大卫·坦波利
伊士曼音乐学院
26 吉布斯街.
罗切斯特, 纽约 14604 美国
dtemperley@esm.rochester.edu
评价体系
对于公制模型
在年轻且快速发展的音乐领域
人工智能, 一个特别活跃的领域
研究一直是计量分析 (也称为
查表, 节拍追踪, 节拍感应,
节奏解析, 和节奏转录)-这
从中提取度量信息的问题
音乐. 的确, 公平地说
该领域没有任何问题如此吸引人-
注意力和能量就像这个. 桌子 1 显示一个列表
的 25 提出计算模型的研究
度量分析. (该表包括所有已发布的
研究——不是硕士和博士学位. 论文——我有
能够识别并获得. 它仅包括
已经实施或至少实施的模型
完全指定的; 音乐界知名模特
Lerdahl 和 Jackendoff 等理论 (1983) 是
因此被排除在外. 型号也被排除在外
仅识别节奏而不识别实际
击败地点, 比如棕色 1993. 在以下情况下
几项研究提出了单一的接近变体
模型, 仅列出一项研究。)
表中型号 1 反映了各种-
对度量分析问题的看法. 他们
可以按照几个不同的方向进行分类.
一个基本区别涉及性质
输入的; 直到最近, 几乎所有系统
从象征性的工作 (''笔记'') 某种输入,
但在过去的几年里,一些型号已经
建议直接从音频数据操作.
一些模型假设量化输入 (为了考试-
普莱, 持续时间用小整数表示
价值观), 而有些则允许波动
人类表现的时间特征; 一些
模型仅生成单一级别的节拍,
而其他人则产生几个. 当然, 这
模型也可以根据它们的特性进行分类
方法 (基于规则的, 联结主义者, 振荡器-
基于, 概率性的, ETC。), 但这是一个更com-
复杂物质, 所以我不在表中考虑它 1.
也许要解决的最基本的问题
一个模型——尽管它并不总是被提及——是它的
电脑音乐杂志, 28:3, PP. 28–44, 落下 2004
(西德:1) 2004 麻省理工学院.
目标. 一些度量分析系统显然处于-
倾向于模拟人类认知; 其他都是SIM卡-
层设计是为了解决实际问题
以任何看起来最有效的方式查表-
主动的. 查表作为认知的重要性-
整个过程似乎是不言而喻的; 米是一个基本的
音乐体验的一部分,并已被证明
也影响音乐认知的其他方面,
比如旋律的相似度 (加布里埃尔森 1973), 前任-
观望 (琼斯等人. 2002), 和谐感知
(坦珀利 2001), 表现表达 (自由
1983; 帕尔默 1997), 和性能错误 (帕尔默
和普福德雷舍 2003). 然而, 实际问题-
莱姆也很重要. 尤其, 生成
一首乐曲的乐谱需要识别
它的米. 正如《坦珀利》中所论证的那样 (2001), 如果我们
将度量结构设想为多层次的
节拍框架 (全音符节拍, 二分音符
节拍, 等等, 直至最小的节奏
作品中的水平), 一首乐曲的格律结构
本质上提供了所需的信息
有节奏地记下它. 和, 正是因为
格律结构在音乐齿轮中的核心作用-
尼尼申 (如上所述), 它将不可避免地到来
参与音乐工程的其他问题.
例如, 任务,例如将查询与
音乐数据库, 按风格或对作品进行分类
情绪, 或为梅尔生成伴奏-
身体肯定需要考虑公制-
校准信息.
无论度量标准的目标和假设是什么-
校准模型, 一个重要而明显的问题
问是, ‘‘那多好啊?'' 那是, 百分之多少
它实际上能产生正确的结果吗?-
苏尔特? (“正确结果”可以定义为
有能力的听众推断出的格律结构.
可能有, 当然, 存在一些主观差异-
听众之间的关系; 也可能会采取 mu-
代表其节拍的乐曲的 sic 符号. 但
大多数情况下, 我会争辩, 会有同意的-
这些来源之间的变化。) 如果想要一个模型
作为查表的实用工具, 重要性
这个问题几乎不需要辩护. 如果
模型旨在作为关于认知的假设,
28
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
桌子 1. 度量分析模型
参考
朗格-希金斯和斯蒂德曼 (1971)
龙格-希金斯 (1976)
斯蒂德曼 (1977)
查菲等人. (1982)
朗格-希金斯和李 (1982)
波维尔和埃森斯 (1985)
设计和珩磨 (1989)
艾伦和丹能伯格 (1990)
李 (1991)
米勒等人. (1992)
罗森塔尔 (1992)
罗维 (1993)
大和科伦 (1994)
麦考利 (1994)
帕恩卡特 (1994)
谢雷尔 (1998)
坦珀利和斯利特 (1999)
塞姆吉尔等人. (2000A, 2000乙)
狄克逊 (2001A)
埃克 (2001)
后藤 (2001)
拉斐尔 (2001)
塞塔雷斯和斯塔利 (2001)
斯皮罗 (2002)
范扎宁等人. (2003)
输入: 声音的
或象征性的?
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
象征性的
声音的
象征性的
象征性的
符号或音频
象征性的
声音的
象征性的
声音的
象征性的
象征性的
输入: 量化
或已执行?
输出:
多层次?
量子化的
执行的
量子化的
执行的
量子化的
量子化的
执行的
执行的
量子化的
量子化的
执行的
执行的
执行的
执行的
量子化的
执行的
执行的
执行的
执行的
量子化的
执行的
执行的
执行的
量子化的
量子化的
是的
是的
是的
是的
是的
不
是的
不
是的
是的
是的
是的
是的
不
不
不
是的
是的
不
不
是的
是的
是的
是的
是的
其绩效水平的相关性较小
清除. 模型可以完美表现, 生产
完全正确的结构 (IE。, 所推断的
大多数听众) 在 100 病例百分比, 然而
与认知没有任何相似之处
查表过程; 一个模型
正确的 20 百分比的时间可能仍然会出现
捕捉认知专业的重要方面-
过程. 然而,它似乎被认知界普遍接受-
科学表明一个人的表现水平
认知模型至少是一个有效的标准
评估时考虑, 虽然肯定有
其他的. (有人可能会考虑, 例如, 怎么样
该模型与其他实验结果一致-
关于认知过程的科学, 是否
模型的架构和计算需求
在心理上是合理的, 等等。) 给定
两种认知模型 A 和 B, 否则等于
认知合理性, 如果模型A的输出量很大
更好的 (更接近人类) 比 B 型,
这无疑给模型 A 带来了更大的可信度
关于认知的假说.
简而言之, 度量的性能水平
模型对于实际目标至关重要
并且至少对认知有一定的重要性
目标. 考虑到大量的度量模型
已提议的, 然后, 似乎值得
检查他们的表现质量. 这
本文的目的实际上不是要回答
这个问题直接, 而是为了解决一个初步问题-
没有任何问题: “我们怎样才能决定一个
度量模型是?” 在下文中, 我建议一个
用于评估度量模型的系统
衡量他们的表现并进行比较的目标
他们在这方面的优势和劣势.
坦珀利
29
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
评估体系的四个要求
当前的问题体现了一个常见的问题-
人工智能等领域的现状
领域. 最终目标是开发系统
可以从数据中检索某种信息;
有许多模型可用于该任务, 和我们
希望能够评估他们的成功. 对于这样的
评价体系, 我认为有四件事是
需要的: 商定的代表方式
要检索的信息类型; 一个适当大的
和代表性数据集; 正确的分析
语料库的 (表示的信息是
检索到的); 以及商定的比较方法
模型对语料库的分析正确-
ses 并对模型在比赛中的成功进行评分-
进行正确的分析.
考虑一个成功的解决方案是有用的
另一个领域的评估问题——com-
推论语言学. 自该领域诞生以来, A
计算语言学的中心项目
自然系统的开发-
语言解析——恢复句法信息
来自书面或口头文本. 直到最近, 亲-
该领域的进展因困难而受到阻碍
评估模型并将一个模型与一个模型进行比较-
其他. 20世纪90年代初, 这个问题很大程度上是
宾州树库的开发解决了这个问题
(马库斯等人。. 1993). 宾夕法尼亚树库 (Penn Treebank)-
自然发生的数百万字的脓液
从书面和口头收集的文本
来源. 树库附有句法
专家进行的分析——“构成结构”-
ture'' 对于每个显示名词短语的句子, 动词
短语, 条款, ETC. 已提出指标
用于比较“树库式”分析 (布莱克等人
阿尔. 1991), 并且提供了需要两个时间的程序
一组句子的分析——正确的分析
放 (被誉为“黄金档案”) 以及一个由
待评估模型 (一个“测试文件”)——并评估
测试文件分析与测试文件分析的匹配程度如何
金文件.
