CrossWOZ: A Large-Scale Chinese Cross-Domain
Task-Oriented Dialogue Dataset
Qi Zhu1, Kaili Huang2, Zheng Zhang1, Xiaoyan Zhu1, Minlie Huang1∗
1Dept. of Computer Science and Technology, 1Institute for Artificial Intelligence,
1北京国家信息科学技术研究中心,
2Dept. of Industrial Engineering, 清华大学, 北京, 中国
{zhu-q18,hkl16,z-zhang15}@mails.tsinghua.edu.cn
{zxy-dcs,aihuang}@tsinghua.edu.cn
抽象的
To advance multi-domain (跨域) dia-
logue modeling as well as alleviate the short-
age of Chinese task-oriented datasets, 我们
propose CrossWOZ, the first large-scale Chinese
Cross-Domain Wizard-of-Oz task-oriented data-
放. It contains 6K dialogue sessions and
102K utterances for 5 域,
包括
hotel, 餐厅, attraction, metro, and taxi.
而且, the corpus contains rich annotation
of dialogue states and dialogue acts on both
user and system sides. 关于 60% 的
dialogues have cross-domain user goals that
favor inter-domain dependency and encourage
natural transition across domains in conversa-
的. We also provide a user simulator and
several benchmark models for pipelined task-
oriented dialogue systems, which will facilitate
researchers to compare and evaluate their
models on this corpus. The large size and rich
annotation of CrossWOZ make it suitable to
investigate a variety of tasks in cross-domain
dialogue modeling, such as dialogue state
追踪, policy learning, user simulation, ETC.
1 介绍
最近, there have been a variety of task-oriented
dialogue models thanks to the prosperity of neural
架构 (Yao et al., 2013; 文等人。, 2015;
Mrkˇsi´c 等人。, 2017; 彭等人。, 2017; 雷等人。,
2018; G¨ur et al., 2018). 然而, research is still
largely limited by the lack of large-scale high-
quality dialogue data. Many corpora have advanced
the research of task-oriented dialogue systems,
most of which are single domain conversations,
including ATIS (Hemphill et al., 1990), DSTC 2
(Henderson et al., 2014), Frames (El Asri et al.,
2017), KVRET (埃里克等人。, 2017), 沃兹 2.0
(文等人。, 2017), and M2M (Shah et al., 2018).
∗Corresponding author.
281
Despite the significant contributions to the
社区, these datasets are still limited in size,
language variation, or task complexity. 更远-
更多的, there is a gap between existing dialogue
corpora and real-life human dialogue data. 在
real-life conversations, it is natural for humans to
transition between different domains or scenarios
while still maintaining coherent contexts. 因此,
real-life dialogues are much more complicated
than those dialogues that are only simulated
within a single domain. To address this issue,
some multi-domain corpora have been proposed
(布兹安诺夫斯基等人。, 2018乙; 拉斯托吉等人。,
2019). The most notable corpus is MultiWOZ
(布兹安诺夫斯基等人。, 2018乙), a large-scale multi-
domain dataset
that consists of crowdsourced
It contains 10K
human-to-human dialogues.
dialogue sessions and 143K utterances for 7
域, with annotation of system-side dialogue
国家
states and dialogue acts. 然而,
annotations are noisy (埃里克等人。, 2019), and user-
side dialogue acts are missing. The dependency
across domains is simply embodied in imposing
the same pre-specified constraints on different
域, such as requiring both a hotel and an
attraction to locate in the center of the town.
In comparison to the abundance of English
dialogue data, 出奇, there is still no widely
recognized Chinese task-oriented dialogue corpus.
