REVIEW
Deep Learning for Medication Recommendation:
A Systematic Survey
Zafar Ali1†, Yi Huang2, Irfan Ullah3, Junlan Feng2†, Chao Deng2, Nimbeshaho Thierry4,
Asad Khan1, Asim Ullah Jan1, Xiaoli Shen1, Wu Rui1, Guilin Qi1
1School of Computer Science and Engineering, Southeast University, Nanjing 210096, 中国
2China Mobile Research Institute, 北京 100053, 中国
3计算机科学系, Shaheed Benazir Bhutto University, Sheringal 18050, 巴基斯坦
4College of Information and Communication Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210023, 中国
关键词: Deep Learning; Recommendation models; Personalization; Medication recommendation; Systematic
review
引文: Ali, Z。, 黄, Y。, Ullah, 我。, 等人。: Deep Learning for Medication Recommendation: A Systematic Survey. 数据智能
5(2), 303-354 (2023). 土井: https://doi.org/10.1162/dint_a_00197
Submitted: 十一月 29, 2022; 修改: 十二月 26, 2022; 公认: 一月 14, 2023
抽象的
Making medication prescriptions in response to the patient’s diagnosis is a challenging task. The number
of pharmaceutical companies, their inventory of medicines, and the recommended dosage confront a
doctor with the well-known problem of information and cognitive overload. To assist a medical practitioner
in making informed decisions regarding a medical prescription to a patient, researchers have exploited
electronic health records (EHRs) in automatically recommending medication. 最近几年, medication
recommendation using EHRs has been a salient research direction, which has attracted researchers to apply
various deep learning (DL) models to the EHRs of patients in recommending prescriptions. 然而, in the absence
of a holistic survey article, it needs a lot of effort and time to study these publications in order to understand
the current state of research and identify the best-performing models along with the trends and challenges.
To fill this research gap, this survey reports on state-of-the-art DL-based medication recommendation
方法. It reviews the classification of DL-based medication recommendation (MR) 型号, compares their
表现, and the unavoidable issues they face. It reports on the most common datasets and metrics used
in evaluating MR models. The findings of this study have implications for researchers interested in MR models.
†
通讯作者: Zafar Ali (电子邮件: zafarali@seu.edu.cn; ORCID: 0000-0002-6404-645X).
© 2023 Chinese Academy of Sciences. 根据知识共享署名发布 4.0
国际的 (抄送 4.0) 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
t
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
1. 介绍
A recommender system is an information retrieval & filtering mechanism that attempts to mitigate the
negative impact of the well-known problems of information & cognitive overloads resulting due to the
ever-growing size of information repositories [1, 2]. While talking about these huge dumps of information,
medical science cannot be ignored where the abundance of pharmaceutical companies and their growing
number of medicines lay a huge impact on the prescription of a medication for a doctor against the
diagnosis and medical history of a patient. To address this inevitable issue, researchers have considered
electronic health records (EHRs) in automatically recommending medication so that a medical practitioner
can make an informed decision while selecting and including a drug in the prescription. These EHRs present
a comprehensive picture of the medical history of patients and may include previous medications, diagnoses,
laboratory tests, treatment plans, and medical imaging such as x-rays, ultrasounds, and magnetic resonance
成像 (MRI) scans, ETC. [3]. They are the main data carriers for personalized medical research [4]. 在
添加, the recent improvements in the quality of EHRs attracted researchers due to their potential
applications, viz., medical diagnosis and recommendation. They are semantics-rich and represented as a
patient’s temporal admission sequence with a series of clinical events, including procedures, diagnoses,
medications, 等等 [4]. These records when combined with the current clinical status (事件, diagnoses,
ETC。) of a patient and fed into a medication recommendation system result in personalized medication
recommendations, which assist medical practitioners in making informed prescriptions against the current
health condition of the patient [5]. 然而, the recommendation task is not that simple, rather it is
challenging and highly non-trivial with a prolonged history of machine-aided medical diagnoses and
treatment. A medication recommender system can employ either content-based (CB), collaborative (CF), 或者
hybrid filtering [6, 7]. 然而, these traditional filtering approaches produce inadequate results due to
issues like data sparsity, cold-start, and lack of Personalization [8]. In response to these issues, 研究人员
have employed deep learning (DL) in producing quality medication recommendations. Some of the notable
examples of DL-based medication recommendation (MR) models include [9, 10, 11, 12, 13, 3, 14, 15].
Several surveys and review articles [6, 16, 17, 18, 19, 20, 7] have explored the domain of healthcare
and medication recommendation. Sezgin and Ozkan [6] discussed traditional MR models using information
filtering methods. 然而, they were unable to report on the current state of DL-based MR models and
the issues they face.
Hors-Fraile et al. [16] presented a general overview of technical aspects of MR models including filtering
methods and profile adaptation techniques published during 2007–2016. 然而, they presented negligible
works on MR models, most studies are related to health and lifestyle with no analysis of the DL-based MR
型号. Their coverage of the latest DL-based MR models was also limited.
张等人. [17] reviewed ML- and DL-based models for personalized medicine with a little touch to
MR task. They covered challenges in personalized medicine and some future opportunities. 然而, 他们
were unable to cover the technical aspects including filtering methods, and information sources. 他们
performed no analysis of the ML- and DL-based MR models and optimization methods.
304
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Rajkomar et al. [18] presented a general overview of how ML can be used in medicine. They presented
how ML works and the type of input and output medicinal data that power ML algorithms and explored
some challenges in applying ML in medicine. 然而, they were unable to discuss any aspect of ML
algorithms for MR tasks.
Ngiam and Khor [19] presented some benefits and challenges of ML-based models in healthcare delivery.
They discussed several ML platforms and tools that may offer recommendations in addition to other services.
然而, they were unable to report on recommendation-specific details including filtering methods,
information sources, and factors. They covered few works on MR models, where most studies are related
to health care delivery.
Su et al. [20] reported on the network embedding models widely used in the biomedical domain and
assessed their performance. They presented software tools used for network embedding in the biomedical
domain. They also covered challenges faced by network embedding models and presented some future
directions on how to improve them. 然而, they were unable to cover recommendation-specific details
including filtering methods, 来源, 因素, and optimization methods.
Etemadi, Maryam, 等人. [7] presented a systematic review of publications published during 2010–2021
on the technical aspects of medication recommendation including filtering methods (CB, CF, hybrid,
知识- and context-based). 然而, they were unable to cover information sources and factors. 他们
presented few works on MR models, most studies are related to health and lifestyle. Their analysis of
DL-based MR models was also limited with no coverage of optimization methods.
总结, most of the studies discussed above are either related to general medicine, 卫生保健,
and lifestyle or cover MR-specific details including information filtering methods, 来源, and factors.
然而, these studies are unable to give in-depth and analytical coverage to the various aspects of
DL-based MR models, including information filtering methods, 来源, 因素, 评估, and comparative
分析. Even if DL-based MR models are covered, they are few and unable to present the current state of
the field. 此外, these studies investigated a few issues faced by DL-based MR models. These facts
demand a detailed retrospective and in-depth analysis of the latest DL-based MR models, which is the main
aim and theme of this article.
Motivation to conduct this survey. Literature exhibits that seven survey works [6, 7, 16, 17, 18, 19, 20]
investigated the MR domain. 桌子 1 compares our current study with these survey papers to help identify
the contributions of this work. Among these, the study by Sezgin, and Özkan [6] is a relatively old survey
that is unable to examine state-of-the-art DL-based MR models. It explored only a few DL-based MR models
as it covers literature up to the year 2014. It couldn’t explore information factors, DL-based filtering methods,
and recommendations for issues, with no coverage of the datasets and evaluation methods. 相反,
the study by Hors-Fraile et al. [16] examines the domain of healthcare recommendation systems (HRS) 经过
examining 19 HRS covering their information filtering and profile representation methods. They mainly
covered lifestyle recommendations with very little attention to DL-based medication recommendations.
数据智能
305
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
They were unable to explore information factors and issues addressed in the field of DL-based MR models.
还, the study focused on journal articles, 然而, it is known that multiple novel MR models [5, 21, 12,
22] have been proposed in prestigious conferences, which needs to be analyzed. It reported only 19 型号
published during 2007–16. It is an unavoidable fact that new DL-based MR models have been proposed
in the last five years that need a thorough investigation. Etemadi, Maryam, 等人. [7] is the most recent work
presenting a systematic review of HRS. This work studies systems based on information filtering methods,
namely CB, CF, knowledge-based, and hybrid. 而且, the study inspects the utilized datasets and issues.
然而, 喜欢 [16], the study focuses on the healthcare recommendation models and pays little attention to
DL-based MR. Besides, the survey lacks to examine models based on their information factors, 优化
方法, and recommendations to address the issues they face.
桌子 1. Comparison w ith studies exploring the domain of medication recommendation.
模型
reference
Duration
楷模
类型
问题
explored
Sezgin and
Özkan [6]
1998–
2012
General
few issues
仅有的
Hors-Fraile
等人. [16]
2007–
2016
General
Few issues
仅有的
Trends
Strengths and limitations
Limited *No coverage of the issues faced by MR models
*No classifi cation of MR models based on
information sources and fi ltering methods
*No analysis of the DL-based MR models
*Relatively old study with no coverage of latest MR
型号
Derived *Presents technical aspects including fi ltering
方法 (CB, CF), profi le representation, 和
adaptation techniques.
*Negligible works on MR models, most studies are
related to health and lifestyle
*No analysis of the DL-based MR models
*Limited coverage of latest DL-based MR models
张等人.
[17]
N.G ML- 和
DL-based
问题
Limited *Presents ML and DL models for personalized
medicine with a little touch to MR task.
*Covers challenges in personalized medicine and
future opportunities
*No coverage of technical aspects including
fi ltering methods, information sources
*No analysis of the DL-based MR models and
optimization methods
Rajkomar et al.
[18]
N.G General
挑战
Limited *Presents a general overview on how ML can be
used in medicine
*Presents how ML works and the type of input and
output medicinal data that power ML algorithms
* No discussion on any aspect of ML algorithms for
MR task
306
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
桌子 1. Continued
模型
reference
Duration
楷模
类型
问题
explored
Ngiam and
Khor [19]
N.G ML-based Benefi ts and
Issues of ML
算法
Trends
Strengths and limitations
Limited *Presents some benefi ts and challenges of ML-
based models in health-care delivery.
*Covers certain ML platforms and tools that may
offer recommendations in addition to other
服务
*No coverage of recommendation-specifi c details
including fi ltering methods.
*No coverage of information sources and factors
*Few works on MR models, most studies are
related to health care delivery
*No analysis of the DL-based MR models.
*No coverage of optimization methods
Su et al. [20]
N.G DL-based Challenges
Limited *Presents network embedding models widely used
和
机会
in the biomedical domain and assesses their
表现.
*Presents software tools used for network
embedding in the biomedical domain.
*Covers challenges faced by network embedding
models and future directions on how to improve
他们
*No coverage of recommendation-specifi c details
including fi ltering methods, 来源, 因素, 和
optimization methods.
Issues only Derived *Presents technical aspects including fi ltering
方法 (CB, CF, hybrid, 知识- 和背景-
基于).
*No coverage of information sources and factors
*Few works on MR models, most studies are
related to health and lifestyle
*Limited analysis of the DL-based MR models.
*No coverage of optimization methods
Etemadi,
Maryam, 等人.
[7]
General
2010–
2021
This review
2010–
2022
DL-based Issues with
Derived *Classifi cation based on a new taxonomy.
recommenda-
系统蒸发散
*Covers classifi cation of DL-based MR models
employing information factors and fi ltering
方法
*Coverage of recent DL-based MR models
*Coverage of different optimization methods
*Coverage of trends in datasets, 指标, 和
experimental procedures
*No coverage of studies in languages other than
英语
数据智能
307
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Considering the above discussion and the recent emergence of novel DL-based MR models, an inclusive
and comprehensive analysis is required to analyze the area, find interesting trends, and highlight the main
问题. With this study, we explore the domain of MR models that employ DL methods.
Coverage and contributions. This study presents a comprehensive review of the literature on DL-based
MR systems by reporting on 37 MR models that employed deep neural networks and were published during
2013–2022. It classifies these DL models with regard to their platform, problems addressed, DL-based
information filtering, information factors exploited, optimization methods adopted, and the type of
recommendation, viz., personalized vs. non-personalized. This review has implications for researchers
working in the DL-based MR domain by reporting on the strengths, 局限性, and trends in DL-based MR
型号. It also reports on open research issues, 挑战, and research opportunities in DL-based MR
型号.
Structure of this article. The remaining paper has four sections. 部分 2 presents a taxonomy of
MR models by covering platform, information factors, information filtering methods, 优化, 和
recommendation types. 部分 3 covers datasets and metrics used in evaluating these models. 部分 4
presents a comparison of the experimental results of the explored models using different datasets and
evaluation metrics. 部分 5 discusses issues and challenges faced by the reported DL-based MR models
and the opportunities to address them. 部分 5 concludes the article with the main findings and future
directions derived from this study.
2. TAXONOMY OF M ODELS
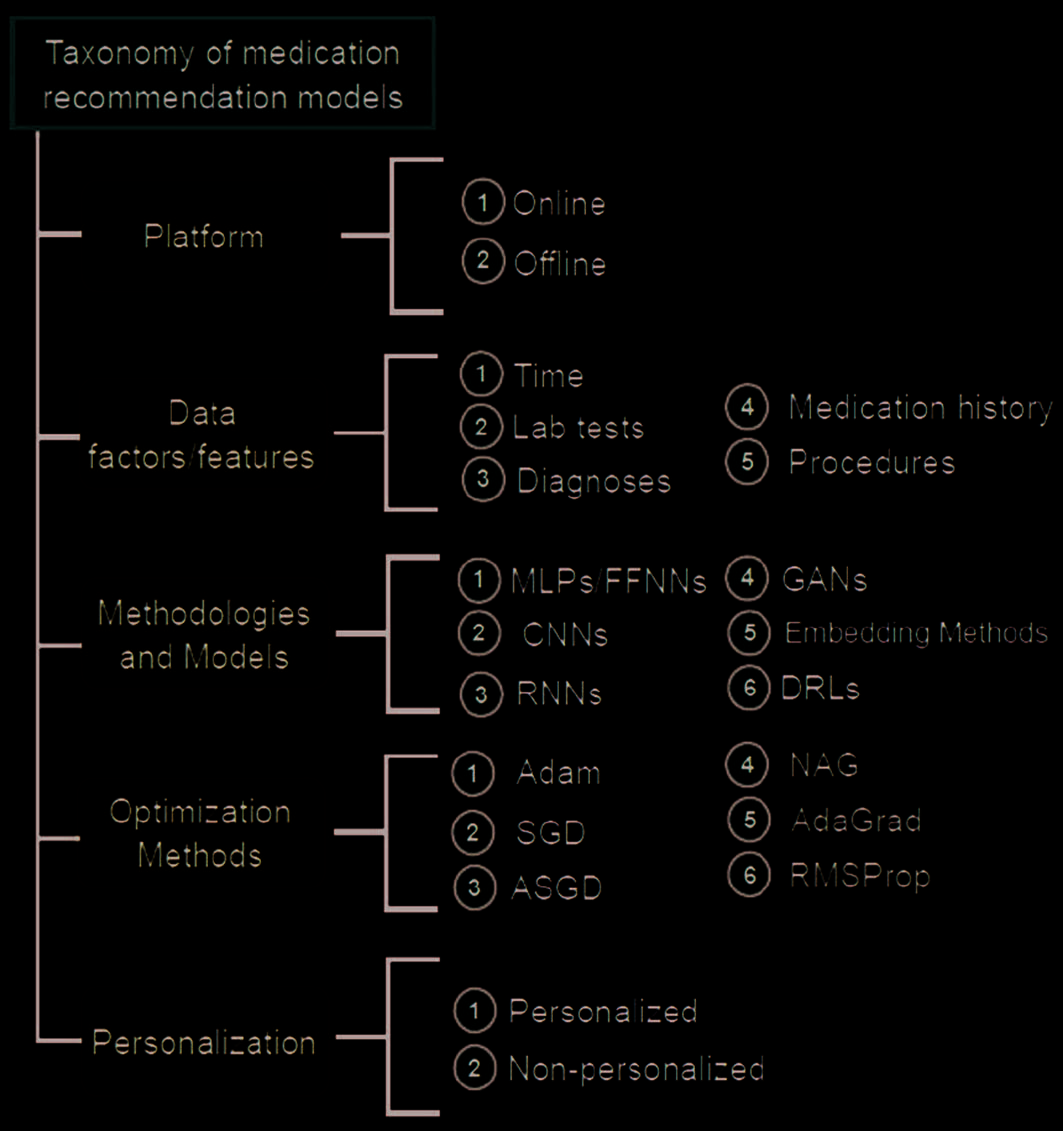
This section presents a taxonomy of DL-based MR models developed by reviewing selected 37 学习
on medication recommendation as illustrated in Figure 1. The classification is based on the platform used
(offline vs. 离线), data features considered, deep neural networks used, issues and challenges they faced,
optimization methods adopted, and recommendation types such as personalized vs. non-personalized. 这
following subsections present this taxonomy.
2.1 Platform
The term platform means whether the MR model has been deployed in a real online recommendation
system or not. This gives the clue that how many MR research works are actually part of practical applications.
If we look at Table 2, it is clear that only one model [23] is part of an online system, and other models
work offline, indicating that most of the proposed models are not used in practical applications.
308
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1. Tax onomy of MR models.
2.2 Information Factors
This section reports on the information sources and features used by reviewed DL-based MR models.
Medication history. An accurate medication history offers the foundation to assess the suitability of
medication in the current therapy of a patient and directs future treatment choices. It helps in preventing
errors in the prescription of medicines and avoids other pharmaceutical issues including poor or non-
adherence to the recommended doses. This is the most important factor adopted in the explored MRs as
adopted in all 37 型号.
https://www.rpharms.com/resources/quick-reference-guides/medication-history
数据智能
309
Deep Learning for Medication Recommendation: A Systematic Survey
T able 2. Classifi cation of DL-based MR models.
