RESEARCH ARTICLE
Covid-on-the-Web: Exploring the COVID-19
scientific literature through visualization of
linked data from entity and argument mining
开放访问
杂志
Olivier Corby
, Alain Giboin
Serena Villata
, Santiago Marro
, and Marco Winckler
Aline Menin
, Franck Michel
, Fabien Gandon
, Raphaël Gazzotti
, Tobias Mayer
, Elena Cabrio
,
,
引文: Menin, A。, Michel, F。, Gandon,
F。, Gazzotti, R。, 敞篷车, E., … Winckler,
中号. (2021). Covid-on-the-Web: Exploring
the COVID-19 scientific literature
through visualization of linked data
from entity and argument mining.
Quantitative Science Studies, 2(4),
1301–1323. https://doi.org/10.1162/qss
_a_00164
DOI:
https://doi.org/10.1162/qss_a_00164
通讯作者:
Aline Menin
aline.menin@inria.fr
University Côte d’Azur, Inria, 法国国家科学研究中心, I3S (UMR 7271), 法国
关键词: argument mining, COVID-19, entity linking, linked data, 可视化
抽象的
The unprecedented mobilization of scientists caused by the COVID-19 pandemic has
generated an enormous number of scholarly articles that are impossible for a human being to
keep track of and explore without appropriate tool support. 在此背景下, we created the
Covid-on-the-Web project, which aims to assist the accessing, querying, and sense-making of
COVID-19-related literature by combining efforts from the semantic web, 自然语言
加工, and visualization fields. 尤其, in this paper we present an RDF data set
(a linked version of the “COVID-19 Open Research Dataset” (CORD-19), enriched via
entity linking and argument mining) and the “Linked Data Visualizer” (LDViz), which assists
the querying and visual exploration of the referred data set. The LDViz tool assists in the
exploration of different views of the data by combining a querying management interface,
which enables the definition of meaningful subsets of data through SPARQL queries, and a
visualization interface based on a set of six visualization techniques integrated in a chained
visualization concept, which also supports the tracking of provenance information. 我们
demonstrate the potential of our approach to assist biomedical researchers in solving domain-
related tasks, as well as to perform exploratory analyses through use case scenarios.
1.
介绍
The COVID-19 pandemic has motivated the scientific community in numerous fields of
research to contribute in a common effort to study, understand, and fight the severe acute
respiratory syndrome coronavirus 2 (SARS-CoV-2). Several data sets covering the publications
about COVID-19 and related coronaviruses and diseases have been compiled to support the
scientific community. 尤其, we focus on the COVID-19 Open Research Dataset
(CORD-19) (王, Lo et al., 2020), which gathers over 500,000 scholarly articles, 包括
超过 200,000 with full text. This deluge of ever-increasing publications in such a short time
frame suggests that it is impossible for any researcher to examine every publication and extract
the relevant information from it without appropriate support. To help researchers find publi-
cations of interest, we employ information visualization techniques to explore the data set and
identify relationships among publications that indicate those that are worthy of further
examination.
版权: © 2021 Aline Menin, 弗兰克
Michel, Fabien Gandon, Raphaël
Gazzotti, Elena Cabrio, Olivier Corby,
Alain Giboin, Santiago Marro, Tobias
Mayer, Serena Villata, and Marco
Winckler. Published under a Creative
Commons Attribution 4.0 国际的
(抄送 4.0) 执照.
麻省理工学院出版社
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
In collaboration with biomedical researchers from the French Institute of Medical Research
(Inserm)1 and the French National Cancer Institute (INCa)2, we created the Covid-on-the-Web
项目, which gathers expertise from various research fields (IE。, the semantic web, natural
语言处理, and visualization) to assist in the exploration of the COVID-19 scientific
文学. Through a series of interviews with our prospective users, we could identify a set of
meaningful use case scenarios, such as determining the right amount of certain substances in
the patients’ organism using baseline information collected from scientific articles, 分析
clinical trials to make evidence-based decisions, studying the relationship between corona-
viruses and other diseases (例如, cancer), and identifying the types of cancer that are likely
to occur in COVID-19 victims, 除其他外. Although some scenarios require exploring the
relationship between components (例如, cancer and coronavirus), others require representing
趋势 (例如, probability of cancer in COVID-19 victims) and analyzing specific attributes
(例如, details about metabolic changes caused by COVID-19). 此外, the analysis of
coauthorship is relevant to health research as it allows us to assess collaboration trends and
identify leading investigators and organizations (Fonseca, Sampaio et al., 2016). 在本文中,
we focus on using visualization to assist the resolution of user queries based on the relation-
ship between components and coauthorship networks, which allow us to answer user queries
such as “Where is research in a particular topic being performed?”
We present two contributions of the Covid-on-the-Web project to the exploration of
COVID-19 scientific literature. The first contribution refers to the Covid-on-the-Web RDF data
放, a linked version of the CORD-19 corpus, enriched via entity linking and argument mining.
现在, the Covid-on-the-Web RDF data set includes and enriches over 100,000 full-text
scholarly articles from the 47th version of the CORD-19 corpus, which corresponds to 1.3
billion RDF triples describing the articles’ metadata, an argumentation, and a named entities
(NE) knowledge graph. The second contribution corresponds to LDViz3, a visualization tool
that enables the exploration of the COVID-19 scientific literature from different perspectives,
such as coauthorship, NE co-occurrence and the relationship between claims and evidence
within publications. We demonstrate the potential of LDViz to support the exploration of
customizable SPARQL result sets extracted from the Covid-on-the-Web data set to assist the
resolution of different domain-related tasks.
Although there have been previous contributions in exploring the CORD-19 corpus
through entity linking approaches (例如, Oniani, Jiang et al., 2020; Reese, Unni et al., 2021),
to the best of our knowledge, the Covid-on-the-Web data set is the first to integrate NE, argu-
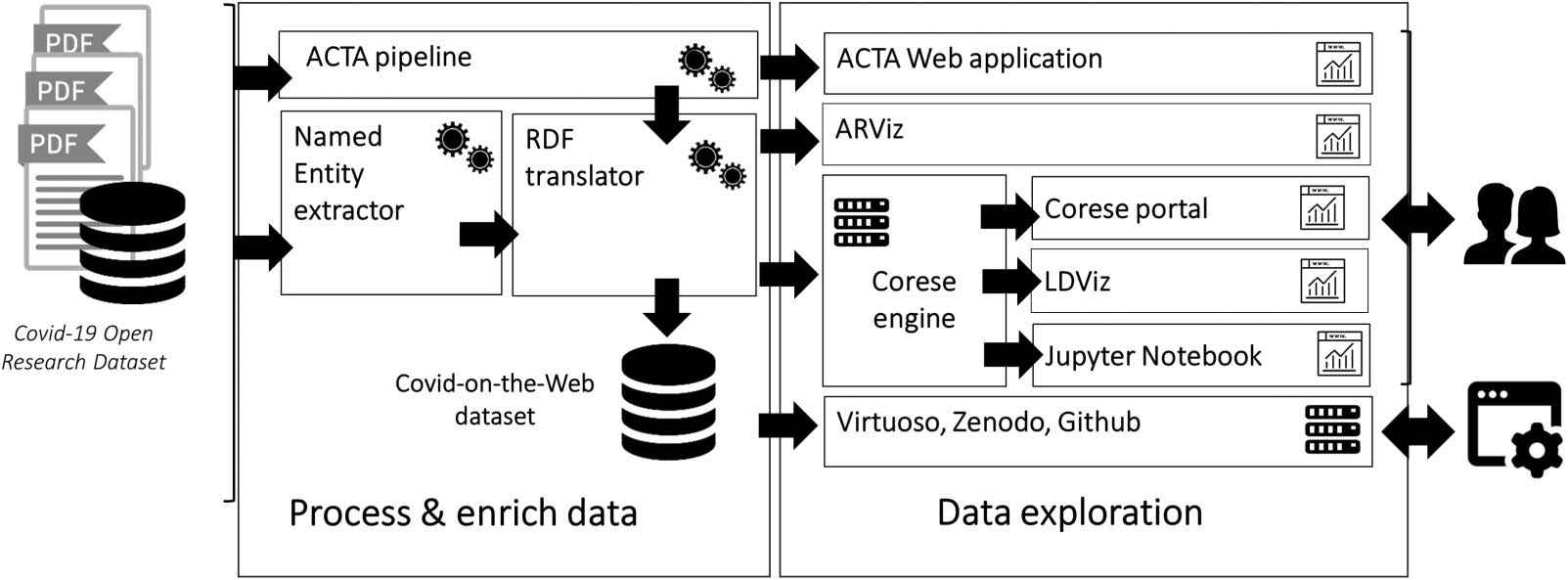
ments and PICO components into a single, coherent whole. 此外, we propose a uni-
fied pipeline (数字 1) that facilitates the extraction and visualization of information from the
CORD-19 corpus by continuously producing and publishing an enriched linked data knowl-
edge graph. 还, our visualization approach differs from previous solutions to exploring the
COVID-19 scientific literature (例如, Hope, Portenoy et al., 2020; Verspoor, Šuster et al., 2020),
by supporting the exploration of meaningful subsets of data suitable to users’ needs through
the definition of custom SPARQL SELECT queries and via multiple, complementary visualiza-
tion techniques and by allowing the user to trace back their exploratory path, which helps
them to understand how they have arrived at a certain outcome.
The remainder of this paper is organized as follows. 部分 2 presents previous data
mining and visualization approaches to exploring the CORD-19 corpus. 部分 3 描述
1 https://www.inserm.fr/
2 https://www.e-cancer.fr/
3 Illustration video of LDViz: https://youtu.be/Cn_IWQ7yVvE
Quantitative Science Studies
1302
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
数字 1. Overview of the Covid-on-the-Web project: Pipeline, 资源, services and applications.
the extraction pipeline to process the CORD-19 corpus and generate the RDF data set and
presents the characteristics of the data set and the available services to exploit it. 部分 4
describes LDViz, which usage and exploration potentials are demonstrated through use case
scenarios in Section 5. 部分 6 discusses future applications and potential impact of the data
放. 最后, 部分 7 concludes the paper.
2. RELATED WORK
Since March 2020, when the CORD-19 corpus was first released, we have seen multiple
efforts towards its analysis and mining through different tools and for various purposes. 我们
have seen initiatives ranging from ad hoc data releases to the repurposing of large existing
项目. 因此, in this section, we will present previous work related to the exploration of
the CORD-19 data set in terms of data enrichment and visualization.
2.1. Data Enrichment
Entity linking is usually the first approach for processing or enriching a data set, which we can
observe in several initiatives throughout the literature, such as the CORD-19-on-FHIR (Oniani
等人。, 2020) 项目, which transforms the CORD-19 corpus in RDF following the HL7-FHIR inter-
change format and annotates articles with concepts related to conditions, medications, 和亲-
cedures; the KG-COVID-19 (Reese et al., 2021) 项目, which seeks the lightweight construction
of KGs for COVID-19 drug repurposing efforts; and the CKG-COVID-19 (Ilievski, Garijo et al.,
2020) 项目, which seeks the discovery of drug repurposing hypotheses through link prediction.
These solutions restrict processing to title and abstract, while we process the full text of the
articles with Entity-fishing, thus providing a high number of NE linked to Wikidata concepts.
此外, these solutions are mostly focused on biomedical ontologies, resulting in NE
strongly related to genes, proteins, 药物, 疾病, phenotypes, and publications, while we
extend the scope of ontologies to include DBpedia and Wikidata, resulting in NE that go
beyond the biological domain to extend the scope of analysis. 此外, we integrate
argumentation structures and NE in a coherent data set.
