oLMpics-On What Language Model Pre-training Captures
Alon Talmor1,2 Yanai Elazar1,3 Yoav Goldberg1,3
Jonathan Berant1,2
1The Allen Institute for AI
2Tel-Aviv University
3Bar-Ilan University
{alontalmor@mail,joberant@cs}.tau.ac.il
{yanaiela,yoav.goldberg}@gmail.com
抽象的
Recent success of pre-trained language models
(LMs) has spurred widespread interest in the
language capabilities that they possess. 如何-
曾经, efforts to understand whether LM repre-
sentations are useful for symbolic reasoning
tasks have been limited and scattered. 在这个
工作, we propose eight reasoning tasks, 哪个
conceptually require operations such as com-
parison, conjunction, and composition. A fun-
damental challenge is to understand whether
the performance of a LM on a task should
be attributed to the pre-trained representations
or to the process of fine-tuning on the task
数据. To address this, we propose an eval-
uation protocol that includes both zero-shot
评估 (no fine-tuning), as well as com-
paring the learning curve of a fine-tuned LM
to the learning curve of multiple controls,
which paints a rich picture of the LM capabil-
实体. Our main findings are that: (A) 不同的
LMs exhibit qualitatively different reasoning
能力, 例如, ROBERTA succeeds in reason-
ing tasks where BERT fails completely; (乙)
LMs do not reason in an abstract manner and
are context-dependent, 例如, while ROBERTA
can compare ages, it can do so only when the
ages are in the typical range of human ages;
(C) On half of our reasoning tasks all models
fail completely. Our findings and infrastruc-
ture can help future work on designing new
datasets, 型号, and objective functions for
pre-training.
1 介绍
Large pre-trained language models (LMs) 有
revolutionized the field of natural language pro-
cessing in the last few years (Dai and Le, 2015;
Peters et al., 2018A; 杨等人。, 2019; 雷德福
等人。, 2019; Devlin et al., 2019). This has insti-
743
gated research exploring what is captured by the
contextualized representations that
these LMs
compute, revealing that they encode substantial
amounts of syntax and semantics (Linzen et al.,
2016乙; Tenney et al., 2019乙, A; Shwartz and
达甘, 2019; 林等人。, 2019; Coenen et al.,
2019).
Despite these efforts, it remains unclear what
symbolic reasoning capabilities are difficult to
learn from an LM objective only. 在本文中, 我们
propose a diverse set of probing tasks for types of
symbolic reasoning that are potentially difficult to
capture using a LM objective (见表 1). 我们的
intuition is that because a LM objective focuses
on word co-occurrence, it will struggle with tasks
that are considered to involve symbolic reasoning
such as determining whether a conjunction of
properties is held by an object, and comparing
the sizes of different objects. Understanding what
is missing from current LMs may help design
datasets and objectives that will endow models
with the missing capabilities.
然而, how does one verify whether pre-
trained representations hold information that is
useful for a particular task? Past work mostly
resorted to fixing the representations and fine-
tuning a simple, often linear, randomly initialized
probe, to determine whether the representations
hold relevant information (Ettinger et al., 2016;
Adi et al., 2016; Belinkov and Glass, 2019;
Hewitt and Manning, 2019; Wallace et al.,
2019; Rozen et al., 2019; Peters et al., 2018乙;
Warstadt et al., 2019). 然而, it is difficult to
determine whether success is due to the pre-trained
representations or due to fine-tuning itself (Hewitt
and Liang, 2019). To handle this challenge, 我们
include multiple controls that improve our under-
standing of the results.
Our ‘‘purest’’ setup is zero-shot: We cast tasks
in the masked LM format, and use a pre-trained
LM without any fine-tuning. 例如, 给定
计算语言学协会会刊, 卷. 8, PP. 743–758, 2020. https://doi.org/10.1162/tacl 00342
动作编辑器: Hinrich Sch¨utze. 提交批次: 2/2020; 修改批次: 7/2020; 已发表 12/2020.
C(西德:13) 2020 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
We introduce eight tasks that test different types
of reasoning, 如表所示 1.1 We run
experiments using several pre-trained LMs, 基于
on BERT (Devlin et al., 2019) and ROBERTA
(刘等人。, 2019). We find that there are clear
qualitative differences between different LMs
with similar architecture. 例如, ROBERTA-
LARGE (ROBERTA-L) can perfectly solve some
reasoning tasks, such as comparing numbers,
even in a zero-shot setup, whereas other models’
performance is close to random. 然而, 好的
performance is highly context-dependent. Specifi-
卡莉, we repeatedly observe that even when a
model solves a task, small changes to the input
quickly derail it to low performance. 例如,
ROBERTA-L can almost perfectly compare peo-
ple’s ages, when the numeric values are in the
expected range (15–105), but miserably fails if
the values are outside this range. 有趣的是, 它
is able to reliably answer when ages are specified
through the birth year in the range 1920–2000.
This highlights that the LMs’ ability to solve
this task is strongly tied to the specific values
and linguistic context and does not generalize to
arbitrary scenarios. 最后的, we find that in four out
of eight tasks, all LMs perform poorly compared
with the controls.
Our contributions are summarized as follows:
• A set of probes that test whether specific
reasoning skills are captured by pre-trained
LMs.
• An evaluation protocol for understanding
whether a capability is encoded in pre-trained
representations or is learned during fine-
tuning.
• An analysis of skills that current LMs
具有. We find that LMs with similar
architectures are qualitatively different, 那
their success is context-dependent, 然后
often all LMs fail.
• Code and infrastructure for designing and
testing new probes on a large set of pre-
trained LMs. The code and models are avail-
able at http://github.com/alontalmor
/oLMpics.
1Average human accuracy was evaluated by two of the
inter-annotator agreement accuracy was
authors. 全面的
92%.
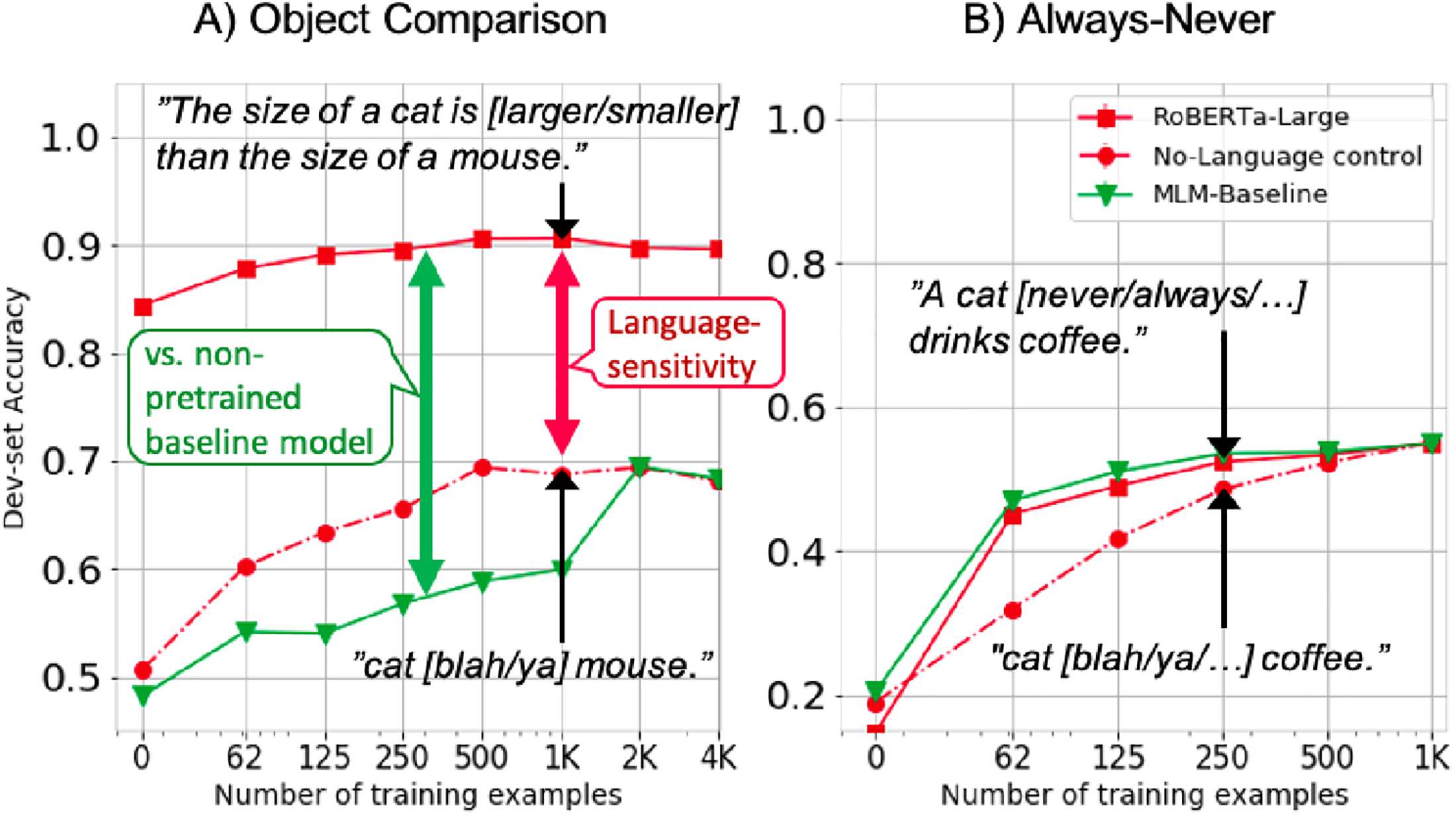
数字 1: Overview of our experimental design. 二
probes are evaluated using learning curves (包括
zero-shot). ROBERTA-L’s (red squares, upper text in
黑色的) accuracy is compared with a NO LANGUAGE
(NO LANG.) 控制 (red circles, lower text in black),
and MLM-BASELINE, which is not pre-trained (绿色的
triangles). 这里, we conclude that the LM representa-
tions are well-suited for task A, whereas in task B the
model is adapting to the task during fine-tuning.
the statement ‘‘A cat is [MASK] than a mouse’’,
an LM can decide if the probability of ‘‘larger’’ is
higher than ‘‘smaller’’ for the a masked word
(数字 1). If a model succeeds without pre-
training over many pairs of objects,
then its
representations are useful for this task. 然而,
if it fails, it could be due to a mismatch between
the language it was pre-trained on and the
language of the probing task (which might be
automatically generated, containing grammatical
错误). 因此, we also compute the learning curve
(数字 1), by fine-tuning with increasing amounts
of data on the already pre-trained masked language
造型 (MLM) output ‘‘head’’, a 1-hidden
layer multilayer perceptron (多层线性规划) on top of the
model’s contextualized representations. A model
that adapts from fewer examples arguably has
better representations for it.