在本文中, we propose CrossWOZ, 一个大的-
scale Chinese multi-domain (跨域) 任务-
oriented dialogue dataset. An dialogue example
is shown in Figure 1. We compare CrossWOZ to
other corpora in Tables 1 和 2. Our dataset has
the following features comparing to other corpora
(particularly MultiWOZ (布兹安诺夫斯基等人。,
2018乙)):
1. The dependency between domains is more
challenging because the choice in one domain
will affect the choices in related domains
计算语言学协会会刊, 卷. 8, PP. 281–295, 2020. https://doi.org/10.1162/tacl 00314
动作编辑器: Bonnie Webber. 提交批次: 10/2019; 修改批次: 1/2020; 已发表 6/2020.
C(西德:13) 2020 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
in CrossWOZ. 如图 1 和
桌子 2, the hotel must be near the attraction
chosen by the user in previous turns, 哪个
requires more accurate context understanding.
2. It is the first Chinese corpus that contains
large-scale multi-domain task-oriented dia-
logues, consisting of 6K sessions and 102K
utterances for 5 域 (attraction, restau-
rant, hotel, metro, and taxi).
3. Annotation of dialogue states and dialogue
acts is provided for both the system side
and user side. The annotation of user states
enables us to track the conversation from
the user’s perspective and can empower
the development of more elaborate user
simulators.
在本文中, we present
the process of
dialogue collection and provide detailed data
the corpus. Statistics show that
analysis of
our cross-domain dialogues are complicated. 到
facilitate model comparison, benchmark models
are provided for different modules in pipelined
task-oriented dialogue systems, including natural
language understanding, dialogue state tracking,
dialogue policy learning, and natural language
一代. We also provide a user simulator,
这将
和
evaluation of dialogue models on this corpus.
The corpus and the benchmark models are
publicly available at https://github.com/
thu-coai/CrossWOZ.
the development
facilitate
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
2 相关工作
According to whether the dialogue agent is human
or machine, we can group the collection methods
of existing task-oriented dialogue datasets into
three categories. The first one is human-to-human
对话. One of the earliest and well-known is
the ATIS dataset (Hemphill et al., 1990) used this
环境, followed by El Asri et al. (2017), Eric et al.
(2017), Wen et al. (2017), Lewis et al. (2017),
Wei et al.
(2018), and Budzianowski et al.
(2018乙). Though this setting requires many human
努力, it can collect natural and diverse dialogues.
The second one is human-to-machine dialogues,
which need a ready dialogue system to converse
with humans. The famous Dialogue State Tracking
Challenges provided a set of human-to-machine
dialogue data (Williams et al., 2013; Henderson
数字 1: A dialogue example. The user state is
initialized by the user goal: Finding an attraction and
one of its nearby hotels, then booking a taxi to commute
between these two places. In addition to expressing pre-
specified informable slots and filling in requestable
插槽, users need to consider and modify cross-domain
informable slots (bold) that vary through conversation.
We only show a few turns (turn number on the left),
each with either user or system state of the current
domain, which are shown above each utterance.
等人。, 2014). The performance of the dialogue
largely influence the quality of
system will
dialogue data. The third one is machine-to-
machine dialogues. It needs to build both user and
282
Type
数据集
语言
Speakers
# Domains
# Dialogues
# Turns
Avg. 域
Avg. 轮流
# Slots
# Values
Single-domain goal
Multi-domain goal
DSTC2 WOZ 2.0 Frames KVRET M2M MultiWOZ Schema CrossWOZ
EN
H2M
1
1,612
23,354
1
14.5
8
212
EN
H2H
1
600
4,472
1
7.5
4
99
EN
H2H
1
1,369
19,986
1
14.6
61
3,871
EN
EN
H2H M2M
3
2,425
12,732
1
5.3
13
1363
2
1,500
14,796
1
9.9
14
138
EN
H2H
7
8,438
115,424
1.80
13.7
25
4,510
EN
M2M
16
16,142
329,964
1.84
20.4
214
14,139
CN
H2H
5
5,012
84,692
3.24
16.9
72
7,871
桌子 1: Comparison of CrossWOZ to other task-oriented corpora (training set). H2H, H2M, 和
M2M represent human-to-human, human-to-machine, machine-to-machine respectively. The average
numbers of domains and turns are for each dialogue.
