计算语言学协会会刊, 卷. 6, PP. 329–342, 2018. 动作编辑器: Ivan Titov.
提交批次: 1/2018; 修改批次: 3/2018; 已发表 5/2018.
2018 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
C
(西德:13)
NativeLanguageCognateEffectsonSecondLanguageLexicalChoiceEllaRabinovich?NYuliaTsvetkov†ShulyWintner??DepartmentofComputerScience,UniversityofHaifaNIBMResearch†LanguageTechnologiesInstitute,CarnegieMellonUniversityellarabi@gmail.com,ytsvetko@cs.cmu.edushuly@cs.haifa.ac.ilAbstractWepresentacomputationalanalysisofcog-nateeffectsonthespontaneouslinguisticpro-ductionsofadvancednon-nativespeakers.In-troducingalargecorpusofhighlycompetentnon-nativeEnglishspeakers,andusingasetofcarefullyselectedlexicalitems,weshowthatthelexicalchoicesofnon-nativesareaf-fectedbycognatesintheirnativelanguage.ThiseffectissopowerfulthatweareabletoreconstructthephylogeneticlanguagetreeoftheIndo-EuropeanlanguagefamilysolelyfromthefrequenciesofspecificlexicalitemsintheEnglishofauthorswithvariousnativelanguages.Wequantitativelyanalyzenon-nativelexicalchoice,highlightingcognatefa-cilitationasoneoftheimportantphenomenashapingthelanguageofnon-nativespeakers.1IntroductionAcquisitionofvocabularyandsemanticknowledgeofasecondlanguage,includingappropriatewordchoiceandawarenessofsubtlewordmeaningcon-tours,arerecognizedasanotoriouslyhardtask,evenforadvancednon-nativespeakers.Whennon-nativeauthorsproduceutterancesinaforeignlan-guage(L2),theseutterancesaremarkedbytracesoftheirnativelanguage(L1).Suchtracesareknownastransfereffects,andtheycanbephonological(aforeignaccent),morphological,词汇的,orsyn-tactic.Specifically,psycholinguisticresearchhasshownthatthechoiceoflexicalitemsisinfluencedbytheauthor’sL1,andthatnon-nativespeakerstendtochoosewordsthathappentohavecognatesintheirnativelanguage.Cognatesarewordsintwolanguagesthatsharebothasimilarmeaningandasimilarphonetic(和,有时,alsoorthographic)形式,duetoacom-monancestorinsomeprotolanguage.Thedefinitionissometimesalsoextendedtowordsthathavesim-ilarformsandmeaningsduetoborrowing.Moststudiesoncognatefacilitationhavebeenconductedwithfewhumansubjects,focusingonfewwords,andtheexperimentalsetupwassuchthatpartici-pantswereaskedtoproducelexicalchoicesinanartificialsetting.Wedemonstratethatcognatesaf-fectlexicalchoiceinL2spontaneousproductiononamuchlargerscale.Usinganewanduniquelargecorpusofnon-nativeEnglishthatweintroduceaspartofthiswork,weidentifyafocussetofover1000words,andshowthattheyaredistributedverydifferentlyacrossthe“Englishes”ofauthorswithvariousL1s.Impor-tantly,wegotogreatlengthstoguaranteethatthesewordsdonotreflectspecificpropertiesofthevar-iousnativelanguages,theculturesassociatedwiththem,orthetopicsthatmayberelevantforparticu-largeographicregions.Rather,theseare“ordinary”words,withverylittleculture-specificweight,thathappentohavesynonymsinEnglishthatmayre-flectcognatesinsomeL1s,butnotallofthem.Con-sequently,theyareuseddifferentlybyauthorswithdifferentlinguisticbackgrounds,totheextentthattheauthors’L1scanbeidentifiedthroughtheiruseofthewordsinthefocusset.ThesignalofL1issopowerful,thatweareabletoreconstructalinguistictypologytreefromthedistributionofthesewordsintheEnglisheswitnessedinthecorpus.Weproposeamethodologyforcreatingafocussetofhighlyfrequent,unbiasedwordsthatweex-pecttobedistributeddifferentlyacrossdifferentEn-glishessimplybecausetheyhappentohavesyn-onymswithdifferentetymologies,eventhoughthey
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
330
carryverylimitedculturalweight.Then,weshowthatsimplelexicalsemanticfeatures(basedonthefocussetofwords)sufficeforclusteringtogetherEnglishtextsauthoredbyspeakersof“closer”lan-guages;wegenerateaphylogenetictreeof31lan-guagessolelybylookingatlexicalsemanticprop-ertiesoftheEnglishspokenbynon-nativespeakersfrom31countries.Thecontributionofthisworkistwofold.First,weintroducetheL2-Redditcorpus:alargecorpusofhighly-advanced,fluent,diverse,non-nativeEn-glish,withsentence-levelannotationsofthenativelanguageofeachauthor.Second,welayoutsoundempiricalfoundationsforthetheoreticalhypothesisonthecognateeffectinL2ofnon-nativeEnglishspeakers,highlightingthecognatefacilitationphe-nomenonasoneoftheimportantfactorsshapingthelanguageofnon-nativespeakers.AfterdiscussingrelatedworkinSection2,wede-scribetheL2-RedditcorpusinSection3.Section4detailsthemethodologyweuseandourresults.WeanalyzetheseresultsinSection5,andconcludewithsuggestionsforfutureresearch.2RelatedWorkThelanguageofbilingualsisdifferent.Themutualpresenceoftwolinguisticsystemsinthemindofthebilingualspeakerinvolvesasignificantcogni-tiveload(Shlesinger,2003;Hvelplund,2014;事先的,2014;Krolletal.,2014);thisburdenislikelytohaveabearingonthelinguisticproductionsofthebilin-gualspeaker.Moreover,thepresenceofmorethanonelinguisticsystemgivesrisetotransfer:tracesofonelinguisticsystemmaybeobservedintheotherlanguage(JarvisandPavlenko,2008).Severalworksaddressedthetranslationchoicesofbilingualspeakers,eitherwithinarichlinguis-ticcontext(e.g.,givenasourcesentence),ordecon-textualized.Forexample,deGroot(1992)demon-stratedthatcognatetranslationsareproducedmorerapidlyandaccuratelythantranslationsthatdonotexhibitphoneticororthographicsimilaritywithasourceword.Thisobservationwasfurtherarticu-latedbyPrioretal.(2007),whoshowedthattrans-lationchoicesofL2speakerswerepositivelycorre-latedwithcross-linguisticformoverlapofastimu-luswordwithitstargetlanguagetranslations.Prioretal.