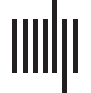方法
A regression framework for brain
network distance metrics
Chal E. Tomlinson1
, Paul J. Laurienti2,3, Robert G. Lyday2,3, and Sean L. Simpson2,4
1生物统计学系, University of North Carolina at Chapel Hill, 教堂山, NC, 美国
2Laboratory for Complex Brain Networks, Wake Forest School of Medicine, Winston-Salem, NC, 美国
3放射科, Wake Forest School of Medicine, Winston-Salem, NC, 美国
4Department of Biostatistics and Data Science, Wake Forest School of Medicine, Winston-Salem, NC, 美国
关键词: Graph theory, Connectivity, 功能磁共振成像, Small-world, 神经影像学, 贾卡德, Kolmogorov–
Smirnov
开放访问
杂志
抽象的
Analyzing brain networks has long been a prominent research topic in neuroimaging.
然而, statistical methods to detect differences between these networks and relate them to
phenotypic traits are still sorely needed. Our previous work developed a novel permutation
testing framework to detect differences between two groups. Here we advance that work to
allow both assessing differences by continuous phenotypes and controlling for confounding
变量. 实现这一目标, we propose an innovative regression framework to relate distances
(or similarities) between brain network features to functions of absolute differences in
continuous covariates and indicators of difference for categorical variables. 我们探索
several similarity metrics for comparing distances (or similarities) between connection
矩阵, and adapt several standard methods for estimation and inference within our
框架: standard F test, F test with individual level effects (ILE), feasible generalized least
正方形 (FGLS), and permutation. Via simulation studies, we assess all approaches for
estimation and inference while comparing them with existing multivariate distance matrix
回归 (MDMR) 方法. We then illustrate the utility of our framework by analyzing the
relationship between fluid intelligence and brain network distances in Human Connectome
项目 (HCP) 数据.
引文: Tomlinson, C. E., Laurienti,
磷. J。, Lyday, 右. G。, & 辛普森, S. L.
(2022). A regression framework for
brain network distance metrics.
网络神经科学, 6(1), 49–68.
https://doi.org/10.1162/netn_a_00214
DOI:
https://doi.org/10.1162/netn_a_00214
支持信息:
https://doi.org/10.1162/netn_a_00214
已收到: 18 六月 2021
公认: 25 十月 2021
利益争夺: 作者有
声明不存在竞争利益
存在.
介绍
通讯作者:
Sean L. 辛普森
slsimpso@wakehealth.edu
处理编辑器:
Bratislav Misic
版权: © 2021
麻省理工学院
在知识共享下发布
归因 4.0 国际的
(抄送 4.0) 执照
麻省理工学院出版社
As brain network analyses have become popular in recent years, neuroimaging researchers
often face the need to statistically compare brain networks (Simpson et al., 2013A). 许多
approaches for relating brain networks to clinical outcomes or demographical variables have
been developed. Such methods include, but are not limited to, traditional network models
(例如, exponential random graph models; Lehmann et al., 2021; Simpson et al., 2011,
2012), tensor regression works on brain network (例如, 张等人。, 2018, 2019), 贝叶斯
方法 (例如, 戴 & 郭, 2017; 王等人。, 2017), statistical learning techniques
(Craddock et al., 2015; Varoquaux & Craddock, 2013; Xia et al., 2020), and testing based
on distance correlation (Székely et al., 2007; Székely & Rizzo, 2009). Despite the advances
制成, analysis methods are still needed that enable the comparison of networks while incor-
porating topological features inherent in each individual’s network. To develop such an
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
分析, we can exploit the fact that brain networks often exhibit consistent organizations
across subjects. 例如, a number of studies have reported that nodes with particular
特征 (例如, high degree) tend to coincide at the same spatial locations across subjects
(哈格曼等人。, 2008; Hayasaka & Laurienti, 2010; Moussa et al., 2011; van den Heuvel
等人。, 2008). Although the set of such nodes may not be exactly the same across subjects, 那里
are large areas of overlap (哈格曼等人。, 2008; Hayasaka & Laurienti, 2010). 此外,
our study on network modules, or communities of highly interconnected nodes, 表明的
that some building blocks of resting-state functional brain networks exhibited remarkable
consistency across subjects (Moussa et al., 2012). It has also been shown that such consistent
organizations differ under different cognitive states (Deuker et al., 2009; Moussa et al., 2011;
Rzucidlo et al., 2013) or in different groups of subjects (巴塞特 & 布莫尔, 2009; Burdette
等人。, 2010; 刘等人。, 2008; Meunier et al., 2009A; Rombouts et al., 2005; Stam等。, 2007;
袁等人。, 2010). 因此, an analysis method sensitive to such differences in spatial locations
or patterns can assess network differences across the entire brain (as opposed to univariate
edge-by-edge or node-by-node comparisons). Toward this end, in previous work we
developed a permutation testing framework that detects whether the spatial location of
网络特性 (such as the location of high degree nodes) mapped back into brain space
differs between two groups of networks, and whether distributions of topological properties
vary by group (Simpson et al., 2013乙). Despite the utility of this method, it has two major
weaknesses. 第一的, it cannot account for confounding variables. This means that while we
can compare maps of hub regions, 例如, between two populations, we cannot control
for differences in characteristics such as age or education. 第二, the method relies on
dichotomous grouping to make comparisons. When making comparisons between groups with
clear divisions (male vs. 女性), this is not an issue. 然而, it is impossible to assess if there is
a significant relationship between network hub location and continuous measures, 例如
intelligence quotient (IQ) score or age.
To address these limitations, we propose an innovative regression framework to relate dis-
tances between brain network features to functions of absolute differences in continuous
covariates and indicators of difference for categorical variables. We will consider several
different types of metrics for establishing distances (IE。, similarity/dissimilarity) 之间
网络. The first type compares degree distributions. We accomplish this by summarizing
similarities in nodal cumulative degree distributions across multiple networks with the
Kolmogorov–Smirnov statistic (K-S statistic), a measure that quantifies the distance between
two cumulative distribution functions (洞, 1933; Smirnov, 1948). The second type
takes into account consistency of key node sets. We do so by summarizing similarities in node
sets across multiple networks with the Jaccard distance (or Jaccard index), a metric that quan-
tifies difference (or similarity) in partitions of a set (Joyce et al., 2010; Meunier et al., 2009乙).
The third type of metric measures similarity of nodal degree by employing Minkowski or
Canberra distances between nodal degree vectors (Lance & 威廉姆斯, 1966).
Within our regression framework we adapt several methods for estimation and inference:
standard F test, F test with individual level effects (ILE), feasible generalized least squares
(FGLS), and permutation. Each observation in the regression framework includes a “distance”
between two individuals, so observations that share individuals are correlated. 因此, the stan-
dard F test is generally not appropriate but presented for comparison. The other methods
attempt to deal with this correlation: (A) F test with ILE—including fixed individual level effects
within the regression, possibly rendering the F test valid; (乙) mixed model—including random
individual level effects; (C) FGLS—proposing an artful way to estimate the covariance matrix
(固执的, 1936); 和 (d) Permutation—similarity and distance metrics have unknown
50
Permutation testing framework:
A method to test statistical
significance by permuting labels.
Mixed model:
Statistical model containing both
固定的 (population-level) 和随机
(individual-level) effects used to
model multivariate data.
网络神经科学
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
Degree distribution:
The probability distribution of the
degree of nodes across a network
(np
2 ): mathematical notation for
“np choose 2,” which represents the
number of pairs one could choose
amongst the np, 数量
参与者.
分布; 因此, a permutation test may be most appropriate (Simpson et al., 2013乙). 每-
mutation tests for these models require permuting the residuals, and we will adapt recent
methods to implement this approach (Kherad-Pajouh & Renaud, 2010, 2014).
在本文中, we detail our proposed regression framework, and discuss several methods for
estimation and inference to be used on a variety of network similarity/dissimilarity metrics. 我们
assess all combinations of methods and metrics within this framework by using simulated fMRI
data with known differences in connectivity matrix distributions. We then apply our frame-
work to functional brain networks derived from the HCP dataset to investigate the relationship
between fluid intelligence and network distances after accounting for known confounders.
方法
Please note the following notational choices: bold font is used to denote vectors or matrices, n =
(np
2 ) = number of observations, np = number of participants, nn = number of nodes, p = number
of covariates (including intercept, if included).
步 1: Network Construction
Assuming fMRI connection matrices have already been obtained (见图 1), let Ci represent
a weighted nn × nn connection matrix for individual i, with matrix entries ranging from 0 (印迪-
cating no connection between the respective nodes) 到 1 (strongest connection). We only con-
sidered undirected networks, so matrices were symmetric, with the number of row = number of
columns = number of nodes (methods are easily adaptable if directed networks are desired).
Let bi represent an nn × 1 binary key node vector for individual i, with an entry of 1 代表-
senting a key node and 0 a node that is not key. As stated in our previous work (Simpson et al.,
2013乙), key nodes can be identified based on nodal characteristics such as high degree, 高的
centrality, or other desired characteristics. Since key nodes were compared across subjects, 它
was important to employ the same criterion in all of the networks (例如, 顶部 10% highest cen-
trality, node degree >200, ETC。). 或者, key nodes can be identified as those belonging
to a particular module or network community, a collection of highly interconnected nodes.
The resulting key nodes would form a set, and the consistency of the spatial location of the
Schematic for generating brain networks from fMRI time series data—recreated from
数字 1.
(Fornito et al., 2012; Simpson et al., 2013A). Functional connectivity between brain areas is esti-
mated based on time series pairs to produce a connection matrix. A threshold is commonly applied
to the matrix to remove negative and/or “weak” connections.
