CARTA
Communicated by Arindam Banerjee
Multilinear Common Component Analysis
via Kronecker Product Representation
Kohei Yoshikawa
yoshikawa.kohei615@gmail.com
Shuichi Kawano
skawano@ai.lab.uec.ac.jp
Graduate School of Informatics and Engineering, La Universidad de
Electro-Communications, Chofu-shi, Tokio 182-8585, Japón
We consider the problem of extracting a common structure from multi-
ple tensor data sets. For this purpose, we propose multilinear common
component analysis (MCCA) based on Kronecker products of mode-wise
covariance matrices. MCCA constructs a common basis represented by
linear combinations of the original variables that lose little information
of the multiple tensor data sets. We also develop an estimation algorithm
for MCCA that guarantees mode-wise global convergence. Numerical
studies are conducted to show the effectiveness of MCCA.
1 Introducción
Various statistical methodologies for extracting useful information from a
large amount of data have been studied over the decades since the appear-
ance of big data. In the present era, it is important to discover a common
structure of multiple data sets. In an early study, Flury (1984) focused on
the structure of the covariance matrices of multiple data sets and discussed
the heterogeneity of the structure. The author reported that population
covariance matrices differ among multiple data sets in practical applica-
ciones. Many methodologies have been developed for treating the hetero-
geneity between covariance matrices of multiple data sets (ver, Flury, 1986,
1988; Flury & Gautschi, 1986; Pourahmadi, Daniels, & Parque, 2007; Wang,
Banerjee, & Boley, 2011; Parque & Konishi, 2020).
Among such methodologies, common component analysis (CCA; Wang
et al., 2011) is an effective tool for statistics. The central idea of CCA is to
reduce the number of dimensions of data while losing as little information
of the multiple data sets as possible. To reduce the number of dimensions,
CCA reconstructs the data with a few new variables that are linear combi-
nations of the original variables. For considering the heterogeneity between
covariance matrices of multiple data sets, CCA assumes that there is a dif-
ferent covariance matrix for each data set. There have been many papers
on various statistical methodologies using multiple covariance matrices:
Computación neuronal 33, 2853–2880 (2021) © 2021 Instituto de Tecnología de Massachusetts.
https://doi.org/10.1162/neco_a_01425
Publicado bajo Creative Commons
Atribución 4.0 Internacional (CC POR 4.0) licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2854
k. Yoshikawa and S. Kawano
discriminant analysis (Bensmail & Celeux, 1996), spectral decomposition
(Boik, 2002), and a likelihood ratio test for multiple covariance matrices
(Manly & Rayner, 1987). It should be noted that principal component anal-
ysis (PCA) (Pearson, 1901; Jolliffe, 2002) is a technique similar to CCA. En
hecho, CCA is a generalization of PCA; PCA can only be applied to one data
colocar, whereas CCA can be applied to multiple data sets.
Mientras tanto, in various fields of research, including machine learning and
computer vision, the main interest has been in tensor data, which has a mul-
tidimensional array structure. In order to apply the conventional statistical
methodologies, such as PCA, to tensor data, a simple approach is to first
transform the tensor data into vector data and then apply the methodol-
ogia. Sin embargo, such an approach causes the following problems:
1. In losing the tensor structure of the data, the approach ignores the
higher-order inherent relationships of the original tensor data.
2. Transforming tensor data to vector data substantially increases the
number of features. It also has a high computational cost.
To overcome these problems, statistical methodologies for tensor data anal-
yses have been proposed that take the tensor structure of the data into
consideration. Such methods enable us to accurately extract higher-order
inherent relationships in a tensor data set. En particular, many existing statis-
tical methodologies have been extended for tensor data, Por ejemplo, mul-
tilinear principal component analysis (MPCA) (Lu et al., 2008) and sparse
PCA for tensor data analysis (allen, 2012; Wang, Sol, Chen, Angustia, & zhou,
2012; Dejar, Xu, Chen, Cual, & zhang, 2014), as well as others (see Carroll &
Chang, 1970; Harshman, 1970; Kiers, 2000; Badeau & Boyer, 2008; Kolda &
Bader, 2009).
In this letter, we extend CCA to tensor data analysis, proposing multi-
linear common component analysis (MCCA). MCCA discovers the com-
mon structure of multiple data sets of tensor data while losing as little of
the information of the data sets as possible. To identify the common struc-
tura, we estimate a common basis constructed as linear combinations of
the original variables. For estimating the common basis, we develop a new
estimation algorithm based on the idea of CCA. In developing the estima-
tion algorithm, two issues must be addressed: the convergence properties
of the algorithm and its computational cost. To determine the convergence
propiedades, we investigate first the relationship between the initial values
of the parameters and global optimal solution and then the monotonic con-
vergence of the estimation algorithm. These analyses reveal that our pro-
posed algorithm guarantees convergence of the mode-wise global optimal
solution under some conditions. To analyze the computational efficacy, nosotros
calculate the computational cost of our proposed algorithm.
The rest of the letter is organized as follows. En la sección 2, we review
the formulation and the minimization problem of CCA. En la sección 3, nosotros
formulate the MCCA model by constructing the covariance matrices of
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2855
tensor data, based on a Kronecker product representation. Then we for-
mulate the estimation algorithm for MCCA in section 4. En la sección 5, nosotros
present the theoretical properties for our proposed algorithm and ana-
lyze the computational cost. The efficacy of the MCCA is demonstrated
through numerical experiments in section 6. Concluding remarks are pre-
sented in section 7. Technical proofs are provided in the appendixes. Nuestro
implementation of MCCA and supplementary materials are available at
https://github.com/yoshikawa-kohei/MCCA.
2 Common Component Analysis
, . . . X(gramo)Ng](cid:2) ∈ RNg×P with
Suppose that we obtain data matrices X(gramo)
Ng observations and P variables for g = 1, . . . , GRAMO, where x(gramo)i is the P-
dimensional vector corresponding to the ith row of X(gramo) and G is the number
of data sets. Then the sample covariance matrix in group g is
= [X(gramo)1
S(gramo)
= 1
Ng
Ng(cid:2)
yo=1
(cid:3)
X(gramo)i
− ¯x(gramo)
(cid:4) (cid:3)
X(gramo)i
− ¯x(gramo)
(cid:4)(cid:2) ,
g = 1, . . . , GRAMO,
(2.1)
∈ SP
where S(gramo)
ces of size P × P, and ¯x(gramo)
group g.
+, in which SP
= 1
Ng
(cid:5)
+ is a set of symmetric positive-definite matri-
Ng
i=1 x(gramo)i is a P-dimensional mean vector in
The main idea of the CCA model is to find the common structure of mul-
tiple data sets by projecting the data onto a common lower-dimensional
space with the same basis as the data sets. Wang et al. (2011) assumed that
the covariance matrices S(gramo) for g = 1, . . . , G can be decomposed to a prod-
uct of latent covariance matrices and an orthogonal matrix for the linear
transformation as
S(gramo)
= V(cid:2)
(gramo)V
(cid:2) + mi(gramo)
,
(cid:2)
s.t. V
V = IR,
(2.2)
(cid:7)
(gramo)
∈ SP
∈ SR
(cid:6)
mi(gramo)i
+ is the latent covariance matrix in group g, V ∈ RP×R is an
dónde (cid:2)
orthogonal matrix for the linear transformation, mi(gramo)
+ is the error matrix
in group g, and IR is the identity matrix of size R × R. mi(gramo) consists of the sum
of outer products for independent random vectors
(gramo)i with mean
(> O) (i = 1, 2, . . . , Ng). V de-
mi
termines the R-dimensional common subspace of the multiple data sets. En
particular, by assuming R < P, the CCA can discover the latent structures
of the data sets. Wang et al. (2011) referred to the model, equation 2.2, as
common component analysis (CCA).
The parameters V and (cid:2)
(g) (g = 1, . . . , G) are estimated by solving the
= 0 and covariance matrix Cov
i=1 e(g)ie(cid:2)
(cid:6)
e(g)i
(cid:5)
Ng
(cid:7)
minimization problem,
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
n
e
c
o
_
a
_
0
1
4
2
5
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2856
K. Yoshikawa and S. Kawano
G(cid:2)
g=1
min
V,(cid:2)
(g)
g=1,...,G
(cid:4)S(g)
− V(cid:2)
(g)V
(cid:2)(cid:4)2
F
,
(cid:2)
s.t. V
V = IR,
(2.3)
where (cid:4) · (cid:4)F denotes the Frobenius norm. The estimator of latent covari-
ance matrices (cid:2)
(g) for g = 1, . . . , G can be obtained by solving the mini-
= V(cid:2)S(g)V. By using the estimated value ˆ(cid:2)
mization problem as ˆ(cid:2)
(g), the
minimization problem can be reformulated as the following maximization
problem:
(g)
⎧
⎨
(cid:2)
⎩V
G(cid:2)
(cid:3)
g=1
max
V
tr
(cid:2)
S(g)VV
S(g)
(cid:4)
⎫
⎬
,
V
⎭
(cid:2)
s.t. V
V = IR,
(2.4)
where tr(·) denotes the trace of a matrix. A crucial issue for solving the
maximization problem 2.4 is the nonconvexity. Certainly the maximization
problem is nonconvex since the problem is defined on a set of orthogonal
matrices, which is a nonconvex set. Generally it is difficult to find the global
optimal solution in nonconvex optimization problems. To overcome this
drawback, Wang et al. (2011) proposed an estimation algorithm in which
the estimated parameters are guaranteed to constitute the global optimal
solution under some conditions.
3 Multilinear Common Component Analysis
In this section, we introduce a mathematical formulation of the MCCA, an
extension of the CCA in terms of tensor data analysis. Moreover, we for-
mulate an optimization problem of MCCA and investigate its convergence
properties.
Suppose that we independently obtain Mth order tensor data X
×...×PM for i = 1, . . . Ng. We set the data sets of the tensors X
×P2
, X
∈
RP1
=
×···×PM×Ng for g = 1, . . . , G, where G is the
[X
number of data sets. Then the sample covariance matrix in group g for the
tensor data set is defined by
(g)Ng] ∈ RP1
, . . . , X
×P2
(g)1
(g)2
(g)i
(g)
S
∗
(g) := S(1)
(g)
⊗ S(2)
(g)
⊗ · · · ⊗ S(M)
(g)
,
(3.1)
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
n
e
c
o
_
a
_
0
1
4
2
5
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
(cid:14)
+, in which P =
∈ SPk
k=1 Pk, ⊗ denotes the Kronecker product op-
+ is the sample covariance matrix for kth mode in group
M
∈ SP
where S∗
(g)
erator, and S(k)
(g)
g defined by
S(k)
(g) :=
1
(cid:14)
j(cid:7)=k Pj
Ng
(cid:15)
X(k)
(g)i
Ng(cid:2)
i=1
(cid:16) (cid:15)
− ¯X(k)
(g)
X(k)
(g)i
− ¯X(k)
(g)
(cid:16)(cid:2)
.
