Interpretability Analysis for Named Entity
Recognition to Understand System
Predictions and How They Can Improve
Oshin Agarwal
宾夕法尼亚大学
Department of Computer and
Information Science
oagarwal@seas.upenn.edu
Yinfei Yang
Google Research
yinfeiy@google.com
Byron C. 华莱士
Northeastern University
Khoury College of Computer Sciences
b.wallace@northeastern.edu
Ani Nenkova
宾夕法尼亚大学
Department of Computer and
Information Science
nenkova@seas.upenn.edu
Named entity recognition systems achieve remarkable performance on domains such as English
消息. It is natural to ask: What are these models actually learning to achieve this? Are they
merely memorizing the names themselves? Or are they capable of interpreting the text and
inferring the correct entity type from the linguistic context? We examine these questions by
contrasting the performance of several variants of architectures for named entity recognition,
with some provided only representations of the context as features. We experiment with GloVe-
based BiLSTM-CRF as well as BERT. We find that context does influence predictions, 但是
main factor driving high performance is learning the named tokens themselves. 此外, 我们
find that BERT is not always better at recognizing predictive contexts compared to a BiLSTM-
CRF model. We enlist human annotators to evaluate the feasibility of inferring entity types from
context alone and find that humans are also mostly unable to infer entity types for the majority
of examples on which the context-only system made errors. 然而, there is room for improve-
蒙特: A system should be able to recognize any named entity in a predictive context correctly
提交材料已收到: 28 四月 2020; 收到修订版: 12 十一月 2020; 接受出版:
8 十二月 2020.
https://doi.org/10.1162/COLI 00397
© 2021 计算语言学协会
根据知识共享署名-非商业性-禁止衍生品发布 4.0 国际的
(CC BY-NC-ND 4.0) 执照
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
and our experiments indicate that current systems may be improved by such capability. 我们的
human study also revealed that systems and humans do not always learn the same contextual
clues, and context-only systems are sometimes correct even when humans fail to recognize the
entity type from the context. 最后, we find that one issue contributing to model errors is the
use of “entangled” representations that encode both contextual and local token information into a
single vector, which can obscure clues. Our results suggest that designing models that explicitly
operate over representations of local inputs and context, 分别, may in some cases improve
表现. In light of these and related findings, we highlight directions for future work.
1. 介绍
Named Entity Recognition (NER) is the task of identifying words and phrases in text
that refer to a person, 地点, or organization name, or some finer subcategory of
these types. NER systems work well on domains such as English news, achieving high
performance on standard data sets like MUC-6 (Grishman and Sundheim 1996), CoNLL
2003 (Tjong Kim Sang and De Meulder 2003), and OntoNotes (Pradhan and Xue 2009).
然而, prior work has shown that the performance deteriorates on entities unseen
in the training data (Augenstein, Derczynski, and Bontcheva 2017; Fu et al. 2020) 和
when entities are switched with a diverse set of entities even within the same data set
(Agarwal et al. 2020).
在本文中, we examine the interpretability of models used for the task, focusing
on the type of textual clues that lead systems to make predictions. 考虑, 例如,
the sentence “Nicholas Romanov abdicated the throne in 1917.” The correct identifica-
tion of “Nicholas Romanov” as a person may be due to (我) knowing that Nicholas is a
fairly common name and that (二) the capitalized word after that ending with “-ov” is
likely a Slavic last name, 也. 或者, (三、) a competent user of language would
know the selectional restrictions (Framis 1994; Akbik et al. 2013; Chersoni et al. 2018)
for the subject of the verb abdicate, 即, that only a person may abdicate the throne.
The presence of two words indicates that it cannot be a pronoun, so X in the context “X
abdicated the throne” can only be a person.
Such probing of the reasons behind a prediction is in line with early work on NER
that emphasized the need to consider both internal (features of the name itself) 和
external (context features) evidence when determining the semantic types of named
实体 (麦当劳 1993). We specifically focus on the interplay between learning names
如 (我), and recognizing constraining contexts as in (三、), given that (二) can be construed
as a more general case of (我), in which word shape and morphological features may
indicate that a word is a name even if the exact name is never explicitly seen by the
系统 (桌子 1 in Bikel, 施瓦茨, 和韦舍德尔 [1999]).
Below are some examples of constraining contexts for different entity types. 这
type of X in each of these contexts should always be the same, irrespective of the identity
of X.
PER My name is X.
LOC The flight to X leaves in two hours.
ORG The CEO of X resigned.
As a foundation for our work, we conduct experiments with BiLSTM-CRF models
using GloVe input representations (黄, 徐, and Yu 2015) modified to use only
context representations or only word identities to quantify the extent to which systems
exploit word and context evidence, 分别 (部分 3). We test these systems on
118
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
three different data sets to identify trends that generalize across corpora. 我们表明
context does somewhat inform system predictions, but the major driver of performance
is recognition of certain words as names of a particular type. We modify the model by
introducing gates for word and context representations to determine what it focuses on.
We find that on average, only the gate value of the word representation changes when
there is a misprediction; the context gate value remains the same. We also examine the
performance of a BERT-based NER model and find that it does not always incorporate
context better than the BiLSTM-CRF models.
We then ask if systems should be expected to do better from the context text
(部分 5). Specifically, we task human annotators with inferring entity types using
仅有的 (sentential) 语境, for the instances on which a BiLSTM-CRF relying solely on
context made a mistake. We find that in the majority of cases, annotators are (还)
unable to choose the correct type. This suggests that it may be beneficial for systems
to similarly recognize situations in which there is a lack of reliable semantic constraints
for determining the entity type. Annotators sometimes make the same mistakes as the
model does. This may hint at why conventional systems tend to ignore context features:
The number of examples for which relying primarily on contextual features will result
in an accurate prediction is almost the same as the number for which relying on the
context will lead to an erroneous prediction. For some cases, 然而, annotators are
able to correctly identify the entity type from the context alone when the system makes
an error, indicating that systems do not identify all constraining contexts and that there
is room for improvement.
We conclude by running “oracle” experiments in Section 3 that show that systems
with access to different parts of the input can be better combined to improve results.
These experiments also show that the GloVe-based BiLSTM-CRF and BERT based only
on the context representation are correct on very different examples; 最后,
combining the two leads to performance gains. There is thus room for better exploiting
the context to develop robust NER systems with improved generalizability.
最后, we discuss the implications of our findings for the direction of future
研究, summarizing the answers to three questions we explore in this article: (1) 什么
do systems learn—word identity vs. 语境? (2) Can context be utilized better so that
generalization is improved? (3) 如果是这样, what are some possible directions for it?
2. 相关工作
Most related prior work has focused on learning to recognize certain words as names,
either using the training data, gazetteers or, 最近, pretrained word representa-
系统蒸发散. Early work on NER did explicitly deal with the task of scoring contexts on their
ability to predict the entity types in that context. More recent neural approaches have
only indirectly incorporated the learning of context, 即, via contextualized word
陈述 (Peters et al. 2018; Devlin et al. 2019).
2.1 Names Seen in Training
NER systems recognize entities seen in training more accurately than entities that were
not present in the training set (Augenstein, Derczynski, and Bontcheva 2017; Fu et al.
2020). The original CoNLL NER task used as a baseline a name look-up table: Each word
that was part of a name that appeared in the training data with a unique class was
correspondingly classified in the test data as well. All other words were marked as
119
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
non-entities. Even the simplest learning systems outperform such a baseline (Tjong Kim
Sang and De Meulder 2003), as it will clearly achieve poor recall. 同时,
overviews of NER systems indicate that the most successful systems, both old (Tjong
Kim Sang and De Meulder 2003) 和最近的 (Yadav and Bethard 2018), make use of
gazetteers listing numerous names of a given type. Wikipedia in particular has been
used extensively as a source for lists of names of given types (Kazama and Torisawa
2007; Ratinov and Roth 2009). The extent to which learning systems are effectively
‘better‘ look-up models—or if they actually learn to recognize contexts that suggest
specific entity types—is not obvious.
Even contemporary systems that do not use gazetteers expand their knowledge
of names through the use of pretrained word representations. With distributed rep-
resentations trained on large background corpora, a name is “seen in training” if its
representation is similar to names that explicitly appeared in the training data for NER.
考虑, 例如, the commonly used Brown cluster features (Brown et al.
1992; 磨坊主, Guinness, and Zamanian 2004). Both in the original paper and the re-
implementation for NER, authors show examples of representations that would be the
same for classes of words (约翰, 乔治, James, Bob or John, Gerald, Phillip, Harold,
分别). 在这种情况下, if one of these names is seen in training, any of the other
names are also treated as seen, because they have the exact same representation.