(2011)emphasizedthat“bilingualsaresensi-tivetothedegreeofformoverlapbetweenthetrans-lationequivalentsinthetwolanguages,andshowapreferencetowardproducingacognatetranslation”.Asanexample,theyshowedthatthepreferredtrans-lationoftheSpanishincidentetoEnglishwasinci-dent,andnotthealternativetranslationevent,de-spitethemuchhigherfrequencyofthelatter.Morerecentworkisconsistentwithpreviousre-searchandadvancesitbyhighlightingphonolog-icallymediatedcross-lingualinfluencesonvisualwordprocessingofsame-anddifferent-scriptbilin-guals(DeganiandTokowicz,2010;Deganietal.,2017).Cognatefacilitationwasalsostudiedusingeyetracking(LibbenandTitone,2009;Copetal.,2017),demonstratingthatthereadingofbilingualsisinfluencedbyorthographicsimilarityofwordswiththeirtranslationequivalentsinanotherlan-guage.Crucially,muchofthisresearchhasbeenconductedinalaboratoryexperimentalsetup;thisimpliesasmallnumberofparticipants,asmallnum-beroftargetwords,andfocusonaverylimitedsetoflanguages.Whileourresearchquestionsaresim-ilar,wepresentacomputationalanalysisoftheef-fectsofcognatesonL2productionsonacompletelydifferentscale:31语言,over1000words,andthousandsofspeakerswhosespontaneouslanguageproductionisrecordedinaverylargecorpus.Corpus-basedinvestigationofnon-nativelan-guagehasbeenaprolificfieldofrecentresearch.NumerousstudiesaddresssyntactictransfereffectsonL2.SuchinfluencesfromL1facilitatevariouscomputationaltasks,includingautomaticdetectionofhighlycompetentnon-nativewriters(TomokiyoandJones,2001;Bergsmaetal.,2012),identifica-tionofthemothertongueofEnglishlearners(Kop-peletal.,2005;Tetreaultetal.,2013;Tsvetkovetal.,2013;Malmasietal.,2017)andtypology-drivenerrorpredictioninlearners’speech(Berzaketal.,2015).Englishtextsproducedbynativespeakersofavarietyoflanguageshavebeenusedtorecon-structphylogenetictrees,withvaryingdegreesofsuccess(NagataandWhittaker,2013;Berzaketal.,2014).Syntacticpreferencesofprofessionaltransla-torswereexploitedtoreconstructtheIndo-Europeanlanguagetree(Rabinovichetal.,2017).Ourstudyisalsocorpus-based;butitstandsoutasitfocusesnotonthedistributionoffunctionwordsor(shallow)syntacticstructures,butratherontheuniqueuseof
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
331
cognatesinL2.Fromthelexicalperspective,L2writershavebeenshowntoproducemoreovergeneralizations,usemorefrequentwordsandwordswithalowerde-greeofambiguity(Hinkel,2002;CrossleyandMc-Namara,2011).Severalstudiesaddressedcross-linguisticinfluencesonsemanticacquisitioninL2,investigatingthedistributionofcollocations(Siyanova-Chanturia,2015;KochmarandShutova,2017)andformulaiclanguage(PaquotandGranger,2012)inlearnercorpora.We,incontrast,addresshighly-fluent,advancednon-nativesinthiswork.NastaseandStrapparava(2017)presentedthefirstattempttoleverageetymologicalinformationforthetaskofnativelanguageidentificationofEnglishlearners.Theysowedtheseedsforexploitationofetymologicalcluesinthestudyofnon-nativelan-guage,buttheirresultswereveryinconclusive.Incontrasttothelearnercorporathatdominatestudiesinthisfield(Granger,2003;Geertzenetal.,2013;Blanchardetal.,2013),ourcorpuscontainsspontaneousproductionsofadvanced,highlyprofi-cientnon-nativespeakers,spanningover80Ktop-icalthreads,by45Kdistinctusersfrom50coun-tries(with46nativelanguages).Tothebestofourknowledge,thisisthefirstattempttocomputation-allystudytheeffectofL1cognatesonL2lexicalchoiceinproductionsofcompetentnon-nativeEn-glishspeakers,certainlyatsuchalargescale.3TheL2-RedditcorpusOnecontributionofthisworkisthecollection,orga-nizationandannotationofalargecorpusofhighly-fluentnon-nativeEnglish.Wedescribethisnewanduniquecorpusinthissection.3.1CorpusminingReddit1isanonlinecommunity-drivenplatformconsistingofnumerousforumsfornewsaggrega-tion,contentrating,anddiscussions.Asof2017,ithasover200millionuniqueusers,rankingthefourthmostvisitedwebsiteintheUS.Contenten-triesareorganizedbyareasofinterestcalledsubred-dits,2rangingfrommainforumsthatreceivemuchattentiontosmalleronesthatfosterdiscussionon1https://www.reddit.com/2Subredditsaretypicallydenotedwithaleadingr/,forex-ampler/linguisticsisthe‘linguistics’subreddit.nicheareas.Subreddittopicsincludenews,科学,电影,图书,音乐,fitnessandmanyothers.CollectionofauthormetadataWecollectedalargedatasetofposts(bothinitialsubmissionsandsubsequentcomments)usinganAPIespe-ciallydesignedforprovidingsearchcapabilitiesonRedditcontent.3Wefocusedonseveralsub-reddits(r/Europe,r/AskEurope,r/EuropeanCulture,r/EuropeanFederalists,r/Eurosceptics)whosecon-tentisgeneratedbyuserswhospecifiedtheircoun-tryasaflair(metadataattribute).Althoughcate-gorizedas‘European’,thesesubredditsareusedbypeoplefromallovertheworld,expressingviewsonpolitics,legislation,经济学,文化,etc.Intheabsenceofarestrictivepolicy,multipleflairalternativesoftenexistforthesamecountry,e.g.,‘CROA’and‘Croatia’forCroatia.Additionally,dis-tinctflairsaresometimesusedforregions,城市,orstatesofbigEuropeancountries,e.g.,‘Bavaria’forGermany.We(manually)groupedflairsrepresent-ingthesamecountryintoasinglecluster,reducing489distinctflairsinto50countries,fromAlbaniatoVietnam.ThepostsintheEurope-relatedsub-redditsconstituteourseedcorpus,comprising9Msentences(160Mtokens)byover45Kdistinctusers.DatasetexpansionAtypicaluseractivityinRed-ditisnotlimitedtoasinglethread,butratherspreadsacrossmultiple,notnecessarilyrelated,areasofin-terest.Oncetheauthors’countryisdeterminedbasedontheirEuropeansubmissions,theirentireRedditfootprintcanbeassociatedwiththeirprofile,和,所以,withtheircountryoforigin.Weex-tendedourseedcorpusbyminingallsubmissionsofuserswhosecountryflairisknown,queryingallRedditdataspanningyears2005-2017.Thefinaldatasetthuscontainsover250Msentences(3.8Btokens)ofnativeandnon-nativeEnglishspeakers,whereeachsentenceisannotatedwithitsauthor’scountryoforigin.Thedatacoverspostsbyover45Kauthorsandspansover80Ksubreddits.4Focuson“large”languagesForthesakeofro-bustness,welimitedthescopeofthisworkto(coun-3https://github.com/pushshift/api4Theannotateddatasetwillfreelyavailableathttp://cl.haifa.ac.il/projects/L2.ToprotecttheanonymityofRedditusers,thereleaseddatasetdoesnotexposeanyauthoridentifyinginformation.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
332
