RESEARCH ARTICLE
Can the quality of published academic journal
articles be assessed with machine learning?
Mike Thelwall
University of Wolverhampton, 英国
开放访问
杂志
关键词: citation analysis, 机器学习, research evaluation, 文本挖掘
引文: Thelwall, 中号. (2022). Can the
quality of published academic journal
articles be assessed with machine
学习? Quantitative Science Studies,
3(1), 208–226. https://doi.org/10.1162
/qss_a_00185
DOI:
https://doi.org/10.1162/qss_a_00185
Peer Review:
https://publons.com/publon/10.1162
/qss_a_00185
已收到: 5 一月 2022
公认: 8 二月 2022
通讯作者:
Mike Thelwall
m.thelwall@wlv.ac.uk
处理编辑器:
Ludo Waltman
版权: © 2022 Mike Thelwall.
在知识共享下发布
归因 4.0 国际的 (抄送 4.0)
执照.
麻省理工学院出版社
抽象的
Formal assessments of the quality of the research produced by departments and universities are
now conducted by many countries to monitor achievements and allocate performance-related
资金. These evaluations are hugely time consuming if conducted by postpublication peer
review and are simplistic if based on citations or journal impact factors. I investigate whether
machine learning could help reduce the burden of peer review by using citations and metadata
to learn how to score articles from a sample assessed by peer review. An experiment is used to
underpin the discussion, attempting to predict journal citation thirds, as a proxy for article quality
scores, for all Scopus narrow fields from 2014 到 2020. The results show that these proxy quality
thirds can be predicted with above baseline accuracy in all 326 narrow fields, with Gradient
Boosting Classifier, Random Forest Classifier, or Multinomial Naïve Bayes being the most
accurate in nearly all cases. 尽管如此, the results partly leverage journal writing styles and
主题, which are unwanted for some practical applications and cause substantial shifts in
average scores between countries and between institutions within a country. There may be
scope for predicting articles’ scores when the predictions have the highest probability.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
1.
介绍
Higher education has become increasingly monitored and managed by national states over the
past half century (Amaral, Meek et al., 2003). As part of this, countries typically have compet-
itive systems in place to fund academic research. In addition to project-based funding, 一些
nations also now directly reward research quality through systematic procedures to assess this
at the departmental level (例如, 波兰: Kulczycki, Korzeń, and Korytkowski (2017); 但不是
德国: Hinze, Butler et al. (2019)). The UK’s Research Excellence Framework (REF) uses
expert postpublication peer review to evaluate the outputs of academic researchers at approx-
imately the departmental level every 6 或者 7 年, combining the results with evaluations of
case studies and institutional environments (Wilsdon, Allen et al., 2015A). New Zealand’s Per-
formance Based Research Fund (Buckle & Creedy, 2019) and Excellence in Research Australia
(Hinze et al. 2019) are similar peer review schemes. Italy also has a performance-based funding
scheme that includes evaluating the quality of researchers’ outputs, albeit exempting journal
articles meeting bibliometric thresholds (Franceschini & Maisano, 2017).
Large-scale post publication peer review is hugely time consuming, employing many
研究人员 (超过 1,000 in the United Kingdom) to make postpublication quality assessments
on the outputs. It is therefore logical to investigate whether the peer review part of this process
could be streamlined in any way, such as by automation. In the UK, academics in 2019 believed
The quality of published academic journal articles
that technology would be used to enhance research assessment in the future (Parks, 罗德里格斯-
Rincon et al., 2019), perhaps thinking of this. 十一月 2021, the four UK higher education
funding bodies published a call for a systematic review of the potential for technology to support
research assessment, and particularly the labor-intensive REF (Gov.uk, 2021). Motivated by this,
the current article uses a dummy automated peer review exercise to underpin a discussion of the
potential for artificial intelligence to replace peer review.
Few previous studies have attempted to automatically score the quality of academic research.
This is presumably because only aggregate scores are made public by national evaluation exer-
cises, so there is no output-level data to leverage to build effective algorithms. 尽管如此,
some have attempted to find indicators that correlate with overall university quality profiles,
such as hyperlinks to university websites (Thelwall, 2002) or citation-based indicators (Traag
& Waltman, 2019). One report by the team organizing the UK REF has analyzed the raw output
scores, 然而, finding moderate correlations with citation-based indicators and altmetrics
(Wilsdon, Allen et al., 2015乙). The task of predicting long-term citations for articles is related
because citation counts in some fields are approximate indicators of scientific impact. Investi-
gations of this possibility, often using regression rather than machine learning, have found a
range of article metadata factors to associate with higher citation counts. These include the
number of authors, the number of countries in the author team, the readability of the abstract,
and keyword repetition (大厅, Vogel et al., 2018; Lei & 严, 2016; 李, 赵等人。, 2019;
McCannon, 2019; Sohrabi & Iraj, 2017; Stegehuis, Litvak, & Waltman, 2015). Text mining
has rarely been used to predict citations but has been used to detect plagiarism (Foltýnek,
Meuschke, & Gipp, 2019) or statistical errors (Nuijten & Polanin, 2020) and to investigate topics
in fields (Heo, Kang et al., 2017), to identify research trends (Kim & Delen, 2018; Nie & Sun,
2017), to map science (陈, 2017), and to predict journal or conference reviewing decisions
(Checco, Bracciale et al., 2021; Thelwall, Papas et al., 2020).
A few papers have used machine learning approaches to predict article citations, 使用
methods including Support Vector Machines (福 & Aliferis, 2010), k-Nearest Neighbors, 和
Bagging (王, Jiao et al., 2020), Stochastic Gradient Descent, Random Forest, XGBoost
classifier, LGBoost classifier (Klemiński, Kazienko, & Kajdanowicz, 2021), Decision Trees
(Su, 2020), and CART (Yuan, Tang et al., 2018). Different deep learning architectures have
been proposed and tested on small full text article sets, apparently convenience samples of
collections of papers with full text online. These include long-term physics article sets (赵
& 冯, 2022), library, 信息, and documentation articles (Ruan, Zhu et al., 2020),
historical Markov chain articles (徐, 李等人。, 2019), two computational linguistics conferences
(李等人。, 2019), and five prestigious journals (using annual citations rather than full text:
Abrishami & Aliakbary, 2019). A comparison of deep learning with other approaches found
Support Vector Machines to be the most accurate for computer science publications (朱 &
Ban, 2018). Almost all previous machine learning studies have focused on a single topic or a
small set of fields. The only exception, which took a science-wide approach, sampled 12,374
random Web of Science articles from 2015, ignoring field classifications rather than comparing
between fields (Akella, Alhoori et al., 2021). 还, no previous study seems to have used a
development set that is separate from the training/testing sets, risking overfitting (当前的
article also does not use separate training/test sets but reports separate scores for 326 fields and
does not customize the methods for any field). The machine learning studies so far have not
given comparative information about the relative attractiveness of machine learning for
different fields of science, and none have addressed the issue of scientific quality estimation.
The research goal for this article is to investigate whether it is possible to assess the quality
of published academic journal articles with machine learning, but the research questions are
Quantitative Science Studies
209
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
only indirectly related to this and hence need justification. Because there are no large-scale
sources of postpublication quality control scores for academic articles (with the partial excep-
tion of biomedical science: Mohammadi & Thelwall, 2013), a proxy source of quality is used.
For this article, the citation rate (defined in detail below) of the publishing journal is used as the
quality proxy. This is a poor proxy but is used in the absence of a better one. Journal impact
factors of various types are widely recognized and are considered to be indicators of scientific
quality to some extent by some researchers, varying between countries and fields. 这是
because in some fields, citations are accepted as (very approximate) indicators of scientific
worth and so journals attracting better articles tend to be more cited. UK evidence suggests
that journal citation rates correlate moderately positively with the quality of the articles that
they publish in the medical and physical sciences and economics, weakly in engineering and
social sciences, and negatively or not at all in the arts and humanities (Wilsdon et al., 2015乙,
Table A18). 而且, in some fields, Journal Impact Factors correlate with researchers’ opin-
ions of journals (Haddawy, Hassan et al., 2016; Serenko & Bontis, 2021; Serenko & Dohan,
2011), although not in others (Maier, 2006). In fields where this logic is accepted, 有一个
tendency for it to become truer over time because there is more competition to be published in
journals with higher impact factors. 另一方面, citations are irrelevant in some fields
and impact factors reflect journal specialisms to some extent. 因此, in this article, average
journal citation rate is used as an approximate indicator of article quality, accepting that in
some fields it is irrelevant to quality. Articles are split into three groups by journal citation rate,
mirroring the UK REF, where articles are allocated a weighting of 0, 0.25 或者 1 for quality-
related funding (https://re.ukri.org/funding/quality-related-research-funding/). The specific
research questions are therefore as follows.
1. How accurately can machine learning identify the journal impact third of published
journal articles from other metadata in different fields and years?
2. Which textual features are most powerful at detecting the journal impact third of pub-
lished journal articles in different fields and years?
3. Do the machine learning results have systematic biases against any genders, 国家
或机构?
2. 方法
The research design was to gather a reasonably comprehensive sample of academic journal arti-
克莱斯, allocate journal impact-based thirds to the articles, and apply machine learning to detect
the probable journal third of each article. The same parameters (sample size, 机器学习
方法, feature set size) were applied to each field so that the results could be compared.
2.1. 数据
Scopus was chosen as the source of journal articles for its wide coverage of academic literature
and fine-grained field classification scheme. The Web of Science could have been used but
Scopus is slightly larger, giving more data. Only documents of type journal article were included
to give consistency. The UK REF excludes review articles, so these were not included.
