数据文件
Identifying User Profile by Incorporating Self-Attention
Mechanism based on CSDN Data Set
Junru Lu1, Le Chen1, Kongming Meng1,2, Fengyi Wang3, Jun Xiang1, Nuo Chen1,
Xu Han4 & Binyang Li1†
1School of Information Science and Technology, University of International Relations, 北京 100091, 中国
2Deep Brain Co. 有限公司, Shanghai 201200, 中国
3University of Chinese Academy of Sciences, 北京 100049, 中国
4College of Information Engineering, Capital Normal University, 北京 100048, 中国
关键词: User profile; Convolutional neural network (CNN); Self-attention; Keyword extraction
引文: J. 鲁, L. 陈, K. 猛, F. 王, J. Xiang, 氮. 陈, X. Han, & 乙. 李. Identifying user profile by incorporating self-
attention mechanism based on CSDN data set. 数据智能 1(2019), 160-175. 土井: 10.1162/dint_a_00009
已收到: 八月 27, 2018; 修改: 十一月 30, 2018; 公认: 十二月 6, 2018
抽象的
With the popularity of social media, there has been an increasing interest in user profiling and its
applications nowadays. This paper presents our system named UIR-SIST for User Profiling Technology
Evaluation Campaign in SMP CUP 2017. UIR-SIST aims to complete three tasks, including keywords
extraction from blogs, user interests labeling and user growth value prediction. 为此, we first extract
keywords from a user’s blog, including the blog itself, blogs on the same topic and other blogs published by
the same user. Then a unified neural network model is constructed based on a convolutional neural network
(CNN) for user interests tagging. 最后, we adopt a stacking model for predicting user growth value. 我们
eventually receive the sixth place with evaluation scores of 0.563, 0.378 和 0.751 on the three tasks,
分别.
1. 介绍
Social media have recently become an important platform that enables its users to communicate and
spread information. User-generated content (UGC) has been used for a wide range of applications, 包括
user profiling. The Chinese Software Developer Network (CSDN) is one of the biggest platforms of software
† 通讯作者: Binyang Li (电子邮件: byli@uir.edu.cn; ORCID: 0000-0001-9013-1386).
© 2019 中国科学院以知识共享署名发表 4.0 国际的 (抄送 4.0)
执照
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
developers in China to share technical information and engineering experiences. Analyzing UGC on the
CSDN can uncover users’ interests in the software development process, such as their past interests and
current focus, even if their user profiles are incomplete or even missing. Apart from the UGC, user behavior
data also contain useful information for user profiling, such as “following,” “replying,” and “sending private
消息,” through which the friendship network is constructed to indicate user gender [1,2,3], 年龄 [4],
political polarity [5, 6] or profession [7].
In SMP CUP 2017 [8], the competition is structured around three tasks based on CSDN blogs: (1)
keywords extraction from blogs, (2) user interests labeling and (3) user growth value prediction. Our team
from School of Information Science and Technology, University of International Relations participated in
all the tasks in User Profiling Technology Evaluation Champaign. This paper describes the framework of our
system UIR-SIST for the competition. We first extract keywords from a user’s blog, including the blog itself,
blogs on the same topic, and other blogs published by the same user. Then a unified neural network model
is constructed with self-attention mechanism for task 2. The model is based on multi-scale convolutional
neural networks with the aim to capture both local and global information for user profiling. 最后, 我们
adopt a stacking model for predicting user growth value. According to SMP CUP 2017’s metrics, our model
achieved scores of 0.563, 0.378 和 0.751 on the three tasks, 分别.
This paper is organized as follows. 部分 2 introduces User Profiling Technology Evaluation Campaign
in details. 部分 3 describes the framework of our system. We present the evaluation results in Section
4. 最后, 部分 5 concludes the paper.
2. EVALUATION OVERVIEW
2.1 Data Set
The data set used in SMP CUP 2017 is provided by CSDN, which is one of the largest information
technology communities in China. The CSDN data set consists of all user generated content and the
behavior data from 157,427 users during 2015, which can be further divided into three parts:
1) 1,000,000 pieces of user blogs, involving blog ID, blog title and the corresponding content;
2)
Six types of user behavior data, including posting, browsing, commenting, voting up, voting down
and adding favorites, and the corresponding date and time information;
Relationship between users, which refers to the records of following and sending private messages.
3)
More details about the size and type of the CSDN data set are shown in Table 1.
https://github.com/LuJunru/SMPCUP2017_ELP
数据智能
161
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
桌子 1. Statistics of the evaluation data set.
属性
Content
尺寸
Format
Blogs
Behavior
邮政
Users’ blogs
Record of posting blogs
1,000,000 D0802938/Title/Content
1,000,000 U0024827/D0874760/2015-02-05
Browse
Record of browsing blogs
3,536,444 U0143891/D0122539/20150919
18:05:49.0
Comment
Record of commenting on blogs
182,273 U0075737/D0383611/2015-10-30
09:48:07
Vote up
Vote down
Add favorites
Relationships Follow
Send private
消息
Record of clicking a “like” button
Record of clicking a “dislike”
button
Record of adding blogs to a user’s
favoriates list
Record of following relationships
Record of sending private
消息
桌子 2 illustrates an example from the given data set.