2.2. Visualization Approaches
The Covid19-PubAnnotation4 repository gathers text annotations regarding the CORD-19 cor-
pus and other COVID-19 data sets. The annotations are recovered from multiple sources and
4 https://covid19.pubannotation.org/
Quantitative Science Studies
1303
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
aligned to the canonical text that is taken from PubMed and PMC archives, which link anno-
tations to each other. 此外, the platform provides simple visualization that allows one
to view the annotations directly on the text and further explore them through interaction.
The SciSight (Hope et al., 2020) tool enables exploratory search of the COVID-19 scientific
literature and supports browsing through networks of biomedical concepts and research
团体. It automatically extracts textual and coauthorship network information from publica-
系统蒸发散, which are then explored through multiple views: A collocation explorer based on a non-
ribbon chord diagram is used to represent the association between terms co-occurring in the
same sentence; the relationship between patient characteristics and interventions (P and I from
PICO elements) can be explored through two coordinated bar charts, which also display the
temporal distribution of publications related to those criteria through a time series chart; and a
network diagram represents the relationship between groups of coauthors defined either by
社会的 (shared authors) or topical affinity.
The COVID-SEE (Scientific Evidence Explorer for COVID-19) interface (Verspoor et al.,
2020) enables the visual exploration of documents from the CORD-19 corpus through three
different views: A Sankey diagram displays the relationship between PICO concepts and allows
us to retrieve the documents where these relations occur; a topic view shows the representa-
tive topics of the selected documents and their distribution according to certain coherence
措施; and a word cloud view displays the representative concepts of a document.
The SemViz (Tu, Verhagen et al., 2020) interface uses semantic visualization to explore the
publications within the CORD-19 and other COVID-19 data sets. It provides three visualiza-
tion techniques: A tag cloud gives an overall view of the most important concepts within the
数据; a heat map represents a pairwise relationship between selected entities in the article
abstracts and journal names; and a data table is used to represent indexed document data,
such as sentences of biomedical relations and corresponding PubMed URLs that link to the
full article.
Sukla, Naskar et al. (2021) propose a visualization interface that allows the user to explore a
set of publications from the CORD-19 corpus retrieved via textual querying. It displays the list
of articles related to the query, from which corresponding NE can be further explored through
a tag cloud chart and a co-occurrence map.
Bras, Gharavi et al. (2020) combine advanced data modeling of large corpora, 信息
映射, and trend analysis to provide a browsing and search interface for discovering topics
and research resources within the CORD-19 data set. The system provides a cluster visualiza-
tion displaying all resources in the data set, where the user can select a resource to explore its
related topics, descriptions, trend analysis, and documents.
The CovidExplorer (Ambavi, Vaishnaw et al., 2020) is a multifaceted AI-based search and
visualization engine that integrates search and recommendation, 统计数据, and social media
discussions to support the exploration of scientific articles from the CORD-19 data set. 它com-
prises a query interface that supports keyword-based search of authors, 文件 (title), and full-
text papers; and a named entity recognition system that computes indicators of first mention of
实体, popular comentioned entities, and year-wise distribution of mention frequencies.
These indicators are visualized through a timeline chart and a Sankey diagram, which shows
the co-occurrence of entities within publications. The system provides a spatiotemporal visu-
alization of tweets regarding COVID-19.
Although we find several visualization tools to support either the exploration of linked data
in general or the COVID-19 scientific literature, such as the ones presented above, 大多数
Quantitative Science Studies
1304
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
them support the exploration of raw data (IE。, the RDF graph, OWL or RDF Schema), 这是
interesting for certain tasks, such as exploring the relevant concepts of an application domain
via ontology representation, inspecting RDF Graphs, and analyzing instances based on their
types/classes. 因此, we propose a flexible tool to enable users to define meaningful data sets
via SPARQL SELECT queries applied to any SPARQL endpoint (illustrated here via the Covid-
on-the-Web data set), so that they can explore multiple aspects of RDF data sets and the LOD
Cloud. It also allows users to perform exploratory searches using various complementary visu-
alization techniques instantiated on demand according to the task at hand, instead of a single
visualization technique that represents the whole data set, restraining the analysis to a single
view to the data. Our approach is also based on a visualization concept that enables users to
track their exploratory path to help them to understand how they arrived to a certain outcome
and to allow them to explore alternative hypotheses generated on the fly through different
exploratory paths. 此外, the visualization together with the additional extractions
(IE。, NEs, 论据) we perform in the Covid-on-the-Web data set, enables a deep and
semantic-aware exploration of the topics and claims of the COVID scientific corpus by
leveraging the combination of semantic processing and exploratory search.
3. THE “COVID-ON-THE-WEB” DATA SET
在这个部分, we describe the Covid-on-the-Web data set which we produced by processing
and analyzing the CORD-19 corpus. The data set cohesively integrates the results of
two mining processes: an NE extraction and linking that defines the links between the
CORD-19 articles and major public data sets of the Web of Data, and an extraction of argu-
mentative components discovered in the articles. These are both represented as RDF knowl-
edge graphs described hereafter.
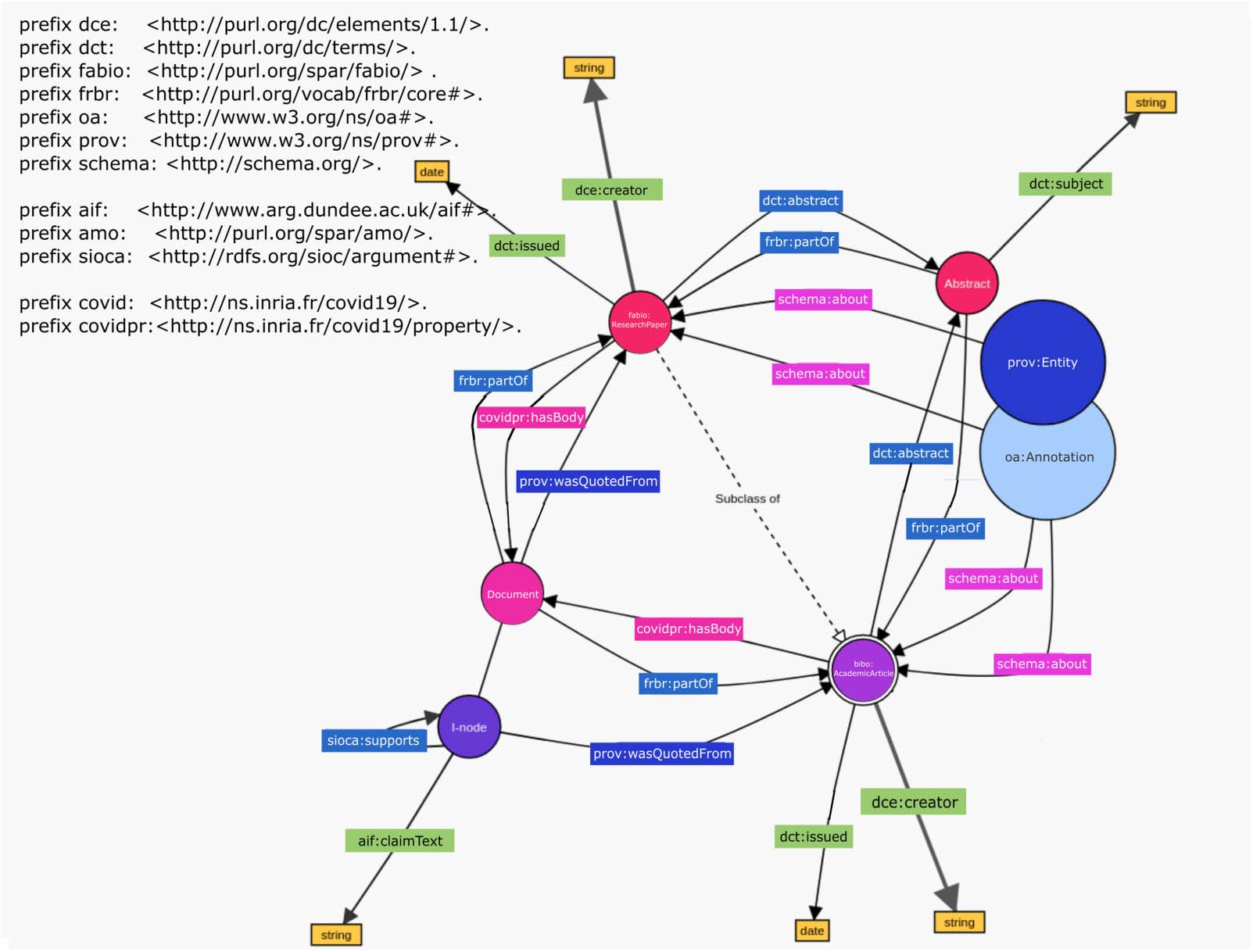
3.1. The CORD-19 Named Entities Knowledge Graph
The CORD-19 Named Entities Knowledge Graph (CORD19-NEKG) represents NE identified
and disambiguated in the articles of the CORD-19 corpus using three tools: DBpedia Spotlight
(Daiber, Jakob et al., 2013) to disambiguate NE against DBpedia entities; the Entity-fishing5
tool to disambiguate NE against Wikidata entities; and NCBO BioPortal Annotator (Jonquet,
Shah et al., 2009) to disambiguate NE against entities found in BioPortal’s ontologies.
CORD19-NEKG uses common, well-adopted terminological resources to represent articles
and NE in RDF. We use DCMI6, FaBiO7, the Bibliographic Ontology8, FOAF9, and Schema
.org10 to represent article metadata such as the title, authors, and DOI, and the Web Annota-
tion Vocabulary11 and Provenance Ontology12 to represent and trace the recognized entities.
These include the text segment recognized as the NE, the location of the segment within the
article’s text, the resource URI (例如, from Wikidata) linked to the NE, and the part of the article
wherein the NE was recognized (IE。, title, 抽象的, or body). 数字 2 presents an extract of the
RDF model, a full description of which, together with examples, is available in the project’s
Github repository.13
5 https://github.com/kermitt2/entity-fishing
6 https://www.dublincore.org/specifications/dublin-core/dcmi-terms/
7 https://sparontologies.github.io/fabio/current/fabio.html
8 https://bibliontology.com/specification.html
9 https://xmlns.com/foaf/spec/
10 https://schema.org/
11 https://www.w3.org/TR/annotation-vocab/
12 https://www.w3.org/TR/prov-o/
Quantitative Science Studies
1305
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 2. Extract of the Covid-on-the-Web RDF graph. Image adapted from an il lustration generated with LD-VOWL (Lohmann, Negru et al.,
2016) (see https://vowl.visualdataweb.org/v2/ for a description of the graphical primitives and color scheme).
3.2. The CORD-19 Argumentative Knowledge Graph
The ACTA (Argumentative Clinical Trial Analysis) (Mayer, 敞篷车, & 维拉塔, 2019) tool was
originally designed to help clinicians make decisions in evidence-based medicine by automat-
ically extracting argumentative components and PICO elements14 from clinical trials. Through
multiple NLP steps, ACTA retrieves the argumentative components in the trial and its PICO
元素, classifies the components into claim (concluding statement) and evidence (observa-
tion or measurement), and infers the relationship between the components (IE。, support or
攻击). 例如, “a new treatment is considered more effective than existing treatments
(宣称), as attested by the measure of certain biological markers within the tested population
(证据).”
The models used in ACTA are trained with SciBert, a language model for scientific text, 那
has been shown to work on texts from different application domains (Beltagy, Lo, & Cohan,
2019). Although the content of articles might differ from clinical trials, the structure of the
abstracts is similar, including elements such as background, 方法, 结果, and conclusions.
因此, as arguments can be extracted from abstracts not necessarily dealing with clinical trials
and PICO elements detection can be generalized to every biomedical article, we repurposed
ACTA to also annotate the articles from the CORD-19 corpus. 因此, we analyzed every
abstract and translated the result into RDF to create the CORD-19 Argumentative Knowledge
13 https://github.com/ Wimmics/covidontheweb
14 PICO is a framework to answer healthcare questions in evidence-based practice that comprises
patients/population (磷), 干涉 (我), control/comparison (C), and outcome (氧).
