Transacciones de la Asociación de Lingüística Computacional, volumen. 5, páginas. 135–146, 2017. Editor de acciones: Hinrich Schütze.
Lote de envío: 9/2016; Lote de revisión: 12/2016; Publicado 6/2017.
2017 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
C
(cid:13)
Enriquecimiento de vectores de palabras con información de subpalabras Piotr Bojanowski∗ y Edouard Grave∗ y Armand Joulina y Tomas Mikolov Facebook AIResearch{bojanowski,agravante,yo conduje,tmikolov}@fb.comRepresentaciones de palabras continuas abstractas,entrenados en grandes corpus sin etiquetar son útiles para muchas tareas de procesamiento del lenguaje natural. Los modelos populares que aprenden tales representaciones ignoran la morfología de las palabras,asignando un vector distinto a cada palabra. Esta es una limitación,especialmente para idiomas con vocabulario extenso y muchas palabras raras.,Proponemos un nuevo enfoque basado en el modelo de skipgram.,dondecadapalabraserepresentacomounabolsadegramas-de-caracteres.Unarepresentaciónvectorialestáasociadaacadagrama-de-caracteres.;palabras siendo representadas como la suma de estas representaciones. Nuestro método es rápido,Permitir entrenar modelos en grandes corporaciones rápidamente y permitirnos calcular representaciones de palabras para palabras que no aparecieron en los datos de entrenamiento. Evaluamos nuestras representaciones de palabras en nueve idiomas diferentes.,tanto en tareas de similitud como de analogía de palabras. Comparando representaciones morfológicas de palabras recientemente propuestas,demostramos que nuestros vectores logran un rendimiento de vanguardia en estas tareas. 1 Introducción El aprendizaje de representaciones continuas de palabras tiene una larga historia en el procesamiento del lenguaje natural(Rumel-hartetal.,1988).Estas representaciones se derivan normalmente de grandes corporaciones sin etiquetar que utilizan estadísticas de coexistencia.(Deerwesteretal.,1990;Proteger,1992;lundandburgess,1996).Un gran cuerpo de trabajo,conocida como semántica distributiva,ha estudiado las propiedades de estos métodos(Turney∗Los dos primeros autores contribuyeron igualmente.etal., 2010;BaroniandLenci,2010).En la comunidad de la red neuronal,collobertandweston(2008)propuesto para aprender la incorporación de palabras mediante una red neuronal de retroalimentación,prediciendo una palabra basada en las dos palabras de la izquierda y las dos palabras de la derecha. Más recientemente,Mikolovetal.(2013b)Los modelos logarítmicos bilineales simples propuestos permitieron aprender representaciones continuas de palabras en corporaciones muy grandes de manera eficiente. La mayoría de estas técnicas representan cada palabra del vocabulario mediante un vector distinto,sin compartir parámetros. En particular,ignoran la estructura interna de las palabras,lo cual es una limitación importante para los idiomas morfológicamente ricos,como turco-ish o finlandés. Por ejemplo,enfrancésoespañol,la mayoría de los verbos tienen más de cuarenta formas flexionadas diferentes,mientras que el idioma finlandés tiene quince casos para sustantivos. Estos idiomas contienen muchas formas de palabras que ocurren raramente(ornotatal)en el corpus de entrenamiento,haciendo que sea difícil aprender buenas representaciones de palabras. Porque muchas formaciones de palabras siguen reglas,Es posible mejorar las representaciones vectoriales de lenguajes morfológicamente ricos mediante el uso de información a nivel de caracteres. En este documento,Proponemos aprender representaciones de gramos de caracteres.,y representar palabras como la suma de vectores de entonces gramos. Nuestra principal contribución es introducir una extensión del modelo continuo de salto de gramos.(Mikolovetal.,2013b),que tiene en cuenta información de subpalabras. Evaluamos este modelo en nueve idiomas que exhiben diferentes morfologías,mostrando el beneficio de nuestro enfoque.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
136
2Trabajo relacionadoRepresentaciones morfológicas de palabras.En años recientes,Se han propuesto muchos métodos para incorporar información morfológica en representaciones de palabras. Para modelar mejor las palabras raras.,Alexan-drescuyKirchhoff(2006)introducidomodelos de lenguaje neuronal factorizado,donde las palabras se representan como conjuntos de características. Estas características podrían incluir información morfológica,y esta técnica se aplicó con éxito a idiomas morfológicamente ricos,comoturco(Saketal.,2010).Recientemente,varios trabajos han propuesto diferentes funciones de composición para derivar representaciones de palabras a partir de morfemas(Lazaridouetal.,2013;Longetal.,2013;BothaandBlunsom,2014;Qiuetal.,2014).Estos diferentes enfoques se basan en la descomposición morfológica de palabras,mientras que el nuestro no. De manera similar,Chenetal.(2015)introdujo un método para aprender conjuntamente incorporaciones de palabras y caracteres chinos. Cuietal.