Rosenfeld, Alex, and Lars Hinrichs. 2023. Capturing Fine-Grained Regional Differences in Language Use through Voting
Precinct Embeddings. 计算语言学, uncorrected proof.
Capturing Fine-Grained Regional Differences
in Language Use through Voting Precinct
Embeddings
∗
Alex Rosenfeld
Leidos
Innovations Center
alexbrosenfeld@gmail.com
Lars Hinrichs
The University of Texas at Austin
Department of English
TxE@utexas.edu
Linguistic variation across a region of interest can be captured by partitioning the region into
areas and using social media data to train embeddings that represent language use in those
地区. Recent work has focused on larger areas, such as cities or counties, to ensure that enough
social media data is available in each area, but larger areas have a limited ability to find fine-
grained distinctions, such as intracity differences in language use. We demonstrate that it
is possible to embed smaller areas, which can provide higher resolution analyses of language
variation. We embed voting precincts, which are tiny, evenly sized political divisions for the
administration of elections. The issue with modeling language use in small areas is that the
data becomes incredibly sparse, with many areas having scant social media data. We propose
a novel embedding approach that alternates training with smoothing, which mitigates these
sparsity issues. We focus on linguistic variation across Texas as it is relatively understudied.
We developed two novel quantitative evaluations that measure how well the embeddings can
be used to capture linguistic variation. The first evaluation measures how well a model can
map a dialect given terms specific to that dialect. The second evaluation measures how well a
model can map preference of lexical variants. These evaluations show how embedding models
could be used directly by sociolinguists and measure how much sociolinguistic information is
contained within the embeddings. We complement this second evaluation with a methodology
for using embeddings as a kind of genetic code where we identify “genes” that correspond to a
sociological variable and connect those “genes” to a linguistic phenomenon thereby connecting
sociological phenomena to linguistic ones. 最后, we explore approaches for inferring isoglosses
using embeddings.
∗ Research performed while attending The University of Texas at Austin.
动作编辑器: Ekaterina Shutova. 提交材料已收到: 24 十月 2022; 收到修订版: 28 行进
2023; 接受出版: 20 可能 2023.
https://doi.org/10.1162/coli a 00487
© 2023 计算语言学协会
根据知识共享署名-非商业性-禁止衍生品发布 4.0 国际的
(CC BY-NC-ND 4.0) 执照
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
1. 介绍
Similar to embeddings that capture word usage, recent work in NLP has developed
methods that generate embeddings for areas that represent language in those areas. 为了
例子, 黄等人。. (2016) developed an embedding method for capturing language
use in counties and Hovy and Purschke (2018) developed an embedding method for
capturing language use in cities. These embeddings can be used for a wide variety of
sociolinguistic analyses as well as downstream tasks.
Given the sheer volume available, social media data is often used to provide the
text data needed to train the embeddings. 然而, one inherent problem that arises
is the imbalance of population distribution across a region of interest, which leads
to an imbalance of social media data across that region. 例如, rural areas use
Twitter less than urban areas (Duggan 2015). This could make it more difficult to capture
language use in rural areas.
One solution to this issue is to use larger areas. 例如, one could focus on
cities and not explore the countryside, such as done in Hovy and Purschke (2018). 或者
one could divide a region of interest into large squares, such as done in Hovy et al.
(2020). Or one could divide a region of interest into counties, such as done in Huang
等人. (2016). While these solutions produce areas with more data, the areas themselves
could be less useful for analysis as (1) there could be important areas that are not
covered (例如, only studying cities and missing the rest of the region), (2) the areas could
have awkward boundaries (例如, dividing regions into squares that ignore geopolitical
边界), 或者 (3) the resolution would be too low to be useful for certain analyses
(例如, using cities as areas prevents analyses of intracity language use).
We propose a novel solution to the data problem. We use smaller areas, 表决
precincts, that provide finer resolution analyses and propose a novel embedding ap-
proach to mitigate the specific data issues related to using smaller areas. Voting precincts
are small, equally sized areas that are used in the administration of elections (in Texas,
each voting precinct has about 1,100 选民). As they are well regulated (voting precincts
are required to fit within county, congressional boundaries), monitored (voting precincts
are a fundamental unit in censuses), 袖珍的 (voting precincts need to be compact to
make elections, polling, and governance more efficient), and cover an entire region, 他们
form a perfect mesh to represent language use across a region. Unlike with using cities,
voting precincts can also capture rural areas. Unlike with using squares, voting precincts
follow geopolitical boundaries. Unlike with counties, voting precincts can better capture
intracity differences in language use. 因此, by developing embedding representations
of these precincts, we can find fine-grained differences in language use across a large
region of interest.
While voting precincts are a great mesh to model language use across a region,
the smaller sizes lead to significant data issues. 例如, less populated areas
use social media less, which can lead to voting precincts that have extremely limited
data or no data at all. To counteract this, we propose a novel embedding technique
where training and smoothing alternate to mitigate the weaknesses of both. Training
has limited potential in voting precincts with little data, so smoothing will provide
extra information to create a more accurate embedding. Smoothing can spread noise,
so training afterwards can refine the embeddings.
We propose novel evaluations that explore how well embeddings can be used to
predict information useful to sociolinguists. The first evaluation explores how well
embeddings can be used to predict where a dialect is spoken using some specific
features of the dialect. We use the Dictionary of American Regional English dataset
2
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
(DAREDS) (Rahimi, Cohn, and Baldwin 2017), which provides key terms for various
American dialects. We evaluate how well embeddings can be used to predict dialect
areas from those key terms.
The second evaluation explores how well embeddings can be used to predict lexical
variation. Lexical variation is the choice between two semantically similar lexical items,
例如, fam versus family, and is a good determiner of linguistic variation (Cassidy,
大厅, and Von Schneidemesser 1985; Carver 1987). We evaluate how well embeddings
can be used to predict choice in lexical variant across a region of interest.
As part of these evaluations, we perform a hyperparameter analysis that demon-
strates that post-training retrofitting can have numerical issues when applied to smaller
地区, so alternating is a necessary step with smaller areas. As mentioned, many smaller
areas lack sufficient data, so retrofitting with these areas can cause the spreading of
noise, which in turn can result in unreliable embeddings.
We then provide a novel methodology to extract novel sociolinguistic insights from
social media data. Area embeddings capture language use in an area, 和语言
use is connected to a wide swath of sociological factors. If we treat embeddings as the
“genetic code” of an area, we can identify sections of the embeddings that act as genes
for sociological phenomena. 例如, we can find the “gene” that encodes how
race and the urban–rural divide affect language use. Then by exploring the predictions
of these “genes” we can then connect the sociological phenomenon with a linguistic
一, 例如, identify novel African American slang via analyzing the expressions
of the “gene” corresponding to Black Percentage.
最后, we use our embeddings to predict geographic boundaries of linguistic
variation, or “isoglosses”. Prior work has used principal component analysis to infer
isoglosses, but with smaller areas, we find that PCA will focus on the urban–rural divide
and ignore regional divides. 反而, we find that t-distributed stochastic neighbor em-
bedding (Van der Maaten and Hinton 2008) is better able to identify larger geographic
distinctions.
2. Prior Work
While there has been a wealth of work that has used Twitter data to explore lexical
variation (例如, Eisenstein et al. 2012, 2014; 厨师, Han, and Baldwin 2014; 多伊尔 2014;
琼斯 2015; 黄等人。. 2016; 库尔卡尼, Perozzi, and Skiena 2016; Grieve, Nini, 和郭
2018), the incorporation of distributional methods is a more recent trend.
黄等人。. (2016) apply a count-based method to Twitter data to represent lan-
guage use in counties across the United States. They use a manually created list of
sociolinguistically relevant variant pairs, such as couch and sofa, from Grieve, Asnaghi,
and Ruette (2013) and embedded a county based on the proportion of each variant.
They then used adaptive kernel smoothing to smooth the counts and used PCA for
dimensionality reduction. They do not perform a quantitative evaluation and instead
perform PCA of the embeddings. One limitation of their approach is that it requires a
list of sociolinguistically relevant variant pairs. Producing such pairs is labor-intensive
and such pairs are specific to certain language varieties (variant pairs that make sense
for American English may not make sense for British English) and may lose relevance
as language use changes over time.
Hovy and Purschke (2018) use document embedding techniques to represent lan-
guage use in cities in Germany, 奥地利, and Switzerland. 在这项工作中, they collected
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
social media data from Jodel,1 a social media platform, and used Doc2Vec (Le and
米科洛夫 2014) to produce an embedding for each city. As their goal was to explore
regional variation, they used retrofitting (Faruqui et al. 2015; Hovy and Fornaciari
2018) to have the embeddings better match the NUTS2 regional break down of those
国家. We discuss these methods further in Section 4. For quantitative evaluation,
they compare clusterings of their embeddings to a German dialect map (Lameli 2013).
While this an excellent evaluation if you have such a map, the constantly evolving
nature of language and the sheer difficulty of hand-creating such a dialect map make
this approach difficult to generalize to analyses of new regions, especially a region as
evolving and large as the state of Texas, which is our focus. The authors also evaluated
their embeddings by measuring how well they could predict the geolocation of the
Tweet. While geolocation is a laudable goal in and of itself, our focus is on linguistic
variation specifically and geolocation is not necessarily a measure of how well the
embeddings capture linguistic variation. 例如, a list of business names in each
area would be fantastic for geolocation, but of less use for analyzing variation.
Hovy et al. (2020) followed up this work by extending their method to cover entire
continents/countries and not just the cities. They did this by dividing their region
of interest into a coordinate grid of 11 km (6.8 mi.) 经过 11 km squares and training
embeddings for each square. They then retrofitted the square embeddings. They did
not perform a quantitative evaluation of their work.
An alternative approach to generating regional embeddings is through using lin-
guistic features as the embedding coordinates. 例如, Bohmann (2020) embedded
Twitter linguistic registers into a space based on 236 linguistic features. They then use
factor analysis on these embeddings to generate 10 dimensions of linguistic variation.
While these kinds of embeddings are more interpretable, they require more a priori
knowledge about relevant linguistic features and the capability to calculate them. 尽管
we do not explore linguistic feature–based embeddings in our work, we do perform a
similar task in extracting smaller dimensional representations when analyzing theoretic
linguistic hypotheses.
Clustering is a well-explored topic in computational dialectology (例如, Grieve,
Speelman, and Geeraerts 2011; Pr ¨oll 2013; Lameli 2013; 黄等人。. 2016). To this effect,
we largely follow the clustering approach in Hovy and Purschke (2018). We also explore
this topic while incorporating newer clustering techniques, such as t-SNE (Van der
Maaten and Hinton 2008). Like Hovy et al. (2020), we do not do hard clustering (喜欢
k-means) and only do soft clustering.
There has been work that has analyzed non-conventional spellings (刘等人. 2011
and Han and Baldwin 2011, 例如), but recent work has explored the use of word
embeddings to study lexical variation through non-conventional spelling (阮和
Grieve 2020). In that work, the authors explored the connection between conventional
and non-conventional forms and found that word embeddings do capture spelling
variation (despite being ignorant of orthography in general) and discovered a link
between the intent of the different spelling and the distance between the embeddings.
While we do not directly interact with this work, their exploration of the connection
between non-conventional spelling and lexical variation may be useful for future work.
There is a wealth of work that uses computational linguistic methods to connect
sociological factors with word use (See Nguyen et al. [2016] for a review of work in
this area as well as computational sociolinguistics in general). One such approach is
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1 https://jodel.com/.
4
Rosenfeld and Hinrichs
Voting Precinct Embeddings
that from Eisenstein, 史密斯, and Xing (2011), which uses a regression model to connect
word use with demographic features. By using a regularization method to focus on
key words, they show which words are connected to specific sociological factors. 尽管
we don’t connect word A with demographic B, we use a similar technique to extract
sections of embeddings that are related to specific demographic differences.
3. Texas Twitter and Precinct Data Collection
Our focus is on language use across the state of Texas. It is large, populous, 并且已经
researched only lightly in sociolinguistics and dialect geography, compared with other
large American states. Both Thomas and Bailey have contributed quantitative studies of
variation in Mainstream (not ethnically specific) Texas English: 托马斯 (1997) 描述
a rural/urban split in Texas dialects, driven by the much-accelerated migration of non-
southerners into Texas and other southern U.S. states since the latter decades of the
二十世纪, a trend that effectively creates “dialect islands in Texas where the
large metropolitan centers lie” (托马斯 1997, 页 309) and relegating canonical fea-
tures of southern U.S. speech (Thomas’s focus is on the monophthongization of PRICE
and the lowering of the nucleus in FACE vowels) to rural areas and small towns. 贝利
等人. (1991), by tracking nine different features of phonetic innovation/conservativeness
in Texas English and resolving findings at the level of the county, identify the most
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
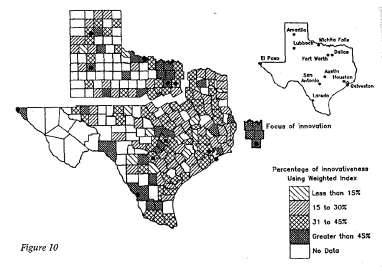
数字 1
Weightedindex for innovative forms, aggregated at the county level. (Reprinted from Bailey,
Wikle, and Sand 1991, withpermission of Johns Benjamin Publishing Co.).
Q1
Q2
5
计算语言学
体积 49, 数字 4
linguistically innovative areas driving change in Texas English as a cluster of five
counties in the Dallas/Fort Worth area.
In addition to these geographic approaches to variation in Texas, there have been a
number of studies focusing on selected features (Bailey and Dyer 1992; Atwood 1962;
Bailey et al. 1991; Bernstein 1993; Di Paolo 1989; Hinrichs, Bohmann, and Gorman
2013; Koops 2010; Koops, Gentry, and Pantos 2008; Walsh and Mote 1974; Tarpley
1970; Wheatley and Stanley 1959) and/or variation and change in minority varieties
(Bailey and Maynor 1989, 1987, 1985; Bayley 1994; Galindo 1988; 加西亚 1976; 贝利
and Thomas 2021; McDowell and McRae 1972).
Outside of computational sociolinguistics, attempts to geographically model lin-
guistic variation in Texas English have been made as part of the established, 大的
initiatives in American dialect mapping. 这些包括:
•
•
•
Kurath’s linguistic atlas project (LAP; see Petyt [1980] for an overview)
that produced the Linguistic Atlas of the Gulf States (Pederson 1986),
based on survey data;
Carver’s (1987) “word geography” atlas of American English dialects,
which visualizes data from the Dictionary of American Regional English
(Cassidy, 大厅, and Von Schneidemesser 1985) on the geographic
distribution of lexical items; 和
the Atlas of North American English (Labov et al. 2006), which maps
phonetic variation in phone interview data from speakers of of American
英语.
3.1 Data Collection
在这个部分, we will describe how we collected Texas Twitter data for our analy-
姐姐. Twitter data has allowed sociolinguists new ways to explore how society affects
语言 (Mencarini 2018). This data is composed of a large selection of natural uses
of language that cut across many social boundaries. 此外, tweets are often
geotagged, which allows researchers to connect examples of language use with location.
We draw our Twitter data from two sources. The first is from archive.org’s collection
of billions of tweets (Archive Team 1996–) that were retrieved between 2011 和 2017.
This collection represents tweets from all over the world and not Texas specifically. 这
second source is a collection of 13.6 million tweets that were retrieved using the Twitter
API between February 16, 2017, and May 3, 2017. We only retrieved tweets that originate
in a rectangular bounding box that contains Texas.
Our preprocessing steps are as follows. 第一的, we remove all tweets that do not
have coordinate information nor a city name in its metadata. Any tweet that does
not have coordinate information, but a city name, we use the simplemaps.org United
States city database2 to give these tweets coordinates based upon its city’s coordinates.
We then remove tweets that were not sent from Texas. We then remove all tweets
that have a hashtag (#) to help remove automatically generated tweets, like highway
accident reports. We then use the ekphrasis Python module to normalize the tweets
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2 https://simplemaps.com/data/us-cities.
6
Rosenfeld and Hinrichs
Voting Precinct Embeddings
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
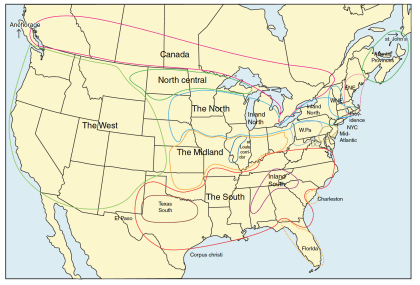
数字 2
Major dialects of North American English. (Reprinted from Labov et al. 2006, p 148, 经过
permission.)
(Baziotis, Pelekis, and Doulkeridis 2017). We do not remove mentions or replace them
with a named entity label. 一起, this results in 2.3 million tweets (1.7 million from
archive.org and 563 thousand from the Twitter API).
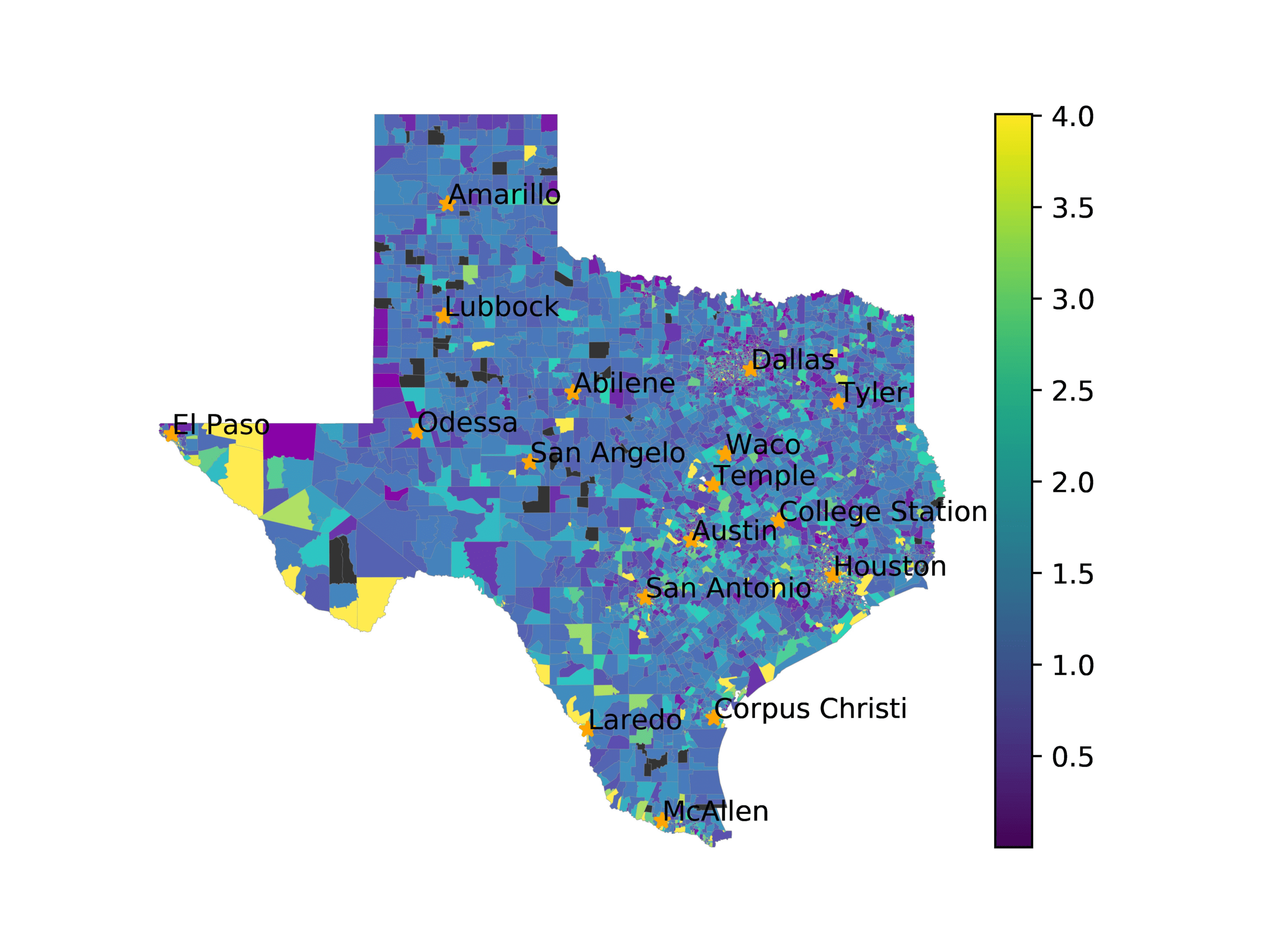
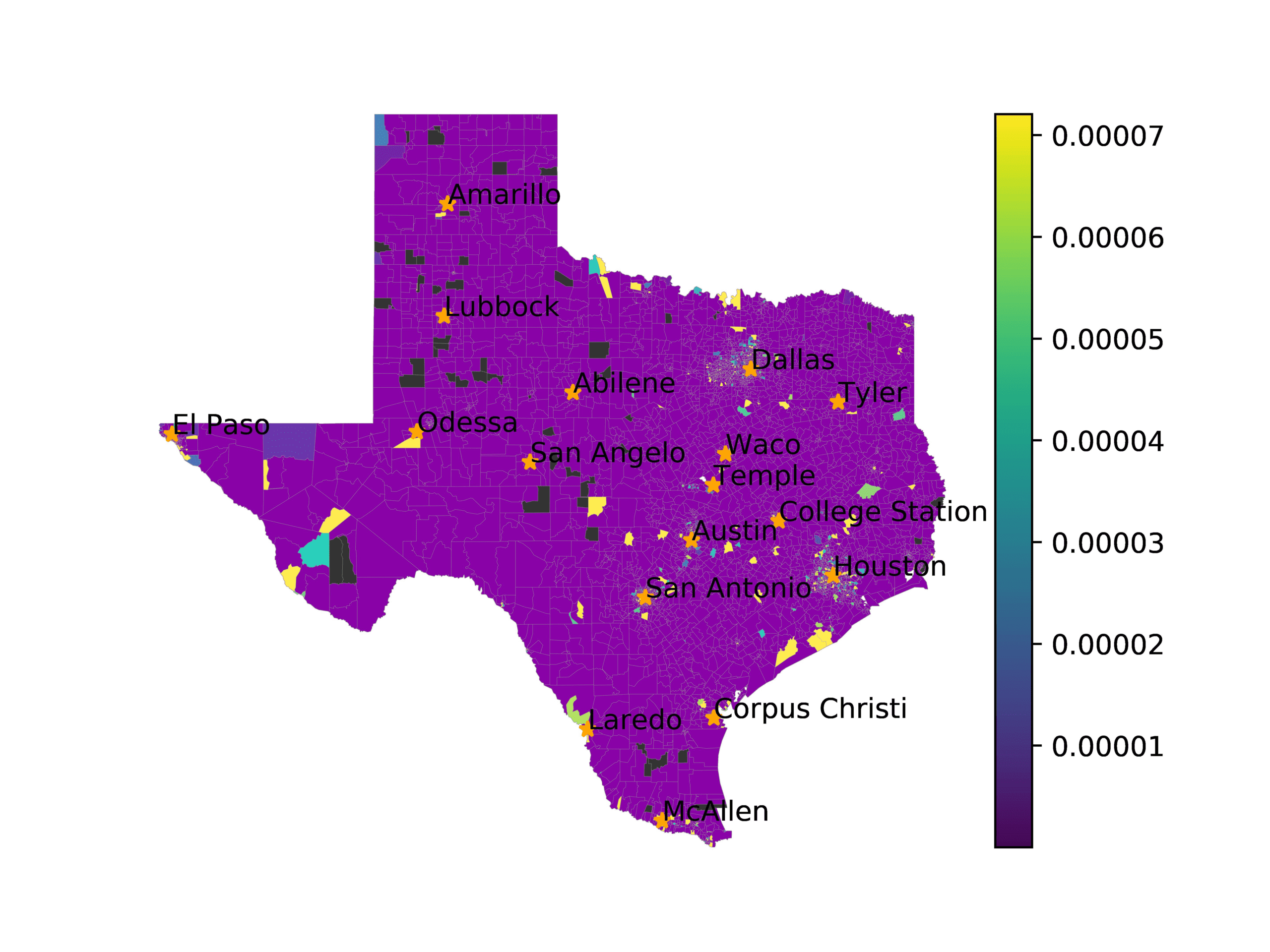
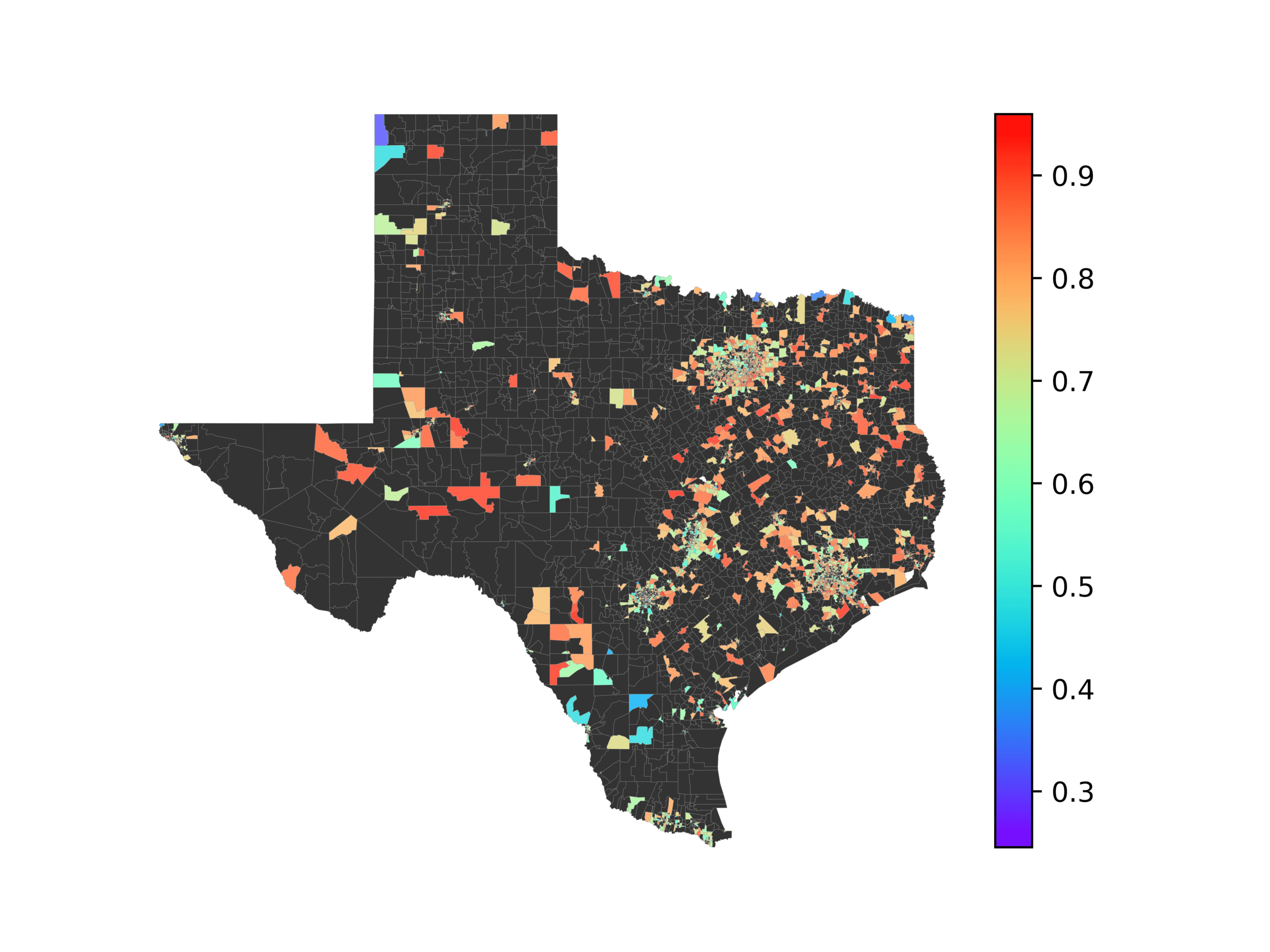
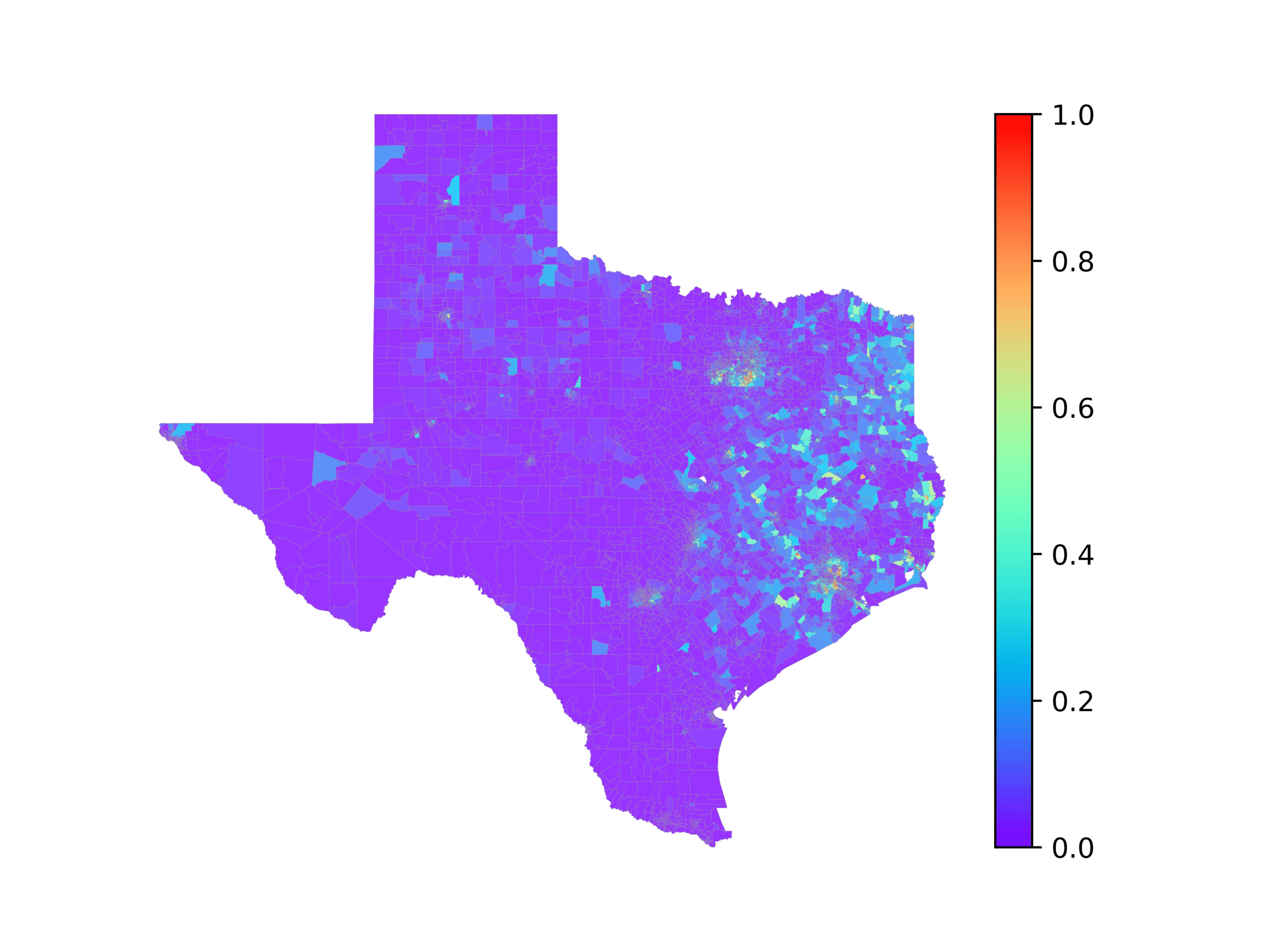
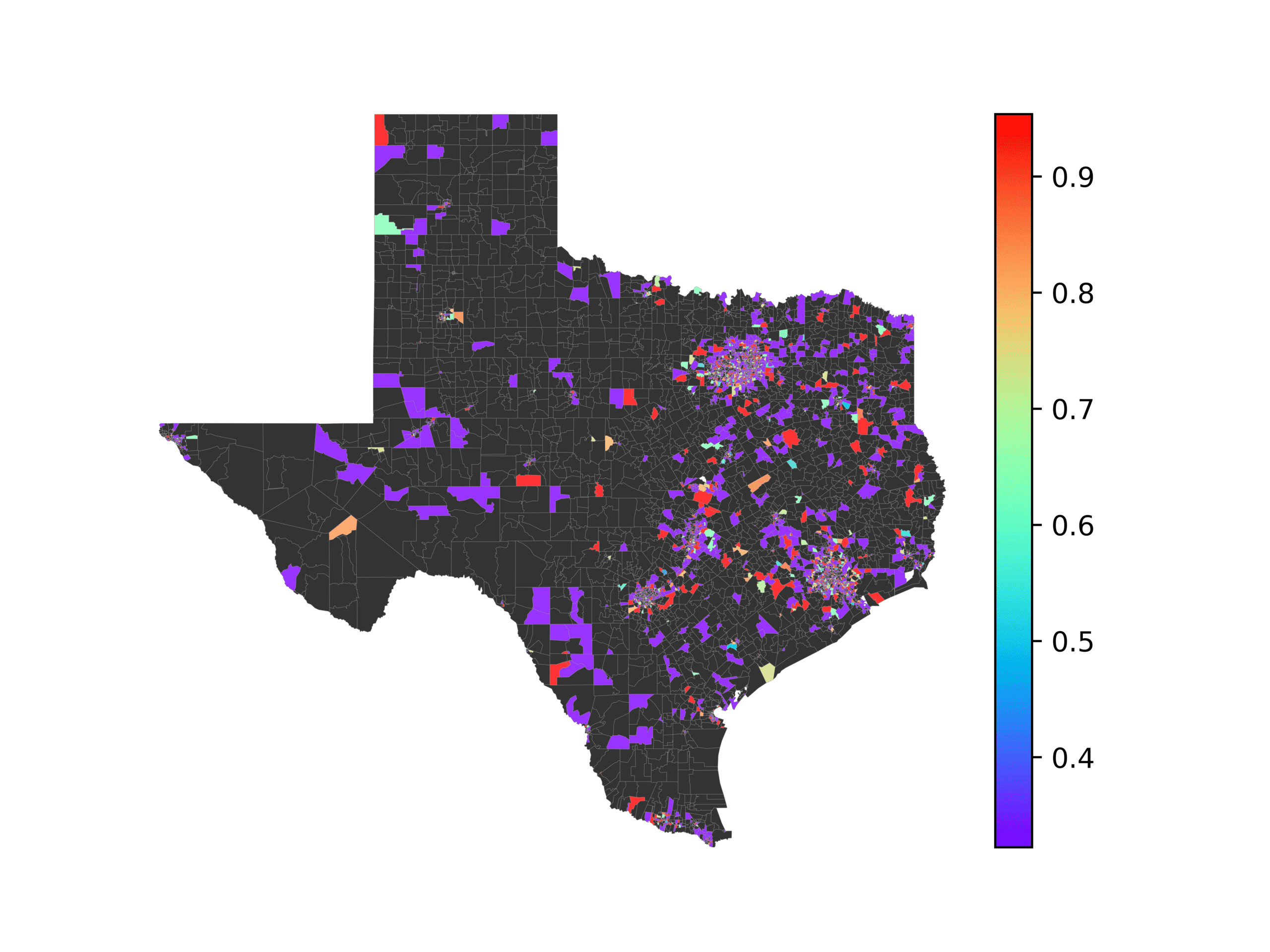
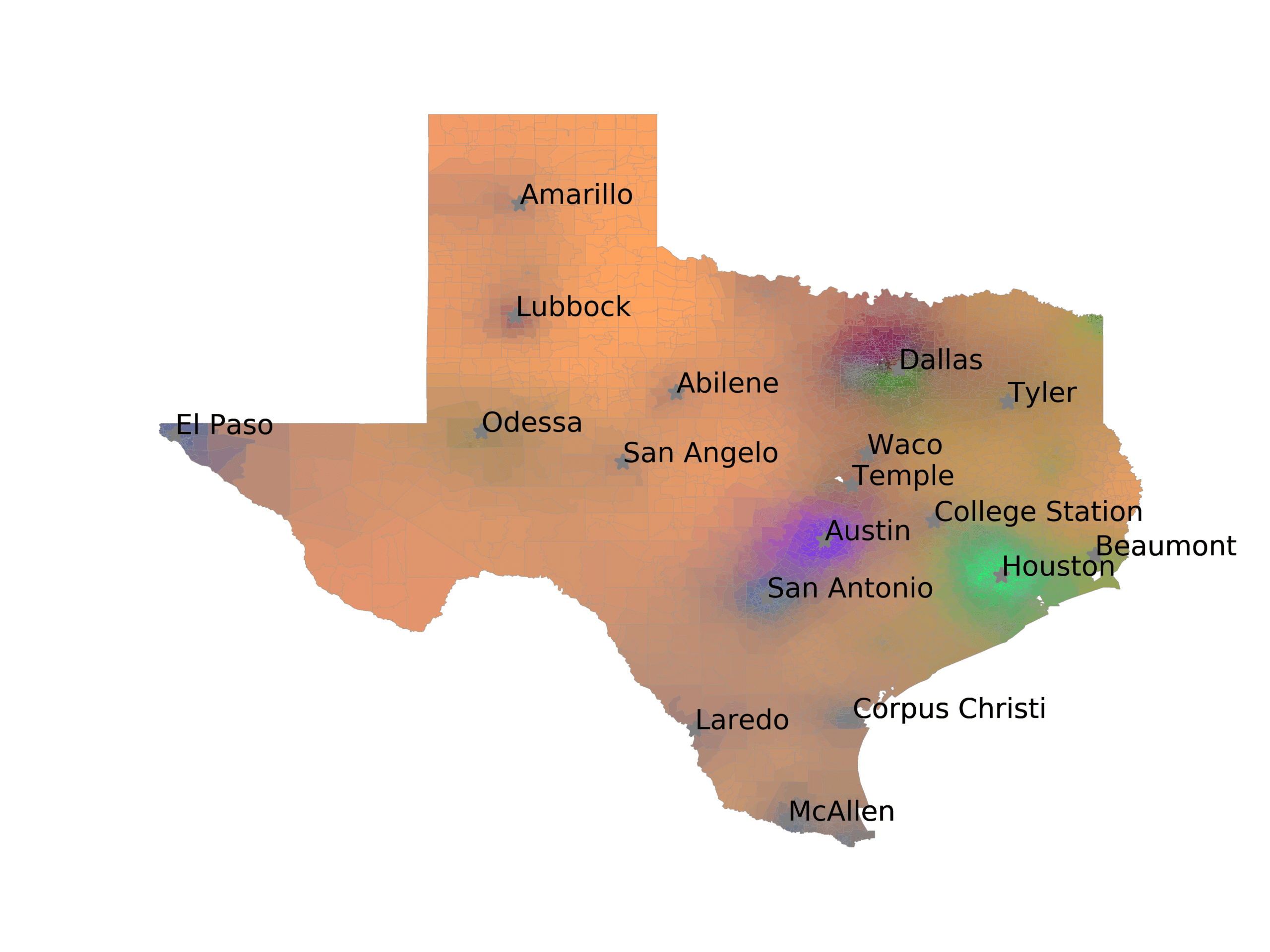
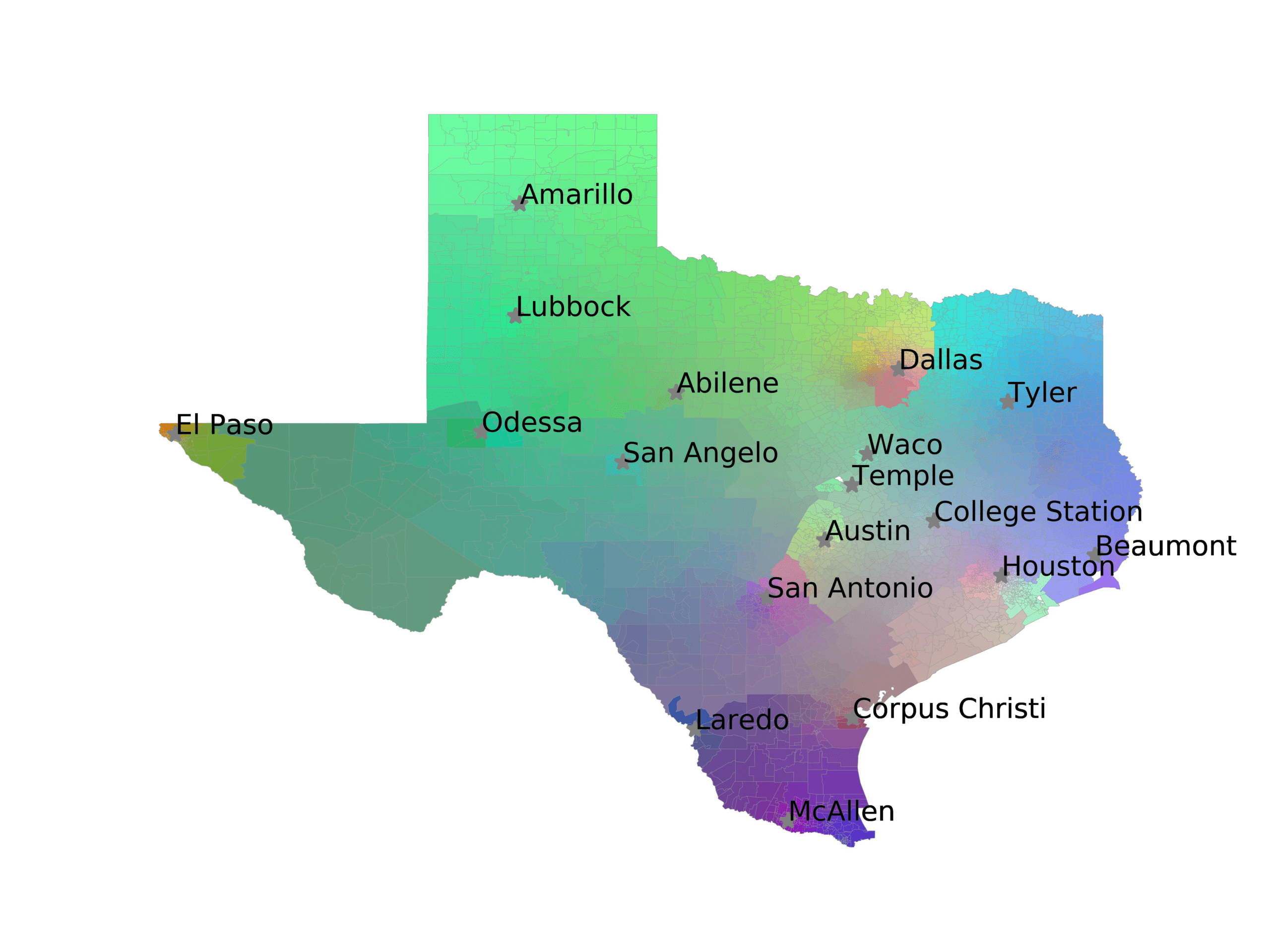
图中 3, we visualize number of tweets in each voting precinct (左边) 和
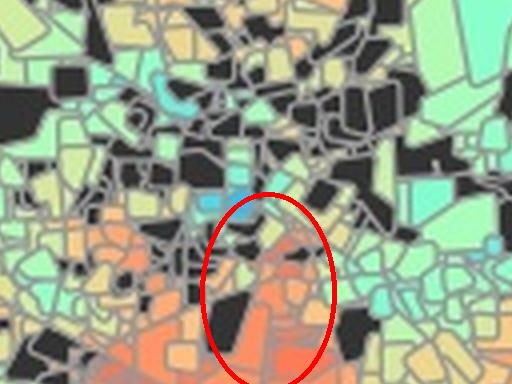
voting precincts that have 10 or fewer tweets (正确的). We see that quite a few voting
precincts have 10 or fewer tweets, especially rural and West Texas. This indicates that
数字 3
The left image visualizes the number of tweets per voting precinct. The right image shows which
voting precincts have 10 or fewer tweets (红色的) or no tweets (黑色的).
