Supervised Gradual Machine Learning for Aspect-Term
Sentiment Analysis
Yanyan Wang†‡ Qun Chen∗†‡ Murtadha H.M. Ahmed†‡ Zhaoqiang Chen†‡
Jing Su†‡ Wei Pan†‡ Zhanhuai Li†‡
†School of Computer Science, Northwestern Polytechnical University, Xi’an, 中国
‡Key Laboratory of Big Data Storage and Management, Northwestern Polytechnical University,
Ministry of Industry and Information Technology, Xi’an, 中国
{wangyanyan@mail., chenbenben@, murtadha@mail., chenzhaoqiang@mail.,
sujing@mail., panwei1002@, lizhh@}nwpu.edu.cn
抽象的
Recent work has shown that Aspect-Term Sen-
timent Analysis (ATSA) can be effectively
performed by Gradual Machine Learning
(GML). 然而,
the performance of the
current unsupervised solution is limited by
inaccurate and insufficient knowledge con-
veyance. 在本文中, we propose a supervised
GML approach for ATSA, which can effec-
tively exploit labeled training data to improve
knowledge conveyance. It leverages binary po-
larity relations between instances, which can
be either similar or opposite, to enable su-
pervised knowledge conveyance. Besides the
explicit polarity relations indicated by dis-
course structures, it also separately supervises
a polarity classification DNN and a binary
Siamese network to extract
implicit polar-
ity relations. The proposed approach fulfills
knowledge conveyance by modeling detected
relations as binary features in a factor graph.
Our extensive experiments on real benchmark
data show that it achieves the state-of-the-art
performance across all the test workloads. 我们的
work demonstrates clearly that, in collabora-
tion with DNN for feature extraction, GML
outperforms pure DNN solutions.
1
介绍
Aspect-Term Sentiment Analysis (ATSA) 是一个
classical fine-grained sentiment classification task
(Pontiki et al., 2015, 2016). Aiming to analyze
detailed opinions towards certain aspects of an
实体, it has attracted extensive research interests.
In ATSA, an aspect-term, also called target, 有
to explicitly appear in a review. 例如,
consider the running example shown in Table 1,
in which ri and sij denote the review and sentence
∗Corresponding author.
723
identifiers, 分别. In r1, ATSA needs to
predict the expressed sentiment polarity, 积极的
or negative, toward the explicit targets of space
and food.
The state-of-the-art solutions of ATSA have
been built upon pre-trained language models, 这样的
as LCF-BERT (Zeng et al., 2019), BAT (Karimi
等人。, 2020A), PH-SUM (Karimi et al., 2020乙),
and RoBERTa+MLP (Dai et al., 2021), 命名
一些. It is noteworthy that the efficacy of these
deep solutions depends on the independent and
identically distributed (i.i.d.) assumption. 如何-
曾经, in real scenarios, there may not be sufficient
labeled training data; even if provided with suf-
ficient training data, the distributions of training
data and target data are almost certainly different
to some extent.
To alleviate the limitation of the i.i.d assump-
的, a solution based on the non-i.i.d paradigm
of Gradual Machine Learning (GML) has recently
been proposed for ATSA (王等人。, 2021).
GML begins with some easy instances, 哪个
can be automatically labeled by the machine with
high accuracy, and then gradually labels more
challenging instances by iterative knowledge con-
veyance in a factor graph. Without exploiting
labeled training data, the current unsupervised
solution relies on sentiment lexicons and explicit
polarity relations indicated by discourse structures
to enable knowledge conveyance. An improved
GML solution leverages unsupervised DNN to ex-
tract sentiment features beyond lexicons (Ahmed
等人。, 2021). It has been empirically shown
that even without leveraging any labeled training
数据, unsupervised GML can achieve competi-
tive performance compared with many supervised
deep models. 然而, unsupervised sentiment
计算语言学协会会刊, 卷. 11, PP. 723–739, 2023. https://doi.org/10.1162/tacl 00571
动作编辑器: Minlie Huang. 提交批次: 11/2022; 修改批次: 1/2023; 已发表 6/2023.
C(西德:3) 2023 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
我
A
C
_
A
_
0
0
5
7
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
ri
r1
r2
sij
s11
s21
s22
Text
Space was limited, but the food
made up for it.
The food is sinful.
The staff was really friendly.
桌子 1: A running example in the domain of
餐厅.
features are usually incomplete and noisy. 意思是-
尽管, even though explicit polarity relations are
accurate, they are usually very sparse in real nat-
ural language corpus. 所以, the performance
of gradual learning is still limited by inaccurate
and insufficient knowledge conveyance.
所以, there is a need to investigate how to
leverage labeled training data to improve gradual
学习. 在本文中, we propose a supervised
solution based on GML for ATSA. As pointed
out by Wang et al. (2021), linguistic hints can be
very helpful for polarity reasoning. 例如,
如表所示 1, the two aspect polarities
of s11 can be reasoned to be opposite because
their opinion clauses are connected by the shift
word of ‘‘but’’, while the absence of any shift
word between s21 and s22 indicates their polar-
ity similarity. Representing the most direct way
of knowledge conveyance, such binary polarity
relations can effectively enable gradual learning.
很遗憾, the binary relations indicated by
discourse structures are usually sparse in real
natural language corpora. 所以, besides ex-
plicit polarity relations, our proposed approach
also separately supervises a DNN for polarity
classification and a Siamese network to extract
implicit polarity relations.
A supervised DNN can usually effectively sep-
arate the instances with different polarities. 作为一个
结果, two instances appearing very close in its
embedding space usually have the same polar-
性. 所以, we leverage a polarity classifier
for the detection of polarity similarity between
close neighbors in an embedding space. It can
also be observed that in natural languages, 那里
are many different types of patterns to associate
opinion words with polarities. 然而, a po-
larity classifier may put the instances with the
same polarity but different association patterns in
far-away places in its embedding space. 在通讯中-
parison, metric learning can cluster the instances
with the same polarity together while separating
those with different polarities as far as possible
(Kaya and Bilge, 2019); it can thus align differ-
ent association patterns with the same polarity.
所以, we also employ a Siamese network for
metric learning, which has been shown to perform
well on semantic textual similarity tasks (Reimers
和古列维奇, 2019), to detect complementary
polarity relations. A Siamese network can detect
both similar and opposite polarity relations be-
tween two arbitrary instances, which may be far
away in an embedding space.
最后, our proposed approach fulfills knowl-
edge conveyance by modeling polarity relations
as binary features in a factor graph. In our imple-
心理状态, we use the state-of-the-art DNN model
for ATSA, RoBERTa+MLP (Dai et al., 2021),
to capture neighborhood-based polarity similarity
while adapting the Siamese network (Chopra et al.,
2005), the classical model of deep metric learning
(Kaya and Bilge, 2019), to extract arbitrary polar-
ity relations. It is worth pointing out that our work
is orthogonal to the research on polarity classi-
fication DNNs and Siamese networks in that the
proposed approach can easily accommodate new
polarity classifiers and Siamese network models.
The main contributions of this paper can be
summarized as follows:
• We propose a supervised GML approach for
ATSA, which can effectively exploit labeled
training data to improve gradual learning;
• We present the supervised techniques to ex-
tract implicit polarity relations for ATSA,
which can be easily instilled into a GML
factor graph to enable supervised knowledge
conveyance;
• We empirically validate the efficacy of the
proposed approach on real benchmark data.
Our extensive experiments have shown that
it consistently achieves the state-of-the-art
performance across all the test datasets.
2 相关工作
Sentiment analysis at different granularity levels,
including document, 句子, and aspect lev-
这, has been extensively studied in the literature
(Ravi and Ravi, 2015). At the document (resp.,
句子) 等级, its goal is to detect the polarity
of the entire document (resp., 句子) 没有
724
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
我
A
C
_
A
_
0
0
5
7
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
regard to the mentioned aspects (张等人。,
2015; Johnson and Zhang, 2017; Qian et al., 2017;
Reimers and Gurevych, 2019). The state-of-the-art
solutions for document-level and sentence-level
sentiment analysis have been built upon various
DNN models (雷等人。, 2018; Long et al., 2017;
Letarte et al., 2018). 然而, they cannot be
directly applied to the finer-grained aspect-level
sentiment analysis because a document or sen-
tence may express different polarities towards
different aspects. The task of aspect-level senti-
ment analysis has been further classified into two
finer subtasks, Aspect-Term Sentiment Analysis
(ATSA) and Aspect-Category Sentiment Analy-
姐姐 (ACSA) (Xue and Li, 2018). ATSA aims to
predict the sentiment polarity associated with an
explicit aspect term appearing in the text while
ACSA deals with both explicit and implicit as-
pects. 在本文中, we focus on the far more
popular subtask of ATSA. 但, as shown in our
experimental evaluation, our proposed approach
is also applicable to ACSA.
