计算语言学协会会刊, 卷. 6, PP. 497–510, 2018. 动作编辑器: Phil Blunsom.
提交批次: 1/2018; 修改批次: 3/2018; 已发表 7/2018.
2018 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
C
(西德:13)
Low-RankRNNAdaptationforContext-AwareLanguageModelingAaronJaechandMariOstendorfDepartmentofElectricalEngineering,UniversityofWashington185StevensWay,PaulAllenCenterAE100R,Seattle,WA{ajaech,ostendor}@uw.eduAbstractAcontext-awarelanguagemodelusesloca-tion,userand/ordomainmetadata(语境)toadaptitspredictions.Inneurallanguagemodels,contextinformationistypicallyrep-resentedasanembeddinganditisgiventotheRNNasanadditionalinput,whichhasbeenshowntobeusefulinmanyapplications.Weintroduceamorepowerfulmechanismforus-ingcontexttoadaptanRNNbylettingthecontextvectorcontrolalow-ranktransforma-tionoftherecurrentlayerweightmatrix.Ex-perimentsshowthatallowingagreaterfrac-tionofthemodelparameterstobeadjustedhasbenefitsintermsofperplexityandclassi-ficationforseveraldifferenttypesofcontext.1IntroductionInmanylanguagemodelingapplications,thespeechortextisassociatedwithsomemetadataorcontex-tualinformation.Forexample,inspeechrecogni-tion,ifauserisspeakingtoapersonalassistantthenthesystemmightknowthetimeofdayortheiden-tityofthetaskthattheuseristryingtoaccomplish.Iftheusertakesapictureofasigntotranslateitwiththeirsmartphone,thesystemwouldhavecontextualinformationrelatedtothegeographiclocationandtheuser’spreferredlanguage.Thecontext-awarelanguagemodeltargetsthesetypesofapplicationswithamodelthatcanadaptitspredictionsbasedontheprovidedcontextualinformation.Therehasbeenmuchworkonusingcontextinfor-mationtoadaptlanguagemodels.Here,wearein-terestedincontextsdescribedbymetadata(vs.wordhistoryorrelateddocuments)andinneuralnetworkapproachesduetotheirflexibilityforrepresentingdiversetypesofcontexts.Specifically,wefocusonrecurrentneuralnetworks(RNNs)duetotheirwidespreaduse.ThestandardapproachtoadaptanRNNlanguagemodelistoconcatenatethecontextrepresentationwiththewordembeddingattheinputtotheRNN(MikolovandZweig,2012).Optionally,thecon-textembeddingisalsoconcatenatedwiththeout-putfromtherecurrentlayertoadaptthesoftmaxlayer.Thisbasicstrategyhasbeenadoptedforvar-ioustypesofadaptationsuchasforLMpersonal-ization(Wenetal.,2013;Lietal.,2016),adaptingtotelevisionshowgenres(Chenetal.,2015),andadaptingtolongrangedependenciesinadocument(Jietal.,2016),etc.Weproposeamorepowerfulmechanismforus-ingacontextvector,whichwecalltheFactorCell.Ratherthansimplyusingcontextasanadditionalinput,itisusedtocontrolafactored(low-rank)transformationoftherecurrentlayerweightmatrix.Themotivationisthatallowingagreaterfractionofthemodelparameterstobeadjustedinresponsetotheinputcontextwillproduceamodelthatismoreadaptableandresponsivetothatcontext.Weevaluatetheresultingmodelsintermsofcontext-dependentperplexityandcontextclassifica-tionaccuracyonsixtasksreflectingdifferenttypesofcontextvariables,comparingtobaselinesthatrep-resentthemostpopularmethodsforusingcontextinneuralmodels.Wechoosetaskswherecontextisspecifiedbymetadata,ratherthantextsamplesasusedinmanypriorstudies.Thecombination
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
我
A
C
_
A
_
0
0
0
3
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
498
ofexperimentsonavarietyofdatasourcespro-videsstrongevidencefortheutilityoftheFactor-Cellmodel,buttheresultsshowthatitcanbeusefultoconsidermorethanjustperplexityintrainingalanguagemodel.Theremainderproceedsasfollows.InSection2,weintroducetheFactorCellmodelandshowhowitdiffersmathematicallyfromalternativeapproaches.Next,Section3describesthesixdatasetsusedtoprobetheperformanceofdifferentmodels.Ex-perimentsandanalysescontrastingperplexityandclassificationresultsforavarietyofcontextvari-ablesareprovidedinSection4,demonstratingcon-sistentimprovementsinbothcriteriafortheFac-torCellmodelbutalsoconfirmingthatperplexityisnotcorrelatedwithclassificationperformanceforallmodels.Analysesexploretheeffectivenessofthemodelforcharacterizinghigh-dimensionalcontextspaces.ThemodeliscomparedtorelatedworkinSection5.Finally,Section6summarizescontribu-tionsandopenquestions.2Context-AwareRNNOurmodelusesadaptationinboththerecurrentlayerandinthebiasvectoroftheoutputlayer.Inthissectionwedescribehowwerepresentcontextasanembeddingandmethodsforadaptingthere-currentlayerandthesoftmaxlayer,showingthatourproposedmodelisageneralizationofpriormethods.Thenoveltyofourmodelisthatinsteadofusingcontextasanadditionalinputtothemodel,itusesthecontextinformationtotransformtheweightsoftherecurrentlayer.Thisisaccomplishedusingalow-rankdecompositioninordertocontroltheex-tentofparametersharingbetweencontexts,whichisimportantforhandlinghigh-dimensional,sparsecontexts.2.1ContextrepresentationWeassumetheavailabilityofcontextualin-formation(metadataorothersideinformation)thatisrepresentedasasetofcontextvariablesf1:n=f1,f2,…fn,fromwhichweproduceak-dimensionalrepresentationintheformofanembed-ding,c∈Rk.Eachofthecontextvariables,fi,rep-resentssometypeofinformationormetadataaboutthesequenceandcanbeeithercategoricalornumer-ical.Theembeddingscaneitherbelearnedoff-lineusingatopicmodel(MikolovandZweig,2012)orend-to-endaspartoftheadaptedLM(Tangetal.,2016).这里,weuseend-to-endlearning,wherethecontextembeddingistheoutputofafeed-forwardnetworkwithaReLUactivationfunction.There-sultingembedding,C,isusedforadaptingboththerecurrentlayerandtheoutputlayeroftheRNN.2.2AdaptingtherecurrentlayerThebasicoperationoftherecurrentlayeristouseamatrixWtotransformtheconcatenationofawordembedding,wt∈Re,withthehiddenstatefromtheprevioustimestep,ht−1∈Rd,andproduceanewhiddenstate,ht,asgivenbyEquation1:ht=σ(W1wt+W2ht−1+b)=σ(瓦[wt,ht−1]+乙).