PAPEL DE DATOS
Microsoft Concept Graph: Mining Semantic
Concepts for Short Text Understanding
Lei Ji1,2†, Yujing Wang1, Botian Shi3, Dawei Zhang4, Zhongyuan Wang5 & Jun Yan6
1Microsoft Research Asia, Haidian District, Beijing 100080, Porcelana
2Institute of Computing Technology, Academia China de Ciencias, Haidian District, Beijing 100049, Porcelana
3Beijing Institute of Technology, Haidian District, Beijing 100081, Porcelana
4MIX Labs, Haidian District, Beijing 100080, Porcelana
5Meituan NLP Center, Chaoyang District, Beijing 100020, Porcelana
6AI Lab of Yiducloud Inc., Huayuan North Road, Haidian District, Beijing 100089, Porcelana
Palabras clave: Knowledge extraction; Conceptualización; Text understanding
Citación: l. Ji, Y. Wang, B. Shi, D. zhang, z. Wang & j. yan. Microsoft concept graph: Mining semantic concepts for short text
comprensión. Data Intelligence 1(2019). doi: 10.1162/dint_a_00013
Recibió: Noviembre 20, 2018; Revised: Febrero 12, 2019; Aceptado: Febrero 19, 2019
ABSTRACTO
Knowlege is important for text-related applications. en este documento, we introduce Microsoft Concept Graph,
a knowledge graph engine that provides concept tagging APIs to facilitate the understanding of human
idiomas. Microsoft Concept Graph is built upon Probase, a universal probabilistic taxonomy consisting of
instances and concepts mined from the Web. We start by introducing the construction of the knowledge
graph through iterative semantic extraction and taxonomy construction procedures, which extract 2.7 millón
concepts from 1.68 billion Web pages. We then use conceptualization models to represent text in the
concept space to empower text-related applications, such as topic search, query recommendation, Web
table understanding and Ads relevance. Since the release in 2016, Microsoft Concept Graph has received
más que 100,000 pageviews, 2 million API calls and 3,000 registered downloads from 50,000 visitors over
64 countries.
† Corresponding author: Lei Ji (Correo electrónico: leiji@microsoft.com; ORCID: 0000-0002-7569-3265).
© 2019 Chinese Academy of Sciences Published under a Creative Commons Attribution 4.0 Internacional (CC POR 4.0)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
1. INTRODUCCIÓN
Concepts are indispensable for humans and machines to understand the semantic meanings underlined
in the raw text. Humans understand an instance, especially an unfamiliar instance, by its basic concept in
an appropriate level, which is defined as Basic-level Categorization (BLC) by psychologists and linguists.
Por ejemplo, people may not understand “Gor Mahia”, but with the concept “football club” described in
Wikipedia, people can capture the semantic meaning easily. Psychologist Gregory Murphy began his highly
acclaimed book [1] with the statement “Concepts are the glue that holds our mental world together”. Naturaleza
magazine book review [2] calls it an understatement, because “Without concepts, there would be no
mental world in the first place”. To enable machines to understand the concept of an instance like human
beings, one needs a knowledge graph consisted of instances, conceptos, as well as their relations. Sin embargo,
we observe two major limitations in existing knowledge graphs, which motivate us to build a brand-new
knowledge taxonomy, Probase [3], to tackle general purpose understanding of human language.
1). Previous taxonomies have limited concept space. Many existing taxonomies are constructed by
human experts and are difficult to be scaled up. Por ejemplo, Cyc project [4] contains about 120,000
concepts after 25 years of evolution. Some other projects, like Freebase [5], resort to crowd sourcing
efforts to increase the concept space, which still lacks general coverage of many other domains and
thus holds a barrier for general purpose text understanding. There are also automatically constructed
gráficos de conocimiento, such as YAGO [6] and NELL [7]. Sin embargo, the coverages of these concept
spaces are still limited. The number of concepts of Probase and some other popular open-domain
taxonomies are shown in Table 1, which demonstrates that Probase has a much larger concept space.
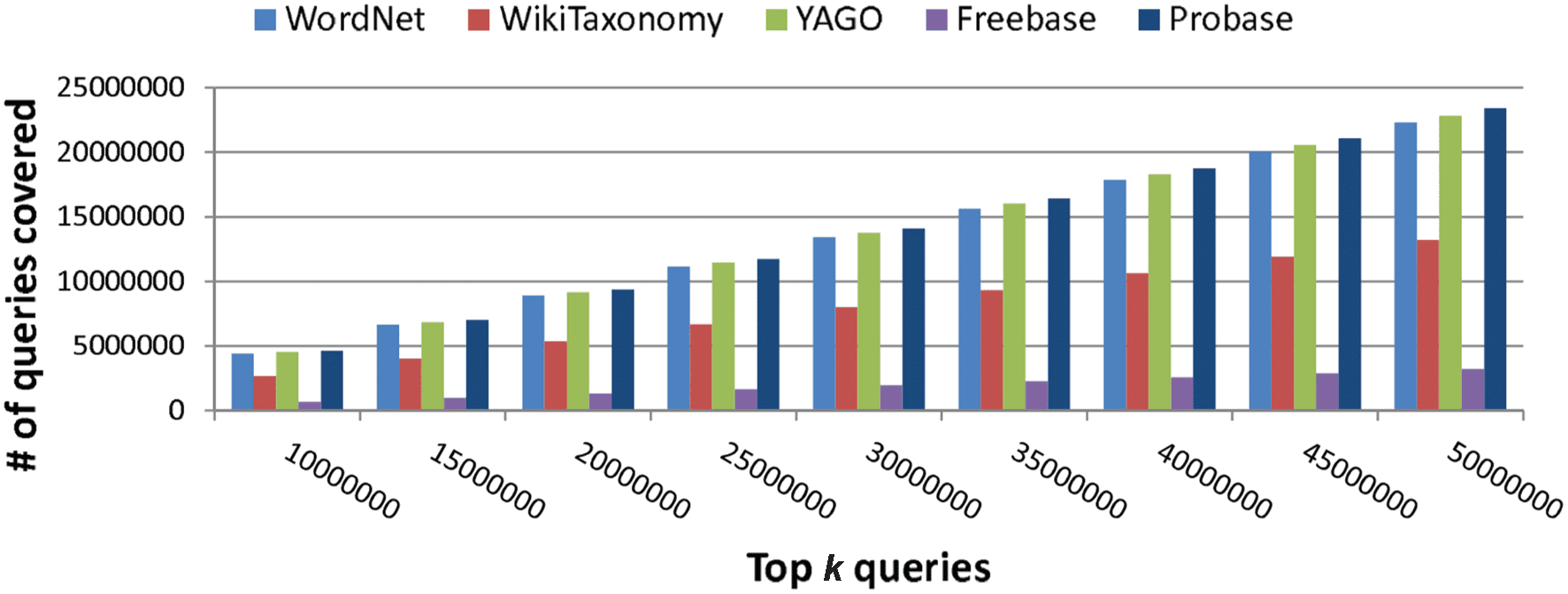
Mesa 1. Concept space comparison of existing taxonomies.
Existing taxonomies
Number of concepts
base libre [5]
WordNet [8]
WikiTaxonomy [9]
YAGO [6]
DBPedia [10]
Cyc [4]
NELL [7]
Probase [3]
1,450
25,229
111,654
352,297
259
≈120,000
123
≈5,400,000
2). Previous taxonomies treat knowledge as black and white. Traditional knowledge base aims at
providing standard, well-defined and consistent reusable knowledge, and treats knowledge as black
and white. Sin embargo, treating knowledge as black and white obviously has restrictions, especially
when the concept space is extremely large, because different knowledge has different confidence
intervals or probabilities, and the best threshold of probabilities depends on the specific application.
Different from previous taxonomies, our philosophy is to annotate knowledge facts with probabilities
and let the application itself decide the best way of using it. We believe this design is more flexible
and can be utilized to benefit a broader range of text-based applications.
239
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Based on the Probase knowledge taxonomy, we propose a novel conceptualization model to learn text
representation in the Probase concept space. The conceptualization model (also known as the Concept
Tagging Model) aims to map text into semantic concept categories with some probabilities. It provides
computers the commonsense computing capability and makes machines “aware” of the mental world of
human beings, through which machines can better understand human communication in text. Based on
the conceptualization model, the Probase taxonomy can be applied to facilitating various text-based
applications, including topic search, query recommendation, Ads relevance, Web table understanding, etc..
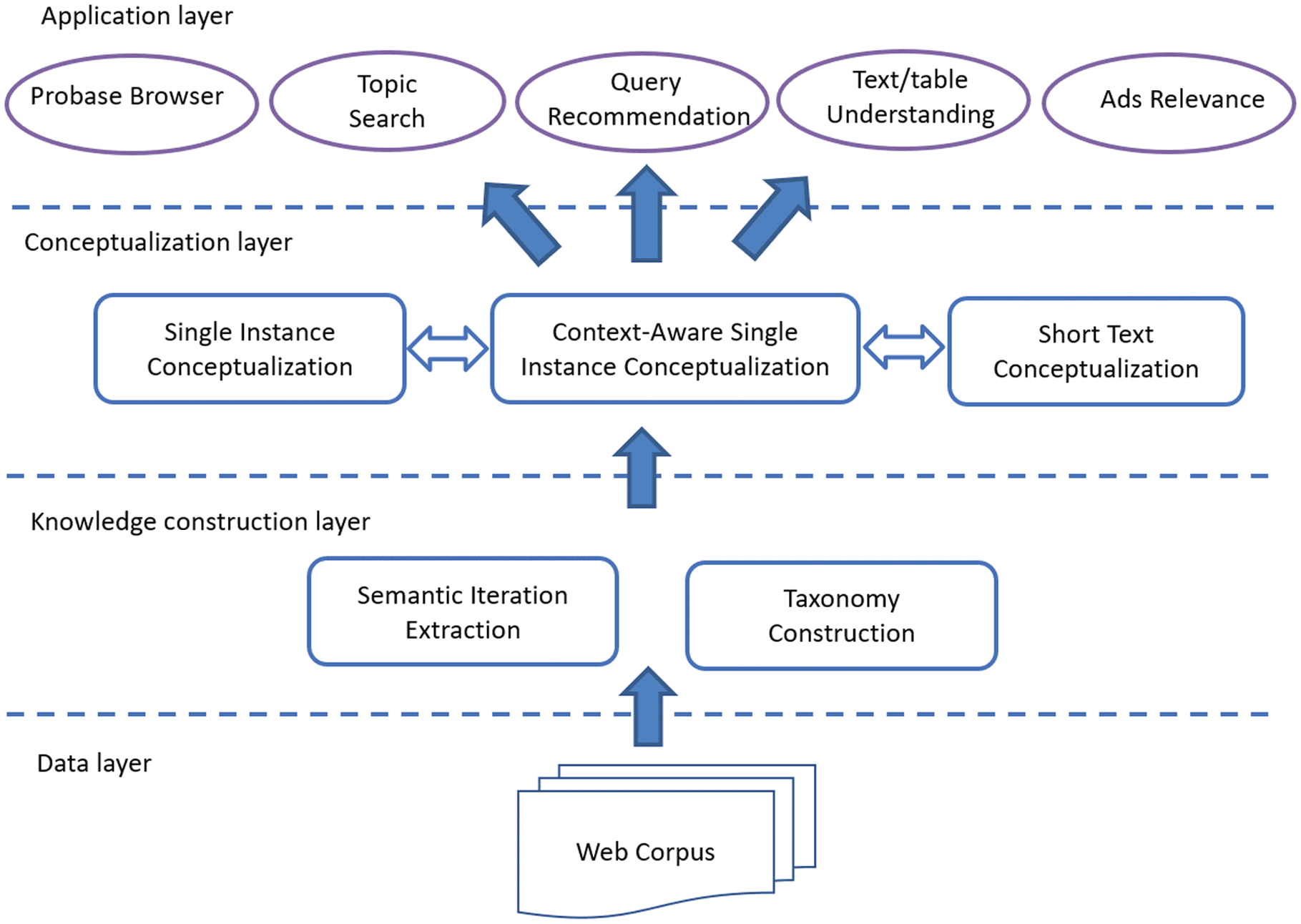
An overview of the entire framework is illustrated in Figure 1, which mainly consists of three layers:
(1) knowledge construction layer, (2) conceptualization layer, y (3) application layer.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. The framework overviews.
1). Knowledge construction layer. In the knowledge construction layer, we address the construction
of Probase knowledge network. Primero, the isA facts are mined automatically from the Web via a
semantic iteration extraction procedure. Segundo, the taxonomy is constructed following a rule-based
taxonomy construction algorithm. Finalmente, we calculate the probability score for each related
instance/concept in the taxonomy.
Data Intelligence
240
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
2). Conceptualization layer. Based on the constructed sematic knowledge network, we design a
conceptualization model to represent raw text in the Probase concept space. The model can be
divided into three major components, a saber (1) single instance conceptualization, (2) contexto-
aware single instance conceptualization, y (3) short text conceptualization.
3). Application layer. The conceptualization model enables us to generate “Bag-of-Concepts”
representation of raw text, which can be utilized to enhance various categories of applications,
including but not limited to topic search, query recommendation, Ads relevance calculation and
Web table understanding. We also build a Probase browser and a tagging model demo in the
application layer, which provide users a quick insight into a specific query.
