Tabula Nearly Rasa: Probing the Linguistic Knowledge of Character-level
Neural Language Models Trained on Unsegmented Text
Michael Hahn∗
斯坦福大学
mhahn2@stanford.edu
Marco Baroni
Facebook AI Research
UPF Linguistics Department
Catalan Institution for Research
and Advanced Studies
mbaroni@gmail.com
抽象的
(RNNs) 有
Recurrent neural networks
reached striking performance in many natural
language processing tasks. This has renewed
兴趣
in whether these generic sequence
processing devices are inducing genuine lin-
guistic knowledge. Nearly all current ana-
lytical studies, 然而, initialize the RNNs
with a vocabulary of known words, 和
feed them tokenized input during training.
We present a multi-lingual study of
这
linguistic knowledge encoded in RNNs trained
as character-level language models, on input
data with word boundaries removed. 这些
networks face a tougher and more cognitively
realistic task, having to discover any useful
linguistic unit from scratch based on input
统计数据. The results show that our ‘‘near
tabula rasa’’ RNNs are mostly able to
solve morphological, syntactic and semantic
tasks that intuitively presuppose word-level
知识, and indeed they learned, to some
extent, to track word boundaries. Our study
这
opens the door to speculations about
necessity of an explicit, rigid word lexicon
in language learning and usage.
1
介绍
Recurrent neural networks (RNNs; Elman, 1990),
in particular in their long short term memory
variant (LSTMs; Hochreiter and Schmidhuber,
1997), are widely used in natural language pro-
cessing. RNNs, often pre-trained on the simple
∗Work partially done while interning at Facebook AI
研究.
467
language modeling objective of predicting the
next symbol in natural text, are a crucial com-
为了
波南特
machine translation, natural language inference,
and text categorization (Goldberg, 2017).
state-of-the-art
架构
的
RNNs are very general devices for sequence
加工, hardly assuming any prior linguistic
知识. 而且, the simple prediction task
they are trained on in language modeling is well-
attuned to the core role that prediction plays in
认识 (例如, Bar, 2007; 克拉克, 2016). RNNs
have thus long attracted researchers interested in
language acquisition and processing. Their recent
success in large-scale tasks has rekindled this
兴趣 (例如, Frank et al., 2013; Lau et al., 2017;
Kirov and Cotterell, 2018; Linzen et al., 2018;
McCoy et al., 2018; Pater, 2018).
The standard pre-processing pipeline of modern
RNNs assumes that the input has been tokenized
into word units that are pre-stored in the RNN
词汇 (Goldberg, 2017). This is a reasonable
practical approach, but it makes simulations less
interesting from a linguistic point of view. 第一的,
discovering words (or other primitive constituents
of linguistic structure) is one of the major chal-
lenges a learner faces, and by pre-encoding them in
the RNN we are facilitating its task in an unnatural
方式 (not even the staunchest nativists would take
specific word dictionaries to be part of our genetic
代码). 第二, assuming a unique tokenization
into a finite number of discrete word units is
in any case problematic. The very notion of what
counts as a word in languages with a rich morphol-
ogy is far from clear (例如, Dixon and Aikhenvald,
2002; Bickel and Z´u˜niga, 2017), 和, universally,
lexical knowledge is probably organized into a
not-necessarily-consistent hierarchy of units at
different levels: morphemes, 字, compounds,
计算语言学协会会刊, 卷. 7, PP. 467–484, 2019. https://doi.org/10.1162/tacl 00283
动作编辑器: Hinrich Sch¨utze. 提交批次: 2/2019; 修改批次: 4/2019; 已发表 9/2019.
C(西德:3) 2019 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
constructions, 等等 (例如, Goldberg, 2005).
的确, it has been suggested that the notion
of word cannot even be meaningfully defined
cross-linguistically (Haspelmath, 2011).
Motivated by these considerations, we study
here RNNs that are trained without any notion
of word in their input or in their architecture.
We train our RNNs as character-level neural
language models (CNLMs, Mikolov et al., 2011;
Sutskever et al., 2011; 格雷夫斯, 2014) by removing
whitespace from their input, so that, like children
learning a language, they don’t have access to
explicit cues to wordhood.1 This set-up is almost
as tabula rasa as it gets. By using unsegmented
orthographic input (and assuming that,
在里面
alphabetic writing systems we work with, 有
a reasonable correspondence between letters and
phonetic segments), we are only postulating that
the learner figured out how to map the continuous
speech stream to a sequence of phonological units,
an ability children already possess a few months
after birth (例如, Maye et al., 2002; Kuhl, 2004).
We believe that focusing on language modeling of
an unsegmented phoneme sequence, abstracting
away from other complexities of a fully realistic
child language acquisition set-up, is particularly
instructive in order to study which linguistic struc-
tures naturally emerge.
We evaluate our character-level networks on
a bank of linguistic tests in German, Italian, 和
英语. We focus on these languages because of
resource availability and ease of benchmark con-
struction. 还, well-studied synthetic languages
with a clear, orthographically driven notion of
word might be a better starting point to test non-
word-centric models, compared with agglutina-
tive or polysynthetic languages, where the very
notion of what counts as a word is problematic.
句法的,
Our tasks require models to develop the latent
ability to parse characters into word-like items
associated to morphological,
和
broadly semantic features. The RNNs pass most
of the tests, suggesting that they are in some
way able to construct and manipulate the right
lexical objects. In a final experiment, 我们看
more directly into how the models are handling
word-like units. We find, confirming an earlier
observation by Kementchedjhieva and Lopez
(2018), that the RNNs specialized some cells to
1We do not erase punctuation marks, reasoning that they
have a similar function to prosodic cues in spoken language.
the task of detecting word boundaries (或者, 更多的
一般来说, salient linguistic boundaries, 从某种意义上说
to be further discussed below). 合在一起,
our results suggest
that character-level RNNs
capture forms of linguistic knowledge that are
traditionally thought to be word-based, 没有
being exposed to an explicit segmentation of their
input and, more importantly, without possessing
an explicit word lexicon. We will discuss the
implications of these findings in the Discussion.2
2 相关工作
On the primacy of words Several linguistic
studies suggest that words, at least as delimited
by whitespace in some writing systems, are neither
necessary nor sufficient units of linguistic anal-
分析. Haspelmath (2011) claims that there is no
cross-linguistically valid definition of the notion
of word (see also Schiering et al., 2010, WHO
address specifically the notion of prosodic word).
Others have stressed the difficulty of characteriz-
ing words in polysynthetic languages (Bickel and
Z´u˜niga, 2017). Children are only rarely exposed
to words in isolation during learning (Tomasello,
2003),3 and it is likely that the units that adult speak-
ers end up storing in their lexicon are of variable
尺寸, both smaller and larger than conventional
字 (例如, 杰肯道夫, 2002; Goldberg, 2005).
From a more applied perspective, Sch¨utze (2017)
recently defended tokenization-free approaches to
自然语言处理, proposing a general non-symbolic approach
to text representation.
We hope our results will contribute to the
theoretical debate on word primacy, suggesting,
that word
through computational simulations,
priors are not crucial to language learning and
加工.
Character-based neural language models
关于-
ceived attention in the last decade because of their
greater generality compared with word-level mod-
这. Early studies (Mikolov et al., 2011; 吸勺
等人。, 2011; 格雷夫斯, 2014) established that CNLMs
might not be as good at language modeling as their
word-based counterparts, but lag only slightly
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
2我们的
input data,
可用的
是
tabula-rasa-rnns.
test sets, and pre-trained models
在https://github.com/m-hahn/
3Single-word utterances are not uncommon in child-
directed language, but they are still rather the exception than
规则, and many important words, such as determiners,
never occur in isolation (Christiansen et al., 2005).
468
behind. This is particularly encouraging in light
of the fact that character-level sentence predic-
tion involves a much larger search space than
prediction at the word level, as a character-level
model must make a prediction after each charac-
特尔, rather than after each word. Sutskever et al.
(2011) and Graves (2014) ran qualitative anal-
yses showing that CNLMs capture some basic
linguistic properties of their input. The latter, WHO
used LSTM cells, also showed, qualitatively, 那
CNLMs are sensitive to hierarchical structure.
尤其, they balance parentheses correctly
when generating text.
Most recent work in the area has focused on
character-aware architectures combining character-
and word-level information to develop state-of-
the-art language models that are also effective in
morphologically rich languages (例如, Bojanowski
等人。, 2016; Kim et al., 2016; Gerz et al., 2018).
例如, Kim and colleagues perform predic-
tion at the word level, but use a character-based
convolutional network to generate word repre-
句子. Other work focuses on splitting words
into morphemes, using character-level RNNs and
an explicit segmentation objective (例如, Kann
等人。, 2016). These latter lines of work are only
distantly related to our interest in probing what
a purely character-level network trained on run-
ning text has implicitly learned about linguistic
结构. There is also extensive work on seg-
mentation of the linguistic signal that does not rely
on neural methods, and is not directly relevant
这里, (例如, Brent and Cartwright, 1996; Goldwater
等人。, 2009; Kamper et al., 2016, and references
therein).
linguistic knowledge
of neural
Probing
language models
is currently a popular research
话题 (李等人。, 2016; Linzen et al., 2016; Shi
等人。, 2016; Adi et al., 2017; Belinkov et al., 2017;
K`ad`ar et al., 2017; Hupkes et al., 2018; Conneau
等人。, 2018; Ettinger et al., 2018; Linzen et al.,
2018). Among studies focusing on character-level
型号, Elman (1990) already reported a proof-
of-concept experiment on implicit learning of word
segmentation. Christiansen et al. (1998) trained
a RNN on phoneme-level
语言建模
of transcribed child-directed speech with tokens
marking utterance boundaries, and found that
the input by
the network learned to segment
predicting the utterance boundary symbol also
at word edges. 最近, Sennrich (2017)
explored the grammatical properties of character-
and subword-unit-level models that are used as
components of a machine translation system. 他
concluded that current character-based decoders
generalize better to unseen words, but capture
less grammatical knowledge than subword units.