相似地, using neural embeddings, words with representations similar to those
seen explicitly in training would likely be treated as “seen” by the system as well.
Tables 6 和 7 in Collobert et al. (2011) show the impact of word representations trained
on small training data also annotated with entity types compared with those making use
of large amounts of unlabeled text. When using only the limited data, the words with
representations closest to france and jesus, 分别, are “persuade, faw, blackstock,
giorgi“ and “thickets, savary, sympathetic, jfk,” which seem unlikely to be useful for
the task of NER. For the word representations trained on Wikipedia and Reuters,1 这
corresponding most similar words are “austria, belgium, germany, italy“ and “god, sati,
christ, satan.” These representations clearly have higher potential for improving NER.
Systems with character-level representations further expand their ability to recog-
nize names via word shape (capitalization, dashes, apostrophes) and basic morphology
(Lample et al. 2016).
We directly compare the lookup baseline with a system that uses only predictive
contexts learned from the training data, and an expanded baseline drawing on pre-
trained word representations that cover many more names than the limited training
data itself.
2.2 Unsupervised Name–Context Learning
Approaches for database completion and information extraction use free unannotated
text to learn patterns predictive of entity types (Riloff and Jones 1999; Collins and Singer
1999; Agichtein and Gravano 2000; Etzioni et al. 2005; Banko et al. 2007) and then use
these to find instances of new names. Given a set of known names, they rank all n-gram
contexts for their ability to predict the type of entities, discovering for example that “the
mayor of X” or “Mr. Y“ or “permanent resident of Z” are predictive of city, 人, 和
国家, 分别.
1 CoNLL data, one of the standard data sets used to evaluate NER systems, is drawn from Reuters.
120
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
Early NER systems also attempted to use additional unannotated data, mostly to ex-
tract names not seen in training but also to identify predictive contexts. 这些, 然而,
had little to no effect on system performance (Tjong Kim Sang and De Meulder 2003),
with few exceptions where both names and contexts were bootstrapped to train a
系统 (Cucerzan and Yarowsky 2011; Nadeau, 特尼, and Matwin 2006; Talukdar
等人. 2006).
Recent work in NLP relies on neural representations to expand the ability of the
systems to learn context and names (黄, 徐, and Yu 2015). In these approaches the
learning of names is powered by the pretrained word representations, as described in
the previous section, and the context is handled by an LSTM representation. 迄今为止, 那里
has not been analysis of which parts of contexts are properly captured by the LSTM
陈述, especially what they do better than more local representations of just
the preceding/following word.
Acknowledged state-of-the-art approaches have demonstrated the value of contex-
tualized word embeddings, as in ELMo (Peters et al. 2018) and BERT (Devlin et al. 2019);
these are representations derived both from input tokens and the context in which they
出现. They have the clear benefit of making use of large data sets for pretraining that
can better capture a diversity of contexts. But at the same time these contextualized
representations make it difficult to interpret the system prediction and which parts of
the input led to a particular output. Contextualized representations can in principle
disambiguate the meaning of words based on their context, 例如, the canonical
example of Washington being a person, a state, or a city, depending on the context. 这
disambiguation may improve the performance of NER systems. 此外, 代币
representations in such models reflect their context by construction, so may specifically
improve performance on entity tokens not seen during training but encountered in
contexts that constrain the type of the entity.
To understand the performance of NER systems, we should be able to probe the
justification for the predictions: Did they recognize a context that strongly indicates
that whatever follows is a name of a given type (as in “Czech Vice-PM ”), or did they
recognize a word that is typically a name of a given type (“Jane”), or a combination
of the two? 在本文中, we present experiments designed to disentangle to the
extent possible the contribution of the two sources of confidence in system predictions.
We perform in-depth experiments on systems using non-contextualized word repre-
sentations and a human/system comparison with systems that exploit contextualized
陈述.
3. Context-Only and Word-Only Systems
Here we perform experiments to disentangle the performance of systems based on the
word identity and the context. We compare two look-up baselines and several systems
that vary the representations fed into a sequential Conditional Random Field (病例报告表)
(拉弗蒂, 麦卡勒姆, 和佩雷拉 2001), described below.
Lookup. Create a table of each word preserving its case, and its most frequent tag from
the training data. In testing, lookup a word in this table and assign its most frequent
tag. If the word does not appear in the training data or there is a tie in the tag frequency,
mark as O (outside, not a named entity).
121
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
LogReg. Logistic Regression using the GloVe representation of the word only (no context
of any kind). This system is equivalent to lookup in both the NER training data and
GloVe representations as determined by the data they were trained on.
GloVe fixed + 病例报告表. This system uses GloVe word representations as features in a linear
chain CRF model. Any word in training or testing that does not have a GloVe represen-
tation is assigned representation equal to the average of all words represented in GloVe.
The GloVe input vectors are fixed in this setting, 那是, we do not backpropagate into
这些.
GloVe fine-tuned + 病例报告表. The same as the preceding model, except that GloVe embedding
parameters are updated during training. This method nudges word representations to
become more similar depending on how they manifest in the NER training data, 和
generally performs better than relying on fixed representations.
FW context + 病例报告表. This system uses LSTM (Hochreiter and Schmidhuber 1997) 代表-
sentations only for the text preceding the current word (IE。, run forward from the start
to this word), with GloVe as inputs. Here we take the hidden state of the previous word
as the representation of the current word. This incorporates non-local information not
available to the two previous systems, from the part of the sentence before the word.
BW context + 病例报告表. Backward context-only LSTM with GloVe as inputs. Here we reverse
the sentence sequence and take the hidden state of the next word in the original se-
quence as the output representation of the current word.
BI context + 病例报告表. Bidirectional context-only LSTM (Graves and Schmidhuber 2005) 和
GloVe as input. We concatenate the forward and backward context-only representations
taking the hidden state as in the two systems above and not the hidden state of the
current word.
BI context + word + 病例报告表. Bidirectional LSTM as in Huang, 徐, and Yu (2015). The feature
representing the word is the hidden state of the LSTM after incorporating the current
word; the backward and forward representations are concatenated.
We use 300 dimensional cased GloVe (Pennington, Socher, and Manning 2014) vec-
tors trained on Common Crawl.2 The models are trained for 10 epochs using Stochastic
Gradient Descent with a learning rate of 0.01 and weight decay of 1e-4. A dropout of 0.5
is applied on the embeddings and the hidden layer dimension used for the LSTM is 100.
We use the IO labeling scheme and evaluate the systems via micro-F1, at the token level.
We use the word-based model for all the above variations, but believe a character-level
model would yield similar results: Such models would differ only in how they construct
the independent context and word representations that we consider.
Although the above systems would show how the model behaves when it has
access to only specific information—context or word—they do not capture what the
model would focus on with access to both types of information. 为此原因, 我们
build a gated system as follows.
2 http://nlp.stanford.edu/data/glove.840B.300d.zip.
