报告
Segmentability Differences Between
Child-Directed and Adult-Directed
Speech: A Systematic Test With
an Ecologically Valid Corpus
Alejandrina Cristia
1, Emmanuel Dupoux1,2,3, Nan Bernstein Ratner4, and Melanie Soderstrom5
开放访问
杂志
1Dept d’Etudes Cognitives, ENS, PSL University, EHESS, 法国国家科学研究中心
2INRIA
3FAIR Paris
4Department of Hearing and Speech Sciences, University of Maryland
5心理学系, University of Manitoba
关键词: 计算建模, learnability, infant word segmentation, statistical learning,
lexicon
抽象的
Previous computational modeling suggests it is much easier to segment words from
child-directed speech (CDS) than adult-directed speech (ADS). 然而, this conclusion is
based on data collected in the laboratory, with CDS from play sessions and ADS between a
parent and an experimenter, which may not be representative of ecologically collected CDS
and ADS. Fully naturalistic ADS and CDS collected with a nonintrusive recording device
as the child went about her day were analyzed with a diverse set of algorithms. 这
difference between registers was small compared to differences between algorithms; 它
reduced when corpora were matched, and it even reversed under some conditions.
These results highlight the interest of studying learnability using naturalistic corpora
and diverse algorithmic definitions.
引文: Cristia A., Dupoux, E., Ratner,
氮. B., & Soderstrom, 中号. (2019).
Segmentability Differences Between
Child-Directed and Adult-Directed
Speech: A Systematic Test With an
Ecologically Valid Corpus. 开放的心态:
认知科学的发现, 3,
13–22. https://doi.org/10.1162/opmi_
a_00022
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
.
/
/
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
/
.
我
DOI:
https://doi.org/10.1162/opmi_a_00022
介绍
补充材料:
https://osf.io/th75g/
已收到: 15 可能 2018
公认: 11 十二月 2018
利益争夺: None of the
authors declare any competing
兴趣.
通讯作者:
Alejandrina Cristia
alecristia@gmail.com
版权: © 2019
麻省理工学院
在知识共享下发布
归因 4.0 国际的
(抄送 4.0) 执照
麻省理工学院出版社
Although children are exposed to both child-directed speech (CDS) and adult-directed speech
(ADS), children appear to extract more information from the former than the latter (例如, Cristia,
2013; Shneidman & Goldin-Meadow, 2012). This has led some to propose that most or all lin-
guistic phenomena are more easily learned from CDS than ADS (例如, Fernald, 2000), 与一个
flurry of empirical literature examining specific phenomena (see Guevara-Rukoz et al., 2018,
for a recent review). Deciding whether the learnability of linguistic units is higher in CDS than
ADS is difficult for at least two reasons: It is difficult to find appropriate CDS and ADS corpora;
and one must have an idea of how children learn to check whether such a strategy is more
successful in one register than the other. 在本文中, we studied a highly ecological corpus
of CDS and child-overheard ADS with a variety of word segmentation strategies.
What is word segmentation? Since there are typically no silences between words in
running speech, infants may need to carve out, or segment, word forms from the continuous
溪流. Several differences between CDS and ADS could affect word segmentation learnability.
Caregivers may speak in a more variable pitch, leading both to increased arousal in the child
(which should boost attention and overall performance; 蒂森, 爬坡道, & 藏红花, 2005) 但
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
also increased acoustic variability (which makes word identification harder; Guevara-Rukoz et al.,
2018). To study word segmentation controlling for other differences (例如, attention capture,
fine-grained acoustics), we use computational models of word segmentation from phonolo-
gized transcripts. Word segmentation may still be easier in CDS than ADS: CDS is characterized
by short utterances, including a high proportion of isolated words (例如, Bernstein Ratner &
鲁尼, 2001, Soderstrom, 2007, PP. 508–509, and Swingley & Humphrey, 2018, for em-
pirical arguments that frequency in isolation matters). Short utterances represent an easier seg-
mentation problem than long ones, since utterance boundaries are also word boundaries, 和
proportionally more boundaries are provided for free. Other features of CDS may be beneficial
or not depending on the segmentation strategy. 例如, CDS tends to have more partial
repetitions than ADS (“Where’s the dog? There’s the dog!”), which may be more helpful to
lexical algorithms (which discover recombinable units) than sublexical algorithms (that look
for local breaks, such as illegal within-word phonotactics or dips in transition probability).
Previous modeling research documents much higher segmentation scores for CDS than
ADS corpora (Batchelder, 1997, 2002; Daland & Pierrehumbert, 2011; Fourtassi, Borschinger,
约翰逊, & Dupoux, 2013). Most of this work compared CDS recorded in the home or in
the lab (in the CHILDES database; MacWhinney, 2014), against lab-based corpora of adult–
adult interviews including open-ended questions ranging from profession to politics (例如, 这
Buckeye corpus; Pitt, 约翰逊, Hume, Kiesling, & 雷蒙德, 2005). 因此, differences in
segmentability could be due to confounded variables: Home recordings capture more informal
speech than interviews do, with shorter utterances and reduced lexical diversity; 而且,
since different researchers transcribed the CDS and ADS corpora, their criteria for utterance
boundaries may not be the same.
