方法
Large-scale directed network inference
with multivariate transfer entropy and
hierarchical statistical testing
Leonardo Novelli
1
, Patricia Wollstadt
4
, Pedro Mediano
1
Michael Wibral
, and Joseph T. Lizier
2,∗
3
,
1Centre for Complex Systems, 工程学院, The University of Sydney, 悉尼, 澳大利亚
2Honda Research Institute Europe, Offenbach am Main, 德国
3Computational Neurodynamics Group, Department of Computing, Imperial College London, 伦敦, 英国
Campus Institute for Dynamics of Biological Networks, Georg-August University, Göttingen, 德国
First authors contributed equally to this work.
∗
4
开放访问
杂志
关键词: Neuroimaging, Directed connectivity, Effective network, Multivariate transfer entropy,
Information theory, Nonlinear dynamics, Statistical inference, Nonparametric tests
抽象的
Network inference algorithms are valuable tools for the study of large-scale neuroimaging
datasets. Multivariate transfer entropy is well suited for this task, being a model-free measure
that captures nonlinear and lagged dependencies between time series to infer a minimal
directed network model. Greedy algorithms have been proposed to efficiently deal with
high-dimensional datasets while avoiding redundant inferences and capturing synergistic
effects. 然而, multiple statistical comparisons may inflate the false positive rate and are
computationally demanding, which limited the size of previous validation studies. 这
algorithm we present—as implemented in the IDTxl open-source software—addresses these
challenges by employing hierarchical statistical tests to control the family-wise error rate and
to allow for efficient parallelization. The method was validated on synthetic datasets
involving random networks of increasing size (最多 100 节点), for both linear and
nonlinear dynamics. The performance increased with the length of the time series, reaching
consistently high precision, 记起, and specificity (>98% on average) 为了 10,000 时间
样品. Varying the statistical significance threshold showed a more favorable
precision-recall trade-off for longer time series. Both the network size and the sample size are
one order of magnitude larger than previously demonstrated, showing feasibility for typical
EEG and magnetoencephalography experiments.
介绍
The increasing availability of large-scale, fine-grained datasets provides an unprecedented op-
portunity for quantitative studies of complex systems. 尽管如此, a shift toward data-driven
modeling of these systems requires efficient algorithms for analyzing multivariate time series,
which are obtained from observation of the activity of a large number of elements.
In the field of neuroscience, the multivariate time series typically obtained from brain record-
ings serve to infer minimal (effective) network models which can explain the dynamics of the
nodes in a neural system. The motivation for such models can be, 例如, to describe a
causal network (Ay & Polani, 2008; 弗里斯顿, 1994) or to model the directed information flow
引文: Novelli, L。, Wollstadt, P。,
Mediano, P。, Wibral, M。, & Lizier, J. 时间.
(2019). Large-scale directed network
inference with multivariate transfer
entropy and hierarchical statistical
testing. 网络神经科学, 3(3),
827–847. https://doi.org/10.1162/
netn_a_00092
DOI:
https://doi.org/10.1162/netn_a_00092
支持信息:
https://doi.org/10.1162/netn_a_00092
https://github.com/pwollstadt/IDTxl
已收到: 24 一月 2019
公认: 24 四月 2019
利益争夺: 作者有
声明不存在竞争利益
存在.
通讯作者:
Leonardo Novelli
leonardo.novelli@sydney.edu.au
处理编辑器:
奥拉夫·斯波恩斯
版权: © 2019
麻省理工学院
在知识共享下发布
归因 4.0 国际的
(抄送 4.0) 执照
麻省理工学院出版社
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
in the system (Vicente et al., 2011) in order to produce a minimal computationally equivalent
网络 (Lizier & 鲁比诺夫, 2012).
Information theory (Cover & 托马斯, 2005; Shannon, 1948) is well suited for the latter
motivation of inferring networks that describe information flow as it provides model-free mea-
sures that can be applied at different scales and to different types of recordings. These mea-
确定, including conditional mutual information (Cover & 托马斯, 2005) and transfer entropy
(Schreiber, 2000), are based purely on probability distributions and are able to identify non-
linear relationships (Paluš et al., 1993). Most importantly, information-theoretic measures al-
low the interpretation of the results from a distributed computation or information processing
看法, by modeling the information storage, transfer, and modification within the system
(Lizier, 2013). 所以, information theory simultaneously provides the tools for building the
network model and the mathematical framework for its interpretation.
The general approach to network model construction can be outlined as follows: for any
target process (element) in the system, the inference algorithm selects the minimal set of pro-
cesses that collectively contribute to the computation of the target’s next state. Every process
can be separately studied as a target, and the results can be combined into a directed network
describing the information flows in the system. This task presents several challenges:
The state space of the possible network models grows faster than exponentially with
respect to the size of the network;
Information-theoretic estimators suffer from the “curse of dimensionality” for large sets
of variables (Paninski, 2003; Roulston, 1999);
In a network setting, statistical significance testing requires multiple comparisons. 这
results in a high false positive rate (type I errors) without adequate family-wise error rate
controls (Dickhaus, 2014) or a high false negative rate (type II errors) with naive control
程序;
Nonparametric statistical testing based on shuffled surrogate time series is computation-
ally demanding but currently necessary when using general information-theoretic esti-
mators (Bossomaier et al., 2016; Lindner et al., 2011).
