他认为他比医生更了解:
BERT for Event Factuality Fails on Pragmatics
Nanjiang Jiang
语言学系
The Ohio State University, 美国
jiang.1879@osu.edu
Marie-Catherine de Marneffe
语言学系
The Ohio State University, 美国
demarneffe.1@osu.edu
抽象的
We investigate how well BERT performs on
predicting factuality in several existing English
datasets, encompassing various linguistic con-
structions. Although BERT obtains a strong
performance on most datasets, it does so by
exploiting common surface patterns that cor-
relate with certain factuality labels, and it fails
on instances where pragmatic reasoning is nec-
essary. Contrary to what the high performance
suggests, we are still far from having a robust
system for factuality prediction.
1
介绍
Predicting event factuality1 is the task of iden-
tifying to what extent an event mentioned in a
sentence is presented by the author as factual. 这是
a complex semantic and pragmatic phenomenon:
in John thinks he knows better than the doctors, 我们
infer that John probably doesn’t know better than
the doctors. Event factuality inference is prevalent
in human communication and matters for tasks
that depend on natural language understanding,
such as information extraction. 例如, 在
the FactBank example (Saur´ı and Pustejovsky,
2009) 表中 1, an information extraction sys-
tem should extract people are stranded without
food but not helicopters located people stranded
without food.
The current state-of-the-art model for factual-
ity prediction on English is the work of Pouran
Ben Veyseh et al. (2019), obtaining the best per-
formance on four factuality datasets: FactBank,
MEANTIME (Minard et al., 2016), UW (李
等人。, 2015), and UDS-IH2 (Rudinger et al., 2018).
传统上, event factuality is thought to be
triggered by fixed properties of lexical items. 这
Rule-based model of Stanovsky et al. (2017) took
such an approach: They used lexical rules and
1The terms veridicality and speaker commitment refer to
the same underlying linguistic phenomenon.
dependency trees to determine whether an event
in a sentence is factual, based on the properties
of the lexical items that embed the event in ques-
的. Rudinger et al. (2018) proposed the first
end-to-end model for factuality with LSTMs.
Pouran Ben Veyseh et al. (2019) used BERT rep-
resentations with a graph convolutional network
and obtained a large improvement over Rudinger
等人. (2018) and over Stanovsky et al.’s (2017)
Rule-based model (except for one metric on the
UW dataset).
然而, it is not clear what these end-to-end
models learn and what features are encoded in
their representations. 尤其, 他们不
seem capable of generalizing to events embedded
under certain linguistic constructions. White et al.
(2018) showed that the Rudinger et al. (2018)
models exhibit systematic errors on MegaVeridi-
cality, which contains factuality inferences purely
triggered by the semantics of clause-embedding
verbs in specific syntactic contexts. Jiang and
de Marneffe (2019A) showed that Stanovsky et al.’s
and Rudinger et al.’s models fail to perform well
on the CommitmentBank (de Marneffe et al.,
2019), which contains events under clause-
embedding verbs in an entailment-canceling envi-
罗门特 (否定, 问题, modal, or antecedent
of conditional).
在本文中, we investigate how well BERT,
using a standard fine-tuning approach,2 performs
on seven factuality datasets, including those fo-
cusing on embedded events that have been shown
to be challenging (White et al., 2018 and Jiang and
de Marneffe 2019a). The application of BERT to
datasets focusing on embedded events has been
limited to the setup of natural language inference
(NLI) (Poliak et al., 2018; Jiang and de Marneffe,
2019乙; Ross and Pavlick, 2019). In the NLI setup,
2We only augment BERT with a task-specific layer,
instead of proposing a new task-specific model as in Pouran
Ben Veyseh et al. (2019).
1081
计算语言学协会会刊, 卷. 9, PP. 1081–1097, 2021. https://doi.org/10.1162/tacl 00414
动作编辑器: Benjamin Van Durme. 提交批次: 1/2021; 修改批次: 5/2021; 已发表 10/2021.
C(西德:2) 2021 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
MegaVeridicality
CB
RP
FactBank
MEANTIME
UW
UDS-IH2
Someone was misinformed that something happened-2.7.
Hazel had not felt so much bewildered since Blackberry had talked about the raft beside the Enborne.
明显地, the stones could not possibly be anything to do with El-ahrairah. It seemed to him that
Strawberry might as well have said that his tail was-1.33 an oak tree.
The man managed to stay3 on his horse. / The man did not manage to stay-2.5 on his horse.
Helicopters are flying3.0 over northern New York today trying3.0 to locate0 people stranded3.0 without food,
heat or medicine.
Alongside both announcements3.0, Jobs also announced3.0 a new iCloud service to sync0 data among all devices.
Those plates may have come1.4 from a machine shop in north Carolina, where a friend of Rudolph worked3.0.
DPA: Iraqi authorities announced2.25 that they had busted2.625 up 3 terrorist cells operating2.625 in Baghdad.
桌子 1: Example items from each dataset. The annotated event predicates are underlined with their
factuality annotations in superscript. For the datasets focusing on embedded events (first group), 这
clause-embedding verbs are in bold and the entailment-canceling environments (如果有的话) are slanted.
an item is a premise-hypothesis pair, with a cat-
egorical label for whether the event described in
the hypothesis can be inferred by the premise.
The categorical labels are obtained by discretiz-
ing the original real-valued annotations. 对于前-
充足, given the premise the man managed to
stay on his horse (RP example in Table 1) 和
hypothesis the man stayed on his horse, a model
should predict that the hypothesis can be inferred
from the premise. In the factuality setup, an item
contains a sentence with one or more spans corre-
sponding to events, with real-valued annotations
for the factuality of the event. By adopting the
event factuality setup, we study whether models
can predict not only the polarity but also the gradi-
ence in factuality judgments (which is removed in
the NLI-style discretized labels). 这里, we provide
an in-depth analysis to understand which kind of
items BERT fares well on, and which kind it fails
在. Our analysis shows that, while BERT can pick
up on subtle surface patterns, it consistently fails
on items where the surface patterns do not lead
to the factuality labels frequently associated with
模式, and for which pragmatic reasoning is
必要的.
2 Event Factuality Datasets
Several event factuality datasets for English have
been introduced, with examples from each shown
表中 1. These datasets differ with respect to
some of the features that affect event factuality.
Embedded Events The datasets differ with re-
spect to which events are annotated for factuality.
The first category, including MegaVeridicality
(White et al., 2018), CommitmentBank (CB), 和
Ross and Pavlick (2019) (RP), only contains sen-
tences with clause-embedding verbs and factuality
is annotated solely for the event described by the
embedded clause. These datasets were used to
study speaker commitment towards the embedded
内容, evaluating theories of lexical semantics
(Kiparsky and Kiparsky, 1970; Karttunen, 1971A;
Beaver, 2010, 除其他外), and probing whether
neural model representations contain lexical se-
mantic information. In the datasets of the second
类别 (FactBank, MEANTIME, UW, and UDS-
IH2), events in both main clauses and embedded
条款 (如果有的话) are annotated. 例如, 前任-
ample for UDS-IH2 in Table 1 has annotations for
the main clause event announced and the embed-
ded clause event busted, while the example for RP
is annotated only for the embedded clause event
stay, but not for the main clause event managed.
Genres The datasets also differ in genre: Fact-
Bank, MEANTIME, and UW are newswire data.
Because newswire sentences tend to describe fac-
tual events, these datasets have annotations bi-
ased towards factual. UDS-IH2, an extension of
White et al. (2016), comes from the English Web
树库 (Bies et al., 2012) containing weblogs,
emails, and other web text. CB comes from three
流派: newswire (Wall Street Journal), fiction
(British National Corpus), and dialog (Switch-
board). RP contains short sentences sampled from
MultiNLI (Williams et al., 2018) 从 10 differ-
ent genres. MegaVeridicality contains artificially
constructed ‘‘semantically bleached’’ sentences
to remove confound of pragmatics and world-
知识, and to collect baseline judgments of
how much the verb by itself affects the factual-
ity of the content of its complement in certain
syntactic constructions.
