Decontextualization: Making Sentences Stand-Alone
Eunsol Choi2∗, Jennimaria Palomaki1, Matthew Lamm1,
Tom Kwiatkowski1, 迪潘詹·达斯1, Michael Collins1
1Google Research
2计算机科学系, The University of Texas at Austin
eunsol@cs.utexas.edu,
{jpalomaki,mrlamm,tomkwiat,dipanjand,mjcollins}@google.com
抽象的
Models for question answering, dialogue agents,
and summarization often interpret the mean-
ing of a sentence in a rich context and use that
meaning in a new context. Taking excerpts of
text can be problematic, as key pieces may not
be explicit in a local window. We isolate and
define the problem of sentence decontextual-
化: taking a sentence together with its
context and rewriting it to be interpretable out
of context, while preserving its meaning. 我们
describe an annotation procedure, collect data
on the Wikipedia corpus, and use the data to
train models to automatically decontextualize
句子. We present preliminary studies that
show the value of sentence decontextualization
in a user-facing task, and as preprocessing for
systems that perform document understanding.
We argue that decontextualization is an impor-
tant subtask in many downstream applications,
and that the definitions and resources provided
can benefit tasks that operate on sentences that
occur in a richer context.
1 介绍
Many applications of natural language processing
need to be able to interpret, or present, text inde-
pendently from the rich context in which it occurs.
例如, summarization systems extract sa-
lient information from documents and present it
in a reduced context. Many systems also segment
documents prior to interpretation of retrieval for
computational efficiency. 在所有这些情况下,
we would like the context-reduction step to be
meaning preserving but, 迄今为止, there has been
no independent method of ensuring this.
∗Work done at Google.
447
In this paper we isolate and define the problem
of sentence decontextualization: taking a sentence
together with its context and rewriting it to be
interpretable out of context if feasible, while pre-
serving its meaning.1 Having defined the problem,
we operationalize this definition into a high qual-
ity annotation procedure; use the resulting data
to train models to automatically decontextualize
句子; and present preliminary results that
show the value of automatic decontextualization
in a user-facing task, and as preprocessing for
systems that perform document understanding.
We argue that decontextualization is an important
sub-task in many downstream applications, 和
we believe this work can benefit tasks that operate
on sentences that occur in a wider context.
One contribution of this work is to release a
dataset of decontextualized sentences that can be
used as training and evaluation data, together with
the evaluation script: On publication of this paper
the data will be available at https://github
.com/google-research/language/tree
/master/language/decontext.
数字 1 shows an example decontextualiza-
的. In this example we have a coreference resolu-
tion step (their → The Croatia national football
team’s) and a bridging step (insertion of the prep-
ositional phrase ‘‘in the FIFA World Cup’’ to
modify ‘‘Croatia’s best result thus far’’). 的-
contextualization involves various linguistic phe-
nomena, including coreference resolution, 全球的
scoping, and bridging anaphora (克拉克, 1975).
We present a linguistically motivated definition
of decontextualiation in Section 2 and show that
this definition can be reliably applied by crowd-
workers in Section 3.
1More precisely the truth-conditional meaning or expli-
cature (Sperber and Wilson, 1986); 参见部分 2 为了
讨论.
计算语言学协会会刊, 卷. 9, PP. 447–461, 2021. https://doi.org/10.1162/tacl 00377
动作编辑器: Chris Brew. 提交批次: 10/2020; 修改批次: 12/2020; 已发表 4/2021.
C(西德:13) 2021 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2 Linguistic Background
We start with the following definition:
Definition 1 (Decontextualization)
Given a
sentence-context pair (s, C), a sentence s′ is a
valid decontextualization of s if: (1) the sentence
s′ is interpretable in the empty context; 和 (2) 这
truth-conditional meaning of s′ in the empty con-
text is the same as the truth-conditional meaning
of s in context c.
A context c is a sequence of sentences preceding
s, and the empty context is the empty sequence.
We have been careful here to use the more
specific term ‘‘truth conditional meaning’’ rather
than ‘‘meaning’’. Here we follow the distinction
in semantics/pragmatics between truth conditional
meaning and implicature, and deliberately exclude
implicatures (which can also be considered part
of the meaning of an utterance) from our defini-
的. There is a rich history of work in semantics
and pragmatics on truth-conditional meaning and
implicatures, going back to Grice (1975). Our con-
cept of ‘‘truth conditional meaning’’ is very close
to ‘‘explicature’’ as used in Relevance Theory
(Sperber and Wilson, 1986). 考虑
这
description of explicature from Birner (2012)
(pages 96–97, our own emphasis added):
The explicature in an utterance is
the result of enriching the semantic
content with the sorts of pragmatic
information necessary to provide us
with a truth-evaluable proposition. 这
includes calculating the referents for
the intended
pronouns, working out
interpretation for deictic phrases like
…, disambiguating
这里
lexically and structurally ambiguous
任何
字
‘‘bridging’’ inferences necessary for
reference resolution … 等等.
短语, 制作
and later
和
We will see in the next section that our anno-
tation task follows this definition quite closely.
an example
作为
交换:
consider
这
following
苏珊: Has the Croatia national football
team ever won the FIFA World Cup?
Jon: Their best result thus far was reach-
ing the 2018 final, where they lost 4-2
to France.
数字 1: An example decontextualization. The sen-
tence to decontextualize is highlighted in gray.
We generate a corpus of decontextualized sen-
tences corresponding to original sentences drawn
from the English Wikipedia. We show that a
high proportion of these original sentences can be
decontextualized using a relatively simple set of
re-write operations, and we use the data to define a
new automatic decontextualization task in which
a computer system needs to create a decontextual-
ized sentence from an original sentence presented
in paragraph context. We discuss the implications
of choosing Wikipedia as a domain in Section 3.4.
We present two methods for automatic decon-
textualization based on state-of-the-art corefer-
恩斯 (Joshi et al., 2020) and generation (拉斐尔
等人。, 2019A) 型号. We evaluate the output of
these models with automatic measures (derived
from Xu et al. [2016]), as well as through human
评估. Both automatic and human evaluations
show that the largest sequence-to-sequence model
produces high quality decontextualizations in the
majority of cases, although it still lags human
performance in the thoroughness and accuracy of
these decontextualization edits.
最后, we present
two demonstrations of
the utility of decontextualization. The first is a
user study giving evidence that decontextualized
sentences can be valuable when presented to users
as answers in a question-answering task—raters
judge that they balance conciseness with infor-
mativeness. In the second one, we use decon-
textualization as a preprocessing component for
generating a retrieval corpus for open domain
question answering. Decontextualizing the sen-
tences to be indexed by retrieval system enables
more efficient answer string retrieval for infor-
mation seeking queries. These demonstrations are
presented as preliminary results, and we argue
that decontextualization is an important sub-task
for a wide range of NLP applications.
448
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Here the truth conditional meaning of Jon’s
reply is equivalent to ‘‘Croatia’s best result thus
far in the FIFA World Cup was reaching the 2018
final, where they lost 4-2 to France’’, 然而
the implicature would be ‘‘the Croatia national
football team has never won the FIFA World
Cup’’ (which answers Susan’s question). In our
definition the decontextualized sentence s′ should
是
preserve the truth-conditional meaning, 但
not required to preserve the implicature(s) 的
sentence.2
Remark (extra-linguistic context): 此外
to its document context, a given sentence s and
its counterpart s′ also come with a temporal, 文化-
tural, and geographic context—that is, where and
when they are being written or read and by
whom.3 We assume that these aspects of context
are preserved during decontextualization. 这
effect of this is that elements of s that derive their
meaning from outside of the document context
will receive equivalent interpretation in s′, 和
hence do not require decontextualization. 对于前-
充足, the expression ‘‘thus far’’ in Figure 1 是
interpreted relative to the time of utterance, 不是
relative to what has been previously said in the
Wikipedia article, and hence it appears in both the
original and decontextualized sentences.