网络神经科学
51
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
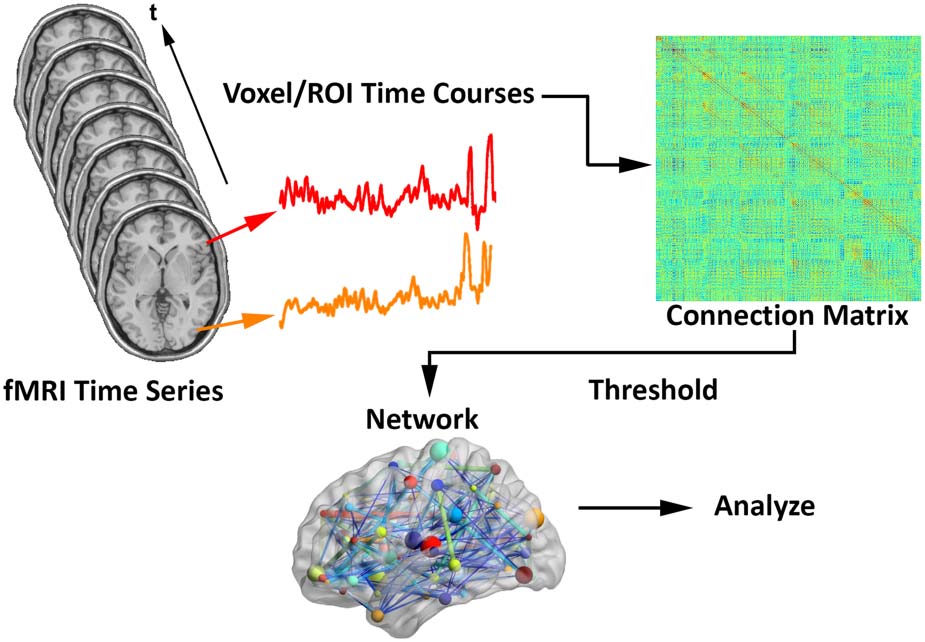
Example visualization of key node sets from voxel-based networks in brain space. The 3D brain images (顶部) are three represen-
数字 2.
tative subjects from each group with the key node sets defined to be those with the top 20% highest degree. Overlap maps (底部) show the
proportion of subjects with key nodes in given areas. Figure recreated from Simpson et al. (2013乙).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
nodes could be compared across groups. An example visualization of key node sets from
voxel-based networks in brain space is given in Figure 2.
We constructed an nn × 1 weighted nodal degree vector di by summing Ci over its rows (或者
equivalently, 列). Each entry in vector di represented the “degree” of its respective node
for individual i. It should be noted here that when the binary key node vector has to do with
node degree, 说 20% highest degree as will used later, bi is just a binarized version of di.
As was described for the binary key node vector in the last paragraph, other weighted nodal
vectors could have been used. 为简单起见, we focused on degree within the methods and
simulation sections. It should also be noted that none of the methods employed here are spe-
cific to nodal vectors. 那是, these methods could also be implemented on differences
between connection matrices, 例如.
步 2: Establish Similarity/Dissimilarity Between Networks
This section covers some of the metrics we used to gauge distances between individual net-
works given the insight they can provide into brain network organizational differences.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Kolmogorov–Smirnov (KS) 统计. Degree distributions, which help quantify the topology of
网络, are likely more similar within distinctive groups than they are between these groups.
We employed the log of the KS statistic to quantify this potential dissimilarity.
(西德:1)
log KSij
(西德:3)
(西德:1)
(西德:4)
(西德:4)
(西德:4)
(西德:4)
¼ log supx Fi xð Þ − Fj xð Þ
(西德:3)
Empirical distribution function:
Estimate of the cumulative
distribution function using the data.
KSij, a scalar, is the Kolmogorov–Smirnov statistic between nodal degree distributions for indi-
viduals i and j. fi(X) represents the empirical distribution function for observations from the
nodal degree vector di. 所以, supx|fi(X) − Fj(X)| gives the biggest difference between the
empirical degree distributions between individuals i and j. Bigger values indicate more
差异.
Logarithmic transformation:
Taking the log of a variable.
A note on the logarithmic transformation of the KS statistic: when all distances are nonneg-
很重要, it is common practice to take a log transformation. Within our simulations, KS was the
网络神经科学
52
A regression framework for brain network distance metrics
力量:
Probability of correctly rejecting the
null hypothesis.
only metric that saw improvements in power or type I error when taking such a transformation.
For ease of interpretability, none of the other distances presented here utilized a logarithmic
转型.
JDij ¼ M01 þ M10
M11 þ M01 þ M10
JDij, a scalar, is the Jaccard distance ( JD) between two (二进制) key node
Jaccard distance.
vectors of individuals i and j, 双, and bj. M11 is the number of nodes such that bi and bj both
have a value of 1, M01 is the number of nodes where bi = 0 and bj = 1, and M10 is the number
of nodes where bi = 1 and bj = 0. JDij gives the proportion of key nodes (in either set) that do
not share key status between individuals i and j. Values of JDij range from 0 (perfect overlap)
到 1 (no overlap).
JIij ¼ 1 − JDij ¼
M11
M11 þ M01 þ M10
JIij, a scalar, is the Jaccard index ( JI) between two (二进制) key node vectors of
Jaccard index.
individuals i and j, 双, and bj. JIij gives the proportion of nodes that share key status between
individuals i and j. Values of JIij range from 1 (perfect overlap—key node networks that are the
相同的) 到 0 (no overlap). Although the JI simply equals 1 − JDij, it is included here to compare a
distance and similarity metric.
(西德:5)
(西德:5)
Eij ¼ di − dj
(西德:5)
(西德:5)
2
¼
X# of nodes
k¼1
!1
2
jdi k½
(西德:2) − dj k½
(西德:2)J2
Euclidean distance. Eij, a scalar, is the Euclidean distance between nodal degree vector i and
nodal degree vector j, where di[k] represents the degree of node k for individual i. Bigger
values of Euclidean distance indicate more dissimilarity.
See the Supporting Information for Minkowski distance and Canberra distance.
步 3: Evaluating Differences Between Networks
Distij ¼ X T
IJ;conβcon þ X T
IJ;coi
b
coi
þ εij
Standard F test. Distij represents the distance between nodal vectors of individuals i and j.
Distij is a generic placeholder for any metric outlined previously in Step 2, 那是, JD ( JDij), KS
统计 (KSij), Minkowski distance (Mp
IJ ), or Canberra distance (Cij).
X T
IJ;骗局, 一个 1 × (p − 1) 向量, contains the intercept and differences in confounding covar-
iates (例如, for our data, 性别, educational attainment, 年龄, and body mass index) between indi-
viduals i and j (with corresponding unknown ( p − 1) × 1 parameter vector β
骗局) to control for
differences that may confound the relationship between the covariate of interest and the given
距离.
X T
IJ;coi, a scalar, contains the difference in the covariate of interest (or an indicator of different
group membership for group-based analyses) between individuals i and j (with corresponding
unknown parameter βcoi).
网络神经科学
53
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
Splitting the design matrix X, an n × p matrix, into confounding and of interest covariates is
IJ;coi can be combined into the 1 × p vector X T
purely a notational preference. X T
(with corresponding unknown p × 1 parameter vector β).
IJ;con and X T
IJ
εij accounts for the random error in the distance ( 贾卡德, KS, ETC。) 价值. If εij were inde-
pendent, homoscedastic, and approximately normally distributed, the F test of a standard lin-
ear regression would be an appropriate test. We expect correlation among observations from
the same individual, so we included this standard testing procedure here mainly for
比较.
举个例子, to test whether there is an association between IQ (连续的) 和
spatial consistency of hub nodes (顶部 20% highest degree) after controlling for age (continu-
乌斯), 性别 (二进制), and treatment (二进制) 地位, our model would be
(西德:7)
(西德:6)
þ 1 Sexi
(西德:6)
þ 1 Trti
6¼ Sexj
6¼ Trtj
þ IQi − IQj
þ Agei − Agej
JDij ¼ β
þ εij
(西德:4)
(西德:4)
(西德:4)b
(西德:4)
(西德:4)b
(西德:4)
(西德:4)
(西德:4)
b
(西德:7)
(西德:4)
(西德:4)
b
3
0
1
2
4
with the associated null hypothesis H0: β4 = 0.
Dist ¼ X T β þ ID1α1 þ … þ IDnp
αnp
þ (西德:2)
Standard F test with individual level fixed effects (F test with ILE). Dist is an n × 1 vector of known
distance metrics (as outlined in Step 2), XT is the n × p design matrix (intercept optional) 的
known covariates with corresponding p × 1 unknown parameter vector β, IDi is the n × 1
known indicator variable for individual i with corresponding unknown parameter αi. 经过
accounting for individual level effects, we hope to induce independence, homoscedasticity,
and normality for the error terms within the n × 1 random vector (西德:2). This would (潜在地)
allow for an F test to appropriately evaluate the covariates of interest.
Random effect:
Variable whose effect varies across
个人.
Fixed effects:
Variables whose effects are constant
across individuals.
It should be mentioned that we attempted a mixed model formulation
Mixed model approach.
where each individual had their own random effect and all other covariates had fixed effects
(where Dist = XTβ + ID1b1 + ⋯ + IDnpbnp + (西德:2) and bi ∼ N(0, G) 我所有). We also attempted bi ∼
氮(0, gi) 我所有. 很遗憾, these calculations were too computationally intensive in the
simulations we ran (using the lmer function of the R package lme4; Bates等。, 2015). 反而,
we tried a generalized least squares approach outlined in the next section.
Dist ¼ X T β þ (西德:2)
Feasible generalized least squares. Dist and XTβ (intercept included) are as before, 但反而
we assume (西德:2) ~ (0, (西德:2)), 在哪里 (西德:2) is the n × n covariance matrix. Generalized least squares (GLS)
allows for estimating parameters when there is correlation among the residuals in ordinary
least squares regression. 然而, GLS requires (西德:2) 被知道. An unrestricted n × n covari-
ance matrix has n(n + 1)/2 parameters to estimate. This is infeasible as we only have n obser-
vations. 因此, we restricted the form of (西德:2) in order to estimate it. For a detailed explanation,
please see Supporting Information.
Permutation test. A permutation test requires no knowledge of how the test statistic of interest
is distributed under the null hypothesis (例如, H0: no significant difference among IQ). dis-
tribution under the null hypothesis is empirically “generated” by permuting data labels. 我们
employed the Freedman–Lane approach (弗里德曼 & Lane, 1983; Kherad-Pajouh & Renaud,
2010) using the lmperm function in the R package permuco (霜冻 & Renaud, 2019A) 和
10,000 permutations, while permuting across individuals to preserve exchangeability. 为一个
网络神经科学
54
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
detailed explanation, please see Supporting Information as well as the package vignette for
permuco (霜冻 & Renaud, 2019乙).
Multivariate distance matrix regression. Multivariate distance matrix regression (MDMR) 是一个
existing method that has been included here for comparison. It tests the significance of asso-
ciations of response profile (迪斯)similarities and a set of predictors. Originally this was done
using only permutation (安德森, 2001), but has been extended to analytic p values as well
(McArtor et al., 2017). MDMR was run using the mdmr function in the MDMR package in R
(McArtor, 2018). Both the permutation and analytic versions were run with the np × np dis-
tance matrix D (the distance matrix analog of Dist) and the np × p design matrix Xp (协变量
of interest for each participant). The permutation method was run with 10,000 permutations.
