信
Communicated by Litian Liu
Understanding Dynamics of Nonlinear Representation
Learning and Its Application
Kenji Kawaguchi
kkawaguchi@fas.harvard.edu
哈佛大学, 剑桥, 嘛 02138, 美国.
Linjun Zhang
linjun.zhang@rutgers.edu
Rutgers University, New Brunswick, 新泽西州 08901
Zhun Deng
zhundeng@g.harvard.edu
Harvard University Cambridge, 嘛 02138, 美国.
Representations of the world environment play a crucial role in artifi-
cial intelligence. It is often inefficient to conduct reasoning and infer-
ence directly in the space of raw sensory representations, such as pixel
values of images. Representation learning allows us to automatically dis-
cover suitable representations from raw sensory data. 例如, 给定
raw sensory data, a deep neural network learns nonlinear representations
at its hidden layers, which are subsequently used for classification (或者
regression) at its output layer. This happens implicitly during training
through minimizing a supervised or unsupervised loss. In this letter, 我们
study the dynamics of such implicit nonlinear representation learning.
We identify a pair of a new assumption and a novel condition, 被称为
the on-model structure assumption and the data architecture alignment
状况. Under the on-model structure assumption, the data architec-
ture alignment condition is shown to be sufficient for the global conver-
gence and necessary for global optimality. 而且, our theory explains
how and when increasing network size does and does not improve the
training behaviors in the practical regime. Our results provide practi-
cal guidance for designing a model structure; 例如, the on-model
structure assumption can be used as a justification for using a particu-
lar model structure instead of others. As an application, we then derive a
new training framework, which satisfies the data architecture alignment
condition without assuming it by automatically modifying any given
training algorithm dependent on data and architecture. Given a stan-
dard training algorithm, the framework running its modified version is
empirically shown to maintain competitive (实际的) test performances
while providing global convergence guarantees for deep residual neural
神经计算 34, 991–1018 (2022)
https://doi.org/10.1162/neco_a_01483
© 2022 麻省理工学院.
在知识共享下发布
归因 4.0 国际的 (抄送 4.0) 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
992
K. Kawaguchi, L. 张, and Z. Deng
networks with convolutions, skip connections, and batch normalization
with standard benchmark data sets, including MNIST, CIFAR-10, CIFAR-
100, Semeion, KMNIST, and SVHN.
1 介绍
乐存, 本吉奥, 和辛顿 (2015) described deep learning as one of hier-
archical nonlinear representation learning approaches:
Deep-learning methods are representation-learning methods with multi-
ple levels of representation, obtained by composing simple but non-linear
modules that each transform the representation at one level (starting with
the raw input) into a representation at a higher, slightly more abstract
等级 (p. 436).
In applications such as computer vision and natural language process-
英, the success of deep learning can be attributed to its ability to learn hi-
erarchical nonlinear representations by automatically changing nonlinear
features and kernels during training based on the given data. This is in con-
trast to classical machine-learning methods where representations or equiv-
alently nonlinear features and kernels are fixed during training.
Deep learning in practical regimes, which has the ability to learn nonlin-
ear representation (本吉奥, 考维尔, & Vincent, 2013), has had a profound
impact in many areas, including object recognition in computer vision (Ri-
fai et al., 2011; 欣顿, Osindero, & Teh, 2006; 本吉奥, Lamblin, Popovici,
& 拉罗谢尔, 2007; Ciregan, Meier, & 施米德胡贝尔, 2012; 克里热夫斯基,
吸勺, & 欣顿, 2012), style transfer (Gatys, Ecker, & Bethge, 2016;
Luan, 巴黎, Shechtman, & Bala, 2017), image super-resolution (Dong, Loy,
他, & 唐, 2014), speech recognition (Dahl, Ranzato, Mohamed, & 欣顿,
2010; Deng et al., 2010; Seide, 李, & 于, 2011; Mohamed, Dahl, & 欣顿,
2011; Dahl, 于, Deng, & Acero, 2011; Hinton et al., 2012), machine transla-
的 (Schwenk, Rousseau, & Attik, 2012; Le, Oparin, Allauzen, Gauvain, &
Yvon, 2012), paraphrase detection (Socher, 黄, Pennington, 的, & 男人-
ning, 2011), word sense disambiguation (Bordes, Glorot, Weston, & 本吉奥,
2012), and sentiment analysis (Glorot, Bordes, & 本吉奥, 2011; Socher, Pen-
nington, 黄, 的, & 曼宁, 2011). 然而, we do not yet know the
precise condition that makes deep learning tractable in the practical regime
of representation learning.
To initiate a study toward such a condition, we consider the following
problem setup that covers deep learning in the practical regime and other
nonlinear representation learning methods in general. We are given a train-
∈ Y ⊆ Rmy
ing data set ((希
are the ith input and the ith target, 分别. We would like to learn a pre-
dictor (or hypothesis) from a parametric family H = { F (·, 我 ) : Rmx → Rmy |
θ ∈ Rd} by minimizing the objective L,
i=1 of n samples where xi
∈ X ⊆ Rmx and yi
, 做))n
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
L(我 ) = 1
n
n(西德:2)
我=1
(西德:3)( F (希
, 我 ), 做),
993
(1.1)
在哪里 (西德:3) : Rmy × Y → R≥0 is the loss function that measures the discrepancy
, 我 ) and the target yi for each sample. 在这个
between the prediction f (希
= xi (for i = 1, . . . , n) to include the setting of
letter, it is allowed to let yi
unsupervised learning. The function f is also allowed to represent a wide
, 我 )
range of machine learning models. 为一个 (深的) neural network,
represents the preactivation output of the last layer of the network, 和
the parameter vector θ ∈ Rd contains all the trainable parameters, 包括
weights and bias terms of all layers.
F (希
例如, one of the simplest models is the linear model in the form
(西德:6)我 , where φ : X → Rd is a fixed function and φ(X) is a non-
of f (X, 我 ) = φ(X)
linear representation of input data x. This is a classical machine learning
model where much of the effort goes into the design of the handcrafted
feature map φ via feature engineering (车工, Fuggetta, Lavazza, & Wolf,
1999; 郑 & Casari, 2018). In this linear model, we do not learn the rep-
resentation φ(X) because the feature map φ is fixed without dependence on
the model parameter θ that is optimized with the data set ((希
, 做))n
我=1.
Similar to many definitions in mathematics, where an intuitive notion in
a special case is formalized to a definition for a more general case, we now
abstract and generalize this intuitive notion of the representation φ(X) 的
linear model to that of all differentiable models as follows:
Definition 1. Given any x ∈ X and differentiable function f , 我们定义
be the gradient representation of the data x under the model f at θ .
∂ f (X,我 )
∂θ
到
(西德:6)我
∂ f (X,我 )
∂θ
= ∂φ(X)
∂θ
This definition recovers the standard representation φ(X) in the linear
= φ(X) and is applicable to all differentiable non-
model as
linear models in representation learning. 而且, this definition captures
the key challenge of understanding the dynamics of nonlinear representa-
tion learning well, as illustrated below. Using the notation of dθ t
= (西德:6)t, 这
dt
dynamics of the model f (X, θ t ) over the time t can be written by
d
dt
F (X, θ t ) =
∂ f (X, θ t )
∂θ t
dθ t
dt
=
∂ f (X, θ t )
∂θ t
(西德:6)t.
(1.2)
这里, we can see that the dynamics are linear in (西德:6)t if there is no gradient
≈ ∂ f (X,我 0 )
. 然而, with representation
representation learning as
∂θ 0
∂ f (X,θ t )
∂θ t
changes depending on t (和
学习, the gradient representation
(西德:6)t), resulting in the dynamics that are nonlinear in (西德:6)t. 所以, the defini-
tion of the gradient representation can distinguish fundamentally different
dynamics in machine learning.
∂ f (X,θ t )
∂θ t
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
994
K. Kawaguchi, L. 张, and Z. Deng
In this letter, we initiate the study of the dynamics of learning gradi-
ent representation that are nonlinear in (西德:6)t. 那是, we focus on the regime
∂ f (X,θ t )
at the end of training time t dif-
where the gradient representation
∂θ t
∂ f (X,我 0 )
∂θ 0
fers greatly from the initial representation
. This regime was stud-
ied in the past for the case where the function φ(X) (西德:8)→ f (X, 我 ) is affine for
some fixed feature map φ (Saxe, 麦克莱兰, & 甘古利, 2014; Kawaguchi,
2016, 2021; Laurent & Brecht, 2018; Bartlett, Helmbold, & 长的, 2019; Zou,
长的, & Gu, 2020; 徐等人。, 2021). Unlike any previous studies, we focus
on the problem setting where the function φ(X) (西德:8)→ f (X, 我 ) is nonlinear and
nonaffine, with the effect of nonlinear (gradient) representation learning.
The results of this letter avoid the curse of dimensionality by studying the
global convergence of the gradient-based dynamics instead of the dynamics
of global optimization (Kawaguchi et al., 2016) and Bayesian optimization
(Kawaguchi, Kaelbling, & Lozano-Pérez, 2015). 重要的, we do not re-
quire any wide layer or large input dimension throughout this letter. 我们的
main contributions are summarized as follows:
1. In section 2, we identify a pair of a novel assumption and a new
状况, called the common model structure assumption and the data-
architecture alignment condition. Under the common model structure
assumption, the data-architecture alignment condition is shown to
be a necessary condition for the globally optimal model and a suffi-
cient condition for the global convergence. The condition is depen-
dent on both data and architecture. 而且, we empirically verify
and deepen this new understanding. When we apply representation
learning in practice, we often have overwhelming options regarding
which model structure to be used. Our results provide a practical
guidance for choosing or designing model structure via the common
model structure assumption, which is indeed satisfied by many rep-
resentation learning models used in practice.
2. In section 3, we discard the assumption of the data-architecture
alignment condition. 反而, we derive a novel training framework,
called the exploration-exploitation wrapper (EE wrapper), which sat-
isfies the data-architecture alignment condition time-independently
a priori. The EE wrapper is then proved to have global convergence
guarantees under the safe-exploration condition. The safe-exploration
condition is what allows us to explore various gradient represen-
tations safely without getting stuck in the states where we cannot
provably satisfy the data-architecture alignment condition. The safe-
exploration condition is shown to hold true for ResNet-18 with stan-
dard benchmark data sets, including MNIST, CIFAR-10, CIFAR-100,
Semeion, KMNIST, and SVHN time-independently.