(2015)propuso restringir palabras morfológicamente similares para que tengan representaciones similares. Soricut y Och(2015)se describe un método para aprender representaciones vectoriales de transformaciones morfológicas,permitiendo obtener representaciones de palabras no vistas mediante la aplicación de estas reglas. Las representaciones de palabras entrenadas en datos anotados morfológicamente fueron introducidas por Cot-terelland Schütze(2015).Lo más cercano a nuestro enfoque,Proteger(1993)representaciones aprendidas de caracteres cuatro gramos mediante descomposición de valores singulares,y obtuve representaciones de palabras sumando las representaciones de cuatro gramos.,Sí, etingenual.(2016)También se propone representar palabras utilizando vectores de recuento de caracteres y gramos.,la función objetiva utilizada para aprender estas representaciones se basa en pares de paráfrasis,mientras que nuestro modelo se puede entrenar en cualquier corpus de texto. Funciones a nivel de caracteres para PNL. Otra área de investigación estrechamente relacionada con nuestro trabajo son los modelos a nivel de caracteres para el procesamiento del lenguaje natural. Estos modelos descartan la segmentación en palabras y un aprendizaje de representaciones del lenguaje directamente a partir de caracteres. La primera clase de tales modelos son las redes neuronales recurrentes,aplicado al modelado del lenguaje(Mikolovetal.,2012;Sutskeveretal.,2011;Tumbas,2013;Bojanowskietal.,2015),normalización del texto(ella estaba crujiendo,2014),etiquetado de parte del discurso(Lingetal.,2015)y analizando(Ballesterosetal.,2015).Otra familia de modelos son redes neuronales convolucionales que se basan en caracteres.,que se aplicaron al etiquetado de parte del discurso(dosSan-tosandZadrozny,2014),análisis sentimental(dosSantosandGatti,2014),clasificación de texto(Zhangetal.,2015)y modelado de lenguaje(Kimetal.,2016).Número de bloque.(2013)introdujo un modelo de lenguaje basado en máquinas Boltzmann restringidas,en el que las palabras se codifican como un conjunto de gramos de caracteres.,trabajos recientes en traducción automática han propuesto el uso de unidades de subpalabras para obtener representaciones de raras palabras(Sennrichetal.,2016;lu-ongandmanning,2016).3ModeloEnestasección,Proponemos nuestro modelo para aprender representaciones de palabras teniendo en cuenta la morfología. Modelamos la morfología considerando unidades de subpalabras.,y representando palabras mediante una suma de sus gra- mas de caracteres. Comenzaremos presentando el marco general que utilizamos para entrenar vectores de palabras.,luego presentaremos nuestro modelo de subpalabras y finalmente describiremos cómo manejamos el diccionario de gramos de caracteres. 3.1 Modelo general Comenzamos revisando brevemente el modelo de salto continuo de gramos presentado por Mikolovetal.(2013b),del cual se deriva nuestro modelo. Damos una palabra vocabulario de tamaño W,donde la palabra se identifica por su índice w∈{1,…,W.},el objetivo es aprender una representación vectorial para cada palabra w. Inspirado en la hipótesis distributiva(harris,1954),las representaciones de palabras están entrenadas para predecir bien las palabras que aparecen en su contexto.,dado un gran corpus de entrenamiento representado como una secuencia de palabras w1,…,peso,el objetivo del modelo de salto de gramática es maximizar la siguiente probabilidad logarítmica:TXt=1Xc∈Ctlogp(WC|peso),dondeelcontextoCeselconjuntodeíndicesdepalabrasque rodeanlapalabrawt.Laprobabilidaddeobservarunapalabradecontextowcdadowtseparametrizaráutilizandolosvectoresdepalabraantesmencionados.Porahora,Consideremos que se nos dan funciones de puntuación que asignan pares de(palabra,contexto)toscoresinR.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
137
Una posible opción para definir la probabilidad de una palabra de contexto es softmax:pag(WC|peso)=es(peso,WC)PWj = 1 es(peso,j).Sin embargo,tal modelo no está adaptado a nuestro caso ya que implica que,dadaunapalabrawt,solo predecimos una palabra de contexto wc. El problema de predecir palabras de contexto puede en cambio enmarcarse como una tarea de clasificación binaria independiente. Entonces el objetivo es predecir de forma independiente la presencia(o ausencia)de palabras de contexto. Para la palabra en la posición, consideramos dos palabras de contexto como ejemplos positivos y muestras negativas al azar del diccionario. Para una posición de contexto elegida,usando la pérdida logística binaria,obtenemos la siguiente probabilidad logarítmica negativa:registro(cid:16)1+e-s(peso,WC)(cid:17)+Xn∈Nt,obstruir(cid:16)1+es(peso,norte)(cid:17),dondeNt,ciunconjuntodeejemplosnegativosmuestreadosdelvocabulario.Aldenotarlafuncióndepérdidalogística‘:x7 → iniciar sesión(1+e-x),podemos reescribir el objetivo como:TXt=1Xc∈Ct‘(s(peso,WC))+Xn∈Nt,do'(−s(peso,norte)).Una parametrización natural para las funciones de puntuación entre una palabra wtan y una palabra de contexto wcis para usar vectores de palabras. Definamos para cada palabra win el vocabulario dos vectores suw y vwin Rd. Estos dos vectores a veces se denominan vectores de entrada y salida en la literatura. En particular,tenemosvectorsuwtandvwc,correspondiente,respectivamente,a palabras wt y wc. Luego, la puntuación se puede calcular como el producto escalar entre palabra y contexto vector-torsass(peso,WC)=u>wtvwc.Themodeldescribedinthissectionistheskipgrammodelwithnegativesampling,presentado por Mikolovetal.(2013b).3.2Modelo de subpalabra mediante el uso de una representación vectorial distinta para cada palabra,elmodelodeomitirgramaignoralaestructurainternadelaspalabras.Enestasección,proponemos diferentes funciones de puntuación,Para tener en cuenta esta información. Cada palabra se representa como una bolsa de caracteres-gramo. Agregamos símbolos de límites especiales