11:18:32.0
95,668 U0111639/D0627490/2015-02-21
9,326 U0019111/D0582423/2015-11-23
10,4723 U0014911/D0552113/2015-06-07
07:05:05
667,037 U0124114/U0020107
46, 572 U0079109/U0055181/2015-12-24
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
桌子 2. Sample of CSDN data set.
属性
Data sample
User ID
Blog ID
Blog content
关键词
Interest tags
邮政
Browse
Comment
Vote up
Vote down
Send private messages
Add favorites
Follow
Growth value
2.2 任务
U00296783
D00034623
Title and content.
Keyword1: TextRank; Keyword2: PageRank; Keyword3: Summary
Tag1: Big data; Tag2: Data mining; Tag3: 机器学习
U00296783/D00034623/20160408 12:35:49
D09983742/20160410 08:30:40
D09983742/20160410 08:49:02
D00234899/20160410 09:40:24
D00098183/20160501 15:11:00
U00296783/U02748273/20160501 15:30:36
D00234899/20160410 09:40:44
U00296783/U02666623/20161119 10:30:44
0.0367
任务 1: To extract three keywords from each document that can well represent the topic or the main idea
of the document.
任务 2: To generate three labels to describe a user’s interests, where the labels are chosen from a given
candidate set (42 in total).
162
数据智能
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
.
/
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
任务 3: To predict each user’s growth value of the next six months according to his/her behavior of the
past year, including the texts, the relationships and the interactions with other users. The growth
value needs to be scaled into [0, 1], 在哪里 0 presents user drop-out.
2.3 指标
To assess the system effectiveness in completing the above-mentioned tasks, the following evaluation
metrics are designed for each individual task.
Score1 is defined to calculate the overlapping ratio between the extracted keywords and the standard
答案, which can be computed in Equation (1):
分数
1
氮
= ∑ ∩ *
K
K
1
|
我
氮
|
|
K
=
我
我
1
我
|
,
(1)
where N is the size of the validation set or the test set, Ki is the extracted keywords set from document i,
and Ki
* is the standard keywords of document i. Note that it is defined that |Ki| = 3 和 |Ki
*| = 5.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
Score2 denotes the overlapping ratio of model tagging and answers, which can be expressed by
方程 (2):
我
A
r
t
我
C
e
–
p
d
F
/
分数
2
氮
= ∑ ∩ *
时间
时间
1
|
我
我
氮
|
|
=
时间
我
1
我
|
,
(2)
where Ti is the automatically generated tag set of user i, and Ti
defined that |Ti| = 3 和 |Ti
*| = 3.
* is the standard tags of user i. It is also
Score3 is calculated by relative error between the predicted growth value and the real growth value of
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
.
/
t
我
用户, which can be expressed by Equation (3):
分数
3
= −
1
1
氮
氮
∑
=
1
我
⎧
⎪
⎨
⎪⎩
0,
v
我
-
v
*
我
max
(
v v
,
我
*
我
)
,
v
我
=
0,
v
*
我
=
0
否则
,
where vi is the predicted growth value of user i, and vi
* is the real growth value of user i.
The overall score can be computed by Equation (4):
分数
全部
=
分数
1
+
分数
2
+
分数
3
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
(3)
(4)
3. SYSTEM OVERVIEW
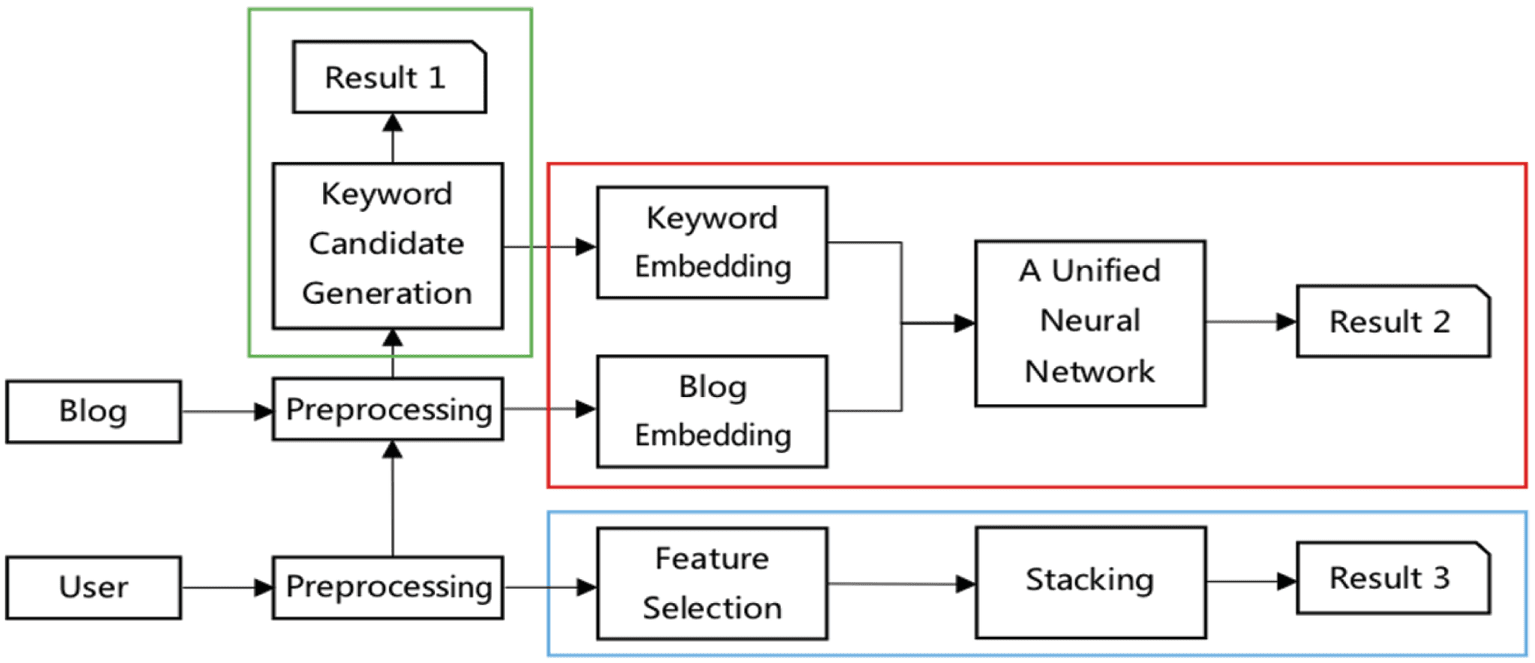
The overall architecture of UIR-SIST is described in Figure 1. UIR-SIST system is comprised of four
模块:
数据智能
163
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
1)
2)
3)
4)
Preprocessing module: To read all blogs of training set and test set. It performs word segmentation,
part-of-speech (销售点) tagging, named entity recognition and semantic role labeling;
Keyword extraction module: To extract three keywords to represent the main idea of a blog, 哪个
