基于检索的系统中公共和私有数据的推理
Simran Arora3, 帕特里克·刘易斯4**, 范安琪1, 雅各布·卡恩2*, and Christopher R´e3∗
1Facebook AI Research, 法国
2Facebook AI Research, 美国
{安吉拉凡, 雅各布卡恩}@fb.com
3斯坦福大学, 美国
{西姆兰, 克里斯姆雷}@cs.stanford.edu
4Cohere, 美国
Patrick@cohere.ai
抽象的
Users an organizations are generating ever-
increasing amounts of private data from a wide
range of sources. 纳入私人骗局-
文本对于个性化开放域很重要
tasks such as question-answering, fact-checking,
and personal assistants. State-of-the-art systems
for these tasks explicitly retrieve information
that is relevant to an input question from a
background corpus before producing an an-
swer. While today’s retrieval systems assume
relevant corpora are fully (例如, publicly) 交流电-
cessible, users are often unable or unwilling
to expose their private data to entities host-
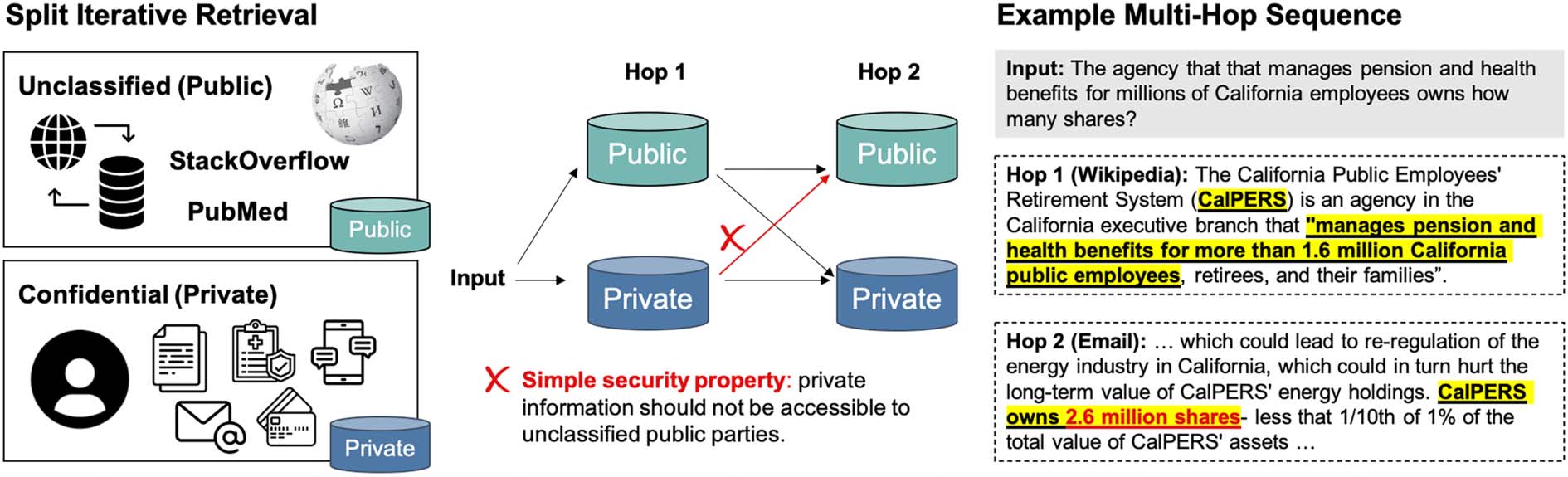
ing public data. We define the SPLIT ITERATIVE
RETRIEVAL (SPIRAL) problem involving iter-
ative retrieval over multiple privacy scopes.
We introduce a foundational benchmark with
which to study SPIRAL, as no existing bench-
mark includes data from a private distribution.
Our dataset, CONCURRENTQA, includes data
from distinct public and private distributions
and is the first textual QA benchmark requir-
ing concurrent retrieval over multiple distribu-
系统蒸发散. 最后, we show that existing retrieval
approaches face significant performance deg-
radations when applied to our proposed re-
trieval setting and investigate approaches with
which these tradeoffs can be mitigated. 我们
release the new benchmark and code to re-
produce the results.1
1
介绍
The world’s information is split between publicly
and privately accessible scopes, and the ability to
simultaneously reason over both scopes is useful
to support personalized tasks. 然而, 恢复-
based machine learning (机器学习) 系统, which first
retrieve relevant information to a user input from
∗Equal contribution.
∗∗Work done at Meta.
1https://github.com/facebookresearch
/concurrentqa.
902
background knowledge sources before providing
an output, do not consider retrieving from private
data that organizations and individuals aggregate
locally. Neural retrieval systems are achieving
impressive performance across applications such
as language-modeling (Borgeaud et al., 2022),
question answering (陈等人。, 2017), and dia-
logue (Dinan et al., 2019), and we focus on the
under-explored question of how to personalize
these systems while preserving privacy.
Consider the following examples that require
retrieving information from both public and pri-
vate scopes. Individuals could ask ‘‘With my GPA
and SAT score, which universities should I ap-
ply to?’’ or ‘‘Is my blood pressure in the normal
range for someone 55+?’’. In an organization, 一个
ML engineer could ask: ‘‘How do I fine-tune a
language model, based on public StackOverflow
and our internal company documentation?’’, 或者
a doctor could ask ‘‘How are COVID-19 vac-
cinations affecting patients with type-1 diabetes
based on our private hospital records and public
PubMed reports?’’. To answer such questions,
users manually cross-reference public and private
information sources. We initiate the study of a
retrieval setting that enables using public (全球的)
data to enhance our understanding of private
(当地的) 数据.
Modern retrieval systems typically collect doc-
uments that are most similar to a user’s question
from a massive corpus, and provide the resulting
documents to a separate model, which reasons
over the information to output an answer (陈
等人。, 2017). Multi-hop reasoning (Welbl et al.,
2018) can be used to answer complex queries
over information distributed across multiple docu-
评论, 例如, news articles and Wikipedia. 对于这样的
queries, we observe that using multiple rounds
of retrieval (IE。, combining the original query
with retrieved documents at round i for use in
计算语言学协会会刊, 卷. 11, PP. 902–921, 2023. https://doi.org/10.1162/tacl 00580
动作编辑器: Jacob Eisenstein. 提交批次: 5/2022; 修改批次: 4/2023; 已发表 8/2023.
C(西德:3) 2023 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
retrieval at round i + 1) provides over 75% im-
provement in quality versus using one round of
恢复 (部分 5). Iterative retrieval is now
common in retrieval (Miller et al., 2016; 费尔德曼
and El-Yaniv, 2019; Asai et al., 2020; Xiong et al.,
2021; Qi et al., 2021; Khattab et al., 2021, 国际米兰
alia).
Existing multi-hop systems perform retrieval
over a single privacy scope. 然而, users and
organizations often cannot expose data to public
实体. Maintaining terabyte-scale and dynamic
data is difficult for many private entities, warrant-
ing retrieval from multiple distributed corpora.
To understand why distributed multi-hop re-
trieval implicates privacy concerns, consider two
illustrative questions an employee may ask. 第一的,
the products our competitors
to answer ‘‘Of
released this month, which are similar to our un-
released upcoming products?’’, an existing multi-
hop system likely (1) retrieves public documents
(例如, news articles) about competitors, 和 (2)
uses these to find private documents (例如, com-
pany emails) about internal products, leaking no
private information. 同时, ‘‘Have any com-
panies ever released similar products to the one
we are designing?’’ entails (1) retrieving pri-
vate documents detailing the upcoming product,
和 (2) performing similarity search for public
products using information from the confidential
文件. The latter reveals private data to an
untrusted entity hosting a public corpus. An effec-
tive privacy model will minimize leakage.
We introduce the SPLIT ITERATIVE RETRIEVAL
(SPIRAL) 问题. Public and private document
distributions usually differ and our first obser-
vation is that all existing textual benchmarks
require retrieving from one data-distribution. 到
appropriately evaluate SPIRAL, we create the
first textual multi-distribution benchmark, CON-
CURRENTQA, which spans Wikipedia in the public
domain and emails in the private domain, 使能
the study of two novel real-world retrieval setups:
(1) multi-distribution and (2) privacy-preserving
恢复:
• Multi-distribution Retrieval The ability for
a model to effectively retrieve over multiple
分布, even in the absence of privacy
constraints, is a precursor to effective SPI-
RAL systems, since it is unlikely for all pri-
vate distributions to be reflected at train time.
然而, the typical retrieval setup requires
retrieving over a single document distribu-
tion with a single query distribution (Thakur
等人。, 2021). We initiate the study of the
real-world multi-distribution setting. We find
that the SoTA multi-hop QA model trained
on 90.4k Wikipedia data underperforms the
same model trained on the 15.2k CONCUR-
RENTQA (Wikipedia and Email) examples by
20.8 F1 points on questions based on Email
passages. 更远, we find the performance
of the model trained on Wikipedia improves
经过 4.3% if we retrieve the top k
2 passages
from each distribution vs. retrieving the over-
all top k passages, which is the standard
协议.
• Privacy-Preserving Retrieval We then pro-
pose a framework for reasoning about the
privacy tradeoffs required for SoTA models
to achieve as good performance on public-
private QA as is achieved in public-QA. 我们
evaluate performance when no private in-
formation is revealed, and models trained
only on public data (例如, 维基百科) are uti-
lized. Under this privacy standard, 型号
sacrifice upwards of 19% performance un-
der SPIRAL constraints to protect document
privacy and 57% to protect query privacy
when compared to a baseline system with
标准, non privacy-aware retrieval me-
chanics. We then study how to manage the
privacy-performance tradeoff using selective
prediction, a popular approach for improving
the reliability of QA systems (Kamath et al.,
2020; 刘易斯等人。, 2021; Varshney et al.,
2022).
