Planning with Learned Entity Prompts for Abstractive Summarization
Shashi Narayan
Google Research
shashinarayan@google.com
Yao Zhao
Google Brain
yaozhaoyz@google.com
Joshua Maynez
Google Research
joshuahm@google.com
Gonc¸alo Sim˜oes
Google Research
gsimoes@google.com
Vitaly Nikolaev
Google Research
vitalyn@google.com
Ryan McDonald∗
ASAPP
ryanmcd@asapp.com
抽象的
We introduce a simple but flexible mechanism
to learn an intermediate plan to ground the gen-
eration of abstractive summaries. 具体来说,
we prepend (or prompt) target summaries with
entity chains—ordered sequences of entities
mentioned in the summary. Transformer-based
sequence-to-sequence models are then trained
to generate the entity chain and then continue
generating the summary conditioned on the
entity chain and the input. We experimented
with both pretraining and finetuning with this
content planning objective. When evaluated
on CNN/DailyMail, XSum, SAMSum, 和
BillSum, we demonstrate empirically that the
grounded generation with the planning objec-
tive improves entity specificity and planning
in summaries for all datasets, and achieves
state-of-the-art performance on XSum and
SAMSum in terms of ROUGE. 而且, 我们
demonstrate empirically that planning with
entity chains provides a mechanism to con-
trol hallucinations in abstractive summaries.
By prompting the decoder with a modified
content plan that drops hallucinated entities,
we outperform state-of-the-art approaches for
faithfulness when evaluated automatically and
by humans.
1
介绍
琼斯 (1993) described text summarization—the
task of generating accurate and concise summaries
from source document(s)—as a three-step pro-
过程: (我) Building the source representation from
the source document(s), (二) Learning a summary
representation from the source representation, 和
(三、) Synthesizing the output summary text. 康姆-
mon to most traditional methods, an input rep-
resentation was learned by semantically analyzing
∗Work done while Ryan McDonald was at Google.
the source text, the summary representation was
then learned by modifying and refining the input
表示, and finally the summary was gen-
erated grounded to the intermediate summary rep-
resentation (Luhn, 1958; McKeown and Radev,
1995; Barzilay and Elhadad, 1997; Mihalcea and
Tarau, 2004).
State-of-the-art neural summarizers are powerful
representation learners and conditional language
型号, thanks to sequence-to-sequence architec-
特雷斯 (seq2seq) with attention and copy mechanisms
(Hochreiter and Schmidhuber, 1997; Bahdanau
等人。, 2015; See et al., 2017), Transformer archi-
tectures with multi-headed self-attention (Vaswani
等人。, 2017), and large pretrained conditional lan-
guage models (Dong et al., 2019; Song et al., 2019;
刘易斯等人。, 2020; Rothe et al., 2020; Raffel et al.,
2019; 张等人。, 2020). 然而, the ground-
ing of summary generation that was inherent to
most traditional methods is yet to be achieved in
neural summarization. The attention mechanism
(Bahdanau et al., 2015), especially in pretrained
encoder-decoder models (刘易斯等人。, 2020;
Raffel et al., 2019; 张等人。, 2020), plays a
key role in aligning summary content to the input,
yet undesired hallucinations are common in gener-
ated summaries (Maynez et al., 2020; Kryscinski
等人。, 2020; Gabriel et al., 2021).
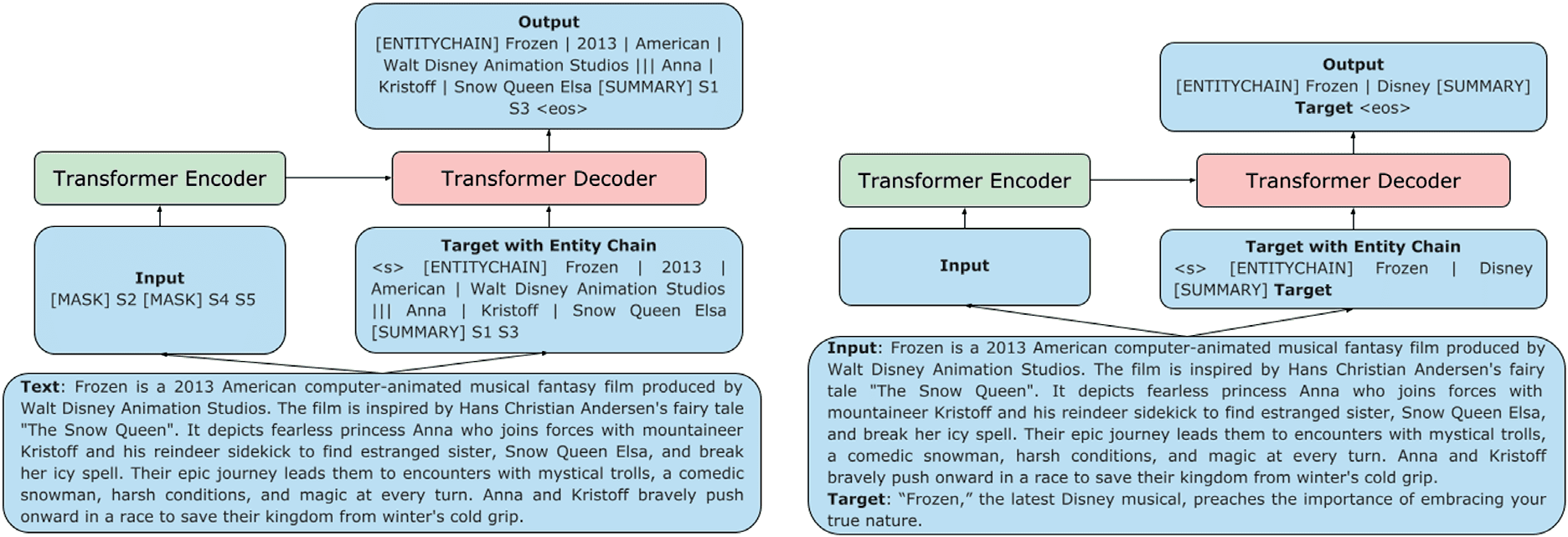
在本文中, we investigate Entity Chains—
ordered sequences of entities1 in the summary—
as an intermediate summary representation to bet-
ter plan and ground the generation of abstractive
summaries. During training, we construct an aug-
mented target summary by extracting and pre-
pending its corresponding entity chain (数字 1,
时间, the model must generate
正确的). 在
测试
1We use the term ‘‘entity’’ broadly and consider named
实体, dates, and numbers to form an entity chain.
1475
计算语言学协会会刊, 卷. 9, PP. 1475–1492, 2021. https://doi.org/10.1162/tacl 00438
动作编辑器: Alexander M. 匆忙. 提交批次: 6/2021; 修改批次: 8/2021; 已发表 12/2021.
C(西德:3) 2021 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1: Pretraining and finetuning for abstractive summarization with entity chains.
both the entity chain followed by the summary.
Concretely, we use Transformer-based encoder-
decoder (Vaswani et al., 2017) 型号; a trans-
former encoder first encodes the input and a
transformer decoder generates (我) an intermediate
summary representation in the form of an entity
链; 和 (二) the summary conditioned on the
entity chain and the input. We evaluate our ap-
proach on four popular summarization datasets:
CNN/DailyMail highlight generation (Hermann
等人。, 2015), XSum extreme summarization
(Narayan et al., 2018), SAMSum dialogue sum-
marization (Gliwa et al., 2019), and BillSum
(Kornilova and Eidelman, 2019), and show that
the state-of-the-art PEGASUS (张等人。, 2020)
pretrained models finetuned with the planning ob-
jective clearly outperform regular finetuning in
terms of entity specificity and planning in gener-
ated summaries on all datasets. We further dem-
onstrate that this simple planning mechanism can
be easily used for pretraining summarization
models to do entity-level content planning and
summary generation. Similar to PEGASUS pretrain-
英, we mask important sentences from an input
文档, extract an entity chain from the masked
句子, and generate these gap-sentences pre-
pended with their entity chain from the rest of the
文档 (数字 1, 左边). We see further gains
with pretraining achieving state of the art perfor-
mance on XSum in terms of ROUGE. We further
demonstrate how the entity-level content planning
in summarization can be easily leveraged to mi-
tigate hallucinations in abstractive summaries. 在
特别的, we modify the predicted entity chain to
only keep entities that are seen in the document
and then generate the summary prompted with
the modified entity chain, outperforming state-
of-the-art approaches when evaluated automati-
cally and by humans for faithfulness. 我们的主要
contributions are as follows:
Planned and Grounded Abstractive Summa-
rization We introduce a novel training objective
to neural summarization models for content plan-
ning with entity chains, and study integrating
it with supervised finetuning and self-supervised
pretraining objectives without altering the models
他们自己. As the entity chains are extracted from
the reference summaries during training, our mod-
els learn to ground the generation of summaries to
the entity chains found in them. 因此, we refer
to this objective by FROST for its ability to try to
‘‘FReeze entity-level infOrmation in abstractive
SummarizaTion with planning.’’