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
138
de los modelos skipgram y cbow del paquete word 2vec2. 4.2 Optimización Resolvemos nuestro problema de optimización realizando un descenso de gradiente estocástico sobre la probabilidad logarítmica negativa presentada antes.,Usamos una caída lineal del tamaño de los pasos. Se proporciona un conjunto de entrenamiento que contiene Tpalabras y un número de pases sobre los datos igual a P.,el tamaño del paso en el momento es igual a γ0(1−tTP),dondeγ0esunparámetrofijo.Realizamoslaoptimizaciónenparalelo,recurriendo a Hogwild(Derechos y otros, 2011).Todos los subprocesos comparten parámetros y actualizan vectores de manera sincrónica. 4.3 Detalles de implementación para el modelo de hora y los experimentos de línea base,utilizamos los siguientes parámetros:losvectoresdepalabratienedimensión300.Paracadaejemplopositivo,wesam-ple5negativosatrandom,conprobabilidadproporcionalalaraízcuadradadelafrecuenciaunigrama.Utilizamosunaventanacontextualdetamañoc,y muestrear uniformemente el tamaño c entre 1 y 5. Para submuestrear las palabras más frecuentes,utilizamos un umbral de rechazo de 10−4(para más detalles,ver(Mikolovetal.,2013b)).Al crear el diccionario de palabras,Mantenemos las palabras que aparecen al menos 5 veces en el conjunto de entrenamiento. El tamaño del paso γ0 está establecido en 0,025 para la línea base del gramo de salto y en 0,05 tanto para el modelo de horas como para la línea base del arco. Estos valores predeterminados se encuentran en el paquete de palabras 2 vec y también funcionan bien para nuestro modelo. Usando esta configuración en datos en inglés,nuestro modelo con gramos de caracteres es aproximadamente 1,5 veces más lento de entrenar que la línea base de salto de gramos.,procesamos 105kpalabras/segundo/hilo versus 145kpalabras/segundo/hilo para la línea base. Nuestro modelo está implementado en C++ y está disponible públicamente. 34.4 Conjuntos de datos excepto para la comparación con trabajos anteriores(Sec.5.3),Entrenamos nuestros modelos en datos de Wikipedia. 4 Descargamos volcados de Wikipedia en nueve idiomas.:Arábica,checo,Alemán,Inglés,2https://code.google.com/archive/p/word2vec3https://github.com/facebookresearch/fastText4https://dumps.wikimedia.orgEspañol,Francés,italiano,rumano y ruso. Normalizamos los datos sin procesar de Wikipedia utilizando el script Perl de preprocesamiento de Matt Mahoney. 5 Todos los conjuntos de datos se mezclan,y entrenamos nuestros modelos haciendo cinco pasadas sobre ellos. 5 Resultados Evaluamos nuestro modelo en cinco experimentos:una evaluación de similitudes y analogías de palabras,acom-parisonto-métodos-de-última generación,unanálisisdelefectodeltamañodelosdatosdeentrenamientoydeltamañodelosgramasdecaracteresqueconsideramos.Describiremosestosexperimentosendetalleenlassiguientessecciones.5.1JuiciodesimilitudhumanaPrimeroevaluamoslacalidaddenuestrasrepresentacionesenlatareadesimilitud/relación de palabras. Lo hacemos calculando el coeficiente de correlación de rangos de Spearman(Lancero,1904)entre el juicio humano y la similitud del coseno entre las representaciones vectoriales.,comparamos modelos diferentes en tres conjuntos de datos:GUR65,GUR350yZG222(Gurévich,2005;ZeschandGurevych,2006).Para inglés,Usamos el conjunto de datos WS353 introducido por Finkelsteinetal.(2001)y otro conjunto de datos de palabras(RW),introducido por Luongetal.(2013).Evaluamos los vectores de palabras francesas en el conjunto de datos traducido RG65(JoubarneandInkpen,2011).Español,Los vectores de palabras en árabe y rumano se evalúan utilizando los conjuntos de datos descritos en(HassanandMihalcea,2009).Los vectores de palabras rusas se evalúan utilizando el conjunto de datos HJ introducido por Panchenkoetal.(2016).Informamos los resultados de nuestro método y las líneas de base para todos los conjuntos de datos en la Tabla 1. Algunas palabras de estos conjuntos de datos no aparecen en nuestros datos de capacitación.,y así,no podemos obtener representación de palabras para estas palabras usando el arco y omitir las líneas base del gramo. Para proporcionar resultados comparables,Proponemos por defecto utilizar vectores nulos para estas palabras. Dado que nuestro modelo explota su información de subpalabras.,También podemos calcular representaciones válidas para palabras sin vocabulario. Lo hacemos tomando la suma de sus vectores de n-gramas. Cuando las palabras OOV se representan usando 5http://mattmahoney.net/dc/textdata
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
139