(3.2)
Multilinear Common Component Analysis
2857
(cid:14)
×(
(cid:14)
(g)
∈
×(
¯X
∈ RPk
= 1
Ng
j(cid:7)=k Pj ) is the mode-k unfolded matrix of X
(cid:5)
Here, X(k)
(g)i, and ¯X(k)
(g)i
(g)
(cid:14)
×(
Ng
RPk
j(cid:7)=k Pj ) is the mode-k unfolded matrix of
i=1
that the mode-k unfolding from an Mth order tensor X ∈ RP1
a matrix X(k) ∈ RPk
j(cid:7)=k Pj ) means that the tensor element (p1
maps to matrix element (pk
(cid:14)
t−1
, p2
m=1,m(cid:7)=k Pm, in which p1
(g)i. Note
×···×PM to
, . . . , pM)
t=1,t(cid:7)=k(pt − 1)Lt with Lt =
, l), where l = 1 +
, . . . , pM denote the indices of the Mth order
tensor X . For a more detailed description of tensor operations, see Kolda
and Bader (2009). A representation of the tensor covariance matrix by Kro-
necker products is often used (Kermoal, Schumacher, Pedersen, Mogensen,
& Frederiksen, 2002; Yu et al., 2004; Werner, Jansson, & Stoica, 2008).
X
×P2
, p2
(cid:5)
M
To formulate CCA in terms of tensor data analysis, we consider CCA for
the kth mode covariance matrix in group g as follows,
S(k)
(g)
= V(k)(cid:2)(k)
(g)V(k)
(cid:2)
+ E(k)
(g)
,
s.t. V(k)
(cid:2)
V(k) = IRk
,
(3.3)
∈ SRk
×Rk is an orthogonal matrix for the linear transformation, and E(k)
(g)
where (cid:2)(k)
+ is the latent kth mode covariance matrix in group g, V(k) ∈
(g)
RPk
∈ SPk
+
is the error matrix in group g. E(k)
(g) consists of the sum of outer products
(cid:5)
= 0 and
with mean E
for independent random vectors
Ng
(cid:18)
(cid:2)
i=1 e(k)
(> oh) (i = 1, 2, . . . , Ng). Since S∗
(gramo)i
(gramo)ie(k)
(cid:17)
mi(k)
(gramo)i
(gramo) can be de-
(gramo) for k = 1, . . . , M in formula 3.1, nosotros
covariance matrix Cov
composed to a Kronecker product of S(k)
obtain the following model,
(cid:17)
mi(k)
(gramo)i
(cid:18)
S
∗
(gramo)
= V
∗(cid:2)∗
(gramo)V
∗(cid:2) + mi
,
∗
(gramo)
s.t. V
∗(cid:2)
∗ = IR,
V
(3.4)
(cid:14)
where R =
⊗ (cid:2)(METRO)
(gramo) , and E∗
METRO
k=1 Rk, V∗ = V(1) ⊗ V(2) ⊗ · · · ⊗ V(METRO), (cid:2)∗
(gramo) is the error matrix in group g. We refer to this model as
= (cid:2)(1)
(gramo)
⊗ (cid:2)(2)
(gramo)
⊗ · · ·
(gramo)
multilinear common component analysis (MCCA).
To find the R-dimensional common subspace between the multiple ten-
sor data sets, MCCA determines V(1), V(2), . . . , V(METRO). As with CCA, we ob-
tain the estimate of (cid:2)∗
. With respect
to V∗
, we can obtain the estimate by solving the following maximization
problema, which is similar to equation 2.4:
(gramo) for g = 1, . . . , G as ˆ(cid:2)∗
(gramo)V∗
S∗
= V∗(cid:2)
(gramo)
⎧
⎨
⎩V
∗(cid:2)
GRAMO(cid:2)
(cid:15)
S
g=1
máximo
V∗
tr
∗
∗
(gramo)V
∗(cid:2)
V
S
∗
(gramo)
(cid:16)
∗
V
⎫
⎬
⎭
,
s.t. V
∗(cid:2)
∗ = IR.
V
(3.5)
Sin embargo, the number of parameters will be very large when we try to
solve this problem directly, and thus results in a high computational cost.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2858
k. Yoshikawa and S. Kawano
Además, it may not be possible to discover the inherent relationships
among the variables in each mode simply by solving problem 3.5.
To solve the maximization problem efficiently and identify the inherent
relaciones, the maximization problem 3.5 can be decomposed into the
mode-wise maximization problems represented in the following lemma.
Lema 1. An estimate of the parameters V(k) for k = 1, 2, . . . , M in the maxi-
mization problem 3.5 can be obtained by solving the following maximization prob-
lem for each mode:
GRAMO(cid:2)
METRO(cid:19)
máximo
V(k)
k=1,2,…,METRO
g=1
k=1
(cid:20)
V(k)
(cid:2)
tr
S(k)
(gramo)V(k)V(k)
(cid:2)
S(k)
(gramo)V(k)
(cid:21)
,
s.t. V(k)
(cid:2)
V(k) = IRk
.
(3.6)
Sin embargo, we cannot simultaneously solve this problem for V(k), k =
1, 2, . . . , METRO. De este modo, by summarizing the terms unrelated to V(k) in maximiza-
tion problem 3.6, we can obtain the maximization problem for kth mode,
máximo
V(k)
fk(V(k)) = max
V(k)
tr
(cid:20)
V(k)
(cid:2)
METRO(V(k))V(k)
(cid:21)
,
s.t. V(k)
(cid:2)
V(k) = IRk
,
(3.7)
where M(V(k)) =
(cid:5)
GRAMO
g=1
w(−k)
(gramo) S(k)
(gramo)V(k)V(k)
(cid:2)
(gramo), in which w(−k)
S(k)
(gramo)
is given by
w(−k)
(gramo)
=
(cid:20)
V( j)
(cid:2)
tr
(cid:19)
j(cid:7)=k
S( j)
(gramo)V( j)V( j)
(cid:2)
S( j)
(gramo)V( j)
(cid:21)
.
(3.8)
Although an estimate of V(k) can be obtained by solving maximization prob-
lem 3.7, this problem is nonconvex, since V(k) is assumed to be an orthog-
onal matrix. De este modo, the maximization problem has several local maxima.
Sin embargo, by choosing the initial values of parameters in the estimation
near the global optimal solution, we can obtain the global optimal solu-
ción. En la sección 4, we develop not only an estimation algorithm but also an
initialization method for choosing the initial values of the parameters near
the global optimal solution. The initialization method helps guarantee the
convergence of our algorithm to the mode-wise global optimal solution.
4 Estimation
Our estimation algorithm consists of two steps: initializing the parameters
and iteratively updating the parameters. The initialization step gives us the
initial values of the parameters near the global optimal solution for each
mode. Próximo, by iteratively updating the parameters, we can monotonically
increase the value of the objective function 3.7 until convergence.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2859
4.1 Initialization. The first step is to initialize the parameters V(k) para
(cid:21)
(cid:4)
each mode. We define an objective function f (cid:8)
w(−k)
(gramo) S(k)
for k = 1, . . . , METRO, where M
(gramo). Próximo, we adopt a max-
imizer of f (cid:8)
k(V(k)) as initial values of the parameters V(k). To obtain the maxi-
(cid:18)
(cid:17)
w(−k)
mizer, we need an initial value of w(k) =
. The initial
(1)
value for w(k) is obtained by solving the quadratic programming problem,
k(V(k)) = tr
(gramo)S(k)
, . . . , w(−k)
(GRAMO)
, w(−k)
(2)
(cid:3)
I(k)
V(k)
GRAMO
g=1
I(k)
(cid:5)
METRO
=
(cid:20)
V(k)
(cid:2)
(cid:3)
(cid:4)
(cid:2)
w(k)
λ(k)
0
λ(k)
0
(cid:2)
w(k),
mín.
w(k)
s.t. w(k) > 0, w(k)
(cid:2)
(cid:2)
λ(k)
1
λ(k)
1
w(k) = 1,
(4.1)
dónde
λ(k)
0
=
λ(k)
1
=
⎡
⎣
Pk(cid:2)
i=Rk
+1
,
λ(k)
(1)i
Pk(cid:2)
i=Rk
+1
, . . . ,
λ(k)
(2)i
(cid:26)
Pk(cid:2)
yo=1
,
λ(k)
(1)i
Pk(cid:2)
yo=1
, . . . ,
λ(k)
(2)i
Pk(cid:2)
yo=1
⎤
(cid:2)
⎦
λ(k)
(GRAMO)i
,
Pk(cid:2)
i=Rk
+1
(cid:27)(cid:2)
λ(k)
(GRAMO)i
,
(4.2)
in which λ( j)
(gramo)i is the ith largest eigenvalue of S( j)
(gramo)S( j)
(gramo).
0 by maximizing f (cid:8)
Using the initial value of w(k), we can obtain the initial value of the pa-
rameter V(k)
k(V(k)) for each mode. The maximizer consists
of Rk eigenvectors, corresponding to the Rk largest eigenvalues, obtained by
(cid:4)
I(k)
eigenvalue decomposition of M
. The theoretical justification for this
initialization is discussed in section 5.
(cid:3)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
4.2 Iterative Update of Parameters. The second step is to update pa-
rameters V(k) for each mode. We update parameters such that the objective
function fk(V(k)) is maximized. Let V(k)
s be the value of V(k) at step s. Entonces
we solve the surrogate maximization problem,
(cid:20)
V(k)
s+1
(cid:2)
METRO(V(k)
s )V(k)
s+1
(cid:21)
,
(cid:2)
s.t. V(k)
s+1
V(k)
s+1
= IRk
.
(4.3)
tr
máximo
V(k)
s+1
The solution of equation 4.3 consists of Rk eigenvectors, correspondiente
to the Rk largest eigenvalues, obtained by eigenvalue decomposition of
METRO(V(k)
s ). By iteratively updating the parameters, the objective function
fk(V(k)) is monotonically increased, which allows it to be maximized. El
monotonically increasing property is discussed in section 5.
Our estimation procedure comprises the above estimation steps. El
procedure is summarized as algorithm 1.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2860
k. Yoshikawa and S. Kawano
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
5 Teoría
This section presents the theoretical and computational analyses for algo-
ritmo 1. Theoretical analyses consist of two steps. Primero, we prove that the
initial values of parameters obtained in section 4.1 are relatively close to
the global optimal solution. If the initial values are close to the global maxi-
mum, then we can obtain the global optimal solution even if the maximiza-
tion problem is nonconvex. Segundo, we prove that the iterative updates of
the parameters in section 4.2 monotonically increase the value of objective
función 3.7 by solving the surrogate problem 4.3. From the monotonically
increasing property, the estimated parameters always converge at a sta-
tionary point. The combination of these two results enables us to obtain
the mode-wise global optimal solution. In the computational analysis, nosotros
calculate computational cost for MCCA and then compare the cost with
conventional methods. By comparing the costs, we investigate the compu-
tational efficacy of MCCA.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2861
5.1 Analysis of Upper and Lower Bounds. This section aims to pro-
vide the upper and lower bounds of the maximization problem 3.7. De
the bounds, we find that the initial values in section 4.1 are relatively close
to the global optimal solution. Before providing the bounds, we define a
contraction ratio.
Definición 1. Dejar
I(k)
tr
be the global maximum of
. Then a contraction ratio of data for kth mode is defined by
(cid:28)
METRO
(cid:4)(cid:29)
(cid:3)
F (cid:8) máximo
k
F (cid:8)
k(V(k)) y M(k) =
a(k) = f (cid:8) máximo
k
METRO(k)
tr
=
(cid:3)
(cid:2)
(cid:20)
V(k)
0
(cid:28)
METRO
tr
METRO
(cid:3)
I(k)
I(k)
V(k)
0
(cid:4)
(cid:4)(cid:29)
(cid:21)
.
(5.1)
Note that a contraction ratio α(k) satisfies 0 ≤ α(k) ≤ 1 and α(k) = 1 si y
only if Rk
= Pk.