Only two studies used matched corpora, which had been collected in the laboratory
as mothers talked to their children and an experimenter. Batchelder (2002) applied a lexical
algorithm onto the American English Bernstein Ratner corpus (Bernstein Ratner, 1984), 和
found a 15% advantage for CDS over ADS. Ludusan, Mazuka, Bernard, Cristia, and Dupoux
(2017) applied two lexical and two sublexical algorithms to the Japanese-spoken Riken cor-
脓 (Mazuka, Igarashi, & Nishikawa, 2006), where the CDS advantage was between 2% 和
10%. 仍然, it is unclear whether either corpus is representative of the CDS and ADS children
hear every day. Being observed might affect parents’ CDS patterns, and thus segmentability.
而且, ADS portions were elicited by unfamiliar experimenters, with whom mothers may
have been more formal than in children’s typical overheard ADS. Experimenter-directed ADS
can differ significantly from ADS addressed to family members even in laboratory settings, 到
the point that phonetic differences across registers are much reduced when using family-based
(rather than experimenter-based) ADS as a benchmark (乙. K. 约翰逊, Lahey, Ernestus, & 卡特勒,
2013). Since prior work used laboratory-recorded samples, it is possible that it has over- 或者
misestimated differences in segmentability between CDS and ADS.
所以, we studied an ecological child-centered corpus containing both ADS and
CDS. We followed Ludusan and colleagues (2017) by using both lexical and sublexical algo-
rithms; 此外, we varied important parameters within these classes and further added two
基线. In all, we aimed to provide a more accurate and generalizable estimate of the size
of segmentability differences in CDS versus ADS.
方法
This article is reproducible thanks to the use of R, papaja, and knitr (Aust & Barth, 2015;
R核心团队, 2015; Xie, 2015). Raw data, supplementary explanations on the methods, 和
supplementary analyses are also available (Cristia, 2018A).
开放的心态: 认知科学的发现
14
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
桌子 1. Characteristics of the ADS and CDS portions of the corpus, depending on whether the human or automatic utterance boundaries
were considered.
人类
Sylls
10,051
24,933
代币
8,224
20,786
Types
1,342
2,015
MTTR
Utts
Sylls
0.93
0.89
1,772
5,320
10,100
24,933
ADS
CDS
Automatic
Types
1,342
2,012
代币
8,267
20,777
MTTR
Utts
0.93
0.89
1,892
5,630
笔记. Tokens differ for the Human versus Automatic because utterances where human coders (mistakenly) changed register within a
continuation were dropped from the Human analyses. ADS = adult-directed speech; CDS = child-directed speech; Sylls = syllables;
tokens and types refer to words; MTTR = Moving average Type to Token Ratio (over a sliding 10-word window); Utts = utterances.
语料库
The dataset consists of 104 recordings transcribed from the Winnipeg Corpus (Soderstrom,
Grauer, Dufault, & McDivitt, 2018; Soderstrom & Wittebolle, 2013; some of the recordings
are archived on homebank.talkbank.org—VanDam et al., 2016), gathered from 35 孩子们
(19 男孩们), aged between 13 和 38 月, recorded using the LENA system1 at home (14 孩子-
德伦), at home daycare (6), or at daycare center (13), with one more child recorded both at
home and home daycare. Soderstrom et al. (2018) report that, 之间 9 a.m. 和 5 p.m., 那里
were 1–4 adults in home recordings (median of 5-min units 1), 1–3 in home daycares (我-
甸 1), and 1–5+ in daycare centers (median 2). Although the caregivers’ sex was not sys-
tematically noted, a majority was female in all settings.
第一个 15 min, one hr into the recording (min 60–75), were independently transcribed
by two undergraduate assistants, who resolved any disagreements by discussion. Transcription
was done at the lexical level adapting the CHILDES minCHAT guidelines for transcription
(MacWhinney, 2009),2 without reproducing details of pronunciation (see Discussion). 这
transcribers also coded whether an utterance was directed to the target child, another child,
an adult, or other, using content and context. Utterances directed to the target child constituted
the CDS corpus; those directed to an adult constituted the ADS corpus.
Although LENA’s utterance boundaries were mostly accurate, coders sometimes split a
single LENA segment into two utterances. Since LENA may miss boundaries, we always divided
segments following human coding. 此外, coders sometimes considered a sequence of
segments as continuations of each other (6% of CDS utterances and 7% of ADS utterances).
We derived several versions of the ADS and CDS subcorpora crossing two factors (看
桌子 1 for characteristics). 第一的, we used the automatic utterance boundaries provided by the
LENA software (“A,” short for “automatic boundaries”), as well as combined together the text
from segments labeled as continuations of each other by coders (“H” for “human boundaries”).
第二, since performance is dependent on corpus size (see Bernard et al., 2018), we had
three versions of each CDS corpus: the full one, a shortened CDS corpus to match the ADS
corpus in number of words, and a shortened CDS corpus to match the ADS corpus in number of
utterances. After crossing these two factors, performance could be compared between, 在
一只手, ADS-A/H (ADS with automatic or human utterance boundaries), 和, 在另一
手, 之一 (1) CDS-A/H-full (corresponding full CDS corpus), (2) CDS-A/H-WM (cut at the
1 The LENA Foundation built a hardware and software system to record and automatically analyze day-long
child-centered recordings. For more information, see Soderstrom and Wittebolle (2013).
