方法
Consensus clustering approach to group brain
connectivity matrices
Javier Rasero
1,2,3
, Mario Pellicoro
6
Daniele Marinazzo
2
, Leonardo Angelini
, and Sebastiano Stramaglia
2,3,4
, Jesus M. 科尔特斯
2,3,4
1,5
,
1Biocruces Health Research Institute. Hospital Universitario de Cruces, Barakaldo, 西班牙
2Dipartimento di Fisica, Università degli Studi Aldo Moro, Bari, 意大利
3Istituto Nazionale di Fisica Nucleare, Sezione di Bari, 意大利
4TIRES-Center of Innovative Technologies for Signal Detection and Processing, Università degli Studi Aldo Moro Bari, 意大利
Ikerbasque, the Basque Foundation for Science, Bilbao, 西班牙
6Faculty of Psychology and Educational Sciences, Department of Data Analysis, Ghent University, Ghent, 比利时
5
开放访问
杂志
关键词: Unsupervised learning, Consensus clustering, Resting fMRI, Structural DTI
抽象的
A novel approach rooted on the notion of consensus clustering, a strategy developed for
community detection in complex networks, is proposed to cope with the heterogeneity
that characterizes connectivity matrices in health and disease. The method can be
summarized as follows: (A) define, 对于每个节点, a distance matrix for the set of subjects
by comparing the connectivity pattern of that node in all pairs of subjects; (乙) cluster the
distance matrix for each node; (C) build the consensus network from the corresponding
partitions; 和 (d) extract groups of subjects by finding the communities of the consensus
network thus obtained. Different from the previous implementations of consensus clustering,
we thus propose to use the consensus strategy to combine the information arising from the
connectivity patterns of each node. The proposed approach may be seen either as an
exploratory technique or as an unsupervised pretraining step to help the subsequent
construction of a supervised classifier. Applications on a toy model and two real datasets
show the effectiveness of the proposed methodology, which represents heterogeneity of a
set of subjects in terms of a weighted network, the consensus matrix.
介绍
In the supervised analysis of human connectome data (Craddock et al., 2013; 斯波恩斯, 2010),
subjects are usually grouped under a common umbrella corresponding to high-level clini-
cal categories (例如, patients and controls), and typical approaches aim at deducing a deci-
sion function from the labeled training data (see Fornito & 布莫尔, 2010). 然而, 这
populations of subjects (healthy as well as patients) are usually highly heterogeneous: clus-
tering algorithms find natural groupings in the data, and therefore constitute a promising
technique for disentangling the heterogeneity that is inherent to many conditions, 并
the cohort of controls. Such an unsupervised classification may also be used as a prepro-
cessing stage, so that the subsequent supervised analysis might exploit the knowledge of the
structure of data. Some studies dealt with similar issues: semisupervised clustering of imag-
ing data was considered in Filipovych, Resnick, and Davatzikos (2011, 2012); other recent
approaches cope with the heterogeneity of subjects using multiplex biomarkers techniques
(Steiner, Guest, Rahmoune, & Martins-de-Souza, 2017) and combinations of imaging and
genetic patterns (Varol, Sotiras, Davatzikos, & Alzheimer’s Disease Neuroimaging Initiative,
2017), while a strategy to overcome intersubject variability while predicting behavioral
引文: Rasero, J。, Pellicoro, M。,
Angelini, L。, 科尔特斯, J. M。, Marinazzo,
D ., & Stramaglia, S. (2017). Consensus
clustering approach to group brain
connectivity matrices. 网络
神经科学, 1(3), 242–253.
https://doi.org/10.1162/netn_a_00017
DOI:
https://doi.org/10.1162/netn_a_00017
支持信息:
https://github.com/jrasero/consensus
https://github.com/CPernet/Robust_
Statistical_Toolbox/
利益争夺: 作者有
声明不存在竞争利益
存在.
通讯作者:
Sebastiano Stramaglia
sebastiano.stramaglia@ba.infn.it
处理编辑器:
奥拉夫·斯波恩斯
版权: © 2017
麻省理工学院
在知识共享下发布
归因 4.0 国际的
(抄送 4.0) 执照
麻省理工学院出版社
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
Brain connectivity network
(connectome):
A network in which the nodes
are brain regions and the links
are anatomical connections
(“anatomical/structural
connectivity”), or statistical
dependencies (“functional
connectivity”).
Consensus matrix:
Given several partitions of a given
set of nodes, for each pair of nodes
the consensus matrix provides the
fraction of partitions in which the
two nodes belong to the same subset.
Distance matrix:
For each node, a distance matrix for
the set of subjects is constructed
based on the Spearman correlation
between the nodal connectivity
patterns of the given node in the
two subjects.
K-medoids:
Clustering algorithm similar to
k-means, which in contrast chooses
data points as center (so-called
medoids), making it more robust to
异常值.
网络神经科学
variables from imaging data has been proposed in Takerkart, Auzias, Thirion, and Ralaivola
(2014). Connectivity features have been used in data-driven approaches for analysis and
classification of MRI data in Amico et al. (2017) and Iraji et al. (2016). The purpose of this
work is to introduce a novel approach that is rooted on the notion of consensus clustering
(Lancichinetti & Fortunato, 2012), a strategy developed for community detection in complex
网络 (巴拉巴斯, 2003).
To introduce our method, let us assume that a connectivity matrix is associated with each
item to be classified (usually a subject, but also individual scans for the same subject as in the
example illustrated below). The goal of supervised analysis is to mine those features of matrices
that provide the best prediction of available environmental and phenotypic factors, such as task
表现, psychological traits, and disease states. When it comes to using unsupervised
analysis of matrices to find groups of subjects, the most straightforward approach would be to
extract a vector of features from each connectivity matrix, and to cluster these vectors using
one of the commonly used clustering algorithms. The purpose of the present work is to propose
a new strategy for unsupervised clustering of connectivity matrices. In the proposed approach
the different features, extracted from connectivity matrices, are not combined in a single vector
to feed the clustering algorithm; 相当, the information coming from the various features are
combined by constructing a consensus network (Lancichinetti & Fortunato, 2012). Consensus
clustering is commonly used to generate stable results out of a set of partitions delivered by
different clustering algorithms (and/or parameters) applied to the same data (Strehl & 戈什,
2002); 这里, 反而, we use the consensus strategy to combine the information about the data
structure arising from different features so as to summarize them in a single consensus matrix.
The unsupervised strategy that we propose here to group subjects, without using phenotypic
措施, can be summarized as follows, and as depicted in Figure 1: (A) define, 对于每个节点,
a distance matrix for the set of subjects; (乙) cluster the distance matrix for each node; (C) 建造
the consensus network from the corresponding partitions; 和 (d) extract groups of subjects by
finding the communities of the consensus network thus obtained. We remark that the proposed
approach provides not only a partition of subjects in communities, but also the consensus
In the next section we
矩阵, which is a geometrical representation of the set of subjects.
describe in detail the method and apply it to a toy model, then we show the application on
two real MRI datasets. 最后, some conclusions are drawn.
