Machine Learning–Driven Language Assessment
Burr Settles and Geoffrey T. LaFlair
Duolingo
Pittsburgh, PA USA
{burr,geoff}@duolingo.com
Masato Hagiwara∗
Octanove Labs
Seattle, WA USA
masato@octanove.com
抽象的
We describe a method for rapidly creating lan-
guage proficiency assessments, and provide
experimental evidence that such tests can be
valid, 可靠的, and secure. Our approach is the
first to use machine learning and natural lan-
guage processing to induce proficiency scales
based on a given standard, and then use linguis-
tic models to estimate item difficulty directly
for computer-adaptive testing. This alleviates
the need for expensive pilot testing with human
subjects. We used these methods to develop an
online proficiency exam called the Duolingo
English Test, and demonstrate that its scores
align significantly with other high-stakes English
assessments. 此外, our approach pro-
duces test scores that are highly reliable, 尽管
generating item banks large enough to satisfy
security requirements.
1 介绍
Language proficiency testing is an increasingly
important part of global society. The need to dem-
onstrate language skills—often through standard-
ized testing—is now required in many situations
for access to higher education, immigration, 和
employment opportunities. 然而, 标准-
ized tests are cumbersome to create and main-
坦. Lane et al. (2016) and the Standards for
Educational and Psychological Testing (AERA
等人。, 2014) describe many of the procedures
and requirements for planning, 创造, revis-
英, administering, 分析, and reporting on
high-stakes tests and their development.
在实践中, test items are often first written by
subject matter experts, and then ‘‘pilot tested’’
with a large number of human subjects for psy-
∗ Research conducted at Duolingo.
247
chometric analysis. This labor-intensive process
often restricts the number of items that can feasibly
be created, which in turn poses a threat to security:
Items may be copied and leaked, or simply used
too often (Cau, 2015; Dudley et al., 2016).
Security can be enhanced through computer-
adaptive testing (CAT), by which a subset of
items are administered in a personalized way
(based on examinees’ performance on previous
项目). Because the item sequences are essentially
unique for each session, there is no single test
form to obtain and circulate (Wainer, 2000), 但
these security benefits only hold if the item bank
is large enough to reduce item exposure (方式,
1998). This further increases the burden on item
writers, and also requires significantly more item
pilot testing.
For the case of language assessment, we tackle
both of these development bottlenecks using
语言
机器学习 (机器学习) and natural
加工 (自然语言处理). 尤其, we propose the
use of test item formats that can be automatically
已创建, graded, and psychometrically analyzed
using ML/NLP techniques. This solves the ‘‘cold
start’’ problem in language test development,
by relaxing manual item creation requirements
and alleviating the need for human pilot testing
altogether.
In the pages that follow, we first summarize
the important concepts from language testing
and psychometrics (§2), and then describe our
ML/NLP methods to learn proficiency scales for
both words (§3) and long-form passages (§4). 我们
then present evidence for the validity, reliability,
and security of our approach using results from
the Duolingo English Test, an online, 操作
English proficiency assessment developed using
these methods (§5). After summarizing other
related work (§6), we conclude with a discussion
of limitations and future directions (§7).
计算语言学协会会刊, 卷. 8, PP. 247–263, 2020. https://doi.org/10.1162/tacl 00310
动作编辑器: Mamoru Komachi. 提交批次: 4/2019; 修改批次: 11/2019; 已发表 4/2020.
C(西德:13) 2020 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
or incorrect, and the next step is to estimate θ
and δi parameters empirically from these grades.
The reader may recognize the Rasch model as
equivalent to binary logistic regression for pre-
dicting whether an examinee will answer item
i correctly (where θ represents a weight for the
‘‘examinee feature,’’ −δi represents a weight for
the ‘‘item feature,’’ and the bias/intercept weight
is zero). Once parameters are estimated, θs for
the pilot population can be discarded, and δis are
used to estimate θ for a future examinee, 哪个
ultimately determines his or her test score.
We focus on the Rasch model because item
difficulty δi and examinee ability θ are interpreted
on the same scale. Whereas other IRT models
exist to generalize the Rasch model in various
方法 (例如, by accounting for item discrimination
or examinee guessing), the additional parameters
make them more difficult to estimate correctly
(Linacre, 2014). Our goal in this work is to esti-
mate item parameters using ML/NLP (而不是
traditional item piloting), and a Rasch-like model
gives us a straightforward and elegant way to do
这.
2.2 Computer-Adaptive Testing (CAT)
Given a bank of test items and their associated
δis, one can use CAT techniques to efficiently
administer and score tests. CATs have been shown
to both shorten tests (Weiss and Kingsbury, 1984)
and provide uniformly precise scores for most
examinees, by giving harder items to subjects of
higher ability and easier items to those of lower
能力 (Thissen and Mislevy, 2000).
Assuming test item independence, the condi-
tional probability of an item response sequence
r = hr1, r2, . . . , rti given θ is the product of all
the item-specific IRF probabilities:
p(r|我) =
t
是
我=1
pi(我)ri (1 − pi(我))1−ri ,
(2)
where ri denotes the graded response to item i
(IE。, ri = 1 if correct, ri = 0 if incorrect).
The goal of a CAT is to estimate a new
examinee’s θ as precisely as possible with as
few items as possible. The precision of θ depends
on the items in r: Examinees are best evaluated
by items where δi ≈ θ. 然而, 因为
true value of θ is unknown (这是, 毕竟,
the reason for testing!), we use an iterative
adaptive algorithm. 第一的, make a ‘‘provisional’’
数字 1: The Rasch model IRF, showing the prob-
ability of a correct response pi(我) for three test item
difficulties δi, across examinee ability level θ.
2 Background
Here we provide an overview of relevant language
testing concepts, and connect them to work in ma-
chine learning and natural language processing.
2.1 Item Response Theory (IRT)
In psychometrics, item response theory (IRT) 是一个
paradigm for designing and scoring measures of
ability and other cognitive variables (Lord, 1980).
IRT forms the basis for most modern high-stakes
standardized tests, and generally assumes:
1. An examinee’s response to a test item is
modeled by an item response function (IRF);
2. There is a unidimensional latent ability for
each examinee, denoted θ;
3. Test items are locally independent.
In this work we use a simple logistic IRF,
also known as the Rasch model (Rasch, 1993).
This expresses the probability pi(我) of a correct
item i as a function of the
response to test
difference between the item difficulty parameter
δi and the examinee’s ability parameter θ:
pi(我) =
1
1 + 经验值(δi − θ)
.
(1)
The response pattern from equation (1) 显示
图中 1. As with most IRFs, pi(我) mono-
tonically increases with examinee ability θ, 和
decreases with item difficulty δi.
In typical standardized test development, 项目
are first created and then ‘‘pilot tested’’ with
human subjects. These pilot tests produce many
hexaminee, itemi pairs that are graded correct
248
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
CEFR
Level Description
Scale
C2
C1
B2
B1
A2
A1
Proficient / Mastery
Advanced / Effective
Upper Intermediate / Vantage
Intermediate / Threshold
Elementary / Waystage
Beginner / Breakthrough
100
80
60
40
20
0
桌子 1: The Common European Framework of
参考 (CEFR) levels and our corresponding test
规模.
estimate ˆθt ∝ argmaxθ p(rt|我) by maximizing
the likelihood of observed responses up to point
t. 然后, select the next item difficulty based on a
‘‘utility’’ function of the current estimate δt+1 =
F (ˆθt). This process repeats until reaching some
stopping criterion, and the final ˆθt determines
the test score. Conceptually, CAT methods are
analogous to active learning in the ML/NLP
文学 (Settles, 2012), which aims to minimize
the effort required to train accurate classifiers by
adaptively selecting instances for labeling. 为了
more discussion on CAT administration and scor-
英, see Segall (2005).
2.3 The Common European Framework of
参考 (CEFR)
The Common European Framework of Reference
(CEFR) is an international standard for describ-
ing the proficiency of foreign-language learners
(Council of Europe, 2001). Our goal is to create
a test integrating reading, 写作, listening, 和
speaking skills into a single overall score that
corresponds to CEFR-derived ability. To that end,
we designed a 100-point scoring system aligned
to the CEFR levels, 如表所示 1.
By its nature, the CEFR is a descriptive (not pre-
scriptive) proficiency framework. 那是, it de-
scribes what kinds of activities a learner should
be able to do—and competencies they should
have—at each level, but provides little guidance
on what specific aspects of language (例如, vocab-
ulary) are needed to accomplish them. This helps
the CEFR achieve its goal of applying broadly
across languages, but also presents a challenge
for curriculum and assessment development for
any particular language. It is a coarse description
of potential target domains—tasks, 上下文, 和
conditions associated with language use (Bachman
and Palmer, 2010; Kane, 2013)—that can be
sampled from in order to create language curricula
or assessments. 因此, it is left to the devel-
opers to define and operationalize constructs based
on the CEFR, targeting a subset of the activities
and competences that it describes.
Such work can be seen in recent efforts under-
taken by linguists to profile the vocabulary and
grammar linked to each CEFR level for specific
语言 (particularly English). We leverage
these lines of research to create labeled data
套, and train ML/NLP models that project item
difficulty onto our CEFR-derived scale.
