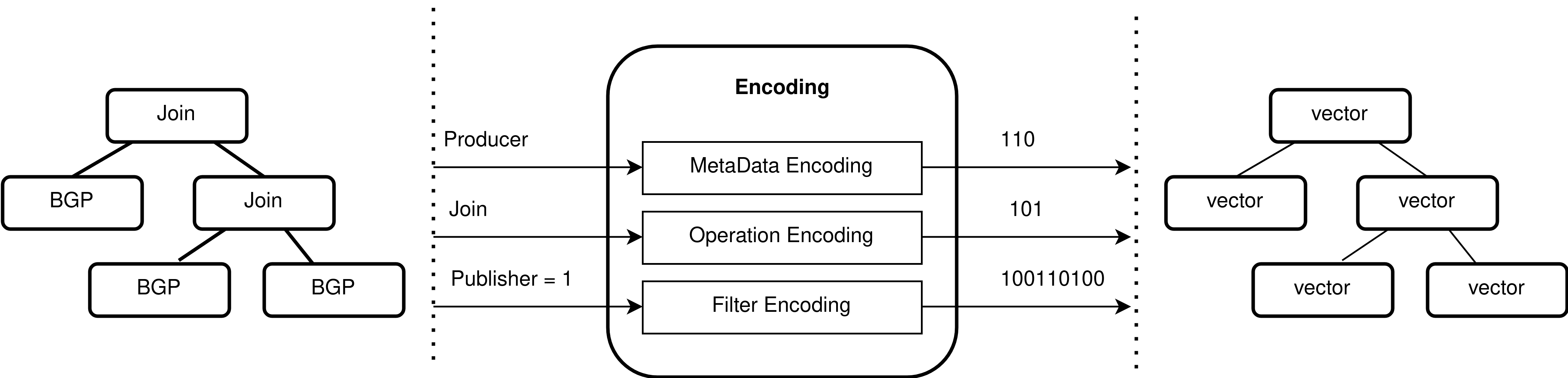
4.1 SPARQL Features Analysis
Our model breaks down the SPARQL query plan into nodes (Figure 7a). Each node
includes a set of query features that significantly affect the query cost (z.B., filter). Der
different features are then encoded using different encoding models. Below, we list those
features and their encoding:
• MetaData: is the set of attributes and entities used in the SPARQL query (z.B., entity
names ’producer’). We encode both attributes and entities using a one-hot vector. Dann
we concatenate each attribute vector with its entities vectors to have a final MetaData
vector.
• Operation: is the set of physical operations used in the SPARQL query, such as Join,
BGP, Projection, OrderBy, and Limit. Each operation is composed of an operator
(z.B., ”>=”) and a list of operands (entities or attributes e.g., [operator=’project’, bei-
tributes=’price, delivery-days’]). Both the operator and its operands are encoded using
a one-hot vector. Endlich, each operation vector in the SPARQL query is the concatena-
tion of an operator vector and its operands vectors.
• Filter: is the set of query filters. A filter is considered a special operation since it
could be either atomic or compound. Each atomic filter is composed of an attribute, ein
operator, and an operand. The filter operand could be either a float or a string value.
Both the attribute and the operator are encoded using a one-hot vector. To encode the
operand, we use a normalized float if its value is numeric; ansonsten, we use a String
representation. The String representation makes use of a Char Embedding model and a
CNN (Convolutional Neural Network [31]) to have a fixed-length dense String vector.
The three resulting vectors are concatenated to form one single filter vector.
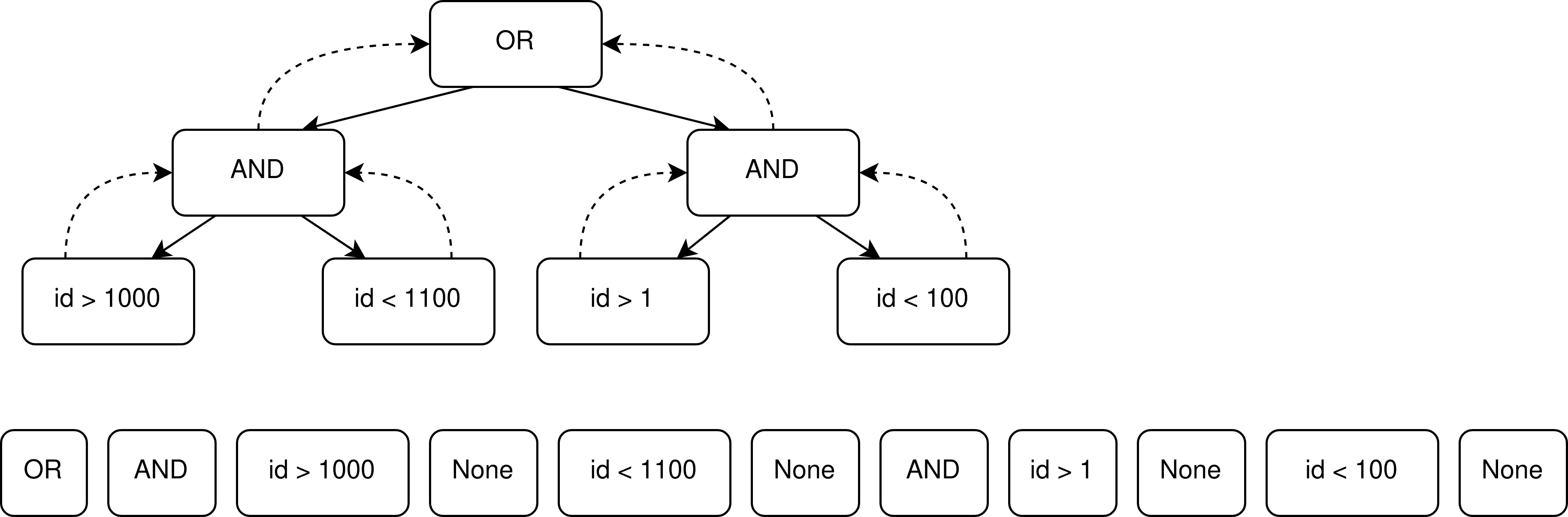
The compound filter is a combination of multiple atomic filters using either AND or
OR operator. Zum Beispiel, ’price > 4000 (atomic) AND price < 20 000 (atomic)’, in
this case, the filter is considered as a compound. To obtain the vector of the compound
filter, we encode each logical operator and atomic filter using one-hot encoding. Next,
a tree filter is created where the root is the one-hot vector of a logical operator (e.g.,
AND), and the nodes are the one-hot vectors of atomic filters (e.g., left node 000111
representing price > 400). Endlich, each node (one-hot vector) is transformed into a
sequence using the Depth First Search algorithm (DFS). At the end of each sequence,
we add an empty node. The sequences are then concatenated following the visited
Befehl.
4.2 Proposed Tree-structured Model
Tree-structured models have been proven more powerful than neural networks at pre-
dictive tasks using tabular data [32]. Inspired by the work presented in [33], we propose
our deep learning model (Figure 7b) that takes as input the encoded features of SPARQL
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
T
.
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
T
.