Using f (cid:8) máximo
and the contraction ratio α(k), we have the following theo-
rem that reveals the upper and lower bounds of the global maximum in
problema 3.7.
k
Teorema 1. Let f max
k
be the global maximum of fk(V(k)). Entonces
a(k) F
(cid:8) máximo
k
≤ f max
k
≤ f
(cid:8) máximo
k
,
donde α(k) is the contraction ratio defined in equation 5.1 yf (cid:8) máximo
maximum of f (cid:8)
k
k(V(k)).
(5.2)
is the global
k
→ f max
0 and w(k), V(k)
This theorem indicates that f (cid:8) máximo
k when α(k) → 1. De este modo, soy yo-
portant to obtain an α(k) that is as close as possible to one. Since α(k) depends
on V(k)
0 depends on w(k). From this dependency, if we could set
the initial value of w(k) such that α(k) is as large as possible, then we could
obtain an initial value of V(k)
. The following
0
theorem shows that we can compute the initial value of w(k) such that α(k)
is maximized.
Teorema 2. Let λ(k)
be the vectors consisting of eigenvalues defined
0
(k = 1, 2, . . . , METRO), suppose
in equation 4.2. For w(k) =
that the estimate ˆw(k) is obtained by solving equation 4.1 for k = 1, 2, . . . , METRO. Entonces
ˆw(k) maximizes α(k).
that attains a value near f max
and λ(k)
(cid:17)
1
w(−k)
(1)
, . . . , w(−k)
(GRAMO)
, w(−k)
(2)
(cid:18)
k
De hecho, a(k) is very close to one with the initial values given in theorem 2
even if Rk is small. This resembles the cumulative contribution ratio in PCA.
5.2 Convergence Analysis. We next verify that our proposed pro-
cedure for iteratively updating parameters maximizes the optimization
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2862
k. Yoshikawa and S. Kawano
problema 3.7. In algorithm 1, the parameter V(k)
s+1 can be obtained by solving
the surrogate maximization problem 4.3. Teorema 3 shows that we can
monotonically increase the value of the function fk(V(k)) in equation 3.7 por
algoritmo 1.
Teorema 3. Let V(k)
valores, obtained by eigenvalue decomposition of M(V(k)
s+1 be Rk eigenvectors, corresponding to the Rk largest eigen-
s ). Entonces
fk(V(k)
s ) ≤ fk(V(k)
s+1).
(5.3)
From theorem 1, we obtain initial values of the parameters that are near
the global optimal solution. By combining theorems 1 y 3, the solution
from algorithm 1 can be characterized by the following corollary.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
Corolario 1. Consider the maximization problem 3.7. Suppose that the initial
value of the parameter is obtained by V(k)
(V(k)), and the parameter
0
(cid:30)
fk
(cid:8)
= arg máx
V(k)
V(k)
is repeatedly updated by algorithm 1. Then the mode-wise global maximum
s
for the maximization problem 3.7 is achieved when all the contraction ratios α(k)
for k = 1, 2, . . . , M go to one.
Algoritmo 1 does not guarantee the global solution due to the fundamen-
tal problem of nonconvexity, but it is enough for pragmatic purposes. Nosotros
investigate the issue of convergence to global solution through numerical
studies in section 6.3.
5.3 Computational Analysis. Primero, we analyze the computational cost.
Pj for j = 1, 2, . . . , METRO. Este
To simplify the analysis, we assume P = arg max
j
implies that P is the upper bound of R j for all j. We then calculate the upper
bound of the computational complexity.
The expensive computations of the each iteration in algorithm 1 estafa-
sist of three parts: the formulation of M(V(k)
s ), the eigenvalue decomposi-
tion of M(V(k)
s ), and updating latent covariance matrices (cid:2)(k)
gramo . These steps
are O(GM2P3), oh(P3), and O(GMP3), respectivamente. The total computational
complexity per iteration is then O(GM2P3).
Próximo, we analyze the memory requirement of algorithm 1. MCCA repre-
sents the original tensor data with fewer parameters by projecting the data
× Rk projection matri-
onto a lower-dimensional space. This requires the Pk
(cid:16)
ces V(k) for k = 1, 2, . . . , METRO. MCCA projects the data with size of N
METRO
k=1 Pk
(cid:5)
GRAMO
to N
g=1 Ng. De este modo, the required size for the pa-
(cid:15)(cid:14)
METRO
k=1 Rk
(cid:16)
, where N =
METRO
k=1 PkRk
. MPCA requires the same amount of
(cid:15)(cid:14)
METRO
k=1 Rk
(cid:5)
rameters is
+ norte
(cid:15)(cid:14)
(cid:16)
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2863
Mesa 1: Comparisons of the Computational Complexity and the Memory
Requirement.
Método
Computational Complexity
PCA
CCA
MPCA
MCCA
oh(P3M )
oh(GP3M )
oh(NMPM+1 )
oh(GM2P3 )
Memory Reqirement
(cid:15)(cid:14)
(cid:15)(cid:14)
R
R
(cid:16)
METRO
k=1 Pk
METRO
k=1 Pk
+ NR
(cid:16)
+ NR
(cid:15)(cid:14)
METRO
k=1 PkRk
METRO
k=1 PkRk
+ norte
+ norte
(cid:15)(cid:14)
METRO
k=1 Rk
METRO
k=1 Rk
(cid:5)
(cid:5)
(cid:16)
(cid:16)
memory as MCCA. Mientras tanto, CCA and PCA need a projection matrix,
. The required size for the parameters is then
(cid:16)
(cid:15)(cid:14)
METRO
k=1 Pk
which is size R
(cid:16)
(cid:15)(cid:14)
METRO
k=1 Pk
R
+ NR.
To compare the computational cost clearly, the upper bounds of compu-
tational complexity and the memory requirement are summarized in Table
1. Mesa 1 shows that the computational complexity of MCCA is superior
to that of the other algorithms and the complexity of MCCA is not limited
by sample size. A diferencia de, the MPCA algorithm is affected by the sample
tamaño (Lu, Plataniotis, & Venetsanopoulos, 2008). Además, MCCA and
MPCA require a large amount of memory when the number of modes in
a data set is large, but their memory requirements are much smaller than
those of PCA and CCA.
6 Experimento
To demonstrate the efficacy of MCCA, we applied MCCA, PCA, CCA, y
MPCA to image compression tasks.
6.1 Experimental Setting. For the experiments, we prepared the follow-
ing three image data sets:
MNIST data set consists of data of handwritten digits 0, 1, . . . , 9 at im-
age sizes of 28 × 28 píxeles. The data set includes a training data set
de 60,000 images and a test data set of 10,000 images. We used the
primero 10 training images of the data set for each group. The MNIST
data set (Lecun, Bottou, bengio, & Haffner, 1998) is available at http:
//yann.lecun.com/exdb/mnist/.
AT&t (ORL) face data set contains gray-scale facial images of 40 gente.
The data set has 10 images sized 92 × 112 pixels for each person. Nosotros
used images resized by a factor of 0.5 to improve the efficiency of the
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2864
k. Yoshikawa and S. Kawano
Mesa 2: Summary of the Data Sets.
Data Set
MNIST
AT&t(ORL)
Cropped AR
Group
Size
Sample Size
(/Group)
Número de
Dimensions
Número
of Groups
Pequeño
Pequeño
Medium
Large
Pequeño
Medium
Large
10
10
14
28 × 28 = 784
46 × 56 = 2576
30 × 41 × 3 = 7380
10
10
20
40
10
25
50
experimento. The AT&T face data set is available at https://git-disl.
github.io/GTDLBench/datasets/att_face_dataset/. All the credits of
this data set go to AT&T Laboratories Cambridge.
Cropped AR database has color facial images of 100 gente. These im-
ages are cropped around the face. The size of images is 120 × 165 × 3
píxeles. The data set contains 26 images in each group, 12 of which
are images of people wearing sunglasses or scarves. We used the
cropped facial images of 50 males who were not wearing sunglasses
or scarves. Due to memory limitations, we resized these images by
a factor of 0.25. The AR database (Martinez & Benavente, 1998; Mar-
tinez & Kak, 2001) is available at http://www2.ece.ohio-state.edu/∼
aleix/ARdatabase.html.
The data set characteristics are summarized in Table 2.
To compress these images, we performed dimensionality reductions by
MCCA, PCA, CCA, and MPCA, como sigue. We vectorized the tensor data
set before performing PCA and CCA. In MCCA, the images were com-
pressed and reconstructed according to the following steps:
1. Prepare the multiple image data sets X
∈ RP1
×P2
×···×PM×Ng for g =
(gramo)
1, 2, . . . , GRAMO.
(gramo) for g = 1, 2, . . . , GRAMO.
2. Compute the covariance matrix of X
3. From these covariance matrices, compute the linear transforma-
for i = 1, 2, . . . , M for mapping to the
×Ri
, . . . , RM)-dimensional latent space.
· · · ×M VM ∈
(gramo)i
is the i-mode product of
to X
×···×RM , where the operator ×
i
tion matrices Vi
(R1
, R2
4. Map the
ith sample X
∈ RPi
1 V1
2 V2
×R2
×
×
(gramo)i
RR1
tensor (Kolda & Bader, 2009).
5. Reconstruct ith sample ˜X
= X
×
1 V1V(cid:2)
1
(gramo)i
×
2 V2V(cid:2)
2
· · · ×M VMV(cid:2)
METRO.
(gramo)i
Mientras tanto, PCA and MPCA each require a single data set. De este modo, we ag-
gregated the data sets as X = [X
g=1 Ng and
performed PCA and MPCA for data set X .
(GRAMO)] ∈ RP1
, . . . , X
×···×PM×
, X
×P2
(2)
(1)
(cid:5)
GRAMO
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2865
6.2 Performance Assessment. For MCCA and MPCA, the reduced di-
mensions R1 and R2 were chosen as the same number, and then we fixed
R3 as two. All computations were performed by the software R (versión 3.6)
(R Core Team, 2019). In the initialization of MCCA, solving the quadratic
programming problem was carried out using the function ipop in the pack-
age kernlab. MPCA was implemented as the function mpca in the package
rTensor. (The implementations of MCCA, PCA, and CCA are available at
https://github.com/yoshikawa-kohei/MCCA.)
To assess their performances, we calculated the reconstruction error rate
(RER) under the same compression ratio (CR). RER is defined by
RER =
(cid:31)
(cid:31)
(cid:31)2
(cid:31)X − (cid:30)X
F
(cid:4)X (cid:4)2
F
,
(6.1)
, (cid:30)X
(cid:30)X = [
(cid:30)X
(gramo)
dónde
tensors
(gramo)2
norm of a tensor X ∈ RP1
(cid:30)X
(1)
= [ ˜X
, . . . , (cid:30)X
(2)
, ˜X
(gramo)1
, . . . , ˜X
×P2
(GRAMO)] is the aggregated data set of reconstructed
(gramo)Ng] for g = 1, 2, . . . , G and (cid:4)X (cid:4)F is the
×···×PM computed by
(cid:4)X (cid:4)F =
!
!
!
»
P1(cid:2)
P2(cid:2)
PM(cid:2)
· · ·
=1
p1
=1
p2
pM=1
x2
p1
,p2
,…,pM
,
(6.2)
in which xp1
fined CR as
,p2
,…,pM is an element (p1
, p2
, . . . , pM) of X . Además, we de-
CR =
{The number of required parameters}
(cid:14)
METRO
k=1 Pk
N ·
.
(6.3)
(cid:5)
METRO
k=1 PkRk
+
(cid:16)
(cid:15)(cid:14)
METRO
k=1 Pk
+ NR.
