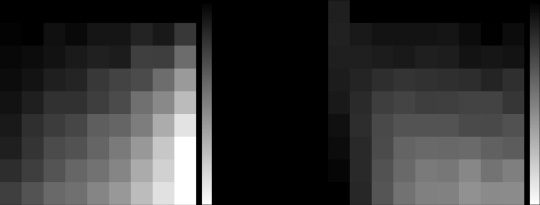文章
Communicated by Ruben Moreno-Bote
Heterogeneous Synaptic Weighting Improves Neural Coding
in the Presence of Common Noise
Pratik S. Sachdeva
pratik.sachdeva@berkeley.edu
Redwood Center for Theoretical Neuroscience and Department of Physics,
加州大学, 伯克利, 伯克利, CA 94720 美国。, and Biological
Systems and Engineering Division, Lawrence Berkeley National Laboratory,
伯克利, CA 94720, 美国.
Jesse A. Livezey
jlivezey@lbl.gov
Redwood Center for Theoretical Neuroscience, 加州大学, 伯克利,
伯克利, CA 94720, 美国。, and Biological Systems and Engineering Division,
Lawrence Berkeley National Laboratory, 伯克利, CA 94720, 美国.
迈克尔·R. 德威斯
deweese@berkeley.edu
Redwood Center for Theoretical Neuroscience, Department of Physics, and Helen
Wills Neuroscience Institute, 加州大学,
伯克利, 伯克利, CA 94720 美国.
Simultaneous recordings from the cortex have revealed that neural ac-
tivity is highly variable and that some variability is shared across neu-
rons in a population. Further experimental work has demonstrated that
the shared component of a neuronal population’s variability is typically
comparable to or larger than its private component. 同时, an abun-
dance of theoretical work has assessed the impact that shared variability
has on a population code. 例如, shared input noise is understood
to have a detrimental impact on a neural population’s coding fidelity.
然而, other contributions to variability, such as common noise, 能
also play a role in shaping correlated variability. We present a network
of linear-nonlinear neurons in which we introduce a common noise in-
put to model—for instance, variability resulting from upstream action
potentials that are irrelevant to the task at hand. We show that by apply-
ing a heterogeneous set of synaptic weights to the neural inputs carrying
the common noise, the network can improve its coding ability as mea-
sured by both Fisher information and Shannon mutual information, 甚至
in cases where this results in amplification of the common noise. 和
a broad and heterogeneous distribution of synaptic weights, a popula-
tion of neurons can remove the harmful effects imposed by afferents that
神经计算 32, 1239–1276 (2020) © 2020 麻省理工学院
https://doi.org/10.1162/neco_a_01287
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1240
磷. Sachdeva, J. Livezey, 和M. 德威斯
are uninformative about a stimulus. We demonstrate that some nonlinear
networks benefit from weight diversification up to a certain population
尺寸, above which the drawbacks from amplified noise dominate over the
benefits of diversification. We further characterize these benefits in terms
of the relative strength of shared and private variability sources. 最后,
we studied the asymptotic behavior of the mutual information and Fisher
information analytically in our various networks as a function of popula-
tion size. We find some surprising qualitative changes in the asymptotic
behavior as we make seemingly minor changes in the synaptic weight
分布.
1 介绍
Variability is a prominent feature of many neural systems: neural responses
to repeated presentations of the same external stimulus typically vary from
trial to trial (沙德伦 & Newsome, 1998). 此外, neural variability
often exhibits pairwise correlations, so that pairs of neurons are more (或者
较少的) likely to be co-active than they would be by chance if their fluctua-
tions in activity to a repeated stimulus were independent. These so-called
noise correlations (which we also refer to as “shared variability”) 已经
observed throughout the cortex (Averbeck, 莱瑟姆, & 假发, 2006; 科恩
& Kohn, 2011), and their presence has important implications for neural
编码 (佐哈拉斯, 沙德伦, & Newsome, 1994; 雅培 & 戴安, 1999).
If the activities of individual neurons are driven by a stimulus shared by
all neurons but corrupted by noise that is independent for each neuron (所以-
called private variability), then the signal can be recovered by simply aver-
aging the activity across the population (雅培 & 戴安, 1999; 马, 贝克,
莱瑟姆, & 假发, 2006). If instead some variability is shared across neu-
罗恩 (IE。, there are noise correlations), naively averaging the activity across
the population will not necessarily recover the signal, no matter how large
人口 (Zohary et al., 1994). An abundance of theoretical work has
explored how shared variability can be either beneficial or detrimental to
the fidelity of a population code (relative to the null model of only private
variability among the neurons), depending on its structure and relationship
with the tuning properties of the neural population (Zohary et al., 1994; Ab-
bott & 戴安, 1999; 因 & Sompolinsky, 1999; Sompolinsky, 因, 炕,
& Shamir, 2001; Averbeck & 李, 2006; 科恩 & Maunsell, 2009; Cafaro &
河, 2010; Ecker, Berens, Tolias, & Bethge, 2011; Moreno-Bote et al., 2014;
Nogueira et al., 2020).
One general conclusion of this work highlights the importance of the ge-
ometric relationship between noise correlations and a neural population’s
signal correlations (Averbeck et al., 2006; 胡, Zylberber, & 牛乳棕色,
2014). To illustrate this, the mean responses of a neural population across
a variety of stimuli (IE。, those responses represented by receptive fields or
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1241
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1: Private and shared variability. (A) The geometric relationship between
neural activity and shared variability. Black curves denote mean responses to
different stimuli. Variability for a specific stimulus (black dot) may be private
(左边), 共享 (中间), or take on the structure of differential correlations (正确的).
The red arrow represents the tangent direction of the mean stimulus response.
(乙) Schematic of the types of variability that a neural population can encounter.
The variability of a neural population contains both private components (例如,
synaptic vesicle release, channel noise, thermal noise) and shared components
(例如, variability of presynaptic spike trains, shared input noise). Shared variabil-
ity can be induced by the variability of afferent connections (which is shared
across a postsynaptic population) or inherited from the stimulus itself. 毛皮-
瑟莫雷, shared variability is shaped by synaptic weighting. (C) Estimates of
the private variability contributions to the total variability of neurons (N= 28)
recorded from auditory cortex of anesthetized rats. Diagonal line indicates the
身份. Figure reproduced from Deweese and Zador (2004).
tuning curves) can be examined in the neural space (see Figure 1a, 黑色的
curves). The correlations among the mean responses for different stimuli
specify the signal correlations for a neural population (Averbeck et al.,
2006). Private variability exhibits no correlational structure, and thus its
1242
磷. Sachdeva, J. Livezey, 和M. 德威斯
relationship with the signal correlations is determined by the mean neural
activity and the individual variances (see Figure 1a, 左边). Shared variability,
然而, may reshape neural activity to lie, 例如, orthogonal to the
mean response curve (see Figure 1a, 中间). In the case of Figure 1a, 中-
dle, neural coding is improved (relative to private variability) 因为
variability occupies regions of the neural space that are not traversed by the
mean response curve (Montijn, Meijer, Lansink, & 宾夕法尼亚州, 2016). Shared
variability can also harm performance, 然而. Recent work has identi-
fied differential correlations—those that are proportional to the products of
the derivatives of tuning functions (see Figure 1a, 正确的)—as particularly
harmful to the performance of a population code (Moreno-Bote et al., 2014).
While differential correlations are consequential, they may serve as a small
contribution to a population’s total shared variability, leaving “nondifferen-
tial correlations” as the dominant component of shared variability (Kohn,
Coen-Cagli, Kanitscheider, & 假发, 2016; Montijn et al., 2019; Kafashan
等人。, 2020).
The sources of neural variability, and their respective contributions to the
private and shared components, will have a significant impact on shaping
the geometry of the population’s correlational structure, and therefore its
coding ability (Brinkman, 韦伯, 河, & 牛乳棕色, 2016). 例如,
private sources of variability such as channel noise or stochastic synaptic
vesicle release could be averaged out by a downstream neuron receiving in-
put from the population (faisal, 马具, & Wolpert, 2008). 然而, 来源
of variability shared across neurons, such as the variability of presynaptic
spike trains from neurons that synapse onto multiple neurons, would in-
troduce shared variability and place different constraints on a neural code
(沙德伦 & Newsome, 1998; Kanitscheider, Coen-Cagli, & 假发, 2015).
尤其, differential correlations are typically induced by shared input
噪音 (IE。, noise carried by a stimulus) or suboptimal computations (贝克,
马, 皮特科, 莱瑟姆, & 假发, 2012; Kanitscheider et al., 2015).
Past work has examined the contributions of private and shared sources
to variability in cortex (Arieli, Sterkin, Grinvald, & 艾尔森, 1996; Deweese
and Zador, 2004). 具体来说, by partitioning subthreshold variability of
a neural population into private components (synaptic, thermal, 渠道
noise in the dendrites, and other local sources of variability) and shared
成分 (variability induced by afferent connections), it was found that
the private component of the total variability was quite small, 而
shared component can be much larger (see Figures 1b and 1c). 因此, 神经
populations must contend with the large shared component of a neuron’s
可变性. The incoming structure of shared variability and its subsequent
shaping by the computation of a neural population is an important con-
sideration for evaluating the strength of a neural code (Zylberber, 假发,
莱瑟姆, & 牛乳棕色, 2017).
Moreno-Bote et al. (2014) demonstrated that shared input noise is detri-
mental to the fidelity of a population code. 这里, we instead examine
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1243
sources of shared variability, which do not necessarily result in differen-
tial correlations (they do not appear as shared input noise) and thus can be
manipulated by features of neural computation such as synaptic weight-
英. We refer to these noise sources as “common noise” to distinguish them
from the special case of shared input noise (Vidne et al., 2012; 库尔卡尼 &
Paninski, 2007). 例如, a common noise source could include an up-
stream neuron whose action potentials are noisy in the sense that they are
unimportant for computing the current stimulus. Common noise, 因为
it is manipulated by synaptic weighting, can serve as a source of nondiffer-
ential correlations (see Figure 1a, 中间), thereby having either a beneficial
or a harmful impact on the strength of the population code. We aim to better
elucidate the nature of this impact.
We consider a linear-nonlinear architecture (Paninski, 2004; Karklin &
Simoncelli, 2011; 枕头, Paninski, Uzzell, Simoncelli, & chichilnisky, 2005)
and explore how its neural representation is affected by both a common
source of variability and private noise sources affecting individual neurons
独立. This simple architecture allowed us to analytically assess
coding ability using both Fisher information (雅培 & 戴安, 1999; 因
& Sompolinsky, 1999; 威尔克 & Eurich, 2002; 吴, Nakahara, & Amari, 2001)
and Shannon mutual information. We evaluated the coding fidelity of both
the linear representation and the nonlinear representation after a quadratic
nonlinearity as a function of the distribution of synaptic weights that shape
the shared variability within the representations (Adelson & 卑尔根, 1985;
艾默生, Korenberg, & Citron, 1992; Sakai & 田中, 2000; Pagan, 西蒙-
celli, & Rust, 2016). We find that the linear stage representation’s coding
fidelity improves with diverse synaptic weighting, even if the weighting
amplifies the common noise in the neural circuit. 同时, the nonlin-
ear stage representation also benefits from diverse synaptic weighting in a
regime where common noise may be amplified, but not too strongly. 更多的-
超过, we found that the distribution of synaptic weights that optimized the
networks performance depended strongly on the relative amount of pri-
vate and shared variability. 尤其, the neural circuit’s coding fidelity
benefits from diverse synaptic weighting when shared variability is the
dominant contribution to the variability. 一起, our results highlight the
importance of diverse synaptic weighting when a neural circuit must con-
tend with sources of common noise.
