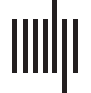RESEARCH ARTICLE
“I updated the ”: The evolution of references
in the English Wikipedia and the implications
for altmetrics
开放访问
杂志
GESIS-Leibniz Institute for the Social Sciences
Olga Zagorova
, Roberto Ulloa
, Katrin Weller
, and Fabian Flöck
关键词: altmetrics, data quality, 数据集, edit histories, Wikipedia editors, Wikipedia references
抽象的
With this work, we present a publicly available data set of the history of all the references
(多于 55 百万) ever used in the English Wikipedia until June 2019. We have applied a
new method for identifying and monitoring references in Wikipedia, so that for each reference
we can provide data about associated actions: creation, modifications, deletions, 和
reinsertions. The high accuracy of this method and the resulting data set was confirmed via a
comprehensive crowdworker labeling campaign. We use the data set to study the temporal
evolution of Wikipedia references as well as users’ editing behavior. We find evidence of a
mostly productive and continuous effort to improve the quality of references: 有一个
persistent increase of reference and document identifiers (DOI, PubMedID, PMC, 国际标准书号, ISSN,
ArXiv ID) and most of the reference curation work is done by registered humans (not bots or
anonymous editors). We conclude that the evolution of Wikipedia references, 包括
dynamics of the community processes that tend to them, should be leveraged in the design of
relevance indexes for altmetrics, and our data set can be pivotal for such an effort.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1.
介绍
The collaborative online encyclopedia Wikipedia incorporates one of the largest reference
repositories in existence. This is primarily due to the guidelines that Wikipedia has put in
place to strongly encourage its users to make all article content verifiable. Enabling verifi-
ability is achieved by providing a pointer to a reliable source that supports the statements or
facts presented in the article text1. These pointers are added in the form of in-text citations
that lead to reference lists. 因此, many Wikipedia articles include reference lists created and
maintained by the community of users who are also collaboratively writing the Wikipedia
文章. Every Wikipedia article text, its cited references, and reference lists are dynamic and
can be modified or removed by users, with all changes being tracked in the article’s revision
历史. Over the course of time, the revision history of the entire English Wikipedia has
documented more than 55 million different sources2. Cited sources can be different types of
出版物, 包括, 例如, formally published scientific papers, 图书, and news
media articles, but also links to websites or any other type of web documents (Lewoniewski,
Węcel, & Abramowicz, 2017).
1 https://en.wikipedia.org/wiki/ Wikipedia:Verifiability
2 This comprises all references ever generated, but not necessarily still present, as of June 2019; see details
about the data set in Section 5 and Zagovora, Ulloa et al. (2020).
引文: Zagorova, 奥。, Ulloa, R。, Weller,
K., & Flöck, F. (2022). “I updated the
”: The evolution of references in
the English Wikipedia and the
implications for altmetrics. Quantitative
Science Studies, 3(1), 147–173. https://
doi.org/10.1162/qss_a_00171
DOI:
https://doi.org/10.1162/qss_a_00171
Peer Review:
https://publons.com/publon/10.1162
/qss_a_00171
支持信息:
https://doi.org/10.1162/qss_a_00171
已收到: 13 十月 2020
公认: 26 十月 2021
通讯作者:
Olga Zagorova
olga.zagovora@gesis.org
处理编辑器:
Ludo Waltman
版权: © 2021 Olga Zagorova,
Roberto Ulloa, Katrin Weller, 和
Fabian Flöck. Published under a
Creative Commons Attribution 4.0
国际的 (抄送 4.0) 执照.
麻省理工学院出版社
“I updated the ”
These references are exposed to an enormous readership, as Wikipedia is accessed by a
wide audience around the world. With more than 250 million page views per day for the
English Wikipedia alone 3, it is one of the top 15 most visited websites in the world4. 尽管
recent studies seem to indicate that a large number of users do not fully engage with references
by visiting links or retrieving the referenced document otherwise (Piccardi, Redi et al., 2020),
references still make statements more credible simply by appearing alongside them; 和他们
are actively being interacted with more than 32 million times a month (measured by mouse-
hovering over the reference footnote [Piccardi et al., 2020]). 此外, Wikipedia content,
including its references, is incorporated into other data sources and projects, and thus reaches
even wider audiences. 例如, Wikipedia content is used as a source for the collabora-
tive knowledge base WikiData5, which is again also used by other platforms. Scholia6, 为了
实例, creates scholarly profile pages based on WikiData.
Given its appeal to the general public, Wikipedia has also attracted a lot of attention in the
scientific community, where it has become a subject of research itself. The research about
Wikipedia includes, 除其他外, the examination of recommendations and pitfalls when
it comes to the analyses of its content (Bayliss, 2013; Denning, Horning et al., 2005; Eijkman,
2010; Luyt & Tan, 2010), studies that evaluate the accuracy of articles (Holman Rector, 2008)
and of references (Bould, Hladkowicz et al., 2014), as well as efforts to attribute ownership of
content to editors, such as WikiWho7 (Flöck & Acosta, 2014).
Wikipedia has also become an object of interest in the field of altmetrics, an area of
research dedicated to studying ways of measuring the impact of scientific work outside of tra-
ditional scholarly citation schemes, and often based on social media interactions (Kousha &
Thelwall, 2017; Priem, Taraborelli et al., 2010). Altmetrics research is looking into different
ways in which users of online platforms may interact with scientific publications (例如, 包括-
ing the link to a publication in a tweet or saving a reference on a bookmarking platform), 作为
these kinds of actions might indicate which publications have some sort of impact in a specific
user community. The term altmetrics may also refer to a line of practical applications and tools
that assign new types of indicators to rate publications’ performance or impact by the interac-
tions they receive through social media or other online platforms, typically based on the quan-
tity of mentions of a publication.
Wikipedia data is considered in altmetrics data implementations (and sold) by aggregators
in the field. Currently the most prominent are Altmetric.com8, PlumX9, CrossRef10, 和
Lagotto11. Their indicators are applied in different settings, such as publishers’ sites or repos-
itories (例如, institutional or discipline-specific publication databases), and they are used to
advertise “impactful” publications (based on quantitative measures from user interactions).
The metrics behind these indicators vary substantially between different aggregators. 那里
是, 例如, no standard for detecting or aggregating Wikipedia references, 虽然它
can be assumed that the use of document identifiers (DIDs), such as PubMed Identifiers
3 https://tools.wmflabs.org/siteviews/?sites=en.wikipedia.org, as of March 10, 2021.
4 https://www.alexa.com/topsites, as of February, 15 2020.
5 https://www.wikidata.org/
6 https://tools.wmflabs.org/scholia/
7 https://www.wikiwho.net/
8 https://www.altmetric.com/explorer/
9 https://plumanalytics.com
10 https://www.crossref.org/
11 https://www.lagotto.io/docs/api/
Quantitative Science Studies
148
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
(PMIDs) or Document Object Identifiers (DOIs), is a common practice among aggregators12
(Haustein, 2016). The specific procedures are not transparent and altmetrics aggregators must
be viewed as black boxes that could be subject to manipulations (Kousha & Thelwall, 2017),
such as researchers adding references to their own publications into Wikipedia articles13, 或者
even strategic campaigns to insert publications from a specific publisher into Wikipedia
articles14.
In the broad context of altmetrics research and applications, the assumed unique value of
Wikipedia as a data source is that it provides an immense repository of literature curated by a
large editor community and likely legitimated as important sources by these “Wikipedians.”
With the self-control mechanisms and guidelines applied within this community, 维基百科
references are expected to meet basic quality standards (Lewoniewski, Węcel, & Abramowicz,
2020). 至少, they are presumed to be topically relevant and ideally, they represent
a comprehensive, up-to-date, and balanced collection of the most relevant sources. Given the
dynamic nature of Wikipedia, it might also be possible to opportunely detect novel and trend-
ing publications through the additions and changes to the community-created repository of
参考. 全面的, A (scientific) publication being cited in a Wikipedia article is considered
an indicator of some form of impact for this publication (Kousha & Thelwall, 2017).
然而, despite the academic interest in Wikipedia references and their practical imple-
mentation in some altmetrics indicators, relatively little is known about the origins of Wikipe-
dia references and about their creators. With this paper, we want to illustrate that a better
understanding about the nature of Wikipedia references can help to clarify their role as poten-
tial indicators for the general public’s view of important sources. 为了这, it needs to be
acknowledged that the dynamic nature of Wikipedia and the ability of users to perform and
undo changes highly shapes Wikipedia’s content and references, leading to various practical
challenges in working with Wikipedia data and technical challenges in identifying and track-
ing references.
To illustrate some of the challenges in incorporating Wikipedia references into reliable alt-
metrics indicators, we will take a closer look at a particular example publication and how it is
cited across articles in the English Wikipedia (as identified by our extraction method and data
set that we will introduce below). Our example is based on several “Wikipedia references”15
across different Wikipedia article pages pointing to (and thus citing) the publication “Roy et al.
12 例如, Altmetric.com is collecting data using the following identifiers https:// help.altmetric.com
/support/solutions/articles/6000234171-how-outputs-are-tracked-and-measured, and CrossRef’s collection
uses DOI and landing page URLs https://www.crossref.org/services/event-data/.
13 Wikipedia’s guidelines about Conflict of Interest include a section on “Citing yourself,” which allows self-
citations within certain boundaries: see https://en.wikipedia.org/wiki/ Wikipedia:Conflict_of_interest. 至
据我们所知, there are no studies that investigate in detail how common self-citations are in Wiki-
pedia or that aim to identify misconduct in the area of self-promoting scientific articles through Wikipedia.
14 One example can be found at: https://web.archive.org/web/20200323131800/https://annualreviewsnews
.org/2020/02/25/seeking-a-wikipedian-in-residence/.
15 Wikipedia’s terminology related to references is not always consistent with the distinct definitions of citations
and references existing in the field of information science. In the context of this paper, a “reference” is tech-
nically defined as the content included inside a Wikipedia tag, which is content pointing to some
external sources (and thus conceptually citing them). This means that in the example, the Roy et al.
(2001) publication is receiving citations from different Wikipedia article pages, as these pages have incor-
porated the respective pointers to the paper in tags (IE。, as Wikipedia references). We will use the term
references thus in the remainder of this paper. See Section 3 for technical details on capturing Wikipedia
references via tags.
Quantitative Science Studies
149
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
(2001) Structure and function of south-east Australian estuaries. Estuarine, Coastal and Shelf
科学 53(3): 351–384.” The first reference citing this publication was added to a Wikipedia
article in August 2012 (数字 1, 蓝线), 多于 10 years after the paper’s release. Nine
months later ( 六月 1, 2013), there were already 53 articles that cited this publication. 所有的
these articles received the reference to this publication from the same editor (Editor A). 如何-
曾经, none of the references included the publication’s existing DOI. The corresponding DOI
to this publication was added to the different existing Wikipedia references during the first
quarter of 2014 (数字 1, orange line), and this was mostly done by one single editor in March
2014 (Editor C). 十一月 2018, another editor (Editor D) 已删除 27 instances (50%) 的
the references, although some of them were quickly reinstated (数字 1, 蓝线).
This basic example illustrates several issues that motivated our work and that are largely
overlooked, despite the widespread popularity and importance of Wikipedia in general and
the use of Wikipedia data in the altmetrics field (mainly via altmetrics aggregators) as outlined
多于. 第一的, the example highlights a weakness of mining Wikipedia references based only on
document identifiers (orange line), which potentially misses numerous references, that led us
to create an alternative method that uses the entire text of the reference (蓝线); DOI-based
approaches would miss the reference for the first 2 years of its existence. 第二, it shows the
impact that a single editor can have on the visibility of a reference by systematically adding or
removing it from different articles—which at least challenges the concept of viewing publica-
tions that receive high numbers of citations from Wikipedia as being recommended by a com-
munity of users. 第三, it exposes the general lack of understanding about Wikipedia editors as
the creators and curators of Wikipedia and their impact of references being implemented.
第四, it illustrates different editing activities (creation, modification, deletion, reinsertion) 那
affect the countable numbers of references, making Wikipedia a somewhat dynamic data
source for altmetrics.
