Parafraseo de modismos chinos
Jipeng Qiang1∗ Yang Li1 Chaowei Zhang1 Yun Li1
Yi Zhu1 Yunhao Yuan1 Xindong Wu2,3
1 Universidad de Yangzhou, Porcelana,
2 Universidad Tecnológica de Hefei, Porcelana,
3 Laboratorio de Zhejiang, Porcelana
{jpqiang,cwzhang,El león,zhuyi,yhyuan}@yzu.edu.cn, xwu@hfut.edu.cn
Abstracto
Idioms are a kind of idiomatic expression
in Chinese, most of which consist of four
Chinese characters. Due to the properties of
non-compositionality and metaphorical mean-
En g, Chinese idioms are hard to be understood
by children and non-native speakers. Este
study proposes a novel task, denoted as Chi-
nese Idiom Paraphrasing (CIP). CIP aims
to rephrase idiom-containing sentences to
non-idiomatic ones under the premise of pre-
serving the original sentence’s meaning. Desde
the sentences without idioms are more eas-
ily handled by Chinese NLP systems, CIP
can be used to pre-process Chinese datasets,
thereby facilitating and improving the perfor-
mance of Chinese NLP tasks, p.ej., machine
translation systems, Chinese idiom cloze, y
Chinese idiom embeddings. en este estudio, nosotros
can treat the CIP task as a special paraphrase
generation task. To circumvent difficulties
in acquiring annotations, we first establish
a large-scale CIP dataset based on human
and machine collaboration, which consists of
115,529 sentence pairs. In addition to three
sequence-to-sequence methods as the base-
líneas, we further propose a novel infill-based
approach based on text infilling. The results
show that the proposed method has better
performance than the baselines based on the
established CIP dataset.
1
Introducción
Idioms, called ‘‘
'' (ChengYu) in Chinese,
are widely used in daily communications and
various literary genres. Idioms are a kind of
compact Chinese expressions that consist of few
words but imply relatively complex social nu-
ances. Además, Chinese idioms are often used
to describe similar phenomena, events, etc., cual
means the idioms cannot be interpreted with their
literal meanings in some cases. De este modo, it has al-
ways been a challenge for non-native speakers,
∗Corresponding author: jpqiang@yzu.edu.cn.
740
and even native speakers, to recognize Chinese
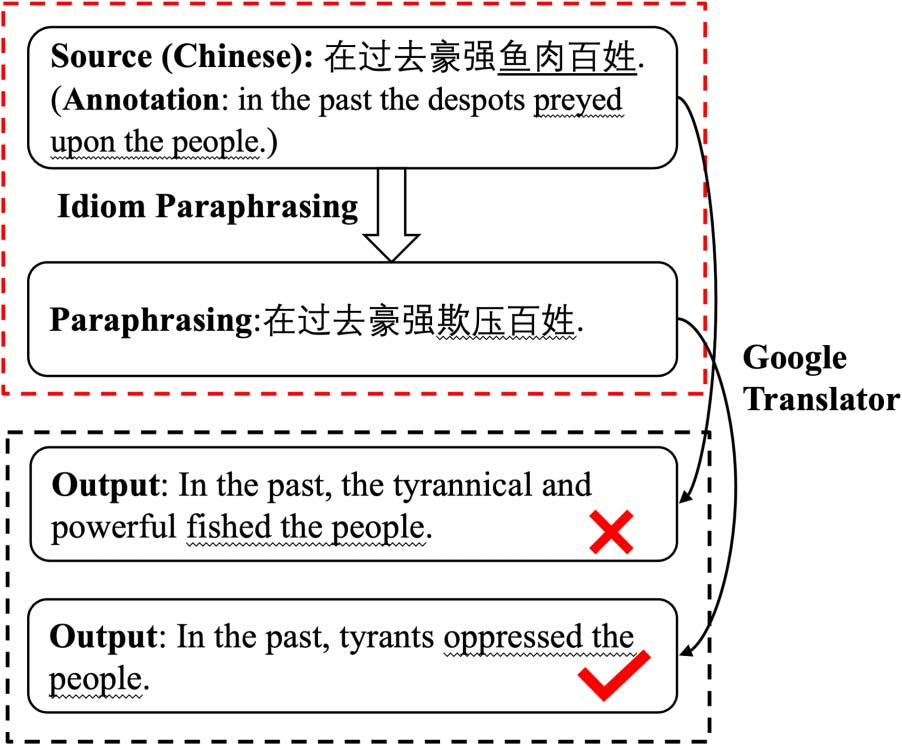
idioms (Zheng et al., 2019). Por ejemplo, el
'' (YuRouBaiXing) shown in
idiom ‘‘
Cifra 1, represents ‘‘oppress the people’’, en cambio
of its literal meaning – ‘‘fish meat the people’’.
In real life, if some people do not understand
the meaning of idioms, we have to explain them
by converting them into a set of word segments
that reflect more intuitive and understandable
paraphrasing. en este estudio, we try to manipu-
late computational approaches to automatically
rephrase idiom-containing sentences into simpler
oraciones (es decir., non-idiom-containing sentences)
for preserving context-based paraphrasing, y
then benefit both Chinese-based natural language
processing and societal applications.
Since idioms are a kind of obstacles for many
NLP tasks, CIP can be used as a pre-processing
phase that facilitates and improves the perfor-
mance of machine translation systems (Ho et al.,
2014; Shao et al., 2018), Chinese idiom cloze
(Jiang et al., 2018; Zheng et al., 2019), and Chi-
nese idiom embeddings (Tan and Jiang, 2021).
Además, CIP-based applications can help spe-
cific groups, such as children, non-native speakers,
and people with cognitive disabilities, to improve
their reading comprehension.
We propose a new task in this study, de-
noted as Chinese Idiom Paraphrasing (CIP), cual
aims to rephrase the idiom-containing sentences
into fluent,
intuitive, and meaning-preserving
non-idiom-containing sentences. We can treat the
CIP task as a special paraphrase generation task.
The general paraphrase generation task aims to
rephrase a given sentence to another one that pos-
sesses identical semantics but various lexicons or
syntax (Kadotani et al., 2021; Lu et al., 2021).
Similarmente, CIP emphasizes rephrasing the idioms
of input sentences to word segments that reflect
more intuitive and understandable paraphrasing.
En décadas recientes, many researchers devoted to
Transacciones de la Asociación de Lingüística Computacional, volumen. 11, páginas. 740–754, 2023. https://doi.org/10.1162/tacl a 00572
Editor de acciones: Minlie Huang. Lote de envío: 12/2022; Lote de revisión: 3/2023; Publicado 7/2023.
C(cid:3) 2023 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
cuerpo. Because the training corpus for the MT
system does not include any idioms, the MT sys-
tem will not translate input English sentences
to idiom-containing Chinese sentences. Entonces, el
MT system is deployed to translate English sen-
tences of the idiom-containing sub-corpus to
the non-idiom-containing sentences. A large-scale
pseudo-parallel CIP dataset can be constructed by
pairing the idiom-containing sentences of idiom-
containing sub-corpus and the translated non-
idiom-containing sentences. Finalmente, we employ
native speakers to validate the generated sentences
and modify defective sentences if necessary.