SIMULATION STUDIES
The following simulation study is done using a factorial approach. There are four different set-
tings (named Simulations 1–4). For each simulation setting, we explore four different metrics
(KS, JD, JI, and Euclidean). For each simulation and metric combination, six different methods
被考虑 (permutation, F test, FGLS, F test ILE, MDMR analytic, and MDMR permuta-
的). Subsequent sections will present details and results for each of these “factors.”
数据
We conducted four simulation settings to assess how well our proposed approaches could
detect various relationships between brain network properties and covariates of interest. 每个
simulation contained 100 主题, with four covariates of interest. A fair coin was flipped
for each subject to determine their sex (SEX = male or female). Half of subjects were
assigned to treatment and the other half were assigned to placebo (TRT = treatment or pla-
cebo). IQ and age were both simulated from a normal distribution with mean of 100 和
标准偏差 15 (rounded to the nearest integer). This resulted in two binary (SEX,
TRT ), and two continuous (年龄, IQ) covariates—variables were given names purely for pur-
poses of explication.
For Simulations 1–3, we simulated fMRI connectivity matrices with 268 nodes each to
mimic the experimental data detailed in the next section. In each simulation, A 268 × 268
symmetric matrix (with entries ranging from 0 到 1) was generated for each subject. Entries
within each connectivity matrix were drawn from three types of distributions: (A) a low-
connectivity noise beta distribution, Beta(4
3, 6); (乙) a high-connectivity noise distribution,
Beta(4, 6); 和 (C) a signal distribution dependent on covariates and signal percentage, Beta(sp ·
人工智能 + (1 − sp) · 4
3, 4 + (IQ1 − 100) * .2 + (Trti = = “Treatment”) * 6) represented the
covariate-dependent parameter and sp represented the signal percentage (从 0 到 100%).
When the signal percent (sp) 曾是 100%, Beta(sp · ai + (1 − sp) · 4
3, 6) = Beta(人工智能, 6). 相似地, 什么时候
signal percent was 0%, Beta(sp · ai + (1 − sp) · 4
3, 6) = Beta(4
3, 6), and was therefore identical to the
noise distribution and no longer dependent on covariates.
3, 6), where ai = max(4
Simulation 1 有一个 15 × 15 region where all individuals had the same high-connectivity
noise distribution, A 15 × 15 region where the signal distribution was dependent on covariates,
and the rest of the 268 × 268 connection matrix was drawn from the low-connectivity noise
分配. Simulation 2 was the same as 1, but the signal distribution dependent on covar-
iates was moved to expand the border of the 15 × 15 high-connectivity signal distribution to a
合并的 21 × 21 地区. Simulation 3 was the same as 1, with two additional 15 × 15 地区
where all individuals had the same high-connectivity distribution. For a drawn to scale
Fair coin:
A coin which has a 50% chance of
landing on either side.
Symmetric matrix:
A matrix which entry aij = aji for all
i and j. In the connectivity matrix
空间, this lets us know we are
considering an undirected network.
Beta distribution:
A family of continuous probability
distributions defined on the closed
间隔 [0, 1].
网络神经科学
55
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
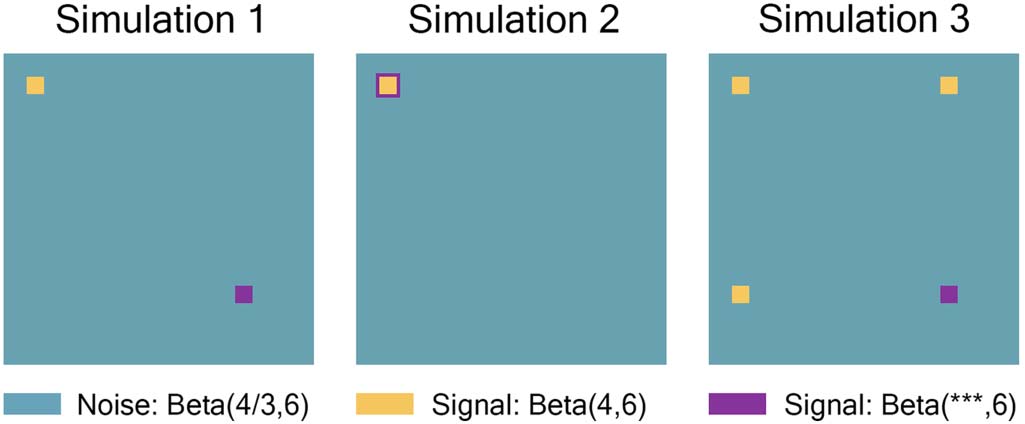
数字 3. Simulation 1 有一个 15 × 15 region where all individuals had the same high-connectivity
noise distribution (shown in yellow), A 15 × 15 region where the signal distribution was dependent
on covariates (shown in purple), and the rest of the 268 × 268 connection matrix was drawn from
the low-connectivity noise distribution (shown in teal). Simulation 2 was the same as 1, 但是
signal distribution dependent on covariates was moved to expand the border of the 15 × 15
high-connectivity signal distribution to a combined 21 × 21 地区. Simulation 3 是一样的
作为 1, with two additional 15 × 15 regions where all individuals had the same high-connectivity
分配. It should be noted that we assumed the connectivity matrices to be symmetric, 和
0 entries along the diagonal. The plots were drawn to scale.
representation of these simulations, 见图 3. It should be noted that we assumed the con-
nectivity matrices to be symmetric, 和 0 entries along the diagonal.
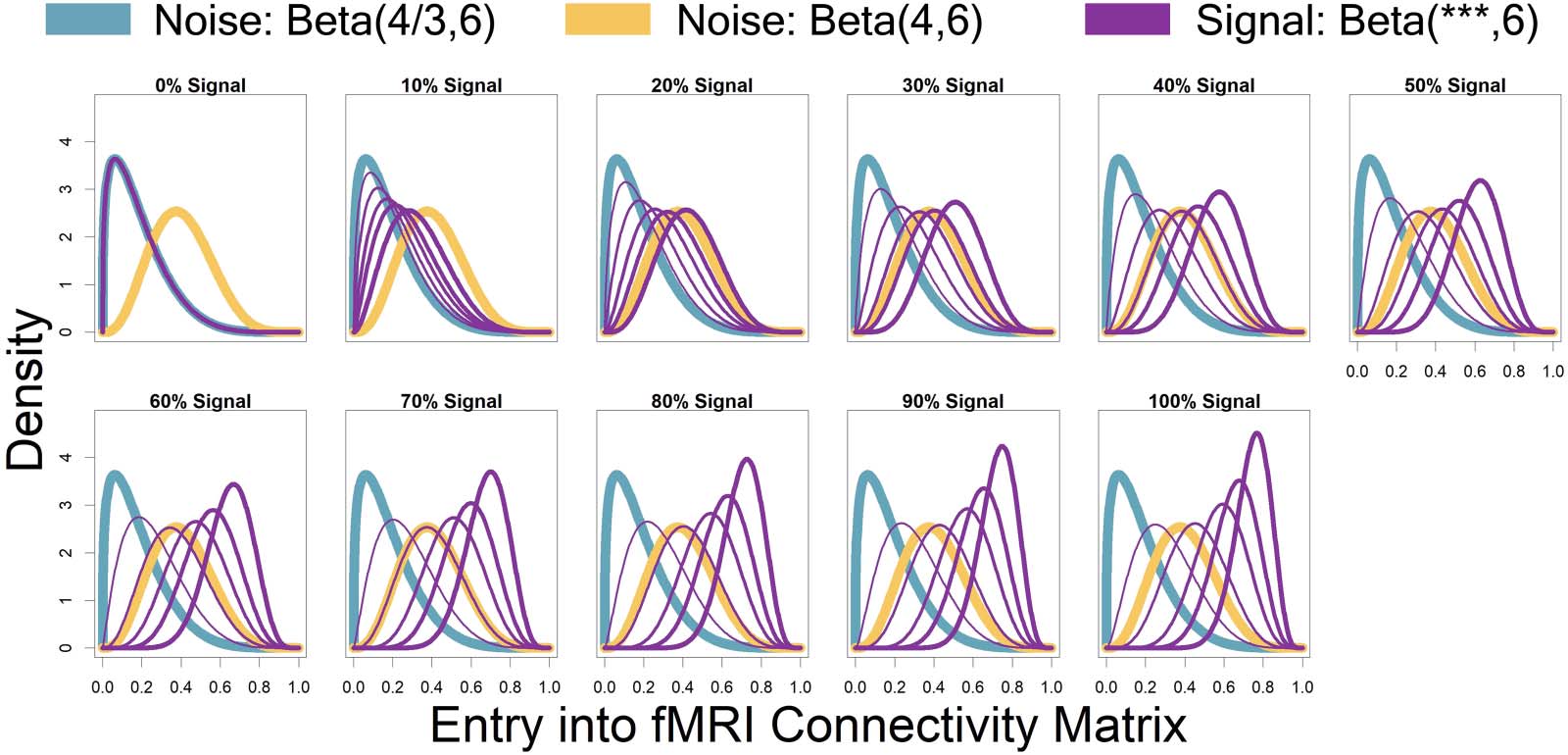
Represented by the same colors from Figure 3 simulated connectivity matrices, 数字 4
displays the distributions used for those matrices as signal percentage increased. The low-
connectivity noise distribution was distributed Beta(4/3, 6) and was shown in teal (not affected
by signal percentage). The high-connectivity noise distribution was distributed Beta(4, 6) 并且是
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
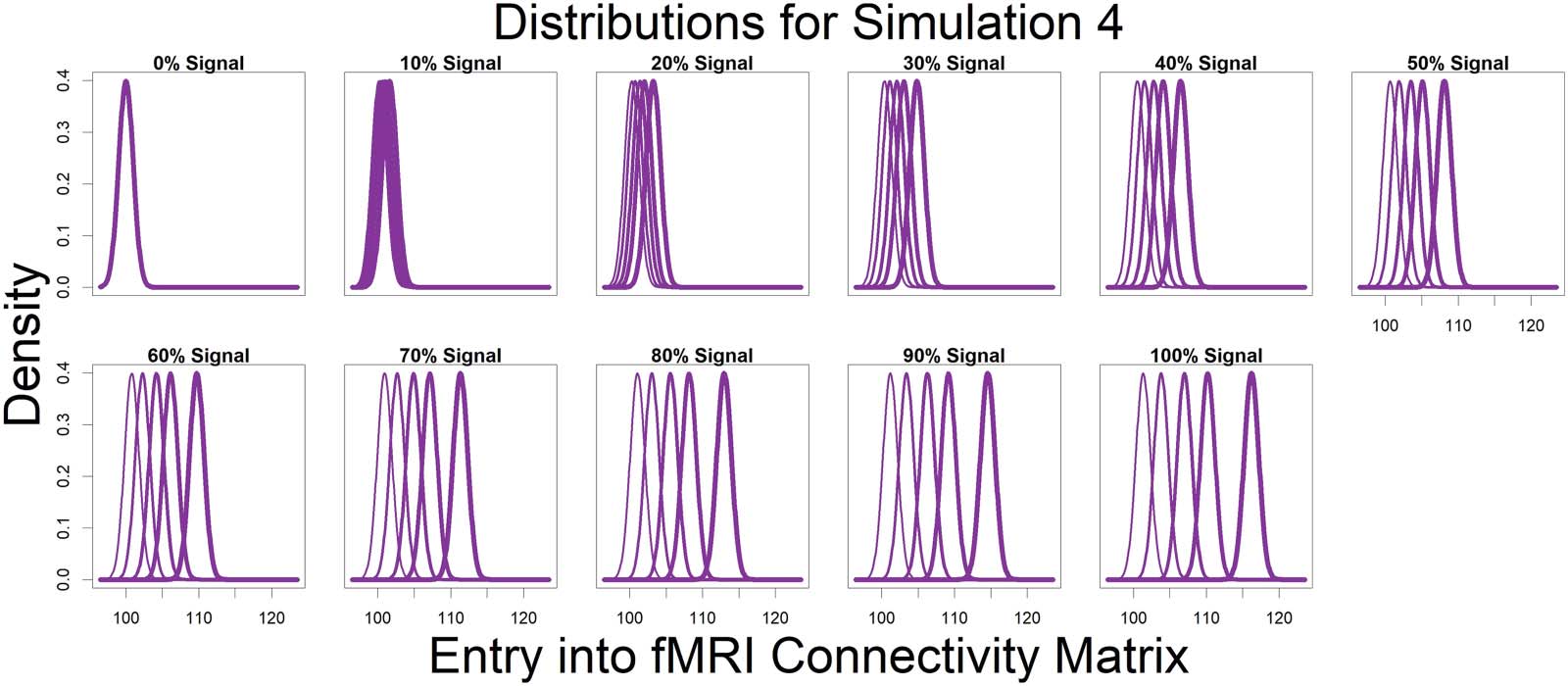
数字 4. Represented by the same colors from Figure 3 simulated connectivity matrices, displayed here are the distributions used for those
matrices as signal percentage increased. The low-connectivity noise distribution was distributed Beta(4/3, 6) and was shown in teal (不是
affected by signal percentage). The high-connectivity noise distribution was distributed Beta(4, 6) and is in yellow (not affected by signal
百分比). The “covariate-dependent” signal region can be seen in purple and was distributed Beta(***, 6). 这 *** parameter had some
distribution based on the underlying covariate distribution and signal percentage. There are five purple distributions in each plot representing
这 0.01, 0.25, 0.5, 0.75, 和 0.99 分位数 (shown in increasing thickness) 从 *** 分配 (例如, 这 0.25 quantile distri-
bution is represented by an individual with an IQ of 69 and a “Treatment” status or an individual with an IQ of 99 and a “Placebo” status; 这