同时, the example captures the value of our investigation as an important step
to close the gap in understanding the nature and quality of Wikipedia references in altmetrics.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1. Wikipedia references in the English Wikipedia pointing to one example paper, as identified by our approach (蓝线) 并由
approaches based only on document identifiers (orange line). Areas highlighted by circles correspond to edits made by one specific Wikipedia
用户: The green circle indicates an editor adding instances of the reference without any document identifier, the pink circle indicates an editor
who modified existing references (例如, by adding a DOI), violet indicates editors who create new references with DOI identifiers and red
indicates editors who deleted references from articles.
Quantitative Science Studies
150
“I updated the ”
It suggests that anomalies in the activity around Wikipedia references can be disclosed by
tracking their origin and evolution within the articles, and that many of the collaborative nego-
tiation processes that govern the inclusion, modification, and deletion of references can reveal
information about the editor community responsible for the maintenance of this asset.
With this in mind, we present a novel data set (Zagovora et al., 2020) that contains indi-
vidual revision histories of all Wikipedia references ever created in the English Wikipedia until
六月 2019. The data set is created by leveraging WikiWho (Flöck & Acosta, 2014), a service
that tracks the additions, 变化, and reinsertions of words (代币) written in Wikipedia. 我们的
评估 (with crowdworkers) demonstrates its high accuracy at tracking references. To show
the value of the data set, we investigate research questions in the following specific areas:
1.
Insights into reference evolution over time. The ongoing transformation and expansion of
Wikipedia content affects the potential (测量的) impact of cited sources by dynamically
increasing or decreasing the number of reference instances that point to them. 所以,
Wikipedia presents a scenario that is different from other settings in citation analysis in alt-
指标. Although the altmetrics field often deals with fluid types of data sources, 像他们
include dynamic material16 such as tweets or Facebook posts that might be deleted or mod-
ified, Wikipedia is unique as it relies on consensuses between members that can take time
to reach an equilibrium, and which might be perturbed again as new information becomes
可用的. References may be added by one person, removed by another, and then rein-
serted or edited again. These processes can repeat indefinitely, and little is known about
how this has affected Wikipedia’s references in the past and how many editing activities
are performed on references overall. This leads to our first two research questions:
(西德:129) (RQ1) How do Wikipedia references evolve over time? We examine the fluctuation
of all references of Wikipedia by analyzing the number of actions performed on
他们, providing the first longitudinal study of the evolution of references across all
revisions in the English Wikipedia.
(西德:129) (RQ2) What is the current and past coverage of references that include document
identifiers (DIDs)? For practical reasons, altmetrics indicators typically use DIDs
for the detection of publications and references that lack DIDs are simply missed
by methods that rely solely on them. We will tackle this question by estimating, 在
different points in time, the proportion of references that include DIDs, 并由
using current knowledge from our 2019 data set to calculate which references
lacked DIDs in the past.
2.
Insights about the editors of Wikipedia references. We are interested in getting a better
understanding of who adds, modifies, or deletes Wikipedia references. Learning more
about the people who produce social media contents is just in its beginnings (Holmberg,
2015; Imran, Akhtar et al., 2018). 我们, therefore set out to answer the following:
(西德:129) (RQ3) Who creates and maintains Wikipedia references, and in which way? 这
question pertains to the characterization of the Wikipedia editor base engaging in
different reference-related activities (例如, automated bots or occasional users), 和
16 Although social media content containing altmetrics indicators (例如, Facebook posts) is deleted to some
extent after the initial altmetrics detection, we are not aware of aggregators’ metrics that take these deletions
into account. 据我们所知, most aggregators are removing only deleted Tweets as per terms
of Twitter data usage.
Quantitative Science Studies
151
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
to the discovery of patterns of interaction with references exhibited by editors
(例如, focusing on reference maintenance). This more fine-grained picture of pos-
sible roles of editors in the reference ecosystem can help to understand the editor
community that is responsible for the activity around the Wikipedia references.
The rest of this paper is organized as follows: 部分 2 will offer an overview of the related
work relevant for Wikipedia references and altmetrics, 部分 3 is dedicated to the description
of methods to build the data set, 部分 4 presents an evaluation of our methods and the
quality of the data set we provide, 部分 5 presents general statistics of the Wikipedia refer-
ences and main findings regarding our research questions, and Sections 6 和 7 conclude and
summarize our findings.
2. RELATED WORK
The most comparable data set to the one we provide is presented by Halfaker, Mansurov et al.
(2019) and Redi and Taraborelli (2018), which also includes a form of historical data about
references in Wikipedia. 然而, the work differs from our approach because it relies on the
presence of standardized DIDs as part of the reference—whereas our method does not—and
thus is not capturing all references and is assigning editors and timestamps of origin to refer-
ences according to the Wikipedia revision in which the identifier was included, even if in fact
the reference as such was created earlier (比照. 数字 1). 最后, modifications and deletions
done to the references after the inclusion of the identifiers were not tracked. While the data
set has been publicly shared with the community and was used (例如, to study topics of cita-
系统蒸发散), to the best of our knowledge it was not used to study the evolution of references or
editing behavior related to references.
Other works only provide static (nonhistorical) snapshots of references in Wikipedia lan-
guage editions, such as Nielsen (2008)17 or Singh, 西方, and Colavizza (2021), that were created
for specific tasks. Nielsen (2008) used the “cite journal” template from references to create a data
set of journal papers that were cited in Wikipedia pages. This data set was then used to cluster
Wikipedia pages and corresponding scientific journals into distinct research topics. Singh et al.
(2021) created a data set of references and classified them into three groups: journal articles,
图书, and other Web content.
最近, research has started to look more closely at how Wikipedia readers interact with
参考. With Wikipedia references being actionable items that users can click on, 他们
have been described as a “bridge to the next layer of academic resources” (Grathwohl,
2011). 然而, recent studies (Piccardi et al., 2020; Redi, 2018) show that not all references
are being equally visited by Wikipedia readers. Piccardi et al. (2020) conclude that, regarding
参考, “readers are more likely to use Wikipedia as a gateway on topics where Wikipedia
is still wanting and where articles are of low quality and not sufficiently informative.” They
found that in most cases where Wikipedia articles are of high quality, readers do not follow
the references but stay at the Wikipedia article as the “final destination” of their information
journey (Piccardi et al., 2020). This kind of work gives us more insights into the consumer
perspective of Wikipedia references, which adds to the general perspective of how Wikipedia
is used (例如, how Wikipedia articles are read or how people are citing from Wikipedia articles:
Bould et al., 2014; Okoli, Mehdi et al., 2014).
17 The data set is available via https:// hendrix.imm.dtu.dk/services/wikipedia/citejournalminer.html.
Quantitative Science Studies
152
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
据我们所知, there are only a few studies focusing on editors as the cre-
ators of references in Wikipedia and thus contributing to the producer perspective. 与一个
comparatively small data sample (∼5,000 articles), Chen and Roth (2012) showed that “a ref-
erence occurs when a set of committed and qualified editors are attracted to the article.”
Huvila (2010) conducted a survey of Wikipedia editors, also including questions broadly
related to reference editing. 具体来说, the survey enabled them to differentiate editors based
on their information behavior and the sources the editors were using for editing articles. 这
results indicate a preference for sources that are available online. Kaffee and Elsahar (2021)
extended the previous study by surveying editors about tools they use to create articles and to
add corresponding references. There is also some specific, ongoing research on other and
more general perspectives on the producer side of Wikipedia (例如, on who edits Wikipedia),
general editing patterns (Flöck, Erdogan, & Acosta, 2017), who becomes a power editor
(Panciera, Halfaker, & Terveen, 2009), or how editors collaborate (Kittur, Suh et al., 2007;
Murić, Abeliuk et al., 2019).
此外, in the field of altmetrics research, a certain focus has been placed on untan-
gling the relations between references in Wikipedia and the scientific publications they are
citing. 例如, altmetrics researchers have scrutinized the relevance of scientific publi-
cations mentioned on Wikipedia (Kousha & Thelwall, 2017; Sugimoto, Work et al., 2017).
Shuai, Jiang et al. (2013) found that papers, authors, and topics that were covered by Wikipe-
dia references have higher citation counts than those that were not mentioned. At the same
时间, only a narrow set of influential scientific works is cited on Wikipedia (Kousha &
Thelwall, 2017). Nielsen (2007) showed that citations from Wikipedia are correlated with
the total number of journal citations, whereas the correlation was weak with the journal
impact factor. 然而, according to Nielsen (2007), Wikipedia editors tend to cite articles from
high-impact journals such as Nature, 科学, or New England Journal of Medicine. Teplitskiy,
鲁, and Duede (2017) conducted a similar experiment with a newer data set and found that
impact factor increases not only the probability of a paper being mentioned on Wikipedia but
also open access principles. According to Mesgari, Okoli et al. (2015), the quality of content
and of referenced sources was one of the major study objects on Wikipedia. 例如,
Lewoniewski et al. (2017) studied the similarity of sources from different Wikipedia language
editions. They found that URLs in references shared many domain names between language
versions, but there were not many cases of exact matches of URLs in references across languages.
Lin and Fenner (2014) showed that ecology and evolution are better covered with references
from PLOS than other subjects. 尽管如此, these results might not show the full picture
when references are reported as incomplete and accompanied by the lack of standardization
(Pooladian & Borrego, 2017).
The altmetrics community has investigated whether a citation in Wikipedia articles indi-
cates that a scientific publication has an impact on the nonscientific audience (林 & Fenner,
2013; Thelwall, 2016). Lin and Fenner (2013) argue that Wikipedia references might capture a
“discussion” group, one of the engagement types with research publications. Our data set can
enable a finer analysis of the revisions of references that can help to detect potential disrup-
系统蒸发散 (例如, sudden appearance of the same reference across various articles, or highly active
individual editors who are responsible for large numbers of new references).
Zahedi and Costas (2018) and Ortega (2018) have started to compare different altmetrics
aggregators to illustrate potential challenges for data quality. Differences start with coverage by
聚合器. In the context of Wikipedia, this means that references appearing on Wikipedia
make up from 2% of publications tracked by Altmetric.com up to 5.1% of those tracked by
Lagotto. Those differences are due to the aggregator’s methodology and the data sets of
Quantitative Science Studies
153
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
publications they are tracking (Zahedi & Costas, 2018). These studies also observe different
mean values for how often publications are mentioned on Wikipedia: Publications in the
Altmetric.com collection are on average cited by 1.7 Wikipedia pages, publications in the
Lagotto collection are on average cited by 2.9 Wikipedia pages, and publications in CrossRef
Event Data are on average cited by 15.7 Wikipedia pages (Zahedi & Costas, 2018). We assume
that these wide differences are not only due to the diverse sets of publications covered by the
aggregators but also due to their distinct methods of tracing Wikipedia references, 哪个是
prone to various errors considering the challenges inherent to Wikipedia data. Besides the
difficulties of keeping track of continuous changes in Wikipedia where references may be
modified or removed, one important source of coverage errors (Sen, Flöck et al., 2021) 是
the reliance on standard document identifiers to trace publications (Ortega, 2018). 相似地,
other approaches that rely on explicit bibliographic information, such as title and first author
姓名 (Kousha & Thelwall, 2017) fail to identify references that do not specify this information
in the provided fields (Pooladian & Borrego, 2017). Given the quality of our data set, it has the
potential to serve as an external base for comparing different data collection approaches used
by altmetrics aggregators, giving them the opportunity to increase their coverage and impact
indexes by looking at different points in time of the revision history.
3. CREATING THE REFERENCE HISTORIES DATA SET
在这个部分, we describe the central concepts and methodological details of the text mining
过程, extended by further information in Appendix A in the Supplementary material.
The resulting data set18 is based on all revisions of all articles in the English Wikipedia edi-
tion since their origin until June 2019. It contains the change history of all 55,503,998 印迪-
vidual references ever created until this point in time, no matter if they contain a document
identifier such as a DOI, 国际标准书号, ETC. 或不. References are pointers to external sources (哪个
may be any type of document) and are inserted into Wikipedia in a standardized way. 他们
appear as “inline citations”19 in the main body of the article, immediately after the statements
they support, and are formatted by …… tags in Wiki markup language. For our
work we consider all such inline citations marked by ref tags as Wikipedia references20.
In the following subsections, we explain our reference tracing and matching approach and
how we extract document identifiers (DIDs) for those references that are assigned one at any
point in time.
