Supertagging the Long Tail with Tree-Structured Decoding
of Complex Categories
Jakob Prange Nathan Schneider
Vivek Srikumar
Georgetown University
University of Utah
{jp1724, nathan.schneider}@georgetown.edu svivek@cs.utah.edu
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
抽象的
Although current CCG supertaggers achieve
high accuracy on the standard WSJ test set,
few systems make use of the categories’
internal structure that will drive the syntac-
tic derivation during parsing. The tagset is tra-
ditionally truncated, discarding the many rare
and complex category types in the long tail.
然而, supertags are themselves trees.
Rather than give up on rare tags, we investigate
constructive models that account for their in-
ternal structure, including novel methods for
tree-structured prediction. Our best tagger is
capable of recovering a sizeable fraction of the
long-tail supertags and even generates CCG
categories that have never been seen in train-
英, while approximating the prior state of the
art in overall tag accuracy with fewer param-
埃特斯. We further investigate how well differ-
ent approaches generalize to out-of-domain
evaluation sets.
1
介绍
Combinatory Categorial Grammar (CCG; 斯蒂德曼,
2000) is a strongly lexicalized grammar formalism
in which rich syntactic categories at the lexical
level impose tight constraints on the constituents
that can be formed. Its syntax-semantics interface
has been attractive for downstream tasks such as
语义解析 (Artzi et al., 2015) and machine
翻译 (Nˇadejde et al., 2017).
Most CCG parsers operate as a pipeline whose
first task is ‘supertagging’, IE。, sequence labeling
with a large search space of complex ‘supertags’
(Clark and Curran, 2004; 徐等人。, 2015; Vaswani
等人。, 2016, inter alia). The complex categories
specify valency information: expected arguments
to the right are signaled with forward slashes,
and expected arguments to the left with backward
243
slashes. 例如, transitive verbs in English
(like ‘‘saw’’ in Figure 1a) are tagged (S\NP)/NP
to indicate that they expect a subsequent object
noun phrase (NP) and a preceding subject NP to
form a clause (S). Given the supertags, 所有这些
remains to parsing is applying general rules of
(binary) combination between adjacent constitu-
ents until the entire input is covered. Supertagging
thus represents the crux of the overall parsing
过程. In contrast to the simpler task of part-
of-speech tagging, supertaggers are required to
resolve most of the syntactic ambiguity in the
输入.
One key challenge of CCG supertagging is that
the tagset is large and open-ended to account for
combinatorial possibilities of syntactic construc-
系统蒸发散. This results in a heavy-tailed distribution
of supertags, which is visualized in Figure 1b;
a large proportion of unique supertags are rare
or unseen (out-of-vocabulary, OOV) even in a
training set as large as the Penn Treebank’s.
Previous CCG supertaggers have surrendered in
the face of this challenge: They treat categories as
a fixed set of opaque labels, rather than modeling
their compositional structure. Following Clark
(2002), the standard approach is to consider only
supertags appearing at least 10 times in the train-
ing data, sacrificing the possibility of predicting
two thirds of the supertag types in CCGbank. Rare
supertags may have little impact on overall token
accuracy—but the cost of this compromise is a
fundamental incapability in truly generalizing to
the task.
在本文中, we confront the long-tail problem
head-on by proposing a constructive framework
in which supertags are built from scratch rather
than predicted as opaque labels (Kogkalidis et al.,
2019). In contrast to prior constructive supertag-
蒙古包 (Kogkalidis et al., 2019; Bhargava and Penn,
2020), our model builds upon the observation
that supertags are themselves tree-structured, 和
计算语言学协会会刊, 卷. 9, PP. 243–260, 2021. https://doi.org/10.1162/tacl 00364
动作编辑器: Reut Tsarfaty. 提交批次: 7/2020; 修改批次: 10/2020; 已发表 3/2021.
C(西德:2) 2021 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1: CCG supertags.
hence can be generated top–down.1 Our experi-
ments on the English CCGbank and its rebanked
version show that constructing supertags as trees
improves our ability to predict rare and even
unseen tags, without sacrificing performance on
the more common ones.
Our contributions are threefold:
1. We introduce a general constructive super-
tagger that generates each lexical category
recursively as a tree. To our knowledge, 这
is the first tree-structured predictor of its kind.
2. We apply this model to English CCG su-
pertagging. On frequent supertags, it matches
the more traditional approach of using a
fixed label set, while on the rare and unseen
那些, we see substantial improvements in
predictive performance.
3. We perform an array of in-depth analyses
that highlight the impact of different mod-
eling and inference choices for the task of
predicting supertags.
2 动机
2.1 Anatomy of a Supertag
The internal structure of any CCG supertag is a
tree licensed by the CFG in Figure 2. Atomic
categories like S and NP are related by slashes
to form functional categories, which can in turn
participate in larger functional categories. By con-
发明, the infix-notation supertag (S\NP)/NP
1Our models
在
https://github.com/jakpra/treeconstructive
-supertagging.
可用的
代码
和
是
244
数字 2: The ‘syntax’ of CCG categories, using infix
notation for complex categories (FxnCat). Our model
generates supertags of type Cat top–down from this
grammar.
is equivalent to the tree in Figure 3a, with prefix
notation (/ (\ S NP) NP), where the slash signals
the direction in which the category can combine,
the right child of any slash is the argument, 和
left child is the result of combining the category
with its argument. These hierarchical supertags
constrain lexical item combination, 例如, specify-
ing subcategorization of verbs for an object NP to
正确的 (/). This flexibility leads to infinite2 pos-
sible supertags; 在实践中, they follow a power
law distribution. CCGbank (comprising the WSJ
portion of the Penn Treebank) contains numerous
rare supertags, including several that occur only
in the test set. Still others can be expected to occur
in a much larger English corpus.
在之前的工作中, CCG supertaggers have
skirted this problem by ignoring the long tail of
supertags: 具体来说, the ones occurring fewer
比 10 times in the training set. The consequences
of such a threshold can be seen from Figure 1b,
which visualizes the distribution of supertag types
in terms of depth (representing supertag complex-
性) and token frequency. The supertags seen in
training that would be ignored under a threshold
2But see §7 for a discussion of how linguistic patterns
limit the set of observed tags.
internal structure of the supertag and incapable
of predicting unseen supertags. This is often
combined with a frequency cutoff: Only the k
supertags seen at least n times in the training data
are considered by the model, making each tag
decision a k-way classification task. 传统上
(克拉克, 2002), systems use a threshold of n = 10
(yielding k = 425 in CCGbank and k = 511 在
CCGrebank). The main motivation for this is to
sidestep the most sparse and possibly noisy region
of the output space without dramatically decreas-
ing token coverage. Below we experiment with
both thresholded and non-thresholded models.
相比之下, a constructive tagger models the
internal structure of supertags (Kogkalidis et al.,
2019). Supertags are constructed from minimal
件 (which for CCG are slashes and atomic cat-
egories).3 There is no frequency cutoff at training
time.4 At test time, supertags are predicted piece
by piece, and there is no constraint that predicted
supertags must have been seen before. This can
be done sequentially or recursively, taking the
categories’ internal tree structure into account.
Two different methods of sequential decoding
have been explored by Kogkalidis et al. (2019)
(hereafter ‘K+19’) and Bhargava and Penn (2020)
(‘BP20’). K+19 used a sequence-to-sequence
模型, with a single target sequence consisting of
all serialized supertags for a sentence (Figure 3c).
They experimented with a type-logical grammar
formalism similar to CCG, and a Dutch cor-
脓. BP20 decoded CCG supertags as a separate
sequence per token, and additionally conditioned
each new supertag on the prediction history.
Here we go a step further and introduce methods
for directly decoding supertags as trees, freeing
the models from having to learn this fundamental
property from sequential data. We hypothesize
that this will produce better and more compact
representations that generalize to the long tail.
3 Tree-Structured Constructive
Supertagging
Given a sequence of words (a sentence), our goal
is to predict each word’s supertag. Constructing a
3For simplicity, we consider linguistic attributes like
dcl (declarative) to be part of the atomic category.
4原则, a constructive model could be trained with
frequency-thresholded training data, but we do not see any
value in pursuing this option, as constructivity in itself already
mitigates noise and sparsity.
245
数字 3: Schematic of our tree-structured supertagger
(左边) in contrast with unstructured (top right) 和
sequential (bottom right) 型号. Supertag depth also
corresponds to decoding steps. Numbers below nodes
denote positions or addresses.
的 10 appear in red, and the test set supertags never
seen in training in dark blue. Though these only
account for 0.2% of tokens in the test set, 他们是
present in nearly 4% of sentences and represent
fully two thirds of supertag types in CCGbank.
更远, we see that rarer categories are increas-
ingly more complex, IE。, their argument and result
types are in turn composed of FxnCats. Note in
particular that the bulk of depth-4 categories and
almost all categories with depth 5 or more fall
below the 10-count threshold.