Plat-
形式
Data factors/
Information used
Methodologies/
networks used
问题
addressed
Recom-
menda-
tion type
y
r
哦
t
s
我
H
n
哦
我
t
A
C
我
d
e
中号
哦
F
n
我
C
我
H
p
A
r
G
哦
米
e
D
s
米
哦
t
p
米
y
S
s
e
s
哦
n
G
A
我
D
e
米
我
时间
s
e
r
你
d
e
C
哦
r
磷
e
n
我
我
n
氧
e
n
我
fl
F
氧
)
G
K
/
/
t
e
氮
H
p
A
r
G
(
G
n
我
d
d
e
乙
米
乙
s
n
哦
我
t
A
n
我
米
A
X
e
我
A
C
我
s
y
H
磷
s
中号
L
磷
/
d
e
s
A
乙
–
s
r
e
米
r
哦
F
s
n
A
r
时间
k
r
哦
w
t
e
氮
n
哦
我
t
n
e
t
t
A
y
t
我
我
我
乙
A
t
e
r
p
r
e
t
n
我
我
D
D
n
哦
我
t
A
z
我
我
A
n
哦
s
r
e
磷
s
s
e
n
t
s
你
乙
哦
右
t
r
A
t
S
–
d
我
哦
C
y
t
我
s
r
A
p
S
d
e
z
我
我
A
n
哦
s
r
e
磷
–
n
哦
氮
d
e
z
我
我
A
n
哦
s
r
e
磷
氮
氮
右
氮
氮
C
L
右
D
s
氮
A
G
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
– –
–
– –
– – –
–
–
–
–
–
–
– –
–
– –
– –
– –
–
–
–
–
–
–
–
– –
–
–
– –
–
–
–
–
–
–
–
–
–
– –
–
–
– –
– –
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
– –
–
– –
– –
– –
–
–
–
–
–
– –
–
– –
– –
–
–
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
–
– – –
– –
– –
–
–
–
–
–
–
–
–
–
– –
– –
– –
–
–
–
–
–
–
–
–
–
–
– –
–
– –
– –
–
–
–
–
–
–
–
–
–
– – –
–
– –
– –
–
–
–
–
–
–
–
– –
–
– – –
– –
–
–
–
–
– –
– –
– – –
–
–
–
–
–
–
–
–
– –
– –
– – –
–
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
–
– –
– –
– –
–
–
–
–
–
–
–
–
–
–
– –
–
– –
– –
–
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
–
– –
–
– –
–
–
–
–
–
–
–
–
–
–
–
–
– –
– –
– –
– –
–
–
–
–
–
–
–
– –
– –
– –
– – – –
–
–
–
–
–
– –
– –
– –
– –
– –
–
–
–
–
–
–
– –
– –
– –
–
–
–
–
–
–
–
–
– –
–
– –
–
–
–
–
–
–
–
–
–
–
–
– – –
–
– –
– –
–
–
–
–
–
–
–
– – –
–
– –
–
–
–
–
–
–
–
–
–
– –
–
– –
– –
–
–
–
–
–
–
–
– –
–
– –
– –
–
–
–
–
–
–
–
–
– –
–
– –
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
数据智能
S.
不. 模型
PREMIER [24]
1 ARMR [9]
2 GAMENet [21]
RETAIN [10]
3
4 MedGCN [23]
5 MeSIN [11]
6
7 G-BERT [25]
SARMR [12]
8
9
TAHDNet [13]
10 COGNet [5]
11 MRSC [26]
12 MERITS [27]
13 DMNC [14]
14 4SDrug [28]
15 DPR [15]
16 SMR [29]
17 LEAP [3]
18 SRL-RNN [30]
19 CompNet [31]
20 MICRON [32]
21 SafeDrug [33]
22 AMANet [34]
23 RA-WCR [35]
24 MedRec [36]
25 SMGCN [37]
26 LSTM-DO-TR [38]
27 LSTM-DE [39]
28 CGL [40]
29 ConCare [22]
30 DRLST [41]
31 SDCNN [42]
32 MetaCare++ [43]
33 MedPath [44]
310
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
桌子 2. Continued
Plat-
形式
Data factors/
Information used
Methodologies/
networks used
问题
addressed
y
r
哦
t
s
我
H
n
哦
我
t
A
C
我
d
e
中号
哦
F
n
我
C
我
H
p
A
r
G
哦
米
e
D
s
e
s
哦
n
G
A
我
D
e
米
我
时间
s
e
r
你
d
e
C
哦
r
磷
e
n
我
我
n
氧
e
n
我
fl
F
氧
S.
不. 模型
34 PMDC-RNN [45]
35 TAMSGC [46]
36 GATE [47]
37 Dipole [48]
– –
–
–
– –
–
– –
– –
)
G
K
/
/
t
e
氮
H
p
A
r
G
(
G
n
我
d
d
e
乙
米
乙
s
中号
L
磷
/
d
e
s
A
乙
–
s
r
e
米
r
哦
F
s
n
A
r
时间
k
r
哦
w
t
e
氮
n
哦
我
t
n
e
t
t
A
y
t
我
我
我
乙
A
t
e
r
p
r
e
t
n
我
s
s
e
n
t
s
你
乙
哦
右
我
D
D
t
r
A
t
S
–
d
我
哦
C
y
t
我
s
r
A
p
S
氮
氮
右
氮
氮
C
L
右
D
s
氮
A
G
– –
–
– –
– –
–
– –
–
–
–
–
–
–
–
–
– –
– –
– –
–
–
–
–
–
–
–
– –
– –
– –
s
n
哦
我
t
A
n
我
米
A
X
e
我
A
C
我
s
y
H
磷
–
–
–
–
s
米
哦
t
p
米
y
S
–
–
–
–
Recom-
menda-
tion type
d
e
z
我
我
A
n
哦
s
r
e
磷
–
n
哦
氮
d
e
z
我
我
A
n
哦
s
r
e
磷
–
–
–
–
n
哦
我
t
A
z
我
我
A
n
哦
s
r
e
磷
–
–
–
–
Time/Temporal dynamics. Time is among the crucial dimensions in generating recommendations [49].
A patient upon feeling sick visits the hospital where the doctors prescribe drugs after examining the lab
测试. This clinical practice leads to the irregular production of medical records. It is generally and widely
assumed that the recent medical records of the patient are more important than the previous ones in
predicting their current health status [22]. 然而, even these irregular historical records have valuable
clinical data that may not exist in the latest record (例如, the extremely abnormal glucose level in the blood).
所以, it is essential to build a time-aware and more adaptive mechanism for learning flexibly the impact
of the time interval for each clinical feature. 此外, it required that the temporal aspect of the conditions
of the patients and their visits to the hospital are considered in recommending medications. In line with
this need, the reported literature (桌子 2) reveals that many models, 29 在......之外 37, used the time factor in
recommending medications [9, 21, 10, 23, 11, 24, 25, 12, 13, 5, 26, 27, 14, 28, 15, 29, 3, 30, 31, 50,
32, 34, 35, 39, 22, 41, 44, 42, 47, 48].
Diagnoses. The process of medical diagnosis allows for determining the relationship of a disease with
the signs and symptoms of a patient. The diagnosis collects the physical examination and medical history
of the patient by employing one or more diagnostic procedures including lab tests. An accurate and timely
diagnosis has a high probability of a positive health outcome for the patient as the correct understanding
of the health problem tailors an effective decision-making [51]. This factor has been used by several studies
如表所示 2.
Symptoms and signs. Symptoms describe a disease from the perspective of the patient, offer subjective
证据, and describe the complaints of the patient that leads her to the health care unit, while signs are
the manifestation of the disease a doctor perceives. Few models [37, 38, 41, 36] have used this feature as
如表所示 2 as symptoms may not support the evidence against a certain disease.
数据智能
311
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
程序. A medical procedure is a general medical intervention that is less invasive and requires no
incision. Examples are body fluid tests including urine and blood tests as well as non-invasive scans such
as magnetic resonance imaging (MRI), x-rays examinations, computed tomography (CT), and ultrasound. A
medical recommender system uses the procedure data to produce improved predictions [5]. The literature
summarized in Table 2 shows that 23 在......之外 37 models used this data in recommending medications [9,
21, 10, 11, 24, 23, 25, 12, 13, 26, 5, 27, 14, 28, 15, 3, 29, 30, 31, 47, 48].
Lab tests and physical examination. The role and value of lab tests is widely acknowledged by medical
practitioners in making clinical decisions and the associated clinical outcomes [52]. These tests have
significance regarding the prevention, diagnosis, and treatment of disease and facilitate in avoiding treatment
delays, 恢复, minimizing disability, and reducing disease progression [52]. In a physical examination,
the physician examines essential signs, including body temperature, heart rate, and blood pressure, 和
evaluates the patient’s body employing observation, palpitation, percussion, and auscultation. If we analyze
the literature, only one model [36] considered physical examination to predict medications.
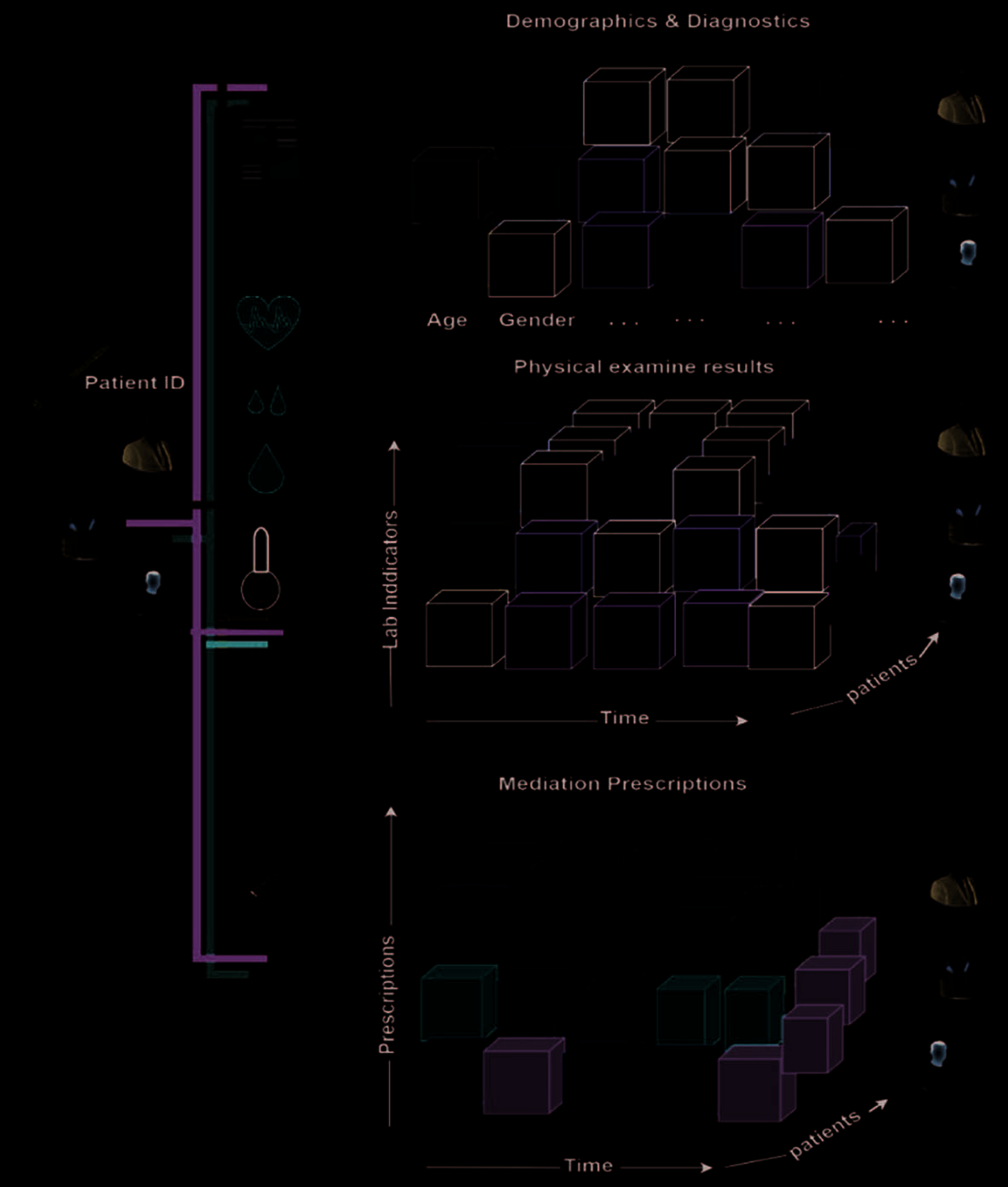
Demographic information. The demographics include the patient’s gender, 年龄, 种族, 地址,
教育, and other relevant details. They have a significant role in clinical decision-making, 例如, 这
design of therapeutic regimen and the selection of dosage. 然而, this information remains static during
hospitalization. 数字 2 shows how LSTM-DE [39] exploits demographics with diagnostics, physical
examination, and prescriptions to recommend medications. 桌子 2 shows that only few models [21, 22,
41, 27, 15, 29, 39] used demographics in recommending medications.
2.3 Methodologies and Models
This section reports on the various DL-based information filtering methods used by MR systems.
Embedding methods. The embedding methods [53] discover continuous representations by encoding
discrete values into lower magnitudes. These methods serve different purposes, 包括 (1) as input to
another DL network, (2) generating recommendations based on nearest neighbors by exploiting user
兴趣, 和 (3) helping visualize concepts and relationships among them. The embedding models are
divided into three categories namely word/document [54], graph/network [55, 2], and knowledge graph
(KG) [56] embedding.
Word embedding is widely used by natural language processing (自然语言处理) in learning the latent representations
of words and phrases. So far several word embedding models have been proposed to capture vigorous
syntactical and semantic information about words and phrases. 然而, the most accepted and widely
used among these include word2vec [54], doc2vec [57], and BERT [58]. They have been exploited in
embedding items, 用户, 文件, and locations [59] into a latent space. In network/graph embedding
[55, 1], the networks/graphs and their nodes are converted into low dimensional representations by
considering the structure of the networks, their topological configurations, their relationships with the
节点, and other auxiliary details including content and attributes. Using graph embedding methods,
meaningful relationships between nodes (medications, 患者, 程序, diagnosis, ETC。) are captured,
which depend on the node-to-node differences in the embedding space [60].
312
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
/
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Fi gure 2. Information factors used in the LSTM-DE Model.
A knowledge graph (KG) is a heterogeneous graph that represents entities by nodes and the relationships
among these entities are denoted with edges among nodes [61]. The KG-embedding models, such as TransD
[62], GCN [63], GNN [64], and GAN [65] allow enriching the representation of users and medications.
Mostly, such models have two modules, 第一的, the graph embedding that learns the representations of its
entities and relationships; 第二, the recommendation module that estimates the preferences of the patient
for a certain medication, so that the medical practitioner can prescribe it if appealing. To this end, 一个
example KG-embedding in MRs using an EHR graph is the GAMENet [21] that embeds the KG of drug-drug
互动 (DDI) via a memory module, which is employed as a GCN [63] defined in Equation 1.
1
(
(西德:2)
A D A I D
2
*
+
=
1
2
)
(西德:2)
(西德:2)
-
-
*
(1)
在哪里, D and I denote diagonal and identity matrices. The model then applies a two-layer GCN on each
graph in learning extended embeddings on drug combinations and DDIs, 分别. Through this model,
the longitudinal patient records are jointly learned as an EHR graph whereas the drug knowledge base as
数据智能
313
Deep Learning for Medication Recommendation: A Systematic Survey
the DDI KG to recommend safe and effective medications. The longitudinal methods such as RETAIN [10]
and DMNC [14] outperform traditional DL baselines, which confirms the importance of temporal data in
medication recommendations. 然而, they recommend a large bunch of medication combinations. 到
address this issue, GAMENet uses KG to improve performance and DDI rate. 然而, the use of the DDI graph
alone may restrict some medication rules considering the external knowledge [27]. The patient representation
and the memory output are exploited in predicting the multi-label medication ŷ t and are defined by
方程 2.
=
ˆ
y
t
(
⎡
t
sigmoid q o o
⎣
d
t
乙
,
,
t
)
⎤
⎦
(2)
d
(
)
t
bo
Where qt is the query at tth visit, ∈R ,
which is the memory output given current memory state Mb and
= softmax
t
is directly retrieved using content attention
M q based on the similarity between patient
A
C
=t
表示 (query) and facts in Mb. 然后,
o M a is obtained using retrieved information from Mb
乙
d
t
via
which is the memory output given current memory state
ca from temporal aspect. 相似地,
d kM with temporal attention
Md, considers patient representation from patient history records
t
t
嘛
A
s
from temporal aspect. In the same direction, G-BERT utilizes GCN [63] to learn the initial embedding of
medical codes using medical ontology. The EHR data is exploited by employing an adaptive BERT [58]
embedding model using the discarded single-visit data and learns the patient’s visit embedding v as follows.
o M M a is obtained using retrieved information from Mb and
最后,
Softmax
t
M q
d k
,
∈R ,
T t
b c
t
做
t
d v
,
t
米
b t
=
=
(
)
)
(
时间
乙
t
d
.
t
t
,
=
v
t
*
Transformer
(
{[
CLS
}
]
∪
t
哦
{
C
*
|
C
*
∈
C
t
*
}
)
[
0]
(3)
在哪里 [CLS] denotes sepcial token utilized in BERT. c* represents medical code, 和
*co denote ontology
embedding vector for leap node c*. 最后, G-BERT applies a prediction layer to generate medication
recommendations. Results of the G-BERT model reveal that it gains improved Jaccard and F-scores compared
to GAMENet and attention-based RETAIN [10] 模型, which exhibits that incorporating hierarchical
ontology information with pre-training procedure results in improved predictions.
