A Systematic Study of Inner-Attention-Based
Sentence Representations in Multilingual
Neural Machine Translation
Raúl Vázquez
赫尔辛基大学
Department of Digital Humanities
raul.vazquez@helsinki.fi
Alessandro Raganato
赫尔辛基大学
Department of Digital Humanities
alessandro.raganato@helsinki.fi
Mathias Creutz
赫尔辛基大学
Department of Digital Humanities
mathias.creutz@helsinki.fi
Jörg Tiedemann
赫尔辛基大学
Department of Digital Humanities
jorg.tiedemann@helsinki.fi
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Neural machine translation has considerably improved the quality of automatic translations
by learning good representations of input sentences. 在本文中, we explore a multilingual
translation model capable of producing fixed-size sentence representations by incorporating an
intermediate crosslingual shared layer, which we refer to as attention bridge. This layer exploits
the semantics from each language and develops into a language-agnostic meaning representation
that can be efficiently used for transfer learning. We systematically study the impact of the size of
the attention bridge and the effect of including additional languages in the model. In contrast to
related previous work, we demonstrate that there is no conflict between translation performance
and the use of sentence representations in downstream tasks. 尤其, we show that larger
intermediate layers not only improve translation quality, especially for long sentences, 但是也
push the accuracy of trainable classification tasks. 尽管如此, shorter representations lead to
increased compression that is beneficial in non-trainable similarity tasks. 相似地, we show
that trainable downstream tasks benefit from multilingual models, whereas additional language
signals do not improve performance in non-trainable benchmarks. This is an important insight
提交材料已收到: 21 行进 2019; 收到修订版: 12 十一月 2019; 接受出版:
29 一月 2020.
https://doi.org/10.1162/COLI_a_00377
© 2020 计算语言学协会
根据知识共享署名-非商业性-禁止衍生品发布 4.0 国际的
(CC BY-NC-ND 4.0) 执照
计算语言学
体积 46, 数字 2
that helps to properly design models for specific applications. 最后, we also include an in-
depth analysis of the proposed attention bridge and its ability to encode linguistic properties.
We carefully analyze the information that is captured by individual attention heads and identify
interesting patterns that explain the performance of specific settings in linguistic probing tasks.
1. 介绍
Neural machine translation (NMT) has rapidly become the new machine translation
(公吨) 标准, significantly improving over the traditional statistical machine trans-
lation model (Bojar et al. 2018). In only about four years, several architectures and
approaches have been proposed, with increasing research efforts toward multilingual
machine translation (Firat et al. 2016; Lakew, Cettolo, and Federico 2018; Wang et al.
2018). Inasmuch as MT is described as the task of translating a sentence from one
language to another, at the recent conferences on MT (WMT18 and WMT19)1 much
interest was put on multilingualism, where a sub-track on multilingual systems was
introduced with the aim of exploiting a third language to improve a bilingual model.
Multilingual neural machine translation comes in many flavors with different archi-
tectures and ways of sharing parameters (Luong et al. 2016; Zoph and Knight 2016; 李,
给, and Hofmann 2017; Dong et al. 2015; Firat, 给, and Bengio 2016; Lu et al. 2018;
Blackwood, Ballesteros, and Ward 2018). The main motivation of multilingual models
is the effect of transfer learning that enables machine translation systems to benefit
from relationships between languages and training signals that come from different
data sets. Common techniques explore multisource encoders, multitarget decoders, 或者
combinations of both. Multilingual models can push the translation performance of
low-resource language pairs but also enable the translation between unseen language
对, so-called zero-shot translation (Ha, Niehues, and Waibel 2016; Johnson et al. 2017;
Gu et al. 2018A).
The effective computation of sentence representations using the translation task
as an auxiliary semantic signal has also drawn interest to MT models (爬坡道, 给, 和
科尔霍宁 2016; McCann et al. 2017; Schwenk and Douze 2017; Subramanian et al.
2018). 的确, recent work makes use of machine translation models to capture syntactic
and semantic properties of the input sentences, later to be used for learning general-
purpose sentence representations (Shi, Padhi, and Knight 2016; Belinkov et al. 2017;
Dalvi et al. 2017; Poliak et al. 2018; Bau et al. 2019). An important feature that enables
an immediate use of the MT-based representations in other downstream tasks is the
effective reduction to a fixed-sized vector; it enables functionality, at the expense of
hampering the performance in the MT task (Britz, Guan, and Luong 2017; Cífka and
Bojar 2018). 然而, it is not fully clear how the properties of the fixed-sized vector
influence the tradeoff between the performance of the model in MT and the information
it encodes as a meaning representation vector. Recent studies either focus on the usage
of such MT-based vector representations in other tasks (Schwenk 2018), on translation
质量 (Lu et al. 2018), on speed comparison (Britz, Guan, and Luong 2017), or only
explore a bilingual scenario (Cífka and Bojar 2018).
对于本研究, we focus on exploring a crosslingual intermediate shared layer
in an MT model. We apply an architecture based on shared inner-attention with
1 http://www.statmt.org/wmt18/translation-task.html.
http://www.statmt.org/wmt19/translation-task.html.
388
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
language-specific encoders and decoders that can easily scale to a large number of
语言 (more details about the architecture in Section 2). 同时地, it addresses
the task of obtaining language-agnostic sentence embeddings (Lin et al. 2017; Cífka and
Bojar 2018; Lu et al. 2018) that can be straightforwardly applied to downstream tasks. 在
Sections 4 和 5, we examine this model with a systematic evaluation on different sizes
of the shared layer and extensive experiments to study the abstractions it learns from
multiple translation tasks.
In contrast to previous work (Cífka and Bojar 2018), we demonstrate that there
is a direct relation between the translation performance and the scores attained on
trainable downstream tasks when adjusting the size of the intermediate layer. 这
trend is different for non-trainable tasks that benefit from the increased compression
that denser representations achieve, which typically hurts the translation performance
because of the decreased capacity of the model. We also show that multilingual models
improve trainable downstream tasks, even further demonstrating the additional ab-
straction that is pushed into the representations through additional translation tasks
involved in training. This even holds in low-resource scenarios as we show empirically
in Section 4.4. 而且, we find that multilingual training leads to a better encoding of
linguistic properties of the sentence, and that a larger size of the shared inner-attention
layer leads to a better syntactic understanding of the sentence rather than semantic (看
部分 5). 此外, we include an in-depth analysis of the attention bridge on the
ability of encoding linguistic properties, investigating systematically each component
of the shared inner-attention layer.
In the following, we will first introduce the architecture that we apply in our exper-
瞬间. 此后, we will discuss translation quality before diving into the detailed
analyses of sentence representations and their applications, which will be the main
focus of this article.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
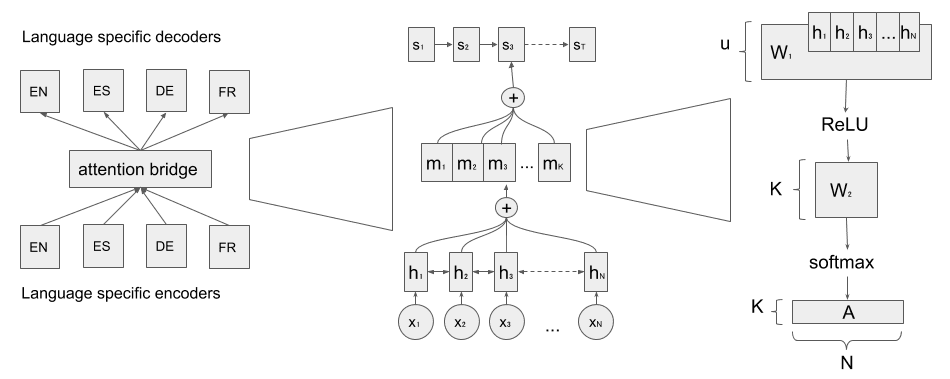
2. Model Architecture
The model we use follows the standard set-up of an encoder–decoder model of machine
translation with a traditional attention mechanism (Bahdanau, 给, and Bengio 2015;
Luong et al. 2016). 然而, to enable multilingual training we augment the network
with language-specific encoders and decoders trainable with a language-rotating sched-
uler (Dong et al. 2015; Schwenk and Douze 2017). We also incorporate an intermediate
inner-attention layer, which summarizes the encoder information in a fixed-size vector
表示, to serve as a language-agnostic layer (Cífka and Bojar 2018; Lu et al.
2018). Because of the attentive connection between encoders and decoders we call this
layer attention bridge, and its architecture is a multilingual adaptation from the model
proposed by Cífka and Bojar (2018). The overall architecture is illustrated in Figure 1.
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
2.1 Background: Attention Mechanism
Given an input X = (x1, . . . , xn), a sequence of embedded tokens into the vector space
Rdx, our goal is to generate a translation Y = (y1, . . . , ym). For the sake of clarity, we as-
sume a recurrent encoder in the following even though the mechanism is not restricted
to this particular type of encoder. A recurrent neural network (RNN)-based encoder
reads each element in X to generate a context vector c. 一般来说, for each token the
389
计算语言学
体积 46, 数字 2
数字 1
Architecture of the proposed multilingual NMT system. 左边: The attention bridge connects the
language-specific encoders and decoders. 中心: Input x1 . . . xn is translated into the decoder
states s1 . . . st via the encoder states h1 . . . hn and the attention bridge M = m1 . . . mk. 正确的:
Computation of the fixed-size attentive matrix A.
RNN generates a hidden state ht ∈ Rdh where the last hidden state of the RNN often
defines c:
ht = f (xt, ht−1)
c = hn
(1)
(2)
and f : Rdx × Rdh −→ Rdh is a non-linear activation function. We use bidirectional long
short-term memory (LSTM) units (Graves and Schmidhuber 2005) as f in this article.
然后, the decoder network sequentially computes (y1, . . . , ym) by optimizing
p(是|X) =
米
(西德:89)
t=1
p(yt|C, Yt−1)
(3)
where Yt−1 = (y1, . . . , yt−1). Each distribution pt = p(yt|C, Yt−1) ∈ Rdv is usually com-
puted with a softmax function over all the words in the vocabulary, taking into account
the current hidden state of the decoder st:
pt = softmax(yt−1, st)
st = ϕ(C, yt−1, st−1)
(4)
(5)
where ϕ is another non-linear activation function and dv is the size of the vocabulary.
Including an attention mechanism in the decoder implies that a different context
vector ct will be computed at each step t, instead of fixing c as in Equation (2) for gen-
erating all output words. This alignment method allows the decoder to assign different
weights to each part of the input at every decoding step by defining ct as the weighted
390
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
sum of hidden states of the encoder ct = (西德:80)n
i=1 αt,iht, where αt,i indicates how much the
i-th input word contributes to generating the t-th output word, and is usually defined as
αt,i =
(西德:80)n
经验值(等,我)
k=1 exp(等,k)
等,i = g(st, 你好)
(6)
(7)
where g is a feedforward neural network.
2.2 Inner-Attention as Semantic Bridge
To enable multilingual training and the possibility to obtain a fixed-size sentence rep-
resentation from the model, we propose to extend the attention-based network (秒-
的 2.1) with the following modifications:
1.
2.
3.
the incorporation of the attention bridge: an inner-attention layer shared
among all language pairs, that serves as a neural “interlingua”;
the use of language-specific encoders and decoders for each language pair,
trainable with a language-rotating scheduler; 和
the introduction of a penalty term in the loss function to avoid redundancy
in the shared inner-attention.
(1) Attention bridge: Each encoder takes as input a sequence of tokens (x1, . . . , xn) 和
produces n hidden states H = (h1, . . . , hn) with hi ∈ Rdh, in our case, using a bidirectional
LSTM (Graves and Schmidhuber 2005).2 下一个, we encode this variable length sentence-
embedding matrix H into a fixed size M ∈ Rdh×k capable of focusing on k different
components of the sentence (Lin et al. 2017; 陈, Ling, and Zhu 2018; Cífka and Bojar
2018), using self-attention as follows:
A = softmax (西德:0)W2ReLU(W1HT )(西德:1)
M = AH
(8)
(9)
where W1 ∈ Rdw×dh and W2 ∈ Rk×dw are weight matrices, with dw a hyperparameter set
arbitrarily, and k the number of attention heads in the attention bridge. Note that each
column of M, mi, is a component focusing on a portion of the sentence, so all of them
together should reflect the overall semantics of the sentence.
Each decoder follows a common attention mechanism in NMT (Luong, Pham, 和
曼宁 2015), with an initial state computed by mean pooling over M, and using M
instead of the hidden states of the encoder for computing the context vector. 正式地,
we only need to compute Equations (6) 和 (7) using the columns of M instead of the
encoder states hi.
(2) Language-specific encoders and decoders: To deal with additional language pairs, 我们
incorporate an encoder for each input language and an attentive decoder for each
2 Note that the attention bridge is independent of the underlying encoder and decoder (Lu et al. 2018).
Although we use a BiLSTM, it could be replaced with a GRU (Cho et al. 2014), a transformer type
网络 (Vaswani et al. 2017), or with a CNN (Gehring et al. 2017)
391
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
output language to be connected via the attention bridge. This adjusts the parameters
of the bridge layer with multilingual information.
数字 1 shows a basic diagram on the left-hand side to illustrate the use of sev-
eral encoders and decoders that are plugged in and out at every change of batch. 到
avoid over-fitting the attention bridge layer toward one specific language-pair, we cycle
through the available target and source languages at each batch uniformly as in Lu et al.
(2018).
(3) Penalty term: The attention bridge matrix M from Equation (9) could potentially suf-
fer from redundancy problems by learning repetitive information for different attention
头. To address this issue, we add a penalty term to the loss function, proven effective
in related work (Lin et al. 2017; 陈, Ling, and Zhu 2018; Tao et al. 2018):
L = −log (西德:0)p (是|X)(西德:1) + (西德:13)
(西德:13)AAT − I
(西德:13)
(西德:13)
2
F
(10)
where A is as in Equation (8) and I is the identity matrix. Note that this term forces each
vector to focus on different aspects of the sentence by making the columns of A to be
approximately orthogonal in the Frobenius norm.