2.4 Test Construct and Item Formats
Our aim is to develop a test of general English
language proficiency. According to the CEFR
global descriptors, this means the ability to under-
stand written and spoken language from varying
主题, 流派, and linguistic complexity, 并
write or speak on a variety of topics and for a
variety of purposes (Council of Europe, 2001).
We operationalize part of this construct using
five item formats from the language testing liter-
ature. These are summarized in Table 2 and col-
lectively assess reading, 写作, listening, 和
speaking skills. Note that these items may not
require examinees to perform all the linguistic
tasks relevant to a given CEFR level (as is true
with any language test), but they serve as strong
proxies for the underlying skills. These formats
were selected because they can be automatically
generated and graded at scale, and have decades
of research demonstrating their ability to predict
linguistic competence.
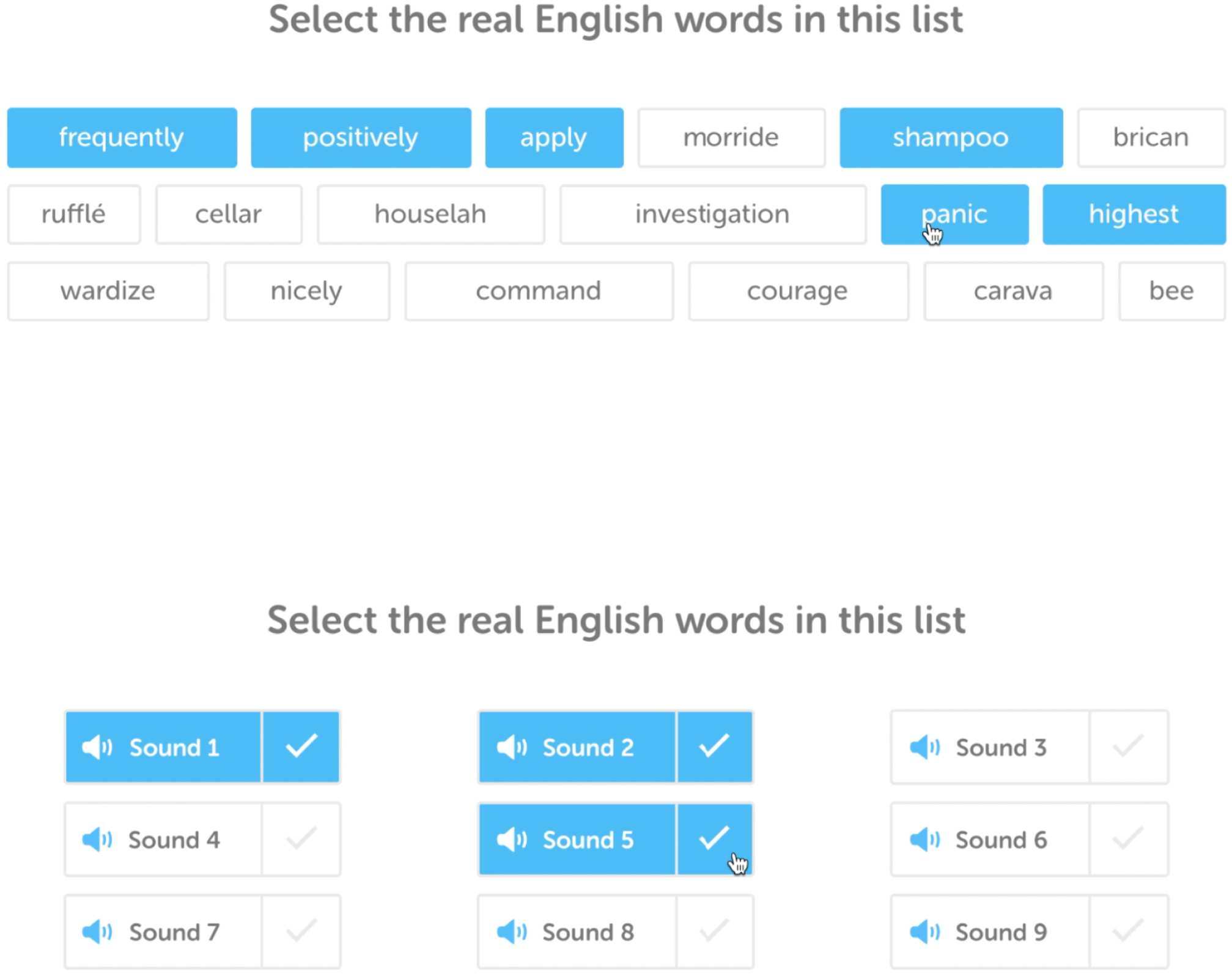
Two of the formats assess vocabulary breadth,
known as yes/no vocabulary tests (数字 2).
These both follow the same convention but vary
in modality (text vs. 声音的), allowing us to mea-
sure both written and spoken vocabulary. 对于这些
项目, the examinee must select, from among text
or audio stimuli, which are real English words
and which are English-like pseudowords (morphol-
ogically and phonologically plausible, but have no
meaning in English). These items target a founda-
tional linguistic competency of the CEFR, 即,
the written and spoken vocabulary required to
meet communication needs across CEFR levels
(Milton, 2010). Test takers who do well on these
tasks have a broader lexical inventory, allowing
for performance in a variety of language use situ-
ations. Poor performance on these tasks indicates
a more basic inventory.
249
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Item Format
Scale Model
Skills
参考
Yes/No (文本)
Yes/No (声音的)
C-Test
Dictation
Elicited Speech
Vocab (§3)
Vocab (§3)
Passage (§4)
Passage (§4)
Passage (§4)
L,右,W Zimmerman et al. (1977); Staehr (2008); Milton (2010)
Milton et al. (2010); Milton (2010)
L,S
右,W Klein-Braley (1997); Reichert et al. (2010); Khodadady (2014)
L,瓦
右,S
Bradlow and Bent (2002, 2008)
Vinther (2002); Jessop et al. (2007); Van Moere (2012)
桌子 2: Summary of language assessment item formats in this work. For each format, we indicate the machine-
learned scale model used to predict item difficulty δi, the linguistic skills it is known to predict (L = listening, 右
= reading, S = speaking, W = writing), and some of the supporting evidence from the literature.
predict other measures of CEFR level (Reichert
等人。, 2010).
The dictation task taps into both listening and
writing skills by having examinees transcribe an
audio recording. In order to respond successfully,
examinees must parse individual words and under-
stand their grammatical relationships prior to
typing what they hear. This targets the linguistic
demands required for overall listening compre-
hension as described in the CEFR. The writing
portion of the dictation task measures examinee
knowledge of orthography and grammar (标记
of writing ability at the A1/A2 level), 并
some extent meaning. The elicited speech task
taps into reading and speaking skills by requiring
examinees to say a sentence out loud. Test takers
must be able to process the input (例如, orthog-
raphy and grammatical structure) and are eval-
uated on their fluency, 准确性, and ability to
use complex language orally (Van Moere, 2012).
This task targets sentence-level language skills
that incorporate simple-to-complex components
of both the reading and speaking ‘‘can-do’’ state-
ments in the CEFR framework. 此外, 两个都
the dictation and elicited speech tasks also measure
working memory capacity in the language, 哪个
is regarded as shifting from lexical competence to
structure and pragmatics somewhere in the B1/B2
范围 (Westhoff, 2007).
3 The Vocabulary Scale
For the experiments in this section, a panel of lin-
guistics PhDs with ESL teaching experience first
compiled a CEFR vocabulary wordlist, synthesiz-
ing previous work on assessing active English lan-
guage vocabulary knowledge (例如, Capel, 2010,
2012; Cambridge English, 2012). This standard-
setting step produced an inventory of 6,823
English words labeled by CEFR level, 大多
). We did not conduct
in the B1/B2 range (
数字 2: Example test
vocabulary scale model to estimate difficulty.
item formats that use the
The other three item formats come out of the
integrative language testing tradition (Alderson
等人。, 1995), which requires examinees to draw
on a variety of language skills (例如, grammar,
话语) and abilities (例如, 阅读, 写作) 在
order to respond correctly. Example screenshots
of these item formats are shown in Figure 4.
