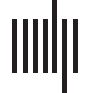RESEARCH ARTICLE
Data citation and the citation graph
Peter Buneman1, Dennis Dosso2
, Matteo Lissandrini3
, and Gianmaria Silvello2
1University of Edinburg
2University of Padua
3Aalborg University
开放访问
杂志
关键词: bibliometrics, citation graph, data citation
引文: Buneman, P。, Dosso, D .,
Lissandrini, M。, & Silvello, G. (2021).
Data citation and the citation graph.
Quantitative Science Studies, 2(4),
1399–1422. https://doi.org/10.1162/qss
_a_00166
DOI:
https://doi.org/10.1162/qss_a_00166
通讯作者:
Dennis Dosso
dennis.dosso@unipd.it
抽象的
The citation graph is a computational artifact that is widely used to represent the domain of
published literature. It represents connections between published works, such as citations and
authorship. 除其他事项外, the graph supports the computation of bibliometric measures
such as h-indexes and impact factors. There is now an increasing demand that we should treat
the publication of data in the same way that we treat conventional publications. 尤其,
we should cite data for the same reasons that we cite other publications. In this paper we
discuss what is needed for the citation graph to represent data citation. We identify two
挑战: to model the evolution of credit appropriately (through references) over time and
to model data citation not only to a data set treated as a single object but also to parts of it. 我们
describe an extension of the current citation graph model that addresses these challenges. 这是
built on two central concepts: citable units and reference subsumption. We discuss how this
extension would enable data citation to be represented within the citation graph and how it
allows for improvements in current practices for bibliometric computations, both for scientific
publications and for data.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1.
介绍
1.1. Citations and the Citation Graph
Citation is essential to the creation and propagation of knowledge and is a well-understood part
of scholarship and scientific publishing. Citations allow us to identify the cited material, retrieve
它, give credit to its creator, date it, and provide partial knowledge of its subject and quality.
The citation graph, or citation network, is a model used to describe how citations link
research entities, typically papers, journals, and books (Harzing & Van der Wal, 2008; 唐
等人。, 2008). It enables a number of important activities such as the following:
(西德:129) Exploration of the graph to find publications of interest.
(西德:129) Tracking of authorship of papers: Citing and following citations is one way to attribute
credit to authors and to keep up to date with the work of others.
(西德:129) Dissemination of research findings: The exploration of citations and cited authors
enables the dispersed communities of researchers to share their findings and engage
in discussions.
(西德:129) Computation of bibliometrics for the analysis of one researcher, venue, or publication
impact in particular fields. The citation graph is the basis for nearly all the currently used
bibliometrics, such as impact factor and h-index.
版权: © 2021 Peter Buneman,
Dennis Dosso, Matteo Lissandrini, 和
Gianmaria Silvello. Published under a
Creative Commons Attribution 4.0
国际的 (抄送 4.0) 执照.
麻省理工学院出版社
Data citation and the citation graph
Throughout this paper, we refer to an idealized “citation graph” as though it were a real and
unique digital artifact that represents papers and the citations between them. 当然, 这是
not unique: Various organizations have distinct implementations of it. Among these, we count:
Google Scholar, the Microsoft Academic Graph (MAG)1, the Open Academic Graph (OAG)
(Tang et al., 2008), Semantic Scholar (SS)2, AMiner (是)3, and PubMed4 (this is more a linked
collection of documents than a full-fledged citation graph), Scopus5, and the Web of Science6.
These graphs differ in many aspects, such as their coverage, their being open- or closed-
使用权, and their schema; but in all of these, the basic structure is a directed graph, 其中
the vertices represent publications and the edges represent citations from one publication to
其他 (Price, 1965).
Most of the information about papers is contained in annotations of the nodes. The edges
are generally typed but not annotated (an exception is MAG, which carries context, 和我们一样
discuss later). Although in early models, nodes only represented papers and the only edges
were “cites” edges, 最近, citation graphs have been extended with richer information
(Peroni & Shotton, 2020). These extensions may carry author nodes with a “wrote” edge
to papers, journal/conference nodes with a “part of” edge from papers, and subject nodes
with the corresponding edges. Although representations differ, the purpose is similar: to pro-
vide the services described above.
1.2. The Need for Data Citation
Scientific publications increasingly rely on curated databases, which are numerous, “pop-
ulated and updated with a great deal of human effort” (Buneman, Cheney et al., 2008), 和
at the core of current scientific research7. 在此背景下, references to data are starting to
be placed alongside traditional references. 因此, there has been a strong demand
(FORCE-11, 2014; CODATA-ICSTI Task Group on Data Citation Standards and Practices,
2013) to give databases the same scholarly status as traditional scientific works and to
define a shared methodology to cite data. Scientific publishers (例如, 爱思唯尔, 公共科学图书馆,
施普林格, 自然) have taken up data citation by instituting policies to include data citations
in the reference lists.
The open research culture (Nosek, Alter et al., 2015) is based on methods and tools to share,
discover, and access experimental data. Moreover papers, journals, and articles should pro-
vide access to all the data that they use (Cousijn, Feeney et al., 2019). Researchers and prac-
titioners (例如, journalists and data scientists) who make use of electronic data should be able to
cite the relevant data as they would cite a document from which they had extracted informa-
的 (Cousijn, Kenall et al., 2017; Nature Physics Editorial, 2016). As we shall see, the citation
graphs can become a fundamental tool in the pursuit of the goal of accessibility and network-
ing between papers and data.
We also observe that data occupy a crucial role today in research, emerging as a driving
instrument in science (Candela, Castelli et al., 2015). Data citations should be given the same
1 https://www.microsoft.com/en-us/research/project/microsoft-academic-graph/
2 https://www.semanticscholar.org/
3 https://www.aminer.cn/
4 https://www.ncbi.nlm.nih.gov/pubmed/
5 https://www.scopus.com/home.uri
6 https://clarivate.com/webofsciencegroup/solutions/web-of-science/
7 参见https://fairsharing.org/databases/ for a detailed list of curated scientific databases commonly used in
研究.
Quantitative Science Studies
1400
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
scholarly status as traditional citations and contribute to bibliometrics indicators (Belter, 2014;
Peters, Kraker et al., 2016). Principles such as Findability, Accessibility, Interoperability, 和
Reusability (FAIR) (Wilkinson, Dumontier et al., 2016) require data to be easily findable and
accessible, qualities that are more readily available once data can be appropriately cited. 在
this sense, we can say that the FAIR principles encourage the adoption of data citation.
The reasons given for data citation are the same those given for a conventional citation
(CODATA-ICSTI Task Group on Data Citation Standards and Practices, 2013): recognition of
the source (例如, a title); credit for the author, curator, or agent; establishment of its currency
(when it was created); where it was located; and how it was extracted. The last three of these
fall under the general heading of provenance and are important when one wants to reproduce
some analysis on the data or establish the trustworthiness of a claim.
Data sets and databases are usually more complex and varied than textual documents, 和
they introduce significant challenges for citation (Silvello, 2018). Text publications have a
fixed form, do not change over time, are interpretable as independent units, share a standard
format and representation model, and are composed of predetermined, albeit domain-
dependent, sets of elements that are considered as citable (例如, the whole paper or book or
a chapter). Scientific databases are structured according to diverse data models and accessed
with a variety of query languages. What can be cited may range from a single datum to data
subsets or aggregations specified by the person or agent that extracts the relevant data, 和
deciding a priori what can and cannot be cited is rarely feasible. Data citation introduces mul-
tiple citation types, besides the classical papers citing papers. These are papers citing data,
data citing papers, and data citing data.
1.3. Data Citation in the Citation Graph
Our purpose in this paper is to discuss whether, in its current form, the current model of the
citation graph can properly accommodate data citation. We claim that, despite all the features
and modifications that have been added to various implementations of the citation graph, 在
least two significant features are generally missing or poorly represented. These shortcomings
already limit what we can represent with existing implementations, and we argue that they
make impossible the proper representation of data citations.
The first shortcoming concerns the assignment of credit when a referenced scientific work is
corrected or augmented with another version. A typical example case is that of a preprint
paper that gets cited before its peer-reviewed version is published. It is common for the authors
to prefer that the preprint citations are merged with those of the peer-reviewed version. 一些-
thing similar happens also when an updated version of a data set is published.
In the case of data, we need to consider that a database may be composed of multiple
independently citable parts (例如, a single record, a table, a view). Every single citable part
can evolve and change over time and obtain citations (also views or downloads, when mon-
itoring other scientometrics signals) at a different point in time. 所以, it can be necessary
to aggregate these statistics over all the versions of the same part to measure its impact and that
of the database. The MAG and S2ORC databases have also an explicit notion of multiple ver-
sions of a paper, for example preprints and final published versions. It is however uncommon
to “move” citations from one version to another, following some criteria or algorithm to cor-
rectly allocate citations. 然而, aggregating citation to a single version of a scientific work would
有, 除其他事项外, the desirable effect of allowing proper evaluation of the impact of
工作.
Quantitative Science Studies
1401
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
The second feature is the representation of context of a citation. Context is required for
various reasons. It is typically used to describe the relevant part (例如, page number) of a cited
文档. It may also carry, as in MAG, the surrounding text within the citing document
helping to understand the reason for the citation; 例如, a simple mention, a confutation,
or a validation, such as those described in the OpenCitations ontology (Daquino, Peroni et al.,
2020). In the case of data citations, the context can contain the query identifying the cited
数据, expressed in different format (例如, a URL, a filename, a SQL or SPARQL query, ETC。).
Despite a great deal of attention dedicated to the citation context—see, 例如, 这
Citation Context Analysis (CCA) discussed as early as the 1980s (弗里曼, Ding, & Milojevic,
2013)—there is no systematic approach to representing it within citation graphs.
实际上, none of the largest citation-based systems, such as Scopus, MAG, and Google
学者, properly take into account scientific databases as objects for use in the research
文学. Google Data Search8 allows us to search for indexed data sets, but it does not
keep track of the citations to data or other types of statistics, such as clicks or downloads.
Web of Science is one notable exception because it models data citations, even though only
at the database level, via the Data Citation Index (DCI), now maintained by Clarivate Ana-
lytics (力量, Robinson et al., 2016). Note that DCI is not publicly available and the data sets
are indexed after a validation process.
