Transacciones de la Asociación de Lingüística Computacional, volumen. 5, páginas. 233–246, 2017. Editor de acciones: Patricio Pantel.
Lote de envío: 11/2016; Lote de revisión: 2/2017; Publicado 7/2017.
C(cid:13)2017 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
Domain-Targeted,HighPrecisionKnowledgeExtractionBhavana Dalvi MishraNiketTandonAllenInstituteforArtificialIntelligence2157NNorthlakeWaySuite110,Seattle,WA98103{bhavanad,nikett,peterc}@allenai.orgPeterClarkAbstractOurgoalistoconstructadomain-targeted,highprecisionknowledgebase(KB),contain-inggeneral(sujeto,predicado,object)state-mentsabouttheworld,insupportofadown-streamquestion-answering(control de calidad)application.Despiterecentadvancesininformationextrac-tion(ES DECIR)técnicas,nosuitableresourceforourtaskalreadyexists;existingresourcesareeithertoonoisy,toonamed-entitycentric,ortooincomplete,andtypicallyhavenotbeenconstructedwithaclearscopeorpurpose.Toaddressthese,wehavecreatedadomain-targeted,highprecisionknowledgeextractionpipeline,leveragingOpenIE,crowdsourcing,andanovelcanonicalschemalearningalgo-rithm(calledCASI),thatproduceshighpre-cisionknowledgetargetedtoaparticulardo-main-inourcase,elementaryscience.TomeasuretheKB’scoverageofthetargetdo-main’sknowledge(its“comprehensiveness”withrespecttoscience)wemeasurerecallwithrespecttoanindependentcorpusofdo-maintext,andshowthatourpipelineproducesoutputwithover80%precisionand23%re-callwithrespecttothattarget,asubstantiallyhighercoverageoftuple-expressiblescienceknowledgethanothercomparableresources.WehavemadetheKBpubliclyavailable1.1IntroductionWhiletherehavebeensubstantialadvancesinknowledgeextractiontechniques,theavailabilityofhighprecision,generalknowledgeabouttheworld,1ThisKBnamedas“AristoTupleKB”isavailablefordown-loadathttp://data.allenai.org/tuple-kbremainselusive.Specifically,ourgoalisalarge,highprecisionbodyof(sujeto,predicado,object)statementsrelevanttoelementaryscience,tosup-portadownstreamQAapplicationtask.Althoughthereareseveralimpressive,existingresourcesthatcancontributetoourendeavor,e.g.,NELL(Carlsonetal.,2010),ConceptNet(SpeerandHavasi,2013),WordNet(Fellbaum,1998),WebChild(Tandonetal.,2014),Yago(Suchaneketal.,2007),FreeBase(Bollackeretal.,2008),andReVerb-15M(Faderetal.,2011),theirapplicabilityislimitedbyboth•limitedcoverageofgeneralknowledge(e.g.,FreeBaseandNELLprimarilycontainknowl-edgeaboutNamedEntities;WordNetusesonlyafew(<10)semanticrelations)•lowprecision(e.g.,manyConceptNetasser-tionsexpressidiosyncraticratherthangeneralknowledge)Ourgoalinthisworkistocreateadomain-targetedknowledgeextractionpipelinethatcanovercometheselimitationsandoutputahighprecisionKBoftriplesrelevanttoourendtask.Ourapproachleveragesexistingtechniquesofopeninformationextraction(OpenIE)andcrowdsourcing,alongwithanovelschemalearningalgorithm.Therearethreemaincontributionsofthiswork.First,wepresentahighprecisionextractionpipelineabletoextract(subject,predicate,object)tuplesrele-vanttoadomainwithprecisioninexcessof80%.Theinputtothepipelineisacorpus,asense-disambiguateddomainvocabulary,andasmallsetofentitytypes.Thepipelineusesacombinationoftextfiltering,OpenIE,Turkerannotationonsam-ples,andprecisionpredictiontogenerateitsoutput. l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u / t a c l / l a r t i c e - p d f / d o i / . 1 0 1 1 6 2 / t l a c _ a _ 0 0 0 5 8 1 5 6 7 4 7 8 / / t l a c _ a _ 0 0 0 5 8 p d . f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 234 Second,wepresentanovelcanonicalschemain-ductionmethod(calledCASI)thatidentifiesclus-tersofsimilar-meaningpredicates,andmapsthemtothemostappropriategeneralpredicatethatcap-turesthatcanonicalmeaning.OpenIE,usedintheearlypartofourpipeline,generatestriplescon-tainingalargenumberofpredicates(expressedasverbsorverbphrases),butequivalencesandgen-eralizationsamongthemarenotcaptured.Syn-onymdictionaries,paraphrasedatabases,andverbtaxonomiescanhelpidentifytheserelationships,butonlypartiallysobecausethemeaningofaverboftenshiftsasitssubjectandobjectvary,somethingthattheseresourcesdonotexplicitlymodel.Toaddressthischallenge,wehavedevel-opedacorpus-drivenmethodthattakesintoaccountthesubjectandobjectoftheverb,andthuscanlearnargument-specificmappingrules,e.g.,therule“(x:Animal,foundin,y:Location)→(x:Animal,livein,y:Location)”statesthatifsomeanimalisfoundinalocationthenitalsomeanstheanimallivesinthelocation.Notethat‘foundin’canhaveverydif-ferentmeaningintheschema“(x:Substance,foundin,y:Material).TheresultisaKBwhosegeneralpredicatesaremorerichlypopulated,stillwithhighprecision.Finally,wecontributethescienceKBitselfasaresourcepubliclyavailable2totheresearchcommu-nity.Tomeasurehow“complete”theKBiswithre-specttothetargetdomain(elementaryscience),weusean(independent)corpusofdomaintexttochar-acterizethetargetscienceknowledge,andmeasuretheKB’srecallathigh(>80%)precisionoverthatcorpus(its“comprehensiveness”withrespecttosci-ence).ThismeasureissimilartorecallatthepointP=80%onthePRcurve,exceptmeasuredagainstadomain-specificsampleofdatathatreflectsthedis-tributionofthetargetdomainknowledge.Compre-hensivenessthusgivesusanapproximatenotionofthecompletenessoftheKBfor(tuple-expressible)factsinourtargetdomain,somethingthathasbeenlackinginearlierKBconstructionresearch.WeshowthatourKBhascomprehensiveness(recallofdomainfactsat>80%precision)of23%withrespecttoscience,asubstantiallyhighercoverage2AristoTupleKBisavailablefordownloadathttp://allenai.org/data/aristo-tuple-kboftuple-expressiblescienceknowledgethanothercomparableresources.WearemakingtheKBpub-liclyavailable.OutlineWediscusstherelatedworkinSection2.InSec-tion3,wedescribethedomain-targetedpipeline,in-cludinghowthedomainischaracterizedtotheal-gorithmandthesequenceoffiltersandpredictorsused.InSection4,wedescribehowtherelation-shipsbetweenpredicatesinthedomainareidenti-fiedandthemoregeneralpredicatesfurtherpop-ulated.FinallyinSection5,weevaluateourap-proach,includingevaluatingitscomprehensiveness(high-precisioncoverageofscienceknowledge).2RelatedWorkTherehasbeensubstantial,recentprogressinknowledgebasesthat(ante