3 Task Definition
An annotator is provided with an entire document
d with a target sentence within the document,
represented as a start and end index sst, send.
第一的, the annotator decides whether the target
sentence can be decontextualized or not, labeling
it as FEASIBLE or INFEASIBLE. If the example is
marked as FEASIBLE, the annotator decontextual-
izes the sentence, producing y, a new sentence
that satisfies the conditions in Definition 1.
3.1 Feasibility
Sentences in FEASIBLE include sentences that do
not require any modification to be decontextu-
alized (例如, ‘‘ ´Emilie du Chˆatelet proposed the
hypothesis of the conservation of total energy,
2We have not necessarily given up on recovering
implicatures: The decontextualized sentence will likely be
a valuable intermediate step in deriving the implicatures of
an utterance.
3Research on text simplification (徐等人。, 2015; Bingel
等人。, 2018) also shows how target output depends on the
expected audience.
数字 2: Decontextualization examples falling into
the INFEASIBLE category. The sentence to be decon-
textualized is highlighted in gray.
as distinct from momentum’’), and sentences that
require edits to stand alone.
In the decontextualization step, we instructed
annotators to make only minor modifications,
which includes copying and pasting a few phrases
from the document to the target sentence and
deleting phrases from the target sentence. When it
is too challenging to decontextualize, it is classi-
fied into the INFEASIBLE category. 经常, 句子
in this category are a part of a narrative story, 或者
rely heavily on the preceding few sentences. 看
数字 2 举些例子.
3.2 Edit Types and Linguistic Phenomena
When an example is classified as FEASIBLE, 这
annotator makes edits to decontextualize the sen-
张力. 桌子 1 shows the different edit types. 他们
fall into four broad categories:
NAME COMPLETION, PRONOUN / NP SWAP
corre-
spond to replacement of a referring expression that
is unclear out of context with a referring expres-
sion that is unambiguous out of context. 考试用-
普莱, replacing the pronoun ‘‘She’’ with ‘‘Cynthia
Nixon’’, the definite NP ‘‘the copper statue’’ with
‘‘The Statue of Liberty’’, or the abbreviated name
‘‘Meg’’ with ‘‘Megan ‘‘Meg’’ Griffin’’.
DM REMOVAL
标记 (DMs) such as ‘‘therefore’’.
involves removal of discourse
BRIDGING, GLOBAL SCOPING involve addition of
a phrase (typically a prepositional phrase) 那
449
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Edit Type
PRONOUN/NP SWAP
描述
Replacement of a definite
pronoun / noun phrase with
another referring expression
NAME COMPLETION
Expansion of acronyms or
partial names
DM REMOVAL
BRIDGING
GLOBAL SCOPING
ADDITION
Removal of discourse
markers that can be only
understood in context
Addition of a modifier
(typically a PP) to a noun
短语
Addition of a phrase
(typically a PP) that modifies
the entire sentence
例子
* -The copper statue , +The Statue of Liberty +, a gift from the
people of France to the people of the United States, was designed
by French sculptor Fr´ed´eric Auguste Bartholdi and built by
Gustave Eiffel.
* -Meg , +Megan ‘‘Meg’’ Griffin + made her first appearance
on television when Family Guy debuted on Fox on January 31,
1999, with the episode ‘‘Death Has a Shadow’’.
* – 例如, + Alaska could be regarded as the highest state
because Denali, 在 20,310 脚, is the highest point in the US.
In all fights * +in the Ultimate Fighting Championship +, each
round can be no longer than five minutes.
The Japanese film Shoplifters, directed by Hirokazu Kore-eda,
won the Palme d’Or * +在 2018 Cannes Film Festival. +
%
40.5
11.5
3.5
13
7
10
Addition of background
information that is not
necessary but helps readability
显著地
Charles Darwin* +, an English naturalist and biologist, + 曾是
among the first to suggest that physiological changes caused
by an emotion had a direct impact on , rather than being just the
consequence of that emotion.
桌子 1: The list of possible edits in decontextualization. The last column represents how frequently the
phenomena occurs in the data, from manual analysis on 200 examples, including examples that belongs to
INFEASIBLE categories and examples that does not require any edits. The bag notation removes x and adds y
(* -X , +y +) at its position.
modifies either a particular noun phrase (‘‘bridg-
ing’’) or the entire sentence (‘‘global scoping’’).
例如, adding ‘‘in the Ultimate Fighting
Championship’’ as a modifier to ‘‘all fights’’, 或者
adding ‘‘at the 2018 Cannes Film Festival’’ at the
end of the sentence. The additional phrase essen-
tially spells out a modifier that is implied by the
语境.
ADDITION inserts background information that
significantly improves readability: 在很多情况下,
this involves adding an appositive or premodi-
fier to a named entity to add useful background
information about that entity. Unlike other edits
如上所述, edits in this category are optional.
例如, replacing ‘‘The Eagles’’ with ‘‘The
American rock band The Eagles.’’
3.3 Variability
We note that for a given sentence frequently there
will be more than one possible decontextualiza-
的. While this inherent subjectivity makes the
task challenging to crowdsource and evaluate, 我们
argue this is important feature, as shown in recent
文学 (Aroyo and Welty, 2015; Pavlick and
Kwiatkowski 2019; Kwiatkowski et al., 2019),
and propose to collect multiple references per
例子. 桌子 2 shows examples where there
can be multiple different correct decontextualiza-
系统蒸发散. In the first example, while the semantics
of the edits are roughly equivalent (IE。, the anno-
tators agreed on what noun phrases have to be
disambiguated and information has to be added),
they differ in how to rewrite the sentence. 在里面
second example, we see disagreement on what
information should be added to the sentence. 我们
do not make any explicit assumptions about what
is known and salient to the reader, and instructed
annotators to use their best judgment to rewrite
such that the new sentence is fluent, 明确的
and clear when posed alone. In the last example,
annotators disagree on the feasibility. While the
sentence is a part of a bigger narrative, two annota-
tors judged it could be edited to alone, by adding a
global scoping modifier, ‘‘In Greek mythology.’’
3.4 Scope of Current Task Formulation
Our data comes from the English portion of
the Wikipedia corpus. We sampled sentences as
如下. We first pick a (问题, 维基百科,
short answer) triple from the Natural Questions
450
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Page title / Section title: We Don’t Talk Anymore (Charlie Puth song) / Music video
Paragraph: The music video premiered on August 2 , 2016 , on BuzzFeed and was directed by Phil Pinto . It shows Puth
and Mirella Cardoso as his love interest . . . .
Decontextualization 1: * -它 , +We Don’t Talk Anymore music video + 节目 * -Puth , +Charlie Puth + and Mirella
Cardoso as his love interest.
Decontextualization 2: * -它 , +The ‘‘We Don’t Talk Anymore’’(Charlie Puth song) music video + shows Puth and
Mirella Cardoso as his love interest.
Page title: The American Baking Competition
Paragraph: CBS placed casting calls for participants on November 14, 2012 . Auditions were held between December 1
and December 15, 2012. The competition took place at the Gibbs Gardens in Ball Ground , Georgia in March 2013.
Decontextualization 1: 这 * -competition , +American Baking Competition + took place at the Gibbs Gardens in Ball
Ground , Georgia in March 2013.
Decontextualization 2: 这 * -competition , +American Baking Competition, a reality competition television series, +
took place at the Gibbs Gardens in Ball Ground , Georgia in March 2013 .