/
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
12
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
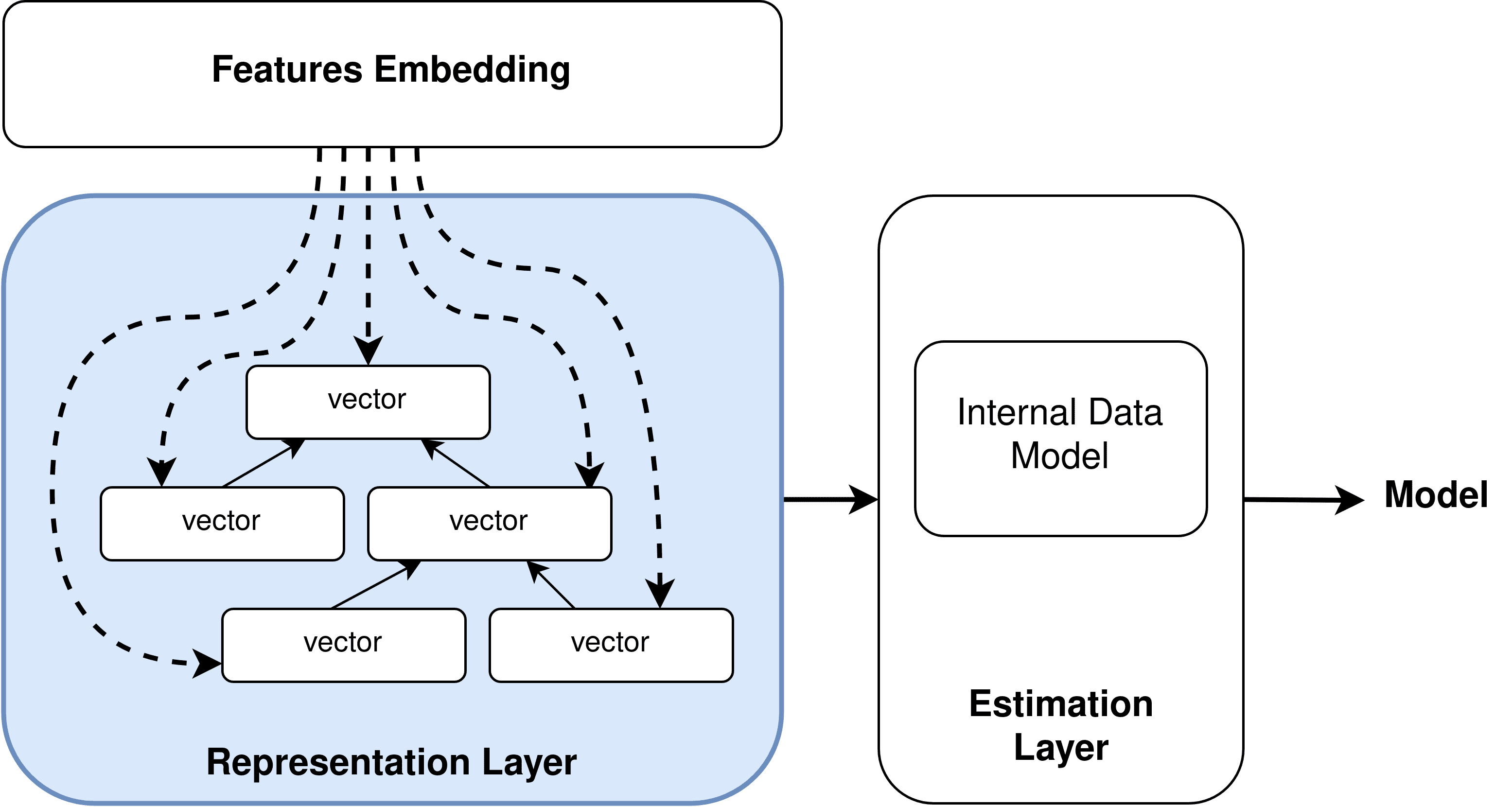
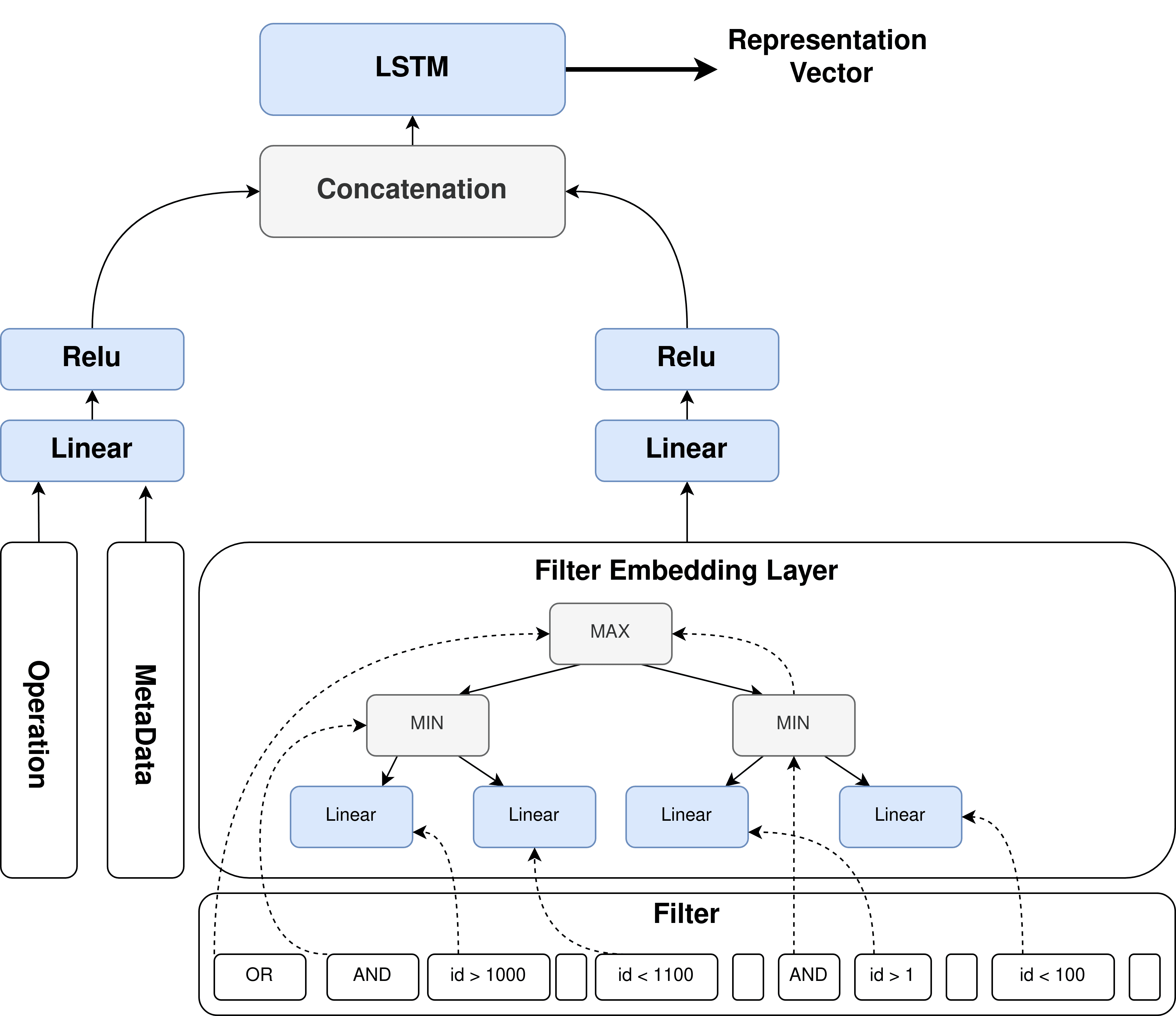
(A) Features Extractor
Feige. 7: Deep Learning: Feature Extraction and Tree-Structured Model
(B) Tree-Structured
query and outputs the optimal virtual data model, GRAPH or TABULAR that has the
lowest cost. Our model consists of an embedding layer to condense the features’ vec-
tors and an estimation layer to estimate the optimal virtual data model. Zusätzlich, Die
model includes an intermediate representation layer to capture the correlation between the
joined star-shaped queries. Im Folgenden, we give a detailed explanation of the model
architecture.