而且, to diagnose whether model perfor-
mance is related to pre-training or fine-tuning, 我们
add controls to every experiment (人物 1, 2).
第一的, we add a control that makes minimal use
of language tokens, 那是, ‘‘cat [MASK] mouse’’
(NO LANG. 图中 1). If a model succeeds given
minimal use of language, the performance can
be mostly attributed to fine-tuning rather than to
the pre-trained language representations. 相似的
logic is used to compare against baselines that
are not pre-trained (except for non-contextualized
word embeddings). 全面的, our setup provides a
rich picture of whether LM representations help
in solving a wide range of tasks.
744
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
例子
Setup
MC-MLM A chicken [MASK] has horns. A. never B. rarely C. sometimes D. often E. always
MC-MLM A 21 year old person is [MASK] than me in age, If I am a 35 year old person. A. younger B. 较老的
MC-MLM The size of a airplane is [MASK] than the size of a house . A. larger B. 较小
MC-MLM It was [MASK] hot, it was really cold . A. not B. really
MC-QA
Probe name
ALWAYS-NEVER
AGE COMPARISON
OBJECTS COMPARISON
ANTONYM NEGATION
What is usually located at hand and used for writing? A. pen B. spoon C. 电脑
PROPERTY CONJUNCTION
TAXONOMY CONJUNCTION MC-MLM A ferry and a floatplane are both a type of [MASK]. A. vehicle B. airplane C. boat
When did the band where Junior Cony played first form? A. 1978 乙. 1977 C. 1980
ENCYC. COMPOSITION
MULTI-HOP COMPOSITION MC-MLM When comparing a 23, A 38 and a 31 year old, 这 [MASK] is oldest A. second B. first C. 第三
MC-QA
Human1
91%
100%
100%
90%
92%
85%
85%
100%
桌子 1: Examples for our reasoning probes. We use two types of experimental setups, explained in
§2. A. is the correct answer.
2 楷模
We now turn to the architectures and loss functions
used throughout the different probing tasks.
2.1 Pre-trained Language Models
All models in this paper take a sequence of tokens
x = (x1, . . . , xn), and compute contextualized
representations with a pre-trained LM, 那是,
h = ENCODE(X) = (h1, . . . , hn). 具体来说,
we consider: (A) BERT (Devlin et al., 2019), a pre-
trained LM built using the Transformer (Vaswani
等人。, 2017) 建筑学, which consists of a
stack of Transformer layers, where each layer
includes a multi-head attention sublayer and a
feed-forward sub-layer. BERT is trained on large
corpora using the MLM, 那是, the model is
trained to predict words that are masked from
输入; including BERT-WHOLE-WORD-MASKING
(BERT-WWM), which was trained using whole-
word-masking; (乙) ROBERTA (刘等人。, 2019),
which has the same architecture as BERT, 但当时
trained on 10x more data and optimized carefully.
2.2 Probing Setups
We probe the pre-trained LMs using two setups:
multichoice MLM (MC-MLM) and multichoice
question answering (MC-QA). The default setup
is MC-MLM, used for tasks where the answer set
is small, consistent across the different questions,
and each answer appears as a single item in the
word-piece vocabulary.2 The MC-QA setup is
used when the answer set substantially varies
between questions, and many of the answers have
more than one word piece.
2Vocabularies of LMs such as BERT and ROBERTA
contain word-pieces, which are sub-word units that are
frequent in the training corpus. For details see Sennrich
等人. (2016).
MC-MLM Here, we convert the MLM setup
to a multichoice setup (MC-MLM). Specifi-
卡莉, the input to the LM is the sequence x =
([CLS], . . . , xi−1, [MASK], xi+1, . . . , [SEP]),
where a single token xi is masked. 然后, 缺点-
textualized representation hi is passed through a
MC-MLM head where V is the vocabulary, 和
F FMLM is a 1-hidden layer MLP:
l = F FMLM(你好) ε R|V|, p = softmax(m ⊕ l),
where ⊕ is element-wise addition and m ∈
{0, −∞}|V| is a mask that guarantees that the
support of the probability distribution will be
over exactly K ∈ {2, 3, 4, 5} candidate tokens:
the correct one and K − 1 distractors. Training
minimizes cross-entropy loss given the gold
masked token. An input, 例如, ‘‘[CLS] Cats
[MASK] drink coffee [SEP]’’, is passed through
该模型, the contextualized representation of
the masked token is passed through the MC-
MLM head, and the final distribution is over the
vocabulary words ‘‘always’’, ‘‘sometimes’’, 和
‘‘never’’, where the gold token is ‘‘never’’, 在这个
案件.
A compelling advantage of this setup, 就是它
reasonable performance can be obtained without
训练, using the original LM representations
and the already pre-trained MLM head weights
(Petroni et al., 2019).
MC-QA Constructing a MC-MLM probe limits
the answer candidates to a single token from the
word-piece vocabulary. To relax this we use in two
tasks the standard setup for answering multichoice
questions with pre-trained LMs (Talmor et al.,
2019; Mihaylov et al., 2018). Given a question q
and candidate answers a1, . . . , aK, we compute
for each candidate answer ak representations h(k)
from the input tokens ‘‘[CLS] q [SEP] ak
[SEP]’’. Then the probability over answers is
obtained using the multichoice QA head:
我(k) = F FQA(H(k)
1 ), p = softmax(我(1), . . . , 我(K)),
745
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
where F FQA is a 1-hidden layer MLP that is
run over the [CLS] (第一的) token of an answer
candidate and outputs a single logit. 注意
in this setup that parameters of F FQA cannot be
initialized using the original pre-trained LM.
2.3 Baseline Models
To provide a lower bound on the performance
of pre-trained LMs, we introduce two baseline
models with only non-contextualized representa-
系统蒸发散.
MLM-BASELINE This serves as a lower-bound
for the MC-MLM setup. The input to F FMLM(·)
is the hidden representation h ∈ R1024 (for large
型号). To obtain a similar architecture with non-
contextualized representations, we concatenate
the first 20 tokens of each example, representing
each token with a 50-dimensional GLOVE vector
(Pennington et al., 2014), and pass this 1000-
dimensional representation of the input through
F FMLM, exactly like in MC-MLM. In all probes,
phrases are limited to 20 代币. If there are less
比 20 tokens in the input, we zero-pad the input.
MC-QA Baseline This serves as a lower-bound
for MC-QA. We use the ESIM architecture over
GLOVE representations, which is known to provide
a strong model when the input
is a pair of
text fragments (陈等人。, 2017). We adapt
the architecture to the multichoice setup using
the procedure proposed by Zellers et al. (2018).
Each phrase and candidate answer are passed
as a list of token ‘[CLS] 短语 [SEP]
回答 [SEP]’ to the LM. The contextualized
representation of the [CLS] token is linearly
projected to a single logit. The logits for candidate
answers are passed through a softmax layer to
obtain probabilities, and the argmax is selected as
the model prediction.
resentations and what was learned during fine-
tuning. 因此, 理想地, one should test LMs using
the pre-trainedweights without fine-tuning (扁豆
等人。, 2016A; Goldberg, 2019). The MC-MLM set-
向上, which uses a pre-trained MLM head, achieves
exactly that. One only needs to design the task
as a statement with a single masked token and
K possible output tokens. 例如, in AGE-
COMPARE, we chose the phrasing ‘‘A AGE-1 year
old person is [MASK] than me in age, If I am
a AGE-2 year old person.’’, where AGE-1 and
AGE-2 are replaced with different integers, 和
possible answers are ‘‘younger’’ and ‘‘older’’.
否则, no training is needed, and the original
representations are tested.