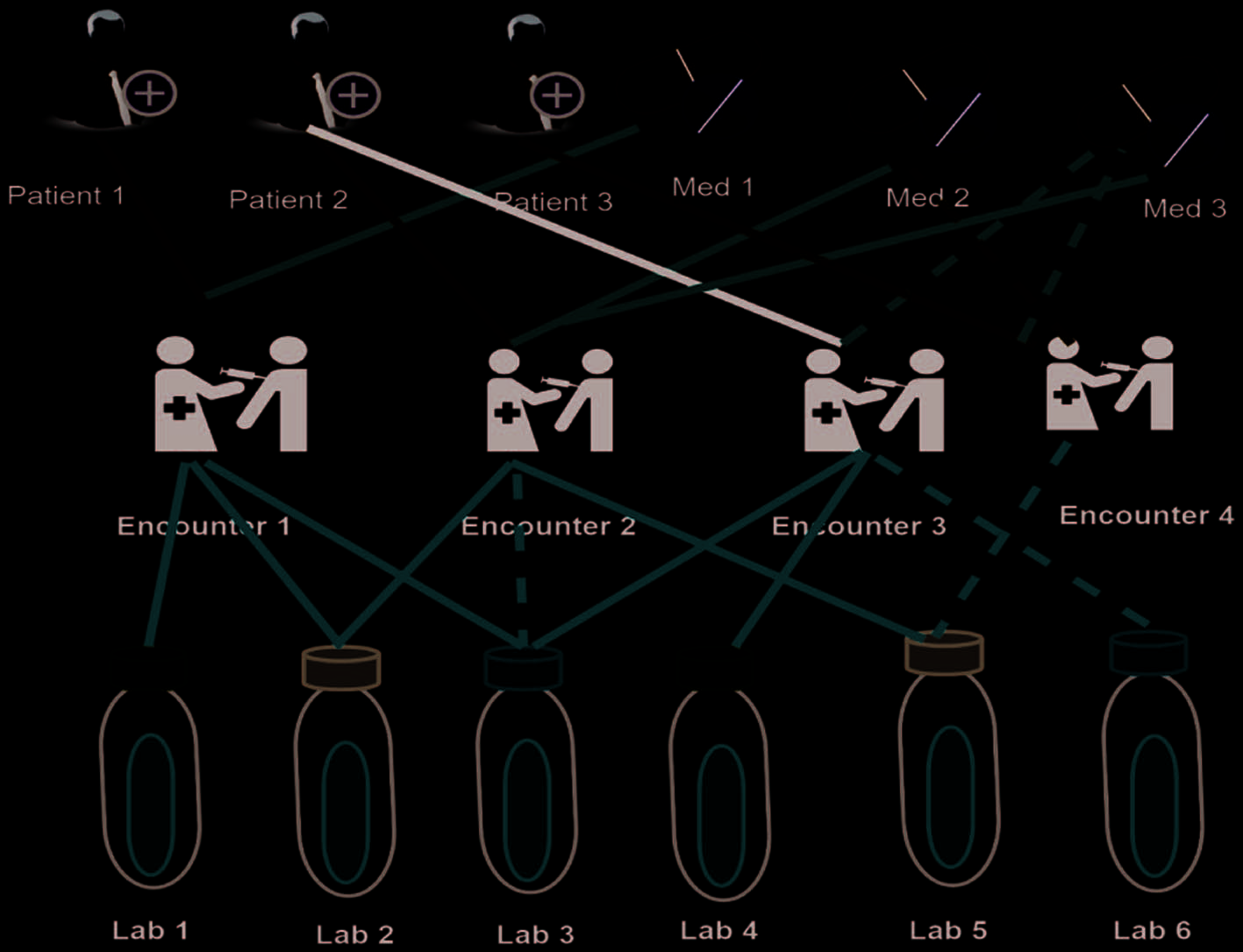
In the same direction, MedGCN [23] makes medication predictions for patients employing incomplete
lab tests. This is explained by the authors with the help of an example scenario illustrated in Figure 3. 这里,
the need is to predict the missing values of lab test results, 例如, for encounters 2, 3, 和 4 and to recommend
full or partial medications list for encounters 3 和 4. MedGCN exploits the relations among entities
(encounters, 患者, medications, and lab tests) using a heterogeneous graph (called MedGraph) of their
inherent features. For each entity in this graph, it learns a vector representation based on GCN [63]. 到
deal with different entities, the model decomposes the heterogeneous graph into multiple subgraphs, each
holding one type of edge (关系) and a single adjacency matrix is used to represent it. In each GCN layer,
the model aggregates the representations of each node in all the subgraphs to learn its final embedding.
F
followed by the
These representations are then fed to two fully-connected neural networks hM
)(
sigmoid activation, IE。,
sigmoid f H and
hM
sigmoid f H for recommending medications
F
and hL
)(
V
(
(
磷
=
=
)
)
hL
e
e
and imputing lab tests, 分别. Where He denotes the final encounter embeddings. 而且, 这
model uses binary cross entropy and mean square error loss functions for medication recommendation and
314
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
lab test imputation, 分别. 而且, the model employs a cross-regularization strategy to alleviate
the overfitting problem for multi-task training, IE。, recommending medications and imputing lab tests.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3. MedGraph, the observed and unknown relationships between any two objects are represented with
solid and dashed lines, 分别.
S
=
=
{
}
s
, k
H
, 氮
……
,
……
,
s s
2,
1
and herbs
{
H h h
2,
1
SMGCN [37] proposed a multi-layer neural network to simulate the interactions between herbs and
}
symptoms for recommending herbs. Given the set of symptoms
as input, it first employs multi-graph embedding layer to generate meaningful representations for all
symptoms from S and for all herbs from H. The model distinguishes symptoms from herbs by processing
the bipartite symptom-herb graph using a bipartite GCN (Bipar-GCN) [66], which propagates symptom-
oriented embedding for the target symptom node and herb-oriented embedding for the target herb node,
分别. This way, symptom representations bs and herb representations bh are learned. 第二, 它
employs synergy graph encoding (SGE) to capture the synergy information of symptom and herb pairs. 这
symptom embedding rs is learned by executing GCN on the symptom-symptom graph for symptom pairs,
constructed based on the concurrent frequency of symptom pairs. In a similar manner, SMGCN gains
knowledge of herb embedding rh from a graph of herbs. 第三, it creates the integrated embeddings for each
symptom (herb) by fusing two types of word embedding b and r from the Bipar-GCN and SGE. 最后, 它
applies the syndrome-aware prediction layer to feed symptoms in the symptom set Sc into an MLP to
produce overall syndrome embeddings esyndrome(sc). 而且, all herb representations are stacked into eH,
IE。, an N × d matrix, where d denotes the dimension of each herb representation. The syndrome embedding
esyndrome(sc) interacts with eH to generate ŷ sc, representing the probability score vector for all herbs from H.
数据智能
315
Deep Learning for Medication Recommendation: A Systematic Survey
总结, it is concluded that embedding models exploit rich semantics using the content and graph
structure information to generate semantic-preserving representations of medications, 患者, and relevant
nodes/entities, which helps generate precise recommendations. This study shows that 18 在......之外 37 型号
utilized embedding techniques [35, 29, 39, 37, 21, 23, 25, 5, 40, 22, 28, 43, 31, 32, 44, 27, 36, 15].
Deep reinforcement learning techniques. Deep reinforcement learning (DRL) mimics the learning
capabilities of humans for machines and software agents so that they can also learn from their actions. 这
models employing DRL either penalize or reward an agent for their actions taken in an environment [67].
The actions that help agents to achieve their goals are rewarded, IE。, reinforced. If an agent performs an
action at time t, the environment assigns a quantitative incentive to the agent in time t, and it alters itself
at the position of the action. The agent repetitively takes these actions until the arrival of some terminal
位置 [68]. These models are most suitable for dynamic and changing environments like medication
recommendations. These models have been used by several researchers for recommending medications.
Zhang et al. [3] proposed the LEAP (LEArn to Prescribe) model to learn the connections between the
categories of medications and multiple diseases and capture the dependencies among medication categories
in recommending medications. They used a recurrent decoder (GRU) for modeling label dependencies and
content-based attention [69] so that label instance mapping can be captured. The prediction at step t is
given using Equation 4.
=
精氨酸
y
t
max
∈
y Y
softmax s
(
t
)
(4)
Where medication and total medication are represented with y and Y, 分别. st represents the variable
这里, 是(.) denotes attention
summarizing the state at step t, which is computed as
X
mechanism employed, yt denotes medication at step t. Note that
where M denotes a
mapping matrix, in which each element Mti indicates the contribution of the tth diagnosis code xi to generating
the tth medication yt. 这样做, the model optimizes the cross-entropy loss function.
)
) .
= ∑| |
,
1
是
(
(
g s
t
M x
的
1
XY
(
,
1
s
t
X
=
y
,
)
-
=
-
t
我
我
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
/
t
我
The basic LEAP model has several issues. 例如, it faces adverse drug interactions due to the non-
availability of negative training samples and thus leads to incomplete medication sequences. To address
this issue, it is fine-tuned via model-free policy-based reinforcement learning [70], which increases the
expected reward of the treatment set Y suggested by the policy as given in Equation 5.
J
H
( |
X
)
=
乙
Y X
(
|
;
H
pY
~
)[ (
R X Y Y
)]
,
,
ˆ
(5)
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
R X Y Y represents a scalar value reward function that assesses the quality of Y, Yˆ is the treatment
(
在哪里
set for X that the doctors have prescribed considering the EHR data.
ˆ
,
)
,
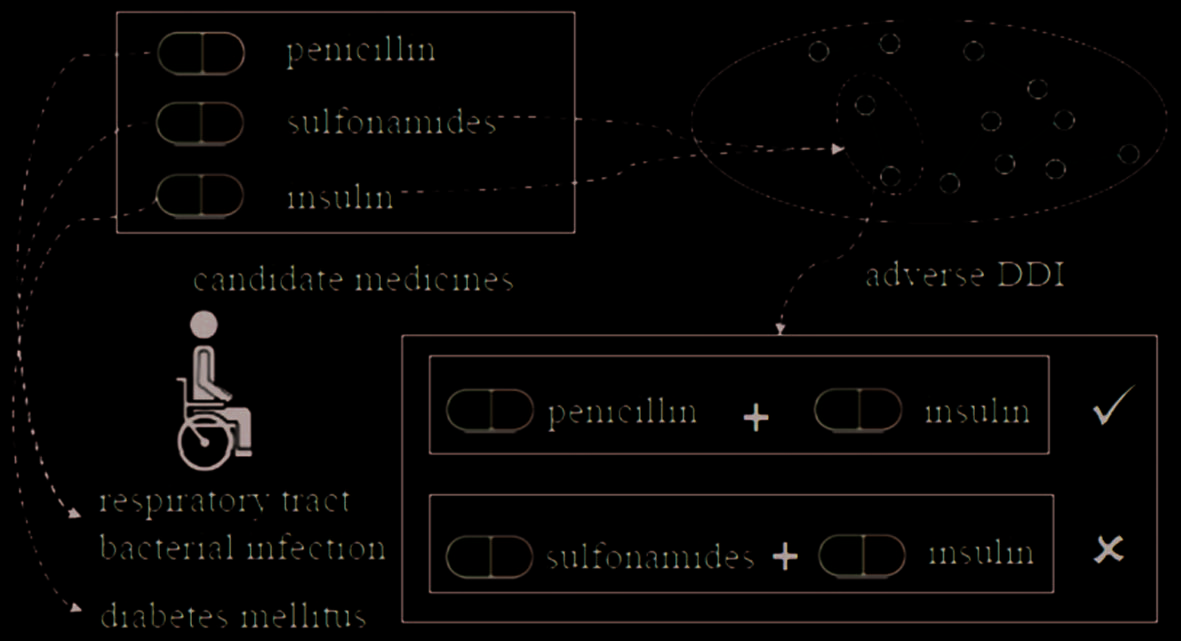
The post-processing and fine-tuning, 例如, using DDI knowledge to remove adverse medication
combinations from the prediction results, which is adopted in existing models like LEAP, affects the optimal
parameters that are learned in the prediction process. This is illustrated in Figure 4, which demonstrates
adverse DDI between “insulin” and “sulfonamides.” By removing “insulin,” the “diabetes” is not treated,
and if “sulfonamides” is removed, the “respiratory tract bacterial infection” receives no treatment.
316
数据智能
Deep Learning for Medication Recommendation: A Systematic Survey
数字 4. Complex medical relationships among medicines.
These issues were addressed in CompNet (Combined Orderfree Medicine Prediction Network), 这是
a graph convolutional reinforcement learning model that alleviates unreasonable assumptions on the
sequence of medicines to leverage the correlations among them. It applies Dual-CNN on EHRs to produce
patient representations, as given in Equation 6.
ˆt
z
= a
Z
t
(6)
= ⊕ p
d
Z z
z that results from concatenating the representation of diagnoses zd and procedures zp
在哪里,
along the first axis. These representations are balanced using attention weights at to make the attention
mechanism more effective. That is, employing DNN, CompNet approximates the Q-function Q(st, 在, H),
which produces a Q-value for each state-action pair (st, 在) at timestamp t. The st is a result of combining
the patient’s representation zˆ t and the KGrepresentation tt of the medicine related to the current predicted
medicines. The model parameters are represented with h. The model applies a greedy approach at each
timestamp t to select a medicine at considering the Q-value.
The doctors reward rt for the selected medicine at. The model updates its policy considering this award.
这里, st is computed as st = s(Wsht), where s is the sigmoid activation function; Ws is the learnable parameter
矩阵; and ht is the hidden state, computed using Equation 7.
=
s
H
t
(
+
W x U h
t
h t
,
H
)-
1
(7)
在哪里, Wh and Uh are parameter matrices, and ht – 1 is the hidden state representation at previous step
t – 1; h0 is a zero vector; and xt is the interaction representation between KGs of patient and medicine
z Here, gt and zˆ t denote the medicine KG-based embedding and
at timestamp t, computed as
t
patient representation at time step t, 分别. CompNet produces a medicine KG to hold dynamic
medical knowledge using the adverse and correlative relations among medicines, which can adjust the
medical knowledge adaptively considering the current predicted medicines.
= (西德:3) .ˆ
X
t
G
t
数据智能
317
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
t
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Wang et al. [30] proposed SRL-RNN (Supervised Reinforcement Learning with RNN) to produce
recommendations for a general dynamic treatment regime (DTR—a sequence of tailored treatments in
response to the dynamic patient states) that involves multiple medications and diseases. It combines
evaluation and indicator signals in learning an integrated policy. The SRL-RNN offers an off-policy actor-
critic framework for learning complex relations among individuals, their diseases, and medications. 这
actor-network recommends time-varying medications in response to the changing states of patients, 在哪里
the supervision of the decisions made by the doctors helps in ensuring safe actions so that the learning
process accelerates by considering the doctors’ knowledge. The critic network encourages or discourages
the recommended treatments by estimating the action value corresponding to the actor-network. The SRL-
RNN model is extended with LSTM to handle the issue of fully observed states in real-world applications,
where the entire historical observations are summarized for capturing the dependence of the temporal and
longitudinal records of the patients. This is achieved by optimizing the loss function given in Equation 8.
J
H
( )
=
-
(1
e
)
J
RL
H
( )
(
-
+
e
)
J
SL
H
( )
(8)
Where JRL(H) is the objective function of the reinforcement learning task that attempts to maximize the
expected return and JSL(H) is the objective function of the supervised learning task. 然而, the limited
experience of doctors and the knowledge gap make unclear the ground truth of “good” treatment strategy
in supervised learning, which may result in imprecise predictions. Compared to the PMDC-RNN and LEAP
型号, SRL-RNN gives better predictions due to its use of reinforcement learning that infers optimal
policies very well on non-optimal prescriptions. According to this study, only four models adopted DRL
[30, 31, 41, 3].
Recurrent neural net works. Unlike feed-forward neural networks, RNNs employ g ates such as input,
输出, forget, ETC。, to hold useful data and long-term dependencies [53]. They are close to CNNs, yet they
preserve the previously learned data by employing the concept of memory to use it in the upcoming
运营. This aspect make these networks suitable for sequential data [71]. They keep previous data using
a directional loop and feed it to the output. Considering the nature of the problem, they have many variants
but gated recurrent units (GRU) [72, 73] and long short-term memory (LSTM) [53] are widely used.
To deal with vanishing gradient problem [72], encountered by traditional RNNs, an extension of RNNs,
viz., GRUs and LSTMs introduced gates. Among these, LTSM uses input, 输出, and forget gats to either
keep or discard the information. 另一方面, GRUs use hidden states to pass information and employ
reset and update gates, which are similar in functionality to the update and forget gate of LSTM, 然而
the reset gate forwards important information to the next level. The RNN model and its variants capture
long-range dependencies and temporal dynamics [72, 74] and thus are more suitable for medication
recommendations, and thus used in various models. 例如, PMDC-RNN [45] predicts multiple
medications by applying a three-layered GRU model [73] on the patients’ diagnosis records, IE。, diagnostic
billing codes. 然而, it may predict imprecise medications due to discontinued medications or missing
billing codes. LSTM-DE [39] is the next-period prescription prediction model that uses a heterogeneous
LSTM with several hidden temporal sequences to capture the dynamics of medical sequences. The model
318
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
constructs one hidden temporal sequence to model the prediction sequence and the other hidden temporal
sequences to model physical examination results. 相应地, one hidden sequence each reflects the
treatment course and recovery progress. 然后, three heterogeneous LSTM models exploit the interactions
of various medical sequences, where a fully connected heterogeneous LSTM keep the interactions of hidden
states bidirectional and parallel. A partially-connected heterogeneous LSTM keeps the interactions from
hidden physical states to treatment hidden states. The physical examination results are directly imposed on
treatment hidden states in decomposed LSTM models. 最后, the model incorporates demographics and
diagnostics in the hidden states to predict the next-time prescriptions. Since the model utilizes auxiliary
information sources, therefore it produces improved area under the receiver operating characteristic curve
(AUROC) and the area under the precision-recall curve (AUPR) scores compared to vanilla LSTM and other
基线.
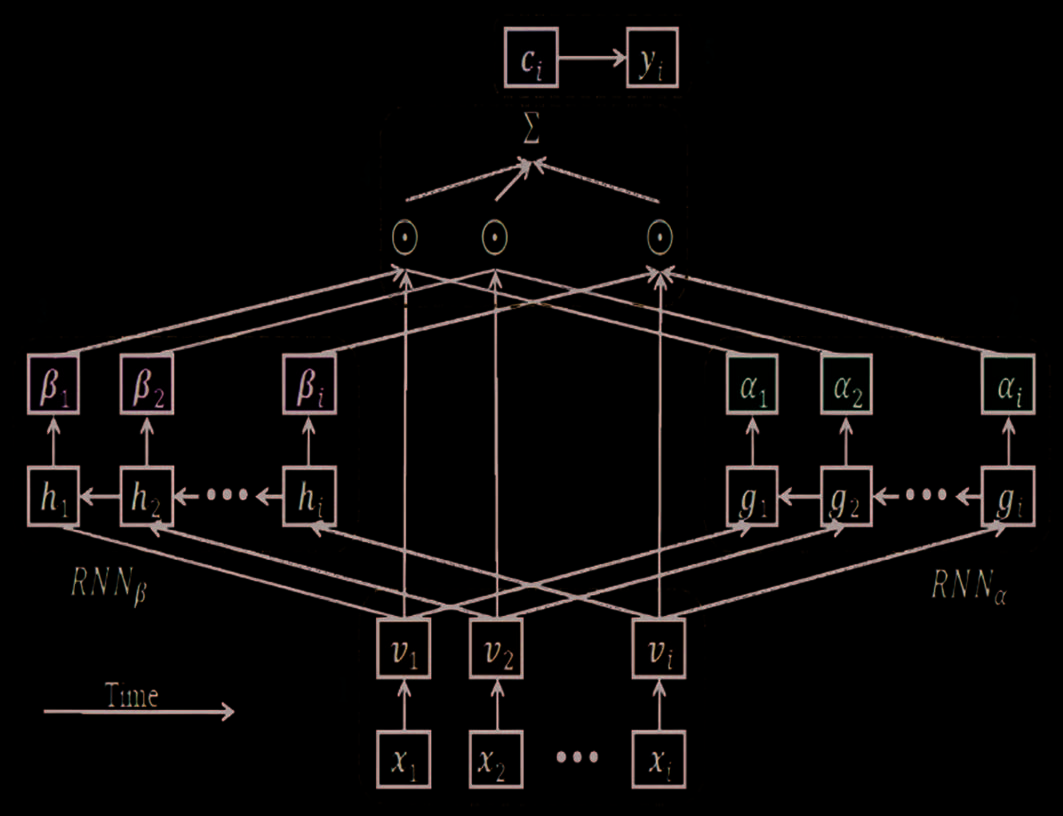
The RETAIN model [10] addressed the interpretability issue by employing a two-level neural attention
for sequential data offering a detailed interpretation of prediction findings while preserving RNN-like
prediction accuracy. For generating more stable attention, it represents physician behavior during an
encounter by looking at the past visits of the patient in reverse temporal sequence. 这边走, it identifies
important visits and quantifies visit-specific properties that contribute to prediction. Because of exploiting
temporal data, it outperforms MLP-based MRS and vanilla GRU, which use no such data [5]. 然而,
considering only the patient’s history, the recommendations produced are of low quality [5]. An unfolded
view of its architecture is shown in Figure 5. In the first step, embeddings are generated. In the second and
third steps, a and b values are produced using RNNa and RNNb, 分别. In the fourth step, 这
generated attentions of the third step are exploited to produce the context vector cj for a patient up to the
jth visit, given by Equation 9.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 5. An unfolded view of the RETAIN framework.
