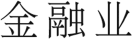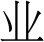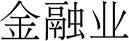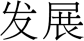A Graph-based Model for Joint Chinese Word Segmentation and
Dependency Parsing
Hang Yan, Xipeng Qiu∗, Xuanjing Huang
School of Computer Science, Fudan University, 中国
Shanghai Key Laboratory of Intelligent Information Processing, Fudan University, 中国
{hyan19, xpqiu, xjhuang}@fudan.edu.cn
抽象的
Chinese word segmentation and dependency
parsing are two fundamental tasks for Chinese
natural language processing. The dependency
parsing is defined at the word-level. 所以
word segmentation is the precondition of
dependency parsing, which makes dependency
parsing suffer from error propagation and
unable to directly make use of character-level
pre-trained language models (such as BERT).
在本文中, we propose a graph-based model
to integrate Chinese word segmentation and
dependency parsing. Different from previous
transition-based joint models, our proposed
model is more concise, which results in fewer
efforts of feature engineering. Our graph-based
joint model achieves better performance than
previous joint models and state-of-the-art
results in both Chinese word segmentation
and dependency parsing. 此外, 什么时候
BERT is combined, our model can substan-
tially reduce the performance gap of depen-
dency parsing between joint models and
gold-segmented word-based models. Our code
is publicly available at https://github.
com/fastnlp/JointCwsParser.
1 介绍
Unlike English, Chinese sentences consist of
continuous characters and lack obvious bound-
aries between Chinese words. Words are usually
regarded as the minimum semantic unit, 那里-
fore Chinese word segmentation (CWS) becomes
a preliminary pre-process step for downstream
Chinese natural language processing (自然语言处理). 为了
例子, the fundamental NLP task, 依赖性
∗Corresponding author.
78
解析, is usually defined at the word-level. 到
parse a Chinese sentence, the process is usually
performed in the following pipeline method: word
segmentation, part-of-speech (销售点) tagging, 和
dependency parsing.
然而, the pipeline method always suffers
from the following limitations:
(1) Error Propagation. In the pipeline method,
once some words are wrongly segmented,
the subsequent POS tagging and parsing will
also make mistakes. 因此, pipeline
models achieve dependency scores of around
75 ~ 80% (Kurita et al., 2017).
(2) Knowledge Sharing. These three tasks (word
segmentation, 词性标注, and dependency
解析) are strongly related. The criterion
of CWS also depends on the word’s gram-
matical role in a sentence. 所以, 这
knowledge learned from these three tasks can
be shared. The knowledge of one task can
help others. 然而, the pipeline method
separately trains three models, each for a sin-
gle task, and cannot fully exploit the shared
knowledge among the three tasks.
A traditional solution to this error propagation
problem is to use joint models (Hatori et al., 2012;
张等人。, 2014; Kurita et al., 2017). 这些
previous joint models mainly adopted a transition-
based parsing framework to integrate the word seg-
心理状态, 词性标注, and dependency parsing.
Based on standard sequential shift-reduce transi-
系统蒸发散, they design some extra actions for word
segmentation and POS tagging. Although these
joint models achieved better performance than
the pipeline model, they still suffer from two
局限性:
(1) The first is the huge search space. 康姆-
transition parsing,
pared with word-level
计算语言学协会会刊, 卷. 8, PP. 78–92, 2020. https://doi.org/10.1162/tacl 00301
动作编辑器: Yue Zhang. 提交批次: 9/2019; 修改批次: 11/2019; 已发表 3/2020.
C(西德:4) 2020 计算语言学协会. 根据 CC-BY 分发 4.0 执照.
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
character-level transition parsing has longer
sequence of actions. The search space is
huge. 所以, it is hard to find the best
transition sequence exactly. 通常, approx-
imate strategies like greedy search or beam
search are adopted in practice. 然而,
approximate strategies do not, 一般来说,
produce an optimal solution. Although exact
searching is possible within O(n3) 复杂的-
性 (Shi et al., 2017), due to their complexity,
these models just focus on unlabeled depen-
dency parsing, rather than labeled depen-
dency parsing.
(2) The second is the feature engineering. 这些
transition-based joint models rely on a de-
tailed handcrafted feature. Although Kurita
等人. (2017) introduced neural models to
reduce partial efforts of feature engineering,
they still require hard work on how to design
and compose the word-based features from
the stack and the character-based features
from the buffer.
最近, graph-based models have made signif-
icant progress for dependency parsing (Kiperwasser
and Goldberg, 2016; Dozat and Manning, 2017),
which fully exploit the ability of the bidirec-
tional long short-term memory network (BiLSTM)
(Hochreiter and Schmidhuber, 1997) 和关注
机制 (Bahdanau et al., 2015) to capture the
interactions of words in a sentence. Different from
the transition-based models, the graph-based mod-
els assign a score or probability to each possible
arc and then construct a maximum spanning tree
from these weighted arcs.
在本文中, we propose a joint model for
CWS and dependency parsing that integrates these
two tasks into a unified graph-based parsing frame-
工作. Because the segmentation is a character-
level task and dependency parsing is a word-level
任务, we first formulate these two tasks into a
character-level graph-based parsing framework.
In detail, our model contains (1) a deep neural
network encoder, which can capture the long-
term contextual features for each character—
it can be a multi-layer BiLSTM or pre-trained
BERT, (2) a biaffine attentional scorer (Dozat
and Manning, 2017), which unifies segmentation
and dependency relations at the character level.
Besides, unlike the previous joint models (Hatori
等人。, 2012; 张等人。, 2014; Kurita et al.,
2017), our joint model does not depend on the
POS tagging task.
In experiments on three popular datasets, 我们
obtain state-of-the-art performance on CWS and
dependency parsing.
在本文中, we claim four contributions:
• 据我们所知, this is the first
graph-based method to integrate CWS and
dependency parsing both in the training phase
and the decoding phase. The proposed model
is very concise and easily implemented.
• Compared with the previous transition-based
joint models, our proposed model is a graph-
based model, which results in fewer efforts of
feature engineering. 此外, our model
can deal with the labeled dependency parsing
任务, which is not easy for transition-based
joint models.
• In experiments on datasets CTB-5, CTB-7,
and CTB-9, our model achieves state-of-
the-art score in joint CWS and dependency
解析, even without the POS information.
• As an added bonus, our proposed model can
directly utilize the pre-trained language model
BERT (Devlin et al., 2019) to boost perfor-
mance significantly. The performance of many
NLP tasks can be significantly enhanced when
BERT was combined (孙等人。, 2019; Zhong
等人。, 2019). 然而, for Chinese, BERT
is based on Chinese characters, whereas de-
pendency parsing is conducted in the word-
等级. We cannot directly utilize BERT to
enhance the word-level Chinese dependency
parsing models. 尽管如此, by using the
our proposed model, we can exploit BERT
to implement CWS and dependency parsing
jointly.
2 相关工作
To reduce the problem of error propagation and
improve the low-level tasks by incorporating the
knowledge from the high-level tasks, many suc-
joint methods have been proposed to
成功的
simultaneously solve related tasks, which can be
categorized into three types.
2.1 Joint Segmentation and POS Tagging
Because segmentation is a character-level task and
POS tagging is a word-level task, an intuitive idea
79
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
is to transfer both the tasks into character-level
and incorporate them in a uniform framework.