2 方法
The code used to conduct the analyses described in this article is publicly
available on Github (https://github.com/pssachdeva/neuronoise).
2.1 Network Architecture. We consider the linear-nonlinear architec-
ture depicted in Figure 2. The inputs to the network consist of a stimulus
s along with common (高斯) noise ξ
C. The N neurons in the network
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1244
磷. Sachdeva, J. Livezey, 和M. 德威斯
数字 2: Linear-nonlinear network architecture. The network takes as its in-
puts a stimulus s and common noise ξ
C. A linear combination of these quan-
tities is corrupted by individual private noises ξ
磷,我. The output of this linear
stage is then passed through a nonlinearity gi((西德:3)) to produce a “firing rate” ri.
The weights for the linear stage of the network, v
我, can be thought of
as synaptic weighting. 重要的, the common noise is distinct from shared
input noise because it is manipulated by the synaptic weighting.
i and w
take a linear combination of the inputs and are further corrupted by inde-
pendent and identically distributed (I.I.D.) private gaussian noise. 因此, 这
output of the linear stage for the ith neuron is
(西德:3)
我
= v
是 + w
我
一个
C
h
C
+ σPξ
磷,我
,
(2.1)
磷,i is the private noise, v
where ξ
and private noise terms are scaled by positive constants σ
linear combination is passed through a nonlinearity gi((西德:3)
can be thought of as a firing rate.
i are the weights, and the common
C and σP. The noisy
我) whose output ri
i and w
因此, the network-wide computation is given by
r = g(与 + wσ
C
h
C
+ σPξP),
(2.2)
where g((西德:3)) is an element-wise application of the network nonlinearity.
2.2 Measures of Coding Strength. In order to assess the fidelity of the
population code represented by (西德:3) or r, we turn to the Fisher information and
the Shannon mutual information (覆盖 & 托马斯, 2012). The former has
largely been used in the context of sensory decoding and correlated vari-
能力 (雅培 & 戴安, 1999; Averbeck et al., 2006; Kohn et al., 2016) 尽管
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1245
the latter has been well studied in the context of efficient coding (Attneave,
1954; 巴洛, 1961; 钟 & Sejnian, 1997; 河, 伍德兰, de Ruyter van
Steveninck, & 二进制, 1999).
The Fisher information sets a limit by which the readout of a popula-
tion code can determine the value of the stimulus. 正式地, it sets a lower
bound to the variance of an unbiased estimator for the stimulus. 就条款而言
of the network architecture, the Fisher information of the representation r
(或者 (西德:3)) quantifies how well s can be decoded given the representation. 为了
gaussian noise models with stimulus-independent covariance, the Fisher
information is equal to the linear Fisher information (LFI):
ILFI(s) =
时间
∂f(s)
∂s
(西德:4)−1(s)
∂f(s)
∂s
,
(2.3)
f(s) 和 (西德:4)(s) are the mean and covariance of the response (这里, r or
(西德:3)) to the stimulus s. 在其他情况下, the LFI serves as a lower bound for the
Fisher information and thus is a useful proxy when the Fisher information
is challenging to calculate analytically. The estimator for ILFI is the locally
optimal linear estimator (Kohn et al., 2016).
The Shannon mutual information quantifies the reduction in uncertainty
of one random variable given knowledge of another:
(西德:2)
我[s, F] =
dsdf p(s, F) 日志
(西德:3)
(西德:4)
.
p(s, F)
p(s)p(F)
(2.4)
Earlier work demonstrated that the Fisher information provides a lower
bound for the Shannon mutual information in the case of gaussian noise
(布鲁内尔 & Nadal, 1998). 然而, more recent work has revealed that the
relationship between the two is more nuanced, particularly in the cases
where the noise model is nongaussian (魏 & Stocker, 2016). 因此, 我们
supplement our assessment of the network’s coding ability by measuring
the mutual information, 我[s, r], between the neural representation r and the
stimulus s. As with the Fisher information, the mutual information is often
intractable but fortunately can be estimated from data. 具体来说, 我们
employ the estimator developed by Kraskov and colleagues, 使用
entropy estimates from k-nearest neighbor distances (Kraskov, Stögbauer,
& Grassberger, 2004).
2.3 Structured Weights. The measures of coding strength are a function
of the weights that shape the interaction of the stimulus and noise in the net-
工作. 因此, the choice of the synaptic weight distribution affects the calcu-
lation of these quantities. We first consider the case of structured weights
in order to obtain analytical expressions for measures of coding strength.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1246
磷. Sachdeva, J. Livezey, 和M. 德威斯
Structured weights take on the form
⎛
⎞
时间
W =
⎝ 1 ··· 1
(西德:7) (西德:8)(西德:9) (西德:10)
N/k times
2 ··· 2
(西德:7) (西德:8)(西德:9) (西德:10)
N/k times
⎠
· · · k · · · k
(西德:7) (西德:8)(西德:9) (西德:10)
N/k times
.
(2.5)
具体来说, the structured weight vectors are parameterized by an integer k
that divides the N weights into k homogeneous groups. The weights across
the groups span the positive integers up to k. 重要的, larger k will only
increase the weights in the vector. 因此, in the above scheme, increased “di-
versity” can be achieved only by increasing k, which will invariably result
in an amplification of the signal to which the weight vector is applied. 在里面
case that k does not evenly divide N, each group is repeated (西德:2)N/k(西德:3) 次,
except the last group, which is only repeated N − (n- 1) · (西德:2)N/k(西德:3) 次 (那
是, the last group is truncated to ensure the weight vector is of size N).
此外, we consider cases in which k is of order N, 例如, k =
N/2. Allowing k to grow with N ensures that typical values for the weights
grow with the population size. This contrasts with the case in which k is a
持续的, such as k = 4, which sets a maximum weight value independent
of the population size.
2.4 Unstructured Weights. While the structured weights allow for an-
alytical results, they possess an unrealistic distribution of synaptic weight-
英. 因此, we also consider the case of unstructured weights, 其中
the synaptic weights are drawn from some parameterized probability
分配:
v ∼ p(v; θv); w ∼ p(w; θw).
(2.6)
We calculate both information-theoretic quantities over many random
draws from these distributions and observe how these quantities behave
as some subset of the parameters θ is varied. 尤其, we focus on the
log-normal distribution (Iyer, Menon, Buice, 科赫, & Mihalas, 2013), 哪个
has been found to describe the distribution of synaptic weights well in slice
electrophysiology (歌曲, Sjöström, Reigl, 纳尔逊, & chklovskii, 2005; Sar-
绅士, Saviane, 尼尔森, DiGregorio, & 银, 2005). 具体来说, the weights
take on the form
w ∼ (西德:7) + Lognormal(m, 一个 ),
(2.7)
在哪里 (西德:7) > 0. For a log-normal distribution, an increase in μ will increase
the distribution’s mean, 中位数, and mode (see Figure 3e, inset). 因此, m
as a parameter acts similar to k for the structured weights in that increased
weight diversity must be accompanied by an increase in their magnitude.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1247
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
= m 2
C
数字 3: Network coding performance of the linear stage representation. 这里,
= 1. Fisher information is shown on the top row
the noise variances are σ 2
磷
and mutual information on the bottom row. (A, 乙) Structured weights. 线性
Fisher information and mutual information are shown as a function of the pop-
ulation size, 氮, across different levels of weight heterogeneity, kw (indicated by
颜色). (C, d) Linear fisher information and mutual information are shown as
a function of weight heterogeneity, kw, for various population sizes, 氮. (e, F)
Unstructured weights. Linear Fisher information and mutual information are
shown as a function of the mean of the log-normal distribution used to draw
common noise synaptic weights. Information quantities are calculated across
1000 random drawings of weights: solid lines depict the means while the shaded
region indicates one standard deviation. Inset: The distribution of weights for
various choices of μ. Increasing μ shifts the distribution to the right, 增加
heterogeneity.
3 结果
We consider the network’s coding ability after both the linear stage ((西德:3)) 和
the nonlinear stage (r). 换句话说, the linear stage can be considered
the output of the network assuming each of the functions gi((西德:3)
我) is the iden-
tity. 此外, due to the data processing inequality, the qualitative con-
clusions we obtain from the linear stage should apply for any one-to-one
非线性.
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1248
磷. Sachdeva, J. Livezey, 和M. 德威斯
3.1 Linear Stage. The Fisher information about the stimulus in the
linear representation can be shown to be (see appendix A.1.1 for the
derivation)
(西德:13)
如果 (s) = 1
一个 2
磷
|v|2
一个 2
磷
=
(西德:14)
一个 2
磷
/一个 2
C
(西德:13)
(西德:14)
(西德:13)
|v|2 +
(一个 2
磷
|v|2|w|2 - (v · w)2
C ) + |w|2
/一个 2
一个 2
/一个 2
磷
C
/一个 2
(一个 2
磷
+ |w|2 sin2 θ
C ) + |w|2
,
(西德:14)
(3.1)
(3.2)
which is equivalent to the linear Fisher information in this case. 在等式中
3.2, θ refers to the angle between v and w. The mutual information can be
expressed as (see appendix A.1.2 for the derivation)
我[s, (西德:3)] = 1
2
(西德:15)
1 + 一个 2
(西德:16)
S IF (s)
.
日志
(3.3)
For the case the mutual information, we have assumed that the prior distri-
bution for the stimulus is gaussian with zero mean and variance σ 2
S .
Examining equation 3.2 reveals that increasing the norm of v without
changing its direction (那是, without changing θ ) will increase the Fisher
信息, while increasing the norm of w without changing its direction
will either decrease or maintain information (自从 0 ≤ sin2 θ ≤ 1). 阿迪-
理论上, if v and w become more aligned while leaving their norms un-
改变了, the Fisher information will decrease (since sin2 θ will decrease).
This decrease in Fisher information is consistent with the observation that
alignment of v and w will produce differential correlations. If v and w are
changed in a way that modulates both their norm and direction, the impact
on Fisher information is less transparent.
To better understand the Fisher information, we impose a parameterized
structure on the weights that allows us to increase weight diversity without
decreasing the magnitude of any of the weights. This weight parameteriza-
的, which we call the structured weights, is detailed in section 2.3. 我们
chose this parameterization for two reasons. 第一的, we desired a scheme in
which an increase in diversity must be accompanied by an amplification of
common noise. We chose this behavior so that any improvement in coding
ability can only be explained by the increase in diversity rather than a po-
tential decrease in common noise. 第二, we desired analytic expressions
for the Fisher information as a function of population size, 这是可能的
with this form of structured weights.
Under the structured weight parameterization, 方程 3.1 和 3.3 能
be explored by varying the choice of k for both v and w (we refer to them
as kv and kw, 分别). It is simplest and most informative to exam-
ine these quantities by setting kv = 1 while allowing kw to vary, as ampli-
fying and diversifying v will only increase coding ability for predictable
原因 (this is indeed the case for our network) (Shamir & Sompolinsky,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1249
2006; Ecker et al., 2011). While increasing kw will boost the overall amount
of noise added to the neural population, it also changes the direction of the
noise in the higher-dimensional neural space. 因此, while we might expect
that adding more noise in the system would hinder coding, the relationship
between the directions of the noise and stimulus vectors in the neural space
also plays a role.