(1)ThesizeofWisd×(e+d).Forsimplicity,ourequationsassumeasimpleRNN.AppendixAshowshowtheequationscanbeadjustedtoworkwithanLSTM.Thestandardapproachtorecurrentlayeradapta-tionistoinclude(viaconcatenation)thecontextem-beddingasanadditionalinputtotherecurrentlayer(MikolovandZweig,2012).Whenthecontextem-beddingisconstantacrossthewholesequence,itiseasytoshowthatthisconcatenationisequivalenttousingacontext-dependentbiasattherecurrentlayer:ht=σ(ˆW[wt,ht−1,c]+乙)=σ(瓦[wt,ht−1]+Vc+b)=σ(瓦[wt,ht−1]+b0),(2)whereˆW=[WV]andb0=Vc+bisthecontext-dependentbias,formedbyaddingalinearprojectionofthecontextembedding.Werefertothisadapta-tionapproachastheConcatCellmodel.OurproposedmodelextendstheConcatCellbyusingacontext-dependentweightmatrixW0=W+A,inplaceofthegenericweightma-trixW.(WerefertoWasgenericbecauseitissharedacrossallcontextsettings.)Theadaptationmatrix,A,isgeneratedbytakingtheproductofthecontextembeddingvectoragainstasetofleftandrightbasistensorstoproducearankrmatrix.Theleftandrightadaptationbasistensorsaregivenas
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
我
A
C
_
A
_
0
0
0
3
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
499
ZL∈Rk×(e+d)×randZR∈Rr×d×k.Thetwobasestensorstogethercanbethoughtofasholdingkdifferentrankrmatrices,Aj=ZL,jZR,j,eachthesizeofW.BytakingtheproductbetweencandthecorrespondingtensormodesofZLandZR(us-ing×itodenotethemode-itensorproduct,i.e.,theproductwiththei-thdimensionofthetensor),thecontextdeterminestheweightedcombinationofthekmatrices:A=(c×1ZL)(ZR×3c|).(3)ThenumberofdegreesoffreedomofAiscontrolledbythedimensionkofthecontextvectorandtherankrofthekweightmatrices.TherankistreatedasahyperparameterandcontrolstheextenttowhichthemodelreliesonthegenericweightmatrixWversusbehavesinamorecontext-specificmanner.WecallthismodeltheFactorCellbecausetheweightmatrixhasbeenadaptedbyaddingafactoredcomponent.TheConcatCellmodelisaspecialcaseoftheFactorCellwhereZLandZRaresettozero.Insummary,theproposedmodelisgivenby:ht=σ(W0[wt,ht−1]+b0)W0=W+(c×1ZL)(ZR×3c)b0=Vc+b.(4)Ifthecontextisknowninadvance,W0canbepre-computed,inwhichcaseapplyingtheRNNattesttimerequiresnomorecomputationthanusinganun-adaptedRNNofthesamesize.Thismeansthatforafixedsizedrecurrentlayer,theFactorCellmodelcanhavemanymoreparametersthantheConcat-Cellmodelbuthardlyanyincreaseincomputationalcost.2.3AdaptingtheSoftmaxBiasThelastlayerofthemodelpredictstheprobabilityofthenextsymbolinthesequenceusingtheoutputfromtherecurrentlayerusingthesoftmaxfunctiontocreateanormalizedprobabilitydistribution.Theoutputprobabilitiesaregivenbyyt=softmax(ELht+bout),(5)whereE∈R|V|×eisthematrixofwordembed-dings,L∈Re×disalinearprojectiontomatchthedimensionoftherecurrentlayer(whene6=d),andbout∈R|V|isthesoftmaxbiasvector.Wetiethewordembeddingsintheinputlayerwiththeonesintheoutputlayer(PressandWolf,2017;Inanetal.,2017).Ifsjistheindicatorrowvectorforthejthwordinthevocabularythenp(wt|w1:t−1)=stytandlogp(w1:时间)=Ptlogswtyt.Adaptingthesoftmaxbiasalterstheunigramdis-tribution.Therearetwowaystoaccomplishthis.Whenthevaluesthatthecontextcantakearecate-goricalwithlowcardinalitythencontext-dependentsoftmaxbiasvectorscanbelearneddirectly.Thisisequivalenttoreplacingcwithaone-hotvector.Oth-erwise,aprojectionofthecontextembedding,QcwhereQ∈R|V|×k,canbeusedtoadaptthebiasvectorasinyt=softmax(ELht+Qc+bout).(6)Theprojectioncanbethoughtofasalow-rankap-proximationtousingtheone-hotcontextvector.Bothstrategiesareexplored,dependingonthena-tureoftheoriginalcontextspace.AsnotedinSection5,adaptationofthesoftmaxbiashasbeenusedinotherstudies.Asweshowintheexperimentalwork,itisusefulforrepresentingphenomenawhereunigramstatisticsareimportant.3DataOurexperimentsmakeuseofsixdatasets:fourtar-getingword-levelsequences,andtwotargetingchar-actersequences.Thecharacterstudiesaremoti-vatedbythegrowinginterestincharacter-levelmod-elsinbothspeechrecognitionandmachinetransla-tion(Hannunetal.,2014;Chungetal.,2016).Byusingmultipledatasetswithdifferenttypesofcon-text,wehopetolearnmoreaboutwhatmakesadatasetamenabletoadaptation.Thedatasetsrangeinsizefromover100millionwordsoftrainingdatato5millioncharactersoftrainingdataforthesmall-estone.Whenusingaword-basedvocabulary,wepreprocessthedatabylowercasing,tokenizingandremovingmostpunctuation.Wealsotruncatesen-tencestobeshorterthanamaximumlengthof60wordsforAGNewsandDBPediaand150to200to-kensfortheremainingdatasets.Summaryinforma-tionisprovidedinTable1,includingthetraining,发展,andtestdatasizesintermsofnumber
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
我
A
C
_
A
_
0
0
0
3
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
500
NameTrainDevTestVocabDocs.ContextAGNews4.6M0.2M0.3M54,492115K4NewspapersectionsDBPedia28.7M0.3M3.6M84,341555K14EntitycategoriesTripAdvisor127.2M2.6M2.6M88,347843K3.5KHotels/5SentimentYelp91.5M0.7M7.1M57,794645K5SentimentEuroTwitter∗5.3M0.8M1.0M19480K9LanguagesGeoTwitter∗51.7M2.2M2.2M203604KLatitude&LongitudeTable1:Datasetstatistics:Datasetsizeinwords(*orcharacters)ofTrain,DevandTestsets,vocabularysize,numberoftrainingdocuments,andcontextvariables.oftokens,vocabularysize,numberoftrainingdoc-uments(i.e.contextsamples),andthecontextvari-ables(f1:n).Thelargestdataset,TripAdvisor,hasover800thousandhotelreviewdocuments,whichaddsuptoover125millionwordsoftrainingdata.Thefirstthreedatasets(AGNews,DBPedia,andYelp)havepreviouslybeenusedfortextclassifica-tion(Zhangetal.,2015).Theseconsistofnewspa-perheadlines,encyclopediaentries,andrestaurantandbusinessreviews,respectively.Thecontextvari-ablesassociatedwiththesecorrespondtothenews-papersection(世界,sports,商业,科学&tech)foreachheadline,thepagecategoryonDBPedia(outof14optionssuchasactor,athlete,building,ETC。),andthestarratingonYelp(fromonetofive).ForAgNews,DBPedia,andYelpweusethesametestdataasinpreviouswork.Ourfourthdataset,fromTripAdvisor,waspreviouslyusedforlanguagemodelingandconsistsoftworelevantcontextvari-ables:anidentifierforthehotelandasentimentscorefromonetofivestars(Tangetal.,2016).SomeofthereviewsarewritteninFrenchorGermanbutmostareinEnglish.Thereare4,333differenthotelsbutwegroupalltheonesthatdonotoccuratleast50timesinthetrainingdataintoasingleentity,leavinguswitharound3,500.Thesefourdatasetsuseword-basedvocabularies.WealsoexperimentontwoTwitterdatasets:Eu-roTwitterandGeoTwitter.EuroTwitterconsistsof80thousandtweetslabeledwithoneofninelanguages:(英语,西班牙语,Galician,Catalan,Basque,Portuguese,法语,德语,andItalian).Thecorpuswascreatedbycombiningportionsofmultiplepublisheddatasetsforlanguageidentifica-tionincludingTwitter70(Jaechetal.,2016),Tweet-LID(Zubiagaetal.,2014),andthemonolingualportionoftweetsfromacode-switchingdetectionworkshop(Molinaetal.,2016).TheGeoTwit-terdatacontainstweetswithlatitudeandlongitudeinformationfromEngland,西班牙,andtheUnitedStates.1Thelatitudeandlongitudecoordinatesaregivenasnumericalinputs.Thisisdifferentfromtheotherfivedatasetsthatallusecategoricalcon-textvariables.4ExperimentswithDifferentContextsThegoalofourexperimentsistoshowthattheFactorCellmodelcandeliverimprovedperformanceovercurrentapproachesformultiplelanguagemodelapplicationsandavarietyoftypesofcon-texts.Specifically,resultsarereportedforcontext-conditionedperplexityandgenerativemodeltextclassificationaccuracy,usingcontextsthatcapturearangeofphenomenaanddimensionalities.Testsetperplexityisthemostwidelyacceptedmethodforevaluatinglanguagemodels,bothforuseinrecognition/translationapplicationsandgenera-tion.Ithastheadvantagethatitiseasytomeasureandiswidelyusedasacriteriaformodelfit,butthelimitationthatitisnotdirectlymatchedtomosttasksthatlanguagemodelsaredirectlyusedfor.Textclas-sificationusingthemodelinagenerativeclassifierisasimpleapplicationofBayesrule:ˆω=argmaxωp(w1:时间|ω)p(ω)(7)wherew1:Tisthetextsequence,p(ω)istheclassprior,whichweassumetobeuniform.Classifica-tionaccuracyprovidesadditionalinformationaboutthepowerofamodel,evenifitisnotbeingdesignedexplicitlyfortextclassification.Further,itallowsustobeabletodirectlycompareourmodelperfor-1Datawasaccessedfromhttp://followthehashtag.com.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
我
A
C
_
A
_
0
0
0
3
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
501
manceagainstpreviouslypublishedtextclassifica-tionbenchmarks.Notethattheuseofclassificationaccuracyforevaluationhereinvolvescountingerrorsassociatedwithapplyingthegenerativemodeltoindependenttestsamples.Thisdiffersfromtheaccuracycriterionusedforevaluatingcontext-sensitivelanguagemod-elsfortextgenerationbasedonaseparatediscrimi-nativeclassifiertrainedongeneratedtext(FiclerandGoldberg,2017;Huetal.,2017).WediscussthisfurtherinSection5.TheexperimentscomparetheFactorCellmodel(equations4and6)totwopopularalternatives,whichwerefertoasConcatCell(equations2and6)andSoftmaxBias(equation6).Asnotedearlier,theSoftmaxBiasmethodisasimplificationoftheConcatCellmodel,whichisinturnasimplificationoftheFactorCellmodel.TheSoftmaxBiasmethodimpactsonlytheoutputlayerandthusonlyuni-gramstatistics.Sincebag-of-wordmodelsprovidestrongbaselinesinmanytextclassificationtasks,wehypothesizethattheSoftmaxBiasmodelwillcap-turemuchoftherelativeimprovementovertheun-adaptedmodelforword-basedtasks.However,insmallvocabularycharacter-basedmodels,theuni-gramdistributionisunlikelytocarrymuchinfor-mationaboutthecontext,soadaptingtherecurrentlayershouldbecomemoreimportantincharacter-levelmodels.WeexpectthatperformancegainswillbegreatestfortheFactorCellmodelforsourcesthathavesufficientstructureanddatatosupportlearningtheextradegreesoffreedom.Anotherpossiblebaselinewouldusemodelsin-dependentlytrainedonthesubsetofdataforeachcontext.Thisisthe“independentcomponent”casein(Yogatamaetal.,2017).Thiswillfailwhenacontextvariabletakesonmanyvalues(orcontinu-ousvalues)orwhentrainingdataislimited,becauseitmakespooruseofthetrainingdata,asshowninthatstudy.Whilewedohavesomedatasetswherethisapproachisplausible,wefeelthatitslimitationshavebeenclearlyestablished.4.1ImplementationDetailsTheRNNvariantthatweuseisanLSTMwithcou-pledinputandforgetgates(Melisetal.,2018).Thedifferentmodelvariantsareimplemented2usingtheTensorflowlibrary.Themodelistrainedwiththestandardnegativeloglikelihoodlossfunction,i.e.minimizingcrossentropy.Dropoutisusedasareg-ularizerintherecurrentconnectionsasdescribedinSemeniutaetal.(2016).TrainingisdoneusingtheAdamoptimizerwithalearningrateof0.001.Forthemodelswithword-basedvocabularies,asampledsoftmaxlossisusedwithaunigramproposaldis-tributionandsampling150wordsateachtime-step(Jeanetal.,2014).Theclassificationexperimentsuseasampledsoftmaxlosswithasamplesizeof8,000words.Thisisanorderofmagnitudefastertocomputewithaminimaleffectonaccuracy.Hyperparametertuningwasdonebasedonmin-imizingperplexityonthedevelopmentsetandus-ingarandomsearch.Hyperparametersincludedwordembeddingsizee,recurrentstatesized,con-textembeddingsizek,andweightadaptationma-trixrankr,thenumberoftrainingsteps,recurrentdropoutprobability,andrandominitializationseed.TheselectedhyperparametervaluesarelistedinTa-ble2.ForanyfixedLSTMsize,theFactorCellhasahighercountoflearnedparameterscomparedtotheConcatCell.However,duringevaluationbothmod-elsuseapproximatelythesamenumberoffloating-pointoperationsbecauseW0onlyneedstobecom-putedoncepersentence.Becauseofthis,webelievelimitingtherecurrentlayercellsizeisafairwaytocomparebetweentheFactorCellandtheConcatCell.4.2Word-basedModelsPerplexitiesandclassificationaccuraciesforthefourword-baseddatasetsarepresentedinTable3.Ineachofthefourdatasets,theFactorCellmodelgivesthebestperplexity.Forclassificationaccuracy,thereisabiggerdifferencebetweenthemodels,andtheFactorCellmodelisthemostaccurateonthreeoutoffourdatasetsandtiedwiththeSoftmaxBiasmodelonAgNews.ForDBPediaandTripAdvisor,mostoftheimprovementinperplexityrelativetotheun-adaptedcaseisachievedbytheSoftmaxBiasmodelwithsmallerrelativeimprovementscomingfromtheincreasedpoweroftheConcatCellandFactorCellmodels.ForYelp,theperplexityimprovementsaresmall;theFactorCellmodelisjust1.3%betterthan2Codeavailableathttp://github.com/ajaech/calm.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