7
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4
Distribution of tweets among voting precincts.
many precincts do not have enough tweets to generate accurate representations on their
own and thus require some from of smoothing. 图中 4, we show how the tweets
are distributed across voting precincts. The voting precincts are ranked by number of
tweets. We see that there is a few that have a vast amount of tweets, but most voting
precincts have a number of tweets in the hundreds.
3.2 Voting Precincts
Our goal is to represent language use across the entirety of Texas (including rural Texas)
as well as capture fine-grained differences in language use (including within a city). 在
prior work, researchers either only used cities (例如, Hovy and Purschke 2018), or used
a coordinate grid (例如, Hovy et al. 2020). The former does not explore rural areas at all
and does not explore within-city divisions. The latter uses boundaries that do not reflect
the geography of the area and are difficult to use for fine-grained analyses.
To achieve our goals, we operate at the voting precinct level. Voting precincts
are relatively tiny political divisions that are used for the efficient administration of
选举. Each voting precinct usually has one polling place and, 在里面 2016 选举,
each voting precinct contained on average 1,547 registered voters nationwide (我们.
Election Assistance Commission 2017). These voting precincts are generally relatively
微小的 (on average containing 3,083 人们), cohesive (each voting precinct must reside
entirely within an electoral district/county), 和平衡 (一般来说, voting precincts
8
Rosenfeld and Hinrichs
Voting Precinct Embeddings
桌子 1
Population Demographics of the 8,148 voting precincts in Texas.
Variable
Land Area
Population
Asian
黑色的
Hispanic
多种的
Native American
其他
Pacific Islander
白色的
Pop/Area Per VP
76.08km2 (± 18.55km2)
3083.0 (± 2601.2)
116.2 (± 309.1)
354.1 (± 681.6)
1160.5 (± 1677.5)
39.1 (± 50.9)
9.8 (± 12.9)
4.1 (± 7.6)
2.1 (± 10.7)
1396.8 (± 1384.4)
Demo % of VP
100.0% (± 0.0%)
2.60% (± 5.48%)
10.6% (± 16.8%)
33.7% (± 27.6%)
1.15% (± 0.90%)
0.36% (± 1.09%)
0.11% (± 0.22%)
0.06% (± 0.66%)
51.3% (± 29.4%)
are designed to contain similar population sizes). 此外, states record meticulous
detail on the demographics of each voting precinct (见表 1 for descriptive statistics).
因此, these voting precincts act as perfect building blocks.3
We note that gerrymandering has very little influence on voting precinct bound-
aries. It is true that congressional districts (and similar) can be heavily gerrymandered
and voting precincts are bound by congressional district boundaries. 然而, 这
practical pressures of administration and the relatively small size of the voting precincts
minimize these effects. Voting precincts are used to administer elections, 意思是
that significant effort is needed to coordinate people to run polling stations and iden-
tify locations where people can vote. 此外, voting precincts are often used to
organize polling and signature collection. Due to these factors, there is a strong need
for all parties involved to make voting precincts as compact and efficient as possible. 在
对比, voting precinct boundaries only decide where you vote and not who you vote
为了, so there is not the pressure to gerrymander in the first place. Voting precincts are
also generally small enough to fit into the nooks and crannies of congressional districts.
Congressional districts have dozens of voting precincts, so voting precincts are small
enough to be compact despite any boundary issues of the larger congressional district.
It is for these reasons that voting precincts are often used as atomic units in redictricting
努力 (例如, Baas n.d.).
The voting precinct information comes from the United States Census and is com-
piled by the Auto-Redistrict project (Baas n.d.). Each precinct in this data comes with
the coordinate bounds of the precinct along with the census demographic data. 更远
processing of the demographic data was done by Murray and Tengelsen (2018).
In order to map tweets to voting precincts, we first extract a representative point
for each voting precinct using the Shapely Python module (Gillies et al. 2007). Repre-
sentative points are computationally efficient approximations to the center of a voting
precinct. We then associate a Tweet to the closest voting precinct by distance from the
Tweet’s coordinates to the representative points.
3 While voting precincts were a better fit for our needs, similar analyses could be done with Census tracts,
Census block groups, or any fine-grained sectioning of a region.
9
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
4. Voting Precinct Embedding Methods
在这个部分, we describe the area embedding methods we will analyze. Area em-
bedding methods generally have two parts: a training part and a smoothing part. 这
training part takes text and uses a machine learning or counting based model to produce
嵌入. The smoothing part averages area embeddings with their neighbors to add
extra information.
4.1 Count-Based Methods
The first approach we explore is a count-based approach from Huang et al. (2016). 这
training part counts the relative frequencies of a manually curated list of sociolinguis-
tically relevant lexical variations. The smoothing part takes a weighted average of the
area embedding and enough nearest neighbors to meet some data threshold.
4.1.1 Training: Mean-Variant-Preference. Grieve, Asnaghi, and Ruette (2013) and Grieve
and Asnaghi (2013) have manually collected sets of lexical variants where the choice
of variant is indicative of local language use. 例如, soda, pop, and Coke are a set
of lexical variants for “soft drink” and regions have a variant preference. 黄等人。.
(2016) count the relative frequency of variants and use these counts as the embedding.
更具体地说, they begin with a manually curated list of sociolinguically-
relevant sets of lexical variants. They designate the most frequent variant as the “main”
variant. In the soft drink example, soda would be the main variant as it is the most
frequent variant among all variants.
Given an area and a set of lexical variants, 黄等人。. (2016) take the relative
frequency of the “main” variant across Twitter users in the area:
MVP(区域, variants) =
1
U(区域)
(西德:88)
users u in the area
times user u used main variant
times user u used any variant
where U(区域) is the number of Twitter users in that area. The embedding for an area
would be each MVP value for set of variants in the list of sets of variants.
As baseline in our analysis, we just use the relative frequency over all tweets:
MVP(区域, variants) = total times main variant was used in the area
times times any variant was used
黄等人。. (2016) derived their list of sets of variants from those in Grieve,
Asnaghi, and Ruette (2013). They then filter this list by removing any sets that appear
in less than 1,000 areas or that have a p-value less than 0.001 according to Moran’s I test
(Moran 1950).
For our count based model, we use the publicly available list of 152 sets in Grieve
and Asnaghi (2013). We similarly use Moran’s I to filter by p-value and remove any sets
that appear in less than 1000 voting precincts. The original list of pairs and our final list
can be found in Table A1.
4.1.2 平滑: Adaptive Kernel Smoothing. One issue with working with area embed-
dings is that there is an uneven distribution of tweets and many areas can lack Tweet
10
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
数据. 黄等人。. (2016) do smoothing by creating neighborhoods that had enough
data then taking a weighted average of the embeddings in the neighborhood.
For an area A, a neighborhood is the smallest set of geographically closest areas to
A that have data above a certain threshold. For a set of lexical variants, this is some
multiple B times the average frequency of those variants across all areas. For soda, pop,
and Coke, this would be B times the average number of times someone used any of those
variants. 黄等人。. (2016) explore B values of 1, 10, 和 100.
黄等人。. (2016) then use adaptive kernel smoothing (AKS) with a Gaussian
kernel to get a weighted average of all embeddings in a neighborhood. The weight of
a neighbor embedding is e to the negative distance between the area and the neighbor.
The new area embedding is calculated as follows:
(西德:80)
−−→
area ←
氮(区域, 乙, altpair) e−dist(区域, neighbor)−−−−−→
氮(区域, 乙) e−dist(区域, neighbor)
neighbor
(西德:80)
where N(区域, 乙, variants) = the neighborhood around area such that the total usage of
the pair is at least B times the average. 黄等人。. (2016) after this smoothing process
use PCA to reduce the dimension of the embeddings to 15.
As we will also explore more traditional embedding models, such as Doc2Vec, 我们
adapt this smoothing approach for unsupervised machine learning models. 反而
of average counts of variants, we use average number of tweets. In that way, each
neighborhood will have a sufficient number of tweets to mitigate the data sparsity
问题.
4.2 Post-training Retrofitting
The approach Hovy and Purschke (2018) and Hovy et al. (2020) took in their analysis is
one where embeddings are first trained on social media data then altered such that
adjacent areas have more similar embeddings. The first step uses Doc2Vec (Le and
米科洛夫 2014), while the second step uses retrofitting (Faruqui et al. 2015).
4.2.1 Training: Doc2Vec. The first part in their approach is to train a Doc2Vec model
(Le and Mikolov 2014) 为了 10 epochs to obtain an embedding for each German-
speaking city (Hovy and Purschke 2018) or coordinate square (Hovy et al. 2020).
Doc2Vec is an extension of word2vec (米科洛夫等人. 2013) that also trains embeddings
for document labels (or in this case, the city/square/voting precinct where the post was
written).
In Doc2Vec, 字, 上下文, and document labels are represented by embeddings
and these embeddings are modeled through the following distribution:
磷(word|语境, documentlabel) = softmax(word · (语境 + 标签))
By maximizing the likelihood of this probability relative to a dataset, the model will fit
这个单词, 语境, and document label embeddings so that the above distribution best
reflects the statistics of the data.
11
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
Doc2vec provides a vector
−→
doc for each document label doc (similarly with voting
precincts and cities). The loss function is similar to word2vec as follows:
loss =
(西德:88)
日志(σ(( (西德:126)w + (西德:126)d) · (西德:126)C)) +
(w,C,d)∈D
(西德:88)
C(西德:48)∼PD
日志(1 − σ(( (西德:126)w + (西德:126)d) · (西德:126)C(西德:48)))
where D is the collection of target word–context word–document label triples extracted
from a corpus and PD is the unigram distribution. We use the gensim implementation
of Doc2Vec ( ˇReh ˚uˇrek and Sojka 2010).
The result of this process is that we have an embedding for each voting precinct (在
our case) or coordinate square/German-speaking city (in Hovy and Purschke’s case).
4.2.2 平滑: Retrofitting. One key insight from Hovy and Purschke (2018) 就是它
Doc2Vec alone can produce embeddings that capture language use in an area, 但
not in a way that captures regional variation as opposed to city specific artifacts. 为了
例子, an embedding for the city of Austin, 德克萨斯州, might capture all of the language
use surrounding specific bus lines in the Austin Public Transportation system, but that
information is less useful for understanding differences in language use across Texas.
The solution, proposed by Hovy and Purschke, is to use retrofitting to modify the
embeddings so that that they better reflect regional information. Retrofitting (Faruqui
等人. 2015) is an approach where embeddings are modified so that they better fit a lexi-
cal ontology. In Hovy and Purschke’s case, their “ontology” is a regional categorization
of German cities or, for their later paper, the adjacency relationship between coordinate
squares. An embedding is averaged with the mean of its adjacent neighbors to smooth
out any data-deficiency issues. This averaging is repeated 50 times to enhance the
平滑化. This process is reflected in the following formula:
−−→
area ← ½
−−→
区域 + ½
1
number of adjacent neighbors
(西德:88)
−−−−−→
neighbor
neighbor of area
4.3 Proposed Models
Given that our divisions are much smaller than those in previous work, 我们建议
several area embedding methods that may perform better under our circumstances.
4.3.1 Geography Only Embedding. 在这个部分, we describe a novel baseline that re-
flects embeddings that effectively only contain geographic information and no Twitter
数据, which we call Geography Only Embedding. In this approach, embeddings are
randomly generated (we use a Doc2Vec model that is initialized, but not trained) 和
then retrofit the embeddings using the same process above.
Despite its simple description, this approach can be seen as one where embeddings
capture solely geographic information. To see this, note that the randomization process
provides each precinct its own completely random embedding. 有效, the embedding
acts as a kind of unique identifier for the precinct as it is incredibly unlikely for two
300 dimensional random vectors to be similar. By retrofitting (IE。, averaging these
unique identifiers precincts), you form unique identifiers for larger subregions. 因此,
each precinct and each area has an embedding that directly reflects where it is located
on the map. 这样, these embeddings capture the geographic properties, 尽管
simultaneously containing no Twitter information.
12
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
4.4 平滑: Alternating
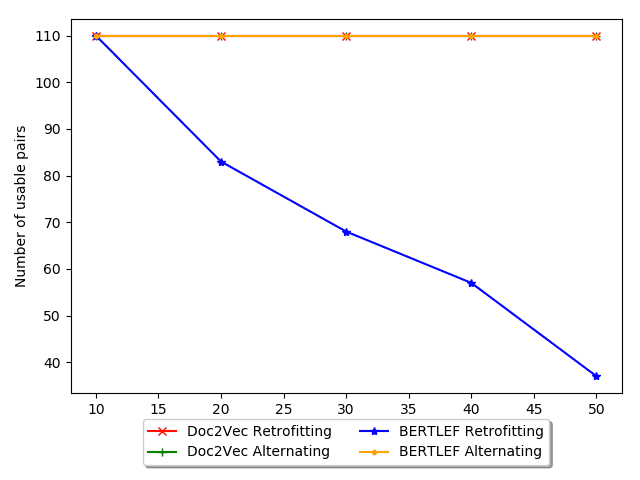
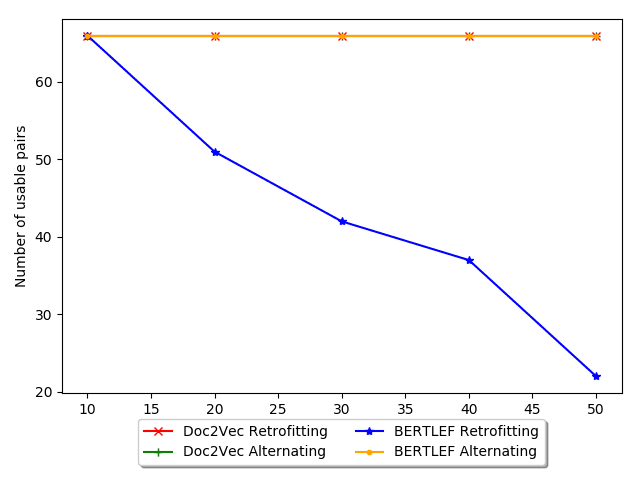
One issue with the Post-training Retrofitting approach in our setting is that it relies on
a large body of tweets per area. In our case, the voting precincts are too small. 尽管
拥有 2.3 million tweets, each voting district only contains about 400 tweets on average
and hundreds of precincts have fewer than 10 tweets. 因此, the initial Doc2Vec step
would lack sufficient data to create quality embeddings. The retrofitting step would
then just be propagating noise.
In order to alleviate this issue, we propose to alternate the Doc2Vec and retrofitting
steps to mitigate the weaknesses of both. In our setting, training injects Tweet infor-
mation into the embeddings, but voting precincts often lack enough data to be used
on its own. 相比之下, retrofitting can send information from adjacent neighbors to
improve an embedding, but can also overwhelm the embedding with noise or irrelevant
信息, 例如, the Austin embedding (a major metropolis) could overwhelm
the Round Rock embedding (a suburb of Austin) even though language use is different
between those areas. If we train after retrofitting, we can correct any wrong information
from the adjacent neighbors. If we retrofit after training, we can provide information
where its lacking. 因此, alternating these steps can mitigate each step’s weakness.
4.5 Training: BERT with Label Embedding Fusion
Since the prior work, there have been advances in document embedding approaches,
such as those that use contextual embeddings. We explore BERT with Label Embedding
Fusion (BERTLEF) (Xiong et al. 2021), which is a recent paper in this area. BERT LEF
combines the label and the document as a sentence pair and trains BERT for up to 5
epochs to predict the label and the document. This is similar to the Paragraph Vectors
flavor of Doc2Vec as it is using the label and document to predict the context. A diagram
showing how this approach works in Figure 5.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 5
Diagram demonstrating the BERT with Label Embedding Fusion architecture (adapted from
Xiong et al., 2021).
13
计算语言学
体积 49, 数字 4
4.6 Approach Summary
We summarize the different approaches we will explore in Table 2. “Model” is the
training part and “Smoothing” is the smoothing part. “Data” indicates if the underlying
data is a manually crafted set of features (“Grieve List”), raw text, or some other data.
“Train epochs” is the number of epochs the models were trained in total. “Smooth Iter”
is the number of smoothing iterations in total. “Dim” is the final dimension size of the
嵌入.
桌子 2
Different embedding methods we explore in our analysis. “Model” is the training approach.
“Smoothing” is the smoothing approach. “Data” is the data used in this approach, 具体来说
raw text or otherwise. “Train Epochs” is the number of train epochs. Doc2vec approaches have
10 epochs and BERTLEF approaches have 5 epochs to follow previous work. “Smooth Iter” is the
number of smoothing iterations. “Dim” is the dimension of the embeddings.
平滑
没有任何
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
数据
Ones
Lat–Long
Grieve list
Grieve list
Grieve list
Grieve list
Grieve list
Grieve list
没有任何
没有任何
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
没有任何
没有任何
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Raw text
Train Epochs
没有任何
没有任何
没有任何
没有任何
没有任何
没有任何
没有任何
没有任何
没有任何
没有任何
10
10
10
10
10
10
10
10
10
没有任何
没有任何
5
5
5
5
5
5
5
5
5
Smooth Iter
没有任何
没有任何
1
1
1
1
1
1
没有任何
50
没有任何
1
1
1
1
1
1
50
50
没有任何
50
没有任何
1
1
1
1
1
1
50
50
Dim
1
2
45
15
45
15
45
15
300
300
300
300
15
300
15
300
15
300
300
768
768
768
768
15
768
15
768
15
768
768
模型
Static
Coordinates
MVP
MVP + PCA
MVP
MVP + PCA
MVP
MVP + PCA
Random 300
Random 300
Doc2Vec
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec
Random 768
Random 768
BERTLEF
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF
14
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
We have six baselines. The first is “Static” which is just a single constant value
and emulates the use of static embeddings. The second is “Coordinates”, which uses a
representative point4 of the voting precinct as the embedding. “Lat–Long” refer to lati-
tude and longitude. “Random 300 None” and “Random 768 None” are random embed-
dings with no smoothing. “Random 300 Retrofitting” and “Random 768 Retrofitting”
are random vectors where retrofitting is applied. As discussed in Section 4.3.1, 这些
correspond to embeddings that capture geographic information and do not contain any
linguistic information.
We then have the count-based approached by Huang et al. (2016). “MVP” is Mean-
Variant-Preference (部分 4.1.1). “AKS” is adaptive kernel smoothing, “B” is the mul-
tiplier, and “PCA” is applying PCA after AKS (部分 4.1.2). “Grieve list” is a list of sets
of sociologically-relevant lexical variants described in Section 4.1.1.
最后, we have the machine learning and iterated smoothing methods. “Doc2Vec”
is Doc2Vec (部分 4.2.1). “BERTLEF” is BERT with Label Embedding Fusion (秒-
的 4.5). “Retrofitting” applies smoothing after training (部分 4.2.2) and “Alternat-
ing” alternates smoothing with training (部分 4.4). “Raw text” means that the model
is trained on text instead of manually crafted features.
5. Quantitative Evaluation
5.1 Prediction of Dialect Area from Dialect-specific Terms
Our first evaluation measures how well embeddings can be used to map a dialect
when provided some words specific to that dialect. We use the dialect divisions in
DAREDS (Rahimi, Cohn, and Baldwin 2017), which divides the United States into 99
dialect regions, each with their own set of unique terms. These regions and terms were
compiled from the Dictionary of American Regional English (Cassidy, 大厅, and Von
Schneidemesser 1985). As our focus is on the state of Texas, we only use the “Gulf
States”, “Southwest”, “Texas”, and “West” dialects, each of which include cities in Texas.
The list of terms that are specific to those regions can be found in Section Appendix B.
We measure the efficacy of an embedding by how well it can be used to predict
how often dialect specific terms are used in a given voting precinct. Given that we have
a set number of tweets in each voting precinct and are trying to predict the amount of
times dialect specific terms are used, we assume that the underlying process is a Poisson
distribution as we are counting the number of times an event is seen (dialect term) 在一个
specific exposure period (number of tweets). A Poisson distribution with rate parameter
λ is a probability distribution on {0, . . . , ∞ with the following probability mass function:
Pois(Y = k) = λke−λ
k!
If an embedding method captures variational language use, then a Poisson re-
gression fit on those embeddings should accurately emulate this Poisson distribution.
Poisson regression is like regular linear regression except it assumes that errors follow
a Poisson distribution around the mean instead of a Normal distribution.
One particular issue that is faced with performing Poisson regression with large
embeddings is that models may not converge due to data separation (Mansournia
等人. 2018). 为了纠正这个问题, we use bias-reduction methods (Firth 1993; Kosmidis and
4 The representative point is produced by Shapely’s (Gillies et al. 2007) representative point method.
15
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
Firth 2009), which are proven to always produce finite parameter estimates (Heinze
and Schemper 2002). We use R’s brglm2 package (Kosmidis 2020) 去做这个.
To evaluate the fit, we use two metrics: Akaike information criterion (AIC) 和
McFadden’s pseudo-R2. AIC is an information theoretic measure of goodness of fit. 我们
choose AIC as its robust to number of parameters and, assuming we are correct about
the underlying distribution being Poisson, it is asymptotically equivalent to Leave One
Out Cross Validation (Stone 1977). AIC is given by the following formula:
AIC = 2 ∗ number of model parameters − 2 ∗ maximum likelihood of model
桌子 3
Results of dialect area prediction evaluation for relevant DAREDS regions. The values are AIC
for each region (lower is better).
Alternation
没有任何
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
DAREDS AIC by Region
Gulf States
4890.32
4859.89
4713.70
4713.31
4696.95
4725.05
4581.97
4584.86
4878.53
4778.34
4599.22
4945.14
4859.17
4907.23
4874.47
5017.93
4880.77
4814.15
4689.96
5345.06
5366.13
5299.95
5292.91
4870.77
5286.53
4870.26
5382.80
4894.13
5450.53
5308.68
Southwest
8793.00
8159.15
8251.73
8492.32
7697.70
8324.49
7421.84
7710.95
7441.02
7196.95
6746.71
7940.38
8706.27
7589.73
8662.70
7916.88
8689.66
7164.03
6919.24
7211.48
7349.66
7211.09
7217.49
8601.52
7390.63
8647.27
7538.72
8639.23
7619.40
7377.52
德克萨斯州
7885.50
7681.31
7214.86
7523.04
7011.86
7483.78
7123.18
7382.14
6780.70
6372.70
6145.31
7498.78
7819.10
7211.45
7827.59
7038.32
7869.85
6433.94
6192.12
6609.13
6534.66
6521.57
6828.36
7860.10
6793.89
7847.80
6630.50
7858.67
6875.99
6511.52
西方
6236.38
6090.05
6078.22
6110.55
5933.71
6060.23
5861.19
5950.82
6065.14
5797.75
5511.69
6088.75
6187.54
6058.02
6153.67
6093.19
6182.27
5802.43
5659.31
6029.10
6221.10
6260.76
6212.75
6208.87
6172.18
6215.73
6176.40
6230.27
6355.34
6124.20
方法
Static
Coordinates
MVP
MVP + PCA
MVP
MVP + PCA
MVP
MVP + PCA
Random 300
Random 300
Doc2Vec
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec
Random 768
Random 768
BERTLEF
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF
16
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
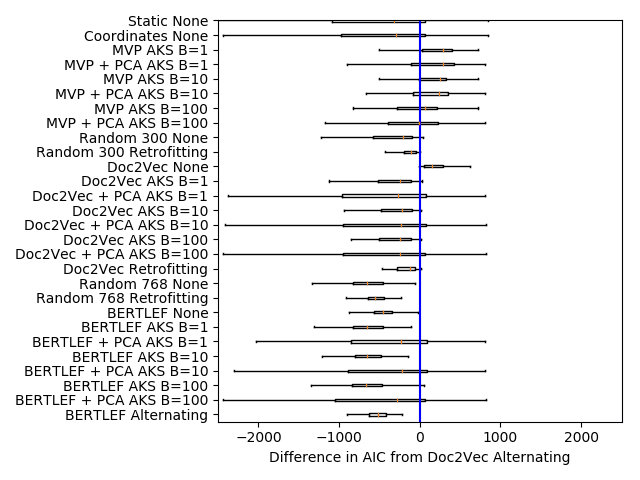
We show the AIC scores for the various precinct embedding approaches in Table 3.
See Section 4.6 for a reference for the method names. In the Gulf States region, 我们
see that methods that use manually crafted lists of lexical variants (MVP models) 是
competitive with machine learning–based models applied to raw text with the largest
neighborhood size outperforming these methods. 然而, in the other regions, 这
Doc2Vec approaches that use Retrofitting and Alternating smoothing greatly outper-
form those approaches. What this indicates is that if we have a priori knowledge of
sociolinguistically relevant lexical variants then we can accurately predict dialect areas.
然而, machine learning methods can achieve similar or greater results with just
raw text. 因此, even when lexical variant information is unavailable, we can still make
accurate predictions.