The advantage of the fixed-size representation is the straightforward application in
下游任务. 然而, selecting a reasonable size of the attention bridge in terms
of attention heads is crucial for the performance both in a bilingual and multilingual
scenario as we will see in our experiments in Sections 3.2 和 4.
3. Translation Quality
Before applying and analyzing sentence representations that can be learned with the
proposed architecture from the previous section, we ought to verify that the model is
indeed capable of learning multilingual translation—the original training objective. 为了
这, we apply the model in two scenarios: a low-resource scenario with a multilingual
image caption translation task (Elliott et al. 2016) and the application to considerably
larger data sets based on experiments with Europarl (科恩 2005) and news translation
任务 (Callison-Burch et al. 2007). In the following we will first discuss multilingual
transfer learning in the low-resource scenario before we analyze the effect of the atten-
tion bridge size on translation quality in the large-data setting.
3.1 Multilingual Translation of Image Captions
Multi30K (Elliott et al. 2016) is a parallel data set containing 29k image captions for
training and 1k sentences for validation in four European languages; Czech (cs), 格尔-
男人 (的), 法语 (fr), and English (在). We test the trained model with the flickr 2016
test data of the same data set and obtain BLEU scores using the sacreBLEU script3 (邮政
2018). The preprocessing pipeline consists of lowercasing, normalizing, and tokenizing
using the scripts provided in the Moses decoder (Koehn et al. 2007), together with
learning and applying a 10k operations byte-pair-encoding (BPE) model per language
(Sennrich, Haddow, and Birch 2016). Each encoder consists of two stacked BiLSTMs
of size dh = 512 (IE。, the hidden states per direction are of size 256). Each decoder is
composed of two stacked unidirectional LSTMs with hidden states of size 512. 为了
3 With signature BLEU+case.lc+numrefs.1+smooth.exp+tok.13a+version.1.2.11.
392
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
桌子 1
BLEU scores obtained in experiments on the Multi30k data set. 左边: Bilingual models, 我们的
基线. 中心: Models trained on {的,Fr,Cs}↔En, with zero-shot translations in italics. 正确的:
Many-to-many model. Both zero-shot and M ↔ M translations improve significantly when
including monolingual data. (Best results shown in bold font).
BILINGUAL
src/tgt
EN
DE
CS
FR
EN
{DE,FR,CS} ↔ EN
CS
DE
–
39.00
35.89
49.54
36.78
–
28.98
32.92
28.00
23.44
–
25.98
55.96
38.22
36.44
–
–
39.39
37.20
48.49
37.85
–
0.65
0.60
29.51
0.35
–
0.30
M ↔ M
EN
DE
CS
FR
–
40.68
38.42
49.92
37.70
–
31.07
34.63
29.67
26.78
–
26.92
55.78
41.07
40.27
–
FR
57.87
0.83
1.02
–
BILINGUAL + ATT BRIDGE
EN
DE
CS
FR
{DE,FR,CS} ↔ EN + MONOLING M ↔ M + MONOLINGUAL
FR
EN
EN
DE
DE
CS
CS
FR
–
38.19
36.41
48.93
35.85
–
27.28
31.70
27.10
23.97
–
25.96
53.03
37.40
36.41
–
–
40.17
37.30
50.41
38.92
–
22.13
25.96
30.27
19.50
–
20.09
57.87
26.46
22.80
–
–
41.82
39.58
50.94
38.48
–
31.51
35.25
30.47
26.90
–
28.80
57.35
41.49
40.87
–
EN
DE
CS
FR
EN
DE
CS
FR
model input and output, the word embeddings have dimension dx = dy = 512. We use
an attention bridge layer with k = 10 attention heads with dw = 1, 024, dimensions of
W1 and W2 from Equation (8).
We use a stochastic gradient descent optimizer with a learning rate of 1.0 and batch
尺寸 64, and for each experiment, we select the best model on the development set. 我们
implement our model on top of an OpenNMT-py (Klein et al. 2017) fork, which we make
available for reproducibility purposes.4
3.1.1 基线. The first experiment we conduct is to corroborate that the proposed
architecture works correctly, and we assess performance in a bilingual setting. We expect
that the models slightly drop in performance when the fixed-size attention bridge is
introduced, because there are no direct crosslingual attention links between the source
and target languages. 然而, we want to see whether the architecture is robust
enough to carry over the essential information needed for translation with the inclusion
of the additional intermediate abstraction layer.
表中 1 we present a comparison of our architecture in contrast with a strong
bilingual baseline consisting of an architecture with the same specifications, 没有
the components of our model. The table presents the scores obtained for each of the
12 bilingual models trained on each language pair. 在这种情况下, we note that the basic
bilingual models without any attention bridge have a slightly better performance in
most cases. The most significant drop occurs when translating English to French, 与一个
difference of over 2 BLEU points, but this case is exceptional. Typically the BLEU score
decreases by less than 1 观点.
This behavior is expected because the information from the encoder has to be
summarized in the 10 heads of the inner-attention layer without (multilingual) infor-
mation from other encoders to boost the states of this bridge. 尽管如此, these tests
justify the validity of the architecture; 即, that the attention bridge does not cause
4 https://github.com/Helsinki-NLP/OpenNMT-py/tree/neural-interlingua.
393
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
a significant problem for the translation model in the bilingual case. We will use the
results of bilingual models both with and without attention bridge as our baselines for
the comparison to the multilingual models that we describe subsequently.
3.1.2 Many-To-One and One-To-Many Models. The expected power of the attention bridge
comes from its ability to share information across various language pairs. We now
look at the effect of including additional languages during training on the translation
performance of individual language pairs. We start by training models that include
many-to-one and one-to-many settings with English as target and source, 分别.
This set-up makes it possible to study the ability of zero-shot translation, 那是, 这
translation between languages that have not been seen together in the training data. 经过
performing zero-shot translation, we can test the abstraction potential of the attention
bridge and its effectiveness in encoding multilingual information.
For the first experiment, we use the many-to-one and one-to-many strategy to
train a {的,Fr,Cs}↔En model. As depicted in Table 1, this attempt already results in
substantial improvements for the language pairs seen during training.
The model exceeds both bilingual baselines from the previous section. 然而,
this model is entirely incapable of performing zero-shot translations. We believe that
this inability of the model to generalize to unseen language pairs arises from the fact
that every non-English encoder (or decoder) only learns to process information that is
to be decoded into English (or encoded from English input). This finding is consistent
with Lu et al. (2018); 所以, to address this problem, we incorporate monolingual data
during training, 那是, for each available language A, we train A → A with identical
copies of the input sentence as the target. 因此, we do not include any additional
数据, but we reincorporate examples from the same parallel training corpus used in all
other experiments. 作为结果, we see a remarkable increase in the BLEU scores,
including a substantial boost for the language pairs not seen during training. 简而言之,
the monolingual data informs the model that other languages can be produced besides
英语, and that English is not the unique source language.
此外, there is a positive effect on the seen language pairs, the cause of
which is not immediately evident. One possibility may be that the shared layer acquires
additional information that can be included in the abstraction process yet not available
to the other models.
3.1.3 Many-to-Many Models. To further examine the capabilities of the proposed archi-
tecture we conduct two experiments under a many-to-many scenario.
第一的, we test the architecture in a many-to-many setting with all language pairs
包括. 桌子 1 summarizes the results of our experiments. As in the previous case,
we compare settings that include monolingual data with their counterparts that do not
include it.
On a first note, the inclusion of language pairs results in an improved performance
when compared to the bilingual baselines, as well as the many-to-one and one-to-many
案例. The only exception is the En→Fr task. 而且, the addition of monolingual
data during training leads to even higher scores, producing the overall best model.
The improvements in BLEU range from 1.40 到 4.43 compared to the standard bilingual
模型.
下一个, we perform a systematic evaluation on zero-shot translation. 为了这, 我们
train six different models where we include all but one of the available language pairs
(例如, En↔De). 然后, we test our models while also performing bidirectional zero-shot
translations for the unseen language pairs. 数字 2 summarizes the results.
394
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
数字 2
For every language pair, we compare the BLEU scores between models trained and tested on the
Multi30k data set: (1) our best model (M ↔ M plus monolingual data), (2) the bilingual model of
that language pair, (3) the zero-shot translation of the many-to-many model trained without that
specific language pair, (4) the Johnson et al.(2017) model using language labels (LL) trained in a
many-to-many scenario, 和 (5) the zero-shot of of LL without that specific language pair.
We observe that these zero-shot translation scores are generally better than the
ones from the previous {的,Fr,Cs}↔En model with monolingual data (桌子 1). 我们也
note that the zero-shot models perform relatively well in comparison with the MANY-
TO-MANY model. 此外, these zero-shot models almost reach the scores of the
bilingual models trained only on the zero-shot language pairs.
As a point of comparison, we also implemented the approach of Johnson et al.
(2017), using a language label at the beginning of the input sentence to specify the
required target language and a single shared model with joint vocabulary. We will refer
to this model as the LL approach herein. We used a combined 40k BPE operations model
trained on the combined corpora and the same architecture specifications from Section
3.1, without the components of the attention bridge model. The results are shown in
数字 2 in the gray bars next to our attention bridge scores. We can see that the many-
to-many LL models perform slightly better than our attention bridge model. 这不是
very surprising as they are based on a model architecture that also performs better in
the bilingual case as we have seen in the comparison between bilingual models with
and without attention bridge in Table 1. 部分 3.2.2 will also show that this is basically
caused by long sentences that are not as well covered by the attention-bridge model.
A similar effect is visible in the zero-shot results that we obtain in the same way as
with our attention bridge model (IE。, leaving one language pair out of the training data).
The differences to our model are sometimes larger than in the supervised set-up. 这
can be explained by the positive effect of sharing all encoder and decoder parameters
in the case of related languages. Having a small data set to start with, the additional
data from the other language pairs seems to be very beneficial and in some cases the
zero-shot performance comes very close to the supervised model with all data included.
In future work, we would like to investigate the effect on more distant languages and
increasing numbers of languages involved in our comparison.
395
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
EnDeDeEnEnCsCsEnEnFrFrEnDeFrFrDeDeCsCsDeCsFrFrCsSourceTarget202530354045505560BLEU38.541.830.539.657.450.941.535.226.931.540.928.834.037.426.930.543.043.832.931.423.125.532.923.735.838.227.136.453.048.937.431.724.027.336.426.035.539.628.932.747.744.638.436.423.928.236.626.939.042.530.540.259.052.243.236.227.032.841.229.0m2m + monolingualbilingual + attBridgezero-shotLL m2mLL zero-shot
计算语言学
体积 46, 数字 2
Also note that the language labeling technique does not produce crosslingual
sentence representations, the main advantage of our approach, which we will test in
multilingual downstream tasks (参见章节 4.2). The language label makes the en-
coder effectively depending on the target language, which makes it difficult to apply
the representations produced by that system to unrelated downstream tasks. 这些
drawbacks and the fact that we produce competitive results with our architecture while
producing directly applicable crosslingual sentence representations motivate the use of
our architecture in multilingual set-ups. 此外, we can also show that the drop in
performance mainly comes from long sentences that are not covered as well as shorter
那些. More details on this effect can be found in Section 3.2.2.
3.1.4 Effect of the Penalty Term. In order to study the effect of the penalty term, 我们
have trained additional bilingual and multilingual models, where the penalty term
方程 (10) was excluded from the loss function. We re-ran all the 36 tests in the lower
row of sub-tables in Table 1. We then compared the BLEU scores between corresponding
set-ups where the penalty term was present and absent. We discovered that in 21 出去
的 36 测试 (58 %) the presence of the penalty term was beneficial. 平均而言, 这
penalty term improves the BLEU scores by 0.11 点, across all tested types of models
and language pairs.
As discussed in Lin et al. (2017), the quantitative effect of the penalty term might not
be significant for some tasks, yet still it maintains the positive effect of encouraging the
attentive matrix to be focused on different aspects of the sentence rather than picking up
redundant information. 的确, as we will see in Section 5.3, adding the penalty term
effectively helps the model to spread the attention of the individual attention heads
once the sentence is covered with token-specific attention. This leads us to keeping it in
the remaining experiments.
3.2 The Effect of the Attention Bridge Size on MT Quality
The study on the Multi30K data set demonstrates the general ability of the attention
bridge model to learn multilingual translation models capable of sharing knowledge
between the various language pairs also enabling zero-shot translation similar to other
multilingual NMT architectures. In the following, we investigate the impact of the size
of the attention bridge on translation performance. 对于本研究, we choose a data set of
a realistic size and a more challenging benchmark with a larger vocabulary and a greater
variety of sentence lengths as one of the most crucial properties influencing the quality
of machine translation. 尤其, we apply the Europarl Corpus v7 (科恩 2005)
with a selection of four languages and news test sets from the the ACL-WMT07 shared
任务 (Callison-Burch et al. 2007), using dev2006 as validation data and devtest2006 plus
test2006 as blind test data, ending up with 2K and 4K sentences, 分别. We focus
on six language pair directions: English–French (EN–FR), English–German (EN–DE),
and English–Spanish (EN–ES), with training data of approximately 2M sentences each.5
The data are pre-processed following the standard MT pipeline, including tokenization
and truecasing. Sentences are then encoded using BPE (Sennrich, Haddow, and Birch
2016), 和 32,000 merge operations for each language. BLEU scores are computed case-
insensitively using SACREBLEU as before.
5 As before, we trained all models including monolingual data, and because of the small size of the Czech
Europarl data, we include Spanish instead.
396
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
桌子 2
BLEU scores for bilingual Europarl models.