Page title: Gemini (Constellation)
Paragraph: In Greek mythology, Gemini was associated with the myth of Castor and Pollux, the children of Leda and
Argonauts both. Pollux was the son of Zeus, who seduced Leda, while Castor was the son of Tyndareus, king of Sparta and
Leda’s husband. Castor and Pollux were also mythologically associated with St. Elmo’s fire in their role as the protectors
of sailors. When Castor died, because he was mortal, Pollux begged his father Zeus to give Castor immortality, and he did,
by uniting them together in the heavens.
Decontextualization 1: INFEASIBLE
Decontextualization 2: * +In Greek mythology, + when Castor died, because he was mortal, Pollux begged his father Zeus
to give Castor immortality, and he did, by uniting them together in the heavens.
桌子 2: Examples showing the diversity of valid decontextualization edits.
(Kwiatkowski et al., 2019) uniformly at random
from the questions that have a short answer. 我们
include the sentence containing the short answer
as one example; as a second example we choose
a sentence at random from the Wikipedia page.
After sampling we exclude (1) sentences under
a ‘‘Plot’’ category as they are often infeasible to
decontextualize; (2) any sentence that is the first
sentence of the page; 和 (3) any sentence from a
paragraph containing only a single sentence.
We designed this data selection process to en-
sure that a large proportion of examples (90%)
could be decontextualized using simple edits de-
scribed in Section 3.2.
Before settling on Wikipedia, we conducted an
initial pilot study which revealed that encyclopedic
文本
is substantially easier to decontextualize
compared to newswire or literary text. In the latter
流派, the context required for the comprehension
of any given sentence appears to be much more
is difficult
complex in structure. 相似地,
to posit decontextualization for sentences that
appear on social media platforms, 因为他们是
situated within complex and highly specific social
上下文. 相比之下, being written for a general
观众, Wikipedia makes limited assumptions
about its reader.
它
Within Wikipedia, we similarly found that
articles on popular historical or cultural entities
and events were
to decontextualize
更轻松
by crowdworkers compared to articles from
technical domains, such as ones on medical
or mathematical concepts. Comprehension of
such articles requires a considerable body of
information from
background knowledge or
preceding paragraphs. Articles in our dataset cover
topics that require little background knowledge to
comprehend.
We focus on decontextualization of sentences,
where the space of edits is restricted, to make the
task easier to quality control and annotate. 如何-
ever alternate formulations, such as decontextual-
ization on paragraphs could also be studied. 一
could even also consider allowing wider range
of edits, such as multi-sentence outputs and edits
beyond copy-and-pasting, such as paraphrasing
and re-ordering. We anticipate exploring such
alternative formulations would help to extend the
scope of decontextualization to the more chal-
lenging domains previously mentioned.
We stress however that in spite of our restriction
to single sentences in Wikipedia, the decontextu-
alization task is nevertheless valuable: 维基百科
(and other encyclopedic sources) contain a wealth
of factual information, and a high proportion (超过
451
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
#
11290
1945
1945
100
par.
len
695
695
711
658
发送.
len
156
162
160
163
FEASIBLE (%)
as is
w/ edit
31
60
21
67
20
68
26
63
INFEA
SIBLE (%)
9
12
12
12
Train
Dev
Test
专家
桌子 3: Data statistics. par. len refers to para-
graph length in bytes, and sent. len refers to sen-
tence length in bytes. All lengths are in bytes.
The development and test set is five-way anno-
tated, and the expert data is four-way annotated.
60%; 见表 3) of sentences both require decon-
textualization and can be decontextualized under
our definitions (仅有的 30% of sentences are inter-
pretable out of context without any edits).
4 Data Collection
Annotation Interface The annotator is pre-
sented a sentence in the context of an entire
Wikipedia page. In the first step the annota-
tor judges whether the example is FEASIBLE or
INFEASIBLE. If the example is marked as FEASI-
BLE, the annotator can use delete, add, or swap
operations within a user interface to produce a
decontextualized string.
Data Statistics We collected one reference for
each example in the training data, and five ref-
erences for each example in the evaluation data.
Annotators are native speakers of English located
在美国, and on average, they took
4 minutes to annotate a single example.
总共, 28 annotators annotated the examples,
和 11 annotators annotating more than 1K ex-
amples each.
桌子 3 represents some overall data statistics.
Decontextualization is possible for the majority
of examples, with the INFEASIBLE category cover-
ing roughly 10% 数据的. We note a slight dis-
crepancy between train and evaluation dataset
分配, potentially due to a change in the an-
notation interface. A small subset of data is an-
notated by the authors to be compared with the
crowd-sourced data (last row in the table).
Annotation Quality We quantify the annota-
tion agreement on the category classification. 这
Fleiss’ kappa on category classification is 0.51
among expert annotators, 并且是 0.30 among the
crowd annotators (binary agreement is at 85%).
We observed more variability in crowdworkers as
annotators’ background is more diverse, 还有一些
annotators have a loose concept of ‘‘stand alone’’
and consistently attempted decontextualization.
We also measured agreement among the indi-
vidual edits. For each of the edit operations (作为
defined in Section 3.2), we compare the output
sentence after the single edit and to a set of
output sentences, each after a single edit by other
annotators. 关于 32.5% of edits were covered.
Because of the inherent annotation variability,
four of the authors manually evaluated 100 人群-
sourced annotations from the evaluation data
based on two measures: (1) whether the sentence
is sufficiently and correctly decontextualized, 和
(2) whether the sentence is grammatically correct
and fluent. 全面的, 88% of annotations were valid
in both, 89% on the content and 88% on form.
5 Automatic Decontextualization
5.1 楷模
We present two models for decontextualization:
a coreference resolution model and a sequence-
to-sequence generation model. For both models,
the input is a concatenation of the title of the
Wikipedia document, the section titles, 和
paragraph containing the target sentence. 期间
the annotation pilots, we found that the document
title is crucial for decontextualization, while sec-
tion headers were frequently necessary or miss-
英. We denote the title of the Wikipedia page
as the sequence of tokens t, section titles of the
paragraph as the sequence of tokens ts and the
n sentences in the paragraph where the target
sentence is coming from as x1 . . . xn, where each
xi is a sequence of tokens, and xt is the target
句子 (1 ≤ t ≤ n). The model considers the
concatenation of a subset of the document,
[CLS]t[S]ts[S]x1· · ·xt−1[S]xt[S]xt+1· · ·xn[S]
在哪里 [S] is a separator token. This representa-
tion differs from the setting of annotators, 在哪里
they were given the full document context. 作为一个
approximation, we include article and section titles
in the inputs, as these often contain salient con-
textual elements. We did experiment with giving
more context, 即, adding the first paragraph
of the article as an additional input, but did not
observe a performance improvement. On the ini-
tial pilot, annotators marked that 10–20% of ex-
amples required access to the full document.
The Coreference Model As many decontextu-
alization edits can be recovered by a coreference
452
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
resolution module, we adapt the output from the
state-of-the-art coreference resolution system of
Joshi et al. (2020), trained on the CoNLL dataset
(Pradhan et al., 2012), as a decontextualization
系统. We used the publicly available pre-trained
checkpoint of SpanBERT-Large with the original
hyper parameters.4
We run this model on the input sequence, 和
map the coreference cluster predictions to modify
the sentence as follows. We only consider clusters
with a mention in the target sentence. For each
such cluster, we find its first mention inside the
target sentence, and find another mention in the
same cluster that was presented earlier in the in-
put and is longer than the current mention. If such
a mention is found, we replace the current en-
tity mention string with the earliest such mention
string (例如, ‘‘She’’ is replaced with ‘‘Taylor
Swift’’). 平均而言, 36.5% of examples were
modified through this process.
The Seq2Seq Generation Model
is based on
the recent T5 model (Raffel et al., 2019乙). We show
two variations of the model, BASE and 11B,
which mainly differ in the model capacity. 我们
fine-tune the model on our crowdsourced training
放, by setting the target sequence to be [CAT]
[SEP]y, 在哪里 [CAT] ∈ {UNNECESSARY, FEASIBLE,
INFEASIBLE} and y is a decontextualized sentence
什么时候 [CAT] = FEASIBLE and the original sen-
tence when [CAT] ∈ {UNNECESSARY, INFEASIBLE}.