Inspired by the recent proposals of Kogkalidis
等人. (2019) and Bhargava and Penn (2020),
we hypothesize that modeling the structure of
supertags, rather than treating them holistically
and thresholding by frequency, can successfully
generalize to rare and unseen tags. 例如,
a good model should draw connections between
words that are NPs themselves, words that take
NPs as arguments (例如, 动词), and words that
yield NPs as their result (例如, determiners). 我们
examine whether such linguistically informed
generalizations can benefit supertags of various
frequency and structures, focusing on the rare and
complex ones.
2.2 Constructivity in Supertagging
We contrast two general paradigms for supertag-
(Our experiments will explore
ging below.
multiple specific modeling strategies within each.)
Most previous supervised CCG supertaggers
and nonconstruc-
assume
tively assign one complete category per word
(Figure 3b). This paradigm is oblivious to the
closed tagset
A
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
supertag from its components requires a scoring
function for the parts that is cognizant of both
surrounding words and categories. Below we des-
cribe the decoding procedure (§3.1) and scoring
功能 (§3.2) we developed for this purpose,
哪个, in line with §2, explicitly incorporate the
categories’ tree structure.
3.1 Predicting Tree-structured Supertags
According to the grammar in Figure 2, each cate-
gory is a binary tree with the following properties:
(1) Slashes are non-terminals with two children:
the category’s argument (the syntactic type it seeks
to combine with), and its result (the type it yields
after combining with its argument). (2) AtomCats
are leaf nodes. (3) The root of the tree is either the
category’s sole AtomCat, or its outermost functor,
whose argument it seeks to combine with first.
Our output supertags are trees, but there is a cru-
cial difference between our work and constituency
parsing of sentences. In the latter case, the yield of
a predicted tree is constrained to be the input sen-
张力, thereby restricting both its depth and width.
But in the case of supertagging, each word is
associated with a binary tree–structured supertag
whose breadth and depth are unknown at inference
时间. We therefore grow supertags for each word
from the top down (Figure 3a). At the tth step, 这
model greedily chooses the most likely node labels
at depth t, conditioned on the word encoding and
the ancestors predicted so far (Figure 3a). 首先
决定 (t = 0) is either an atomic category, 或者
the main functor. In the latter case, the model then
moves on to select the argument and result types,
which may be atomic categories or functors them-
自己. We are thus guaranteed to always generate
well-formed categories. As CCG supertags are not
very deep in practice, we impose an upper limit on
the depth of predicted trees based on the most com-
plex categories found in the training and develop-
ment data, with the main advantage that memory
allocation during training can be bounded.5
5The limits on depth and arity are practical simplifications
that follow from our task (supertags are always binary trees)
and data distribution (there are no categories with depth > 6
in any of the training or development sets we use). 然而,
our model can be generalized to trees of arbitrary depth, 和
not as easily, but conceivably, to a different or even variable
arity. It turns out that none of the evaluation sets contain
categories that are deeper that what is seen in training (除了
the redistributed test set in Figure 4, which contains one), 所以
this measure has virtually no impact on tagging performance.
3.2 Modeling Supertags
All supertagging models we compare consist
的 (A) a sequence encoder, which generates a
d-dimensional contextualized representation hk,0
for each word k in a sentence x (方程 (1),
together forming the |X| × d matrix H0); (乙) 一个
output-positional encoder, which generates the
hidden representation hk,i for a position indexed
by i within the kth word’s category tree; 和
(C) a fully-connected 2-layer perceptron (多层线性规划)
with a final softmax layer which maps such a
representation to a probability distribution ok,我
over the inventory of possible labels L (atomic
categories and slashes; 方程 (2)). We use the
term position and the index i to refer to any atomic
part of a category for which a labeling decision
has to be made. This could be, 例如, 这
positions of the S category in Figure 3a and 3c, 或者
the single output in Figure 3b.
H0 = Encoder (X)
ok,i = MLP (hk,我)
(1)
(2)
The label yk,i is the most probable one per the
MLP’s prediction.
Contextualized Word Embeddings.
In all con-
版本, we encode sentences using the pretrained
RoBERTa-base encoder (刘等人。, 2019), fine-
tuning it for our task.6 Several recent studies have
shown that such models can capture syntactic
properties and relations (例如, Jawahar et al., 2019;
Clark et al., 2019; Hewitt and Manning, 2019).
Output-positional Encoding. We experiment
with two alternative ways of deriving hidden
states for category-internal positions (k, 我), 在哪里
i > 0: a tree-structured recursive neural network
(TreeRNN; Tai et al., 2015, inter alia), and a
deterministic addressing function that accesses
each node directly (AddrMLP). Both variants,
described below, also take into account
这
current node’s ancestors.
The TreeRNN (方程 (3)) computes the
hidden representation for a child node c(我) 从
a vector embedding of its parent’s label yk,i and
the hidden representation hk,我. The encodings are
separately computed for child nodes representing
the result (c = ‘left’) and argument (c = ‘right’)
of the parent. Following K+19, we use the trans-
pose of the last layer of the MLP to embed labels.
6We also experimented with a BiGRU encoder, 但
obtained consistently worse results.
246
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Our experiments use gated recurrent units (GRUs;
Cho et al., 2014).
hk,C(我) = GRUc (Embed (yk,我) , hk,我)
(3)
MLP from equation (2).10
(西德:2)
(西德:3)
α = SoftMax
hk,iH(西德:3)
ok,i = MLP (hk,我 + αH0)
0
(5)
(6)
Using tree-structured RNNs for
top–down
3.3 学习
generation is reminiscent of Zhang et al. (2016).
For the AddrMLP, we represent
the posi-
tion i of a node and the Slashes7 in its ancestors
(denoted by Yk,anc(我)) as a single feature vector that
augments the contextualized word embedding:
(西德:3)(西德:3)
(西德:2)
(西德:2)
hk,i = hk,0 + Linear
Features
我, Yk,anc(我)
(4)
We use a binary addressing scheme to refer
to individual nodes: Each node in a category’s
tree representation is addressed by a sequence of
bits a0a1a2 . . . aT , corresponding to a top-down
traversal of the tree. The value at>0 = 0 (或者, 1)
is interpreted as branching to the left (或者, 正确的) 在
depth t. The root a0 has an arbitrary placeholder
价值 (说, 1).8 In the example in Figure 3, 这
inner NP argument (the argument of the top-level
结果) is addressed as 101. We represent the posi-
tion of a node by a vector of elements in its address,
mapping at>0 = 0 到 1 and at>0 = 1 to −1 and
ignoring a0. The slashes in node’s ancestors are
similarly mapped to a vector consisting of 1s for
forward slashes and −1 for backward slashes. 我们
使用 0 to pad feature vectors to a fixed maximum
length. We then use a single linear layer to project
these features into the encoder’s hidden space
before adding it
to the word’s contextualized
encoding.9
Attention. While each word’s contextualized
encoding contains some information about all
other words in the sentence, we hope to increase
the model’s output consistency using attention
(Bahdanau et al., 2015; Kim et al., 2017; 吴
等人。, 2017) over the encoder’s hidden state. 我们
compute attention weights α as in equation (5)
and then add the α-weighted context values to the
hidden state, 方程 (6), replacing the simpler
7Only Slash operators can have children (数字 2).
8Prepending all addresses with 1 has several represen-
tational advantages, the most straightforward of which is
that addresses can alternatively be read as binary numbers
enumerating category pieces in breadth-first traversal.
9The featurized encoder is, to a large extent, made possible
by fixing the arity and maximum depth of categories. 这
TreeRNN will likely better admit more general setups, 在哪里
outputs of unbounded depth and/or variable arity are allowed.
247
We train the model using the AdamW optimizer
(Loshchilov and Hutter, 2019) and apply teacher
强迫 (Williams and Zipser, 1989) to avoid a
noisy feedback loop during learning.
Loss function. To achieve our goal of construct-
ing correct and complete categories, we need our
models to be correct in each atomic decision, 甚至
and especially for more complex categories. 我们
make the loss function sensitive to this by normal-
izing the cross-entropy between the predictions
and the ground-truth only over the number of
words in a batch and retaining the unnormalized
sum over individual atomic category decisions.
This naturally scales with category complexity.
也,
If instead we were normalizing over atomic
决定,
the loss contribution of, 例如,
NP when it occurs inside a complex category
(S\NP)/NP with size 5, 将会 5 times smaller
than when it occurs as a complete category on its
own. The disadvantage that complex categories
already have as they tend to be rarer than simpler
那些 (Figure 1b) would be reinforced. By keeping
the atomic losses unnormalized, we therefore
essentially put higher weight on the long tail in
order to counterbalance this trend and improve
generalizability.
4 实验装置
Per our quest to supertag the long tail, we com-
pare our TreeRNN and AddrMLP models to the
following baselines:
1) Thresholded classification (多层线性规划 10): 我们
compute the output probabilities directly
from the encoder’s hidden state. (因为
there is always exactly one output position
for each input word, no additional encoding
function is needed.) Only categories that are
见过 10 times or more in training are consid-
埃雷德. Supertags that fall below the threshold
are replaced with an
训练.
10We also tried self-attention over previously predicted
partial outputs but did not find an increase in performance.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2) Non-thresholded classification (多层线性规划 1):
Like MLP 10, except that all tags seen in
training may be predicted no matter their
频率.