todo)encodeknowledgeaboutNamedEntities,includingFreebase(Bol-lackeretal.,2008),KnowledgeVault(Dongetal.,2014),DBPedia(Aueretal.,2007),andothersthathierarchicallyorganizenounsandnamedentities,e.g.,Yago(Suchaneketal.,2007).WhiletheseKBsarerichinfactsaboutnamedentities,theyaresparseingeneralknowledgeaboutcommonnouns(e.g.,thatbearshavefur).KBscoveringgeneralknowledgehavereceivedlessattention,althoughtherearesomenotableexceptionsconstructedusingmanualmethods,e.g.,WordNet(Fellbaum,1998),crowdsourcing,e.g.,ConceptNet(SpeerandHavasi,2013),y,morerecently,usingautomatedmeth-ods,e.g.,WebChild(Tandonetal.,2014).Whileuseful,theseresourceshavebeenconstructedtotar-getonlyasmallsetofrelations,providingonlylim-itedcoverageforadomainofinterest.Toovercomerelationsparseness,theparadigmofOpenIE(Bankoetal.,2007;Soderlandetal.,2013)extractsknowledgefromtextusinganopensetofrelationships,andhasbeenusedtosuccess-fullybuildlarge-scale(arg1,relation,arg2)resourcessuchasReVerb-15M(containing15milliongeneraltriples)(Faderetal.,2011).Althoughbroadcov-erage,sin embargo,OpenIEtechniquestypicallypro-ducenoisyoutput.OurextractionpipelinecanbeviewedasanextensionoftheOpenIEparadigm:westartwithtargetedOpenIEoutput,andthenap-plyasequenceoffilterstosubstantiallyimprovethe
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
235
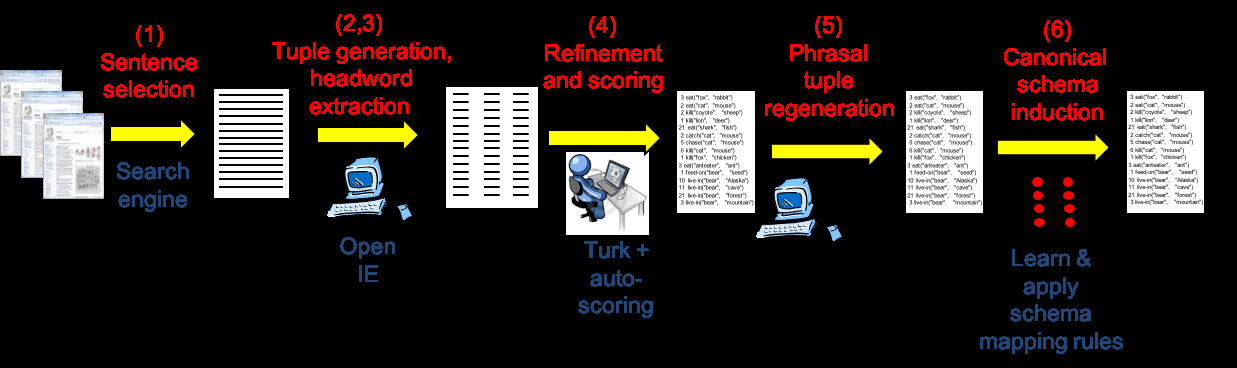
Figure1:Theextractionpipeline.Avocabulary-guidedsequenceofopeninformationextraction,crowdsourcing,andlearningpredicaterelationshipsareusedtoproducehighprecisiontuplesrelevanttothedomainofinterest.output’sprecision,andlearnandapplyrelationshipsbetweenpredicates.Thetaskoffindingandexploitingrelationshipsbetweendifferentpredicatesrequiresidentifyingbothequivalencebetweenrelations(e.g.,clusteringtofindparaphrases),andimplication(hierarchicalorganizationofrelations).Oneclassofapproachistouseexistingresources,e.g.,verbtaxonomies,asasourceofverbalrelationships,p.ej.,(GrycnerandWeikum,2014),(Grycneretal.,2015).How-ever,thehierarchicalrelationshipbetweenverbs,outofcontext,isoftenunclear,andsomeverbs,e.g.,“have”,areambiguous.Toaddressthis,wechar-acterizesemanticrelationshipsnotonlybyaverbbutalsobythetypesofitsarguments.Asec-ondclassofapproachistoinducesemanticequiva-lencefromdata,e.g.,usingalgorithmssuchasDIRT(LinandPantel,2001),RESOLVER(YatesandEt-zioni,2009),WiseNet(MoroandNavigli,2012),andAMIE(Gal´arragaetal.,2013).Theseallowrelationalequivalencestobeinferred,butarealsonoisy.Inourpipeline,wecombinethesetwoap-proachestogether,byclusteringrelationsusingasimilaritymeasurecomputedfrombothexistingre-sourcesanddata.Anovelfeatureofourapproachisthatwenotonlyclusterthe(typed)relaciones,butalsoidentifyacanonicalrelationthatalltheotherrelationsinaclustercanbemappedto,withoutrecoursetohumanannotatedtrainingdataoratargetrelationalvocab-ulary(e.g.,fromFreebase).Thismakesourprob-lemsettingdifferentfromthatofuniversalschema(Riedeletal.,2013)wheretheclustersofrelationsarenotexplicitlyrepresentedandmappingtocanon-icalrelationscanbeachievedgivenanexistingKBlikeFreebase.Althoughnoexistingmethodscanbedirectlyappliedinourproblemsetting,theAMIE-basedschemaclusteringmethodof(Gal´arragaetal.,2014)canbemodifiedtodothisalso.Wehaveimplementedthismodification(calledAMIE*,de-scribedinSection5.3),andweuseitasabaselinetocompareourschemaclusteringmethod(CASI)against.Finally,interactivemethodshavebeenusedtocreatecommonsenseknowledgebases,forex-ampleConceptNet(SpeerandHavasi,2013;LiuandSingh,2004)includesasubstantialamountofknowledgemanuallycontributedbypeoplethroughaWeb-basedinterface,andusedinnumerousap-plications(FaaborgandLieberman,2006;Dinakaretal.,2012).Morerecentlytherehasbeenworkoninteractivemethods(Dalvietal.,2016;Wolfeetal.,2015;Soderlandetal.,2013),whichcanbeseenasa“machineteaching”approachtoKBcon-struction.Theseapproachesfocusonhuman-in-the-loopmethodstocreatedomainspecificknowledgebases.Suchapproachesareproventobeeffectiveondomainswhereexperthumaninputisavailable.Incontrast,ourgoalistocreateextractiontech-niquesthatneedlittlehumansupervision,andresultincomprehensivecoverageofthetargetdomain.3TheExtractionPipelineWefirstdescribetheoverallextractionpipeline.Thepipelineisachainoffiltersandtransformations,out-putting(sujeto,predicado,object)triplesattheend.Itusesanovelcombinationoffamiliartechnologies,plusanovelschemalearningmodule,describedin
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
236