trieswhoseL1sare)theIndo-European(IE)lan-guages;andonlytothosecountrieswhoseusershadatleast500Ksentencesinthecorpus.Additionally,weexcludedmultilingualcountries,suchasBel-giumandSwitzerland.Consequently,thefinalsetofRedditauthorsconsideredinthisworkoriginatefrom31countries,whichrepresentthethreemainIElanguagefamilies:Germanic(奥地利,丹麦,德国,冰岛,荷兰,Norway,瑞典);浪漫(法国,意大利,墨西哥,Portugal,Roma-nia,西班牙);andBalto-Slavic(波斯尼亚,Bulgaria,Croatia,Czech,拉脱维亚,立陶宛,波兰,俄罗斯,Serbia,斯洛伐克,Slovenia,Ukraine).Inaddition,wehavedataauthoredbynativeEnglishspeakersfromAustralia,加拿大,爱尔兰,NewZealand,theUKandtheUS.CorrelationofcountryannotationwithL1Weviewthecountryinformationasanaccurate,albeitnotperfect,proxyforthenativelanguageoftheau-thor.5WeacknowledgethattheL1informationisnoisyandmayoccasionallybeinaccurate.Wethere-foreevaluatedthecorrelationofthecountryflairwithL1bymeansofsupervisedclassification:ourassumptionisthatifwecanaccuratelydistinguishamongusersfromvariouscountriesusingfeaturesthatreflectlanguage,ratherthancultureorcontent,thensuchacorrelationindeedexists.Weassumethatthenativelanguageofspeakers“shinesthrough”mainlyintheirsyntacticchoices.Consequently,weoptedfor(shallow)syntacticstructures,realizedbyfunctionwords(FW)andn-gramsofpart-of-speech(销售点)tags,ratherthangeo-graphicalandtopicalmarkers,thatarereflectedbestbycontentwords.Aimingtodisentangletheef-fectofnativelanguagewerandomlyshuffledtextsproducedbyallauthorsfromeachcountry,thereby“blurringout”anytopical(i.e.,subreddit-specific)orauthorialtrace.Consequently,weassumethattheseparabilityoftextsbycountrycanbeattributedtotheonlydistinguishinglinguisticvariableleft:thedimensionofthenativelanguageofaspeaker.Weclassified200chunksof100randomlysam-pledsentencesfromeachcountryinto(我)nativevs.non-nativeEnglishspeakers,(二)thethreeIElan-guagefamilies,和(三、)45individualL1s,where5Wethereforeusetheterms‘usercountry’,‘nativelan-guage’and‘L1’interchangeablyhenceforth.thesixEnglish-speakingcountriesareunifiedunderthenative-Englishumbrella.Usingover400func-tionwordsandtop-300mostfrequentPOS-trigrams,weobtained10-foldcross-validationaccuracyof90.8%,82.5%and60.8%,forthethreescenarios,respectively.Weconclude,所以,thatthecoun-tryflaircanbeviewedasaplausibleproxyforthenativelanguageofRedditauthors.InitialpreprocessingSeveralpreprocessingstepswereappliedonthedataset.We(我)removedtextbyuserswhochangedtheircountryflairwithintheirperiodofactivity;(二)excludednon-Englishsen-tences;6和(三、)eliminatedsentencescontainingsinglenon-alphabetictokens.Thefinalcorpuscom-prisesover230Msentencesand3.5Btokens.3.2EvaluationofauthorproficiencyUnlikemostcorporaofnon-nativespeakers,whichfocusonlearners(e.g.,ICLE(Granger,2003),EF-CAMDAT(Geertzenetal.,2013),ortheTOEFLdataset(Blanchardetal.,2013)),ourcorpusisuniqueinthatitiscomposedbyfluent,advancednon-nativespeakersofEnglish.Weverifiedthat,onaverage,Reddituserspossessexcellent,near-nativecommandofEnglishbycomparingthreedistinctpopulations:(我)RedditnativeEnglishauthors,de-finedasthosetaggedforoneoftheEnglish-speakingcountries:澳大利亚,加拿大,爱尔兰,NewZealand,andtheUK.WeexcludedtextsproducedbyUSauthorsduetothehighratiooftheUSimmigrantpopulation;(二)Redditnon-nativeEnglishauthors;和(三、)ApopulationofEnglishlearners,usingtheTOEFLdataset(Blanchardetal.,2013);这里,theproficiencyofauthorsisclassifiedaslow,interme-diate,orhigh.Wecomparedthesepopulationsacrossvariousin-dices,assessingtheirproficiencywithseveralcom-monlyacceptedlexicalandsyntacticcomplexitymeasures(LuandAi,2015;KyleandCrossley,2015).Lexicalrichnesswasevaluatedthroughtype-to-tokenratio(TTR),averageage-of-acquisition(inyears)oflexicalitems(Kupermanetal.,2012),andmeanwordrank,wheretherankwasretrievedfromalistoftheentireRedditdatasetvocabulary,sortedbywordfrequencyinthecorpus.Syntacticcom-6Weusedthepolyglotlanguagedetectiontool(http://polyglot.readthedocs.io).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
333
plexitywasassessedusingmeanlengthofT-units(TU;theminimalterminableunitoflanguagethatcanbeconsideredagrammaticalsentence),andtheratioofcomplexT-units(thosecontainingadepen-dentclause)toallT-unitsinasentence.Table1reportstheresults.Acrossalmostallin-dices,thelevelofRedditnon-nativesismuchhigherthaneventheadvancedTOEFLlearners,andalmostonparwithRedditnatives.4L1cognateeffectsonL2lexicalchoice4.1HypothesesCognatesarewordsintwolanguagesthatsharebothasimilarmeaningandasimilarform.Ourmainhy-pothesisisthatnon-nativespeakers,whenrequiredtopickanEnglishwordthathasasetofsynonyms,aremorelikelytoselectalexicalitemthathasacog-nateintheirL1.WethereforeexpecttheeffectofL1cognatestobereflectedinthefrequencyoftheirEn-glishcounterpartsinthespontaneousproductionsofL2speakers.Moreover,weexpectsimilareffects,perhapstoalesserextent,inthecontextualusageofcertainwords,reflectingcollocationsandsubtlecon-toursofwordmeaningsthataretransferredfromL1.Thedifferentcontextsthatcertainwordsareembed-dedin(intheEnglishesofspeakerswithdifferentL1backgrounds)canbecapturedbythemeansofdistributionalsemantics.Furthermore,wehypothesizethattheeffectofL1ispowerfultoanextentthatfacilitatesclusteringofEnglishesproducedbynon-nativeswith“similar”L1s;具体来说,L1sthatbelongtothesamelan-guagefamily.“Similar”L1smayreflectbothty-pologicalandarealcloseness:forexample,weex-pecttheEnglishspokenbyRomanianstobesimi-larbothtotheEnglishofItalians(asbothareRo-mancelanguages)andtotheEnglishofBulgarians(asbothareBalkanlanguages).