我
A
C
_
A
_
0
0
0
3
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
502
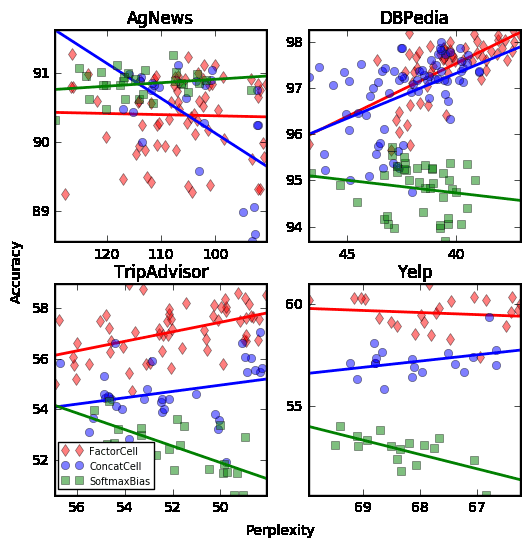
AgNewsDBPediaEuroTwitterGeoTwitterTripAdvisorYelpWordEmbed150114-12035-4042-50100200LSTMdim110167-180250250200200Steps4.1-5.5K7.5-8.0K6.0-8.0K6.0-11.1K8.4-9.9K7.2-8.8KDropout0.51.000.95-1.000.99-1.000.97-1.001.00Ctx.Embed2123-58-2420-302-3Rank1219220129Table2:Selectedhyperparametersforeachdataset.WhenarangeislisteditmeansthatadifferentvalueswereselectedfortheFactorCell,ConcatCell,SoftmaxBiasorUnadaptedmodels.AGNewsDBPediaTripAdvisorYelpModelPPLACCPPLACCPPLACCPPLACCUnadapted96.2–44.1–51.6–67.1–SoftmaxBias95.190.640.495.548.851.966.951.6ConcatCell93.889.739.597.848.356.066.856.9FactorCell92.390.637.798.248.258.266.258.8Table3:Perplexityandclassificationaccuracyonthetestsetforthefourword-baseddatasets.theunadaptedmodel.FromYogatamaetal.(2017),weseethatforAG-News,muchmoresothanforotherdatasets,theun-igramstatisticscapturethediscriminatinginforma-tion,anditistheonlydatasetinthatworkwhereanaiveBayesclassifieriscompetitivewiththegener-ativeLSTMforthefullrangeoftrainingdata.ThefactthattheSoftmaxBiasmodelgetsthesameac-curacyastheFactorCellmodelonthistasksuggeststhattopicclassificationtasksmaybenefitlessfromadaptingtherecurrentlayer.FortheDBPediaandYelpdatasets,theFactor-Cellmodelbeatspreviouslyreportedclassificationaccuraciesforgenerativemodels(Yogatamaetal.,2017).然而,itisnotcompetitivewithstate-of-the-artdiscriminativemodelsonthesetaskswiththefulltrainingset.Withlesstrainingdata,itprobablywouldbe,basedontheresultsin(Yogatamaetal.,2017).ThenumbersinTable3donotadequatelyconveythefactthattherearehyperparameterswhoseeffectonperplexityisgreaterthanthesometimessmallrelativedifferencesbetweenmodels.Eventheseedfortherandomweightinitializationcanhavea“ma-jorimpact”onthefinalperformanceofanLSTM(ReimersandGurevych,2017).WeuseFigure1toshowhowthethreeclassesofmodelsperformacrossarangeofhyperparameters.Thefigurecomparesperplexityonthex-axiswithaccuracyonthey-axiswithbothmetricscomputedonthedevelopmentset.Eachpointinthisfigurerepresentsadifferentin-stanceofthemodeltrainedwithrandomhyperpa-rametersettingsandthebestresultsareintheup-perrightcornerofeachplot.Thecolor/shapediffer-encesofthepointscorrespondtothethreeclassesofmodels:FactorCell,ConcatCell,andSoftmaxBias.Figure1:Accuracyvs.perplexityfordifferentclassesofmodelsonthefourword-baseddatasets.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
我
A
C
_
A
_
0
0
0
3
5
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
503
Withinthesamemodelclassbutacrossdifferenthyperparametersettings,thereismuchmorevaria-tioninperplexitythaninaccuracy.TheLSTMcellsizeismainlyresponsibleforthis;ithasamuchbig-gerimpactonperplexitythanonaccuracy.Itisalsoapparentthatthemodelswiththelowestperplexityarenotalwaystheoneswiththehighestaccuracy.SeeSection4.4forfurtheranalysis.Figure2isavisualizationoftheper-wordloglikelihoodratiobetweenamodelassuminga5starreviewandthesamemodelassuminga1starreview.Likelihoodswerecomputedusinganensembleofthreemodelstoreducevariance.Theanalysisisre-peatedforeachclassofmodel.Wordshighlightedinbluearegivenahigherlikelihoodunderthe5starassumption.Unigramswithstrongsentimentsuchas“lovely”and“friendly”arewell-representedbyallthreemodels.Thereadermaynotconsiderthetokens“craziness”or“5-8pm”tobestrongindicatorsofapositivereviewbutthewaytheyareusedinthisre-viewisrepresentativeofhowtheyaretypicallyusedacrossthecorpus.Asexpected,theConcatCellandFactorCellmodelcapturethesentimentofmulti-tokenphrases.Asanexample,theunigram“enough”is3%morelikelytooccurina5starreviewthanina1starre-view.However,“doenough”is30timesmorelikelytoappearina5starreviewthanina1starreview.Inthisexample,theFactorCellmodeldoesabetterjobofhandlingtheword“enough.”4.3Character-basedModelsNext,weevaluatetheEuroTwitterandGeoTwittermodelsusingbothperplexityandaclassificationtask.ForEuroTwitter,theclassificationtaskistoidentifythelanguage.WithGeoTwitter,itislessob-viouswhattheclassificationtaskshouldbebecausethecontextvaluesarecontinuousandnotcategori-cal.WeselectedsixcitiesandthenassignedeachsentencethelabeloftheclosestcityinthatlistwhilestillretainingtheexactcoordinatesoftheTweet.Therearetwocitiesfromeachcountry:曼彻斯特,伦敦,Madrid,巴塞罗那,NewYorkCity,andLosAngeles.Tweetsfromlocationsfurtherthan300kmfromthenearestcityonthelistwerediscardedwhenevaluatingtheclassificationaccuracy.Perplexitiesandclassificationaccuraciesarepre-SoftmaxBiasConcatCellFactorCellFigure2:Loglikelihoodratiobetweenamodelthatas-sumesa5starreviewandthesamemodelthatassumesa1starreview.Blueindicatesahigher5starlikelihoodandredisahigherlikelihoodforthe1starcondition.sentedinTable4.TheFactorCellmodelhasthelowestperplexityandthehighestaccuracyforbothdatasets.Again,theFactorCellmodelclearlyim-provesontheConcatCellasmeasuredbyclassifi-cationaccuracy.Consistentwithourhypothesis,adaptingthesoftmaxbiasisnoteffectiveforthesesmallvocabularycharacter-basedtasks.TheSoft-maxBiasmodelhassmallperplexityimprovements(<1%)andlowclassificationaccuracies.EuroTwitterGeoTwitterModelPPLACCPPLACCUnadapted6.35–4.64–SoftmaxBias6.2943.04.6329.9ConcatCell6.1791.54.5442.2FactorCell6.0793.34.5263.5Table4:PerplexityandclassificationaccuraciesfortheEuroTwitterandGeoTwitterdatasets.Figure3comparesperplexityandclassificationaccuracyfordifferenthyperparametersettingsofthecharacter-basedmodels.Again,weseethatitispos-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