A popular method is to assign a cross-tag to
each character (Ng and Low, 2004). The cross-
tag is composed of a word boundary part and a
POS part, 例如, ‘‘B-NN’’ refers to the first
character in a word with POS tag ‘‘NN’’. 因此,
the joint CWS and POS tagging can be regarded
as a sequence labeling problem. Following this
工作, Zheng et al. (2013), Chen et al. (2017),
and Shao et al. (2017) utilized neural models to
alleviate the efforts of feature engineering.
Another line of the joint segmentation and POS
tagging method is the transition-based method
(Zhang and Clark, 2008, 2010), in which the joint
decoding process is regarded as a sequence of
action predictions. 张等人. (2018) used a
simple yet effective sequence-to-sequence neu-
ral model to improve the performance of the
transition-based method.
2.2 Joint POS Tagging and
Dependency Parsing
Because the POS tagging task and dependency
parsing task are word-level tasks, it is more natural
to combine them into a joint model.
Hatori et al. (2012) proposed a transition-based
joint POS tagging and dependency parsing model
and showed that the joint approach improved the
accuracies of these two tasks. Yang et al. (2018)
extended this model by neural models to alleviate
the efforts of feature engineering.
李等人. (2011) utilized the graph-based model
to jointly optimize POS tagging and dependency
parsing in a unique model. They also proposed
an effective POS tag pruning method that could
greatly improve the decoding efficiency.
By combining the lexicality and syntax into
a unified framework, joining POS tagging and
dependency parsing can improve both tagging and
parsing performance over independent modeling
显著地.
2.3 Joint Segmentation, POS Tagging, 和
Dependency Parsing
Compared with the above two kinds of joint tasks,
it is non-trivial to incorporate all the three tasks
into a joint model.
Hatori et al. (2012) first proposed a transition-
based joint model for CWS, 词性标注, 和
dependency parsing, which stated that dependency
information improved the performances of word
segmentation and POS tagging. 张等人. (2014)
expanded this work by using intra-character struc-
tures of words and found the intra-character de-
pendencies were helpful in word segmentation
and POS tagging. 张等人. (2015) proposed
joint segmentation, 词性标注, and dependency
re-ranking system. This system required a base
parser to generate some candidate parsing results.
Kurita et al. (2017) followed the work of Hatori
等人. (2012); 张等人. (2014) and used the
BiLSTM to extract features with n-gram character
string embeddings as input.
A related work is the full character-level neural
dependency parser (李等人。, 2018), but it focuses
on character-level parsing without considering the
word segmentation and word-level POS tagging
and parsing. Although a heuristic method could
transform the character-level parsing results to
word-level, the transform strategy is tedious and
the result is also worse than other joint models.
Besides, there are some joint models for constit-
uency parsing. Qian and Liu (2012) proposed a
joint inference model for word segmentation, 销售点
tagging, and constituency parsing. 然而, 他们的
model did not train three tasks jointly and suffered
from the decoding complexity due to the large
combined search space. Wang et al. (2013) 第一的
segmented a Chinese sentence into a word lattice,
and then predicted the POS tags and parsed tree
based on the word lattice. A dual decomposition
method was used to encourage the tagger and
parser to predict agreed structures.
The above methods show that syntactic parsing
can provide useful feedback to word segmentation
and POS tagging and the joint inference leads to
improvements in all three sub-tasks. 而且,
there is no related work on joint Chinese word
segmentation and dependency parsing, 没有
词性标注.
3 Proposed Model
Previous joint methods are mainly based on the
transition-based model, which modifies the stan-
dard ‘‘shift-reduce’’ operations by adding some
extra operations, such as ‘‘app’’ and ‘‘tag’’. Dif-
ferent from previous methods, we integrate word
segmentation and dependency parsing into a
graph-based parsing framework, which is simpler
and easily implemented.
第一的, we transform the word segmentation to
a special arc prediction problem. 例如,
80
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
数字 1: The unified framework for joint CWS and dependency parsing. The green arc indicates the word-level
dependency relation. The dashed blue arc with ‘‘app’’ indicates its connected characters belong to a word.
‘‘
(金融的
two intra-word dependent
秒-
a Chinese word
arcs:
托尔)’’ has
‘‘ ← ’’ and ‘‘ ← ’’. Both intra-word de-
pendent arcs have the label ‘‘app’’. 在这项工作中,
all characters in a word (excluding the last
特点) depend on their latter character, 作为
the ‘‘
(financial sector)’’ in Figure 1. A
character-based dependency parsing arc has also
been used in Hatori et al. (2012) and Zhang et al.
(2014), but their models were transition-based.
第二, we transform the word-level depen-
dency arcs to character-level dependency arcs.
Assuming that there is a dependency arc between
words w1 = xi:j and w2 = xu:v, where xi:j denotes
the continuous characters from i to j in a sentence,
we make this arc to connect the last characters
xj and xv of each word. 例如,
这
arc ‘‘
(financial sector)’’
is translated to ‘‘ → ’’. 数字 1 说明
the framework for joint CWS and dependency
解析.
(发展)→
因此, we can use a graph-based parsing model
to conduct these two tasks. Our model contains
two main components: (1) a deep neural network
encoder to extract the contextual features, 哪个
converts discrete characters into dense vectors,
和 (2) a biaffine attentional scorer (Dozat and
曼宁, 2017), which takes the hidden vectors
for the given character pair as input and predicts a
label score vector.
数字 2 illustrates the model structure for
joint CWS and dependency parsing. The detailed
description is as follows.
3.1 Encoding Layer
The encoding layer is responsible for converting
discrete characters into contextualized dense rep-
数字 2: Proposed joint model when the encoder
layer is BiLSTM. For simplicity, we omit the predic-
tion of the arc label, which uses a different biaffine
classifier.
resentations. 在本文中, we tried two different
kinds of encode layers. The first one is multi-
layer BiLSTM, the second one is the pre-trained
language model BERT (Devlin et al., 2019) 哪个
is based on self-attention.
3.1.1 BiLSTM-based Encoding Layer
Given a character sequence X = {x1, . . . , xN },
in neural models, the first step is to map discrete
language symbols into distributed embedding
空间. 正式地, each character xi
is mapped
as ei ∈ Rde ⊂ E, where de is a hyper-parameter
indicating the size of character embedding, 和
E is the embedding matrix. Character bigrams
and trigrams have been shown highly effective
for CWS and POS tagging in previous studies
(Pei et al., 2014; 陈等人。, 2015; Shao et al.,
2017; 张等人。, 2018). Following their settings,
we combine the character bigram and trigram to
enhance the representation of each character. 这
81
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
⊕ exixi+1
final character representation of xi is given by
ei = exi
⊕ exixi+1xi+2, where e denotes
the embedding for unigram, bigram, and trigram,
and ⊕ is the concatenation operator.
To capture the long-term contextual informa-
的, we use a deep BiLSTM (Hochreiter and
施米德胡贝尔, 1997) to incorporate information
from both sides of a sequence, which is a preva-
lent choice in recent research for NLP tasks.