Several previous studies (Faes et al., 2011; Lizier & 鲁比诺夫, 2012; 孙等人。, 2015; Vlachos
& Kugiumtzis, 2010) proposed greedy algorithms to tackle the first two challenges outlined
多于 (see a summary by Bossomaier et al., 2016, 秒 7.2). These algorithms mitigate the curse
of dimensionality by greedily selecting the random variables that iteratively reduce the uncer-
tainty about the present state of the target. The reduction of uncertainty is rigorously quantified
by the information-theoretic measure of conditional mutual information (CMI), which can also
be interpreted as a measure of conditional independence (Cover & 托马斯, 2005). In partic-
他们是, these previous studies employed multivariate forms of the transfer entropy, 那是, 骗局-
ditional and collective forms (Lizier et al., 2008, 2010). 一般来说, such greedy optimization
algorithms provide a locally optimal solution to the NP-hard problem of selecting the most
informative set of random variables. An alternative optimization strategy—also based on con-
ditional independence—employs a preliminary step to prune the set of sources (Runge et al.,
2012, 2018). Despite this progress, the computational challenges posed by the estimation of
multivariate transfer entropy have severely limited the size of problems investigated in previous
validation studies in the general case of nonlinear estimators, 例如, Montalto et al.
(2014) 用过的 5 nodes and 512 样品; Kim et al. (2016) 用过的 6 nodes and 100 样品;
Runge et al. (2018) 用过的 10 nodes and 500 样品. 然而, modern neural recordings
often provide hundreds of nodes and tens of thousands of samples.
网络神经科学
828
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
IDTxl:
The “Information Dynamics Toolkit
xl” is an open-source Python
package available on GitHub (看
支持信息).
Markovian with finite memory:
The present state of the target does
not depend on the past values of the
target and the sources beyond a
maximum finite lag l
中号.
These computational challenges, as well as the multiple testing challenges described above,
are addressed here by the implementation of rigorous statistical tests, which represent the main
theoretical contribution of this paper. These tests are used to control the family-wise error rate
and are compatible with parallel processing, allowing the simultaneous analysis of the targets.
This is a crucial feature, which enabled an improvement on the previous greedy algorithms.
Exploiting the parallel computing capabilities of high-performance computing clusters and
graphics processing units (GPUs) enabled the analysis of networks at a relevant scale for brain
recordings—up to 100 nodes and 10,000 样品. Our algorithm has been implemented in
the recently released IDTxl Python package (the “Information Dynamics Toolkit xl”; Wollstadt
等人。, 2019).
We validated our method on synthetic datasets involving random structural networks of
increasing size (also referred to as ground truth) and different types of dynamics (vector auto-
regressive processes and coupled logistic maps). 一般来说, effective networks are able to re-
flect dynamic changes in the regime of the system and do not reflect an underlying structural
网络. 尽管如此, in the absence of hidden nodes (and other assumptions, including sta-
tionarity and the causal Markov condition), the inferred information network was proven to
reflect the underlying structure for a sufficiently large sample size (孙等人。, 2015). Experi-
ments under these conditions provide arguably the most important validation that the algorithm
performs as expected, and here we perform the first large-scale empirical validation for non-
Gaussian variables. As shown in the Results, the performance of our algorithm increased with
the length of the time series, reaching consistently high precision, 记起, and specificity (>98%
一般) 为了 10,000 time samples. Varying the statistical significance threshold showed a
more favorable precision-recall trade-off for longer time series.
方法
Definitions and assumptions
Let us consider a system of N discrete-time stochastic processes for which a finite number of
samples have been recorded (over time and/or in different replications of the same experiment).
一般来说, let us assume that the stochastic processes are stationary in each experimental
time-window and Markovian with finite memory l
中号. Further assumptions will be made for the
validation study. The following quantities are needed for the setup and formal treatment of the
algorithm and are visualized in Figure 1 和图 2:
Target process Y: a process of interest within the system (where Y = {Yt | t ∈ N}); 这
choice of the target process is arbitrary and all the processes in the system can separately
be studied as targets.
Source processes X i: the remaining processes within the system (where i = 1, . . . , N − 1 和
X i = {席,t | t ∈ N}).
Sample number (or size) 时间: the number of samples recorded over time.
Replication number R: the number of replications of the same experiment (例如, 试验).
Target present state Yt: the random variable (RV) representing the state of the target at time t
(where t ≤ T), whose information contributors will be inferred.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Candidate target past Y
C
j,S; Yt|是
j,1; Yt|是
2. Compute the maximum CMI value over candidates I∗
s
n,s) for each
surrogate s = 1, . . . , S. 这里, n denotes the number of candidates and hence the number
of comparisons. The obtained values I∗
1 , . . . , I∗
S provide the (empirical) null distribution
of the maximum statistic (见表 1).
1,s, . . . , 我(西德:5)
:= max(我(西德:5)
3. Calculate the p value for I∗
as the fraction of surrogate maximum statistic values that are
larger than I∗
I∗
.
4.
is deemed significant if the p value is smaller than αmax (IE。, the null hypothesis of
conditional independence for the candidate variable with the maximum CMI contribu-
tion is rejected at level αmax).
The variables and quantities used in the above algorithm are presented in Table 1. 钥匙
goal in the surrogate generation is to preserve the temporal order of samples in the target time
series Yt (which is not shuffled) and preserve the distribution of the sources Cj while destroying
any potential relationships between the sources and the target (Vicente et al., 2011). This can
be achieved in multiple ways. If multiple replications (例如, 试验) 可用, surrogate data is
generated by shuffling the order of replications for the candidate Cj while keeping the order of
replications for the remaining variables intact. When the number of replications is not sufficient
to guarantee enough permutations, the embedded source samples within individual trials are
shuffled instead (see Chávez et al., 2003; Lizier et al., 2011; Verdes, 2005; Vicente et al., 2011;
and the summary by Lizier, 2014, Appendix A.5). Note that the generation of surrogates (脚步
1-3) can be avoided when the null distributions can be derived analytically, 例如, 和
Gaussian estimators (Barnett & Bossomaier, 2012).