对于自然语言解析问题, 然后,
可以看出,列出的所有四个要求
以上已满足. 这一成就导致了
自然语言解析的进步激增. (为了
讨论, 参见曼宁和舒茨 2000.) 在
接下来是什么, 我考虑这些问题的可能解决方案
度量模型评估的四个要求-
化问题.
先前的评估工作
度量模型
大部分情况下, 评估问题已重新-
格律文献中很少受到关注
分析. 许多研究没有给出定量的结果-
所提出模型的性能测量. 在里面
过去几年, 然而, 一些重要的建议
已在该领域提供.
评估指标的适当方法
模型取决于模型的性质. 我们
可能首先区分接受的模型
仅量化输入和接受的输入-
形成的输入. 在量化输入模型中, 时间-
点通常表示为a的倍数
短节奏值或“基本单位”,”比如一个
十六分音符. 此类模型通常假设
格律结构是完全规则的-
出去. 在这种情况下, 格律结构的每一层-
ture 可以用两个数字来表征: 一
表明其时期 (以基本单位表示), 或距离
节拍之间; 另一个表示相位
(再次以基本单位表示)——开始后多久
乐曲的第一个节拍出现. 生成一个级别
如果该模型的 pe 可以说是正确的-
Riod 和 Phase 与中的级别之一完全匹配
正确的格律结构. 这本质上是
Desain 和 Honing 使用的方法 (1999).
Desain 和 Honing 评估三种度量模型
(龙格-希金斯和李的模型 1982 和
它的两个后来的变体) 使用三个测试语料库: A
一组随机生成的节奏, 一组‘‘metri-
校准节奏 (其中每个音符都是一个
在某些韵律水平上拍长), 和一个语料库
国歌旋律. 三个mod中的每一个-
els 测试仅生成单个节拍级别. 为了
每个型号, 作者提供了有关
模型的输入案例的比例
节拍与正确的主节拍级别匹配
结构 (在时期和阶段上); 他们还强调-
将模型的节拍与其他节拍进行比较的数据
正确结构中的层次. (范扎宁等人.
30
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
2003 使用相同的国歌语料库和类似的
测试策略。) 设计和珩磨的方法
对于评估量化输入似乎非常明智
型号. 下文中, 我们主要关注
执行输入模型; 从表中可以看出
1, 近年来大多数模型都解决了每个-
形成的输入.
一种评估执行输入满足的方法-
Cemgil 等人提出了现实模型. (2000乙).
这需要包含节拍位置的数据
明确指出. (只有一个级别的节拍是
假定。) 假设正确的节拍级别为
件是S (西德:2) s1, s2, . . ., 和 (其中每个 sn 是时间
节拍点), 以及模型的输出节拍水平
是 T (西德:2) t1, t2, . . ., tJ. 接近度得分W
任意两个节拍 si 和 tj 使用高斯表示-
正弦窗函数 (这样两个完全同时-
neousbeats 得分为 1). 相似度
那么S和T之间的函数是
我
最大电阻宽度 (s , t )
j
(我 (西德:3) J) / 2
我
j
• 100
这个公式计算每个正确的节拍, 将其与
模型输出中与其最接近的节拍, 和
将这些节拍对的 W 分数相加.
然后除以 I 和 J 的平均值
(这意味着模型的输出将为 pe-
如果它的节拍比正确的节拍多得多,则已确定
结构) 并乘以 100. 结果是
粗略表示百分比的单个数字-
与正确心跳相匹配的年龄
模特的节拍. 使用这种评估技术,
塞姆吉尔等人. (2000乙) 测试了他们自己的模型
披头士乐队歌曲“Yester”的键盘演奏-
天,》由不同表演者多次演奏
并在不同的节奏指令下 (快速地, 也不-
马尔, 或慢). (该模型本质上是给定的
正确的初始速度和相位。) 狄克逊 (2001乙)
后来将他的模型与 Cemgil 等人的模型进行了测试.
使用类似的评估方法和相同的
数据集, 他报告了总分 94 (西德:4) 9
对于他的模型与 91 (西德:4) 7 对于 Cem 模型-
吉尔等人.
提出了一种有点类似的方法
后藤和村冈 (1997) 用于测试音频输入
度量模型. 系统要求音频
输入用标记补充, 添加者
手, 指示正确的节拍位置. 后藤
Muraoka 提出了一种音频输入模型
输出多级节拍; 模型正在评估-
按以下方式评价. 对于每个正确的节拍
中文, 模型输出中最接近的节拍 Bm 是
成立, 并计算出一个错误, 现在是什么时间
Cn 和 Bm 之间的差值占
正确节拍之间的间隔. 最长的芯-
找到了该作品的正确跟踪部分 (IE。, 这
误差小于 cer 的最长跨度-
保持价值). 测试集包括 40 歌曲 (从
没有鼓的流行音乐录音), 每个在
至少 1 敏龙, 由各种艺术家. 非盟-
作者将正确的分析定义为:
(1) 最长的正确跟踪部分开始于 no
晚于 45 乐曲开始后几秒
并延伸到最后, 和 (2) 平均值, 方差,
和最大误差都在一定的范围内-
厄斯. (例如, 平均误差必须小于
0.2.) 按照这个标准, 模型分析 87.5 每-
输入歌曲的四分音符正确的分数
等级.
Cemgil 等人的方法. 和后藤和
村冈为
执行输入度量模型的评估.
然而, 他们也会遇到一些困难.
尤其, 他们需要每个节拍的位置
准确指定, 事实上,确切的地点-
节拍的重刑往往有些不确定.
考虑生成的古典乐曲的 MIDI 文件
来自钢琴演奏 (或音频文件, 为了那个原因
事情). 可能会有很多和弦
几个音符被理解为同时和
与特定的节拍一致. 但最有可能的是他们
不会完全同时播放; 那么在哪里
正是节拍? 也可能有节拍
没有一致的音符, 所以再次准确的位置
节拍不确定. 这个问题可以解决
通过让人类注释者提供节拍信息-
根据他们的直觉. 但是这个解决方案-
化离理想还很远; 这样的手工注释是
耗时且有些主观. 它
看来, 在评估度量分析时, 我们
应重点关注格律结构方面-
清晰且无争议的事实. 肯定
节拍与某些音符相对应, 和别的
节拍可能介于两者之间,但不一定位于
坦珀利
31
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
确定的地点. (这方面的具体例子
稍后会给出。)
解决这个问题的一种方法是
可以称为“得分-时间”系统. 在这个
系统, 一首乐曲的正确格律结构是
用于生成量化的节奏表示-
化,使每个事件都有正确的位置或
作品中的“得分时间”. 例如, 如果季度-
音符节拍被定义为整数, 关于的注释
第一个四分音符节拍是在得分时间 0.0, 一个注释
下一个节拍是在 1.0, 和一个音符八分之一-
请注意稍后在 1.5. 这种有节奏的重复系统-
怨恨被用于各种目的——
例子, 分数与表现匹配 (你好
等人. 2000). 然后可以运行度量模型
通过为每个音符分配一个得分时间; 该模型
可以根据 (例如) 这
被分配正确的音符的比例
得分时间. 请注意,这样的模型不需要-
确定不确定节拍的确切位置
不包含任何注释. 然而, 该制度已生效
只代表一级米: 一般来说
主节拍级别或“tactus”。得分时间不包含在-
表示更高的韵律级别, 例如, 是否是塔克图斯
节拍分为二重奏或三重奏 (虽然这样
信息可以用其他方式表示; 看
例如 Cemgil 等人. 2000A). 这项措施是
也比较不灵活. 如果模型额外插入一个
在乐曲开头附近节拍, 那么所有的
将判定后续赛事的得分时间
不正确, 这似乎过于严厉.
下文中, 我建议使用替代应用程序-
度量评估方法. 这建立在
“得分时间”理念, 但允许多个度量
水平,还可以进行更灵活的比较
计量分析. 应该在out处注明-
设置该系统主要用于
符号输入模型. 是否也会是
对于音频输入模型有用是一个悬而未决的问题; 我
返回文章末尾处.