UNNECESSARY are examples where the original
sentence without any edit can stand alone.
We limit the input/output to 512/128 代币
for both variants, and fine-tuned from pre-trained
checkpoints5 with a batch size of 100 examples
until the validation loss stopped decreasing, 后
about 32K for the larger and 500K steps for the
smaller model.
5.2 评估
5.2.1 Feasibility Detection
We first evaluate the accuracy of models in mak-
ing the feasible vs. infeasible decision. 要做到这一点
we compute the binary agreements with all human
references and average them to get an accuracy.
Results For the feasible vs. infeasible classifica-
tion task, a baseline that always predicts FEASIBLE
4https://github.com/facebookresearch
/SpanBERT/.
will have 88% 准确性. The larger variant of T5,
T5-11B, achieves 89% 准确性, outperforming
human agreement (85% 准确性), affirming the
strong performance of pre-trained language mod-
els on classification tasks (Devlin et al., 2018).
This model predicts the INFEASIBLE category infre-
quently for the larger variant (5% of examples),
while humans classify an example as INFEASIBLE
为了 12% of examples. We observe the smaller
variant, T5-Base, is less accurate, over-predicting
the INFEASIBLE category (为了 20% of examples),
getting 77% 准确性. The coreference model
cannot decide the decontextualization feasibility,
as an untrained baseline.
5.2.2 Decontextualized Sentence Generation
/
Setup For development
test examples, 我们
have five human annotations per example. 我们
only consider examples marked by three or more
annotators (out of five) as FEASIBLE for decontex-
tualized sentence generation. For each of these
examples, we discard annotations which mark the
example as INFEASIBLE. For automatic evaluation
and comparison, we need a human output, 哪个
will be compared to model outputs, and a set of
reference annotations that will be considered as
正确的, gold annotations. The single human output
provides a reference point for evaluation measures
to which the automatic output can be compared.
We observed comparing a longer decontextu-
alized sentence to shorter decontextualized sen-
tences often erroneously results in low scores
automatic metrics (例如, in the last example of
桌子 2, adding extra information will be erro-
neously punished). 因此, instead of randomly
selecting one annotation to be used as the repre-
sentative human output, we sort the annotations
by the length of the output sentence (raw bytes),
and take the annotation with median length6 as a
human output and take the remaining annotations
as a set of reference annotations. From manual
inspection of the data the median-length output
appeared often to be optimal in terms of balancing
length versus accuracy of the decontextualization.
Metric For each model prediction and human
输出, we report:
• Length increase,
the average value of
(len(decontext)-len(original)) / len(original).
5https://github.com/google-research/text
6When there are four references, we take the second
-to-text-transfer-transformer.
shortest sentence.
453
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
• % edited, the proportion of examples that
were modified for decontextualization (作为
opposed to being left unchanged).
• Sentence match, a binary score computed be-
tween the output and a set of references, 在-
dicating whether the output matches any of
the references after normalization (stripping
away articles and punctuation and lowercas-
英). We report two numbers, a score on all
examples, and a score on examples where all
references edited the sentence.
• SARI (system output against references and
against the input sentence) metric (徐等人。,
2016). To compute this, for each reference,
we calculate a set of add edits, 相应的
to which unigrams are seen in the reference
but not in the original sentence. 反过来,
we can calculate the set of delete edits,
corresponding to unigrams that are in the
original sentence but not in the reference.
We calculate precision/recall/F1-measure on
add and delete edits. We look at unigrams
仅有的, and use fractional counts for the words
in the references (IE。, a word appearing in
one of r references will be counted as 1/r).
We compute micro average across examples,
那是, globally by counting the total true
积极的一面, false negatives, and false positives,
as many examples do not require any edits.7
While the sentence match score is the easiest to
interpret, it punishes longer outputs, making com-
parisons across systems producing outputs of dif-
ferent lengths challenging, and it overly rewards
conservative strategies that simply copy across
the original sentence. 因此, we use the SARI met-
ric as our main evaluation metric. SARI can be
thought of as a precision/recall measure on topics
(unigrams) that should be added or deleted.
Automatic Evaluation Tables 4 和 5 展示
development and test performance. A successful
decontextualization system would result in high
sentence match, adequate changed ratio (experts
edited about 79% of examples), and length change
比率 (the experts’ ratio is 1.19), as well as high
7Similar to BLEU in machine translation, SARI is a useful
measure for comparing different systems; 然而, due to
the relatively large space of possible decontextualizations it
will not be possible to achieve anything close to 100% F1
on SARI measures, and thus the absolute score is harder to
interpret. A SARI score of for example 50% should not be
interpreted as indicating a system with 50% 准确性.
len % 编辑
ited
inc.
0
0
42
7
40
8
59
12
76
24
匹配
全部 / edited
38 / 0
39 / 13
48 / 21
53 / 32
45 / 29
SARI add SARI del
F1 (P/R)
F1 (P/R)
0 (0/0)
0 (0/0)
31 (34/28)
22 (51/14)
40 (54/32)
29 (67/19)
46 (49/43)
42 (72/30)
58 (61/55)
56 (64/49)
Repeat
Coref
T5-Base
T5-11B
人类
桌子 4: Development set performance. Len inc.
is the average percentage increase in length from
decontextualization. % edited is the proportion of
examples that have at least one edit. match-all
shows percentage of outputs that have at least
one match in the human references; match-edited
shows the match value calculated on cases where
all references include at least one edit.
len % 编辑
ited
inc.
0
0
Repeat
Coref
42
8
T5-11B 13
61
77
23
人类
匹配
全部 / edited
36 / 0
38 / 13
52 / 32
44 / 28
SARI add SARI del
F1 (P/R)
F1 (P/R)
0 (0/0)
0 (0/0)
36 (40/32)
23 (50/15)
47 (49/46)
43 (69/31)
58 (61/56)
56 (64/49)
桌子 5: Test set results. 见表 4 caption for a
钥匙.
SARI addition and deletion scores. As a sanity
查看, we report REPEAT, which outputs the orig-
inal sentence. This alone results in high sentence
match score, 大约 40%, meaning that on this
number of examples, at least one of the annotators
deemed the sentence can stand alone without any
edits.
The coreference system has an exact match of
关于 13% of examples that require edits, 没有
any task-specific fine-tuning. Its SARI add scores
shows high precision and low recall, and its dele-
tion scores are low as it cannot delete discourse
标记. The Seq2seq generation model achieves
high scores across all measures. The bigger variant
is substantially better, editing more than its smaller
variant without losing precision. We observe the
larger variants outperform the average human on
sentence match measure, but not in SARI mea-
确定. The T5 model modifies fewer examples
than the annotator, and edits involve fewer tokens,
benefiting it on the sentence match measure. 如何-
曾经, the model is more likely to miss required
edits, as shown in low recall for the SARI add and
deletion measures. We discuss this further in the
following human evaluation section.
Human Evaluation We sampled 100 examples
in the evaluation set, where at least two annotators
454
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
T5
任何一个
Annotator
Sum
T5
13
7
1
21
任何一个
12
22
15
49
Annotator
2
4
24
30
Sum
27
33
40
100
桌子 6: Preference between T5 output and hu-
man annotation. Columns represents the judge-
ment of the expert A, rows that of the expert B.