The same test is performed during the selection of the variables in the candidate sources
S
)
临界点
临界点
, . . . , In ≤ i
)
临界点
Ij ≤ i
(西德:3)
临界点
(西德:2)
磷
= 1 -
= 1 − P (I1 ≤ i
n
∏
j=1
= 1 − P (I1 ≤ i
= 1 - (1 − v
临界点
)n
FPR
)n
(1)
(2)
所以,
v
FPR
= 1 - (1 − αmax)1/n
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
有趣的是, 方程 2 shows that the maximum statistic correction is equivalent to the
Dunn-Šidák correction (Šidák, 1967). Performing a Taylor expansion of Equation 2 大约
αmax = 0 yields:
-
j−1
∏
k=0
(kn − 1)
j!
(西德:5)j
(西德:4) αtarget
n
v
FPR
=
∞
∑
j=1
Truncating the Taylor series at j = 1 yields the first-order approximation
v
FPR
≈
αmax
n
,
(3)
(4)
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
which coincides with the false positive rate resulting from the Bonferroni correction (Dickhaus,
2014). 而且, since the summands in Equation 3 are positive for every j, the Taylor series
is lower bounded by any truncated series. 尤其, the false positive rate resulting from
the Bonferroni correction is a lower bound for the v
FPR (the false positive rate for a single
variable resulting from the maximum statistic test), 那是, the maximum statistic correction is
less stringent than the Bonferroni correction.
Let us now study the effect of the maximum statistic test on the family-wise error rate t
FPR
for a single target while accounting for all the iterations performed during the step-down
网络神经科学
835
Large-scale network inference with multivariate transfer entropy
测试, (IE。, t
我们有:
FPR is the probability that at least one of the selected sources is a false positive).
t
FPR
=
=
n
∑
j=1
n
∑
j=1
磷(“the source selected on step j is false positive”)
(西德:7)
(西德:6)
αj
max
= αmax
1 − αn
max
1 − αmax
所以,
t
FPR
≈ αmax
(5)
(6)
for the typical small values of αmax used in statistical testing (even in the limit of large n), 哪个
shows that αmax effectively controls the family-wise error rate for a single target.
The minimum statistic test is employed during the third main step of
Minimum statistic test.
the algorithm (pruning step) to remove the selected variables that have become redundant in
S
the context of the final set of selected source past variables X
recall was unchanged using S = 10, 000 for T = 100.) For longer time series (T = 10, 000),
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
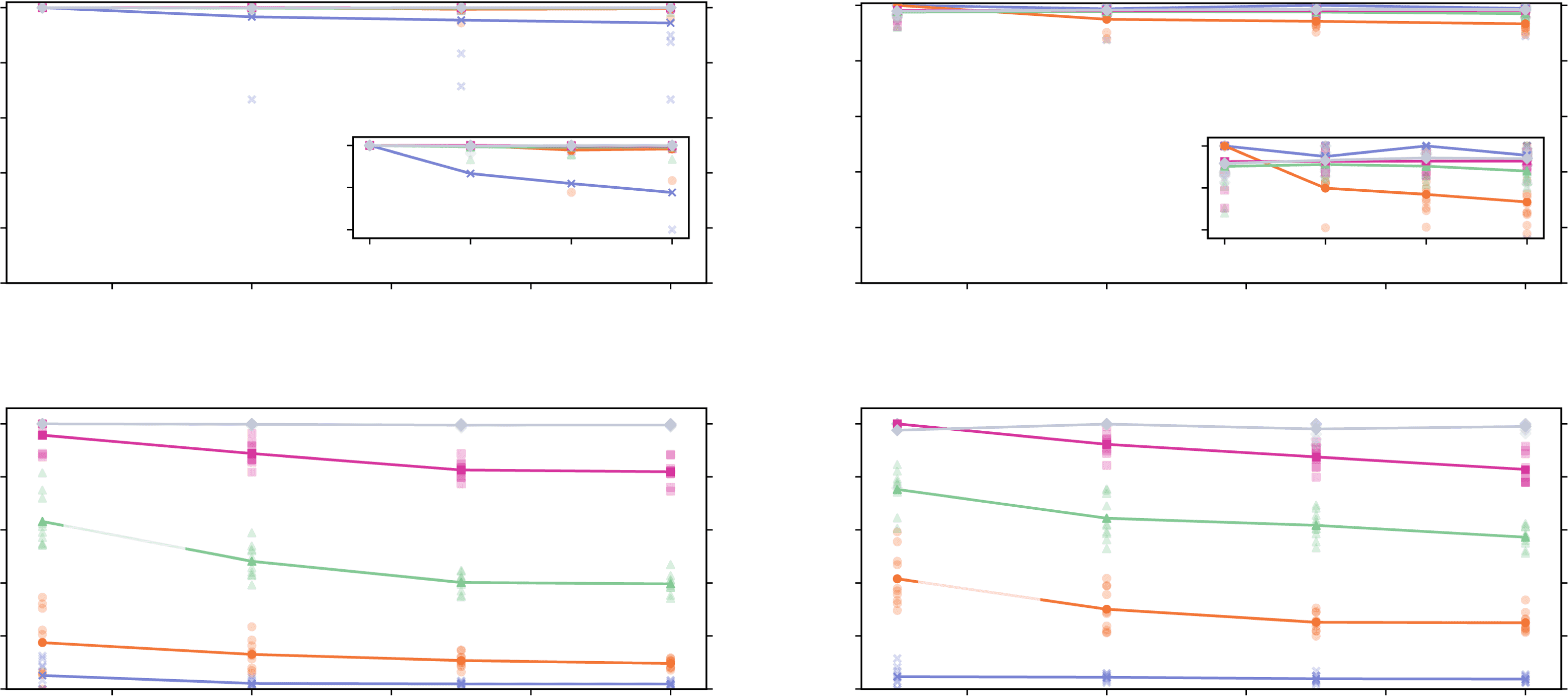
数字 3. Precision (顶部) and recall (底部) for different network sizes, sample sizes, and dynamics. 左边: Vector autoregressive process;
正确的: Coupled logistic maps. Each subplot shows five curves, corresponding to different time series lengths (T = 100, 300, 1,000, 3,000,
10,000). The results for 10 simulations from different initial conditions are shown (low-opacity markers) in addition to the mean values (solid
标记). All the random networks have an average in-degree N p = 3.
