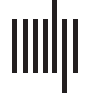SPECIAL ISSUE:
Cognitive Computational Neuroscience of Language
Localizing Syntactic Composition with Left-Corner
Recurrent Neural Network Grammars
Yushi Sugimoto1
, Ryo Yoshida1, Hyeonjeong Jeong2
Jonathan R. Brennan4
, and Yohei Oseki1
, Masatoshi Koizumi3
,
开放访问
杂志
1Graduate School of Arts and Sciences, University of Tokyo, 东京, 日本
2Graduate School of International Cultural Studies, Tohoku University, Sendai, 日本
3语言学系, Graduate School of Arts and Letters, Tohoku University, Sendai, 日本
4语言学系, 密歇根大学, 安娜堡, MI, 美国
关键词: 功能磁共振成像, left-corner parsing, naturalistic reading, recurrent neural network grammar,
令人惊讶的, syntax
抽象的
In computational neurolinguistics, it has been demonstrated that hierarchical models such as
recurrent neural network grammars (RNNGs), which jointly generate word sequences and
their syntactic structures via the syntactic composition, better explained human brain activity
than sequential models such as long short-term memory networks (LSTMs). 然而, 这
vanilla RNNG has employed the top-down parsing strategy, which has been pointed out in the
psycholinguistics literature as suboptimal especially for head-final/left-branching languages,
and alternatively the left-corner parsing strategy has been proposed as the psychologically
plausible parsing strategy. 在本文中, building on this line of inquiry, we investigate not only
whether hierarchical models like RNNGs better explain human brain activity than sequential
models like LSTMs, but also which parsing strategy is more neurobiologically plausible,
by developing a novel fMRI corpus where participants read newspaper articles in a
head-final/left-branching language, namely Japanese, through the naturalistic fMRI experiment.
The results revealed that left-corner RNNGs outperformed both LSTMs and top-down RNNGs
in the left inferior frontal and temporal-parietal regions, suggesting that there are certain brain
regions that localize the syntactic composition with the left-corner parsing strategy.
介绍
Recent developments in computational linguistics and natural language processing have
developed various kinds of computational models that can be employed to investigate neural
computations in the human brain (例如, Schrimpf et al., 2021), providing a new approach to the
neurobiology of language (Hale et al., 2022). 具体来说, computational models have played
an important role to test linguistic theories against human brain activity, and the previous lit-
erature have examined whether natural languages are represented as hierarchical syntactic
structures or linear word sequences (Chomsky, 1957; Everaert et al., 2015). 例如, Frank
等人. (2015) demonstrated that sequential models like recurrent neural networks (RNNs) suc-
cessfully predict human electroencephalography (EEG) relative to context-free grammars
(CFGs), suggesting that human language processing is insensitive to hierarchical syntactic
结构. 相比之下, the positive results of hierarchical models like CFGs and more expres-
sive grammar formalisms like minimalist grammars and combinatory categorial grammars
引文: Sugimoto, Y。, Yoshida, R。,
Jeong, H。, Koizumi, M。, Brennan,
J. R。, & Oseki, 是. (2023). Localizing
syntactic composition with left-corner
recurrent neural network grammars.
Neurobiology of Language. Advance
出版物. https://doi.org/10.1162
/nol_a_00118
DOI:
https://doi.org/10.1162/nol_a_00118
支持信息:
https://doi.org/10.1162/nol_a_00118
已收到: 6 一月 2023
公认: 24 七月 2023
利益争夺: 作者有
声明不存在竞争利益
存在.
通讯作者:
Yushi Sugimoto
yushis@g.ecc.u-tokyo.ac.jp
处理编辑器:
Evelina Fedorenko
版权: © 2023
麻省理工学院
在知识共享下发布
归因 4.0 国际的
(抄送 4.0) 执照
麻省理工学院出版社
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
n
哦
/
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
n
哦
_
A
_
0
0
1
1
8
2
1
5
6
6
2
2
n
哦
_
A
_
0
0
1
1
8
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
have also been confirmed against human EEG (Brennan & 黑尔, 2019) as well as functional
magnetic resonance imaging (功能磁共振成像) (Brennan et al., 2016; Stanojević et al., 2023).
而且, the hybrid computational model of RNNs and CFGs has been proposed in the
computational linguistics/natural language processing literature, namely recurrent neural net-
work grammars (RNNGs; Dyer et al., 2016) which jointly generate word sequences and their
syntactic structures via the syntactic composition. 有趣的是, RNNGs outperformed sequen-
tial models like long short-term memory networks (LSTMs) in predicting not only syntactic
dependencies (Kuncoro et al., 2018; Wilcox et al., 2019) and human eye movement (Wilcox
等人。, 2020; Yoshida et al., 2021), but also human brain activity like EEG (Hale et al., 2018)
and fMRI (Brennan et al., 2020). These results indicate that RNNGs are the neurobiologically
plausible computational model of human language processing.
然而, the vanilla RNNG in Hale et al. (2018) and Brennan et al. (2020) has employed
the top-down parsing strategy, which has been pointed out in the psycholinguistics literature
as suboptimal especially for head-final/left-branching languages, and alternatively the left-
corner parsing strategy has been proposed as the psychologically plausible parsing strategy
(阿布尼 & 约翰逊, 1991; Resnik, 1992). 此外, the recent result reported the positive
results of the left-corner parsing strategy modeling self-paced reading and human eye move-
蒙特 (Oh et al., 2022).
在本文中, building on this line of inquiry, we investigate not only whether hierarchical
models like RNNGs better explain human brain activity than sequential models like LSTMs,
but also which parsing strategy is more neurobiologically plausible. 具体来说, there are two
components in this paper. The first component is to construct a novel fMRI corpus named
BCCWJ-fMRI where participants read newspaper articles selected from the Balanced Corpus
of Contemporary Written Japanese (BCCWJ; Maekawa et al., 2014) through the naturalistic
fMRI experiment. The second component is to evaluate computational models such as LSTMs,
top-down RNNGs, and left-corner RNNGs against the novel fMRI corpus developed above.
Importantly for the purpose here, given that Japanese is a head-final/left-branching language,
this language should serve as an excellent testing ground to differentiate top-down and left-
corner parsing strategies. To preview our results, we demonstrate that left-corner RNNGs out-
perform both LSTMs andtop-down RNNGs in the left inferior frontal and temporal-parietal
地区, suggesting that there are certain brain regions that localize the syntactic composition
with the left-corner parsing strategy.
材料和方法
fMRI Corpus
In this subsection, we describe a novel fMRI corpus named BCCWJ-fMRI, 那是, BCCWJ
experimentally annotated with human fMRI.
Participants and stimuli
Forty-two Japanese native speakers were recruited (19 females and 23 males, 范围: 18–24 years
老的, mean age = 21.1, 标准差= 1.7). At the time of the experiment, all of them were under-
graduate and graduate students at Tohoku University, which is located in the northern part of
日本. All participants were right handed and had normal or corrected-to-normal vision with-
out any neurological deficits. For each participant, written informed consent was obtained
prior to the experiment.
Neurobiology of Language
2
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
n
哦
/
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
.
/
/
1
0
1
1
6
2
n
哦
_
A
_
0
0
1
1
8
2
1
5
6
6
2
2
n
哦
_
A
_
0
0
1
1
8
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Stimuli for this experiment consisted of 20 newspaper articles from the BCCWJ (Maekawa
等人。, 2014). BCCWJ consists of 100 万字, which includes various texts such as
图书, 报纸, 博客, 法律, 等等. Like BCCWJ-EEG (Oseki & Asahara, 2020),
the newspaper articles were all segmented into phrasal units instructed by the National Insti-
tute for Japanese Language and Linguistics. 这 20 newspaper articles were divided into four
blocks (A, 乙, C, D). Each block lasted for around 7 min excluding the first 20 s that the stimuli
were not presented and 31 s for reading and answering the comprehension questions.
程序
During scanning, the stimuli were presented using rapid serial visual presentation (RSPVP)
with PsychoPy (Peirce, 2007, 2009) where each segment was presented for 500 ms followed
by a blank screen for 500 多发性硬化症. Each participant read all blocks (A, 乙, C, D) in a randomized
命令. For each article, one yes–no comprehension question was given.
MRI acquisition and preprocessing
Scanning was conducted using the Philips Achieva 3.0T MRI scanner. During fMRI scanning,
T2*-weighted MR signals were measured using a echo planar imaging pulse sequence (param-
埃特斯: repetition time [TR] = 2,000 多发性硬化症, echo time = 30 多发性硬化症, flip angle = 80°, slice thickness = 4 毫米,
no slice gap, field of view = 192 毫米, matrix = 64 × 64, and voxel size = 3 × 3 × 4). T1-weighted
high-resolution anatomical images were also obtained (参数: thickness = 1 毫米, field of
view = 256 毫米, matrix = 368 × 368, repetition time = 1,100 多发性硬化症, echo time = 5.1 多发性硬化症) from each
participant to use for preprocessing.
The obtained fMRI data were pre-processed using MATLAB (MathWorks, Natick, 嘛, 美国)
and Statistical Parametric Mapping (SPM12) 软件. The preprocessing included correction
for head motion (realignment), slice timing correction, co-registration to theanatomical image,
segmentation for normalization, spatial normalization using the Montreal Neurological Insti-
图特 (MNI) template, and smoothing using a Gaussian filter with a full-width at a half-
maximum (FWHM) 的 8 毫米.
Computational Models
5-gram models
5-gram models are a sequential model, which processes a word sequence without explicitly
modeling its hierarchical structures. 5-gram models treat the context as a fixed window
(Markov model), so it works as a weak sequential baseline for hierarchical models. We used
5-gram models (a fifth-order Markov language model with Keneser-Ney Smoothing) imple-
mented with KenLM (Heafield, 2011
).
Long short-term memory networks
LSTMs (Hochreiter & 施米德胡贝尔, 1997) are a sequential model, which processes a word
sequence without explicitly modeling its hierarchical structure. LSTMs can maintain the whole
context as a single vector representation, so they work as a strong sequential baseline for hier-
archical models. We used 2-layer LSTMs with 256 hidden and input dimensions. The imple-
mentation by Gulordava et al. (2018) was employed.
Recurrent neural network grammars
Recurrent neural network grammars (RNNGs) are a hierarchical model, which jointly models a
word sequence and its syntactic structure. RNNGs rely on a stack LSTM to keep the previously
Neurobiology of Language
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
n
哦
/
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
/
.
1
0
1
1
6
2
n
哦
_
A
_
0
0
1
1
8
2
1
5
6
6
2
2
n
哦
_
A
_
0
0
1
1
8
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Q1
Localizing syntactic composition with left-corner RNNG
processed partial parse and compress them into a single vector representation. At each step of
加工, one of the following actions is selected:
(西德:129)
(西德:129)
(西德:129)
GEN: Generate a terminal symbol.
NT: Open a nonterminal symbol.
REDUCE: Close a nonterminal symbol that was opened by NT.
During a REDUCE action, the composition function based on the bidirectional LSTMs is
executed; in both directions, constituents of the closed nonterminal are encoded and the
single phrasal representation is calculated from the output of the forward and reverse LSTMs.