Hidden dim d
Activation
Dropout
AdamW β’s
AdamW (西德:4)
768
gelu
.2
.9, .999
1e-6
Weight decay
LRs
Seeds
.01
1e-4, 1e-5 (英尺)
14112, 36125,
92225
6
Max cat depth
3) Per-sentence sequential (K+19): Kogkalidis
等人. (2019) construct type-logical super-
tags by generating for each sentence a sin-
gle sequence of atomic types and functors
(Figure 3c). Trees are unwrapped in prefix
notation and complete tags are separated from
one another by a special token. We adapt
K+19’s implementation of the sequence-to-
sequence Transformer model (Vaswani et al.,
2017), accommodating its decoding proce-
dure and memory requirements by training
with a batch size of 32 for up to 256 纪元.
We achieve the best performance using a
cosine-annealed learning rate schedule that
is warmed up over 10% of the total train-
ing steps and with a warm restart after 128
纪元 (Loshchilov and Hutter, 2017).
4) Per-tag sequential (RNN): Instead of gen-
erating a single sequence for each sentence,
Bhargava and Penn (2020) generate each
word’s supertag separately with an RNN. 我们
implement a simplified version of Bhargava
and Penn’s model, omitting their prediction
history connections between supertags, 和
using GRUs for decoding. We train this
model for up to 50 纪元 (batch sizes and
learning rates are as with the tree-structured
and nonconstructive models).
If not indicated otherwise, we train the models
with a batch size of 8 for a maximum of 10 纪元,
and use early stopping based on the best develop-
ment set performance.11 All reported results are
平均超过 3 random restarts.
For downstream parsing evaluation (§6.3), 我们
run the C&C parser (Clark and Curran, 2007;
Clark et al., 2015) with the pretrained CCGbank
model and default hyperparameters, providing as
input our supertaggers’ 1-best predictions and
POS tags automatically obtained using Stanza
(Qi et al., 2020).
11Preliminary experiments showed that best dev perfor-
mance is usually reached within 10 纪元; batches larger
比 8 make our (单身的) GPU run out of memory.
桌子 1: Hyperparameters used in our experi-
评论. We use separate learning rates (LR) 为了
fine-tuning (英尺) the RoBERTa-base model.
cat types
≥ 100
10–99 (medium rare)
< 10 (very rare)
atomic
sentences
tokens
medium rare cat
very rare cat
CCGbank Rebank
1,285
172
253
860
34
39,604
929,552
7,549
2,055
1,574
199
312
1,063
37
39,604
943,204
9,640
2,527
Table 2: Statistics of the CCG training corpora we
use in our experiments.
4.1 Model Details and Hyperparameters
In Table 1 we report the model and training
hyperparameters we use to facilitate replication
of our results. We performed manual grid-search
based on the development data to find workable
learning rates. We chose a hidden dimensional-
ity of 768 to match RoBERTa’s. We kept the
default values for the AdamW hyperparameters.
We follow Kogkalidis et al. (2019) in setting up
the sequential Transformer model with 8 decoder
heads and 2 decoder layers, but swap out the
from-scratch encoder with RoBERTa-base.
4.2 Datasets
We use two versions of the English CCGbank as
in-domain (financial news) training and test sets:
the original (Hockenmaier and Steedman, 2007)
and Honnibal et al. (2010) ‘‘rebanked’’, i.e., cor-
rected and enriched version (training sets reported
in Table 2; the results tables show test set counts).
The original CCGbank and Rebank differ in
a number of conventions for atomic categories
and category construction (Honnibal et al., 2010).
Rebank has a larger and more diverse category
space, due in large part to a more principled
treatment of NP argument structure. Hence, we
conduct our main experiments with Rebank and
248
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
l
a
c
_
a
_
0
0
3
6
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
text types, including literary and biblical texts
(PMB; Abzianidze et al., 2017). The Wikipedia
dataset follows CCGbank in terms of category
conventions, while PMB is more similar
to
Rebank; we evaluate models trained on one
style only on in- and out-of-domain test sets
matching that style. That said, PMB contains
an unusually large number of unseen categories
following idiosyncratic conventions that even
Rebank-trained models are unlikely to pick up on
without additional training data.
5 Results
We report our main results on Rebank in Table 3.
In terms of overall accuracy, the tree-structured
constructive supertaggers (best: 94.70%) outper-
form the sequential ones (90.68%, 93.92%) and
are roughly on par with the nonconstructive classi-
fiers (best: 94.83). Performance is generally very
similar across all systems, except K+19. We con-
jecture that the main disparities between K+19 and
the other models lie in the increased ‘‘cognitive
load’’ of having to learn the correct structure of
categories, as well as the missing hard alignment
between words and supertags at test time.
Regarding the long tail, we ask: Can construc-
tive models accurately predict rare and complex
categories without sacrificing performance on the
head of the distribution? To answer this question,
we break down performance by the frequency
of category types in the training data. The base-
line is the thresholded classifier MLP 10, which
performs well on frequent categories but cannot
access rare categories occurring less than 10
times in training. The simplest way of resolving
this main hurdle is to remove the threshold, and
indeed we find that MLP 1 is able to predict
about a quarter of long-tail categories correctly.
Can we do better? The sequence-to-sequence
model by K+19 does a lot better on the tail and
even retrieves some unseen categories, but at the
cost of frequent ones. The per-tag recurrent and
tree-recursive generators (RNN and TreeRNN)
come close to to the nonconstructive classifiers,
but do not convincingly improve over them. The
AddrMLP model, finally, outperforms all others
on the rare tail while matching nonconstructive
taggers on frequent and simple ones.
For comparison with existing work (Table 5),
we also report results on the original CCGbank
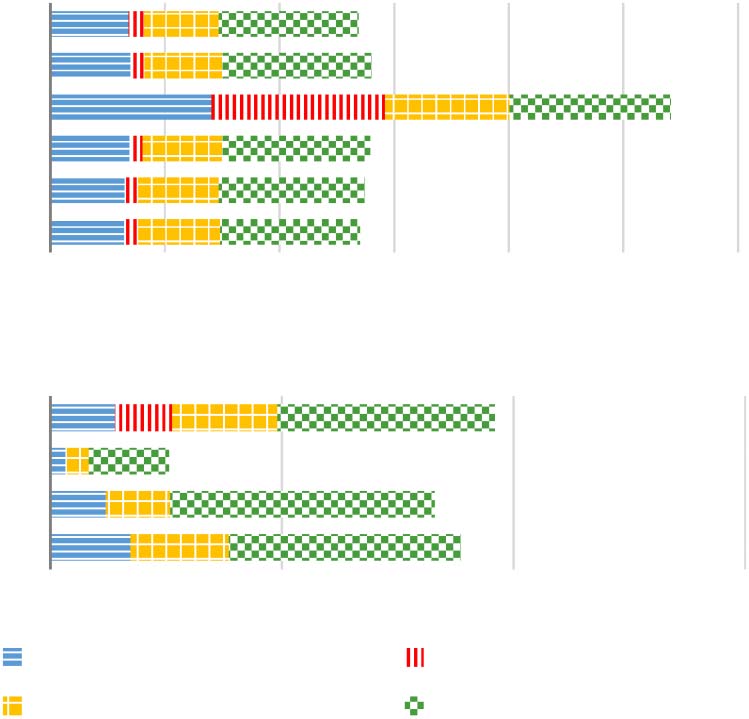
Figure 4: Shifting the tail to evaluation. The new
test set (right) consists of those sentences in sections
02–21 that contain a category type occurring less than
10 times, and the new training set of the remaining
sentences (left). As a result, we evaluate on many more
category types that are not seen at all in training (dark
blue circles/right-most horizontal offset for each depth)
than before (Figure 1b).
use the original CCGbank for comparisons with
prior work.
A limitation of standard test sets for studying
the long tail is that category types appearing rarely
in training are even less frequent in evaluation
(the Rebank test set contains just 107 tokens of
categories seen 1–9 times in training, and only
27 tokens of OOV categories). Scores computed
over these small samples may thus not reliably
estimate the models’ generalization capacity. We
counteract
this in two ways: 1) by explicitly
redistributing the training and test splits; and 2)
by evaluating on out-of-domain data, with the
assumption that a shift in domains means a shift
in category distribution.
In the first case, we train the models on
sentences containing exclusively the higher-
frequency (≥10) categories, and evaluate them
only on sentences with at least one rare category.
We split
the usual Rebank training set (WSJ
sections 02–21) in this way—the distribution fol-
lows Figure 4.12 In comparison with the default
data splits (Figure 1b), we see that this sampling
method captures precisely the long tail of cat-
egories, while leaving the rest of the category
distribution largely unchanged.
For out-of-domain evaluation we use Honnibal
et al. (2009) (English) Wikipedia gold standard
and the (English) gold section of the Parallel
Meaning Bank, v3.0, which comprises multiple
12The few supertags in the 1–9 range of the new training
set are those which occurred slightly above 9 times in the
original training set, but some of their tokens were moved
due to occurring in the same sentence as a low-frequency tag.