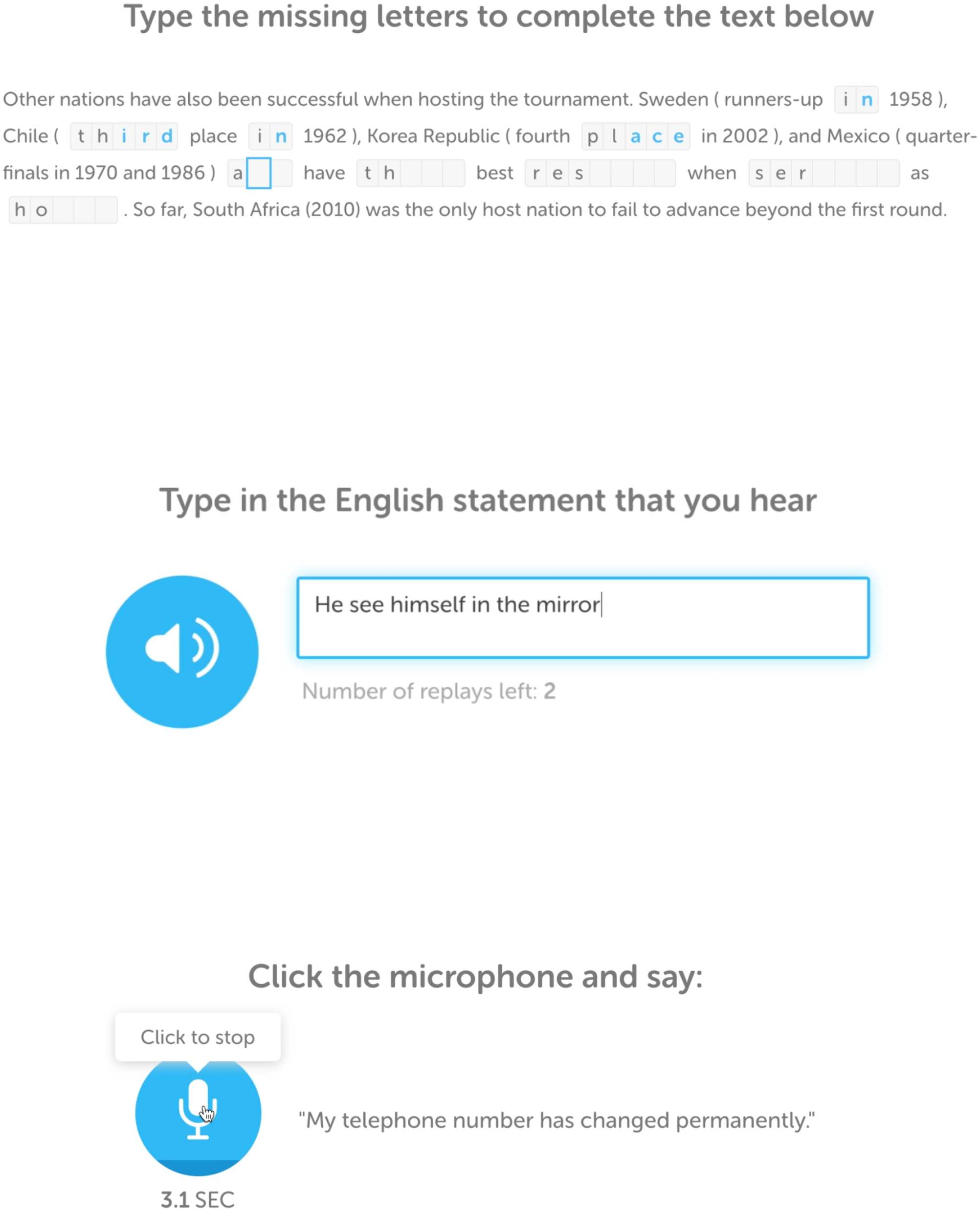
The c-test format is a measure of reading ability
(并且在某种程度上, 写作). These items contain
passages of text in which some of the words have
been ‘‘damaged’’ (by deleting the second half
of every other word), and examinees must com-
plete the passage by filling in missing letters
from the damaged words. The characteristics of
the damaged words and their relationship to the
text ranges from those requiring lexical, phrasal,
clausal, and discourse-level comprehension in
order to respond correctly. These items indicate
how well test takers can process texts of varied
abstractness and complexity versus shorter more
concrete texts, and have been shown to reliably
250
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
any formal annotator agreement studies, 和
inventory does include duplicate entries for types
at different CEFR levels (例如, for words with
multiple senses). We used this labeled wordlist
to train a vocabulary scale model that assigns δi
scores to each yes/no test item (数字 2).
3.1 Features
Culligan (2015) found character length and corpus
frequency to significantly predict word difficulty,
according IRT analyses of multiple vocabulary
测试 (including the yes/no format). 这使得
them promising features for our CEFR-based vo-
cabulary scale model.
Although character length is straightforward,
corpus frequencies only exist for real English
字. 为了我们的目的, 然而, the model must
also make predictions for English-like pseudo-
字, since our CAT approach to yes/no items
requires examinees to distinguish between words
and pseudowords drawn from a similar CEFR-
based scale range. As a proxy for frequency, 我们
trained a character-level Markov chain language
model on the OpenSubtitles corpus1 using modi-
fied Kneser-Ney smoothing (Heafield et al., 2013).
We then use the log-likelihood of a word (or pseu-
doword) under this model as a feature.
We also use the Fisher score of a word under the
language model to generate more nuanced ortho-
graphic features. The Fisher score ∇x of word x
is a vector representing the gradient of its log-
likelihood under the language model, parameter-
ized by m: ∇x = ∂
∂m log p(X|米). These features
are conceptually similar to trigrams weighted by tf-
idf (Elkan, 2005), and are inspired by previous
work leveraging information from generative se-
quence models to improve discriminative classi-
fiers (Jaakkola and Haussler, 1999).
3.2 楷模
We consider two regression approaches to model
linear and
the CEFR-based vocabulary scale:
weighted-softmax. Let yx be the CEFR level of
word x, and δ(yx) be the 100-point scale value
corresponding to that level from Table 1.
For the linear approach, we treat the difficulty of
a word as δx = δ(yx), and learn a linear function
with weights w on the features of x directly. 为了
weighted-softmax, we train a six-way multinomial
1We found movie subtitle counts (Lison and Tiedemann,
2016) to be more correlated with the expert CEFR judgments
than other language domains (例如, Wikipedia or newswire).
Vocabulary Scale Model
Linear regression
w/o character length
w/o log-likelihood
w/o Fisher score
Weighted-softmax regression
w/o character length
w/o log-likelihood
w/o Fisher score
rALL
.98
.98
.98
.38
.90
.91
.89
.46
rXV
.30
.31
.34
.38
.56
.56
.51
.46
桌子 3: Vocabulary scale model evaluations.
≈ δ English Words
Pseudowords
90
70
50
30
10
loft, 诉讼程序
brutal, informally
delicious, unfairly
进入, rabbit
egg, 母亲
fortheric, retray
insequent, vasera
anage, compatively
knoce, thace
cload, eut
桌子 4: Example words and pseudowords, rated
for difficulty by the weighted-softmax vocabulary
模型.
regression (MaxEnt) classifier to predict CEFR
等级, and treat difficulty δx = Py δ(y)p(y|X, w)
as a weighted sum over the posterior p(y|X, w).
3.3 实验
Experimental results are shown in Table 3. 我们
report Pearson’s r between predictions and expert
CEFR judgments as an evaluation measure. 这
rALL results train and evaluate using the same data;
this is how models are usually analyzed in the
applied linguistics literature, and provides a sense
of how well the model captures word difficulty
for real English words. The rXV results use 10-fold
cross-validation; this is how models are usually
evaluated in the ML/NLP literature, and gives us
a sense of how well it generalizes to English-like
pseudowords (as well as English words beyond
the expert CEFR wordlist).
Both models have a strong, positive relation-
ship with expert human judgments (rALL ≥ .90),
although they generalize to unseen words less well
(rXV ≤ .60). Linear regression appears to dras-
tically overfit compared to weighted-softmax,
since it reconstructs the training data almost
perfectly while explaining little of the variance
among cross-validated labels. The feature abla-
tions also reveal that Fisher score features are
251
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
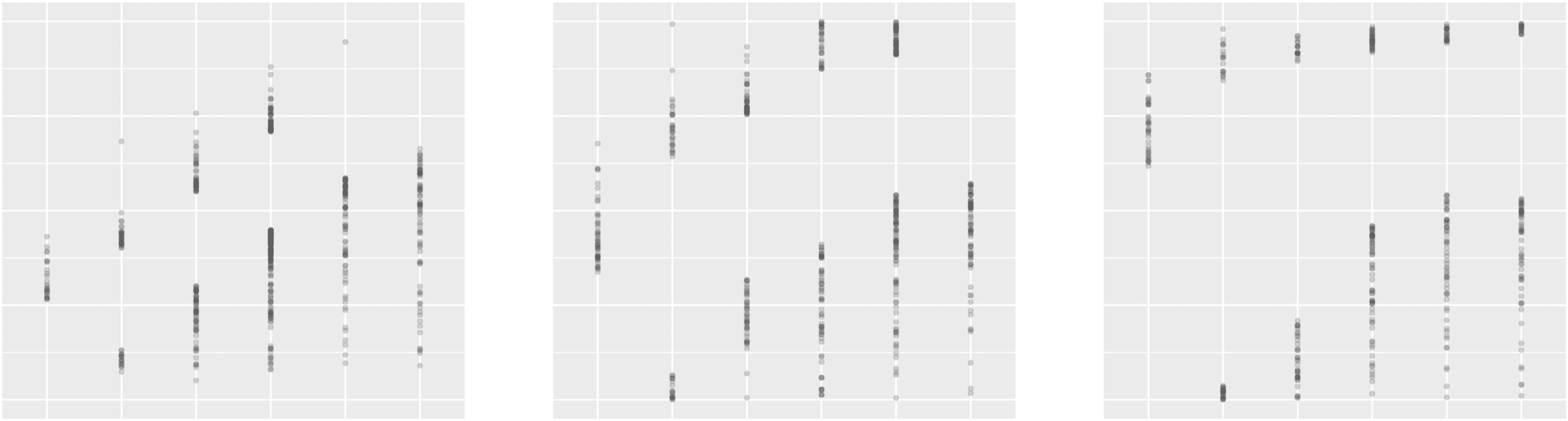
数字 3: Boxplots and correlation coefficients evaluating our machine-learned proficiency scale models. (A) 结果
for the weighted-softmax vocabulary model (n = 6,823). (乙) Cross-validation results for the weighted-softmax
passage model (n = 3,049). (C) Results applying the trained passage model, post-hoc, to a novel set of ‘‘blind’’
texts written by ESL experts at targeted CEFR levels (n = 2,349).
the most important, while character length has
little impact (possibly because length is implicitly
captured by all the Fisher score features).