多WOZ
CrossWOZ
usr: I’m looking for a college type attraction. usr:
. . .
Hello, could you recommend an attraction with a rating of 4.5 or higher?
usr: I would like to visit in town centre please. 系统:
. . .
Tiananmen, Gui Street, and Beijing Happy Valley are very nice places.
usr: Can you find an Indian restaurant for me usr:
that is also in the town centre?
模式
usr: I want a hotel in San Diego and I want to
check out on Thursday next week.
系统:
usr:
. . .
usr: I need a one way flight to go there.
I like Beijing Happy Valley. What hotels are around this attraction?
There are many, such as hotel A, hotel B, and hotel C.
Great! I am planning to find a hotel to stay near the attraction.
Which one has a rating of 4 or higher and offers wake-up call service?
桌子 2: Cross-domain dialog examples in MultiWOZ, 模式, and CrossWOZ. The value of cross-
domain constraints(bold) are underlined. Some turns are omitted to save space. Names of hotels are
replaced by A,乙,C for simplicity. Cross-domain constraints are pre-specified in MultiWOZ and Schema,
while determined dynamically in CrossWOZ. In CrossWOZ, the choice in one domain will greatly affect
related domains.
(彭等人。, 2017)
system simulators to generate dialogue outlines,
到
then use templates
generate dialogues or
further use people to
paraphrase the dialogues to make them more
natural (Shah et al., 2018; 拉斯托吉等人。, 2019).
It needs much less human effort. 然而, 这
complexity and diversity of dialogue policy are
limited by the simulators. To explore dialogue
policy in multi-domain scenarios, and to collect
natural and diverse dialogues, we resort to the
human-to-human setting.
Most of the existing datasets only involve
single domain in one dialogue, except MultiWOZ
(布兹安诺夫斯基等人。, 2018乙) and Schema (Rastogi
等人。, 2019). The MultiWOZ dataset has attracted
much attention recently, due to its large size and
multi-domain characteristics. It is at least one
order of magnitude larger than previous datasets,
amounting to 8,438 dialogues and 115K turns in
the training set. It greatly promotes the research
on multi-domain dialogue modeling, 例如
policy learning (Takanobu et al., 2019), 状态
追踪 (Wu et al., 2019), and context-to-text
一代 (布兹安诺夫斯基等人。, 2018A). 最近
the Schema dataset has been collected in a
machine-to-machine fashion, 导致 16,142
dialogues and 330K turns for 16 domains in
the multi-domain
the training set. 然而,
dependency in these two datasets is only embodied
in imposing the same pre-specified constraints on
283
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
different domains, such as requiring a restaurant
and an attraction to locate in the same area, 或者
city of a hotel and the destination of a flight to be
相同 (桌子 2).
桌子 1 presents a comparison between our
dataset with other task-oriented datasets. 在通讯中-
parison to MultiWOZ, our dataset has a com-
parable scale: 5,012 dialogues and 84K turns in
the training set. The average number of domains
and turns per dialogue are larger than those
of MultiWOZ, which indicates that our task is
更复杂. The cross-domain dependency in
our dataset is natural and challenging. 考试用-
普莱, 如表所示 2, the system needs to
recommend a hotel near the attraction chosen by
the user in previous turns. 因此, both system
recommendation and user selection will dynam-
ically impact the dialogue. We also allow the
same domain to appear multiple times in a user
goal since a tourist may want to go to more than
one attraction.
To better track the conversation flow and model
user dialogue policy, we provide annotation of
user states in addition to system states and
对话行为. While the system state tracks the
dialogue history, the user state is maintained by
the user and indicates whether the sub-goals have
been completed, which can be used to predict
user actions. This information will facilitate the
construction of the user simulator.