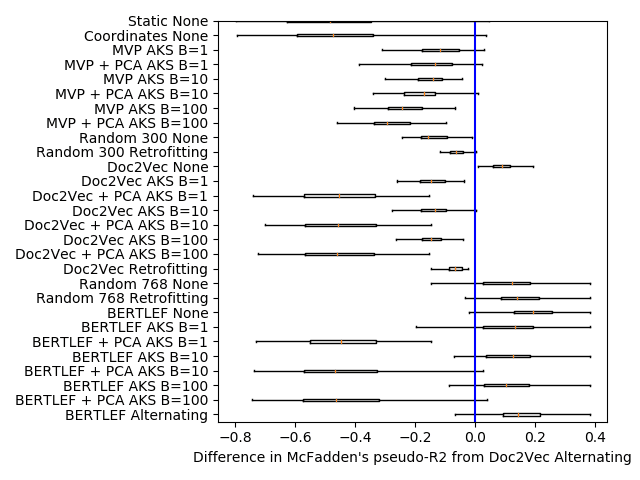
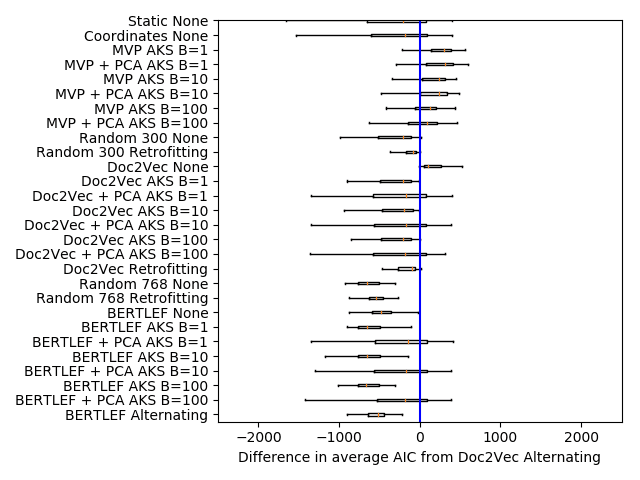
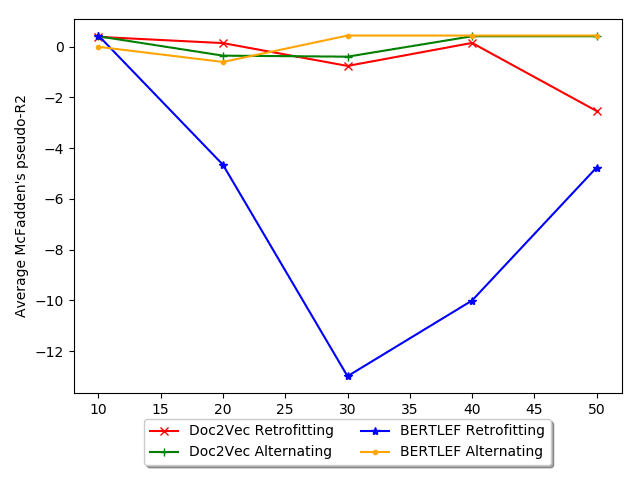
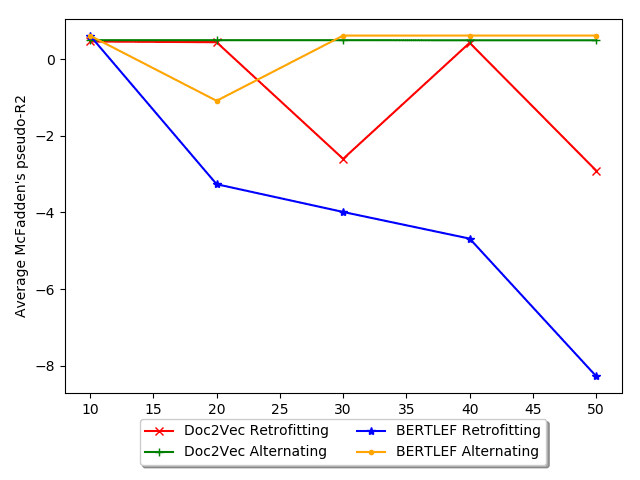
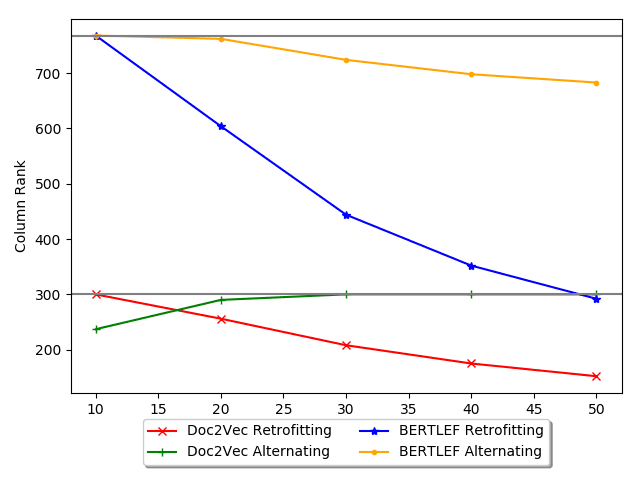
Among the Doc2Vec approaches, we see that Alternating smoothing does better
than all other forms of smoothing. 比那更多的, Alternating smoothing is the only
one that consistently beats the geography only baseline (Random 300 Retrofitting). 在
也就是说, the other smoothing approaches may not be leveraging as much linguistic
information as they could and may be overpowered by the geography signal. 在骗子-
特拉斯特, alternating smoothing and training produces embeddings that provide more than
what can be provided by geography alone.
In the table, we see that Doc2Vec without smoothing outperforms Doc2Vec with
平滑化. We see similar phenomenon with the BERTLEF models. The nature of the
task may benefit Doc2Vec without smoothing as counts in an area are going to be higher
in places with more data. 然而, we see that Doc2Vec Alternating smoothing does