总之: (1) We are the first to report on
problems with applying existing neural retrieval
systems to the public and private retrieval setting,
(2) We create CONCURRENTQA, the first textual
multi-distribution benchmark to study the prob-
莱姆斯, 和 (3) We provide extensive evaluations of
existing retrieval approaches under the proposed
real-world retrieval settings. We hope this work
encourages further research on private retrieval.
2 Background and Related Work
2.1 Retrieval-Based Systems
Open-domain applications, such as question an-
swering and personal assistants, must support user
903
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
inputs across a broad range of topics. Implicit-
memory approaches for these tasks focus on
memorizing the knowledge required to answer
questions within model parameters (Roberts et al.,
2020). Instead of memorizing massive amounts of
knowledge in model parameters, retrieval-based
systems introduce a step to retrieve information
that is relevant to a user input from a massive
corpus of documents (例如, 维基百科), 进而
provide this to a separate task model that produces
the output. Retrieval-free approaches have not
been shown to work convincingly in multi-hop
settings (Xiong et al., 2021).
2.2 Multi-hop Retrieval
We focus on open-domain QA (ODQA), a classic
application for retrieval-based systems. ODQA
entails providing an answer a to a question q,
expressed in natural language and without ex-
plicitly provided context from which to find the
回答 (Voorhees, 1999). A retriever collects rel-
evant documents to the question from a corpus,
then a reader model extracts an answer from
selected documents.
Our setting is concerned with complex queries
where supporting evidence for the answer is
distributed across multiple (public and private)
文件, termed multi-hop reasoning (Welbl
等人。, 2018). To collect the distributed evidence,
systems use multiple hops of retrieval: Represen-
tations of the top passages retrieved in hopi are
used to retrieve passages in hopi+1 (Miller et al.,
2016; Feldman and El-Yaniv, 2019; Asai et al.,
2020; Wolfson et al., 2020; Xiong et al., 2021;
Qi et al., 2021; Khattab et al., 2021).2 最后,
we discuss the applicability of existing multi-hop
benchmarks to our problem setting in Section 4.
2.3 Privacy Preserving Retrieval
Information retrieval is a long-standing topic span-
ning the machine learning, databases, and privacy
社区. We discuss the prior work and con-
siderations for our setup along three axes: (1)
Levels of privacy. Prior private retrieval system
designs guarantee privacy for different compo-
nents across both query and document privacy.
Our setting requires both query and document
privacy. (2) Relative isolation of document stor-
2Note that beyond multi-hop QA, retrieval augmented
language models and dialogue systems also involve iterative
恢复 (Guu et al., 2020).
age and retrieval computation. The degree to
which prior retrieval and database systems store
or send private data to centralized machines (和
or without encryption) varies. Our work struc-
tures dataflow to eliminate processing of private
documents on public retrieval infrastructure. (3)
Updatability and latency. Works make differ-
ent assumptions about how a user will interact
with the system. 这些包括 (1) tolerance of
high-latency responses and (2) whether corpora
are static or changing. Our setting focuses on
open-domain questions for interactive applica-
tions with massive, temporally changing corpora
and requiring low-latency.
Isolated systems with document and query
privacy but poor updatability. To provide the
strongest possible privacy guarantee (IE。, no in-
formation about the user questions or passages
is revealed), prior work considers when purely
local search is possible (Cao et al., 2019) (IE。,
search performed on systems controlled exclu-
sively by the user). This guarantee provides no
threat opportunities, assuming that both data (文档-
uments and queries) and computation occur on
controlled infrastructure. Scaling the amount of
locally hosted data and updating local corpora
with quickly changing public data is challenging;
we build a system that might meet such demands.
民众, updatable database systems provid-
ing query privacy. A distinct line of work ex-
plores how to securely perform retrieval such that
the user query is not revealed to a public entity
that hosts and updates databases. Private infor-
mation retrieval (PIR) (Chor et al., 1998) 在里面
cryptography community refers to a setup where
users know the entry in a remote database that
they want to retrieve (Corrigan-Gibbs and Kogan,
2020). The threat model is directly related to the
cryptographic scheme used to protect queries and
retrieval computation. 这里, the document con-
taining the answer is assumed to be known; leak-
ing the particular corpus containing the answer
may implicitly leak information about the query.
相比之下, we focus on open-domain applica-
系统蒸发散, where users ask about any topic imagin-
able and do not know which corpus item holds
the answer. Our setting also considers document
privacy, as discussed in Section 6.
民众, updatable but high-latency secure
nearest neighbor search with document and
query privacy. The next relevant line of work fo-
cuses on secure nearest neighbor search (NNS)
904
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1: Multi-hop retrieval systems use beam search to collect information from a massive corpus: Retrieval in
hopi+1 is conditioned on the top documents retrieved in hopi. The setting of retrieving from corpora distributed
across multiple privacy scopes is unexplored. 这里, the content of a private document retrieved in hopi is revealed
to the entity hosting public data if used to retrieve public documents in hopi+1.
(Murugesan et al., 2010; 陈等人。, 2020A;
Schoppmann et al., 2020; Servan-Schreiber,
2021), where the objective is to securely (1)
compute similarity scores between the query and
passages, 和 (2) select the top-k scores. The speed
of cryptographic tools (secure multi-party compu-
站, secret sharing) that are used to perform
these steps increase as the sparsity of the query
and passage representations increases. Perform-
ing the secure protocol over dense embeddings
can take hours per query (Schoppmann et al.,
2020). As before, threats in this setting are re-
lated to vulnerabilities in cryptographic schemes
or in actors gaining access to private document
indices if not directly encrypted. Prior work re-
laxes privacy guarantees and computes approx-
imate NNS; speeds, 然而, are still several
seconds per query (Schoppmann et al., 2020;
陈等人。, 2020A). This is prohibitive for iterative
open domain retrieval applications.
Partial query privacy via fake query aug-
从
mentation for high-latency retrieval
public databases. Another class of privacy tech-
niques for hiding the user’s intentions is query-
obfuscation or k-anonymity. The user’s query is
combined with fake queries or queries from other
users to increase the difficulty of linking a partic-
ular query to the user’s true intentions (Gervais
等人。, 2014). This multiplies communication costs
since nearest neighbors must be retrieved for each
of the k queries; iterative retrieval worsens this
cost penalty. 更远, the private query is revealed
among the full set of k; the threat of identifying
the user’s true query remains (Haeberlen et al.,
2011).
最后, we note that our primary focus is on
inference-time privacy concerns and note that dur-
ing training time, federated learning (FL) 和
differential privacy (DP) is a popular strategy for
training models without exposing training data
(McMahan et al., 2016; Dwork et al., 2006).
全面的, despite significant interest in IR, 那里
is limited attention towards characterizing the pri-
vacy risks as previously observed (Si and Yang,
2014). Our setting, which focuses on support-
ing open-domain applications with modern dense
retrievers, is not well-studied. 更远, the prior
works do not characterize the privacy concerns
associated with iterative retrieval. Studying this
setting is increasingly important with the preva-
lence of API-hosted large language models and
服务. 例如, users may want to incor-
porate private knowledge into systems that make
multiple calls to OpenAI model endpoints (棕色的
等人。, 2020; Khattab et al., 2022). Code assis-
短裤, which may be extended to interact with
both private repositories and public resources like
Stack Overflow, are also seeing widespread use
(陈等人。, 2021).
3 Problem Definition
Objective Given a multi-hop input q, 一套
private documents p ∈ DP , and public documents
d ∈ DG, the objective is to provide the user
with the correct answer a, which is contained
in the documents. 数字 1 (正确的) provides an
例子. 全面的, the SPLIT ITERATIVE RETRIEVAL
(SPIRAL) problem entails maximizing quality,
while protecting query and document privacy.
905
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
标准, Non-Privacy Aware QA Standard
non-private multi-hop ODQA involves answering
q with the help of passages d ∈ DG, using beam
搜索. In the first iteration of retrieval, the k
passages from the corpus, d1, . . . , dk, that are most
relevant to q are retrieved. The text of a retrieved
passage is combined with q using function f (例如,
concatenating the query and passages sequences)
to produce qi = f (q, 的), for i ∈ [1..k]. Each qi
(which contains di) is used to retrieve k more
passages in the following iteration.
We now introduce the SPIRAL retrieval prob-
莱姆. The user inputs to the QA system are the
private corpus DP and questions q. 那里有两个
key properties of the problem setting.
财产 1: Data is likely stored in multiple
enclaves and personal documents p ∈ DP can
not leave the user’s enclave. Users and organi-
zations own private data, and untrustworthy (例如,
云) services own public data. 第一的, we assume
users likely do not want to publicly expose their
data to create a single public corpus nor blindly
write personal data to a public location. 下一个, 我们
also assume it is challenging to store global data
locally in many cases. This is because not only are
there terabytes of public data and user-searches
follow a long tail (Bernstein et al., 2012) (IE。, 它
is challenging to anticipate all a user’s informa-
tion needs), but public data is also constantly be-
ing updated (Zhang and Choi, 2021). 因此, DP
and DG are hosted as separate corpora.
现在, given q, the system must perform one
retrieval over DG and one over DP , rank the re-
sults such that the top-k passages will include kP
private and kG public passages, and use these
for the following iteration of retrieval. 如果
retrieval-system stops after a single-hop, 那里
is no document privacy risk since no p ∈ DP is
publicly exposed and no query privacy risk if the
system used to retrieve from DP is private, 作为
is assumed. However for multi-hop questions, 如果
kP > 0 for an initial round of retrieval, 意义
there exists some pi ∈ DP which was in the top-k
passages, it would sacrifice privacy if f (q, pi)
were to be used to perform the next round of
retrieval from DG. 因此, for the strongest privacy
guarantee, public retrievals should precede private
document retrievals. For less privacy-sensitive use
案例, this strict ordering can be weakened.
财产 2: Inputs that entirely rely on private
information should not be revealed publicly.