0.75 quantile distribution is represented by an individual with an IQ of 101 and a “Treatment” status or an individual with an IQ of 131 和
“Placebo” status). 此外, the “covariate-dependent” (purple) signal region’s distribution goes from being the same as the low-
connectivity noise region’s distribution (在 0% 信号) to more and more different than the noise region’s distribution as signal percentage
增加.
网络神经科学
56
A regression framework for brain network distance metrics
黄色 (not affected by signal percentage). The “covariate-dependent” signal region can be
seen in purple and was distributed Beta(***, 6). 这 *** parameter had some distribution based
on the underlying covariate distribution and signal percentage. There are five purple distribu-
tions in each plot representing the 0.01, 0.25, 0.5, 0.75, 和 0.99 分位数 (shown in increasing
thickness) 从 *** 分配 (例如, 这 0.25 quantile distribution is represented by
an individual with an IQ of 69 and a “Treatment” status or an individual with an IQ of 99 和
“Placebo” status; 这 0.75 quantile distribution is represented by an individual with an IQ of 101
and a “Treatment” status or an individual with an IQ of 131 and a “Placebo” status). 此外,
the “covariate-dependent” (purple) signal region’s distribution goes from being the same as the
low-connectivity noise region’s distribution (在 0% 信号) to more and more different than the
noise region’s distribution as signal percentage increases.
For Simulation 4, we simulated nodal degree vectors of length 268 (而不是 268 × 268
connectivity matrices as in Simulations 1–3) to assess the method’s ability to detect distribu-
tional differences rather than location differences. All entries of each individual’s degree vector
were simulated Normal(100 + sp · ai, 1), where sp (signal percent) and ai (covariate-dependent
parameter for individual i) were as described with Simulations 1–3. Within Figure 5, 有
five purple distributions in each plot, 代表 0.01, 0.25, 0.5, 0.75, 和 0.99 分位数
(shown in increasing thickness) from the distribution of the mean parameter, 100 + sp · ai. 在
0% 信号, all individual’s nodal degree vectors were drawn from Normal(100, 1). As signal
percentage increased, the mean parameter of the covariate-dependent distributions became
more and more distinct.
结果
We assessed methods with the four simulation scenarios detailed in the previous section. 每个
simulation was run 10,000 次. Nodal degree vectors (used for the KS and Euclidean dis-
坦斯) were created by summing across rows of the connectivity matrices. Key nodes of inter-
东方 (binary degree vectors used for the JD and JI) based on node degree were identified,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 5. For simulation 4, we simulated nodal degree vectors of length 268 (而不是 268 × 268 connectivity matrices as in Simulations 1–3)
to assess the method’s ability to detect distributional differences rather than location differences. All entries of each individual’s degree vector
were simulated Normal(100 + sp · ai, 1), where sp (signal percent) and ai (covariate-dependent parameter for individual i) were as described
with Simulations 1–3. There were five purple distributions in each plot, 代表 0.01, 0.25, 0.5, 0.75, 和 0.99 分位数 (shown in
increasing thickness) from the distribution of the mean parameter, 100 + sp · ai. 在 0% 信号, all individual’s nodal degree vectors were
drawn from Normal(100, 1). As signal percentage increased, the mean parameter of the covariate-dependent distributions became more and
more distinct.
网络神经科学
57
A regression framework for brain network distance metrics
selecting the top 20% highest degree (hub) nodes and mapping those to 1 while mapping all
remaining nodes to 0. The KS statistic and Euclidean distance were calculated for each pair of
individuals using their nodal degree vectors. The JD and JI were calculated for each pair of
individuals using their binary degree vectors.
The percentages of p values less than α = 0.05 for the covariates of interest were recorded
for each combination of signal percent (0%, 10%, ……, 100%), distance metric (KS, JD, JI, Euclid-
ean), and testing framework (F test, permutation, GLS, F test with individual level effects,
MDMR analytic and MDMR permutation). 在这个部分, we discuss whether type I error
rate was controlled and at what signal percent the 80% power threshold was reached. 然后,
we compare results with MDMR. For a visual display of the results, 见图 6. For more plots
and a visual display with additional distance metrics, please see Supporting Information. 这
standard F test did not control type I error when testing age. It was included in the Figure for
参考, but is not mentioned any further in this section.
Type I error rate:
Probability of incorrectly rejecting
the null hypothesis.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
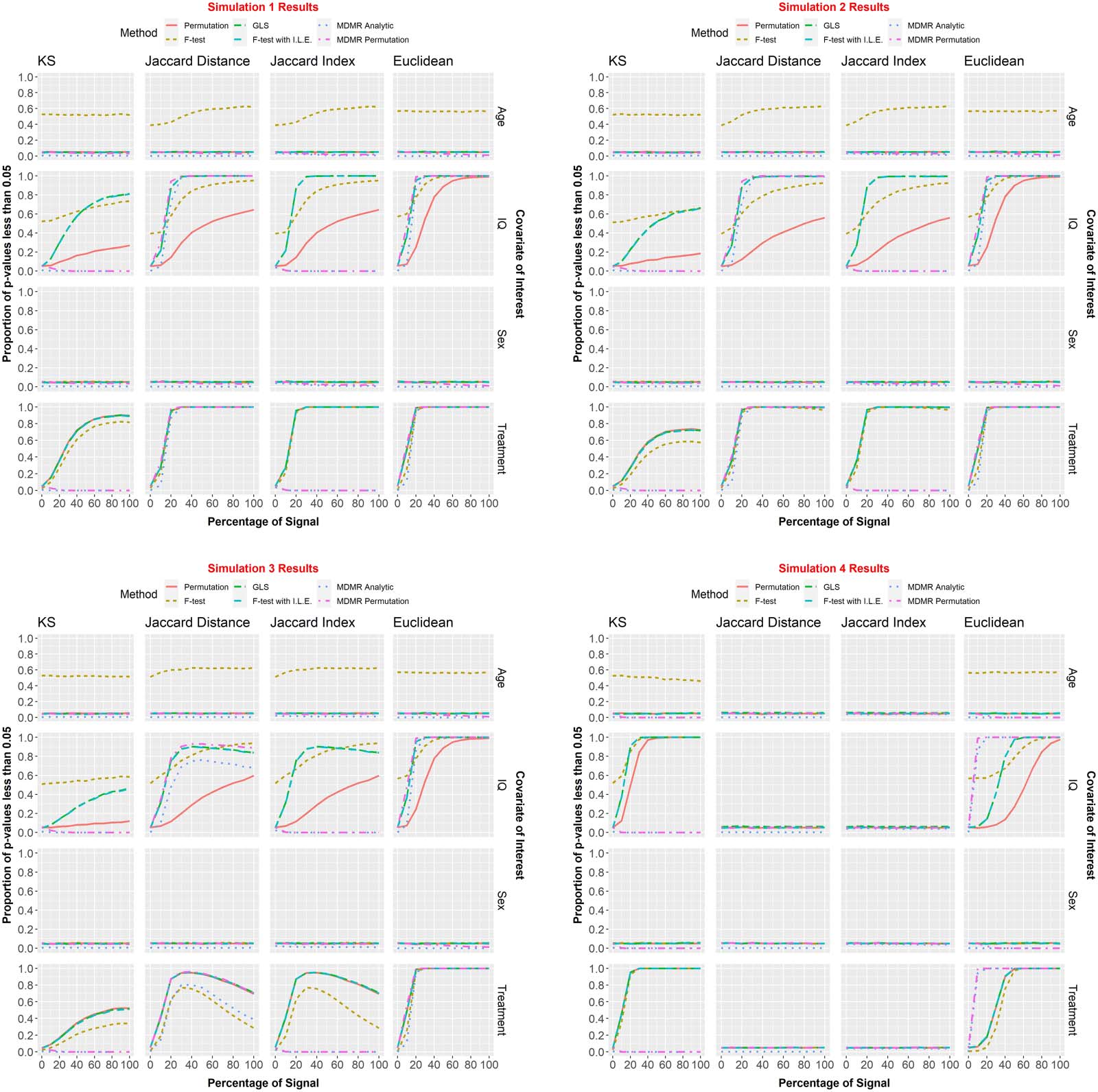
数字 6. We assessed methods with the four simulation scenarios detailed in the Results section. Each simulation was run 10,000 次. 这
percentages of p values less than α = 0.05 for the covariates of interest were recorded for each combination of signal percent (0%, 10%, ……,
100%), distance metric (KS, JD, JI, Euclidean), and testing framework (F test, permutation, GLS, F test with individual level effects, MDMR
analytic and MDMR permutation). It should be noted here that Age and Sex are “null” covariates (that have no bearing on the data generating
过程) and are included to assess type I error control of the methods on both continuous and categorical variables.