We see high agreement between two expert an-
notators, despite one expert annotator (柱子
annotator) is ambivalent more frequently.
and our best model made decontextualization
edits. We randomized the order or presentation of
the T5 and human outputs so as to not bias the
注解. On this set, 我们 (two of the authors)
conducted a manual evaluation. Given two decon-
textualized sentences, one from the best model
and another randomly selected from a set of anno-
tations with decontextualization edits, we evalu-
ated each on two dimensions: (A) is it fluent and
grammatically correct? (乙) is it sufficiently and
correctly decontextualized? 最后, we chose the
preference between two outputs (A, 乙, or either).
Expert annotators marked as ‘‘sufficient’’ those
items for which all possible referential ambiguities
had been resolved. Given the subjective nature
任务的, some ‘‘insufficient’’ decontextualiza-
tions by the expert annotator could be valid for the
another annotator with a different world knowl-
边缘. We report averaged binary scores from two
experts. The model output scored 88.0% on flu-
ency, 和 67.5% on correct decontextualization,
while the human reference output scored 84.5%
on fluency and 78.5% on correct decontextual-
化. Both annotators found T5 to be slightly
more fluent, while humans are more thorough and
accurate in decontextualizating. 桌子 6 节目
the preferences of two annotators. Both preferred
human output, and their preferences exhibit high
协议 (matching on 37 在......之外 40 examples
when both had preferences).
We briefly characterize common error patterns
for annotators and the T5 model. Similar error pat-
terns emerge between the annotations and model
outputs. Both occasionally fail to identify gener-
ics that need to be replaced with referring NPs,
phrases that require bridging, and temporal con-
texts that should be provided. 此外, 我们
noticed that the T5 model heavily relies on the
title cues, and sometimes fail to clarify ambiguous
entities that are not the main entity of the page. 我们
Prefer
Opt.A vs. Opt.B A
Dec. 与. Ori.
Dec. 与. 帕.
Ori. 与. 帕.
730 426
850 456
741 505
B either
364
234
274
log odds
intercept [CI]
0.85 [0.4,1.3]
0.55 [0.1,1.0]
0.31 [−0.2,0.8]
桌子 7: User study results. Dec. refers to decon-
textualized sentence answer, Ori. means original
sentence answer, 帕. means paragraph answer.
We present raw counts of preferences and the log
odds of preferring option A and its 95% 骗局-
fidence interval.
noticed very few examples where T5 hallucinates
factually incorrect contents.
6 Two Applications
We present
two demonstrations of the utility
of decontextualization. 第一的, we argue that the
decontextualized sentences can be valuable in
themselves in question answering, and show that
they can be useful as a preprocessing step.
6.1 Decontextualized Answer As Is
We showcase a use case of decontextualized
sentences as providing a succinct yet informa-
tive answer to open domain factoid questions
(Kwiatkowski et al., 2019). We design a user
study where people compare a decontextualized-
sentence answer with an original-sentence answer
and a paragraph answer to the same query.8
Setup Given a question and two presentations of
the same answer, raters were tasked with marking
their preference between the two answer presen-
tations (option A, option B, or either). The actual
short span answer in the sentence is always high-
lighted (similar to seen in Table 8) (见图 3
for a screenshot).
We conduct three comparison studies on the
same set of 150 问题: (A) decontextualized
sentence vs. original sentence, (乙) original sen-
tence vs. original paragraph, (C) decontextualized
sentence vs. original paragraph. For each exam-
ple in each study, 我们收集了 10 user ratings.
The questions are randomly chosen from a set
of questions that have a short answer, and such
that the sentence containing the short answer is
categorized as FEASIBLE by the annotators and
8Understanding how to present answers to users is a
complex problem with many desiderata, 例如, preserving the
original content, crediting the source, interaction with the
user interface, which we are not covering comprehensively.
455
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3: A screenshot of the instruction and an example instance comparing the original sentence answer and the
paragraph answer shown to annotators for the user study.
Query
when was the rising
of the moon written
what is the most
viewed video on
youtube in 24 小时
Decontextualized answer
The Rising of the Moon, Irish ballad
recounting a battle between the United
Irishmen and the British Army has been
in circulation since circa 1865 .
The most viewed music video within
24 hours of its release is Taylor Swift ’s
Look What You Made Me Do .
when was last time
england got to quarter
finals in world cup
The England national football team have
reached the quarter – finals on nine
场合, the latest of which were at
这 2002 和 2006 .
Paragraph answer (sentence answer highlighted)
Decont. Ori.
The ballad has been in circulation since circa 1865 . −2.09 −1.53
The earliest verifiable date found in publication is
1867 .
This list of most viewed online videos in the first 24
hours contains the top 30 online videos that received
the most views within 24 hours of release across the
世界. This list excludes movie trailers , 哪个是
featured on the list of most viewed online trailers in the
第一的 24 小时. The most viewed music video in this
time period is Taylor Swift ’s Look What You Made
Me Do .
England did not enter the competition until 1950. . .
Their best ever performance is winning the Cup in the
1966, whilst they also finished in fourth place in 1990,
并在 2018. Other than that, the team have reached the
quarter – finals on nine occasions, the latest of which
were at the 2002 和 2006 .
1.06 −0.48
1.40
0.70
桌子 8: Examples from the user study. The last column represent coefficients for preferring original
sentence over the original paragraph, and the fourth column presents coefficients for decontextualized
sentence over the paragraph. Positive values means preference towards the sentence-length answer over
the paragraph-length answer.
edits were necessary to decontextualize. We use
crowd-sourced annotations of decontextualized
句子. 数字 3 shows the screenshot of the
user study interface.
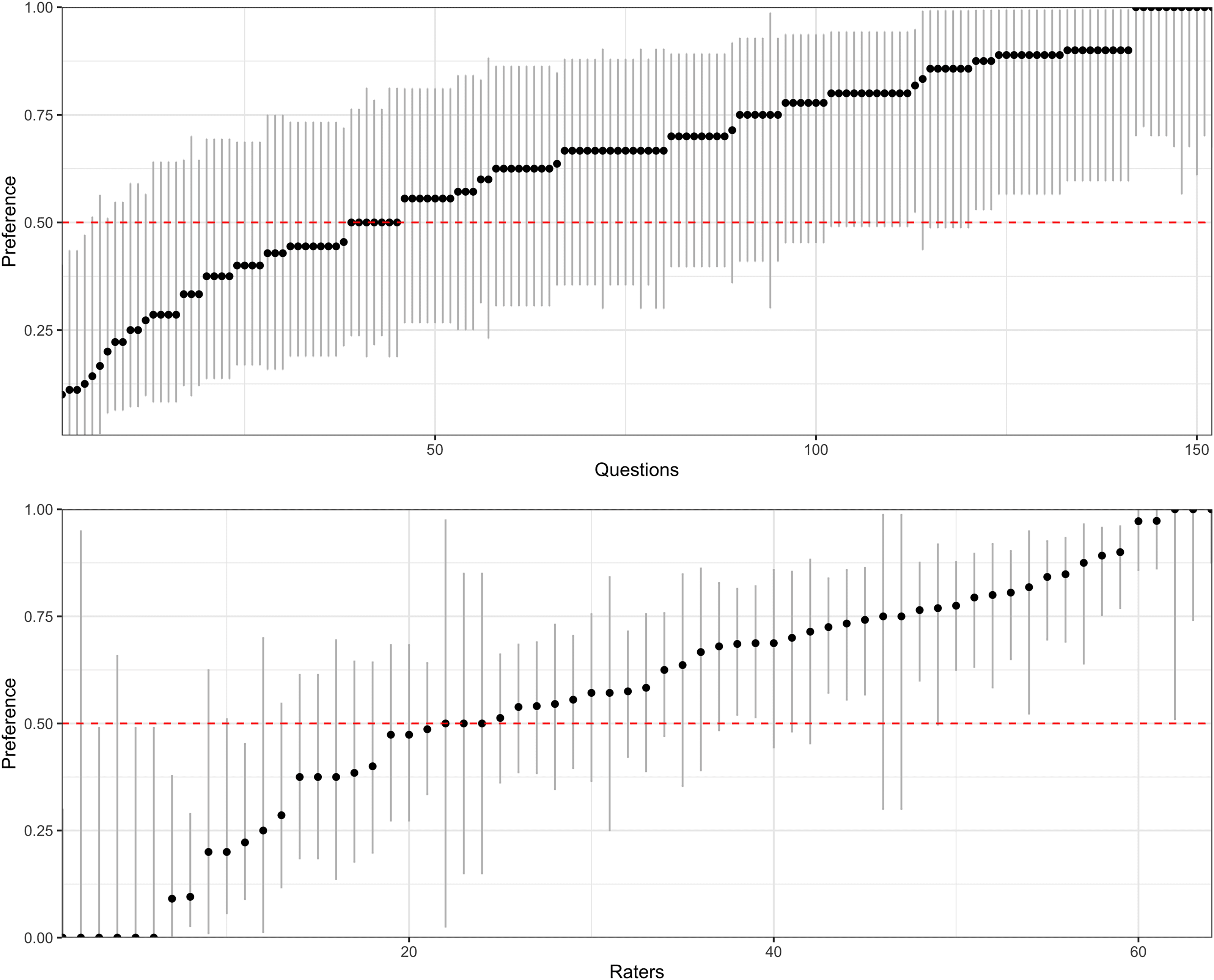
Result Table 7 shows the results of the user
学习. We observe that decontextualized sentence
answers are preferred to both the original sentence
answers and the original paragraph answers. 我们
also note that the users preferred sentence answer
compared to paragraph answer in general.