3.1. Extracting the Revision History of Individual References
The main content corpus of the Wikipedia encyclopedia is organized in articles. Each article A
consists of an ordered list of revisions R (IE。, A = [R0, ……, Rn]), where each revision is a new
version of the text that was contributed by editor e at timestamp z. For the front-end HTML
18 We also provide a Python notebook with examples on how to process the data, and the code can be directly
executed on the GESIS Notebooks server. More details on the data format are in Zagovora et al. (2020).
19 The Wikipedia community utilizes the term inline citation, which broadly speaking corresponds to the “in-
text citation” as known from bibliometrics. See more details here https://en.wikipedia.org/wiki/ Wikipedia:
Inline_citation.
20 此外, some references can be added automatically by dedicated templates. We are not considering
materials that are not referenced as inline citations (例如, publications from the “Additional reading” section),
as the guidelines recommend to include references via tags (inline citations) as the standard (https://在
.wikipedia.org/wiki/ Wikipedia:Citing_sources).
Quantitative Science Studies
154
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
桌子 1.
参考, and the second column the description of such an action
Type of actions that can be applied to a reference. The first column indicates the name of the actions that can be applied to
行动
Creation (*)
Modification
Deletion
Reinsertion
* Note that only one creation per reference is possible.
描述
First time the reference appears in an article
Changes to tokens of the reference (例如, by correcting the name of an author)
Complete removal of the reference
Complete addition of a reference that was previously removed
表示, text inside the …… tags is converted by a Wikitext parser into a
readable reference, placed at the bottom of the Wikipedia article in a dedicated reference
部分.
The revision history of a reference is given by the article revisions in which it was added
and changed, either in its entirety or partially. As each revision within an article is associated
with exactly one editor e (参见章节 5.2 for a typology of editors), so is each action (看
桌子 1) performed on a specific reference through that revision.
Identifying the specific revisions in which the changes of Table 1 are applied to a given
uniquely identified reference in Wikipedia presents two major challenges:
1. Tracking changes of any target text sequence is often error prone in Wikipedia (Flöck &
Acosta, 2014). In these instances, standard text difference algorithms lose track of
sequences and erroneously assign them as new content or as deleted21.
2. Even if all changes to a reference are correctly tracked, deciding if a reference corre-
sponds to another reference in two consecutive article revisions is nontrivial. 考试用-
普莱, a large part of the reference might have been replaced or key tokens such as the
title might have been modified.
To address these issues, we take advantage of WikiWho, an algorithmic approach that
solves the change attribution problem at a token level with over 95% 准确性 (Flöck &
Acosta, 2014). Each token ever inserted in an article has been assigned a token ID that
uniquely identifies it through all revisions. 数字 2 illustrates the allocation of token IDs for
the two first revisions of a reference.
Our data set of references is organized per Wikipedia article, and we do not—for this
work—match references across articles. 正式地, for each article A, the data set contains a
list of tuples Hf = [
of actions afi (“creation,” “insertion,” “deletion,” or “reinsertion”) performed over reference f,
在哪里:
>, ……,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Examples of token ID assignments before and after an edit. 例子 (A): For Revision 1, we assume the reference to be already
数字 2.
existing and having been assigned token IDs 1–7. In Revision 2, “Benjamin” (蓝色的) is inserted and WikiWho assigns token ID 8. Note how the
older instance of “Benjamin” (ID 6) is tracked as a distinct token. 例子 (乙): In Revision 2, “Charles” and “by means of …” (蓝色的) are inserted
and new token IDs (8–24) are assigned. Another reference “Crawford (1859) …” is added in Revision 2 with the tokens identified as new.22
To build this data set, we mine all inline citations of all Wikipedia revisions using the Wiki-
Who token IDs that correspond to the string tags …… 和 ……
; the void tags (IE。, the one-sided tags ) are excluded because they
correspond to duplications of existent references. For each revision Ri in each article A, 我们
then have a list of references that belong to that revision Gi = [f0, ……, fm], where each reference
fj is a tuple
The next step is to associate the references in Gi to those in Gi+k, so that two references are
added to Hf if they are equivalent (IE。, they refer to the same publication).
In trivial cases, a reference f does not change between article revisions so we use the hash
values to match all identical references across all G, and we store the matched references of f
in Hf. 目前, each Hf is incomplete, as there could be two reference histories Hf and Hg that
belong together, because with this procedure, even a small modification is enough to change
the hash value. 所以, all actions af are tagged as “unknown.”
In the nontrivial cases, the references have been modified between two consecutive revi-
西翁. We then rely on the Jaccard similarity between the lists of WikiWho token IDs of the
参考. The core idea is that a reference f 0 is considered the successor of the reference f if
the Jaccard similarity between f 0 and f is higher than 0.2 (see the evaluation in Section 4), or if
the token IDS of f are all contained in f 0 (IE。, tf ⊂ tf 0); F 0 is not already the successor of another
reference; and the revision rf 0 happened after the revision rf (IE。, zf 0 > zf ). 还, if f 0 is a suc-
cessor of f, then the action is considered a modification if the revision rf 0 发生了
22 These toy examples do not track punctuation for simplicity, while WikiWho does so in practice.
Quantitative Science Studies
156
“I updated the ”
immediately after the revision rf (IE。, there is no revision between rf and rf 0). 否则, a dele-
tion occurred in revision rf and a reinsertion in rf 0. The exact details of the procedure applied to
each reference f is presented in Figure A1 of Appendix A in the Supplementary material.
3.2. Tracking of DID References
The content of a reference may include different types of document identifiers (DID) 具有
been assigned to the referenced source during its publication process (例如, a Digital Object
Identifier: DOI). DIDs can easily be used to trace individual references unambiguously, 两个都
within Wikipedia and outside of it. While with our approach and data set we extract and mon-
itor all references in a Wikipedia article, we take a closer look at the subset of references con-
taining DIDs for two reasons: 第一的, this enables comparisons with previous works, which have
relied exclusively on document identifiers to extract references for Wikipedia articles. 第二,
Wikipedia includes references to publications that range from strictly refereed and well-
reputed scientific outlets to everyday blogs, Twitter profiles, and Reddit posts, and we aim
to utilize DIDs to put one focus of our investigation on such publications relevant to altmetrics
and the academic community and compare them to the complete set of references. 虽然
DIDs can be an indicator that a reference is academic23, we are mindful that references with
DIDs are not necessarily academic works. 然而, they provide a viable filter to concentrate on
references relevant in the context of this work.
所以, an important aspect of the evolution of Wikipedia references is the point in time
at which DIDs are added to references in the version history. A reference that currently has a
DID could have been missing it in the past. By using the present information and by looking
back into the past, we can estimate how many references were lacking DIDs, and thus would
have been omitted by approaches that rely solely on the presence of DIDs for identifying and
counting Wikipedia references.
We distinguish between several types of references based on DID information (桌子 2).
The term DID-Reference (DID-R) corresponds to references that by the time of our data col-
lection ( 六月 2019) had a DID. If the DID was immediately included when the reference was
已创建, we refer to it as DID-Born Reference (DBorn). 否则, if the DID was added after
the reference was created—usually because the referenced work had been assigned a DID at a
later point in time or it was erroneously omitted upon reference creation—we call it DID-
Lagged Reference (DLag). Their counterparts (IE。, references that by the data collection date
did not have a DID) are called No-DID References. Note that this classification depends on the
time of data collection, as some of the DID-Lagged References would have been classified as
No-DID References in previous years and current No-DID References may still receive a DID
at a future point in time.
After we trace the history of all references for each Wikipedia article as explained in the pre-
vious subsection, we proceed to extract the DIDs for all the versions of each reference. We used
modified versions of regular expressions based on Halfaker et al. (2019) to extract the following
DIDs: Digital Object Identifier (DOI), International Standard Book Number (国际标准书号), 考研
Identifier (PMID), PubMed Central identifier (PMCID), International Standard Serial Number
(ISSN) and arxiv.org Identifiers (ArXiv ID). Once we extract the DIDs (see Figure D2 in
Appendix D of the Supplementary material for distributions), we can retroactively recognize
the DLag references and their content (tfi
), as our data set already contains historical information
23 We use the term academic instead of scientific to indicate the inclusion of all works not only from “harder”
sciences but also from social sciences and humanities. This is in line with Halfaker et al. (2019).
Quantitative Science Studies
157
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
Types of references according to if and when a DID was added. The first and second columns indicate the names that we use to
桌子 2.
identify the type and subtype of reference respectively. The third column describes the subtype of references based on when the DID was
added
Type
DID Reference
(DID-R)
Subtype
DID-Born Reference
(DBorn)
References that already included a DID when they were created.
描述
DID-Lagged Reference
(DLag)
References that did not include a DID when they were created, but were
assigned a DID at a later point, before the time of our data collection.
No-DID Reference
(No-DID)
References that did not include a DID by the time of data collection. 这些
might receive a DID later (after our data collection) if a DID in fact exists
for the referenced publication.
for each reference (Hf). Our method properly handles cases in which a reference has two iden-
tifiers (例如, correction of a DID, or one DOI and one ISBN). We keep the timestamp (zfi
) 和
编辑 (efi
) that introduced or modified the DID, so that we can further analyze the dynamics
of creation and addition of the DIDs.
4. EVALUATION OF THE REFERENCE CHANGE TRACKING METHOD
在这个部分, we evaluate the performance of our method for tracking version histories for
参考. We describe a gold standard data set that we created for evaluation purposes using
crowdworkers, present the overall performance, and compare our method to a baseline relying
on cosine similarity.
4.1. Gold Standard Data Set
To make sure that our method correctly identifies references in different forms across histories,
we created a gold standard data set of 952 pairs of references, in which each pair looks similar
to the example in Figure 2(A). The pairs are labeled as Equivalent or Distinct, 根据
whether each pair corresponds to the same bibliographical resource or not. Each pair of refer-
ences was judged by at least three FigureEight24 crowdworkers. Each worker indicated if the pair
corresponds to the same resource or different resources, or if it was not clear. See Appendix B in
the Supplementary material for the instructions we provided for FigureEight crowdworkers, 一个
example question, and a note on fair payment (Zaldivar, Tomlinson et al., 2018).
If the agreement25 between the workers fell below the limit of 0.7, additional crowdworkers
were assigned to the task until the agreement reached the required limit (0.7), or until at least
five individuals had made judgments. Prior to the task, each worker was trained with a selec-
tion taken from 115 examples that illustrated different cases, and they had to correctly label at
least five out of six test pairs of references. All the answers from a given worker were discarded
(and a new worker assigned) if their accuracy fell below 0.8. Training and test items have been
prelabeled by the authors of this paper.
24 https://www.figure-eight.com (formerly known as Dolores Labs, CrowdFlower) was acquired and renamed
by Appen as of April 8, 2020.
25 We adopted the “confidence score of the row” of the FigureEight platform. This value describes the level of
agreement between multiple contributors, where the sum of the contributors’ trust scores of the most com-
mon answer is divided by the sum of the trust scores of respondents to that question. See details here: https://
success.appen.com/hc/en-us/articles/201855939-How-to-Calculate-a-Confidence-Score.