仍然, his character-based systems lagged only
marginally behind the subword architectures on
grammatical tasks such as handling agreement
and negation. Radford et al. (2017) focused on
CNLMs deployed in the domain of sentiment
分析, where they found the network to special-
ize a unit for sentiment tracking. We will discuss
below how our CNLMs also show single-unit
specialization, but for boundary tracking. Godin
等人. (2018) investigated the rules implicitly used
by supervised character-aware neural morpholog-
ical segmentation methods, finding linguistically
sensible patterns. Alishahi et al. (2017) probed the
linguistic knowledge induced by a neural network
that receives unsegmented acoustic input. Focus-
ing on phonology, they found that the lower layers
of the model process finer-grained information,
layers are sensitive to more
whereas higher
abstract patterns. Kementchedjhieva and Lopez
(2018) recently probed the linguistic knowledge
of an English CNLM trained with whitespace in
输入. Their results are aligned with ours. 这
model is sensitive to lexical and morphological
结构, and it captures morphosyntactic cate-
gories as well as constraints on possible morpheme
曲目
combinations.
word/morpheme boundaries through a single spe-
cialized unit, suggesting that such boundaries are
突出的 (at least when marked by whitespace, 如
their experiments) and informative enough that it
is worthwhile for the network to devote a special
mechanism to process them. We replicated this
finding for our networks trained on whitespace-
free text, as discussed in Section 4.4, where we
discuss it in the context of our other results.
Intriguingly,
该模型
3 Experimental Set-up
We extracted plain text from full English, 德语,
and Italian Wikipedia dumps with WikiExtractor.4
We randomly selected test and validation sections
consisting of 50,000 paragraphs each, and used
the remainder for training. The training sets
contained 16M (德语), 9中号 (Italian), and 41M
(英语) 段落, corresponding to 819M,
4https://github.com/attardi/wikiextractor.
469
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
463中号, and 2,333M words, 分别. Paragraph
order was shuffled for training, without attempting
to split by sentences. All characters were
lower-cased. For benchmark construction and
word-based model
训练, we tokenized and
tagged the corpora with TreeTagger (Schmid,
1999).5 We used as vocabularies the most frequent
characters from each corpus, setting thresholds
so as to ensure that all characters representing
phonemes were included, resulting in vocabularies
of sizes 60 (英语), 73 (德语), 和 59
(Italian). We further constructed word-level neural
language models (WordNLMs); their vocabulary
included the most frequent 50,000 words per
语料库.
We trained RNN and LSTM CNLMs; 我们
will refer to them simply as RNN and LSTM,
分别. The ‘‘vanilla’’ RNN will serve as
a baseline to ascertain if/when the longer-range
information-tracking abilities afforded to the
LSTM by its gating mechanisms are necessary.
Our WordNLMs are always LSTMs. For each
model/language, we applied random hyperpa-
rameter search. We terminated training after 72
hours.6 None of the models had overfitted, 作为
measured by performance on the validation set.7
Language modeling performance on the test
partitions is shown in Table 1. Recall that we re-
moved whitespace, which is both easy to
predict, and aids prediction of other characters.
最后, the fact that our character-level
models are below the state of the art is expected.8
例如, the best model of Merity et al. (2018)
达到了 1.23 English bits per character (BPC) 在
a Wikipedia-derived dataset. On EuroParl data,
Cotterell et al. (2018) 报告 0.85 for English, 0.90
for German, 和 0.82 for Italian. 仍然, our English
BPC is comparable to that reported by Graves
5http://www.cis.uni-muenchen.de/∼schmid/
tools/TreeTagger/.
6This was due to resource availability. The reasonable
language-modeling results in Table 1 suggest that no model
is seriously underfit, but the weaker overall RNN results in
particular should be interpreted in the light of the following
qualification: models are compared given equal amount of
训练, but possibly at different convergence stages.
7Hyperparameter details are in Table 8. Chosen
架构 (layers/embedding size/hidden size): LSTM:
En. 3/200/1024, 锗. 2/100/1024, 它. 2/200/1024; RNN:
En. 2/200/2048, 锗. 2/50/2048,
它. 相同的; WordNLM;
En. 2/1024/1024, 锗. 2/200/1024, 它. 相同的.
8Training our models with whitespace, without further
hyperparameter tuning, resulted in BPCs of 1.32 (英语),
1.28 (德语), 和 1.24 (Italian).
英语
德语
Italian
LSTM
1.62
1.51
1.47
RNN
2.08
1.83
1.97
WordNLM
48.99
37.96
42.02
桌子 1: Performance of language models. 为了
CNLMs, we report bits-per-character (BPC). 为了
WordNLMs, we report perplexity.
(2014) for his static character-level LSTM trained
on space-delimited Wikipedia data, suggesting
that we are achieving reasonable performance.
The perplexity of the word-level model might not
be comparable to that of highly optimized state-
of-the-art architectures, but it is at the expected
等级
for a well-tuned vanilla LSTM language
模型. 例如, Gulordava et al. (2018)
报告 51.9 和 44.9 perplexities, 分别, 在
English and Italian for their best LSTMs trained
on Wikipedia data with same vocabulary size as
ours.
4 实验
4.1 Discovering morphological categories
Words belong to part-of-speech categories, 这样的
as nouns and verbs. 而且, they typically carry
inflectional features such as number. We start by
probing whether CNLMs capture such properties.
We use here the popular method of ‘‘diagnostic
classifiers’’ (Hupkes et al., 2018). 那是, we treat
the hidden activations produced by a CNLM
whose weights were fixed after language model
training as input features for a shallow (logistic)
classifier of the property of interest (例如, plural
与. singular). If the classifier is successful, 这
means that the representations provided by the
model are encoding the relevant information. 这
classifier is deliberately shallow and trained on a
small set of examples, as we want to test whether
the properties of interest are robustly encoded in
the representations produced by the CNLMs, 和
amenable to a simple linear readout (Fusi et al.,
2016). In our case, we want to probe word-level
properties in models trained at the character level.
要做到这一点, we let the model read each target word
character-by-character, and we treat the state of
its hidden layer after processing the last character
in the word as the model’s implicit representation
of the word, on which we train the diagnostic
classifier. The experiments focus on German
和意大利语, as it is harder to design reliable test
470
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
sets for the impoverished English morphological
系统.
suffixes
Although we
Word classes (nouns vs. 动词) For both
German and Italian, we sampled 500 verbs and
500 nouns from the Wikipedia training sets,
requiring that they are unambiguously tagged in
the corpus by TreeTagger. Verbal and nominal
forms are often cued by suffixes. We removed
this confound by selecting examples with the
same ending across the two categories (-en in
德语: Westen ‘west’,9 stehen ‘to stand’; 和
-re in Italian: autore ‘author’, dire ‘to say’). 我们
randomly selected 20 training examples (10 nouns
和 10 动词), and tested on the remaining items.
We repeated the experiment 100 times to account
for random train-test split variation.
controlled for
作为
如上所述, it could still be the case that
other substrings reliably cue verbs or nouns. 我们
thus considered a baseline trained on word-internal
information only, 即, a character-level LSTM
autoencoder trained on the Wikipedia datasets to
reconstruct words in isolation.10 The hidden state
of the LSTM autoencoder should capture dis-
criminating orthographic features, 但, by design,
will have no access to broader contexts. 我们
further considered word embeddings from the
output layer of the WordNLM. Unlike CNLMs,
the WordNLM cannot make educated guesses
about words that are not in its training vocabulary.
These out of vocabulary (OOV) words are by con-
struction less frequent, and thus likely to be in gen-
eral more difficult. To get a sense of both ‘‘best-
case scenario’’ and more realistic WordNLM
表现, we report its accuracy both exclud-
ing and including OOV items (WordNLMsubs. 和
WordNLM in Table 2, 分别). In the lat-
ter case, we let the model make a random guess
for OOV items. The percentage of OOV items
over the entire dataset, balanced for nouns and
动词, 曾是 92.3% for German and 69.4% 为了
Italian. Note that none of the words were OOV
9German nouns are capitalized; this cue is unavailable to
the CNLM as we lower-case the input.
10The autoencoder is implemented as a standard LSTM
sequence-to-sequence model (Sutskever et al., 2014). 为了
each language, autoencoder hyperparameters were chosen
using random search, as for the language models; 细节
are in supplementary material to be made available upon
出版物. For both German and Italian models, the fol-
lowing parameters were chosen: 2 layers, 100 embedding
方面, 1024 hidden dimensions.
471
Random
Autoencoder
LSTM
RNN
WordNLM
WordNLMsubs.