moredetailinSection4.3.1InputsandOutputsUnlikemanypriorefforts,ourgoalisadomain-focusedKB.TospecifytheKB’sextentandfocus,weusetwoinputs:1.Adomainvocabularylistingthenounsandverbsrelevanttothedomain.Inourparticularapplication,thedomainisElementaryscience,andthedomainvocabularyisthetypicalvocab-ularyofaFourthGrader(∼10yearoldchild),augmentedwithadditionalsciencetermsfrom4thGradeSciencetexts,comprisingofabout6000nouns,2000verbos,2000adjectives,and600adverbs.2.Asmallsetoftypesforthenouns,listingtheprimarytypesofentityrelevanttothedomain.Inourdomain,weuseamanuallyconstructedinventoryof45types(animal,artifact,bodypart,measuringinstrument,etc.).Inaddition,thepipelinealsouses:3.alarge,searchabletextcorpustoprovidesen-tencesforknowledgeextraction.Inourcase,weusetheWebviaasearchengine(Bing),fol-lowedbyfilterstoextractcleansentencesfromsearchresults.3.2WordSensesAlthough,ingeneral,nounsareambiguous,inatargeteddomainthereistypicallyaclear,primarysensethatcanbeidentified.Forexample,whileingeneraltheword“pig”canrefertoananimal,aper-son,amold,orablockofmetal,in4thGradeSci-enceituniversallyreferstoananimal3.Weleveragethisforourtaskbyassumingonesensepernouninthedomainvocabulary,andnotatethesesensesbymanuallyassigningeachnountooneoftheentitytypesinthetypeinventory.Verbsaremorechallenging,becauseevenwithinadomaintheyareoftenpolysemousoutofcon-text(e.g.,“have”).Tohandlethis,werefertoverbsalongwiththeirargumenttypes,thecom-binationexpressedasaverbalschema,p.ej.,(Ani-mal,“have”,BodyPart).Thisallowsustodistinguish3Thereareexceptions,e.g.,in4thGradeScience“bat”canrefertoeithertheanimalorthesportingimplement,butthesecasesarerare.differentcontextualusesofaverbwithoutintroduc-ingaproliferationofverbsensesymbols.Othershavetakenasimilarapproachofusingtyperestric-tionstoexpressverbsemantics(Panteletal.,2007;DelCorroetal.,2014).3.3ThePipelineThepipelineissketchedinFigure1andexemplifiedinTable1,andconsistsofsixsteps:3.3.1SentenceSelectionThefirststepistoconstructacollectionof(loosely)domain-appropriatesentencesfromthelargercorpus.Therearemultiplewaysthiscouldbedone,butinourcasewefoundthemosteffectivewaywasasfollows:a.Listthecoretopicsinthedomainofinter-est(ciencia),hereproducing81topicsderivedfromsyllabusguides.b.Foreachtopic,author1-3querytemplates,pa-rameterizedusingoneormoreofthe45do-maintypes.Forexample,forthetopic“animaladapation”,atemplatewas“[Animal]adapta-tionenvironment”,parameterizedbythetypeAnimal.Thepurposeofquerytemplatesistosteerthesearchenginetodomain-relevanttext.c.Foreachtemplate,automaticallyinstantiateitstype(s)inallpossiblewaysusingthedomainvocabularymembersofthosetypes.d.Useeachinstantiationasasearchqueryoverthecorpus,andcollectsentencesinthetop(aquí,10)documentsretrieved.Inourcase,thisresultedinagenerallydomain-relevantcorpusof7Msentences.3.3.2TupleGenerationSecond,werunanopeninformationextractionsystemoverthesentencestogenerateaninitialsetof(np,vp,np)tuples.Inourcase,weuseOpenIE4.2(Soderlandetal.,2013;Mausametal.,2012).3.3.3HeadwordExtractionandFilteringThird,thenpargumentsarereplacedwiththeirheadwords,byapplyingasimpleheadwordfilteringutility.Wediscardtupleswithinfrequentvpsorver-balschemas(herevpfrequency<10,schemafre-quency<5).
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
-
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
237
PipelineExampleOutputs:Entradas:corpus+vocabulary+types1.Sentenceselection:“Inaddition,greenleaveshavechlorophyll.”)2.TupleGeneration:(“greenleaves”“have”“chlorophyll”)3.HeadwordExtraction:(“leaf”“have”“chlorophyll”)4.RefinementandScoring:(“leaf”“have”“chlorophyll”)@0.89(puntaje)5.Phrasaltuplegeneration:(“leaf”“have”“chlorophyll”)@0.89(puntaje)(“greenleaf”“have”“chlorophyll”)@0.89(puntaje)6.RelationCanonicalization:(“leaf”“have”“chlorophyll”)@0.89(puntaje)(“greenleaf”“have”“chlorophyll”)@0.89(puntaje)(“leaf”“contain”“chlorophyll”)@0.89(puntaje)(“greenleaf”“contain”“chlorophyll”)@0.89(puntaje)Table1:Illustrativeoutputsofeachstepofthepipelinefortheterm“leaf”.3.3.4RefinementandScoringFourth,toimproveprecision,Turkersareaskedtomanuallyscoreaproportion(inourcase,15%)ofthetuples,thenamodelisconstructedfromthisdatatoscoretheremainder.FortheTurktask,Turkerswereaskedtolabeleachtupleastrueorfalse/nonsense.Eachtupleislabeled3times,andamajorityvoteisappliedtoyieldtheoveralllabel.Thesemanticsweapplytotuples(andwhichweex-plaintoTurkers)isoneofplausibility:ifthefactistrueforsomeofthearg1’s,thenscoreitastrue.Forexample,ifitistruethatsomebirdslayeggs,thenthetuple(bird,lay,egg)shouldbemarkedtrue.Thedegreeofmanualvs.automatedcanbeselectedheredependingontheprecision/costconstraintsoftheendapplication.Wethenbuildamodelusingthisdatatopredictscoresonothertuples.Forthismodel,weuselo-gisticregressionappliedtoasetoftuplefeatures.Thesetuplefeaturesincludenormalizedcountfea-tures,schemaandtypelevelfeatures,PMIstatis-ticsandsemanticfeatures.Normalizedcountfea-turesarebasedonthenumberofoccurrencesoftu-ples,andthenumberofuniquesentencesthetupleisextractedfrom.Schemaandtypelevelfeaturesarederivedfromthesubjectandobjecttype,andfrequencyofschemainthecorpus.Semanticfea-turesarebasedonwhethersubjectandobjectareab-stractvs.concrete(usingTurneyetal’sabstractnessdatabase(Turneyetal.,2011)),andwhetherthereareanymodalverbs(e.g.may,shouldetc.)intheoriginalsentence.PMIfeaturesarederivedfromthecountstatisticsofsubject,predicado,objectanden-tiretripleintheGooglen-gramcorpus(BrantsandFranz,2006).3.3.5PhrasalTupleGenerationFifth,foreachheadwordtuple(norte,vp,norte),retrievetheoriginalphrasaltriples(np,vp,np)itwasde-rivedfrom,andaddsub-phraseversionsofthesephrasaltuplestotheKB.Forexample,ifaheadwordtuple(cat,chase,ratón)wasderivedfrom(Ablackfurrycat,chased,agreymouse)thenthealgorithmconsidersadding(blackcat,chase,ratón)(blackfurrycat,chase,ratón)(blackcat,chase,greymouse)(blackfurrycat,chase,greymouse)Validnounphrasesarethosefollowingapattern“
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
238
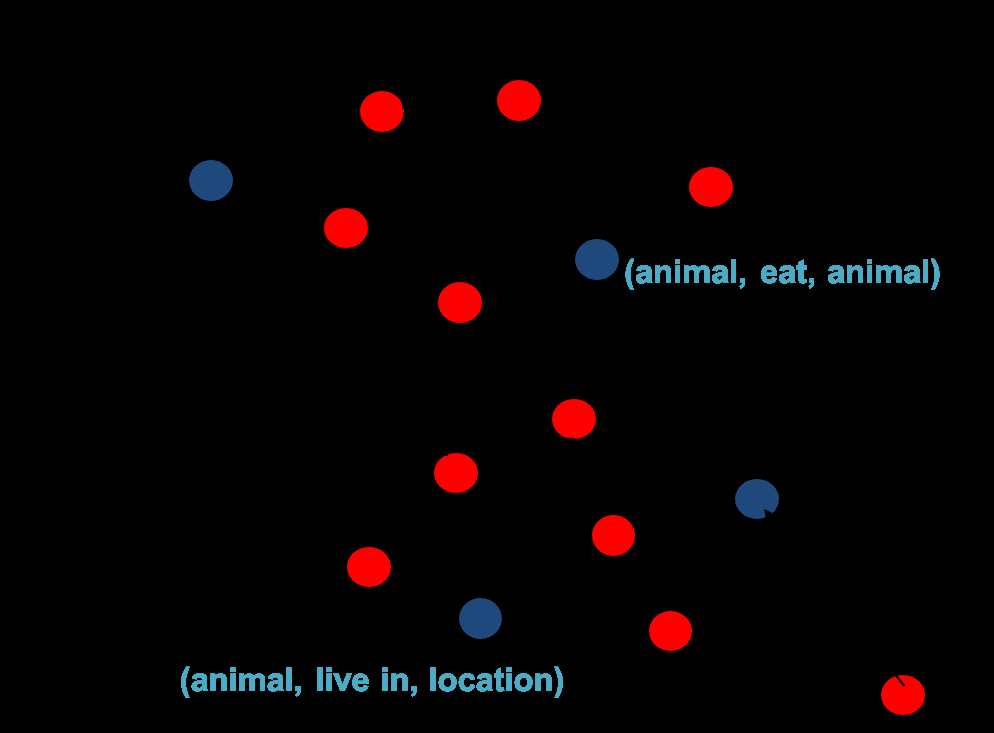