249
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
l
a
c
_
a
_
0
0
3
6
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Acc
All
n=56,395
N =538
Model
MLP 10
MLP 10@
Nonconstructive Classification
94.77 ± .07
94.76 ± .17
94.83 ± .09
94.75 ± .18
MLP 1
MLP 1@
Constructive: Sequential
K+19
RNN
RNN@
90.68 ± .15
93.92 ± .01
94.48 ± .08
Constructive: Tree-structured
94.62 ± .12
94.44 ± .22
94.58 ± .16
94.70 ± .05
AddrMLP
AddrMLP@
TreeRNN
TreeRNN@
≥100
n=55,698
N =199
95.26 ± .07
95.25 ± .18
95.27 ± .10
95.18 ± .17
91.10 ± .16
94.39 ± .02
94.93 ± .04
95.10 ± .11
94.95 ± .20
95.01 ± .16
95.11 ± .06
Acc by cat frequency in training
10–99
n=563
N =222
1–9
n=107
N =91
68.32 ± 1.42
68.98 ± 0.89
68.68 ± 1.09
70.16 ± 0.81
–
–
23.99 ± 1.08
27.10 ± 1.62
63.65 ± 0.21
65.48 ± 0.62
66.90 ± 2.32
34.58 ± 1.62
19.00 ± 2.35
27.41 ± 5.31
64.24 ± 2.60
62.17 ± 3.03
67.44 ± 1.45
68.86 ± 0.57
25.55 ± 0.54
22.43 ± 1.87
34.89 ± 2.35
36.76 ± 2.86
Acc by cat depth
OOV
n=27
N =26
0
n=19,67
N =18
1–2
n=33,409
N =253
3–6
n=3,315
N =267
–
–
–
–
7.41 ± 0.00
0.00 ± 0.00
1.23 ± 2.14
2.47 ± 2.14
0.00 ± 0.00
3.70 ± 0.00
4.94 ± 2.14
97.80 ± .14
97.73 ± .16
97.71 ± .16
97.84 ± .18
91.71 ± .29
95.25 ± .09
97.72 ± .11
97.70 ± .21
97.61 ± .05
97.73 ± .13
97.85 ± .16
94.25 ± .08
94.29 ± .23
94.37 ± .14
94.26 ± .52
91.28 ± .02
94.33 ± .04
93.88 ± .09
94.14 ± .08
93.95 ± .33
94.02 ± .17
94.11 ± .03
82.01 ± .18
81.88 ± .29
82.39 ± .11
82.33 ± .51
78.43 ± .77
81.77 ± .78
81.33 ± .16
81.14 ± .90
80.61 ± .63
81.47 ± .24
81.92 ± .26
Table 3: Main results on Rebank evaluation set (WSJ section 23). Accuracy scores are computed
for bins based on the order of magnitude of category occurrences in training, and complexity of
categories in depth, with depth=0 corresponding to atomic categories like NP (Figure 3a has depth
2). Token (n) and type (N ) counts for each bin are given in the first two rows. ‘@’ refers to model
variants that use an attention mechanism over the encoder’s hidden states. (As a Transformer model,
the K+19 model attends to both the encoder and previously predicted outputs by default.) In each
column, we highlight all results r that fall within the standard deviation of the best result b, i.e., when
r + stdev(r) > b − stdev(乙). 用于比较, the overall tagging accuracy reported in Honnibal et al.
(2010) 是 92.2%.
Acc
全部
n=55,371
N =435
Acc by cat freq in training
≥100
n=54,825
N =171
10–99
n=442
N =176
1–9
n=82
N =67
OOV
n=22
N =21
Parsing
LF
Parseability
n=2,407
模型
Nonconstructive
MLP 10@ 96.09 ± .07
96.22 ± .06
多层线性规划 1
Constructive
96.50 ± .08 67.27 ± 1.02
96.58 ± .07 70.29 ± 2.35 23.17 ± 3.23
–
–
–
90.78 ± .09 86.95 ± 0.75
90.91 ± .09 88.26 ± 0.39
92.12 ± .21
K+19
95.10 ± .07
RNN@
AddrMLP@ 96.09 ± .07
92.46 ± .20 65.38 ± 0.99 34.55 ± 4.28 1.52 ± 2.62
95.48 ± .07 65.76 ± 1.71 26.02 ± 0.70 0.00 ± 0.00
96.44 ± .08 68.10 ± 1.38 37.40 ± 1.41 3.03 ± 2.62
87.66 ± .19 91.14 ± 0.13
90.63 ± .04 89.53 ± 0.18
90.79 ± .08 86.03 ± 1.72
桌子 4: Results on the original CCGbank evaluation set (WSJ section 23). The population n for
computing Parseability is the number of sentences in the test set. In each column, we highlight all
results that fall within the standard deviation of the best result.
(桌子 4). Our best constructive and noncon-
structive models are on par with the previously
reported state of the art in terms of overall accu-
活泼的. Tian et al. (2020) only report performance
on categories seen at least 10 times in training, IE。,
the union of our ‘‘≥ 100’’ and ‘‘10-99’’ bins; 我们的
top-3 results on this subset are MLP 1: 96.37%,
MLP 10@: 96.27%, AddrMLP@: 96.22%. 这
rise in absolute scores from Table 3 to Table 4 是
consistent with Honnibal et al. (2010) finding that
Rebank is more difficult to supertag and parse than
CCGbank due to its sparser category space. 我们
therefore encourage future researchers to conduct
experiments on Rebank and report detailed results
for frequency- and complexity-binned subsets
of the output space to facilitate more in-depth
comparisons.
的
Evaluating Generalizability. 一
这
inherent problems of the supertagging task is the
sparsity of the output space. 这是, 然而,
not sufficiently captured by standard evaluation
套, as illustrated in Figure 1b. To test how
well the models really generalize to the long
250
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Acc
≥ 10 OOV
Parsing
LF
P/ability
模型
全部
Nonconstructive
V+16
94.24
C+18
96.05
–
T+20
Constructive
–
–
96.39
BP20
96.00
–
–
–
–
5
88.32
–
90.68
–
–
–
90.9
96.2
桌子 5: Relevant baselines reported in previous
工作 (on the original CCGbank): Vaswani et al.
(2016), Clark et al. (2018), Tian et al. (2020), 和
Bhargava and Penn (2020).
Acc
全部
n=53,765
N =1,351
Acc by cat freq
≥100 10–99 1–9 OOV
n=50,754 n=989 n=292 n=1,730
N =188 N =240 N =118 N =805
模型
Nonconstructive
多层线性规划 10
多层线性规划 1
Sequential
88.76
88.79
92.86
92.87
55.71 13.24
55.61 19.29
–
–
K+19
RNN
Tree-structured
80.20
88.73
TreeRNN 88.78
AddrMLP 89.01
83.49
92.64
47.72 25.11 11.62
5.38
52.92 23.52
92.54
92.70
49.90 20.55
9.62
54.03 26.48 10.96
桌子 6: Performance of the best systems (这
variants with attention for each paradigm) 在
redistributed Rebank train/test splits. Frequency
bins are based on the new training set.
tail, we evaluate them on alternatively sampled
training and evaluation splits of the WSJ data
(桌子 6) as well as in domains diverging from
the WSJ training set (桌子 7). These experiments
largely confirm our findings from the standard
Rebank evaluation set, while the change in
category distribution has several important effects
on our ability to evaluate model generalization:
第一的, OOV performance is much higher on the
redistributed data (桌子 6) than on the standard
test splits in Tables 3, 4, 和 7, highlighting
all of the constructive models’ generalization
capability, and in turn suggesting that the OOV
categories in WSJ section 23 and PMB are
truly difficult, 嘈杂, or otherwise inconsistent
with the training data. 第二, the proportion of
evaluation tokens of categories less than 10 次
in training is 1.6% in PMB and 3.8% in our
PMB
Wiki
Acc
全部
≥100 10–99 1–9 OOV
n=4,151 n=53,739 n=52,010 n=870 n=191 n=668
N =138 N =243 N =129 N =47 N =14 N =53
模型
Nonconstructive
92.54
92.31
多层线性规划 10
多层线性规划 1
Constructive
90.11
90.27
92.10 57.05
92.10 63.41 29.14
–
–
–
87.29
K+19
RNN
92.00
AddrMLP 92.46
84.39
89.52
90.16
86.13 55.86 32.64 0.20
91.38 61.42 24.26 0.25
92.02 59.00 36.30 1.55
桌子 7: Performance of the best systems (这
variants with attention for each paradigm) 在
Wikipedia and PMB13 datasets. The state of the art
on the Wikipedia data is 90.00% (徐等人。, 2015).
redistributed Rebank evaluation data, compared
to only ≈0.2% in the standard CCGbank and
Rebank test sets. This 7x–16x increase in relative
size renders the tail much more consequential
for overall performance. And indeed we observe
slightly smaller gaps in overall accuracy between
the best-performing nonconstructive and the best-
performing constructive systems in Table 7 (0.08
on Wiki, 0.11 on PMB) 相比 0.13 在
Tables 3 和 4, while in Table 6 AddrMLP even
clearly outperforms the nonconstructive models.