The rest of this paper is organized as follows. Sección 2 discusses related works, y Sección 3 presents
the construction of the Probase semantic network. Sección 4 introduces the conceptualization model built
upon the sematic network, y Sección 5 shows some example applications. Además, Sección 6 lists the
data sets and statistics. Finalmente, we make a conclusion in Section 7.
2. RELATED WORKS
Knowledge graph has attracted great interests in many research fields. There are many existing knowledge
graphs built either manually or automatically.
1). WordNet [8] Different from traditional thesauruses, WordNet groups words together based on their
meanings instead of morphology. Terms are grouped into synsets, where each term represents a
distinct concept. Synsets are interlinked by conceptual semantics and lexical relations. WordNet
has more than 117,000 synsets for 146,000 terms. WordNet is widely used for term disambiguation
as it defines various senses for a term.
2). DBpedia [10] is a project of extracting Wikipedia Infobox into knowledge facts which can be
semantically queried using SPARQL. The knowledge in DBpedia is extracted from Wikipedia and
collaboratively edited by the community. DBpedia has released 670 million triples in RDF format.
DBpedia provides an ontology including 280 classes, 3.5 million entities and 9,000 atributos.
3). YAGO [6], abbreviation for Yet Another Great Ontology, is an open sourced huge semantic knowledge
base, which has fused knowledge extracted from WordNet, GeoNames and Wikipedia. YAGO
combines the taxonomy of WordNet with the Wikipedia category to assign entities to more than
200,000 classes. YAGO is comprised by more than 120 million facts about 3 million entities. Basado
on manual evaluation, the accuracy of YAGO is about 95%. YAGO also attaches temporal and
special information to the entities and relations by some declarative extraction rules.
http://www.geonames.org/
https://www.wikipedia.org/
241
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
4). base libre [5] is a large knowledge base containing a lot of human labeled data contributed by
community members. Freebase extracts data from many sources including Wikipedia, NNDB,
Fashion Model Directory and MusicBrainz. Freebase has more than 125 million facts, 4,000 types
y 7,000 propiedades. Después 2016, all data in Freebase have been transferred to Wikidata.
5). ConceptNet [11] is a semantic network aiming to build a large commonsense knowledge base in
a crowd sourcing manner, which focuses on the commonsense relations including isA, partOf,
usedFor and capableOf. ConceptNet contains over 21 million edges and over 8 million nodes.
6). NELL [7] is a continuously running system which extracts facts from text in hundreds of millions of
Web pages in an iterative way, while patterns are boosted during the process. NELL has accumulated
more than 50 million candidate beliefs and has extracted 2,810,379 asserted instances of 1,186
different categories and relations.
7). WikiTaxonomy [9] presents a taxonomy automatically generated from the categories in Wikipedia,
which generates 105,418 isA links from a network of 127,325 categories and 267,707 Enlaces. El
system achieves 87.9 balanced F-measure according to a manual evaluation on the taxonomy.
8). KnowItAll [12] aims to automate the process of extracting large collections of facts from the
Web in an unsupervised, domain-independent and scalable manner. The system has three major
componentes: Pattern Learning (PL), Subclass Extraction (SE) and List Extraction (LE), achieving great
improvements on the recall while maintaining precision and enhancing the extraction rate.
The existing knowledge graphs suffer from low coverage and lack of well-organized taxonomies.
Además, none of them focuses on extracting the super-concepts and sub-concepts of an instance. A
automatically generate the taxonomy, we propose Probase which automatically constructs the semantic
network of isA facts.
3. SEMANTIC NETWORK CONSTRUCTION
The entire data construction procedure of the Probase semantic network will be introduced in detail in
the following subsections. Primero, en la sección 3.1, we describe the iterative data extraction process; entonces, el
taxonomy construction step is introduced in Section 3.2; Sección 3.3 introduces the algorithm of probability
calculation.
3.1 Iterative Extraction
The Probase semantic network [3] is built upon isA facts extracted from the Web. The isA facts can be
formulated as pairs consisting of a super-concept and a sub-concept. Por ejemplo, “cat isA animal” forms
a pair, where “cat” is the sub-concept and “animal” is the super-concept. En este trabajo, we propose a method
based on semantic iteration to mine the isA pairs from Web.
http://www.nndb.com/
https://www.fashionmodeldirectory.com/
https://musicbrainz.org
https://www.wikidata.org
Data Intelligence
242
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
3.1.1 Syntactic vs. Semantic Iteration
Before our work, the state-of-the-art information extraction methods [7, 8, 12] rely on a syntactic
integrative (bootstrapping) acercarse. It starts with a set of seed patterns to discover example pairs with high
confidence. Entonces, we can derive new patterns from the extracted pairs and use the new patterns to extract
more pairs. The iterative process is continued until a certain stop criterion is reached. Sin embargo, we observe
in practice that the syntactic iteration methods have indispensable barriers in deep knowledge acquisition
because high quality syntactic patterns are rare. Por lo tanto, we propose a semantic interactive approach by
which the new pairs can be extracted with high confidence based on knowledge accumulated from existing
pares.
3.1.2 The Semantic Iteration Algorithm
Primero, we extract a set of candidate pairs by Hearst patterns [13] (Mesa 2). For instance, if we have
sentence “… animals such as cat …”, we can extract a pair
A veces, there is ambiguity in the pattern matching process. Por ejemplo, in the sentence “… animals
other than dogs such as cats …”, we can extract two candidate pairs
The algorithm must have the ability to decide which one is the correct super-concept among “animals” and
“dogs”. Another example is “… companies such as IBM, Nokia, Proctor and Gamble …”. En este caso, nosotros
have multiple choices in the sub-concept, a saber,
Mesa 2. Hearst patterns examples.
Patrón
NP such as {notario público,}*{(o | y)} notario público
Such NP as {notario público,}*{(o | y)} notario público
notario público{,} incluido {notario público,}* {(o | y)} notario público
notario público{,notario público}*{,} and other NP
notario público{,notario público}*{,} or other NP
notario público{,} especially {notario público,}*{(o | y)} notario público
ID
1
2
3
4
5
6
We denote the candidate set of super-concepts for sentence s as Xs, and the candidate set of sub-concepts
for sentence s as Ys. Γ is the set of isA pairs that have already been extracted as ground truth. El restante
task for the algorithm is to detect the correct super-concepts and sub-concepts from Xs and Ys, respectivamente,
based on the knowledge accumulated i n Γ. For each sentence s, if we have multiple choices for the super-
conceptos, we must choose one as the correct super-concept. It is based on the observation that when
ambiguity exists in super-concept matching, there is only one correct answer. After determining the correct
super-concept, the goal is to filter out the correct sub-concepts from candidates in Ys. Unlike the super-
concept case, we may expect more than one valid sub-concept, and the result sub-concepts should be a
subset of Ys.
243
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
3.1.3 Super-Concept Detection
Dejar
X
s
=
x x
,
{
1
2
…
,
,
X
},
metro
we compute likelihood p(xk|Ys) for each candidate xk. We assume
y y
2,
1
are independent with each other given any super-concept xk, and then we have
… ∈
,
y
, norte
Y
s
p x Y
k
s
|
(
∝
)
p x p Y x
)
(
|
(
k
s
= ∏
p x
(
)
k
)
k
norte
=
1
i
p y x
i
|
(
),
k
(1)
where p(xk) is the percentage of pairs in Γ that contain xk as the super-concept, y P(yi|xk) is the percentage
of pairs in Γ that have yi as the sub-concept when the super-concept is xk. There are pairs that do not exist
in Γ, and therefore, we let p(yi|xk) = ε if no existence can be found for that pair; where ε is set to be a small
positive number. Without losing generality, we assume x1 and x2 are the top two candidates with the highest
probability scores, y P(x1|Ys) > p(x2|Ys). Entonces, we can compute the ratio of two probabilities as follows:
∏
p x
)
(
1
∏
)
p y x
)
i
1
r x x
(
,
1
p x
(
(2)
=
i
norte
=
|
(
,
)
)
2
norte
1
2
p y x
i
|
(
2
=
1
i
x1 will be chosen as the correct super-concept if r(x1,x2) is larger than a pre-defined threshold. If not, este
sentence is skipped in the current iteration and may be recovered in a later round when Γ is more informative.
Intuitivamente, the likelihood p (animals|cats) should be much larger than p (perros|cats); entonces, we can correctly
select “animals” as the result super-concept.
3.1.4 Sub-Concept Detection
In our implementation, sub-concept detection is based on the features extracted from the original
oraciones, which is motivated by two basic observations.
Observation 1: The closer a candidate sub-concept is to the pattern keyword, the more likely it is a
valid sub-concept.
Observation 2: If we are certain that a candidate sub-concept at the k-th position (calculated by the
distance from the pattern keyword) is valid, the candidate sub-concepts from position 1 to position k−1 are
also likely to be correct.
Por ejemplo, consider the following sentence: “… representatives in North America, Europa, the Middle
East, Australia, México, Brasil, Japón, Porcelana, and other countries …”. Here “and other” is the pattern
keyword; China is the candidate sub-concept closest to the pattern keyword. Obviamente, China is a correct
sub-concept. Además, if we know that Australia is a legal sub-concept of “countries”, we can be more
confident that Mexico, Brazil and Japan are all correct sub-concepts of the same category; while North
America, Europe and the Middle East are less likely to be the instances of the same category.
Específicamente, we find the largest k such that the likelihood p(yk|X) is above a pre-defined threshold. Entonces,
y1, y2,…, yk are all treated as valid sub-concepts of the super-concept x. Note that there are sometimes
ambiguity in the sub-concept yi. Por ejemplo, in the sentence “… companies such as IBM, Nokia, Proctor
Data Intelligence
244
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
and Gamble…” at position 3, the noun phrase can be “Proctor” or “Proctor and Gamble”. Suppose the
candidate at the position k to be c1, c2,…, we calculate the conditional probability of each candidate given
the super-concept x as well as all sub-concepts before position k:
p y
(
k
=
c x y y
| ,
,
1
i
…
,
,
y
2
)
1
−
k
=
(
p c x
|
i
)
−
k
1
∏
=
1
j
p y c x
|
j
(
,
i
),
(3)
As before, y1, y2,…, yk–1 are assumed to be independent given the super-concept x; pag(ci|X) is the percentage
of existing pairs in Γ where ci is a sub-concept when x is the super-concept; pag(yj|ci, X) is the likelihood that
yj is a valid sub-concept given x is the super-concept and ci is another valid sub-concept in the same
oración. Suppose c1 and c2 are the top 2 ranked concepts, and we pick c1 as the final concept if r(c1, c2)
exceeds a certain ratio. The value of r(c1, c2) can be calculated as:
r c c
,
(
1
2
)
=
p c x
(
| )
1
p c
(
2
X
| )
∏
∏
−
1
k
=
−
1
1
j
k
=
1
j
p y c x
|
j
,
1
(
)
p y c x
|
(
,
)
2
j
,
(4)
Intuitivamente, the probability p(Proctor and Gamble|companies) should be much larger than p(Proctor|
companies) after Γ accumulates enough knowledge, and thus the algorithm is able to select the correct
candidate automatically.
3.2 Taxonomy Construction
The taxonomy construction procedure mainly consists of three steps, (1) local taxonomy construction,
(2) horizontal merge and (3) vertical merge. Primero, we build the local taxonomy for each sentence. Entonces,
we perform horizontal merge and vertical merge in sequence on the local taxonomy collection to construct
a global taxonomy.
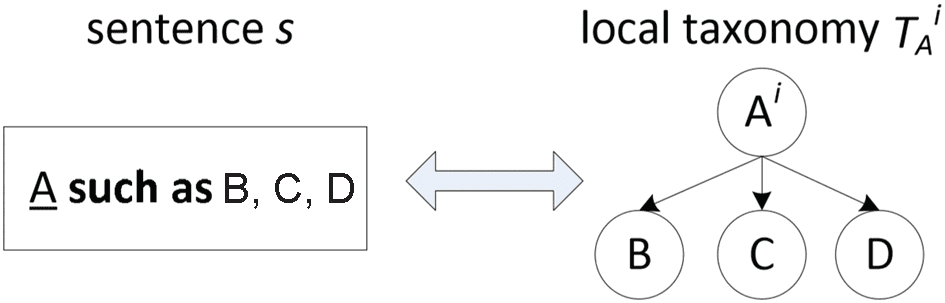
1). Local Taxonomy Construction. Cifra 2 illustrates the process to build a local taxonomy from
each sentence. Por ejemplo, in the sentence “A such as B, C, D”, we can get three pairs
a local taxonomy with A as the root node and B, C, D as child nodes.
Cifra 2. Local taxonomy construction.
245
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
2). Horizontal Merge. After the local taxonomy for each sentence is built, the next step is horizontal
merge. Suppose we have two local taxonomies T 1
A whose root is A1 and A2, respectivamente, dónde
A1 and A2 correspond to the same surface form. If we are sure that A1 and A2 express the same sense,
we can merge the two trees horizontally, as shown in Figure 3. We design a similarity function to
calculate the probability that A1 and A2 are semantically equal. Intuitivamente, if the children of A1 and
A2 are more overlapped, we can be more confident that they are of the same sense. Por lo tanto, nosotros
; y un
adopt absolute overlap for the similarity calculation function, es decir.,
constant threshold d is used to determine whether two local taxonomies can be horizontally merged.
(
1
f A A
,
A and T 2
1
A
∩
A
=
)
2
2
Cifra 3. Horizontal merge.