Another effort is the Scholix framework (Burton, Koers et al., 2017), which can be regarded
as a set of guidelines and lightweight models that can be quickly adopted and expanded to
facilitate interoperability among link providers. 最后, an example of an initiative that
includes data and databases among the entities of the graph is the OpenAIRE Research Graph
Data Model (Manghi, Bardi et al., 2019), which leverages the OpenAIRE services to populate a
research graph whose nodes include scientific results, 组织, funding agencies, com-
社区, and data sources.
The conventional approach is to treat a data set as a single entity, in the same way, 一
would treat a scientific publication. 然而, this is far from ideal as typically only a small
part of the data set or database is cited, and the authorship—the people who have contributed
to the database—can vary widely with the part of the database being cited (Buneman, 戴维森,
& Frew, 2016).
在本文中, we discuss the extension of the current model to enable the proper inclusion
of data citations in the citation graph; and we discuss the evolution of a database: What hap-
pens to citations when new versions of the database appear? For the versioning issue, 我们
describe a relation between scientific works (either papers or data) called subsumption.
Through different policies, this relationship models effectively how credit should be transferred
through time when updated versions of data appear in the graph. 最后, we discuss how to
introduce data in the citation graph, considering the most common data citation strategies cur-
rently used in the world of research. 尤其, we take inspiration from one of the solutions
proposed by the Research Data Alliance (RDA)9. The RDA is a community-driven initiative
launched in 2013 by different commissions. One of its working groups, the “Working Group
on Data Citation: Making Dynamic Data Citable” ( WGDC), has as one of its goals the iden-
tification and citation of arbitrary views of data. As a potential solution, the WGDC recom-
mends an identification method based on PIDs assigned to queries.
8 https://datasetsearch.research.google.com/
9 https://www.rd-alliance.org/
Quantitative Science Studies
1402
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
The focus of this work is on data citation; but to ease the comprehension of the paper, 我们
first discuss the limitations of the citation graph and the possible extensions we propose by
focusing on textual documents, and then we extend the reasoning to data citation.
The paper is organized as follows: 部分 2 describes some preliminary concepts and the
limits of the citation graphs; in Section 3 we discuss the proposed solutions for the first three
问题; 部分 4 presents the proposed solution for the introduction of data in the citation
图形; 部分 5 sums up our main proposals and discusses possible lines of research and
发展; 部分 6 describes the related work; 最后, 部分 7 presents conclusions
and future work.
2. THE CITATION GRAPH: CONCEPTS AND LIMITS
2.1. Core Concepts
2.1.1. Citable unit
By citable unit (CU), we mean a published entity—be it a paper, a chapter, or portion of
data—which presents all the qualities necessary to be considered as a “citable work.” The
characterization of a CU that we use, given in Wilke (2015), requires that: it must be uniquely
and unambiguously identifiable and citable; it must be available in perpetuity and in
unchanged form; it must be accessible; and it must be self-contained and complete. 自己-
contained and complete means that whatever new contribution is contained inside the piece
of work, that contribution needs to be fully and clearly explained. This is not always the case
for certain publications. Consider the slides of a scientific presentation. As they are used
merely as a support for the oral presentation, they often cannot be fully understood without
the corresponding talk. 还, the combination slides/registration of the talk may be incomplete,
as many presenters tend to skip technical details during their presentations, referring to the
complete published work.
Although some of these requirements are subjective, and not straightforward in databases,
they still provide a workable starting point. The requirement that is most problematic for data-
bases is that the citable unit must be unchanged. Databases evolve rapidly, and creating a cit-
able unit for each version may be counterproductive. This is something we address in Section
4.2. 一般来说, what constitutes a citable unit is decided by convention. We should also note
that some citable units comprise other citable units. The proceedings of a conference may be
cited as may be a book on a topic whose chapters are written by different people and may also
be individually cited. There is thus a “part-of” relationship between CUs that we discuss later.
在 (Daquino et al., 2020) a similar concept, bibliographic resource, is defined as a resource
that cites and can be cited by other resources.
2.1.2. 参考
At the end of this paper, there is a list of references. 传统上, a reference is a pointer to,
and a brief description of, another publication in the literature. It is a short text composed of
fields such as title, authors, 年, venue, 和别的, that enables us to identify and find the
实体 (IE。, a paper, a book, or a survey) being referenced. Depending on aspects of the citing
CU’s nature, like its field of research, the publication venue, or even language, different attri-
butes of the reference may vary such as the format or the fields composing the reference. 在
物理, 例如, titles are often omitted.
The important point is that, apart from the stylistic rendition of the reference, its contents are
determined by the cited CU; 因此, to within stylistic variations, the reference to a CU will be
Quantitative Science Studies
1403
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
the same in any paper. 在本文中, the reference determines the existence of a directed edge
between two CUs: the citing and the cited one.
2.1.3. 引文
There is no universal agreement on the distinction between reference and citation, and the two
terms are often used interchangeably (奥特曼 & Crosas, 2014; Daquino et al., 2020; Osareh,
1996; Price & 理查森, 2008).
One distinction proposed in Gilbert and Woolgar (1974) is that “reference” refers to the
works mentioned in the reference section or bibliography of a paper. A reference may be men-
tioned once or many times in an article. Each of these mentions is considered a citation.
The distinction is crucial to our understanding of the citation graph. If we look at what goes
in the body of a paper, we may find, 例如, “Austen, J. (2004). pp 101–104.” We note
that this textual artifact contains two parts. The first one is “Austen, J. (2004),” which we call a
reference pointer. A reference pointer is, 一般来说, a textual means that is used to denote a
single bibliographic reference in the reference section when mentioned in the body of a paper.
The second part of the citation is composed of some additional information, 在这种情况下
“pp 101–104,” which may help the reader locate specific information within the cited paper.
Note that the same reference pointer can occur several times in a paper and may have differing
additional information, such as “pp 10–25” and “pp 110–120.”
所以, we can say that a citation is composed of the combination of the reference
pointer with the (optional) information added to it in the paper’s body. The optional informa-
tion in the paper’s body may be referred to as a form of context for the citation. This implies
that there is a many-one relationship between citations and references, a fact that is supported
by some discussions on the topic, for example “… the second necessary part of the citation or
reference is the list of full references, which provides complete, formatted detail about the
来源, so that anyone reading the article can find it and verify it.” (维基百科, 2021).
2.1.4. Reference annotation
We shall call this extra information, such as “pp 101–104,” reference annotation. 在本文中,
the reference annotation consists of all the information added to a reference pointer to qualify
how it is used. This information is not part of the reference and can change depending on how
that particular resource is used.
The Citation Typing Ontology (Shotton, 2010) is replete with examples of other kinds of
annotations such as “refutes,” or “ridicules,” which are clearly about the relationship between
the citing and cited documents. In the Microsoft Academic Graph (Sinha, Shen et al., 2015),
the context—the text surrounding a citation in the source document—may be recorded as
another form of annotation. The OpenCitations ontology (Daquino et al., 2020) contains a
class called annotation10 attached to the in-text citation and to a reference which has a similar
角色. 这里, we do not need to distinguish between the context of a reference pointer and its
reference annotation: For our purposes these two concepts are the same, however it may be
that certain applications will require some finer distinctions.
These definitions differ slightly from those in Daquino, Peroni, and Shotton (2018) 和
Daquino et al. (2020), where a reference (called a bibliographic reference) and a reference
pointer are manifestations of a citation. 而且, in our example, the part “pp. 101–104”
is a reference annotation, whereas in Daquino et al. (2020) it is a specialization of the citation.
10 https://www.w3.org/ns/oa#Annotation
Quantitative Science Studies
1404
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
We do not specifically model the concept of specialization, as it can be inferred from the con-
tent of the reference annotation. 还, in Daquino et al. (2020) the pointer may include addi-
tional information, but the citation does not.
Summing up, we consider a reference annotation as a “box” that can contain information
derived from the context of a reference pointer.
Generally speaking, the Citation Context Analysis (CCA), whose basis was first developed in
the early 1980s, is the syntactic and semantic analysis of citation content, used to analyze the
context of research behavior (Freeman et al., 2013). CCA has been used as a promising addition
to traditional quantitative citation analysis methods. One of the main aspects of CCA is that it
incorporates qualitative factors, such as how one cites. In Daquino et al. (2020) this idea is
captured by the concept of citation function, which is the function or purpose of the citation
(例如, to cite as background, extend, agree with the cited entity) to which each in-text reference
pointer relates. In our proposal, this qualitative factor, or citation function, can be located in the
reference annotation, and it could be inferred from the context of the reference pointer.
Even in a citation graph that represents conventional citations it is necessary to be able to
attach information to a reference to create proper citations. 然而, in some citation graph imple-
mentations, this is impossible, because the reference relationship is represented as a directed
but unannotated edge. 如上所述, an exception is the Microsoft Academic Graph, 哪个
contains two kinds of edges between publications: unannotated edges and edges annotated
with context. The reason for this omission may be the difficulty of collecting the relevant infor-
运动; it may also be that it is not needed in the computation of most bibliometrics.
2.1.5. Part-of
The part-of relationship exists between two citable units in the graph; it describes the situation
where one citation unit is somehow “contained” in the other. This is the case of papers pub-
lished in an instance of a venue (例如, 这 2020 version of the ACM SIGMOD), and these issues
being part of the venues themselves (例如, ACM SIGMOD). This information is present for
example in databases such as MAG and AMiner.
In the case of data, the part-of relationship is particularly important. Many databases and
data sets have a hierarchical structure and may be cited at different levels of detail.
2.1.6. Database categories and citation
There is a broad spectrum of databases for which citation is appropriate. In discussing data
citation it is helpful to divide them into three rough categories.
(西德:129) Static databases, which are used to support claims in a publication. These are typically
“one-off” results of a set of experiments. For these databases, systems such as Mendeley11
store data alongside the publication, so that a citation to the publication also serves as a
citation to the data. Data journals (Candela et al., 2015) (IE。, journals publishing papers
describing data sets) are also employed as proxies to cite static data sets.