Quantitative Science Studies
158
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
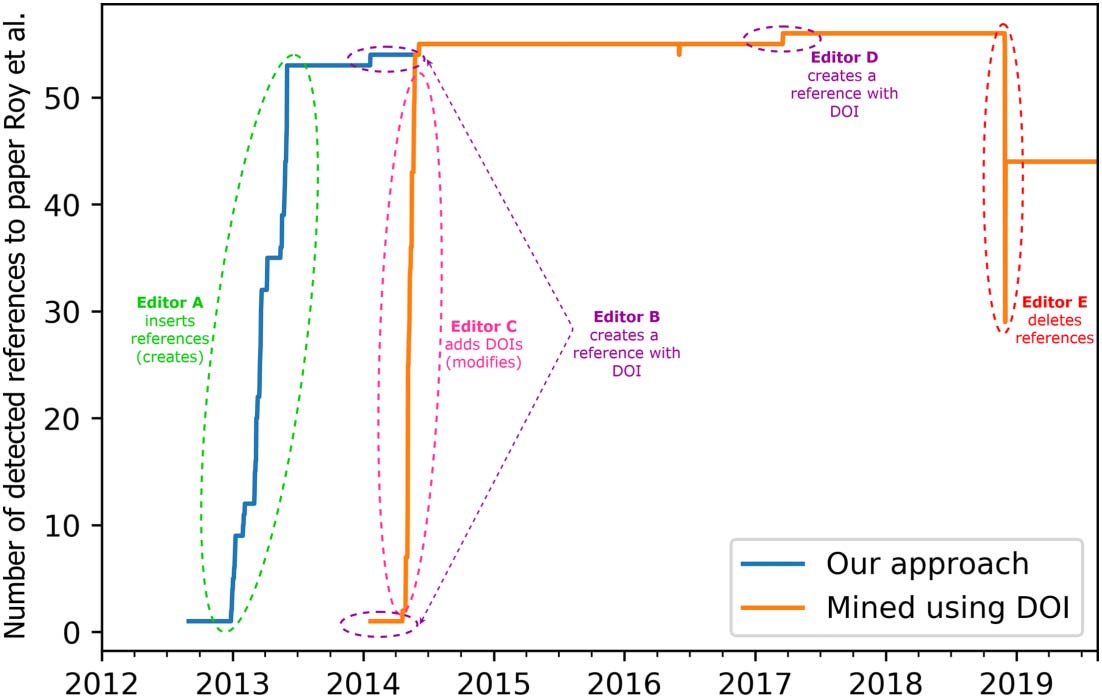
数字 3. Performance metrics for identifying equivalent references. The x-axis shows the threshold of Jaccard similarity between pairs and
the y-axis shows the Precision (Blue), Recall (Orange), Accuracy (绿色的), and F1 (Red) scores.
One thousand items were presented to the workers, out of which 952 were labeled as either
Equivalent or Distinct. No final annotation was reached for 48 pairs of references (IE。, 五
assigned workers did not agree above the 0.7 limit26).
The set of 1,000 items was taken using a stratified random sample from all the references in
Wikipedia revisions (Appendix C in the Supplementary material). The set consists of eight strata
with similarities from 0 到 1 和 0.125 脚步, 和 125 pairs of references per stratum. 所以,
we make sure that our sample covers the full range of the Jaccard similarity scores used in our
方法, as with a pure random sampling most pairs of references would have fallen into the
extreme values of similarity (IE。, 0 或者 1) and would have constituted mostly trivial examples.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
4.2. Performance
We compared the 952 pairs of references labeled by the crowdworkers against the labels
assigned using our method. 数字 3 illustrates the performance metrics for different Jaccard
similarity thresholds in our method. Based on this data, we selected a threshold of 0.2 作为一个
trade-off between precision and recall.
To find the overall performance metrics for our method we resampled our stratified
sample so that it is representative of the original distribution of Jaccard similarities (calculated
与一个 100,000 sample) of pairs of references extracted in the same fashion as described in
部分 3.1. 桌子 3 presents the micro-average performance metrics for the identification of
the same and different references between revisions.
Upon labeling the 48 cases—in which the crowdworkers could not agree—ourselves, 我们
found that in 30 cases our method was able to decide appropriately based on the contextual
information that is encoded in the WikiWho data model. 全面的, our method maps identical
references between revisions with very high confidence.
26 One of the researchers closely inspected these cases and confirmed that the low agreement score stemmed
from the ambiguity of the items. The inspection was done using contextual information from the text sur-
rounding the references in previous revisions, testing URLs, and external resources (例如, search engines,
archive.org).
Quantitative Science Studies
159
“I updated the ”
桌子 3. Micro-average performance metrics for the labeling of pairs of references. The three metrics are calculated so that they represent the
original distribution of Jaccard similarities in the method by resampling from the stratified sample. Each evaluated pair of references contributes
equally to the score (regardless of the strata they belong to)
Precision
0.96
Recall
0.96
F1 score
0.96
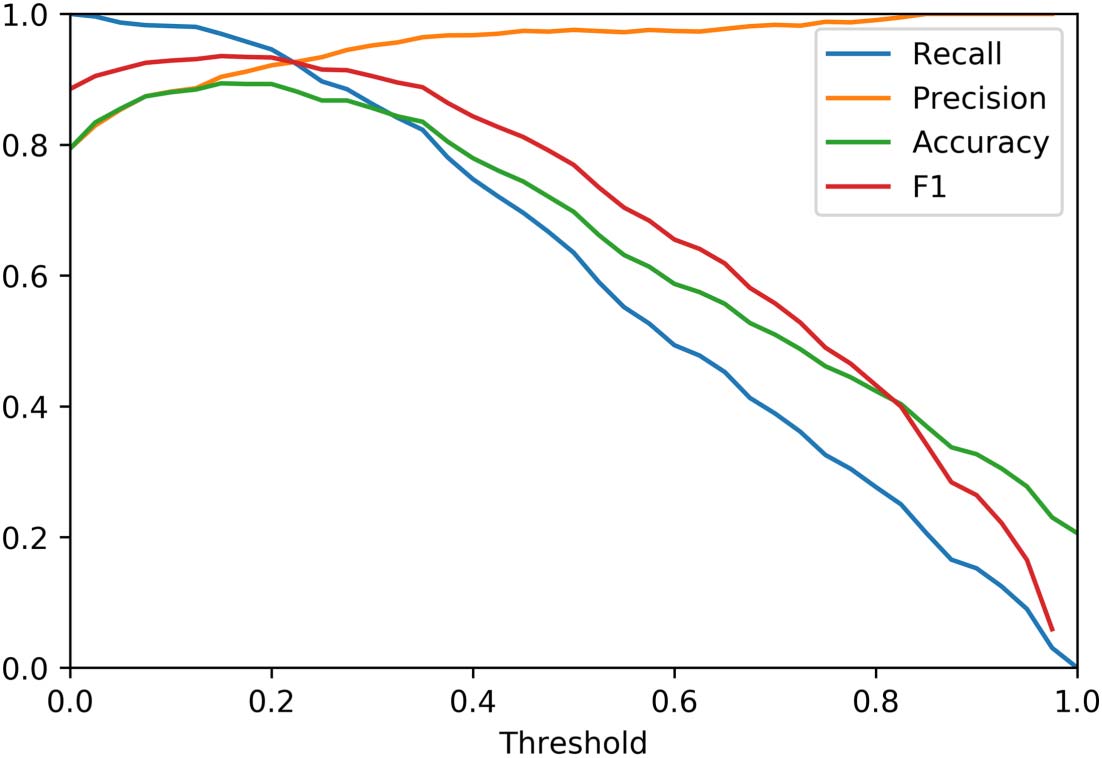
4.3. Baseline Comparison
To our knowledge, there is currently no other approach that maps references over Wikipedia
revisions, and thus no direct comparison for our approach. 所以, we implemented a
straightforward baseline that maps references using cosine similarity between Bag of Words
representations of the strings of the Gold Standard reference pairs. We then resampled using
the distribution of cosine similarities calculated in the original data. To estimate the distribution
we used the same procedure of random sampling (部分 4.1) but we assume that the buckets
have an infinite size (Appendix C in the Supplementary material, Step 1), and stop after
100,000 pairs of references have been sampled. 数字 4 shows how our method, leveraging
WikiWho and Jaccard similarities, outperforms the alternative based on cosine similarity
between reference strings through all possible thresholds.
5. DATA SET COMPOSITION AND ANALYSIS
Our data set contains the references of 6,073,708 nonredirect27 articles in the English Wiki-
pedia. It comprises 55,503,998 references with 164,530,374 行动. The actions consist of
33.73% creations, 31.3% modifications, 23.15% deletions, 和 11.81% reinsertions. We find
那 77.21% of the articles (4,690,046) have at least one reference (median = 4, μ = 11.83, max =
12,797). But out of those articles, 78.42% do not yet have any DID-Rs (3.68 百万; IE。, 60.54%
of total articles, Figure D1 in Appendix D in the Supplementary material). The rest of the articles
(1,012,289) have at least one DID-R, 和 50,615 (5%) articles contain more than 50% DID-Rs.
多于 88% of the DIDs currently used to track the references correspond to ISBNs and DOIs
(Figure D2 in Appendix D in the Supplementary material).
As of June 2019, 仅有的 7.11% (3,943,984) of all references include one of the identifiers we
were tracking. The distribution of articles according to the number of references when either
all of them are included or when only DID-Rs are included, suggests a power law distribution;
然而, the distribution is smoother for all references (α = 1.66) compared to only DID-Rs
(α = 2.38); see Figure D3 in Appendix D.
关于 10% of all DID References are DID-Lagged References (IE。, they did not have DIDs in
their early Wikipedia article revisions; 桌子 2). By now—and in the future—this number will
likely be higher, as DIDs can still be added to the references that were classified as No-DID Ref-
erences in our 2019 数据集. We also observe that 12.1% of actions on the DID References
occurred during the initial revisions in which the references did not yet have a DID; 因此, 这
information would not be considered in any approach that relies only on DIDs for identifying
and monitoring references.
27 We excluded Wikipedia pages that are redirects. Redirects are Wikipedia pages that automatically send vis-
itors to another page and do not have their own content. 例子: https://en.wikipedia.org/w/index.php?title
=Symbiont&redirect=no.
Quantitative Science Studies
160
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
数字 4. ROC curves to compare our method and a simple method based on cosine similarity. The light blue line shows the ROC curve for
our method based on Jaccard similarity over WikiWho token IDs, and the orange line the ROC curve for a method based on cosine similarity
of strings. Each data point is calculated for each possible threshold in the sample data.
In the following section, we will take a closer look at the data to find answers to our research
问题. We will first look at the temporal evolution of different types of references (基于
the presence of DIDs), and second at the editors who are creating and editing the references.
5.1. Wikipedia References Over Time
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
The first reference in an article of the English Wikipedia edition was introduced in December
2005. 自那以后, more and more references have been added yearly (数字 5). There was an
initial steep increment of new references per year until 2010, in which more than 4 百万
参考 (which corresponds to 7.4% of all references) were created. After that, the incre-
ment of yearly created references continued more moderately, and it seems to have settled in
2017 和 2018: 关于 5.58 百万 (10.05%) 和 5.64 百万 (10.15%) of all references were
added in the respective years.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
After references have been created, some of them have never changed in any way, 尽管
others have been either deleted or modified at least once. According to our data, modifications
are the most common action (∼51.5 million) that happens to references after their creation.
The number of modifications per year has not grown monotonically as we have seen for cre-
ations; 例如, there is a peak of modifications between 2016 和 2018: 6.41 百万
2016, 8.10 百万 2017, and back to 6.71 百万 2018. We suspect that the increase in
modifications 2016–2018 is due to the WikiCite28 project and a sequence of editing events
that started in 2016. The ratio of modifications to creations has been increasing, but during that
时期 (2016–2018) the ratio went above 1 (IE。, there were more modifications than crea-
系统蒸发散), reaching 1.4 在 2017 (Appendix N in the Supplementary material).