504
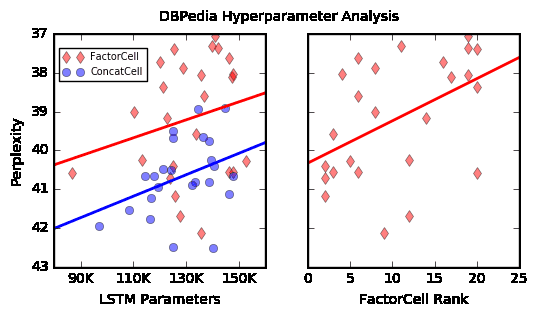
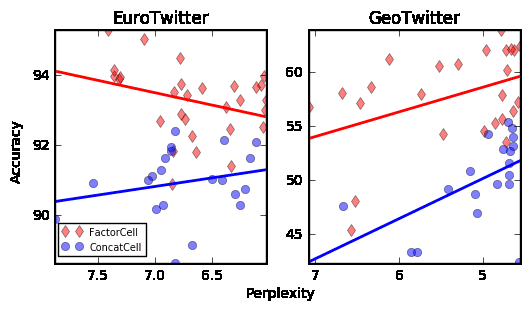
Figure3:Accuracyvs.Perplexityfordifferentclassesofmodelsonthetwocharacter-baseddatasets.sibletotrade-offsomeperplexityforgainsinclassi-ficationaccuracy.ForEuroTwitter,iftuningisdoneonaccuracyratherthanperplexitythentheaccuracyofthebestmodelisashighas95%.Sometimestherecanbelittletonoperplexityim-provementbetweentheunadaptedmodelandtheFactorCellmodel.Thiscanbeexplainedifthepro-videdcontextvariablesaremostlyredundantgiventheprevioustokensinthesequence.Toinvestigatethisfurther,wetrainedalogisticregressionclas-sifiertopredictthelanguageusingthestatefromtheLSTMatthelasttimestepontheunadaptedmodelasafeaturevector.Usingjust30labeledex-amplesperclassitispossibletoget74.6%accu-racy.Furthermore,wefindthatasingledimensioninthehiddenstateoftheunadaptedmodelisoftenenoughtodistinguishbetweendifferentlanguageseventhoughthemodelwasnotgivenanysupervi-sionsignal.Thisfindingisconsistentwithprevi-ousworkthatshowedthatindividualdimensionsofLSTMhiddenstatescanbestrongindicatorsofcon-ceptslikesentiment(Karpathyetal.,2015;Radfordetal.,2017).Figure4visualizesthevalueofthedimensionofthehiddenlayerthatisthestrongestindicatorofSpanishonthreedifferentcode-switchedtweets.Code-switchingisnotapartofthetrainingdatabutitprovidesacompellingvisualizationoftheabil-ityoftheunsupervisedmodeltoquicklyrecognizethelanguage.Thefactthatitissoeasyfortheunadaptedmodeltopick-upontheidentityofthecontextualvariablefitswithourexplanationforthesmallrelativegaininperplexityfromtheadaptedmodelsinthesetwotasks.Figure4:ThevalueofthedimensionoftheLSTMhiddenstateinanunadaptedmodelthatisthestrongestindicatorforSpanishtextforthreedifferentcode-switchedtweets.4.4HyperparameterAnalysisThehyperparameterwiththestrongesteffectonper-plexityisthesizeoftheLSTM.Thiswasconsis-tentacrossallsixdatasets.Theeffectonclassifi-cationaccuracyofincreasingtheLSTMsizewasmixed.Increasingthecontextembeddingsizegen-erallyhelpedwithaccuracyonalldatasets,butithadamoreneutraleffectonTripAdvisorandYelpandincreasedperplexityonthetwocharacter-baseddatasets.FortheFactorCellmodel,increasingtherankoftheadaptationmatrixtendedtoleadtoin-creasedclassificationaccuracyonalldatasetsandseemedtohelpwithperplexityonAGNews,DBPe-dia,andTripAdvisor.Figure5:ComparisonoftheeffectofLSTMparametercountandFactorCellrankhyperparametersonperplexityforDBPedia.Figure5comparestheeffectonperplexityoftheLSTMparametercountandtheFactorCellrankhy-perparameters.Eachpointinthoseplotsrepresentsaseparateinstanceofthemodelwithvariedhy-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
505
perparameters.IntherightsubplotofFigure5,weseethatincreasingtherankhyperparameterim-provesperplexity.Thisisconsistentwithourhy-pothesisthatincreasingtherankcanletthemodeladaptmore.Thevarianceislargebecausediffer-encesinotherhyperparameters(suchashiddenstatesize)alsohaveanimpact.IntheleftsubplotwecomparetheperformanceoftheFactorCellwiththeConcatCellasthesizeofthewordembeddingsandrecurrentstatechange.Thex-axisisthesizeoftheWrecurrentweightmatrix,specifically3(e+d)dforanLSTMwith3gates.Sincetheadaptedweightscanbeprecomputed,thecomputationalcostisroughlythesameforpointswiththesamex-value.Forafixed-sizehiddenstate,theFactorCellmodelhasabetterperplexitythantheConcatCell.Sinceperformancecanbeimprovedbothbyin-creasingtherecurrentstatedimensionand/orbyin-creasingrank,weexaminedtherelativebenefitsofeach.TheperplexityofaFactorCellmodelwithanLSTMsizeof120Kwillimproveby5%whentherankisincreasedfrom0to20.Togetthesamede-creaseinperplexitybychangingthesizeofthehid-denstatewouldrequire160Kparameters,resultinginasignificantcomputationaladvantagefortheFac-torCellmodel.Usingaone-hotvectorforadaptingthesoftmaxbiaslayerinplaceofthecontextembeddingwhenadaptingthesoftmaxbiasvectortendedtohavealargepositiveeffectonaccuracyleavingperplexitymostlyunchanged.RecallfromSection2.3thatifthenumberofvaluesthatacontextvariablecantakeonissmallthenwecanallowthemodeltochoosebetweenusingthelow-dimensionalcontextembed-dingoraone-hotvector.Thisoptionisnotavail-ablefortheTripAdvisorandtheGeoTwitterdatasetsbecausethedimensionalityoftheirone-hotvectorswouldbetoolarge.Themethodofadaptingthesoft-maxbiasisthemainexplanationforwhysomeCon-catCellmodelsperformedsignificantlyabove/belowthetrendlineforDBPediainFigure1.Weexperimentedwithanadditionalhyperparam-eterontheYelpdataset,namelytheinclusionoflayernormalization(Baetal.,2016).