BILINGUAL MODELS
基线
k=1
k=10
k=25
k=50
22.72
30.28
25.88
24.28
28.16
25.39
15.04
22.8
18.97
17.22
19.33
17.46
20.25
27.3
23.49
22.53
25.2
22.1
21.26
28.52
24.42
23.18
26.49
22.4
21.87
29.15
25.07
23.59
28.16
24.22
DE
ES
FR
EN
EN
DE
ES
FR
We will first look at the impact of attention bridge size on bilingual and multilingual
models before we discuss the impact of sentence length on our model. 一般来说, 我们
expect that the positive effect of transfer learning in translation will fade out as the
bilingual baseline models become stronger and outperform the attention bridge model
with their additional bottleneck of a fixed size intermediate representation. This will
mainly affect long sentences that are not properly summarized in the shared layer,
causing a less effective access to encoder information through the crosslingual attention
(more detailed analyses are presented in Section 3.2.2).
3.2.1 The Impact of Attention Bridge Size on Bilingual and Multilingual Models. 为了
following experiments, we apply the same architecture and hyperparameters as in
部分 3.1. Regarding the attention bridge, we experiment with four different numbers
of attention heads: k = 1, 10, 25, 50. In the training we use the Adam optimizer (Kingma
and Ba 2015) with a learning rate of 0.0004 and batch size 256, for at most 100,000
steps per language pair. We select the best model according to the BLEU score on the
validation set. For multilingual systems, we select only one model with the best overall
BLEU score across the validation set of all the language pairs involved.
We adopt different training strategies: First we train bilingual models for the lan-
guage pairs of interest; then we train a {DE,ES,FR}↔EN model using the many-to-
one and one-to-many strategy; lastly we train a many-to-many model involving all
translation directions between the three languages (IE。, we also include DE–ES, DE–FR,
and ES–FR).6
桌子 2 shows the BLEU scores of our models with varying k, the number of the
attention heads in the attention bridge, compared with a baseline, a traditional encoder-
decoder model with attention mechanism (Luong, Pham, and Manning 2015). Among
the attention bridge models, we can see that the performance consistently increases
when k grows. The model with 50 heads achieves the best results among our models.
It obtains scores that range in the same ballpark as the baseline, only in a few cases
there is a degradation of around 1 BLEU point. 此外, the performance of this
model compared with the one with one attention head is substantial: 多于 6 蓝线
points on average, corroborating previous findings (Britz, Guan, and Luong 2017; Cífka
and Bojar 2018). 直观地, a large number of attention heads manage to encode richer
6 Data coming from the same Europarl source: http://opus.nlpl.eu/Europarl.php.
397
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
桌子 3
BLEU scores for multilingual Europarl models with various sizes k of the attention bridge. 为了
比较, the table includes results of a multi-way multilingual NMT model (Firat, 给, 和
本吉奥 2016) and a completely shared architecture with language labels: LL (Johnson et al. 2017) .
DE
ES
FR
EN
EN
DE
ES
FR
k=1
14.66
21.82
17.8
16.97
18.38
17.52
k=10
19.87
27.55
23.35
21.39
25.39
21.93
M ↔ EN
k=25
20.61
28.41
24.36
23.42
27.01
24.4
k=50
20.83
28.13
23.79
24
27.12
23.9
Firat
18.49
27.73
23.22
24.8
25.7
24.52
LL
21.63
29.48
25.56
25.96
28.41
26.93
M ↔ M
k=50
20.47
27.6
24.15
24.4
26.98
24.47
k=1
14.89
21.4
17.62
17.38
19.43
17.47
LL
21.7
29.53
25.51
25.84
28.67
25.47
information about the source sentence improving the performance of the model for
公吨. Those results verify that BLEU and meaning representations do not have to be
in opposition, as suggested by Cífka and Bojar (2018).
For the multilingual settings, we train a {DE,ES,FR}↔EN model using the many-to-
one and one-to-many strategy, and a many-to-many model as discussed in Sections 3.1.2
和 3.1.3. 桌子 3 shows the comparison between the multilingual models. 一般来说,
we observe the same trend as in the bilingual evaluation concerning the size of the
attention bridge. 即, more attention heads lead to a higher BLEU score. 尤其,
we do not see any increase in translation quality from the {DE,ES,FR}↔EN model to the
many-to-many model; the BLEU scores for all six translation directions are statistically
equivalent. Besides, when we compare the bilingual and multilingual models for a
given k, we do not note any apparent degradation or improvement regarding the BLEU
score when incorporating multilingual data into the models.
用于比较, we again add results from the language-labeling approach by
Johnson et al. (2017) and also from another popular approach that has been proposed by
Firat, 给, and Bengio (2016). The latter refers to a multi-way multilingual NMT system
with a shared crosslingual attention mechanism, a model that is quite similar in spirit
with our approach but without a fixed-size shared layer between encoder and decoder
that bridges the crosslingual attention.
The multiway architecture produces lower scores for most language pairs. 笔记
that we only show results for the {DE,ES,FR}↔EN set-up as the used implementation
no longer holds for current standards,7 training is very slow and would be prohibitively
expensive in the many-to-many set-up. We expect that the trend will be the same and the
scores are below our proposed architecture. The language-label approach by Johnson
等人. (2017), 另一方面, is again very effective and produces the overall best
结果. Sharing all parameters is also beneficial in the Europarl experiments similar
to what we have seen in the Multi30K results. 再次, we have to note that the bilin-
gual baseline will be higher and that we also focus on related languages again that
benefit from a strong overlap in linguistic properties. 然而, 再次, we can see
that our model produces competitive results with the additional benefit of producing
crosslingual fixed-size representations that are directly applicable in downstream tasks
including crosslingual ones.
7 https://github.com/nyu-dl/dl4mt-multi.
398
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
3.2.2 Length Analysis. In the previous section, we could see that there is a strong cor-
relation between the size of the attention bridge and the quality of the translations
produced. We could also see that the attention bridge model is capable of translating
with a similar performance even though it creates an additional bottleneck of fixed-size
陈述. 尽管如此, the performance drops slightly and, in this section, 我们
would like to investigate the reasons for that drop by looking at the effect on different
subsets of the test data.
One of the main motivations for having more attention heads lies in the better
support of longer sentences. To study the effect, following previous work (Bahdanau,
给, and Bengio 2015; Tu et al. 2017; Dou et al. 2018), we group sentences of similar
length and compute the BLEU score for each group. As we can see from Figure 3,
a larger number of attention heads has, 的确, a positive impact when translating
longer sentences. Long sentences do require a bigger attention bridge, and it affects
both bilingual and multilingual models. Interestingly enough, on sentences with up to
45 字, there is no real gap between the results of the baseline model and our bridge
models with a high number of attention heads. It looks like the performance drop of the
attention bridge models is entirely due to sentences longer than 45 字. The same is
true in comparison to the language-label approach. This also suggests that the increased
performance of that model is due to the better coverage of long sentences.
此外, we notice that multilingual models with 50 attention heads lose more
on long sentences than bilingual ones. We hypothesize that this might be due to the
increasing syntactic divergences between the languages that have to be encoded. 这
shared inner-attention layer needs to learn to focus on different parts of a sentence
depending on the language it reads and, with increasing lengths of a sentence, 这
ability becomes harder and more difficult to pick up from the data alone.
3.3 讨论
Our results demonstrate that the attention bridge model proposed in this paper imple-
ments an effective approach to multilingual machine translation. The shared layer suc-
cessfully bridges language-dependent encoder and decoder networks enabling efficient
transfer learning and improved sentence representation learning. Using the multi30k
benchmark, the results of the multilingual models consistently outperform a strong
数字 3
The BLEU scores obtained by the models with respect to different sentence length. The left figure
shows the bilingual models, the middle one the many-to-one models, and the figure to the right
illustrates the many-to-many models.
399
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
153045>451520253035BLEUbaselinebilingual k=1bilingual k=10bilingual k=25bilingual k=50153045>45SENTENCE LENGTH1520253035baselineMEn k=1MEn k=10MEn k=25MEn k=50MEn LLFirat153045>451520253035baselineMM k=1MM k=50MM LL
计算语言学
体积 46, 数字 2
bilingual model. This advantage, 然而, fades out with larger data sets. This is ex-
pected because of the limits of the fixed-size representations that bridge the gap between
the various languages. But our analysis shows that this is mainly due to the problem
with long sentences, an issue that needs to be addressed in future work. Our analysis
also reveals that the size of the attention bridge plays a crucial role on translation quality
and we will further discuss this below in the application of the sentence representations
to unrelated downstream tasks. This brings us to the main point of this article, 即,
the discussion of the quality of representations that can be learned from translations
using the proposed multilingual architecture.
4. MT-Based Representations in Downstream Tasks
The main motivation for our study is to investigate the sentence representations that
the MT model picks up during training. 所以, the most important part is the
assessment of these representations in unrelated downstream tasks and the analyses of
the internal structure (which we will discuss in Section 5). In the following, we will first
briefly introduce the tasks we consider before applying our models to each of them. 我们的
MT models are trained on the Europarl data. 然而, in Section 4.4 we also include a
study on downstream tasks with representations learned from limited resources, 使用
the Multi30K data set, to further demonstrate that useful representations can be picked
up even from tiny data sets. This is in contrast to related work where huge amounts of
training data are typically applied to obtain reasonable performance.
Our assumption is that multilinguality contributes to a higher level of semantic
abstraction that can be learned from the translation objective. To test this claim, we apply
standard benchmarks collected in the SentEval toolkit (Conneau and Kiela 2018), 这
XNLI evaluation corpus (Conneau et al. 2018C), as well as the Yelp challenge data set.8
The SentEval toolkit contains three benchmark types: 分类, 相似, 和
linguistic probing tasks. In the classification tasks, a classifier is trained on top of a
sentence embedding involving various data sets: CR—product reviews (Hu and Liu
2004), MR—movie reviews (Pang and Lee 2005), MPQA—opinion polarity (Wiebe,
Wilson, and Cardie 2005), SUBJ—subjectivity/objectivity status (Pang and Lee 2004),
SST—binary and fine-grained sentiment analysis (索切尔等人. 2013), TREC—question-
type classification (Voorhees and Tice 2000), MRPC—paraphrase detection (Dolan,
Quirk, and Brockett 2004), and SICK and SNLI—textual entailment and natural lan-
guage inference (Marelli et al. 2014; Bowman et al. 2015).
In contrast to the classification tasks mentioned above, the similarity tasks do not
involve any training and, 反而, correlate the cosine distance between two sentence
representations with a human labeled score using Pearson and Spearman coefficients.
The data sets come from the SemEval Semantic Textual Similarity (超导系统) task series, 从
2012 到 2016 (Agirre et al. 2012, 2013, 2014, 2015, 2016). The only exceptions are the SICK
and STSB data set (Marelli et al. 2014; Cer et al. 2017), where training data are provided.
此外, the SentEval toolkit contains probing tasks to study how linguistic
features are encoded within a fixed-size vector (Conneau et al. 2018A).
All SentEval tasks are designed for English only. 所以, we find it valuable
to evaluate our sentence representations on multilingual classification tasks as well.
For this purpose we make use of the XNLI evaluation corpus (Conneau et al. 2018C)
8 http://www.yelp.com/dataset.
400
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
for language transfer and crosslingual sentence classification, as well as a multilingual
subset of the Yelp challenge data set.
We run the evaluation following the recommended default settings, 那是, 训练
a logistic regression classifier for the classification tasks, with the Adam optimizer (batch
尺寸: 64, epoch size: 4). For the probing tasks we use a multilayer perceptron classifier
with sigmoid nonlinearity, 200 hidden units, 和 0.1 dropout rate. In order to obtain a
sentence vector out of multiple attention heads we apply mean pooling over M, 如
Lu et al. (2018).
We present our experiments and their results in the following order: First we present
the classification tasks, the SentEval classification tasks on English (部分 4.1) 还有
as multilingual classification based on XNLI and Yelp reviews (部分 4.2). 下一个, 我们
turn to the similarity tasks in SentEval (部分 4.3). In all these set-ups we use models
trained on Europarl data. Afterwards, in Section 4.4 we turn to a low-resource scenario
and study SentEval classification and similarity on the Multi30k data set. The SentEval
probing tasks are studied in depth as part of the analysis in Section 5.
4.1 SentEval Classification Tasks
数字 4 shows the average performance of our models on the various classification
下游任务. The most frequent baseline achieves an average score of 48.19, 哪个
all our models beat by a wide margin. We can see that the multilingual models work
best with the many-to-many model, clearly outperforming the rest on average. 这
figure also illustrates the impact of increasing the number of attention heads. 让我们
have a closer look at individual classification tasks to get a more detailed picture of the
performance in the various settings.
Tables 4 和 5 show the performance of our models on the different downstream
任务. We report the accuracy on each individual test set, including the following
comparison scores: a baseline of the most frequent class; a bag-of-vectors baseline
obtained by averaging GloVe word embeddings (Pennington, Socher, and Manning
2014); an average of word embeddings as well as the CLS fixed-size sentence vector
representation obtained from the large-scale pretrained language model BERT (Devlin
等人. 2019; Reimers and Gurevych 2019); a state of the art general-purpose model that
exploits large-scale multitask learning on different tasks including machine translation
(Subramanian et al. 2018); and the performance from other MT systems by Hill, 给,
and Korhonen (2016) and Conneau et al. (2018A).9
The experiments reveal two important findings:
1.
In contrast with the results from Cífka and Bojar (2018), our scores
demonstrate that an increasing number of attention heads is beneficial for
classification-based downstream tasks. All models perform best with more
than one attention head and the general trend is that the accuracies
improve with larger representations. The previous claim was that there is
the opposite effect and that lower numbers of attention heads lead to
9 We only report the best result across the various NMT systems presented by Hill, 给, and Korhonen
(2016) and Conneau et al. (2018A).