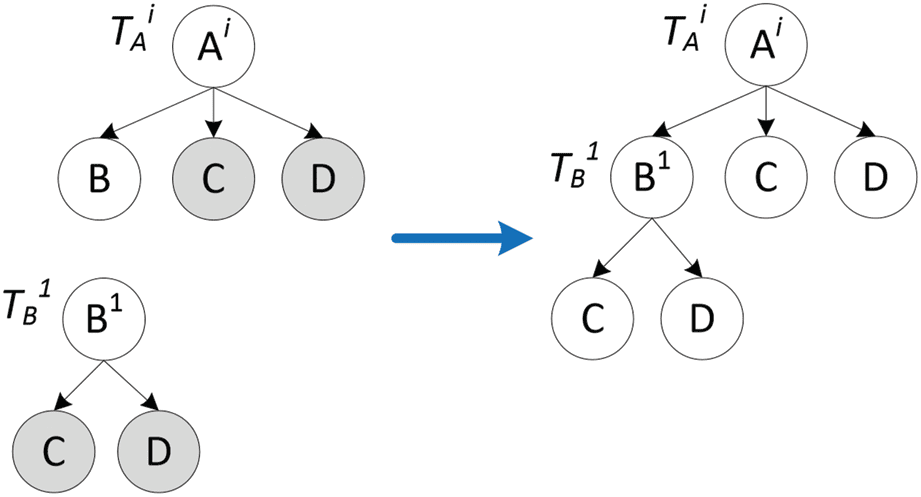
3). Vertical Merge. Given two local taxonomies rooted by Ai and B1, where B is a child of Ai. Si nosotros
are confident that B is of the same sense as B1, we can merge the two taxonomies vertically. Como
como se muestra en la figura 4, after merging, Ai is the root; the original subtree B is merged with the taxonomy
rooted by B1; and the other subtrees C and D remain at the same position. To determine if B and B1
are of the same sense, we calculate the absolute overlap of R1’s children and B’s siblings (emphasized
by colored nodes in Figure 4).
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
Cifra 4. Vertical merge: single sense alignment.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
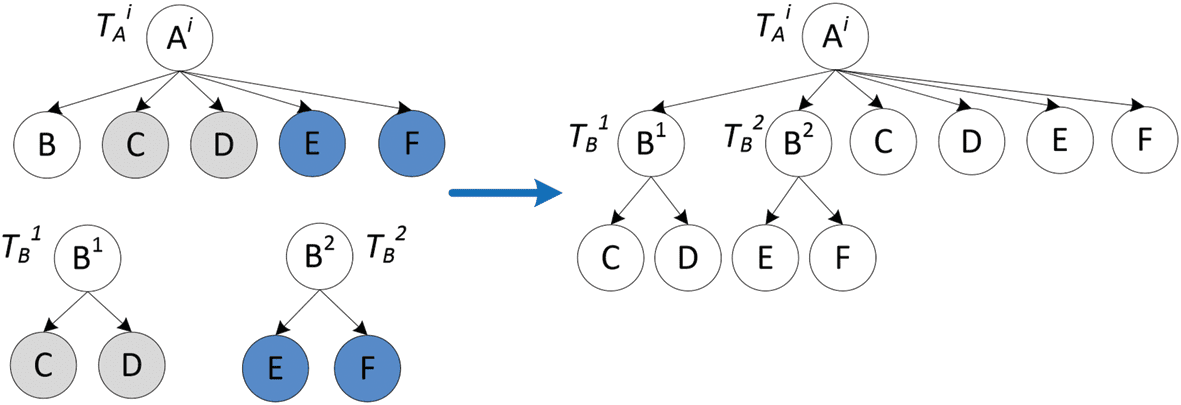
There is another case which is more complicated (Cifra 5). Both T 1
A, as the child nodes of R1 and R2 have considerable overlap with B’s siblings in T i
B can be vertically merged
with T i
A. Sin embargo, el
child nodes of R1 and R2 do not have enough overlap, indicating that R1 and R2 may express different senses.
En este caso, we split two senses in the merged taxonomy, es decir., t 1
B are merged as two distinct sub-
trees in taxonomy T i
A.
B and T 2
B and T 2
Data Intelligence
246
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Cifra 5. Vertical merge: multiple sense alignment.
3.3 Probability Calculation
Probability is an important feature of our taxonomy design. Different from previous approaches which
treat knowledge as black and white, our solution is to live with noisy data with probability scores and let
the application make the best use of it. We provide two kinds of probability scores, namely plausibility and
typicality.
Plausibility is the joint probability of an isA pair. For each isA claim E, we use p(mi) to denote its
probability to be true. Here we adopt a simple noisy-or model to calculate the probability. Assume E is
derived from a set of sentences {s1, s2, …, sn}, a claim is false if every piece of evidence from {s1, s2, …, sn}
is false. Assuming every piece of evidence is independent, tenemos:
( )
mi
pag
= -
1
pag
( )
mi
= -
1
norte
−∏
(1
=
1
i
p s
(
i
)),
(5)
where p(si) is the probability of evidence si to be true. We characterize each si by a set of features Fi
incluido: (1) the PageRank score of the Web page from which sentence si is extracted; (2) the Hearst pattern
used to extract evidence pair
the number of sentences with y as the sub-concept; (5) the number of sub-concepts extracted from sentence
si; (6) position of y in the sub-concepts list from sentence si. Supposing the features are independent, nosotros
apply Naïve Bayes [14] to derive p(si) based on the corresponding feature set Fi. We exploit WordNet to
build a training set used for learning the Naïve Bayes Model. Given a pair
WordNet, if there is a path between x and y in the WordNet taxonomy, (es decir., x is an ancestor of y), nosotros
regard the pair as a positive example; de lo contrario, we treat the pair as negative.
Typicality is the conditional probability between a super-concept and its instance (sub-concept).
Intuitivamente, robin is more typical of the concept bird than is ostrich, while Microsoft is more typical of the
concept company than is Xyz inc. Por lo tanto, we need a probability score to stand for the typicality of an
instancia (sub-concept) to its corresponding super-concept. The typicality measure of an instance i to a
super-concept x is formulated as:
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(
C
i x
|
)
=
∑
⋅
n x i p x i
( , )
( , )
′
n x i p x i
)
( ,
( ,
∈′
I
i
X
,
′
)
(6)
247
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
where x is a super-concept, i is an instance of x, norte(X, i) is the number of appearance that supports i as an
instance of x; pag(X, i) is the plausibility of pair
X. Por ejemplo, suppose x = Company, i = Microsoft, j = Xyz inc. It can be imagined that n(X, i) debería
be much larger than n(X, j), so Microsoft should obtain a much bigger typicality score than Xyz Inc with
respect to Company. Similarmente, we can also define the typicality score denoting the probability of a concept
x to instance i.
(
C
x i
|
)
=
∑
⋅
n x i p x i
( , )
′
′
(
( , )
(
n x i p x i
, )
, )
∈′
x I
i
.
(7)
4. CONCEPTUALIZATION
En esta sección, we introduce the conceptualization model which leverages the Probase semantic
knowledge network to facilitate text understanding. Conceptualization model (also known as the Concept
Tagging model) aims to map text into semantic concept categories with some probabilities. It provides
computers the common sense of semantics and makes machines “aware” of the mental world of human
beings, through which the machines can better understand human communication in text.
We consider three sub-tasks for building a conceptualization model. (1) Single Instance Conceptualization,
which returns Basic-Level Categorization (BLC) for a single instance. Como ejemplo, “Microsoft” could be
automatically mapped to Software Company and Fortune 500 company, etc., with some prior probabilities.
(2) Context-Aware Single Instance Conceptualization, which produces the most appropriate concepts based
on different contexts. Como ejemplo, “Apple” could be mapped to Fruit or Company without context, pero
with context word “pie”, “Apple” should be mapped to Fruit with higher probability. (3) Short Text
Conceptualización, which returns the types and concepts related to a short sequence of text. Por ejemplo,
in the sentence “He is playing game on Apple iPhone and eating an apple”, the first “Apple” is Company
while the second “Apple” is Fruit.
4.1 Single Instance Conceptualization
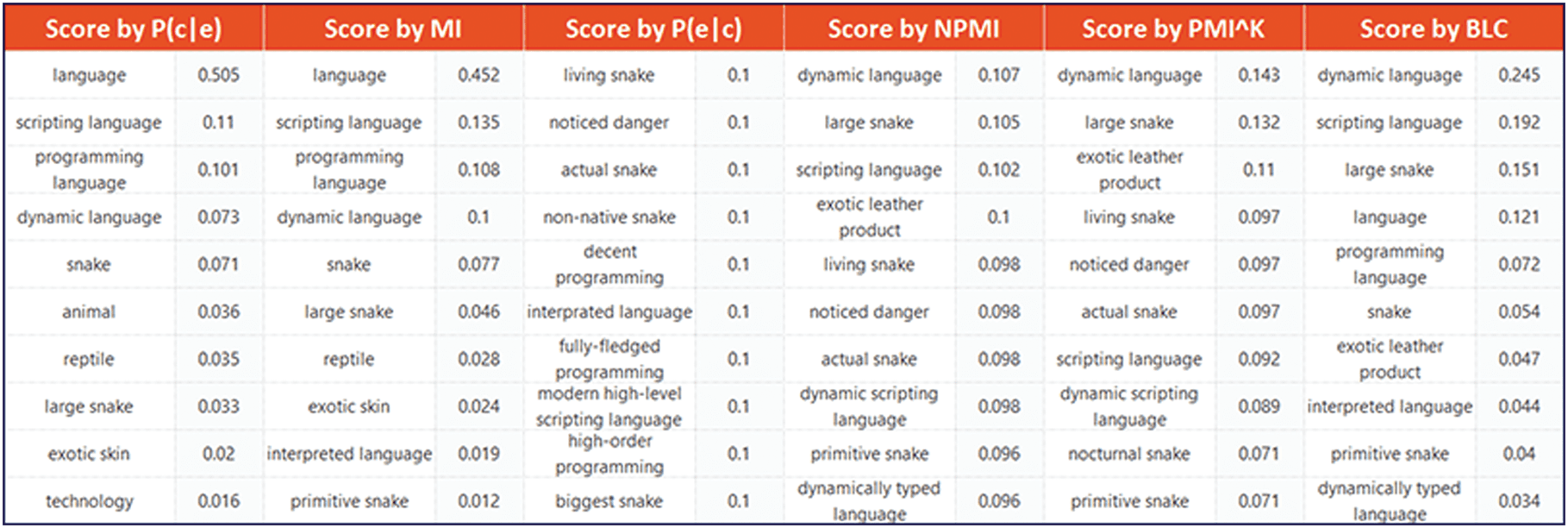
Assume e is an instance, and c is a super-concept; we can obtain the Basic-Level Categorization (BLC)
results based on typicality scores P(mi|C) y P(C|mi), where P(mi|C) denotes the typicality of an instance e to
concept c, y P(C|mi) denotes the typicality of a concept c to instance e. We propose several metrics as
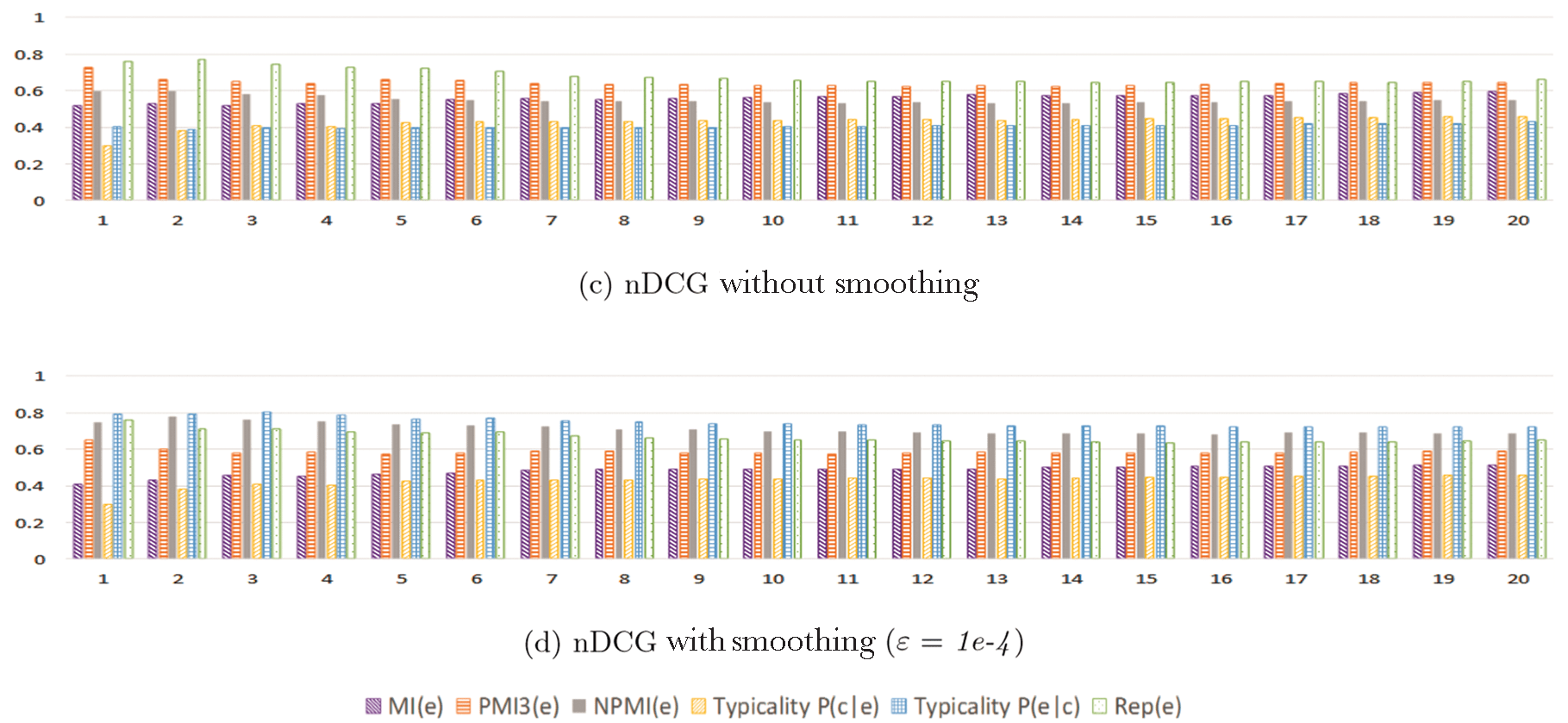
representative measures used for BLC [15].