Two types of RNNGs were tested in our experiment; top-down RNNGs and left-corner
RNNGs, 即, RNNGs that process the sentence and its syntactic structure in a top-down
or left-corner fashion, 分别. We used RNNGs that had 2-layer stack LSTMs with 256
hidden and input dimensions. The implementation by Noji and Oseki (2021) was employed.
For inference of RNNGs, word-synchronous beam search (Stern et al., 2017) 曾是
受雇的. Word-synchronous beam search retains a collection of the most likely syntactic
structures that are predicted given an observed partial sentence and marginalizes their prob-
abilities to approximate the next word probability given the context. Although RNNGs can be
employed in different beam sizes, we used the top-down RNNG with beam size k = 1,000 和
the left-corner RNNG with beam size k = 400 for this study, based on Yoshida et al. (2021).
We utilized the computational models trained by Yoshida et al. (2021). Yoshida et al. (2021)
trained these language models (LMs) on the National Institute for Japanese Language and Lin-
guistics Parsed Corpus of Modern Japanese (2016), which comprises 67,018 sentences anno-
tated with syntactic structures. The sequential LMs, the 5-gram model and LSTM, were trained
with terminals only (IE。, word sequences), while hierarchical LMs, top-down RNNGs and left-
corner RNNGs, were trained with terminals and their syntactic structures. See Yoshida et al.
(2021) for the details of hyperparameter settings.
To quantify the quality of the models, the perplexity for each model was calculated. 这
models were computed for the texts that consist of 20 Japanese newspaper articles from
BCCWJ. The perplexity for each model is as follows: 5-gram models (195.58), LSTMs
(166.52), the top-down RNNG with beam size 1,000 (177.84), and the left-corner RNNG with
beam size 400 (166.92). The full list of the perplexity for each LM, including different beam
size RNNGs is summarized in the Table 1.
Evaluation Metrics
Surprisal
In order to test the output of LMs against fMRI data, surprisal was employed (黑尔, 2001, 2016;
征收, 2008). Surprisal, an information-theoretic metric, logarithmically links probability esti-
mation from the computational models with cognitive efforts from humans. 正式地, 令人惊讶的
is calculated as the negative log probability of the segment in its context.
− log p segmentjcontext
Þ
ð
When the surprisal increases, there should be longer reading times or greater neural activities.
In this study, we utilized the blood oxygen level-dependent (大胆的) signal as the measure of
cognitive effort from humans.
Neurobiology of Language
4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
n
哦
/
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
n
哦
_
A
_
0
0
1
1
8
2
1
5
6
6
2
2
n
哦
_
A
_
0
0
1
1
8
p
d
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
桌子 1.
Perplexities for all language models.
5-gram model
195.58219659288633
LSTM
166.5213055276006
RNNGs_LC
170.60928610079003
RNNGs_TD
242.71035859949953
168.48339005024133
210.0192442957164
166.9281371024315
190.74082279178688
166.47254386281034
183.05484955898646
166.2157373706272
180.354934799703
165.99643995526114
177.8459006375216
Beam size
100
200
400
600
800
1,000
笔记. LSTM = long short-term memory.
Distance
In addition to surprisal, distance for RNNGs was employed in this study. This metric quantifies
“syntactic work” where the number of parser actions (例如, GEN, NT, REDUCE) is counted (黑尔
等人。, 2018). Since RNNGs jointly model a word sequence and its syntactic structure, 这
word-synchronous beam search algorithm (Stern et al., 2017) is adopted to resolve the imbal-
ance of the probability of the strings and the probability of the trees that RNNGs generate. 这
algorithm resolves this imbalance by considering “enough” potential parser actions. Distance
is calculated by counting the number of these actions in the beam for each segment. 因为
this metric considers the number of actions in the beam, it is a more direct way of exploring the
measure of cognitive effort of the syntactic processing in the brain.
Intuitively speaking, this metric is similar to the node count metric (例如, Brennan et al.,
2012, 2016), but not identical. These two metrics are similar in that they consider syntactic
结构. The difference is that node count is applied to syntactic structures that are already
constructed (IE。, a perfect oracle; 比照. Brennan, 2016; 黑尔, 2014), whereas distance is count-
ing the process and considering alternative structures that are potentially correct structures at
the end of the sentence. Since this metric can only be employed for RNNGs, distance becomes
relevant when RNNGs with different parsing strategies are compared in this study.
统计分析
Before the statistical analysis, data from four participants were excluded due to an incomplete
acquisition issue during the scanning in the MRI scanner (the scan stopped earlier than the
designed time due to the experimenter’s error). Data from two participants were excluded
due to the excessive head movement and data from two participants were excluded due to
poor performance of the comprehension questions. 因此, 数据来自 34 participants were used
for data analysis.
Regions of interest analyses
Eight regions of interest (ROIs) in the left hemisphere were selected for this study based on
previous work on the cognitive neuroscience of language literature (Bemis & Pylkkänen,
Neurobiology of Language
5
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
n
哦
/
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
n
哦
_
A
_
0
0
1
1
8
2
1
5
6
6
2
2
n
哦
_
A
_
0
0
1
1
8
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
2011, 2013; Friederici, 2017; Hagoort, 2016; Matchin & Hickok, 2020; Zaccarella &
Friederici, 2015). The ROIs chosen are the pars operularis (IFGoperc), the pars triangularis
(IFGtriang), the pars orbitalis (IFGorb), the inferior parietal lobule (IPL), the angular gyrus
(AG), the superior temporal gyrus (STG), the superior temporal pole (sATL), and the middle
temporal pole (mATL). These regions were defined by automated anatomical labeling (AAL)
atlas (Tzourio-Mazoyer et al., 2002). These regions are also motivated by the recent compu-
tational neurolinguistics literature (Brennan et al., 2016, 2020; 李 & 黑尔, 2019; Lopopolo
等人。, 2017, 2021; Stanojević et al., 2021). In order to extract the BOLD signals for the ROI
分析, the parcellation was provided by AAL Atlas using nilearn ( Version 0.9.2; Abraham
等人。, 2014; Nilearn, 2010; Pedregosa et al., 2012), a Python package for statistical analysis of
neuroimaging data.
在这项工作中, we used control predictors that are not our theoretical interests but yet reflect
human language processing. Word rate (word_rate) is an indicator that assigns 1 to the offset
of the segment that was presented in the screen for 500 ms and 0 别处. This predictor
tracks the rate at which the segment is presented during participants read segments, 哪个
covers the broad brain activities that have to do with language comprehension (比照. Brennan
等人。, 2012). Word length (word_length) was also used as a predictor for the baseline
模型, which counts the number of characters for each segment. Word frequency (word_freq)
is a predictor for the log mean of the word frequencies for each segment. The value of sentence
ID (sentid) is the number that was assigned to sentences in each block and the value of
the sentence position (sentpos) indicates the number of the position of segments within a
sentence for each article. 全面的, we included 11 control predictors including six head
movement parameters (dx, 迪, dz, rx, 里, rz).
The predictors of our theoretical interests are the surprisal estimated from the 5-gram model
and LSTM, the surprisal computed from the top-down RNNG (surp_RNNG_TD) and the left-
corner RNNG (surp_RNNG_LC), and the distance computed from the top-down RNNG
(dis_RNNG_TD) and the left-corner RNNG (dis_RNNG_LC). These predictors were trans-
formed into estimated BOLD signals via a canonical hemodynamic response function (HRF)
为了. (我) We created segment-by-segment time series for the values of surprisal computed
from the 5-gram model, LSTM, and RNNGs, and time series for the values of distance
estimated from RNNGs.
(二) These values as well as the values from control predictors
(word_rate, word_length, word_freq, sentid, and sentpos) were convolved with
the HRF using nilearn (更具体地说, using the function compute_regressor). 这
head movement parameters were excluded from this computation. (三、) The convolved
values from the 5-gram model, LSTM, and RNNGs were orthogonalized against word_rate
to isolate each predictor’s effect from the broad language processing effects. (四号) compute_
regressor was done with re-sampling the values to 0.5 Hz to match the time series of the
fMRI data (TR = 2.0). After executing compute_regressor, the output was concatenated
with the fMRI time series from 34 individuals in the eight ROIs that are extracted using AAL
Atlas via nilearn.
表中 2, the Pearson correlation matrix between predictors excluding six head movement
parameters is shown.
Among predictors, word rate is highly correlated with word frequency (r (word rate, word
freq) = 0.996) as well as word length (r (word rate, word freq) = 0.84). Word frequency and
word length are also highly correlated (r (word freq, word length) = 0.83). Sentence ID is
relatively correlated with word rate (r (word rate, sentid) = 0.68), word length (r (word length,
sentid) = 0.67), and word frequency (r (word freq, sentid) = 0.69). The similar pattern can be
Neurobiology of Language
6
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
n
哦
/
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
/
.
1
0
1
1
6
2
n
哦
_
A
_
0
0
1
1
8
2
1
5
6
6
2
2
n
哦
_
A
_
0
0
1
1
8
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
桌子 2.
Correlations among predictors (Pearson’s r ).
word rate
word
length
word
freq
word
速度
1.00
sentid
sentpos
5-公克
LSTM RNNG_TD
RNNG_LC
RNNG_TD
RNNG_LC
Surprisal
Distance
word length
0.84
1.00
word freq
0.996
0.83
sentid
sentpos
5-公克
LSTM
0.68
0.64
<0.01
<0.01
surp_RNNG_TD
<0.01
surp_RNNG_LC
<0.01
dis_RNNG_TD
<0.01
dis_RNNG_LC
<0.01
0.67
0.49
0.49
0.48
0.48
0.48
0.39
0.33
Note. LSTM = long short-term memory.
1.00
0.69
0.65
−0.015
−0.017
−0.017
−0.02
1.00
0.40
0.14
0.14
0.14
0.15
1.00
−0.13
−0.14
−0.13
−0.14
0.018
0.13
−0.034
0.015
0.15
0.13
1.00
0.98
0.98
0.98
0.58
0.48
1.00
0.99
0.99
0.53
0.43
1.00
0.99
0.54
0.43
1.00
0.54
0.44
1.00
0.84
1.00
seen for sentence position as well. In terms of predictors of our interests, 5-gram is highly cor-
related with LSTM and surp_RNNGs (r (5-gram, LSTM) = 0.98, r (5-gram, surp_RNNG_TD) =
0.98, and r (5-gram, surp_RNNG_LC) = 0.98). LSTM, and two surp_RNNGs are also highly
correlated with each other (r (LSTM, surp_RNNG_TD) = 0.99, r (LSTM, surp_RNNG_LC) =
0.99, and r (surp_RNNG_TD, surp_RNNG_LC) = 0.99). The two predictors for distance are
also relatively correlated (r (dis_RNNG_TD, dis_RNNG_LC) = 0.84), while these two predic-
tors do not have a high correlation with the predictors such as 5-gram and LSTM (e.g., r (LSTM,
dis_RNNG_LC) = 0.43).
Before analyzing data on R (Bates & Sarkar, 2006), we removed the first 20 s of the data for
each block and all the predictors were standardized. The outliers were also removed from the
values for each ROI. The baseline model was created using the function lmer from the lme4
package in R. For fixed effects, we included word rate, word length, word frequency, sentence
ID, sentence position, and six head movement parameters. A random intercept by participant
was also included. The baseline model was defined below using the Wilkinson-Rogers
notation.