We first consider how the Fisher information and mutual information
are affected by the choice of kw. In the structured regime, 我们有
|v|2 = n,
v · w = N
k
|w|2 = n
k
k(西德:17)
我=1
k(西德:17)
我=1
i = N(k + 1)
2
,
i2 = N(k + 1)(2k + 1)
6
,
which allows us to rewrite equation 3.1 作为
如果 (s) = IF = N
2一个 2
磷
12(一个 2
磷
/一个 2
/一个 2
C ) + 氮(k2 − 1)
C ) + 氮(2k2 + 3k + 1)
6(一个 2
磷
(3.4)
(3.5)
(3.6)
(3.7)
.
The form of the mutual information follows directly from plugging equa-
的 3.7 into equation 3.3.
The analytical expressions for the structured regime reveal the asymp-
totic behavior of the information quantities. Neither quantity saturates as a
function of the number of neurons, 氮, except in the case of kw = 1 (见图-
ures 3a and 3b). In this regime, increasing the population size of the system
also enhances coding fidelity. 此外, both quantities are monotoni-
cally increasing functions of the common noise synaptic heterogeneity, kw
(see Figures 3c and 3d), implying that decoding is enhanced despite the fact
that the amplitude of the common noise is magnified for larger kw. Our ana-
lytical results show linear and logarithmic growth for the Fisher and mutual
信息, 分别, as one might expect in the case of gaussian noise
(布鲁内尔 & Nadal, 1998). These qualitative results hold for essentially any
choice of (一个
In the case of kw = 1, the signal and common noise are aligned perfectly
in the neural representation. 因此, the common noise becomes equivalent in
form to shared input noise. 作为结果, we observe the saturation of
both Fisher information and mutual information as a function of the neural
人口. This saturation implies the existence of differential correlations,
consistent with the observation that information-limiting correlations occur
under the presence of shared input noise (Kanitscheider et al., 2015).
, σP, 一个
C).
S
The structured weight distribution we described allows us to derive ana-
lytical results, but the limitation to only a fixed number of discrete synaptic
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1250
磷. Sachdeva, J. Livezey, 和M. 德威斯
weight values is not realistic for biological networks. 因此, we use unstruc-
tured weights, 节中描述 2.4, in which the synaptic weights are
drawn from a log-normal distribution. 在这种情况下, we estimate the linear
Fisher information and the mutual information over many random draws
according to w
~ (西德:7) + Lognormal(m, 一个 2). We are primarily concerned with
我
varying μ, as an increase in this quantity uniformly increases the mean, 我-
甸, and mode of the log-normal distribution (see Figure 3e, inset), akin to
increasing kw for the structured weights.
Our numerical analysis demonstrates that increasing μ increases the av-
erage Fisher information and average mutual information across popula-
tion sizes (see Figures 3e and 3f: bold lines). 此外, the benefits of
larger weight diversity are felt more strongly by larger populations (见图-
ures 3e and 3f: different colors).
In the structured weight regime, our analytical results show that weight
heterogeneity can ameliorate the harmful effects of additional information-
limiting correlations induced by common noise mimicking shared input
噪音. They do not imply that weight heterogeneity prevents differential
相关性, as the common noise in this model is manipulated by synap-
tic weighting, in contrast with true shared input noise. For unstructured
重量, we once again observe that larger heterogeneity affords the net-
work improved coding performance, despite the increased noise in the sys-
TEM. 一起, these results show that linear networks could manipulate
common noise to prevent it from causing induced differential correlations.
然而, 神经回路, which must perform other computations that may
dictate the structure of the weights on the common noise inputs, can still
achieve good decoding performance provided that the circuits’ synaptic
weights are heterogeneous.
3.2 Quadratic Nonlinearity. We next consider the performance of the
network after a quadratic nonlinearity gi(X) = x2 for all neurons i. This non-
linearity has been used in a neural network model to perform quadratic dis-
criminant analysis (Pagan et al., 2016) and as a transfer function in complex
cell models (Adelson & 卑尔根, 1985; Emerson et al., 1992; Sakai & 田中,
2000). 此外, we chose this nonlinearity because we were able to cal-
culate the linear Fisher information analytically (as an approximation to the
Fisher information); see appendix A.3 for a numerical analysis with an ex-
ponential nonlinearity. 然而, the mutual information is apparently not
analytically tractable; we performed a numerical approximation using sim-
ulated data.
3.2.1 Linear Fisher Information. An analytic expression of the linear Fisher
information is calculated in appendix A.1.3. Its analytic form is too compli-
cated to be restated here, but we will examine it numerically for both the
structured and unstructured weights. The qualitative behavior of the Fisher
information depends on the magnitude of the common variability (一个
C) 和
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1251
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
= m
C
= 5, 一个
C
= 1). (C) Normalized Fisher information. For a choice of σ
数字 4: Linear Fisher information after quadratic nonlinearity in a network
with structured weights. (A) Fisher information as a function of population size
= 1, 那是, private and common noise have equal variances.
when σ
磷
Solid lines denote constant k while dashed lines denote k scaling with popu-
lation size. (乙) Same as panel a, but for a network where private variance dom-
inates (一个
磷,
磷
the Fisher information is calculated for a variety of kw (y-axis) and divided
by the maximum Fisher information (across the kw, for the choice of σ
磷). 为了
a given σ
磷, the normalized Fisher information is equal to one at the value of
kw, which maximizes decoding performance. (d) Behavior of the Fisher infor-
mation as a function of synaptic weight heterogeneity for various population
= 1). (e) Same as panel d, but for networks where private variance
= m
尺寸 (一个
C
磷
= 1). (F) The coefficient of the linear term in the asymp-
= 5, 一个
dominates (一个
C
磷
totic series of the Fisher information at different levels of private variability. 在
kw = 1, 2, the coefficient of N is exactly zero.
private variability (σP) in a more complicated fashion than the linear stage,
which depends on these variables primarily through their ratio σ
/σP. 因此,
C
we separately consider how common and private variability affect coding
efficacy under various synaptic weight structures.
和以前一样, we first consider the structured weights with kv set to 1 尽管
= 1 (IE。, 平等的
only varying kw. We start with the special case where σP = σ
C
private and common noise variance). 这里, the Fisher information satu-
rates for both kw = 1 and kw = 2, but increases without bound for larger kw
(see Figure 4a). We can also consider the case where the structured weight
heterogeneity grows in magnitude with the population size (IE。, kw is a
1252
磷. Sachdeva, J. Livezey, 和M. 德威斯
function of N). 在这种情况下, the Fisher information is much smaller and
saturates (see Figure 4a, 虚线).
The information saturation (or growth) for various kw can be under-
stood in terms of the geometry of the covariance describing the neural
population’s variability. Information saturation occurs if the principal
eigenvector(s) of the covariance align closely (but not necessarily exactly)
with the differential correlation direction, F(西德:6)
, while the remaining eigenvec-
tors quickly become orthogonal to f(西德:6)
as population size increases (莫雷诺-
Bote et al., 2014; see appendix A.2 for more details). When kw = 1, com-
mon noise aligns perfectly with the stimulus, and so the principal eigen-
vector of the covariance aligns exactly with f(西德:6)
(as in Figure 1a, 正确的). 什么时候
kw > 1, the principal eigenvector aligns closely, but not exactly, with the dif-
ferential correlation direction. 然而, when kw = 2, the remaining eigen-
vectors become orthogonal quickly enough for information to saturate. 这
does not occur when kw > 2. The case of kw ∼ O(氮), 同时, is slightly
不同的. 这里, the variances of the covariance matrix scale with population
尺寸, so that the neurons simply exhibit too much variance for any meaning-
ful decoding to occur. 然而, we believe that it is unreasonable to expect
that the synaptic weights of a neural circuit scale with the population size,
making this scenario biologically implausible.
When private variability dominates, we observe qualitatively different
finite network behavior (σP = 5; see Figure 4b). For N = 1000, both kw = 1
and kw = 2 exhibit better performance relative to larger values of kw (经过
对比, the case with kw ∼ O(氮) quickly saturates). 我们注意到这一点, unsur-
prisingly, the increase in private variability has decreased the Fisher infor-
mation for all cases we considered compared to σP = 1 (compare the scales
of Figures 4a and 4b). Our main interest, 然而, is identifying effective
synaptic weighting strategies given some amount of private and common
可变性.
The introduction of the squared nonlinearity produces qualitatively dif-
ferent behavior at the finite network level. In contrast with Figure 3, 在-
creased heterogeneity does not automatically imply improved decoding.
实际上, there is a regime in which increased heterogeneity improves Fisher
信息, beyond which we see a reduction in decoding performance
(see Figure 4d). If the private variability is increased, this regime shrinks
or becomes nonexistent, depending on the population size (see Figure 4e).
此外, entering this regime for higher private variability requires
smaller kw (IE。, less weight heterogeneity).
The results shown in Figures 4d and 4e imply that there exists an inter-
esting relationship among the network’s decoding ability, its private vari-
能力, and its synaptic weight heterogeneity kw. To explore this further, 我们
examine the behavior of the Fisher information at a fixed population size
(N= 1000) as a function of both σP and kw (see Figure 4c). To account for the
fact that an increase in private variability will always decrease the Fisher
信息, we calculate the normalized Fisher information: for a given
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1253
choice of σP, each Fisher information is divided by the maximum across
a range of kw values. 因此, a normalized Fisher information allows us to
determine what level of synaptic weight heterogeneity maximizes coding
fidelity, given a particular level of private variability σP.
Figure 4c highlights three interesting regimes. When the private variabil-
ity is small, the network benefits from larger weight heterogeneity on the
common noise. But as the neurons become noisier, the “Goldilocks zone” in
which the network can leverage larger noise weights becomes constrained.
When the private variability is large, the network achieves superior coding
fidelity by having less heterogeneous weights, despite the threat of induced
differential correlations from the common noise. Between these regimes,
there are transitions for which many choices of kw result in equally good
解码性能.
It is important to point out that Figures 4a to 4e capture only finite
network behavior. 所以, we extended our analysis by validating the
asymptotic behavior of the Fisher information as a function of the pri-
vate noise by examining its asymptotic series at infinity (see Figure 4f). 为了
kv = 1, 2, the coefficient of the linear term is zero for any choice of σP, 我是-
plying that the Fisher information always saturates. 此外, 当。。。的时候
common noise weights increase with population size (IE。, kw ∼ O(氮)), 这
asymptotic series is always sublinear (not shown in Figure 4f). 因此, 那里
are multiple cases in which the structure of synaptic weighting can induce
differential correlations in the presence of common noise. Increased hetero-
geneity allows the network to escape these induced differential correlations
and achieve linear asymptotic growth. If kw becomes too large, 然而, 这
linear asymptotic growth begins to decrease. Once kw scales as the popula-
tion size, differential correlations are once again significant.
下一个, we reproduce the analysis with unstructured weights. 和以前一样,
we draw 1000 samples of common noise weights from a shifted log-normal
distribution with varying μ. The behavior of the average (线性) 费舍尔
information is qualitatively similar to that of the structured weights (看
数字 5). There exists a regime for which larger weight heterogeneity im-
proves the decoding performance, beyond which coding fidelity decreases
(see Figure 5a). If the private noise variance dominates, this regime begins
to disappear for smaller networks (see Figure 5b). 因此, with very noisy
神经元, the coding fidelity of the network is improved when the synaptic
weights are less heterogeneous (and therefore smaller).