can be captured from three aspects to generate the candidate keywords set, including the blog
内容, other blogs published by the same user, and the blogs on the same topic, as shown in the
green part;
User interests tagging module: To construct a neural network combined with user content
embedding and keyword and user tag embedding for user interests tagging, as shown in the red part;
User growth value prediction module: To incorporate users’ interaction information and the behavior
features into a supervised learning model for growth value prediction, as shown in the blue part.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
数字 1. System architecture.
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
.
t
/
我
3.1 Keywords Extraction
The objective of task 1 is to extract three keywords from each blog that can represent the main idea of
the blog. In our opinion, the main idea can be extracted from the following three aspects, the blog itself,
other blogs published by the same user, and the blogs on the same topic. Based on this assumption, 我们
adopt three different models that can capture each aspect to generate a candidate keywords set, 包括
tf-idf, TextRank and LDA, which are proved very effective in the relevant tasks. Then three keywords are
extracted from the candidate set by using different rules.
We first adopt the classic tf-idf term weighting scheme to reflect the content of the blog itself. 然后
we rank the keywords based on the tf-idf score, and select the top 100 keywords to form the candidate
keyword set.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
164
数据智能
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
Regarding the blogs on the same topic, we adopt TextRank approach [9] to cluster these blogs together.
同时, all the keywords will be weighed during this process. We finally select the top 300 keywords.
而且, we utilize topic information to extract the keywords. 自从 42 categories of tags are given in
任务 2, we assume that these 42 topics are extracted from all the blogs. 所以, we use Latent Dirichlet
Allocation (LDA) 模型 [10] to extract top 100 keywords for each category from 1,000,000 博客, 因此
obtain the interspecific distribution information of these 4,200 subject keywords.
总之, we consider three aspects in order to reflect the blog content and obtain three independent
candidate keywords sets, which are extracted through tf-idf model, TextRank model and LDA model. 后
那, we only save the intersection data set. In our training set of task 1, 关于 5,000 keywords are provided,
which are collected after extraction and deduplication.
A drawback of the classic tf-idf model is that it simply presupposes that the rarer a word is in corpus,
the more important it is, and the greater its contribution is to the main idea of the text. 然而, 什么时候
referring to a group of articles, which mainly use the same keywords and describe some similar concepts,
the calculation results will have many errors. This is also the reason why we use tf-idf in the short blog,
while we use the TextRank model in the long blog collection published by the same user.
此外, in order to enhance its cross-topic analysis ability, we borrow the idea of 2016 Big Data &
Computing Intelligence Contest sponsored by China Computer Federation (CCF), and implement the
improvements on the results of traditional tf-idf calculation, and obtain the result of S-TFIDF(w) by using
方程 (5):
)
S TFIDF w TFIDF w
-
=
(
(
)
*
⎛
⎜
⎝
1
C
w
-
⎞
1
,
⎠
⎟
42
(5)
where Cw is the frequency of word w appearing in 42 类别.