Controlled Abstractive Summarization with
Entity Chains FROST provides a very effective
knob for entity-level content modification in ab-
stractive summaries. In this paper we empirically
demonstrate how FROST is critical for faithfulness
by enabling the drop-prompt mechanism where
we drop out hallucinated entities from the pre-
dicted content plan and prompt the decoder with
this modified plan to generate faithful summaries.
We further qualitatively demonstrate that FROST
enables generation of summaries (我) with topi-
cal diversity by choosing different sets of entities
from the source to plan what we want to discuss
in the summary, 和 (二) with style diversity by
reordering entities in the predicted plan to get an
equivalent summary but with a different entity
emphasis.
Our codes to process summarization datasets to
do FROST-style content planning and generation,
1476
models and predictions are available at https://
github.com/google-research/google
-research/tree/master/frost.
2 相关工作
Content Planning for Summarization. 传统-
tional methods argue on the granularity of lin-
guistic, domain, and communicative information
included in the source representation needed in
order to plan and build better summary representa-
系统蒸发散. Some argued to use a deep semantic analysis
of the source text, such as Rhetorical Struc-
ture Theory (RST; 曼和汤普森, 1988)
or MUC-style representations (McKeown and
Radev, 1995) to interpret the source texts, 尽管
others used a shallow semantic analysis using only
word frequency (Luhn, 1958) or lexical chains
(Barzilay and Elhadad, 1997).
Recent encoder-decoder models for text genera-
的 (Bahdanau et al., 2015; Sutskever et al., 2014;
Vaswani et al., 2017; Rothe et al., 2020; Lewis
等人。, 2020; Raffel et al., 2019; 张等人。, 2020)
tend to perform text generation in an end-to-end
环境, which means that most approaches do not
explicitly model content planning. Wiseman et al.
(2018) and Hua and Wang (2020) start the gen-
eration process by building templates which are
then used for realization. In data-to-text genera-
的, Puduppully et al. (2019) generate a content
plan highlighting which information should be
mentioned in the table and in which order. In story
一代, there has been some work on exploring
事件 (Martin et al., 2018) or sequences of words
(Yao et al., 2019) to plan ahead when creating a
consistent story. We are not aware of any similar
work on content planning for summarization using
encoder-decoder models.
Pretraining for Summarization and Planning.
Pretrained transformer-based models have dra-
matically changed the text generation space, 和
summarization is no exception to this. 最多
models focus on task-agnostic pretraining us-
ing the left-to-right language modeling objective
(Radford et al., 2018; Khandelwal et al., 2019;
Dong et al., 2019) or reconstructing the corrupted
input text using a sequence-to-sequence frame-
工作 (Song et al., 2019; 刘易斯等人。, 2020; 拉斐尔
等人。, 2019). There have been few attempts to-
wards task-specific pretraining for summarization
to teach models to do better content selection.
张等人. (2020) proposed to select important
sentences from an input document as a proxy for
human-authored summary and then to generate
them from the rest of the document. Narayan et al.
(2020) proposed question generation pretraining
to better align with summarization. To the best of
our knowledge we are the first to propose a so-
lution that incorporates content planning directly
into pretraining.
Controlled Abstractive Summarization. 那里
is a growing interest in enabling users to spec-
ify high-level characteristics such as length, 钥匙-
字, and topic in order to generate summaries
that better suit their needs. 在多数情况下, 这些
features are first manually provided or estimated
using third-party content selectors, and then either
(我) encoded along with the input (Fan et al., 2018;
He et al., 2020; Dou et al., 2021) 或者 (二) used to
filter beams for lexically constrained decoding
(Mao et al., 2020), to control the summary gen-
进化. 相反, our approach is more
generic as we do not rely on external systems or
data to augment the input; users can prompt the
decoder with a desired content plan in the form
of an entity chain to control the summary.
3 Content Planning with Entity Chains
We introduce a new training objective for
encoder-decoder generative models to do content
planning while summarizing.
Model Formulation. Let d be an input docu-
蒙特, we aim to teach our model to first generate
a content plan c for the summary s as p(C|d),
and then generate the summary s as p(s|C, d). 我们
define the ordered chain of entities observed in the
summary s as its content plan. Instead of modeling
p(C|d) 和 p(s|C, d) separately, we take a simpler
方法, we train an encoder-decoder model to
encode the document d and generate the concate-
nated content plan and summary sequences c; s,
essentially the decoder first predicts the entity
chain c and then continues predicting the sum-
mary s using both c and d. We prefix c and s with
special markers ‘‘[ENTITYCHAIN]’’ and ‘‘[SUM-
MARY]’’, 分别, 如图 1. 如果
s consists of multiple sentences, we use sentence
markers ‘‘|||’’ to mark them in c. The model
is trained with the standard maximum-likelihood
objective generating the augmented target c; s.
1477
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Pretraining Content Plans. We modified
PEGASUS (张等人。, 2020) to pretrain our mod-
els for entity-level content planning and summary
generation.2 In particular, we select a maximum
of n most important sentences using self-ROUGE
from an input document, the selected sentences
work as a proxy for a human-authored abstractive
summaries for the rest of the document. 我们
construct a target by prepending the selected sen-
tences dynamically with their entity chain. 我们的
model is then trained to generate this target from
the rest of the document.3
to learn entity-level
Modeling Entity-Level Lexical Cohesion and
Coherence. As entities in the summary con-
tribute to the continuity of lexical meaning of the
summary, we hypothesize that by learning to pre-
dict the entity chain c in advance, we enforce
our model
lexical cohe-
锡安 (Barzilay and Elhadad, 1997) and coherence
(Halliday and Hasan, 1976; Azzam et al., 1999) 在
the summary. We hope that by doing so our model
will be better at predicting pertinent entities (实体
specificity) in their right order (entity planning) 在
generated summaries; the prediction of entities in
the entity chain c (as p(C|d) in FROST) will be
less susceptible to local correlations compared to
when predicting them directly in the summary s
(as p(s|d)). 此外, as c is predicted in ad-
vance and the generation of s is grounded to c,4
our model will be better equipped to predict cor-
rect events relating to different entities in c with
full access to c and not just entities to the left,
already decoded.
Controlled Generation with Entity Prompts.
An advantage of training to generate the summary
s following the generation of the plan c using the
same decoder is that now during the inference
time the decoder can be easily prompted with any
desired content plan c(西德:4) to control the content in the
2We experimented with PEGASUS, but our technique
can be used with any pretraining objectives that require
sentence-level input corruptions.
3The PEGASUS objective uses a summary-document length
ratio to select n. This could lead to an undesirably long
summary when the input document is very long. Modeling
such summaries prepended with long entity chains effectively
is beyond the limit of our decoders (256 sentencepieces).
因此, we set n = 5.
4这里, s is not strictly constrained to the entity chain c. 我们
hope that this will happen given c is extracted from s during
the training time. Future work will focus on constraining s
to c, 例如, using a checklist model (Kiddon et al., 2016) 或者
entity-chain constrained decoding (Mao et al., 2020).
output summary s(西德:4) with a probability of p(s(西德:4)|C(西德:4), d).
在部分 5, we prompt our decoder with modified
content plans to mitigate hallucinations and to
generate diverse summaries.
4 实验装置
4.1 Base and Large Models
We experiment with both base and large trans-
former architectures (Vaswani et al., 2017).
The base architecture has L = 12, H = 768,
F = 3072, A = 12 (223M parameters) 和
the large architecture has L = 16, H = 1024,
F = 4096, A = 16 (568M parameters), 在哪里
L denotes the number of layers for encoder and
decoder Transformer blocks, H for the hidden
尺寸, F for the feed-forward layer size, 和一个
for the number of self-attention heads. All pre-
trainings are done with a batch size of 1024,
whereas all finetuning experiments are done with
a smaller batch size of 256. For optimization,
we use Adafactor (Shazeer and Stern, 2018) 和
square root learning rate decay and dropout rate
的 0.01 during pretraining and 0.0001 during fine-
tuning. All finetuned models were decoded with a
beam size of 8 and a length-penalty of 0.8.
