文章
Communicated by Shun-ichi Amari
On the Achievability of Blind Source Separation
for High-Dimensional Nonlinear Source Mixtures
Takuya Isomura
takuya.isomura@riken.jp
Laboratory for Neural Computation and Adaptation and Brain Intelligence Theory
Unit, 日本理化学研究所脑科学中心, 你的, 埼玉 351-0198, 日本
Taro Toyoizumi
taro.toyoizumi@riken.jp
Laboratory for Neural Computation and Adaptation, RIKEN Center for Brain
科学, 你的, 埼玉 351-0198, 日本, and Department of Mathematical
Informatics, Graduate School of Information Science and Technology,
University of Tokyo, Bunkyo-ku, 东京 113-8656, 日本
多年, a combination of principal component analysis (PCA)
and independent component analysis (ICA) has been used for blind
source separation (BSS). 然而, it remains unclear why these lin-
ear methods work well with real-world data that involve nonlinear
source mixtures. This work theoretically validates that a cascade of lin-
ear PCA and ICA can solve a nonlinear BSS problem accurately—when
the sensory inputs are generated from hidden sources via nonlinear map-
pings with sufficient dimensionality. Our proposed theorem, termed the
asymptotic linearization theorem, theoretically guarantees that applying
linear PCA to the inputs can reliably extract a subspace spanned by the
linear projections from every hidden source as the major components—
and thus projecting the inputs onto their major eigenspace can effectively
recover a linear transformation of the hidden sources. Then subsequent
application of linear ICA can separate all the true independent hidden
sources accurately. Zero-element-wise-error nonlinear BSS is asymptoti-
cally attained when the source dimensionality is large and the input di-
mensionality is sufficiently larger than the source dimensionality. 我们的
proposed theorem is validated analytically and numerically. 而且,
the same computation can be performed by using Hebbian-like plastic-
ity rules, implying the biological plausibility of this nonlinear BSS strat-
egy. Our results highlight the utility of linear PCA and ICA for accurately
and reliably recovering nonlinearly mixed sources and suggest the im-
portance of employing sensors with sufficient dimensionality to identify
true hidden sources of real-world data.
神经计算 33, 1433–1468 (2021) © 2021 麻省理工学院.
https://doi.org/10.1162/neco_a_01378
在知识共享下发布
归因 4.0 国际的 (抄送 4.0) 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1434
1 介绍
时间. Isomura and T. Toyoizumi
Blind source separation (BSS) involves the separation of mixed sensory in-
puts into their hidden sources without knowledge of the manner in which
they were mixed (Cichocki, Zdunek, Phan, & Amari, 2009; Comon & Jut-
ten, 2010). Among the numerous BSS methods, a combination of principal
成分分析 (PCA) (皮尔逊, 1901; Oja, 1982, 1989; Sanger, 1989; 徐,
1993; Jolliffe, 2002) and independent component analysis (ICA) (Comon,
1994; 钟 & Sejnowski, 1995, 1997; Amari, Cichocki, & 哪个, 1996; Hy-
varinen & Oja, 1997) is one of the most widely used approaches. 在这个
combined PCA–ICA approach, PCA yields a low-dimensional concise rep-
resentation (IE。, the major principal components) of sensory inputs that
most suitably describes the original high-dimensional redundant inputs.
Whereas, ICA provides a representation (IE。, encoders) that separates the
compressed sensory inputs into independent hidden sources. A classical
setup for BSS assumes a linear generative process (钟 & Sejnowski, 1995),
in which sensory inputs are generated as a linear superposition of indepen-
dent hidden sources. The linear BSS problem has been extensively studied
both analytically and numerically (Amari, 陈, & Cichocki, 1997; Oja &
Yuan, 2006; Erdogan, 2009), where the cascade of PCA and ICA is guaran-
teed to provide the optimal linear encoder that can separate sensory inputs
into their true hidden sources, up to permutations and sign-flips (Baldi &
Hornik, 1989; 陈, Hua, & 严, 1998; Papadias, 2000; Erdogan, 2007).
Another crucial perspective is the applicability of BSS methods to real-
world data generated from a nonlinear generative process. 尤其,
the aim of nonlinear BSS is to identify the inverse of a nonlinear generative
process that generates sensory inputs and thereby infer their true indepen-
dent hidden sources based exclusively on the sensory inputs. 虽然
cascade of linear PCA and ICA has been applied empirically to real-world
BSS problems (Calhoun, 刘, & Adali, 2009), no one has yet theoretically
proven that this linear BSS approach can solve a nonlinear BSS problem. 到
address this gap, this work demonstrates mathematically that the cascade
of PCA and ICA can solve a nonlinear BSS problem accurately when the
source dimensionality is large and the input dimensionality is sufficiently
larger than the source dimensionality so that various nonlinear mappings
from sources to inputs can be determined from the inputs themselves.
一般来说, there are five requirements for solving the nonlinear BSS
问题. The first two requirements are related to the representation capac-
ity of the encoder: (1) the encoder’s parameter space must be sufficiently
large to accommodate the actual solution that can express the inverse of
the true generative process. (2) 然而, this parameter space should not
be too large; 否则, a nonlinear BSS problem can have infinitely many
spurious solutions wherein all encoders are independent but dissimilar to
the true hidden sources (Hyvarinen & Pajunen, 1999; Jutten & Karhunen,
2004). 因此, it is important to constrain the representation capacity of the
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1435
encoder in order to satisfy these opposing requirements. A typical approach
for solving the nonlinear BSS problem involves using a multilayer neu-
ral network—with nonlinear activation functions—that learns the inverse
of the generative process (Lappalainen & Honkela, 2000; Karhunen, 2001;
欣顿 & Salakhutdinov, 2006; Kingma & Welling, 2013; Dinh, Krueger, &
本吉奥, 2014). The remaining three requirements are related to the unsu-
pervised learning algorithms used to identify the optimal parameters for
the encoder: (3) the learning algorithm must have a fixed point at which
the network expresses the inverse of the generative process; (4) the fixed
point must be linearly stable so that the learning process converges to the
解决方案; 和 (5) the probability of not converging to this solution should
be small, 那是, most realistic initial conditions must be within the basin of
attraction of the true solution.
Approaches using a nonlinear multilayer neural network satisfy require-
蒙特 1 when the number of neurons in each layer is sufficient (univer-
sality: Cybenko, 1989; Hornik, Stinchcombe, & 白色的, 1989; Barron, 1993);
而且, learning algorithms that satisfy requirements 3 和 4 are also
已知的 (Dayan, 欣顿, Neal, & Zemel, 1995; 弗里斯顿, 2008; 弗里斯顿, Trujillo-
Barreto, & Daunizeau, 2008). 然而, reliable identification of the true
hidden sources is still necessary because the encoder can have infinitely
many spurious solutions if its representation capacity is too large (IE。, if re-
quirement 2 is violated). As previously indicated, to the best of our knowl-
边缘, there is no theoretical proof that confirms a solution for a nonlinear
BSS problem (Hyvarinen & Pajunen, 1999; Jutten & Karhunen, 2004), 前任-
cept for some cases wherein temporal information—such that each inde-
pendent source has its own dynamics—is available (Hyvarinen & Morioka,
2016, 2017; Khemakhem, Kingma, Monti, & Hyvarinen, 2020). 而且,
even when requirement 2 is satisfied, there is no guarantee that a learning
algorithm will converge to the true hidden source representation because
it might be trapped in a local minimum wherein outputs are still not inde-
pendent of each other. 因此, for a nonlinear BSS problem, it is of paramount
importance to simplify the parameter space of the inverse model in order
to remove spurious solutions and prevent the learning algorithm from at-
taining a local minimum (to satisfy requirements 2 和 5) while retaining
its capacity to represent the actual solution (requirement 1). 因此, 在这个
工作, we apply a linear approach to solving a nonlinear BSS problem in
order to ensure requirements 2 和 5 are satisfied. We demonstrate that the
cascade of PCA and ICA can reliably identify a good approximation of the
inverse of nonlinear generative processes asymptotically under the condi-
tion where the source dimensionality is large and the input dimensionality
is sufficiently larger than the source dimensionality (thus satisfying require-
ments 1–5). Although such a condition is different from the case typically
considered by earlier work—where the sources and inputs have the same
dimensionality—the condition we consider turns out to be apt for the math-
ematical justification of the achievability of the nonlinear BSS.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1436
时间. Isomura and T. Toyoizumi
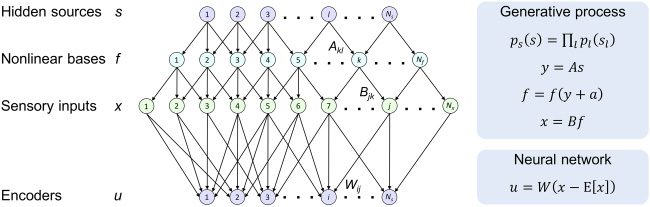
, . . . , fN f )时间 , where A = {Akl
数字 1: Structures of nonlinear generative process (顶部) and linear neural
, . . . , sNs )T generate sensory inputs
网络 (底部). Hidden sources s = (s1
, . . . , xNx )T via nonlinear mappings characterized by nonlinear bases f =
x = (x1
, . . . , aN f )T are gaussian-distributed
( f1
} is a lower-
higher-layer mixing weights and offsets, 分别, and B = {B jk
layer mixing weight matrix. Encoders comprise a single-layer linear neural net-
} is a synaptic
工作, where u = (u1
weight matrix. Equations on the right-hand-side panels summarize the genera-
tion of sensory inputs from hidden sources through nonlinear mixtures and the
inversion of this process using a linear neural network.
, . . . , uNs )T are neural outputs and W = {Wi j
} and a = (a1
2 结果
2.1 Overview. Our proposed theorem, referred to as asymptotic lin-
earization theorem, is based on an intuition that when the dimensionality
of sensory inputs is significantly larger than that of hidden sources, 这些
inputs must involve various linear and nonlinear mappings of all hidden
sources—thus providing sufficient information to identify the true hidden
sources without ambiguity using an unsupervised learning approach. 我们
consider that Ns-dimensional hidden sources s ≡ (s1
, . . . , sNs )T generate Nx-
dimensional sensory inputs x ≡ (x1
, . . . , xNx )T through a generative process
characterized by an arbitrary nonlinear mapping x ≡ F(s) (见图 1).
这里, the hidden sources are supposed to follow independently an identical
probability distribution with zero mean and unit variance ps(s) ≡
i pi(si).
A class of nonlinear mappings F(s) can be universally approximated by a
×Ns and
specific but generic form of two-layer network. Suppose A ∈ RN f
B ∈ RNx×N f as higher- and lower-layer mixing matrices, 分别; a ∈
RN f as a constant vector of offsets; y ≡ As as a linear mixture of sources,
F (•) : 右 (西德:4)→ R as a nonlinear function; and f ≡ ( f1
, . . . , fN f )T ≡ f (作为 +
A) ≡ f (y + A) as N f -dimensional nonlinear bases. The sensory inputs are
given as
(西德:2)
x = B f (作为 + A),
(2.1)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1437
或者, equivalently, x = B f (y + A) = B f . This expression using the two-layer
network is universal in the component-wise sense1 (Cybenko, 1989; Hornik
等人。, 1989; Barron, 1993) and each element of x can represent an arbitrary
mapping x = F(s) as N f increases by adjusting parameters a, A, 和乙.
We further suppose that each element of A and a is independently gener-
ated from a gaussian distribution N [0, 1/Ns], which retains its universal-
性 (Rahimi & Recht, 2008A, 2008乙) as long as B is tuned to minimize the
mean squared error E[|B f − F(s)|2]. 这里, 乙[•] describes the average over
ps(s). The scaling of A is to ensure that the argument of f is of order 1.
−1/2
The N
order offset a is introduced to this model to express any genera-
s
tive process F(s); 然而, it is negligibly small relative to As for large Ns.
The whole system, including the generative process and neural network, 是
如图所示 1 (左边). The corresponding equations are summarized in
数字 1 (正确的).
For analytical tractability, we decompose nonlinear bases f
进入
sum of linear and nonlinear parts of hidden sources as follows: 线性
components of the hidden sources in the bases are defined as Hs using a
coefficient matrix H that minimizes the mean squared error, H ≡
arg minH E[| f − E[ F ] − Hs|2]. Such a coefficient matrix is computed as H =
乙[ f sT ]. The remaining part φ ≡ f − E[ F ] − Hs is referred to as nonlinear
components of the hidden sources, which are orthogonal (uncorrelated) 到
s (IE。, 乙[φsT ] = O). This definition of linear and nonlinear components is
独特的. 因此, the sensory inputs (参见方程 2.1) are decomposed into
linear and nonlinear transforms of the hidden sources:
x − E[X] = BHs
(西德:3)(西德:4)(西德:5)(西德:6)
+ Bφ
(西德:3)(西德:4)(西德:5)(西德:6)
.
signal
残差
(2.2)
The first term on the right-hand side represents the signal comprising the
linear components of the hidden sources, whereas the second term repre-
sents the residual introduced by the nonlinearity in the generative process.
更远, because φ is uncorrelated with s, the covariance of the bases is
decomposed into their linear and nonlinear counterparts Cov[ F ] ≡ E[( f −
乙[ F ])( f − E[ F ])时间 ] = Cov[Hs] + Cov[φ] = HHT + (西德:3), 在哪里 (西德:3) ≡ Cov[φ] 在-
dicates the covariance of φ. 因此, the covariance of the sensory inputs
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1
在这项工作中, based on the literature (Cybenko, 1989), we define the universality in the
component-wise sense as the condition wherein each element of x = F(s) is approximated
using the two-layer network with an approximation error smaller than an arbitrary δ > 0,
那是, sups[|Fj (s) − B j f (作为 + A)|] < δ for j = 1, . . . , Nx when N f is sufficiently large. Note
that Fj (s) is the jth element of F(s) and B j is the jth row vector of B. It is known that when
f is a sigmoidal function and parameters are selected appropriately, the approximation
−1
(Barron, 1993); hence, E[|Fj (s) − B j f (As +
error can be upper-bounded by the order N
f
a)|2] ≤ O(N
(cid:7) Ns (cid:7) 1, irrespective of Nx.