All Scopus documents of type journal article with publication years between 2014 和
2020 were downloaded from Scopus in January 2021 using its API. The years 2014 到 2020
were chosen to mimic REF2021, and January 2021 citation data is appropriate because it
would be available at the start of the original assessment period (although the start was delayed
due to the COVID-19 pandemic). The quality of the citation data thus varies between years,
Quantitative Science Studies
210
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
和 2014 citation data being relatively mature and 2020 citation data being poor quality due
to December 2020 articles having almost no time to attract citations, whereas January 2020
article had about a year. This is taken into account in the discussion but not in the methods.
Journal thirds were identified for each Scopus narrow field with a multistage approach.
第一的, the Normalized Log-transformed Citation Score (NLCS) (Thelwall, 2017) was calculated
for each article. This uses log transformation to reduce the skewing of citation count data so
that the result is not dominated by a small number of highly cited articles. The score for an
article is 1 if its citation rate is the world average, with scores above 1 indicating a greater
citation rate than the world average and scores below 1 indicating fewer citations than the
world average. These scores are normalized within the Scopus narrow field in which an article
is classified (or the average of all fields for articles in multiple fields). 第二, the arithmetic
mean of the NLCS for all articles in each journal was calculated as its average citation score,
called here JMNLCS ( Journal Mean NLCS). This differs from the Journal Impact Factor ( JIF) 在
that the average is calculated from articles in a single year, includes all citations to date, 和
uses NLCS instead of raw citation counts. This should be less affected by skewing than JIFs and
should be more relevant to articles from the year with the data used for the calculation. 最后,
JMNLCS thresholds were calculated to split the articles into approximately equal thirds. 在
一些案例, this was not possible due to single very large journals dominating categories
and the split generated approximate halves instead of thirds.
2.2. Features Analyzed
The machine learning stage requires a set of data about the articles to predict from. 因为
journal citation rates are used as a quality proxy for articles, they cannot also be used as inputs
for the machine learning process. 还, because the purpose of quality control is to assess
individuals or institutions, it is inappropriate to include these as inputs. The following features
were included.
(西德:129) NLCS for each article: This is a citation-based indicator, normalized for fields and year
to be comparable between articles. The log transformation reduces skewing, 哪个
may make the feature more powerful for learning with linear-based algorithms.
(西德:129) Number of authors: Articles with more authors are likely to be more cited in many fields.
(西德:129) Number of country affiliations: Articles with authors from more countries are likely to be
more cited in many fields.
(西德:129) Word unigrams, 二元组, 和卦象: The quality of an article is presumably encoded
in its text and figures. While full-text analysis is impractical and likely to confuse an
algorithm with many irrelevant details from a paper, the title, 抽象的, and keywords
may be helpful as a succinct summary. These were therefore extracted and added as
特征. Individual words and short phrases of two or three words were extracted, 和
those occurring only once in a field being discarded.
Abstracts were preprocessed to remove standard texts, such as publisher copyright state-
ments and structured abstract headings. A large set of heuristics had been developed to
remove these for previous automated text analyses of abstracts (Fairclough & Thelwall,
2022; Thelwall & Nevill, 2021) and these were reused for the current paper. These heuristics
vary from generic (例如, remove the first or last sentence if the first character is a copyright
symbol or the first word is Copyright; remove the phrase, All rights reserved.) to publisher-
specific (例如, remove the first abstract sentence if it contains Elsevier and a copyright symbol;
remove the first sentence if it contains Maney & Son Ltd starting in the first 20 characters). 这
Quantitative Science Studies
211
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
heuristics included a list of common structured abstract headings, such as “Results:” and “PAR-
TICIPANTS”. Articles with abstracts with fewer than 500 characters after this stage were
已删除. This standardizes the machine learning task by ignoring articles without abstracts
or with relatively trivial abstracts.
Each field and year combination formed a separate data set for training and evaluation.
有 330 nonempty fields per year, 一般, 超过 7 年, so this gave 2,310 数据
sets to analyze. The smaller sets had too few articles to analyze, 然而, so the final number
of field/year combinations analyzed was slightly less. The total number of articles analyzed
曾是 31,273,062, varying between 3,846,106 在 2014 和 5,694,904 在 2020. This counts
articles multiple times when they occur in multiple narrow fields but excludes articles with
short or no abstracts. Exact numbers for each field and year are in the online supplement (坳-
umn B of worksheet “Acc aboveAll Fig 1” in spreadsheet “All files and methods – accuracy fig
1,6 chi square 2014.xlsx”: https://doi.org/10.6084/m9.figshare.17912009).
2.3. Machine Learning
There are many different machine learning algorithms and all have advantages and disadvan-
塔盖斯, so there is not an obvious candidate for the machine learning task. Twenty classification
or regression algorithms were compared (桌子 1), as implemented in the standard scientific
machine learning system scikit-learn on Python with their default settings. These include three
that are general-purpose and accurate on a wide range of tasks: Support Vector Machines
(Linear Support Vector Classification here), Gradient Boosting Classifier, and Random Forest
Classifier. Two were discarded for the full testing (see table footnotes). All the classifiers were
run a second time as ordinal classifiers by classifying two separate two-class problems: 1 与 (2
和 3) 和 (1 和 2) 与. 3, giving the result 1 from the first problem, 3 from the second task, 和
否则 2. Any cases classified as both 1 和 3 were instead classed as 2. This procedure
takes into account the ordering of the classifications, so should, in theory, be superior to both
classification (unordered) and sometimes regression (when it assumes a linear relationship).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
Feature reduction (IE。, selecting a subset of the inputs to feed into each algorithm) was per-
formed using the chi-square method, except forcing the citation, 作者, and country information
to be kept. Tests with a range of training set sizes and feature set sizes suggested that the perfor-
mance of the algorithms increases as either or both increases, so there was not an optimal choice
for either one. As a compromise, 1,000 features and 1,000 articles for training were selected as
large enough to be close to the optimal accuracy without slowing the algorithms too much.
Fields were trained on 90% of the articles or 1,000 文章 (whichever was the smaller) 和
evaluated on the remainder. The algorithms were trained and evaluated on 30 separate random
test/train splits (而不是, 例如, 30-fold cross-validation, because the training set size
needs to be fixed) and the average accuracy reported. The predictions from the first iteration
on each field data set were saved for further analysis of the individual predictions.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
2.4. 分析
Overall accuracy statistics (precision) were calculated separately for each field/year combina-
tion as the average accuracy of the 30 algorithm iterations on the evaluation sets. Recall and
F1 measure were not calculated because the small number of classes (三) means that they
give little extra information, and they are in any case subsumed in the score-based tests of the
influence of the results, 下面讨论. For ease of comparison between fields, the main
statistic reported is the level of accuracy above the baseline (the percentage of articles in
Quantitative Science Studies
212
The quality of published academic journal articles
桌子 1. Machine learning methods initially tested for regression and classification. Those marked
with “/o” have an ordinal version of the classification.
Code
bnb/o
cnb/o
gbc/o
knn/o
lsvc/o
log/o
mnb/o
pac/o
per/o
rfc/o
rid/o
sgd/o
svc/o
elnr
krr
lasr
lr
ridr
sgdr
svr
方法
Bernoulli Naive Bayes
Complement Naive Bayes
Gradient Boosting Classifier
k Nearest Neighbors
Linear Support Vector Classification
Logistic Regression
Multinomial Naive Bayes
Passive Aggressive Classifier
Perceptron
Random Forest Classifier
Ridge classifier
Stochastic Gradient Descent
Support Vector Classification
Elastic-net regression
Kernel Ridge Regression
Lasso Regression
Linear Regression
Ridge Regression
Stochastic Gradient Descent Regressor
Support Vector Regression
Type
班级
班级
班级
班级
班级
班级
班级
班级
班级
班级
班级
班级
Class*
Reg
Reg
Reg
Reg
Reg
Reg
Reg**
* Almost the same results as lsvc and so was not used for the full testing.
** Inaccurate and slow in all tests with 1,000 features and so was not use for the full testing.
the most common class). This is fairer than comparing accuracy between fields, because some
fields have substantially higher baseline accuracies than others.
To assess the influence of the machine learning on the overall scores of countries, institu-
系统蒸发散, and two genders, for each field, the weighted average true score ( JMNLCS thirds) 和
machine learning predicted scores were compared. Within each country, the results were
compared between institutions and male/female first author genders. Any differences suggest
a machine learning bias (accidental or systematic) towards or away from the group in question.
First author genders were assigned by checking their first name against a list of country-based
gendered first names from Gender-API.com, allocating a gender only when the probability of a
correct assignment was above 95%. These tests were reported for the main three machine
learning methods only, to avoid reporting low-value information.
To identify the types of term with the greatest discriminatory power in the machine learning,
chi-square tests were conducted on all terms used for the machine learning stage in each field
Quantitative Science Studies
213
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
and the top term selected for all 314 Scopus narrow fields in 2014 with three categories. 这些
terms were informally investigated using the Key Word In Context (KWIC) approach by iden-
tifying their most common single context in the field that caused their high chi-square values.