4.2 Datasets and Entity Annotations
Pretraining Datasets. Following Zhang et al.
(2020), our model pretraining also relied on two
large Web corpora which were processed to look
like plain text: (我) C4 (Raffel et al., 2019) is com-
posed of 350M Web pages that were obtained from
Common Crawl, 和 (二) HugeNews (张等人。,
2020) is composed of 1.5B news and news-like
articles from 2013–2019. This dataset includes ar-
ticles from multiple allowlisted sources includ-
ing news publishers, high-school newspapers,
and blogs.
Abstractive Summarization Datasets. 我们
evaluate our models on four summarization
datasets: CNN/DailyMail highlight generation
(Hermann et al., 2015), XSum extreme sum-
marization (Narayan et al., 2018), SAMSum
dialogue summarization (Gliwa et al., 2019), 和
BillSum summarizing US Congressional bills
(Kornilova and Eidelman, 2019). We use the
publicly available versions through the TFDS
Summarization Datasets.5 We use the original
5https://www.tensorflow.org/datasets/catalog.
1478
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
尺寸
平均.
平均.
平均.
% 目标
全部的
Target Summaries (验证)
数据集
train/dev/test
Case sent.
耳鼻喉科.
uniq. 耳鼻喉科. (no ent.) named date number
18.9k/–/3.3k
BillSum
CNN/DailyMail 287k/13.4k/11.5k cased 4.11
14.7k/818/819
SAMSum
cased 2.03
204k/11.3k/11.3k cased 1.00
XSum
cased 4.38 14.78
7.55
3.59
2.81
11.10
6.92
3.01
2.80
0.18
0.10
0.37
5.97
28931 2578 16646
74292 3569 23094
33
2594
309
6287
777
24682
桌子 1: Abstractive summarization datasets studied in this work. We report on their train/validation/test
sizes and how they were processed (cased/uncased). To better understand the effect of summary planning
with entity chains, we report on average number of sentences (平均. sent.), average number of entities
(平均. ent.) and average number of unique entities (平均. uniq. ent.), per target in validation sets. 我们也
report on total number of named entities, 日期, and number in target summaries.
train/validation/test splits for them. For BillSum,
where the validation split was not provided, 我们
split 10% of the training set to serve as validation.
Inputs and outputs were truncated to 512 和
128 for XSum and SAMSum, 和 1024 和
256 for CNN/DailyMail and BillSum. 桌子 1
provides more insights into these datasets to
better understand the effect of summary planning
with entity chains.
Entity Chain Annotation. We experimented
with entity chains consisting of named entities,
dates, and numbers. We annotate the whole docu-
ment in the pretraining datasets to allow dynamic
construction of summaries and their entity chains
during pretraining. We only annotate the ref-
erence summaries for the finetuning summari-
zation datasets. We use a BERT-based tagger
trained on CoNLL-2003 data (Tjong Kim Sang
and De Meulder, 2003) to identify named entities,
and regular expressions to identify dates and num-
bers (Guu et al., 2020). 见表 1 for the number
of named entities, dates and numbers found in
different datasets.
Tables 6 和 7 in Appendix A present hyper-
parameters used for pretraining and finetuning
PEGASUS and FROST base and large-sized models.
We used Cloud TPU v3 accelerators for training.
4.3 Evaluation Measures
We evaluate our FROST models on ROUGE, 在-
tity specificity, entity planning, faithfulness using
automatic and human evaluations, 和总体
quality by humans. Our models predict a summary
plan in the form of an entity chain, 其次是
a summary. All evaluations are done on the sum-
mary, the predicted entity chains are stripped out.
Summary-level ROUGE. We report ROUGE F1
scores (Lin and Hovy, 2003) to assess generated
summaries.6
Entity Planning. We evaluate the quality of
content plans learned by our models by assessing
the entities and the order in which they appear
in the summary. We annotate both predicted and
reference summaries with named entities, dates,
and numbers, and report on ROUGE F1 scores for
entity chains found in the predicted summaries
against corresponding reference entity chains.
Entity Specificity. We compare entities in
predicted and reference summaries, 并报告
average entity F1-scores (ENTF1) in predicted
summaries. We lower-case and remove dupli-
cate entities; we report on the exact match with
reference entities.
Faithfulness. For entity-level faithfulness, 我们
report on ENTPREC, measuring the precision of
entities in predicted summaries against their input
文件. ENTF1, in comparison, evaluates pre-
dicted summaries for entity specificity against
reference summaries and is not a measure for
faithfulness. For summary-level faithfulness, 我们
follow Maynez et al. (2020) and report on textual
entailment (Pasunuru and Bansal, 2018; Falke
等人。, 2019; Kryscinski et al., 2020). In par-
针状的, we report the probability of a summary
6We lowercased candidate and reference summaries and
used pyrouge with parameters ‘‘-a -c 95 -m -n 4 -w 1.2.’’
1479
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
entailing (Entail.)
its input document using
an entailment classifier trained by fine-tuning
an uncased BERT-Large pretrained model (Devlin
等人。, 2019) on the Multi-NLI dataset (威廉姆斯
等人。, 2018).
We further assess summary faithfulness by hu-
芒斯. Our annotators, proficient in English, 是
tasked to read the document carefully and then
grade its summary on a scale of 1–5 (fully un-
faithful, somewhat unfaithful, 50-50, 有些
faithful, and fully faithful); a summary is ‘‘fully
faithful’’ if all of its content is fully supported or
can be inferred from the document.
Overall Summary Quality. 最后, we assess
the overall quality of summaries by humans. 我们
ask our annotators to read the document carefully
and then grade its summary on a scale of 1–5 (贫穷的
summary, better than poor, okay summary, 更好的
than okay, and great summary). To improve the
annotator agreement, we clearly define 4 特征
that a ‘‘great summary’’ should have: Relevant
(summary should have most important informa-
tion from the document), Accurate (summary
should be accurate with respect to the document or
the expert knowledge),7 Concise (summary should
not have redundant or less-important content), 和
Fluent (summary should be grammatically correct
and coherent). A great summary should pass on
全部 4 特征, a better than okay should have 3 出去
的 4 特征, 等等.
For both human assessments, 我们收集了 3
ratings for each (文档, summary) pair and
report the average of all assigned labels (1–5) 到
a system. We conducted 3 pilot studies for each
setup to train our annotators with examples to
improve their understanding of the task. 阿迪-
理论上, extra measures were taken to improve
agreements among our annotators. 例如,
for the faithfulness assessment, when one of some-
what unfaithful, 50-50, and somewhat
faithful
were selected, annotators were asked to also spec-
ify what was faithful or unfaithful in the summary.
Similarly for the overall quality assessment, 什么时候
one of better than poor, okay summary, and better
than okay were selected, they were asked to list
all features on which the candidate summary fails.
7With accurate we mean factual
to the background
knowledge and not just faithful to the document; as it is nat-
ural to construct summaries that integrate with the author’s
background knowledge (Maynez et al., 2020).
数字 2: An example of
和
summary-level entity chains along with the reference
summary.
sentence-level
人物 9 和 10 in Appendix B show detailed in-
structions for human evaluations for faithfulness
and overall quality of summaries, 分别.
5 结果
5.1 FROST Ablations
Sentence-Level vs Summary-Level Planning.
the summary s consists of m sentences
Let
s1 . . . sm and ci be the entity chain for the sen-
tence si, we consider generating the summary
s in two ways. Sentence-level approach trains a
model to generate s by consecutively generat-
ing the sentence-level content plan ci followed
by its summary sentence si with a probability
p(cisi|c1s1 . . . ci−1si−1; d); d is the input docu-
蒙特. Summary-level approach first generates a
summary-level content plan c = c1||| . . . |||cm and
then continue generating the summary s with
a probability p(s|C; d); ||| are sentence markers.
The summary-level planning is arguably better
suited for summarization than the sentence-level
规划. By planning the whole summary be-
forehand, the summary-level planner would be
(我) less susceptible to local correlations than the
sentence-level planning while generating the en-
乳头, 和 (二) a better microplanner in deciding
sentence boundaries and avoiding verbose sum-
maries (Reiter and Dale, 1997). See examples for
sentence-level and summary-level entity chains in
数字 2.
We finetuned our large models initialized with
the PEGASUS checkpoint on the CNN/DailyMail
1480
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3: Sentence-level vs summary-level entity
chains. We report summary-level ROUGE-L (RL-Sum),
entity chain-level ROUGE-2 (R2-EPlan), and ENTF1 on
the CNN/DailyMail validation set. Similar observa-
tions were made for other measures.
dataset for sentence-level vs summary-level entity
chain ablations. We did not do this study on
the XSum dataset as the XSum summaries are
single sentences, which means that sentence-level
and summary-level entity chains are the same. 在
对比, the CNN/DailyMail summaries consists
of multi-sentence highlights. Results are presented
图中 3.