Given the multiple indices, DP and DG, q may
be entirely answerable using multiple hops over
the DP index, in which case, q would never
need to leave the user’s device. 例如,
the query from an employee standpoint, Does
the search team use any infrastructure tools that
our personal assistant team does not use?, 是
fully answerable with company information. 事先的
work demonstrates that queries are very revealing
of user interests, intents, and backgrounds (徐
等人。, 2007; Gervais et al., 2014). There is an
observable difference in the search behavior of
users with privacy concerns (Zimmerman et al.,
2019) and an effective system will protect queries.
4 CONCURRENTQA Benchmark
Here we develop a testbed for studying public-
private retrieval. We require questions spanning
two corpora, DP and DG. 第一的, we consider us-
ing existing benchmarks and describe the limita-
tions we encounter, motivating the creation of
our new benchmark, CONCURRENTQA. Then we
describe the dataset collection process and its
contents.
4.1 Adapting Existing Benchmarks
We first adapt the widely used benchmark, Hot-
potQA (杨等人。, 2018), to study our problem.
HotpotQA contains multi-hop questions, 哪个
are each answered using two Wikipedia passages.
We create HotpotQA-SPIRAL by splitting the
Wikipedia corpus into DG and DP . This results
in questions entirely reliant on p ∈ DP , entirely
on d ∈ DG, or reliant on a mix of one private
and one public document, allowing us to evalu-
ate performance under SPIRAL constraints.
最终, 然而, DP and DG come from
a single Wikipedia distribution in HotpotQA-
SPIRAL. Private and public data will often re-
flect different
linguistic styles, 结构, 和
主题. We observe all existing textual multi-hop
benchmarks require retrieving from a single dis-
贡品. We cannot combine two existing bench-
marks over two corpora because this will not
yield questions that rely on both corpora simulta-
neously. To evaluate with a more realistic setup,
we create a new benchmark: CONCURRENTQA. 我们
quantitatively demonstrate the limitations of us-
ing HotpotQA-SPIRAL in the experiments and
分析.
906
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
问题
Hop 1 and Hop 2 Gold Passages
What was the estimated 2016 population of
the city that generates power at the Hetch
Hetchy hydroelectric dams?
Hop 1 An email mentions that San Francisco gener-
ates power at the Hetch Hetchy dams.
Hop 2 The Wikipedia passage about San Francisco
reports the 2016 census-estimated population.
Which firm invested in both the 5th round
of funding for Extraprise and first round of
funding for JobsOnline.com?
Hop 1 An email lists 5th round Exraprise investors.
Hop 2 An email
lists round-1 investors for
JobsOnline.com.
桌子 1: Example CONCURRENTQA queries based on Wikipedia passages (DG) and emails (DP ).
Split
全部的
EE
EW WE WW
Train
Dev
Test
15,239
1,600
1,600
3762
400
400
4002
400
400
3431
400
400
4044
400
400
桌子 2: Size statistics. The evaluation splits are
balanced between questions with gold passages as
emails (乙) 与. 维基百科 (瓦) passages for Hop1
and Hop2.
4.2 CONCURRENTQA Overview
We create and release a new multi-hop QA data-
放, CONCURRENTQA, which is designed to more
closely resemble a practical use case for SPI-
RAL. CONCURRENTQA contains questions span-
ning Wikipedia documents as DG and Enron
employee emails (Klimt and Yang, 2004) as DP .3
We propose two unique evaluation settings for
CONCURRENTQA: 表现 (1) conditioned on
the sub-domains in which the question evidence
can be found (部分 5), 和 (2) conditioned on
the degree of privacy protection (部分 6).
Example questions from ConcurrentQA are
included in Table 1. The corpora contain 47k
emails (DP ) and 5.2M Wikipedia passages (DG),
and the benchmark contains 18,439 examples
(桌子 2). Questions require three main reason-
ing patterns: (1) bridge questions require iden-
tifying an entity or fact in Hop1 on which the
second retrieval is dependent, (2) attribute ques-
tions require identifying the entity that satisfies
all attributes in the question, where attributes are
distributed across passages, 和 (3) 比较
questions require comparing two similar entities,
each appearing in a separate passage. We esti-
mate the benchmark is 80% 桥, 12% attri-
3The Enron Corpus includes emails written by 158
employees of Enron Corporation and are in the public domain.
bute, 和 8% comparison questions. We focus on
factoid QA.
Benchmark Design Each benchmark example
includes the question that requires reasoning over
multiple documents, answer which is a span of
text from the supporting documents, and the spe-
cific supporting sentences in the documents which
are used to arrive at the answer and can serve as
supervision signals.
As discussed in Yang et al. (2018), collecting a
high quality multi-hop QA dataset is challenging
because it is important to provide reasonable
pairs of supporting context documents to the
worker—not all article pairs are conducive to a
good multi-hop question. There are four types of
pairs we need to collect for the Hop1 and Hop2
passages: Private and Private, Private and Pub-
利克, Public and Private, and Public and Public.
We use the insight that we can obtain meaning-
ful passage-pairs by showing workers passages
that mention similar or overlapping entities. 全部
crowdworker assignments contain unique passage
对. A detailed description of how the passage
pairs are produced is in Appendix C and we release
all our code for creating the passage pairs.
Benchmark Collection We used Amazon Turk
for collection. The question generation stage be-
gan with an onboarding process in which we
provided training videos, documents with exam-
ples and explanations, and a multiple-choice exam.
Workers completing the onboarding phase were
given access to pilot assignments, which we man-
ually reviewed to identify individuals with high
quality submissions. We worked with these indi-
viduals to collect the full dataset. We manually
reviewed over 2.5k queries in the quality-check
process and prioritized including the manually
verified examples in the final evaluation splits.
907
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
In the manual review, examples of the crite-
ria that led us to discard queries included: 这
query (1) could be answered using one passage
独自的, (2) had multiple plausible answers either
in or out of the shown passages, 或者 (3) lacked
clarity. During the manual review, we developed
a multiple-choice questionnaire to streamline the
checks along the identified criteria. We then used
this to launch a second Turk task to validate the
generated queries that we did not manually re-
看法. Assembling the cohort of crowdworkers for
the validation task again involved onboarding and
pilot steps, in which we manually reviewed per-
formance. We shortlisted ∼20 crowdworkers with
high quality submissions who collectively vali-
dated examples appearing in the final benchmark.
4.3 Benchmark Analysis
Emails and Wiki passages differ in several ways.
Format: Wiki passages for entities of the same
type tend to be similarly structured, while emails
introduce many formats—for example, certain
emails contain portions of forwarded emails, 列表
of articles, or spam advertisements. Noise: Wiki
passages tend to be typo-free, while the emails
contain several typos, URLs, and inconsistent cap-
italization. Entity Distributions: Wiki passages
tend to focus on details about one entity, 尽管
a single email can cover multiple (possibly un-
有关的) 主题. Information about email entities
is also often distributed across passages, 然而
public-entity information tends to be localized to
one Wiki passage. We observe that a private entity
occurs 9× on average in gold training data pas-
sages while a public entity appears 4× on average.
There are 22.6k unique private entities in the gold
training data passages, and 12.8k unique public
实体. Passage Length: 最后, emails are 3×
longer than Wiki passages on average.4
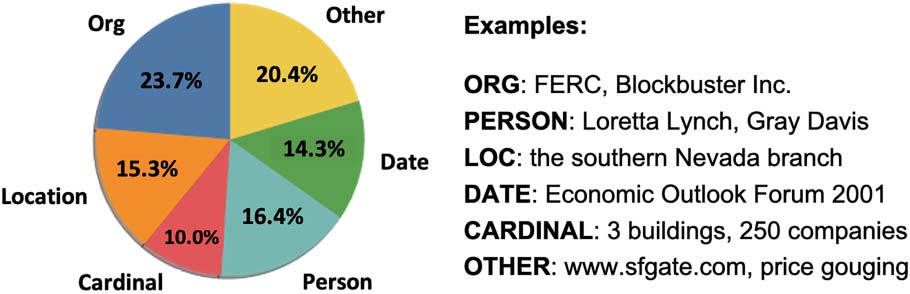
Answer Types CONCURRENTQA is a factoid QA
task so answers tend to be short spans of text
containing nouns, or entity names and properties.
数字 2 shows the distribution NER tags across
answers and examples from each category.
Limitations As in HotpotQA, workers see the
gold supporting passages when writing questions,
which can result in lexical overlap between the
4Since information density is generally lower in emails vs.
Wiki passages, this helps crowdworkers generate meaningful
问题. Lengths chosen within model context window.
数字 2: NER types for CONCURRENTQA answers.
questions and passages. We mitigate these effects
through validation task filtering and by limiting
the allowed lexical overlap via the Turk interface.
下一个, our questions are not organic user searches,
however existing search and dialogue logs do not
contain questions over public and private data to
our knowledge. 最后, Enron was a major public
corporation; data encountered during pretraining
could impact the distinction between public and
private data. We investigate this in Section 5.
Ethics Statement The Enron Dataset is already
widely used in NLP research (Heller, 2017). 那
说, we acknowledge the origin of this data as
collected and made public by the U.S. FERC
during their investigation of Enron. We note that
many of the individuals whose emails appear in
the dataset were not involved in wrongdoing. 我们
defer to using inboxes that are frequently used in
prior work.
In the next sections, we evaluate CONCURRENT-
QA in the SPIRAL setting. We first ask how a
range of SoTA retrievers perform in the multi-
domain retrieval setting in Section 5, then intro-
duce baselines for CONCURRENTQA under a strong
privacy guarantee in which no private information
is revealed whatsoever in Section 6.
5 Evaluating Mixed-Domain Retrieval
Here we study the SoTA multi-hop model per-
formance on CONCURRENTQA in the novel multi-
distribution setting. The ability for models trained
on public data to generalize to private distribu-
系统蒸发散, with little or no labeled data, is a precursor
to solutions for SPIRAL. In the commonly stud-
ied zero-shot retrieval setting (Guoa et al., 2021;
Thakur et al., 2021), the top k of k passages will
be from a single distribution, however users often
have diverse questions and documents.