(西德:129) Evolving databases of source data such as weather data (Philipp, Bartholy et al., 2010) 或者
satellite image data (Shanableh, Al-Ruzouq et al., 2019) that are collected for a wide
range of purposes. Zenodo12, like Mendeley, stores data together with its representative
出版物. 然而, a publication about a data set and the data set itself can also have
11 https://www.mendeley.com/
12 https://zenodo.org/
Quantitative Science Studies
1405
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
separate and unrelated DOIs. In this case the citation to the publication and to the data-
base are distinguished. 而且, it allows multiple versions of the same database to be
deposited, with new DOIs for each one, thus keeping track of usage statistics like the
number of downloads and views on each version. A citation to the database, or even to a
document that describes the whole database, is generally regarded as inadequate. Usu-
盟友, only a portion is used; 因此, one needs to know the part (the sensor, the location of
图像, or the time range) from which the data was extracted.
(西德:129) 最后, we have curated databases. These have largely replaced conventional biological
reference works (Buneman et al., 2008), and like the works they replace, involve sub-
stantial human effort. One advantage is that they are readily accessible and easy to
搜索. 而且, there are few limits on their size and complexity, and they can evolve
rapidly with the subject matter. 对于这些, the citation is a complex issue but it is just as
crucial for curated databases as it is for the reference works that they replace.
The distinction between these three categories is not sharp, and there are many examples
that lie in the overlap. 例如, most source data databases involve a degree of curation.
2.2. Existing Limitations of the Citation Graph
Although implementations of the citation graph differ, the basic model consists of a directed
graph G = (V, 乙 ), where V is the set of papers and E ⊆ V × V is the set of directed edges cor-
responding to the citations among them: An edge hp1, p2i connects the papers p1 and p2, if p1
cites p2. The following limitations of this simple model are obstacles to the representation of
data citation, but can already be seen in conventional citations to papers.
2.2.1.
Lack of context
Although in the basic model of the citation graph the nodes often contain information such as
the title, the list of authors, or the venue of publication, it is lacking the information about the
context of the citation, 那是, all that kind of information that could be inferred from the con-
text of the reference pointers, such as the specialization of the citation or the citation function.
The only information provided by the edge hp1, p2i is that p1 cites p2, but it does not specify
the why or the how of this citation. 在文献中, we find the contextual citation graphs,
which make apparent the textual contexts of each citation (Bird, Dale et al., 2008; Daquino
等人。, 2020; Lo, 王等人。, 2019). These graphs contain information about reference anno-
tations, which is what, in this work, we consider as the citation context.
Note that a lack of citation context is an issue that is related to not only data citation but the
whole scientific citation infrastructure and ecosystem. How one document is cited in another,
whether cited as a piece of evidence or a tool, could greatly influence how the scientific bib-
liographic universe is built and how credit should be assigned between researchers.
2.2.2. Versions
理想情况下, the papers in the citation graph should only cite papers in the past (IE。, papers that
already exist when the new paper is introduced in the graph [Lo et al., 2019]). If this is the
案件, the citation graph is a DAG (Directed Acyclic Graph).
然而, this often is not true because some of the papers in V go through revisions and
modifications. This happens for many reasons and with many variations. Among the possible
案例: It may be that several copies of one work are to be found on the internet; that one ver-
sion is an “abstract” and is published in some conference proceedings, and a “full version” is
Quantitative Science Studies
1406
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
later published in some journal; or that one version is published in some archive online and
then a fully fledged paper is released in a conference or journal.
To receive credit, it is generally in the authors’ interest to have these documents seen as
一. What appears to happen in Google Scholar, 例如, is that all versions are clustered
一起, and one of them, the “main” version, is selected to be the recipient of all references.
Consider the following situation: document A is published, and a document P citing A is
subsequently published. Document B, a revision and possibly an extension of A, is then pub-
列出, taking A’s place in the graph. If this new version B contains new outgoing citations to P,
then a cycle is created, and the graph is no longer a DAG (P → A ⇝ B → P). This problem may
be solved by separating A and B.
Another source for cycles in citation graphs that cannot be avoided are papers by the
same authors created at the same time (例如, a full paper written together with a demo
paper or extended abstract). 在这种情况下, the problem can be solved, 例如, 通过骗局-
flating the papers.
Another problem arises when the system, for some reason, decides that B becomes the
“main” representative of the publication. 在这种情况下, what happens with services such as
Google Scholar is that the references first given to A are rerouted to B. This can be confusing
as the reference annotation (例如, the page number) may no longer be valid.
2.2.3. Citations to data
One of the primary roles of data citation is to give credit and attribution to the work of data
creators and curators (CODATA-ICSTI Task Group on Data Citation Standards and Practices,
2013). If integrated into the citation graph data citations can be represented and analyzed as if
they were conventional citations, with data CUs and corresponding authors receiving citations
and thus credit for their work. 然而, services such as Google Scholar or Scopus do not
allow databases into their citation graph.
Data journals (Candela et al., 2015) enable the publication of papers describing a database
that works as a proxy for it and its authors and receives its citations. This is a possible solution,
but it is not complete as it does not consider citations referring to general queries.
To give appropriate credit to the contributors to the various parts of a complex curated data-
根据, one approach to data citation (Buneman, Christie et al., 2020) is to automatically create
short papers, citation summaries, for each citable part of the database and publish them in a
dedicated online journal. This enables the contributors to receive proper bibliometric credit for
their contributions to the database. In this approach, a new summary for a view is generated
whenever that view changes substantially. This summary can then be included in the current
implementations of citation graphs and receive citations.
To conclude, unless there is some form of representation of the cited database or the cited
query in the form of a paper or journal, current citation graphs do not include databases as
nodes and citations to data as edges.
3. EXTENDING THE CITATION GRAPH
We describe two key extensions to the citation graph needed to deal with both the structural
complexity and evolution of databases. These extensions already exist in a limited form in
some implementations of the citation graph. 然而, we need to specify them precisely
and understand how they help with the limitations described above and with data citations.
Quantitative Science Studies
1407
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
数字 1. Use of references and reference annotations. Each reference is an edge connecting one citing unit to the cited one, 和, if it exists, 它
is unique. One reference may have one or more reference annotations, each giving rise to a citation.
What we propose is independent of any specific implementation of the citation graph and, 为了
大部分, it can be incorporated as extensions to those implementations rather than requir-
ing a completely new implementation of the supporting database.
3.1. Reference Annotation
As discussed above, a reference is represented by an edge in the citation graph. 然而, 到
represent a citation accurately, we need to add reference annotations. 那是, 我们需要
annotate the edges. 很遗憾, most data models currently implemented do not support
data on edges13, so for consistency with these models, our diagrams include a new kind of
node rather than a new kind of edge.
Consider Figure 1. Two papers, P1 and P2, are represented with circular nodes. We use
these nodes to represent citable units. They are annotated with all the information that usually
constitutes one reference, such as title, authors, year of publication, journal name, and DOI.
In this example P1 references P2. We can imagine the reference appearing in the “Refer-
ences” section of P1 as something similar to “Johansson, L. C. 等人. (2019). XFEL structures
of the human MT 2 melatonin receptor reveal the basis of subtype selectivity. 自然, 569
(7755), 289–292. 土井: 10.1038/s41586-019-1144-0.” The use of this reference in the paper
is reflected by the presence of the reference edge between P1 and P2 and the reference node
reference_1. This is a different kind of node, which contains information such as the edge
类型 (reference), the timestamp of when the citation was registered by the system and the type
of reference (in this case from a paper to another paper). The actual information contained by
the node can be modeled according to whatever model we decide to follow (例如, the afore-
mentioned Open Citation ontology).
Suppose now that P1 cites P2 twice. Each time, it does not merely refer to the whole paper
P2, but specific parts of it. The node reference_1 has two other neighbor nodes, 被称为
reference annotation nodes, ra_1 and ra_2. These two nodes contain the information
describing the reference annotations found in P1 used to cite P2, such as the context, 参考-
ences to particular tables or images, comment on the nature of the citation (例如, 那
authors of P1 agree or disagree with P2). In the example, these annotations carry page numbers.
因此, the combination of reference_1 with ra_1 makes one citation.
13 Property graphs are an exception because they allow data to be assigned to edges.
Quantitative Science Studies
1408
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
Reference and reference annotation nodes are the addition that we make to the citation
graph to face the first problem.
3.2. Subsumption
Often new documents take the place of older versions, becoming also the recipients of both
new and old citations. This behavior is handled behind the scenes by some existing implemen-
tations of the citation graph (notably Google Scholar). To deal with this phenomenon transpar-
ently, we propose the introduction in the citation graph of a new relation, called subsumes.
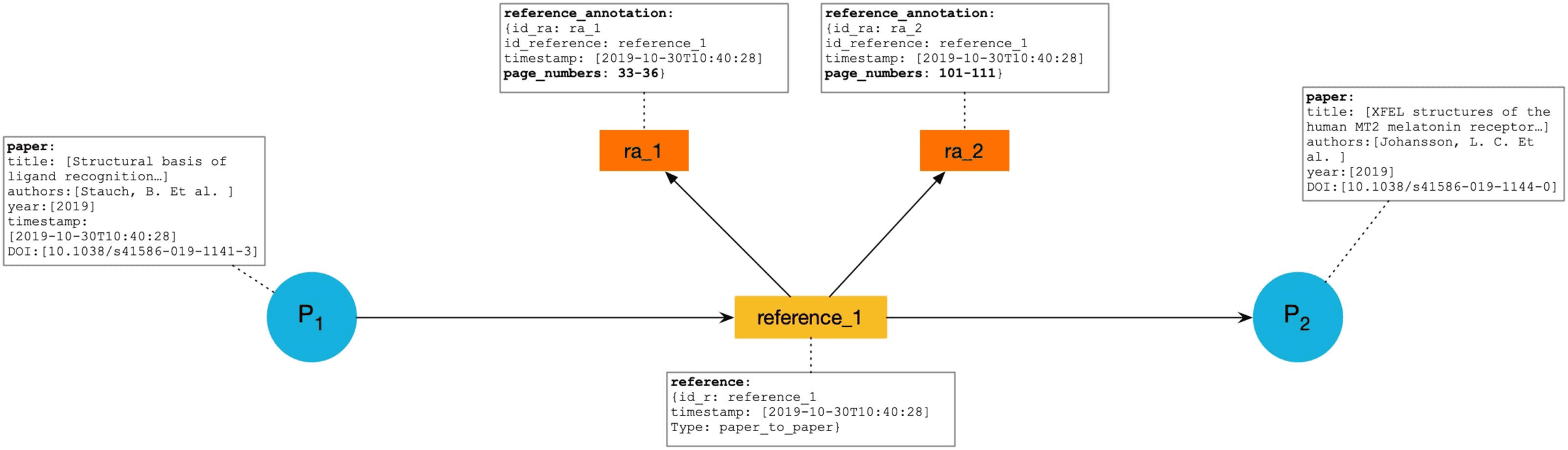
图中 2 we see a situation similar to the one of Figure 1, where P1 is citing P2 at time 1.