401
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
数字 4
Average scores over the 10 SentEval classification tasks. Results shown for the different trained
型号.
higher performances in downstream tasks, but we do not see that effect in
our set-up, at least not in the classification tasks.
2.
The second outcome is the positive effect of multilingual training. 我们可以
see that multilingual training objectives are generally helpful for the
trainable downstream tasks.
Previous work has focused more on the evaluation of translation alone in the
multilingual set-up (Dong et al. 2015) and with our results we can now demonstrate
that multilinguality indeed boosts the abstraction power of a fixed-size sentence vector
that can be trained with the machine translation objective. Particularly interesting is the
fact that the many-to-many model performs best on average even though it does not add
any further training examples for English (compared to the other multilingual models),
which is the target language of the downstream tasks. This suggests that the model is
able to improve generalizations even from other language pairs (DE–ES, FR–ES, FR–DE)
that are not directly involved in training the representations of English sentences.
For completeness we also include a comparison with other approaches, 虽然
the comparison is only partly fair, for several reasons (different underlying architecture,
different set of hyperparameters, different training data and preprocessing techniques).
首先, as a sanity check, we observe that our best model reaches far better
results than the majority-class baseline. 下一个, we can see that the results of our best
model are better than the best systems by Hill, 给, and Korhonen (2016) and Cífka and
Bojar (2018).
402
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
桌子 4
Accuracies of different models in eight different classification tasks. The average accuracy in the
right-most column illustrates the overall trend that a higher number of attention heads and
multilingual models are beneficial. Results marked with † taken from Cífka and Bojar (2018);
with ‡ from Conneau et al. (2018A); 和 (西德:93) from Reimers and Gurevych (2019).
EN-DE
EN-DE
EN-DE
EN-DE
EN-ES
EN-ES
EN-ES
EN-ES
EN-FR
EN-FR
EN-FR
EN-FR
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
M ↔ EN k=1
M ↔ EN k=10
M ↔ EN k=25
M ↔ EN k=50
M ↔ M k=1
M ↔ M k=50
Most frequent baseline†
爬坡道, 给, and Korhonen
(2016) en→fr†
en→cs (2018) †
GloVe-BOW†
CR MR MPQA SUBJ SSTB SSTF TREC MRPC AVG
75.47 68.10
74.33 69.29
73.93 69.38
74.41 68.42
74.41 66.67
72.21 68.72
73.72 67.96
74.06 67.38
75.68 68.77
74.67 68.89
74.41 67.98
74.86 69.25
75.28 69.58
74.07 70.66
75.36 69.43
75.28 69.87
87.49
87.66
87.86
87.63
86.95
87.93
87.75
87.80
87.27
87.72
87.67
88.26
88.15
88.42
88.21
88.26
85.25 71.77 37.15
85.89 75.12 38.37
86.13 72.98 38.19
87.42 73.26 38.28
84.75 70.90 35.93
86.38 72.05 37.33
85.79 73.59 36.83
85.84 72.16 36.65
85.18 71.72 36.97
86.62 73.59 39.77
86.33 74.19 38.64
87.02 75.29 38.06
86.98 74.46 38.96
87.63 75.84 38.55
87.33 75.67 39.19
87.71 75.12 39.64
77.60
73.60
81.40
79.60
78.40
77.20
80.00
81.20
77.40
75.60
80.00
82.06
79.60
75.80
81.80
80.00
70.84
71.83
72.46
72.35
70.67
71.83
72.87
67.94
70.38
71.65
71.13
72.52
70.20
71.48
72.93
70.14
71.71
72.01
72.79
72.67
71.08
71.70
72.31
71.63
71.67
72.31
72.54
73.42
72.90
72.81
73.74
73.25
75.92 71.23
74.72 70.47
88.07
88.39
87.64 75.84 39.73
87.98 77.16 40.14
78.8
83.00
73.28
72.58
73.81
74.31
63.80 50.00
70.10 64.70
68.80
81.50
50.00 49.90 23.10 18.80
82.80
84.90
–
–
66.50
69.10
48.86
–
76.00 68.20
78.20 77.00
84.90
87.90
86.90 72.00 35.70 89.00
91.10 81.00 44.40 82.00
70.70
72.30
72.92
76.74
Conneau et al. (2018A) en→fi‡
Subramanian et al. (2018)‡
Avg. BERT embeddings(西德:93)
BERT CLS-vector(西德:93)
81.10 77.00
88.60 82.40
86.25 78.66
84.85 78.68
90.00
90.70
88.66
88.23
91.50 80.30 43.40 87.20
94.00
93.80 85.10
92.80
94.37 84.40
91.40
94.21 84.13
–
–
–
75.00
78.30
69.45
71.13
–
–
–
–
爬坡道, 给, and Korhonen (2016) train a standard RNN encoder–decoder based sys-
TEM (Cho et al. 2014) on all available English–French data from the 2015 Workshop on
Statistical Machine Translation (WMT’15).10 Similarly to our system, their training set
incorporates 2 million English–French sentence pairs from the Europarl corpus. 他们
use additional English–French data, whereas we train on additional English–German
and English–Spanish data. We outperform their system in every single classification
任务 (桌子 4) when we use multilingual data. Even if we limit ourselves to English–
French data, as they did, we outperform them in all tasks but TREC. This suggests that
our model is superior in both its way to exploit multilingual data and in its architecture.
10 www.statmt.org/wmt15/translation-task.html.
403
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
桌子 5
Results of the two natural language inference (NLI) tasks in SentEval. SICKE = SICK entailment
放. Results marked with † taken from Cífka and Bojar (2018); with ‡ from Conneau et al. (2018A).
EN-DE
EN-DE
EN-DE
EN-DE
EN-ES
EN-ES
EN-ES
EN-ES
EN-FR
EN-FR
EN-FR
EN-FR
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
SNLI
SICKE
63.86
65.30
65.13
65.30
62.79
66.02
65.20
65.49
63.71
65.64
65.68
65.47
77.09
78.77
79.34
79.36
76.76
77.65
79.30
78.83
76.19
78.08
79.97
79.14
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ M
M ↔ M
k=1
k=10
k=25
k=50
k=1
k=50
SNLI
SICKE
65.56
67.01
66.94
67.38
66.92
67.73
77.96
79.48
79.85
80.54
77.82
81.12
Most frequent baseline†
34.30
56.70
GloVe-BOW†
en→cs (2018)†
en→fi (2018A)‡
Subramanian et al. (2018)‡
66.00
69.30
–
–
78.20
80.80
81.70
87.40
爬坡道, 给, and Korhonen (2016) use the last state of the encoder as their sentence
表示, whereas we use the attention bridge layer.
The model by Cífka and Bojar (2018) is based on a very similar architecture as ours,
but they train on bilingual data, 57 million English–Czech sentence pairs. We train on
a considerably smaller, but multilingual, 数据集 (3 次 2 million sentence pairs of
EN–FR, EN–DE, and EN-ES). Yet our system outperforms theirs in six out of nine tasks
listed in Tables 4 和 5. This again demonstrates the power of multilingual models.
In futher comparisons, we can see that our model outperforms the competitive
baseline of GloVe-BOW (Kruszewski et al. 2015; Arora, 梁, and Ma 2017; Adi et al.
2017) in five tasks out of ten. 然而, Conneau et al. (2018A) and Subramanian et al.
(2018) perform better than us in all the classification and NLI tasks. We believe that
the strong performance of the latter models is explained by orders of magnitudes of
more training data. GloVe-BOW and the Conneau et al. (2018A) model are based on
word embeddings, which have been pretrained on several billions of words of text.
The large vocabularies of the pretrained embeddings provide better representations for
low-frequency as well as out-of-vocabulary words. Subramanian et al. (2018) 使用 124
million sentence pairs for training, 这是 20 times more than we have. The BERT
型号, trained on 3.3 十亿字, do not quite reach the level of Subramanian et al.
(2018).
Although our aim is not to beat the state of the art, but rather to understand the
impact of various sizes of attention heads in a bilingual and multilingual scenario, 我们
argue that a larger attention bridge and multilinguality constitute a preferable starting
point to learn more meaningful sentence representations. With this, we can contrast
and extend previous findings, leading the way to further extensions of the MT-based
framework for crosslingual representation learning.
4.2 Multilingual Classification Tasks
In the previous section, we focused on downstream tasks that consider English only.
The main point was to show that reasonable representations can be learned from the
404
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
translation objective and that multilingual data help to improve the abstractions that
can be derived. Even more intriguing is the fact that our shared representation combines
language-specific encoders with language agnostic representations. This makes it possi-
ble to directly test crosslingual downstream tasks, which we will focus on in this section.
The interest in crosslingual NLP leads to a number of benchmarks and downstream
applications and here we will consider the framework of crosslingual NLI as defined
by the XNLI challenge (Conneau et al. 2018C) and crosslingual review classification
as proposed by Lu et al. (2018). We start with the XNLI results and then turn to the
multilingual classifier based on Yelp reviews.11
4.2.1 XNLI. The idea of the XNLI challenge is that the provided corpus enables us to test
natural language inference across different languages. The test pairs are all translated
进入 14 语言, which makes it possible to obtain comparable results across various
language pairs. 因此, a classifier can be trained on one language and be tested on
另一个. In order to make this work, one essentially needs to produce crosslingual
sentence representations that are useful for the task in all test languages. 桌子 6 和-
marizes the results obtained for different settings. We rely on our multilingual attention
bridge model trained in a many-to-many fashion.
用于比较, we include representations obtained from large pretrained word
嵌入. Note that those embeddings are trained on vastly more data than our
模型, which is trained on the parallel Europarl corpus. 尤其, 我们使用
multilingual word embeddings from the fastText (Grave et al. 2018) and the MUSE
(Conneau et al. 2018乙) libraries. The fastText algorithm is based on word2vec and
produces word embeddings compounded from character n-grams (Bojanowski et al.
2017), which is to be preferred for morphologically richer languages in a multilingual
环境. The fastText word vectors are pretrained in CommonCrawl and Wikipedia
using CBOW with position weights, whereas MUSE word embeddings are Wikipedia
fastText vectors from 30 languages aligned in a supervised way into a single vector
空间. Because fastText vectors are not aligned into the same space we only present the
accuracies on the relevant languages for each case. To obtain sentence representations,
we compute the average of the individual word vectors.
We use the XNLI corpus to train multilingual classifiers that are then to be tested for
zero-shot classification. Logistic regression classifiers are trained on top of the sentence
embeddings produced with the English, 德语, 法语, and Spanish training data,
or a combination of these, and then tested in all four languages. We observe that our
model is clearly better than the fastText and MUSE benchmarks. Besides, it reaches
results equal to the XCBOW model presented in Conneau et al. (2018C)—a model that
incorporates an additional multilingual loss to enhance the performance in the task,
and is based on a feed-forward neural network classifier instead of simple logistic
regression. Note that the XCBOW results are taken directly from the original paper
and only available for a classifier trained on English. Even though the comparison with
XCBOW scores is not completely fair because the data sets we applied in training are
much smaller and narrow in domain (Europarl only), we reach similar performance. 它
is certainly re-assuring that our model is capable of creating language-agnostic repre-
sentations that are properly aligned with language-specific encoders. 此外, 我们的
model outperforms the crosslingually aligned MUSE word embeddings by a significant
margin, which demonstrates the importance of a proper sentence encoder also in the
11 http://www.yelp.com/dataset.
405
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
桌子 6
Accuracy obtained in the XNLI task comparing our multilingual model with pretrained vector
embedings. Results marked with † taken from Conneau et al. (2018C) and use a feed-forward
neural network as a classifier as opposed to all others that use a logistic regression.
M ↔ M k=50
MUSE
fastText
X-CBOW†
M ↔ M k=50
MUSE
fastText
M ↔ M k=50
MUSE
fastText
M ↔ M k=50
MUSE
fastText
M ↔ M k=50
MUSE
M ↔ M k=50
MUSE
M ↔ M k=50
MUSE
M ↔ M k=50
MUSE
Classifier
trained on
EN
DE
FR
ES
EN+DE
EN+FR
EN+ES
EN+DE+FR+ES
EN
65.0
55.9
53.1
64.5
58.9
50.5
–
62.6
45.9
–
61.2
49.2
–
65.3
55.4
65.2
55.0
64.9
54.5
64.8
54.8
DE
59.0
47.8
–
61.0
62.6
53.1
52.9
60.9
43.3
–
59.0
44.5
–
62.8
53.4
61.6
46.5
60.9
46.9
62.8
51.7
FR
55.9
42.5
–
60.3
54.8
39.2
–
63.5
53.0
48.6
56.3
43.1
–
58.6
40.1
63.8
52.8
58.5
43.4
63.0
51.6
ES
58.0
42.8
–
60.7
57.9
42.5
–
61.9
41.8
–
63.8
52.5
50.6
60.8
43.1
61.7
44.5
64.6
52.0
63.6
51.2
crosslingual setting. The same effect can be seen in comparison to the non-aligned
language-specific fastText word embeddings that have been trained on huge amounts
of training data.
Looking at the different combinations of training data and the difference between
supervised and zero-shot classification, we can see that our model is quite robust across
the different settings. The drop in performance when moving to zero-shot classification
is rather modest in most cases and in some of them we achieve scores that are close to
the fully supervised mode (看, 例如, the results for Spanish with the classifier
trained on French). The results also show that all languages seem to be equally covered
and the supervised scores end up to be around 63–65% accuracy with zero-shot scores
ranging from roughly 56–62%. Interesting to note is that a combination of training
languages can lead to improvements of zero-shot classification. 例如, results for
Spanish and French are improved when combining English and German in the training
数据. The same happens for German and Spanish when combining English and French,
等等.