德语
50.0
65.1 (± 0.22)
89.0 (± 0.14)
82.0 (± 0.64)
53.5 (± 0.18)
97.4 (± 0.05)
Italian
50.0
82.8 (± 0.26)
95.0 (± 0.10)
91.9 (± 0.24)
62.5 (± 0.26)
96.0 (± 0.06)
桌子 2: Accuracy of diagnostic classifier on
predicting word class, with standard errors across
100 random train-test splits. ‘subs.’ marks in-
vocabulary subset evaluation, not comparable
with the other results.
for the CNLM, as they all were taken from the
Wikipedia training set.
Results are in Table 2. All language models
outperform the autoencoders, showing that they
learned categories based on broader distributional
证据, not just typical strings cuing nouns and
动词. 而且, the LSTM CNLM outperforms
the RNN, probably because it can track broader
上下文. 不出所料, the word-based model
fares better on in-vocabulary words, but the gap,
especially in Italian, is rather narrow, 在那里
is a strong negative impact of OOV words (作为
预期的, given that WordNLM is at random on
他们).
Number We turn next to number, a more gran-
ular morphological feature. We study German,
as it possesses a rich system of nominal classes
forming plural through different morphological
流程. We train a diagnostic number clas-
sifier on a subset of these classes, and test on
其他, in order to probe the abstract number
generalization capabilities of the tested models.
If a model generalizes correctly, it means that
the CNLM is sensitive to number as an abstract
feature, independently of its surface expression.
We extracted plural nouns from the Wiktionary
and the German UD treebank (McDonald et al.,
2013; 布兰茨等人。, 2002). We selected nouns with
plurals in -n, -s, or -e to train the classifier (例如,
Geschichte(n) ‘story(-是的)’, 收音机(s) ‘radio(s)’,
Pferd(e) ‘horse(s)’, 分别). We tested on
plurals formed with -r (例如, Lieder for singular
Lied ‘song’), or through vowel change (Umlaut,
例如, ¨Apfel from singular Apfel ‘apple’). 肯定
nouns form plurals through concurrent suffixing
and Umlaut. We grouped these together with
nouns using the same suffix, reserving the Umlaut
group for nouns only undergoing vowel change
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
-r
test classes
train classes
-n/-s/-e
50.0
Random
61.4 (± 0.9) 50.7 (± 0.8) 51.9 (± 0.4)
Autoencoder
71.5 (± 0.8) 78.8 (± 0.6) 60.8 (± 0.6)
LSTM
65.4 (± 0.9) 59.8 (± 1.0) 56.7 (± 0.7)
RNN
77.3 (± 0.7) 77.1 (± 0.5) 74.2 (± 0.6)
WordNLM
WordNLMsubs. 97.1 (± 0.3) 90.7 (± 0.1) 97.5 (± 0.1)
Umlaut
50.0
50.0
桌子 3: German number classification accuracy,
with standard errors computed from 200 random
‘subs.’ marks in-vocabulary
train-test splits.
subset evaluation, not comparable to the other
结果.
(例如, Saft/S¨afte ‘juice(s)’ would be an instance
of -e suffixation). The diagnostic classifier was
trained on 15 singulars and plurals randomly se-
lected from each training class. As plural suffixes
make words longer, we sampled singulars and
plurals from a single distribution over lengths,
to ensure that their lengths were approximately
matched. 而且, because in uncontrolled sam-
ples from our training classes a final -e- vowel
would constitute a strong surface cue to plurality,
we balanced the distribution of this property across
singulars and plurals in the samples. For the test
放, we selected all plurals in -r (127) or Umlaut
(38), with their respective singulars. We also used
all remaining plurals ending in -n (1,467), -s (98),
and -e (832) as in-domain test data. 控制为
the impact of training sample selection, we report
accuracies averaged over 200 random train-test
splits and standard errors over these splits. 为了
WordNLM OOV, there were 45.0% OOVs in the
training classes, 49.1% among the -r forms, 和
52.1% for Umlaut.
Results are in Table 3. The classifier based on
word embeddings is the most successful. It out-
performs in most cases the best CNLM even
in the more cogent OOV-inclusive evaluation.
This confirms the common observation that word
embeddings reliably encode number (米科洛夫
等人。, 2013乙). 再次, the LSTM-based CNLM
is better than the RNN, but both significantly
outperform the autoencoder. The latter is near-
random on new class prediction, confirming that
we properly controlled for orthographic confounds.
We observe a considerable drop in the LSTM
CNLM performance between generalization to
-r and Umlaut. 一方面, the fact that
performance is still clearly above chance (和
autoencoder) in the latter condition shows that
472
the LSTM CNLM has a somewhat abstract
notion of number not tied to specific orthographic
exponents. On the other, the -r vs. Umlaut dif-
ference suggests that the generalization is not com-
pletely abstract, as it works more reliably when
the target is a new suffixation pattern, albeit one
that is distinct from those seen in training, 比
when it is a purely non-concatenative process.
4.2 Capturing syntactic dependencies
Words encapsulate linguistic information into
units that are then put into relation by syntac-
tic rules. A long tradition in linguistics has even
claimed that syntax is blind to sub-word-level
流程 (例如, Chomsky, 1970; Di Sciullo and
威廉姆斯, 1987; Bresnan and Mchombo, 1995;
威廉姆斯, 2007). Can our CNLMs, 尽管
lack of an explicit word lexicon, capture relational
syntactic phenomena, such as agreement and case
assignment? We investigate this by testing them
on syntactic dependencies between non-adjacent
字. We adopt the ‘‘grammaticality judgment’’
paradigm of Linzen et al. (2016). We create mini-
mal sets of grammatical and ungrammatical phrases
illustrating the phenomenon of interest, and let the
language model assign a likelihood to all items in
集合. The language model is said to ‘‘prefer’’
the grammatical variant if it assigns a higher like-
lihood to it than to its ungrammatical counterparts.
We must stress two methodological points. 第一的,
because a character-level language model assigns
a probability to each character of a phrase, 和
phrase likelihood is the product of these values
(all between 0 和 1), minimal sets must be con-
trolled for character length. This makes existing
benchmarks unusable. 第二, the ‘‘distance’’ of a
relation is defined differently for a character-level
is not straightforward to quan-
模型, and it
tify. Consider the German phrase in Example (1)
以下. For a word model, two items separate the
article from the noun. 为一个 (space-less) 特点
模型, eight characters intervene until the noun
onset, but the span to consider will typically be
更长. 例如, Baum could be the beginning
of the feminine noun Baumwolle ‘cotton’, 哪个
would change the agreement requirements on the
文章. 所以, until the model finds evidence that it
fully parsed the head noun, it cannot reliably check
协议. This will typically require parsing at
least the full noun and the first character following
它. We again focus on German and Italian, as their
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1: Accuracy in the German syntax tasks, as a function of number of intervening words.
richer inflectional morphology simplifies the task
of constructing balanced minimal sets.
4.2.1 德语
Article-noun gender agreement Each German
noun belongs to one of three genders (masculine,
feminine, neuter), morphologically marked on
the article. As the article and the noun can be
separated by adjectives and adverbs, we can probe
knowledge of lexical gender together with long-
distance agreement. We create stimuli of the form
(1)
{这, die, das}
这
sehr
非常
rote
红色的
Baum
树
where the correct nominative singular article (这,
在这种情况下) matches the gender of the noun.
We then run the CNLM on the three versions
of this phrase (removing whitespace) and record
the probabilities it assigns to them. If the model
assigns the highest probability to the version with
the right article, we count it as a hit for the model.
To avoid phrase segmentation ambiguities (如
the Baum/Baumwolle example above), we present
phrases surrounded by full stops.
To build the test set, we select all 4,581 nomina-
tive singular nouns from the German UD treebank:
49.3% feminine, 26.4% masculine, 和 24.3%
neuter. WordNLM OOV noun ratios are: 40.0%
for masculine, 36.2% for feminine, 和 41.5% 为了
neuter. We construct four conditions varying the
number of adverbs and adjectives between article
and noun. We first consider stimuli where no
material intervenes. In the second condition, 一个
adjective with the correct case ending, randomly
selected from the training corpus, is added. Cru-
cially, the ending of the adjective does not reveal
the gender of the noun. We only used adjectives
occurring at least 100 次, and not ending in
-r.11 We obtained a pool of 9,742 adjectives to
sample from, also used in subsequent experi-
评论. A total of 74.9% of these were OOV for
the WordNLM. In the third and fourth conditions,
一 (sehr) or two adverbs (sehr extrem) intervene
between article and adjective. These do not cue
gender either. We obtained 2,290 (m.), 2,261 (f.),
和 1,111 (n.) 刺激, 分别. 控制为
surface co-occurrence statistics in the input, 我们
constructed an n-gram baseline picking the article
most frequently occurring before the phrase in the
training data, breaking ties randomly. OOVs were
excluded from WordNLM evaluation, 导致
an easier test for this rival model. 然而, 这里
and in the next two tasks, CNLM performance on
this reduced set was only slightly better, 和我们
do not report it. We report accuracy averaged over
nouns belonging to each of the three genders. 经过
设计, the random baseline accuracy is 33%.
Results are presented in Figure 1 (左边). WordNLM
performs best, followed by the LSTM CNLM.
The n-gram baseline performs similarly to the
CNLM when there is no intervening material,
which is expected, as a noun will often be pre-
ceded by its article in the corpus. 然而, 它是
accuracy drops to chance level (0.33) 在里面
presence of an adjective, whereas the CNLM is
still able to track agreement. The RNN variant
is much worse. It is outperformed by the n-gram
model in the adjacent condition, and it drops
to random accuracy as more material intervenes.