据我们所知, CrossWOZ is the
first large-scale Chinese dataset for task-oriented
dialogue systems, 这将
largely alleviate
the shortage of Chinese task-oriented dialogue
corpora that are publicly available.
信息. 反而, we can call the API
directly if necessary.
2. Goal Generation: A multi-domain goal
generator was designed based on the
数据库. The relation across domains is
captured in two ways. One is to constrain two
targets that locate near each other. 另一个
is to use a taxi or metro to commute between
two targets in HAR domains mentioned in
the context. To make workers understand
the task more easily, we crafted templates
to generate natural language descriptions for
each structured goal.
3. Dialogue Collection: Before the formal data
collection starts, we required the workers to
make a small number of dialogues and gave
them feedback about the dialogue quality.
然后, well-trained workers were paired to
converse according to the given goals. 这
workers were also asked to annotate both
user states and system states.
4. Dialogue Annotation: We used some rules
to automatically annotate dialogue acts
according to user states, system states,
and dialogue histories. To evaluate the
quality of the annotation of dialogue acts
and states, three experts were employed to
manually annotate dialogue acts and states
为了 50 对话. The results show that
our annotations are of high quality. 最后,
each dialogue contains a structured goal, A
task description, user states, system states,
对话行为, and utterances.
3 Data Collection
3.1 Database Construction
Our corpus is to simulate scenarios where a
traveler seeks tourism information and plans her
or his travel in Beijing. Domains include hotel,
attraction, 餐厅, metro, and taxi. The data
collection process is summarized as follows:
1. Database Construction: We crawled travel
information in Beijing from the Web,
including Hotel, Attraction, and Restaurant
域
(hereafter we name the three
domains as HAR domains). 然后, we used
the metro information of entities in HAR
domains to build the metro database. 为了
taxi domain, there is no need to store the
We collected 465 attractions, 951 restaurants, 和
1,133 hotels in Beijing from the Web. 一些
statistics are shown in Table 3. There are three
types of slots for each entity: common slots
such as name and address; binary slots for
hotel services such as wake-up call; and nearby
attractions/restaurants/hotels slots that contain
nearby entities in the attraction, 餐厅, 和
hotel domains. Because it is not usual to find
another nearby hotel in the hotel domain, we did
not collect such information. This nearby relation
allows us to generate natural cross-domain goals,
such as ‘‘find another attraction near the first
one’’ and ‘‘find a restaurant near the attraction’’.
284
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Domain
Attract. Rest.
Hotel
Id Domain
Slot
# Entities
# Slots
Avg. nearby attract.
Avg. nearby rest.
Avg. nearby hotels
465
9
4.7
6.7
2.1
951
10
3.3
4.1
2.4
1133
8 + 37∗
0.8
2.0
–
桌子 3: Database statistics. ∗ indicates that there
是 37 binary slots for hotel services such as wake-
up call. The last three rows show the average
number of nearby attractions/restaurants/hotels for
each entity. We did not collect nearby hotels
information for the hotel domain.
Nearest metro stations of HAR entities form the
metro database. 相比之下, we provided the
pseudo car type and plate number for the taxi
domain.
3.2 Goal Generation
To avoid generating overly complex goals, each
goal has at most five sub-goals. To generate
more natural goals, the sub-goals can be of the
same domain, such as two attractions near each
其他. The goal is represented as a list of (子-
goal id, domain, slot, 价值) tuples, named as
semantic tuples. The sub-goal
id is used to
distinguish sub-goals, which may be in the same
domain. There are two types of slots: informable
the user
插槽, which are the constraints that
needs to inform the system, and requestable
插槽, which are the information that the user
needs to inquire from the system. As shown in
桌子 4, besides common informable slots (italic
价值观) whose values are determined before the
conversation, we specially design cross-domain
informable slots (bold values) whose values refer
to other sub-goals. Cross-domain informable slots
utilize sub-goal id to connect different sub-goals.
Thus the actual constraints vary according to the
different contexts instead of being pre-specified.