To summarize these results, we once again plot the normalized Fisher in-
形成 (this time, normalized across choices of μ and averaged over 1000
samples from the log-normal distribution) for a range of private variabili-
领带 (see Figure 5c). The heat map exhibits a similar transition at a specific
level of private variability. At this transition, a wide range of μ’s provide
the network with similar decoding ability. For smaller σP, we see behavior
comparable to Figure 5a, where there exists a regime of improved Fisher
信息. Beyond the transition, the network performs better with less
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1254
磷. Sachdeva, J. Livezey, 和M. 德威斯
数字 5: Linear Fisher information after quadratic nonlinearity, 非结构化
重量. In contrast to Figure 4, panels a and b are plotted on a log scale. (A) 林-
ear Fisher information as a function of the mean, m, of the log-normal distribu-
tion used to draw the common noise synaptic weights. Solid lines denote means,
while shaded regions denote one standard deviation across the 1000 图纸
of weights from the log-normal distribution. (乙) Same as panel a but for net-
= 1). (C) 归一化
works in which private variability dominates (一个
磷
linear Fisher information. Same plot as Figure 4c, but the average Fisher infor-
mation across the 1000 samples is normalized across μ (akin to normalizing
across kw).
= 5, 一个
C
diverse synaptic weighting, though it becomes less stringent as σP increases.
The behavior exhibited by this heat map is similar to Figure 4c but contains
fewer uniquely identifiable regions. This may imply that the additional re-
gions in Figure 4c are an artifact of the structured weights.
The amount of the common noise will also affect how the network be-
haves and what levels of synaptic weight heterogeneity are optimal. 为了
例子, consider a network with private noise variability set to σP = 1.
When common noise is small, the Fisher information is comparable among
various choices of synaptic weight diversity (see Figure 6a). When the com-
mon noise dominates, 然而, the network benefits strongly from diverse
weighting (see Figure 4b), though it is punished less severely for having
kw scale with N (see Figure 6b, 虚线; compare to Figure 4b). 这些
observations are true at finite population size. 和以前一样, the Fisher informa-
tion saturates for kw = 1, 2 and kw ∼ O(氮), no matter the choice of common
noise variance.
We calculated the normalized Fisher information across a range of com-
mon noise strengths to determine the optimal synaptic weight distribution.
The results for structured weights and unstructured weights are shown
in Figures 6c and 6d, 分别. While they strongly resemble Figures
4c and 5c, they exhibit opposite qualitative behavior. 和以前一样, 有
three identifiable regions in Figure 6c, each divided by abrupt transitions
where many choices of kw are equally good for decoding. For small common
噪音, the coding fidelity is improved with less heterogeneous weights, 但
as the common noise increases, the network enters the Goldilocks regions.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1255
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
数字 6: The relationship among common noise, private noise, and synaptic
weight heterogeneity. (A, 乙) Fisher information as a function of population size,
氮, when common noise contribution is drowned out by private noise (A) 和
= 1) (乙). Solid lines indicate constant kw, 尽管
common noise dominates (一个
磷
dashed lines refer to kw that scales with N. (C, d) Normalized Fisher informa-
tion as a function of common noise for structured weights (C) and unstructured
重量 (d). For unstructured weights, each Fisher information is calculated by
averaging over 1000 networks with their common noise weights drawn from
the respective distribution. (e) The value of kw that maximizes the network’s
Fisher information for a given choice of σ
C. The maximum is taken over
kw ∈ [1, 10]. (F) The value of μ that maximizes the average Fisher information
超过 1000 draws for a given choice of σ
P and σ
P and σ
C.
1256
磷. Sachdeva, J. Livezey, 和M. 德威斯
After another abrupt transition near σ
C
greatly improved by heterogeneous weights.
≈ 0.34, the network performance is
因此, common noise and private noise seem to have opposite impacts
on the optimal choice of synaptic weight heterogeneity. When private noise
dominates, the Fisher information is maximized under a set of homoge-
neous weights, since coding ability is harmed by amplification of common
噪音. When common noise dominates, the network coding is improved
under diverse weighting: this prevents additional differential correlations
and helps the network cope with the punishing effects on coding due to the
amplified noise.
How should we choose the synaptic weight distribution within the ex-
tremes of private or common noise dominating? We assess the behavior of
the Fisher information as both σP and σ
C are varied over a wide range. 为了
the structured weights, we calculate the choice of kw that maximized the
network’s Fisher information (within the range kw ∈ [1, 10]; see Figure 6e).
For the unstructured weights, we calculate the choice of μ that maximizes
the network’s average Fisher information over 1000 drawings of w from the
log-normal distribution specified by μ (see Figure 6f).
Figures 6e and 6f reveal that the network is highly sensitive to the val-
ues of σP and σ
C. Figure 6e exhibits a bandlike structure and abrupt transi-
tions in the value of kw, which maximizes Fisher information. This bandlike
structure would most likely continue to form for smaller σP if we allowed
kw > 10. One might expect that the bandlike structure is due to the artifi-
cial structure in the weights; 然而, we see that Figure 6f also exhibits
these types of bands. Note that the regime of interest for us is when private
variability is a smaller contribution to the total variability than the common
可变性. When this is the case, Figures 6e and 6f imply that a population
of neurons will be best served by having a diverse set of synaptic weights,
even if the weights amplify irrelevant signals.
一起, these results highlight how the introduction of the nonlinearity
in the network reveals an intricate relationship among the amount of shared
可变性, private variability, and the optimal synaptic weight heterogene-
性. Our observations that the network benefits from increased synaptic
weight heterogeneity in the presence of common noise are predicated on the
size of the network (see Figures 4a and 4b and 6a and 6b) and the amount
of private and shared variability (see Figures 4c, 6C, and 6d). 尤其,
when shared variability is the more significant contribution to the overall
可变性, the coding performance of the network benefits from increased
heterogeneity, whether the weights are structured or unstructured (见图-
ures 6e and 6f). This implies that in contrast to the linear network, there exist
regimes where increasing the synaptic weight heterogeneity beyond a point
will harm coding ability (see Figures 4d and 4e and 5a and 5b), demonstrat-
ing that there is a trade-off between the benefits of synaptic weight hetero-
geneity and the amplification of common noise it may introduce.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1257
数字 7: Mutual information computed by applying the KSG estimator on
data simulated from the network with quadratic nonlinearity and structured
重量. The estimates consist of averages over 100 数据集, 每个包含
100,000 样品. Standard error bars are smaller than the size of the markers.
(A) Mutual information as a function of common noise weight heterogeneity for
various population sizes N. We consider smaller N than in the case of Fisher in-
formation as computation time becomes prohibitive for larger dimensionalities.
= 0.5. (乙) The behavior of mutual information for various choices
这里, 一个
磷
= 0.5. (C) The behavior of mutual information for various choices
of σ
= 0.5.
of σ
= m
C
磷, while σ
C, while σ
C
磷
3.2.2 Mutual Information. When the network possesses a quadratic non-
linearity, the mutual information I[s, r] is far less tractable than for the linear
案件. 所以, we computed the mutual information numerically on data
simulated from the network, using an estimator built on k-nearest neigh-
bor statistics (Kraskov et al., 2004). We refer to this estimator as the KSG
估计器.
We applied the KSG estimator to 100 unique data sets, each contain-
英 100,000 samples drawn from the linear-nonlinear network. 然后我们
estimated the mutual information within each of the 100 数据集. com-
putational bottleneck for the KSG estimator lies in finding nearest neigh-
bors in a kd-tree, which becomes prohibitive for large dimensions (∼20), 所以
we considered much smaller population sizes than in the case of Fisher in-
形成. 此外, the KSG estimator encountered difficulties when
samples became too noisy, so we limited our analysis to smaller values of
(σP, 一个
C). Due to these constraints, we are only able to probe the finite net-
work behavior of the mutual information.
Our results for the structured weights are shown in Figure 7. When uti-
lizing estimators of mutual information from data, caution should be taken
before comparing across different dimensions due to bias in the KSG esti-
mator (高, Ver Steeg, & Galstyan, 2015). 因此, we restrict our observations
to within a specified population size. 第一的, we evaluated the mutual infor-
mation for various population sizes (N= 8, 10, 12, 14) in the case where
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1258
磷. Sachdeva, J. Livezey, 和M. 德威斯
一个
= σP = 0.5. Observe that, 和以前一样, the mutual information increases
C
with larger weight heterogeneity (kw; see Figure 7a). The improvement in
information occurs for all four population sizes.
Decreasing the private variability increases mutual information (见图-
ure 7b). 然而, the network sees a greater increase in information with
diverse weighting when σP is small. This is consistent with the small σP
regime highlighted in Figure 4c: the smaller the private variability, the more
the network benefits from larger synaptic weight heterogeneity. 相似地,
decreasing the common variability increases mutual information (见图-
ure 7c). If the common variability is small enough (例如, 一个
= 1), then larger
C
kw harms the encoding. 因此, when the common noise is small enough, 这
amplification of noise that results when kw is increased harms the network’s
编码. It is only when the common variability becomes the dominant
contribution to the variability that the diversification provided by larger kw
improves the mutual information.
As for the unstructured weights, we calculated the mutual information
我[s, r] 超过 100 synaptic weight distributions drawn from the aforemen-
tioned log-normal distribution. For each synaptic weight distribution, 我们
applied the KSG estimator to 100 unique data sets, each consisting of 10,000
样品. 因此, the mutual information estimate for a given network was
computed by averaging over the individual estimates across the 100 数据
套. With this procedure, we explored how the mutual information behaves
as a function of the private noise variability, common noise variability, 和
mean of the log-normal distribution.
Similar to the normalized Fisher information, we present the normal-
ized mutual information as a function of the private and common vari-
愤怒 (见图 8). For a given σP or σ
C, the mutual information is
calculated across a range of μ ∈ [−1, 1]. The normalized mutual informa-
tion is obtained by dividing each individual mutual information by the
maximum value across the μ. 因此, for a given σP, the value of μ whose
normalized mutual information is 1 specifies the log-normal distribution
that maximizes the network’s encoding performance. As private variabil-
ity increases, the network benefits more greatly benefits diverse weighting
(larger μ; see Figure 8a). As common variability increases, the network once
again prefers more diverse weighting. If the common variability is small
足够的, 然而, the network is better suited to homogeneous weights
(see Figure 8b). 所以, the analysis using the unstructured weights
largely corroborates our findings for the structured weights shown in
数字 7.
因此, these results highlight that there exist regimes where neural cod-
英, as measured by the Shannon mutual information, benefits from in-
creased synaptic weight heterogeneity. 此外, similar to the case of
the linear Fisher information, the improvement in coding occurs more sig-
nificantly when shared variability is large relative to private variability.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1259
数字 8: Normalized mutual information for common and private variability.
For a given μ, 100 networks were created by drawing common noise weights
w from the corresponding log-normal distribution. The mutual information
shown is the average across the 100 网络. For a specified network, the mu-
tual information was calculated by averaging KSG estimates over 100 模拟
数据集, 每个包含 10,000 样品. 最后, for a choice of (一个
C), 在-
磷
tual information is normalized to the maximum across values of μ. (A) 普通的-
= 0.5).
ized mutual information as a function of μ and private variability (一个
C
(乙) Normalized mutual information as a function of μ and common variability
(一个
= 0.5).
, 一个
磷
4 讨论
We have demonstrated in a simple model of neural activity that if synap-
tic weighting of common noise inputs is broad and heterogeneous, cod-
ing fidelity is actually improved despite inadvertent amplification of
common noise inputs. We showed that for squaring nonlinearities, 那里
exists a regime of heterogeneous weights for which coding fidelity is max-
模仿. We also found that the relationship between the magnitude of pri-
vate and shared variability is vital for determining the ideal amount of
synaptic heterogeneity. In neural circuits where shared variability is dom-
inant, as has been reported in some parts of the cortex (Deweese & Zador,
2004), larger weight heterogeneity results in better coding performance (看
Figure 6e).