方法
(结构性的) N × N connectivity matrix
Let us consider m subjects whose functional
(鲁比诺夫 & 斯波恩斯, 2010), where N is the number of nodes, will be denoted by {A(我, j)A},
α = 1, . . . , m and i, j = 1, . . . , 氮. For each node i, we build a distance matrix for the set
of subjects as follows. Consider a pair of subjects α and β, and consider the corresponding
nodal connectivity patterns {A(我, :)A} 和 {A(我, :)β}; let r be their Spearman correlation. 作为
the distance between the two subjects, for the node i, we take dαβ = 1 − r; other choices for
2(1 − r), where r is the Pearson corre-
the distance can be used, 喜欢, for example dαβ =
关系. The m × m distance matrix dαβ corresponding to node i will be denoted by Di, 和
i = 1, . . . , 氮. The set of D matrices may be seen as corresponding to layers of a multilayer
网络 (Boccaletti et al., 2014), each brain node providing a layer.
(西德:2)
Each distance matrix Di is then partitioned into k groups of subjects using k-medoids method
(Brito, Bertrand, Cucumel, & Carvalho, 2007). 随后, an m × m consensus matrix C is
evaluated: its entry Cαβ indicates the number of partitions in which subjects α and β are as-
signed to the same group, divided by the number of partitions N. The number of clusters k may
243
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1. Flowchart of the proposed methodology.
be kept fixed, thus rendering the consensus matrix depending on k; a better strategy, 然而,
is to average the consensus matrix over k ranging in an interval, so as to fuse, in the consensus
矩阵, information about structures at different resolutions.
The consensus matrix, obtained as explained before, is eventually partitioned in commu-
nities by modularity maximization, with the consensus matrix C being compared against the
ensemble of all consensus matrices one may obtain randomly and independently permuting
the cluster labels obtained after applying the k-medoids algorithm to each of the set of distance
matrices. 更确切地说, a modularity matrix is evaluated as
B = C − P,
where P is the expected coassignment matrix, uniform as a consequence of the null ensemble
chosen here, obtained by repeating many times the permutation of labels; the modularity
matrix B is eventually submitted to a modularity optimization algorithm to obtain the output
partition by the proposed approach. We used the community Louvain routine in the Brain
Connectivity Toolbox (鲁比诺夫 & 斯波恩斯, 2010), which admits modularity matrices instead of
connectivity matrices as input.
网络神经科学
244
Consensus clustering approach to group brain connectivity matrices
We remark that the proposed approach has similarities with the one adopted in Shehzad
等人. (2014), where techniques from genome-wide association studies coping with the prob-
lem of a huge number of comparisons were applied to connectomes, thus identifying nodes
whose whole-brain connectivity patterns vary significantly with a phenotypic variable. The ap-
proach in Shehzad et al. (2014) consists of two steps. 第一的, for each node in the connectome, A
whole-brain functional connectivity map is evaluated, and then the similarity between the con-
nectivity maps of all possible pairings of participants, using spatial correlation, is calculated.
然后, in the second stage, a statistic is evaluated for each node, indicating the strength of the
relationship between a phenotypic measure and variations in its connectivity patterns across
subjects. The main similarity with the proposed approach is that in both methods, for each
node in the connectome, the comparison between the connectivity maps yields a distance
matrix in the space of subjects.
A TOY MODEL
As a toy model to describe the application of our method, we simulate a set of 100 subjects,
divided in four groups of 25 each. The subjects are supposed to be described by 30 节点.
We will compare our proposed approach with a standard procedure such as averaging the dis-
tance matrices and then applying the clustering algorithm to the average distance
矩阵.
The distance matrices corresponding to the first 10 nodes are constructed in the following
方式: the distance for pairs belonging to the same group is sampled uniformly in the interval
[0.1, 0.4], while the distance for pairs belonging to different groups is sampled uniformly in
the interval [0.2, 0.4]. The distance matrices corresponding to the 20 remaining nodes have
all the entries sampled uniformly in the interval [0.2, 0.4]. It follows that in our toy model only
10 节点, 在......之外 30, carry information about the presence of the four groups.
First of all, we evaluate the distance matrix among subjects, averaged over the 30 节点,
and apply the k-medoids algorithm to this matrix , searching for k = 4 clusters (thus exploiting
the knowledge of the number of classes present in data); this procedure leads to an accuracy
的 0.89, measured as follows. Let us call {Gα}, α = 1, . . . , 4 the four groups in the model and
let M be the minimum between 4 and the number of clusters found by modularity maximiza-
tion clustering; we denote {Ci}, i = 1, . . . , M the largest M clusters found by clustering. 这
accuracy is then given by
1
米
中号
∑
我=1
maxα|Gα ∩ Ci|,
在哪里 |Gα ∩ Ci| is the cardinality of the intersection of the two sets, and m = 100 is the total
number of subjects.
随后, we run the proposed approach by applying separately to each distance
matrix for each of the 30 nodes the k-medoids algorithm with varying k. We then build the
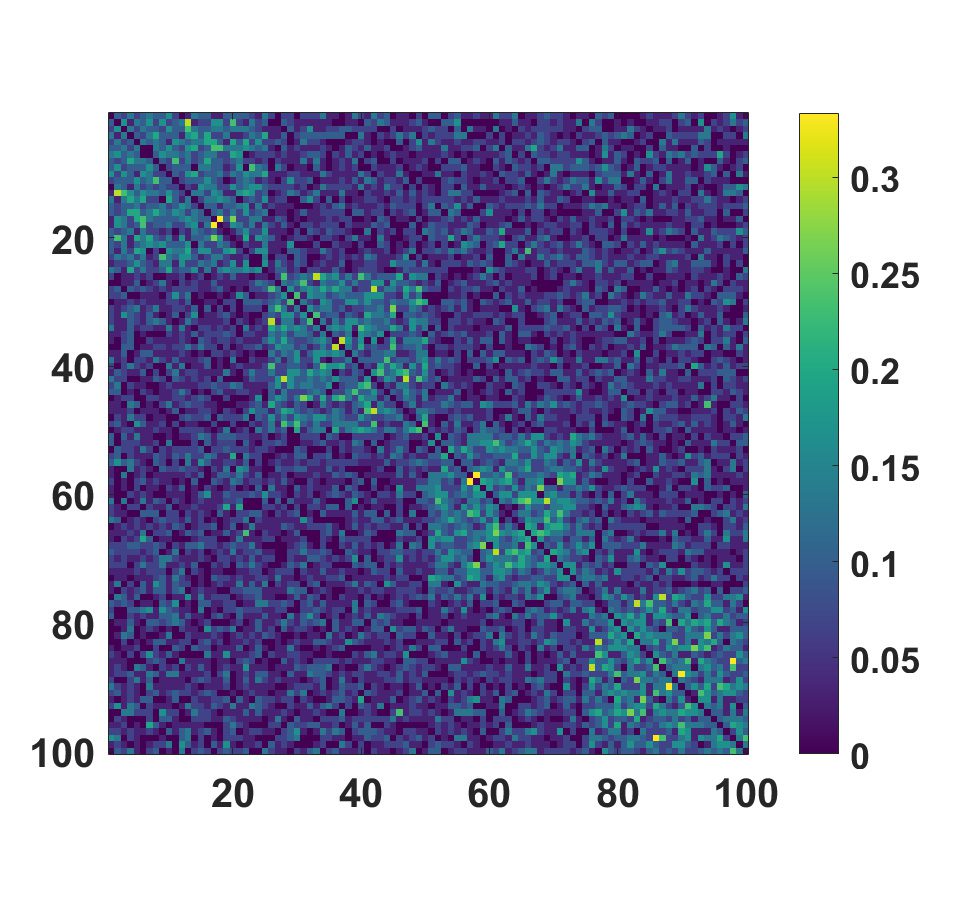
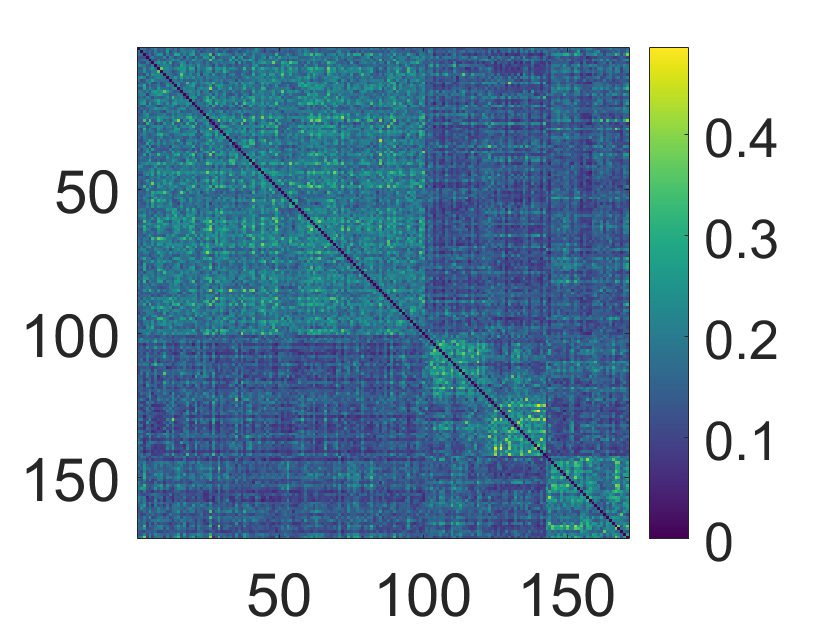
corresponding consensus matrix. 例如, 图中 2 the consensus matrix among sub-
jects is depicted as obtained by applying k-medoids with k = 10 separately to each of the
30 layers. 然后, the communities of the consensus matrices have been estimated as described
in the previous section.