Entailment-canceling Environments The three
datasets in the first category differ with respect
1082
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
to whether the clause-embedding verbs are un-
der some entailment-canceling environment, 这样的
as negation. Under the framework of implicative
signatures (Karttunen, 1971A; Nairn et al., 2006;
Karttunen, 2012), a clause-embedding verb (在一个
certain syntactic frame—details later) has a lexi-
cal semantics (a signature) indicating whether the
content of its complement is factual (+), nonfac-
tual (-), or neutral (哦, no indication of whether
the event is factual or not). A verb signature has
the form X/Y, where X is the factuality of the
content of the clausal complement when the sen-
tence has positive polarity (not embedded under
any entailment-canceling environment), and Y is
the factuality when the clause-embedding verb is
under negation. In the RP example in Table 1,
manage to has signature +/- 哪个, in the posi-
tive polarity sentence the man managed to stay on
his horse, predicts the embedded event stay to be
factual (such intuition is corroborated by the +3
human annotation). 反过来, in the negative
polarity sentence the man did not manage to stay
on his horse, 这 – signature signals that stay is
nonfactual (again corroborated by the −2.5 hu-
man annotation). For manage to, negation cancels
the factuality of its embedded event.
the complement
While such a framework assumes that differ-
ent entailment-canceling environments (否定,
modal, 问题, and antecedent of conditional)
have the same effects on the factuality of the
(Chierchia and
content of
McConnell-Ginet, 1990), there is evidence for
varying effects of environments. Karttunen (1971乙)
points out that, while the content of complement
of verbs such as realize and discover stays factual
under negation (compare (1) 和 (2)), 它不是
under a question (3) or in the antecedent of a
conditional (4).
(1)
(2)
(3)
(4)
I realized that I had not told the truth.+
I didn’t realize that I had not told the truth.+
Did you realize that you had not told the trutho?
If I realize later that I have not told the trutho,
I will confess it to everyone.
Smith and Hall (2014) provided experimental
evidence that the content of the complement of
know is perceived as more factual when know is
under negation than when it is in the antecedent
of a conditional.
In MegaVeridicality, each positive polarity sen-
tence is paired with a negative polarity sentence
where the clause-embedding verb is negated. 辛-
ilarly in RP, for each naturally occurring sentence
of positive polarity, a minimal pair negative po-
larity sentence was automatically generated. 这
verbs in CB appear in four entailment-canceling
环境: 否定, modal, 问题, 和-
tecedent of conditional.
Frames Among the datasets in the first category,
the clause-embedding verbs are under different
syntactic contexts/frames, which also affect the
factuality of their embedded events. 例如,
forget has signature +/+ in forget that S, 但 -/+
in forget to VP. 那是, in forget that S, 缺点-
tent of the clausal complement S is factual in both
someone forgot that S and someone didn’t forget
that S. In forget to VP, the content of the infinitival
complement VP is factual in someone didn’t forget
to VP, but not in someone forgot to VP.
CB contains only VERB that S frames. RP con-
tains both VERB that S and VERB to VP frames.
MegaVeridicality exhibits nine frames, 组成
of four argument structures and manipulations of
active/passive voice and eventive/stative embed-
ded VP: VERB that S, was VERBed that S, VERB
for NP to VP, VERB NP to VP-eventive, VERB NP
to VP-stative, NP was VERBed to VP-eventive, NP
was VERBed to VP-stative, VERB to VP-eventive,
VERB to VP-stative.
Annotation Scales The original FactBank and
MEANTIME annotations are categorical values.
We use Stanovsky et al.’s (2017) unified repre-
sentations for FactBank and MEANTIME, 哪个
contain labels in the [−3, 3] range derived from to
the original categorical values in a rule-based man-
ner. The original annotations of MegaVeridicality
contain three categorical values yes/maybe/no,
which we mapped to 3/0/−3, 分别. 我们
then take the mean of the annotations for each
item. The original annotations in RP are integers
在 [−2, 2]. We multiply each RP annotation by 1.5
to obtain labels in the same range as in the other
datasets. The mean of the converted annotations
is taken as the gold label for each item.
3 Linguistic Approaches to Factuality
Most work in NLP on event factuality has taken
a lexicalist approach, tracing back factuality to
1083
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
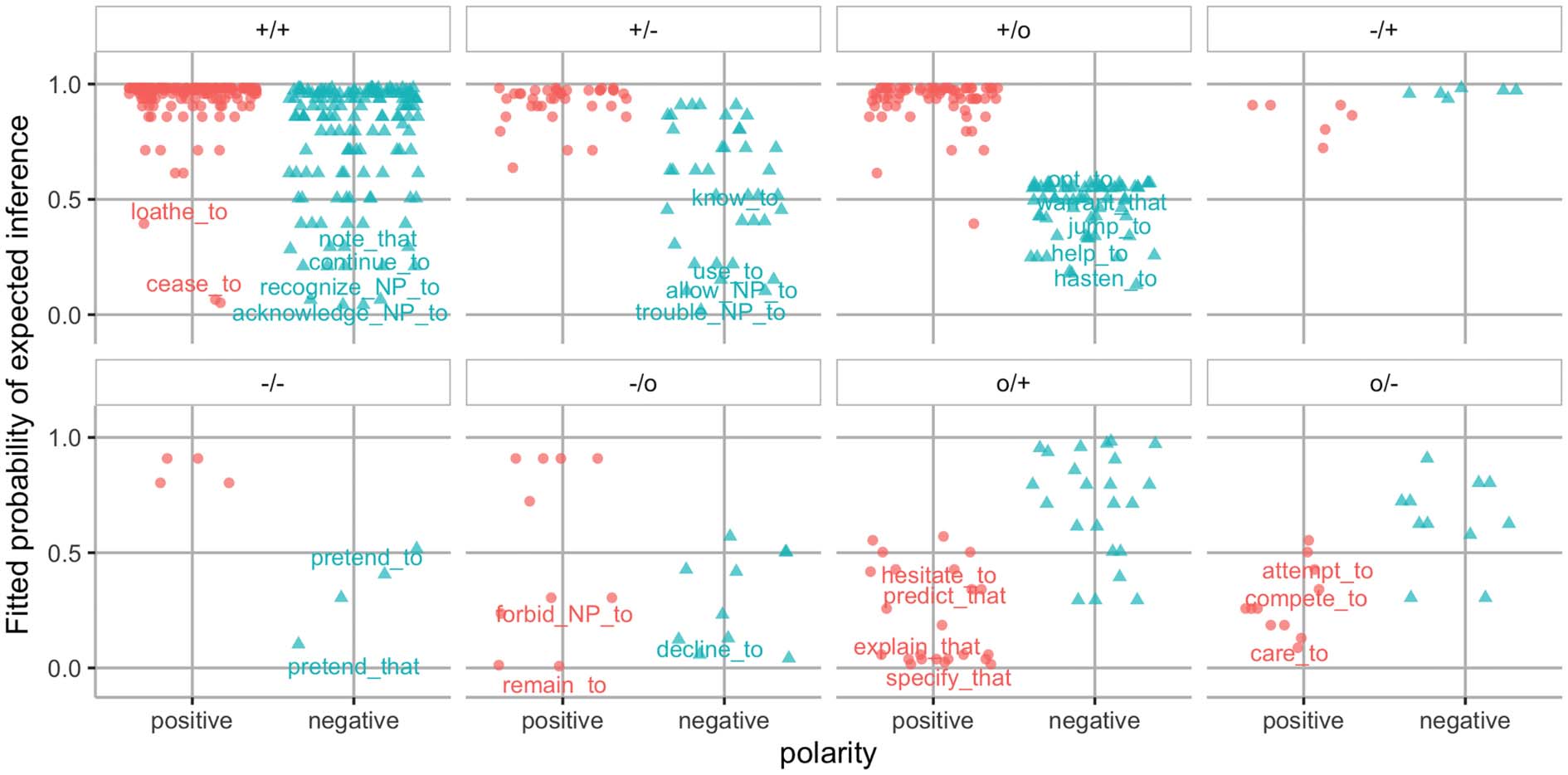
数字 1: Fitted probabilities of true expected inference category predicted by the label of each item given by the
ordered logistic regression model, organized by the signature and polarity. Some examples of verb-frame with
mean probability less than 0.5 are labeled.
fixed properties of lexical items. Under such an ap-
普罗奇, properties of the lexical patterns present in
the sentence determine the factuality of the event,
without taking into account contextual factors. 我们
will refer to the inference calculated from lexical
patterns only as expected inference. 例如,
在 (5), the expected inference for the event had
embedded under believe is neutral. 的确, 是-
cause both true and false things can be believed,
one should not infer from A believes that S that S is
true (换句话说, believe has as o/o signature),
making believe a so-called ‘‘non-factive’’ verb by
opposition to ‘‘factive’’ verbs (such as know or
意识到, which generally entail the truth of their
complements both in positive polarity sentences
(1) and in entailment-canceling environments (2),
Kiparsky and Kiparsky [1970]). 然而, 词汇的
theories neglect the pragmatic enrichment that is
pervasive in human communication and fall short
in predicting the correct inference in (5), 在哪里
people judged the content of the complement to
be true (as indicated by the annotation score of
2.38).