2 The transcription manual is available from https://osf.io/rvdbq/.
开放的心态: 认知科学的发现
15
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
same number of word tokens found in the corresponding ADS), 或者 (3) CDS-A/H-UM (cut at the
same number of utterances). As shown in the results, these different boundaries and matching
conditions only clarify our main conclusions that CDS-ADS differences are very small.
Processing and Evaluation
Scripts used for corpus preprocessing, phonologization, and segmentation are available
(Cristia, 2018乙). During preprocessing, all extraneous codes (such as marks for overlapping
speech or lexical reference for unusual pronunciations) were removed, leaving only the or-
thographic representation of the adults’ speech. These were phonologized using the American
English voice of Festival Text-to-Speech (泰勒, 黑色的, & Caley, 1998), which provides pho-
nemically based transcriptions, including syllable boundaries. These transcriptions emerge
mostly from dictionary lookup, but the system can also perform grapheme–phoneme con-
versions for neologisms, which are frequent in child-directed speech. Spaces between words
are removed from the resulting corpus to provide input to the algorithms. Each algorithm then
returns the corpus with spaces where word boundaries are hypothesized.
Each algorithm (with default parameters, except as noted below) was run using the
WordSeg package (Bernard et al., 2018), which also performs the evaluation. Due to space
restrictions, we cannot provide fuller descriptions here, but we refer readers to Bernard et al.
(2018), where the algorithms and the evaluation are explained. In a nutshell, both training
and evaluation are done over the whole corpus because these algorithms are unsupervised,
and thus there is no risk of overfitting. In the case of incremental algorithms, performance was
calculated on an output corpus that represented the algorithm’s segmentation level in the last
20% 数据的.
We provide pseudo-confidence intervals estimated as two standard deviations over
10 runs of resampling with replacement. 那是, we created 10 versions of each corpus by
resampling children’s transcripts to achieve approximately the same number of utterances as
in the original. 例如, in one of the runs, the ADS corpus may be composed of the data
from child 2’s day 1, 24’s day 3, 5’s day 1, 等等. We then extracted the standard deviation
in performance across resamples for each algorithm and corpus version.
For comparability with previous work, we focus on lexical token F-scores, derived by
comparing the gold-standard version of the input against the parsed version returned by the
algorithm. Precision measures what proportion of the word tokens posited by a given algorithm
correspond to tokens found in the gold segmentation, while recall measures what proportion
of the gold word tokens were correctly segmented by the algorithm. 例如, for the gold
phrase “here we go,” if an algorithm returns “here wego,” precision is .5 (one out of two
posited tokens is correct) and recall is .3 (one out of three gold words is correct). 整体
F-score ranges from 0 到 1, as it is the harmonic mean of precision P and recall R, 即,
2 × (P × R/(磷 + 右)), which is multiplied by 100 and reported as percentages here. Results for
all other possible alternative metrics, and further discussion on these methods, are provided
in the Supplemental Materials (Cristia, 2018A).
Segmentation Algorithms
There were two variants for each of two popular sublexical algorithms. The first one, DiBS
(short for Diphone-Based Segmentation; Daland & Pierrehumbert, 2011), posits word bound-
aries where phonotactic probabilities are low. The “gold” version (phonotactic-gold) sets the
diphone probability threshold based on gold word boundaries. The unsupervised version
(phonotactic-unsupervised) sets the threshold using utterance boundaries only. The phonotactics
开放的心态: 认知科学的发现
16
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
/
.
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
were computed on the concatenation of CDS and ADS versions of the corpus. 第二
algorithm, labeled TP, posits boundaries using transition probabilities between syllables, 作为
proposed in Saffran, Aslin, and Newport
(1996). The first version uses a relative dip in prob-
能力 (henceforth TP-relative). 那是, given the syllable sequence WXYZ, a boundary is
posited between X and Y if the transition probability between the X-Y is lower than between
W-X and Y-Z. The second version uses average transitions over all pairs of syllables in the
corpus as the threshold (TP-average; Saksida, Langus, & Nespor, 2017).
的
the three lexical algorithms,
two are variants on the Adaptor Grammar by
中号. Johnson and Goldwater (2009). 在这个系统中, there is a set of generic rules, such as “a
word is a sequence of phonemes, an utterance is a sequence of words,” and the algorithm
further learns, based on the corpus, particular instances of these rules (“d + 哦 + g is a word”) 作为
well as all of the rules’ probabilities. One variant relied on the simple rules just defined (词汇的-
unigram). The other variant, which we call lexical-multigram, is based on a more complicated
rule set with hierarchically defined levels that are both smaller and larger than words (细节
in the Supplemental Materials, Cristia, 2018A; 中号. 约翰逊, Christophe, Dupoux, & Demuth,
2014). The third lexical algorithm, lexical-incremental, implements a very different approach
(Monaghan & Christiansen, 2010). It processes the corpus one utterance at a time. For each, 它
checks whether the utterance contains a subsequence that is in its long-term lexicon; 如果是这样, 它
checks whether extracting that subsequence would result in phonotactically legal remainders
(with phonotactics derived from the lexicon). 否则, the whole utterance is stored in its
lexicon.
To these seven algorithms we add two baselines, introduced to provide segmentation
results for relatively uninformed strategies. One posits word boundaries at utterance edges
(henceforth base-utt). The other posits word boundaries at syllable edges (henceforth base-
syll). The latter is likely to be effective for English CDS, which has a very high proportion of
monosyllabic words (例如, Swingley, 2005).