Quantitative Science Studies
1306
Covid-on-the-Web
图形 (CORD19-AKG), which represent the argumentative components through the Argument
Model Ontology (AMO)15, the SIOC Argumentation Module (SIOCA)16, and the Argument
Interchange Format17. 更远, the PICO elements are described as annotations of the argu-
mentative components in a similar way to the NE and disambiguated against UMLS concepts
and semantic types.
3.3. Publishing and Querying the Covid-on-the-Web Data Set
The Covid-on-the-Web data set has a DOI and can be downloaded from Zenodo18. It can also
be queried through our public SPARQL endpoint19. The RDF data set embeds detailed meta-
data describing licensing, authorship, provenance, interlinking, and access information, 和
the vocabularies used.20 Additional information regarding reproducibility and sustainability
have been detailed and discussed in Michel, Gandon et al. (2020).
4. LINKED DATA VISUALIZER
The Linked Data Visualizer is a generic visualization tool for the Semantic Web of Linked
数据. It enables the exploration of custom subsets of linked data sets defined via SPARQL
queries. 数字 3 provides an overview of the LDViz architecture. It comprises a querying man-
agement interface, where users can manage predefined queries, by viewing, editing and visu-
alizing their results, as well as cloning them to create new queries. The interface contains a
query editing form, where the user can type their own queries. Upon submitting a query, 这
obtained results undergo a transformation process, which output data corresponds to the
expected format for the visualization. The user can then explore the resulting data using
the MGExplorer visualization framework.
在这个部分, we describe the operational mode of LDViz with particular focus to the que-
rying management and the visualization interfaces. We further demonstrate the versatility of
LDViz to explore the Covid-on-the-Web data set through a set of use case scenarios presented
in Section 5.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
4.1. Query Management Interface
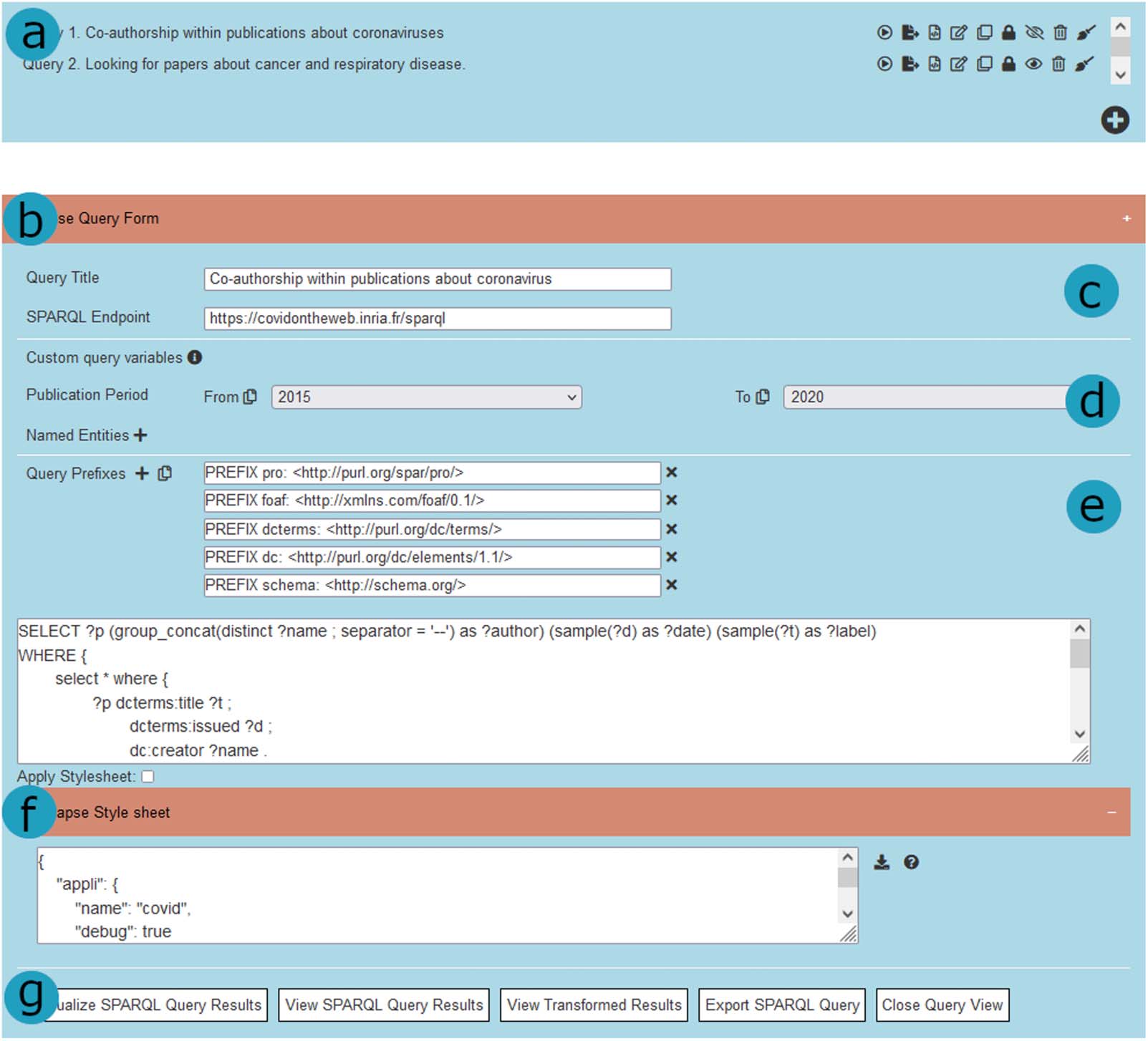
The query management interface (数字 4) allows users to create and edit their own SPARQL
queries. In Figure 4a, we can see the menu that lists and allows managing predefined queries,
and Figure 4b–e depict the interface areas enabling the addition and customization of queries.
This interface also enables the preview and exporting of a query’s results (see Figure 4f). 这些
can be visualized via the MGExplorer graphic library and/or exported as JSON files containing
either the results in the SPARQL JSON format or the transformed results used as input to the
可视化. The user can type the query in a text area, which can include customizable
parameters specified through HTML forms, such as the publication date. Upon submitting a
query, the results are processed by a transformation engine that converts the SPARQL JSON
format into the JSON format expected by the graphic library.
The transformation engine is generic enough to support the exploration of different vari-
ables of the data set. This flexibility allows us to explore graphs with different topologies
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
15 https://purl.org/spar/amo/
16 https://rdfs.org/sioc/argument#
17 https://www.arg.dundee.ac.uk/aif#
18 https://doi.org/10.5281/zenodo.4247134
19 https://covidontheweb.inria.fr/sparql
20 https://ns.inria.fr/covid19/covidontheweb-1-2
Quantitative Science Studies
1307
Covid-on-the-Web
数字 3. Linked Data Visualizer architecture overview: the Query Management Interface, the Transformation engine, and the Visualization
Interface supported by the MGExplorer visualization tool.
(例如, with nodes featuring publications, authors, NE). In the context of LDViz, this is made
possible by using a SPARQL query that requires at least three variables: ?s and ?哦, 哪个
describe the nodes (例如, authors or NE) related by a particular document identified by a
variable ?p. 替代方案 ?s and ?o is the variable ?作者, which contains a list of
authors. In addition to these variables, the system allows three other reserved variables that
serve to describe the edges (?p) of the output graph visualization: ?类型, ?标签, 和
?日期. The variable ?type can be used to type the edges of the output graph (例如, 经过
publication type). Due to people’s perceptual and cognitive limits regarding visualizations,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4. The Query Management Interface. (A) The listing of predefined queries and associated actions. (乙) The querying area features: (C)
query title and SPARQL endpoint, (d) custom parameters form, 和 (e) a query editing area. (F ) The graph style sheet editing area. (G) 这
visualization and exporting of results.
Quantitative Science Studies
1308
Covid-on-the-Web
Listing 1.
within publications about “coronavirus” between 2015 和 2021.
SPARQL query used in Use Case Scenarios 1 和 4 to retrieve the coauthorship network
only a certain number of graphic elements can be drawn on the screen. 因此, we allow the
variable ?type to be bound to only four different values describing the edges. When it is
bound to more than four distinct values in the SPARQL query result, the system automatically
determines the three most relevant ones based on the number of bindings and classifies the
remaining values as “Other.” The ?label variable allows us to provide a description of the
edges in natural language (例如, the value of rdfs:label properties describing resources).
最后, 这 ?date variable is used to provide a visual representation of the distribution of
edges over time (例如, publication year).
When dealing with a new data set, researchers often have to debug and test multiple
queries to discover the contents of the data set. To ease the customization of queries and
the use of the interface by the domain expert, we provide query templates that allow one to
interactively define the value of certain parameters, such as the publication period and NE of
兴趣 (see Listing 1 for an example).
A Graph Style Sheet language (GSS) serves to transform the default node-link diagrammatic
representation through the declarative specification of visibility, layout, and styling rules
applied to its nodes and arcs (Pietriga, 2006). Based on this concept, we associate each query
to a GSS that the user can edit (see Figure 4e) to customize the resulting node-link diagram (看
Listings 2 和 3 for an example). Further to modifying the colors and shape of nodes and
边缘, we enable, through the GSS, the linking of external services to the visualization inter-
face as a way of extending the analysis. 例如, the Corese engine (Corby, Gaignard
等人。, 2012) is an RDF processor that enables, 除其他事项外, the production of new
knowledge through inference rules. 因此, one could include this service on the GSS, 哪个
would allow the exploration of the visualized resources through the Corese engine. 更远,
we can use this feature to support on-the-fly exploration of argumentative graphs of publica-
tions identified throughout the visual exploration process by including the ACTA service (看
部分 5.5 for more details).
Although we demonstrate the usage of the querying and visualization interfaces for explor-
ing the Covid-on-the-Web dataset, LDViz can be used to query and visualize data from any
Listing 2. Graph Style Sheet used in Use Case Scenarios 2 和 5.
Quantitative Science Studies
1309
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Listing 3.
cancer and coronavirus.
SPARQL query used in Use Case Scenarios 2 和 5 to retrieve the co-occurrence network within publications of NE related to
SPARQL endpoint. The querying form contains a field where the user enters the endpoint URL,
and the only requirement is that the query returns values for the above-listed predefined set of
变量. 因此, what we propose with LDViz is a generic visualization tool for the Semantic
Web of Linked Data.