3. In section 3.4, the EE wrapper is shown to not degrade practical per-
formances of ResNet-18 for the standard data sets, MNIST, CIFAR-10,
CIFAR-100, Semeion, KMNIST, and SVHN. To our knowledge, 这
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
995
letter provides the first practical algorithm with global convergence
guarantees without degrading practical performances of ResNet-18
on these standard data sets, using convolutions, skip connections,
and batch normalization without any extremely wide layer of the
width larger than the number of data points. To the best of our knowl-
边缘, we are not aware of any similar algorithms with global conver-
gence guarantees in the regime of learning nonlinear representations
without degrading practical performances.
It is empirically known that increasing network size tends to improve
training behaviors. 的确, the size of networks correlates well with the
training error in many cases in our experiments (例如, see Figure 1b). 如何-
曾经, the size and the training error do not correlate well in some ex-
实验 (例如, see Figure 1c). Our new theoretical results explain that
the training behaviors correlate more directly with the data-architecture
alignment condition instead. The seeming correlation with the network
size is caused by another correlation between the network size and the
data-architecture alignment condition. This is explained in more detail in
部分 2.3.
2 Understanding Dynamics via Common Model Structure
and Data-Architecture Alignment
在这个部分, we identify the common model structure assumption and
study the data-architecture alignment condition for the global convergence
in nonlinear representation learning. We begin by presenting an overview
of our results in section 2.1, deepen our understandings with experiments
in section 2.2, discuss implications of our results in section 2.3, and establish
mathematical theories in section 2.4.
2.1 Overview. We introduce the common model structure assumption
in section 2.1.1 and define the data-architecture alignment condition in sec-
的 2.1.2. Using the assumption and the condition, we present the global
convergence result in section 2.1.3.
2.1.1 Common Model Structure Assumption. Through examinations of
representation learning models used in applications, we identified and for-
malized one of their common properties as follows:
Assumption 1 (Common Model Structure Assumption). There exists a sub-
set S ⊆ {1, 2, . . . , d} such that f (希
for any i ∈
, 我 ) =
{1, . . . , n} and θ ∈ Rd.
k=1 1{k ∈ S}我
(西德:4) ∂ f (希
,我 )
k
(西德:3)
∂θ
(西德:5)
d
k
Assumption 1 is satisfied by common machine learning models, 这样的
as kernel models and multilayer neural networks, with or without convo-
lutions, batch normalization, pooling, and skip connections. 例如,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
996
K. Kawaguchi, L. 张, and Z. Deng
d
k(
k=1 1{k ∈ S}我
consider a multilayer neural network of the form f (X, 我 ) = Wh(X, 你) + 乙,
where h(X, 你) is an output of its last hidden layer and the parameter
vector θ consists of the parameters (瓦, 乙) at the last layer and the pa-
rameters u in all other layers as θ = vec([瓦, 乙, 你]). 这里, for any matrix
M ∈ Rm× ¯m, we let vec(中号) ∈ Rm ¯m be the standard vectorization of the ma-
trix M by stacking columns. 然后, assumption 1 holds because f (X, 我 ) =
(西德:3)
∂ f (希
,我 )
k : k ∈ S} = {vec([瓦, 乙])k :
), where S is defined by {我
∂θ
k
k = 1, 2, . . . , ξ } with vec([瓦, 乙]) ∈ Rξ
. Since h is arbitrary in this example,
the common model structure assumption holds, 例如, for any mul-
tilayer neural networks with a fully connected last layer. 一般来说, 是-
cause the nonlinearity at the output layer can be treated as a part of the
loss function (西德:3) while preserving convexity of q (西德:8)→ (西德:3)(q, y) (例如, cross-entropy
loss with softmax), this assumption is satisfied by many machine learning
型号, including ResNet-18 and all models used in the experiments in this
letter (as well as all linear models). 而且, assumption 1 is automatically
satisfied in the next section by using the EE wrapper.
, . . . , y(西德:3)
n)
2.1.2 Data-Architecture Alignment Condition. Given a target matrix Y =
(西德:6) ∈ Rn×my and a loss function (西德:3), we define the modified tar-
, y2
, . . . , yn)
(y1
, y(西德:3)
(西德:6) ∈ Rn×my by Y(西德:3) = Y for the squared loss (西德:3),
get matrix Y(西德:3) = (y(西德:3)
2
1
- 1 为了 (binary and multiclass) cross-entropy losses
= 2Yi j
并由 (是(西德:3))我j
(西德:6) ∈ Rn×mx , 这
(西德:3) with Yi j
∈ {0, 1}. Given input matrix X = (x1
output matrix fX (我 ) ∈ Rn×my is defined by fX (我 )我j
ε R. 对于任何
matrix M ∈ Rm× ¯m, we let Col(中号) ⊆ Rm be its column space. With these
notations, we are now ready to introduce the data-architecture alignment
状况:
, . . . , xn)
, 我 ) j
= f (希
, x2
Definition 2 (Data-Architecture Alignment Condition). Given any data set
(X, 是), differentiable function f , and loss function (西德:3), the data-architecture align-
ment condition is said to be satisfied at θ if vec(是(西德:3)) ∈ Col(
∂vec( fX (我 ))
∂θ
).
The data-architecture alignment condition depends on both data
(through the target Y and the input X) and architecture (through the model
F ). It is satisfied only when the data and architecture align well to each
(西德:6)θ ∈ R, 这
其他. 例如, in the case of linear model f (X, 我 ) = φ(X)
condition can be written as vec(是(西德:3)) ∈ Col((西德:8)(X )) 在哪里 (西德:8)(X ) ∈ Rn×d and
(西德:8)(X )我j
= φ(希) j. In definition 2, fX (我 ) is a matrix of the preactivation out-
puts of the last layer. 因此, in the case of classification tasks with a nonlinear
activation at the output layer, fX (我 ) and Y are not in the same space, 哪个
is the reason we use Y(西德:3) here instead of Y.
重要的, the data-architecture alignment condition does not make
∈ Rnmy×d:
any requirements on the the rank of the Jacobian matrix
is allowed to be smaller than nmy and d. 因此, 对于前任-
the rank of
充足, the data-architecture alignment condition can be satisfied depend-
ing on the given data and architecture even if the minimum eigenvalue of
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
997
(
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
)(西德:6) is zero, in both cases of overparameteriza-
the matrix
的 (例如, d (西德:9) n) and underparameterization (例如, d (西德:10) n). This is further
illustrated in section 2.2 and discussed in section 2.3. We note that we fur-
ther discard the assumption of the data-architecture alignment condition in
部分 3 as it is automatically satisfied by using the EE wrapper.
2.1.3 Global Convergence. Under the common model structure assump-
的, the data-architecture alignment condition is shown to be what lets us
avoid the failure of the global convergence and suboptimal local minima.
More concretely, we prove a global convergence guarantee under the data-
architecture alignment condition as well as the necessity of the condition
for the global optimality:
Theorem 1 (Informal Version). Let assumption 1 hold. Then the following two
statements hold for gradient-based dynamics:
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
(我) The global optimality gap bound decreases per iteration toward zero at the
|时间 |) for any T such that the data-architecture alignment con-
√
rate of O(1/
dition is satisfied at θ t for t ∈ T .
(二) For any θ ∈ Rd, the data-architecture alignment condition at θ is necessary
to have the globally optimal model fX (我 ) = ηY(西德:3) at θ for any η ∈ R.
Theorem 1i guarantees the global convergence without the need to sat-
isfy the data-architecture alignment condition at every iteration or at the
limit point. 反而, it shows that the bound on the global optimality gap
decreases toward zero per iteration whenever the data-architecture align-
ment condition holds. Theorem 1ii shows that the data-architecture align-
ment condition is necessary for the global optimality. 直观地, 这是
because the expressivity of a model class satisfying the common model
structure assumption is restricted such that it is required to align the archi-
tecture to the data in order to contain the globally optimal model fX (我 ) =
ηY(西德:3) (for any η ∈ R).
To better understand the statement of theorem 1i, consider a counterex-
ample with a data set consisting of the single point (X, y) = (1, 0), 该模型
F (X, 我 ) = θ 4 − 10θ 2 + 6我 + 100, and the squared loss (西德:3)(q, y) = (q − y)2. 在
this example, we have L(我 ) = f (X, 我 )2, which has multiple suboptimal
local minima of different values. 然后, via gradient descent, 该模型
converges to the closest local minimum and, 尤其, does not neces-
sarily converge to a global minimum. 的确, this example violates the com-
mon model structure assumption (assumption 1) (although it satisfies the
data-architecture alignment condition), showing the importance of the
common model structure assumption along with the data-architecture
结盟. This also illustrates the nontriviality of theorem 1i in that the
data-architecture alignment is not sufficient, and we needed to understand
what types of model structures are commonly used in practice and formal-
ize the understanding as the common model structure assumption.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
998
K. Kawaguchi, L. 张, and Z. Deng
To further understand the importance of the common model structure
assumption in theorem 1, we now consider the case where we do not re-
quire the assumption. 的确, we can guarantee the global convergence
without the common model structure assumption if we ensure that the min-
imum eigenvalue of the matrix
is nonzero. This can be
proved by the following derivation. Let θ be an arbitrary stationary point
of L. Then we have 0 = ∂L(我 )
n
, which implies
我=1(
那
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
∂(西德:3)(q,做 )
∂q
= 1
n
∂ f (希
∂θ
q= f (希
,我 ))
(西德:6)
)
(西德:3)
,我 )
∂θ
(
|
∂vec( fX (我 ))
∂θ
v = 0,
(2.1)
|
,我 ))
q= f (x1
∂(西德:3)(q,u1 )
∂q
(西德:6), . . . , (
where v = vec((
∂(西德:3)(q,uN )
∂q
is nonzero,
if the minimum eigenvalue of the matrix
= 0 for all i ∈ {1, 2, . . . , n}. Using the con-
then we have v = 0:
vexity of the map q (西德:8)→ (西德:3)(q, y) (which is satisfied by the squared loss and
cross-entropy loss), this implies that for any q1
) ∈ Rnmy . 所以,
, . . . , qn ∈ Rmy ,
(西德:6)
q= f (xn,我 ))
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
∂(西德:3)(q,ui )
∂q
q= f (希
, q2
(西德:6)
)
,我 )
(
|
|
n(西德:2)
(西德:3)( F (希
, 我 ), 做)
(西德:3)(qi
, 做) -
(西德:6)
∂(西德:3)(q, ui)
∂q
(西德:8)
(西德:7)
(西德:7)
(西德:7)
(西德:7)
q= f (希
,我 )
(2.2)
(西德:8)
(qi
− f (希
, 我 ))
(2.3)
(西德:3)(qi
, 做).