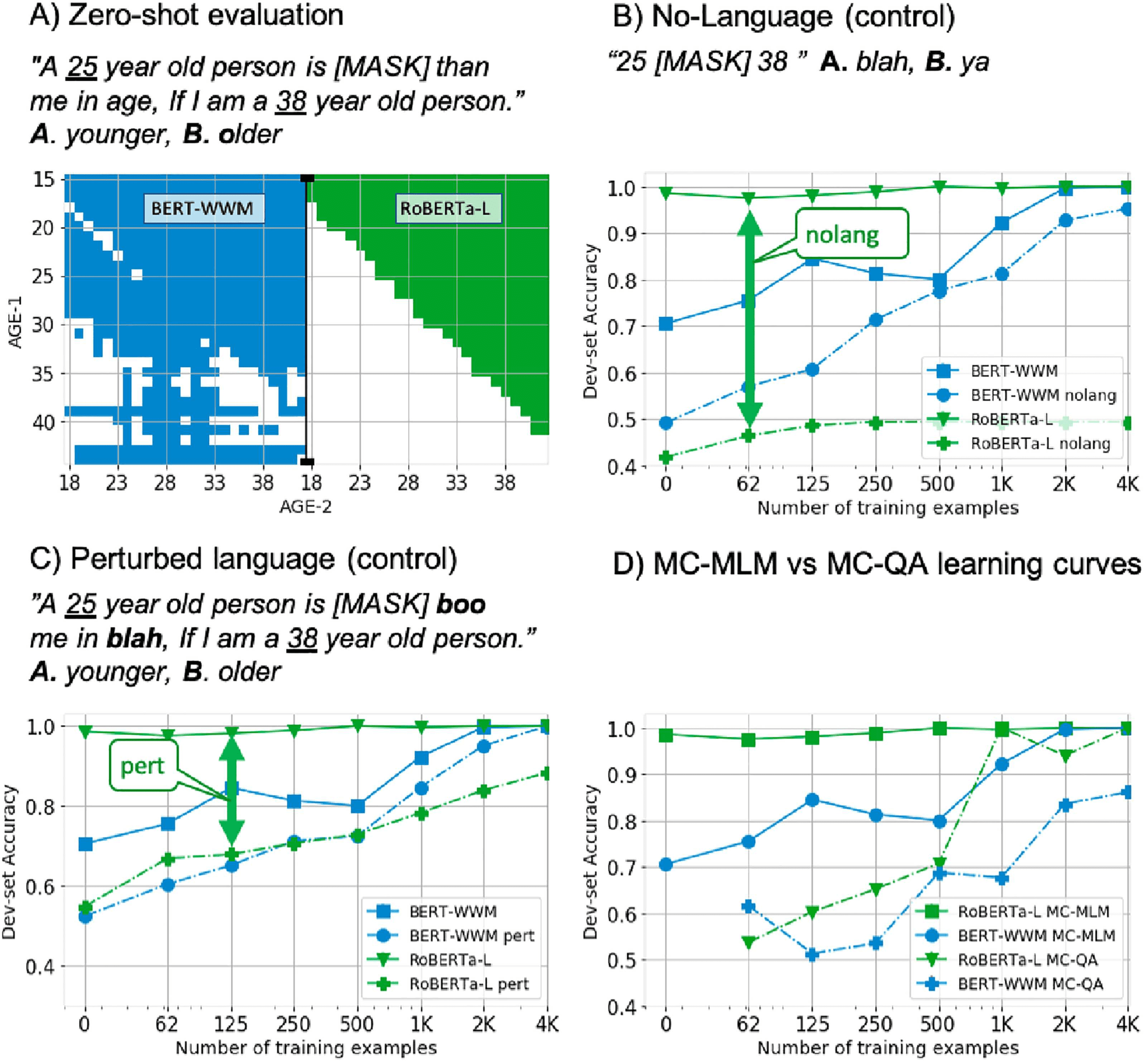
Figure 2A provides an example of such zero-
shot evaluation. Different values are assigned to
AGE-1 and AGE-2, and the pixel is colored
when the model predicts ‘‘younger’’. Accuracy
(acc.) is measured as the proportion of cases when
the model output is correct. The performance
of BERT-WWM, is on the left (蓝色的), 和的
ROBERTA-L on the right (绿色的). The results in
Figure 2A and Table 2 show that ROBERTA-L
compares numbers correctly (98% acc.), BERT-
WWM achieves higher than random acc. (70%
acc.), while BERT-L is random (50% acc.). 这
performance of MLM-BASELINE is also random, 作为
the MLPMLM weights are randomly initialized.
We note that picking the statement for each
task was done through manual experimentation.
We tried multiple phrasings (Jiang et al., 2019)
and chose the one that achieves highest average
zero-shot accuracy across all tested LMs.
A case in point …
因此, if a model performs well, one can infer
that it has the tested reasoning skill. 然而,
failure does not entail that the reasoning skill is
丢失的, as it is possible that there is a problem
with the lexical-syntactic construction we picked.
3 Controlled Experiments
3.2 Learning Curves
We now describe the experimental design and
controls used to interpret the results. We use the
AGE-COMPARE task as a running example, 在哪里
models need to compare the numeric value of
年龄.
3.1 Zero-shot Experiments with MC-MLM
Fine-tuning pre-trained LMs makes it hard to
disentangle what is captured by the original rep-
Despite the advantages of zero-shot evaluation,
performance of a model might be adversely
affected by mismatches between the language the
pre-trained LM was trained on and the language
of the examples in our tasks (Jiang et al., 2019).
To tackle this, we fine-tune models with a
small number of examples. We assume that if the
LM representations are useful for a task, it will
require few examples to overcome the language
746
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
模型
Zero MLPMLM
LINEAR
LANGSENSE
shot WS MAX WS MAX pert nolang
RoBERTa-L
98
BERT-WWM 70
50
BERT-L
68
RoBERTa-B
49
BERT-B
49
Baseline
98
82
52
75
49
58
100
100
57
91
50
79
97
69
50
69
50
–
100
85
51
84
50
–
31
13
1
24
0
0
51
15
0
25
0
0
桌子 2: AGE-COMPARE results. Accuracy over two
answer candidates (random is 50%). LANGSENSE
are the Language Sensitivity controls, pert is
PERTURBED LANG. and nolang is NO LANG. 这
baseline row is MLM-BASELINE.
For AGE-COMPARE, the solid lines in Figure 2B
illustrate the learning curves of ROBERTA-L and
BERT-WWM, 和表 2 shows the aggregate
统计数据. We fine-tune the model by replacing
AGE-1 and AGE-2 with values between 43 和
120, but test with values between 15 和 38, 到
guarantee that the model generalizes to values
unseen at
training time. 再次, we see that
the representations learned by ROBERTA-L are
already equipped with the knowledge necessary
for solving this task.
3.3 Controls
Comparing learning curves tells us which model
learns from fewer examples. 然而, 因为
highly parameterized MLPs, as used in LMs,
can approximate a wide range of functions, 它
is difficult to determine whether performance is
tied to the knowledge acquired at pre-training
时间, or to the process of fine-tuning itself. 我们
present controls that attempt to disentangle these
two factors.
Are LMs sensitive to the language input?
We are interested in whether pre-trained repre-
sentations reason over language examples. 因此,
a natural control is to present the reasoning task
without language and inspect performance. 如果
learning curve of a model does not change when
the input is perturbed or even mostly deleted, 然后
the model shows low language sensitivity and
the pre-trained representations do not explain the
probe performance. This approach is related to
work by Hewitt and Liang (2019), who proposed
a control task, where the learning curve of a model
is compared to a learning curve when words are
数字 2: An illustration of our evaluation protocol.
We compare ROBERTA-L (绿色的) and BERT-WWM
(蓝色的), controls are in dashed lines and markers are
described in the legends. Zero-shot evaluation on the
top left, AGE-1 is ‘‘younger’’ (彩色的) 与. ‘‘older’’
(in white) than AGE-2.
mismatch and achieve high performance. In most
案例, we train with N ∈ {62, 125, 250, 500, 1K,
2K, 4K} examples. To account for optimization
instabilities, we fine-tune several
times with
different seeds, and report average accuracy across
种子. The representations h are fixed during fine-
tuning, and we only fine-tune the parameters of
MLPMLM.
评估
and Learning-curve Metrics
Learning curves are informative, but inspecting
many learning curves can be difficult. 因此, 我们
summarize them using two aggregate statistics.
We report: (A) MAX, 那是, the maximal accuracy
on the learning curve, used to estimate how well
the model can handle the task given the limited
amount of examples. (乙) The metric WS, 哪个
is a weighted average of accuracies across the
learning curve, where higher weights are given to
points where N is small.3 WS is related to the area
under the accuracy curve, and to the online code
metric, proposed by Yogatama et al. (2019) 和
Blier and Ollivier (2018). The linearly decreasing
weights emphasizes our focus on performance
given little training data, as it highlights what was
encoded by the model before fine-tuning.
3We use the decreasing weights W = (0.23, 0.2, 0.17,
0.14, 0.11, 0.08, 0.07).
747
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
associated with random behavior. We propose
two control tasks:
NO LANGUAGE control We remove all
输入
代币, 除了 [MASK] and the arguments
任务的, 即, the tokens that are necessary
for computing the output. In AGE-COMPARE, 一个
example is reduced to the phrase ‘‘24 [MASK]
55’’, where the candidate answers are the words
‘‘blah’’, for ‘‘older’’, and ‘‘ya’’, for ‘‘younger’’.
If the learning curve is similar to when the full
example is given (low language sensitivity), 然后
the LM is not strongly using the language input.
The dashed lines in Figure 2B illustrate the
learning curves in NO LANG.: ROBERTA-L (绿色的)
shows high language sensitivity, while BERT-
WWM (蓝色的) has lower language sensitivity. 这
suggests it handles this task partially during fine-
tuning. 桌子 2 paints a similar picture, 在哪里
the metric we use is identical to WS, 除了
that instead of averaging accuracies, we average
the difference in accuracies between the standard
model and NO LANG. (rounding negative numbers
to zero). For ROBERTA-L the value is 51, 因为
ROBERTA-L gets almost 100% acc. in the presence
语言的, and is random (50% acc.) 没有
语言.
PERTURBED LANGUAGE control A more targeted
language control, is to replace words that are
central for the reasoning task with nonsense words.
具体来说, we pick key words in each probe
template, and replace these words by randomly
sampling from a list of 10 words that carry
relatively limited meaning.4 For example,
在
PROPERTY CONJUNCTION, we can replace the word
‘‘and’’ with the word ‘‘blah’’ to get the example
‘‘What is located at hand blah used for writing?’’.
If the learning curve of PERTURBED LANG. is similar
to the original example, then the model does not
utilize the pre-trained representation of ‘‘and’’ to
solve the task, and may not capture its effect on
the semantics of the statement.
Targeted words change from probe to probe.
例如, in AGE-COMPARE, the targeted words
are ‘‘age’’ and ‘‘than’’, resulting in examples like
‘‘A AGE-1 year old person is [MASK] blah me in
和, If i am a AGE-2 year old person.’’ Figure 2C
shows the learning curves for ROBERTA-L and
BERT-WWM, where solid lines corresponds to
the original examples and dashed lines are the
4The list of substitutions is: ‘‘blah’’, ‘‘ya’’, ‘‘foo’’,
‘‘snap’’, ‘‘woo’’, ‘‘boo’’, ‘‘da’’, ‘‘wee’’, ‘‘foe’’ and ‘‘fee’’.
PERTURBED LANG. 控制. Despite this minor
the performance of ROBERTA-L
perturbation,
substantially decreases, implying that the model
needs the input. 反过来, BERT-WWM perfor-
mance decreases only moderately.
Does a linear transformation suffice? In MC-
MLM, the representations h are fixed, 并且只有
the pre-trained parameters of MLPMLM are fine-
tuned. As a proxy for measuring ‘‘how far” 这
representations are from solving a task, we fix
the weights of the first layer of MLPMLM, 和
only train the final layer. Succeeding in this setup
means that only a linear transformation of h is
必需的. 桌子 2 shows the performance of this
setup (LINEAR), compared with MLPMLM.