We emphasized at the outset of this section that
11Adjectives ending in -r often reflect
lemmatization
问题, as TreeTagger occasionally failed to remove the
inflectional suffix -r when lemmatizing. We needed to extract
lemmas, as we constructed the appropriate inflected forms on
their basis.
473
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
CNLMs must
track agreement across much
wider spans than word-based models. The LSTM
variant ability to preserve information for longer
might play a crucial role here.
Article-noun case agreement We selected the
two determiners dem and des, which unambig-
uously indicate dative and genitive case, 重新指定-
主动地, for masculine and neuter nouns:
(2)
A. {民主, des} sehr roten Baum
乙.
very red tree (dative)
这
{民主, des} sehr roten Baums
这
very red tree (genitive)
We selected all noun lemmas of the appropri-
ate genders from the German UD treebank, 和
extracted morphological paradigms from Wik-
tionary to obtain case-marked forms, retaining
only nouns unambiguously marking the two cases
(4,509 nouns). We created four conditions, vary-
ing the amount of intervening material, 如在
gender agreement experiment (4,509 stimuli per
状况). 为了 81.3% of the nouns, at least one of
the two forms was OOV for the WordNLM, 和
we tested the latter on the full-coverage subset.
Random baseline accuracy is 50%.
Results are in Figure 1 (中心). 再次, WordNLM
has the best performance, but the LSTM CNLM
is competitive as more elements intervene. Accu-
racy stays well above 80% even with three inter-
vening words. The n-gram model performs well
if there is no intervening material (again reflect-
ing the obvious fact that article-noun sequences
are frequent in the corpus), and at chance other-
明智的. The RNN CNLM accuracy is above chance
with one and two intervening elements, but drops
considerably with distance.
Prepositional case subcategorization German
verbs and prepositions lexically specify their
object’s case. We study the preposition mit ‘with’,
which selects a dative object. We focus on mit, 作为
it unambiguously requires a dative object, 它是
extremely frequent in the Wikipedia corpus we are
使用. To build the test set, we select objects whose
head noun is a nominalized adjective, with regular,
overtly marked case inflection. We use the same
adjective pool as in the preceding experiments.
We then select all sentences containing a mit
prepositional phrase in the German Universal
Dependencies treebank, subject to the constraints
474
那 (1) the head of the noun phrase governed
by the preposition is not a pronoun (replacing
such items with a nominal object often results
in ungrammaticality), 和 (2) the governed noun
phrase is continuous, in the sense that it is not
interrupted by words that do not belong to it.12 We
obtained 1,629 such sentences. For each sentence,
we remove the prepositional phrase and replace
it by a phrase of the form
(3)
mit
和
这
这
sehr
非常
{rote, roten}
red one
where only the -en (dative) version of the adjec-
tive is compatible with the case requirement of the
preposition (and the intervening material does not
disambiguate case). We construct three conditions
by varying the presence and number of adverbs
(sehr ‘very’, sehr extrem ‘very extremely’, sehr
extrem unglaublich ‘very extremely incredibly’).
Note that here the correct form is longer than
the wrong one. As the overall likelihood is the
product of character probabilities ranging between
0 和 1, if this introduces a length bias, 后者
will work against the character models. Note also
that we embed test phrases into full sentences
(例如, Die Figur hat mit der roten gespielt und
meistens gewonnen. ‘The figure played with the
red one and mostly won’). We do this because this
will disambiguate the final element of the phrase
作为名词 (not an adjective), and exclude the
reading in which mit is a particle not governing the
noun phrase of interest (Dudenredaktion, 2019).13
When running the WordNLM, we excluded OOV
adjectives as in the previous experiments, but did
not apply further OOV filtering to the sentence
frames. For the n-gram baseline, we only counted
occurrences of the prepositional phrase, omitting
the sentential contexts. Random baseline accuracy
是 50%.
We also created control stimuli where all words
up to and including the preposition are removed
(the example sentence above becomes: der roten
gespielt und meistens gewonnen). If a model’s
accuracy is lower on these control stimuli than on
the full ones, its performance cannot be simply
12The main source of noun phrase discontinuity in the
German UD corpus is extraposition, a common phenomenon
where part of the noun phrase is separated from the rest by
the verb.
13An example of this unintended reading of mit is: Ich war
mit der erste, der hier war. ‘I was one of the first who arrived
here.’ In this context, dative ersten would be ungrammatical.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
explained by the different unigram probabilities
of the two adjective forms.
Results are shown in Figure 1 (正确的). 仅有的
the n-gram baseline fails to outperform control
准确性 (dotted). 出奇, the LSTM CNLM
slightly outperforms the WordNLM, 虽然
the latter is evaluated on the easier full-lexical-
coverage stimulus subset. Neither model shows
accuracy decay as the number of adverbs in-
creases. As before, the n-gram model drops to
chance as adverbs intervene, whereas the RNN
CNLM starts with low accuracy that progressively
decays below chance.
4.2.2 Italian
Article-noun gender agreement Similar
到
德语, Italian articles agree with the noun in
性别; 然而, Italian has a relatively extended
paradigm of masculine and feminine nouns dif-
fering only in the final vowel (-o and -a, 重新指定-
主动地), allowing us to test agreement in fully
controlled paradigms such as the following:
(4)
A. {il, 这} congeniale candidato
这
congenial candidate (m.)
乙.
{il, 这} congeniale candidata
这
congenial candidate (f.)
The intervening adjective, ending in -e, 做
not cue gender. We constructed the stimuli with
words appearing at least 100 times in the training
语料库. We required moreover the -a and -o
forms of a noun to be reasonably balanced in
频率 (neither form is more than twice as
frequent as the other), or both rather frequent
(appear at least 500 次). As the prenominal
adjectives are somewhat marked, we only con-
sidered -e adjectives that occur prenominally
with at least 10 distinct nouns in the training
语料库. Here and below, stimuli were manually
checked, removing nonsensical adjective-noun
(以下, adverb-adjective) combinations. 最后,
adjective-noun combinations that occurred in the
training corpus were excluded, so that an n-
gram baseline would perform at chance level.
We obtained 15,005 stimulus pairs in total. 35.8%
of them contained an adjective or noun that was
OOV for the WordNLM. 再次, we report this
CNLM
LSTM
93.1
99.5
99.0
RNN
79.2
98.9
84.5
WordNLM
97.4
99.5
100.0
Noun Gender
Adj. 性别
Adj. 数字
桌子 4: Italian agreement results. Random base-
line accuracy is 50% in all three experiments.
model’s results on its full-coverage subset, 在哪里
the CNLM performance is only slightly above the
one reported.
Results are shown on the first line of Table 4.
WordNLM shows the strongest performance,
closely followed by the LSTM CNLM. The RNN
CNLM performs strongly above chance (50%),
but again lags behind the LSTM.
Article-adjective gender agreement We next
consider agreement between articles and adjec-
tives with an intervening adverb:
(5)
A.
乙.
il
这 (m.) 较少的
较少的 {alieno, aliena}
alien one
这
这 (f.) 较少的
较少的 {alieno, aliena}
alien one
where we used the adverbs pi`u ‘more’, 较少的
‘less’, tanto ‘so much’. We considered only ad-
jectives that occurred 1K times in the training
语料库 (as adjectives ending in -a/-o are very com-
mon). We excluded all cases in which the adverb-
adjective combination occurred in the training
语料库, obtaining 88 stimulus pairs. 由于
the restriction to common adjectives, there were
no WordNLM OOVs. Results are shown on the
second line of Table 4; all three models perform
almost perfectly. Possibly, the task is made easy
by the use of extremely common adverbs and
形容词.
Article-adjective number agreement Finally,
we constructed a version of the last test that
probed number agreement. For feminine forms,
it is possible to compare same-length phrases
例如:
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
较少的 {aliena, aliene}
alien one(s)
较少的 {aliena, aliene}
这
这 (s.) 较少的
le
这 (p.) 较少的
alien one(s)
(6)
A.
乙.
475
Stimulus selection was as in the last experiment,
but we used a 500-occurrences threshold for ad-
jectives, as feminine plurals are less common,
obtaining 99 对. 再次, no adverb-adjective
combination was attested. There were no OOV
items for the WordNLM. Results are shown on
the third line of Table 4; the LSTMs perform
almost perfectly, and the RNN is strongly above
机会.
4.3 Semantics-driven sentence completion
We probe whether CNLMs are capable of track-
ing the shallow form of word-level semantics
required in a fill-the-gap test. We turn now to
英语, as for this language we can use the
Microsoft Research Sentence Completion task
(Zweig and Burges, 2011). The challenge consists
of sentences with a gap, 和 5 possible choices
to fill it. Language models can be directly applied
to the task, by calculating the likelihood of sen-
tence variants with all possible completions, 和
selecting the one with the highest likelihood.
The creators of the benchmark took mul-
tiple precautions to ensure that success on
the task implies some command of seman-
抽动症. The multiple choices were controlled for
频率, and the annotators were encour-
aged to choose confounders whose elimination
required ‘‘semantic knowledge
and logical
(Zweig and Burges, 2011). 为了
inference’’
the right choice in ‘‘Was she his
例子,
[client|musings|discomfiture|选择|机会],
his friend, or his mistress? depends on the cue
that the missing word is coordinated with friend
and mistress, and the latter are animate entities.