We found that the summary-level planning is
not only superior to the sentence-level planning,
it helps with generating better quality summaries
in terms of summary-level ROUGE (RL-Sum), 在-
tity planning (R2-EPlan), and entity specificity
(ENTF1). For the rest of the pretraining or finetun-
ing experiments, we focused on summary-level
planning unless specified otherwise.
for Planning
Pretraining
from Scratch.
We pretrained three base-sized models from
scratch: PEGASUS-base pretrained with the original
gap-sentence objective (张等人。, 2020) 为了
1.5m steps, FROST(F)-base pretrained with the gap-
sentences prepended with their entity chain for
1.5m steps, and FROST(P+F)-base first pretrained
with the PEGASUS objective for 1m steps and then
with the FROST objective for another 500k steps.
Maximum input and output lengths were set to
512 和 256 sentencepieces during pretraining,
分别. We finetuned these three models on
the XSum dataset. Results are shown in Figure 4.
First of all, our results confirm that the pretrain-
ing for planning is beneficial for summarization;
both FROST(F) and FROST(P+F) learned better con-
tent plans (in terms of entity chain-level ROUGE and
ENTF1) than PEGASUS without sacrificing the sum-
mary quality (in terms of summary-level ROUGE)
显著地. 有趣的是, the FROST(P+F) fine-
数字 4: Finetuning results on the XSum validation
set using one of the base-sized pretrained models:
PEGASUS, FROST(F), and FROST(P+F). All pretrained
models were trained for 1.5m steps. See text for more
细节. We only report on a subset of measures, 相似的
observations were made for other measures.
tuned model outperformed FROST(F) on all mea-
sures confirming that the pretraining for planning
and summarization is more effective when started
with summarization pretrained models such as
PEGASUS than when trained jointly from scratch.
因此, for our future pretraining experiments we
initialize our model with existing PEGASUS check-
point and continue pretraining for content planning
and refer to them as FROST for simplicity.
Effect of Pretraining Longer for Planning.
Based on our
发现, we pretrain a large
FROST model for planning for summarization start-
ing with an existing PEGASUS-Large checkpoint.
数字 5 presents results for finetuning these mod-
els on the XSum and CNN/DailyMail datasets at
various steps during pretraining.
Similar to our findings in Figure 4, our results
with large models further confirm the advantages
of the pretraining for planning; improvement over
the PEGASUS baseline were larger for the XSum
dataset than for the CNN/DailyMail dataset. 我们
achieved the best performance on both datasets
at the 1m pretraining step. We use the FROST
model at 1m pretraining step for our finetuning
实验.
5.2 Abstractive Summarization Results
桌子 2 presents our final results from finetuning
our large models on summarization datasets. 为了
1481
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
模型
Summary
R1/R2/RL
Entity Planning
R1/R2/RL
Specificity
ENTF1
LEAD-3
∗
EXT-ORACLE
RoBERTaShare
MASS
UniLM
T5
捷运
ProphetNet
PEGASUS
GSum
CTRLsum
PEGASUS (ours)
FROST (ECP)
FROST (ECPP)
LEAD-1
∗
EXT-ORACLE
RoBERTaShare
MASS
捷运
GSum
PEGASUS
PEGASUS (ours)
FROST (ECP)
FROST (ECPP)
CNN/DailyMail
40.31/17.83/36.45
57.03/34.38/53.12
39.25/18.09/36.45
42.12/19.50/39.01
43.33/20.21/40.51
43.52/21.55/40.69
44.16/21.28/40.90
44.20/21.17/41.30
44.16/21.56/41.30
45.94/22.32/42.48
45.65/22.35/42.50
44.05/21.69/40.98
44.85/21.83/41.80
45.11/22.11/42.01
XSum
16.66/1.85/12.26
28.81/8.61/21.97
38.52/16.12/31.13
39.75/17.24/31.95
45.14/22.27/37.25
45.40/21.89/36.67
47.60/24.83/39.64
47.56/24.87/39.40
47.44/24.54/39.24
47.80/25.06/39.76
SAMSum
57.41/42.32/47.16
68.79/55.77/59.02
–
–
–
–
–
–
–
–
62.19/48.35/52.53
61.12/46.46/52.40
64.34/49.85/54.98
64.28/49.86/54.96
21.45/4.36/19.48
32.64/13.34/28.85
–
–
–
–
–
62.15/39.76/56.36
63.57/40.45/57.65
64.09/41.07/58.18
(Gliwa et al., 2019)
40.99/17.72/38.30
–
PEGASUS (ours)
FROST (ECP)
FROST (ECPP)
52.27/28.34/47.83
52.39/27.70/47.82
51.86/27.67/47.52
72.42/51.07/64.85
74.42/55.32/66.35
75.02/55.19/66.80
BillSum
PEGASUS
59.67/41.58/47.59
–
PEGASUS (ours)
FROST (ECP)
FROST (ECPP)
59.33/41.60/54.80
58.76/40.34/54.03
59.50/41.17/54.85
69.99/62.79/66.17
70.84/63.59/66.86
71.67/64.56/67.79
46.22
59.91
–
–
–
–
–
–
–
–
51.69
49.93
53.17
53.22
5.36
18.78
–
–
–
–
–
53.48
54.62
55.49
–
81.17
83.60
83.60
–
61.91
62.38
63.38
桌子 2: Final results on abstractive summariza-
tion datasets compared with the previous SOTA.
We report results from RoBERTaShare (Rothe et al.,
2020), MASS (Song et al., 2019), UniLM
(Dong et al., 2019), T5 (Raffel et al., 2019), 捷运
(刘易斯等人。, 2020), ProphetNet (Qi et al., 2020),
(Gliwa et al., 2019), CTRLsum (He et al., 2020),
GSum (Dou et
and PEGASUS
(张等人。, 2020). We also include commonly
reported LEAD-n baselines (selecting top n sen-
tences from the document) and extractive oracle
(EXT-ORACLE; selecting best set of sentences from
the document with the most overlapping content
with its reference summary), for the CNN/Daily-
Mail and XSum datasets. EXT-ORACLEs are marked
with ∗ and are not directly comparable. All results
are reported on the publicly available test sets.
等人。, 2021),
our methods to controlled summarization systems
such as CTRLsum can be found in Section 5.5.
5.3 Controlling Hallucinations
We demonstrate in two ways that planning
with entity chains can be useful in mitigating
hallucinations in summarization: data filtering
数字 5: Finetuning results on the XSum (in blue) 和
CNN/DailyMail (红色的) validation sets at various steps
during pretraining FROST-Large. Instead of pretraining
from scratch, we start with a PEGASUS-Large checkpoint,
and continue pretraining for additional 1.5m steps with
the planning objective. We report finetuning results for
the PEGASUS finetuned baseline and our models at 0.1m,
1米, and 1.5m steps.
each dataset, we first report results from earlier
work directly taken from corresponding papers;
our results are in the bottom blocks for each
dataset. We finetune our own PEGASUS using the
standard approach (document to summary). 我们
report results from FROST (ECP; Entity Chain Plan-
ning), 那是, PEGASUS finetuned with the FROST
客观的 (document to content plan and sum-
mary). 最后, we report on FROST (ECPP; Entity
Chain Planning with Pretraining), our models both
pretrained and finetuned with the FROST objective.
We find that even simply finetuning an existing
PEGASUS pretrained model to do content planning
and summarization (as in FROST (ECP)) leads to
improvements in entity specificity (ENTF1) 和
the quality of entity plans in summaries (Entity
Planning ROUGE), across all datasets. 实际上, 在
一些案例, better content plans lead to large
improvements in summary-level ROUGE as well,
例如, FROST (ECP) improve on PEGASUS
从 44.05/21.69/40.98 到 44.85/21.83/41.80 在
ROUGE scores for CNN/DailyMail summaries.
The pretraining for content planning and gen-
eration in FROST (ECPP) further improves the
entity chain quality for CNN/DailyMail, XSum
and BillSum, and the summary-level ROUGE for
CNN/DailyMail and XSum. Our FROST models
establish new state-of-the-art ROUGE results on
XSum. For CNN/DailyMail, we perform infe-
rior to CTRLsum (He et al., 2020) and GSum
(Dou et al., 2021) on ROUGE scores. 然而,
we outperform CTRLsum on entity planning
and specificity. Further discussion on comparing
1482
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
and drop-prompt mechanism with entity chains.