The hidden state of LSTM for the i-th character
是
−→
h i−1,
←−
hi+1, 我),
hi = BiLSTM(不,
←−
−→
hi are the hidden states at posi-
h i and
在哪里
tion i of the forward and backward LSTMs re-
spectively, and θ denotes all the parameters in the
BiLSTM layer.
(1)
3.1.2 BERT-based Encoding Layer
Other than using BiLSTM as the encoder layer,
pre-trained BERT can also been used as the
encoding layer (Devlin et al., 2019; Cui et al.,
2019). The input of BERT is the character
sequence X = {x1, . . . , xN }, the output of the
last layer of BERT is used as the representation of
characters. More details on the structure of BERT
can be found in Devlin et al. (2019).
3.2 Biaffine Layer
To predict the relations of each character pair,
we use the biaffine attention mechanism (Dozat
and Manning, 2017) to score their probability on
the top of encoding layers. According to Dozat
and Manning (2017), biaffine attention is more
effectively capable of measuring the relationship
between two elementary units.
3.2.1 Unlabeled Arc Prediction
For the pair of the i-th and j-th characters, 我们
first take the output of the encoding layer hi
and hj, then feed them into an extension of bi-
linear transformation called a biaffine function to
obtain the score for an arc from xi (头) to xj
(dependent).
r(arc−head)
我
r(arc−dep)
j
= MLP(arc−head)(你好),
= MLP(arc−dep)(hj),
ij = r(arc−head)
s(arc)
我
+r(arc−head)时间
U (arc)r(arc−dep)
j
你(arc),
我
(2)
(3)
(4)
82
where MLP is a multi-layer perceptron. A weight
matrix U (arc) determines the strength of a link
from xi to xj while u(arc) is used in the bias term,
which controls the prior headedness of xi.
= [s(arc)
1j
] is the scores
of the potential heads of the j-th character,
then a softmax function is applied to obtain the
probability distribution.
因此, s(arc)
; ··· ; s(arc)
T j
j
In the training phase, we minimize the cross-
entropy of golden head-dependent pair. In the test
phase, we ensure that the resulting parse is a well-
formed tree by the heuristics formulated in Dozat
and Manning (2017).
ij
3.2.2 Arc Label Prediction
After obtaining the best predicted unlabeled tree,
we assign the label scores s(标签)
∈ RK for every
arc xi → xj, in which the k-th element cor-
responds to the score of k-th label and K is the size
of the label set. In our joint model, the arc label set
consists of the standard word-level dependency
labels and a special label ‘‘app’’ indicating the
intra-dependency within a word.
For the arc xi → xj, we obtain s(标签)
ij
和
r(label−head)
我
r(label−dep)
j
r(标签)
ij
s(标签)
ij
= MLP(label−head)(你好),
= MLP(label−dep)(hj),
= r(label−head)
= r(label−head)
j
我
我
+ 瓦 (标签)(r(标签)
ij
⊕ r(label−dep)
U (标签)r(label−dep)
j
(5)
(6)
(7)
,
) + 你(标签),
(8)
where U (标签) ∈ RK×p×p is a third-order tensor,
瓦 (标签) ∈ RK×2p is a weight matrix, 和
你(标签) ∈ RK is a bias vector. The best label of
arc xi → xj is determined according to s(标签)
.
ij
yij = arg max
标签
s(标签)
ij
(9)
In the training phase, we use golden head-
dependent relations and cross-entropy to optimize
arc label prediction. Characters with continuous
‘‘app’’ arcs can be combined into a single word.
If a character has no leftward ‘‘app’’ arc, it is a
single-character word. The arc with label ‘‘app’’
is constrained to occur in two adjacent characters
and is leftward. When decoding, we first use
the proposed model to predict the character-level
labeled dependency tree, and then recover the
word segmentation and word-level dependency
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
as Wang et al. (2011), 张等人. (2014), 和
Kurita et al. (2017). For CTB-9, we use the dev
and test files proposed by Shao et al. (2017), 和
we regard all left files as the training data.
4.2 Measures
Following Hatori et al. (2012), 张等人.
(2014, 2015), and Kurita et al. (2017), 我们用
standard measures of word-level F1, precision,
and recall scores to evaluate word segmentation
and dependency parsing (for both unlabeled and
labeled scenario) 任务. We detail them in the
following.
• F 1seg: F1 measure of CWS. This is the stan-
dard metric used in the CWS task (Qiu et al.,
2013; 陈等人。, 2017).
• F 1udep: F1 measure of unlabeled dependency
解析. Following Hatori et al. (2012), 张
等人. (2014, 2015), and Kurita et al. (2017),
we use standard measures of word-level
F1, precision, and recall score to evaluate
dependency parsing. In the scenario of joint
word segmentation and dependency parsing,
the widely used unlabeled attachment score
(UAS) is not enough to measure the perfor-
曼斯, since the error arises from two as-
pects: One is caused by word segmentation
and the other is due to the wrong prediction
on the head word. A dependent-head pair is
correct only when both the dependent and
head words are accurately segmented and
the dependent word correctly finds its head
word. The precision of unlabeled dependency
解析 (denoted as Pudep) is calculated by
the correct dependent-head pair versus the
total number of dependent-head pairs (即
the number of segmented words). The recall
of unlabeled dependency parsing (denoted as
Rudep) is computed by the correct dependent-
head pair versus the total number of golden
dependent-head pairs (即, 的数量
golden words). The calculation of F 1udep is
like F 1seg.
• F 1ldep: F1 measure of labeled dependency
解析. The only difference from F 1udep is
that except for the match between the head
and dependent words, the pair must have
the same label as the golden dependent-head
pair. The precision and recall are calculated
correspondingly. Because the number of
数字 3: Label prediction for word segmentation only.
The arc with ‘‘app’’ indicates its connected characters
belong to a word, and the arc with ‘‘seg’’ indicates its
connected characters belong to different words.
tree based on the predicted character-level arc
labels. The characters with continuous ‘‘app’’ are
regarded as one word. And the predicted head
character of the last character is viewed as this
word’s head. Because the predicted arc points to
a character, we regard the word that contains this
head character as the head word.
3.3 Models for Word Segmentation Only
The proposed model can be also used for the
CWS task solely. Without considering the parsing
任务, we first assign a leftward unlabeled arc by
default for every two adjacent characters, 进而
predict the arc labels that indicate the boundary
of segmentation. In the task of word segmentation
仅有的, there are two kinds of arc labels: ‘‘seg’’ and
‘‘app’’. ‘‘seg’’ means there is a segmentation be-
tween its connected characters, and ‘‘app’’ means
its connected characters belong to one word. 是-
cause the unlabeled arcs are assigned in advance,
we just use Eq. (5) ~ (8) to predict the labels:
‘‘seg’’ and ‘‘app’’. 因此, the word segmentation
task is transformed into a binary classification
问题.
数字 3 gives an illustration of the labeled arcs
for the task of word segmentation only.
4 实验
4.1 数据集
We use the Penn Chinese Treebank 5.0 (CTB-
5),1 7.0 (CTB-7),2 和 9.0 (CTB-9)3 datasets to
evaluate our models (Xue et al., 2005). For CTB-5,
the training set is from sections 1∼270, 400∼931,
and 1001∼1151, the development set is from
section 301∼325, and the test set is from section
271∼300; this splitting was also adopted by Zhang
and Clark (2010), 张等人. (2014), and Kurita
等人. (2017). For CTB-7, we use the same split
1https://catalog.ldc.upenn.edu/LDC2005T01.