(Wehadruled-outusinglayernormalizationinpreliminaryworkontheAGNewsdatabeforeweunderstoodthatAG-Newsisnotrepresentative,soonlyonetaskwasexploredhere.)LayernormalizationsignificantlyhelpedtheperplexityonYelp(≈2%relativeim-provement)andallofthetop-performingmodelsontheheld-outdevelopmentdatahaditenabled.4.5AnalysisforSparseContextsTheTripAdvisordataisaninterestingcasebecausetheoriginalcontextspaceishighdimensional(3500hotels×5userratings)andsparse.Sincethemodelappliesend-to-endlearning,wecaninvestigatewhatthecontextembeddingslearn.Inparticular,welookedatlocation(hotelsarefrom25citiesintheUnitedStates)andclassofhotel,neitherofwhichareinputtothemodel.Allofwhatitlearnsabouttheseconceptscomefromextractinginformationfromthetextofthereviews.Tovisualizetheembedding,weuseda2-dimensionalPCAprojectionoftheembeddingsofthe3500hotels.Wefoundthatthemodellearnstogroupthehotelsbasedongeographicregion;theprojectedembeddingsforthelargestcitiesareshowninFigure6,plottingthe1.5σellipsoidoftheGaussiandistributionofthepoints.(Actualpointsarenotshowntoavoidclutter.)Notonlyarehotelsfromthesamecitygroupedtogether,citiesthatareclosegeographicallyappearclosetoeachotherintheembeddingspace.CitiesintheSouthwestap-pearontheleftofthefigure,theWestcoastisontopandtheEastcoastandMidwestisontherightside.Thisislikelydueinparttotheimpactoftheregiononactivitiesthatguestsmaymention,buttherealsoappearstobeageographicsamplingbiasinthehotelclassthatmayimpactlanguageuse.Classisaratingfromanindependentagencythatindicatesthelevelofserviceandamenitiesthatcus-tomerscanexpecttoreceiveatahotel.Whereas,thestarratingistheaveragescoregiventoeachestab-lishmentbythecustomerswhoreviewedit.Hotelclassdoesnotdeterminestarratingalthoughtheyarecorrelated(r=0.54).Thedatasetdoesnotcontainauniformsampleofhotelclassesfromeachcity.ThehotelsincludedfromBoston,Chicago,andPhillyarealmostexclusivelyhighclassandtheonesfromL.A.andSanDiegohappentobelowclass,sotheembeddingdistributionsalsoreflecthotelclass:lowerclasshotelstowardsthetopleftandhigherclasshotelstowardsthebottomright.Thevisual-izationfortheConcatCellandSoftmaxBiasmodels
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
506
Figure6:DistributionofaPCAprojectionofhotelem-beddingsPCAfromtheTripAdvisorFactorCellmodelshowingthegroupingofthehotelsbycity.aresimilar.AnotherwayofunderstandingwhatthecontextembeddingsrepresentistocomputethesoftmaxbiasprojectionQcandexaminethewordsthatexperi-encethebiggestincreaseinprobability.WeshowthreeexamplesinTable5.Ineachcase,thetopwordsarestronglyrelatedtogeographyandincludenamesofneighborhoods,localattractions,andotherhotelsinthesamecity.Thetopboostedwordsarerelativelyunaffectedbychangingtherating.(Recallthatthehotelidentifierandtheuserratingaretheonlytwoinputsusedtocreatethecontextembed-ding.)Thistablecombinedwiththeothervisualiza-tionsindicatesthatlocationeffectstendtodominateintheoutputlayer,whichmayexplainwhythetwomodelsadaptingtherecurrentnetworkseemtohaveabiggerimpactonclassificationperformance.5PriorWorkTherehavebeenmanystudiesofneurallanguagemodelsthatcanbedynamicallyadaptedbasedoncontext.Methodshavebeenreferredtoascontext-dependentmodels(MikolovandZweig,2012),context-awaremodels(Tangetal.,2016),condi-tionedmodels(FiclerandGoldberg,2017),andcon-trollabletextgeneration(Huetal.,2017).Thesemodelshavebeenusedinscoringwordsequences(suchasforspeechrecognitionormachinetrans-lation),fortextclassification,andforgeneration.Insomework,contextcorrespondstothepreviouswordhistory.Here,weinsteadconsiderknownfac-torssuchasuser,locationanddomainmetadata,thoughtheframeworkcouldbeusedwithhistory-basedcontext.ThestudiesthatmostdirectlyrelatetoourworkareneuralmodelsthatcorrespondtospecialcasesofthemoregeneralFactorCellmodel,includingthosethatleveragewhatwecalltheSoftmaxBiasmodel(Diengetal.,2017;Tangetal.,2016;Yogatamaetal.,2017;FiclerandGoldberg,2017)andothersthatusetheConcatCellapproach(MikolovandZweig,2012;Wenetal.,2013;Chenetal.,2015;Ghoshetal.,2016).Onestudy(Jietal.,2016)comparesthetwoapproaches,whichtheyrefertoasccDCLMandcoDCLM.Theyfindthatbothapproachesgivesim-ilarperplexities,buttheirConcatCellstylemodeldoesbetteratanauxiliarysentenceorderingtask.Thisisconsistentwithourfindingthatadaptingattherecurrentlayercanbenefitcertaintaskswhilehavingonlyaminorimpactonperplexity.Theydonottestanymodelsthatadaptboththerecurrentandoutputlayers.Hoangetal.(2016)alsoconsideradaptingatthehiddenlayervs.atthesoftmaxlayer,buttheirarchitecturedoesnotfitcleanlyintotheframeworkoftheSoftmaxBiasmodelbecausetheyuseanextraperceptronlayer;thus,itisdifficulttocomparetheexperimentalfindingswithours.TheFactorCellmodelisdistinguishedbyhav-inganadditive(factored)context-dependenttrans-formationoftherecurrentlayerweightmatrix.Arelatedadditivecontext-dependenttransformationhasbeenproposedforlog-bilinearsequencemod-els(Eisensteinetal.,2011;Hutchinsonetal.,2015),butthesearelesspowerfulthantheRNN.Asome-whatdifferentuseoflow-rankfactorizationhaspre-viouslybeenusedtoreducetheparametercountinanLSTMLM(KuchaievandGinsburg,2017),find-ingthatthereducednumberofparametersleadstofastertraining.Thereisalonghistoryofadaptingn-gramlan-guagemodels(seeDeMoriandFederico(1999)orBellegarda(2004)forasurvey).OnerecentexampleisChelbaandShazeer(2015)wherea34%relativeimprovementinperplexitywasobtainedwhenus-inggeographicfeaturesforadaptation.Wehypoth-esizethattheimpressiveimprovementinperplexityispossiblebecausethelanguageintheirdatasetofGooglemobilesearchqueriesisparticularlysensi-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
507