数据智能
319
Deep Learning for Medication Recommendation: A Systematic Survey
j
= ∑a b (西德:3)
我
我
C
j
=
1
我
v
我
(9)
在哪里, 六, vi – 1, ……, v1 represents visit embeddings in a reverse order and (西德:3) represents element-wise
multiplication. In the fifth step, the context vector cj ∈Rn predicts the true label yj ∈{0, 1}, given by
方程 10.
(西德:2)
y
j
=
Softmax
(
Wc
j
)
乙
+
(10)
Le, 特兰, and Svetha [14] proposed DMNC that uses a memory-augmented neural network (MANN) 到
address the problem of long-term dependencies and asynchronous interactions. 这里, three neural
controllers and two external memories are employed that resulting in a dual-memory neural computer. 到
model the intra-view interactions, each view has its own controller and memory. The controller is responsible
for reading input events, updating the memory, reading vectors from memory at each timestamp, 和
generating output considering its current hidden state. The intra-view interactions are of two types namely
early-fusion and late-fusion memories. During the encoding process, no information is exchanged between
these two memories as the late-fusion mode keeps memory space for each view independent and separated.
In the decoding process, the read values of the memories are used to generate inter-view knowledge. 这里,
unlike the late-fusion, the views share the addressing space of the memory to ensure information sharing.
This asynchronous sharing is offered by temporary holding the write values of each time step in a cache
so that information from different time steps can be written to the memories simultaneously. The decoding
process employs a write-protected mechanism on the memory to improve inference efficiency. Each encoder
employs LSTM to convert embedding vectors to h-dimensional vectors. Although DMNC uses attention-
based DNC blocks, which enables it to recognize the interactions between sequences, it ignores considering
medications during history visits [11]. In a similar way, the previously prescribed medications are ignored
by AMANet [34]. 然而, it captures the intra- and inter-correlations of heterogeneous sequences using
multiple attention networks, which helps in achieving a relatively better performance.
Some models treat drugs as mutually independent by ignoring their latent DDI. 例如, DPR [15]
considers the interaction effects within drugs that can be affected by the conditions of the patient in
recommending drug packages. 进一步来说, a pre-training method is applied that uses collaborative
filtering to get the initial embeddings of drugs and patients. A DDI graph is then produced considering
domain knowledge and medical records. A drug package recommendation (DPR) framework is employed
in two variants using a weighted graph (DPR-WG) and attributed graph (DPR-AG), where each interaction
is described respectively by assigned weights or attribute vectors.
In embedding the package, a mask layer captures the impact of the patient’s condition, and graph neural
网络 (GNNs) perform the final graph induction. During pre-training, MLP and char-LSTM [75] 学习
the disease document and admission note, 分别. DPR [15] outperforms AMANet [34] as the latter
is unable to capture evolution information, including disease progression via temporal sequence learning
320
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
网络, which is still a significant information source for decision-making. 相似地, MeSIN [11] addressed
the complexity of EHR data, having a large number of patient records, 访问, and sequential laboratory
结果, by introducing an interactive and multi-level selective network to recommend medications. 这
interactive LSTM is employed to reinforce the interactions among multi-level medical sequences in EHR
data by employing an enhanced input gate and a calibrated memory-augment cell. An attentional selective
module assigns flexible attention scores to various medical code representations on the basis of their
relatedness to the suggested medications in each admission. 最后, a global selective fusion module
incorporates the embeddings of information from multiple sources into the representations of patients for
recommending medication.
A patient’s health representation is a compact and indicative vector that represents the patient’s status,
defined by diagnosis and procedure information, to enable doctors to recommend medications [50]. 在这个
看待, MICRON [50] learns the sequential data locally considering two consecutive visits, IE。, (t – 1)th and
the tth, and propagates them visit-by-visit to keep the longitudinal information of the patient. Given the
health representations, IE。, H(t – 1) and h(t), the model learns a prescription network
从
the hidden embedding space for two visits, separately to recommend medications. 正式地,
(西德:4)右
s
NET
右|
中号
|
:
和
(
ˆ t
米
-
)
=1
NET
和
( )
ˆ t
米
=
NET
和
-
)
1
)
(
(
t
H
(
H
( )
t
)
(11)
(12)
(
)−1
ˆ t
( )
米
∈R
中号
|
|
ˆ tm and
represent the representations of medications, each entry quantifies a real value
在哪里
for the corresponding medication. 这里, a fully connected neural network implements NETmed. 正式地,
H(t – 1) – h(t) = r(t), is called residual health representation that encodes the alterations in clinical health
measurements, indicates an update in the health condition of the patient. This health update r(t) causes an
update in the resulting medication representation u(t). 所以, the authors were motivated that if NETmed
can map a complete h(t)) into a complete m(t)), then r(t) should also be mapped into an update in the same
representation space through NETmed. 换句话说, r(t) and u(t) shall also follow the same NETmed. 其他
字,
=( )
t
你
NET
和
(
r
t
( )
)
(13)
According to the authors, 方程 11 和 13 could be learned using the medication combinations in
the dataset as supervision, 然而, formulating direct supervision of Equation 13 is challenging. 所以,
they proposed modeling the addition and the removal of medication sets separately. 所以, 他们
( )ˆ tm by both unsupervised and supervised regularization.
considered reconstructing u(t) 从
MICRON is different from existing MR models, 包括, viz., Gamenet [21] and Retain [10] in the sense
that it learns sequential information locally, whereas the later ones use global sequential patterns using
RNNs.
ˆ tm and
)−1
(
数据智能
321
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
t
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
The ConCare [22] captures the interdependencies among features using a self-attention mechanism[76],
where fixed positional encoding is used to offer relative position information for timestamps [77]. 它
separately embeds time series of features by employing multi-channel GRU, using Equation 14.
H
n
H
……
n T
,
,
,1,
=
(
GRU r
n
n
,
r
n T
,
……
,1 ,
)
(14)
在哪里, the time series of feature n is represented as
The hidden representation is
summarized for the whole time span. Time-aware attention is employed for capturing the impact of time
intervals in each sequence. An attention function maps the query and the set of key-value pairs to an output
[76]. The hidden representation produces the query vector and key vectors, where the former is produced
at the last time step T. 正式地, these are described using Equation 15 and Equation 16:
r
n T
,
r
n
r
n
右
,1
,:
= … ∈
,
.时间
q
嵌入
n T
,
=
⋅
q
W h
n
, ,
n T
k
嵌入
n t
,
=
⋅
k
W h
n
, ,
n t
(15)
(16)
嵌入
n Tq
,
嵌入
n tk
,
are the query and key vectors, 分别, 和
在哪里
projection matrices for obtaining them. 方程 17 defines the time-aware attention weights.
nW and
和
nW are the corresponding
q
k
a a
n
n
,1
,2
…… =
A
,
n T
,
Softmax
(
z
n
,
,1
z
n
,2
……
,
z
n T
,
)
,
在哪里,
=
z
n t
,
tanh
⎛
⎜
⎜
⎝
乙
n
⋅
日志
(
+
e
嵌入
n T
,
-
q
(
1
s
⋅
k
(
q
嵌入
n t
,
嵌入
n T
,
⎞
⎟
⎟
⎠
)
)
)
⋅ Δ
t
⋅
k
嵌入
n t
,
(17)
(18)
This alignment model qualifies the contribution of each hidden representation to the densely summarized
representation for each feature. 这里, Δt is the time interval to the latest record, s represents the sigmoid
function, and bn is a feature-specific learnable parameter for controlling the impact of time interval on the
corresponding feature. The attention weight an,T decays significantly, 如果:
•
•
•
The Δt is long, meaning that the value was recorded a long time ago. A feature’s most recent value,
IE。, Δt = 0 decays slightly, IE。, 日志(e) = 1.
The time-decay ratio bn is high, meaning that only recently recorded value for a particular feature
事情. If the influence of a clinical feature persists, IE。, BN, it will be decayed slightly.
k⋅
The historical record has no active response to the current health condition, IE。,
q
嵌入
n T
,
嵌入
,1 .
n
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
F
n
⋅
H
n
.
,1
A
n t
,
=
我
1
=
嵌入
根据
The learned weights are exploited in deriving time-aware contextual feature representation as
=
此外, the demographic base line data is embedded into the same hidden space of
∑
⋅
时间
嵌入
瓦
F
根据
根据, 在哪里
baseW is an embedding matrix. 因此, the patent data is represented by a F as
F
n
这
a sequence of vectors, where each represents one feature of the patient over time:
inter-dependencies among dynamic features are captured using visits and the static baseline data, 然而
self-attention enables further re-encoding of the feature embedding under personal context. During feature
(
= …
F
1
F
根据
F
n
.,
F
)
.
,
322
数据智能
Deep Learning for Medication Recommendation: A Systematic Survey
processing by ConCare, a better encoding is attempted by looking at other features for clues. 此外,
it employs a multi-head mechanism to improve the attention layer with multiple representation subspaces.
The heads for self-attention are expected to capture dependencies from different aspects. 然而, 在
实践, they may tend to learn similar dependencies [76], 所以, non-redundant or diverse
陈述 [78, 79] are employed by minimizing the cross-covariance of hidden activations across
different heads. A cross-head decorrelation module is employed to enable models to focus on different
features by following [78].
The RETAIN model [10] uses two RNNs to learn time and feature attention and combines the weighted
visit embedding for prediction. 然而, it lacks advanced feature extraction with limited prediction
准确性 [80, 81]. In this direction, Lee et al. [82] proposed a medical contextual attention-based RNN
that uses the individual information derived from conditional variational auto-encoders. 然而, 这些
studies could not explore the inter-dependencies among dynamic records and static baseline data from a
global view. 另一方面, ConCare adaptively captures the relations among clinical features to
produce personalized recommendations for patients in diverse health contexts. It performs better than
positional encoding-based methods such as SAnD [77], Transformer-Encoder, attention-based RETAIN [10],
and time-aware approaches such as T-LSTM [74], showing that considering each feature’s time-decay
impact separately in a global view is far better than decaying the hidden memory of all visits directly. 这
study shows that a huge number of authors use RNNs and their variants [11, 45, 24, 10, 34, 39, 14, 38,
30, 9, 12, 26, 33, 3, 15, 47, 48].
Convolutional neural network. A convolutional neural network (CNN) [83] is a DL-based model that
produces efficient results with little pre-processing and lesser memory for training than RNNs. A CNN
structure has several layers including input, convolutional, sub-sampling, fully connected, and output layers
with functionalities such as receiving input data, performing convolution, pooling, learning non-linear
combinations among features, and producing final predictions, 分别. A CNN model creates a feature
map, which is implemented as a non-linear function, and computed using Equation 19.
=
C
我
f h x
( *
i i
:
+ -
我
1
+
乙
)
(19)
在哪里, * represents the convolution operator. Let a sentence of size n has a raw key x1:n, and a filter h
applies to the word embedding matrix x1:n, where l(l ≤ n) is the window’s length of the filter and b ∈ R as
a bias. This way, the execution cost reduces with the reduction in the size of the layer. These similar
operations are carried out repeatedly on various layers to enable them to find useful features, which enable
CNN to work as a classifier. The second last year computes the probability for every class of any item being
classified. The last layer produces the final classification results [53] using the softmax function. 不同的
objective functions, including Cross Entropy, are employed.
The SD_CNN [42] uses the CNN [83] framework to learn patients’ similarity [84]. The framework maps
patient A’s one-hot feature matrix via the embedding layer to a low-dimensional sparse matrix. The maximum
pooling and convolution are applied to each of these matrices and their eigenvectors are aggregated to
数据智能
323
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
make a composite vector. the same embedding and CNN parameters are obtained for Patient B. By matching
matrix and conversion layers, The composite vector of these patients obtains a similarity feature vector,
which is used to obtain their similarity probability via the softmax layer. 另一方面, GAMENet [21]
combines DDI KG with a memory module implemented as a GCN, using longitudinal records of the patient
as the query in recommending medications.
The framework of TAHDNet [13] holds three blocks namely 1D-CNN, transformer, and time-aware block.
The model uses 1D-CNN for local dependency, a transformer for global dependency, and a time-aware
block for dynamic time-aware attention to learn hierarchical dependencies on longitudinal EHR data (在哪里
each record is represented as a multivariate sequence). A new representation for each patient is produced
by concatenating the outputs of these blocks, which is then fed to the prediction layer for recommending
medication. The mode uses DDI loss for co-determining the final recommendation. It adapts transformer
structure and uses a pre-trained transformer-based module by following G-BERT[25] to model the global
dependency considering the whole patient records. Each patient’s input data is represented by E = (e1,
e2,……er). A pre-trained transformer is then used in learning the interactions among medical ontologies as
(西德:2)R is the latent space representation with global dependencies.
hT = Trans former (e1, e2,……er) 在哪里
The 1D-CNN block takes a visit’s multivariate sequence [
as the input to learn the
dependencies between neighbor visits to model the local dependency information. 方程 20 computes
the procedure embedding.
]
… ∈R
X
时间
Th =
X X
,
1
×
T C
|
*|
2
H
在哪里,
(西德:2)
h C
×∈′
右
ch
*
(西德:2)
is the output of 1D-CNN’s the hidden layer and h
represents its hidden size.
=
′
H
C
(
CNN X X
d
1
,
1
2
……
X
时间
)
(20)
TAHDNet avoids internal covariate shift by introducing layer normalization into ID-CNN: hc = LayerNorm
)
where m is a layer’s mean value, s2 is its variance, a and b are the parameter vectors
(西德:3)
乙
+
-
=
A
X
(
′
H
C
米
+
e
2
s
for scaling and translation, 分别. In the time-aware block, TAHDNet introduces a fused decay
function to consider periodic and monotonic decay, and then using the transformer’s self-attention
机制 [76], it computes the attention weights and produces the latent space representation of
time intervals:
=
w
t
Attention Q K V
,
(
,
=
)
时间
V
, where Q, K, and V are matrices comprising of [q1, q2…qT],
QK
d
k
[k1, k2…kT], 和 [v1, v2…vT], 分别. These are concatenated based on the latent space representation
(西德:2)右 . 最后, TAHDNET uses an MLP
to produce patient representation as h′ = Concat(小时, HC, h1) 在哪里
base prediction layer to predict MR codes. Our observations from Table 2 report that CNNs have been
adopted by three models [42, 13, 84] 仅有的.
×∈′
5 H
H
324
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 6. Workfl ow of the ARMR model.
Generative adversarial networks. The generative adversarial networks (GANs) adopt an unsupervised
learning approach that automatically discovers and learns the patterns or regularities in the data to enable the
model to output or generate new examples that could have been possibly drawn from the original data [85].
These models adopt an intelligent approach to train a generative model by employing two sub-models
including a generator and discriminator. The former generates new samples and the latter classifies them
as either real (IE。, from the domain) or fake (IE。, 生成的). They are trained in an adversarial manner until
the latter is fooled for about half the time, which means that the former is producing plausible samples [53].
To this end, ARMR [9] model uses two GRU networks [71] to build an encoder that exploits patient
diagnoses and procedures to generate robust patient representations. 然后, it uses a key-value memory
网络 [86] to keep historical representations and associated medications as pairs and performs multi-hop
reading on the memory network for obtaining case-based similar information from historical EHRs, 用过的
in updating patient’s embedding. It combines encoder and memory network [86] to build Medication
Recommendation (MedRec) module. The model makes a GAN model by fusing the encoder as a generator
with a discriminator and treats as real data the representations of the patients having DDI rates smaller than
a preset threshold to enable the GAN model to shape the distribution of patient representations generated
by the encoder to reduce DDI. MedRec and GAN are trained jointly within each mini-batch with two
目标: a traditional error criterion corresponding to recommending medication and an adversarial
training criterion to regularize distribution. 这边走, ARMR learns meaningful patient representations and
regulates data distribution for maintaining low DDI, 同时地.
数据智能
325
Deep Learning for Medication Recommendation: A Systematic Survey
t
t
de and
t
pe correspond to procedures
For a patient’s tth visit, the model generates embeddings
t
pc using
t
dh and
embedding matrices Wd and Wp, which are given as input to two RNNs. The model then integrates
ph using a linear embedding layer to learn representation rt that is processed employing a separate GRU
unit that produces the final embedding qt. 下一个, the model builds a key-value memory network KV using
T∈
[1,
the keys of the KV are the historical representations qt and values are represented using
全部
Meantime, ARMR uses qT to fit Gaussian distribution, which provides the real
relevant medications
data for GAN, while the encoder is responsible for generating the fake data. During regularization, 第一的,
fq , then it is confused
the GAN model updates the discriminator to distinguish real data p(z) from fake data
by updating the generator, where the cost function for regularizing GAN is defined using Equation 21 [85].
mc
* .
tq t
(
1]),
-
时间
我
minmax
G
D
乙
z p
~
z
⎡
⎣
日志
D
(
)
⎤
⎦
Z
+
乙
[
日志
(1
X P X
~ (
)
-
(
D G
(
)
)
]
X
(21)
在哪里, D and G denote discriminator and generator networks, 分别. Experiments exhibit that ARMR
gains improved results in terms of DDI rate and medication prediction compared to other competitive
baselines namely LAEP, DMNC, RETAIN, GAMENet, and MedRec because the proposed model regulates
the distribution of the patient representations that result in improved performance.
To deal with DDI’s fatal side effects, SARMR [12] processes raw EHRs to get the probability distributions
of patient representations related to safe combinations of medication in the feature space. It then adversarially
regularizes these distributions to get reduced DDI rates by applying knowledge as true data. The model
treats and regularizes patients with different DDI rates as different cohorts, 这边走, the model avoids the
adverse impacts on generalization caused by treating them as a single cohort. In contrast to SARMR, 这
RNN-based baselines including LEAP, RE-TAIN, and DMNC are limited in capturing important factors that
affect the patient’s health state to the highest degree. GAMENet uses additional DDI knowledge as a
memory component to alleviate DDI, 然而, its reasoning capability over interactions between patients
and doctors is limited and results in lower figures using Jaccard and F-score. 最后, If we look at the
statistics of the examined works, we notice that this area still needs further research as very few models
[24, 9, 12] used GANs in MRMs.