122
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
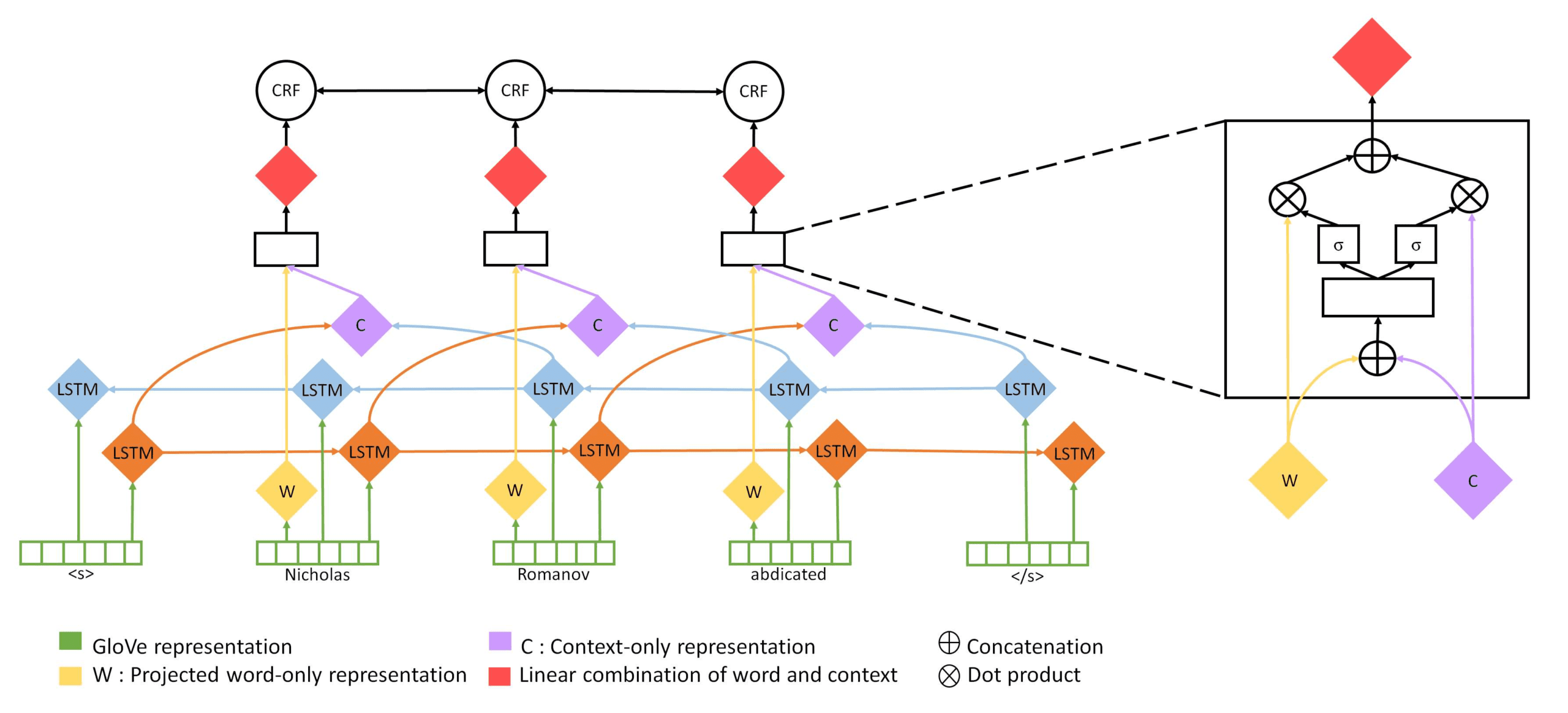
Gated BI + word + 病例报告表. This system comprises a bidirectional LSTM that uses both
context and the word, but the two representations are combined using gates. 这
provides a mechanism for revealing the degree to which the prediction was influenced
by the word versus the context.
More concretely, let X = (x1, x2, . . . , xn) be the input sequence where xi ∈ Rd is the
pretrained word embedding of the ith word in the sequence. The input representation
of each word is projected to a lower dimensional space, yielding a word-only represen-
tation xw
i ∈ Rdw.
xw
i = Wwxi
For each word, we also induce a context-only representation using two LSTMs.
One computes the representation of the forward context h fw
; the other reverses the
我
sequence to derive a representation of the backward context hbw
. 如前所述,
我
these hidden states incorporate the representation of the ith word. Because we want
a context-only representation, we instead use the hidden state for the previous word in
the fw LSTM, and hidden state for the following word yielded from the bw LSTM. 我们
concatenate these to form a context-only representation xc
i ∈ Rdc .
xc
i =
(西德:104)
h fw
i−1; hbw
i+1
(西德:105)
Next we combine the word-only and context-only representations using parameter-
ized gates:
(西德:3)(西德:1)
gw = σ (西德:0)Wgw (西德:2)xw
gc = σ (西德:0)Wgc (西德:2)xw
i = gwxw
xwc
我 ; xc
我
我 ; xc
我
我 + gcxc
我
(西德:3)(西德:1)
This is followed by a linear layer that consumes the resultant xwc
我
陈述
and produces logits for potential class assignments for tokens that are subsequently
decoded using a linear chain CRF. This architecture is illustrated in Figure 1.
In addition to the above systems that are based on GloVe representations, we also
perform experiments using the following systems that use contextual representations,
for the sake of completeness.
Full BERT. We use the original public large model3 and apply the default fine-tuning
战略. We use the NER fine-tuning implementation in Wolf et al. (2020) and train the
model for three epochs with a learning rate of 5e-06 and maximum sequence length of
128. We use the default values of all other hyperparameters as in the implementation.
Word-only BERT. Fine-tuned using only the word as the input resulting in a non-
contextual word-only representation. Each word token can appear multiple times with
various entity types in the training data and the frequency for each is maintained in the
training data.
3 cased L-24 H-1024 A-16.
123
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
数字 1
Architecture of the gated system. For each word, a token-only (黄色的) and a context-only
(purple) representation is learned. These are combined using gates, as illustrated on the right,
and fed into a CRF.
Context-only BERT. Because decomposition of BERT representations into word-only and
context-only is not straightforward,4 we adopt an alternate strategy to test how BERT
fares without seeing the word itself. We use a reserved token from the vocabulary
“[unused0]” as a mask for the input token so that the system is forced to make decisions
based on the context and does not have a prior entity type bias associated with the mask.
We do this for the entire data set, masking one word at a time. It is important to note
that the word is only masked during testing and not during fine-tuning.
4. 结果
We evaluate these systems on the CoNLL 2003 and MUC-6 data. Our goal is to quantify
how well the models can work if the identity of the word is not available, and to com-
pare that to situations in which only the word identity is known. 此外, we eval-
uate the systems trained on CoNLL data on the Wikipedia data set (Balasuriya et al.
2009), to assess how data set–dependent the performance of the system is. 桌子 1
reports our results. The first line in the table (BI context + word + 病例报告表) corresponds
to the system presented in Huang, 徐, and Yu (2015).
4.1 Word-Only Systems
The results in the Word only rows are as expected: We observe low recall and high preci-
锡安. All systems that rely on the context alone, without taking the identity of the word
into account, have worse F1 than the Lookup system. The results are consistent across
CoNLL as well as MUC6 data sets. On the cross domain evaluation, 然而, 什么时候
the system trained on CoNLL is evaluated on Wikigold, the recall drops considerably.
4 We tried a few techniques such as projecting the BERT representations into word and context spaces by
learning to predict the word itself and the context words as two simultaneous tasks, but this did not work
出色地.
124
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
桌子 1
Performance of GloVe word-level BiLSTM-CRF and BERT. All rows are for the former and only
the last two rows for BERT. Local context refers to high precision constraints due to sequential
病例报告表. Non-local context refers to the entire sentence. No document level context is included. 这
first two panels were trained on the Original English CoNLL 03 training data and tested on the
original English CoNLL 03 test data and the WikiGold data. The last panel was trained and
tested on the respective splits of MUC-6. Highest F1 in each panel is boldfaced, excluding the
full systems.
系统
CoNLL
右
磷
F1
维基百科
右
磷
F1
MUC-6
右
磷
F1
Full system
BI context + word + 病例报告表
Words only
Lookup
LogReg
Words + local context
GloVe fixed + 病例报告表
GloVe fine-tuned + 病例报告表
Non-local context-only
FW context-only + 病例报告表
BW context-only + 病例报告表
BI context-only + 病例报告表
BERT
Full
Word-only
Context-only
90.7
91.3
91.0
66.6
60.8
63.6
90.1
91.8
90.9
84.1
80.2
56.6
74.3
67.7
77.2
66.3
58.8
28.5
48.9
39.8
53.4
81.4
75.1
54.4
71.7
65.2
73.4
67.9
80.8
63.4
77.3
65.6
79.0
53.7
63.3
37.6
45.8
44.2
53.1
74.1
82.1
68.1
77.0
70.9
79.5
71.3
69.5
70.1
91.9
80.0
43.1
39.4
47.7
52.1
93.1
80.5
64.1
50.8
56.6
59.8
92.5
80.3
51.6
53.3
46.6
51.2
75.4
61.6
39.7
19.3
21.7
21.4
75.1
54.8
76.2
28.4
29.6
30.2
75.2
58.0
52.2
71.9
74.0
66.4
96.1
77.9
75.6
58.9
49.4
56.5
97.2
75.3
71.6
64.7
59.2
61.1
96.7
76.5
73.5
This behavior may be attributed to the data set: Many of the entities in the CoNLL
training data also appear in testing, a known undesirable fact (Augenstein, Derczynski,
and Bontcheva 2017). 我们发现 64.60% 和 64.08% of entity tokens in CoNLL and
MUC6 test are seen in the respective training sets. 然而, 仅有的 41.55% of entity tokens
in Wikigold are found in the CoNLL training set.