2, is published and inserted in the cita-
2 should also have a version number or something that
2 and P2 indicates that the former is a
现在, imagine that a new version of the same paper, 磷 0
tion graph at time 2. The reference for P 0
distinguishes it from P2. The relation subsumes between P 0
new version of the latter, 并且是, from now on, the paper to consult and reference.
In some scientific areas, a journal “paper” P 0
2 may be treated as a version of an earlier con-
ference “abstract” P2, even though the two differ substantially. Because of this we do not want
to destroy the original link from P1 to P2; to do so would be to “rewrite history” and remove
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 2. The “subsumes” relation between two CUs.
Quantitative Science Studies
1409
Data citation and the citation graph
information from the graph, and we strongly feel this should not be the case with the citation
图形. The subsumes relation is present to indicate that one paper is a version of another and,
关键地, that author credit can be transferred from the subsuming paper to the subsumed
纸. 一方面, the transfer of credit enables a more comprehensive measure of author
contributions (例如, increasing the number of citations on the latest version of the publication).
另一方面, credit transfer also transparently reflects the impact that the publication, 见过
as the aggregation of its different versions, has on the research community. Different types of
subsumption can be defined, such as the kind of subsumption that propagates the citations to
the single papers to their journal, thus computing its impact factor.
It would be wrong to transfer the credit for writing a paper to more than one other paper, 所以
the subsumption relation is many-one. It is necessarily acyclic, thus it is a forest with the roots
of the trees in that forest being the papers that are designated to receive the credit. It may be
useful to have a term for a root node on the subsumption graph, perhaps primary citable units
(PCU). It is interesting to note a similar approach in the MAG14, which lists the CU P2 under
the PCU P 0
2 distinct, and reports, 例如, “124
citations” for P2, “325 citations” for P 0
2, keeps the citation count for P2 and P 0
2, “449 citations for all.”
2 but adds, to P 0
4. DATA IN THE CITATION GRAPH
Here we discuss how we place databases in the citation graph. We shall find that the two
extensions we have discussed—edge annotation and subsumption—are essential to accom-
modating databases. 尤其, they allow us to deal with databases, which tend to be
updated and thus change much more frequently than papers. We could treat each version
or instance of the database as a distinct document, but—at least for author credit—this would
be a limitation, if not counterproductive.
First of all, we use the term “database” in the most general sense to refer to a conventional
relational database, an ontology, some form of graph database, or a database that is a collec-
tion of files (Buneman et al., 2016). One might then say that anything one has termed a data-
base is a citable unit. The problem is that parts of the database may also be citable units. 这
reason we need to discuss parts of the database is twofold: 第一的, where in the database one
finds something is, like page numbers, a form of location or partial provenance; 第二
authorship may vary with what part of the database is being cited (Buneman et al., 2016).
With “part” of a database we intend a view (Buneman et al., 2016). A view is a query which
we again generalize to being anything from a relational query for a relational database, A
directory path or URI for a collection of files, or some query in one of the several languages
that have been developed for ontologies and graph databases. It is assumed that the database
administrators will define these views and hence the citable units. MODIS (正义, Vermote
等人。, 1998) is an example of a large evolving database of Earth images for which various
subcollections have different authorship; and GtoPdb (Southan, Sharman et al., 2015) 是一个
complex curated relational database in which authorship is represented within the database
and can be assigned to views determined by the curators.
4.1. Part-of and Reference Annotation
考虑, for simplicity, the case in which the database is static, or that we are only interested
in representing citations for one version of the database (we address the more complex case of
dynamic databases in the next section). The first observation is that by defining the CUs as
14 https://tinyurl.com/y9clyx8d, retrieved March 16, 2020
Quantitative Science Studies
1410
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
意见, we immediately obtain a part-of relationship: view V1 is a part of view V2 if V1 can be
answered from the result of V2. 正式地, V1 is part of V2 if there is a query Q such that for all
possible instances of the database, V1(D) = Q(V2(D)).
We have already discussed reference annotations and the information they carry. Among
other things, they contain information about where in the cited document the relevant infor-
mation being cited is to be found. If we look at data citation, this notion of location has much
greater importance. 例如, the DataCite schema (DataCite Metadata Working Group,
2016; Starr & Gastl, 2011) contains the support for the depiction of geospatial data, with prop-
erties such as GeoLocation and in particular the subproperty GeoLocationBox, 哪个
specifies a bounding box, that is the spatial limits of a box. Most generally we can describe
the “location” in the database as a query that extracted the relevant information. This is the
approach taken in systems that provide accurate provenance (Pröll & Rauber, 2013). It meshes
perfectly with what we are suggesting: The query used to extract the data is a fundamental part
of the data citation itself, and the query—or possibly a URL which contains that query—is an
essential part of the reference annotation in the citation.
Many approaches can now be defined to decide how to introduce the CU corresponding to
data in the citation graph. Here we explore two possibilities, stemming from two of the most
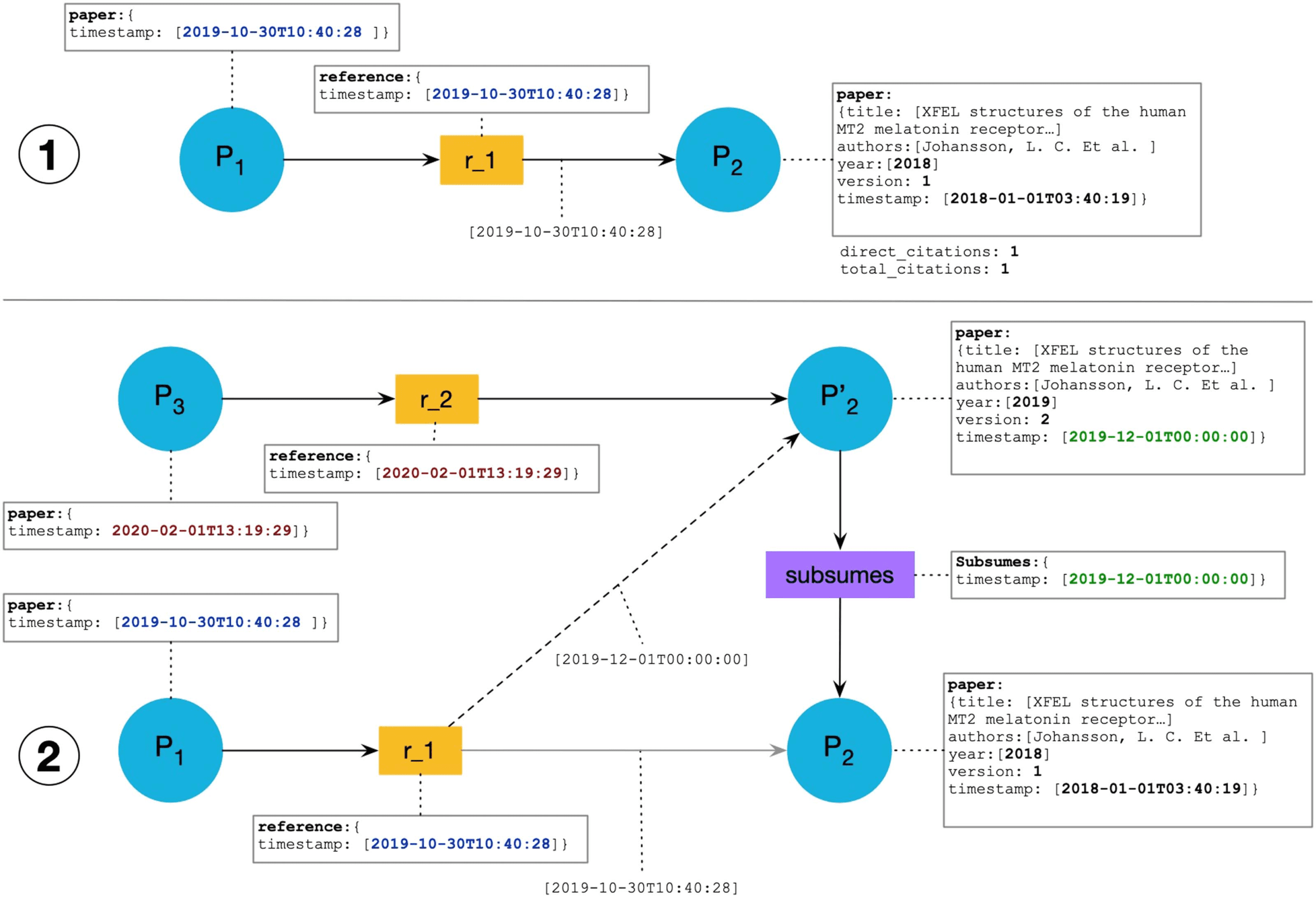
used strategies in the research world today. We exemplified these two possible strategies in
数字 3.
In Figure 3A we see that a database is represented with a node, DB1. A whole database is a
citable unit, and every time a paper wants to cite data in that database, it cites the entire data-
根据. The reference annotations contain the queries to get the cited data. The paper P1 presents
two citations to DB1. 所以, it has one reference and two reference annotations containing
the two different queries being used. P2 is citing DB1 only once. The total count of citations to
DB1 is two in this case.
With this solution DB1 is the only recipient of citations. This means that its number of citations
can become very high. 另一方面, it may happen that the rightful authors and curators of
the parts of the database being actually cited do not receive any credit for their work.