better than every other smoothing variant across the board. 尤其, Alternating
smoothing outperforms the AKS approaches. What that indicates is that the effective-
ness of MVP models is due to the manually crafted list of lexical variants and less due
to the smoothing approach.
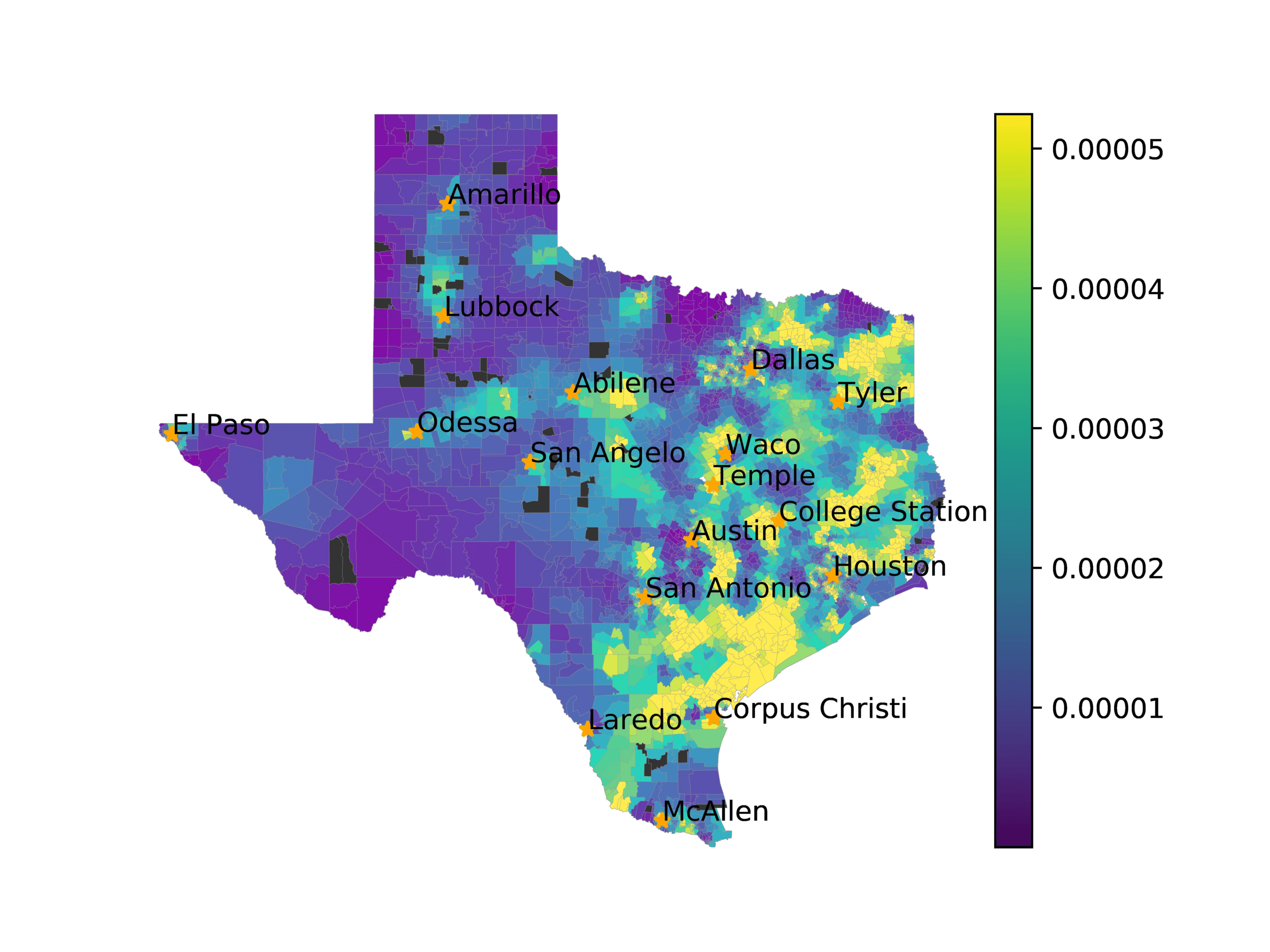
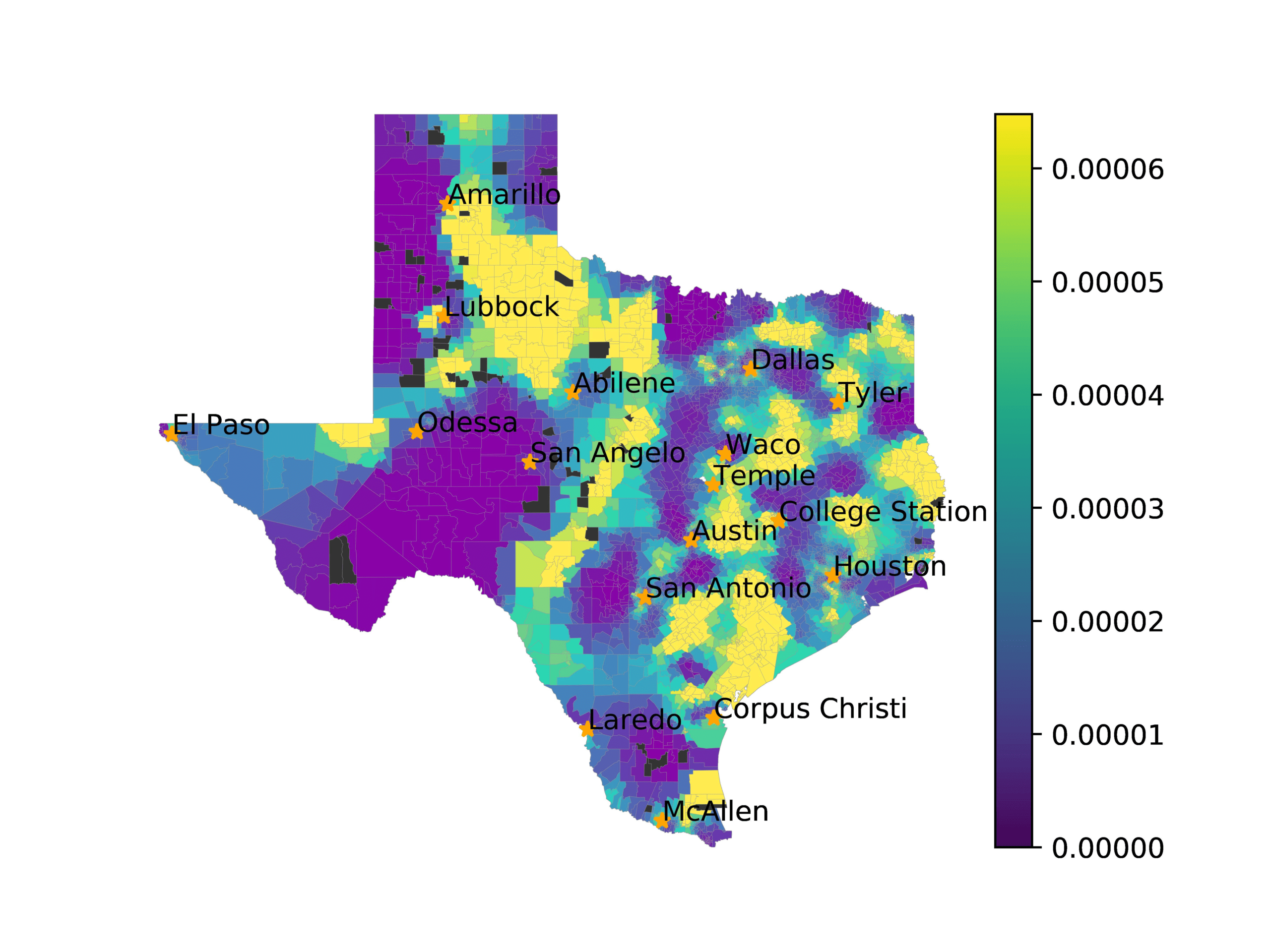
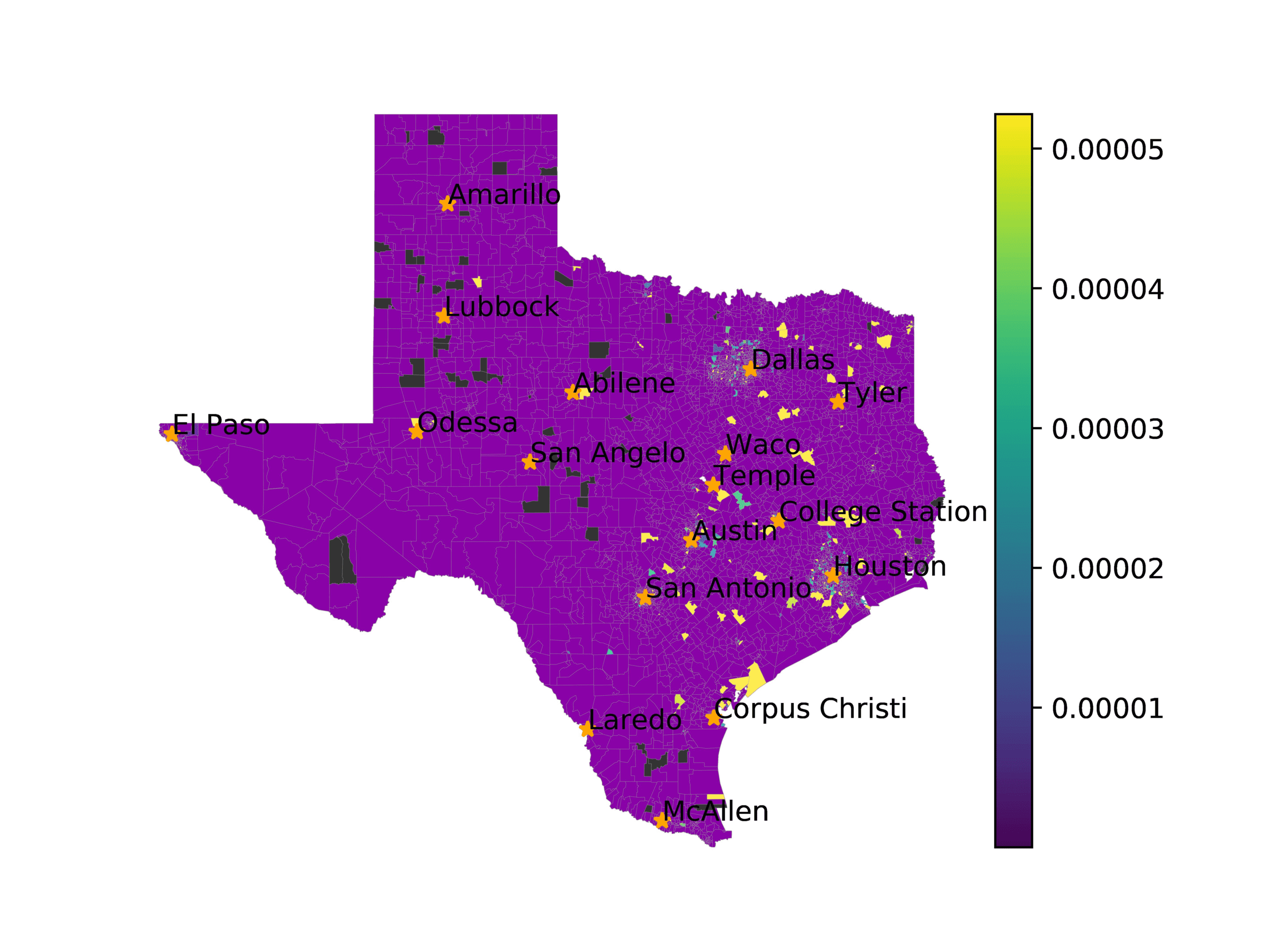
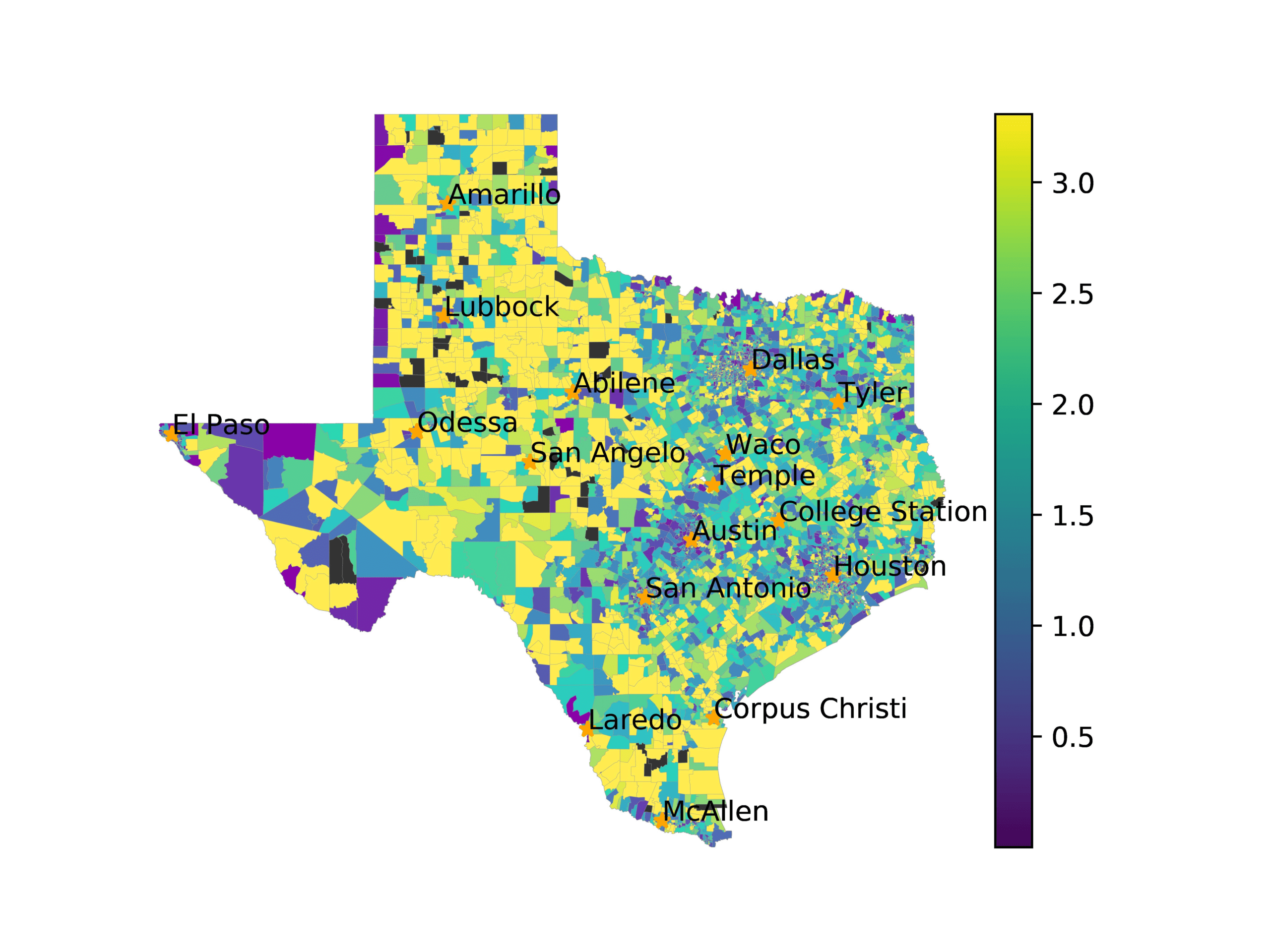
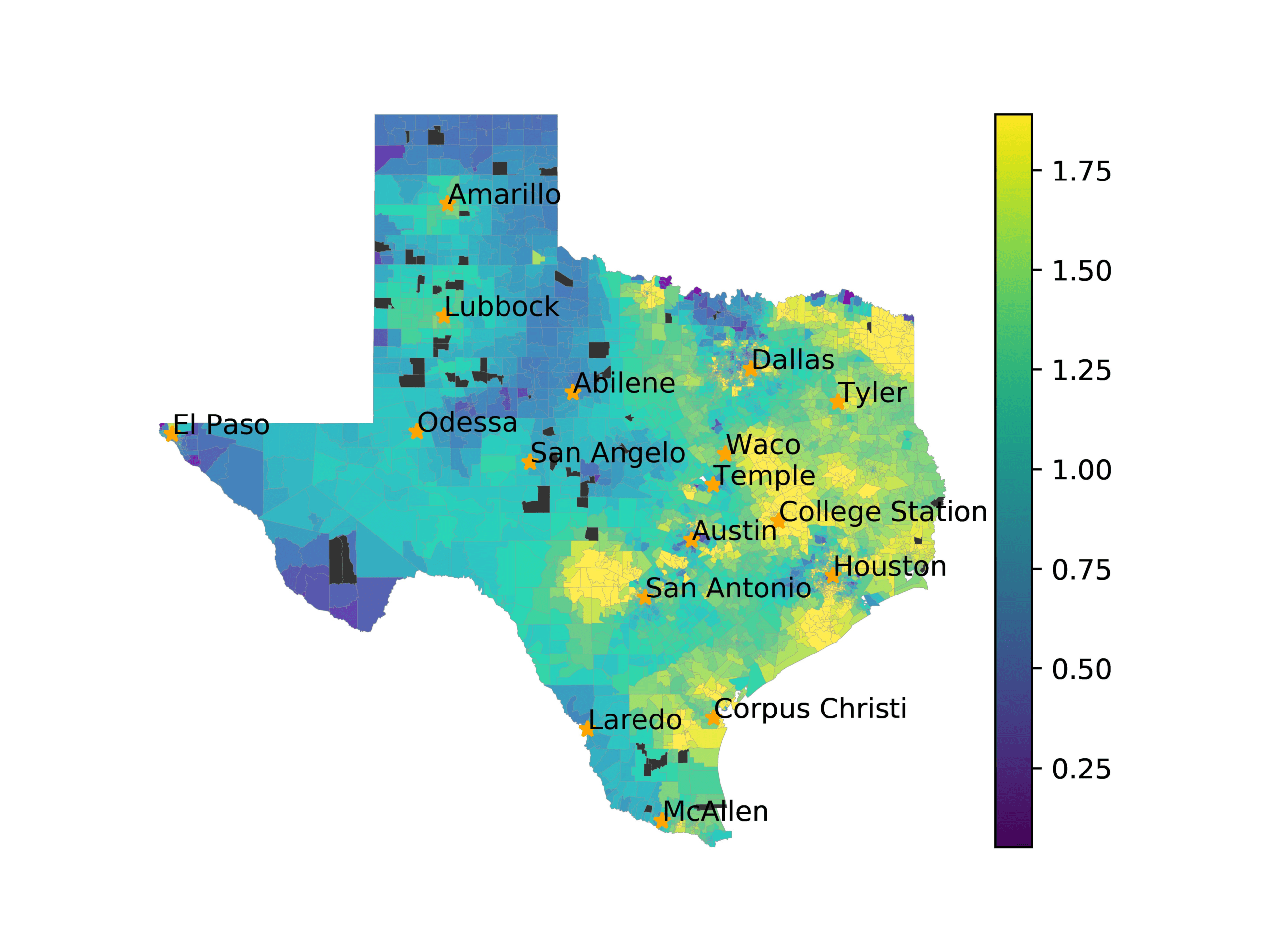
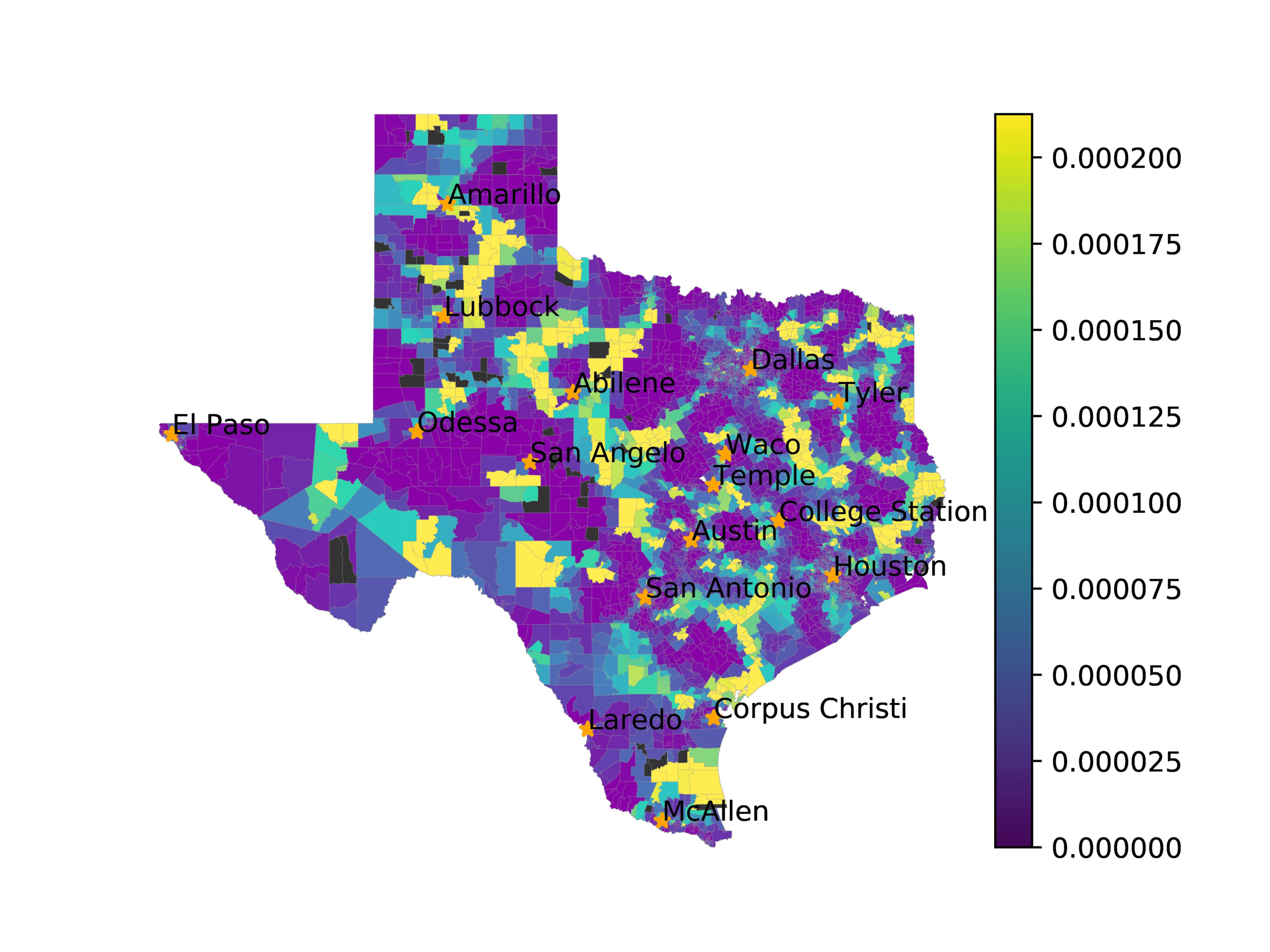
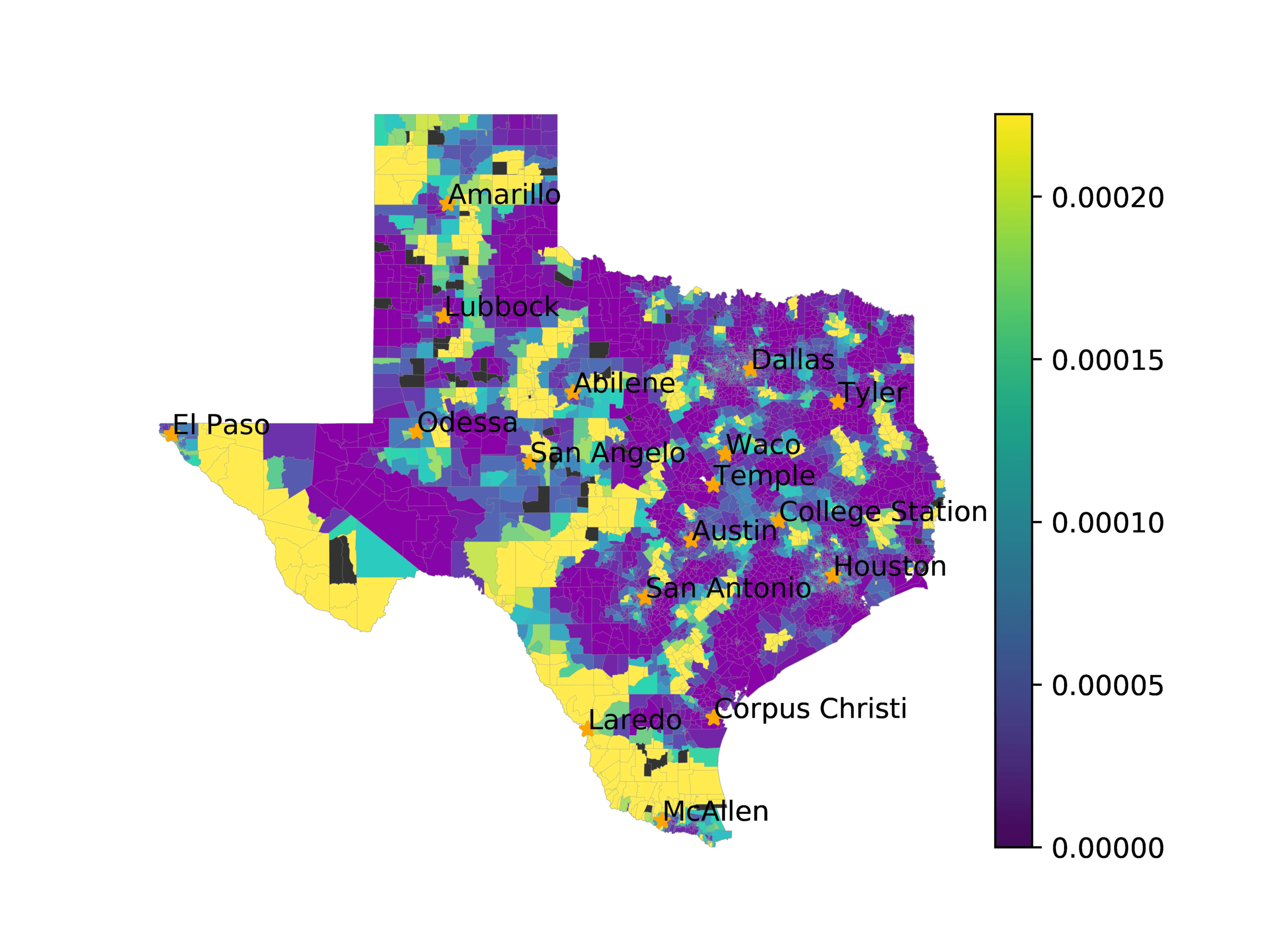
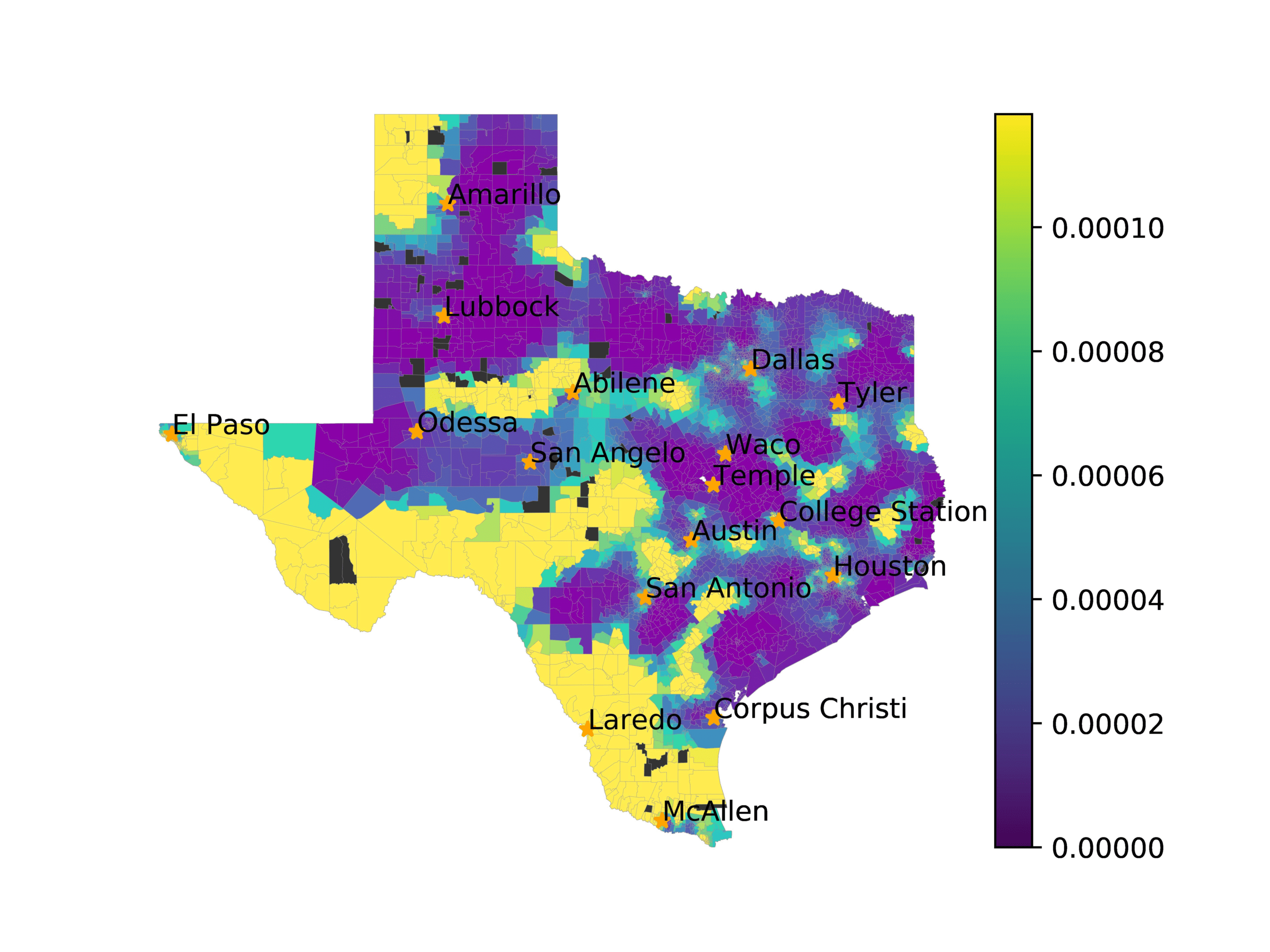
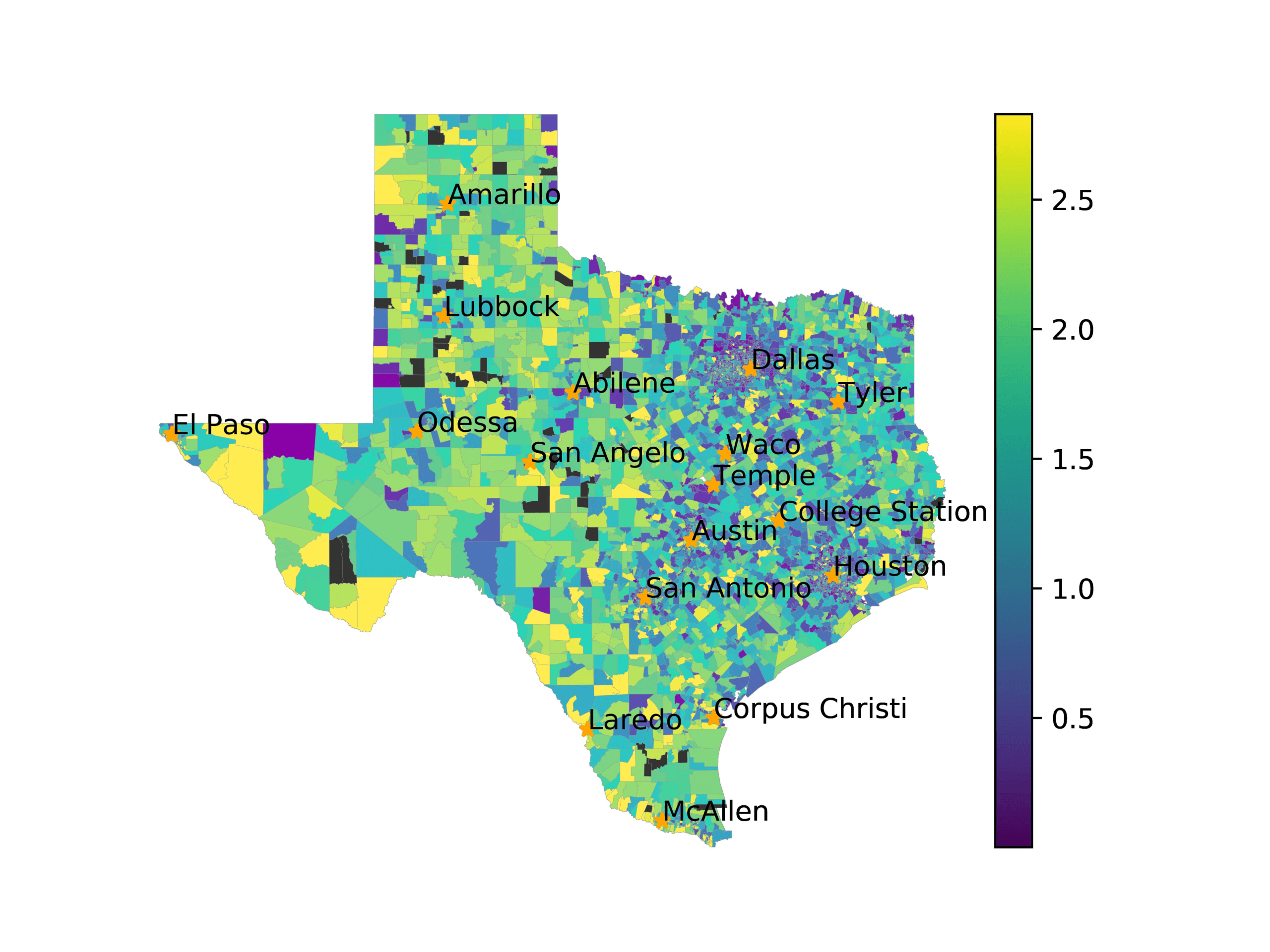
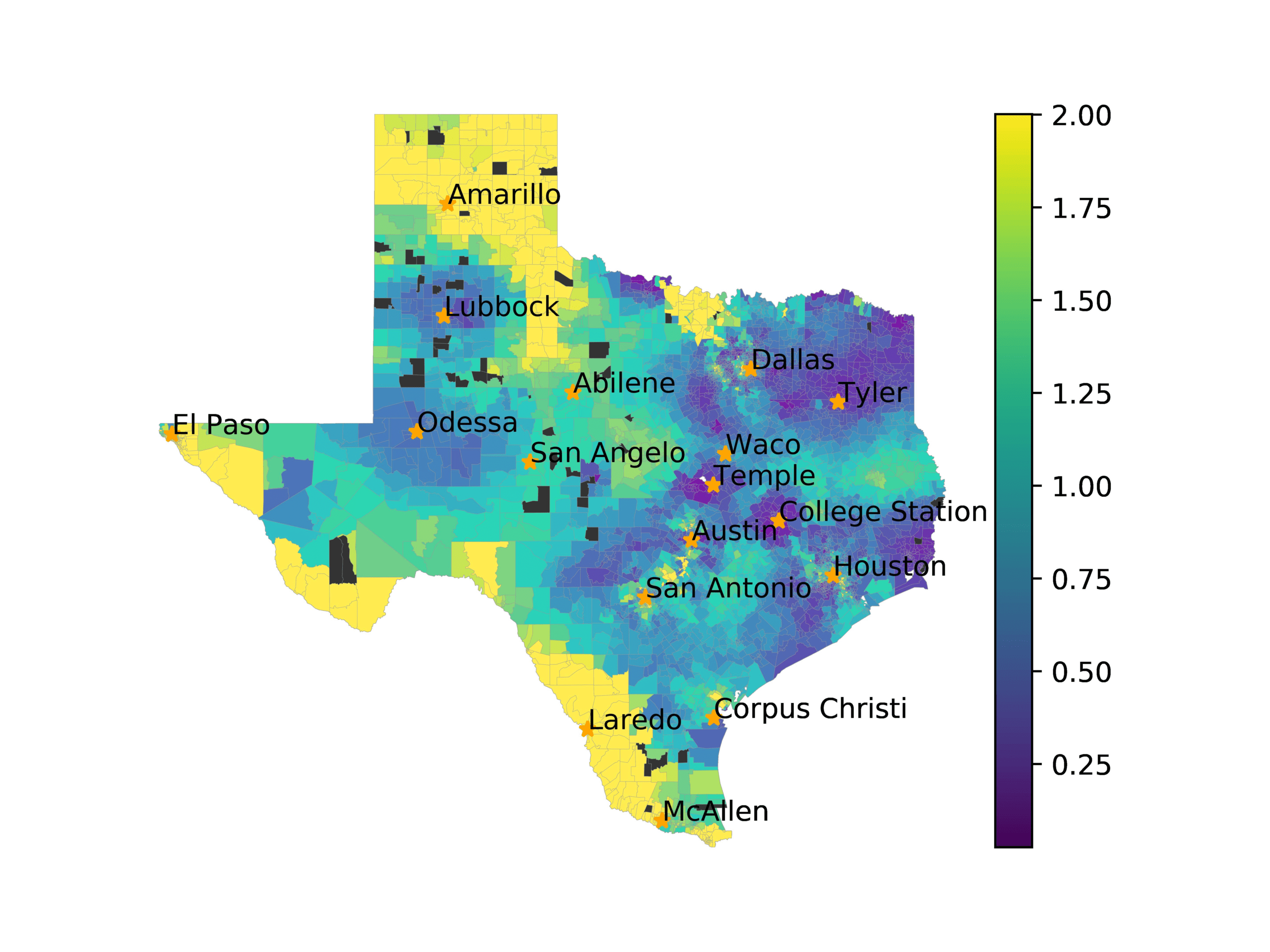
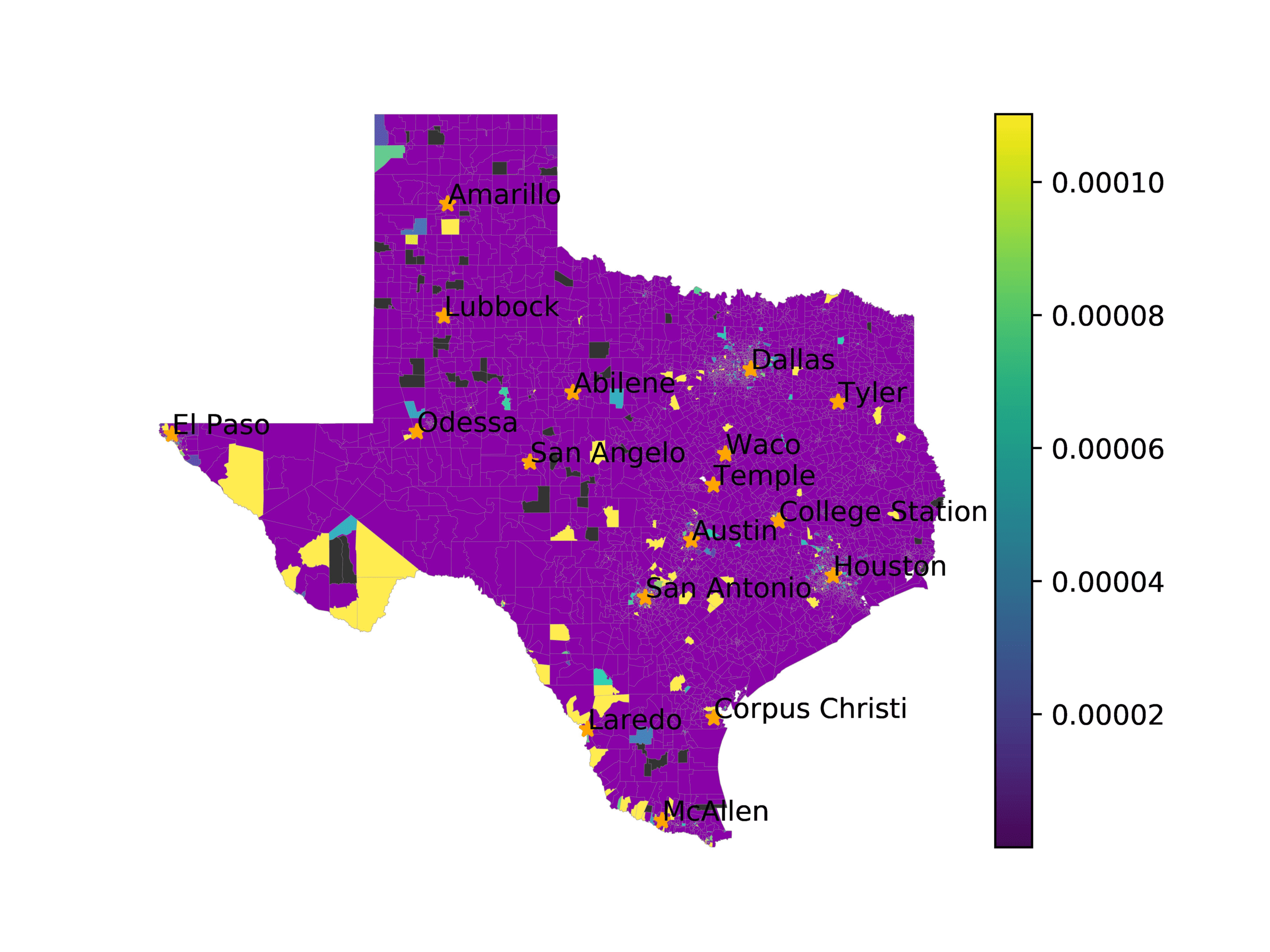
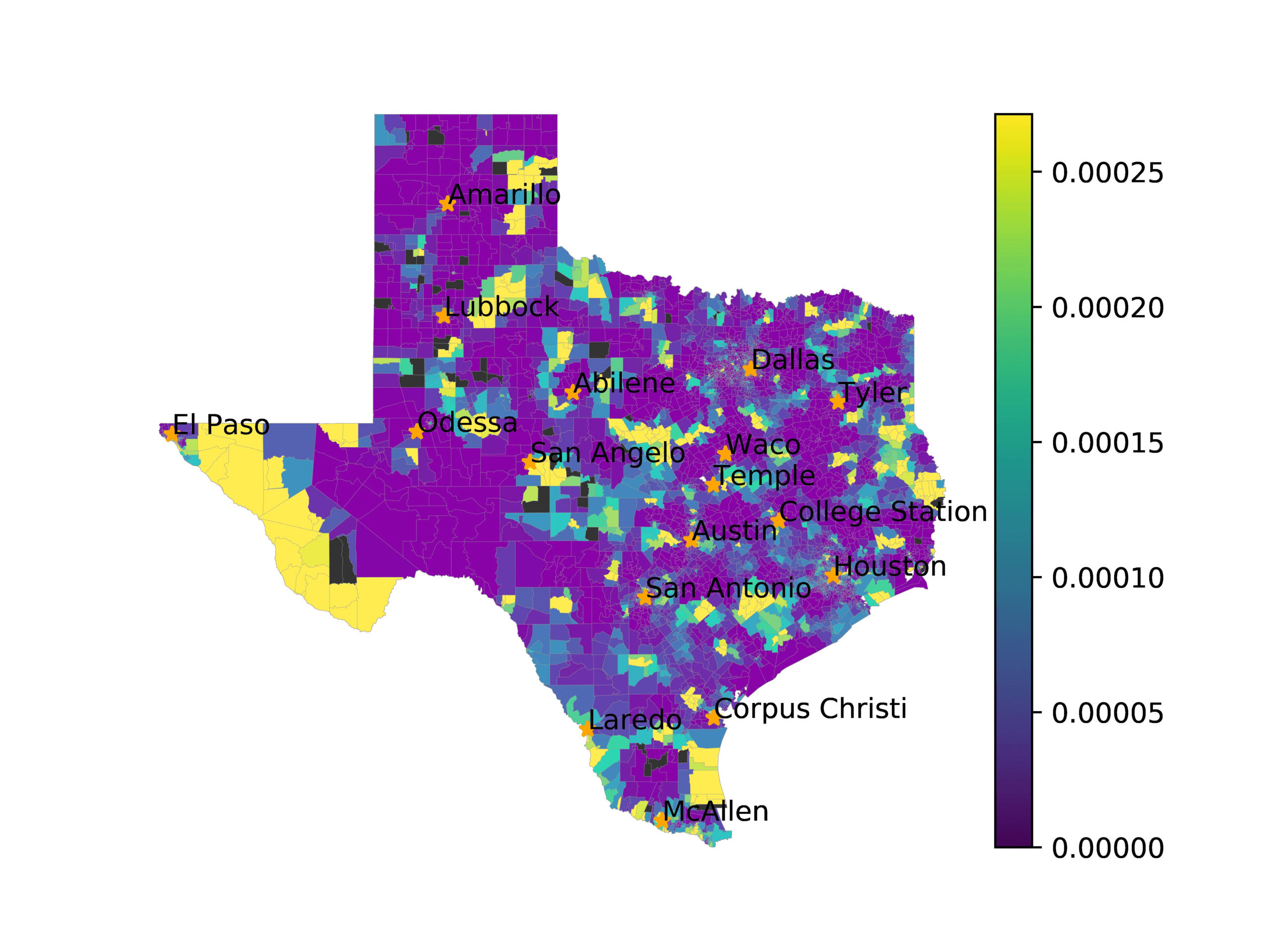
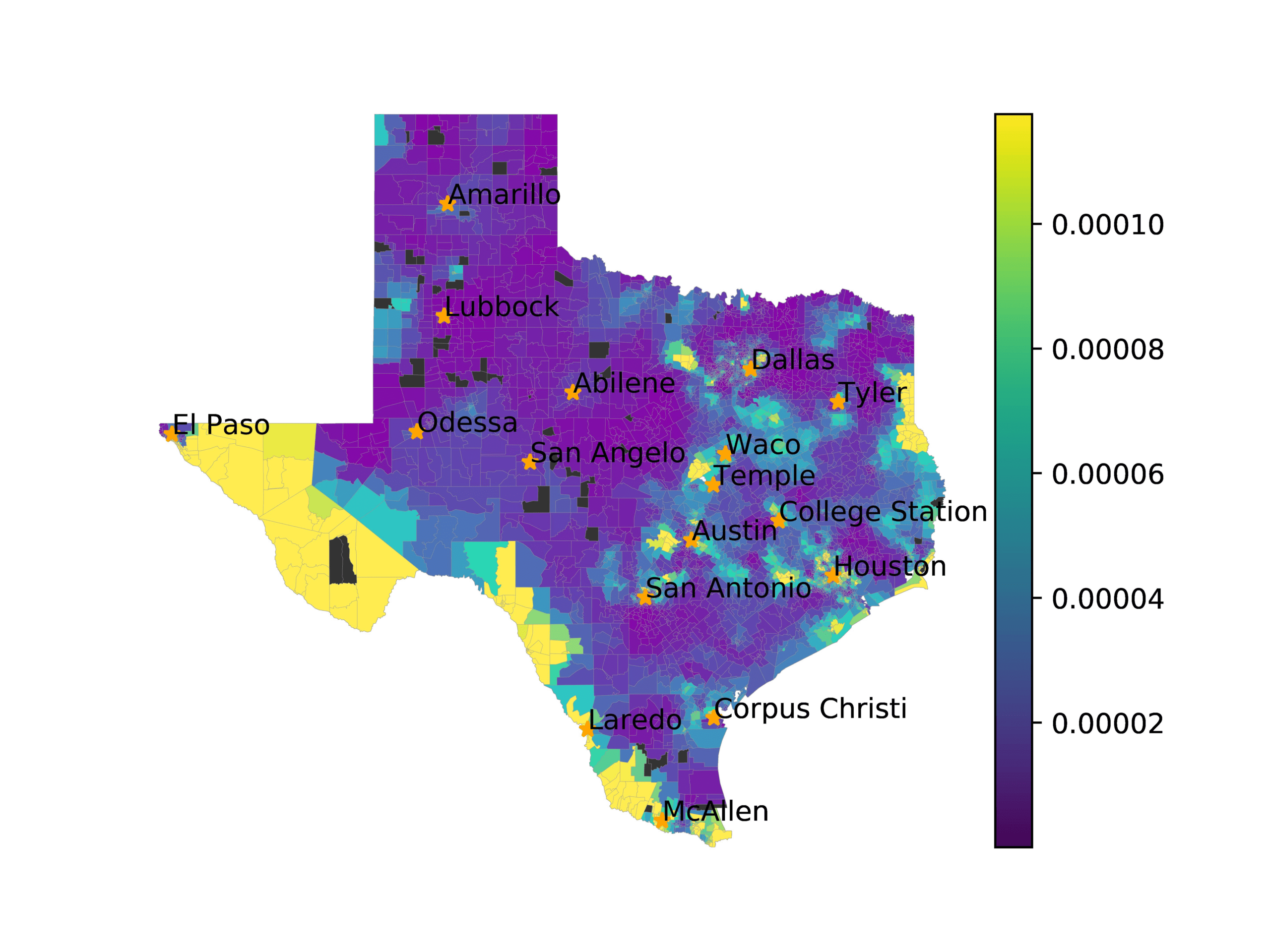
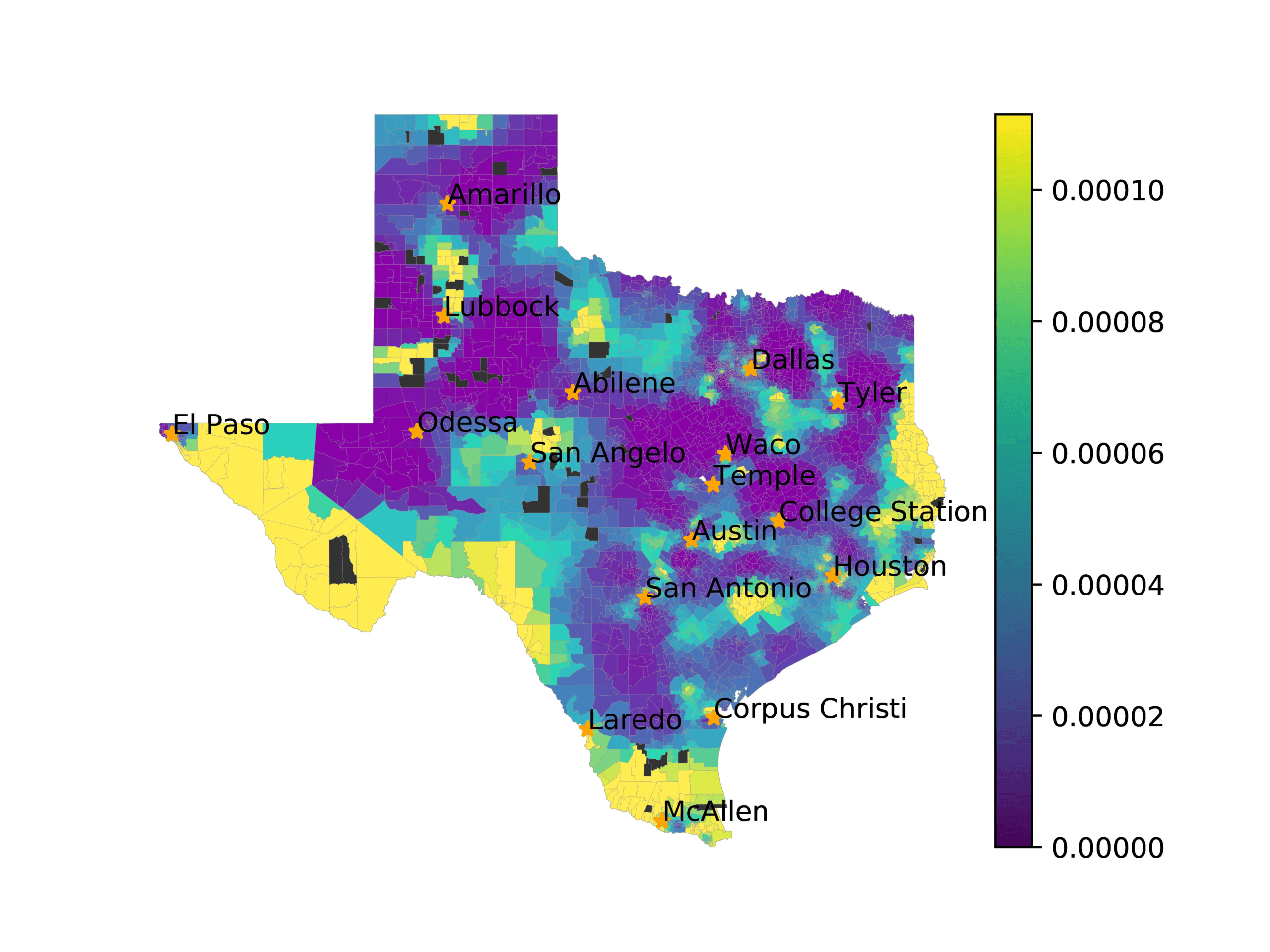
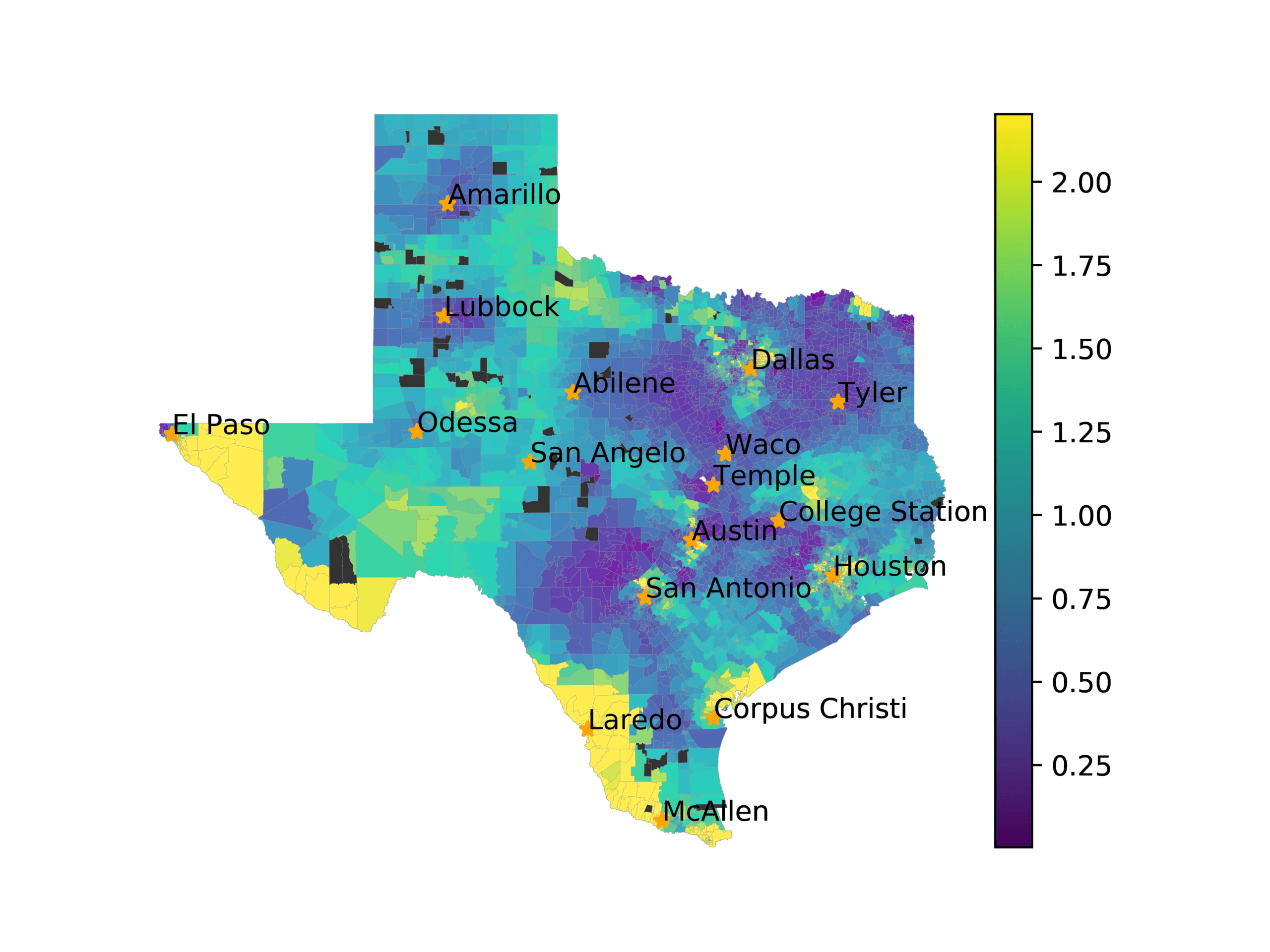
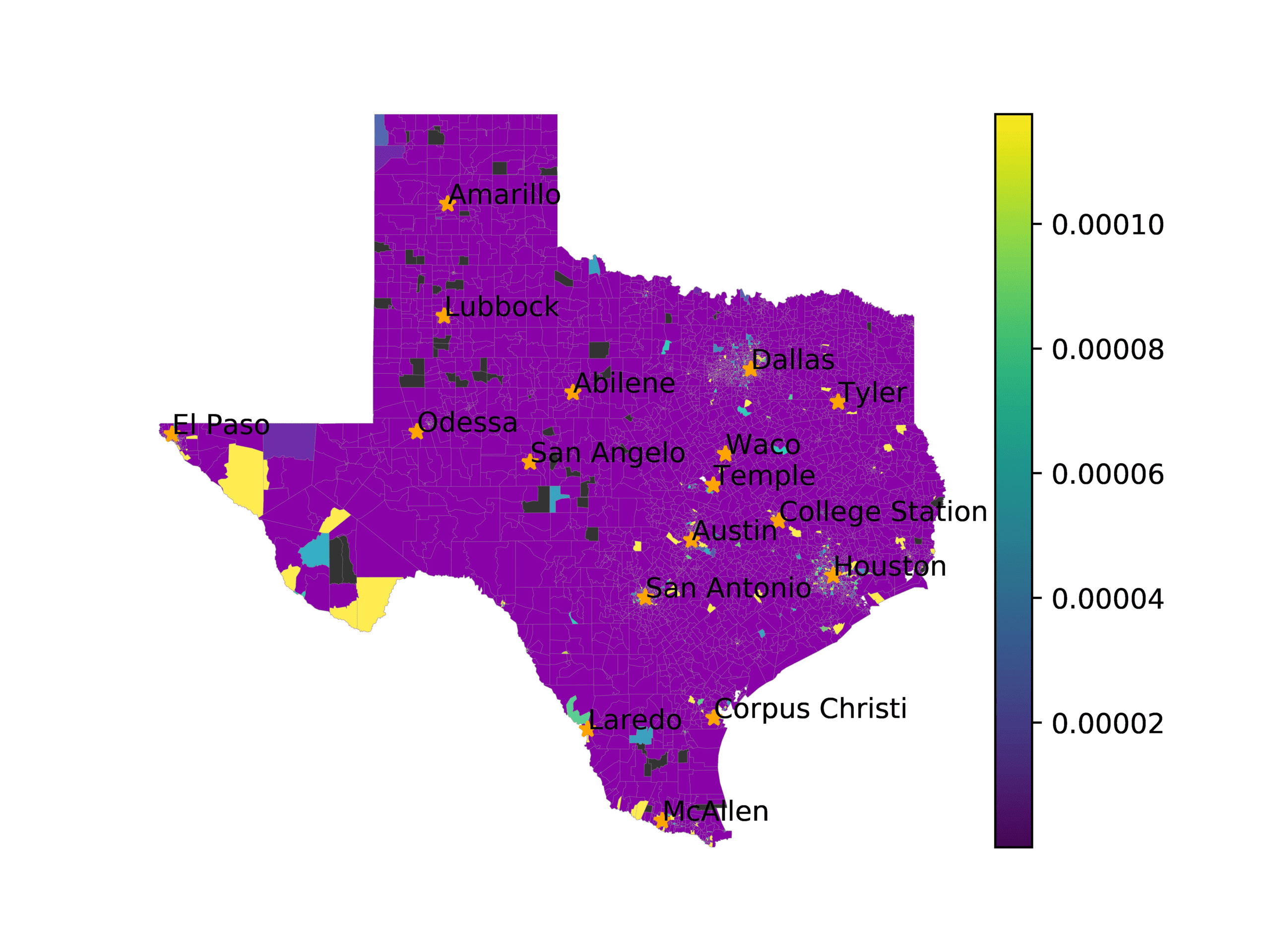
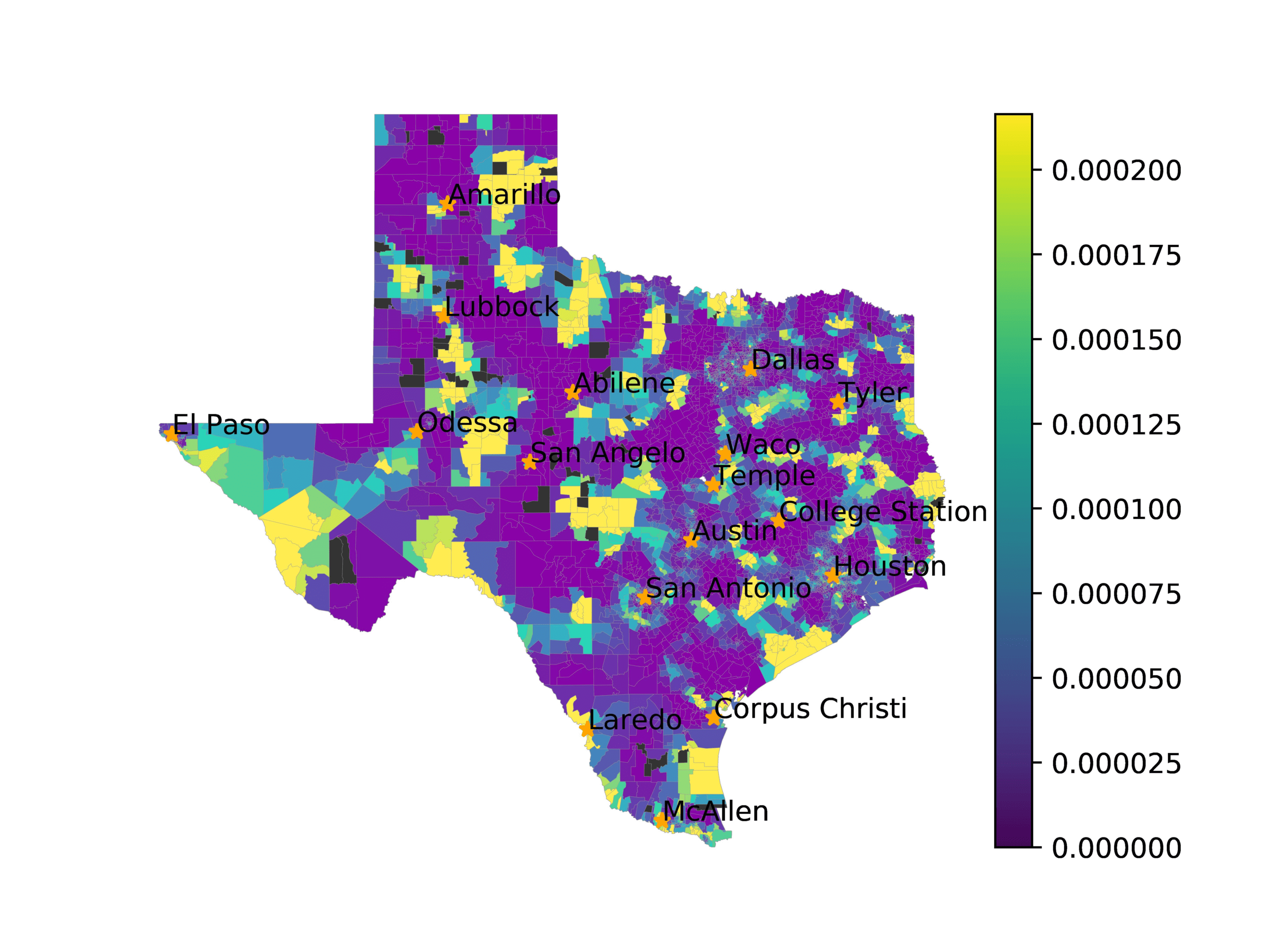
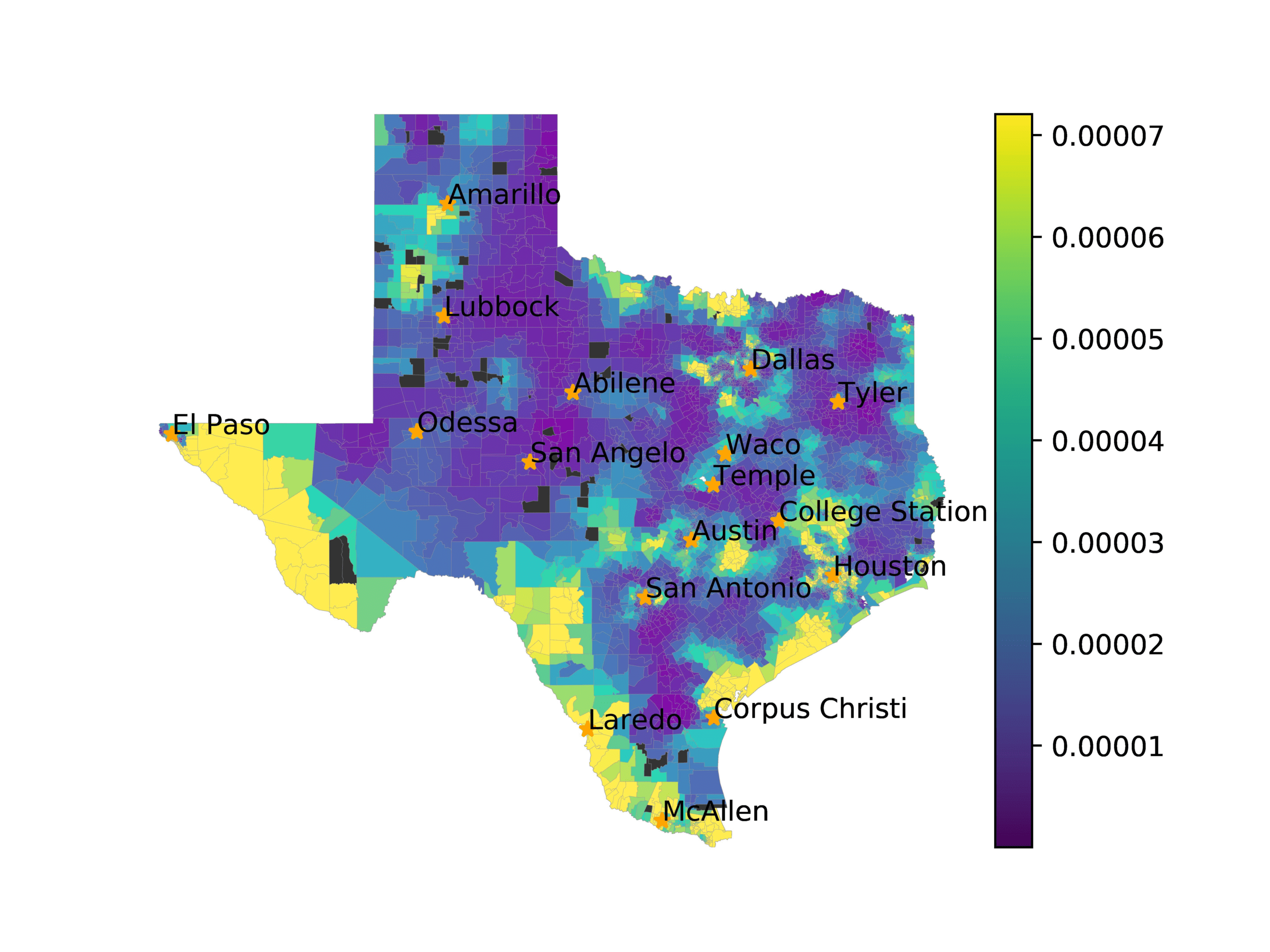
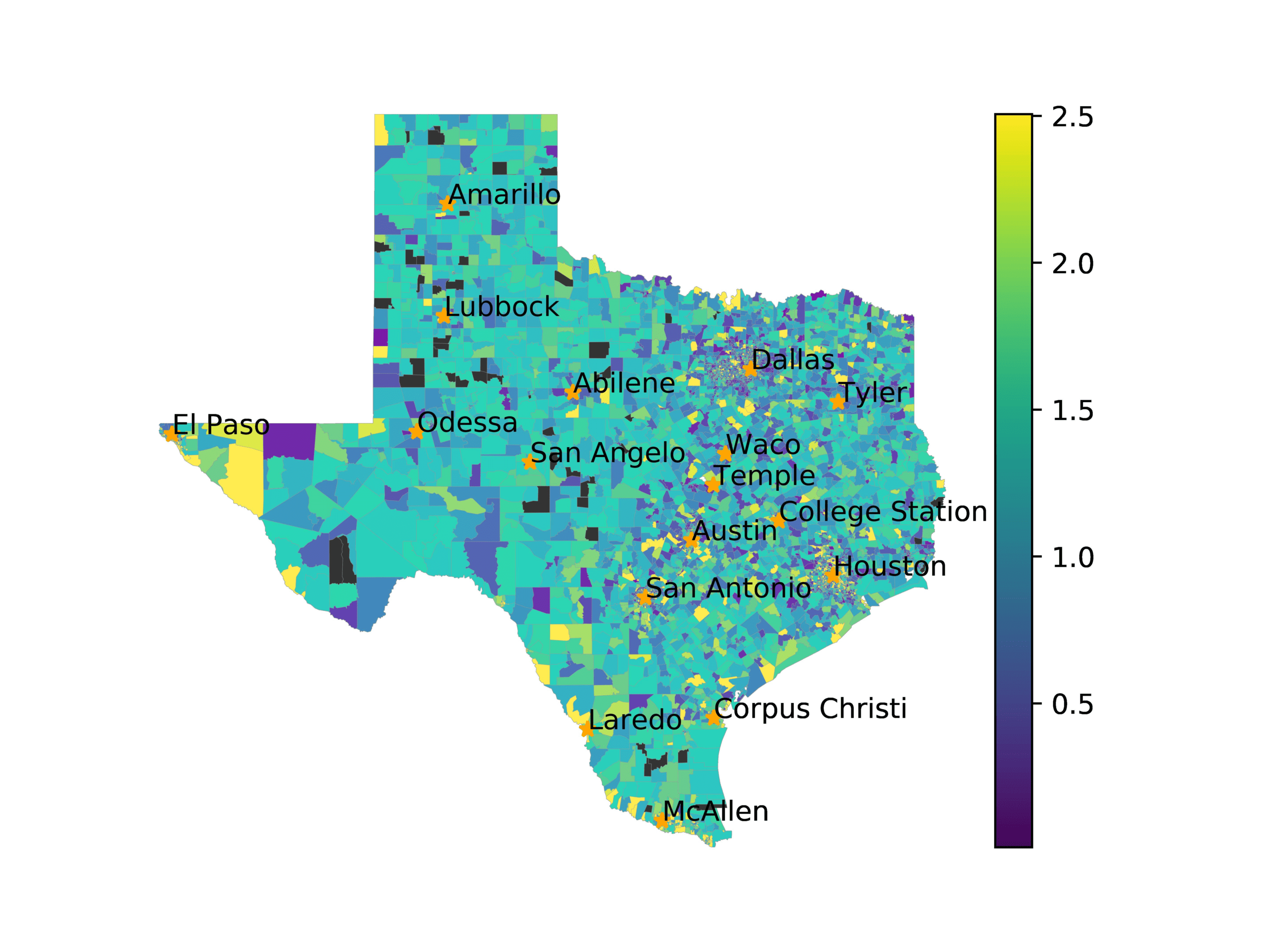
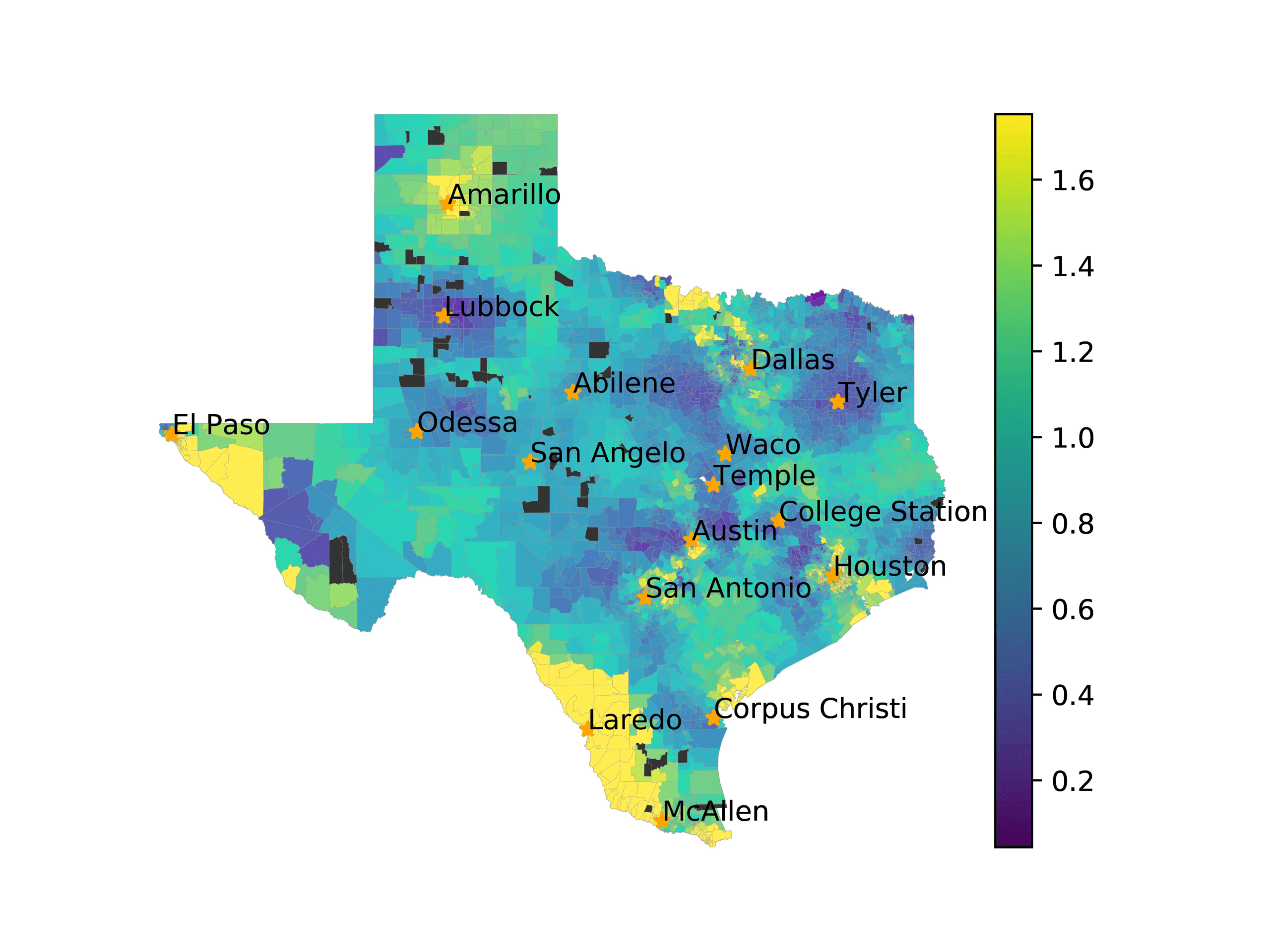