(2.4)
L(我 ) = 1
n
≤ 1
n
≤ 1
n
我=1
n(西德:2)
(西德:6)
我=1
n(西德:2)
我=1
(
(西德:6)
)
the minimum eigenvalue of
Since f (x1), F (x2), . . . , F (xn) ∈ Rmy , this implies that any stationary point
θ is a global minimum if
the matrix
∂vec( fX (我 ))
∂vec( fX (我 ))
is nonzero, without the common model structure as-
∂θ
∂θ
消费 (see assumption 1). 的确, in the above example with the model
F (X, 我 ) = θ 4 − 10θ 2 + 6我 + 100, the common model structure assumption is
violated, but we still have the global convergence if the minimum eigen-
F (X, 我 ) = y = 0 at any stationary point θ
value is nonzero—for example,
such that the minimum eigenvalue of the matrix
是
nonzero. 相比之下, theorem 1 allows the global convergence even when
the minimum eigenvalue of the matrix
is zero by uti-
lizing the common model structure assumption.
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
(西德:6)
)
(西德:6)
)
(
(
The formal version of theorem 1 is presented in section 2.4 and is proved
in appendix A in the supplementary information that relies on the addi-
tional previous works of Clanuwat et al. (2019), Krizhevsky and Hinton
(2009), Mityagin (2015), Netzer et al. (2011), Paszke et al. (2019A, 2019乙),
and Poggio et al. (2017). Before proving the statement, we first examine the
meaning and implications of our results through illustrative examples in
sections 2.2 和 2.3.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
999
2.2 Illustrative Examples in Experiments. Theorem 1 suggests that
data-architecture alignment condition vec(是(西德:3)) ∈ Col(
) has the abil-
ity to distinguish the success and failure cases, even when the minimum
is zero for all t ≥ 0. 在这个
eigenvalue of the matrix
部分, we conduct experiments to further verify and deepen this theoret-
ical understanding.
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
(西德:6)
)
(
We employ a fully connected network having four layers with 300 新-
rons per hidden layer, and a convolutional network, LeNet (LeCun et al.,
1998), with five layers. For the fully connected network, we use the two-
moons data set (Pedregosa et al., 2011) and a sine wave data set. To create
the sine wave data set, we randomly generated the input xi from the uni-
form distribution on the interval [−1, 1] and set yi
= 1{罪(20希) < 0} ∈ R
for all i ∈ [n] with n = 100. For the convolutional network, we use the Se-
meion data set (Srl & Brescia, 1994) and a random data set. The random
data set was created by randomly generating each pixel of the input im-
∈ R16×16×1 from the standard normal distribution and by sampling
age xi
yi uniformly from {0, 1} for all i ∈ [n] with n = 1000. We set the activation
functions of all layers to be softplus ¯σ (z) = ln(1 + exp(ςz))/ς with ς = 100,
which approximately behaves as the ReLU activation as shown in appendix
C in the supplementary information. See appendix B in the supplementary
information for more details of the experimental settings.
The results of the experiments are presented in Figure 1. In each panel
of the figure, the training errors and the values of QT are plotted over time
T. Here, QT counts the number of Y(cid:3) not satisfying the condition vec(Y(cid:3)) ∈
Col(
) during t ∈ {0, 1, . . . , T} and is defined by
∂vec( fX (θ t ))
∂θ t
QT =
T(cid:2)
t=0
(cid:9)
1
vec(Y(cid:3)) /∈ Col
(cid:10)
∂vec( fX (θ t ))
∂θ t
(cid:11)(cid:12)
.
(2.5)
Figure 1a shows the results for the fully connected network. For the two-
moons data set, the network achieved the zero training error with QT = 0
for all T (i.e., vec(Y(cid:3)) ∈ Col(
) for all T). For the sine wave data
set, it obtained high training errors with QT = T for all T (i.e., vec(Y(cid:3)) /∈
) for all T). This is consistent with our theory. Our theory ex-
Col(
plains that what makes a data set easy to be fitted or not is whether the
condition vec(Y(cid:3)) ∈ Col(
) is satisfied or not.
∂vec( fX (θ T ))
∂θ T
∂vec( fX (θ T ))
∂θ T
∂vec( fX (θ t ))
∂θ t
Figures 1b and 1c show the results for the convolutional networks with
two random initial points using two different random seeds. In the fig-
ure panels, we report the training behaviors with different network sizes
mc = 1, 2, and 4; the number of convolutional filters per convolutional layer
is 8 × mc and the number of neurons per fully connected hidden layer is
128 × mc. As can be seen, with the Semeion data set, the networks of all
sizes achieved zero error with QT = 0 for all T. With the random data set,
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
c
o
_
a
_
0
1
4
8
3
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1000
K. Kawaguchi, L. Zhang, and Z. Deng
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
Figure 1: Training error and the value of QT over time steps T. The legend
of panel b is shown in panel c. The value of QT measures the number of Y(cid:3)
not satisfying the condition of vec(Y(cid:3)) ∈ Col(
). This figure validates
our theoretical understanding that the bound on the global optimality gap de-
creases at any iteration when QT does not increase at the iteration—that is,
when the QT value is flat. The minimum eigenvalue of the matrix M(θ t ) =
∂vec( fX (θ ))
)(cid:6) is zero at all iterations in Figures 1b and 1c for all cases
∂θ
with mc
∂vec( fX (θ ))
(
∂θ
= 1.
∂vec( fX (θt ))
∂θt
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
c
o
_
a
_
0
1
4
8
3
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
the deep networks yielded the zero training error whenever QT is not lin-
early increasing over the time or, equivalently, whenever the condition of
vec(Y(cid:3)) ∈ Col(
) holds sufficiently many steps T. This is consistent
with our theory.
∂vec( fX (θ T ))
∂θ T
Finally, we also confirmed that gradient representation
significantly from the initial one
∂ f (x,θ 0 )
∂θ 0
in our experiments. That is, the
∂ f (x,θ t )
∂θ t
changed
Understanding Nonlinear Representation Learning
1001
Table 1: The Change of the Gradient Representation during Training, (cid:13)M(θ ˆT ) −
∂vec( fX (θ ))
M(θ 0)(cid:13)2
∂θ
)(cid:6) and ˆT Is the Last Time Step.
F, Where M(θ ) := ∂vec( fX (θ ))
∂θ
(
a. Fully-Connected Network
Data Set
Two moons
Sine wave
2.09 × 1011
3.95 × 109
b. Convolutional Network
mc = 4
mc = 2
mc = 1
seed#1
Data Set
Semeion 8.09 × 1012
Random 3.73 × 1012
seed#2
5.19 × 1012
1.64 × 1012
seed#1
9.82 × 1012
3.43 × 107
seed#2
3.97 × 1012
4.86 × 1012
seed#1
2.97 × 1012
1.40 × 107
seed#2
5.41 × 1012
8.57 × 1011
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
values of (cid:13)M(θ T ) − M(θ 0)(cid:13)2
F were significantly large and tended to increase
as T increases, where the matrix M(θ ) ∈ Rnmy×nmy is defined by M(θ ) =
∂vec( fX (θ ))
)(cid:6). Table 1 summarizes the values of (cid:13)M(θ T ) − M(θ 0)(cid:13)2
∂θ
F
∂vec( fX (θ ))
∂θ
(
at the end of the training.
2.3 Implications. In section 2.1.3, we showed that an uncommon model
structure f (x, θ ) = θ 4 − 10θ 2 + 6θ + 100 does not satisfy assumption 1, and
assumption 1 is not required for global convergence if the minimum eigen-
value is nonzero. However, in practice, we typically use machine learning
models that satisfy assumption 1 instead of the model f (x, θ ) = θ 4 − 10θ 2 +
6θ + 100, and the minimum eigenvalue is zero in many cases. In this con-
text, theorem 1 provides the justification for common practice in nonlinear
representation learning. Furthermore, theorem 1i contributes to the litera-
ture by identifying the common model structure assumption (assumption
1) and the data-architecture alignment condition (definition 1) as the novel
and practical conditions to ensure the global convergence even when the
minimum eigenvalue becomes zero. Moreover, theorem 1ii shows that this
condition is not arbitrary in the sense that it is also necessary to obtain the
globally optimal models. Furthermore, the data-architecture alignment con-
dition is strictly more general than the condition of the minimum eigen-
value being nonzero, in the sense that the latter implies the former but not
vice versa.
Our new theoretical understanding based on the data-architecture align-
ment condition can explain and deepen the previously known empirical
observation that increasing network size tends to improve training be-
haviors. Indeed, the size of networks seems to correlate well with the
training error to a certain degree in Figure 1b. However, the size and the
training error do not correlate well in Figure 1c. Our new theoretical under-
standing explains that the training behaviors correlate more directly with
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
c
o
_
a
_
0
1
4
8
3
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
1002
K. Kawaguchi, L. Zhang, and Z. Deng
∂vec( fX (θ t ))
∂θ t
the data-architecture alignment condition of vec(Y(cid:3)) ∈ Col(
) in-
stead. The seeming correlation with the network size is indirect and caused
by another correlation between the network size and the condition of
vec(Y(cid:3)) ∈ Col(
)
more likely tends to hold when the network size is larger because the matrix
∂vec( fX (θ t ))
is of size nmy × d where d is the number of parameters: that is, by
∂θ t
) to increase
). That is, the condition of vec(Y(cid:3)) ∈ Col(
increasing d, we can increase the column space Col(
the chance of satisfying the condition of vec(Y(cid:3)) ∈ Col(
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
that
∂vec( fX (θ ))
∂θ
the minimum eigenvalue of
the matrix M(θ t ) =
Note
∂vec( fX (θ ))
)(cid:6) is zero at all iterations in Figures 1b and 1c for
∂θ
all cases of mc = 1. Thus, Figures 1b and 1c also illustrate the fact that while
having the zero minimum eigenvalue of the matrix M(θ t ), the dynamics
can achieve the global convergence under the data-architecture alignment
condition. Moreover, because the multilayer neural network in the lazy
training regime (Kawaguchi & Sun, 2021) achieves zero training errors
for all data sets, Figure 1 additionally illustrates that our theoretical and
empirical results apply to the models outside of the lazy training regime
and can distinguish “good” data sets from “bad” data sets given a learning
algorithm.