Even though early work on deep learning for
ATSA employed non-attention models (Dong
等人。, 2014; Tang et al., 2016), more recent pro-
posals leveraged various attention mechanisms
to output aspect-specific sentiment features, 这样的
as Interactive Attention Networks (Ma et al.,
2017), Recurrent Attention Network (陈等人。,
2017), Content Attention Model (刘等人。, 2018),
Multi-grained Attention Network (Fan et al.,
2018), Segmentation Attention Network (王
and Lu, 2018), Attention-over-Attention Neural
网络 (Huang et al., 2018), and Effective At-
tention Modeling (He et al., 2018) to name a few.
Most recently, the focus has experienced a consid-
erable shift towards how to leverage pre-trained
language models for ATSA, 例如, BERT-SPC
(Song et al., 2019), AEN-BERT (Attentional
Encoder Network)
(Song et al., 2019), 和
LCF-BERT (Local Context Focus) (Zeng et al.,
2019). Since BERT is trained on Wikipedia arti-
cles and has limited ability to understand review
文本, Xu proposed to first post-train BERT on
both domain knowledge and task knowledge, 和
then fine-tune the resulting model of BERT-PT on
supervised domain data (徐等人。, 2019). 自从
然后, many models built upon BERT-PT have
been proposed (Karimi et al., 2020A,乙). 其他
variants of BERT for ATSA include Adapted
BERT (BERT-ADA) (Rietzler et al., 2020), Ro-
bustly Optimized BERT (RoBERTa) (Dai et al.,
2021), and BERT with Disentangled Attention
(DeBERTa) (Silva and Marcacini, 2021).
Since syntax structures are helpful for as-
pects to find their contextual words, 许多
syntax-enhanced models have been recently pro-
posed for ATSA, such as Proximity-Weighted
Convolution Network (PWCN) (张等人。,
2019), Relational Graph Attention Network
(RGAT) (Bai et al., 2021), Graph Convolutional
网络 (GCN) (赵等人。, 2020), Depen-
dency Graph Enhanced Dual-Transformer net-
工作 (DGEDT) (Tang et al., 2020), Type-aware
Graph Convolutional Networks (T-GCN) (Tian
等人。, 2021), and Knowledge-aware Gated Recur-
rent Memory Network with Dual Syntax Graph
(KaGRMN-DSG) (Xing and Tsang, 2022). 他们
focused on how to exploit explicit syntactic in-
formation provided by dependency-based parse
树. Other proposals investigated how to induce
implicit syntactic information from pre-trained
型号 (Dai et al., 2021).
The GML paradigm was first proposed for the
task of entity resolution (Hou et al., 2022). 自从
然后, it has also been applied to the task of ATSA
(王等人。, 2021; Ahmed et al., 2021). 没有
exploiting labeled training data, the performance
of unsupervised GML is usually limited by inac-
curate and insufficient knowledge conveyance. 在
这篇论文, we focus on how to leverage labeled
examples to improve gradual learning for ATSA.
3 The GML Framework
在这个部分, we illustrate the GML framework
by the existing unsupervised GML solution for
ATSA (王等人。, 2021). Given a corpus of
reviews, 右, the goal of ATSA is to predict the
sentiment polarity of each aspect unit in R, ti =
(rj, sk, 阿尔), where rj denotes a review, sk denotes
a sentence in the review rj, and al denotes an
explicit aspect appearing in the sentence sk. 在
这篇论文, we suppose that an aspect polarity is
either positive or negative.
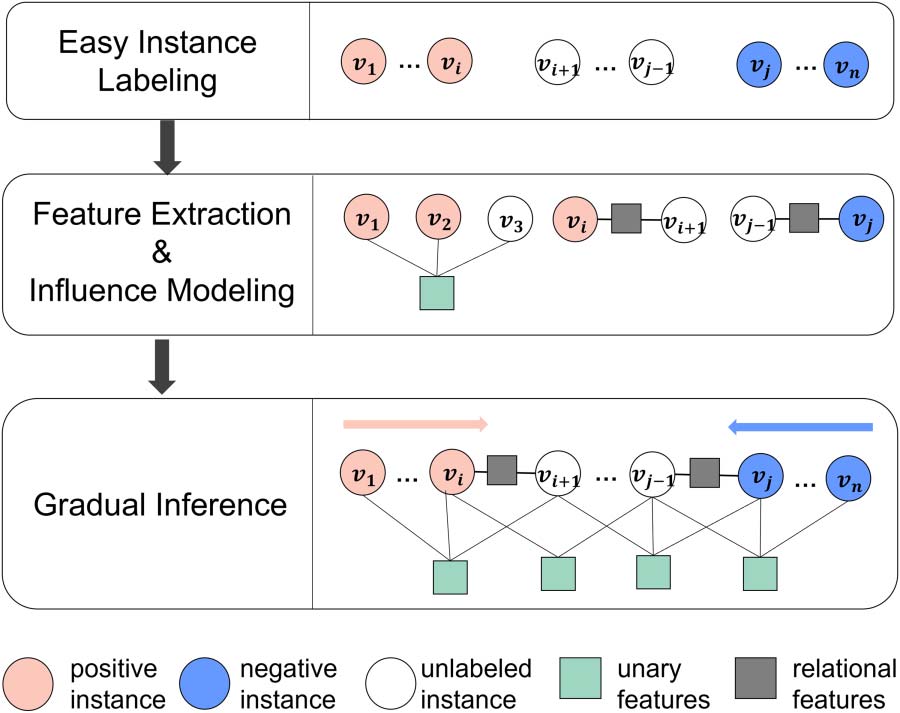
如图 1, the framework consists
of the following three essential steps:
3.1 Easy Instance Labeling
Gradual machine learning begins with some easy
instances. 所以, high label accuracy of easy
instances is critical for GML’s ultimate perfor-
曼斯. The existing unsupervised solution for
ATSA employs simple user-specified rules to
725
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
我
A
C
_
A
_
0
0
5
7
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
features as unary and binary factors in a factor
graph respectively.
3.3 Gradual Inference
This step gradually labels the instances with in-
creasing hardness. Gradual learning is fulfilled by
iterative inference on a factor graph, G, 哪个
consists of evidence variables representing la-
beled instances, inference variables representing
unlabeled instances, and factors representing their
特征. The values of evidence variables once
labeled remain unchanged while the values of in-
ference variables need to be gradually inferred
based on G.
正式地, suppose that a factor graph, G, 骗局-
sists of a set of evidence variables, Λ, a set
of inference variables, 六、, and a group of factor
functions of variables indicating their correlations,
denoted by φwi(维). In the case of ATSA, each
variable in the factor graph is a boolean variable
indicating the polarity of an aspect unit, the value
的 1 for positive and 0 for negative. 然后, the joint
probability distribution over V = {Λ, 六、 } of G
can be formulated as
Pw(Λ, 六、 ) =
1
Zw
米(西德:2)
我=1
φwi(维),
(1)
where Vi denotes a set of variables, wi denotes a
factor weight, m denotes the total number of fac-
托尔斯, and Zw denotes the normalization constant.
Factor inference on G learns factor weights by
minimizing the negative log marginal likelihood
of evidence variables as follows:
ˆw = arg min
w
−log
(西德:3)
六、
Pw(Λ, 六、 ).
(2)
In each iteration, GML generally chooses to
label the inference variable with the highest degree
of evidential certainty. Given an inference variable
v, GML measures its evidential certainty by the
inverse of entropy as follows:
乙(v) =
1
H(v)
(西德:4)
=
-
i=0,1
1
圆周率(v) · log2Pi(v)
, (3)
in which E(v) 和H(v) denote the evidential
certainty and entropy of v respectively, and Pi(v)
denotes the inferred probability of v having the
label of 0 或者 1. The iteration is repeatedly invoked
until all the instances are labeled.