网络神经科学
58
A regression framework for brain network distance metrics
Kolmogorov–Smirnov statistic. For the KS metric, all methods (not including F test) adequately
controlled type I error. For Simulation 1, the GLS and F test with ILE methods reached 80%
power within 100% of signal for continuous covariates. The Permutation method never
到达 80% power for continuous covariates. For binary covariates, all four methods reached
80% power within 60% of signal. For Simulations 2–3, no methods reached 80% power at any
level of covariate-dependent signal. For Simulation 4, the GLS and F test with ILE methods
reached the power threshold within 20% of signal. Permutation reached the threshold within
30% of signal. All three methods controlled type I error.
Jaccard distance and Jaccard index. Please note, p values for all methods used within our
regression framework were the same whether the JD or the JI were used (this is not true
of the MDMR methods). For the JD and JI, all methods (not including F test) adequately
controlled type I error. For Simulations 1–3, IQ, the GLS and F test with ILE methods
reached the power threshold within 20–30% of signal; the permutation method never
reached the minimum power requirement. For Simulations 1–3, Treatment, the GLS, F test
with ILE, and Permutation methods reached the power threshold within 20% of signal.
出奇, as signal percentage increased, some situations had decreasing power with
some even falling far back below the power threshold. This only occurred with the Jaccard
指标. For Simulation 4, no methods could detect significance. All methods’ power levels
hovered around α = 0.05, the significance level. This behavior was expected. For a given
个人, all entries of the nodal degree vector are drawn independently and identically
分散式 (iid). 然后, highest valued entries of the vector are selected as key nodes.
Because all nodes are iid, the distribution set of “key nodes” is uniform on its support. 尽管
the centrality parameter of the distribution varies from person to person based on their
协变量, this location shift is effectively canceled out by the binarization. 因此, a differ-
ence in the mean of the distributions does not lead to a difference in the distribution of the
key node vectors, and so it is unsurprising that the power in this setting appears to be 5%. 它
is not that the Jaccard is causing power issues here, 相当, it is because the null is actually
true here.
Euclidean. For the Euclidean metric, all methods (not including F test) adequately controlled
type I error. For Simulations 1–3, IQ, the GLS and F test with ILE methods reached the power
threshold within 20% 信号. The permutation method reached the minimum power require-
ment within 50% of signal. For Simulations 1–3, Treatment, all methods reached the power
threshold within 20% 信号. For Simulation 4, IQ, the GLS and F test with ILE methods
reached the power threshold within 50% 信号. The permutation method reached the mini-
mum power requirement within 80% of signal. For Simulation 4, Treatment, all methods
reached the power threshold within 40% 信号.
Comparison with MDMR. For KS and JI, neither MDMR permutation nor MDMR analytic had
adequate power for the KS statistic. Our approaches vastly outperformed them for all simula-
tion scenarios. For Simulations 1–3, JD and Euclidean, the MDMR permutation method had
comparable power with the GLS and F test with ILE methods, while MDMR analytic had
slightly less power. For Simulation 4, 贾卡德, see explanation in section JD and JI above.
For Simulation 4, Euclidean, both MDMR methods had considerably more power than any
of the methods within our framework. MDMR analytic type I error rate remained close to 0
for all simulations. MDMR permutation started off with the expected type I error rate of approx-
立即地 0.05, but as signal increased, type I error rate approached 0 还有.
网络神经科学
59
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
EXPERIMENTAL STUDIES
数据
The HCP data released to date include 1,200 个人 (Van Essen等。, 2013). 那些,
1,113 (606 女性; 283 少数民族) have complete MRI images, cognitive testing, and detailed
demographic information. 这 397 subjects used are what remained after quality control
assessment of head motion and global signal changes for both scan types, removal of those
with missing data, and random selection of one individual from each family to ensure
between-subject independence. Participants in the HCP completed two resting-state scans
and two working memory scans. The two scans were collected with different phase encoding
(right to left vs. left to right). The resting-state scans were collected back-to-back while partic-
ipants quietly viewed a fixation point. The 2-back task was a block design that interleaved the
2-back condition with a 0-back condition and a rest period. The working memory task utilized
photos and different blocks had different photo types (面孔, 身体部位, 房屋, 和工具).
Participants were alerted prior to each block to indicate the task type. For the 2-back they were
instructed to respond anytime the current stimulus being presented matched the stimulus two
trials back. The HCP performed extensive testing and development to ensure comparable
imaging at the two sites (Van Essen等。, 2012). The blood oxygenation level-dependent
(大胆的)–weighted images were collected using the following parameters: TR = 720 多发性硬化症, =
33.1 多发性硬化症, 体素大小 2 MM3, 72 切片, 1,200 图片.
The main covariate of interest for this analysis was fluid intelligence. Other covariates
included in model formulation were age, body mass index (BMI), 教育, handedness,
收入, alcohol abuse, alcohol dependence, 种族, 种族, 性别, and smoking status. 为一个
summarization and explanation of the variables, 见表 1 和表 2.
Data Processing and Network Generation
The current project used the minimally processed fMRI data provided by the HCP (格拉瑟
等人。, 2013) for resting-state and working memory. Additional preprocessing steps included
motion correction using ICA-AROMA (Pruim et al., 2015), removal of the first 14 volumes from
each scan, and band-pass filtering (0.009–0.08 Hz) to remove physiological noise and low-
frequency drift. It was necessary to account for the block design of the working memory task.
第一的, the block design was modeled in SPM12, yielding regressors for the 0-back and rest
blocks as well as the cues. 此外, since each scan was collected twice with different
phase encoding, the scans were concatenated and a scan-specific regressor was added. 全部
桌子 1.
Summarization and explanation of HCP covariates treated as continuous (within the regression framework)
年龄
BMI
教育
Fluid intelligence
Handedness
收入
意思是 (标清)
28.7 (3.7)
26.5 (5.1)
15.0 (1.7)
17.3 (4.7)
65.1 (43.6)
5.0 (2.1)
笔记
In years
Body mass index
Integer values 11 到 17 (years pf education completed)
Integer valued from 4 到 24
Values range from −100 to 100 经过 5 (−100, −95, ……, 95, 100)
SSAGA income score – Total household income: <$10,000 = 1, 10K–19,999 = 2, 20K–29,999 = 3, 30K–39,999 = 4, 40K–49,999 = 5, 50K–74,999 = 6, 75K–99,999 = 7, >=100,000 = 8
网络神经科学
60
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
桌子 2.
Summarization and explanation of HCP covariates treated as categorical (within the regression framework)
Alcohol abuse
Alcohol dependence
种族
种族
性别
54 met the DSM4 criteria for alcohol abuse, 343 没有
28 met the DSM4 criteria for alcohol dependence, 369 没有
41 西班牙裔/拉丁裔, 351 Not Hispanic/Latino, 5 Unknown or Not Reported
1 是. Indian/Alaskan Nat., 31 Asian/Nat. Hawaiian/Other Pacific Is., 48 黑色的
or African Am., 13 超过一个, 10 Unknown or Not Reported, 294 白色的
207 女性, 190 男性
Smoking status
69 reported as still smoking, 328 没有
回归器, including the total gray matter, 白质, and cerebrospinal fluid signals and
realignment parameters were used in a single regression analysis. The residual signal following
regression of the extraneous variables was retained only for periods aligned with the 2-back
块. The blocks of data were then concatenated into a single time series containing 274
BOLD images. Resting-state data followed a similar pipeline, but without the task-specific
回归器. The resulting resting-state data contained 2,372 BOLD images. 预处理后,
the brain was parcellated into 268 regions as defined in the Shen Atlas (Shen等。, 2013), 和
the signal from all voxels within each region was averaged for each participant. A functional
network was constructed for each participant by computing the Pearson (满的) 相关性
between the resultant time series for each region pair. Negative correlation values were set
to zero because the neurobiological interpretation of positive and negative edges are very dif-
ferent (Parente et al., 2017; 施瓦茨 & McGonigle, 2011), and since the distributions of net-
work variables (such as degree) are different for positive and negative edges (Fraiman et al.,
2009; Saberi et al., 2021). Although negative correlations are not regularly used in network
神经科学, if they are used, positive and negative networks should be generated and
assessed separately (施瓦茨 & McGonigle, 2011). For the current work we focused on pos-
itive networks, but one could simply perform an additional analysis on negative networks
if so desired.
结果
Nodal degree vectors (used for the KS and Euclidean distances) were created by summing
across rows of the connectivity matrices. Key nodes of interest (binary degree vectors used
for the JD) based on node degree were identified, selecting the top 20% highest degree
(hub) nodes and mapping those to 1 while mapping all remaining nodes to 0. KS statistic
and Euclidean distance were calculated for each pair of individuals using their nodal degree
vectors. The JD was calculated for each pair of individuals using their binary degree vectors.