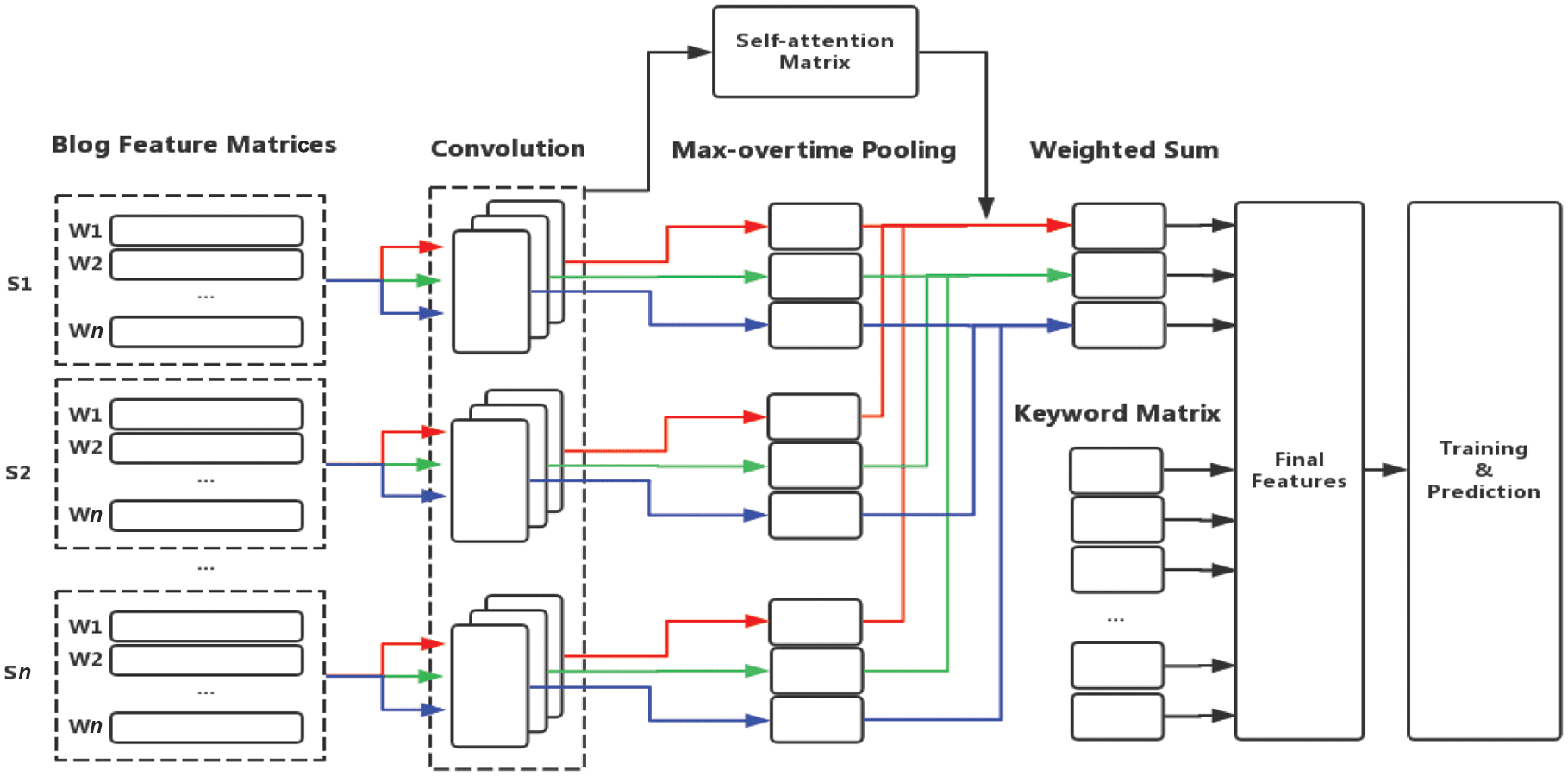
3.2 User Interests Tagging
The objective of this task is to tag a user’s interests with three labels from 42 given ones. We model this
task with neural networks, and the model structure is shown in Figure 2. Each blog is represented by a blog
embedding [11] through convolution and max-pooling layers. Then we obtain a user’s content embedding
from weighted sum of all of his or her blog embeddings. The weighted value of each blog embedding is
counted by self-attention mechanism. Content embedding and keyword embedding are concatenated as
user embedding, and finally fed to the output layer.
https://github.com/coderSkyChen/2016CCF_BDCI_Sougou
数据智能
165
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
数字 2. Framework of CNNs model based on weighted-blog-embeddings in task 2.
In our system, a convolutional neural network (CNN) model is constructed for blog representation instead
of a recurrent neural network (RNN), since more global information will be captured for indicating the user
interests and the time efficiency will also be enhanced. It is widely acknowledged that a multi-scale
convolutional neural network [12] has been implemented due to its outstanding achievement on computer
想象 [13], and TextCNNs designed by arraying word embedding vertically has also shown quite high
effectiveness for natural language processing (自然语言处理) 任务 [14].