The number of required parameters for MCCA and MPCA is
(cid:16)
(cid:15)(cid:14)
METRO
k=1 Rk
norte
, whereas that for CCA and PCA is R
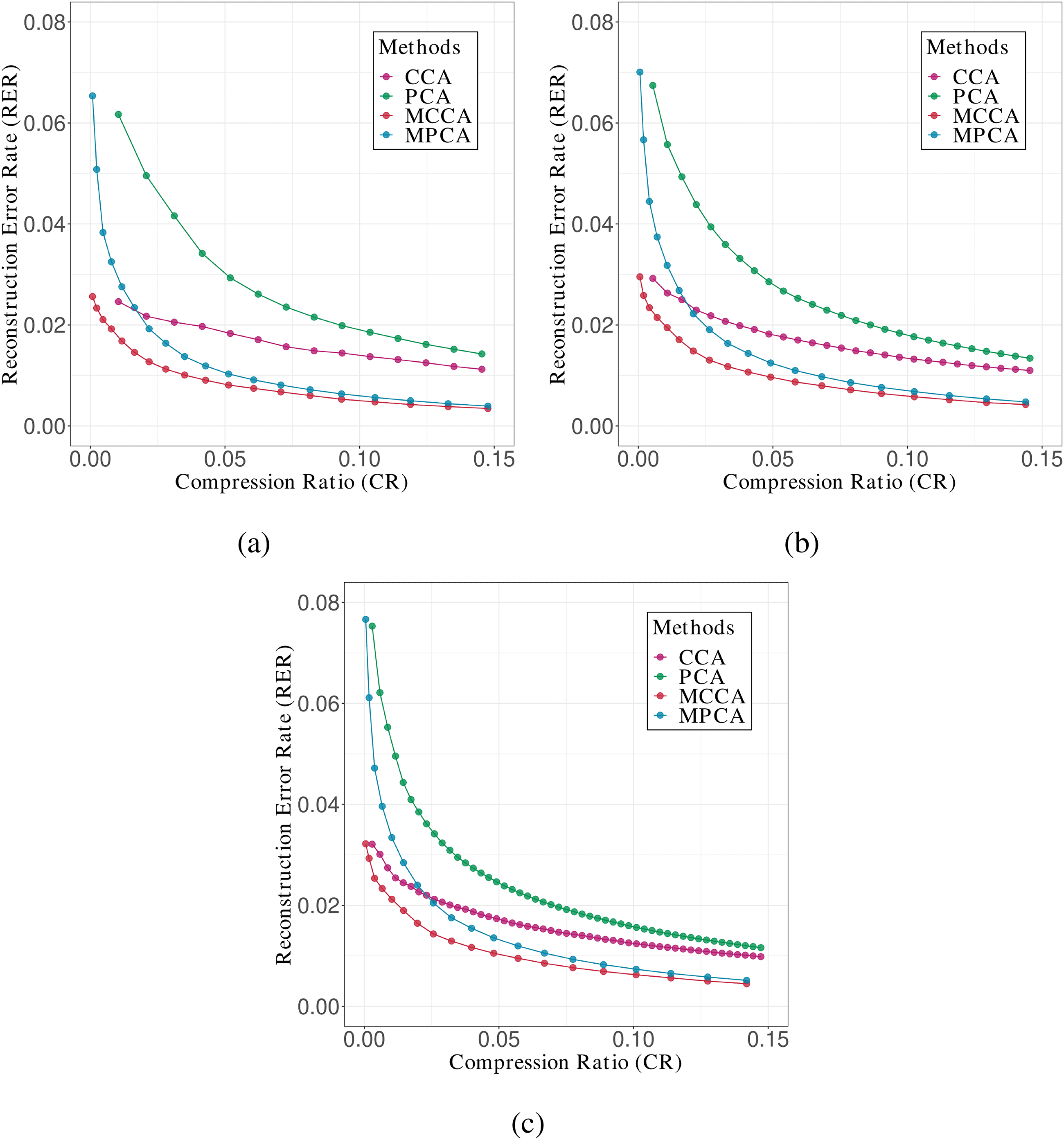
Cifra 1 plots the RER obtained by estimating various reduced dimen-
sions for the AT&t(ORL) data set with group sizes of small, medio, y
grande. As the figures for the results of the other data sets were similar to
Cifra 1, we show them in the supplementary materials S1.
From Figure 1, we observe that the RER material MCCA is the smallest
for any value of CR. This indicates that MCCA performs better than the
other methods. Además, note that CCA performs better than MPCA only
for fairly small values of CR, even though it is a method for vector data,
whereas MPCA performs better for larger values of CR. This implies the
limitations of CCA for vector data.
Next we consider group size by comparing panels a, b, and c in Figure 1.
The value of CR at the intersection of CCA and MPCA increases with
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2866
k. Yoshikawa and S. Kawano
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
Cifra 1: Plots of RER versus CR for the AT&t(ORL) data set of various group
sizes: (a) pequeño, (b) medio, y (C) grande.
increasing the group size. This indicates that MPCA has more trouble ex-
tracting an appropriate latent space as the group size increases. Since MPCA
does not consider the group structure, it is not possible to properly estimate
the covariance structure when the group size is large.
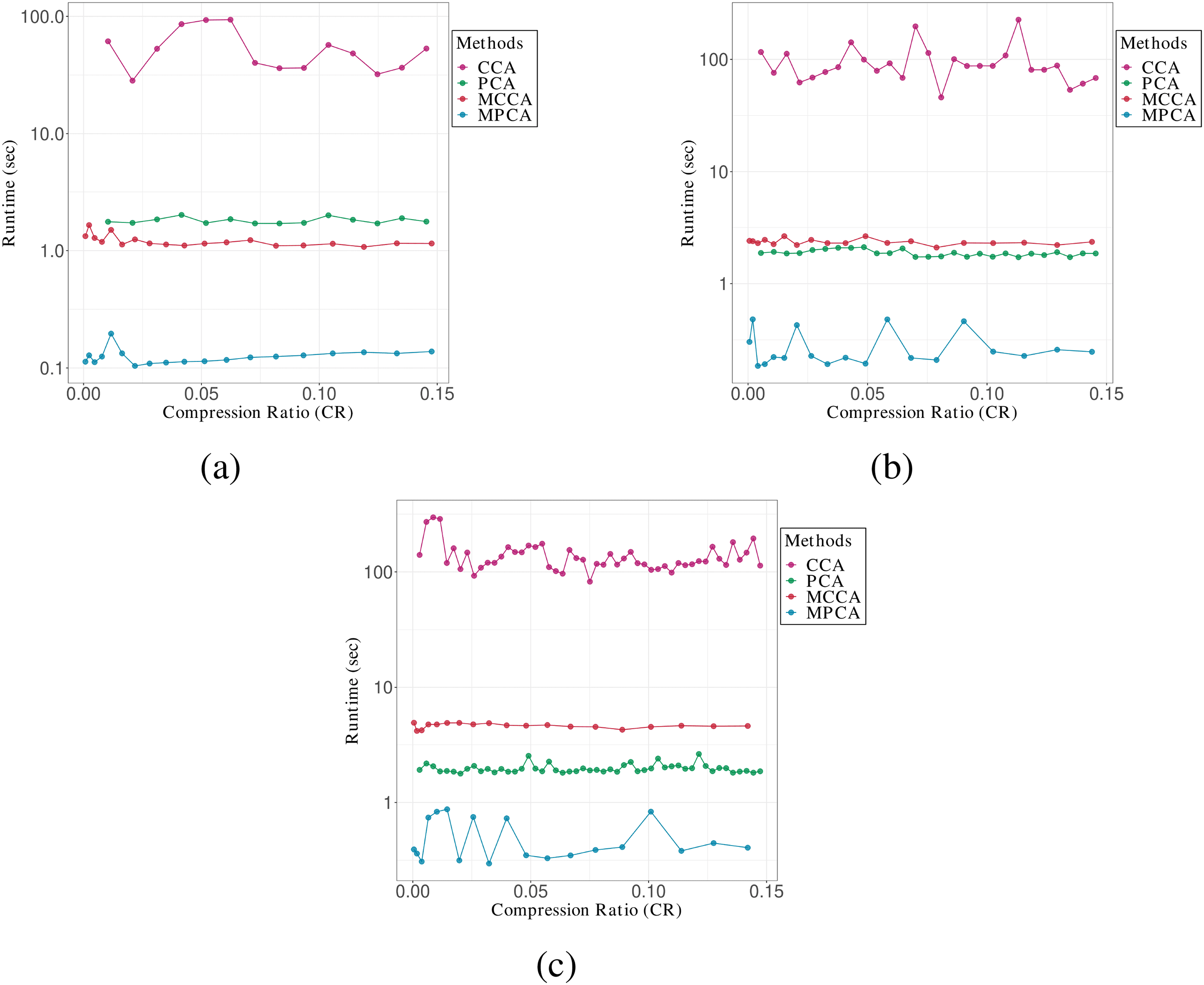
Cifra 2 shows the comparison of runtime for the AT&t(ORL) data set
with group sizes of small, medio, y largo. Although Table 1 gives the
superiority of the computational complexity for MCCA, Cifra 2 muestra
that MCCA is slower than MPCA for any size of data set. This probably
arises from the difference of implementation of MCCA and MPCA: MCCA
is implemented by our hand-built source code, while MPCA is done by
the package rTensor. But when we compare MCCA with CCA, MCCA is
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2867
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2: Plots of runtime versus CR for the AT&t(ORL) data set of various
group sizes: (a) pequeño, (b) medio, y (C) grande.
superior to CCA in terms of both computational complexity and the run-
time comparisons.
Cifra 3 plots the reconstructed images for the AT&t(ORL) data set with
group sizes of the medium. This figure can be obtained by performing four
= 5 and R = 2. By setting the number
methodologies when we set R1
of the ranks in this way, we can compare the images with almost the same
CR, PCA, CCA, and MPCA can recover the average structure of face images,
but they cannot deal with changes in the angle of the face. MCCA can also
recover the detailed differences in each image.