Distance covariates for each pair of individuals were calculated. A continuous variable’s
距离 (年龄, 例如) was calculated as |Agei − Agej| for the pair of individuals i and j. A
binary or categorical variable’s distance (教育, 例如) was calculated as 1{Edui ≠
Eduj} for the pair of individuals i and j.
We evaluated differences between networks using the standard F test with ILE, as it was the
best in our simulations at controlling type I error and providing sufficient power across all dis-
tance metrics (while also being computationally inexpensive). Parameter and standard error
estimates can be found in Supporting Information Tables S1 and S2. Each parameter estimate
represented the average amount the given brain distance metric (KS, 贾卡德, ETC。) 改变了
网络神经科学
61
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
P values for HCP resting-state and working memory brain scans when modeled with our
桌子 3.
given regression framework and tested using the standard F test with fixed individual level effects
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
笔记. Parameter estimates and standard errors can be found in Supporting Information.
based on a one-unit difference in the respective covariate, after controlling for other covari-
ates. A complete list of p values for both resting-state and working memory can be seen in
桌子 3. Given the high degree of dependence between these results, and the illustrative and
exploratory nature of our analysis, there have been no adjustments for multiple comparisons.
After adjusting for the other confounding variables, the covariate of interest, fluid intelli-
根杰斯, had a statistically significant relationship with all distance metrics (KS, JD, Euclidean)
for resting-state fMRI, and non-KS distance metrics for working memory fMRI. The level of
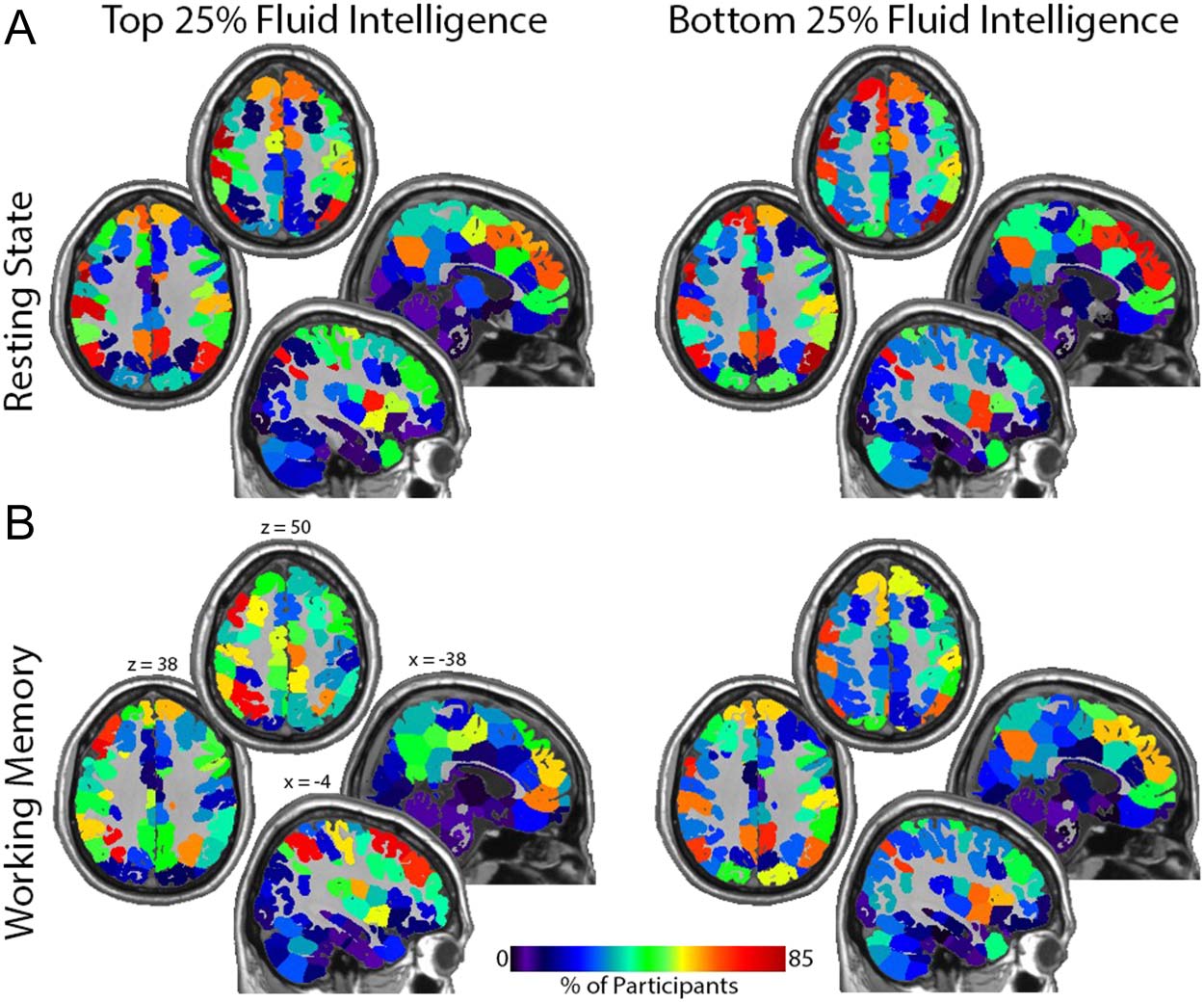
significance was considerably higher for the resting-state data. Figure 7A shows that the
resting-state spatial distribution of brain hubs are relatively concentrated in the brain regions
making up the default mode network (known to have high degree at rest). 然而, 有一个
higher concentration of hubs localized to the default mode network in the bottom quartile of
fluid intelligence compared to those in the top quartile. Figure 7B shows that hub locations
during the working memory task shift from default mode areas to regions that make up the
central executive attention network (CEN) more so in the top quartile of fluid intelligence.
Note that in those individuals in the bottom quartile of intelligence, the hubs are most
网络神经科学
62
A regression framework for brain network distance metrics
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 7. Maps showing the location of network hubs (顶部 20% 程度) for the top and bottom
intelligence quartiles. (A) Resting state: note the high incidence of hubs in the medial and lateral
parietal cortex and the medial frontal lobe in both groups. These regions are central components of
the default mode network. The significant association between degree location and intelligence is
demonstrated by the reduction in default mode network hubs with increases in fluid intelligence. (乙)
Working memory: hubs are more concentrated in the central executive network as intelligence
增加. This shift is best appreciated in the top quartile group where hubs are concentrated in
lateral rather than medial frontal regions and in more superior parietal areas. Note that the hubs
remain fairly localized to the default mode network for the bottom quartile group. Each quadrant
shows two axial and two sagittal images. The Montreal Neurological Institute (mni) 坐标
shown in the bottom left quadrant apply to all quadrants. Calibration bar applies to all images.
prominent in the areas of the default mode network even during the working memory task,
although the magnitude of the overlap is lower. The CEN maps onto what is sometimes
referred to as the fronto-parietal network. There is evidence that the density of structural con-
nectivity in that network predicts working memory capacity, with higher capacity individuals
exhibiting greater connectivity (Ekman et al., 2016).
Among the confounding variables, some had significant relationships with all distance met-
rics except for the JD (age and alcohol abuse within resting state). There were also certain
variables that were significant for one fMRI task but not the other (alcohol abuse, BMI, 和
教育). Some covariates were significant for all location-specific metrics but not for the
distance between distribution comparator KS statistic (BMI – rest; gender – rest and working
记忆; 年龄, fluid intelligence and race – working memory). This was indicative of a detect-
able difference in location-specific degree, but not in distribution.
In addition to our primary analysis detailed above, we also examined these relationships
with respect to differences in modularity between individuals employing scaled inclusivity,
given that modularity analyses can capture the spatial distribution of intrinsic brain networks
that are associated with various cognitive tasks (Moussa et al., 2012). The description of this
secondary analysis, along with the corresponding results and figures can be found in the Sup-
porting Information.
网络神经科学
63
A regression framework for brain network distance metrics
讨论
It is of great interest to compare differences in fMRI connection matrices between individuals
by covariates. Our previous work developed a novel permutation testing framework to detect
differences between two groups (Simpson et al., 2013乙). 这里, we advanced that work to
allow both assessing differences by continuous phenotypes and controlling for confounding
变量. We proposed an innovative regression framework to relate distances between brain
network features to functions of absolute differences in continuous covariates and indicators of
difference for categorical variables, and explored several similarity metrics for comparing dis-
tances between connection matrices. The KS statistic measures how different distributions of
topological properties vary between two individuals. Key node metrics (like the JD) quantify
how much the spatial location of key brain network regions differs between two networks. 这
Euclidean norm (along with Canberra, Minkowski, Weighted Jaccard, ETC。) measures whether
the spatial location of degree-weighted brain network regions differ. Several additional
similarity/dissimilarity metrics mentioned below were also assessed, but details were left out
for the sake of brevity. The binary network-based metrics left out included the Similarity
Matching, Russel-Rao, Kulczynski, and Baroni-Urbani and Buser. Little difference or improve-
ment was found (in Simulations 1–3) for any of these metrics when compared with the
commonly used Jaccard. The weighted network-based metrics left out included the Weighted
贾卡德, Manhattan, and Maximum distances, with none different or better than the already
presented Canberra or Minkowski distances (when tested in Simulations 1–3). Any other dis-
tance or similarity metrics could be used. Future work might include (A) testing other metrics,
(乙) further investigating the behavior of the Jaccard metric, 和 (C) taking a deeper dive into
understanding when and how to choose a distance metric.
Several standard methods for estimation and inference were adapted to fit into our regres-
sion framework: standard F test, F test with ILE, GLS, and permutation (inference only). 全部
combinations of these approaches and the distance metrics were assessed via four simulation
方案. The KS statistic was found to have low power (relative to the other distance metrics)
when testing location-specific differences. 然而, if interested in comparing distributions,
the KS statistic was preferred. The JD did not have consistent or predictable power, 还有
work should investigate the reasons underlying this. An argument could be made for several
different distance metrics when detecting location-specific differences between degree vec-
托尔斯, as they had very similar results. We prefer to use Euclidean distance, as it is commonly
recognized and had the best overall (轻微地) type I error control and power. Future work could
include a further investigation into how and when to choose specific distance metrics. 看待-
ing the comparison of estimation and testing methods (standard F test, F test with ILE, GLS,
permutation), we recommend the F test with ILE as it was among the best at controlling type
I error and providing sufficient power while also being computationally inexpensive.
An FGLS approach for estimation and inference was proposed in this framework.
Although it is slower (computationally) than the standard F test with ILE, the FGLS approach
performed just as well as the recommended Standard F test with ILE (in terms of type I and
type II error).