2https://catalog.ldc.upenn.edu/LDC2010T07.
3https://catalog.ldc.upenn.edu/LDC2016T13.
83
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
golden labeled dependent-head pairs and
predicted labeled dependent-head pairs are
the same with the counterparts of unlabeled
dependency parsing, the value of F 1ldep can-
not be higher than F 1udep.
A more detailed description of dependency
parsing metrics can be found in K¨ubler et al.
(2009). The U AS, LAS equal to the value of the
recall of unlabeled dependency parsing (Rudep)
and the recall of labeled dependency parsing
(Rldep), 分别. We also report these two
values in our experiments.
4.3 Experimental Settings
Pre-trained Embedding Based on Shao et al.
(2017); 张等人. (2018), n-grams are of great
benefit to CWS and POS tagging tasks. 因此
we use unigram, bigram, and trigram embeddings
for all of our character-based models. We first
pre-train unigram, bigram, and trigram embed-
dings on the Chinese Wikipedia corpus by the
method proposed in Ling et al. (2015), 哪个
improves standard Word2Vec by incorporating
token order information. For a sentence with char-
acters ‘‘abcd…’’, the unigram sequence is ‘‘a b c
…’’; the bigram sequence is ‘‘ab bc cd …’’; 和
trigram sequence is ‘‘abc bcd …’’. For our word
dependency parser, we use Tencent’s pre-trained
word embeddings (Song et al., 2018). 因为
Tencent’s pre-trained word embedding dimension
是 200, we set both pre-trained and random word
embedding dimension as 200 for all of our word
dependency parsing models. All pre-trained em-
beddings are fixed during our experiments. 在
addition to the fixed pre-trained embeddings, 我们
also randomly initialize embeddings, and element-
wisely add the pre-trained and random embed-
dings before other procedures. For a model with
BERT encoding layer, we use the Chinese BERT-
base released in Cui et al. (2019).
Hyper-parameters The development set is used
for parameter tuning. All random weights are ini-
tialized by Xavier normal initializer (Glorot and
本吉奥, 2010).
For BiLSTM based models, we generally fol-
low the hyper-parameters chosen in Dozat and
曼宁 (2017). The model
is trained with
the Adam algorithm (Kingma and Ba, 2015) 到
minimize the sum of the cross-entropy of arc pre-
dictions and label predictions. After each training
Embedding dimension
BiLSTM hidden size
Gradients clip
Batch size
Embedding dropout
LSTM dropout
Arc MLP dropout
Label MLP dropout
LSTM depth
MLP depth
Arc MLP size
Label MLP size
Learning rate
Annealing
β1, β2
Max epochs
100
400
5
128
0.33
0.33
0.33
0.33
3
1
500
100
2e-3
.75t/5000
0.9
100
桌子 1: Hyper-parameter settings.
epoch, we test the model on the dev set, 和
models with the highest F 1udep in development
set are used to evaluate on the test sets; 结果
reported for different datasets in this paper are all
on their test set. Detailed hyper-parameters can be
found in Table 1.
For BERT based models, we use the AdamW
optimizer with a triangle learning rate warmup, 这
maximum learning rate is 2e − 5 (Loshchilov and
Hutter, 2019; Devlin et al., 2019). It optimizes for
five epochs, the model with the best development
set performance is used to evaluate on the test sets.
4.4 Proposed Models
在这个部分, we introduce the settings for our
proposed joint models. Based on the way the
model uses dependency parsing labels and encod-
ing layers, we divide our models into four kinds.
We enumerate them as follows.
• Joint-SegOnly model: The proposed model
can be also used for word segmentation task
仅有的. In this scenario, the dependency arcs
are just allowed to appear in two adjacent
characters and label ∈ {应用程序, seg}. 这
model is described in Section 3.3.
• Joint-Binary model: This scenario means
label ∈ {应用程序, dep}. 在这种情况下,
这
label information of all the dependency arcs
is ignored. Each word-level dependency arc
is labeled as dep,
the intra-word depen-
dency is regarded as app. Characters with
84
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
楷模
Hatori et al. (2012)
张等人. (2014) STD
张等人. (2014) EAG
张等人. (2015)
Kurita et al. (2017)
Joint-Binary
Joint-Multi
Joint-Multi-BERT
CTB-5
CTB-7
CTB-9
F 1seg
97.75
97.67
97.76
98.04
98.37
98.45
98.48
98.46
F 1udep
81.56
81.63
81.70
82.01
81.42
87.24
87.86
89.59
F 1seg
95.42
95.53
95.39
-
95.86
96.57
96.64
97.06
F 1udep
73.58
75.63
75.56
-
74.04
81.34
81.80
85.06
F 1seg
-
-
-
-
-
97.10
97.20
97.63
F 1udep
-
-
-
-
-
81.67
82.15
85.66
STD and EAG in Zhang et al. (2014) denote the arc-standard and the arc-eager models.
F 1seg and F 1udep are the F1 score for Chinese word segmentation and unlabeled dependency parsing,
分别.
桌子 2: Main results in the test set of different datasets. Our Joint-Multi model achieves superior performance
than previous joint models. The Joint-Multi-BERT further enhances the performance of dependency parsing
显著地.
continuous app label will be joined together
and viewed as one word. The dep label
indicates this character is the end of a word.
• Joint-Multi model: This scenario means
label ∈ {应用程序, dep1, ··· , depK }, where K
is the number of types of dependency arcs.
The intra-word dependency is viewed as app.
The other labels are the same as the original
arc labels. But instead of representing the
relationship between two words, the labeled
arc represents the relationship between the
last character of the dependent word and the
last character of the head word.
• Joint-Multi-BERT model: For this kind of
模型, the encoding layer is BERT. And it
uses the same target scenario as the Joint-
Multi model.
4.5 Comparison with the Previous
Joint Models
在这个部分, we mainly focus on the perfor-
mance comparison between our proposed models
and the previous joint models. Because the pre-
vious models just deal with the unlabeled depen-
dency parsing, we just report the F 1seg and F 1udep
这里.
As presented in Table 2, our model (Joint-
Binary) outpaces previous methods with a large
margin in both CWS and dependency parsing,
even without the local parsing features that were
extensively used in previous transition-based joint
工作 (Hatori et al., 2012; 张等人。, 2014,
2015; Kurita et al., 2017). Another difference
between our joint models and previous works is
the combination of POS tags; the previous models
all used the POS task as one componential task.
Despite the lack of POS tag information, our mod-
els still achieve much better results. 然而,
according to Dozat and Manning (2017), 销售点
tags are beneficial to dependency parsers, 那里-
fore one promising direction of our joint model
might be incorporating POS tasks into this joint
模型.
Other than the performance distinction between
previous work, our joint model with or without
dependency labels also differ from each other. 它
is clearly shown in Table 2 that our joint model
with labeled dependency parsing (Joint-Multi)
outperforms its counterpart (Joint-Binary) in both
CWS and dependency parsing. With respect to the
enhancement of dependency parsing caused by
the arc labels, we believe it can be credited to two
aspects. The first one is the more accurate CWS.