In Figure 3B we see the strategy adopted by the RDA. Every time a paper cites a data subset
extracted through a new query, a citable unit is created in the citation graph; we represent this
CU as a view, corresponding to that query. 在这种情况下, P1 is citing DB1 twice by using two
different queries, thus there are two distinct references, corresponding to the two views being
引用, V1 and V2. P2 citing DB1 with the query Q3, generates another view (IE。, V3).
With this solution, new views are created every time it is necessary. This can produce an
explosion in the number of nodes in the citation graph, many of which receive only one cita-
的. 然而, in this way it is possible to cite the exact set of data extracted by the query and
to give the credit for the citation to the rightful authors of that data. 而且, the three views
of the example are connected to DB1 by a “part-of” relationship. This means that DB1 may
inherit all their citations when needed.
We note that to assign only a single CU for the whole database and dispense with the part-
of relationship fails when, 例如, authorship varies with the part of the database being
引用. This is the case with both MODIS and GtoPdb. 在这种情况下, we reiterate that it is up to
the curators or database administrators to determine the views that define the CUs.
In the case of GtoPdb, both the curators and the contributors agree that the PCU should be
the data summary (Buneman et al., 2020) for the most recent view of the database. 不幸-
内特利, the PCU is not determined by the curators but by the system that scans the dedicated
Quantitative Science Studies
1411
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3. Two examples of possible strategies when citing data. A: Always cite the database. 乙: Create a view for every new query issued, if it
does not already exist, and cite that view.
Quantitative Science Studies
1412
Data citation and the citation graph
journal and creates citation graphs. For a given database, it is the responsibility of the curators
or administrators to determine the subsumption relation. Even for conventional publications,
we believe that the subsumption relation should be determined by the authors and publishers.
4.2. Dealing with Dynamic Data: Subsumption for Data
Most databases are not static. Unlike documents, they are expected to evolve over time. 如果
versions of a database are released, 说, every year, it might be appropriate to treat each ver-
sion as a new CU. 另一方面, as we discussed, a database in the Citation Graph can
present a hierarchy of CUs connected among them through the part-of property. 甚至
though a database may change rapidly, the result of a view, part-of a database, may remain
unchanged. The lower a CU is in the part-of hierarchy, the less frequently it will change.
还, even if a part-of CU does change, we may want to treat it as a new version of the
previous CU rather than an entirely unrelated new CU, just as we treat an extended or
improved version of a paper.
Given these observations about the introduction of dynamic data, it is necessary to answer
these questions:
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(西德:129) When is it necessary to introduce a new CU representing a view?
(西德:129) If a new CU has been introduced, when can it be considered a new version of the pre-
vious CU or an entirely new entity?
(西德:129) If a new CU has been introduced, how do we connect older CUs with the new ones and
still keep track of their citation counts?
The answer to the first two questions can only be given by the database administrators.
Every time a new version of the database is released, the administrators go through the differ-
ent CUs that compose the part-of hierarchy of the database and decide which ones need a
new version. Recall that subsumption was needed to transfer credit, in the case of papers, 从
one CU to another: the primary CU (PCU) (IE。, the root of the part-of hierarchy). The same can
be done with data.
As we have defined CUs by views when the database changes, we only need to consider
creating a new CU if the view changes. More precisely if D and D 0 are successive versions of
the database and V is a view, if V(D) = V(D 0) the reference for V(D) needs no change, and no
new CU is necessary. However if V(D) ≠ V(D 0), we may want to create a new CU.
Once it has been decided that a new CU needs to be created, it is necessary to determine
whether the CU associated with V(D 0) is a new version of the CU for V(D), or whether it is,
反而, an entirely new CU. The model we propose accommodates both the possibilities;
再次, this is something that the database administrators or curators can decide. If the content
is different in the sense that there is some kind of structural change, then an entirely different
CU may be appropriate. 而且, if the authorship changes, then a different CU may be
desirable, as the two versions of the same CU are typically expected to have the same author-
船. These are only two examples of reasons why the DBAs may decide to consider the new
CU a new, 独立的, 实体.
另一方面, normally the change will be such that we want the CUs associated with
V(D) 和V(D 0) to be versions of each other, and the PCU can now become the later version V
(D 0). This preserves the accuracy of the references and allows credit to accumulate on the
latest version of the view.
Quantitative Science Studies
1413
Data citation and the citation graph
In this second case, it is possible to connect the CU representing V(D) to the one repre-
senting V(D 0) through the subsumption relationship. This new relationship has precedence
over the part-of relationship, and thus new citations to the older version will be propagated
to the new CU, and not upward to the older hierarchy.
5. 讨论
Because citation graphs are currently unsuited for representing databases as first-class citizens,
we have proposed how to instead extend them to represent data citation in the citation graph.
除其他事项外, this allows us to capture the many citations given to databases and to give
credit to the relevant authors or contributors. The new model that we propose is based on a
few adjustments, and builds on emerging practices in the world of data citation. 首先, 它
has the goal of enabling easy adoption, as it is proposed as an extensions of existing models
without requiring drastic changes. We argue that, with these extensions of the current model
for citation graphs, we can fully achieve the goal of enabling data citation without jeopardiz-
ing the existing infrastructures.
The main limitation of existing models on which we have focused are the lack of context on
citations between citable units; the inability to deal with different versions of the same CU; 和
consequently the inability of introduce data, data evolution, and data citation (down to citable
portion of a data set) in the citation graph. We showed how, by solving the first two problems
through the introduction of reference annotations and the subsumption property, we are also
able to model data citation appropriately in the citation graph.
Unlike traditional scholarly publications, databases present a greater range of granularities
and are subject to more frequent change. Concerning the granularity of data, although it is
possible to consider various scenarios, we work with two main cases: either only the whole
database is treated as a node, or each time a new query is issued, a new node is added to the
图形, connected to the whole database through a part-of relationship.
The first solution is similar to what already happens with papers in data journals. 在这个
案件, the whole database is represented through a single CU (IE。, one node in the graph).
Every time a paper cites data in the database, the citation goes to the database. 信息
such as the query and the rightful authors of the citation may be inserted in the reference anno-
tation of the citation. This solution is simple, but gives all the citations to the whole database,
thus without explicit recognition for the rightful curators of the cited data. 所以, 更多的
computations are necessary to obtain the citation counts of the single queries and the corre-
sponding authors.
With the second solution, which follows the RDA specifications (Rauber, Asmi et al., 2015),
every time a new query is issued to the database, a new CU (因此, a new node) is created. 在
这个案例, the graph represents explicitly what is cited, and thus the rightful owners receive
their citations without further computations. 然而, this solution may result in an explosion
of nodes. To mitigate this problem different techniques could be deployed. 例如, 它
could be possible to use algorithms of query containment to decide when a query behind a
citation can be answered from a CU already deployed. 在这种情况下, that CU could receive that
citation, instead of creating a new node. 当然, query containment is, 一般来说, an NP-
hard problem, and it could become computationally prohibitive to exploit this solution, 在
particular in situations where many nodes have already been created. 或者, 系统
could present to the interested user a series of precomputed queries, corresponding to already
instantiated CUs, which may suit their citing needs. 这样, the system already knows to
which node to assign the citation.
Quantitative Science Studies
1414
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
We also observe that it could be possible to extend the proposed data model where, 反而
of nodes presenting the metadata of the papers, the CUs are represented using or including the
annotated full text of a paper. 这样, annotations on the paper can be used to keep track
of different types of information, such as references and reference annotations. Although this
solution has greater expressive power, it also increases the size and complexity of the model.
As already discussed, the model proposed in this paper has the advantage of being easy to
implement on top of already existing systems. A new model, considering the whole annotated
text of a paper presents new implementation challenges, and thus requires the creation of a
new application from scratch.
It is important also to note how, as of today, there are many challenges to the implemen-
tation and proper operation of data citation in general. Often the RDA guidelines for dynamic
data citation are not implemented by many databases; it is often difficult to automatically pro-
duce context and thus reference annotations that are machine readable; and there are also
many bad practices among researchers, such as that of depositing PDFs, 图片, and tables
of their papers in data repositories, calling them research data. Although there are still many
hindrances to the correct implementation of data citation, the research community has still
showed a great desire for the implementation of common techniques and best practices for
the correct application of these guidelines. Databases such as Eagle-i15 already provide data
citation snippets, whereas others, like GtoPdb, automatically produce PDFs of their pages to
allow an easier citation of their data in form of CUs. 因此, it is our conviction that as data
citation gets more traction and is implemented appropriately, it would be crucial to account
for it and integrate such information in the common citation graph. 尤其, a model such
as the one we propose in this paper will allow a better and fairer implementation of data cita-
tion to be achieved, and will also benefit all researchers and become more and more needed
as we transition toward the fourth paradigm of science. The more we learn about the current
limits of data citation and how to address them, the faster we will come to the final goal of a
correct system for citing data.
Considering new possible research problems, we note that the citation graph in fact is,
除其他事项外, a historical record, 那是, a record of how researchers interacted with
information and other works to build their expertise and new knowledge. Given this interpre-
站, then the graph should not be rewritable, 那是, it should not be possible to rewrite
历史. 所以, the graph should be a timestamped “append-only” structure in a way sim-
ilar to the distributed ledgers. 因此, it should only be possible to insert data in it without the
possibility to overwrite or modify already existing information.
Among others, these requirements are necessary for the computation of impact factors
(Garfield, 2006) where it is necessary to know the number of citations received by a journal
in the past 2 年. It is therefore mandatory that this information is not modified over time.
This is true also for other types of statistics that researchers may be interested in.
在我们的例子中, we have taken care to timestamp every element of information to make
this possible. The timestamps in particular indicate the moments the events “occurred” (例如,
when a citation happened), not when they were inserted in the graph. 然而, 有
several issues concerning the semantics and representation of temporal information in the cita-
tion graph that require further investigation.
If this property is correctly implemented, it should enable one to perform different types of
query on the graph. 那是, past versions of the database should be accessible for accurate
15 https://www.eagle-i.net/
Quantitative Science Studies
1415
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
provenance. 理想情况下, given the state of the graph in the present, it should be possible to rebuild
a previous state at any given time in the past. We call this property history preservation.