As for any visualization, user queries must be translated to a query language that recovers
the necessary data from the database to solve the exploratory task. 在本文中, the user
queries were identified during interviews with users from INCa and Inserm and translated into
SPARQL queries by data scientists. 因此, the query management interface is intended to help
expert users (developers and data scientists) to create suitable SPARQL queries for exploring
the data set. 然而, expert users such as biomedical researchers do not need to know
SPARQL to visualize and interact with the results of queries. 的确, they may benefit from a
public vitrine21 simply by selecting a predefined query to explore the results with MGExplorer
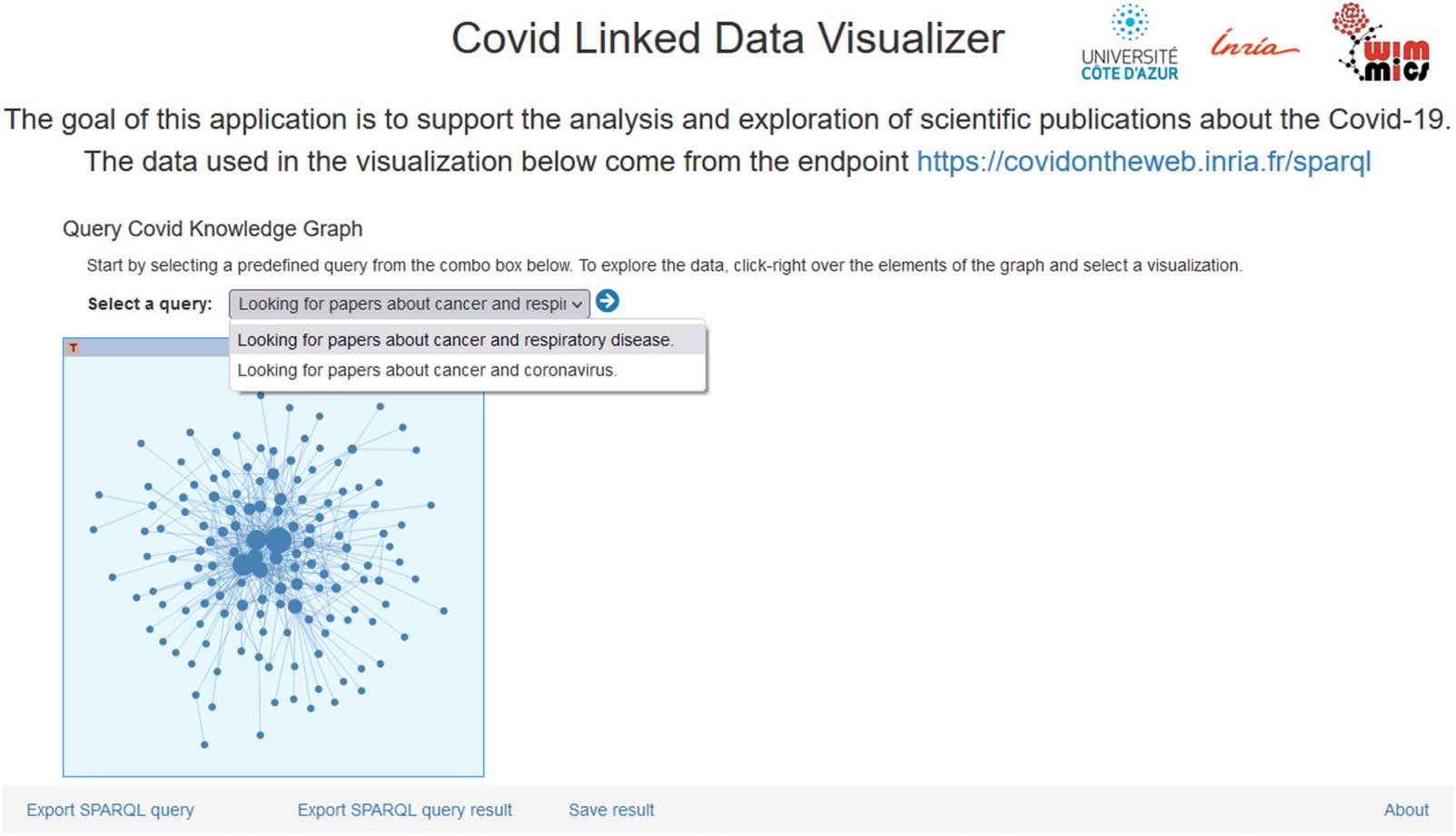
without having to deal with SPARQL expressions (数字 5). The visibility of the predefined
queries in the vitrine is settled when queries are created at the query management interface.
In the next section, we describe how users can interact with the data resulting from those
queries by means of an information visualization interface.
4.2. Visualization Interface
As mentioned earlier, LDViz uses the MGExplorer (Multidimensional Graph Explorer) (Menin,
Cava et al., 2021) graphic library to support the visual exploration of the Covid-on-the-Web
数据集. More than a collection of charts, MGExplorer is a visualization tool based on the
concept of chained views, which supports the exploration of multidimensional network data,
21 Accessible at https://covid19.i3s.unice.fr:8080/
Quantitative Science Studies
1310
Covid-on-the-Web
数字 5. Public vitrine of Covid-19 Linked Data Visualizer.
while keeping provenance information to enable further study of users’ reasoning based on
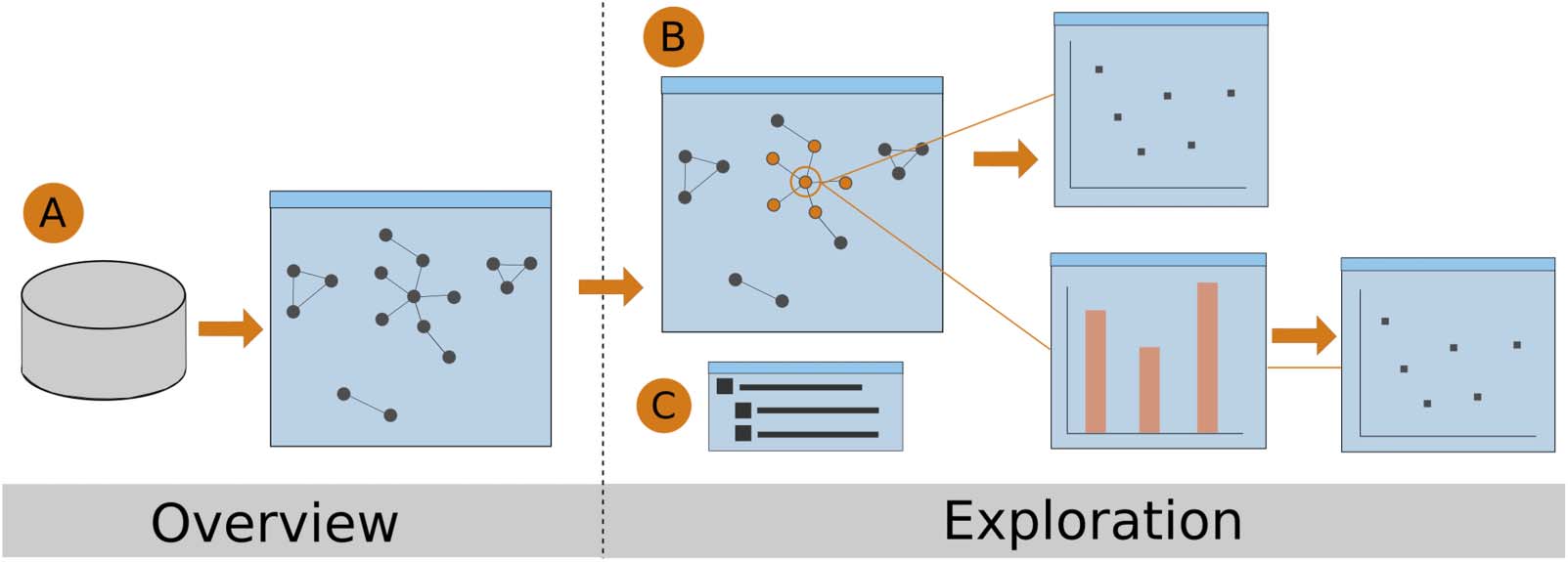
their interactions with the system. The visual exploration process in MGExplorer consists of
two phases, described as follows:
1.
2.
the overview phase, which consists of visualizing the network defined by the SPARQL
query results through a node-link diagram (see description below). This visualization
allows the user to get an overall understanding of the clusters within the data; 和
the exploratory phase, where the user can further explore items of interest by selecting
them directly on the visualizations, which subsets the data to be explored via a new
suitable visualization technique.
The generic aspect of MGExplorer enables the combination of multiple visualizations to
support the comparison of two or more different subsets of data through a particular perspec-
tive provided by a particular visualization, and the comparison of different perspectives of the
same subset of data using multiple, complementary visualization techniques. 尤其, 我们
currently support data exploration through six views, summarized in Table 1 and described as
如下:
(西德:129) The node-link diagram shows a set of nodes, which represent data items (例如, authors),
and their relationships represented through line segments connecting them. In MGEx-
plorer, this visualization technique provides an overview of the relationships within
items of the input data. In our use case scenarios (部分 5), the relationships are
defined by scientific publications, either to reveal coauthorship networks or the co-
occurrence of NE.
(西德:129) The ClusterVis technique (Cava, Freitas et al., 2017) enables the inspection of clusters
and data attributes (例如, publication type) within the subset of items (例如, authors or
NE). The visualization has a multiring layout, where the innermost ring is formed by dots
representing data items, and the remaining rings display the data attributes, 哪个
can be customized and reordered by the user. The items in the innermost ring that
Quantitative Science Studies
1311
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
桌子 1. Classification of visualization techniques available in MGExplorer according to the type
of analysis they provide
belong to the same subcluster are connected via curved lines, which one can highlight
by hovering over the items. The remaining rings are formed by bars where height and
color encode different data attributes (例如, the height encodes count and the color
encodes the types of publications of a specific author).
(西德:129) The IRIS technique represents the pairwise relationships between an item of interest
(例如, an author) and the remaining items in a particular subset of data, which relation-
ship is described by data attributes (例如, publication count and type) (Cava, Freitas et al.,
2014). This technique is inspired by the eye’s iris, which can only focus on a certain
amount of information at the time (IE。, what is visible within our field of view). 这
selected item is represented in the IRIS as a circle at the center of the view, surrounded
by its related items, which are displayed in a way that the ones in the field of view (gray
区域) are larger than the ones outside this zone, easing information extraction. The user
can place any item in the field of view by clicking on it, switching the focus of the IRIS.
To represent data attributes describing those pairwise relationships, we use the height
and color of a bar placed in between the item of interest and each of its related items.
(西德:129) The GlyphMatrix technique (Cava & Freitas, 2013) features a matrix where rows and
columns represent data items (例如, authors or NE), and the intersection cell between
each pair of items contains a glyph encoding the data attributes describing that relation-
船. The default glyph is based on a radar chart, where each axis displays the count of a
different data attribute (例如, publication type). The technique supports sorting of rows
and columns to facilitate information extraction, and hovering over cells to make the
glyph larger and more visible through a tooltip feature. This visualization technique
could be seen as a combination of the ClusterVis and IRIS by displaying the relationship
between an item of interest and other items in a pairwise manner, as well as the rela-
tionships within the remaining items in the group.
(西德:129) The Bar chart technique shows the distribution of publications according to a given
variable. In our case study, the x-axis encodes temporal information, and the y-axis
encodes the counting of publications. The data are displayed as a single bar per time-
period or multiple colored bars to represent categorical information of attributes.
(西德:129) The Listing technique lists the items that form the relationship between two or more
nodes in the graph. In our case study, it displays the list of publications coauthored
by two or more authors or the publications where two or more NE co-occur, 根据
to the subset of data being explored. Each item of the list contains a link to a descriptive
web page of the publication, where the user can obtain more information about it.
此外, if enabled by the GSS, each item contains a context menu to enable further
exploration using an external service (例如, ACTA).
Quantitative Science Studies
1312
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
数字 6. Overview of MGExplorer. Panel A: The node-link diagram provides an overview of the data set. Panel B: Filtering operations enable
further exploration of items/subsets of interest through different visualization techniques. Panel C: A history panel records users’ actions
throughout the exploration process. Image retrieved from Menin, Cava et al. (2021).
Each view is a self-contained element, which includes a visualization technique and sup-
ports subsetting operations, enabling further exploration of subsets of data through different
意见. The views can be dragged, allowing the user to rearrange the visualization space in
meaningful ways to the ongoing analysis. They are connected via line segments, which reveal
their dependencies and enable tracing back the exploration path, thus preserving provenance
信息.
Upon submitting a SPARQL query in the query management interface, the data goes
through a transformation process, and MGExplorer self-starts with the overview phase. 这
node-link diagram and a History panel (Figure 6C) are visible during the whole exploration.
The history panel displays the exploration path in a hierarchical format to indicate the depen-
dencies between views, and supports quick recovery of the multiple analytical paths that
emerge from a particular view. The history panel allows the user to clean the visualization
space while focusing on what is relevant to the ongoing analysis by hiding currently displayed
visualizations and/or showing any of the previous visualizations.