We further investigated the statistical signifi-
cance of the preferences reported in Table 7. 我们
noticed a quite large amount of question and rater
variability—some raters consistently preferred a
sentence answer, valuing conciseness, while some
raters behaved in the other direction. 相似地,
for some questions, all raters preferred a sentence
回答. 数字 4 visualizes such variability based
on the questions and raters.
To control for the correlations induced by the
rater and question groups, we fit a generalized
linear mixed model (GLMM) using the brm R
包裹 (B¨urkner, 2017). For this analysis, 我们
excluded data points where users did not show a
preference (selected either). We used the formula:
p ∼ 1 + (1|r) + (1|q), where p is whether
a rater chose one option over the other; r is the
rater id; and q is the question id. This formula
specifies a regression of the log-odds of the rater
preference while allowing for random effects in
the raters (r) and questions (q). The last column
456
cifically, we construct a passage retrieval corpus
for open domain question answering (陈等人。,
2017) with decontextualized sentences. Experi-
ment shows that decontextualized sentences ensure
completeness of the passages while minimizing
their length (thus computational cost).
Background Open domain question answering
typically consists of pair a passage retrieval (刘
and Croft, 2002) and transformer-based answer
extractor (reading comprehension model) 基于
on the retrieved passages (Guu et al., 2020;
Karpukhin et al., 2020; Izacard and Grave, 2020).
And the computational cost is dominated by the
cost of co-encoding the query with the retrieved
passages (typically paragraphs or overlapping 100
word windows).
Setup We create a corpus using the 7k docu-
评论 (233k paragraphs, 868k sentences) 从
the documents associated with the questions in
the NQ-open development set (李等人。, 2019).
We consider a retrieved passage to be correct if it
contains one of the answer strings9 and investigate
the number of questions for which we can retrieve
a correct passage for a fixed computational cost.
Under this measure, we compare paragraphs, 赢-
dows of 100 字, 句子, and decontextual-
ized sentences as a set of retrieval passages. 这些
segmentation approaches generate different num-
ber of passages for the same article (paragraph and
a window of 100 words segmentation make fewer
passages compared to sentences-level segmen-
站). To generate decontextualized sentences
process all paragraphs with T5-11B model, 哪个
are trained on all annotated data (including devel-
opment and test set). For about 40% 句子数,
the model classified the sentence as infeasible to
decontextualize or unnecessary to make any edits,
we use the original sentence. On the other 60%
the model tended to add more information. 为了
例子, for a sentence ‘‘Bush was widely seen
as a ‘pragmatic caretaker’ president who lacked
a unified and compelling long-term theme in his
efforts.’’, the decontextualized sentence will be
‘‘George H.W. Bush was widely seen as a ‘prag-
matic caretaker’ president of the United States
who lacked a unified and compelling long-term
theme in his efforts.’’ A paragraph would be the
entire paragraph containing this sentence, and a
9We adopt the answer match heuristics from Lee et al.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
我
A
C
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(2019).
457
数字 4: Each dot represents how frequently the
decontextualized answer is preferred for a single
问题 / rater to the original sentence for a single
问题 (top plot) and single rater (bottom plot).
问题 (top plot) and raters (bottom plot) are sorted
by its preference towards the decontextualized answer.
The red line is where both are equally preferred,
and above the line represents question / rater where
decontextualized answers were preferred. While the
decontextualized answer is preferred overall, we see a
large variability.
of Table 7 shows the fixed effect coefficients and
their confidence intervals. The intercept repre-
sents the strength of preference towards option
A. We found a statistically significant preference
for decontextualized sentences over both original
sentences and the paragraphs (p-value was smaller
比 0.05 for both studies).
Examples We qualitatively investigated which
examples benefit from decontextualization, 并在
which examples raters prefer paragraph answers.
桌子 8 shows questions together with two ans-
wer presentations, along with the predicted fixed
effect question coefficient towards decontextual-
ized answer in study (乙) and towards the sentence
answer in study (C). In the first row, the added in-
formation from the decontextualization is not rel-
evant to the question, thus we observe preference
against decontextualization. In the second and
third row, the decontextualized sentence answer
is preferred as it provides enough evidence to ans-
wer the query, while the original sentence answer
不.
6.2 Decontextualizing System Inputs
Having shown the benefits of decontextualization
in a user-facing task, we now investigate the use of
decontextualizaton as a preprocessing step. Spe-
100-word window will be a chunk without using
a sentence boundary as a segmentation. For all,
we prepend the document title to the passage,
following the literature and use the TFIDF as a
retriever model.
我 . . . 一个
Metric Let qi be a question; let Ai = [a0
我 ]
我 . . . ck
be the set of valid answers; let Ci = [c1
我 ]
be a ranked list of evidence passages; 然后让
H(Ai, Ci) be the index of the top ranked context
that contains one of the valid answers (or k + 1
if there is no such context). We first define the
cost of encoding a single question and passage,
C(qi, 厘米
我 |)2. This captures
the fact that the Transformer’s computation cost
scales quadratically with the length of the encoded
文本 (问题 + separator + evidence passage).
我 ) = (|qi| + 1 + |厘米
氧(qi, Ai, Ci) =
H(Ai,Ci)
X
m=1
C(qi, 厘米
我 ).
Given the per example cost defined above,
we define the recall of the retrieval system at
computational cost budget t to be:
1
氮
氮
X
i=0
1 [氧(qj, aj, Cj) < t]
(1)
where N is the total number of examples and 1 is
an indicator function. We use this as an evaluation
measure instead of mean reciprocal rank or recall
at N, to compare across different retrieval passage
length.