MI is the mutual information between e and c, defined as:
PMI denotes the pointwise mutual information, which is a widely used measure of the association
(
MI e c
,
)
=
)
P e c log
,
(
P e c
)
( ,
( )
P e P c
(
)
.
(8)
between two discrete variables.
PMI e c
( ,
)
=
registro
P e c
)
( ,
( )
P e P c
(
)
=
registro
Data Intelligence
)
P e c P c
(
|
(
( )
P e P c
)
(
)
=
(
log P e c
|
)
−
logP e
( ).
(9)
248
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
NPMI is a normalized version of PMI, which is proposed to make PMI less sensitive to occurrence
frequency and is more interpretable.
NPMI e c
( ,
)
=
PMI e c
( ,
)
−
logP e c
( ,
)
=
)
(
log P e c
|
−
logP e c
( ,
logP e
( )
)
−
.
(10)
Both PMI and NPMI suffer from the trade-off between general and specific concepts. Por un lado,
general concepts may be the correct answer, but they do not have the capability to distinguish instances
of different sub-categories; por otro lado, specific concepts may be more representative, but the
coverage is low. Por lo tanto, we further propose PMIk and Graph Traversal measures to tackle this problem.
PMIk makes a compromise to avoid producing either too general or too specific concepts.
(
Rep e c
,
)
=
)
P c e P e c
(
|
|
(
).
If we take the logarithm of scoring function Rep(mi,C), we get:
registro
Rep e c
( ,
)
=
registro
2
P e c
)
( ,
( )
P e P c
(
)
=
(
PMI e c
,
)
+
registro ( ,
P e c
).
This in fact corresponds to PMI2, which is a normalized form in the PMIk Family [16].
(11)
(12)
Graph Traversal is a common way to calculate the relatedness of two nodes in a large network. El
scores calculated by general graph transversal can be formulated as:
(
Time e c
,
)
=
∑
∞
=
1
k
(
)
k
2 *
(
P e c
k
,
)
=
=
t
∑
(
t
2
+
k
(
1
+
)
(
P e c
k
,
2 *
k
(
)
∑
1 *
1
−
t
)
+
= +
∞
k T
∑
(
P e c
k
,
1
)
)
=
1
k
(
)
k
2 *
(
P e c
k
,
)
≥
∑
(
)
k
2 *
(
P e c
k
,
)
t
=
1
k
(13)
,
where Pk(mi,C) is the probability of staring from e to c and back to e in 2k steps. When k = 2 que representa
a 4-step random walk, tenemos:
′
Time e c
( ,
=
) 2 *
)
P c e P e c
|
(
(
|
)
+
4 * (1
−
P c e P e c
| ))
|
(
(
= -
)) 4 2 * ( | )
P c e P e c
|
(
)
= -
4 2 *
Rep e c
( ,
).
(14)
De este modo, it is verified that the simple, easy-to-compute scoring method of Rep(mi,C) is equivalent to a graph
traversal approach under the constraint of 4-step random walk.
4.2 Context-Aware Single Instance Conceptualization
One instance may be mapped to distinct concepts according to different contexts. Por ejemplo, para
“apple ipad”, we want to annotate “apple” with company or brand, and “ipad” with device or product.
The major challenge is how to distinguish and detect the correct concepts in different contexts. We propose
a framework of context-aware single instance conceptualization [17] which consists of two parts: (1) offline
knowledge graph construction and (2) online concept inference.
249
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
4.2.1 Offline Knowledge Graph Construction
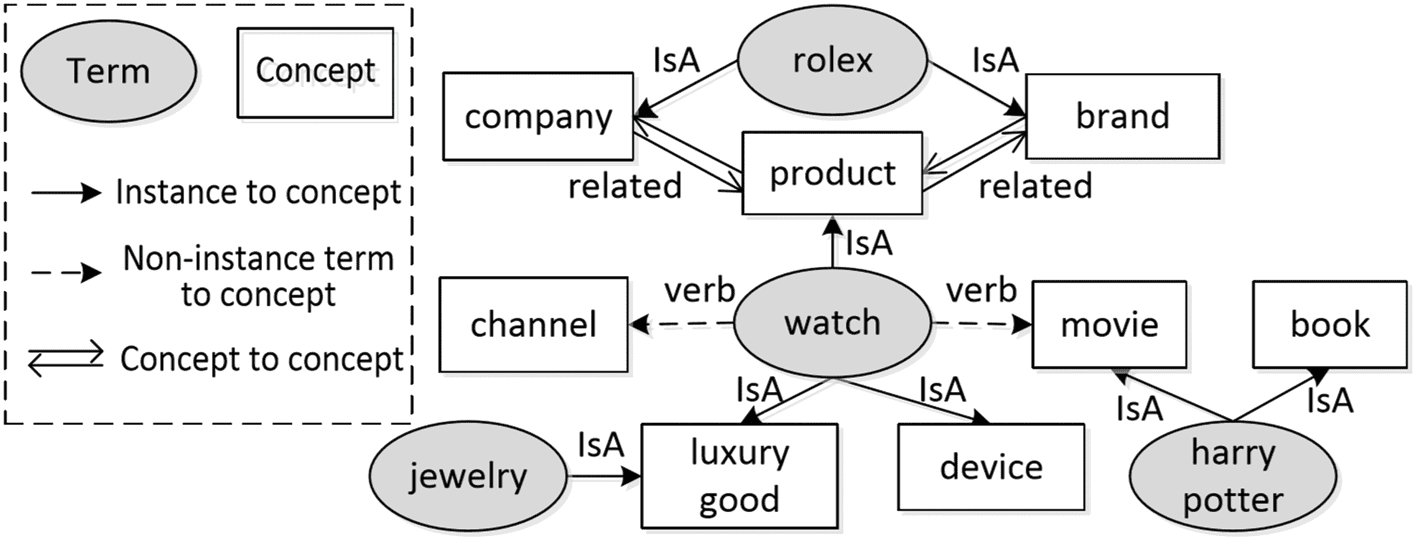
There are millions of concepts in the Probase semantic network. We first perform clustering on all the
concepts to construct the concept clusters. Concretely, we adopt a K-Medoids clustering algorithm [18] a
group the concepts into 5,000 grupos. We adopt concept clusters instead of concepts themselves in the
graph for noise reduction and computation efficiency. In the rest of this section, we use concept to denote
concept cluster. We build a large knowledge graph offline, which is comprised of three kinds of sub-graphs,
incluido (1) instance to concept graph, (2) concept to concept graph and (3) non-instance term to concept
graph. Cifra 6 shows a piece of the graph around the term watch.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 6. A subgraph of heterogeneous semantic network around watch.
Instance to concept graph. We directly use the Probase semantic network as the instance to concept
graph. PAG(C|mi) is served as the typicality probability of concept (grupo) c to instance e, which can be
computed by
(
P c e
|
)
= ∑
*
(
*
P c e
|
C
∈
*
C
)
,
(15)
where c* represents a concept belonging to cluster c, P*(c*|mi) is the typicality of the concept c* to instance e.
Concept to concept graph. We assign a transition probability P(c2|c1) to the edge between two concepts
c1 and c2. The probability is derived by aggregating the co-occurrences between all (unambiguous) instancias
of the two concepts.
(
P c c
2
1
|
)
=
∑
∑ ∑
∈
c C
∈
e c e
i
,
1
n e e
i
(
,
2
)
j
∈
C
j
∈
e c e
i
,
1
n e e
i
∈
C
,
(
j
,
)
j
(16)
where c denotes a set containing all concepts (grupos), and the denominator is applied for normalization.
En la práctica, we only take the top 25 related concepts for each concept for edge construction.
Non-instance term to concept graph. There are terms that cannot be matched to any instances or
conceptos, es decir., verbs or adjectives. For better understanding of the short text, we also mine lexical relationships
Data Intelligence
250
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
between non-instance terms and concepts. Específicamente, we use the Stanford Parser [19] to obtain POS
tagging and dependency relationships between tokens in the text, and the POS tagging results reveal the
tipo (p.ej., adjective, verb, etc.) of each token. Our goal is to obtain the following two distributions.
PAG(z|t) stands for the prior probability that a term t is of a particular type z. Por ejemplo, the word watch
dónde
is a verb with probability P(verb|watch) = 0.8374. We compute the probability as
norte(t, z) is the frequency term t annotated as type z in the corpus, y N(t) is the total frequency of term t.
n t z
( ,
n t
( )
(
P z t
|
=
)
,
)
PAG(C|t, z) denotes the probability of a concept c, given the term t of a specific type z. Por ejemplo,
PAG(movie|watch, verb) depicts how likely the verb watch is associated with the concept movie lexically.
Específicamente, we detect co-occurrence relationships between instances, verbs and adjectives in Web
documents parsed by the Stanford Parser. To obtain meaningful co-occurrence relationships, we require
that the co-occurrence be embodied by dependency, rather than merely appearing in the same sentence.
We first obtain P(mi|t, z), which denotes how likely a term t of type z co-occurs with instance e:
(
P e t z
| ,
)
=
n e t
( , )
z
*
n e t
(
, )
*
z
mi
∑
,
(17)
where nz(mi, t) is the frequency of term t and instance e having a dependency relationship when t is of type
z. Entonces, taking instances as the bridge, we calculate the relatedness between non-instance terms (adjectives/
verbos) and concepts.
(
P c t z
| ,
)
=
∑
(
P c e t z
, | ,
)
=
∑
P c e
| )
(
×
P e t z
| ,
(
).
(18)
In Equation (18), e ∈ c means that e is an instance of concept c, and we make an assumption that a
concept c is conditionally independent with term t and type z when the instance e is given.
∈
e c
∈
e c
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
4.2.2 Online Concept Inference
We adopt the heterogeneous semantic graph built offline to annotate the concepts for a query. Primero, nosotros
segment the query into a set of candidate terms which use Probase as lexicon and identify all occurrences
of terms in the query. Segundo, we retrieve the subgraph out of the heterogeneous semantic graph by
concentrating on the query terms. Finalmente, we perform multiple random walks on the sub-graph to find the
concepts with the highest weights after convergence.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
4.3 Short Text Conceptualization
Short text is hard to understand in three aspects: (1) Compared with long sentences, short sentences lack
syntactic features and cannot directly apply POS tagging; (2) Short texts do not have sufficient statistical
signals; (3) Short text is usually ambiguous due to the lack of context terms. Many research works focus on
statistical approaches like topic models [20], which extract latent topics as implicit semantics. Sin embargo,
we argue that semantic knowledge is needed to get a better understanding of short texts. De este modo, we aim to
251
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
utilize the semantic knowledge network to enhance short text understanding [21]. Different from the
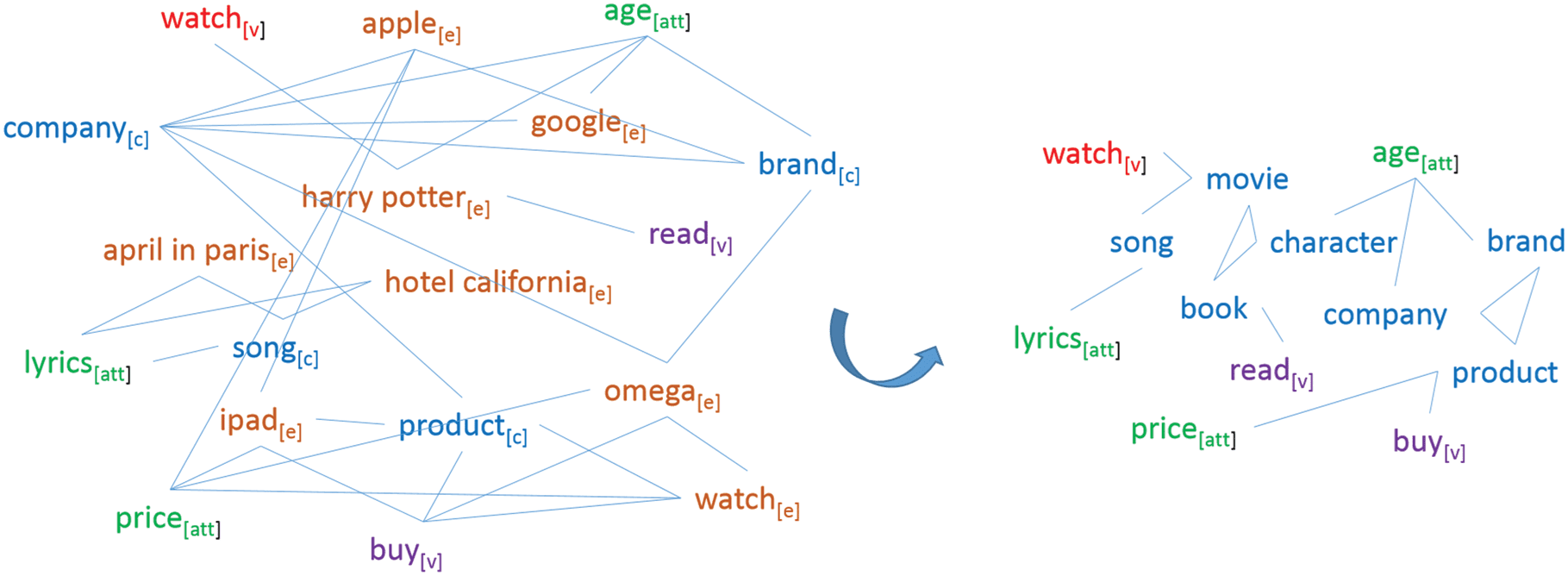
knowledge graph built for context-aware single instance conceptualization (Sección 4.2), we add a novel
sub-graph, typed-term co-occurrence graph, which is an undirected graph where nodes are typed-terms
and edge weights represent the lexical co-occurrence between two typed-terms. Sin embargo, the number
of typed-terms is extremely large, which will increase storage cost and affect the efficiency of calculation
on the network. Por lo tanto, we compress the original typed-term co-occurrence network by retrieving
Probase concepts for each instance. Entonces, the typed-terms can be replaced by the related concept clusters
and the edge weights are aggregated accordingly. Cifra 7 shows an example of the compression procedure.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 7. The compression procedure of typed-term co-occurrence network.