Sample predictions from the weighted-softmax
vocabulary scale model are shown in Table 4.
The more advanced words (higher δ) are rarer and
mostly have Greco-Latin etymologies, 然而
the more basic words are common and mostly have
Anglo-Saxon origins. These properties appear to
hold for non-existent pseudowords (例如, ‘cload’
seems more Anglo-Saxon and more common than
‘fortheric’ would be). Although we did not con-
duct any formal analysis of pseudoword difficulty,
these illustrations suggest that the model captures
qualitative subtleties of the English lexicon, 作为
they relate to CEFR level.
Boxplots visualizing the relationship between
our learned scale and expert judgments are shown
图中 3(A). Qualitative error analysis reveals
that the majority of mis-classifications are in fact
under-predictions simply due to polysemy. 对于前-
充足: ‘a just cause’ (C1) 与. ‘I just left’ (δ = 24),
and ‘to part ways’ (C2) 与. ‘part of the way’
(δ = 11). Because these more basic word senses
do exist, our correlation estimates may be on
the conservative side. 因此, using these predicted
word difficulties to construct yes/no items (和我们一样
do later in §5) seems justified.
4 The Passage Scale
For the experiments in this section, we leverage a
variety of corpora gleaned from online sources,
and use combined regression and ranking tech-
niques to train longer-form passage scale models.
252
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 4: Example test item formats that use the passage
scale model to estimate difficulty.
These models can be used to predict difficulty
for c-test, dictation, and elicited speech items
(数字 4).
In contrast to vocabulary, little to no work has
been done to profile CEFR text or discourse fea-
tures for English, and only a handful of ‘‘CEFR-
labeled’’ documents are even available for model
训练. 因此, we take a semi-supervised learning
方法 (Zhu and Goldberg, 2009), first by learn-
ing to rank passages by overall difficulty, 进而
by propagating CEFR levels from a small number
of labeled texts to many more unlabeled texts that
have similar linguistic features.
4.1 Features
Average word length and sentence length have
long been used to predict text difficulty, 事实上
measures based solely on these features have been
shown to correlate (r = .91) with comprehension
in reading tests (DuBay, 2006). Inspired by our
vocabulary model experiments, we also trained a
word-level unigram language model to produce
log-likelihood and Fisher score features (这是
similar to a bag of words weighted by tf-idf ).
4.2 语料库
We gathered an initial training corpus from on-
line English language self-study Web sites (例如,
free test preparation resources for popular English
proficiency exams). These consist of reference
phrases and texts from reading comprehension
exercises, all organized by CEFR level. We seg-
mented these documents and assigned documents’
CEFR labels to each paragraph. This resulted in
3,049 CEFR-labeled passages, containing very
).
few A1 texts, and a peak at the C1 level (
We refer to this corpus as CEFR.
Due to the small size of the CEFR corpus and
its uncertain provenance, we also downloaded
pairs of articles from English Wikipedia2 that
had also been rewritten for Simple English3 (一个
alternate version that targets children and adult
English learners). Although the CEFR alignment
for these articles is unknown, we hypothesize that
the levels for texts on the English site should be
higher than those on the Simple English site; 因此
by comparing these article pairs a model can learn
features related to passage difficulty, 因此
the CEFR level (in addition to expanding topical
coverage beyond those represented in CEFR). 这
corpus includes 3,730 article pairs resulting in
18,085 段落 (from both versions combined).
We refer to this corpus as WIKI.
We also downloaded thousands of English
sentences from Tatoeba,4 a free, crowd-sourced
database of self-study resources for language
learners. We refer to this corpus as TATOEBA.
2https://en.wikipedia.org.
3https://simple.wikipedia.org.
4https://tatoeba.org.
Passage Ranking Model
AUCCEFR AUCWIKI
Linear (rank) regression
w/o characters per word
w/o words per sentence
w/o log-likelihood
w/o Fisher score
.85
.85
.84
.85
.79
.75
.72
.75
.76
.84
桌子 5: Passage ranking model evaluations.
4.3 Ranking Experiments
To rank passages for difficulty, we use a linear
approach similar to that of Sculley (2010). Let x
be the feature vector for a text with CEFR label
y. A standard linear regression can learn a weight
vector w such that δ(y) ≈ x⊺w. Given a pair of
文本, one can learn to rank by ‘‘synthesizing’’ a
label and feature vector representing the difference
它们之间: [δ(y1)−δ(y2)] ≈ [x1 −x2]⊺w. 这
resulting w can still be applied to single texts (IE。,
by subtracting the 0 向量) in order to score them
for ranking. Although the resulting predictions are
not explicitly calibrated (例如, to our CEFR-based
规模), they should still capture an overall ranking
of textual sophistication. This also allows us to
combine the CEFR and WIKI corpora for training,
since relative difficulty for the latter is known
(even if precise CEFR levels are not).
To train ranking models, we sample 1% of par-
agraph pairs from CEFR (最多 92,964 instances),
and combine this with the cross of all paragraphs
in English × Simple English versions of the same
article from WIKI (最多 25,438 instances). 我们
fix δ(y) = 25 for Simple English and δ(y) = 75
for English in the WIKI pairs, under a working
assumption that (一般) the former are at the
A2/B1 level, and the latter B2/C1.
Results using cross-validation are shown in
桌子 5. For each fold, we train using pairs from
the training partition and evaluate using individual
instance scores on the test partition. We report
the AUC, or area under the ROC curve (Fawcett,
2006), which is a common ranking metric for clas-
sification tasks. Ablation results show that Fisher
score features (IE。, weighted bag of words) 再次
have the strongest effect, although they improve
ranking for the CEFR subset while harming WIKI. 我们
posit that this is because WIKI is topically balanced
(all articles have an analog from both versions of
the site), so word and sentence length alone are in
fact good discriminators. The CEFR results indicate
253
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
≈ δ
90
50
10
Candidate Item Text
A related problem for aerobic organisms is oxidative stress. 这里, processes including oxidative phosphorylation and
the formation of disulfide bonds during protein folding produce reactive oxygen species such as hydrogen peroxide.
These damaging oxidants are removed by antioxidant metabolites such as glutathione, and enzymes such as catalases
and peroxidases.
在 1948, Harry Truman ran for a second term as President against Thomas Dewey. He was the underdog and everyone
thought he would lose. The Chicago Tribune published a newspaper on the night of the election with the headline
‘‘Dewey Defeats Truman.’’ To everyone’s surprise, Truman actually won.
Minneapolis is a city in Minnesota. It is next to St. 保罗, Minnesota. 英石. Paul and Minneapolis are called the ‘‘Twin
Cities’’ because they are right next to each other. Minneapolis is the biggest city in Minnesota with about 370,000
人们. People who live here enjoy the lakes, parks, and river. The Mississippi River runs through the city.
桌子 6: Example WIKI paragraphs, rated for predicted difficulty by the weighted-softmax passage model.
那 85% 当时的, the model correctly ranks a
more difficult passage above a simpler one (和
respect to CEFR level).5
4.4 Scaling Experiments
Given a text ranking model, we now present exper-
iments with the following algorithm for propagat-
ing CEFR levels from labeled texts to unlabeled
ones for semi-supervised training:
1. Score all individual passages in CEFR, WIKI,
and TATOEBA (using the ranking model);
2. For each labeled instance in CEFR, propagate
its CEFR level to the five most similarly
ranked neighbors in WIKI and TATOEBA;
3. Combine the label-propagated passages from
WIKI and TATOEBA with CEFR;
4. Balance class labels by sampling up to 5,000
passages per CEFR level (30,000 全部的);
5. Train a passage scale model using the result-
ing CEFR-aligned texts.
Cross-validation results for this procedure are
如表所示 7. The weighted-softmax regres-
sion has a much stronger positive relationship with
CEFR labels than simple linear regression. 毛皮-
瑟莫雷, the label-propagated WIKI and TATOEBA
supplements offer small but statistically signif-
icant improvements over training on CEFR texts
独自的. Since these supplemental passages also ex-
pand the feature set more than tenfold (IE。, 经过
5AUC is also the effect size of the Wilcoxon rank-sum
测试, which represents the probability that the a randomly
chosen text from WIKI English will be ranked higher than
Simple English. For CEFR, 桌子 5 reports macro-averaged
AUC over the five ordinal breakpoints between CEFR levels.