Segundo, we propose one novel
infill-based
method to rephrase the input idiom-containing
oración. Since the constructed dataset is used as
the training dataset, we treat the CIP task as a
paraphrase generation task. We adopt three differ-
ent sequence-to-sequence (Seq2Seq) methods as
baselines: LSTM-based approach, Transformador-
based approach, and mT5-based approach, dónde
mT5 is a massively multilingual pre-trained
text-to-text Transformer (Xue et al., 2021). Nuestro
proposed infill-based method is only required to
rephrase the idioms of the sentence, which means
that we only need to generate context-based in-
terpretations of idioms, rather than the whole
oración. Específicamente, a CIP sentence pair can be
processed to produce a (corrupted) input sentence
by replacing both the idioms of the source sentence
and a corresponding target extracted from the sim-
plified sentence. The mT5-based CIP method is
fine-tuned to reconstruct the corresponding target.
Experimental results show that, compared with the
baselines evaluated on the constructed CIP dataset,
our infill-based method can output high-quality
paraphrasing of sentences that are grammatically
correct and semantically appropriate.
As the use of the Chinese language becomes
more widespread, the need for effective Chinese
paraphrasing methods may increase, conduciendo a
further research and development in this area.
The constructed dataset and employed baselines
that are used to accelerate this research are
open-source, available on Github.2
2 Trabajo relacionado
Paraphrase Generation: Paraphrase genera-
to extract paraphrases of given
tion aims
2https://www.github.com/jpqiang/Chinese
Cifra 1: Given a Chinese idiom-containing sen-
tence, we aim to output a fluent,
intuitive, y
meaning-preserving non-idiom-containing sentence.
An idiom-containing sentence is hard to process by
NLP applications. Por ejemplo, this idiom-containing
sentence is translated by the newest Google Translator.1
After processing the idiom-containing sentence using
the proposed CIP method, we can output the correct
traducción. In the example, the idiom is undelined.
paraphrase generation (McKeown, 1979; Meteer
and Shaked, 1988) have struggled due to the lack
of a reliable supervision dataset (Meng et al.,
2021). Inspired by the challenge, we establish a
large-scale training dataset in this work for the
CIP task.
Contributions. This study produces two main
contributions toward the development of CIP
sistemas.
Primero, a large-scale benchmark is established for
the CIP task. The benchmark comprises 115,529
sentence pairs, which of 8,421 are idioms. A re-
current challenge in crowdsourcing NLP-oriented
datasets at scale is that human writers frequently
utilize repetitive patterns to fabricate examples,
leading to a lack of linguistic diversity (Liu et al.,
2022). A new large-scale CIP dataset is created in
this study by taking advantage of the collaboration
between humans and machines.
In detail, we initially divide a large-scale
Chinese-English machine translation corpus into
two parts (idiom-containing sub-corpus, y
non-idiom-containing sub-corpus) by judging if
a Chinese sentence contains idioms. Próximo, nosotros
train an English-to-Chinese machine translation
(MONTE) system using the non-idiom-containing sub-
1translate.google.com. Accessed in: 2022-12-01.
-Idiom-Paraphrasing.
741
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
oraciones. The extracted paraphrases can pre-
serve the original meaning of the sentence, pero
are assembled with different words or syntactic
estructuras (McKeown, 1979; Meteer and Shaked,
1988; Zhou and Bhat, 2021).
Most recent neural paraphrase generation methods
primarily take advantage of the sequence-to-
sequence framework, which can achieve con-
siderable performance improvements compared
with traditional approaches (Zhou and Bhat,
2021). Some approaches use reinforcement learn-
ing or multi-task learning to improve the quality
and diversity of generated paraphrases (Xie et al.,
2022). A long-standing issue embraced in para-
phrase generation studies is the lack of reliable
supervised datasets. The issue can be avoided by
constructing manually annotated paired-paraphrase
conjuntos de datos (Kadotani et al., 2021) or designing un-
supervised paraphrase generation methods (Meng
et al., 2021).
Differ from existing paraphrase generation re-
buscar, we take our attention to Chinese idiom
paraphrasing that rephrases idiom-containing sen-
tences to non-idiom-containing ones.
Text Infilling: Originating from cloze tests
(taylor, 1953), text infilling aims to fill in missing
blanks in a sentence or paragraph by making use
of the preceding and subsequent text, to make the
text complete and meaningful.
Current text infilling methods may be cate-
gorized into four groups. GAN-based methods
train GANs to ensure that the generator gen-
erates highly dependable infilling content that
can trick the discriminator (Fedus et al., 2018).
Intricate inference-based methods use dynamic
programming or gradient search to locate infilling
content that is highly probable within its sur-
rounding context (Zaidi et al., 2020). Masked
LM-based methods generate infilling content
based on its bidirectional contextual word em-
bedding (Shen et al., 2020). LM-based methods
fine-tune off-the-shelf LMs in an auto-regressive
manner, and some approaches modify the input
format by putting an infilling answer after the
masked input (Donahue et al., 2020), mientras
others do not modify the input format (Zhu et al.,
2019). In contrast to the aforementioned methods,
our goal in this paper is not only to make the
text complete, but also to maintain the sentence’s
meaning when creating paraphrases. Como resultado,
we employ a sequence-to-sequence framework to
identify infilling content.
Idioms: Idiom is an interesting linguistic phe-
nomenon in the Chinese language. Compared
with other types of words, mayoría
idioms are
unique in perspective of non-compositionality
and metaphorical meaning. Idiom understanding
plays an important role in the research area of
Chinese language understanding. Many types of
research related to Chinese idiom understanding
have been proposed that can benefit a variety
of related down-streaming tasks. Por ejemplo,
Shao et al. (2018) focused on evaluating the qual-
ity of idiom translation of machine translation
sistemas. Zheng et al. (2019) provided a bench-
mark to assess the abilities of multiple models
on Chinese idiom-based cloze tests, and evaluated
how well the models can comprehend Chinese
idiom-containing texts. Liu et al. (2019) studied
how to improve essay writing skills by recom-
mending Chinese idioms. Tan and Jiang (2021)
investigated the tasks on learning and quality
evaluation of Chinese idiom embeddings. En esto
paper, we study a novel CIP task that is dif-
ferent from the above tasks. Since the proposed
CIP method can rephrase idiom-containing sen-
tences to non-idiom-containing ones, it is expected
that CIP can benefit tasks related to idiom rep-
resentation and idiom translation.
Pershina et al. (2015) studied a new task of
English idiom paraphrases aiming to determine
whether two idioms have alike or similar mean-
ings. They collected idioms’ definitions in a
dictionary and utilized word embedding model-
ings to represent idioms to calculate the similarity
between two idioms. Qiang et al. (2021) propuesto
a Chinese lexical simplification method, cual
focuses on replacing complex words in given
sentences with simpler and meaning-equivalent
alternatives. It is noteworthy that the substitutes
in Chinese lexical simplification are all made up
of a single word, but an idiom typically cannot be
substituted by a single word to express original
concepts or ideas.
3 Human and Machine Collaborative
Dataset Construction
This section describes the process of constructing
a large-scale parallel dataset for CIP. A qualified
CIP dataset needs to meet the following two re-
quirements: (1) The two sentences in a sentence
pair have to convey the same meaning; y (2) A
sentence pair has to contain an idiom-containing
742
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2: A pipelined illustration of creating a CIP dataset based on a Chinese-English MT corpus. (a) The corpus
is split into an idiom-containing sub-corpus and a non-idiom-containing sub-corpus based on a Chinese idiom
lista. (b) We train a MT system using the non-idiom-containing sub-corpus, and create a pseudo-CIP Dataset by
pairing the original Chinese idiom-containing sentences and the translated non-idiom-containing sentences using
the trained MT system. (C) We ask human annotators to revise the translated Chinese sentence of the pairs to
strengthen the quality of the created CIP dataset.
sentence and an idiom-containing one. We outline
a three-stage pipeline for dataset construction,
which takes advantage of both the generative
strength of machine translation (MONTE) methods and
the evaluative strength of human annotators. Hu-
man annotators are generally reliable in correcting
examples, but it is challenging while crafting di-
verse and creative examples at scale. Por lo tanto,
we deploy a machine translator to automatically
create an initial CIP dataset, and then inquire
annotators to proofread each generated instance.