We first evaluate multi-hop retrievers. 然后
we apply strong single-hop retrievers to the set-
ting, to understand the degree to which iterative
retrieval is required in CONCURRENTQA.
908
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Retrieval Method
CONCURRENTQA-MDR
HotpotQA-MDR
Subsampled HotpotQA-MDR
BM25
Oracle
OVERALL
Domain-Conditioned
EM
48.9
45.0
37.2
33.2
74.1
F1
56.5
53.0
43.9
40.8
83.4
EE
49.5
28.7
23.8
44.2
66.5
EW
66.4
61.7
51.1
30.7
87.5
WE
41.8
41.1
28.6
50.2
89.4
WW
68.3
81.3
72.1
30.5
90.4
桌子 3: CONCURRENTQA results using four retrieval approaches, and oracle retrieval. On the right, 我们
show performance (F1 scores) by the domains of the Hop1 and Hop2 gold passages for each question
(email is ‘‘E’’, Wikipedia is ‘‘W’’, and ‘‘EW’’ indicates the gold passages are email for Hop1 and
Wikipedia for Hop2).
5.1 Benchmarking Multi-Hop Retrievers
Retrievers We evaluate the multi-hop dense re-
trieval model (MDR) (Xiong et al., 2021), 哪个
achieves SoTA on multi-hop QA and multi-hop
implementation of BM25, a classical bag-of-
words method, as prior work indicates its strength
in OOD retrieval (Thakur et al., 2021).
MDR is a bi-encoder model consisting of a
query encoder and passage encoder. Passage em-
beddings are stored in an index designed for ef-
ficient retrieval (Johnson et al., 2017). In Hop1,
the embedding for query q is used to retrieve the
k passages d1, . . . , dk with the highest retrieval
score by the maximum inner product between
question and passage encodings. For multi-hop
MDR,
those retrieved passages are each ap-
pended to q and encoded, and each of the k re-
sulting embeddings are used to collect k more
passages in Hop2, yielding k2 passages. 这
top-k of the passages after the final hop are in-
puts to the reader, ELECTRA-Large (Clark et al.,
2020). The reader selects a candidate answer in
each passage.5 The candidate with the highest
reader score is outputted.
Baselines We evaluate using four
恢复
基线: (1) CONCURRENTQA-MDR, a dense
retriever trained on the CONCURRENTQA train
放 (15.2k examples), to understand the value
(2)
的
HotpotQA-MDR, trained on HotpotQA (90.4K
examples), to understand how well a publicly
trained model performs on the multi-distribution
benchmark; (3) Subsampled HotpotQA-MDR,
in-domain training data for
the task;
5Xiong et al. (2021) compare ELECTRA and other readers
such as FiD (Izacard and Grave, 2021), finding similar
表现. We follow their approach and use ELECTRA.
909
数字 3: F1 score vs training data size, training MDR
on subsampled HotpotQA (HPQA) and subsampled
CONCURRENTQA (CQA) training data. 我们还展示
trends by the question domain for CQA (dotted lines).
trained on subsampled HotpotQA data of the same
size as the CONCURRENTQA train set, to investigate
the effect of dataset size; 和 (4) BM25 sparse
恢复. Results are in Table 3. Experimental
details are in Appendix A.6
Training Data Size Strong dense retrieval per-
formance requires a large amount of training data.
Comparing CONCURRENTQA-MDR and Subsam-
pled HotpotQA-MDR, the former outperforms by
12.6 F1 points as it is evaluated in-domain. 如何-
曾经, the HotpotQA-MDR baseline, trained on
the full HotpotQA training set, performs nearly
equal to CONCURRENTQA-MDR. 数字 3 节目
6We check for dataset leakage stemming from the ‘‘pub-
lic’’ models potentially viewing ‘‘private’’ email information
in pretraining. Using the MDR and ELECTRA models
fine-tuned on HotpotQA, we evaluate on CONCURRENTQA
using a corpus of only Wiki passages. Test scores are 72.0
和 3.3 EM for questions based on two Wiki and two email
passages respectively, suggesting explicit access to emails is
重要的.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
the performance as training dataset size varies.
Next we observe that the sparse method matches
the zero-shot performance of the Subsampled
HotpotQA model on CONCURRENTQA. For larger
dataset sizes (HotpotQA-MDR) and in-domain
training data (CONCURRENTQA-MDR), dense out-
performs sparse retrieval. 尤其,
可能是
difficult to obtain training data for all private
or temporally arising distributions.
Domain Specific Performance Each retriever
excels in a different subdomain of the bench-
标记. 桌子 3 shows the retrieval performance of
each method based on whether the gold support-
ing passages for Hop1 and Hop2 are email (乙)
or Wikipedia (瓦) passages (EW is Email-Wiki
for Hop1-Hop2). HotpotQA-MDR performance
on WW questions is far better than on questions
involving emails. The sparse retriever performs
worse than the dense models on questions involv-
ing W, but better on questions with E in Hop2.
When training on CONCURRENTQA, 表现
on questions involving E improves significantly,
but remains low on W-based questions. 最后,
we explicitly provide the gold supporting pas-
sages to the reader model (Oracle). EE oracle
performance also remains low, indicating room to
improve the reader.
How well does the retriever trained on pub-
lic data perform in the SPIRAL setting? 我们
is biased
observe the HotpotQA-MDR model
towards retrieving Wikipedia passages. On ex-
amples where the gold Hop1 passage is an email,
15% 当时的, no emails appear in the top-k
Hop1 results; 同时, this only occurs 4%
of the time when Hop1 is Wikipedia. On the slice
of EE examples, 64% of Hop2 passages are E,
while on the slice of WW examples, 99.9% 的
Hop2 passages are W. If we simply force equal
恢复 ( k
2 ) from each domain on each hop, 我们
observe 2.3 F1 points (4.3%) improvement in CON-
CURRENTQA performance, compared to retrieving
the overall top-k. Optimally selecting the alloca-
tion for each domain is an exciting question for
future work.
Performance on WE questions is notably
worse than on EW questions. We hypothesize
that this is because several emails discuss each
Wikipedia-entity, which may increase the noise in
Hop2 (IE。, WE is a one-to-many hop, while for
EW, W typically contains one valid entity-specific
方法
Recall@10
Two-hop MDR
One-hop MDR
Contriever
Contriever MS-MARCO
77.5
45.7
52.7
64.3
桌子 4: Comparing the retrieval quality using
one-hop MDR, Contriever, and Contriever fine-
tuned on MS-MARCO to the quality of two-hop
MDR. Results are over the HotpotQA dataset.
passage). The latter is intuitively because individ-
uals refer to a narrow set of public entities in
private discourse.
5.2 Benchmarking Single-Hop Retrieval
在部分 3, we identify that iterative retrieval
implicates document privacy. 所以, an im-
portant preliminary question is to what degree
multiple hops are actually required? We inves-
tigate this question using both HotpotQA and
CONCURRENTQA. We evaluate MDR using just
the first-hop results and Contriever (Izacard et al.,
2021), the SoTA single-hop dense retrieval model.
结果
表中 4, we summarize the retrieval
results from using three off-the-shelf models for
HotpotQA: (1) the HotpotQA MDR model for
one-hop, (2) the pretrained Contriever model,
和 (3) the MS-MARCO (Nguyen et al., 2016)
fine-tuned variant of Contriever. We observe a
sizeable gap between the one and two hop base-
线. Strong single-hop models trained over more
diverse publicly available data may help ad-
dress the SPIRAL problem as demonstrated by
Contriever fine-tuned on MS-MARCO.
然而, when evaluating the one-hop base-
lines on CONCURRENTQA, we find Contriever
underperforms the two-hop baseline more sig-
nificantly, as shown in Appendix Table 8. 这是
consistent with prior work that finds Contriever
quality degrades on tasks that increasingly dif-
fer from the pretraining distribution (Zhan et al.,
2022). By sub-domain, Contriever MS-MARCO
returns the gold first-hop passage for 85% 的
questions where both gold passages are from
维基百科, but for less than 39% of questions
when at least one gold passage (Hop1 and/or
Hop2) is an email. By hop, we find Contriever
MS-MARCO retrieves the first-hop passage 49%
910
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
of the time and second-hop passage 25% 的
时间.
最后, to explore whether a stronger single-
hop retriever may further improve the one-hop
基线, we continually fine-tune Contriever on
CONCURRENTQA. We follow the training protocol
and use the code released in Izacard et al. (2021),
and include these details in Appendix A. 这
fine-tuned model achieves 39.7 Recall@10 and
63.6 Recall@100, while two-hop MDR achieves
55.9 Recall@10 and 73.8 Recall@100 (桌子 9
in the Appendix). We observe Contriever’s one-
hop Recall@100 of 63.6 exceeds the two-hop
MDR Recall@10 of 55.9, suggesting a tradeoff
space between the number of passages retrieved
per hop (which is correlated with cost) 和
ability to circumvent iterative retrieval (我们
identify implicates privacy concerns).
6 Evaluation under Privacy Constraints
This section provides baselines for CONCURRENT-
QA under privacy constraints. We concretely
study a baseline in which no private informa-
tion is revealed publicly whatsoever. 我们相信
this is an informative baseline for two reasons:
1. The privacy setting we study is often cat-
egorized as an access-control framework—
different parties have different degrees of
access to different degrees of privileged in-
形成. While this setting is quite restric-
主动的, this privacy framework is widely used
in practice for instance in the government
and medical fields (Bell and LaPadula, 1976;
Hu et al., 2006).
2. There are many possible privacy constraints
as users find different types of information to
be sensitive (徐等人。, 2007). Studying these
is an exciting direction that we hope is facil-
itated by this work. Because the appropriate
privacy relaxations are subjective, we focus
on characterizing the upper (部分 5) 和
lower bounds (部分 6) of retrieval quality
in our proposed setting.