Attention networks and transformer-based models. Attention networks are much popular among
研究人员 [87, 88] as they produce robust recommendations by paying more attention to the salient
信息 [89, 90]. They have been successful in producing interpretable and explainable medication
recommendations [91]. To this end, RE-TAIN [10] employs the attention mechanism and GRU [71] 到
leverage sequence information and improve prediction interpretability. 尤其, it relies on an attention
mechanism modeled to illustrate the behavior of physicians during an encounter. To encode physician
behaviors, RETAIN analyzes a patient’s past visits in reverse time order, enabling a more stable attention
一代. 最后, RETAIN determines the most significant visits and quantifies visit-specific features
that contribute to medication predictions. Most of the existing models namely PREMIER [24], GAMENet [21]
and SRL-RNN [30] propose the longitudinal EHRs from few patients having multiple visits but ignore many
patients with a single visit, which leads to selection bias. 此外, hierarchical knowledge such as the
hierarchy of diagnosis, which is important from the recommendation perspective, is not considered in
326
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
representation learning. G-BERT [25] addresses these issues by employing graph attention network [65] 为了
representing hierarchical structures of medical codes using ontology embedding. It uses BERT [76] in pre-
training each visit from EHR in order to consider the EHR data that has even a single hospital visit. It fine-
tunes the pre-trained visit and representation for downstream predictions on longitudinal EHRs (number of
C and
访问) from patients having multiple visits. A visit is the combination of medical diagnoses codes
C . The model concatenates the average of previous diagnoses
medication codes
visit embedding, last diagnoses visit embedding, and medication visit embedding and inputs it to MLP to
recommend the medication codes by optimizing the categorical cross-entropy loss function. 实验的
results demonstrate that G-BERT outperforms competitive baselines, including RETAIN, LEAP, and GAMENet
in terms of precision, 记起, AUC (PR-AUC), F1, and Jaccard scores.
C denoted as
X C
= ∪
t
d
t
米
t
米
t
d
t
In this direction, COGNet [5] recommends a combination of medications considering the current health
conditions of the patient via an encoder-decoder generation network. The encoder contains two transformer-
based networks [76], which use a multi-head self-attention mechanism, to encode the diagnosis and
procedure information, and two graph convolutional encoders [63] to model the relations between
medications. The copy module evaluates the current health conditions against previous visits to copy
reusable medications in prescribing drugs for the current visit considering changes in the health condition.
A hierarchical selection mechanism combines the visit- and medication-level scores to compute the copy
probability for each medication. The copy module outperforms other counterparts including LEAP, RETAIN,
DMNC, GAMENet, MICRON, and SafeDrug because, in clinical practice, the recommendations for the
same patients are closely related. In contrast to COGNet, these baseline models ignore the historical visit
information of the patient. 而且, they consider no relationship between the medication recommendations
of the same patient and are unable to capture long-range visit dependency. 最后, we can notice a positive
trend towards using BERT-based and attention networks as adopted by ten models [11, 42, 10, 34, 22, 25,
26, 5, 47, 48] in recent years.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
t
/
我
Hybrid and other networks. A hybrid network integrates two or more DL methods to capture their
inherent benefits and alleviate their potential limitations in producing robust medication recommendations.
例如, an unavoidable challenge is handling the difficulty in learning the inter-view interactions due
to the unaligned nature of multiple sequences. This is addressed by a hybrid model, AMANet [34] 那
integrates memory network [92] and attention by employing three main components. These include a neural
controller that uses self-attention to capture the intra-view interactions by encoding the input sequence.
The inter-view interaction is learned by employing an inter-attention mechanism, which learns the inter-
view interaction. To connect the positions of a single sequence, either a self-attention or intra-attention
mechanism is used. 这里, the intra-attention obtains the relationship between different elements in the
same sequence. 此外, the inter-attention connects positions in two sequences. 具体来说, in the
inter-attention, one input embedding projects the query, and another projects key and value. The sequence’s
encoding vector is then produced by concatenating the inter-attention and self-attention vectors. The history
attention memory keeps the previous encoding vectors of the same object. The dynamic external memory
stores the common knowledge about data and is shared by all training objects. The predictions are generated
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数据智能
327
Deep Learning for Medication Recommendation: A Systematic Survey
by concatenating the encoding vector, read vector, and historical attention vector. 然而, the AMANet
model is unable to fully exploit the captured evolution information including disease progression through
temporal sequence learning networks, which if exploited, could lead to more robust recommendations [11].
The ARMR [9] model proposes an encoder with two GRU networks [73] to exploit diagnoses and
procedures to produce patient representations. The model updates patient representations by storing
historical representations and association medication in a key-value memory network [93] and reads it via
multi-hop reading for extracting case-based similar data from historical EHRs to update patient
陈述. This results in a medication recommendation (MedRec) module that comprises of encoder
and memory network. The model integrates the encoder as a generator with a discriminator to produce
GAN model [85]. The GAN model reduces DDI by exploiting patient representations having DDI rates
smaller than a preset threshold as real data to shape the distribution of patient representations produced
by the encoder. 一起, MedRec and GAN are jointly trained within each mini-batch to get a traditional
error criterion for recommending medications and an adversarial training criterion for regulating distribution.
This strategy allows the model to learn meaningful patient representation and maintain low DDI at the same
时间, which leads to quality medication recommendations.
Avoiding fatal DDI is among the prominent challenges in recommending medications. This issue is
addressed by the SARMR model [12] that processes raw EHRs to get the probability distributions of patient
representations for safe medication combinations. It reduces DDI by adversarially regularizing the
distributions of patient representations using the knowledge as real data. It uses and regularizes patients
having varying DDI rates as distinct cohorts to avoid the negative effects on the generalization, 这可能
occur if they are treated as a single cohort. Firstly, it models the interactions between patients and physicians
by encoding EHRs with GRUs [73] and then constructs a key-value memory neural network [93] with keys
denoting admission and values showing the corresponding medications. 第二, it uses the representation
of the most recent admission as a query to carry out multi-reading on the MemNN [93] with GCN [63]
embedding module of the read results. The medications are recommended considering the updated query.
下一个, it uses records of all patients, with no regard to their DDI rates, to recommend medications and
regularize adversarial distribution with GAN [85] on the basis of representations obtained from the first
step to achieve both reduction in DDI and effective medication combinations. The final results are predicted
as Equation 22.
(
(
⎡
S g q v
⎣
,
时间
)
)
中号
,
我
⎤
⎦
(22)
=
ˆ
y
Where qT is the patient representation, vM is multi-hop reading result, i is the medication with weighted
嵌入, G(.) is fully-connected layer, 和S(.) is the sigmoid function.
To consider the consecutive correlation in dynamic prescription history and understand irregular time-
series dependencies, MERITS [27] employs neural ordinary differential equations (Neural-ODE) so that the
continuous inner process can be better modeled. It employs an encoder-decoder architecture in predicting
next medication sequence and combines static and dynamic using self-attention. In the meantime, 它
embeds and uses the knowledge about drugs and the experience of the doctors by exploiting three graphs,
328
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
namely sequential, DDI, and co-occurrence graphs to represent drug sequential relationships, 冲突,
and co-occurrences. The encoder has three modules, 即, a medical embedding module that employs
a self-attention module [76] and RNN for capturing sequential information; a dynamic encoding module
that models irregular time series data at a specific timestamp using Neural ODE; and a patient aggregation
module that uses the simple linear map to model the patient’s state by aggregating the sequential medications,
and static as well as dynamic features The encoder produces a representation of the patient at the current
timestamp by extracting medication strategies and patient status from irregularly sampled time series data.
The decoder employs a medication generator and graph attention module. It recommends medications at
timestamp t + 1 using the patient representation and graphs that establish the relationships between drugs
in the medication history.
The TAHDNet model [13] captures the dependence information between medications and patients at
local and global levels by adopting hierarchical learning. 数字 7 presents its architecture consisting of a
transformer, time-aware, and 1D-CNN blocks. It employs 1D-CNN [83] in learning the patient’s local
representation and uses adapted transformer-based learning [25] in learning her global representation via
a self-supervised pre-training process. It models the disease progression by employing a fused temporal
decay function with monotonic and periodic decay for dynamic time-aware attention, which leads to a
more realistic evaluation of disease progression. The model outperforms several baseline models including
LEAP [3], RETAIN [10], G-BERT [25] and GAMENet [21]. 这里, LEAP, which is instance-based, 执行的
lower than the RETAIN temporal method. This advocate for the importance of temporal data in EHRs.
然而, G-BERT performed comparatively well and outperformed GAMENet due to learning additional
information about DDI and procedure codes. This discussion demonstrates that transformer-based models
are more effective for recommending medications. 然而, G-BERT considers no temporal information and thus
is unable to learn the disease progression information, which is one of the main causes of its sub-optimal
表现. TAHDNet gives better results due to its capability of extracting as many details as possible
from EHRs while reducing noise.
Recommending medications is a time-consuming process for experienced medical practitioners and
error-prone for inexperienced ones, especially in complicated cases. The COGNet model [5] addresses this
issue by employing a generation network based on an encoder-decoder to recommend suitable medications
in a sequential manner. It represents the patient’s historical health conditions by encoding all her medical
codes from previous visits in the encoder network. It represents the patient’s current health condition by
encoding the diagnosis and procedure codes from the tth visit. It employs a decoder to generate the
medication procedure codes of the tth visit one by one to represent the patient’s current drug combination
suggestions. The decoder collects information by procedures, diagnoses, and medications to suggest the
next medication during each decoding step. If the current visit’s diseases are consistent with previous visits,
the copy module copies the associated medications immediately from the historical medicines combinations.
换句话说, the copy module extends the basic model by comparing the health conditions of historical
and current visits and then copying the reusable medications to write prescriptions for the current visit
based on condition changes. Diagnosis and procedure encoders are transformer-based networks [76] 和
different parameters.
数据智能
329
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 7. The archit ecture of TAHDNet model.
The set of patient’s symptoms and medications define the input to the medication recommender, 然而,
this input still lacks sufficient details that can relate these two entities. MedRec [36] addresses this issue by
including knowledge about medicines and their attribute graphs in its model to connect medications with
symptoms. A medical KG of symptoms and medications is created which results in their richer representation.
This KG holds four key nodes including physical examination, symptom, 疾病, and medicine. An edge
connects two related nodes. 例如, a disease has certain symptoms and requires specific medications,
all three are connected with different edges. The attribute graph models the interrelationships among
medicines. If two medicines belong to the same category or have the same sub-molecular structure, 然后
they are related. In recommending medications, MedRec first applies multi-relational GCN [63] 学习
the embeddings of entities and relations and uses the objective function of the link-prediction task to
optimize the model. 相似地, the embeddings of medicines and symptoms are produced. It fuses the
attention mechanism with the embedding of each symptom to produce a syndrome representation. MedRec
employs GCN [63] to get the embedding of an attribute graph, which is used in combination with medical
KG to produce the overall representation of a medicine. 最后, it produces the prediction scores by
learning the interaction of medicine and syndrome. 数字 8 illustrates the architecture of MedRec, 显示
that it recommends medicines with an embedding matrix using attributes and medical KGs against the
symptom set of the patient. 从数学上来说, for the symptom set representation esc and embeddin g matrix
eM of the medicines M, 方程 23 describes the medication recommendation.
330
数据智能
Deep Learning for Medication Recommendation: A Systematic Survey
(
=
score sc M sigmoid e
)
,
(
sc
)
⋅
时间
e
中号
(23)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 8. The architecture of the MedRec model.
The score(sc, 中号) characterizes the ranking score in recommending medicines. Given symptom set sc,
the ground truth set is represented as a multi-hot vector mc in dimension |中号| and score(sc, 中号), 这是
the output probability vector for all medicines, the mean square loss between score (sc, 中号) and mc is
computed using Equation 24.
=
L
RS
中号
|
|
(
∑
=
1
j
-
mc
j
score sc M
(
,
)
2
)
j
(24)
一般来说, the drugs are considered as individual items by the medicine recommenders and thus neglect
the unique requirements of recommending drugs as a set of items while keeping DDIs as much as possible.
This issue is addressed by 4SDrug [28] which recommends medications by performing set-to-set comparison
for designing set-oriented representation and similarity measurement for both medicines and symptoms. 它
takes the set of medicines Di and symptoms Si as inputs and employs three modules in recommending
Sh for the symptom set ith and
medicines against a symptom. The set-to-set comparison module employs
Dh for medicine set ith to represent Si and Di via the set-oriented representation and measure the relationship
我
Si and Di through the set-oriented similarity measurement g{.,.}. The symptom set module reformulates
Sh
using importance-based set aggregation.
我
我
数据智能
331
Deep Learning for Medication Recommendation: A Systematic Survey
The drug set module recommends sets of medicine using the intersection-based set augmentation and a
hybrid DDI penalty mechanism for ensuring the principle of a small and safe drug set. 数字 9 说明
an example of this recommendation, showing that two patients Jack and Lisa share similar symptoms, 这样的
as fever, cough, chills, and headache, and thus the same disease, IE。, viral influenza has the maximum
chances. 所以, they will be recommended the same medication, such as Ibuprofen, Ambroxol, 和
Oseltamivir. 因此, the physical status of the patient can be judged from their symptoms without disclosing
any personal data [94, 95]. 所以, symptom-based medication recommenders can be widely adopted
in drug prescriptions to avoid privacy issues. Using the set of symptoms S(j) and medicines D(j) can be
(
Dh to compute the similarity between them using Equation 25, 在哪里
represented respectively via
di represents a drug in the training phase.
(
Sh and
)j
)j
{
j
(
Sim h h
D
(
S
,
)
j
}
)
=
1
j
(
D
)
)
jD
(
∑
=
1
我
{
j
(
f h d
S
,
)
}
我
The model uses Equation 26 to optimize the objective function.
=
j
(
)
L
rec
∑
∈
d D
我
(
j
)
(
logf h d
,
)
j
(
S
)
我
+
∑
(
∈ −
d D D
我
日志
)
(
j
)
(
1
-
{
j
(
f h d
S
,
)
在哪里, D(j)) are the medicines used in the treatment of symptoms S(j).
(25)
(26)
}
)
我
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 9. A toy instance of the symptom-based set-to-set medicine recommendatio n.
The experimental results indicate that 4SDrug outperforms other competitors including GAMENet and
LEAP. 那是, it outperforms GAMENet because the latter lacks considering the number of recommended
drugs and outputs an undesirable DDI rate, consistent with the results in the current work [33]. 此外,
4SDrug gives better computational space and complexity due to requiring comparatively lesser complex
neural architecture and is compatible with efficient mini-batch training. GAMENet [21] requires more space
due to a large memory bank, whereas LEAP [3] is computationally complex due to sequential modeling
332
数据智能
Deep Learning for Medication Recommendation: A Systematic Survey
and recommending medications one by one. Considering all these factors, 4SDrug is more suitable for
real-world industrial applications as it is more efficient and adaptable.
2.4 Optimization Methods
A DL model employs its algorithm to generalize the data so that it can make predictions against unseen
数据. 所以, it is always required to find an algorithm that not only makes such predictions but also
optimizes the results. By optimization, we mean finding a way that discovers those values of the parameters
or weights that reduces the chances of errors and enhances model accuracy while mapping inputs to
outputs. Such an optimization accelerates training and helps improve performance while learning from
数据. 然而, finding the optimal weights for a DL model is challenging due to the millions of parameters
within it. 所以, the need to choose an appropriate optimization algorithm is the key to success [96].
This section discusses the most widely used optimization algorithms used in employing DL algorithms for
recommending medications.
Gradient descent. The gradient descent is an iterative first-order algorithm that attempts to find a local
minimum/maximum for a given function [97].
Stochastic gradient descent. The stochastic gradient descent extends gradient descent by reducing its
computational intensiveness as the latter computes the derivative of one point at a time [96].
Momentum. A gradient descent algorithm finds it challenging to navigate ravines, IE。, the areas having
surface curves steeper among different dimensions, most common around local optima. To address this,
stochastic gradient descent oscillates across the ravine’s slopes while making tentative progress toward the
local optimum. The momentum extends gradient descent to speed up stochastic gradient descent in an
appropriate direction and keep the oscillations of noisy gradients to the minimum [97, 96].
RMSProp. Root Mean Squared Prop is another adaptive learning rate method that tries to improve
AdaGrad [98] that takes the cumulative sum of squared gradients. RMSProp takes the exponential moving
average. Both have an identical first step, 然而, RMSProp divides the learning rate by an exponentially
decaying average [99].
亚当. 亚当 [99, 97] combines the advantages of Momentum and RMSProp to compute the adaptive
learning rate for each parameter. It stores the previous decaying average of the squared gradients and holds
the average of past gradients similar to that of Momentum. 桌子 3 shows that the majority of the models,
IE。, 24 在......之外 37 models used Adam and its variants. The possible reason behind the usage of Adam could
be its capability to converge faster. Gradient descent and its variants stand in the second position, 哪个
is employed by 8 型号. Only one model used AdaGrad while others share no details regarding their
optimization method.
数据智能
333
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
桌子 3. Optimization methods used by the explored models.
Optimization method
Gradient Descent & extensions
亚当 & extensions
Adagrad & extensions
2.5 Recommendation Types
Models references
[31, 3, 38, 42, 29, 30, 45, 48]
[28, 22, 34, 40, 5, 14, 41, 21, 77, 31, 15, 25, 39, 23, 44, 27, 11, 24, 33, 12,
13, 46, 74, 32, 47]
[48]
A drug recommendation can be personalized or non-personalized. In the first case, recommendations
are made on the basis of the user profile and personal interests. 例如, patients’ medical history,
diagnosis, 程序, symptoms, and temporal dynamics related to their visits for understanding their
medical status and generating individualized predictions. A non-personalized medication recommender
system considers generic features and exploits no additional rich semantics corresponding to the patients.
桌子 2 reports that most of the models adopted a personalized approach.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
A
_
0
0
1
9
7
p
d
.
t
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
3. E VALUATION METHODS
This section gives a brief account of the evaluation methodology (datasets and evaluation metrics)
adopted by the MR models in evaluating their experimental results.
3.1 Evaluation Metrics
W e provide details of the evaluation metrics that are commonly used in the literature of medication
recommendation.
Recall. assesses an MR model’s significance on the basis of the percentage of relevant recommendations
appearing in its top-k results. Most of the models select values for k in k = {20, 40, 60, 80, 100}. 方程 27
describes recall mathematically.
Recall
1 问
= ∑
问
=
1
j
右
p
∩
时间
p
时间
p
(27)
在哪里, Q and Rp denote all target medicines and the list of top-k recommendations delivered for the seed
medications p, 分别.
Mean average precision. assesses an MR model’s significance by checking if the relevant medicines
appear in the list of top-k recommendations. 此外, the errors appearing in the top@k are penalized.