第三, performance on rare and unseen categories
can now be measured much more reliably due
to the larger absolute counts of rare and unseen
类别. We provide in-depth analyses of this
subset of tags in § 6.2.
In both in-domain and out-of-domain data, 这
performance gap between the nonconstructive
MLPs and AddrMLP on the most
经常的
categories is minimal and in fact lies within the
标准差. Given the trend we observe
from Tables 3 和 4 to Tables 6 和 7, the ability
to generalize to the long tail may well outweigh
any minor improvement on the most frequent
categories when applied to even more diverse data,
within other languages, and across languages.
13Because we did not train any models on PMB itself,
we analyze performance on all of PMB-gold, but for future
comparisons, we also report accuracy on the suggested eval-
uation split: K+19: 85.43%; RNN@: 90.24%; AddrMLP@:
90.78%; MLP 1@: 90.88%; MLP 10@: 90.91%.
251
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
图中 5 we take a closer look at the mod-
els’ ability to predict categories of the appropriate
深度. For the sake of brevity, we only con-
sider three extreme cases: 多层线性规划 10, K+19, 和
AddrMLP. Compared with MLP 10, which tends
to choose one of the very frequent but relatively
shallow categories of depth 1 或者 2, AddrMLP
prefers both standalone atomic (深度-0) 美食-
gories and those of depth 3 和 4 (column totals in
the top left matrix). On the head, AddrMLP con-
fuses depth-1 for depth-0 categories and overpre-
dicts the depth of depth-2 and depth-3 categories
more frequently than the baseline. On the subset
of rare categories (which are deeper than more
frequent categories on average), AddrMLP is con-
sistently better at predicting categories of the cor-
rect depth (diagonal in the bottom left matrix); 这
thresholded model consistently chooses categories
that are too shallow here. The sequential tagger
by K+19 struggles with predicting the correct
depth for frequent categories much more than the
tree-structured model (top right matrix), 这是
almost certainly a result of its lack of an inductive
bias for the tree structure of categories. On the rare
tail, 然而, its ability to guess the right depth
is almost as good as that of AddrMLP (底部
正确的).
数字 5: Confusion matrices by category depth, 基于
on the standard Rebank evaluation set. Rows (columns)
correspond to gold (预测的) categories with the
respective depth. 因此, cells above (以下) the diagonal
refer to categories predicted too deep (shallow). 全部
numbers are absolute differences between confusions
made by AddrMLP@ and MLP 10@ / K+19, res-
pectively. 因此, positive numbers (红色的) are more typical
for AddrMLP@ and negative numbers (蓝色的) are more
typical for one of the other systems.
6 Detailed Analysis
6.2 Generation Behavior and Unseen Tags
6.1 Constructing Complex Categories
Whereas nonconstructive taggers do not distin-
guish between categories of varying complexity
(each supertag prediction is a single k-way deci-
锡安), constructive taggers are always required to
make multiple atomic decisions whenever assign-
ing a complex category, all of which need to be
correct in order for the full category to be counted
as correct. This raises the question: How difficult
are categories of varying complexity for each of
the systems?
As Figure 1b shows, deeper, IE。, more com-
丛, categories tend to be rarer and thus are more
difficult than simple ones in general, for all mod-
这. Surprisingly however, we can see in the three
rightmost columns of Table 3 that it is not dramat-
ically more difficult for constructive systems to
generate complex categories of depth ≥ 1 than it is
for nonconstructive systems to simply assign them
(apart from K+19, which underperforms on fre-
quent categories regardless of their complexity).
Are there any distinct patterns in the output of
the different models? By manually searching the
语料库, we find that even in the cases where a tag-
ger assigns a category with an incorrect structure,
there are systematic confusions such as between
argument and adjunct PPs and between fixed
particle verbs and (aspectual) adjunct particles.
This is difficult to measure at a large scale, 但
we present two examples in Tables 8 和 9. 这
thresholded tagger has the option to output an
category is not in the tagset. It makes use of this
option for 0.25% of tokens on average (0.11%
with standard train/test splits); when it does, 这
correct category is indeed missing from the tagset
关于 2/3 当时的. This happens, 例如, 和
WH-words in elliptical questions, as in Table 10.
表中 11 we quantify the structural and
labeling errors more generally, based on the redis-
tributed evaluation set to ensure reliable estimates
on rare phenomena. A substantial portion of erro-
neous categories actually do have the correct
252
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
从
1984 到 1986
garnered
(S[pss]\NP)
(西德:2)
(西德:2)
(西德:2)
(西德:2)
金子
多层线性规划 10
多层线性规划 1
K+19
RNN
AddrMLP (S[pss]\NP)/PP (PP/ADV)/NP
(ADV/ADV)/NP
(西德:2)
(西德:2)
(西德:2)
(西德:2)
金子
多层线性规划 10
多层线性规划 1
K+19
RNN
AddrMLP
为什么
constructive
S[wq]/(S[adj]\NP) S[adj]\NP
?
(S/S)/(S[adj]\NP)
(西德:2)
(西德:2)
(西德:2)
(西德:2)
(西德:2)
(西德:2)
(西德:2)
(西德:2)
桌子 8: AddrMLP treats ‘‘garnered’’ as expecting
a PP argument (which would be correct for a
source-PP, 例如, ‘‘garnered information from the
internet’’, but this is a different sense of ‘‘from’’).
The other models correctly identify ‘‘garnered’’
as an intransitive passive verb with ‘‘from’’
introducing an adverbial PP adjunct. The gold
category of ‘‘from’’ is so complicated because it is
correlated with ‘‘to’’: First it expects an NP object
on the right (‘‘1984’’), then an adverbial adjunct
on the right (the to-PP), after which it produces
an adjunct to a VP.14 AddrMLP’s predictions for
‘‘garnered’’ and ‘‘from’’ are consistent in treating
the entire construction ‘‘from 1984 to 1986’’ as an
argument of the verb.
orders began
piling
向上
金子
多层线性规划 10
多层线性规划 1
K+19
RNN
AddrMLP
(S[ng]\NP)/PR
S[ng]\NP
S[ng]\NP
S[ng]\NP
PR
ADV
ADV
ADV
(S[ng]\NP)/PP S[adj]\NP
(西德:2)
(西德:2)
the intended treatment of the
桌子 9: 这里,
particle (PR) ‘‘up’’ is as an argument selected
by the predicate. Only AddrMLP gets this right.
We assume this is preferable over treating it as
a VP adjunct (as the nonconstructive and K+19
taggers do) from a semantic perspective, 因为
‘‘pile up’’ is a fixed expression with a meaning
distinct from that of ‘‘(到) pile’’ or ‘‘pile in’’. 这
RNN categories are both wrong and inconsistent
(the ‘‘piling’’ category expects a PP and the ‘‘up’’
category is predicative).
结构 ((西德:2) struct).15 For these cases, we perform
a detailed error analysis, whose results we present
图中 6. 实际上, if the structure is correct, 这
14ADV is not an actual atomic category. We use it to
abbreviate the VP-adjunct category (S\NP)\(S\NP). PP is a
conventionalized atomic category for argument-PPs.
15E.g.,
为了
‘‘piling’’
表中 9 the RNN predicts
(S[ng]\NP)/PP, which exhibits the correct structure (X\X)/X
with an incorrect atomic label (PP instead of PR).
253
桌子 10: Supertags for WH-words tend to be
rare or unseen in training. 这里, 多层线性规划 10
correctly identifies that
it cannot predict
the true category for ‘‘why’’ and instead
outputs
an incorrect tag. The constructive taggers are
able to generate the correct category.
模型
正确的 (西德:2)struct (西德:2)formed ✗ formed
Incorrect
我
我
A
47,542
MLP 10@
47,552
MLP 1@
43,120
K+19
47,704
RNN@
TreeRNN@ 47,733
AddrMLP@ 47,851
d K+19
e
t
n
e
v
n
我
RNN@
TreeRNN@
AddrMLP@
201
93
162
190
1,345
1,401
2,706
1,395
1,373
1,352
96
26
83
89
4,746
4,811
7,812
4,661
4,659
4,562
160
71
213
240
–
–
127
5
1
1
127
5
1
1
桌子 11: Analysis of predicted supertag
structures in the redistributed evaluation set.
Incorrect predictions are broken down in terms
of having the correct structure ((西德:2) struct: 相同
number and arrangement of slashes, 论据,
and results as the gold category), an incorrect
but well-formed structure ((西德:2) 形成的: diverging
arrangement of arguments, but still obeying the
grammar in Figure 2), or an invalid structure
(✗
形成的, 例如, missing arguments to slashes).
predicted category is often only off by the direction
of a single slash or the attribute of a single atomic
类别. K+19 additionally struggles with atomic
decisions beyond just differences in attributes.
To what extent can the constructive models gen-
erate categories that were unseen during training?