Setup We use models trained on Wikipedia
data to evaluate performance under privacy re-
strictions both in the in-distribution multi-hop
HotpotQA-SPIRAL (an adaptation of the Hotpot-
QA benchmark to the SPIRAL setting [杨等人。,
2018]) and multi-distribution CONCURRENTQA
settings. Motivating the latter setup, sufficient
training data is seldom available for all private
分布. We use the multi-hop SoTA model,
MDR, which is representative of the iterative re-
trieval procedure that is used across multi-hop so-
lutions (Miller et al., 2016; Feldman and El-Yaniv,
2019; Xiong et al., 2021, inter alia).
We construct Hotpot-SPIRAL by randomly as-
signing passages to the private (DP ) 和公众
(DG) 语料库. To enable a clear comparison, 我们
ensure that the sizes of DP and DG, 和
proportions of questions for which the gold doc-
uments are public and private in Hop1 and Hop2
match those in CONCURRENTQA.
6.1 评估
We evaluate performance when no private infor-
运动 (neither queries nor documents) is revealed
whatsoever. We compare four baselines, shown in
桌子 6. (1) No Privacy Baseline: We combine all
public and private passages in one corpus, 忽略
privacy concerns. (2) No Privacy Multi-Index:
We create two corpora and retrieve the top k from
each index in each hop, and retain the top-k of
these 2k documents for the next hop, without ap-
plying any privacy restriction. Note performance
should match single-index performance. (3) 医生-
ument Privacy: We use the process in (2), 但
cannot use a private passage retrieved in Hop1 to
subsequently retrieve from public DG. (4) Query
Privacy: The baseline to keep q entirely private is
to only retrieve from DP .
We can answer many complex questions while
revealing no private information whatsoever (看
桌子 5). 然而, in maintaining document pri-
vacy, the end-to-end QA performance degrades
经过 9% HotpotQA and 19% for CONCURRENTQA
compared to the quality of the non-private sys-
TEM; degradation is worse under query privacy.
We hope the resources we provide facilitate future
work under alternate privacy frameworks.
6.2 Managing the Privacy-Quality Tradeoff
Alongside improving the retriever’s quality, 一个
important area of research for end-to-end QA
systems is to avoid providing users with incorrect
预测, given existing retrievers. Significant
work focuses on equipping QA-systems with
this selective-prediction capability (Chow, 1957;
El-Yaniv and Wiener, 2010; Kamath et al., 2020;
Jones et al., 2021, inter alia). Towards improving
911
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Privacy Level
Answered with
No Privacy, 但
not under Document
Privacy
Answered with
Document Privacy
Answered with
Query Privacy
Sample Questions Answered under Each Privacy Level
Q1 In which region is the site of a meeting between Dabhol manager Wade
Cline and Ministry of Power Secretary A. K. Basu located?
Q2 What year was the state-owned regulation board that was in conflict
with Dabhol Power over the DPC project formed?
Q1 The U.S. Representative from New York who served from 1983 到 2013
requested a summary of what order concerning a price cap complaint?
Q2 How much of the company known as DirecTV Group does GM own?
Q1 Which CarrierPoint backer has a partner on SupplySolution’s board?
Q2 At the end of what year did Enron India’s managing director responsible
for managing operations for Dabhol Power believe it would go online?
*All evidence is in private emails and not in Wikipedia.
桌子 5: Examples of queries answered under different privacy restrictions. Bold indicates private
信息.
模型
No Privacy Baseline
No Privacy Multi-Index
Document Privacy
Query Privacy
HOTPOTQA-SPIRAL
CONCURRENTQA
EM
62.3
62.3
56.8
34.3
F1
75.3
75.3
68.8
43.3
EM
45.0
45.0
36.1
19.1
F1
53.0
53.0
43.0
23.8
桌子 6: Multi-hop QA datasets using the dense retrieval baseline (MDR) under each privacy setting.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4: Risk-coverage curves using the model trained on Wikipedia data for HotpotQA-PAIR and multi-
distribution CONCURRENTQA retrieval, both under No Privacy and Document Privacy, where privacy is achieved
by restricting P rivate to P ublic retrieval altogether. The left shows the overall test results, and the right is split
by the the domains of the gold supporting passages for the question at hand, for Hop1 to Hop2.
912
the reliability of the QA system, we next evaluate
selective prediction in our novel retrieval setting.
Setup Selective prediction aims to provide the
user with an answer only when the model is con-
fident. The goal is to answer as many questions
尽可能 (high coverage) with as high perfor-
mance as possible (low risk). Given query q, 和
a model which outputs (ˆa, C), where ˆa is the pre-
dicted answer and c ∈ R represents the model’s
confidence in ˆa, we output ˆa if c ≥ γ for some
threshold γ ∈ R, and abstain otherwise. As γ in-
creases, risk and coverage both tend to decrease.
The QA model outputs an answer and score for
each of the top-k retrieved passages—we com-
pute the softmax over the top-k scores and use the
top softmax score as c (Hendrycks and Gimpel,
2017; Varshney et al., 2022). Models are trained
on HotpotQA, representing the public domain.
Results Risk-coverage curves for HotpotQA
and CONCURRENTQA are in Figure 4. Under Doc-
ument Privacy, the ‘‘No Privacy’’ score of 75.3
F1 for HotpotQA and 53.0 F1 for CONCURRENT-
QA are achieved at 85.7% 和 67.8% 覆盖范围,
分别.
In the top plots, in the absence of privacy
担忧, the risk-coverage trends are worse for
CONCURRENTQA vs. HotpotQA (IE。, quality de-
grades more quickly as the coverage increases).
Out-of-distribution selective prediction is actively
这
studied (Kamath et al., 2020). 然而,
setting differs from the standard setup. The bot-
tom plots show on CONCURRENTQA that that the
risk-coverage trends differ widely based on the
sub-domains of the questions; the standard re-
trieval setup typically has a single distribution
(Thakur et al., 2021).
下一个, privacy restrictions correlate with de-
gredations in the risk-coverage curves on both
CONCURRENTQA and HotpotQA. Critically, Hot-
potQA is in-distribution for the retriever. Strate-
gies beyond selective prediction via max-prob,
the prevailing approach in NLP (Varshney et al.,
2022), may be useful for the SPIRAL setting.
7 结论
We ask how to personalize neural retrieval-
systems in a privacy-preserving way and report
on how arbitrary retrieval over public and pri-
vate data poses a privacy concern. We define the
SPIRAL retrieval problem, present the first tex-
tual multi-distribution benchmark to study the
novel setting, and empirically characterize the
privacy-quality tradeoffs faced by neural retrieval
系统.
We motivated the creation of a new benchmark,
as opposed to repurposing existing benchmarks
through our analysis. We qualitatively identified
differences between the public Wikipedia and pri-
vate emails in Section 4.3, and quantitatively dem-
onstrated the effects of applying models trained
on one distribution (例如, 民众) to the mixed-
分配 (例如, public and private) setting in
Sections 5 和 6. Private iterative retrieval is un-
derexplored and we hope the benchmark-resource
and evaluations we provide inspire further re-
search on this topic, for instance under alternate
privacy models.
致谢
We thank Jack Urbaneck, Wenhan Xiong, 和
Gautier Izacard for their advice and feedback.
We gratefully acknowledge the support of NIH
under grant no. U54EB020405 (Mobilize), 美国国家科学基金会
under grant nos. CCF1763315 (Beyond Sparsity),
CCF1563078 (Volume to Velocity), 和 1937301
(RTML); US DEVCOM ARL under grant no.
W911NF-21-2-0251 (Interactive Human-AI Team-
英); ONR under grant no. N000141712266
(Unifying Weak Supervision); ONR N00014-
20-1-2480: Understanding and Applying Non-
Euclidean Geometry in Machine Learning;
N000142012275 (NEPTUNE); NXP, Xilinx,
LETI-CEA, Intel, 国际商业机器公司, Microsoft, NEC, Toshiba,
TSMC, ARM, Hitachi, BASF, 埃森哲,
爱立信, Qualcomm, Analog Devices, 谷歌
Cloud, Salesforce, 全部的, the HAI-GCP Cloud
Credits for Research program, the Stanford Data
Science Initiative (SDSI), Stanford Graduate
Fellowship, and members of the Stanford DAWN
项目: Facebook, 谷歌, and VMWare. 这
我们. Government is authorized to reproduce and
distribute reprints for Governmental purposes
notwithstanding any copyright notation thereon.
有什么意见, 发现, and conclusions or rec-
ommendations expressed in this material are those
of the authors and do not necessarily reflect the
意见, 政策, or endorsements, either expressed
or implied, of NIH, ONR, or the U.S. 政府.
913
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
参考
Akari Asai, Kazuma Hashimoto, Hannaneh
Hajishirzi, Richard Socher, and Caiming Xiong.
2020. Learning to retrieve reasoning paths over
wikipedia graph for question answering. 在
International Conference on Learning Repre-
句子 (ICLR). https://doi.org/10
.48550/arXiv.1911.10470
David E. Bell and Leonard J. LaPadula. 1976.
Secure computer system: Unified exposition
and multics interpretation. The MITRE Cor-
poration. https://doi.org/10.21236
/ADA023588
Jonathan Berant, Andrew Chou, Roy Frostig,
and Percy Liang. 2013. Semantic parsing on
freebase from question-answer pairs. In Pro-
ceedings of the 2013 Conference on Empiri-
cal Methods in Natural Language Processing
(EMNLP).
Michael S. Bernstein, Jaime Teevan, 苏珊
Dumais, Daniel Liebling, and Eric Horvitz.