sgcbowsisg-sisgARWS35351525455DEGUR35061626470GUR6578788181ZG22235384144ENRW434 34647WS35372737171ESWS35357585859FRRG6570697575ROWS35348525154RUHJ59606066Tabla1:Correlación entre el juicio humano y las puntuaciones de similitud en conjuntos de datos de similitud de palabras. Entrenamos ambos modelos de hora y la línea base de palabra 2vec en volcados normalizados de Wikipedia. Los conjuntos de datos de evaluación contienen palabras que no forman parte del conjunto de capacitación,sowerepresentthemusingnullvectors(hermana-).Sin nuestro modelo,También calculamos vectores para palabras no vistas sumando vectores de luego gramos.(sisg).los vectores nulos fueron referidos a nuestro método dassisg-andsisgotherwise(SubpalabraInformaciónSkipGram).Primero,Estaba mirando la Tabla 1, notamos que el modelo propuesto(sisg),que utiliza información de subpalabras,supera las líneas de base en todos los conjuntos de datos excepto el conjunto de datos inglés WS353.,vectores informáticos para palabras sin vocabulario(sisg)siempre es al menos que no lo hagan(hermana-).Esto demuestra la ventaja de utilizar información de subpalabras en forma de caracteres-gramas.,observamos que el efecto del uso de caracteres-gramas es más importante para el árabe,alemányrusoqueparainglés,El francés o el español. El alemán y el ruso exhiben declinaciones gramaticales con cuatro casos para el alemán y seis para el ruso.,muchas palabras alemanas son palabras compuestas;por ejemplo, la frase nominal “tableten-nis” se escribe en una sola palabra como “Tischtennis”. Explotando las similitudes a nivel de carácter entre “Tischtennis” y “Tennis”,nuestro modelo no representa las dos palabras como palabras completamente diferentes. Finalmente,observamos que en el conjunto de datos de English Rare Words(RW),nuestroenfoquerealizalosgcbowsisgCSSemantic25.727.627.5Syntactic52.855.077.8DESemantic66.566.862.3Syntactic44.545.056.4ENSemantic78.578.277.8Syntactic70.169.974.9ITSemantic52.354. 752.3Sintáctico51.551.862.7Tabla2:Precisión de nuestros modelos y líneas de base en las tareas de analogía de palabras para el checo,Alemán,Inglés e italiano. Informamos los resultados de las analogías semánticas y sintácticas por separado. Líneas de base, mientras que no lo hace en el conjunto de datos WS353 en inglés. Esto se debe al hecho de que las palabras en el conjunto de datos WS353 en inglés son palabras comunes para las cuales se pueden obtener buenos vectores sin explotar la información de las subpalabras. Al evaluar palabras menos frecuentes,Vemos que usar similitudes a nivel de caracteres entre palabras puede ayudar a aprender buenos vectores de palabras. 5.2 Tareas de analogía de palabras Ahora evaluamos nuestro enfoque con preguntas de analogía de palabras,de la formaAistoBasCistoD,donde D debe ser predicho por los modelos. Usamos los conjuntos de datos introducidos por Mikolovetal.(2013a)parainglés,por Svoboda y Brychcin(2016)para checo,por número de compradores.(2015)por German y por Berardietal.(2015)para italiano. Algunas preguntas contienen palabras que no aparecen en nuestro corpus de formación,Por lo tanto, excluimos estas preguntas de la evaluación. Informamos la precisión de los diferentes modelos en la Tabla 2. Observamos que la información morfológica mejora significativamente las tareas sintácticas.;nuestro enfoque supera las líneas de base.,no ayuda para preguntas semánticas,e incluso califica el rendimiento para alemán e italiano. Tenga en cuenta que esto está estrechamente relacionado con la elección de la longitud de los caracteres-gramos que consideramos. Mostramos en la Sección 5.5 que cuando el tamaño de entonces-gramos se elige de manera óptima,estas analogías manticas se degradan
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
140
DEENESFRGUR350ZG222WS353RWWS353RG65Luongetal.(2013)–6434–Qiuetal.(2014)–6533–SorricutingOch(2015)642271424767sisg734373485469BothaandBlunsom(2014)562539302845sisg663454414952Tabla3:Coeficiente de correlación de rango de Spearman entre el juicio humano y las puntuaciones de los modelos para diferentes métodos que utilizan la morfología para aprender representaciones de palabras. Mantenemos todos los pares de palabras del conjunto de evaluación y obtenemos representaciones de palabras fuera del vocabulario con nuestro modelo sumando los vectores de gramos de caracteres. Nuestro modelo fue entrenado en los mismos conjuntos de datos con los que comparamos los métodos.(de ahí las dos líneas de resultados de nuestro enfoque).menos. Otra observación interesante es que,esperado,la mejora sobre las líneas de base es más importante para lenguajes morfológicamente ricos,como el checo y el alemán. 5.3 Comparación con representaciones morfológicas También comparamos nuestro enfoque con trabajos anteriores sobre vectores de palabras que incorporan información de subpalabras sobre tareas de similitud de palabras.:la red neuronal recursiva de Luongetal.(2013),el arco morfemec de Qiuetal.