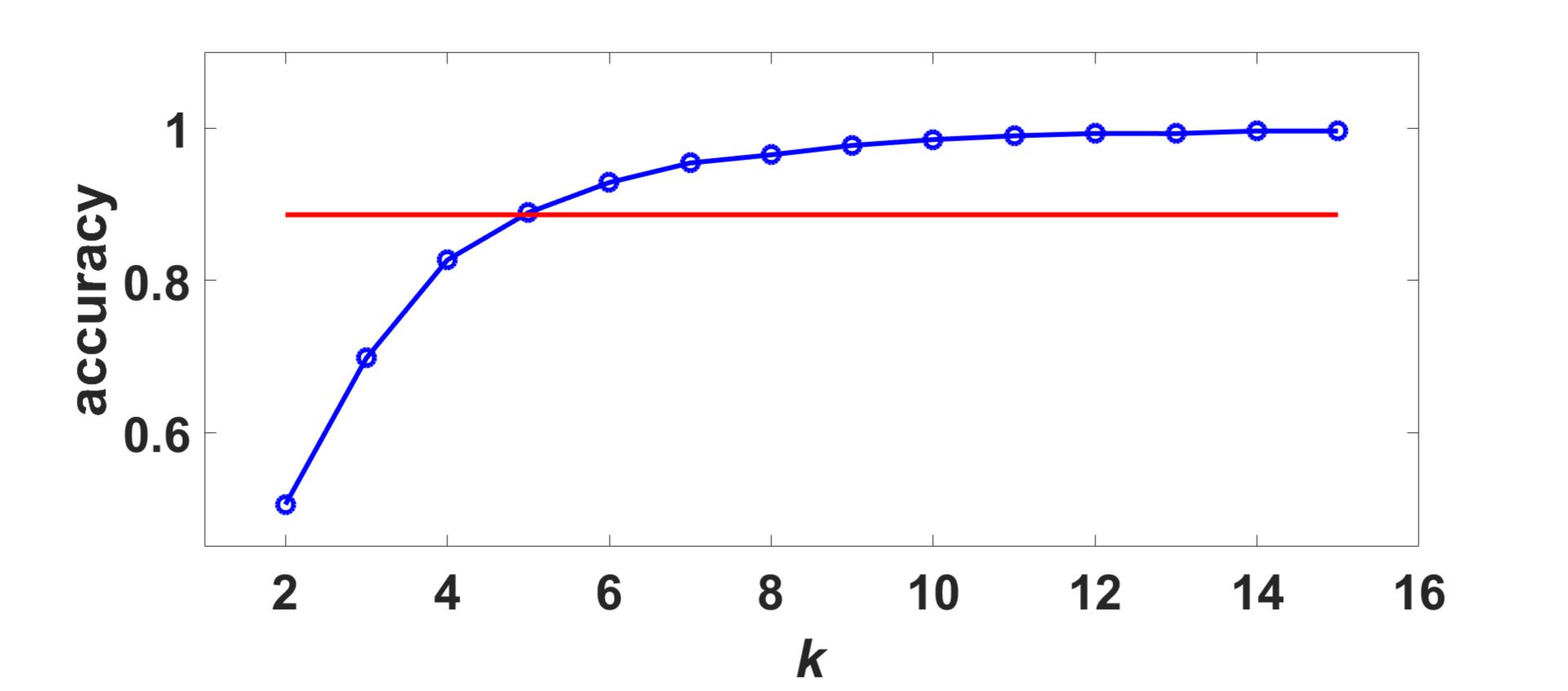
图中 3 the accuracy of the partition, provided by modularity maximization on the
consensus matrix, is depicted versus k, in order to show how it varies with k: it shows that
the proposed method performs better than the partition of the average distance matrix on
this example, for large k; we remark that the accuracy 0.89 is reached by k-medoids on the
网络神经科学
245
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 2. Consensus matrix among subjects in the toy model, obtained by applying k-medoids
with k = 10 separately to each of the 30 layers. Each entry Cαβ of the matrix represents the number
of partitions in which subjects α and β were assigned to the same group, divided by the number of
partitions N.
average distance using k = 4, that is exploiting the knowledge of the number of groups
present in the dataset, while the proposed algorithm determines both the number of clus-
ters and the partition. 直观地, the proposed approach works better in this example for large
k, because in the distance matrix corresponding to an informative node, due to chance, 这
block corresponding to a group is seen as fragmented in smaller pieces; those pieces can
be retrieved using k-medoids with large k. 另一方面, when the consensus is made
across the different informative nodes, all those pieces merge in the consensus matrix and
build the block corresponding to the four groups.
It is also worth noting that the accuracy by clustering the averaged consensus matrix
(over the values of k) is one, 那是, perfect group reconstruction. Averaging over the values
of k appears then to be a convenient strategy. 而且, averaging over values of parame-
ters is a common strategy for consensus clustering, hence building the consensus matrix
while joining several values of k is in line with the philosophy of consensus clustering
(Lancichinetti & Fortunato, 2012).