The task domain (Sherlock Holmes novels) 是
very different from the Wikipedia dataset on
which we originally trained our models. 为一个
fairer comparison with previous work, we re-
trained our models on the corpus provided with
基准, consisting of 41 万字
from 19th century English novels (我们删除了
whitespace from this corpus as well).
Results are in Table 5. We confirm the im-
portance of in-domain training, as the models
trained on Wikipedia perform poorly (but still
above chance level, which is at 20%). With in-
domain training, the LSTM CNLM outperforms
many earlier word-level neural models, 并且是
only slightly below our WordNLM. The RNN is
not successful even when trained in-domain,
476
Our models (wiki/in-domain)
LSTM
RNN
WordNLM
34.1/59.0
24.3/24.0
37.1/63.3
From the literature
Skipgram
40.0
Skipgram + RNNs
45.0
采购经理人指数
56.0
Context-Embed
60.7
KN5
Word RNN
Word LSTM
LdTreeLSTM
48.0
58.9
61.4
65.1
桌子 5: Results on MSR Sentence Completion. 为了
our models (顶部), we show accuracies for Wikipedia
(左边) and in-domain (正确的) 训练. 我们比较
with language models from prior work (左边): Kneser-
Ney 5-gram model (米科洛夫, 2012), Word RNN
(Zweig et al., 2012), Word LSTM and LdTreeLSTM
(张等人。, 2016). We further
report models
incorporating distributional encodings of semantics
(正确的): Skipgram(+RNNs) from Mikolov et al. (2013A),
the PMI-based model of Woods (2016), 和
Context-Embedding-based approach of Melamud et al.
(2016).
contrasting with the word-based vanilla RNN from
the literature, whose performance, while still
below LSTMs, is much stronger. Once more, 这
suggests that capturing word-level generalizations
with a word-lexicon-less character model requires
the long-span processing abilities of an LSTM.
4.4 Boundary tracking in CNLMs
The good performance of CNLMs on most tasks
above suggests that, although they lack a hard-
coded word vocabulary and they were trained on
unsegmented input, there is enough pressure from
the language modeling task for them to learn to
track word-like items, and associate them with
various morphological, 句法的, and semantic
特性. 在这个部分, we take a direct look at
how CNLMs might be segmenting their input.
Kementchedjhieva and Lopez (2018) found a
single unit in their English CNLM that seems,
qualitatively, to be tracking morpheme/word bound-
aries. Because they trained the model with white-
this unit could
空间,
simply be to predict the very frequent whitespace
特点. We conjecture instead (like them) 那
the ability to segment the input into meaningful
items is so important when processing language
that CNLMs will specialize units for boundary
tracking even when trained without whitespace.
the main function of
To look for ‘‘boundary units,’’ we created a
random set of 10,000 positions from the training
放, balanced between those corresponding to a
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
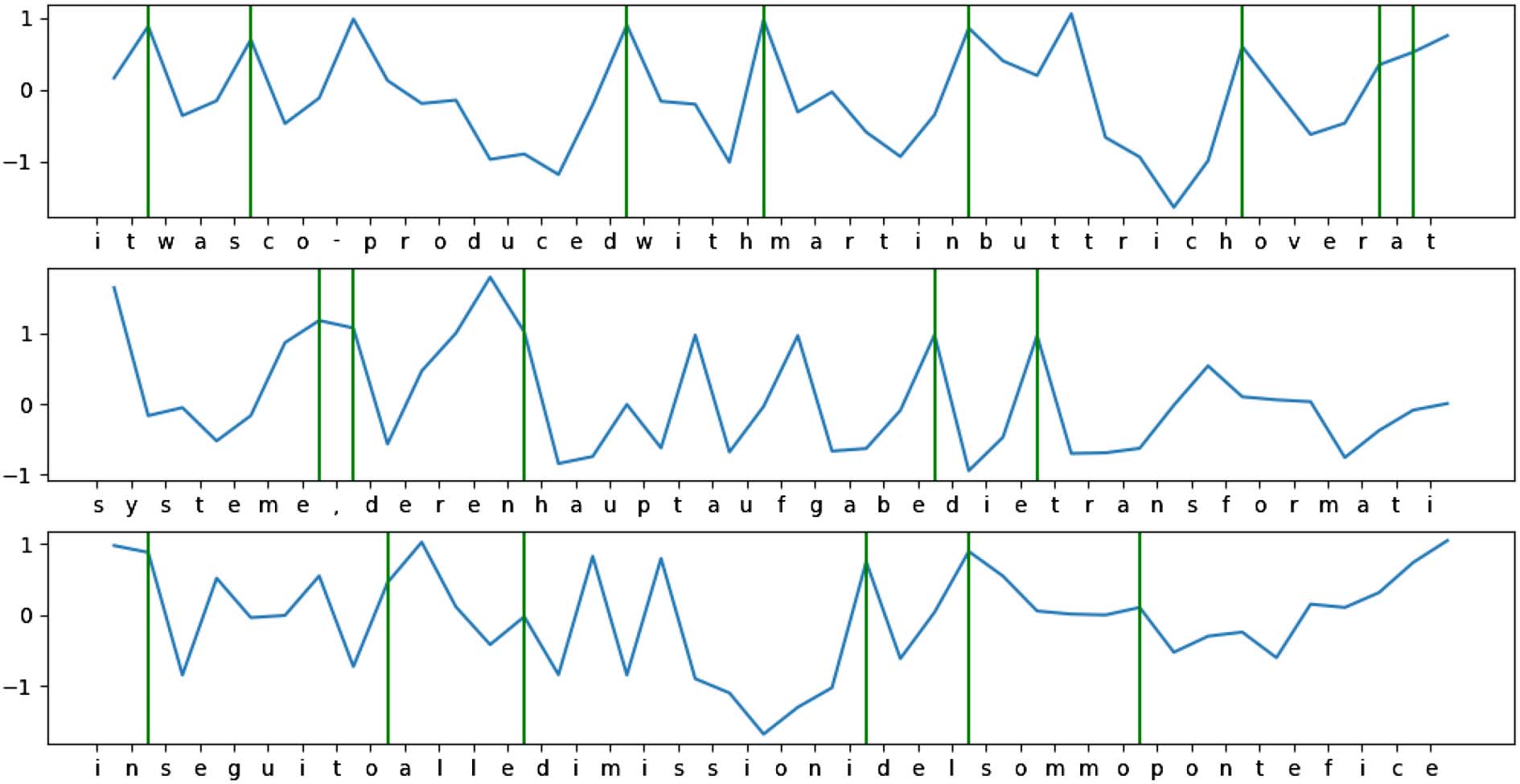
数字 2: Examples of the LSTM CNLM boundary unit activation profile, with ground-truth word boundaries
marked in green. 英语: It was co-produced with Martin Buttrich over at. . . . 德语: Systeme, deren
Hauptaufgabe die transformati(-在) ‘systems, whose main task is the transformation. . . ’. Italian: in seguito alle
dimissioni del Sommo Pontefice ‘following the resignation of the Supreme Pontiff. . . ’.
word-final character and those occurring word-
initially or word-medially. We then computed,
for each hidden unit, the Pearson correlation be-
tween its activations and a binary variable that
takes value 1 in word-final position and 0 别的-
在哪里. For each language and model (LSTM or
RNN), we found very few units with a high cor-
relation score, suggesting that the models have
indeed specialized units for boundary tracking.
We further study the units with the highest corre-
lations, 哪个是, for the LSTMs, 0.58 (英语),
0.69 (德语), 和 0.57 (Italian). For the RNNs,
the highest correlations are 0.40 (英语), 和
0.46 (German and Italian).14
Examples We looked at the behavior of the
selected LSTM units qualitatively by extracting
random sets of 40-character strings from the
development partition of each language (左边-
aligned with word onsets) and plotting the cor-
responding boundary unit activations. 数字 2
reports illustrative examples. In all languages,
most peaks in activation mark word boundaries.
然而, other interesting patterns emerge. 在
英语, we see how the unit reasonably treats
14In an early version of this analysis, we arbitrarily imposed
a minimum 0.70 correlation threshold, missing the presence
of these units. We thank the reviewer who encouraged us to
look further into the matter.
共- and produced in co-produced as separate
元素, and it also posits a weaker boundary
after the prefix pro-. As it proceeds left-to-right,
with no information on what follows, 网络
posits a boundary after but in Buttrich. 在里面
German example, we observe how the complex
word Hauptaufgabe (‘main task’) is segmented
into the morphemes haupt, auf and gabe. 辛-
伊拉利, in the final transformati- 分段, 我们
observe a weak boundary after the prefix trans.
In the pronoun deren ‘whose’, the case suffix -n is
in seguito a is a lexi-
separated. 意大利语,
calized multi-word sequence meaning ‘following’
(literally: ‘in continuation to’). The boundary
unit does not spike inside it. 相似地,
这
fixed expression Sommo Pontefice (referring to
the Pope) does not trigger inner boundary unit
activation spikes. 另一方面, we notice
peaks after di and mi in dimissioni. 再次, 在
left-to-right processing, the unit has a tendency
to immediately posit boundaries when frequent
function words are encountered.