The use of word representations (LogReg row) contributes substantially to system
表现, especially for the MUC-6 data set in which few names appear in both
train and test. Given the impact of the word representations, it would seem important
to track how the choice and size of data for training the word representations influences
system performance.
4.2 Word and Local Context Combinations
下一个, we consider the systems in the Word + local context rows. CRFs help to recognize
high precision entity-type local contextual constraints, 例如, force a LOC in
the pattern “ORG ORG LOC” to be an ORG as well. Another type of high-precision
constraining context is word-identity based, similar to the information extraction work
discussed above, and constrains X in the pattern “X said” to be PER. Both of these
125
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
桌子 2
Mean gate values in CoNLL when entities and non-entities are correct and incorrect. For entities,
the average value of context gates remains the same irrespective of the predicted values. 为了
both entities and non-entities, the word gate has a much higher value when the prediction is
正确的. The word identity itself is the major driver of performance.
Context Word
ENT correct
ENT incorrect
O correct
O incorrect
0.906
0.906
0.613
0.900
0.831
0.651
0.897
0.613
context types were used in Liao and Veeramachaneni (2009) for semi-supervised NER.
The observed improved precision and recall of GloVe fine-tuned + CRF over LogReg
indicates that the CRF layer modestly improves performance. 然而, fine-tuning the
representations on the training set is far more important than including such constraints
with CRFs as fixed GloVe + CRF performs consistently worse than LogReg.
4.3 Context Features Only
We compare Context-only systems with non-local context. In CoNLL data, the context
after a word appears to be more predictive, whereas in MUC-6 the forward context is
more predictive. In CoNLL, some of the right contexts are too corpus-specific, 例如
“X 0 Y 1” being predictive of X and Y as organizations with the example occurring in
reports of sports games, such as “France 0 Italy 1.” We find that 32.37% of the ORG
entities in CoNLL test split occur in such sentences. MUC-6, 另一方面, 包含
many examples that include honorifics, such as “Mr. X.” In the MUC-6 test split, 35.08%
of PER entities are preceded by an honorific, whereas in CoNLL and MUC6, 这是
case only for 2.5% 和 4.6% 实体, 分别. Statistics on these two patterns are
如表所示 3. We provide the list of honorifics and regular expressions for sports
scores used to calculate this in the Appendix.
最后, we note that combining the backward and forward contexts by concatenat-
ing their representations results in a better system for CoNLL but not for MUC-6.
清楚地, systems with access to only word identity perform better than those with
access to only the context (drop of ∼20 F1 in all the three data sets). 下一个, 我们使用
Gated BI + word + CRF system in Figure 1 to investigate what the system focuses on
when it has access to both the word and to the context, as distinct input representations.
We compare the average value of the word and context gates when the system is correct
与. incorrect in Table 2. For entities, while the context gate value is higher than the word
gate value, its average remains the same irrespective of whether the prediction is correct
或不. 另一方面, the word gate value drops considerably when the system
makes an error. 相似地, the word gate value drops considerably for non-entities as
well on error. 出奇, the context gate value increases for non-entities when an
error is made. These results suggest that systems over-rely on word identity to make
their predictions.
而且, whereas one would have expected that the context features have high
precision and low recall, this is indeed not the case: The precision of the BI+CRF system
is consistently lower than the precision for the full system and the logistic regression
126
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
桌子 3
Repetitive context patterns in the data sets. In CoNLL, a large percentage of organizations occur
in sports scores. In MUC-6, a large percentage of PER entities are preceded by an honorific.
Honorifics Sports Scores
% PER
% ORG
CoNLL train
CoNLL testa
CoNLL testb
维基百科
MUC-6 train
MUC-6 test
2.74
2.19
2.59
4.65
27.46
35.08
25.89
22.13
32.37
0.00
0.00
0.00
模型. This means that a better system will not only learn to recognize more contexts
but also would be able to override contextual predictions based on features of the word
在这种情况下.
4.4 Contextualized Word Representations
最后, we experiment with BERT (Devlin et al. 2019). Word-only BERT is fine-tuned
using only one word at a time without any context. Full BERT and context-only BERT
are the same system fine-tuned on the original unchanged data set and differ only in
inference. For context-only BERT, a reserved vocabulary token “[unused0]” is used to
hide one word at a time to get a context-only prediction. We report these results in the
last two rows of Table 1. Full BERT improves in F1 over the GloVe-based BiLSTM-CRF
as reported in the original paper. Word-only BERT performs better than the context-only
BERT but the difference in performance is not as pronounced as in the case of the GloVe-
based BiLSTM-CRF, except on the CoNLL corpus due to the huge overlap of the training
and testing set entities, as noted earlier. We also note the difference in performance of
the context-only systems using GloVe and BERT. Context-only BERT performs better or
worse than context-only BiLSTM, depending on the corpora. These results show that
BERT is not always better at capturing contextual clues. Although it is better in certain
案例, it also misses these clues in some instances for which the BiLSTM makes a correct
prediction.
在部分 6, we provide a more detailed oracle experiment that demonstrates that
the BiLSTM-CRF and BERT context-only systems capture different aspects of context
and make errors on different examples. Here we preview this difference in strengths
by examining BERT performance on a sample of sentences for which BiLSTM context
representations are sufficient to make a correct prediction, and a sample of sentences
where it is not. We randomly sampled 200 examples from CoNLL 03 where the context-
only LSTM was correct (Sample-C) 和另一个 200 where it was incorrect (Sample-I).
Context-only BERT is correct on 71.5% examples in Sample-C but fails to make the
correct prediction on the remaining 28.5% that are easy for the BiLSTM context rep-
resentation. 相比之下, it is also able to correctly recognize the entity type in 53.22% 的
the cases in Sample-I, where BiLSTM context is insufficient for prediction.
Similar to the gated system, we looked at the attention values in the case of BERT.
然而, these are much harder to interpret as compared to the gate values in the
LSTM. The gated LSTM had only one value for the entire context and one value for
127
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
the entire word. 相比之下, BERT has an attention value for each subword in the
context and each subword in the word. 而且, there are multiple attention heads.
It is unclear how to interpret the individual values and combine them into a single
number for the context and the word. We looked into this by taking the maximum (或者
意思是) value for each subword across all heads and maximum (or mean) value of all
subwords in the context and the word but found similar final values for both in all
案例.
5. Human Evaluation
在这个部分, we describe a study with humans, assessing if they tend to be more suc-
cessful at using contextual cues to infer entity types. 用于比较, we also conduct
another study to assess the success of humans in using just the word to infer entity type.
5.1 Context-Only
We performed a human study to determine if humans can infer entity types solely from
the context in which they appear. Only sentence-level context is used as all systems
operate at the sentence-level. For each instance with a target word in a sentence context,
we show three annotators the sentence with the target word masked and ask them
to determine its type as PER, ORG, LOC, MISC, or O (not a named entity). We allow
them to select multiple options. We divide all examples into batches of 10. We ensure
the quality of the annotation by repeating one example in every batch and removing
annotators that are not consistent on this repeated example. 此外, we include
an example either directly from the instructions or very similar to an example in the
instructions. If an annotator does not select the type from the example at a minimum,
we assume that they either did not read the instructions carefully, or that they did not
understand the task, and we remove them as well. Since humans are allowed to select
multiple options, we do not expect them to fully agree on all of the options. The goal is
to select the most likely option and so we take as the human answer the option with the
most votes: We will refer to this as the majority label.
Similar to the comparison between BiLSTM and BERT, we now compare BiLSTM
behavior and that of humans. For the study, we select 20 instances on which the
context-only BiLSTM model was correct and 200 instances for which the context-only
BiLSTM made errors. The sample from correct prediction is smaller because we see
overwhelming evidence that whenever the BiLSTM prediction is correct, humans can
also easily infer the correct entity type from contextual features alone. 为了 85% of these
correctly labeled instances, the majority label provided by the annotators was the same
as the true (and predicted) 标签. 桌子 4 shows the three (在......之外 20) examples in which
humans did not agree on the category or made a wrong guess. 这些 20 instances serve
as a sanity check as well as a check for annotator quality for the examples where the
system made incorrect predictions.
We received a variety of responses for the 200 instances in sentences where the
context-only BiLSTM-CRF model made an incorrect prediction. Below we describe the
results from the study. We break down the human predictions in two classes. Examples
of each are shown in Table 5.
Error class 1. Humans correct: The human annotators were able to correctly determine
the label for 23.5% (47) of the sentences where the context-only BiLSTM-CRF made
错误, indicating some room for improvement in a context-only system.