(5)
Annabel could hardly believe that she had2.38 a
daughter about to go to university.
In FactBank, Saur´ı and Pustejovsky (2009) took
a lexicalist approach, seeking to capture only the
effect of lexical meaning and knowledge local
to the annotated sentence: Annotators were lin-
uistically trained and instructed to avoid using
knowledge from the world or from the surround-
ing context of the sentence. 然而, it has been
shown that such annotations do not always align
with judgments from linguistically naive annota-
托尔斯. de Marneffe et al. (2012) and Lee et al. (2015)
re-annotated part of FactBank with crowdworkers
who were given minimal guidelines. They found
that events embedded under report verbs (例如,
说), annotated as neutral in FactBank (自从, 模拟-
ilarly to believe, one can report both true and false
事物), are often annotated as factual by crowd-
工人. Ross and Pavlick (2019) 表明
their annotations also exhibit such a veridicality
bias: Events are often perceived as factual/
nonfactual, even when the expected inference spe-
cified by the signature is neutral. The reason be-
hind this misalignment is commonly attributed to
pragmatics: Crowdworkers use various contex-
tual features to perform pragmatic reasoning that
overrides the expected inference defined by lexical
语义学. There has been theoretical linguistics
work arguing that factuality is indeed tied to the
discourse structure and not simply lexically con-
trolled (除其他外, Simons et al., 2010).
更远, our analysis of MegaVeridicality
shows that there is also some misalignment be-
tween the inference predicted by lexical semantics
and the human annotations, even in cases without
1084
not continue to signature: +/+, 预期的: +, observed: –
A particular person didn’t continue to do-0.33 a particular thing.
A particular person didn’t continue to have-1.5 a particular thing.
They did not continue to sit-3 in silence.
He did not continue to talk-3 about fish.
not pretend to signature: -/-, 预期的: -, observed: closer to o
Someone didn’t pretend to have-1.2 a particular thing.
He did not pretend to aim-0.5 at the girls.
{add/warn} that signature: o/+, 预期的: 哦, observed: +
Someone added that a particular thing happened2.1.
Linda Degutis added that interventions have2.5 to be monitored.
Someone warned that a particular thing happened2.1.
It warns that Mayor Giuliani ’s proposed pay freeze could destroy
the NYPD ’s new esprit de corps2.5.
不是 {decline/refuse} to signature: -/哦, 预期的: 哦, observed: +
A particular person didn’t decline to do1.5 a particular thing.
We do not decline to sanction2.5 such a result.
A particular person didn’t refuse to do2.1 a particular thing.
The commission did not refuse to interpret2.0 it.
桌子 2: Items with verbs that often behave dif-
ferently from the signatures. The semantically
bleached sentences are from MegaVeridicality,
the others from RP. Gold labels are superscripted.
pragmatic factors. Recall that MegaVeridicality
contains semantically bleached sentences where
the only semantically loaded word is the embed-
ding verb. We used ordered logistic regression to
predict the expected inference category (+, 哦, -)
specified by the embedding verb signatures de-
fined in Karttunen (2012) from the mean human
annotations.3 The coefficient for mean human an-
notations is 1.488 (和 0.097 standard error):
因此, 全面的, the expected inference aligns with
the annotations.4 However, there are cases where
they diverge. 数字 1 shows the fitted probability
of the true expected inference category for each
item, organized by the signatures and polarity.
If the expected inference was always aligning
with the human judgments, the fitted probabilities
would be close to 1 for all points. 然而, 许多
points have low fitted probabilities, 尤其
when the expected inference is o (例如, negative
polarity of +/o and -/o, positive polarity of
o/+ and o/-), showing that there is veridicality
bias in MegaVeridicality, similar to RP. 桌子 2
gives concrete examples from MegaVeridicality
and RP, for which the annotations often differ
from the verb signatures: Events under not refuse
to are systematically annotated as factual, 反而
3The analysis is done on items with verb-frame combina-
系统蒸发散 (and their passive counterparts) for which Karttunen
(2012) gives a signature (IE。, 618 items from Mega-
Veridicality).
4The threshold for -|o is −2.165 with SE 0.188. 这
threshold for o|+ 是 0.429 with SE 0.144.
of the expected neutral. The RP examples contain
minimal content information (but the mismatch in
these examples may involve pragmatic reasoning).
任何状况之下, given that neural networks are func-
tion approximators, we hypothesize that BERT
can learn these surface-level lexical patterns in the
training data. But items where pragmatic reason-
ing overrides the lexical patterns would probably
be challenging for the model.
4 Model and Experiment Setup
To analyze what BERT can learn, 我们使用
seven factuality datasets in Table 1.
Data Preprocessing The annotations of CB and
RP have been collected by asking annotators to
rate the factuality of the content of the comple-
蒙特, which may contain other polarity and mo-
dality operators, whereas in FactBank annotators
rated the factuality of the normalized complement,
without polarity and modality operators. 对于前-
充足, the complement anything should be done in
the short term contains the modal operator should,
while the normalized complement would be any-
thing is done in the short term. In MEANTIME,
UW, and UDS-IH2, annotators rated the factuality
of the event represented by a word in the original
句子, which has the effect of removing such
operators. 所以, to ensure a uniform interpre-
tation of annotations between datasets, we semi-
automatically identified items in CB and RP where
the complement is not normalized,5 for which we
take the whole embedded clause to be the span for
factuality prediction. 否则, we take the root
of the embedded clause as the span.
We also excluded 236 items in RP where the
event for which annotations were gathered cannot
be represented by a single span from the sentence.
例如, for The Post Office is forbidden from
ever attempting to close any office, annotators
were asked to rate the factuality of the Post Office
is forbidden from ever closing any office. Simply
taking the span close any office corresponds to the
event of the Post Office close any office, but not to
the event for which annotations are collected.
5We automatically identified whether the complement
contains a neg dependency relation, modal operators (应该,
可以, 能, must, 也许, 可能, 或许, 可能, shall, have to,
会), or adverbs, and manually verified the output.
1085
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
MegaVeridicality
CommitmentBank
RP
FactBank
MEANTIME
UW
UDS-IH2
火车
dev
测试
2,200
250
1,100
6,636
1,012
9,422
22,108
626
56
308
2,462
195
3,358
2,642
2,200
250
1,100
663
188
864
2,539
桌子 3: Number of events in each dataset split.
Excluding Data with Low Agreement Annota-
tion There are items in RP and CB that exhibit
bimodal annotations. 例如, the sentence in
RP White ethnics have ceased to be the dominant
force in urban life received 3 annotation scores:
−3/nonfactual, 1.5/between neutral and factual,
and 3/factual. By taking the mean of such bimodal
注释, we end up with a label of 0.5/neutral,
which is not representative of the judgments in
the individual annotations. For RP (where each
item received three annotations), we excluded 250
items where at least two annotations have different
迹象. For CB (where each item received at least
8 注释), we follow Jiang and de Marneffe
(2019A) by binning the responses into [−3, −1],
[0], [1, 3] and discarding items if less than 80% 的
the annotations fall in the same bin.
Data Splits We used the standard train/dev/test
split for FactBank, MEANTIME, UW, and UDS-
IH2. As indicated above, we only use the high
agreement subset of CB with 556 项目, with splits
from Jiang and de Marneffe (2019乙). We ran-
domly split MegaVeridicality and RP with stra-
tified sampling to keep the distributions of the
clause-embedding verbs similar in each split. Ta-
布莱 3 gives the number of items in each split.
Model Architecture The task is to predict a
scalar value in [−3, 3] for each event described by
a span in the input sentence. A sentence is fed into
BERT and the final-layer representations for the
event span are extracted. Because the spans have
variable lengths, the SelfAttentiveSpanExtractor
(Gardner et al., 2018) is used to weightedly com-
bine the representations of multiple tokens and
create a single vector for the original event span.