28 https://meta.wikimedia.org/wiki/ WikiCite_2016
Quantitative Science Studies
161
“I updated the ”
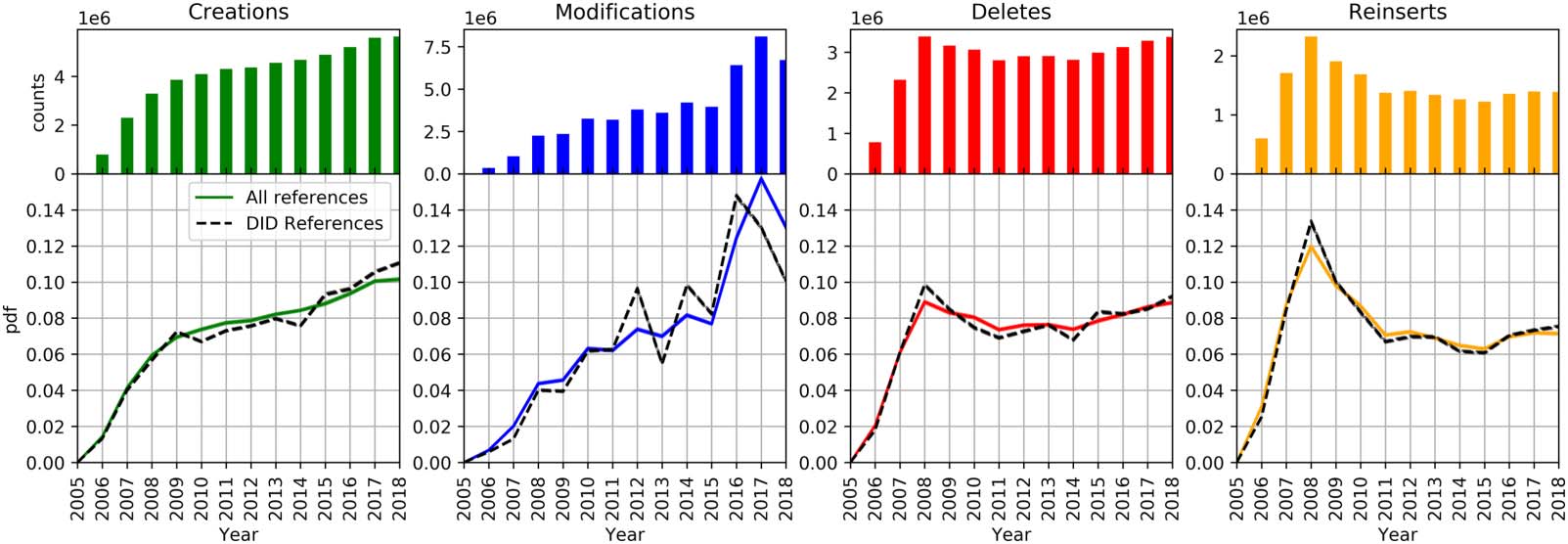
数字 5. Distribution of actions over time. Each of the four plots depicts the dynamics of one of the actions: creations, modifications, dele-
系统蒸发散, and reinsertions. On the top subplot of each action, bars represent the number of actions ( y-axis) performed over all references per year
(x-axis). 例如, 大约 2.3 million references were created in 2007. On the bottom subplot of each action, the solid lines represent the
proportion of actions ( y-axis) that occurred yearly (x-axis) for all references. The dashed lines represent the proportion of actions that occurred
yearly (x-axis) for only the DID References (DID-Rs). 例如, 大约 8.9% of all deletions were done in 2008, whereas for DID-Rs around
9.9% of deletions were done in 2008.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
Apart from 2005 和 2006 (years with small reference counts), the proportion of deletions
has shown a decreasing trend until 2014. This was most likely due to cleanup efforts of initial
reference additions, plus high volatility (例如, because of disagreements), also shown in the
high reinsertion counts until 2010, 哪个是, by definition, a reaction to previous deletions.29
Starting at its high count in 2008, the number of reinsertions dropped unevenly from 2.33 百万
(11.98%) actions in 2008 到 1.39 百万 (7.14%) actions in 2018.
One might expect the same distribution of actions across years for DID References (IE。, 那
they would be treated by editors in the same way as general references). 然而, there are some
differences between general references and DID-Rs. The most distinct patterns are noticeable
in the creations and modifications of references (the dashed and solid lines in Figure 5):
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
(西德:129) Until 2009 the number of creations of DID-Rs was aligned with creations of all refer-
恩塞斯 (overlap of the dashed and continued line). 然而, 之间 2010 和 2014
更少 (than expected) DID-Rs were created, and after 2015 the trend was reversed. 为了
实例, 在 2018, 大约 11.06% of new DID-Rs (相对 10.15% of general references)
have been added to Wikipedia articles.
(西德:129) There is no clear trend in the modifications of DID-Rs (the second plot from the left in
数字 5), as the plot shows multiple peaks and troughs across the years. We observe
fewer modifications of DID-Rs in 2007–2009, 2013, 2017, 和 2018; and more modi-
fications in 2012 and 2014–2016. The highest number of modifications was reached in
2016 (1.02 million actions or 14.79%) 和 2017 (0.9 million actions or 13.03%).
(西德:129) The relatively small differences in deletions of some years (2008, 2010–2012, 2014, 和
2015 图中 5) do not necessarily mean that their presence ended in those years
(because they can be reinserted). 然而, we found that DID-Rs have a higher survival
速度: They are deleted (without further reinsertions) at a lower rate than the rest of the
references at any point in time (see Figure E1 of Appendix E in the Supplementary
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
29 The years 2006–2010 in the English Wikipedia have been pointed out as a highly volatile period before
(Flöck et al., 2017).
Quantitative Science Studies
162
“I updated the ”
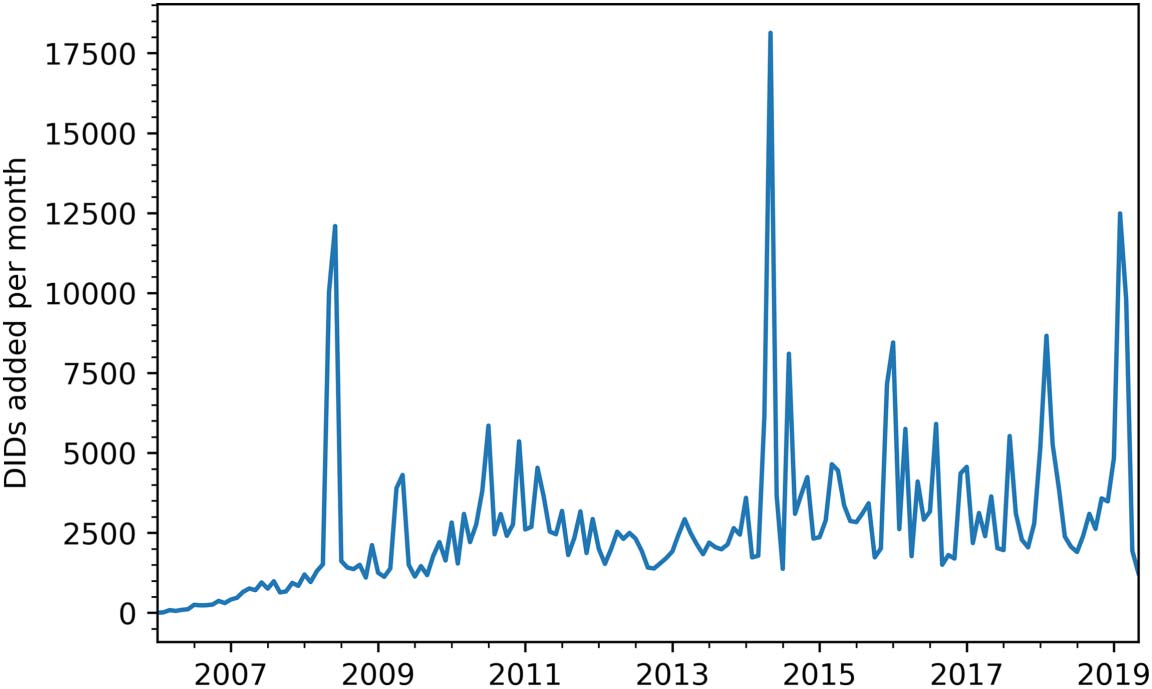
数字 6. Monthly total of modifications that added a DID to existing references. The x-axis displays the year and y-axis the number of
modifications—no matter which year the reference was originally added (例如, 在 2019, references from several years earlier were changed
along with references created the same year). Only modifications in which a DID was added to a reference are considered.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
材料). As of June 2019, 大约 31.8% (17.02 百万) references had been deleted
(without further reinsertions) 之间 2005 和 2019; 0.97 million of them are DID-Rs,
representing only 25.7% of all DID-Rs. This speaks to a higher value of these references
to the editor community, possibly because of their perceived trustworthiness.
We observed in Figure 5 (second subplot from the left) that there are differences in the over-
all number of modifications, and the number of modifications of DID references. Some of
these modifications are of particular interest because they are the ones in which DIDs are
added to already existing references (DLag, 桌子 2). 所以, we have closely investigated
these modifications (数字 6). The highest peaks of newly added DIDs occurred during (A)
May and June 2008 和 22,126 DIDs added during two months, (乙) 可能 2014 和
18,131 DIDs added, 和 (C) 二月 2019 和 12,486 DIDs added. This indicates the pres-
ence of campaigns (or individual editors’ efforts, with the help of scripts or bots) that targeted
missing DIDs. Based on information until June 2019, these three peaks correspond, 重新指定-
主动地, 到 (A) 19–26%, (乙) 17%, 和 (C) 56% of references that at the time should have had
a DID (see Appendix F in the Supplementary material for statistics of other peaks). Putting it
the other way around, 44–83% of the references remained without a DID even after pro-
nounced waves of DID additions.
The reported percentages of missing DIDs will be even higher in the future (after June
2019), as more DIDs will be added to references that existed at those peaks. 因此, we also
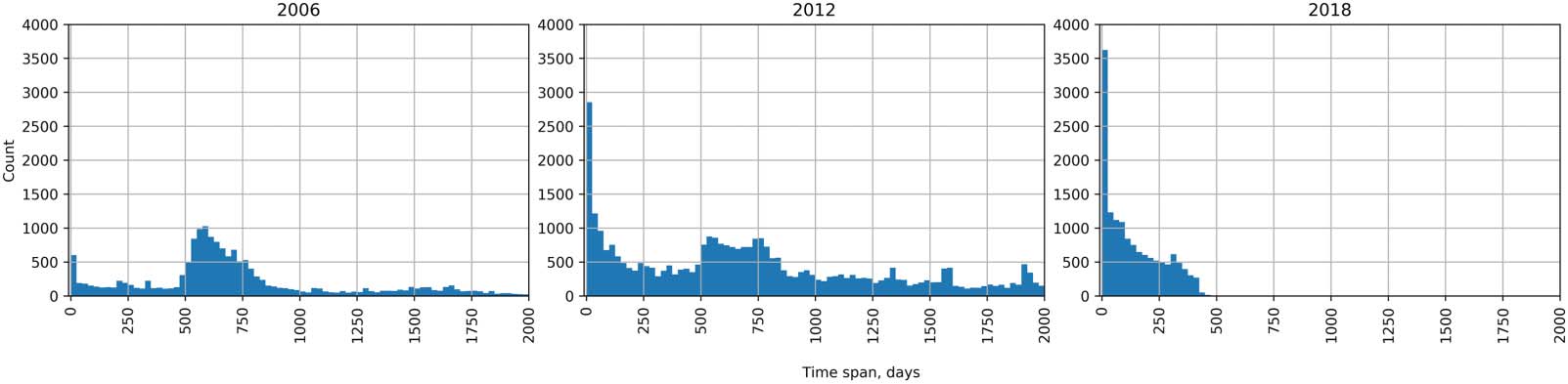
analyze how long it takes for the reference to be attributed with DIDs. 数字 7 presents the
distribution of time spans between reference creation and DID introduction for references cre-
ated in three different years (see Appendix G in the Supplementary material for all the years). 在
2006, it took between 500 和 1,000 days for most of the references to gain their DID. 在
contrast in 2018, it took less than 10 days for most of the references to get a DID. 那里
are clear peaks in the plots corresponding to 2006 和 2012 (数字 7), 大约 500 和
750 days after the reference was created. These peaks can be associated with the spikes of
DID additions in May and June 2008 and May 2014 (图中 6). 然而, the spike of February
2019 (数字 6) can barely be observed in the 2018 plot (∼300 days, 数字 7), indicating that
most of the modifications of 2019’s spike corresponded to references created before 2018. 这
Quantitative Science Studies
163
“I updated the ”
数字 7. Distribution of the time spans between the creation of the references and the introduction of their DID for the years 2006, 2012, 和
2018. The x-axis shows the time span in days between reference creation and the introduction of their DIDs—only including the references
created in each of the years in the titles of the plot. The y-axis shows the frequency for each of the time spans. See Appendix G in the Sup-
plementary material for distributions of all other years.
suggests that the editor community and infrastructure have been getting more effective at iden-
tifying and adding missing DIDs for references.
As we have already mentioned, DID References correspond to 7% of all the references in
我们的 2019 数据集. Had we collected the data set in other years, the percentages would have
been slightly different (solid line, Figure H1 of Appendix H in the Supplementary material),
especially before 2010. 例如, there would have been around 6.6% DID References
at the beginning of 2007. 后 2010, the number of DID References has stabilized around
7%, with a small increase in the last four years.