tuplesthataremappedtoageneralizedform,wein-steadretainthemincaseaqueryismadetotheKBthatrequirestheoriginalfine-graineddistinctions.Inthenextsection,wedescribehowtheseschemamappingrulesarelearned.4CanonicalSchemaInduction(CASI)4.1Tarea:InduceschemamappingrulesTheroleoftheschemamappingrulesistomakegeneralizationsamongseeminglydisparatetuplesexplicitintheKB.Todothis,thesystemidenti-fiesclustersofrelationswithsimilarmeaning,andmapsthemtoacanonical,generalizedrelation.Themappingsareexpressedusingasetofschemamap-pingrules,andtherulescanbeappliedtoinferad-ditional,generaltriplesintheKB.Informally,map-pingrulesshouldcombineevidencefrombothex-ternalresources(e.g.,verbtaxonomies)anddata(tuplesintheKB).Thisobservationallowsustoformallydefineanobjectivefunctiontoguidethesearchformappingrules.Wedefine:•aschemaisastructure(type1,verbphrase,type2)herethetypesarefromtheinputtypeinventory.•aschemamappingruleisaruleoftheformschemai→schemajstatingthatatripleusingschemaicanbere-expressedusingschemaj.•acanonicalschemaisaschemathatdoesnotoccurontheleft-handsideofanymappingrule,i.e.,itdoesnotpointtoanyotherschema.Tolearnasetofschemamappingrules,weselectfromthespaceofpossiblemappingrulessoasto:•maximizethequalityoftheselectedmappingrules,i.e.,maximizetheevidencethatthese-lectedrulesexpressvalidparaphrasesorgen-eralization.Thatiswearelookingforsynony-mousandtype-ofedgesbetweenschemas.Thisevidenceisdrawnfrombothexistingresources(e.g.,WordNet)andfromstatisticalevidence(amongthetuplesthemselves).•satisfytheconstraintthateveryschemapointstoacanonicalschema,orisitselfacanonicalschema.Wecanviewthistaskasasubgraphselectionprob-leminwhichthenodesareschemas,anddirectededgesarepossiblemappingrulesbetweenschemas.Thelearningtaskistoselectsubgraphssuchthatallnodesinasubgrapharesimilar,andpointtoasin-gle,canonicalnode(Figure2).WerefertothebluenodesinFigure2asinducedcanonicalschemas.Tosolvethisselectionproblem,weformulateitasasalinearoptimizationtaskandsolveitusinginte-gerlinearprogramming(ILP),aswenowdescribe.Figure2:Learningschemamappingrulescanbeviewedasasubgraphselectionproblem,whoseresult(illus-trated)isasetofclustersofsimilarschemas,allpointingtoasingle,canonicalform.4.2FeaturesforlearningschemamappingrulesToassessthequalityofcandidatemappingrules,wecombinefeaturesfromthefollowingsources:Moby,WordNet,associationrulesandstatisticalfeaturesfromourcorpus.Thesefeaturesindicatesynonymyortype-oflinksbetweenschemas.ForeachschemaSie.g.(Animal,livein,Location)wedefinethere-lationriasbeingtheverbphrase(e.g.“livein”),andviastherootverbofri(e.g.“live”).•Moby:WealsouseverbphrasesimilarityscoresderivedfromtheMobythesaurus.MobyscoreMijforaschemapairiscomputedbyalookupinthisdatasetforrelationpairri,rjorrootverbpairvi,vj.Thisisalsoadirectedfea-ture,i.e.Mij6=Mji.•WordNet:Ifthereexistsatroponymlinkpathfromschemaritorj,thenwedefinetheWord-NetscoreWijforthisschemapairasthein-verseofthenumberofedgesthatneedtobe
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
239
TypeUsewhichpartsofschema?Whatkindofrelationsdotheyencode?Featuresourcesemanticdistributionalsubjectpredicateobjectsynonymtype-oftemporalimplicationMobyXXXXWordNetXXXAMIE-typedXXXXXXAMIE-untypedXXXXXXTable2:Thedifferentfeaturesusedinrelationcanonicalizationcapturedifferentaspectsofsimilarity.maximize{Xij}Xi,jXij(cid:0)λ1∗Mij+λ2∗Wij+λ3∗ATij+λ4∗AUij+λ5∗Sij(cid:1)−δ∗kXk1subjectto,Xij∈{0,1},∀hi,jiXijareboolean.Xij+Xji≤1,∀i,jschemamappingrelationisasymmetric.XjXij≤1,∀iselectatmostoneparentperschema.Xij+Xjk−Xik≤1,∀hi,j,kischemamappingrelationistransitive.(1)Figure3:TheILPusedforcanonicalschemainductiontraveledtoreachrjfromri.Ifsuchapathdoesnotexist,thenwelookforapathfromvitovj.SincewedonotknowtheexactWord-Netsynsetapplicableforeachschema,wecon-siderallpossiblesynsetchoicesandpickthebestscoreasWij.Thisisadirectedfeaturei.e.,Wij6=Wji.NotethateventhoughWord-Netisahighqualityresource,itisnotcom-pletelysufficientforourpurposes.Outof955uniquerelations(verbphrases)inourKB,only455(47%)arepresentinWordNet.WecandealwiththeseoutofWordNetverbphrasesbyre-lyingonothersetsoffeaturesdescribednext.•AMIE:AMIEisanassociationrulemin-ingsystemthatcanproduceassociationrulesoftheform:“?aeat?b→?aconsume?b”.WehavetwosetsofAMIEfea-tures:typedanduntyped.Untypedfeaturesareoftheformri→rj,e.g.,eat→consume,whereastypedfeaturesareoftheformSi→Sj,p.ej.,(Animal,eat,Food)→(Animal,consume,Food).AMIEproducesrealvaluedscores5between0to1foreachrule.WedefineAUijandATijasuntypedandtypedAMIErulescoresrespectively.5WeusePCAconfidencescoresproducedbyAMIE.•Specificity:Wedefinespecificityofeachre-lationasitsIDFscoreintermsofthenumberofargumentpairsitoccurswith,comparedtototalnumberofargumenttypepairsinthecor-pus.Thespecificityscoreofaschemamappingrulefavorsmoregeneralpredicatesonthepar-entsideoftherules.specificity(r)=IDF(r)SP(r)=specificity(r)maxr0specificity(r0)Sij=SP(ri)−SP(rj)Más,wehaveasmallsetofverygenericre-lationslike“have”and“be”thatareconsideredasrelationstopwordsbysettingtheirSP(r)scoresto1.Thesefeaturesencodedifferentaspectsofsimi-laritybetweenschemasasdescribedinTable2.Inthisworkwecombinesemantichigh-qualityfea-turesfromWordNet,Mobythesauruswithweakdis-tributionalsimilarityfeaturesfromAMIEtogener-ateschemamappingrules.Wehaveobservedthatthesaurusfeaturesareveryeffectiveforpredicateswhicharelessambiguouse.g.eat,consume,livein.Associationrulefeaturesontheotherhandhaveev-idenceforpredicateswhichareveryambiguouse.g.have,be.Thusthesefeaturesarecomplementary.Further,thesefeaturesindicatedifferentkindsof
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
240