The second one is that label information between
two characters will give extra supervision for the
search of head characters. The reason why labeled
dependency parsing is conducive to CWS will be
also analyzed in Section 4.6.
Owing to the joint decoding of CWS and de-
pendency parsing, we can utilize the character-
level pre-trained language model BERT. 最后一个
row of Table 2 displays that the F 1udep can be
substantially increased when BERT is used, 甚至
when the performance of CWS not improve too
much. We presume this indicates that BERT can
better extract the contextualized information to
help the dependency parsing.
85
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
楷模
Tag Set
LSTM+MLP
LSTM+CRF
LSTM+MLP
{乙, 中号, 乙, S}
{乙, 中号, 乙, S}
{应用程序, seg}
{应用程序, seg}
{应用程序, dep}
CTB-5
CTB-7
CTB-9
F 1seg Pseg Rseg
F 1seg Pseg Rseg
F 1seg Pseg Rseg
98.47 98.26 98.69
98.48 98.33 98.63
98.40 98.14 98.66
95.45 96.44 96.45
96.46 96.45 96.47
96.41 96.53 96.29
97.11 97.19 97.04
97.15 97.18 97.12
97.09 97.16 97.02
98.50 98.30 98.71
Joint-SegOnly
98.45 98.16 98.74
Joint-Binary
{应用程序, dep1, ··· , depK} 98.48 98.17 98.80
Joint-Multi
Joint-Multi-BERT {应用程序, dep1, ··· , depK} 98.46 98.12 98.81
96.50 96.67 96.34
96.57 96.66 96.49
96.64 96.68 96.60
97.06 97.05 97.08
97.09 97.15 97.04
97.10 97.16 97.04
97.20 97.31 97.19
97.63 97.68 97.58
The upper part refers the models based on sequence labeling.
The lower part refers our proposed joint models which are detailed in Section 4.4. The proposed joint models
achieve near or better F 1seg than models trained only on Chinese word segmentation.
F 1seg, Pseg, and Rseg are the F1, precision, and recall of CWS, 分别.
桌子 3: Results of Chinese word segmentation.
4.6 Chinese Word Segmentation
In this part, we focus on the performance of our
model for the CWS task only.
Most of state-of-the-art CWS methods are based
on sequence labeling, in which every sentence is
transformed into a sequence of {乙, 中号, 乙, S} tags.
B represents the begin of a word, M represents the
middle of a word, E represents the end of a word,
and S represents a word with only one character.
We compare our model with these state-of-the-art
方法.
• LSTM+MLP with {乙, 中号, 乙, S} tags. 福尔-
lowing Ma et al. (2018), we tried to do CWS
without conditional random fields (CRFs).
After BiLSTM, the hidden states of each
character further forwards into a multi-layer
perceptron (多层线性规划), so that every character
can output a probability distribution over the
label set. The Viterbi algorithm is utilized
to find the global maximum label sequence
when testing.
• LSTM+CRF with {乙, 中号, 乙, S} tags. 这
only difference between this scenario and
the previous one is whether using CRF after
the MLP (Lafferty et al., 2001; 陈等人。,
2017).
• LSTM+MLP with {应用程序, seg} tags. The seg-
mentation of a Chinese sentence can be
represented by a sequence of {应用程序, seg},
where app represents that the next character
and this character belongs to the same word,
and seg represents that this character is the
last character of a word. 所以, CWS
can be viewed as a binary classification prob-
莱姆. Except for the tag set, this model’s
architecture is similar to the LSTM+MLP
scenario.
All of these models use the multi-layer BiLSTM
as the encoder; they differ from each other in their
way of decoding and the tag set. 的数量
BiLSTM layers is 3 and the hidden size is 200.
The performance of all models are listed in
桌子 3. The first two rows present the difference
between whether utilizing CRF on the top of
多层线性规划. CRF performance is slightly better than its
对方. The first row and the third row display
the comparison between different tag scenarios,
这 {乙, 中号, 乙, S} tag set is slightly better than the
{应用程序, seg} tag set.
Different from the competitor sequence labeling
模型 (LSTM+MLP with {应用程序, seg} tag set),
our joint-SegOnly model uses the biaffine to
model the interaction between the two adjacent
characters near the boundary and achieves slightly
better or similar performances on all datasets. 这
empirical results in the three datasets suggest that
modeling the interaction between two consecutive
characters are helpful to CWS. If two characters
are of high probability to be in a certain depen-
dency parsing relationship, there will be a greater
chance that one of the characters is the head
特点.
The lower part of Table 3 shows the segmen-
tation evaluation of the proposed joint models.
Jointly training CWS and dependency parsing
achieves comparable or slightly better CWS than
training CWS alone. Although head prediction is
not directly related to CWS, the head character can
86
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
楷模
CTB-5
CTB-7
CTB-9
F 1seg F 1udep U AS F 1ldep LAS F 1seg F 1udep U AS F 1ldep LAS F 1seg F 1udep U AS F 1ldep LAS
-
88.81
-
85.63 -
-
86.06
-
81.33 -
-
86.21
-
81.57
86.71 83.46 83.67 96.50
88.08 85.08 85.23 96.64
89.97 85.94 86.3
97.06
† The results are evaluated by a word-level biaffine parser on the gold-segmented sentences.
§ The pipeline model first uses the Joint-SegOnly model to segment the sentence, then uses the word-level biaffine parser to obtain the
80.49 76.58 76.46 97.09
81.80 77.84 77.83 97.20
85.12 80.71 80.76 97.63
81.61 77.34 77.40
82.23 78.08 78.14
85.74 81.71 81.77
80.62
81.80
85.06
86.50
87.86
89.59
81.54
82.15
85.66
-
Biaffine†
Pipeline§
98.50
Joint-Multi
98.48
Joint-Multi-BERT 98.46
parsing result.
桌子 4: Comparison with the pipeline model. Our Joint-Multi models outperform the pipeline models in a large
margin. When BERT is used, the dependency parsing performance was significantly improved, 虽然
Chinese word segmentation does not meliorate a lot.
楷模
CTB-5
CTB-7
CTB-9
F 1seg F 1udep U AS F 1ldep LAS F 1seg F 1udep U AS F 1ldep LAS F 1seg F 1udep U AS F 1ldep LAS
Joint-Multi
98.48
-pre-trained 97.72
-n-gram
97.72
87.86
82.56
83.44
88.08
82.70
83.60
85.08
79.8
80.24
85.23 96.64
70.93 95.52
80.41 95.21
81.80
76.35
77.37
81.80
76.22
77.11
77.84
72.16
72.94
77.83 97.20
72.04 96.56
72.69 95.85
82.15
78.93
78.55
82.23
78.93
78.41
78.08
74.35
73.94
78.14
74.37
73.81
The ‘-pre-trained’ means the model is trained without the pre-trained embeddings.
The ‘-n-gram’ means the model is trained by removing the bigram and trigram embeddings, only randomly initialized and pre-trained
character embeddings are used.
桌子 5: Ablation experiments for Joint-Multi models.
only be the end of a word, therefore combination
between CWS and character dependency pars-
ing actually introduces more supervision for the
former task. On CTB-5, the Joint-Binary and Joint-
Multi models are slightly worse than the Joint-
SegOnly model. The reason may be that the CTB-5
dataset is relatively small and the complicated
models suffer from the overfitting. From the last
row of Table 3, BERT can further enhance the
model’s performance on CWS.