406
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
4.2.2 Yelp. Another crosslingual task is the multilingual review classification task pro-
posed by Lu et al. (2018). The idea is to train a classifier to label online reviews based on
their ratings to decide whether reviews in another language are received in a positive
or in a negative way. 桌子 7 shows the scores achieved by an English-reviews clas-
sifier when tested on French, 德语, and Spanish sentences. To make the results as
comparable as possible to Lu et al. (2018) we use the same settings as they did, 和
the addition of including Spanish in our experiments. 即, we took a subset of
5,000 reviews in English from the Yelp review data set (圆形的 13) to train a simple
logistic regression classifier, as well as test sets of French, 英语, 德语, and Spanish
reviews, 的 1,000 sentences each. As in their approach, we extracted the non-English
reviews by applying a language detection tool (Joulin et al. 2017). We use binary review
scores, 在哪里 4- and 5-star reviews are labeled as positive, we do not use 3 stars, 和 1-
and 2-star reviews are labeled as negative. We treat each review as a sentence and use
the shared intermediate representations produced by our multilingual systems as input
to the classifier. As before, we compare our results to MUSE and fastText baselines,
obtaining the sentence representations by averaging the word embeddings of a full
review.
表中 7 we present models with different sizes of the attention bridge for the
many-to-English set-up and, finally, also the results for representations coming from a
many-to-many model. We only include classifiers trained on English as there are not
enough data for the other languages to train a reliable classifier.
The results show that our representations perform well across all languages with
scores mostly around 83–87% accuracy. The most interesting thing is that there is
basically no deterioration when moving to zero-shot classification for languages other
than English. Note that the class distribution is quite skewed here and the majority class
baseline is quite high, especially for German and French. This makes it rather difficult
to interpret the results at least for those languages with a heavy over-representation of
positive reviews. Spanish might be the most reliable zero-shot language in our test set
with a more balanced distribution and, 这里, we can see a clear improvement over the
majority-class baseline when applying the representations coming from our multilin-
gual translation model. We also clearly outperform MUSE in that case demonstrating
the ability of our sentence encoders in creating reliable crosslingual representations.
再次, MUSE and fastText are not directly comparable as they have been trained on
much larger and more diverse data sets. 尽管如此, we also outperform fastText-
based representations in the supervised case in all settings except one. The picture about
桌子 7
Accuracy for crosslingual Yelp binary review classification.
% Positive
MUSE
fastText
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ M
k=1
k=10
k=25
k=50
k=50
EN
75.3
81.5
82.5
84.9
83.7
81.2
83.3
82.6
DE
86.6
86.7
–
84.6
84.4
85.7
79.6
87.1
FR
83.0
83.1
–
83.5
83.6
76.1
83.8
84.1
ES
69.7
76.0
–
79.6
83.6
83.8
83.4
81.8
407
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
the perfect size for the attention bridge is not very clear. 在某些情况下, a small size is
preferable whereas in others a larger size is beneficial. 还, the effect of additional
language pairs is not entirely clear but on average the many-to-many set-up produces
better scores compared with the similar set-up with many-to-English models. 一些
additional studies might reveal further insights, which we will leave for future work.
4.3 SentEval Similarity Tasks
The next evaluation refers to the similarity tasks of SentEval—that is, English data only.
桌子 8 summarizes the results using Pearson’s correlation coefficient as well as the
average on all tasks. As comparison we include the bag-of-vectors baseline (GloVe-
BOW) as in the earlier SentEval classification tasks, the best model from Cífka and Bojar
(2018), and the InferSent model (Conneau et al. 2017) as a state-of-the-art model that is
pretrained on a natural language inference (NLI) 任务. As discussed earlier, note that the
SICK and STSB benchmarks provide training data where a classifier learns to predict the
probability distribution of the relatedness scores (Tai, Socher, and Manning 2015). 二
different trends become visible:
我) On the unsupervised textual similarity tasks, having fewer attention heads is
beneficial. Contrary to the results in the classification tasks, the best overall model is
桌子 8
Results from seven similarity tasks, measured using Pearson’s correlation coefficients; 这
Spearman’s coefficients exhibit the same trend. The average values are displayed in the
right-most column. Results marked with † taken from Cífka and Bojar (2018).
SICK STSB
STS12
STS13
STS14
STS15
STS16 AVG
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=50
0.74
0.76
0.78
0.78
0.73
0.77
0.77
0.78
0.74
0.75
0.77
0.77
0.76
0.78
0.78
0.79
0.77
0.79
0.80
0.81
0.88
0.69
0.69
0.67
0.65
0.68
0.68
0.64
0.63
0.66
0.67
0.65
0.63
0.69
0.69
0.68
0.66
0.71
0.69
0.64
0.73
0.76
0.57
0.52
0.50
0.47
0.54
0.53
0.50
0.48
0.56
0.53
0.50
0.46
0.53
0.51
0.46
0.45
0.53
0.47
0.52
0.46
0.59
0.46
0.41
0.39
0.36
0.42
0.37
0.35
0.31
0.44
0.36
0.36
0.38
0.38
0.34
0.32
0.30
0.39
0.30
0.50
0.32
0.59
0.58
0.54
0.50
0.46
0.53
0.52
0.47
0.40
0.57
0.51
0.48
0.45
0.52
0.47
0.42
0.36
0.52
0.35
0.55
0.45
0.70
0.63
0.58
0.57
0.54
0.60
0.58
0.56
0.49
0.62
0.57
0.55
0.53
0.56
0.56
0.51
0.47
0.58
0.45
0.56
0.53
0.71
0.62
0.56
0.50
0.46
0.60
0.55
0.48
0.44
0.62
0.58
0.48
0.45
0.57
0.55
0.43
0.43
0.59
0.41
0.51
0.47
0.71
0.61
0.58
0.56
0.53
0.58
0.57
0.54
0.51
0.59
0.57
0.54
0.52
0.57
0.56
0.51
0.50
0.59
0.50
0.59
0.54
0.70
EN-DE
EN-DE
EN-DE
EN-DE
EN-ES
EN-ES
EN-ES
EN-ES
EN-FR
EN-FR
EN-FR
EN-FR
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ M
M ↔ M
GloVe-BOW†
en→cs (2018)†
InferSent†
408
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
provided by a bilingual setting with only one attention head. This is in line with the find-
ings of Cífka and Bojar (2018) and could also be expected as the model is more strongly
pushed into a dense semantic abstraction that is beneficial for measuring similarities
without further training. More surprising is the negative effect of the multilingual
型号. We believe that the multilingual information encoded jointly in the attention
bridge hampers the results for the monolingual semantic similarity measured with the
cosine distance, while it becomes easier in a bilingual scenario where the vector encodes
only one source language data, English in this case.
二) On the supervised textual similarity tasks, we find a similar trend as in the image-
caption models for SICK: Both a higher number of attention heads and multilinguality
contribute to better scores. For STSB, we notice a different pattern. 即, 包括
multilingual data in the models helps the performance in this task. The many-to-many
models score better than the best bilingual models. 而且, when increasing k, 这
multilingual models scores are not as badly hampered as the bilingual ones.
Comparing against two baseline systems, GloVe-BOW and the best model by Cífka
and Bojar (2018), our best model on average achieves better results showing the poten-
tials of our approach. The strength of the InferSent model is probably explained by the
pre-trained word embeddings extracted from billions of words as well as their training
数据, which was taken from the NLI domain rather than parallel corpora of translated
句子.
4.4 Downstream Tasks in a Low-Resource Setting
Another important test is whether our model is capable of learning reasonable represen-
tations from limited resources. In order to study this, we applied the Multi30k models
from Section 3.1 to the SentEval tasks in the same way as the Europarl models discussed
多于. Note that these scores are not directly comparable to other models trained on
large-scale data sets because the Multi30K models were trained on very limited data
套; they contain 30k sentences on the specific domain of image captioning. Tables 9
和 10 summarize the scores on downstream tasks we obtain for bilingual and for
multilingual models. We ran each experiment with five different seeds, 我们提出
the average of these scores.
We notice that for the classification and NLI tasks of the SentEval collection, 这
sentence embeddings produced by the multilingual models show consistent improve-
评论, with only two exceptions. 而且, we observe that our many-to-many model
obtains better results in the SICK Relatedness (SICKR) and STS-Benchmark (STS-B), 那
桌子 9
Accuracies of models trained with limited data in eight different classification tasks. 包括
more languages during training boosts the performance.
EN-DE
EN-CS
EN-FR
M ↔ EN
M ↔ M
CR
68.37
67.79
68.52
68.32
69.01
MR
59.76
59.71
60.08
60.4
61.80
MPQA
SUBJ
SSTB
SSTF
TREC
MRPC
73.19
73.16
73.51
72.98
73.28
75.26
75.32
77.25
78.64
80.88
61.87
61.92
61.91
62.02
62.24
31.15
30.43
30.55
32.10
31.83
67.44
67.75
61.04
69.84
66.4
69.13
68.23
70.96
68.83
70.43
409
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
桌子 10
SentEval NLI and semantic similarity tasks results for the models trained with limited data
obtained. We present the Pearson’s correlation coefficient for the similarity tasks. Models trained
with more languages get better scores in trainable tasks, whereas the non-trainable tasks show a
different behavior.
NLI TASKS
SEMANTIC SIMILARITY TASKS
EN-DE
EN-CS
EN-FR
M ↔ EN
M ↔ M
SNLI
61.45
61.75
60.95
64.52
65.12
SICKE
72.82
73.89
74.85
75.46
76.92
TRAINABLE
SICKR
0.618
0.652
0.646
0.659
0.677
STS-B
0.564
0.616
0.574
0.618
0.630
STS12
0.393
0.385
0.359
0.323
0.327
NON-TRAINABLE
STS14
0.426
0.380
0.428
0.353
0.415
STS15
0.489
0.505
0.476
0.418
0.460
STS13
0.265
0.234
0.220
0.190
0.256
STS16
0.430
0.422
0.430
0.375
0.400
是, the trainable semantic similarity tasks. 然而, the results of the non-trainable (和-
mantic similarity) tasks exhibit a different behavior (see the rightmost part of Table 10),
which can be explained by the fact that the additional information encoded in multi-
lingually trained embeddings cannot be effectively separated from the information that
is necessary for monolingual similarity measures. 换句话说, the attention bridge
layer of the multilingual models outputs vectors that contain information shared across
语言, rendering them incomparable with the cosine similarity.
5. Linguistic Analyses of Inner-Attention-Based Sentence Representations
在这个部分, we take a closer look at the representations and what they actually
encode. 为此, we use the probing tasks that are available in the SentEval toolkit,
which make it possible to study specific linguistic features of a given representation
(see Sections 5.1 和 5.2). 此外, we add a careful analysis of the individual
attention heads to further study the information that is encoded by the internal shared
representation layer (参见章节 5.3).
5.1 Probing Tasks in SentEval
The SentEval probing tasks inspect three different linguistic categories: surface infor-
mation on the length and word content of the sentence (Adi et al. 2017); several probing
tasks regarding syntactic properties, such as word ordering, top constituent task (Shi,
Padhi, and Knight 2016); and semantic properties, such as subject/object number, 奇怪的
man out, and coordination inversion, to name a few. To assess how our representations
correlate with linguistic properties, we carry out an evaluation on the various categories
of these tasks. 桌子 11 shows the accuracies on the three linguistic classes.
The results show a clear correlation between the number of attention heads and
the syntactic power of the representations: An increased number of attention heads
corresponds to a higher syntactic score (最多 5 点). 直观地, more attention
heads can learn long-range dependencies better, which are essential for a better syn-
tactic understanding of the sentence. For the semantic probing test, 最好的结果
are provided by the models with one attention head, in line with the findings of
410
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
桌子 11
Average accuracy of the syntactic and semantic probing tasks (Europarl models). The accuracy
on the surface information tasks is shown on the rightmost columns.
Average
句法的
Average
semantic
EN-DE
EN-DE
EN-DE
EN-DE
EN-ES
EN-ES
EN-ES
EN-ES
EN-FR
EN-FR
EN-FR
EN-FR
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ EN
M ↔ M
M ↔ M
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=10
k=25
k=50
k=1
k=50
55.87
57.97
59.10
59.97
54.90
58.37
59.27
59.70
55.37
58.13
58.63
59.40
57.83
61.33
60.87
61.70
59.43
60.97
72.52
71.04
70.58
71.84
72.48
71.36
71.44
72.26
72.04
71.16
71.30
72.42
73.86
72.60
72.78
73.60
74.20
73.40
Surface info
Length
82.20
85.40
86.90
86.00
82.30
87.50
88.00
87.30
82.30
86.70
86.40
86.30
89.10
90.30
91.50
92.10
91.30
90.70
WC
63.80
61.40
56.70
49.60
56.50
60.80
52.80
46.50
60.60
61.50
53.80
45.70
58.70
54.20
41.20
34.50
58.90
35.60
部分 4.3, except that we do not observe a high degradation with more attention
头. Regarding the surface information, it is clear that more attention heads con-
tribute to understanding the length of the sentence better, while forgetting about word
内容.
5.2 Probing Tasks with Limited Resources
Similar to Section 4.4, we also apply the same probing tasks to the Multi30K models to
demonstrate the ability of the models to learn from limited resources.
桌子 12 compares scores between bilingual and multilingual models. 再次, 我们
observe improvements in the majority of cases when adding multiple languages to the
training procedure. 值得注意的是, we observe a significant increment on the accuracy for
the specific tasks of Length (superficial property), Top Constituents (syntactic property),
and Object Number (semantic information) when training the encoders with multilin-
gual data. Some of the tests result in better scores with the many-to-English setting
compared to the many-to-many set-up, which is slightly surprising. 尽管如此, mul-
tilingual models outperform the bilingual models in all but one test.
5.3 Analysis of Individual Attention Heads
So far we have evaluated sentence representations that are based on attention bridges
of different sizes, 范围从 1 到 50 attention heads. The attention bridge matrix as
411
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
计算语言学
体积 46, 数字 2
v
n
我
d
r
哦
哦
C
氧
中号
氧
S
米
你
氮
j
乙
氧
米
你
氮
j
乙
你
S
e
s
n
e
时间
t
F
我
H
S
乙
t
s
n
哦
C
p
哦
时间
H
t
p
e
D
5
0
1
6
.