).
(
In sum, our new theoretical understanding has the ability to explain
and distinguish the successful case and failure case based on the data-
architecture alignment condition for the common machine learning mod-
els. Because the data-architecture alignment condition is dependent on data
and architecture, theorem 1, along with our experimental results, shows
why and when the global convergence in nonlinear representation learning
is achieved based on the relationship between the data (X, Y) and architec-
ture f . This new understanding is used in section 3 to derive a practical
algorithm and is expected to be a basis for many future algorithms.
2.4 Details and Formalization of Theorem 1. This section presents the
precise mathematical statements that formalize the informal description of
theorem 1. In the following sections, we devide the formal version of theo-
rem 1 into theorem 2, theorem 3, and proposition 1.
2.4.1 Preliminaries. Let (θ t )∞
t=0 be the sequence defined by θ t+1 = θ t −
αt ¯gt with an initial parameter vector θ 0, a learning rate αt, and an update
vector ¯gt. The analysis in this section relies on the following assumption on
the update vector ¯gt:
Assumption 2. There exist ¯c, c > 0 such that c(西德:13)∇L(θ t )(西德:13)2 ≤ ∇L(θ t )
(西德:13) ¯gt(西德:13)2 ≤ ¯c(西德:13)∇L(θ t )(西德:13)2 for any t ≥ 0.
(西德:6) ¯gt and
Assumption 2 is satisfied by using ¯gt = Dt∇L(θ t ), where Dt
positive-definite symmetric matrix with eigenvalues in the interval [C,
is any
√
¯c].
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1003
If we set Dt = I, we have gradient descent, and assumption 2 is satisfied
with c = ¯c = 1. This section also uses the standard assumption of differen-
tiability and Lipschitz continuity:
Assumption 3. For every i ∈ [n], the function (西德:3)
tiable and convex, the map fi : 我 (西德:8)→ f (希
)(西德:13) ≤ L(西德:13)θ − θ (西德:16)(西德:13) for all θ , 我 (西德:16)
∇L(我 (西德:16)
我 : q (西德:8)→ (西德:3)(q, 做) is differen-
, 我 ) is differentiable, 和 (西德:13)∇L(我 ) -
in the domain of L for some L ≥ 0.
The assumptions on the loss function in assumption 3 are satisfied by
using standard loss functions, including the squared loss, logistic loss, 和
cross-entropy loss. Although the objective function L is nonconvex and
non-invex, the function q (西德:8)→ (西德:3)(q, 做) is typically convex.
, y∗
For any matrix Y∗ = (y∗
2
1
(西德:6) ∈ Rn×my , 我们定义
, . . . , y∗
n)
L∗
∗
(是
) = 1
n
n(西德:2)
我=1
(西德:3) (y
∗
我
, 做) .
(2.6)
例如, for the squared loss (西德:3), the value of L∗
minimum value of L as
(是(西德:3)) is at most the global
(2.7)
L∗
(是(西德:3)) ≤ L(我 ), ∀θ ∈ Rd,
(西德:3)
(西德:13)2
2
n
我=1
− yi
(是(西德:3)) = 1
n
∂vec( fX (我 ))
∂θ
since L∗
(西德:13)做
= 0 ≤ L(我 ) ∀θ ∈ Rd. This letter also uses
the notation of [k] = {1, 2, . . . , k} for any k ∈ N+
和 (西德:13) · (西德:13) = (西德:13) · (西德:13)
2 (Euclidean
norm). 最后, we note that for any η ∈ R, the condition of vec(是(西德:3)) ∈
) is necessary to learn a near-global optimal model fX (我 ) =
上校(
ηY(西德:3):
Proposition 1. Suppose assumption 1 holds. If vec(是(西德:3)) /∈ Col(
fX (我 ) (西德:19)= ηY(西德:3) for any η ∈ R.
Proof. All proofs of this letter are presented in appendix A in the supple-
(西德:2)
mentary information.
∂vec( fX (我 ))
∂θ
), 然后
(ηY∗
) for any Y∗
such that vec(Y∗
2.4.2 Global Optimality at the Limit Point. The following theorem shows
that every limit point ˆθ of the sequence (θ t )t achieves a loss value L( ˆθ ) 不
worse than infη∈R L∗
) 为了
all t ∈ [t, ∞) with some τ ≥ 0:
Theorem 2. Suppose assumptions 1 到 3 hold. Assume that the learning rate se-
序列 (αt )t satisfies either (我) (西德:14) ≤ αt ≤ c(2-(西德:14))
对于一些 (西德:14) > 0 或者 (二) limt→∞ αt =
αt = ∞. Then for any Y∗ ∈ Rn×my , if there exists τ ≥ 0 这样
0 和
vec(Y∗
) for all t ∈ [t, ∞), every limit point ˆθ of the sequence
(θ t )t satisfies
(西德:3)∞
t=0
) ∈ Col(
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
) ∈ Col(
L ¯c
L( ˆθ ) ≤ L∗
(ηY
∗
), ∀η ∈ R.
(2.8)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1004
K. Kawaguchi, L. 张, and Z. Deng
例如, for the squared loss (西德:3)(q, y) = (西德:13)q − y(西德:13)2, theorem 2 implies
that every limit point ˆθ of the sequence (θ t )t is a global minimum as
L( ˆθ ) ≤ L(我 ), ∀θ ∈ Rd,
(2.9)
if vec(是(西德:3)) ∈ Col(
L( ˆθ ) ≤ L∗
∂vec( fX (θ t ))
∂θ t
) for t ∈ [t, ∞) with some τ ≥ 0. 这是因为
(是(西德:3)) ≤ L(我 ) ∀θ ∈ Rd from theorem 2 and equation 2.7.
在实践中, one can easily satisfy all the assumptions in theorem 2 前任-
cept for the condition that vec(Y∗
) for all t ∈ [t, ∞). 乙酰胆碱-
) ∈ Col(
cordingly, we now weaken this condition by analyzing optimality at each
iteration so that the condition is verifiable in experiments.
∂vec( fX (θ t ))
∂θ t
2.4.3 Global Optimality Gap at Each Iteration. The following theorem states
that under standard settings, the sequence (θ t )t∈T converges to a loss value
no worse than infη∈R L∗
) at the rate of O(1/
这样的
that vec(Y∗) ∈ Col(
) for t ∈ T :
Theorem 3. Suppose assumptions 1 和 3 hold. Let (αt, ¯gt ) = ( 2A
L
an arbitrary α ∈ (0, 1). Then for any T ⊆ N
) for all t ∈ T , it holds that
上校(
, ∇L(θ t )) 和
0 and Y∗ ∈ Rn×my such that vec(Y∗) ∈
|时间 |) for any T and Y∗
(ηY∗
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
√
L(θ t ) ≤ L∗
(ηY
∗
min
t∈T
) + 1√
|时间 |
(西德:13)
LζηL(θ t0 )
2A(1 − α)
,
(2.10)
for any η ∈ R, where t0
这)(西德:13)2),
ˆβ(我 , 这) := η((
我
k for all k ∈ S and ν(我 )k
的 1.
= min{t : t ∈ T }, ζη := 4 maxt∈T max((西德:13)ν(θ t )(西德:13)2, (西德:13) ˆβ(θ t,
∂vec( fX (我 ))
=
∂θ
= 0 for all k /∈ S with the set S being defined in assump-
(西德:6) ∂vec( fX (我 ))
)
∂θ
), and ν(我 )k
∂vec( fX (我 ))
∂θ
vec(Y∗
)†(
(西德:6)
)
For the squared loss (西德:3), theorem 3 implies the following for any T ≥ 1: 为了
any T ⊆ [时间] such that vec(是(西德:3)) ∈ Col(
∂vec( fX (θ t ))
∂θ t
) for all t ∈ T , 我们有
min
t∈[时间]
L(θ t ) ≤ inf
θ ∈Rd
(西德:14)
L(我 ) + 氧(1/
|时间 |).
This is because L∗
≤ mint∈T L(θ t ) from T ⊆ [时间].
(是(西德:3)) ≤ infθ ∈Rd L(我 ) 从方程 2.7 and mint∈[时间]
(2.11)
L(θ t )
相似地, for the binary and multiclass cross-entropy losses, theorem 3
implies the following for any T ≥ 1: for any T ⊆ [时间] such that vec(是(西德:3)) ∈
上校(
) for all t ∈ T , we have that for any η ∈ R,
∂vec( fX (θ t ))
∂θ t
L(θ t ) ≤ L∗
min
t∈[时间]
(西德:14)
(ηY(西德:3)) + 氧(η2/
|时间 |).
(2.12)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1005
Given any desired (西德:14) > 0, since L∗
(ηY(西德:3)) → 0 as η → ∞, setting η to be suf-
ficiently large obtains the desired (西德:14) value as mint∈T L(θ t ) ≤ (西德:14) in equation
2.12 作为
|时间 | → ∞.
√
3 Application to the Design of Training Framework
The results in the previous section show that the bound on the global
optimality gap decreases per iteration whenever the data-architecture
alignment condition holds. Using this theoretical understanding, 在这个
部分, we propose a new training framework with prior guarantees while
learning hierarchical nonlinear representations without assuming the data-
architecture alignment condition. 因此, we made significant improve-
ments over the most closely related study on global convergence guarantees
(Kawaguchi & Sun, 2021). 尤其, whereas the related study requires a
wide layer with a width larger than n, our results reduce the requirement to
n. 例如, the MNIST data set has
a layer with a width larger than
n = 60,000 and hence previous studies require 60,000 neurons at a layer,
60,000 ≈ 245 neurons at a layer. Our require-
whereas we only require
ment is consistent and satisfied by the models used in practice that typically
have from 256 到 1024 neurons for some layers.
√
√
We begin in section 3.1 with additional notations and then present the
training framework in section 3.2 and convergence analysis in section 3.3.
We conclude in section 3.4 by providing empirical evidence to support our
理论.
(我)
3.1 Additional Notations. We denote by θ
∈ Rdl the vector of all the
trainable parameters at the lth layer for l = 1, . . . , H where H is the depth or
the number of trainable layers (IE。, one plus the number of hidden layers).