Several databases have this property. Weather data and geospatial data are generally accu-
mulative (Justice et al., 1998). Blockchains are also based on the idea that once added, 一个块
cannot be removed or modified, to guarantee the preservation of the history of the
交易.
另一方面, curated databases are not, 一般来说, history preserving, in the sense
that they are updated and change with time. This is particularly problematic for data citation
because one of its desiderata is that a citation should always allow retrieving or at least knowing
what was cited (Buneman, 2006). 所以, we see the correct extension and implementation
of history preservation as an important future challenge to be tackled in the implementation of
a data-aware citation graph.
6. RELATED WORK
6.1. Databases in Relation to Data Citation
As we mentioned above, there are three main categories of databases that can be cited: 静止的
databases; evolving databases; and curated databases. As a reasonable generalization, 这
problem of data citation is easily solved for the first category, as many systems and practices
have been developed for static databases. 在这种情况下, databases are treated as they were tra-
ditional publications because they are never updated, the list of authors does not change, 和
even though only a portion of the database is cited, the citation goes to the whole database. 在
这个案例, when we consider the citation graph, we have one single node representing a data-
base receiving all the citations from papers and data.
For the other two cases, data citation remains problematic. One relevant open issue is the
citation of data subsets generated on the fly by issuing general queries to the database. 在这个
案件, the main problems are how to guarantee the persistence and accessibility of the data in
the cited form and automatically provide a complete and correct textual reference for the cited
数据.
The first problem is tackled by the RDA16. The RDA is a community-driven initiative
launched in 2013 by different commissions, including the European Commission and the
US government’s National Science Foundation. Its goal is to build the social and technical
infrastructures to enable open sharing and reuse of data. The RDA “Working Group on Data
引文: Making Dynamic Data Citable” ( WGDC)17 (Rauber, Ari et al., 2016) has been work-
ing in recent years on large, dynamic, and changing data sets. Although the WGDC first
focused on RDBMs as the first forms of pilot solutions, many other types of databases followed
(XML, CSV, files, Git repositories, distributed databases such as VAMDC (Zwölf, Moreau
等人。, 2019), and multidimensional data cubes such as NetCDF/CCCA (Schubert, 2017)).
The working group has finished the development of its guidelines, and has now moved
on into an adoption phase.
尤其, among the goals of the RDA WGDC (Rauber et al., 2015), there is the iden-
tification and citation of arbitrary views of data. As potential solution, WGDC recommends an
identification method based on assigning PIDs to queries, that are then used as proxies for the
data subset to be cited. The access to a data subset is enabled by reissuing the stored query and
16 https://www.rd-alliance.org/
17 https://www.rd-alliance.org/groups/data-citation-wg.html
Quantitative Science Studies
1416
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
a citation is associated with the PID of the query identifying the data (Rauber et al., 2016). A
PID is an identifier meant to uniquely and persistently (IE。, continually during the course of
时间) identify an object such as a publication, 数据集, or person, usually in the context of
digital objects that are accessible over the internet. Considering the citation graph, this method
based on PID adds a new citable unit every time a new query is cited and requires to check
query equivalence (and/or containment) to avoid the creation of a new citable unit for an
already cited query.
The second aspect is characterized as a computational problem (Buneman et al., 2016) 和
some solutions based on “query rewriting using views” (戴维森, Buneman et al., 2017) 有
been proposed, targeting general queries citations for relational databases (Alawini, 戴维森
等人。, 2017乙; 吴, Alawini et al., 2018; 吴, Alawini et al., 2019) and graph databases
(Alawini, 陈等人。, 2017A).
全面的, most approaches do not consider the evolution of data and the fact that databases
are not monolithic objects. When those features are considered, some of the existing models
propose the trivial solution of treating databases and views as standalone objects. In our
模型, 反而, we explicitly model citable units and their subsumption relationships, 哪个
allow the appropriate distribution of credit.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
6.2. Available Citation Graphs
The citation graph, or citation network, as a model of a graph where the vertices represent
academic papers, has long been in use in the literature (Price, 1965) and has evolved consid-
erably. There are different implementations of citation graphs, which favor certain aspects of
the information regarding publications, citations, and authors, depending on the considered
任务. Some of them are provided explicitly for navigational purposes (例如, the Open Academic
图形 (OAG)). 其他的, 反而, are the backbone of services allowing search and exploration
of scholarly works; these are the Microsoft Academic Graph (MAG), Google Scholar, 考研,
Web of Science, Scopus, and Semantic Scholar.
The Microsoft Academic Graph (MAG) (Färber, 2019; 王, Shen et al., 2019) is the back-
bone of the Microsoft Academic Service (MAS), and its nodes represent five different entities:
field of study, 作者, 机构, 纸, venue, and event. An RDF version of MAG, 被称为
Microsoft Academic Knowledge Graph18 (MAKG) is also available and connected to the
Linked Open Data cloud.
The Open Academic Graph (OAG)19 is an open-source citation graph generated from the
linking of two other large academic graphs: MAG and ArnetMiner (or AMiner) (Wan, 张
等人。, 2019) (a free online service used to index, 搜索, and mine big scientific data), 设计的
to search and perform data mining against academic publications available on the Internet.
This graph contains entities similar to those of MAG, and it can be used as a unified sizable
academic graph for the study of citation networks, paper content, and the integration of mul-
tiple academic graphs with different fields and information.
The OpenAIRE Research Graph (Manghi et al., 2019) is the implementation of a fully
fledged Open Science Graph. It is a collection of metadata and links connecting research enti-
领带, including articles, data sets, 软件, ETC。, together with other elements such as organi-
zations, 资助者, funding streams, 项目, research communities, and data sources20. 这
18 https://ma-graph.org
19 https://aminer.org/open-academic-graph
20 https://graph.openaire.eu
Quantitative Science Studies
1417
Data citation and the citation graph
graph today contains around 110 million publications, 10 million data sets, 180,000 软件
research products, 和 7 million other products with 480 million links between them. The aim
of the OpenAIRE RG is to bring discovery, 监控, and assessment of science into the
hands of the scientific community (Fava, 2020).
The PID Graph (Fenner, 2020; Fenner & Aryani, 2019) is another example of implementa-
tion of a citation graph based around the concept of PID (Persistent IDentifier). The PID Graph
targets citations aggregation: for all versions of a data set or software source code; for all data
sets hosted in a particular repository, funded by a particular funder, or aggregated by a partic-
ular researcher; and for a research object, such as a publication or the data used in the paper,
together with the software and samples used to create the data set. The PID graph adopts the
outputs of the RDA WGDC. One peculiarity of the PID graph is that it includes not only meta-
data about connections but also metadata about the resources and implicit relations about
resources identified by the PIDs. This enables queries based on these metadata, making them
more expressive.
Google Scholar, 考研, Web of Science, and Scopus are all relevant services providing
citation graphs, but their data is not directly accessible as a graph.
Google Scholar is an open general-purpose graph focusing on traditional publications and
covering multiple languages and publication venues. 考研, 反而, focuses on medicine
and biomedical sciences (罗伯茨, 2001). It covers medical bibliography from 1949 直到
今天, with abstracts, review articles, and free full-text articles. Web of Science ( WoS) 提供
subscription-based access to multiple databases with comprehensive citation data for many
different academic disciplines (Falagas, Pitsouni et al., 2008). 最后, Scopus is Elsevier’s
abstract and indexing (closed) database featuring open access titles, indexes of web pages
and patents, and links to both citing and cited documents (Burnham, 2006). Although PubMed
is an important resource for clinicians and researchers, Scopus covers a wider journal range,
offering also the capability for citation analysis, although limited with respect to WoS, 哪个
covers articles published before 1995. Google Scholar, 另一方面, presents all the pros
and cons of a web search engine: It can help in the retrieval also of oblique information, 但它
may present inadequate and less often updated citation information (Falagas et al., 2008).
Semantic Scholar is a project developed at the Allen Institute for Artificial Intelligence and
is an AI-backed search engine for scientific journal articles. It uses a combination of machine
学习, natural language processing, and machine vision to produce a semantic analysis of
the papers of the network and to extract figures, 实体, and venues from the documents. 这是
designed to highlight the most important and influential articles and to identify the connections
它们之间 (Fricke, 2018).
As we can see, many of these graphs and systems could work as good starting points for
the implementation of the proposed model. MAG and OAG already present the context,
which can be used as reference annotation, but lack the ability to accurately cite data
and manage their versions. 另一方面, the OpenAIRE graph is able to deal with
granularity and different versions, but it still lacks the possibility to cite its data with refer-
ence annotations; thus de facto it is still unable to deal with data citations. 尽管如此,
many of the systems implemented are close to the proposed model, and usually they lack
one aspect (like the versioning of the data or the presence of context). 所以, we believe
that a viable way forward would be to implement the approach we propose on top of the
already existing infrastructures.
Applications of the citation graphs are disparate. Some examples include prediction of user
queries over the graph; recommendation systems for the generation of suggestions leveraging
Quantitative Science Studies
1418
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
the relationships across the different types of entities; exploration of papers, 研究人员, affil-
iations, and other entities; data integration; data analysis; and knowledge discovery of schol-
arly data through expert finding, geographic search, trend analysis, review recommendation,
association search, course search, academic performance evaluation, and topic modeling
(Wan et al., 2019).
Given the vital role of citation graphs and data citation, we argue that it is of crucial impor-
tance that existing citation graphs be extended with the appropriate tools to model data cita-
tion in various forms. Most of the existing citation graph do not expose their internal data
模型. 尽管如此, we can see they focus on the same core assumption that citable objects
are atomic elements with no citable portions and where evolution through time is not consid-
埃雷德. 因此, none of the models above tackle explicitly and directly the issues linked to the
task of modeling databases and subsets of databases, as well as the evolution of citable ele-
ments through time, which is instead the goal of this work.
7. CONCLUSIONS AND FUTURE WORK
Starting from a basic model of the citation graph in which the nodes are the papers, 和
edges are the citations between them, we highlighted three limitations of this model. 他们是
the lack of context for citations, 那是, information about the how and why the citation is used
along with which part of the referenced object is used; the absence of a unified strategy of
management of the versions of the papers in the graph; and the difficulty of representing cita-
tions to databases and data generated by queries in the graph.