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
/
.
t
我
In our CNN model, we treat a blog as a sequence of words x = [x1, x2, …… , x1] where each one is
represented by its word embedding vector, and returns a feature matrix S of the blog. The narrow convolution
layer attached after the matrix is based on a kernel W ∈ Rkd of width k, a nonlinear function f and a bias
variable b as described by Equation (6):
(
f W
X
=
H
我
+ -
i j k
:
1
)
,
+
乙
(6)
where xi:j refers specifically to the concatenation of the sequence of words’ vectors from position i to
position j. In this task, we use several kernel sizes to obtain multiple local contextual feature maps in the
convolution layer, and then apply the max-overtime pooling [15] to extract some of the most important
特征.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
166
数据智能
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
The output of that is the low-dimensional dense and quantified representation of each single blog. 后
那, each user’s relevant blogs are computable. We simply average their blogs’ vectors to obtain the content
embedding c(你) for an individual user:
( )
c u
1 时间
= ∑
时间
=
1
我
s
我
,
(7)
where T is the total number of a user’s related blogs.
然而, different sources of blogs imply the extent of a user’s interest in different topics. 例如,
a blog posted by a user may be generated from an article written by himself, reposted by other users, 或者
shared by users from another platform. It is natural that we may pay attention to these blogs in varying
degrees when we infer this user’s interests. 因此, a self-attention mechanism is introduced, 哪个
automatically assigns different weights to the value of each user’s blog after training. The user context
representation is given by weighted summation of all blogs’ vectors:
=
A
)
,
exp e
(
我
时间
∑
e
j
=
1
j
=
e
我
时间
v tanh Ws Uh
我
(
我
+
( )
c u
时间
= ∑ a
H
,
我
我
=
1
我
),
(8)
(9)
(10)
where ai is the weight of the i-th blog, si is the one-hot source representation vector of the blog, v ∈ Rn,
W ∈ Rn’ × m, U ∈ Rn’ × n, si ∈ Rm, hi ∈ Rn, and m is the number of all source platforms.
When we finish a user’s context representation, the keyword matrix of all blogs’ keywords extracted by
our model in task 1 will be concatenated. The final features are the output of above whole feature
工程. Afterwards, an ANN layer trains the user embeddings from the training set and predicts
probability distribution of users’ interests among 42 tags in validation and test set according to their
嵌入.
3.3 User Growth Value Prediction
According to the description of task 3, the growth value can be estimated as the degree of activeness.
所以, our basic idea is to incorporate a users’ interaction information and his or her behavior statistical
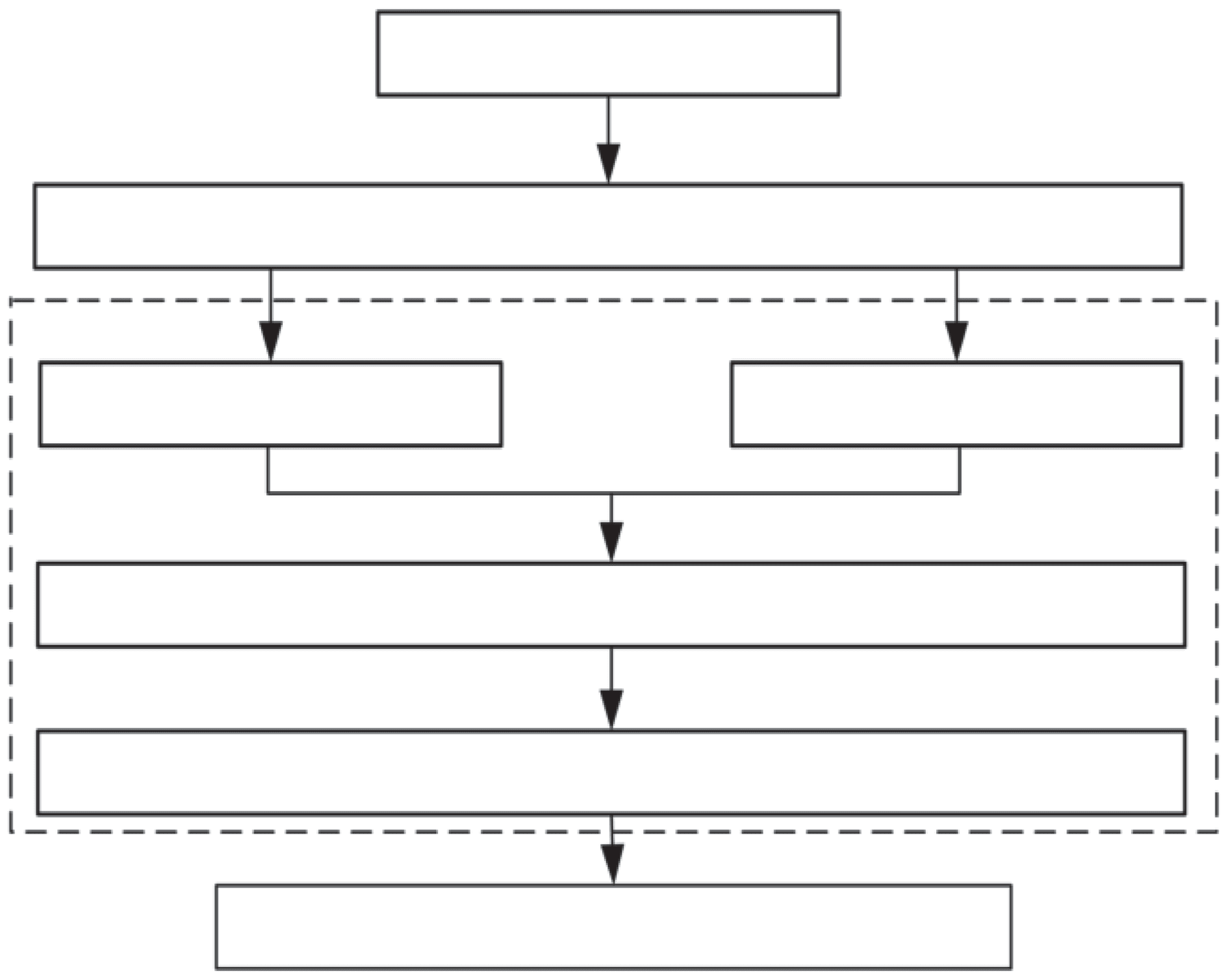
features into a supervised learning model. The procedure of task 3 is demonstrated by Figure 3.
数据智能
167
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
Behavior Statistics
Feature Selection
Passive Aggressive
Gradient Boosting
Feature Extraction
NuSVR
Final Result
数字 3. Framework of the stacking model in task 3.
总体上, we use a stacking framework [16] to enhance the accuracy of final prediction. After the
basic behavior statistics analysis, the original features are selected as the inputs incorporated into the
stacking model. 然后, the stacking model is divided into two layers, the base layer and the stacking layer.
In the base layer, we choose Passive Aggressive Regressor [17] and Gradient Boosting Regressor [18, 19]
as the group of basic regressors due to their excellent performance. In the stacking layer, we still use the