3. 结果
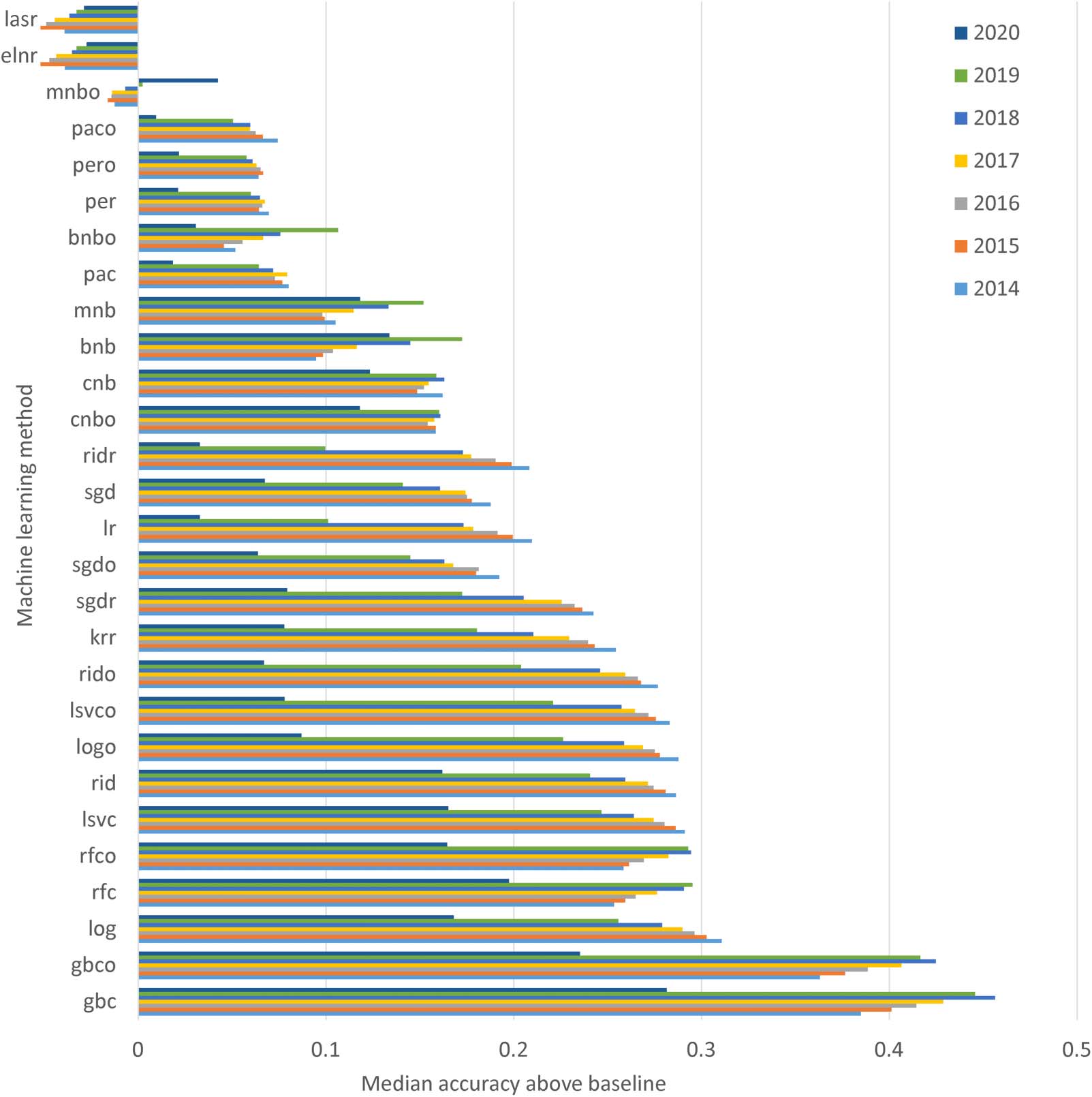
3.1. Comparison of Methods and Years
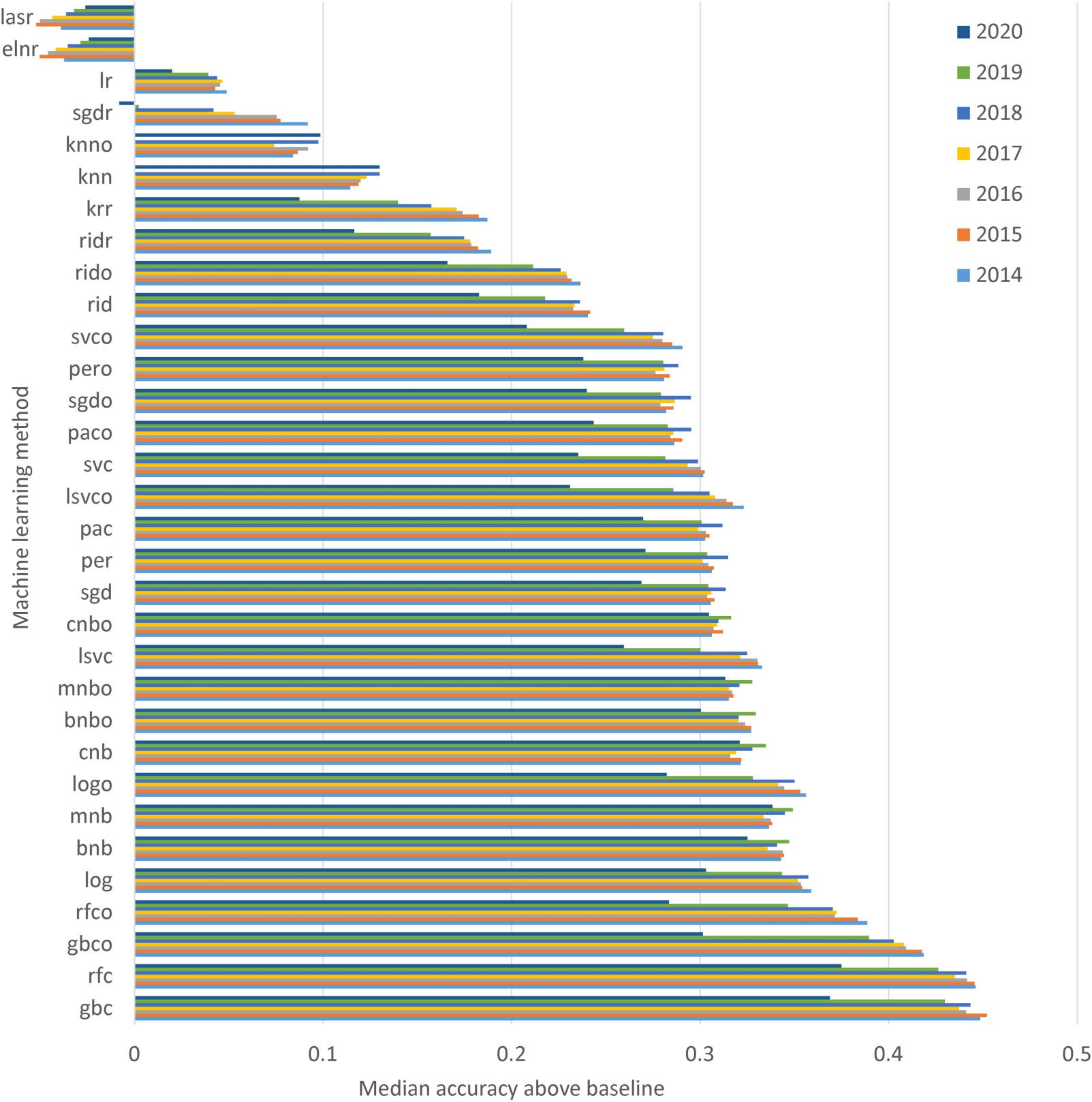
The single most accurate method was gbc 46% 当时的, followed by rfc (45%) and mnb
(3%). The mnb method was rarely accurate for the early years but was relatively more accurate
在 2020 数据. 全面的, gbc and rfc had similar levels of accuracy, but all were substantially
more accurate than all 30 other methods, 一般. The regression classifiers had relatively
poor accuracy, and the ordinal versions of classifiers surprisingly tended to be less accurate
overall than the standard versions (数字 1).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1. Average (从 30 尝试) accuracy above baseline (on a scale of 0 = baseline to 1 = 100% accurate) across the 326 Scopus narrow
fields for 32 different machine learning methods. Each has a training set of 1,000 文章, 使用 1,000 features selected by chi-square, 和
evaluated on the remaining articles.
Quantitative Science Studies
214
The quality of published academic journal articles
Accuracy is generally highest in 2014 and substantially lower in 2020 than in other years,
和 2019 also being lower than 2014-2018. 为了 2014, this confirms that citations are useful in
helping to predict journal thirds. Accuracy is presumably lower in 2019 和 2020 因为
early published articles have a substantial citation advantage over late published articles
due to longer citation windows. This tends to confirm that citations are less valuable for newer
文章. Another possible explanation is that the journal thirds are less coherent for 2020
because the citation data has had less time to mature.
3.2. Fields with Highest and Lowest Relative Accuracy
The Scopus narrow fields in 2014 with the highest accuracy for any machine learning method
tended to be small (少于 1,000 文章) for “miscellaneous” (mixed) fields, 或两者
(桌子 2). Small fields may be easier to predict because they contain fewer journals, so pre-
diction is a simpler problem. 例如, Review and Exam Preparation had three journals:
one in the top third (Clinical Teacher), two in the mid third ( Journal for Nurses in Professional
Development and Journal of Continuing Education in Nursing), and none in the bottom third.
Miscellaneous fields may be easier to predict because they contain journals from relatively
different topics, so making journal-related predictions from text may be easier (因为
abstracts would contain more distinctive terms for each journal). 例如, Veterinary
(misc.) includes relatively different titles, such as Brazilian Journal of Veterinary Pathology,
Journal of Fish Diseases, and Parasite. The top chi-square words/phrases for this narrow field
suggested another cause, 然而. They were “opinion,” “opinion on,” “opinion on the,” “sci-
entific,” “scientific opinion,” and “scientific opinion on,” which all originated primarily from
the titles of articles in the EFSA Journal (例如, https://doi.org/10.2903/j.efsa.2014.3573). This is a
publication of the European Food Standards Agency that published its outputs, which seem to
be conclusions of expert scientific committees after deliberation. It is not a peer reviewed aca-
demic journal, even though it publishes expert scientific outputs. The standardization of title
phrases has made its articles easily identified by machine learning. No similar standard
phrases were discovered for the other three miscellaneous categories, although some near-
桌子 2.
for any machine learning algorithm (training set 1,000, 或者 90% if under 1,000; 1,000 特征)
这 10 在......之外 324 Scopus narrow fields in 2014 with the highest accuracy above baseline
Narrow field (2014)
2923 审查 & Exam Preparation
文章
150
Baseline
57%
3401 Veterinary (misc.)
3604 Emergency Medical Services
3603 Complementary & Manual Therapy
1504 Chemical Health and Safety
2920 Pharmacology (nursing)
1301 Biochemistry, 遗传学 & Molecular
生物学 (misc.)