Detecting word boundaries To gain a more
quantitative understanding of how well
这
boundary unit is tracking word boundaries, 我们
trained a single-parameter diagnostic classifier on
the activation of the unit (the classifier simply
sets an optimal threshold on the unit activation
477
LSTM
单身的
87.7
86.6
85.6
LSTM
满的
93.0
91.9
92.2
RNN
单身的
65.6
70.4
71.3
RNN
满的
90.5
85.0
91.5
英语
德语
Italian
LSTM
单身的
77.5
80.8
75.5
LSTM
满的
90.0
79.7
82.9
RNN
单身的
65.9
67.0
71.4
RNN
满的
76.8
75.8
75.9
英语
德语
Italian
桌子 6: F1 of single-unit and full-hidden-state
word-boundary diagnostic classifiers, trained and
tested on uncontrolled running text.
to separate word boundaries from word-internal
positions). We ran two experiments. In the first,
following standard practice, we trained and tested
the classifier on uncontrolled running text. 我们
used 1k characters for training, 1M for testing,
both taken from the left-out Wikipedia test
partitions. We will report F1 performance on this
任务.
to the constraint
We also considered a more cogent evaluation
政权, in which we split training and test data
so that the number of boundary and non-boundary
conditions are balanced, and there is no overlap
between training and test words. 具体来说,
we randomly selected positions from the test
partitions of the Wikipedia corpus, 这样
half of these were the last character of a token,
and the other half were not. We sampled the
那
test data points subject
这个单词 (in the case of a boundary position)
or word prefix (in the case of a word-internal
位置) ending at the selected character does not
overlap with the training set. This ensures that a
classifier cannot succeed by looking for encodings
reflecting specific words. For each datapoint, 我们
fed a substring of the 40 preceding characters to
the CNLM. We collected 1,000 such points for
训练, and tested on 1M additional datapoints. 在
这个案例, we will report classification accuracy as
figure of merit. For reference, in both experiments
we also trained diagnostic classifiers on the full
hidden layer of the LSTMs.
Looking at the F1 results on uncontrolled run-
ning text (桌子 6), we observe first that the
LSTM-based full-hidden-layer classifier has strong
performance in all 3 语言, confirming that
the LSTM model encodes boundary information.
而且, in all languages, a large proportion
of this performance is already accounted for by
the single-parameter classifier using boundary unit
activations. This confirms that tracking boundaries
is important enough for the network to devote a
specialized unit to this task. Full-layer RNN results
桌子 7: Accuracy of single-unit and full-hidden-
state word-boundary
classifiers,
trained and tested on balanced data requiring
new-word generalization. Chance accuracy is at
50%.
diagnostic
are below LSTM-level but still strong. 有,
然而, a stronger drop from full-layer to single-
unit classification. This is in line with the fact that,
as reported above, the candidate RNN boundary
units have lower boundary correlations than the
LSTM ones.
Results for the balanced classifiers tested on
new-word generalization are shown in Table 7
(because of the different nature of the experiments,
these are not directly comparable to the F1
results in Table 6). 再次, we observe a strong
performance of
the LSTM-based full-hidden-
layer classifier across the board. The LSTM
single-parameter classifier using boundary unit
activations is also strong, even outperforming
the full classifier in German. 而且, 在这个
more cogent setup, the single-unit LSTM classifier
is at least competitive with the full-layer RNN
classifier in all languages. The weaker results of
RNNs in the word-centric tasks of the previous
sections might in part be due to their poorer overall
ability to track word boundaries, as specifically
suggested by this stricter evaluation setup.
Error analysis As a final way to characterize
the function and behaviour of the boundary units,
we inspected the most frequent under- and over-
segmentation errors made by the classifier based
on the single boundary units, in the more difficult
balanced task. We discuss German here, as it is
the language where the classifier reaches highest
准确性, and its tendency to have long, 摩尔-
phologically complex words makes it particularly
interesting. 然而, similar patterns were also
detected in Italian and, to a lesser extent, 英语
(in the latter, there are fewer and less interpretable
common oversegmentations, probably because
words are on average shorter and morphology
more limited).
Considering first the 30 most common under-
segmentations, the large majority (24 的 30) 是
478
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Batch Size
Embedding Size
Dimension
Layers
Learning Rate
Decay
BPTT Length
Hidden Dropout
Embedding Dropout
Input Dropout
Nonlinearity
LSTM
锗.
512
100
1024
2
2.0
1.0
50
0.0
0.01
0.0
–
En.
128
200
1024
3
3.6
0.95
80
0.01
0.0
0.001
–
它.
128
200
1024
2
3.2
0.98
80
0.0
0.0
0.0
–
RNN
锗.
256
50
2048
2
0.1
0.95
30
0.0
0.0
0.01
tanh
En.
256
200
2048
2
0.01
0.9
50
0.05
0.01
0.001
ReLu
它.
256
50
2048
2
0.1
0.95
30
0.0
0.0
0.01
tanh
WordNLM
锗.
128
200
1024
2
0.9
1.0
50
0.15
0.1
0.001
–
En.
128
1024
1024
2
1.1
1.0
50
0.15
0.0
0.01
–
它.
128
200
1024
2
1.2
0.98
50
0.05
0.0
0.01
–
桌子 8: Chosen hyperparameters.
to’),
common sequences of grammatical terms or very
frequent items that can sometimes be reasonably
re-analyzed as single function words or adverbs
(例如, bis zu, ‘up to’ (点亮. ‘until
je nach
‘depending on’ (点亮. ‘per after’), bis heute ‘to
date’ (点亮. ‘until today’)). Three cases are multi-
word city names (天使们). The final 3 案例
interestingly involve Bau ‘building’ followed by
von ‘of’ or genitive determiners der/des. 在其
eventive reading,
this noun requires a patient
licensed by either a preposition or the genitive
determiner (例如, Bau der Mauer ‘building of the
wall’ (点亮. ‘building the-GEN wall’)). Apparently
the model decided to absorb the case assigner into
the form of the noun.
We looked next at
这 30 most common
oversegmentations, 那是, at the substrings that
were wrongly segmented out of the largest number
of distinct words. We limited the analysis to
those containing at least 3 characters, 因为
shorter strings were ambiguous and hard to
interpret. Among then top oversegmentations, 6
are prefixes that can also occur in isolation as
‘on’, nach
prepositions or verb particles (auf
‘after’, ETC。). Seven are content words that form
many compounds (例如, haupt ‘main’, occurring
in Hauptstadt
‘main
station’; Land ‘land’, occurring in Deutschland
‘Germany’, Landkreis ‘district’). 其他 7 项目
can be classified as suffixes (例如, -lich as in s¨udlich
‘southern’, wissenschaftlich ‘scientific’), 虽然
segmentation is not always canonical
他们的
the expected -schaft
-chaft
(例如,
in Wissenschaft ‘science’). Four very common
function words are often wrongly segmented out of
longer words (例如, sie ‘she’ from sieben ‘seven’).
The kom and kon cases are interesting, 作为
‘capital’, Hauptbahnhof
而不是
model segments them as stems (or stem fragments)
in forms of the verbs kommen ‘to come’ and
k¨onnen ‘to be able to’, 分别 (例如, kommt
and konnte), but it also treats them as pseudo-
affixes elsewhere (komponist ‘composer’, kontakt
‘contact’). The remaining 3 oversegmentations,
rie, run and ter don’t have any clear interpretation.
To conclude, the boundary unit, even when
analyzed through the lens of a classifier that was
optimized on word-level segmentation, is actually
tracking salient linguistic boundaries at different
级别. Although in many cases these boundaries
naturally coincide with words (hence the high
classifier performance),
the CNLM is also
sensitive to frequent morphemes and compound
元素, as well as to different types of multi-
word expressions. This is in line with a view
of wordhood as a useful but ‘‘soft’’, emergent
财产, rather than a rigid primitive of linguistic
加工.
5 讨论
We probed the linguistic information induced by
a character-level LSTM language model trained
on unsegmented text. The model was found to
possess implicit knowledge about a range of
intuitively word-mediated phenomena, 例如
sensitivity to lexical categories and syntactic and
shallow-semantics dependencies. A model ini-
tialized with a word vocabulary and fed
tokenized input was in general superior, 但
the performance of the word-less model did
不是
lag much behind, suggesting that word
priors are helpful but not strictly required. A
character-level RNN was less consistent
比
the latter’s ability
the LSTM, suggesting that
479
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
to track information across longer time spans is
important to make the correct generalizations. 这
character-level models consistently outperformed
n-gram controls, confirming they are tapping into
more abstract patterns than local co-occurrence
统计数据.
As a first step towards understanding how
character-level models handle supra-character
现象, we searched and found specialized
boundary-tracking units in them. These units
are not only and not always sensitive to word
边界, but also respond to other salient items,
such as morphemes and multi-word expressions,
in accordance with an ‘‘emergent’’ and flexible
view of
语言
the basic constituents of
(Schiering et al., 2010).
那
Our results are preliminary in many ways. 我们的
tests are relatively simple. We did not attempt,
例如, to model long-distance agreement
in presence of distractors, a challenging task
even for humans (Gulordava et al., 2018). 这
results on number classification in German sug-
gest
the models might not be capturing
linguistic generalizations of the correct degree
of abstractness, settling for shallower heuristics.
仍然, as a whole, our work suggests that a large
语料库, combined with the weak priors encoded in
an LSTM, might suffice to learn generalizations
about word-mediated linguistic processes without
a hard-coded word lexicon or explicit wordhood
cues.