To deal with these limitations, we proposed an implementation-agnostic model that
includes reference annotations. These annotations contain the context of a citation (例如, 这
page numbers of the citation, the query issued to obtain the data, or the considered bounding
盒子).
We also discussed the subsumption property, which is used when a new version of a paper
or a database is introduced in the graph. This property indicates that the new version “takes the
place” of the previous one for the purpose of assigning credit. The old citations can be inher-
ited from the new version or, depending on the context, such as situations where authors have
改变了, different policies can be put in place.
Using these extensions to the basic model, we discussed how to represent data citation in
the graph. Although important, this work is preliminary, and further work is needed if we are
fully to incorporate citations or other kinds of cross-reference between databases into the cita-
tion graph.
(西德:129) Although we have used subsumption partly to deal with the evolution of citable units within
databases, we believe there is much more to be said about evolution in databases and in the
citation graph itself. We believe that all scientific databases should support “time travel”: 它
should be possible to ask queries on some previous state of the database as easily as one
asks queries on the current state. For many databases, especially “source data,” it is impor-
tant to support longitudinal queries, and this is true of the citation graph itself.
(西德:129) We have dealt with citations to databases, but what about citations from databases? 如果, 作为
happens in many curated databases, conventional citations are included within the data-
根据, then there should be few problems, but what happens when a part of one database
is created by a query from another database? How is the citation represented; and how is
it included in the citation graph?
Quantitative Science Studies
1419
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
(西德:129) 最后, once we have properly supported databases within the citation graph, 什么
kinds of bibliometric measures are possible? 我们有, 例如, h-indexes and
impact factors for conventional publications. How can we appropriately measure the
impact of databases?
We note that there is currently marginal interest to cite software and code, 虽然
interesting initiatives, such as the FORCE 11 working group21, have been taking place and
research groups are working on the topic (Alliez, Di Cosmo et al., 2020; Katz, 尼迈耶
等人。, 2016; Katz, Bouquin et al., 2019). This task presents a new set of problems, 尤其
regarding authorship, because code is often copied or adapted from other repositories, passing
from hand to hand, undergoing modifications. The characteristics of the life cycle of software
open a whole new set of problems and research questions about who is the righteous author of
that piece of cited code and who should receive credit from the citation.
致谢
The authors would like to thank the reviewers for their detailed comments and suggestions.
作者贡献
Following the CRediT guidelines22, all authors contributed equally to the conceptualization,
调查, 方法论, and writing of the paper.
COMPETING INTERESTS
The authors declare that they do not have any competing interest.
资金信息
The work was partially supported by the ExaMode project, as part of the European Union
H2020 program under Grant Agreement No. 825292. Matteo Lissandrini is supported
by the European Union H2020 research and innovation program under the Marie
Skłodowska-Curie grant agreement No. 838216.
DATA AVAILABILITY
Not applicable.
参考
Alawini, A。, 陈, L。, 戴维森, S. B., Portilho Da Silva, N。, &
Silvello, G. (2017A). Automating data citation: The eagle-i expe-
里恩斯. 在 2017 ACM/IEEE Joint Conference on Digital Libraries,
JCDL 2017 (PP. 169–178). IEEE Computer Society. https://土井
.org/10.1109/JCDL.2017.7991571, 考研: 29599662
Alawini, A。, 戴维森, S. B., 胡, W., & 吴, 是. (2017乙). Automating
data citation in CiteDB. Proceedings of the VLDB Endowment,
10(12), 1881–1884. https://doi.org/10.14778/3137765.3137799
Alliez, P。, Di Cosmo, R。, Guedj, B., Girault, A。, Hacid, 中号. S。, ……
Rougier, 氮. 磷. (2020). Attributing and referencing (研究) soft-
器皿: Best practices and outlook from Inria. Computing in Sci-
ence Engineering, 22(1), 39–52. https://doi.org/10.1109/MCSE
.2019.2949413
奥特曼, M。, & Crosas, 中号. (2014). The evolution of data citation:
From principles to implementation. IAssist Quarterly, 37(1–4),
62. https://doi.org/10.29173/iq504
Belter, C. 瓦. (2014). Measuring the value of research data: A citation
analysis of oceanographic data sets. PLOS ONE, 9(3), e92590.
https://doi.org/10.1371/journal.pone.0092590, 考研: 24671177
Bird, S。, 戴尔, R。, 多尔, 乙. J。, 吉布森, 乙. R。, 约瑟夫, 中号. T。, … Tan,
是. F. (2008). The ACL anthology reference corpus: A reference
dataset for bibliographic research in computational linguistics.
In Proceedings of the International Conference on Language
Resources and Evaluation, LREC. European Language Resources
协会. https://www.lrec-conf.org/proceedings/ lrec2008
/summaries/445.html
21 https://www.force11.org/group/software-citation-working-group
22 https://casrai.org/credit/
Quantitative Science Studies
1420
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
Buneman, 磷. (2006). How to cite curated databases and how to
make them citable. In 18th International Conference on Scientific
and Statistical Database Management (PP. 195–203). https://土井
.org/10.1109/SSDBM.2006.28
Buneman, P。, 切尼, J。, Tan, W.-C., & Vansummeren, S. (2008).
Curated databases. In Proceedings of the 27th ACM-SIGMOD-
SIGACT-SIGART Symposium on Principles of Database Systems
(PP. 1–12). https://doi.org/10.1145/1376916.1376918
Buneman, P。, Christie, G。, 戴维斯, J. A。, Dimitrellou, R。, Harding,
S. D ., … Wu, 是. (2020). Why data citation isn’t working, 以及什么
to do about it. Database, 体积 2020, 2020, baaa022. https://
doi.org/10.1093/databa/baaa022, 考研: 32367113
Buneman, P。, 戴维森, S。, & Frew, J. (2016). Why data citation is a
computational problem. ACM 通讯, 59(9),
50–57. https://doi.org/10.1145/2893181, 考研: 29151602
Burnham, J. F. (2006). Scopus database: A review. Biomedical Dig-
ital Libraries, 3(1), 1. https://doi.org/10.1186/1742-5581-3-1,
考研: 16522216
Burton, A。, Koers, H。, Manghi, P。, Stocker, M。, Fenner, M。, … Schindler,
U. (2017). Scholix metadata schema for exchange of scholarly com-
munication links. 日内瓦, 瑞士: CERN. https://doi.org/10
.5281/zenodo.1120275
Candela, L。, Castelli, D ., Manghi, P。, & Tani, A. (2015). Data jour-
nals: 一项调查. Journal of the Association for Information Science
and Technology, 66(9), 1747–1762. https://doi.org/10.1002/asi
.23358
CODATA-ICSTI Task Group on Data Citation Standards and Prac-
泰斯. (2013). Out of cite, out of mind: The current state of prac-
泰斯, 政策, and technology for the citation of data. Data Science
杂志, 12, CIDCR1–CIDCR7. https://doi.org/10.2481/dsj
.OSOM13-043
Cousijn, H。, Feeney, P。, Lowenberg, D ., Presani, E., & Simons, 氮.
(2019). Bringing citations and usage metrics together to make
data count. Data Science Journal, 18(1), 9. https://doi.org/10
.5334/dsj-2019-009
Cousijn, H。, Kenall, A。, Ganley, E., Harrison, M。, Kernohan, D ., ……
克拉克, 时间. (2017). A data citation roadmap for scientific publishers.
bioRxiv. https://doi.org/10.1101/100784
Daquino, M。, Peroni, S。, & Shotton, D. (2018). The OpenCitations
data model. Figshare. https://doi.org/10.6084/m9.figshare
.3443876.v7
Daquino, M。, Peroni, S。, Shotton, D ., Colavizza, G。, Ghavimi, B., ……
Zumstein, 磷. (2020). The OpenCitations data model. In Interna-
tional Semantic Web Conference (PP. 447–463). https://doi.org
/10.1007/978-3-030-62466-8_28
DataCite Metadata Working Group. (2016). DataCite metadata
schema for the publication and citation of research data. Version
4.0. https://doi.org/10.5438/0012
戴维森, S. B., Buneman, P。, 多伊奇, D ., Milo, T。, & Silvello, G.
(2017). Data citation: A computational challenge. In Proceed-
ings of the 36th ACM SIGMOD-SIGACT-SIGAI Symposium on
Principles of Database Systems (PP. 1–4). 纽约: ACM
按. https://doi.org/10.1145/3034786.3056123, 考研:
29051698
Falagas, 中号. E., Pitsouni, 乙. 我。, Malietzis, G. A。, & Pappas, G. (2008).
Comparison of PubMed, Scopus, Web of Science, and Google
学者: Strengths and weaknesses. FASEB Journal, 22(2),
338–342. https://doi.org/10.1096/fj.07-9492LSF, 考研:
17884971
Färber, 中号. (2019). The Microsoft Academic Knowledge Graph: A
linked data source with 8 billion triples of scholarly data. 在
ISWC (2) (卷. 11779, PP. 113–129). 施普林格. https://doi.org/10
.1007/978-3-030-30796-7_8
Fava, 我. (2020). OpenAIRE research graph: Connecting open science –
consultation phase. https://www.openaire.eu/openaire-research
-graph-open-for-comments, retrieved September 2020.
Fenner, 中号. (2020). Powering the PID graph: Announcing the Data-
Cite GraphQL API. https://doi.org/10.5438/yfck-mv39, 检索到的
九月 2020.
Fenner, M。, & Aryani, A. (2019). Introducing the PID graph. FREYA
Blog. https://doi.org/10.5438/jwvf-8a66, retrieved September
2020.
力量, M。, 罗宾逊, N。, Matthews, M。, Auld, D ., & Boletta, 中号.
(2016). Research data in journals and repositories in the Web
of Science: Developments and recommendations. Bulletin of
IEEE Technical Committee on Digital Libraries, Special Issue on
Data Citation, 12(1), 27–30.
FORCE-11. (2014). Data Citation Synthesis Group: Joint declaration
of data citation principles (中号. Martone, 埃德。). FORCE11, 桑
Diego, CA, 美国.