Given a piece of short text, each term is associated with the type and corresponding concepts. Definimos
the types as instance, verb, adjective and concept. For each term with type instance, we also learn the
corresponding concepts for the term. Given a piece of short text, the online inference procedure contains
three steps, including text segmentation, type detection and concept labeling. An example is illustrated in
Cifra 8. Given the query “b ook disneyland hotel california”, the algorithm first segments it as “book
disneyland hotel california”; entonces, it detects the type for each segment; at last, the concepts are labeled for
each instance. As shown in the figure, the output is “book[v] disneyland[mi](park) hotel[C] california[mi](estado)", cual
means that book is a verb, disneyland is an instance of the concept park, hotel is a concept, and california
is an instance of the concept state.
Cifra 8. An example of short text understanding.
Data Intelligence
252
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
4.3.1 Text Segmentation
The goal of text segmentation is to divide a short text into a sequence of meaningful components. A
determine a valid segmentation, we define two heuristic rules: (1) except for stop words, each word belongs
to one and only one term; (2) terms are coherent (es decir., terms mutually reinforce each other). Intuitivamente,
{april in paris lyrics} is a better segmentation of “april in paris lyrics” than {april in paris lyrics}, since “lyrics”
is more semantically related to songs than months or cities. Similarmente, {vacation april in paris} is a better
segmentation of “vacation april in paris” than {vacation april in paris}, because “vacation”, “april” and
“paris” are highly coherent with each other, while “vacation” and “april in paris” are less coherent.
The text segmentation algorithm can be conducted in the following steps. Primero, we construct a term graph
(TG) which consists of candidate terms and their relationships. Próximo, we add an edge between two candidate
terms when they are not mutually exclusive and set the edge weight to reflect the strength of mutual
reforzamiento. Finalmente, the problem of finding the best segmentation is transformed into the task of finding
a clique in the original TG, con 100% word coverage while maximizing the average edge weights.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
4.3.2 Type Detection
The type detection procedure annotates the type for each term as verb, adjective, instance or concept.
Por ejemplo, term “watch” appears in the instance-list, concept-list, as well as verb-list of our vocabulary,
and thus the possible typed-terms of “watch” are watch[C], watch[mi] and watch[v]. For each term, the type
detection algorithm determines the best typed-term from the set of possible candidates. In the case of
“watch free movie”, the best typed-terms for “watch”, “free”, and “movie” are watch[v], gratis[adj] and movie[C],
respectivamente.
Traditional approaches resort to POS tagging algorithms which consider lexical features only, p.ej., Markov
Modelo [22]. Sin embargo, such surface features are insufficient to determine types of terms especially in the
case of short text. In our solution, we calculate the probability by considering both traditional lexical
features and semantic coherence features. We formulate the problem of type detection into a graph model
and propose two models, namely Chain model and Pairwise model.
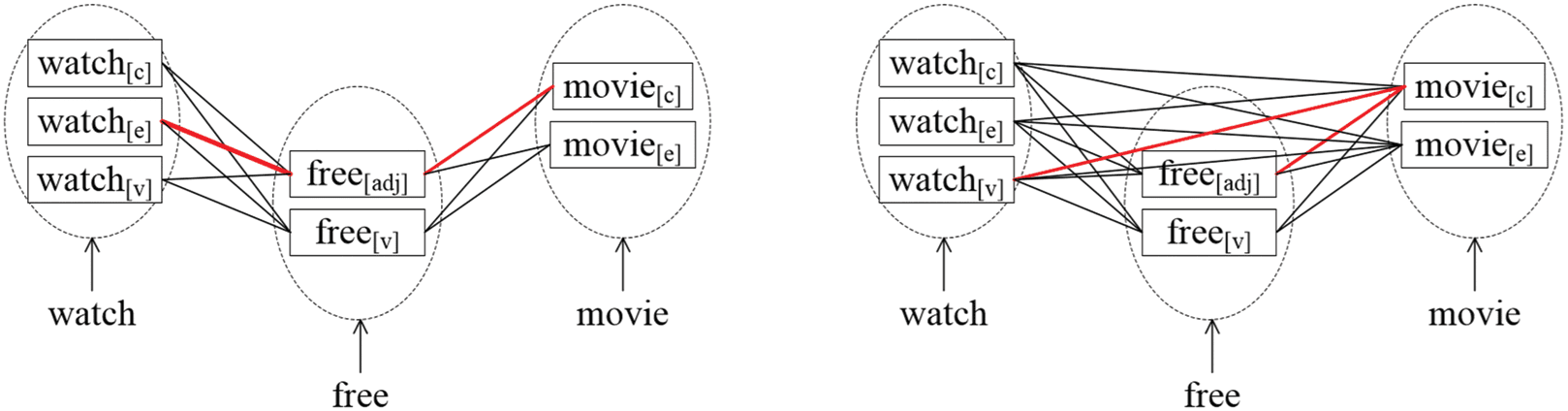
Chain model borrows the idea of first order bilexical grammar and considers topical coherence between
adjacent typed-terms. En particular, we build a chain-like graph where nodes are typed-terms retrieved from
the original short text. Edges are added between each pair of typed-terms mapped from adjacent terms in
the original text sequence, and the edge weights between typed-terms are calculated by affinity scores (ver
the example in Figure 9(a)). Chain model only considers semantic relations between consecutive terms
which will lead to mistakes.
Pairwise model adds edges between typed-terms mapped from each pair of terms rather than adjacent
terms only. As an example, in Figure 9 (b), there are edges between non-adjacent terms “watch” and
“movie”. The goal of the Pairwise Model is to find the best sequence of typed-terms which guarantees that
the maximum spanning tree (MST) constructed by the selected sequence has the largest total weight. Como
253
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
como se muestra en la figura 9 (b), as long as the total weight of edges between (watch[v], movie[C]) y (gratis[adj], movie[C])
is the largest, {watch[v], gratis[adj], movie[C]} can be successfully recognized as the best sequence of type
detection for the query “watch free movie”. We employ the Pairwise model in our system as it achieves
higher accuracy experimentally compared with the Chain model.
(a) Type detection result of “watch free movie
using the Chain model is {watch[mi], gratis[ad j],
movie[C]}".
(b) Type detection result of “watch free movie
using the Pairwise model is {watch[v], gratis[ad j],
movie[C]}".
Cifra 9. Example of Chain model and Pairwise model.
4.3.3 Concept Labeling
The goal of concept labeling is to re-rank the candidate concepts according to the context for each
instancia. The most challenging task in concept labeling is to deal with ambiguous instances. Our intuition
is that a concept is appropriate for an instance only if it is a common semantic concept of that instance
and is supported by the surrounding context at the same time. Take “hotel California eagles” as an example,
where both animal and music band are popular semantic concepts to describe “eagles”. If we find a concept
song in the context, we can be more confident that music band should be the correct concept for “eagles”.
After type detection, we have obtained a set of instances for concept labeling. For each instance, nosotros
collect a set of concept candidates and perform instance disambiguation based on a Weighted-Vote
acercarse, which is a combination of Self-Vote and Context-Vote. Self-Vote denotes the original affinity
weight (calculated by normalized co-occurrence) of a concept cluster c associated to the target instance;
while Context-Vote leverages the affinity weights between the target instance and other concepts found in
the context. In the case of “hotel california eagles”, the original concept vector of the instance eagles is
(
context “hotel california” is (
…). After disambiguation by Weighted-Vote, the final conceptualization result of eagles is (
Data Intelligence
254
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
5. APPLICATION
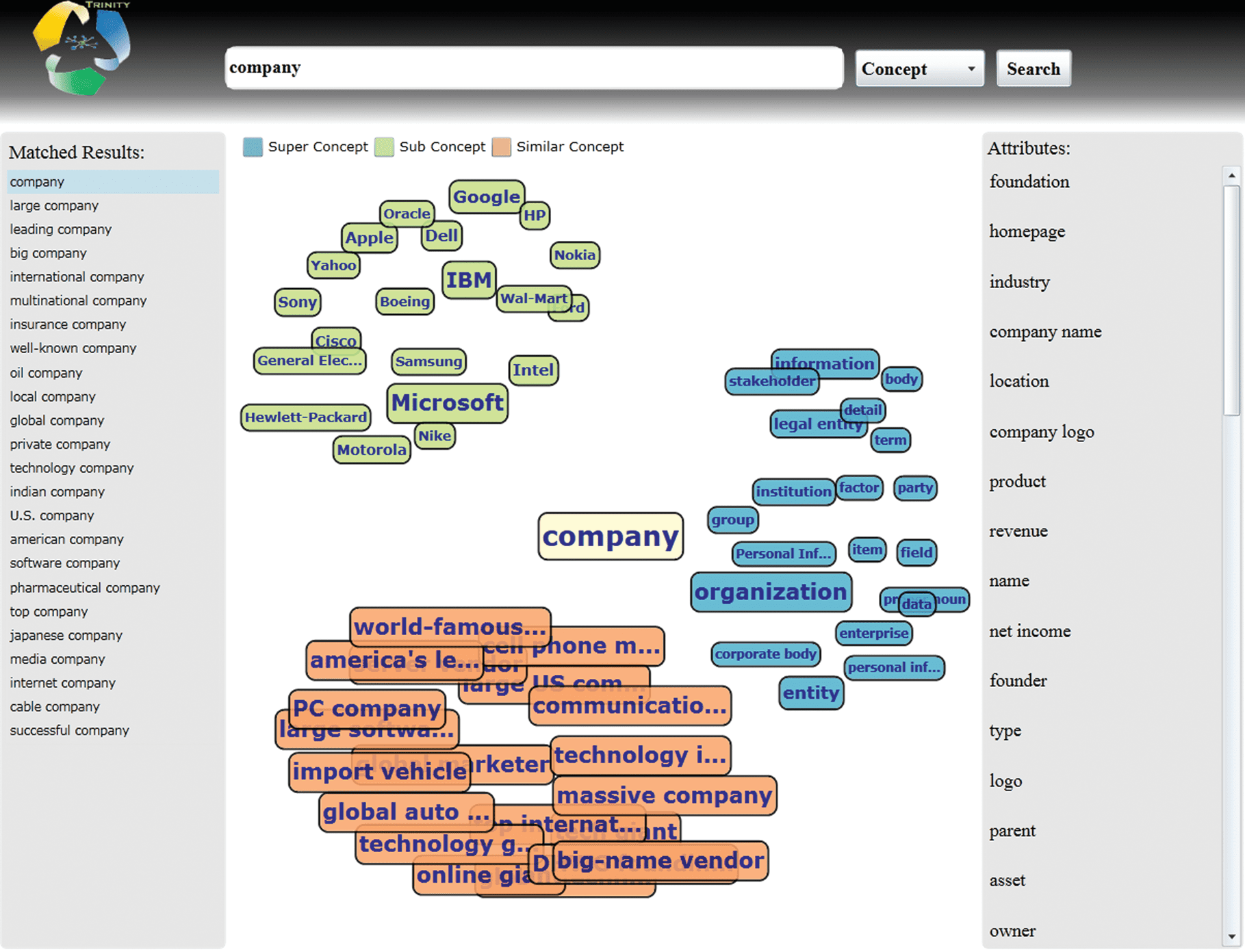
Probase Browser shows the backbone of the Probase taxonomy and provides an interface to search for
super-concepts, sub-concepts, as well as similar concepts corresponding to the given query. Cifra 10 es un
snapshot of the Probase browser.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 10. A snapshot of the Probase browser.