Another noticeable phenomenon from the lower
part of Table 3 is that the labeled dependency pars-
ing brings benefit to CWS. We assume this is be-
cause the extra supervision from dependency parsing
labels is informative for word segmentation.
4.7 Comparison with the Pipeline Model
In this part, we compare our joint model with
the pipeline model. The pipeline model first uses
our best Joint-SegOnly model to obtain segmenta-
tion results, then applies the word-based biaffine
parser to parse the segmented sentence. The word-
level biaffine parser is the same as in Dozat and
曼宁 (2017) but without POS tags. Just like
the joint parsing metric, for a dependent-head
word pair, only when both head and dependent
words are correct can this pair be viewed as a right
一.
桌子 4 obviously shows that in CTB-5, CTB-7,
and CTB-9, the Joint-Multi model consistently
outperforms the pipeline model in F 1udep, U AS,
F 1ldep, and LAS. Although the F 1seg difference
between the Joint-Multi model and the pipeline
model is only −0.02, +0.14, +0.11 in CTB-5,
CTB-7, and CTB-9, 分别, the F 1udep of
the Joint-Multi is higher than the pipeline model
经过 +1.36, +1.18, 和 +0.61, 分别; 我们
believe this indicates the better resistance to error
propagation of the Joint-Multi model.
此外, when BERT is used, F 1udep,
U AS, F 1ldep, and LAS are substantially im-
证实, which represents that our joint model can
take advantage of the power of BERT. In CTB-5,
the joint model even achieves better U AS than the
gold-segmented word-based model. And for the
LAS, Joint-Multi-BERT models also achieve
better results in CTB-5 and CTB-9. We presume
the reason that performance of CWS does not
improve as much as dependency parsing is that
the falsely segmented words in Joint-Multi-BERT
are mainly segmenting a long word into several
short words or recognizing several short words as
one long word.
4.8 Ablation Study
As our model uses various n-gram pre-trained em-
beddings, we explore the influence of these pre-
trained embeddings. The second row in Table 5
shows the results of the Joint-Multi model without
pre-trained embeddings; it is clear that pre-trained
87
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
楷模
CTB-5
CTB-7
Pudep Seg-wrong Head-wrong Pudep Seg-wrong Head-wrong Pudep Seg-wrong Head-wrong
CTB-9
Pipeline
Joint-Multi
Joint-Multi-BERT 89.22% 3.2%
86.28% 3.49%
87.65% 3.43%
10.23%
8.92%
7.58%
80.75% 7.10%
81.81% 6.80%
85.01% 6.10%
12.15%
11.39%
8.89%
81.48% 6.76%
82.08% 6.55%
85.59% 5.74%
11.76%
11.37%
8.89%
The value of Pudep is the percentage that the predicted arc is correct. ‘Seg-wrong’ means that either head or dependent
(或两者) is wrongly segmented. ‘Head-wrong’ means that the word is correctly segmented but the predicted head word is
wrong.
桌子 6: Error analysis of unlabeled dependency parsing in the test set of different datasets.
embeddings are important for both the word seg-
mentation and dependency parsing.
We also tried to remove the bigram and tri-
公克. Results are illustrated in the third row of
桌子 5. Compared with the Joint-Multi model,
without bigram and trigram, it performs worse
in all metrics. 然而, the comparison between
the second row and the third row shows diver-
gence in CWS and dependency parsing for datasets
CTB-5 and CTB-7. For CWS, the model without
pre-trained embeddings obtains superior perfor-
mance than without the bigram and trigram fea-
真实, whereas for all dependency parsing related
指标, the model with pre-trained character em-
bedding obtains better performance. We assume
the n-gram features are important to Chinese word
segmentation. For the dependency parsing task,
然而, the relation between two characters are
more beneficial; when pre-trained embeddings are
合并的, the model can exploit the relationship
encoded in the pre-trained embeddings. Addition-
盟友, for CTB-5 and CTB-7, even though the third
row has inferior F 1seg (一般 0.16% 降低
than the second row), it still achieves much better
F 1udep (一般 0.95% higher than the second
排). We believe this is a proof that joint CWS
and dependency parsing is resistant to error prop-
agation. The higher segmentation and dependency
parsing performance for the model without pre-
trained embedding in CTB-9 might be owing to its
large training set, which can achieve better results
even from randomly initialized embeddings.
4.9 误差分析
Apart from performing the standard evaluation, 我们
investigate where the dependency parsing head
prediction error comes from. The errors can be
divided into two kinds, (1) either the head or
dependent (或两者) is wrongly segmented, 或者 (2)
there is the wrong choice on the head word. 这
ratio of these two mistakes is presented in Table 6.
For the Joint-Multi model, more mistakes caused
by segmentation in CTB-7 is coherent with our
observation that CTB-7 bears lower CWS per-
formance. Based on our error analysis, the wrong
prediction of head word accounts for most of the
错误, therefore further joint models addressing
head prediction error problem might result in
more gain on performance.
此外, although from Table 4 迪斯-
tinction of F 1seg between the Joint-Multi model
and the Pipeline model is around +0.1% 平均-
年龄, the difference between the Head-wrong is
more than around +0.82% in average. We think
this is caused by the pipeline model, in which is
more sensitive to word segmentation errors and
suffers more from the OOV problem, as depicted
图中 4. From the last row of Table 4, Joint-
Multi-BERT achieves excellent performance on
dependency parsing because it can significantly
reduce errors caused by predicting the wrong
头.
5 Conclusion and Future Work
在本文中, we propose a graph-based model for
joint Chinese word segmentation and dependency
解析. Different from the previous joint models,
our proposed model is a graph-based model and
is more concise, which results in fewer efforts of
feature engineering. Although no explicit hand-
crafted parsing features are applied, our joint
model outperforms the previous feature-riched
joint models by a large margin. The empirical re-
sults in CTB-5, CTB-7, and CTB-9 show that
the dependency parsing task is also beneficial to
Chinese word segmentation. 此外, labeled
dependency parsing not only is good for Chinese
word segmentation, but also avails the dependency
parsing head prediction.
Apart from good performance, the comparison
between our joint model and the pipeline model
88
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
数字 4: Parsing results of different models. The red dashed box means the dependency label is wrong. 这
red dashed edge means this dependency arc does not exist. Although the pipeline model has the right word
segmentation, ‘‘
’’ is an out-of-vocabulary word. 所以, it fails to find the right dependency
relation and adversely affects predictions afterward. The Joint-Multi model can still have a satisfying outcome
even with wrong segmentation, which depicts that the Joint-Multi model is resistant to wrong word segmentations.
The Joint-Multi-BERT correctly finds the word segmentation and dependency parsing.
shows great potentialities for character-based
Chinese dependency parsing. And owing to the
joint decoding between Chinese word segmen-
tation and dependency parsing, our model can use
a pre-trained character-level language model (这样的
as BERT) to enhance the performance further.
After the incorporation of BERT,
the perfor-
mance of our joint model increases substantially,
resulting in the character-based dependency pars-
ing performing near the gold-segmented word-
based dependency parsing. Our proposed method
not merely outpaces the pipeline model, 但
also avoids the preparation for pre-trained word
embeddings that depends on a good Chinese word
segmentation model.