1501 Chemical Engineering (misc.)
3601 Health Professions (misc.)
2917 Oncology (nursing)
957
137
405
365
114
702
1,313
508
592
49%
69%
45%
55%
81%
40%
41%
45%
35%
Top
mnb
gbc
mnb
cnb
cnb
mnb
cnb
gbc
cnb
gbc
AOB
99.0%
86.8%
86.8%
83.4%
82.9%
82.7%
80.2%
80.1%
78.7%
78.3%
215
Quantitative Science Studies
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
桌子 3.
for any machine learning algorithm (training set 1,000, 或者 90% if under 1,000; 1,000 特征)
这 10 在......之外 324 Scopus narrow fields in 2014 with the lowest accuracy above baseline
Narrow field (2014)
2602 Algebra & Number Theory
文章
2,841
Baseline
42%
Top
rfc
AOB
27.2%
2000 经济学, Econometrics and Finance (全部)
1205 Classics
8,178
627
3206 Neuropsychology & Physiological Psychology
3,507
2607 Discrete Mathematics & Combinatorics
2608 Geometry & Topology
1208 Literature & Literary Theory
2600 Mathematics (全部)
1212 Religious Studies
1200 艺术 & 人文学科 (全部)
2,546
2,378
5,496
12,392
4,785
4,820
49%
41%
42%
44%
44%
44%
48%
42%
84%
gbc
26.6%
mnb
25.0%
rfc
gbc
gbc
25.0%
24.3%
24.3%
rfco
24.1%
gbc
gbc
23.2%
23.0%
mnb
19.3%
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
top terms (sixth to ninth highest) from Health Professions (misc.) were from an unusual struc-
tured abstract phrase, “Conclusions and implications for practice,” in the Psychiatric Rehabil-
itation Journal that had not been filtered out.
The Scopus narrow fields with the lowest accuracy attainable with the 32 methods include
three general fields with “all” in their title, four humanities fields, and two mathematical fields.
General “all” fields may contain journals with relatively similar or general scopes that are dif-
ficult to detect through word frequency analyses because their abstract texts tend to contain
similar words. Humanities fields may contain many small specialist journals with highly
diverse topics, complicating the machine learning problem (桌子 3). Mathematics journals,
桌子 4.
for any machine learning algorithm (training set 1,000, 或者 90% if under 1,000; 1,000 特征)
这 10 在......之外 326 Scopus narrow fields in 2020 with the highest accuracy above baseline
Narrow field (2020)
3503 Dental Hygiene
文章
120
Baseline
82%
Top
gbc, lsvc
AOB
100.0%
2923 审查 & Exam Preparation
3613 Podiatry
2920 Pharmacology (nursing)
3404 Small Animals
3402 Equine
1801 Decision Sciences (misc.)
3401 Veterinary (misc.)
3001 Pharmacology, Toxicology &
Pharmaceutics (misc.)
170
316
254
1,331
1,243
211
1,222
2,042
46%
51%
70%
40%
43%
38%
46%
59%
logo
rfc
mnbo
gbc
gbc
mnb, cnb
gbc
rfc
87.7%
85.9%
84.6%
84.3%
84.3%
83.7%
83.0%
82.3%
3601 Health Professions (misc.)
2,510
56%
mnb
81.9%
Quantitative Science Studies
216
The quality of published academic journal articles
桌子 5.
for any machine learning algorithm (training set 1,000, 或者 90% if under 1,000; 1,000 特征)
这 10 在......之外 326 Scopus narrow fields in 2020 with the lowest accuracy above baseline
Narrow field (2020)
3304 教育
1205 Classics
2603 分析
3002 Drug Discovery
3200 心理学 (全部)
1202 历史
2602 Algebra & Number Theory
2600 Mathematics (全部)
1507 Fluid Flow & Transfer Processes
17,493
2101 Energy (misc.)
6,818
文章
55,756
Baseline
35%
671
7,297
22,715
15,162
15,986
4,585
22,277
70%
36%
48%
42%
36%
43%
41%
79%
88%
Top
rfc
mnb
mnb
AOB
22.4%
22.1%
21.5%
gbc,rfc
21.0%
gbc
mnb
rfc
rfc
rfc
mnb
20.9%
20.9%
17.7%
16.1%
5.2%
4.9%
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
相比之下, may be jargon-dense, with little overlap between articles in the terminologies used
for the relatively specialist topic addressed in each one. As citations have little relevance to
mathematics and the humanities, the citation data may also not be useful in these fields.
The high accuracy set for 2020 has four overlaps with the 2014 set and a similar pattern of
mainly small or miscellaneous narrow fields (桌子 4). The top chi-square terms for the highest
scoring narrow field with at least 1,000 文章, Small Animals, suggest a combination of
animal-specificity and incompletely cleaned structured abstracts. The top and third terms
are “and relevance” and “relevance”, from the nonstandard structured abstract phrase “Con-
clusions and relevance” in the Journal of Feline Medicine and Surgery. This journal also had
other nonstandard abstract headings, such as “Case summary” and “Relevance and novel
information.” The second and fifth terms were animal-specific, “cats” and “in cats,” associat-
ing with the two feline journals. The high accuracy was also helped by the presence of a jour-
nal specializing in reproduction, Theriogenology, which is associated with a set of relatively
unique terminology with high chi-square scores, including “embryo,” “sperm,” “pregnancy,”
and “oocytes.”
The low accuracy set for 2020 has three overlaps with the 2014 set and a similar pattern of
two general “all” narrow fields, three mathematics fields, and two humanities fields (桌子 5).
尽管如此, some other fields do not fit this pattern. 尤其, Energy (misc.) is an anom-
aly. This Scopus field had its top third dominated by a single general journal, Energies (5,219
文章), and the generalities of the topics in this journal make the task of machine learning
difficult from text. A similar issue occurred for Fluid Flow and Transfer Processes, with a dif-
ferent single large general top third journal: Applied Sciences (8,396 文章).
3.3. Terms with the Highest Chi-Square Value in Each Field
A manual analysis of the terms with the highest chi-square value for each of the 314 Scopus
narrow fields from 2014 with three categories (the remainder had two) revealed three main
上下文 (桌子 6). 在 13% of cases, the term most discriminating between journal thirds, 在
least in terms of the highest chi-square value, originated from journal mandatory text, 这样的
Quantitative Science Studies
217
The quality of published academic journal articles
桌子 6.
Contexts found for the top chi-square term for the 314 Scopus narrow fields from 2014 with three categories
Context
话题
Fields
139 (44%)
描述
The term associates with a topic or method.
Style
134 (43%)
The term is a stylistic device, 无论
optional or journal mandated.
Boilerplate
41 (13%)
The term occurs within journal
boilerplate text, such as structured
abstract headings.
Examples
“for nursing management,” “early childhood,”
“brain injury,” “fixed point,” “librarians,”
“Romania,” “setting participants,” “urban,”
“consumers,” “electrochemical,” “education,”
“energy,” “p,” “painter,” “vaccine,”
“wastewater,” “wound”
“we,” “our,” “was proposed,” “this paper,”
“this article,” “this letter,” “find that,”
“here we,” “study on,” “the author,”
“results show,” “the present study”
Structured abstract headings: “Key points,”
“Research purpose,” “Statement of problem”;
Journal added keyword: “issue”
(例如, “issue 91”); 其他: “available online”.
as structured abstract headings or (presumably) mandated keywords. While the initial data
cleaning was designed to remove all structured abstract headings, many rare structured head-
ings had not been removed. 理论上, these could be removed with additional data filtering
脚步, although this is time-consuming.
不出所料, in almost half (44%) of all narrow fields checked from 2014, topic-related
terms were the most discriminatory between journal thirds. This category includes some
methods-related terms (例如, “p” [-价值], “setting participants”) that may primarily differentiate
between empirical and conceptual papers, but this dichotomy was not explored due to the
difficulty in making this distinction. Some of the topic words also specified a geographic loca-
tion that may be secondary to the main topic of a paper (例如, “Romania”) for categories with
nationally focused journals. The commonness of topic terms is unsurprising because almost all
journals have topic specializations, although generalist journals might span the entire scope of
a Scopus narrow field. 当然, a topic term can be discriminatory if only one journal in a
Scopus narrow field has a narrow scope, as its topic terms will associate with its journal third.
因此, it seems likely that some topic terms are discriminatory in all Scopus narrow fields, 甚至
though they are the top terms in under a half.
Perhaps more surprisingly, stylistic devices are the top discriminatory terms in 43% 全部的
Scopus narrow fields. These terms may be optional custom and practice followed by authors in
some journals. 反过来, some stylistic terms might be mandated by journals, 例如
use of the active voice or first-person plural “we” rather that the passive voice when describing
方法. Journals might also suggest or give examples of phrases that might be useful for
authors to include in their abstract (例如, “in this study we show”) to ensure that key points
are not omitted.