Why are we afforded improved neural coding under increased synaptic
weight heterogeneity? An increase in heterogeneity, as we have defined it,
ensures that the common noise is magnified in the network. 同样
时间, 然而, the structure of the correlated variability induced by the
common noise is altered by increased heterogeneity. Previous work has
demonstrated that the relationship between signal correlations and noise
correlations is important in assessing decoding ability; 例如, 标志
rule states that noise correlations are beneficial if they are of opposite sign
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1260
磷. Sachdeva, J. Livezey, 和M. 德威斯
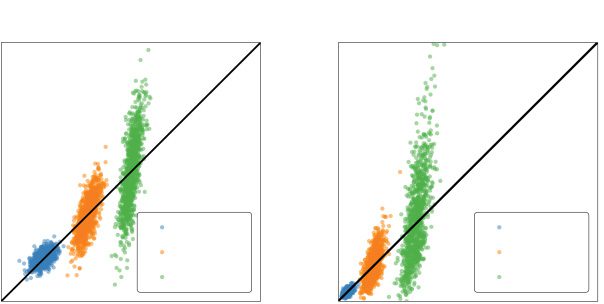
数字 9: The benefits of increased synaptic weight heterogeneity. (A) 那里-
sponses of a pair of neurons against the signal space, taken after the linear stage.
Colors indicate different choices of kw (while kv = 1). Each cloud contains 1000
sampled points. (乙) Same as panel a, but responses are taken after the quadratic
非线性.
as the signal correlation (Hu et al., 2014). Geometrically, the sign rule is a
consequence of the intuitive observation that decoding is easier when the
noise correlations lie perpendicular to the signal manifold (Averbeck et al.,
2006; Zylberber, Cafaro, 车工, 牛乳棕色, & 河, 2016; Montijn et al.,
2016).
例如, consider the correlated activity for two neurons in the net-
work against their signal space (see the black lines in Figures 9a and 9b) 作为一个
function of kw. Note that the signal space is linear. After the linear stage, 这
larger weight heterogeneity pushes the cloud of neural activity to lie more
orthogonal to the signal space. 同时, the variance becomes ob-
servably larger due to the magnification of the common noise (见图
9A). 重要的, note that the variability for kw = 1 lies parallel to the sig-
nal space, signifying the presence of differential correlations. The correlated
variability after the nonlinear stage is similar in that orthogonality to the sig-
nal space increases with kw. There is a notable difference: squaring the linear
stage ensures nonnegative activities, thereby limiting the response space.
因此, for large enough kw, the rectification manifests strongly enough that
the network enters a regime where increased heterogeneity harms decod-
英. These figures only demonstrate the relationship between a pair of neu-
罗恩, while the collective correlated variability structure ultimately dictates
解码性能. 他们是这样, 然而, shed light on how the distribu-
tion of synaptic weights can radically shape the common noise and thereby
the overall structure of the shared variability.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1261
The linear stage of the network constitutes a noisy projection of two sig-
nals (one of which is not useful to the network) in a high-dimensional space.
因此, we can assess the entire population by examining the relationship
between the projecting vectors v and w. We might expect that improved
decoding occurs when these signals are farther apart in the N-dimensional
空间 (希瑟, 2009). For a chosen kv, this occurs as kw is increased when
the weights are structured. When the weights are unstructured, 平均数
angle between the stimulus and weight vectors is large as either μv or μw in-
折痕. Increased heterogeneity implies access to a more diverse selection
of weights, thus pushing the two signals apart. 从这个角度来看, 这
nonlinear stage acts as a mapping on the high-dimensional representation.
Given that no noise is added after the nonlinear processing stage in the net-
作品, if the nonlinearities were one-to-one, the data processing inequality
would ensure that the results from the linear stage would hold. But as we
observed earlier, the nonlinear stage benefits from increased heterogeneity
only in certain regimes. 因此, the behavior of the nonlinearity is important:
the application of the quadratic nonlinearity restricts the high-dimensional
space that the neural code can occupy, and thus limits the benefits of diverse
synaptic weighting. Validating and characterizing these observations for
other nonlinearities (such as an exponential nonlinearity or a squared rec-
tified linear unit) and within the framework of a linear-nonlinear-Poisson
cascade model will be interesting to pursue in future studies. 考试用-
普莱, we performed a simple experiment numerically assessing the behavior
of the linear Fisher information under an exponential nonlinearity. We ob-
served that synaptic weight heterogeneity benefits coding, but information
may saturate for a wide range of kw (see appendix A.3). 因此, the choice of
nonlinearity may affect the coding performance in the presence of common
噪音.
在这项工作中, we considered the coding ability of a network in which
a stimulus is corrupted by a single common noise source. 然而, 科尔-
tical circuits receive many inputs and must likely contend with multiple
common noise inputs. 因此, it is important to examine how our analysis
changes as the number of inputs increases. Naively, the neural circuit could
structure weights to collapse all common noise sources on a single sub-
空间, but this strategy will fail if the circuit must perform multiple tasks
(例如, the circuit may be required to decode among many of the inputs us-
ing the same set of weights). 此外, there are brain regions in which
the dimensionality is drastically reduced, such as cortex to striatum (10 到
1 reduction) or striatum to basal ganglia (300 到 1 reduction; Bar-Gad, Mor-
里斯, & 伯格曼, 2003; Seger, 2008). 在这些情况下, the number of inputs may
scale with the size of the neural circuit. In such an underconstrained sys-
TEM, linear decoding will be unable to properly extract estimates of the rel-
evant stimulus. This implies that linear Fisher information, which relies on a
linear decoder, may be insufficient to judge the coding fidelity of these
人口. 因此, future work could examine how the synaptic weight
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1262
磷. Sachdeva, J. Livezey, 和M. 德威斯
distribution affects neural coding with multiple common noise inputs. 这
includes the case when the number of common noise sources is smaller than
the population size or when they are of similar scale, 后者
may require alternative coding strategies (Davenport, Duarte, Eldar, & 到-
tyniok, 2012; Garfinkle & Hillar, 2019).
It may seem unreasonable that the neural circuit possesses the ability to
weight common noise inputs. 然而, excitatory neurons receive many
excitatory synapses in circuits throughout the brain. Some subset of com-
mon inputs across a neural population will undoubtedly be irrelevant for
the underlying neural computation, even if these signals are not strictly
speaking “noise” and could be useful for other computations. 因此, 这些
populations must contend with common noise sources contributing to their
overall shared variability and potentially hampering their ability to encode
a stimulus. Our work demonstrates that neural circuits, armed with a good
set of synaptic weights, need not suffer adverse impacts due to inadver-
tently amplifying potential sources of common noise. 反而, broad, het-
erogeneous weighting ensures that common noise sources will project the
signal and noise into a high-dimensional space in such a way that is bene-
ficial for decoding. This observation is in agreement with recent work that
explored the relationship between heterogeneous weighting and degrees
of synaptic connectivity (Litwin-Kumar, 哈里斯, Axel, Sompolinsky, & Ab-
bott, 2017). 此外, synaptic input, irrelevant on one trial, may be-
come the signal on the next: heterogeneous weighting provides a general,
robust principle for neural circuits to follow.
We chose the simple network architecture in order to maintain analytic
易处理性, which allowed us to explore the rich patterns of behavior it
exhibited. Our model is limited, 然而. It is worthwhile to assess how
our qualitative conclusions hold with added complexity in the network.
例如, interesting avenues to consider include the implementation
of recurrence, spiking dynamics, and global fluctuations. 此外, 这些
networks could also be equipped with varying degrees of sparsity and in-
hibitory connections. 重要的, the balance of excitation and inhibition in
networks has been shown to be vital in decorrelating neural activity (Renart
等人。, 2010). Past work has explored how to approximate both information-
theoretic quantities studied here in networks with some subset of these fea-
特雷斯 (贝克, Bejjanki, & 假发, 2011; Yarrow, Challis, & Seriès, 2012). 因此,
analyzing how common noise and synaptic weighting interact in more com-
plex networks is of interest for future work.
We established correlated variability structure in the linear-nonlinear
network by taking a linear combination of a common noise source and pri-
vate noise sources (though our model ignores any noise potentially carried
by the stimulus). This was sufficient to establish low-dimensional shared
variability observed in neural circuits. 作为结果, our model as de-
vised enforces stimulus-independent correlated variability. Recent work,
然而, has demonstrated that correlated variability is in fact stimulus
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1263
dependent. Such work used both phenomenological (林, Okun, Carandini,
& 哈里斯, 2015; Franke et al., 2016) and mechanistic (Zylberberg et al., 2016)
models in producing fits to the stimulus-dependent correlated variability.
These models all share a doubly stochastic noise structure, stemming from
both additive and multiplicative sources of noise (Goris, Movshon, & 和-
猴子, 2014). It is therefore worthwhile to fully examine how both ad-
ditive and multiplicative modulation interact with synaptic weighting to
influence neural coding. 例如, Arandia-Romero et al. (2016) demon-
strated that such additive and multiplicative modulation, modulated by
overall population activity, can redirect information to specific neuronal
assemblies, increasing information for some but decreasing it for others.
Synaptic weight heterogeneity, attuned by plasticity, could serve as a mech-
anism for additive and multiplicative modulation, thereby gating informa-
tion for specific assemblies.
A Appendix
A.1 Calculation of Fisher and Mutual Information Quantities.
A.1.1 Calculation of Fisher Information, Linear Stage. All variability after
the linear stage is gaussian; 因此, the Fisher information can be expressed
作为 (雅培 & 戴安, 1999; 凯, 1993)
(西德:6)
如果 (s) = f
(西德:6)
(s)时间 (西德:4)−1(s)F
(西德:15)
(s) + 1
2
tr
(西德:4)(西德:6)
(s)(西德:4)−1(s)(西德:4)(西德:6)
(西德:16)
(s)(西德:4)−1(s)
.
(A.1)
Our immediate goal is to calculate f(s), the average response of the linear
阶段, 和 (西德:4), the covariance between the responses. The output of the ith
neuron after the linear stage is
(西德:3)
我
= v
是 + w
我
一个
C
h
C
+ σPξ
磷,我
,
so that the average response as a function of s is
fi(s) = (西德:9)(西德:3)
我
(西德:10) = v
是.
(西德:6)
F(s) = vs ⇒ f
(s) = v,
因此,
和
(西德:9)(西德:3)
我
(西德:3)
j
(西德:10) = (西德:9)(v
= v
v
我
是 + w
我
js2 + w
一个
C
h
C
w
我
j
+ σPξ
+ 一个 2
一个 2
磷
C
磷,我)(v
,
d
我j
js + w
一个
C
h
C
j
+ σPξ
磷, j )(西德:10)
(A2)
(A.3)
(A.4)
(A.5)
(A.6)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1264
so that
(西德:9)
我j
= (西德:9)(西德:3)
我
(西德:3)
(西德:10) - (西德:9)(西德:3)
我
j
(西德:10)(西德:9)(西德:3)
(西德:10)
j
= m 2
磷
d
我j
+ w
w
我
一个 2
C
j
⇒ (西德:4) = m 2
p i + 一个 2
C wwT .
磷. Sachdeva, J. Livezey, 和M. 德威斯
(A.7)
(A.8)
(A.9)
Notice that the covariance matrix does not depend on s, so the second term
in equation A.1 will vanish. 我们做, 然而, need the inverse covariance
matrix for the first term:
(西德:4)−1 = 1
一个 2
磷
(西德:18)
I −
一个 2
C
+ 一个 2
C
一个 2
磷
|w|2
(西德:19)
wwT
.