Passage Scale Model
Weighted-softmax regression
w/o TATOEBA propagations
w/o WIKI propagations
w/o label-balancing
Linear regression
rcefr
.76
.75
.74
.72
.13
桌子 7: Passage scale model evaluations.
increasing the model vocabulary for Fisher score
特征), we claim this also helps the model gen-
eralize better to unseen texts in new domains.
Boxplots illustrating the positive relationship
between scale model predictions and CEFR labels
are shown in Figure 3(乙). 这, while strong, 可能
also be a conservative correlation estimate, 自从
we propagate CEFR document labels down to
paragraphs for training and evaluation and this
likely introduces noise (例如, C1-level articles may
well contain A2-level paragraphs).
Example predictions from the WIKI corpus are
如表所示 6. We can see that the C-level
文本 (δ ≈ 90) is rather academic, with complex
sentence structures and specialized jargon. 上
另一方面, the A-level text (δ ≈ 10) is more
accessible, with short sentences, few embedded
条款, and concrete vocabulary. The B-level text
(δ ≈ 50) is in between, discussing a political topic
using basic grammar, but some colloquial vocab-
ulary (例如, ‘underdog’ and ‘headline’).
4.5 Post-Hoc Validation Experiment
The results from §4.3 and §4.4 are encouraging.
然而, they are based on data gathered from
互联网, of varied provenance, using possibly
noisy labels. 所以, one might question
whether the resulting scale model correlates well
with more trusted human judgments.
254
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
To answer this question, we had a panel of
four experts—PhDs and graduate students in lin-
guistics with ESL teaching experience—compose
大致 400 new texts targeting each of the six
CEFR levels (2,349 全部的). These were ultimately
converted into c-test items for our operational
English test experiments (§5), but because they
were developed independently from the passage
scale model, they are also suitable as a ‘‘blind’’
test set for validating our approach. Each passage
was written by one expert, and vetted by another
(with the two negotiating the final CEFR label in
the case of any disagreement).
Boxplots illustrating the relationship between
the passage scale model predictions and expert
judgments are shown in Figure 3(C), which shows
a moderately strong, positive relationship. 这
flattening at the C1/C2 level is not surprising, 自从
the distinction here is very fine-grained, 并且可以
be difficult even for trained experts to distinguish
or produce (Isbell, 2017). They may also be de-
pendent on genre or register (例如, textbooks), 因此
the model may have been looking for features in
some of these expert-written passages that were
missing for non-textbook-like writing samples.
5 Duolingo English Test Results
The Duolingo English Test6 is an accessible, 在-
线, computer-adaptive English assessment ini-
tially created using the methods proposed in this
纸. 在这个部分, we first briefly describe
how the test was developed, 管理的, 和
scored (§5.1). 然后, we use data logged from
many thousands of operational tests to show that
our approach can satisfy industry standards for
psychometric properties (§5.2), criterion validity
(§5.3), reliability (§5.4), and test item security
(§5.5).
5.1 Test Construction and Administration
Drawing on the five formats discussed in §2.4, 我们
automatically generated a large bank of more than
25,000 test items. These items are indexed into
eleven bins for each format, such that each bin
corresponds to a predicted difficulty range on our
100-point scale (0–5, 6–15, . . . , 96–100).
The CAT administration algorithm chooses the
first item format to use at random, 进而
cycles through them to determine the format for
each subsequent item (IE。, all five formats have
6https://englishtest.duolingo.com.
equal representation). Each session begins with a
‘‘calibration’’ phase, where the first item is sam-
pled from the first two difficulty bins, 第二
item from the next two, 等等. After the
first four items, we use the methods from §2.2 to
iteratively estimate a provisional test score, 选择
the difficulty δi of the next item, and sample ran-
domly from the corresponding bin for the next
格式. This process repeats until the test exceeds
25 items or 40 minutes in length, whichever comes
第一的. Note that because item difficulties (δis) 是
on our 100-point CEFR-based scale, so are the
resulting test scores (θs). See Appendix A.1 for
more details on test administration.
For the yes/no formats, we used the vocabulary
scale model (§3) to estimate δx for all words in
an English dictionary, 加 10,000 pseudowords.7
These predictions were binned by δx estimate, 和
test items created by sampling both dictionaries
from the same bin (each item also contains at
至少 15% words and 15% pseudowords). Item
difficulty δi = ¯δx is the mean difficulty of all
words/pseudowords x ∈ i used as stimuli.
For the c-test format, we combined the expert-
written passages from §4.5 with paragraphs ex-
tracted from other English-language sources,
including the WIKI corpus and English-language
literature.8 We followed standard procedure
(Klein-Braley, 1997) to automatically generate
c-test
这
items from these paragraphs. 为了
dictation and elicited speech formats, we used
sentence-level candidate texts from WIKI, TATOEBA,
English Universal Dependencies,9 也
custom-written sentences. All passages were then
manually reviewed for grammaticality (制作
corrections where necessary) or filtered for inap-
propriate content. We used the passage scale
模型 (§4) to estimate δi for these items directly
from raw text.
For items requiring audio (IE。, audio yes/no and
elicited speech items), we contracted four native
二
English-speaking voice actors (two male,
女性) with experience voicing ESL instructional
材料. Each item format also has its own stat-
7We trained a character-level LSTM RNN (格雷夫斯, 2014)
on an English dictionary to produce pseudowords, 进而
filtered out any real English words. Remaining candidates
were manually reviewed and filtered if they were deemed too
similar to real words, or were otherwise inappropriate.
8https://www.wikibooks.org.
9http://universaldependencies.org.
255
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
我
A
C
_
A
_
0
0
3
1
0
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
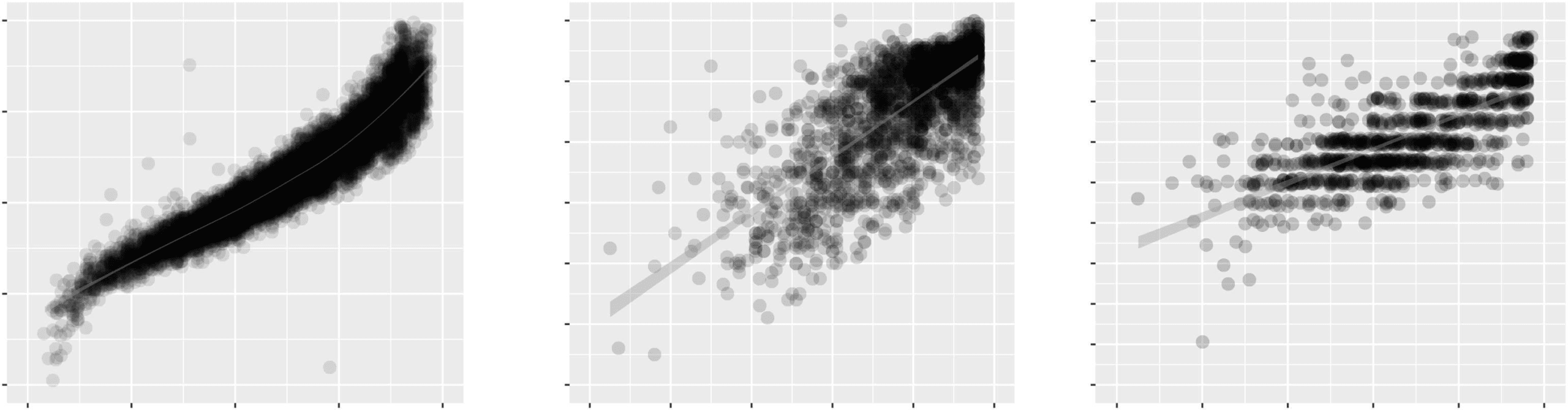
数字 5: Scatterplots and correlation coefficients showing how Duolingo English Test scores, based on our
ML/NLP scale models, relate to other English proficiency measures. (A) Our test score rankings are nearly
identical to those of traditional IRT θ estimates fit to real test session data (n = 21,351). (b–c) Our test scores
correlate significantly with other high-stakes English assessments such as TOEFL iBT (n = 2,319) and IELTS
(n = 991).
istical grading procedure using ML/NLP. 看
Appendix A.2 for more details.
5.3 Relationship with Other English
Language Assessments
5.2 Confirmatory IRT Analysis
Recall that the traditional approach to CAT devel-
opment is to first create a bank of items, 然后
pilot test them extensively with human subjects,
and finally use IRT analysis to estimate item
δi and examinee θ parameters from pilot data.
What is the relationship between test scores based
on our machine-learned CEFR-derived scales
and such pilot-tested ability estimates? A strong
relationship between our scores and θ estimates
based on IRT analysis of real test sessions would
provide evidence that our approach is valid as an
alternative form of pilot testing.
To investigate this, we analyzed 524,921 hex-
aminee, itemi pairs from 21,351 of the tests ad-
ministered during the 2018 calendar year, 和
fit a Rasch model to the observed response data
post-hoc.10 Figure 5(A) shows the relationship be-
tween our test scores and more traditional ‘‘pilot-
tested’’ IRT θ estimates. The Spearman rank
correlation is positive and very strong (ρ = .96),
indicating that scores using our method produce
rankings nearly identical to what traditional IRT-
based human pilot testing would provide.