128
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
桌子 4
Examples of human evaluation where the context-only system was correct but humans incorrect.
句子
Word
Label Human
Lang said he
Fair Trading, which was asked to examine the case last month.
conditions proposed by Britain’s Office of
supported
氧
Vigo 15 5 5 5 17 17 20
The years I spent as manager of the Republic of were the
best years of my life.
Celta
爱尔兰
ORG
LOC
–
氧
–
Error class 2. Human incorrect or no majority: For the remaining 76.5% instances, 胡-
mans could not predict the entity type from only the context.
为了 55.5% of the cases, there was a human majority label but it was not the same
as the true label. In these cases, the identity of the word would have provided clues
conflicting those in the context alone. The large number of such cases—where context
and word cues need to be intelligently combined—may provide a clue as to why
modern NER systems largely ignore context: They do not have the comprehension and
reasoning abilities to combine the semantic evidence, and instead resort to over-reliance
on the word identity, which in such cases would override the contextual cues in human
comprehension.
为了 21%, there was no majority label in the human study, suggesting that the context
did not sufficiently constrain the entity type. 在这种情况下, clearly the identity of the
words would dominate the interpretation.
总共, humans could correctly guess the type without seeing the target word
for less than a quarter of the errors made by the BiLSTM-CRF. 值得注意的是, BERT has
correct as well as incorrect predictions on the examples from both BiLSTM-CRF error
类. It was correctly able to determine the entity type for 65.9% of cases in error
班级 1 和 49.3% of cases in error class 2. These results show that neither system is
learning the same contextual clues as humans. Humans find the context insufficient in
error class 2 but BERT is able to capture something predictive in the context. 未来
work could collect more human annotations with humans specifying the reason for
selecting an answer. A carefully designed framework would collect human reasoning
for their answers and incorporate this information while building a system.
5.2 Word-Only
For completeness, we also performed human evaluation to determine whether humans
can infer the type solely from the word identity. 在这种情况下, we do not show the
annotators any context. We follow the same annotation and quality control process as
多于. Because words are ambiguous (Washington can be PER, LOC, or ORG), and data
sets have different priors for words being of each type, we do not expect the annotators
to get all of the answers correct. 然而, we do expect them to be correct more often
than they were in the context-only evaluation.
We select the same 200 instances for the evaluation. We consider the GloVe-based
LogReg system for comparison as it does not include any context at all. Out of these 200,
the LogReg system was correct on 146 (73%) instances and incorrect for the remaining
27% instances. 的 146 cases in LogReg-correct, humans are correct for 116 (79.4%)
instances. For the remaining instances in LogReg-correct, humans are incorrect due to
129
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
桌子 5
Examples of human evaluation.
句子
Word
Label Human GloVe BERT
Error Class 1
Norilisk
ORG
(西德:88)
氧
氧
’s debts, is highly unlikely to bring
Analysts said the government, while anxious
关于
the nickel, copper, cobalt, platinum and platinum
group metals producer to its knees or take
measures that could significantly affect output.
6. Germany III ( Dirk Wiese, Jakobs
) 1:46.02
– Gulf Mexico:
关于 200 Burmese students marched briefly
from troubled Yangon
northern Rangoon on Friday towards the University
of Yangon six km ( four miles ) away,
and returned to their campus, witnesses said.
of Technology in
is a trader specialising
笔记 – Sangetsu Co
in interiors.
Russ Berrie and Co Inc said on Friday that A.
Cooke will retire as president and chief
operating officer effective July 1, 1997 .
ASEAN groups Brunei, 印度尼西亚, Malaysia,
这
, 新加坡, Thailand and Vietnam .
Their other marksmen were Brazilian
defender Vampeta
Belgian striker
Luc Nilis, his 14th of the season.
On Monday and Tuesday, students from the
YIT and the university launched street protests
against what they called unfair handling
by police of a brawl between some of their
colleagues and restaurant owners in
Alessandra Mussolini, the granddaughter of
’s Fascist dictator Benito Mussolini, 说
.
on Friday she had rejoined the far-right
National Alliance ( AN ) party she quit over
policy differences last month.
Public Service Minister David Dofara, 谁是
the head of the national Red Cross, told
Reuters he had seen the bodies of former
interior minister
who was not named.
The longest wait to load on the West was
13 天.
, 41, was put to death in
Friday.
Grelombe and his son,
’s electric chair
Wall Street, since the bid, has speculated that
any deal between Newmont and
would be a “bear hug, ” or a reluctantly
negotiated agreement where the buyer is not
necessarily a friendly suitor.
铁
Marco
的
研究所
Ltd
Curts
PER
LOC
ORG
ORG
PER
菲律宾
LOC
(西德:88)
(西德:88)
(西德:88)
(西德:88)
(西德:88)
(西德:88)
氧
MISC
氧
氧
氧
LOC
氧
ORG
氧
(西德:88)
(西德:88)
(西德:88)
(西德:88)
Error Class 2
和
氧
PER
PER
十月
氧
LOC
LOC LOC
意大利
LOC
PER
O MISC
Christophe
PER ORG
氧
(西德:88)
Coast
Florida
Santa
O MISC LOC LOC
LOC
ORG
–
–
氧
(西德:88)
LOC LOC
domain/data set priors. 例如, in CoNLL, cities such as Philadelphia are sports
teams and hence ORG (not LOC), but without that knowledge, humans categorize them
as LOC. Out of all 54 instances in LogReg-incorrect, humans were correct on 16. 尽管
130
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
桌子 6
Performance (F1) of GloVe word-based BiLSTM-CRF and BERT. 系统 1 denotes the oracle
combination of separate systems which access to specific input representation only. 系统 2
refers to a single system with access to all the input of the various systems in system 1. 第一个
two panels were trained on the Original English CoNLL 03 training data and tested on the
original English CoNLL 03 test data and the WikiGold data. The last panel was trained and
tested on the respective splits of MUC-6.
系统 1 (Oracle)
系统 2
FW context – BW context
LSTM-CRF
Bi context
LSTM-CRF
CoNLL Wikipedia MUC-6
系统 1 系统 2 系统 1 系统 2 系统 1 系统 2
75.3
59.8
49.3
30.2
85.3
61.1
FW context – BW context
– GloVe fine-tuned LSTM-CRF
Full LSTM-CRF
92.2
91.0
72.4
63.6
94.9
90.9
Full system – FW context
– BW context – GloVe
fine-tuned LSTM-CRF
word-only – context-only
BERT
Full – word-only
– context-only BERT
Full LSTM-CRF
95.1
91.0
76.8
63.6
96.1
90.9
Full BERT
92.5
92.5
86.8
75.2
93.7
96.7
Full BERT
96.5
92.5
90.1
75.2
98.5
96.7
this may seem to suggest room for system improvement, it is due to the same ambiguity
and data set bias. 例如, CoNLL has a bias for cities like the Philadelphia example
above to be sports teams and hence ORGs but there are a few instances where the city
name is actually LOC. In these cases, the LogReg system is incorrect but humans are
正确的.
总结一下, human evaluation using only the word identity is consistent with
predictions of the word-only system and observed differences are likely due to data set
biases and so expected.
6. Oracle Experiments
In the human evaluation we saw some mixed results, with some room for improvement
在 23.5% of the errors on one side and some errors that seem to be due to over-reliance
on context on the other. This motivates investigating whether a more sophisticated
approach that decides how to combine cues would be a better approach.
6.1 Combining All Systems
We perform an oracle experiment where the oracle knows which of the systems is
正确的. If neither is correct, it defaults to one of the systems. We report results in Table 6.
The default system in each case is the one listed first. 排 1 in the table shows that an
oracle combination of the forward context-only and backward context-only does much
better than the system that simply concatenates both context representations to make
预测. The gains are about 15, 20, 和 24 points F1 on CoNLL, Wiki, and MUC-
6, 分别. This improvement captures 22 的 47 examples (46.8%) that human
annotators got right but not the context-only system in Section 5.
131
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
桌子 7
Oracle combination of the context-only systems using GloVe and BERT. min and max denote the
minimum and maximum F1 of the systems combined and comb denotes the F1 of the combined
系统. The first two panels were trained on the Original English CoNLL 03 training data and
tested on the original English CoNLL 03 test data and the WikiGold data. The last panel was
trained and tested on the respective splits of MUC-6.