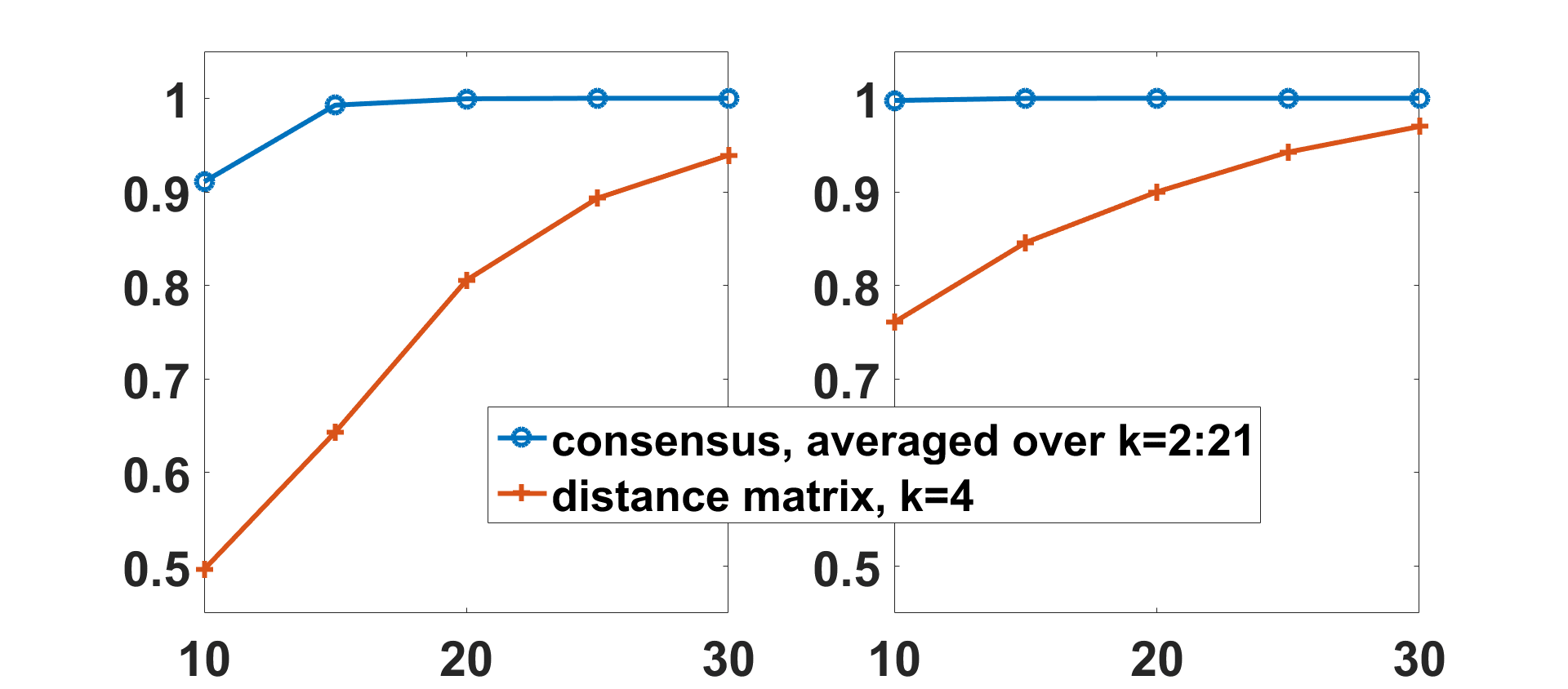
In order to show the effectiveness of the proposed approach under different conditions, 我们
change the toy model by varying the number of informative nodes and the number of groups.
We also use different parameters with reference to the previous simulations; the distance for
网络神经科学
246
Consensus clustering approach to group brain connectivity matrices
数字 3. The accuracy of the partition, provided by modularity maximization on the consensus
矩阵, is depicted versus k. The horizontal line represents the accuracy obtained by clustering the
average distance matrix using k-medoids and k = 4.
pairs belonging to the same group are still sampled uniformly in the interval [0.1, 0.4], 而
distance for pairs belonging to different groups is sampled uniformly in the interval [0.15, 0.4].
The results, displayed in Figure 4, show that the proposed approach works better than the
application of k-medoids to the average distance matrix.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4. The accuracy of the partition, provided by modularity maximization on the consensus
matrix averaged over 20 values of k, is depicted versus the number of informative nodes (什么时候
这是 30, all the nodes are informative).
In the left panel, the plots correspond to four groups of
25 subjects; the blue curve is the accuracy by the proposed method and the red line is the accuracy
obtained by clustering the average distance matrix using k-medoids and k = 4. In the right panel, 这
case of two groups, 每一个 50 subjects, is considered; the blue line is the accuracy by the proposed
method and the red line is the accuracy obtained by clustering the average distance matrix using
k-medoids and k = 2. In all cases the consensus approach gives better results.
网络神经科学
247
Consensus clustering approach to group brain connectivity matrices
Resting-state fMRI:
Functional magnetic resonance
imaging acquired while the subject is
simply instructed to stay awake.
APPLICATION TO REAL DATASETS
Longitudinal dataset
Growing interest is devoted to longitudinal phenotyping in cognitive neuroscience: 符合-
ingly we consider here data from the MyConnectome project
(Laumann et al., 2015;
Poldrack et al., 2015), where fMRI scans from a single subject were recorded over 18 月.
In Shine, Koyejo, & Poldrack (2016), the presence of two distinct temporal states has been
identified, which fluctuated over the course of time. These temporal states were associated
with distinct patterns of time-resolved blood oxygen level dependent (大胆的) 连接性
within individual scanning sessions and also related to significant alterations in global ef-
ficiency of brain connectivity as well as differences in self-reported attention. These data
Its accession number is ds000031. The func-
were obtained from the OpenfMRI database.
tional MRI (功能磁共振成像) data were preprocessed with FSL (FMRIB Software Library v5.0). 第一个
10 volumes were discarded for correction of the magnetic saturation effect. The remaining
volumes were corrected for motion, after which slice timing correction was applied to correct
for temporal alignment. All voxels were spatially smoothed with a 6 mm FWHM (full width at
half maximum) isotropic Gaussian kernel and after intensity normalization, a band pass filter
was applied between 0.01 和 0.08 赫兹. 此外, linear and quadratic trends were removed.
We next regressed out the motion time courses, the average cerebrospinal fluid (CSF) signal,
and the average white matter signal. Global signal regression was not performed. Data were
transformed to the MNI152 template, such that a given voxel had a volume of 3 mm × 3 mm ×
3 毫米. 最后, 我们得到了 268 time series, each corresponding to an anatomical region of
兴趣 (ROI), by averaging the voxel signals according to the functional atlas described in
沉, Tokoglu, Papademetris, & Constable (2013).