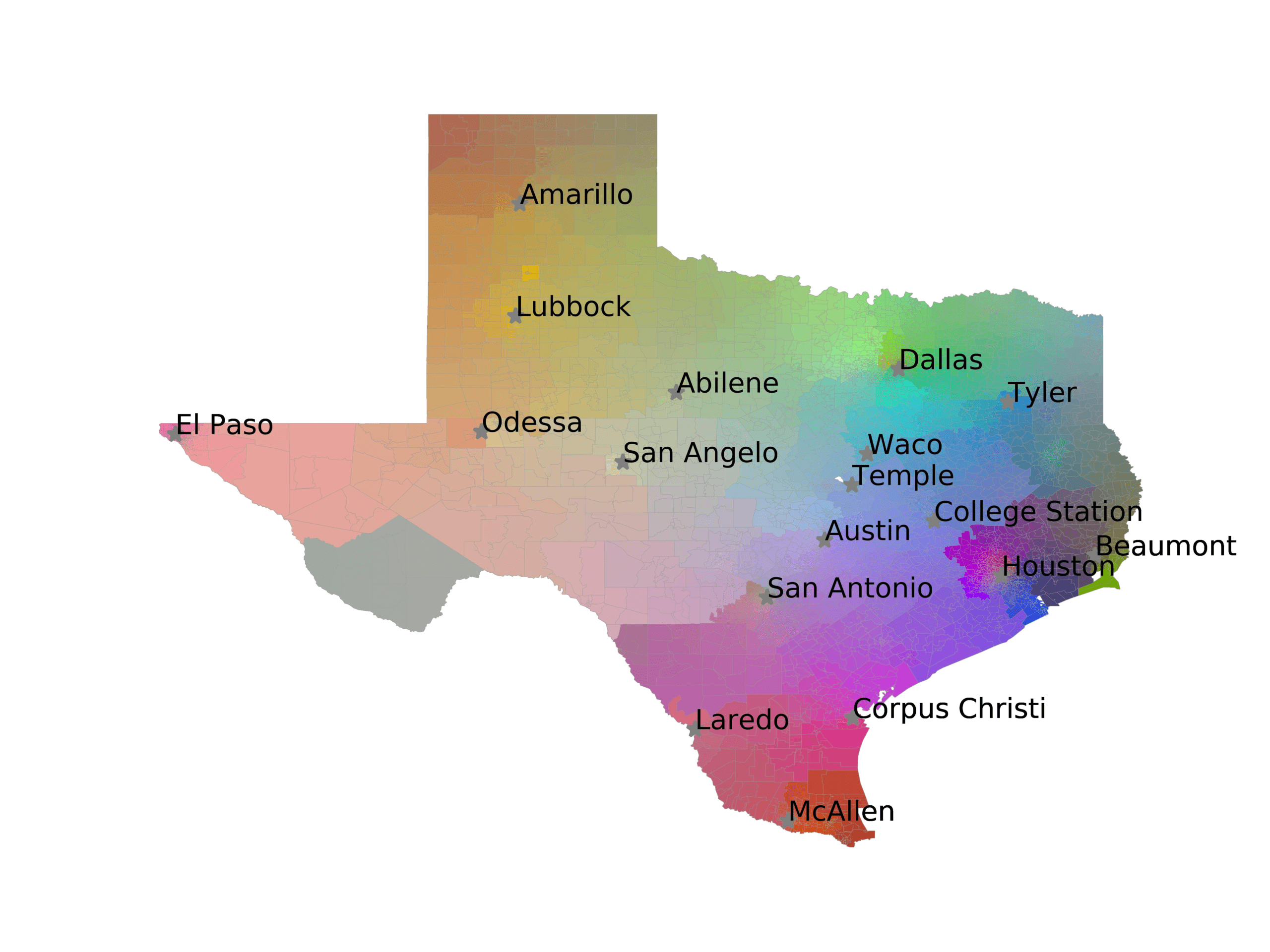
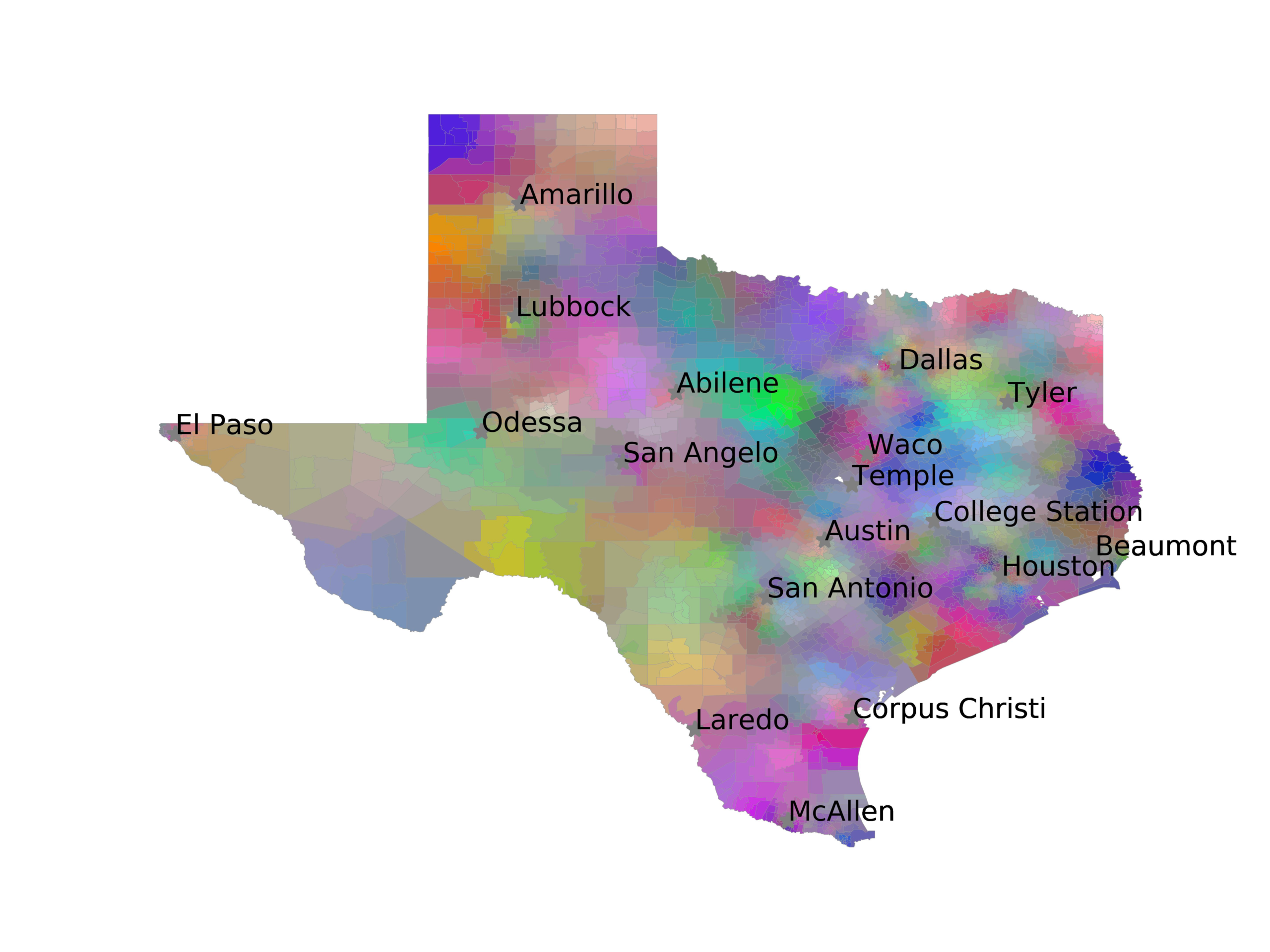
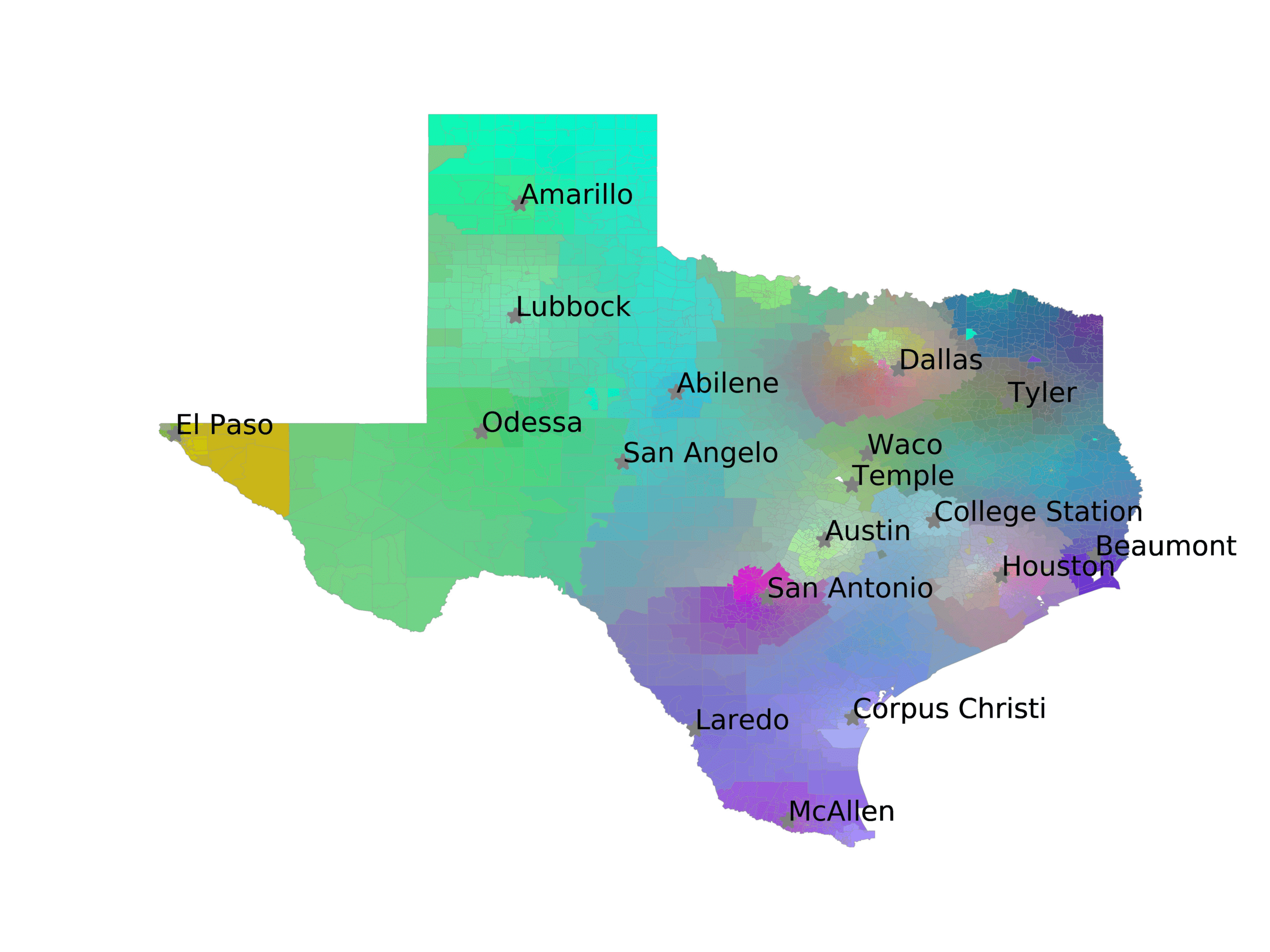
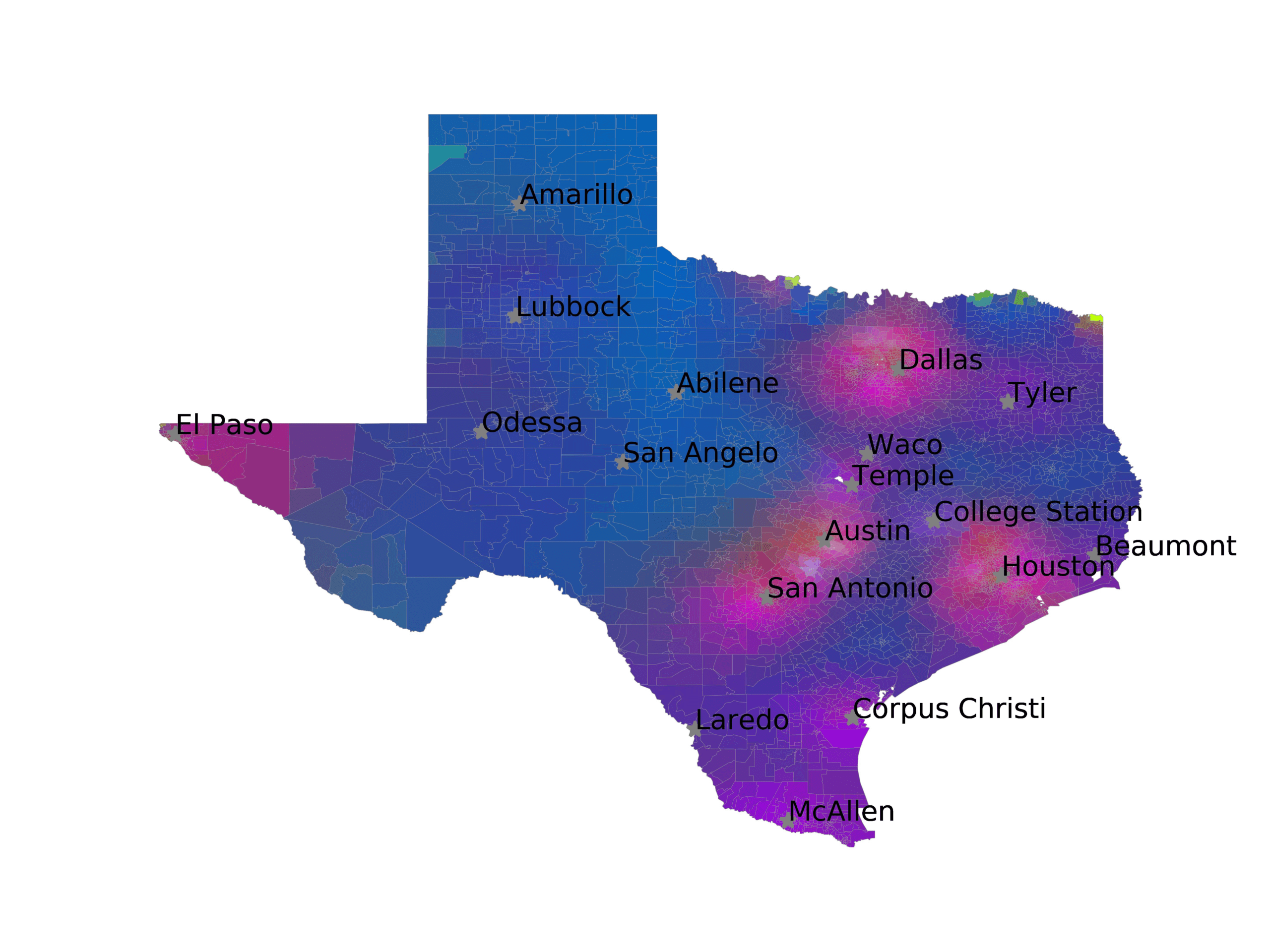
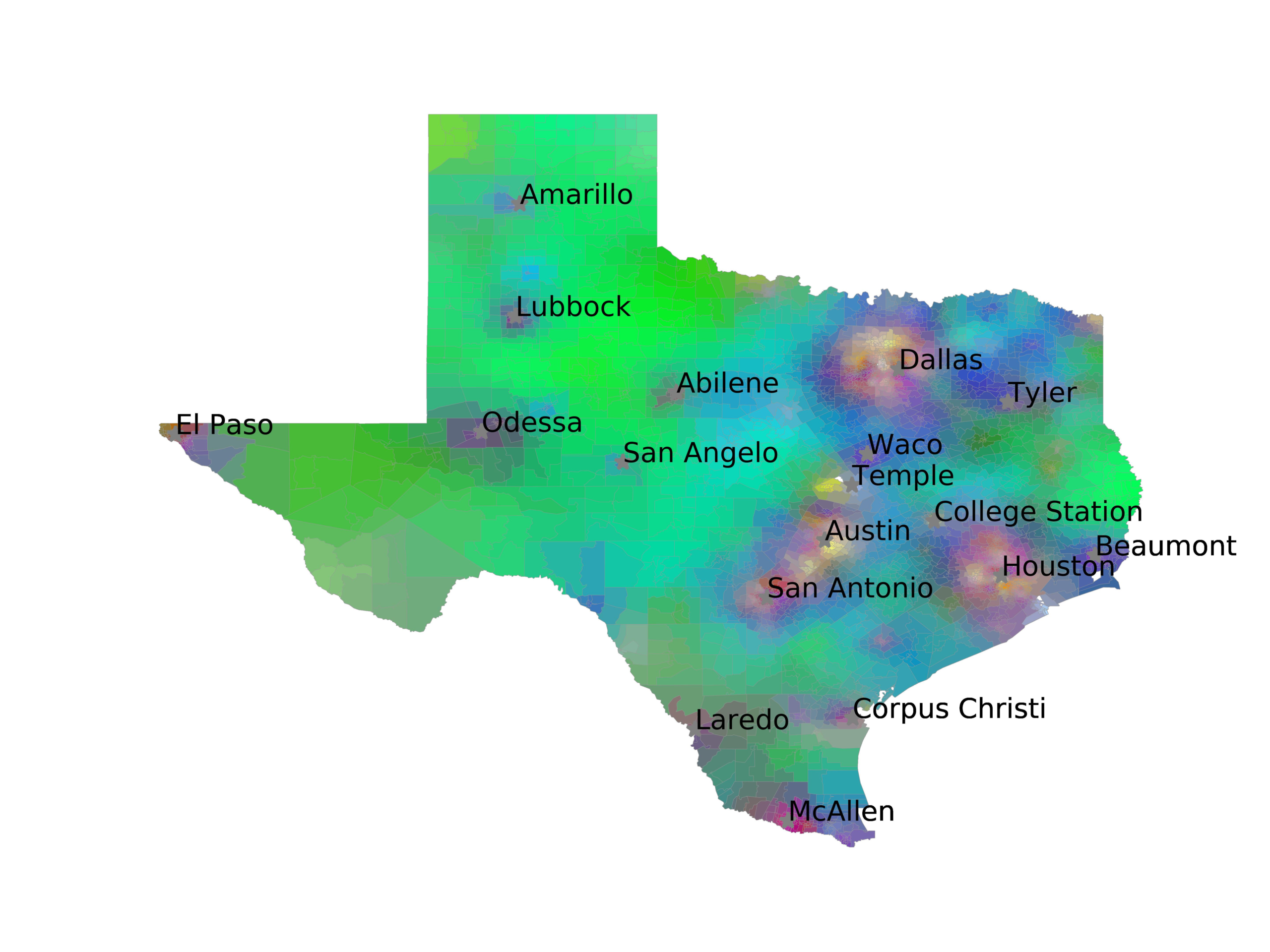
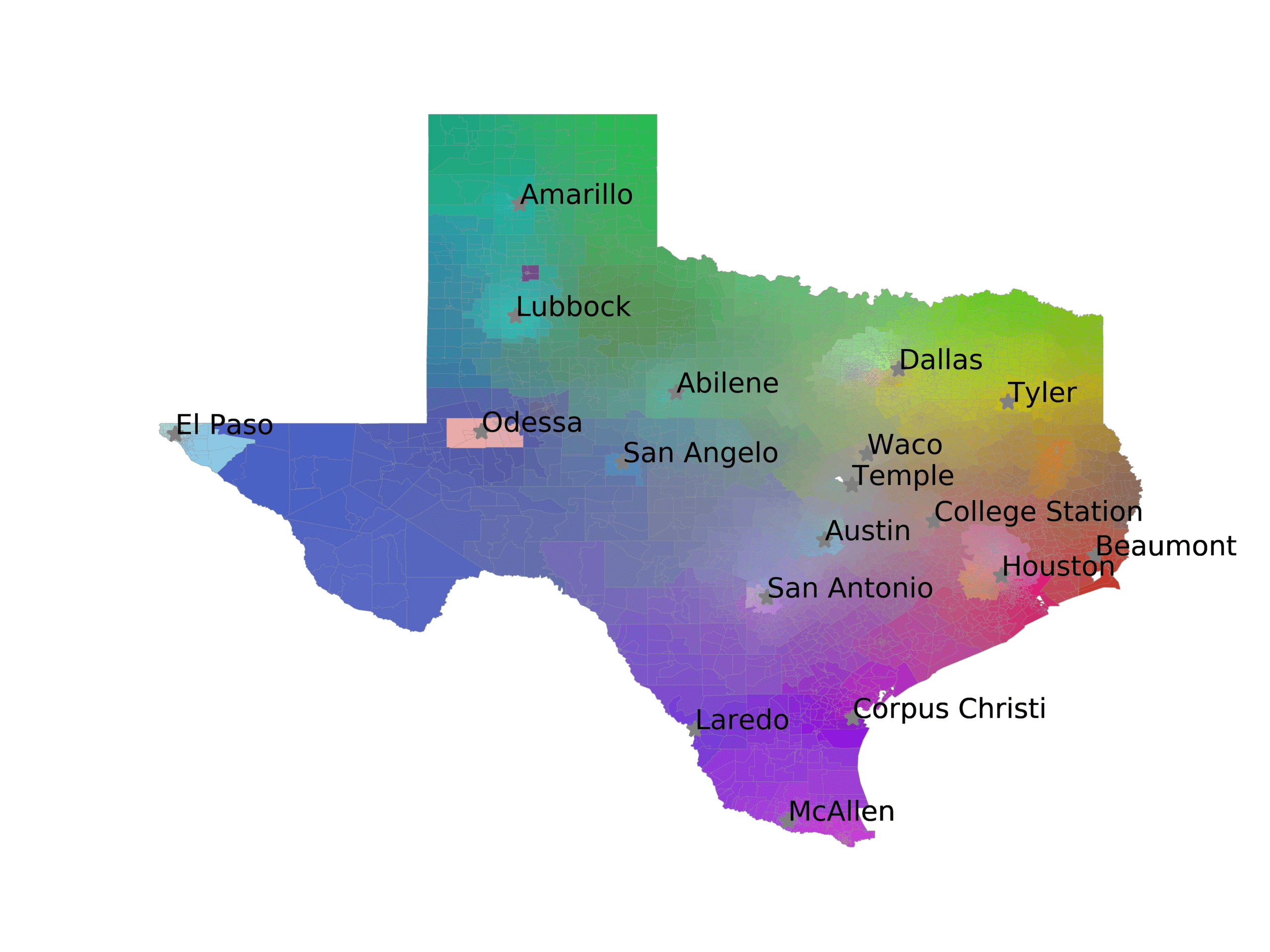
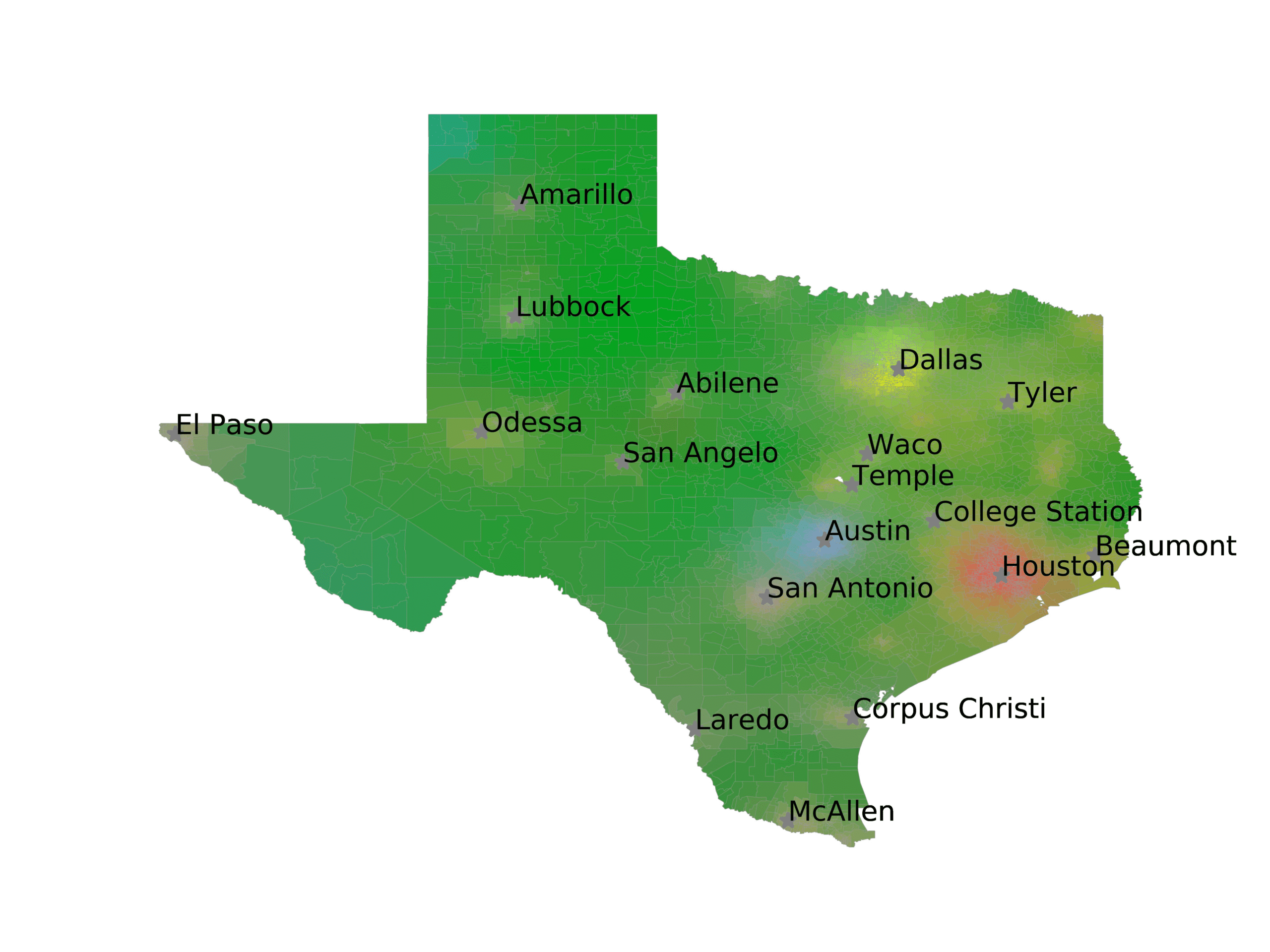
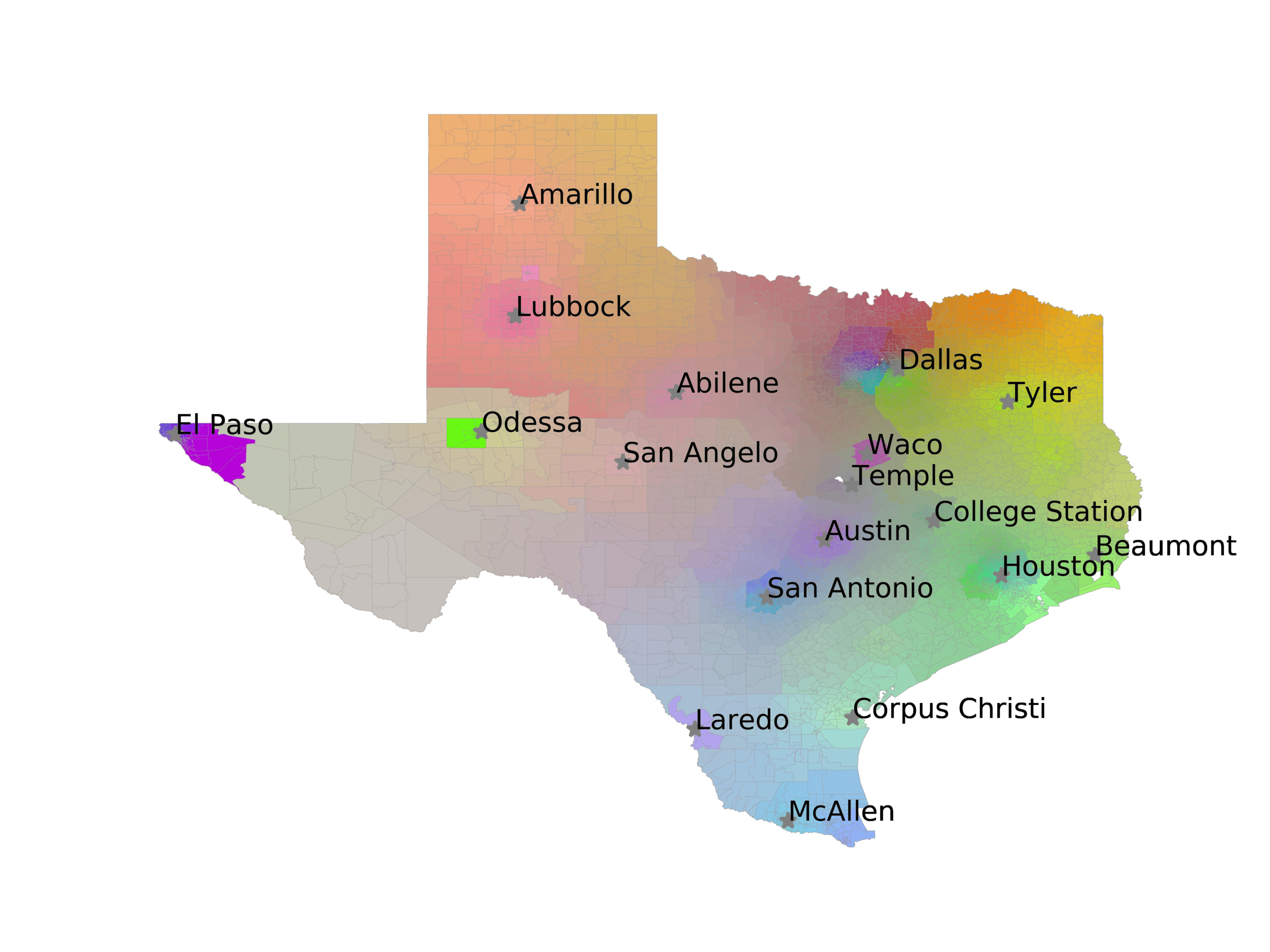
In Figures 6–9, we visualize the predictions of a select set of methods for the
relevant DAREDS regions.5 In each one, we see that Doc2Vec None produces a noisy,
largely indiscernable pattern, indicating that the high score may be related to the model
learning the artifacts of the dataset. 相比之下, the Doc2Vec Alternating (panel e)
and MVP AKS B=100 (panel b) produce patterns that make sense, 例如, 这
prediction of the “Gulf States” region is near the Gulf of Mexico (southeast of Texas)
for which the region is named. 相似地, these models predict the “Southwest” and
“West” regions are to the southwest and west, 分别. Of particular note, 这些
predictions match the locations of where the words were used, as shown in subfigure a.