(2014)y las transformaciones morfológicas de Soricut y Och(2015).Para que los resultados sean comparables,Entrenamos nuestro modelo con los mismos conjuntos de datos que el método que estamos comparando con:los datos de Wikipedia en inglés publicados por Shaou y Westbury(2010),y los datos de rastreo de noticias de la tarea compartida WMT 2013 para,EspañolyFrancés.Tambiéncomparamosnuestroenfoqueconelmodelodelenguajelog-bilinealintroducidoporBothayBlunsom(2014),que fue capacitado en los corpus de comentarios de noticias de Europarland.,Entrenamos nuestro modelo con los mismos datos para que los resultados sean comparables.,obtenemos representaciones de palabras fuera del vocabulario sumando las representaciones de gramos de caracteres. Informamos los resultados en la Tabla 3. Observamos que nuestro enfoque simple funciona bien en relación con las técnicas basadas en información de subpalabras obtenida de segmentos morfológicos. También observamos que nuestro enfoque supera a Soricut y Och(2015)método,que se basa en el análisis de prefijos y sufijos. La gran mejora para el alemán se debe al hecho de que su enfoque no modela conceptos no compuestos,al contrario del nuestro. 5.4 Efecto del tamaño de los datos de entrenamiento ya que explotamos las similitudes a nivel de carácter entre palabras,somos capaces de modelar mejor palabras poco frecuentes.,También deberíamos ser más sólidos en cuanto al tamaño de los datos de entrenamiento que utilizamos.,Proponemos evaluar el rendimiento de nuestros vectores de palabras en la tarea de similitud de la función del tamaño de los datos de entrenamiento.,Entrenamos nuestro modelo y la línea base del arco en porciones de Wikipedia de tamaño creciente. Usamos el corpus de Wikipedia descrito anteriormente y aislamos el primer 1, 2, 5, 10, 20 y 50 por ciento de los datos.,todossonsubconjuntosdeotros.SeinformaronlosresultadosenlaFig.1.ComoenelexperimentopresentadoenlaSección5.1,notodaslaspalabrasdelconjuntodeevaluaciónestánpresentesenlosdatosdeWikipedia.Nuevamente,por defecto,utilizamos un vector anulo para estas palabras(hermana-)o calcularavec-torsumandolasrepresentacionesdeentoncesgramas(sisg).La tasa de falta de vocabulario está creciendo a medida que el conjunto de datos se reduce,y, por lo tanto, el rendimiento de sisg-ycbow necesariamente se degrada.,el modelo propuesto(sisg)asigna vectores no triviales a palabras no vistas anteriormente. Primero,notamos que para todos los conjuntos de datos,y todos los tamaños,el enfoque propuesto(sisg)funciona mejor que
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
141
020406080100porcentaje de datos30354045505560657075rango de lancerocbowsisg-sisg(a)DE-GUR350020406080100porcentaje de datos1520253035404550rango de lancerocbowsisg-sisg(b)ES-RWFigura 1:Influencia del tamaño de los datos de entrenamiento en el rendimiento. Calculamos vectores de palabras siguiendo el modelo propuesto utilizando conjuntos de datos de tamaño creciente. En este experimento,entrenamos modelos en una fracción del volcado completo de Wikipedia.,el rendimiento del modelo de arco de línea base mejora a medida que hay más y más datos disponibles. Nuestro modelo,por otro lado,parece saturarse rápidamente y agregar más datos no siempre conduce a mejores resultados. Segundo,y lo más importante,notamos que el enfoque propuesto proporciona muy buenos vectores de palabras incluso cuando se utilizan conjuntos de datos de entrenamiento muy pequeños.,en el conjunto de datos alemán GUR350,nuestro modelo(sisg)entrenado en el 5% de los datos logra un mejor rendimiento(66)que la línea base del arco entrenada en el conjunto de datos completo(62).Por otro lado,en el conjunto de datos RW en inglés,Usando el 1% del corpus de Wikipedia logramos un coeficiente de correlación de 45, que es mejor que el rendimiento de cbow entrenado en el conjunto de datos completo.(43).Esto tiene implicaciones prácticas muy importantes.:Los vectores de palabras con buen rendimiento se pueden calcular en conjuntos de datos de tamaño restringido y aún funcionan bien con palabras no vistas anteriormente.,cuando se utilizan representaciones de palabras vectoriales en aplicaciones específicas,Se recomienda volver a entrenar el modelo en datos textuales relevantes para la aplicación.,Este tipo de datos específicos de tareas relevantes suele ser muy escaso y aprender de una cantidad reducida de datos de entrenamiento es una gran ventaja. 5.5 Efecto del tamaño de n-gramos El modelo propuesto se basa en el uso de palabras presentes en el almacén de caracteres-gramas como vectores. Como se mencionó en la Sección 3.2, decidimos utilizar engramas que van de 3 a 6 caracteres. Esta elección fue arbitraria,motivado por el hecho de que n-gramos de estas longitudes cubrirán una amplia gama de información. Incluirían sufijos cortos(correspondiente a conjugaciones y declinaciones, por ejemplo)así como raíces más largas. En este experimento,Comprobamos empíricamente la influencia del rango de n-gramas que utilizamos en el rendimiento. Informamos nuestros resultados en la Tabla 4 para inglés y alemán sobre conjuntos de datos de similitud y analogía de palabras. Observamos eso tanto para inglés como para alemán.,nuestra elección arbitraria de 3-6 fue una decisión razonable,ya que proporciona un rendimiento satisfactorio en todos los idiomas. La elección óptima de rangos de longitud depende de la tarea y el idioma considerados y debe ajustarse adecuadamente. Sin embargo,debido a la escasez de datos de prueba,No implementamos ningún procedimiento de validación adecuado para seleccionar automáticamente los mejores parámetros.,tomar un rango grande como 3-6 proporciona una cantidad razonable de información de subpalabras. Este experimento también muestra que es importante incluir n-gramos largos,como columnas correspondientes ≤5 y n≤6 funcionan mejor. Esto es especialmente cierto para el alemán,ya que muchos sustantivos son compuestos formados por varias unidades que sólo pueden capturarse mediante secuencias de caracteres más largas.,observamos que el uso de gramos más grandes ayuda a establecer analogías mánticas.,Los resultados siempre mejoran tomando n≥3 en lugar de n≥2, lo que muestra que los caracteres 2 gramos no son informativos para esa tarea. Como se describe en la Sección 3.2, antes de calcular