relationsbetweentwoschemas:synonymy,type-ofandtemporalimplication(referTable2).Inthiswork,wewanttolearntheschemamappingrulesthatcapturesynonymyandtype-ofrelationsanddiscardthetemporalimplications.Thismakesourproblemsettingdifferentfromthatofknowl-edgebasecompletionmethodse.g.,(Socheretal.,2013).OurproposedmethodCASIusesanensem-bleofsemanticandstatisticalfeaturesenablingustopromotethesynonymyandtype-ofedges,andtoselectthemostgeneralschemaascanonicalschemapercluster.4.3ILPmodelusedinCASIThefeaturesdescribedinSection4.2providepar-tialsupportforpossibleschemamappingrulesinourdataset.Thefinalsetofrulesweselectneedstocomplywithasymmetry,transitiveclosureandatmostoneparentperschemaconstraints.Weuseanintegerlinearprogramtofindtheoptimalsetofschemamappingrulesthatsatisfytheseconstraints,shownformallyinFigure3.Wedecomposetheschemamappingproblemintomultipleindependentsub-problemsbyconsideringschemasrelatedtoapairofargumenttypes,p.ej,allschemasthathavedomainorrangetypesAn-imal,Locationwouldbeconsideredasaseparatesub-problem.Thiswaywecanscaleourmethodtolargesetsofschemas.TheILPforeachsub-problemispresentedinEquation1.InEquation1,eachXijisabooleanvariablerepresentingwhetherwepicktheschemamappingruleSi→Sj.AsdescribedinSection4.2,Mij,Wij,ATij,AUij,Sijrepresentthescorespro-ducedbyMoby,WordNet,AMIE-typed,AMIE-untypedandSpecificityfeaturesrespectivelyfortheschemamappingruleSi→Sj.Theobjectivefunc-tionmaximizestheweightedcombinationofthesescores.Further,thesolutionpickedbythisILPsat-isfiesconstraintssuchasasymmetry,transitiveclo-sureandatmostoneparentperschema.WealsoapplyanL1sparsitypenaltyonX,retainingonlythoseschemamappingedgesforwhichthemodelisreasonablyconfident.Fornschemas,thereareO(n3)transitivitycon-straintswhichmaketheILPveryinefficient.Berantetal.(2011)proposedtwoapproximationstohandlealargenumberoftransitivityrulesbydecomposingtheILPorsolvingitinanincrementalway.Insteadwere-writetheILPrulesinsuchawaythatwecanefficientlysolveourmappingproblemwithoutintro-ducinganyapproximations.ThelasttwoconstraintsofthisILPcanberewrittenasfollows:(cid:0)PjXij≤1,∀iANDXij+Xjk−Xik≤1,∀hi,j,ki(cid:1)=⇒If(Xij=1)thenXjk=0∀kThisresultsinO(n2)constraintsandmakestheILPefficient.Impactofthistechniqueintermsofrun-timeisdescribedinSection5.3.Wethenuseanoff-the-shelfILPoptimizationen-ginecalledSCPSolver(PlanatscherandSchober,2015)tosolvetheILPproblems.TheoutputofourILPmodelistheschemamappingrules.WethenapplytheserulesontoKBtuplestogenerateaddi-tional,generaltuples.Someexamplesofthelearnedrulesare:(Organism,tener,Phenomenon)→(Organism,undergo,Phenomenon)(Animal,tener,Event)→(Animal,experiencia,Event)(Bird,occupy,Location)→(Bird,inhabit,Location)5Evaluation5.1KBComprehensivenessOuroverallgoalisahigh-precisionKBthathasrea-sonably“comprehensive”coverageoffactsinthetargetdomain,onthegroundsthatthesearethefactsthatadomainapplicationislikelytoqueryabout.ThisnotionofKBcomprehensivenessisanimpor-tantbutunder-discussedaspectofknowledgebases.Forexample,intheautomaticKBconstructionlit-erature,whileaKB’ssizeisoftenreported,thisdoesnotrevealwhethertheKBisnear-completeormerelyadropintheoceanofthatrequired(Razniewskietal.,2016;StanovskyandDagan,2016).Moreformally,wedefinecomprehensive-nessas:recallathigh(>80%)precisionofdomain-relevantfacts.ThismeasureissimilartorecallatthepointP=80%onthePRcurve,exceptrecallismea-suredwithrespecttoadifferentdistributionoffacts(namelyfactsaboutelementaryscience)ratherthanaheld-outsampleofdatausedtobuildtheKB.Theparticulartargetprecisionvalueisnotcritical;qué
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
241
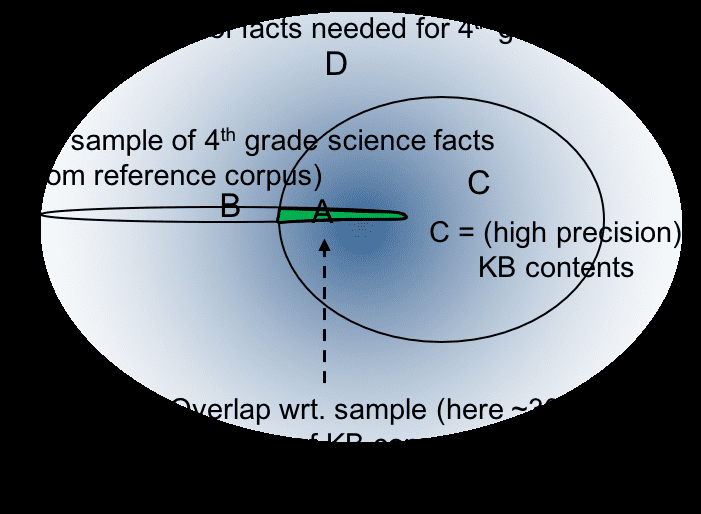
KBPrecisionCoverageofTuple-ExpressibleKBcomprehensivenessw.r.t.SciencedomainScienceKnowledge(Sciencerecall@80%precision)(RecallonscienceKB)WebChild89%3.4%3.4%NELL85%0.1%0.1%ConceptNet40%8.4%n/a(pag<80%)ReVerb-15M55%11.5%n/a(p<80%)OurKB81%23.2%23.2%Table3:Precisionandcoverageoftuple-expressibleelementaryscienceknowledgebyexistingresourcesvs.ourKB.Precisionestimatesarewithin+/-3%with95%confidenceinterval.isimportantisthatthesameprecisionpointisusedwhencomparingresults.Wechoose80%assubjec-tivelyreasonable;atleast4outof5queriestotheKBshouldbeansweredcorrectly.Thereareseveralwaysthistargetdistributionofrequiredfactscanbemodeled.Tofullyrealizetheambitionofthismetric,wewoulddirectlyidentifyasampleofrequiredend-taskfacts,e.g.,byman-ualanalysisofquestionsposedtotheend-tasksys-tem,orfromlogsoftheinteractionbetweentheend-tasksystemandtheKB.However,giventhepracti-calchallengesofdoingthisatscale,wetakeasim-plerapproachandapproximatethisend-taskdistri-butionusingfactsextractedfroman(independent)domain-specifictextcorpus(wecallthisareferencecorpus).Notethatthesefactsareonlyasampleofdomain-relevantfacts,nottheentirety.Otherwise,wecouldsimplyrunourextractorovertherefer-encecorpusandhaveallweneed.Nowweareinastrongposition,becausethereferencecorpusgivesusafixedpointofreferencetomeasurecomprehen-siveness:wecansamplefactsfromitandmeasurewhatfractiontheKB“knows”,i.e.,cananswerastrue(Figure4).ForourspecifictaskofelementaryscienceQA,wehaveassembledareferencecorpus6of∼1.2Msentencescomprisingofmultipleelementarysci-encetextbooks,multipledictionarydefinitionsofallfourthgradevocabularywords,andsimpleWikipediapagesforallfourthgradevocabularywords(wheresuchpagesexist).TomeasureourKB’scomprehensiveness(offactswithintheex-pressivepowerofourKB),werandomlysampled4147facts,expressedasheadwordtuples,from6Thiscorpusnamedas“AristoMINICorpus”isavail-ablefordownloadathttp://allenai.org/data/aristo-tuple-kbFigure4:Comprehensiveness(frequency-weightedcov-erageCoftherequiredfactsD)canbeestimatedusingcoverageAofareferenceKBBasasurrogatesamplingofthetargetdistribution.thereferencecorpus.Theseweregeneratedsemi-automaticallyusingpartsofourpipeline,namelyin-formationextractionthenTurkerscoringtoobtaintruefacts7.WecallthesefactstheReferenceKB8.TotheextentourtupleKBcontainsfactsinthisReferenceKB(andunderthesimplifyingassump-tionthatthesefactsarerepresentativeofthesci-enceknowledgeourQAapplicationneeds),wesayourtupleKBiscomprehensive.Doingthisyieldsavalueof23%comprehensivenessforourKB(Ta-ble3).Wealsomeasuredtheprecisionandsciencecov-erageofother,existingfactKBs.Forprecision,wetookarandomsampleof1000factsineachKB,andfollowedthesamemethodologyasearliersothatthe7Thismethodwillofcoursemissmanyfactsinthereferencecorpus,e.g.,whenextractionfailsorwhenthefactisinanon-sententialform,e.g.,atable.However,weonlyassumethatthedistributionofextractedfactsisrepresentativeofthedomain.8These4147testfactsarepublishedwiththedatasetathttp://allenai.org/data/aristo-tuple-kb l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u / t a c l / l a r t i c e - p d f / d o i / . 