). This relationship holds true when N f
−1
f
1438
T. Isomura and T. Toyoizumi
Cov[x] ≡ BCov[ f ]BT can be decomposed into the signal and residual
covariances:
Cov[x] = BHHT BT
(cid:6)
(cid:4)(cid:5)
(cid:3)
+
B(cid:3)BT
(cid:3) (cid:4)(cid:5) (cid:6)
.
(2.3)
signal covariance
residual covariance
Crucially, the signal covariance has only Ns nonzero eigenvalues when
> Ns owing to low-column-rank matrix H, whereas the eigenvalues of
N f
the residual covariance are distributed in the N f -dimensional eigenspace.
This implies that if the norms of the linear and nonlinear components in the
inputs are in a similar order and Ns is sufficiently large, the eigenvalues of
/Ns order times larger
the signal covariance (IE。, linear components) are N f
than those of the residual covariance (IE。, nonlinear components). 我们将
prove in the following sections that when Ns (西德:7) 1, this property is derived
from the fact that elements of A are gaussian distributed and singular values
of B are of order 1.
下文中, we demonstrate that owing to the aforementioned prop-
厄蒂, the first Ns major principal components of the input covariance pre-
cisely match the signal covariance when the source dimensionality is large
and the input dimensionality is sufficiently larger than the source dimen-
sionality. 最后, projecting the inputs onto the subspace spanned
by major eigenvectors can effectively extract the linear components in the
输入. 而且, the same projection can effectively filter out the nonlin-
ear components in the inputs because the majority of the nonlinear com-
ponents are perpendicular to the major eigenspace. 因此, applying PCA to
the inputs enables the recovery of a linear transformation of all the true hid-
den sources of the mixed sensory inputs with a small estimation error. 这
财产, termed asymptotic linearization, enables the reduction of the orig-
inal nonlinear BSS problem to a simple linear BSS problem, 最后
satisfying requirements 1 到 5. In the remainder of this article, we mathemat-
ically validate this theorem for a wide range of nonlinear setups and thereby
demonstrate that linear encoder neural networks can perform the nonlin-
ear BSS in a self-organizing manner.2 We assume that Nx = N f
(西德:7) Ns (西德:7) 1
throughout the article.3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
2
在本文中, we refer to the neural network as the encoder because networks that
convert the input data into a different (lower-dimensional) code or representation are
widely recognized as encoders in the literature on machine learning (欣顿 & Salakhut-
dinov, 2006; 好人, 本吉奥 & 考维尔, 2016). 然而, one may think that the
generative process encodes the hidden sources into the sensory inputs through nonlin-
ear mixtures. From this viewpoint, one may term the neural network as the decoder that
decodes the inputs to recover the original sources.
Our numerical simulations suggest that the system behaves similarly for Nx ≥ N f
Ns > 1 在某些情况下, although our theorem holds mathematically only when Nx = N f
Ns (西德:7) 1.
≥
(西德:7)
3
Achievability of Nonlinear Blind Source Separation
1439
2.2 PCA Can Extract Linear Projections of All True Hidden Sources.
在这个部分, we first demonstrate that the major principal components
(西德:7)
of the input covariance precisely match the signal covariance when N f
Ns (西德:7) 1 by analytically calculating eigenvalues of HHT and (西德:3) for the afore-
mentioned system. For analytical tractability, we assume that f (•) is an odd
nonlinear function. This assumption does not weaken our proposed theo-
rem because the presumed generative process in equation 2.1 remains uni-
凡尔赛宫. We further assume that ps(s) is a symmetric distribution.
Each element of—and any pair of two elements in—a vector y ≡ As is
approximately gaussian distributed for large Ns due to the central limit
, y j ) 从
theorem. The deviation of their marginal distribution p(做
, y j ) ≡ N [0, ˜A ˜AT ] 是
corresponding zero-mean gaussian distribution pN (做
order N−1
s because the source distribution is symmetric, where ˜A ∈ R2×Ns
indicates a submatrix of A comprising its ith and jth rows (see lemma
1 and its proof in section 4.1). This asymptotic property allows us to
compute H and (西德:3) based on the expectation over a tractable gaussian
, y j )—as
distribution pN (做
the leading order for large Ns, despite the fact that s actually follows a
, y j )
nongaussian distribution (ensure that p(做
, y j ) 作为
in the large Ns
(西德:7)
to distinguish it from E[•]. The latter can
EN [•] ≡
•pN (做
be rewritten as E[•] = EN [•(1 + G(做
, y j )/Ns)] using an order-one function
, y j ); 因此,
, y j ) from pN (做
G(做
the deviation caused by this approximation is negligibly smaller than the
leading order in the following analyses.
limit). We denote the expectation over pN (做
, y j )dyidy j
, y j )—as a proxy for the expectation over p(做
, y j ) that characterizes the deviation of p(做
, y j ) converges to pN (做
(西德:7)
(西德:7)
f p(西德:9)
氮 (y)T dy AAT =
Owing to this asymptotic property, the coefficient matrix H is com-
puted as follows: the pseudo-inverse of A, A+ ≡ (AT A)−1AT , satisfies
A+A = I and A+T = AT+. 因此, we have H = HAT A+T = E[ f yT ]A+T .
It can be approximated by EN [ f yT ]A+T as the leading order from
引理 1. From the integration by parts, we obtain EN [ f yT ] =
diag[ F (西德:9)]pN (y)dy AAT = diag[EN [ F (西德:9)]]AAT . 这
-
relationship is also known as the Bussgang theorem (Bussgang, 1952).
−1/2
因此, EN [ f yT ]A+T = diag[EN [ F (西德:9)]]A is order N
for a generic odd func-
s
tion f (•) (as it is the product of order 1 diagonal matrix diag[EN [ F (西德:9)]] 和
−1/2
order N
matrix A). According to lemma 1, the difference between H
s
−3/2
and diag[EN [ F (西德:9)]]A is order N
s order times smaller than the
s
leading order (see remark 1 in section 4.1 欲了解详情). 因此, we obtain
as it is N−1
H = diag[EN [ F
(西德:9)
]]A + 氧
(西德:9)
(西德:8)
−3/2
氮
s
= f (西德:9)A + 氧
(西德:8)
(西德:9)
.
−1
氮
s
(2.4)
F (西德:9)
In the last equality,
√
(西德:7)
(ξ ) 经验值(−ξ 2/2)dξ /
able ξ . The order N−1
s
F (西德:9) ≡
the scalar coefficient
2π using the expectation over a unit gaussian vari-
error term includes the nongaussian contributions
is expressed as
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1440
时间. Isomura and T. Toyoizumi
s
diagonal matrix (diag[EN [ F (西德:9)]] − f (西德:9)我) and order N
−1/2
deviation of diag[EN [ F (西德:9)]] from f (西德:9),
of y and the effect of the order N
s
where the latter yields the order N−1
error owing to the product of order
−1/2
−1/2
氮
s matrix A. Due
s
to the low column rank of matrix A, AAT has Ns nonzero eigenvalues,
/Ns as the leading order, because elements of A are
all of which are N f
independent and identically distributed variables sampled from a gaus-
sian distribution N [0, 1/Ns] (Marchenko & Pastur, 1967). The same scaling
of eigenvalues also holds for HHT because the difference between the
−1/2
nonzero singular values of H and those of f (西德:9)A—caused by the order N
s
deviation of diag[EN [ F (西德:9)
]] from f (西德:9)I—is smaller than order (N f
下一个, we characterize the covariance matrix (西德:3) = Cov[φ] using the
asymptotic property. The nonlinear components can be cast as a function of
y, φ(y) = f (y + A) − E[ F ] − E[ f yT ]A+T A+y. For large Ns, the covariance of y,
Cov[y] = AAT , is close to the identity matrix—and the deviation (AAT − I)
−1/2
is order N
for each element—because elements of A are gaussian dis-
s
tributed. This weak correlation between yi and y j (我 (西德:11)= j) leads to a weak cor-
relation of their functions φ
j. 因此, by computing the Taylor expan-
j] ≡ EN [φ
, φ
sion of CovN [φ
j] with respect to the small
, y j] ≡ EN [yiy j], we obtain (Toyoizumi & Abbott, 2011)
covariance CovN [做
(see lemma 2 in section 4.2):
i and φ
φ
我
j] − EN [φ
/Ns)1/2.
我]EN [φ
我
CovN [φ
我
, φ
j] =
∞(西德:10)
EN
(西德:12)
(西德:11)
φ(n)
我
EN
(西德:12)
(西德:11)
φ(n)
j
n=1
n!
CovN [做
, y j]n
(2.5)
我
我
我
我
, φ
, φ
] = O(N−1
s
−n/2
, y j]n is order N
s
) 和 |EN [φ(n)
. 相比之下, the ith diagonal element CovN [φ
. Because EN [φ(1)
for i (西德:11)= j. 这里, CovN [做
),
−1/2
]| ≤ O(1) for n ≥ 3 hold with a generic
] = O(氮
EN [φ(2)
s
odd function f (•) (see remark 2 in section 4.2 欲了解详情), CovN [φ
j] 是
我
−3/2
order N
我] is order 1.
s
These observations conclude that eigenvalues of CovN [φ]—and therefore
those of (西德:3) according to lemma 1 (see remark 1 in section 4.1 欲了解详情)—
−3/2
are not larger than order max[1, N f N
]; 因此, all nonzero eigenvalues
s
/Ns—are sufficiently greater than those of (西德:3)
of HHT —which are order N f
(西德:7) Ns (西德:7) 1.
when N f
, y j]n = ((AAT )
One can further proceed to the calculation of (西德:3) by explicitly comput-
ing the coefficients EN [φ(n)
] up to the fourth order. Because f (•) is an
(西德:13)n)我j, 方程 2.5 becomes
odd function, using CovN [做
j] = EN [ F (3)(做)]EN [ F (3)(y j )]{aia j((AAT )
/6}
/2 + ((AAT )
, φ
CovN [φ
我
−5/2
+ 氧(氮
) (see remark 2 in section 4.2 欲了解详情). This analytical ex-
s
pression involves the Hadamard (element-wise) power of matrix AAT
(西德:13)3 ≡ (AAT ) (西德:13) (AAT ) (西德:13) (AAT ). 什么时候
(denoted by (西德:13)), 例如, (AAT )
/N2
N f
s
(as the leading order) with the corresponding eigenvectors that match the
(西德:13)3 has Ns major eigenvalues—all of which are 3N f
(西德:7) 1, (AAT )
> N2
s
(西德:13)2)我j
(西德:13)3)我j
我
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1441
(西德:13)3 − diag[(AAT )
− Ns) minor eigenvalues that are negligibly
directions of AAT —and (N f
/N2
smaller than order N f
s (see lemma 3 in section 4.3). This property yields
(西德:13)3] = (3/Ns)(AAT − diag[AAT ])
an approximation (AAT )
(西德:7) 1,
up to the negligible minor eigenmodes. Note that when N2
s
(西德:13)3 are negligible compared to diagonal
off-diagonal elements of (AAT )
(西德:13)2 has one major eigenvalue,
elements of (西德:3) (见下文). 相似地, (AAT )
/Ns, in the direction of (1, …, 1)时间 , while other minor eigenmodes of it
N f
are negligible. These approximations are used to compute off-diagonal
elements of (西德:3).
> N f
因此, (西德:3) is analytically expressed as
(西德:13)
(西德:3) =
F 2 − f (西德:9)2
(西德:14)
2
我 + F (3)
2Ns
(AAT + aaT ) + (西德:7).
(2.6)
(西德:7)
√
) using f 2 ≡
= f 2 − f (西德:9)2 + 氧(氮
F (3)(ξ ) 经验值(−ξ 2/2)dξ /
−1/2
2π up to order N
s
这里, 从 (西德:3) = Cov[ F ] − HHT and equation 2.4, each diagonal element is
−1/2
expressed as (西德:3)
F 2(ξ ) 经验值(−ξ 2/2)dξ /
√
二
s
2圆周率, which yields the first term of equation 2.6 (where the error term is
involved in the third term). The second term is generated from equation
2.5 followed by lemma 3, where EN [ F (3)(做)] is approximated by f (3) ≡
(西德:7)
. The third term is the er-
ror matrix (西德:7) that summarizes the deviations caused by the nongaussian-
, y j ) (see lemma 1; see also remark 1 in section 4.1), higher-order
ity of p(做
(西德:13)2 和
terms of the Taylor series in equation 2.5, minor eigenmodes of (AAT )
−1/2
(西德:13)3, and the effect of the order N
(AAT )
deviations of coefficients (例如,
s
乙[ F 2
我 ]) from their approximations (例如, F 2). Due to its construction, eigen-
values of (西德:7) are smaller than those of the first or second term of equation
2.6. This indicates that for large Ns, either the first or second term of equa-
的 2.6 provides the largest eigenvalue of (西德:3), which is order max[1, N f
/N2
s ].
因此, (西德:7) is negligible for the following analyses.