结果
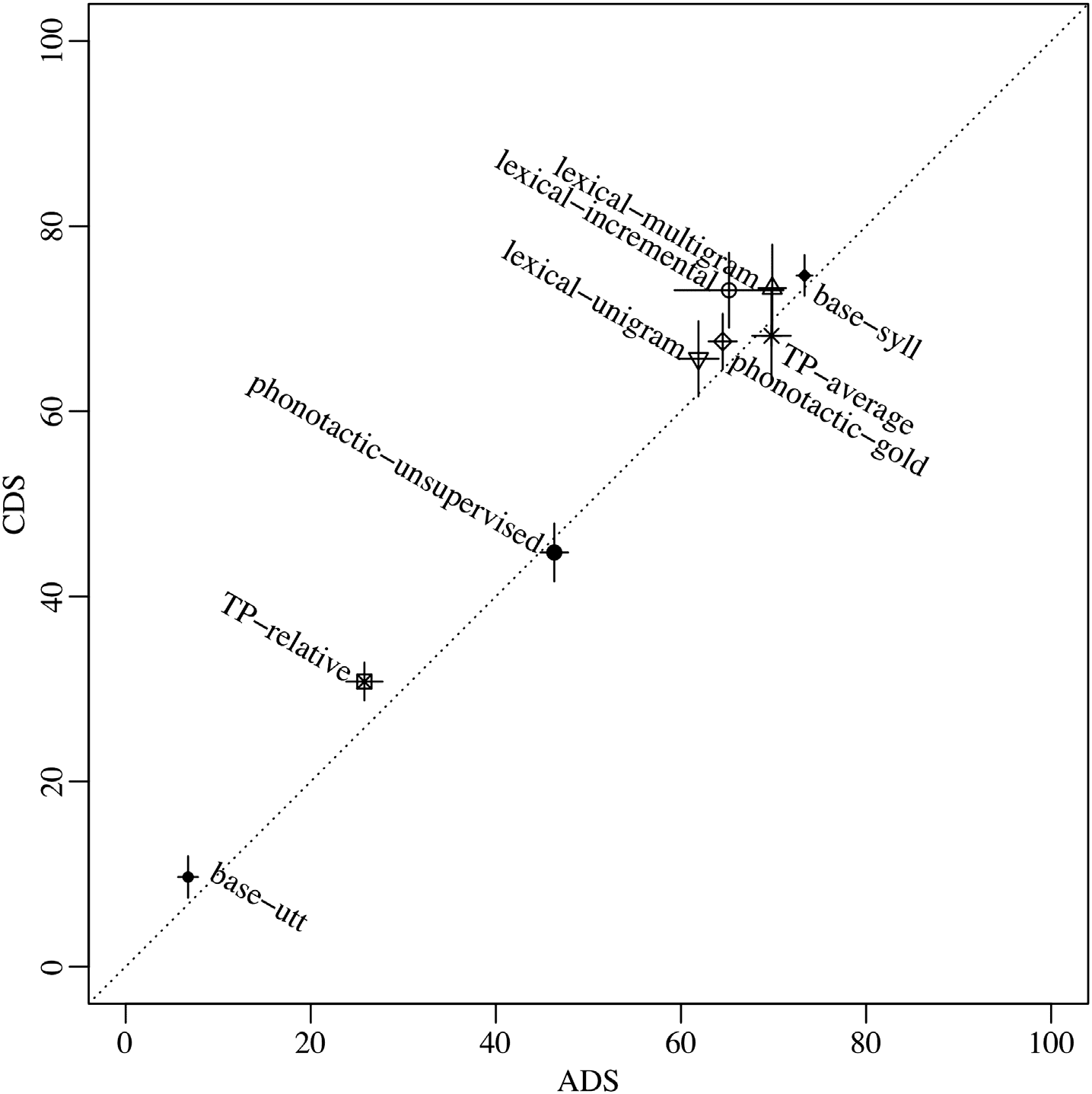
数字 1 illustrates token F-scores in CDS as a function of that in ADS, when using the full
corpora and the human-based utterance boundaries (for figures on all other conditions and
dependent variables, please see Supplemental Materials; Cristia, 2018A). If CDS input is eas-
ier to segment, then points should be above the 45-degree, equal-performance dotted line. 这
is the case for most points. 然而, the median difference across registers (CDS minus ADS,
in each algorithm separately) 曾是 3%, ranging from −2% to 8%. 而且, for most points,
the pseudo-confidence intervals (defined as two times the standard deviation over 10 样品)
cross the equal performance line, meaning that only for lexical-incremental, TP-relative, 和
base-utt are differences above this measure of sampling error. 最后, 数字 1 conveys register
differences in the larger context: The greatest source of variation in performance clearly is due
to the different algorithms, with token F-scores for the full CDS corpus ranging from 10% 到
75%. 这 65% difference is much greater than the CDS–ADS differences (maximally 8%).
How stable are these differences as a function of utterance-boundary and size-matching
决定? We looked at performance in various conditions, varying whether utterance bound-
aries were purely automatic (which is less likely to reflect human-coder bias than human-
utterance boundary placement) and whether CDS and ADS were matched in length (自从
several algorithms’ performance is affected by corpus size). Positive difference scores, 在-
dicative of better CDS than ADS performance, were found in most matching conditions, 关于-
gardless of whether automatic or human-utterance boundaries were used (桌子 2). 然而,
开放的心态: 认知科学的发现
17
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
.