3.4. Prediction Accuracy by Gender, 国家, and Institution
If the predicted scores are compared to the actual scores for each article separately for male
and female first authors, it is possible to detect whether the prediction algorithms indirectly
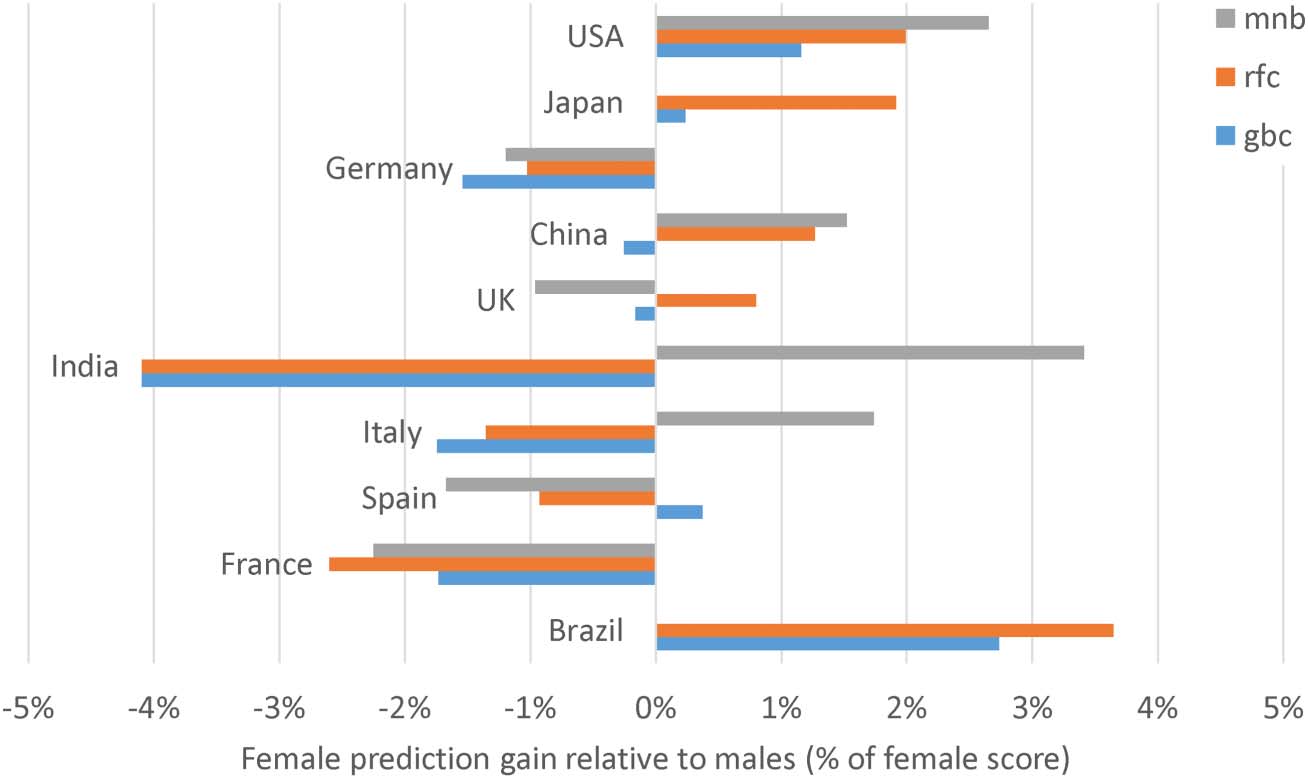
favor one of these two genders compared to the other (数字 2). The results do not show uni-
versal patterns. The predictions favor females in the United States, 日本, and Brazil but males
in Germany and France. The gender advantage varies between method for the other five of the
Quantitative Science Studies
218
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
数字 2. 这 2014 relative score increases for women compared to men for the 10 countries with
the most articles with a gendered first author. The scores are expressed as a percentage of the orig-
inal female score.
10 countries with the most gendered first authors. No method seems to systematically favor
one of the two genders. The effects are relatively large, 然而, accounting for a gender shift
of up to 4%.
Changing the proxy scores with predictions would have an even more substantial impact
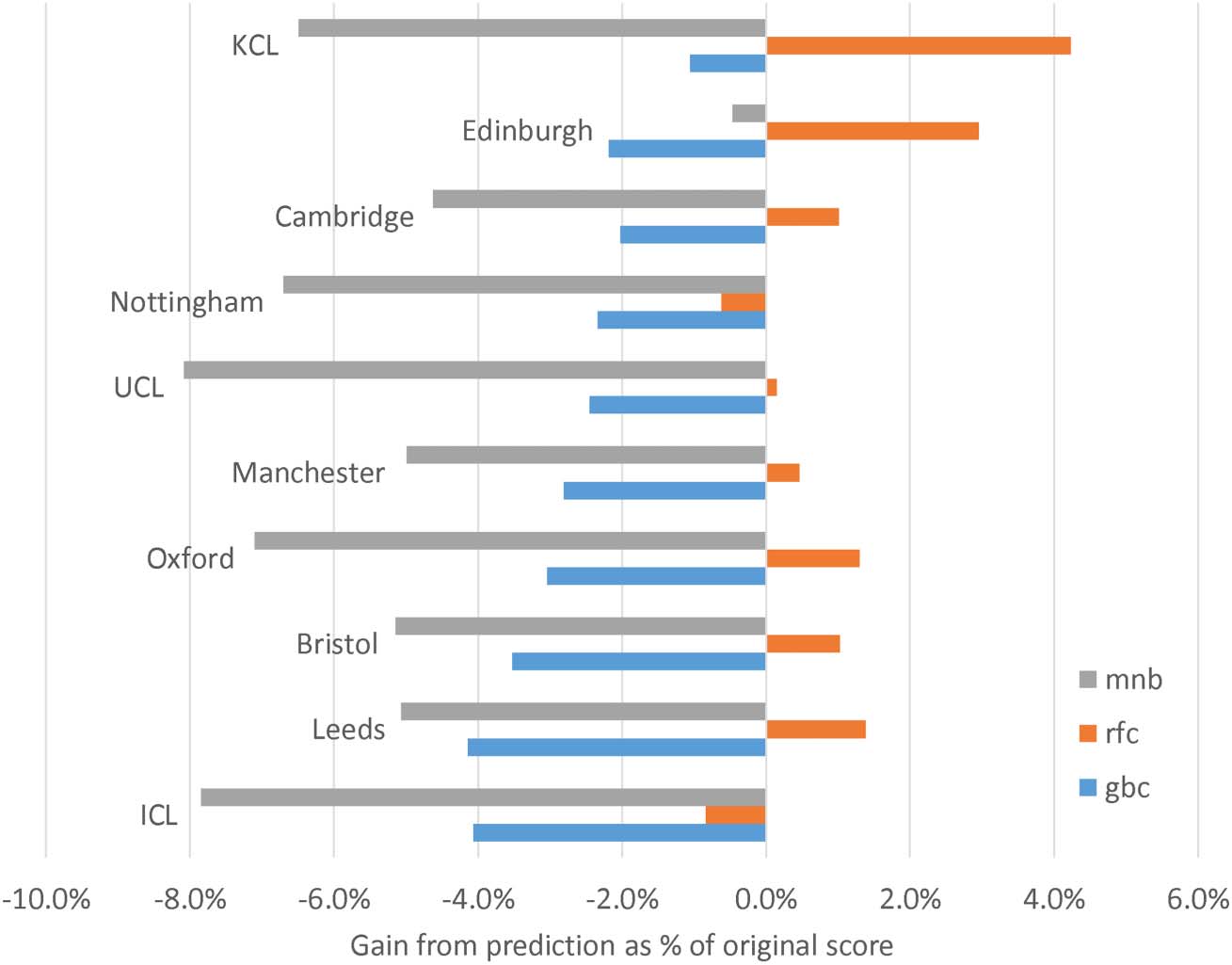
on the overall scores of individual institutions (数字 3). Taking the 10 largest institutional
affiliation addresses in the United Kingdom as an example (not merging different affiliations
for the same overall university), machine learning could introduce a 7% shift in relative score
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3. 这 2014 relative score increases for the 10 UK institutions with the most articles. 这
scores are expressed as a percentage of the original institution’s score.
Quantitative Science Studies
219
The quality of published academic journal articles
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
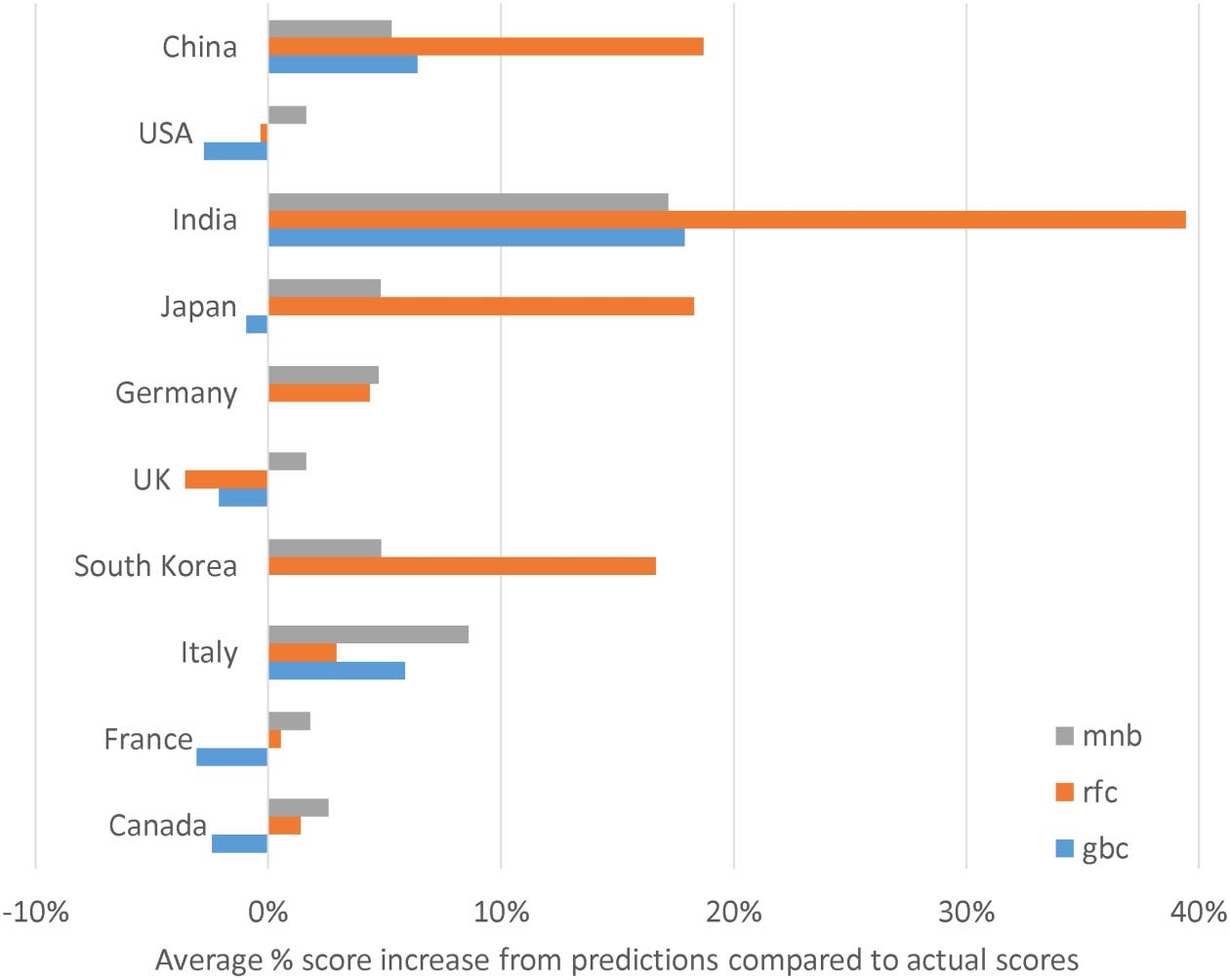
数字 4. 这 2014 relative score increases for the 10 countries with the most articles. The scores
are expressed as a percentage of the original institution’s score.