2012. Direct answers for search queries in the
long tail. SIGCHI. https://doi.org/10
.1145/2207676.2207710
Sebastian Borgeaud, Arthur Mensch,
约旦
Hoffmann, Trevor Cai, Eliza Rutherford,
Katie Millican, George van den Driessche,
Jean-Baptiste Lespiau, Bogdan Damoc, Aidan
克拉克, Diego de Las Casas, Aurelia Guy, 雅各布
Menick, Roman Ring, Tom Hennigan, Saffron
黄, Loren Maggiore, Chris Jones, Albin
Cassirer, Andy Brock, Michela Paganini,
Geoffrey Irving, Oriol Vinyals, Simon Osindero,
Karen Simonyan, Jack W. Rae, Erich Elsen,
and Laurent Sifre. 2022. Improving language
models by retrieving from trillions of tokens.
In Proceedings of the 39th International Con-
ference on Machine Learning (PMLR).
Tom Brown, Benjamin Mann, Nick Ryder,
Melanie Subbiah, Jared D. 卡普兰, Prafulla
Dhariwal, Arvind Neelakantan, Pranav Shyam,
Girish Sastry, Amanda Askell, Sandhini
阿加瓦尔, Ariel Herbert-Voss, Gretchen Krueger,
Tom Henighan, Rewon Child, Aditya Ramesh,
Daniel M. Ziegler, Jeffrey Wu, Clemens Winter,
Christopher Hesse, Mark Chen, Eric Sigler,
Mateusz Litwin, Scott Gray, Benjamin Chess,
Jack Clark, Christopher Berner, Sam McCandlish,
Alec Radford, Ilya Sutskev, and Dario Admodei.
2020. Language models are few-shot learn-
呃. Advances in Neural Information Process-
ing Systems (神经信息处理系统), 33:1877–1901.
Qingqing
曹, Noah Weber, Niranjan
Balasubramanian, and Aruna Balasubramanian.
2019. Deqa: On-device question answering. 在
The 17th Annual International Conference on
Mobile Systems, 应用领域, and Services
(MobiSys). https://doi.org/10.1145
/3307334.3326071
Danqi Chen, Adam Fisch, Jason Weston, 和
Antoine Bordes. 2017. Reading wikipedia to
answer open-domain questions. In Associa-
tion for Computational Linguistics (前交叉韧带).
https://doi.org/10.18653/v1/P17
-1171
Hao Chen, Ilaria Chillotti, Yihe Dong, Oxana
Poburinnaya, Ilya Razenshteyn, 和M. Sadegh
Riazi. 2020A. Sanns: Scaling up secure approx-
imate k-nearest neighbors search. In USENIX
Security Symposium.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming
Yuan, Henrique Ponde de Oliveira Pinto, Jared
卡普兰, Harri Edwards, Yuri Burda, 尼古拉斯
约瑟夫, Greg Brockman, Alex Ray, Raul
Puri, Gretchen Krueger, Michael Petrov, Heidy
Khlaaf, Girish Sastry, Pamela Mishkin, 布鲁克
Chan, Scott Gray, Nick Ryder, Mikhail Pavlov,
Alethea Power, Lukasz Kaiser, Mohammad
Bavarian, Clemens Winter, Philippe Tillet,
Felipe Petroski Such, Dave Cummings, 马蒂亚斯
Plappert, Fotios Chantz, Elizabeth Barnes, Ariel
Herbert-Voss, William Hebgen Guss, Alex
Nichol, Alex Paino, Nikolas Tezak, Jie Tang,
Igor Babuschkin, Suchir Balaji, Shantanu Jain,
William Saunders, Christopher Hesse, 安德鲁
氮. Carr, Jan Leike, Josh Achiam, Vedant
Misra, Evan Morikawa, Alec Radford, 马修
骑士, Miles Brundage, Mira Murati, Katie
Mayer, Peter Welinder, Bob McGrew, Dario
Amodei, Sam McCandlish, 伊利亚·苏茨克维尔, 和
Wojciech Zaremba. 2021. Evaluating large lan-
guage models trained on code. arXiv 预印本
arXiv:2107.03374.
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan
Xiong, Hong Wang, and William Wang. 2020乙.
Hybridqa: A dataset of multi-hop question
answering over tabular and textual data. 在
Findings of the Association for Computational
914
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
语言学 (EMNLP). https://doi.org/10
.18653/v1/2020.findings-emnlp.91
Benny Chor, Eyal Kushilevitz, Oded Goldreich,
and Madhu Sudan. 1998. Private informa-
tion retrieval. Journal of the ACM (JACM),
45(6):965–981. https://doi.org/10.1145
/293347.293350
Chao-Kong Chow. 1957. An optimum character
recognition system using decision functions.
In IRE Transactions on Electronic Computers.
https://doi.org/10.1109/TEC.1957
.5222035
Kevin Clark, Minh-Thang Luong, Quoc V. Le,
and Christopher D. 曼宁. 2020. Electra:
Pre-training text encoders as discriminators
rather than generators. In International Con-
ference on Learning Representations (ICLR).
Emily Dinan, Stephen Roller, Kurt Shuster,
Angela Fan, Michael Auli, and Jason Weston.
2019. Wizard of wikipedia: Knowledge-powered
conversational agents. In International Confer-
ence on Learning Representations (ICLR).
Dheeru Dua, Yizhong Wang, Pradeep Dasigi,
Gabriel Stanovsky Sameer Singh, and Matt
加德纳. 2019. Drop: A reading comprehen-
sion benchmark requiring discrete reasoning
over paragraphs. 在诉讼程序中 2019
Conference of the North American Chapter of
the Association for Computational Linguistics:
人类语言技术 (全国AACL).
Cynthia Dwork, Frank McSherry, Kobbi Nissim,
and Adam Smith. 2006. Calibrating noise to
sensitivity in private data analysis. In Theory
of Cryptography Conference (TCC). https://
doi.org/10.1007/11681878 14
Ran El-Yaniv and Yair Wiener. 2010. 上
foundations of noise-free selective classifica-
的. Journal of Machine Learning Research
(JMLR).
Yair Feldman and Ran El-Yaniv. 2019. Multi-hop
paragraph retrieval for open-domain question
answering. In Proceedings of the 57th Annual
Meeting of the Association for Computational
语言学 (前交叉韧带). https://doi.org/10
.18653/v1/P19-1222
ference on Computer and Communications
安全 (SIGSAC). https://doi.org/10
.1145/2660267.2660367
Mandy Guoa, Yinfei Yanga, Daniel Cera, Qinlan
Shenb, and Noah Constant. 2021. Multireqa:
A cross-domain evaluation for retrieval ques-
tion answering models. 在诉讼程序中
Second Workshop on Domain Adaptation for
自然语言处理.
Kelvin Guu, Kenton Lee, Zora Tung, Panupong
Pasupat, and Ming-Wei Chang. 2020. Realm:
Retrieval augmented language model pre-
训练. 在诉讼程序中
the 37th Inter-
national Conference on Machine Learning
(ICML).
Andreas Haeberlen, Benjamin C. Pierce, 和
Arjun Narayan. 2011. Differential privacy
under fire. In USENIX Security Symposium,
体积 33, 页 236.
Nathan Heller. 2017. What the enron e-mails say
about us.
Dan Hendrycks and Kevin Gimpel. 2017. A
baseline for detecting misclassified and out-
of-distribution examples in neural networks.
In International Conference on Learning Rep-
resentations (ICLR).
Xanh Ho, Anh-Khoa Duong Nguyen, Saku
Sugawara, and Akiko Aizawa. 2020. Construct-
ing a multi-hop qa dataset for comprehensive
evaluation of reasoning steps. In Proceedings
of the 28th International Conference on Com-
putational Linguistics (科林). https://
doi.org/10.18653/v1/2020.coling-main
.580
文森特·C. 胡, David F. Ferraiolo, and Rick D.
Kuhn. 2006. Assessment of access control
系统. National Institute of Standards and
技术 (NIST).
Gautier Izacard, Mathilde Caron, Lucas Hosseini,
Sebastian Riedel, Piotr Bojanowski, Armand
Joulin, and Edouard Grave. 2021. Unsupervised
dense information retrieval with contrastive
学习. In Transactions on Machine Learn-
ing Research (TMLR). https://doi.org
/10.48550/arXiv.2112.09118
Arthur Gervais, Reza Shokri, Adish Singla, Srdjan
Capkun, and Vincent Lenders. 2014. 普通话-
In ACM Con-
tifying web-search privacy.
Gautier Izacard and Edouard Grave. 2021. Lever-
aging passage retrieval with generative mod-
els for open domain question answering. 在
915
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Proceedings of the 16th Conference of the Euro-
the Association for Com-
pean Chapter of
putational Linguistics (EACL). https://土井
.org/10.18653/v1/2021.eacl-main.74
Jeff Johnson, Matthijs Douze, and Herv´e J´egou.
2017. Billion-scale similarity search with
GPUs. IEEE Transactions on Big Data.
Erik Jones, Shiori Sagawa, Pang Wei Koh,
Ananya Kumar, and Percy Liang. 2021. 硒-
lective classification can magnify disparities
across groups. In International Conference on
Learning Representations (ICLR).
Amita Kamath, Robin Jia, and Percy Liang.
2020. Selective question answering under do-
main shift. In Proceedings of the 58th Annual
Meeting of the Association for Computational
语言学 (前交叉韧带). https://doi.org/10
.18653/v1/2020.acl-main.503
Vladimir Karpukhin, Barlas Oguz, Sewon Min,
Patrick Lewis, Ledell Wu, Sergey Edunov,
Danqi Chen, and Wen tau Yih. 2020. Dense
passage retrieval for open-domain question
answering. 在诉讼程序中 2020 骗局-
ference on Empirical Methods in Natural Lan-
guage Processing (EMNLP). https://土井
.org/10.18653/v1/2020.emnlp-main.550
Omar Khattab, Christopher Potts, and Matei
Zaharia. 2021. Baleen: Robust multi-hop rea-
soning at scale via condensed retrieval. In 35th
Conference on Neural Information Processing
系统 (神经信息处理系统).