3.1 Pipeline
Cifra 2 exhibits the details of the pipeline. Nuestro
pipeline starts with an existing English-Chinese
machine translation dataset denoted as D. En primer lugar,
we refer to a collect Chinese idiom list I to
the MT dataset D into two parts: non-
dividir
idiom-containing sub-dataset D1 and idiom-
containing sub-dataset D2 (Stage 1). All the data
items in both D1 and D2 are in forms of sentence
pares. Entonces, we train a neural machine translation
system M using D1, which can translate En-
glish sentences to non-idiom-containing Chinese
oraciones. Después, we input English sen-
tences in D2 to M to output non-idiom-containing
Chinese sentences. Después, the Chinese sen-
tences in D2 and the generated sentences are
paired to construct a large-scale initial parallel
CIP dataset (Stage 2). Finalmente, the constructed
dataset is reviewed and revised by annotators for
quality assurance (Stage 3).
Stage 1: Corpus Segmentation. The English-
Chinese MT dataset D we applied in the re-
search are grabbed from WMT18 (Bojar et al.,
2018), which contains 24,752,392 sentence pairs.
We extract a Chinese idiom list I that embraces
31,114 idioms.3 Since the list enables determining
whether the Chinese sentence in a pair contains
idioms, D can be split as D1 and D2. El
sub-dataset D1 is used to train a special MT
system M that can translate English sentences to
non-idiom-containing Chinese sentences. En nuestro
experimentos, solo 0.2% of the translated Chinese
sentences contain idioms (ver tabla 6). After re-
moving redundant Chinese sentences, the number
of sentence pairs in D2 is 105,559.
Stage 2: Pseudo-CIP Dataset. Giving a sen-
tence pair (ci, ei) in D2, we input the English
sentence ei into MT system M, and output a
Chinese translation ti. We pair Chinese sentence
ci and Chinese translation ti as a pseudo-CIP sen-
tence pair. De este modo, a CIP dataset can be built up
by pairing original Chinese sentences and cor-
responding translated English-to-Chinese ones in
D2. The pseudo-CIP dataset D2(cid:4) can meet the two
requirements of CIP dataset construction. On one
mano, the pseudo-CIP data is from the MT dataset,
which can guarantee that the paired sentences de-
liver the same meanings. On another hand, todo
original sentences include one or more idioms,
and all the translated sentences do not contain
idioms.
3https://github.com/pwxcoo/chinese-xinhua.
743
sentence pairs
simbólico
In-domain
Tren
95,560
desarrollador
5,000
Prueba
4,999
Out-of-domain
desarrollador
4,994
Prueba
4,976
Total
115,529
3,390,179
173,001
169,793
225,850
221,673
4,180,496
Fuente
Avg. sentence length
35
oración
All Idioms
Unique Idioms
102,997
7,609
35
5,423
5,225
34
5,494
5,279
45
5,808
5,149
45
5,800
5,128
36
251,055
8,421
Reference
tokens
3,454,127
175,083
172,028
239,578
224,907
4,265,723
oración
Avg. sentence length
Avg. edit disatance
36
7.85
35
7.26
34
7.37
48
6.21
45
5.36
36
7.62
Mesa 1: The statistics of the CIP dataset.
Freq. Interval
En
Out
Valid
Prueba
Valid
Prueba
0
415
421
279
284
[1,10)
[10,20)
[20,30)
[30,40)
[40,50)
[50,68)
1,787
1,814
1,871
1,854
941
946
808
810
1,159
1,171
1,120
1,108
1,026
1,057
1,643
1,657
67
60
62
66
28
25
25
21
Mesa 2: Frequency statistics for idiomatic usage in Dev and Test.
Stage 3: Human Review. As the final stage
of the pipeline, we recruit five human annotators
to review each sentence pair (ci, de) in the pseudo-
CIP dataset D2(cid:4). These annotators are all under-
graduate native Chinese speakers. Given (ci, de),
annotators are asked to revise and improve
the quality of ti. de
is required to be non-
idiom-containing and fully meaning-preserving.
3.2 Corpus Statistics
The statistical details of the CIP dataset are shown
en mesa 1. The dataset D2(cid:4) is treated as in-domain
datos, which contains 105,559 instances including
8,261 different idioms. D2(cid:4) is partitioned into three
partes: a training set Train, a development set Dev,
and a test set Test. The number of instances in
Tren, desarrollador, and Test are 95,560, 5,000, y 4,999,
respectivamente.
We observe that both the Train and Test
datasets come from the same distribution. Cómo-
alguna vez, when models are deployed in real-world
applications, the inference might be performed
on the data from different distributions,
es decir.,
out-of-domain (Desai and Durrett, 2020). Allá-
delantero, we additionally collected 9,970 oraciones
with idioms from modern vernacular classics, en-
cluding prose and fiction, as out-of-domain data,
to assess the generalization ability of CIP methods.
Unlike the MT corpus, these sentences have no
English sentences as their references, we manually
modify them to non-idiom-containing sentences
with the help of Chinese native speakers.
There are three significant differences between
in-domain and out-of-domain data. Primero, the av-
erage length of sentences in in-domain data is
alrededor 35 palabras, while it is about 45 words for
out-of-domain data. Segundo, the average number
of idioms in in-domain data is 1.07, which is lower
than that of out-of-domain data (es decir., 1.17). Tercero,
the sentence pairs in out-of-domain data need
fewer modifications than that in in-domain data.
En este caso, a lack of linguistic diversity might be
taken place due to human annotators often relying
on repetitive patterns to generate sentences.
To verify the scalability and generalization abil-
ity of the CIP methods, we adopt the following
strategy to construct Dev and Test. We counted
the frequency of each idiom in the corpus, dónde
the minimum and the maximum idiom frequency
son 1 y 68, respectivamente. Based on the number
of idioms in each frequency interval, we extract
the instances into the Dev and Test. The id-
iom frequency statistics on the Dev and Test
se muestran en la tabla 2. We can see that those
low-frequency idioms occupy a higher proportion
of all the idiom occurrences (62.76% y 62.71%
744
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
’’ in CIP dataset. c and e are a machine learning
Mesa 3: The examples contain the idiom ‘‘
sentence pair, t is the CIP reference sentence of c generated by collaborating machine translation and
human intervention. The words in underlined are idioms, and their translations and their interpretations
are marked in wave line.
for low-frequency interval [0,20) in in-domain
Dev and Test). Hay 421 y 415 instancias
containing idioms in in-domain Dev and Test that
are never seen in the Train.
3.3 Some Examples in the CIP Dataset
some examples of
the idiom
We present
'' (reclusive) in the CIP dataset, mostrado
‘‘
en mesa 3. The idiom ‘‘
’’ can be
rephrased with different descriptions, displaying
the linguistic diversity.
4 Métodos
Based on our constructing CIP dataset, the CIP
task can be treated as a sentence paraphrasing task
(Sección 4.1). Además, we propose a novel
infill-based method to solve it (Sección 4.2).