between institutions. Because the scores translate into money, this would mean a relative 7%
shift in research funding. There is a tendency for the Random Forest Classifier to make predic-
tion gains and the others to make prediction losses for these institutions, but this is not relevant
because the funding is shared from a fixed amount for the United Kingdom. The swing is larg-
est for mnb (7%), followed by rfc (5%) and gbc (3%). As the ultimate goal of the REF is to
allocate funding to institutions on the basis of the scores, gbc has a substantial advantage over
the other two algorithms.
It is relevant to examine international differences in the effect of replacing scores with pre-
措辞, in case international organizations, such as the European Union, adopt this approach.
The results show that the predictions have an enormous impact on the relative scores of coun-
尝试, with some increasing substantially and others decreasing (数字 4). Although based on
an artificial experiment, these figures suggest that international comparisons with machine
learning would be highly problematic.
4. 讨论
The results are limited by the coverage of Scopus and its categorization of articles into fields
primarily at the journal level, which is not optimal (Klavans & Boyack, 2017). Although a large
set of machine learning algorithms have been tested, different results may have been gained
来自别人的, including an appropriate deep learning framework. Different training set sizes and
feature set sizes may also change the results. 相似地, more accurate predictions could be
expected if additional features had been included, such as author-level career achievements
and citing-cited document information. The results are also limited by the incomplete removal
of journal boilerplate text, although this seemed to influence a minority of fields. The JMNLCS
is equal to the NLCS for journals with a single article in a year, giving an unfair advantage,
although this did not seem to be common. The lack of a development set to select the model to
Quantitative Science Studies
220
The quality of published academic journal articles
use for each field is also likely to have resulted in slight overestimation of the accuracy achiev-
able with machine learning models in Tables 2 和 4 reporting the highest accuracy of any
方法, although it should not affect the scores for the individual methods (例如, 数字 1).
最后, from an interpretation perspective, recall that associating average citation levels with
the quality of the articles in them is inaccurate in all fields. While there may be a moderate
statistical association between article quality and journal citation rates in some fields (例如,
Biological Sciences, Clinical Medicine, 经济学) there is a weak or even a negative asso-
ciation in others (例如, the arts and humanities, 一些社会科学) (Wilsdon et al., 2015乙,
Table A18).
Compared to previous investigations of machine learning for citation prediction, this study
evaluates the most different algorithms and analyzes the most different separate fields. 它也是
has a different target to all previous studies (predicting journal thirds rather than citation counts
or citation percentiles), so the results are not directly comparable. 尽管如此, 结果
confirm the relative accuracy of Support Vector Machines (朱 & Ban, 2018) and Random
Forest and Gradient Boosting Classifiers (Klemiński et al., 2021) for citation-related tasks. 在
对比, Multinomial Naïve Bayes is suggested here for the first time as the most accurate
algorithm for a minority of narrow fields.
The results show that machine learning can predict the citation-based journal third of arti-
cles in all Scopus narrow fields based on its citations and article metadata (excluding journal-
related information). While the prediction accuracy tends to be higher for older papers (2014),
the same is also true in the worst case for 2020 文章, with citation information collected at
the end of the publication year (IE。, 一月 2021 for articles published in 2020). One implicit
factor that text mining machine learning studies can exploit is the topic of papers (陈 &
张, 2015): By learning highly cited topics, they can predict how often a paper is likely
to be cited from its topic. This factor may help to explain the above-chance predictions for
all Scopus narrow fields in 2020, but the predictions can also leverage natural variations
between journals in topics (including methods and contexts) and writing styles. 因此, 预-
dictions may be based on topic rather than citations. The substantially greater accuracy for
older years suggests that citation factors are important, 然而, so the predictions tend to
be more successful when they can leverage citation-related factors.
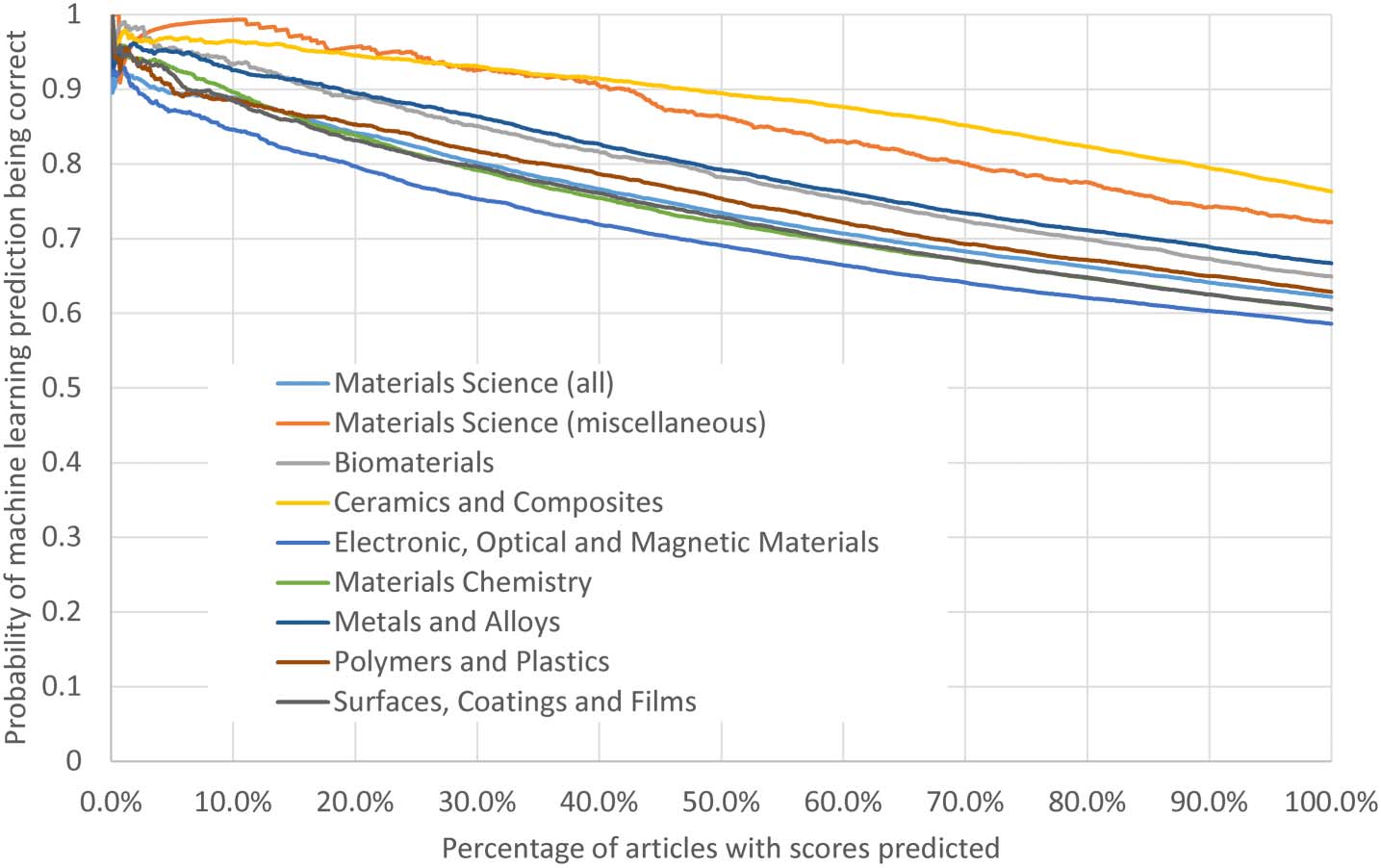
4.1. Prediction Accuracy for Individual Documents
The accuracy of the predictions for each narrow field can be increased by focusing on a subset
of articles for which the algorithm reports a higher probability of a correct prediction, as fol-
lows. Some of the algorithms (including the top three) report a probability that each document
falls within each class. The documents for which the probability for one class is much higher
than for the other two classes tend to have a higher probability of the prediction being correct
than average. If the documents predicted are arranged in descending order of this difference
(highest class probability minus second-highest class probability) then a subset of documents
can be identified with relatively high prediction accuracy. This would allow an accuracy
threshold to be set, accepting the machine learning results for documents falling above the
threshold and using an additional round of human reviewer evaluation for the remaining doc-
uments. The proportion of articles that can be predicted with a high level of accuracy varies
between fields, 然而. Taking the materials science narrow fields as an example, 40% 的
articles in both Materials Science (全部) and Ceramics and Composites can have their classes
predicted with above 90% 准确性, 相比 5% for Materials Science (misc.) 和 2%
for Electrical, Optical and Magnetic Materials (数字 5).