因此, the Fisher information is
(西德:18)
vT
I −
(西德:14)
(西德:13)
一个 2
磷
/一个 2
C
如果 (s) = 1
一个 2
磷
= 1
一个 2
磷
(西德:19)
v
|w|2
wwT
一个 2
C
+ 一个 2
C
(西德:13)
|v|2|w|2 - (v · w)2
C ) + |w|2
一个 2
磷
|v|2 +
(一个 2
磷
/一个 2
(A.10)
(A.11)
(A.12)
(西德:14)
.
A.1.2 Calculation of Mutual Information, Linear Stage. The mutual infor-
mation is given by
(西德:2)
我[s, (西德:3)] =
d(西德:3)dsP[s]磷[(西德:3)|s] 日志
(西德:2)
(西德:2)
磷[(西德:3)|s]
磷[(西德:3)]
= h[(西德:3)] +
dsP[s]
d(西德:3)磷[(西德:3)|s] 日志p[(西德:3)|s].
(A.13)
(A.14)
Note that P[(西德:3)] 和P[(西德:3)|s] are both multivariate gaussians. 这 (differential)
entropy of a multivariate gaussian random variable X with mean μ and
covariance (西德:4) 由
H[X] = 1
2
日志 (这 (西德:4)) + 氮
2
(1 + 日志(2圆周率 )).
(A.15)
所以, by the gaussianity of the involved distributions,
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
磷[(西德:3)|s] =
(西德:20)
1
σ N−1
磷
(2圆周率 )氮(一个 2
磷
(西德:21)
+ 一个 2
C
|w|2)
(西德:18)
× exp
- 1
2一个 2
磷
((西德:3) − vs)时间
I −
(西德:19)
(西德:22)
((西德:3) − vs)
(A.16)
一个 2
CwwT
+ 一个 2
C
|w|2
一个 2
磷
Heterogeneous Synaptic Weighting under Common Noise
1265
磷[(西德:3)] =
(西德:20)
1
(2圆周率 )Nσ 2N−4
磷
k
(西德:23)
- 1
2
(西德:13)
(西德:3)时间
经验值
一个 2
p i + 一个 2
S vvT + 一个 2
C wwT
在哪里
k = (一个 2
磷
+ 一个 2
C
|w|2)(一个 2
磷
+ 一个 2
S
|v|2) -s 2
C
S (v · w)2.
一个 2
因此,
H[(西德:3)] = 1
2
(西德:13)
日志
σ 2N−4
磷
k
(西德:14)
+ 氮
2
(1 + 日志(2圆周率 ))
(西德:14)−1 (西德:3)
(西德:24)
,
(A.17)
(A.18)
(A.19)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
和
(西德:2)
d(西德:3)磷[(西德:3)|s] 日志p[(西德:3)|s] = - 1
2
− N
2
日志(σ 2N−2
磷
(一个 2
磷
+ 一个 2
C
|w|2))
(1 + 日志(2圆周率 )),
(A.20)
which is notably independent of s. 因此, the integral over s will marginalize
away. We are left with
(西德:18)
(西德:19)
我[s, (西德:3)] = 1
2
日志
(西德:13)
日志
= 1
2
磷
k
+ 一个 2
C
(西德:14)
S IF (s)
磷 (一个 2
一个 2
1 + 一个 2
|w|2)
.
(A.21)
(A.22)
A.1.3 Calculation of Linear Fisher Information, Quadratic Nonlinearity. 我们
repeat the calculation of the first section, but after the nonlinear stage. 在
这个案例, we consider a quadratic nonlinearity. Instead of the Fisher infor-
运动, we calculate the linear Fisher information (since it is analytically
tractable). The output of the network is
RI
= (v
= v 2
是 + w
我
i s2 + w2
+ σPξ
一个
h
C
C
+ 一个 2
h 2
一个 2
磷
C
C
我
磷,我)2
h 2
磷,我
+ 2sv
w
一个
C
h
C
我
我
+ 2sv
σPξ
我
磷,我
+ 2w
一个
C
σPξ
C
我
h
磷,我
.
(A.23)
因此, the average is then
fi(s) = (西德:9)RI
(西德:10) = v 2
i s2 + w2
我
一个 2
C
+ 一个 2
磷
,
(A.24)
(A.25)
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1266
磷. Sachdeva, J. Livezey, 和M. 德威斯
这意味着
(西德:9)RI
(西德:10)(西德:9)r j
(西德:10) = (v 2
i s2 + w2
我
+ s2σ 2
+ 一个 2
一个 2
C
+ v 2
= m 4
磷
我
磷 (v 2
w2
j
我
+ s2σ 2
C (v 2
+ v 2
j
j
磷 )(v 2
j ) + 一个 2
我 ) + s4v 2
w2
j s2 + w2
C (w2
一个 2
v 2
j
磷
我
我
一个 2
C
+ 一个 2
磷 )
+ w2
j )
+ 一个 4
C
w2
我
w2
j
.
下一个, the covariate can be written as
(西德:9)rir j
(西德:10) = m 4
磷
+ s2σ 2
+ v 2
磷 (v 2
我
+ 3一个 4
C
磷
j ) + 一个 2
w2
j
C (w2
一个 2
v
+ 4s2σ 2
C
我
w2
我
+ w2
v
我
j
w
我
C (v 2
我
j ) + s2σ 2
.
w
j
+ s4v 2
我
v 2
j
The off-diagonal terms of the covariance matrix are then
(西德:9)rir j
(西德:10) - (西德:9)RI
(西德:10)(西德:9)r j
(西德:10) = 2σ 4
C
w2
我
w2
j
+ 4s2σ 2
C
v
我
v
j
w
我
w
.
j
(A.26)
(A.27)
w2
j
+ v 2
j
w2
我 )
(A.28)
(A.29)
最后, the variance of ri (the diagonal terms of the covariance matrix) 是
给出的
我们的(RI) = (西德:9)R2
我
= 3σ 4
磷
(西德:13)
(西德:10)2
(西德:10) - (西德:9)RI
+ 6s2σ 2
磷
v 2
我
+ 6一个 2
磷
一个 2
C
(西德:14)
2
w2
我
+ 6s2σ 2
C
v 2
我
w2
我
+ s4v 4
我
+ 3一个 4
C
w4
我
(A.30)
-
i s2 + w2
v 2
w4
我
一个 2
我
C
+ 4s2σ 2
C
+ 一个 2
磷
+ 2一个 4
磷
w2
我
v 2
我
= 2σ 4
C
+ 4s2σ 2
磷
v 2
我
+ 4一个 2
磷
一个 2
C
w2
我
.
(A.31)
(A.32)
因此, the total covariance, which takes the variance into consideration, 是
(西德:9)
我j
= d
我j
(西德:13)
2一个 4
磷
+ 4一个 2
磷 (s2v 2
我
(西德:14)
w2
我 )
+ 一个 2
C
+ 4s2σ 2
C
v
我
v
j
w
我
w
j
+ 2一个 4
C
w2
我
w2
j
.
(A.33)
In vector notation, this can be expressed as
(西德:4) = 2σ 4
p i + 4一个 2
P s2diag(V) + 4一个 2
磷
C diag(瓦) + 4s2σ 2
一个 2
C XXT + 2一个 4
CWWT ,
在哪里
V = v (西德:12) v,
W = w (西德:12) w,
X = v (西德:12) w,
(A.34)
(A.35)
(A.36)
(A.37)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1267
在哪里 (西德:12) indicates the Hadamard product (element-wise product). We now
proceed to the linear Fisher information:
(西德:6)
ILFI(s) = f
(s)时间 (西德:4)(s)
(西德:6)
−1f
(s).
(A.38)
We start by calculating the inverse covariance matrix, which we will achieve
with repeated applications of the Sherman-Morrison formula (谢尔曼 &
莫里森, 1950). We can write
(西德:4)−1 = (中号 + 2一个 4
−1
C WWT )
−1 − M−1(2一个 4
1 + 2一个 4
= 米
CWWT )M−1
CWT M−1W
2一个 4
C
C WT M−1W
= 米
−1 −
1 + 2一个 4
−1WWT M
−1,
中号
在哪里
−1 ≡
中号
(西德:13)
2一个 4
磷
-
+ 4一个 2
P s2v 2
我
一个 4
磷
+ 2s2σ 2
C
一个 2
磷
(西德:14)−1 δ
我j
w2
我
+ 4一个 2
一个 2
磷
C
s2σ 2
C
(西德:17)
我
v 2
我
+ 2s2v 2
我
w
w
j
(西德:14) (西德:25)
j
我
一个 2
磷
一个 2
磷
v
v
我
w2
我
w2
我
+ 2一个 2
C
w2
我
+ 2s2v 2
我
+ 2一个 2
C
+ 2s2v 2
j
(西德:26) .
+ 2一个 2
C
w2
j
×
(西德:13)
一个 2
磷
注意
(西德:6)
F
(s) = 2sV,
so the Fisher information is
(西德:18)
ILFI(s) = 4s2
VT M
−1V −
2一个 4
C
C WT M−1W
1 + 2一个 4
(西德:18)
= 4s2
VT M
−1V −
2一个 4
C
C WT M−1W
1 + 2一个 4
VT M
−1WWT M
-1V
(西德:13)
VT M
−1W
(西德:14)
2
(西德:19)
.
(A.44)
(A.45)
To facilitate the matrix multiplications, we will define the following nota-
的:
{v, w}
=
米,n
(西德:17)
一个 2
磷
我
v m
我
+ 2s2v 2
我
wn
我
+ 2一个 2
C
.
w2
我
(A.46)
(A.39)
(A.40)
(A.41)
(A.42)
(A.43)
(西德:19)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1268
因此,
磷. Sachdeva, J. Livezey, 和M. 德威斯
VT M
−1V = 1
2一个 2
磷
(西德:17)
一个 2
磷
我
v 4
我
+ 2s2v 2
我
w2
我
+ 2一个 2
C
(西德:18)
(西德:17)
-
s2σ 2
C
一个 2
磷
+ 2s2σ 2
C
一个 4
磷
{v, w}
2,2
一个 2
磷
我
(西德:19)
2
w
v 3
我
我
+ 2一个 2
+ 2s2v 2
C
我
w2
我
(A.47)
= 1
2一个 2
磷
{v, w}
4,0
-
s2σ 2
C
一个 2
磷
+ 2s2σ 2
C
一个 4
磷
{v, w}
2,2
{v, w}2
3,1
.
(A.48)
此外,
WT M
−1W = 1
2一个 2
磷
{v, w}
0,4
-
s2σ 2
C
一个 2
磷
+ 2s2σ 2
C
一个 4
磷
{v, w}
2,2
{v, w}2
1,3
(A.49)
和, 最后,
VT M
−1W = 1
2一个 2
磷
{v, w}
2,2
-
s2σ 2
C
一个 2
磷
+ 2s2σ 2
C
一个 4
磷
{v, w}
2,2
{v, w}
1,3
{v, w}
.