4.1 Paraphrasing for CIP
This can be defined as follows. Given a source
sentence c = {c1, . . . , cj, . . . , cm} with one or
more idioms, we intend to produce a paraphrase
sentence t = {t1, . . . , de, …tn}. More specifi-
cally, t is expected to be non-idiom-containing
and meaning-preserving, where cj or ti refers
to a Chinese character. en este estudio, we sup-
pose to design a supervised method to approach
this monolingual machine translation task. Nosotros
adopt a Sequence-to-Sequence (Seq2Seq) marco-
work that directly predicts the probability of the
character-sequential translation from source sen-
tences to target ones (Bahdanau et al., 2015),
where the probability is calculated using the
following equation 1:
PAG (t | C) =
norte(cid:2)
yo=1
PAG (de | t
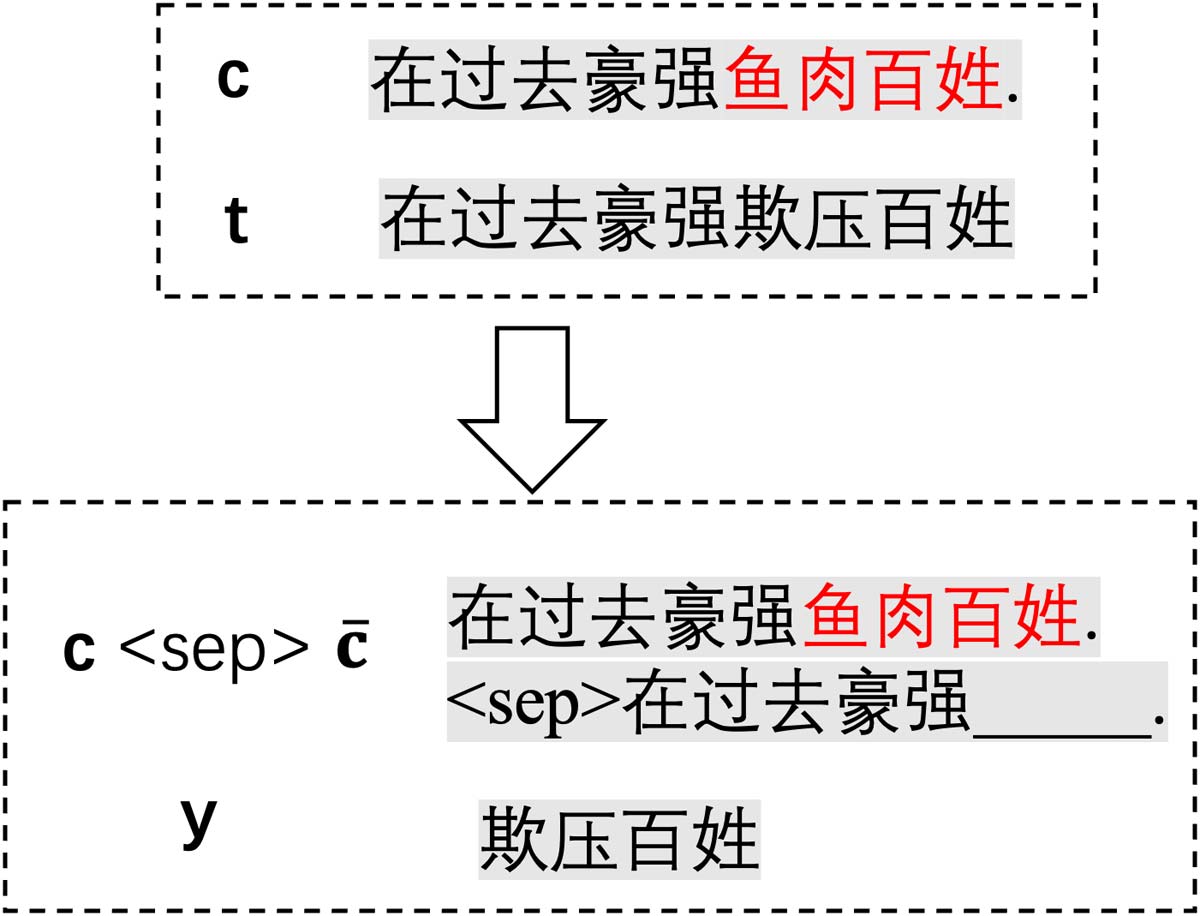
lows by ‘−’ in Diff. We get the following two
’> and
matching sequence pairs <‘
’>. A sequence
<‘
’,‘
pair will be ignored by the model
if no id-
iom is included. In this example, we obtain the
’>,
sequence pair <‘
’’ rep-
where ‘‘
resent an idiom and corresponding interpretation.
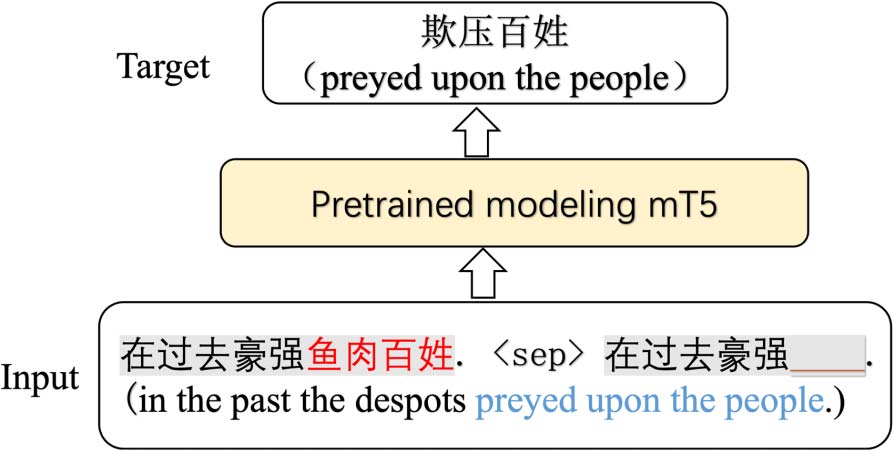
Training. Given one sentence pair {c,t}, we first
construct a new sentence pair {c
como se muestra en la figura 3. Entonces, we employ the Seq2Seq
methods to accomplish this task, as shown in
Cifra 4. Aquí, we make two modifications. (1)
’’ and ‘‘
','
4https://github.com/paulgb/simplediff.
746
Cifra 3: Infill-based CIP method as the sequence-
to-sequence task. An sentence pair {C,t} is transferred
into the input ‘‘c
Cifra 4: An example of the infill-based CIP method.
The input sequence fed into mT5-based Seq2Seq mod-
eling is composed of an original sentence and a target
oración, in which the idiom of the original sentence is
replaced by one blank. The interpretation of the idiom
is treated as the reference sentence, rather than the
target sentence.
If c is directly fed to the encoder, the information
of the idiom of c is ignored. We concatenate the
original c and the sentence c as the input sequence.
(2) When a sentence has two or more idioms, nosotros
construct one {C
C. We only use one blank for one idiom instead
of multiple blanks for all idioms, because we can
preserve enough information when generating the
sequences to infill the blank.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Given training data consisting of { C, C, y}, él
is straightforward to optimize the following ob-
jective function according to maximum likelihood
estimations:
(cid:3)
Loss = −
registro P (y|C, C; i)
(2)
mT5 is a pre-trained span masked language
modelado (MLM) to build a Seq2Seq modeling.
In contrast to MLM in BERT (Devlin et al., 2019),
span MLM reconstructs consecutive spans of in-
put tokens and masks them with a blank. With the
help of mT5, the proposed method enables recon-
structing the idiom I’s interpretation of sentence c
via replacing the idiom with the blank. Por lo tanto,
our infill-based method adopts mT5 to learn how
to fill the black.
During inference, if a sentence has multiple
idioms, we iteratively decode each idiom to a
corresponding representation.