We focused on the XSum dataset for these
experiments.8
Data Filtering using Entity Chains. 期间
training FROST prepends reference summaries with
their entity chains to better plan them. We leverage
this to filter the dataset
to only keep exam-
ples where summaries have fully extractive entity
chains; an entity chain is fully extractive if all en-
tities in it can be found in the input document. 它是
notable that this filtered dataset will not contain
novel entities in the summary targets. FROST mod-
els trained on this data will ground the summary
generation to extracted entity chains while allow-
ing abstraction for non-entity related generations.
The resulting XSum dataset has 62.7k/3.5k/3.5k
train/validation/test instances. We finetune our
models from Table 2 on this filtered dataset and
report their performance on the filtered test set
(3.5k). We also evaluate them on the rest of the
test set (7.8k) where reference entity chains are
not fully extractive to their input documents.9
见图 6 举些例子.
Drop-Prompt Mechanism. FROST decoders are
trained to generate the summary s following the
generation of its plan c. To improve faithfulness,
we take the predictions from FROST (ECPP)10 和
modify the generated plan c to cdrop by dropping
实体 (or parts of them) that are not found in the
input document. We then prompt our decoder with
cdrop to generate a new summary. We conduct this
with both models, one trained on the full dataset
and another on the filtered subset. We also report
results for the oracle entity chain prompts coracle
for a comparison.
Effect on Summary-level ROUGE, Entity Plan-
ning, and Specificity. Results are presented in
桌子 3. First of all, similar to our results in Table 2
8The CNN/DailyMail summaries are mostly extractive in
自然, these studies are less interesting as they don’t lead to
significant differences when assessing faithfulness (He et al.,
2020).
9Such data divergence is not unique to XSum, 大约
30% of CNN/DailyMail summaries also have reference entity
chains that are not fully extractive to their input documents.
Writing these summaries requires either document-level in-
ference or the background knowledge of the input documents
to generate novel entities or numbers.
10The drop-prompt mechanism can be used with FROST
(ECP) 还, we have simply used the best among FROST (ECP)
and FROST (ECPP) on the XSum set in terms of summary-level
ROUGE, entity planning and ENTF1.
数字 6: Example XSum predictions for models pre-
sented in Tables 3 和 4. We highlight entities in orange
that are not faithful to the input document. Entities in
green are faithful to the input document.
on the full XSum test set, our results with the mod-
els trained on the original dataset further validate
that the pretraining and finetuning with the content
planning objective is equally useful for both test
套: one where entities are simply copied from the
input documents and another where novel entities
were inferred, to generate corresponding targets.
The data filtering using entity chains are par-
ticularly useful for test cases with extractive
reference entity chains; models trained on the fil-
tered data lead to much higher ENTF1 (例如, 65.97
与 63.03, for FROST (ECPP)) and higher quality entity
计划 (entitly-level ROUGE of 66.43/30.00/62.48
与 63.73/30.08/60.10 for FROST (ECPP)), 和-
out sacrificing the summary quality substantially
(summary-level ROUGE of 44.87/22.05/36.79 与
45.08/22.01/36.80 for FROST (ECPP)). Unsurpris-
英利, these models don’t do well on the test set
with non-extractive reference entity chains, 这样的
examples were not seen during training.
The drop-prompt mechanism works particu-
larly well for models trained on the full dataset
and evaluated on the test set with extrac-
tive reference entity chains. 例如, 这
entity planning ROUGE scores and ENTF1 for
1483
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Test set with Extractive Entity Chains Only (3.5k)
Test set with Non-Extractive Entity Chains Only (7.8k)
模型
Summary
R1/R2/RL
Entity Planning
R1/R2/RL
Specificity
ENTF1
Summary
R1/R2/RL
Entity Planning
R1/R2/RL
Specificity
ENTF1
Models trained on the original XSum dataset (204k/11.3k/11.3k)
PEGASUS
FROST (ECP)
FROST (ECPP)
(d → cdrop; s)
(d → coracle; s)∗
44.67/21.75/36.37
44.53/21.38/36.28
45.08/22.01/36.80
44.97/21.97/36.77
50.26/27.33/43.12
61.54/28.84/58.02
63.60/29.20/60.01
63.73/30.08/60.10
67.10/30.19/63.58
98.55/53.94/98.53
60.88
62.04
63.03
64.41
98.36
48.85/26.26/40.75
48.74/25.95/40.56
49.02/26.42/41.08
44.93/21.41/37.39
61.80/40.55/56.20
62.42/44.64/55.62
63.56/45.48/56.60
64.25/45.98/57.32
48.89/30.58/43.76
99.10/92.10/99.08
Models trained on the filtered set with extractive entity chains only (62.7k/3.5k/3.5k)
PEGASUS
FROST (ECP)
FROST (ECPP)
(d → cdrop; s)
(d → coracle; s)∗
44.10/21.24/35.87
44.29/21.26/36.04
44.87/22.05/36.79
44.56/21.80/36.53
49.60/26.64/42.41
65.66/28.69/61.86
67.05/29.11/63.02
66.43/30.00/62.48
65.94/29.51/62.04
97.53/53.35/97.51
63.47
64.69
65.97
65.08
97.41
44.72/21.80/36.94
44.02/20.91/36.21
44.28/21.15/36.59
42.93/19.41/35.40
59.80/38.00/54.10
52.87/35.39/46.99
49.59/31.16/43.55
52.17/34.40/46.25
47.29/28.27/41.95
97.95/90.57/97.84
50.17
51.31
52.12
33.68
98.69
40.77
38.97
39.10
31.17
97.11
桌子 3: Performance on XSum summaries when models are trained on the dataset with extractive entity
chains only (data filtering, the bottom block) and when novel entities are dropped from the predicted
entity chains using the drop-prompt mechanism (cdrop). Results with ∗ are with oracle entity chain
prompts. We report results on the filtered test set with extractive entity chains only (3.5k) 和其余的
of the test set with novel entities in the targets (7.8k). Best results are bold faced.
Test set with Extractive Entity Chains Only (3.5k)
Test set with Non-Extractive Entity Chains Only (7.8k)
Faithfulness
全面的
Faithfulness
全面的
模型
Entail. ENTPREC Human Agree. Human Agree. Entail. ENTPREC Human Agree. Human Agree.
PEGASUS
FROST (ECP)
FROST (ECPP)
(d → cdrop; s)
PEGASUS
FROST (ECP)
FROST (ECPP)
(d → cdrop; s)
0.613
0.606
0.589
0.650
0.667
0.581
0.502
0.533
Models trained on the original XSum dataset (204k/11.3k/11.3k)
0.800
0.770
0.751
0.943
4.20
4.22
4.13
4.09
0.74
0.75
0.72
0.73
4.09
4.23
4.11
4.09
0.69
0.70
0.66
0.64
0.402
0.379
0.371
0.441
0.361
0.317
0.357
0.746
3.15
3.11
3.31
3.53
0.71
0.73
0.79
0.75
Models trained on the filtered set with extractive entity chains only (62.7k/3.5k/3.5k)
0.887
0.858
0.806
0.943
4.39
4.27
4.19
4.41
0.80
0.76
0.77
0.75
4.14
4.16
4.19
4.18
0.69
0.66
0.66
0.72
0.389
0.442
0.465
0.453
0.501
0.548
0.491
0.826
3.37
3.43
3.55
3.85
0.79
0.72
0.76
0.74
2.93
2.85
2.81
3.13
3.09
3.01
3.16
3.46
0.80
0.77
0.77
0.79
0.76
0.73
0.76
0.77
桌子 4: Faithfulness assessment using automatic (Entailment and ENTPREC) and human evaluations,
and overall quality assessment by humans for models presented in Table 3. Following Durmus et al.
(2020), 协议 (Agree.) is computed by taking the percentage of the annotators that annotate the
majority class for the given (文档, summary) pair. Best results are bold faced.
FROST models improve from 63.73/30.08/60.10
到 67.10/30.19/63.58, 和, 63.03 到 64.41, 关于-
spectively. 有趣的是, we do not observe a
significant drop in the summary-level ROUGE scores
(45.08/22.01/36.80 与 44.97/21.97/36.77). Basi-
卡莉, our results demonstrate that when models
are trained on the noisy data (with data diver-
gence issues, common in summarization datasets
(Dhingra et al., 2019; Maynez et al., 2020)), 这
drop-prompt mechanism is very effective in gen-
erating high quality summaries when entities need
to be simply copied from the input documents.