4
7
0
6
.
8
3
1
6
.
7
5
0
6
.
1
2
2
6
.
0
7
9
4
.
1
1
9
4
.
0
9
9
4
.
6
4
9
4
.
2
1
0
5
.
4
9
.
7
6
2
2
.
7
6
1
0
.
0
7
9
1
.
2
7
9
2
.
3
7
8
1
.
6
6
1
2
.
4
6
5
5
.
8
6
7
6
.
9
6
9
8
.
9
6
9
6
.
5
6
7
0
.
6
6
1
6
.
7
6
6
3
.
9
6
7
2
.
8
6
1
4
.
7
5
6
7
.
6
5
2
2
.
7
5
5
3
.
8
5
6
7
.
9
5
4
7
.
9
3
8
3
.
9
3
2
1
.
0
4
4
0
.
4
4
6
7
.
9
3
6
4
.
1
3
1
2
.
0
3
4
1
.
2
3
5
0
.
3
3
6
.
1
3
C
瓦
2
0
.
0
1
5
5
.
9
6
6
.
9
6
5
.
9
3
1
.
9
H
t
G
n
e
L
9
6
.
5
7
6
7
.
0
8
0
0
.
0
8
6
7
.
4
8
1
4
.
5
8
乙
D
–
氮
乙
S
C
–
氮
乙
右
F
–
氮
乙
氮
乙
↔
中号
中号
↔
中号
.
)
s
我
e
d
哦
米
k
0
3
我
t
我
你
中号
(
s
k
s
A
t
G
n
我
乙
哦
r
p
我
A
v
乙
t
n
e
S
e
H
t
r
哦
F
s
e
r
哦
C
S
2
1
e
我
乙
A
时间
412
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
C
哦
我
我
/
我
A
r
t
我
C
e
–
p
d
F
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
C
哦
我
我
_
A
_
0
0
3
7
7
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
a whole has been used in our experiments. An interesting further step is to investigate
whether specialized roles are assigned to the different attention heads (columns in the
矩阵) and whether they effectively learn to focus on different parts of the sentence.
In order to analyze this, we conduct additional studies on the Europarl models,
and we further assess the performance of individual heads on the SentEval linguistic
probing tasks. Our aim is to identify whether some attention heads are particularly
important in some probing task, and whether we see differences in how the roles of the
heads are distributed depending on the size of the attention bridge.
We compare attention bridges of sizes 10, 25, 和 50, 和, to study the effect of the
individual attention heads, we detach one attention head at a time to be used as the
representation of the sentence and apply them in the various probing tasks. 数字 5
shows two scenarios, attention bridges of sizes 10 和 50 taken from the many-to-
many Europarl model. In both scenarios, the accuracy of each probing task is shown
for each attention head, separately. To test stability, we trained the probing tasks with
five different seeds and present the average accuracy score in the figure. The variance is
very small (of order ≤1e-1) in all cases and, 因此, the trends shown in the illustration
are reliable.
If the attention heads obtain different, specialized roles, we expect to see a higher
accuracy on one probing task for a specific attention head and a higher accuracy on
some other task for another one. In the case of 10 attention heads (k = 10), it is hard
to see any clear pattern. 相比之下, 和 50 头 (k = 50) there are some tasks in
which the performance of the heads with a higher index (> 40) is clearly better than
the performance of the ones with low indexes (< 15). The probing tasks, in which this
phenomenon is particularly pronounced, are word content, top constituents, number of the
subject (subjnumber), number of the object (objnumber), and possibly verb tense (tense).
However, rather than differentiation there is strong relation between these tasks, such
that an attention head that performs well on one task also performs well on the other
tasks.
Figure 5
Performance of each attention head on the probing tasks. Mean accuracy along different runs of
SentEval probing tasks using the trained {DE,FR,CS} ↔ EN models with k = 10 and 50.
413
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
20406080246810attention headmeank = 1025507502468101214161820222426283032343638404244464850attention headmeank = 50
Computational Linguistics
Volume 46, Number 2
From the illustration, we can see that there is an interesting pattern with increasing
performance on attention heads with higher index. This can be seen especially on tasks
like wordcontent, topconstituents, subjnumber, and objnumber. The differences are small
but this trend is still clearly visible and rather unexpected. In order to check whether
this observation is purely coincidental, we computed the average accuracy scores over
all Europarl models in our experiments averaging the numbers from the ones with the
same size of the attention bridge (in number of heads). This includes bilingual, many-
to-one, and many-to-many models. Figure 6 shows the average accuracy scores and
their variance on four tasks: wordcontent, topconstituents, subjnumber, and objnumber. In
this case, we also show figures from the k = 25 settings. The most striking outcome
of this study is that the same positive trend can be observed for all independently
trained models with larger attention bridges without aligning the inner-attention heads
or enforcing this behavior, instead of consistently having a large range and a stationary
mean accuracy, as one would expect from combining without any alignment the results
of the inner-attention layers of models trained independently. In the smallest attention
bridge (k = 10) it is difficult to see whether any head performs better than any other. In
the medium size attention bridge (k = 25), there is already a hint at higher performance
on the tasks topconstituents and subjnumber for the attention heads with the highest
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Figure 6
Mean accuracy across the different models with k = 10, 25, 50 on four probing tasks. Gray lines
surrounding the mean values are the min and max values obtained for each head across models.
414
objnumbersubjnumbertopconstituentswordcontent24681024681024681024681030507090attention headmeank = 10objnumbersubjnumbertopconstituentswordcontent0510152025051015202505101520250510152025305070attention headmeank = 25objnumbersubjnumbertopconstituentswordcontent01020304050010203040500102030405001020304050255075attention headmeank = 50
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
indexes. In the largest attention bridge (k = 50), on all four tasks, accuracies clearly
increase with high indexes.
We can also see that the variance is generally higher in the case of a small attention
bridge, while the scores become more stable with larger attention bridges and to some
extent higher attention head indexes. This seems to suggest that there are indeed certain
attention heads that specialize on specific tasks. The system does not have any explicit
mechanism to ensure that the attention heads will be aligned. This means that it is
possible that exactly the same information encoded by head i in one training would
be encoded by head j during another training. We observe that the first attention heads
indeed follow this behavior, whereas the later ones start behaving in a similar way. Why
part of this specialization is happening in the same order is less clear and this is probably
due to some internals of the underlying implementation of the training algorithms.
To have a better understanding on why the last attention heads seem to be the best
ones in some of the probing tasks, we plotted heat maps of which areas of a sentence
each of them focuses on. An example sentence (“We cannot afford to lose more of the mo-
mentum that existed in the beginning of the Nineties.”) is shown in Figure 7. For each
scenario (k = 1, 10, 25, 50) the patterns for the attention heads are shown, such that
every line illustrates the main focus areas of one of them. We obtain similar pictures for
(a) k = 1
(b) k = 10
(c) k = 25
(d) k = 50
Figure 7
Heat map showing where each attention head (rows) focuses, using an example sentence. Four
different attention bridges from the {DE,FR,CS} ↔ EN models are used in the visualization,
where k is the number of heads in the bridge.
415
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 46, Number 2
other sentences and different models (bilingual, many-to-one, or many-to-many) and
the figure is just a good example of the general picture we get.
The illustration suggests that the model learns to distribute attention to individual
words or bigrams among the attention heads until the sentence is sufficiently covered.
The order of positions seems rather random and not consistent as the variance of
probing task results suggest. Once there are additional attention heads available, the
remaining heads start picking up longer word sequences, predominantly from the
beginning of the sentence. This effect seems to explain the increasing performance on
the probing tasks that we have observed above.
The main clause is often in the beginning of a sentence, which explains why we see
high accuracies on the tasks top constituents, number of subject, and number of object. The
goal in the top constituents task is to determine the high level syntactic structure of the
sentence in terms of the top constituents immediately below the sentence (S) node in a
phrase structure grammar; an example of such a structure is: ADVP NP VP, as in “Then it
happened.” In the number of subject task, we need to determine whether the subject of the
main clause of the sentence is in singular or plural number. The number of the subject
is marked on the subject itself (plural -s), but also in determiners (a, an) and sometimes
in the predicate verb (third person singular -s). Similarly, in the task number of object, we
need to decide whether the object of the main clause is in singular or plural. In order
to excel in these tasks, it is crucial to be able to identify the area of the sentence where
the main clause is located, which apparently the last attention heads are often capable
of doing.
Furthermore, especially in the tasks top constituents and word content it is necessary
to analyze multiple words. The aim of the word content task is to identify which words in
a set of 1,000 preselected mid-frequency words are present in the sentence. An attention
head covering a larger area is naturally more likely to recognize a larger number
of words and, hence, performs better on that task. This also explains why the word
content task works well with an attention bridge consisting of only one attention head
(k = 1). If there is only one head available, the attention needs to be spread over a
broader range of words, which is beneficial for some tasks and detrimental for other
tasks (see Section 5.1).
Our hypothesis of differentiated roles of the separate attention heads has been
partly confirmed. Different attention heads do focus on different areas of the sentence.
However, they do not seem to specialize on information that is beneficial for a specific
downstream probing task. Rather, we see significant correlation, such that some atten-
tion heads are particularly strong at multiple probing tasks concurrently.
We can also observe that the attention of individual heads is in general very fo-
cused with a low kurtosis in its distribution until the sentence is covered. Once this
point is reached, the penalty term forces the inner-attention to explore collocational
relationships typically from the beginning of the sentence incrementally extending its
span. Interestingly, this behavior is accentuated by the penalty term in the loss function
that we introduced in Section 2.2. To illustrate this, we computed the entropy over the
attention heads of a model trained with and without penalty term using the following
procedure:
We randomly sampled 10K sentences of length up to 40 tokens from the English
monolingual NewsCrawl corpus 2018,12 and calculated the entropy values over the
weights A from Equation (6) using the EN-DE models with 50 attention heads. In
12 http://www.statmt.org/wmt19/translation-task.html.
416
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
Table 13
Comparison of entropy values for models trained with and without penalty term.
With Penalty Term Without Penalty Term
k ∈ [1, 50]
k ∈ [1, ni]
k ∈ [ni, 50]
1.20
0.49
1.73
0.63
0.43
0.82
Table 13 we present three different entropy values using (i) all the attention heads,
k ∈ [1, 50], (ii) the initial ni attention heads until reaching the length of the sentence,
k ∈ [1, ni], and (iii) the final 50 − ni attention heads, k ∈ [ni, 50]; where ni is the length of
sentence i.
A higher entropy value indicates a broader spread of the attention, which leads us
to the conclusion that the penalty term is indeed forcing to scatter the attention once
the initial (position-specific) attention heads have covered the whole sentence. Up to
the length of the sentence (k ∈ [1, ni]) its presence does not make a significant difference
(entropy values 0.49 vs. 0.43). However, for the attention heads beyond the sentence
length (k ∈ [ni, 50]), we see that the model without it ends up focusing on a much
smaller portion of the sentence (entropy 0.82) compared with the model incorporating
the penalty term (entropy 1.73). Manual inspection of selected heat maps verifies this
result with redundant attention mostly fixed on the first token of the sentence in models
where the penalty term is left out.
In future work, we would like to investigate the behavior of attention in our model
with a larger diversity of languages and tasks. An interesting question is whether we
can see the same trend with less related languages included in our data and whether we
can force specialization using certain constraints or augmented loss functions during
training. We also want to explore the effect of adding other tasks that can be modeled
with the same architecture including speech recognition, sequence labeling, or parsing.
6. Related Work
Before concluding the paper, we briefly summarize related work.
Multilingual NMT has been widely studied and developed in different pathways
during recent years (Dong et al. 2015; Luong et al. 2016; Chen et al. 2017; Johnson
et al. 2017). Work has been done with networks that use language specific encoders and
decoders, such as Dong et al. (2015), who used a separate attention mechanism for each
decoder on one-to-many translation. Zoph and Knight (2016) exploited a multi-way
parallel corpus in a many-to-one multilingual scenario, while Firat, Cho, and Bengio
(2016) used language-specific encoders and decoders that share a traditional attention
mechanism in a many-to-many scheme. Another approach is the use of universal
encoder–decoder networks that share embedding spaces to improve the performance
of the model, like the one proposed by Gu et al. (2018b) for improving translation on
low-resourced languages and the one from Johnson et al. (2017), where the term zero-
shot translation was coined. Even though the latter model is proven to be effective and
appealing thanks to its simplicity, it does not scale well to the use of many languages.
Sharing all parameters of the model leads to a strongly degrading performance when
covering many diverse languages and new languages cannot easily be added on neither
417
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 46, Number 2
encoder nor decoder side. Furthermore, it does not provide a straightforward meaning
representation that can be used for downstream tasks.
Sentence meaning representation has also been vastly studied under NMT settings.
When introducing the encoder–decoder architectures for MT, Sutskever, Vinyals, and Le
(2014) showed that seq2seq models are better at encoding the meaning of sentences into
vector spaces than the bag-of-words model. Recent work includes that of Schwenk and
Douze (2017), who used multiple encoders and decoders that are connected through
a shared layer, albeit with a different purpose than performing translations; Platanios
et al. (2018) showed an intermediate representation that can be decoded to any target
language while describing a parameter generation method for universal NMT; Britz,
Guan, and Luong (2017) made a computational efficiency analysis for MT using a
fixed-size attention layer; Artetxe and Schwenk (2019) used a shared LSTM with max
pooling to learn sentence embeddings on 93 translation directions; Cífka and Bojar
(2018) introduced an architecture with a self-attentive layer to extract sentence meaning
representations of fixed size. Here we use a similar architecture but in a multilingual
setting.