AP k
@
=
1
GTP
k
∑
=
1
我
TPseen
我
(28)
Where TPseen represents total true positives till k. 一般来说, AP@10 is set as the cut-off value for the
average precision (AP).
334
数据智能
Deep Learning for Medication Recommendation: A Systematic Survey
Normalized discounted cumulative gain. nDCG [100] assesses position/rank of true relevant
medications in the list of top-N recommendations. It adopts graded relevance to assess the effectiveness of
an MR model using Equation 29.
nDCG
G
=
DCG
G
IDCG
G
(29)
在哪里, nDCGg represents the accumulated normalized gain for a rank g. G is the list of relevant medications
in the collection up to position g. To ensure that the top relevant medications appear at the top of the
recommendations list, a weighted sum of the relevance degrees of suggested medications is defined and
referred to as discounted cumulative gain (DCG). This leads to IDCGg, which represents the DCG of ideal
ordering, used in normalizing the DCG scores. Mean reciprocal rank. analyzes an MR model’s capability
to suggest relevant medications in the list of top k results, and computed using Equation 30.
MRR
=
1/
问
时间
∑
∈
q Q
时间
1/
rank
q
(30)
在哪里, QT is the testing set and rankq is the rank of its first ground truth medicines.
Accuracy. computes the superiority of medication predictions, IE。, an incorrect/correct guess of the
next medicine recommended [101]. 方程 31 computes it.
Accuracy n
@
=
TruePositive n
D
@
测试
(31)
在哪里 |Dtest| is the test set and n represents the number of top suggestions against the query medicine.
F-measure. combines precision and recall through a harmonic mean [102]. Comparatively, it gives a
better assessment of the suggested medications than accuracy and can be calculated using Equation 32.
-
F Measure
=
2 *
Precision Recall
Precision Recall
*
+
(32)
Area under curve. is considered for MR models that formulate recommendation as a classification task.
方程 33 computes it.
(
|
我
,
AUC
=
)
(
)
(
)
j Rank p
N N
p
n
j
<
(
Rank n
k
)
|
(33)
where pj denotes the predicted score of j-th positive sample, while nk is the predicted score computed for
the k-th negative sample. Np and Nn represent the total number of positive and negative samples, respectively.
Jaccard similarity. is a common proximity measurement that computes the similarity between two
nodes/vectors. It is defined using Equation 34 as the ratio of intersection of ground truth Yt and predicted
result ˆ tY to the union of Yt and ˆ tY , where N is the total number of patients.
Jaccard
=
1
N
=
t
Σ
1
N
∑
=
1
t
|
|
Y
Y
t
t
∪
∪
t
t
ˆ
Y
ˆ
Y
|
|
Data Intelligence
(34)
335
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
DDI rate. measures the medication safety of a model, which defines as the percentage of medication
recommendation that contains DDIs.
N
∑ ∑ ∑
T
k
k
t
i
,
j
DDIRate
=
{
)
(
∈
ˆ
Y
c c
,
t
i
∑ ∑ ∑
T
k
N
j
k
t
1
,
j
i
(
k
)
(
|
c c
,
i
j
)
∈
e
d
}
(35)
Where, the set will count each medication pair (ci, cj) in the recommendation set ˆY if the pair belongs to
the edge set ed of the DDI graph. Here N is the size of test dataset and Tk is the number of visits of the
kth patient.
Table 4 reports that the most widely used metrics are F-Score (24 out of 37) and AUC (23 out of 37),
indicating a greater interest of researchers in generating accurate medication predictions. These are followed
by Jaccard (20 out of 37) showing that a considerable number of MR models treat recommendation as a
classification problem. This is followed by the DDI rate (13 out of 37) and recall (11 out of 37). In addition,
the majority of the models adopted a combination of metrics together.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
The classification or ranking accuracy measures are employed to optimize recommendations with the
aim of finding the most relevant medications for a patient. Most of the reported MR models use accuracy
measures of different types, including coverage and precision (recall, precision), rank-based measures
(nDCG or MRR), and prediction measures (RMSE). Finally, we noticed that the majority of models (21 out
of 37) used three or more evaluation metrics, which shows that an evaluation based on many metrics makes
the experiments of MR models more robust.
3.2 Datasets
Table 5 reports on the most widely used medication recommendation datasets. This section gives a brief
overview of these datasets to enable researchers to choose the right dataset for their experiments.
MIMIC-III. medical information mart for intensive care (MIMIC-III) is the most rich dataset, developed
by the computational physiology lab of Massachusetts Institute of Technology (MIT), provides access to
information sources including patients, diagnosis records, clinical events, procedures, medicines, and
symptoms. Therefore, the majority of the models, i.e. 24 out of 37 used this dataset [9, 21, 23, 11, 24, 25,
45, 13, 5, 14, 28, 29, 103, 41, 46].
NELL. NELL [104] is the most recently released dataset, which has been used in only one model. This
dataset provides access to information sources such as 2, 78, 388 clinical events, and 230 medicines.
ICD-9. The International Classification of Diseases version 9 (ICD-9) is the official standard codes of
diagnosis and procedures. It contains 13000 disease codes in tabular form. The codes specify that each
disease has a unique code and is used in EHR for the billing mechanism. Several models utilized ICD-9
based datasets [29, 42, 44].
https://mimic.physionet.org
336
Data Intelligence
Deep Learning for Medication Recommendation: A Systematic Survey
Table 4. The metrics utilized conducting the experiments of the explored recommendation models.
Models
Preci-
sion
Recall Jaccard
DDI
rate
F-Score MAP AUC nDCG MRR
Moral-
ity
Hit
ratio
Others
1 ARMR [9]
2 GAMENet [21]
3 RETAIN [10]
4 MedGCN [23]
5 MeSIN [11]
6 PREMIER [24]
7 G-BERT [25]
8 SARMR [12]
9 TAHDNet [13]
10 COGNet [5]
11 MRSC [26]
12 MERITS [27]
13 DMNC [14]
14 4SDrug [28]
15 DPR [15]
16 SMR [29]
17 LEAP [3]
18 SRL-RNN [30]
19 CompNet [31]
20 MICRON [32]
21 SafeDrug [33]
22 AMANet [34]
23 RA-WCR [35]
24 MedRec [36]
25 SMGCN [37]
26 LSTM-DO-TR [38]
27 LSTM-DE [39]
28 CGL [40]
29 ConCare [22]
30 DRLST [41]
31 SDCNN [42]
32 MetaCare++ [43]
33 MedPath [44]
34 PMDC-RNN [45]
35 TAMSGC [46]
36 GATE [47]
37 Dipole [48]
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
Data Intelligence
337
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Table 5. Datasets employed in conducting the experiments of the explored recommendation models.
Models
Non-
public
MIM-
IC-III
NME-
DW
Sutter NELL TCM Others
Drug-
Bank
ICD-9 eICU IQVIA
PRI-
VATE
1 ARMR [9]
2 GAMENet [21]
3 RETAIN [10]
4 MedGCN [23]
5 MeSIN [11]
6 PREMIER [24]
7 G-BERT [25]
8
SARMR [12]
9 TAHDNet [13]
10 COGNet [5]
11 MRSC [26]
12 MERITS [27]
13 DMNC [14]
14 4SDrug [28]
15 DPR [15]
16 SMR [29]
17 LEAP [3]
18 SRL-RNN [30]
19 CompNet [31]
20 MICRON [32]
21 SafeDrug [33]
22 AMANet [34]
23 RA-WCR [35]
24 MedRec [36]
25 SMGCN [37]
26 LSTM-DO-TR [38]
27 LSTM-DE [39]
28 CGL [40]
29 ConCare [22]
30 DRLST [41]
31 SDCNN [42]
32 MetaCare++ [43]
33 MetaPath [44]
34 PMDC-RNN [45]
35 TAMSGC [46]
36 GATE [47]
37 Dipole [48]
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
eICU. eICU [43] is a Collaborative Research Database in which deidentified health records of critical
patients are stored who are admitted to Intensive Care Unit (ICU). In this dataset, different information
factors are included such as diagnosis, vital signs, care plan, the severity of illness, and treatment information.
The eICU dataset contains over 200,000 patients’ data across the United States. The dataset is freely
available and widely used by a number of research communities in different application domains.
338
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Proprietary and non-public datasets. Several studies developed proprietary and non-public datasets
to evaluate their MR models. Table 5 reports that six models have used such datasets, making it challenging
for researchers to compare the results of these models with other models [10, 27, 15, 36, 38, 39, 22]. Some
other datasets adopted by explored models include Sutter [3], TCM [36, 37], DrugBank [29], IQVIA [90]
and PRIVATE [11, 24]. Since these datasets give access to limited information sources, therefore employed
by a few studies.
Table 6. The details of the datasets used in evaluating MR models by the reported studies.
Datasets
#patients
#clinical
events
MIMIC-III3
Sutter4
NMEDW5
PRIVATE6
NELL7
DrugBank8
TCM9
5,847
13,727
258K 2,415,414
1,260
865
-
13,640
278,388
-
-
-
-
-
#diagnoses #procedures #medicines
#related
DDI pairs
#symptoms
Release
year
1,954
-
-
11
-
-
-
1,352
-
-
-
-
-
-
138
7,516
57
134
230
14,752
811
460
-
-
-
-
1,180
-
1,113
-
-
-
17,898
-
390
2015
2017
2015
2021
2022
2014
2018
4. COMPARATIVE ANALYSIS OF THE EXPERIMENTAL RESULTS OF THE MODELS
This section is dedicated to the comparison of experimental results generated by the examined models
using different evaluation metrics and datasets. If we look at the results of models using the MIMIC-III
dataset in Table 7, The best performance on MIMIC-III is gained by the DMNC [14]. The DMNC attained
the best performance due to the introduction of a new memory-augmented neural network model that aims
to model these complex interactions between two asynchronous sequential views. DMNC uses two
encoders for reading from and writing to two external memories for encoding input views. The intra-view
interactions and the long-term dependencies are captured by the use of memories during this encoding
process. There are two modes of memory accessing in DMNC [14] system: late-fusion and early-fusion,
corresponding to late and early inter-view interactions. In the late-fusion mode, the two memories are
separated, containing only view-specific contents. In the early-fusion mode, the two memories share the
same addressing space, allowing cross-memory accessing. In both cases, the knowledge from the memories
will be combined by a decoder to make predictions over the output space.
The second best performance is attained by the COGNet model [5] because it utilizes a generation
network based on an encoder-decoder to recommend suitable medications in a sequential manner. It
represents the patient’s historical health conditions by encoding all her medical codes from previous visits
in the encoder network. It represents the patient’s current health condition by encoding the diagnosis and
procedure codes from the patient’s visit. It employs a decoder to generate the medication procedure codes
of the visit one by one to represent the patient’s current drug combination suggestions. The decoder collects
information by procedures, diagnoses, and medications to suggest the next medication during each decoding
step. If the current visit’s diseases are consistent with previous visits, the copy module copies the associated
medications immediately from the historical medicines combinations.
Data Intelligence
339
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
.
s
l
e
d
o
m
d
e
n
i
m
a
x
e
e
h
t
y
b
d
e
t
r
o
p
e
r
s
t
l
u
s
e
r
l
a
t
n
e
m
i
r
e
p
x
e
e
h
t
g
n
i
s
u
n
o
s
i
r
a
p
m
o
c
e
c
n
a
m
r
o
f
r
e
P
.
7
e
l
b
a
T
o
i
t
a
R
t
i
H
-
l
a
t
r
o
M
y
t
i
R
R
M
G
C
D
n
C
U
A
P
A
M
e
r
o
c
s
-
F
e
t
a
r
I
D
D
d
r
a
c
c
a
J
l
l
a
c
e
R
n
o
i
s
i
c
e
r
P
s
l
e
d
o
M
s
t
e
s
a
t
a
D
340
-
0
7
0
8
.
0
-
3
1
6
7
.
0
4
0
9
6
.
0
-
-
9
5
5
6
.
0
1
8
0
6
.
0
7
1
9
3
.
0
9
4
7
0
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
1
6
2
9
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
7
5
1
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
0
2
@
8
1
6
3
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
5
@
5
2
7
3
.
0
-
-
-
-
-
0
2
@
8
0
1
3
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
0
2
@
6
1
7
5
.
0
-
0
1
@
7
9
8
4
.
0
-
-
-
4
8
6
5
.
0
0
8
7
.
0
0
6
9
6
.
0
8
8
6
7
.
0
5
8
2
7
.
0
9
3
7
7
.
0
5
0
7
7
.
0
6
7
8
.
0
-
-
-
-
-
-
7
4
6
7
.
0
2
7
7
7
.
0
6
9
5
6
.
0
2
0
0
8
.
0
6
6
5
8
.
0
2
0
7
8
.
0
-
-
0
5
0
7
.
0
7
8
0
7
.
0
5
0
7
8
.
0
8
4
9
.
0
-
-
1
5
5
8
.
0
9
0
2
8
.
0
-
-
8
4
7
.
0
7
2
9
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
0
0
6
0
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
9
2
2
0
.
0
-
-
0
7
6
5
.
0
1
8
6
.
0
2
5
1
6
.
0
8
0
6
6
.
0
8
7
4
6
.
0
9
6
8
6
.
0
8
1
6
6
.
0
4
3
7
.
0
1
8
5
6
.
0
-
-
-
8
6
7
4
.
0
8
7
7
6
.
0
8
6
7
6
.
0
9
0
8
6
.
0
9
9
6
5
.
0
-
8
6
2
7
.
0
-
-
-
5
2
2
6
.
0
5
1
3
6
.
0
-
4
5
9
.
0
2
6
1
5
.
0
-
0
3
9
2
.
0
-
-
2
4
2
8
.
0
6
2
6
.
0
-
-
-
-
-
5
7
0
.
0
-
-
-
2
5
8
0
.
0
-
-
7
1
.
0
3
2
.
0
-
8
7
2
0
.
0
5
9
6
0
.
0
9
8
5
0
.
0
-
-
-
-
-
-
-
6
2
0
5
.
0
9
0
5
4
.
0
-
5
7
9
3
.
0
7
2
5
.
0
5
6
5
4
.
0
9
3
0
5
.
0
9
0
9
4
.
0
6
3
3
5
.
0
7
4
0
5
.
0
-
1
4
0
5
.
0
-
2
8
5
5
.
0
6
2
4
.
0
1
5
2
3
.
0
4
3
2
5
.
0
3
1
2
5
.
0
9
5
2
5
.
0
3
3
0
4
.
0
-
-
-
-
-
3
6
7
0
.
0
-
-
1
6
6
4
.
0
2
4
7
4
.
0
-
3
8
0
.
0
7
1
9
.
0
-
-
-
-
1
0
2
.
0
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
6
0
6
3
.
0
4
1
2
5
0
.
-
-
-
0
2
@
5
7
3
4
.
0
5
@
7
6
6
2
.
0
0
2
@
9
8
6
4
.
0
5
@
8
2
9
2
.
0
-
-
-
4
3
9
5
.
0
3
5
7
0
.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
2
2
6
.
0
-
-
-
-
-
9
9
8
0
.
-
3
1
1
6
.
0
-
-
-
-
-
-
-
0
4
@
6
2
8
4
.
0
-
-
0
1
@
0
2
9
1
.
0
-
-
-
-
-
-
-
-
-
7
1
3
5
.
0
-
-
-
-
-
5
0
7
5
.
0
3
5
5
4
.
0
]
1
2
[
t
e
N
E
M
A
G
]
3
2
[
N
C
G
d
e
M
]
4
2
[
R
E
I
M
E
R
P
]
1
1
[
N
I
S
e
M
]
3
1
[
t
e
N
D
H
A
T
]
5
2
[
T
R
E
B
-
G
]
2
1
[
R
M
R
A
S
]
5
[
t
e
N
G
O
C
]
4
1
[
C
N
M
D
]
8
2
[
g
u
r
D
S
4
]
6
2
[
C
S
R
M
]
9
2
[
R
M
S
]
3
[
P
A
E
L
]
0
3
[
N
N
R
-
L
R
S
]
1
3
[
t
e
N
p
m
o
C
]
2
3
[
N
O
R
C
M
I
]
3
3
[
g
u
r
D
e
f
a
S
]
4
3
[
t
e
N
A
M
A
]
5
3
[
R
C
W
A
R
-
]
9
3
[
-
E
D
M
T
S
L
]
2
2
[
e
r
a
C
n
o
C
]
1
4
[
T
S
L
R
D
]
0
4
[
L
G
C
]
9
[
R
M
R
A
I
I
I
-
I
C
M
M
I
]
3
4
[
+
+
e
r
a
C
a
t
e
M
]
6
4
[
C
G
S
M
A
T
]
7
4
[
E
T
A
G
]
0
1
[
I
N
A
T
E
R
c
i
l
b
u
p
-
n
o
N
4
5
9
0
.
8
8
4
5
.
0
7
5
9
.
0
0
6
2
5
.
0
0
2
@
8
0
0
7
.
0
5
@
0
5
6
0
.
0
]
7
2
[
I
S
T
R
E
M
]
5
1
[
R
P
D
]
6
3
[
c
e
R
d
e
M
0
1
@
0
7
1
1
.
0
]
8
3
[
R
T
-
O
D
M
T
S
L
-
]
2
2
[
e
r
a
C
n
o
C
]
9
2
[
R
M
S
]
2
4
[
N
N
C
D
S
]
4
4
[
h
t
a
P
d
e
M
]
5
4
[
N
N
R
-
C
D
M
P
]
3
4
[
+
+
e
r
a
C
a
t
e
M
]
6
3
[
c
e
R
d
e
M
]
7
3
[
N
C
G
M
S
]
4
2
[
R
E
I
M
E
R
P
9
-
D
C
I
M
C
T
e
t
a
v
i
r
P
U
C
I
e
]
3
2
[
N
C
G
d
e
M
W
D
E
M
N
]
8
2
[
g
u
r
D
S
4
]
3
[
P
A
E
L
r
e
t
t
u
S
L
L
E
N
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
/
t
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
-
-
-
5
8
4
3
.
0
-
-
-
-
-
-
1
4
3
5
.
0
8
1
6
2
.
0
0
1
@
0
4
6
5
.
0
-
-
-
-
-
-
-
1
4
6
.
0
2
7
2
.
0
0
4
5
.
0
0
5
6
.
0
2
3
6
0
.
Deep Learning for Medication Recommendation: A Systematic Survey
Diagnosis and procedure encoders are transformer-based network [76] with different parameters. On this
dataset, the third best performer is the PREMIER [24] model. PREMIER [24] is a two-stage recommender
system comprising attention-based RNNs to model patient visits and graph networks to model drug
co-occurrences in the EHR and known drug interactions. PREMIER adapts GAT to incorporate the varying
importance of drug interactions to learn effective drug embeddings for the task of medication recommendation.
PREMIER [24] justifies the key reasons for recommending a particular medication by providing the
percentage of contributions among the diagnosis, procedures, and previously prescribed medications.