3,1
(A.50)
Inserting this expression into equation A.45 and simplifying, 我们可以写
the Fisher information as
ILFI(s) = 4s2
(西德:25)
1
一个 2
磷
{v, w}
4,0
-
2s2σ 2
C
{v,w}
一个 2
C
+2s2σ 2
磷
一个 2
磷
2,2
{v, w}2
3,1
+
一个 4
磷
+一个 2
磷 (一个 4
C
一个 2
一个 4
磷
C
{v,w}
{v,w}
2,2
+2s2σ 2
C
+2s2σ 6
{v,w}
C ({v,w}
2,2 )+2s2σ 6
-2{v,w}
C ({v,w}
2,2
1,3
0,4
0,4
{v,w}
{v,w}
3,1 )
2,2
-2{v,w}2
1,3 )
(西德:26)
. (A.51)
A.2 Information Saturation and Differential Correlations. 在节中
3.2.1, we observed that the Fisher information saturates in particular in-
stances of the nonlinear network. 具体来说, for the nonlinear network,
Fisher information saturates for kw = 1 and kw = 2, but not for kw > 3. Ad-
ditionally, Fisher information saturates for kw ∼ O(氮). To understand why
we observe saturation in some cases and not others, it is helpful to exam-
ine the eigenspectrum of the covariance matrix (西德:4) describing the neural re-
响应. 这里, we rely on an analysis in the supplement of Moreno-Bote
等人. (2014).
The linear Fisher information can be written in terms of the eigenspec-
trum of (西德:4) 作为
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1269
ILFI = f
(西德:6)时间 (西德:4)−1f
(西德:6)
(西德:17)
= f
(西德:6)
(西德:6)T f
k
cos2 θ
一个 2
k
k
,
(A.52)
(A.53)
k is the kth eigenvalue and θ
其中σ 2
k is the angle between the kth eigenvec-
tor and f(西德:6). We consider the cases in which ILFI saturates with the population
尺寸n. 第一的, note that the squared norm of the tuning curve derivative f(西德:6)T f(西德:6)
will scale as O(氮), since there are N terms in the sum. This implies that the
summation must shrink at least as fast as O(1/氮) for information to satu-
速度. This implies that any eigenvalues scaling as O(1) must have their cor-
responding cosineangles shrink faster than O(1/氮). If there are O(氮) 这样的
eigenvalues, they must shrink faster than O(1/N2).
In the case of kw = 1, one eigenvalue grows as O(氮) while the others
remain constant (see Figure 10a, 左边). 同时, the cosine-angles of the
constant eigenvalues are effectively zero. This case is the easiest to under-
站立: the principal eigenvector aligns with f(西德:6) while all other directions are
effectively orthogonal to f(西德:6). For kw ≥ 1, 然而, two eigenvalues grow as
氧(氮) while the others grow as O(1) (see Figure 10a, middle and right). 在
这个案例, the behavior of the cosine-angles corresponding to the constant
growth eigenvalues varies depending on kw.
As in Moreno-Bote et al. (2014) we split up equation A.53 into two
团体: those with eigenvalues that scale as O(氮), denoted by the set SN,
and those that scale as O(1), denoted by the set S1:
ILFI = f
(西德:6)T f
(西德:17)
m∈SN
cos2 θm
一个 2
米
+ F
(西德:6)
(西德:6)T f
(西德:17)
n∈S1
cos2 θn
一个 2
n
.
(A.54)
The left sum contains one term when kw = 1 and two terms when kw > 1.
Information saturation is dictated by the right sum, which we call Rkw :
=
Rkw
(西德:17)
n∈S1
cos2 θn
一个 2
n
.
(A.55)
The addends of Rkw correspond to the O(1) eigenvalues, whose eigenvec-
tors must have cosine-angles that vanish more quickly than O(1/氮) 自从
there are O(氮) such eigenvalues. 正如预期的那样, for kw = 1, R1 quickly van-
ishes (see Figure 10a: gray line). We observe similar behavior for kw = 2:
the summation R2 eventually vanishes as well (see Figure 10b: 红线).
然而, for kw > 2, this no longer occurs: the cosine-angles scale to zero
slowly enough that R3 approaches a constant value (thereby preventing in-
formation saturation). 因此, going to larger kw ensures that the majority of
the eigenvectors of (西德:4) do not become orthogonal to f(西德:6)
quickly enough for
information saturation to occur.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1270
磷. Sachdeva, J. Livezey, 和M. 德威斯
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
数字 10: Characterizing the scaling of the eigenvalues and the shrinking of
the cosine-angles for the nonlinear stage covariance. (A) Behavior of the largest
3 for the cases of kw = 1, 2, 3. The aspect ratio is
three eigenvalues σ 2
chosen so that unit steps on each axis appear of equal length. (乙) The behavior
of cosine-angle sum Ri corresponding to the constant-growth eigenvalues, 为了
each of kw = 1, 2, 3. The inset depicts the same curves, but on a log-log scale.
2 , and σ 2
1 , 一个 2
In the case of kw ∼ O(氮), 然而, the behavior of the covariance matrix
is different. Recall that the covariance matrix takes on the form
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
(西德:4) = 2σ 4
p i + 4一个 2
P s2diag(V) + 4一个 2
磷
Cdiag(瓦) + 4s2σ 2
一个 2
C XXT + 2一个 4
CWWT .
(A.56)
The dominant contribution to the covariance matrix is 2σ 4
scaling of the trace of (西德:4) 是
C WWT . 因此, 这
Heterogeneous Synaptic Weighting under Common Noise
1271
tr[(西德:4)] ∼ Tr[WWT ] = tr[(w (西德:12) w)(w (西德:12) w)时间 ].
= (w (西德:12) w)时间 (w (西德:12) w)
氮(西德:17)
(西德:14)
(西德:13)
i2
~
我=1
2 ∼ O(N5).
(A.57)
(A.58)
(A.59)
Since the trace of the covariance matrix is equal to the sum of the eigen-
价值观, some subset of the eigenvalues can scale as O(N5) 还有. 实际上,
all eigenvalues scale at least as O(氮), with the largest eigenvalue scaling as
氧(N5). 在这种情况下, the Fisher information must saturate because the
cosine-angle can at most scale to a constant. In plainer terms, the variances
of the covariance matrix scale so quickly that the differential correlation
direction is irrelevant. We interpret this behavior as the neurons simply ex-
hibiting too much variance for any meaningful decoding to occur. 笔记,
然而, that the saturation can be avoided if the behavior of f(西德:6)
, 我们
assumed scales as O(氮), instead scales more quickly. This can occur, 为了
例子, when kv ∼ O(氮). 然而, it is unreasonable to expect that the
synaptic weights of a neural circuit scale with the population size, 制作
this scenario biologically implausible.
A.3 Linear Fisher Information under an Exponential Nonlinearity.
The application of an exponential nonlinearity to the output of the linear
stage gi((西德:3)
我) implies that the output of the network r = g((西德:3)) 如下
a multivariate log-normal distribution (since the linear stage is gaussian).
The linear stage is described by the distribution
我) = exp((西德:3)
(西德:3) ∼ N (m, (西德:4)L),
μ = vs,
(西德:4)L = σ 2
p i + 一个 2
C wwT .
(A.60)
(A.61)
(A.62)
The multivariate log-normal distribution has first- 和二阶统计-
tics given by
(西德:23)
乙 [r]我
= exp
m
我
(西德:24)
(西德:9)L
二
,
+ 1
2
(西德:23)
(西德:16)
(西德:15)
ri j
我们的
= exp
m
我
+ m
j
+ 1
2
(西德:25)
(西德:26)(西德:24) (西德:25)
(西德:26)
(西德:9)L
二
+ (西德:9)L
j j
经验值((西德:9)L
我j ) - 1
.
(A.64)
(A.63)
因此, the mean activity and its derivative with respect to s are given by
fi(s) = exp
(西德:23)
1
2
+ v
一个 2
磷
是 + 1
2
(西德:24)
一个 2
C
w2
我
,
(A.65)
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1272
磷. Sachdeva, J. Livezey, 和M. 德威斯
数字 11: The behavior of linear Fisher information for an exponential non-
linearity as a function of population size. Colors denote different choices of kw.
Inset shows the same plot but on a regular scale.
(西德:6)
我 (s) = v
F
i exp
(西德:23)
1
2
+ v
一个 2
磷
是 + 1
2
(西德:24)
一个 2
C
w2
我
.
(A.66)
These equations provide us the tools to calculate the linear Fisher infor-
运动. The inversion of the covariance matrix (see equation A.64) 不是
tractable, but we can proceed numerically.
We calculated the linear Fisher information numerically under the same
conditions as in Figure 4a, but with kw = 1, . . . , 5 and for a wider range
of population sizes. 图中 11, we plot the linear Fisher information as
a function of N for these choices of kw. We observe that for large enough
氮, synaptic weight heterogeneity results in improved coding performance.
然而, we also observe what appears to be saturation of the Fisher infor-
运动. Since we cannot write the Fisher information as a function of N, 我们
cannot validate this observation analytically. This does, 然而, 建议
that the choice of nonlinearity can have a dramatic impact on the behavior
of the linear Fisher information.
致谢
We thank Ruben Coen-Cagli for useful discussions. P.S.S. was supported
by the Department of Defense through the National Defense Science and
Engineering Graduate Fellowship Program. J.A.L. was supported through
the Lawrence Berkeley National Laboratory-internal LDRD “Deep Learn-
ing for Science” led by Prabhat. M.R.D. was supported in part by the U.S.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1273
Army Research Laboratory and the U.S. Army Research Office under Con-
tract No. W911NF-13-1-0390.
参考
雅培, L. F。, & 戴安, 磷. (1999). The effect of correlated variability on the accuracy
of a population code. 神经计算, 11(1), 91–101.
Adelson, 乙. H。, & 卑尔根, J. 右. (1985). Spatiotemporal energy models for the
perception of motion. Journal of the Optical Society of America A, 2(2), 284–
299.
Arandia-Romero, 我。, Tanabe, S。, Drugowitsch, J。, Kohn, A。, & Moreno-Bote, 右. (2016).
Multiplicative and additive modulation of neuronal tuning with population ac-
tivity affects encoded information. 神经元, 89(6), 1305–1316.
Arieli, A。, Sterkin, A。, Grinvald, A。, & 艾尔森, A. (1996). Dynamics of ongoing ac-
活力: Explanation of the large variability in evoked cortical responses. 科学,
273(5283), 1868–1871.
Attneave, F. (1954). Some informational aspects of visual perception. 心理
审查, 61(3), 183.
Averbeck, 乙. B., 莱瑟姆, 磷. E., & 假发, A. (2006). Neural correlations, 人口
coding and computation. 自然评论神经科学, 7(5), 358.
Averbeck, 乙. B., & 李, D. (2006). Effects of noise correlations on information encod-
ing and decoding. 神经生理学杂志, 95(6), 3633–3644.
Bar-Gad, 我。, 莫里斯, G。, & 伯格曼, H. (2003). Information processing, 尺寸-
ity reduction and reinforcement learning in the basal ganglia. Progress in Neuro-
生物学, 71(6), 439–473.
巴洛, H. 乙. (1961). Possible principles underlying the transformation of sensory
消息. Sensory Communication, 1, 217–234.
贝克, J。, Bejjanki, V. R。, & 假发, A. (2011). Insights from a simple expression for lin-
ear Fisher information in a recurrently connected population of spiking neurons.
神经计算, 23(6), 1484–1502.
贝克, J. M。, 马, 瓦. J。, 皮特科, X。, 莱瑟姆, 磷. E., & 假发, A. (2012). 不吵, 只是
错误的: 次级推断在行为变异性中的作用. 神经元, 74(1),
30–39.
钟, A. J。, & Sejnian, 时间. J. (1997). The “independent components” of natural scenes
are edge filters. 视觉研究, 37(23), 3327–3338.
Brinkman, 乙. A。, 韦伯, A. 我。, 河, F。, & 牛乳棕色, 乙. (2016). How do efficient
coding strategies depend on origins of noise in neural circuits? PLOS Computa-
tional Biology, 12(10), e1005150.
布鲁内尔, N。, & Nadal, J.-P. (1998). Mutual information, Fisher information, and pop-
ulation coding. 神经计算, 10(7), 1731–1757.