因此, all nonzero eigenvalues of HHT —that are order N f
/Ns—
are much greater than the maximum eigenvalue of (西德:3)—that is, 命令
max[1, N f
(西德:7) Ns (西德:7) 1. 因此, unless B specifically attenuates
one of Ns major eigenmodes of HHT or significantly amplifies a particular
eigenmode of (西德:3), 我们有
s ]—when N f
/N2
min eig[HT BT BH] (西德:7) max eig[乙(西德:3)BT ]
(2.7)
(西德:7) Ns (西德:7) 1. 这里, eig[•] indicates a set of eigenvalues of •.
for Nx = N f
/Ns min eig[BT B],
Because min eig[HT BT BH] is not smaller than order N f
while max eig[乙(西德:3)BT ] is not larger than order max[1, N f
/N2
s ] max eig[BT B],
/Ns and Ns are much greater than
不等式 2.7 holds at least when N f
max eig[BT B]/ min eig[BT B]. This is the case, 例如, if all the sin-
gular values of B are order 1. We call B sufficiently isotropic when
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1442
时间. Isomura and T. Toyoizumi
max eig[BT B]/ min eig[BT B] can be upper-bounded by a (possibly large)
finite constant and focus on such B, because the effective input dimension-
ality is otherwise much smaller than Nx. 换句话说, one can redefine
Nx of any system by replacing the original sensory inputs with their com-
pressed representation to render B isotropic.
When inequality 2.7 holds, the first Ns major eigenmodes of Cov[X] pre-
cisely match the signal covariance, while minor eigenmodes are negligibly
小的. 因此, there is a clear spectrum gap between the largest Ns eigen-
values and the rest. This indicates that one can reliably identify the signal
covariance and source dimensionality based exclusively on PCA of Cov[X]
in an unsupervised manner. 因此, 什么时候 (西德:8)M ∈ RNs×Ns is a diagonal matrix
that arranges the first Ns major eigenvalues of Cov[X] in descending order,
with the corresponding eigenvector matrix PM ∈ RNx×Ns , we obtain
下午(西德:8)MPT
中号
(西德:14) BHHT BT .
(2.8)
The corrections of (西德:8)M and PM due to the presence of the residual covariance
are estimated as follows: by the first-order perturbation theorem (Griffiths,
2005), the correction of the ith major eigenvalue of Cov[X] is upper-bounded
by max eig[乙(西德:3)BT ], while the norm of the correction of the ith eigenvector
is upper-bounded by max eig[乙(西德:3)BT ]/ min eig[HT BT BH]. These corrections
are negligibly smaller than the leading-order terms, when inequality 2.7
holds. Further details are provided in section 4.4.
所以, applying PCA to Cov[X] can extract the signal covariance
as the major principal components with high accuracy when Nx = N f
(西德:7)
Ns (西德:7) 1 and B is sufficiently isotropic. This property is numerically val-
idated. The major principal components of Cov[X] suitably approximate
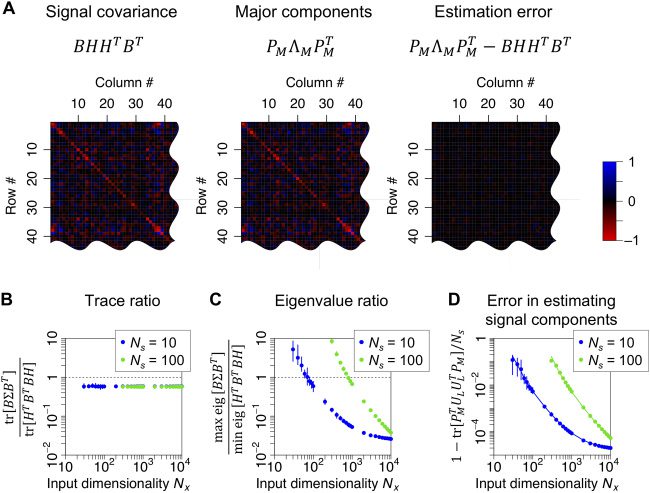
the signal covariance (see Figure 2A). In the simulations, elements of B
are sampled from a gaussian distribution with zero mean. The trace ra-
tio tr[乙(西德:3)BT ]/tr[HT BT BH] (IE。, the ratio of the eigenvalue sum of residual
covariance tr[乙(西德:3)BT ] to that of signal covariance tr[HT BT BH]) retains the
value of about 0.6 irrespective of Ns and Nx, indicating that the large-
scale systems we consider are fairly nonlinear (see Figure 2B). 相比之下,
the eigenvalue ratio max eig[乙(西德:3)BT ]/ min eig[HT BT BH] monotonically con-
verges to zero when Nx increases; 因此, 不等式 2.7 holds for large Nx (看
Figure 2C). 最后, PM approximates nonzero eigenmodes of the sig-
nal covariance accurately (see Figure 2D). These results indicate that PCA is
a promising method for reliably identifying the linear components in sen-
sory inputs. 下文中, we explicitly demonstrate that projecting the
inputs onto the major eigenspace can recover true hidden sources of sen-
sory inputs accurately.
2.3 Asymptotic Linearization Theorem. We now consider a linear en-
coder comprising a single-layer linear neural network,
u ≡ W (x − E[X]) ,
(2.9)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1443
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
= 10 and Nx
数字 2: PCA can identify linear components comprising linear projections
from every true hidden source. 这里, hidden sources s are independently gen-
erated from an identical uniform distribution with zero mean and unit vari-
= Nx and f (•) = sign(•) are fixed; elements of A, a are independently
安斯; N f
sampled from N [0, 1/Ns]; and elements of B are independently sampled from
氮 [0, 1/N f ]. PCA is achieved via eigenvalue decomposition. (A) Comparison be-
tween the signal covariance and major principal components of sensory inputs,
= 103. (乙) Trace ratio tr[乙(西德:3)BT ]/tr[HT BT BH]. (C) Eigen-
when Ns
value ratio max eig[乙(西德:3)BT ]/ min eig[HT BT BH]. (D) Error in extracting nonzero
eigenmodes of signal covariance as major components, which is scored by
∈ RNx×Ns indicates the left-singular vectors of
1 − tr[PT
BH. As Nx increases, PMPT
L reliably and accurately. Solid
lines indicate theoretical values of estimation errors: 参见方程 4.24 for de-
tails. Circles and error bars indicate the means and areas between maximum
and minimum values obtained with 20 different realizations of s, A, 乙, A, 在哪里
some error bars are hidden by the circles.
M converges to ULU T
L PM]/Ns, where UL
MULU T
, . . . , uNs )T are Ns-dimensional neural outputs and W ∈
where u ≡ (u1
RNs×Nx is a synaptic weight matrix. Suppose that by applying PCA to the
输入, one obtains W, which represents a subspace spanned by the ma-
jor eigenvectors, W = (西德:9)中号(西德:8)−1/2
中号, 在哪里 (西德:9)M is an arbitrary Ns × Ns or-
thogonal matrix expressing an ambiguity. A normalization factor (西德:8)−1/2
M PT
中号
1444
时间. Isomura and T. Toyoizumi
is multiplied so as to ensure Cov[你] = I. Neural outputs with this W in-
deed express the optimal linear encoder of the inputs because it is the
solution of the maximum likelihood estimation that minimizes the loss
to reconstruct the inputs from lower-dimensional encoder u using a lin-
ear network under gaussian assumption (see Xu, 1993, and Wentzell, 一个-
drews, 汉密尔顿, Faber, & Kowalski, 1997, for related studies). 其他
字, when we assume that the loss follows a unit gaussian distribution,
arg minW E[|x − E[X] − W +u|2] = (西德:9)中号(西德:8)−1/2
M PT
M holds under the constraint
of dim[你] = Ns and Cov[你] = I, where W +
indicates the pseudo inverse
of W.
至关重要的是, 方程 2.8 directly provides the key analytical expression to
represent a subspace spanned by the linear components:
瓦 (西德:14) (西德:9)(BH)
+.
(2.10)
+ ≡ (HT BT BH)
−1HT BT is the pseudo inverse of BH, 和 (西德:9) is an-
这里, (BH)
+
other arbitrary Ns × Ns orthogonal matrix. Error in approximating (BH)
is negligible for the following calculations as long as inequality 2.7 holds
(参见部分 4.4 for more details). 方程 2.10 indicates that the directions
of the linear components can be computed under the BSS setup—up to an
arbitrary orthogonal ambiguity factor (西德:9). 因此, we obtain the following
theorem:
Theorem 1 (Asymptotic Linearization). When inequality 2.7 holds, from equa-
系统蒸发散 2.2, 2.9, 和 2.10, the linear encoder with optimal matrix W = (西德:9)中号(西德:8)−1/2
M PT
中号
can be analytically expressed as
u = (西德:9)(s + ε)
using a linearization error ε ≡ (BH)
+Bφ with the covariance matrix of
+
Cov[ε] = (BH)
乙(西德:3)BT (BH)
+时间 .
(2.11)
(2.12)
The maximum eigenvalue of Cov[ε] is upper-bounded by max eig[乙(西德:3)BT ]/
min eig[HT BT BH], which is sufficiently smaller than one from inequality 2.7. 在
特别的, when ps(s) is a symmetric distribution, F (•) is an odd function, 和乙
is sufficiently isotropic, using equation 2.6, Cov[ε] can be explicitly computed as
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Cov[ε] = Ns
N f
(西德:15)
(西德:16)
- 1
F 2
F (西德:9)2
(我 + (西德:11)) + F (3)
2
2Ns f (西德:9)2 我
(2.13)
as the leading order. Symmetric matrix (西德:11) ≡ UT
anisotropy of BT B in the directions of the left-singular vectors of A, UA
A (BT B − I)2UA characterizes the
×Ns ,
∈ RN f
Achievability of Nonlinear Blind Source Separation
1445
wherein max eig[(西德:11)] is upper-bounded by max eig[(BT B − I)2] = O(1). 一起,
we conclude that
u = (西德:9)s + 氧
(西德:15)(西德:17)
(西德:16)
Ns
N f
+ 氧
(西德:18)
(西德:19)
.
1√
Ns
(2.14)
The derivation detail of equation 2.13 is provided in section 4.5. 方程
/Ns
2.13 indicates that the linearization error monotonically decreases as N f
and Ns increase; 因此, u converges to a linear mixture of all the true hidden
来源 (u → (西德:9)s) in the limit of large N f
/Ns and Ns. Only the anisotropy
of BT B in the directions of UA increases the linearization error. 在本质上,
applying PCA to the inputs effectively filters out nonlinear components in
the inputs because the majority of nonlinear components are perpendicular
to the directions of the signal covariance.
Although the obtained encoder is not independent of each other because
of the multiplication with (西德:9), it is remarkable that the proposed approach
enables the conversion of the original nonlinear BSS problem to a simple
linear BSS problem. This indicates that u can be separated into each inde-
pendent encoder by further applying a linear ICA method (Comon, 1994;
钟 & Sejnowski, 1995, 1997; Amari et al., 1996; Hyvarinen & Oja, 1997)
to it, and these independent encoders match the true hidden sources up to
permutations and sign-flips. Zero-element-wise-error nonlinear BSS is at-
/Ns and Ns. As a side note, PCA can indeed
tained in the limit of large N f
recover a linear transformation of true hidden sources in the inputs even
when these sources have higher-order correlations if the average of these
correlations converges to zero with high source dimensionality. This prop-
erty is potentially useful, 例如, for identifying true hidden states of
time series data generated from nonlinear systems (Isomura & Toyoizumi,
2021).
总之, we analytically quantified the accuracy of the optimal linear
encoder—obtained through the cascade of PCA and ICA—in inverting the
nonlinear generative process to identify all hidden sources. The encoder
/Ns and Ns increase and asymptotically attains
increases its accuracy as N f
the true hidden sources.
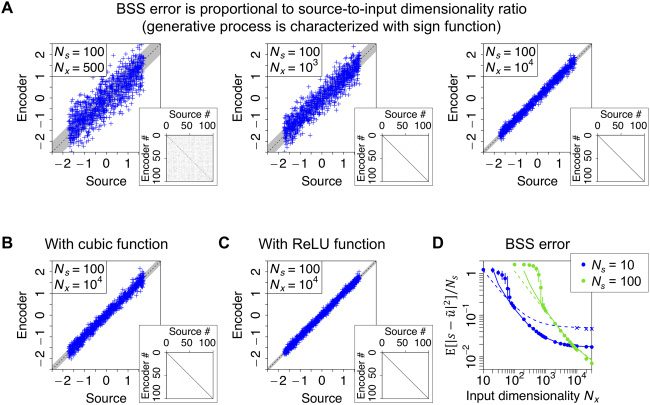
The proposed theorem is empirically validated by numerical simula-
系统蒸发散. Each element of the optimal linear encoder obtained by the PCA–ICA
cascade represents a hidden source, wherein BSS errors (the difference be-
tween the true and estimated sources) decrease as Nx increases (见图
3A). The PCA–ICA cascade performs the nonlinear BSS with various types
of nonlinear basis functions (see Figures 3B and 3C). This is a remarkable
property of the PCA–ICA cascade because these results indicate that it can
perform the nonlinear BSS without knowing the true nonlinearity that char-
acterizes the generative process. Although equation 2.13 is not applicable
to non-odd nonlinear basis function f (•), empirical observations indicate
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1446
时间. Isomura and T. Toyoizumi
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
数字 3: BSS error can be characterized by the source and input dimensional-
= Nx
实体. In all panels, s is generated by an identical uniform distribution; N f
is fixed; 和一个, 乙, a are sampled from gaussian distributions as in Figure 2. En-
, . . . , ˜uNs )T are obtained by applying the PCA–ICA cascade to sen-
coders ˜u = ( ˜u1
sory inputs. For visualization purpose, elements of ˜u are permuted and sign-
flipped to ensure that ˜ui encodes si. (A) Each element of ˜u encodes a hidden
来源, wherein an error in representing a source monotonically decreases when
= 100 and f (•) =
Nx increases. The generative process is characterized with Ns
sign(•). Shaded areas represent theoretical values of the standard deviation
computed using equation 2.13. As elements of B are gaussian distributed, (西德:11) = I
holds. Inset panels depict the absolute value of covariance matrix |Cov[ ˜u, s]|
with gray-scale values ranging from 0 (白色的) 到 1 (黑色的). A diagonal covari-
ance matrix indicates the successful identification of all the true hidden sources.