support vector machines (支持向量机) 模型, 尤其, the NuSVR model, which can control its error rate.
最后, we obtain the final results of user growth value.
3.3.1 Original Feature Selection
数字 4 illustrates an example of the daily statistics of user behaviors, including posting, browsing,
commenting, voting up, voting down, adding favorites, following, and sending private messages. To predict
the user growth value, it is noted that the dynamic changes of behaviors along the time line are more useful.
To avoid the sparse data problem, we adopt the monthly statistics of user behaviors rather than daily
统计数据.
数字 4. Example of daily statistics of user behaviors. 笔记: “Add” refers to “add favoriates,” and “send” refers to
“send private messages.”
168
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
/
.
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
Then we use correlation analysis to exclude the “vote down” behavior because of its negative contribution
to model prediction. After that, through feature selection, we use the average, log calculation and growth
rate of the original data to obtain features for the stacking model.
(
LOG d
)
=
log d
(
+
1),
(
GR d
t
)
=
d
1
+ -
t
+
d
t
t
d
1
,
(11)
(12)
where LOG(d) represents the calculation results of data d after adjustment, and GR(dt) represents the
calculation results of growth value from data dt in month t to data dt+1 in month t+1.
3.3.2 PAR/GDR-NuSVR-Stacking Model (PGNS)
Once we have obtained monthly statistics and derivative features as described above, the combination
of them will be sent as inputs into Passive Aggressive Regressor and Gradient Boosting Regressor
independently. By averaging the predictions of those two base models, a new feature will be created and
input into the stacking model NuSVR. Because of the inherent randomness of base models, we adopt a
self-check mechanism of 10-fold cross validation.
If the trained model obtains a score higher than the threshold S* under given scoring rules, we will enter
the corresponding features of validation set or test set into the model for a prediction value, which will be
saved into a candidate set. 相反, if the trained model obtains a 10-fold cross validation score
that is lower than S*, the model will be discarded and the program will return to the training session shown
in the dotted box for a new round of training.
In order to reduce the errors of a single round of training, we set at least R* rounds for training and add
all predictions that obtain higher scores than S* to the candidate set. According to our experience, the ratio
of the size of a candidate set to R* is about 0.45. When all rounds of trainings are completed, all predictions
in the candidate set will be calculated to generate an average prediction as the final results.
4. EVALUATION
In our model, we first adopt Jieba toolkit for Chinese word segmentation, and then train a word
embedding with the dimensions of 300 [11].
桌子 3 shows the comparison results of our proposed approach for task 1. It is observed that the best
results are achieved when data of all the three aspects are used for capturing the main ideas of blogs.
https://github.com/fxsjy/jieba
数据智能
169
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
.
t
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
桌子 3. Comparison on task 1 with different aspects.
Approach
双: Blog itself
英石: Same topic
SU: Same user
BI+ST+SU
结果
0.505
0.371
0.436
0.563
Besides, we also test performance of our combined neural network with different embedding inputs.