表示系统
我们首先要考虑如何表示输入
data——要分析的数据. 关注了很多
其他型号, 我将假设一个代表骗局-
包含用“ontime”编码的注释列表和
''下班时间'' (两者均以毫秒为单位) 和音调 (在整数注释中-
的, 中间有C (西德:2) 60). 这样的表示,
类似于 MIDI 文件, 有时被称为
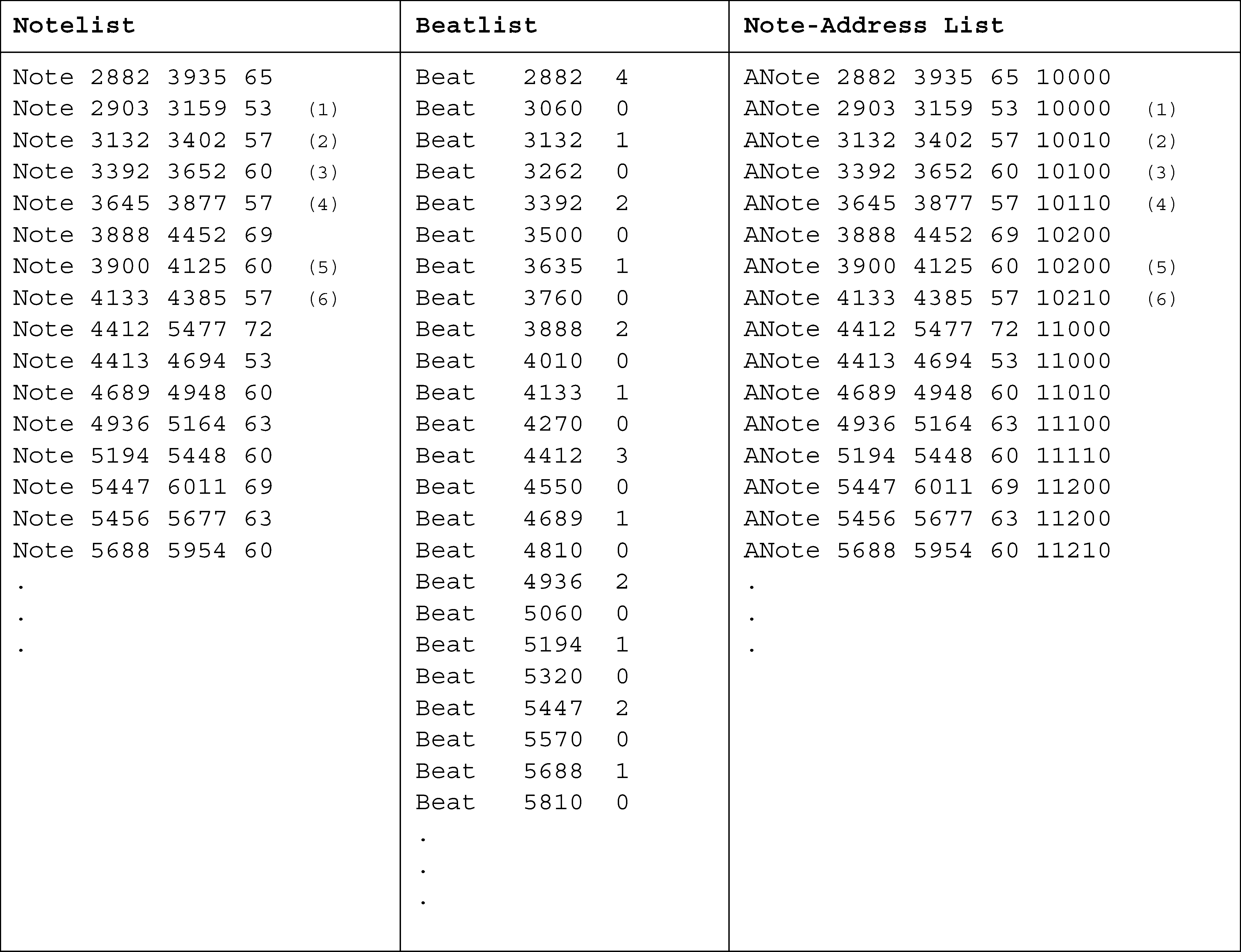
‘‘笔记列表’。”图 1 显示莫扎特的开场
钢琴奏鸣曲; 分数下方最左边的一列
显示前两个小节的注释列表. (这
括号内的数字已添加以供参考-
出现在下面的讨论中。) 请注意,这
系统不假设事件是定量的-
第十 (除了非常低的毫秒水平); 不-
图中的电话列表 1 是从表演中产生的
在 MIDI 键盘上, 可以看出
时间安排有些不规律.
我们现在转向度量的表示-
结构本身. 大多数度量模型产生
与节拍对齐的某种表示
作为输入给出的音乐. 节拍很简单
时间点, 主观上理解为重音,
尽管不一定与任何事件同时发生.
一些系统 (如上所述) 生成几个
节拍级别, 或者——换句话说——节拍
不同强度, 存在“强”节奏的地方
在较高水平上,“弱”节拍仅在较低水平下
级别. 可以表示一个度量结构
以图形方式呈现为点的框架 (勒达尔和
杰肯道夫 1983), 如图 1 上面的
职员. 位于坦珀利和斯利特 (1999), 我们提议
将这样的结构编码为节拍状态列表-
评论, 每个都有一个时间点和一个级别编号-
ber 代表最高级别
节拍存在; 前两张专辑的“beatlist”-
图中度量网格的确定 1 显示在
分数下方的中间栏. 我们假设一个
五个度量层次的结构, 编号为 0–4,
数字越大代表级别越高;
等级 2 是“tactus”或主节拍, 该季度-
在这种情况下注意级别. (假设五级-
els 似乎最适合常见的音乐练习
一般的, 尽管有些作品可能需要更多或
更少的级别; 参见勒达尔和杰肯多夫 1983 和
坦珀利 2001 供讨论。)
鉴于此表示方案, 一种可能
评价体系的思路如下. 让我们
假设一个由片段或摘录组成的语料库
笔记列表格式. 每个摘录都可以注释
32
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1. 莫扎特, 奏鸣曲
电压 332, 我, 毫米. 1–5, 展示-
格律网格 (多于
工作人员), 笔记列表, 节拍列表,
和注释地址列表.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
与正确的节拍列表; 这可能是 com-
与模型生成的节拍列表进行比较
经测试 (类似于 Goto 和 Mu 的方法-
拉奥卡 1997 和塞姆吉尔等人. 2000乙). 一个问题
出现在这里, 正如已经提到的: 罗-
节拍的阳离子通常是不确定的. 图中 1,
右手和左手的第一个音符
被理解为与第一个节拍一致, 但
它们并不完全同时. 是节奏吗-
满足于 2882, 2903, 或介于两者之间?
(图中的beatlist 1 任意调整节拍
与这两次发作中的第一次相比。) 此外,
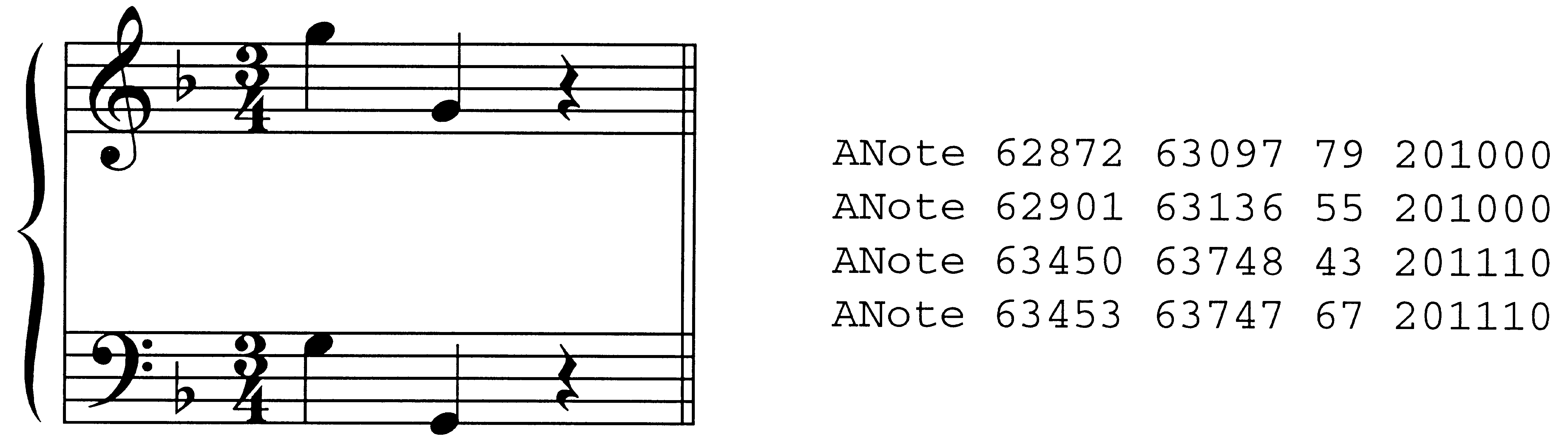
许多节拍没有重合的音符. 在图2a中
和2b (摘录自同一篇文章的后面部分),
第二个四分音符节拍到底在哪里
米. 12, 或 m 的第三个四分音符节拍. 40? 这
所有级别都可以这样说-0 图中节拍
1, 没有一个与注释一致. 的确, 一
可能会质疑是否水平-0 节拍甚至是 pres-
进入这一段. 这些探测器的位置-
坦珀利
33
数字 2. 三段摘录
选自莫扎特, 索纳塔KV
332, 我, 显示注释-
地址列表在右侧.