4.2.1 SPARQL Embedding Layer
The SPARQL Query Embedding Layer (Figure 8a) embeds a sparse vector into a
dense vector. It takes as inputs three types of feature vectors: MetaData, Operation, Und
Filter. Erste, the MetaData vector along with the Operation vector are embedded using a
fully connected neural network layer7 with ReLU (Rectified Linear Unit) activator, welche
is a piecewise linear function that outputs the input directly if it is positive. The structure
of the Filter vector is more complicated in the case of compound filters. daher, Wir
adapted a Min-Max-Pooling operation to embed the Filter vector.
The Min-Max-Pooling model is a tree-structured model that takes the structure of the
Filter tree. For leaf nodes, we use a fully connected neural network. For conjunction
Knoten, we use the max pooling layer for ‘OR’ operator and the min pooling layer for
‘AND’ operator. The max pooling layer is the maximum number of estimated results
satisfying the atomic predicates, while the min pooling layer is the minimum number of
estimated results satisfying the atomic predicates. Thus representing the SPARQL query
filters explicitly.
4.2.2 SPARQL Representation Layer
Learning complex structure representations such as tree structure using classic neu-
ral networks has many challenges. Erste, the neural networks can learn much information
from the leaf nodes but fails at capturing the correlation among upper nodes. Das ist
known as the vanishing gradient problem. Zweite, capturing correlations between mul-
tiple tree nodes requires storing a lot of intermediate results, which leads the space to
grow exponentially. This is known as the gradient explosion problem. To handle those
7Fully connected network: a linear regression a0x +..+ anx, 2 linear regressions connected means the output of the first one is
the input of the second one.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
.
T
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
T
/
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA13
two problems, we designed an intermediate layer (detailed in Figure 8b) that captures
the global cost information from leaf nodes to the root by training representations for
nodes recursively. We use fully connected networks that have the same structure and
share common parameters. Each layer has three inputs: an embedding vector, a repre-
sentation vector of the right child, and a representation vector of the left child. Wir verwendeten
Long Short-Term Memory (LSTM) [34] as a recurrent model. The LSTM model uses the
concept of ’memory’ to store information of previous nodes, which makes them capable
of learning order dependence in the tree structure. This helps prevent the information loss
Problem. Andererseits, the forget gate of Sigmoid helps LSTM to address the space
explosion problem.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
(A) Tree Representation
Feige. 8: Deep Learning: Tree and Representation Model
(B) Representation Model
4.2.3 Virtual Model Classification Layer
It is a binary classification model that takes the representation vector of query tree
nodes as input and outputs the optimal virtual data model, GRAPH or TABULAR, mit
the lower cost (d.h., we set GRAPH with value 1 for SPARQL queries that are faster than
TABULAR and label TABULAR with value 0 for SPARQL queries that are faster than
GRAPH). The classification layer includes two fully connected neural networks with a
ReLU activator. The output layer is a Sigmoid function that returns a number from 0.0
Zu 1.0, representing the probability that the input belongs to. If the output is closer to 1.0
then the predicted virtual data model is of type GRAPH; ansonsten, if the output is closer
Zu 0.0, then the predicted virtual data model is of type TABULAR.
Product
database type Cassandra MongoDB
# of tuples
50000
data size
˜4MB
50000
˜90MB
Offer Review Person
Neo4j
CSV
50000
50000
˜3MB
70MB
Producer
MySQL
50000
14MB
Tisch 1: table 1a: Data & Queries Characteristics
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
.
/
T
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
.
T
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
14
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
Q7
✓
✓
✓
Q8
✓
✓
✓
Q9
✓
✓
Q10 Q11 Q12 Q13 Q14 Q15
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
Q5
✓
✓
Q2 Q3
✓
✓
✓
✓
✓
✓
Q4
✓
✓
✓
✓
✓
Q6
✓
✓
✓
✓
✓
Q1
✓
✓
✓
Product
Offer
Rezension
Person
Producer
PROJECT
FILTER
ORDERBY
LIMIT
DISTINCT ✓
✓
✓16
✓16
✓1
✓1
✓300 ✓2
✓
✓
✓
✓5 ✓29 ✓45 ✓24 ✓45 ✓38 ✓38 ✓24 ✓34 ✓4
✓
✓
✓
✓
✓12 ✓1
✓1
✓20 ✓4
✓
✓
✓
✓5
✓1
✓1
✓1
✓20 ✓20 ✓80
✓
✓
✓
✓1
✓1
✓
✓
✓10
✓
✓
✓
✓6 ✓32 ✓34 ✓4
✓4
✓1
✓1
✓1
✓1
✓13 ✓19 ✓1000 ✓1000
✓
✓
✓
✓
Q16
✓
✓
✓5
✓
Q17 Q18 Q19 Q20
✓
✓
✓
✓
✓
✓
✓
✓9 ✓45 ✓45 ✓5
✓
✓
✓
✓
✓
✓
✓
✓
✓2
✓3
✓1
✓
✓
✓
✓
Tisch 2: Tables and Operations involved in Queries.
5.
Implementation and Experimental Setup
OPTIMA – an implementation of our approach, is an OBDA system that calls
Graphx and Apache-Spark8 to implement two virtual data model, GRAPH and TABU-
LAR. The virtual data model is the model defined by the computation unit of these two
query engines9. Graphx and Apache-Spark already implement wrappers called connec-
tors, of which we used five types to load data that is stored in Neo4j (property graph),
MongoDB (document-based), Cassandra (wide-column), MySQL (relational), and CSV
(tabular). As for transformation, we used Graphx and Apache-Spark functions10 e.g.,
flaMap(x=>y). OPTIMA calls a deep learning model to get the predicted optimal
virtual data; it uses NumPy for encoding data and PyTorch for the prediction model. OP-
TIMA is available on GitHub at https://github.com/chahrazedbb/OPTIMA.