The extracted span vectors are fed into a two-layer
feed-forward network with tanh activation func-
tion to predict a single scalar value. Our architec-
ture is similar to Rudinger et al.’s (2018) 线性-
biLSTM model, except that the input is encoded
with BERT instead of bidirectional LSTM, and a
span extractor is used. The model is trained with
the smooth L1 loss.6
Evaluation Metrics Following previous work,
we report mean absolute error (MAE), measur-
ing absolute fit, and Pearson’s r correlation, 事物-
suring how well models capture variability in the
数据. r is considered more informative since some
datasets (MEANTIME in particular) are biased
towards +3.
Model Training For all experiments, we fine-
tuned BERT using the bert large cased
模型. Each model is fine-tuned with at most 20
纪元, with a learning rate of 1e − 5. Early stop-
ping is used: Training stops if the difference be-
tween Pearson’s r and MAE does not increase for
多于 5 纪元. Most training runs last more
比 10 纪元. The checkpoint with the highest
difference between Pearson’s r and MAE on the
dev set is used for testing. We explored several
training data combinations:
-Single: Train with each dataset individually;
-Shared: Treat all datasets as one;
-多: Datasets share the same BERT pa-
rameters while each has its own classifier
参数.
The Single and Shared setups may be combined
with first fine-tuning BERT on MultiNLI, denoted
by the superscript M . We tested on the test set of
the respective datasets.
We also tested whether BERT improves on pre-
vious models on its ability to generalize to embed-
ded events. The models in Rudinger et al. (2018)
were trained on FactBank, MEANTIME, UW, 和
UDS-IH2 with shared encoder parameters and sep-
arate classifier parameters, and an ensemble of the
four classifiers. To make a fair comparison, 我们
followed Rudinger et al.’s setup by training BERT
on FactBank, MEANTIME, UW, and UDS-IH2
6The code and data are available at https://github
.com/njjiang/factuality_bert. The code is based
on the toolkit jiant v1 (王等人。, 2019).
1086
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
右
Shared SharedM Single SingleM Multi
0.89†
0.831
0.865
0.87†
0.867
0.806
0.876†
0.857
0.857
0.914†
0.903
0.836
0.491
0.503
0.557
0.868†
0.865
0.776
0.855†
0.853
0.845
0.869
0.813
0.873
0.845
0.572†
0.787
0.843
0.878
0.867
0.863
0.901
0.513
0.868
0.854
CB
RP
MegaVeridicality
FactBank
MEANTIME
UW
UDS-IH2
Previous MAE
SotA
0.903
0.702
0.83
0.909
Shared SharedM Single SingleM Multi
0.617†
0.777
0.713
0.608†
0.621
0.733
0.533
0.531
0.508
0.228†
0.236
0.42
0.319†
0.355
0.333
0.349†
0.351
0.532
0.76†
0.766
0.794
0.722
0.714
0.501†
0.417
0.338
0.523
0.804
0.648
0.619
0.523
0.241
0.345
0.351
0.763
以前的
SotA
0.31
0.204
0.42
0.726
桌子 4: Performance on the test sets under different BERT training setups. The best score obtained by
our models for each dataset under each metric is marked by †. The overall best scores are highlighted.
Each score is the average from three runs with different random initialization. The previous state-
of-the-art results are given when available. All come from Pouran Ben Veyseh et al. (2019), except the
MAE score on UW, which comes from Stanovsky et al. (2017).
with one single set of parameters7 and tested on
MegaVeridicality and CommitmentBank.8
5 结果
桌子 4 shows performance on the various test sets
with the different training schemes. These models
perform well and obtain the new state-of-the-art
results on FactBank and UW, and comparable
performance to the previous models on the other
datasets (except for MEANTIME9). Comparing
Shared vs. SharedM and Single vs. SingleM , 我们
see that transferring with MNLI helps all datasets
on at least one metric, except for UDS-IH2 where
MNLI-transfer hurts performance. The Multi and
Single models obtain the best performance on
almost all datasets other than MegaVeridicality
and MEANTIME. The success of these models
confirms the findings of Rudinger et al. (2018) 那
having dataset-specific parameters is necessary for
optimal performance. Although this is expected,
since each dataset has its own specific features,
the resulting model captures data-specific quirks
rather than generalizations about event factuality.
This is problematic if one wants to deploy the
system in downstream applications, since which
dataset the input sentence will be more similar to
is unknown a priori.
7Unlike the Hybrid model of Rudinger et al. (2018), 那里
is no separate classifier parameters for each dataset.
8For both datasets, examples from all splits are used,
following previous work.
9The difference in performance for MEANTIME might
come from a difference in splitting: Pouran Ben Veyseh
et al.’s (2019) test set has a different size. Some of the gold
labels in MEANTIME also seem wrong.
MegaVeridicality CB
MAE
r
r MAE
BERT
Stanovsky et al.
Rudinger et al.
0.60
–
0.64
1.09
–
–
0.59 1.40
0.50 2.04
0.33 1.87
桌子 5: Performance on MegaVeridicality and
CommitmentBank across all splits of the previous
模型 (Stanovsky et al. 2017 and Rudinger et al.
2018) and BERT trained on the concatenation of
FactBank, MEANTIME, UW, UDS-IH2 using
one set of parameters. White et al. (2018) 没有
report MAE results for MegaVeridicality.
然而, looking at whether BERT improves
on the previous state-of-the-art results for its abil-
ity to generalize to the linguistic constructions
without in-domain supervision, the results are less
promising. 桌子 5 shows performance of BERT
trained on four factuality datasets and tested on
MegaVeridicality and CB across all splits, 和
Rule-based and Hybrid models’ performance re-
ported in Jiang and de Marneffe (2019A) 和
White et al. (2018). BERT improves on the other
systems by only a small margin for CB, and ob-
tains no improvement for MegaVeridicality. 的-
spite having a magnitude more parameters and
pretraining, BERT does not generalize to the em-
bedded events present in MegaVeridicality and
CB. This shows that we are not achieving robust
自然语言理解, unlike what the
near-human performance on various NLU bench-
marks suggests.
最后, although RoBERTa (刘等人。, 2019)
has exhibited improvements over BERT on many
different tasks, 我们发现, 在这种情况下, 使用
1087
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
pretrained RoBERTa instead of BERT does not
yield much improvement. The predictions of the
two models are highly correlated, 和 0.95 科尔-
relation over all datasets’ predictions.
6 Quantitative Analysis: Expected
推理
这里, we evaluate our hypothesis that BERT can
learn subtle lexical patterns, regardless of whether
they align with lexical semantics theories, 但
struggles when pragmatic reasoning overrides the
lexical patterns. 这样做, we present results from a
quantitative analysis using the notion of expected
inference. To facilitate meaningful analysis, 我们
generated two random train/dev/test splits of the
same sizes as in Table 3 (besides the standard split)
for MegaVeridicality, CB, and RP. All items are
present at least once in the test sets. We trained
the Multi model using three different random
initializations with each split.10 We use the mean
predictions of each item across all initializations
and all splits (unless stated otherwise).
6.1 方法
如上所述, the expected inference of an
item is the factuality label predicted by lexical
patterns only. We hypothesize that BERT does
well on items where the gold labels match the
expected inference, and fails on those that do not.
How to Get the Best Expected Inference? 到
identify the expected inference, the approach var-
ies by dataset. For the datasets focusing on em-
bedded events (MegaVeridicality, CB, and RP),
we take, as expected inference label, 平均值
labels of training items with the same combina-
tion of features as the test item. Theoretically, 这
signatures should capture the expected inference.
然而, as shown earlier, the signatures do not
always align with the observed annotations, 和
not all verbs have signatures defined. The mean
labels of training items with the same features
captures what the common patterns in the data are
and what the model is exposed to. In MegaVeridi-
cality and RP, the features are clause-embedding
10There is no model performing radically better than the
其他的. The Multi model achieves better results than the
Single one on CB and is getting comparable performance to
the Single model on the other datasets.
数据集
FactBank
MEANTIME
UW
MegaVeridicality
CB
RP
A
−0.039
−0.058
0.004
0.134
0.099
0.059
SE(A)
β
SE(β)
0.018
0.033
0.016
0.008
0.020
0.011
0.073
0.181
0.261
0.142
0.265
0.468
0.015
0.024
0.016
0.006
0.016
0.012
桌子 6: Estimated random intercepts (A) 和
slopes (β) for each dataset and their standard
错误. The fixed intercept is 0.228 with standard
错误 0.033.