ROI ∼ word rate þ word length þ word freq þ sentid þ sentpos þ dx þ dy þ dz þ rx þ ry
Þ
þ rz þ 1jsubject number
ð
Then we added the predictors in the following order; 5-gram, LSTM, surp_RNNG_TD, and
surp_RNNG_LC. This order reflects the richness of the architectures, the hierarchical informa-
tion, and the model performance shown in Yoshida et al. (2021). Model comparisons were
done by the function anova(). After applying this function, the statistical significance was
corrected for each p value by Bonferroni correction (α = 0.05/8 = 0.00625). Model compar-
ison was also done with a model that includes control predictors, 5-gram, and LSTM, and a
model that includes surp_RNNG_LC as well as the control predictors, and 5-gram, and LSTM
to test whether surp_RNNG_LC has above-and-beyond effect forLSTM. We also constructed a
model that includes control predictors, 5-gram, LSTM, surp_RNNG_LC and a model that
Neurobiology of Language
7
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
includes surp_RNNG_TD as well as control predictors, 5-gram, LSTM, surp_RNNG_LC for
model comparison to test whether the top-down RNNG has above-and-beyond effects for
the left-corner RNNG.
Regarding distance, we constructed a regression model that includes the control predictors,
5-gram, and LSTM. Then we only added dis_RNNG_TD, and applied anova() to the model
without dis_RNNG_TD and the model that includes dis_RNNG_TD. Then we added
dis_RNNG_LC to the model to test whether the left-corner RNNG has above-and-beyond
effects for the top-down RNNG. Model comparison was also done with a model that includes
the control predictors, 5-gram, and LSTM, and a model that includes dis_RNNG_LC as well as
the control predictors, 5-gram, and LSTM to test whether dis_RNNG_LC has above-and-
beyond effect for LSTM. We also tested dis_RNNG_TD whether the top-down RNNG has
above-and-beyond effects for the left-corner RNNG in the same way. The following list sum-
marizes what this study tested in the ROI analyses. The boldface text indicates what we tested
in this article.
1.
2.
3.
4.
baseline model < n-gram < LSTM < surp_RNNG_TD < surp_RNNG_LC
baseline model < n-gram < LSTM < surp_RNNG_LC < surp_RNNG_TD
baseline model < n-gram < LSTM < dis_RNNG_TD < dis_RNNG_LC
baseline model < n-gram < LSTM < dis_RNNG_LC < dis_RNNG_TD
Whole brain analyses
In addition to the ROI analyses, we also did an exploratory analysis independently. This anal-
ysis confirms the regions that are activated with respect to each predictor. Using nilearn pack-
age, the design matrices were created for the first-level general linear model. All predictors
were included except for head movement parameters. The participant coefficient map was
saved for the second-level analysis.
For the second-level analysis, one-sample t tests were performed. The threshold maps were
z-valued and the threshold was defined as follows; false discovery rate was α = 0.05 and a
threshold of the cluster size was 100 voxels. For the masking, Yeo et al.’s (2011) cortical mask
was used and a FWHM Gaussian smoothing (8 mm) was applied. AtlasReader (Notter et al.,
2019) was used for identifying the regions of peaks for each cluster size.
RESULTS
Behavioral Results
The mean number of correct responses across participants for the comprehension questions
was 13.6 (SD = 3.6) out of 20 (68%).
ROI Analyses
Table 3 shows the results of the model comparisons of 5-gram, LSTM, surp_RNNG_TD, and
surp_RNNG_LC. These comparisons were done by sequentially adding terms of theoretical
interests. We found no statistically significant effects across ROIs for both 5-gram and LSTM
models. Furthermore, there are no statistically significant effects by just adding
surp_RNNG_TD across ROIs. However, when surp_RNNG_LC was added and compared with
the model without it, all ROIs except for mATL showed statistically significant effects even after
corrected for multiple comparisons.
Neurobiology of Language
8
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
.
/
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Table 3.
Results of the model comparisons for 5-gram, LSTM, surp_RNNG_TD, and surp_RNNG_LC Q2
.
ROIs
IFGoperc
Model comparisons
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
IFGtriang
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
IFGorb
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
IPL
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
AG
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
STG
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
sATL
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
mATL
baseline < 5-gram
5-gram < LSTM
LSTM < RNNG_TD
RNNG_TD < RNNG_LC
LogLik
−9092.3
−9091.9
−9090.8
−9072.5
−11061
−11060
−11060
−11041
−17918
−17918
−17918
−17913
−12705
−12704
−12702
−12667
−13413
−13412
−13410
−13390
−13841
−13839
−13837
−13822
−19064
−19064
−19062
−19057
−23917
−23917
−23917
−23916
χ2
6.1327
0.7985
2.2179
p
0.17
0.372
0.136
36.622
<0.001*
0.8954
2.708
0.3085
0.344
0.0998
0.578
37.239
<0.001*
0.1266
0.4371
0.0008
9.2683
4.6624
1.8846
5.9362
0.721
0.508
0.977
0.002*
0.03
0.169
0.051
70.28
<0.001*
5.4511
2.0618
3.7982
0.019
0.151
0.051
41.065
<0.001*
1.6733
2.8784
4.0574
0.195
0.089
0.043
31.524
<0.001*
3.2966
0.0072
2.7917
10.01
5.2513
0.0261
0.583
1.5699
0.069
0.932
0.094
0.002*
0.021
0.871
0.445
0.21
Note. ROI = region of interest, IFG = inferior front gyrus pars opercularis, IFGtriang = IFG pars triangularis, IFGorb =
IFG pars orbitalis, IPL = inferior parietal lobule, AG = angular gyrus, STG = superior temporal gyrus, sATL = superior
temporal pole, mATL = middle temporal pole. Bonferroni correction (α = 0.05/8 = 0.00625) was applied.
Neurobiology of Language
9
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Results of the model comparisons for testing whether either surp_RNNG_TD or surp_
Table 4.
RNNG_LC improves the model fit to the fMRI data against LSTM (LSTM < {surp_RNNG_TD, surp_
RNNG_LC
}).
Q3
ROIs
IFGoperc
IFGtriang
IFGorb
IPL
AG
STG
sATL
mATL
surp_RNNG_TD
LogLik
−9090.8
χ2
2.2179
p
0.136
LogLik
−9085.2
surp_RNNG_LC
χ2
13.33
p
<0.001*
−11060
−17918
−12702
−13410
−13837
−19062
−23917
0.3085
0.578
8e−04
0.977
4.0516
0.044
3.7982
0.051
4.0574
0.043
2.7917
0.094
0.583
0.445
−11050
−17915
−12691
−13406
−13835
−19063
−23917
18.427
<0.001*
5.3059
0.021
25.851
<0.001*
13.17
<0.001*
8.8692
0.0029*
1.7879
0.2148
0.181
0.643
Note. Bonferroni correction (α = 0.05/8 = 0.00625) was applied.
As Table 4 shows, we also tested whether surp_RNNG_LC has the above-and-beyond
effects for LSTM. The results confirmed such effects in IFGoperc, IFGtriang, IPL, AG, and STG.
The next statistical analysis summarized in Table 5 shows that surp_RNNG_TD better fits to
IFGoperc, IFGtriang, IPL, AG, STG, and sATL, compared to surp_RNNG_LC.
Regarding dis_RNNG_TD and dis_RNNG_LC, the results are summarized in Table 6. The
results show that both dis_RNNG_TD and dis_RNNG_LC have statistically significant effects
in several ROIs against LSTM; IFGoperc, IFGtriang, IPL, AG, and sATL for dis_RNNG_TD; and
IFGoperc, IFGtriang, IFGorb, IPL, AG, STG, and sATL for dis_RNNG_LC respectively.
Table 7 shows the results for testing whether dis_RNNG_LC better explains the fMRI data
than dis_RNNG_TD. The results showed statistically significant effects in IFGoperc, IFGtriang,
Table 5.
beyond effects for surp_RNNG_LC (surp_RNNG_LC < surp_RNNG_TD
Results of the model comparison for testing whether surp_RNNG_TD has above-and-
ROIs
IFGoperc
IFGtriang
IFGorb
IPL
AG
STG
sATL
mATL
LogLik
−9072.5
−11041
−17913
−12667
−13390
−13822
−19057
−23916
χ2
25.51
19.12
3.9633
48.48
31.693
26.712
11.014
1.938
Note. Bonferroni correction (α = 0.05/8 = 0.00625) was applied.
Neurobiology of Language
).
p
<0.001*
<0.001*
0.0465
<0.001*
<0.001*
<0.001*
<0.001*
0.1639
10
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
.
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
Q4
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Results of the model comparisons for testing whether either dis_RNNG_TD or dis_
Table 6.
RNNG_LC improves the model fit to the fMRI data against LSTM (LSTM < {dis_RNNG_TD, dis_
RNNG_LC
}).
Q5
ROIs
IFGoperc
IFGtriang
IFGorb
IPL
AG
STG
sATL
mATL
LogLik
−9082.1
dis_RNNG_TD
χ2
p
19.688
<0.001*
dis_RNNG_LC
χ2
59.778
LogLik
−9062.0
p
<0.001*
−11055
−17915
−12695
−13402
−13836
−19051
−23916
8.7038
0.0031*
5.0968
0.023
17.437
<0.001*
19.663
<0.001*
6.948
0.008391
25.276
<0.001*
2.7588
0.096
−11039
−17907
−12682
−13397
−13824
−19051
−23915
42.006
<0.001*
21.882
<0.001*
44.454
<0.001*
29.849
<0.001*
30.705
<0.001*
25.276
<0.001*
4.3622
0.036
Note. Bonferroni correction (α = 0.05/8 = 0.00625) was applied.
IFGorb, IPL, AG, and STG. On the other hand, there were no statistically significant effects in
any ROIs when we tested whether dis_RNNG_TD better fits to the fMRI data, compared to
dis_RNNG_LC (Table 8).
Table 9 summarizes the results of ROI analyses in this study.
A reviewer raised the question whether the beam size differences for RNNGs make different
results. In order to answer this question, we did model comparison analyses where a regres-
sion model that includes the control predictors as well as 5-gram and LSTM and a model that
includes one RNNG as well as the control predictors, 5-gram, and LSTM were tested via
anova() using (i) different beam sizes (k = 100, 200, 400, 600, 800, 1,000), (ii) different pars-
ing strategies (top-down or left-corner), and (iii) different complexity metrics (surprisal and
Table 7.
beyond effects for dis_RNNG_TD (dis_RNNG_TD < dis_RNNG_LC
Results of the model comparison for testing whether dis_RNNG_LC has above-and-
).
ROIs
IFGoperc
IFGtriang
IFGorb
IPL
AG
STG
sATL
mATL
LogLik
−9060.4
−11035
−17905
−12681
−13397
−13822
−19051
−23915
χ2
43.331
40.385
19.752
28.113
10.587
28.142
0.099
1.6405
Note. Bonferroni correction (α = 0.05/8 = 0.00625) was applied.
p
<0.001*
<0.001*
<0.001*
<0.001*
0.0011*
<0.001*
0.753
0.2003
11
Neurobiology of Language
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
.