网络神经科学
839
Large-scale network inference with multivariate transfer entropy
high performance according to all measures was achieved for both the VAR and CLM pro-
过程, regardless of the size of the network. The high precision and specificity are due to
the effective control of the false positives, in accordance with the strict statistical significance
level αmax = 0.001 (the influence of αmax is further discussed in the following sections). 这
inference algorithm was therefore conservative in the classification of the links.
Validation of False Positive Rate
The critical alpha level for statistical significance αmax is a parameter of the algorithm that is
designed to control the number of false positives in the network inference. As discussed in
the Statistical Tests section in the Methods, αmax controls the probability that a target is a false
积极的, 那是, that at least one of its sources is a false positive. This approach is in line with
the perspective that the goal of the network inference is to find the set of relevant sources for
each node.
A validation study was carried out to verify that the final number of false positives is consis-
tent with the desired level αmax after multiple statistical tests are performed. The false positive
rate was computed after performing the inference on empty networks, where every inferred
link is a false positive by definition (IE。, under the complete null hypothesis). The rate was
in good accordance with the critical alpha threshold αmax for all network sizes, 如图所示
数字 4.
fMRI data from the Human Connectome Project resting-state dataset
The false positive rate validation was replicated in a scenario where the null hypothesis
(看
held for real
支持信息). The findings are presented in the Supporting Information, 一起
with a note on autocorrelation. 尤其, the results on fMRI data are in agreement with the
results on synthetic data shown in Figure 4.
False positive rate:
FP/(FP + TN).
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4. Validation of false positive rate for a single target (t
FPR) on empty networks. The points
indicate the average false positive rate over 50 simulations of a vector autoregressive process
(T = 10,000). The horizontal marks indicate the corresponding 5th and 95th percentiles of the
expected range. These were computed empirically from the distribution of the random variable
(西德:10)Xj/N(西德:11), where Xj ∼ Binomial(氮, αmax) are i.i.d. random variables, and the angular brackets in-
dicate the finite average over 50 repetitions. The 5th percentile for N = 10 and N = 40 和
αmax = 10−3
are equal to zero and therefore omitted from the log-log plot. The identity function is
plotted as a reference (dashed line).
网络神经科学
840
Large-scale network inference with multivariate transfer entropy
Influence of Critical Level for Statistical Significance
Given the conservative results obtained for both the VAR and CLM processes (数字 3), A
natural question is to what extent the recall could be improved by increasing the critical alpha
level αmax and to what extent the precision would be negatively affected as a side effect.
In order to elucidate this trade-off, the analysis described above (数字 3) was repeated for
increasing values of αmax, with results shown in Figure 5. For the shortest time series (T = 100),
increasing αmax resulted in a higher recall and a lower precision, as expected; 在另一
手, for the longest time series (T = 10,000), the performance measures were not significantly
做作的. 有趣的是, for the intermediate case (T = 1,000), increasing αmax resulted in higher
recall without negatively affecting the precision.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 5.
Influence of statistical significance threshold on network inference performance. 产品-
sion versus recall for different statistical significance levels (αmax = 0.05, 0.01, 0.001), correspond-
ing to different colors. The plots summarize the results for different dynamics (Top: Vector autore-
gressive process; Bottom: Coupled logistic maps), different time series lengths (T = 100, 1,000,
10,000), and different network sizes (N= 10, 40, 70, 100, not distinguished). The arrows join
the mean population values for the lowest and highest significance levels, illustrating the average
trade-off between precision loss and recall gain.
网络神经科学
841
Large-scale network inference with multivariate transfer entropy
Inference of Coupling Lags
迄今为止, the performance evaluation focused on the identification the correct set of sources
for each target node, regardless of the coupling lags. 然而, since the identification of the
correct coupling lags is particularly relevant in neuroscience (see Wibral et al., 2013, 和
references therein), the performance of the algorithm in identifying the correct coupling lags
was additionally investigated.
By construction, a single coupling lag was imposed between each pair of processes (选择的
at random between one and five discrete time steps, as described in the Methods). The average
absolute error between the real and the inferred coupling lags was computed on the correctly
recalled sources and divided by the value expected at random (which is the average absolute
difference between two i.i.d. random integers in the [1, 5] 间隔). In line with the previous
results on precision, the absolute error on coupling lag is consistently much smaller than that
expected at random, even for the shortest time series (数字 6). 此外, 1,000 样品
were sufficient to achieve nearly optimal performance for both the VAR and the CLM processes,
regardless of the size of the network. Note that as T increases and the recall increases, the lag
error can increase (比照. T = 100 到 300 for the CLM process). This is perhaps because while the
larger T permits more weakly contributing sources to be identified, it is not large enough to
reduce the estimation error to make lag identification on these sources precise.
Estimators
Given its speed, the Gaussian estimator is often used for large datasets or as a first exploratory
step, even when the stationary distribution cannot be assumed to be Gaussian. The availability
of the ground truth allowed us to compare the performance of the Gaussian estimator and the
nearest-neighbor estimator on the nonlinear CLM process, which does not satisfy the Gaus-
sian assumption. 正如预期的那样, the performance of the Gaussian estimator was lower than the
performance of the nearest-neighbor estimator for all network sizes (数字 7).
The hierarchical tests introduced in the Methods section allow running the network infer-
ence algorithm in parallel on a high-performance computing cluster. Such parallelization is
especially needed when employing the nearest-neighbor estimator. 尤其, each target
node can be analyzed in parallel on a CPU (employing one or more cores) or a GPU, 哪个
is made possible by the CPU and GPU estimators provided by the IDTxl package (custom
数字 6. Average absolute error between the real and the inferred coupling lags, relative to the value expected at random. Results for
different dynamics (左边: Vector autoregressive process; 正确的: Coupled logistic maps), different time series lengths (T = 100, 300, 1,000,
3,000, 10,000), and different network sizes (N= 10, 40, 70, 100). The error bars indicate the standard deviation over 10 simulations from
different initial conditions.