The values of common informable slots are
sampled randomly from the database. Based on
the informable slots, users are required to gather
the values of requestable slots (blank values in
桌子 4) through conversation.
There are four steps in goal generation. 第一的, 我们
generate independent sub-goals in HAR domains.
For each domain in HAR domains, with the same
probability P we generate a sub-goal, while with
1 Attraction
1 Attraction
1 Attraction
2 Hotel
2 Hotel
2 Hotel
Taxi
3
Taxi
3
Taxi
3
Taxi
3
fee
姓名
nearby hotels
姓名
wake-up call
rating
从
到
car type
plate number
Value
自由的
near (id = 1)
是的
(id = 1)
(id = 2)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
桌子 4: A user goal example (translated into
英语). Slots with bold/italic/blank value are
cross-domain informable slots, common inform-
able slots, and requestable slots. 在这个例子中,
the user wants to find an attraction and one of
its nearby hotels, then book a taxi to commute
between these two places.
的概率 1 − P we do not generate
any sub-goal for this domain. Each sub-goal has
common informable slots and requestable slots.
如表所示 5, all slots of HAR domains
can be requestable slots, while the slots with an
asterisk can be common informable slots.
第二, we generate cross-domain sub-goals
in HAR domains. For each generated sub-goal
(例如, the attraction sub-goal in Table 4), if its
requestable slots contain ‘‘nearby hotels’’, 我们
generate an additional sub-goal in the hotel domain
(例如, the hotel sub-goal in Table 4) 与
probability of Pattraction→hotel. 当然, 这
selected hotel must satisfy the nearby relation to
the attraction entity. 相似地, we do not generate
any additional sub-goal in the hotel domain with
的概率 1 − Pattraction→hotel. This also
works for the attraction and restaurant domains.
Photel→hotel = 0 because we do not allow the user
to find the nearby hotels of one hotel.
第三, we generate sub-goals in the metro and
taxi domains. With the probability of Ptaxi, 我们
generate a sub-goal in the taxi domain (例如, 这
taxi sub-goal in Table 4) to commute between
two entities of HAR domains that are already
生成的. It is similar for the metro domain and
we set Pmetro = Ptaxi. All slots in the metro or
taxi domain appear in the sub-goals and must be
filled. 如表所示 5, from and to slots are
285
Attraction domain
name∗, rating∗, fee∗, duration∗, 地址, 电话,
nearby attract., nearby rest., nearby hotels
Restaurant domain
name∗, rating∗, cost∗, dishes∗, 地址, 电话,
打开, nearby attract., nearby rest., nearby hotels
Hotel domain
name∗, rating∗, price∗, type∗, 37 services∗,
电话, 地址, nearby attract., nearby rest.
Taxi domain
从, 到, car type, plate number
Metro domain
从, 到, from station, to station
桌子 5: All slots in each domain (翻译的
into English). Slots in bold can be cross-domain
informable slots. Slots with asterisk are inform-
able slots. All slots are requestable slots except
‘‘from’’ and ‘‘to’’ slots in the taxi and metro
域. The ‘‘nearby attractions/restaurants/
hotels’’ slots and the ‘‘dishes’’ slot can be multiple
valued (a list). The value of each ‘‘service’’ is
either yes or no.
always cross-domain informable slots, 然而
others are always requestable slots.
最后的, we rearrange the order of the sub-goals to
generate more natural and logical user goals. 我们
require that a sub-goal should be followed by its
referred sub-goal as immediately as possible.
To make the workers aware of this cross-domain
feature, we additionally provide a task description
for each user goal in natural language, 这是
generated from the structured goal by hand-crafted
模板.
Compared with the goals whose constraints are
all pre-specified, our goals impose much more
dependency between different domains, 哪个
will significantly influence the conversation. 这
exact values of cross-domain informable slots
are finally determined according to the dialogue
语境.