(图 2a 和 2b 显示
五值票据地址;
图 2c 显示了六值
注意地址。)
(A) 米. 12
(乙) 米. 40
(C) 米. 8
34
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
终止节拍也许可以确定
感性术语——我们确实有一些直觉
关于m的第二拍在哪里. 12 发生 (问题-
大约介于第一和第三之间
四分音符节拍)——但是对于人类注释者来说
得出正确答案将非常困难-
邪教.
正如之前所建议的, 出于度量的目的
评估, 我们应该关注哪些是失控的-
维西尔. 有些事情确实看起来没有争议:
在图2a中, 第一个和弦的音符落在
打, 即使它们可能不完全同时-
尼厄斯. 接下来是一个空拍 (尽管
其确切时间点不确定), 其次是
小节第三拍的另一个和弦.
(还要注意节拍的确切位置 2 米数.
12 不需要用于转换的目的
将节拍列表转换为乐谱. 只要知道
第一个和弦与第一个 2 级节拍一致
措施的, 和第二个和弦
第三级2节拍, 与另一个 2 级节拍
介于两者之间, 这就是所需要的全部。)
满足这一要求的一种表示系统-
要求就是我所说的“注释地址”
系统——如图右栏所示
1 莫扎特奏鸣曲节选的开场. 它
可以看到这里的事件列表包含了所有
原始笔记列表的信息, 但是
Note 语句已成为 ANote 语句,
包括准时, 下班时间, 沥青, 和‘‘注意
地址”——代表票据位置的数字-
格律网格中的重刑. 这个数字应该重新-
ally 被认为是一个五值向量, 但它可以
表示为单个整数, 因为没有一个
值曾经超过 9 除了最左边的那个.
(我们暂时假设五个级别, 虽然原则上
可以使用更多或更少。) 中的每个值
矢量对应于度量网格的级别
(最右边的值对应级别 0). 这
值表示该级别的节拍数
从那以后在这篇文章的那一点上已经过去了
下一个级别的上一个节拍.
举个例子, 考虑前六个八分音符
左手的, 由括号中的数字表示-
论文. 对于四分音符级别 (对应于
注释地址中从右数第三位数字),
这些注释中的第一个和第二个具有以下值 0
(自上次以来没有出现四分音符节拍
附点半音符节拍), 第三个和第四个有
价值 1 (发生了一拍), 以及第五个和
第六个有价值 2 (发生了两次节拍). 这
最高级别 (最左边) 地址的值, 哪个
始终设置为 1 在乐曲的开头, 代表-
发送的最高级别节拍的数量
整个作品中的逝去 (因为没有
从更高级别开始计数). 最终这个
可能成为 2- 或 3 位数字, 制作广告-
穿着像 20-1-0-0-0 (如图2b所示). 一个可以
实际上为节拍本身分配地址;
在完全规则的双重网格中, 这将是
相当于计算二进制数 (10000,
10001, 10010, 10011, 10100, . . .), 与除了-
最左边的数字不是二进制的. 然而,
如果我们只为笔记分配地址, 我们避免
之前讨论过的必须做出决定的问题
不确定节拍的位置.
注释地址系统也解决了这个问题
由名义上同时的音符创建. 作为观察-
较早送达, 和弦的音符通常是un-
被理解为发生在同一节拍上 (并且会
以这种方式表示), 但他们是
很少完全同时执行. 因此作为-
将“节拍”标记为单个时间点是不同的-
邪教——确实不可能, 如果我们想要所有的笔记
和弦被表示为与
打. note-address提供的解决方案
系统见图 1. 单位:米. 1, 第一个
可以给出右手和第一个左手音符
相同地址, 即使他们并不完全
重合, 表示它们被理解为
在韵律上是同时的并且应该
以这种方式注明.
注释地址系统的进一步细化-
需要 TEM. 它在公制中被普遍接受
并非所有音符都必然符合的理论
节拍; 一些, 像颤音, 轮流, 和装饰音, 是
“度量外” (坦珀利 2001). 图2c显示
m 的一个例子. 8 莫扎特的选段. 二
右手边的注释 (以小注记下-
头, 按照惯例) 并没有真正发生在任何
打. 为了容纳度量外注释, 我们在-
再介绍一位 (最右边的) 注释的数字-
地址. 这个数字是 0 对于任何一致的注释
有节奏地; 对于两个节拍之间的音符,
坦珀利
35
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
该注释的地址是前一个的地址-
乌斯节拍, 除了 1 作为最后一位数字. 如果有
是多个, 两者之间的音符不一致
节拍, 他们地址的最后一位数字反映了他们的
及时订购: 图中第一个度量外注释-
ure 2c 已标记 410111, 第二 410112. (问题-
如果超过九个,就会出现 lems
两个节拍之间不一致的音符, 但是这个
似乎不太可能发生。) 因此请注意地址
有六个值, 我们将其称为级别 4, 3,
2, 1, 0 (对于五个度量级别), 和 –1 (前任-
横轴水平).
注释地址系统并不完美. 对于一个
事物, 不仅不能代表位置
没有重合音符的节拍, 有时它
甚至无法代表他们的存在. 在图2a中,
例如, 没有明确表明
小节的第二拍 (这将在广告中-
裙子 61100). 在这种情况下, 小姐的存在-
ingbeat 隐含在以下事实中:
注释有地址 61200; 这意味着有
一定是一个 61100 还有. 更令人担忧的是
案例如图2b所示. 这里, 第三拍
米. 40 甚至没有隐式地表示. 如果我们只是
查看了该段落的注释地址 (甚至
包括以下悲观的地址,
210000), 我们甚至无法确定 m. 40
是三米尺测量. 我们应该忍耐
头脑, 然后, 某些误差度量模型
可能会导致不被承认
注释地址系统: 例如, 如果一个度量
模型省略了 m 中的第三拍. 40, 或添加了一个
第四拍 (或额外十拍) 在结束时
措施. 这个问题的严重性不言而喻-
清除; 这取决于度量模型交流的频率-
实际上犯了这些错误. (问题
可以通过多种方式解决, 例如, 经过
用信息补充每个最高级别的节拍-
关于二重或三重划分的信息
每个级别的网格。) 的一些其他限制
注释地址系统将在稍后讨论-
系统蒸发散.
语料库
在选择语料库进行测试时, 两个考虑
很重要. 第一的, 组装时使用的标准
语料库应尽可能系统化.
而不是选择 20 人们所知道的部分和
恰好有得心应手的, 一个应该, 如果可能的话, 的-
纳入语料库的客观标准.
(危险在于, 当然, 那些我们
知道并方便的很可能是我们
用过的, 或者至少考虑过, 在发展我们的
模型。)
另一个要求是语料库应该是
较大语料库的代表性样本
要测试的模型旨在分析.
这在当前情况下是有问题的. 许多模组-
他们特别致力于
“常见”音乐 (粗略地说,
西方艺术音乐从 1700 到 1900). (即使在这里,
对于什么可能没有完全一致
常见的音乐包括。) 其他型号
试图适应其他类型的音乐,
比如爵士乐, 岩石, 和非西方音乐
(谢雷尔 1998; 塞姆吉尔等人. 2000乙; 后藤 2001; 硒-
泰瑞斯和斯塔利 2001). 因此, 我当然不
声称下面提出的语料库将是
适合或公平的一款适用于列出的所有型号
桌子 1.