Note that to obtain the results of individual embedding, we train a new CNN model for blog embedding,
and compute the similarity between blog content and keywords in the embedding representation. 这
experimental results are summarized in Table 4. It is observed that the embedding of blog content proves
more effective than that of keywords, while they together achieve the best run.
桌子 4. Comparison of different aspects on task 2.
Approach
Blog embedding
Keywords embedding
Blog + keywords embedding
结果
0.301
0.245
0.378
桌子 5 displays the overall performance of our system’s best run on each individual task, which achieved
the sixth place in the competition.
桌子 5. Performance of UIR-SIST system in SMP CUP 2017.
Training set (10 Fold)
Validation set
Test set
任务 1
0.610
0.560
0.563
任务 2
0.390
0.390
0.378
任务 3
0.765
0.730
0.751
全部的
1.765
1.680
1.692
5. CONCLUSIONS AND FUTURE WORK
在本文中, we present our system built for the User Profiling Technology Evaluation Campaign of SMP
CUP 2017. To complete task 1, we propose to extract keywords from three aspects from a user’s blogs,
including the blog itself, blogs on the same topic, and other blogs published by the same user. Then a
unified neural network model with self-attention mechanism is constructed for task 2. The model is based
on multi-scale convolutional neural networks with the aim to capture both local and global information
for user profiles. 最后, we adopt a stacking model for predicting user growth value. According to SMP
CUP 2017’s metrics, our model runs achieved the final scores of 0.563, 0.378 和 0.751 on three tasks,
分别.
170
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
.
t
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
Future work includes analysis of the relationships between users and blogs. We only use the users’
behavior in task 2 in the current system, but the time when blogs are published is ignored. We plan to
include network embedding into our model. 而且, we will collect more blogs with real time information,
and attempt to incorporate the time information into our weighting schema in those tasks.
作者贡献
乙. 李 (byli@uir.edu.cn, corresponding author) is the leader of the UIR-SIST system, who drew the whole
framework of the system. J. 鲁 (lj1230@nyu.edu) was responsible for building the model for keyword
extraction, while L. 陈 (lec@boyabigdata.cn) and K. 猛 (kmmeng@uir.edu.cn) were responsible for
the model construction of user interests tagging. F. 王 (wangfengyi18@mails.ucas.ac.cn) summarized
the user growth value prediction, while J. Xiang (xiang.j@husky.neu.edu) and N. 陈 (nchen@uir.edu.cn)
summarized the evaluation and made error analysis. X. Han (hanxu@cnu.edu.cn) drafted the whole paper.
All authors revised and proofread the paper.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
t
.
/
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
ACKNOWLEDGEMENTS
This work is partially supported by the National Natural Science Foundation of China (Grant numbers:
61502115, 61602326, U1636103 and U1536207), and the Fundamental Research Fund for the Central
Universities (Grant numbers: 3262017T12, 3262017T18, 3262018T02 and 3262018T58).
参考
[1] 中号. Ciot, 中号. Sonderegger, & D. Ruths. Gender inference of twitter users in non-English contexts. 在: Proceed-
ings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013, PP. 1136–1145.
土井: 10.1126/science.328.5974.38.
L. Wendy, & 右. Derek. What’s in a name? Using first names as features for gender inference in Twitter.
在: 诉讼程序 2013 AAAI Spring Symposium: Analyzing Microtext, 2013, PP. 10–16. 土井: 10.1103/
PhysRevB.76.054113.
[2]
[3] 瓦. 刘, F.A. Zamal, & D. Ruths. Using social media to infer gender composition of commuter populations.
在: Proceedings of the International Conference on Weblogs and Social Media. Available at: http://万维网.
ruthsresearch.org/static/publication_files/LiuZamalRuths_WCMCW.pdf.
[4] D. 饶, & D. Yarowsky. Detecting latent user properties in social media. 在: Proceedings of the NIPS MLSN
作坊, 2010, PP. 1–7. 土井: 10.1007/s10618-010-0210-x.
[5] 中号. Pennacchiotti, & A.M. Popescu. A machine learning approach to Twitter user classification. 在:
Proceedings of the Fifth International Conference on Weblogs and Social Media, 2011, 281–288. 土井:
10.1145/2542214.2542215.
[6] M.D. Conover, J. Ratkiewicz, 中号. Francisco, 乙. Gonçalves, A. Flammini, & F. Menczer. Political polarization
on Twitter. 在: Proceedings of the Fifth International Conference on Weblogs and Social Media, 2011, 89–96.
可用于: https://journalistsresource.org/wp-content/uploads/2014/10/2847-14211-1-PB.pdf?x12809.
数据智能
171
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
[7] C. Tu, Z. 刘, & 中号. Sun. PRISM: Profession identification in social media with personal information and
community structure. 在: Proceedings of Social Media Processing, 2015, PP. 15–27. 土井: 10.1007/978-981-
10-0080-5_2.
SMP CUP 2017. 可用于: http://www.cips-smp.org/smp2017/.