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
Q6
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Table 8.
beyond effects for dis_RNNG_LC (dis_RNNG_LC < dis_RNNG_TD).
Results of the model comparison for testing whether dis_RNNG_TD has above-and-
ROIs
IFGoperc
IFGtriang
IFGorb
IPL
AG
STG
sATL
mATL
LogLik
−9060.4
−11035
−17905
−12681
−13397
−13822
−19051
−23915
χ2
3.2412
7.0826
2.9665
1.0961
0.4008
4.385
0.099
0.0371
p
0.0718
0.0077
0.085
0.295
0.526
0.036
0.753
0.847
Note. Bonferroni correction (α = 0.05/8 = 0.00625) was applied.
distance) of RNNGs. The details of the results are summarized in the Supporting Information,
available at https://doi.org/10.1162/nol_a_00118. Overall, regardless of the beam size differ-
ences or complexity metrics, the left-corner RNNGs improve the model fit to the fMRI data,
compared to LSTM. On the other hand, the surprisal estimated from top-down RNNGs only
improve the model fit to the fMRI data when the beam size is small (k = 100, 200). The dis-
tance computed from top-downRNNGs improves the model fit to the fMRI data regardless of
the beam size differences.
Whole Brain Analyses
For the control predictors, the following results were obtained from the whole brain analysis
(Table 10 and Figures 1–5).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
.
/
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
Model comparison
LSTM < surp_RNNG_LC
LSTM < surp_RNNG_TD
Table 9.
The summary of the main results from ROI analyses.
IFGoperc
<0.001
IFGtriang
<0.001
IFGorb
IPL
<0.001
AG
<0.001
STG
0.0029
sATL
mATL
LSTM < dis_RNNG_LC
<0.001
<0.001
<0.001
<0.001
<0.001
<0.001
<0.001
LSTM < dis_RNNG_TD
<0.001
0.003
<0.001
<0.001
<0.001
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
surp_RNNG_TD < surp_RNNG_LC
<0.001
<0.001
<0.001
<0.001
<0.001
<0.001
surp_RNNG_LC < surp_RNNG_TD
<0.001
<0.001
<0.001
<0.001
<0.001
<0.001
dis_RNNG_TD < dis_RNNG_LC
<0.001
<0.001
<0.001
<0.001
<0.001
<0.001
dis_RNNG_LC < dis_RNNG_TD
Note. p value was corrected by Bonferroni correction (α = 0.05/8 = 0.00625) for each model comparison.
Neurobiology of Language
12
Localizing syntactic composition with left-corner RNNG
Table 10.
The coefficient results of GLM for word rate, word length, word frequency, sentence ID and sentence position.
Predictors
word_rate
MNI coordinates
peak_y
−46
peak_x
44
−42
42
−38
32
−48
−42
−24
40
−16
−40
−16
42
−42
−56
−58
32
52
−4
54
−40
−2
58
−64
−48
−20
56
14
24
−12
6
−54
10
8
−68
12
−10
−64
−16
−80
18
36
10
−56
−68
−24
−70
−40
−58
−16
6
−90
−60
−20
−24
−60
−2
−64
−58
−66
18
word_length
word_freq
Neurobiology of Language
peak_z
−16
−14
28
26
30
−22
−40
40
−40
−12
−32
56
26
−16
28
12
28
4
30
10
26
18
28
−14
54
68
−34
−12
70
−12
48
peak_stat (z)
6.86467
Cluster size (mm3)
26,728
8.28593
8.17836
7.02740
6.07489
5.53063
4.51107
3.27936
3.98876
7.13176
3.42982
5.40559
−7.97979
−5.50034
7.28381
4.78592
−6.83518
−5.47845
5.68754
4.09421
−5.70568
4.10801
5.47120
3.62544
3.15662
4.09517
3.69464
3.62328
3.39034
3.66282
−3.28625
23,624
14,200
11,608
7,256
6,552
1,424
544
504
60,352
840
32,456
23,384
22,016
19,464
19,384
17,960
17,320
14,352
13,800
6,152
5,640
4,312
4,096
3,256
2,840
1,976
1,672
1,600
1,536
1,184
Region (AAL)
Fusiform_R
Fusiform_L
Frontal_Inf_Oper_R
Frontal_Inf_Oper_L
Occipital_Mid_R
Temporal_Pole_Sup_L
Temporal_Inf_L
Occipital_Mid_L
no_label
Lingual_L
Temporal_Pole_Mid_L
Frontal_Sup_2_L
Frontal_Inf_Oper_R
Fusiform_L
no_label
Temporal_Sup_L
Occipital_Mid_R
Temporal_Mid_R
Precuneus_L
Rolandic_Oper_R
Frontal_Inf_Oper_L
Cuneus_L
Angular_R
Temporal_Mid_L
Postcentral_L
Parietal_Sup_L
Temporal_Inf_R
Lingual_R
Parietal_Sup_R
Cerebelum_6_L
Supp_Motor_Area_R
13
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
.
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Predictors
sentid
MNI coordinates
peak_y
−54
peak_x
16
peak_z
66
peak_stat (z)
10.05250
Cluster size (mm3)
694,224
Region (AAL)
Parietal_Sup_R
Table 10.
(continued )
sentpos (uncorrected)
−22
−32
−56
50
−10
−40
58
−22
8
36
−28
−50
32
−34
2
26
44
−20
−16
−2
−36
−70
−38
−72
54
−12
−60
28
32
4
0
8
38
−84
−46
14
−82
62
−44
−28
8
4
32
8
−38
72
40
38
58
−30
58
44
14
74
38
18
20
3.06418
2.22755
3.98667
3.26623
2.61551
2.80792
2.59958
2.59144
2.49773
2.38693
2.57084
2.66369
2.40335
2.23455
2.19358
2.21470
2.07152
2.08603
2.00798
1,512
56
18,664
12,440
3,776
3,144
3,120
1,640
1,368
1,104
1,072
1,016
832
768
640
240
176
112
32
Fusiform_L
Cerebelum_4_5_L
Temporal_Mid_L
Temporal_Mid_R
Precuneus_L
Frontal_Mid_2_L
Temporal_Inf_R
Parietal_Sup_L
Frontal_Sup_Medial_R
Frontal_Mid_2_R
Frontal_Mid_2_L
Temporal_Mid_L
Frontal_Mid_2_R
Frontal_Mid_2_L
Calcarine_L
Postcentral_R
Frontal_Inf_Oper_R
Occipital_Mid_L
Frontal_Sup_2_L
Note. Thresholded with a false discovery rate = 0.05 and a cluster threshold of 100 voxels. The regions were identified by using AtlasReader (Notter et al.,
2019). MNI = Montreal Neurological Institute, AAL = automated anatomical labeling.
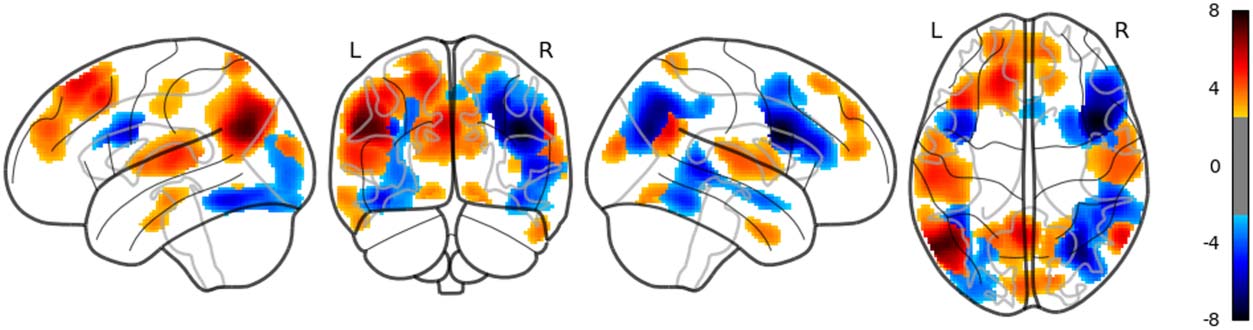
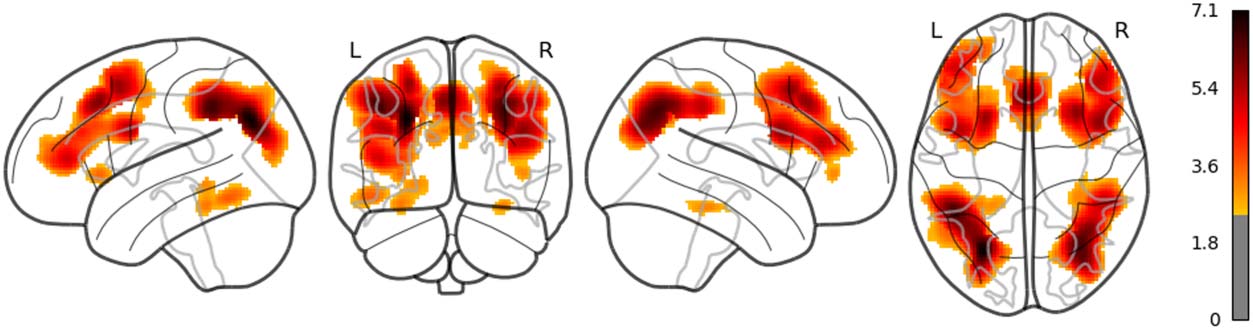
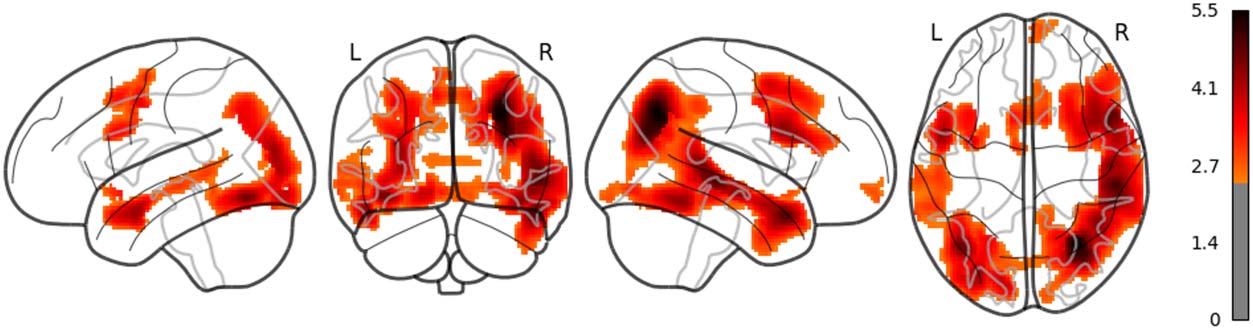
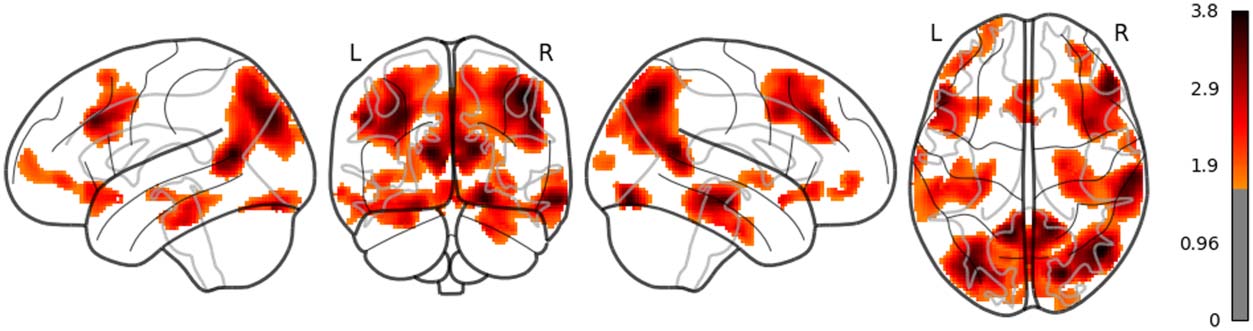
The main results are reported as follows: Word rate (Figure 1) was associated with the acti-
vation in the bilateral fusiform gyri, bilateral middle occipital lobes, and the bilateral inferior
frontal gyri (opercular part). Word length (Figure 2) was associated with the activation in the
left lingual gyrus and the left middle temporal pole. Part of these results indicate that word rate
and word length predictors are involved in the activities in the visual processing and the visual
word form area.