数字 1: Unsupervised GML Solution for ATSA.
identify non-ambiguous instances as easy ones
(王等人。, 2021). 具体来说, if a sentence
contains some strong positive (resp., negative)
sentiment words, but no negation, 对比, and hy-
pothetical connectives, it can be reliably reasoned
to be positive (resp., negative). 值得注意的是
that since this paper considers ATSA in the su-
pervised setting, in which some labeled training
data are supposed to be available, these training
data with ground-truth labels can naturally serve
as initial easy instances.
3.2 Feature Extraction and
Influence Modeling
Features serve as the medium to convey the
knowledge obtained from labeled easy instances
to unlabeled harder ones. This step extracts the
common features shared by the labeled and unla-
beled instances. To facilitate effective knowledge
conveyance, it is desirable that a wide variety
of features are extracted to capture diverse infor-
运动. For each extracted feature, this step also
needs to model its influence over the labels of
relevant instances.
The existing unsupervised solution for ATSA
presented in Wang et al. (2021) relies on sentiment
lexicons and explicit polarity relations indicated
by discourse structures to enable knowledge con-
veyance. 具体来说, given a sentiment word,
积极或消极, any sentence containing the
word is supposed to have the same polarity as the
word. 相似地, a similar (resp., opposite) polar-
ity relation between two instances indicates that
they are expected to have the same (resp., oppo-
site) polarities. GML models word and relation
726
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
我
A
C
_
A
_
0
0
5
7
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
Algorithm 1: Scalable Gradual Inference
1 while there exists any unlabeled variable in
2
3
4
5
6
7
8
9
10
11
G do
V (西德:4) ← all the unlabeled variables in G;
for v ∈ V (西德:4) 做
Measure the evidential support of v
in G;
Select top-m unlabeled variables with the
most evidential support (denoted by
Vm) ;
for v ∈ Vm do
Approximately rank the entropy of v
in Vm;
Select top-k most promising variables in
terms of entropy in Vm (denoted by Vk) ;
for v ∈ Vk do
Compute the probability of v in G by
factor graph inference over a
subgraph of G;
Label the variable with the minimal
entropy in Vk;
To improve efficiency, GML usually imple-
ments gradual inference by a scalable approach,
as sketched in Algorithm 1. It consists of three
脚步: measurement of evidential support, approx-
imate ranking of entropy, and construction of
inference subgraph. It first selects the top-m unla-
beled variables with the most evidential support in
G as the inference candidates. For each unlabeled
实例, GML measures its evidential support
from each feature by the degree of labeling confi-
dence indicated by labeled observations, 进而
aggregates them based on the Dempster-Shafer
theory.1 It then approximates entropy estimation
by an efficient algorithm on the m candidates and
selects only the top-k most promising variables
among them for factor graph inference. 最后, 它
estimates the probabilities of the finally chosen k
variables by factor graph inference.
4 Supervised GML for ATSA
The overview of the proposed approach, denoted
by S-GML, is shown in Figure 2. 在这个部分,
we first describe how to extract relational features,
and then present their factor modeling.
1https://en.wikipedia.org/wiki/Dempster
-Shafer theory.
4.1 Polarity Relation Extraction
As mentioned in the Introduction, there exist some
discourse relations between clauses or sentences
that can provide helpful hints for polarity reason-
英. 具体来说, if two sentences are connected
with a shift word (例如, ‘‘but’’ and ‘‘however’’),
they usually have opposite polarities. 在骗子-
特拉斯特, two neighboring sentences without any shift
word between them usually have similar polari-
领带. S-GML uses the same rules as presented in
Wang et al. (2021) to extract the explicit relations
indicated by discourse structures. 所以, 我们
focus on how to extract implicit polarity relations
in the rest of this subsection.
4.1.1 By Polarity Classification DNN
Since a supervised DNN can effectively sepa-
rate the instances with different polarities, 二
instances appearing very close in its embedding
space usually have the same polarity. 所以,
we supervise a DNN to automatically generate
polarity-sensitive vector representations, 进而
exploit them for polarity similarity detection based
on the nearest neighborhood.
如图 2(乙), we extract kn-nearest
neighbors of each unlabeled instance from both la-
beled training data and unlabeled test data, 在哪里
vector distance is measured by cosine distance. 到
ensure that only very close instances in the embed-
ding space are considered to be similar, we also set
a high threshold (例如, 0.05 in our implementation)
to filter out unreliable pairs. Our experiments have
demonstrated that the performance of supervised
GML is robust w.r.t. the value of kn provided that it
is set within a reasonable range (之间 5 和 9).
In the implementation, we use RoBERTa+MLP
(Dai et al., 2021), the-state-of-art deep model for
ATSA, to learn polarity-sensitive vector represen-
tations. 然而, other deep models for ATSA
can also be applied.
4.1.2 By Siamese Network
A polarity classifier may put the instances with
the same polarity but different opinion association
patterns in far-away places in its embedding space.
To extract complementary polarity relations, 我们
also employ metric learning, which can cluster the
instances with the same polarity together while
separating those with different polarities as far
尽可能, to align different association patterns
with the same polarity. Metric learning can de-
tect both similar and opposite polarity relations
727
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
我
A
C
_
A
_
0
0
5
7
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
我
A
C
_
A
_
0
0
5
7
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
数字 2: The overview of S-GML: 1) it extracts three types of polarity relations; 2) it models the extracted
relations as binary factors to enable gradual learning.
between two arbitrary instances, which may be far
away in an embedding space. In our implemen-
站, we use the Siamese network, which has
been shown to perform well on semantic textual
similarity tasks (Reimers and Gurevych, 2019),
to detect polarity relations between two arbitrary
instances.
The structure of the Siamese network has
been shown in Figure 2(C). Given two instances,
t1 = (r1, s1, a1) and t2 = (r2, s2, a2), it first gen-
erates their vector representations by feeding the
sequence of ‘‘[CLS] + aspect + [SEP] + 文本 +
[SEP]’’ into the BERT model, then computes their
mutual information by multiplication, 最后
uses a linear layer to predict their polarity relation,
0 for opposite and 1 for similar. The whole process
can be represented by
v1 = BERT (t1),
v2 = BERT (t2),
pr = sof tmax([v1 (西德:7) v2] ∗ W ),
(4)
(5)
(6)
where dm denotes the dimension of the BERT
模型, v1, v2 ∈ Rdm denote the pooled vector
陈述, W ∈ Rdm×2 denotes the weights
of the linear layer, (西德:7) denotes the element-wise
multiplication, and pr ∈ R1×2 denotes the output
of the Siamese network, pr = [d, 1 − d], 在哪里
d denotes the predicted dissimilarity probability
obtained from the softmax layer.
The training of a Siamese network aims to
minimize the binary entropy loss defined as
L = −y log ˆy − (1 − y) 日志(1 − ˆy),
(7)
where ˆy denotes the prediction output of two in-
stances having the same polarity, and y denotes
the ground-truth label indicating whether they are
similar or opposite. Since the Siamese network is
supposed to predict binary labels, 0 或者 1, 照常,
we set the threshold at 0.5. 当然, its predic-
tions are noisy, containing some false positives
and false negatives. 然而, gradual learning
does not require all the predicted relations to be
正确的; instead a set of noisy relations can cor-
rectly predict the label of a target instance pro-
vided that the majority of them are correct.
For the training of the Siamese network, S-GML
randomly selects a fixed number of binary rela-
系统蒸发散 (例如, 80 in our implementation), half of
which are similar ones and the other half are
opposite ones. In the prediction phase, for each
unlabeled instance, S-GML randomly selects ks
from both labeled and unlabeled instances to ex-
tract its binary relations. Since polarity relation
detection between two arbitrary instances is gen-
erally more challenging than polarity similarity
detection between close neighbors in an embed-
ding space, the number of relations constructed
based on Siamese network per instance, denoted
by ks, is suggested to be set to be not greater
than the number of its extracted nearest neigh-
bors, namely ks <= kn. Our experiments have
demonstrated that the performance of supervised
GML is robust w.r.t. the values of kn and ks
provided that they are set to be within a rea-
sonable range (between 3 and 9). It is notewor-
thy that the total number of relations extracted
by the Siamese network can be represented by
O(m × ks), in which m denotes the number of
728
unlabeled instances in a target workload. Due to
the limited value of ks, relation extraction by the
Siamese network can be executed very efficiently.