(乙, C) Nonlinear BSS when the generative process is characterized by f (•) = (•)3
or f (•) = ReLU(•). ReLU(•) outputs • for • > 0 或者 0 否则. In panel C, 这
shaded area is computed using equation 2.12. (D) The quantitative relationship
between the source and input dimensionalities and element-wise BSS error is
scored by the mean squared error E[|s − ˜u|2]/Ns. 这里,
F (•) = sign(•) is sup-
摆出姿势. Circles and error bars indicate the means and areas between maximum
and minimum values obtained with 20 different realizations of s, A, 乙, A, 在哪里
some error bars are hidden by the circles. Solid and dashed lines represent
theoretical values computed using equations 2.12 和 2.13, 分别. 这些
(西德:7) 1, although some deviations
lines fit the actual BSS errors when Nx
occur when Ns or Nx is small. Blue cross marks indicate actual BSS errors for
= 10 when hidden sources are sampled from a symmetric truncated normal
Ns
分配.
(西德:7) Ns
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1447
that the PCA–ICA cascade can identify the true hidden sources even with
non-odd function f (•) (see Figure 3C), as long as H = E[ f sT ] is nonzero.
The log-log plot illustrates that the magnitude of element-wise BSS
errors—scored by the mean squared error—decreases inversely propor-
tional to Nx/Ns; 然而, it saturates around Nx = N2
s (see Figure 3D). 这些
observations validate equation 2.13 which asserts that the linearization er-
ror is determined by the sum of Ns/N f and 1/Ns order terms. 虽然
方程 2.13 overestimates the BSS error when Ns = 10, this is because
each dimension of As significantly deviates from a gaussian variable due
to small Ns—as s is sampled from a uniform distribution in these simula-
系统蒸发散. We confirm that when hidden sources are generated from a distribu-
tion close to gaussian, actual BSS errors shift toward the theoretical value
of equation 2.13 even when Ns = 10 (see the cross marks in Figure 3D). 在-
契据, this deviation disappears for large Ns according to the central limit
theorem. 所以, 方程 2.13 is a good approximation of actual BSS
errors for Nx = N f
(西德:7) Ns (西德:7) 1, and the proposed theorem suitably predicts
the performance of the PCA–ICA cascade for a wide range of nonlinear BSS
setups.
2.4 Hebbian-Like Learning Rules Can Reliably Solve Nonlinear BSS
Problem. As a corollary of the proposed theorem, a linear neural network
can identify true hidden sources through Hebbian-like plasticity rules in the
nonlinear BSS setup under consideration. Oja’s subspace rule (Oja, 1989)—
which is a modified version of the Hebbian plasticity rule (参见部分 4.6)—
is a well-known PCA approach that extracts the major eigenspace without
yielding a spurious solution or attaining a local minimum (Baldi & Hornik,
1989; 陈等人。, 1998). 因此, with generic random initial synaptic weights,
this Hebbian-like learning rule can quickly and reliably identify an optimal
linear encoder that can recover true hidden sources from their nonlinear
mixtures in a self-organizing or unsupervised manner.
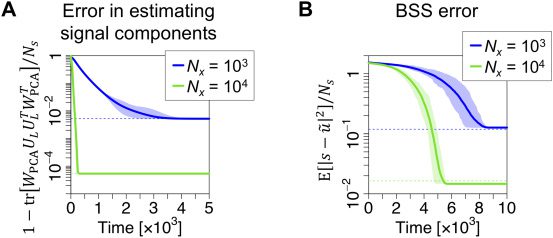
Numerical experiments demonstrate that regardless of the random ini-
∈ RNs×Nx , Oja’s subspace rule up-
tialization of synaptic weight matrix WPCA
dates WPCA to converge to the major eigenvectors, 那是, the directions
of the linear components. The accuracy of extracting the linear compo-
nents increases as the number of training samples increases, and reaches
the same accuracy as an extraction via eigenvalue decomposition (见图-
ure 4A). Because the original nonlinear BSS problem has now been trans-
formed to a simple linear BSS problem, the following linear ICA approach
(Comon, 1994; 钟 & Sejnowski, 1995, 1997; Amari et al., 1996; Hyvarinen
& Oja, 1997) can reliably separate all the hidden sources from the features
extracted using Oja’s subspace rule. Amari’s ICA algorithm (Amari et al.,
1996), which is another Hebbian-like rule (参见部分 4.6), updates synaptic
∈ RNs×Ns to render neural outputs independent of each
weight matrix WICA
其他. The obtained independent components accurately match the true
hidden sources of the nonlinear generative process up to their permutations
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1448
时间. Isomura and T. Toyoizumi
数字 4: Hebbian-like learning rules can identify the optimal linear encoder.
=
As in Figures 2 和 3, s is generated by an identical uniform distribution; Ns
= Nx, and f (•) = sign(•) are fixed; 和一个, 乙, a are sampled from gaus-
100, N f
sian distributions. (A) Learning process of Oja’s subspace rule for PCA. Synap-
∈ RNs×Nx —initialized as a random matrix—converges
tic weight matrix WPCA
to PT
M up to multiplication of an orthogonal matrix from the left-hand side.
This indicates that Oja’s rule extracts the linear components according to the
proposed theorem. Dashed lines indicate the estimation errors when eigen-
value decomposition is applied (see Figure 2C). (乙) Learning process of Amari’s
∈ RNs×Ns —initialized as a random
ICA algorithm. Synaptic weight matrix WICA
matrix—learns to separate the compressed inputs WPCA(x − E[X]) into indepen-
dent signals. Because PCA yields a linear transformation of hidden sources,
the ensuing independent encoder ˜u ≡ WICAWPCA(x − E[X]) identifies all the true
hidden sources with a small BSS error. Elements of ˜u are permuted and sign-
flipped to ensure that ˜ui encodes si. Dashed lines are computed using equation
= 0.02, 重新指定-
2.13. In panels A and B, learning rates are η
主动地. Solid lines represent the mean estimation errors, while shaded areas rep-
resent areas between maximum and minimum values obtained with 20 不同的
realizations of s, A, 乙, A.
= 10−3 and η
PCA
ICA
and sign-flips (see Figure 4B). These results highlight that the cascade of
PCA and ICA—implemented via Hebbian-like learning rules—can self-
organize the optimal linear encoder and therefore identify all the true hid-
den sources in this nonlinear BSS setup, with high accuracy and reliability
when Nx = N f
(西德:7) Ns (西德:7) 1.
3 讨论
在这项工作中, we theoretically quantified the accuracy of nonlinear BSS
performed using the cascade of linear PCA and ICA when sensory in-
puts are generated from a two-layer nonlinear generative process. 第一的, 我们
demonstrated that as the dimensionality of hidden sources increases and
the dimensionalities of sensory inputs and nonlinear bases increase rela-
tive to the source dimensionality, the first Ns major principal components
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1449
approximately express a subspace spanned by the linear projections from
all hidden sources of the sensory inputs. Under the same condition, 我们
then demonstrated that the optimal linear encoder obtained by projecting
the inputs onto the major eigenspace can accurately recover all the true
hidden sources from their nonlinear mixtures. This property is termed the
asymptotic linearization theorem. The accuracy of the subspace extraction
/Ns and Ns increase, because the gap between the minimum
increases as N f
eigenvalue of the linear (IE。, signal) components and maximum eigenvalue
of the nonlinear (IE。, 残差) components becomes significantly large.
Hebbian-like plasticity rules can also identify the optimal linear encoder
by extracting major principal components in a manner equal to PCA. Sub-
sequent application of linear ICA on the extracted principal components
can reliably identify all the true hidden sources up to permutations and
sign-flips. Unlike conventional nonlinear BSS methods that can yield spu-
rious solutions (Hyvarinen & Pajunen, 1999; Jutten & Karhunen, 2004), 这
PCA–ICA cascade is guaranteed to identify the true hidden sources in the
asymptotic condition because it successfully satisfies requirements 1 到 5
specified earlier.
The unique identification of true hidden sources s (up to permutations
and sign-flips) is widely recognized only under the linear BSS setup. 在
对比, it is well known that conventional nonlinear BSS approaches us-
ing nonlinear neural networks do not guarantee the identification of true
hidden sources under the general nonlinear BSS setup (Hyvarinen & 帕-
junen, 1999; Jutten & Karhunen, 2004). One may ask if nonlinear BSS meth-
ods may find a component-wise nonlinear transformation of the original
sources s(西德:9) = g(s) instead of s because s(西德:9)
is still an independent source rep-
resentation. This is observed when conventional nonlinear BSS approaches
based on the nonlinear ICA are employed because the nonlinear ICA finds
one of many representations that minimize the dependency among outputs.
然而, such nonlinear BSS approaches do not guarantee the identifica-
tion of true sources. This is because when g(西德:9)
(s) is a component-wise nonlin-
ear transformation that renders a nongaussian source gaussian distributed,
a transformation s(西德:9)(西德:9) = g(Rg(西德:9)
(s))—characterized by some orthogonal matrix
R and component-wise nonlinear transformation g—can yield an arbitrary
independent representation s(西德:9)(西德:9)
that differs from the original sources. 这
以前的 (s(西德:9)
). Even in the former case, finding
s(西德:9)
transformed by a highly nonlinear, nonmonotonic function g(s) is prob-
莱马蒂克. 因此, the general nonlinear BSS is essentially an ill-posed problem.
Having said this, earlier works typically investigated the case in which the
sources and inputs have the same dimensionality, while the other condi-
tions have not been extensively analyzed. 因此, in the current work, 我们佛-
(西德:7) Ns (西德:7) 1.
cused on the nonlinear BSS under the condition where Nx = N f
A remarkable aspect of the proposed nonlinear BSS approach is that
it utilizes the linear PCA to extract the linear components of the orig-
inal sources from the mixed sensory inputs. This is the process that
) is a special case of the latter (s(西德:9)(西德:9)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1450
时间. Isomura and T. Toyoizumi
enables the reduction of the original nonlinear BSS to a simple linear BSS
and consequently ensures the reliable identification of the true sources. 在
也就是说, the proposed approach does not rely on the nonlinear ICA;
因此, no concerns exist regarding the creation of the already noted spurious
solutions. We mathematically demonstrated the absence of such spuri-
(西德:7) Ns (西德:7) 1. 具体来说, we adopted a minimal
ous solutions when Nx = N f
assumption about the relationship between B and the system dimen-
/Ns and Ns are much greater than max eig[BT B]/
sionalities such that N f
min eig[BT B]. Our mathematical analyses demonstrate that this condition is
sufficient to asymptotically determine the possible form of hidden sources,
which can generate the observed sensory inputs x, in a unique manner. 在
/Ns and Ns, no nonlinear transformation of
对比, in the limit of large N f
s (IE。, s(西德:9)
) can generate the observed sensory inputs while satisfying the
aforementioned condition.4 Thus, when inequality 2.7 holds, the true hid-
den sources s are uniquely determined up to permutations and sign-flips
ambiguities without component-wise nonlinear ambiguity. (反过来, 如果
不等式 2.7 does not hold, it might not be possible to distinguish true hid-
den sources and their nonlinear transformations in an unsupervised man-
ner.) 因此, under the condition we consider, the nonlinear BSS is formally
reduced to a simple linear BSS, wherein only permutations and sign-flips
ambiguities exist while no nonlinear ambiguity remains. This property is
crucial for identifying the true sources under the nonlinear BSS setup, 和-
out being attracted by spurious solutions such as s(西德:9)
and s(西德:9)(西德:9)
or s(西德:9)(西德:9)
.
The nonlinear generative processes that we considered in this work are
sufficiently generic. Owing to the universality of two-layer networks, each
element of an arbitrary generative process x = F(s) can be approximated
using equation 2.1 with a high degree of accuracy in the component-wise
(西德:7) Ns (西德:7) 1.5 This allows one to analyze the achievabil-
sense when Nx = N f
ity of the nonlinear BSS using a class of generative processes comprising
4
(西德:9)
(西德:9)
M PT
/Ns and Ns. 此外, we define s
This property can be understood as follows. Because x is generated through x =
B f (作为 + A) with a sufficiently isotropic B that satisfies inequality 2.7, from the proposed
theorem, the encoder u = (西德:8)−1/2
中号(x − E[X]) = (西德:9)(s + ε) asymptotically becomes u → (西德:9)s
(西德:9) = g(s) ∈ RNs as a nonlinear
in the limit of large N f
(西德:9)
(西德:9) + A
(西德:9)
(西德:9)
transformation of s. If there is another generative process x = B
F
s
(A
) that can gen-
(西德:9)
(西德:9)
erate the observed x while satisfying inequality 2.7—where A
and a
are gaussian dis-
tributed matrix and vector, F
is a nonlinear function (not the derivative of f , unlike in
(西德:9)
the main text), 和乙
is a sufficiently isotropic matrix—the encoder can also be expressed
(西德:9) = (西德:8)−1/2
M PT
as u
), which asymptotically becomes u
在里面
limit of large N f
M and PM are the same as above because x does
(西德:9)
not change. 然而, while u ≡ u
for any orthogonal
matrices (西德:9) 和 (西德:9)(西德:9)
(西德:9)
because s
is a nonlinear transformation of s. 因此, such a generative
(西德:9)
(西德:9) + A
(西德:9)
(西德:9)
process x = B
s
(A
/Ns and Ns.