In order to fully explore the possibility of graph-
based Chinese dependency parsing, future work
should be done to incorporate POS tagging into
this framework. 此外, as illustrated in
张等人. (2014), a more reasonable intra-word
dependent structure might further boost the perfor-
mance of all tasks.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
89
致谢
We would like to thank the action editor and the
anonymous reviewers for their insightful com-
评论. We also thank the developers of fastNLP,4
Yunfan Shao and Yining Zheng, for developing
this handy natural language processing package.
This work was supported by the National Key
Research and Development Program of China
(不. 2018YFC0831103), National Natural Science
Foundation of China (不. 61672162), Shanghai
Municipal Science and Technology Major Project
(不. 2018SHZDZX01), and ZJLab.
参考
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
本吉奥. 2015. Neural machine translation by
jointly learning to align and translate. In 3rd
International Conference on Learning Repre-
句子, ICLR 2015, 圣地亚哥, CA, 美国,
May 7–9, 2015, Conference Track Proceedings.
Xinchi Chen, Xipeng Qiu, and Xuanjing Huang.
2017. A feature-enriched neural model for joint
Chinese word segmentation and part-of-speech
tagging. In Proceedings of the Twenty-Sixth
International Joint Conference on Artificial
智力, IJCAI 2017, 墨尔本, 澳大利亚,
August 19–25, 2017.
Xinchi Chen, Xipeng Qiu, Chenxi Zhu, Pengfei
刘, and Xuanjing Huang. 2015. Long Short-
Term Memory Neural Networks for Chinese
Word Segmentation. 在诉讼程序中
这
2015 实证方法会议
自然语言处理, EMNLP 2015,
里斯本, Portugal, September 17–21, 2015.
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin,
Ziqing Yang, Shijin Wang, and Guoping Hu.
2019. Pre-training with whole word masking
for Chinese BERT. CoRR, abs/1906.08101v2.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, 和
Kristina Toutanova. 2019. BERT: pre-training
of deep bidirectional transformers for language
理解. 在诉讼程序中
这 2019
Conference of the North American Chapter of
the Association for Computational Linguistics:
人类语言技术, NAACL-HLT
4https://github.com/fastnlp/fastNLP.
2019, 明尼阿波利斯, 明尼苏达州, 美国, June 2–7, 2019,
体积 1 (Long and Short Papers).
Timothy Dozat and Christopher D. 曼宁.
2017. Deep biaffine attention for neural depen-
dency parsing. In 5th International Conference
on Learning Representations,
ICLR 2017,
Toulon, 法国, April 24–26, 2017, 会议
Track Proceedings.
Xavier Glorot and Yoshua Bengio. 2010. 在下面-
standing the difficulty of training deep feed-
forward neural networks. 在诉讼程序中
Thirteenth International Conference on Arti-
ficial Intelligence and Statistics, AISTATS 2010,
Chia Laguna Resort, Sardinia,
意大利, 可能
13–15, 2010.
Jun Hatori, Takuya Matsuzaki, Yusuke Miyao,
and Jun’ichi Tsujii. 2012. Incremental joint
approach to word segmentation, 词性标注,
and dependency parsing in Chinese. In The
50th Annual Meeting of
the Association
for Computational Linguistics, 会议记录
the Conference, July 8–14, 2012, Jeju Island,
韩国 – 体积 1: Long Papers.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. 神经计算,
9(8):1735–1780.
Diederik P. Kingma and Jimmy Ba. 2015. 亚当:
A method for stochastic optimization. In 3rd
International Conference on Learning Repre-
句子, ICLR 2015, 圣地亚哥, CA, 美国,
May 7–9, 2015, Conference Track Proceedings.
Eliyahu Kiperwasser and Yoav Goldberg. 2016.
Simple and accurate dependency parsing us-
ing bidirectional LSTM feature representations.
Transactions of the Association for Computa-
tional Linguistics TACL, 4:313–327.
Sandra K¨ubler, Ryan T. 麦当劳, and Joakim
Nivre. 2009. Dependency Parsing. Synthesis
Lectures on Human Language Technologies.
摩根 & Claypool Publishers.
联合模型
Shuhei Kurita, Daisuke Kawahara, and Sadao
Kurohashi. 2017. Neural
为了
transition-based Chinese syntactic analysis. 在
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics,
前交叉韧带 2017, Vancouver, 加拿大, 七月 30 –
八月 4, 体积 1: Long Papers.
90
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
John D. 拉弗蒂, Andrew McCallum, 和
Fernando C. 氮. 佩雷拉. 2001. Conditional ran-
dom fields: Probabilistic models for segment-
ing and labeling sequence data. In Proceedings
of the Eighteenth International Conference on
Machine Learning (ICML 2001), Williams Col-
lege, Williamstown, 嘛, 美国, 六月 28 – 七月 1,
2001.
Haonan Li, Zhisong Zhang, Yuqi Ju, and Hai
赵. 2018. Neural character-level dependency
parsing for Chinese. In Proceedings of the Thirty-
Second AAAI Conference on Artificial Intelli-
根杰斯, (AAAI-18), the 30th innovative Applications
of Artificial Intelligence (IAAI-18), and the 8th
AAAI Symposium on Educational Advances in
人工智能 (EAAI-18), New Orleans,
Louisiana, 美国, February 2–7, 2018.
Zhenghua Li, Min Zhang, Wanxiang Che, Ting
刘, Wenliang Chen, and Haizhou Li. 2011.
Joint models for Chinese POS tagging and
dependency parsing. 在诉讼程序中 2011
Conference on Empirical Methods in Natural
语言处理, EMNLP 2011, 27–31
七月 2011, John McIntyre Conference Centre,
爱丁堡, 英国, A meeting of SIGDAT, a Spe-
cial Interest Group of the ACL.
Wang Ling, Chris Dyer, Alan W. 黑色的, and Isabel
Trancoso. 2015. Two/too simple adaptations
of word2vec for syntax problems. In NAACL
赫勒特 2015, 这 2015 Conference of the North
American Chapter of the Association for Com-
putational Linguistics: Human Language
Technologies, 丹佛, 科罗拉多州, 美国, 可能 31 –
六月 5, 2015.
Ilya Loshchilov and Frank Hutter. 2019. 的-
coupled weight decay regularization. In 7th
International Conference on Learning Repre-
句子, ICLR 2019, New Orleans, 这, 美国,
May 6–9, 2019.
Ji Ma, Kuzman Ganchev, and David Weiss. 2018.
State-of-the-art Chinese word segmentation with
bi-LSTMs. 在诉讼程序中 2018 Confer-
ence on Empirical Methods in Natural Language
加工, 布鲁塞尔, 比利时, 十月 31 –
十一月 4, 2018.
Hwee Tou Ng and Jin Kiat Low. 2004. Chinese
part-of-speech tagging: One-at-a-time or all-
at-once? Word-based or character-based? 在
诉讼程序 2004 Conference on Em-
pirical Methods in Natural Language Pro-
cessing, EMNLP 2004, A meeting of SIGDAT,
a Special Interest Group of the ACL, 举行于
conjunction with ACL 2004, 25–26 July 2004,
巴塞罗那, 西班牙.