We conducted an empirical study to evaluate OPTIMA performance with respect to
the following sub-research questions of our problem: RQ1: What is the query perfor-
mance using OPTIMA? RQ2: Is the time of prediction plus the time of query execution
using an optimal virtual model equal to the fixed one? RQ3: What is the query perfor-
mance when using TABULAR versus GRAPH? RQ4: What is the accuracy of OPTIMA
and machine learning? RQ5: What is the query performance of OPTIMA compared to
the state-of-the-art, z.B., Squerall [12]? RQ6: What is the impact of involving more data
sources in a join query? RQ7: What is the resource consumption (CPU, Erinnerung) von
OPTIMA while running various queries? RQ8: What is the time taken by each transfor-
mation process?
5.1 Benchmark, Queries, and Environment
There is no benchmark dedicated to assessing ontology-based big data access sys-
Systeme. We end up using BSBM* [12] to evaluate the performance of OPTIMA. BSBM* is
an adapted version of BSBM benchmark [35] where five tables, Product, Offer, Rezension,
Person, and Producer, are distributed among different data storage. To test OPTIMA,
we use the five tables to enable up to 4-chain joins. These tables are loaded in five dif-
ferent data sources Neo4j, MongoDB, Cassandra, MySQL, and CSV. Tisch 1 zeigt die
described information about data. We generated 5150 queries with 0-4 joins, 0-45 se-
lection, Und 0-16 for the filter, limit, and orderBy. The characteristics of these queries
8for Apache-Spark, a small part of OPTIMA is based on Squerall’s code (https://github.com/EIS-Bonn/Squerall)
9RDD is an immutable distributed collection of elements, while DataFrame is an immutable distributed collection of data
organized into named columns. RDD is distinct from DataFrame in that the former is considered schema-less.
10https://spark.apache.org/docs/latest/graphx-programming-guide.html, https://spark.apache.org/docs/2.2.0/rdd-
programming-guide.html
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
/
T
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA15
Query
SELECT DISTINCT ?productLabel ?producerLabel
WHERE { product rdfs:label ?productLabel .
?producer rdfs:label ?producerLabel .
?product rdf:type bsbm:Product .
?product bsbm:producer ?producer .}
OPTIMA
Sqyerall
[’Bar Mix Lemon’,’Coke Classic 355 Ml’]
[’Bar Mix Lemon’,’Coke Classic 355 Ml’]
(A) Query Result Returned by OPTIMA & Squer-
alle
Metrics
CPU average (%)
Max memory (GB)
OPTIMA
0.21
1.0
Squerall
0.20
0.97
(C) Resource Consumption
Time (MS)
System
OPTIMA 2400
4200
Squerall
(B) Avg Time
Tisch 3: OPTIMA Performance
are presented in Table 2. We take 4120 queries for training the model and 1030 Abfragen
for validation. We run the evaluation on Ubuntu Version 20.04 64-bit with an Intel(R)
Core(TM) i7-8550U CPU @ 1.80GHz, allocating 8GB of RAM.
Training paradigm
In diesem Abschnitt, we provide a detailed description of the training paradigm of our deep
learning model. The training data typically involves the following steps:
• Data collection and preprocessing: To the best of our knowledge, no large datasets of
SPARQL queries exist. daher, we generated more than 5000 SPARQL queries that
combine all possible elements of a SPARQL query, as described in Table 1. Diese
queries are then preprocessed (see an example of SPARQL query in Appendix A.1)
to extract features (see Appendix A.2) and then convert them into a tree-structured
representation (see Appendix A.3) suitable for input into our deep-learning model. Wir
run each query on both GRAPH and TABULAR. We set GRAPH with a value of 1 für
SPARQL queries that are faster than TABULAR and label TABULAR with a value of
0 for SPARQL queries that are faster than GRAPH.
• Tree construction: The tree structure is constructed based on the query plan, in other
Wörter, into query result clause and query pattern and query. Zum Beispiel, the tree’s
root node represents the query plan, while the child nodes represent the query result
clause and query pattern and query, and the leaf nodes of the query result clause would
represent clause type such as the ”SELECT” operation (see Appendix A.3).
• Supervised learning: To enable the model to learn the relationships between the
SPARQL query elements (z.B., plan, Betreiber, usw.) and the execution time of each
data model GRAPH or TABULAR. We trained our deep learning model using feed-
forward neural network with multiple hidden layers and non-linear activation functions
ReLU and Sigmod, including two fully connected neural networks, each with 16 neu-
rons. We trained the model on 80% of queries using the mean squared error as the loss
function and the Adam optimization algorithm. The model is trained for 100 Epochen,
and the validation loss is monitored to prevent overfitting.
• Model evaluation: We evaluated our trained model’s accuracy, and we obtained good
results after iterations.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
.
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
T
/
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
16
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
System
OPTIMA
Squerall
Time Difference
Q1
1291
4098
2807
Q2
1254
2519
1265
Q3
730
3091
2361
Q4
10299
10283
16
Q5
10199
10191
8
Q6
1553
7984
6431
Q7
7104
7089
15
Q8
8442
8427
15
Q9
10094
10088
6
Q10
4694
4684
10
Q11
2575
2561
14
Q12
233
1400
1167
Q13
4673
4644
29
Q14
4487
4469
18
Q15
2397
3885
1488
Q16
2881
2875
6
Q17
1698
3314
1616
Q18
4607
8742
4135
Q19
2804
9059
6255
Q20
5648
7407
1759
Tisch 4: Time in ms per Query of OPTIMA & Squerall
5.2 Metrics
To evaluate OPTIMA, we use the following metrics:
• OPTIMA Accuracy. We compare the results returned by OPTIMA against the results
returned by Squerall.
• Classification. We use two metrics to evaluate the OPTIMA classification model:
Cross-entropy loss and Accuracy function. Assuming the real result is denoted as r = ri,
the predicted result is denoted as p = pi, and the correctly predicted results as t p = t pi,
Wo 1 <= i <= N, we compute these metrics as follows: CE(r, p) = ∑ ri ∗ log(pi),
Acc(t p, p) = ∑t pi/ ∑ pi
• Memory and CPU consumption as described in [36]. Specifically, we measure how
much the memory and CPU are active during the computation.
• Execution Time. We measure the time OPTIMA takes from query submission to the
delivery of the answer. The time is measured using the absolute wall-clock system time
reported by the Scala time() function.
5.3 Method
We consider two studies:
• In the first study, we compare OPTIMA’s results with SPARK-based Squerall’s results.
Our comprehensive literature review did not reveal any single work except Squerall that
is available and that supports most data sources. Squerall uses two big data engines,
Presto and SPARK: Presto-based, where the virtual model of presto engine (which can-
not be controlled by users) is used for query processing, and SPARK-based, where
DataFrames are created as a virtual data model. To make the results comparable, we
choose SPARK-based Squerall and extend it to support Neo4j. We assess the accuracy
of OPTIMA in terms of (1) results (accuracy), (2) time, and (3) CPU and memory usage
compared to SPARK-based Squerall. We should note that comparing the overall exe-
cution time of OPTIMA against an original system, e.g., relational for a given query, is
impossible because we are querying various heterogeneous formats and models.