Our main interests are the results of the whole brain analysis for LSTM, the top-down
RNNG, and the left-corner RNNG, which are summarized in Table 11 (see also Figures 6–11).
The main results are as follows: As for LSTM, although the threshold is uncorrected, the
increased activities were confirmed in the right middle temporal pole and the left IFGtriang
(Figure 7). Notice that even though the AtlasReader indicates no_label, the increasing activity
Neurobiology of Language
14
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
.
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Figure 1. The result of whole brain analysis of word_rate.
Figure 2. The result of whole brain analysis of word_length.
Figure 3. The result of whole brain analysis of word_freq.
Figure 4. The result of whole brain analysis of sentid.
Figure 5. The result of whole brain analysis of sentpos (uncorrected).
Neurobiology of Language
15
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Table 11.
The coefficient results of GLM for the 5-gram, LSTM, surp_RNNG_TD, surp_RNNG_LC, dis_RNNG_TD, and dis_RNNG_LC.
Predictors
5-gram
LSTM (uncorrected)
surp_RNNG_TD (uncorrected)
surp_RNNG_LC (uncorrected)
Neurobiology of Language
MNI coordinates
peak_y
16
peak_x
30
peak_z
52
peak_stat (z)
5.72940
Cluster size (mm3)
31,824
Region (AAL)
Frontal_Mid_2_R
−26
−26
32
−4
−48
−30
32
−30
−64
38
−58
54
50
58
−8
36
−22
−38
2
30
46
50
64
−52
−28
−22
22
22
4
34
12
−68
−66
24
−56
−42
−36
24
−56
6
22
−10
−28
32
62
−88
−86
−52
−82
54
−68
30
−24
24
−28
−82
−82
−16
8
52
54
34
40
44
−14
−18
−20
0
16
−38
12
−42
−4
4
26
−12
−10
−24
2
26
48
38
−16
34
−28
−20
−16
−34
−16
−4
5.63596
7.14751
6.49177
5.85200
3.55410
3.26173
3.15951
3.42302
4.05139
2.74617
2.57767
2.26472
2.57079
2.03234
2.04844
3.72838
2.92842
2.90338
2.11779
2.17667
3.83603
3.56834
3.56804
3.49083
2.74120
3.11502
3.65646
2.69411
2.63855
2.39320
30,648
29,608
28,344
14,128
3,504
2,432
1,352
1,096
23,904
2,752
1,432
552
480
56
40
6,864
1,808
344
272
208
54,024
13,624
7,208
6,264
4,280
3,416
3,328
3,264
2,128
592
Frontal_Mid_2_L
Occipital_Mid_L
Occipital_Sup_R
Frontal_Sup_Medial_L
Temporal_Inf_L
Fusiform_L
Fusiform_R
Insula_L
no_label
Temporal_Pole_Mid_R
Frontal_Inf_Tri_L
no_label
Temporal_Mid_R
Frontal_Inf_Tri_R
Frontal_Sup_Medial_L
Occipital_Inf_R
Fusiform_L
Fusiform_L
Lingual_L
Frontal_Mid_2_R
Angular_R
Frontal_Mid_2_R
Temporal_Mid_R
Frontal_Mid_2_L
Fusiform_L
Cerebelum_Crus1_L
Fusiform_R
no_label
no_label
Frontal_Mid_2_R
16
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
.
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Table 11.
(continued )
Predictors
dis_RNNG_TD
dis_RNNG_LC (uncorrected)
MNI coordinates
peak_y
44
peak_x
−40
peak_z
−4
−30
−66
66
−24
−42
22
−34
44
−10
64
14
−60
−50
64
−14
8
12
−54
30
−38
−16
12
44
−12
56
24
−68
60
56
20
−12
−4
64
−18
−94
−74
−68
−58
−32
−54
−34
10
−30
16
−32
56
−12
24
−56
−72
24
−4
52
−4
6
−14
−6
2
60
−10
−2
6
−26
8
40
44
14
−18
14
40
10
46
60
−58
28
−28
−18
66
66
56
−6
30
52
−24
10
−38
−44
peak_stat (z)
2.31943
2.26635
2.39706
2.18952
2.04272
2.11997
1.99267
4.21833
3.99230
3.93825
3.64786
3.97503
3.42344
3.64759
3.14897
3.53704
2.38765
2.58213
2.60976
2.50757
2.30140
2.51366
2.57717
2.36271
2.32030
2.17256
2.23977
2.04049
2.06499
2.18495
Cluster size (mm3)
Region (AAL)
544
400
296
232
176
152
24
6,104
4,488
1,280
872
808
15,392
11,472
10,424
5,760
1,928
1,240
880
832
784
768
752
664
336
304
240
128
64
48
Frontal_Mid_2_L
Frontal_Mid_2_L
Temporal_Mid_L
Temporal_Sup_R
Frontal_Sup_2_L
Temporal_Inf_L
Occipital_Sup_R
Parietal_Inf_L
Angular_R
Precuneus_L
Temporal_Inf_R
Precuneus_R
Parietal_Inf_L
Frontal_Inf_Oper_L
SupraMarginal_R
Frontal_Sup_2_L
no_label
Frontal_Sup_Medial_R
Temporal_Inf_L
Insula_R
no_label
no_label
Supp_Motor_Area_R
Insula_R
Frontal_Sup_2_L
Frontal_Mid_2_R
ParaHippocampal_R
no_label
Temporal_Inf_R
no_label
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Note. Thresholded with a false discovery rate = 0.05 and a cluster threshold of 100 voxels. The regions were identified by using AtlasReader (Notter et al.,
2019).
Neurobiology of Language
17
Localizing syntactic composition with left-corner RNNG
Figure 6. The result of whole brain analysis of 5-gram.
Figure 7. The result of whole brain analysis of LSTM (uncorrected).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
Figure 8. The result of whole brain analysis of surp_RNNG_TD (uncorrected).
l
.
/
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
Figure 9. The result of whole brain analysis of surp_RNNG_LC (uncorrected).
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 10. The result of whole brain analysis of dis_RNNG_TD.
Neurobiology of Language
18
Localizing syntactic composition with left-corner RNNG
Figure 11. The result of whole brain analysis of dis_RNNG_LC (uncorrected).
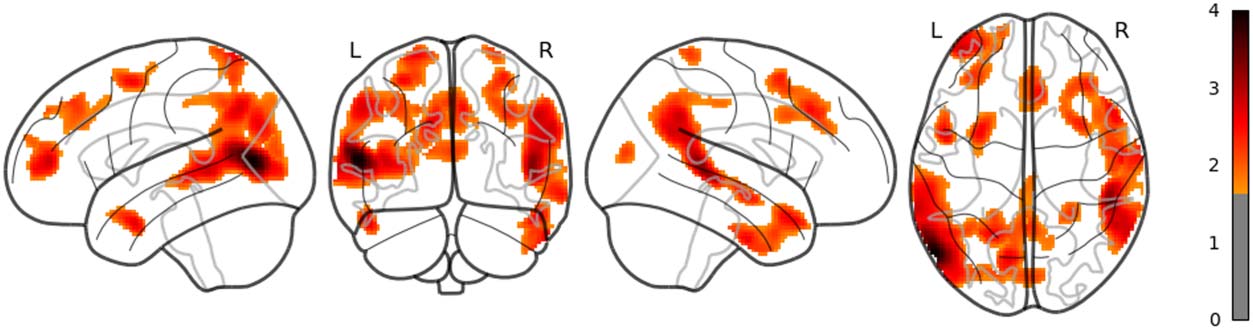
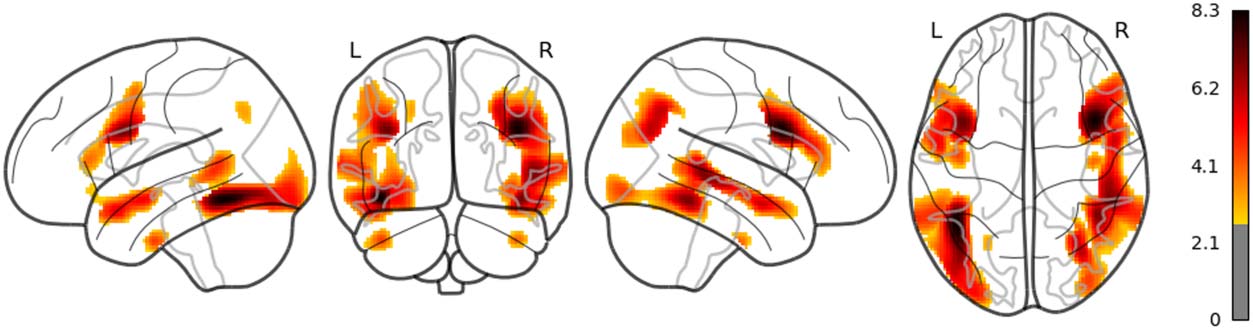
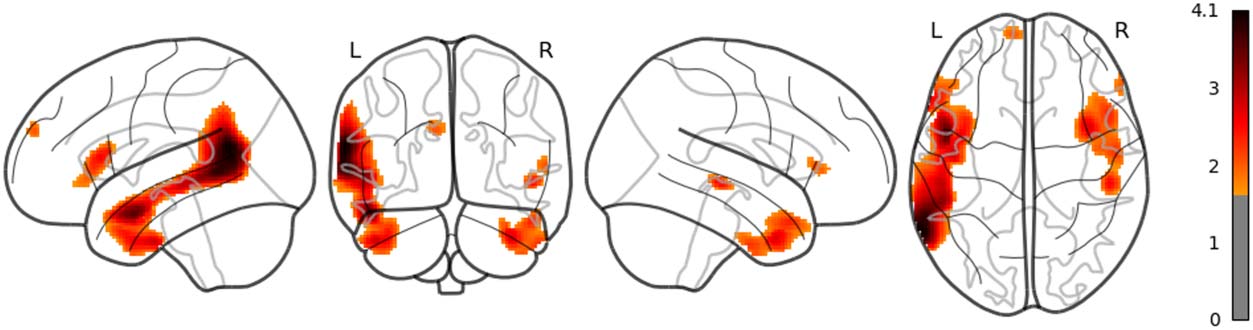
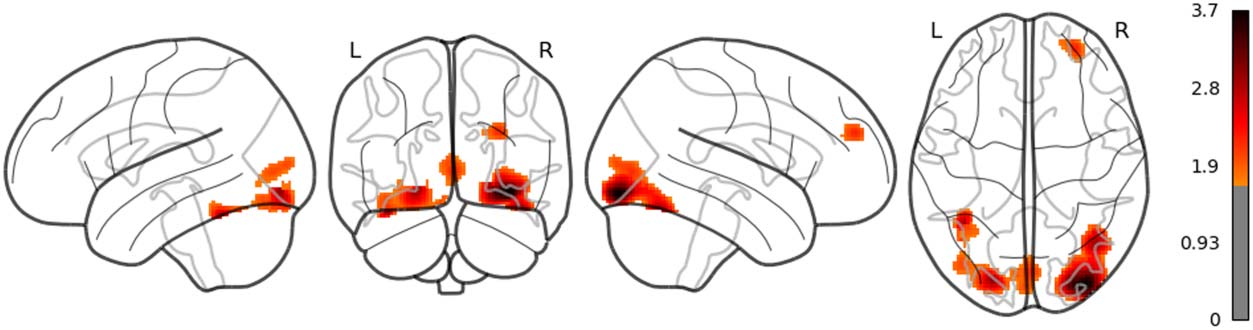
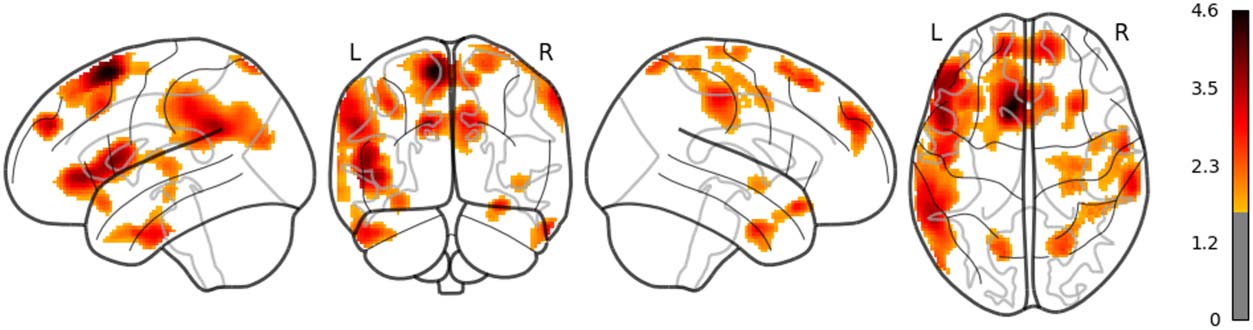
in the left posterior temporal lobe (PTL) can be observed in Figure 7. Surp_RNNG_TD was
associated with the activities in the left fusiform gyrus and the right inferior occipital lobe
(using an uncorrected threshold; see Figure 8). Surp_RNNG_LC was associated with activities
in the right AG, the right middle temporal lobe and the left middle frontal gyrus (uncorrected;
Figure 9). Dis_RNNG_TD was associated with activities in the left parietal lobule, the right AG
as well as bilateral precuneus (Figure 10). As for dis_RNNG_LC (uncorrected; Figure 11), the
main increased activities were observed in the left parietal lobule and the left IFGoperc.
DISCUSSION
Our goal for this study was to test not only whether RNNGs better explain human fMRI data
than LSTMs, but also whether the left-corner RNNGs outperform the top-down RNNGs. We
localized the syntactic composition effects of the left-corner RNNG in certain brain regions,
using the information-theoretic metric, such as surprisal, and a metric that measures the syn-
tactic work, that is, distance, to quantify the computational models. Surprisal is assumed to
associate with the amount of the cognitive effort in the brain during language comprehension,
which has been attested in the previous studies (Bhattasali & Resnik, 2021; Brennan et al.,
2020; Henderson et al., 2016; Lopopolo et al., 2017; Willems et al., 2015). In Brennan
et al. (2020), the surprisal estimated from LSTM had statistically significant effects for their ROIs
such as the left ATL, the left IFG, the left PTL, and the left IPL, against a baseline model. How-
ever, our results did not show such effects for the 5-gram model and LSTM across all ROIs. We
also adopted another complexity metric, distance, which was tested in Hale et al. (2018) and
Brennan et al. (2020) for RNNGs. In Brennan et al. (2020), it was shown that distance calcu-
lated from the top-down RNNG had statistically significant effects in the left ATL, the left IFG,
and the left PTL, compared to what they called RNNG-comp (a degraded version of RNNGs