Relation to Previous Work. Comparado con
the sentence paraphrasing task (Zhou and Bhat,
2021; Xie et al., 2022), our infill-based method
only requires us to rephrase the idioms of the
oración, rather than the whole sentence. De hecho,
our method is inspired by the text infilling method
of Zhu et al. (2019). But our method is different
from the existing text infilling method, porque
our aim is to rephrase the original sentence, y el
aim of text infilling is to make the text complete
and meaningful.
5 experimentos
5.1 Configuración del experimento
Detalles de implementacion.
In this experiment
diseño, four CIP methods are deployed, incluir-
En g: LSTM-based Seq2Seq modeling (LSTM),
Transformer-based Seq2Seq modeling (Trans-
anterior), mT5-based Seq2Seq modeling (mT5),
and infill-based CIP method (Infill). We im-
plement LSTM and Transformer methods using
fairseq (Ott et al., 2019). mT5 and Infill meth-
ods are mT5-based, and are fulfilled using
HuggingFace transformers (Wolf et al., 2020).
Además, the sentence tokenization is accom-
plished using the Jieba Chinese word segmenter5
and BPE tokenization. The size of the vocabu-
lary is set to 32K. The LSTM-based Seq2Seq
method adopts the Adam optimizer configured
with β = (0.9, 0.98), 3e−4 learning rate, y
0.2 dropout rate. The Transformer-based Seq2Seq
method maintains the hyperparameters of the base
Transformador (Vaswani et al., 2017) (base), cual
contains a six-layered encoder and a six-layered
decoder. The three parameters (β of Adam op-
timizer, learning rate, and dropout rate) en el
Transformer-based method are equivalent to those
in the LSTM-based method. It’s noteworthy that
the learning rate is gradually increased to 3e−4
by 4k steps and correspondingly decays according
to the inverse square root schedule. For mT5 and
Infill, we adopt the mt5 version that is re-trained
on Chinese corpus.6 We train the three methods
with the Adam optimizer (Kingma and Ba, 2015)
and an initial learning rate of 3e−4 up to 20 epochs
using early stopping on development data. El
training will be stopped when the accuracy on
the development set does not improve within 5
epochs. We used a beam search with 5 beams for
inferencia.
Métrica. As we mentioned above,
the CIP
task can be treated as a sentence paraphrasing
tarea. Por lo tanto, We apply four metrics to eval-
uate sentence paraphrasing task namely, AZUL
(Papineni et al., 2002), BERTScore (Zhang et al.,
2020), and ROUGE-1 and ROUGE-2 (lin, 2004).
BLEU is a widely used machine translation
métrico, which measures opposed references to
evaluate lexical overlaps with human intervention
(Papineni et al., 2002). BERTScore is chosen as
another metric due to its high correlation with
human judgments (Zhang et al., 2020). Com-
pared to BLEU, BERTScore is measured using
token-wise cosine similarity between representa-
tions produced by BERT. We measure semantic
overlaps between generated sentences and ref-
erence ones using ROUGE scores (lin, 2004).
ROUGE is often used to evaluate text summariza-
ción. The two metrics ROUGE1 and ROUGE2
refer to the overlaps of unigram and bigram
between the system and reference summaries,
respectivamente.
Since generated paraphrases often only need to
rewrite the idioms of the original sentence, evalu-
ating the whole sentence cannot accurately reflect
the quality of paraphrase generation. In order to
better evaluate the quality of idiom paraphrasing,
we only evaluate the rewrite part of the gener-
ating paraphrases instead of the whole sentence
using the above metrics. Específicamente, given an
original sentence c, a reference sentence t, y
the generated paraphrase sentence u, we first find
the common words in all the sentences c, t, y
tu, and remove the common words from t and
tu. We evaluate the remaining words of t and u
using the above metrics, denoted as (BERT-E,
BERTScore-E, ROUGE1-E, and ROUGE2-E).
Líneas de base. In this research, we adopt
tres
Seq2Seq methods to handle CIP tasks that are
5https://github.com/fxsjy/jieba.
6www.github.com/ZhuiyiTechnology/t5-pegasus.
747
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Método
BLEU/BLEU-E
BERTS/BERTS-E
ROU1/ROU1-E
ROU2/ROU2-E
Re-translation
BERT
LSTM
Transformador
mT5
Infill
27.37/2.67
74.75/1.39
81.99/31.87
82.19/32.58
82.98/33.87
78.73/64.43
91.53/62.99
93.79/78.73
94.00/79.41
94.22/80.36
57.01/24.46
83.05/18.36
87.83/55.52
88.16/56.70
88.13/57.44
31.93/5.32
73.64/5.11
80.20/43.40
80.50/44.58
80.78/45.89
83.55/(34.26 ± 0.02) 94.46/(80.94±0.05) 88.68/(58.44±0.03) 81.57/(47.96±0.03)
Mesa 4: The results of different methods on the in-domain test set using the metrics: AZUL, BERTS,
ROUGE1, and ROUGE2, where BERTS, ROU1, and ROU2 refer to BERTScore, ROUGE-1, y
ROUGE-2, respectivamente. ‘‘±’’ means the standard deviation of five runs.
LSTM-based, Transformer-based, and mT5-based
modelos, respectivamente. We additionally provide
two zero-shot methods that can facilitate solv-
ing the CIP problem, a saber, Re-translation and
BERT-CLS.
(1) The LSTM-based Seq2Seq method is a ba-
sic Seq2Seq method, which uses an LSTM (largo
short-term memory [Hochreiter and Schmidhuber,
1997]) to convert a sentence to a dense, fixed-
length vector representation. In contrast to vanilla
form of RNNs, LSTM can handle long sequences,
but it fails to maintain the global information of
the sequences.
(2) The Transformer-based Seq2Seq method
(Vaswani et al., 2017) is a state-of-the-art Seq2Seq
method that has been widely adopted to process
various NLP tasks, such as machine translation,
abstractive summarization, etc.. Transformer ap-
plies a self-attention mechanism that directly mod-
els the relationships among all words of an input
sequence regardless of words’ positions. A diferencia de
LSTM, Transformer handles the entire input se-
quence at once, rather than iterating words one
by one.
(3) mT5 is a Seq2Seq method that uses the
framework of Transformer. Actualmente, most down-
stream NLP tasks build their models by fine-
tuning pre-trained language models (Rafael y col.,
2020). mT5 is a massively multilingual pre-trained
language model that is implemented in a form of
unified «text-to-text» to process different down-
stream NLP problems. en este estudio, we fine-tune
the mT5-based approach to handle CIP task.
(4) Re-translation is implemented by utiliz-
ing the back-translation techniques of machine
translation methods. We first translate an idiom-
containing sentence to an English sentence using
an efficient Chinese-English translation system,
and then translate the generated English sentence
using our
trained English-Chinese translation
sistema (introduced by Section 3.1) to generate
a non-idiom-containing Chinese sentence. El
Chinese-English translation system can be eas-
ily accessed online.7 The trained English-Chinese
translation system is a transformer-based Seq2Seq
método.
(5) BERT-CLS is an existing BERT-based Chi-
nese lexical simplification method (Qiang et al.,
2021). en esta tarea, an idiom is treated as a complex
word that will be replaced with a simpler word.
5.2 Performance of CIP Methods
Mesa 4 summarizes the evaluation results on our
established CIP dataset using two types of met-
rics. The supervised CIP methods (LSTM, Trans-
anterior, mT5, and Infill) are significantly better
than two zero-shot methods (Re-translation and
BERT) in perspectives of the four metrics. El
results reveal that the dataset is a high-quality
cuerpo, which can help to benefit CIP task.