4.2 Factor Modeling of Polarity Relations
An example of a GML factor graph for ATSA
is shown in Figure 2(d). S-GML models polar-
ity relations as binary factors to enable gradual
knowledge conveyance from labeled instances to
unlabeled ones.
Formally, the constructed factor graph G de-
fines a joint probability distribution over its
variables V by
Pw(V = v) =
1
Zw
(cid:2)
f ∈F
φf (vi, vj),
(8)
where vi denotes a Boolean variable indicating
the polarity of an aspect unit, F = Fc ∪ Fk ∪ Fs
denotes the set of all binary factors corresponding
to context-based, KNN-based and Siamese-based
relational features respectively, and the binary
factor φf (vi, vj) is formulated as
(cid:5)
φf (vi, vj) =
ewf
1
if vi = vj;
otherwise;
(9)
where vi and vj denote the two variables sharing
the binary feature f , and wf denotes the weight
of f . It
is noteworthy that a factor function,
which aims to measure the correlation between
variables, is usually defined as an exponential
function (Kschischang et al., 2001). It should take
non-negative values, and have larger values if its
correlated variables take desired values. There-
fore, in Eq. 9, the weight of a similar factor is
positive, or wf > 0, while the weight of an op-
posite factor is negative, or wf < 0. It can be
observed that such way of encoding would force
two variables sharing a similar factor to hold the
same polarity, while forcing two variables sharing
an opposite factor to hold the opposite polarities.
In S-GML, we have five types of relational fac-
tors, two modeling explicit relations (similar and
opposite), one modeling implicit relations detected
by polarity classifier (only similar), and the re-
maining two modeling implicit relations detected
by Siamese network (similar and opposite). The
factors of the same type are supposed to have the
same weight. In our implementation, the weights
of similar factors are initially set to 2 while the
weights of opposite factors are set to −2. However,
all the five factor weights have to be continuously
learned in the process of gradual inference.
5 Empirical Evaluation
In this section, we empirically evaluate the per-
formance of the proposed approach, denoted by
S-GML, on real benchmark data. We compare
S-GML with the existing GML solution as well
as the state-of-the-art DNN models. Even though
the focus of this paper is on ATSA, the pro-
posed approach can also be applied to the task of
ACSA. Therefore, we also compare S-GML with
its alternatives on ACSA.
The rest of this section is organized as follows:
Section 5.1 describes the experimental setup. Sec-
tion 5.2 presents the evaluation results on ATSA.
Section 5.3 presents the evaluation results of
parameter sensitivity. Section 5.4 presents the
evaluation results on ACSA.
5.1 Experimental Setup
We have used benchmark datasets in three do-
mains (restaurant,
laptop, and neighborhoods)
from the SemEval-2014 Task 4,2 SemEval-2015
Task 12,3 SemEval-2016 Task 5,4 and Senti-
Hood.5 This paper considers both ATSA and
ACSA as binary classification tasks. Note that
we use the annotated labels provided by Wang
et al. (2021) when aspect terms are not specified
in ATSA. In all the datasets, we ignore neutral
instances and label aspect polarities as positive or
negative.
the default
For performance evaluation, as usual, we ran-
training data of each
domly split
benchmark dataset into two parts by the ratio
of 8 : 2, which specifies the proportions of train-
ing and validation data, respectively. Since we run
each approach multiple times, we leverage vali-
dation data to pick the best model in each run. On
Sentihood, we use the default partition of training
and validation data. We use the classical metrics of
Accuracy and Macro-F1 to measure performance,
and conduct pairwise t-test on both metrics to
verify whether the achieved improvements are
statistically significant.
2https://alt.qcri.org/semeval2014/task4.
3https://alt.qcri.org/semeval2015/task12.
4https://alt.qcri.org/semeval2016/task5/.
5https://github.com/HSLCY/ABSA-BERT-pair
/tree/master/data/sentihood.
729
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Compared Approaches. For ATSA, the com-
pared GML solutions include:
• Unsupervised Lexicon-based GML (Wang
et al., 2021). The first unsupervised solution
relies on sentiment lexicons and explicit po-
larity relations indicated by discourse struc-
tures for knowledge conveyance.
• Unsupervised DNN-based GML (Ahmed
et al., 2021). As an improvement of lexicon-
based GML, it leverages an unsupervised
attention-based neural network to automati-
cally extract sentimental features for knowl-
edge conveyance.
• Hybrid GML (Ahmed et al., 2021). Built
upon the unsupervised DNN-based GML, it
leverages labeled training data in a naive
way by simply integrating the outputs of
supervised DNN as unary factors into a
factor graph to give a hybrid prediction.
It is noteworthy that for fair comparison,
the hybrid approach uses the same labeled
data as S-GML to train DNN models. The
original solution used the DNN model of
PH-SUM. Since RoBERTa+MLP has been
empirically shown to outperform PH-SUM,
the hybrid solution with
we implement
RoBERTa+MLP as its DNN model in this
paper.
Since the deep models for ATSA based
on the pre-trained language models have been
empirically shown to outperform their earlier
alternatives, we compare S-GML with these
state-of-the-art models, which include:
• BERT-SPC (Song et al., 2019). It feeds the
sequences of ‘‘[CLS] + context + [SEP] +
target + [SEP]’’ into the basic BERT model
for sentence pair classification.
• AEN-BERT (Song et al., 2019). It uses
an Attentional Encoder Network (AEN) to
model the correlation between context and
target.
• LCF-BERT (Zeng et al., 2019). It uses a Lo-
cal Context Focus (LCF) mechanism based
on Multi-head Self-Attention (MHSA) to pay
more attention to local context words.
• BERT-PT (Xu et al., 2019). It uses post-
trained BERT on task-aware knowledge to
enhance BERT fine-tuning.
• BAT (Karimi et al., 2020a). It uses ad-
training to fine-tune BERT for
versarial
ATSA.
• PH-SUM (Karimi et al., 2020b). It uses two
simple modules named Parallel Aggregation
and Hierarchical Aggregation on the top of
BERT for ATSA.
• RGAT (Bai et al., 2021). It uses a novel
relational graph attention network to integrate
typed syntactic dependency information for
ATSA.
• RoBERTa+MLP (Dai et al., 2021). It uses
RoBERTa to generate context-based word
embeddings of explicit aspect terms, and then
leverages an MLP layer for polarity output.
Implementation Details. We have implemented
S-GML based on the open-sourced GML solu-
tion for ATSA (Wang et al., 2021). To extract
neighborhood-based polarity similarity relations,
we use the model of RoBERTa+MLP, whose per-
formance has been empirically shown to be state of
the art. In the implementation of RoBERTa+MLP,
we use the split set of default training data and
the default parameter settings as presented in
Dai et al. (2021). Specifically, the size of hid-
den layer is set at 768, batch size at 32, learning
rate at 2e − 5, dropout at 0.5, and the number of
epoches at 40. In the implementation of Siamese
network, we use the post-trained BERT (Xu et al.,
2019), which was trained using an uncased version
of BERT-base on the domains of restaurant and
laptop. To generate training data for the Siamese
network, for each labeled instance in the training
set, we randomly select totally 80 polarity rela-
tions, 40 of which are similar while the remaining
40 are opposite. With regard to Siamese network,
we set the size of hidden layer at 768, the maxi-
mum length of inputs at 80, learning rate at 3e − 5
and batch size at 32.