相比之下, the Doc2Vec Retrofitting (panel d) and BERTLEF Alternating (panel f) 展示
some appropriate regional patterns, but are much messier than Doc2Vec Alternating,
which corroborates their score.
BERT based models generally do worse than their Doc2Vec counterparts. 一
possibility is that the added value of using a BERT model doesn’t outgain the increase in
参数 (768 parameters in BERT to 300 parameters in Doc2Vec). What this indicates
is that the added pretraining done with BERT may not provide the obvious boost in
analyzing lexical variation as is seen in other kinds of tasks. 此外, while we
see that Alternating smoothing does better than Retrofitting, both are worse than the
AKS smoothing methods and Retrofitting smoothing is worse than the random vector
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
5 As Poisson regressions can go to infinity, we cap the values to a standard deviation above the mean to
prevent particularly large predictions hiding other predictions.
17
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
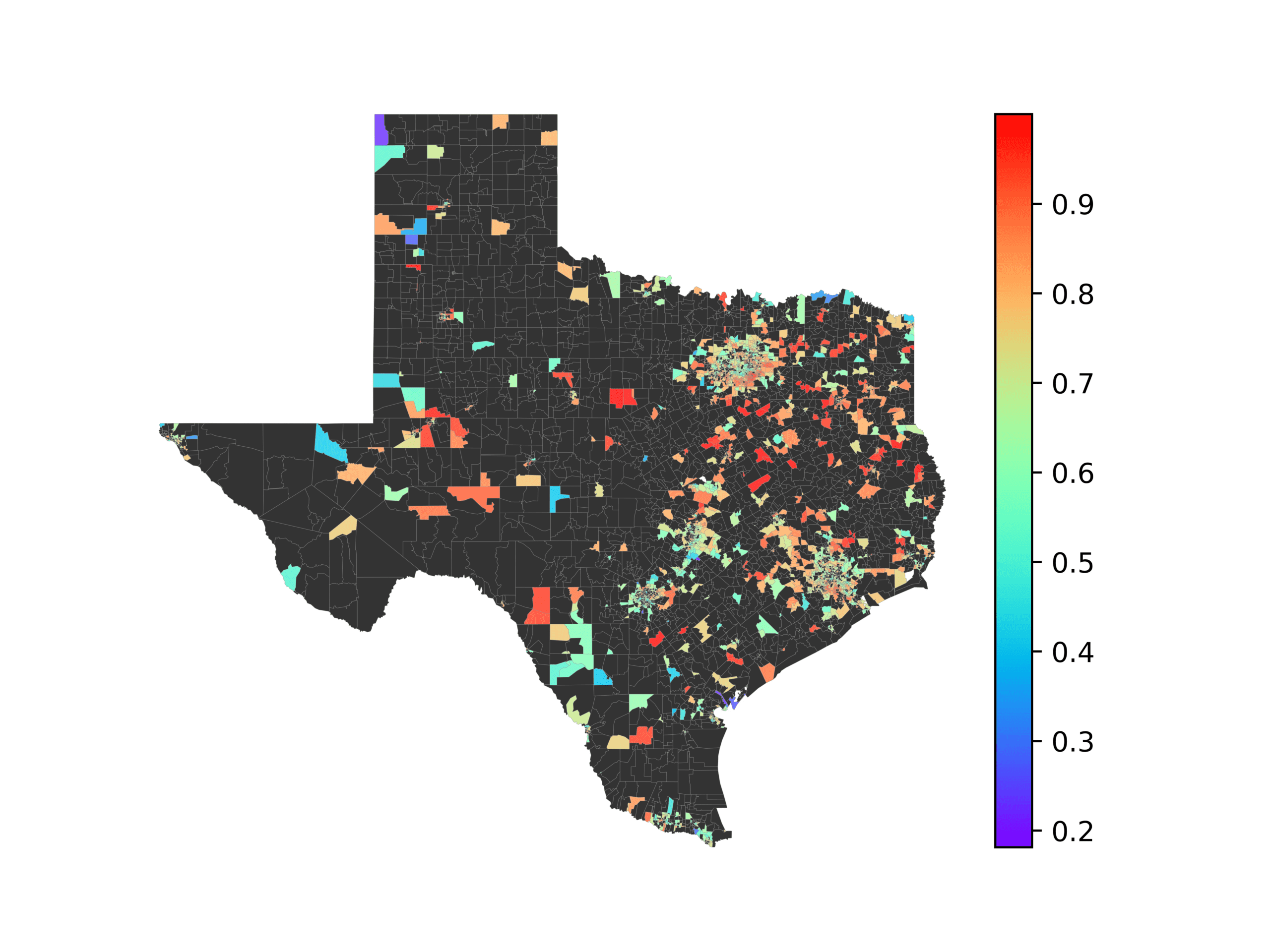
(A) Frequency of terms for “Gulf States” dialect
(乙) MVP AKS B=100
(C) Doc2Vec None
(d) Doc2Vec Retrofitting
(e) Doc2Vec Alternating
(F) BERTLEF Alternating
数字 6
Predicted location of “Gulf States” dialect using various embedding approaches.
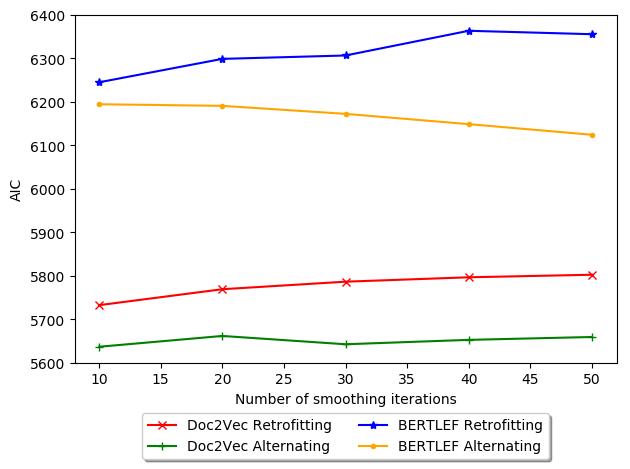
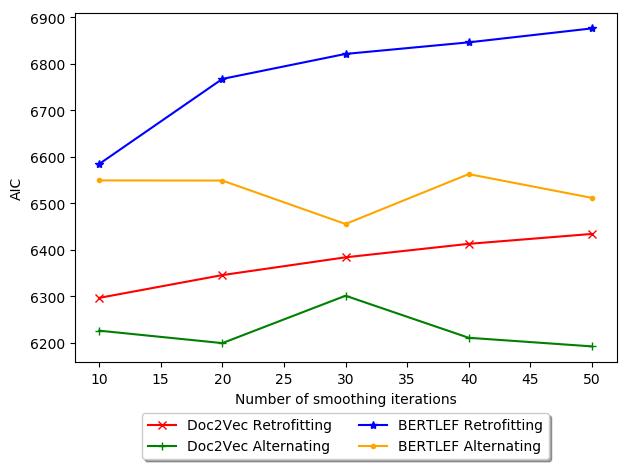
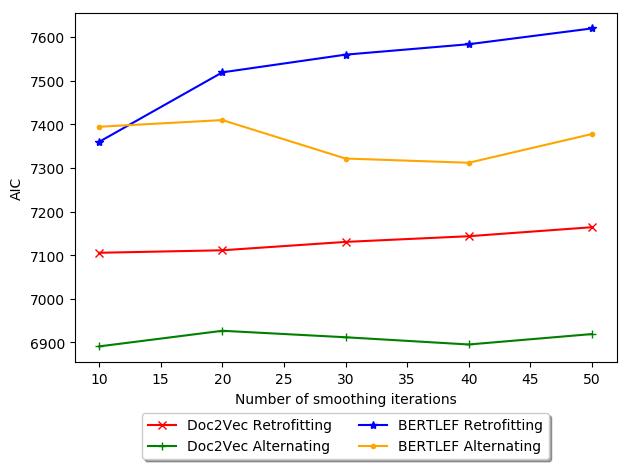
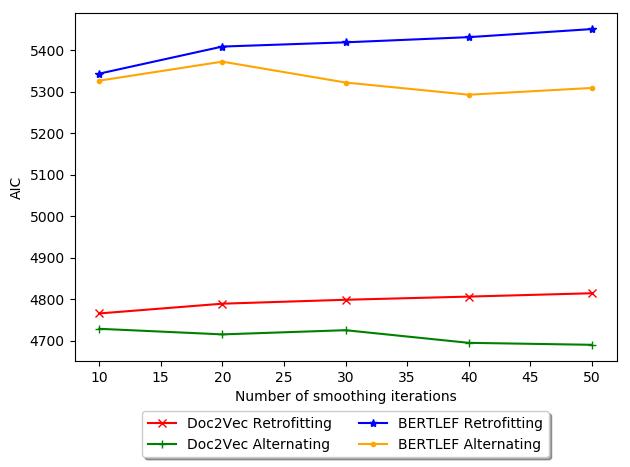
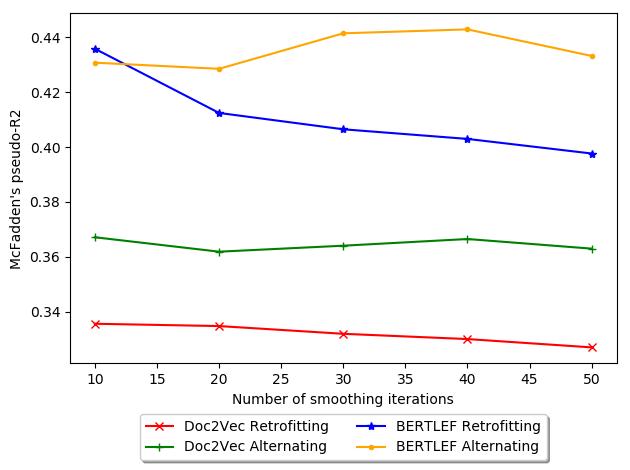
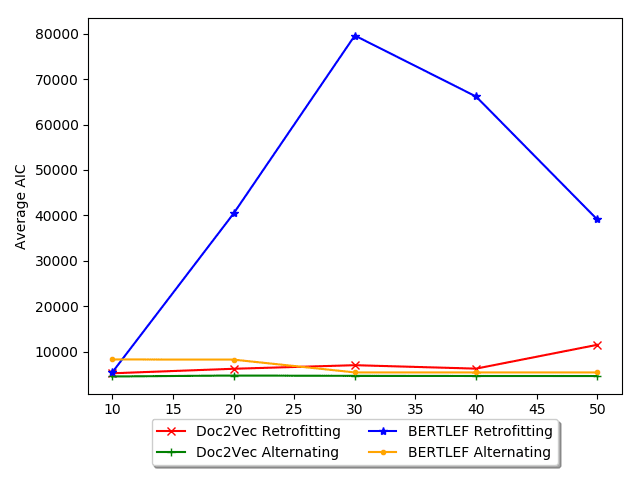
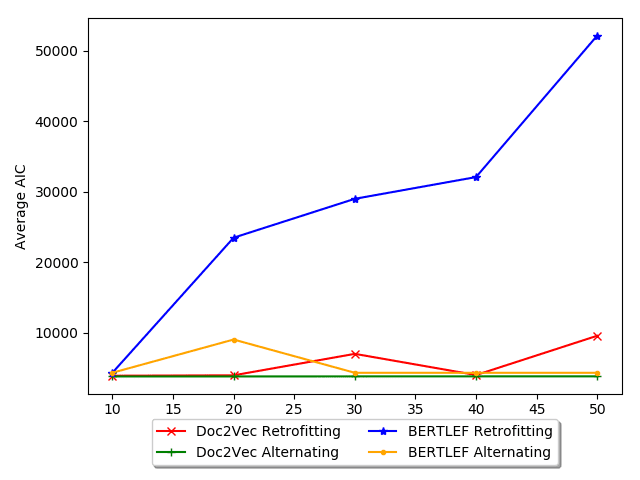
基线. 图中 10, we show a possible explanation and explore this phenomenon
in more detail in the next evaluation. The figure shows the tradeoff between number
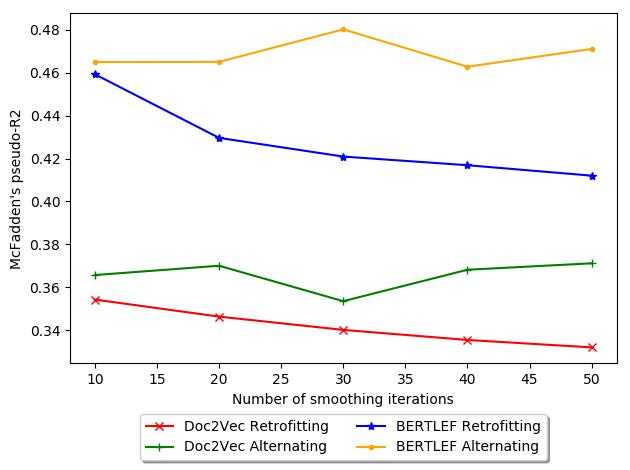
of smoothing iterations and AIC. 一般来说, Retrofitting increases in AIC with more
迭代, which is bad. 因此, for our data, retrofitting may actually be detrimental
and therefore fewer iterations would be less harmful. 相比之下, with Alternating
18
Rosenfeld and Hinrichs
Voting Precinct Embeddings
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
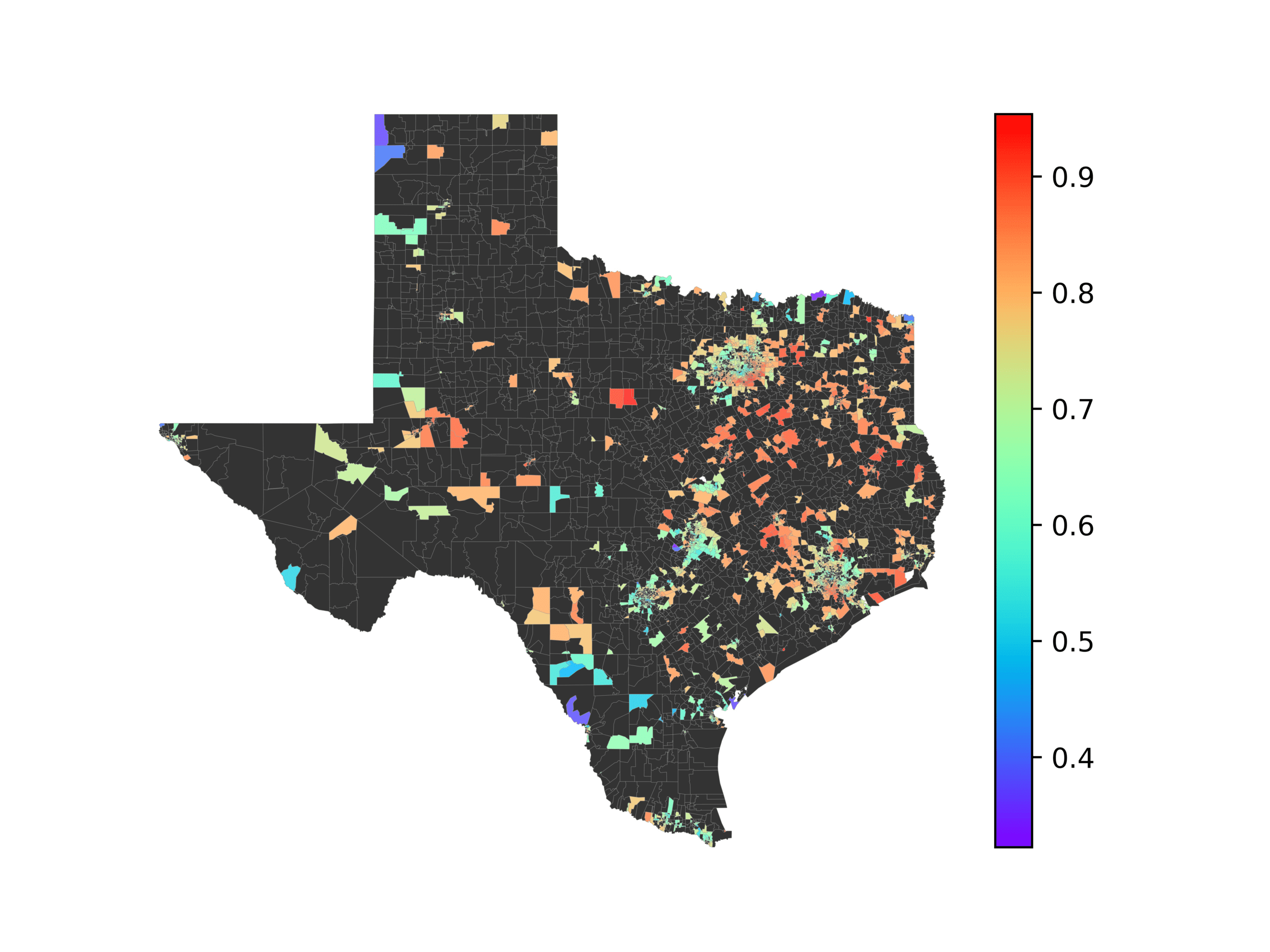
(A) Frequency of terms for “Southwest” dialect
(乙) MVP AKS B=100
(C) Doc2Vec None
(d) Doc2Vec Retrofitting
(e) Doc2Vec Alternating
(F) BERTLEF Alternating
数字 7
Predicted location of “Southwest” dialect using various embedding approaches.
平滑化, we do not see an increase in AIC, which indicates that alternating training
and smoothing may mitigate any harm that could be brought from smoothing the data.
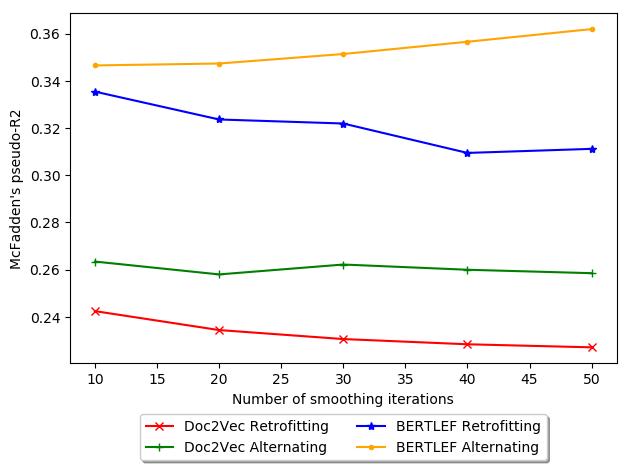
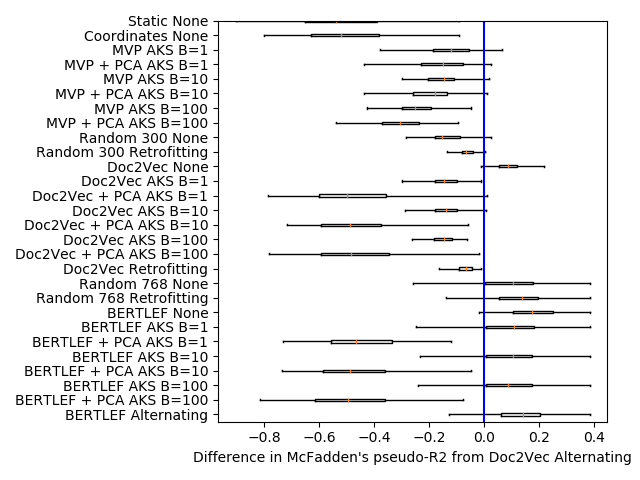
The other metric we explore is McFadden’s pseudo-R2 (McFadden et al. 1973).
McFadden’s pseudo-R2 is a generalization of the coefficient of determination (R2) 那
is more appropriate for generalized linear models, such as Poisson regression. Whereas
19
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
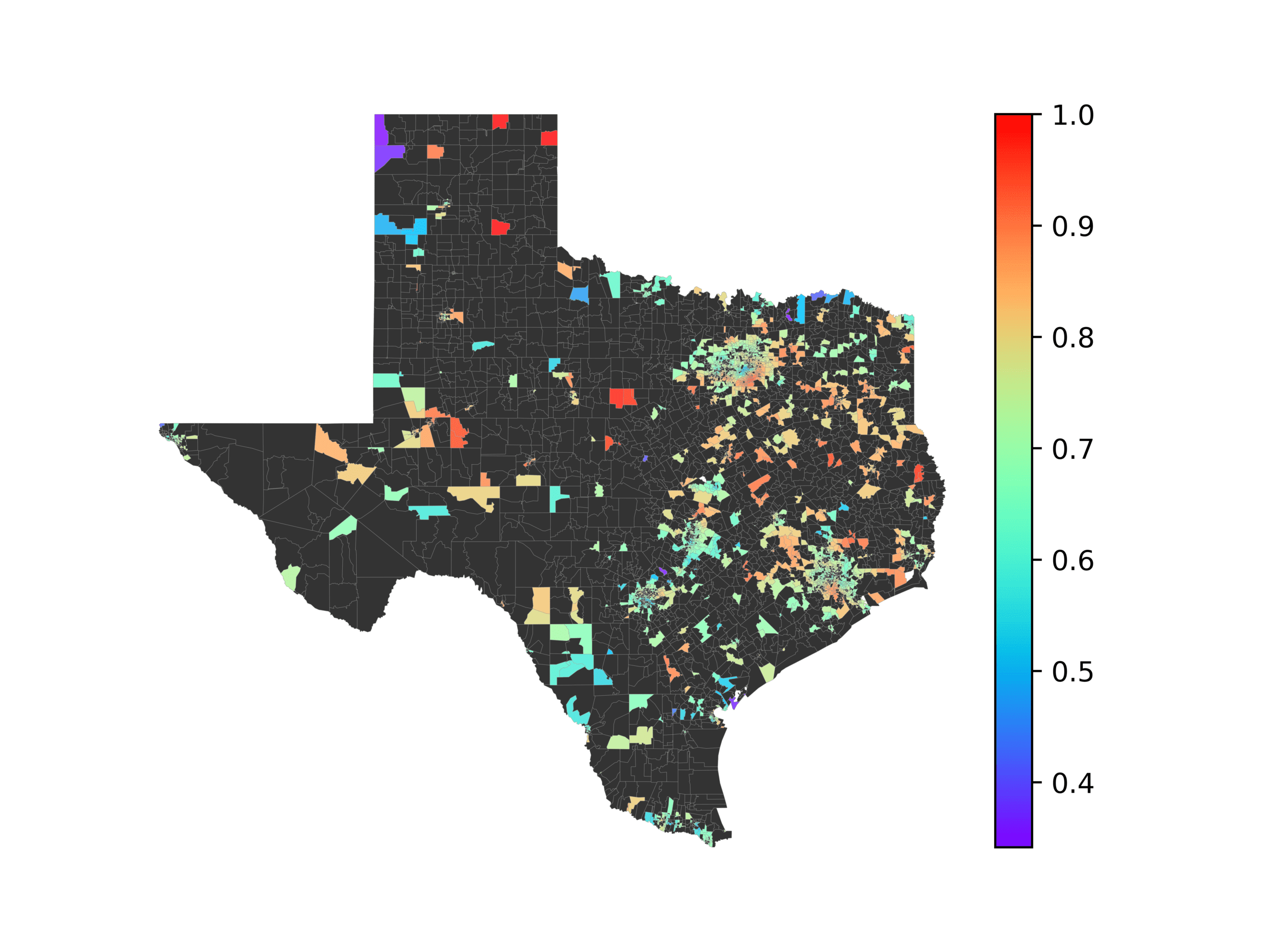
(A) Frequency of terms for “Texas” dialect
(乙) MVP AKS B=100
(C) Doc2Vec None
(d) Doc2Vec Retrofitting
(e) Doc2Vec Alternating
(F) BERTLEF Alternating
数字 8
Predicted location of “Texas” dialect using various embedding approaches.
the coefficient of determination is 1 minus the residual sum of squares divided by the
total sum of squares, McFadden’s pseudo-R2 is 1 minus the residual deviance over the
null deviance. The deviance of a model is the log-likelihood of the predicted values
of the model minus the log-likelihood of the actual values of the model. The residual
deviance is the deviance of the model in question and the null deviance is the deviance
20
Rosenfeld and Hinrichs
Voting Precinct Embeddings
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) Frequency of terms for “West” dialect
(乙) MVP AKS B=100
(C) Doc2Vec None
(d) Doc2Vec Retrofitting
(e) Doc2Vec Alternating
(F) BERTLEF Alternating
数字 9
Predicted location of “West” dialect using various embedding approaches.
of a model where the probability is the same for every voting precinct (only has an
intercept and no embedding information).
McFadden’s pseudo-R2 = 1 − residual deviance
null deviance
We chose this metric as well as it produces easier to understand values (1 是最好的,
0 means the model is just as good as a constant model, negative numbers indicate that
21
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) Gulf States dialect
(乙) Southwest dialect
(C) Texas dialect
(d) West dialect
数字 10
Hyperparameter analysis that compares number of smoothing iterations with AIC.
the model is worse than just using a constant model). 然而, it does not have many
of the nice properties that AIC has.
We provide the corresponding evaluation scores in Table 4 and hyperparameter
analysis graphs in Figure 11. R2 values are largely connected to number of parameters
(MVP scores are lower than Doc2Vec scores, which are lower than BERTLEF scores), 所以
comparing models with different parameter sizes is of limited help. What the pseudo-
R2 do tell us is that the embeddings are useful for capturing dialect areas as they
are positive (如, more useful than a constant model). More than this, as values
之间 0.2 和 0.4 are seen as indicators of excellent fit (McFadden 1977), we see that
the Doc2Vec and BERTLEF approaches with Retrofitting and Alternating smoothing
provide excellent fits for the data.
5.2 Prediction of Lexical Variant Preference
在这个部分, we evaluate embeddings based on their ability to predict lexical variant
preference. Lexical variation is the choice between two semantically similar lexical
项目, such as pop versus soda. Lexical variation is a good determiner of linguistic
variation (Cassidy, 大厅, and Von Schneidemesser 1985; Carver 1987). 因此, if a voting
22
Rosenfeld and Hinrichs
Voting Precinct Embeddings
桌子 4
Results of dialect area prediction evaluation for relevant DAREDS regions.
The value is McFadden’s pseudo-R2 for each region (higher is better).
DAREDS R2 by Region
方法
Static
Coordinates
MVP
MVP + PCA
MVP
MVP + PCA
MVP
MVP + PCA
Random 300
Random 300
Doc2Vec
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec
Random 768
Random 768
BERTLEF
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF
Alternation
没有任何
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
Gulf States
0.00
0.01
0.07
0.06
0.08
0.05
0.11
0.09
0.17
0.20
0.25
0.15
0.02
0.16
0.01
0.13
0.01
0.19
0.22
0.30
0.30
0.32
0.32
0.01
0.32
0.01
0.29
0.01
0.27
0.31
Southwest
0.00
0.09
0.09
0.05
0.17
0.07
0.21
0.16
0.29
0.32
0.39
0.21
0.02
0.26
0.02
0.22
0.02
0.33
0.36
0.46
0.44
0.46
0.46
0.03
0.43
0.03
0.41
0.03
0.40
0.43
德克萨斯州
0.00
0.03
0.12
0.06
0.16
0.07
0.14
0.09
0.28
0.34
0.38
0.16
0.02
0.21
0.01
0.23
0.01
0.33
0.37
0.46
0.47
0.47
0.42
0.01
0.43
0.01
0.45
0.01
0.41
0.47
西方
0.00
0.03
0.05
0.03
0.09
0.05
0.10
0.07
0.17
0.23
0.29
0.16
0.02
0.17
0.02
0.16
0.02
0.23
0.26
0.38
0.34
0.33
0.34
0.01
0.35
0.01
0.35
0.01
0.31
0.36
precinct embedding approach can be used to predict lexical variation, the embeddings
should be reflective of linguistic variation.
We model lexical variation as a binomial distribution. We suppose a population
can choose between two variants lex1 and lex2, 例如, pop and soda. Each voting
precinct acts like a weighted coin where heads is one variant and tails is the other.
Given n mentions of soft drinks, this corresponds to n flips of the weighted coin. 因此,
the number of times a voting precinct uses one form over the other is a binomial
分配.
23
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) Gulf States dialect
(乙) Southwest dialect
(C) Texas dialect
(d) West dialect
数字 11
Hyperparameter analysis that compares number of smoothing iterations with McFadden’s
pseudo-R2.
If voting precinct embedding approach captures linguistic variation, then they
should be able to predict the probability of a voting precinct choosing lex1 over lex2.
换句话说, we use binomial regression to predict the probability of a lexical choice
from the embeddings. The benefit of this approach is that it naturally handles differ-
ences in data size (less data in a precinct just means smaller n) and reliability of the
probability (a probability of 50% is more reliable when n = 500 than when n = 2).
We derive our lexical variation pairs from two Twitter lexical normalization datasets
from Han and Baldwin (2011) and Liu et al. (2011). The Han and Baldwin (2011) dataset
was formed from three annotators normalizing 1,184 out of vocabulary tokens from
549 English tweets. The Liu et al. (2011) dataset was formed from Amazon Turkers
normalizing 3,802 nonstandard tokens (tokens that are rare and diverge from a standard
形式) 从 6,150 tweets. In both cases, humans manually annotated what appears to
be “non standard” uses of tokens with their “standard” variants. These pairs therefore
reflect lexical variation6. We filter out pairs that have data in less than 500 表决
6 We note that these pairs contain pairs that do not necessarily reflect lexical variation, such as typos.
然而, drawing the line between typo and variation is a difficult question of its own and beyond the
scope of our analysis.
24
Rosenfeld and Hinrichs
Voting Precinct Embeddings
precincts. This leads to a list of 66 pairs from Han and Baldwin (2011) 和 110 对
from Liu et al. (2011). See Sections Appendix C and Appendix D in the Appendix for
the list of pairs and statistics. For each voting precinct, we derive the frequency of each
variant in a pair directly from our Twitter data.
桌子 5
Results of lexical variation evaluation for the Han and Baldwin (2011) and Liu et al. (2011) 对.
“AIC” and “R2” are average AIC and McFadden’s pseudo-R2 across pairs. Lower AIC is better
and higher pseudo-R2 is better. “Pairs” are the number of lexical pairs where the binomial
regression was fit successfully. “Shared number of pairs” are the number of pairs that succeeded
on all models. As BERTLEF with Retrofitting succeeded very few times, we remove it from our
分析.
Han and Baldwin
刘等人.