位于坦珀利 (2001), 我介绍了“科斯特卡”-
佩恩语料库” (以下为 KP 语料库)——一组
46 常见做法的摘录
摘自 Stefan 随附的练习册
Kostka 和 Dorothy Payne 的教科书 Tonal Har-
金钱 (1995). 该语料库包括以下内容的所有摘录
长度至少为八小节的练习册;
它总共包含 541 已注明的措施和
9,057 笔记. 虽然语料库不是特别
大的 (更大的肯定是可取的), 它
有两个重要的优点: 摘录是
按客观标准选择; 他们跨越了
期间范围, 流派, 以及该领域内的作曲家
惯用语, 这样语料库就可以
被认为是常见的相当好的样本-
练习音乐. 为所有的文件生成了注释文件
语料库中的摘录; 这些笔记文件是 quan-
第十 (IE。, 从符号生成) 从而有
完全有规律的计时 (使用看起来的节奏
对我来说合理). 然而, 为了 19 摘录
选自钢琴独奏语料库, 我有一个熟练的
(博士级) 钢琴家演奏选段并
也从中生成了笔记文件. (我们会打电话
36
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
这是 KP 执行语料库。) 在量化的
笔记文件, 不包含度量外注释; 在
执行的笔记文件, 表演者被允许
包括任何度量外注释-
父亲. 表演中包含一些额外的内容-
笔记 (性能错误) 那是
随后从执行的文件中删除 (噢-
很难决定“正确”
这些的度量位置); 注释错误地省略-
执行的文件中的ted未恢复.
为所有摘录生成注释地址文件
在语料库中 (量化文件和每-
形成的) 使用前面 ex 中所示的格式-
阿普莱斯 (具体来说, 六值地址格式
如图2c所示). 这是通过运行来完成的
通过 Melisma 抄表专业版输入文件-
公克 (稍后讨论), 有时调整pa-
以特殊方式使用参数以使输出尽可能接近
尽可能纠正,然后手工纠正任何
剩余错误. 除极少数例外, 这
没问题: 这很干净, 既为泉-
tized 文件和执行的文件, 什么是正确的
每个注释的地址应该是. 有时候
应该定义哪个度量级别并不明显
作为塔克图斯 (等级 2); 我用了我自己的音乐评委-
对这些决定的支持. (在一些缓慢的动作中-
评论, 例如, tactus 跳动的长度如果
该符号是按字面意思理解的,例如, 四分音符
节拍在 2/4 米——将超过两秒,
超出了大多数人对上限范围的估计
感知的塔克塔斯。) 注意地址已编码
仅限于中注明的措施
分数; “超量度”水平 (高于测量值)
由于其主观性质而未包括在内.
比较黄金文件和测试文件
我们现在有一种表示格律结构的方法-
特雷斯 (注释地址系统), 数据集,
并正确分析所需的数据-
垫. 最终的要求是一种比较方法
由度量模型生成的注释地址文件 (A
‘‘测试文件’’) 并通过正确的分析 (“黄金档案”).
我们现在假设黄金文件和测试文件
包含完全相同的事件 (由他们所识别的
音调和时间点), 虽然我们会修改
这个假设略低于. 所以, 那里
匹配事件中应该没有困难
goldfile 及其在测试中的相应事件-
文件. 问题是比较注释地址
对于两个文件之间的对应事件.
一种非常简单的方法是使用“ex-
行为匹配,'' 那是, 对测试文件进行评分
准确分配的事件比例
黄金文件中的相同地址. 这将是一个
相当严厉和无情的衡量标准. 例如,
假设模型错误地插入了额外的 mea-
当然在作品的开头,但除此之外-
完全正确地分析了这件作品. 最左边的
插入mea后每个注释地址的值-
肯定是不正确的 (测试文件中更大的一个
比黄金档案中的), 所以几乎每个音符的地址
这篇文章中的内容是不正确的——尽管
模型的分析实际上几乎完全正确-
直角. (“分数”也出现了类似的问题-
“时间”的计量表示方法, 正如所讨论的
早些时候。)
更公平的方法是将测试文件分配给
每个级别的分数, 表示比例
在该级别正确标记的事件.
这是这里采用的方法, 实施于
名为“compare-na”的程序. 该程序将作为
输入两个注释地址文件, 黄金档案和测试-
文件. 对于注释中存在的每个级别 L-
黄金文件中的地址 (除了顶层——
这稍后会解释), 分配的分数是
表示其注释的事件的比例-
L 级的地址值与测试文件中的相同
就像黄金档案中那样. 该程序还产生一个
总分, 这只是 in 的平均值-
个人等级分数. (不清楚是什么意思-
满这是. 也可以考虑加权
分数, 具有某些级别,例如, 塔克图斯水平——
比其他人更重. 或者, 正如我
更喜欢, 人们可以简单地获取独立的水平分数-
分别作为模型在
触摸水平, 更高水平, 和更低的水平。)
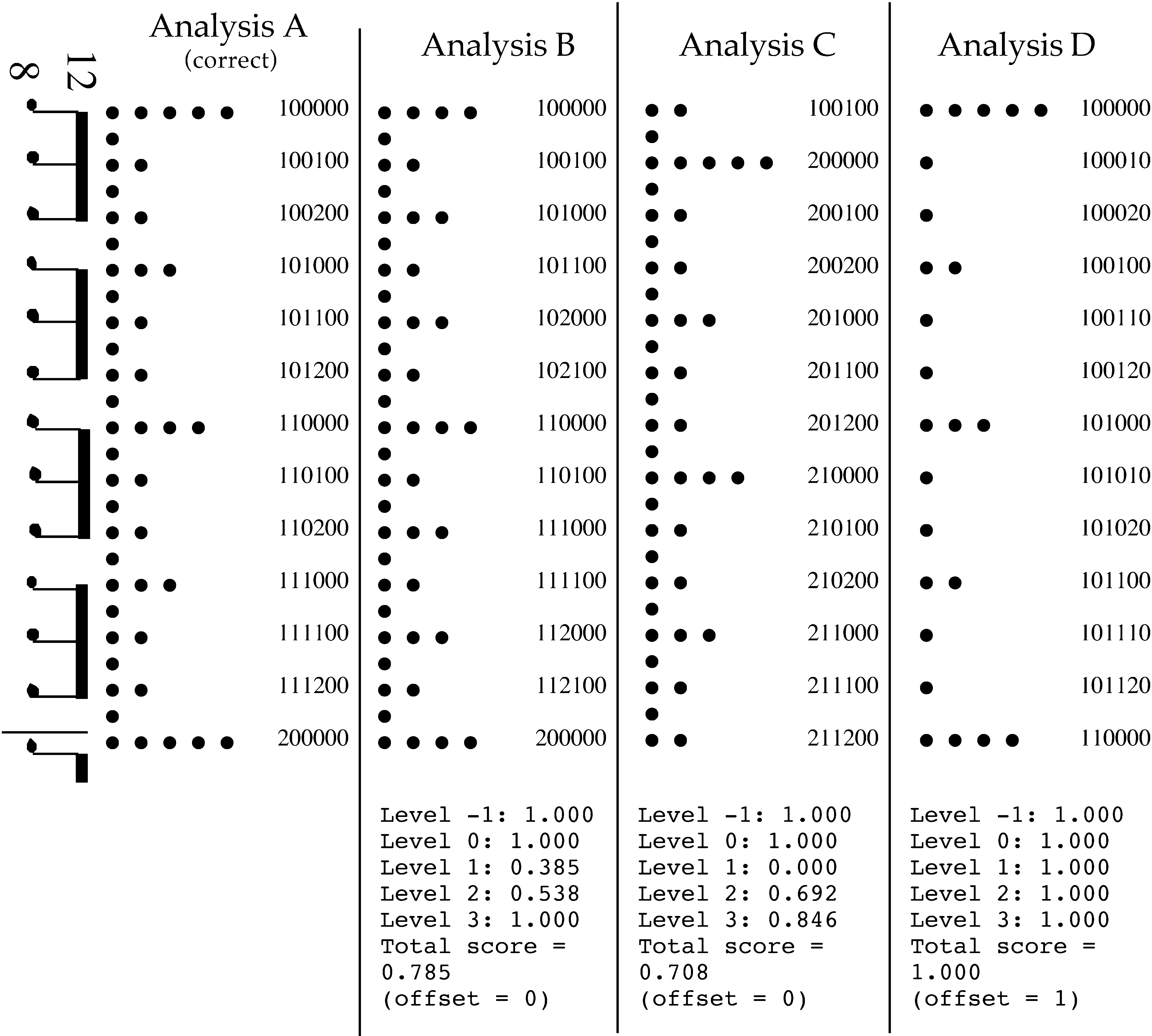
示例如图所示 3 赋予风味
这个评分系统的. 有节奏的模式是
如左图所示——一个简单的八分音符模式
12/8 仪表. 四种分析形式显示为
坦珀利
37
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
数字 3. 有节奏的拍打-
tern 显示四种分析
作为度量网格和注释-
地址列表. 分析A是
正确的分析. 为了
分析B, C, 和D, 这
每次分析的分数
与分析A相比,
根据注释-
地址评估系统,
如下所示.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
格律网格, 正确的一个 (分析A) 和
三个不正确的; 隐含的注释地址列表
按每个网格 (对于模式的每个音符) 显示
在右边. Compare-na 产生的分数
分析B, C, 和D, 与分析相比
A, 下面显示了每个分析. 在所有四个分析中-
塞斯, 没有笔记被分析为度量外, 因此
最右边的数字是 0 对于所有笔记. 因为所有
分析与级别 –1 的分析 A 完全一致,
他们都得到了分数 1.000 在这个级别. 在
分析B和C, 如分析 A 所示, 每个音符都是一个-
分析为符合水平 1 打, 所以
右数第二位数字是 0 对于所有注释
出色地. (我们稍后将讨论分析 D。)
在分析B中, 唯一级别 2 度量网格是
不正确: 本质上, 该段落被分析为 6/4
而不是 12/8. 在这种情况下, 的 2 级值
地址大多不正确, 水平也一样-
1 价值观, 导致水平分数低 2 (0.538)
和水平 1 (0.385). 在分析C中, 级别 2, 3, 和 4
全部“异相”一个八分音符节拍 (仿佛
该作品被注明为 12/8 与小节线一
注意太晚了). 许多级别的地址值
2 和 3 现在不正确, 和所有级别一样 1
价值观. 级别值 0 和 –1, 然而, 有一个-
做作的.