It should be noted that unlike the condition we considered (IE。, Nx = N f
(西德:7) Ns (西德:7) 1),
(西德:7) Nx, one may observe a counterexample of the proposed theorem such that
when N f
the major principal components are dissimilar to a linear transformation of the true hid-
den sources, as is well-known in the literature on nonlinear ICA (Hyvarinen & Pajunen,
中号(x − E[X]) = (西德:9)(西德:9)
/Ns and Ns. 注意 (西德:8)
holds by construction, (西德:9)s (西德:11)≡ (西德:9)(西德:9)
) does not exist in the limit of large N f
(西德:9) → (西德:9)(西德:9)
(西德:9) + ε(西德:9)
(西德:9)
s
(西德:9)
s
(s
F
5
(西德:9)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1451
random basis functions, as a proxy for investigating x = F(s). As a gen-
eral property of such generative processes, the eigenvalues of the signal
covariance (IE。, linear components) become significantly larger than those
of the residual covariance (IE。, nonlinear components) when Nx = N f
(西德:7)
Ns (西德:7) 1. Sufficient system dimensionalities to exhibit this property are de-
termined depending on matrix B that characterizes the generative pro-
/Ns and Ns
过程. 即, this observation holds true at least when both N f
are much greater than max eig[BT B]/ min eig[BT B]. The existence of such
Ns and N f is guaranteed if we consider sufficiently isotropic B wherein
max eig[BT B]/ min eig[BT B] is upper-bounded by a large, finite constant.
同时, with such a large constant, the two-layer networks can approx-
imate each element of x = F(s) accurately. This in turn means that as N f
/Ns
and Ns increase, the proposed theorem becomes applicable to a sufficiently
broad class of nonlinear generative processes.
= Hks + φ
This asymptotic property can be understood as follows. When adding
a new random basis ( fk
k) to the existing large-scale system,
the linear component of fk (Hks) must be placed within the existing low-
dimensional subspace spanned only by Ns ((西德:15) N f ) linear projections of
来源. 相比之下, its nonlinear component (φ
k) is almost uncorrelated
with other nonlinear components (φ), as shown in equation 2.6, 因为
these components are characterized by gaussian distributed A. 因此, 这
former increases the eigenvalues of the signal covariance in proportion to
/Ns, while the latter adds a new dimension in the subspace of nonlin-
N f
ear components without significantly increasing the maximum eigenvalue
of the residual covariance. Owing to this mechanism, the eigenvalues of
/Ns times larger than those of the residual
the signal covariance become N f
covariance when Ns (西德:7) 1. 因此, the linear PCA is sufficient to reduce the
nonlinear BSS to a linear BSS.
Nonlinear variants of PCA such as autoencoders (欣顿 & Salakhut-
dinov, 2006; Kingma & Welling, 2013) have been widely used for rep-
resentation learning. Because natural sensory data are highly redundant
and do not uniformly cover the entire input space (钱德勒 & Field,
2007), finding a concise representation of the sensory data is essential to
characterize its properties (Arora & Risteski 2017). 一般来说, if a large,
nonlinear neural network is used, many equally good solutions will be pro-
推导出来的 (Kawaguchi, 2016; 鲁 & Kawaguchi, 2017; 阮 & Hein, 2017).
在这种情况下, there is no objective reason to select one solution over an-
other if they have similar reconstruction accuracy. 然而, this prop-
erty also leads to infinitely many spurious solutions if the aim is the
(西德:7) Nx, a general B may not be
1999; Jutten & Karhunen, 2004). This is because when N f
(西德:7) Nx corresponds to the case wherein Nx is in-
sufficiently isotropic. 换句话说, N f
sufficient to ensure inequality, 方程 2.7; 因此, Nx needs to be greater. 因此, it is re-
markable that the proposed theorem specifies the condition under which the achievability
of the nonlinear BSS is mathematically guaranteed.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1452
时间. Isomura and T. Toyoizumi
identification of the true hidden sources (Hyvarinen & Pajunen, 1999; Jut-
ten & Karhunen, 2004). 最后, the outcomes of these approaches
using nonlinear neural networks are intrinsically ambiguous, and obtained
solutions highly depend on the heuristic design of the regularization pa-
rameters used in the networks and learning algorithms (Dahl, 于, Deng,
& Acero, 2012; 欣顿, Srivastava, 克里热夫斯基, 吸勺, & Salakhutdi-
nov, 2012; Wan, Zeiler, 张, 乐存, & 弗格斯, 2013). 然而, unlike
those nonlinear approaches, we proved that the cascade of linear PCA and
ICA ensures that the true hidden sources of sensory inputs are obtained if
there are sufficient dimensionalities in mappings from hidden sources to
sensory inputs. 因此, this linear approach is suitable to solve the nonlin-
ear BSS problem while retaining the guarantee to identify the true solution.
Its BSS error converges in proportion with the source-to-input dimensional-
ity ratio for a large-scale system comprising high-dimensional sources. 毛皮-
瑟莫雷, if needed, its outcomes can be used as a plausible initial condition
for nonlinear methods to further learn the forward model of the generative
过程.
Because most natural data (including biological, 化学, 和社会的
数据) are generated from nonlinear generative processes, the scope of ap-
plication of nonlinear BSS is quite broad. The proposed theorem provides a
theoretical justification for the application of standard linear PCA and ICA
to nonlinearly generated natural data to infer their true hidden sources.
An essential lesson from the proposed theorem is that an artificial intelli-
gence should employ a sufficient number of sensors to identify true hidden
sources of sensory inputs accurately, because the BSS error is proportional
to the source-to-input dimensionality ratio in a large-scale system.
In the case of computer vision, low-dimensional representations (typi-
cally 10–104 components) are extracted from up to millions of pixels of the
high-dimensional raw images. Our theory implies that the linear PCA–ICA
cascade can be utilized to identify the true hidden sources of natural im-
age data. This has been demonstrated using video images (Isomura & Toy-
oizumi, 2021). 尤其, a combination of the proposed theorem with
another scheme that effectively removes unpredictable noise from sequen-
tial data (IE。, video sequence) is a powerful tool to identify the true hidden
sources of real-world data. By this combination, one can obtain data with
minimal irrelevant or noise components—an ideal condition for the asymp-
totic linearization theorem—from the original noisy observations. Such a
combination enables the reliable and accurate estimations of hidden sources
that generate the input sequences, even in the presence of considerable ob-
servation noise. The source estimation performance was demonstrated by
using sequential visual inputs comprising hand-digits, rotating 3D objects,
and natural scenes. These results support the applicability of the proposed
theorem to the natural data and further highlight that the PCA–ICA cas-
cade can extract true or relevant hidden sources when the natural data are
sufficiently high-dimensional. (See Isomura & Toyoizumi, 2021, for details.)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1453
此外, a few works have cited a preprint version of this article to
justify the application of their linear methods to real-world nonlinear BSS
任务, in the contexts of wireless sensor networks (van der Lee, Exarchakos,
& de Groot, 2019) and single-channel source separation (Mika, Budzik, &
Józwik, 2020). These works demonstrated that linear methods work well
with nonlinear BSS tasks, as our theorem predicts. The asymptotic lineariza-
tion theorem is of great importance in justifying the application of these
linear methods to real-world nonlinear BSS tasks.
In terms of the interpretability of the outcomes of the PCA–ICA cas-
cade, one may ask if applying the cascade to natural image patches sim-
ply yields less interpretable Gabor-filter-like outputs, which are usually not
considered to be certain nonlinear, higher-order features underlying natural
图片. 然而, when we applied the PCA–ICA cascade—featuring a
separate noise-reduction technique that we developed—to natural image
data with a high-dimensionality reduction rate, we obtained outputs or im-
ages that represent features relevant to hidden sources, such as the cate-
gories of objects (Isomura & Toyoizumi, 2021). Based on our observations,
three requirements to render the PCA–ICA cascade extract features rele-
vant to hidden sources are considered. 第一的, the dimensionality reduction
rate should be high relative to that of the conventional PCA application. 在-
契据, when the dimensionality reduction rate was low, we observed that the
obtained encoders exhibit Gabor-filter-like patterns. 第二, the PCA–ICA
cascade should be applied not to image patches but to entire images. 图像
patches contain only a fraction of information about the original hidden
来源; 因此, it is likely that the original hidden sources cannot be recov-
ered from image patches. 第三, PCA should be applied to denoised data
wherein observation noise is removed in advance using a separate scheme,
as in our case. When PCA is applied to noisy data, sufficient information for
recovering hidden sources cannot be extracted as the major principal com-
ponents because PCA preferentially extracts large noise owing to its extra
方差. 因此, when the requirements are satisfied, the outcome of the
PCA–ICA cascade can exhibit a high interpretability, wherein the extracted
features are relevant to hidden sources.
As a side note, to utilize the asymptotic linearization theorem to estimate
the accuracy of source separation, one cannot use up-sampling techniques
to increase the input dimensionality beyond the resolution of the origi-
nal data or images. This is because these techniques simply yield linear or
nonlinear transformations of the original data, which typically do not in-
crease information about true hidden sources. 换句话说, the resolu-
tions of the original data determine the effective input dimensionality, 所以
that these up-samplings merely render matrix B singular (thereby violating
the condition of isotropic B).
此外, an interesting possibility is that living organisms might
have developed high-dimensional biological sensors to perform nonlin-
ear BSS using a linear biological encoder because this strategy guarantees
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1454
时间. Isomura and T. Toyoizumi
robust nonlinear BSS. 尤其, this might be the approach taken by the
human nervous system using large numbers of sensory cells, such as ap-
近似地 100 million rod cells and 6 million cone cells in the retina, 和
大约 16,000 hair cells in the cochlea, to process sensory signals
(坎德尔, 施瓦茨, 杰塞尔, 海豹树, & 哈德斯佩斯, 2013).
Neuronal networks in the brain are known to update their synapses by
following Hebbian plasticity rules (Hebb, 1949; Malenka & Bear, 2004), 和
researchers believe that the Hebbian plasticity plays a key role in represen-
tation learning (Dayan & Abbott, 2001; Gerstner & Kistler, 2002) and BSS
(棕色的, Yamada, & Sejnowski, 2001) in the brain—in particular, the dy-
namics of neural activity and plasticity in a class of canonical neural net-
works can be universally characterized in terms of representation learning
or BSS from a Bayesian perspective (Isomura & 弗里斯顿, 2020). 因此, it fol-
lows that major linear BSS algorithms for PCA (Oja, 1982, 1989) and ICA
(钟 & Sejnowski, 1995, 1997; Amari et al., 1996; Hyvarinen & Oja, 1997) 是
formulated as a variant of Hebbian plasticity rules. 而且, in vitro neu-
ronal networks learn to separately represent independent hidden sources in
(and only in) the presence of Hebbian plasticity (Isomura, Kotani, & Jimbo,
2015; Isomura & 弗里斯顿, 2018). 尽管如此, the manner in which the brain
can possibly solve a nonlinear BSS problem remains unclear, 虽然
it might be a prerequisite for many of its cognitive processes such as vi-
sual recognition (DiCarlo et al., 2012). While Oja’s subspace rule for PCA
(Oja, 1989) and Amari’s ICA algorithm (Amari et al., 1996) were used in this
文章, these rules can be replaced with more biologically plausible local
Hebbian learning rules (褶皱, 1990; Linsker, 1997; Pehlevan, Mohan, &
Chklovskii, 2017; Isomura & Toyoizumi, 2016, 2018, 2019; Leugering & Pipa,
2018) that require only directly accessible signals to update synapses. A re-
cent work indicated that even a single-layer neural network can perform
both PCA and ICA through a local learning rule (Isomura & Toyoizumi,
2018), implying that even a single-layer network can perform a nonlinear
BSS.
总之, we demonstrated that when the source dimensionality is
large and the input dimensionality is sufficiently larger than the source di-
mensionality, a cascaded setup of linear PCA and ICA can reliably identify
the optimal linear encoder to decompose nonlinearly generated sensory in-
puts into their true hidden sources with increasing accuracy. 这是因为
the higher-dimensional inputs can provide greater evidence about the hid-
den sources, which removes the possibility of finding spurious solutions
and reduces the BSS error. As a corollary of the proposed theorem, Hebbian-
like plasticity rules that perform PCA and ICA can reliably update synap-
tic weights to express the optimal encoding matrix and can consequently
identify the true hidden sources in a self-organizing or unsupervised man-
ner. This theoretical justification is potentially useful for designing reliable
and explainable artificial intelligence, and for understanding the neuronal
mechanisms underlying perceptual inference.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1455
4 方法
4.1 Lemma 1.
Definition 1. Suppose ps(s) is a symmetric distribution, ˜y ≡ (做
, y j )T ≡ ˜As is a
, . . . , A jNs ) 是
two-dimensional subvector of y = As, and ˜A ≡ (Ai1
A 2 × Ns submatrix of A. The expectation of an arbitrary function F( ˜y) over ps(s)
is denoted as E[F( ˜y)], whereas when ˜y is sampled from a gaussian distribution
pN ( ˜y) ≡ N [0, ˜A ˜AT ], the expectation of F( ˜y) over pN ( ˜y) is denoted as EN [F( ˜y)] ≡
(西德:7)
, . . . , AiNs
; A j1
F( ˜y)pN ( ˜y)d ˜y.