that does not include the composition function). In our results, dis_RNNG_LC showed statis-
tically significant effects in the IFGoperc, IFGtriang, IFGorb, IPL, AG, STG and sATL, compared
to LSTM (Table 6). Our results also found that dis_RNNG_TD improves the model fits to the
fMRI data in the IFGoperc, IFGtriang, IPL, AG, and sATL, compared to LSTM. Considering
these, we showed in addition to Brennan et al. (2020), that the hierarchical models better
explain the fMRI data compared to sequential models.
The results of the whole brain analysis showed that some control predictors such as word
rate and word length were involved in regions that are related to the visual processing and the
visual word form area such as the fusiform gyrus and the occipital lobe. Since the task was
reading sentences segment by segment, the activation of these regions is expected. In terms of
sequential models, the activity in the left PTL was associated with LSTM. However, again, the
ROI analyses did not show any statistically significant effects for 5-gram < LSTM, and it
remains unclear how to interpret the activity in the left PTL for LSTM, at least in this study.
Although the surprisal estimated from the 5-gram model and LSTM did not fit the fMRI data
well, the results of our ROI analyses showed that the left-corner RNNG had statistically
Neurobiology of Language
19
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
significant effects in several ROIs, compared to LSTM (Table 4 and Table 6). These results sug-
gest that the syntactic composition with the left corner parser strategy is involved in these
regions, and our results align with the previous studies. For example, the surprisal computed
from a top-down context-free parser in Henderson et al. (2016) was associated with the activ-
ities in the IFG including pars opercularis (BA44), compared to lexical surprisal. There is also a
piece of evidence for STG associated with phrase structure grammar. Although they did not
use surprisal, in Lopopolo et al. (2021), node count from structures generated by phrase struc-
ture grammar was used as a complexity metric, and it showed a significant effect in STG,
whereas the dependency grammar (which describes the relationship between a head and its
dependent) did not show such an effect in this region, but the middle temporal pole was
responsible for this grammar. The result that the node count effect was shown in STG is com-
patible with our surp_RNNG_LC and dis_RNNG_LC results, but not compatible with the
results of surp_RNNG_TD and dis_RNNG_TD. As mentioned above, on the other hand,
Henderson et al. (2016) did show the effect in IFG for the surprisal computed from CFGs,
but they also reported that they did not observe the effect in STG. These mixed results
make it hard to evaluate the effect of STG, though it is considered to be involved in
sentence-level comprehension (e.g., Nelson et al., 2017; Pallier et al., 2011).
The regions such as IFGoperc and IPL for dis_RNNG_LC appeared to be important based
on our ROI analyses, and the whole brain analyses confirmed the strong activation in these
regions. IFG has been attested in the literature in which a simple composition was examined
(Friederici, 2017; Maran et al., 2022; Zaccarella & Friederici, 2015). However, several other
studies suggest that there is no comprehensive understanding regarding the locus of the com-
position in the brain (Pylkkänen, 2019, 2020; Pylkkänen & Brennan, 2020). Our results from
dis_RNNG_LC partially aligns with Brennan et al.’s (2020) results where the distance com-
puted from top-down RNNGs had a significant effect in IFGoperc as well as in ATL and
PTL in their results. Brennan and Pylkkänen (2017) showed that the left-corner CFG was asso-
ciated with the activation in the left ATL, which our ROI analysis results did not show in the
results of dis_RNNG_TD < dis_RNNG_LC (Table 7). However, the sATL effect for
dis_RNNG_TD and dis_RNNG_LC was found against LSTM. This might indicate that sATL
is involved in composition, but not involved in the effect of the left-corner parsing strategy,
compared to the effect of the top-down parsing strategy.
So far, we have discussed the regions that were associated with the left-corner RNNG,
but we have not discussed how surprisal or distance computed from the left-corner RNNG
modulates in the brain. In previous studies, it has been unclear which brain region is
responsible for which component of computational models since the role of the syntactic
processing for each study has been observed using different grammars with different com-
plexity metrics: for example, surprisal estimated from part-of-speech (Lopopolo et al., 2017);
surprisal computed from CFGs (Henderson et al., 2016); node count from the structures
generated by CFGs (Brennan et al., 2012; Brennan & Pylkkänen, 2017; Giglio et al.,
2022; Lopopolo et al., 2021); node count from the structures generated by combinatory
categorial grammars (Stanojević et al., 2021, 2023); node count from the structures gener-
ated by minimalist grammars (Brennan et al., 2016; Li & Hale, 2019); surprisal and distance
computed from top-down RNNGs (Brennan et al., 2020). It might be a case where surprisal
and the metrics that express the process of the steps (e.g., node count, distance) play roles
in designated regions of the brain separately. For example, the steps of structure building
might be involved in the PTL (Flick & Pylkkänen, 2020; Matar et al., 2021; Matchin &
Hickok, 2020; Murphy et al., 2022), which is compatible with some previous studies
(Brennan et al., 2016, 2020; Li & Hale, 2019; Stanojević et al., 2023). Surprisal, on the
Neurobiology of Language
20
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
.
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
other hand, might be modulated in more broad regions that have to do with language pro-
cessing in addition to the process of the steps. This point should be clarified in future work
that can test different complexity metrics with different grammars or computational models
using the same human data. Related to this discussion, the attempt for identifying the locus
of composition has not been converged in the neurobiology of language literature; some stud-
ies have argued that a specific part of the Broca’s area is for syntactic composition (or merge;
Zaccarella & Friederici, 2015; Zaccarella et al., 2017), while others have claimed that the
ATL is the locus of semantic composition (Bemis & Pylkkänen, 2011, 2013; Zhang &
Pylkkänen, 2015). Another candidate for the syntactic composition is the PTL (Flick &
Pylkkänen, 2020; Matar et al., 2021; Matchin & Hickok, 2020; Murphy et al., 2022). Or,
the connection between two regions (IFG and PTL) might be a source of syntactic composi-
tion (cf. Hardy et al., 2023; Maran et al., 2022; Wu et al., 2019). Although these candidates
for syntactic composition are compatible with our results, future work needs to be done.