网络神经科学
842
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
t
/
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
数字 7. Gaussian versus nearest-neighbor estimator on the coupled logistic maps process. The precision (左边) and recall (正确的) are plotted
against the network size and a fixed time series length (T = 10,000 样品). The results for 10 simulations from different initial conditions
are shown (low-opacity markers) in addition to the mean values (solid markers). The statistical significance level αmax = 0.05 was employed;
an even larger gap between the recall of the estimators is obtained with αmax = 0.001.
OpenCL kernels were written for the GPU implementation). A summary of the CPU and GPU
run times is provided in the Supporting Information.
讨论
The algorithm presented in this paper provides robust statistical tests for network inference to
control the false positive rate. These tests are compatible with parallel computation on high-
performance computing clusters, which enabled the validation study on synthetic sparse net-
works of increasing size (10 到 100 节点), using different dynamics (linear autoregressive
processes and nonlinear coupled logistic maps) and increasingly longer time series (100 到
10,000 样品). Both the network size and the sample size are one order of magnitude larger
than previously demonstrated, showing feasibility for typical EEG and MEG experiments. 这
results demonstrate that the statistical tests achieve the desired false positive rate and success-
fully address the multiple-comparison problems inherent in network inference tasks (数字 4).
The ability to control the false positives while building connectomes is a crucial prerequisite
for the application of complex network measures, to the extent that Zalesky et al. (2016) 骗局-
cluded that “specificity is at least twice as important as sensitivity (IE。, 记起) when estimating
key properties of brain networks, including topological measures of network clustering, 网-
work efficiency and network modularity.” The reason is that false positives occur more preva-
lently between network modules than within them, and the spurious intermodular connections
have a dramatic impact on network topology (Zalesky et al., 2016).
The trade-off between precision and recall when relaxing the statistical significance thresh-
old was further investigated (数字 5). When only 100 samples were used, the average recall
gain was more than five times smaller than the average precision loss. In our opinion, this result
is possibly due to the sparsity of the networks used in this study and suggests a conservative
choice of the threshold for sparse networks and short time series. The trade-off was reversed for
longer time series: 什么时候 1,000 samples were used, the average recall gain was more than five
times larger than the average precision loss. 最后, 为了 10,000 样品, high precision and
recall were achieved (>98% on average) for both the vector autoregressive and the coupled
logistic maps processes, regardless of the statistical significance threshold.
For both types of dynamics, the network inference performance increased with the length of
the time series and decreased with the size of the network (数字 3). This is to be expected since
larger systems require more statistical tests and hence stricter conditions to control the family-
网络神经科学
843
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
t
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
wise error rate (false positives). Specifically, larger networks result in wider null distributions
of the maximum statistic (IE。, larger variance), whereas longer time series have the opposite
影响. 所以, for large networks and short time series, controlling the false positives can
have a negative impact on the ability to identify the true positives, particularly when the effect
尺寸 (IE。, the transfer entropy value) is small.
此外, the superior ability of the nearest-neighbor estimator over the Gaussian estima-
tor in detecting nonlinear dependencies was quantified. There is a critical motivation for this
比较: the general applicability of the nearest-neighbor estimators comes at the price
of higher computational complexity and a significantly longer run time, so that the Gaussian
estimator is often used for large datasets (or at least as a first exploratory step), even when the
Gaussian hypothesis is not justified. To investigate such a scenario, the Gaussian estimator was
tested on the nonlinear logistic map processes: while the resulting recall was significantly lower
than the nearest-neighbor estimator for all network sizes, it was nonetheless able to identify
over half of the links for a sufficiently large number (10,000) of time samples (数字 7).
The stationarity assumption about the time series corresponds to assuming a single regime
of neuronal activity in real brain recordings. If multiple regimes are recorded, which is typical
in experimental settings (例如, sequences of tasks or repeated presentation of stimuli interleaved
with resting time windows), different stationary regimes can be studied by performing the anal-
ysis within each time window. The networks obtained in different time windows can either
be studied separately and compared against each other or collectively interpreted as a single
evolving temporal network. To obtain a sufficient amount of observations per window, 多种的
replications of the experiment under the same conditions are typically carried out. Replica-
tions can be assumed to be cyclo-stationary and estimation techniques exploiting this property
have been proposed (Gómez-Herrero et al., 2015; Wollstadt et al., 2014); these estimators are
also available in the IDTxl Python package. The convergence to the (未知) causal net-
work was only proven under the hypotheses of stationarity, causal sufficiency, and the causal
Markov condition (孙等人。, 2015). 然而, conditional independence holds under milder
assumptions (Runge, 2018) and the absence of links is valid under general conditions. 这
conditional independence relationships can, 所以, be used to exclude variables in follow-
ing intervention-based causal experiments, making network inference methods valuable for
exploratory studies.
实际上, the directed network is only one part of the model and provides the scaffold over
which the information-theoretic measures are computed. 所以, even if the structure of a
system is known and there is no need for network inference, information theory can still pro-
vide nontrivial insights on the distributed computation by modeling the information storage,
transfer, and modification within the system (Lizier, 2013). This decomposition of the predic-
tive information into the active information storage and transfer entropy components is one
out of many alternatives within the framework proposed by Chicharro & Ledberg (2012). 氩气-
guably, the storage-transfer decomposition reflects the segregation-integration dichotomy that
has long characterized the interpretation of brain function (斯波恩斯, 2010; Zeki & Shipp, 1988).
Information theory has the potential to provide a quantitative definition of these fundamental
but still unsettled concepts (李等人。, 2019). 此外, information theory provides a new
way of testing fundamental computational theories in neuroscience, 例如, predictive
编码 (Brodski-Guerniero et al., 2017).