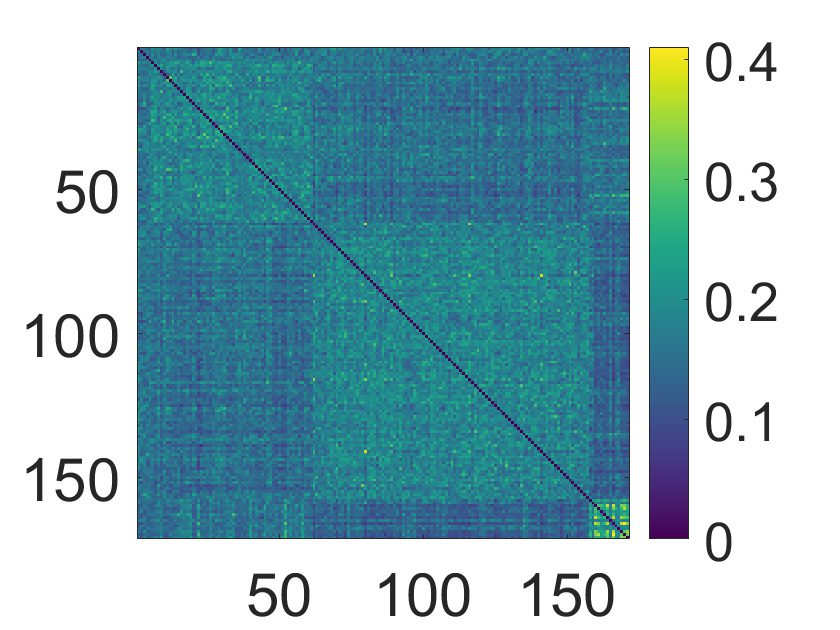
CONSENSUS MATRIX
DISTANCE MATRIX
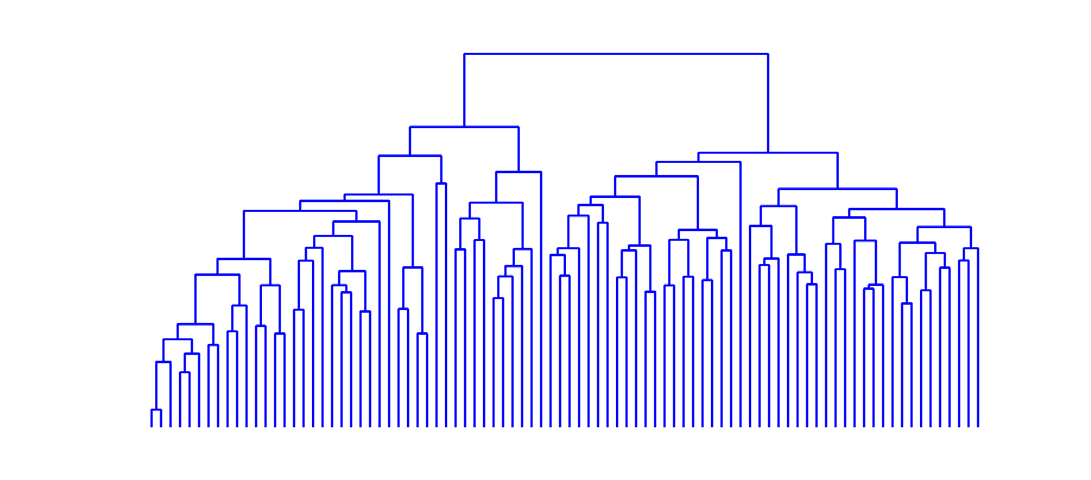
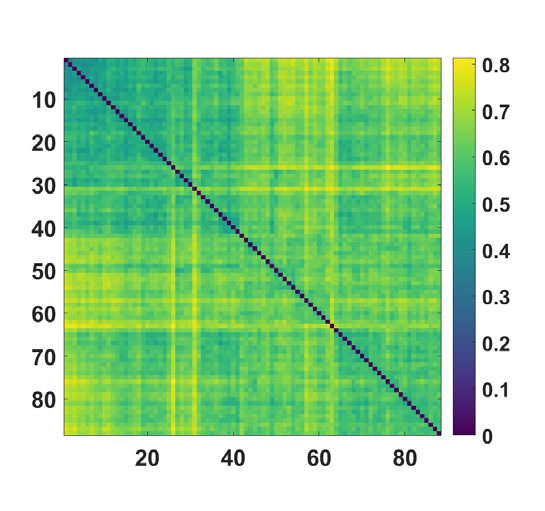
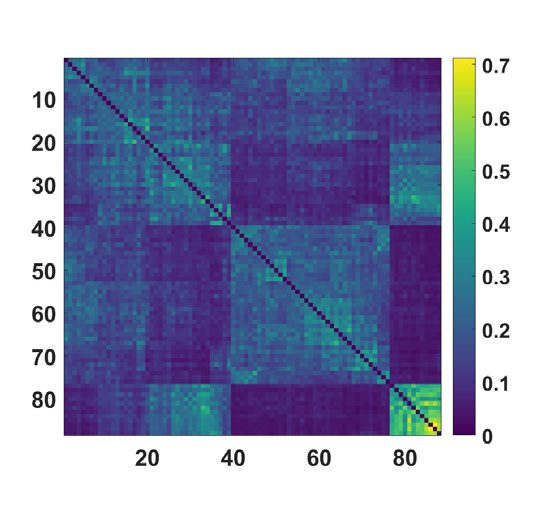
数字 5.
(Top) Concerning the MyConnectome dataset, the consensus matrix, obtained averag-
ing over k, by the proposed approach is displayed with nodes ordered according to hierarchical
clustering, with the corresponding dendrogram. (Bottom) The average distance matrix, among the
different sessions of the same subject, and the corresponding dendrogram.
网络神经科学
248
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
PANAS (Positive and Negative
Affect Schedule):
The PANAS comprises two mood
scales, one that measures positive
affect and one that measures negative
影响. Participants in the PANAS are
required to respond to a 20-item test.
Each of the 89 sessions resulted in a 268 × 268 matrix of Pearson correlation coefficients.
We treated the sessions as if they were connectivity matrices of different subjects, and applied
the proposed methodology.
图中 5 we depict the distance matrix, among the different
sessions of the same subject, and the consensus matrix, obtained averaging over 10 values of
k. Sessions are ordered, 在这两种情况下, according to hierarchical clustering; the corresponding
dendrograms are also shown in the figure. It is clear that the consensus matrix shows a hier-
archical structure. Maximization of the modularity provides two communities with modular-
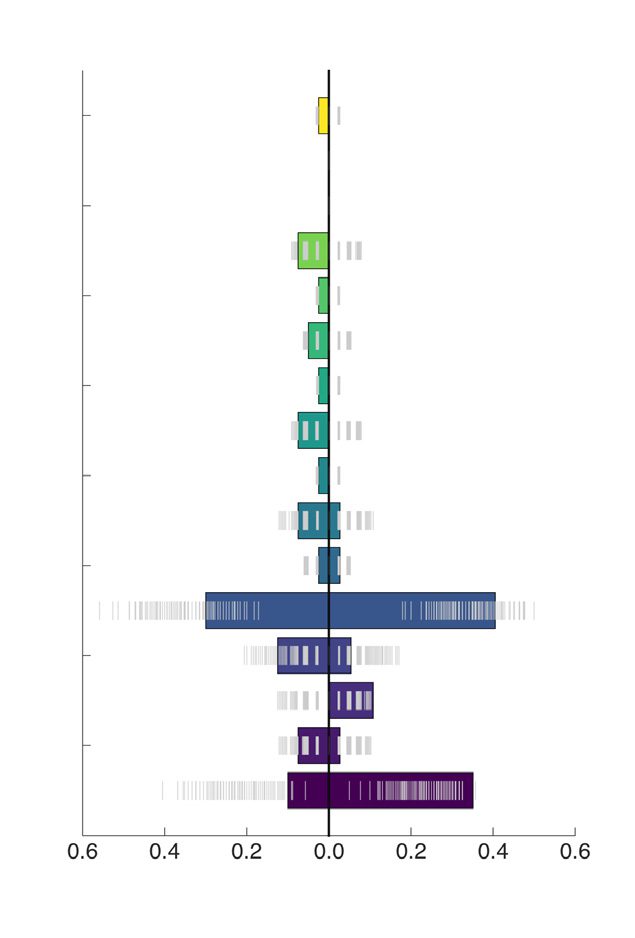
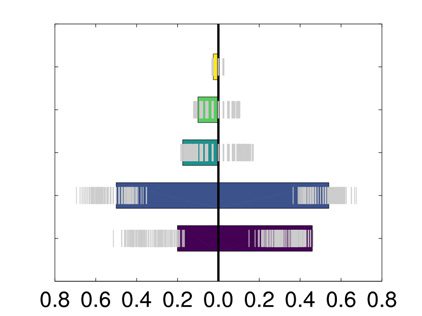
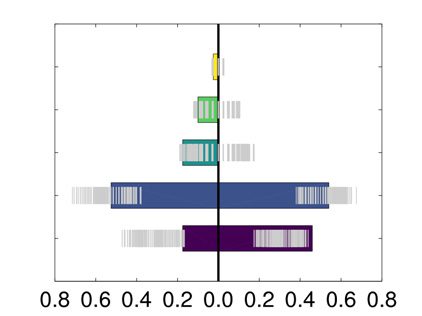
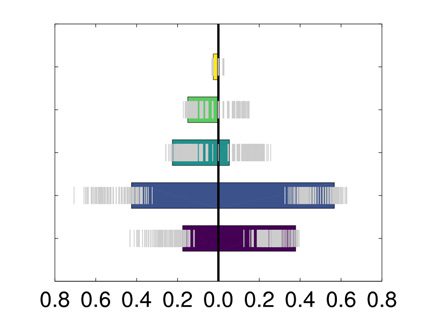
ity equal to 0.175. As depicted in Figure 6, the two communities are significantly different
for several PANAS scores, all associated with tiredness. This is assessed visually using a null
distribution obtained by shuffling 500 times the pairing between behavioral variable and con-