Tagging Service provides the capability of tagging a piece of text with a concept vector, based on which
the semantic similarity can be calculated, and various text processing applications can be affiliated. Cifra
11 shows a snapshot of the instance conceptualization demo when querying a single instance “python”.
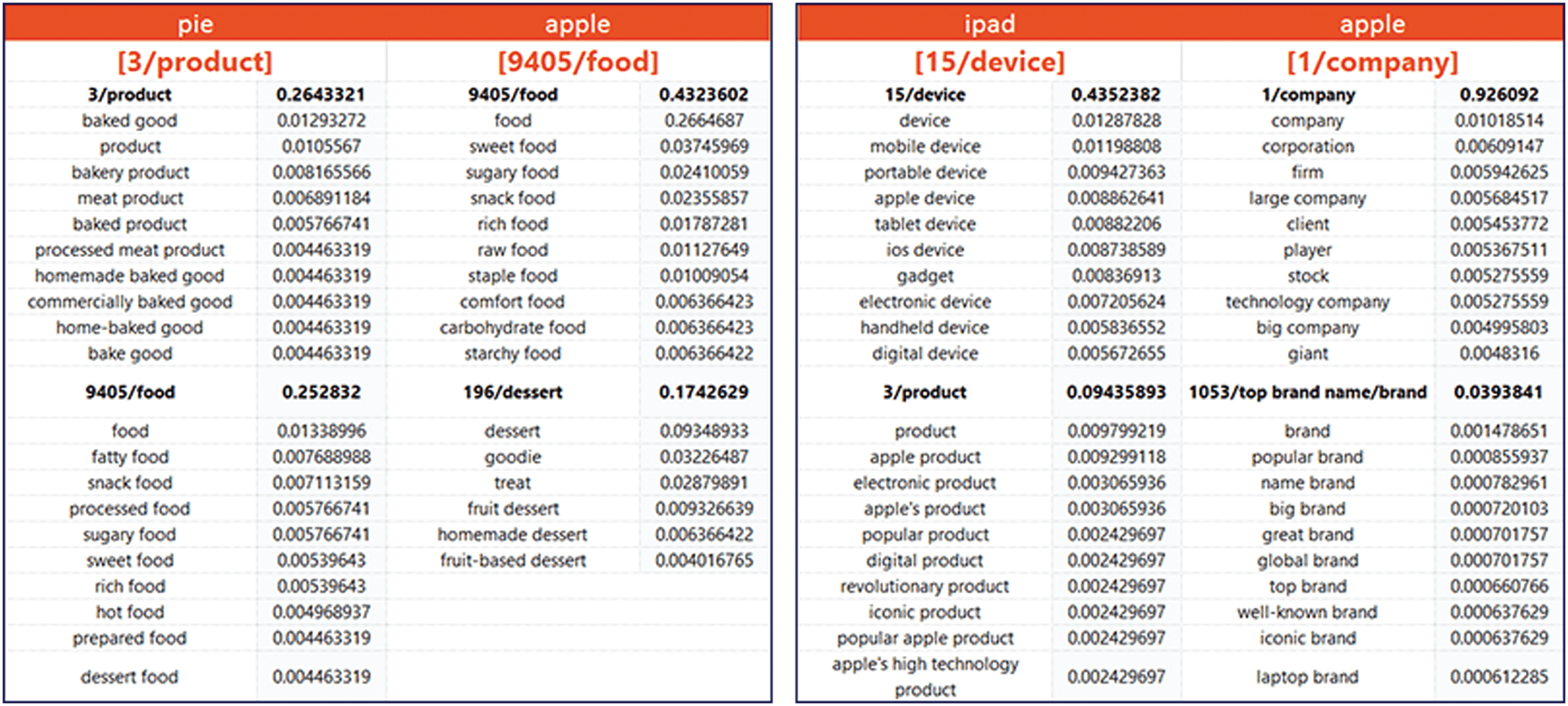
Cifra 12 shows the snapshot given “apple” in the context “pie” and “ipad”, respectivamente. As shown in the
cifra, our tagging service can map the term “apple” into correct concepts under different contexts. Un
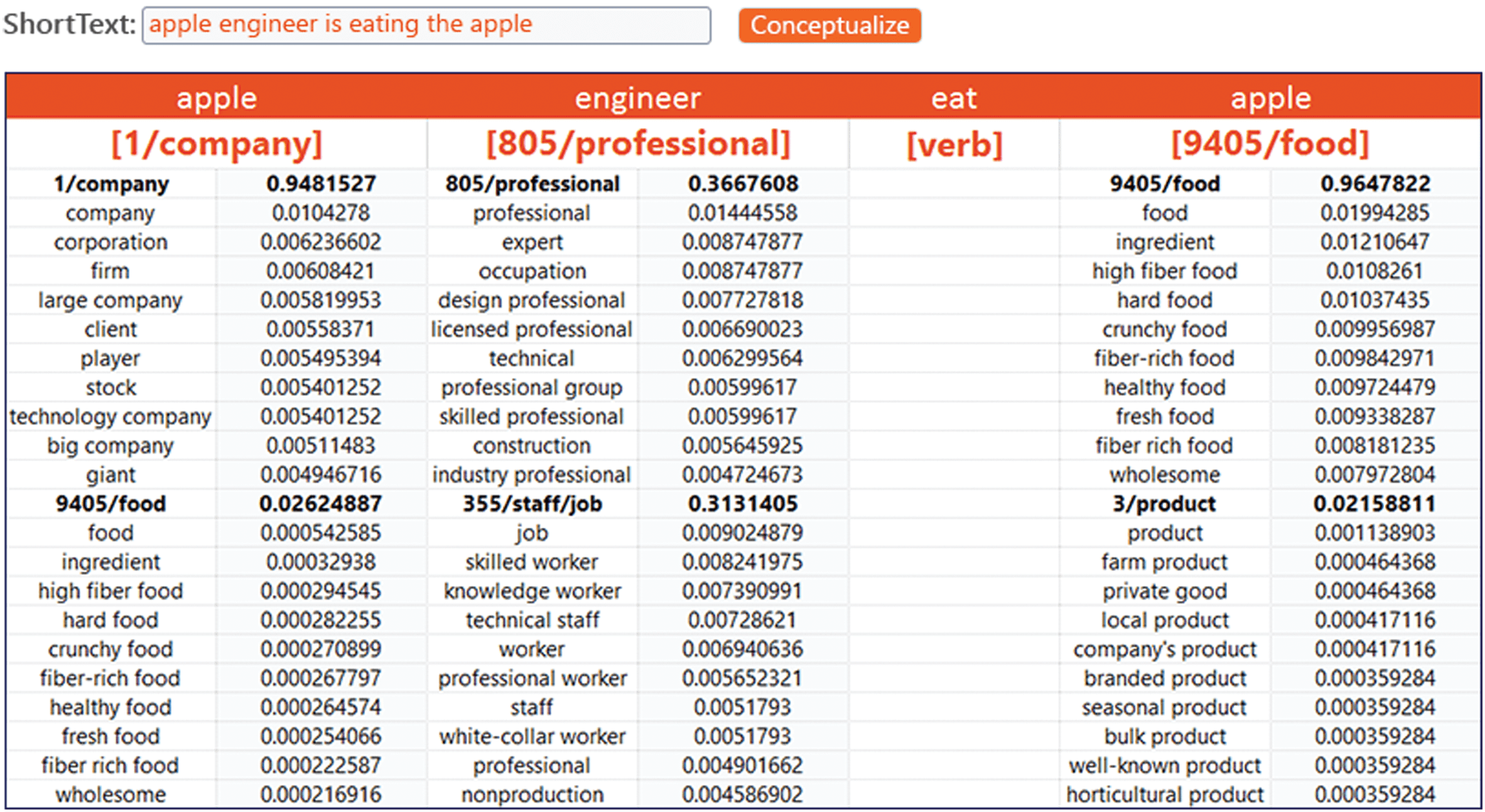
example of short text conceptualization is illustrated in Figure 13 by querying the tagging service with
“apple engineer is eating the apple”. The result shows the capability of our tagging algorithm to distinguish
different senses of “apple” in the short text scenario.
255
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Cifra 11. Snapshot of single instance conceptualization.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
Cifra 12. Snapshot of context-aware single instance conceptualization.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Data Intelligence
256
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 13. An example of short text conceptualization.
Topic Search [23] aims at understanding the topic underlined in each query for better search relevance.
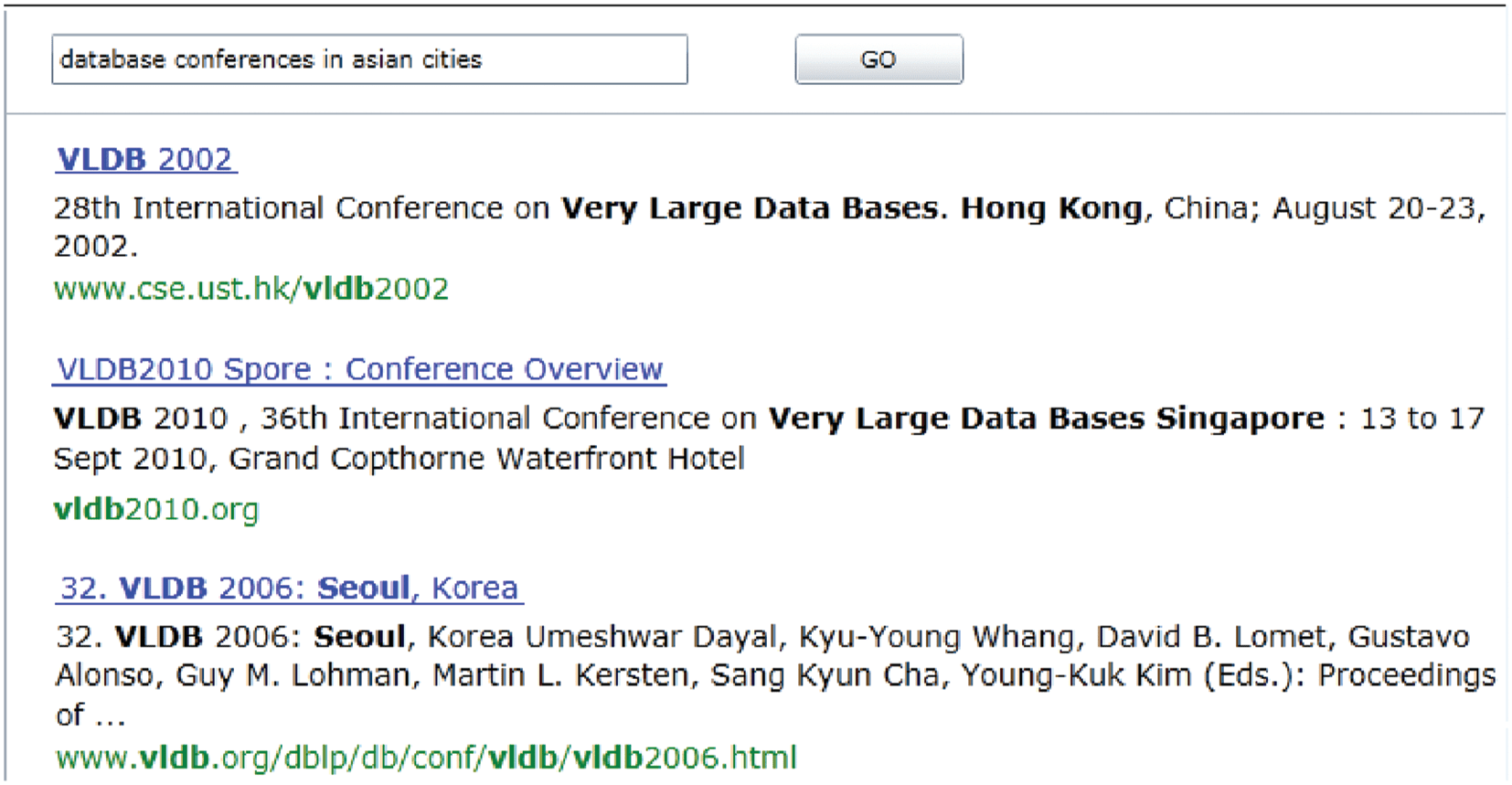
Cifra 14 shows a snapshot when a user queries “database conference in Asian cities”. As shown in the
cifra, the search results correctly rank VLDB 2002, 2006, y 2010 at the top, which are held in Hong
kong, Seoul and Singapore, respectivamente. Traditional Web search takes queries as sequences of keywords
instead of understanding the semantic meanings, so it is hard to generate the correct answers for the
example query. To achieve this goal, we present a framework that improves Web search experiences using
Probase knowledge and the conceptualization models. Primero, it classifies Web queries into different patterns
according to the concepts and entities in addition to keywords contained in the queries. Entonces, it produces
answers by interpreting the queries with the help of Probase semantic concepts. Our preliminary results
showed that the framework was able to understand various types of topic-like queries and achieved much
higher user satisfaction.
257
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 14. The framework of topic search.