Why is MC-MLM preferred over MC-QA?
Figure 2D compares the learning curves of MC-
MLM and MC-QA in AGE-COMPARE. Because in
MC-QA, the network MLPQA cannot be initialized
by pre-trained weights, zero-shot evaluation is
not meaningful, and more training examples are
needed to train MLPQA. 仍然, the trends observed
in MC-MLM remain, with ROBERTA-L achieving
best performance with the fewest examples.
4 The oLMpic Games
We now move to describe the research questions
and various probes used to answer these questions.
For each task we describe how it was constructed,
show results via a table as described in the controls
部分, and present an analysis.
Our probes are mostly targeted towards
symbolic reasoning skills (桌子 1). We examine
the ability of
language models to compare
numbers, to understand whether an object has
a conjunction of properties, to perform multi-hop
composition of facts, 除其他外. 然而,
since we generate examples automatically from
existing resources, some probes also require
background knowledge, such as sizes of objects.
而且, as explained in §3.1, we test models
on a manually-picked phrasing that might interact
with the language abilities of the model. 因此,
when a model succeeds this is evidence that
it has the necessary skill, but failure could be
attributed to issues with background knowledge
and linguistic abilities as well. In each probe,
we will explicitly mention what knowledge and
language abilities are necessary.
748
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
4.1 Can LMs perform robust comparison?
Comparing two numeric values requires repre-
senting the values and performing the comparison
运营. In §3 we saw the AGE-COMPARE task,
in which ages of two people were compared. 我们
found that ROBERTA-L and to some extent BERT-
WWM were able to handle this task, performing
well under the controls. We expand on this to
related comparison tasks and perturbations that
assess the sensitivity of LMs to the particular
context and to the numerical value.
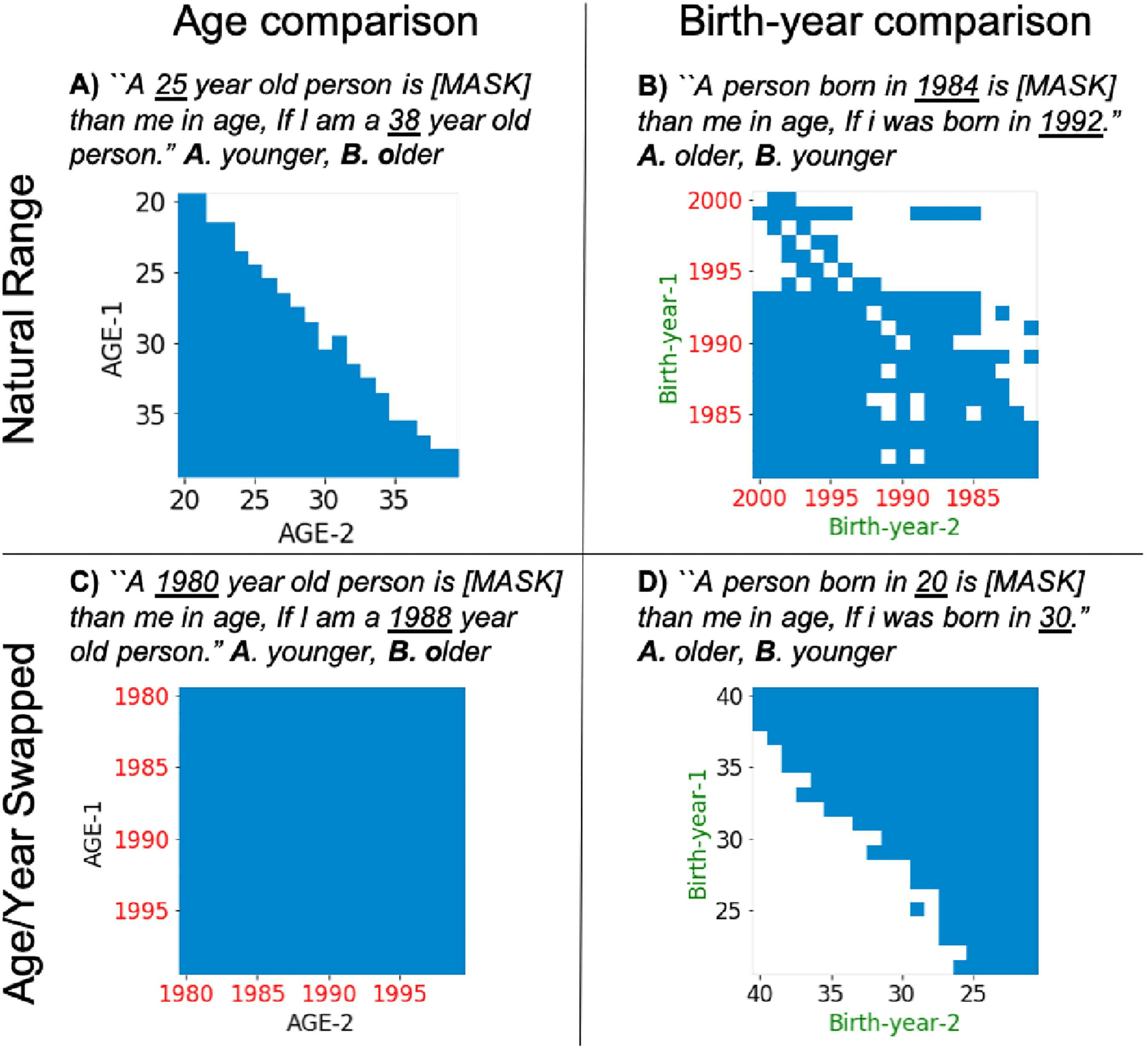
Is ROBERTA-L comparing numbers or ages?
ROBERTA-L obtained zero-shot acc. 的 98% 在
AGE-COMPARE. But is it robust? We test this using
perturbations to the task and present the results in
数字 3. Figure 3A corresponds to the experiment
from §3, where we observed that ROBERTA-L
predicts ‘‘younger’’ (blue pixels) and ‘‘older’’
(white pixels) almost perfectly.
To test whether ROBERTA-L can compare ages
given the birth year rather than the age, 我们使用
statement ‘‘A person born in YEAR-1 is [MASK]
than me in age, If i was born in YEAR-2.’’
Figure 3B shows that it correctly flips ‘‘younger’’
to ‘‘older’’ (76% acc.), reasoning that a person
born in 1980 is older than one born in 2000.
然而, when evaluated on the exact same
statement, but with values corresponding to typical
ages instead of years (Figure 3D), ROBERTA-L
obtains an acc. 的 12%, consistently outputting
the opposite prediction. With ages as values and
not years, it seems to disregard the language,
performing the comparison based on the values
仅有的. We will revisit this tendency in §4.4.
Symmetrically, Figure 3C shows results when
numeric values of ages are swapped with typical
years of birth. ROBERTA-L is unable to handle this,
always predicting ‘‘older’’.5 This emphasizes that
the model is sensitive to the argument values.
Can Language Models compare object sizes?
Comparing physical properties of objects requires
knowledge of the numeric value of the property
and the ability to perform comparison. 以前的
work has shown that such knowledge can be
extracted from text and images (Bagherinezhad
等人。, 2016; Forbes and Choi, 2017; 杨等人。,
2018A; Elazar et al., 2019; Pezzelle and Fern´andez,
5We observed that in neutral contexts models have a
slight preference for ‘‘older’’ over ‘‘younger’’, which could
potentially explain this result.
749
数字 3: AGE COMPARISON perturbations. Left side
graphs are age-comparison, right side graphs are age
comparison by birth-year. In the bottom row, the values
of ages are swapped with birth-years and vice versa.
In blue pixels the model predicts ‘‘older’’, in white
‘‘younger’’. (A) is the correct answer.
2019). Can LMs do the same? Probe Construction
We construct statements of the form ‘‘The size
of a OBJ-1 is usually much [MASK] 比
size of a OBJ-2.’’, where the candidate answers
are ‘‘larger’’ and ‘‘smaller’’. To instantiate the
两个物体, we manually sample from a list of
objects from two domains: 动物 (例如. ‘‘camel’’)
and general objects (例如. ‘‘sun’’), and use the
first domain for training and the second for
评估. We bucket different objects based on
the numerical value of their size based on their
median value in DOQ (Elazar et al., 2019), 和
then manually fix any errors. This probe requires
prior knowledge of object sizes and understanding
of a comparative language construction. 全面的,
我们收集了 127 和 35 objects for training
and development, 分别. We automatically
instantiate object slots using objects that are in the
same bucket.
Results ROBERTA-L excels in this task, starting
从 84% acc. in the zero-shot setup and reaching
MAX of 91% (桌子 3). Other models start with
random performance and are roughly on par with
MLM-BASELINE. ROBERTA-L shows sensitivity
to the language, suggesting that the ability to
compare object sizes is encoded in it.
Analysis Table 4 shows results of
running
ROBERTA-L in the zero-shot setup over pairs
of objects, where we sampled a single object
from each bucket. Objects are ordered by their
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
模型
Zero MLPMLM
LINEAR
LANGSENSE
模型
Zero MLPMLM
LINEAR
LANGSENSE
shot WS MAX WS MAX pert nolang
shot WS MAX WS MAX pert nolang
RoBERTa-L
84
BERT-WWM 55
52
BERT-L
56
BERT-B
50
RoBERTa-B
46
Baseline
88
65
56
55
61
57
91
81
66
72
74
74
86
63
53
53
57
–
90
77
56
56
66
–
22
9
5
2
8
2
26
9
4
3
0
1
RoBERTa-L
14
BERT-WWM 10
22
BERT-L
11
BERT-B
15
RoBERTa-B
20
Baseline
44
46
45
44
43
46
55
57
55
56
53
56
26
32
36
30
25
–
41
52
50
52
44
–
3
2
3
3
2
1
5
3
8
8
6
2
桌子 3: Results for the OBJECTS COMPARISON
probe. Accuracy over two answer candidates
(random is 50%).
桌子 5: Results for the ALWAYS-NEVER probe.