3.3 Dialogue Collection
We developed a specialized website that allows
two workers to converse synchronously and make
annotations online. On the website, workers are
free to choose one of the two roles: tourist (用户)
or system (wizard). 然后, two paired workers are
sent to a chatroom. The user needs to accomplish
the allocated goal
through conversation while
the wizard searches the database to provide the
necessary information and gives responses. 前
the formal data collection, we trained the workers
to complete a small number of dialogues by giving
them feedback. 最后, 90 well-trained workers
participated in the data collection.
相比之下, 多WOZ (布兹安诺夫斯基等人。,
2018乙) hired more than a thousand workers to
converse asynchronously. Each worker received a
dialogue context to review and had to respond for
only one turn at a time. The collected dialogues
may be incoherent because workers may not
understand the context correctly and multiple
workers contributed to the same dialogue session,
possibly leading to more variance in the data qual-
性. 例如, some workers expressed two
mutually exclusive constraints in two consecutive
user turns and failed to eliminate the system’s
confusion in the next several turns. 比较的
with MultiWOZ, our synchronous conversation
setting may produce more coherent dialogues.
3.3.1 User Side
The user state is the same as the user goal before
a conversation starts. At each turn, the user needs
到 1) modify the user state according to the system
response at the preceding turn, 2) select some
semantic tuples in the user state, which indicates
the dialogue acts, 和 3) compose the utterance
according to the selected semantic tuples. 在
addition to filling the required values and updating
cross-domain informable slots with real values in
the user state, the user is encouraged to modify
the constraints when there is no result under such
constraints. The change will also be recorded in
the user state. Once the goal is completed (all the
values in the user state are filled), the user can
terminate the dialogue.
3.3.2 Wizard Side
We regard the database query as the system
状态, which records the constraints of each
domain till the current turn. At each turn, 这
wizard needs to 1) fill the query according to the
previous user response and search the database if
必要的, 2) select the retrieved entities, 和
3) respond in natural
language based on the
information of the selected entities. If none of the
286
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
entities satisfy all the constraints, the wizard will
try to relax some of them for a recommendation,
resulting in multiple queries. The first query
records original user constraints while the last
one records the constraints relaxed by the system.
3.4 Dialogue Annotation
After collecting the conversation data, we used
some rules to annotate dialogue acts automati-
卡莉. Each utterance can have several dialogue
行为. Each dialogue act is a tuple that consists of
intent, domain, slot, and value. We pre-define 6
types of intents and use the update of the user state
and system state as well as keyword matching to
obtain dialogue acts. For the user side, dialogue
acts are mainly derived from the selection of
semantic tuples that contain the information of
domain, slot, and value. 例如,
如果 (1,
Attraction, fee, 自由的) 表中 4 is selected by
the user, 然后 (通知, Attraction, fee, 自由的) 是
) is selected,
labelled. 如果 (1, Attraction, 姓名,
然后 (Request, Attraction, 姓名, none) is labeled.
如果 (2, Hotel, 姓名, near (id=1)) is selected, 然后
(Select, Hotel, src domain, Attraction) is labeled.
This intent is specially designed for the ‘‘nearby’’
约束. For the system side, we mainly applied
keyword matching to label dialogue acts. 通知
intent is derived by matching the system utterance
with the information of selected entities. 什么时候
the wizard selects multiple retrieved entities and
recommend them, Recommend intent is labeled.
When the wizard expresses that no result satisfies
user constraints, NoOffer is labeled. For General
intents such as ‘‘goodbye’’, ‘‘thanks’’ at both user
and system sides, keyword matching is applied.
We also obtained a binary label for each seman-
tic tuple in the user state, which indicates whether
this semantic tuple has been selected to be
expressed by the user. This annotation directly
illustrates the progress of the conversation.