Quantitative Science Studies
221
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
数字 5. The probability of the machine learning results for the Gradient Boosting Classifier being
correct against the prediction likelihood percentile, as reported by the algorithm. The results are for
Scopus narrow fields within the Materials Science Scopus broad field in 2014.
4.2. Prediction Accuracy Without Text
Text factors can be excluded from the machine learning inputs to reduce dependency on arti-
cle topics, leaving three factors: NLCS, number of authors, and number of countries. 这
reduces the median accuracy for most algorithms (数字 6, compared to Figure 1) and years,
especially for 2020. This reduced number of inputs especially reduces the accuracy of Mul-
tinomial Naïve Bayes and the Random Forest Classifier. The leading partial exception is the
Gradient Boosting Classifier in 2019 和 2018, although it is not clear why it performs rela-
tively well in these two years. The Gradient Boosting Classifier and its ordinal variant are still
considerably more accurate than the remaining algorithms on this reduced set of inputs.
4.3.
Implications for Post Peer Review Score Prediction
Returning to the motivating goal of this paper, the results give some insights into the potentials
and limitations of estimating the quality of an academic article from citation counts and meta-
data available at publication time, including title, abstract and keyword text and the number of
authors and countries. Author-related factors (例如, h-index) and journal-related factors (例如, JIF)
were not included because they were potentially inappropriate for this type of exercise, 在哪里
the focus is on evaluating the quality of individual outputs, irrespective of publishing platform or
语境. Using publishing journal thirds as approximate proxies for article quality (例如, an article
is assumed to be more likely to be high quality if it is in a journal in the top citation third than if it is
in a journal in the other two citation thirds), the results suggest that article quality prediction with
machine learning is possible to some extent for all fields. 尽管如此, the results are not
convincing because the algorithms partly leverage topic and style. 更重要的是, 事实
that the algorithms leverage both topic and style suggests that both have strong associations with
journals. Algorithms directly learning article quality from human reviewer scores (而不是
using journal impact as a proxy for article quality, as used here) are therefore likely to indirectly
learn which journals predominantly publish from one quality category (高的, medium, 低的). 作为
Quantitative Science Studies
222
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
数字 6. Average (从 30 尝试) accuracy above baseline (on a scale of 0 = baseline to 1 = 100% accurate) across the 326 Scopus narrow
fields for 29 different machine learning methods (excluding three slow and inaccurate methods compared to Figure 1). Each has a training set
的 1,000 文章, using three features (NLCS, authors, 国家), and evaluated on the remaining articles.
journals can be learned from article styles or topics, algorithms can predict article quality thirds
at least partly from the publishing journal. In the UK REF this is a potential cause for concern
because of the explicit instructions to reviewers to ignore publication venues when allocating
quality scores. 当然, the human reviewers may consciously or subconsciously leverage
similar factors to the machine learning algorithms when making their decisions.
In addition to the journal-related factors discussed above, leveraging topic when predicting
article quality (rather than journal third) may be an unwanted characteristic for machine learn-
ing for another reason. It would reward weak articles on topics with generally strong results
and penalize strong articles in weak research areas (例如, debunking the weak research or sur-
passing it by a quantum increase in quality). If topic-related information is excluded then
machine learning accuracy is reduced (数字 6), so this issue needs careful consideration.
In terms of the potential for machine learning to introduce biases, the country-level results
strongly suggest that international comparisons based on machine learning are inappropriate
due to the potential for substantial shifts in scores caused by predictions. There is also a small
Quantitative Science Studies
223
The quality of published academic journal articles
gender effect of prediction, but varying in size and direction between countries. This may be a
second-order effect of gender differences in research topics and methods (Thelwall, 贝利
等人。, 2019). Most worryingly for the United Kingdom, the results suggest that replacing some
or all human peer review scores with machine learning predictions could result in substantial
shifts between institutions in the allocation of the block funding grant based on output scores
(数字 3). If the accurate classifier giving the least variation, gbc, is used, then this amounts to
3% in the worst case for the 10 largest institutions, which represents a substantial amount of
钱. For institutions with fewer articles, the shift can be larger, 例如 18.5% 转移
from Kingston University (277 articles in 2014; loss of 9.7% from predictions) to Edge Hill
大学 (113 articles in 2014; gain of 8.8% from predictions). Although these figures are
based on an artificial task, they illustrate the potential for machine learning to systematically
skew results for or against institutions even in the absence of institutional and author career
信息.
5. 结论
The results suggest that journal citation-based thirds can be predicted with above baseline
accuracy in all Scopus narrow fields, even at the end of the year of publication. 他们还
show that the Gradient Boosting Classifier or Random Forest Classifier are the most accurate
from the set tested in almost all fields, with Multinomial Naïve Bayes being the most accurate
in a minority. Deep learning methods were not tested. The results also show that machine
learning can leverage topics and writing styles, which can associate with journals. 因此, 甚至
if all journal-level information is excluded from article quality prediction and all journal boil-
erplate text is removed, algorithms can still leverage indirect indicators of the publishing jour-
纳尔. This undermines the goal of generating algorithms that predict the quality of an article on
its own merits rather than indirectly through its publishing journal. Organizations wishing to
evaluate article quality without journal-level influences must therefore investigate and discuss
further to consider whether the influences found are substantial enough to rule out machine
learning altogether. Organizations should also carefully consider the influence of topic on the
预测, irrespective of publishing journals. As topic seems much easier to detect than
质量, machine learning algorithms may tend to predict quality primarily based on topic,
which may generate a perverse incentive to focus on high citation topics.
In terms of practical applications of machine learning for article quality prediction for com-
parisons between countries or institutions, the results seem to rule out its use for international
comparisons due to variability between countries in results. Differences in average scores
between institutions are also substantially affected by the machine learning methods for the
task here, so this aspect needs to be seriously considered with testing on post peer review
scores before any such approach can be implemented. The gender differences in results are
perhaps less of a concern because they are smaller than institutional differences but should
also be considered as a potential unwanted indirect influence on the scores.
COMPETING INTERESTS
The author has no competing interests.
资金信息
This research was not funded, but was preparatory work for a project (Gov.uk, 2021) that was
funded after the final version of this article was written.
Quantitative Science Studies
224
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
DATA AVAILABILITY
Code and processed data, including the data behind all figures is on Figshare: https://doi.org
/10.6084/m9.figshare.17912009.
参考
Abrishami, A。, & Aliakbary, S. (2019). Predicting citation counts
based on deep neural network learning techniques. 杂志
Informetrics, 13(2), 485–499. https://doi.org/10.1016/j.joi.2019
.02.011
Akella, A. P。, Alhoori, H。, Kondamudi, 磷. R。, 弗里曼, C。, & 周,
H. (2021). Early indicators of scientific impact: Predicting cita-
tions with altmetrics. Journal of Informetrics, 15(2), 101128.
https://doi.org/10.1016/j.joi.2020.101128
Amaral, A。, Meek, V. L。, Larsen, 我. M。, Larsen, 我. M。, & Lars, 瓦.
(编辑。). (2003). The higher education managerial revolution?
Springer Science & Business Media. https://doi.org/10.1007/978
-94-010-0072-7
Buckle, 右. A。, & Creedy, J. (2019). The evolution of research quality
in New Zealand universities as measured by the performance-
based research fund process. New Zealand Economic Papers,
53(2), 144–165. https://doi.org/10.1080/00779954.2018
.1429486
Checco, A。, Bracciale, L。, Loreti, P。, Pinfield, S。, & Bianchi, G.
(2021). AI-assisted peer review. Humanities and Social Sciences
通讯, 8(1), 1–11. https://doi.org/10.1057/s41599
-020-00703-8
陈, C. (2017). Science mapping: a systematic review of the liter-
ature. Journal of Data and Information Science, 2(2), 1–40.