Accuracy over five answer candidates (random
是 20%).
nail
pen
laptop
桌子
房子
airplane
城市
sun
nail
pen
laptop
桌子
房子
airplane
城市
sun
–
较小
larger
larger
larger
larger
larger
larger
较小
–
larger
larger
larger
larger
larger
larger
较小
较小
–
larger
larger
larger
larger
larger
较小
较小
larger
–
larger
larger
larger
larger
较小
较小
较小
较小
–
larger
larger
larger
较小
较小
较小
larger
larger
–
larger
larger
较小
较小
较小
较小
较小
larger
–
larger
较小
较小
较小
larger
larger
larger
larger
–
桌子 4: ROBERTA-L Zero-shot SIZE COMP.
预测.
size from small to large. 全面的, ROBERTA-L
correctly predicts ‘‘larger’’ below the diagonal,
and ‘‘smaller’’ above it. 有趣的是, errors are
concentrated around the diagonal, due to the
more fine-grained differences in sizes, 什么时候
we compare objects to ‘‘sun’’, mostly emitting
‘‘larger’’, ignoring the rest of the statement.
4.2 Do LMs know ‘‘always’’ from ‘‘often’’?
Adverbial modifiers such as ‘‘always’’, ‘‘some-
times’’, or ‘‘never’’, tell us about the quantity or
frequency of events (Lewis, 1975; Barwise and
库珀, 1981). Anecdotally, when ROBERTA-L
predicts a completion for the phrase ‘‘Cats usually
drink [MASK].’’, the top completion is ‘‘coffee’’,
a frequent drink in the literature it was trained on,
rather then ‘‘water’’. 然而, humans know that
‘‘Cats NEVER drink coffee’’. Prior work explored
retrieving the correct quantifier for a statement
(Herbelot and Vecchi, 2015; 王等人。, 2017).
Here we adapt this task to a masked language
模型.
The ‘‘Always-Never’’ task We present state-
评论, such as ‘‘rhinoceros [MASK] have fur’’,
with answer candidates, such as ‘‘never’’ or
‘‘always’’. To succeed, the model must know
the frequency of an event, and map the appropriate
adverbial modifier to that representation. 林-
guistically, the task tests how well the model
predicts frequency quantifiers (or adverbs) 模组-
ifying predicates in different statements (Lepore
and Ludwig, 2007).
Probe Construction We manually craft templates
that contain one slot for a subject and another
for an object, 例如, ‘‘FOOD-TYPE is [MASK]
part of a ANIMAL’s diet.’’ (more examples avail-
able in Table 6). The subject slot is instantiated
the correct semantic type,
with concepts of
according to the isA predicate in CONCEPTNET.
In the example above we will find concepts
that are of type FOOD-TYPE and ANIMAL. 这
object slot
is then instantiated by forming
masked templates of the form ‘‘meat is part of
A [MASK]’s diet.’’ and ‘‘cats have [MASK].’’ and
letting BERT-L produce the top-20 completions.
We filter out completions that do not have
the correct semantic type according to the isA
predicate. 最后, we crowdsource gold answers
using Amazon Mechanical Turk. Annotators were
presented with an instantiated template (与
masked token removed), such as ‘‘Chickens have
horns.’’ and chose the correct answer from 5
candidates: ‘‘never’’, ‘‘rarely’’, ‘‘sometimes’’,
‘‘often’’, and ‘‘always’’.6 We collected 1,300
examples with 1,000 used for training and 300
for evaluation.
We note that some examples in this probe are
similar to OBJECTS COMPARISON (线 4 表中 5).
然而, the model must also determine if sizes
can be overlapping, which is the case in 56% 的
the examples.
Results Table 5 shows the results, 其中随机
accuracy is 20%, and majority vote accuracy is
35.5%. In the zero-shot setup, acc. is less than
random. In the MLPMLM and LINEAR setup acc.
reaches a maximum of 57% in BERT-L, 但
6The class distribution over the answers is ‘‘never’’:
24%, ‘‘rarely’’: 10%, ‘‘sometimes’’: 34%, ‘‘often’’: 7%, 和
‘‘always’’: 23%.
750
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
问题
A dish with pasta [MASK] contains pork .
stool is [MASK] placed in the box .
A lizard [MASK] has a wing .
A pig is [MASK] smaller than a cat .
meat is [MASK] part of a elephant’s diet .
A calf is [MASK] larger than a dog .
Answer
有时
never
never
rarely
never
有时
Distractor Acc.
有时
有时
always
always
有时
经常
75
68
61
47
41
30
桌子 6: Error analysis for ALWAYS-NEVER. 模型
predictions are in bold, and Acc. shows acc. 每
template.
MLM-BASELINE obtains similar acc.,
implying
that the task was mostly tackled at fine-tuning
时间, and the pre-trained representations did not
contribute much. Language controls strengthen
this hypothesis, where performance hardly drops
in the PERTURBED LANG. control and slightly drops
in the NO LANG. 控制. Figure 1B compares the
learning curve of ROBERTA-L with controls. MLM-
BASELINE consistently outperforms ROBERTA-L,
which display only minor language sensitivity,
suggesting that pre-training is not effective for
solving this task.
Analysis We generated predictions from the
best model, BERT-WWM, and show analysis
results in Table 6. For reference, we only selected
examples where human majority vote led to the
correct answer, and thus the majority vote is near
100% on these examples. Although the answers
‘‘often’’ and ‘‘rarely’’ are the gold answer in 19%
of the training data, the LMs predict these answers
in less than 1% of examples. In the template ‘‘A
dish with FOOD-TYPE [MASK] contains FOOD-
TYPE.’’ the LM always predicts ‘‘sometimes’’.
全面的, we find models do not perform well.
Reporting bias (Gordon and Van Durme, 2013)
may play a role in the inability to correctly
determine that ‘‘A rhinoceros NEVER has fur.’’
有趣的是, behavioral research conducted on
blind humans shows they exhibit a similar bias
(Kim et al., 2019).
4.3 Do LMs Capture Negation?
理想情况下, the presence of the word ‘‘not’’ should
affect the prediction of a masked token. 然而,
Several recent works have shown that LMs do
not take into account the presence of negation
in sentences (Ettinger, 2019; Nie et al., 2020;
Kassner and Sch¨utze, 2020). 这里, we add to this
文学, by probing whether LMs can properly
use negation in the context of synonyms vs.
antonyms.
751
模型
Zero MLPMLM
LINEAR
LANGSENSE
shot WS MAX WS MAX pert nolang
RoBERTa-L
75
BERT-WWM 57
51
BERT-L
52
BERT-B
57
RoBERTa-B
47
Baseline
85
70
70
68
74
67
91
81
82
81
87
80
77
61
58
59
63
–
84
73
74
74
78
–
14
5
5
2
10
0
21
6
9
9
16
0
桌子 7: Results for the ANTONYM NEGATION
probe. Accuracy over two answer candidates
(random is 50%).
Do LMs Capture the Semantics of Antonyms?
In the statement ‘‘He was [MASK] 快速地, 他是
very slow.’’, [MASK] should be replaced with
‘‘not’’, since ‘‘fast’’ and ‘‘slow’’ are antonyms.
反过来, in ‘‘He was [MASK] 快速地, 他是
very rapid’’, the LM should choose a word like
‘‘very’’ in the presence of the synonyms ‘‘fast’’
and ‘‘rapid’’. An LM that correctly distinguishes
between ‘‘not’’ and ‘‘very’’, demonstrates knowl-
edge of the taxonomic relations as well as the
ability to reason about the usage of negation in
这个上下文.
Probe Construction We sample synonym and
antonym pairs from CONCEPTNET (Speer et al.,
2017) and WORDNET (Fellbaum, 1998), and use
Google Books Corpus to choose pairs that occur
frequently in language. We make use of the state-
ments introduced above. Half of the examples
are synonym pairs and half antonyms, generat-
英 4,000 training examples and 500 for evalu-
化. Linguistically, we test whether the model
appropriately predicts a negation vs. intensifica-
tion adverb based on synonymy/antonymy rela-
tions between nouns, adjectives and verbs.
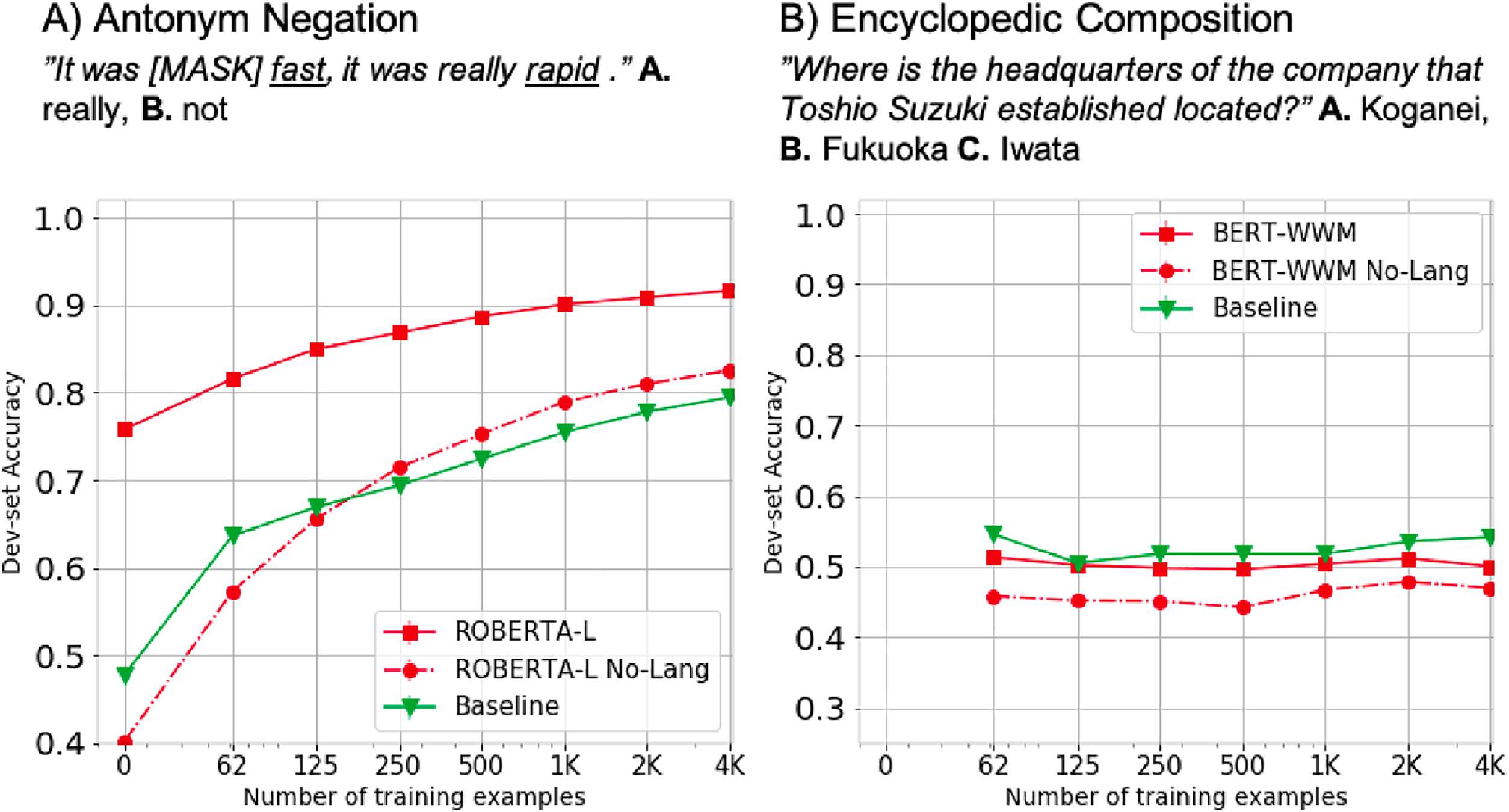
Results ROBERTA-L shows higher than chance
acc. 的 75% in the zero-shot setting, as well as high
Language Sensitivity (桌子 7). MLM-BASELINE,
equipped with GloVe word embeddings, is able to
reach a comparable WS of 67 and MAX of 80%,
suggesting they do not have a large advantage on
this task.