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
142
2345625764676969365687070470707156971670(a)DE-GUR3502345625955565960360586062462626356464665(b)DESemántico2345624550535455351555556454565655656654(C)DESintáctico2345624142464748344464848447484854848648(d)EN-RW2345627876757676378777877479797958079680(mi)ENSemántica2345627071737473372747574474757557474672(F)ESTablaSintáctica4:Estudiodelefectodelostamañosden-gramosconsideradossobreelrendimiento.Calculamosvectoresdepalabrasutilizandogramasdecaracteresconnin{i,…,j}e informamos sobre el rendimiento de varios valores de un dj. Evaluamos este efecto en alemán e inglés,y representar palabras fuera del vocabulario utilizando información de subpalabras.gramas de caracteres,anteponemos y agregamos caracteres posicionales especiales para almacenar el principio y el final de la palabra.,2-gramos no será suficiente para capturar adecuadamente los sufijos que corresponden a conjugaciones o declinaciones,ya que están compuestos por un solo carácter y posición adecuados. 5.6 Modelado del lenguaje en esta sección,Describimos una evaluación de los vectores de palabras obtenidos con nuestra tarea metodológica de modelado del lenguaje. Evaluamos nuestro modelo de lenguaje en cinco idiomas.(CS,DE,ES,FR,RU)utilizando los conjuntos de datos introducidos por Botha y Blunsom(2014).Cada conjunto de datos contiene aproximadamente un millón de tokens de entrenamiento,y utilizamos el mismo preprocesamiento y división de datos que ambos y Blunsom.(2014).Nuestro modelo es una red neuronal recurrente con 650 unidades LST,regularizadosin abandono(con probabilidad de 0,5)y decaimiento de peso(parámetro de regularización de 10-5).AprendemoslosparámetrosutilizandoelgoritmoAdagradalconunatasadeaprendizajede0.1,recortandolosgradientesquetienenunanormalidadmayorque1.0.Inicializamoselpesodelaredenelrango[−0,05,0,05],y utilice un tamaño de lote de 20. Se consideran dos líneas de base:comparamos nuestro enfoque con el modelo de lenguaje log-bilineal de Botha y Blunsom(2014)y el modelo de lenguaje consciente de los personajes de Kimetal.(2016).Entrenamos vectores de palabras con gramos de caracteres en el conjunto de entrenamiento de la tarea de modelado de lenguaje y los utilizamos para inicializar la tabla de búsqueda de nuestro modelo de lenguaje. Informamos la perplejidad de prueba de nuestro modelo sin usar vectores de palabras previamente entrenados(LSTM),con vectores de palabras previamente entrenados sin información de subpalabras(sg)yconnuestrosvectores(sisg).Los resultados se presentan en la Tabla 5. Observamos que inicializar la tabla de búsqueda del modelo de idioma con representaciones de palabras previamente entrenadas mejora la perplejidad de la prueba sobre el LSTM de línea base. La observación más importante es que el uso de representaciones de palabras entrenadas con información de subpalabras supera al modelo de diagrama de salto simple.(8%reduccióndeperplejidadsobresg)y ruso(13%reducción).La mejora es menos significativa para lenguas romanas como el español.(3%reducción)o francés(2%reducción).Esto muestra la importancia de la información de las subpalabras en las tareas de modelado del lenguaje y muestra la utilidad
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
143
CSDEESFRRUVocab.size46k37k27k25k63kCLBL465296200225304CANLM371239165184261LSTM366222157173262sg339216150162237sisg312206145159206Table5:Pruebe la perplejidad en la tarea de modelado del lenguaje,Para 5 idiomas diferentes. Comparamos dos enfoques de estado del corazón.:CLBL se refiere al trabajo de Botha y Blunsom(2014)y CANLM se refiere al trabajo de Kimetal.(2016).delosvectoresqueproponemosparalenguajesmorfológicamentericos.6Análisiscualitativo6.1Vecinosmáscercanos.SeinformaronmuestrasresultadoscualitativosenlaTabla7.Parapalabrasseleccionadas,mostramos los vecinos más cercanos según la similitud del coseno para los vectores entrenados utilizando el enfoque propuesto y para la línea base de salto de gramo.,los vecinos más cercanos para el complejo,Las palabras técnicas y poco frecuentes que utilizan nuestro enfoque son mejores que las obtenidas utilizando el modelo de línea base. 6.2 Gramas de caracteres y morfemas Queremos evaluar cualitativamente si los n-gramas más importantes de una palabra corresponden o no a morfemas.,tomamos un vector de palabra que construimos como la suma de n-gramos. Como se describe en la Sección 3.2, cada palabra se representa como la suma de sus n-gramas:uw=Pg∈Gwzg.Foreachn-gramg,proponemos calcular la representación restringida obtenida omitiendo:uwg=Xg0∈G−{gramo}zg0. Luego clasificamos los n-gramos aumentando el valor del coseno entre uwanduwg. Mostramos los n-gramas clasificados para palabras seleccionadas en tres idiomas en la Tabla 6. Para el alemán,que tiene muchos sustantivos compuestos,weobservethatthemostimportantn-gramscor-wordn-gramsautofahrerfahrfahrerautofreundeskreiskreiskreis>