= R2
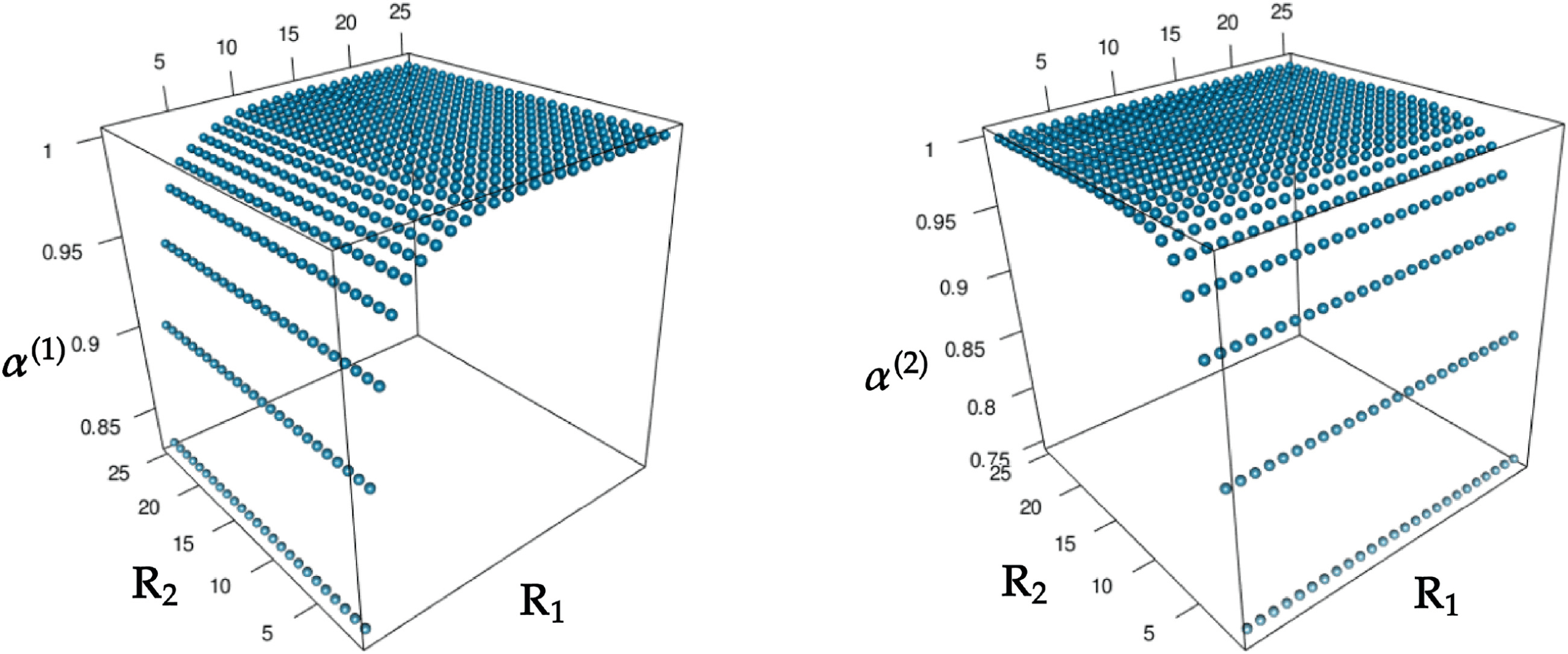
6.3 Behavior of Contraction Ratio. We examined the behavior of con-
traction ratio α(k). We performed MCCA on the AT&t(ORL) data set with
the medium group size and computed α(1) and α(2) with the various pairs
of reduced dimensions (R1
, R2) ∈ {1, 2, . . . , 25} × {1, 2, . . . , 25}.
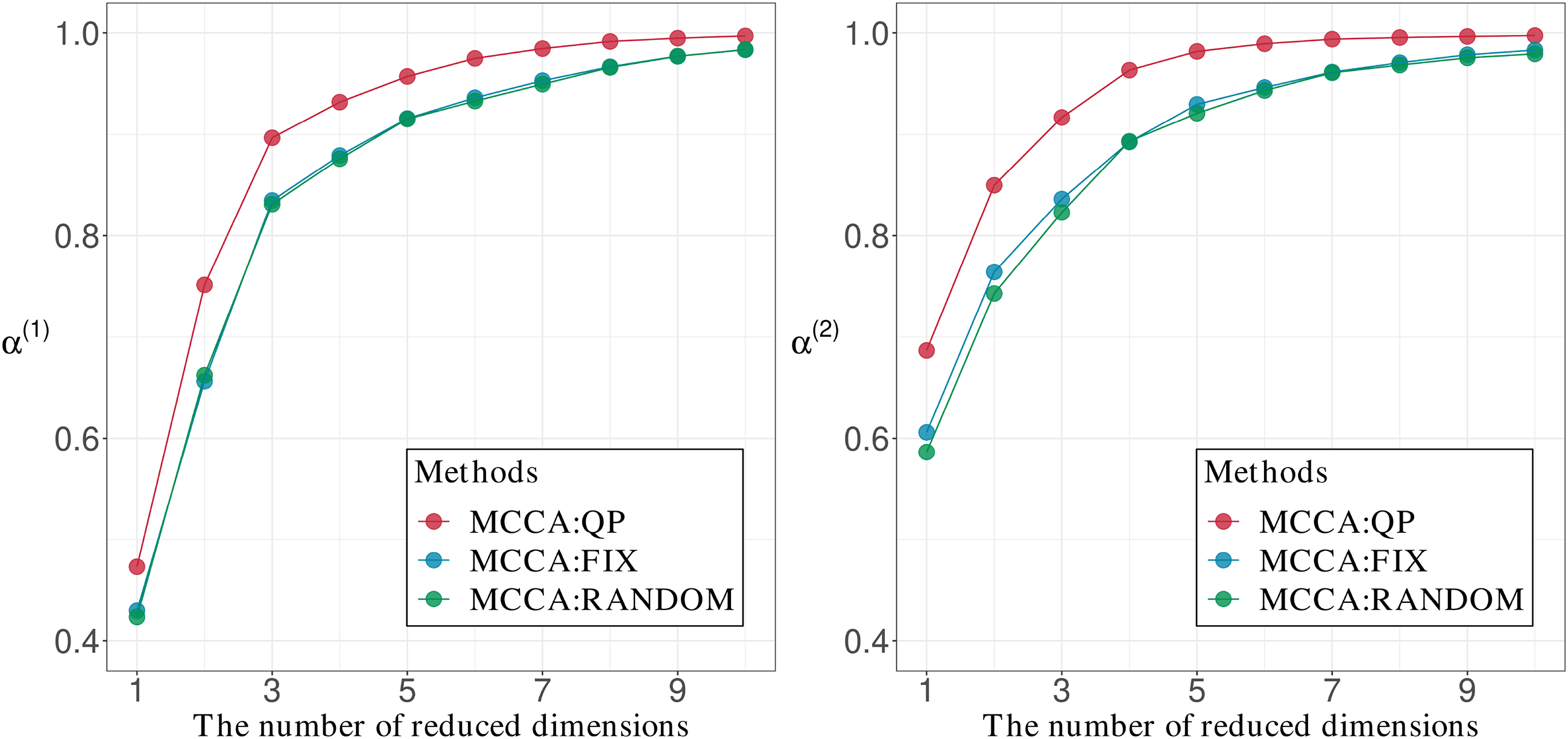
Cifra 4 shows the values of α(1) and α(2) for all pairs of R1 and R2. Como
mostrado, a(1) and α(2) were invariant to variations in R2 and R1, respectivamente.
Por lo tanto, to facilitate visualization of changes in α(k), we draw Figure 5,
2868
k. Yoshikawa and S. Kawano
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
Cifra 3: The reconstructed images for the AT&t(ORL) data set with the
medium group sizes under almost
the same CR. Image source: AT&t
Laboratories Cambridge.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4: a(1) and α(2) versus pairs of reduced dimensions (R1
, R2).
which represents α(1) and α(2) para, respectivamente, R2
= 1. De
estos, we observe that when both R1 and R2 are greater than eight, ambos
a(1) and α(2) are close to one.
= 1 and R1
6.4 Efficacy of Solving the Quadratic Programming Problem. We in-
vestigated the usefulness of determining the initial value of w(k) by solv-
ing the quadratic programming problem 4.1. We applied MCCA to the
Multilinear Common Component Analysis
2869
Cifra 5: a(1) and α(2) versus R1 and R2, respectivamente.
AT&t(ORL) data set with the small, medio, and large number of groups.
Además, we used the smaller group size of three. For determining
the initial value of w(k), we consider three methods: solving the quadratic
programming problem 4.1 (MCCA:QP); setting all values of w(k) to one
(MCCA:FIX); and setting the values by random sampling according to the
uniform distribution U(0, 1) (MCCA:RANDOM). We computed the α(k)
= R2 (∈ {1, 2, . . . , 10}) for each of these
with the reduced dimensions R1
methods.
To evaluate the performance of these methods, we compared the val-
ues of α(k) and the number of iterations in the estimation. The number of
iterations in the estimation is the number of repetitions of lines 7 a 9 in al-
gorithm 1. For MCCA(RANDOM), we performed 50 trials and calculated
averages of each of these indices.
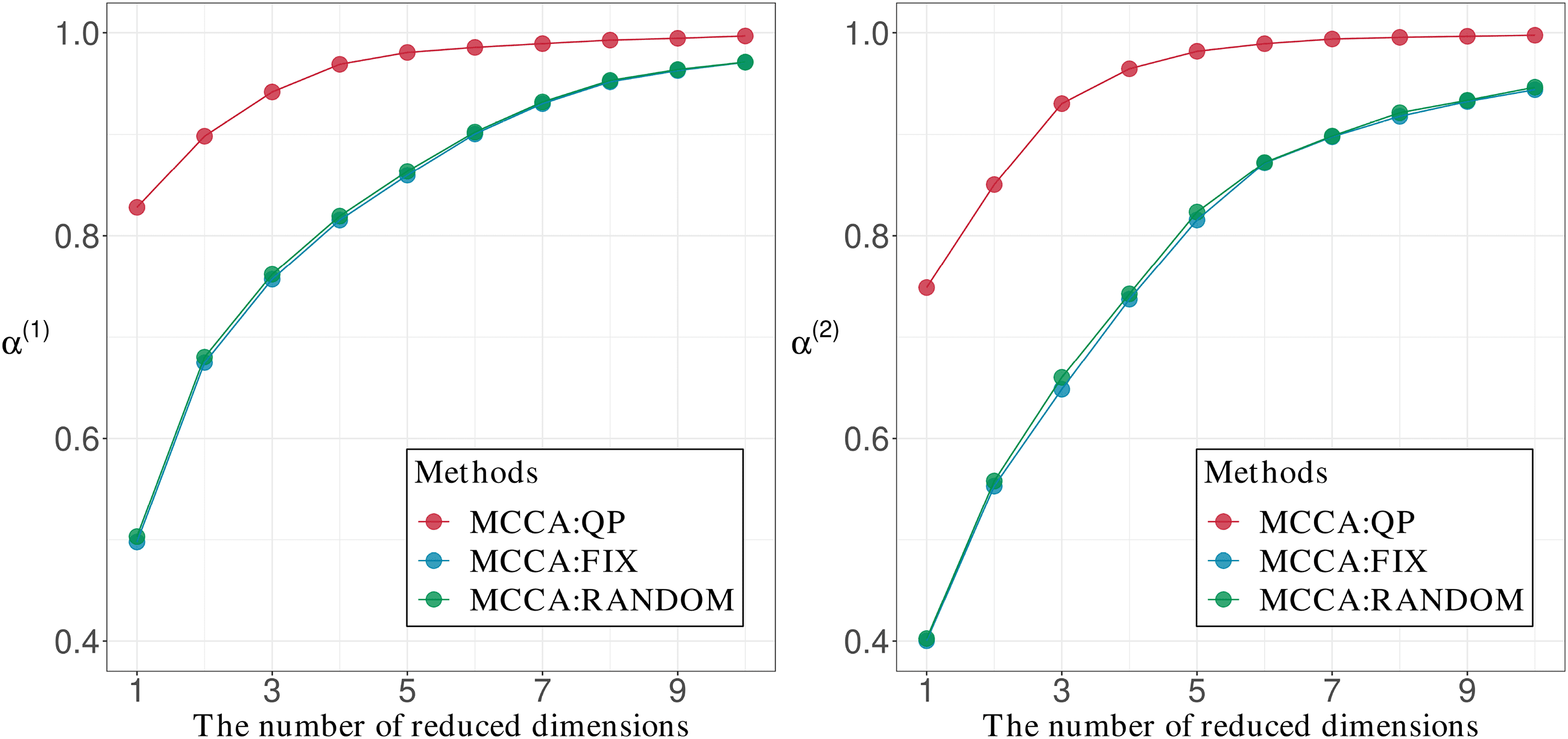
Cifra 6 shows the comparisons of α(1) and α(2) when the initializa-
tion was performed by MCCA:QP, MCCA:FIX, and MCCA:RANDOM for
the AT&t(ORL) data set with a group size of three. It was confirmed that
MCCA:QP provides the largest values of α(1) and α(2). Cifra 7 shows the
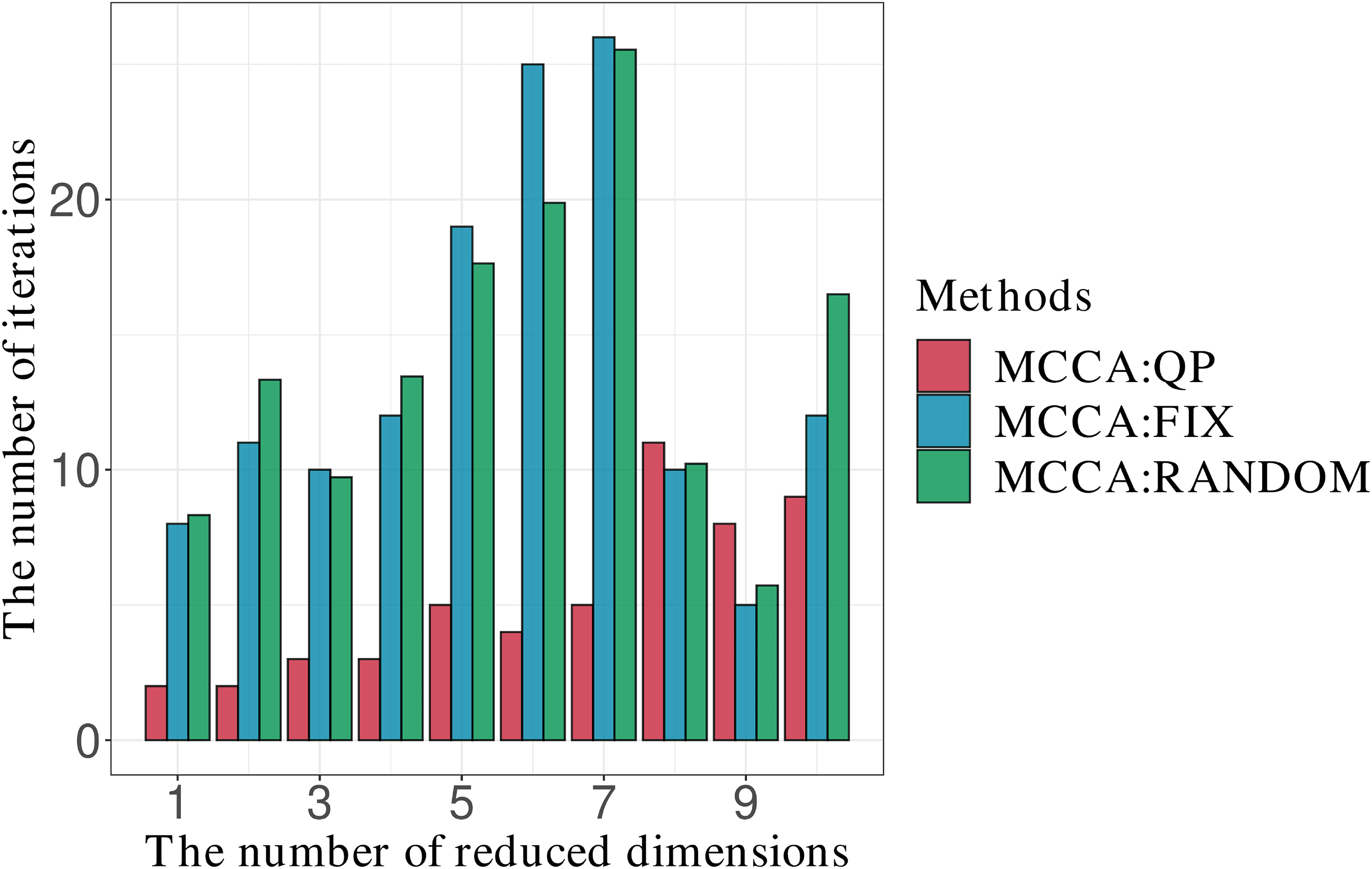
number of iterations. MCCA:QP gives the smallest number of iterations
for almost all values of the reduced dimensions. This result indicates that
MCCA:QP converges to a solution faster than the other initialization meth-
probabilidades. Sin embargo, when the reduced dimension is greater than or equal to eight,
the other methods are competitive with MCCA:QP. A lack of difference in
the number of iterations could result from the closeness of the initial values
and the global optimal solution. Note that when the R1 and R2 are greater