5. USE CASE SCENARIOS
In this section we illustrate the usage of COVID LDViz to explore the Covid-on-the-Web data
放. The goal is to demonstrate what kind of data one can explore using this interface and how
the data processing between the query management and the visualization interfaces support a
multiperspective exploration of the dataset.
5.1. Scenario 1: Clusters Visualization
Based on the premise that COVID-19 has increased the collaboration between researchers
from diverse disciplines around the world (Naujokaitytė, 2021), a biomedical researcher from
INCa was interested on searching for information about existing collaborations on the theme
of the relationship between COVID-19 and cancer (or more generally between COVID-19 and
other diseases) in order to analyze the nature of these collaborations, their impact, 和他们的
evolution. In this scenario, we illustrate how LDViz could assist this analysis by exploring
coauthorship networks.
We use a subset of data describing the coauthorship network within publications related to
coronavirus families retrieved with the query presented in Listing 1, 这导致 4,238
RDF triples corresponding to publications having the word “coronavirus” in the title. 这些
Quantitative Science Studies
1313
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
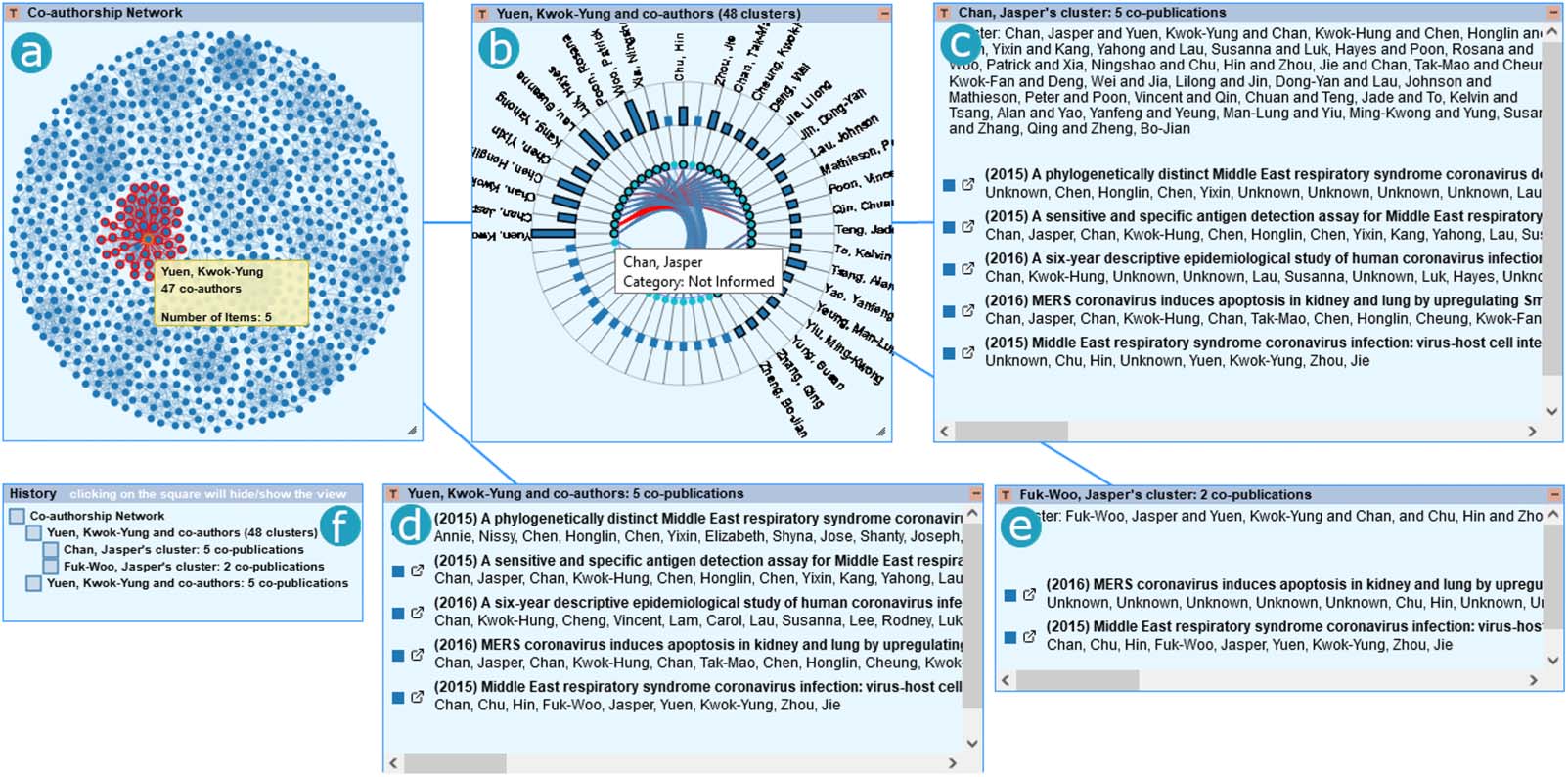
数字 7. Exploratory path of Scenario 1. (A) We use the NodeEdge diagram to identify an author of interest for exploration. (乙) The ClusterVis
reveals the subclusters within the set of coauthors and their copublications. (C)–(e) The views depict the publications produced within each
subcluster. (e) The total publications of the author of interest. (F ) The history shows which charts were opened, their order, and inner
dependencies.
results were then transformed into a graph with 879 节点 (authors) 和 4,053 边缘 (connec-
tions between authors). 数字 7 depicts the exploratory path that we follow during this sce-
成员, which illustrates how one can explore clusters of coauthors and related information to
their copublications. As mentioned earlier, the MGExplorer visualization interface self-starts
with an overview of coauthorship clusters through the node-link diagram and the history tree
of the exploratory process, which is progressively completed based on the user’s interactions.
In the node-link diagram, we identify a dense subgraph related to the author Yuen, Kwok-
Yung (Figure 7a), who will be our author of interest for this exploration. We hover over the
node representing the author, where we observe that they have 47 共同作者, with whom five
scholarly articles have been published. 随后, we right-click on the node to activate a
context menu that allows subsetting the data and explore it with another visualization tech-
nique. We choose the ClusterViz view, where we can explore the different clusters within the
subset of coauthors selected in the node-link (Figure 7c). For two different clusters, we subset
the data by hovering over a particular author and display the list of publications which they
coauthored together (Figure 7d–e). 最后, we could compare the contributions made within
those clusters and the complete list of publications coauthored by our author of interest
(Figure 7f), to understand the impact of these coauthorship relationships in terms of the
number and quality of publications they have together.
5.2. Scenario 2: Customizing the Graph Topology
The generic structure of LDViz allows the construction of graphs with different topologies. 这
user can choose the variables that correspond to the nodes and the connection between them
(例如, in the previous scenario, nodes correspond to a variable that describes the authors’
names and the edges correspond to a variable that describe the documents they coauthored).
Together with biomedical researchers, we have identified the task “to identify the articles that
mention both a type of cancer and a virus of the corona family” as being relevant for their
分析. 因此, in this scenario, we illustrate how we can use LDViz to solve this domain-
related task. Using the query presented in Listing 3, we retrieve the RDF triples that correspond
Quantitative Science Studies
1314
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
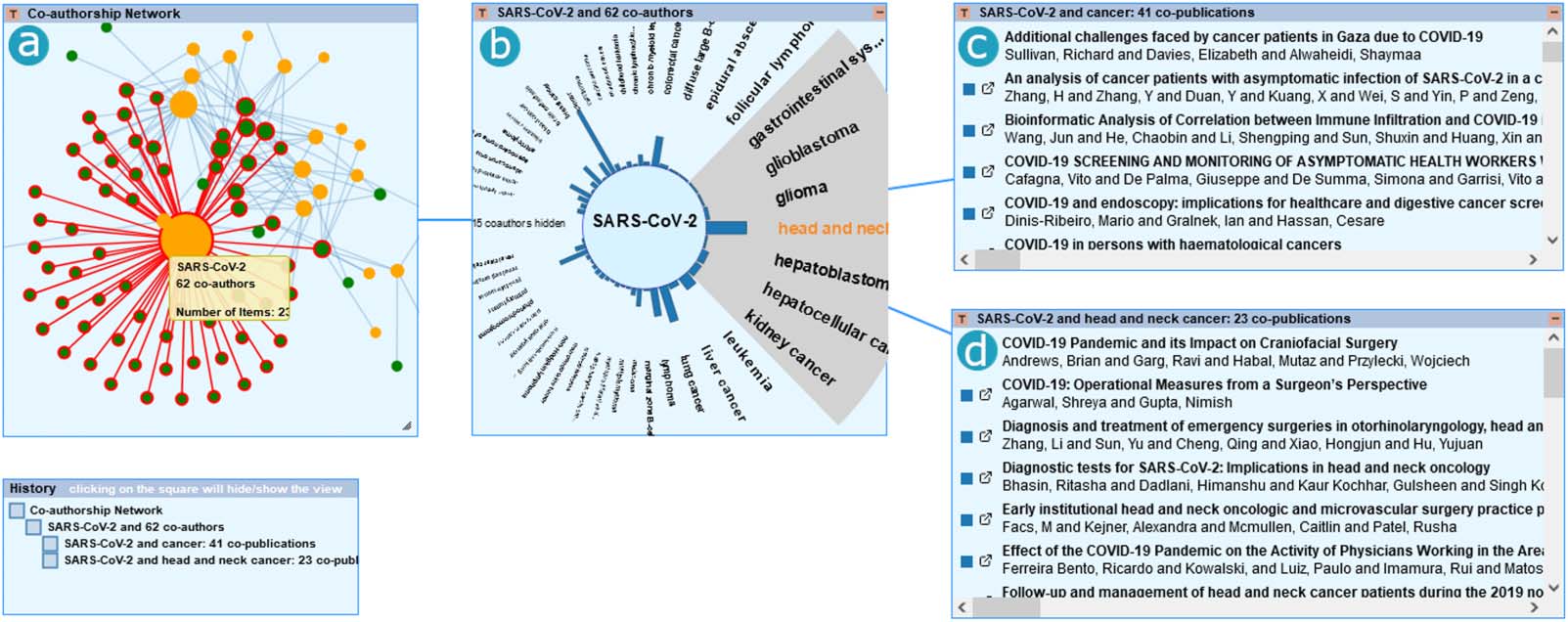
数字 8. Exploratory path of Scenario 2. (A) In the node-link diagram we see the connection between types of cancer (绿色的) and viruses from
the coronavirus family (orange). (乙) The IRIS shows relationship between SARS-CoV-2 and different types of cancer in a pairwise manner. (C)
The list of publications related to SARS-CoV-2 and cancer in general, 和 (d) head and neck cancer.
to the pattern ?s → ?p → ?哦, 在哪里 ?s and ?o are, 分别, NE related to (IE。, equal to,
subclass of, or instance of ) “cancer” and “coronavirus” NE, 和 ?p refers to the publications
that contain these NE on their text body. The relationships are determined by publications;
然而, unlike the Scenario 1, this query modifies the topology of the graph to represent
the relationships between NE instead of coauthors.
数字 8 depicts the exploratory path followed in this scenario to solve the above-described
domain-related task. We explore a data set that contains 452 RDF triples, which results in a
graph with 94 nodes and 169 边缘. Because in this data set, we deal with two types of nodes
(IE。, related to either “cancer” or “coronavirus”), we use the GSS feature (see Listing 2) to color
these different types of nodes accordingly (IE。, green encodes cancer and orange encodes
coronavirus), easing the visual identification of the relationship between the cancer- 和
coronavirus-related nodes directly in the node-link diagram (Figure 8a). Due to the nature
数据的, we can easily spot a large subgraph originating from the SARS-CoV-2 named
实体, which is associated with 62 types of cancer through 232 出版物. We further
explore the subset of data within this subgraph by right-clicking on the node representing
SARS-CoV-2 and choosing the IRIS visualization, which displays the relationships of this
named entity with the different types of cancer in a pairwise manner (Figure 8b). We could
observe via the longest bar in the IRIS that SARS-CoV-2 mostly co-occurs with “cancer” in 41
出版物 (Figure 8c); which types are not specified. 更远, we observe that the second
most recurrent co-occurrence of SARS-CoV-2 is with “head and neck cancer,” for which we
observe the existence of 23 出版物 (Figure 8d). The Listing view displays the publications
together with links to their descriptive pages in the Covid-on-the-Web data set, where the user
can find more information about each document22.