In the default setting of S-GML, we select
top-5 nearest neighbors from labeled training
data and unlabeled test data for each unlabeled
instance based on the learned embedding of
RoBERTa+MLP (or kn = 5 in Subsection 4.1.1),
and randomly select 3 instances from both labeled
training data and unlabeled test data to extract
polarity relations based on the Siamese network
(or ks = 3 in Subsection 4.1.2). Our sensitiv-
ity evaluation results presented in Subsection 5.3
730
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
RES14
RES15
RES16
Model
BERT-SPC
AEN-BERT
LCF-BERT
BERT-PT
BAT
PH-SUM
RGAT
RoBERTa+MLP
Unsupervised Lexicon-based GML
Unsupervised DNN-based GML
Hybrid GML(RoBERTa+MLP)
S-GML
S-GML vs RoBERTa+MLP (p-value) 7.98e − 8 † 5.56e − 8 † 0.0183 † 0.0192 † 1.52e − 5 † 1.86e − 5 †
0.0008 †
S-GML vs Hybrid GML (p-value)
Acc
Macro-F1
93.61%
87.60%
91.77%
87.11%
93.94%
87.05%
95.50%
90.27%
95.45%
91.67%
95.87%
91.49%
95.45%
88.90%
95.74%
91.05%
83.83%
80.33%
87.05%
81.15%
91.64%
95.92%
96.90% 95.33% 90.83% 89.70% 96.00% 93.65%
Macro-F1 Acc Macro-F1
90.47% 85.80% 83.75%
88.17% 87.52% 85.88%
90.87% 85.99% 84.23%
93.24% 88.52% 87.37%
93.12% 89.17% 87.86%
93.69% 89.44% 88.21%
92.89% 85.70% 83.60%
93.53% 89.51% 88.04%
79.34% 80.22% 78.94%
82.93% 81.19% 79.92%
93.86% 89.70% 88.29%
Acc
92.06%
91.22%
91.89%
93.62%
94.76%
94.56%
92.53%
94.37%
85.64%
86.31%
94.88%
1.28e − 6 † 6.65e − 7 † 0.0247 † 0.0252 †
0.0007 †
Model
BERT-SPC
AEN-BERT
LCF-BERT
BERT-PT
BAT
PH-SUM
RGAT
RoBERTa+MLP
Unsupervised Lexicon-based GML
Unsupervised DNN-based GML
Hybrid GML(RoBERTa+MLP)
S-GML
S-GML vs RoBERTa+MLP (p-value)
S-GML vs Hybrid GML (p-value)
LAP14
LAP15
Acc Macro-F1
LAP16
Macro-F1
89.84%
91.65%
90.20%
91.78%
91.55%
91.30%
90.76%
92.83%
79.41%
83.33%
93.12%
Macro-F1
Acc
85.37%
89.45% 88.53%
91.68%
84.74%
90.99% 90.32%
93.39%
85.29%
88.93% 88.30%
91.90%
86.38%
93.10% 92.72%
93.22%
86.20%
93.51% 93.07%
93.13%
86.15%
92.12% 91.67%
92.84%
86.09%
90.75% 90.51%
93.12%
87.44%
93.06% 92.62%
94.24%
78.74%
82.42% 81.52%
82.25%
80.07%
84.05% 83.26%
85.84%
94.46%
87.68%
93.39% 92.93%
95.10% 93.95% 93.70% 93.26% 89.77% 88.49%
0.0016 †
0.0261 †
Acc
86.64%
86.64%
86.85%
87.72%
87.93%
87.61%
87.55%
88.73%
80.31%
81.62%
88.94%
0.0002 † 0.0006 †
0.0111 † 0.0227 †
0.0053 †
0.0236 †
0.0006 †
0.0098 †
0.0016 †
0.0106 †
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Table 2: Comparative Evaluation Results on ATSA: 1) RES and LAP stand for Restaurant and Laptop
domains respectively; 2) the best accuracies are highlighted in bold; 3) the marker † indicates p-value
< 0.05.
demonstrate that the performance of S-GML is
very robust w.r.t. the parameters of kn and ks
provided that their values are set to be within a
reasonable range (between 3 and 9). Our imple-
mentations of S-GML have been available at our
website.6
5.2 Comparative Evaluation on ATSA
The detailed comparative results on ATSA
in which Hybrid
are presented in Table 2,
GML(RoBERTa+MLP) denotes the Hybrid GML
6https://chenbenben.org/sgml.html.
solution with RoBERTa+MLP as its DNN model.
The reported results are the averages over 25 runs.
To verify statistical significance of S-GML’s per-
formance advantage, we have conducted pairwise
t-test between S-GML and its best alternatives,
RoBERTa+MLP and Hybrid GML.
It can be observed that S-GML consistently
achieves the state-of-the-art performance on all
the datasets. It outperforms the best DNN model
by the margins between 1% and 2% on most
datasets. For instance, on RES14, RES15, and
RES16,
the improvements are close to 2.0%
in terms of Macro-F1. On LAP14 and LAP16,
731
Model
S-GML(w/o knn)
S-GML(w/o Siamese)
S-GML(w/o context)
S-GML
Model
S-GML(w/o knn)
S-GML(w/o Siamese)
S-GML(w/o context)
S-GML
RES14
RES15
RES16
Acc
96.44%
95.14%
96.68%
96.90%
Macro-F1
94.68%
92.55%
95.00%
95.33%
Acc
89.02%
88.25%
90.55%
90.83%
Macro-F1
87.58%
86.77%
89.38%
89.70%
Acc
95.66%
93.00%
95.80%
96.00%
Macro-F1
93.19%
88.85%
93.35%
93.65%
LAP14
LAP15
LAP16
Acc
93.60%
91.90%
94.67%
95.10%
Macro-F1
92.16%
89.69%
93.48%
93.95%
Acc
93.06%
90.51%
93.66%
93.70%
Macro-F1
92.55%
89.95%
93.23%
93.26%
Acc
88.10%
89.35%
88.10%
89.77%
Macro-F1
86.69%
88.05%
86.73%
88.49%
Table 3: The evaluation results of ablation study on ATSA.
the improvements are more than 1% in terms of
Macro-F1. S-GML also beats previous unsuper-
vised GML solutions by large margins; in terms
of accuracy, S-GML outperforms Unsupervised
DNN-based GML by the margins between 8% and
10% across all the test workloads. It is noteworthy
that S-GML consistently beats the Hybrid GML,
which achieves overall better performance than the
state-of-the-art deep model (RoBERTa+MLP).
For instance, in terms of Macro-F1, the improve-
ment margins are around 1.5%, 1.5%, and 2%
on RES14, RES15, and RES16, respectively. Due
to the widely recognized challenge of ATSA, the
achieved improvements can be considerable.
It can also be observed that with regard to
pairwise t-test, the p-values of S-GML against
RoBERTa+MLP and Hybrid GML are all below
0.05, which means the performance improvements
are statistically significant. These experimental
results clearly demonstrate the efficacy of S-GML.
Ablation Study. The evaluation results are
presented in Table 3, where S-GML(w/o knn),
S-GML(w/o Siamese), and S-GML(w/o context)
denote the ablated models with the components
of knn-based, Siamese-based and context-based
relational features removed, respectively. It can
be observed that without either KNN relations
or Siamese relations, the performance of S-GML
drops on all the test workloads. This observa-
tion clearly indicates that KNN and Siamese
relations are complementary to each other and
their combined modeling in GML achieves better
performance than either of them. However, it can
also be observed that compared with knn relations,
the performance of GML drops more considerably
without Siamese relations. The KNN relations
capture only similarity features, while the Siamese
relations can capture both similarity and opposite,
or more diverse, relations. It is noteworthy that
these experimental results are consistent with the
expected characteristic of GML that more di-
verse features can usually facilitate knowledge
conveyance more effectively.
An Illustrative Example. We illustrate the effi-
cacy of S-GML by the examples extracted from
RES14, which are shown in Figure 3. Based on
GML, the instance t1 has the most evidential sup-
port, followed by t2, t3, and finally t4. Meanwhile,
the instances t1 and t2 have less evidential conflict
than t3 and t4. Therefore, S-GML labels them
in the order of t1, t2, t3, and t4. In spite of the
noisy relations of t4, S-GML can correctly label
t4 because after t1, t2, and t3 are labeled, the
majority of evidence neighbors provide correct
polarity hints.