系统
context-only LSTM
– context-only BERT
CoNLL
维基百科
min max comb min max comb min max comb
MUC-6
51.6
59.8
83.7
30.2 52.2
79.0
61.1 73.5
84.6
We performed more such experiments with the full system and the word-only and
context-only systems. These are shown in rows 2 和 3. 在每种情况下, there are gains
over the full BiLSTM-CRF. An oracle with the four systems (排 3) shows the highest
gains with ∼4 points F1 on CoNLL and 6 points F1 on MUC-6. The gains are especially
pronounced in the case of cross-domain evaluation, 即, the system trained on
CoNLL when evaluated on Wikipedia has an increase of 13 points F1.
These results indicate that when given access to different components—word, 为了-
ward context, backward context—systems recognize different entities correctly, 像他们
应该. 然而, when all of these components are thrown at the system at once, 他们
are not able to combine these in the best possible way.
6.2 Combining BERT Variants
We performed similar experiments with the full, word-only, and context-only BERT as
出色地 (rows 4 和 5). Remember that the context-only BERT is the same trained system
as the full BERT and the difference comes from masking the word during evaluation.
The word-only and context-only combination shows no improvement over full BERT
on CoNLL but does so on the two other data sets. 然而, even for CoNLL, 这
oracle of these two systems is correct on somewhat different examples than the full
BERT as evident in the last row where combining all three systems gives improvement
on all three data sets. 再次, the improvement is highest on cross-domain evaluation
on the Wikipedia data set as with the combination of the GloVe-based systems. 我们
hypothesize that the attention on the current word likely dominates in the output
contextual representation, because of which the relevant context words do not end up
contributing much. 然而, when the word is masked in the context-only variant, 这
attention weight on it will likely be small because we use one of the tokens unused
in the vocabulary and the relevant context words end up contributing to the final
表示. Future work could involve some regularization to reduce the impact
of the current word in a few random training examples so that systems do not overfit to
the word identity and focus more on the context.
6.3 Combining Context-Only LSTM and BERT
最后, we performed an oracle experiment with the context-only LSTM-CRF and the
context-only BERT (见表 7). We see the biggest jumps in performance with this
particular experiment: 24, 27, 和 11 points F1 on CoNLL, Wiki, and MUC-6, 重新指定-
主动地. Both the systems use the context differently and are correct on a large number
132
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
of different examples, again showing that better utilization of context is possible. 笔记
that the human study showed that the room for improvement from context is small. 这
study was based on 200 random examples, where BERT was able to get some correct
even when humans could not. We hypothesize that while the context was possibly not
sufficient to identify the type, a similar context had been seen in the training data that
was learned by BERT .
All the oracle experiments show room for improvement and future work would in-
volve looking into strategies/systems to combine these components better. The progress
toward this can be measured by breaking down the systems and conducting oracle
experiments as done here.
7. Discussion and Future Work
We started the article with three questions about the workings of NER systems. 这里,
we return to these questions and synthesize the insights related to each gained from the
experiments presented in the article. We zeroed in on the question of interpretability
of NER systems, specifically examining the performance of systems that represent
differently the current word, the context, and their combination. We tested the systems
on two corpora and one tested across domains and show that some of the answers to
these questions are at times corpus dependent.
7.1 What Do Systems Learn?
Word types, 大多.
We find that current systems, including those build on top of contextualized word
陈述, pay more attention to the current word than to the contextual features.
Partly this is due to the fact that contextual features do not have high precision and
in many cases need to be overridden by evidence from the current word. 而且,
we find that contextual representations, 即, BERT, are not always better at captur-
ing context as compared to systems such as GloVe-based BiLSTM-CRFs. Their higher
performance could be the results of better pretraining data and learning the subword
structure better. We leave this analysis for future work and instead focus on the extent
of word versus context utilization with more focus on context utilization for better
generalization.
7.2 Can Context Be Utilized Better?
Only a bit better, if we want to emulate humans. But a lot better if willing to incorporate the
superhuman abilities of transformer models.
We carry out a study to test the ability of human annotators to predict the type of an
entity without seeing the entity word. Humans seem to easily do the task on examples
where the context-only system predicts the entity type correctly. The examples on which
the context-only system makes a mistake are difficult for humans as well. Humans can
guess the correct label only in about a quarter of all such examples. The opportunity for
improvement from better contextual representations that recognize more constraining
contexts exists but is relatively small.
133
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
7.3 How Can We Utilize Context Better?
By developing reasoning, more flexible combination of evidence, and informed regularization.
Based on our experiments, several avenues for better context utilization emerge.
Human-like reasoning. Our human study shows that systems are not capturing the same
information from textual context as humans do. BERT is able in many cases to correctly
recognize the type from the context even when humans fail to do so. A direction for
future work would involve collecting human reasoning behind their answers and incor-
porating this information in building the systems. This means learning to identify when
the context is constraining and possibly what makes it constraining.
Avoiding concatenation. Another promising direction for the overall improvement of the
GloVe-based BiLSTM-CRF system appears to be the better combination of features
representing different types of context and the word. Oracle experiments show that
different parts of the sentence—word, forward context, backward context—can help
recognize entities correctly when used standalone but not when used together. A simple
concatenation of features is not as meaningful and a smarter combination of several
types of features can lead to better performance.
Attention regularization. Oracle experiments involving BERT show that hiding the word
itself can sometimes correctly identify the word type even when seeing the word leads
to an incorrect prediction. BERT uses attention weights to combine different parts of
the input instead of concatenation as in the just discussed BiLSTM approaches. 我们
hypothesize that the attention on the word is likely much larger than on the rest of the
input because of which the relevant context words do not end up contributing much.
Future work could involve some regularization to reduce the impact of the current word
in a few random training examples so that it does not overfit to the word identity and
can focus more on the context.
最后, another direction for future work could expand the vocabulary of entities
instead of trying to learn context better so that more entities are seen either directly
in the training data or have similar representation in the embedding space by virtue
of being seen in the pretraining data. This could be done by having an even larger
pretraining data from diverse sources for better coverage or by incorporating resources
such as knowledge bases and gazetteers in the contextual systems.
附录
Entity Recognition vs. Typing
Entity recognition results are shown in
桌子 8. 这里, we check if a word is cor-
rectly recognized as an entity, even if the
type is wrong. The results are better than
Recognition + Typing results in Table 1
for all systems and data sets but still not
very high. 所以, the errors made are
in both recognition and typing. 相同
performance pattern is observed with
word-only systems better than context-
only systems even in entity recognition.
The word-only systems have an F1 much
higher than context-only systems, 意思是-
ing that looking at a word, it is much
easier to say whether it is an entity or
不是. But looking at context, it is still hard
to say whether something is an entity
或不. The breakdown by type is also
如表所示 9 for all three data sets
for Full BERT.
134
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
桌子 8
Performance of GloVe word-level BiLSTM-CRF and BERT on entity recognition (no typing). 全部
rows are for the former and only the last two rows for BERT. Local context refers to high
precision constraints due to sequential CRF. Non-local context refers to the entire sentence. 不
document level context is included. The first two panels were trained on the Original English
CoNLL 03 training data and tested on the original English CoNLL 03 test data and the WikiGold
数据. The last panel was trained and tested on the respective splits of MUC-6.
系统
Full system
BI context + word + 病例报告表
Words only
Lookup
LogReg
Words + local context
GloVe fixed + 病例报告表
GloVe fine-tuned + 病例报告表
Non-local context-only
FW context-only + 病例报告表
BW context-only + 病例报告表
BI context-only + 病例报告表
BERT
Full
Word-only
Context-only
Honorifics
CoNLL
维基百科
MUC-6
磷
右
F1
磷
右
F1
磷
右
F1
96.2
96.8
96.5
86.7
79.2
82.8
94.5
96.3
95.4
96.2
93.8
83.2
91.9
78.8
76.6
78.0
97.0
94.8
50.3
64.8
86.9
77.6
88.0
43.6
52.6
58.0
98.3
95.4
74.7
77.4
90.2
80.3
89.9
56.1
62.3
66.5
97.7
95.1
60.1
93.4
89.9
81.6
88.6
65.8
62.0
64.8
88.3
93.0
47.7
40.1
74.8
57.1
64.1
23.9
28.9
27.1
87.9
82.8
91.5
56.1
81.6
67.2
74.4
35.0
39.5
38.2
88.1
87.6
62.7
93.6
87.5
83.5
91.3
76.6
76.8
72.1
97.2
93.1
77.7
62.6
83.6
76.7
85.6
62.8
51.2
61.4
98.3
89.9
73.5
75.0
85.5
80.0
88.4
69.0
61.4
66.3
97.7
91.5
75.5
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
Data sets have different common context
图案. 例如, forward context
is highly predictive in MUC-6. In MUC-6
测试, 35.08% of PER entities are preceded
by an honorific whereas in CoNLL and
MUC-6, this number is only 2.5% 和
4.6%, 分别. Following is the list of
honorifics (mostly English, owing to the
nature of the data sets) used to calculate
these numbers — Dr, 先生, Ms, Mrs, Mstr,
Miss, Dr., Mr., Ms., Mrs., Mx., Mstr., 米斯-
特尔, 教授, Doctor, 总统, Senator,
Judge, Governor, Officer, General, Nurse,
Captain, Coach, Reverend, Rabbi, Ma’am,
Sir, 父亲, Maestro, Madam, Colonel,
Gentleman, Sire, Mistress, Lord, Lady,
Esq, Excellency, Chancellor, Warden,
Principal, Provost, Headmaster, Head-
mistress, Director, Regent, 院长, Chair-
男人, Chairwoman, Chairperson, Pastor.