nectome matrix and with a nonparametric Wilcoxon rank sum test: drowsy (Bonferroni cor-
rected p value = 0.028), tired (Bonferroni corrected p value = 0.041), sluggish (Bonferroni
corrected p value = 0.026), sleepy (Bonferroni corrected p value = 0.012), fatigue (Bonferroni
corrected p value = 0.022). This confirms the presence of two distinct temporal states. 如何-
曾经, the hierarchical structure of the consensus matrix that we obtained suggests that longer
longitudinal recordings are needed to further evidence the richness of distinct functional states
for single subjects.
它
the proposed algorithm:
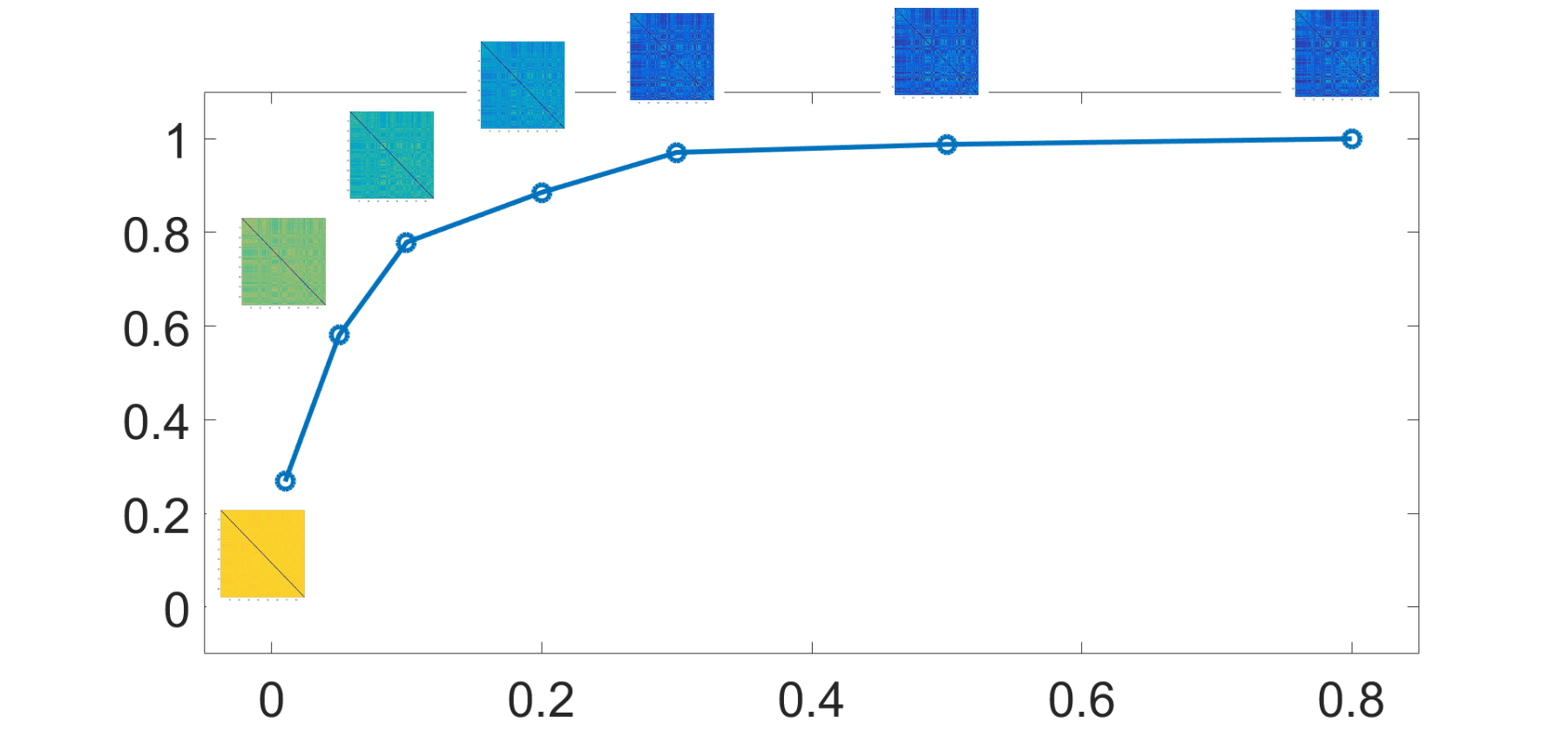
is also worth considering the effects of network thresholding on the performance
的
thresholding is a relevant problem in brain connectivity
(Fallani, Latora, & Chavez, 2017; Van Wijk, 斯塔姆, & Daffertshofer, 2010). The functional net-
works in this dataset are thresholded so as to retain a varying fraction (density) of the largest
图中 7 we plot the similarity between the consensus matrices obtained by the
entries.
proposed algorithm after thresholding and the corresponding consensus matrix in the absence
of thresholding, as a function of the density. The similarity between the consensus matrices is
evaluated as the Pearson correlation between the entries of the two matrices. On one side the
results show the robustness of the proposed approach to moderate thresholding; 的确, 最多
C1
C2
C1
C2
+
乙
U
G
我
时间
A
F
–
C1
C2
+
D
乙
右
我
时间
–
+
H
S
我
G
G
U
L
S
–
C1
C2
C1
C2
+
是
磷
乙
乙
L
S
–
+
是
S
瓦
氧
右
D
–
数字 6. MyConnectome dataset: distributions of the values of the PANAS scores that are sig-
nificantly different among the two communities found by modularity optimization on the consen-
sus matrix provided by the proposed approach. An expected null distribution, whose quantiles are
reported in gray, was obtained by shuffling the association between the PANAS score and connec-
tome matrix.