5.3 Sensitivity Evaluation
To evaluate sensitivity, we vary the values of the
parameters kn and ks, which denote the number
of nearest neighbors selected by polarity classifier
and the number of relations randomly selected
based Siamese network, respectively, within the
range between 3 and 9. Since polarity relation
detection between two arbitrary instances is gen-
erally more challenging than polarity similarity
detection between close neighbors in an em-
bedding space, we set kn ≥ ks. The detailed
evaluation results are presented in Table 4. It
732
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Figure 3: The illustrated examples of S-GML: the four subfigures show the extracted relational features of four
instances respectively, in which a true factor (resp. false factor) means that its corresponding polarity relation is
true (resp. false).
kn
ks
5
5
7
7
7
9
9
9
9
3
5
3
5
7
3
5
7
9
kn
ks
5
5
7
7
7
9
9
9
9
3
5
3
5
7
3
5
7
9
RES14
RES15
RES16
Acc
96.90%
97.04%
96.61%
96.66%
96.61%
96.61%
96.63%
96.61%
96.57%
Acc
95.10%
94.88%
94.46%
94.67%
94.46%
94.88%
95.10%
95.10%
94.88%
Macro-F1
95.33%
95.55%
94.87%
94.94%
94.86%
94.87%
94.90%
94.86%
94.81%
LAP14
Macro-F1
93.95%
93.70%
93.18%
93.46%
93.21%
93.70%
93.95%
93.95%
93.70%
Acc
90.83%
90.96%
90.79%
90.68%
90.77%
90.87%
90.70%
90.74%
90.74%
Acc
93.70%
93.70%
93.40%
93.32%
93.28%
93.32%
93.36%
93.43%
93.47%
Macro-F1
89.70%
89.86%
89.63%
89.50%
89.62%
89.74%
89.54%
89.59%
89.59%
LAP15
Macro-F1
93.26%
93.26%
92.96%
92.89%
92.85%
92.87%
92.92%
93.00%
93.04%
Acc
96.00%
95.93%
95.80%
95.83%
95.83%
95.76%
95.68%
95.76%
95.74%
Acc
89.77%
89.35%
89.98%
89.56%
89.56%
89.77%
89.56%
89.56%
89.35%
Macro-F1
93.65%
93.53%
93.28%
93.34%
93.36%
93.22%
93.11%
93.23%
93.19%
LAP16
Macro-F1
88.49%
88.05%
88.84%
88.34%
88.38%
88.62%
88.34%
88.38%
88.13%
Table 4: Sensitivity evaluation results on ATSA.
733
can be observed that the performance of S-GML
fluctuates very marginally with different value
combinations of kn and ks. These experimental
results clearly demonstrate that the performance
of S-GML is very robust w.r.t. to the parameter
setting of kn and ks. They bode well for S-GML’s
applicability in real scenarios.
5.4 Comparative Evaluation on ACSA
For ACSA, we compare performance on all the
RES and LAP workloads except LAP14 because
it does not provide implicit aspect categories.
Additionally, we compare performance on the
benchmark dataset of SentiHood, which is usu-
ally considered as a task of targeted aspect-based
sentiment analysis. In SentiHood, aspect category
consists of two parts: explicit entity (e.g., location
1) and implicit category (e.g., safety).
We compare S-GML with the following
BERT-based models specifically targeting ACSA:
1) BERT-pair-QA-M (Sun et al., 2019). It con-
verts ACSA to a sentence-pair classification task,
where the auxiliary sentence is a question. 2)
BERT-pair-NLI-M (Sun et al., 2019). It converts
ACSA to a sentence-pair classification task and
learns aspect-specific representations by pseudo-
sentence natural language inference. 3) QACG-
BERT (Wu and Ong, 2021). Asanimproved variant
of CG-BERT model
(Context-Guided BERT),
it learns quasi-attention weights in a composi-
tional manner to enable subtractive attention lack-
ing in softmax-attention. Since many deep models
proposed for ATSA, e.g., BRET-SPC, AEN-BERT,
LCF-BERT, BERT-PT, BAT, and PH-SUM, can
be directly applied to the task of ACSA, we also
compare S-GML with these models. However, we
do not compare S-GML with RoBERTa+MLP and
Hybrid GML because they cannot directly handle
implicit aspects.
In the implementation of S-GML for ACSA,
we extract neighborhood-based polarity simi-
larity based the model of BAT (Karimi et al.,
2020a), whose performance has been empirically
shown to be state of the art. We use the same
Siamese network proposed for ATSA to extract
binary relations between arbitrary instances.
The detailed comparative results on ACSA are
presented in Table 5. We have also conducted
pairwise t-test between S-GML and its best al-
ternative, BAT, over 25 runs. It can be observed
that similar to what have been reported on ATSA,
S-GML outperforms the best alternatives by the
margins between 1% and 2% on all the test work-
loads. For instance, in terms of Macro-F1, S-GML
beats BAT by around 2.0%, 1.5%, and 1.5% on
RES14, RES15, and RES16, respectively. With re-
gard to pairwise t-test, it can be observed that the
p-values of S-GML against BAT are all well below
0.05, which means the achieved improvements
are statistically significant. These experimental
results clearly demonstrate the efficacy of S-GML
on ACSA.
6 Conclusion and Future Work
In this paper, we have proposed a novel supervised
GML approach for ATSA that can effectively
exploit labeled examples to improve gradual learn-
ing. It leverages both polarity classification DNN
and Siamese network to extract implicit polarity
relations between instances, and then instills them
into a factor graph to enable supervised knowl-
edge conveyance. Our extensive empirical study
has validated its efficacy. Our work has demon-
strated clearly that in collaboration with DNN
for feature extraction, GML can outperform pure
DNN solutions.
For future work, it can be observed that even
though the proposed solution is built upon the spe-
cific polarity classifier and Siamese network for
aspect-level sentiment analysis, similar classifiers
and Siamese networks are readily available or
can be constructed for other binary classification
tasks, especially NLP tasks. Therefore, the pro-
posed collaboration approach of DNN and GML
can be potentially generalized to other binary
classification tasks.
Generalization to Multi-class Classification
Tasks.
It is worth pointing out that even though
this paper focuses on binary classification, the
proposed approach can be potentially generalized
to multi-class classification tasks. In principle, in-
stead of binary values, a variable in a factor graph
can take one out of multiple values, each of which
corresponds to a specific class. Relational fac-
tors can also be similarly constructed to indicate
similar or different label relations between vari-
ables. We briefly illustrate the generalization by
the example of three-class aspect-based sentiment
analysis, whose candidate polarities include pos-
itive, negative, and neutral. The technical details
however need further investigation in the future.
734
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Model
BERT-SPC
AEN-BERT
LCF-BERT
BERT-PT
BAT
PH-SUM
BERT-pair-QA-M
BERT-pair-NLI-M
QACG-BERT
S-GML
S-GML vs BAT (p-value)
Model
BERT-SPC
AEN-BERT
LCF-BERT
BERT-PT
BAT
PH-SUM
BERT-pair-QA-M
BERT-pair-NLI-M
QACG-BERT
S-GML
S-GML vs BAT (p-value)
RES14
RES15
RES16
Acc
93.90%
94.68%
94.74%
94.51%
95.22%
94.99%
94.81%
95.13%
94.31%
96.72%
4.22e − 8 †
Macro-F1
91.87%
92.86%
93.02%
92.75%
93.58%
93.36%
93.17%
93.57%
92.47%
95.71%
1.01e − 7 †
Acc
88.41%
87.09%
88.86%
87.14%
88.80%
89.02%
88.25%
88.58%
87.31%
90.14%
0.0007 †
Macro-F1
88.12%
86.78%
88.56%
86.79%
88.51%
88.70%
88.00%
88.30%
86.93%
89.86%
0.0016 †
Acc
90.71%
91.20%
91.98%
92.14%
93.62%
93.25%
92.64%
92.27%
91.17%
94.87%
2.06e − 9 †
Macro-F1
88.39%
89.01%
89.95%
90.04%
92.05%
91.53%
90.80%
90.16%
88.96%
93.52%
4.66e − 9 †
SentiHood
LAP15
LAP16
Acc
92.06%
91.45%
93.08%
91.53%
93.16%
91.68%
93.36%
92.85%
92.85%
93.83%
0.0077 †
Macro-F1
91.14%
90.33%
92.29%
90.40%
92.29%
90.59%
92.56%
91.97%
91.91%
93.05%
0.0084 †
Acc
89.95%
90.92%
91.18%
91.51%
92.56%
91.15%
90.83%
91.13%
90.44%
93.74%
2.24e − 5 †
Macro-F1
89.35%
90.38%
90.65%
90.92%
92.15%
90.65%
90.28%
90.61%
89.86%
93.36%
2.56e − 5 †
Acc
87.03%
87.88%
88.74%
89.13%
89.51%
89.03%
88.12%
88.47%
87.22%
90.52%
1.08e − 6 †
Macro-F1
86.26%
86.73%
87.68%
88.29%
88.71%
88.20%
87.19%
87.51%
86.21%
89.79%
2.56e − 7 †
Table 5: Comparative Evaluation Results on ACSA: the marker † indicates p-value < 0.05.
ri
r1
r2
r3
r4
sij
s11
s21
s31
s41
Text
The manager then told us we could order from
whatever menu we wanted but by that time we were so
annoyed with the waiter and the resturant that we let
and went some place else.