10Because the test
is adaptive, 最多
items are rarely
管理的 (§5.5). 因此, we limit this analysis to items
with >15 observations to be statistically sound. We also omit
sessions that went unscored due to evidence of rule-breaking
(§A.1).
One source of criterion validity evidence for
our method is the relationship between these test
scores and other measures of English proficiency.
A strong correlation between our scores and other
major English assessments would suggest that our
approach is well-suited for assessing language
proficiency for people who want to study or work
in and English-language environment. 为了这,
we compare our results with two other high-stakes
English tests: TOEFL iBT11 and IELTS.12
After completing our test online, we asked ex-
aminees to submit official scores from other tests
(if available). This resulted in a large collection
of recent parallel scores to compare against.
The relationships between our test scores with
TOEFL and IELTS are shown in Figures 5(乙)
和 5(C), 分别. Correlation coefficients
between language tests are generally expected
to be in the .5–.7 range (Alderson et al., 1995),
so our scores correlate very well with both tests
(r > .7). Our relationship with TOEFL and IELTS
appears, 实际上, to be on par with their published
relationship with each other (r = .73, n = 1,153),
which is also based on self-reported data (ETS,
2010).
5.4 Score Reliability
Another aspect of test validity is the reliability
or overall consistency of its scores (墨菲
11https://www.ets.org/toefl.
12https://www.ielts.org/.
256
Reliability Measure
n
Estimate
Internal consistency
Test-retest
9,309
526
.96
.80
桌子 8: Test score reliability estimates.
Security Measure
Item exposure rate
Test overlap rate
意思是
.10%
.43%
Median
.08%
<.01%
Table 9: Test item bank security measures.
and Davidshofer, 2004). Reliability coefficient
estimates for our test are shown in Table 8. Impor-
tantly, these are high enough to be considered
appropriate for high-stakes use.
Internal consistency measures the extent
to
which items in the test measure the same under-
lying construct. For CATs, this is usually done
using the ‘‘split half’’ method: randomly split the
item bank in two, score both halves separately,
and then compute the correlation between half-
scores, adjusting for test length (Sireci et al.,
1991). The reliability estimate is well above .9, the
threshold for tests ‘‘intended for individual diag-
nostic, employment, academic placement, or other
important purposes’’ (DeVellis, 2011).
Test–retest reliability measures the consistency
of people’s scores if they take the test multiple
times. We consider all examinees who took the test
twice within a 30-day window (any longer may
reflect actual learning gains, rather than measure-
ment error) and correlate the first score with the
second. Such coefficients range from .8–.9 for
standardized tests using identical forms, and .8 is
considered sufficient for high-stakes CATs, since
adaptively administered items are distinct between
sessions (Nitko and Brookhart, 2011).
5.5 Item Bank Security
Due to the adaptive nature of CATs, they are
usually considered to be more secure than fixed-
form exams, so long as the item bank is suffi-
ciently large (Wainer, 2000). Two measures for
quantifying the security of an item bank are the
item exposure rate (Way, 1998) and test overlap
rate (Chen et al., 2003). We report the mean and
median values for these measures in Table 9.
The exposure rate of an item is the proportion of
tests in which it is administered; the average item
exposure rate for our test is .10% (or one in every
1,000 tests). While few tests publish exposure
rates for us to compare against, ours is well below
the 20% (one in five tests) limit recommended for
unrestricted continuous testing (Way, 1998). The
test overlap rate is the proportion of items that
are shared between any two randomly-chosen test
sessions. The mean overlap for our test is .43%
(and the median below .01%), which is well below
the 11–14% range reported for other operational
CATs like the GRE13 (Stocking, 1994). These
results suggest that our proposed methods are
able to create very large item banks that are quite
secure, without compromising the validity or reli-
ability of resulting test scores.
6 Related Work
There has been little to no work using ML/NLP to
drive end-to-end language test development as we
do here. To our knowledge, the only other example
is Hoshino and Nakagawa (2010), who used a
support vector machine to estimate the difficulty of
cloze14 items for a computer-adaptive test. How-
ever, the test did not contain any other item for-
mats, and it was not intended as an integrated
measure of general language ability.
Instead, most related work has leveraged ML/
NLP to predict test item difficulty from operational
test logs. This has been applied with some suc-
cess to cloze (Mostow and Jang, 2012), vocabulary
(Susanti et al., 2016), listening comprehension
(Loukina et al., 2016), and grammar exercises
(Perez-Beltrachini et al., 2012). However, these
studies all use multiple-choice formats where dif-
ficulty is largely mediated by the choice of dis-
tractors. The work of Beinborn et al. (2014) is
perhaps most relevant to our own; they used ML/
NLP to predict c-test difficulty at the word-gap
level, using both macro-features (e.g., paragraph
difficulty as we do) as well as micro-features
(e.g., frequency, polysemy, or cognateness for
each gap word). These models performed on par
with human experts at predicting failure rates for
English language students living in Germany.
Another area of related work is in predicting text
difficulty (or readability) more generally. Napoles
13https://www.ets.org/gre.
14Cloze tests and c-tests are similar, both stemming from
the ‘‘reduced redundancy’’ approach to language assessment
(Lin et al., 2008). The cloze items in the related work cited
here contain a single deleted word with four multiple-choice
options for filling in the blank.
257
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
and Dredze (2010) trained classifiers to discrim-
inate between English and Simple English Wiki-
pedia, and Vajjala et al. (2016) applied English
readability models to a variety of Web texts (in-
cluding English and Simple English Wikipedia).
Both of these used linear classifiers with features
similar to ours from §4.
Recently, more efforts have gone into using ML/
NLP to align texts to specific proficiency frame-
works like the CEFR. However, this work mostly
focuses on languages other than English (e.g.,
Curto et al., 2015; Sung et al., 2015; Volodina
et al., 2016; Vajjala and Rama, 2018). A notable
exception is Xia et al. (2016), who trained clas-
sifiers to predict CEFR levels for reading passages
from a suite of Cambridge English15 exams, tar-
geted at learners from A2–C2. In addition to
lexical and language model features like ours (§4),
they showed additional gains from explicit dis-
course and syntax features.
The relationship between test item difficulty and
linguistic structure has also been investigated in
the language testing literature, both to evaluate the
validity of item types (Brown, 1989; Abraham and
Chapelle, 1992; Freedle and Kostin, 1993, 1999)
and to establish what features impact difficulty so
as to inform test development (Nissan et al., 1995;
Kostin, 2004). These studies have leveraged both
correlational and regression analyses to examine
the relationship between passage difficulty and
linguistic features such as passage length, word
length and frequency, negations, rhetorical orga-
nization, dialogue utterance pattern (question-
question, statement-question), and so on.
7 Discussion and Future Work
We have presented a method for developing
computer-adaptive language tests, driven by ma-
chine learning and natural language processing.
This allowed us to rapidly develop an initial
version of the Duolingo English Test for the
experiments reported here, using ML/NLP to
directly estimate item difficulties for a large
item bank in lieu of expensive pilot testing with
human subjects. This test correlates significantly
with other high-stakes English assessments, and
satisfies industry standards for score reliability
and test security. To our knowledge, we are the
15https://www.cambridgeenglish.org.
first to propose language test development in this
way.
The strong relationship between scores based
on ML/NLP estimates of item difficulty and the
IRT estimates from operational data provides evi-
dence that our approach—using items’ linguistic
characteristics to predict difficulty, a priori to any
test administration—is a viable form of test devel-
opment. Furthermore, traditional pilot analyses
produce inherently norm-referenced scores (i.e.,
relative to the test-taking population), whereas it
can be argued that our method yields criterion-
referenced scores (i.e., indicative of a given stan-
dard, in our case the CEFR). This is another
conceptual advantage of our method. However,
further research is necessary for confirmation.
We were able to able to achieve these results
using simple linear models and relatively straight-
forward lexical and language model feature engi-
neering. Future work could incorporate richer
syntactic and discourse features, as others have
done (§6). Furthermore, other indices such as nar-
rativity, word concreteness, topical coherence,
etc., have also been shown to predict text difficulty
and comprehension (McNamara et al., 2011). A
wealth of recent advances in neural NLP that may
also be effective in this work.
Other future work involves better understanding
how our large, automatically-generated item bank
behaves with respect to the intended construct.
Detecting differential item functioning (DIF)—the
extent to which people of equal ability but dif-
ferent subgroups, such as gender or age, have
(un)equal probability of success on test items—is
an important direction for establishing the fairness
of our test. While most assessments focus on de-
mographics for DIF analyses, online administra-
tion means we must also ensure that technology
differences (e.g., screen resolution or Internet
speed) do not affect item functioning, either.
It is also likely that the five item formats pre-
sented in this work over-index on language recep-
tion skills rather than production (i.e., writing and
speaking). In fact, we hypothesize that the ‘‘clip-
ping’’ observed to the right in plots from Figure 5
can be attributed to this: Despite being highly
correlated, the CAT as presented here may over
estimate overall English ability relative to tests
with more open-ended writing and speaking exer-
cises. In the time since the present experiments
were conducted, we have updated the Duolingo
258
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
English Test to include such writing and speak-
ing sections, which are automatically graded and
combined with the CAT portion. The test–retest
reliability for these improved scores is .85, and
correlation with TOEFL and IELTS are .77 and
.78, respectively (also, the ‘‘clipping’’ effect dis-
appears). We continue to conduct research on
the interpretations and uses
the quality of
interested
of Duolingo English Test scores;
readers are able to find the latest ongoing
research at https://go.duolingo.com/
dettechnicalmanual.