那是, the Hth layer is the last layer containing the trainable parameter
(H) at the last layer. For any pair (我, 我(西德:16)) 这样 1 ≤ l ≤ l(西德:16) ≤ H, 我们
vector θ
define θ
(我:我(西德:16) )
(我)
if l = l(西德:16)
. We consider a family of training algorithms that update the param-
eter vector θ as follows: for each l = 1, . . . , H,
(西德:16) —for example, 我
(我(西德:16) )](西德:6) ∈ Rdl:我
= θ and θ
= [我 (西德:6)
(我)
, . . . , 我 (西德:6)
= θ
(我:我(西德:16) )
(1:H)
θ t+1
(我)
= θ t
(我)
− gt
(我)
,
gt
(我)
∼ G
(我)(θ t, t),
(3.1)
(我) outputs a distribution over the vector gt
where the function G
(我) and dif-
fers for different training algorithms. 例如, 为了 (minibatch) stochas-
tic gradient descent (SGD), gt
(我) represents a product of a learning rate
(我) at the time t. We define G =
and a stochastic gradient with respect to θ
(G
(H)) to represent a training algorithm.
, . . . , G
For an arbitrary matrix M ∈ Rm×m(西德:16)
tor in Rm, Mi∗ be its ith row vector in Rm(西德:16)
We define M ◦ M(西德:16)
, we let M∗ j be its jth column vec-
, and rank(中号) be its matrix rank.
to be the Hadamard product of any matrices M and M(西德:16)
.
(1)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1006
K. Kawaguchi, L. 张, and Z. Deng
For any vector v ∈ Rm, we let diag(v ) ∈ Rm×m be the diagonal matrix with
diag(v )二
i for i ∈ [米]. We denote by Im the m × m identity matrix.
= v
3.2 Exploration-Exploitation Wrapper. 在这个部分, we introduce the
exploration-exploitation (EE) wrapper A. The EE wrapper A is not a stand-
alone training algorithm. 反而, it takes any training algorithm G as its
input and runs the algorithm G in a particular way to guarantee global con-
vergence. We note that the exploitation phase in the EE wrapper does not
optimize the last layer; 反而, it optimizes hidden layers, whereas the ex-
ploration phase optimizes all layers. The EE wrapper allows us to learn the
表示
that differs significantly from the initial representa-
∂ f (X,我 0 )
∂θ 0 without making assumptions on the minimum eigenvalue of
the matrix
by leveraging the data-architecture align-
ment condition. The data-architecture alignment condition is ensured by
the safe-exploration condition (defined in section 3.3.1), which is time inde-
pendent and holds in practical common architectures (as demonstrated in
部分 3.4).
∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
∂ f (X,θ t )
∂θ t
的
(西德:6)
)
(
3.2.1 Main Mechanisms. Algorithm 1 outlines the EE wrapper A. 期间
the exploration phase in lines 3 到 7 of algorithm 1, the EE wrapper A freely
explores hierarchical nonlinear representations to be learned without any
restrictions. 然后, during the exploitation phase in lines 8 到 12, it starts
exploiting the current knowledge to ensure vec(是(西德:3)) ∈ Col(
) 对全部
t to guarantee global convergence. The value of τ is the hyperparameter
that controls the time when it transitions from the exploration phase to the
exploitation phase.
∂vec( fX (θ t ))
∂θ t
In the exploitation phase, the wrapper A only optimizes the parame-
ter vector θ t
(H−1) 在 (H − 1)th hidden layer, instead of the parameter
vector θ t
(H) at the last layer or the Hth layer. Despite this, the EE wrap-
per A is proved to converge to global minima of all layers in Rd. The ex-
ploitation phase still allows us to significantly change the representations
as M(θ t ) (西德:19)≈ M(θ τ
) for t > τ . This is because we optimize the hidden layers
instead of the last layer without any significant overparameterizations.
The exploitation phase uses an arbitrary optimizer ˜G with the update
(H−1)(θ t, t) with ˜gt = αt ˆgt ∈ RdH−1 . During the two phases, 我们
vector ˜gt ∼ ˜G
can use the same optimizers (例如, SGD for both G and ˜G) or different opti-
mizers (例如, SGD for G and L-BFGS for ˜G).
3.2.2 Model Modification. This section defines the details of the model
modification at line 2 of algorithm 1. Given any base network ¯f , 这
wrapper A first checks whether the last two layers of the given network
¯f are fully connected. 如果不, one or two fully connected last layers are
added such that the output of the network ¯f can be written by ¯f (X, ¯θ ) =
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1007
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
(1:H−2))). 这里, z(X, 我
¯W (H) ¯σ ( ¯W (H−1)z(X, 我
(1:H−2)) is the output of the (H − 2)th
层, and the function z is arbitrary and can represent various deep net-
作品. 而且, ¯σ is a nonlinear activation function, and ¯W (H−1) and ¯W (H)
are the weight matrices of the last two layers. The wrapper A then modi-
fies these last two layers as follows. In the case of my = 1, the model ¯f is
modified to
F (X, 我 ) = W (H)σ (瓦 (H−1), z(X, 我
(1:H−2))),
(3.2)
where W (H−1) ∈ RmH ×mH−1 and W (H) ∈ Rmy×mH are the weight matrices of the
last two layers. The nonlinear activation σ is defined by σ (q, q(西德:16)
) ○
(qq(西德:16)
), where ˜σ is some nonlinear function. 例如, we can set ˜σ (q) =
q (sigmoid) with any hyperparameter ς (西德:16) > 0, for which it holds that as
1
1+e−ς (西德:16)
ς (西德:16) → ∞,
) = ˜σ (qq(西德:16)
F (X, 我 ) → W (H)relu(瓦 (H−1)z(X, 我
(1:H−2))).
(3.3)
1008
K. Kawaguchi, L. 张, and Z. Deng
We generalize equation 3.2 to the case of my ≥ 2 作为
F (X, 我 ) j
= W (H)
j∗ σ
j(瓦 (H−1, j), z(X, 我
(1:H−2))),
(3.4)
j
= σ until line 10. At line 10, the wrapper A replaces σ
右( j) (q, q(西德:16)
for j ∈ [我的] where W (H−1, j) ∈ RmH ×mH−1 is the weight matrix at the (H − 1)th
layer and σ
j by
σ
=
右( j) where σ
(瓦 (H−1, j))(西德:6). To consider the bias term, we include the constant neuron to the
(1:H−2))(西德:6), 1](西德:6) ∈ RmH−1 ,
output of the (H − 1)th layer as z(X, 我
where ¯z(X, 我
(1:H−2)) is the output without the constant neuron.
) with R( j) = θ τ
(1:H−2)) = [ ¯z(X, 我
(H−1, j) and θ
) = ˜σ (右( j)q(西德:16)
) ○ (qq(西德:16)
(H−1, j)
3.3 Convergence Analysis. 在这个部分, we establish global conver-
gence of the EE wrapper A without using assumptions from the previous
部分. Let τ be an arbitrary positive integer and ε be an arbitrary posi-
tive real number. Let (θ t )
t=0 be a sequence generated by the EE wrapper A.
(H)) and B ¯(西德:14) = minθ
-
We define ˆL(我
(1:H−2)
θ τ
(H−1)),  ̄(西德:14)) for any ¯(西德:14) ≥ 0.
(H−1)
(H−1)) = L(θ τ
 ̄(西德:14) = argminθ
, θ τ
, 我
(H−1)
max( ˆL(我
(西德:13) 在哪里 (西德:19)
(H−1)
∈(西德:19)  ̄(西德:14)
(西德:13)我
(H−1)
∞
(H−1)
3.3.1 Safe-Exploration Condition. The mathematical analysis in this sec-
tion relies on the safe-exploration condition, which allows us to safely
explore deep nonlinear representations in the exploration phase with-
out getting stuck in the states of vec(是(西德:3)) /∈ Col(
). The safe-
exploration condition is verifiable, time-independent, data-dependent, 和
architecture-dependent. The verifiability and time independence make the
assumption strong enough to provide prior guarantees before training. 这
data dependence and architecture dependence make the assumption weak
enough to be applicable for a wide range of practical settings.
∂vec( fX (θ t ))
∂θ t
For any q ∈ RmH−1
×mH , we define the matrix-valued function φ(q, 我
(1:H−2))
∈ Rn×mH mH−1 by
⎡
⎢
⎢
⎣
φ(q, 我
(1:H−2)) =
˜σ (z(西德:6)
˜σ (z(西德:6)
1
1 q∗1)z(西德:6)
…
n q∗1)z(西德:6)
n
···
. . .
···
⎤
⎥
⎥
⎦ ,
˜σ (z(西德:6)
˜σ (z(西德:6)
1
1 q∗mH )z(西德:6)
…
n q∗mH )z(西德:6)
n
, 我
= z(希
(1:H−2)) ∈ RmH−1 and ˜σ (z(西德:6)
∈ R1×mH−1 for all i ∈ [n] 和
where zi
k ∈ [mH]. Using this function, the safe exploration condition is formally
stated as:
Assumption 4 (Safe-Exploration Condition). There exist a q ∈ RmH−1
and a θ
∈ Rd1:H−2 such that rank(φ(q, 我
i q∗k)z(西德:6)
(1:H−2))) = n.
(1:H−2)
×mH
我
The safe-exploration condition asks for only the existence of one param-
(1:H−2))) = n. 它
eter vector in the network architecture such that rank(φ(q, 我
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1009
is not about the training trajectory (θ t )t. Since the matrix φ(q, 我
(1:H−2)) 是
of size n × mHmH−1, the safe-exploration condition does not require any
wide layer of size mH ≥ n or mH−1
≥ n. 反而, it requires a layer of size
≥ n. This is a significant improvement over the most closely re-
mHmH−1
lated study (Kawaguchi & Sun, 2021) where the wide layer of size mH ≥
≥ n does not imply the safe-
n was required. Note that having mHmH−1
≥ n is a necessary condition to sat-
exploration condition. 反而, mHmH−1
isfy the safe-exploration condition, whereas mH ≥ n or mH−1
≥ n was a nec-
essary condition to satisfy assumptions in previous papers, 包括
most closely related study (Kawaguchi & Sun, 2021). The safe-exploration
condition is verified in experiments in section 3.4.