than or equal to eight, a(1) and α(2) are sufficiently close to one, Residencia en
Cifra 6. This indicates that the initial values are close to the global optimal
solution obtained from theorem 1. Por eso, the result shows almost the same
number of iterations for the three methods.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2870
k. Yoshikawa and S. Kawano
Cifra 6: Comparisons of α(1) and α(2) computed by using the initial values ob-
tained from the initializations MCCA:QP, MCCA:FIX, and MCCA:RANDOM
with the AT&t(ORL) data set for a group size of three.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 7: Comparison of the number of iterations when the initialization
was performed by MCCA:QP, MCCA:FIX, and MCCA:RANDOM with the
AT&t(ORL) data set for a group size of three.
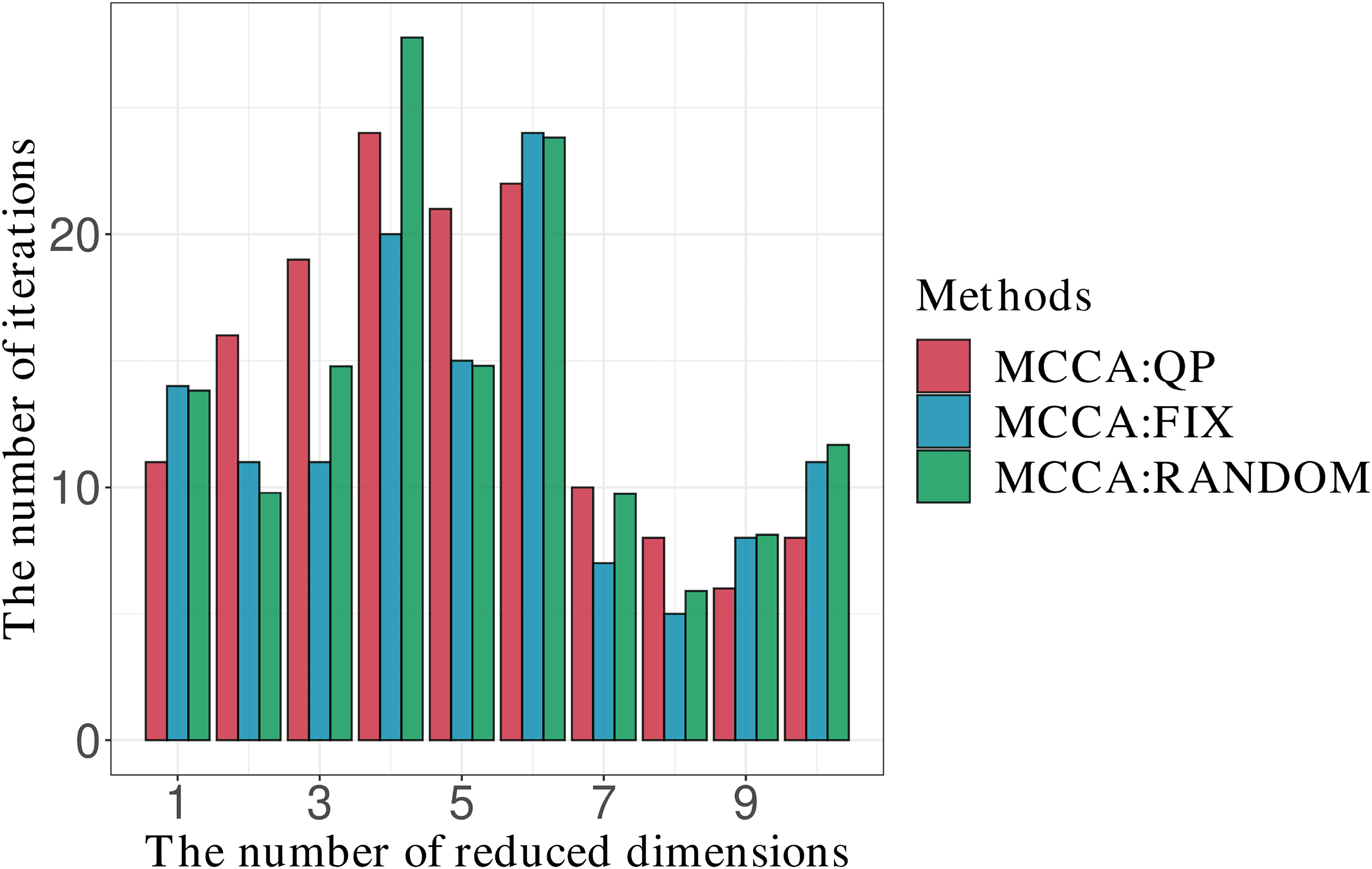
Figures 8 y 9 show comparisons for the AT&t(ORL) data set with the
medium group size. Since the figures for the results of other group sizes are
similar to Figures 8 y 9, we show them in the supplementary materials
S2. Cifra 8 shows results similar those in Figure 6, whereas Figure 9 muestra
competitive performances for all reduced dimensions.
Multilinear Common Component Analysis
2871
Cifra 8: Comparisons of α(1) and α(2) computed using the initial values ob-
tained from the initialization of MCCA:QP, MCCA:FIX, and MCCA:RANDOM
with the AT&t(ORL) data set and the medium group size.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 9: Comparison of the number of iterations when the initialization
was perfomed by MCCA:QP, MCCA:FIX, and MCCA:RANDOM with the
AT&t(ORL) data set and the medium group size.
7 Conclusión
We have developed the multilinear common components analysis (MCCA)
by introducing a covariance structure based on the Kronecker product. A
efficiently solve the nonconvex optimization problem for MCCA, tenemos
2872
k. Yoshikawa and S. Kawano
proposed an iteratively updating algorithm that exhibits some superior the-
oretical convergence properties. Numerical experiments have shown the
usefulness of MCCA.
Específicamente, MCCA was shown to be competitive among the initializa-
tion methods in terms of the number of iterations. As the number of groups
aumenta, the overall number of samples increases. This may be the reason
why all methods required almost the same number of iterations for small,
medio, and large groups. Note that in this study, we used the Kronecker
product representation to estimate the covariance matrix for tensor data
conjuntos. Greenewald, zhou, and Hero (2019) used the Kronecker sum repre-
sentation for estimating the covariance matrix, and it would be interesting
to extend the MCCA to this and other covariance representations.
Apéndice A: Proof of Lemma 1
We provide two basic lemmas about Kronecker products before we prove
lema 1.
Lema 2. For matrices A, B, C, and D such that matrix products AC and BD
can be calculated, the following equation holds:
(A ⊗ B)(C ⊗ D) = AC ⊗ BD.
Lema 3. For square matrices A and B, the following equation holds:
tr(A ⊗ B) = tr(A)tr(B).
These lemmas are known as the mixed-product property and the spec-
trum property, respectivamente. See Harville (1998) for detailed proofs.