• In the second study, we inspect OPTIMA’s main components: machine learning, data
wrappers, and query execution. We observed the behavior of query execution for
GRAPH and TABULAR in terms of time. For the data wrapper, we investigate the
time taken for the transformation process from data sources to GRAPH or TABULAR.
As for the machine learning component, we compare our model with the LSTM model
in terms of accuracy and time. The LSTM model takes as input the encoded features
vectors without any correlation and outputs the data model.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
.
/
t
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
6
2
1
2
7
0
2
9
d
n
_
a
_
0
0
2
1
6
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA17
5.4 Experiment 1: OPTIMA vs SPARK-based Squerall
In this experiment, we load BSBM* as described above to obtain the results from
OPTIMA and SPARK-based Squerall. Then, we run 5150 SPARQL queries and compare
the results.
• Validation of Results and Overall Execution Time: this comparison allows us to
confirm the correctness of the results returned by OPTIMA. Table 3a shows the results
of OPTIMA and SPARK-based Squerall of a complex SPARQL query Q21. The results
are the same for both systems, which confirms that OPTIMA is able to support and join
large data coming from different datasets.
Table 4 illustrates the execution time returned by both systems. As can be observed,
OPTIMA excels Squerall for queries that involve multiple joins. The time difference
ranges from 0 to 80000 milliseconds (ms). This difference is due to the predicted virtual
data model e.g., Q19, Q20, in which deep learning predicted that the Virtual model of
type GRAPH is optimal. We also observe a small difference in the execution time
(ranging from 0 to 30 ms) in favor of Squerall compared to OPTIMA for queries that
involve multiple projections e.g., Q7, Q10. This is explained by the fact that the optimal
virtual model is identical to Squerall’s, and both Squerall and OPTIMA used the same
APIs to call data (wrapper); however, the data model prediction time added to OPTIMA
makes it slightly slower than Squerall. Furthermore, the average execution time of
Squerall is greater than 4000 ms compared to the average execution time of OPTIMA
2400 ms as shown in table 3b. These results illustrate the benefits of OPTIMA over
existing systems; thus, RQ1 and RQ5 are answered.
• Data Model Execution Time. As shown in Table 5, the analysis of experimental results
indicates that GRAPH is faster than TABULAR in most cases, except for queries like
Q8 and Q10. It has comparable to slightly lower performance in Q16. This confirms
that the optimal model is very important in reducing the execution time of queries. The
total execution time ranges from 50 to 90000 ms, with 90% of all cases being about or
below 3000 ms. OPTIMA virtual data model of type GRAPH is faster in queries that
involve joins (ranging from 50 to 40000 ms), while the TABULAR model outperforms
the GRAPH model in queries involving more projections (ranging from 200 to 90000
ms).
This is explained by the fact that the GRAPH is designed to store connections between
data. Therefore, queries do not scan the entire graph to find the nodes that meet the
search criteria. It looks only at nodes that are directly connected to other nodes, while
SQL-like methods used by the TABULAR model require expensive join operations be-
cause they traverse all data to find the data that meets the search criteria. On the other
hand, the TABULAR model is faster when handling projections because the data struc-
ture is already known, and data can be easily accessed by column names. Conversely,
the GRAPH model does not have a predefined structure for the data, and each node
attribute has to be examined individually during the projection query.
The number of joins has a decisive impact on query performance; it should be taken
into consideration with other factors, e.g., size of involved data, presence of filters, and
selected variables. For example, Q2 joins only two data sources, Product and Review
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
/
t
.
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
6
2
1
2
7
0
2
9
d
n
_
a
_
0
0
2
1
6
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
18
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
Prediction Time
GRAPH
TABULAR
Q1
3
1143
4098
Q2
3
1161
2519
Q3
4
1239
3091
Q4
6
1243
10283
Q5
4
306
10191
Q6
5
3181
7984
Q7
5
7168
7089
Q8
6
12237
8427
Q9
2
4977
10088
Q10
4
16681
4684
Q11
5
1211
2561
Q12
1
3567
1400
Q13
5
482
4644
Q14
5
1285
4469
Q15
4
766
3885
Q16
3
2883
2875
Q17
2
6639
3314
Q18
4
1366
8742
Q19
4
3370
9059
Q20
4
1723
7407
Table 5: Time in ms per Query of Prediction, GRAPH & TABULAR
(1254 ms) but has comparable performance with Q1 (1291 ms), which joins four entities
(Product, Offer, Review, and Producer). This may be due to filtering in Q1 (16 filters),
significantly reducing intermediate results to join. Q3 involves four data sources, yet
it is among the fastest queries. This is because it involves the small entities Person
and Producer, which is another reason to reduce intermediate results to join. With five
data sources to join, Q4 is among the most expensive queries (10299 ms). This can be
attributed to the fact that the filter on Product is selective (?language = ”en”), which
results in large intermediate results to join, in contrast to Q6 (?price < 8000). Although
the four-source join Q7 and Q8 involve the small entity Producer, they are the most
expensive queries that execute over the GRAPH model; this can be attributed to a large
number of projections (38 attributes). Thus, we answer RQ3 and RQ6 and suggest that
operations can affect query execution time.
• Resource Consumption: finally, we record the Resource Consumption (i.e., Memory
and CPU) taken by OPTIMA and SPARK-based Squerall. The results reported in Ta-
ble 3c show that the CPU is not fully used by OPTIMA and SPARK-based Squerall
(around 0.21% was used). This means that the complexity of queries does not impact
CPU consumption. As for the total memory reserved, OPTIMA consumed around 1GB
over 8GB per node, while SPARK-based Squerall used at most 1GB. Having the same
CPU and memory could be explained by the fact that both are using the same query
engine - SPARK, and the distribution of CPU between the nodes for loading and trans-
formation. This answers RQ7.
5.5 Experiment 2: Performance of OPTIMA’s Predictive Model
In this study, we evaluate the main components of OPTIMA.
• Deep Learning Accuracy. We evaluated our model with LSTM and Regression
models to assess our encoding techniques and prediction model. We used 5150
queries; 80% for training and 20% for validation. We trained all models on the
same dataset and computed the accuracy and Cross-entropy loss function. Results
in Table 6a show that our tree-structure-based method outperforms the LSTM and
Regression models with an average accuracy of 0.831 for our model against 0.708
and 0.717 for LSTM and Regression, respectively. The cross-entropy loss is equal
to 0.00018 for our model compared to 1.92027 and 6.51098 for LSTM and Re-
gression, respectively. This is explained by the fact that both models, LSTM and
Regression, rely on the independent assumption among different operations and
attributes, while our model achieves the best performance as it captures more cor-
relations. Thus answering RQ4.