4.4 Can LMs handle conjunctions of facts?
We present two probes where a model should
understand the reasoning expressed by the word
和.
conjunction CONCEPTNET
财产
A
Knowledge-Base that describes the properties of
millions of concepts through its (主题,
是
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
模型
LEARNCURVE
LANGSENSE
WS MAX
pert
nolang
RoBERTa-L
49
BERT-WWM 46
48
BERT-L
47
BERT-B
40
RoBERTa-B
39
Baseline
87
80
75
71
57
49
2
0
2
2
0
0
4
1
5
1
0
0
桌子 8: Results for the PROPERTY CONJUNCTION
probe. Accuracy over three answer candidates
(random is 33%).
predicate, 目的) 三元组. 我们
使用
CONCEPNET to test whether LMs can find concepts
for which a conjunction of properties holds. 为了
例子, we will create a question like ‘‘What is
located in a street and is related to octagon?’’,
is ‘‘street sign’’.
where the correct answer
Because answers are drawn from CONCEPTNET,
they often consist of more than one word-piece,
thus examples are generated in the MC-QA setup.
Probe Construction To construct an example, 我们
first choose a concept that has two properties in
CONCEPTNET, where a property is a (predicate,
目的) pair. 例如, stop sign has
the properties (atLocation,street) 和
(relatedTo, octagon). 然后, we create two
distractor concepts, for which only one prop-
erty holds: car has the property (atLocation,
street), and math has the property (relatedTo,
octagon). Given the answer concept, 迪斯-
tractors and the properties, we can automatically
generate pseudo-langauge questions and answers
by mapping 15 CONCEPTNET predicates to natural
language questions. We split examples such that
concepts in training and evaluation are disjoint.
This linguistic structure tests whether the LM
can answer questions with conjoined predicates,
requiring world knowledge of object and relations.
Results In MC-QA, we fine-tune the entire
network and do not freeze any representations.
Zero-shot cannot be applied because the weights
of MLPQA are untrained. All LMs consistently
improve as the number of examples increases,
reaching a MAX of 57% 到 87% (桌子 8). 这
high MAX results suggest that the LMs generally
have the required pre-existing knowledge. The WS
of most models is slightly higher than the baselines
(49% MAX and 39 WS). Language Sensitivity is
slightly higher than zero in some models. 全面的,
results suggest the LMs do have some capability
in this task, but proximity to baseline results, 和
low language selectivity make it hard to clearly
determine whether it existed before fine-tuning.
To further validate our findings, we construct a
parallel version of our data, where we replace
the word ‘‘and’’ by the phrase ‘‘but not’’.
In this version, the correct answer is the first
distractor in the original experiment, where one
property holds and the other does not. 全面的,
we observe a similar trend (with an increase
in performance across all models): MAX results
are high (79-96%), pointing that the LMs hold
the relevant information, but improvement over
ESIM-Baseline and language sensitivity are low.
For brevity, we omit the detailed numerical results.
Taxonomy conjunction A different operation is
to find properties that are shared by two concepts.
具体来说, we test whether LMs can find the
mutual hypernym of a pair of concepts. 为了
例子, ‘‘A germ and a human are both a type
的 [MASK].’’, where the answer is ‘‘organism’’.
Probe Construction We use CONCEPTNET and
WORDNET to find pairs of concepts and their
hypernyms, keeping only pairs that frequently
appear in the GOOGLE BOOK CORPUS. The example
template is ‘‘A ENT-1 and a ENT-2 are both
a type of [MASK].’’, where ENT-1 and ENT-2
are replaced with entities that have a common
hypernym, which is the gold answer. Distractors
are concepts that are hypernyms of ENT-1, 但
not ENT-2, or vice versa. For evaluation, 我们
keep all examples related to food and animal
taxonomies, 例如, ‘‘A beer and a ricotta
are both a type of [MASK].’’, where the answer
is ‘‘food’’ and the distractors are ‘‘cheese’’ and
‘‘alcohol’’. This phrasing requires the model to
handle conjoined co-hyponyms in the subject
位置, based on lexical relations of hyponymy /
hypernymy between nouns. For training, 我们用
examples from different taxonomic trees, 这样的
that the concepts in the training and evaluation
sets are disjoint.
Results Table 9 shows that models’ zero-shot
acc. is substantially higher than random (33%),
but overall even after fine-tuning acc. is at most
59%. 然而, the NO LANG. control shows some
language sensitivity, suggesting that some models
have pre-existing capabilities.
752
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
模型
Zero MLPMLM
LINEAR
LANGSENSE
模型
LEARNCURVE
LANGSENSE
shot WS MAX WS MAX pert nolang
WS
MAX
pert
nolang
RoBERTa-L
45
BERT-WWM 46
53
BERT-L
47
BERT-B
46
RoBERTa-B
33
Baseline
50
48
54
48
50
33
56
52
57
50
59
47
45
46
53
47
47
–
46
46
54
47
49
–
0
0
0
0
0
1
3
7
15
12
18
2
RoBERTa-L
BERT-WWM
BERT-L
BERT-B
RoBERTa-B
ESIM-Baseline
42
47
45
43
41
49
50
53
51
48
46
54
0
1
1
0
0
3
2
4
4
3
0
0
桌子 9: Results for the TAXONOMY CONJUNCTION
probe. Accuracy over three answer candidates
(random is 33%).
桌子 10: Results for ENCYCLOPEDIC COMPOSITION.
Accuracy over three answer candidates (random
是 33%).
Analysis Analyzing the errors of ROBERTA-L, 我们
found that a typical error is predicting for ‘‘A
crow and a horse are both a type of [MASK].’’
that the answer is ‘‘bird’’, rather than ‘‘animal’’.
具体来说, LMs prefer hypernyms that are closer
in terms of edge distance on the taxonomy tree.
因此, a crow is first a bird, and then an animal.
We find that when distractors are closer to one of
the entities in the statement than the gold answer,
the models will consistently (80%) choose the
distractor, ignoring the second entity in the phrase.
4.5 Can LMs do multi-hop reasoning?
Questions that require multi-hop reasoning, 这样的
as ‘‘Who is the director of
the movie about
a WW2 pacific medic?’’, have recently drawn
注意力 (杨等人。, 2018乙; Welbl et al., 2018;
Talmor and Berant, 2018) as a challenging task
for contemporary models. But do pre-trained LMs
have some internal mechanism to handle such
问题?
To address this question, we create two probes,
one for compositional question answering, 和
the other uses a multi-hop setup, building upon
our observation (§3) that some LMs can compare
年龄.
Encyclopedic composition We construct ques-
tions such as ‘‘When did the band where John
Lennon played first form?’’. Here answers require
multiple tokens, thus we use the MC-QA setup.
Probe Construction We use the following three
模板: (1) ‘‘when did the band where ENT
played first form?’’, (2) ‘‘who is the spouse of the
actor that played in ENT?’’ and (3) ‘‘where is the
headquarters of the company that ENT established
located?’’. We instantiate ENT using information
from WIKIDATA (Vrandeˇci´c and Kr˝otzsch, 2014),
choosing challenging distractors. 例如,
the distractor will be a year
for template 1,
753
数字 4: Learning curves in two tasks. For each task,
the best performing LM is shown alongside the NO
LANG. control and baseline model. (A) is the correct
回答.
close to the gold answer, and for template 3,
it will be a city in the same country as the gold
answer city. This linguistic structure introduces
A (restrictive) relative clauses that requires a)
Correctly resolving the reference of the noun
modified by the relative clause, 乙) Answering
the full question subsequently.
To solve the question, the model must have
knowledge of all single-hop encyclopedic facts
required for answering it. 因此, we first fine-tune
the model on all such facts (例如, ‘‘What company
did Bill Gates establish? Microsoft’’) 从
training and evaluation set, and then fine-tune on
multi-hop composition.
Results Results are summarized in Table 10. 全部
models achieve low acc. in this task, 和
baseline performs best with a MAX of 54%. 兰-
guage sensitivity of all models is small, and MLM-
BASELINE performs slightly better (Figure 4B),
suggesting that the LMs are unable to resolve
compositional questions, but also struggle to learn
it with some supervision.