1 0 1 1 6 2 / t l a c _ a _ 0 0 0 5 8 1 5 6 7 4 7 8 / / t l a c _ a _ 0 0 0 5 8 p d . f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 242 comparisonisvalid:Turkerslabeleachfactastrueorfalse/nonsense,eachfactislabeled3times,andthemajoritylabelistheoveralllabel.Thepreci-sionsareshowninTable3.ForConceptNet,weusedonlythesubsetoffactswithfrequency>1,asfrequency=1factsareparticularlynoisy(thustheprecisionofthefullConceptNetwouldbelower).Wealsocomputedthesciencecoverage(=com-prehensiveness,ifp>80%)usingourreferenceKB.NotethattheseotherKBswerenotdesignedwithelementaryscienceinmindandso,notsurprisingly,theydonotcovermanyoftherelationsinourdo-main.Tomakethecomparisonasfairaspossible,giventheseotherKBsusedifferentrelationalvocab-ularies,wefirstconstructedalistof20verygeneralrelations(similartotheConceptNetrelations,e.g.,causes,usos,part-of,requerimiento),andthenmappedre-lationsusedinbothourreferencefacts,andintheotherKBs,tothese20relations.TocompareifareferencefactisinoneoftheseotherKBs,onlythegeneralrelationsneedtomatch,andonlythesubjectandobjectheadwordsneedtomatch.Thisallowssubstantiallinguisticvariationtobepermitteddur-ingevaluation(e.g.,“contain”,.“comprise”,“partof”etc.wouldallbeconsideredmatching).Inotherwords,thisisagenerousnotionof“aKBcontainingafact”,inordertobeasfairaspossible.AsTable4illustrates,theseotherKBscoververylittleofthetargetscienceknowledge.InthecaseofWebChildandNELL,theprimaryreasonforlowrecallislowoverlapbetweentheirtargetandours.NELLhasalmostnopredicateoverlapwithourRef-erenceKB,reflectingit’sNamedEntitycentriccon-tent.WebChildisrichinpart-ofandlocationin-formation,andcovers60%ofpart-ofandlocationfactsinourReferenceKB.However,theseareonly4.5%ofallthefactsintheReferenceKB,resultinginanoverallrecall(andcomprehensiveness)of3%.Incontrast,ConceptNetandReVerb-15Mhavesub-stantiallymorerelationaloverlapwithourReferenceKB,hencetheirrecallnumbersarehigher.However,bothhavelowerprecision,limitingtheirutility.Thisevaluationdemonstratesthelimitedsciencecoverageofexistingresources,andthedegreetowhichwehaveovercomethislimitation.Theextrac-tionmethodsusedtobuildtheseresourcesarenotdirectlycomparablesincetheyarestartingwithdif-ferentinput/outputsettingsandinvolvesignificantlydifferentdegreesofsupervision.Rather,theresultssuggestthatgeneral-purposeKBs(e.g.,NELL)mayhavelimitedcoverageforspecificdomains,andthatourdomain-targetedextractionpipelinecansignifi-cantlyalleviatethisintermsofprecisionandcover-agewhenthatdomainisknown.Extractionstage#schemas#tuples%Avg.outputprecision2.Tuplegeneration-7.5M54.23.Headwordtuples29.3K462K68.04.Tuplescoring15.8K156K87.25.Phrasaltuples15.8K286K86.56.Canonicalschemas15.8K340K80.6Table4:EvaluationofKBatdifferentstagesofextrac-tion.Precisionestimatesarewithin+/-3%with95%con-fidenceinterval.5.2PerformanceoftheExtractionPipelineInaddition,wemeasuredtheaverageprecisionoffactspresentintheKBaftereverystageofthepipeline(Table4).Wecanseethatthepipelinetakeasinput7.5MOpenIEtupleswithprecisionof54%andproducesagoodqualityscienceKBofover340Kfactswith80.6%precisionorganizedinto15Kschemas.TheTablealsoshowsthatprecisionislargelypreservedasweintroducephrasaltriplesandgeneraltuples.5.3EvaluationofCanonicalSchemaInductionInthissectionwewillfocusonusefulnessandcor-rectnessofourcanonicalschemainductionmethod.TheparametersoftheILPmodel(seeEquation1)i.e.,λ1…λ5andδaretunedbasedonsampleaccu-racyofindividualfeaturesourcesandusingasmallschemamappingproblemwithschemasapplicabletovocabularytypesAnimalandBody-Part.λ1=0.7,λ2=0.9,λ3=0.3,λ4=0.1,λ5=0.2,δ=0.7Further,withO(n3)transitivityconstraintswecouldnotsuccessfullysolveasingleILPproblemwith100schemaswithinatimelimitof1hour.Whereas,whenwerewritethemwithO(n2)con-straintsasexplainedinSection4.3,wecouldsolve443ILPsub-problemswithin6minuteswithaver-ageruntimeperILPbeing800msec.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
243
CanonicalschemainductionmethodComprehensivenessNone20.0%AMIE*20.9%CASI(ourmethod)23.2%Table5:UseoftheCASI-inducedschemassignificantly(atthe99%confidencelevel)improvescomprehensive-nessoftheKB.AsdiscussedinSection2,wenotonlyclusterthe(typed)relaciones,butalsoidentifyacanoni-calrelationthatalltheotherrelationsinaclustercanbemappedto,withoutrecoursetohumanan-notatedtrainingdataoratargetrelationalvocab-ulary.Althoughnoexistingmethodsdothisdi-rectly,theAMIE-basedschemaclusteringmethodof(Gal´arragaetal.,2014)canbeextendedtodothisbyincorporatingtheassociationruleslearnedbyAMIE(bothtypedanduntyped)insideourILPframeworktooutputschemamappingrules.Wecallthisexten-sionAMIE*,anduseitasabaselinetocomparetheperformanceofCASIagainst.5.3.1CanonicalSchemaUsefulnessThepurposeofcanonicalizationistoallowequiv-alencebetweenseeminglydifferentschematoberecognized.Forexample,theKBquery(“polarbear”,“residein”,“tundra”)?9canbeansweredbyaKBtriple(“polarbear”,“inhabit”,“tundra”)ifschemamappingrulesmaponeorbothtothesamecanonicalforme.g.,(“polarbear”,“livein”,“tun-dra”)usingtherules:(Animal,inhabit,Location)→(Animal,livein,Location)(Animal,residein,Location)→(Animal,livein,Location)Onewaytoquantitativelyevaluatethisistomea-suretheimpactofschemamappingonthecom-prehensivenessmetric.Table5showsthat,beforeapplyinganycanonicalschemainductionmethod,thecomprehensivenessscoreofourKBwas20%.TheAMIE*methodimprovesthisscoreto20.9%,whereasourmethodachievesacomprehensivenessof23.2%.ThislatterimprovementovertheoriginalKBisstatisticallysignificantatthe99%confidence9e.g.,posedbyaQAsystemtryingtoanswerthequestion“Whichisthelikelylocationinwhichapolarbeartoresidein?