最终,weaimtoreconstructtheIElanguagephylogeny,reflectinghistoricalandarealevolutionofthesubsetsofGer-manic,RomanceandBalto-Slaviclanguagesoverthousandsofyears,fromnon-nativeEnglishonly.WhilelexicaltransferfromL1isaknownphe-nomenoninlearnerlanguage,wehypothesizethatitssignalispresentalsointhelanguageofhighlycompetentnon-nativespeakers.Masteringthenu-ancesoflexicalchoice,includingsubtlecontoursofwordmeaningandthecorrectcontextinwhichwordstendtooccur,arekeyfactorsinadvancedlan-guagecompetence.TheL2-Redditcorpusprovidesaperfectenvironmentfortestingthishypothesis.4.2SelectionofafocussetofwordsOurgoalistoinvestigatenon-nativespeakers’choiceoflexicalitemsinEnglish.WeaddressthistaskbydefiningasetofEnglishwordsthathaveatleastonesynonym;理想地,wewouldlikethevar-ioussynonymstohavedifferentetymologies,andinparticular,tohavedifferentcognatesindifferentlanguagefamilies.Englishhappenstobeaparticu-larlygoodchoiceforthistask,sinceinspiteofitsGermanicorigins,muchofitsvocabularyevolvedfromRomance,asagreatnumberofwordswereborrowedfromOldFrenchduringtheNormanoc-cupationofBritaininthe11thcentury.TotracetheetymologicalhistoryofEnglishwordsweusedEtymologicalWordNet(EW),adatabasethatcontainsinformationabouttheances-torsofover100KEnglishwords,about25KofthemincontemporaryEnglish(deMelo,2014).ForeachwordrecordedinEW,thefullpathtoitsrootcanbereconstructed.Intuitively,anEnglishwordwithLatinrootsmayexhibithigher(phoneticandortho-graphic)proximitytoitsRomancelanguages’coun-terparts.Conversely,anEnglishwordwithaProto-Germanicancestormaybetterresembleitsequiva-lentsinGermaniclanguages.WeselectedfromEWallthenouns,动词,andadjectives.Foreachsuchwordw,weidentifiedthesynsetofwinWordNet,choosingonlythefirst(i.e.,mostprominent)senseofw(和,inpar-ticular,correspondingtothemostfrequentpart-of-speech(销售点)categoryofwintheL2-Redditdataset).然后,weretainedonlythosewordsthathadsynonyms,andonlythosewhosesynonymshadatleasttwodifferentetymologicalpaths,i.e.,syn-onymsrootedindifferentancestors.Forexample,weretainedthesynset{heaven,paradise},sincetheformerisderivedfromProto-Germanic*himin-,whilethelatterisderivedfromGreekπαράδεισος(viaLatinandOldFrench).此外,tocapturethebiasofnon-nativespeakerstowardtheirL1cognate,itmakessensetofocusonasetofeasilyinterchangeablesynonyms,例如,{划分,split}.Incontrast,consideranunbal-
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
334
PopulationMeanTUlengthComplexTUratioTTRMeanwordrankAoALearners(低的)15.5830.5130.0891172.195.186Learners(medium)16.3570.5340.1061504.015.317Learners(高的)17.4680.5280.1241852.645.562Redditnon-natives19.5280.6330.1741960.625.524Redditnatives20.1540.6580.1792063.895.575Table1:EvaluationoftheEnglishproficiencyofnon-nativeRedditusers.ancedsynset{kiss,buss,osculation}:presumably,theprevalentalternativekissislikelytobeusedbyallspeakers,regardlessoftheirnativelanguage.Toeliminatesuchcases,weexcludedsynsetsthatweredominatedbyasinglealternative(withafrequencyofover90%inourcorpus),comparedtoothersyn-onymouschoices.Table2illustratesafewexamplesofsynonymsetswiththeiretymologicalorigins.EliminatingculturalbiasAlthoughourRedditcorpusspansover80Ktopicalthreadsand45Kusers,postsproducedbyauthorsfromneighboringcountriesmaycarryovermarkerswithsimilargeo-graphicalorculturalflavor.Forexample,wemayexpecttoencountersovietmorefrequentlyinpostsbyRussiansandUkrainians,wineintextsofFrenchorItalianauthors,andrefugeesinpostsbyGermanusers.Whiletheymaybetypicaltoacertainpopu-lationgroup,suchtermsaretotallyunrelatedtothephenomenonweaddresshere,andwethereforewishtoeliminatethemfromthefocussetofwords.Acommonwaytoidentifyelementsthataresta-tisticallyover-representedinaparticularpopulation,comparedtoanother,islog-oddsratioinformativeDirichletprior(Monroeetal.,2008).Weemployedthisapproachtodiscoverwordsthatwereoverusedbyauthorsofacertaincountry,wherepostsfromeachcountry(acategoryundertest)werecomparedtoalltheothers(thebackground).Weusedthestrictlog-oddsscoreof−5asathresholdforfilteringouttermsassociatedwithacertaincountry.7AmongthetermseliminatedbythisprocedureweregenocideforArmenia,hockeyforCanadaandindependencefortheUK.Thefinalfocussetofwordsthusconsistsofneutral,ubiquitoussetsofsynonyms,varyingintheiretymologicalroots.Itcomprises540synonymsetsand1143distinctwords.7Thethresholdwassetbypreliminaryexperiments,withoutanyfurthertuning.4.3ModelWehypothesize(Section4.1)thatL1effectsonlex-icalchoicearesopowerful,evenwithadvancednon-nativespeakers,thatitispossibletoreconstructtheIElanguagephylogeny,reflectinghistoricalandarealevolutionoverthousandsofyears,fromnon-nativeEnglishonly.WenowdescribeasimpleyeteffectiveframeworkforclusteringtheEnglishesofauthorswithdifferentL1s,integratingbothwordfrequenciesandsemanticwordrepresentationsofthewordsinourfocusset(Section4.2).4.3.1DatacleanupandabstractionAimingtolearnwordrepresentationsforthelex-icalitemsinourfocusset,wewantthecontextualinformationtobeasfreeaspossiblefromstronggeographicalandculturalcues.Wethereforepro-cessthecorpusfurther.First,weidentifiednamedentities(NEs)andsystematicallyreplacedthembytheirtype.WeusedtheimplementationavailableinthespacyPythonpackage,8whichsupportsawiderangeofentities(e.g.,namesofpeople,nationali-ties,国家,产品,事件,booktitles,ETC。),atstate-of-the-artaccuracy.Likeotherweb-basedusergeneratedcontent,theRedditcorpusdoesnotadheretostrictcasingrules,whichhasdetrimentaleffectsontheaccuracyofNEidentification.Toimprovethetaggingaccuracy,weappliedapreprocessingstepof‘truecasing’,whereeachtokenwwasassignedthecase(降低,upper,orupper-initial)thatmax-imizedthelikelihoodoftheconsecutivetri-gramhwpre,w,wpostiintheCorpusofContemporaryAmericanEnglish(COCA).9Forexample,thetri-gram‘theuspeople’wasconvertedto‘theUSpeo-ple’,but‘letusknow’remainedunchanged.Whenatri-gramwasnotfoundintheCOCAn-gramcorpus,8https://spacy.io9https://www.ngrams.info
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
335