网络神经科学
249
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
H
时间
我
瓦
氮
氧
我
时间
A
L
乙
右
右
氧
C
X
我
右
时间
A
中号
L
L
U
F
DENSITY
数字 7. The consensus matrix evaluated by the proposed approach, on the brain connectivity
matrices of the MyConnectome dataset, is compared with the consensus matrix from the proposed
method on thresholded matrices. The linkwise similarity between the two consensus matrices is
evaluated as the Pearson correlation of the corresponding entries in the two matrices, and is plotted
versus the density of retained largest entries.
20% thresholding, the consensus matrix is very close to what is obtained using the full matrices.
另一方面, the consensus matrix by the proposed approach is substantially different for
sparser networks. This might speak to the fact that the correlation value is a debatable choice
of a thresholding criterion for correlation matrices, and that the proposed approach is suited
for weighted networks.
Resting healthy subjects, functional and structural connectivity
In this case the networks have 118 节点.
We consider 171 healthy subjects from the NKI Rockland dataset (Nooner et al., 2012); 为了
each subject we use both the structural diffusion tensor imaging (DTI) network and the func-
tional network, already obtained from processed data as described in Brown, Rudie,
在
Bandrowski, VanHorn, & Bookheimer, 2012.
数字 8 we depict the consensus matrix for both DTI and fMRI networks; modularity max-
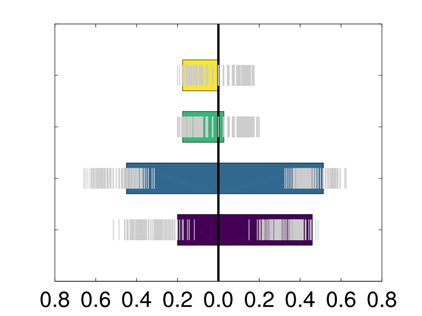
imization yields three communities for DTI networks and four communities for fMRI. 骗局-
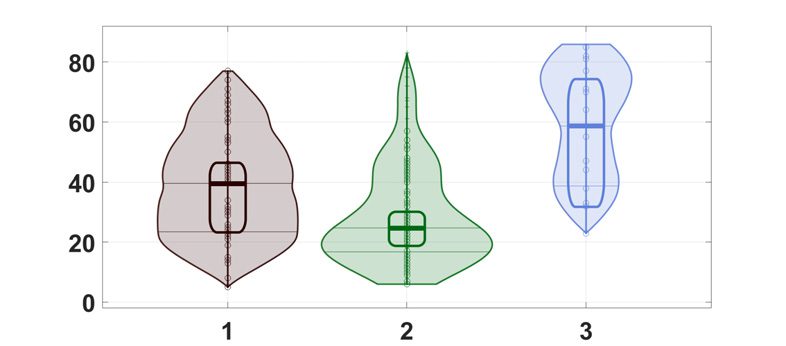
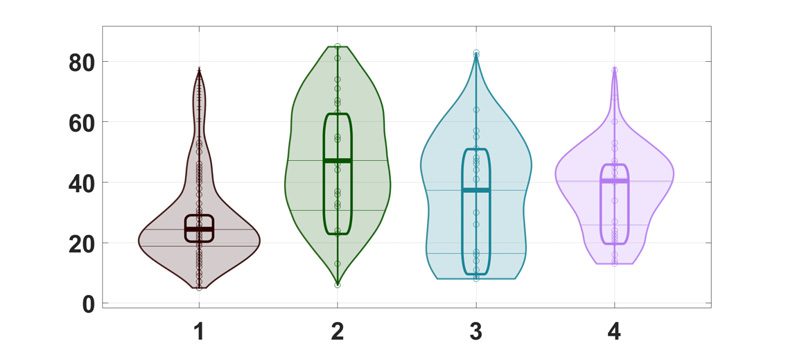
cerning DTI, the three communities are significantly characterized by different ages, 和
p values equal to 9 × 10−4
, 和 0.003 for the group comparisons 1-2, 2-3, 和
1-3 分别 (见图 8). Considering fMRI data, the first group by the proposed algo-
rithm has a different age than the second, the third, and the fourth ones (taken as a whole) 和
probability 7 × 10−4
. P values reported here refer to a nonparametric rank sum test; 相似的
significance was found using parametric tests. We remark that our method performs different
from k-medoids over the average distance, where we obtain two groups with different ages,
t test with probability 10−3
using the functional distance, while no significant difference in age
using the structural connectivity.
, 2 × 10−5
Inspired by the results found by our method, we also performed a multivariate distance
regression (Shehzad et al., 2014), that allowed us to build a pseudo F statistic to test whether
age correlates with the differences observed in the distance matrix for each node. 我们有
网络神经科学
250
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
STRUCTURAL
FUNCTIONAL
乙
G
A
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
COMMUNITY
COMMUNITY
数字 8.
(Top) Concerning the NKI dataset, the consensus matrices found by the proposed ap-
proach are shown for structural (top left) and functional (top right) 连接性. (Bottom) The dis-
tribution of age values (in years) in the resulting communities are reported. The rectangles indicate
the estimator with 95% high density interval, calculated by Bayesian bootstrap. The shaded areas
indicate random average shifted histograms, with a kernel density estimate. The code for these plots
is available at Pernet (2017).
achieved this by comparing the observed F statistic with the pseudo F distribution (那是, 不是
普通的) 后 105
data permutations. 正如预期的那样, for both structural and functional data, 我们
成立 124 和 76 nodes statistically related with age respectively, thus suggesting that age is
one of the variables responsible for the community structure found by our method.
结论
An important issue such as dealing with the heterogeneity that characterizes healthy condi-
系统蒸发散, as well as diseases, requires the development of effective methods capable of highlight-
ing the structure of sets of subjects at varying resolutions. The approach that we propose here
is applied to sets of subjects, each described by a connectivity matrix. We propose a strategy,
rooted in complex networks theory, to obtain a consensus matrix that describes the geometry
of the dataset, providing at different resolutions groups of similar subjects. While the straight-
forward application of consensus clustering to a given data set combines the output from dif-
ferent clustering, our proposal is to apply a clustering algorithm separately to the connectivity
map of each node. Hence the consensus strategy is exploited to combine the information aris-
ing from the different nodes. 明显地, the choice of k-medoids as the clustering algorithm
for the individual layers is not mandatory; other algorithms can be used, as well as the defi-
nition of the distance among subjects to be used by this algorithm. 而且, 在现在
work the features that we considered are the connectivity maps resulting from the whole-brain
connectivity pattern of each node; 然而, other subsets of entries of matrices can be taken as
出色地, and the same strategy can be applied to fuse the different layers and produce a consensus
矩阵. 同样地, our framework is not limited to considering the whole brain, and therefore it
网络神经科学
251
Consensus clustering approach to group brain connectivity matrices
can be applied to analyze specific regions relevant to the problem at hand so as to exploit the
benefits of our method. 总结一下, our approach aims to disentangle the heterogeneity
of groups corresponding to high-level categories, like healthy and diseased, finding natural
groups within the cohort of patients (and within the cohort of controls). While dealing with
data with both healthy and controls, it can be seen as a preprocessing step, which helps the
subsequent construction of a supervised classifier healthy/subject.
致谢
The authors are grateful to Richard Betzel (宾夕法尼亚大学) and an anonymous
referee for valuable suggestions. They also thank Guillaume Rousselet for valuable suggestions
on data representation.