Our work on multilingual MT and sentence representations is closely related to the
study from Lu et al. (2018). There, the authors attempt to build a neural interlingua
by using language-independent encoders and decoders which share an attentive LSTM
layer. Our approach differs on the choice of the crosslingual shared layer; we use a
shared inner-attention mechanism in contrast to having a feedforward layer on top
of a shared LSTM. Additionally, we also experiment in a multilingual many-to-many
setting, instead of only exploring the one-to-many or many-to-one scenarios.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
7. Conclusions
We have shown that fixed-size sentence representations can effectively be learned with
multilingual machine translation using an inner-attention layer and scheduled training
with multiple translation tasks. The performance of the model heavily depends on the
size of the intermediate representation layer and we can show that a higher number
of attention heads leads to improved translation and stronger representations in super-
vised downstream tasks, a result that contradicts earlier findings.
Multilinguality also helps boost the performance in the aforesaid downstream
tasks although it does not necessarily contribute to improve translation performance
when trained with large data sets. However, multilinguality does substantially benefit
translation performance in low-resource scenarios. The multilingual training objectives
enable effective transfer learning that leads to an improvement of up to 4.43 absolute
BLEU points in an established image caption translation task. We can observe that even
languages that are different from both, the source and the target language of the test
case, help the overall model to achieve a better translation quality. This indirectly hints
at the additional semantic abstraction that the model can pick up from the multilingual
signal.
Our further analysis reveals that the attention bridge model mainly struggles with
long sentences. In fact, the decrease in performance that we observe on the Europarl
domain and the large-data scenario is entirely due to the drop in performance on
sentences above 45 tokens. Here we can see the limits of the fixed-size attention bridge
and the results are not particularly surprising. A future research direction is to study
ways to prevent this behavior and to investigate the impact of increasing the linguistic
diversity in translation performance.
418
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
The main purpose of the model is to act as an efficient way of learning language-
agnostic representations using translation as the auxiliary training objective. We verify
on the larger data set that the system is able to produce sentence embeddings that
encode essential syntactic and semantic information in a sentence. The results on down-
stream tasks in the large data set-up follow the same trend as we have shown in the low-
resource scenario. Punctually, multilinguality helps in supervised tasks. Generalizations
can be improved even from language pairs not involving the language we test on
(English).
We make a careful study on the impact of the size of the attention bridge and the role
of individual attention heads in encoding linguistic information. In short, increasing
the size of the bridge does not only lead to better translation performance but also
to improved results in supervised downstream tasks. To further study the impact of
individual attention heads on sentence encoding, we detach each of them in turn and
test their ability to perform a number of linguistic probing tasks. This experiment
reveals a surprising trend in which the attention heads with a high index in the attention
bridge perform better on various tests. Looking at the regions of sentences where these
higher-index heads focus on shows that they spread their attention more broadly than
their lower-index counterparts across the encoded sentence, which is beneficial for those
probing tasks. A similar explanation can be found for attention bridges of limited size
that perform well on the same probing tasks, in which an attention head spreads the
focus over larger regions of the sentence. This analysis provides important insights
about the process of encoding and its applicability in other tasks.
Our findings open many directions for future research. First of all, we would like
to study the impact of increasingly diverse training material on sentence representa-
tions that can be learned in the translation set-up. This includes the use of additional
languages from different language families and the integration of multiple domains
and textual genres, as well as the effect of using resource-rich language pairs on the
performance of low-resource languages. We would like to further investigate the lin-
guistic properties that a system picks up and, for example, study the implicit relational
structure (syntactic and semantic) that is captured by inner-attention in a multilingual
encoder. For this, we will also increase the complexity of the shared architecture with
additional layers and connections. We will systematically look at different training
schedules that vary the amounts of shared parameters depending on linguistic and
typological properties that we want to investigate.
Acknowledgments
This work is part of the FoTran project,
funded by the European Research Council
(ERC) under the European Union’s Horizon
2020 research and innovation programme
(grant agreement no 771113). The authors
gratefully acknowledge the support of the
Academy of Finland through project 314062
from the ICT 2023 call on Computation,
Machine Learning and Artificial Intelligence
and projects 270354 and 273457. Finally, we
would also like to acknowledge CSC – IT
Center for Science, Finland, for
computational resources, as well as NVIDIA
and their GPU grant.
References
Adi, Yossi, Einat Kermany, Yonatan Belinkov,
Ofer Lavi, and Yoav Goldberg. 2017.
Fine-grained analysis of sentence
embeddings using auxiliary prediction
tasks. 5th International Conference on
Learning Representations, ICLR 2017,
Conference Track (Poster),
Toulon.
Agirre, Eneko, Carmen Banea, Claire Cardie,
Daniel Cer, Mona Diab, Aitor
Gonzalez-Agirre, Weiwei Guo, Inigo
Lopez-Gazpio, Montse Maritxalar, Rada
Mihalcea et al. 2015. SemEval-2015 Task 2:
Semantic textual similarity, English,
Spanish and pilot on interpretability. In
Proceedings of the 9th International Workshop
419
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 46, Number 2
on Semantic Evaluation (SemEval 2015),
pages 252–263, Denver, CO.
Agirre, Eneko, Carmen Banea, Claire Cardie,
Daniel Cer, Mona Diab, Aitor
Gonzalez-Agirre, Weiwei Guo, Rada
Mihalcea, German Rigau, and Janyce
Wiebe. 2014. SemEval-2014 Task 10:
Multilingual semantic textual similarity. In
Proceedings of the 8th International Workshop
on Semantic Evaluation (SemEval 2014),
pages 81–91, Dublin.
Agirre, Eneko, Carmen Banea, Daniel Cer,
Mona Diab, Aitor Gonzalez-Agirre, Rada
Mihalcea, German Rigau, and Janyce
Wiebe. 2016. SemEval-2016 Task 1:
Semantic textual similarity, monolingual
and cross-lingual evaluation. In Proceedings
of the 10th International Workshop on
Semantic Evaluation (SemEval-2016),
pages 497–511, San Diego, CA.
Agirre, Eneko, Daniel Cer, Mona Diab, Aitor
Gonzalez-Agirre, and Weiwei Guo. 2013.
*SEM 2013 shared task: Semantic textual
similarity. In Second Joint Conference on
Lexical and Computational Semantics (*SEM),
Volume 1: Proceedings of the Main Conference
and the Shared Task: Semantic Textual
Similarity, volume 1, pages 32–43,
Atlanta, GA.
Agirre, Eneko, Mona Diab, Daniel Cer, and
Aitor Gonzalez-Agirre. 2012.
SemEval-2012 Task 6: A pilot on semantic
textual similarity. In Proceedings of the First
Joint Conference on Lexical and Computational
Semantics-Volume 1: Proceedings of the Main
Conference and the Shared Task, and Volume 2:
Proceedings of the Sixth International
Workshop on Semantic Evaluation,
pages 385–393, Montreal.
Arora, Sanjeev, Yingyu Liang, and Tengyu
Ma. 2017. A simple but tough-to-beat
baseline for sentence embeddings. 5th
International Conference on Learning
Representations, ICLR 2017, Conference
Track (Poster), Toulon.
Artetxe, Mikel and Holger Schwenk. 2019.
Massively multilingual sentence
embeddings for zero-shot cross-lingual
transfer and beyond. Transactions of the
Association for Computational Linguistics,
7:597–610.
Bahdanau, Dzmitry, Kyunghyun Cho, and
Yoshua Bengio. 2015. Neural machine
translation by jointly learning to align and
translate. 3rd International Conference on
Learning Representations, ICLR 2015,
Conference Track, San Diego, Ca.
Bau, Anthony, Yonatan Belinkov, Hassan
Sajjad, Nadir Durrani, Fahim Dalvi, and
James Glass. 2019. Identifying and
controlling important neurons in neural
420
machine translation. 7th International
Conference on Learning Representations, ICLR
2019, Conference Track (Poster), New
Orleans, LA.
Belinkov, Yonatan, Nadir Durrani, Fahim
Dalvi, Hassan Sajjad, and James Glass.
2017. What do neural machine translation
models learn about morphology? In
Proceedings of the 55th Annual Meeting of the
Association for Computational Linguistics
(Volume 1: Long Papers), volume 1,
pages 861–872, Vancouver.
Blackwood, Graeme, Miguel Ballesteros, and
Todd Ward. 2018. Multilingual neural
machine translation with task-specific
attention. In Proceedings of the 27th
International Conference on Computational
Linguistics, pages 3112–3122,
Santa Fe, NM.
Bojanowski, Piotr, Edouard Grave, Armand
Joulin, and Tomas Mikolov. 2017.
Enriching word vectors with subword
information. Transactions of the Association
for Computational Linguistics,
5:135–146.
Bojar, Ondˇrej, Rajen Chatterjee, Christian
Federmann, Mark Fishel, Yvette Graham,
Barry Haddow, Matthias Huck,
Antonio Jimeno Yepes, Philipp Koehn,
Christof Monz, Matteo Negri, Aurélie
Névéol, Mariana Neves, Matt Post, Lucia
Specia, Marco Turchi, and Karin Verspoor.
2018. In Proceedings of the Third Conference
on Machine Translation: Research Papers,
Brussels.
Bowman, Samuel R., Gabor Angeli,
Christopher Potts, and Christopher D.
Manning. 2015. A large annotated corpus
for learning natural language inference. In
Proceedings of the 2015 Conference on
Empirical Methods in Natural Language
Processing, pages 632–642, Lisbon.
Britz, Denny, Melody Guan, and
Minh-Thang Luong. 2017. Efficient
attention using a fixed-size memory
representation. In Proceedings of the 2017
Conference on Empirical Methods in Natural
Language Processing, pages 392–400,
Copenhagen.
Callison-Burch, Chris, Philipp Koehn,
Cameron Shaw Fordyce, and Christof
Monz, editors. 2007. Proceedings of the
Second Workshop on Statistical Machine
Translation, Prague.
Cer, Daniel, Mona Diab, Eneko Agirre, Inigo
Lopez-Gazpio, and Lucia Specia. 2017.
SemEval-2017 Task 1: Semantic textual
similarity multilingual and crosslingual
focused evaluation. In Proceedings of the
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
11th International Workshop on Semantic
Evaluation (SemEval-2017), pages 1–14,
Vancouver.
Chen, Qian, Zhen-Hua Ling, and Xiaodan
Zhu. 2018. Enhancing sentence embedding
with generalized pooling. In Proceedings of
the 27th International Conference on
Computational Linguistics, pages 1815–1826,
Santa Fe, NM.
Chen, Yun, Yang Liu, Yong Cheng, and
Victor O. K. Li. 2017. A teacher-student
framework for zero-resource neural
machine translation. In Proceedings of the
55th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 1925–1935, Vancouver.
Cho, Kyunghyun, Bart van Merriënboer,
Caglar Gulcehre, Dzmitry Bahdanau, Fethi
Bougares, Holger Schwenk, and Yoshua
Bengio. 2014. Learning phrase
representations using RNN
encoder–decoder for statistical machine
translation. In Proceedings of the 2014
Conference on Empirical Methods in Natural
Language Processing (EMNLP),
pages 1724–1734, Doha.
Cífka, Ondˇrej and Ondˇrej Bojar. 2018. Are
BLEU and meaning representation in
opposition? In Proceedings of the 56th
Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 1362–1371.
Conneau, Alexis and Douwe Kiela. 2018.
SentEval: An Evaluation Toolkit for
Universal Sentence Representations. In
Proceedings of the Eleventh International
Conference on Language Resources and
Evaluation (LREC 2018), pages 1699–1704.
Conneau, Alexis, Douwe Kiela, Holger
Schwenk, Loïc Barrault, and Antoine
Bordes. 2017. Supervised learning of
universal sentence representations from
natural language inference data. In
Proceedings of the 2017 Conference on
Empirical Methods in Natural Language
Processing, pages 670–680,
Copenhagen.
Conneau, Alexis, Germán Kruszewski,
Guillaume Lample, Loïc Barrault, and
Marco Baroni. 2018a. What you can cram
into a single vector: Probing sentence
embeddings for linguistic properties. In
Proceedings of the 56th Annual Meeting of the
Association for Computational Linguistics
(Volume 1: Long Papers), pages 2126–2136,
Melbourne.
Conneau, Alexis, Guillaume Lample,
Marc’Aurelio Ranzato, Ludovic Denoyer,
and Hervé Jégou. 2018b. Word translation
without parallel data. 6th International
Conference on Learning Representations, ICLR
2018, Conference Track (Poster),
Vancouver.
Conneau, Alexis, Ruty Rinott, Guillaume
Lample, Adina Williams, Samuel R.
Bowman, Holger Schwenk, and Veselin
Stoyanov. 2018c. XNLI: Evaluating
cross-lingual sentence representations. In
Proceedings of the 2018 Conference on
Empirical Methods in Natural Language
Processing, pages 2475–2485, Brussels.
Dalvi, Fahim, Nadir Durrani, Hassan Sajjad,
Yonatan Belinkov, and Stephan Vogel.
2017. Understanding and improving
morphological learning in the neural
machine translation decoder. In Proceedings
of the Eighth International Joint Conference on
Natural Language Processing (Volume 1: Long
Papers), volume 1, pages 142–151.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee,
and Kristina Toutanova. 2019. BERT:
Pre-training of deep bidirectional
transformers for language understanding.
In Proceedings of the 2019 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies, Volume 1 (Long and Short
Papers), pages 4171–4186, Minneapolis, MN.
Dolan, Bill, Chris Quirk, and Chris Brockett.
2004. Unsupervised construction of large
paraphrase corpora: Exploiting massively
parallel news sources. In COLING 2004:
Proceedings of the 20th International
Conference on Computational Linguistics,
pages 350–356, Geneva.
Dong, Daxiang, Hua Wu, Wei He, Dianhai
Yu, and Haifeng Wang. 2015. Multi-task
learning for multiple language translation.