Omar Khattab, Keshav Santhanam, Xiang Lisa
李, David Hall, Percy Liang, Christopher
波茨, and Matei Zaharia. 2022. Demonstrate-
search-predict: Composing retrieval and lan-
guage models for knowledge-intensive NLP.
arXiv 预印本 arXiv:2212.14024.
乙. Klimt and Y. 哪个. 2004. Introducing the
enron corpus. In Proceedings of the 1st Con-
ference on Email and Anti-Spam (CEAS).
Henry Corrigan-Gibbs and Dmitry Kogan. 2020.
Private information retrieval with sublinear on-
line time. In Annual International Conference
on the Theory and Applications of Crypto-
graphic Techniques (EUROCRYPT). https://
doi.org/10.1007/978-3-030-45721-1 3
Tom Kwiatkowski, Jennimaria Palomaki, Olivia
Redfield, Michael Collins, Ankur Parikh, Chris
Alberti, Danielle Epstein,
Illia Polosukhin,
Matthew Kelcey, Jacob Devlin, Kenton Lee,
Kristina N. Toutanova, Llion Jones, Ming-Wei
张, Andrew Dai, Jakob Uszkoreit, Quoc
Le, and Slav Petrov. 2019. Natural ques-
系统蒸发散: A benchmark for question answering
研究. Transactions of the Association of
计算语言学 (处理), 7:453–466.
https://doi.org/10.1162/tacl 00276
Patrick Lewis, Yuxiang Wu, Linqing Liu, Pasquale
Minervini, Heinrich K¨uttler, Aleksandra Piktus,
Pontus Stenetorp, and Sebastian Riedel. 2021.
包裹: 65 million probably-asked questions and
what you can do with them. In Transactions of
the Association for Computational Linguistics
(处理), 9:1098–1115. https://doi.org
/10.1162/tacl a 00415
Brendan McMahan, Eider Moore, Daniel Ramage,
Seth Hampson, and Blaise Ag¨uera y Arcas.
2016. Communication-efficient
learning of
deep networks from decentralized data. 在
Proceedings of the 20th International Confer-
ence on Artificial Intelligence and Statistics
(AISTATS).
Alexander H. 磨坊主, Adam Fisch, Jesse Dodge,
Amir-Hossein Karimi, Antoine Bordes, 和
Jason Weston. 2016. Key-value memory net-
在
works for directly reading documents.
诉讼程序 2016 Conference on Empir-
ical Methods in Natural Language Processing
(EMNLP). https://doi.org/10.18653
/v1/D16-1147
Mummoorthy Murugesan, Wei
Jiang, Chris
克利夫顿, Luo Si, and Jaideep Vaidya. 2010.
Efficient privacy-preserving similar document
detection. The International Journal on Very
Large Data Bases (VLDB). https://土井
.org/10.1007/s00778-009-0175-9
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng
高, Saurabh Tiwary, Rangan Majumder, 和
Li Deng. 2016. MS MARCO: A human gen-
erated machine reading comprehension dataset.
CoCo@NIPS.
Fabio Petroni, Aleksandra Piktus, Angela
Fan, Patrick Lewis, Majid Yazdani, Nicola
De Cao,
Jernite,
Vladimir Karpukhin, Jean Maillard, Vassilis
James Thorne, Yacine
916
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Plachouras, Tim Rockt¨aschel, and Sebastian
Riedel. 2021. KILT: A benchmark for knowl-
edge intensive language tasks. In Proceedings
的 2021 Conference of the North American
Chapter of the Association for Computational
语言学: 人类语言技术
(NAACL-HLT), pages 2523–2544. https://
doi.org/10.18653/v1/2021.naacl-main
.200
Peng Qi, Haejun Lee, Oghenetegiri Sido, 和
Christopher D. 曼宁. 2021. Retrieve, read,
rerank, then iterate: Answering open-domain
questions of varying reasoning steps from text.
https://doi.org/10.48550/arXiv.2010
.12527
Nils Reimers and Iryna Gurevych. 2019. 句子-
BERT: Sentence embeddings using siamese
BERT-networks. 在诉讼程序中 2019
Conference on Empirical Methods in Natural
语言处理 (EMNLP). https://
doi.org/10.18653/v1/D19-1410
Adam Roberts, Colin Raffel, and Noam Shazeer.
2020. How much knowledge can you pack
into the parameters of a language model? 在
诉讼程序 2020 Conference on Empir-
ical Methods in Natural Language Processing
(EMNLP). https://doi.org/10.18653
/v1/2020.emnlp-main.437
Phillipp Schoppmann, Lennart Vogelsang, Adri`a
Gasc´on, and Borja Balle. 2020. Secure and
scalable document similarity on distributed
databases: Differential privacy to the rescue.
Proceedings on Privacy Enhancing Technolo-
吉斯 (PETS). https://doi.org/10.2478
/popets-2020-0024
Sacha Servan-Schreiber. 2021. Private nearest
neighbor search with sublinear communica-
tion and malicious security. 在 2022 IEEE
Symposium on Security and Privacy (SP).
https://doi.org/10.1109/SP46214
.2022.9833702
Luo Si and Hui Yang. 2014. Privacy-preserving
和: When information retrieval meets privacy
and security. In Proceedings of the 37th Inter-
national Conference on Research and Develop-
ment in Information Retrieval (ACM SIGIR).
https://doi.org/10.1145/2600428
.2600737
Alon Talmor and Jonathan Berant. 2018. The web
as a knowledge-base for answering complex
问题. In Conference of the North Ameri-
can Chapter of the Association for Computa-
tional Linguistics (全国AACL). https://土井
.org/10.18653/v1/N18-1059
Nandan Thakur, Nils Reimers, Andreas Ruckle,
Abhishek Srivastav, and Iryna Gurevych. 2021.
Beir: A heterogeneous benchmark for zero-shot
evaluation of information retrieval models. 在
Thirty-fifth Conference on Neural Information
Processing Systems Datasets and Benchmarks
Track (神经信息处理系统).
Harsh Trivedi, Niranjan Balasubramanian, Tushar
Kho, and Ashish Sabharwal. 2021. MuSiQue:
Multihop questions via single-hop question
作品. In Transactions of the Associa-
tion for Computational Linguistics (处理),
10:539–554. https://doi.org/10.1162
/tacl a 00475
Neeraj Varshney, Swaroop Mishra, and Chitta
Baral. 2022. Investigating selective prediction
approaches across several tasks in iid, ood,
这
and adversarial
计算语言学协会
(前交叉韧带), pages 1995–2002, 都柏林,
爱尔兰.
https://doi.org/10.18653/v1/2022
.findings-acl.158
settings. Findings of
Ellen M. Voorhees. 1999. The trec-8 question
answering track report. In TREC. https://
doi.org/10.1145/381258.381260
Johannes Welbl, Pontus Stenetorp, and Sebastian
Riedel. 2018. Constructing datasets for multi-
hop reading comprehension across documents.
In Transactions of the Association for Computa-
tional Linguistics (处理), 6:287–302. https://
doi.org/10.1162/tacl 00021
Tomer Wolfson, Mor Geva, Ankit Gupta, 马特
加德纳, Yoav Goldberg, Daniel Deutch, 和
Jonathan Beran. 2020. Break it down: A ques-
tion understanding benchmark. In Transactions
of the Association for Computational Linguis-
抽动症 (处理), 8:183–198. https://doi.org
/10.1162/tacl a 00309
Wenhan Xiong, Xiang Lorraine Li, 斯里尼瓦桑
Iyer, Jingfei Du, Patrick Lewis, William Wang,
Yashar Mehdad, Wen tau Yih, Sebastian Riedel,
Douwe Kiela, and Barlas Oguz. 2021. 一个-
swering complex open-domain questions with
917
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
multi-hop dense retrieval. In International Con-
ference on Learning Representations (ICLR).
Yabo Xu, Benyu Zhang, Zheng Chen, and Ke
王. 2007. Privacy-enhancing personalized
web search. In Proceedings of the 16th Interna-
tional Conference on World Wide Web (万维网).
https://doi.org/10.1145/1242572
.1242652
Zhilin Yang, Peng Qi, Saizheng Zhang,
Yoshua Bengio, William W. 科恩, Ruslan
Salakhutdinov, and Christopher D. 曼宁.
2018. HotpotQA: A dataset for diverse, 解释-
able multi-hop question answering. In Proceed-
ings of
这 2018 Conference on Empirical
Methods in Natural Language Processing
(EMNLP). https://doi.org/10.18653
/v1/D18-1259
Wentau Yih, Matthew Richardson, Christopher
Meek, Ming-Wei, and Chang Jina Suh. 2016.
The value of semantic parse labeling for knowl-
edge base question answering. In Proceedings
的
the Associ-
ation for Computational Linguistics (前交叉韧带).
https://doi.org/10.18653/v1/P16
-2033
the 54th Annual Meeting of
Jingtao Zhan, Qingyao Ai, Yiqun Liu, Jiaxin
Mao, Xiaohui Xie, Min Zhang, and Shaoping
Ma. 2022. Disentangled modeling of domain
and relevance for adaptable dense retrieval.
arXiv 预印本 arXiv:2208.05753.
迈克尔·J. 问. Zhang and Eunsol Choi. 2021.
SituatedQA: Incorporating extra-linguistic con-
texts into QA. In Proceedings of the Conference
on Empirical Methods in Natural Language
加工 (EMNLP).
Steven Zimmerman, Alistair Thorpe, Chris Fox,
and Udo Kruschwitz. 2019. Investigating the
interplay between searchers’ privacy concerns
and their search behavior. 在诉讼程序中
the 42nd International ACM Conference on
in Information
Research and Development
Retrieval (SIGIR). https://doi.org/10
.1145/3331184.3331280
A Experimental Details
模型
Avg-PR
Learning Rate
Batch Size
Maximum passage length
Maximum query length at initial hop
Maximum query length at 2nd hop
Warmup ratio
Gradient clipping norm
Traininig epoch
Weight decay
5e–5
150
300
70
350
0.1
2.0
64
0
桌子 7: Retrieval hyperparameters for MDR
training on CONCURRENTQA and Subsampled-
HotpotQA experiments.