To evaluate the quality of the annotation of
dialogue acts and states (both user and system
状态), three experts were employed to manually
annotate dialogue acts and states for the same 50
对话 (806 utterances), 10 for each goal type
(参见章节 4). Because dialogue act annotation is
not a classification problem, we didn’t use Fleiss’
kappa to measure the agreement among experts.
We used dialogue act F1 and state accuracy to
measure the agreement between each two ex-
perts’ annotations. The average dialogue act F1 is
Train
Valid
Test
# Dialogues
# Turns
# 代币
Vocab
Avg. sub-goals
Avg. STs
Avg. 轮流
Avg. 代币
5,012
84,692
1,376,033
12,502
3.24
14.8
16.9
16.3
500
8,458
137,736
5,202
3.26
14.9
16.9
16.3
500
8,476
137,427
5,143
3.26
15.0
17.0
16.2
桌子 6: Data statistics. The average numbers
of sub-goals, 轮流, and STs (semantic tuples)
are for each dialogue. The average number of
tokens is for each turn.
94.59% and the average state accuracy is 93.55%.
We then compared our annotations with each
expert’s annotations, which are regarded as gold
标准. The average dialogue act F1 is 95.36%
and the average state accuracy is 94.95%, 哪个
indicates the high quality of our annotations.
4 统计数据
After removing uncompleted dialogues, we collec-
特德 6,012 dialogues in total. The dataset is split
randomly for training/validation/test, 哪里的
statistics are shown in Table 6. The average
number of sub-goals in our dataset
是 3.24,
which is much larger than that in MultiWOZ
(1.80) (布兹安诺夫斯基等人。, 2018乙) and Schema
(1.84) (拉斯托吉等人。, 2019). The average number
of turns (16.9) is also larger than that in MultiWOZ
(13.7). These statistics indicate that our dialogue
data are more complex.
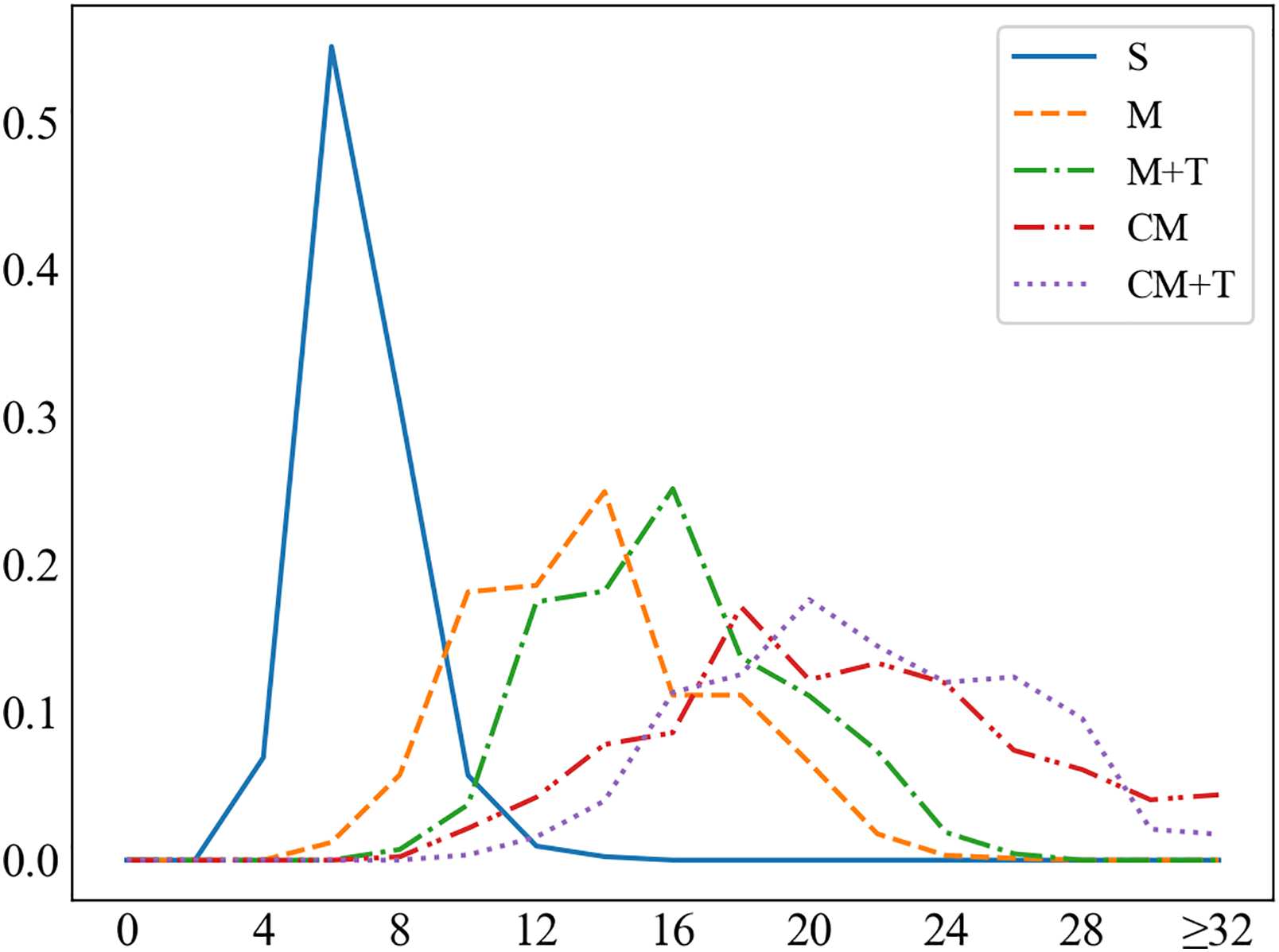
According to the type of user goal, we group the