SUPPORTING INFORMATION
The code for the construction of the consensus matrix, out of the set of connectivity matrices,
is available at Rasero (2017).
作者贡献
Javier Rasero: 数据管理; 方法; 软件; 写作——复习 & 编辑. 马里奥
Pellicoro:
调查; 软件; 写作——复习 & 编辑. Leonardo Angelini: Investi-
gation; 写作——复习 & 编辑. Jesus M. 科尔特斯: 调查; 写作——复习 & edit-
英. Daniele Marinazzo: 概念化; 数据管理; 调查; 写作——复习 &
编辑. Sebastiano Stramaglia: 概念化; 调查; 方法; 监督;
Writing – original draft.
资金信息
JR acknowledges financial support from the Minister of Education, Language Policy and Culture
(Basque government) under the Doctoral Research Staff Improvement Programme.
参考
Amico, E., Marinazzo, D ., Di Perri, C。, Heine, L。, Annen, J。, Martial,
(2017). Mapping the functional connectome
C。, . . . 戈尼, J.
traits of levels of consciousness. 神经影像, 148, 201–211.
巴拉巴斯, A.-L.
(2003).
链接: The new science of networks.
剑桥, 嘛: Perseus.
Boccaletti, S。, Bianconi, G。, Criado, R。, Del Genio, C. 我。, Gómez-
Gardenes, J。, 浪漫, M。, . . . Zanin, 中号. (2014). The structure
and dynamics of multilayer networks. Physics Reports, 544(1),
1–122.
Brito, P。, Bertrand, P。, Cucumel, G。, & Carvalho, F. D.
(2007).
Clustering by means of medoids. Selected contributions in data
analysis and classification. 柏林/海德堡: Springer Science
& Business Media.
棕色的, J. A。, Rudie, J. D ., Bandrowski, A。, Van Horn, J. D ., &
(2012). The UCLA multimodal connectivity
Bookheimer, S. 是.
数据库: A web-based platform for brain connectivity matrix
sharing and analysis. 神经信息学前沿, 6, 28.
Craddock, 右. C。,
Jbabdi, S。, 严, C.-G., Vogelstein,
Castellanos, F. X。, Di Martino, A。, . . . Milham, 中号. 磷.
J. T。,
(2013).
Imaging human connectomes at the macroscale. Nature Meth-
消耗臭氧层物质, 10(6), 524–539.
Fallani, F. D. 五、, Latora, 五、, & Chavez, 中号.
(2017). A topological
criterion for filtering information in complex brain networks.
公共科学图书馆计算生物学, 13(1), e1005305.
Filipovych, R。, Resnick, S. M。, & Davatzikos, C.
(2011). Semi-
supervised cluster analysis of imaging data. 神经影像, 54(3),
2185–2197.
Filipovych, R。, Resnick, S. M。, & Davatzikos, C.
Joint-
MMCC: Joint maximum-margin classification and clustering of
IEEE Transactions on Medical Imaging, 31(5),
imaging data.
1124–1140.
(2012).
假如, A。, & 布莫尔, 乙. 时间.
(2010). What can spontaneous
fluctuations of the blood oxygenation-level-dependent signal tell
us about psychiatric disorders? Current Opinion in Psychiatry,
23(3), 239–249.
Iraji, A。, Calhoun, V. D ., Wiseman, 氮. M。, Davoodi-Bojd, E.,
Avanaki, 中号. R。, Haacke, 乙. M。, & Kou, Z.
这
connectivity domain: Analyzing resting state fmri data using
(2016).
网络神经科学
252
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Consensus clustering approach to group brain connectivity matrices
feature-based data-driven and model-based methods. Neuro-
图像, 134, 494–507.
Lancichinetti, A。, & Fortunato, S. (2012). Consensus clustering in
复杂网络. Scientific reports, 2.
劳曼, 时间. 奥。, Gordon, 乙. M。, Adeyemo, B., 斯奈德, A. Z。, Joo,
S. J。, 陈, M.-Y., . . . 彼得森, S. 乙.
(2015). Functional sys-
tem and areal organization of a highly sampled individual human
脑. 神经元, 87(3), 657–670.
Nooner, K. B., Colcombe, S。, Tobe, R。, Mennes, M。, Benedict, M。,
Moreno, A。, . . . Milham, 中号. 磷.
(2012). The NKI-Rockland
sample: A model for accelerating the pace of discovery science
in psychiatry. Frontiers in Neuroscience, 6, 152.
Pernet, C. (2017). Robust statistical toolbox, GitHub, https://github.
com/CPernet/Robust_Statistical_Toolbox/
Poldrack, 右. A。, 劳曼, 时间. 奥。, Koyejo, 奥。, Gregory, B., Hover,
A。, 陈, M.-Y., . . . Mumford, J. A.
(2015). Long-term neural
and physiological phenotyping of a single human. Nature Com-
通讯, 6.
Rasero, J. (2017). Code to calculate a consensus matrix from a set of
distance matrices using k-medoids, GitHub, https://github.com/
jrasero/consensus
鲁比诺夫, M。, & 斯波恩斯, 氧. (2010). 复杂的网络措施
大脑连接: 用途和解释. 神经影像, 52(3),
1059–1069.
Shehzad, Z。, 凯莉, C。, Reiss, 磷. T。, Craddock, 右. C。, Emerson,
J. W., 麦克马洪, K., . . . Milham, 中号. 磷. (2014). A multivariate
distance-based analytic framework for connectome-wide asso-
ciation studies. 神经影像, 93, 74–94.
沉, X。, Tokoglu, F。, Papademetris, X。, & Constable, 右. 时间. (2013).
Groupwise whole-brain parcellation from resting-state fMRI
data for network node identification. 神经影像, 82, 403–415.
Shine, J. M。, Koyejo, 奥。, & Poldrack, 右. A. (2016). Temporal meta-
states are associated with differential patterns of time-resolved
连接性, network topology, 和关注. 会议记录
the National Academy of Sciences, 201604898.
(2010). Networks of the brain. 剑桥, 嘛: 和
斯波恩斯, 氧.
按.
J。, Guest, 磷. C。, Rahmoune, H。, & Martins-de-Souza,
Steiner,
(2017). The application of multiplex biomarker techniques
D.
为了
improved stratification and treatment of schizophrenia
患者. Multiplex Biomarker Techniques: Methods and Appli-
阳离子, 19–35.
Strehl, A。, & 戈什, J.
(2002). Cluster ensembles: A knowledge
In AAAI/IAAI
reuse framework for combining partitionings.
(PP. 93–99).
Takerkart, S。, Auzias, G。, Thirion, B., & Ralaivola, L. (2014). 图形-
based inter-subject pattern analysis of fMRI data. PloS ONE, 9(8),
e104586.
Van Wijk, 乙. C。, 斯塔姆, C. J。, & Daffertshofer, A. (2010). Comparing
brain networks of different size and connectivity density using
图论. PloS ONE, 5(10), e13701.
Varol, E., Sotiras, A。, Davatzikos, C。, & Alzheimer’s Disease
(2017). HYDRA: Revealing hetero-
Neuroimaging Initiative.
imaging and genetic patterns through a multiple
geneity of
max-margin discriminative analysis framework. 神经影像,
145, 346–364.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
1
3
2
4
2
1
0
9
2
0
7
2
n
e
n
_
A
_
0
0
0
1
7
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
网络神经科学
253