Sports Scores
We use the following three regular ex-
pressions to determine if a sentence con-
tains sports scores –
([0-9]+. )?([A-Za-z]+ ){1,3}([0-9]+ ){0,6}(([0-9]+)(?!))( 12)?( -)?
和
([A-Za-z]+){1,3}([0-9]+){1,3}([A-Za-z]+){1,3}
([0-9]+){0,2}[0-9]
和
([A-Z]+ ){1,3}AT ([A-Z]+ ){1,2}[A-Z]+
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Human Labels Breakdown
Here we provide the breakdown be-
tween the different labels as marked by
the human annotators. Note that the an-
notators could select multiple options
and the majority label was selected as
the final label. The results are shown in
桌子 10.
135
计算语言学
体积 47, 数字 1
桌子 9
Confusion matrices for BERT-Full. Rows represent the true class and columns represent the
predicted class.
PER ORG LOC MISC
氧
2,709
33
8 2,320
6
10
18
15
86
72 1,789
25
77
22
81
1,509
14
50 1,362
14
22
51
13
200
141 1,013
61
74
230
154
11
5
35
47
19
39
736
70
126 38,076
92
6
154
192
240
39
291
944
312 31,827
584
6
0
0
3
4
830
0
0
41
1
5
105
0
1
1
0
22
0
4
0
0
0
0 12,498
CoNLL
PER
ORG
LOC
MISC
氧
维基百科
PER
ORG
LOC
MISC
氧
MUC-6
PER
ORG
LOC
MISC
氧
136
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
桌子 10
Breakdown of human labels. The majority label is selected as the final label.
句子
Word
True
Label
Human label
PER ORG LOC MISC O
Error Class 1
Analysts said the government, while anxious about
Norilisk
ORG
0
2
1
0
0
’s debts, is highly unlikely to bring the nickel, copper,
cobalt, platinum and platinum group metals producer
to its knees or take measures that could significantly
affect output.
6. Germany III ( Dirk Wiese, Jakobs
) 1:46.02
– Gulf Mexico:
Marco
的
关于 200 Burmese students marched briefly from troubled Institute
of Technology in northern Rangoon on Friday
Yangon
towards the University of Yangon six km ( four miles )
away, and returned to their campus, witnesses said.
笔记 – Sangetsu Co
interiors.
is a trader specialising in
Ltd
Russ Berrie and Co Inc said on Friday that A.
will retire as president and chief operating officer
effective July 1, 1997.
库克
Curts
PER
LOC
ORG
ORG
PER
ASEAN groups Brunei, 印度尼西亚, Malaysia, 这
新加坡, Thailand and Vietnam.
,
菲律宾
LOC
Error Class 2
Their other marksmen were Brazilian defender Vampeta
和
Belgian striker Luc Nilis, his 14th of the season.
On Monday and Tuesday, students from the YIT and the
university launched street protests against what they
called unfair handling by police of a brawl between some
of their colleagues and restaurant owners in
.
十月
氧
氧
2
1
0
0
3
1
2
1
1
0
2
3
0
0
0
0
1
2
1
0
0
2
1
3
1
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
Alessandra Mussolini, the granddaughter of
Fascist dictator Benito Mussolini, said on Friday she had
rejoined the far-right National Alliance ( AN ) party she
quit over policy differences last month.
’s
Public Service Minister David Dofara, who is the head of
the national Red Cross, told Reuters he had seen the
bodies of former interior minister
儿子, who was not named.
Grelombe and his
The longest wait to load on the West was 13 天 .
, 41, was put to death in
’s electric chair Friday .
Wall Street, since the bid, has speculated that any deal
between Newmont and
Fe would be a “bear hug, ”
or a reluctantly negotiated agreement where the buyer is
not necessarily a friendly suitor.
意大利
LOC
3
0
1
1
0
Christophe
PER
1
2
0
0
0
Coast
Florida
Santa
氧
LOC
ORG
Sanity check errors
Lang said he
of Fair Trading, which was asked to examine the case last
月.
conditions proposed by Britain’s Office
supported
氧
Vigo 15 5 5 5 17 17 20
The years I spent as manager of the Republic of were
the best years of my life.
Celta
爱尔兰
ORG
LOC
1
0
2
0
0
1
0
2
2
0
1
2
0
2
1
0
0
2
2
0
0
2
0
0
0
0
0
2
2
0
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
137
计算语言学
体积 47, 数字 1
致谢
This material is based upon work supported
in part by the National Science Foundation
under grant no. 美国国家科学基金会 1901117.
参考
阿加瓦尔, Oshin, Yinfei Yang, Byron C.
华莱士, and Ani Nenkova. 2020.
Entity-switched data sets: An approach to
auditing the in-domain robustness of
named entity recognition models.
Agichtein, Eugene and Luis Gravano. 2000.
Snowball: Extracting relations from large
plain-text collections. 在诉讼程序中
fifth ACM Conference on Digital Libraries,
pages 85–94, San Antonio, TX. DOI:
https://doi.org/10.1145/336597.336644
Akbik, 艾伦, Larysa Visengeriyeva, 约翰内斯
Kirschnick, and Alexander L ¨oser. 2013.
Effective selectional restrictions for
unsupervised relation extraction. 在
Proceedings of the Sixth International Joint
Conference on Natural Language Processing,
pages 1312–1320, Nagoya.
Augenstein, Isabelle, Leon Derczynski, 和
卡琳娜·邦切娃. 2017. Generalisation in
named entity recognition: A quantitative
分析. Computer Speech & 语言,
44:61–83. DOI: https://doi.org
/10.1016/j.csl.2017.01.012
Balasuriya, Dominic, Nicky Ringland, Joel
Nothman, Tara Murphy, and James R.
柯兰. 2009. Named entity recognition in
维基百科. 在诉讼程序中 2009
Workshop on The People’s Web Meets NLP:
Collaboratively Constructed Semantic
资源 (People’s Web), pages 10–18,
Suntec. DOI: https://doi.org/10.3115
/1699765.1699767
Banko, 米歇尔, 迈克尔·J. Cafarella, 斯蒂芬
Soderland, Matthew Broadhead, and Oren
Etzioni. 2007. Open information extraction
from the web. 在诉讼程序中
International Joint Conference on Artificial
智力, 7:2670–2676, 纽约, 纽约.
Bikel, Daniel M., Richard Schwartz, 和
Ralph M. Weischedel. 1999. An algorithm
that learns what’s in a name. 机器
学习, 34(1-3):211–231. DOI: https://
doi.org/10.1023/A:1007558221122
棕色的, Peter F., Vincent J. Della Pietra,
Peter V. deSouza, Jenifer C. Lai, 和
罗伯特·L. 美世. 1992. Class-based
n-gram models of natural language.
计算语言学, 18(4):467–480.
Chersoni, Emmanuele, Adri`a
Torrens Urrutia, Philippe Blache, 和
Alessandro Lenci. 2018. Modeling
138
violations of selectional restrictions with
distributional semantics. 在诉讼程序中
the Workshop on Linguistic Complexity and
自然语言处理, pages 20–29,
圣达菲, NM.
柯林斯, Michael and Yoram Singer. 1999.
Unsupervised models for named entity
分类. 在 1999 Joint SIGDAT
Conference on Empirical Methods in Natural
Language Processing and Very Large Corpora,
pages 100–110.
Collobert, Ronan, Jason Weston, L´eon
波图, Michael Karlen, Koray
Kavukcuoglu, and Pavel Kuksa. 2011.