这些例子指出了一个重要的, 和
相当违反直觉, 注释地址的方面
系统. 通常被认为是
特定度量级别的错误通常会出现-
不仅影响该级别的地址值, 但
以及下一个较低级别的值. 为了这
原因, 还, 比较似乎是多余的
地址的最高度量级别, 因为
该级别的任何差异都会导致
下一级. 由此评价体系
38
电脑音乐杂志
仅比较注释地址直至并包括
黄金档案中第二高的水平.
(注意分配给乐观者的地址
分析C. 对于乐曲的第一拍, 我们分配
值为 1 达到目前的最高水平
节拍列表; 所有其他值均设置为 0 除了
该节拍出现的最高级别——级别 1
在本例中——设置为 1.)
这里出现了关于如何
两个格律结构之间的相似性应该
被评判. 按一个标准, 分析 A 和 C
数字 3 非常相似: 两者都反映了 12/8 米-
钙结构, 结构也一样
就时期而言 (节拍之间的间隔) 在
每个级别. 然而每个事件的度量强度
不正确; 的确, 从这个角度来看, 分析-
C 姐最大的错误是. 在分析B中, 这
''拍号'' (二重/三重关系
级别之间) 不正确, 但至少有一些
事件具有正确的度量强度. 哪一个
这两个分析与分析A更相似?
注释地址系统, 随着比较-
这里提出的儿子方法, 似乎相当公平-
关于之间相似性的直观结果
结构. 例如, 分析B得分更高
总体而言比这里的分析C (0.785 相对 0.708), 作为
我认为应该. 然而, 可能没有单一的
在这方面的正确答案; 这可能取决于
该模型的具体目标.
认为, 对于如图所示的节奏模式-
乌尔 3, 模型产生的输出如肛门所示-
分析D. 该分析与分析基本相符
A, 除了这两个分析的水平是
未对齐: 触摸 (附点四分音符) 是水平的
2 在黄金档但水平 1 在测试文件中. 这是联合国-
明确这种情况应该如何处理. 如果
两个地址列表的比较完全一致
是, 测试文件将收到非常低的总体
分数为 0.462. 这个解决方案确实太苛刻了;
分析 D 并不像分数那样不正确 0.462
会建议.
另一种方法是比较每个
测试文件中的级别与
goldfile 地址最匹配. 这是
Compare-na 采取的方法: 不同的‘关’-
尝试测试文件相对于黄金文件的“集合”,
并选择产生最佳匹配的那个.
该程序还输出偏移值
选择的; 的偏移量 1 意味着L级
goldfile 与测试文件中的 L–1 级相匹配. 在
的偏移量 1, 分析 D 得出完美的整体
分数为 1.000. (黄金档案中的第 –1 级没有任何问题-
测试文件中的响应级别; 所有地址值
假设测试文件中没有明确指出
成为 0.) 有些人可能也会考虑这种方法
宽容的. 一般来说, 对某种事物的认知
假定节拍级别为 tactus 或主节拍
成为韵律认知的一个重要方面; 这
这个级别的正确识别很可能是重新-
被视为抄表问题的一部分. (一
解决方案是考虑不同的对齐方式
黄金文件和测试文件地址, 但保理
对水平未对准的惩罚。)
Compare-na 程序还包含一个容忍程序-
计时的ance参数. 部分型号, 例如
坦珀利和斯利特的模型 (1999), 轻微地
改变事件的时间点. 原因之一
是它允许很少演奏的和弦音符
完全同时——同时进行
从而与相同的节拍对齐. 一旦有时间-
测试文件中事件的点被更改, 这
可能会导致事件匹配出现问题
测试文件和黄金文件之间. 耐受性
参数解决了这个问题; 如果容忍度
是 50 毫秒, 开始时间为 的黄金事件
T 可以匹配相同的任何测试文件事件
起始时间为 T 的音调 (西德:4) 50 毫秒. (如果对于
由于某种原因,在测试文件中没有匹配的事件
为黄金事件找到指定的容差,
该黄金档案在各个级别上都被认为是无与伦比的。)
给定一系列输出 (来自不同的部分或
摘录) 来自比较-na, 程序统计由-
计算整个cor中每个级别的数字-
脓 (对语料库中的每个摘录赋予同等的权重).
tally-na 的示例输出如下所示:
级别–1: 平均比例正确 (西德:2) 0.998 (46)
等级 0: 平均比例正确 (西德:2) 0.966 (46)
等级 1: 平均比例正确 (西德:2) 0.928 (46)
等级 2: 平均比例正确 (西德:2) 0.899 (44)
等级 3: 平均比例正确 (西德:2) 0.814 (29)
语料库总分 (西德:2) 0.931; 带零的数
抵消 (西德:2) 36 在......之外 46
括号内的数字表示数量
该级别有资格获得的摘录
坦珀利
39
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
黄金档案数据中的评估. (请记住
goldfile 仅处理 ex 的反射级别-
符号中明确指出, 并且还认为
地址的最高级别永远不会被评估.
这意味着, 例如, 等级 3 仅是 eligi-
ble 用于评估 if 级别 4 存在于黄金档案中
地址。) 还给出了总体语料库分数,
这只是对所有总分进行平均
每个摘录. 该程序还提供了信息
关于有多少测试文件分析反映了正确的结果-
直角 (''零'') 水平偏移.
Melisma 实验
作为评估系统pro的说明-
上面提出的, 我对仪表进行评估-
Temperley 和 Sleator 提出的寻找计划
(1999), Melisma 音乐分析系统的一部分-
姐姐 (坦珀利 2001). 需要简要描述
Melisma 度量模型. 该模型是一个
考虑大量的偏好规则系统-
可能的分析的误码率并选择一个
在几个标准的平衡上达到最佳.