Hypothetically, one could collect the histories of references using only DIDs (see Appendix
I in the Supplementary material). In that case, one would observe ∼4.4% DID References in
2007 (dashed line, Figure H1 of Appendix H in the Supplementary material) while the true
number should have been at least 6.6% 参考; the alternative method would have missed
37.5% (∼2.2% out of ∼6.6%) of references that got their corresponding DID after the hypo-
thetical data collection. These differences are discussed in more detail in Section 6.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
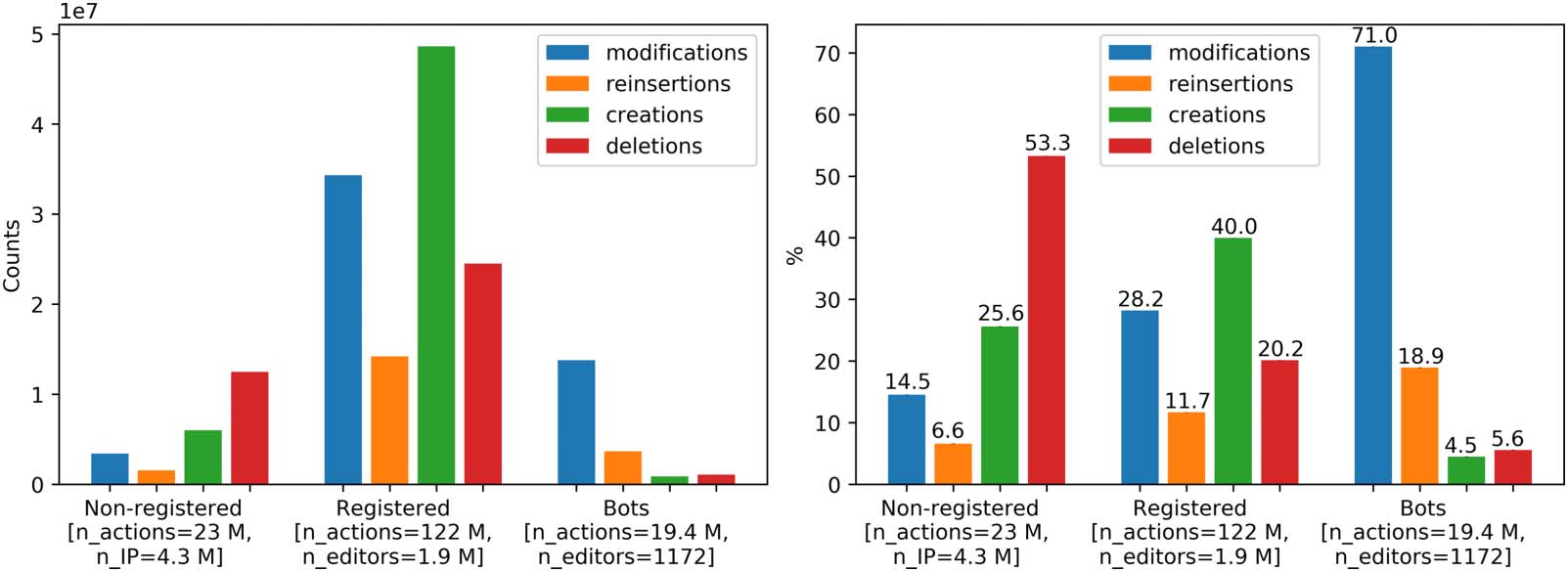
5.2. The Editors of Wikipedia References
In the context of altmetrics, the focus is often placed on which scholarly works receive men-
tions or interactions from social media or other alternative platforms, while relatively little is
known about who is behind these mentions and interactions. In collaborative platforms such
as Wikipedia, it is relevant to understand the actors who participate in the inclusion of schol-
arly publications, as this has a direct impact on visibility. In contrast to traditional publications,
where the decision about which material should be cited is attributed to the authors of each
出版物, in a collaborative environment, the decision is not straightforward but may have
to be negotiated over different article revisions. 在这个部分, we investigate whether contri-
butions come from registered editors, bots, or nonregistered sessions (IP addresses) (看
桌子 4), and explore the behavior of these actors within Wikipedia. We are interested in
whether those who edit Wikipedia references differ from the overall Wikipedia editor commu-
本质, and we inquire if there exist subcommunities of editors that specialize in different types of
editing activities.
我们发现 1,910,66730 编辑, 1,172 bots, 和 23,459,838 edits by 4,286,160 IP addresses
that worked with Wikipedia references (桌子 4). 数字 8 presents the distributions of actions
per user type. Registered editors are responsible for most actions: 多于 122 百万 (74%
30 用于比较, the English Wikipedia had 35.7 million registered editors as of July 2019.
Quantitative Science Studies
164
“I updated the ”
桌子 4.
actions that we encounter in our data set. The second column elaborates on each
Types of Wikipedia editors. The first column lists the types of editors, the number of reference-editing actors of each type, 和他们的
Type of editors
Registered editors
演员: 1,910,667
Actions: 121,681,174
Bots
演员: 1,172
Actions: 19,386,851
Nonregistered editors
演员: N/A
Actions: 23,459,838
描述
These correspond to individual users who have registered their profile on Wikipedia and
edited at least one reference.
Bots were identified from bot lists of Wikimedia plus an additional list of bots’ names
that we created. These sources were combined into a final list consisting of 10,262
unique account names (see Appendix J in the Supplementary material for the sources),
out of which 1,172 were associated with at least one action in Wikipedia references.
Edits coming from nonregistered IP addresses cannot be attributed to specific anonymous
编辑. Several persons can share the same IP address (例如, university addresses or
libraries), and one editor can connect via several IPs.
of all actions in our data set). Registered editors focused on the creation of new references
(40% of their actions) and modification of existing ones (28.2% of their actions). Bots, in com-
parison, 和 19.4 百万 (13.7%) of all actions, were focused on modifications (71% of their
行动). Nonregistered editors are responsible for only 14.3% of the actions in our data set.
And although registered editors made most deletions (大约 24.5 百万; left plot in
数字 8), nonregistered editors appear to specialize in them (right plot): Nonregistered ses-
sions have proportionally more deletions (53.3% of all their actions) than either registered edi-
托尔斯 (20.2%) or bots (5.6%), not unlikely due to large amounts of vandalism, especially blanket
deletions of large chunks of text. The nonregistered editors generally comprise a diverse and
occasional set of editors, 和 89.8% of IPs have fewer than 10 行动. Some IPs might be
associated with several editors (例如, school IPs), while a user might also use several IPs. 给定
the comparably low figures of actions for nonregistered editors but mostly the difficulties of
attributing actions to specific actors, we will exclude them from the rest of the analysis in this
部分.
数字 8. Distribution of actions performed by each type of editors. The left plot shows the total actions ( y-axis) per type of account (x-axis),
and type of action (legend). The right plot shows the percentage ( y-axis) of the type of actions (legend) within the account type (x-axis). 这
x-axis also presents the total number of actions (n_actions) and editors or IP addresses (n_editors or n_IP) for each account type.
Quantitative Science Studies
165
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
桌子 5. Classification of registered editors according to the type of activity. The first column presents the cluster id and the percentage of
registered editors in parentheses. The second column describes the group of registered editors in terms of the actions they perform (Figure L1a
of Appendix L in the Supplementary material)
Cluster (% of all editors)
0 (39.56%)
1 (20.55%)
2 (10.3%)
3 (11.17%)
4 (4.06%)
5 (14.36%)
Only create new references
Only delete references
Type of activity
Modify references in 90% of the cases, create new ones in 6% of the cases
Mostly delete and create references (42% of cases for each action), modify in 10% cases and
do a few reinsertions
Mostly (70%) reinsert deleted references and do a few deletions, creations and modifications
Mostly create (55%) and modify (35%), and do a few deletions and reinsertions
Most registered editors have performed only a few actions on references in Wikipedia arti-
克莱斯, whereas the top contributors have contributed millions of actions (Figure K1, Appendix K
in the Supplementary material). We also studied the number of different articles in which each
editor has performed actions on references. We see a similar trend as with the number of
行动 (例如, the top user has edited references in 226,334 文章). This seems to suggest that
some editors are specifically focusing on reference editing beyond a specific topical area of
兴趣.
Using a manually curated list of Wikipedia bots (10,262 unique bot account names; 看
桌子 4), 我们发现 1,172 bots (0.1% of editors) have taken part in the editing of refer-
恩塞斯. On a per user basis, bots performed more actions on references than registered users
(Mann-Whitney U test, p < 0.001; Figure K2, Appendix K in the Supplementary material).
Bots and registered editors display very different behavior that is evident by directly looking
at the types and quantity of actions (Figure 8). Within the group of registered editors, we were
interested in identifying subgroups of users who behave similarly (and distinct from other sub-
groups), as measured by the types of actions that they usually perform. We use the K-means
clustering algorithm with Euclidian distance to find such groups. Each registered editor is rep-
resented by four features, one per type of action, that contain the distribution (in percentages)
of actions of that editor. We applied the algorithm on a sample of 10,000 random editors.
Similarity of action groups with most active Wikipedians. The first column displays the criteria used for our ranking. The second to
Table 6.
seventh columns show the Jaccard similarity of top x editors of both rankings. The last two columns represent the RBO scores for two values of
the parameter p of RBO
Jaccard similarity of top x
RBO scores for p = x
Actions
Total
Modifications
Creations
Deletions
Reinsertions
10
0.05
0.11
0.00
0.11
0.05
100
0.25
0.18
0.12
0.17
0.09
500
0.32
0.25
0.20
0.25
0.16
1,000
0.38
0.29
0.26
0.31
0.20
5,000
0.48
0.42
0.37
0.41
0.34
10,000
0.52
0.46
0.41
0.42
0.37
0.95
0.001
0.002
0.003
0.001
0.001
Quantitative Science Studies
0.9999995
0.635
0.428
0.449
0.363
0.297
166
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
q
s
s
/
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
a
_
0
0
1
7
1
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
“I updated the ”
数字 9. RBO scores between ranked lists of the 10,000 active Wikipedians and the 10,000 most active editors of references. The x-axis
shows the decrease of the RBO with increasing weight on the top of the ranked lists. The sharp decrease even at low levels of top weight points
to the dissimilarity of the editors at the very top.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
To determine the optimal number of clusters the following analyses were performed: silhou-
ette coefficients (Rousseeuw, 1987), presented in Appendix L in the Supplementary material,
and clustering tree algorithm (Zappia & Oshlack, 2018) with Sugiyama layout (Sugiyama,
Tagawa, & Toda, 1981) for tree depiction (Appendix M in the Supplementary material).
According to this analysis, we choose to divide the editors into six clusters (k = 6, mean sil-
houette score of 0.69), which are summarized in Table 5.
A clear behavioral pattern can be observed for each of the six clusters. We observe that
clusters 0 和 1 are perfectly defined (IE。, all their members dedicate themselves exclusively
to creating references [cluster 0] or deleting them [cluster 1]), clusters 2 和 4 focus on mod-
ifications and reinsertions respectively, and clusters 3 和 5 are slightly more mixed, focusing
on two actions each.
此外, we investigate whether editors of references are different from the general
Wikipedia editor community ( Wikipedians). We therefore compared the 10,000 most active
reference editors in our data set with the most active Wikipedians according to the Wikimedia
Foundation.31 The ranking of the most active Wikipedians is based on the total number of
revisions they have created, whereas we have used five different rankings of reference editors
based on the total counts of actions, modifications, creations, deletions, and reinsertions.
To see if highly active reference editors correspond to highly active Wikipedians, we look at
the general overlap of the two lists via Jaccard similarity (桌子 6) of different top k groups of
编辑. We find that the very elites of the reference editors and general editors differ; 52% 的
editors are in both lists of 10,000 most active users. The lack of overlap is more notable for
groups specialized in certain types of actions. 例如, the most active reinserters have a
Jaccard similarity of 0.37 (for the top 10,000) with active Wikipedians (last row of Table 6).
We also consider the positions of each editor in the two main rankings (most active Wiki-
pedians and the 10,000 most active editors of references) by looking at the rank-biased overlap
(RBO) by Webber, Moffat, and Zobel (2010). The RBO similarity scores are relatively high
(数字 9) only when the RBO top weight parameter (called p, 0 ≤ p ≤ 1) is over 0.9999;
31 https://en.wikipedia.org/wiki/ Wikipedia:List_of_Wikipedians_by_number_of_edits
Quantitative Science Studies
167
“I updated the ”
such a high value places very low importance on the top of the two lists. For values lower
比 0.9999 (placing more importance on the top of the lists), the similarity of both lists is very
低的 (0.001 for p = 0.95). 换句话说, the very elite editors for general edits are substantially
different from those working on references, while for the complete lists of 10,000, a moderate
rank correlation exists that differs for lists regarding different types of changes.