We take a closer look at categories the constructive
taggers invented in the bottom halves of Table 11
和图 6. K+19 is the most willing to invent
类别, closely followed by the tree-structured
models and finally RNN, which is rather conserva-
tive in this respect (see sums of the last four rows
表中 11). Merely generating more new cate-
gories irrespective of their correctness is of course
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Predicted sequence
Predicted supertag
Gold sequence
Gold supertag
bring
/ / \S[乙] NP \NP
((S[乙]\NP)/(NP\
– ))/-
/ \S[乙] NP NP
(S[乙]\NP)/NP
桌子 12: A malformed supertag extracted from
a sequence predicted by K+19. Underscores ‘ ’
indicate gaps in the tree structure resulting from
predicted surplus slashes.
(every 66th sentence in the standard Rebank test
放). A common source of errors is that too many
slashes are predicted, whose argument and result
slots can then not be filled by the predicted atomic
类别. We show an example in Table 12.
And vice versa, are there any categories that
are not generated despite being seen in train-
英? 有 80 category types in the standard
Rebank test set that none of the tree-structured
taggers ever predict correctly, although they are
attested in the training data, and there are 93 类型
that are never retrieved by K+19, 73 其中
重叠. Out of these 73, no one occurs more
than three times in the test set and almost all
appear fewer than 50 times in training, 与三个
例外情况: (NP\NP)\(NP\NP) (68 times in train-
英), ((N\N)\(N\N))/NP (50 次), 和 (NP\NP)/氮
(50 次). The first one is usually used for the last
part of complex numerical expressions (例如
dates and ranges), but the one token bearing this
category in the test set is ‘‘not’’ in ‘‘they might
not miss one at all’’, which is likely an annotation
error.17 The second one encodes prepositions
modifying an appositive bare noun, typically an
appellation or postposed proper noun. The third
one is for determiners of appositions or paren-
theticals. 67 的 73 types that are problematic
for the constructive models are never accurately
predicted by the nonconstructive models either.
6.3 Parts of Speech and Sentence Parsing
Parsing performance is computed using labeled
F1-score (LF) over CCG dependencies in all
句子, following Clark and Curran (2007),
and Parseability, IE。, the proportion of sentences
for which a complete CCG derivation can be
17There are a few more instances of such implausible lex-
ical categories in the training data, like S or ((:\NP)/PP)/NP.
数字 6: Fine-grained analysis of correctly structured
incorrectly labeled predictions ('(西德:2) struct’
但
在
桌子 11). ‘Attribute error’ means that the predicted
atomic category is correct except for a wrong or missing
linguistic attribute (例如, S vs. S[dcl]); ‘atom error’
means that an entirely wrong atomic category has been
选择的 (例如, PP vs. NP); and ‘slash error’ means
confusing / 和 \.
not necessarily an advantage, but it is encouraging
to see the models make use of their freedom to
do so at an adequate rate, rather than only repro-
ducing known categories or vastly overgenerating
invented ones. 有趣的是, given that a incorrect
invented category has the same structure as the
gold category, we again see that the majority of
errors are due to only a single attribute or slash,
suggesting that in these cases the models get the
general idea of the category right and only err in
fine-grained and context-sensitive subcategoriza-
的. In the case of a slash mistake, they are notably
also able to recover from it in later predictions.
While the tree-structured taggers are guaranteed
to produce valid categories,16 it is possible for the
sequential taggers to generate structurally invalid
类别, IE。, sequences of atomic categories
and slashes that are not licensed by the grammar
图中 2. With the tag-wise RNN generator,
which generally refrains from inventing new
类别, this only happens extremely rarely,
but in the case of K+19, every 14th sentence is
affected by an ill-formed supertag on average
16That TreeRNN and AddrMLP still produced one
malformed category can be considered a bug: They attempted
to generate a category deeper than the maximally allowed
depth and were unable to complete it. This is avoidable in
实践.
254
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Nouns Verbs WH Other
n=29,968
n=16,946 n=7,915
n=542
N =83
N =296 N =54
N =436
模型
f =1,158
MLP 10@ 98.58
98.62
多层线性规划 1
95.58
K+19
RNN@
98.60
AddrMLP@ 98.56
f =129
f =38
93.18 92.25
93.49 92.68
90.54 90.04
93.17 91.88
93.62 93.11
f =358
95.51
95.65
90.62
93.68
95.43
桌子 13: Performance by part-of-speech, 基于
on the original CCGbank test set. n and N refer
to token and type counts in the test set, as before;
f refers to the average frequency with which a
supertag belonging to the respective POS class
is seen in training.
constructed.18 Nearly all the models we compare
outperform the state of the art in labeled depen-
dency F1-score (right-most columns in Table 4).
有趣的是,
the K+19 model produces more
parseable supertag sequences than others, 尽管
consistently lagging behind in terms of category
准确性. Apparently this tagger prefers to be
self-consistent over producing the actual correct
类别, either due to its multihead attention
机制, the fact that decisions towards the
end of the sequence have access to all previously
predicted categories in their entirety (而不是
just parts of them), 或两者.
Dependencies. 我们
Long-range
examine
supertagging performance by POS class (a few are
如表所示 13) and find that constructive and
nonconstructive taggers perform similarly across
类, with one notable exception: WH-words,
whose supertags are rarely seen in training and
have a high type/token ratio at test time. 他们的
special syntactic status raises the question: 如何
important are constructivity, tree structure, 和
long-tail recall for recovering categories involved
in long-range dependencies?
Somewhat surprisingly, we find that the RNN
is best for these dependencies (数字 7), 哪个
might be related to the two parsing metrics
表中 4: RNN@ strikes a good balance
between LF and Parseability. We further exam-
ine the average dependency length per category,
and contrary to our expectation, dependencies
18The C&C parser also reports coverage, the proportion of
sentences for which at least one dependency relation can be
recovered. Coverage is 100% in all our conditions.
数字 7: Parsing F1-score for varying dependency
lengths, measured in terms of linear distance of the two
words involved in the dependency.
involving WH-categories are relatively short
(usually 3–4 intervening words). We find that
the supertags with the longest dependencies on
average largely are functioning as subordina-
托尔斯, sentence adverbials, and inverted speech
verbs such as (S[dcl]\S[dcl])\NP. These supertags
have in common that they all contain sentential
result/argument pairs of the form S[X]|S[X] (在哪里
x is an optional attribute). The autoregressive
nature of the RNN may be conducive to model-
ing the matching atomic categories of argument
and result. Exploring various decoding orders for
both sequential and tree-structured constructive
taggers in order to more explicitly take advantage
of these intra-category relations is an interest-
ing avenue for future work. We also expect a
major boost in Parseability from incorporating
inter-category prediction history into our models
(Bhargava and Penn, 2020). But this is nontrivial
for tree-structured decoding and goes beyond our
scope here.
6.4 Runtime and Model Size
While the constructive taggers need to make
more individual decisions for each supertag than
nonconstructive ones, they only have to consider
a much smaller and denser output space. 这
trade-off between time and space complexity
should be considered in addition to tagging accu-
racy when evaluating each model. Thus we ask:
How do the constructive supertaggers compare
to nonconstructive ones in terms of efficiency? 在
桌子 14 we report model sizes (IE。, 的数量
255
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
模型
Params Train time Infer speed
millions
sents/s
小时
Nonconstructive Classification
多层线性规划 10
多层线性规划 1
2.0
2.4
9
11
Constructive: Sequential
K+19
RNN
120
68
Constructive: Tree-structured
11.8
4.8
TreeRNN
AddrMLP
8.3
1.3
10
10
191
195
0.3
135
125
126
桌子 14: Model size and time required for training
and inference. All models use the RoBERTa en-
编码员, 谁的 124.6 million parameters are not
included here. Training times are approximate
and include development set evaluation at every
epoch.
learned parameters), training time until develop-
ment performance plateaus, and inference speed.
As model size and runtime vary greatly between
different constructive taggers, the answer to our
question depends on how supertags are modeled
and inferred.
The K+19 sequential Transformer model has
low efficiency for two reasons: The Transformer
architecture itself has a large number of param-
埃特斯; and sequential inference is slow because
individual predictions for the same sentence can-
not be parallelized and the number of inference
steps per input sentence is linear in the sum of
all category sizes (the number of atomic pieces)
for that sentence. The GRUs in the RNN and
TreeRNN models are much smaller than the
Transformer of K+19, but the TreeRNN with its
two GRUs for argument and result transitions
ends up having almost as many parameters as the
Transformer in total. The nonconstructive models
map hidden representations into a much larger and
sparser output space than the constructive models
(and the output space of MLP 1, 反过来, is larger
and sparser than that of MLP 10). AddrMLP,
另一方面, consists exclusively of feed-
forward layers, resulting in the smallest model
size among the ones we compare.
The sequential models require relatively many
training epochs to converge. The reason total
training time is still comparable between K+19
256
and RNN despite the extreme disparity in infer-
the Transformer is trained
ence speed is that
non-autoregressively and thus performs inference
only between epochs, for evaluation on the devel-
opment set, whereas RNN training inherently
relies on inference. The nonconstructive and tree-
structured models converge within the first 10
纪元.