模型
Two-hop MDR
Contriever
Contriever MS-MARCO
Recall@10
55.9
12.1
36.9
桌子 8: Comparison of one-hop baseline models
evaluated on the two-hop CONCURRENTQA task
without finetuning.
the softmax over all passages. We consider two
methods of collecting negative passages: 第一的,
we use random passages from the corpus that
do not contain the answer (random), 第二个,
we use one top-ranking passage from BM25 that
does not contain the answer as a hard-negative
paired with remaining random negatives. We do
not observe much difference between the two
approaches for CONCURRENTQA-results (also ob-
served in Xiong et al. [2021]), and thus use ran-
dom negatives for all experiments.
The number of passages retrieved per hop, k, 是
an important hyperparameter; increasing k tends
to increase recall, but sacrifice precision. A larger
k is also less efficient at inference time. We use
k = 100 for all experiments in the paper and
桌子 9 studies the effect of using different val-
ues of k.
We find the hyperparameters in Table 7 在
the Appendix work best and train on up to 8
NVidia-A100 GPUs.
The MDR retriever is trained with a contrastive
loss as in Karpukhin et al. (2020), where each
query is paired with a (gold annotated) 积极的
passage and m negative passages to approximate
Sparse Retrieval For the sparse retrieval base-
线, we use Pyserini with default parameters.7
7https://github.com/castorini/pyserini.
918
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
k
k = 1
k = 10
k = 25
k = 50
k = 100
Avg-PR
41.4
55.9
63.3
68.4
73.8
F1
33.5
44.7
48.0
50.4
53.0
桌子 9: Retrieval performance (Average Passage-
Recall@k, F1) for k ∈ {1, 10, 25, 50, 100} 关于-
trieved passages per hop using the retriever trained
on HotpotQA for OOD CONCURRENTQA test data.
k
k = 1
k = 10
k = 25
k = 50
k = 100
F1
22.0
34.6
37.8
39.3
40.8
桌子 10: F1 score on the CONCURRENTQA test
data for k ∈ {1, 10, 25, 100} per hop using
BM25.
We consider different values of k ∈ {1, 10, 25,
100} per retrieval, reported in Table 10 在里面
附录. We generate the second hop query by
concatenating the text of the initial query and first
hop passages.
QA Model We use the provided ELECTRA-
Large reader model checkpoint from Xiong et al.
(2021) for all experiments. The model was trained
on HotpotQA training data. Using the same reader
to understand how retrieval quality
is useful
affects performance,
in the absence of reader
modifications.
Contriever Model We use the code released
by for zero-shot and fine-tuning implementation
和评价 (Izacard et al., 2021).8 We per-
form a hyperparamter search for the learning rate
∈ {1e − 4, 1e − 5}, temperature ∈ {0.5, 1}, 和
number of negatives ∈ {5, 10}. We found a learn-
ing rate of 1e − 5 with a linear schedule and 10
negative passages to be best. These hyperparame-
ters are chosen following the protocol in Izacard
等人. (2021).
8https://github.com/facebookresearch/contriever.
B Additional Analysis
We include two figures to further characterize
the differences between the Wikipedia and Enron
分布.
数字 5 (左边, 中间) in the Appendix shows
the UMAP plots of CONCURRENTQA questions us-
ing BERT-base representations, split by whether
the gold hop passages are both from the same do-
主要的 (例如, two Wikipedia or two email passages)
or require one passage from each domain. 这
plots reflect a separation between Wiki-based and
email-based questions and passages.
C CONCURRENTQA Details
Here we compare CONCURRENTQA to available
textual QA benchmarks and provide additional
details on the benchmark collection procedure.
C.1 Overview
CONCURRENTQA is the first multi-distribution tex-
tual benchmark. Existing benchmarks in this cate-
gory are summarized in Table 11 in the Appendix.
We note that HybridQA (陈等人。, 2020乙) 和
similar benchmarks also include multi-modal doc-
uments. 然而, these only contain questions
that require one passage from each domain for
all questions, IE。, one table and one passage. 我们的
benchmark considers text-only documents, 在哪里
questions can require arbitrary retrieval patterns
across the distributions.
C.2 Benchmark Construction
We need to generate passage pairs for Hop1,
Hop2 of two Wikipedia documents (民众, Pub-
利克), an email and a Wikipedia document (Pub-
利克, Private and Private, 民众), and two emails
(Private, Private).
Public-Public Pairs For Public-Public Pairs,
we use a directed Wikipedia Hyperlink Graph,
G where a node is a Wikipedia article and an
边缘 (A, 乙) represents a hyperlink from the first
paragraph of article a to article b. The entity as-
sociated with article b, is mentioned in article a
and described in article b, so b forms a bridge, 或者
commonality, between the two contexts. Crowd-
workers are presented the final public document
对 (A, 乙) ∈ G. We provide the title of b as a
hint to the worker, as a potential anchor for the
multi-hop question.
919
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 5: UMAP of BERT-base embeddings, using Reimers and Gurevych (2019), of CONCURRENTQA ques-
tions based on the domains of the gold passage chain to answer the question (left and middle). I.e., 问题
that require an Email passage for hop 1 and Wikipedia passage for hop 2 are shown as ‘‘Wiki-Email’’. Embed-
dings for all gold passages are also shown, split by domain (正确的).
数据集
WebQuestions (Berant et al., 2013)
WebQSP (Yih et al., 2016)
WebQComplex (Talmor and Berant, 2018)
MuSiQue (Trivedi et al., 2021)
DROP (Dua et al., 2019)
HotpotQA (杨等人。, 2018)
2Wiki2MultiHopQA (Ho et al., 2020)
Natural-QA (Kwiatkowski et al., 2019)
CONCURRENTQA
尺寸
6.6K
4.7K
34K
25K
96K
112K
193K
300K
18.4K
Domain
Freebase
Freebase
Freebase
Wiki
Wiki
Wiki
Wiki
Wiki
电子邮件 & Wiki
桌子 11: Existing textual multi-hop benchmarks are designed over a single-domain.
To initialize the Wikipedia hyperlink graph, 我们
use the KILT KnowledgeSource resource (Petroni
等人。, 2021) to identify hyperlinks in each of
the Wikipedia passages.9 To collect passages that
share enough in common, we eliminate entities
b which are too specific or vague, having many
plausible correspondences across passages. 为了
例子, given a representing a ‘‘company’’, 它
may be challenging to write a question about its
connection to the ‘‘business psychology’’ doctrine
the company ascribes to (b is too specific) 或者
the ‘‘country’’ in which the company is located
(b is too general). To determine which Wiki en-
tities to permit for a and b pairings shown to the
工人, we ensure that the entities come from a
restricted set of entity-categories. The Wikidata
knowledge base stores type categories associated
with entities (例如, ‘‘Barack Obama’’ is a ‘‘politi-
cian’’ and ‘‘lawyer’’). We compute the frequency
of Wikidata types across the 5.2 million entities
and permit entities containing any type that occurs
至少 1000 次. We also restrict to Wikipedia
documents containing a minimum number of sen-
tences and tokens. The intuition for this is that
highly specific types entities (例如, a legal code or
scientific fact) and highly general types of enti-
领带 (例如, 国家) occur less frequently.
Pairs with Private Emails Unlike Wikipedia,
hyperlinks are not readily available for many un-
structured data sources including the emails, 和
the non-Wikipedia data contains both private and
民众 (例如, Wiki) 实体. 因此, we design the
following approach to annotate the public and
private entity occurrences in the email passages:
1. We collect candidate entities with SpaCy.10
2. We split the full set into candidate public
and candidate private entities by identifying
Wikipedia linked entities amongst the spans
tagged by the NER model. We annotate
9https://github.com/facebookresearch/KILT.
10https://spacy.io/.
920
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
the text with the open-source SpaCy entity-
linker, which links the text to entities in
the Wiki knowledge base, to collect candi-
date occurrences of global entities.11 We use
heuristic rules to filter remaining noise in the
public entity list.
Private-Private Pairs are pairs of emails that
mention the same private entity e. 私人-
Public and Public-Private are pairs of emails men-
tioning public entity e and the Wikipedia passage
for e. In both cases, we provide the hint that e is
a potential anchor for the multi-hop question.
3. We post-process the private entity lists to
improve precision. High precision entity-
linking is critical for the quality of the
benchmark: A query assumed to require the
retrieval of private passages a and b should
not be unknowingly answerable by public
passages. After curating the private entity
列表, we restrict to candidates which occur
至少 5 times in the deduplicated set of
passages.
A total of 43.4k unique private entities and 8.8k
unique public entities appear in the emails, 和
1.6k private and 2.3k public entities occur at least
5 times across passages. We present crowd work-
ers emails containing at least three total entities
to ensure there is sufficient information to write
the multi-hop question.
Comparison Questions For comparison ques-
系统蒸发散, Wikidata types are readily available for
public entities, and we use these to present the
crowdworker with two passages describing enti-
ties of the same type. For private emails, 有
no associated knowledge graph so we heuristically
assigned types to private entities, by determining
whether type strings occurred frequently along-
side the entity in emails (例如, if ‘‘politician’’ is
frequently mentioned in the emails in which an
entity occurs, assign the ‘‘politician’’ type).
最后, crowdworkers are presented with a pas-
sage pair and asked to write a question that requires
information from both passages. We use separate
interfaces for bridge vs. comparison questions and
guide the crowdworker to form bridge questions
by using the passages in the desired order for
Hop1 and Hop2.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
5
8
0
2
1
5
3
2
1
8
/
/
t
我
A
C
_
A
_
0
0
5
8
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
11https://github.com/egerber/spaCy-entity
-linker.
921