On the contrary, the MERITS [27] model produces superior results for the Non-public dataset compared
to other models based on precision, recall, F-score, and AUC metrics. It is credited for its use of neural
ordinary differential equations (Neural ODE) to represent the irregular time-series dependencies, which can
better learn the continuous inner process. Moreover, it incorporates static and dynamic features through
self-attention and uses the encoder-decoder architecture to forecast the next sequence of medications. In
the same direction, SMGCN [37] generates better results than its counterpart MedRec [36] based on the
TCM dataset employing precision and recall metrics. The possible reason behind the improved results of
SMGCN could be the combination of MLP and GCN to fuse symptom representations into the overall
implicit syndrome embedding and learn symptom and herb representations, respectively. On the other
hand, MedRec employs a knowledge graph to link symptoms, diseases, medicines, and examinations. Using
similar characteristics and molecular structures, an attribute graph is used to link many medications. The
combined learning representations of symptoms and medicines is then employed in medication
recommendations.
Finally, if we see the results reported on other datasets, viz., Private, eICU, NMEDW, Sutter, and NELL,
we cannot make meaningful implications since these datasets have been utilized by one model each to
report their performance.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
/
t
i
5. OPEN ISSUES AND OPPORTUNITIES
This section reports on the problems faced by the chosen MR approaches and presents research
opportunities in addressing them by examining the research examined in this article.
5.1 Cold-start Problem
One of the well-known issues that MR methods encounter is the “cold-start” issue [53], which is further
classified as cold-start patients and medications. In these situations, the approach cannot provide trustworthy
medication recommendations due to insufficient knowledge about patients and medications. For example,
when a new patient appears, the system has insufficient patient information, and therefore, it is unable to
create reasonable recommendations. To address the cold-start issue, most of the models employed medication
history, time, diagnoses, and procedures. For instance, SMR [29] first connects medical knowledge and
EMRs graphs in order to construct a superior heterogeneous graph. The approach then encodes patients,
diseases, medications, and their related relationships in a common lower-dimensional space. Finally, in
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence
341
Deep Learning for Medication Recommendation: A Systematic Survey
order to build the medication recommendation into a link prediction task, SMR also considers the patient’s
diagnoses of adverse drug reactions. Likewise, MetaCare++ [43] introduced a meta-learning technique to
address the cold-start diagnosis task that dynamically forecasts future diagnoses and timestamps for
infrequent patients and explicitly encodes the impact of disease progression over time as a generalization
prior.
5.2 Sparsity
This issue is most common in CF techniques [8], faced by several MR models when the dataset or patient
information is sparse. It is difficult for the method to produce pertinent recommendations due to the lack
of information. If the number of medications in the database is relatively less than that of patients then the
MR model faces network sparsity or data sparsity problems. The examined studies exhibit that sparsity
problems have been resolved by employing secondary information. In the case of network sparsity problems,
side information enhances MR models’ knowledge about patients by extending the network of connections
with new objects and relations. The new node, for example, indicates the association between medication,
patients, diseases, symptoms, and lab tests. Most of the approaches investigated in this study employ hybrid
strategies that combine CF and CB to address data sparsity. The DL technique used to generate personalized
medication recommendations is the main distinction between them. For the task of recommending herbs,
SMGCN [37] utilizes a multi-layer neural network model that simulates the interactions between syndromes
and herbs. The representations of the symptoms in an intended symptom set are then combined using an
MLP to produce the overall implied syndrome representation. The model combines syndrome representation
with herb embeddings to produce final predictions.
In the same direction, MedRec [36] uses a knowledge graph to link medications, diseases, examinations,
and symptoms. Additionally, it relates medications through common molecular structures and attributes
using an attribute graph. As a result, the two graphs improve the relationship between symptoms and
treatments, which solves the problem of data scarcity.
5.3 Drug-Drug Adverse Interactions
The recommendation model should take seriously into consideration the interaction between drugs. If a
model recommends drugs that have adverse interactions, then it can cause serious damage to a patient’s
health. Different models in the literature proposed solutions to tackle this problem. For instance, GAMENet
[21] combines the DDI KG using a memory module implemented as a GCN, which models patients’
longitudinal records to produce safe and personalized drug recommendations. Similarly, 4SDrug [28]
introduces a drug set module by devising intersection-based set augmentation, knowledge-based, and data-
driven penalties to ensure small and safe drug sets recommendations. COGNet [5] uses a basic module to
recommend the medication combination based on the patient’s health condition in the current visit using
an encoder-decoder architecture. Moreover, to consider the patient’s historical visit information, the model
introduces a copy module that evaluates the current health conditions against previous visits to copy
reusable medications in prescribing drugs for the current visit considering changes in the health condition.
342
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
/
t
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
A hierarchical selection mechanism combines the visit- and medication-level scores to compute the copy
probability for each medication. Comparably, ARMR [9] initially utilizes RNNs to generate patient
representations and employs a key-value memory system to contain historical representations and associated
medications. As a result, a case-based approach with related results can be employed for medication
recommendation. To accomplish DDI reduction, ARMR incorporates a GAN model that aligns the distribution
of patient representations to a previous Gaussian distribution. The MedRec component and GAN model
are conversely trained with double objectives in a mini-batch. The majority of available techniques impede
models by adding more DDI knowledge in an effort to address the DDI problem. To overcome this issue,
SARMR [12] extracts from raw patient records the target distribution linked with safer drug combinations
for adversarial regularization. The technique can modify patient representation distributions in this way to
lessen DDI. With a great deal of flexibility, SafeDrug [33] adaptively merges supervised loss and unsupervised
DDI constraints. Specifically, if the DDI rate of individual samples is higher than a specific threshold /target
during training, the negative DDI signal will be highlighted and back-propagated.
5.4 Capturing Temporal Dynamics
The patient’s recent health conditions and tests play a vital role in recommending precise medications.
Moreover, there are certain diseases such as flu that depend on the recent patient’s clinical records. On the
other hand, certain diseases like cardiovascular diseases need patient’s previous records to contain valuable
information and help predict precise recommendations. To this end, RETAIN [10] predicts future diagnosis
by calculating a visit’s attention weights at time t, considering the medical information in the current visit
and the hidden state of the recurrent neural network at time t, to predict the visit at time t + 1. However,
the relationships among all visits from time 1 to t are ignored. Dipole [48] handles this issue by embedding
high-dimensional medical codes into a low code-level space. These code representations are then fed to
an attention-based bidirectional GRU [71] to produce the hidden state representation by employing a
softmax layer that predicts the medical codes in future visits. On the other hand, Concare [22] proposes a
multichannel medical feature embedding architecture to learn the representation of various feature
sequences through separate GRUs and uses time-aware attention to capture the effect of time intervals
between records adaptively. Similarly, MeSIN [11] employs an interactive temporal sequence learning
network to incorporate the intra-correlations of several visits within a single medical sequence and the
inter-correlations of various sequences of EHR data. In particular, the improved laboratory findings
embeddings are fed into the temporal sequence learning network i.e long-short temporal neural network
(LSTM) for combining with the historical laboratory results. To provide a more accurate representation for
the prediction task, TAHDNet [13] incorporated a Time-aware block to reflect the irregular time intervals.
Specifically, an interval gate is utilized to fuse the two decay functions in order to take into account both
periodic decay and monotonic decay.
5.5 Personalized Patient’s Modeling
The patient’s medical needs evolve during time periods. In particular, a patient may visit a hospital to
get treatment for the flu, but next time her/his visit might be to treat stomach issues. Therefore, it is pertinent
Data Intelligence
343
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
to exploit such evolving factors to capture the patient’s recent medical requirements. To this end, ConCare
[22] uses multi-head self-attention to extract the dependencies among clinical features explicitly to learn
the personal health context and regenerate the feature embedding under the context. The diversity among
heads is encouraged using cross-head decorrelation. A multichannel medical feature embedding architecture
is employed to learn the representation of various feature sequences via separate GRUs and the effect of
time intervals between the records of each feature is adaptively captured using time-aware attention.
Similarly, G-BERT [25] employs GCN [63] and BERT [58] to learn medical code representation and
medication recommendation, respectively. In particular, the approach integrates the GNN representation
into a transformer-based visit encoder and pre-trains it on EHR data from patients with a single visit. In
order to address the issue of asynchronous multi-view learning, AMANet [34] combines attention mechanism
and memory. Self-attention and inter-attention mechanisms are utilized to learn intra-view interaction and
inter-view interaction, respectively. Information about a specific object is maintained by historical attention
memory and is employed as a local knowledge storage system. On contrary, dynamic external memory is
utilized to keep the global knowledge for each view. MERITS [27] uses neural ordinary differential
equations(Neural ODE) to capture irregular time-series dependencies. In the meantime, the model employs
a DDI knowledge graph and two learned medication relation graphs to investigate the medications’
co-occurrence and sequential correlations. It also applies an attention-based encoder-decoder framework
for combining patient and medication history from the EMR.
Finally, ARMR [9] model utilizes two GRU networks [71] to build an encoder that exploits patient
diagnoses information and procedures to generate robust patient representations, which are employed in
generating final predictions.
6. CONCLUSION AND IMPLICATIONS
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
/
t
i
This paper explored DL-based MR models with respect to the platform, information filtering, information
features and factors, recommendation type, evaluation methodology including datasets and metrics, the
issues they face, and opportunities in addressing them. The following points summarize some of the main
findings of this study.
•
•
The majority of the examined models utilized medication history, diagnoses, time, and procedures
as data factors, which are important aspects when making a personalized medication prediction for
a patient. Besides, models that employ auxiliary information, such as medication history, diagnoses,
time, procedures, symptoms, and physical examinations, can provide precise recommendations and
alleviate the sparsity problem because such techniques exploit rich information and enrich knowledge
about the patient’s disease.
The embedding-based methods are most common in DL-based MR approaches due to their ability
to exploit multiple information sources and capture the users’ preference dynamics. These are followed
by RNNs due to their good performance in NLP tasks and capturing long-range dependencies. They
are also useful in the MR domain that considers the updates in patient’s health over time. These are
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
344
Data Intelligence
Deep Learning for Medication Recommendation: A Systematic Survey
•
•
•
•
followed by the CNN variants, as they can exploit contextual details and capture local relevant
features.
Recently, transformer-based models with attention networks are getting popular because they capture
salient information factors and features regarding patients and medication and consider complex
relations among them. We have found 10 out of 37 MR models that employed transformers to
recommend medications.
According to the survey, the majority of models viz. 24 out of 37 used the Adam optimization
technique, while eight used gradient descent. One model employs Adagrad. Similarly, one of the 37
models used RMSprop. The possible reason behind the usage of Adam and SGD could be their
capability to converge and generalize better compared to others.
The main issues experienced by researched models are personalization, exploiting temporal dynamics,
and DDI. As a consequence of a lack of sufficient information about the patient’s disease, some of
the models struggled with the sparsity and cold-start problems. The interpretability is the least explored
by the selected models. According to the study results, embedding methods and RNNs have better-
addressed personalization, robustness, and DDI problems. The main reason is that embedding
methods exploit robust semantic relations in EHR networks. Moreover, RNNs can better capture
long-range dependencies and perform better on NLP tasks. On the contrary, the survey demonstrates
that graph/network embedding methods have better addressed the sparsity and cold start issues. The
primary reason for this is that GCN embeds diseases, symptoms, medicines, patients, and their
corresponding relationships into a shared lower-dimensional space.
MIMIC-III dataset contains rich information sources, namely patient information, diagnosis records,
clinical events, procedures, medicines, and symptoms. As a result, the survey found that the MIMIC-
III dataset is the most commonly used in the domain of medication recommendations. Generally,
other datasets are employed by a few models. For instance, NELL is the most newly published dataset
and has only been used in one approach.
We hope the research avenues identified in this survey will assist researchers to explore interesting trends
and devise robust medication recommender systems.
ACKNOWLEDGMENTS
This project is funded by Southeast University-China Mobile Research Institute Joint Innovation Center
under grant no. CMYJY-202200475.
CREDIT AUTHORSHIP CONTRIBUTION STATEMENT
Zafar Ali (email: zafarali@seu.edu.cn, ORICID: 0000-0002-6404-645X) Conceptualization, Research
methodology, Drafting Yi Huang (email: huangyi@chinamobile.com) Study conception and design Irfan
Ullah (email: irfan@sbbu.edu.pk, ORICID: 0000-0003-0693-5467) Conceptualization, Validation, Writing
- review & editing. Junlan Feng (email: fengjunlan@chinamobile.com) Designed the study framework
Data Intelligence
345
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Chao Deng (email: dengchao@chinamobile.com) Methodology, study conception, and design Nimbeshaho
Thierry (email: thierrynimbeshaho@njupt.edu.cn, ORICID: 0000-0003-3425-7229) Data collection,
drafting, and Validation Asad Khan (email: asadkhanciit5568@gmail.com, ORICID: 0000-0002-4674-
4123) Data collect ion, drafting, and Validation Asim Ullah Jan (email: asim.ibms@gmail.com, oricid:
0000-0002-2910-6795) Data collection, and Validation Xiaoli Shen (email: 0000-0003-3136-1995,
ORICID: 0000-0003-3136-1995) Data collection, drafting, and Validation Wu Ruia (email: rhyswu@
outlook.com, ORICID: 0000-0002-3858-596X) Data collection, drafting, and Validation Guilin Qi (email:
gqi@seu.edu.cn, ORICID: 0000-0003-0150-7236) Supervision, Conceptualization.
DECLARATION OF COMPETING INTEREST
The authors declare that they have no known competing financial interests or personal relationships that
could have appeared to influence the work reported in this paper.
REFERENCES
[1] Ali, Z., Qi, G.L., Muhammad, K., et al.: Paper recommendation based on heterogeneous network embedding.
K nowledge-Based Systems 210, 106438 (2020)
[2] Ali, Z., Qi, G.L., Muhammad, K., et al.: Global citation recommendation employing multi-view heterogeneou s
network embedding. In: 2021 55th Annual Conference on Information Sciences and Systems (CISS), pp. 1–6
(2021)
[3] Zhang, Y.T., Chen, R., Tang, J., et al.: Leap: learning to prescribe effective and safe treatment combinations
for multimorbidity. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pp. 1315–132 4 (2017)
Su, C.H., Gao, S., Li, S.: Gate: Graph-attention augmented temporal neural network for medication
recommendation. IEEE Access 8, 1 25447–125458 (2020)
[4]
[5] Wu, R., Qiu, Z.P., Jiang, J.Ch., et al.: Conditional generation net for medication recommendation. In:
[6]
[7]
Proceedings of the ACM W eb Conference 2022, pp. 935–945 (2022)
Sezgin, E., Özkan, S.: A systematic literature review on health recommender systems. E-Health and
Bioengineering Conference (E HB), pp 1–4. IEEE (2013)
Etemadi, M., Abkenar, S.B., et al: A systematic review of healthcare recommender systems: Open issues,
challenges, and techniques. Expert Systems with Applicat ions, pp. 118823 (2022)
[8] Khusro, S., Ali, Z., Ullah, I.: Recommender systems: issues, challenges, and research opportunities. In
Information Science and Applications (ICISA) 2016, pp. 1179–1189. Springer (2016)
[9] Wang, Y., Chen, W., et al: Adversarially regularized medication recommendation model with multi-hop
memory network. Know ledge and Information Systems 63(1), 125–142 (2021)
[10] Choi, E., Bahadori, M.T., Sun, J., et al: Retain: An interpretable predictive model for healthcare using reverse
time attention mechanism. Advances in Neural Information Processing Systems 29 (2016)
[11] An, Y., Zhang, L., You, M., et al: Multilevel selective and interactive network for medication recommendation.
Knowledge-Based Systems 233, 107534 (2021)
[12] Wang, Y., Chen, W., Pi, D., et al: Self-supervised adversarial distribution regularization for medication
recommendation. In IJCAI, pp. 3134–3140 (2021)
346
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
[13] Su, Y., Shi, Y., Lee, W., et al: Tahdnet: Time-aware hierarchical dependency network for medication
recommendation. Journal of Biomedical Informatics 129, 104069 (2022)
[14] Le, H., Tran, T., Venkatesh, S.: Dual control memory augmented neural networks for treatment
recommendations. In Pacific- Asia Conference on Knowledge Discovery and Data Mining, pp. 273–284.
Springer (2018)
[15] Zheng, Z., Wang, C., Xu, T., et al: Drug package recommen dation via interaction-aware graph induction.
In: Proceedings of the Web Conference 2021, pp. 1284–1295 (2021)
[16] Hors-Fraile, S., Rivera-Romero, C., Schneider, F., el al: Analyzing recommender systems for health promotion
using a multidisciplinary taxonomy: A scoping review. International Journal of Medical Informatics 114,
143–155 (2018)
[17] Zhang, S., Bamakan, S.M.H., Qu, Q., et al: Learning for personalized medicine: A comprehensive review
from a deep learning perspective. IEEE Reviews in Biomedical Engineering 12, 194–208 (2019)
[18] Rajkom, A., Dean, J., Kohane, I.: Machine learning in medicine. New England Journal of Medicine 380(14),
1347–1358 ( 2019)
[19] Ngiam, K.Y., Khor, W.: Big data and machine learning algorithms for health-care delivery. The Lancet
Oncology 20(5), e262–e273 ( 2019)
[20] Su, C., Tong, J., Zhu, Y., et al.: Network embedding in biomedical data science. Briefings in Bioinformatics
21(1), 182–197 (2020)
[21] Shang, J., Xiao, C., Ma, T., et al.: Graph augmented memory networks for recommending medication
combination. In: proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 1126–1133
(2019)
[22] M a, L., Zhang, C., Wang, Y., et al.: Personalized clinical feature embedding via capturing the healthcare
context. In: Proceedings of the AAAI Conference on Artificial Intelligence, v olume 34, pp. 833–840 (2020)
[23] Mao, C., Yao, L., Luo, Y.: Medgcn: Medication recommendation and lab test imputation via graph convolutional
networks. J ournal of Biomedical Informatics 127, 104000 (2022)
[24] Bhoi, S., Lee, S.L., Hsu, W., et al.: Personalizing medication recommendation with a g raph-based approach.
ACM Transactions on Information Systems (TOIS) 40(3), 1–23 (2021)
[25] Shang, J., Ma, T., Xiao, C., et al.: Pre-training of graph augmented transformers for medication recommendation.
a rXiv preprint arXiv:1906.00346 (2019)
[26] Wang, Y., Chen, W., Pi, D., et al.: Multi-hop reading on memory neural network with selective coverage for
medication recommendation. In: Proceedings of the 30th ACM International Conference on Information &
Knowledge Management, p p. 2020–2029 (2021)
[27] Zhang, S., Li, J., Zhou, H., et al.: Medication recommendation for chronic d isease with irregular time-series.