Mesa 4 and Table 5 show that the performance
of LSTM-based baseline is inferior to the other
three baselines on in-domain and out-of-domain
test datasets. En general, the two mT5-based CIP
methods (mT5 and Infill) outperform the other
two methods (LSTM and Transformer), cual
suggests that CIP methods fine-tuned on mT5 can
improve CIP performance. It is observed that Infill
yields the best results on the in-domain test set
compared with other CIP methods, which verifies
that Infill is quite effective. On the out-of-domain
test set, BERT-based method achieves the best
results on ROU1 and ROU2, and obtains the
worst results on ROU1-E and ROU2-E, porque
7huggingface.co/Helsinki-NLP/opus-mt-zh-en.
748
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Método
BLEU/BLEU-E
BERTS/BERTS-E
ROU1/ROU1-E
ROU2/ROU2-E
Re-translation
BERT
LSTM
Transformador
mT5
Infill
13.65/0.87
84.95/1.63
81.20/7.81
80.14/8.07
84.76/9.29
72.63/61.87
94.79/63.07
93.50/67.03
93.55/67.36
94.58/68.05
47.18/22.73
89.84/19.95
87.66/31.08
87.63/31.62
89.20/31.82
19.47/2.65
85.10/5.99
81.69/14.14
81.56/14.48
83.76/14.64
86.60/(10.68±0.03) 94.98/(68.54±0.05) 89.70/(31.10±0.03) 84.89/(15.85±0.02)
Mesa 5: The results of different methods on the out-of-domain test set. ‘‘±’’ means the standard
deviation of five runs.
Método
Reference
BERT
LSTM
Transformador
mT5
Infill
En
Out
Simp. Significado
Fluency
4.41
3.28
3.58
3.48
3.85
4.02
4.26
2.24
3.33
3.29
3.57
3.78
4.29
2.58
3.27
3.22
3.62
3.81
Avg
4.32
2.70
3.39
3.33
3.68
3.87
Simp. Significado
Fluency
4.00
2.98
3.26
3.16
3.23
3.72
3.86
2.06
3.02
3.01
3.02
3.49
3.77
2.26
2.89
2.89
2.97
3.42
Avg
3.88
2.44
3.06
3.02
3.07
3.54
Mesa 6: The results of human evaluation. ‘‘Simp.’’ denotes ‘‘simplicity’’, ‘‘Avg’’ denotes ‘‘average’’.
it makes minor modifications on the source sen-
tence. It means that the type of metrics (BLEU-E,
BERTS-E, ROU1-E, and ROU2-E) are more rea-
sonable as the evaluation metrics for CIP task.
Our proposed Infill-based method is still the best
option for CIP task on the out-of-domain test set.
Our proposed method Infill is superior to the
baselines in several key ways. Primero, our approach
is more efficient, allowing us to achieve better
results in less time, because infill-based method
only needs to rephrase the idioms of the input sen-
tence. Segundo, our method is more robust, desde
it achieves the best results in both in-domain and
out-of-domain test sets. Finalmente, our method has
been extensively tested and validated, giving us
confidence in its reliability and accuracy through
human evaluation. En general, our method represents
a significant improvement over the existing base-
lines and is the best option for solving the CIP
problem at hand.
5.3 Human Evaluation
For further evaluating the CIP methods, we adopt
human evaluation to analyze the deployed CIP
methods. We choose 184 sentences from the in-
domain test set and 197 sentences from the out-
Método
Re-translation
BERT
LSTM
Transformador
mT5
Infill
En
99.82%
78.18%
85.64%
87.26%
87.54%
87.98%
Out
99.86%
69.21%
84.65%
85.13%
72.07%
81.29%
Mesa 7: The proportion between the times of
idiom paraphrasing and the number of all idioms.
of-domain test set. To verify the scalability and
generalization ability of the CIP methods, nosotros
show the performance of CIP methods when they
are used to solve the problems where the idioms
are never seen in the corpus. Por lo tanto, we choose
49 y 48 test sentences for in-domain and out-
of-domain test sets containing idioms that do not
appear in the training set, respectivamente. We ask
five native speakers to rate each generated sen-
tence using three features: simplicity, significado,
and fluency. The five-point Likert scale is adopted
to rate these features, and the average scores of
749
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
sui Dynasty began to (cid:2)(cid:2)(cid:2)(cid:2)
abierto (cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)
branches(cid:2)(cid:2)a(cid:2)(cid:2)(cid:2)(cid:2)llevar(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)
disabilities, also taking the first scholar.
they said what I tried to attain was a(cid:2)(cid:2)(cid:2)(cid:2)pipe(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)(cid:2)
dream and nothing more.
familia.
You are not young anymore, you should be able to (cid:2)(cid:2)(cid:2)comenzar(cid:2)(cid:2)a (cid:2)(cid:2)(cid:2)(cid:2)(cid:2)
Sent1
Inglés
Reference
LSTM, Trans., mT5
Infill
Sent2
Inglés
Reference
LSTM
Trans.
mT5
Infill
Sent3
Inglés
Reference
LSTM, Trans.
mT5
Infill
Mesa 8: The outputting paraphrasing of CIP methods when the idioms do not appear in the training set.
‘‘Trans.’’ denotes ‘‘Transformer’’.
the features are calculated correspondingly. (1)
Simplicity is responsible for evaluating whether
re-paraphrased idioms of generated sentences are
easily understandable, which means idioms in
the original sentences should be rewritten with
simpler and more common words. (2) Significado
assesses whether generated sentences preserve the
meaning of the original sentences. (3) Fluency is
used to judge if a generated sentence is fluent and
does not contain grammatical errors.
The results of the human evaluation are shown
en mesa 6. We calculate the scores of annotated
sentences t, denoted as Reference. We see that
the infill-based mT5 method outperforms other
methods on in-domain and out-of-domain test
conjuntos, which means Infill is an effective method on
the CIP task. The conclusions are consistent with
the results using automatic metric. Comparado con
Reference, our method has a significant potential
for improvement.
Además, we calculated the inter-annotator
agreement among different annotators. Specifi-
cally, we computed Fleiss’ Kappa (Fleiss, 1971)
scores for different domain test sets. The scores
son 0.199 y 0.097 in in-domain and out-of-
domain test sets, respectivamente. This indicates that
the evaluation of Chinese idiom paraphrasing was
relatively subjective but still managed to achieve
a modest level of agreement. We acknowledge
the limitations of human judgment in evaluating
the quality of paraphrasing and believe that the
diversity of opinions among raters is a valuable
insight into the complexity of the CIP task.
5.4 Proportion of Idiom Paraphrasing
CIP aims to rephrase an input idiom-containing
sentence to a meaning-preserving and non-idiom-
containing sentence. In this subsection, we count
the number of idiom-containing sentences that are
rephrased to non-idiom-containing sentences. El
results are shown in Table 7. The result shows that
Re-translation achieves the best results, cual
can rephrase almost all
idioms to non-idiom-
containing representations. That means that our
idea on CIP dataset construction using machine
translation method is feasible. Teóricamente, si
the trained English-Chinese machine translation
método (Stage 2 in the pipeline) can output
high-quality results, we do not need to ask annota-
tors to optionally revise Chinese translations. Nosotros
observe that the proportions of these CIP methods
(LSTM, Transformador, mT5, and Infill) are nearly
90%, which means they have great potential for
dealing with idiom paraphrasing. Además, a
750
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
small number of idioms cannot be rephrased, ser-
cause some idioms are simple, thereby are re-
tained in the training set.