• Deep learning reduces the overall execution time.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
.
t
/
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
6
2
1
2
7
0
2
9
d
n
_
a
_
0
0
2
1
6
p
d
/
t
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA19
Cost
Regression model
LSTM
Our Model
Loss
1.92027
6.51098
0.00018
Accuracy
0.708
0.717
0.831
Condition
Machine Learning
Only GRAPH
Only TABULAR
Avg. time (ms)
12
1320
2862
(a) Loss & Accuracy of Deep Learning Models
(b) Time of Deep Learning, GRAPH & TABULAR
Table 6: Deep Learning Performance
To check if deep learning is reducing the overall execution time of OPTIMA by
selecting the optimal virtual data model. We illustrate first the time taken by OP-
TIMA’s components: machine learning algorithm, query execution over GRAPH
model, and query execution over TABULAR against SPARK-based Squerall. We
run OPTIMA and Squerall over 1030 queries. Results are shown in table 6b. The
average execution time of the machine learning component is a very short 12 ms,
while the average time for GRAPH is 1320 ms and TABULAR is 2862 ms. Results
show that for most queries, GRAPH is faster than TABULAR, even with prediction
time. In summary, only 14% of the queries were initially faster for OPTIMA (using
GRAPH as a virtual model) compared to Squerall and become in the later favor.
This is explained by the fact that for those queries, there is a slight difference in
execution time using GRAPH compared to Squerall. This answers RQ2.
Model
GRAPH
TABULAR
Neo4j
138
3275
JDBC CSV Cassandra MongoDB
954
199
196
255
7695
5319
188
330
Loading
4.327
7.141
Table 7: Time (ms) of Data transformation to GRAPH & TABULAR
5.5.1 Data wrapper Time
To answers RQ8, we evaluate, in this study, the time needed to load the data from
data sources to the virtual data model of type GRAPH or TABULAR (see Table 7). Since
the transformation process is different, we expect different behavior from the wrappers. In
the table, we illustrate the time needed by each wrapper with the following observations:
• Neo4j connector loads 50000 nodes from Neo4j within 138 ms into GRAPH, compared
to 3275 ms in TABULAR. This is explained by the fact that the graph property used by
Neo4j has the same exact structure as the GRAPH model.
• CSV connector loads 50000 rows within 196 ms from CSV files into GRAPH, com-
pared to 255 ms in TABULAR, even though CSV files save data into tables. This can
be explained by the fact that GRAPH virtual model is a schema-less model that loads
data directly without the need to preserve data structure, while TABULAR takes time
to build the data schema.
• JDBC connector loads 50000 rows from MySQL database within 954 ms into GRAPH,
compared to 199 ms in TABULAR. This can be explained by the fact that MySQL uses
a relational model, which has the same data structure as the Virtual TABULAR model.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
t
/
/
.
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
6
2
1
2
7
0
2
9
d
n
_
a
_
0
0
2
1
6
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
20
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
• MongoDB connector loads 50000 rows from MongoDB within 188 ms into GRAPH,
compared to 330 ms in TABULAR. This can be explained by the fact that MongoDB is
document-based i.e., it is schema-less, the same as the GRAPH Virtual model, unlike
the TABULAR model, which needs to build a data schema.
• Cassandra connector loads 50000 rows within 7695 ms into GRAPH, compared to 5319
ms in TABULAR. This can be explained by the fact that Cassandra uses a columnar
data model, which is more close to the TABULAR model even though it is a NoSQL
database.
6. Related Work
Our literature review reveals two categories addressing data virtualization. These
two categories are namely ”ontology-based data access” and ”non-ontology-based data
access” [12]. Non-ontology-based data access approaches mostly use SQL-like as query
language and implement a virtual relational model [37,38], defining views of relevant data
from sources having a relational model. Those views are generated based on mapping as-
sertions that associate the general relational schema with the data source schemata. The
shortcomings of these approaches are that the schema modifications and extensions are
very rigid due to mappings and may depend on complex constraints. Furthermore, these
approaches use Self-Contained Query [24] where users cannot control the structure of the
virtual data model. OBDA [39] approaches use SPARQL as a unified access language and
detect relevant data from sources to be joined through ontologies and standardized map-
pings. This provides flexibility in modifying and extending the ontology and mappings
with semantic differences found across the data schemata.
Exiting Systems implemented OBDA over relational databases, e.g., Ontop [40],
Stardog (http://www.stardog.com), which are using virtual knowledge graphs. These so-
lutions are not designed to query large-scale data sources, e.g., NoSQL stores or HDFS.
Our study’s scope focuses on works that query large-scale data sources using OBDA.
Optique [10] is an OBDA platform that accesses both static and streaming data. It im-
plements a relational model (implicitly a TABULAR) as a virtual model while querying
data sources such as SQL databases and other sources e.g., CSV, and XML. There was
no clear description of how Optique accesses NoSQL stores and distributed file systems
(e.g., HDFS). Ontario [11] focuses on query rewriting, planning, and federation, with a
strong stress on RDF data as input. Query plans are built and optimized based on a set of
heuristics. The virtual model used by Ontario is the GRAPH model (explicitly an RDF).
Squerall [12], recent and close work to OPTIMA leverages Big Data engines SPARK
and Presto to query on-the-fly heterogeneous large data sources. The virtual data model
imposed by Presto is TABULAR and does not offer users to control it, while SPARK
can offer control over the virtual data model, Squerall uses DataFrame as a virtual model
which is TABULAR. However, the decision behind the virtual data model implemented
by all these systems is rather based on use and flexibility and not on solid evidence to
improve query processing. There is no work that (1) implements the different optimal
virtual models, and (2) selects the optimal one based on query behavior. For machine
learning, some works [14,15,16] addressed the cost estimation of SPARQL queries to op-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
.
/
/
t
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
6
2
1
2
7
0
2
9
d
n
_
a
_
0
0
2
1
6
p
d
t
.
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA21
timize query execution plan e.g., performance prediction, however, all these approaches
are designed for a single query on one single data source.
7. Conclusion
We presented a new approach that reduces the time execution of querying large het-
erogeneous data by predicting the optimal virtual data model based on query behavior.
OPTIMA - a realization of our approach, implements two virtual models, GRAPH and
TABULAR within the query engine SPARK (Graphx and Apache-Spark). The effective
deep learning model built on top of OPTIMA’s architecture estimates the cost of the query
against both virtual models to select the optimal one for the given query. It extracts signif-
icant features such as the query plan and query operation and returns the optimal virtual
data model. Once selected, OPTIMA gets a unified view of the data from multiple data
sources on-the-fly by decomposing the input SPARQL query into star-shaped queries.
Next, it uses ontology-based mappings to detect relevant entities from original sources.
Those relevant entities are then loaded by the wrappers into the predicted virtual model,
GRAPH or TABULAR to be joined. In the case of GRAPH, a set of vertex and edges are
joined while for TABULAR, a set of tables is combined. Finally, the results are returned
by applying the operation on the FINAL joined GRAPH or TABULAR. Extensive experi-
ments showed a reduction in query execution time of over 40% for the TABULAR model
and over 30% for the GRAPH model.
A. Appendix: Training Data
In this appendix, we present an example of the data collection and preprocessing of
the training model.
SELECT DISTINCT
WHERE{
? v e n d o r ? c o u n t r y ? p r o d u c e r P u b l i s h e r
? p r o d u c e r edm : c o u n t r y ? c o u n t r y .
? p r o d u c e r bsbm : p u b l i s h e r ? r o d u c e r P u b l i s h e r .