动词, polarity, and frames. In CB, they are verb
and entailment-canceling environment.11
For FactBank, UW, and MEANTIME, the ap-
proach above does not apply because these data-
sets contain matrix-clause and embedded events.
We take the predictions from Stanovsky et al.’s
Rule-based model12 as the expected inference,
since the Rule-based model uses lexical rules in-
cluding the signatures. We omitted UDS-IH2 from
this analysis because there are no existing pre-
dictions by the Rule-based model on UDS-IH2
可用的.
6.2 结果
We fitted a linear mixed effect model using the
absolute error between the expected inference and
the label to predict the absolute error of the model
预测, with random intercepts and slopes for
each dataset. Results are shown in Table 6. 我们
see that the slopes are all positive, suggesting that
the error of the expected inference to the label is
positively correlated with the error of the model,
as we hypothesized.
The slope for FactBank is much smaller than
the slopes for the other datasets, meaning that for
FactBank, the error of the expected inference does
not predict the model’s errors as much as in the
other datasets. This is due to the fact that the errors
in FactBank consist of items for which the lexical-
ist and crowdsourced annotations may differ. 这
模型, which has been trained on crowdsourced
11 The goal is to take items with the most matching features.
If there are no training items with the exact same combination
of features, we take items with the next best match, going
down the list if the previous features are not available:
– MegaVeridicality and RP: verb-polarity, 动词, polarity.
– CB: 动词, 环境.
12https://github.com/gabrielStanovsky/unified
-factuality/tree/master/data/predictions on test.
1088
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 2: Multi model’s predictions compared to gold labels for all CB items present
entailment-canceling environment. Diagonal line shows perfect prediction.
in all splits, 经过
datasets, makes predictions that are more in line
with the crowdsourced annotations but are errors
compared to the lexicalist labels. 例如,
44% of the errors are reported events (例如, X said
那 . . . ) annotated as neutral in FactBank (给定
that both true or false things can be reported) 但
predicted as factual. Such reported events have
been found to be annotated as factual by crowd-
工人 (de Marneffe et al., 2012; 李等人。,
2015). 另一方面, the expected inference
(from the Rule-based model) also follows a lex-
icalist approach. Therefore labels align well with
the expected inference, but the predictions do so
poorly.
7 Qualitative Analysis
The quantitative analysis shows that the model
predictions are driven by surface-level features.
不出所料, when a gold label of an item di-
verges from the label of items with similar surface
图案, the model does not do well. 这里, 我们
unpack which surface features are associated with
labels, and examine the edge cases in which sur-
face features diverge from the observed labels. 我们
focus on the CB, RP, and MegaVeridicality data-
sets because they focus on embedded events well
studied in the literature.
7.1 CB
数字 2 shows the scatterplot of the Multi model’s
prediction vs. gold labels on CB, divided by each
entailment-canceling environment. As pointed out
by Jiang and de Marneffe (2019乙), the interplay
between the entailment-canceling environment
and the clause-embedding verb is often the de-
ciding factor for the factuality of the complement
in CB. Items with factive embedding verbs tend
indeed to be judged as factual (most blue points
图中 2 are at the top of the panels). ‘‘Neg-
raising’’ items contain negation in the matrix
条款 (不是 {think/believe/know} φ) but are inter-
preted as negating the content of the complement
条款 ({think/believe/know} not φ). Almost all
items involving a construction indicative of ‘‘Neg-
raising’’ I don’t think/believe/know φ have non-
factual labels (see × in first panel of Figure 2).
Items in modal environment are judged as factual
(second panel where most points are at the top).
In addition to the environment and the verb,
there are more fine-grained surface patterns pre-
dictive of human annotations. Polar question items
with nonfactive verbs often have near-0 factual-
ity labels (third panel, orange circles clustered
in the middle). In tag-question items, the label
of the embedded event often matches the matrix
clause polarity, 例如 (6) with a matrix clause of
positive polarity and a factual embedded event.
(6)
[. . . ] I think it went1.09 [1.52]
didn’t it?
to Lockheed,
规律性,
Following these statistical
这
model obtains good results by correctly predicting
the majority cases. 然而, it is less successful
on cases where the surface features do not lead
to the usual label, and pragmatic reasoning is re-
询问. The model predicts most of the neg-raising
items correctly, which make up 58% 数据的
under negation. But the neg-raising pattern leads
the model to predict negative values even when
the labels are positive, 如 (7).13
13We use the notation event spanlabel [prediction] throughout
the rest of the paper.
1089
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3: Multi model’s predictions compared to gold labels for certain verbs and frames in RP. Diagonal line
shows perfect prediction.
(7)
[. . . ] And I think society for such a long time
说, 出色地, 你知道, you’re married, now you
need to have your family and I don’t think
it’s been1.25 [-1.99] until recently that they had
decided that two people was a family.
It also wrongly predicts negative values for
items where the context contains a neg-raising-like
substring (don’t think/believe), even when the
targeted event is embedded under another environ-
蒙特: question for (8), antecedent of conditional
为了 (9).
(8)
(9)
乙: All right, 出色地. A: Um, 短期, I don’t
think anything’s going to be done about it or
probably should be done about it. 乙: 正确的.
Uh, are you saying you (西德:2)(西德:2)(西德:2)(西德:2)(西德:2)
think anything
should be done in the short term0 [-1.73]?
don’t (西德:2)(西德:2)(西德:2)(西德:2)(西德:2)
[. . . ] 我 (西德:2)(西德:2)做(西德:2)(西德:2)(西德:2)不是(西德:2)(西德:2)(西德:2)(西德:2)(西德:2)(西德:2)
believe I am being unduly boast-
ful if I say that very few ever needed2.3 [-1.94]
amendment.
7.2 RP
The surface features impacting the annotations in
RP are the clause-embedding verb, its syntactic
frame, and polarity. 数字 3 shows the scatterplot
of label vs. prediction for items with certain verbs
and frames, for which we will show concrete ex-
amples later. The errors (circled points) in each
panel are often far away from the other points of
the same polarity on the y-axis, confirming the
findings above that the model fails on items that
diverge from items with similar surface patterns.
一般来说, points are more widespread along the
y-axis than the x-axis, meaning that the model
makes similar predictions for items which share
the same features, but it cannot account for vari-
ability among such items. 的确, the mean var-
iance of the predictions for items of each verb,
frame, and polarity is 0.19, while the mean var-
iance of the gold labels for these items is 0.64.
Compare (10) 和 (11): They consist of the
same verb convince with positive polarity and
they have similar predictions, but very different
gold labels. Most of the convince items of positive
polarity are between neutral and factual (之间 0
和 1.5), 例如 (10). The model learned that from
the training data: All convince items of positive
polarity have similar predictions ranging from 0.7
到 1.9, 与平均值 1.05 (also shown in the first panel
of Figure 3). 然而, (11) has a negative label
of −2 unlike the other convince items, 因为
the following context I was mistaken clearly states
that the speaker’s belief is false, and therefore the
event they would fetch up at the house in Soho is
not factual. Yet the model fails to take this into
帐户.
(10)
(11)
I was convinced that the alarm was given
when Mrs. Cavendish was in the room1.5 [1.13].
I was convinced that they would fetch up at
the house in Soho-2 [0.98], but it appears I was
mistaken.
7.3 MegaVeridicality
As shown in the expected inference analysis,
MegaVeridicality exhibits the same error pattern
as CB and RP (failing on items where gold labels
differ from the ones of items sharing similar sur-
face features). Unlike CB and RP, MegaVeridical-
ity is designed to rule out the effect of pragmatic
推理. Thus the errors for MegaVeridicality
cannotbe due to pragmatics. Where are those stem-
ming from? It is known that some verbs behave
very differently in different frames. 然而, 这
model was not exposed to the same combination
of verb and frame during training and testing,
which leads to errors. 例如, mislead14 in
the VERBed NP to VP frame in positive polarity,
14Other verbs with the same behavior and similar meaning
include dupe, deceive, fool.
1090
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
如 (12), and its passive counterpart (13), 苏格-
gests that the embedded event is factual (someone
did something), while in other frame/polarity, 这
event is nonfactual, 如 (14) 和 (15). The model,
following the patterns of mislead in other contexts,
fails on (12) 和 (13) because the training set did
not contain instances with mislead in a factual
语境.