HotelCityClassRatingTopBoostedWordsAmalfiChicago4.05amalfi,chicago,allegro,burnham,sable,michi-gan,acme,conrad,talbott,wrigleyBLVDHotelSuitesLosAngeles2.53hollywood,kodak,highland,universal,reseda,griffith,grauman’s,beverly,venturaFourPointsSheratonSeattle3.01seattle,pike,watertown,deca,needle,pikes,pike’smonorail,uw,safecoTable5:ThetopboostedwordsintheSoftmaxbiaslayerfordifferentcontextsettingsinaFactorCellmodel.tivetolocation.Comparedton-grambasedLMs,ourmodelhastwoadvantagesinthewaythatithan-dlescontext.First,asweshowedinourGeoTwitterexperiments,wecanadapttogeographyusingGPScoordinatesasinputwithoutusingpredefinedgeo-graphicregionsasinChelbaandShazeer.Second,ourmodelsupportsthejointeffectofmultiplecon-textualvariables.Neuralmodelshaveanadvantageoverdiscretemodelsasthenumberofcontextvari-ablesincreases.Muchoftheworkoncontext-adaptiveneurallan-guagemodelshasfocusedonincorporatingdoc-umentortopicinformation(MikolovandZweig,2012;Jietal.,2016;Ghoshetal.,2016;Diengetal.,2017),wherecontextisdefinedintermsofwordorn-gramstatistics.Ourworkdiffersfromthesestudiesinthatthecontextisdefinedbyavarietyofsources,includingdiscreteand/orcontinuousmetadata,whichismappedtoacon-textvectorinend-to-endtraining.Context-sensitivelanguagemodelsfortextgenerationtendtoin-volveotherformsofcontextsimilartotheob-jectiveofourwork,includingspeakercharacter-istics(Luanetal.,2016;Lietal.,2016),dialogact(Wenetal.,2015),sentimentandotherfactors(Tangetal.,2016;Huetal.,2017),andstyle(FiclerandGoldberg,2017).Asnotedearlier,someofthisworkhasuseddiscriminativetextclassificationtoevaluategeneration.InpreliminaryexperimentswiththeYelpdataset,wefoundthatthegenerativeclassifieraccuracyofourmodelishighlycorrelatedwithdiscriminativeclassfieraccuracy(r≈0.95).Thus,bythismeasure,weanticipatethatthemodelwouldbeusefulforgenerationapplications.Anec-dotally,wefindthatthemodelgivesmorecoherentgenerationresultsforDBPediadata,butfurtherval-idationwithhumanratingsisnecessarytoconfirmthebenefitsonmoresources.6ConclusionsInsummary,thispaperhasintroducedanewmodelforadapting(orcontrolling)alanguagemodelde-pendingoncontextualmetadata.TheFactorCellmodelextendspriorworkwithcontext-dependentRNNsbyusingthecontextvectortogeneratealow-rank,factored,additivetransformationoftherecur-rentcellweightmatrix.ExperimentswithsixtasksshowthattheFactorCellmodelmatchesorexceedsperformanceofalternativemethodsinbothperplex-ityandtextclassificationaccuracy.Findingsholdforavarietyoftypesofcontext,includinghigh-dimensionalcontexts,andtheadaptationofthere-currentlayerisparticularlyimportantforcharacter-levelmodels.Formanycontexts,thebenefitoftheFactorCellmodelcomeswithessentiallynoad-ditionalcomputationalcostattesttime,sincethetransformationscanbepre-computed.Analysesofadatasetwithahigh-dimensionalsparsecontextvec-torshowthatthemodellearnscontextsimilaritiestofacilitateparametersharing.Inallsixtasksthatareexploredhere,allcontextfactorsareavailableforalltrainingandtestingsam-ples.Insomescenarios,itmaybepossibleforsomecontextfactorstobemissing.Asimplesolutionforhandlingthisistousetheexpectedvalueforthemissingvariable(s),sincethisisequivalenttousingaweightedcombinationoftheadaptationmatricesforthedifferentpossiblevaluesofthemissingvari-ables.Inthiswork,theexperimentscenariosallusedmetadatatospecifycontext,sincethistypeofcon-textcanbemoresensitivetodatasparsityandhasbeenlessstudied.Incontrast,inmanypriorstudiesoflanguagemodeladaptation,contextisspecifiedintermsoftextsamples,suchasprioruserqueries,priorsentencesinadialog,otherdocumentsrelated
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
508
intermsoftopicorstyle,etc.TheFactorCellframe-workintroducedhereisalsoapplicabletothistypeofcontext,butthebestencodingofthetextintoanembedding(e.g.usingbagofwords,sequencemod-els,etc.)islikelytovarywiththeapplication.TheFactorCellcanalsobeusedwithonlinelearningofcontextvectors,e.g.totakeadvantageofprevioustextfromaparticularauthor(orspeaker)(JaechandOstendorf,2018).Themodelsevaluatedhereweretunedtomini-mizeperplexity,asistypicalforlanguagemodel-ing.Inanalysesofperformancewithdifferenthy-perparametersettings,wefindthatperplexityisnotalwayspositivelycorrelatedwithaccuracy,butthecriteriaaremoreoftencorrelatedforapproachesthatadapttherecurrentlayer.Whilenotsurprising,theresultsraiseconcernsaboutusingperplexityasthesoleevaluationmetricforcontext-awarelanguagemodels.Moreworkisneededtounderstandtherel-ativeutilityoftheseobjectivesforlanguagemodeldesign.AcknowledgmentsThisresearchwassupportedinpartbyaGoogleFacultyResearchAward.ReferencesJimmyLeiBa,JamieRyanKiros,andGeoffreyEHin-ton.2016.Layernormalization.arXivpreprintarXiv:1607.06450.JeromeR.Bellegarda.2004.Statisticallanguagemodeladaptation:Reviewandperspectives.SpeechCommu-nication,42(1):93–108.CiprianChelbaandNoamShazeer.2015.Sparsenon-negativematrixlanguagemodelingforgeo-annotatedquerysessiondata.InProc.IEEEWorkshoponAuto-maticSpeechRecognitionandUnderstanding,pages8–14.XieChen,TianTan,XunyingLiu,PierreLanchantin,MoquanWan,MarkJ.F.Gales,andPhilipC.Wood-land.2015.Recurrentneuralnetworklanguagemodeladaptationformulti-genrebroadcastspeechrecogni-tion.InProc.Interspeech,pages3511–3515.JunyoungChung,KyunghyunCho,andYoshuaBengio.2016.Acharacter-leveldecoderwithoutexplicitseg-mentationforneuralmachinetranslation.Proc.An-nualMeetingoftheAssoc.forComputationalLinguis-tics(Proc.ACL),pages1693–1703.RenatoDeMoriandMarcelloFederico.1999.Languagemodeladaptation.InComputationalModelsofSpeechPatternProcessing,pages280–303.Springer.AdjiB.Dieng,ChongWang,JianfengGao,andJohnPaisley.2017.TopicRNN:Arecurrentneuralnetworkwithlong-rangesemanticdependency.InProc.Int.Conf.LearningRepresentations(Proc.ICLR).JacobEisenstein,AmrAhmed,andEricXing.2011.Sparseadditivegenerativemodelsoftext.InProc.Int.Conf.MachineLearning(Proc.ICML).JessicaFiclerandYoavGoldberg.2017.Control-linglinguisticstyleaspectsinneurallanguagegenera-tion.InProc.Conf.onEmpiricalMethodsinNaturalLanguageProcessing(EMNLP)WorkshoponStylisticVariation,pages94–104.ShaliniGhosh,OriolVinyals,BrianStrope,ScottRoy,TomDean,andLarryHeck.2