https://doi.org/10.1515/jdis-2017-0006
陈, J。, & 张, C. (2015). Predicting citation counts of papers. 在
2015 IEEE 14th International Conference on Cognitive Informatics
& Cognitive Computing (ICCI&CC) (PP. 434–440). Los Alamitos:
IEEE Press. https://doi.org/10.1109/ICCI-CC.2015.7259421
Fairclough, R。, & Thelwall, 中号. (2022). Questionnaires mentioned in
academic research 1996–2019: Rapid increase but declining
citation impact. Learned Publishing. https://doi.org/10.1002
/leap.1417
Foltýnek, T。, Meuschke, N。, & Gipp, 乙. (2019). Academic plagia-
rism detection: A systematic literature review. ACM Computing
Surveys (CSUR), 52(6), 1–42. https://doi.org/10.1145/3345317
Franceschini, F。, & Maisano, D. (2017). Critical remarks on the Ital-
ian research assessment exercise VQR 2011–2014. 杂志
Informetrics, 11(2), 337–357. https://doi.org/10.1016/j.joi.2017
.02.005
福, L。, & Aliferis, C. (2010). Using content-based and bibliometric
features for machine learning models to predict citation counts in
the biomedical literature. Scientometrics, 85(1), 257–270. https://
doi.org/10.1007/s11192-010-0160-5
Gov.uk. (2021). PS21219 The responsible use of technology-
assisted research assessment. https://www.contractsfinder.service
.gov.uk/Notice/a24d1724-c7cd-48eb-8baf-6ed34c8af428
Haddawy, P。, Hassan, S. U。, Asghar, A。, & Amin, S. (2016). A com-
prehensive examination of the relation of three citation-based
journal metrics to expert judgment of journal quality. 杂志
Informetrics, 10(1), 162–173. https://doi.org/10.1016/j.joi.2015
.12.005
大厅, K. L。, 沃格尔, A. L。, 黄, G. C。, Serrano, K. J。, 米, 乙. L。, ……
Fiore, S. 中号. (2018). The science of team science: A review of the
empirical evidence and research gaps on collaboration in sci-
恩斯. American Psychologist, 73(4), 532. https://doi.org/10
.1037/amp0000319, 考研: 29792466
Heo, G. E., Kang, K. Y。, 歌曲, M。, & 李, J. H. (2017). Analyzing the
field of bioinformatics with the multi-faceted topic modeling
技术. BMC Bioinformatics, 18(7), 45–57. https://doi.org/10
.1186/s12859-017-1640-x, 考研: 28617229
Hinze, S。, 管家, L。, 唐纳, P。, & McAllister, 我. (2019). 不同的
流程, 类似的结果? A comparison of performance assess-
ment in three countries. In Springer handbook of science and
technology indicators (PP. 465–484). 柏林: 施普林格. https://
doi.org/10.1007/978-3-030-02511-3_18
Kim, 是. M。, & Delen, D. (2018). Medical informatics research trend
分析: A text mining approach. Health Informatics Journal, 24(4),
432–452. https://doi.org/10.1177/1460458216678443, 考研:
30376768
Klavans, R。, & Boyack, K. 瓦. (2017). Which type of citation anal-
ysis generates the most accurate taxonomy of scientific and
technical knowledge? Journal of the Association for Information
Science and Technology, 68(4), 984–998. https://doi.org/10.1002
/asi.23734
Klemiński, R。, Kazienko, P。, & Kajdanowicz, 时间. (2021). 在哪里
should I publish? Heterogeneous, networks-based prediction of
paper’s citation success. Journal of Informetrics, 15(3), 101200.
https://doi.org/10.1016/j.joi.2021.101200
Kulczycki, E., Korzeń, M。, & Korytkowski, 磷. (2017). 迈向一个
excellence-based research funding system: 证据来自
波兰. Journal of Informetrics, 11(1), 282–298. https://doi.org
/10.1016/j.joi.2017.01.001
Lei, L。, & 严, S. (2016). Readability and citations in information
科学: Evidence from abstracts and articles of four journals
(2003–2012). Scientometrics, 108(3), 1155–1169. https://doi.org
/10.1007/s11192-016-2036-9
李, S。, 赵, 瓦. X。, Yin, 乙. J。, & Wen, J. 右. (2019). A neural citation
count prediction model based on peer review text. In Proceedings
的 2019 Conference on Empirical Methods in Natural Language
Processing and the 9th International Joint Conference on Natural
语言处理 (EMNLP-IJCNLP) (PP. 4914–4924). https://
doi.org/10.18653/v1/D19-1497
Maier, G. (2006). Impact factors and peer judgment: The case of
regional science journals. Scientometrics, 69(3), 651–667.
https://doi.org/10.1007/s11192-006-0175-0
McCannon, 乙. C. (2019). Readability and research impact. 生态-
nomics Letters, 180, 76–79. https://doi.org/10.1016/j.econlet
.2019.02.017
Mohammadi, E., & Thelwall, 中号. (2013). Assessing non-standard arti-
cle impact using F1000 labels. Scientometrics, 97(2), 383–395.
https://doi.org/10.1007/s11192-013-0993-9
Nie, B., & Sun, S. (2017). Using text mining techniques to identify
research trends: A case study of design research. Applied Sci-
恩塞斯, 7(4), 401. https://doi.org/10.3390/app7040401
Nuijten, 中号. B., & Polanin, J. 右. (2020). “statcheck”: Automatically
detect statistical reporting inconsistencies to increase reproduc-
ibility of meta-analyses. Research Synthesis Methods, 11(5),
574–579. https://doi.org/10.1002/jrsm.1408, 考研:
32275351
Parks, S。, Rodriguez-Rincon, D ., Parkinson, S。, & Manville, C.
(2019). The changing research landscape and reflections on
national research assessment in the future. https://dera.ioe.ac.uk
Quantitative Science Studies
225
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3
The quality of published academic journal articles
/34336/2/ RAND%20summary.pdf. https://doi.org/10.7249
/RR3200
Ruan, X。, 朱, Y。, 李, J。, & Cheng, 是. (2020). Predicting the citation
counts of individual papers via a BP neural network. 杂志
Informetrics, 14(3), 101039. https://doi.org/10.1016/j.joi.2020
.101039
Serenko, A。, & Bontis, 氮. (2021). Global ranking of knowledge
management and intellectual capital academic journals: A 2021
update. Journal of Knowledge Management, 26(1), 126–145.
https://doi.org/10.1108/JKM-11-2020-0814
Serenko, A。, & Dohan, 中号. (2011). Comparing the expert survey and
citation impact journal ranking methods: Example from the field
of artificial intelligence. Journal of Informetrics, 5(4), 629–648.
https://doi.org/10.1016/j.joi.2011.06.002
Sohrabi, B., & Iraj, H. (2017). The effect of keyword repetition in
abstract and keyword frequency per journal in predicting citation
计数. Scientometrics, 110(1), 243–251. https://doi.org/10.1007
/s11192-016-2161-5
Stegehuis, C。, Litvak, N。, & Waltman, L. (2015). Predicting the
long-term citation impact of recent publications. Journal of Infor-
指标, 9(3), 642–657. https://doi.org/10.1016/j.joi.2015.06.005
Su, Z. (2020). Prediction of future citation count with machine
learning and neural network.
在 2020 Asia-Pacific Confer-
ence on Image Processing, Electronics and Computers (IPEC)
(PP. 101–104). Los Alamitos, CA: IEEE Press. https://doi.org/10
.1109/IPEC49694.2020.9114959
Thelwall, 中号. (2002). Conceptualizing documentation on the web:
An evaluation of different heuristic-based models for counting
links between university web sites. Journal of the American Soci-
ety for Information Science and Technology, 53(12), 995–1005.
https://doi.org/10.1002/asi.10135
Thelwall, 中号. (2017). Three practical field normalised alternative
indicator formulae for research evaluation. Journal of Infor-
指标, 11(1), 128–151. https://doi.org/10.1016/j.joi.2016.12
.002
Thelwall, M。, 贝利, C。, 托宾, C。, & Bradshaw, 氮. A. (2019).
Gender differences in research areas, methods and topics: Can
people and thing orientations explain the results? 杂志
Informetrics, 13(1), 149–169. https://doi.org/10.1016/j.joi.2018
.12.002
Thelwall, M。, Papas, 乙. R。, Nyakoojo, Z。, 艾伦, L。, & Weigert, V.
(2020). Automatically detecting open academic review praise
and criticism. Online Information Review, 44(5), 1057–1076.
https://doi.org/10.1108/OIR-11-2019-0347
Thelwall, 中号. & Nevill, 时间. (2021). Is research with qualitative data
more prevalent and impactful now? Interviews, case studies,
focus groups and ethnographies. Library & Information Science
研究, 43(2), 101094. https://doi.org/10.1016/j.lisr.2021
.101094
Traag, V. A。, & Waltman, L. (2019). Systematic analysis of agree-
ment between metrics and peer review in the UK REF. Palgrave
通讯, 5(1), 1–12. https://doi.org/10.1057/s41599
-019-0233-X
王, M。, Jiao, S。, 张, J。, 张, X。, & 朱, 氮. (2020). Identi-
fication high influential articles by considering the topic charac-
teristics of articles. IEEE Access, 8, 107887–107899. https://土井
.org/10.1109/ACCESS.2020.3001190
Wilsdon, J。, 艾伦, L。, Belfiore, E., 坎贝尔, P。, Curry, S。, … Johnson,
乙. (2015A). The metric tide. Report of the independent review of
the role of metrics in research assessment and management.
https://www.hefce.ac.uk/pubs/rereports/ Year/2015/metrictide
/标题,104463,en.html. https://doi.org/10.4135/9781473978782
Wilsdon, J。, 艾伦, L。, Belfiore, E., 坎贝尔, P。, Curry, S。, … Johnson,
乙. (2015乙). The metric tide. Report of the independent review of
the role of metrics in research assessment and management.
Correlation analysis supplement. https://doi.org/10.6084/m9
.figshare.17912009
徐, J。, 李, M。, Jiang, J。, 锗, B., & Cai, 中号. (2019). Early prediction of
scientific impact based on multi-bibliographic features and con-
volutional neural network. IEEE Access, 7, 92248–92258. https://
doi.org/10.1109/ACCESS.2019.2927011
Yuan, S。, 唐, J。, 张, Y。, 王, Y。, & Xiao, 时间. (2018). Modeling
and predicting citation count via recurrent neural network with
long short-term memory. arXiv, arXiv:1811.02129. https://doi.org
/10.48550/arXiv.1811.02129
赵, Q., & 冯, X. (2022). Utilizing citation network structure to
predict paper citation counts: A deep learning approach. 杂志
of Informetrics, 16(1), 101235. https://doi.org/10.1016/j.joi.2021
.101235
朱, X. P。, & Ban, Z. (2018). Citation count prediction based on
academic network features. 在 2018 IEEE 32nd International
Conference on Advanced Information Networking and Applica-
系统蒸发散 (AINA) (PP. 534–541). Los Alamitos, CA: IEEE Press. https://
doi.org/10.1109/AINA.2018.00084
Quantitative Science Studies
226
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
2
0
8
2
0
0
8
4
3
1
q
s
s
_
A
_
0
0
1
8
5
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
9
S
e
p
e
米
乙
e
r
2
0
2
3