Prior Probability of the Event Whether the
event described is likely to be true is known to
influence human judgments of event factuality
(Tonhauser et al., 2018; de Marneffe et al., 2019).
Events that are more likely to be factual a priori
are often considered as factual even when they are
embedded, 如 (16). 反过来, events that are
unlikely a priori are rated as nonfactual when
embedded, 如 (17).
(12)
(13)
(14)
(15)
Someone misled a particular person to
do2.7 [-1.6] a particular thing.
A particular person was misled to do2.7 [-1.21]
a particular thing.
(16)
Someone was misled that a particular thing
happened-1.5 [-2.87].
Someone wasn’t misled to do-0.3 [-0.6] A
particular thing.
(17)
This shows that the model’s ability to reason is
still limited to pattern matching: It fails to induce
how verb meaning interacts with syntactic frames
that are unseen during training. If we augment
MegaVeridicality with more items of verbs in
these contexts (currently there is one example of
each verb under either polarity in most frames)
and add them to the training set, BERT would
probably learn these behaviors.
而且, the model here exhibits a different
pattern from White et al. (2018), who found that
their model cannot capture inferences whose po-
larity mismatches the matrix clause polarity, 作为
their model fails on items with verbs that suggest
nonfactuality of their complement such as fake,
misinform under positive polarity. As shown in
the expected inference analysis in Section 6, 我们的
model is successful at these items, since it has
memorized the lexical pattern in the training data.
7.4 Error Categorization
在这个部分, we study the kinds of reasoning that
is needed to draw the correct inference in items
that the system does not handle correctly. 为了
顶部 10% of the items sorted by absolute error in
CB and RP, two linguistically trained annotators
annotated which factors lead to the observed fac-
tuality inferences, according to factors put forth
in the literature, as described below.15
15This is not an exhaustive list of reasoning types present
in the data, and having one of these properties is not sufficient
for the model to fail.
1091
[. . . ] He took the scuffed leather document
case off the seat beside him and banged the
door shut with the violence of someone who
had not learned that car doors do not need
the same sort of treatment as those of railway
carriages2.63 [0.96]
In a column lampooning Pat Buchanan, Royko
did not write that Mexico was-3 [-0.3] a useless
country that should be invaded and turned
over to Club Med.
Context Suggests (Non)Factuality The context
may directly describe or give indirect cues about
the factuality of the content of the complement. 在
(18), the preceding context they’re French clearly
indicates that the content of the complement is
错误的. The model predicts −0.28 (the mean label
for training items with wish under positive polarity
is −0.5), suggesting that the model fails to take
the preceding context into account.
(18)
but wish
They’re
were-2.5 [-0.28] mostly Caribbean.
法语,
那
他们
The effect of context can be less explicit, 但
nonetheless there. 在 (19), the context which it’s
mainly just when it gets real, real hot elaborates
on the time of the warnings, carrying the presup-
position that the content of the complement they
have warnings here is true. 在 (20), the preced-
ing context Although Tarzan is now nominally
in control, with the marker although and nom-
inally suggesting that Tarzan is not actually in
收费, makes the complement Kala the Ape-
Mom is really in charge more likely.
(19)
[…] 乙: 哦, gosh, I think I would hate to live
in California, the smog there. A: Uh-huh. 乙:
I mean, I can’t believe they have2.33 [0.327]
warnings here, which it’s mainly just when it
gets real, real hot.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(20)
Although Tarzan is now nominally in control,
one does not suspect that Kala the Ape-Mom,
the Empress Dowager of the Jungle, is2.5 [-0.23]
really in charge.
Discourse Function When sentences are uttered
in a discourse, there is a discourse goal or a ques-
tion under discussion (QUD) that the sentence is
trying to address (罗伯茨, 2012). 根据
Tonhauser et al. (2018), the contents of embedded
complements that do not address the question
under discussion are considered as more factual
than those that do address the QUD. Even for items
that are sentences in isolation, as in RP, 读者
interpreting these sentences probably reconstruct a
discourse and the implicit QUD that the sentences
are trying to address. 例如, (21) 包含
the factive verb see, but its complement is labeled
as nonfactual (−2).
(21)
Jon did not see that they were-2 [1.45] 难的
pressed.
Such a label is compatible with a QUD asking
what is the evidence that Jon has to whether
they were hard pressed. The complement does not
answer that QUD, but the sentence affirms that
Jon lacks visual evidence to conclude that they
were hard pressed. 在 (22), the embedded event is
annotated as factual although it is embedded under
a report verb (tell). 然而, the sentence in (22)
can be understood as providing a partial answer to
the QUD What was the vice president told?. 这
content of the complement does not address the
QUD, and is therefore perceived as factual.
(22)
The Vice President was not told that the Air
Force was trying2 [-0.15] to protect the Secretary
of State through a combat air patrol over
华盛顿.
Tense/Aspect The tense/aspect of the clause-
embedding verb and/or the complement affects
the factuality of the content of the complement
(Karttunen, 1971乙; de Marneffe et al., 2019).
在 (23), the past perfect had meant implies that
the complement did not happen (−2.5), 然而
在 (24) in the present tense, the complement is
interpreted as neutral (0.5).
(23)
(24)
She had meant to warn-2.5 [-0.24] 先生. 棕色的
about Tuppence.
A bigger contribution means to support0.5 [1.45]
candidate Y.
Subject Authority/Credibility The authority of
the subject of the clause-embedding verb also
affects factuality judgments (Schlenker 2010,
de Marneffe et al., 2012, 除其他外). 这
subjects of (25), a legal document, 和 (26), 这
tenets of a religion, have the authority to require
or demand. Therefore what the legal document re-
quires is perceived as factual, and what the tenets
do not demand is perceived as nonfactual.
(25)
(26)
部分 605(乙) 需要
Counsel gets2.5 [0.53] the statement.
那
the Chief
The tenets of Jainism do not demand that
everyone must be wearing shoes when they
come into a holy place-2 [-0.28].
另一方面, the perceived lack of author-
ity of the subject may suggest that the embedded
event is not factual. 在 (27), although remember
is a factive verb, the embedded event only re-
ceives a mean annotation of 1, probably because
the subject a witness introduces a specific situ-
ational context questioning whether to consider
someone’s memories as facts.
(27)
A witness remembered that there were1 [2.74]
four simultaneous decision making processes
going on at once.
Subject-Complement Interaction for Prospec-
tive Events Some clause-embedding verbs,
such as decide and choose, introduce so-called
‘‘prospective events’’, which could take place in
未来 (Saur´ı, 2008). The likelihood that these
events will actually take place depends on sev-
eral factors: the content of the complement itself,
the embedding verb, and the subject of the verb.
When the subject of the clause-embedding verb
is the same as the subject of the complement, 这
prospective events are often judged as factual, 作为
在 (28). 在 (29), the subjects of the main verb
and the complement verb are different, 和
complement is judged as neutral.
(28)
(29)
He decided that he must
unturned2.5 [0.43].
leave no stone
Poirot decided that Miss Howard must be kept
in the dark0.5 [1.49].
Even when subjects are the same, the nature of
the prospective event itself also affects whether
it is perceived as factual. Compare (30) 和 (31)
1092
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
both featuring the construction do not choose to:
(30) is judged as nonfactual whereas (31) is neu-
tral. This could be due to the difference in the
extent to which the subject entity has the ability to
fulfill the chosen course of action denoted by the
embedded predicate. 在 (30), Hillary Clinton can
be perceived to be able to decide where to stay,
and therefore when she does not choose to stay
somewhere, one infers that she indeed does not
stay there. 另一方面, the subject in (31)
is not able to fulfill the chosen course of action
(where to be buried), since he is presumably dead.
(30)
不是
Hillary Clinton
stay-2.5 [-0.92] at Trump Tower.
做
选择
到
(31)
He did not choose to be buried0.5 [-0.75] 那里.
Lexical Inference An error item is categorized
under ‘‘lexical inference’’ if the gold label is inline
with the signature of its embedding verb. 这样的
errors happen on items of a given verb for which
the training data do not exhibit a clear pattern
because the training items contains items where
the verb follows its signature as well as items
where pragmatic factors override the signature
解释. 例如, (32) gets a factual
解释, consistent with the factive signature
of see.
(32)
He did not see that Manning had glanced2 [0.47]
at him.