In Proceedings of the 53rd Annual Meeting of
the Association for Computational Linguistics
and the 7th International Joint Conference on
Natural Language Processing (Volume 1: Long
Papers), volume 1, pages 1723–1732.
Dou, Zi Yi, Zhaopeng Tu, Xing Wang,
Shuming Shi, and Tong Zhang. 2018.
Exploiting deep representations for neural
machine translation. In Proceedings of the
2018 Conference on Empirical Methods in
Natural Language Processing,
pages 4253–4262.
Elliott, D., S. Frank, K. Sima’an, and L.
Specia. 2016. Multi30k: Multilingual
English-German image descriptions. In
Proceedings of the 5th Workshop on Vision and
Language, pages 70–74, Berlin.
Firat, Orhan, Kyunghyun Cho, and Yoshua
Bengio. 2016. Multi-way, multilingual
neural machine translation with a shared
421
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 46, Number 2
attention mechanism. In Proceedings of
NAACL-HLT, pages 866–875, San Diego,
CA.
Firat, Orhan, Baskaran Sankaran, Yaser
Al-Onaizan, Fatos T. Yarman Vural, and
Kyunghyun Cho. 2016. Zero-resource
translation with multi-lingual neural
machine translation. In Proceedings of the
2016 Conference on Empirical Methods in
Natural Language Processing,
pages 268–277, Austin, TX.
Gehring, Jonas, Michael Auli, David
Grangier, Denis Yarats, and Yann N.
Dauphin. 2017. Convolutional Sequence to
Sequence Learning. In Proceedings of the
34th International Conference on Machine
Learning (ICML 2017), pages 1243–1252,
Sydney.
Grave, Edouard, Piotr Bojanowski, Prakhar
Gupta, Armand Joulin, and Tomas
Mikolov. 2018. Learning word vectors for
157 languages. In Proceedings of the
International Conference on Language
Resources and Evaluation (LREC 2018),
pages 3483–3487, Miyazaki.
Graves, Alex and Jürgen Schmidhuber. 2005.
Framewise phoneme classification with
bidirectional LSTM and other neural
network architectures. Neural Networks,
18(5–6):602–610.
Gu, Jiatao, Hany Hassan, Jacob Devlin, and
Victor O. K. Li. 2018a. Universal neural
machine translation for extremely low
resource languages. In Proceedings of the
2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
Volume 1 (Long Papers), volume 1,
pages 344–354, New Orleans, LA.
Gu, Jiatao, Hany Hassan, Jacob Devlin, and
Victor O. K. Li. 2018b. Universal neural
machine translation for extremely low
resource languages. In Proceedings of the
2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
Volume 1 (Long Papers), pages 344–354,
New Orleans, LA.
Ha, Thanh Le, Jan Niehues, and Alexander
Waibel. 2016. Toward multilingual neural
machine translation with universal
encoder and decoder. Proceedings of the
International Workshop on Spoken Language
Translation, IWSLT 2016.
Hill, Felix, Kyunghyun Cho, and Anna
Korhonen. 2016. Learning distributed
representations of sentences from
unlabelled data. In Proceedings of the 2016
Conference of the North American Chapter of
the Association for Computational Linguistics:
422
Human Language Technologies,
pages 1367–1377, San Diego, CA.
Hu, Minqing and Bing Liu. 2004. Mining and
summarizing customer reviews. In
Proceedings of the Tenth ACM SIGKDD
International Conference on Knowledge
Discovery and Data Mining, pages 168–177,
Seattle, WA.
Johnson, Melvin, Mike Schuster, Quoc V. Le,
Maxim Krikun, Yonghui Wu, Zhifeng
Chen, Nikhil Thorat, Fernanda Viégas,
Martin Wattenberg, Greg Corrado, et al.
2017. Google’s multilingual neural
machine translation system: Enabling
zero-shot translation. Transactions of the
Association for Computational Linguistics,
5(1):339–351.
Joulin, Armand, Edouard Grave, Piotr
Bojanowski, and Tomas Mikolov. 2017. Bag
of tricks for efficient text classification. In
Proceedings of the 15th Conference of the
European Chapter of the Association for
Computational Linguistics: Volume 2, Short
Papers, pages 427–431, Valencia.
Kingma, Diederik P. and Jimmy Ba. 2015.
Adam: A method for stochastic
optimization. 3rd International Conference
on Learning Representations, ICLR 2015,
Conference Track (Poster), San Diego, CA.
Klein, Guillaume, Yoon Kim, Yuntian Deng,
Jean Senellart, and Alexander M. Rush.
2017. OpenNMT: Open-source toolkit for
neural machine translation. In Proceedings
of ACL 2017, System Demonstrations,
Vancouver.
Koehn, Philipp. 2005. Europarl: A parallel
corpus for statistical machine translation.
In MT Summit, volume 5, pages 79–86.
Koehn, Philipp, Hieu Hoang, Alexandra
Birch, Chris Callison-Burch, Marcello
Federico, Nicola Bertoldi, Brooke Cowan,
Wade Shen, Christine Moran, Richard
Zens, Chris Dyer, Ondrej Bojar, and
Alexandra Constantinand Evan Herbst.
2007. Moses: Open source toolkit for
statistical machine translation. Annual
Meeting of the Association for Computational
Linguistics (ACL), Demo and Poster
Sessions.
Kruszewski, Germán, Angeliki Lazaridou,
Marco Baroni, et al. 2015. Jointly
optimizing word representations for
lexical and sentential tasks with the
c-phrase model. In Proceedings of the 53rd
Annual Meeting of the Association for
Computational Linguistics and the 7th
International Joint Conference on Natural
Language Processing (Volume 1: Long
Papers), volume 1, pages 971–981.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Vázquez et al. A Systematic Study of Inner-Attention-Based Sentence Representations in NMT
Lakew, Surafel Melaku, Mauro Cettolo, and
Marcello Federico. 2018. A comparison of
transformer and recurrent neural networks
on multilingual neural machine
translation. In Proceedings of the 27th
International Conference on Computational
Linguistics, pages 641–652, Santa Fe, NM.
Lee, Jason, Kyunghyun Cho, and Thomas
Hofmann. 2017. Fully character-level
neural machine translation without
explicit segmentation. Transactions of the
Association for Computational Linguistics,
5:365–378.
Lin, Zhouhan, Minwei Feng, Cicero
Nogueira dos Santos, Mo Yu, Bing Xiang,
Bowen Zhou, and Yoshua Bengio. 2017. A
structured self-attentive sentence
embedding. In 5th International Conference
on Learning Representations, ICLR 2017,
Conference Track (Poster).
Lu, Yichao, Phillip Keung, Faisal Ladhak,
Vikas Bhardwaj, Shaonan Zhang, and
Jason Sun. 2018. A neural interlingua for
multilingual machine translation. In
Proceedings of the Third Conference on
Machine Translation: Research Papers,
pages 84–92, Brussels.
Luong, Minh Thang, Quoc V. Le, Ilya
Sutskever, Oriol Vinyals, and Lukasz
Kaiser. 2016. Multi-task sequence to
sequence learning. 4th International
Conference on Learning Representations, ICLR
2016, Conference Track (Poster), San Juan.
Luong, Thang, Hieu Pham, and
Christopher D. Manning. 2015. Effective
approaches to attention-based neural
machine translation. In Proceedings of the
2015 Conference on Empirical Methods in
Natural Language Processing,
pages 1412–1421, Lisbon.
Marelli, Marco, Stefano Menini, Marco
Baroni, Luisa Bentivogli, Raffaella
Bernardi, Roberto Zamparelli, et al. 2014.
A SICK cure for the evaluation of
compositional distributional semantic
models. In LREC, pages 216–223,
Reykjavik.
McCann, Bryan, James Bradbury, Caiming
Xiong, and Richard Socher. 2017. Learned
in translation: Contextualized word
vectors. In Advances in Neural Information
Processing Systems, pages 6294–6305,
Long Beach, CA.
Pang, Bo and Lillian Lee. 2004. A sentimental
education: Sentiment analysis using
subjectivity summarization based on
minimum cuts. In Proceedings of the 42nd
Annual Meeting of the Association for
Computational Linguistics, pages 271–278,
Barcelona.
Pang, Bo and Lillian Lee. 2005. Seeing stars:
Exploiting class relationships for sentiment
categorization with respect to rating scales.
In Proceedings of the 43rd Annual Meeting of
the Association for Computational Linguistics,
pages 115–124, Ann Arbor, MI.
Pennington, Jeffrey, Richard Socher, and
Christopher D. Manning. 2014. GloVE:
Global vectors for word representation. In
Empirical Methods in Natural Language
Processing (EMNLP), pages 1532–1543,
Doha.
Platanios, Emmanouil Antonios, Mrinmaya
Sachan, Graham Neubig, and Tom
Mitchell. 2018. Contextual parameter
generation for universal neural machine
translation. In Proceedings of the 2018
Conference on Empirical Methods in Natural
Language Processing, pages 425–435, Doha.
Poliak, Adam, Yonatan Belinkov, James
Glass, and Benjamin Van Durme. 2018. On
the evaluation of semantic phenomena in
neural machine translation using natural
language inference. In Proceedings of the
2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
Volume 2 (Short Papers), volume 2,
pages 513–523, New Orleans, LA.
Post, Matt. 2018. A call for clarity in
reporting BLEU scores. In Proceedings of the
Third Conference on Machine Translation:
Research Papers, pages 186–191, Brussels.
Reimers, Nils and Iryna Gurevych. 2019.
Sentence-BERT: Sentence embeddings
using Siamese BERT-networks. In
Proceedings of the 2019 Conference on
Empirical Methods in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 3973–3983,
Hong Kong.
Schwenk, Holger. 2018. Filtering and mining
parallel data in a joint multilingual space.
Proceedings of the 56th Annual Meeting of the
Association for Computational Linguistics
(Volume 2: Short Papers), pages 228–234.
Schwenk, Holger and Matthijs Douze. 2017.
Learning joint multilingual sentence
representations with neural machine
translation. In ACL Workshop on
Representation Learning for NLP,
pages 157–167, Vancouver.
Sennrich, Rico, Barry Haddow, and
Alexandra Birch. 2016. Neural machine
translation of rare words with subword
units. In Proceedings of the 54th Annual
Meeting of the Association for Computational
423
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 46, Number 2
Tao, Chongyang, Shen Gao, Mingyue Shang,
Wei Wu, Dongyan Zhao, and Rui Yan.
2018. Get The Point of My Utterance!
Learning Towards Effective Responses
with Multi-Head Attention Mechanism. In
Proceedings of the Twenty-Seventh
International Joint Conference on Artificial
Intelligence, pages 4418–4424, Stockholm.
Tu, Zhaopeng, Yang Liu, Zhengdong Lu,
Xiaohua Liu, and Hang Li. 2017. Context
gates for neural machine translation.
Transactions of the Association for
Computational Linguistics, 5:87–99.
Vaswani, Ashish, Noam Shazeer, Niki
Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Łukasz Kaiser, and Illia
Polosukhin. 2017. Attention is all you
need. In Advances in Neural Information
Processing Systems, pages 5998–6008.
Voorhees, Ellen M. and Dawn M. Tice. 2000.
Building a question answering test
collection. In Proceedings of the 23rd Annual
International ACM SIGIR Conference on
Research and Development in Information
Retrieval, pages 200–207, Athens.
Wang, Yining, Jiajun Zhang, Feifei Zhai,
Jingfang Xu, and Chengqing Zong. 2018.
Three strategies to improve one-to-many
multilingual translation. In Proceedings of
the 2018 Conference on Empirical Methods in
Natural Language Processing,
pages 2955–2960, Brussels.
Wiebe, Janyce, Theresa Wilson, and Claire
Cardie. 2005. Annotating expressions of
opinions and emotions in language.
Language Resources and Evaluation,
39(2–3):165–210.
Zoph, Barret and Kevin Knight. 2016.
Multi-source neural translation. In
Proceedings of NAACL-HLT, pages 30–34,
San Diego, CA.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
6
2
3
8
7
1
8
4
7
6
4
0
/
c
o
l
i
_
a
_
0
0
3
7
7
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Linguistics (Volume 1: Long Papers),
volume 1, pages 1715–1725, Berlin.
Shi, Xing, Inkit Padhi, and Kevin Knight.
2016. Does string-based neural MT learn
source syntax? In Proceedings of the 2016
Conference on Empirical Methods in Natural
Language Processing, pages 1526–1534,
Austin, TX.
Socher, Richard, Alex Perelygin, Jean Wu,
Jason Chuang, Christopher D. Manning,
Andrew Ng, and Christopher Potts. 2013.
Recursive deep models for semantic
compositionality over a sentiment
treebank. In Proceedings of the 2013
Conference on Empirical Methods in Natural
Language Processing, pages 1631–1642,
Seattle, WA.
Subramanian, Sandeep, Adam Trischler,
Yoshua Bengio, and Christopher J. Pal.
2018. Learning general purpose
distributed sentence representations via
large scale multi-task learning. 6th
International Conference on Learning
Representations, ICLR 2018, Conference
Track (Poster), Vancouver.
Sutskever, Ilya, Oriol Vinyals, and Quoc V.
Le. 2014. Sequence to sequence learning
with neural networks. In Ghahramani, Z.,
M. Welling, C. Cortes, N. D. Lawrence, and
K. Q. Weinberger, editors, Advances in
Neural Information Processing Systems 27,
Curran Associates, Inc., pages 3104–3112.
Tai, Kai Sheng, Richard Socher, and
Christopher D. Manning. 2015. Improved
semantic representations from
tree-structured long short-term memory
networks. In Proceedings of the 53rd Annual
Meeting of the Association for Computational
Linguistics and the 7th International Joint
Conference on Natural Language Processing
(Volume 1: Long Papers), volume 1,
pages 1556–1566, Beijing.
424