The drop-prompt mechanism doesn’t help mod-
els when they are already trained on the filtered
training set. Also this mechanism is counter in-
tuitive to use for the test set where novel entities
need to be inferred to generate targets, we observe
drops for models irrespective of how they were
trained, either using the full training set or the
filtered set.
Effect on Faithfulness. The planning objective
in FROST itself does not ensure faithfulness; plan-
ning is done with the entities in the target, 如果
target is noisy, its plan may also be noisy (看
数字 6 for predicted entity chains with hal-
lucinated entities). 但
the planning with the
entity chains facilitates the data filtering and
1484
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
我
A
C
_
A
_
0
0
4
3
8
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
the drop-prompt mechanism, using entity chains.
桌子 4 presents our results assessing them for
faithfulness. 我们随机选择了 50 docu-
ments for each of test sets (with extractive or
non-extractive reference entity chains) 并作为-
sessed their summaries from all 8 系统 (除了
with coracle) from Table 3.
为了
The data filtering using entity chains is ex-
improving faithfulness in
tremely useful
summaries. We see improvements for all mod-
els trained on the filtered set (桌子 4, 底部)
compared to their counterparts trained on the full
training set (桌子 4, 顶部), when evaluated us-
ing ENTPREC and by humans for faithfulness. 我们
don’t observe similar improvements in entailment.
Contrary to findings in Maynez et al. (2020), 我们的
results suggest that the entailment scores are not
a reliable indicator of faithfulness for documents
with extractive reference entity chains.
The drop-prompt mechanism is also very pow-
erful in improving faithfulness. Irrespective of
which training data were used to train the models
and which test sets they were evaluated on, 我们
see improvements in entailment scores, ENTPREC,
and the human assessment of faithfulness across
the board, except for a single case where the en-
tailment score slightly drops from 0.465 到 0.453.
数字 6 demonstrates how we drop hallucinated
entities ‘Liam’, ‘two’, and ‘Conor’ from entity
chains to enforce models to generate faithful sum-
maries grounded to the modified entity chains.
We achieve the best performance in terms of
ENTPREC and the human assessment of faithfulness
when both the data filtering and the drop-prompt
mechanism were used. We achieve 0.943 为了
ENTPREC and 4.41 for faithfulness for the test
set with extractive entity chains only, 和 0.826
for ENTPREC and 3.85 for faithfulness for the test
set with non-extractive entity chains. Humans also
found that the predictions from these models were
the best in terms of overall summary quality.11
最后, we carried out pairwise comparisons
for human assessments for faithfulness and over-
all summary quality for all models (using a
11The extractive systems (LEAD and EXT-ORACLE, 报道
表中 2) will have perfect ENTPREC scores and will always
be faithful to the document. 然而, it is not worth evaluating
them by humans on XSum. These extractive systems are
highly inferior to abstractive systems in terms of ROUGE; 甚至
the best extractive system (EXT-ORACLE) gets ROUGE scores
的 28.81/8.61/21.97, far below than 47.80/25.06/39.76 为了
FROST (ECPP), on the full test set.
数字 7: An example of generating summaries with
topical and style diversity using modified entity
prompts cmod on XSum.
one-way ANOVA with post-hoc Tukey HSD
测试; p < 0.01). Interestingly, differences among
all model pairs for both faithfulness and overall
summary quality are insignificant when evalu-
ated on the test set with extractive reference
entity chains only. On the more challenging
test set with non-extractive entity chains, FROST
(ECPP) trained on the filtered training set and with
the drop-prompt mechanism is significantly bet-
ter than all other models except for (i) FROST
(ECPP) trained on the filtered training set but with-
out the drop-prompt mechanism and (ii) FROST
(ECPP) trained on the original training set and with
the drop-prompt mechanism, for both faithfulness
and overall summary quality. All other pairwise
differences are insignificant.
5.4 Generating Diverse Summaries
FROST provides a handle to easily control or ma-
nipulate content plan for predicted summaries. In
Figure 6, we saw how we can use this to con-
trol entity-level hallucinations, but the strength
of FROST models go beyond this. Figure 7 shows
how FROST models can be effectively used in gen-
erating summaries with different entity focus by
simply modifying the entity prompt. Future work
will focus on how to leverage FROST for synthetic
data generation for training improvements.
1485
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
XSum
CNN/DailyMail
Model
PEGASUS (d → s)
CTRLsum (k; d → s)
FROST (d → c; s)
CTRLsum (koracle; d → s)
PEGASUS (d; coracle → s)
PEGASUS (coracle; d → s)
FROST (d → coracle; s)
Summary
R1/R2/RL
Entity Planning
R1/R2/RL
Specificity
ENTF1
Avg.
Length
Summary
R1/R2/RL
Entity Planning
R1/R2/RL
Specificity
ENTF1
Avg.
Length
47.56/24.87/39.40
–
47.80/25.06/39.76
–
56.58/34.64/49.87
57.60/35.62/51.11
58.24/36.47/52.16
62.15/39.76/56.36
–
64.09/41.07/58.18
–
94.48/75.17/93.32
98.13/79.27/97.58
98.93/80.32/98.91
53.48
–
55.49
–
93.59
97.90
98.59
22.27
–
21.09
–
22.12
22.13
21.80
44.05/21.69/40.98
45.65/22.35/42.50
45.11/22.11/42.01
64.72/40.56/61.02
56.46/33.62/53.51
61.66/38.43/58.75
61.85/38.95/59.00
61.12/46.46/52.40
62.19/48.35/52.53
64.28/49.86/54.96
78.18/67.39/66.17
86.35/80.54/83.76
97.97/96.11/97.72
98.02/96.19/97.96
49.93
51.69
53.22
71.35
82.41
97.43
97.31
68.65
74.46
65.75
71.76
64.84
64.24
63.86
Table 5: Comparison of FROST with encoder-guided control summarization. The results in the top block
are repeated from Table 2 for comparison. The bottom block presents oracle results with access to oracle
keywords (koracle) in CTRLSum or oracle entity promts (coracle) in FROST and PEGASUS. d and s stand
for the input document and the output summary, respectively. All the results are reported on the full
test sets.
5.5 Comparison with Encoder-Guided
Control Summarization
We compare the decoding strategy in FROST to
encoder-guided control summarization systems
(He et al., 2020; Dou et al., 2021). Table 5 presents
our results. In particular, we report on CTRLsum
(He et al., 2020); first, a keyword extraction sys-
tem (BERT-based sequence tagger) is used to
extract keywords (k) from the input document
d, and then, the extracted keywords are encoded
along with the input document (as k; d) to gener-
ate the summary. We also finetune PEGASUS where
the entity chain (c) is encoded along with the in-
put document d (as d; c or c; d). We only report
the oracle results (with coracle) for these models;
like CTRLsum, generating an entity chain c dur-
ing inference will require training an additional
entity chain generator, which is out of scope of
this paper.
There are several advantages of FROST-style
decoding. Unlike encoder-guided control sum-
marization systems, FROST models can be used
in a usual way to generate summaries for input
documents without relying on external systems
to augment them during inference. Additionally,
users can modify the generated entity prompts or
provide their desired entity prompts to control the
generated summaries (see Section 5.3 and 5.4).
To the best of our knowledge, FROST is the first
decoder-prompted control summarization model.
Our results in Table 5 show that the prompt-
ing the decoder with entity prompts are more
effective in generating high-quality and grounded
summaries compared to when entity prompts are
encoded with the input, especially for abstractive
summaries; both PEGASUS versions (d; coracle and
coracle; d) perform inferior to FROST (d → coracle; s)
in terms of summary-level ROUGE, entity-level
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 8: CNN/DailyMail example predictions from
FROST and CTRLSum along with their entity prompts
and keywords, respectively.
ROUGE and ENTF1 on the XSum dataset. CTRL-
sum (koracle; d → s) achieves better ROUGE scores
than FROST (d → coracle; s) on CNN/DailyMail
(64.72/40.56/61.02 vs 61.85/38.95/59.00). This is
not surprising as the oracle keywords koracle in
CTRLSum retain most words from the summary
found in the source document; as such due to the
extractive nature of CNN/DailyMail summaries,
koracle tend to be closer to the surface forms of the
reference summaries (ROUGE scores between koracle
and reference summaries are 52.70/17.37/44.37).
The difference in ROUGE scores narrows down be-
tween CTRLsum and FROST to 45.65/22.35/42.50
1486
vs 45.11/22.11/42.01 with automatically extracted
keywords. FROST outperforms CTRLsum on entity
planning and specificity. It is not clear how well
CTRLsum’s keyword extraction system will gen-
eralize to more abstractive datasets where words
in reference summaries are often not found in the
source document.