3.3.2 Additional Assumptions. We also use the following assumptions:
我(q) − ∇(西德:3)
Assumption 5. For any i ∈ [n], the function (西德:3)
和 (西德:13)∇(西德:3)
Assumption 6. For each i ∈ [n], the functions θ
q (西德:8)→ ˜σ (q) are real analytic.
)(西德:13) ≤ L(西德:3)(西德:13)q − q(西德:16)(西德:13) for all q, q(西德:16) ε R.
我(q(西德:16)
我 : q (西德:8)→ (西德:3)(q, 做) is differentiable,
(1:H−2)
(西德:8)→ z(希
, 我
(1:H−2)) 和
迪
(西德:3)
(西德:3)
k=1 yk log exp(qk )
(西德:16) 经验值(qk
Assumption 5 is satisfied by using standard loss functions such
as the squared loss (西德:3)(q, y) = (西德:13)q − y(西德:13)2 and cross-entropy loss (西德:3)(q, y) =
-
(西德:16) ) . The assumptions of the invexity and convex-
ity of the function q (西德:8)→ (西德:3)(q, 做) in sections 3.3.3 和 3.3.4 also hold
for these standard loss functions. Using L(西德:3) in assumption 5, we de-
fine ˆL = L(西德:3)
(H, j)) ⊗
n
ImH−1 ](φ(θ τ
(西德:13)Z(西德:13)2, where Z ∈ Rn is defined by Zi
(西德:6)
= (瓦 (H)
j∗ )
= max j∈[我的]
(西德:6)(西德:13) with θ
(西德:13)[diag(θ τ
(1:H−2))i∗)
(H−1, j)
(H, j)
, θ τ
.
k
Assumption 6 is satisfied by using any analytic activation function
such as sigmoid, hyperbolic tangents, and softplus activations q (西德:8)→ ln(1 +
经验值(ςq))/ς with any hyperparameter ς > 0. This is because a composition
of real analytic functions is real analytic, and the following are all real ana-
lytic functions in θ
(1:H−2): the convolution, affine map, average pooling, skip
联系, and batch normalization. 所以, the assumptions can be sat-
isfied by using a wide range of machine learning models, including deep
neural networks with convolution, skip connection, and batch normaliza-
的. 而且, the softplus activation can approximate the ReLU activation
for any desired accuracy, 那是, ln(1 + 经验值(ςq))/ς → relu(q) as ς → ∞,
where ReLU represents the ReLU activation.
3.3.3 Global Optimality at the Limit Point. The following theorem proves
the global optimality at limit points of the EE wrapper with a wide range
of optimizers, including gradient descent and modified Newton methods:
Theorem 4. Suppose assumptions 4 到 6 hold and that the function (西德:3)
我 : q (西德:8)→
(西德:3)(q, 做) is invex for any i ∈ [n]. Assume that there exist ¯c, c > 0 这样
(H−1))(西德:13)2 for any t ≥ τ .
C(西德:13)∇ ˆL(θ t
(西德:6) ˆgt and (西德:13) ˆgt(西德:13)2 ≤ ¯c(西德:13)∇ ˆL(θ t
(H−1))(西德:13)2 ≤ ∇ ˆL(θ t
(H−1))
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1010
K. Kawaguchi, L. 张, and Z. Deng
Assume that the learning rate sequence (αt )t≥τ satisfies either (我) (西德:14) ≤ αt ≤ c(2-(西德:14))
ˆL ¯c
对于一些 (西德:14) > 0 或者 (二) limt→∞ αt = 0 和
t=τ αt = ∞. Then with probabil-
ity one, every limit point ˆθ of the sequence (θ t )t is a global minimum of L as
L( ˆθ ) ≤ L(我 ) for all θ ∈ Rd.
(西德:3)∞
3.3.4 Global Optimality Gap at Each Iteration. We now present global con-
vergence guarantees of the EE wrapper A with gradient decent and SGD:
Theorem 5. Suppose assumptions 4 到 6 hold and that the function (西德:3)
我 : q (西德:8)→
(西德:3)(q, 做) is convex for any i ∈ [n]. 然后, with probability one, the following two
statements hold:
(我) (Gradient descent) if ˆgt = ∇ ˆL(θ t
(H−1)) and αt = 1
ˆL
for t ≥ τ , then for any
 ̄(西德:14) ≥ 0 and t > τ ,
L(θ t ) ≤ inf
θ ∈Rd
 ̄(西德:14) ˆL
max(L(我 ),  ̄(西德:14)) + B2
2(t − τ )
.
(二) (SGD) if E[ ˆgt|θ t] = ∇ ˆL(θ t
(西德:3)∞
t=τ (αt )2 < ∞ and (H−1)) (almost surely) with E[(cid:13) ˆgt(cid:13)2] ≤ G2, and t=τ αt = ∞ for t ≥ τ , then for any ¯(cid:14) ≥ 0 (cid:3)∞ if αt ≥ 0, and t > t ,
乙[L(θ t∗
)] ≤ inf
θ ∈Rd
max(L(我 ),  ̄(西德:14)) + B2
 ̄(西德:14) + G2
(西德:3)
t
2
(西德:3)
t
k=τ α2
k
k=τ α
k
(3.5)
where t∗ ∈ argmink∈{t,τ +1,…,t}L(θ k).
√
In theorem 5ii, with αt ∼ O(1/
t), the optimality gap becomes
∗
乙[L(θ t
)] − inf
θ ∈Rd
max(L(我 ),  ̄(西德:14)) = ˜O(1/
t).
√
3.4 实验. This section presents empirical evidence to support
our theory and what is predicted by a well-known hypothesis. We note
that there is no related work or algorithm that can guarantee global con-
vergence in the setting of our experiments where the model has convolu-
系统蒸发散, skip connections, and batch normalizations without any wide layer
(of the width larger than n). 而且, unlike any previous studies that pro-
pose new methods, our training framework works by modifying any given
方法.
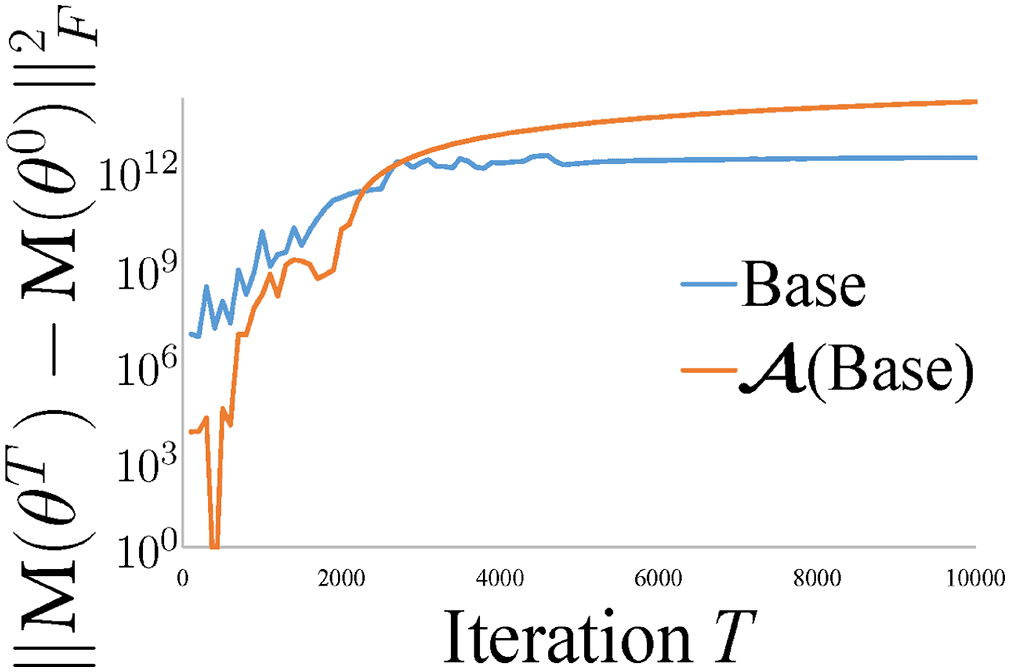
3.4.1 Sine Wave Data Set. We have seen in section 2.2 that gradient de-
scent gets stuck at suboptimal points for the sine wave data set. 使用
same setting as that in section 2.2 with ε = 0.01, τ = 2000, and ˜G = G, 我们
confirm in Figure 2 that the EE wrapper A can modify gradient descent to
avoid suboptimal points and converge to global minima as predicted by our
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1011
数字 2: Training errors for three random trials.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
数字 3: Changes of the representations where M(我 ) := ∂vec( fX (我 ))
∂θ
∂vec( fX (我 ))
∂θ
(
)(西德:6).
理论. 数字 3 shows the value of the change of the gradient representa-
的, (西德:13)中号(θ T ) − M(我 0)(西德:13)2
F, for each time step T. As can be seen, the values of
(西德:13)中号(θ T ) − M(我 0)(西德:13)2
F are large for both methods. 尤其, the EE wrapper A
of the base case significantly increases the value of (西德:13)中号(θ T ) − M(我 0)(西德:13)2
F even
in the exploitation phase after τ = 2000 as we are optimizing the hidden
层. See appendix B in the supplementary information for more details of
the experiments for the sine wave data set.
3.4.2 Image Data Sets. The standard convolutional ResNet with 18 layers
(他, 张, Ren, & Sun, 2016) is used as the base model ¯f . We use ResNet-
18 for the illustration of our theory because it is used in practice and it has
卷积, skip connections, and batch normalization without any width
larger than the number of data points. This setting is not covered by any of
the previous theories for global convergence. We set the activation to be the
softplus function q (西德:8)→ ln(1 + 经验值(ςq))/ς with ς = 100 for all layers of the
base ResNet. This approximates the ReLU activation well, as shown in ap-
pendix C in the supplementary information. We employ the cross-entropy
loss and ˜σ (q) = 1
1+e−q . We use a standard algorithm, SGD, with its standard
hyperparameter setting for the training algorithm G with ˜G = G—that is,
−5, 莫-
we let the minibatch size be 64, the weight decay rate be 10
mentum coefficient be 0.9, the learning rate be αt = 0.1, and the last epoch
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1012
K. Kawaguchi, L. 张, and Z. Deng
桌子 2: Verification of the Safe-Exploration Condition (Assumption 4).