Lemma 1. When F( ˜y) is order 1, the difference between E[F( ˜y)] and EN [F( ˜y)] 是
upper-bounded by order N−1
as a corollary of the central limit theorem. In partic-
他们是, 乙[F( ˜y)] can be expressed as EN [F( ˜y)(1 + G( ˜y)/Ns)], where G( ˜y) = O(1) 是
a function that characterizes the deviation of p( ˜y) from pN ( ˜y).
s
Proof. The characteristic function of p( ˜y) is given as ψ (t ) ≡ E[eiτ T ˜y] 作为一个
function of τ ∈ R2, and its logarithm is denoted as (西德:15)(t ) ≡ log ψ (t ). 这
第一的- to fourth-order derivatives of (西德:15)(t ) with respect to τ are provided
作为
(西德:15) (1) = E[i ˜yeiτ T ˜y]/ψ,
(西德:15) (2) = E[(i ˜y)
(西德:15) (3) = E[(i ˜y)
⊗2eiτ T ˜y]/ψ − ((西德:15) (1))
⊗3eiτ T ˜y]/ψ − E[(i ˜y)
⊗2,
⊗2eiτ T ˜y]/ψ ⊗ (西德:15) (1) - (西德:15) (2) ⊗ (西德:15) (1)
- (西德:15) (1) ⊗ (西德:15) (2)
= E[(i ˜y)
(西德:15) (4) = E[(i ˜y)
⊗3eiτ T ˜y]/ψ − 2(西德:15) (2) ⊗ (西德:15) (1) - ((西德:15) (1))
⊗4eiτ T ˜y]/ψ − E[(i ˜y)
⊗3eiτ T ˜y]/ψ ⊗ (西德:15) (1) - 2(西德:15) (3) ⊗ (西德:15) (1)
⊗3 − (西德:15) (1) ⊗ (西德:15) (2),
- 3((西德:15) (2))
- ((西德:15) (1))
⊗2 − (西德:15) (2) ⊗ ((西德:15) (1))
⊗2 ⊗ (西德:15) (2) - (西德:15) (1) ⊗ (西德:15) (3).
⊗2 − (西德:15) (1) ⊗ (西德:15) (2) ⊗ (西德:15) (1)
(4.1)
When τ = 0,
(西德:15) (3)(0) = 0, 和 (西德:15) (4)(0) = E[ ˜y⊗4] − 3E[ ˜y⊗2]
source distribution ps(s).
他们成为 (西德:15)(0) = 0, (西德:15) (1)(0) = 0, (西德:15) (2)(0) = −E[ ˜y⊗2],
⊗2 owing to the symmetric
They are further computed as E[ ˜y⊗2]=Vec[ ˜A ˜AT ] and E[ ˜y⊗4]=Vec[乙[( ˜y ˜yT )
⊗ ( ˜y ˜yT )]] = 3Vec[ ˜A ˜AT ]
k] - 3 在-
Ns
k=1( ˜A•k ˜AT
•k)
dicates the kurtosis of the source distribution and ˜A•k denotes the kth
˜A. 而且, (西德:15) (2)(0) · τ ⊗2 = −τ T ˜A ˜AT τ and (西德:15) (4)(0) · τ ⊗4 =
column of
(西德:20)
−3/2
κVec[
Ns
)
s
hold. 这里, a quartic function of τ ,
因为
k=1(τ T ˜A•k)4 = 3κ (τ T τ )2/Ns + 氧(氮
k=1(τ T ˜A•k)4, is order N−1
⊗2], where κ ≡ E[s4
•k)⊗2] · τ ⊗4 = κ
Ns
k=1( ˜A•k ˜AT
⊗2 + κVec[
(西德:20)
(西德:20)
(西德:20)
Ns
s
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1456
时间. Isomura and T. Toyoizumi
˜A•k is sampled from N [0, 1/Ns]. 因此, the Taylor expansion of (西德:15)(t ) 是
expressed as
(西德:15)(t ) =
∞(西德:10)
n=0
(西德:15) (n)(0)
n!
· τ ⊗n = − 1
2
τ T ˜A ˜AT τ +
(τ T τ )2 + 氧
(西德:8)
(西德:9)
.
−3/2
氮
s
κ
8Ns
(4.2)
−3/2
from ψ (t ) = exp[−τ T ˜A ˜AT τ /2 + κ (τ T τ )2/8Ns + 氧(氮
s
)] =
)), p( ˜y) is computed as follows (这
−3/2
s
因此,
e−τ T ˜A ˜AT τ /2(1 + κ (τ T τ )2/8Ns + 氧(氮
inversion theorem):
(西德:21)
p( ˜y) = 1
(2圆周率 )2
−iτ T ˜yψ (t )λ(dτ )
e
(西德:18)
R2
(西德:21)
−iτ T ˜y− 1
e
2
τ T ˜A ˜AT τ
1 +
= 1
(2圆周率 )2
= pN ( ˜y)
R2
(西德:18)
(西德:19)
,
1 + G( ˜y)
Ns
κ
8Ns
(τ T τ )2 + 氧
(西德:19)
(西德:9)
(西德:8)
−3/2
氮
s
λ(dτ )
(4.3)
where λ denotes the Lebesgue measure. 这里, G( ˜y) = O(1) indicates a func-
tion of ˜y that characterizes the difference between p( ˜y) and pN ( ˜y). 因此,
the expectation over p( ˜y) can be rewritten using that over pN ( ˜y):
(西德:21)
(西德:21)
乙[F( ˜y)] =
(西德:21)
=
F( ˜y)ps(s)ds =
(西德:18)
F( ˜y)p( ˜y)d ˜y
(西德:19)
F( ˜y)pN ( ˜y)
(西德:22)
(西德:18)
1 + G( ˜y)
Ns
(西德:19)(西德:23)
d ˜y
= EN
F( ˜y)
1 + G( ˜y)
Ns
.
(4.4)
(西德:2)
Remark 1. For equation 2.4, from the Bussgang theorem (Bussgang, 1952),
we obtain
乙[ F ( ˜y) ˜yT ] = EN
F ( ˜y) ˜yT
(西德:22)
(西德:18)
(西德:19)(西德:23)
1 + G( ˜y)
Ns
(西德:18)
1 + G( ˜y)
Ns
(西德:8)
( ˜y)]
(西德:9)
(西德:9)
(西德:22)
diag[ F
= EN
(西德:8)
=
diag[EN [ F
( ˜y)]] ˜A + 氧
−3/2
氮
s
(西德:19)
(西德:23)
G(西德:9)
( ˜y)时间
Ns
˜A ˜AT
(4.5)
+ F ( ˜y)
(西德:9)(西德:9)
˜AT
−1/2
as ˜A is order N
s
−3/2
氧(氮
).
s
. 因此, we obtain H = E[ f yT ]A+T = diag[EN [ F (西德:9)
]]A +
For equation 2.5, because yi and y j are only weakly correlated with
彼此, (1 + G( ˜y)/Ns) can be approximated as (1 + G( ˜y)/Ns) (西德:14) (1 +
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1457
G(做)/Ns)(1 + G(y j )/Ns) as the leading order using newly defined functions
G(做) and G(y j ). 因此, we obtain
Cov[φ
我
, φ
j] = E[(φ
我
(西德:22)(西德:24)
− E[φ
我])(φ
j
(西德:14) EN
(φ
我
− E[φ
我])
− E[φ
j])]
(西德:18)
1 + G(做)
Ns
(西德:19)(西德:25)(西德:24)
(φ
j
− E[φ
j])
(西德:19)(西德:25)(西德:23)
(西德:18)
1 + G(y j )
Ns
= CovN [φ∗
我
(西德:11)
φ∗(n)
我
, φ∗
j ]
(西德:12)
∞(西德:10)
EN
=
n=1
EN
n!
(西德:12)
(西德:11)
φ∗(n)
j
CovN [做
, y j]n
(4.6)
我
j
我
≡ (φ
− E[φ
− E[φ
] from EN [φ(n)
for i (西德:11)= j as the leading order, where φ∗
我])(1 + G(做)/Ns) 和
≡ (φ
我
φ∗
j])(1 + G(y j )/Ns) are modified nonlinear components. 这
j
last equality holds according to lemma 2 (见下文), wherein EN [φ∗(n)
] 美联社-
]. As a corollary of lemma 1, the deviation of EN [φ∗(n)
proximates E[φ(n)
] (西德:14)
] due to the nongaussianity of yi is order N−1
乙[φ(n)
. 是-
s
我
−1/2
] = O(N−1
] = O(氮
cause CovN [做
),
s
和 |EN [φ(n)
]| ≤ O(1) for n ≥ 3 hold with a generic odd function f (•) (看
remark 2 欲了解详情), the difference between CovN [φ∗
j]
我
−5/2
is order N
j] can be characterized by computing
s
, φ
CovN [φ
j] as a proxy up to the negligible deviation; 最后, 平等-
的 2.6 is obtained.
−n/2
, y j]n = O(氮
s
j ] and CovN [φ
. 因此, Cov[φ
), EN [φ(2)
), EN [φ(1)
, φ∗
, φ
, φ
s
我
我
我
我
我
我
我
我
我
4.2 Lemma 2.
Lemma 2. Suppose v and w are gaussian variables with zero mean, σv and σw
are their standard deviations, and their correlation c ≡ Cov[v, w]/σv σw is smaller
比 1. For an arbitrary function g(•),
Cov[G(v ), G(w)] =
∞(西德:10)
n=1
v σ n
σ n
wE[G(n)(v )]乙[G(n)(w)]
.
中文
n!
(4.7)
√
Proof. Because the correlation between v and w is c, w can be cast as w =
σwcv/σv + σw
1 − c2ξ using a new a zero-mean and unit-variance gaussian
variable ξ that is independent of v. When we define the covariance between
G(v ) and g(w) 作为 (西德:19)(C) ≡ Cov[G(v ), G(w)], its derivative with respect to c is
given as
(西德:22)
(西德:18)
(西德:19)(西德:9)
(C) = Cov
(西德:22)
(西德:9)
G(v ), G
(西德:26)
+ σw
1 − c2ξ
σwcv
σv
(西德:19) (西德:18)
(西德:19)(西德:23)
σwv
σv
σwcξ
1 − c2
-
√
(西德:19) (西德:18)
= E
(西德:9)
(G(v ) − E[G(v )])G
(西德:18)
σwcv
σv
(西德:26)
+ σw
1 − c2ξ
σwv
σv
-
√
σwcξ
1 − c2
(西德:19)(西德:23)
.
(4.8)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1458
时间. Isomura and T. Toyoizumi
By applying the Bussgang theorem (Bussgang, 1952) with respect to v, 我们
obtain
(西德:22)
乙
(西德:22)
(西德:9)
(G(v ) − E[G(v )])G
(西德:18)
(西德:18)
σwcv
σv
(西德:26)
(西德:26)
(西德:19)
(西德:23)
+ σw
1 − c2ξ
v
(西德:19)
= E
(西德:9)
G
(西德:9)
(v )G
+ σw
1 − c2ξ
σwcv
σv
(西德:9)(西德:9)
+ (G(v ) − E[G(v )])G
(西德:18)
σwcv
σv
(西德:26)
+ σw
1 − c2ξ
(西德:19)
(西德:23)
v .
σ 2
σwc
σv
(4.9)
相似地, applying the same theorem with respect to ξ yields
(西德:18)
(西德:19)
(西德:23)
(西德:22)
(西德:26)
乙
(西德:9)
(G(v ) − E[G(v )])G
(西德:22)
= E
(西德:9)(西德:9)
(G(v ) − E[G(v )])G
(西德:18)
σwcv
σv
σwcv
σv
+ σw
1 − c2ξ
ξ
(西德:26)
(西德:19)
(西德:26)
(西德:23)
+ σw
1 − c2ξ
σw
1 − c2
.
(4.10)
As equation 4.8 comprises equations 4.9 和 4.10, (西德:19)(西德:9)
(C) becomes
(西德:22)
(西德:18)
(西德:19)(西德:9)
(C) = σv σwE
(西德:9)
G
(西德:9)
(v )G
(西德:26)
(西德:19)(西德:23)
+ σw
1 − c2ξ
.
σwcv
σv
因此, for an arbitrary natural number n, we obtain
(西德:19)(n)(C) = σ n
v σ n
wE
(西德:18)
(西德:22)
G(n)(v )G(n)
σwcv
σv
(西德:26)
(西德:19)(西德:23)
+ σw
1 − c2ξ
.
(4.11)
(4.12)
wE[G(n)(v )]乙[G(n)(w)]
When c = 0, (西德:19)(n)(C) = σ n
holds, where we again regard σwξ = w. 因此, from the Taylor expansion
with respect to c, we obtain
wE[G(n)(v )]乙[G(n)(σwξ )] = σ n
v σ n
v σ n
(西德:19)(C) =
∞(西德:10)
n=1
(西德:19)(n)(0)
=
中文
n!
∞(西德:10)
n=1
v σ n
σ n
wE[G(n)(v )]乙[G(n)(w)]
.
中文
n!
(4.13)
(西德:2)
Remark 2. For φ(y) = f (y + A) − E[ F ] − E[ f yT ]A+T A+y,
coeffi-
cients EN [φ(n)
] can be computed as follows (up to the fourth or-
这): because applying the Bussgang theorem (Bussgang, 1952)
yields EN [ f yT ]A+T A+ = diag[EN [ F (西德:9)
the difference between
乙[ f yT ]A+T A+
(due to the nongaussian
]] = O(1),
]] is order N−1
s
and diag[EN [ F (西德:9)
这
我
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1459
contributions of y;
乙[ f yT ]A+T A+
, 我们有
看
引理 1). 因此,
from φ(1) = diag[ F (西德:9)
] -
EN [φ(1)] = EN
(西德:11)
diag[ F
(西德:9)
] − diag[EN [ F
(西德:9)
−1
]] + 氧(氮
s
(西德:12)
)
−1
= O(氮
s
).