5.3. Scenario 3: Exploring Data Attributes
The previous exploration scenarios allow the user to see the relationship between coauthors or
NE, which can be characterized by the number of related publications. 因此, this scenario
illustrates how we can use LDViz to explore custom data attributes of a coauthorship network
within coronavirus-related publications. 尤其, we will use a data set that describes
22 Example of a document descriptive page in the Covid-on-the-Web dataset: https://covidontheweb.inria.fr
/describe/?url=http://ns.inria.fr/covid19/28ecacb70247f4fb6a4923a99d0905153c23f88a
Quantitative Science Studies
1315
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
Listing 4. SPARQL query used in Use Case Scenario 3 to retrieve the coauthorship network within
publications about “coronavirus” described by research subject.
publications through the research topic retrieved with the query presented in Listing 4. 在里面
context of the Covid-on-the-Web dataset, this information originates from the schema:关于
财产, which refers to a set of NE that can be used to describe the research topic of the
出版物. The resulting data set has 1,265 RDF triples, which were transformed in a graph
和 356 节点 (authors) 和 1,262 边缘 (copublications). From the resulting data, 系统
identified the values “sequence alignment,” “reverse transcriptase,” and “transfection” as the
most relevant research topics to describe the publications within the data and classified the
remaining under the “other” category.
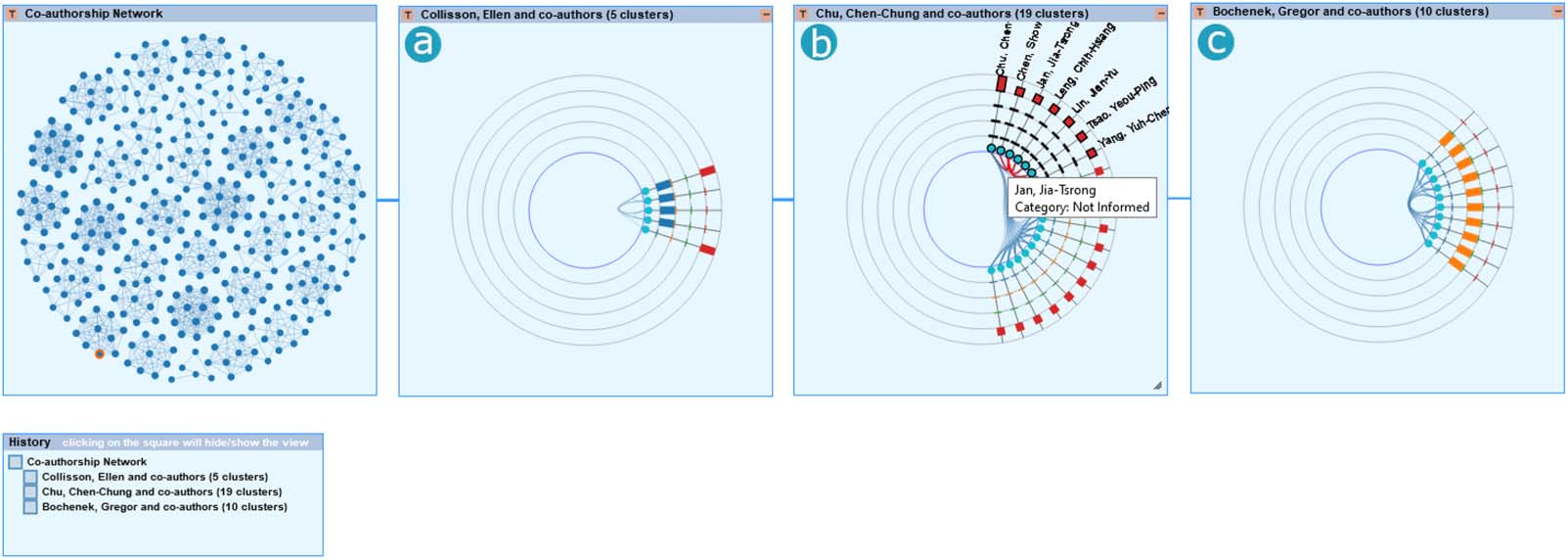
数字 9 depicts the exploratory path of this scenario. We inspect the clusters of coauthor-
ship within the associations of different authors through the ClusterViz visualization. 我们可以
observe, 例如, that the researcher Collisson, Ellen (Figure 9a) has publications about
different topics (IE。, sequence alignment and other) within different clusters of coauthorship,
and the publications coauthored by Chu, Chen-Chung (Figure 9b) refer to the “other” cate-
gory of topics and are distributed throughout different clusters of coauthorship. 最后, 我们
数字 9. Exploratory path of Scenario 3. (A)–(C) The ClusterViz visualizations depicts the clusters of different authors, where we see their
collaborations in different research topics (blue encodes “sequence alignment,” green encodes “reverse transcriptase,” and orange encodes
other subjects).
Quantitative Science Studies
1316
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
observe that the publication coauthored by Bocheneck, Gregor (Figure 9c), 例如, refers
to the topic of “reverse transcriptase.”
5.4. Scenario 4: Exploring the Temporal Aspect of Relationships
Studying the evolution over time of coauthor relationships or NE co-occurrence could help
understand when collaborations between authors were stronger or when certain research
topics were of greater interest, which information could be further explained with context
(例如, nowadays the research around the coronavirus topic is stronger than ever due to the
COVID-19 pandemic). 因此, in this scenario, we illustrate how one can use the LDViz
interface to explore the temporal aspects of relationships, particularly coauthorship within
publications related to coronaviruses (see Listing 1).
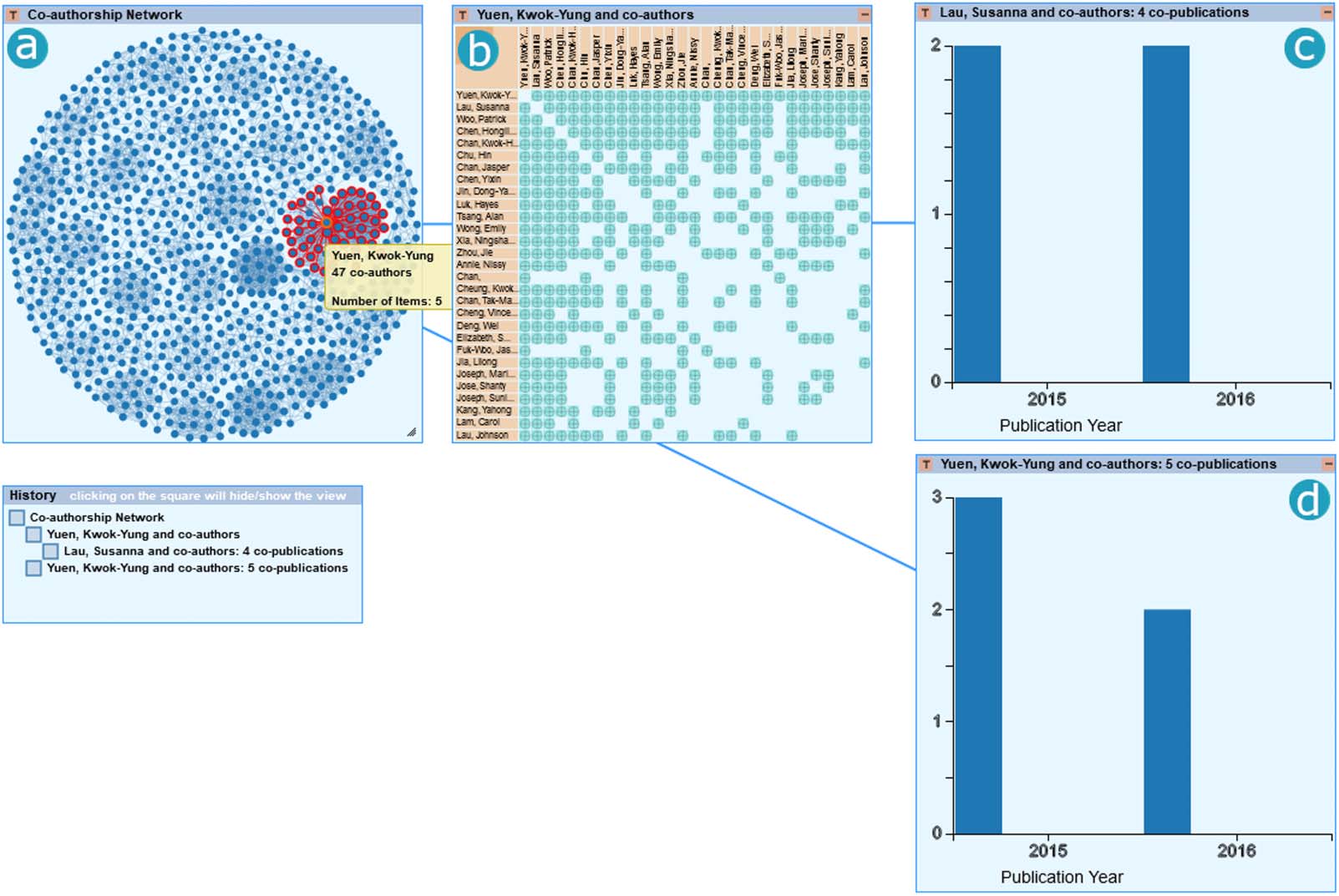
数字 10 depicts the exploratory path used in this scenario. Similar to Scenario 1, 我们用
the node-link diagram to identify the author with the most coauthors (IE。, Yuen, Kwok-Yung;
hereafter called author A) 和 47 coauthors associated through five publications (Figure 10a).
We further explore the relationship between author A and their coauthors through the
GlyphMatrix visualization, which shows the types and number of copublications between
author A and every other coauthor, as well as the copublications among author A’s coauthors.
By ordering rows and columns by the number of copublications, we can observe in the
GlyphMatrix that author A’s most recurrent coauthor is Lau, Susanna (hereafter called author
乙) (Figure 10b), with whom they have four publications. 因此, to verify when these collabo-
rations happened, we explore the temporal distribution of copublications between those
authors by subsetting the data in the GlyphMatrix visualization and exploring it on the
Histogram technique (Figure 10c). We observe that they had collaborations in 2015 和
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Exploratory path of Scenario 4. (A) We identify on the NodeEdge diagram the author of interest. (乙) In the GlyphMatrix, we identify
数字 10.
their most recurrent coauthor at the top-left cells, 和我们 (C) explore the temporal distribution of their copublications using the Histogram,
which we compare with (d) the temporal distribution of publications coauthored by the author of interest.