5.5 Case Study
The in-domain test set contains idioms that are
never seen in Train. We show the paraphrasing
results of different CIP methods in Table 8.
Our method consistently outperforms all other
approaches in the case study. We found that LSTM-
based and Transformer-based methods tend to re-
tain or output part of the idioms, because they
cannot learn any knowledge of these idioms from
the training corpus. We found that both mT5-based
and Infill-based methods based on the pretrained
language model mT5 can generate correct inter-
pretations for some of the idioms, as the mT5
model has learned the knowledge of these id-
ioms. The mT5-based method generates a whole
new sentence for the original sentence, cual
can lead to some incorrect interpretations. en contra-
contraste, the Infill-based method only rephrases the
idioms within the sentence based on their context,
which can produce higher-quality interpretations
compared to the mT5-based method.
5.6 The Translations of Chinese Idioms
Not only do idioms present a challenge for peo-
ple to understand, but they also present a greater
challenge for Chinese-based NLP applications.
Aquí, we use Chinese-English machine transla-
tion as an example of an NLP application to eval-
uate the usefulness of CIP methods. Given an
input sentence containing an idiom, we first use
our CIP method as a preprocessing technique to
rephrase the sentence, and then translate the para-
phrased version into an English sentence.
We give some examples to compare the dif-
ferences, and the results are shown in Table 9.
Because many idioms cannot be translated with
their literal meaning, our method helps to identify
and paraphrase these idioms, making them easier
for the machine translation system to process.
6 Conclusión
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 9: The following examples demonstrate
how our CIP method can improve a Chinese-
English machine translation system. ‘‘Tran1’’
is the translation of the original sentence us-
ing Google Translate,8 ‘‘Para’’ is the paraphrased
version generated by our infill-based method, y
‘‘Tran2’’ is the translation of the paraphrased
sentence using Google Translate.
en este documento, we propose a novel Chinese idiom
paraphrasing (CIP) tarea, which aims to rephrase
sentences containing idioms into non-idiomatic
versions. The CIP task can be treated as a special
case of paraphrase generation and can be ad-
dressed using Seq2Seq modeling. We construct
8https://translate.google.com/. Accedido
en: 2022-12-01.
751
a large-scale training dataset for CIP by taking
the collaborations between humans and machines.
Específicamente, we first design a framework to con-
struct a pseudo-CIP dataset and then ask workers
to revise and evaluate the dataset. en este estudio, nosotros
deploy three Seq2Seq methods and propose one
novel CIP methods (Infill) for the CIP task. Ex-
perimental results reveal that our proposed meth-
ods trained on our dataset can yield good results.
This could have a positive impact on the perfor-
mance of machine translation systems, también
as other natural language processing applications
that involve Chinese idioms. In our subsequent
investigación, our proposed methods will be used as
strong baselines, and the established dataset will
also be used to accelerate the study on this topic.
Expresiones de gratitud
This research is partially supported by the National
Natural Science Foundation of China under grants
62076217, 62120106008, y 61906060, y el
Blue Project of Yangzhou University.
Referencias
Dzmitry Bahdanau, Kyunghyun Cho, y yoshua
bengio. 2015. Traducción automática neuronal por
aprender juntos a alinear y traducir. en 3ro
International Conference on Learning Rep-
resentaciones, ICLR 2015.
Ond rej Bojar, Christian Federmann, Mark Fishel,
Yvette Graham, Barry Haddow, Matthias Huck,
Philipp Koehn, and Christof Monz. 2018.
Findings of the 2018 conference on machine
traducción (wmt18). En procedimientos de
el
Third Conference on Machine Translation, volumen-
ume 2: Shared Task Papers, pages 272–307,
Bélgica, Bruselas. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/W18-6401
Shrey Desai and Greg Durrett. 2020. Calibration
of pre-trained transformers. En procedimientos de
el 2020 Conferencia sobre métodos empíricos
en procesamiento del lenguaje natural (EMNLP),
pages 295–302, En línea. Asociación para Com-
Lingüística putacional. https://doi.org
/10.18653/v1/2020.emnlp-main.21
comprensión. En Actas de la 2019 Estafa-
ference of the North American Chapter of the
Asociación de Lingüística Computacional: Hu-
man Language Technologies, Volumen 1 (Largo
and Short Papers), páginas 4171–4186. https://
https://doi.org/10.18653/v1/N19-1423
Chris Donahue, Mina Lee, y Percy Liang. 2020.
Enabling language models to fill in the blanks.
In Proceedings of the 58th Annual Meeting of
la Asociación de Lingüística Computacional,
pages 2492–2501.
William Fedus, Ian J. Goodfellow, y andres
METRO. dai. 2018. Maskgan: Better text genera-
. In 6th International
tion via filling in the
Conferencia sobre Representaciones del Aprendizaje, ICLR
2018, vancouver, BC, Canada, Abril 30 –
Puede 3, 2018, Conference Track Proceedings.
OpenReview.net.
Joseph L. Fleiss. 1971. Measuring nominal scale
agreement among many raters. Psicológico
Boletín, 76(5):378. https://doi.org/10
.1037/h0031619
Wan Yu Ho, Christine Kng, Shan Wang, y
Francis Bond. 2014. Identifying idioms in
Chinese translations. In LREC, pages 716–721.
Sepp Hochreiter y Jürgen Schmidhuber. 1997.
Memoria larga a corto plazo. Computación neuronal,
https://doi.org/10
9(8):1735–1780.
.1162/neco.1997.9.8.1735, PubMed:
9377276
Zhiying Jiang, Boliang Zhang, Lifu Huang,
and Heng Ji. 2018. Chengyu cloze test. En
Proceedings of the Thirteenth Workshop on In-
novative Use of NLP for Building Educational
Aplicaciones, pages 154–158.
Sora Kadotani, Tomoyuki Kajiwara, Yuki Arase,
and Makoto Onizuka. 2021. Edit distance
based curriculum learning for paraphrase gen-
eration. In Proceedings of the 59th Annual
Meeting of the Association for Computational
Linguistics and the 11th International Joint
Conferencia sobre procesamiento del lenguaje natural:
Student Research Workshop, pages 229–234.
https://doi.org/10.18653/v1/2021
.acl-srw.24
Jacob Devlin, Ming-Wei Chang, Kenton Lee, y
Kristina Toutanova. 2019. BERT: Pre-entrenamiento
de transformadores bidireccionales profundos para el lenguaje
Diederik P. Kingma, and Jimmy Ba. 2015.
A method for stochastic optimization. https://
doi.org/10.48550/arXiv.2203.16634
752
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Chin-Yew Lin. 2004. ROUGE: A package for
automatic evaluation of summaries. In Text
Summarization Branches Out, pages 74–81,
Barcelona, España. Asociación de Computación-
lingüística nacional.
Alisa Liu, Swabha Swayamdipta, Noah A. Herrero,
and Yejin Choi. 2022. WANLI: Worker and
AI collaboration for natural language inference
dataset creation. In Findings of the Associa-
ción para la Lingüística Computacional: EMNLP
2022, pages 6826–6847, Abu Dhabi, United
Arab Emirates. Asociación de Computación
Lingüística.
Yuanchao Liu, Bo Pang, and Bingquan Liu. 2019.