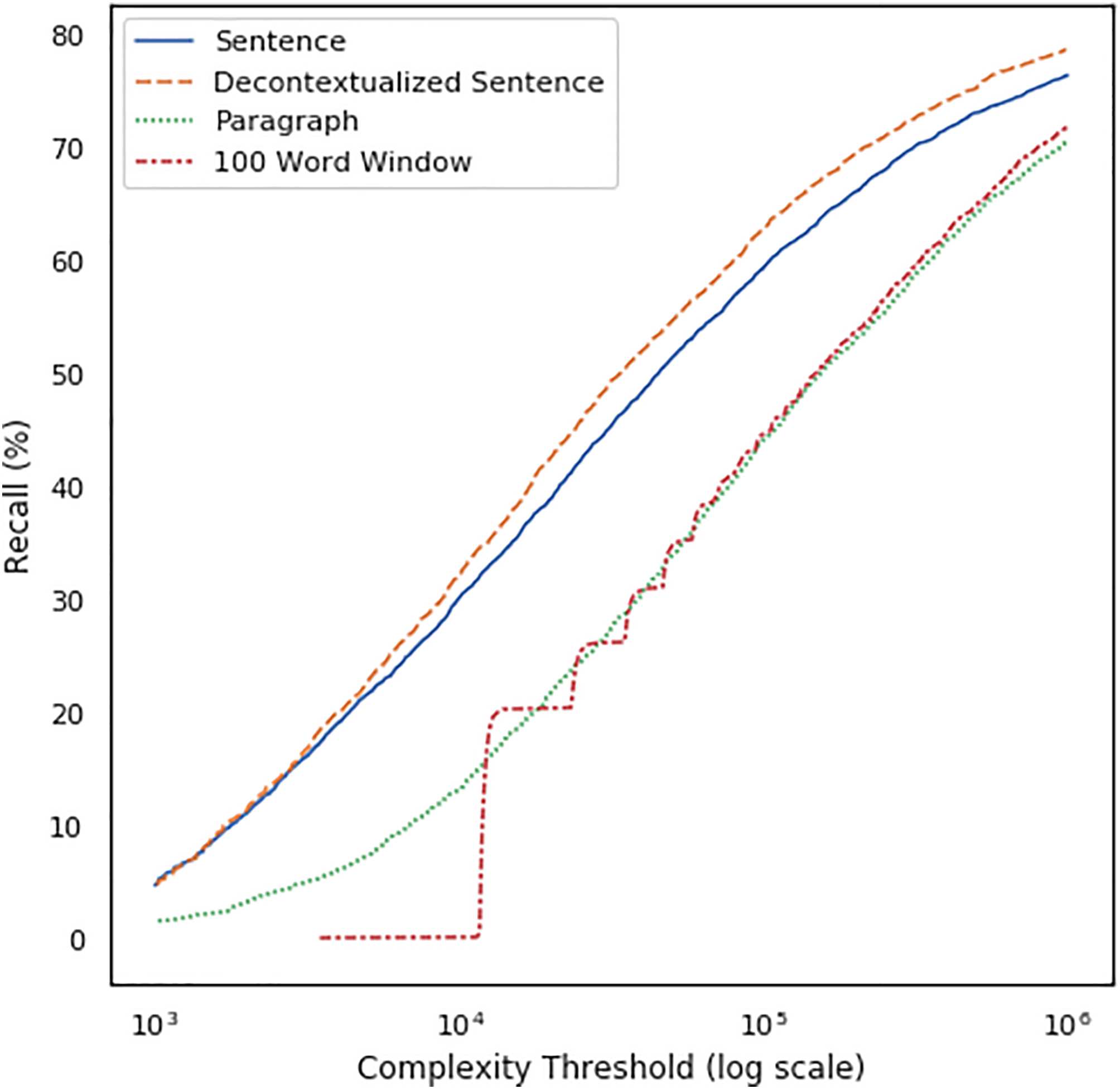
Results Figure 5 plots the recall of each retrieval
corpus at different computational cost budget t
on the whole NQ-open evaluation set. The graph
shows that sentence level segmentation is more
cost-effective than paragraph or 100-word level
segmentation, and using decontextualized sen-
tences is more cost effective than using the orig-
inal sentences. Decontextualized sentences near
the performance of commonly used 100-word
windows with 1/10th the cost.
This result exemplifies the way in which decon-
textualization can be used to ensure that the input
to natural language understanding system is con-
cise yet complete. We think this way of using
decontextualization as a preprocessing could also
aid tasks such as summarization.
7 Related Work
Prior literature in summarization studied how arti-
cle context affects the understanding of sentences
Figure 5: Retrieval recall plotted against computational
cost budget (Eqn 1) for different methods of document
segmentation.
within an article. It has been observed that disam-
biguating entity mentions and correctly resolving
anaphora is crucial for automatic summarization
(Otterbacher et al., 2002; Steinberger et al., 2007)
and for evaluation of summarization systems
(Pitler et al., 2010). Li et al. (2016) identified
that information missing from a sentence could be
identified in the article context in newswire text
60% of the time. This is considerably less fre-
quent than for the encyclopedic text studied here,
but nevertheless hints that decontextualization for
newswire text could be feasible. It remains unclear
whether information accessible in newswire con-
texts can be readily incorprated into sentences
using controlled edits of the type we employ.
Successful decontextualization models must
resolve entity and event coreferences (Humphreys
et al., 1997) as well as other forms of anaphora
(R¨osiger et al., 2018). These are necessary but
insufficient
for decontextualization however,
which also involves discourse marker removal,
acronym expansion, and fluent and grammatical
sentence generation.
The term decontextualization was introduced
in a recent table-to-text generation dataset (Parikh
et al., 2020) where a sentence from a Wikipedia
document was decontextualized such that it can be
interpretable when presented with a table alone.
They cover only the sentences that are relevant
to the table, and adapt it to the table context. In
a recent image captioning dataset (Sharma et al.,
458
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
l
a
c
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2018), sentences are re-written such that infor-
mation that cannot be inferred from the image is
removed. For example, entity names are replaced
with generics (e.g., * -Tom Cruz , +A man + is
waiting.’’).
sonalized text simplification. In Proceedings of
the 27th International Conference on Compu-
tational Linguistics, pages 245–258, Santa Fe,
New Mexico, USA. Association for Computa-
tional Linguistics.
8 Conclusion
We define decontextualization, the task of rewrit-
ing a sentence from a document to be interpretable
in an empty context, while preserving its meaning.
We build a crowdsourced dataset and a model for
decontextualization, and demonstrate how decon-
textualization can be used in a user-facing task
and as a sub-component of an application system.
We believe that decontextualization will also
be helpful in a wide range of other applications.
For example, in multi-document summarization
(Fabbri et al., 2019), co-referring entities and
events must be resolved across different docu-
ments and removing ambiguous references may
help; extractive summarization (Cheng and Lapata,
2016) could benefit from the type of pre-processing
that we presented for open-domain QA; anaphora
resolution is crucial for both summarization and
machine translation (Susanne et al., 1992); and
decontextualizing sentences may help in recov-
ering explicit mentions of entities and relations
which can help information extraction (Narasimhan
et al., 2016). The current formulation focuses on
the English encyclopedic corpus and rewriting for
an empty context, and future work can explore
different domains of text as well as mapping to a
different context.
Acknowledgments
We would like to thank members of Google AI,
especially Jacob Eisenstein, Kenton Lee, Santiago
Ontanon, Ankur Parikh, Daniel Andor, Chris
Alberti, and Slav Petrov for helpful discussions
and comments. Lastly, we would like to thank our
annotators.
References
Lora Aroyo and Chris Welty. 2015. Truth is a
lie: Crowd truth and the seven myths of hu-
man annotation. AI Magazine, 36:15–24. DOI:
https://doi.org/10.1609/aimag.v36i1
.2564
Joachim Bingel, Gustavo Paetzold, and Anders
Søgaard. 2018. Lexi: A tool for adaptive, per-
Betty J. Birner. 2012. Introduction to Pragmatics,
1st edition. Wiley Publishing.
Paul-Christian B¨urkner. 2017. brms: An R pack-
age for Bayesian multilevel models using Stan.
Journal of Statistical Software, 80(1):1–28.