方法
Static
Coordinates
MVP
MVP + PCA
MVP
MVP + PCA
MVP
MVP + PCA
Random 300
Random 300
Doc2Vec
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec + PCA
Doc2Vec
Doc2Vec
Random 768
Random 768
BERTLEF
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF + PCA
BERTLEF
BERTLEF
Shared Number of pairs
Alternation
没有任何
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
没有任何
Retrofitting
没有任何
AKS B=1
AKS B=1
AKS B=10
AKS B=10
AKS B=100
AKS B=100
Retrofitting
Alternating
AIC
5037.90
4820.86
3968.56
4100.76
3946.91
4108.08
4160.22
4263.89
4469.52
4173.60
3720.66
4601.33
4953.07
4460.91
4914.14
6322.71
5247.45
10318.41
3991.38
4652.19
4501.30
4446.72
4675.30
4896.52
4639.71
4922.05
4698.94
4942.70
N/A
4488.41
R2
−0.00
0.02
0.37
0.34
0.34
0.30
0.25
0.21
0.34
0.42
0.57
0.33
0.03
0.34
0.04
−0.86
−1.00
−3.26
0.48
0.56
0.59
0.63
0.56
0.05
0.56
0.04
0.56
0.03
N/A
0.59
AIC
7332.17
7242.46
5855.48
6248.76
5810.90
6199.99
5948.60
6495.72
5614.97
6033.76
4274.39
5785.18
7038.40
5905.68
7102.57
13100.68
7139.56
12927.14
5064.28
5570.99
8982.39
5360.23
5576.14
6860.40
5579.60
7055.13
5679.19
7269.16
N/A
5880.80
R2
−0.00
0.01
0.38
0.34
0.35
0.32
0.28
0.22
0.26
0.40
0.53
0.35
0.05
−0.35
−0.10
−1.34
0.05
−2.94
0.46
0.45
0.00
0.51
0.46
0.07
0.46
0.06
0.46
−0.13
N/A
0.49
Pairs
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
66
62
66
64
66
64
66
22
66
60
Pairs
109
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
103
110
107
110
103
110
35
110
96
25
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
With the frequency data, we fit binomial regression models for each pair of words
with each voting precinct as a datapoint. Models that have a stronger fit indicate that the
corresponding embeddings better capture the choice of variant in the voting precincts.
We present the results of this evaluation in Table 5. See Section 4.6 for a reference for
the method names. We see many of the same insights as in the dialect area prediction
分析. We see that MVP approaches are competitive with Doc2Vec Alternating on
the Han and Baldwin (2011) and underperform Doc2Vec Alternating on the Liu et al.
(2011) dataset. We see that Doc2Vec does better with Alternating smoothing than other
approaches and BERTLEF approaches can do worse than baseline.
图中 12, we present the difference in AIC and McFadden’s pseudo-R2 across
对. As different pairs may naturally easier or harder to predict, we compare the
Doc2Vec Alternating to provide a more neutral comparison of methods. We see that the
MVP approaches tend to have more rightward AIC boxes. Together with the averages
(A) AIC metric with Han and Baldwin (2011)
对.
(乙) AIC metric with Liu et al. (2011) 对.
(C) McFadden’s psuedo-R2 metric with Han and
Baldwin (2011) 对.
(d) McFadden’s psuedo-R2 metric with Liu et al.
(2011) 对.
数字 12
Box and whisker plots that show the difference in AIC and pseudo-R2 between the various
methods and Doc2Vec Alternating across lexical variant pairs. The blue line is where the method
has an equal AIC/R2 to Doc2Vec Alternating. Points right of the blue line are pairs where the
model outperformed Doc2Vec Alternating.
26
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
being close, this indicates that MVP approaches do better than Doc2Vec Alternating
更频繁地, but perform much worse when they do perform worse. For the approaches
that are applied to raw text (and use smoothing), we see that the boxes are to the left
of the blue line, which indicates that they do worse than Doc2Vec Alternating. 什么
this indicates is that among approaches that do not requires manually crafted features,
Doc2Vec Alternating performs the best.
桌子 5 does also highlight some very different conclusions than the previous
评估. In the previous evaluation, all methods had a positive McFadden’s pseudo-
R2, whereas here we see that many approaches have a negative R2, which is a sign
that predictions are extremely off the mark. We also see that some models, 尤其
Doc2Vec Retrofitting, have AICs that are nearly double the others, which is also a sign
of poor prediction. 此外, we see issues in fitting the binomial regression models
in the first place. The “Pairs” column indicates how many of the 66 Han and Baldwin
(2011) pairs and 110 刘等人. (2011) pairs were fit successfully and did not throw
collinearity errors. 例如, BERTLEF AKS B=1 only had 62 pairs with complete
fitting, 意思是 4 pairs failed to fit. The BERTLEF Retrofitting model succeeded on
only about a third of the pairs, so was thrown out. 换句话说, we see that several
models have severe issues in this evaluation.
图中 13, we compare the number of smoothing iterations to the average AIC
(top graphs), average McFadden’s pseudo-R2 (middle graphs), and number of pairs
that were successfully fit. We see that Retrofitting approaches get substantially worse
with more iterations. BERTLEF approaches are particularly susceptible to this issue.7 In
对比, the Alternating smoothing approaches do not have these issues. The Doc2Vec
Alternating approach is stable from start to finish and the BERTLEF Alternating ap-
proach has more minor deviations.
We believe the cause of these problems is that retrofitting, with voting precinct
level data, causes the embeddings to become collinear and thus susceptible to modeling
问题. 图中 14, we compare number of smoothing iterations to the column rank
of the embedding matrix (as calculated by NumPy’s matrix rank method). The gray
lines are the desired rank. Doc2Vec approaches have a dimension of 300 so should have
a column rank of 300. BERTLEF have a dimension of 768 so should have a column
rank of 768. In the figure, we see that, for Retrofitting approaches, the rank sharply
declines, which indicates that smoothing after training causes the embedding dimen-
sions to rapidly become collinear and thus have limited predictive value. 相比之下,
the Doc2Vec Alternating approach does not suffer any decrease in column rank and the
BERTLEF Alternating approach only suffers minor loss in column rank.
The lesson to draw from this is that, for working with fine-grained areas like voting
precincts, alternating training and smoothing is not just a model improvement, 但是一个
necessary part to prevent severe numerical issues. With large areas like cities, retrofitting
has enough data to prevent the kinds of issues seen here. 然而, to gain insight at a
much smaller resolution, alternating is not just a nice to have, but a necessity.
5.3 Finer Resultion Analyses Through Variant Maps
As with dialect area prediction, we can generate maps that predict where one variant
of a word is chosen over another. This may allow sociolinguists to better explore
7 While BERTLEF Retrofitting results do appear to climb back up, the number of pairs that are being
averaged over are decreasing, so may indicate survivor bias and not improvement.
27
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) Number of smoothing iterations vs AIC for
Han and Baldwin (2011) 对. Lower is better.
(乙) Number of smoothing iterations vs AIC for
刘等人. (2011) 对. Lower is better.
(C) Number of smoothing iterations vs McFad-
den’s pseudo-R2 for Han and Baldwin (2011)
对. Higher is better.
(d) Number of smoothing iterations vs Mc-
Fadden’s pseudo-R2 for Liu et al. (2011) 对.
Higher is better.
(e) Number of smoothing iterations vs number
of successfully fit pairs for Han and Baldwin
(2011) 对. Higher is better.
(F) Number of smoothing iterations vs number
of successfully fit pairs for Liu et al. (2011) 对.
Higher is better.
数字 13
Hyperparameter analysis of lexical variation evaluation.
28
Rosenfeld and Hinrichs
Voting Precinct Embeddings
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 14
Number of smoothing iterations vs embedding matrix rank. The top gray bar is 768 (full rank for
BERT-based methods) and the bottom gray bar is 300 (full rank for Doc2Vec-based methods).
Higher is better.
sociolinguistic phenomena. We show an example of this with bro vs brother in
数字 15.
In panel (A), we have the percentage of times bro was used. In panel (乙), 我们有
the Black percentage throughout Texas. We include this as bro has been recognized as
African American slang (Widawski 2015). The bottom four panels are the predicted
percentages from various models. We see that both the gold values and Black Percentage
have an East–West divide. We also see that the models predict a similar divide with the
Retrofitting/Alternating models having a clearer distinction.
A more interesting facet appears when we focus on the divide in bro vs brother
around Houston, 德克萨斯州 (数字 16). In panel (A), we show the Black Percentage de-
mographics around Houston and see that Black people are not uniformly distributed
throughout the city and that there are sections of the city where Black people are more
concentrated (highlighted with a red ellipse is one such section). In panel (乙), we show
our predictions for bro vs brother from the Doc2Vec Alternating model and see that
the predictions are also not uniformly distributed throughout the city and instead are
concentrated in the same areas that the Black population are (also highlighted with an
ellipse). What this indicates is that using voting precincts as our subregions, we are able
to narrow down our analyses to specific, relatively tiny areas.
29
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) Relative frequency of bro vs brother
(乙) Black percentage across Texas.
(C) Doc2Vec None
(d) Doc2Vec Retrofitting
(e) Doc2Vec Alternating
(F) BERTLEF Alternating
数字 15
Predicted location of bro vs brother using various embedding approaches. Values are min–max
scaled. Black shaded precincts are where neither bro nor brother are used.
相比之下, larger areas, such as cities and counties, cannot capture these insights.
If we use counties instead of voting precincts, as in Huang et al. (2016), we see in panel
(C)8 that the bro–brother distinction we identified would be enveloped by a single area.
If we use cities instead of voting precincts, as in Hovy and Purschke (2018), we see
8 Images come from US News and World Report and Wikipedia.
30
Rosenfeld and Hinrichs
Voting Precinct Embeddings
(A) Black population percentage around
Houston, 德克萨斯州. Red indicates high per-
centage, blue mid, purple low.
(乙) Predicted percentage of bro over
brother within Houston Texas. Red indi-
cates high percentage, blue mid, purple
低的.
(C) Section of Harris County that is at
the same scale and location as the maps
多于. The red circle is the same indi-
cated area.
(d) Section of City of Houston Map that is
at the same scale as the maps above. 这
black ellipse indicates the same area.
(e) Larger image of above for context.
(F) Larger image of above for context.
数字 16
Section of Houston to highlight need for more fine grained areas.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
31
计算语言学
体积 49, 数字 4
in panel (d) that we would also envelop that area and similarly be completely unable to
make any finer-grained analyses. 因此, we have shown that finer-grained subregions
can produce finer-grained insights. 然而, as discussed in previous sections, 一
needs to use a different modeling approach in order to be able to gain these insights
and not run into the data issues.
5.4 Embeddings as Linguistic Gene to Connect Language Use with Sociology
The previous sections describe various embedding methods for representing language
use in a voting precinct. Language use in any area is connected to race, socioeconomic
地位, population density, among many, many other factors and these factors are all
represented within the embedding. 在这个部分, we explore how we can extractions
of these embeddings that correlate to sociological factors and use these extractions to
make sociolinguistic analyses.
Our proposed methodology is similar to how genes are used as a nexus to con-
nect two different biological phenomena. 例如, consider the HOX genes. HOX
genes are common throughout animal genetic sequences and are responsible for limb
形成 (such as determining whether a human should grow an arm or a leg out of
their shoulder) (Grier et al. 2005). By looking at expressions of HOX genes, 研究人员
have found a connection between HOX genes and genetic disorders related to finger
development—for example, synpolydactyly and brachydactyly. 由此, 研究人员
identified a possible connection between limb formation and finger development via
the HOX gene link.
We use a similar strategy to link sociological phenomena with linguistic phenom-
ena. We have embeddings for each voting precinct (genetic sequences for each species).
We can identify what portion of these embeddings correspond to a sociological variable
of interest (find the genes for limb formation). We can use these portions to predict
a linguistic phenomenon (use gene expressions to predict a separate physiological
现象). 然后, if successful, we can then link the sociological phenomenon with
the linguistic phenomenon (connect limb formation and finger disorders through the
HOX genes).
To extract the section of the embedding that corresponds to a sociological variable,
we use Orthogonal Matching Pursuit (OMP) which is a linear regression that zeros out
all but a fixed number of weights. We can train an OMP model to predict the sociological
variable from the voting precinct embeddings. The coordinates with non-zero weights
are the section of the embedding that correspond to how the sociological phenomenon
interacts with language use in an area. 例如, if we use the embeddings to predict
Black Percentage in a voting precinct, the extracted section should correlate with how
race intersects with language use.
更正式一点, OMP is a linear regression model where all but a fixed upper bound
of weights is zero. For input matrix X, 例如, where each row is a voting precinct
embedding, output vector y, 例如, the corresponding variable, and number of
non-zero weights n, OMP minimizes the following loss:
||y − Xw|| where w are the regression weights, ||w||0 ≤ n and n > 0.
We use OMP to extract the 10 coordinates in the precinct embeddings that most
correspond to a sociological variable of interest. 例如, if our sociological variable
was Black Percentage, OMP would give us the 10 coordinates that more correlate with
Black Percentage. We can connect Black Percentage to other linguistic phenomenon by
how well those 10 coordinates predict a linguistic phenomenon of interest as well as
identify new linguistic phenomena that could be related to the sociological variable.
32
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
第一的, we explore what insights we can derive from the Black Percentage “gene”
in voting precincts’ language “genetic code”. We use OMP to identify 10 coordinates
that highly correlate with Black Percentage. We can connect this “gene” to linguistic
phenomena by using it to predict lexical variation. We can then look at how increase in
accuracy by using the gene than the entire genetic code. If we find a lexical variant pair
that is better modeled with the gene than the entire embedding, that is an indication
that the pair is connected to the sociological variable, here Black Percentage.
We measure increase in accuracy by percent decrease in AIC or percent increase in
McFadden’s pseudo-R2. We use percentage increase/decrease to account for different
pairs having natural ease of modeling. If a pair has a high percentage increase/decrease,
then they are likely to be connected to the underlying sociological variable. 我们也
compare to using the sociological variable directly and the percentage improvement.
In Tables 6 和 7 we show the top 30 lexical variant pairs from Han and Baldwin
(2011) and Liu et al. (2011). The Gene columns are the rankings as derived from using
the extracted embedding section and the SV columns are using the sociological variables
独自的. 从这些, a sociolinguist can look at the rankings and possibly identify insights
that were previously missed.
To produce an estimate of the accuracy of these lists, we use the African American
slang dictionary in Widawski (2015) as our gold labels and use them to calculate the
average precision (AP). We see that using McFadden’s pseudo-R2 provides the best
结果, with using the “gene” performing slightly better than using the sociological
variable on its own. We also see that the “gene” approach provides different predictions
from solely using the sociological variable, such as the prediction that the til versus until
distinction was possibly connected to Black Percentage.
This indicates that our approach can provide lexical variants that are connected
to sociological variables and thus can be used by sociologists to find new variants that
could be useful in research. Our approach is completely unsupervised, so novel changes
and spread in different communities can be monitored and continually updated with
新数据, which is not feasible for traditional methods.
We perform a similar experiment with the Population Density variable. We show
the top ranked pairs in Tables 8 和 9. As g-dropping is a well explored phenomenon
for rural vs urban divide Campbell-Kibler (2005), we use this as our gold data. 这里,
we see that AIC performs best overall with the “gene” approach slightly outperforming
the sociological variable. From these lists, it appears that there is a connection between
shortening words and population density, 例如, convo vs conversation, gf vs
girlfriend, bf vs boyfriend, txt vs text, and prolly vs probably. By using genes, we might
be able to identify new connections that we may not found otherwise.
6. Dialect Map Prediction via Visualization
在这个部分, we use dimensionality reduction techniques applied to the precinct
embeddings to geographic boundaries of linguistic variation, or “isoglosses”. 这
precinct embeddings are reduced to RGB color values and hard transition in colors
indicate a boundary. To project embeddings into RGB color coordinates, we explore
two approaches. The first is principal component analysis (PCA), which is previously
used in prior work (Hovy et al. 2020). The second is t-distributed stochastic neighbor
embedding (t-SNE) (Van der Maaten and Hinton 2008), which is a probablistic approach
often used for visualizing word embedding clusters.
33
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
桌子 6
Ranking of lexical variation pairs when using extractions from embeddings (基因) versus using
the sociological variable directly (SV). The ranking is done by percentage increase in
R2/percentage decrease in AIC from the original embedding to the extraction/sociological
variable. AP is the average precision. Bold pairs are pairs that previous research has identified to
being relevant to the sociological variable.
SV AIC
数据集: Han and Baldwin (2011)
Sociological Variable: Black Percentage
Rank
Gene AIC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
AP
umm-um
convo-conversation
freakin-freaking
gf-girlfriend
sayin-saying
chillin-chilling
yess-yes
playin-playing
lawd-lord
bf-boyfriend
txt-text
cus-because
ahh-ah
prolly-probably
ohh-oh
bs-bullshit
nothin-nothing
hahah-haha
naw-no
tht-that
pics-pictures
talkin-talking
hahahaha-haha
doin-doing
bb-baby
til-till
fb-facebook
comin-coming
thx-thanks
kno-know
0.055
umm-um
convo-conversation
freakin-freaking
gf-girlfriend
sayin-saying
chillin-chilling
bf-boyfriend
txt-text
yess-yes
lawd-lord
bs-bullshit
ohh-oh
cus-because
pics-pictures
ahh-ah
prolly-probably
hahah-haha
hahahaha-haha
talkin-talking
til-till
naw-no
nothin-nothing
playin-playing
hahaha-haha
tht-that
gon-gonna
doin-doing
fuckin-fucking
bb-baby
goin-going
0.057
Gene R2
SV R2
til-until
lil-little
bro-brother
convo-conversation
tha-the
fb-facebook
hrs-hours
comin-coming
playin-playing
fam-family
btw-between
lookin-looking
de-the
dawg-dog
yu-you
thx-thanks
cuz-because
def-definitely
da-the
jus-just
bday-birthday
ahh-ah
mis-miss
mins-minutes
gettin-getting
kno-know
doin-doing
gon-gonna
soo-so
yr-year
0.252
lil-little
bro-brother
umm-um
tha-the
gon-gonna
da-the
yu-you
fb-facebook
cuz-because
bs-bullshit
ppl-people
dat-that
dawg-dog
kno-know
chillin-chilling
til-until
jus-just
bday-birthday
wat-what
goin-going
de-the
prolly-probably
gettin-getting
nd-and
fuckin-fucking
lookin-looking
naw-no
fam-family
cus-because
mis-miss
0.237
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
6.1 Principal Component Analysis
PCA is widely used in the humanities for descriptive analyses of data. If we have a
collection of continuous variables, PCA essentially creates a new set of axes that cap-
tures the greatest variance in the original variables. 尤其, the first axis captures
34
Rosenfeld and Hinrichs
Voting Precinct Embeddings
桌子 7
Ranking of lexical variation pairs when using extractions from embeddings (基因) versus using
the sociological variable directly (SV). The ranking is done by percentage increase in
R2/percentage decrease in AIC from the original embedding to the extraction/sociological
variable. AP is the average precision. Bold pairs are pairs that previous research has identified to
being relevant to the sociological variable.
SV AIC
数据集: 刘等人. (2011)
Sociological Variable: Black Percentage
Rank
Gene AIC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
AP
wheres-whereas
quiero-query
max-maximum
tv-television
homies-homes
re-regarding
bbq-barbeque
cali-california
convo-conversation
trippin-tripping
freakin-freaking
mines-mine
gf-girlfriend
sayin-saying
chillin-chilling
yess-yes
playin-playing
lawd-lord
txt-text
cus-because
cutie-cute
nun-nothing
wen-when
wut-what
prolly-probably
ohh-oh
thot-thought
nada-nothing
turnt-turn
sis-sister
0.080
wheres-whereas
quiero-query
max-maximum
tv-television
bbq-barbeque
homies-homes
cali-california
trippin-tripping
convo-conversation
freakin-freaking
gf-girlfriend
mines-mine
sayin-saying
chillin-chilling
txt-text
cutie-cute
yess-yes
nun-nothing
lawd-lord
bs-bullshit
ohh-oh
cus-because
wen-when
pics-pictures
wut-what
prolly-probably
sis-sister
thot-thought
feelin-feeling
talkin-talking
0.077
Gene R2
homies-homes
cali-california
re-regarding
mo-more
trippin-tripping
lil-little
bro-brother
convo-conversation
fa-for
wit-with
tha-the
th-the
fb-facebook
bout-about
hrs-hours
tho-though
comin-coming
fr-for
playin-playing
dis-this
fam-family
fml-family
fav-favorite
yo-you
hwy-highway
app-application
thru-through
sum-some
lookin-looking
yu-you
0.264
SV R2
trippin-tripping
lil-little
bro-brother
tha-the
wit-with
yo-you
bout-about
tho-though
da-the
yea-yeah
cause-because
yu-you
fb-facebook
dis-this
gon-going
cuz-because
bs-bullshit
ppl-people
dat-that
sum-some
fr-for
kno-know
quiero-query
chillin-chilling
tv-television
jus-just
thang-thing
mo-more
bday-birthday
wat-what
0.110
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
the greatest variance in the data, the second axis captures the second greatest vari-
安斯, 等等. By quantifying the connection between the original variables and
the axes, researchers can explore what variables have the most impact in the data. 为了
例子, 黄等人。. (2016) use this approach to explore the geographic information
contained inside area embeddings.
35
计算语言学
体积 49, 数字 4
桌子 8
Ranking of lexical variation pairs when using extractions from embeddings (基因) versus using
the sociological variable directly (SV). The ranking is done by percentage increase in
R2/percentage decrease in AIC from the original embedding to the extraction/sociological
variable. AP is the average precision. Bold pairs are pairs that previous research has identified to
being relevant to the sociological variable.
SV AIC
Gene AIC
数据集: Han and Baldwin (2011)
Sociological Variable: Population Density (log scaled)
Rank
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
AP
umm-um
convo-conversation
freakin-freaking
gf-girlfriend
sayin-saying
yess-yes
chillin-chilling
bf-boyfriend
txt-text
cus-because
lawd-lord
ahh-ah
playin-playing
ohh-oh
prolly-probably
bs-bullshit
hahah-haha
pics-pictures
nothin-nothing
naw-no
hahahaha-haha
talkin-talking
tht-that
mis-miss
til-till
doin-doing
hahaha-haha
bb-baby
fuckin-fucking
gon-gonna
0.293
umm-um
convo-conversation
freakin-freaking
gf-girlfriend
sayin-saying
txt-text
chillin-chilling
bf-boyfriend
yess-yes
lawd-lord
cus-because
ohh-oh
bs-bullshit
hahah-haha
ahh-ah
prolly-probably
pics-pictures
hahahaha-haha
talkin-talking
naw-no
til-till
nothin-nothing
hahaha-haha
playin-playing
tht-that
fuckin-fucking
bb-baby
doin-doing
goin-going
pic-picture
0.278
Gene R2
SV R2
de-the
til-until
convo-conversation
dawg-dog
mis-miss
hrs-hours
mins-minutes
yu-you
fb-facebook
comin-coming
tha-the
playin-playing
lookin-looking
bro-brother
ahh-ah
cus-because
gon-gonna
fam-family
congrats-congratulations
pic-picture
nd-and
thx-thanks
lil-little
cuz-because
prolly-probably
fuckin-fucking
yess-yes
da-the
yr-year
wat-what
0.164
til-until
fuckin-fucking
hahaha-haha
lookin-looking
hahah-haha
btw-between
hahahaha-haha
yess-yes
talkin-talking
naw-no
cus-because
de-the
prolly-probably
mis-miss
fam-family
freakin-freaking
til-till
goin-going
lil-little
hrs-hours
bs-bullshit
pls-please
nah-no
congrats-congratulations
def-definitely
da-the
sayin-saying
tht-that
dawg-dog
txt-text
0.264
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Hovy et al. (2020) use PCA to produce variation maps by reducing area embeddings
to three dimensions and then standardizing these dimensions to between 0 和 1 成为
used as RGB values. We perform a similar analysis for a select set of methods in the
left images in Figures 17 和 18. We see that the geography only approach (Random
300 Retrofitting) produces a mostly random pattern of areas while the Doc2Vec None
approach produces some regionalization, but is rather noisy.
36
Rosenfeld and Hinrichs
Voting Precinct Embeddings
桌子 9
Ranking of lexical variation pairs when using extractions from embeddings (基因) versus using
the sociological variable directly (SV). The ranking is done by percentage increase in
R2/percentage decrease in AIC from the original embedding to the extraction/sociological
variable. AP is the average precision. Bold pairs are pairs that previous research has identified to
being relevant to the sociological variable.
SV AIC
Gene AIC
数据集: 刘等人. (2011)
Sociological Variable: Population Density (log scaled)
Rank
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
AP
wheres-whereas
quiero-query
max-maximum
tv-television
homies-homes
bbq-barbeque
re-regarding
cali-california
convo-conversation
trippin-tripping
freakin-freaking
mines-mine
gf-girlfriend
sayin-saying
yess-yes
chillin-chilling
txt-text
cutie-cute
cus-because
nun-nothing
lawd-lord
playin-playing
ohh-oh
wut-what
prolly-probably
bs-bullshit
nada-nothing
wen-when
feelin-feeling
sis-sister
0.197
wheres-whereas
quiero-query
max-maximum
tv-television
bbq-barbeque
homies-homes
cali-california
trippin-tripping
convo-conversation
freakin-freaking
gf-girlfriend
mines-mine
sayin-saying
txt-text
chillin-chilling
yess-yes
cutie-cute
nun-nothing
lawd-lord
wut-what
cus-because
ohh-oh
bs-bullshit
prolly-probably
pics-pictures
talkin-talking
sis-sister
bby-baby
wen-when
feelin-feeling
0.196
Gene R2
homies-homes
cali-california
mo-more
re-regarding
fa-for
dis-this
trippin-tripping
th-the
convo-conversation
mi-my
ft-feet
hrs-hours
hr-hour
mins-minutes
yu-you
fav-favorite
hwy-highway
fb-facebook
comin-coming
fml-family
tha-the
tho-though
wit-with
playin-playing
fr-for
lookin-looking
nada-nothing
bro-brother
cus-because
yea-yeah
0.119
SV R2
mo-more
th-the
hr-hour
ft-feet
wut-what
fuckin-fucking
lookin-looking
bby-baby
dis-this
fa-for
yess-yes
mi-my
nun-nothing
em-them
talkin-talking
naw-no
bout-about
cus-because
prolly-probably
yo-you
fml-family
fam-family
freakin-freaking
fr-for
quiero-query
til-till
goin-going
lil-little
hrs-hours
bs-bullshit
0.151
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
The smoothing approaches generally highlight the cities (possibly with coloring the
cities differently) and leave the countryside a uniform color. 换句话说, using PCA
to produce an isogloss map, we only see the urban–rural divide and do not see larger
region divides. The reason that is that the urban–rural divide appears to be the biggest
37
计算语言学
体积 49, 数字 4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) PCA Visualization of MVP AKS B=100
Embeddings
(乙) t-SNE Visualization of MVP AKS B=100
Embeddings
(C) PCA Visualization of Random 300
Retrofitting Embeddings
t-SNE Visualization of Random 300
(d)
Retrofitting Embeddings
(e) PCA Visualization of Doc2Vec None
嵌入
(F) t-SNE Visualization of Doc2Vec None
嵌入
数字 17
Visualization of voting precinct embeddings using PCA (左边) and t-SNE (正确的).
source of variation in the data and PCA is designed to extract the biggest sources of
variation. 然而, by attaching itself to the strongest signal, PCA is unable to find
key regional differences in language use. 因此, while PCA approaches are useful for
analyzing the information contained in embeddings, it has limited ability to produce
isogloss boundaries.
38
Rosenfeld and Hinrichs
Voting Precinct Embeddings
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(A) PCA Visualization of Doc2Vec Retrofitting
嵌入
(乙) t-SNE Visualization of Doc2Vec Retrofitting
嵌入
(C) PCA Visualization of Doc2Vec Alternating
嵌入
(d) t-SNE Visualization of Doc2Vec Alternating
嵌入
(e) PCA Visualization of BERTLEF Alternating
嵌入
(F) t-SNE Visualization of BERTLEF Alternat-
ing embeddings
数字 18
Visualization of voting precinct embeddings using PCA (左边) and t-SNE (正确的).
6.2 t-Distributed Stochastic Neighbor Embedding
To fix the above issue, we explore a different dimensionality reduction approach, t-SNE
(Van der Maaten and Hinton 2008). Unlike PCA, which tries to find the strongest signals
39
计算语言学
体积 49, 数字 4
全面的, t-SNE instead tries to make sure that points that are similar in the original space
are similar in the reduced space. As retrofitting enforces places that are geographically
close to have similar embeddings, t-SNE may be much more capable of capturing
地区.
The right images in Figures 17 和 18 use t-SNE to visualize embeddings. We see
that there are largely three blocks: one block to the East, one block to the Southwest,
and one block to the Northwest. This indicates that t-SNE may be better at identifying
isoglosses than PCA.
By comparing to the dialect areas in our DAREDS analysis (部分 5.1), we see that
the block to the East overlaps nicely with the predicted “Gulf States” dialect region.
相似地, we see that the Southwest block overlaps nicely with the West and Southwest
blocks. 最后, the Northwest region seems distinct from the other regions. 这个印迪-
cates that we may have a region that is not accounted for by the Dictionary of American
Regional English (Cassidy, 大厅, and Von Schneidemesser 1985). It may be because in
the nearly 40 years since publication, Texas may have experienced a great linguistic
转移. 或者, the region may be understudied and thus may reflect a dialect we
know little about. 在任一情况下, the t-SNE graphs may have shown a particular region
of Texas that warrants further investigation.
7. Summary
We demonstrated that it is possible to embed areas as small as voting precincts and
that doing so can lead to higher resolution analyses of sociolinguistic phenomena. 到
make this feasible, we proposed a novel embedding approach that alternates training
with smoothing. We showed that both training and smoothing have negative effects
when it comes to embedding voting precincts and that smoothing in particular can
cause numerical issues. 相比之下, we found that alternating training and smoothing
mitigates these issues.
We also proposed new evaluations that reflect how voting precinct embeddings
can be used directly by sociolinguists. The first explores how well different models are
able to predict the location of a dialect given terms specific to that dialect. 第二
explores how well different models are able to capture preferences in lexical variants,
such as the preference between pop and soda. We then propose a methodology where we
identify portions of the embeddings that correspond to sociological variables and use
these portions to find novel linguistic insights, thereby connecting sociological variables
with linguistic expression. 最后, we explored approaches for using the embeddings
to identify isoglosses and showed that PCA overly focuses on the urban–rural divide
while t-SNE produces distinct regions.
7.1 Future Work
最后, we present some directions for future work:
•
Although we can produce embeddings that reflect language use in an
区域, further research is needed to produce more interpretable
陈述 (while retaining accuracy and ease of construction) 和
more informative uses of regional embeddings. We do propose a method
of connecting linguistic phenomena to lexical variation using regional
40
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
•
•
嵌入, but much more work is needed to devise methods that
directly address linguists’ needs.
现在, there is a divide between traditional linguistic approaches to
analyzing variation and computational linguistic approaches to
analyzing variation. Given access to a wide variety of social media data,
one goal may be to close the gap between these approaches and develop
definitions of variation that can represent linguistic insights as well as are
rigorous and scalable. There is work that uses linguistic features to define
regional embeddings (Bohmann 2020), but this still operates under
traditional linguistic metrics and region-insensitive methodology
(嵌入). Future work could build on our results to produce a
flexible definition of variation that could directly leverage Twitter data.
最后, a future direction could be to connect the regional embedding
work with temporal embedding work (例如, 汉密尔顿, Leskovec, 和
Jurafsky 2016; Rosenfeld and Erk 2018) to have a unified spacio–temporal
exploration of Twitter data. There is quite a bit of work that does do
spacio–temporal work with Twitter data (例如, Goel et al. 2016; Eisenstein
等人. 2014), but this work makes limited use of embedding models.
Future work could better explain movement of language patterns with
greater accuracy and resolution.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
41
计算语言学
体积 49, 数字 4
附录A. Grieve and Asnaghi (2013) Lexical Variation Pairs
In Table A1, we provide the list of alternates used in our count-based models.
Table A1: Lexical variants from Grieve and Asnaghi (2013) using in our count-based
型号. “Main” is the variant with the largest frequency. “Alternates” is the list of other
variants. “Num VP” are the number of voting precincts that include use of at least one
variant. “Main total” is the total frequency of the “Main” variant. “Alt total” is the total
frequency of the alternative variants. “P-Value” is the p-value from Moran’s I. Gray lines
are variant sets that were removed for having a p-value below 0.001 or appear in less
比 1000 precincts.
Alternates
Num VP Main Total Alt Total P-Value
afore
alley
automobile
婴儿
sack
prohibit, forbid
plead
最伟大的
wager
大的
purchased
mesa
taxi
中间
衣服
comprehend
溪流
父亲
supper
drowsy
另一个
embrace
faithful
genuine
gym
running
tennis shoes
truthful
hurry
生病的
不正确
shoes,
shoes,
4416
2684
6425
5117
2026
4297
2261
5750
5750
4979
1630
1342
1664
3314
1733
2761
1332
4705
2490
1894
1552
2947
1336
6559
216
2675
2874
7266
3364
16267
14615
309589
21176
4217
29532
5268
32971
36660
24258
2289
2250
3736
24299
2342
4937
5075
16457
7873
2898
2164
8201
1410
67748
256
4724
4753
223879
7136
33
2939
162
187
381
235
138
1408
29
1326
147
872
288
3878
1254
50
1179
2344
275
37
170
326
644
307
85
51
1867
5173
62
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
主要的
前
车道
car
baby
bag
禁止
beg
最好的
赌注
大的
bought
butte
cab
中心
衣服
understand
creek
dad
dinner
sleepy
彼此
hug
loyal
真实的
sneakers
honest
rush
患病的
wrong
42
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
little
或许
mom
需要的
prairie
student
快速地
sad
stomach
trash
尽管
smart
holiday
island
slim
尤其
obviously
rude
grandma
bathroom
garage sale
icing
grandpa
稀有的
任何地方
ping pong
pharmacy
sunset
dawn
bucket
brag
madness
错误的
昂贵的
全球的
couch
spine
fridge
porch
小的
也许
母亲
必需的
plains
pupil
quick, 迅速的
unhappy
belly, tummy
garbage, rubbish
whilst
聪明的
vacation
isle
slender
特别
clearly
impolite
祖母,
granny, nana
restroom,
washroom
rummage sale, tag
sale, yard sale
frosting
grandfather
scarce
anyplace
table tennis
drug store
sundown
daybreak
pail
boast
insanity
untrue
昂贵
全世界
sofa
backbone
refrigerator
veranda
5227
3296
5727
2007
540
1383
4325
5000
1778
1248
3950
1521
1542
881
492
1269
1357
1262
2259
1005
182
579
860
691
737
101
392
941
340
666
370
612
336
459
460
810
186
333
340
24025
6423
27826
4526
3896
5573
11958
23613
2110
1726
12434
2453
1850
2261
916
1816
1141
1860
1739
3846
178
5489
445
476
34
7274
192
1419
248
48
225
1339
1091
11
38
777
2
2339
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
1151
443
0.000
218
899
1024
1063
979
184
3243
7725
523
974
403
780
512
520
1007
891
191
324
526
94
0.000
62
140
12
8
2
5
115
92
32
43
185
12
22
329
400
93
73
36
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
43
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
grass,
jacuzzi
abrupt
billfold
instantaneously
corridor
vanish
blow up
clorox
bookshop
有礼貌
deadly, lethal
by accident
achievement
courageous
aside from
aubergine
mow the
mow the lawn
aloud
basement
movie theater
akin to
shall not
comforter
improper
sun up
graveyard
adequate
enquire
suv
coffin
flourish
ferocious
insufferable
inexplicable
stamina
disobey
moisten
impassioned
droopy
farthest
consent to
hot tub
sudden
wallet
instantly
hallway
消失
explode
bleach
bookstore
有礼貌的
fatal
on accident
accomplishment
brave
除了
eggplant
cut the grass
out loud
cellar
cinema
similar to
shant
quilt
inappropriate
sunrise
cemetery
sufficient
inquire
jeep
casket
thrive
fierce
unbearable
unexplainable
endurance
defy
dampen
passionate
saggy
furthest
agree to
44
159
525
337
157
313
324
358
209
90
97
286
160
249
356
299
46
28
278
147
397
70
120
94
133
485
191
81
28
524
92
131
181
45
24
80
50
8
159
49
62
90
154
590
465
170
313
340
218
241
153
101
431
107
186
480
285
56
18
284
259
1221
68
82
181
130
3486
318
56
49
873
70
224
250
42
18
90
48
8
205
38
40
93
40
14
1
2
161
44
181
6
14
10
348
71
185
68
52
2
10
55
148
174
12
60
33
40
14
120
33
2
199
60
57
19
4
8
28
9
1
1
14
25
3
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.000
0.001
0.001
0.001
0.001
0.003
0.004
0.008
0.028
0.050
0.058
0.067
0.067
0.079
0.105
0.114
0.166
0.183
0.208
0.263
0.294
0.361
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
food processor
somewhere else
skillet
mailman
afire
inadequate
enclose
husk
ski doo
slow cooker
flammable
murderous
entrust
unarm
shoelace
water fountain
incarcerate
leaned in
cuisinart
别处
frying pan
postman
ablaze, aflame
insufficient
inclose
shuck
snowmobile
crock pot
inflammable
homicidal
intrust
disarm
shoestring
drinking fountain
imprison
leaned forward
3
197
65
23
31
22
9
253
2
19
5
11
19
33
21
22
17
4
3
147
93
22
29
11
10
330
1
16
8
6
14
47
16
23
9
4
2
62
6
6
19
11
1
129
1
8
4
5
9
3
8
4
8
1
0.439
0.443
0.493
0.566
0.575
0.612
0.656
0.662
0.671
0.745
0.754
0.760
0.799
0.857
0.884
0.890
0.908
0.909
附录B. DAREDS Dialect-Specific Terms
In Table A2, we provide the list of dialect-specific terms used in our dialect prediction
评估.