An analysis of the HCP data was completed using the standard F test with ILE and several
distance metrics. After adjusting for the other confounding variables, the covariate of interest,
fluid intelligence, was significantly related with all distance metrics (KS, 贾卡德, Euclidean) 为了
both fMRI tasks (休息状态, 工作记忆). This analysis suggested the hubs become
more strongly concentrated in default mode network regions at rest with decreasing fluid
智力. As intelligence increases, there are greater shifts in the spatial locations of hubs
网络神经科学
64
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
from the default mode network at rest to the central executive network during a working
memory task.
Many existing methods exist for relating network metrics and phenotypes. Such methods
包括, but are not limited to traditional network models (例如, exponential random graph
型号; Lehmann et al., 2021; Simpson et al., 2011, 2012), tensor regression works on brain
网络 (例如, 张等人。, 2018, 2019), Bayesian approaches (例如, 戴 & 郭, 2017; 王
等人。, 2017), statistical learning techniques (Craddock et al., 2015; Varoquaux & Craddock,
2013; Xia et al., 2020), and testing based on distance correlation (Székely et al., 2007; Székely
& Rizzo, 2009). We believe our method most closely relates to MDMR. MDMR tests the sig-
nificance of associations of response profile (迪斯)similarities and a set of predictors. 起初
this was done using only permutation (安德森, 2001) but has been extended to analytic
p values as well (McArtor et al., 2017). Via simulation, a comparison to our regression frame-
work showed that MDMR performs relatively well for the Euclidean and Jaccard distances (作为
well as other Minkowski distances—see Supporting Information) in terms of power. 然而,
its type I error rate properties were not well understood. For many covariates, 附近 0% 的
tests had p values less than 0.05. Further investigation should be done to better understand this
财产. 此外, MDMR was not able to detect differences on either the KS statistic or JI.
Our framework vastly outperformed MDMR for these two metrics for all simulation scenarios
except for Simulation 4/Jaccard in which the results were comparable (see section Jaccard
distance and Jaccard index in Results for an explanation).
We have developed a testing framework that detects whether the spatial location of key
brain network regions and distributions of topological properties differ by phenotype (继续-
uous and discrete) after controlling for confounding variables in static networks. 更多通用-
盟友, this framework allows relating distances between networks (例如, 贾卡德, KS distance) 到
covariates of interest. Our chosen method, F test with ILE, is computationally inexpensive,
generally interpretable, and well understood by most scientists. We believe this adds a con-
venient tool to the neuroscience toolbox. Future work plans to extend this approach by cre-
ating a dynamic network analog that uncovers whether within- and across-task time-varying
changes in these spatial and distributional patterns differ by phenotype.
致谢
The authors thank Hongtu Zhu, Professor of Biostatistics at University of North Carolina at
教堂山, for suggesting that we assess the logarithmic transformations of the distance met-
RICS. We also thank Dale Dagenbach, Professor of Psychology at Wake Forest University, 为了
his insights into interpreting our HCP results regarding IQ.
支持信息
本文的支持信息可在HTTPS上获得://doi.org/10.1162/netn_a_00214.
Simulation and HCP code is available: https://github.com/applebrownbetty/braindist_regression.
HCP data is publicly available for download.
作者贡献
Chalmer E. Tomlinson: 概念化; 数据管理; 形式分析; 调查;
方法; 项目管理; 资源; 监督; 验证; 可视化;
写作 - 原始草稿; 写作——复习 & 编辑. Paul J. Laurienti: 数据管理; 资源;
可视化; 写作 - 原始草稿; 写作——复习 & 编辑. Robert G. Lyday: 数据
策展; 可视化; 写作 - 原始草稿; 写作——复习 & 编辑. Sean L. 辛普森:
网络神经科学
65
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
概念化; 数据管理; 形式分析; 资金获取; 调查;
方法; 项目管理; 资源; 监督; 验证; 可视化;
写作 - 原始草稿; 写作——复习 & 编辑.
资金信息
Sean L. 辛普森, National Institute of Biomedical Imaging and Bioengineering (https://dx.doi
.org/10.13039/100000070), 奖项ID: R01EB024559. Sean L. 辛普森, Wake Forest Clinical
and Translational Science Institute, 奖项ID: NCATS UL1TR001420.
参考
固执的, A. C. (1936). On least-squares and linear combinations of
观察. Proceedings of the Royal Society of Edinburgh, 55,
42–48. https://doi.org/10.1017/S0370164600014346
安德森, 中号. J. (2001). A new method for non-parametric multivar-
iate analysis of variance. Austral Ecology, 26, 32–46. https://土井
.org/10.1111/J.1442-9993.2001.01070.PP.X
巴塞特, D. S。, & 布莫尔, 乙. 时间. (2009). Human brain networks in
health and disease. Current Opinion in Neurology. https://doi.org
/10.1097/ WCO.0b013e32832d93dd, 考研: 19494774
贝茨, D ., Mächler, M。, Bolker, B., & 沃克, S. (2015). Fitting linear
mixed-effects models using lme4. 统计软件杂志,
67, 1–48. https://doi.org/10.18637/JSS.V067.I01
Burdette, J. H。, Laurienti, 磷. J。, Espeland, 中号. A。, 摩根, A。, Telesford,
问:, Vechlekar, C. D ., Hayasaka, S。, Jennings, J. M。, Katula, J. A。,
卡夫, 右. A。, & Rejeski, 瓦. J. (2010). Using network science to
evaluate exercise-associated brain changes in older adults.
衰老神经科学领域, 2. https://doi.org/10.3389
/fnagi.2010.00023, 考研: 20589103
Craddock, 右. C。, Tungaraza, 右. L。, & Milham, 中号. 磷. (2015).
Connectomics and new approaches for analyzing human brain
功能连接. Gigascience, 4. https://doi.org/10.1186
/S13742-015-0045-X, 考研: 25810900
戴, T。, & 郭, 是. (2017). Predicting individual brain functional
connectivity using a Bayesian hierarchical model. 神经影像,
147, 772–787. https://doi.org/10.1016/j.neuroimage.2016.11
.048, 考研: 27915121
Deuker, L。, 布莫尔, 乙. T。, 史密斯, M。, 克里斯滕森, S。, 内森, 磷. J。,
Rockstroh, B., & 巴塞特, D. S. (2009). Reproducibility of graph
metrics of human brain functional networks. 神经影像, 47,
1460–1468. https://doi.org/10.1016/j.neuroimage.2009.05.035,
考研: 19463959
埃克曼, M。, Fiebach, C. J。, Melzer, C。, Tittgemeyer, M。, & Derrfuss,
J. (2016). Different roles of direct and indirect frontoparietal
pathways for individual working memory capacity. 杂志
神经科学, 36, 2894–2903. https://doi.org/10.1523
/JNEUROSCI.1376-14.2016, 考研: 26961945
假如, A。, 扎莱斯基, A。, Pantelis, C。, & 布莫尔, 乙. 时间. (2012).
Schizophrenia, neuroimaging and connectomics. 神经影像.
https://doi.org/10.1016/j.neuroimage.2011.12.090, 考研:
22387165
弗雷曼, D ., Balenzuela, P。, 福斯, J。, & chialvo, D. 右. (2009). Ising-
like dynamics in large-scale functional brain networks. 身体的
Review E, 79, 061922. https://doi.org/10.1103/ PhysRevE.79
.061922, 考研: 19658539
弗里德曼, D ., & Lane, D. (1983). A nonstochastic interpretation
of reported significance levels. Journal of Business & 经济的
统计数据, 1, 292–298. https://doi.org/10.1080/07350015.1983
.10509354
霜冻, J。, & Renaud, 氧. (2019A). permuco: Permutation tests for
回归, (repeated measures) ANOVA/ANCOVA and compar-
ison of signals [电脑软件使用说明书].
霜冻, J。, & Renaud, 氧. (2019乙). Permutation tests for regression,
ANOVA and comparison of signals: The permuco package. 右
Packag. 版本 1.1.0.
格拉瑟, 中号. F。, 索蒂罗普洛斯, S. N。, 威尔逊, J. A。, Coalson, 时间. S。,
菲舍尔, B., 安德森, J. L。, 徐, J。, jbabdi, S。, 韦伯斯特, M。,
波利梅尼, J. R。, 范·埃森(Van Essen), D. C。, & 詹金森, 中号. (2013). 这
minimal preprocessing pipelines for the Human Connectome
项目. 神经影像, 80, 105–124. https://doi.org/10.1016/j
.neuroimage.2013.04.127, 考研: 23668970
哈格曼, P。, 卡蒙, L。, 巨人, X。, 买, R。, 蜂蜜, C. J。,
Van Wedeen, J。, & 斯波恩斯, 氧. (2008). Mapping the structural core
of human cerebral cortex. 公共科学图书馆生物学, 6, 1479–1493. https://
doi.org/10.1371/journal.pbio.0060159, 考研: 18597554
Hayasaka, S。, & Laurienti, 磷. J. (2010). Comparison of characteris-
tics between region-and voxel-based network analyses in
resting-state fMRI data. 神经影像, 50, 499–508. https://土井
.org/10.1016/j.neuroimage.2009.12.051, 考研: 20026219
Joyce, K. E., Laurienti, 磷. J。, Burdette, J. H。, & Hayasaka, S. (2010). A
new measure of centrality for brain networks. 公共图书馆一号, 5. https://
doi.org/10.1371/journal.pone.0012200, 考研: 20808943
Kherad-Pajouh, S。, & Renaud, 氧. (2010). An exact permutation
method for testing any effect in balanced and unbalanced fixed
effect ANOVA. Computational Statistics & 数据分析, 54,
1881–1893. https://doi.org/10.1016/j.csda.2010.02.015
Kherad-Pajouh, S。, & Renaud, 氧. (2014). A general permutation
approach for analyzing repeated measures ANOVA and mixed-
model designs. Statistical Papers, 56, 947–967. https://doi.org/10
.1007/s00362-014-0617-3
洞, A. (1933). Sulla determinazione empirica di una lgge di
distribuzione. Giornale dellʼIstituto Italiano degli Attuari, 4, 83–91.
Lance, G. N。, & 威廉姆斯, 瓦. 时间. (1966). Computer programs for
hierarchical polythetic classification (“similarity analyses”).