然而, the training instances with see under
negation have labels ranging from −2 to 2 (看
the orange ×’s in the fourth panel of Figure 3).
Some items indeed get a negative label because of
the presence of pragmatic factors, 比如在 (21),
but the system is unable to identify these factors.
It thus fails to learn to tease apart the factual and
nonfactual items, predicting a neutral label that
is roughly the mean of the labels of the training
items with see under negation.
Annotation Error As in all datasets, 它似乎
that some human labels are wrong and the model
actually predicts the right label. 例如, (33)
should have a more positive label (而不是 0.5),
as realize is taken to be factive and nothing in the
context indicates a nonfactual interpretation.
Prior probability of the event
Context suggests (非)factuality
Question Under Discussion (QUD)
Tense/aspect
Subject authority/credibility
Subject-complement interaction
Lexical inference
Annotation error
Total items categorized
CB
# %
5
9.1
34 61.8
1
1
1.8
1.8
12 21.8
2
3.6
55
RP
# %
32 12.8
29 11.6
8.0
20
3.2
8
14
5.6
26 10.4
88 35.2
33 13.2
250
桌子 7: Numbers (#) and percentages (%) 的
error items categorized for CB and RP.
总共, 55 项目 (with absolute errors ranging
从 1.10 到 4.35, and a mean of 1.95) were anno-
tated in CB out of 556 项目, 和 250 in RP (和
absolute errors ranging from 1.23 到 4.36, and a
mean of 1.70) 在......之外 2,508 项目. 桌子 7 gives
the numbers and percentages of errors in each cat-
egory. The two datasets show different patterns
that reflect their own characteristics. CB has rich
preceding contexts, and therefore more items ex-
hibit inferences that can be traced to the effect of
语境. RP has more item categorized under lex-
ical inference, because there is not much context
to override the default lexical inference. RP also
has more items under annotation errors, due to the
limited amount of annotations collected for each
item (3 annotations per item).
Although we only systematically annotated CB
and RP (given that these datasets focus on em-
bedded events), the errors in the other datasets fo-
cusing on main-clause events also exhibit similar
inferences as the ones we categorized above, 这样的
as effects of context and lexical inference (更多的
广义解释).16 Most of the errors concern
nominal events. In the following examples—(34)
和 (35) from UW, 和 (36) from MEANTIME—
model failed to take into account the surrounding
context which suggests that the events are non-
factual. 在 (34), the lexical meaning of dropped
clearly indicates that the plan is nonfactual. 在 (35),
the death was faked, 并在 (36) production was
brought to an end, indicating that the death did
not happen and there is no production anymore.
(34)
在 2011, the AAR consortium attempted to
block a drilling joint venture in the Arctic
(33)
I did not realize that John had fought0.5 [2.31]
with his mother prior to killing her.
16Some of the error categories only apply to embedded
事件, including the effect of QUD and subject authority.
1093
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(35)
(36)
between BP and Rosneft through the courts
and the plan-2.8 [1.84] was eventually dropped.
The day before Raymond Roth was pulled
超过, his wife, Evana, showed authorities
e-mails she had discovered that appeared to
detail a plan between him and his son to fake
his death-2.8 [1.35]
Boeing Commercial Airplanes on Tuesday
delivered the final 717 jet built to AirTran
Airways in ceremonies in Long Beach,
加利福尼亚州, bringing production-3 [3.02]
的
McDonnell Douglas jets to an end.
在 (37), from FactBank, just what NATO will
do carries the implication that NATO will do
something, and the do event is therefore annotated
as factual.
(37)
Just what NATO will do3 [-0.05] with these
eager applicants is not clear.
例子 (38) from UDS-IH2 features a specific
meaning of the embedding verb say: Here say
makes an assumption instead of the usual speech
报告, and therefore suggests that the embedded
event is not factual.
(38)
Say after I finished-2.25 [2.38] 那些 2 years and
I found a job.
Inter-annotator Agreement for Categorization
Both annotators annotated all 55 items in CB. 为了
RP, one of the annotators annotated 190 examples,
and the other annotated 100 examples, 和 40
annotated by both. Among the set of items that
were annotated by both annotators, annotators
agreed on the error categorization 90% 当时的
for the CB items and 80% of the time for the RP
项目. This is comparable to the agreement level
in Williams et al. (2020), in which inferences
types for the ANLI dataset (Nie et al., 2020) 是
annotated.
8 结论
在本文中, we showed that, although fine-tuning
BERT gives strong performance on several fac-
tuality datasets, it only captures statistical regu-
larities in the data and fails to take into account
pragmatic factors that play a role on event fac-
tuality. This aligns with Chaves’s (2020) 发现
for acceptability of filler-gap dependencies: 新-
ral models give the impression that they capture
island constraints well when such phenomena can
be predicted by surface statistical regularities, 但
the models do not actually capture the underlying
mechanism involving various semantic and prag-
matic factors. Recent work has found that BERT
models have some capacity to perform pragmatic
inferences: Schuster et al. (2020) for scalar impli-
catures in naturally occurring data, Jeretiˇc et al.
(2020) for scalar implicatures and presuppositions
triggered by certain lexical items in constructed
数据. 这是, 然而, possible that the good perfor-
mance on those data is solely driven by surface
features as well. BERT models still only have
limited capabilities to account for the wide range
of pragmatic inferences in human language.
Acknowledgment
We thank TACL editor-in-chief Brian Roark and
action editor Benjamin Van Durme for the time
they committed to the review process, 也
the anonymous reviewers for their insightful feed-
后退. We also thank Micha Elsner, Cory Shain,
Michael White, and members of the OSU Clip-
pers discussion group for their suggestions and
comments. This material is based upon work sup-
ported by the National Science Foundation under
授予号. IIS-1845122.
参考
David Beaver. 2010. Have you noticed that
your belly button lint colour is related to the
colour of your clothing? In Rainer B¨auerle,
Uwe Reyle, and Thomas Ede Zimmermann,
编辑, Presuppositions and Discourse: 随笔
Offered to Hans Kamp, pages 65–99. Leiden,
荷兰人: Brill. https://doi.org/10
.1163/9789004253162 004
Ann Bies, Justin Mott, Colin Warner, and Seth
Kulick. 2012. English Web Treebank. Linguis-
tic Data Consortium, 费城, PA.
Rui P. Chaves. 2020. What don’t RNN language
models learn about filler-gap dependencies?
Proceedings of the Society for Computation in
语言学, 3(1):20–30.
1094
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Gennaro Chierchia and Sally McConnell-Ginet.
1990. Meaning and Grammar. 与新闻界.
tational Linguistics. https://doi.org/10
.18653/v1/D19-1630
Marie-Catherine de Marneffe, Christopher D.
曼宁, and Christopher Potts. 2012. Did it
发生? The pragmatic complexity of veridi-
cality assessment. 计算语言学,
38(2):301–333. https://doi.org/10.1162
/大肠杆菌a 00097
Marie-Catherine de Marneffe, Mandy Simons,
and Judith Tonhauser. 2019. The Commit-
mentBank: Investigating projection in naturally
occurring discourse. In Sinn und Bedeutung 23.
Matt Gardner, Joel Grus, Mark Neumann, Oyvind
Tafjord, Pradeep Dasigi, Nelson F. 刘,
Matthew Peters, Michael Schmitz, and Luke
Zettlemoyer. 2018. AllenNLP: A deep semantic
natural language processing platform. In Pro-
ceedings of Workshop for NLP Open Source
软件 (NLP-OSS), pages 1–6, 墨尔本,
澳大利亚. Association for Computational Lin-
语言学. https://doi.org/10.18653/v1
/W18-2501
Paloma Jeretiˇc, Alex Warstadt, Suvrat Bhooshan,
and Adina Williams. 2020. Are natural language
inference models IMPPRESsive? Learning IM-
Plicature and PRESupposition. In Proceedings
of the 58th Annual Meeting of the Association
for Computational Linguistics. 协会
for Computational Linguistics. https://土井
.org/10.18653/v1/2020.acl-main.768
Nanjiang Jiang and Marie-Catherine de Marneffe.
2019A. Do you know that Florence is packed
with visitors? Evaluating state-of-the-art mod-
els of speaker commitment. 在诉讼程序中
the 57th Annual Meeting of the Association for
计算语言学, pages 4208–4213,
Florence, 意大利. Association for Computational
语言学. https://doi.org/10.18653
/v1/P19-1412
Nanjiang Jiang and Marie-Catherine de Marneffe.