Wenzhe Pei, Tao Ge, and Baobao Chang. 2014.
Max-margin tensor neural network for Chinese
word segmentation. In Proceedings of the 52nd
Annual Meeting of the Association for Com-
putational Linguistics, 前交叉韧带 2014, June 22–27,
2014, 巴尔的摩, 医学博士, 美国, 体积 1: 长的
文件.
Xian Qian and Yang Liu. 2012. Joint Chinese
word segmentation, POS tagging and parsing.
在诉讼程序中 2012 Joint Conference
on Empirical Methods in Natural Language
Processing and Computational Natural Lan-
guage Learning, EMNLP-CoNLL 2012, 七月
12–14, 2012, Jeju Island, 韩国.
Xipeng Qiu, Jiayi Zhao, and Xuanjing Huang.
2013. Joint Chinese word segmentation and
POS tagging on heterogeneous annotated cor-
pora with multiple task learning. In Proceedings
的 2013 经验方法会议
自然语言处理博士, EMNLP 2013,
18–21 October 2013, Grand Hyatt Seattle, Seattle,
华盛顿, 美国, A meeting of SIGDAT, A
Special Interest Group of the ACL.
Yan Shao, Christian Hardmeier, J¨org Tiedemann,
and Joakim Nivre. 2017. Character-based joint
segmentation and POS tagging for Chinese
using bidirectional RNN-CRF. In Proceedings
of the Eighth International Joint Conference on
自然语言处理, IJCNLP 2017,
Taipei, 台湾, 十一月 27 – 十二月 1,
2017 – 体积 1: Long Papers.
Tianze Shi, Liang Huang, and Lillian Lee. 2017.
训练
Fast(是) exact decoding and global
for transition-based dependency parsing via
a minimal feature set. 在诉讼程序中
2017 实证方法会议
自然语言处理, EMNLP 2017,
哥本哈根, 丹麦, September 9–11, 2017.
Yan Song, Shuming Shi, Jing Li, and Haisong
张. 2018. Directional skip-gram: Explic-
itly distinguishing left and right context for
word embeddings. 在诉讼程序中 2018
91
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3
Conference of the North American Chapter of
the Association for Computational Linguistics:
人类语言技术, NAACL-HLT,
New Orleans, Louisiana, 美国, June 1–6, 2018,
体积 2 (Short Papers).
Chi Sun, Luyao Huang, and Xipeng Qiu. 2019.
Utilizing BERT for aspect-based sentiment
analysis via constructing auxiliary sentence. 在
诉讼程序 2019 Conference of the
North American Chapter of the Association for
计算语言学: Human Language
Technologies, NAACL-HLT 2019, 明尼阿波利斯,
明尼苏达州, 美国, June 2–7, 2019, 体积 1 (Long and
Short Papers).
Yiou Wang, Jun’ichi Kazama, Yoshimasa Tsuruoka,
Wenliang Chen, Yujie Zhang, and Kentaro
Torisawa. 2011. Improving Chinese word seg-
mentation and POS tagging with semi-supervised
methods using large auto-analyzed data. 在
Fifth International Joint Conference on Natural
语言处理, IJCNLP 2011, 蒋
Mai, Thailand, November 8–13, 2011.
Zhiguo Wang, Chengqing Zong, and Nianwen
薛. 2013. A lattice-based framework for joint
Chinese word segmentation, POS tagging and
解析. In Proceedings of the 51st Annual
Meeting of the Association for Computational
语言学, 前交叉韧带 2013, 4–9 August 2013, Sofia,
Bulgaria, 体积 2: Short Papers.
Naiwen Xue, Fei Xia, Fu-Dong Chiou, and Martha
帕尔默. 2005. The Penn Chinese treebank:
Phrase structure annotation of a large corpus.
Natural Language Engineering, 11(2):207–238.
Liner Yang, Meishan Zhang, Yang Liu, Maosong
Sun, Nan Yu, and Guohong Fu. 2018. Joint
POS tagging and dependence parsing with
transition-based neural networks. IEEE/ACM
反式. 声音的, Speech & 语言处理,
26(8):1352–1358.
Meishan Zhang, Nan Yu, and Guohong Fu.
2018. A simple and effective neural model for
joint word segmentation and POS tagging.
IEEE/ACM Trans. 声音的, Speech & 语言
加工, 26(9).
Meishan Zhang, Yue Zhang, Wanxiang Che, 和
Ting Liu. 2014. Character-level Chinese depen-
dency parsing. 在诉讼程序中
the 52nd
Annual Meeting of the Association for Com-
putational Linguistics, 前交叉韧带 2014, June 22–27,
2014, 巴尔的摩, 医学博士, 美国, 体积 1: 长的
文件.
Yue Zhang and Stephen Clark. 2008. Joint word
segmentation and POS tagging using a single
perceptron. In ACL 2008, 诉讼程序
46th Annual Meeting of the Association for
计算语言学, June 15–20, 2008,
Columbus, 俄亥俄州, 美国.
Yue Zhang and Stephen Clark. 2010. A fast
decoder for joint word segmentation and pos-
tagging using a single discriminative model.
这 2010 会议
在诉讼程序中
Empirical Methods
in Natural Language
加工, EMNLP 2010, 9–11 October 2010,
MIT Stata Center, 马萨诸塞州, 美国, A
meeting of SIGDAT, a Special Interest Group
of the ACL.
Yuan Zhang, Chengtao Li, Regina Barzilay, 和
Kareem Darwish. 2015. Randomized greedy
inference for joint segmentation, 词性标注
and dependency parsing. In NAACL HLT 2015,
这 2015 Conference of the North American
Chapter of the Association for Computational
语言学: 人类语言技术,
丹佛, 科罗拉多州, 美国, 可能 31 – 六月 5,
2015.
Xiaoqing Zheng, Hanyang Chen, and Tianyu Xu.
2013. Deep learning for Chinese word seg-
mentation and POS tagging. 在诉讼程序中
这 2013 实证方法会议
自然语言处理, EMNLP 2013,
18–21 October 2013, Grand Hyatt Seattle,
Seattle, 华盛顿, 美国, A meeting of SIGDAT,
a Special Interest Group of the ACL.
Ming Zhong, Pengfei Liu, Danqing Wang, Xipeng
Qiu, and Xuanjing Huang. 2019. Searching for
effective neural extractive summarization: 什么
works and what’s next. 在诉讼程序中
57th Conference of the Association for Com-
putational Linguistics, 前交叉韧带 2019, Florence,
意大利, 七月 28 – 八月 2, 2019, 体积 1: 长的
文件.
92
我
D
哦
w
n
哦
A
d
e
d
F
r
哦
米
H
t
t
p
:
/
/
d
我
r
e
C
t
.
米
我
t
.
e
d
你
/
t
A
C
我
/
我
A
r
t
我
C
e
–
p
d
F
/
d
哦
我
/
.
1
0
1
1
6
2
/
t
我
A
C
_
A
_
0
0
3
0
1
1
9
2
3
6
2
4
/
/
t
我
A
C
_
A
_
0
0
3
0
1
p
d
.
F
乙
y
G
你
e
s
t
t
哦
n
0
8
S
e
p
e
米
乙
e
r
2
0
2
3