Finally, in some sense what we have proposed
here is partly a solution to the ‘‘cold start’’
problem facing language test developers: How
does one estimate item difficulty without any
response data to begin with? Once a test is in pro-
duction, however, one can leverage the operational
data to further refine these models. It is exciting to
think that such analyses of examinees’ response
register
patterns (e.g.,
types, and pragmatic uses of language in the texts)
can tell us more about the underlying proficiency
scale, which in turn can contribute back to the
theory of frameworks like the CEFR.
topical characteristics,
Acknowledgments
We would like to thank Micheline Chalhoub-
Deville, Steven Sireci, Bryan Smith, and Alina
von Davier for their input on this work, as well
as Klinton Bicknell, Erin Gustafson, Stephen
Mayhew, Will Monroe, and the TACL editors
and reviewers for suggestions that improved this
paper. Others who have contributed in various
ways to research about our test to date include
Cynthia M. Berger, Connor Brem, Ramsey
Cardwell, Angela DiCostanzo, Andre Horie,
Jennifer Lake, Yena Park, and Kevin Yancey.
References
R. G. Abraham and C. A. Chapelle. 1992. The
meaning of cloze test scores: An item difficulty
perspective. The Modern Language Journal,
76(4):468–479.
AERA, APA, and NCME. 2014. Standards for
Educational and Psychological Testing.
J. C. Alderson, C. Clapham, and D. Wall. 1995.
Language Test Construction and Evaluation,
Cambridge University Press.
D. Andrich. 1978. A rating formulation for
ordered response categories. Psychometrika,
43(4):561–573.
L. Bachman and A. Palmer. 2010. Language
in Practice. Oxford University
Assessment
Press.
L. Beinborn, T. Zesch, and I. Gurevych. 2014.
Predicting the difficulty of language proficiency
tests. Transactions of
the Association for
Computational Linguistics, 2:517–530.
A. R. Bradlow and T. Bent. 2002. The clear speech
effect for non-native listeners. Journal of the
Acoustical Society of America, 112:272–284.
A. R. Bradlow and T. Bent. 2008. Perceptual
adaptation to non-native speech. Cognition,
106:707–729.
J. D. Brown. 1989. Cloze item difficulty. JALT
Journal, 11:46–67.
Cambridge English. 2012. Preliminary wordlist.
A. Capel. 2010. A1–B2 vocabulary: Insights and
issues arising from the English Profile Wordlists
project. English Profile Journal, 1.
A. Capel. 2012. Completing the English Vocab-
ulary Profile: C1 and C2 vocabulary. English
Profile Journal, 3.
S. Cau. 2015. TOEFL questions, answers leaked
in China. Global Times.
S. Chen, R. D. Ankenmann, and J. A. Spray.
2003. Exploring the relationship between item
exposure rate and item overlap rate in com-
puterized adaptive testing. Journal of Educa-
tional Measurement, 40:129–145.
Council of Europe. 2001. Common European
Framework of Reference for Languages: Learn-
ing, Teaching, Assessment. Cambridge Univer-
sity Press.
B. Culligan. 2015. A comparison of three test
formats to assess word difficulty. Language
Testing, 32(4):503–520.
P. Curto, N. J. Mamede, and J. Baptista. 2015.
Automatic text difficulty classifier-assisting the
selection of adequate reading materials for
European Portuguese teaching. In Proceedings
259
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
of the International Conference on Computer
Supported Education, pages 36–44.
for computer-adaptive testing. Research in
Computing Science, 46:279–292.
P. T. de Boer, D. P. Kroese, S. Mannor, and
R. Y. Rubinstien. 2005. A tutorial on the
cross-entropy method. Annals of Operations
Research, 34:19–67.
D. Isbell. 2017. Assessing C2 writing ability on the
Certificate of English Language Proficiency:
Rater and examinee age effects. Assessing Writ-
ing, 34:37–49.
R. F. DeVellis. 2011. Scale Development: Theory
and Applications, Number 26 in Applied Social
Research Methods. SAGE Publications.
W. H. DuBay. 2006. Smart Language: Readers,
Readability, and the Grading of Text, Impact
Information.
R. Dudley, S. Stecklow, A. Harney, and I. J. Liu.
2016. As SAT was hit by security breaches,
College Board went ahead with tests that had
leaked. Reuters Investigates.
C. Elkan. 2005, Deriving TF-IDF as a Fisher
kernel. In M. Consens and G. Navarro, editors,
String Processing and Information Retrieval,
volume 3772 of Lecture Notes in Computer
Science, pages 295–300. Springer.
ETS. 2010, Linking TOEFL iBT scores to IELTS
scores - A research report. ETS TOEFL Report.
T. Fawcett. 2006. An introduction to ROC anal-
ysis. Pattern Recognition Letters, 27(8):861–874.
R. Freedle and I. Kostin. 1993, The prediction of
TOEFL reading comprehension item difficulty
for expository prose passages for three item
types: Main idea, inference, and supporting
idea items. ETS Research Report 93-13.
R. Freedle and I. Kostin. 1999. Does the text matter
in a multiple-choice test of comprehension?
the case for the construct validity of TOEFL’s
minitalks. Language Testing, 16(1):2–32.
A. Graves. 2014. Generating sequences with re-
current neural networks. arXiv, 1308.0850v5
[cs.NE].
K. Heafield, I. Pouzyrevsky, J. H. Clark, and
P. Koehn. 2013. Scalable modified Kneser-Ney
language model estimation. In Proceedings of
the Association for Computational Linguistics
(ACL), pages 690–696.
A. Hoshino and H. Nakagawa. 2010. Predicting
the difficulty of multiple-choice close questions
T. Jaakkola and D. Haussler. 1999. Exploiting
generative models in discriminative classifiers.
In Advances in Neural Information Processing
Systems (NIPS), volume 11, pages 487–493.
L. Jessop, W. Suzuki, and Y. Tomita. 2007.
Elicited imitation in second language acqui-
sition research. Canadian Modern Language
Review, 64(1):215–238.
M.T. Kane. 2013. Validating the interpretations
and uses of test scores. Journal of Educational
Measurement, 50:1–73.
E. Khodadady. 2014. Construct validity of C-tests:
A factorial approach. Journal of Language
Teaching and Research, 5(6):1353–1362.
C. Klein-Braley. 1997. C-Tests in the context
of reduced redundancy testing: An appraisal.
Language Testing, 14(1):47–84.
I. Kostin. 2004, Exploring item characteristics that
are related to the difficulty of TOEFL dialogue
items. ETS Research Report 04-11.
S. Lane, M. R. Raymond, and S. M. Downing,
editors . 2016. Handbook of Test Development,
2nd edition. Routledge.
W. Y. Lin, H. C. Yuan, and H. P. Feng. 2008.
Language reduced redundancy tests: A re-
examination of cloze test and c-test. Journal of
Pan-Pacific Association of Applied Linguistics,
12(1):61–79.
J. M. Linacre. 2014. 3PL, Rasch, quality-control
and science. Rasch Measurement Transactions,
27(4):1441–1444.
P. Lison and J. Tiedemann. 2016. OpenSubtitles-
2016: Extracting large parallel corpora from
movie and TV subtitles. In Proceedings of the
International Conference on Language Re-
sources and Evaluation (LREC), pages 923–929.
F. M. Lord. 1980. Applications of Item Re-
sponse Theory to Practical Testing Problems,
Routledge.
260
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A. Loukina, S. Y. Yoon, J. Sakano, Y. Wei,
and K. Sheehan. 2016. Textual complexity as
a predictor of difficulty of listening items in
language proficiency tests. In Proceedings of
the International Conference on Computational
Linguistics (COLING), pages 3245–3253.
G. N. Masters. 1982. A Rasch model for partial
credit scoring. Psychometrika, 47(2):149–174.
D. S. McNamara, A. C. Graesser, Z. Cai, and
J. Kulikowich. 2011. Coh-Metrix easability
components: Aligning text difficulty with the-
ories of text comprehension. In Annual Meeting
of the American Educational Research Asso-
ciation (AERA).
the CEFR levels.
J. Milton. 2010, The development of vocabulary
breadth across
In I.
Bartning, M. Martin, and I. Vedder, editors,
Communicative Proficiency and Linguistic
Development: Intersections Between SLA and
Language Testing Research, volume 1 of
EuroSLA Monograph Series, pages 211–232.
EuroSLA.
J. Milton, J. Wade, and N. Hopkins. 2010.
Aural word recognition and oral competence in
English as a foreign language. In R. Chac´on-
Beltr´an,C. Abello-Contesse, and M. Torreblanca-
Into Non-Native
Insights
L´opez,
Vocabulary Teaching and Learning, volume 52,
pages 83–98. Multilingual Matters.
editors,
J. Mostow and H. Jang. 2012. Generating diag-
nostic multiple choice comprehension cloze
questions. In Proceedings of the Workshop on
Building Educational Applications Using NLP,
pages 136–146.