Data Set
n
mH−1
MNIST
CIFAR-10
CIFAR-100
Semeion
KMNIST
SVHN
60,000
50,000
50,000
1,000
60,000
73,257
513
513
513
513
513
513
mH
234
195
195
4
234
286
Assumption 4
Verified
Verified
Verified
Verified
Verified
Verified
= (西德:23)2(n/mH−1 )(西德:24) where n is the number of
笔记: mH
training data, mH is the width of the last hidden layer,
and mH−1 is the width of the penultimate hidden layer.
0 ˆT were selected from ε ∈ {10
ˆT be 200 (with data augmentation) 和 100 (without data augmentation).
−5} 和
The hyperparameters ε and τ = τ
t
∈ {0.4, 0.6, 0.8} by only using training data. 那是, we randomly divided
0
each training data set (100%) into a smaller training data set (80%), and a
validation data set (20%) for a grid search over the hyperparameters. 看
appendix B in the supplementary information for the results of the grid
search and details of the experimental setting. This standard setting satis-
fies assumptions 5 和 6, leaving assumption 4 to be verified.
−3, 10
Verification of Assumption 4. 桌子 2 summarizes the verification results
of the safe-exploration condition. Because the condition only requires an
existence of a pair (我 , q) satisfying the condition, we verified it by using
a randomly sampled q from the standard normal distribution and a θ re-
= 513
turned by a common initialization scheme (He et al., 2015). As mH−1
(512 + the constant neuron for the bias term) for the standard ResNet, 我们
set mH = (西德:23)2(n/mH−1)(西德:24) throughout all the experiments with the ResNet. 为了
each data set, the rank condition was verified twice by the two standard
方法: one from Press, Teukolsky, Vetterling, and Flannery (2007) 和
another from Golub and Van Loan (1996).
Test Performance. One well-known hypothesis is that the success of deep-
learning methods partially comes from its ability to automatically learn
deep nonlinear representations suitable for making accurate predictions
from data (LeCun et al., 2015). As the EE wrapper A keeps this ability of
representation learning, the hypothesis suggests that the test performance
of the EE wrapper A of a standard method is approximately comparable to
that of the standard method. Unlike typical experimental studies, our ob-
jective here is to confirm this prediction instead of showing improvements
over a previous method. We empirically confirmed the prediction in Tables
3 和 4 where the numbers indicate the mean test errors (and standard de-
viations are in parentheses) over five random trials. 正如预期的那样, the values
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1013
桌子 3: Test Error (%): Data Augmentation.
Data Set
标准
A(标准)
MNIST
CIFAR-10
CIFAR-100
Semeion
KMNIST
SVHN
0.40 (0.05)
7.80 (0.50)
32.26 (0.15)
2.59 (0.57)
1.48 (0.07)
4.67 (0.05)
0.30 (0.05)
7.14 (0.12)
28.38 (0.42)
2.56 (0.55)
1.36 (0.11)
4.43 (0.11)
桌子 4: Test Error (%): No Data Augmentation.
Data Set
标准
A(标准)
MNIST
CIFAR-10
CIFAR-100
0.52 (0.16)
15.15 (0.87)
54.99 (2.29)
0.49 (0.02)
14.56 (0.38)
46.13 (1.80)
数字 4: Training Loss with Data Augmentation.
的 (西德:13)中号(θ ˆT ) − M(我 0)(西德:13)2
2 were also large—for example, 4.64 × 1012 for the stan-
dard method and 3.43 × 1012 for wrapper A of the method with the Semeion
数据集.
Training Behavior. 数字 4 shows that the EE wrapper A can improve
training loss values of the standard SGD algorithm in the exploitation phase
without changing its hyperparameters because ˜G = G in these experiments.
In the figure, the plotted lines indicate the mean values over five random
试验, and the shaded regions show error bars with 1 标准差.
Computational Time. The EE wrapper A runs the standard SGD G in the
exploration phase and the SGD ˜G = G only on the subset of the weights
我
(H−1) in the exploitation phase. 因此, the computational time of the EE
wrapper A is similar to that of the SGD in the exploration phase, and it
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1014
K. Kawaguchi, L. 张, and Z. Deng
桌子 5: Total Wall-Clock Time in a Local GPU Workstation.
Data Set
标准
A(标准)
Semeion
CIFAR-10
364.60 (0.94)
3616.92 (10.57)
356.82 (0.67)
3604.5 (6.80)
桌子 6: Test Errors (%) of A(标准) with ˜G = L-BFGS.
(A) with data augmentation
(乙) without data augmentation
t
0
ε
−3
−5
10
10
0.4
0.6
0.8
0.26
0.37
0.38
0.32
0.37
0.37
t
0
ε
−3
−5
10
10
0.4
0.6
0.36
0.42
0.43
0.35
0.8
0.42
0.35
tends to be faster than the SGD in the exploitation phase. To confirm this,
we measure computational time with the Semeion and CIFAR-10 data sets
under the same computational resources (例如, without running other jobs
in parallel) in a local workstation for each method. The mean wall-clock
时间 (in seconds) over five random trials is summarized in Table 5, 在哪里
the numbers in parentheses are standard deviations. It shows that the EE
wrapper A is slightly faster than the standard method, as expected.
Effect of Learning Rate and Optimizer. We also conducted experiments on
the effects of learning rates and optimizers using the MNIST data set with
data augmentation. Using the best learning rate from {0.2, 0.1, 0.01, 0.001}
for each method (with ˜G = G = SGD), the mean test errors (%) over five ran-
dom trials were 0.33 (0.03) for the standard base method and 0.27 (0.03) 为了
the A wrapper of the standard base method (the numbers in parentheses
are standard deviations). 而且, 桌子 6 reports the preliminary results
on the effect of optimizers with ˜G being set to the limited-memory Broyden–
Fletcher–Goldfarb–Shanno algorithm (L-BFGS) (with G = the standard
SGD). By comparing Tables 3 和 6, we can see that using a different op-
timizer in the exploitation phase can potentially lead to performance im-
证明. A comprehensive study of this phenomenon is left to future
工作.
4 结论
Despite the nonlinearity of the dynamics and the noninvexity of the objec-
主动的, we have rigorously proved convergence of training dynamics to global
minima for nonlinear representation learning. Our results apply to a wide
range of machine learning models, allowing both underparameterization
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1015
and overparameterization. 例如, our results are applicable to the
)(西德:6) 是
case where the minimum eigenvalue of the matrix
zero for all t ≥ 0. Under the common model structure assumption, 型号
that cannot achieve zero error for all data sets (except some “good” data
套) are shown to achieve global optimality with zero error exactly when
the dynamics satisfy the data-architecture alignment condition. Our results
provide guidance for choosing and designing model structure and algo-
rithms via the common model structure assumption and data-architecture
alignment condition.
∂vec( fX (θ t ))
∂θ t
∂vec( fX (θ t ))
∂θ t
(
The key limitation in our analysis is the differentiability of the func-
tion f . For multilayer neural networks, this is satisfied by using stan-
dard activation functions, such as softplus, sigmoid, and hyperbolic tan-
gents. Whereas softplus can approximate ReLU arbitrarily well, 直接的
treatment of ReLU in nonlinear representation learning is left to future
工作.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
Our theoretical results and numerical observations uncover novel math-
ematical properties and provide a basis for future work. 例如,
we have shown global convergence under the data-architecture alignment
. The EE wrapper A is only one way
condition vec(是(西德:3)) ∈ Col
to ensure this condition. There are many other ways to ensure the data-
architecture alignment condition, and each way can result in a new algo-
rithm with guarantees.
(西德:4) ∂vec( fX (θ t ))
∂θ t
(西德:5)
参考
Bartlett, 磷. L。, Helmbold, D. P。, & 长的, 磷. 中号. (2019). Gradient descent with identity
initialization efficiently learns positive-definite linear transformations by deep
residual networks. 神经计算, 31(3), 477–502. 10.1162/neco_a_01164,
考研: 30645179
本吉奥, Y。, 考维尔, A。, & Vincent, 磷. (2013). Representation learning: A review and
new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence,
35(8), 1798–1828. 10.1109/TPAMI.2013.50, 考研: 23787338
本吉奥, Y。, Lamblin, P。, Popovici, D ., & 拉罗谢尔, H. (2007). Greedy layerwise train-
ing of deep networks. 在乙. Schölkopf, J. Platt, & 时间. Hoffman (编辑。), 进展
神经信息处理系统, 19 (p. 153). 红钩. 纽约: 柯兰.
Bordes, A。, Glorot, X。, Weston, J。, & 本吉奥, 是. (2012). Joint learning of words and
meaning representations for open-text semantic parsing. 在诉讼程序中
15th International Conference on Artificial Intelligence and Statistics, 22 (PP. 127–
135).
Ciregan, D ., Meier, U。, & 施米德胡贝尔, J. (2012). Multi-column deep neural networks
for image classification. 在诉讼程序中 2012 IEEE Conference on Computer Vi-
sion and Pattern Recognition (PP. 3642–3649). 皮斯卡塔韦, 新泽西州: IEEE.
Clanuwat, T。, Bober-Irizar, M。, Kitamoto, A。, Lamb, A。, Yamamoto, K., & Ha, D.
(2019). Deep learning for classical Japanese literature. In NeurIPS Creativity Work-
店铺 2019.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1016
K. Kawaguchi, L. 张, and Z. Deng
Dahl, G。, Ranzato, M。, Mohamed, A.-r., & 欣顿, G. 乙. (2010). Phone recogni-
tion with the mean-covariance restricted Boltzmann machine. 在J. 拉弗蒂, C.
威廉姆斯, J. Shawe-Taylor, 右. Zemel, & A. Culotta (编辑。), Advances in neural infor-
mation processing systems, 23 (PP. 469–477). 红钩, 纽约: 柯兰.
Dahl, G. E., 于, D ., Deng, L。, & Acero, A. (2011). Context-dependent pre-trained deep
neural networks for large-vocabulary speech recognition. IEEE Transactions on
声音的, Speech, and Language Processing, 20(1), 30–42. 10.1109/TASL.2011.2134090
Deng, L。, Seltzer, 中号. L。, 于, D ., Acero, A。, Mohamed, A.-r., & 欣顿, G. (2010). Binary
coding of speech spectrograms using a deep auto-encoder. 在诉讼程序中
Eleventh Annual Conference of the International Speech Communication Association.
红钩, 纽约: 柯兰.
Dong, C。, Loy, C. C。, 他, K., & 唐, X. (2014). Learning a deep convolutional net-
work for image super-resolution. In Proceedings of the European Conference on Com-
puter Vision (PP. 184–199). 柏林: 施普林格.