Table A2: Dialect specific terms from DAREDS used in our analysis. “Num VP” is the
number of voting precincts the term appears in. “Total Freq” is the total frequency of
the term.
DAREDS Dialect
学期
Num VP
Total Freq
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
aguardiente
bogue
cavalla
chinaberry
cooter
curd
doodlebug
jambalaya
loggerhead
maguey
nibbling
nig
1
1
1
1
12
17
1
27
1
4
3
72
1
1
1
3
23
18
1
27
3
5
3
76
45
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
pollywog
redfish
sardine
scratcher
shinny
squinch
whoop
acequia
agarita
agave
aguardiente
alacran
alberca
albondigas
alcalde
alegria
armas
arriero
arroba
arrowwood
atajo
atole
ayuntamiento
azote
baile
bajada
baldhead
barranca
basto
beaner
blinky
booger
burro
caballo
caliche
camisa
carcel
carga
1
14
4
8
3
1
488
2
1
38
1
1
12
3
5
20
8
1
1
2
1
7
1
1
41
1
2
3
5
31
3
47
17
12
1
16
2
7
1
20
4
8
4
1
588
5
1
72
1
1
12
3
6
21
16
1
1
5
1
7
3
1
54
30
2
3
5
32
4
49
44
13
1
16
2
39
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Gulf States
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
46
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
cargador
carreta
cenizo
chalupa
chaparreras
chapo
chaqueta
charco
charro
chicalote
chicharron
chiquito
cholo
cienaga
cocinero
colear
comadre
comal
compadre
concha
conducta
cowhand
cuidado
cuna
dinero
dueno
enchilada
encinal
estufa
fierro
freno
frijole
garbanzo
goober
gotch
greaser
grulla
jacal
8
5
2
17
1
47
2
7
27
1
4
20
39
1
1
1
11
31
37
15
4
2
25
4
75
2
39
4
1
16
5
2
5
26
6
3
5
2
9
6
2
17
1
67
2
8
39
1
4
25
40
1
1
1
12
124
97
18
4
2
29
5
84
2
47
9
1
77
5
2
9
29
6
3
8
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
47
计算语言学
体积 49, 数字 4
junco
kiva
lechuguilla
loafer
maguey
malpais
menudo
mescal
mestizo
milpa
nogal
nopal
olla
paisano
pasear
pelado
peon
picacho
pinole
plait
potrero
potro
pozo
pulque
quelite
ranchero
reata
runaround
seesaw
serape
shorthorn
slouch
tamale
tinaja
tomatillo
tostada
tule
vaquero
2
9
1
4
4
1
94
1
3
2
4
8
6
14
7
1
17
2
2
2
4
6
3
2
1
14
6
3
3
6
1
2
47
2
5
16
3
19
3
25
1
4
5
2
107
1
8
3
5
9
9
73
8
1
17
11
2
2
4
12
4
2
1
19
28
3
3
12
1
2
64
2
21
23
6
37
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
Southwest
48
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
Southwest
Southwest
Southwest
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
vara
wetback
zaguan
agarita
banquette
blackland
bluebell
borrego
cabrito
caliche
camote
cenizo
cerillo
chicharra
coonass
ducking
firewheel
foxglove
goatsbeard
granjeno
grulla
guayacan
hardhead
huisache
icehouse
juneteenth
kinfolk
lechuguilla
mayapple
mayberry
norther
piloncillo
pinchers
piojo
praline
priss
redhorse
resaca
2
18
1
1
3
3
14
10
5
1
1
2
1
1
3
66
19
3
1
1
5
2
1
4
46
12
88
1
1
8
3
1
1
18
14
5
1
5
2
18
3
1
3
4
15
17
27
1
1
2
1
1
3
68
114
3
2
3
8
3
1
7
132
16
96
1
1
8
3
1
1
20
17
5
1
5
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
49
计算语言学
体积 49, 数字 4
retama
sabino
scissortail
sendero
shallot
sharpshooter
sook
sotol
spaniard
squinch
tecolote
trembles
tush
vamos
vaquero
vara
washateria
wetback
arbuckle
barefooted
barf
bawl
biddy
blab
blat
boudin
breezeway
buckaroo
bucking
bunkhouse
caballo
cabeza
cack
calaboose
capper
chapping
chileno
chippy
11
2
1
9
1
3
1
6
2
1
2
1
4
31
2
3
26
1
3
1
28
2
1
6
1
4
392
580
19
2
16
18
8
2
44
10
3
3
3
29
6
9
19
4
12
70
4
1
2
1
1
7
37
2
24
18
25
2
47
10
6
3
3
36
10
10
21
5
13
74
4
2
2
1
1
12
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
德克萨斯州
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
50
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
clabber
clunk
cribbage
cutback
dally
dogger
entryway
freighter
frenchy
gaff
gesundheit
glowworm
goop
grayback
groomsman
hackamore
hardhead
hardtail
headcheese
heave
heinie
highline
hoodoo
husk
irrigate
jibe
jimmies
kaput
kike
latigo
lockup
longear
lunger
maguey
makings
manzanita
mayapple
mochila
1
1
1
1
3
2
7
1
4
2
1
1
5
1
1
1
1
2
1
3
1
4
1
1
1
4
4
1
15
3
3
1
1
4
7
5
1
4
1
1
1
1
3
3
8
1
5
7
1
1
5
2
2
2
1
5
1
3
1
8
2
1
1
5
8
1
16
4
4
1
1
5
30
6
1
4
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
51
计算语言学
体积 49, 数字 4
nester
nighthawk
paintbrush
partida
peddle
peeler
pincushion
pith
plastered
podunk
pollywog
prat
puncher
riffle
ringy
rustle
rustler
seep
serape
sinker
sizzler
snoozer
snuffy
sprangletop
sunfish
superhighway
swamper
tallboy
tamarack
tenderfoot
tennie
tumbleweed
vamos
waddy
waken
washateria
weedy
wienie
1
6
19
5
3
1
3
1
9
2
1
1
5
1
1
1
3
4
6
11
5
1
2
1
1
1
2
2
2
2
1
11
392
2
9
16
1
4
1
10
29
5
3
1
6
1
9
2
1
1
5
1
1
1
4
4
12
15
5
1
2
1
1
1
4
2
3
4
1
37
580
2
9
24
1
4
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
西方
52
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
西方
西方
wrangle
zori
4
1
5
1
附录C. Han and Baldwin (2011) Lexical Variants
Table A3: Lexical variants from Han and Baldwin (2011) used in our lexical variant
评估. “Canonical” is the canonical form as identified by annotators and “Variant”
is the non-standard variant. “Var VP” and “Var Freq” are the number of voting precincts
that contain the variant and the total frequency. “Can VP” and “Can Freq” are similar
for the Canonical form.
Variant
Canonical
Var VP Var Freq Can VP Can Freq
Shared VP
ahh
bb
bc
bday
bf
bro
bs
btw
chillin
comin
ah
baby
因为
birthday
boyfriend
brother
bullshit
之间
chilling
未来
congrats
congratulations
convo
conversation
cus
cuz
和
dat
dawg
的
def
doin
fam
fb
freakin
fuckin
gettin
gf
goin
因为
因为
这
那
狗
这
definitely
doing
家庭
freaking
fucking
getting
girlfriend
going
1009
665
2808
1281
974
3735
953
686
1174
563
1542
521
541
2288
2326
1648
806
3267
617
941
2040
1127
554
1891
1380
772
1446
1319
861
6220
2033
1194
12036
1308
862
1653
681
2945
586
675
3959
5497
2900
1240
21053
2575
1272
3921
1637
654
3064
1992
942
2089
1162
4828
4802
4650
2172
2747
1395
1890
888
3612
881
960
4802
4802
7669
7134
2356
7669
1832
4153
3862
1246
1555
4209
5066
1474
5881
1800
17472
17280
19210
3398
5263
1952
6710
1185
10765
1765
1259
17280
17280
598549
142061
5337
598549
3224
11681
12856
1962
2157
12868
21187
2087
33556
1839
4908
5276
4814
2653
4535
2016
2288
1773
3737
2002
1336
4876
5162
7670
7145
2750
7692
2141
4334
4376
2037
1884
4547
5226
1959
5949
53
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
gon
hahah
hahaha
hahahaha
小时
jus
kno
lawd
lil
lookin
mins
mis
nah
naw
ND
gonna
haha
haha
haha
小时
只是
知道
主
little
looking
minutes
miss
不
不
和
nothin
nothing
oh
picture
pictures
playing
请
请
人们
probably
说
所以
说
这
那
谢谢
till
直到
文本
um
your
什么
是的
年
你
ohh
pic
pics
playin
pls
plz
ppl
prolly
sayin
soo
talkin
tha
tht
thx
到
到
txt
umm
ur
wat
yess
yr
yu
54
1227
901
2597
1201
739
1011
929
510
2990
1134
1583
561
2882
882
1972
692
736
2675
1521
585
1107
840
2164
709
626
1467
1029
1394
531
713
1401
1401
713
555
2810
983
576
566
1082
1914
1104
4730
1595
1393
1537
1377
634
7405
1534
14602
948
5869
1234
4823
839
869
6195
2483
679
1635
1313
3896
847
744
2019
1385
2630
738
1031
2279
2279
886
625
5917
1318
665
809
2144
5327
4667
4667
4667
3043
7074
6425
1938
4913
4499
2352
5103
6526
6526
7449
4074
5264
2981
2123
3163
4164
4164
5882
2968
2831
7105
3790
7669
7134
4707
2887
3842
4102
826
6729
6617
4924
4530
7550
22704
15314
15314
15314
8568
131656
55510
3244
21558
55830
5244
19099
66786
66786
349628
10591
20804
6474
3707
7102
12972
12972
34714
5624
5194
123174
9014
598549
142061
19000
5588
11761
10789
1090
83776
67576
18365
16848
476752
5449
4793
5097
4821
3284
7082
6453
2185
5435
4690
3164
5171
6604
6539
7455
4213
5343
4066
2881
3350
4388
4340
6020
3242
3055
7117
4027
7672
7135
4791
3435
4301
4229
1265
6794
6634
4997
4614
7551
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
Appendix D. 刘等人. (2011) Lexical Variants
Table A4: Lexical variants from Liu et al. (2011) used in our lexical variant evaluation.
“Canonical” is the canonical form as identified by annotators and “Variant” is the non-
standard variant. “Var VP” and “Var Freq” are the number of voting precincts that
contain the variant and the total frequency. “Can VP” and “Can Freq” are similar for
the Canonical form.
Variant
Canonical
Var VP
Var Freq
Can VP
Can Freq
Shared VP
aye
乙
bae
bb
bby
bc
bday
bout
bro
bros
bs
butt
C
原因
chillin
comin
convo
cus
cutie
cuz
和
dat
def
民主
迪斯
doin
嗯
F A
fam
fav
fb
是的
是
baby
baby
baby
因为
birthday
关于
brother
brothers
bullshit
但
看
因为
chilling
未来
conversation
因为
cute
因为
这
那
definitely
他们
这
doing
他们
为了
家庭
favorite
feelin
feeling
1055
2915
3001
665
814
2808
1281
3295
3735
635
953
1312
2332
4439
1174
563
521
541
692
2288
2326
1648
617
556
891
941
2585
607
2040
1422
1127
753
1409
8312
6203
861
958
6220
2033
8238
12036
1066
1308
1846
7926
13497
1653
681
586
675
880
3959
5497
2900
2575
767
1269
1272
5577
942
3921
2199
1637
950
4924
7081
4828
4828
4828
4802
4650
6463
2747
1145
1395
6808
6259
4802
888
3612
960
4802
3951
4802
7669
7134
1832
5320
7247
4153
5320
7429
3862
3531
1246
3300
18365
212570
17472
17472
17472
17280
19210
94613
5263
1899
1952
86579
132803
17280
1185
10765
1259
17280
10397
17280
598549
142061
3224
23430
392504
11681
23430
438864
12856
10655
1962
7215
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
5037
7108
5312
4908
4949
5276
4814
6594
4535
1561
2016
6825
6358
5735
1773
3737
1336
4876
4073
5162
7670
7145
2141
5361
7249
4334
5578
7431
4376
3920
2037
3511
55
计算语言学
体积 49, 数字 4
fml
fr
家庭
为了
freakin
freaking
英尺
fuckin
gettin
gf
goin
gon
homie
小时
小时
二
jus
k
kno
lawd
lil
脚
fucking
getting
girlfriend
going
going
home
小时
小时
我
只是
ok
知道
主
little
lookin
looking
luv
米
嘛
mi
min
mines
mins
mo
n
nada
nah
naw
ND
nothin
nun
ohh
pic
pics
love
am
我的
我的
minutes
mine
minutes
更多的
和
nothing
不
不
和
nothing
nothing
oh
picture
pictures
playin
playing
pls
请
56
750
1059
554
1273
1891
1380
772
1446
1227
1343
852
739
770
1011
3145
929
510
2990
1134
1030
2507
783
2204
1203
510
1583
585
3408
508
2882
882
1972
692
622
736
2675
1521
585
1107
898
1672
654
11113
3064
1992
942
2089
1914
2249
2624
1393
9871
1537
7414
1377
634
7405
1534
1390
7994
1231
6510
2314
589
14602
20581
17544
712
5869
1234
4823
839
788
869
6195
2483
679
1635
3862
7429
1555
1303
4209
5066
1474
5881
5881
5314
2404
3043
7699
7074
3940
6425
1938
4913
4499
6698
5176
7512
7512
2352
2755
2352
5669
7449
4074
6526
6526
7449
4074
4074
5264
2981
2123
3163
4164
12856
438864
2157
1916
12868
21187
2087
33556
33556
27569
5606
8568
621319
131656
71563
55510
3244
21558
55830
76733
25099
309237
309237
5244
5078
5244
31459
349628
10591
66786
66786
349628
10591
10591
20804
6474
3707
7102
12972
4053
7436
1884
2173
4547
5226
1959
5949
5936
5442
2838
3284
7699
7082
4824
6453
2185
5435
4690
6714
5507
7512
7551
2941
2968
3164
5706
7478
4187
6604
6539
7455
4213
4195
5343
4066
2881
3350
4388
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
plz
ppl
请
人们
prolly
probably
点
r
rd
sayin
姐姐
soo
和
talkin
th
tha
部分
是
路
说
sister
所以
一些
说
这
这
thang
事物
tho
thot
thru
tht
thx
到
尽管
想法
通过
那
谢谢
till
trippin
tripping
turnt
tx
txt
你
ur
w
wat
wen
wit
wut
y
ya
yea
yess
yo
yr
yu
yup
转动
texas
文本
你
your
和
什么
什么时候
和
什么
为什么
你
yeah
是的
你
年
你
是的
840
2164
709
570
2280
2123
626
857
1467
990
1029
3238
1394
691
3959
607
1406
531
713
1401
790
684
6275
713
5375
2810
4195
983
524
1769
582
3107
4484
2418
576
3677
566
1082
1056
1313
3896
847
2138
5466
15149
744
1219
2019
1541
1385
17089
2630
876
11480
791
2281
738
1031
2279
975
836
456640
886
34958
5917
28363
1318
653
3389
724
11552
15215
4617
665
10918
809
2144
1499
4164
5882
2968
2647
6657
2022
2831
2714
7105
6017
3790
7669
7669
4434
3879
3690
3400
7134
4707
2887
558
2918
4983
4102
7550
6729
7043
6617
6637
7043
6617
5974
7550
4499
4924
7550
4530
7550
4924
12972
34714
5624
11220
76873
5075
5194
5257
123174
42637
9014
598549
598549
12995
9628
8510
8800
142061
19000
5588
669
5943
96986
10789
476752
83776
146575
67576
67470
146575
67576
36088
476752
13843
18365
476752
16848
476752
18365
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
4340
6020
3242
2823
6712
3220
3055
3022
7117
6052
4027
7672
7672
4550
5092
3844
3818
7135
4791
3435
1204
3161
6869
4229
7578
6794
7124
6634
6650
7054
6627
6182
7563
4938
4997
7559
4614
7551
5040
57
计算语言学
体积 49, 数字 4
致谢
The authors thank Axel Bohmann, Katrin
Erk, John Beavers, Danny Law, Ray Mooney,
and Jessy Li for their helpful discussions.
The authors also thank the Texas Advanced
Computing Center for the computer
resources provided.
参考
Archive Team. 1996. The twitter stream grab.
Atwood, 乙. Bagby. 1962. The Regional
Vocabulary of Texas. University of Texas
按. https://doi.org/10.7560/733497
Baas, Kevin. n.d. Auto-redistrict.
http://autoredistrict.org/.
贝利, Guy and Margie Dyer. 1992. 一个
approach to sampling in dialectology.
American Speech, 67(1):3–20.
https://doi.org/10.2307/455756
贝利, Guy and Natalie Maynor. 1985. 这
present tense of be in southern black folk
speech. American Speech, 60(3):195–213.
https://doi.org/10.2307/454884
贝利, Guy and Natalie Maynor. 1987.
Decreolization? Language in Society,
16(4):449–473. https://doi.org/10
.1017/S0047404500000324
贝利, Guy and Natalie Maynor. 1989. 这
divergence controversy. American Speech,
64(1):12–39. https://doi.org/10
.2307/455110
贝利, Guy and Erik Thomas. 2021. 一些
aspects of african-american vernacular
english phonology. In African-American
英语. 劳特利奇, pages 93–118.
https://doi.org/10.4324
/9781003165330-5
贝利, Guy, Tom Wikle, and Lori Sand. 1991.
The focus of linguistic innovation in Texas.
English World-Wide, 12(2):195–214.
https://doi.org/10.1075/eww.12
.2.03bai
贝利, Guy, Tom Wikle, Jan Tillery, and Lori
Sand. 1991. The apparent time construct.
Language Variation and Change,
3(3):241–264. https://doi.org/10.1017
/S0954394500000569
Bayley, 罗伯特. 1994. Consonant Cluster
Reduction in Tejano English, 体积 6.
剑桥大学出版社. https://
doi.org/10.1017/S0954394500001708
Baziotis, Christos, Nikos Pelekis, 和
Christos Doulkeridis. 2017. Datastories at
semeval-2017 task 4: Deep lstm with
attention for message-level and
topic-based sentiment analysis. 在
Proceedings of the 11th International
Workshop on Semantic Evaluation
58
(SemEval-2017), pages 747–754.
https://doi.org/10.18653/v1/S17-2126
Bernstein, Cynthia. 1993. Measuring social
causes of phonological variation in Texas.
American Speech, 68(3):227–240.
https://doi.org/10.2307/455631
Bohmann, Axel. 2020. Situating twitter
discourse in relation to spoken and written
文本: A lectometric analysis. Zeitschrift f ¨ur
Dialektologie und Linguistik, 87(2):250–284.
https://doi.org/10.25162/zdl-2020
-0009
Campbell-Kibler, Kathryn. 2005. Listener
Perceptions of Sociolinguistic Variables: 这
Case of (ING). 博士. 论文, 斯坦福大学
大学.
Carver, Craig M. 1987. American Regional
Dialects: A Word Geography. 大学
Michigan Press. https://doi.org/10
.3998/mpub.12484
Cassidy, Frederic G., Joan Houston Hall, 和
Luanne Von Schneidemesser. 1985.
Dictionary of American Regional English,
体积 1. Belknap Press of Harvard
大学.
厨师, 保罗, Bo Han, and Timothy Baldwin.
2014. Statistical methods for identifying
local dialectal terms from gps-tagged
文件. Dictionaries: Journal of the
Dictionary Society of North America,
35(35):248–271. https://doi.org/10
.1353/dic.2014.0020
Di Paolo, Marianna. 1989. Double modals as
single lexical items. American Speech,
64(3):195–224. https://doi.org/10
.2307/455589
多伊尔, Gabriel. 2014. Mapping dialectal
variation by querying social media. 在
Proceedings of the 14th Conference of the
European Chapter of the Association for
计算语言学, pages 98–106.
https://doi.org/10.3115/v1/E14-1011
Duggan, Maeve. 2015. Mobile Messaging
and Social Media 2015. Pew Research
中心. https://www.pewinternet.org
/2015/08/19/mobile-messaging-and
-social-media-2015/.
Eisenstein, 雅各布, Brendan O’Connor, Noah
A. 史密斯, and Eric P. Xing. 2014. Diffusion
of lexical change in social media. PloS
ONE, 9(11):e113114. https://doi.org
/10.1371/journal.pone.0113114,
考研: 25409166
Eisenstein, 雅各布, Brendan O’Connor, Noah
A. 史密斯, and Eric P. Xing. 2012. 测绘
the geographical diffusion of new words.
In Proceedings of the NIPS Workshop on
Social Network and Social Media Analysis:
方法, Models and Applications, 页 13.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
Eisenstein, 雅各布, 诺亚A. 史密斯, and Eric P.
Xing. 2011. Discovering sociolinguistic
associations with structured sparsity. 在
Proceedings of the 49th Annual Meeting of the
计算语言学协会:
Human Language Technologies-Volume 1,
pages 1365–1374.
Faruqui, Manaal, Jesse Dodge, Sujay Kumar
Jauhar, Chris Dyer, Eduard Hovy, 和
诺亚A. 史密斯. 2015. Retrofitting word
vectors to semantic lexicons. In Proceedings
的 2015 Conference of the North American
Chapter of the Association for Computational
语言学: 人类语言技术,
pages 1606–1615. https://doi.org
/10.3115/v1/N15-1184
Firth, 大卫. 1993. Bias reduction of
maximum likelihood estimates. Biometrika,
80(1):27–38. https://doi.org/10.1093
/biomet/80.1.27
Galindo, D. Letticia. 1988. Towards a
description of Chicano English: A
sociolinguistic perspective. In Linguistic
Change and Contact (Proceedings of the 16th
Annual Conference on New Ways of
Analyzing Variation in Language),
pages 113–23. 语言学系,
University of Texas at Austin.
加西亚, Juliet Villarreal. 1976. The Regional
Vocabulary of Brownsville, 德克萨斯州. 这
University of Texas at Austin.
Gillies, Sean, 等人. 2007. Shapely:
Manipulation and analysis of geometric
objects in the cartesian plane. URL:
https://pypi.org/project/Shapely/.
Goel, Rahul, Sandeep Soni, Naman Goyal,
John Paparrizos, Hanna Wallach,
Fernando Diaz, and Jacob Eisenstein. 2016.
The social dynamics of language change in
online networks. In International Conference
on Social Informatics, pages 41–57. https://
doi.org/10.1007/978-3-319-47880-7_3
Grier, D. G。, Alexander Thompson, A.
Kwasniewska, G. J. McGonigle, H. L.
Halliday, 和T. 右. Lappin. 2005. 这
pathophysiology of HOX genes and their
role in cancer. The Journal of Pathology: A
Journal of the Pathological Society of Great
Britain and Ireland, 205(2):154–171.
https://doi.org/10.1002/path.1710,
考研: 15643670
Grieve, Jack and Costanza Asnaghi. 2013. A
lexical dialect survey of American English
using site-restricted web searches. 在
American Dialect Society Annual Meeting,
波士顿, pages 3–5.
Grieve, 杰克, Costanza Asnaghi, and Tom
Ruette. 2013. Site-restricted web searches
for data collection in regional dialectology.
American Speech, 88(4):413–440. https://
doi.org/10.1215/00031283-2691424
Grieve, 杰克, Andrea Nini, and Diansheng
Guo. 2018. Mapping lexical innovation on
American social media. Journal of English
语言学, 46(4):293–319. https://
doi.org/10.1177/0075424218793191
Grieve, 杰克, Dirk Speelman, and Dirk
Geeraerts. 2011. A statistical method for
the identification and aggregation of
regional linguistic variation. 语言
Variation and Change, 23(2):193–221.
https://doi.org/10.1017
/S095439451100007X
汉密尔顿, William L., 尤雷·莱斯科维奇, 和
Dan Jurafsky. 2016. Cultural shift or
linguistic drift? Comparing two
computational measures of semantic
改变. In Proceedings of the Conference on
自然语言的经验方法
加工. 经验方法会议
自然语言处理博士,
体积 2016, pages 2116–2121. https://
doi.org/10.18653/v1/D16-1229,
考研: 28580459
Han, Bo and Timothy Baldwin. 2011. 词汇
normalisation of short text messages:
Makn sens a# twitter. 在诉讼程序中
49th Annual Meeting of the Association for
计算语言学: Human Language
Technologies, pages 368–378.
Heinze, Georg and Michael Schemper. 2002.
A solution to the problem of separation in
logistic regression. Statistics in Medicine,
21(16):2409–2419. https://doi.org
/10.1002/sim.1047, 考研: 12210625
Hinrichs, Lars, Axel Bohmann, and Kyle
Gorman. 2013. Real-time trends in the
texas english vowel system: F2 trajectory
in goose as an index of a variety’s ongoing
delocalization. Rice Working Papers in
语言学, 4.
蓝色的, Dirk and Tommaso Fornaciari. 2018.
Increasing in-class similarity by retrofitting
embeddings with demographic
信息. 在诉讼程序中 2018
Conference on Empirical Methods in Natural
语言处理, pages 671–677.
https://doi.org/10.18653/v1/D18-1070
蓝色的, Dirk and Christoph Purschke. 2018.
Capturing regional variation with
distributed place representations and
geographic retrofitting. 在诉讼程序中
2018 实证方法会议
自然语言处理,
pages 4383–4394. https://doi.org
/10.18653/v1/D18-1469
蓝色的, Dirk, Afshin Rahimi, Timothy
Baldwin, and Julian Brooke. 2020.
59
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 49, 数字 4
Visualizing regional language variation
across Europe on twitter. Handbook of the
Changing World Language Map,
pages 3719–3742. https://doi.org
/10.1007/978-3-030-02438-3 175
黄, Yuan, Diansheng Guo, Alice
Kasakoff, and Jack Grieve. 2016.
Understanding us regional linguistic
variation with twitter data analysis.
电脑, Environment and Urban Systems,
59:244–255. https://doi.org/10.1016
/j.compenvurbsys.2015.12.003
琼斯, 泰勒. 2015. Toward a description of
African American vernacular English
dialect regions using “Black twitter”.
American Speech, 90(4):403–440. https://
doi.org/10.1215/00031283-3442117
Koops, Christian. 2010. /u/-fronting is not
monolithic: Two types of fronted/u/in
Houston Anglos. 宾夕法尼亚大学
Working Papers in Linguistics, 16(2):14.
Koops, Christian, Elizabeth Gentry, 和
Andrew Pantos. 2008. 的效果
perceived speaker age on the perception of
pin and pen vowels in Houston, 德克萨斯州.
University of Pennsylvania Working Papers in
语言学, 14(2):12.
Kosmidis, Ioannis. 2020. brglm2: Bias
reduction in generalized linear models.
R包版本 0.6, 2:635.
Kosmidis, Ioannis and David Firth. 2009.
Bias reduction in exponential family
nonlinear models. Biometrika,
96(4):793–804. https://doi.org/10
.1093/biomet/asp055
库尔卡尼, Vivek, Bryan Perozzi, and Steven
Skiena. 2016. Freshman or fresher?
Quantifying the geographic variation of
language in online social media. 在
Proceedings of the International AAAI
Conference on Web and Social Media,
体积 10, pages 615–618.
https://doi.org/10.1609/icwsm
.v10i1.14798
Labov, 威廉, Sharon Ash, Charles Boberg,
等人. 2006. The Atlas of North American
英语: Phonetics, Phonology, and Sound
改变: a Multimedia Reference Tool,
体积 1. Walter de Gruyter. https://
doi.org/10.1515/9783110167467
Lameli, Alfred. 2013. Strukturen im
Sprachraum: Analysen zur arealtypologischen
Komplexit¨at der Dialekte in Deutschland,
体积 54. Walter de Gruyter. https://
doi.org/10.1515/9783110331394
Le, Quoc and Tomas Mikolov. 2014.
Distributed representations of sentences
and documents. In International Conference
on Machine Learning, pages 1188–1196.
60
刘, Fei, Fuliang Weng, Bingqing Wang, 和
Yang Liu. 2011. Insertion, deletion, 或者
substitution? Normalizing text messages
without pre-categorization nor
supervision. In Proceedings of the 49th
Annual Meeting of the Association for
计算语言学: Human Language
Technologies, pages 71–76.
Mansournia, Mohammad Ali, Angelika
Geroldinger, Sander Greenland, and Georg
Heinze. 2018. Separation in logistic
regression: Causes, 结果, 和
控制. American Journal of Epidemiology,
187(4):864–870. https://doi.org/10
.1093/aje/kwx299, 考研: 29020135
麦克道尔, John and Susan McRae. 1972.
Differential response of the class and
ethnic components of the austin speech
community to marked phonological
变量. Anthropological Linguistics,
pages 228–239.
McFadden, Daniel. 1977. Quantitative
methods for analyzing travel behaviour of
个人: Some recent developments.
Cowles Foundation Discussion Papers 474,
Cowles Foundation for Research in
经济学, Yale University.
McFadden, Daniel. 1973. Conditional logit
analysis of qualitative choice behavior. 在
磷. Zarembka, 编辑, Frontiers in
Econometrics. 学术出版社, PP. 105–142.
Mencarini, Letizia. 2018. The potential of the
computational linguistic analysis of social
media for population studies. 在
Proceedings of the Second Workshop on
Computational Modeling of People’s Opinions,
Personality, and Emotions in Social Media,
pages 62–68. https://doi.org/10
.18653/v1/W18-1109
米科洛夫, 托马斯, 伊利亚·苏茨克维尔, Kai Chen,
格雷格小号. 科拉多, 和杰夫·迪恩. 2013.
单词和的分布式表示
短语及其组合性. 在
神经信息处理的进展
系统, 第 3111–3119 页.
Moran, Patrick A. 磷. 1950. Notes on
continuous stochastic phenomena.
Biometrika, 37(1/2):17–23. https://
doi.org/10.1093/biomet/37.1-2.17,
考研: 15420245
穆雷, Ryan and Ben Tengelsen. 2018.
Optimal districts. https://github.com
/btengels/optimaldistricts.
阮, Dong, A. Seza Do ˘gru ¨oz, Carolyn P.
Ros´e, and Franciska de Jong. 2016.
Computational sociolinguistics: 一项调查.
计算语言学, 42(3):537–593.
https://doi.org/10.1162/COLI
00258
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Rosenfeld and Hinrichs
Voting Precinct Embeddings
阮, Dong and Jack Grieve. 2020. 做
word embeddings capture spelling
variation? In Proceedings of the 28th
国际计算会议
语言学, pages 870–881. https://
doi.org/10.18653/v1/2020.coling
-main.75
Pederson, 李. 1986. Linguistic Atlas of the
Gulf States, 体积 2. 大学
Georgia Press.
Petyt, Keith Malcolm. 1980. The Study of
Dialect: An Introduction to Dialectology.
西景出版社.
Pr ¨oll, 西蒙. 2013. Detecting structures in
linguistic maps—fuzzy clustering for
pattern recognition in geostatistical
dialectometry. Literary and Linguistic
计算, 28(1):108–118. https://
doi.org/10.1093/llc/fqs059
Rahimi, Afshin, Trevor Cohn, and Timothy
Baldwin. 2017. A neural model for user
geolocation and lexical dialectology. 在
Proceedings of the 55th Annual Meeting of the
计算语言学协会
(体积 2: Short Papers), pages 209–216.
https://doi.org/10.18653/v1/P17
-2033
ˇReh ˚uˇrek, Radim and Petr Sojka. 2010.
Software framework for topic modelling
with large corpora. 在诉讼程序中
LREC 2010 Workshop on New Challenges for
NLP Frameworks, pages 45–50. http://
is.muni.cz/publication/884893/en.
Rosenfeld, Alex and Katrin Erk. 2018. Deep
neural models of semantic shift. 在
诉讼程序 2018 Conference of the
North American Chapter of the Association for
计算语言学: Human Language
Technologies, pages 474–484. https://
doi.org/10.18653/v1/N18-1044
Stone, Mervyn. 1977. An asymptotic
equivalence of choice of model by
cross-validation and Akaike’s criterion.
Journal of the Royal Statistical Society: Series
乙 (Methodological), 39(1):44–47. https://
doi.org/10.1111/j.2517-6161.1977
.tb01603.x
Tarpley, Fred. 1970. From Blinky to Blue-John:
A Word Atlas of Northeast Texas. 大学
按.
托马斯, Erik R. 1997. A rural/metropolitan
split in the speech of Texas Anglos.
Language Variation and Change,
9(3):309–332. https://doi.org/10.1017
/S0954394500001940
我们. Election Assistance Commission. 2017.
EAVS deep dive: Poll workers and polling
地方. https://www.eac.gov/sites
/default/files/document library
/files/EAVSDeepDive pollworkers
pollingplaces nov17.pdf.
Van der Maaten, Laurens and Geoffrey
欣顿. 2008. Visualizing data using t-sne.
Journal of Machine Learning Research,
9(11):2579–2605.
Walsh, Harry and Victor L. Mote. 1974. A
Texas dialect feature: Origins and
分配. American Speech,
49(1/2):40–53. https://doi.org/10
.2307/3087917
Wheatley, Katherine E. and Oma Stanley.
1959. Three generations of East Texas
speech. American Speech, 34(2):83–94.
https://doi.org/10.2307/454372
Widawski, Maciej. 2015. African American
slang: A Linguistic Description. 剑桥
大学出版社. https://doi.org/10
.1017/CBO9781139696562
Xiong, Yijin, Yukun Feng, Hao Wu, Hidetaka
Kamigaito, and Manabu Okumura. 2021.
Fusing label embedding into bert: 一个
efficient improvement for text
分类. In Findings of the Association
for Computational Linguistics: ACL-IJCNLP
2021, pages 1743–1750. https://doi.org
/10.18653/v1/2021.findings-acl.152
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
C
哦
我
我
/
_
A
_
0
0
4
8
7
2
1
5
5
9
8
1
/
C
哦
我
我
_
A
_
0
0
4
8
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
61