Finally, our FROST models work as a better mi-
croplanner and produce concise summaries than
those generated by systems without doing content
planning or when its done on the input side. For
example, the average lengths of CNN/DailyMail
test summaries are 68.65, 74.46, 65.75 and 60.70
tokens for PEGASUS, CTRLSum, FROST, and hu-
mans, respectively. See example predictions com-
paring CTRLSum and FROST in Figure 8.
6 Conclusion
In this work, we proposed the use of entity chains,
both during pretraining and finetuning, to bet-
ter plan and ground the generation of abstractive
summaries. Our approach achieves state-of-the-art
ROUGE results in XSum and SAMSum, and com-
petitive results in CNN/Dailymail. Compared
to other guided summarization models, CTRL-
Sum and GSum, which perform slightly better
in CNN/Dailymail, our approach is drastically
simpler to implement, trains by augmenting the
targets only, utilizes no additional parameters than
the baseline PEGASUS model, and does not rely on
any external systems to augment the inputs during
inference. We further demonstrate that by modify-
ing the entity chain prompts, we can easily control
hallucinations in summaries.
Acknowledgments
We thank the reviewers and the action editor for
their valuable feedback. We would like to thank
Rahul Aralikatte, Ankur Parikh, and Slav Petrov
for their insightful comments. Many thanks also
to Ashwin Kakarla and his team for help with the
human evaluations.
References
Saliha Azzam, Kevin Humphreys, and Robert
Gaizauskas. 1999. Using coreference chains
for text summarization. In Coreference and Its
Applications. https://doi.org/10.3115
/1608810.1608825
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
jointly learning to align and translate. CoRR,
abs/1409.0473.
Regina Barzilay and Michael Elhadad. 1997. Us-
ing lexical chains for text summarization. In
Intelligent Scalable Text Summarization.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. In Proceedings of
the 2019
Conference of the North American Chapter
of the Association for Computational Linguis-
tics: Human Language Technologies, Volume 1
(Long and Short Papers), pages 4171–4186,
Minneapolis, Minnesota. Association for Com-
putational Linguistics.
Bhuwan Dhingra, Manaal Faruqui, Ankur Parikh,
Ming-Wei Chang, Dipanjan Das, and William
Cohen. 2019. Handling divergent reference
texts when evaluating table-to-text generation.
In Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 4884–4895, Florence, Italy. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/P19-1483
Li Dong, Nan Yang, Wenhui Wang, Furu Wei,
Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming
Zhou, and Hsiao-Wuen Hon. 2019, Unified lan-
guage model pre-training for natural language
understanding and generation. In H. Wallach,
H. Larochelle, A. Beygelzimer, F. Alch´e-Buc,
E. Fox, and R. Garnett, editors, Advances in
Neural Information Processing Systems 32,
pages 13042–13054. Curran Associates, Inc.
the 2021 Conference of
Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi,
Zhengbao Jiang, and Graham Neubig. 2021.
framework for guided
GSum: A general
In Pro-
neural abstractive summarization.
ceedings of
the
North American Chapter of
the Associa-
tion for Computational Linguistics: Human
Language Technologies, pages 4830–4842,
Online. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2021.naacl-main.384
Esin Durmus, He He, and Mona Diab. 2020.
FEQA: A question answering evaluation
1487
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
framework for faithfulness assessment in ab-
stractive summarization. In Proceedings of the
58th Annual Meeting of the Association for
Computational Linguistics, pages 5055–5070,
Online. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2020.acl-main.454
Tobias
Falke, Leonardo
F. R. Ribeiro,
Prasetya Ajie Utama, Ido Dagan, and Iryna
Gurevych. 2019. Ranking generated summaries
by correctness: An interesting but challenging
application for natural language inference. In
Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 2214–2220, Florence, Italy. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/P19-1213
Angela Fan, David Grangier, and Michael
Auli. 2018. Controllable abstractive summa-
rization. In Proceedings of the 2nd Workshop
on Neural Machine Translation and Gen-
eration, pages 45–54. Melbourne, Australia.
Association for Computational Linguistics.
Saadia Gabriel, Asli Celikyilmaz, Rahul Jha,
Yejin Choi, and Jianfeng Gao. 2021. GO
factuality
FIGURE: A meta evaluation of
the As-
In Findings of
in summarization.
sociation
for Computational Linguistics:
ACL-IJCNLP 2021, pages 478–487. Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.findings-acl.42
Junxian He, Wojciech Kry´sci´nski, Bryan McCann,
Nazneen Fatema Rajani, and Caiming Xiong.
2020. CTRLsum: Towards generic controllable
text summarization. CoRR, abs/2012.04281.
Karl Moritz Hermann, Tomas Kocisky, Edward
Grefenstette, Lasse Espeholt, Will Kay,
Mustafa Suleyman, and Phil Blunsom. 2015.
Teaching machines to read and comprehend.
In C. Cortes, N. D. Lawrence, D. D. Lee,
M. Sugiyama, and R. Garnett, editors, Advances
in Neural Information Processing Systems 28,
pages 1693–1701. Curran Associates, Inc.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural Computation,
https://doi.org/10
9(8):1735–1780.
.1162/neco.1997.9.8.1735, Pubmed:
9377276
Xinyu Hua and Lu Wang. 2020. PAIR: Planning
and iterative refinement in pre-trained trans-
formers for long text generation. In Proceedings
of the 2020 Conference on Empirical Meth-
ods in Natural Language Processing (EMNLP),
pages 781–793, Online. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2020.emnlp-main.57
Karen Sparck Jones. 1993. What might be in a
summary? Information Retrieval, pages 9–26.
Urvashi Khandelwal, Kevin Clark, Dan Jurafsky,
and Lukasz Kaiser. 2019. Sample efficient
text summarization using a single pre-trained
transformer. CoRR, abs/1905.08836.
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and
Aleksander Wawer. 2019. SAMSum corpus: A
human-annotated dialogue dataset for abstrac-
tive summarization. In Proceedings of the 2nd
Workshop on New Frontiers in Summarization,
pages 70–79, Hong Kong, China. Association
for Computational Linguistics. https://
doi.org/10.18653/v1/D19-5409
Chlo´e Kiddon, Luke Zettlemoyer, and Yejin Choi.
2016. Globally coherent text generation with
neural checklist models. In Proceedings of the
2016 Conference on Empirical Methods in Nat-
ural Language Processing, pages 329–339,
Austin, Texas. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D16-1032
and Ming-Wei Chang.
Kelvin Guu, Kenton Lee, Zora Tung, Panupong
Pasupat,
2020.
REALM: Retrieval-augmented language model
pre-training. In Proceedings of the 37th In-
ternational Conference on Machine Learning.
PMLR.
Anastassia Kornilova and Vladimir Eidelman.
2019. BillSum: A corpus for automatic sum-
marization of US legislation. In Proceedings of
the 2nd Workshop on New Frontiers in Sum-
marization, pages 48–56, Hong Kong, China.
Association for Computational Linguistics.
M. A. K. Halliday and Ruqaiya Hasan. 1976.
Cohesion in English. Longman. London.
Wojciech Kryscinski, Bryan McCann, Caiming
Xiong, and Richard Socher. 2020. Evaluating the
1488
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
factual consistency of abstractive text summa-
rization. In Proceedings of the 2020 Conference
on Empirical Methods in Natural Language
Processing (EMNLP), pages 9332–9346, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.emnlp-main.750
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Levy, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
translation, and comprehension. In Proceed-
ings of
the
Association for Computational Linguistics,
pages 7871–7880, Online. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/2020.acl-main.703
the 58th Annual Meeting of
Chin-Yew Lin and Eduard Hovy. 2003. Auto-
matic evaluation of summaries using n-gram
In Proceedings of
co-occurrence statistics.
the 2003 Human Language Technology Con-
the North American Chapter of
ference of
the Association for Computational Linguistics,
pages 150–157.
Hans Peter Luhn, USA. 1958. The automatic
creation of literature abstracts. IBM Journal
of Research and Development, 2(2):159–165.
https://doi.org/10.1147/rd.22.0159
William C. Mann and Sandra A. Thompson.
1988. Rhetorical Structure Theory: Toward a
functional theory of text organization. Text,
8(3):243–281.
Yuning Mao, Xiang Ren, Heng Ji, and Jiawei Han.
2020. Constrained abstractive summarization:
Preserving factual consistency with constrained
generation. CoRR, abs/2010.12723.