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
144
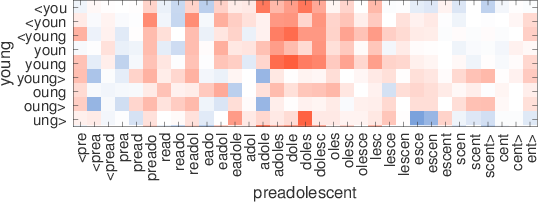
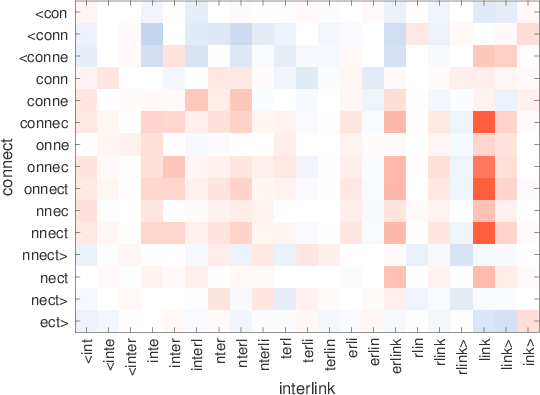
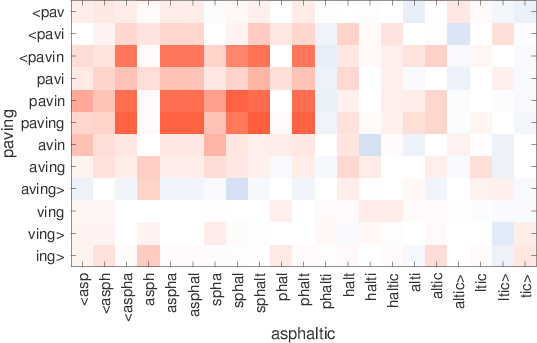
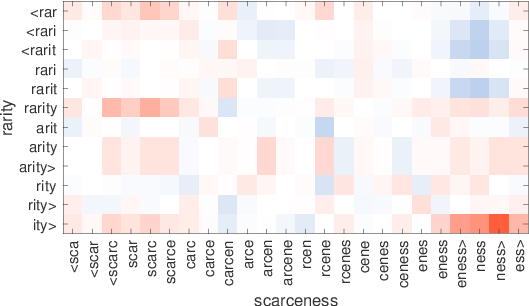
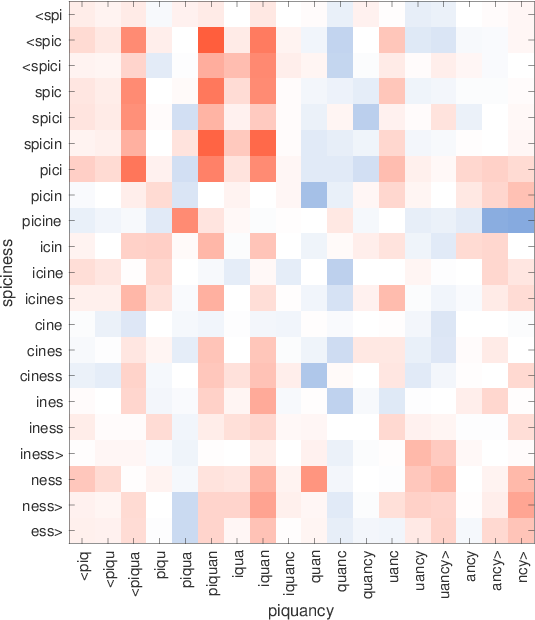
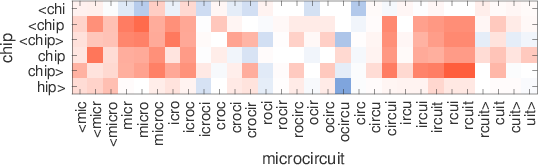
consultatilingtech-richinglish-bornmicromanagingrestaurantesdendriticsisgtiletech-dominadobritish-bornmicromanagerestaurantsdendriteflooringtech-heavypolaco-bornmicromanagedeateriedendritesssglibrerostecnología-heavymost-cappeddefangrestaurantsepitelialintegrados.ixicex-scotlandinternalisedelisp53Table7:Los vecinos más cercanos usan palabras raras que usan nuestras representaciones y se saltan el diagrama. Estos ejemplos cuidadosamente seleccionados son para ilustración. Figura 2:Ilustración de la similitud entre gramos de caracteres en palabras que no están en el vocabulario. Para cada par,solounapalabraesOOV,ysemuestraenelejex.Redindicacosenopositivo,mientras que azul negativo.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
145
enlaspalabras.ParasimularunaconfiguraciónconunnúmeromayordepalabrasOOV,Usamos modelos entrenados en el 1% de los datos de Wikipedia como en la Sección 5.4. Los resultados se presentan en la Fig. 2. Observamos patrones interesantes.,mostrando que las subpalabras coinciden correctamente.,para la palabra chip,Vemos claramente que hay dos grupos de n-gramos en el microcircuito que combinan bien. Estos corresponden aproximadamente al microcircuito y al circuito.,yn-gramas intermedios no coinciden bien. Otro ejemplo interesante es el par rareza y escasez.,escasamente coincide con la rareza, mientras que el sufijo-ness coincide muy bien con-ity.,la palabra preadolescente coincide bien con joven gracias a la subpalabra adolescente. Esto demuestra que construimos representaciones de palabras sólidas donde los prefijos y sufijos pueden ignorarse si la forma gramatical no se encuentra en el diccionario. 7 Conclusión en este documento,Investigamos un método simple para aprender representaciones de palabras teniendo en cuenta la información de las subpalabras. Nuestro enfoque,que incorpora gramos de caracteres en el modelo de skipgram,está relacionado con una idea que fue introducida por Schütze(1993).Por su simplicidad,nuestro modelo se entrena rápido y no requiere ningún preprocesamiento ni supervisión. Demostramos que nuestro modelo supera las líneas base que no tienen en cuenta la información de subpalabras.,así como métodos que se basan en el análisis morfológico. Abriremos el código fuente para la implementación de nuestro modelo,Con el fin de facilitar la comparación de trabajos futuros sobre el aprendizaje de las representaciones de subpalabras. Agradecimientos Agradecemos a Marco Baroni,HinrichSchützeylosrevisoresanónimosporsusperspicacescomentarios.ReferenciasAndreiAlexandrescuyKatrinKirchhoff.2006.Factoredneurallanguagemodels.InProc.NAACL.Miguel Ballesteros,ChrisDyer,y Noah A.Smith.2015. Análisis mejorado basado en transiciones mediante modelado de caracteres en lugar de palabras con LSTM. InProc.EMNLP. Marco Baroni y Alessandro Lenci. 2010. Memoria distributiva:Un marco general para la semántica basada en corpus. Lingüística computacional,36(4):673–721.Giacomo Berardi,andreaesuli,y Diego Marcheg-giani.2015.WordembeddingsgotoItaly:una comparación comparativa de modelos y conjuntos de datos de formación. Taller italiano de recuperación de información. Piotr Bojanowski,Armand Joulin,andTomášMikolov.2015.Estructuras alternativas para RNN a nivel de carácter.InProc.ICLR.JanA.BothaandPhilBlunsom.2014.Morfología composicional para representaciones de palabras y modelado de lenguaje.InProc.ICML.XinxiongChen,LeiXu,ZhiyuanLiu,Maosongsol,andHuanboLuan.2015.Jointlearningofcharacterandwordembeddings.InProc.IJCAI.GrzegorzChrupała.2014.Normalizingtweetswitheditscriptsandrecurrentneuralembeddings.InProc.ACL.RonanCollobertandJasonWeston.2008.Aunifiedar-chitecturefornaturallanguageprocessing:Redes neuronales profundas con aprendizaje multitarea.InProc.ICML.RyanCotterellandHinrichSchütze.2015.Morphologi-calword-embeddings.InProc.NAACL.QingCui,BinGao,JiangBian,SiyuQiu,HanjunDai,y Tie-YanLiu.2015.KNET:Un marco general para aprender a incorporar palabras utilizando conocimientos morfológicos. ACM Transactions on Information Systems,34(1):4:1–4:25.ScottDeerwester,SusanT.Dumais,George W. Furnas,Thomas Landauer,y Richard Harshman.1990.Indexingbylatentsemanticanalysis.JournaloftheAmericanSocietyforInformationScience,41(6):391–407.Cicero Nogueirados Santos y Maira Gatti.2014. Redes neuronales convolucionales profundas para el análisis de sentimientos de textos cortos. InProc.COLING.Cicero Nogueirados Santos y Bianca Zadrozny.2014.,EvgeniyGabrilovich,Yossi Matías,EhudRivlin,ZachSolan,GadiWolfman,y EytanRuppin.2001. Colocando la búsqueda en contexto:Elconceptorevisitado.EnProc.WWW.AlexGraves.2013.Generatingsequenceswithrecurrentneuralnetworks.arXivpreprintarXiv:1308.0850.Iryna Gurevych.2005.Usandolaestructuradeunaredconceptualenlainformáticadelarelaciónsemántica.InProc.IJCNLP.ZelligSHarris.1954.Distributionalstructure.Word,10(2-3):146–162.Samer HassanandRadaMihalcea.2009.Relación semántica multilingüe usando conocimiento enciclopédico.InProc.EMNLP.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