像这样, information-theoretic methods should not be seen as opposed to model-based
方法, but complementary to them (Friston et al., 2013). If certain physically motivated
网络神经科学
844
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
parametric models are assumed, the two approaches are equivalent for network inference:
maximizing the log-likelihood is asymptotically equivalent to maximizing the transfer entropy
(Barnett & Bossomaier, 2012; Cliff et al., 2018). 而且, different approaches can be com-
bined; 例如, the recent large-scale application of spectral DCM was made possible by
using functional connectivity models to place prior constraints on the parameter space (Razi
等人。, 2017). Networks inferred using bivariate transfer entropy have also been employed to
reduce the model space prior to DCM analysis (Chan et al., 2017).
综上所述, the continuous evolution and combination of methods show that network in-
ference from time series is an active field of research and there is a current trend of larger valida-
tion studies, statistical significance improvements, and reduction of computational complexity.
Information-theoretic approaches require efficient tools to employ nearest-neighbor estimators
on large datasets of continuous-valued time series, which are ubiquitous in large-scale brain
录音 (calcium imaging, EEG, 乙二醇, 功能磁共振成像). The algorithm presented in this paper is com-
patible with parallel computation on high-performance computing clusters, which enabled the
study of synthetic nonlinear systems of 100 nodes and 10,000 样品. Both the network size
and the sample size are one order of magnitude larger than previously demonstrated, bring-
ing typical EEG and MEG experiments into scope for future information-theoretic network
inference studies. 此外, the statistical tests presented in the Methods are generic and
compatible with any underlying conditional mutual information or transfer entropy estimators,
meaning that estimators applicable to spike trains (Spinney et al., 2017) can be used with this
algorithm in future studies.
致谢
The authors acknowledge the Sydney Informatics Hub and the University of Sydney’s high-
performance computing cluster Artemis for providing the high-performance computing re-
sources that have contributed to the research results reported within this paper. 此外,
the authors thank Aaron J. Gutknecht for commenting on a draft of this paper, and Oliver Cliff
for useful discussions and comments.
SUPPORTING INFORMATION
The network inference algorithm described in this paper is implemented in the open-source
Python software package IDTxl (Wollstadt et al., 2019), which is freely available on GitHub
(https://github.com/pwollstadt/IDTxl). 在本文中, we refer to the current release (v1.0) 在
time of writing (土井:10.5281/zenodo.2554339).
The raw data used for the experiment presented in the Supporting Information (https://土井.
org/10.1162/netn_a_00092) is openly available on the MGH-USC Human Connectome Project
数据库 (https://ida.loni.usc.edu/login.jsp).
ROLE INFORMATION
Leonardo Novelli: 概念化; Data Curation; Formal Analysis; 调查; Soft-
器皿; 验证; 可视化; Writing – Original Draft; Writing – 审查 & Editing. Patricia
Wollstadt: 概念化; 软件; Writing – 审查 & Editing. Pedro Mediano: 软件;
Writing – 审查 & Editing. Michael Wibral: 概念化; Funding Acquisition; 方法-
ology; 软件; 监督; Writing – 审查 & Editing. Joseph T. Lizier: 概念化;
Funding Acquisition; 方法; 软件; 监督; Writing – 审查 & Editing.
网络神经科学
845
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
t
/
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
资金信息
Joseph T. Lizier, Universities Australia/German Academic Exchange Service (DAAD) 澳大利亚-
Germany Joint Research Cooperation Scheme Grant: “Measuring Neural Information Synthe-
sis and Its Impairment,” Award Id: 57216857. Michael Wibral, Universities Australia/German
Academic Exchange Service (DAAD) Australia-Germany Joint Research Cooperation Scheme
授予: “Measuring Neural Information Synthesis and Its Impairment,” Award Id: 57216857.
Joseph T. Lizier, Australian Research Council DECRA Grant, Award Id: DE160100630. 迈克尔
Wibral, 德国研究基金会 (DFG) 授予, Award Id: CRC 1193 C04. Joseph T.
Lizier, Australian Research Council Discovery Grant, Award Id: DP160102742.
参考
Atay, F. M。, & Karabacak, Ö. (2006). Stability of coupled map net-
works with delays. SIAM Journal on Applied Dynamical Systems,
5(3), 508–527.
Ay, N。, & Polani, D. (2008). Information flows in causal networks.
Advances in Complex Systems, 11(01), 17–41.
Barnett, L。, Barrett, A. B., & 赛斯, A. K. (2009). Granger causality
and transfer entropy are equivalent for Gaussian variables. Phys-
ical Review Letters, 103(23), 238701.
Barnett, L。, & Bossomaier, 时间. (2012). Transfer entropy as a log-
likelihood ratio. 物理评论快报, 109(13), 138105.
Benjamini, Y。, & Hochberg, 是. (1995). Controlling the false discov-
ery rate: a practical and powerful approach to multiple testing.
Journal of the Royal Statistical Society. Series B (Methodological),
57(1), 289–300.
Bossomaier, T。, Barnett, L。, Harré, M。, & Lizier, J. 时间. (2016). An In-
troduction to Transfer Entropy. Springer International Publishing,
Chambridge, 英国.
Brodski-Guerniero, A。, Paasch, G.-F., Wollstadt, P。, Özdemir, 我。,
Lizier, J. T。, & Wibral, 中号. (2017). Information-theoretic evidence
for predictive coding in the face-processing system. The Journal
of Neuroscience, 37(34), 8273–8283.
Chan, J. S。, Wibral, M。, Wollstadt, P。, Stawowsky, C。, Brandl, M。,
Helbling, S。, . . . Kaiser, J. (2017). Predictive coding over the
lifespan: Increased reliance on perceptual priors in older adults—
a magnetoencephalography and dynamic causal modelling
学习. bioRxiv Preprint, 页 178095.