Lara J. Martin, Prithviraj Ammanabrolu, Xinyu
Wang, William Hancock, Shruti Singh, Brent
Harrison, and Mark O. Riedl. 2018. Event
representations for automated story generation
with deep neural nets. In Proceedings of the
Thirty-Second AAAI Conference on Artificial
Intelligence, (AAAI-18), the 30th innovative Ap-
plications of Artificial Intelligence (IAAI-18),
and the 8th AAAI Symposium on Educational
Advances in Artificial Intelligence (EAAI-18),
New Orleans, Louisiana, USA, February 2–7,
2018, pages 868–875. AAAI Press.
Joshua Maynez, Shashi Narayan, Bernd Bohnet,
and Ryan McDonald. 2020. On faithfulness
summariza-
and factuality in abstractive
the 58th Annual
In Proceedings of
tion.
Meeting of
the Association for Computa-
tional Linguistics, pages 1906–1919, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.acl-main.173
In Proceedings of
Kathleen McKeown and Dragomir R. Radev.
1995. Generating summaries of multiple news
the 18th An-
articles.
nual International ACM SIGIR Conference
in Informa-
on Research and Development
tion Retrieval, SIGIR’95, pages 74–82, New
York, NY, USA. Association for Computing
Machinery. https://doi.org/10.1145
/215206.215334
Rada Mihalcea and Paul Tarau. 2004. TextRank:
Bringing order into text. In Proceedings of
the 2004 Conference on Empirical Methods in
Natural Language Processing, pages 404–411,
Barcelona, Spain. Association for Computa-
tional Linguistics.
Shashi Narayan, Shay B. Cohen, and Mirella
Lapata. 2018. Don’t give me the details, just
the summary! Topic-aware convolutional neu-
ral networks for extreme summarization. In
Proceedings of the 2018 Conference on Empir-
ical Methods in Natural Language Processing,
pages 1797–1807, Brussels, Belgium. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D18-1206
Shashi Narayan, Gonc¸alo Sim˜oes, Ji Ma, Hannah
Craighead, and Ryan T. McDonald. 2020.
QURIOUS: Question generation pretraining for
text generation. CoRR, abs/2004.11026.
Ramakanth Pasunuru and Mohit Bansal. 2018.
Multi-reward reinforced summarization with
saliency and entailment. In Proceedings of
the 2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
Volume 2 (Short Papers), pages 646–653,
New Orleans, Louisiana. Association for
Computational Linguistics.
1489
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Ratish Puduppully, Li Dong, and Mirella Lapata.
2019. Data-to-text generation with content
selection and planning. Proceedings of
the
AAAI Conference on Artificial Intelligence,
33(1):6908–6915. https://doi.org/10
.1609/aaai.v33i01.33016908
Weizhen Qi, Yu Yan, Yeyun Gong, Dayiheng
Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang,
and Ming Zhou. 2020. ProphetNet: Predict-
ing future n-gram for sequence-to-Sequence-
Pre-training. In Findings of the Association
for Computational Linguistics: EMNLP 2020,
pages 2401–2410, Online. Association for
Computational Linguistics.
Alec Radford, Karthik Narasimhan, Tim Salimans,
and Ilya Sutskever. 2018. Improving language
understanding by generative pre-training. Tech-
nical report, OpenAI.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.
2019. Exploring the limits of transfer learning
with a unified text-to-text transformer. CoRR,
abs/1901.07291.
Ehud Reiter and Robert Dale. 1997. Building
applied natural language generation systems.
Natural Language Engineering, 3(1):57–87.
Sascha Rothe, Shashi Narayan, and Aliaksei
Severyn. 2020. Leveraging pre-trained check-
points for sequence generation tasks. Trans-
actions of the Association for Computational
Linguistics, 8:264–280. https://doi.org
/10.1017/S1351324997001502
Abigail See, Peter J. Liu, and Christopher D.
Manning. 2017. Get
to the point: Summa-
rization with pointer-generator networks. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Long Papers), pages 1073–1083,
Vancouver, Canada. Association for Computa-
tional Linguistics.
Noam Shazeer and Mitchell Stern. 2018. Adafac-
tor: Adaptive learning rates with sublinear
memory cost. In International Conference on
Machine Learning, pages 4596–4604. PMLR.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and
Tie-Yan Liu. 2019. MASS: Masked sequence
to sequence pre-training for language genera-
tion. In Proceedings of the 36th International
Conference on Machine Learning, volume 97,
pages 5926–5936. PMLR.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.
2014. Sequence to sequence learning with neu-
ral networks. In Z. Ghahramani, M. Welling,
C. Cortes, N. D. Lawrence, and K. Q. Wein-
berger, editors, Advances in Neural Information
Processing Systems 27, pages 3104–3112.
Curran Associates, Inc.
Erik F. Tjong Kim Sang and Fien De Meulder.
2003. Introduction to the CoNLL-2003 shared
task: Language-independent named entity re-
cognition. In Proceedings of the Seventh Con-
ference on Natural Language Learning at
HLT-NAACL 2003, pages 142–147. https://
doi.org/10.3115/1119176.1119195
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017.
Attention is all you need. In Advances in
Neural Information Processing Systems 30,
pages 5998–6008.
Adina Williams, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through
inference. In Proceedings of the 2018 Con-
ference of
the North American Chapter of
the Association for Computational Linguis-
tics: Human Language Technologies, Volume
1 (Long Papers), pages 1112–1122, New
Orleans, Louisiana. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/N18-1101
Sam Wiseman, Stuart Shieber, and Alexander
Rush. 2018. Learning neural
templates for
text generation. In Proceedings of the 2018
Conference on Empirical Methods in Natu-
ral Language Processing, pages 3174–3187,
Brussels, Belgium. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1356
Lili Yao, Nanyun Peng, Ralph M. Weischedel,
Kevin Knight, Dongyan Zhao, and Rui Yan.
2019. Plan-and-write: Towards better automatic
storytelling. In The Thirty-Third AAAI Con-
ference on Artificial Intelligence, AAAI 2019,
The Thirty-First Innovative Applications of
Artificial Intelligence Conference, IAAI 2019,
1490
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
in Artificial
The Ninth AAAI Symposium on Educational
Intelligence, EAAI
Advances
2019, Honolulu, Hawaii, USA, January 27 –
February 1, 2019, pages 7378–7385. AAAI
Press. https://doi.org/10.1609/aaai
.v33i01.33017378
A Hyperparameters for Pretraining
and Finetuning
Tables 6 and 7 present hyperparameters used for
pretraining and finetuning PEGASUS and FROST base
and large sized models.
Jingqing Zhang, Yao Zhao, Mohammad Saleh,
and Peter J. Liu. 2020. PEGASUS: Pre-training
with extracted gap-sentences for abstractive
summarization. In Proceedings of the 37th In-
ternational Conference on Machine Learning.
PMLR.
B Human Evaluation Instructions
instruc-
Figures 9 and 10 show the exact
tions and the template used by our annotators
for faithfulness and overall summary quality,
respectively.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1491
Model, Size
Learning rate Label smoothing
Init.
Steps Batch size
Corpus
input
target
PEGASUS, base
FROST(F), base
FROST(P+F), base
FROST(P+F), large
0.01
0.01
0.01
0.01
0.1
0.1
0.1
0.1
random
random
PEGASUS (1m)
1.5m
1.5m
0.5m
PEGASUS (1.5m) 1.5m
1024
1024
1024
1024
C4/Hugenews
C4/Hugenews
C4/Hugenews
512
512
512
C4/Hugenews
512
256
256
256
256
Table 6: Hyperparameters used for pretraining PEGASUS and FROST base (223M parameters) and large
(568M parameters) models. See text in Section 5.1 for more details and how these models were ablated.
Lengths (token)
Dataset
Learning rate Label smoothing
Steps Batch size Beam size Beam alpha
input
target
BillSum
CNN/DailyMail
Samsum
XSum
1e-4
1e-4
1e-4
1e-4
0.1
0.1
0.1
0.1
200k
175k
20k
100k
256
256
256
256
8
8
8
8
0.8
0.8
0.8
0.8
1024
1024
512
512
256
256
128
128
Table 7: Hyperparameters used for finetuning PEGASUS and FROST models on summarization datasets.
Lengths (token)
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
3
8
1
9
7
9
3
4
8
/
/
t
l
a
c
_
a
_
0
0
4
3
8
p
d
.
Figure 9: Instructions for human evaluations for faithfulness.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 10: Instructions for human evaluations for overall quality of summaries.
1492