(A)Tundra(B)Desert(C)Grassland”level(samplesizeisthe4147factssampledfromthereferencecorpus).5.3.2CanonicalSchemaCorrectnessAsecondmetricofinterestisthecorrectnessoftheschemamappingrules(justbecausecomprehen-sivenessimprovesdoesnotimplyeverymappingruleiscorrect).Weevaluatecorrectnessofschemamappingrulesusingfollowingmetric:Precisionofschemamappingrules:WeaskedTurkerstodirectlyassesswhetherparticularschemamappingruleswerecorrect,forarandomsampleofrules.Tomakethetaskclear,Turkerswereshowntheschemamappingrule(expressedinEn-glish)alongwithanexamplefactthatwasrewrit-tenusingthatrule(togiveaconcreteexampleofitsuse),andtheywereaskedtoselectoneoption“correctorincorrectorunsure”foreachrewriterule.WeaskedthisquestiontothreedifferentTurkersandconsideredthemajorityvoteasfinalevaluation10.ThecomparisonresultsareshowninTable6.Startingwith15.8Kschemas,AMIE*canonicalizedonly822ofthoseinto102canonicalschemas(using822schemamappingrules).Incontrast,ourmethodCASIcanonicalized4.2Kschemasinto2.5Kcanon-icalschemas.Werandomlysampled500schemamappingrulesgeneratedbyeachmethodandaskedTurkerstoevaluatetheircorrectness,asdescribedearlier.AsshowninTable6,theprecisionofrulesproducedwasCASIis68%,comparedwithAMIE*whichachieved59%onthismetric.ThusCASIcouldcanonicalizefivetimesmoreschemaswith9%moreprecision.5.4DiscussionandFutureWorkNext,weidentifysomeofthelimitationsofourap-proachanddirectionsforfuturework.1.ExtractingRicherRepresentationsofKnowl-edge:Whiletriplescancapturecertainkindsofknowledge,thereareotherkindsofinformation,e.g.detaileddescriptionsofeventsorprocesses,thatcannotbeeasilyrepresentedbyasetofindependenttuples.Anextensionofthisworkwouldbetoextracteventframes,capableofrepresentingarichersetof10Wediscardedtheunsurevotes.Formorethan95%oftherules,atleast2outof3Turkersreachedclearconsensusonwhethertheruleis“correctvs.incorrect”,indicatingthattheTurkertaskwasclearlydefined.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
244
Canonicalschema#input#schema#inducedPrecisionofinductionmethodschemasmappingrulescanonicalschemasschemamappingrulesAMIE*15.8K82210259%CASI(ourmethod)15.8K4.2K2.5K68%Table6:CASIcanonicalizesfivetimesmoreschemasthanAMIE*,andalsoachievesasmall(9%)increaseinpreci-sion,demonstratinghowadditionalknowledgeresourcescanhelpthecanonicalizationprocess(Section4.2).Precisionestimatesarewithin+/-4%with95%confidenceinterval.rolesinawidercontextcomparedtoatriplefact.Forexampleinthenewsdomain,whilerepresentinganevent“publicshooting”,onewouldliketostoretheshooter,victims,weaponused,fecha,tiempo,loca-tionandsoon.Buildinghigh-precisionextractiontechniquesthatcangobeyondbinaryrelationsto-wardseventframesisapotentialdirectionoffutureresearch.2.RicherKBOrganization:Ourapproachor-ganizesentitiesandrelationsintoflatentitytypesandschemaclusters.Animmediatedirectionforex-tendingthisworkcouldbeabetterKBorganizationwithdeepsemantichierarchiesforpredicatesandar-guments,allowinginheritanceofknowledgeamongentitiesandtriples.3.Improvingcomprehensivenessbeyond23%:Ourcomprehensivenessscoreiscurrentlyat23%in-dicating77%ofpotentiallyusefulsciencefactsarestillmissingfromourKB.Therearemultiplewaystoimprovethiscoverageincludingbutnotlimitedto1)processingmoresciencecorporathroughourextractionpipeline,2)runningstandardKBcom-pletionmethodsonourKBtoaddthefactsthatarelikelytobetruegiventheexistingfacts,and3)im-provingourcanonicalschemainductionmethodfur-thertoavoidcaseswherethequeryfactispresentinourKBbutwithaslightlinguisticvariation.4.QuantificationSharpening:SimilartootherKBs,ourtupleshavethesemanticsofplausibility:Ifthefactisgenerallytrueforsomeofthearg1s,thenscoreitastrue.Althoughfrequencyfilteringtypicallyremovesfactsthatarerarelytrueforthearg1s,thereisstillvariationinthequantifierstrengthoffacts(i.e.,doesthefactholdforall,mayoría,orsomearg1s?)thatcanaffectdownstreaminference.Weareexploringmethodsforquantificationsharpening,p.ej.,(GordonandSchubert,2010),toaddressthis.5.Canthepipelinebeeasilyadaptedtoanewdomain?Ourproposedextractionpipelineexpectshigh-qualityvocabularyandtypesinformationasinput.Inmanydomains,itiseasytoimporttypesfromexistingresourceslikeWordNetorFreeBase.Forotherdomainslikemedicine,legalitmightrequiredomainexpertstoencodethisknowledge.However,webelievethatmanuallyencodingtypesisamuchsimplertaskascomparedtomanuallydefiningalltheschemasrelevantforanindividualdomain.Further,variousdesignchoices,e.g.,precisionvs.recalltradeoffoffinalKB,theamountofexpertinputavailable,etc.woulddependonthedomainandendtaskrequirements.6ConclusionOurgoalistoconstruct,adomain-targeted,highprecisionknowledgebaseof(sub-ject,predicado,object)triplestosupportanele-mentaryscienceapplication.Wehavepresentedascalableknowledgeextractionpipelinethatisabletoextractalargenumberoffactstargetedtoaparticulardomain.ThepipelineleveragingOpenIE,crowdsourcing,andanovelschemalearningalgorithm,andhasproducedaKBofover340,163factsat80.6%precisionforelementaryscienceQA.Wehavealsointroducedametricofcomprehen-sivenessformeasuringKBcoveragewithrespecttoaparticulardomain.ApplyingthismetrictoourKB,wehaveachievedacomprehensivenessofover23%ofsciencefactswithintheKB’sexpressivepower,substantiallyhigherthanthesciencecoverageofothercomparableresources.Mostimportantly,thepipelineoffersforthefirsttimeaviablewayofex-tractinglargeamountsofhigh-qualityknowledgetargetedtoaspecificdomain.WehavemadetheKBpubliclyavailableathttp://data.allenai.org/tuple-kb.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