Even when the chef is not in the house, the food and
service are right on target.
My friend had a burger and I had these wonderful
blueberry pancakes.
It’s about $7 for lunch and they have take-out or
dine-in.
Aspect polarities
(manager, neutral), (menu,
neutral), (waiter, negative)
(chef, neutral), (food,
positive), (service, positive)
(burger, neutral), (blueberry
pancakes, positive)
(lunch, neutral), (take-out,
neutral), (dine-in, neutral)
Table 6: Illustrative examples of three-class aspect-based sentiment analysis.
Since the open-source GML inference en-
gine7 can effectively support gradual inference
on multi-class factor graphs and modeling rela-
tional features as binary factors in a factor graph
7https://github.com/gml-explore/gml.
is straightforward, we focus on how to extract
relational features for the task of three-class sen-
timent analysis. Similar to the case of binary
sentiment analysis, we can extract explicit rela-
tions by analyzing discourse structures, and im-
plicit ones by supervising a classification deep
735
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
model and a Siamese network separately as
follows:
• For explicit relations, we can similarly ex-
tract opposite relations based on the presence
of shift words, because they can reliably
indicate polarity shift regardless of actual
sentiments. For instance, as shown in Table 6,
the shift words ‘‘but’’ and ‘‘even’’ in s11 and
s21 shift polarity from neutral to negative
and positive respectively. However, identi-
fying similar relations may be more subtle.
Since the neutral polarity usually does not
involve any opinion word, two aspect polar-
ities can be reasoned to be similar if no shift
word exists between them, and both of them
contain opinion words or neither of them
does. As shown in Table 6, the two aspect
polarities in s41 can be reasoned to be similar
due to the absence of shift words and opinion
words, while the two aspect polarities in s31
cannot because its second part contains the
opinion word of ‘‘wonderful’’.
• For implicit relations, we can similarly lever-
age the SOTA polarity classifiers (e.g.,
RoBERTa) and Siamese network for their de-
tection. Since the SOTA polarity classifiers
can naturally support three-class classifica-
tion, they can be trained to detect polarity
similarity based on vector neighborhood as
in binary classification. As for a Siamese
network, it can be similarly trained to detect
similar and dissimilar relations between po-
larities provided that training data sufficiently
cover different combinations of polarities.
Acknowledgments
Our work has been supported by National Nat-
ural Science Foundation of China (62172335,
61732014, and 61672432). We would also like
to thank the action editor, and anonymous review-
ers for their insightful comments and suggestions,
which have significantly strengthened the paper.
References
Murtadha H. M. Ahmed, Qun Chen, Yanyan
Wang, Youcef Nafa, Zhanhuai Li, and Tianyi
Duan. 2021. DNN-driven gradual machine
learning for aspect-term sentiment analysis. In
Findings of the Association for Computational
Linguistics, ACL/IJCNLP, pages 488–497.
Xuefeng Bai, Pengbo Liu, and Yue Zhang.
2021. Investigating typed syntactic dependen-
cies for targeted sentiment classification using
graph attention neural network. IEEE/ACM
Transactions on Audio, Speech, and Language
Processing, 29: 503–514. https://doi
.org/10.1109/TASLP.2020.3042009
Peng Chen, Zhongqian Sun, Lidong Bing, and
Wei Yang. 2017. Recurrent attention network
on memory for aspect sentiment analysis.
the 2017 Conference
In Proceedings of
on Empirical Methods
in Natural Lan-
guage Processing, EMNLP, pages 452–461.
https://doi.org/10.18653/v1/D17
-1047
Sumit Chopra, Raia Hadsell, and Yann LeCun.
2005. Learning a similarity metric discrimina-
tively, with application to face verification. In
Proceedings of the 2005 IEEE Computer Soci-
ety Conference on Computer Vision and Pattern
Recognition, CVPR, pages 539–546.
Junqi Dai, Hang Yan, Tianxiang Sun, Pengfei Liu,
and Xipeng Qiu. 2021. Does syntax matter? A
strong baseline for aspect-based sentiment anal-
ysis with roberta. In Proceedings of the 2021
Conference of the North American Chapter of
the Association for Computational Linguistics:
Human Language Technologies, NAACL-HLT,
pages 1816–1829. https://doi.org/10
.18653/v1/2021.naacl-main.146
Li Dong, Furu Wei, Chuanqi Tan, Duyu Tang,
Ming Zhou, and Ke Xu. 2014. Adaptive re-
cursive neural network for target-dependent
twitter sentiment classification. In Proceed-
ings of
the
Association for Computational Linguistics,
ACL, pages 49–54. https://doi.org/10
.3115/v1/P14-2009
the 52nd Annual Meeting of
Feifan Fan, Yansong Feng, and Dongyan Zhao.
2018. Multi-grained attention network for
aspect-level sentiment classification. In Pro-
ceedings of the 2018 Conference on Empirical
Methods in Natural Language Processing,
EMNLP, pages 3433–3442. https://doi
.org/10.18653/v1/D18-1380
736
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Ruidan He, Wee Sun Lee, Hwee Tou Ng,
and Daniel Dahlmeier. 2018. Effective at-
tention modeling for aspect-level sentiment
the 27th
classification.
International Conference on Computational
Linguistics, COLING, pages 1121–1131.
In Proceedings of
Boyi Hou, Qun Chen, Yanyan Wang, Youcef
Nafa, and Zhanhuai Li. 2022. Gradual machine
learning for entity resolution. IEEE Transac-
tions on Knowledge and Data Engineering,
34(4):1803–1814. https://doi.org/10
.1109/TKDE.2020.3006142
Binxuan Huang, Yanglan Ou, and Kathleen M.
Carley. 2018. Aspect
level sentiment clas-
sification with attention-over-attention neural
In Social, Cultural, and Behav-
networks.
ioral Modeling - 11th International Conference,
SBP-BRiMS, pages 197–206. https://doi
.org/10.1007/978-3-319-93372-6 22
Rie Johnson and Tong Zhang. 2017. Deep
pyramid convolutional neural networks for
text categorization. In Proceedings of the 55th
Annual Meeting of the Association for Com-
putational Linguistics, ACL, pages 562–570.
https://doi.org/10.18653/v1/P17
-1052
Akbar Karimi, Leonardo Rossi, and Andrea Prati.
2020a. Adversarial training for aspect-based
sentiment analysis with BERT. In Proceedings
the 25th International Conference on
of
Pattern Recognition, ICPR, pages 8797–8803.
https://doi.org/10.48550/arXiv
.2010.11731
Akbar Karimi, Leonardo Rossi, and Andrea
Prati. 2020b. Improving BERT performance for
aspect-based sentiment analysis. arXiv preprint
arXiv:2010.11731.
Mahmut Kaya and Hasan Sakir Bilge. 2019.
Deep metric learning: A survey. Symmetry,
11(9):1066. https://doi.org/10.3390
/sym11091066
Frank R. Kschischang, Brendan J. Frey, and
Hans-Andrea Loeliger. 2001. Factor graphs
and the sum-product algorithm. IEEE Transac-
tions on Information Theory, 47(2):498–519.
https://doi.org/10.1109/18.910572
Zeyang Lei, Yujiu Yang, and Yi Liu. 2018.
LAAN: A linguistic-aware attention network
for sentiment analysis. In Companion of the
The Web Conference 2018 on The Web Confer-
ence 2018, WWW, pages 47–48. https://
doi.org/10.1145/3184558.3186922
Ga¨el Letarte, Fr´ed´erik Paradis, Philippe Gigu`ere,
and Franc¸ois Laviolette. 2018. Importance of
self-attention for sentiment analysis. In Pro-
ceedings of
the Workshop: Analyzing and
Interpreting Neural Networks for NLP, Black-
boxNLP@EMNLP, pages 267–275. https://
doi.org/10.18653/v1/W18-5429
Qiao Liu, Haibin Zhang, Yifu Zeng, Ziqi Huang,
and Zufeng Wu. 2018. Content attention model
for aspect based sentiment analysis. In Pro-
ceedings of the 2018 Web Conference, WWW,
pages 1023–1032. https://doi.org/10
.1145/3178876.3186001
Yunfei Long, Qin Lu, Rong Xiang, Minglei
Li, and Chu-Ren Huang. 2017. A cognition
based attention model for sentiment analysis.
the 2017 Conference
In Proceedings of
in Natural Lan-
on Empirical Methods
guage Processing, EMNLP, pages 462–471.
https://doi.org/10.18653/v1/D17
-1048
Dehong Ma, Sujian Li, Xiaodong Zhang, and
Houfeng Wang. 2017. Interactive attention net-
works for aspect-level aentiment classification.