Nearly all contemporary linguistics recognizes
a central role to the lexicon (看, 例如, Sag et al.,
2003; Goldberg, 2005; 雷德福, 2006; Bresnan
等人。, 2016; Jeˇzek, 2016, for very different
perspectives). Linguistic formalisms assume that
the lexicon is essentially a dictionary of words,
possibly complemented by other units, not unlike
the list of words and associated embeddings in
a standard word-based NLM. Intriguingly, 我们的
CNLMs captured a range of lexical phenomena
without anything resembling a word dictionary.
Any information a CNLM might acquire about
units larger than characters must be stored in
its recurrent weights. This suggests a radically
different and possibly more neurally plausible
view of the lexicon as implicitly encoded in a
distributed memory, that we intend to characterize
more precisely and test in future work (相似的
ideas are being explored in a more applied NLP
看法, 例如, Gillick et al., 2016; 李等人。,
2017; Cherry et al., 2018).
Concerning the model input, we would like
to study whether the CNLM successes crucially
depend on the huge amount of training data it
receives. Are word priors more important when
learning from smaller corpora? In terms of com-
parison with human learning, the Wikipedia text
we fed our CNLMs is far from what children
acquiring a language would hear. Future work
should explore character/phoneme-level learning
from child-directed speech corpora. 仍然, 经过
feeding our networks ‘‘grown-up’’ prose, we are
arguably making the job of identifying basic
constituents harder than it might be when pro-
cessing the simpler utterances of early child-
directed speech (Tomasello, 2003).
语言)
As discussed, a rigid word notion is problematic
both cross-linguistically (比照. polysynthetic and
agglutinative
and within single
linguistic systems (比照. the view that the lexicon
hosts units at different levels of the linguistic
等级制度, from morphemes to large syntactic
constructions; 例如,
杰肯道夫, 1997; Croft
and Cruse, 2004; Goldberg, 2005). This study
provided a necessary initial check that word-free
models can account for phenomena traditionally
seen as word-based. Future work should test
whether such models can also account
为了
grammatical patterns that are harder to capture
in word-based formalisms, exploring both a
typologically wider range of languages and a
broader set of grammatical tests.
致谢
We would like to thank Piotr Bojanowski, Alex
Cristia, Kristina Gulordava, Urvashi Khandelwal,
Germ´an Kruszewski, Sebastian Riedel, Hinrich
Sch¨utze, and the anonymous
为了
feedback and advice.
reviewers
参考
Yossi Adi, Einat Kermany, Yonatan Belinkov,
Ofer Lavi, and Yoav Goldberg. 2017. Fine-
grained analysis of sentence embeddings using
In Proceedings
auxiliary prediction tasks.
of ICLR Conference Track. Toulon, 法国.
Published online: https://openreview.
net/group?id=ICLR.cc/2017/conference
Afra Alishahi, Marie Barking, and Grzegorz
Chrupała. 2017. Encoding of phonology in a
480
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
recurrent neural model of grounded speech.
In Proceedings of CoNLL, pages 368–378,
Vancouver.
Moshe Bar. 2007. The proactive brain: Using anal-
ogies and associations to generate predictions.
Trends in Cognitive Science, 11(7):280–289.
Yonatan Belinkov, Nadir Durrani, Fahim Dalvi,
Hassan Sajjad, and James Glass. 2017. 什么
do neural machine translation models learn
about morphology? In Proceedings of ACL,
pages 861–872, Vancouver.
Balthasar Bickel and Fernando Z´u˜niga. 2017. 这
‘word’ in polysynthetic languages: Phonol-
ogical and syntactic challenges, In Michael
Fortescue, Marianne Mithun, and Nicholas
埃文斯, 编辑, Oxford Handbook of Polysynthe-
姐姐, pages 158–186. 牛津大学出版社,
牛津.
Piotr Bojanowski, Armand Joulin, and Tomas
米科洛夫. 2016. Alternative structures
为了
character-level RNNs. In Proceedings of ICLR
Workshop Track. San Juan, Puerto Rico.
Published online: https://openreview.
net/group?id=ICLR.cc/2016/workshop.
Sabine Brants, Stefanie Dipper, Silvia Hansen,
Wolfgang Lezius, and George Smith. 2002.
在诉讼程序中
TIGER 树库.
the Workshop on Treebanks and Linguistic
Theories, 体积 168.
Michael Brent and Timothy Cartwright. 1996.
phonotactic
规律性
segmentation.
有用
Distributional
constraints
认识, 61:93–125.
和
是
为了
Joan Bresnan, Ash Asudeh, Ida Toivonen, 和
Stephen Wechsler. 2016. Lexical-Functional
Syntax, 2nd 版。, 布莱克威尔, Malden, 嘛.
Joan Bresnan and Sam Mchombo. 1995. 这
词汇的
integrity principle: 证据来自
Bantu. Natural Language and Linguistic
理论, 181–254.
Colin Cherry, George Foster, Ankur Bapna,
Orhan Firat, and Wolfgang Macherey. 2018.
Revisiting character-based neural machine
translation with capacity and compression.
arXiv 预印本 arXiv:1808.09943.
481
Noam Chomsky. 1970, Remarks on nominaliza-
的, In Roderick Jacobs and Peter Rosenbaum,
编辑, Readings in English Transformational
语法, pages 184–221. Ginn, Waltham,
嘛.
Morten Christiansen, Christopher Conway, 和
Suzanne Curtin. 2005. Multiple-cue integration
in language acquisition: A connectionist model
of speech segmentation and rule-like behav-
ior, James Minett and William Wang, 编辑,
Language Acquisition, Change and Emer-
根杰斯: Essays in Evolutionary Linguistics,
pages 205–249. City University of Hong Kong
按, 香港.
Morten Christiansen, Allen Joseh, and Mark
segment
1998. 学习
塞登伯格.
speech using multiple cues: A connectionist
模型. Language and Cognitive Processes,
13(2/3):221–268.
到
Andy Clark. 2016. Surfing Uncertainty, 牛津
大学出版社, 牛津.
Alexis Conneau, Germ´an Kruszewski, Guillaume
Lample, Lo¨ıc Barrault, and Marco Baroni.
2018. What you can cram into a single
$&!#* 向量: Probing sentence embeddings
for linguistic properties. In Proceedings of ACL,
pages 2126–2136, 墨尔本.
Ryan Cotterell, Sebastian J. Mielke,
Jason
艾斯纳, and Brian Roark. 2018. Are all
languages equally hard to language-model? 在
诉讼程序 2018 Conference of the
North American Chapter of the Association for
计算语言学: Human Language
Technologies, 体积 2 (Short Papers),
体积 2, pages 536–541.
William Croft and Alan Cruse. 2004. 认知的
语言学, 剑桥大学出版社,
剑桥.
Anna-Maria Di Sciullo and Edwin Williams.
1987. On the Definition of Word, 与新闻界,
剑桥, 嘛.
Robert Dixon and Alexandra Aikhenvald, 编辑.
2002. Word: A cross-linguistic typology, 剑桥
大学出版社, 剑桥.
Dudenredaktion. 2019, mit
(Adverb), Duden
在线的. https://www.duden.de/node/
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
152710/revision/152746, retrieved June 3,
2019.
Alex Graves. 2014. Generating sequences with re-
current neural networks. CoRR, abs/1308.0850v5.
Jeffrey Elman. 1990. Finding structure in time.
认知科学, 14:179–211.
Allyson Ettinger, Ahmed Elgohary, Colin
Phillips, and Philip Resnik. 2018. Assessing
composition in sentence vector representations.
COLING 论文集, pages 1790–1801.
圣达菲, NM.
Robert Frank, Donald Mathis, and William
Badecker. 2013. The acquisition of anaphora
recurrent networks. 语言
by simple
Acquisition, 20(3):181–227.
Stefano Fusi, Earl Miller, and Mattia Rigotti.
2016. Why neurons mix: High dimensionality
for higher cognition. Current Opinion in
Neurobiology, 37:66–74.
Daniela Gerz, Ivan Vuli´c, Edoardo Maria Ponti,
Jason Naradowsky, Roi Reichart, and Anna
科尔霍宁. 2018. Language modeling for mor-
phologically rich languages: Character-aware
modeling for word-level prediction. Transac-
tions of
the Association for Computational
语言学, 6:451–465.
Dan Gillick, Cliff Brunk, Oriol Vinyals, 和
Amarnag Subramanya. 2016. Multilingual
language processing from bytes. In Proceedings
of NAACL-HLT, pages 1296–1306.
Fr´ederic Godin, Kris Demuynck, Joni Dambre,
Wesley De Neve, and Thomas Demeester.
2018. Explaining
neural
networks for word-level prediction: Do they
discover linguistic rules? 在诉讼程序中
EMNLP. 布鲁塞尔.
character-aware
Adele Goldberg. 2005. Constructions at Work:
The Nature of Generalization in Language,
牛津大学出版社, 牛津.
Yoav Goldberg. 2017. Neural Network Methods
for Natural Language Processing, 摩根 &
Claypool, 旧金山, CA.
Sharon Goldwater, 托马斯·L. Griffiths, and Mark
约翰逊. 2009. A Bayesian framework for word
segmentation: Exploring the effects of context.
认识, 112(1):21–54.
Kristina Gulordava, Piotr Bojanowski, Edouard
Grave, Tal Linzen, and Marco Baroni. 2018.