Computer Journal, 9, 60–64. https://doi.org/10.1093/comjnl/9.1.60
网络神经科学
66
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
Lehmann, 乙. C. L。, 亨森, 右. N。, Geerligs, L。, Cam-CAN, &
白色的, S. 右. (2021). Characterising group-level brain connec-
活力: A framework using Bayesian exponential random graph
型号. 神经影像, 225. https://doi.org/10.1016/j.neuroimage
.2020.117480, 考研: 33099009
刘, Y。, 梁, M。, 周, Y。, 他, Y。, 豪, Y。, 歌曲, M。, 于, C。, 刘,
H。, 刘, Z。, & 江, 时间. (2008). Disrupted small-world networks in
精神分裂症. 脑, 131, 945–961. https://doi.org/10.1093
/brain/awn018, 考研: 18299296
McArtor, D. 乙. (2018). MDMR: Multivariate Distance Matrix
回归. R包版本 0.5.1. https://CRAN.R-project
.org/package=MDMR [cran.r-project.org].
McArtor, D. B., Lubke, G. H。, & Bergeman, C. S. (2017). Extending
multivariate distance matrix regression with an effect size mea-
sure and the asymptotic null distribution of the test statistic. Psy-
chometrika, 82, 1052. https://doi.org/10.1007/S11336-016-9527
-8, 考研: 27738957
莫尼耶, D ., Achard, S。, Morcom, A。, & 布莫尔, 乙. (2009A). 年龄-
related changes in modular organization of human brain func-
tional networks. 神经影像, 44, 715–723. https://doi.org/10
.1016/j.neuroimage.2008.09.062, 考研: 19027073
莫尼耶, D ., 兰比奥特, R。, 假如, A。, 埃雷什, K. D ., & 布莫尔,
乙. 时间. (2009乙). Hierarchical modularity in human brain functional
网络. 神经信息学前沿, 3. https://doi.org/10
.3389/neuro.11.037.2009, 考研: 19949480
Moussa, 中号. N。, Steen, 中号. R。, Laurienti, 磷. J。, & Hayasaka, S. (2012).
Consistency of network modules in resting-state fMRI connec-
tome data. 公共图书馆一号, 7. https://doi.org/10.1371/journal.pone
.0044428, 考研: 22952978
Moussa, 中号. N。, Vechlekar, C. D ., Burdette, J. H。, Steen, 中号. R。,
Hugenschmidt, C. E., & Laurienti, 磷. J. (2011). Changes in cogni-
tive state alter human functional brain networks. 前沿
人类神经科学. https://doi.org/10.3389/fnhum.2011
.00083, 考研: 21991252
Parente, F。, Frascarelli, M。, Mirigliani, A。, Di Fabio, F。, Biondi, M。, &
Colosimo, A. (2017). Negative functional brain networks. 脑
Imaging and Behavior, 12, 467–476. https://doi.org/10.1007
/S11682-017-9715-X, 考研: 28353136
Pruim, 右. H. R。, Mennes, M。, Van Rooij, D ., Llera, A。, Buitelaar,
J. K., & 贝克曼, C. F. (2015). ICA-AROMA: A robust
ICA-based strategy for removing motion artifacts from fMRI data.
神经影像, 112, 267–277. https://doi.org/10.1016/j
.neuroimage.2015.02.064, 考研: 25770991
rombout, S. A. 右. 乙, 巴克霍夫, F。, Goekoop, R。, 斯塔姆, C. J。, &
Scheltens, 磷. (2005). Altered resting state networks in mild cogni-
tive impairment and mild Alzheimer’s disease: An fMRI study.
人脑图谱, 26, 231–239. https://doi.org/10.1002
/hbm.20160, 考研: 15954139
Rzucidlo, J. K., 罗斯曼, 磷. L。, Laurienti, 磷. J。, & Dagenbach, D. (2013).
Stability of whole brain and regional network topology within
and between resting and cognitive states. 公共图书馆一号, 8. https://
doi.org/10.1371/journal.pone.0070275, 考研: 23940554
分配, M。, Khosrowabadi, R。, Khatibi, A。, Misic, B., & Jafari, G.
(2021). Topological impact of negative links on the stability of
resting-state brain network. Scientific Reports, 11. https://doi.org
/10.1038/S41598-021-81767-7, 考研: 33500525
施瓦茨, A. J。, & McGonigle, J. (2011). Negative edges and soft
thresholding in complex network analysis of resting state
functional connectivity data. 神经影像, 55, 1132–1146. https://
doi.org/10.1016/j.neuroimage.2010.12.047, 考研: 21194570
沉, X。, Tokoglu, F。, Papademetris, X。, & Constable, 右. 时间. (2013).
Groupwise whole-brain parcellation from resting-state fMRI data
for network node identification. 神经影像, 82, 403–415.
https://doi.org/10.1016/j.neuroimage.2013.05.081, 考研:
23747961
辛普森, S. L。, 鲍曼, F. D. B., & Laurienti, 磷. J. (2013A). Ana-
lyzing complex functional brain networks: Fusing statistics and
network science to understand the brain. Statistical Surveys, 7,
1–36. https://doi.org/10.1214/13-SS103, 考研: 25309643
辛普森, S. L。, Hayasaka, S。, Laurienti, 磷. J. (2011). Exponential ran-
dom graph modeling for complex brain networks. 公共图书馆一号, 6.
https://doi.org/10.1371/journal.pone.0020039, 考研:
21647450
辛普森, S. L。, Lyday, 右. G。, Hayasaka, S。, 沼泽, A. P。, & Laurienti,
磷. J. (2013乙). A permutation testing framework to compare groups
of brain networks. Frontiers in Computational Neuroscience, 7,
1–13. https://doi.org/10.3389/fncom.2013.00171, 考研:
24324431
辛普森, S. L。, Moussa, 中号. N。, & Laurienti, 磷. J. (2012). An expo-
nential random graph modeling approach to creating
group-based representative whole-brain connectivity networks.
神经影像, 60, 1117–1126. https://doi.org/10.1016/j
.neuroimage.2012.01.071, 考研: 22281670
Smirnov, 氮. (1948). Table for estimating the goodness of fit of
empirical distributions. 数学统计年鉴, 19,
279–281. https://doi.org/10.1214/aoms/1177730256
斯塔姆, C. J。, 琼斯, 乙. F。, 诺尔特, G。, 断裂, M。, & Scheltens, 磷.
(2007). Small-world networks and functional connectivity in
阿尔茨海默氏病. 大脑皮层, 17, 92–99. https://doi.org
/10.1093/cercor/bhj127, 考研: 16452642
Székely, G. J。, & Rizzo, 中号. L. (2009). Brownian distance covari-
安斯. Annals of Applied Statistics, 3, 1236–1265. https://doi.org
/10.1214/09-AOAS312, 考研: 20574547
Székely, G. J。, Rizzo, 中号. L。, & Bakirov, 氮. K. (2007). Measuring and
testing dependence by correlation of distances. Annals of Statistics,
35, 2769–2794. https://doi.org/10.1214/009053607000000505
van den Heuvel, 中号. P。, 斯塔姆, C. J。, Boersma, M。, & Hulshoff Pol,
H. 乙. (2008). Small-world and scale-free organization of
voxel-based resting-state functional connectivity in the human
脑. 神经影像, 43, 528–539. https://doi.org/10.1016/j
.neuroimage.2008.08.010, 考研: 18786642
范·埃森(Van Essen), D. C。, 史密斯, S. M。, 尊重, D. M。, 贝伦斯, 时间. 乙. J。,
Yacoub, E., & Ugurbil, K. (2013). The WU-Minn Human Connec-
tome Project: 概述. 神经影像, 80, 62–79. https://土井
.org/10.1016/j.neuroimage.2013.05.041, 考研: 23684880
范·埃森(Van Essen), D. C。, Ugurbil, K., 奥尔巴赫, E., 尊重, D ., 贝伦斯,
时间. 乙. J。, Bucholz, R。, 张, A。, 陈, L。, 科尔贝塔, M。, Curtiss,
S. W., 笔下的, S。, 范伯格, D ., 格拉瑟, 中号. F。, 哈雷尔, N。,
希思, A. C。, Larson-Prior, L。, 马库斯, D ., Michalareas, G。,
Moeller, S。, 伊斯特菲尔德, R。, 彼得森, S. E., 事先的, F。, 施拉加尔,
乙. L。, 史密斯, S. M。, 斯奈德, A. Z。, 徐, J。, & Yacoub, 乙. (2012). 这
人类连接项目: A data acquisition perspective.
神经影像. https://doi.org/10.1016/j.neuroimage.2012.02.018,
考研: 22366334
Varoquaux, G。, & Craddock, 右. C. (2013). Learning and comparing
functional connectomes across subjects. 神经影像, 80, 405–415.
网络神经科学
67
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
A regression framework for brain network distance metrics
https://doi.org/10.1016/J.NEUROIMAGE.2013.04.007, 考研:
23583357
王, L。, Durante, D ., 荣格, 右. E., & Dunson, D. 乙. (2017). 贝叶斯
network–response regression. Bioinformatics, 33, 1859–1866.
https://doi.org/10.1093/ BIOINFORMATICS/ BTX050, 考研:
28165112
夏, C. H。, 马, Z。, 哪个, Z。, Bzdok, D ., Thirion, B., 巴塞特, D. S。,
Satterthwaite, 时间. D ., 筱原, 右. T。, & 维滕, D. 中号. (2020).
Multi-scale network regression for brain-phenotype associations.
人脑图谱, 41, 2553–2566. https://doi.org/10.1002
/hbm.24982, 考研: 32216125
元, K., 秦, W., 刘, J。, 郭, 问:, 董, M。, 太阳, J。, 张, Y。,
刘, P。, 王, W., 王, Y。, 李, 问:, 哪个, W., von Deneen,
K. M。, 金子, 中号. S。, 刘, Y。, & 天,
(2010). Altered
small-world brain functional networks and duration of heroin
use in male abstinent heroin-dependent individuals. 神经科学
信件, 477, 37–42. https://doi.org/10.1016/j.neulet.2010.04.032,
考研: 20417253
J.
张, J。, 太阳, 瓦. W., & 李, L. (2018). Network response regression
for modeling population of networks with covariates. arXiv
预印型arxiv:1810.03192v2.
张, Z。, 艾伦, G. 我。, 朱, H。, & Dunson, D. (2019). Tensor
network factorizations: Relationships between brain structural
connectomes and traits. 神经影像, 197, 330–343. https://
doi.org/10.1016/j.neuroimage.2019.04.027, 考研:
31029870
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
6
1
4
9
1
9
8
4
2
1
8
n
e
n
_
A
_
0
0
2
1
4
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
网络神经科学
68