Neural-based Chinese idiom recommendation
for enhancing elegance in essay writing. En
Actas de la 57ª Reunión Anual de
la Asociación de Lingüística Computacional,
pages 5522–5526. Florencia, Italia. Asociación
para Lingüística Computacional. https://doi
.org/10.18653/v1/P19-1552
Xinyu Lu, Jipeng Qiang, Yun Li, Yunhao Yuan,
and Yi Zhu. 2021. An unsupervised method for
building sentence simplification corpora in mul-
tiple languages. In Findings of the Association
para Lingüística Computacional: EMNLP 2021,
pages 227–237, Punta Cana, Dominican Repub-
lic. Asociación de Lingüística Computacional.
https://doi.org/10.18653/v1/2021
.findings-emnlp.22
Kathleen R. McKeown. 1979. Paraphrasing us-
ing given and new information in a question-
answer system. In 17th Annual Meeting of
la Asociación de Lingüística Computacional,
pages 67–72, La Jolla, California, EE.UU. también-
ciation for Computational Linguistics.
Yuxian Meng, Xiang Ao, Qing He, Xiaofei Sun,
Qinghong Han, Fei Wu, Chun Fan, and Jiwei Li.
2021. ConRPG: Paraphrase generation using
contexts as regularizer. En Actas de la
2021 Conference on Empirical Methods in Nat-
ural Language Processing, pages 2551–2562.
https://doi.org/10.18653/v1/2021
.emnlp-main.199
for effective paraphrasing.
Marie Meteer and Varda Shaked. 1988. Strate-
In COL-
gies
ING Budapest 1988 Volumen 2: Internacional
Congreso sobre Lingüística Computacional,
431–436. https://doi.org/10
paginas
.3115/991719.991724
Myle Ott, Sergey Edunov, Alexei Baevski, Angela
Admirador, Sam Gross, Nathan Ng, David Grangier,
and Michael Auli. 2019. fairseq: A fast, ex-
tensible toolkit
En
Actas de la 2019 Conference of the
North American Chapter of the Association
para Lingüística Computacional (Demonstra-
ciones), pages 48–53. https://doi.org/10
.18653/v1/N19-4009
for sequence modeling.
Kishore Papineni, Salim Roukos, Todd Ward,
y Wei-Jing Zhu. 2002. AZUL: Un método para
evaluación automática de la traducción automática.
In Proceedings of the 40th Annual Meeting
de
the Association for Computational Lin-
guísticos, páginas 311–318. https://doi.org
/10.3115/1073083.1073135
Maria Pershina, Yifan He, and Ralph Grishman.
2015. Idiom paraphrases: Seventh heaven vs
cloud nine. In Proceedings of the First Work-
shop on Linking Computational Models of
Lexical, Sentential and Discourse-level Seman-
tics, pages 76–82. Lisbon, Portugal. asociación-
ción para la Lingüística Computacional. https://
doi.org/10.18653/v1/W15-2709
Jipeng Qiang, Xinyu Lu, Yun Li, Yun-Hao
Yuan, and Xindong Wu. 2021. Chinese lex-
ical simplification. IEEE/ACM Transactions
on Audio, Discurso, and Language Processing,
pages 1819–1828. https://doi.org/10
.1109/TASLP.2021.3078361
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Miguel
mañana, Yanqi Zhou, wei li, y Pedro J.. Liu.
2020. Explorando los límites del aprendizaje por transferencia
con un transformador unificado de texto a texto. Diario
de Investigación sobre Aprendizaje Automático, 21:1–67.
Yutong Shao, Rico Sennrich, Bonnie Webber,
and Federico Fancellu. 2018. Evaluating ma-
chine translation performance on Chinese id-
ioms with a blacklist method. En procedimientos
of the Eleventh International Conference on
Language Resources and Evaluation (LREC
2018).
Tianxiao Shen, Victor Quach, Regina Barzilay,
and Tommi Jaakkola. 2020. Blank language
modelos. En Actas de la 2020 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando (EMNLP), pages 5186–5198.
Minghuan Tan and Jing Jiang. 2021. Aprendiendo
and evaluating Chinese idiom embeddings.
753
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
In Proceedings of the International Confer-
ence on Recent Advances in Natural Language
Procesando (RANLP 2021), pages 1387–1396.
reconstruction. En hallazgos de
the Associa-
ción para la Lingüística Computacional: LCA 2022,
pages 1234–1243.
Wilson L. taylor. 1953. ‘‘Cloze procedure’’: A
new tool for measuring readability. Diario-
ism Quarterly, 30(4):415–433. https://doi
.org/10.1177/107769905303000401
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Leon Jones, Aidan N..
Gómez, lucas káiser, y Illia Polosukhin.
2017. Attention is all you need. In Advances
en sistemas de procesamiento de información neuronal,
pages 5998–6008.
Tomás Lobo, Debut de Lysandre, Víctor Sanh,
Julien Chaumond, Clemente Delangue, Antonio
moi, Pierric Cistac, Tim Rault, R´emi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drama, Quintín
Lhoest, and Alexander M. Rush. 2020. Trans-
formadores: State-of-the-art natural language pro-
cesando. En Actas de la 2020 Conferencia
on Empirical Methods in Natural Language Pro-
cesando: Demostraciones del sistema, páginas 38–45,
En línea. Asociación de Lin Computacional-
guísticos. https://doi.org/10.18653/v1
/2020.emnlp-demos.6
Yanling Xiao, Lemao Liu, Guoping Huang, Qu
Cual, Shujian Huang, Shuming Shi, and Jiajun
Chen. 2022. BiTIIMT: A bilingual text-infilling
method for interactive machine translation. En
Actas de la 60ª Reunión Anual de
la Asociación de Lingüística Computacional
(Volumen 1: Artículos largos), pages 1958–1969,
Dublín,
Irlanda. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/2022.acl-long.138
Xuhang Xie, Xuesong Lu, and Bei Chen.
2022. Multi-task learning for paraphrase gen-
eration with keyword and part-of-speech
Linting Xue, Noé constante, Adam Roberts,
Col rizada hábil, Rami Al-Rfou, Aditya Siddhant,
Aditya Barua, y Colin Raffel. 2021. mT5: A
massively multilingual pre-trained text-to-text
transformador. En Actas de la 2021 Estafa-
ference of the North American Chapter of the
Asociación de Lingüística Computacional: Hu-
man Language Technologies, pages 483–498,
En línea. Asociación de Lin Computacional-
guísticos. https://doi.org/10.18653/v1
/2021.naacl-main.41
Najam Zaidi, Trevor Cohn, and Gholamreza
Haffari. 2020. Decoding as dynamic pro-
gramming for recurrent autoregressive models.
En Conferencia Internacional sobre Aprendizaje
Representaciones.
Yuhui Zhang, Chenghao Yang, Zhengping Zhou,
and Zhiyuan Liu. 2020. Enhancing transformer
with sememe knowledge. En procedimientos de
the 5th Workshop on Representation Learning
for NLP, pages 177–184, En línea. Asociación
para Lingüística Computacional.
Chujie Zheng, Minlie Huang, and Aixin Sun.
2019. ChID: A large-scale Chinese IDiom
dataset for cloze test. In Proceedings of the 57th
Annual Meeting of the Association for Compu-
lingüística nacional, pages 778–787. https://
doi.org/10.18653/v1/P19-1075
Jianing Zhou and Suma Bhat. 2021. Paraphrase
generación: A survey of the state of the art. En
Actas de la 2021 Conferencia sobre Empiri-
Métodos cal en el procesamiento del lenguaje natural,
pages 5075–5086. https://doi.org/10
.18653/v1/2021.emnlp-main.414
Wanrong Zhu, Zhiting Hu, and Eric P. Xing.
2019. Text infilling. CORR, abs/1901.00158.
https://doi.org/10.48550/arXiv.1901
.00158
754
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
7
2
2
1
4
3
2
7
9
/
/
t
yo
a
C
_
a
_
0
0
5
7
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3