[8]
[9] 右. Mihalcea, & 磷. Tarau. TextRank: Bringing order into text. 在: Proceedings of the 2004 Conference on
Empirical Methods in Natural Language Processing, 2004. 可用于: http://www.aclweb.org/anthology/
W04-3252.
[10] D.M. Blei, A.Y. 的, & M.I. 约旦. Latent dirichlet allocation. Journal of Machine Learning Research 3(2003),
993–1022. 可用于: https://dl.acm.org/citation.cfm?id=944937]&preflayout=flat#source.
[11] 时间. 米科洛夫, K. 陈, G. 科拉多, & J. 院长. Efficient estimation of word representations in vector space.
在: Proceedings of Workshop at International Conference on Learning Representations (LCLR). 可用于:
https://www.researchgate.net/publication/234131319_Efficient_Estimation_of_Word_Representations_in_
Vector_Space.
[12] 是. 乐存, 乙. Boser, J.S. Denker, D. Henderson, R.E. 霍华德, 瓦. Hubbard, & L.D. Jackel. Handwritten digit
recognition with a backpropagation network. 在: Proceedings of Advances in Neural Information Processing
系统, 1990, PP. 396–404. 可用于: https://dl.acm.org/citation.cfm?id=109279%22.
[13] A. 克里热夫斯基, 我. 吸勺, & G. 欣顿. ImageNet classification with deep convolutional neural networks.
在: Proceedings of Advances in Neural Information Processing Systems, 2012, 土井: 10.1145/3065386.
[14] 是. Kim. Convolutional neural networks for sentence classification. 在: 诉讼程序 2014 会议
on Empirical Methods in Natural Language Processing, 2014, PP. 1746–1751. 可用于: https://arxiv.org/
pdf/1408.5882.pdf.
[15] 右. Collobert, J. Weston, L. 波图, 中号. Karlen, K. Kavukcuoglu, & 磷. Kuksa. Natural language processing
(almost) from scratch. The Journal of Machine Learning Research 12(2011), 2493–2537. 土井: 10.1016/
j.chemolab.2011.03.009.
[16] D.H. Wolpert. Original contribution: Stacked generalization. Neural Netw 5(2)(1992), 241–259. 土井:
10.1016/S0893-6080(05)80023-1.
[17] K. Crammer, 氧. Dekel, J. Keshet, S. Shalev-Shwartz, & 是. 歌手. Online passive-aggressive algorithms.
Journal of Machine Learning Research 7(3)(2006), 551–585. Available at: http://www.jmlr.org/papers/v7/
crammer06a.html.
[18] J.H. 弗里德曼. Greedy function approximation: A gradient boosting machine. Annals of Statistics 29(5)
(2001), 1189–1232. 土井: 10.1214/aos/1013203451.
[19] J. 弗里德曼. Stochastic gradient boosting. Computational Statistics & 数据分析 38(4)(2002), 367–378.
土井: /10.1016/S0167-9473(01)00065-2.
172
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
t
/
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
作者简介
Junru Lu is currently a Master’s Degree candidate in the Center of Urban
Science and Progress, 纽约大学. He received his Bachelor Degree
from University of International Relations in 2018. His research interests
include natural language processing, text mining and social computing.
Le Chen received his Bachelor Degree from University of International
Relations in 2018. He is now working as a data analyst in Beijing Boya
Bigdata Co. Ltd. His research interests include text mining and social
计算.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
/
.
t
我
Kongming Meng is currently working as a data engineer in the DeepBrain
公司. He received his Bachelor Degree from University of International
Relations in 2018. His research interests include data mining and data
分析.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
数据智能
173
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
Fengyi Wang is currently a master student in the University of Chinese
Academy of Sciences (CAS). She received her Bachelor Degree from University
of International Relations in 2018. Her research interests include natural
language processing and social network analysis.
Jun Xiang is currently a master student in the program of Computer Systems
Engineering, Northeastern University. She received her Bachelor Degree from
University of International Relations in 2018. She has published two papers
in international conferences and Chinese journals during her undergraduate
学习.
Nuo Chen got her Bachelor Degree from the School of Information Science
and Technology, University of International Relations in 2018. Her research
interest is knowledge graph.
174
数据智能
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
.
/
t
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Identifying User Profi le by Incorporating Self-Attention Mechanism based on CSDN Data Set
Xu Han received her PhD Degree in 2011. She is an assistant professor at
the Capital Normal University and her research interests are artificial
intelligence and mobile cloud computing. She has published over 30 研究
papers in major international journals and conferences.
Binyang Li received his PhD Degree from the Chinese University of Hong
Kong in 2012. He is now working as an associate professor in the School of
Information Science and Technology, University of International Relations.
His research interests include natural language processing, sentiment analysis
and social computing. He has published over 50 research papers in major
international journals and conferences.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
d
n
/
我
t
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
1
2
1
6
0
1
4
7
6
7
0
0
d
n
_
A
_
0
0
0
0
9
p
d
/
t
.
我
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
数据智能
175