In Proceedings of the 26th International Joint
Conference on Artificial Intelligence, IJCAI,
pages 4068–4074.
Maria
Pontiki, Dimitris Galanis, Haris
Papageorgiou, Ion Androutsopoulos, Suresh
Manandhar, Mohammad Al-Smadi, Mahmoud
Al-Ayyoub, Yanyan Zhao, Bing Qin, Orph´ee
De Clercq, V´eronique Hoste, Marianna
Apidianaki, Xavier Tannier, Natalia V.
Loukachevitch, Evgeniy Kotelnikov, N´uria
Bel, Salud Mar´ıa Jim´enez Zafra, and G¨ulsen
Eryigit. 2016. SemEval-2016 Task 5: As-
pect based sentiment analysis. In Proceedings
of
the 10th International Workshop on Se-
mantic Evaluation, SemEval@NAACL-HLT,
https://doi.org/10
pages
19–30.
.18653/v1/S16-1002
Maria
Pontiki, Dimitris Galanis, Haris
Papageorgiou, Suresh Manandhar, and Ion
Androutsopoulos. 2015. SemEval-2015 Task
737
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
12: Aspect based sentiment analysis. In Pro-
ceedings of the 9th International Workshop on
Semantic Evaluation, SemEval@NAACL-HLT,
486–495. https://doi.org/10
pages
.18653/v1/S15-2082
Qiao Qian, Minlie Huang, Jinhao Lei, and Xiaoyan
Zhu. 2017. Linguistically regularized LSTM
for sentiment classification. In Proceedings
the Asso-
of
ciation for Computational Linguistics, ACL,
pages 1679–1689. https://doi.org/10
.18653/v1/P17-1154
the 55th Annual Meeting of
Kumar Ravi and Vadlamani Ravi. 2015. A sur-
vey on opinion mining and sentiment analysis:
Tasks, approaches and applications. Knowledge-
Based Systems, 89:14–46. https://doi.org
/10.1016/j.knosys.2015.06.015
Nils Reimers
and Iryna Gurevych. 2019.
Sentence-BERT: Sentence embeddings using
siamese BERT-networks. In Proceedings of
the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Nat-
ural Language Processing, EMNLP-IJCNLP,
pages 3980–3990. https://doi.org/10
.18653/v1/D19-1410
Alexander Rietzler, Sebastian Stabinger, Paul
Opitz, and Stefan Engl. 2020. Adapt or get
left behind: Domain adaptation through BERT
language model finetuning for aspect-target
In Proceedings of
sentiment classification.
The 12th Language Resources and Evaluation
Conference, LREC, pages 4933–4941.
Emanuel H. Silva and Ricardo M. Marcacini.
2021. Aspect-based sentiment analysis using
BERT with disentangled attention. In Pro-
ceedings of the LatinX in AI (LXAI) Research
workshop at ICML 2021.
Jiahai Wang, Tao
and Yanghui Rao.
Jiang,
Youwei Song,
2019.
Zhiyue Liu,
targeted
Attentional encoder network for
preprint
arXiv
sentiment
arXiv:1902.09314. https://doi.org/10
.48550/arXiv.1902.09314
classification.
Chi Sun, Luyao Huang, and Xipeng Qiu. 2019.
Utilizing BERT for aspect-based sentiment
analysis via constructing auxiliary sentence. In
Proceedings of the 2019 Conference of the
North American Chapter of the Association for
738
Computational Linguistics: Human Language
Technologies, NAACL-HLT, pages 380–385.
Duyu Tang, Bing Qin, Xiaocheng Feng,
and Ting Liu. 2016. Effective LSTMs for
target-dependent sentiment classification. In
Proceedings of the 26th International Confer-
ence on Computational Linguistics, COLING,
pages 3298–3307.
Hao Tang, Donghong Ji, Chenliang Li, and
Qiji Zhou. 2020. Dependency graph enhanced
structure for aspect-based
dual-transformer
In Proceedings of
sentiment classification.
the 58th Annual Meeting of
the Associ-
ation for Computational Linguistics, ACL,
pages 6578–6588. https://doi.org/10
.18653/v1/2020.acl-main.588
Yuanhe Tian, Guimin Chen, and Yan Song.
2021. Aspect-based sentiment analysis with
type-aware graph convolutional networks and
layer ensemble. In Proceedings of the 2021
Conference of the North American Chapter of
the Association for Computational Linguistics:
Human Language Technologies, NAACL-HLT,
pages 2910–2922. https://doi.org/10
.18653/v1/2021.naacl-main.231
Bailin Wang and Wei Lu. 2018. Learning latent
opinions for aspect-level sentiment classifica-
tion. In Proceedings of the 32nd Conference
on Artificial Intelligence, AAAI, the 30th in-
novative Applications of Artificial Intelligence,
IAAI, and the 8th AAAI Symposium on Educa-
tional Advances in Artificial Intelligence, EAAI,
pages 5537–5544. https://doi.org/10
.1609/aaai.v32i1.12020
Yanyan Wang, Qun Chen, Jiquan Shen, Boyi
Hou, Murtadha Ahmed, and Zhanhuai Li.
2021. Aspect-level sentiment analysis based on
gradual machine learning. Knowledge-Based
Systems, 212:106509. https://doi.org
/10.1016/j.knosys.2020.106509
Zhengxuan Wu and Desmond C. Ong. 2021.
targeted aspect-
Context-guided BERT for
based sentiment analysis. In Proceedings of
35th AAAI Conference on Artificial Intelli-
gence, AAAI, 33rd Conference on Innovative
Applications of Artificial Intelligence, IAAI,
The 11th Symposium on Educational Ad-
Intelligence, EAAI,
vances
in Artificial
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
pages 14094–14102. https://doi.org
/10.1609/aaai.v35i16.17659
if you refer
Bowen Xing and Ivor W. Tsang. 2022.
Understand me,
to aspect
knowledge: Knowledge-aware gated recur-
rent memory network. IEEE Transactions on
Emerging Topics in Computational
Intelli-
gence, 6(5):1092–1102. https://doi.org
/10.1109/TETCI.2022.3156989
Hu Xu, Bing Liu, Lei Shu, and Philip S. Yu. 2019.
BERT post-training for review reading compre-
hension and aspect-based sentiment analysis.
In Proceedings of the 2019 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies, NAACL-HLT, pages 2324–2335.
Wei Xue and Tao Li. 2018. Aspect based
sentiment analysis with gated convolutional
networks. In Proceedings of the 56th Annual
Meeting of
the Association for Computa-
tional Linguistics, ACL, pages 2514–2523.
https://doi.org/10.18653/v1/P18
-1234
Biqing Zeng, Heng Yang, Ruyang Xu, Wu Zhou,
and Xuli Han. 2019. LCF: A local context
focus mechanism for aspect-based sentiment
classification. Applied Sciences, 9(16):3389.
https://doi.org/10.3390/app9163389
Chen Zhang, Qiuchi Li, and Dawei Song. 2019.
Syntax-aware aspect-level sentiment classifi-
cation with proximity-weighted convolution
network. In Proceedings of the 42nd Inter-
national ACM SIGIR Conference on Research
and Development in Information Retrieval, SI-
GIR, pages 1145–1148. https://doi.org
/10.1145/3331184.3331351
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun.
2015. Character-level convolutional networks
for text classification. In Advances in Neu-
ral
Information Processing Systems, NIPS,
pages 649–657.
Pinlong Zhao, Linlin Hou, and Ou Wu. 2020.
Modeling sentiment dependencies with graph
convolutional networks for aspect-level sen-
timent classification. Knowledge-Based Sys-
tems, 193:105443. https://doi.org/10
.1016/j.knosys.2020.106292
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
7
1
2
1
4
1
0
0
1
/
/
t
l
a
c
_
a
_
0
0
5
7
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
739