Natural language processing (almost) 从
scratch. Journal of Machine Learning
研究, 12(八月):2493–2537.
Cucerzan, Silviu and David Yarowsky, 2002.
Language independent NER using a
unified model of internal and contextual
证据. In COLING-02: The 6th Conference
on Natural Language Learning 2002
(CoNLL-2002). https://www.aclweb.org
/anthology/W02-2007
Devlin, 雅各布, Ming-Wei Chang, Kenton Lee,
and Kristina Toutanova. 2019. BERT:
Pre-training of deep bidirectional
transformers for language understanding.
在诉讼程序中 2019 Conference of the
North American Chapter of the Association for
计算语言学: Human Language
Technologies, 体积 1 (Long and Short
文件), pages 4171–4186, 明尼阿波利斯,
明尼苏达州.
Etzioni, Oren, Michael Cafarella, Doug
Downey, Ana-Maria Popescu, Tal Shaked,
Stephen Soderland, Daniel S. Weld, 和
Alexander Yates. 2005. Unsupervised
named-entity extraction from the web: 一个
experimental study. 人工智能,
165(1):91–134. DOI: https://doi.org
/10.1016/j.artint.2005.03.001
Framis, Francesc Ribas. 1994. An experiment
on learning appropriate selectional
restrictions from a parsed corpus. 在
科林 1994 体积 2: The 15th
国际计算会议
语言学, pages 769–774, Kyoto. DOI:
https://doi.org/10.3115/991250
.991270
福, Jinlan, Pengfei Liu, Qi Zhang, 和
Xuanjing Huang. 2020. Rethinking
generalization of neural models: A named
entity recognition case study. DOI:
https://doi.org/10.1609/aaai.v34i05
.6276
格雷夫斯, Alex and J ¨urgen Schmidhuber. 2005.
Framewise phoneme classification with
bidirectional LSTM networks. 在
会议记录. 2005 IEEE International Joint
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Agarwal et al.
Interpretability Analysis for NER
Conference on Neural Networks, 2005,
4:2047–2052.
Grishman, Ralph and Beth Sundheim. 1996.
Message Understanding Conference- 6: A
brief history. In COLING 1996 体积 1:
The 16th International Conference on
计算语言学, pages 466–471,
哥本哈根. DOI: https://doi.org/10
.1162/neco.1997.9.8.1735, PMID:
9377276
Hochreiter, Sepp and J ¨urgen Schmidhuber.
1997. Long short-term memory. Neural
计算, 9(8):1735–1780.
黄, Zhiheng, Wei Xu, and Kai Yu. 2015.
Bidirectional LSTM-CRF models for
sequence tagging. arXiv 预印本 arXiv:
1508.01991.
Kazama, Jun’ichi and Kentaro Torisawa.
2007. Exploiting Wikipedia as external
knowledge for named entity recognition.
在诉讼程序中 2007 Joint Conference on
自然语言的经验方法
Processing and Computational Natural
Language Learning (EMNLP-CoNLL),
pages 698–707, Prague.
拉弗蒂, John D., Andrew McCallum, 和
Fernando C. 氮. 佩雷拉. 2001. Conditional
random fields: Probabilistic models for
segmenting and labeling sequence data. 在
Proceedings of the Eighteenth International
Conference on Machine Learning, ICML ’01,
pages 282–289, 旧金山, CA.
Lample, Guillaume, Miguel Ballesteros,
Sandeep Subramanian, Kazuya
Kawakami, and Chris Dyer. 2016. Neural
architectures for named entity recognition.
在诉讼程序中 2016 Conference of the
North American Chapter of the Association for
计算语言学: Human Language
Technologies, pages 260–270, 圣地亚哥, CA.
DOI: https://doi.org/10.18653/v1/N16
-1030
Liao, Wenhui and Sriharsha
Veeramachaneni. 2009. A simple
semi-supervised algorithm for named
entity recognition. 在诉讼程序中
NAACL HLT 2009 Workshop on
Semi-Supervised Learning for Natural
语言处理, SemiSupLearn ’09,
pages 58–65, Stroudsburg, PA. DOI: https://
doi.org/10.3115/1621829.1621837,
PMID: 18992300
麦当劳, 大卫. 1993. Internal and
external evidence in the identification and
semantic categorization of proper names.
In Acquisition of Lexical Knowledge from Text.
与新闻界, pages 32–43.
磨坊主, 斯科特, Jethran Guinness, and Alex
Zamanian. 2004. Name tagging with word
clusters and discriminative training. 在
Proceedings of the Human Language
Technology Conference of the North American
Chapter of the Association for Computational
语言学: HLT-NAACL 2004,
pages 337–342, 波士顿, 嘛.
Nadeau, 大卫, Peter D. 特尼, and Stan
Matwin. 2006. Unsupervised named-entity
认出: Generating gazetteers and
resolving ambiguity. In Conference of the
Canadian Society for Computational Studies of
智力, pages 266–277, 柏林. DOI:
https://doi.org/10.1007/11766247 23
Pennington, 杰弗里, Richard Socher, 和
Christopher Manning. 2014. GloVe: 全球的
vectors for word representation. 在
诉讼程序 2014 会议
自然语言的经验方法
加工 (EMNLP), pages 1532–1543,
Doha. DOI: https://doi.org/10.3115
/v1/D14-1162
Peters, 马修, Mark Neumann, Mohit
伊耶尔, Matt Gardner, Christopher Clark,
Kenton Lee, and Luke Zettlemoyer. 2018.
Deep contextualized word representations.
在诉讼程序中 2018 Conference of the
North American Chapter of the Association for
计算语言学: Human Language
Technologies, 体积 1 (Long Papers),
pages 2227–2237, New Orleans, 这. DOI:
https://doi.org/10.18653/v1/N18
-1202
Pradhan, Sameer S. and Nianwen Xue. 2009.
OntoNotes: 这 90% 解决方案. 在
Proceedings of Human Language Technologies:
这 2009 Annual Conference of the North
American Chapter of the Association for
计算语言学, Companion
体积: Tutorial Abstracts, pages 11–12,
博尔德, 一氧化碳. DOI: https://doi.org/10
.3115/1620950.1620956
Ratinov, Lev and Dan Roth. 2009. 设计
challenges and misconceptions in named
entity recognition. 在诉讼程序中
Thirteenth Conference on Computational
Natural Language Learning (CoNLL-2009),
pages 147–155, 博尔德, 一氧化碳. DOI: https://
doi.org/10.3115/1596374.1596399
Riloff, Ellen and Rosie Jones. 1999. 学习
dictionaries for information extraction by
multi-level bootstrapping. 在诉讼程序中
the Sixteenth National Conference on Artificial
Intelligence and the Eleventh Innovative
Applications of Artificial Intelligence
Conference Innovative Applications of
人工智能, AAAI ’99/IAAI ’99,
pages 474–479, 美国.
Talukdar, Partha Pratim, Thorsten Brants,
Mark Liberman, and Fernando Pereira.
2006. A context pattern induction method
139
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 47, 数字 1
for named entity extraction. In Proceedings
of the Tenth Conference on Computational
Natural Language Learning (CoNLL-X),
pages 141–148, New York City.
Tjong Kim Sang, Erik F. and Fien
De Meulder. 2003. Introduction to the
CoNLL-2003 shared task: 语言-
independent named entity recognition. 在
Proceedings of the Seventh Conference on
Natural Language Learning at HLT-NAACL
2003, pages 142–147.
Wolf, 托马斯, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue,
Anthony Moi, Pierric Cistac, Tim Rault,
Remi Louf, Morgan Funtowicz, 乔
Davison, Sam Shleifer, Patrick von Platen,
Clara Ma, Yacine Jernite, Julien Plu,
Canwen Xu, Teven Le Scao, Sylvain
古格, Mariama Drame, 和别的. 2020.
Transformers: State-of-the-art natural
语言处理. 在诉讼程序中
2020 实证方法会议
自然语言处理: 系统
Demonstrations, pages 38–45. DOI: https://
doi.org/10.18653/v1/2020.emnlp-demos.6,
PMCID: PMC7365998
Yadav, Vikas and Steven Bethard. 2018.
A survey on recent advances in named
entity recognition from deep learning
型号. In Proceedings of the 27th
国际计算会议
语言学, pages 2145–2158, 圣达菲, NM.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
7
1
1
1
7
1
9
1
1
4
7
9
/
C
哦
我
我
_
A
_
0
0
3
9
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
140