Chávez, M。, 马蒂内里, J。, & Le Van Quyen, 中号. (2003). Statistical
assessment of nonlinear causality: application to epileptic EEG
signals. Journal of Neuroscience Methods, 124(2), 113–128.
Chicharro, D ., & Ledberg, A. (2012). Framework to study dynamic
dependencies in networks of interacting processes. Physical Re-
view E, 86(4), 041901.
Cliff, 奥。, Prokopenko, M。, & Fitch, 右. (2018). Minimising the
Kullback-Leibler divergence for model selection in distributed
nonlinear systems. Entropy, 20(2), 51.
Cover, 时间. M。, & 托马斯, J. A. (2005). Elements of Information The-
奥里. 约翰·威利 & Sons, 霍博肯, 新泽西州, 美国, 2 版.
Dickhaus, 时间. (2014). Simultaneous Statistical Inference. 施普林格
Berlin Heidelberg, 柏林, Heidelberg.
Erd ˝os, P。, & Rényi, A. (1959). On random graphs. Publicationes
Mathematicae Debrecen, 6, 290–297.
Faes, L。, 我不想, G。, & Porta, A. (2011). Information-based detec-
tion of nonlinear Granger causality in multivariate processes via
a nonuniform embedding technique. Physical Review E, 83(5),
051112.
Frenzel, S。, & Pompe, 乙. (2007). Partial mutual information for cou-
pling analysis of multivariate time series. 物理评论快报,
99(20), 204101.
弗里斯顿, K. J. (1994). Functional and effective connectivity in neu-
roimaging: a synthesis. 人脑图谱, 2(1-2), 56–78.
弗里斯顿, K. J。, Moran, R。, & 赛斯, A. K. (2013). Analysing connectivity
with Granger causality and dynamic causal modelling. 当前的
Opinion in Neurobiology, 23(2), 172–178.
Garland, J。, James, 右. G。, & Bradley, 乙. (2016). Leveraging infor-
mation storage to select forecast-optimal parameters for delay-
coordinate reconstructions. Physical Review E, 93(2), 022221.
Gómez-Herrero, G。, 吴, W., Rutanen, K., Soriano, M。, Pipa, G。, &
Vicente, 右. (2015). Assessing coupling dynamics from an ensem-
ble of time series. Entropy, 17(4), 1958–1970.
Granger, C. 瓦. J. (1969). Investigating causal relations by econo-
metric models and cross-spectral methods. Econometrica, 37(3),
424–438.
Kim, P。, 罗杰斯,
(2016). Causation
entropy identifies sparsity structure for parameter estimation
of dynamic systems. Journal of Computational and Nonlinear
Dynamics, 12(1), 011008.
J。, & Bollt, 乙. 中号.
J。, Sun,
Kraskov, A。, Stögbauer, H。, & Grassberger, 磷. (2004). Estimating mu-
tual information. Physical Review E, 69(6), 066138.
李, M。, Han, Y。, Aburn, 中号. J。, Breakspear, M。, Poldrack, 右. A。, Shine,
J. M。, & Lizier, J. 时间. (2019). Transitions in brain-network level
information processing dynamics are driven by alterations in neu-
ral gain. bioRxiv Preprint, 页 581538.
林德纳, M。, Vicente, R。, Priesemann, 五、, & Wibral, 中号. (2011).
TRENTOOL: A Matlab open source toolbox to analyse informa-
tion flow in time series data with transfer entropy. BMC Neuro-
科学, 12, 119.
Lizier, J. 时间. (2013). The Local Information Dynamics of Distributed
Computation in Complex Systems. Springer Berlin, Heidelberg.
Lizier, J. 时间. (2014). JIDT: An information-theoretic toolkit for study-
ing the dynamics of complex systems. Frontiers in robotics and
人工智能, 1, 11.
Lizier,
J. T。, Heinzle,
J。, Horstmann, A。, Haynes,
J.-D., &
Prokopenko, 中号. (2011). Multivariate information-theoretic mea-
sures reveal directed information structure and task relevant
changes in fMRI connectivity. Journal of Computational Neuro-
科学, 30(1), 85–107.
网络神经科学
846
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Large-scale network inference with multivariate transfer entropy
Lizier, J. T。, Prokopenko, M。, & Zomaya, A. 是. (2008). Local infor-
mation transfer as a spatiotemporal filter for complex systems.
Physical Review E, 77(2), 026110.
Lizier, J. T。, Prokopenko, M。, & Zomaya, A. 是. (2010). 信息
modification and particle collisions in distributed computation.
Chaos, 20(3), 037109.
Lizier, J. T。, Prokopenko, M。, & Zomaya, A. 是. (2012). Local mea-
sures of information storage in complex distributed computation.
信息科学, 208, 39–54.
Lizier, J. T。, & 鲁比诺夫, 中号. (2012). Multivariate construction of effec-
tive computational networks from observational data. Technical
Report Preprint 25/2012, Max Planck Institute for Mathematics
in the Sciences.
Lorenz, H.-W. (1993). Chaotic dynamics in discrete-time economic
型号. In Nonlinear Dynamical Economics and Chaotic Motion
(pages 119–166). 施普林格, 柏林.
Montalto, A。, Faes, L。, & Marinazzo, D. (2014). MuTE: A MATLAB
toolbox to compare established and novel estimators of the
multivariate transfer entropy. PLoS ONE, 9(10), e109462.
Nichols, T。, & Hayasaka, S. (2003). Controlling the familywise error
rate in functional neuroimaging: a comparative review. Statistical
Methods in Medical Research, 12(5), 419–446.
Paluš, M。, Albrecht, 五、, & Dvoák, 我. (1993). Information theoretic test
for nonlinearity in time series. Physics Letters A, 175(3-4), 203–209.
Paninski, L. (2003). Estimation of entropy and mutual information.
神经计算, 15(6), 1191–1253.