016.ContextualLSTMmodelsforlargescaleNLPtasks.arXivpreprintarXiv:1602.06291.AwniHannun,CarlCase,JaredCasper,BryanCatan-zaro,GregDiamos,ErichElsen,RyanPrenger,San-jeevSatheesh,ShubhoSengupta,AdamCoates,etal.2014.Deepspeech:Scalingupend-to-endspeechrecognition.arXivpreprintarXiv:1412.5567.CongDuyVuHoang,TrevorCohn,andGholamrezaHaf-fari.2016.Incorporatingsideinformationintore-currentneuralnetworklanguagemodels.InProc.HumanLanguageTechnologyConf.andConf.NorthAmericanChapterAssoc.forComputationalLinguis-tics(HLT-NAACL),pages1250–1255.ZhitingHu,ZichaoYang,XiaodanLiang,RuslanSalakhutdinov,andEricP.Xing.2017.Controllabletextgeneration.Proc.ICML.BrianHutchinson,MariOstendorf,andMaryamFazel.2015.Asparsepluslow-rankexponentiallanguagemodelforlimitedresourcescenarios.IEEETrans.Au-dio,SpeechandLanguageProcessing,23(3):494–504.HakanInan,KhashayarKhosravi,andRichardSocher.2017.Tyingwordvectorsandwordclassifiers:Alossframeworkforlanguagemodeling.InProc.ICLR.AaronJaechandMariOstendorf.2018.Personalizedlanguagemodelforqueryauto-completion.InProc.ACL,pages2–6.AaronJaech,GeorgeMulcaire,ShobhitHathi,MariOs-tendorf,andNoahA.Smith.2016.Hierarchicalcharacter-wordmodelsforlanguageidentification.InProc.EMNLPWorkshoponNaturalLanguagePro-cessingforSocialMedia.S´ebastienJean,KyunghyunCho,RolandMemisevic,andYoshuaBengio.2014.Onusingverylargetargetvocabularyforneuralmachinetranslation.InProc.AnnualMeetingoftheAssociationforComputationalLinguisticsandtheInternationalJointConferenceonNaturalLanguageProcessing,pages1–10.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
509
YangfengJi,TrevorCohn,LingpengKong,ChrisDyer,andJacobEisenstein.2016.Documentcontextlan-guagemodels.InProc.ICLR.AndrejKarpathy,JustinJohnson,andLiFei-Fei.2015.Visualizingandunderstandingrecurrentnetworks.InProc.ICLR.OleksiiKuchaievandBorisGinsburg.2017.Factoriza-tiontricksforLSTMnetworks.InProc.ICLR.JiweiLi,MichelGalley,ChrisBrockett,JianfengGao,andBillDolan.2016.Apersona-basedneuralconver-sationmodel.InProc.ACL,pages994–1003.YiLuan,YangfengJi,andMariOstendorf.2016.LSTMbasedconversationmodels.arXivpreprintarXiv:1603.09457.G´aborMelis,ChrisDyer,andPhilBlunsom.2018.Onthestateoftheartofevaluationinneurallanguagemodels.InProc.ICLR.TomasMikolovandGeoffreyZweig.2012.Contextde-pendentrecurrentneuralnetworklanguagemodel.InProc.IEEESpokenLanguageTechnologyWorkshop(SLT),pages234–239.GiovanniMolina,FahadAlGhamdi,MahmoudGhoneim,AbdelatiHawwari,NicolasRey-Villamizar,MonaDiab,andThamarSolorio.2016.Overviewforthesecondsharedtaskonlanguageidentifica-tionincode-switcheddata.InProc.WorkshoponComputationalApproachestoCodeSwitching,pages40–49.OfirPressandLiorWolf.2017.Usingtheoutputem-beddingtoimprovelanguagemodels.InProc.Eu-ropeanChapterAssoc.forComputationalLinguistics(EACL),pages157–1763.AlecRadford,RafalJozefowicz,andIlyaSutskever.2017.Learningtogeneratereviewsanddiscoveringsentiment.arXivpreprintarXiv:1704.01444.NilsReimersandIrynaGurevych.2017.Reportingscoredistributionsmakesadifference:PerformancestudyofLSTM-networksforsequencetagging.InProc.EMNLP,pages338–348.StanislauSemeniuta,AliakseiSeveryn,andErhardtBarth.2016.Recurrentdropoutwithoutmemoryloss.InProc.Int.Conf.ComputationalLinguistics(COL-ING),pages1757–1766.JianTang,YifanYang,SamCarton,MingZhang,andQiaozhuMei.2016.Context-awarenaturallanguagegenerationwithrecurrentneuralnetworks.arXivpreprintarXiv:1611.09900.Tsung-HsienWen,AaronHeidel,Hung-yiLee,YuTsao,andLin-ShanLee.2013.Recurrentneuralnetworkbasedlanguagemodelpersonalizationbysocialnet-workcrowdsourcing.InProc.Interspeech,pages2703–2707.Tsung-HsienWen,MilicaGasic,NikolaMrksic,Pei-HaoSu,DavidVandyke,andSteveYoung.2015.Semanti-callyconditionedLSTM-basednaturallanguagegen-erationforspokendialoguesystems.InProc.EMNLP,pages1711–1721.DaniYogatama,ChrisDyer,WangLing,andPhilBlun-som.2017.Generativeanddiscriminativetextclassi-ficationwithrecurrentneuralnetworks.arXivpreprintarXiv:1703.01898.XiangZhang,JunboZhao,andYannLeCun.2015.Character-levelconvolutionalnetworksfortextclassi-fication.InProc.Annu.Conf.NeuralInform.Process.Syst.(NIPS),pages649–657.ArkaitzZubiaga,InakiSanVicente,PabloGamallo,Jos´eRamomPichelCampos,I˜nakiAlegr´ıaLoinaz,NoraAranberri,AitzolEzeiza,andV´ıctorFresno-Fern´andez.2014.OverviewofTweetLID:Tweetlan-guageidentificationatSEPLN2014.InTweetLIDWorkshopattheAnnualConferenceoftheSpanishSocietyforNaturalLanguageProcessing(SEPLN),pages1–11.ALSTMFactorCellEquationsOnlytrivialchangesareneededtousetheFactor-CellmethodonanLSTMinsteadofavanillaRNN.Here,welisttheequationsforanLSTMwithcou-pledinputandforgetgates,whichiswhatwasusedinourexperiments.TheweightmatrixWfromEquation1isnowsize3d×(e+d)andbisdimension3d,where3isthenumberofgates.Likewise,ZRfromEquation3ismadetobeofsizer×3d×k.TheweightmatrixW0isasdefinedinEquation4andaftercomputingit’sproductwiththeinput[wt,ht−1],theresultissplitintothreevectorsofequalsize:it,ft,andot[it,ft,ot]=W0[wt,ht−1]+b,(8)whereit,ftandotareusedintheinputgate,theforgetgate,andtheoutputgate,respectively.Usingthesethreevectorsweperformthegatingoperationstocomputehtusingthememorycellmtasfollows:ft←sigmoid(ft+1.0)mt=mt−1(cid:12)ft+(1.0−ft)(cid:12)tanh(it)ht=tanh(mt)(cid:12)sigmoid(ot)(9)Notethatequation2,whichshowsthatacon-textvectorconcatenatedwithinputisequivalenttoanadditivebiasterm,extendstoequation8.In
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
0
3
5
1
5
6
7
6
6
0
/
/
t
l
a
c
_
a
_
0
0
0
3
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
510
otherwords,intheLSTMversionoftheConcatCellmodel,thecontextvectoreffectivelyintroducesanextrabiastermforeachofthe3gates.