SynonymsetEtymologicalpathtorootcargo(氮)西班牙语:cargo←Spanish:cargar←LateLatin:carricarefreight(氮)Mid.English:freyght←Mid.LowGerman:vrecht←Proto-Germanic*fra-+*aihtizweary(Adj)Mid.English:wery←OldEnglish:w¯eri˙g←Proto-Germanic:*w¯or¯ıgazfatigue(Adj)法语:fatigue←French:fatiguer←Latin:fatigareexaggerate(V)Latin:exaggerare←Latin:ex-+Latin:aggerareoverdo(V)英语:over+doTable2:Etymologicalrootsofexamplesynonymsetswithcorrespondingpart-of-speech.weemployedfallbacktounigramprobabilityesti-mation.Additionally,wereplacedallnon-Englishwordswiththetoken‘UNK’;andallweblinks,sub-reddit(e.g.,r/compling)anduser(u/userid)pointerswiththe‘URL’token.104.3.2DistanceestimationandclusteringBammanetal.(2014)introducedamodelforin-corporatingcontextualinformation(suchasgeogra-phy)inlearningvectorrepresentations.Theypro-posedajointmodelforlearningwordrepresenta-tionsinasituatedlanguage,amodelthat“includesinformationaboutasubject(i.e.,thespeaker),al-lowingtolearnthecontoursofaword’smeaningthatareshapedbythecontextinwhichitisuttered”.Usingalargecorpusoftweets,theirjointmodellearnedwordrepresentationsthatweresensitivetogeographicalfactors,demonstratingthattheusageofwickedintheUnitedStates(meaningbadorevil)differsfromthatinNewEngland,whereitisusedasanadverbialintensifier(myboy’swickedsmart).WeleveragedthismodeltouncoverlinguisticvariationgroundedinthedifferentL1backgroundsofnon-nativeRedditspeakers.Weusedequal-sizedrandomsamplesof500Ksentencesfromeachcoun-trytotrainamodelofvectorrepresentations.Themodelcomprisesrepresentationofeveryvocabularyitemineachofthe31Englishes;e.g.,31vectorsaregeneratedforthewordfatigue,presumablyreflect-ingthesubtledivergencesofwordsemantics,rootedinthevariousL1backgroundsoftheauthors.InordertoclustertogetherEnglishesofspeakerswith“similar”L1s,weneedameasureofdistancebetweentwoEnglishtexts.Thismeasureisbased10Thecleaned,abstractedsubsetofthecorpusisalsoavailableathttp://cl.haifa.ac.il/projects/L2.Thecleanupcodeisavailableathttps://github.com/ellarabi/reddit-l2.ontwoconstituents:wordfrequenciesandwordem-beddings.GiventwoEnglishtextsoriginatingfromdifferentcountries,wecomputedforeachwordwinourfocusset(我)thedifferenceinthefrequencyofwinthetwotexts;和(二)thedistancebetweenthevectorrepresentationsofwinthesetexts,estimatedbycosinesimilarityofthetwocorrespondingwordvectors.Weemployedthepopularweightedprod-uctmodeltointegratethetwoarguments.Thewordvectorcomponentwasassignedahigherweightasthefrequencyofwinthecollectionincreases;thisismotivatedbytheintuitionthatlearningtheseman-ticrelationshipsofawordbenefitsfromvastusageexamples.Wethereforeweightheembeddingcon-stituentproportionallytotheword’sfrequencyinthedataset,andassignthecomplementaryweighttothedifferenceoffrequencies.Formally,giventwoEnglishtextsELiandELj,withLiandLjnativelanguages,andgivenawordwinthefocusset,letfiandfjdenotethefrequen-ciesofwinELiandELj,respectively.Letpwbetheprobabilityofwintheentirecollection.Wefur-therdenotethevectorspacerepresentationofwinELibyvi,andtherepresentationofwinELjbyvj.Then,thedistancebetweenELiandELjwithrespecttothewordwis:Dij(w)=(|fi−fj|)1−pw×(1−cos(六,vj))pw.(1)ThefinaldistancebetweenELiandELjisgivenbyaveragingDijoverallwordsinthefocussetFS:Dij=(Pw∈FSDij(w))|FS|.最后,weconstructedasymmetricdistancema-trix(31×31)MbysettingM[我,j]=Dij.Weused
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
336
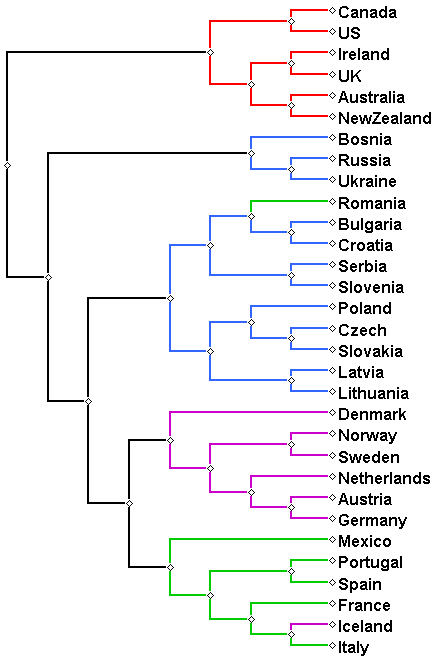
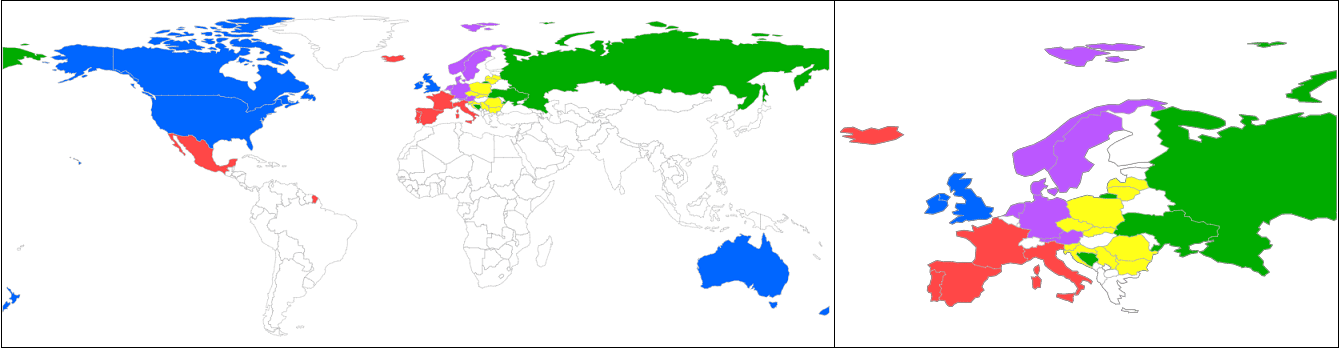
Ward’shierarchicalclustering11withtheEuclideandistancemetrictoderiveatreefromthedistancema-trixM.Weconsideredseveralotherweightingalterna-tives,includingassignmentofconstantweightstothetwofactorsinEquation1;theyallresultedininferioroutcomes.Wealsocorroboratedtherela-tivecontributionofthetwocomponentsbyusingeachofthemalone.Whileconsideringonlyfrequen-ciesresultedinaslightlyinferioroutcome(seeSec-tion4.5),usingwordrepresentationsaloneproducedacompletelyarbitraryresult.4.4ResultsTheresultingtreeisdepictedinFigure1.There-constructedlanguagetypologyrevealsseveralin-terestingobservations.First,andmuchexpect-edly,allnativeEnglishspeakersaregroupedto-getherintoasingle,distantsub-tree,implyingthatsimilaritiesexhibitedbythelexicalchoicesofna-tivespeakersgobeyondgeographicalandculturaldifferences.TheEnglishesofnon-nativespeak-ersareclusteredintothreemainlanguagefami-lies:Germanic,浪漫,andBalto-Slavic.No-tably,Spanish-speakingMexicoisclusteredwithitsRomancecounterparts.ThefirmBalto-Slavicclus-terrevealshistoricalrelationsbetweenlanguagesbygeneratingcoherentsub-branches:theCzechRe-publicandSlovakia,LatviaandLithuania,aswellastherelativeproximityofSerbiaandCroatia.Infact,formerYugoslaviaisclusteredtogether,exceptforBosnia,whichissomewhatdetached.SimilarclosetiescanbeseenbetweenAustriaandGermany,andbetweenPortugalandSpain.AnotherinterestingphenomenoniscapturedbyEnglishtextsofauthorsfromRomania:theirlan-guageisassignedtotheBalto-Slavicfamily,imply-ingthatthedeep-rootedarealandculturalBalkanin-fluenceslefttheirtracesintheRomanianlanguage,whichinturn,isreflectedintheEnglishproductionsofnativeRomanianauthors.Unfortunately,wecan-notexplainthelocationofIceland.Ageographicalviewmirroringthelanguagephy-logenyispresentedinFigure3.Flatclusterswereobtainedfromthehierarchyusingthescipyfcluster11https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.linkage.htmlmethod12withdefaults.Figure1:Languagetypologyreconstructedfromnon-nativeEnglishesusingfeaturesreflectinglexicalchoice.Countriesthatbelongtothesamephylogeneticfamily(accordingtothegoldtree)shareidenticalcolor.E.g.,Icelandiscoloredpurple,likeotherGermaniclanguages,eventhoughitisassignedtotheRomancecluster.Thisoutcome,obtainedusingonlylexicalseman-ticproperties(wordfrequenciesandwordembed-dings)ofEnglishauthoredbyvariousnon-nativespeakers,isastrongindicationofthepowerofL1influenceonL2speakers,evenhighlyfluentones.Theseresultsarestronglydependentonthechoiceoffocuswords:wecarefullyselectedwordsthatononehandlackanyculturalorgeographicalbiastowardonegroupofnon-natives,butontheotherhandhavesynonymswithdifferentetymologies.As12https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.fcluster.html
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
337
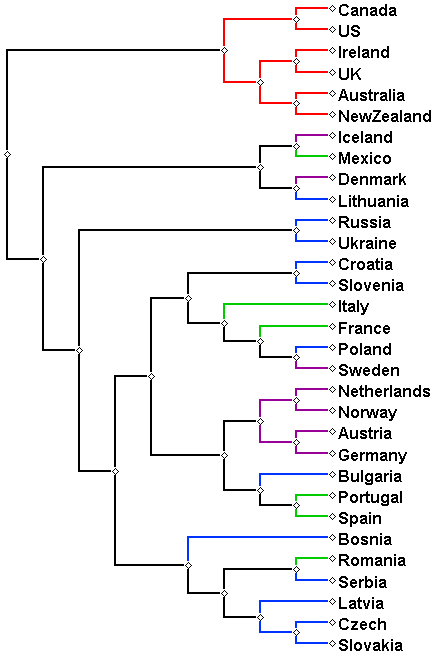