Cafaro, J。, & 河, F. (2010). Noise correlations improve response fidelity and stim-
ulus encoding. 自然, 468(7326), 964.
科恩, 中号. R。, & Kohn, A. (2011). Measuring and interpreting neuronal correlations.
自然神经科学, 14(7), 811.
科恩, 中号. R。, & Maunsell, J. H. (2009). Attention improves performance primarily
by reducing interneuronal correlations. 自然神经科学, 12(12), 1594.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
/
e
d
你
n
e
C
哦
A
r
t
我
C
e
–
p
d
/
我
F
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
C
哦
_
A
_
0
1
2
8
7
p
d
.
/
F
乙
y
G
你
e
s
t
t
哦
n
0
7
S
e
p
e
米
乙
e
r
2
0
2
3
1274
磷. Sachdeva, J. Livezey, 和M. 德威斯
覆盖, 时间. M。, & 托马斯, J. A. (2012). Elements of information theory. 霍博肯, 新泽西州:
威利.
Davenport, 中号. A。, Duarte, 中号. F。, Eldar, 是. C。, & Kutyniok, G. (2012). Introduction to
compressed sensing. 在y. Eldar& G. Kutyniok (编辑。), Compressed sensing: 理论
and applications (PP. 1–64). 剑桥: 剑桥大学出版社.
Deweese, 中号. R。, & Zador, A. 中号. (2004). Shared and private variability in the auditory
皮质. 神经生理学杂志, 92(3), 1840–1855.
Ecker, A. S。, Berens, P。, Tolias, A. S。, & Bethge, 中号. (2011). The effect of noise corre-
lations in populations of diversely tuned neurons. 神经科学杂志, 31(40),
14272–14283.
艾默生, 右. C。, Korenberg, 中号. J。, & Citron, 中号. C. (1992). Identification of complex-
cell intensive nonlinearities in a cascade model of cat visual cortex. Biological Cy-
bernetics, 66(4), 291–300.
faisal, A. A。, 马具, L. P。, & Wolpert, D. 中号. (2008). 神经系统中的噪音. 自然
评论 神经科学, 9(4), 292.
弗兰克, F。, Fiscella, M。, Sevelev, M。, Roska, B., Hierlemann, A。, & da Silveira, 右. A.
(2016). Structures of neural correlation and how they favor coding. 神经元, 89(2),
409–422.
高, S。, Ver Steeg, G。, & Galstyan, A. (2015). Efficient estimation of mutual informa-
tion for strongly dependent variables. In Proceedings of the Eighteenth International
Conference onArtificial Intelligence and Statistics (PP. 277–286).
Garfinkle, C. J。, & <, C. J., (2019). On the uniqueness and stability of dictionaries
for sparse representation of noisy signals. IEEE Transactions on Signal Processing,
67(23), 5884–5892.
Goris, R. L., Movshon, J. A., & Simoncelli, E. P. (2014). Partitioning neuronal vari-
ability. Nature Neuroscience, 17(6), 858.
Hu, Y., Zylberberg, J., & Shea-Brown, E. (2014). The sign rule and beyond: Bound-
ary effects, flexibility, and noise correlations in neural population codes. PLOS
Computational Biology, 10(2), e1003469.
Iyer, R., Menon, V., Buice, M., Koch, C., & Mihalas, S. (2013). The influence of synap-
tic weight distribution on neuronal population dynamics. PLOS Computational
Biology, 9(10), e1003248.
Kafashan, M., Jaffe, A., Chettih, S. N., Nogueira, R., Arandia-Romero, I., Harvey, C.
D., Drugowitsch, J. (2020). Scaling of information in large neural populations reveals
signatures of information-limiting correlations. bioRxiv:2020.01.10.90217.
Kanerva, P. (2009). Hyperdimensional computing: An introduction to computing
in distributed representation with high-dimensional random vectors. Cognitive
Computation, 1(2), 139–159.
Kanitscheider, I., Coen-Cagli, R., & Pouget, A. (2015). Origin of information-limiting
noise correlations. Proceedings of the National Academy of Sciences, 112(50), E6973–
E6982.
Karklin, Y., & Simoncelli, E. P. (2011). Efficient coding of natural images with a pop-
ulation of noisy linear-nonlinear neurons. In J. Shawe-Taylor, R. S. Zemel, P. L.
Bartlett, F. Pereira, & K. Q. Weinberger (Eds.), Advances in neural information pro-
cessing systems, 24 (pp. 999–1007). Red Hook, NY: Curran.
Kay, S. M. (1993). Fundamentals of statistical signal processing. Upper Saddle River, NJ:
Prentice Hall.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
c
o
_
a
_
0
1
2
8
7
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Heterogeneous Synaptic Weighting under Common Noise
1275
Kohn, A., Coen-Cagli, R., Kanitscheider, I., & Pouget, A. (2016). Correlations and
neuronal population information. Annual Review of Neuroscience, 39, 237–256.
Kraskov, A., Stögbauer, H., & Grassberger, P. (2004). Estimating mutual information.
Physical Review E, 69(6), 066138.
Kulkarni, J. E., & Paninski, L. (2007). Common-input models for multiple neural
spike-train data. Network: Computation in Neural Systems, 18(4), 375–407.
Lin, I.-C., Okun, M., Carandini, M., & Harris, K. D. (2015). The nature of shared cor-
tical variability. Neuron, 87(3), 644–656.
Litwin-Kumar, A., Harris, K. D., Axel, R., Sompolinsky, H., & Abbott, L. (2017). Op-
timal degrees of synaptic connectivity. Neuron, 93(5), 1153–1164.
Ma, W. J., Beck, J. M., Latham, P. E., & Pouget, A. (2006). Bayesian inference with
probabilistic population codes. Nature Neuroscience, 9(11), 1432.
Montijn, J. S., Liu, R. G., Aschner, A., Kohn, A., Latham, P. E., & Pouget, A. (2019).
Strong information-limiting correlations in early visual areas. bioRxiv:842724.
Montijn, J. S., Meijer, G. T., Lansink, C. S., & Pennartz, C. M. (2016). Population-level
neural codes are robust to single-neuron variability from a multidimensional cod-
ing perspective. Cell Reports, 16(9), 2486–2498.
Moreno-Bote, R., Beck, J., Kanitscheider, I., Pitkow, X., Latham, P., & Pouget, A.
(2014). Information-limiting correlations. Nature Neuroscience, 17(10), 1410.
Nogueira, R., Peltier, N. E., Anzai, A., DeAngelis, G. C., Martínez-Trujillo, J., &
Moreno-Bote, R. (2020). The effects of population tuning and trial-by-trial vari-
ability on information encoding and behavior. Journal of Neuroscience, 40(5), 1066–
1083.
Pagan, M., Simoncelli, E. P., & Rust, N. C. (2016). Neural quadratic discriminant anal-
ysis: Nonlinear decoding with V1-like computation. Neural Computation, 28(11),
2291–2319.
Paninski, L. (2004). Maximum likelihood estimation of cascade point-process neural
encoding models. Network: Computation in Neural Systems, 15(4), 243–262.
Pillow, J. W., Paninski, L., Uzzell, V. J., Simoncelli, E. P., & Chichilnisky, E. (2005).
Prediction and decoding of retinal ganglion cell responses with a probabilistic
spiking model. Journal of Neuroscience, 25(47), 11003–11013.
Renart, A., De La Rocha, J., Bartho, P., Hollender, L., Parga, N., Reyes, A., & Harris, K.
D. (2010). The asynchronous state in cortical circuits. Science, 327(5965), 587–590.
Rieke, F., Warland, D., de Ruyter van Steveninck, R., & Bialek, W. S. (1999). Spikes:
Exploring the neural code. Cambridge, MA: MIT Press.
Sakai, K., & Tanaka, S. (2000). Spatial pooling in the second-order spatial structure
of cortical complex cells. Vision Research, 40(7), 855–871.
Sargent, P. B., Saviane, C., Nielsen, T. A., DiGregorio, D. A., & Silver, R. A. (2005).
Rapid vesicular release, quantal variability, and spillover contribute to the pre-
cision and reliability of transmission at a glomerular synapse. Journal of Neuro-
science, 25(36), 8173–8187.
Seger, C. A. (2008). How do the basal ganglia contribute to categorization? Their roles
in generalization, response selection, and learning via feedback. Neuroscience and
Biobehavioral Reviews, 32(2), 265–278.
Shadlen, M. N., & Newsome, W. T. (1998). The variable discharge of cortical neu-
rons: Implications for connectivity, computation, and information coding. Journal
of Neuroscience, 18(10), 3870–3896.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
c
o
_
a
_
0
1
2
8
7
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1276
P. Sachdeva, J. Livezey, and M. DeWeese
Shamir, M., & Sompolinsky, H. (2006). Implications of neuronal diversity on popu-
lation coding. Neural Computation, 18(8), 1951–1986.
Sherman, J., & Morrison, W. J. (1950). Adjustment of an inverse matrix corresponding
to a change in one element of a given matrix. Annals of Mathematical Statistics,
21(1), 124–127.
Sompolinsky, H., Yoon, H., Kang, K., & Shamir, M. (2001). Population coding in neu-
ronal systems with correlated noise. Physical Review E, 64(5), 051904.
Song, S., Sjöström, P. J., Reigl, M., Nelson, S., & Chklovskii, D. B. (2005). Highly non-
random features of synaptic connectivity in local cortical circuits. PLOS Biology,
3(3), e68.
Vidne, M., Ahmadian, Y., Shlens, J., Pillow, J. W., Kulkarni, J., Litke, A. M., Paninski,
L. (2012). Modeling the impact of common noise inputs on the network activity
of retinal ganglion cells. Journal of Computational Neuroscience, 33(1), 97–121.
Wei, X.-X., & Stocker, A. A. (2016). Mutual information, Fisher information, and ef-
ficient coding. Neural Computation, 28(2), 305–326.
Wilke, S. D., & Eurich, C. W. (2002). Representational accuracy of stochastic neural
populations. Neural Computation, 14(1), 155–189.
Wu, S., Nakahara, H., & Amari, S.-I. (2001). Population coding with correlation and
an unfaithful model. Neural Computation, 13(4), 775–797.
Yarrow, S., Challis, E., & Seriès, P. (2012). Fisher and Shannon information in finite
neural populations. Neural Computation, 24(7), 1740–1780.
Yoon, H., & Sompolinsky, H. (1999). The effect of correlations on the Fisher informa-
tion of population codes. In M. J. Kearns, S. A. Solla, & D. A. Cohn (Eds.), Ad-
vances in neural information processing systems, 11 (pp. 167–173). Cambridge, MA:
MIT Press.
Zohary, E., Shadlen, M. N., & Newsome, W. T. (1994). Correlated neuronal discharge
rate and its implications for psychophysical performance. Nature, 370(6485), 140.
Zylberberg, J., Cafaro, J., Turner, M. H., Shea-Brown, E., & Rieke, F. (2016). Direction-
selective circuits shape noise to ensure a precise population code. Neuron, 89(2),
369–383.
Zylberberg, J., Pouget, A., Latham, P. E., & Shea-Brown, E. (2017). Robust informa-
tion propagation through noisy neural circuits. PLOS Computational Biology, 13(4),
e1005497.
Received September 25, 2019; accepted February 24, 2020.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
n
e
c
o
a
r
t
i
c
e
-
p
d
/
l
f
/
/
/
/
3
2
7
1
2
3
9
1
8
6
4
9
4
1
n
e
c
o
_
a
_
0
1
2
8
7
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3