Proof of Lemma 1. For the maximization problem 3.5, move the summa-
tion over index g out of the tr(·) and replace S∗
⊗
· · · ⊗ S(METRO)
(gramo) and V∗
(gramo) and V(1) ⊗ V(2) ⊗ · · · ⊗ V(METRO), respectivamente. Entonces
with S(1)
(gramo)
⊗ S(2)
(gramo)
GRAMO(cid:2)
g=1
máximo
V(k)
k=1,2,…,METRO
(cid:15)
#(cid:15)
tr
V(1) ⊗ · · · ⊗ V(METRO)
(cid:16)(cid:2) (cid:15)
S(1)
(gramo)
(cid:16) (cid:15)
(cid:16)
⊗ · · · ⊗ S(METRO)
(gramo)
V(1) ⊗ · · · ⊗ V(METRO)
V(1) ⊗ · · · ⊗ V(METRO)
(cid:16)(cid:2) (cid:15)
S(1)
(gramo)
(cid:16) (cid:15)
(cid:16)$
⊗ · · · ⊗ S(METRO)
(gramo)
V(1) ⊗ · · · ⊗ V(METRO)
,
s.t. V(k)
(cid:2)
V(k) = IRk
.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2873
By lemmas 2 y 3, tenemos
GRAMO(cid:2)
(cid:20)(cid:15)
tr
V(1)
g=1
(cid:2)
S(1)
(gramo)V(1)V(1)
(cid:2)
S(1)
(gramo)V(1)
(cid:16)
máximo
(cid:2)
V(k)
V(k) =IRk
k=1,2,…,METRO
(cid:15)
V(METRO)
(cid:2)
· · ·
S(METRO)
(gramo) V(METRO)V(METRO)
(cid:2)
(cid:16)(cid:21)
S(METRO)
(gramo) V(METRO)
(cid:21)
= max
V(k)
(cid:2)
V(k) =IRk
k=1,2,…,METRO
(cid:20)
V(k)
(cid:2)
tr
S(k)
(gramo)V(k)V(k)
(cid:2)
GRAMO(cid:2)
METRO(cid:19)
g=1
k=1
S(k)
(gramo)V(k)
.
This leads to the maximization problem in lemma 1.
(cid:2)(cid:2)
apéndice B: Proof of Theorem 1
Teorema 1 can be easily shown from the following lemma.
Lema 4. Consider the maximization problem
máximo
V(k)
F
(cid:8)
k(V(k)) = max
V(k)
tr
⎧
⎨
⎩V(k)
⎛
(cid:2)
⎝
GRAMO(cid:2)
g=1
⎞
⎠ V(k)
⎫
⎬
⎭
.
(B.1)
w(−k)
(gramo) S(k)
(gramo)S(k)
(gramo)
Let M(k) = tr
(cid:20)(cid:5)
GRAMO
g=1
w(−k)
(gramo) S(k)
(gramo)S(k)
(gramo)
(cid:21)
. Entonces
F (cid:8)
k(V(k))2
METRO(k)
≤ fk(V(k)) ≤ f
(cid:8)
k(V(k)).
Proof of Lemma 4. Primero, we prove fk(V(k)) ≤ f (cid:8)
onal matrix V(k) ∈ RPk
×(Pk
V(k)
V(k)
k(V(k)). For any orthog-
×Rk , we can always find an orthogonal matrix
(cid:2) +
⊥ = O. Then the equation V(k)V(k)
−Rk ) that satisfies V(k)(cid:2)V(k)
= IPk holds. By definition,
⊥ ∈ RPk
(cid:2)
⊥ V(k)
⊥
fk(V(k)) = tr
≤ tr
⎧
⎨
⎩V(k)
⎧
⎨
⎩V(k)
⎛
(cid:2)
GRAMO(cid:2)
⎝
g=1
⎛
(cid:2)
GRAMO(cid:2)
⎝
g=1
⎞
w(−k)
(gramo) S(k)
(gramo)V(k)V(k)
(cid:2)
S(k)
(gramo)
⎠ V(k)
⎫
⎬
⎭
w(−k)
(gramo) S(k)
(gramo)
(cid:15)
V(k)V(k)
(cid:2)
(cid:16)
(cid:2)
+ V(k)
⊥ V(k)
⊥
⎞
S(k)
(gramo)
⎠ V(k)
⎫
⎬
⎭
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2874
k. Yoshikawa and S. Kawano
⎞
⎠ V(k)
⎫
⎬
⎭
w(−k)
(gramo) S(k)
(gramo)S(k)
(gramo)
⎧
⎨
⎩V(k)
⎛
(cid:2)
GRAMO(cid:2)
⎝
g=1
= tr
= f
(cid:8)
k(V(k)).
De este modo, we have obtained fk(V(k)) ≤ f (cid:8)
k(V(k)).
Próximo, we prove f (cid:8)
k (V(k) )2
METRO(k)
matrices:
≤ fk(V(k)). We define the following block
)*
)*
A =
B =
w(−k)
(1) S(k)
(1)
1
2 V(k)V(k)
(cid:2)
S(k)
(1)
1
2 , . . . ,
*
+
w(−k)
(1) S(k)
(1)
, . . . ,
w(−k)
(GRAMO) S(k)
(GRAMO)
.
*
w(−k)
(GRAMO) S(k)
(GRAMO)
1
2 V(k)V(k)
(cid:2)
S(k)
(GRAMO)
+
1
2
,
Note that since S(k)
decomposed to S(k)
(gramo)
respectivamente:
1
2 S(k)
(gramo)
(gramo) is a symmetric positive-definite matrix, S(k)
(gramo) can be
2 . We calculate the traces of AA, AB, and BB,
1
,
–
w(−k)
(gramo) tr
S(k)
(gramo)
1
2 V(k)V(k)
(cid:2)
S(k)
(gramo)
1
2 S(k)
(gramo)
1
2 V(k)V(k)
(cid:2)
1
2
S(k)
(gramo)
GRAMO(cid:2)
g=1
GRAMO(cid:2)
tr (AA) =
=
w(−k)
(gramo) tr
(cid:20)
(cid:2)
V(k)
S(k)
(gramo)V(k)V(k)
(cid:2)
S(k)
(gramo)V(k)
(cid:21)
g=1
⎧
⎨
⎩V(k)
= tr
⎛
(cid:2)
GRAMO(cid:2)
⎝
g=1
⎞
w(−k)
(gramo) S(k)
(gramo)V(k)V(k)
(cid:2)
S(k)
(gramo)
⎠ V(k)
⎫
⎬
⎭
= fk(V(k)),
tr (AB) =
=
=
GRAMO(cid:2)
g=1
GRAMO(cid:2)
g=1
GRAMO(cid:2)
g=1
S(k)
(gramo)
1
2 V(k)V(k)
(cid:2)
S(k)
(gramo)
1
2 S(k)
(gramo)
–
w(−k)
(gramo) tr
,
,
w(−k)
(gramo) tr
S(k)
(gramo)
1
2 V(k)V(k)
(cid:2)
S(k)
(gramo)
1
2 S(k)
(gramo)
1
2 S(k)
(gramo)
1
2
–
(cid:20)
w(−k)
(gramo) tr
(cid:2)
V(k)
(gramo)S(k)
S(k)
(gramo)V(k)
(cid:21)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2875
⎞
⎠ V(k)
⎫
⎬
⎭
w(−k)
(gramo) S(k)
(gramo)S(k)
(gramo)
⎧
⎨
⎩V(k)
⎛
(cid:2)
GRAMO(cid:2)
⎝
g=1
= tr
= f
(cid:8)
k(V(k)),
tr (BB) = tr
⎛
GRAMO(cid:2)
⎝
g=1
⎞
⎠ = M(k).
w(−k)
(gramo) S(k)
(gramo)S(k)
(gramo)
From the Cauchy–Schwarz inequality, tenemos
fk(V(k))METRO(k) = tr (AA) tr (BB) ≥
(cid:28)
tr (AB)
(cid:29)
2 = f
(cid:8)
k(V(k))2.
By dividing both sides of the inequality by M(k), we obtain f
(cid:8)
k (V(k) )2
METRO(k)
≤ fk(V(k)).
(cid:2)
Proof of Theorem 1. sea f (cid:8) máximo
F (cid:8)
V(k)
k(V(k)). From lemma 4 and the definition of α(k), tenemos
0
be the global maximum of f (cid:8)
k(V(k)) y
k
= arg máx
V(k)
a(k) F
(cid:8) máximo
k
= f (cid:8)
0 )2
k(V(k)
METRO(k)
≤ fk(V(k)
0 ).
Let f max
k
f max
. De este modo,
k
be the global maximum of fk(V(k)). It then holds that fk(V(k)
0 ) ≤
a(k) F
(cid:8) máximo
k
≤ f max
k
.
Let V(k)
0∗ = arg max
V(k)
fk(V(k)). From lemma 4, tenemos
f max
k
= fk(V(k)
0∗ ) ≤ f
(cid:8)
k(V(k)
0∗ ).
Since f (cid:8)
k(V(k)
0∗ ) ≤ f (cid:8) máximo
k
, tenemos
f max
k
≤ f
(cid:8) máximo
k
.
Por eso, we have obtained α(k) F (cid:8) máximo
k
≤ f max
k
≤ f (cid:8) máximo
k
.
(cid:2)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2876
k. Yoshikawa and S. Kawano
Apéndice C: Proof of Theorem 2
Proof of Theorem 2. By definition
(cid:15)(cid:5)
(cid:2)
a(k) = f (cid:8) máximo
k
METRO(k)
tr
=
(cid:20)
V(k)
0
GRAMO
g=1
GRAMO
g=1
w(−k)
(gramo) S(k)
w(−k)
(gramo) S(k)
(gramo)S(k)
(gramo)
(cid:21)
(gramo)S(k)
(gramo)
(cid:20)(cid:5)
tr
(cid:16)
(cid:21)
V(k)
0
.
(C.1)
By using the eigenvalue representation, we can rewrite the numerator of
a(k) como
(cid:8) máximo
k
F
=
GRAMO(cid:2)
g=1
w(−k)
(gramo)
Rk(cid:2)
yo=1
.
λ(k)
(gramo)i
The denominator of α(k) can be represented as the sum of eigenvalues as
follows:
METRO(k) =
GRAMO(cid:2)
g=1
w(−k)
(gramo)
Pk(cid:2)
yo=1
.
λ(k)
(gramo)i
De este modo, we can transform α(k) como sigue:
a(k) =
(cid:5)
(cid:5)
GRAMO
g=1
GRAMO
g=1
w(−k)
(gramo)
w(−k)
(gramo)
(cid:5)
(cid:5)
Rk
yo=1
Pk
yo=1
λ(k)
(gramo)i
λ(k)
(gramo)i
.
When we set
⎡
⎣
Pk(cid:2)
i=Rk
+1
,
λ(k)
(1)i
Pk(cid:2)
i=Rk
+1
, . . . ,
λ(k)
(2)i
(cid:26)
Pk(cid:2)
yo=1
(cid:17)
w(−k)
(1)
,
λ(k)
(1)i
Pk(cid:2)
yo=1
, . . . ,
λ(k)
(2)i
, w(−k)
(2)
, . . . , w(−k)
(GRAMO)
Pk(cid:2)
yo=1
(cid:18)(cid:2)
,
λ(k)
0
=
λ(k)
1
=
w(k) =
⎤
(cid:2)
⎦
λ(k)
(GRAMO)i
,
Pk(cid:2)
i=Rk
+1
(cid:27)(cid:2)
λ(k)
(GRAMO)i
,
we can reformulate α(k) como
(cid:15)
(cid:16)(cid:2)
a(k) =
λ(k)
1
− λ(k)
0
(cid:2)
λ(k)
1
w(k)
w(k)
.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2877
De este modo, we obtain the following maximization problem:
(cid:15)
λ(k)
1
máximo
w(k)
(cid:16)(cid:2)
w(k)
− λ(k)
0
(cid:2)
λ(k)
1
w(k)
,
s.t. w(k) > 0.