/
/
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
数字 1. Token F-score (in percentage) achieved by each algorithm in child-directed speech
(CDS) as a function of that in adult-directed speech (ADS) in the full Winnipeg corpus with human-
set utterance boundaries. Error bars indicate two standard deviations (超过 10 resamples; see main
text and Supplemental Materials, Cristia, 2018A, 欲了解详情).
我
/
/
.
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
桌子 2. CDS F-score minus ADS F-score (in percentages) by algorithm, type of match, and whether
人类 (H) or automatic (A) utterance boundaries were considered.
Algo
H: full H: UM H: WM A: 满的
A: UM A: WM Median
base-utt
2.9
1.3
base-syll
phonotactic-unsupervised −1.6
3
phonotactic-gold
5
TP-relative
−1.6
TP-average
7.9
lexical-incremental
3.8
lexical-unigram
3.4
lexical-multigram
3
Median
1.4
−0.2
−2.5
2.6
0.7
−2.9
−0.6
2.9
1.9
0.7
1.5
0
−2.5
2.8
0.9
−2.8
1.6
3.6
0.2
0.9
3.3
1.2
−1.3
3.1
5
−1.5
7.1
2.8
3.1
3.1
1.8
−0.2
−2.3
2.8
0.4
−2.9
1.2
2.3
−0.8
0.4
1.9
−0.3
−2.4
2.8
0.7
−3.1
2.3
2.4
0.4
0.7
1.85
−0.1
−2.35
2.8
0.8
−2.85
1.95
2.85
1.15
1.15
笔记. Full means the full child-directed speech (CDS) corpus was used; UM = utterance match:
CDS corpus shortened to have as many utterances as the adult-directed speech (ADS) 语料库;
WM = word match: idem for words.
开放的心态: 认知科学的发现
18
Segmentability of Child- and Adult-Directed Speech Cristia et al.
phonotactic-unsupervised and TP-average showed a consistent CDS disadvantage in all bound-
ary and matching conditions. 而且, the difference between CDS and ADS was reduced
when considering automatic rather than human-utterance boundaries; and length-matched
CDS rather than the full CDS.
简而言之, we observe smaller CDS advantages than those found in previous work. 到
check whether this was due to algorithms or corpora, we applied our extensive suite of algo-
rithms onto the Bernstein Ratner corpus (analyzed by Batchelder, 2002). 结果显示
a more consistent and larger CDS advantage than in the Winnipeg corpus (median of 6%,
range −2–17%; see details in the Supplemental Materials; Cristia, 2018A).
讨论
Previous computational work using laboratory-based CDS and ADS corpora have documented
an impressive CDS advantage in segmentability (15% in Batchelder, 2002—although reduced
到 6% when more varied algorithms are considered; 10% in Ludusan et al., 2017). 然而,
when applying these diverse segmentation algorithms to an ecological CDS–ADS corpus, 这
evidence of increased segmentability for CDS than ADS was less compelling. The CDS advan-
tage was numerically small (median of 3%), and often within the margin of error estimated
via resampling (1–6%). These conclusions were based on the full CDS and ADS corpora, 和
human-coded utterance boundaries, where the CDS performance was based on twice the in-
put and potentially biased utterance-boundary decisions. The CDS advantage was even smaller
when considering length-matched corpora with automatic utterance boundaries (medians of
0.4–0.7%).
A key strength of the present work lies in the use of a unique corpus, in which both CDS
and ADS were collected from the children’s everyday input. It is unlikely that the difference
in conclusions drawn by previous authors and those we draw is due to corpus size or child
年龄 (见表 3; note also that we and previous authors all considered corpus size differences
in some analyses). 反而, the most salient difference is the setting of the recording, which in
our case is at home or in the daycare, and the fact that our ADS arises naturally in this context,
rather than in an interview-like situation with an experimenter. By sampling from the home and
two types of daycare environments, the CDS is likely to represent a wide range of interactions
between children and a variety of caregivers, and the ADS captures speech between colleagues
(例如, professional carers in the daycares), partners (例如, mother and father in the home), 和
other adult relationships (例如, visitor, delivery person, interlocutor over the phone). 注意
our ADS is only representative of the ADS present in infants’ input rather than all ADS styles
(from presidential speech to intimate bedside conversations). Another interesting feature of
桌子 3. Characteristics of ADS and CDS studied in past and present work
语料库
Addressee(s)
Bernstein Ratner
Riken
Winnipeg
Experimenter
Children 9–27 months
Experimenter
Children 18–24 months
Adults
Children 13–38 months
代币
19,753
30,996
22,844
51,315
8,224
20,786
Types
1,797
1,501
2,022
2,850
1,342
2,015
Utterances
2,668
8,252
3,582
14,570
1,772
5,320
笔记. ADS = adult-directed speech; CDS = child-directed speech; MTTR for the Bernstein Ratner
ADS was .93; CDS .88.
开放的心态: 认知科学的发现
19
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
/
.