Multi-hop Comparison Multi-hop reasoning
can be found in many common structures in
自然语言. In the phrase ‘‘When comparing
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
模型
Zero MLPMLM
LINEAR
LANGSENSE
shot WS MAX WS MAX pert nolang
RoBERTa-L
29
BERT-WWM 33
33
BERT-L
32
BERT-B
33
RoBERTa-B
34
Baseline
36
41
32
33
32
35
49
65
35
35
40
48
31
32
31
33
29
–
41
36
34
35
33
–
2
6
0
0
0
1
2
4
3
2
0
0
桌子 11: Results for COMPOSITIONAL COMPARISON.
Accuracy over three answer candidates (random
是 33%).
A 83 year old, A 63 year old and a 56 year old,
这 [MASK] is oldest’’ one must find the oldest
人, then refer to its ordering: 第一的, 第二, 或者
第三.
Probe Construction We use the template above,
treating the ages as arguments, and ‘‘first’’, ‘‘sec-
ond’’, and ‘‘third’’ as answers. Age arguments
are in the same ranges as in AGE-COMPARE. Linguis-
抽搐地, the task requires predicting the subject of
sentences whose predicate is in a superlative form,
where the relevant information is contained in a
‘‘when’’-clause. The sentence also contains nom-
inal ellipsis, also known as fused-heads (Elazar
and Goldberg, 2019).
Results All
three possible answers appear
in ROBERTA-L’s top-10 zero-shot predictions,
indicating that the model sees the answers as viable
choices. Although successful in AGE-COMPARE, 这
performance of ROBERTA-L is poor in this probe
(桌子 11), With zero-shot acc. that is almost
random, WS slightly above random, MAX lower
than MLM-BASELINE (48%), and close to zero
language sensitivity. All LMs seem to be learning
the task during probing. Although BERT-WWM
was able to partially solve the task with a MAX of
65% when approaching 4,000 training examples,
the models do not appear to show multi-step
capability in this task.
5 Medals
We summarize the results of the oLMpic Games in
桌子 12. 一般来说, the LMs did not demonstrate
strong pre-training capabilities in these symbolic
reasoning tasks. BERT-WWM showed partial
success in a few tasks, whereas ROBERTA-L
showed high performance in ALWAYS-NEVER,
OBJECTS COMPARISON and ANTONYM NEGATION, 和
emerges as the most promising LM. 然而,
RoBERTa
大的
BERT BERT RoBERTa BERT
Base
WWM Large
Base
X
X
X
X
ALWAYS-NEVER
AGE COMPARISON
OBJECTS COMPAR.
ANTONYM NEG.
PROPERTY CONJ.
TAXONOMY CONJ.
ENCYC. COMP.
MULTI-HOP COMP.
桌子 12: The oLMpic games medals, 和-
marizing per-task success. X indicate the LM has
achieved high accuracy considering controls and
基线, X–indicates partial success.
when perturbed, ROBERTA-L has failed to demon-
strates consistent generalization and abstraction.
Analysis of correlation with pre-training data
A possible hypothesis for why a particular model
is successful in a particular task might be that the
language of a probe is more common in the corpus
it was pre-trained on. To check that, we compute
the unigram distribution over the training corpus
of both BERT and ROBERTA. We then compute
the average log probability of the development set
under these two unigram distributions for each task
(taking into account only content words). 最后,
we compute the correlation between which model
performs better on a probe (ROBERTA-L vs.
BERT-WWM) and which training corpus induces
higher average log probability on that probe. 我们
find that the Spearman correlation is 0.22, hinting
that the unigram distributions do not fully explain
the difference in performance.
6 讨论
We presented eight different tasks for evaluating
the reasoning abilities of models, alongside an
evaluation protocol for disentangling pre-training
from fine-tuning. We found that even models that
have identical structure and objective functions
differ not only quantitatively but also qualitatively.
具体来说, ROBERTA-L has shown reasoning
abilities that are absent from other models. 因此,
with appropriate data and optimization, 型号
can acquire from an LM objective skills that might
be surprising intuitively.
然而, when current LMs succeed in a
reasoning task, they do not do so through ab-
straction and composition as humans perceive it.
The abilities are context-dependent, if ages are
compared–then the numbers should be typical
年龄. Discrepancies from the training distribution
754
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
lead to large drops in performance. 最后的,
这
performance of LM in many reasoning tasks is
贫穷的.
Our work sheds light on some of the blind spots
of current LMs. We will release our code and
data to help researchers evaluate the reasoning
abilities of models, aid the design of new probes,
and guide future work on pre-training, 客观的
functions and model design for endowing models
with capabilities they are currently lacking.
致谢
This work was completed in partial fulfillment for
the PhD degree of the first author. We thank
our colleagues at The Allen Institute of AI,
especially Kyle Richardson, Asaf Amrami, Mor
Pipek, Myle Ott, Hillel Taub-Tabib, and Reut
Tsarfaty. This research was partially supported
by The Israel Science Foundation grant 942/16,
The Blavatnik Computer Science Research
Fund and The Yandex Initiative for Machine
学习, and the European Union’s Seventh
Framework Programme
(FP7) under grant
agreements no. 802774-ERC-iEXTRACT and no.
802800-DELPHI.
参考
Yossi Adi, Einat Kermany, Yonatan Belinkov,
Ofer Lavi, and Yoav Goldberg. 2016. Fine-
grained analysis of sentence embeddings using
auxiliary prediction tasks. arXiv 预印本
arXiv:1608.04207.
Hessam Bagherinezhad, Hannaneh Hajishirzi,
Yejin Choi, and Ali Farhadi. 2016. Are ele-
phants bigger than butterflies? reasoning about
sizes of objects. In Thirtieth AAAI Conference
on Artificial Intelligence.
Jon Barwise and Robin Cooper. 1981. Generalized
quantifiers and natural language, Philosophy,
语言, and artificial intelligence, 施普林格,
pages 241–301. DOI: https://doi.org
/10.1007/978-94-009-2727-8 10
Yonatan Belinkov and James Glass. 2019. Anal-
ysis methods in neural language processing:
一项调查. 协会的交易
计算语言学, 7:49–72. DOI:
https://doi.org/10.1162/tacl 00254
L´eonard Blier and Yann Ollivier. 2018. The de-
scription length of deep learning models. 在
神经信息处理的进展
系统, pages 2216–2226.
Qian Chen, Xiaodan Zhu, Zhen-Hua Ling, Si Wei,
Hui Jiang, and Diana Inkpen. 2017. Enhanced
LSTM for natural language inference. In Pro-
ceedings of the 55th Annual Meeting of the
计算语言学协会
(体积 1: Long Papers), pages 1657–1668,
Vancouver, 加拿大. Association for Compu-
tational Linguistics. DOI: https://土井
.org/10.18653/v1/P17-1152
Andy Coenen, Emily Reif, Ann Yuan, Been Kim,
Adam Pearce, Fernanda Vi´egas, and Martin
Wattenberg. 2019. Visualizing and measuring
the geometry of BERT. arXiv 预印本 arXiv:
1906.02715.
安德鲁·M. Dai and Quoc V. Le. 2015, Semi-
supervised sequence learning, C. 科尔特斯, 氮. D.
劳伦斯, D. D. 李, 中号. Sugiyama, 和R.
加内特, 编辑, Advances in Neural Informa-
tion Processing Systems 28, pages 3079–3087.
柯伦联合公司, 公司,
J. Devlin, 中号. 张, K. 李, and K. Toutanova.
2019. BERT: Pre-training of deep bidirectional
transformers for language understanding. 在
North American Association for Computational
语言学 (全国AACL).
Yanai Elazar and Yoav Goldberg. 2019. Wheres
my head? 定义, 数据集, and models for
numeric fused-head identification and resolu-
的. Transactions of
the Association for
计算语言学, 7:519–535. DOI:
https://doi.org/10.1162/tacl 00280
Yanai
Elazar, Abhijit Mahabal, Deepak
Ramachandran, Tania Bedrax-Weiss, and Dan
Roth. 2019. How large are lions? inducing
distributions over quantitative attributes. 在
Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 3973–3983, Florence, 意大利. 协会
for Computational Linguistics. DOI: https://
doi.org/10.18653/v1/P19-1388
Allyson Ettinger. 2019. What BERT is not:
Lessons from a new suite of psycholinguistic
diagnostics for language models. arXiv 预印本
arXiv:1907.13528. DOI: https://doi.org
/10.1162/tacl a 00298
755
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Allyson Ettinger, Ahmed Elgohary, and Philip
Resnik. 2016. Probing for semantic evidence
of composition by means of simple classifica-
tion tasks. In Proceedings of the 1st Workshop
on Evaluating Vector-Space Representations
for NLP, pages 134–139. DOI: https://
doi.org/10.18653/v1/W16-2524
C. Fellbaum. 1998. WordNet: An Electronic Lex-
ical Database. 与新闻界. DOI: https://
doi.org/10.7551/mitpress/7287.001
.0001
Maxwell Forbes and Yejin Choi. 2017. 动词
物理: Relative physical knowledge of
actions and objects. 在诉讼程序中
这
55th Annual Meeting of the Association for
计算语言学 (体积 1: 长的
文件), pages 266–276. DOI: https://
doi.org/10.18653/v1/P17-1025
Yoav Goldberg. 2019. Assessing BERT’s syntac-
tic abilities. arXiv 预印本 arXiv:1901.05287.
Jonathan Gordon and Benjamin Van Durme. 2013.
Reporting bias and knowledge acquisition.
在诉讼程序中
这 2013 Workshop on
Automated Knowledge Base Construction,
pages 25–30. ACM.
Aur´elie Herbelot and Eva Maria Vecchi. 2015.
Building a shared world: Mapping distribu-
tional to model-theoretic semantic spaces. 在
诉讼程序 2015 Conference on Em-
pirical Methods in Natural Language Pro-
cessing, pages 22–32. DOI: https://土井
.org/10.18653/v1/D15-1003
John Hewitt and Percy Liang. 2019. 设计
任务.
and interpreting probes with control
这 2019 会议
在诉讼程序中
Empirical Methods
in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 2733–2743. DOI:
https://doi.org/10.18653/v1/D19-1275
John Hewitt and Christopher D. 曼宁. 2019.
A structural probe for finding syntax in word
陈述. In Proceedings of the Con-
ference of
the North American Chapter of
the Association for Computational Linguistics:
人类语言技术, NAACL-HLT,
pages 4129–4138.