For the per-tag constructive models RNN,
TreeRNN, and AddrMLP we parallelize infer-
ence across all supertags in a batch, and for the
tree-structured ones, we further parallelize the
prediction of the children of slash functors, 麦-
ing their inference time logarithmic in the size of
the largest predicted category in a sentence.
AddrMLP is both time- and space-efficient
全面的. Its parameter count is only ≈1/10 of the
K+19 model and ≈1/2 of the nonconstructive
那些.
7 Discussion and Related Work
许久, researchers have addressed the
large search space of CCG supertags. Baldridge
(2008) and Ravi et al. (2010) were particu-
larly concerned with high lexical ambiguity and
counteracted this, 分别, by improving lex-
icon initialization using linguistic principles, 和
explicitly minimizing model sizes. Deoskar et al.
(2013), working with lexico-syntactic dependen-
cies similar to supertags, addressed difficulties
arising from the long tail of rare and unseen
字; and Deoskar et al. (2014) addressed a
similar issue specifically for generalizing a CCG
parser. The problem of out-of-vocabulary words
has gotten much less severe with the advent of
deep contextualized sentence encoders operating
on subword units.
An alternative way of reducing the burden on
the supertagger is to couple it with the parser and
jointly optimize lexical and phrasal categories,
subject to the combinatory rules of CCG (Auli and
洛佩兹, 2011; Garrette et al., 2015). Garrette et al.
(2015) notably included a fully constructive proba-
bilistic model of categories in a weakly-supervised
grammar-induction scenario. In the context of
grammar induction for semantic parsing specifi-
卡莉, Kwiatkowski et al. (2011) and Artzi et al.
(2015) have explored template-based methods
to generalize a limited initial lexicon to likely
alternative syntactic usages of observed words.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
In the special case that all categories in a sen-
tence but one are known, the combinatory rules
of CCG can be reverse-engineered to infer the
missing category. As an efficient and scalable
example of this, Thomforde and Steedman (2011)
have proposed Chart Inference.
Since the beginning of the neural era, virtually
all advances in CCG supertagging have involved
different means of deep sequence encoding, typ-
ically in the form of (Bi)LSTMs, with techniques
包括: predicting categories directly from the
word-level encoder (徐等人。, 2015; 刘易斯等人。,
2016); giving credit to likely category sequences
(Vaswani et al., 2016; Kadari et al., 2018); forc-
ing the model to distribute its attention over a
fixed-size window of neighboring words (吴
等人。, 2017); training the encoder specifically to
be aware of each word’s neighboring categories
(‘cross-view training’; Clark et al., 2018); 和
latently modeling parse chunks with a graph-
convolutional network over word n-grams (Tian
等人。, 2020).
相似的
techniques have been applied to
supertagging in the related formalism Tree-
Adjoining Grammar (TAG) (Kasai et al., 2017,
2018). Zhu and Sarkar (2019) have formulated
TAG supertagging as multitask learning with
respect to certain aspects of the elementary trees’
internal structure. Their system predicts the cat-
egory that optimizes the weighted sum of the
scores for each subtask.
A possible objection to generating categories
entirely productively is that universal linguistic
patterns constrain the shape of categories and the
syntactic relations they may engage in (Chomsky
and Lasnik, 1993; Baldridge and Kruijff, 2003),
and for any given language, word order and other
language-specific properties further restrict the
underlying grammar. Note that for a FxnCat shape
with given argument and result types, the direc-
tion of its Slash functors is largely determined by
global word order properties of the respective lan-
规格. Consider the prototypical category shape
for adpositions, (NP|NP)|NP, where ‘|’ stands for
either forward or backward direction. 用英语, A
predominantly prepositional (as opposed to post-
positional) language with postnominal-PP mod-
ifiers, this shape is most commonly instantiated
作为 (NP\NP)/NP, but different ordering patterns
may dominate in other languages. Languages
with more flexible word orders will show a
greater variance in slash directionality than those
with fixed word orders. While our approach is
in principle equipped to pick up on such patterns
from data, we do not explicitly prohibit unlikely
category types. One potential way of incorporat-
ing such information is via logical constraints at
training and/or inference time in the style of Li
and Srikumar (2019); 李等人. (2019). 其他
approach could be a hybrid one, bridging between
constructive and nonconstructive tagging in a
more fluid way. We plan to explore these avenues
in future work.
8 结论
We introduced a novel, explicitly tree-structured
CCG supertagging method, advancing the nascent
paradigm of constructive supertagging. Our analy-
sis of complex and long-tail categories highlights
the positive impact of different modeling and
inference choices within this paradigm: 结构性的
inductive bias as well as adequate contextual-
ization via, 例如, attention contribute to more
efficient, robust, and self-consistent models. 我们
hope that our proposed method can be instrumen-
tal in researching and applying not only CCG
and related syntactic formalisms, but also other
paradigms like morphological (的)composition of
complex words in morphologically rich languages,
or compositional semantic parsing.
致谢
We would like to thank Aditya Bhargava and
Konstantinos Kogkalidis for assistance with rep-
licating their experiments and extended discuss-
ions of constructive models; Mark Steedman,
Julia Hockenmaier, and Noah Smith for their
deep insight into CCG; Kilian Evang and Lasha
Abzianidze for explanations of data formats and
conventions; Tao Li, Yichu Zhou, and Sean
MacAvaney for help with implementing our
models in PyTorch; and members of the NERT lab
at Georgetown for feedback on an early abstract.
We are indebted to our TACL action editor Reut
Tsarfaty and editor-in-chief Ani Nenkova, 还有
as the anonymous reviewers for their diligent
assessment and handling of logistics. This research
was supported in part by NSF award IIS-1812778
and a generous gift from Google.
257
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
参考
Lasha Abzianidze, Johannes Bjerva, Kilian Evang,
Hessel Haagsma, Rik van Noord, 皮埃尔
Ludmann, Duc-Duy Nguyen, and Johan Bos.
2017. The Parallel Meaning Bank: Towards a
multilingual corpus of translations annotated
with compositional meaning representations.
In Proceedings of EACL, pages 242–247,
Valencia, 西班牙. DOI: https://doi.org
/10.18653/v1/E17-2039
Yoav Artzi, Kenton Lee, and Luke Zettlemoyer.
2015. Broad-coverage CCG semantic parsing
In Proceedings of EMNLP,
with AMR.
pages 1699–1710, 里斯本, Portugal.
Michael Auli and Adam Lopez. 2011. A
comparison of Loopy Belief Propagation
and Dual Decomposition for integrated CCG
supertagging and parsing. 在诉讼程序中
ACL-HLT, pages 470–480, Portland, 或者, 美国.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
本吉奥. 2015. Neural Machine Translation
by jointly learning to align and translate. 在
Proceedings of ICLR. 圣地亚哥, CA, 美国.
Jason Baldridge. 2008. Weakly supervised
supertagging with grammar-informed initializa-
的. COLING 论文集, pages 57–64,
曼彻斯特, 英国.
Kevin Clark, Urvashi Khandelwal, Omer Levy,
and Christopher D. 曼宁. 2019. 什么
does BERT look at? An analysis of BERT’s
In Proceedings of BlackboxNLP,
注意力.
意大利. DOI:
页面
https://doi.org/10.18653/v1/W19
-4828, PMID: 31709923
276–286,
Florence,
Kevin Clark, Minh-Thang Luong, Christopher
D. 曼宁, and Quoc Le. 2018. Semi-
supervised sequence modeling with cross-view
EMNLP,
会议记录
训练.
pages 1914–1925, 布鲁塞尔, 比利时. DOI:
https://doi.org/10.18653/v1/D18
-1217
在
的
Stephen Clark. 2002. Supertagging for Combi-
natory Categorial Grammar. 在诉讼程序中
TAG+, pages 19–24, Universitá di Venezia.
Stephen Clark and James R. 柯兰. 2004. 这
importance of supertagging for wide-coverage
CCG parsing. COLING 论文集,
pages 282–288, 日内瓦, 瑞士.
Stephen Clark and James R. 柯兰. 2007.
Wide-coverage efficient statistical parsing with
CCG and log-linear models. 计算型
语言学, 33(4):493–552. DOI: https://
doi.org/10.1162/coli.2007.33.4
.493
Jason Baldridge and Geert-Jan M. Kruijff.
2003. Multi-modal Combinatory Categorial
语法. In Proceedings of EACL. 布达佩斯,
匈牙利.
Stephen Clark, Darren Foong, Luana Bulat, 和
Wenduan Xu. 2015. The Java version of the
C&C Parser: Version 0.95. Technical report,
University of Cambridge Computer Laboratory.
Aditya Bhargava and Gerald Penn. 2020. Super-
tagging with CCG primitives. In Proceedings
of RepL4NLP, pages 194–204, 在线的.
Kyunghyun Cho, Bart van Merri¨enboer, Dzmitry
Bahdanau, and Yoshua Bengio. 2014. 在
the properties of Neural Machine Translation:
Encoder–decoder approaches. In Proceedings
of SSST-8, pages 103–111, Doha, Qatar.
Noam Chomsky and Howard Lasnik. 1993.