Razi, A。, Seghier, 中号. L。, 周, Y。, McColgan, P。, Zeidman, P。,
公园, H.-J., 斯波恩斯, 奥。, Rees, G。, & 弗里斯顿, K. J. (2017). 大的-
scale DCMs for resting-state fMRI. 网络神经科学, 1(3),
222–241.
Roulston, 中号. S. (1999). Estimating the errors on measured entropy
信息. Physica D: Nonlinear Phenomena,
and mutual
125(3-4), 285–294.
鲁比诺夫, M。, 斯波恩斯, 奥。, van Leeuwen, C。, & Breakspear, 中号. (2009).
Symbiotic relationship between brain structure and dynamics.
BMC Neuroscience, 10, 55.
Runge, J. (2018). Causal network reconstruction from time se-
里斯: from theoretical assumptions to practical estimation. Chaos,
28(7), 075310.
Runge, J。, Heitzig, J。, Petoukhov, 五、, & Kurths, J. (2012). Escaping
the curse of dimensionality in estimating multivariate transfer en-
tropy. 物理评论快报, 108(25), 258701.
Runge, J。, Nowack, P。, Kretschmer, M。, Flaxman, S。, & Sejdinovic,
D. (2018). Detecting causal associations in large nonlinear time
series datasets. arXiv Preprint. arXiv: 1702.07007.
Schreiber, 时间. (2000). Measuring information transfer. Physical Re-
view Letters, 85(2), 461–464.
Schreiber, T。, & Schmitz, A. (2000). Surrogate time series. Physica
D: Nonlinear Phenomena, 142(3-4), 346–382.
Shannon, C. 乙. (1948). A mathematical theory of communication.
Bell System Technical Journal, 27(3), 379–423.
Šidák, Z. (1967). Rectangular confidence regions for the means of
multivariate normal distributions. Journal of the American Statis-
tical Association, 62(318), 626–633.
西姆斯, C. A. (1980). Macroeconomics and reality. Econometrica,
48(1), 1–48.
Spinney, 右. E., Prokopenko, M。, & Lizier, J. 时间. (2017). Transfer en-
tropy in continuous time, with applications to jump and neural
spiking processes. Physical Review E, 95(3), 032319.
Spirtes, P。, Glymour, C。, & Scheines, 右. (1993). Causation, 预-
措辞, and Search, 体积 81 of Lecture Notes in Statistics.
Springer New York.
斯波恩斯, 氧. (2010). Networks of the Brain. MIT Press Cambridge,
嘛.
Strogatz, S. H. (2015). Nonlinear Dynamics and Chaos. CRC Press,
Boca Raton, FL.
Sun, J。, 泰勒, D ., & Bollt, 乙. 中号. (2015). Causal network inference by
optimal causation entropy. SIAM Journal on Applied Dynamical
系统, 14(1), 73–106.
Takens, F. (1981). Detecting strange attractors in turbulence. 在
Rand, D. and Young, L。, 编辑, Dynamical Systems and Turbu-
伦斯, pages 366–381. 施普林格, 柏林.
Vakorin, V. A。, Krakovska, 氧. A。, & McIntosh, A. 右. (2009). 骗局-
founding effects of indirect connections on causality estimation.
Journal of Neuroscience Methods, 184(1), 152–160.
Valdes-Sosa, 磷. A。, Roebroeck, A。, Daunizeau, J。, & 弗里斯顿, K. J.
(2011). Effective connectivity: influence, causality and biophysi-
cal modeling. 神经影像, 58(2), 339–361.
Vejmelka, M。, & Paluš, 中号. (2008). Inferring the directionality of cou-
pling with conditional mutual information. Physical Review E,
77(2), 026214.
Verdes, 磷. F. (2005). Assessing causality from multivariate time se-
里斯. Physical Review E, 72(2), 026222.
Vicente, R。, Wibral, M。, 林德纳, M。, & Pipa, G. (2011). Transfer
entropy—a model-free measure of effective connectivity for the
neurosciences. 计算神经科学杂志, 30(1),
45–67.
Vlachos, 我。, & Kugiumtzis, D. (2010). Nonuniform state-space recon-
struction and coupling detection. Physical Review E, 82(1), 016207.
Wibral, M。, Pampu, N。, Priesemann, 五、, 七只母鸡, F。, Seiwert,
H。, 林德纳, M。, . . . Vicente, 右. (2013). Measuring information-
transfer delays. PLoS ONE, 8(2), e55809.
Wollstadt, P。, Lizier, J. T。, Vicente, R。, 芬恩, C。, Martínez-Zarzuela,
M。, Mediano, P。, . . . Wibral, 中号. (2019). IDTxl: The Information
Dynamics Toolkit xl: a Python package for the efficient analy-
sis of multivariate information dynamics in networks. 杂志
Open Source Software, 4(34), 1081.
Wollstadt, P。, Martínez-Zarzuela, M。, Vicente, R。, Díaz-Pernas, F. J。,
& Wibral, 中号. (2014). Efficient transfer entropy analysis of non-
stationary neural time series. PLoS ONE, 9(7), e102833.
扎莱斯基, A。, 假如, A。, Cocchi, L。, Gollo, L. L。, & Breakspear,
(2014). Time-resolved resting-state brain networks. Pro-
the National Academy of Sciences, 111(28),
中号.
ceedings of
10341–10346.
扎莱斯基, A。, 假如, A。, Cocchi, L。, Gollo, L. L。, van den Heuvel,
中号. P。, & Breakspear, 中号. (2016). Connectome sensitivity or speci-
ficity: which is more important? 神经影像, 142, 407–420.
Zeki, S。, & Shipp, S. (1988). The functional logic of cortical connec-
系统蒸发散. 自然, 335, 311–317.
网络神经科学
847
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
/
t
e
d
你
n
e
n
A
r
t
我
C
e
–
p
d
我
F
/
/
/
/
/
3
3
8
2
7
1
0
9
2
4
6
7
n
e
n
_
A
_
0
0
0
9
2
p
d
.
t
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3