6. 讨论
This section discusses our data set and the results from Section 5.
6.1. Quality and Applications of the Data Set
据我们所知, we have created the most comprehensive data set of English
Wikipedia references to date, preserving the traceability of each reference across all revisions
with very high accuracy. We also contribute a gold standard set based on judgments by 523
crowdworkers as part of this work. According to our evaluation against the cosine similarity
(部分 4), the gold standard meets the highest quality standards and could be used to eval-
uate other bibliometric matching algorithms, such as those provided by the Centre for Science
和技术研究 (CWTS), the Institute for Research Information and Quality Assur-
安斯 (iFQ), or Web of Science ( WoS)32 (Olensky, 施密特, & van Eck, 2016). While those
methods might not perform well against our gold standard data set because they depend on
bibliographical fields, which are often missing in Wikipedia references (Pooladian & Borrego,
2017), the data set could be used to tune such algorithms or develop new algorithms (例如,
based on machine learning) that are able to handle the more unstructured data we have col-
lected and annotated here.
Our full data set is a contribution to the altmetrics community with several application
地区. 例如, it can be used to compare different data collection approaches (例如, 用过的
by altmetrics aggregators), or to retrospectively analyze previous data sets evaluating the his-
torical evolution of their collected references or the types of editors responsible for their cre-
化. It offers the opportunity to investigate additional research questions related to coverage
of specific types of publications over time, background information for evolutions of highly
cited publications, topical distributions of references, and the surrounding editors dynamics.
这里, we provided insights into the evolution of references based on edit types (行动), DID
覆盖范围, and editor characterization, but we believe that a host of further research questions
can be answered based on this data.
6.2. Evolution of Wikipedia References
For our first research question (RQ1) we investigated how Wikipedia references evolve over
时间. Our data clearly highlights that references in Wikipedia are by no means static entities
but are subject to amendments or “retractions” by the community in various ways. 这些
insights imply that the point of data collection is crucial for observations: Citation counts
for publications based on Wikipedia data will not only increase but may as well decrease over
时间; 例如, 之间 19.4% 和 31.8% of total references (之间 10.8% 和 25.7%
of DID-Rs) were deleted every year (从 2007 到 2019) and never reinserted again. These full
deletions could cause erroneous assumptions drawn from statistics and imply an instability of
32 https://apps.webofknowledge.com
Quantitative Science Studies
168
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
Wikipedia references as a measurement instrument. In classical bibliometric approaches, com-
parable issues are negligible, as changes to the reference lists in papers are almost impossible,
and retractions of papers (together with their referencing lists) are very rare events (Shema,
Hahn et al., 2019). But for altmetrics, the phenomenon of citation data volatility needs to
be discussed in the community.
We further find evidence that there is a continuous effort to increase the quality of Wikipe-
dia references, expressed in the constant rise of references added to Wikipedia and the
increase of the ratio of modifications to creations, with the peak in the last three years, 在哪里
there were 20–40% more modifications than creations. 此外, assuming that the pres-
ence of DIDs is an indicator of quality, we can include two further indicators: the increase of
new references that include a DID (DBorn) and the presence of modifications directly targeting
the absence of DIDs, at an increasing pace (见图 7).
We also find evidence that that DID-Rs are treated very differently by the Wikipedia com-
munity than general references, even if they are not yet marked as such via a DID. 第一的, 我们
detected periods of time with peaks of modifications only targeting DID-Rs representing efforts
to add missing DIDs, as the peaks are often followed by low values (troughs)—probably
because there is a decrease in the amount of missing DID-R that can be detected by the normal
editor community. 第二, the Wikipedia editor community seems to also perceive the refer-
ence with DID as more credible, given that DID-Rs are deleted with lower rates than all
参考.
6.3. The Role of Identifiers and Potential Effects on Altmetrics
Not only because of the discovered differences in the ways Wikipedia editors treat DID-Rs, 但
also because of the general importance of document identifiers (例如, for tracking publications
that were cited by Wikipedia articles), we placed an additional focus on the evolution of doc-
ument identifiers as elements within Wikipedia references (RQ2).
Full deletions of references clearly disrupt the measurement of impact based on Wikipedia
参考, and it affects references with or without DIDs in the same way. We note that the
only modifications that have a direct impact are those that change the reference in such a way
that either they make it point to a new resource (IE。, the equivalent of removing and adding a
reference), or they make the reference detectable (by adding a DID) or invisible (by removing
the DID, depending on the mining method).
Assuming that some of the altmetrics aggregators take advantage of the presence of DIDs for
identifying and counting references from Wikipedia, we have looked at the specific modifica-
tions that introduced a DID to an existing reference in more detail. We analyzed the DID-
Lagged References that did not include a reference upon their first introduction but received
it through later edits. Those references would potentially have been ignored during their initial
lifespans before getting their DID. We were able to show that they correspond to a consider-
able fraction of DID-Rs (10% 对应于 12.1% actions before the introduction of the
DID). We found important periods regarding the evolution of the DID-Lagged References
(dashed line, Figure H1 of Appendix H in the Supplementary material). 前 2010, a method
that relied only on DIDs would have missed up to 37.5% (2007) of references for which we
know that they should have had a DID (as we see that their DIDs were added by June 2019).
The situation quickly improved between 2009 和 2010 (11.3%), and then continued doing so
until our data collection. Our findings show that mining methods that rely on DIDs are vul-
nerable to coverage errors (Sen et al., 2021) that can misrepresent the importance of academic
works in the altmetrics community.
Quantitative Science Studies
169
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
6.4. Towards Understanding Who Edits Wikipedia References
For our last research question, we investigated the editor community that creates and main-
tains Wikipedia references (RQ3). These contributors play a crucial role within Wikipedia, 作为
they judge the relevance of references and shape what Wikipedia readers consume, 还
influencing whether an article is perceived as relevant or trustworthy based on the presence
of references.
We found that most of the references (87.6%) are created by registered editors, 然而
bots were only responsible for 1.6% of new references. The concern that the presence of bots
(Nielsen, 2008) was dominating reference creation cannot be confirmed. 用于比较, 这
has been the case in Twitter, where Robinson-Garcia, Costas et al. (2017) found that bots (和
thoughtless bot-like retweets of user accounts) were responsible for most of the activity con-
taining scholarly articles. These findings support the idea that Wikipedia references are curated
by humans and thus involve deliberate selection of sources and materials.
We further demonstrated that according to our similarity metrics ( Jaccard and RBO), regis-
tered editors shaping Wikipedia references are considerably different from the rest of Wikipe-
dia’s most active users in terms of general edits: Only about half of the top Wikipedia general
editors are among the top 10,000 reference editors. We were able to identify clusters of edi-
托尔斯; two of these clusters are fully specialized in creations and deletions and together add up
to ∼61% of the editors. We also found single editors that edited references in many different
Wikipedia articles (例如, one editor has edited references in more than 226,000 文章), 和
thus appeared to be highly specialized on reference editing, independent of topical domains.
Bots, 另一方面, have been to the largest extent only used to maintain (modify) 参考-
恩塞斯, throughout Wikipedia history.
These observations deserve additional attention in the future, as they remind us of our intro-
ductory example (数字 1). Despite Wikipedia being a community effort, individuals can have
substantial influence over certain areas. A single editor has the potential to largely affect the
representation of a specific reference.
6.5. Limitations
The collection method covers references indicated as inline citations via ref tags, following
Wikipedia’s recommendation for how references should be added to articles and implying
some quality control for inline citations based on Wikipedia’s standards. 然而, 我们的确是
not include other forms of references, such as parenthetical references33 or wikilinks to full
references using templates34. These forms are not uniform, and we could not guarantee that
their extraction would be accurate. We are not sure to what extend this strategy is used among
altmetrics aggregators, 但, 至少, we found that altmetric.com also only considers ref tags for
identifying references35.
The data set was created based on the English Wikipedia as of June 2019, and more DIDs
已经 (or will be) added after that date. We also worked with a selection of common types
of document identifiers: DOI, PubMedID, PMC, 国际标准书号, ISSN, and arXiv ID. The list corresponds
to that used by the Wikimedia Foundation project (Halfaker et al., 2019), as it is supposed to
33 https://en.wikipedia.org/wiki/ Wikipedia:Parenthetical_referencing
34 例如, shortened footnote template (例如, {{sfn}}), Harvard style templates (例如, {{harvnb}}), or freehand
anchors (例如, [[#anchor_id]]) https://en.wikipedia.org/wiki/ Wikipedia:Citing_sources/ Further
_considerations#Wikilinks_to_full_references.
35 https://help.altmetric.com/support/solutions/articles/6000235982-wikipedia
Quantitative Science Studies
170
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
capture most academic citations. We use the presence of identifiers as a weak indicator of the
quality of the referenced publications (参见章节 6.2 for a discussion), and not as a way to
identify types of publications (例如, scientific vs. nonscientific).
7. 结论
在本文中, we have introduced an overview of the evolution of Wikipedia references, 他-
lyzed the historical coverage of reference-mining methods that are based on DIDs, and offered
a characterization of the Wikipedia editors. In the scope of our research questions, 我们骗-
clude that the quality of Wikipedia references has been slowly but persistently increasing.
Although our findings do highlight limitations, we believe that the historical registry of Wiki-
pedia contains information that can be leveraged to create more robust methods of mining and
assigning importance to references in Wikipedia. We recommend that such methods use this
record to reduce manipulations and biases that blur the visibility of references, to increase the
overall coverage of references (by looking at all revisions), and to assign impact based on his-
torical activity and the community of (例如, reputable) editors that surround the references.
These recommendations only open a different path for the creation of altmetrics based on
维基百科, and there is certainly more to be done. The high-quality data set that accompanies
this paper offers the opportunity to extend the research in this direction, for example the
following:
(西德:129) analyzing the longevity and activity of references distinguishing between academic and
nonacademic (see Singh et al. (2021) for a classification approach),
(西德:129) exploring the dynamics of references according to different knowledge fields,
(西德:129) further investigating the editors by mining (with natural language processing techniques)
their profile pages and extract demographics,
(西德:129) modeling the co-editors network to find important actors and communities, 和
(西德:129) predicting which references are still missing a document identifier, as our data set
already provides this information for existing references.
致谢
We would like to thank all the *metrics project members, as well as Prof Dr Isabella Peters and
Prof Dr Claudia Wagner for their supervision and feedback, student assistants Tara Morovatdar
and Alexandra Stankevich for their help with the data curation, and Kenan Erdogan for the
insights about the WikiWho service.
作者贡献
Olga Zagovora: 概念化, 数据管理, 形式分析, 资金获取,
调查, 方法, 资源, 软件, 验证, 可视化, Writing—original
草稿, Writing—review & 编辑. Roberto Ulloa: 概念化, 形式分析, 软件,
可视化, Writing—original draft, Writing—review & 编辑. Katrin Weller: Conceptuali-
扎化, 资金获取, 项目管理, 监督, Writing—original draft,
Writing—review & 编辑. Fabian Flöck: 概念化, 资金获取, Methodol-
奥吉, 资源, 监督, 验证, Writing—original draft, Writing—review & 编辑.
COMPETING INTERESTS
The authors have no competing interests.
Quantitative Science Studies
171
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
资金信息
This research was supported by the Deutsche Forschungsgemeinschaft, DFG, project number
314727790. Fabian Flöck acknowledges support from the Volkswagen Foundation (grant
92136). The publication of this article was funded by the Open Access Fund of the Leibniz
协会.
DATA AVAILABILITY
The data set is made available on Zenodo (Zagovora et al., 2020). We also provide a Python
notebook with examples on how to process the data, and the code can be directly executed on
the GESIS Notebooks server.