DOI: https://doi.org/10.18637/jss
.v080.i01
Danqi Chen, Adam Fisch, Jason Weston, and
Antoine Bordes. 2017. Reading Wikipedia to
answer open-domain questions. Proceedings
the Association
of
the Annual Meeting of
(ACL). DOI:
for Computation Linguistics
https://doi.org/10.18653/v1/P17
-1171, PMCID: PMC5579958
Jianpeng Cheng and Mirella Lapata. 2016. Neural
summarization by extracting sentences and
the 54th Annual
words. In Proceedings of
Meeting of the Association for Computational
Linguistics, pages 484–494. Berlin, Germany,
Association for Computational Linguistics.
DOI: https://doi.org/10.18653/v1
/P16-1046, PMCID: PMC4738087
Herbert H. Clark. 1975. Bridging. In Theoretical
issues in natural language processing. DOI:
https://doi.org/10.3115/980190
.980237, PMID: 1166311
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2018. BERT: Pre-training
of deep bidirectional transformers for language
understanding.
Alexander R. Fabbri, Irene Li, Tianwei She, Suyi
Li, and Dragomir R. Radev. 2019. Multi-news:
A large-scale multi-document summarization
dataset and abstractive hierarchical model. In
Proceedings of
the
Association for Computation Linguistics (ACL).
DOI: https://doi.org/10.18653/v1
/P19-1102
the Annual Meeting of
H. Paul Grice. 1975. Logic and conversation.
In Peter Cole and Jerry L. Morgan, editors,
Speech Acts, volume 3 of Syntax and Semantics,
pages 41–58. Academic Press, New York.
459
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
l
a
c
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Kelvin Guu, Kenton Lee, Zora Tung, Panupong
Pasupat, and Ming-Wei Chang. 2020. Realm:
Retrieval-augmented language model pre-
training. DOI: https://doi.org/10.3115
/1598819.1598830
K. Humphreys, R. Gaizauskas, and Saliha
Azzam. 1997. Event coreference for infor-
mation extraction. DOI: https://doi.org
/10.3115/1598819.1598830
Gautier
Izacard and Edouard Grave. 2020.
Leveraging passage retrieval with generative
models for open domain question answering.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S.
Weld, Luke Zettlemoyer, and Omer Levy. 2020.
SpanBERT: Improving pre-training by rep-
resenting and predicting spans. Transactions
of
the Association for Computational Lin-
guistics, 8:64–77. DOI: https://doi.org
/10.1162/tacl a 00300
V. Karpukhin, B. O˘guz, S. Min, L. Wu, S. Edunov,
D. Chen, and W.-T. Yih. 2020. Dense passage
retrieval for Open-Domain question answering.
Proceedings of the Conference on Empirical
Methods in Natural Language Processing
(EMNLP). DOI: https://doi.org/10
.18653/v1/2020.emnlp-main.550
Tom Kwiatkowski, Jennimaria Palomaki, Olivia
Redfield, Michael Collins, Ankur Parikh, Chris
Alberti, Danielle Epstein,
Illia Polosukhin,
Matthew Kelcey, Jacob Devlin, Kenton Lee,
Kristina N. Toutanova, Llion Jones, Ming-Wei
Chang, Andrew Dai, Jakob Uszkoreit, Quoc
Le, and Slav Petrov. 2019. Natural questions:
A benchmark for question answering research.
the Association of Compu-
Transactions of
tational Linguistics. DOI: https://doi
.org/10.1162/tacl a 00276
Kenton Lee, Ming-Wei Chang, and Kristina
Toutanova. 2019. Latent retrieval for weakly
supervised open domain question answering.
arXiv preprint 1906.00300.
Junyi
Jessy Li, Bridget O’Daniel, Y. Wu,
W. Zhao, and A. Nenkova. 2016. Improving the
annotation of sentence specificity. In LREC.
X. Liu and W. Croft. 2002. Passage retrieval
based on language models. In CIKM ’02. DOI:
460
https://doi.org/10.1145/584792
.584854
Karthik Narasimhan, Adam Yala, and Regina
Barzilay. 2016.
Improving information ex-
traction by acquiring external evidence with
reinforcement learning. In Proceedings of the
Conference on Empirical Methods in Nat-
ural Language Processing (EMNLP). DOI:
https://doi.org/10.18653/v1/D16
-1261
Jahna Otterbacher, Dragomir R. Radev, and
improve
Airong Luo. 2002. Revisions that
cohesion in multi-document summaries: a
preliminary study. In Proceedings of the Annual
Meeting of the Association for Computation
Linguistics (ACL). DOI: https://doi.org
/10.3115/1118162.1118166
Ankur P. Parikh, Xuezhi Wang, Sebastian
Gehrmann, Manaal Faruqui, Bhuwan Dhingra,
Diyi Yang, and Dipanjan Das. 2020. ToTTo:
A controlled table-to-text generation dataset.
Proceedings of the Conference on Empirical
Methods in Natural Language Processing
(EMNLP), abs/2004.14373. DOI: https://
doi.org/10.18653/v1/2020.emnlp
-main.89
Ellie Pavlick and Tom Kwiatkowski. 2019.
Inherent disagreements
in human textual
inferences. Transactions of the Association for
Computational Linguistics, 7:677–694. DOI:
https://doi.org/10.1162/tacl a
00293
Emily Pitler, Annie Louis, and Ani Nenkova.
2010. Automatic
linguistic
quality in multi-document summarization. In
the
Proceedings of
Association for Computation Linguistics (ACL).
the Annual Meeting of
evaluation of
Sameer Pradhan, Alessandro Moschitti, Nianwen
Xue, Olga Uryupina, and Yuchen Zhang. 2012.
ConLL-2012 shared task: Modeling multilin-
gual unrestricted coreference in ontonotes. In
EMNLP-CoNLL Shared Task.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.
2019a. Exploring the limits of transfer learning
with a unified text-to-text transformer. arXiv
preprint 1910.10683.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
l
a
c
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.
2019b. Exploring the limits of transfer learning
with a unified text-to-text transformer. ArXiv,
abs/1910.10683.
Josef Steinberger, Massimo Poesio, Mijail A.
Kabadjov, and Karel Jeek. 2007. Two uses
of anaphora resolution in summarization.
Information Processing and Management,
43(6):1663–1680. DOI: https://doi.org
/10.1016/j.ipm.2007.01.010
Ina R¨osiger, Arndt Riester, and Jonas Kuhn.
2018. Bridging resolution: Task definition,
corpus resources and rule-based experiments.
In Proceedings of the International Conference
on Computational Linguistics (COLING).
Piyush Sharma, Nan Ding, Sebastian Goodman,
and Radu Soricut. 2018. Conceptual captions:
A cleaned, hypernymed, image alt-text dataset
for automatic image captioning. In Proceed-
ings of the Annual Meeting of the Associa-
tion for Computation Linguistics (ACL). DOI:
https://doi.org/10.18653/v1/P18
-1238, PMCID: PMC6266124
Dan Sperber and Deirdre Wilson. 1986. Rele-
vance: Communication and Cognition. Harvard
University Press, USA.
Preusz
Susanne, Birte
Hauenschild,
Anaphora resolution in machine translation.
and Carla Umbach.
Schmitz, Christa
1992.
Wei Xu, Chris Callison-Burch, and Courtney
Napoles. 2015. Problems in current text sim-
plification research: New data can help. Trans-
actions of the Association for Computational
Linguistics, 3:283–297. DOI: https://doi
.org/10.1162/tacl a 00139
Wei Xu, Courtney Napoles, Ellie Pavlick, Quanze
Chen, and Chris Callison-Burch. 2016. Opti-
mizing statistical machine translation for text
simplification. Transactions of the Association
for Computational Linguistics, 4:401–415.
DOI: https://doi.org/10.1162/tacl
a 00107
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
7
7
1
9
2
4
2
3
4
/
/
t
l
a
c
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
461