(4.14)
而且, for the second- to fourth-order derivatives, we obtain
EN [φ(2)
我
] = EN [ F (2)(做
+ 人工智能)] = EN [ F (3)(做)]人工智能
−3/2
+ 氧(氮
s
−1/2
) = O(氮
s
),
EN [φ(3)
我
] = EN [ F (3)(做
EN [φ(4)
我
] = EN [ F (4)(做
−1
+ 人工智能)] = EN [ F (3)(做)] + 氧(氮
s
−1/2
+ 人工智能)] = O(氮
s
).
) = O(1),
(4.15)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
the Taylor expansion with respect
is applied, 在哪里
这里,
EN [ F (2)(做)] = EN [ F (4)(做)] = 0 owing to odd function f (•). For n ≥ 5,
(西德:13)n)i j is order
|EN [φ(n)
−n/2
氮
s
]| ≤ O(1) holds. 因此, because CovN [做
我
, 方程 2.5 becomes
, y j]n = ((AAT )
to ai
CovN [φ
我
, φ
j] = EN [φ(1)
(西德:3)
我
](AAT )我j
(西德:6)
+ 1
2
]EN [φ(1)
j
(西德:4)(西德:5)
−5/2
氧(氮
s
)
EN [φ(2)
我
]EN [φ(2)
j
]((AAT )
(西德:13)2)我j
+ 1
6
+ 1
24
(西德:3)
EN [φ(3)
我
]EN [φ(3)
j
]((AAT )
(西德:13)3)我j
EN [φ(4)
我
]EN [φ(4)
j
(西德:4)(西德:5)
−3
氧(氮
s
)
]((AAT )
(西德:13)4)我j
(西德:6)
−5/2
+ 氧(氮
s
)
= EN [ F (3)(做)]EN [ F (3)(y j )]
(西德:24)
aia j((AAT )
(西德:13)2)我j
1
2
+ 1
6
×
4.3 Lemma 3.
(西德:25)
((AAT )
(西德:13)3)我j
−5/2
+ 氧(氮
s
).
(4.16)
×Ns are independently sampled from a gaus-
Lemma 3. When elements of A ∈ RN f
(西德:13)3 ≡ (AAT ) (西德:13) (AAT ) (西德:13)
sian distribution N [0, 1/Ns] and N f
> N2
s
(AAT ) has Ns major eigenmodes—all of which have the eigenvalue of 3N f
s (作为
the leading order) with the corresponding eigenvectors that match the directions
− Ns) randomly distributed nonzero minor eigenmodes
of AAT —and up to (N f
whose eigenvalues are order max[1, N f
s ] 一般. 因此, the latter are neg-
ligibly smaller than the former when N f
(西德:7) 1, (AAT )
/N3
> N2
s
(西德:7) 1.
/N2
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1460
时间. Isomura and T. Toyoizumi
Proof. Suppose N f
≡ (A1k
as A•k
, . . . , AN f k)T ∈ RN f , (AAT )
(西德:13)3 becomes
> N2
s
(西德:7) 1. When the kth column vector of A is denoted
(AAT )
(西德:13)3 =
Ns(西德:10)
Ns(西德:10)
Ns(西德:10)
k=1
l=1
m=1
(A•k
(西德:13) A•l
(西德:13) A•m)(A•k
(西德:13) A•l
(西德:13) A•m)时间
Ns(西德:10)
=
(A
(西德:13)3
•k )(A
(西德:13)3
•k )时间 + 3
(西德:10)
k(西德:11)=l
(A
(西德:13)2
•k
(西德:13)2
(西德:13) A•l )(A
•k
(西德:13) A•l )时间
(A•k
(西德:13) A•l
(西德:13) A•m)(A•k
(西德:13) A•l
(西德:13) A•m)时间 .
(4.17)
k=1
+ 6
(西德:10)
k
超过, we define an orthogonal matrix UN ∈ RNx×(Nx−Ns ) such that it is per-
pendicular to UL and that multiplying it by the residual covariance B(西德:3)BT
from both sides diagonalizes B(西德:3)BT . 因此, (UL, 和 )(UL, 和 )T = I holds, 和
NB(西德:3)BTUN ∈ R(Nx−Ns )×(Nx−Ns ) is a diagonal matrix that arranges its
XNN ≡ U T
diagonal elements in descending order. Without loss of generality, 乙(西德:3)BT is
decomposed into three matrix factors:
乙(西德:3)BT = (UL, 和 )
(西德:15)
(西德:16) (西德:15)
(西德:16)
XLL XT
NL
XNL XNN
U T
L
U T
氮
.
(4.19)
L B(西德:3)BTUL ∈ RNs×Ns
这里, XLL ≡ U T
is a symmetric matrix and XNL ≡
NB(西德:3)BTUL ∈ R(Nx−Ns )×Ns is a vertically long rectangular matrix. This de-
U T
composition separates B(西德:3)BT into components in the directions of UL and
其余的部分. From equations 2.3 和 4.19, we obtain the key equality that
links the eigenvalue decomposition with the decomposition into signal and
residual covariances:
(西德:15)
(西德:16) (西德:15)
(西德:16)(西德:15)
(西德:15)
(西德:16)
(西德:16)
(下午, Pm)
(西德:8)M O
氧 (西德:8)米
= (UL, 和 )
S2
L
PT
中号
PT
米
+ XLL XT
NL
XNN
XNL
U T
L
U T
氮
.
(4.20)
The left-hand side is the eigenvalue decomposition of Cov[X], 在哪里 (西德:8)M ∈
RNs×Ns and (西德:8)m ∈ R(Nx−Ns )×(Nx−Ns ) are diagonal matrices of major and minor
eigenvalues, 分别, and PM ∈ RNx×Ns and Pm ∈ RNx×(Nx−Ns ) are their
+ XLL is suf-
corresponding eigenvectors. When inequality 2.7 holds, S2
L
ficiently close to a diagonal matrix and XNL is negligibly small relative
+ XLL; 因此, the right-hand side can be viewed as the zeroth-order
to S2
L
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1462
时间. Isomura and T. Toyoizumi
approximation of the eigenvalue decomposition of Cov[X]. Owing to the
uniqueness of eigenvalue decomposition, we obtain (下午, Pm) = (UL, 和 ),
(西德:8)M = S2
L
+ diag[XLL], 和 (西德:8)m = XNN as the leading order.
下一个, we compute an error in the first order by considering a small per-
turbation that diagonalizes the right-hand side of equation 4.20 more accu-
率地. 认为 (我, ET ; −E, 我) ∈ RNx×Nx as a block matrix that comprises Ns ×
Ns and (Nx − Ns) × (Nx − Ns) identity matrices and a rectangular matrix
E ∈ R(Nx−Ns )×Ns with small value elements. 作为 (我, ET ; −E, 我)(我, ET ; −E, 我)T =
我 + 氧(|乙|2), it is an orthogonal matrix as the first-order approximation. 是-
cause the middle matrix on the right-hand side of equation 4.20 已经
almost diagonalized, a small perturbation by (我, ET ; −E, 我) can diagonalize
it with higher accuracy. By multiplying (我, ET ; −E, 我) and its transpose by
the near-diagonal matrix from both sides, we obtain
(西德:16)
(西德:16) (西德:15)
(西德:16) (西德:15)
(西德:15)
我
−E
ET
我
S2
L
+ XLL XT
NL
XNN
XNL
I −ET
乙
我
(西德:15)
=
S2
L
−E(S2
L
+ XLL + ET XNL + XT
NLE
+ XLL) + XNL + XNNE
+ XLL)ET + XT
-(S2
NL
L
−XNLET − EXT
NL
+ ET XNN
+ XNN
(西德:16)
+ 氧(|乙|2)
(4.21)
up to the first order of E. 方程 4.21 is diagonalized only when −E(S2
L
XLL) + XNL + XNNE = O. 因此, we obtain
+
Vec[乙] =
(西德:27)
I ⊗ (S2
L
⇐⇒ E ≈ XNLS
+ XLL) − XNN ⊗ I
−2
L
(西德:28)−1
Vec[XNL] ≈
(西德:9)
(西德:8)
I ⊗ S
−2
L
Vec[XNL]
(4.22)
as the first-order approximation. Substituting E = XNLS
into equation
4.21 yields the first-order approximation of major and minor eigenvalues:
−2
L
(西德:8)
(西德:8)M = S2
L
(西德:8)m = XNN − 2diag[XNLS
(西德:9)
−2
L diag[XLL] + 氧(|乙|2)
−2
L XT
我 + S
NL] + 氧(|乙|2).
,
(4.23)
而且, the first-order approximation of their corresponding eigenvec-
tors is provided as
(西德:15)
(下午, Pm) = (UL, 和 )
(西德:16)
I −ET
乙
我
=
=
(西德:8)
UL + UNE, UN − ULET
(西德:8)
UL + UNXNLS
−2
L
(西德:9)
, UN − ULS
(西德:9)
−2
L XT
NL
+ 氧(|乙|2).
(4.24)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1463
The accuracy of these approximations is empirically validated using nu-
merical simulations (see Figure 2D), wherein an error in approximating
UL using PM is analytically computed as tr[ET E]/Ns = tr[S
L B(西德:3)BT (I −
−2
L ]/Ns as the leading order. This error is negligibly small
ULU T
relative to the linearization error in equation 2.12 when inequality 2.7
holds.
L )乙(西德:3)BTULS
−2
L U T
4.5 Derivation of Linearization Error Covariance. 方程 2.13 is de-
rived as follows: from equation 2.4, (BH)
) holds
when B is sufficiently isotropic. 因此, 从方程 2.6 和 2.12, 我们
obtain
+ + 氧(N−1
s
+ = f (西德:9)
(BA)
−1
Cov[ε] =
(西德:15)
(西德:16)
- 1
+
(BA)
F 2
F (西德:9)2
BBT (BA)
2
+时间 + F (3)
2Ns f (西德:9)2 我
(4.25)
as the leading order. 这里, aaT and (西德:7) in equation 2.6 are negligibly smaller
than the leading-order eigenmodes when inequality 2.7 holds and B is suf-
×Ns ,
ficiently isotropic. If we define the left-singular vectors of A as UA
/Ns)1/2
because A has Ns singular values with the leading-order term of (N f
/Ns)1/2UA holds approximately. 因此,
(Marchenko & Pastur, 1967), A = (N f
−1U T
(BA)
+ = (Ns/N f )1/2(U T
∈ RN f
A BT BUA)
更远, as B is isotropic, UT
A BT BUA)
trix; 因此, (U T
proximation. 相似地, U T
is sufficiently close to the identity matrix. 因此,
A BT BBT BUA
= I + U T
A
−1 ≈ I − U T
A BT holds as the leading order.
A BT BUA is sufficiently close to the identity ma-
A (BT B − I)UA provides the first-order ap-
{2(BT B − I) + (BT B − I)2}UA
+
(BA)
BBT (BA)
+T ≈ Ns
N f
(西德:27)
我 + U T
A (BT B − I)2UA
(西德:28)
(4.26)
holds as the leading order. 因此, 使用 (西德:11) ≡ UT
方程 2.13.
A (BT B − I)2UA, we obtain
4.6 Hebbian-Like Learning Rules. Oja’s subspace rule for PCA (Oja,
1989) is defined as
(西德:29)
˙WPCA
∝ E
uPCA(x − E[X] − W T
PCAuPCA)时间
(西德:30)
,
(4.27)
∈ RNs×Nx is a synaptic weight matrix, uPCA
≡ WPCA(x − E[X]) ∈
where WPCA
RNs is a vector of encoders, and the dot over WPCA denotes a temporal
derivative. This rule can extract a subspace spanned by the first Ns princi-
pal components (IE。, WPCA
中号) in a manner equal to PCA via eigen-
value decomposition. Although Oja’s subspace rule does not have a cost
function, a gradient descent rule for PCA, based on the least mean squared
→ (西德:9)MPT
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1464
时间. Isomura and T. Toyoizumi
PCAuPCA
错误, is known (徐, 1993), whose cost function is given as E[|x − E[X] -
|2]. 的确, this equals the maximum likelihood estimation of
W T
x − E[X] using a lower-dimensional linear encoder uPCA under the assump-
tion that the loss follows a unit gaussian distribution. The gradient descent
on this cost function is equal to Oja’s subspace rule up to an additional term
that does not essentially change the behavior of the algorithm.
For BSS of uPCA, Amari’s ICA algorithm is considered (Amari et al.,
1996). Using encoders ˜u ≡ WICAuPCA
∈ RNs with synaptic weight ma-
∈ RNs×Ns , the ICA cost function is defined as the Kullback–
trix WICA
Leibler divergence between the actual distribution of ˜u, p( ˜u), and its prior
belief p0( ˜u) ≡
吉隆坡[p( ˜u)||p0( ˜u)] ≡ E[log p( ˜u) − log p0( ˜u)].
The natural gradient of D
KL yields Amari’s ICA algorithm,
i p0( ˜ui), D
≡ D
(西德:2)
吉隆坡
˙WICA
∝ −
∂D
吉隆坡
∂WICA
W T
ICAWICA
= (I − E
(西德:30)
(西德:29)
G( ˜u) ˜uT
)WICA
,
(4.28)
where g( ˜u) ≡ −d log p0( ˜u)/d ˜u is a nonlinear activation function.
致谢
This work was supported by RIKEN Center for Brain Science (T.I. and T.T.),
Brain/MINDS from AMED under grant JP21dm020700 (T.T.), and JSPS
KAKENHI grant JP18H05432 (T.T.). The funders had no role in the study
设计, data collection and analysis, decision to publish, or preparation of
the manuscript.