245
AcknowledgmentsWearegratefultoPaulAllenwhoselong-termvisioncontinuestoinspireourscientificendeav-ors.WewouldalsoliketothankPeterTurneyandIsaacCowheyfortheirimportantcontributionstothisproject.ReferencesS.Auer,C.Bizer,J.Lehmann,G.Kobilarov,R.Cyga-niak,andZ.Ives.2007.DBpedia:Anucleusforawebofopendata.InInISWC/ASWC.MicheleBanko,MichaelJ.Cafarella,StephenSoderland,MatthewBroadhead,andOrenEtzioni.2007.Openinformationextractionfromtheweb.InIJCAI,vol-ume7,pages2670–2676.JonathanBerant,IdoDagan,andJacobGoldberger.2011.Globallearningoftypedentailmentrules.InACL.KurtBollacker,ColinEvans,PraveenParitosh,TimSturge,andJamieTaylor.2008.Freebase:Acollabo-rativelycreatedgraphdatabaseforstructuringhumanknowledge.InSIGMOD.ThorstenBrantsandAlexFranz.2006.Web1T5-gramversion1LDC2006T13.Philadelphia:Linguis-ticDataConsortium.AndrewCarlson,JustinBetteridge,BryanKisiel,BurrSettles,EstevamRHruschkaJr,andTomMMitchell.2010.Towardanarchitecturefornever-endinglan-guagelearning.InAAAI,volume5,page3.BhavanaDalvi,SumithraBhakthavatsalam,ChrisClark,PeterClark,OrenEtzioni,AnthonyFader,andDirkGroeneveld.2016.IKE-AnInteractiveToolforKnowledgeExtraction.InAKBC@NAACL-HLT.LucianoDelCorro,RainerGemulla,andGerhardWeikum.2014.Werdy:Recognitionanddisambigua-tionofverbsandverbphraseswithsyntacticandse-manticpruning.In2014ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,pages374–385.ACL.KarthikDinakar,BiragoJones,CatherineHavasi,HenryLieberman,andRosalindPicard.2012.Commonsensereasoningfordetection,prevention,andmitiga-tionofcyberbullying.ACMTransactionsonInterac-tiveIntelligentSystems(TiiS),2(3):18.XinDong,EvgeniyGabrilovich,GeremyHeitz,WilkoHorn,NiLao,KevinMurphy,ThomasStrohmann,ShaohuaSun,andWeiZhang.2014.Knowledgevault:aweb-scaleapproachtoprobabilisticknowl-edgefusion.InKDD.AlexanderFaaborgandHenryLieberman.2006.Agoal-orientedwebbrowser.InProceedingsoftheSIGCHIconferenceonHumanFactorsincomputingsystems,pages751–760.ACM.AnthonyFader,StephenSoderland,andOrenEtzioni.2011.Identifyingrelationsforopeninformationex-traction.InProceedingsoftheConferenceonEmpiri-calMethodsinNaturalLanguageProcessing,pages1535–1545.AssociationforComputationalLinguis-tics.ReVerb-15Mavailableathttp://openie.cs.washington.edu.ChristianeFellbaum.1998.WordNet.WileyOnlineLi-brary.LuisGal´arraga,ChristinaTeflioudi,KatjaHose,andFabianM.Suchanek.2013.AMIE:associationruleminingunderincompleteevidenceinontologicalknowledgebases.InWWW.LuisGal´arraga,GeremyHeitz,KevinMurphy,andFabianM.Suchanek.2014.Canonicalizingopenknowledgebases.InCIKM.JonathanGordonandLenhartKSchubert.2010.Quan-tificationalsharpeningofcommonsenseknowledge.InAAAIFallSymposium:CommonsenseKnowledge.AdamGrycnerandGerhardWeikum.2014.Harpy:Hy-pernymsandalignmentofrelationalparaphrases.InCOLING.AdamGrycner,GerhardWeikum,JayPujara,JamesR.Foulds,andLiseGetoor.2015.RELLY:Inferringhy-pernymrelationshipsbetweenrelationalphrases.InEMNLP.DekangLinandPatrickPantel.2001.DIRT-discov-eryofinferencerulesfromtext.InProceedingsoftheseventhACMSIGKDDinternationalconferenceonKnowledgediscoveryanddatamining,pages323–328.ACM.HugoLiuandPushSingh.2004.ConceptNet:aprac-ticalcommonsensereasoningtool-kit.BTtechnologyjournal,22(4):211–226.Mausam,MichaelSchmitz,StephenSoderland,RobertBart,andOrenEtzioni.2012.Openlanguagelearningforinformationextraction.InEMNLP.AndreaMoroandRobertoNavigli.2012.WiSeNet:buildingawikipedia-basedsemanticnetworkwithon-tologizedrelations.InCIKM.PatrickPantel,RahulBhagat,BonaventuraCoppola,TimothyChklovski,andEduardHHovy.2007.ISP:Learninginferentialselectionalpreferences.InHLT-NAACL,pages564–571.HannesPlanatscherandMichaelSchober.2015.SCPsolver.http://scpsolver.org.SimonRazniewski,FabianMSuchanek,andWernerNutt.2016.Butwhatdoweactuallyknow?InProc.AKBC’16.SebastianRiedel,LiminYao,AndrewMcCallum,andBenjaminM.Marlin.2013.Relationextractionwith
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
8
1
5
6
7
4
7
8
/
/
t
yo
a
C
_
a
_
0
0
0
5
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
246
matrixfactorizationanduniversalschemas.InHLT-NAACL.RichardSocher,DanqiChen,ChristopherD.Manning,andAndrewY.Ng.2013.Reasoningwithneuralten-sornetworksforknowledgebasecompletion.InNIPS.StephenSoderland,JohnGilmer,RobertBart,OrenEt-zioni,andDanielS.Weld.2013.OpenInformationExtractiontoKBPRelationsin3Hours.InTAC.RobertSpeerandCatherineHavasi.2013.Concept-net5:Alargesemanticnetworkforrelationalknowl-edge.InThePeoplesWebMeetsNLP,pages161–176.Springer.GabrielStanovskyandIdoDagan.2016.Creatingalargebenchmarkforopeninformationextraction.InEMNLP.FabianM.Suchanek,GjergjiKasneci,andGerhardWeikum.2007.Yago:ACoreofSemanticKnowl-edge.InWWW.NiketTandon,GerarddeMelo,FabianSuchanek,andGerhardWeikum.2014.WebChild:HarvestingandOrganizingCommonsenseKnowledgefromtheWeb.InWSDM.PeterD.Turney,YairNeuman,DanAssaf,andYohaiCo-hen.2011.Literalandmetaphoricalsenseidentifica-tionthroughconcreteandabstractcontext.InEMNLP.TravisWolfe,MarkDredze,JamesMayfield,PaulMc-Namee,CraigHarman,TimothyW.Finin,andBen-jaminVanDurme.2015.Interactiveknowledgebasepopulation.CoRR,abs/1506.00301.AlexanderYatesandOrenEtzioni.2009.Unsupervisedmethodsfordeterminingobjectandrelationsynonymsontheweb.JournalofArtificialIntelligenceResearch.