Colorless green recurrent networks dream
hierarchically. In Proceedings of NAACL, 页面
1195–1205. New Orleans, 这.
Martin Haspelmath. 2011. The indeterminacy
of word segmentation and the nature of
morphology and syntax. Folia Linguistica,
45(1):31–80.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. 神经计算,
9(8):1735–1780.
Dieuwke Hupkes, Sara Veldhoen, and Willem
Zuidema. 2018. Visualisation and ‘‘diagnostic
classifiers’’ reveal how recurrent and recursive
neural networks process hierarchical structure.
Journal of Artificial Intelligence Research,
61:907–926.
Ray Jackendoff. 1997. Twistin’ the night away.
语言, 73:534–559.
Ray Jackendoff. 2002. Foundations of Language:
Brain, 意义, 语法, 进化, 牛津
大学出版社, 牛津.
Elisabetta
2016. The Lexicon: 一个
介绍, 牛津大学出版社, 牛津.
Jeˇzek.
`Akos K`ad`ar, Grzegorz Chrupała, and Afra
Alishahi. 2017. Representation of linguistic
form and function in recurrent neural networks.
计算语言学, 43(4):761–780.
Herman Kamper, Aren Jansen, and Sharon
Goldwater. 2016. Unsupervised word segmen-
tation and lexicon discovery using acoustic
IEEE Transactions on
word embeddings.
声音的, Speech and Language Processing,
24(4):669–679.
Katharina Kann, Ryan Cotterell, and Hinrich
Sch¨utze. 2016. Neural morphological analysis:
Encoding-decoding canonical
在
Proceedings of EMNLP, pages 961–967.
Austin, TX.
细分市场.
Yova Kementchedjhieva and Adam Lopez.
2018. ‘‘Indicatements’’ that character language
482
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
models learn English morpho-syntactic units
and regularities. In Proceedings of the EMNLP
BlackboxNLP Workshop, pages 145–153.
布鲁塞尔.
刺激: Hierarchical generalization without a
hierarchical bias in recurrent neural networks.
In Proceedings of CogSci, pages 2093–2098,
麦迪逊, WI.
Yoon Kim, Yacine Jernite, David Sontag, 和
Alexander Rush. 2016. Character-aware neural
language models. In Proceedings of AAAI,
pages 2741–2749, Phoenix, AZ.
Christo Kirov and Ryan Cotterell. 2018. Recurrent
neural networks in linguistic theory: Revisiting
Pinker and Prince (1988) and the past
tense debate. Transactions of the Association
for Computational Linguistics. arXiv 预印本
arXiv:1807.04783v2.
Patricia Kuhl. 2004. Early language acquisition:
Cracking the speech code. 自然评论
神经科学, 5(11):831–843.
Jey Han Lau, Alexander Clark, and Shalom Lappin.
2017. 语法性, acceptability, and proba-
能力: A probabilistic view of linguistic knowl-
边缘. 认知科学, 41(5):1202–1241.
Jason Lee, Kyunghyun Cho,
and Thomas
Hofmann. 2017. Fully character-level neural
machine translation without explicit segmen-
站. Transactions of
the Association for
计算语言学, 5:365–378.
Jiwei Li, Xinlei Chen, Eduard Hovy, and Dan
Jurafsky. 2016. Visualizing and understanding
neural models in NLP. 在诉讼程序中
全国AACL, pages 681–691, 圣地亚哥, CA.
Tal Linzen, Grzegorz Chrupała,
and Afra
在诉讼程序中
Alishahi, 编辑. 2018.
the EMNLP BlackboxNLP Workshop, 前交叉韧带,
布鲁塞尔.
Tal Linzen, Emmanuel Dupoux, and Yoav
Goldberg. 2016. Assessing the ability of LSTMs
to learn syntax-sensitive dependencies. 反式-
actions of the Association for Computational
语言学, 4:521–535.
Jessica Maye, Janet Werker, and Lou Ann
Gerken. 2002. Infant sensitivity to distributional
information can affect phonetic discrimination.
认识, 82(3):B101–B111.
Thomas McCoy, Robert Frank,
and Tal
扁豆. 2018. Revisiting the poverty of the
483
Ryan McDonald,
乔金·尼弗尔, Yvonne
Quirmbach-Brundage, Yoav Goldberg, Dipanjan
这, Kuzman Ganchev, Keith Hall, Slav
Petrov, Hao Zhang, Oscar T¨ackstr¨om, 等人.
2013. Universal dependency annotation for
multilingual parsing. 在诉讼程序中
这
51st Annual Meeting of the Association for
计算语言学 (体积 2: Short
文件), 体积 2, pages 92–97.
Oren Melamud,
Jacob Goldberger, and Ido
达甘. 2016. context2vec: Learning generic
context embedding with bidirectional lstm. 在
Proceedings of The 20th SIGNLL Conference
on Computational Natural Language Learning,
pages 51–61.
Stephen Merity, Nitish Shirish Keskar, 和
Richard Socher. 2018. An analysis of neural
language modeling at multiple scales. arXiv
preprint arXiv:1803.08240.
Tomas Mikolov. 2012. Statistical Language Mod-
els Based on Neural Networks. Dissertation,
Brno University of Technology.
Tomas Mikolov, Kai Chen, Greg Corrado, 和
Jeffrey Dean. 2013A. Efficient estimation of
word representations in vector space. CoRR,
abs/1301.3781.
Tomas Mikolov, 伊利亚·苏茨克维尔, Anoop Deoras,
and Jan
Hai-Son Le, Stefan Kombrink,
Cernock´y. 2011. Subword language modeling
with neural networks. http://www.fit.
vutbr.cz/∼imikolov/rnnlm/.
Tomas Mikolov, Wen-tau Yih, and Geoffrey
在
茨威格. 2013乙. Linguistic
规律性
continuous space word representations.
在
Proceedings of NAACL, pages 746–751,
亚特兰大, 遗传算法.
Joe Pater. 2018. Generative linguistics and neural
networks at 60: 基础, friction, and fusion.
语言. 土井:10.1353/lan.2019.0005.
Alec Radford, Rafal
and Ilya
产生
吸勺.
reviews and discovering sentiment. CoRR,
abs/1704.01444.
J´ozefowicz,
到
2017. 学习
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Andrew Radford. 2006. Minimalist syntax re-
访问过. http://www.public.asu.edu/
∼gelderen/Radford2009.pdf.
Ivan Sag, Thomas Wasow, and Emily Bender.
2003. Syntactic Theory: A Formal Introduction,
CSLI, 斯坦福大学, CA.
Ren´e Schiering, Balthasar Bickel, and Kristine
Hildebrandt. 2010. The prosodic word is not
universal, but emergent. Journal of Linguistics,
46(3):657–709.
Helmut Schmid. 1999. Improvements in part-of-
speech tagging with an application to german,
In Natural Language Processing Using Very
Large Corpora, pages 13–25. 施普林格.
Hinrich Sch¨utze. 2017. Nonsymbolic text repre-
sentation. In Proceedings of EACL, pages 785–796.
Valencia.
Rico Sennrich. 2017. How grammatical
是
character-level neural machine translation?
contrastive
assessing MT quality with
In Proceedings of EACL
translation pairs.
(Short Papers), pages 376–382, Valencia.
neural
和
Neural
pages 3104–3112.
网络.
In Advances
Information Processing
在
系统,
迈克尔·托马塞洛. 2003. Constructing a Lan-
规格: A Usage-Based Theory of Lan-
guage Acquisition, 哈佛大学出版社,
剑桥, 嘛.
Edwin Williams. 2007. Dumping lexicalism, 在
Gillian Ramchand and Charles Reiss, 编辑,
The Oxford Handbook of Linguistic Interfaces,
牛津大学出版社, 牛津.
Aubrie Woods. 2016. Exploiting linguistic fea-
tures for sentence completion. In Proceedings
of the 54th Annual Meeting of the Association
for Computational Linguistics (体积 2: Short
文件), 体积 2, pages 438–442.
Xingxing Zhang, Liang Lu,
and Mirella
警告. 2016. Top-down tree long short-
term memory networks. 在诉讼程序中
这 2016 Conference of the North American
Chapter of the Association for Computational
语言学: 人类语言技术,
pages 310–320.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
2
8
3
1
9
2
3
5
4
3
/
/
t
我
A
C
_
A
_
0
0
2
8
3
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Xing Shi,
Inkit Padhi, and Kevin Knight.
2016. Does string-based neural MT learn
source syntax? In Proceedings of EMNLP,
pages 1526–1534, Austin, TX.
Geoffrey Zweig and Christopher Burges. 2011.
The Microsoft Research sentence completion
challenge, Technical Report MSR-TR-2011-
129, Microsoft Research.
Geoffrey Zweig, John C. Platt, Christopher Meek,
克里斯托弗·J. C. 布尔吉斯, Ainur Yessenalina,
2012. 计算型
and Qiang
在
completion.
句子
方法
Proceedings of the 50th Annual Meeting of the
计算语言学协会:
Long Papers-Volume 1, pages 601–610.
刘.
到
伊利亚·苏茨克维尔, James Martens, and Geoffrey
欣顿. 2011. Generating text with recurrent
神经网络. In Proceedings of ICML, 页面
1017–1024, Bellevue, WA.
伊利亚·苏茨克维尔, Oriol Vinyals, and Quoc V.
Le. 2014. Sequence to sequence learning
484