Understanding Web Tables [24]. We use Probase to help interpret and understand Web tables, cual
unlocks the wealth of information hidden in the Web pages. To tackle this problem, we build a pipeline
for detecting Web tables, understanding their contents, and applying the derived knowledge to support
semantic search. De 300 million Web documents, we extract 1.95 billion raw HTML tables. Many of
them do not contain useful or relational information (p.ej., used for page layout purpose); others have
structures that are too complicated for machines to understand. We use a rule-based filtering method to
acquire 65.5 million tables (3.4% of all the raw tables) that contain potentially useful information. We adopt
Probase taxonomy to facilitate the understanding of table content, by associating the table content with
one or more semantic concepts in Probase. Based on the knowledge mined from Web tables, we build a
semantic search engine over tables to demonstrate how structured data can empower information retrieval
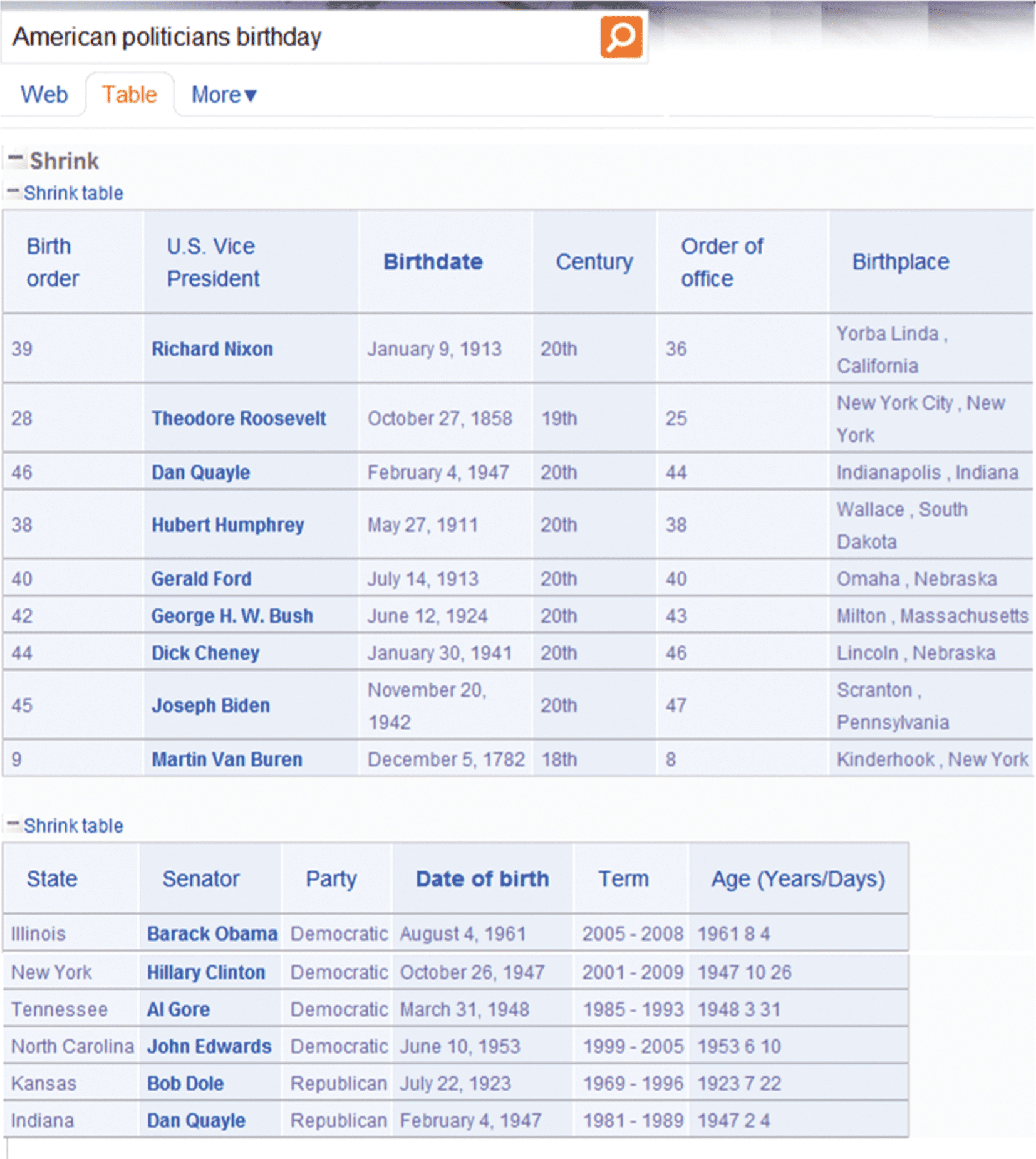
on the Web. A snapshot of our semantic search engine is shown in Figure 15. As illustrated in the figure,
when a user queries “American politicians birthday”, the search engine returns with aggregated Web tables
consisting of birthday and other related knowledge of various American politicians.
Data Intelligence
258
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 15. Snapshot of the Web tables.
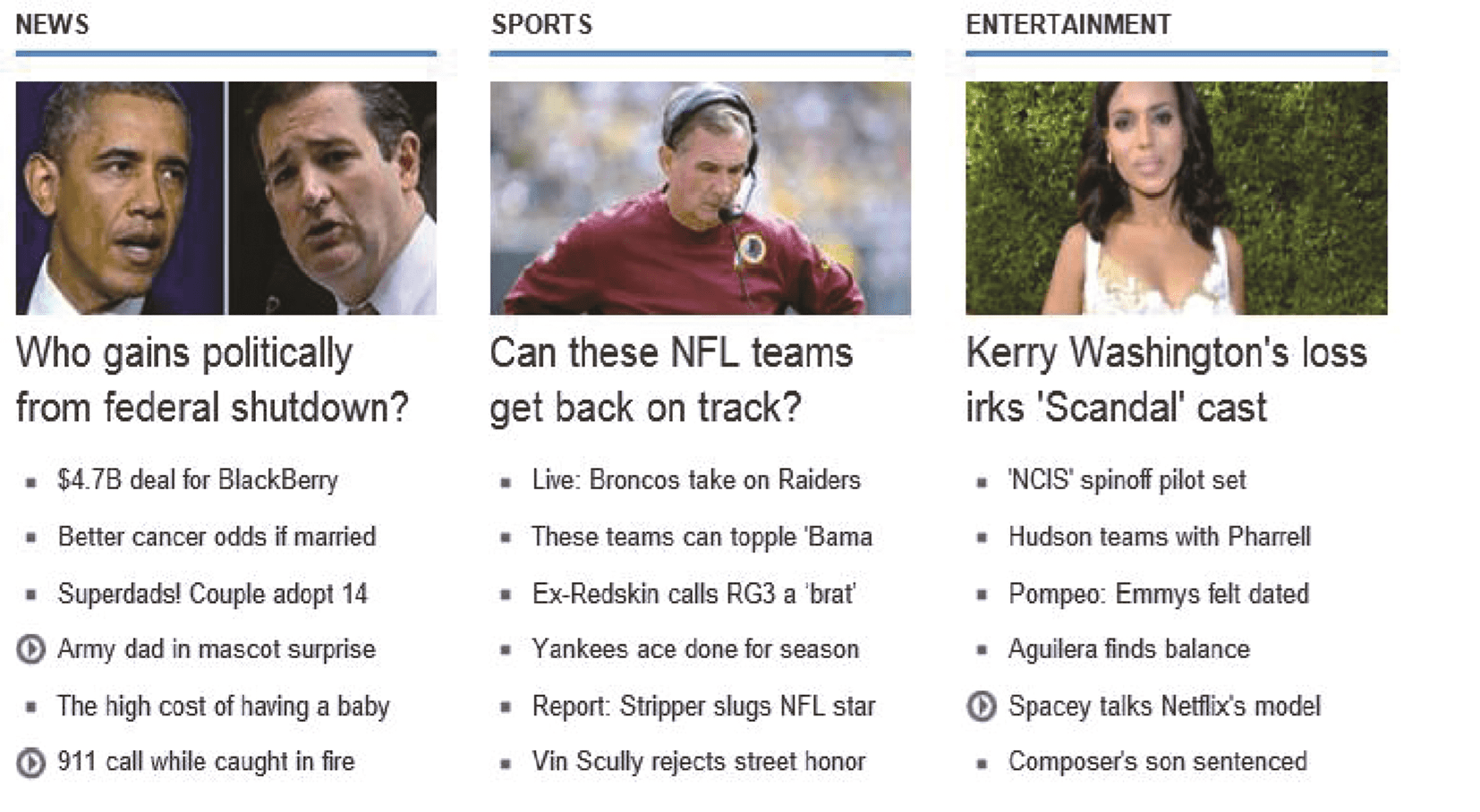
Channel-based Query Recommendation [25] aims to anticipate user search needs when browsing
different channels, by recommending the hottest and highly related queries for a given channel. As shown
En figura 16, there are three channels, Noticias, Sports and Entertainment, and several queries are recommended
under each channel to enable the users to explore the hottest topics related to the target channel. Uno de
the main challenges is how to represent queries and channels which are short pieces of text. Tradicional
259
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
representation methodology treats text as bag of words, which suffers from mismatch of surface forms
of words, especially when text is short. Por lo tanto, we leverage the Probase taxonomy to obtain a “Bag of
Concepts” representation for each query and channel, in order to avoid surface mismatching and handle
the problem of synonym and polysemy. By leveraging the large taxonomy knowledge base of Probase, nosotros
learn a concept model for each category, and conceptualize a short text to a set of relevant concepts.
Además, a concept-based similarity mechanism is presented to classify the given short text to the most
similar category. Experiments showed that our framework could map queries to channels with a high degree
of precision (average precision = 90.3%).
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
Cifra 16. Query recommendation snapshot.
Ads Relevance [3]. In sponsored search, the search engine maps each query to the related ad bidding
keywords. Since both the query and bidding keywords are short, the traditional bag-of-words approaches
do not work well in this scenario. Por lo tanto, we can leverage Probase concept taxonomy to enhance Ads
relevance calculation. For each short text, we first identify instances from it, and map it to basic-level
concepts with score Rep(mi, C); entonces, we merge the concepts to generate a concept vector representing the
semantics of the target text. Finalmente, the relevance score can be calculated through the cosine similarity
measure between the concept vectors of the query and bidding keywords. We conduct our experiments
on real Ads click logs collected from Microsoft Bing search engine. We calculate the relevance score of
each candidate pair of query and bidding keywords, divide the pairs into 10 buckets based on the relevance
puntaje, and report the average clickthrough rate (CTR) within each bucket. The result is demonstrated in
Cifra 17, which shows that the CTR numbers have a strong linear correlation with the relevance scores
calculated by our model.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Data Intelligence
260
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 17. The correlation of C TR with Ads relevance score.
5. DATA AND ANALYSIS
5.1 Datos
The Microsoft Concept Graph can be downloaded at https://concept.research.microsoft.com/, cual es
a sub-graph of the semantic network we introduce in this paper. The core taxonomy of Microsoft Concept
Graph contains above 5.4 million concepts, whose distribution is shown in Figure 18, where Y axis is the
number of instances each concept contains (logarithmic scale), and on the X axis are the 5.4 millón
concepts ordered by their size. Our concept space is much larger than other existing knowledge bases
(Freebase contains no more than 2,000 conceptos, and Cyc has about 120,000 conceptos).
261
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Cifra 18. The distribution of concepts in Microsoft Concept Graph.
5.2 Concept Coverage
Based on the query logs of Microsoft Bing search engine, we estimate the coverage of concepts mined
by our methodology. If at least one concept can be found in a query, the query is considered to be covered.
We thus calculate the percentage of queries that can be covered by Probase and compare the metrics
against the other four taxonomies. We utilize the top 50 million queries in Bing’s query log to compute the
coverage metrics, and the results are shown in Figure 19. We can see clearly from the figure that Probase
has the largest coverage, YAGO ranks the second, and Freebase has a rather low coverage although its
instance space is large. It demonstrates that Freebase’s instance distribution is very skew (most instances
are distributed in several top categories and lack the general coverage of other concepts).
Data Intelligence
262
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Cifra 19. Concept coverage of different taxonomies.
5.3 Precision of isA pairs
To estimate the correctness of extracted isA pairs in Probase, we create a benchmark data set of 40
concepts in various domains. For each concept, we randomly pick up 50 instancias (sub-concepts) and ask
human reviewers to evaluate their correctness. Cifra 20 depicts the precision of isA pairs for all the 40
concepts we manually evaluate. The overall precision is 92.8% by averaging over all the concepts.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
Cifra 20. Precision of extracted isA pairs on 40 conceptos.
We further draw the curve of average precision after each iteration (como se muestra en la figura 21). Además, el
number of concepts and isA pairs discovered after each iteration are drawn in Figure 22. It is obvious that
the precision degrades after each round while the number of discovered concepts and isA pairs increases.
So, the best iteration number must be chosen as a trade-off between precision and facts number (set as 11
in our implementation).
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
263
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Cifra 21. Precision of isA pairs after each iteration.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 22. The number of discovered concepts and isA pairs after each iteration.
5.4 Conceptualization Experiment
En esta sección, we mainly present the experimental results of conceptualization for both single instance
and short text.
1). Single Instance Conceptualization
Data set preparation. We asked human labelers to manually annotate the correctness of the concepts.
The label is defined in four categories as shown in Table 3. Cada (instancia, concepto) is assigned to three
labelers to annotate. The final label is defined by the majority label. We will ask the fourth annotator to
make the final vote for records without majority label. En todo, hay 5,049 labeled records.
Mesa 3. Labeling guideline for conceptualization.