Conclusion
In this article, we investigated whether hierarchical models like RNNGs better explain human
brain activity than sequential models like LSTMs, as well as which parsing strategy is more
neurobiologically plausible. As a result, the surprisal metric computed from left-corner RNNGs
significantly explained the brain regions including IFGoperc, IFGtriang, IPL, AG, and STG rel-
ative to LSTMs, though the surprisal metrics estimated from 5-gram models, LSTMs, and top-
down RNNGs did not show any significant effects across eight regions in the ROI analyses. In
addition, the distance metric computed from left-corner RNNGs did show significant effects in
IFGoperc, IFGtriang, IFGorb, IPL, AG, and STG, relative to the distance metric estimated from
top-down RNNGs, but notvice versa. Overall, our results suggest that left-corner RNNGs are
the neurobiologically plausible computational model of human language processing, and
there are certain brain regions that localize the syntactic composition with the left-corner pars-
ing strategy.
ACKNOWLEDGMENTS
We thank Haining Cui for fMRI data collection. We are also grateful to two anonymous
reviewers for helpful suggestions and comments.
FUNDING INFORMATION
Yohei Oseki, Japan Society for the Promotion of Science (https://dx.doi.org/10.13039
/501100000646), Award ID: JP21H05061. Yohei Oseki, Japan Society for the Promotion of
Science (https://dx.doi.org/10.13039/501100000646), Award ID: JP19H05589. Yohei Oseki,
Japan Science and Technology Agency (https://dx.doi.org/10.13039/501100002241), Award
ID: JPMJPR21C2.
AUTHOR CONTRIBUTIONS
Yushi Sugimoto: Formal analysis: Lead; Investigation: Lead; Methodology: Equal; Software:
Lead; Visualization: Lead; Writing – original draft: Lead. Ryo Yoshida: Conceptualization: Sup-
porting; Writing – review & editing: Supporting. Hyeonjeong Jeong: Methodology: Supporting.
Masatoshi Koizumi: Project administration: Lead. Jonathan Brennan: Methodology: Support-
ing. Yohei Oseki: Conceptualization: Lead; Funding acquisition: Lead; Methodology: Support-
ing; Project administration: Lead; Resources: Lead; Supervision: Lead; Writing – review &
editing: Supporting.
Neurobiology of Language
21
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
DATA AND CODE AVAILABILITY STATEMENT
The fMRI corpus will be made publicly available in the future. The statistical maps from the
whole brain analyses are available on NeuroVault (https://identifiers.org/neurovault
.collection:14567). The code for fMRI analyses is available at https://github.com/osekilab
/RNNG-fMRI, which is modified from https://github.com/dgd45125/LPPxORCxEN-CN. The
code for language models is available at https://github.com/osekilab/RNNG-LC.
REFERENCES
Abney, S. P., & Johnson, M. (1991). Memory requirements and local
ambiguities of parsing strategies. Journal of Psycholinguistic
Research, 20(3), 233–250. https://doi.org/10.1007/BF01067217
Abraham, A., Pedregosa, F., Eickenberg, M., Gervais, P., Mueller,
A., Kossaifi, J., Gramfort, A., Thirion, B., & Varoquaux, G.
(2014). Machine learning for neuroimaging with scikit-learn.
Frontiers in Neuroinformatics, 8, Article 14. https://doi.org/10
.3389/fninf.2014.00014, PubMed: 24600388
Bates, D., & Sarkar, D. (2006). lme4: Linear mixed-effects models
using S4 classes [R package version 0.9975-10].
Bemis, D., & Pylkkänen, L. (2011). Simple composition: A magne-
toencephalography investigation into the comprehension of
minimal linguistic phrases. Journal of Neuroscience, 31(8),
2801–2814. https://doi.org/10.1523/JNEUROSCI.5003-10.2011,
PubMed: 21414902
Bemis, D., & Pylkkänen, L. (2013). Basic linguistic composition
recruits the left anterior temporal lobe and left angular gyrus
during both listening and reading. Cerebral Cortex, 23(8),
1859–1873. https://doi.org/10.1093/cercor/ bhs170, PubMed:
22735156
Bhattasali, S., & Resnik, P. (2021). Using surprisal and fMRI to map
the neural bases of broad and local contextual prediction during
natural language comprehension. In Findings of the Association for
Computational Linguistics: ACL-IJCNLP 2021 (pp. 3786–3798).
ACL. https://doi.org/10.18653/v1/2021.findings-acl.332
Brennan, J. R. (2016). Naturalistic sentence comprehension in the
brain. Language and Linguistics Compass, 10(7), 299–313.
https://doi.org/10.1111/lnc3.12198
Brennan, J. R., Dyer, C., Kuncoro, A., & Hale, J. T. (2020). Localiz-
ing syntactic predictions using recurrent neural network gram-
mars. Neuropsychologia, 146, Article 107479. https://doi.org
/10.1016/j.neuropsychologia.2020.107479, PubMed: 32428530
Brennan, J. R., & Hale, J. T. (2019). Hierarchical structure guides
rapid linguistic predictions during naturalistic listening. PLOS
ONE, 14(1), Article e0207741. https://doi.org/10.1371/journal
.pone.0207741, PubMed: 30650078
Brennan, J. R., Nir, Y., Hasson, U., Malach, R., Heeger, D. J., &
Pylkkänen, L. (2012). Syntactic structure building in the anterior
temporal lobe during natural story listening. Brain and Language,
120(2), 163–173. https://doi.org/10.1016/j.bandl.2010.04.002,
PubMed: 20472279
Brennan, J. R., & Pylkkänen, L. (2017). MEG evidence for incre-
mental sentence composition in the anterior temporal lobe. Cog-
nitive Science, 41(S6), 1515–1531. https://doi.org/10.1111/cogs
.12445, PubMed: 27813182.
Brennan, J. R., Stabler, E. P., Van Wagenen, S. E., Luh, W.-M., &
Hale, J. T. (2016). Abstract linguistic structure correlates with
temporal activity during naturalistic comprehension. Brain and
Language, 157–158, 81–94. https://doi.org/10.1016/j.bandl
.2016.04.008, PubMed: 27208858
Chomsky, N. (1957). Syntactic structures. Mouton. https://doi.org
/10.1515/9783112316009
Dyer, C., Kuncoro, A., Ballesteros, M., & Smith, N. A. (2016).
Recurrent neural network grammars. In Proceedings of the
2016 conference of the North American chapter of the Associa-
tion for Computational Linguistics: Human language technolo-
gies (pp. 199–209). ACL. https://doi.org/10.18653/v1/N16-1024
Everaert, M. B., Huybregts, M. A., Chomsky, N., Berwick, R. C., &
Bolhuis, J. J. (2015). Structures, not strings: Linguistics as part of
the cognitive sciences. Trends in Cognitive Sciences, 19(12),
729–743. https://doi.org/10.1016/j.tics.2015.09.008, PubMed:
26564247
Flick, G., & Pylkkänen, L. (2020). Isolating syntax in natural lan-
guage: MEG evidence for an early contribution of left posterior
temporal cortex. Cortex, 127, 42–57. https://doi.org/10.1016/j
.cortex.2020.01.025, PubMed: 32160572
Frank, S. L., Otten, L. J., Galli, G., & Vigliocco, G. (2015). The ERP
response to the amount of information conveyed by words in
sentences. Brain and Language, 140, 1–11. https://doi.org/10
.1016/j.bandl.2014.10.006, PubMed: 25461915
Friederici, A. D. (2017). Language in our brain: The origins of a
uniquely human capacity. MIT Press. https://doi.org/10.7551
/mitpress/9780262036924.001.0001
Giglio, L., Ostarek, M., Sharoh, D., & Hagoort, P. (2022). Diverging
neural dynamics for syntactic structure building in naturalistic
speaking and listening. bioRxiv. https://doi.org/10.1101/2022.10
.04.509899
Gulordava, K., Bojanowski, P., Grave, E., Linzen, T., & Baroni, M.
(2018). Colorless green recurrent networks dream hierarchically.
In Proceedings of the 2018 conference of the North American
chapter of the Association for Computational Linguistics: Human
language technologies ( Volume 1: Long Papers, pp. 1195–1205).
ACL. https://doi.org/10.18653/v1/N18-1108
Hagoort, P. (2016). MUC (memory, unification, control): A model
on the neurobiology of language beyond single word processing.
In G. Hickok & S. L. Small (Eds.), Neurobiology of language
(pp. 339–347). Academic Press. https://doi.org/10.1016/B978-0
-12-407794-2.00028-6
Hale, J. (2001). A probabilistic Earley parser as a psycholinguistic
model. In Second meeting of the North American chapter of
the Association for Computational Linguistics. ACL. https://
aclanthology.org/N01-1021
Hale, J. (2014). Automaton theories of human sentence comprehen-
sion. CSLI Publication.
Hale, J. (2016). Information-theoretical complexity metrics. Lan-
guage and Linguistics Compass, 10(9), 397–412. https://doi.org
/10.1111/lnc3.12196
Hale, J., Campanelli, L., Li, J., Bhattasali, S., Pallier, C., & Brennan,
J. R. (2022). Neurocomputational models of language processing.
Annual Review of Linguistics, 8(1), 427–446. https://doi.org/10
.1146/annurev-linguistics-051421-020803
Hale, J., Dyer, C., Kuncoro, A., & Brennan, J. (2018). Finding syntax
in human encephalography with beam search. In Proceedings of
the 56th annual meeting of the Association for Computational
Neurobiology of Language
22
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
.
/
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Linguistics ( Volume 1: Long Papers, pp. 2727–2736). ACL.
https://doi.org/10.18653/v1/P18-1254
Hardy, S. M., Jensen, O., Wheeldon, L., Mazaheri, A., & Segaert, K.
(2023). Modulation in alpha band activity reflects syntax compo-
sition: An MEG study of minimal syntactic binding. Cerebral Cor-
tex, 33(3), 497–511. https://doi.org/10.1093/cercor/ bhac080,
PubMed: 35311899
Heafield, K. (2011). KenLM: Faster and smaller language model
queries. In Proceedings of the sixth workshop on statistical
machine translation (pp. 187–197). ACL. https://aclanthology
.org/ W11-2123
Henderson, J. M., Choi, W., Lowder, M. W., & Ferreira, F. (2016).
Language structure in the brain: A fixation-related fMRI study of
syntactic surprisal in reading. NeuroImage, 132, 293–300.
https://doi.org/10.1016/j.neuroimage.2016.02.050, PubMed:
26908322
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory.
Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162
/neco.1997.9.8.1735, PubMed: 9377276
Kuncoro, A., Dyer, C., Hale, J., Yogatama, D., Clark, S., & Blunsom,
P. (2018). LSTMs can learn syntax-sensitive dependencies well,
but modeling structure makes them better. In Proceedings of
the 56th annual meeting of the Association for Computational
Linguistics ( Volume 1: Long Papers, pp. 1426–1436). ACL.
https://doi.org/10.18653/v1/P18-1132
Levy, R. (2008). Expectation-based syntactic comprehension. Cog-
nition, 106(3), 1126–1177. https://doi.org/10.1016/j.cognition
.2007.05.006, PubMed: 17662975
Li, J., & Hale, J. (2019). Grammatical predictors for fMRI
time-courses. In R. C. Berwick & E. P. Stabler (Eds.), Minimalist
parsing (pp. 159–173). Oxford University Press. https://doi.org/10
.1093/oso/9780198795087.003.0007
Lopopolo, A., Frank, S. L., van den Bosch, A., & Willems, R. M.