主要标准如下: (1) 更喜欢节拍
每个级别都与事件发生保持一致, 这
发作次数越多越好; (2) 更喜欢节拍
与较长的事件保持一致; (3) 更喜欢节拍
每个级别都有规律地间隔. (在塔克图斯层面,
“规律性”仅仅意味着每个节拍之间-
val——两个相邻节拍之间——应该接近
与前一个节拍间隔的长度; 在更高的
和更低的水平, 规律性是指关系-
在关卡之间运送, IE。, 一致的双重或三重-
级别之间具有良好的关系是优选的。) 这
模型包含大约十几个用户可设置的参数-
埃特斯 (关于偏好的相对权重-
规则和其他东西); 这些被设置在
试错法, 在进行任何测试之前
使用 KP 语料库.
桌子 2 显示了一些测试的结果
KP 语料库和 KP 执行语料库.
对于每个语料库, 第一行显示, 每个级别,
该级别为 el 的摘录数量-
值得考虑. 接下来显示的是性能-
使用 Melisma 模型的曼斯统计
模型的默认参数 (如定义在
最近发布的 2001 系统版本).
回想一下,每个级别的分数表示一个模拟-
该级别的所有分数的平均值
摘录. 不出所料, 整体表现
在KP文件上 (0.931) 略高于
关于 KP 执行的文件 (0.908)——回想一下
前者是根据符号生成的, 后者来自
MIDI 键盘演奏——尽管有所不同-
ence不是很大. 关于 diff 的值-
不同水平, 应该记住的是,错误
在某一层面上主要体现在分数上
下一级, 所以相对较低的分数
级别 2 和 3 KP语料库中主要表示er-
不同级别的错误 3 和 4. (等级高分 3 在
KP 执行语料库令人惊讶, 但仅
九个已执行的摘录包含符合条件的
级别数据 3, 所以样本相当小。)
作为进一步的测试, Melisma 程序已运行
披头士乐队歌曲“米歇尔”的钢琴演奏
和“昨天”使用的表演
Cemgil 等人进行的测试. (2000乙) 和迪克森 (2001乙).
(这些 MIDI 文件可在网上公开获取:
www.nici.kun.nl/mmm/archives。) 塞姆吉尔等人.
迪克森使用了许多相同的表演
两首歌; 目前的测试只使用了一个perfor-
每首歌的曼斯 (的第一次表演
“古典”类别中的第一个主题, 玩过一个
“正常”时间). 正确的注释地址文件是
生成的, 并将这些与外部进行比较-
Melisma 程序的 put. 结果显示
表中 3. 在《昨天,” tactus 水平是
基本正确 (如高值所示
等级 1), 和较低水平一样; 等级 3 不一样
好的, 当它从双米切换到三米时-
作品的一个部分之三. 关于“米歇尔,'' 这
程序的分析几乎完全正确;
唯一的错误是由于一些三重四分之一
笔记, 和一些“污迹”的和弦 (其中注释
旨在同时并没有被解释为
这样的程序).
以及允许模型之间的比较,
这里提出的评价体系可能会极大地
促进发展和改进
型号. 现在很容易, 例如, 做一个
Melisma 仪表系统的变化, 运行系统-
KP 语料库上的术语, 生成注释地址文件
40
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
桌子 2. 使用注释地址在 Kostka-Payne 语料库上测试 Melisma Meter 模型
评价体系
使用的语料库和模型
等级 3
等级 2
等级 1
等级 0
–1级
正确的
抵消
全面的
分数
KP语料库 (46 摘录)
# 数据摘录
梅利斯玛评分
使用默认参数
不考虑长度因素
具有谐波因数
29
44
46
46
46
0.814
0.664
0.707
0.899
0.774
0.926
0.928
0.895
0.921
0.966
0.955
0.965
0.998
0.997
0.997
KP 执行语料库 (19 摘录)
# 数据摘录
9
18
19
19
19
梅利斯玛评分
使用默认参数
不考虑长度因素
具有谐波因数
0.984
0.620
0.892
0.778
0.524
0.855
0.922
0.740
0.880
0.945
0.850
0.947
0.960
0.937
0.963
—
36
36
37
—
15
13
15
—
0.931
0.877
0.923
—
0.908
0.743
0.909
桌子 3. Melisma 模型对披头士乐队歌曲的测试
输入件
等级 3
等级 2
等级 1
等级 0
–1级
''昨天''
“米歇尔”
0.836
1.000
0.755
0.971
0.958
0.971
0.986
0.980
1.000
1.000
正确的
抵消?
是的
是的
全面的
分数
0.907
0.984
自动从生成的节拍列表中, 和
将它们与正确的注释地址文件进行比较
看看改变是否会带来更好的结果, 更差, 或联合国-
改变了性能.
举个例子, 人们可能想知道有多重要
长度的考虑 (的偏好
将节拍与较长的音符对齐) 用于仪表-
寻找过程. 这是通过改变一个来检查的
Melisma 系统的参数,以便所有音符
被假设为只是 0.1 秒长 (更短
比绝大多数实际音符)-因此, 在EF中-
影响, 消除音符之间的长度差异.
结果见表 2. 对于 KP Cor-
脓, 忽略音符长度的区别会导致
性能下降幅度相当小 0.931
到 0.877; 对于 KP 执行语料库, 的损失
长度信息有更大的影响, 减少
表现来自 0.908 到 0.743.
我们也在努力改善 Me-
通过结合其他 fac 的 Lisma 模型-
托尔斯. 一个明显的因素是和谐. 这是
人们普遍认为调和结构可以
对格律结构影响很大 (特别是在
更高的韵律水平), 因为强烈的节拍往往
在谐波变化点被感知 (勒达尔
和杰肯道夫 1983; 坦珀利 2001). 我正在合并-
评价和谐的影响力, KP 语料库是
执行 Melisma 和谐计划, 创造-
对标记为的段进行谐波分析
根; 音符列表加上谐波信息是
然后“通过管道”返回到仪表程序, 莫迪-
包含对强节奏的偏好
和谐的变化. 经过一些参数调整后-
英, 可以获得的最佳性能是
如表所示 2 对于 KP 语料库和
KP 执行语料库. 对于两个语料库, 它可以是
看到等级分数 2 确实有点
改进的, 但分数的水平 3 和 1 是坏事-
伊德; 全面的, “谐波因子”模型和
默认模型的性能大致相同
(他们的总分之间的差异较小
比 1 量化百分比和每百分比-
坦珀利
41
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
形成的语料库). 在这样的情况下, 一个更大的
语料库将是可取的; 表现上的差异-
曼斯的 1 百分比可能并不显着
KP语料库. (还希望有
语料库的很大一部分用于模型开发-
调整和参数调整, 另一个“举行-
out'' 部分进行测试。)
结论
希望这里介绍的系统能够-
促进度量的测试和比较
型号. 虽然系统确实有一定的
局限性, 如上所述, 它提供了一个理性的
比较度量结构的方法,其结果
相当符合直觉. KP 科尔-
这里介绍的脓液也有局限性, 尤其
事实上它仅代表惯例
音乐, 这对某些人的目标可能不公平
韵律模型. 当然, 注释地址系统-
tem 也可以与不同的语料库一起使用 (作为
通过对披头士乐队歌曲的测试来说明
多于), 假设语料库带有注释
备注地址信息. 请注意,系统
不以任何方式要求注释地址
五个级别; 它可以完美地与,
说, 三个级别.
也许是笔记最大的限制-
地址系统的缺点是它仅限于符号-
放. 这是不幸的, 鉴于相当大的
近年来提出的模型数量
将音频数据作为输入. 注释地址系统
可以, 原则, 与音频模型一起使用. 这
问题是节拍位置的不确定性
遇到符号输入要大得多
带音频输入. 即使只有一个音符, 在下面-
与节拍一致, 常常不清楚
音符到底从哪里开始 (因此其中
节拍位于). 为了解决这个问题, 输入
文件必须用标记进行注释-
指定节拍位置; 此时 ap-
proach 变得与 Goto 非常相似并且
呼吸 (1997). 然而, 笔记广告的想法-
连衣裙可能仍然有用; 即使有音频输入-
放, 有人可能会争辩说,某些节拍地点是
比其他人更确定 (例如, 节拍的位置
与音符一致的比与音符一致的更确定
击败不), 度量模型应该
也许只能根据其识别来评估
越确定的. 另一个问题是, 在
符号输入情况, 模特收到广告-
着装地点——即, 音符开始——而在
音频输入案例, 这是模型任务的一部分
找到这些位置. (在音频情况下, A
模型可能会断言没有地址的地址
一个或在有一个的地方未能断言一个。)
因此, 注释地址系统的用处
音频输入度量模型仍有待观察.
致谢
感谢 Henkjan Honing 的宝贵贡献
对本文早期版本的反馈.