参考
Bayliss, G. (2013). Exploring the cautionary attitude toward Wiki-
pedia in higher education: Implications for higher education
机构. New Review of Academic Librarianship, 19(1), 36–57.
https://doi.org/10.1080/13614533.2012.740439
Bould, 中号. D ., Hladkowicz, 乙. S。, Pigford, A.-A. E., Ufholz, L.-A.,
Postonogova, T。, … Boet, S. (2014). References that anyone can
edit: Review of Wikipedia citations in peer reviewed health sci-
ence literature. British Medical Journal, 348, g1585. https://土井
.org/10.1136/bmj.g1585, 考研: 24603564
陈, C.-C., & Roth, C. (2012). {{Citation needed}}: The dynamics
of referencing in Wikipedia. Proceedings of the Eighth Annual
International Symposium on Wikis and Open Collaboration
(PP. 1–4). https://doi.org/10.1145/2462932.2462943
Denning, P。, Horning, J。, Parnas, D ., & Weinstein, L. (2005). Wiki-
pedia risks. ACM 通讯, 48(12), 152. https://土井
.org/10.1145/1101779.1101804
Eijkman, H. (2010). Academics and Wikipedia: Reframing Web 2.0+
as a disruptor of traditional academic power-knowledge arrange-
评论. Campus-Wide Information Systems, 27(3), 173–185.
https://doi.org/10.1108/10650741011054474
Flöck, F。, & Acosta, 中号. (2014). WikiWho: Precise and efficient attri-
bution of authorship of revisioned content. Proceedings of the 23rd
International Conference on World Wide Web (PP. 843–854).
https://doi.org/10.1145/2566486.2568026
Flöck, F。, Erdogan, K., & Acosta, 中号. (2017) TokTrack: A complete
token provenance and change tracking dataset for the English
维基百科. Eleventh International AAAI Conference on Web
and Social Media. https://arxiv.org/abs/1703.08244
Grathwohl, C. (2011). Wikipedia comes of age. Chronicle of Higher
教育, 57. https://www.chronicle.com/article/ Wikipedia
-Comes-of-Age/125899
Halfaker, A。, Mansurov, B., Redi, M。, & Taraborelli, D. (2019). Cita-
tions with identifiers in Wikipedia. figshare. https://doi.org/10
.6084/m9.figshare.1299540
Haustein, S. (2016). Grand challenges in altmetrics: Heterogeneity,
data quality and dependencies. Scientometrics, 108(1), 413–423.
https://doi.org/10.1007/s11192-016-1910-9
Holman Rector, L. (2008). Comparison of Wikipedia and other
encyclopedias for accuracy, breadth, and depth in historical arti-
克莱斯. Reference Services Review, 36(1), 7–22. https://doi.org/10
.1108/00907320810851998
Holmberg, K. J. (2015). Altmetrics for information professionals:
过去的, present and future. Chandos Publishing. https://万维网
.sciencedirect.com/science/book/9780081002735
Huvila, 我. (2010). Where does the information come from? 信息
source use patterns in Wikipedia. Information Research, 15(3).
https://www.informationr.net/ir/15-3/paper433.html
Imran, M。, Akhtar, A。, Said, A。, Iqra, S。, Hassan, S.-U., & Aljohani,
氮. 右. (2018). Exploiting social networks of Twitter in altmetrics
big data. STI 2018 Conference Proceedings (PP. 1339–1344).
https://hdl.handle.net/1887/65219
Kaffee, L.-A., & Elsahar, H. (2021). References in Wikipedia: 这
editors’ perspective. 8th Wiki Workshop at The Web Conference.
https://arxiv.org/abs/2102.12511. https://doi.org/10.1145
/3442442.3452337
Kittur, A。, Suh, B., Pendleton, 乙. A。, & 志, 乙. H. (2007). He says, 她
说: Conflict and coordination in Wikipedia. 诉讼程序
SIGCHI 计算系统中的人为因素会议
(PP. 453–462). https://doi.org/10.1145/1240624.1240698
Kousha, K., & Thelwall, 中号. (2017). Are Wikipedia citations impor-
tant evidence of the impact of scholarly articles and books? Jour-
nal of the Association for Information Science and Technology,
68(3), 762–779. https://doi.org/10.1002/asi.23694
Lewoniewski, W., Węcel, K., & Abramowicz, 瓦. (2017). 分析
of references across Wikipedia languages. 在R中. Damaševičius
& V. Mikašytė (编辑。), Information and Software Technologies
(PP. 561–573). Springer International Publishing. https://doi.org
/10.1007/978-3-319-67642-5_47
Lewoniewski, W., Węcel, K., & Abramowicz, 瓦. (2020). Modeling
popularity and reliability of sources in multilingual Wikipedia.
信息, 11(5), 263. https://doi.org/10.3390/info11050263
林, J。, & Fenner, 中号. (2013). Altmetrics in evolution: Defining and
redefining the ontology of article-level metrics. Information Stan-
dards Quarterly, 25(2), 20. https://doi.org/10.3789/isqv25no2
.2013.04
林, J。, & Fenner, 中号. (2014). An analysis of Wikipedia references
across PLOS publications. Expanding Impacts and Metrics, 一个
ACM Web Science Conference 2014 作坊 (PP. 23–26).
https://doi.org/10.6084/m9.figshare.1048991.v3
Luyt, B., & Tan, D. (2010). Improving Wikipedia’s credibility: Ref-
erences and citations in a sample of history articles. Journal of the
American Society for Information Science and Technology, 61(4),
715–722. https://doi.org/10.1002/asi.21304
Mesgari, M。, Okoli, C。, Mehdi, M。, Nielsen, F. Å., & Lanamäki, A.
(2015). “The sum of all human knowledge”: A systematic review
of scholarly research on the content of Wikipedia. 杂志
the Association for Information Science and Technology, 66(2),
219–245. https://doi.org/10.1002/asi.23172
Quantitative Science Studies
172
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
“I updated the ”
Murić, G。, Abeliuk, A。, Lerman, K., & Ferrara, 乙. (2019). Collabora-
tion drives individual productivity. Proceedings of the ACM on
Human-Computer Interaction, 3(CSCW) (PP. 74:1–74:24).
https://doi.org/10.1145/3359176
Nielsen, F. Å. (2007). Scientific citations in Wikipedia. 第一的
Monday, 12(8). https://doi.org/10.5210/fm.v12i8.1997
Nielsen, F. Å. (2008). Clustering of scientific citations in Wikipedia.
Wikimania 2008. https://arxiv.org/abs/0805.1154
Okoli, C。, Mehdi, M。, Mesgari, M。, Nielsen, F. Å., & Lanamäki, A.
(2014). Wikipedia in the eyes of its beholders: A systematic
review of scholarly research on Wikipedia readers and reader-
船. Journal of the Association for Information Science and
技术, 65(12), 2381–2403. https://doi.org/10.1002/asi
.23162
Olensky, M。, 施密特, M。, & van Eck, 氮. J. (2016). Evaluation of the
citation matching algorithms of CWTS and iFQ in comparison to
the Web of science. Journal of the Association for Information
Science and Technology, 67(10), 2550–2564. https://doi.org/10
.1002/asi.23590
Ortega, J. L. (2018). Reliability and accuracy of altmetric providers:
A comparison among Altmetric.com, PlumX, and Crossref Event
数据. Scientometrics, 116(3), 2123–2138. https://doi.org/10.1007
/s11192-018-2838-z
Panciera, K., Halfaker, A。, & Terveen, L. (2009). Wikipedians are
born, not made: A study of power editors on Wikipedia. Proceed-
ings of the ACM 2009 International Conference on Supporting
Group Work – GROUP ’09 (PP. 51–60). https://doi.org/10.1145
/1531674.1531682
Piccardi, T。, Redi, M。, Colavizza, G。, & 西方, 右. (2020). Quantify-
ing engagement with citations on Wikipedia. Proceedings of The
Web Conference 2020 ( WWW ’20) (PP. 2365–2376). https://土井
.org/10.1145/3366423.3380300
Pooladian, A。, Borrego, Á. (2017). Methodological issues in mea-
suring citations in Wikipedia: A case study in library and infor-
mation science. Scientometrics, 113, 455–464. https://doi.org/10
.1007/s11192-017-2474-z
Priem, J。, Taraborelli, D ., Groth, P。, & Neylon, C. (2010). Altmetrics:
A manifesto. https://altmetrics.org/manifesto/
Redi, 中号. (2018). 研究: Characterizing Wikipedia citation usage.
https://meta.wikimedia.org/wiki/ Research:Characterizing
_Wikipedia_Citation_Usage
Redi, M。, & Taraborelli, D. (2018). Accessibility and topics of cita-
tions with identifiers in Wikipedia. https://doi.org/10.6084/m9
.figshare.6819710.v1
Robinson-Garcia, N。, Costas, R。, Isett, K., Melkers, J。, & 希克斯, D.
(2017). The unbearable emptiness of tweeting—About journal
文章. PLOS ONE, 12(8), e0183551. https://doi.org/10.1371
/journal.pone.0183551, 考研: 28837664
Rousseeuw, 磷. J. (1987). Silhouettes: A graphical aid to the interpre-
tation and validation of cluster analysis. Journal of Computational
and Applied Mathematics, 20, 53–65. https://doi.org/10.1016
/0377-0427(87)90125-7
Sen, 我。, Flöck, F。, Weller, K., Weiß, B., & 瓦格纳, C. (2021). A total
error framework for digital traces of human behavior on online
platforms. Public Opinion Quarterly, 85(S1), 399–422. https://
doi.org/10.1093/poq/nfab018
Shema, H。, Hahn, 奥。, Mazarakis, A。, & Peters, 我. (2019). Retractions
from altmetric and bibliometric perspectives. Information –
Wissenschaft & Praxis, 70(2–3), 98–110. https://doi.org/10.1515
/iwp-2019-2006
Shuai, X。, Jiang, Z。, 刘, X。, & Bollen, J. (2013). A comparative study
of academic and Wikipedia ranking. Proceedings of the 13th
ACM/IEEE-CS joint conference on Digital libraries (PP. 25–28).
https://doi.org/10.1145/2467696.2467746
辛格, H。, 西方, R。, & Colavizza, G. (2021). Wikipedia citations: A
comprehensive dataset of citations with identifiers extracted from
English Wikipedia. Quantitative Science Studies, 2(1), 1–19.
https://doi.org/10.1162/qss_a_00105
Sugimoto, C. R。, 工作, S。, Larivière, 五、, & Haustein, S. (2017).
Scholarly use of social media and altmetrics: A review of the lit-
erature. Journal of the Association for Information Science and
技术, 68(9), 2037–2062. https://doi.org/10.1002/asi
.23833
Sugiyama, K., Tagawa, S。, & Toda, 中号. (1981). Methods for visual
understanding of hierarchical system structures. IEEE Transac-
tions on Systems, 男人, and Cybernetics, 11(2), 109–125.
https://doi.org/10.1109/TSMC.1981.4308636
Teplitskiy, M。, 鲁, G。, & Duede, 乙. (2017). Amplifying the impact of
open access: Wikipedia and the diffusion of science. 杂志
the Association for Information Science and Technology, 68(9),
2116–2127. https://doi.org/10.1002/asi.23687
Thelwall, 中号. (2016). Does astronomy research become too dated for
the public? Wikipedia citations to astronomy and astrophysics
journal articles 1996–2014. El Profesional de La Información,
25(6), 893–900. https://doi.org/10.3145/epi.2016.nov.06
Webber, W., Moffat, A。, & Zobel, J. (2010). A similarity measure for
indefinite rankings. ACM Transactions on Information Systems
(TOIS), 28(4), 20:1–20:38. https://doi.org/10.1145/1852102
.1852106
Zagovora, 奥。, Ulloa, R。, Weller, K., & Flöck, F. (2020). 个人
edit histories of all references in the English Wikipedia [Data set].
Zenodo. https://doi.org/10.5281/zenodo.3964990
Zahedi, Z。, & Costas, 右. (2018). General discussion of data quality
challenges in social media metrics: Extensive comparison of four
major altmetric data aggregators. PLOS ONE, 13(5). https://土井
.org/10.1371/journal.pone.0197326, 考研: 29772003
Zaldivar, 中号. S. S。, 乙. Tomlinson, 右. LaPlante, J. Ross, L。, & Irani, A.
(2018). Responsible research with crowds: Pay crowdworkers at
least minimum wage. ACM 通讯, 61(3), 39–41.
https://doi.org/10.1145/3180492
Zappia, L。, & Oshlack, A. (2018). Clustering trees: A visualization
for evaluating clusterings at multiple resolutions. GigaScience,
7(7). https://doi.org/10.1093/gigascience/giy083, 考研:
30010766
Quantitative Science Studies
173
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
3
1
1
4
7
2
0
0
8
3
7
1
q
s
s
_
A
_
0
0
1
7
1
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3