anadditionalvalidationstep,wegeneratedalan-guagetreeusingexactlythesamemethodologybutadifferentsetoffocuswords.Werandomlysam-pled1143wordsfromthecorpus,controllingforcountry-specificbiasbutnotfortheexistenceofsyn-onymswithdifferentetymologies.Althoughsomeoftheintra-familytieswerecaptured(inparticular,allnativespeakerswereclusteredtogether),there-sultingtree(Figure2)isfarinferior.Figure2:Languagetypologyreconstructedfromaran-domlyselectedfocussetof1143words.Wealsoconductedanadditionalexperiment,in-cludingmultilingualBelgiumandSwitzerlandinthesetofcountries.WhiletheL1ofspeakerscannotbedeterminedforthesetwocountries,presumablyBelgiumisdominatedbyDutchandFrench,andSwitzerlandbyGermanandFrench.Indeed,bothcountrieswereassignedintotheGermaniclanguagefamilyinourclusteringexperiments.4.5EvaluationTobetterassessthequalityofthereconstructedtreeswenowprovideaquantitativeevaluationofthelan-guagetypologiesobtainedbythevariousexperi-ments.WeadopttheevaluationapproachofRa-binovichetal.(2017),whointroducedadistancemetricbetweentwotrees,definedasthesumofthesquaredifferencesbetweenallleaf-pairdistancesinthetwotrees.Morespecifically,givenatreeofNleaves,li,i∈[1..氮],thedistancebetweentwoleavesli,ljinatreeτ,denotedDτ(li,lj),isdefinedasthelengthoftheshortestpathbetweenliandlj.ThedistanceDist(t,G)betweenageneratedtreeτandthegoldtreegisthencalculatedbysummingthesquaredifferencesbetweenallleaf-pairdistancesinthetwotrees:Dist(t,G)=Xi,j∈[1..氮];i6=j(Dτ(li,lj)−Dg(li,lj))2.WeusedtheIndo-EuropeantreeinGlottolog13asourgoldstandard,pruningittocontainthesetof31languagesconsideredinthiswork.Forthesakeofcomparison,wealsopresentthedistanceobtainedforacompletelyrandomtree,generatedbysamplingarandomdistancematrixfromtheuniform(0,1)distribution.Thereportedrandomtreeevaluationscoreisaveragedover100experiments.Table3presentstheresults.Alldistancesarenor-malizedtoazero-onescale,wherethebounds,zeroandone,representtheidenticalandthemostdistanttreewithrespecttothegoldstandard,respectively.Muchexpectedly,therandomtreeistheworstone,followedcloselybythetreereconstructedfromarandomsampleofover1000wordssampledfromthecorpus(Figure2).Thebestresultisobtainedbyconsideringbothwordfrequenciesandrepresen-tations,beingonlyslightlysuperiortothetreere-constructedusingwordfrequenciesalone.Thelat-terresultcorroboratestheaforementionedobserva-tion(Section4.3.2)andfurtherpositswordfrequen-ciesasthemajorfactoraffectingtheshapeoftheobtainedphylogeny.13http://glottolog.org/
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
338
Figure3:Countriesbyclusters:世界(ontheleft)andEurope(ontheright)views.Countriesassignedtothesameflatclusterbytheclusteringprocedure(Section4.4)shareidenticalcolor,e.g.,thewronglyassignedIcelandsharestheredcolorwiththeRomance-languagespeakingcountries.Countriesnotincludedinthisworkareuncolored.FeaturesusedDistanceRandomtree1.000Randomlysampledwords(Figure2)0.857Focussetwithfrequenciesonly0.497+embeddings(Figure1)0.469Table3:Normalizeddistancebetweenareconstructedandthegoldtree;lowerdistancesindicatebetterresult.5AnalysisTheresultsdescribedinSection4.4empiricallysup-porttheintuitionthatcognatesareoneofthefac-torsthatshapelexicalchoiceinproductionsofnon-nativeauthors.Inthissectionweperformacloseranalysisofthedata,aimingtocapturethesubtleyetsystematicdistortionsthathelpdistinguishbetweenEnglishtextsofspeakerswithdifferentL1s.QuantitativeanalysisGivenasynonymsets∈FS,consistingofwordshw1,w2,…,wni,andtwoEnglishtextswithtwodifferentL1s,ELiandELj,wecomputedthecountsofthesynsetwordsinthesetexts,andfurthernormalizedthecountsbythetotalsum,yieldingprobabilities.Wedenotetheprobabil-itydistributionofasynsets=hw1,w2,…,wniinELiby:Psi=hpi(w1),pi(w2),…,pi(wn)i.ThedifferentusagepatternsofasynonymsetsacrosstwoEnglishescanthenbeestimatedusingtheJensen-Shannondivergence(JSD)betweenthetwoprobabilitydistributions:divij(s)=JSD(Psi,Psj).(2)Weexpectthat“close”L1swillhavelowerdiver-gence,whereasL1sfromdifferentlanguagefamilieswillexhibithigherdivergences.Table4presentsthetoptwentysynonymsetsforthearbitrarilychosenGermany–Spaincountrypair,rankedbydivergence(Equation2).TheoveruseofhinderbyGermanauthorsmaybeattributedtoitsGermanbehinderncognate,whereasSpanishusers’preferenceofimpedeisprobablyattributabletoitsSpanishimpedirequivalent.ASpanishcognateforplantation,plantación,possiblyexplainstheclearpreferenceofSpanishnativespeakersforthisalter-native,comparedtothemorepopularchoiceofGer-manauthors,grove,whichhasGermanicetymolog-icalorigins.The{weariness,tiredness,fatigue}synsetrevealsthepreferenceofSpanishnativespeakersforfa-tigue,whoseSpanishequivalentfatigaresemblesittoagreatextent;weariness,然而,isslightlymorefrequentinthetextsofGermanspeakers,po-tentiallyreflectingitsProto-Germanic*w¯or¯ıgazan-cestor.Aninterestingphenomenonisrevealedbythesynset{conceivable,imaginable}:whilebothwordshaveLatinorigins,imaginableismoreubiq-uitousintheEnglishlanguage,renderingitmorefre-quentintextsofGermannativespeakers,comparedtothemorebalancedchoiceofSpanishauthors.Us-agepatternsin{overdo,exaggerate}和{inspect,audit,scrutinize}canbeattributedtothesamephe-
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
339