? o f f e r bsbm : p r o d u c e r ? p r o d u c e r .
? o f f e r bsbm : v e n d o r ? v e n d o r .
? o f f e r
FILTER ( ? c o u n t r y = ”DE” ) .
FILTER ( ? p r o d u c e r P u b l i s h e r = ” 1 ”
FILTER ( ? v e n d o r >= 50 ) .
r d f : t y p e schema : O f f e r .
) .
}
Listing A.1: SPARQL query
A . [ DISTINCT , B , H, ICH , J , K]
B . [ PROJECT , ? v e n d o r , ? c o u n t r y , p r o d u c e r P u b l i s h e r ]
C . [ BGP , D, E ]
D . [ TRIPLE , ? p r o d u c e r , ? c o u n t r y ]
E . [ TRIPLE , ? p r o d u c e r , ? p r o d u c e r P u b l i s h e r ]
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
T
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
T
.
/
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
22
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
F . [ BGP , G]
G . [ TRIPLE , ? o f f e r , ? v e n d o r ]
H . [ JOIN , C , F ]
ICH . [ FILTER ,
J . [ FILTER ,
K . [ FILTER ,
=
=
>=
, ? c o u n t r y , ” DE” ]
, ? p r o d u c e r P u b l i s h e r , ” 1 ” ]
, ? v e n d o r , 5 0 ]
Listing A.2: Feature extraction from SPARQL queryA.1
{
” P l a n ” :
{
” DISTINCT ” : ” ”
, ” PROJECT ” :
[
” ? v e n d o r ”
, ” ? c o u n t r y ”
, ” ? p r o d u c e r P u b l i s h e r ”
]
, ” JOIN ” :
{
”TYPE” : ” l e f t ”
, ”BGP” :
{
[ ” p r o d u c e r ” ]
”TABLE” :
, ” TRIPLE ” :
, ” TRIPLE ” :
[ ” ? p r o d u c e r ” , ” ? c o u n t r y ” ]
[ ” ? p r o d u c e r ” , ” ? p r o d u c e r P u b l i s h e r ” ]
}
, ”BGP” :
{
”TABLE” :
, ” TRIPLE ” :
[ ” o f f e r ” ]
[ ” ? o f f e r ” , ” ? v e n d o r ” ]
}
}
, ” FILTER ” :
{
” o p t y p e ” : ” Compare ”
, ” o p e r a t o r ” : ”=”
, ” l e f t v a l u e ” : ” ? c o u n t r y ”
, ” r i g h t v a l u e ” : ”DE”
}
, ” FILTER ” :
{
” o p t y p e ” : ” Compare ”
, ” o p e r a t o r ” : ”=”
, ” l e f t v a l u e ” : ” ? p r o d u c e r P u b l i s h e r ”
, ” r i g h t v a l u e ” : ” 1 ”
}
, ” FILTER ” :
{
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
T
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
T
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA23
” o p t y p e ” : ” Compare ”
, ” o p e r a t o r ” : ”>=”
, ” l e f t v a l u e ” : ” ? v e n d o r ”
, ” r i g h t v a l u e ” : ” 5 0 ”
}
}
}
Listing A.3: Tree Represenation of SPARQl QueryA.1
Danksagungen
The authors acknowledge the financial support of Fraunhofer Cluster of Excellence (CCIT) and Dr. Mo-
hamed Najib Mami for the valuable comments that helped to implement our work.
VERWEISE
1. D. Alter, “2025: The digitization of the world–from edge to core,” Farmingham, MA.,
2020.
2. C. Snijders, U. Matzat, and U.-D. Reips, “” big data”: big gaps of knowledge in the
field of internet science,” International journal of internet science, Bd. 7, NEIN. 1, 2012,
S. 1–5.
3. A. Gandomi and M. Haider, “Beyond the hype: Big data concepts, Methoden, Und
Analytik,” International journal of information management, Bd. 35, NEIN. 2, 2015,
S. 137–144.
4. A. Cuzzocrea, L. Bellatreche, and I. Song, “Data warehousing and OLAP over big
Daten: current challenges and future research directions,” in Proceedings of the six-
teenth international workshop on Data warehousing and OLAP, DOLAP 2013, San
Francisco, CA, USA, Oktober 28, 2013. ACM, 2013, S. 67–70.
5. M. N. Mami, “Strategies for a semantified uniform access to large and heterogeneous
data sources,„Ph.D. dissertation, University of Bonn, Deutschland, 2021.
6. M. Rouse, “What is data virtualization,” 2011.
7. N. Miloslavskaya and A. Tolstoy, “Big data, fast data and data lake concepts,” Pro-
cedia Computer Science, Bd. 88, 2016, S. 300–305.
8. A. Poggi, D. Lembo, D. Calvanese, G. De Giacomo, M. Lenzerini, and R. Rosati,
“Linking data to ontologies,” Journal on Data Semantics X. Springer, 2008.
9. H. Dehainsala, G. Pierra, and L. Bellatreche, “Ontodb: An ontology-based database
for data intensive applications,” in Advances in Databases: Concepts, Systems and
Applications, 12th International Conference on Database Systems for Advanced Ap-
plications, DASFAA Thailand. Springer, 2007, S. 497–508.
10. M. Giese, A. Soylu, G. Vega-Gorgojo, A. Waaler, P. Haase, E. Jim´enez-Ruiz,
D. Lanti, M. Rezk, G. Xiao, ¨O. ¨Ozc¸ep et al., “Optique: Zooming in on big data,”
Computer, Bd. 48, NEIN. 3, 2015.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
.
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
T
/
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
24
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
11. K. M. Endris, P. D. Rohde, M.-E. Vidal, and S. Auer, “Ontario: Federated query
processing against a semantic data lake,” in International Conference on Database
and Expert Systems Applications. Springer, 2019, S. 379–395.
12. M. N. Mami, D. Graux, S. Scerri, H. Jabeen, S. Auer, and J. Lehman, “Squerall:
Virtual ontology-based access to heterogeneous and large data sources,” Proceedings
of 18th International Semantic Web Conference, 2019.
13. S. T. Al-Amin, C. Ordonez, and L. Bellatreche, “Big data analytics: Exploring graphs
with optimized SQL queries,” in Database and Expert Systems Applications – DEXA
2018 International Workshops, BDMICS, BIOKDD, and TIR, Regensburg, Deutschland,
September 3-6, 2018, Verfahren. Springer, 2018, S. 88–100.
14. W. E. Zhang, Q. Z. Sheng, Y. Qin, K. Taylor, and L. Yao, “Learning-based SPARQL
query performance modeling and prediction,” World Wide Web, Bd. 21, NEIN. 4, 2018,
S. 1015–1035.
15. R. Hasan and F. Gandon, “A machine learning approach to sparql query performance
prediction,” in International Joint Conferences on Web Intelligence and Intelligent
Agent Technologies, 2014, S. 266–273.
16. R. Singh, “Inductive learning-based sparql query optimization,” Data Science and
Intelligent Applications, 2021, S. 121–135.