IEEE International Conference on Data Mining (ICDM), pp. 1481–1486 (2021)
[28] Tan, Y., Kong, C., Yu, L., et al.: 4sdrug: Symptom-based set-to-set small and safe drug recommendation. In:
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 3970–
3980 (2022)
[29] Gong, F., Wang, M., Wang, H., et al.: Smr: medical knowledge graph embedding for safe medicine
recomm endation. Big Data Research 23, 100174 (2021)
[30] Wang, L., Zhang, W., He, X., et al.: Supervised reinforcement learning with recurrent neural network for
dynamic treatment recommendation. In: Proceedings of the 24th ACM SIGKDD international conference on
knowledge discovery & data mining, p p. 2447–2456 (2018)
[31] Wang, S., Ren, P., Chen, Z., et al.: Order-free medicine combination prediction with graph convolutional
reinforcement learning. In: Proceedings of the 28th ACM International Conference on Information and
Knowledge M anagement, pp. 1623–1632 (2019)
Data Intelligence
347
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
[32] Yang, C., Xiao, C., Glass, L., et al.: Change matters: Medication change prediction with recurrent residual
networks. In IJCAI (2021)
[33] Yang, C., Xiao, C., Ma, F., et al.: Dual molecular graph encoders for recommending effective a nd safe drug
combinations. In IJCAI, pp. 3735–3741 (2021)
[34] He, Y., Wang, C., Li, N., et al.: Attention and memory-augmented networks for dual-view sequential learning.
In: P roceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,
pp. 125–134 (2020)
[35] Balashankar, A., Beutel, A., Subramanian, L.: Enhancing neural recommender models through domain-
specific c oncordance. In WSDM, pp. 1002–1010 (2021)
[36] Zhang, Y., Wu, X., Fang, Q., et al.: Knowledge-enhanced attributed multi-task learning for m edicine
recommendation. ACM Transactions on Information Systems (TOIS) (2022)
[37] Jin, Y., Zhang, W., He, X., et al.: Syndrome-aware herb recommendation with multi-graph conv olution
network. In 2020 IEEE 36th International Conference on Data Engineering (ICDE), pp. 145–156 (2020)
[38] Lipton, Z.C., Kale, D.C., Elkan, C.P., et al.: Learning to diagnose with lstm recurrent neural networks. CoRR,
abs/1511.03677 (2016)
[39] Jin, B., Yang, H., Sun, L., et al.: A treatment engine by predicting next-period prescriptions. In: Proceedings
of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 1608–
1616 (2018)
[40] Lu, C., Reddy, C.K., Chakraborty, P., et al.: Collaborative graph learning with auxiliary text f or temporal event
prediction in healthcare. ArXiv, abs/2105.07542 (2021)
[41] Yu, C., Ren, G., Liu, J.: Deep inverse reinforcement learning for sepsis treatment. 2019 IEEE International
Conference on H ealthcare Informatics (ICHI), pp. 1–3 (2019)
[42] Cheng, L., Shi, Y., Zhang, K.: Medical treatment migration behavior prediction and recommendation based
on health insurance d ata. World Wide Web 23(3), 2023–2044 (2020)
[43] Tan, Y., Yang, C., Wei, X., et al.: Metacare++: Meta-l earning with hierarchical subtyping for cold-start
diagnosis prediction in healthcare data (2022)
[44] Ye, M., Cui, S., Wang, Y., et al.: Medpath: Augmenting health risk prediction via medical k nowledge paths.
In: Proceedings of the Web Conference 2021, pp. 1397–1409 (2021)
[45] B ajor, J.M., Lasko, T.A.: Predicting medications from diagnostic codes with recurrent neural networks. In
ICLR (2017)
[46] Wang, H., Wu, Y., Gao, C., et al.: Medication combination prediction using t emporal attention mechanism
and simple graph convolution. IEEE Journal of Biomedical and Health Informatics 25(10), 3995–4004 (2021)
[47] Su, C., Gao, S., Li, S.: Gate: Graph-Attention Augmented Temporal Neural Network for Medication
Recommendation. IEEE A ccess 8, 125447–125458 (2020)
[48] Ma, F., Chitta, R., Zhou, J., et al.: Diagnosis prediction in healthcare via attention-based bidirectional
recurrent neural networks. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pp. 1903–1911 (2017)
[49] M a, S., Zhang, H., Zhang, C., et al.: Chronological citation recommendation with time preference (2021)
[50] Yang, C., Xiao, C., Glass, L., et al.: Change matters: Medication change prediction with recurrent residual
networks. a rXiv preprint arXiv:2105.01876 (2021)
[51] Crombie, D.L.: Diagnostic process. The Journal of the College of General Practitioners 6(4), 579 (1963)
[52] Si karis, K.A.: Enhancing the clinical value of medical laboratory testing. The Clinical Biochemist Reviews
38(3), 107 (2017)
[53] Ali, Z., Kefalas, P., Muhammad, K., et al.: Deep learning in citation recommendation models survey. E xpert
Systems with Applications, pp 113790 (2020)
348
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
[54] Mikolov, T., Sutskever, I., Chen, K., et al.: Distributed representations of words and phrases and their
co mpositionality. Advances in Neural Information Processing Systems 26, 3111–3119 (2013)
[55] Cui, P., Wang, X., Pei, J., et al.: A survey on network embedding. IEEE Transactions on Knowledge and Data
Engineering 31 (5), 833–852 (2018)
[56] Guo, Q., Zhuang, F., Qin, C., et al.: A survey on knowledge graph-based recomme nder systems. IEEE
Transactions on Knowledge and Data Engineering (2020)
[57] Le, Q., Mikolov, T.: Distributed Representations of Sentences and Documents. In International Conference
on Machine Learning, pp . 1188–1196 (2014)
[58] Devlin, J., Chang, M.C., Lee, K., et al.: Bert: Pre-training of deep bidirectional transformers for language
un derstanding. arXiv preprint arXiv:1810.04805 (2018)
[59] Christoforidis, G., Kefalas, P., Papadopoulos, A., et al.: Recommendation of points-of-interest using gr aph
embeddings. In 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA),
pp. 31–40 (2018)
[60] Choi, E., Bahadori, M.T., Searles, E., et al.: Multi-Layer Representation Learning for Medical Concepts. In:
Proceedings of The 22nd ACM SIGKDD International Conference o n Knowledge Discovery and Data Mining,
pp. 1495–1504 (2016)
[61] Wang, Q., Mao, Z., Wang, B., et al.: Knowledge Graph Embedding: A Survey of Approaches and Applications.
IEEE Tr ansactions on Knowledge and Data Engineering 29(12), 2724–2743 (2017)
[62] Ji, G., He, S., Xu, L., et al.: Knowledge Graph Embedding via Dynamic Mapping Matrix. In: Proceedings of
The 53rd Annual Meeting of The Association for Computational Linguistics and The 7th International Joint
Conference on Natural Language Pr ocessing (volume 1: Long papers), pp. 687–696 (2015)
[63] Welling, M., Kipf, T.N.: Semi-supervised classification with graph convolutional networks. In J. International
Conference on Le arning Representations (ICLR 2017) (2016)
[64] Zhou, J., Cui, G., Hu, S., et al.: Graph ne ural Networks: A Review of Methods and Applications. AI Open 1,
57–81 (2020)
[65] Velickovic, P., Cucurull, G., Casanova, A., et al.: Graph attention networks. Stat 10 50, 20 (2017)
[66] Gasse, M., Chételat, D., Ferroni, N., et al.: Exact Combinatorial Optimization with Graph Convolutio nal
Neural Networks. Advances in Neural Information Processing Systems 32 (2019)
[67] Li , Y.: Deep reinforcement learning: An overview. arXiv preprint arXiv:1701.07274 (2017)
[68] Lavet, V.F., Henderson, P., Islam, R., et al.: An introduction to deep reinforcement lea rning. arXiv preprint
arXiv:1811.12560 (2018)
[69] Vin yals, O., Bengio, S., Kudlur, M.: Order matters: Sequence to sequence for sets. CoRR, abs/1511.06391
(2016)
[70] Sutton, R.S., McAllester, D., Singh, S., et al.: Policy gradient methods for reinforcement learning with function
app roximation. Advances in Neural Information Processing Systems 12 (1999)
[71] Abro, W.A., Qi, G., Gao, H., et al.: Multi-turn intent determination for goal-oriented dialogue sys tems. In
2019 International Joint Conference on Neural Networks (IJCNN), pp. 1–8 (2019)
[72] Abro, W.A., Qi, G., Ali, Z., et al.: Multi-turn intent determination and slot filling with neu ral networks and
regular expressions. Knowledge-Based Systems 208, 106428 (2020)
[73] Cho, K., Merriënboer, B.N., Gulcehre, C., et al.: Learning phrase representations using rnn encoder-decoder
for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
[74] Baytas, I.M., Xiao, C., Zhang, X., et al.: Patient Subtyping via Time-Aware LSTM Networks. In: Proceedings
of t he 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 65–74
(2017)
Data Intelligence
349
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
[75] Lample, G., Ballesteros, M., Subramanian, S., et al.: Neural architectures for named entity reco gnition. arXiv
preprint arXiv:1603.01360 (2016)
[76] Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is a ll you need. Advances in Neural Information
Processing Systems 30 (2017)
[77] Song, H., Rajan, D., Thiagarajan, J., et al.: Attend and diagnose: Clinical time series analysis using attention
mode ls. In: Proceedings of the AAAI Conference on Artificial Intelligence, volume 32 (2018)
[78] Cogswell, M., Ahmed, F., Girshick, R., et al.: Reducing overfitting in deep networks by decorrelating
repr esentations. arXiv preprint arXiv:1511.06068 (2015)
[79] Chu, X., Lin, Y., Wang, Y., et al.: Mlrda: A multi-task semi-supervised learning framework for drug-drug
interaction prediction. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence,
pp. 4518–4524 (2019 )
[80] Ma, T., Xiao, C., Wang, F.: Health-atm: A deep architecture for multifaceted patient health record representation
and risk prediction . In: Proceedings of the 2018 SIAM International Conference on Data Mining, pp. 261–
269 (2018)
[81] Ma, F., Gao, J., Suo, Q.: Risk prediction on electronic health records with prior medical knowledge. In:
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,
pp. 1910 –1919 (2018)
[82] Lee, W., Park, S., Joo, W., et al.: Diagnosis prediction via medical context attention networks using deep
generative modeling. In 2018 IEEE International Conference on Data Mining (ICDM), pp. 1104–1109 (2018)
[83] Kiran yaz, S., Avci, O., Abdeljaber, O., et al.: 1d convolutional neural networks and appl ications: A survey.
Mechanical Systems and Signal Processing 151, 107398 (2021)
[84] Suo, Q., Ma, F., Yuan, Y., et al.: Personalized disease prediction using a cnn-based similarity learning method.
In 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp. 811–816 (2017 )
[85] Goodfellow, I.J., Abadie, J.P., Mirza, M., et al.: Gener ative adversarial networks. arXiv preprint arXiv:1406.2661
(2014)
[86] Weston, J., Chopra, S., Bordes, A.: Memory networks. In 3rd International Conference on Learning
Representations, ICLR 2015 (2015)
[87] Wang, H., Zhang, F., Xie, X., et al.: Dkn: Deep knowledge-aware network for news recommendation. In:
Proceedings of th e 2018 World Wide Web Conference, pp. 1835–1844 (2018)
[88] Amir, N., Jabeen, F., Ali, Z., et al.: On the current state of deep learning for news reco mmendation. Artificial
Intelligence Review, pp. 1–44 (2022)
[89] Zhu, Q., Zhou, X., Song, Z., et al.: Dan: Deep attention neural network for news recommendation. In:
Proc eedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 5973–5980 (2019)
[90] Wu, C., Wu, F., Ge, S., et al.: Neural news recommendation with multi-head self-attention. In: Proceedings
of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint
Conference on Na tural Language Processing (EMNLP-IJCNLP), pp. 6390–6395 (2019)
[91] Liu, P., Zhang, L., Gulla, J.A.: Dynamic attention-based explainable recommendation with textual and visual
fusion. Information Processing & Management 57(6), 102099 (2020)
[92] Westo n, J., Chopra, S., Bordes, A.: Memory networks. arXiv preprint arXiv:1410.3916 (2014)
[93] Miller, A., Fisch, A., Dodge, J., et al.: Key-value memory networks for direc tly reading documents. arXiv
preprint arXiv:1606.03126 (2016)
[94] Tang, K.F., Kao, H.C., Chou, C.N., et al.: Inquire and diagnose: Neural symptom checking ensemble using
deep reinforcement learning. In NIPS Workshop on Deep Reinforcement Learning (2016)
[95] Kao, H.C., Tang, K.F., Chang, E.: Context-aware symptom checking for disease diagnosis using hierarchical
reinforcement learn ing. In: Proceedings of the AAAI Conference on Artificial Intelligence, volume 32 (2018)
350
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
[96] Le, Q.V., Ngiam, J., Coates, A., et al.: On optimization methods for deep learning. In: Pr oceedings of the 28th
International Conference on International Conference on Machine Learning, pp. 265–272 (2011)
[97] Soydaner, D.: A comparison of optimization algorithms for deep learning. International Journal of Pattern
Recognition and Artificial Intel ligence 34(13), 2052013 (2020)
[98] Zhang, N., Lei, D., Zhao, J.F.: An improved adagrad gradient descent optimization algorithm. In 2018 Chinese
Automation Congress (CAC), pp. 23 59–2362 (2018)
[99] Zaheer, R., Shaziya, H.: A study of the optimization algorithms in deep learning. In 2019 Third International
Conference on In ventive Systems and Control (ICISC), pp. 536–539 (2019)
[100] Wu, C., Wu, F., An, M., et al.: Npa: Neural news recommendation with personalized attention. In: Proceedings
of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 25 76–
2584 (2019)
[101] Wang, W., Yin, H., Sadiq, S., et al.: Spore: A sequential personalized spatial item recommender system. In
2016 IEEE 32nd International Conference on Data Engineering (ICDE), pp. 954–965 (2016)
[102] Ali, Z., Khusro, S., Ullah, I. A hybrid book recommender system based on table of contents (toc) and
association rule mining. Asso ciation for Computing Machinery INFOS ’16, pp. 68–76 (2016)
[103] Karimi, M., Jannach, D., Jugovac, M.: News recommender systems–survey and roads ahead. Information
Processing & Manag ement 54(6), 1203–1227 (2018)
[104] Gulla, J.A., Zhang, L., Liu, P., et al.: The adressa dataset for news recommendation. In: Proceedings of the
international conference on web intelligence, pp. 1042–1048 (2017)
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence
351
Deep Learning for Medication Recommendation: A Systematic Survey
AUTHOR BIOGRAPHY
Zafar Ali received his M.Sc. degree in computer science (2011) from
university of Peshawar. Then he completed his MS degree (2017) in web
engineering from the same university. Recently, Zafar Ali has completed his
Ph.D. degree in the field of Computer Science and Engineering from the
Southeast University, China. He is currently working as a postdoctoral fellow
in the School of Computer Science and Engineering, Southeast University,
China. He has published more than thirty research papers in reputed
conferences and SCI journals. He is reviewer in different prestigious journals
and conferences including Knowledge-based systems, AI Review, Information
Fusion, Scientometrics, Soft Computing, IEEE Access, Information Processing
& Management and CIKM. His research interests include recommender
systems, information retrieval, natural language processing, graph embedding,
deep learning, and machine learning.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
t
.
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Guilin Qi received the Ph.D. degree in computer science from Queen’s
University Belfast in 2006. He was with the Institute AIFB, University of
Karlsruhe, for three years. He is currently a Professor at Southeast University,
China, where he is also the Head of the Knowledge Science and Engineering
Lab and the Director of the Institute of Cognitive Science. He has published
over 100 papers in these areas, many of which were published in proceedings
of major conferences or journals. He is a Work Package Leader of an EU FP7
Marie Curie IRSES Project and a Co-Investigator of an ARC Discovery Project.
He has published a book on knowledge management for the semantic Web
in 2015. His research interests include knowledge representation and
reasoning, knowledge graph, uncertainty reasoning, and semantic Web. He
received the Best Short Paper Runner-Up Award from CIKM 2017 and has a
paper received the Best-Student Paper Award in ICTAI 2015. He is an Executive
Editor-in-Chief of Data Intelligence and an Associate Editor of the Journal of
Web Semantics.
352
Data Intelligence
Deep Learning for Medication Recommendation: A Systematic Survey
Dr. Irfan Ullah is working as Assistant Professor in the Department of
Computer Science, Shaheed Benazir Bhutto University, Sheringal, Pakistan.
He has received PhD and MS degrees in Computer Science specializing in
Web Engineering from Department of Computer Science, University of
Peshawar, Pakistan. He has received BS degree in Computer Science from the
Department of Computer Science, University of Malakand, Pakistan with a
Gold Medal. He has more than twelve years of teaching and research
experience. He is the author of more than fourty research papers published
in national and international journals and conferences. His research interests
include Information Retrieval, Interactive Information Retrieval, Information
Service Engineering, Web Semantics, Linked Open Data, Ontology
Engineering, Social Web, and Social Book Search.
Asad khan did MS-CS from the department of Computer Science, Comsats
University Islamabad Abbottabad campus. He has done BS in Computer
science from Gomal University Dera Ismail khan. He is currently enrolled in
a doctoral degree in Computer Science at Southeast University, Nanjing,
China. His research interest is in the field of Data Mining, Deep Learning,
bioinformatics, Recommender Systems, Sentiment Analysis, and Natural
Language Processing.
Asim Ullah Jan did MS-CS from department of Computer Science, University
of Peshawar. He has done BS in Information Technology from Institute of
Business and Management Sciences, Agriculture University Peshawar. He is
currently working as a Lecturer in the Department of Computing, Abasyn
University Peshawar. His research interest is in the field of Data Mining, Deep
Learning, Recommender Systems, Sentiment Analysis and Natural Language
Processing.
Data Intelligence
353
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Deep Learning for Medication Recommendation: A Systematic Survey
Shen Xiaoli born in January 2001. She is currently working as a senior
student at the School of Artificial Intelligence at Southeast University. She is
mainly engaged in research on knowledge graph and natural language
processing.
Rui Wu received the B.S. degree in Computer Science in 2019 and the M.S.
degree in Software Engineering in 2022 from Southeast University, Nanjing,
China. As a student, he won the title of excellent graduate twice, and got the
principal scholarship and Huawei scholarship. In 2021, he also served in
Tencent as a research intern. Rui Wu is currently working as a machine
learning engineer in Ant Group. His research interests include deep learning,
nature language processing and AI for healthcare. He has published several
papers at academic conferences such as WWW, DASFAA and so on.
NIMBESHAHO Thierry graduated from Thiruvalluvar University with a
master’s degree in information technology in 2018. He is a Ph.D. student at
Nanjing University of Posts and Telecommunications. His current research
fields are machine learning, deep learning, and recommendation systems.
354
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
3
0
3
2
0
8
9
8
2
3
d
n
_
a
_
0
0
1
9
7
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3