SynonymsetsPsGermanyPsSpainhhinderimpedei(0.909,0.091)(0.69,0.31)hgroveorchardplantationi(0.643,0.214,0.143)(0.227,0.068,0.705)hwearinesstirednessfatiguei(0.167,0.208,0.625)(0.017,0.119,0.864)hyarnrecitalnarrationi(0.55,0.1,0.35)(0.22,0.15,0.63)hbloomblossomfloweri(0.25,0.143,0.607)(0.085,0.098,0.817)hconceivableimaginablei(0.22,0.78)(0.415,0.585)hoverdoexaggeratei(0.556,0.444)(0.319,0.681)hinspectauditscrutinizei(0.667,0.25,0.083)(0.446,0.429,0.125)hsharpacutei(0.886,0.114)(0.717,0.283)hsteadystiffunwaveringfirmi(0.364,0.172,0.017,0.447)(0.278,0.083,0.007,0.632)hecstasyrapturei(0.593,0.407)(0.412,0.588)hsizeableamplei(0.597,0.403)(0.429,0.571)hscummyabjectmiserablei(0.167,0.028,0.806)(0.067,0.053,0.88)hdriftdisplacei(0.835,0.165)(0.734,0.266)hwaiveabandonforegoi(0.095,0.845,0.061)(0.043,0.899,0.058)hweighconsidercounti(0.028,0.605,0.367)(0.024,0.582,0.394)hquickfastrapidi(0.328,0.649,0.024)(0.326,0.643,0.031)hstumblestaggerlurchi(0.889,0.097,0.014)(0.7,0.114,0.186)homenpresagei(1.0,0.0)(0.9,0.1)hfreightcargoi(0.215,0.785)(0.19,0.81)Table4:Top-20examplesofthemostdivergentusagepatternsofsynsetsintextsofGermanvs.Spanishauthors.Wordswith(记录的)Germanicoriginsareinblueandwordswith(记录的)Latinoriginsareinred.nomenon,wheretheGermanequivalentforinspect(inspizieren)resemblesitsEnglishcounterpartde-spiteadifferentetymologicalroot.UsageexamplesTable5presentsexamplesen-tenceswrittenbyRedditauthorswithFrenchandItalianL1s,furtherillustratingdiscrepanciesinlexi-calchoice(presumably)stemmingfromcognatefa-cilitationeffects.TheFrenchrapideisatransla-tionequivalentoftheEnglishsynset{迅速的,quick,快速地},butitsEnglishrapidcognateismorecon-strainedtocontextsofmovementorgrowth,render-ingthecollocationrapidchecksomewhatmarked.TheFrenchnounapprobationismorefrequentincontemporaryFrenchthanitsEnglish(practicallyunused)equivalentapprobation;thismakesitsuseinEnglishsoundunnatural.InourRedditcorpus,approbationappears48timesinL1-Frenchtexts,comparedto5,4,and4inequal-sizedtextsbyau-thorsfromtheUK,IrelandandCanada,respectively.OneofthefrequentEnglishsynonymalternatives{approval,acceptance}wouldbetterfitthiscontext.Finally,whiletheItalianexpressionseraprecedenteiscommon,itsEnglishequivalentprecedenteveningisveryinfrequent,yetitisusedinEnglishproduc-tionsofItalianspeakers.6ConclusionWepresentedaninvestigationofL1cognateeffectsontheproductionsofadvancednon-nativeRedditauthors.Theresultsareaccompaniedbyalargedatasetofnativeandnon-nativeEnglishspeakers,annotatedforauthorcountry(和,presumably,alsoL1)atthesentencelevel.Severalopenquestionsremainforfutureresearch.Fromatheoreticalperspective,wewouldliketoex-tendthisworkbystudyingwhetherthetendencytochooseanEnglishcognateismorepowerfulinL1swithbothphoneticandorthographicsimilaritytoEnglish(Romanscript)thaninL1swithphoneticsimilarityonly(e.g.,Cyrillicscript).Wealsoplantomorecarefullyinvestigateproductionsofspeak-ersfrommultilingualcountries,likeBelgiumandSwitzerland.Anotherextensionofthisworkmaybroadentheanalysistoincludeadditionallanguagefamilies.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
340
L1SentenceFrenchIhavetogototheDr.todoarapidcheckonmyheartstability.FrenchMaybeputeverynamethroughamanualapprobationpipelinesoitensuresquality.FrenchPollshaveshownpublicapprobationforthislawissomewherebetween58%and65%,andithasbeenastrongpromiseduringthepresidentialcampaign.ItalianTheeventwasevenmoreshockingbecausetheprecedenteveninghewasn’tsickatall.Table5:CognatefacilitationphenomenainusageexamplesbyRedditauthors.Therearealsovariouspotentialpracticalapplica-tionstothiswork.First,weplantoexploitthepoten-tialbenefitsofourfindingstothetaskofnativelan-guageidentificationof(highlyadvanced)non-nativeauthors,invariousdomains.Second,ourresultswillbeinstrumentalforpersonalizationoflanguagelearningapplications,basedontheL1backgroundofthelearner.Forexample,errorcorrectionsystemscanbeenhancedwiththenativelanguageoftheau-thortoofferrootcauseanalysisofsubtlediscrepan-ciesintheusageoflexicalitems,consideringboththeirfrequenciesandcontext.GiventheL1ofthetargetaudience,lexicalsimplificationsystemscanalsobenefitfromcognatecues,e.g.,byprovidinganinformedchoiceofpotentiallychallengingcan-didatesforsubstitutionwithasimplifiedalternative.Weleavesuchapplicationsforfutureresearch.AcknowledgmentsThisworkwaspartiallysupportedbytheNationalScienceFoundationthroughawardIIS-1526745.WewouldliketothankAnatPriorandSteffenEgerforvaluablesuggestions.WearealsogratefultoSivanRabinovichformuchadviseandhelpfulcom-ments.Finally,wearethankfultoouractioneditor,IvanTitov,andthreeanonymousreviewersfortheirconstructivefeedback.ReferencesDavidBamman,ChrisDyer,andNoahA.Smith.Dis-tributedrepresentationsofgeographicallysituatedlan-guage.InProceedingsofthe52ndAnnualMeet-ingoftheAssociationforComputationalLinguistics(Volume2:ShortPapers),pages828–834,Baltimore,Maryland,June2014.AssociationforComputationalLinguistics.URLhttp://www.aclweb.org/anthology/P14-2134.ShaneBergsma,MattPost,andDavidYarowsky.Stylo-metricanalysisofscientificarticles.InProceedingsofthe2012ConferenceoftheNorthAmericanChap-teroftheAssociationforComputationalLinguistics:HumanLanguageTechnologies,pages327–337.As-sociationforComputationalLinguistics,2012.YevgeniBerzak,RoiReichart,andBorisKatz.Recon-structingnativelanguagetypologyfromforeignlan-guageusage.InProceedingsoftheEighteenthConfer-enceonComputationalNaturalLanguageLearning,pages21–29,June2014.URLhttp://aclweb.org/anthology/W/W14/W14-1603.pdf.YevgeniBerzak,RoiReichart,andBorisKatz.Con-trastiveanalysiswithpredictivepower:TypologydrivenestimationofgrammaticalerrordistributionsinESL.InProceedingsofthe19thConferenceonComputationalNaturalLanguageLearning,pages94–102,July2015.URLhttp://aclweb.org/anthology/K/K15/K15-1010.pdf.DanielBlanchard,JoelTetreault,DerrickHiggins,AoifeCahill,andMartinChodorow.TOEFL11:Acorpusofnon-nativeEnglish.ETSResearchReportSeries,2013(2):i–15,2013.UschiCop,NicolasDirix,EvaVanAssche,DenisDrieghe,andWouterDuyck.Readingabookinoneortwolanguages?AneyemovementstudyofcognatefacilitationinL1andL2reading.Bilingualism:Lan-guageandCognition,20(4):747–769,2017.ScottA.CrossleyandDanielleS.McNamara.SharedfeaturesofL2writing:Intergrouphomogeneityandtextclassification.JournalofSecondLanguageWrit-ing,20(4):271–285,122011.ISSN1060-3743.doi:10.1016/j.jslw.2011.05.007.AnnetteM.deGroot.Determinantsofwordtranslation.JournalofExperimentalPsychology:学习,Mem-ory,andCognition,18(5):1001,1992.GerarddeMelo.EtymologicalWordNet:Tracingthehis-toryofwords.InProceedingsofthe9thLanguageResourcesandEvaluationConference(LREC2014),巴黎,法国,2014.ELRA.TamarDeganiandNatashaTokowicz.Semanticambi-guitywithinandacrosslanguages:Anintegrativere-view.TheQuarterlyJournalofExperimentalPsychol-ogy,63(7):1266–1303,2010.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