The theory of principles and parameters,
Joachim Jacobs, Arnim von Stechow, Wolfgang
Sternefeld, and Theo Vennemann, 编辑,
的
Syntax: 一个
Contemporary Research, 1, pages 506–569,
Walter de Gruyter, 柏林, 德国.
International Handbook
Tejaswini Deoskar, Christos Christodoulopoulos,
Alexandra Birch, and Mark Steedman. 2014.
Generalizing a strongly lexicalized parser
using unlabeled data. In Proceedings of EACL,
pages 126–134, Gothenburg, 瑞典. DOI:
https://doi.org/10.3115/v1/E14
-1014
Tejaswini Deoskar, Markos Mylonakis, and Khalil
Sima’an. 2013. Learning structural dependen-
cies of words in the Zipfian tail. 杂志
Logic and Computation, 24(2):433–453. DOI:
https://doi.org/10.1093/logcom
/exs062
Dan Garrette, Chris Dyer, Jason Baldridge, 和
诺亚A. 史密斯. 2015. A supertag-context model
258
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
for weakly-supervised CCG parser learning.
In Proceedings of CoNLL, pages 22–31,
北京, 中国. DOI: https://doi.org
/10.18653/v1/K15-1003
In Proceedings of NAACL-HLT,
网络.
pages 1181–1194, New Orleans, 这, 美国.
DOI: https://doi.org/10.18653/v1
/N18-1107
John Hewitt and Christopher D. 曼宁. 2019.
A structural probe for finding syntax in word
陈述. In Proceedings of NAACL-
赫勒特, pages 4129–4138, 明尼阿波利斯, 明尼苏达州,
美国.
Julia Hockenmaier and Mark Steedman. 2007.
CCGbank: A corpus of CCG derivations
and dependency structures extracted from the
Penn Treebank. 计算语言学,
33(3):355–396. DOI: https://doi.org
/10.1162/coli.2007.33.3.355
Matthew Honnibal, James R. 柯兰, and Johan
Bos. 2010. Rebanking CCGbank for improved
NP interpretation. In Proceedings of ACL,
pages 207–215, Uppsala, 瑞典.
Matthew Honnibal, Joel Nothman, and James R.
柯兰. 2009. Evaluating a statistical CCG
在诉讼程序中
parser on Wikipedia.
People’s Web, pages 38–41, Suntec, 新加坡.
DOI: https://doi.org/10.3115/1699765
.1699771
Ganesh Jawahar, Benoît Sagot, and Djamé
Seddah. 2019. What does BERT learn about
the structure of language? 在诉讼程序中
前交叉韧带, pages 3651–3657, Florence, 意大利. DOI:
https://doi.org/10.18653/v1/P19
-1356
Rekia Kadari, Yu Zhang, Weinan Zhang, and Ting
刘. 2018. CCG supertagging via Bidirectional
LSTM-CRF neural architecture. Neurocomput-
英, 283:31–37. DOI: https://doi.org
/10.1016/j.neucom.2017.12.050
Jungo Kasai, Bob Frank, Tom McCoy, 欧文
and Alexis Nasr. 2017. TAG
Rambow,
parsing with neural networks and vector
representations of supertags. In Proceedings
of EMNLP, pages 1712–1722, 哥本哈根,
丹麦. DOI: https://doi.org/10
.18653/v1/D17-1180
Yoon Kim, Carl Denton, Luong Hoang, 和
Alexander M. 匆忙. 2017. Structured attention
网络. In Proceedings of ICLR, Toulon,
法国.
Konstantinos Kogkalidis, Michael Moortgat,
and Tejaswini Deoskar. 2019. Constructive
type-logical supertagging with self-attention
In Proceedings of RepL4NLP,
网络.
pages 113–123, Florence, 意大利. DOI: https://
doi.org/10.18653/v1/W19-4314
Tom Kwiatkowski, Luke Zettlemoyer, Sharon
Goldwater, and Mark Steedman. 2011. 词汇
generalization in CCG grammar induction for
语义解析. In Proceedings of EMNLP,
pages 1512–1523, 爱丁堡, 苏格兰, 英国.
Mike Lewis, Kenton Lee, and Luke Zettlemoyer.
2016. LSTM CCG parsing. 在诉讼程序中
NAACL-HLT, pages 221–231, 圣地亚哥, CA,
美国. DOI: https://doi.org/10.18653
/v1/N16-1026 PMCID: PMC5024747
Tao Li, Vivek Gupta, Maitrey Mehta, and Vivek
Srikumar. 2019. A logic-driven framework for
consistency of neural models. In Proceed-
ings of EMNLP-IJCNLP, pages 3924–3935,
香港, 中国. DOI: https://土井
.org/10.18653/v1/D19-1405, PMID:
31251625, PMCID: PMC6767096
networks with
Tao Li and Vivek Srikumar. 2019. Augmenting
neural
逻辑.
In Proceedings of ACL, pages 292–302,
Florence, 意大利. DOI: https://doi.org
/10.18653/v1/P19-1028
first-order
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar
Joshi, Danqi Chen, Omer
征收, Mike Lewis, Luke Zettlemoyer, 和
Veselin Stoyanov. 2019. RoBERTa: A robustly
optimized BERT pretraining approach. arXiv
preprint arXiv:1907.11692.
Jungo Kasai, Robert Frank, Pauli Xu, 威廉
Merrill, and Owen Rambow. 2018. End-to-
end graph-based TAG parsing with neural
Ilya Loshchilov and Frank Hutter. 2017. SGDR:
Stochastic gradient descent with warm restarts.
Proceedings of ICLR.
259
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Ilya Loshchilov and Frank Hutter. 2019.
在
Decoupled weight decay regularization.
Proceedings of ICLR. New Orleans, 这, 美国.
In Proceedings of EMNLP, pages 6037–6044,
在线的. DOI: https://doi.org/10.18653
/v1/2020.emnlp-main.487, PMID: 32060988
Ashish Vaswani, Yonatan Bisk, Kenji Sagae,
and Ryan Musa. 2016. Supertagging with
In Proceedings of NAACL-HLT,
LSTMs.
pages 232–237, 圣地亚哥, CA, 美国. DOI:
https://doi.org/10.18653/v1/N16
-1027
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017.
Attention is all you need. 在诉讼程序中
神经信息处理系统, pages 5998–6008, Long Beach, CA,
美国.
Ronald J. Williams and David Zipser. 1989.
A learning algorithm for continually running
fully recurrent neural networks. Neural Com-
putation, 1(2):270–280. DOI: https://土井
.org/10.1162/neco.1989.1.2.270
Huijia Wu, Jiajun Zhang, and Chengqing Zong.
2017. A dynamic window neural network for
CCG supertagging. In Proceedings of AAAI.
旧金山, CA, 美国.
Wenduan Xu, Michael Auli, and Stephen Clark.
2015. CCG supertagging with a recurrent neural
In Proceedings of ACL-IJCNLP,
网络.
pages 250–255, 北京, 中国.
Xingxing Zhang, Liang Lu, and Mirella Lapata.
2016. Top-down Tree Long Short-Term Mem-
ory networks. In Proceedings of NAACL-HLT,
pages 310–320, 圣地亚哥, CA, 美国. DOI:
https://doi.org/10.18653/v1/N16
-1035
Zhenqi
朱
and Anoop
2019.
Deconstructing supertagging into multi-task
sequence prediction. In Proceedings of CoNLL,
pages 12–21, 香港, 中国.
Sarkar.
Maria Nˇadejde, Siva Reddy, Rico Sennrich,
Tomasz Dwojak, Marcin Junczys-Dowmunt,
Philipp Koehn, and Alexandra Birch. 2017.
language CCG supertags
Predicting target
improves Neural Machine Translation.
在
Proceedings of WMT, pages 68–79, Copen-
hagen, 丹麦. DOI: https://doi.org
/10.18653/v1/W17-4707
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason
Bolton, and Christopher D. 曼宁. 2020.
Stanza: A Python natural language processing
toolkit for many human languages. In Pro-
ceedings of ACL, pages 101–108, 在线的.
Sujith Ravi, Jason Baldridge, and Kevin Knight.
and grammar-
2010. Minimized models
informed initialization for supertagging with
highly ambiguous lexicons. 在诉讼程序中
前交叉韧带, pages 495–503, Uppsala, 瑞典.
Mark Steedman. 2000. The Syntatic Process, 和
按, 剑桥, 嘛, 美国.
Kai Sheng Tai, Richard Socher, and Christopher
D. 曼宁. 2015. Improved semantic repre-
sentations from tree-structured Long Short-
In Proceedings
Term Memory networks.
of ACL-IJCNLP, pages 1556–1566, 北京,
中国.
Emily Thomforde and Mark Steedman. 2011.
Semi-supervised CCG lexicon extension. 在
Proceedings of EMNLP, pages 1246–1256,
爱丁堡, 苏格兰, 英国.
Yuanhe Tian, Yan Song, and Fei Xia. 2020. Su-
pertagging Combinatory Categorial Grammar
with Attentive Graph Convolutional Networks.
260
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
6
4
1
9
2
4
1
2
6
/
/
t
我
A
C
_
A
_
0
0
3
6
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3