0
5
1
1
5
6
7
4
4
2
/
/
t
yo
a
C
_
a
_
0
0
0
5
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
146
Colette Joubarne y Diana Inkpen.2011. Comparación de similitud semántica para diferentes idiomas utilizando el corpus google n-gram y medidas de co-ocurrencia de segundo orden. InProc. Conferencia Canadiense sobre Inteligencia Artificial. YoonKim,YacineJernite,domingo de david,y Alexan-derMRush.2016.Modelos de lenguaje neuronal conscientes de los caracteres.InProc.AAAI.MaximilianKöper,ChristianScheible,y Sabine Schulteim Walde.2015. Confiabilidad multilingüe y estructura “semántica” de espacios de palabras continuos. Proc.IWCS2015.AngelikiLazaridou,Marco Marelli,RobertoZamparelli,y MarcoBaroni.2013. Representaciones derivadas de la composición de palabras morfológicamente complejas en semántica distributiva. InProc.ACL.WangLing,ChrisDyer,AlanW.Black,IsabelTrancoso,RamonFermandez,SilvioAmir,Luis Marujo,y TiagoLuis.2015.Encontrarfuncióninformar:Modelos de caracteres compositivos para la representación de palabras de vocabulario abierto. InProc.EMNLP.Kevin LundandCurtBurgess.1996.Producción de espacios semánticos de alta dimensión a partir de la coexistencia léxica.Métodos de investigación del comportamiento,Instrumentos,&Computadoras,28(2):203–208.Minh-ThangLuong y Christopher D.Manning.2016.Logrando una traducción automática neuronal de vocabulario abierto con modelos híbridos de palabras y caracteres.InProc.ACL.ThangLuong,RichardSocher,yChristopherD.Man-ning.2013.Betterwordrepresentationswithrecur-siveneuralnetworksformorphology.InProc.CoNLL.TomášMikolov,Ilya Sutskever,anoopdeoras,Hai-SonLe,StefanKombrink,y JanˇCernocký.2012.Modelado de lenguaje de subpalabras con redes neuronales.Informe técnico,Facultad de Tecnología de la Información,Universidad Tecnológica de Brno.TomášMikolov,KaiChen,GregD.Corrado,yJeffreyDean.2013a.Estimación eficiente de representaciones de palabras en el espacio vectorial.arXivpreprintarXiv:1301.3781.TomašMikolov,Ilya Sutskever,KaiChen,GregS.Cor-rado,y JeffDean.2013b. Representaciones distribuidas de palabras y frases y su composicionalidad. En Adv.NIPS.Alexander Panchenko,DmitryUstalov,Nikolay Arefyev,DenisPaperno,Natalia Konstantinova,NataliaLoukachevitch,yChrisBiemann.2016.Juicios humanos y de máquinas para la relación semántica rusa.InProc.AIST.SiyuQiu,Qing Cui,JiangBian,BinGao,y Tie-YanLiu.2014. Coaprendizaje de representaciones de palabras y representaciones de morfemas. InProc.COLING.BenjaminRecht,christopherre,EstebanWright,y FengNiu.2011.Hogwild:Un enfoque sin bloqueo para paralelizar el descenso de gradiente estocástico. En Adv.NIPS.DavidE.Rumelhart,GeoffreyE.Hinton,y Ronald J.Williams.1988.Neurocomputación:Fundamentosdeinvestigación.capítuloRepresentaciones de aprendizaje mediante errores de propagación hacia atrás,páginas 696–699.MITPress.Ha¸simSak,Murat Saraclar,y TungaGungör.2010.Modelado de lenguajes secundarios y basados en morfología para el reconocimiento de voz turco.InProc.ICASSP.HinrichSchütze.1992.Dimensionsofmeaning.InProc.IEEEConferenceonSupercomputing.HinrichSchütze.1993.Wordspace.InAdv.NIPS.RicoSennrich,BarryHaddow,andAlexandraBirch.2016.Neuralmachinetranslationofrarewordswithsubwordunits.InProc.ACL.CyrusShaoulandChrisWestbury.2010.TheWestburylabWikipediacorpus.RaduSoricutandFranzOch.2015.Unsupervisedmorphologyinductionusingwordembeddings.InProc.NAACL.CharlesSpearman.1904.Theproofand medición de la asociación entre dos cosas. The American Journal of Psychology,15(1):72–101.HenningSperr,JanNiehues,y Alexander Waibel.2013. Codificación de entrada basada en gramos de letras para modelos de lenguaje espacial continuo. En proceso del taller sobre modelos espaciales vectoriales continuos y su composicionalidad en ACL. Ilya Sutskever,James Martens,y GeoffreyEHinton.2011.Generación de texto con redes neuronales recurrentes.InProc.ICML.LukášSvoboda y TomášBrychcin.2016.Nuevo corpus de analogía de palabras para explorar incrustaciones de palabras checas.InProc.CICLING.PeterD.Turney,patriciopantel,etal.2010.Defrecuenciaalsignificado:Modelos espaciales vectoriales de semántica. Revista de investigación de inteligencia artificial,37(1):141–188.,mohitbansal,KevinGimpel,yKarenLivescu.2016.CHARAMGRAMA:Incrustar palabras y oraciones a través de caracteres-gramas. InProc.EMNLP.TorstenZeschandIrynaGurevych.2006.Creación automática de conjuntos de datos para medidas de relación semántica.InProc.WorkshoponLinguisticDistances.XiangZhang,JunboZhao,y YannLeCun.2015. Redes convolucionales a nivel de caracteres para clasificación de texto. InAdv.NIPS.