17. ICH. Zouaghi, A. Mesmoudi, J. Galicia, L. Bellatreche, and T. Aguili, “Query optimiza-
tion for large scale clustered RDF data,” in Proceedings of the 22nd International
Workshop on Design, Optimization, Languages and Analytical Processing of Big
Data co-located with EDBT/ICDT 2020 Joint Conference, DOLAP@EDBT/ICDT
2020,Denmark, 2020, S. 56–65.
18. E. Gallinucci, M. Golfarelli, and S. Rizzi, “Schema profiling of document-oriented
databases,” Information Systems, Bd. 75, 2018.
19. A. Senk, M. Valenta, and W. Benn, “Distributed evaluation of xpath axes queries over
large XML documents stored in mapreduce clusters,” in 25th International Workshop
on Database and Expert Systems Applications, Deutschland, 2014, 2014, S. 253–257.
20. J. F. Sequeda, M. Arenas, and D. P. Miranker, “On directly mapping relational
databases to rdf and owl,” in Proceedings of the 21st international conference on
World Wide Web, 2012, S. 649–658.
21. M. A. Rodriguez and P. Neubauer, “The graph traversal pattern,” in S. Sakr and
E. Pardede, (Hrsg.), Graph Data Management: Techniques and Applications.
IGI
Global, 2011, S. 29–46.
22. M. Y. Santos and C. Costa, “Data warehousing in big data: From multidimensional
to tabular data models,” in Proceedings of the Ninth International C* Conference on
Computer Science & Software Engineering, Portugal, 2016. ACM, 2016, S. 51–60.
23. M. Vidal, E. Ruckhaus, T. Lampo, A. Mart´ınez, J. Sierra, and A. Polleres, “Efficiently
joining group patterns in SPARQL queries,” 2010, S. 228–242.
24. M. N. Mami, D. Graux, S. Scerri, H. Jabeen, S. Auer, and J. Lehmann, “Uniform
access to multiform data lakes using semantic technologies,” in Proceedings of the
21st International Conference iiWAS2019. ACM, 2019, S. 313–322.
25. J. E. Gonzalez, R. S. Xin, A. Dave, D. Crankshaw, M. J. Franklin, and I. Stoica,
„{GraphX}: Graph processing in a distributed dataflow framework,” in 11th USENIX
symposium on operating systems design and implementation (OSDI 14), 2014, S.
599–613.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
.
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
T
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
PREDICTING AN OPTIMAL VIRTUAL DATA MODEL FOR UNIFORM ACCESS TO LARGE HETEROGENEOUS DATA25
26. S. Salloum, R. Dautov, X. Chen, P. X. Peng, and J. Z. Huang, “Big data analytics
on apache spark,” International Journal of Data Science and Analytics, Bd. 1, NEIN. 3,
2016, S. 145–164.
27. D. Crankshaw, A. Dave, R. S. Xin, J. E. Gonzalez, M. J. Franklin, and I. Stoica, “The
graphx graph processing system,” UC Berkeley AMPLab.
28. M.-E. Vidal, E. Ruckhaus, T. Lampo, A. Mart´ınez, J. Sierra, and A. Polleres, “Effi-
ciently joining group patterns in sparql queries,” in Extended Semantic Web Confer-
enz. Springer, 2010, S. 228–242.
29. M. Henderson and R. Lawrence, “Are multi-way joins actually useful?.” in ICEIS (1),
2013, S. 13–22.
30. ICH. Elghandour, A. Kara, D. Olteanu, and S. Vansummeren, “Incremental techniques
for large-scale dynamic query processing,” in Proceedings of the 27th ACM Inter-
national Conference on Information and Knowledge Management, 2018, S. 2297–
2298.
31. K. Er, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,”
in European conference on computer vision. Springer, 2016, S. 630–645.
32. Y. Yang, ICH. G. Morillo, and T. M. Hospedales, “Deep neural decision trees,” CoRR,
Bd. abs/1806.06988, 2018.
33. J. Sun and G. Li, “An end-to-end learning-based cost estimator,” Proc. VLDB Endow.,
Bd. 13, NEIN. 3, 2019, S. 307–319.
34. S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation,
Bd. 9, NEIN. 8, 1997, S. 1735–1780.
35. C. Bizer and A. Schultz, “The berlin SPARQL benchmark,” International Journal on
Semantic Web and Information Systems (IJSWIS), Bd. 5, NEIN. 2, 2009, S. 1–24.
36. D. Graux, L. Jachiet, P. Geneves, and N. Laya¨ıda, “A multi-criteria experimental
ranking of distributed sparql evaluators," In 2018 IEEE International Conference on
Big Data.
IEEE, 2018, S. 693–702.
37. R. F. van der Lans, “Architecting the multi-purpose data lake with data virtualization,”
Denodo whitepapers, 2018.
38. D. Chatziantoniou and V. Kantere, “Just-in-time modeling with datamingler,” in Pro-
ceedings of the ER Demos and Posters 2021 co-located with 40th International Con-
ference on Conceptual Modeling (ER 2021), Kanada, Bd. 2958. CEUR-WS.org,
2021, S. 43–48.
39. D. Calvanese, G. D. Giacomo, D. Lembo, M. Lenzerini, A. Poggi, M. Rodriguez-
Muro, and R. Rosati, “Ontologies and databases: The dl-lite approach,” in Reasoning
Web International Summer School. Springer, 2009, S. 255–356.
40. D. Calvanese, B. Cogrel, S. Komla-Ebri, R. Kontchakov, D. Lanti, M. Rezk,
M. Rodriguez-Muro, and G. Xiao, “Ontop: Answering sparql queries over relational
databases,” Semantic Web, Bd. 8, NEIN. 3, 2017, S. 471–487.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
T
/
.
/
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
/
T
.
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00216 5
26
CHAHRAZED B.BACHIR BELMEHDI, ABDERRAHMANE KHIAT AND NABIL KESKES
Chahrazed BACHIR-BELMEHDI received the BSc de-
gree in Information System, In 2017 and the MSc degree in In-
formation Systems engineering, In 2019 from the Djillali Liabes
Universität, Algeria. She is working toward the doctoral degree
in LabRI laboratory at ESI-SBA, Algeria. Her research inter-
ests include Big Data Analysis, Machine Learning and Software
Maschinenbau.
Abderrahmane Khiat holds a PhD in Knowledge Engi-
neering from the University of Oran1, Algeria (2017) and cur-
rently works as a Senior Researcher at Fraunhofer IAIS, Ger-
viele. He ranked fifth among the top young inventors in the
Middle East and Africa in the ”Stars of Science-2021”. He ob-
tained the price of The Best Paper Awards for Young Scientists
Researchers in 2014. His research includes Knowledge Graphs,
Big Data Integration and Data Mining.
Nabil Keskes has completed Prof (2020), M.Sc.(2006),
Ph.D.(2012). Currently he is a full professor in high School of
Computer Science in Algeria. His research interests are geared
towards web service selection and pragmatic web.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
D
N
/
ich
T
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
ich
/
T
/
.
1
0
1
1
6
2
D
N
_
A
_
0
0
2
1
6
2
1
2
7
0
2
9
D
N
_
A
_
0
0
2
1
6
P
D
.
/
T
ich
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3