K. R. Murphy and C. O. Davidshofer. 2004. Psy-
chological Testing: Principles and Applica-
tions, Pearson.
C. Napoles and M. Dredze. 2010. Learning Sim-
ple Wikipedia: A cogitation in ascertaining
abecedarian language. In Proceedings of the
Workshop on Computational Linguistics and
Writing: Writing Processes and Authoring Aids,
pages 42–50.
S. Nissan, F. DeVincenzi, and K. L. Tang.
1995. An analysis of factors affecting the dif-
ficulty of dialogue items in TOEFL listening
comprehension. ETS Research Report 95-37.
A. J. Nitko and S. Brookhart. 2011. Educational
Assessment of Students. Merrill.
L. Perez-Beltrachini, C. Gardent,
and G.
Kruszewski. 2012. Generating grammar ex-
ercises. In Proceedings of the Workshop on
Building Educational Applications Using NLP,
pages 147–156.
G. Rasch. 1993. Probabilistic Models for Some
Intelligence and Attainment Tests, MESA Press.
M. Reichert, U. Keller, and R. Martin. 2010. The
C-test, the TCF and the CEFR: A validation
study. In The C-Test: Contributions from Cur-
rent Research, pages 205–231. Peter Lang.
D. Sculley. 2010. Combined regression and rank-
the Conference on
ing. In Proceedings of
Knowledge Discovery and Data Mining (KDD),
pages 979–988.
D. O. Segall. 2005, Computerized adaptive testing.
In K. Kempf-Leonard, editor, Encyclopedia of
Social Measurement. Elsevier.
B. Settles. 2012. Active Learning. Synthesis Lec-
tures on Artificial Intelligence and Machine
Learning. Morgan & Claypool.
S. G. Sireci, D. Thissen, and H. Wainer. 1991. On
the reliability of testlet-based tests. Journal of
Educational Measurement, 28(3):237–247.
L. S. Staehr. 2008. Vocabulary size and the skills
of listening, reading and writing. Language
Learning Journal, 36:139–152.
M. L. Stocking. 1994, Three practical issues for
modern adaptive testing item pools. ETS Re-
search Report 94-5.
Y. T. Sung, W. C. Lin, S. B. Dyson, K. E.
Change, and Y. C. Chen. 2015. Leveling L2
texts through readability: Combining multilevel
linguistic features with the CEFR. The Modern
Language Journal, 99(2):371–391.
Y. Susanti, H. Nishikawa, T. Tokunaga, and
H. Obari. 2016. Item difficulty analysis of
english vocabulary questions. In Proceedings
of the International Conference on Computer
Supported Education, pages 267–274.
D. Thissen and R. J. Mislevy. 2000. Testing
algorithms. In H. Wainer, editor, Computerized
Adaptive Testing: A Primer. Routledge.
261
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
S. Vajjala, D. Meurers, A. Eitel, and K. Scheiter.
2016. Towards grounding computational lin-
guistic approaches to readability: Modeling
reader-text interaction for easy and difficult
texts. In Proceedings of the Workshop on Com-
putational Linguistics for Linguistic Complex-
ity, pages 38–48.
S. Vajjala and T. Rama. 2018. Experiments with
universal CEFR classification. In Proceedings
of the Workshop on Innovative Use of NLP for
Building Educational Applications, pages 147–153.
A. Van Moere. 2012. A psycholinguistic ap-
proach to oral assessment. Language Testing,
29:325–344.
T. Vinther. 2002. Elicited imitation: A brief
overview. International Journal of Applied Lin-
guistics, 12(1):54–73.
E. Volodina,
I. Pil´an, and D. Alfter. 2016.
Classification of Swedish learner essays by
CEFR levels. In Proceedings of EUROCALL,
pages 456–461.
J. Zimmerman, P. K. Broder, J. J. Shaughnessy,
and B. J. Underwood. 1977. A recognition test
of vocabulary using signal-detection measures,
and some correlates of word and nonword
recognition. Intelligence, 1(1):5–31.
A Appendices
A.1 Test Administration Details
Tests are administered remotely via Web browser
at https://englishtest.duolingo.com.
Examinees are required to have a stable Internet
connection and a device with a working micro-
phone and front-facing camera. Each test session
is recorded and reviewed by human proctors
before scores are released. Prohibited behaviors
include:
• Interacting with another person in the room
• Using headphones or earbuds
• Disabling the microphone or camera
• Moving out of frame of the camera
• Looking off screen
H. Wainer. 2000. Computerized Adaptive Testing:
• Accessing any outside material or devices
A Primer. Routledge.
W. D. Way. 1998. Protecting the integrity of com-
puterized testing item pools. Educational Mea-
surement: Issues and Practice, 17(4):17–27.
D. J. Weiss and G. G. Kingsbury. 1984. Applica-
tion of computerized adaptive testing to edu-
cational problems. Journal of Educational
Measurement, 21:361–375.
G. Westhoff. 2007. Challenges and opportunities
of the CEFR for reimagining foreign language
pedagogy. The Modern Language Journal,
91(4):676–679.
M. Xia, E. Kochmar, and T. Briscoe. 2016. Text
readability assessment for second language
learners. In Proceedings of the Workshop on
Building Educational Applications Using NLP,
pages 12–22.
X. Zhu and A. B. Goldberg. 2009. Introduction to
Semi-Supervised Learning. Synthesis Lectures
on Artificial Intelligence and Machine Learn-
ing. Morgan & Claypool.
• Leaving the Web browser
Any of these behaviors constitutes rule-breaking;
such sessions do not have their scores released,
and are omitted from the analyses in this paper.
A.2 Item Grading Details
The item formats in this work (Table 2) are
not multiple-choice or true/false. This means
responses may not be simply ‘‘correct’’ or ‘‘incor-
rect,’’ and require more nuanced grading proce-
dures. While partial credit IRT models do exist
(Andrich, 1978; Masters, 1982), we chose instead
to generalize the binary Rasch framework to
incorporate ‘‘soft’’ (probabilistic) responses.
The maximum-likelihood estimation (MLE)
estimate used to score the test (or select the next
item) is based on the log-likelihood function:
LL(ˆθt) = log
t
Y
i=1
pi(ˆθt)ri(1 − pi(ˆθt))1−ri ,
which follows directly from equation (2). Note that
maximizing this is equivalent
to minimizing
cross-entropy (de Boer et al., 2005), a measure
262
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
of disagreement between two probability distri-
butions. As a result, ri can just as easily be a
probabilistic response (0 ≤ ri ≤ 1) as a binary
one (ri ∈ {0, 1}). In other words, this MLE
optimization seeks to find ˆθt such that the IRF pre-
diction pi(ˆθt) is most similar to each probabilistic
response ri. We believe the flexibility of this gen-
eralized Rasch-like framework helps us reduce
test administration time above and beyond a
binary-response CAT, since each item’s grade
summarizes multiple facets of the examinee’s
performance on that item. To use this general-
ization, however, we must specify a probabilistic
grading procedure for each item format. Since an
entire separate manuscript can be devoted to this
topic, we simply summarize our approaches here.
The yes/no vocabulary format (Figure 2) is tra-
ditionally graded using the sensitivity index d′—
a measure of separation between signal (word)
and noise (pseudoword) distributions from signal
detection theory (Zimmerman et al., 1977). This
index is isomorphic with the AUC (Fawcett, 2006),
which we use as the graded response ri. This can
be interpreted as ‘‘the probability that the exam-
inee can discriminate between English words and
pseudowords at level δi.’’
C-test items (Figure 4(a)) are graded using
a weighted average of the correctly filled word-
gaps, such that each gap’s weight is proportional to
its length in characters. Thus, ri can be interpreted
as ‘‘the proportion of this passage the examinee
understood, such that longer gaps are weighted
more heavily.’’ (We also experimented with other
grading schemes, but this yielded the highest test
score reliability in preliminary work.)
The dictation (Figure 4(b)) and elicited speech
(Figure 4(c)) items are graded using logistic re-
gression classifiers. We align the examinee’s
submission (written for dictation;
transcribed
using automatic speech recognition for elicited
speech) to the expected reference text, and ex-
tract features representing the differences in the
alignment (e.g., string edit distance, n-grams of
insertion/substitution/deletion patterns at both
the word and character level, and so on). These
models were trained on aggregate human judg-
ments of correctness and intelligibility for tens of
thousands of test item submissions (stratified by
δi) collected during preliminary work. Each item
received ≥ 15 independent binary judgments from
fluent English speakers via Amazon Mechanical
Turk,16 which were then averaged to produce
‘‘soft’’ (probabilistic) training labels. Thus ri can
be interpreted as ‘‘the probability that a random
English speaker would find this transcription/
utterance to be faithful, intelligible, and accurate.’’
For the dictation grader, the correlation between
human labels and model predictions is r = .86
(10-fold cross-validation). Correlation for the
elicited speech grader is r = .61 (10-fold cross-
validation).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
1
0
1
9
2
3
2
4
3
/
/
t
l
a
c
_
a
_
0
0
3
1
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
16https://www.mturk.com/.
263