Data Availability
All relevant data are within the article. The Matlab scripts are available at
https://github.com/takuyaisomura/asymptotic_linearization.
参考
Amari, S. 我。, 陈, 时间. P。, & Cichocki, A. (1997). Stability analysis of learning algo-
rithms for blind source separation. Neural Networks, 10(8), 1345–1351.
Amari, S. 我。, Cichocki, A。, & 哪个, H. H. (1996). A new learning algorithm for blind
signal separation. 在D中. S. Touretzky, 中号. C. Mozer, & 中号. 乙. Hasselmo (编辑。), Ad-
vances in neural information processing systems, 8 (PP. 757–763). 剑桥, 嘛:
与新闻界.
Arora, S。, & Risteski, A. (2017). Provable benefits of representation learning. arXiv:1706.
04601.
Baldi, P。, & Hornik, K. (1989). Neural networks and principal component analysis:
Learning from examples without local minima. Neural Networks, 2(1), 53–58.
Barron, A. 右. (1993). Universal approximation bounds for superpositions of a sig-
moidal function. IEEE Trans. Info. 理论, 39(3), 930–945.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1465
钟, A. J。, & Sejnowski, 时间. J. (1995). An information-maximization approach to blind
separation and blind deconvolution. Neural Comput., 7(6), 1129–1159.
钟, A. J。, & Sejnowski, 时间. J. (1997). The “independent components” of natural scenes
are edge filters. Vision Res., 37(23), 3327–3338.
棕色的, G. D ., Yamada, S。, & Sejnowski, 时间. J. (2001). Independent component analysis
at the neural cocktail party. Trends Neurosci., 24(1), 54–63.
Bussgang, J. J. (1952). Cross-correlation functions of amplitude-distorted gaussian signals
(技术报告 216). 剑桥, 嘛: MIT Research Laboratory of Electronics.
Calhoun, V. D ., 刘, J。, & Adali, 时间. (2009). A review of group ICA for fMRI data and
ICA for joint inference of imaging, genetic, and ERP data. 神经影像, 45(1), S163–
S172.
钱德勒, D. M。, & Field, D. J. (2007). Estimates of the information content and di-
mensionality of natural scenes from proximity distributions. J. Opt. Soc. 是. A,
24(4), 922–941.
陈, T。, Hua, Y。, & 严, 瓦. 是. (1998). Global convergence of Oja’s subspace al-
gorithm for principal component extraction. IEEE Trans. Neural Netw., 9(1), 58–
67.
Cichocki, A。, Zdunek, R。, Phan, A. H。, & Amari, S. 我. (2009). Nonnegative matrix and
tensor factorizations: Applications to exploratory multi-way data analysis and blind
source separation. 霍博肯, 新泽西州: 威利.
Comon, 磷. (1994). Independent component analysis, a new concept? 说. Process,
36(3), 287–314.
Comon, P。, & Jutten, C. (2010). Handbook of blind source separation: Independent compo-
nent analysis and applications. 奥兰多, FL: 学术出版社.
Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. 数学
Control Signals Syst., 2(4), 303–314.
Dahl, G. E., 于, D ., Deng, L。, & Acero, A. (2012). Context-dependent pretrained
deep neural networks for large-vocabulary speech recognition. IEEE Trans. 声音的
Speech Lang. Proc., 20(1), 30–42.
Dayan, P。, & Abbott, L. F. (2001). Theoretical neuroscience: Computational and mathemat-
ical modeling of neural systems. 剑桥, 嘛: 与新闻界.
Dayan, P。, 欣顿, G. E., Neal, 右. M。, & Zemel, 右. S. (1995). The Helmholtz machine.
Neural Comput., 7(5), 889–904.
DiCarlo, J. J。, Zoccolan, D ., & Rust, N.C. (2012). How does the brain solve visual
object recognition? 神经元, 73(3), 415–434.
Dinh, L。, Krueger, D ., & 本吉奥, 是. (2014). NICE: Non-linear independent components
estimation. arXiv:1410.8516.
Erdogan, A. 时间. (2007). Globally convergent deflationary instantaneous blind source
separation algorithm for digital communication signals. IEEE Trans. Signal Pro-
cess., 55(5), 2182–2192.
Erdogan, A. 时间. (2009). On the convergence of ICA algorithms with symmetric orthog-
onalization. IEEE Trans. Signal Process., 57(6), 2209–2221.
Földiák, 磷. (1990). Forming sparse representations by local anti-Hebbian learning.
Biol. Cybern., 64(2), 165–170.
弗里斯顿, K. (2008). Hierarchical models in the brain. PLOS Comput. Biol., 4, e1000211.
弗里斯顿, K., Trujillo-Barreto, N。, & Daunizeau, J. (2008). DEM: A variational treatment
of dynamic systems. 神经影像, 41(3), 849–885.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1466
时间. Isomura and T. Toyoizumi
Gerstner, W., & Kistler, 瓦. 中号. (2002). Spiking neuron models: Single neurons, 大众-
系统蒸发散, plasticity. 剑桥: 剑桥大学出版社.
好人, 我。, 本吉奥, Y。, & 考维尔, A. (2016). 深度学习. (剑桥, 嘛:
与新闻界).
Griffiths, D. J. (2005). Introduction to quantum mechanics (2nd 版。). Upper Saddle River,
新泽西州: Pearson Prentice Hall.
Hebb, D. 氧. (1949). The organization of behavior: A neuropsychological theory. 纽约:
威利.
欣顿, G. E., & Salakhutdinov, 右. 右. (2006). Reducing the dimensionality of data
with neural networks. 科学, 313(5786), 504–507.
欣顿, G. E., Srivastava, N。, 克里热夫斯基, A。, 吸勺, 我。, & Salakhutdinov, 右. 右.
(2012). Improving neural networks by preventing co-adaptation of feature detectors.
arXiv:1207.0580.
Hornik, K., Stinchcombe, M。, & 白色的, H. (1989). Multilayer feedforward networks
are universal approximators. Neural Netw., 2(5), 359–366.
Hyvärinen, A。, & Morioka, H. (2016). Unsupervised feature extraction by time-
contrastive learning and nonlinear ICA. 在D中. 李, 中号. Sugiyama, U. Luxburg,
我. Guyon, & 右. 加内特 (编辑。), Advances in neural information processing systems, 29
(PP. 3765–3773). 红钩, 纽约: 柯兰.
Hyvärinen, A. J。, & Morioka, H. (2017). Nonlinear ICA of temporally depen-
dent stationary sources. In Proceedings of the Conference on Machine Learn
研究.
Hyvärinen, A。, & Oja, 乙. (1997). A fast fixed-point algorithm for independent com-
ponent analysis. Neural Comput., 9(7), 1483–1492.
Hyvärinen, A。, & Pajunen, 磷. (1999). Nonlinear independent component analysis:
Existence and uniqueness results. Neural Netw., 12(3), 429–439.
Isomura, T。, & 弗里斯顿, K. (2018). In vitro neural networks minimise variational free
活力. Sci. Rep., 8, 16926.
Isomura, T。, & 弗里斯顿, K. (2020). Reverse engineering neural networks to character-
ize their cost functions. Neural Comput., 32(11), 2085–2121.
Isomura, T。, Kotani, K., & Jimbo, 是. (2015). Cultured cortical neurons can perform
blind source separation according to the free-energy principle. PLOS Comput.
Biol., 11(12), e1004643.
Isomura, T。, & Toyoizumi, 时间. (2016). A local learning rule for independent component
分析. Sci. Rep., 6, 28073.
Isomura, T。, & Toyoizumi, 时间. (2018). Error-gated Hebbian rule: A local learning rule
for principal and independent component analysis. Sci. Rep., 8, 1835.
Isomura, T。, & Toyoizumi, 时间. (2019). Multi-context blind source separation by error-
gated Hebbian rule. Sci. Rep., 9, 7127.
Isomura, T。, & Toyoizumi, 时间. (2021). Dimensionality reduction to maximize predic-
tion generalization capability. Nat. Mach. Intell., in press.
Jolliffe, 我. 时间. (2002). Principal component analysis (2nd 版。). 柏林: 施普林格.
Jutten, C。, & Karhunen, J. (2004). Advances in blind source separation (BSS) 并在-
dependent component analysis (ICA) for nonlinear mixtures. Int. J. Neural. Syst.,
14(5), 267–292.
坎德尔, 乙. R。, 施瓦茨, J. H。, 杰塞尔, T。, M。, 海豹树, S. A。, & 哈德斯佩斯, A. J.
(2013). Principles of neural science (5第三版。). 纽约: 麦格劳-希尔.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Achievability of Nonlinear Blind Source Separation
1467
Karhunen, J. (2001). Nonlinear independent component analysis. 在S. 罗伯茨 &
右. Everson (编辑。), Independent component analysis: Principles and practice (PP. 113–
134). 剑桥: 剑桥大学出版社.
Kawaguchi, K. (2016). Deep learning without poor local minima. 在D中. 李, 中号.
Sugiyama, U. Luxburg, 我. Guyon, & 右. 加内特 (编辑。), Advances in neural infor-
mation processing systems, 29. 红钩, 纽约: 柯兰.
Khemakhem, 我。, Kingma, D ., Monti, R。, & Hyvarinen, A. (2020). Variational autoen-
coders and nonlinear ICA: A unifying framework. In Proceedings of the Interna-
tional Conference on Artificial Intelligence and Statistics 2207–2217. ML Research
按.
Kingma, D. P。, & Welling, 中号. (2013). Auto-encoding variational Bayes. arXiv:1312.6114.
Lappalainen, H。, & Honkela, A. (2000). Bayesian non-linear independent component
analysis by multi-layer perceptrons. 在米. Girolami, (埃德。), Advances in independent
成分分析 (PP. 93–121). 伦敦: 施普林格.
Leugering, J。, & Pipa, G. (2018). A unifying framework of synaptic and intrinsic plas-
ticity in neural populations. Neural Comput., 30(4), 945–986.
Linsker, 右. (1997). A local learning rule that enables information maximization for
arbitrary input distributions. Neural Comput., 9(8), 1661–1665.
鲁, H。, & Kawaguchi, K. (2017). Depth creates no bad local minima. arXiv:1702.08580.
Malenka, 右. C。, & Bear, 中号. F. (2004). LTP and LTD: An embarrassment of riches.
神经元, 44(1), 5–21.
Marchenko, V. A。, & Pastur, L. A. (1967). Distribution of eigenvalues for some sets
of random matrices. Mat. Sbornik, 114, 507–536.
Mika, D ., Budzik, G。, & Józwik, J. (2020). Single channel source separation with ICA-
based time-frequency decomposition. Sensors, 20(7), 2019.
阮, Q., & Hein, 中号. (2017). The loss surface of deep and wide neural networks.
arXiv:1704.08045.
Oja, 乙. (1982). Simplified neuron model as a principal component analyzer. J. 数学.
Biol., 15(3), 267–273.
Oja, 乙. (1989). Neural networks, principal components, and subspaces. Int. J. Neural.
Syst., 1(10), 61–68.
Oja, E., & Yuan, Z. (2006). The FastICA algorithm revisited: Convergence analysis.
IEEE Trans. Neural Netw., 17(6), 1370–1381.
Papadias, C. 乙. (2000). Globally convergent blind source separation based on a mul-
tiuser kurtosis maximization criterion. IEEE Trans. Signal Process., 48(12), 3508–
3519.
皮尔逊, K. (1901). On lines and planes of closest fit to systems of points in space.
Philos. Mag., 2(11), 559–572.
Pehlevan, C。, Mohan, S。, & Chklovskii, D. 乙. (2017). Blind nonnegative source sepa-
ration using biological neural networks. Neural Comput., 29(11), 2925–2954.
Rahimi, A。, & Recht, 乙. (2008A). Uniform approximation of functions with random
bases. In Proceedings of the 46th Annual Allerton Conference on Communication, 骗局-
控制, and Computing (PP. 555–561). 红钩, 纽约: 柯兰.
Rahimi, A。, & Recht, 乙. (2008乙). Weighted sums of random kitchen sinks: Replacing
minimization with randomization in learning. 在D中. Koller, D. Schuurmans, 是.
本吉奥, & L. 波图 (编辑。), Advances in neural information processing systems, 21
(PP. 1313–1320). 剑桥, 嘛: 与新闻界.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1468
时间. Isomura and T. Toyoizumi
Sanger, 时间. D. (1989). Optimal unsupervised learning in a single-layer linear feedfor-
ward neural network. Neural Netw., 2(6), 459–473.
Toyoizumi, T。, & Abbott, L. F. (2011). Beyond the edge of chaos: Amplification and
temporal integration by recurrent networks in the chaotic regime. Phys. 牧师. E.,
84(5), 051908.
van der Lee, T。, Exarchakos, G。, & de Groot, S. H. (2019). In-network Hebbian plas-
ticity for wireless sensor networks. In Proceedings of the International Conference on
Internet and Distributed Computing Systems (PP. 79–88). 占婆: 施普林格.
Wan, L。, Zeiler, M。, 张, S。, 乐存, Y。, & 弗格斯, 右. (2013). Regularization of neural
networks using DropConnect. In Proceedings of Machine Learning Research (28)3,
1058–1066.
Wentzell, 磷. D ., Andrews, D. T。, 汉密尔顿, D. C。, Faber, K., & Kowalski, 乙. 右. (1997).
Maximum likelihood principal component analysis. J. Chemom., 11(4), 339–366.
徐, L. (1993). Least mean square error reconstruction principle for self-organizing
neural–nets. Neural Netw., 6(5), 627–648.
Received July 26, 2020; accepted December 23, 2020.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
3
6
1
4
3
3
1
9
1
6
3
6
4
n
e
C
哦
_
A
_
0
1
3
7
8
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3