Quantitative Science Studies
1317
Covid-on-the-Web
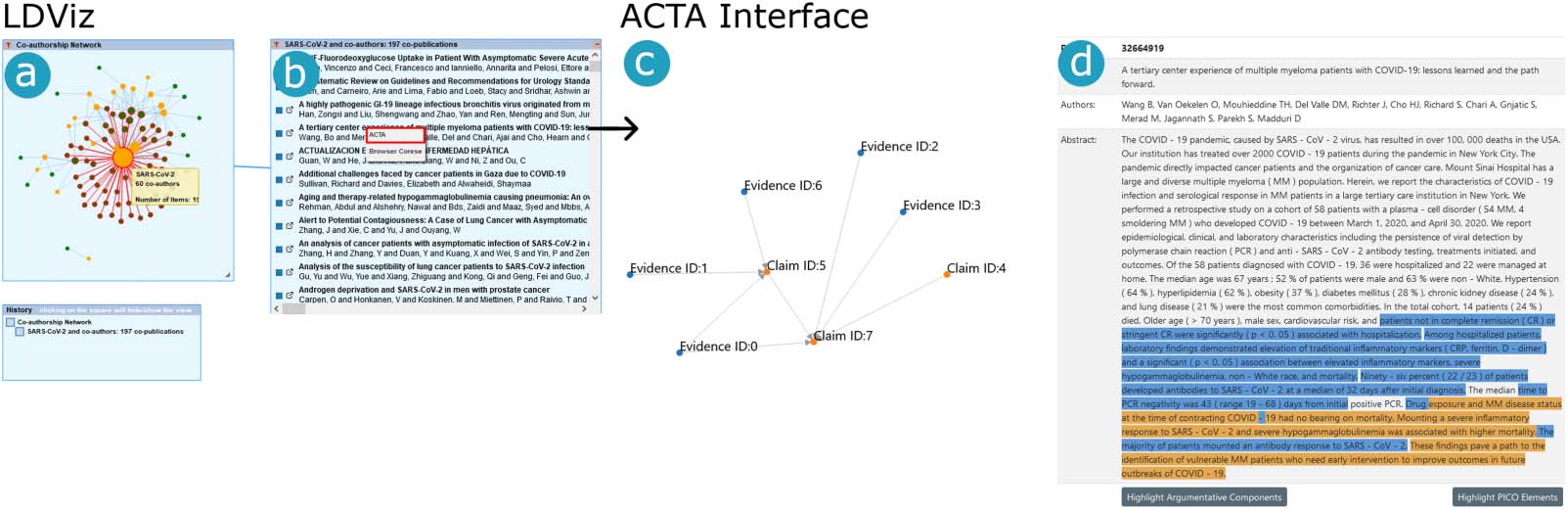
数字 11. The exploratory path of Scenario 5. In the LDViz interface we (A) find a node of interest, 和 (乙) explore its related publications
through the Papers List view. We right-click on a document and explore it using the ACTA interface, where we can (C) visualize the argumen-
tative graph and (d) explore where the claims, evidence and PICO elements appear in the document’s abstract.
2016. When comparing to the totality of copublications related to author A (Figure 10d), 我们
observe that four out of five publications are coauthored by author B, which could indicate a
strong collaboration between those authors in copublications related to the coronavirus topic.
We can also observe that this collaboration appears to have ended 5 几年前, as the data set
contains publications from 2015 到 2021.
5.5. Scenario 5: Exploring Argumentation Graphs with the ACTA Interface
As mentioned earlier, the GSS feature allows the user to include external services in LDViz,
such as a service that enables further exploration of the resources currently being visualized
with the LDViz interface. In this scenario, we explore the subset of data used in Scenario 2
(IE。, the set of publications where NE related to “cancer” and “coronavirus” co-occur) 到
illustrate how one can use the ACTA interface to visualize the argumentative graph of a certain
publication identified during the exploratory process. As one can see in Listing 2, the GSS form
associated with the query contains an object called “services” that provides the redirection
information for the ACTA interface (IE。, a call to “https://134.59.134.234:8081
/analyseddocs?search=”). The documents used in the Covid-on-the-Web data set often origi-
nate from the PubMed archive23, where each document has an unique identifier. 因此, 之上
the selection of a document, the LDViz system launches the ACTA service by redirecting the
user to the given URL, while providing the document identifier as a parameter.
数字 11 depicts the exploratory path used in Scenario 5. As for Scenario 2, we identify the
larger subgraph in the node-link diagram, which is the one connecting to the node that cor-
responds to the named entity “SARS-Cov-2” (Figure 11a). Using the Histogram, we display the
232 publications where this named entity occurs (Figure 11b). 随后, we can choose
any of the listed publications for which we would like to visualize the argumentative graph
using ACTA. We right-click on the publication of interest and choose the “ACTA” option on the
context menu that appears. This action redirects the user to the ACTA interface, 哪个
retrieves the selected document from the PubMed server, analyzes it, and displays the resulting
argumentative graph with the relationships between claims and evidence, and PICO elements
(Figure 11c). One can also inspect these elements using the textual information (Figure 11d),
where we can choose to highlight the argumentative sentences or the PICO elements. Alter-
natively, one can query the CORD19-AKG24 data set to explore claims and evidence graph
23 https://pubmed.ncbi.nlm.nih.gov/
24 https://ns.inria.fr/covid19/graph/acta
Quantitative Science Studies
1318
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
related to one or more publications directly on LDViz by using a SPARQL query where ?s and
?o correspond to claims and evidence, 和 ?p variable corresponds to the publication(s)
where they were identified.
6. 讨论
The Covid-on-the-Web project integrates knowledge from diverse research areas (IE。, seman-
tic web, 自然语言处理, and visualization) to assist researchers, particularly in the biomedical field, 到
explore the COVID-19 scientific literature. For this purpose, we created a linked data version
of the CORD-19 data set and enriched it via entity linking and argument mining. To the best
of our knowledge, the Covid-on-the-Web data set is the first public knowledge graph on the
Web integrating publication metadata, NE, 论据, and PICO elements into a single,
coherent whole. The openness aspect of our data set and code should enable contributors to
advance the current state of knowledge on this disease. 更远, we believe the Covid-on-the-
Web data set could serve as a foundation for Semantic Web applications and benchmarking
算法.
而且, we proposed a set of visualization interfaces to assist in the exploration of the
Covid-on-the-Web data set from different perspectives, enabling the resolution of various
domain-related questions. 在本文中, we have particularly focused on the LDViz visualiza-
tion tool, which supports the visual exploration of subsets of data defined by SPARQL queries.
The tool is based on the MGExplorer visualization framework, which proposes a collection of
charts linked together through a chained visualization approach that allows us to keep track of
the exploration path, assisting with the understanding of the sense-making process. This visu-
alization aims to help users understand the relationships within the results: 例如, 用户
can run a query to visualize a coauthorship network; then use IRIS and ClusterVis to understand
who is working together and on which research topics. An interesting aspect of our approach is
that one can change the graph topology to explore relationships between different kinds of items.
例如, the user could execute a query that looks for papers mentioning the COVID-19 and
diverse types of cancer, as illustrated in Use Case Scenario 2 (参见章节 5.2). Another strong
aspect of LDViz relies on the possibility of exploring the relationships within any subset of data
originating from any SPARQL endpoint thanks to the data transformation engine that adapts the
query’s results to the data format required by the visualization.
In addition to our partners from the Inserm and INCa institutes, the resources and services
proposed in the Covid-on-the-Web project have aroused the interest of other institutions, 这样的
as Antibes and Nice Hospital. 尤其, we have shown in this paper that our approach
supports the different types of analyses evoked by domain users: the analysis of clinical trials to
make evidence-based decisions, which we support via argumentative graphs; the study of the
relationship between coronaviruses and other diseases, such as cancer, which we provide
through co-occurrence networks that assist their search for scientific articles on the topic;
and the identification of researchers, 机构, or countries working on the topic via coau-
thorship network analysis.
Although a first level of evaluation is shown by translating the user queries to SPARQL
queries to visual data in LDViz, which shows that our data set and visualization services sup-
port the resolution of users’ queries, user evaluations are essential to validate the usability and
utility of a visualization. 然而, evaluating LDViz (as well as any visualization) is not a triv-
ial task because it has been designed to support exploratory tasks, which are the hardest ones
to replicate in an experiment (Ellis & Dix, 2006). 此外, the value of LDViz can only be
assessed when used by professionals on the application domain (例如, biomedical researchers),
Quantitative Science Studies
1319
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
who are difficult to recruit because they are not necessarily available to take part in experi-
评论. Future work includes implementing user-based evaluations to investigate the usability
of LDViz tool for exploring linked data sets in general, and in particular its suitability for ana-
lyzing the COVID-19 scientific literature and assisting in the resolution of domain-related
任务.
The generic aspects of our tools allow us to later on apply the resources to a wider set of use
case scenarios, which possibility has been evoked by our biomedical partners, who would like
to perform similar analyses over issues other than the COVID-19. 实际上, the LDViz interface
has been applied to two other publication data sets (IE。, HAL open archive25 and the Microsoft
Academic Knowledge Graph26, for which a set of predefined queries are available at https://
covid19.i3s.unice.fr:8080/hal). The genericity of our approach enables the exploration of data
from any SPARQL endpoint, such as DBpedia27, from which we explored the ontology and
RDF Schema information, as well as a costarring relationship using movie information28.
The tool also has a generic service that enables the querying and visualization of any SPARQL
endpoint, which URL can embed a SPARQL query and the URL of a SPARQL endpoint29,
to directly visualize the resulting data. 此外, from a linked data perspective, one can
use the Corese SPARQL service30 to combine data from different SPARQL endpoints using fed-
erated queries.
通常, in an exploratory visualization, the user has no defined goal and is looking for no
particular outcome (Leng, 2011). 虽然, in context of LDViz, the user does have an initial
query and would, 所以, have an exploratory goal in mind, throughout the exploratory pro-
cess one can make new discoveries that might not be directly related to the initial query but
that could be equally interesting. The user could yet be interested in exploring the same data
through different visualization techniques, which could provide them with a different perspec-
tive on the data and would create an alternative exploratory path to solve the same query. 在
这个上下文, because visualization can help to recall, revisit, and reproduce the sense-making
process through visual representations of provenance data, MGExplorer visually represents the
dependencies between views through line segments and uses the history panel to display
exploratory actions hierarchically, retaining parenting and visualization information such as
the data and technique used. The interactive aspect of the history panel allows the user to trace
back their exploratory path, while allowing them to start an alternative exploratory path from a
given point in history. Future work includes implementing querying support for alternative data
sets through a mechanism of follow-up queries, which allows users to launch a new query
based on an item or subset of items of interest identified in a view, bringing together comple-
mentary data from external data sets to enrich the analysis.
A strong aspect of the LDViz interface, and in particular, the MGExplorer visualization tool,
is the ability to record and visualize provenance information. 现在, this information is
restricted to the subsets of data and the visualizations used during the analysis. 因此, we also
intend to increase the variety of provenance information we record, considering the several
interactions used during the exploration (例如, clicks, hovering, data sorting, ETC) that might be
relevant to understanding users’ reasoning, as well as to include a feature that allows users to
25 https://data.archives-ouvertes.fr/doc/sparql
26 https://makg.org/sparql
27 https://fr.dbpedia.org/sparql
28 Available at https://covid19.i3s.unice.fr:8080/ ldviz
29 https://covid19.i3s.unice.fr:8080/ ldviz?query=
30 https://corese.inria.fr/sparql
Quantitative Science Studies
1320
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
make annotations throughout the process regarding the historic items. Future work also
includes the analysis of the resulting provenance data. 例如, we could analyze the
resulting data to identify the most common usages of the system (standard choices of visual-
izations and instantiating order) according to different types of tasks, which could be used to
introduce the system to new users, suggest some well-known workflows of analysis, 并
improve overall user experience. 此外, we could validate these usage patterns through
user-based evaluations involving experts in the application domain, who would evaluate
whether and at which level the common detected workflows respond to their needs and
how it could be improved (IE。, which alternative exploratory path one would follow to solve
specific user queries).
For the purpose of extending the range of resources and services of the Covid-on-the-Web
project and, 因此, extending and improving the supported types of analyses, future work
includes integrating new visualization services, such as ARViz (Menin, Cadorel et al., 2021),
which allows the visual exploration of association rules describing patterns of co-occurring
NE within publications through three complementary visualization techniques: a scatter plot,
a chord diagram, and an association graph31. The tool currently works separately with a
pretreated subset of data extracted from the Covid-on-the-Web data set. 然而, the associ-
ation mining algorithm can process any RDF data set, the results of which could then be
explored with ARViz. 因此, future work includes the integration of this visualization interface
in the LDViz tool, where the user could analyze and explore meaningful data defined via
SPARQL queries, similarly to what is done with the MGExplorer, resulting in a completely inte-
grated tool for extracting and exploring knowledge from scientific literature through various
perspectives.