Gatys, L. A。, Ecker, A. S。, & Bethge, 中号. (2016). Image style transfer using convolu-
tional neural networks. In Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (PP. 2414–2423). 皮斯卡塔韦, 新泽西州: IEEE.
Glorot, X。, Bordes, A。, & 本吉奥, 是. (2011). Domain adaptation for large-scale senti-
ment classification: A deep learning approach. 国际会议录
Conference on Machine Learning. 纽约: ACM.
Golub, G. H。, & Van Loan, C. F. (1996). Matrix computations. 巴尔的摩, 医学博士: Johns
Hopkins University Press.
他, K., 张, X。, Ren, S。, & Sun, J. (2015). Delving deep into rectifiers: Surpassing
human-level performance on ImageNet classification. In Proceedings of the IEEE
International Conference on Computer Vision (PP. 1026–1034). 皮斯卡塔韦, 新泽西州: IEEE.
他, K., 张, X。, Ren, S。, & Sun, J. (2016). Identity mappings in deep residual net-
作品. In Proceedings of the European Conference on Computer Vision (PP. 630–645).
柏林: 施普林格.
欣顿, G。, Deng, L。, 于, D ., Dahl, G. E., Mohamed, A.-r., Jaitly, N。, . . . Kingsbury,
乙. (2012). Deep neural networks for acoustic modeling in speech recognition: 这
shared views of four research groups. IEEE Signal Processing Magazine, 29(6), 82–
97. 10.1109/MSP.2012.2205597
欣顿, G. E., Osindero, S。, & Teh, Y.-W. (2006). A fast learning algorithm for deep
belief nets. 神经计算, 18(7), 1527–1554. 10.1162/neco.2006.18.7.1527,
考研: 16764513
Kawaguchi, K. (2016). Deep learning without poor local minima. 在D中. 李, 中号.
Sugiyama, U. Luxburg, 我. Guyon, & 右. 加内特 (编辑。), Advances in neural infor-
mation processing systems, 29 (PP. 586–594). 红钩, 纽约: 柯兰.
Kawaguchi, K. (2021). On the theory of implicit deep learning: Global conver-
gence with implicit layers. In Proceedings of the International Conference on Learning
Representations.
Kawaguchi, K., Kaelbling, L. P。, & Lozano-Pérez, 时间. (2015). Bayesian optimization
with exponential convergence. 在C中. 科尔特斯, 氮. 劳伦斯, D. 李, 中号. Sugiyama,
& 右. 加内特 (编辑。), Advances in neural information processing systems, 28 (PP. 2809–
2817). 红钩. 纽约: 柯兰.
Kawaguchi, K., Maruyama, Y。, & 郑, X. (2016). Global continuous optimization
with error bound and fast convergence. Journal of Artificial Intelligence Research,
56, 153–195. 10.1613/jair.4742
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Understanding Nonlinear Representation Learning
1017
Kawaguchi, K., & Sun, 问. (2021). A recipe for global convergence guarantee in deep
神经网络. In Proceedings of the AAAI Conference on Artificial Intelligence, 35
(PP. 8074–8082). 帕洛阿尔托, CA: AAAI.
克里热夫斯基, A。, & 欣顿, G. (2009). Learning multiple layers of features from tiny images
(Technical report). Citeseer.
克里热夫斯基, A。, 吸勺, 我。, & 欣顿, G. 乙. (2012). ImageNet classification with
deep convolutional neural networks. 在F中. 佩雷拉, C. J. C. 布尔吉斯, L. 波图, &
K. 问. 温伯格 (编辑。), Advances in neural information processing systems, 25 (PP.
1097–1105). 红钩. 纽约: 柯兰.
Laurent, T。, & Brecht, J. (2018). Deep linear networks with arbitrary loss: All local
minima are global. In Proceedings of the International Conference on Machine Learning
(PP. 2902–2907).
Le, H.-S., Oparin, 我。, Allauzen, A。, Gauvain, J.-L., & Yvon, F. (2012). Structured output
layer neural network language models for speech recognition. IEEE Transactions
on Audio, Speech, and Language Processing, 21(1), 197–206.
乐存, Y。, 本吉奥, Y。, & 欣顿, G. (2015). 深度学习. 自然, 521(7553), 436–444.
10.1038/nature14539, 考研: 26017442
乐存, Y。, 波图, L。, 本吉奥, Y。, & Haffner, 磷. (1998). Gradient-based learning
applied to document recognition. In Proceedings of the IEEE, 86(11), 2278–2324.
10.1109/5.726791
Luan, F。, 巴黎, S。, Shechtman, E., & Bala, K. (2017). Deep photo style transfer. 在
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (PP.
4990–4998). 皮斯卡塔韦, 新泽西州: IEEE.
Mityagin, 乙. (2015). The zero set of a real analytic function. arXiv:1512.07276.
Mohamed, A.-r., Dahl, G. E., & 欣顿, G. (2011). Acoustic modeling using deep
belief networks. IEEE Transactions on Audio, Speech, and Language Processing, 20(1),
14–22. 10.1109/TASL.2011.2109382
Netzer, Y。, 王, T。, Coates, A。, Bissacco, A。, 吴, B., & 的, A. 是. (2011). Reading
digits in natural images with unsupervised feature learning. In NIPS Workshop
on Deep Learning and Unsupervised Feature Learning.
Paszke, A。, 总的, S。, Massa, F。, Lerer, A。, Bradbury, J。, Chanan, G。, . . . Chintala, S.
(2019A). Pytorch: An imperative style, high-performance deep learning library. 在
H. 瓦拉赫, H. 拉罗谢尔, A. 贝格尔齐默, F. 阿尔谢比克, 乙. 狐狸, & 右. 加内特
(编辑。), Advances in neural information processing systems, 32 (PP. 8026–8037). Red
Hook. 纽约: 柯兰.
Paszke, A。, 总的, S。, Massa, F。, Lerer, A。, Bradbury, J。, Chanan, G。, . . . Chintala, S.
(2019乙). Pytorch: An imperative style, high-performance deep learning library. 在
H. 瓦拉赫, H. 拉罗谢尔, A. 贝格尔齐默, F. 阿尔谢比克, 乙. 狐狸, & 右. 加内特
(编辑。), Advances in neural information processing systems, 32 (PP. 8024–8035). Red
Hook. 纽约: 柯兰.
Pedregosa, F。, Varoquaux, G。, Gramfort, A。, Michel, 五、, Thirion, B., Grisel, . . . Duches-
nay, E., (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learn-
ing Research, 12, 2825–2830.
Poggio, T。, Kawaguchi, K., Liao, Q., Miranda, B., Rosasco, L。, Boix, X。, Hidary, J。, &
Mhaskar, H. (2017). Theory of deep learning III: Explaining the non-overfitting puzzle.
arXiv:1801.00173.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
1018
K. Kawaguchi, L. 张, and Z. Deng
按, 瓦. H。, Teukolsky, S. A。, Vetterling, 瓦. T。, & Flannery, 乙. 磷. (2007). Numerical
recipes: The art of scientific computing. (3rd ed.). 剑桥: 剑桥大学
按.
Rifai, S。, Dauphin, 是. N。, Vincent, P。, 本吉奥, Y。, & 穆勒, X. (2011). The manifold tan-
gent classifier. 在J. Shawe-Taylor, 右. Zemel, 磷. Bartlett, F. 佩雷拉, & K. 问. Wein-
berger (编辑。), Advances in neural information processing systems, 24 (PP. 2294–2302).
红钩. 纽约: 柯兰.
Saxe, A. M。, 麦克莱兰, J. L。, & 甘古利, S. (2014). Exact solutions to the nonlinear
dynamics of learning in deep linear neural networks. In Proceedings of the Inter-
national Conference on Learning Representations.
Schwenk, H。, Rousseau, A。, & Attik, 中号. (2012). 大的, pruned or continuous space
language models on a GPU for statistical machine translation. 在诉讼程序中
the NAACL-HLT 2012 作坊: Will We Ever Really Replace the N-gram Model? 在
the Future of Language Modeling for HLT (PP. 11–19). Stroudsburg, PA: 协会
for Computational Linguistics.
Seide, F。, 李, G。, & 于, D. (2011). Conversational speech transcription using context-
dependent deep neural networks. In Proceedings of the Twelfth Annual Conference
of the International Speech Communication Association. 纽约: ACM.
Socher, R。, 黄, 乙. H。, Pennington, J。, 的, A. Y。, & 曼宁, C. D. (2011). Dy-
namic pooling and unfolding recursive autoencoders for paraphrase detection.
在J. Shawe-Taylor, 右. Zemel, 磷. Bartlett, F. 佩雷拉, & K. 问. 温伯格 (编辑。),
Advances in neural information processing systems, 24 (PP. 801–809). 红钩, 纽约:
柯兰.
Socher, R。, Pennington, J。, 黄, 乙. H。, 的, A. Y。, & 曼宁, C. D. (2011). Semi-
supervised recursive autoencoders for predicting sentiment distributions. In Pro-
ceedings of the 2011 Conference on Empirical Methods in Natural Language Processing
(PP. 151–161). Stroudsburg, PA: 计算语言学协会.
Srl, 乙. T。, & Brescia, 我. (1994). Semeion handwritten digit data set. 罗马, 意大利: Semeion
Research Center of Sciences of Communication.
车工, C. R。, Fuggetta, A。, Lavazza, L。, & Wolf, A. L. (1999). A conceptual ba-
sis for feature engineering. Journal of Systems and Software, 49(1), 3–15. 10.1016/
S0164-1212(99)00062-X
徐, K., 张, M。, Jegelka, S。, & Kawaguchi, K. (2021). Optimization of graph neural
网络: Implicit acceleration by skip connections and more depth. In Proceed-
ings of the International Conference on Machine Learning.
郑, A。, & Casari, A. (2018). Feature engineering for machine learning: Principles and
techniques for data scientists. Sebastopol, CA: O’Reilly Media.
Zou, D ., 长的, 磷. M。, & Gu, 问. (2020). On the global convergence of training
deep linear ResNets. In Proceedings of the International Conference on Learning
Representations.
Received July 16, 2021; accepted November 24, 2021.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
4
4
9
9
1
2
0
0
3
0
8
5
n
e
C
哦
_
A
_
0
1
4
8
3
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3