参考
艾伦, P。, 和R. 丹能伯格. 1990. 《追踪音乐剧》
时间的节拍。”会议记录 1990 国际的
电脑音乐会议. 旧金山: 内特纳-
国家计算机音乐协会, PP. 140–143.
黑色的, E., 等人. 1991. “定量方法
比较英语语法的句法覆盖范围-
火星。”第四次 DARPA 演讲和
自然语言研讨会. 旧金山: 摩根
考夫曼, PP. 306–311.
棕色的, J. C. 1993. 《穆西米的测定》-
通过自相关计算的校准分数。”《声学杂志》-
美国加州学会 94:1953–1957.
杰姆吉尔, A. T。, 磷. 设计, 和乙. 切. 2000A. ''韵律
转录量化。”计算机音乐
杂志 24(2):60–76.
杰姆吉尔, A. T。, 等人. 2000乙. 《论节奏追踪》: 温度-
程序表示和卡尔曼滤波。”杂志
新音乐研究系 29:259–273.
摩擦, C。, 乙. 雷诺山, 和L. 匆忙. 1982. ” 向着
数字音频的智能编辑器: 认可
音乐结构。”计算机音乐杂志
6(1):30–41.
设计, P。, 和H. 珩磨. 1989. ” 的量化
音乐时间: 联结主义方法。”计算机
音乐杂志 13(3):56–66.
设计, P。, 和H. 珩磨. 1999. “计算模型
42
电脑音乐杂志
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
节拍感应: 基于规则的方法。”杂志
新音乐研究系 28:29–42.
狄克逊, S. 2001A. “自动提取节奏和
来自富有表现力的表演的节拍。”《新杂志》
音乐研究 30:39–58.
狄克逊, S. 2001乙. “节奏的实证比较
跟踪器。”第八届巴西计算机研讨会
音乐, n.p., 832–840.
埃克, D. 2001. “节律的实证模型-
cal Beat Induction。”新音乐研究杂志
30:187–200.
麦考利, J. 1994. “时间作为相位”: 动态模型
时间感知。”第十六届会议论文集-
认知科学学会年会. 丘陵-
戴尔, 新泽西州: 埃尔鲍姆, PP. 607–612.
磨坊主, 乙. 奥。, D. L. 士嘉堡, 和 J. A. 琼斯. 1992.
“论对韵律的感知”,《M》. 巴拉班,
K. 埃布奇奥卢, 和O. 射击, 编辑. 理解音乐
与人工智能: 音乐认知的观点. 剑桥,
马萨诸塞州: AAAI出版社, PP. 428–447.
帕尔默, C. 1997. “音乐表演”年度回顾
心理学系 48:115–138.
加布里埃尔森, A. 1973. “节奏研究。”大学学报-
帕尔默, C。, 和P. 问. 普福德雷舍. 2003. ''增量
乌普萨林的 7:3–19.
后藤, 中号. 2001. “基于音频的实时节拍轨道-
带或不带鼓声的音乐系统。”
新音乐研究杂志 30:159–171.
后藤, M。, 和 Y. 呼吸. 1997. “评估中的问题
节拍跟踪系统。”IJCAI-97 研讨会问题
人工智能和音乐硕士——评估和评估, n.p.,
9–16.
你好, H。, 等人. 2000. “让我匹配: 评价-
不同的评分表现方法
匹配。”计算机音乐杂志 24(1):43–56.
琼斯, 中号. R。, 等人. 2002. “刺激的时间方面-
驱动参加动态阵列。”心理学
科学 13:313–319.
序列制作中的规划。”心理研究-
看法 110:683–712.
帕恩卡特, 右. 1994. “脉冲显着性的感知模型
和音乐节奏中的韵律口音。”音乐每-
塞申斯 11:409–464.
命令, D.-J。, 和P. 食物. 1985. 『对节奏的感知』-
ral Patterns。”音乐感知 2:411–440.
拉斐尔, C. 2001. “自动节奏转录。”
第二届国际研讨会论文集-
音乐信息检索研讨会. 布卢明顿,
印第安纳州: 印第安纳大学, PP. 99–107.
罗森塔尔, D. 1992. “模拟人类节奏-
接收。”计算机音乐杂志 16(1):64–76.
罗维, 右. 1993. 互动音乐系统. 剑桥,
踝, S。, 和D. 佩恩. 1995. Tonal Har 练习册-
马萨诸塞州: 与新闻界.
金钱. 纽约: 麦格劳-希尔.
大的, 乙. W., 和 J. F. 煤炭. 1994. ''共振和
音乐节拍的感知。”连接科学
6:177–208.
李, C. 1991. 《对格律结构的感知》:
实验证据和模型。’’ In P. 豪厄尔,
右. 西方, 和我. 叉, 编辑. 代表音乐结构-
真实. 伦敦: 学术出版社, PP. 59–127.
勒达尔, F。, 和R. 杰肯道夫. 1983. 生成式-
调性音乐理论. 剑桥, 马萨诸塞州: 和
按.
龙格-希金斯, H. C. 1976. “旋律的感知。”
自然 263:646–653.
龙格-希金斯, H. C。, 和C. S. 李. 1982. ''每-
音乐节奏的认知。’’感知 11:115–128.
隆格-希金斯, H. C。, 和M. J. 斯蒂德曼. 1971. ''在
解读巴赫。”机器智能 6:221–41.
曼宁, C. D ., 和H. 舒茨. 2000. 的基础
统计自然语言处理. 剑桥,
马萨诸塞州: 与新闻界.
马库斯, 中号. P。, 乙. 圣托里尼岛, 和M. A. 马尔辛凯维奇.
1993. “建立一个大型英语注释语料库:
宾夕法尼亚大学树库。”计算语言学
19:313–330.
谢雷尔, 乙. D. 1998. 《节奏和节拍分析》
声学音乐信号。”声学杂志
美国协会 103:588–601.
塞塔雷斯, 瓦. A。, 和T. 瓦. 斯塔利. 2001. ''米和周缘-
音乐表演中的丑陋。”《新穆杂志》-
碳化硅研究 30:149–158.
自由, J. A. 1983. 《音乐剧的传播》
钢琴演奏节拍。”季刊
实验心理学 35:377–396.
斯皮罗, 氮. 2002. “结合基于语法和
基于记忆的时间信号感知模型-
ture 和 Phase。”C 语言. 阿纳格诺斯托普卢, 中号. 费朗,
和一个. 斯迈尔, 编辑. 音乐与人工智能.
柏林: 施普林格, PP. 183–194.
斯蒂德曼, 中号. 1977. 《音乐节奏的感知》
and Metre.’’ Perception 6:555–569.
坦珀利, D. 2001. The Cognition of Basic Musical
结构. 剑桥, 马萨诸塞州: 与新闻界.
坦珀利, D ., 和D. Sleator. 1999. ‘‘Modeling Meter
and Harmony: A Preference-Rule Approach.’’ Com-
电脑音乐杂志 23(1):10–27.
van Zaanen, M。, 右. Bod, 和H. 珩磨. 2003. ‘‘A
Memory-Based Approach to Meter Induction.’’ Pro-
ceedings of ESCOM 2003, n.p., PP. 250–253.
坦珀利
43
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
附录A
All of the materials (data files and programs) 的-
scribed here are available at the Melisma Web site,
www.link.cs.cmu.edu/melisma. (Programs are writ-
ten in C and are available in source form.) 这些
包括以下内容:
1. Notefiles for the complete KP Corpus
(notefiles/kp) and KP Performed Corpus
(notefiles/kp-perf). (These files are also
available as MIDI files: midifiles/kp,
midifiles/kp-perf.)
2. The correct note-address files for the KP
Corpus and KP Performed Corpus (nafiles/
kp-correct, nafiles/kp-perf-correct).
3. compare-na: a program that compares two
note-address files and evaluates their simi-
劳动.
4. tally-na: a program that takes a series of
outputs of compare-na and averages them.
5. The source code for the Melisma meter-
finding program.
6. gen-add: a program for generating note-
address files from the ‘‘note-beat files’’ (笔记-
list plus beatlist) produced by the Melisma
meter program. (This could be useful for
those who wish to experiment with modifi-
cations of the Melisma program. It may also
be useful, perhaps with some alterations, 到
those whose models already produce a note-
beat file or something similar to it and who
wish to convert this to note-address format.)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
米
j
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
44
电脑音乐杂志