2019乙. Evaluating BERT for natural language
inference: A case study on the Commit-
mentBank. 在诉讼程序中 2019 骗局-
ference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
cessing (EMNLP-IJCNLP), pages 6086–6091,
香港, 中国. Association for Compu-
Lauri Karttunen. 1971A.
Implicative verbs.
语言, 47(2):340–358. https://doi.org
/10.2307/412084
Lauri Karttunen. 1971乙. Some observations on
factivity. Paper in Linguistics, 4(1):55–69.
https://doi.org/10.1080/08351817109370248
Lauri Karttunen. 2012. Simple and phrasal im-
plicatives. In Proceedings of the First Joint
Conference on Lexical and Computational Se-
曼蒂克 – 体积 1: Proceedings of the Main
Conference and the Shared Task, and Volume 2:
Proceedings of the Sixth International Work-
shop on Semantic Evaluation, pages 124–131.
Paul Kiparsky and Carol Kiparsky. 1970. Fact.
在米. Bierwisch and K. 乙. Heidolph, edi-
托尔斯, Progress in Linguistics, pages 143–173.
Mouton, The Hague, 巴黎.
Kenton Lee, Yoav Artzi, Yejin Choi, and Luke
Zettlemoyer. 2015. Event detection and factual-
ity assessment with non-expert supervision. 在
诉讼程序 2015 Conference on Empir-
ical Methods in Natural Language Processing,
pages 1643–1648.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du,
Mandar
Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. ROBERTA: A robustly op-
timized BERT pretraining approach. CoRR,
abs/1907.11692.
Anne-Lyse Myriam Minard, Manuela Speranza,
Ruben Urizar, Begona Altuna, Marieke van
Erp, Anneleen Schoen, and Chantal van Son.
2016. MEANTIME, the newsreader multilin-
gual event and time corpus. In Proceedings
of the 10th International Conference on Lan-
guage Resources and Evaluation (LREC 2016),
pages 4417–4422.
Rowan Nairn, Cleo Condoravdi, and Lauri
Karttunen. 2006. Computing relative polarity
for textual inference. 在诉讼程序中
Fifth International Workshop on Inference in
Computational Semantics (ICoS-5).
Yixin Nie, Adina Williams, Emily Dinan, Mohit
Bansal, Jason Weston, and Douwe Kiela.
1095
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2020. Adversarial NLI: A new benchmark for
自然语言理解. In Proceedings
of the 58th Annual Meeting of the Association
for Computational Linguistics. 协会
计算语言学. https://doi.org
/10.18653/v1/2020.acl-main.441
Adam Poliak, Aparajita Haldar, Rachel Rudinger,
J. Edward Hu, Ellie Pavlick, Aaron Steven
白色的, and Benjamin Van Durme. 2018.
Collecting diverse natural language inference
problems for sentence representation evalua-
的. 在诉讼程序中 2018 会议
on Empirical Methods in Natural Language
加工, pages 67–81. 布鲁塞尔, 比利时,
计算语言学协会.
https://doi.org/10.18653/v1/D18-1007
Amir Pouran Ben Veyseh, Thien Huu Nguyen,
and Dejing Dou. 2019. Graph based neu-
ral networks for event factuality prediction
using syntactic and semantic structures. 在
Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 4393–4399, Florence, 意大利. 协会
for Computational Linguistics. https://土井
.org/10.18653/v1/P19-1432
Craige Roberts. 2012. Information structure in
话语: Towards an integrated formal theory
of pragmatics. Semantics and Pragmatics,
5(6):1–69. https://doi.org/10.3765/sp
.5.6
Alexis Ross and Ellie Pavlick. 2019. How well do
NLI models capture verb veridicality? In Pro-
ceedings of the 2019 Conference on Empirical
Methods in Natural Language Processing and
the 9th International Joint Conference on Nat-
ural Language Processing (EMNLP-IJCNLP),
pages 2230–2240, 香港, 中国. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1228
Rachel Rudinger, Aaron Steven White, 和
Benjamin Van Durme. 2018. Neural models
of factuality. 在诉讼程序中 2018 骗局-
ference of the North American Chapter of the
计算语言学协会,
pages 731–744. https://doi.org/10.18653
/v1/N18-1067
Roser Saur´ı. 2008. FactBank 1.0. 注解
guidelines.
Roser Saur´ı and James Pustejovsky. 2009.
FactBank: A corpus annotated with event fac-
tuality. 语言资源与评估,
43(3):227. https://doi.org/10.1007/s10579
-009-9089-9
Philippe Schlenker.
2010. 当地的
上下文
and local meanings. Philosophical Studies,
https://doi.org/10
151(1):115–142.
.1007/s11098-010-9586-0
Sebastian Schuster, Yuxing Chen, and Judith
Degen. 2020. Harnessing the richness of the
in predicting pragmatic in-
linguistic signal
ferences. In Proceedings of the 58th Annual
Meeting of the Association for Computational
语言学. Association for Computational
语言学. https://doi.org/10.18653
/v1/2020.acl-main.479
Mandy Simons, Judith Tonhauser, David Beaver,
and Craige Roberts. 2010. What projects and
为什么. In Proceedings of Semantics and Linguis-
tic Theory 20. CLC Publications. https://
doi.org/10.3765/salt.v20i0.2584
E Allyn Smith and Kathleen Currie Hall. 2014.
The relationship between projection and em-
bedding environment. 在诉讼程序中
48th Meeting of
the Chicago Linguistics
社会. Citeseer.
Gabriel
埃克-科勒,
Judith
Stanovsky,
Yevgeniy Puzikov,
Ido Dagan, and Iryna
古列维奇. 2017. Integrating deep linguistic fea-
tures in factuality prediction over unified data-
套. In Proceedings of the 55th Annual Meeting
of the Association for Computational Linguis-
抽动症 (体积 2: Short Papers), pages 352–357.
https://doi.org/10.18653/v1/P17
-2056
Judith Tonhauser, David I. Beaver, and Judith
Degen. 2018. How projective is projective con-
帐篷? Gradience in projectivity and at-issueness.
Journal of Semantics, 35(3):495–542. https://
doi.org/10.1093/jos/ffy007
Alex Wang, Ian F. Tenney, Yada Pruksachatkun,
Phil Yeres, Jason Phang, Haokun Liu, Phu Mon
Htut, Katherin Yu, Jan Hula, Patrick Xia, Raghu
Pappagari, Shuning Jin, 右. Thomas McCoy,
Roma Patel, Yinghui Huang, Edouard Grave,
Najoung Kim, Thibault F´evry, Berlin Chen,
1096
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Nikita Nangia, Anhad Mohananey, Katharina
Kann, Shikha Bordia, Nicolas Patry, 大卫
Benton, Ellie Pavlick, and Samuel R. Bowman.
2019. jiant 1.3: A software toolkit for re-
search on general-purpose text understanding
型号. http://jiant.info/
Aaron Steven White, Drew Reisinger, Keisuke
Sakaguchi, Tim Vieira, Sheng Zhang, 雷切尔
Rudinger, Kyle Rawlins, and Benjamin Van
Durme. 2016. Universal decompositional se-
mantics on Universal Dependencies. In Pro-
ceedings of the 2016 Conference on Empirical
Methods in Natural Language Processing,
pages 1713–1723, Austin, 德克萨斯州. 协会
for Computational Linguistics.
Aaron Steven White, Rachel Rudinger, Kyle
Rawlins, and Benjamin Van Durme. 2018.
Lexicosyntactic inference in neural models.
在诉讼程序中
这 2018 会议
Empirical Methods in Natural Language Pro-
cessing, pages 4717–4724, 布鲁塞尔, 比利时.
计算语言学协会.
Adina Williams, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through
inference. 在诉讼程序中 2018 骗局-
the North American Chapter of
ference of
the Association for Computational Linguis-
抽动症: 人类语言技术, 体积 1
(Long Papers), pages 1112–1122. 协会
for Computational Linguistics. https://土井
.org/10.18653/v1/N18-1101
Adina Williams, Tristan Thrush, and Douwe
Kiela. 2020. ANLIzing the adversarial nat-
dataset. CoRR,
ural
inference
语言
abs/2010.12729.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
4
1
4
1
9
6
6
2
1
3
/
/
t
我
A
C
_
A
_
0
0
4
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1097