dialogues in the training set into five categories:
Single-domain (S) 417 dialogues have only one
sub-goal in HAR domains.
Independent multi-domain (中号)1,573 对话
have multiple sub-goals (2∼3) in HAR do-
电源. 然而, these sub-goals do not have
cross-domain informable slots.
Independent multi-domain + traffic (M+T) 691
dialogues have multiple sub-goals in HAR
domains and at least one sub-goal in the
metro or taxi domain (3∼5 sub-goals). 这
sub-goals in HAR domains do not have
cross-domain informable slots.
287
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
1
4
1
9
2
3
5
2
5
/
/
t
我
A
C
_
A
_
0
0
3
1
4
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Goal type
S M M+T CM CM+T
417 1573 691 1759 572
# Dialogues
0.10 0.22 0.22 0.61 0.55
NoOffer rate
0.06 0.07 0.07 0.14 0.12
Multi-query rate
0.10 0.28 0.31 0.69 0.63
Goal change rate
Avg. 对话行为 1.85 1.90 2.09 2.06 2.11
1.00 2.49 3.62 3.87 4.57
Avg. sub-goals
4.5 11.3 15.8 18.2 20.7
Avg. STs
6.8 13.7 16.0 21.0 21.6
Avg. 轮流
13.2 15.2 16.3 16.9 17.0
Avg. 代币
桌子 7: Statistics for dialogues of different goal
types in the training set. NoOffer rate and Goal
change rate are for each dialogue. Multi-query rate
is for each system turn. The average number of
dialogue acts is for each turn.
Cross multi-domain (CM) 1,759 dialogues have
multiple sub-goals (2∼5) in HAR domains
with cross-domain informable slots.
Cross multi-domain + traffic (CM+T) 572 dia-
logues have multiple sub-goals in HAR
domains with cross-domain informable slots
and at least one sub-goal in the metro or taxi
domain (3∼5 sub-goals).
The data statistics are shown in Table 7. 作为
mentioned in Section 3.2, we generate indepen-
dent multi-domain, cross multi-domain, and traffic
domain sub-goals one by one. Thus in terms of
the task complexity, we have S