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
the Winnipeg corpus is that its automatic annotation contains utterance boundaries defined
bottom-up (using talker switch or lengthy pauses). These features lead us to argue that our
results represent the input naturally available to English-learning Canadian children well, 和,
in this input, CDS and ADS do not differ greatly in word segmentation learnability. Our results
are compatible with the hypothesis proposed by Benders (2013), 除其他外, whereby CDS
is shaped less by the caregivers’ attempt to specifically promote language acquisition than
other potential functions (such as communicating affect).
Another strength of this work is that we employed multiple word segmentation algo-
rithms. This is important not only because results change even as minor parameters are set but
also because there is no clear evidence as to which algorithm infants use. Children may
even take advantage of diverse procedures depending on context and previous experience, 为了
例子, using transition probabilities when nothing else is available (Saffran et al., 1996) 和
utilizing their budding lexicon when probabilities are less clear (Mersad & Nazzi, 2012). 在-
creasing the diversity of algorithms allows us to revise Ludusan and colleagues’ (2017) conclu-
sion that there may be greater CDS advantages when using local cues (which perform overall
更差, at about 30% Token F-score in the Riken corpus) rather than lexical algorithms (和
performance at about 50%). 相比之下, we find that sublexical algorithms can lead to poor
or good performances depending on their parametrization (compare phonotactic-gold versus
phonotactic-unsupervised; TP-average versus TP-relative; base-utt versus base-syll). 更远,
we do not see larger CDS advantages for better performing or lexical algorithms compared to
worse performing or sublexical algorithms. 实际上, we see divergences even within two versions
of the same algorithm, 和, 例如, phonotactic-gold and TP-relative leading to a CDS
优势, whereas phonotactic-unsupervised and TP-average lead to a CDS disadvantage.
We see two promising paths that future computational work should take. 第一的, 甚至
though our algorithms covered a wide range of hypotheses regarding early word segmentation,
they may differ in critical ways from the algorithms and input used by infants. 例如,
words here were systematically attributed a pronunciation from a dictionary, and thus did not
capture the possible application of phonological rules and other sources of variation that cause
a single underlying word to have many different surface forms (see Buckler, Goy, & 约翰逊,
2018, for phonetic variability in CDS versus ADS differently; and Elsner, Goldwater, 费尔德曼,
& Wood, 2013, for a possible incorporation of phonetic variability in segmentation algo-
rithms). Such variability will most greatly affect the discovery of paradigms (IE。, figuring out
that “what is that” can also be pronounced “whaz that”), and not necessarily segmentation of
word forms. 所以, it would be most interesting to study it in the context of morphologi-
cal discovery rather than only segmentation. 最终, we may want to test algorithms that
operate directly from the acoustic representation (Ludusan et al., 2014; Versteegh et al., 2015).
第二, we studied only North American English. We look forward to extending the
current approach to ecologically valid databases in additional typologically diverse languages,
although none containing both CDS and ADS is currently available, and therefore a priority in
future research should be to build larger, matched, multilingual corpora. We predict segmenta-
tion scores are lower in languages where words and syllable boundaries are less well-aligned
than in English (Loukatou, Stoll, Blasi, & Cristia, 2018), but regardless of overall performance
级别, there will be no or little learnability advantages for CDS versus ADS for segmentation:
North American English has been described as having more marked CDS–ADS differences than
other languages (例如, Japanese; Fernald et al., 1989). 所以, one might expect the greatest
learnability advantages to be found in North American English—suggesting that cross-linguistic
work is even less likely to find results supporting a segmentation advantage for CDS.
开放的心态: 认知科学的发现
20
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Segmentability of Child- and Adult-Directed Speech Cristia et al.
To conclude, we found that advantages in segmentability for CDS over ADS in an ecolog-
ical corpus were smaller and more inconsistent than previous estimations based on laboratory
CDS–ADS. 全面的, our word segmentation results align with other work on sound discrim-
inability (Martin et al., 2015) and word discriminability (Guevara-Rukoz et al., 2018), 苏格-
gesting that the high learnability attributed to CDS may have been overestimated. 研究
assessing the learnability properties of child-directed speech at other levels (例如, syntax) 会
benefit from using similarly natural corpora, as well as a variety of algorithmic approaches.
致谢
We are grateful to Mark Johnson, Robert Daland, and Amanda Saksida for helpful discussions
and comments on previous versions of this manuscript; and to members of the LAAC, CoML,
and Language teams at the LSCP for helpful discussion.
资金信息
AC acknowledges financial support from Agence Nationale de la Recherche (ANR-14-CE30-
0003 MechELex); ED from European Research Council (ERC-2011-AdG-295810 BOOTPHON),
the Fondation de France, the Ecole de Neurosciences de Paris, the Region Ile de France (DIM
cerveau et pensée); MS from SSHRC (Insight Development Grant 430-2011-0459, and Insight
授予 435-2015-0628). AC and ED acknowledge the institutional support of Agence Nationale
de la Recherche (ANR-17-EURE-0017).
作者贡献
AC: 概念化: 带领; 数据管理: 带领; 形式分析: 带领; 资金获取:
带领; 方法: 带领; 项目管理: 带领; 资源: 带领; 软件: 带领; Val-
idation: 带领; 可视化: 带领; Writing – original draft: 带领; 写作——复习 & 编辑:
带领. ED: 概念化: 配套; 形式分析: 配套; 方法: Sup-
移植; 软件: 配套; 可视化: 配套; 写作——复习 & 编辑: 支持-
英. NBR: 概念化: 配套; 资源: 配套; 写作——复习 & 编辑:
配套. MS: 概念化: 配套; 方法: 配套; 资源: 带领;
验证: 配套; 可视化: 配套; 写作——复习 & 编辑: 配套.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
.