Zhengbao Jiang, Frank F. 徐, Jun Araki, 和
Graham Neubig. 2019. How can we know
what language models know? arXiv 预印本
arXiv:1911.12543. DOI: https://doi.org
/10.1162/tacl a 00324
在诉讼程序中
Nora Kassner and Hinrich Sch¨utze. 2020.
Negated and misprimed probes for pretrained
language models: Birds can talk, but cannot
the 58th Annual
fly.
Meeting of the Association for Computational
语言学, pages 7811–7818, 在线的. Asso-
ciation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/2020
.acl-main.698
Judy S. Kim, Giulia V. Elli, and Marina Bedny.
2019. Knowledge of animal appearance among
sighted and blind adults. 诉讼程序
美国国家科学院, 116(23):
11213–11222. DOI: https://doi.org/10
.1073/pnas.1900952116, PMID: 31113884,
PMCID: PMC6561279
Ernest Lepore and Kirk Ludwig. 2007. Donald
Davidson’s truth-theoretic semantics. 牛津
大学出版社. DOI: https://doi.org
/10.1093/acprof:oso/9780199290932
.001.0001
David Lewis. 1975. Adverbs of quantifica-
的. Formal semantics-the essential readings,
178:188. DOI: https://doi.org/10.1002
/9780470758335.ch7
Yongjie Lin, Yi Chern Tan, and Robert Frank.
2019. Open sesame: Getting inside BERTs
linguistic knowledge. 在诉讼程序中
2019 ACL Workshop BlackboxNLP: Analyzing
and Interpreting Neural Networks for NLP,
pages 241–253.
Tal Linzen, Emmanuel Dupoux, and Yoav
Goldberg. 2016A. Assessing the ability of
LSTMs to learn syntax-sensitive dependencies.
处理, 4:521–535. DOI: https://土井
.org/10.1162/tacl a 00115
Tal Linzen, D. Emmanuel, and G. Yoav. 2016乙.
Assessing the ability of LSTMs to learn
syntax-sensitive dependencies. Transactions of
the Association for Computational Linguis-
抽动症 (处理), 4. DOI: https://doi.org
/10.1162/tacl a 00115
756
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. Roberta: A robustly optimized
bert pretraining approach. arXiv 预印本
arXiv:1907.11692.
Todor Mihaylov, Peter Clark, Tushar Khot, 和
Ashish Sabharwal. 2018. Can a suit of armor
conduct electricity? A new dataset for open
book question answering. In EMNLP.
Yixin Nie, Adina Williams, Emily Dinan,
Mohit Bansal, Jason Weston, and Douwe
Kiela. 2020. Adversarial NLI: A new bench-
mark for natural language understanding. 在
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 4885–4901, 在线的. 协会
计算语言学.
J. Pennington, 右. Socher, 和C. D. 曼宁.
2014. GloVe: Global vectors for word re-
presentation. In Empirical Methods in Nat-
(EMNLP),
ural
pages 1532–1543. DOI: https://doi.org
/10.3115/v1/D14-1162
加工
语言
中号. 乙. Peters, 中号. 诺伊曼, 中号.
伊耶尔, 中号.
加德纳, C. 克拉克, K. 李, 和L. Zettlemoyer.
2018A. Deep contextualized word represen-
tations. In North American Association for
计算语言学 (全国AACL). DOI:
https://doi.org/10.18653/v1/N18-1202
Matthew Peters, Mark Neumann,
卢克
Zettlemoyer, and Wen-tau Yih. 2018乙. Dissect-
ing contextual word embeddings: Architecture
和代表. 在诉讼程序中 2018
Conference on Empirical Methods in Natural
语言处理, pages 1499–1509. DOI:
https://doi.org/10.18653/v1/D18-1179
Fabio Petroni, Tim Rockt¨aschel, Sebastian
Riedel,
Patrick Lewis, Anton Bakhtin,
Yuxiang Wu, and Alexander Miller. 2019.
Language models as knowledge bases? 在
诉讼程序 2019 Conference on Em-
pirical Methods
语言
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 2463–2473. DOI:
https://doi.org/10.18653/v1/D19-1250
in Natural
757
上下文.
leveraging visual
Sandro Pezzelle and Raquel Fern´andez. 2019.
Is the red square big? malevic: Modeling
形容词
在
这 2019 会议
会议记录
Empirical Methods
in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 2858–2869. DOI:
https://doi.org/10.18653/v1/D19-1285
Alec Radford, Jeffrey Wu, Rewon Child, 大卫
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI Blog, 1(8).
Ohad Rozen, Vered Shwartz, Roee Aharoni,
and Ido Dagan. 2019. Diversify your data-
套: Analyzing generalization via controlled
variance in adversarial datasets. In Proceed-
ings of
the 23rd Conference on Comput-
ational Natural Language Learning (CoNLL),
pages 196–205. DOI: https://doi.org
/10.18653/v1/K19-1019
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of rare
words with subword units. 在诉讼程序中
the 54th Annual Meeting of the Association
(体积 1:
for Computational Linguistics
1715–1725. DOI:
Long Papers),
https://doi.org/10.18653/v1/P16-1162
页面
Vered Shwartz and Ido Dagan. 2019. Still a
pain in the neck: Evaluating text represent-
ations on lexical composition. In Transactions
的
the Association for Computational Lin-
语言学 (处理). DOI: https://doi.org
/10.1162/tacl a 00277
Robyn Speer, Joshua Chin, and Catherine Havasi.
2017. Conceptnet 5.5: An open multilingual
graph of general knowledge. In Thirty-First
AAAI 人工智能会议.
A. Talmor and J. Berant. 2018. The web
as knowledge-base for answering complex
问题. In North American Association for
计算语言学 (全国AACL).
A. Talmor,
J. Herzig, 氮. Lourie,
和
J. Berant. 2019. Commonsenseqa: A question
answering challenge targeting commonsense
知识. In North American Association for
计算语言学 (全国AACL).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Ian Tenney, Dipanjan Das, and Ellie Pavlick.
2019A, Jul. BERT rediscovers the classical NLP
pipeline. In Proceedings of the 57th Annual
Meeting of the Association for Computational
语言学, pages 4593–4601. Florence, 意大利.
计算语言学协会.
Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang,
Adam Poliak, R Thomas McCoy, Najoung
Kim, Benjamin Van Durme, Sam Bowman,
Dipanjan Das, and Ellie Pavlick. 2019乙.
What do you learn from context? Probing
for sentence structure in contextualized word
陈述. In International Conference on
Learning Representations.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017.
In Advances
Attention is all you need.
in Neural Information Processing Systems,
pages 5998–6008.
D. Vrandeˇci´c and M. Kr˝otzsch. 2014. Wikidata:
A free collaborative knowledgebase. Commu-
nications of the ACM, 57. DOI: https://
doi.org/10.1145/2629489
Eric Wallace, Yizhong Wang, Sujian Li, Sameer
辛格, and Matt Gardner. 2019. Do NLP models
know numbers? Probing numeracy in embed-
丁斯. 在诉讼程序中 2019 会议
on Empirical Methods in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 5310–5318. DOI:
https://doi.org/10.18653/v1/D19-1534
Mingzhe Wang, Yihe Tang, Jian Wang, and Jia
Deng. 2017. Premise selection for theorem
proving by deep graph embedding, 我. Guyon,
U. V. Luxburg, S. 本吉奥, H. 瓦拉赫,
右. 弗格斯, S. Vishwanathan, 和R. 加内特,
信息
编辑, Advances
Processing Systems 30, pages 2786–2796.
柯伦联合公司, Inc.
in Neural
analysis methods with NPIS.
在
Five
这 2019 会议
会议记录
Empirical Methods
in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 2870–2880. DOI:
https://doi.org/10.18653/v1/D19-1286
Johannes Welbl,
Stenetorp,
和
Pontus
Sebastian Riedel. 2018. Constructing datasets
for multi-hop reading comprehension across
文件. 协会的交易
计算语言学, 6287–302. DOI:
https://doi.org/10.1162/tacl 00021
Yiben Yang, Larry Birnbaum, Ji-Ping Wang,
and Doug Downey.
2018A. Extracting
commonsense properties from embeddings with
limited human guidance. 在诉讼程序中
the 56th Annual Meeting of the Association
(体积 2:
for Computational Linguistics
644–649. DOI:
Short
页面
https://doi.org/10.18653/v1/P18-2102
文件),
Z. 哪个, 磷. 齐, S. 张, 是. 本吉奥, 瓦. 瓦.
科恩, 右. Salakhutdinov, 和C. D. 曼宁.
2018乙. HotpotQA: A dataset for diverse, 前任-
plainable multi-hop question answering. 在
in Natural Language
Empirical Methods
加工 (EMNLP). DOI: https://土井
.org/10.18653/v1/D18-1259, PMCID:
PMC6156886
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime
Carbonell, Russ R. Salakhutdinov, and Quoc V.
Le. 2019. Xlnet: Generalized autoregressive
在
pretraining for
神经方面的进展
information processing
系统, pages 5753–5763.
language understanding.
D. Yogatama, C. de M. d’Autume, J. Connor,
时间. Kocisky, 中号. Chrzanowski, L. 孔,
A. Lazaridou, 瓦. Ling, L. 于, C. Dyer, 和
Phil Blunson. 2019. Learning and evaluating
general linguistic intelligence. arXiv 预印本
arXiv:1901.11373.
Alex Warstadt, Yu Cao,
Ioana Grosu, Wei
彭, Hagen Blix, Yining Nie, 安娜
Alsop, Shikha Bordia, Haokun Liu, Alicia
Parrish, Sheng-Fu Wang,
Jason Phang,
Anhad Mohananey, Phu Mon Htut, Paloma
Jeretiˇc,
and Samuel R. Bowman. 2019.
Investigating BERTs knowledge of language:
Rowan Zellers, Yonatan Bisk, Roy Schwartz,
and Yejin Choi. 2018. Swag: A large-
scale adversarial dataset for grounded com-
monsense inference. 在诉讼程序中
这
2018 实证方法会议
自然语言处理 (EMNLP). DOI:
https://doi.org/10.18653/v1/D18-1009
758
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
4
2
1
9
2
3
7
1
6
/
/
t
我
A
C
_
A
_
0
0
3
4
2
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3