Note that the constraints can be obtained by the definition of w(k). In addi-
ción, this maximization problem can be reformulated as
(cid:15)
λ(k)
1
máximo
w(k)
(cid:16)(cid:2)
w(k)
− λ(k)
0
(cid:2)
λ(k)
1
w(k)
= max
w(k)
1 −
(cid:2)
(cid:2)
w(k)
w(k)
λ(k)
0
λ(k)
1
= min
w(k)
(cid:2)
(cid:2)
w(k)
w(k)
.
λ(k)
0
λ(k)
1
(cid:2)
(cid:2)
w(k)/λ(k)
1
Since λ(k)
w(k) is nonnegative, solving the optimization problem
0
for the squared function of the objective function maintains generality.
De este modo, we can consider the following minimization problem:
mín.
w(k)
w(k)
w(k)
(cid:2)
(cid:2)
(cid:2)λ(k)
0
(cid:2)λ(k)
1
λ(k)
0
λ(k)
1
w(k)
w(k)
,
s.t. w(k) > 0.
Además, from the invariance under multiplication of w(k) by a constant,
we obtain the following objective function of the quadratic programming
problema:
(cid:2)
w(k)
λ(k)
0
λ(k)
0
(cid:2)
w(k),
mín.
w(k)
s.t. w(k) > 0, w(k)
(cid:2)
(cid:2)
λ(k)
1
λ(k)
1
w(k) = 1.
(cid:2)
Apéndice D: Proof of Theorem 3
Proof of Theorem 3. We define the following block matrices:
)*
As =
w(−k)
(1) S(k)
(1)
1
2 V(k)
s V(k)
s
(cid:2)
S(k)
(1)
1
2 , . . . ,
*
w(−k)
(GRAMO) S(k)
(GRAMO)
1
2 V(k)
s V(k)
s
+
1
2
.
(cid:2)
S(k)
(GRAMO)
Aquí, we calculate the traces of AsAs, AsAs+1, and As+1As+1. The calcula-
tions of tr (AsAs) and tr (As+1As+1) are the same as that of tr (AA) by replac-
ing V(k) with V(k)
s+1, respectivamente, in lemma 4. De este modo, nosotros
obtener
s and V(k) with V(k)
tr (AsAs) = fk(V(k)
s ),
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2878
k. Yoshikawa and S. Kawano
tr (AsAs+1) =
=
GRAMO(cid:2)
g=1
GRAMO(cid:2)
,
w(−k)
(gramo) tr
S(k)
(gramo)
1
2 V(k)
s V(k)
s
(cid:2)
S(k)
(gramo)
1
2 S(k)
(gramo)
1
2 V(k)
s+1V(k)
s+1
–
(cid:2)
1
2
S(k)
(gramo)
w(−k)
(gramo) tr
(cid:20)
V(k)
s+1
(cid:2)
S(k)
(gramo)V(k)
s V(k)
s
(cid:2)
(cid:21)
(gramo)V(k)
S(k)
s+1
⎞
w(−k)
(gramo) S(k)
(gramo)V(k)
s V(k)
s
(cid:2)
S(k)
(gramo)
⎠ V(k)
s+1
⎫
⎬
⎭
,
g=1
⎧
⎨
⎩V(k)
s+1
= tr
⎛
(cid:2)
GRAMO(cid:2)
⎝
g=1
tr (As+1As+1) = fk(V(k)
s+1).
Since V(k)
s+1
= arg máx
V(k)
tr
(cid:15)(cid:5)
(cid:2)
(cid:20)
V(k)
GRAMO
g=1
w(−k)
(gramo) S(k)
(gramo)V(k)
s V(k)
s
(cid:16)
(cid:21)
V(k)
, tenemos
(cid:2)
S(k)
(gramo)
fk(V(k)
s ) = tr
≤ tr
⎛
GRAMO(cid:2)
⎝
g=1
⎛
(cid:2)
s
⎧
⎨
⎩V(k)
⎧
⎨
⎩V(k)
s+1
w(−k)
(gramo) S(k)
(gramo)V(k)
s V(k)
s
⎞
(cid:2)
S(k)
(gramo)
⎠ V(k)
s
⎫
⎬
⎭
(cid:2)
GRAMO(cid:2)
⎝
g=1
w(−k)
(gramo) S(k)
(gramo)V(k)
s V(k)
s
⎞
(cid:2)
S(k)
(gramo)
⎠ V(k)
s+1
⎫
⎬
⎭
= tr (AsAs+1) .
From the positivity of both sides of the inequality, it holds that
fk(V(k)
s )2 ≤ [tr (AsAs+1)]2 .
Además, from the Cauchy–Schwarz inequality, tenemos
fk(V(k)
s ) fk(V(k)
s+1) = tr (AsAs) tr (As+1As+1)
≥ [tr (AsAs+1)]2 .
De este modo,
fk(V(k)
s ) fk(V(k)
s+1) ≥ [tr (AsAs+1)]2 ≥ fk(V(k)
s )2.
Entonces, we have obtained fk(V(k)
sides of the inequality by fk(V(k)
fk(V(k)
s+1).
s ) fk(V(k)
s )2 ≤ fk(V(k)
s ), we obtain the inequality fk(V(k)
s+1). By dividing both
s ) ≤
(cid:2)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Multilinear Common Component Analysis
2879
Expresiones de gratitud
We thank the reviewer for helpful comments and constructive suggestions.
S.K. was supported by JSPS KAKENHI grants JP19K11854 and JP20H02227,
and MEXT KAKENHI grants JP16H06429, JP16K21723, and JP16H06430.
Referencias
allen, GRAMO. (2012). Sparse higher-order principal components analysis. En procedimientos
of the Fifteenth International Conference on Artificial Intelligence and Statistics (páginas.
27–36).
Badeau, r., & Boyer, R. (2008). Fast multilinear singular value decomposition for
structured tensors. SIAM Journal on Matrix Analysis and Applications, 30(3), 1008–
1021.
Bensmail, h., & Celeux, GRAMO. (1996). Regularized gaussian discriminant analysis
through eigenvalue decomposition. Journal of the American Statistical Association,
91(436), 1743–1748.
Boik, R. j. (2002). Spectral models for covariance matrices. Biometrika, 89(1), 159–182.
Carroll, j. D., & Chang, J.-J. (1970). Analysis of individual differences in multidi-
mensional scaling via an N-way generalization of “Eckart-Young” decomposi-
ción. Psychometrika, 35(3), 283–319.
Flury, B. norte. (1984). Common principal components in K groups. Journal of the Amer-
ican Statistical Association, 79(388), 892–898.
Flury, B. norte. (1986). Asymptotic theory for common principal component analysis.
Annals of Statistics, 14(2), 418–430.
Flury, B. norte. (1988). Common principal components and related multivariate models. Nuevo
york: wiley.
Flury, B. NORTE., & Gautschi, W.. (1986). An algorithm for simultaneous orthogonal trans-
formation of several positive definite symmetric matrices to nearly diagonal
forma. SIAM Journal on Scientific and Statistical Computing, 7(1), 169–184.
Greenewald, K., zhou, S., & Hero III, A. (2019). Tensor graphical Lasso (TeraLasso).
Journal of the Royal Statistical Society: Serie B (Statistical Methodology), 81(5), 901–
931.
Harshman, R. A. (1970). Foundations of the PARAFAC procedure: Models and con-
ditions for an “explanatory” multimodal factor analysis. UCLA Working Papers in
Phonetics, 16(1), 84.
Harville, D. A. (1998). Matrix algebra from a statistician’s perspective. Nueva York:
Editorial Springer.
Jolliffe, I. (2002). Principal component analysis. Nueva York: Editorial Springer.
Kermoal, j. PAG., Schumacher, l., Pedersen, k. I., Mogensen, PAG. MI., & Frederiksen, F.
(2002). A stochastic MIMO radio channel model with experimental validation.
IEEE Journal on Selected Areas in Communications, 20(6), 1211–1226.
Kiers, h. A. (2000). Towards a standardized notation and terminology in multiway
análisis. Journal of Chemometrics, 14(3), 105–122.
Kolda, t. GRAMO., & Bader, B. W.. (2009). Tensor decompositions and applications. SIAM
Revisar, 51(3), 455–500.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2880
k. Yoshikawa and S. Kawano
Dejar, Z., Xu, y., Chen, P., Cual, J., & zhang, D. (2014). Multilinear sparse principal
component analysis. IEEE Transactions on Neural Networks and Learning Systems,
25(10), 1942–1950.
Lecun, y., Bottou, l., bengio, y., & Haffner, PAG. (1998). Gradient-based learning ap-
plied to document recognition. In Proceedings of the IEEE, 86(11), 2278–2324.
Lu, h., Plataniotis, k. NORTE., & Venetsanopoulos, A. norte. (2008). MPCA: Multilinear prin-
cipal component analysis of tensor objects. IEEE Transactions on Neural Networks,
19(1), 18–39.
Manly, B. F. J., & Rayner, j. C. W.. (1987). The comparison of sample covariance ma-
trices using likelihood ratio tests. Biometrika, 74(4), 841–847.
Martinez, A., & Benavente., R. (1998). The AR face database (CVC Technical Report
24).
Martinez, A. METRO., & Kak, A. C. (2001). PCA versus LDA. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 23(2), 228–233.
Parque, h., & Konishi, S. (2020). Sparse common component analysis for multiple high-
dimensional datasets via noncentered principal component analysis. Statistical
Documentos, 61, 2283–2311.
Pearson, k. (1901). LIII. On lines and planes of closest fit to systems of points in space.
Londres, Edimburgo, and Dublin Philosophical Magazine and Journal of Science, 2(11),
559–572.
Pourahmadi, METRO., Daniels, METRO. J., & Parque, t. (2007). Simultaneous modelling of the
Cholesky decomposition of several covariance matrices. Journal of Multivariate
Análisis, 98(3), 568–587.
R Core Team (2019). R: A language and environment for statistical computing. Viena,
Austria: R Foundation for Statistical Computing.
Wang, h., Banerjee, A., & Boley, D. (2011). Common component analysis for multiple
covariance matrices. In Proceedings of the 17th ACM SIGKDD International Confer-
ence on Knowledge Discovery and Data Mining (páginas. 956–964). Nueva York: ACM.
Wang, S., Sol, METRO., Chen, y., Angustia, MI., & zhou, C. (2012). STPCA: Sparse tensor prin-
cipal component analysis for feature extraction. In Proceedings of the 21st Interna-
tional Conference on Pattern Recognition (páginas. 2278–2281). Piscataway, Nueva Jersey: IEEE.
Werner, K., Jansson, METRO., & Stoica, PAG. (2008). On estimation of covariance matrices
with Kronecker product structure. IEEE Transactions on Signal Processing, 56(2),
478–491.
Yu, K., Bengtsson, METRO., Ottersten, B., McNamara, D., Karlsson, PAG., & Beach, METRO. (2004).
Modeling of wide-band MIMO radio channels based on NLOS indoor measure-
mentos. IEEE Transactions on Vehicular Technology, 53(3), 655–665.
Received November 20, 2020; accepted April 27, 2021.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
norte
mi
C
oh
a
r
t
i
C
mi
–
pag
d
/
yo
F
/
/
/
/
3
3
1
0
2
8
5
3
1
9
8
2
2
5
6
norte
mi
C
oh
_
a
_
0
1
4
2
5
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3