/
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
.
/
我
参考
Aust, F。, & Barth, 中号. (2015). Papaja: Create APA manuscripts with
RMarkdown. Retrieved from https://github.com/crsh/papaja
Batchelder, 乙. 氧. (1997). Computational evidence for the use of
frequency information in discovery of the infant’s first lexicon
(未发表的博士论文). 纽约: The City University
纽约的.
Batchelder, 乙. 氧. (2002). Bootstrapping the lexicon: A computa-
tional model of infant speech segmentation. 认识, 83,
167–206.
Benders, 时间. (2013). Mommy is only happy! Dutch mothers’ re-
alisation of speech sounds in infant-directed speech expresses
情感, not didactic intent. Infant Behavior and Development,
36, 847–862.
Bernard, M。, Thiolliere, R。, Saksida, A。, Loukatou, G。, Larsen, E.,
约翰逊, M。, . . . Cristia, A. (2018). WordSeg: Standardizing
unsupervised word form segmentation from text. Preprint.
Retrieved from https://osf.io/5qkm3/
Bernstein Ratner, 氮.
(1984). Patterns of vowel modification in
mother–child speech. Journal of Child Language, 11, 557–578.
Bernstein Ratner, N。, & 鲁尼, 乙.
(2001). How accessible is
the lexicon in Motherese? Language Acquisition and Language
Disorders, 23, 71–78.
Buckler, H。, Goy, H。, & 约翰逊, 乙. K. (2018). What infant-directed
speech tells us about the development of compensation for
assimilation. Journal of Phonetics, 66, 45–62.
Cristia, A. (2013). Input to language: The phonetics and perception
of infant-directed speech. Language and Linguistics Compass, 7(3),
157–170.
Cristia, A. (2018A, 四月 18). Segmentability differences between
child-directed and adult-directed speech: A systematic test with
an ecologically valid corpus. 开放的心态: Discoveries in Cogni-
tive Science, 3, 13–22. Retrieved from https://osf.io/th75g/
Cristia, A. (2018乙). Segmentation recipes for CDS versus ADS in the
Winnipeg corpus. Computer code. Retrieved from https://github.
com/alecristia/seg_cds_ads_winnipeg
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
开放的心态: 认知科学的发现
21
Segmentability of Child- and Adult-Directed Speech Cristia et al.
Daland, R。, & Pierrehumbert, J. 乙. (2011). Learning diphone-based
segmentation. 认知科学, 35, 119–155.
Elsner, M。, Goldwater, S。, 费尔德曼, N。, & Wood, F. (2013). A joint
learning model of word segmentation, lexical acquisition, 和
phonetic variability. In Proceedings of Empirical Methods in
自然语言处理 (PP. 42–54). Seattle, WA.
Fernald, A. (2000). Speech to infants as hyperspeech: Knowledge-driven
processes in early word recognition. Phonetica, 57, 242–254.
Fernald, A。, Taeschner, T。, Dunn, J。, Papousek, M。, de Boysson-
Bardies, B., & Fukui, 我. (1989). A cross-language study of pro-
sodic modifications in mothers’ and fathers’ speech to preverbal
婴儿. Journal of Child Language, 16, 477–501.
Fourtassi, A。, Borschinger, B., 约翰逊, M。, & Dupoux, 乙.
(2013).
Whyisenglishsoeasytosegment. In Proceedings of the Fourth An-
nual Workshop on Cognitive Modeling and Computational Lin-
语言学 (PP. 1–10). Sofia, Bulgaria.
Guevara-Rukoz, A。, Cristia, A。, Ludusan, B., Thiolliére, R。, 马丁,
A。, Mazuka, R。, & Dupoux, 乙. (2018). Are words easier to learn
from infant- than adult-directed speech? A quantitative corpus-
based investigation. 认知科学, 42, 1586–1617.
约翰逊, 乙. K., Lahey, M。, Ernestus, M。, & 卡特勒, A. (2013). 一个多-
modal corpus of speech to infant and adult listeners. The Journal
of the Acoustical Society of America, 134, EL534–EL540.
约翰逊, M。, Christophe, A。, Dupoux, E., & Demuth, K. (2014,
六月). Modelling function words improves unsupervised word
the Annual Conference of
segmentation.
the Association for Computational Linguistics (PP. 282–292).
巴尔的摩, 医学博士.
在诉讼程序中
约翰逊, M。, & Goldwater, S. (2009). Improving nonparameteric
Bayesian inference: Experiments on unsupervised word segmen-
tation with adaptor grammars. In Proceedings of the Annual
the Association for Computational Linguistics
Conference of
(PP. 317–325). Suntec, 新加坡.
Loukatou, G。, Stoll, S。, Blasi, D ., & Cristia, A. (2018, 可能). Modeling
infant segmentation of two morphologically diverse languages.
In V. Claveau & 磷. Sébillot (编辑。), Actes de la conférence Traite-
ment Automatique de la Langue Naturelle, TALN 2018. 体积 1:
Articles longs, articles courts de TALN (PP. 47–57). 雷恩,
法国.
Ludusan, B., Mazuka, R。, Bernard, M。, Cristia, A。, & Dupoux, 乙.