弗里曼, G。, Ding, Y。, & Milojevic, S. (2013). Citation content anal-
分析 (CCA): A framework for syntactic and semantic analysis of
citation content. Journal of the American Society for Information
Science and Technology, 64(7), 1490–1503. https://doi.org/10
.1002/asi.22850
Fricke, S. (2018). Semantic Scholar. Journal of the Medical Library
协会: JMLA, 106(1), 145. https://doi.org/10.5195/ JMLA
.2018.280
Garfield, 乙. (2006). The history and meaning of the journal impact
因素. JAMA, 295(1), 90–93. https://doi.org/10.1001/jama.295.1
.90, 考研: 16391221
吉尔伯特, G. N。, & Woolgar, S. (1974). Essay review: The quantitative
study of science: An examination of the literature. Science Studies,
4(3), 279–294. https://doi.org/10.1177/030631277400400305
Harzing, A.-W. K., & Van der Wal, 右. (2008). Google Scholar as a
new source for citation analysis. Ethics in Science and Environ-
mental Politics, 8(1), 61–73. https://doi.org/10.3354/esep00076
正义, C. 奥。, Vermote, E., Townshend, J. R。, Defries, R。, Roy, D. P。,
… Barnsley, 中号. J. (1998). The Moderate Resolution Imaging Spec-
troradiometer (MODIS): Land remote sensing for global change
研究. IEEE Transactions on Geoscience and Remote Sensing,
36(4), 1228–1249. https://doi.org/10.1109/36.701075
Katz, D. S。, Bouquin, D ., 洪, 氮. 磷. C, Hausman, J。, 琼斯, C。, ……
张, 问. (2019). Software citation implementation challenges.
arXiv, arXiv:1905.08674. https://arxiv.org/abs/1905.08674
Katz, D. S。, 尼迈耶, K. E., 史密斯, A. M。, 安德森, 瓦. L。, Boettiger,
C。, … Rios, F. (2016). Software vs. data in the context of citation.
PeerJ Preprints (4), e2630v1. https://doi.org/10.7287/peerj
.preprints.2630v1
Lo, K., 王, L. L。, 诺伊曼, M。, Kinney, R。, & Weld, D. S. (2019).
GORC: A large contextual citation graph of academic papers.
arXiv, arXiv:1911.02782. https://arxiv.org/abs/1911.02782v1
Manghi, P。, Bardi, A。, Atzori, C。, Baglioni, M。, Manola, N。, ……
Principe, 磷. (2019). The OpenAIRE research graph data model
(version 1.3). Zenodo. https://doi.org/10.5281/zenodo.2643199
Nature Physics Editorial. (2016). A statement about data. 自然
Physics, 12(10), 889. https://doi.org/10.1038/nphys3923
Nosek, 乙. A。, Alter, G。, Banks, G. C。, Borsboom, D ., Bowman,
S. D ., … Yarkoni, 时间. (2015). Promoting an open research culture.
科学, 348(6242), 1422–1425. https://doi.org/10.1126/science
.aab2374, 考研: 26113702
Open Polytechnic. (2020). What’s the difference between refer-
ences and in-text citations? https://www.openpolytechnic.ac.nz
/current-students/study-tips-and-techniques/apa-referencing-and
-avoiding-plagiarism/the-difference-between-references-and
-citations/ (retrieved March 2020).
Quantitative Science Studies
1421
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Data citation and the citation graph
Osareh, F. (1996). Bibliometrics, citation analysis and co-citation
分析: A review of literature I. Libri, 46(3), 149–158. https://
doi.org/10.1515/libr.1996.46.3.149
Peroni, S。, & Shotton, D. (2020). Opencitations, an infrastructure
organization for open scholarship. Quantitative Science Studies,
1(1), 428–444. https://doi.org/10.1162/qss_a_00023
Peters, 我。, Kraker, P。, Lex, E., Gumpenberger, C。, & Gorraiz, J.
(2016). Research data explored: An extended analysis of citations
and altmetrics. Scientometrics, 107(2), 723–744. https://doi.org
/10.1007/s11192-016-1887-4, 考研: 27122647
Philipp, A。, Bartholy, J。, Beck, C。, Erpicum, M。, Esteban, P。, ……
Tymvios, F. S. (2010). Cost733cat–a database of weather and cir-
culation type classifications. Physics and Chemistry of the Earth,
Parts A/ B/C, 35(9–12), 360–373. https://doi.org/10.1016/j.pce
.2009.12.010
Price, D. J. de Solla. (1965). Networks of scientific papers. 科学,
149(3683), 510–515. https://doi.org/10.1126/science.149.3683
.510, 考研: 14325149
Price, G。, & 理查森, 乙. (2008). MHRA style guide: A handbook
for authors, 编辑, and writers of theses. MHRA.
Pröll, S。, & Rauber, A. (2013). Scalable data citation in dynamic, 大的
databases: Model and reference implementation. 在诉讼程序中
这 2013 IEEE International Conference on Big Data (PP. 307–312).
https://doi.org/10.1109/BigData.2013.6691588
Rauber, A。, Ari, A。, van Uytvanck, D ., & Pröll, S. (2016). Identifica-
tion of reproducible subsets for data citation, sharing and re-use.
Bulletin of IEEE Technical Committee on Digital Libraries, Special
Issue on Data Citation, 12(1), 6–15.
Rauber, A。, Asmi, A。, van Uytvanck, D ., & Proell, S. (2015). 数据
citation of evolving data: Recommendations of the Working
Group on Data Citation ( WGDC). Result of the RDA Data Cita-
tion WG, 20.
罗伯茨, 右. J. (2001). PubMed Central: The GenBank of the pub-
lished literature. 美国国家科学院院刊-
恩塞斯, 98(2), 381–382. https://doi.org/10.1073/pnas.98.2.381,
考研: 11209037
Schubert, C. (2017). Implementing the RDA data citation recommen-
dations by the Climate Change Centre Austria (CCCA) for a repository
of NetCDF files webinar. https://www.rd-alliance.org/implementing
-rda-data-citation-recommendations-climate-change-centre-austria
-ccca-repository-netcdf, retrieved December 2020.
Shanableh, A。, Al-Ruzouq, R。, Gibril, 中号. 乙. A, Flesia, C。, &
Al-Mansoori, S. (2019). Spatiotemporal mapping and monitoring
of whiting in the semi-enclosed gulf using moderate resolution
imaging spectroradiometer (MODIS) time series images and a
generic ensemble tree-based model. Remote Sensing, 11(10),
1193. https://doi.org/10.3390/rs11101193
Shotton, D. (2010). CiTO, the Citation Typing Ontology. 杂志
Biomedical Semantics, 1(1), S6. https://doi.org/10.1186/2041
-1480-1-S1-S6, 考研: 20626926
Silvello, G. (2018). Theory and practice of data citation. 杂志
the American Society for Information Science and Technology,
69(1), 6–20. https://doi.org/10.1002/asi.23917
Sinha, S。, 沉, Z。, 歌曲, Y。, Ma, H。, Eide, D ., … Wang, K. (2015).
An overview of Microsoft Academic Service (MAS) and applica-
系统蒸发散. In Proceedings of the 24th International Conference on
World Wide Web (PP. 243–246). https://doi.org/10.1145
/2740908.2742839
Southan, C。, Sharman, J. L。, 本森, H. E., Faccenda, E., Pawson,
A. J。, … Davies, J. A. (2015). The IUPHAR/BPS Guide to PHAR-
MACOLOGY in 2016: Towards curated quantitative interactions
之间 1300 protein targets and 6000 ligands. Nucleic Acids
研究, 44(D1), D1054–D1068. https://doi.org/10.1093/nar
/gkv1037, 考研: 26464438
Starr, J。, & Gastl, A. (2011). isCitedBy: A metadata scheme for Data-
Cite. D-Lib Magazine, 17(1/2). https://doi.org/10.1045
/january2011-starr
唐, J。, 张, J。, Yao, L。, 李, J。, 张, L。, & Su, Z. (2008).
ArnetMiner: Extraction and mining of academic social networks.
In Proceedings of the 14th ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining (PP. 990–998). https://
doi.org/10.1145/1401890.1402008
Wan, H。, 张, Y。, 张, J。, & 唐, J. (2019). AMiner: 搜索
and mining of academic social networks. 数据智能, 1(1),
58–76. https://doi.org/10.1162/dint_a_00006
王, K., 沉, Z。, 黄, C。, 吴, C。, Eide, D ., … Rogahn, 右.
(2019). A review of Microsoft Academic Services for science of
science studies. Frontiers in Big Data, 2, 45. https://doi.org/10
.3389/fdata.2019.00045, 考研: 33693368
维基百科. (2021). Citing Sources. https://en.wikipedia.org/wiki
/维基百科:Citing_sources. (retrieved December 2021).
威尔克, C. (2015). What constitutes a citable scientific work? https://
serialmentor.com/ blog/2015/1/2/what-constitutes-a-citable
-scientific-work
Wilkinson, 中号. D ., Dumontier, M。, Aalbersberg, 我. J。, Appleton, G。,
Axton, M。, … Mons, 乙. (2016). The FAIR guiding principles for sci-
entific data management and stewardship. Scientific Data, 3,
160018. https://doi.org/10.1038/sdata.2016.18, 考研: 26978244
吴, Y。, Alawini, A。, 戴维森, S. B., & Silvello, G. (2018). Data cita-
的: Giving credit where credit is due. 诉讼程序 2018
International Conference on Management of Data (PP. 99–114).
ACM Press. https://doi.org/10.1145/3183713.3196910
吴, Y。, Alawini, A。, 多伊奇, D ., Milo, T。, & 戴维森, S. (2019).
ProvCite: Provenance-based data citation. 诉讼程序
VLDB Endowment, 12(7), 738–751. https://doi.org/10.14778
/3317315.3317317
Zwölf, C. M。, Moreau, N。, Ba, 是. A。, & Dubernet, 中号. L. (2019).
Implementing in the VAMDC the new paradigms for data citation
from the Research Data Alliance. Data Science Journal, 18(1), 4.
https://doi.org/10.5334/dsj-2019-004
Quantitative Science Studies
1422
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
9
9
2
0
0
7
9
0
3
q
s
s
_
A
_
0
0
1
6
6
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3