341
TamarDegani,AnatPrior,andWalaaHajajra.Cross-languagesemanticinfluencesindifferentscriptbilin-guals.Bilingualism:LanguageandCognition,pages1–23,2017.JeroenGeertzen,TheodoraAlexopoulou,andAnnaKo-rhonen.AutomaticlinguisticannotationoflargescaleL2databases:TheEF-Cambridgeopenlanguagedatabase(EFCAMDAT).InProceedingsofthe31stSecondLanguageResearchForum,Somerville,嘛,2013.CascadillaProceedingsProject.SylvianeGranger.TheInternationalCorpusofLearnerEnglish:ANewResourceforForeignLanguageLearningandTeachingandSecondLanguageAcquisi-tionResearch.TesolQuarterly,pages538–546,2003.EliHinkel.Secondlanguagewriters’text:Linguisticandrhetoricalfeatures.Routledge,2002.KristianTangsgaardHvelplund.Eyetrackingandthetranslationprocess:Reflectionsontheanalysisandin-terpretationofeye-trackingdata.MonTI.MonografíasdeTraduccióneInterpretación,pages201–223,2014.ScottJarvisandAnetaPavlenko.Crosslinguisticinflu-enceinlanguageandcognition.Routledge,2008.EkaterinaKochmarandEkaterinaShutova.Modellingsemanticacquisitioninsecondlanguagelearning.InProceedingsofthe12thWorkshoponInnovativeUseofNLPforBuildingEducationalApplications,pages293–302,2017.MosheKoppel,JonathanSchler,andKfirZigdon.Deter-mininganauthor’snativelanguagebyminingatextforerrors.InProceedingsoftheeleventhACMSIGKDDinternationalconferenceonKnowledgediscoveryindatamining,pages624–628.ACM,2005.JudithF.Kroll,SusanC.Bobb,andNorikoHoshino.Twolanguagesinmind:Bilingualismasatooltoinvesti-gatelanguage,认识,andthebrain.CurrentDi-rectionsinPsychologicalScience,23(3):159–163,Jun2014.doi:10.1177/0963721414528511.VictorKuperman,HansStadthagen-Gonzalez,andMarcBrysbaert.Age-of-acquisitionratingsfor30,000En-glishwords.BehaviorResearchMethods,44(4):978–990,Dec2012.ISSN1554-3528.doi:10.3758/s13428-012-0210-4.URLhttps://doi.org/10.3758/s13428-012-0210-4.KristopherKyleandScottA.Crossley.Automaticallyassessinglexicalsophistication:Indices,工具,find-ings,andapplication.TesolQuarterly,49(4):757–786,2015.MayaR.LibbenandDebraA.Titone.Bilinguallexi-calaccessincontext:Evidencefromeyemovementsduringreading.JournalofExperimentalPsychology:学习,记忆,andCognition,35(2):381,2009.XiaofeiLuandHaiyangAi.Syntacticcomplex-ityincollege-levelEnglishwriting:Differ-encesamongwriterswithdiverseL1back-grounds.JournalofSecondLanguageWrit-ing,29,2015.ISSN1060-3743.doi:https://doi.org/10.1016/j.jslw.2015.06.003.URLhttp://www.sciencedirect.com/science/article/pii/S1060374315000405.ShervinMalmasi,KeelanEvanini,AoifeCahill,JoelTetreault,RobertPugh,ChristopherHamill,DianeNapolitano,andYaoQian.Areportonthe2017na-tivelanguageidentificationsharedtask.InProceed-ingsofthe12thWorkshoponInnovativeUseofNLPforBuildingEducationalApplications,pages62–75,2017.BurtL.Monroe,MichaelP.Colaresi,andKevinM.Quinn.Fightin’words:Lexicalfeatureselectionandevaluationforidentifyingthecontentofpoliticalcon-flict.PoliticalAnalysis,16(4):372–403,2008.RyoNagataandEdwardW.D.Whittaker.ReconstructinganIndo-Europeanfamilytreefromnon-nativeEnglishtexts.InProceedingsofthe51stAnnualMeetingoftheAssociationforComputationalLinguistics,pages1137–1147,August2013.URLhttp://aclweb.org/anthology/P/P13/P13-1112.pdf.ViviNastaseandCarloStrapparava.Wordetymologyasnativelanguageinterference.InProceedingsofthe2017ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,pages2702–2707.AssociationforComputationalLinguistics,2017.URLhttp://aclweb.org/anthology/D17-1286.MagaliPaquotandSylvianeGranger.Formulaiclan-guageinlearnercorpora.AnnualReviewofAppliedLinguistics,32:130–149,2012.AnatPrior.Bilingualism:Interactionsbetweenlan-guages.InPatriciaJ.BrookandVeraKempe,编辑,EncyclopediaofLanguageDevelopment.SagePubli-cations,2014.URLhttp://dx.doi.org/10.4135/9781483346441.AnatPrior,BrianMacWhinney,andJudithF.Kroll.TranslationnormsforEnglishandSpanish:Theroleoflexicalvariables,wordclass,andL2proficiencyinnegotiatingtranslationambiguity.BehaviorResearchMethods,39(4):1029–1038,2007.AnatPrior,ShulyWintner,BrianMacwhinney,andAlonLavie.Translationambiguityinandoutofcontext.AppliedPsycholinguistics,32(1):93–111,2011.EllaRabinovich,NoamOrdan,andShulyWintner.Foundintranslation:Reconstructingphylogeneticlanguagetreesfromtranslations.InProceedingsofthe55thAnnualMeetingoftheAssociationfor
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
0
2
4
1
5
6
7
6
2
4
/
/
t
我
A
C
_
A
_
0
0
0
2
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
342
ComputationalLinguistics(Volume1:LongPapers),pages530–540.AssociationforComputationalLin-guistics,July2017.URLhttp://aclweb.org/anthology/P17-1049.MiriamShlesinger.Effectsofpresentationrateonwork-ingmemoryinsimultaneousinterpreting.TheInter-preters’Newsletter,12:37–49,2003.URLhttp://hdl.handle.net/10077/2470.AnnaSiyanova-Chanturia.Collocationinbeginnerlearnerwriting:Alongitudinalstudy.System,53:148–160,2015.JoelTetreault,DanielBlanchard,andAoifeCahill.Are-portonthefirstnativelanguageidentificationsharedtask.InProceedingsoftheEighthWorkshoponBuild-ingEducationalApplicationsUsingNLP.AssociationforComputationalLinguistics,June2013.LauraMayfieldTomokiyoandRosieJones.You’renotfrom’roundhere,areyou?:NaiveBayesdetectionofnon-nativeutterancetext.InProceedingsofthesecondmeetingoftheNorthAmericanChapteroftheAssoci-ationforComputationalLinguistics,pages1–8.Asso-ciationforComputationalLinguistics,2001.YuliaTsvetkov,NaamaTwitto,NathanSchneider,NoamOrdan,ManaalFaruqui,VictorChahuneau,ShulyWintner,andChrisDyer.IdentifyingtheL1ofnon-nativewriters:theCMU-Haifasystem.InProceedingsoftheEighthWorkshoponInnovativeUseofNLPforBuildingEducationalApplications,pages279–287.AssociationforComputationalLinguistics,June2013.URLhttp://www.aclweb.org/anthology/W13-1736.