(2017). Using stochastic language models (SLM) to map lexical,
syntactic, and phonological information processing in the brain.
PLOS ONE, 12(5), Article e0177794. https://doi.org/10.1371
/journal.pone.0177794, PubMed: 28542396
Lopopolo, A., van den Bosch, A., Petersson, K.-M., & Willems,
R. M. (2021). Distinguishing syntactic operations in the brain:
Dependency and phrase-structure parsing. Neurobiology of Lan-
guage, 2(1), 152–175. https://doi.org/10.1162/nol_a_00029,
PubMed: 37213416
Maekawa, K., Yamazaki, M., Ogiso, T., Maruyama, T., Ogura, H.,
Kashino, W., Koiso, H., Yamaguchi, M., Tanaka, M., & Den, Y.
(2014). Balanced corpus of contemporary written Japanese. Lan-
guage Resources and Evaluation, 48(2), 345–371. https://doi.org
/10.1007/s10579-013-9261-0
Maran, M., Friederici, A. D., & Zaccarella, E. (2022). Syntax
through the looking glass: A review on two-word linguistic pro-
cessing across behavioral, neuroimaging and neurostimulation
studies. Neuroscience & Biobehavioral Reviews, 142, Article
104881. https://doi.org/10.1016/j.neubiorev.2022.104881,
PubMed: 36210580
Matar, S., Dirani, J., Marantz, A., & Pylkkänen, L. (2021). Left posterior
temporal cortex is sensitive to syntax within conceptually matched
Arabic expressions. Scientific Reports, 11(1), Article 7181. https://
doi.org/10.1038/s41598-021-86474-x, PubMed: 33785801
Matchin, W., & Hickok, G. (2020). The cortical organization of syn-
tax. Cerebral Cortex, 30(3), 1481–1498. https://doi.org/10.1093
/cercor/bhz180, PubMed: 31670779
Murphy, E., Woolnough, O., Rollo, P. S., Roccaforte, Z. J., Segaert,
K., Hagoort, P., & Tandon, N. (2022). Minimal phrase composi-
tion revealed by intracranial recordings. Journal of Neuroscience,
42(15), 3216–3227. https://doi.org/10.1523/JNEUROSCI.1575
-21.2022, PubMed: 35232761
National Institute for Japanese Language and Linguistics. (2016).
NINJAL parsed corpus of modern Japanese ( Version 1.0) [Data-
base]. https://npcmj.ninjal.ac.jp/interfaces
Nelson, M. J., Karoui, I. E., Giber, K., Yang, X., Cohen, L., Koopman,
H., Cash, S. S., Naccache, L., Hale, J. T., Pallier, C., & Dehaene, S.
(2017). Neurophysiological dynamics of phrase-structure building
during sentence processing. Proceedings of the National Academy
of Sciences, 114(18), E3669–E3678. https://doi.org/10.1073/pnas
.1701590114, PubMed: 28416691
Nilearn. (2010). Nilearn ( Version 0.9.2) [Software]. https://nilearn
.github.io/stable/index.html
Noji, H., & Oseki, Y. (2021). Effective batching for recurrent neural
network grammars. In Findings of the Association for Computa-
tional Linguistics: ACL-IJCNLP 2021 (pp. 4340–4352). ACL.
https://doi.org/10.18653/v1/2021.findings-acl.380
Notter, M. P., Gale, D., Herholz, P., Markello, R., Notter-Bielser,
M.-L., & Whitaker, K. (2019). AtlasReader: A Python package
to generate coordinate tables, region labels, and informative
figures from statistical MRI images. Journal of Open Source
Software, 4(34), 1257. https://doi.org/10.21105/joss.01257
Oh, B.-D., Clark, C., & Schuler, W. (2022). Comparison of struc-
tural parsers and neural language models as surprisal estimators.
Frontiers in Artificial Intelligence, 5, Article 777963. https://doi
.org/10.3389/frai.2022.777963, PubMed: 35310956
Oseki, Y., & Asahara, M. (2020). Design of BCCWJ-EEG: Balanced
corpus with human electroencephalography. In Proceedings of
the twelfth language resources and evaluation conference
(pp. 189–194). European Language Resources Association.
https://aclanthology.org/2020.lrec-1.24
Pallier, C., Devauchelle, A.-D., & Dehaene, S. (2011). Cortical rep-
resentation of the constituent structure of sentences. Proceedings
of the National Academy of Sciences, 108(6), 2522–2527. https://
doi.org/10.1073/pnas.1018711108, PubMed: 21224415
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B.,
Grisel, O., Blondel, M., Müller, A., Nothman, J., Louppe, G.,
Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos,
A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, É.
(2012). Scikit-learn: Machine learning in Python. arXiv:1201.0490.
https://doi.org/10.48550/arXiv.1201.0490
Peirce, J. W. (2007). PsychoPy—Psychophysics software in Python.
Journal of Neuroscience Methods, 162(1–2), 8–13. https://doi.org
/10.1016/j.jneumeth.2006.11.017, PubMed: 17254636
Peirce, J. W. (2009). Generating stimuli for neuroscience using
PsychoPy. Frontiers in Neuroinformatics, 2, Article 10. https://
doi.org/10.3389/neuro.11.010.2008, PubMed: 19198666
Pylkkänen, L. (2019). The neural basis of combinatory syntax and
semantics. Science, 366(6461), 62–66. https://doi.org/10.1126
/science.aax0050, PubMed: 31604303
Pylkkänen, L. (2020). Neural basis of basic composition: What we
have learned from the red–boat studies and their extensions.
Philosophical Transactions of the Royal Society B: Biological
Sciences, 375(1791), Article 20190299. https://doi.org/10.1098
/rstb.2019.0299, PubMed: 31840587
Pylkkänen, L., & Brennan, J. R. (2020). The neurobiology of syntac-
tic and semantic structure building. In The cognitive neurosci-
ences (pp. 859–867). MIT Press. https://doi.org/10.7551
/mitpress/11442.003.0096
Resnik, P. (1992). Left-corner parsing and psychological plausi-
bility. In Proceedings of the 14th conference on computational
linguistics - (Volume 1, pp. 191–197). ACL. https://doi.org/10
.3115/992066.992098
Neurobiology of Language
23
Q7
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
/
/
.
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
/
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Localizing syntactic composition with left-corner RNNG
Schrimpf, M., Blank, I. A., Tuckute, G., Kauf, C., Hosseini, E. A.,
Kanwisher, N., Tenenbaum, J. B., & Fedorenko, E. (2021). The
neural architecture of language: Integrative modeling converges
on predictive processing. In Proceedings of the National Acad-
emy of Sciences. 118(45), Article e2105646118. https://doi.org
/10.1073/pnas.2105646118, PubMed: 34737231
Stanojević, M., Bhattasali, S., Dunagan, D., Campanelli, L.,
Steedman, M., Brennan, J. R., & Hale, J. (2021). Modeling incre-
mental language comprehension in the brain with combinatory
categorial grammar. In Proceedings of the workshop on cognitive
modeling and computational linguistics (pp. 23–38). ACL. https://
doi.org/10.18653/v1/2021.cmcl-1.3
Stanojević, M., Brennan, J. R., Dunagan, D., Steedman, M., & Hale,
J. T. (2023). Modeling structure-building in the brain with CCG
parsing and large language models. Cognitive Science, 47(7),
Article e13312. https://doi.org/10.1111/cogs.13312, PubMed:
37417470
Stern, M., Fried, D., & Klein, D. (2017). Effective inference for genera-
tive neural parsing. In Proceedings of the 2017 conference on
empirical methods in natural language processing (pp. 1695–1700).
ACL. https://doi.org/10.18653/v1/D17-1178
Tzourio-Mazoyer, N., Landeau, B., Papathanassiou, D., Crivello, F.,
Etard, O., Delcroix, N., Mazoyer, B., & Joliot, M. (2002). Auto-
mated anatomical labeling of activations in SPM using a macro-
scopic anatomical parcellation of the MNIMRI single-subject
brain. NeuroImage, 15(1), 273–289. https://doi.org/10.1006
/nimg.2001.0978, PubMed: 11771995
Wilcox, E. G., Gauthier, J., Hu, J., Qian, P., & Levy, R. (2020). On
the predictive power of neural language models for human
real-time comprehension behavior. arXiv:2006.01912. https://
doi.org/10.48550/arXiv.2006.01912
Wilcox, E. G., Qian, P., Futrell, R., Ballesteros, M., & Levy, R.
(2019). Structural supervision improves learning of non-local
grammatical dependencies. In Proceedings of the 2019 confer-
ence of the North American chapter of the Association for
Computational Linguistics: Human language technologies ( Vol-
ume 1: Long and Short Papers, pp. 3302–3312). ACL. https://
doi.org/10.18653/v1/N19-1334
Willems, R. M., Frank, S. L., Nijhof, A. D., Hagoort, P., & van den
Bosch, A. (2015). Prediction during natural language compre-
hension. Cerebral Cortex, 26(6), 2506–2516. https://doi.org/10
.1093/cercor/bhv075, PubMed: 25903464
Wu, C.-Y., Zaccarella, E., & Friederici, A. D. (2019). Universal neu-
ral basis of structure building evidenced by network modulations
emerging from Broca’s area: The case of Chinese. Human Brain
Mapping, 40(6), 1705–1717. https://doi.org/10.1002/ hbm
.24482, PubMed: 30468022
Yeo, B. T. T., Krienen, F. M., Sepulcre, J., Sabuncu, M. R., Lashkari, D.,
Hollinshead, M., Roffman, J. L., Smoller, J. W., Zöllei, L., Polimeni,
J. R., Fischl, B., Liu, H., & Buckner, R. L. (2011). The organization of
the human cerebral cortex estimated by intrinsic functional con-
nectivity. Journal of Neurophysiology, 106(3), 1125–1165. https://
doi.org/10.1152/jn.00338.2011, PubMed: 21653723
Yoshida, R., Noji, H., & Oseki, Y. (2021). Modeling human
sentence processing with left-corner recurrent neural network
grammars. In Proceedings of the 2021 conference on empirical
methods in natural language processing (pp. 2964–2973). ACL.
https://doi.org/10.18653/v1/2021.emnlp-main.235
Zaccarella, E., & Friederici, A. D. (2015). Merge in the human
brain: A sub-region based functional investigation in the left pars
opercularis. Frontiers in Psychology, 6, Article 1818. https://doi
.org/10.3389/fpsyg.2015.01818, PubMed: 26640453
Zaccarella, E., Meyer, L., Makuuchi, M., & Friederici, A. D. (2017).
Building by syntax: The neural basis of minimal linguistic struc-
tures. Cerebral Cortex, 27(1), 411–421. https://doi.org/10.1093
/cercor/bhv234, PubMed: 26464476
Zhang, L., & Pylkkänen, L. (2015). The interplay of composition
and concept specificity in the left anterior temporal lobe: An
MEG study. NeuroImage, 111, 228–240. https://doi.org/10.1016
/j.neuroimage.2015.02.028, PubMed: 25703829
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
l
.
/
/
1
0
1
1
6
2
n
o
_
a
_
0
0
1
1
8
2
1
5
6
6
2
2
n
o
_
a
_
0
0
1
1
8
p
d
.
/
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Neurobiology of Language
24