Label
Significado
Examples
Excellent
Well matched concepts at the basic level
(bluetooth, wireless communication protocol)
Bien
Fair
Bad
A little general or specific
(bluetooth, accessory)
Too general or specific
Non-sense concepts
(bluetooth, feature)
(bluetooth, issue)
Data Intelligence
264
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Measurement. We employ Precision@k and nDCG to evaluate the effectiveness. For Precision@k, nosotros
treat Good/Excellent as score 1, and Bad/Fair as 0. We calculate the precision of top-k concepts as follows:
Precision@
k
=
∑
rel
i
,
k
i
=
1
k
(19)
where reli is the score we define above. For nDCG, we treat Bad as 0, Fair as 1, Good as 2, and Excellent
como 3. Then we calculate nDCG as follows:
nDCG
=
rel
i
+
∑
k
=
i
2
ideal
_
rel
i
+
∑
k
=
i
2
rel
i
logi
ideal
_
logi
,
rel
i
(20)
where reli is the relevance score of the result at rank i, and ideal reli is the relevance score at rank i of an
ideal list, obtained by sorting all relevant concepts in decreasing order of the relevance score.
Experimental result. Cifra 23 shows the evaluation of the top 20 results using both Precision and
nDCG with and without smoothing. We compare our proposed scoring functions with various baselines:
MI, NPMI, and PMI3. Where PMI3 is defined as:
From the result, we can see that our proposed scoring function outperforms baseline on both precision
3
PMI
(
e c
,
)
=
registro
3
p e c
)
( ,
( )
p e p c
(
)
.
(21)
and nDCG.
2). Short Text Conceptualization
Data set preparation. To validate our generalizability, we build two data sets to evaluate our algorithm
including user search query and tweets. To build a query data set, we first manually picked 11 ambiguous
terms including “apple”, “fox” with instance ambiguity, “watch”, “book”, “pink”, “blue”, “population”,
“birthday” with type ambiguity, and “April in Paris”, “hotel California” with segmentation ambiguity. Entonces
we randomly selected 1,100 queries containing 11 ambiguous terms. Además, we randomly sampled
otro 400 queries without any restriction. In all, there are 1,500 consultas. To build tweets data set, nosotros
also randomly sampled 1,500 tweets using Twitter’s API. To clean the tweets, we removed some tweet-
specific features, such as @username, hashtags, urls, etc.. We asked human labelers to manually annotate
the correctness. For each record, we assign at lease three labelers and pick up the majority vote as final
label.
Experimental result. To evaluate the effectiveness of the algorithm, we compared our methods with
several baseline methods. [27] conducts instance disambiguation in queries based on similar instances,
[28] conducts instance disambiguation in queries based on related instances, y [26] conducts instance
disambiguation in tweets based on both similar and related instances. Mesa 4 presents the results which
show that our conceptualization is not only effective but also robust.
265
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
Cifra 23. Precision and nDCG comparison.
Mesa 4. Precision of short text understanding.
Query
Tweet
[27]
0.694
–
[28]
0.701
–
[26]
–
0.841
Ours
0.943
0.922
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Data Intelligence
266
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
6. CONCLUSIÓN
en este documento, we present the end-to-end framework of building and utilizing the Microsoft Concept
Graph, which consists of three major layers, namely semantic network construction, concept conceptualization
and applications. In the semantic network construction layer, we focus on the knowledge extraction and
taxonomy construction procedures to build an open-domain and probabilistic taxonomy known as Probase.
Like human mental process, we then represent text by concept space using conceptualization models, y
empower many applications including topic search, query recommendation, Ads relevance calculation as
well as Web table understanding. The system has received wide public attention ever since released in
2016 (more than 100,000 pageviews, 2 million API calls and 3,000 registered downloads from 50,000
visitors over 64 countries).
CONTRIBUCIONES DE AUTOR
All of the authors contributed equally to the work. j. yan (jun.yan@yiducloud.cn), z. Wang (wzhy@
outlook.com) y D. zhang (zhangdawei@outlook.com) used to be the leaders of the Microsoft Concept
Graph system, and now L. Ji (leiji@microsoft.com, Autor correspondiente) is the leader and is developing
new component for V2.0. Y. Wang (Yujing.Wang@microsoft.com) y yo. Ji summarized the methodology
part of this paper. Y. Wang and B. Shi (botianshi@bit.edu.cn) summarized the applications and experiment.
All authors have made meaningful and valuable contributions in revising and proofreading the manuscript.
REFERENCIAS
[1] GRAMO. Murphy. The big book of concepts. Cambridge, MAMÁ: La prensa del MIT, 2004. isbn: 9780262632997.
[2] PAG. Bloom. Glue for the mental world. Naturaleza 421 (2003), 212–213. doi: 10.1038/421212a.
[3] W.. Wu, h. li, h. Wang, & k. Zhu. Probase: A probabilistic taxonomy for text understanding. En: Actas
del 2012 ACM SIGMOD International Conference on Management of Data, ACM, 2012, páginas. 217–228.
doi: 10.1145/2213836.2213891.
[4] D.B. Lenat, & R.V. Guha. Building large knowledge-based systems: Representation and inference in the Cyc
proyecto. Reading, MAMÁ: Addison-Wesley, 1990. isbn: 9780201517521.
[6]
[5] k. Bollacker, C. evans, PAG. Paritosh, t. Sturge, & j. taylor. base libre: A collaboratively created graph database
for structuring human knowledge. En: Actas de la 2008 ACM SIGMOD International Conference on
Management of Data, ACM, 2008, páginas. 1247–1250. doi: 10.1145/1376616.1376746.
F.M. Suchanek, GRAMO. Kasneci, & GRAMO. Weikum. YAGO: A core of semantic knowledge. En: Proceedings of the 16th
International Conference on World Wide Web, ACM, 2007, páginas. 697–706. doi: 10.1145/1242572.1242667.
[7] A. Carlson, j. Betteridge, B. Kisiel, B. Settles, E.R.H. Jr., & T.M. mitchell. Toward an architecture for never-
ending language learning. En: Proceedings of the 24th Conference on Artificial Intelligence, AAAI, 2010,
páginas. 1306–1313. doi: 10.1145/1807406.1807449.
[8] G.A. Molinero. WordNet: A lexical database for English. Communications of the ACM 38(11) (1995), 39–41.
[9]
doi: 10.1145/219717.219748.
S.P. Ponzetto, & METRO. Strube. Deriving a large-scale taxonomy from Wikipedia. En: Proceedings of the 22nd
National Conference on Artificial Intelligence, AAAI, 2007, páginas. 1440–1445. Disponible en: http://www.aaai.
org/Papers/AAAI/2007/AAAI07-228.pdf.
[10] S. Auer, C. Bizer, GRAMO. Kobilarov, j. Lehmann, R. Cyganiak, & z. Ives. DBpedia: A nucleus for a web of open
datos. En: Proceedings of the 6th International Semantic Web Conference/Asian Semantic Web Conference,
Saltador, 2007, páginas. 722–735. doi: 10.1007/978-3-540-76298-0_52.
267
Data Intelligence
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
[11] R. Speer, & C. Havasi. Representing general relational knowledge in ConceptNet 5. En: Actas de la
8th International Conference on Language Resources and Evaluation, 2012, páginas. 3679–3686. Disponible en:
http://www.lrec-conf.org/proceedings/lrec2012/pdf/1072_Paper.pdf.
[12] oh. Etzioni, METRO. Cafarella, D. Downey, A.P. Shaked, S. Soderland, D.S. Weld, & A. Yates. Web-scale
information extraction in knowitall: Preliminary results. En: Proceedings of the 13th International Conference
on World Wide Web, ACM, 2004, páginas. 100–110. doi: 10.1145/988672.988687.
[13] MAMÁ. Hearst. Automatic acquisition of hyponyms from large text corpora. En: Proceedings of the 14th confer-
ence on Computational linguistics, LCA, 1992, páginas. 539–545. doi: 10.3115/992133.992154.
[14] A. McCallum, & k. Nigam. A comparison of event models for naive bayes text classification. En: Actas
of AAAI-98 Workshop on Learning for Text Categorization, AAAI, 1998, páginas. 41–48.
[15] z. Wang, H.X. Wang, j. Wen, & Y. xiao. An inference approach to basic level of categorization. En: Proceed-
ings of the 24th ACM International Conference on Information and Knowledge Management (CIKM), ACM,
2015, páginas. 653–662. doi: 10.1145/2806416.2806533.
[16] B. Daille. Approche mixte pour l’extraction de terminologie: Statistique lexicale et filtres linguistiques. PhD
disertación, Université Paris VII, 1994.
[17] z. Wang, k. zhao, h. Wang, X. Meng, & j. Wen. Query understanding through knowledge-based conceptu-
alización. En: Proceedings of the 24th International Joint Conference on Artificial Intelligence, AAAI, 2015,
páginas. 3264–3270.
[18] PAG. li, h. Wang, k. Zhu, z. Wang, & X. Wu. Computing term similarity by large probabilistic isA knowledge.
En: Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge
Management, ACM, 2013, páginas. 1401–1410. doi: 10.1145/2505515.2505567.
[19] D. Marneffe, B. MacCartney, & C.D. Manning. Generating typed dependency parses from phrase structure
parses. En: Proceedings of the 5th International Conference on Language Resources and Evaluations, 2006,
páginas. 449–454.
[20] D. Blei, A.Y. Ng, & M.I. Jordán. Latent dirichlet allocation. Journal of Machine Learning Research 3(Ene)
(2003), 993–1022. Disponible en: http://jmlr.csail.mit.edu/papers/v3/blei03a.html.
[21] W.. Hua, z. Wang, h. Wang, k. Zheng, & X. zhou. Short text understanding through lexical-semantic
análisis. En: IEEE 31st International Conference on Data Engineering, IEEE, páginas. 495–506. doi: 10.1109/
ICDE.2015.7113309.
[22] j. Kupiec. Robust part-of-speech tagging using a hidden Markov model. Computer Speech & Idioma
6(3) (1992), 225–242. doi: 10.1016/0885-2308(92)90019-z.
[23] Y. Wang, h. li, h. Wang, & K.Q. Zhu. Toward topic search on the web. Technical report, Microsoft Research,
2010. Disponible en: https://www.microsoft.com/en-us/research/publication/toward-topic-search-on-the-web/
?from=http%3A%2F%2Fresearch.microsoft.com%2Fapps%2Fpubs%2Fdefault.aspx%3Fid%3D166386.
[24] j. Wang, h. Wang, z. Wang, & K.Q. Zhu. Understanding tables on the web. En: Proceedings of the 31st
International Conference on Conceptual Modeling, Saltador, 2012, páginas. 1–14. doi: 10.1007/978-3-642-
34002-4_11.
[25] F. Wang, z. Wang, z. li, & j. Wen. Concept-based short text classification and ranking. En: Actas de
the 23rd ACM International Conference on Conference on Information and Knowledge Management, ACM,
2014. doi: 10.1145/2661829.2662067.
[26] PAG. Ferragina, & Ud.. Scaiella. TAGME: On-the-fly annotation of short text fragments (by wikipedia entities). En:
Proceedings of the 19th ACM International Conference on Information and Knowledge Management, ACM,
2010, páginas. 1625–1628. doi: 10.1145/1871437.1871689.
[27] Y. Song, h. Wang, z. Wang, h. li, & W.. Chen. Short text conceptualization using a probabilistic knowledge-
base. En: Proceedings of the 22nd International Joint Conference on Artificial Intelligence, AAAI, 2011,
páginas. 2330–2336. doi: 10.5591/978-1-57735-516-8/IJCAI11-388.
[28] D. kim, h. Wang, & A. Oh. Context-dependent conceptualization. En: Proceedings of the 23rd International
Conferencia conjunta sobre inteligencia artificial, AAAI, 2013, páginas. 2654–2661.
Data Intelligence
268
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
AUTHOR BIOGRAPHY
Lei Ji received her Bachelor and Master degrees from Beijing Institute of
Technology and is currently a PhD student in computer science from Institute
of Computing Technology, Academia China de Ciencias. She is currently
a researcher at Microsoft Research Asia. Her research interests include
knowledge graph, cross-modality visual and language learning.
Yujing Wang received her Bachelor and Master degrees from Peking
Universidad. She is currently a Researcher at Microsoft Research Asia. Su
research interests include AutoML, text understanding and knowledge graph.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
t
.
i
Botian Shi is currently a PhD student in computer science from Beijing
Institute of Technology, who conducted this work during internship at MSRA.
His research interests include natural language processing and multi-modal
knowledge based image/video understanding.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
269
Data Intelligence
Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding
Dawei Zhang received his Master degree from Peking University. He is
currently the Founder of MIX Labs. His research interests include machine
aprendiendo, natural language processing and knowledge graph.
Zhongyuan Wang received his Bachelor, Master, and PhD degrees in
computer science at Renmin University of China in 2007, 2010, y 2015,
respectivamente. He is currently a Senior Researcher and Senior Director of
Meituan-Dianping. His research interests include knowledge base, Web data
mining, online advertising, machine learning and natural language processing.
Jun Yan received his PhD degree in school of mathematical science at Peking
Universidad. He is currently the Chief AI Scientist of Yiducloud. His research
interests include medical AI research, knowledge graph mining and online
advertising.
Data Intelligence
270
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
1
3
2
3
8
6
8
3
8
0
2
d
norte
_
a
_
0
0
0
1
3
pag
d
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3