7. 结论
在本文中, we presented the data set and software resources provided by the Covid-on-the-
Web project, with a particular focus on the visualization services proposed to support the
exploration of the COVID-19 scientific literature. Based on the needs of biomedical
研究人员, who are partners of the project, we designed and published a linked data knowl-
edge graph describing the NE mentioned in the articles of the CORD-19 corpus and the
argumentative graphs they include. The knowledge graph generation pipeline has been pub-
lished to allow the scientific community to reuse, enrich, and adapt both the data set and the
pipeline in meaningful ways to assist users’ needs.
此外, we described and demonstrated the use of LDViz, a visualization interface
dedicated to the exploration of linked data, which is based on a SPARQL querying interface
and the MGExplorer interface, a generic visualization framework designed to explore multidi-
mensional graph data. We have shown the potential of this interface to explore different
perspectives to the Covid-on-the-Web data set, supporting the resolution of diverse domain-
related tasks.
Future work includes evaluating our resources and services with the participation of expert
users in the biomedical domain in terms of usability and suitability to solve the domain-related
任务; developing a querying feature that allows us to dynamically import data into the explor-
atory process from external data sets, aiming to enrich the ongoing analysis and explore on-
the-fly hypotheses; studying provenance information aiming to improve user experience and
31 Available at https://covid19.i3s.unice.fr:8080/arviz/
Quantitative Science Studies
1321
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Covid-on-the-Web
the visualization’s effectiveness; and integrating new visualization services to extend the
support for different domain-related tasks.
致谢
We gratefully acknowledge the contributions of Valentin Ah-Kane and Mathieu Simon and our
research partners of Inserm and INCa institutions. We also acknowledge the contribution of
Carla Freitas and Ricardo Cava for the initial work on the MGExplorer framework.
作者贡献
Aline Menin: 概念化, 调查, 方法, 软件, Writing—original
草稿, Writing—review & 编辑. Franck Michel: 数据管理, 调查, 资源, Soft-
器皿, Writing—review & 编辑. Fabien Gandon: 资金获取, Writing—review &
编辑. Raphaël Gazzotti: 资源, Writing—review & 编辑. Elena Cabrio: 监督.
Olivier Corby: 软件. Alain Giboin: 调查, 方法, Writing—review & 编辑.
Santiago Marro: 资源. Tobias Mayer: 资源. Serena Villata: 监督. Marco
Winckler: 概念化, 形式分析, 方法, 监督, Writing—original
草稿, Writing—review & 编辑.
COMPETING INTERESTS
The authors have no competing interests.
资金信息
This work is partly funded by the French government labeled PIA program under its IDEX
UCAJEDI project (ANR-15-IDEX-0001) and the 3IA Côte d’Azur (19-P3IA-0002) 也
the CovidOnTheWeb project funded by Inria.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
.
/
参考
Ambavi, H。, Vaishnaw, K., Vyas, U。, Tiwari, A。, & 辛格, 中号. (2020).
CovidExplorer: A multi-faceted AI-based search and visualization
engine for COVID-19 information. Proceedings of the 29th ACM
International Conference on Information & Knowledge Manage-
蒙特 (PP. 3365–3368). https://doi.org/10.1145/3340531.3417428
Beltagy, 我。, Lo, K., & Cohan, A. (2019). SciBERT: Pretrained language
model for scientific text. EMNLP, arXiv 预印本 arXiv:1903.10676.
https://doi.org/10.18653/v1/D19-1371
Bras, 磷. L。, Gharavi, A。, Robb, D. A。, Vidal, A. F。, Padilla, S。, &
Chantler, 中号. J. (2020). Visualising COVID-19 research. arXiv
preprint arXiv:2005.06380.
Cava, R。, & Freitas, C. D. S. (2013). Glyphs in matrix representation
of graphs for displaying soccer games results. The 1st Workshop
on Sports Data Visualization. IEEE, 13, 15. https://作坊
.sportvis.com/papers/cavaSoccerMatches.pdf
Cava, R。, Freitas, C. 中号. D. S。, & Winckler, 中号. (2017). ClusterVis:
Visualizing nodes attributes in multivariate graphs. 会议记录
of the Symposium on Applied Computing (PP. 174–179).
https://doi.org/10.1145/3019612.3019684
Cava, R。, Freitas, C. M。, Barboni, E., Palanque, P。, & Winckler, 中号.
(2014). Inside-in search: An alternative for performing ancillary
search tasks on the web. 2014 9th Latin American Web Congress
(PP. 91–99). https://doi.org/10.1109/LAWeb.2014.21
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Corby, 奥。, Gaignard, A。, Faron-Zucker, C。, & Montagnat, J. (2012).
KGRAM versatile data graphs querying and inference engine. 在
Proceedings of the IEEE/ WIC/ACM International Conference on
Web Intelligence. https://dl.acm.org/doi/10.5555/2457524
.2457672
Daiber, J。, Jakob, M。, Hokamp, C。, & Mendes, 磷. 氮. (2013). Improv-
ing efficiency and accuracy in multilingual entity extraction.
Proceedings of the 9th International Conference on Semantic Sys-
特姆斯 (PP. 121–124). https://doi.org/10.1145/2506182.2506198
Ellis, G。, & Dix, A. (2006). An explorative analysis of user evalua-
tion studies in information visualisation. 诉讼程序 2006
AVI Workshop on BEyond Time and Errors: Novel Evaluation
Methods for Information Visualization (PP. 1–7). https://doi.org
/10.1145/1168149.1168152
Fonseca, 乙. d. 磷. F. e., Sampaio, 右. B., de Araújo Fonseca, 中号. 五、, &
Zicker, F. (2016). Co-authorship network analysis in health
研究: Method and potential use. Health Research Policy
and Systems, 14(1), 1–10. https://doi.org/10.1186/s12961-016
-0104-5, 考研: 27138279
Hope, T。, Portenoy, J。, Vasan, K., Borchardt, J。, Horvitz, E., … 西方, J.
(2020). SciSight: Combining faceted navigation and research group
detection for COVID-19 exploratory scientific search. arXiv 预印本
arXiv:2005.12668. https://doi.org/10.1101/2020.05.23.112284
Quantitative Science Studies
1322
Covid-on-the-Web
Ilievski, F。, Garijo, D ., Chalupsky, H。, Divvala, 氮. T。, Yao, Y。, ……
Szekely, 磷. (2020). KGTK: A toolkit for large knowledge graph
manipulation and analysis. The Semantic Web – ISWC 2020
(PP. 278–293). https://doi.org/10.1007/978-3-030-62466-8_18
Jonquet, C。, Shah, 氮. H。, & Musen, 中号. A. (2009). The open bio-
medical annotator. Summit on Translational Bioinformatics,
2009 (p. 56). https://www.ncbi.nlm.nih.gov/pmc/articles
/PMC3041576/. 考研: 21347171
Leng, J. (2011). Handbook of research on computational science
和工程: Theory and practice (卷. 2). IGI Global.
https://doi.org/10.4018/978-1-61350-116-0
Lohmann, S。, Negru, S。, Haag, F。, & Ertl, 时间. (2016). Visualizing
ontologies with VOWL. 语义网, 7(4), 399–419. https://
doi.org/10.3233/SW-150200
Mayer, T。, 敞篷车, E., & 维拉塔, S. (2019). ACTA a tool for argumen-
tative clinical trial analysis. Proceedings of the 28th International
Joint Conference on Artificial Intelligence (IJCAI) (PP. 6551–6553).
https://doi.org/10.24963/ijcai.2019/953
Menin, A。, Cadorel, L。, Tettamanzi, A。, Giboin, A。, Gandon, F。, &
Winckler, 中号. (2021). ARViz: Interactive visualization of associa-
tion rules for RDF data exploration. 25th International Confer-
ence Information Visualisation. https://doi.org/10.1109/IV53921
.2021.00013
Menin, A。, Cava, R。, Freitas, C. 中号. D. S。, Corby, 奥。, & Winckler, 中号.
(2021). Towards a visual approach for representing analytical prove-
nance in exploration processes. 25th International Conference Infor-
mation Visualisation. https://doi.org/10.1109/IV53921.2021.00014
Michel, F。, Gandon, F。, Ah-Kane, 五、, Bobasheva, A。, 敞篷车, E., ……
Winckler, 中号. (2020). Covid-on-the-Web: Knowledge graph and
services to advance COVID-19 research. 在J. Z. Pan, V. Tamma,
C. d’Amato, K. Janowicz, 乙. 福, A. Polleres, 氧. Seneviratne, & L.
Kagal (编辑。), The Semantic Web – ISWC 2020 (PP. 294–310).
施普林格. https://doi.org/10.1007/978-3-030-62466-8_19
Naujokaitytė, G. (2021). COVID-19 triggered unprecedented col-
laboration in research. https://sciencebusiness.net/covid-19
/news/covid-19-triggered-unprecedented-collaboration-research
(七月访问 6, 2021).
Oniani, D ., Jiang, G。, 刘, H。, & 沉, F. (2020). Constructing
co-occurrence network embeddings to assist association extrac-
tion for COVID-19 and other coronavirus infectious diseases.
Journal of the American Medical Informatics Association, 27(8),
1259–1267. https://doi.org/10.1093/jamia/ocaa117, 考研:
32458963
Pietriga, 乙. (2006). Semantic web data visualization with graph style
sheets. 诉讼程序 2006 ACM Symposium on Software
可视化 (PP. 177–178). https://doi.org/10.1145/1148493
.1148532
Reese, J. T。, Unni, D ., Callahan, 时间. J。, Cappelletti, L。, Ravanmehr, 五、,
… Mungall, C. J. (2021). KG-COVID-19: A framework to produce
customized knowledge graphs for COVID-19 response. Patterns,
2(1), 100155. https://doi.org/10.1016/j.patter.2020.100155,
考研: 33196056
Sukla, A。, Naskar, A。, Goel, T。, Sangwan, S。, Rai, A。, … Dey, L.
(2021). Concept driven search and visualization system for
exploring scientific repositories. 8th ACM IKDD CODS and
26th COMAD (PP. 395–399). https://doi.org/10.1145/3430984
.3430991
Tu, J。, Verhagen, M。, Cochran, B., & 普斯特约夫斯基, J. (2020). Explo-
ration and discovery of the COVID-19 literature through seman-
tic visualization. arXiv 预印本 arXiv:2007.01800. https://doi.org
/10.18653/v1/2021.naacl-srw.11
Verspoor, K., Šuster, S。, Otmakhova, Y。, Mendis, S。, Zhai, Z。, …
Martinez, D. (2020). COVID-SEE: Scientific Evidence Explorer
for COVID-19 related research. arXiv 预印本 arXiv:2008.07880.
https://doi.org/10.1007/978-3-030-72240-1_65
王, L. L。, Lo, K., Chandrasekhar, Y。, Reas, R。, 哪个, J。, Eide, D .,
Funk, K., Kinney, 右. M。, 刘, Z。, Merrill, W., Mooney, P。, Murdick,
D. A。, Rishi, D ., Sheehan, J。, 沉, Z。, Stilson, B., Wade, A. D .,
王, K., Wilhelm, C。, . . . Kohlmeier, S. (2020). CORD-19: 这
Covid-19 Open Research Dataset. ArXiv, abs/2004.10706.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
q
s
s
/
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
2
4
1
3
0
1
2
0
0
7
9
9
0
q
s
s
_
A
_
0
0
1
6
4
p
d
/
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Quantitative Science Studies
1323