(2017). The role of prosody and speech register in word segmen-
站: A computational modelling perspective. 在诉讼程序中
the Annual Conference of the Association for Computational Lin-
语言学 (体积 2: Short papers) (PP. 178–183). Vancouver, 加拿大.
Ludusan, B., Versteegh, M。, Jansen, A。, Gravier, G。, 曹, X.-N., 约翰逊,
M。, & Dupoux, 乙. (2014). Bridging the gap between speech tech-
nology and natural language processing: An evaluation toolbox
for term discovery systems. In Proceedings of Language Resources
and Evaluation Conference (PP. 560–576). Reykjavik, 冰岛.
MacWhinney, 乙.
(2009). The CHILDES project part 1: The CHAT
transcription format. 纽约: Psychology Press.
MacWhinney, 乙. (2014). The CHILDES project part II: The database.
纽约: Psychology Press.
马丁, A。, Schatz, T。, Versteegh, M。, Miyazawa, K., Mazuka, R。,
Dupoux, E., & Cristia, A. (2015). Mothers speak less clearly to
infants than to adults: A comprehensive test of the hyperarticula-
tion hypothesis. 心理科学, 26, 341–347.
Mazuka, R。, Igarashi, Y。, & Nishikawa, K. (2006). Input for learning
Japanese: RIKEN Japanese Mother-Infant Conversation Corpus.
Technical Report of IEICE, Tl2006-16, 106(165), 11–15.
Mersad, K., & Nazzi, 时间.
(2012). When Mommy comes to the
rescue of statistics: Infants combine top-down and bottom-up
cues to segment speech. Language Learning and Development,
8, 303–315.
Monaghan, P。, & Christiansen, 中号. H. (2010). Words in puddles of
声音: Modelling psycholinguistic effects in speech segmenta-
的. Journal of Child Language, 37, 545–564.
Pitt, 中号. A。, 约翰逊, K., Hume, E., Kiesling, S。, & 雷蒙德, 瓦.
(2005). The Buckeye corpus of conversational speech: Labeling
conventions and a test of transcriber reliability. Speech Commu-
nication, 45, 89–95.
R核心团队. (2015). 右: 统计语言和环境
计算. 维也纳, 奥地利: R Foundation for Statistical Comput-
英. Retrieved from http://www.R-project.org/
藏红花, J. R。, Aslin, 右. N。, & Newport, 乙. L. (1996). Statistical learn-
ing by 8-month-old infants. 科学, 274, 1926–1928.
Saksida, A。, Langus, A。, & Nespor, 中号. (2017). Co-occurrence sta-
tistics as a language-dependent cue for speech segmentation.
Developmental Science, 20(3). 土井:10.1111/desc.12390
Shneidman, L. A。, & Goldin-Meadow, S.
(2012). Language input
and acquisition in a Mayan village: How important is directed
speech? Developmental Science, 15, 659–673.
Soderstrom, 中号. (2007). Beyond babytalk: Re-evaluating the nature
and content of speech input to preverbal infants. Developmental
审查, 27, 501–532.
Soderstrom, M。, Grauer, E., Dufault, B., & McDivitt, K. (2018). Influ-
ences of number of adults and adult:child ratios on the quantity
of adult language input across childcare settings. First Language,
38, 563–581.
Soderstrom, M。, & Wittebolle, K. (2013). When do caregivers talk?
The influences of activity and time of day on caregiver speech
and child vocalizations in two childcare environments. 公共科学图书馆一号,
8(11), e80646.
Swingley, D.
(2005). Statistical clustering and the contents of the
infant vocabulary. 认知心理学, 50, 86–132.
Swingley, D ., & Humphrey, C. (2018). Quantitative linguistic pre-
dictors of infants’ learning of specific English words. Child De-
发展, 89, 1247–1267.
泰勒, P。, 黑色的, A. W., & Caley, 右. (1998, 十一月). The architec-
ture of the FESTIVAL speech synthesis system. 在诉讼程序中
the 3rd European Speech Communication Association Workshop
on Speech Synthesis (PP. 147–151). Jenolan Caves, 澳大利亚.
蒂森, 乙. D ., 爬坡道, E., & 藏红花, J. 右.
(2005).
Infant-directed
speech facilitates word segmentation. Infancy, 7, 53–71.
VanDam, M。, Warlaumont, A. S。, Bergelson, E., Cristia, A。,
Soderstrom, M。, De Palma, P。, & MacWhinney, 乙. (2016). Home-
Bank: An online repository of daylong child-centered audio
录音. Seminars in Speech and Language, 37(2), 128.
Versteegh, M。, Thiolliere,R。, Schatz, T。, 曹, X.-N., Anguera,
X。, Jansen, A。, & Dupoux, 乙. (2015, 九月). The Zero Re-
source Speech Challenge 2015. In Proceedings of Interspeech
(PP. 316–3173). Dresden, 德国.
Xie, 是.
(2015). Dynamic documents with R and knitr (2nd 版。).
Retrieved from http://yihui.name/knitr/
开放的心态: 认知科学的发现
22
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
哦
p
米
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
我
/
/
.
1
0
1
1
6
2
哦
p
米
_
A
_
0
0
0
2
2
1
8
6
8
3
4
8
哦
p
米
_
A
_
0
0
0
2
2
p
d
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3